Navigation World Models
Amir Bar1^{1}1 Gaoyue Zhou2^{2}2 Danny Tran3^{3}3 Trevor Darrell3^{3}3 Yann LeCun1,2^{1,2}1,2
1^{1}1FAIR at Meta 2^{2}2New York University 3^{3}3Berkeley AI Research
1^{1}1FAIR at Meta 2^{2}2New York University 3^{3}3Berkeley AI Research
Abstract
Navigation is a fundamental skill of agents with visual-motor capabilities. We introduce a Navigation World Model (NWM), a controllable video generation model that predicts future visual observations based on past observations and navigation actions. To capture complex environment dynamics, NWM employs a Conditional Diffusion Transformer (CDiT), trained on a diverse collection of egocentric videos of both human and robotic agents, and scaled up to 1 billion parameters. In familiar environments, NWM can plan navigation trajectories by simulating them and evaluating whether they achieve the desired goal. Unlike supervised navigation policies with fixed behavior, NWM can dynamically incorporate constraints during planning. Experiments demonstrate its effectiveness in planning trajectories from scratch or by ranking trajectories sampled from an external policy. Furthermore, NWM leverages its learned visual priors to imagine trajectories in unfamiliar environments from a single input image, making it a flexible and powerful tool for next-generation navigation systems1.
Project page: https://amirbar.net/nwm

1. Introduction
Navigation is a fundamental skill for any organism with vision, playing a crucial role in survival by allowing agents to locate food, shelter, and avoid predators. In order to successfully navigate environments, smart agents primarily rely on vision, allowing them to construct representations of their surroundings to assess distances and capture landmarks in the environment, all useful for planning a navigation route.
When human agents plan, they often imagine their future trajectories considering constraints and counterfactuals. On the other hand, current state-of-the-art robotics navigation policies ([1, 2]) are "hard-coded", and after training, new constraints cannot be easily introduced (e.g. "no left turns"). Another limitation of current supervised visual navigation models is that they cannot dynamically allocate more computational resources to address hard problems. We aim to design a new model that can mitigate these issues.
In this work, we propose a Navigation World Model (NWM), trained to predict the future representation of a video frame based on past frame representation(s) and action(s) (see Figure 1(a)). NWM is trained on video footage and navigation actions collected from various robotic agents. After training, NWM is used to plan novel navigation trajectories by simulating potential navigation plans and verifying if they reach a target goal (see Figure 1(b)). To evaluate its navigation skills, we test NWM in known environments, assessing its ability to plan novel trajectories either independently or by ranking an external navigation policy. In the planning setup, we use NWM in a Model Predictive Control (MPC) framework, optimizing the action sequence that enables NWM to reach a target goal. In the ranking setup, we assume access to an existing navigation policy, such as NoMaD ([1]), which allows us to sample trajectories, simulate them using NWM, and select the best ones. Our NWM achieves state-of-the-art standalone performance and competitive results when combined with existing methods.
NWM is conceptually similar to recent diffusion-based world models for offline model-based reinforcement learning, such as DIAMOND ([3]) and GameNGen ([4]). However, unlike these models, NWM is trained across a wide range of environments and embodiments, leveraging the diversity of navigation data from robotic and human agents. This allows us to train a large diffusion transformer model capable of scaling effectively with model size and data to adapt to multiple environments. Our approach also shares similarities with Novel View Synthesis (NVS) methods like NeRF ([5]), Zero-1-2-3 ([6]), and GDC ([7]), from which we draw inspiration. However, unlike NVS approaches, our goal is to train a single model for navigation across diverse environments and model temporal dynamics from natural videos, without relying on 3D priors.
To learn a NWM, we propose a novel Conditional Diffusion Transformer (CDiT), trained to predict the next image state given past image states and actions as context. Unlike a DiT ([8]), CDiT’s computational complexity is linear with respect to the number of context frames, and it scales favorably for models trained up to 1B1B1B parameters across diverse environments and embodiments, requiring 4×4\times4× fewer FLOPs compared to a standard DiT while achieving better future prediction results.
In unknown environments, our results show that NWM benefits from training on unlabeled, action- and reward-free video data from Ego4D. Qualitatively, we observe improved video prediction and generation performance on single images (see Figure 1(c)). Quantitatively, with additional unlabeled data, NWM produces more accurate predictions when evaluated on the held-out Stanford Go ([9]) dataset.
Our contributions are as follows. We introduce a Navigation World Model (NWM) and propose a novel Conditional Diffusion Transformer (CDiT), which scales efficiently up to 1B1B1B parameters with significantly reduced computational requirements compared to standard DiT. We train CDiT on video footage and navigation actions from diverse robotic agents, enabling planning by simulating navigation plans independently or alongside external navigation policies, achieving state-of-the-art visual navigation performance. Finally, by training NWM on action- and reward-free video data, such as Ego4D, we demonstrate improved video prediction and generation performance in unseen environments.
2. Related Work
Goal conditioned visual navigation is an important task in robotics requiring both perception and planning skills ([1, 10, 11, 12, 13, 14, 15]). Given context image(s) and an image specifying the navigation goals, goal-conditioned visual navigation models ([1, 10]) aim to generate a viable path towards the goal if the environment is known, or to explore it otherwise. Recent visual navigation methods like NoMaD ([1]) train a diffusion policy via behavior cloning and temporal distance objective to follow goals in the conditional setting or to explore new environments in the unconditional setting. Previous approaches like Active Neural SLAM ([13]) used neural SLAM together with analytical planners to plan trajectories in the 3D3D3D environment, while other approaches like ([16]) learn policies via reinforcement learning. Here we show that world models can use exploratory data to plan or improve existing navigation policies.
Differently than in learning a policy, the goal of a world model ([17]) is to simulate the environment, e.g. given the current state and action to predict the next state and an associated reward. Previous works have shown that jointly learning a policy and a world model can improve sample efficiency on Atari ([18, 19, 3]), simulated robotics environments ([20]), and even when applied to real world robots ([21]). More recently, [22] proposed to use a single world model that is shared across tasks by introducing action and task embeddings while [23, 24] proposed to describe actions in language, and [25] proposed to learn latent actions. World models were also explored in the context of game simulation. DIAMOND ([3]) and GameNGen ([4]) propose to use diffusion models to learn game engines of computer games like Atari and Doom. Our work is inspired by these works, and we aim to learn a single general diffusion video transformer that can be shared across many environments and different embodiments for navigation.
In computer vision, generating videos has been a long standing challenge ([26, 27, 28, 29, 30, 31, 32]). Most recently, there has been tremendous progress with text-to-video synthesis with methods like Sora ([33]) and MovieGen ([34]). Past works proposed to control video synthesis given structured action-object class categories ([35]) or Action Graphs ([36]). Video generation models were previously used in reinforcement learning as rewards ([37]), pretraining methods ([38]), for simulating and planning manipulation actions ([39, 40]) and for generating paths in indoor environments ([41, 42]). Interestingly, diffusion models ([43, 44]) are useful both for video tasks like generation ([45]) and prediction ([46]), but also for view synthesis ([47, 48, 49]). Differently, we use a conditional diffusion transformer to simulate trajectories for planning without explicit 333 D representations or priors.
3. Navigation World Models
3.1 Formulation
Next, we turn to describe our NWM formulation. Intuitively, a NWM is a model that receives the current state of the world (e.g. an image observation) and a navigation action describing where to move and how to rotate. The model then produces the next state of the world with respect to the agent's point of view.
We are given an egocentric video dataset together with agent navigation actions D={(x0,a0,...,xT,aT)}i=1nD = \{(x_0, a_0, ..., x_T, a_T)\}^{n}_{i=1}D={(x0,a0,...,xT,aT)}i=1n, such that xi∈RH×W×3x_i\in \mathbb{R}^{H\times W \times 3}xi∈RH×W×3 is an image and ai=(u,ϕ)a_i=(u, \phi)ai=(u,ϕ) is a navigation command given by translation parameter u∈R2u\in\mathbb{R}^{2}u∈R2 that controls the change in forward/backward and right/left motion, as well as ϕ∈R\phi \in \mathbb{R}ϕ∈R that controls the change in yaw rotation angle.1
This can be naturally extended to three dimensions by having and defining yaw, pitch and roll. For simplicity, we assume navigation on a flat surface with fixed pitch and roll.
The navigation actions ai{a_i}ai can be fully observed (as in Habitat ([50])), e.g. moving forward towards a wall will trigger a response from the environment based on physics, which will lead to the agent staying in place, whereas in other environments the navigation actions can be approximated based on the change in the agent's location.
Our goal is to learn a world model FFF, a stochastic mapping from previous latent observation(s) sτ\mathbf{s}_\tausτ and action aτa_\tauaτ to future latent state representation st+1s_{t+1}st+1:
Where sτ=(sτ,...,sτ−m)\mathbf{s_\tau}=({s_\tau, ..., s_{\tau-m}})sτ=(sτ,...,sτ−m) are the past mmm visual observations encoded via a pretrained VAE ([27]). Using a VAE has the benefit of working with compressed latents, allowing to decode predictions back to pixel space for visualization.
Due to the simplicity of this formulation, it can be naturally shared across environments and easily extended to more complex action spaces, like controlling a robotic arm. Different than [19], we aim to train a single world model across environments and embodiments, without using task or action embeddings like in [22].
The formulation in Equation 1 models action but does not allow control over the temporal dynamics. We extend this formulation with a time shift input k∈[Tmin,Tmax]k\in[{T_\text{min}}, {T_\text{max}}]k∈[Tmin,Tmax], setting aτ=(u,ϕ,k)a_\tau = (u, \phi, k)aτ=(u,ϕ,k), thus now aτa_\tauaτ specifies the time change kkk, used to determine how many steps should the model move into the future (or past). Hence, given a current state sτs_\tausτ, we can randomly choose a timeshift kkk and use the corresponding time shifted video frame as our next state sτ+1s_{\tau+1}sτ+1. The navigation actions can then be approximated to be a summation from time τ\tauτ to m=τ+k−1m=\tau+k-1m=τ+k−1:
This formulation allows learning both navigation actions, but also the environment temporal dynamics. In practice, we allow time shifts of up to ±16\pm16±16 seconds.
One challenge that may arise is the entanglement of actions and time. For example, if reaching a specific location always occurs at a particular time, the model may learn to rely solely on time and ignore the subsequent actions, or vice versa. In practice, the data may contain natural counterfactuals—such as reaching the same area at different times. To encourage these natural counterfactuals, we sample multiple goals for each state during training. We further explore this approach in Section 4.
3.2 Diffusion Transformer as World Model
As mentioned in the previous section, we design FθF_{\theta}Fθ as a stochastic mapping so it can simulate stochastic environments. This is achieved using a Conditional Diffusion Transformer (CDiT) model, described next.
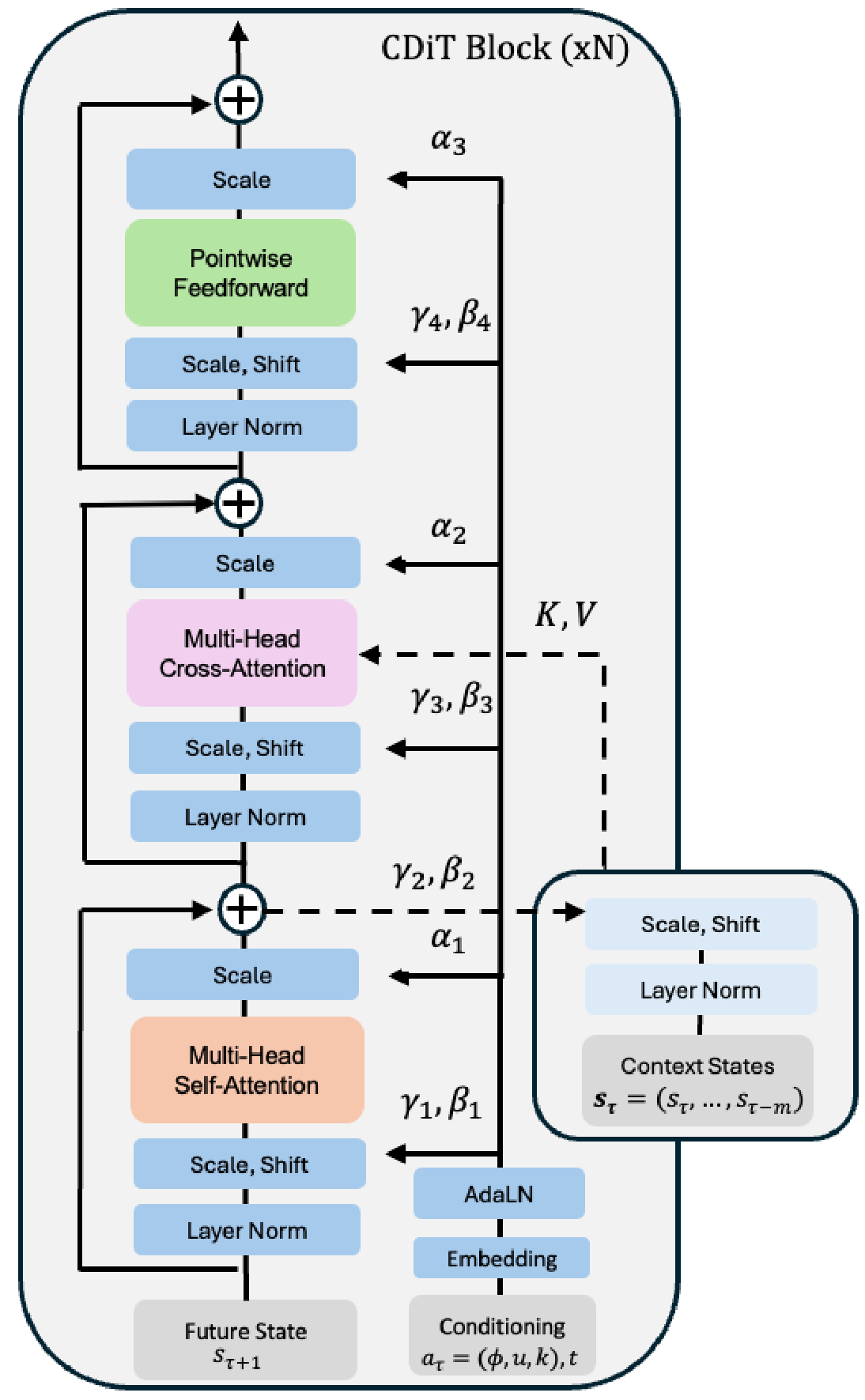
Conditional Diffusion Transformer Architecture. The architecture we use is a temporally autoregressive transformer model utilizing the efficient CDiT block (see Figure 2), which is applied ×N\times N×N times over the input sequence of latents with input action conditioning.
CDiT enables time-efficient autoregressive modeling by constraining the attention in the first attention block only to tokens from the target frame which is being denoised. To condition on tokens from past frames, we incorporate a cross-attention layer, such that every query token from the current target attends to tokens from past frames, which are used as keys and values. The cross-attention then contextualizes the representations using a skip connection layer.
To condition on the navigation action a∈R3a\in\mathbb{R}^3a∈R3, we first map each scalar to Rd3\mathbb{R}^\frac{d}{3}R3d by extracting sine-cosine features, then applying a 222-layer MLP\text{MLP}MLP, and concatenating them into a single vector ψa∈Rd\psi_a \in \mathbb{R}^dψa∈Rd. We follow a similar process to map the timeshift k∈Rk\in\mathbb{R}k∈R to ψk∈Rd\psi_k\in\mathbb{R}^dψk∈Rd and the diffusion timestep t∈Rt\in\mathbb{R}t∈R to ψk∈Rd\psi_k\in\mathbb{R}^dψk∈Rd. Finally we sum all embeddings into a single vector used for conditioning:
ξ\xiξ is then fed to an AdaLN ([51]) block to generate scale and shift coefficients that modulate the Layer Normalization ([52]) outputs, as well as the outputs of the attention layers. To train on unlabeled data, we simply omit explicit navigation actions when computing ξ\xiξ (see Equation 3).
An alternative approach is to simply use DiT ([8]), however, applying a DiT on the full input is computationally expensive. Denote nnn the number of input tokens per frame, and mmm the number of frames, and ddd the token dimension. Scaled Multi-head Attention Layer ([53]) complexity is dominated by the attention term O(m2n2d)O(m^2n^2d)O(m2n2d), which is quadratic with context length. In contrast, our CDiT block is dominated by the cross-attention layer complexity O(mn2d)O(mn^2d)O(mn2d), which is linear with respect to the context, allowing us to use longer context size. We analyze these two design choices in Section 4. CDiT resembles the original Transformer Block ([53]), without applying expensive self-attention over the context tokens.
💭 Click to ask about this figure
Diffusion Training. In the forward process, noise is added to the target state sτ+1s_{\tau+1}sτ+1 according to a randomly chosen timestep t∈{1,…,T}t \in \{1, \dots, T\}t∈{1,…,T}. The noisy state sτ+1(t)s_{\tau+1}^{(t)}sτ+1(t) can be defined as: sτ+1(t)=αtsτ+1+1−αtϵs_{\tau+1}^{(t)} = \sqrt{\alpha_t} s_{\tau+1} + \sqrt{1 - \alpha_t} \epsilonsτ+1(t)=αtsτ+1+1−αtϵ, where ϵ∼N(0,I)\epsilon \sim \mathcal{N}(0, I)ϵ∼N(0,I) is Gaussian noise, and {αt}\{\alpha_t\}{αt} is a noise schedule controlling the variance. As ttt increases, sτ+1(t)s_{\tau+1}^{(t)}sτ+1(t) converges to pure noise. The reverse process attempts to recover the original state representation sτ+1s_{\tau+1}sτ+1 from the noisy version sτ+1(t)s_{\tau+1}^{(t)}sτ+1(t), conditioned on the context sτ\mathbf{s}_{\tau}sτ, the current action aτa_\tauaτ, and the diffusion timestep ttt. We define Fθ(sτ+1∣sτ,aτ,t)F_\theta(s_{\tau+1} | \mathbf{s}_{\tau}, a_\tau, t)Fθ(sτ+1∣sτ,aτ,t) as the denoising neural network model parameterized by θ\thetaθ. We follow the same noise schedule and hyperparams of DiT ([8]).
Training Objective. The model is trained to minimize the mean-squared between the clean and predicted target, aiming to learn the denoising process:
In this objective, the timestep ttt is sampled randomly to ensure that the model learns to denoise frames across varying levels of corruption. By minimizing this loss, the model learns to reconstruct sτ+1s_{\tau+1}sτ+1 from its noisy version sτ+1(t)s_{\tau+1}^{(t)}sτ+1(t), conditioned on the context sτ\mathbf{s}_{\tau}sτ and action aτa_{\tau}aτ, thereby enabling the generation of realistic future frames. Following ([8]), we also predict the covariance matrix of the noise and supervise it with the variational lower bound loss Lvlb\mathcal{L}_\text{vlb}Lvlb [54].
3.3 Navigation Planning with World Models
Here we move to describe how to use a trained NWM to plan navigation trajectories. Intuitively, if our world model is familiar with an environment, we can use it to simulate navigation trajectories, and choose the ones which reach the goal. In an unknown, out of distribution environments, long term planning might rely on imagination.
Formally, given the latent encoding s0s_0s0 and navigation target s∗s^*s∗, we look for a sequence of actions (a0,...,aT−1)(a_0, ..., a_{T-1})(a0,...,aT−1) that maximizes the likelihood of reaching s∗s^*s∗. Let S(sT,s∗)\mathcal{S}({s}_T, s^*)S(sT,s∗) represent the unnormalized score for reaching state s∗s^*s∗ with sTs_TsT given the initial condition s0s_0s0, actions a=(a0,…,aT−1)\mathbf{a}=(a_0, \dots, a_{T-1})a=(a0,…,aT−1), and states s=(s1,…sT)\mathbf{s}=({s}_1, \dots {s}_T)s=(s1,…sT) obtained by autoregressively rolling out the NWM: s∼Fθ(⋅∣s0,a)\mathbf{s}\sim F_{\theta}(\cdot|s_0, \mathbf{a})s∼Fθ(⋅∣s0,a).
We define the energy function E(s0,a0,…,aT−1,sT)\mathcal{E}(s_0, a_0, \dots, a_{T-1}, s_T)E(s0,a0,…,aT−1,sT), such that minimizing the energy corresponds to maximizing the unnormalized perceptual similarity score and following potential constraints on the states and actions:
The similarity is computed by decoding s∗s^*s∗ and sTs_TsT to pixels using a pretrained VAE decoder ([27]) and then measuring the perceptual similarity ([55, 56]). Constraints like "never go left then right" can be encoded by constraining aτa_\tauaτ to be in a valid action set Avalid\mathcal{A}_{\text{valid}}Avalid, and "never explore the edge of the cliff" by ensuring such states sτs_\tausτ are in Ssafe\mathcal{S}_{\text{safe}}Ssafe. I(⋅)\mathbb{I}(\cdot)I(⋅) denotes the indicator function that applies a large penalty if any action or state constraint is violated.
The problem then reduces to finding the actions that minimize this energy function:
This objective can be reformulated as a Model Predictive Control (MPC) problem, and we optimize it using the Cross-Entropy Method ([57]), a simple derivative-free and population-based optimization method which was recently used with with world models for planning ([58]). We include an overview of the Cross-Entropy Method and the full optimization technical details in Section 7.
Ranking Navigation Trajectories. Assuming we have an existing navigation policy Π(a∣s0,s∗)\Pi(\mathbf{a}|s_0, s^*)Π(a∣s0,s∗), we can use NWMs to rank sampled trajectories. Here we use NoMaD ([1]), a state-of-the-art navigation policy for robotic navigation. To rank trajectories, we draw multiple samples from Π\PiΠ and choose the one with the lowest energy, like in Equation 5.
4. Experiments and Results
We describe the experimental setting, our design choices, and compare NWM to previous approaches. Additional results are included in the Supplementary Material.

💭 Click to ask about this figure
💭 Click to ask about this figure
4.1 Experimental Setting
Datasets. For all robotics datasets (SCAND ([59]), TartanDrive ([60]), RECON ([61]), and HuRoN ([62])), we have access to the location and rotation of robots, allowing us to infer relative actions compare to current location (see Equation 2). To standardize the step size across agents, we divide the distance agents travel between frames by their average step size in meters, ensuring the action space is similar for different agents. We further filter out backward movements, following NoMaD ([1]). Additionally, we use unlabeled Ego4D ([63]) videos, where the only action we consider is time shift. SCAND provides video footage of socially compliant navigation in diverse environments, TartanDrive focuses on off-road driving, RECON covers open-world navigation, HuRoN captures social interactions. We train on unlabeled Ego4D videos and GO Stanford ([9]) serves as an unknown evaluation environment. For the full details, see Section 8.1.
Evaluation Metrics. We evaluate predicted navigation trajectories using Absolute Trajectory Error (ATE) for accuracy and Relative Pose Error (RPE) for pose consistency ([64]). To check how semantically similar are world model predictions to ground truth images, we apply LPIPS ([65]) and DreamSim ([56]), measuring perceptual similarity by comparing deep features, and PSNR for pixel-level quality. For image and video synthesis quality, we use FID ([66]) and FVD ([67]) which evaluate the generated data distribution. See Section 8.1 for more details.
Baselines. We consider all the following baselines.
- DIAMOND ([3]) is a diffusion world model based on the UNet ([68]) architecture. We use DIAMOND in the offline-reinforcement learning setting following their public code. The diffusion model is trained to autoregressively predict at 565656 x 565656 resolution alongside an upsampler to obtrain 224224224 x 224224224 resolution predictions. To condition on continuous actions, we use a linear embedding layer.
- GNM ([2]) is a general goal-conditioned navigation policy trained on a dataset soup of robotic navigation datasets with a fully connected trajectory prediction network. GNM is trained on multiple datasets including SCAND, TartanDrive, GO Stanford, and RECON.
- NoMaD ([1]) extends GNM using a diffusion policy for predicting trajectories for robot exploration and visual navigation. NoMaD is trained on the same datasets used by GNM and on HuRoN.
Implementation Details. In the default experimental setting we use a CDiT-XL of 1B1B1B parameters with context of 444 frames, a total batch size of 102410241024, and 444 different navigation goals, leading to a final total batch size of 409640964096. We use the Stable Diffusion ([27]) VAE tokenizer, similar as in DiT ([8]). We use the AdamW ([69]) optimizer with a learning rate of 8e−58e-58e−5. After training, we sample 555 times from each model to report mean and std results. XL sized model are trained on 888 H100 machines, each with 888 GPUs. Unless otherwise mentioned, we use the same setting as in DiT-*/2 models.
4.2 Ablations
Models are evaluated on single-step 444 seconds future prediction on validation set trajectories on the known environment RECON. We evaluate the performance against the ground truth frame by measuring LPIPS, DreamSim, and PSNR. We provide qualitative examples in Figure 3.
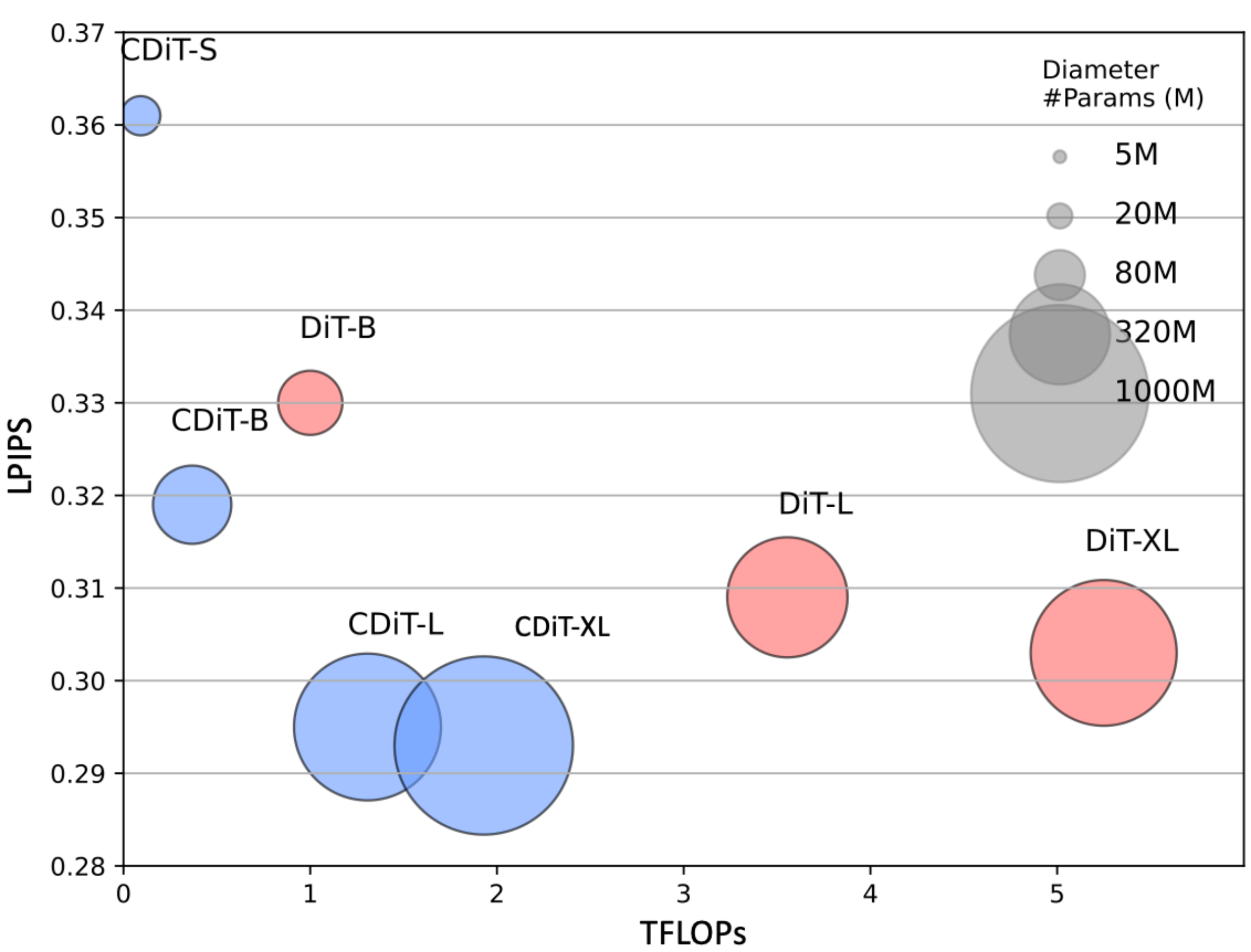
Model Size and CDiT. We compare CDiT (see Section 3.2) with a standard DiT in which all context tokens are fed as inputs. We hypothesize that for navigating known environments, the capacity of the model is the most important, and the results in Figure 5, indicate that CDiT indeed performs better with models of up to 111 B parameters, while consuming less than 2×2\times2× FLOPs. Surprisingly, even with equal amount of parameters (e.g, CDiT-L compared to DiT-XL), CDiT is 4×4\times4× faster and performs better.
Number of Goals. We train models with variable number of goal states given a fixed context, changing the number of goals from 111 to 444. Each goal is randomly chosen between ±16\pm16±16 seconds window around the current state. The results reported in Table 1 indicate that using 444 goals leads to significantly improved prediction performance in all metrics.
Context Size. We train models while varying the number of conditioning frames from 111 to 444 (see Table 1). Unsurprisingly, more context helps, and with short context the model often "lose track", leading to poor predictions.
Time and Action Conditioning. We train our model with both time and action conditioning and test how much each input contributes to the prediction performance (we include the results in Table 1. We find that running the model with time only leads to poor performance, while not conditioning on time leads to small drop in performance as well. This confirms that both inputs are beneficial to the model.
![**Figure 6:** **Ranking an external policy's trajectories using NWM.** To navigate from the observation image to the goal, we sample trajectories from NoMaD ([1]), simulate each of these trajectories using NWM, score them (see Equation 4), and rank them. With NWM we can accurately choose trajectories that are closer to the groundtruth trajectory. **Click the image to play examples in a browser**.](https://ittowtnkqtyixxjxrhou.supabase.co/storage/v1/object/public/public-images/u7zjypv8/sacson_nomad_rollout_fig.png)
💭 Click to ask about this figure
4.3 Video Prediction and Synthesis
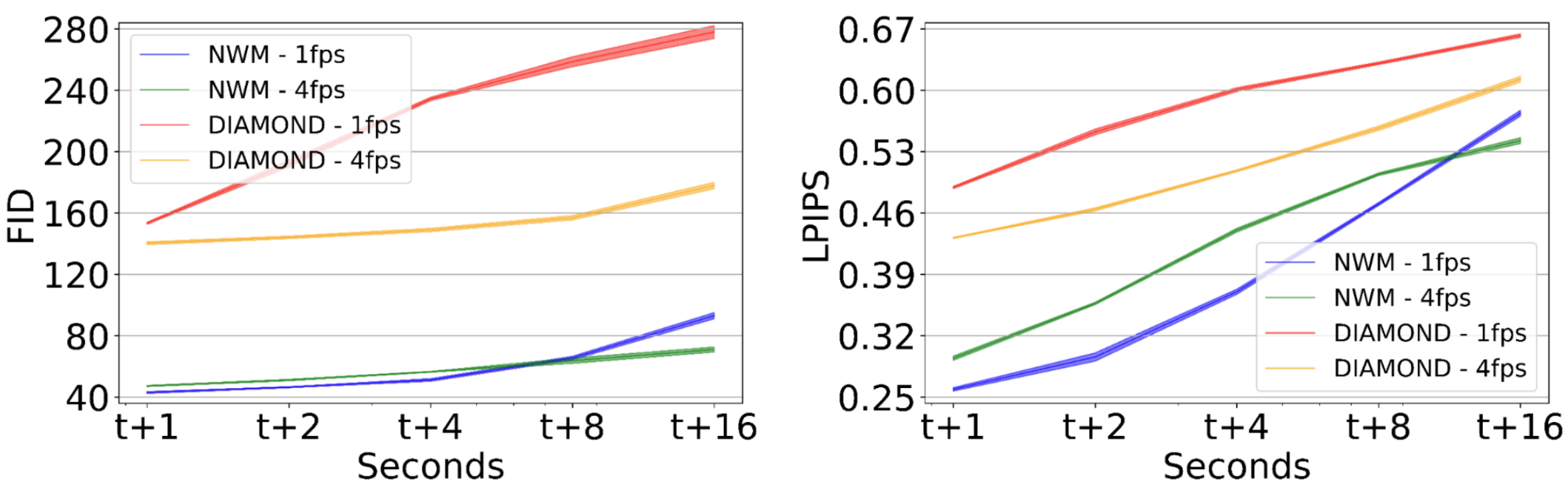
We evaluate how well our model follows ground truth actions and predicts future states. The model is conditioned on the first image and context frames, then autoregressively predicts the next state using ground truth actions, feeding back each prediction. We compare predictions to ground truth images at 111, 222, 444, 888, and 161616 seconds, reporting FID and LPIPS on the RECON dataset. Figure 4 shows performance over time compared to DIAMOND at 444 FPS and 111 FPS, showing that NWM predictions are significantly more accurate than DIAMOND. Initially, the NWM 111 FPS variant performs better, but after 888 seconds, predictions degrade due to accumulated errors and loss of context and the 444 FPS becomes superior. See qualitative examples in Figure 3.
Generation Quality. To evaluate video quality, we auto-regressively predict videos at 444 FPS for 161616 seconds to create videos, while conditioning on ground truth actions. We then evaluate the quality of videos generated using FVD, compared to DIAMOND ([3]). The results in Figure Table 2 indicate that NWM outputs higher quality videos.

4.4 Planning Using a Navigation World Model
Next, we turn to describe experiments that measure how well can we navigate using a NWM. We include the full technical details of the experiments in Section 8.2.
Standalone Planning. We demonstrate that NWM can be effectively used independently for goal-conditioned navigation. We condition it on past observations and a goal image, and use the Cross-Entropy Method to find a trajectory that minimizes the LPIPS similarity of the last predicted image to the goal image (see Equation 5). To rank an action sequence, we execute the NWM and measure LPIPS between the last state and the goal 333 times to get an average score. We generate trajectories of length 888, with temporal shift of k=0.25k=0.25k=0.25. We evaluate the model performance in Table 3. We find that using a NWM for planning leads to competitive results with state-of-the-art policies.

💭 Click to ask about this figure
Planning with Constraints. World models allow planning under constraints—for example, requiring straight motion or a single turn. We show that NWM supports constraint-aware planning. In forward-first, the agent moves forward for 5 steps, then turns for 3. In left-right first, it turns for 3 steps before moving forward. In straight then forward, it moves straight for 3 steps, then forward. Constraints are enforced by zeroing out specific actions; e.g., in left-right first, forward motion is zeroed for the first 3 steps, and Standalone Planning optimizes the rest. We report the norm of the difference in final position and yaw relative to unconstrained planning. Results (Table 4) show NWM plans effectively under constraints, with only minor performance drops (see examples in Figure 8).
Using a Navigation World Model for Ranking. NWM can enhance existing navigation policies in a goal-conditioned navigation. Conditioning NoMaD on past observations and a goal image, we sample n∈{16,32}n \in \{16, 32\}n∈{16,32} trajectories, each of length 888, and evaluate them by autoregressively following the actions using NWM. Finally, we rank each trajectory's final prediction by measuring LPIPS similarity with the goal image (see Figure 6). We report ATE and RPE on all in-domain datasets (Table 3) and find that NWM-based trajectory ranking improves navigation performance, with more samples yielding better results.
4.5 Generalization to Unknown Environments
Here we experiment with adding unlabeled data, and ask whether NWM can make predictions in new environments using imagination. In this experiment, we train a model on all in-domain datasets, as well as a susbet of unlabeled videos from Ego4D, where we only have access to the time-shift action. We train a CDiT-XL model and test it on the Go Stanford dataset as well as other random images. We report the results in Table 5, finding that training on unlabeled data leads to significantly better video predictions according to all metrics, including improved generation quality. We include qualitative examples in Figure 7. Compared to in-domain (Figure 3), the model breaks faster and expectedly hallucinates paths as it generates traversals of imagined environments.
5. Limitations

We identify multiple limitations. First, when applied to out of distribution data, the model tends to slowly lose context and generates next states that resemble the training data, a phenomena that was observed in image generation and is known as mode collapse ([70, 71]). We include such an example in Figure 9. Second, while the model can plan, it struggles with simulating temporal dynamics like pedestrian motion (although in some cases it does). Both limitations are likely to be solved with longer context and more training data. Additionally, the model currently utilizes 333 DoF navigation actions, but extending to 666 DoF navigation and potentially more (like controlling the joints of a robotic arm) are possible as well, which we leave for future work.
6. Discussion
Our proposed Navigation World Model (NWM) offers a scalable, data-driven approach to learning world models for visual navigation; However, we are not exactly sure yet what representations enable this, as our NWM does not explicitly utilize a structured map of the environment. One idea, is that next frame prediction from an egocentric point of view can drive the emergence of allocentric representations [72]. Ultimately, our approach bridges learning from video, visual navigation, and model-based planning and could potentially open the door to self-supervised systems that not only perceive but can also plan to inform action.
Acknowledgments. We thank Noriaki Hirose for his help with the HuRoN dataset and for sharing his insights, and to Manan Tomar, David Fan, Sonia Joseph, Angjoo Kanazawa, Ethan Weber, Nicolas Ballas, and the anonymous reviewers for their helpful discussions and feedback.
Navigation World Models
Supplementary Material
The structure of the Appendix is as follows: we start by describing how we plan navigation trajectories via Standalone Planning in Section 7, and then include more experiments and results in Section 8.
7. Standalone Planning Optimization
As described in Section 3.3, we use a pretrained NWM to standalone-plan goal-conditioned navigation trajectories by optimizing Equation 5. Here, we provide additional details about the optimization using the Cross-Entropy Method ([57]) and the hyperparameters used. Full standalone navigation planning results are presented in Section 8.2.
We optimize trajectories using the Cross-Entropy Method, a gradient-free stochastic optimization technique for continuous optimization problems. This method iteratively updates a probability distribution to improve the likelihood of generating better solutions. In the unconstrained standalone planning scenario, we assume the trajectory is a straight line and optimize only its endpoint, represented by three variables: a single translation uuu and yaw rotation ϕ\phiϕ. We then map this tuple into eight evenly spaced delta steps, applying the yaw rotation at the final step. The time interval between steps is fixed at k=0.25k=0.25k=0.25 seconds. The main steps of our optimization process are as follows:
- Initialization: Define a Gaussian distribution with mean μ=(μΔx,μΔy,μϕ)\mu = (\mu_{\Delta x}, \mu_{\Delta y}, \mu_\phi)μ=(μΔx,μΔy,μϕ) and variance Σ=diag(σΔx2,σΔy2,σϕ2)\Sigma = \mathrm{diag}(\sigma_{\Delta x}^2, \sigma_{\Delta y}^2, \sigma_\phi^2)Σ=diag(σΔx2,σΔy2,σϕ2) over the solution space.
- Sampling: Generate N=120N=120N=120 candidate solutions by sampling from the current Gaussian distribution.
- Evaluation: Evaluate each candidate solution by simulating it using the NWM and measuring the LPIPS score between the simulation output and input goal images. Since NWM is stochastic, we evaluate each candidate solution MMM times and average to obtain a final score.
- Selection: Select a subset of the best-performing solutions based on the LPIPS scores.
- Update: Adjust the parameters of the distribution to increase the probability of generating solutions similar to the top-performing ones. This step minimizes the cross-entropy between the old and updated distributions.
- Iteration: Repeat the sampling, evaluation, selection, and update steps until a stopping criterion (e.g. convergence or iteration limit) is met.
For simplicity, we run the optimization process for a single iteration, which we found effective for short-horizon planning of two seconds, though further improvements are possible with more iterations. When navigation constraints are applied, parts of the trajectory are zeroed out to respect these constraints. For instance, in the "forward-first" scenario, the translation action is u=(Δx,0)u=(\Delta x, 0)u=(Δx,0) for the first five steps and u=(0,Δy)u=(0, \Delta y)u=(0,Δy) for the last three steps.
8. Experiments and Results
8.1 Experimental Study
We elaborate on the metrics and datasets used.
Evaluation Metrics. We describe the evaluation metrics used to assess predicted navigation trajectories and the quality of images generated by our NWM.
For visual navigation performance, Absolute Trajectory Error (ATE) measures the overall accuracy of trajectory estimation by computing the Euclidean distance between corresponding points in the estimated and ground-truth trajectories. Relative Pose Error (RPE) evaluates the consistency of consecutive poses by calculating the error in relative transformations between them ([64]).
To more rigorously assess the semantics in the world model outputs, we use Learned Perceptual Image Patch Similarity (LPIPS) and DreamSim ([56]), which evaluate perceptual similarity by comparing deep features from a neural network ([55]). LPIPS, in particular, uses AlexNet ([73]) to focus on human perception of structural differences. Additionally, we use Peak Signal-to-Noise Ratio (PSNR) to quantify the pixel-level quality of generated images by measuring the ratio of maximum pixel value to error, with higher values indicating better quality.
To study image and video synthesis quality, we use Fréchet Inception Distance (FID) and Fréchet Video Distance (FVD), which compare the feature distributions of real and generated images or videos. Lower FID and FVD scores indicate higher visual quality ([66, 67]).
Datasets. For all robotics datasets, we have access to the location and rotation of the robots, and we use this to infer the actions as the delta in location and rotation. We remove all backward movement which can be jittery following NoMaD ([1]), thereby splitting the data to forward walking segments for SCAND ([59]), TartanDrive ([60]), RECON ([61]), and HuRoN ([62]). We also utilize unlabeled Ego4D videos, where we only use time shift as action. Next, we describe each individual dataset.
- SCAND ([59]) is a robotics dataset consisting of socially compliant navigation demonstrations using a wheeled Clearpath Jackal and a legged Boston Dynamics Spot. SCAND has demonstrations in both indoor and outdoor settings at UT Austin. The dataset consists of 8.78.78.7 hours, 138138138 trajectories, 252525 miles of data and we use the corresponding camera poses. We use 484484484 video segments for training and 121121121 video segments for testing. Used for training and evaluation.
- TartanDrive ([60]) is an outdoor off-roading driving dataset collected using a modified Yamaha Viking ATV in Pittsburgh. The dataset consists of 555 hours and 630630630 trajectories. We use 1,0001, 0001,000 video segments for training and 251251251 video segments for testing.
- RECON ([61]) is an outdoor robotics dataset collected using a Clearpath Jackal UGV platform. The dataset consists of 404040 hours across 999 open-world environments. We use 9,4689, 4689,468 video segments for training and 2,3672, 3672,367 video segments for testing. Used for training and evaluation.
- HuRoN ([62]) is a robotics dataset consisting of social interactions using a Robot Roomba in indoor settings collected at UC Berkeley. The dataset consists of over 757575 hours in 555 different environments with 4,0004, 0004,000 human interactions. We use 2,4512, 4512,451 video segments for training and 613613613 video segments for testing. Used for training and evaluation.
- GO Stanford ([9, 74]), a robotics datasets capturing the fisheye video footage of two different teleoperated robots, collected at at least 272727 different Stanford building with around 252525 hours of video footage. Due to the low resolution images, we only use it for out of domain evaluation.
- Ego4D ([63]) is a large-scale egocentric dataset consisting of 3,6703, 6703,670 hours across 747474 locations. Ego4D consists a variety of scenarios such as Arts &\&& Crafts, Cooking, Construction, Cleaning &\&& Laundry, and Grocery Shopping. We use only use videos which involve visual navigation such as Grocery Shopping and Jogging. We use a total 161916191619 videos of over 908908908 hours for training only. Only used for unlabeled training unlabeled training. The videos we use are from the following Ego4D scenarios: "Skateboard/scooter", "Roller skating", "Football", "Attending a festival or fair", "Gardener", "Mini golf", "Riding motorcycle", "Golfing", "Cycling/jogging", "Walking on street", "Walking the dog/pet", "Indoor Navigation (walking)", "Working in outdoor store", "Clothes/other shopping", "Playing with pets", "Grocery shopping indoors", "Working out outside", "Farmer", "Bike", "Flower Picking", "Attending sporting events (watching and participating)", "Drone flying", "Attending a lecture/class", "Hiking", "Basketball", "Gardening", "Snow sledding", "Going to the park".
Visual Navigation Evaluation Set. Our main finding when constructing visual navigation evaluation sets is that forward motion is highly prevalent, and if not carefully accounted for, it can dominate the evaluation data. To create diverse evaluation sets, we rank potential evaluation trajectories based on how well they can be predicted by simply moving forward. For each dataset, we select the 100100100 examples that are least predictable by this heuristic and use them for evaluation.
Time Prediction Evaluation Set. Predicting the future frame after kkk seconds is more challenging than estimating a trajectory, as it requires both predicting the agent's trajectory and its orientation in pixel space. Therefore, we do not impose additional diversity constraints. For each dataset, we randomly select 500500500 test prediction examples.
8.2 Experiments and Results
Training on Additional Unlabeled Data. We include results for additional known environments in Table 6 and Figure 10. We find that in known environments, models trained exclusively with in-domain data tend to perform better, likely because they are better tailored to the in-domain distribution. The only exception is the SCAND dataset, where dynamic objects (e.g. humans walking) are present. In this case, adding unlabeled data may help improve performance by providing additional diverse examples.
Known Environments. We include additional visualization results of following trajectories using NWM in the known environments RECON (Figure 11), SCAND (Figure 12), HuRoN (Figure 13), and Tartan Drive (Figure 14). Additionally, we include full FVD comparison of DIAMOND and NWM in Table 7.
Planning (Ranking). Full goal-conditioned navigation results for all in-domain datasets are presented in Table 8. Compared to NoMaD, we observe consistent improvements when using NWM to select from a pool of 161616 trajectories, with further gains when selecting from a larger pool of 323232. For Tartan Drive, we note that the dataset is heavily dominated by forward motion, as reflected in the results compared to the "Forward" baseline, a prediction model that always selects forward-only motion.
Standalone Planning. For standalone planning, we run the optimization procedure outlined in Section 7 for 111 step, and evaluate each trajectories for 3 times. For all datasets, we initialize μΔy\mu_{\Delta y}μΔy and μϕ\mu_\phiμϕ to be 0, and σΔy2\sigma_{\Delta y}^2σΔy2 and σϕ2\sigma_\phi^2σϕ2 to be 0.1. We use different (μΔx,σΔx2)(\mu_{\Delta x}, \sigma_{\Delta x}^2)(μΔx,σΔx2) across each dataset: (−0.1,0.02)(-0.1, 0.02)(−0.1,0.02) for RECON, (0.5,0.07)(0.5, 0.07)(0.5,0.07) for TartanDrive, (−0.25,0.04)(-0.25, 0.04)(−0.25,0.04) for SCAND, and (−0.33,0.03)(-0.33, 0.03)(−0.33,0.03) for HuRoN. We include the full standalone navigation planning results in Table 8. We find that using planning in the stand-alone setting performs better compared to other approaches, and specifically previous hard-coded policies.
Real-World Applicability. A key bottleneck in deploying NWM in real-world robotics is inference speed. We evaluate methods to improve NWM efficiency and measure their impact on runtime. We focus on using NWM with a generative policy (Section 3.3) to rank 323232 four-second trajectories. Since trajectory evaluation is parallelizable, we analyze the runtime of simulating a single trajectory. We find that existing solutions can already enable real-time applications of NWM at 2-10HZ (Table 9).
Inference time can be accelerated by composing every adjacent pair of actions (via Equation 2) then simulating only 888 future states instead of 161616 ("Time Skip"), which does not degrade navigation performance. Reducing the diffusion denoising steps from 250250250 to 666 by model distillation [76] further speeds up inference with minor visual quality loss.3 Taken together, these two ideas can enable NWM to run in real time. Quantization to 4-bit, which we haven't explored, can lead to a ×4\times4×4 speedup without performance hit [75].
Using the distillation implementation for DiTs from https://github.com/hao-ai-lab/FastVideo
Test-time adaptation. Test-time adaptation has shown to improve visual navigation [15, 77]. What is the relation between planning using a world model and test-time adaptation? We hypothesize that the two ideas are orthogonal, and include test-time adaptation results. We consider a simplified adaptation approach by fine-tuning NWM for 222 k steps on trajectories from an unknown environment. We show that this adaptation improves trajectory simulation in this environment (see "ours+TTA" in Table 10), where we also include additional baselines and ablations.

💭 Click to ask about this figure

💭 Click to ask about this figure

💭 Click to ask about this figure

💭 Click to ask about this figure

💭 Click to ask about this figure
References
[1] Ajay Sridhar, Dhruv Shah, Catherine Glossop, and Sergey Levine. Nomad: Goal masked diffusion policies for navigation and exploration. In 2024 IEEE International Conference on Robotics and Automation (ICRA), pages 63–70. IEEE, 2024.
[2] Dhruv Shah, Ajay Sridhar, Arjun Bhorkar, Noriaki Hirose, and Sergey Levine. Gnm: A general navigation model to drive any robot. In 2023 IEEE International Conference on Robotics and Automation (ICRA), pages 7226–7233. IEEE, 2023.
[3] Eloi Alonso, Adam Jelley, Vincent Micheli, Anssi Kanervisto, Amos Storkey, Tim Pearce, and François Fleuret. Diffusion for world modeling: Visual details matter in atari. In Thirty-eighth Conference on Neural Information Processing Systems.
[4] Dani Valevski, Yaniv Leviathan, Moab Arar, and Shlomi Fruchter. Diffusion models are real-time game engines. arXiv preprint arXiv:2408.14837, 2024.
[5] Ben Mildenhall, Pratul P Srinivasan, Matthew Tancik, Jonathan T Barron, Ravi Ramamoorthi, and Ren Ng. Nerf: Representing scenes as neural radiance fields for view synthesis. Communications of the ACM, 65(1):99–106, 2021.
[6] Ruoshi Liu, Rundi Wu, Basile Van Hoorick, Pavel Tokmakov, Sergey Zakharov, and Carl Vondrick. Zero-1-to-3: Zero-shot one image to 3d object. In Proceedings of the IEEE/CVF international conference on computer vision, pages 9298–9309, 2023.
[7] Basile Van Hoorick, Rundi Wu, Ege Ozguroglu, Kyle Sargent, Ruoshi Liu, Pavel Tokmakov, Achal Dave, Changxi Zheng, and Carl Vondrick. Generative camera dolly: Extreme monocular dynamic novel view synthesis. 2024.
[8] William Peebles and Saining Xie. Scalable diffusion models with transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 4195–4205, 2023.
[9] Noriaki Hirose, Amir Sadeghian, Marynel Vázquez, Patrick Goebel, and Silvio Savarese. Gonet: A semi-supervised deep learning approach for traversability estimation. In 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 3044–3051. IEEE, 2018.
[10] Dhruv Shah, Ajay Sridhar, Nitish Dashora, Kyle Stachowicz, Kevin Black, Noriaki Hirose, and Sergey Levine. Vint: A foundation model for visual navigation. In 7th Annual Conference on Robot Learning.
[11] Deepak Pathak, Parsa Mahmoudieh, Guanghao Luo, Pulkit Agrawal, Dian Chen, Yide Shentu, Evan Shelhamer, Jitendra Malik, Alexei A Efros, and Trevor Darrell. Zero-shot visual imitation. In Proceedings of the IEEE conference on computer vision and pattern recognition workshops, pages 2050–2053, 2018.
[12] Piotr Mirowski, Razvan Pascanu, Fabio Viola, Hubert Soyer, Andy Ballard, Andrea Banino, Misha Denil, Ross Goroshin, Laurent Sifre, Koray Kavukcuoglu, et al. Learning to navigate in complex environments. In International Conference on Learning Representations, 2022.
[13] Devendra Singh Chaplot, Dhiraj Gandhi, Saurabh Gupta, Abhinav Gupta, and Ruslan Salakhutdinov. Learning to explore using active neural slam. In International Conference on Learning Representations.
[14] Zipeng Fu, Ashish Kumar, Ananye Agarwal, Haozhi Qi, Jitendra Malik, and Deepak Pathak. Coupling vision and proprioception for navigation of legged robots. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 17273–17283, 2022.
[15] J Frey, M Mattamala, N Chebrolu, C Cadena, M Fallon, and M Hutter. Fast traversability estimation for wild visual navigation. Robotics: Science and Systems Proceedings, 19, 2023.
[16] Tao Chen, Saurabh Gupta, and Abhinav Gupta. Learning exploration policies for navigation. In International Conference on Learning Representations.
[17] David Ha and Jürgen Schmidhuber. World models. arXiv preprint arXiv:1803.10122, 2018.
[18] Danijar Hafner, Timothy P Lillicrap, Mohammad Norouzi, and Jimmy Ba. Mastering atari with discrete world models. In International Conference on Learning Representations, b.
[19] Danijar Hafner, Timothy Lillicrap, Jimmy Ba, and Mohammad Norouzi. Dream to control: Learning behaviors by latent imagination. In International Conference on Learning Representations, a.
[20] Younggyo Seo, Danijar Hafner, Hao Liu, Fangchen Liu, Stephen James, Kimin Lee, and Pieter Abbeel. Masked world models for visual control. In Conference on Robot Learning, pages 1332–1344. PMLR, 2023.
[21] Philipp Wu, Alejandro Escontrela, Danijar Hafner, Pieter Abbeel, and Ken Goldberg. Daydreamer: World models for physical robot learning. In Conference on robot learning, pages 2226–2240. PMLR, 2023.
[22] Nicklas Hansen, Hao Su, and Xiaolong Wang. Td-mpc2: Scalable, robust world models for continuous control. In The Twelfth International Conference on Learning Representations.
[23] Sherry Yang, Yilun Du, Seyed Kamyar Seyed Ghasemipour, Jonathan Tompson, Leslie Pack Kaelbling, Dale Schuurmans, and Pieter Abbeel. Learning interactive real-world simulators. In The Twelfth International Conference on Learning Representations.
[24] Jessy Lin, Yuqing Du, Olivia Watkins, Danijar Hafner, Pieter Abbeel, Dan Klein, and Anca Dragan. Learning to model the world with language, 2024b.
[25] Jake Bruce, Michael D Dennis, Ashley Edwards, Jack Parker-Holder, Yuge Shi, Edward Hughes, Matthew Lai, Aditi Mavalankar, Richie Steigerwald, Chris Apps, et al. Genie: Generative interactive environments. In Forty-first International Conference on Machine Learning, 2024.
[26] Dan Kondratyuk, Lijun Yu, Xiuye Gu, Jose Lezama, Jonathan Huang, Grant Schindler, Rachel Hornung, Vighnesh Birodkar, Jimmy Yan, Ming-Chang Chiu, et al. Videopoet: A large language model for zero-shot video generation. In Forty-first International Conference on Machine Learning.
[27] Andreas Blattmann, Tim Dockhorn, Sumith Kulal, Daniel Mendelevitch, Maciej Kilian, Dominik Lorenz, Yam Levi, Zion English, Vikram Voleti, Adam Letts, et al. Stable video diffusion: Scaling latent video diffusion models to large datasets. arXiv preprint arXiv:2311.15127, 2023.
[28] Rohit Girdhar, Mannat Singh, Andrew Brown, Quentin Duval, Samaneh Azadi, Sai Saketh Rambhatla, Akbar Shah, Xi Yin, Devi Parikh, and Ishan Misra. Emu video: Factorizing text-to-video generation by explicit image conditioning. arXiv preprint arXiv:2311.10709, 2023.
[29] Lijun Yu, Yong Cheng, Kihyuk Sohn, José Lezama, Han Zhang, Huiwen Chang, Alexander G Hauptmann, Ming-Hsuan Yang, Yuan Hao, Irfan Essa, et al. Magvit: Masked generative video transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10459–10469, 2023.
[30] Jonathan Ho, William Chan, Chitwan Saharia, Jay Whang, Ruiqi Gao, Alexey Gritsenko, Diederik P Kingma, Ben Poole, Mohammad Norouzi, David J Fleet, et al. Imagen video: High definition video generation with diffusion models. arXiv preprint arXiv:2210.02303, 2022.
[31] Sergey Tulyakov, Ming-Yu Liu, Xiaodong Yang, and Jan Kautz. Mocogan: Decomposing motion and content for video generation. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 1526–1535, 2018b.
[32] Omer Bar-Tal, Hila Chefer, Omer Tov, Charles Herrmann, Roni Paiss, Shiran Zada, Ariel Ephrat, Junhwa Hur, Guanghui Liu, Amit Raj, et al. Lumiere: A space-time diffusion model for video generation. arXiv preprint arXiv:2401.12945, 2024.
[33] Tim Brooks, Bill Peebles, Connor Holmes, Will DePue, Yufei Guo, Li Jing, David Schnurr, Joe Taylor, Troy Luhman, Eric Luhman, et al. Video generation models as world simulators, 2024.
[34] Adam Polyak, Amit Zohar, Andrew Brown, Andros Tjandra, Animesh Sinha, Ann Lee, Apoorv Vyas, Bowen Shi, Chih-Yao Ma, Ching-Yao Chuang, et al. Movie gen: A cast of media foundation models. arXiv preprint arXiv:2410.13720, 2024.
[35] Sergey Tulyakov, Ming-Yu Liu, Xiaodong Yang, and Jan Kautz. MoCoGAN: Decomposing motion and content for video generation. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 1526–1535, 2018a.
[36] Amir Bar, Roei Herzig, Xiaolong Wang, Anna Rohrbach, Gal Chechik, Trevor Darrell, and Amir Globerson. Compositional video synthesis with action graphs. In International Conference on Machine Learning, pages 662–673. PMLR, 2021.
[37] Alejandro Escontrela, Ademi Adeniji, Wilson Yan, Ajay Jain, Xue Bin Peng, Ken Goldberg, Youngwoon Lee, Danijar Hafner, and Pieter Abbeel. Video prediction models as rewards for reinforcement learning. Advances in Neural Information Processing Systems, 36, 2024.
[38] Manan Tomar, Philippe Hansen-Estruch, Philip Bachman, Alex Lamb, John Langford, Matthew E. Taylor, and Sergey Levine. Video occupancy models, 2024.
[39] Chelsea Finn and Sergey Levine. Deep visual foresight for planning robot motion. In 2017 IEEE International Conference on Robotics and Automation (ICRA), pages 2786–2793. IEEE, 2017.
[40] Junbang Liang, Ruoshi Liu, Ege Ozguroglu, Sruthi Sudhakar, Achal Dave, Pavel Tokmakov, Shuran Song, and Carl Vondrick. Dreamitate: Real-world visuomotor policy learning via video generation, 2024.
[41] Noriaki Hirose, Fei Xia, Roberto Mart'ın-Mart'ın, Amir Sadeghian, and Silvio Savarese. Deep visual mpc-policy learning for navigation. IEEE Robotics and Automation Letters, 4(4):3184–3191, 2019b.
[42] Jing Yu Koh, Honglak Lee, Yinfei Yang, Jason Baldridge, and Peter Anderson. Pathdreamer: A world model for indoor navigation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 14738–14748, 2021.
[43] Jascha Sohl-Dickstein, Eric Weiss, Niru Maheswaranathan, and Surya Ganguli. Deep unsupervised learning using nonequilibrium thermodynamics. In International conference on machine learning, pages 2256–2265. PMLR, 2015.
[44] Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. Advances in neural information processing systems, 33:6840–6851, 2020.
[45] Vikram Voleti, Alexia Jolicoeur-Martineau, and Chris Pal. Mcvd-masked conditional video diffusion for prediction, generation, and interpolation. Advances in neural information processing systems, 35:23371–23385, 2022.
[46] Han Lin, Tushar Nagarajan, Nicolas Ballas, Mido Assran, Mojtaba Komeili, Mohit Bansal, and Koustuv Sinha. Vedit: Latent prediction architecture for procedural video representation learning, 2024a.
[47] Eric R. Chan, Koki Nagano, Matthew A. Chan, Alexander W. Bergman, Jeong Joon Park, Axel Levy, Miika Aittala, Shalini De Mello, Tero Karras, and Gordon Wetzstein. Generative novel view synthesis with 3d-aware diffusion models. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 4217–4229, 2023.
[48] Ben Poole, Ajay Jain, Jonathan T Barron, and Ben Mildenhall. Dreamfusion: Text-to-3d using 2d diffusion. In The Eleventh International Conference on Learning Representations.
[49] Joseph Tung, Gene Chou, Ruojin Cai, Guandao Yang, Kai Zhang, Gordon Wetzstein, Bharath Hariharan, and Noah Snavely. Megascenes: Scene-level view synthesis at scale. In Computer Vision – ECCV 2024, pages 197–214, Cham, 2025. Springer Nature Switzerland.
[50] Manolis Savva, Abhishek Kadian, Oleksandr Maksymets, Yili Zhao, Erik Wijmans, Bhavana Jain, Julian Straub, Jia Liu, Vladlen Koltun, Jitendra Malik, et al. Habitat: A platform for embodied ai research. In Proceedings of the IEEE/CVF international conference on computer vision, pages 9339–9347, 2019.
[51] Jingjing Xu, Xu Sun, Zhiyuan Zhang, Guangxiang Zhao, and Junyang Lin. Understanding and improving layer normalization, 2019.
[52] Jimmy Lei Ba, Jamie Ryan Kiros, and Geoffrey E Hinton. Layer normalization. ArXiv e-prints, pages arXiv–1607, 2016.
[53] A Vaswani. Attention is all you need. Advances in Neural Information Processing Systems, 2017.
[54] Alexander Quinn Nichol and Prafulla Dhariwal. Improved denoising diffusion probabilistic models. In Proceedings of the 38th International Conference on Machine Learning, pages 8162–8171. PMLR, 2021.
[55] Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang. The unreasonable effectiveness of deep features as a perceptual metric. In CVPR, 2018a.
[56] Stephanie Fu, Netanel Tamir, Shobhita Sundaram, Lucy Chai, Richard Zhang, Tali Dekel, and Phillip Isola. Dreamsim: Learning new dimensions of human visual similarity using synthetic data. Advances in Neural Information Processing Systems, 36, 2024.
[57] Reuven Y Rubinstein. Optimization of computer simulation models with rare events. European Journal of Operational Research, 99(1):89–112, 1997.
[58] Gaoyue Zhou, Hengkai Pan, Yann LeCun, and Lerrel Pinto. Dino-wm: World models on pre-trained visual features enable zero-shot planning, 2024.
[59] Haresh Karnan, Anirudh Nair, Xuesu Xiao, Garrett Warnell, Sören Pirk, Alexander Toshev, Justin Hart, Joydeep Biswas, and Peter Stone. Socially compliant navigation dataset (scand): A large-scale dataset of demonstrations for social navigation. IEEE Robotics and Automation Letters, 7(4):11807–11814, 2022.
[60] Samuel Triest, Matthew Sivaprakasam, Sean J Wang, Wenshan Wang, Aaron M Johnson, and Sebastian Scherer. Tartandrive: A large-scale dataset for learning off-road dynamics models. In 2022 International Conference on Robotics and Automation (ICRA), pages 2546–2552. IEEE, 2022.
[61] Dhruv Shah, Benjamin Eysenbach, Gregory Kahn, Nicholas Rhinehart, and Sergey Levine. Rapid exploration for open-world navigation with latent goal models. arXiv preprint arXiv:2104.05859, 2021.
[62] Noriaki Hirose, Dhruv Shah, Ajay Sridhar, and Sergey Levine. Sacson: Scalable autonomous control for social navigation. IEEE Robotics and Automation Letters, 2023.
[63] Kristen Grauman, Andrew Westbury, Eugene Byrne, Zachary Chavis, Antonino Furnari, Rohit Girdhar, Jackson Hamburger, Hao Jiang, Miao Liu, Xingyu Liu, et al. Ego4d: Around the world in 3,000 hours of egocentric video. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18995–19012, 2022.
[64] Jürgen Sturm, Wolfram Burgard, and Daniel Cremers. Evaluating egomotion and structure-from-motion approaches using the tum rgb-d benchmark. In Proc. of the Workshop on Color-Depth Camera Fusion in Robotics at the IEEE/RJS International Conference on Intelligent Robot Systems (IROS), page 6, 2012.
[65] Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang. The unreasonable effectiveness of deep features as a perceptual metric. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 586–595, 2018b.
[66] Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilibrium. Advances in neural information processing systems, 30, 2017.
[67] Thomas Unterthiner, Sjoerd van Steenkiste, Karol Kurach, Raphaël Marinier, Marcin Michalski, and Sylvain Gelly. Fvd: A new metric for video generation. 2019.
[68] Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U-net: Convolutional networks for biomedical image segmentation. In Medical image computing and computer-assisted intervention–MICCAI 2015: 18th international conference, Munich, Germany, October 5-9, 2015, proceedings, part III 18, pages 234–241. Springer, 2015.
[69] I Loshchilov. Decoupled weight decay regularization. arXiv preprint arXiv:1711.05101, 2017.
[70] Hoang Thanh-Tung and Truyen Tran. Catastrophic forgetting and mode collapse in gans. In 2020 international joint conference on neural networks (ijcnn), pages 1–10. IEEE, 2020.
[71] Akash Srivastava, Lazar Valkov, Chris Russell, Michael U Gutmann, and Charles Sutton. Veegan: Reducing mode collapse in gans using implicit variational learning. Advances in neural information processing systems, 30, 2017.
[72] Benigno Uria, Borja Ibarz, Andrea Banino, Vinicius Zambaldi, Dharshan Kumaran, Demis Hassabis, Caswell Barry, and Charles Blundell. A model of egocentric to allocentric understanding in mammalian brains. bioRxiv, 2022.
[73] Alex Krizhevsky, Ilya Sutskever, and Geoffrey E Hinton. Imagenet classification with deep convolutional neural networks. Advances in neural information processing systems, 25, 2012.
[74] Noriaki Hirose, Amir Sadeghian, Fei Xia, Roberto Mart'ın-Mart'ın, and Silvio Savarese. Vunet: Dynamic scene view synthesis for traversability estimation using an rgb camera. IEEE Robotics and Automation Letters, 2019a.
[75] Elias Frantar, Saleh Ashkboos, Torsten Hoefler, and Dan Alistarh. Gptq: Accurate post-training quantization for generative pre-trained transformers. arXiv preprint arXiv:2210.17323, 2022.
[76] Fu-Yun Wang, Zhaoyang Huang, Alexander Bergman, Dazhong Shen, Peng Gao, Michael Lingelbach, Keqiang Sun, Weikang Bian, Guanglu Song, Yu Liu, et al. Phased consistency models. Advances in Neural Information Processing Systems, 37:83951–84009, 2024.
[77] Junyu Gao, Xuan Yao, and Changsheng Xu. Fast-slow test-time adaptation for online vision-and-language navigation. In Proceedings of the 41st International Conference on Machine Learning, pages 14902–14919. PMLR, 2024.