Executive Summary: Large language models (LLMs) power many AI applications, such as intelligent agents that interact with tools and environments or specialized systems for tasks like financial analysis. These systems often improve by adapting their inputs—called contexts—with instructions, strategies, or evidence, rather than retraining the model's core parameters. However, current methods face key challenges: they tend to favor short summaries that omit vital details, a problem known as brevity bias, and they can lose important information over repeated updates, leading to context collapse. This matters now because AI systems are scaling to handle complex, real-world tasks where retaining domain-specific knowledge is crucial for reliability, especially as long-context models become more practical for deployment.
This document introduces Agentic Context Engineering (ACE), a framework designed to build and evolve contexts as detailed, structured playbooks that grow over time without losing key insights. ACE aims to enable self-improving LLMs in agent-based and domain-specific applications by accumulating strategies from experience while avoiding the pitfalls of existing approaches.
The authors developed ACE through a modular process involving three roles: a generator that creates reasoning steps for tasks, a reflector that analyzes successes and failures to extract lessons, and a curator that adds these lessons as small, targeted updates to the context. They tested it on benchmarks like AppWorld, which simulates agent interactions with apps and APIs, and finance tasks involving document analysis and calculations. Evaluations used open-source LLMs like DeepSeek-V3.1 over training and test data splits, focusing on offline (pre-task optimization) and online (real-time adaptation) scenarios. No ground-truth labels were always needed; instead, the system relied on natural feedback like execution outcomes. Key assumptions included access to reliable signals from task runs and a context window up to 128,000 tokens.
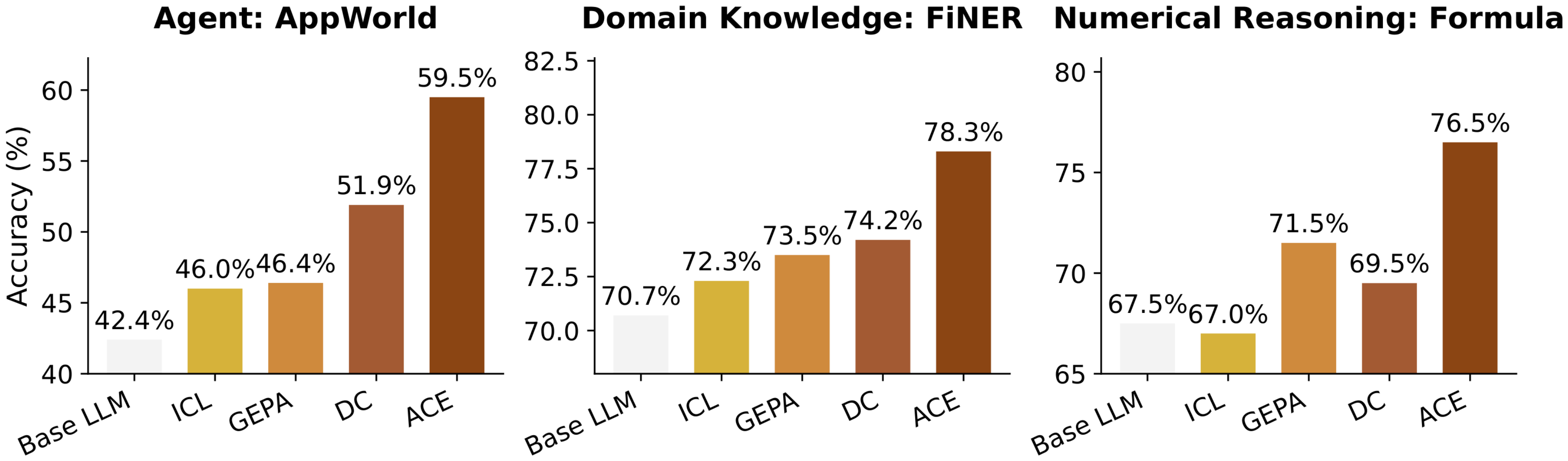
The main findings highlight ACE's effectiveness. First, on agent tasks in AppWorld, ACE improved accuracy by 10.6% on average over baselines like in-context learning and prompt optimizers, reaching 59.4% overall—matching the top production agent on the leaderboard despite using a smaller model. Second, in finance benchmarks, it boosted performance by 8.6%, excelling at tasks requiring precise entity recognition and numerical reasoning by building rich playbooks of rules and heuristics. Third, ACE worked well without labeled data, gaining 14.8% in unsupervised agent settings by drawing on execution feedback. Fourth, it reduced adaptation time by up to 87% and token costs by 75–84% compared to rivals, thanks to incremental updates that avoid full rewrites. Fifth, ablation tests confirmed that features like the reflector and multi-pass refinement each added 5–12% gains, and ACE generalized across different LLMs.
These results show that treating contexts as evolving playbooks unlocks more reliable AI performance without heavy compute, differing from prior methods that compress information and risk errors in complex scenarios. For agents, this means better handling of multi-step interactions, reducing risks like hallucination or tool misuse, while in domains like finance, it enhances compliance and accuracy by preserving specialized knowledge. Overall, ACE lowers costs for self-improvement, making it feasible to deploy adaptable systems that evolve with use, potentially shortening development timelines and improving outcomes in high-stakes applications.
Leaders should prioritize adopting ACE for agentic systems and knowledge-intensive tools, starting with offline optimization on training data to build initial playbooks, then enabling online adaptation for real-time refinement. For options, pair it with strong LLMs for the reflector role to maximize gains, or use lighter models for cost-sensitive setups, trading some performance for efficiency. Further work is needed in pilots to integrate ACE with existing pipelines and gather more data on noisy environments.
Confidence in these findings is high for agent and finance tasks, based on consistent results across models and settings, but readers should note limitations: ACE depends on quality feedback signals, so it may underperform without them, such as in label-scarce domains, and it suits complex tasks over simple ones. Additional analysis on edge cases like adversarial inputs would strengthen deployment decisions.
Agentic Context Engineering: Evolving Contexts for Self-Improving Language Models
Qizheng Zhang$^{1*}$, Changran Hu$^{2*}$, Shubhangi Upasani$^2$, Boyuan Ma$^2$, Fenglu Hong$^2$, Vamsidhar Kamanuru$^2$, Jay Rainton$^2$, Chen Wu$^2$, Mengmeng Ji$^2$, Hanchen Li$^3$, Urmish Thakker$^2$, James Zou$^1$, Kunle Olukotun$^1$
$^1$Stanford University $^2$SambaNova Systems, Inc. $^3$UC Berkeley
[email protected], [email protected], [email protected]
GitHub ace-agent/ace 🌐 ace-agent.github.io
$^{*}$Equal contribution.
#### Abstract
Large language model (LLM) applications such as agents and domain-specific reasoning increasingly rely on context adaptation: modifying inputs with instructions, strategies, or evidence, rather than weight updates. Prior approaches improve usability but often suffer from brevity bias, which drops domain insights for concise summaries, and from context collapse, where iterative rewriting erodes details over time. We introduce ACE (Agentic Context Engineering), a framework that treats contexts as evolving playbooks that accumulate, refine, and organize strategies through a modular process of generation, reflection, and curation. ACE prevents collapse with structured, incremental updates that preserve detailed knowledge and scale with long-context models. Across agent and domain-specific benchmarks, ACE optimizes contexts both offline (*e.g., * system prompts) and online (*e.g., * agent memory), consistently outperforming strong baselines: +10.6% on agents and +8.6% on finance, while significantly reducing adaptation latency and rollout cost. Notably, ACE could adapt effectively without labeled supervision and instead by leveraging natural execution feedback. On the AppWorld leaderboard, ACE matches the top-ranked production-level agent on the overall average and surpasses it on the harder test-challenge split, despite using a smaller open-source model. These results show that comprehensive, evolving contexts enable scalable, efficient, and self-improving LLM systems with low overhead.
1. Introduction
Section Summary: Modern AI systems powered by large language models increasingly use context adaptation, which enhances performance by adding detailed instructions, reasoning steps, or specialized data directly to the model's inputs rather than altering its core training. However, current methods often suffer from brevity bias, which strips away essential details, and context collapse, where instructions gradually shorten and lose value over time, limiting effectiveness in complex tasks like interactive agents or financial analysis. To counter this, the authors propose ACE, a framework that builds evolving, comprehensive "playbooks" of knowledge through a process of generation, reflection, and refinement, achieving significant performance gains over baselines in agent and domain-specific applications without needing labeled data and using fewer resources.
Modern AI applications based on large language models (LLMs), such as LLM agents ([1, 2]) and compound AI systems ([3]), increasingly depend on context adaptation. Instead of modifying model weights, context adaptation improves performance after model training by incorporating clarified instructions, structured reasoning steps, or domain-specific input formats directly into the model's inputs. Contexts underpin many AI system components, including system prompts that guide downstream tasks ([4, 5]), memory that carries past facts and experiences ([6, 7]), and factual evidence that reduces hallucination and supplements knowledge ([8]).
Adapting through contexts rather than weights offers several key advantages. Contexts are interpretable and explainable for users and developers ([9, 10]), allow rapid integration of new knowledge at runtime ([11, 12]), and can be shared across models or modules in a compound system ([13]). Meanwhile, advances in long-context LLMs ([14]) and context-efficient inference such as KV cache reuse ([15, 16]) are making context-based approaches increasingly practical for deployment. As a result, context adaptation is emerging as a central paradigm for building capable, scalable, and self-improving AI systems.
Despite this progress, existing approaches to context adaptation face two limitations. First, brevity bias: many prompt optimizers prioritize concise applicable instructions over comprehensive accumulation. For example, GEPA ([5]) highlights brevity as a strength, but such abstraction can omit domain-specific heuristics, tool-use guidelines, or common failure modes that matter in practice ([17]). This objective aligns with validation metrics in some settings, but often fails to capture the detailed strategies required by agents and knowledge-intensive applications. Second, context collapse: methods that rely on monolithic rewriting by an LLM often degrade into shorter, less informative summaries over time, causing sharp performance declines (Figure 2). In domains such as interactive agents ([18, 19, 20]), domain-specific programming ([21, 22, 23, 24]), and financial or legal analysis ([25, 26, 27]), strong performance depends on retaining detailed, task-specific knowledge rather than compressing it away.
As applications like agents and knowledge-intensive reasoning demand greater reliability, recent work has shifted toward saturating contexts with abundant, potentially useful information ([28, 29, 30]), enabled by advances in long-context LLMs ([14, 31]).
We argue that contexts should function not as concise summaries, but as comprehensive, structured playbooks that are detailed, inclusive, and rich with domain insights. Unlike humans, who often benefit from concise generalization, LLMs are more effective when provided with long, detailed contexts and can distill relevance autonomously ([28, 32, 6]). Thus, instead of compressing away domain-specific heuristics and tactics, contexts should preserve them, allowing the model to decide what matters during inference time.
To address these limitations, we introduce $\textsc{ACE}$ (Agentic Context Engineering), a framework for comprehensive context adaptation in both offline settings (*e.g., * system prompt optimization) and online settings (*e.g., * test-time memory adaptation). Rather than compressing contexts into distilled summaries, $\textsc{ACE}$ treats them as evolving playbooks that accumulate and organize strategies over time. By design, $\textsc{ACE}$ incorporates a modular workflow of generation, reflection, and curation, while adding structured, incremental updates guided by a grow-and-refine principle. This design preserves detailed, domain-specific knowledge, prevents context collapse, and yields contexts that remain comprehensive and scalable throughout adaptation.
We evaluate $\textsc{ACE}$ on two categories of LLM applications that most benefit from comprehensive, evolving contexts: (1) agents ([18]), which require multi-turn reasoning, tool use, and environment interaction, where accumulated strategies can be reused across episodes; and (2) domain-specific benchmarks, which demand specialized tactics and knowledge, like financial analysis ([25, 27]). Our key findings are:
- $\textsc{ACE}$ consistently outperforms strong baselines, yielding average gains of 10.6% on agents and 8.6% on domain-specific benchmarks, across both offline and online adaptation settings.
- $\textsc{ACE}$ is able to construct effective contexts without labeled supervision, instead leveraging execution feedback and environment signals, key ingredients for self-improving LLMs and agents.
- On the AppWorld benchmark leaderboard ([33]), $\textsc{ACE}$ surpasses the top-1-ranked production-level agent IBM-CUGA ([34]) (powered by GPT-4.1) while using an open-source model (DeepSeek-V3.1).
- $\textsc{ACE}$ requires significantly fewer rollouts and achieves lower adaptation latency than existing adaptive methods, demonstrating that scalable self-improvement can be achieved with both higher accuracy and lower cost.
2. Background and Motivation
Section Summary: Context adaptation improves the performance of large language models by carefully editing their inputs using natural language feedback, rather than changing the model's core programming, with techniques like Reflexion and GEPA allowing the model to learn from its mistakes and refine prompts over time for better results in tasks like planning or problem-solving. However, these methods often suffer from brevity bias, where prompts shrink into vague, repetitive instructions that lose important details, and context collapse, where lengthy accumulated information gets summarized too aggressively, erasing key insights and causing sudden drops in accuracy, as seen in benchmarks like AppWorld. These issues highlight the need for more robust ways to build and maintain detailed, useful contexts without losing valuable knowledge.
2.1 Context Adaptation
Context adaptation (or context engineering) refers to methods that improve model behavior by constructing or modifying inputs to an LLM, rather than altering its weights. The current state of the art leverages natural language feedback ([35, 36, 5]). In this paradigm, a language model inspects the current context along with signals such as execution traces, reasoning steps, or validation results, and generates natural language feedback on how the context should be revised. This feedback is then incorporated into the context, enabling iterative adaptation. Representative methods include Reflexion ([35]), which reflects on failures to improve agent planning; TextGrad ([36]), which optimizes prompts via gradient-like textual feedback; GEPA ([5]), which refines prompts iteratively based on execution traces and achieves strong performance, even surpassing reinforcement learning approaches in some settings; and Dynamic Cheatsheet ([37]), which constructs an external memory that accumulates strategies and lessons from past successes and failures during inference. These natural language feedback methods represent a major advance, offering flexible and interpretable signals for improving LLM systems beyond weight updates.
2.2 Limitations of Existing Context Adaptation Methods
Brevity Bias
A recurring limitation of context adaptation methods is brevity bias: the tendency of optimization to collapse toward short, generic prompts. Gao et al. ([17]) document this effect in prompt optimization for test generation, where iterative methods repeatedly produced near-identical instructions (*e.g., *, “Create unit tests to ensure methods behave as expected”), sacrificing diversity and omitting domain-specific detail. This convergence not only narrows the search space but also propagates recurring errors across iterations, since optimized prompts often inherit the same faults as their seeds. More broadly, such bias undermines performance in domains that demand detailed, context-rich guidance—such as multi-step agents, program synthesis, or knowledge-intensive reasoning—where success hinges on accumulating rather than compressing task-specific insights.
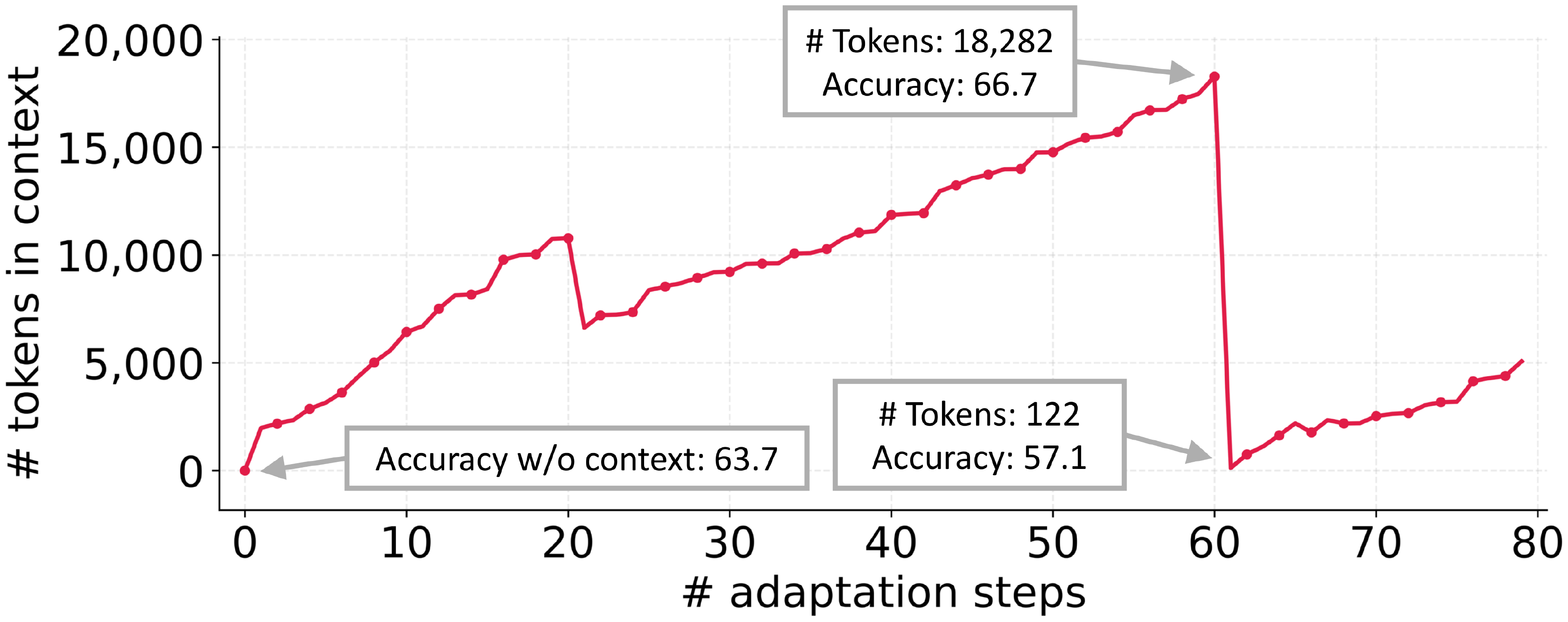
Context Collapse
In a case study on the AppWorld benchmark ([18]), we observe a phenomenon we call context collapse, which arises when an LLM is tasked with fully rewriting the accumulated context at each adaptation step. As the context grows large, the model tends to compress it into much shorter, less informative summaries, causing a dramatic loss of information. For instance, at step 60 the context contained 18, 282 tokens and achieved an accuracy of 66.7, but at the very next step it collapsed to just 122 tokens, with accuracy dropping to 57.1—worse than the baseline accuracy of 63.7 without adaptation. While we highlight this through Dynamic Cheatsheet ([6]), the issue is not specific to that method; rather, it reflects a fundamental risk of end-to-end context rewriting with LLMs, where accumulated knowledge can be abruptly erased instead of preserved.

3. Agentic Context Engineering (ACE)
Section Summary: ACE, or Agentic Context Engineering, is a framework that helps AI systems adapt their instructions and knowledge dynamically, treating them like evolving guides that build up strategies through trial and reflection, much like how people learn from experience. It divides tasks among three specialized parts: a Generator that creates problem-solving steps, a Reflector that pulls out useful lessons from what works or fails, and a Curator that adds these insights as small, targeted updates to the main guide. This approach avoids bulky rewrites by using incremental changes and periodic cleanups to keep things efficient and organized, making it suitable for long-term or complex applications.
We present ACE (Agentic Context Engineering), a framework for scalable and efficient context adaptation in both offline (*e.g., * system prompt optimization) and online (*e.g., * test-time memory adaptation) scenarios. Instead of condensing knowledge into terse summaries or static instructions, ACE treats contexts as evolving playbooks that continuously accumulate, refine, and organize strategies over time. Inspired by the agentic design of Dynamic Cheatsheet ([6]), ACE introduces a structured division of labor across three roles (Figure 4): the Generator, which produces reasoning trajectories; the Reflector, which distills concrete insights from successes and errors; and the Curator, which integrates these insights into structured context updates. This mirrors how humans learn: experimenting, reflecting, and consolidating, while avoiding the bottleneck of overloading a single model with all responsibilities.
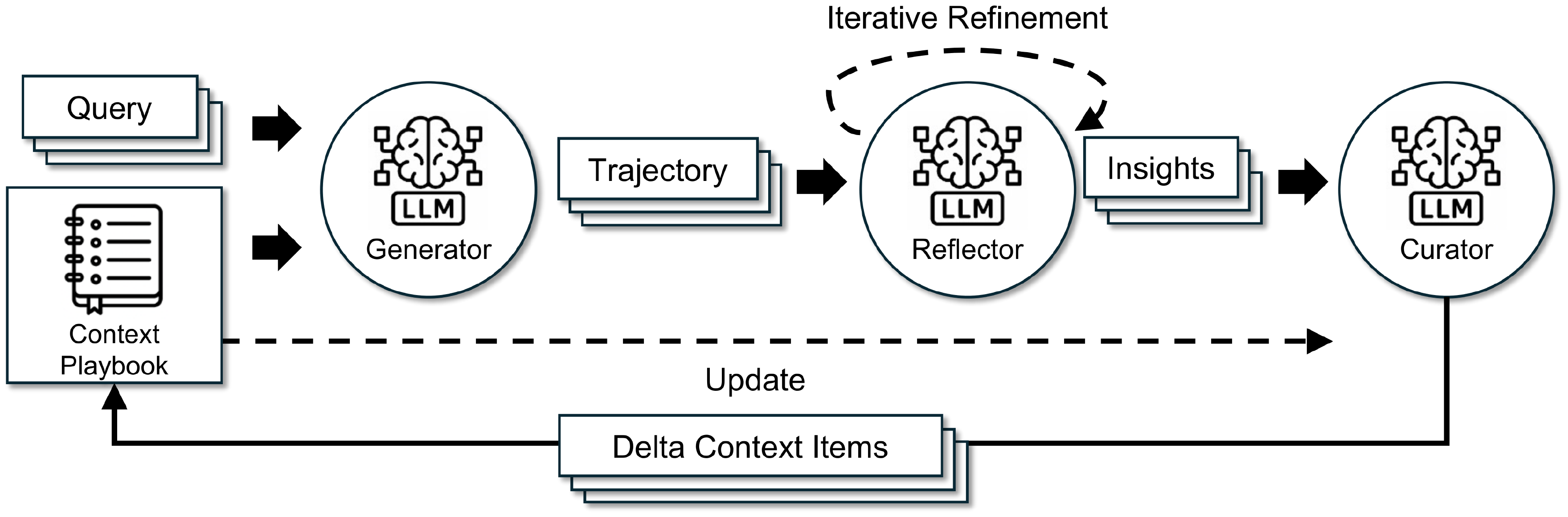
To address the limitations of prior methods discussed in § 2.2 (notably brevity bias and context collapse) ACE introduces three key innovations: (1) a dedicated Reflector that separates evaluation and insight extraction from curation, improving context quality and downstream performance (§ 4.6); (2) incremental delta updates (§ 3.1) that replace costly monolithic rewrites with localized edits, reducing both latency and compute cost (§ 4.7); and (3) a grow-and-refine mechanism (§ 3.2) that balances steady context expansion with redundancy control.
As shown in Figure 4, the workflow begins with the Generator producing reasoning trajectories for new queries, which surface both effective strategies and recurring pitfalls. The Reflector critiques these traces to extract lessons, optionally refining them across multiple iterations. The Curator then synthesizes these lessons into compact delta entries, which are merged deterministically into the existing context by lightweight, non-LLM logic. Because updates are itemized and localized, multiple deltas can be merged in parallel, enabling batched adaptation at scale. ACE further supports multi-epoch adaptation, where the same queries are revisited to progressively strengthen the context.
3.1 Incremental Delta Updates
A core design principle of ACE is to represent context as a collection of structured, itemized bullets, rather than a single monolithic prompt. The concept of a bullet is similar to the concept of a memory entry in LLM memory frameworks like Dynamic Cheatsheet ([6]) and A-MEM ([7]), but builds on top of that and consists of (1) metadata, including a unique identifier and counters tracking how often it was marked helpful or harmful; and (2) content, capturing a small unit such as a reusable strategy, domain concept, or common failure mode. When solving new problems, the Generator highlights which bullets were useful or misleading, providing feedback that guides the Reflector in proposing corrective updates.
This itemized design enables three properties: (1) localization, so only the relevant bullets are updated; (2) fine-grained retrieval, so the Generator can focus on the most pertinent knowledge; and (3) incremental adaptation, allowing efficient merging, pruning, and de-duplication during inference.
Rather than regenerating contexts in full, ACE incrementally produces compact delta contexts: small sets of candidate bullets distilled by the Reflector and integrated by the Curator. This avoids the computational cost and latency of full rewrites, while ensuring that past knowledge is preserved and new insights are steadily appended. As contexts grow, this approach provides the scalability needed for long-horizon or domain-intensive applications.
3.2 Grow-and-Refine
Beyond incremental growth, ACE ensures that contexts remain compact and relevant through periodic or lazy refinement. In grow-and-refine, bullets with new identifiers are appended, while existing bullets are updated in place (*e.g., * incrementing counters). A de-duplication step then prunes redundancy by comparing bullets via semantic embeddings. This refinement can be performed proactively (after each delta) or lazily (only when the context window is exceeded), depending on application requirements for latency and accuracy.
Together, incremental updates and grow-and-refine maintain contexts that expand adaptively, remain interpretable, and avoid the potential variance introduced by monolithic context rewriting.
4. Results
Section Summary: The ACE system demonstrates strong performance in enhancing AI agents and specialized reasoning tasks by dynamically improving their input contexts based on feedback, achieving up to 17.1% higher accuracy on the challenging AppWorld benchmark for agent interactions like email and file management, without relying on labeled data. It also delivers an average 8.6% gain on financial analysis benchmarks by building detailed strategy guides with domain knowledge, with similar benefits shown in medical diagnosis and database querying tasks. Ablation tests confirm that key features like reflection mechanisms and efficient updates drive these results while cutting adaptation time by nearly 87% and reducing overall costs compared to baseline methods such as standard prompting or other optimizers.
Our evaluation of $\textsc{ACE}$ shows that:
- Enabling High-Performance, Self-Improving Agents. ACE enables agents to self-improve by dynamically refining their input context, both in offline and online settings. It boosts accuracy on the AppWorld benchmark by up to 17.1% by learning to engineer better contexts from execution feedback alone, without needing ground-truth labels. (§ 4.3)
- Large Gains on Domain-Specific Benchmarks. On complex financial reasoning benchmarks, ACE delivers an average performance gain of 8.6% over strong baselines by constructing comprehensive playbooks with domain-specific concepts and insights. (§ 4.4)
- Effective by Design. Ablation studies confirm our design choices are key to success, with components like the Reflector, multi-epoch refinement, and incremental delta update each contributing substantial performance gains. (§ 4.6)
- Lower Cost and Adaptation Latency. ACE achieves these gains efficiently, reducing adaptation latency by 86.9% on average, while requiring fewer rollouts and lower token dollar costs. (§ 4.7)
4.1 Tasks and Datasets
We evaluate $\textsc{ACE}$ on two categories of LLM applications that benefit most from evolving contexts: (1) LLM agent, which require multi-turn reasoning, tool use, and environment interaction; with ACE, agents can accumulate and reuse strategies across episodes and environments; and (2) domain-specific reasoning, which demand mastery of specialized concepts and tactics; we focus on financial analysis as a main case study, and show additional results on medical reasoning and text-to-SQL.
- LLM Agent: AppWorld ([18]) is a suite of autonomous agent tasks involving API understanding, code generation, and environment interaction. It provides a realistic execution environment with common applications and APIs (*e.g., * email, file system) and tasks of two difficulty levels (normal and challenge). A public leaderboard ([33]) tracks performance, where, at the time of submission, the best system achieved only 60.3% average accuracy, highlighting the benchmark’s difficulty and realism.
- Domain-Specific Reasoning: Financial, Medical, and Text-to-SQL Benchmarks We use finance as our main case study in § 4.4. For financial analysis, we focus on FiNER ([25]) and Formula ([27]), which test LLMs on financial reasoning tasks that rely on the eXtensible Business Reporting Language (XBRL). FiNER requires labeling tokens in XBRL financial documents with one of 139 fine-grained entity types, a key step for financial information extraction in regulated domains. Formula focuses on applying financial concepts and performing computations to answer queries, *i.e., * numerical reasoning. Beyond finance, we evaluate on two additional domain tasks from StreamBench ([38]): DDXPlus ([39]) (medical reasoning) and BIRD-SQL ([40]) (text-to-SQL).
Evaluation Metrics
For AppWorld, we follow the official benchmark protocol and report Task Goal Completion (TGC) and Scenario Goal Completion (SGC) on both the test-normal and test-challenge splits. For FiNER, Formula and DDXPlus, we follow the original setup and report accuracy, measured as the proportion of predicted answers that exactly match the ground truth. For BIRD-SQL, we use GPT-4o-mini ([41]) under LLM-as-a-judge ([42]).
All datasets follow the original train/validation/test splits. For offline context adaptation, methods are optimized on the training split and evaluated on the test split with pass@1 accuracy. For online context adaptation, methods are evaluated sequentially on the test split: for each sample, the model first predicts with the current context, then updates its context based on that sample. The same shuffled test split is used across all methods.
4.2 Baselines and Methods
Base LLM
The base model is evaluated directly on each benchmark without any context engineering, using the default prompts provided by dataset authors. For AppWorld, we follow the official ReAct ([1]) implementation released by the benchmark authors, and build all other baselines and methods on top of this framework.
In-Context Learning (ICL) ([43])
ICL provides the model with task demonstrations in the input prompt (few-shot or many-shot). This allows the model to infer the task format and desired output without weight updates. We supply all training samples when they fit within the model’s context window; otherwise, we fill the window with as many demonstrations as possible.
MIPROv2 ([4])
MIPROv2 is a popular prompt optimizer for LLM applications that works by jointly optimizing system instructions and in-context demonstrations via bayesian optimization. We use the official DSPy implementation ([44]), setting auto="heavy" to maximize optimization performance.
GEPA ([5])
GEPA (Genetic-Pareto) is a sample-efficient prompt optimizer based on reflective prompt evolution. It collects execution traces (reasoning, tool calls, intermediate outputs) and applies natural-language reflection to diagnose errors, assign credit, and propose prompt updates. A genetic Pareto search maintains a frontier of high-performing prompts, mitigating local optima. Empirically, GEPA outperforms reinforcement learning methods such as GRPO and prompt optimizers like MIPROv2, achieving up to 10–20% higher accuracy with as much as 35× fewer rollouts. We use the official DSPy implementation ([45]), setting auto="heavy" to maximize optimization performance.
Dynamic Cheatsheet (DC) ([6])
DC is a test-time learning approach that introduces an adaptive external memory of reusable strategies and code snippets. By continuously updating this memory with newly encountered inputs and outputs, DC enables models to accumulate knowledge and reuse it across tasks, often leading to substantial improvements over static prompting methods. A key advantage of DC is that it does not require ground-truth labels: the model can curate its own memory from its generations, making the method highly flexible and broadly applicable. We use the official implementation released by the authors ([46]) and set it to use the cumulative mode (DC-CU).
ACE (ours)
ACE optimizes LLM contexts for both offline and online adaptation through an agentic context engineering framework. To ensure fairness, we use the same LLM for the Generator, Reflector, and Curator (non-thinking mode of DeepSeek-V3.1 ([47])), preventing knowledge transfer from a stronger Reflector or Curator to a weaker Generator. This isolates the benefit of context construction itself. We additionally evaluate ACE with other backbone LLMs in the appendix, where we observe consistent gains. We adopt a batch size of 1 (constructing a delta context from each sample). We set the maximum number of Reflector refinement rounds and the maximum number of epoch in offline adaptation to 5.
4.3 Results on Agent Benchmark
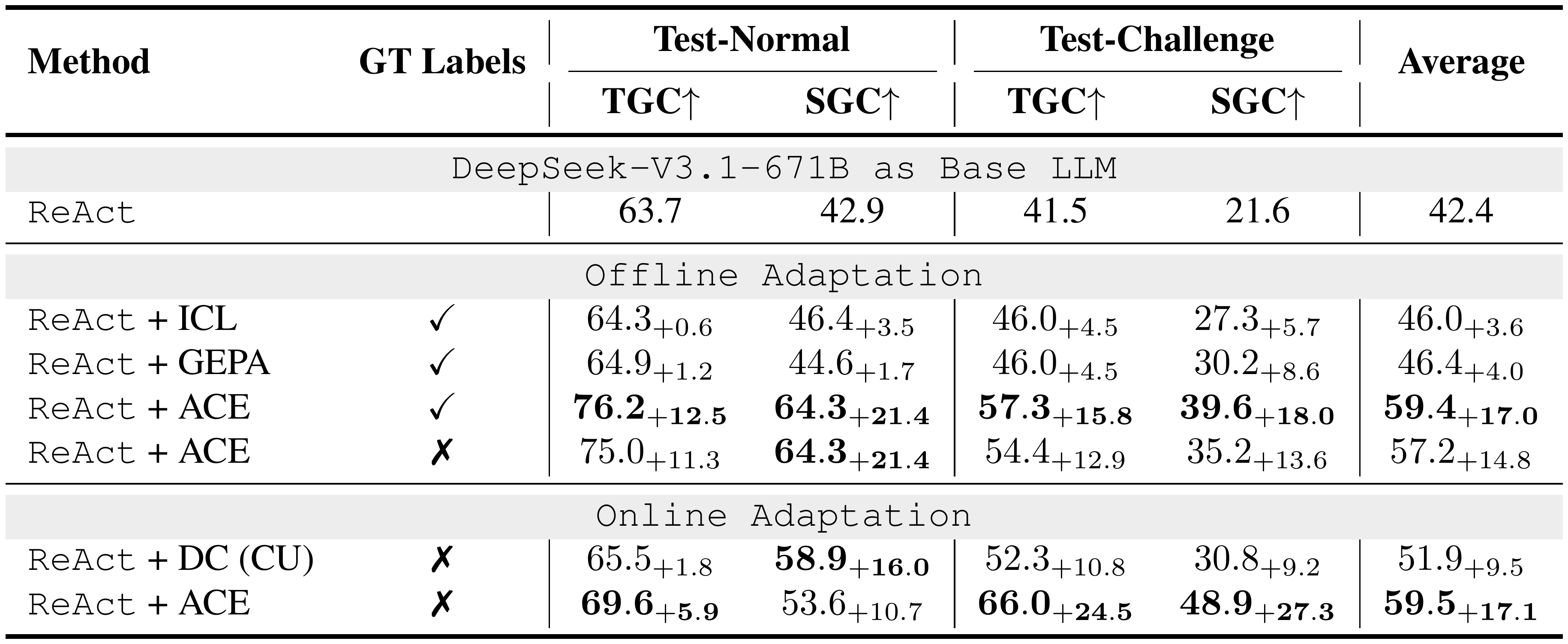
::: {caption="Table 1: Results on the AppWorld Agent Benchmark (DeepSeek-V3.1-671B as the Base LLM). "GT labels" indicates whether ground-truth labels are available to the Reflector during adaptation. We evaluate the ACE framework against multiple baselines on top of the official ReAct implementation, both for offline and online context adaptation. ReAct + ACE outperforms selected baselines by an average of 10.6%, and could achieve good performance even without access to GT labels."}
:::
Analysis: AppWorld
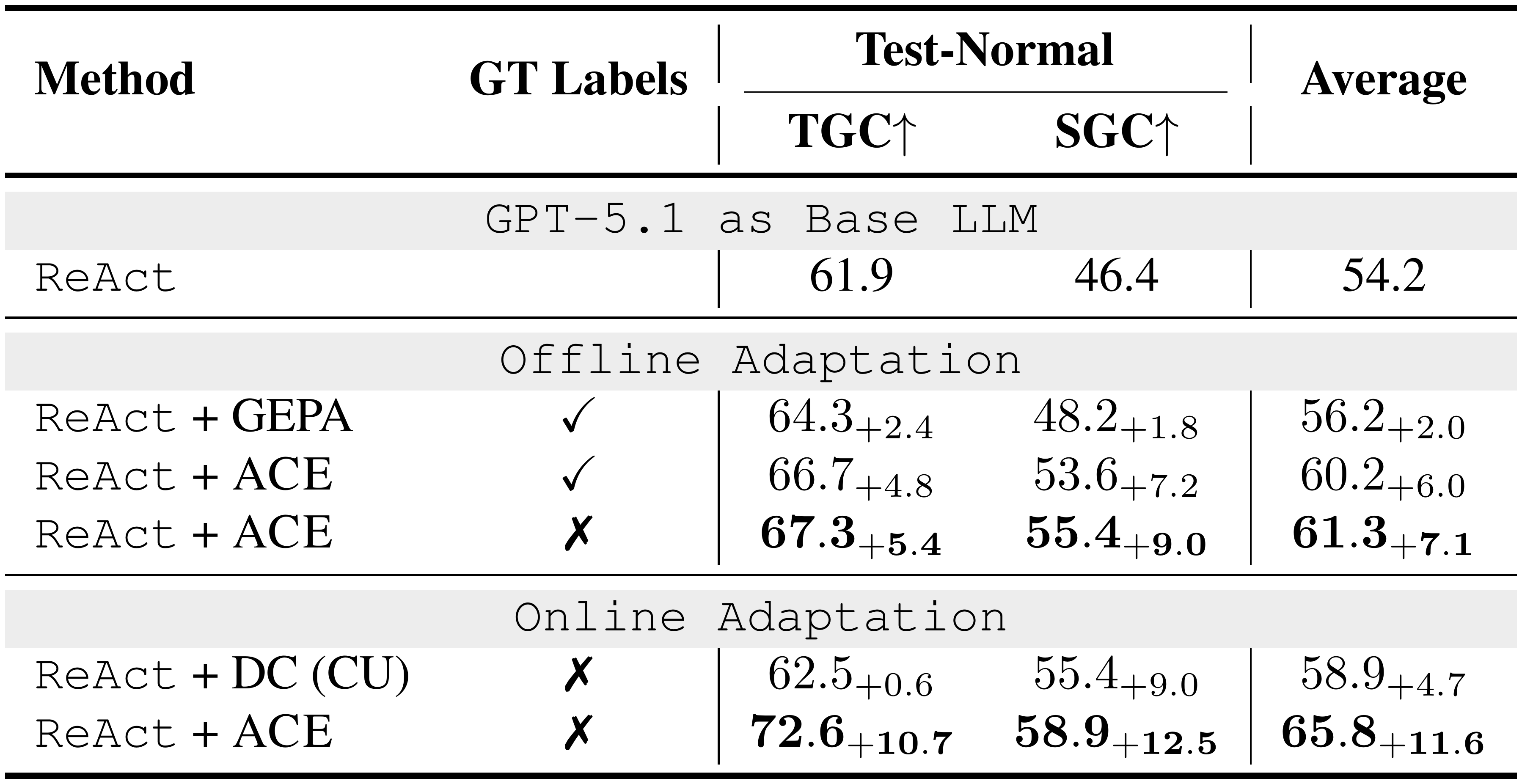
As shown in Table 1, ACE consistently improves over strong baselines on AppWorld. In the offline setting, ReAct + ACE outperforms both ReAct + ICL and ReAct + GEPA by significant margins (12.3% and 11.9%, respectively), demonstrating that structured, evolving, and detailed contexts enable more effective agent learning than fixed demonstrations or single optimized instruction prompts. These gains extend to the online setting, where ACE continues to outperform prior adaptive methods such as Dynamic Cheatsheet by an average of 7.6%.
In the agent use case, ACE remains effective even without access to ground-truth labels during adaptation: ReAct + ACE achieves an average improvement of 14.8% over the ReAct baseline in this setting. This robustness arises because ACE leverages signals naturally available during execution (*e.g., * code execution success or failure) to guide the Reflector and Curator in forming structured lessons of successes and failures. Together, these results establish ACE as a strong and versatile framework for building self-improving agents that adapt reliably both with and without labeled supervision.
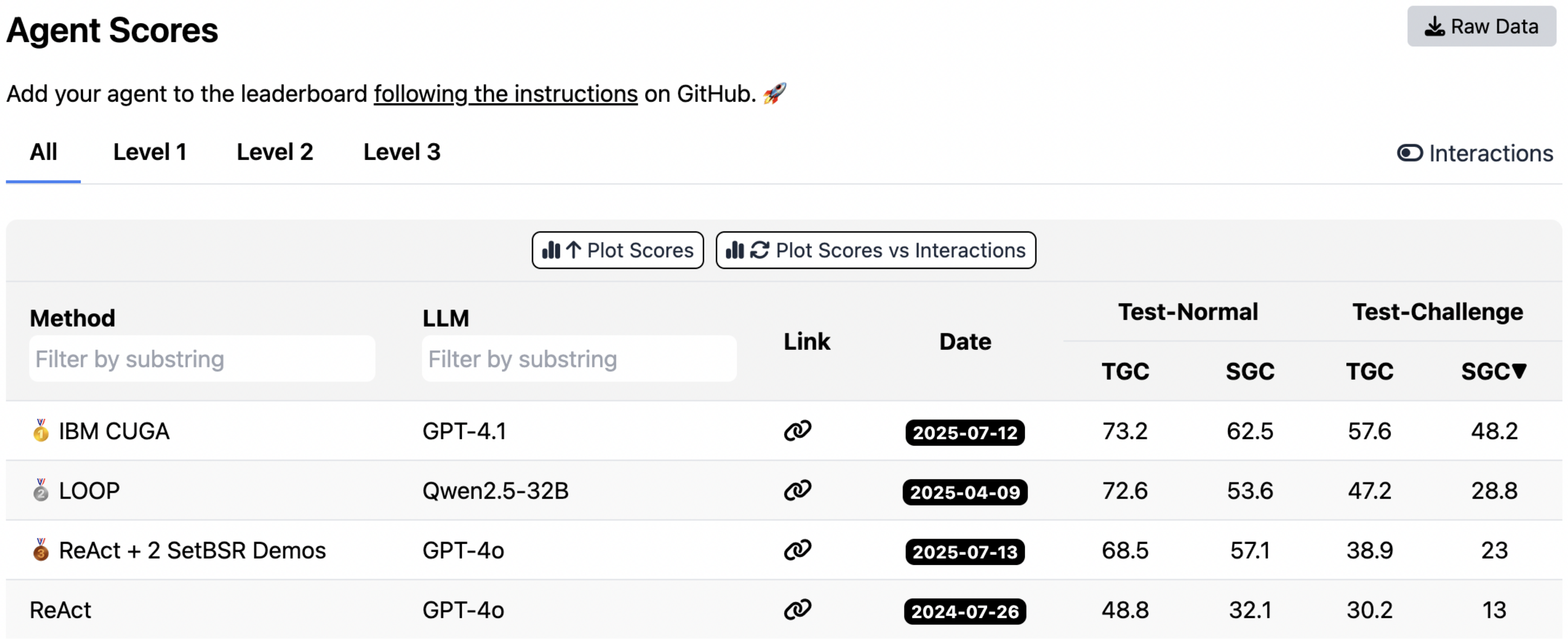
Notably, on the latest AppWorld leaderboard (as of September 20, 2025; Figure 5), ReAct + ACE (59.4% average) matches the top-1-ranked IBM CUGA (60.3%)[^1], a production-level GPT-4.1–based agent ([34]), despite using the much smaller open-source model DeepSeek-V3.1. With online adaptation, ReAct + ACE even surpasses IBM CUGA by 8.4% in TGC and 0.7% in SGC on test-challenge, underscoring the effectiveness of $\textsc{ACE}$ in building comprehensive and self-evolving contexts for agents.
[^1]: We mention IBM CUGA as a rough contextual reference to show that ACE operates in a similar performance range on the AppWorld leaderboard. It is not used as a methodological baseline, and we do not make direct comparisons. CUGA’s internal design differs from ACE’s context-adaptation focus, and all baselines are evaluated under identical setups to isolate methodological effects rather than agent-engineering choices.
4.4 Results on Domain-Specific Benchmark
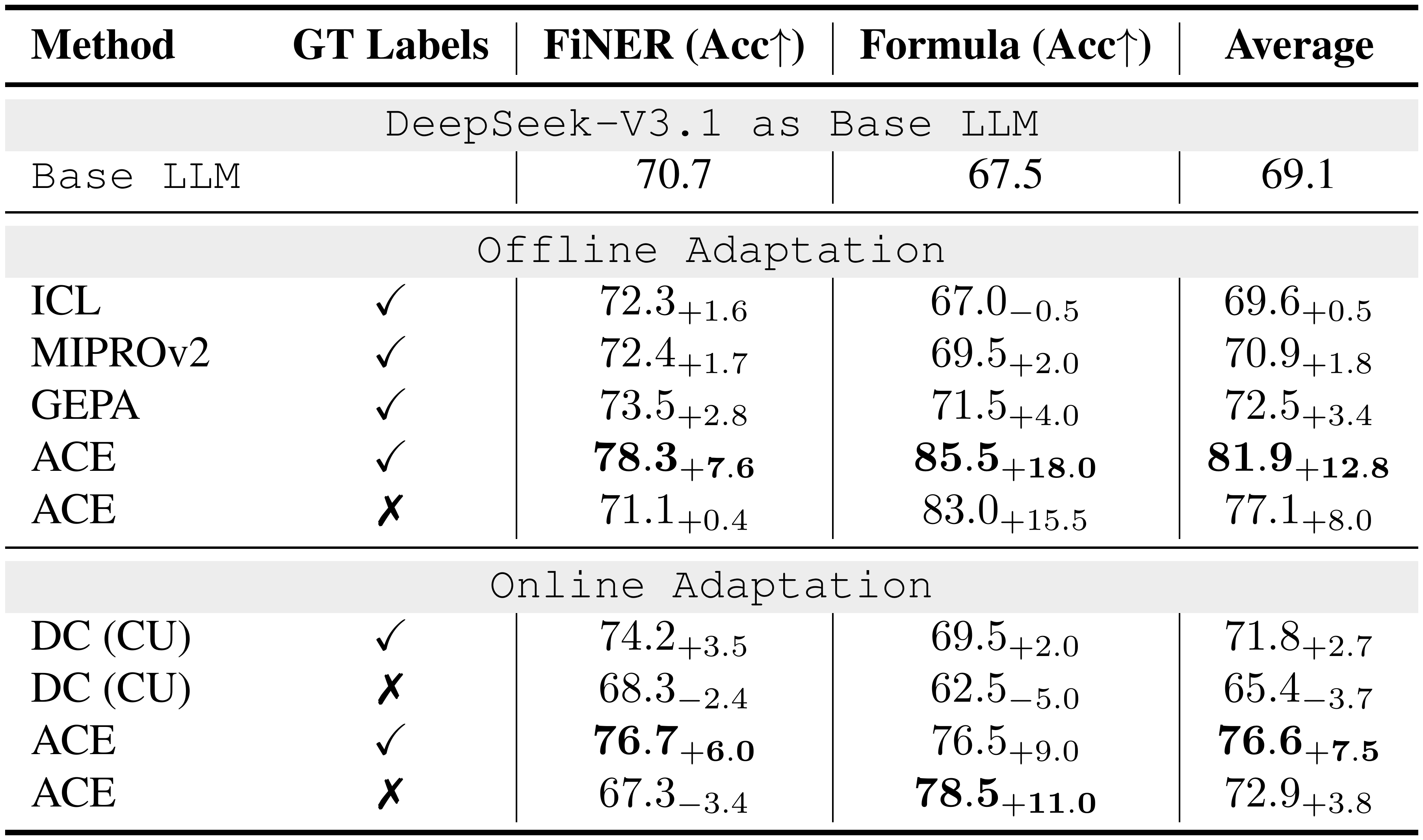
::: {caption="Table 2: Results on Financial Analysis Benchmark (DeepSeek-V3.1-671B as the Base LLM). "GT labels" indicates whether ground-truth labels are available to the Reflector during adaptation. With GT labels, ACE achieves consistent improvements in both offline and online settings, highlighting the advantage of structured and evolving contexts for domain-specific reasoning. However, we also observe that in the absence of reliable feedback signals (*e.g., * ground-truth labels or execution outcomes), both ACE and other adaptive methods such as Dynamic Cheatsheet may degrade, suggesting that context adaptation depends critically on feedback quality."}
:::
Analysis: Finance Benchmark
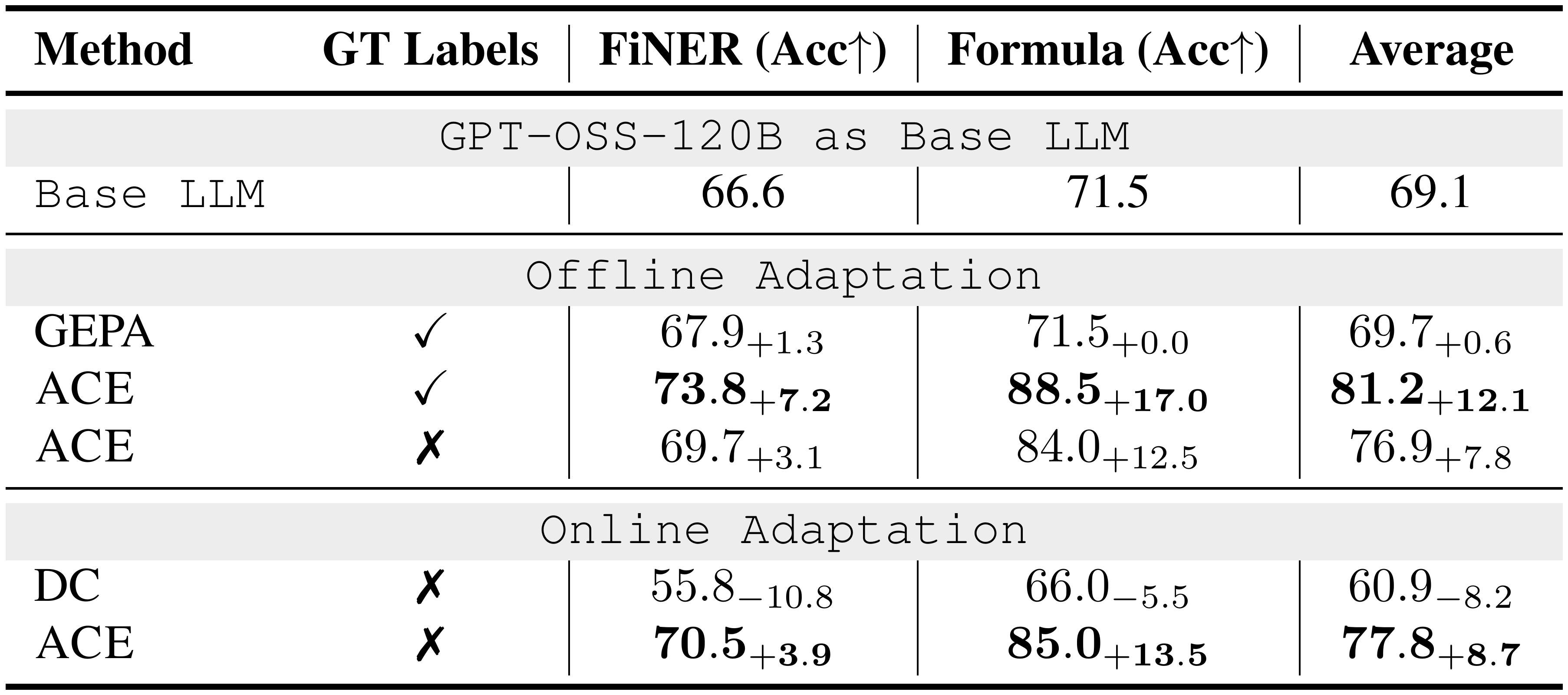
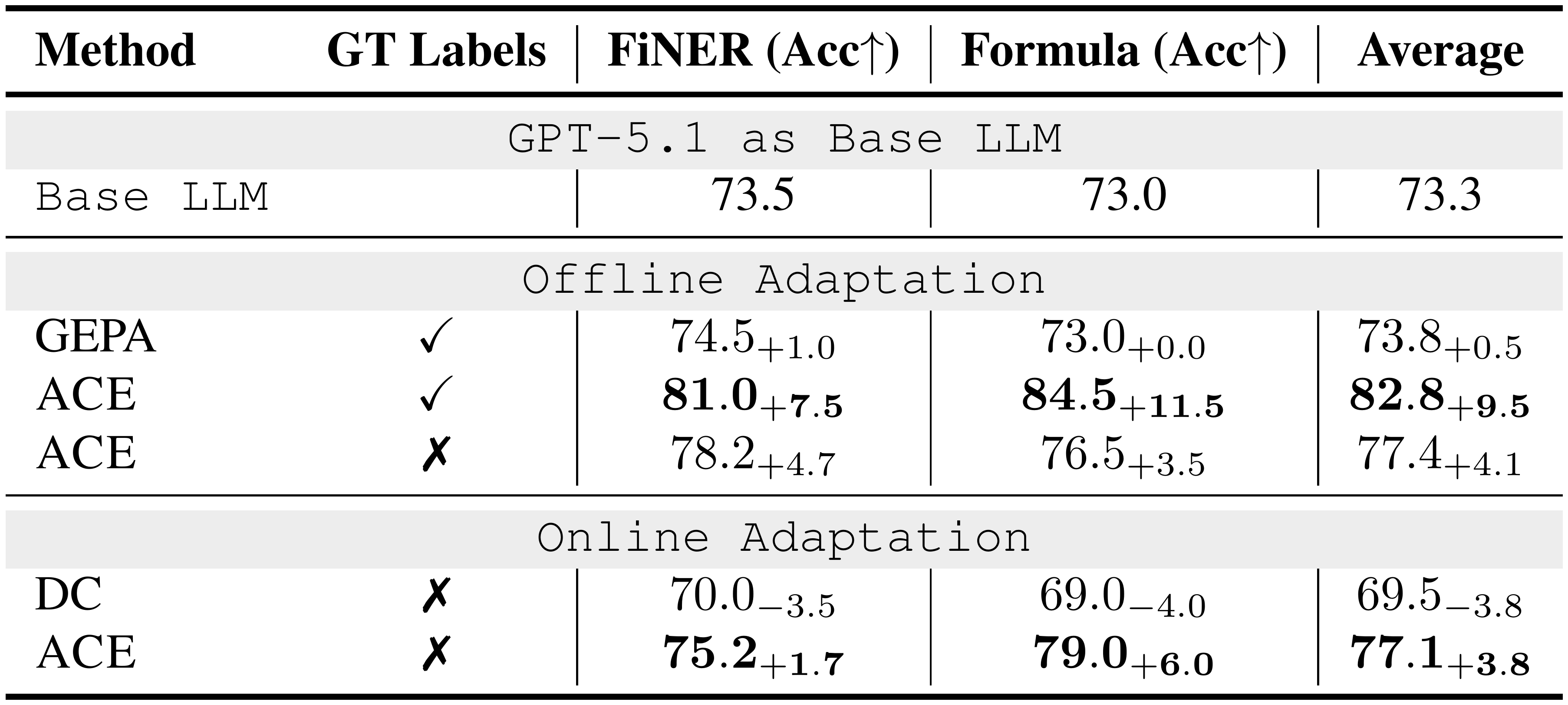
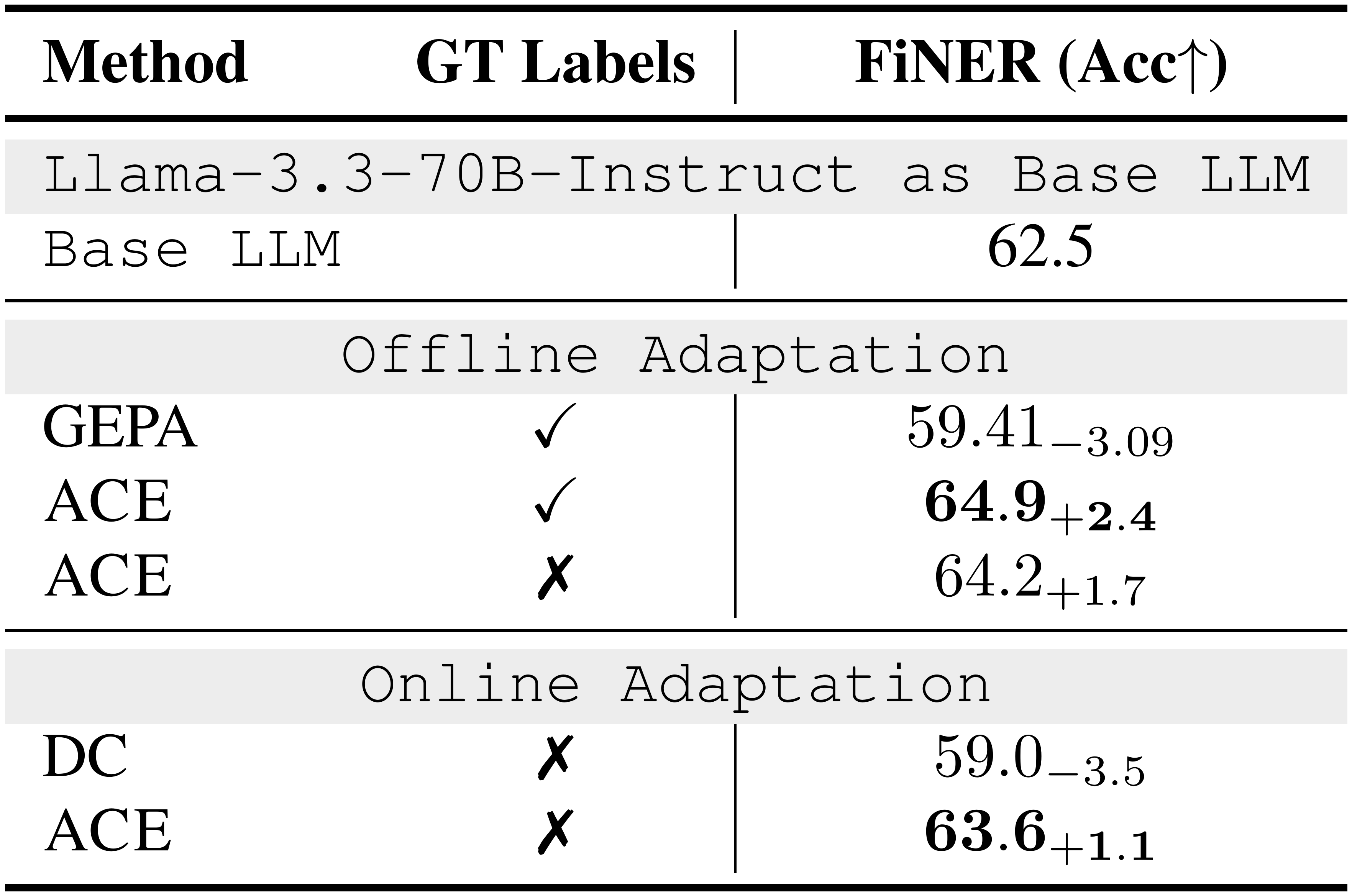
As shown in Table 2, ACE delivers strong improvements on financial analysis benchmarks. In the offline setting, when provided with ground-truth answers from the training split, ACE surpasses ICL, MIPROv2, and GEPA by clear margins (an average of 10.9%), showing that structured and evolving contexts are particularly effective when tasks require precise domain knowledge (*e.g., * financial concepts, XBRL rules) that goes beyond fixed demonstrations or monolithic optimized prompts. In the online setting, ACE continues to exceed prior adaptive methods such as DC by an average of 6.2%, further confirming the benefit of agentic context engineering for accumulating reusable insights across specialized domains.
Moreover, we also observe that when ground-truth supervision or reliable execution signals are absent, both ACE and DC may degrade in performance. In such cases, the constructed context can be polluted by spurious or misleading signals, highlighting a potential limitation of inference-time adaptation without reliable feedback. This suggests that while ACE is robust under rich feedback (*e.g., * code execution results or formula correctness in agent tasks), its effectiveness depends on the availability of signals that allow the Reflector and Curator to make sound judgments. We return to this limitation in § 5.
Analysis: Medical and Text-to-SQL Benchmark
While this subsection focuses on finance as a detailed case study, ACE is not finance-specific: we also see consistent gains on other domain-specific tasks, including medical reasoning and text-to-SQL, suggesting that the same playbook-style context adaptation transfers across domains. Full results are reported in Appendix § A.2.
4.5 Generalization across LLMs
Table 1 and Table 2 use our default backbone (DeepSeek-V3.1), but ACE is not specific to this model. We can swap in other LLMs without changing the algorithm or prompts, and still see consistent gains on AppWorld and Finance benchmarks. Appendix § A.1 reports full results on GPT-OSS-120B, GPT-5.1, and Llama-3.3-70B-Instruct, where ACE improves over the corresponding base agents or models. These results suggest ACE is a generalizable method for test-time context evolution across LLM families.
4.6 Ablation Study and Sensitivity Analysis
Ablation Study
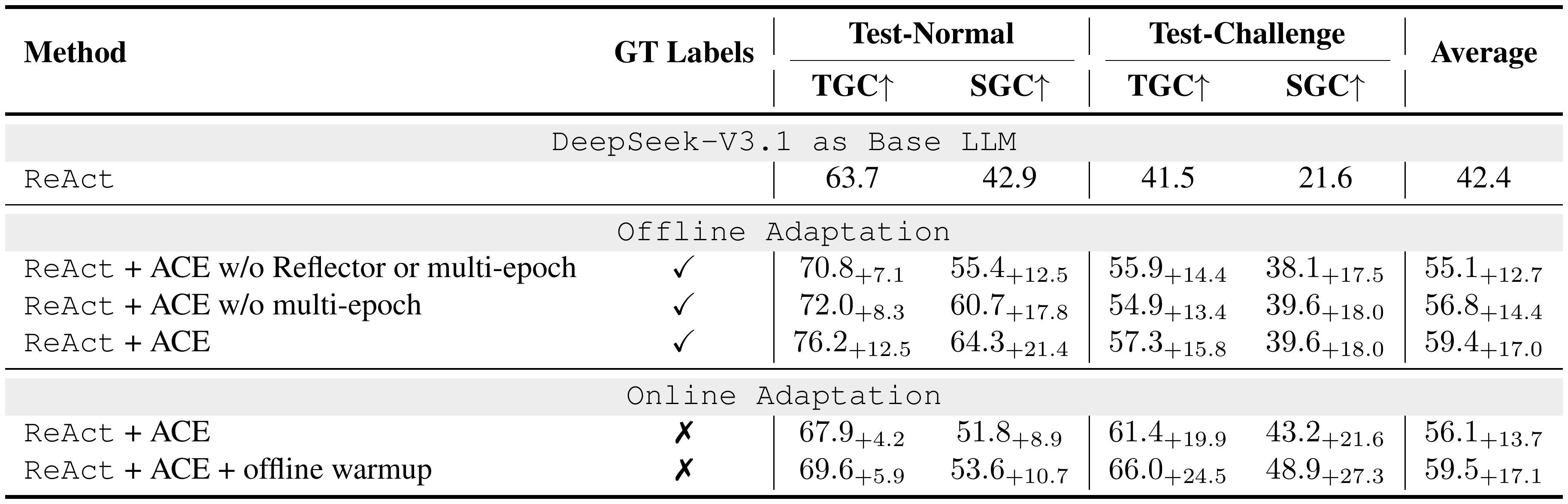
Table 3 reports ablation studies on AppWorld, analyzing how individual design choices of $\textsc{ACE}$ contribute to effective context adaptation. We examine three factors: (1) the Reflector with iterative refinement, our addition to the agentic framework beyond Dynamic Cheatsheet, (2) multi-epoch adaptation, which refines contexts over training samples multiple times, and (3) offline warmup, which initializes the context through offline adaptation before online adaptation begins. Additionally, we study the effect of incremental context update and why it is a key enabler for ACE's performance gain in Appendix § A.5.
::: {caption="Table 3: Ablation Studies on AppWorld. We study how particular design choices of $\textsc{ACE}$ (iterative refinement, multi-epoch adaptation, and offline warmup) could help high-quality context adaptation."}
:::
Robustness to Reflection Quality
$\textsc{ACE}$ is robust to reflection quality: it remains effective with a much weaker Reflector and shows only modest additional gains from stronger reflectors, and it degrades gracefully under noisy/harmful reflections, staying above the base model except under fully adversarial updates every iteration. Full experiment results are in Appendix § A.4.
Sensitivity to Hyperparameter Choice
$\textsc{ACE}$ 's gains are stable across a wide range of reasonable hyperparameter settings (*e.g., * Reflector refinement rounds, number of adaptation epochs, and grow-and-refine thresholds): performance changes are modest, and ACE consistently remains above the corresponding baselines. Full discussion and detailed results are reported in Appendix § A.6.
4.7 Cost and Speed Analysis
Due to its support for incremental, "delta" context updates and non-LLM-based context merging and de-duplication, $\textsc{ACE}$ demonstrates particular advantages in reducing the cost (in terms of the number of rollouts or the amount of dollar cost for token ingestion/generation) and latency of adaptation.
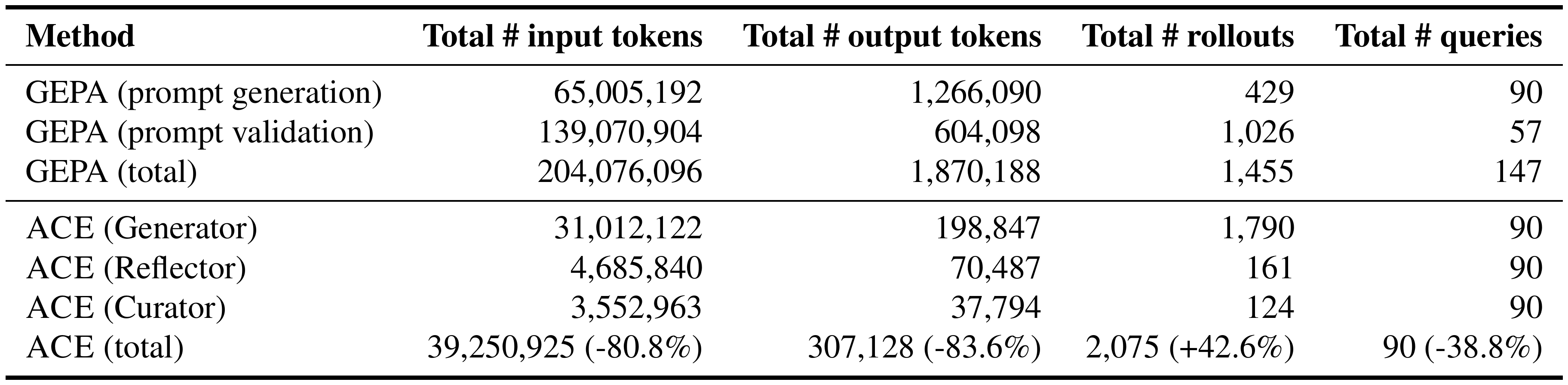
As examples, on the offline adaptation of AppWorld, ACE achieves 82.3% reduction in adaptation latency and 75.1% reduction in the number of rollouts as compared to GEPA (Table 4(a)). On the online adaptation of FiNER, ACE achieves 91.5% reduction in adaptation latency and 83.6% reduction in token dollar cost for token ingestion/generation as compared to DC (Table 4(b)).
::: {caption="Table 4: Cost and Speed Analysis. We measure the context adaptation latency, number of rollouts, and dollar costs of $\textsc{ACE}$ against GEPA (offline) and DC (online)."}
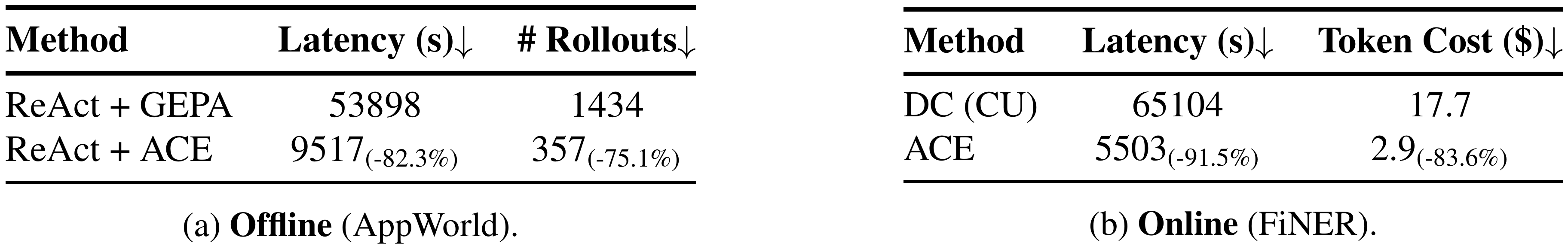
:::
Fine-Grained Cost Analysis
We conduct a fine-grained cost analysis of $\textsc{ACE}$ and GEPA (as a representative baseline). On AppWorld, $\textsc{ACE}$ is substantially cheaper during offline adaptation, reducing input/output token usage by 80.8%/83.6% vs. GEPA: $\textsc{ACE}$ avoids GEPA's prompt-validation loop and replaces repeated full rewrites with localized delta updates. At evaluation time, while $\textsc{ACE}$ may use more raw input tokens due to a richer playbook, this does not necessarily translate to higher billed serving cost because a large fraction of the context is reused by KV caching; we quantify this effect in the next paragraph. Full results, including a component-wise token breakdown for both methods, are in Appendix § A.3.
KV Cache Reuse: Longer Context $\ne$ Higher Serving Cost
Although $\textsc{ACE}$ produces longer contexts than methods such as GEPA, this does not translate to linearly higher inference cost or GPU memory usage. Modern serving infrastructures are increasingly optimized for long-context workloads through techniques such as the reuse ([15, 16]), compression ([48, 49]), and offload ([50, 51]) of KV cache. These mechanisms allow frequently reused context segments to be cached locally or remotely, avoiding repetitive and expensive prefill operations. Ongoing advances in ML systems suggest that the amortized cost of handling long contexts is likely to decrease, making context-rich approaches like $\textsc{ACE}$ increasingly practical in deployment. In our prompt-caching study with the OpenAI API (GPT-5.1), we find that $\textsc{ACE}$ achieves high cache reuse: 91.8% of input tokens are served from cache during evaluation stage, which reduces billed input-token cost by 82.6% relative to counting raw context tokens.
5. Discussion
Section Summary: ACE provides a flexible and cost-effective way to adapt machine learning models for ongoing learning scenarios, such as handling changing data or limited training resources, and it allows for targeted removal of outdated or sensitive information to meet privacy and legal needs. However, its effectiveness depends on a reliable "Reflector" component to generate useful insights; if this fails, the added context can become cluttered or unhelpful, much like similar techniques. ACE works best for tasks requiring in-depth knowledge, complex tools, or unique strategies, rather than simple ones that need only basic instructions.
Implications for Online and Continual Learning
Online and continual learning are key research directions in machine learning for addressing issues like distribution shifts ([52, 53]) and limited training data ([54, 55, 56]). $\textsc{ACE}$ offers a flexible and efficient alternative to conventional model fine-tuning, as adapting contexts is generally cheaper than updating model weights ([57, 58, 59, 60]). Moreover, because contexts are human-interpretable, $\textsc{ACE}$ enables selective unlearning ([61, 62, 63]), whether due to privacy or legal constraints ([64, 65]), or when outdated or incorrect information is identified by domain experts. These are promising directions for future work, where $\textsc{ACE}$ could play a central role in advancing continuous and responsible learning.
Limitations and Challenges
A limitation of $\textsc{ACE}$ is its reliance on a reasonably strong Reflector: if the Reflector fails to extract meaningful insights from generated traces or outcomes, the constructed context may become noisy or even harmful. In domain-specific tasks where no model can extract useful insights, the resulting context will naturally lack them. This dependency is similar to Dynamic Cheatsheet ([6]), where the quality of adaptation hinges on the underlying model’s ability to curate memory. We also note that not all applications require rich or detailed contexts. Tasks like HotPotQA ([66]) often benefit more from concise, high-level instructions (*e.g., * how to retrieve and synthesize evidence) than from long contexts. Similarly, games with fixed strategies such as Game of 24 ([6]) may only need a single reusable rule, rendering additional context redundant. Overall, $\textsc{ACE}$ is most beneficial in settings that demand detailed domain knowledge, complex tool use, or environment-specific strategies that go beyond what is already embedded in model weights or simple system instructions.
Acknowledgement
Section Summary: The authors express gratitude to the anonymous reviewers and area chair for their helpful feedback, which strengthened the paper. Qizheng Zhang's work is funded by grants from the National Science Foundation (award CNS-2211384) and DARPA (award TFAWI-HR00112520038). They also acknowledge Lakshya A. Agrawal, Xuekai Zhu, Yuhan Liu, Junchen Jiang, and Azalia Mirhoseini for valuable discussions.
We thank the anonymous reviewers and area chair for their constructive feedback, which improved this paper. Qizheng Zhang is supported by NSF award CNS-2211384 and DARPA award TFAWI-HR00112520038. We also thank Lakshya A Agrawal, Xuekai Zhu, Yuhan Liu, Junchen Jiang, and Azalia Mirhoseini for helpful discussions.
Ethics Statement
Section Summary: This research raises no specific ethical concerns, as it centers on developing algorithms and frameworks to improve how large language models adapt to different contexts. All experiments used publicly available benchmarks and open-source models, without involving human participants, sensitive data, or privacy matters. There are also no conflicts of interest.
This work does not raise specific ethical concerns. Our contributions focus on developing algorithms and system frameworks for effective context adaptation in large language models (LLMs). All experiments are conducted on publicly available benchmarks with open-source models, without involving human subjects, sensitive data, or privacy-related information. No potential conflicts of interest are present.
Reproducibility Statement
Section Summary: The researchers have shared their code on GitHub at github.com/ace-agent/ace, making it easy for others to access. They explain their experiments in detail, including the data sources, tests they ran, success measurements, comparison approaches, and model settings. Additional specifics, like prompts for large language models and expanded setups, appear in the appendix, so people with ordinary computer resources should be able to recreate the results.
Our code is available at github.com/ace-agent/ace. We provide detailed descriptions of our experimental setup, including datasets, benchmarks, evaluation metrics, baselines, and hyperparameter choices. Additional details, such as prompts for large language models and extended experimental settings, are included in the appendix. With this information, readers with reasonable computational resources should be able to reproduce our results.
Appendix
Section Summary: The appendix explores how the ACE framework, which enhances AI language models without relying on their specific designs, performs across various models like GPT-OSS-120B, GPT-5.1, and Llama-3.3-70B-Instruct, showing consistent improvements of 5 to 12 points over baselines in tasks like app navigation and financial analysis, whether using ground-truth labels or not, with the online version often yielding the best results. It also extends ACE to new areas beyond finance, such as medical diagnosis reasoning where it boosts accuracy by 15 points and text-to-SQL generation with steady gains, outperforming or matching competitors like GEPA. Additionally, the section begins a detailed breakdown of ACE's computational costs, though full details are not provided here.
A. Extended Results
A.1 Generalization across Different LLMs
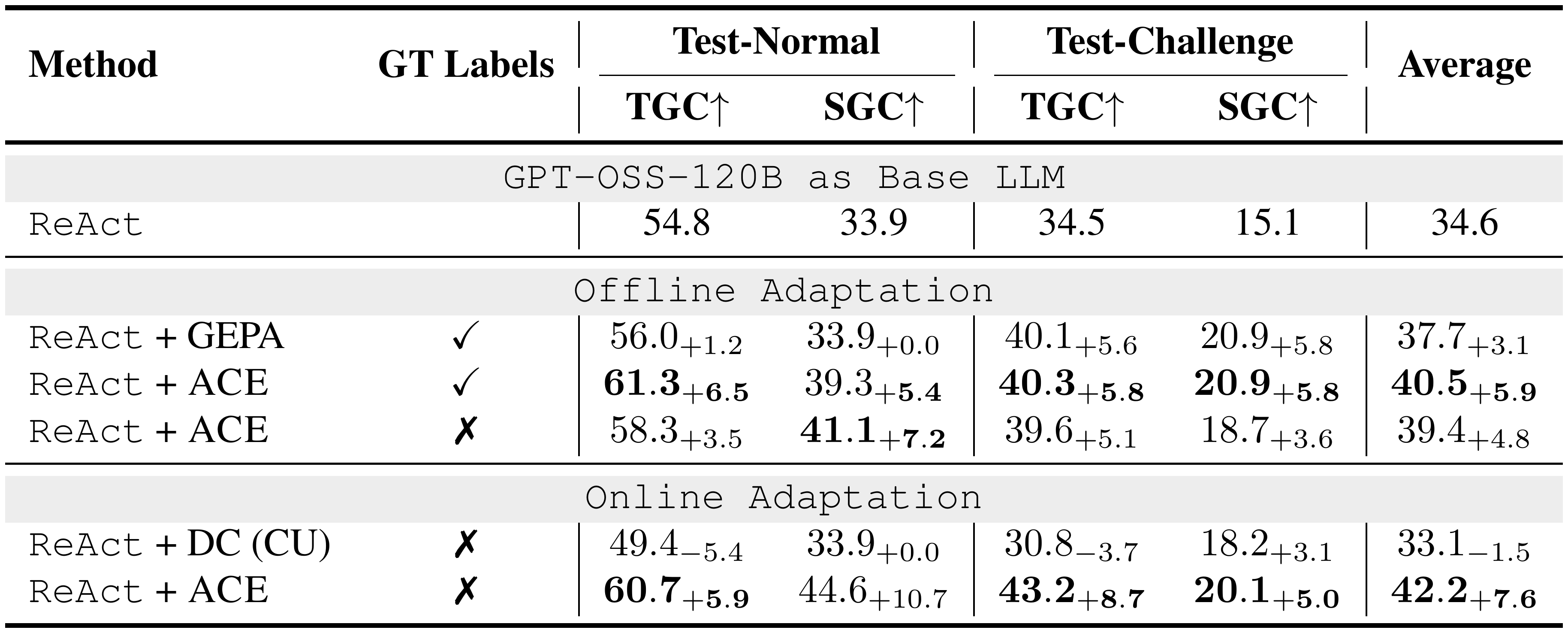
$\textsc{ACE}$ is a model-agnostic framework that operates on execution traces and contextual deltas, and does not rely on any architectural or training-specific features of DeepSeek-V3.1 (the default backbone we use in the main text). We evaluated $\textsc{ACE}$ with three additional models of varying size, cost, and capability: GPT-OSS-120B (Table 5 and Table 7), GPT-5.1 (Table 6 and Table 8), and Llama-3.3-70B-Instruct (Table 9). In each case, the Generator, Reflector, and Curator were all switched to the new model without changes to the algorithm.
Analysis
Across all four LLM families we tested (DeepSeek-V3.1, GPT-OSS-120B, GPT-5.1, and Llama-3.3-70B-Instruct), $\textsc{ACE}$ consistently improves performance over both the base LLM/agent, GEPA, and other baselines, often by 5 to 12 points depending on the task and supervision setting. The relative gains of $\textsc{ACE}$ remain stable even when switching to models that differ significantly in size, cost, and training recipe, and $\textsc{ACE}$ delivers benefits with or without ground-truth labels, validating the robustness of its context adaptation mechanism. The online variant reliably achieves the strongest performance across all models.
We note that the magnitude of improvement can vary across model families: for example, Llama-3.3-70B-Instruct shows smaller gains compared to GPT-5.1 or GPT-OSS-120B. This is expected since $\textsc{ACE}$ relies on the quality of intermediate reflections and calibrations, and smaller or weaker models naturally generate noisier feedback. Even in these cases, however, $\textsc{ACE}$ remains beneficial, demonstrating that the framework is broadly applicable while still reflecting the inherent capability limits of the underlying LLM, as we discussed in the “Limitations and Challenges” paragraph in § 5.
::: {caption="Table 5: Results on the AppWorld Agent Benchmark (GPT-OSS-120B as the Base LLM). "GT labels" indicates whether ground-truth labels are available to the Reflector during adaptation. We evaluate the $\textsc{ACE}$ framework against multiple baselines on top of the official ReAct implementation, both for offline and online context adaptation."}
:::
::: {caption="Table 6: Results on the AppWorld Agent Benchmark (GPT-5.1 as the Base LLM). "GT labels" indicates whether ground-truth labels are available to the Reflector during adaptation. We evaluate the $\textsc{ACE}$ framework against multiple baselines on top of the official ReAct implementation, both for offline and online context adaptation."}
:::
::: {caption="Table 7: Results on Financial Analysis Benchmark (GPT-OSS-120B as the Base LLM). "GT labels" indicates whether ground-truth labels are available to the Reflector during adaptation."}
:::
::: {caption="Table 8: Results on Financial Analysis Benchmark (GPT-5.1 as the Base LLM). "GT labels" indicates whether ground-truth labels are available to the Reflector during adaptation."}
:::
::: {caption="Table 9: Results on Financial Analysis Benchmark (Llama-3.3-70B-Instruct as the Base LLM). "GT labels" indicates whether ground-truth labels are available to the Reflector during adaptation."}
:::
A.2 Beyond Finance: Additional Domain Tasks
We evaluate $\textsc{ACE}$ on two additional domain tasks from StreamBench ([38]) under the non-streaming setting (*i.e., * offline adaptation): DDXPlus ([39]) for medical reasoning (Table 10) and BIRD-SQL ([40]) for Text-to-SQL generation (Table 11). For $\textsc{ACE}$, we perform offline adaptation using 1000 randomly sampled training examples. For GEPA, we use the same 1000 examples for training, and reserve a separate validation set of 500 examples for BIRD-SQL or 372 examples for DDXPlus (StreamBench provides 1372 train/val examples for DDXPlus in total). All other settings follow the main-text configuration unless stated otherwise.
Analysis
On DDXPlus, $\textsc{ACE}$ substantially improves over the base LLM, rising from 75.2 to 90.2 accuracy (+15.0). In contrast, GEPA yields a much smaller gain (76.4, +1.2). This suggests that $\textsc{ACE}$ 's test-time evolving context transfers well to multi-step, domain-heavy diagnostic reasoning. On BIRD-SQL, $\textsc{ACE}$ also improves consistently over the base model on all splits, achieving better overall average (52.9, +5.1). The gains are driven mainly by the Simple subset (53.5, +7.1). While GEPA yields larger gains on Moderate and Challenging, $\textsc{ACE}$ still improves over the base model on both splits. Overall, these results indicate that $\textsc{ACE}$ generalizes beyond finance to both knowledge-intensive reasoning and structured code generation tasks.
::: {caption="Table 10: Results on Medical Reasoning Benchmark (DeepSeek-V3.1-671B as the Base LLM). We use DDXPlus from StreamBench."}

:::
::: {caption="Table 11: Results on Text-to-SQL Benchmark (DeepSeek-V3.1-671B as the Base LLM). We use BIRD-SQL from StreamBench."}

:::
A.3 Fine-Grained Cost Analysis
We perform a fine-grained cost analysis of $\textsc{ACE}$ and GEPA for both the adaptation and evaluation stages (offline adaptation setting), using AppWorld as a representative application. For $\textsc{ACE}$, we run offline adaptation with 1 epoch and 1 reflector refinement round. While increasing the number of epochs or refinement rounds will increase cost, the qualitative trends below should remain: $\textsc{ACE}$ avoids expensive validation-time re-evaluation and performs localized updates rather than repeated full rewrites. For GEPA, we use the official DSPy implementation ([44]) with auto="heavy" to maximize optimization strength.
Adaptation Stage
Across adaptation (Table 12 and Table 13), $\textsc{ACE}$ reduces input-token usage by 80.8% relative to GEPA (204.1M $\rightarrow$ 39.3M) and output-token usage by 83.6% (1.87M $\rightarrow$ 0.31M). This gap is primarily driven by (1) GEPA's prompt-validation loop, which repeatedly evaluates candidate prompts on a held-out validation set (57 queries), incurring substantial additional LLM calls and validation tokens, and (2) $\textsc{ACE}$ 's incremental context updates, which replace full prompt rewrites with localized Generator-Reflector-Curator updates.
Evaluation Stage
At evaluation time (Table 14 and Table 15), $\textsc{ACE}$ uses more raw input tokens per query than GEPA due to its richer, more actionable playbook. However, output-token usage is similar (115.0 vs. 101.8), and the number of rollouts is comparable across methods. Moreover, under modern prompt/KV-caching infrastructures, the additional input tokens can be largely amortized: using OpenAI's default prompt caching, 91.8% of $\textsc{ACE}$ 's input tokens are served from cache, resulting in an 82.6% reduction in billed input-token cost (see § 4.7).
::: {caption="Table 12: Adaptation-Stage Aggregate Cost Statistics on AppWorld. The percentages compare $\textsc{ACE}$ (total) against GEPA (total)."}
:::
::: {caption="Table 13: Adaptation-Stage Average Cost Statistics on AppWorld. The percentages compare $\textsc{ACE}$ (total) against GEPA (total)."}

:::
:Table 14: Evaluation-Stage Aggregate Cost Statistics on AppWorld. The percentages compare ACE against GEPA.
| Method | Total # input tokens | Total # output tokens | Total # rollouts | Total # eval queries |
|---|---|---|---|---|
| Base ReAct | 27, 460, 411 | 289, 802 | 2, 430 | 160 |
| GEPA | 26, 960, 675 | 251, 442 | 2, 470 | 160 |
| $\textsc{ACE}$ | 58, 623, 267 (+117.4%) | 270, 652 (+7.6%) | 2, 354 (-4.7%) | 160 (+0.0%) |
:Table 15: Evaluation-Stage Average Cost Statistics on AppWorld. The percentages compare ACE against GEPA.
| Method | Avg # input / rollout | Avg # output / rollout | Avg # input / query | Avg # output / query | Total # rollouts | Total # eval queries |
|---|---|---|---|---|---|---|
| Base ReAct | 11, 298.5 | 119.3 | 171, 627.6 | 1, 811.3 | 2, 430 | 160 |
| GEPA | 10, 918.5 | 101.8 | 168, 504.2 | 1, 571.5 | 2, 470 | 160 |
| $\textsc{ACE}$ | 24, 912.4 (+128.2%) | 115.0 (+13.0%) | 366, 395.4 (+117.4%) | 1, 691.6 (+7.6%) | 2, 354 (-4.7%) | 160 (+0.0%) |
A.4 Robustness to Reflection Quality
We conduct two analyses to evaluate $\textsc{ACE}$ 's sensitivity to reflection quality. Unless otherwise noted, experiments are run on FiNER with $\textsc{ACE}$ offline adaptation.
Using Weaker Reflector Models
To test whether $\textsc{ACE}$ requires a strong reflector, we vary the Reflector across three models with substantially different capability: GPT-OSS-120B, DeepSeek-V3.1-671B, and GPT-5.1 (Table 16). Across all choices, $\textsc{ACE}$ consistently improves over the base LLM, including when the Reflector is much weaker. While stronger reflectors yield larger gains, the method remains effective across a wide range of reflector strengths.
Robustness to Noisy or Harmful Reflector Feedback
We further stress-test $\textsc{ACE}$ with actively harmful reflector outputs by injecting adversarial or conflicting bullets: we invoke a "harmful" reflector that is explicitly instructed to inject harmful reflection once every $X$ adaptation steps, where larger $X$ means less frequent corruption (Table 17). $\textsc{ACE}$ is robust to moderate noise levels: performance degrades gradually as corruption becomes more frequent and stays above the base LLM except in the extreme case of injecting harmful updates every iteration. This suggests that $\textsc{ACE}$ 's update mechanism tolerates substantial noise in the reflection stream, with failures emerging only under intentionally adversarial conditions.
Takeaway and Mitigation
$\textsc{ACE}$ is not highly sensitive to reflector quality: (1) weaker reflectors still provide substantial gains, (2) moderate noise or conflicting updates are largely tolerated, and (3) performance drops below the base model only under sustained adversarial corruption. In practice, $\textsc{ACE}$ 's bullet-point analyzer ("grow-and-refine"; § 3.2), which merges and deduplicates semantically similar bullets and can filter entries flagged as potentially harmful via metadata, serves as a first line of defense against context noise. Additional safeguards (*e.g., * contradiction detection, prompting the Curator to prioritize high-confidence updates, or periodic pruning of outdated entries) are compatible extensions that could further improve playbook compactness and consistency ([67]).
:Table 16: Weaker Reflector Models on FiNER. We vary the Reflector while keeping the Generator/Curator fixed. Parentheses report deltas vs. the base LLM.
| Method | Generator LLM | Reflector LLM | Curator LLM | Accuracy ($\uparrow$) |
|---|---|---|---|---|
| Base LLM | DeepSeek-V3.1 | - | - | 70.7 |
| $\textsc{ACE}$ | DeepSeek-V3.1 | GPT-OSS-120B | DeepSeek-V3.1 | 76.6 (+5.9) |
| $\textsc{ACE}$ | DeepSeek-V3.1 | DeepSeek-V3.1 | DeepSeek-V3.1 | 78.3 (+7.6) |
| $\textsc{ACE}$ | DeepSeek-V3.1 | GPT-5.1 | DeepSeek-V3.1 | 78.5 (+7.8) |
::: {caption="Table 17: Robustness to Noisy or Harmful Reflector Feedback on FiNER. We invoke a harmful reflector once every $X$ adaptation steps. Parentheses report deltas vs. the base LLM."}

:::
A.5 Ablation on Incremental Context Update
In this ablation, we run offline context adaptation on AppWorld using $\textsc{ACE}$ with and without incremental context updates, and evaluate on the test-normal split with DeepSeek-V3.1. We find that incremental updates are critical: by preserving useful information that would otherwise be lost to context collapse, they account for a large share of $\textsc{ACE}$ ’s gains.
::: {caption="Table 18: Ablation on Incremental Context Updates (AppWorld, DeepSeek-V3.1). We run offline context adaptation with $\textsc{ACE}$ with/without incremental updates and evaluate on test-normal. Improvements are relative to ReAct."}

:::
A.6 Sensitivity Analysis on Hyperparameter Choice
Reflection Iterations
This parameter trades off (1) extracting enough high-quality insights from the inference traces and (2) avoiding "overthinking" that introduces noisy or unnecessary updates. Empirically, 5 rounds offers a good balance. On AppWorld, 1 round under-extracts useful strategy fragments and leaves clear headroom, while too many rounds (*e.g., * 10) can degrade performance.
::: {caption="Table 19: Effect of Reflection Iterations (AppWorld, DeepSeek-V3.1). We report test-normal results under offline context adaptation. Improvements are relative to running ReAct without $\textsc{ACE}$."}

:::
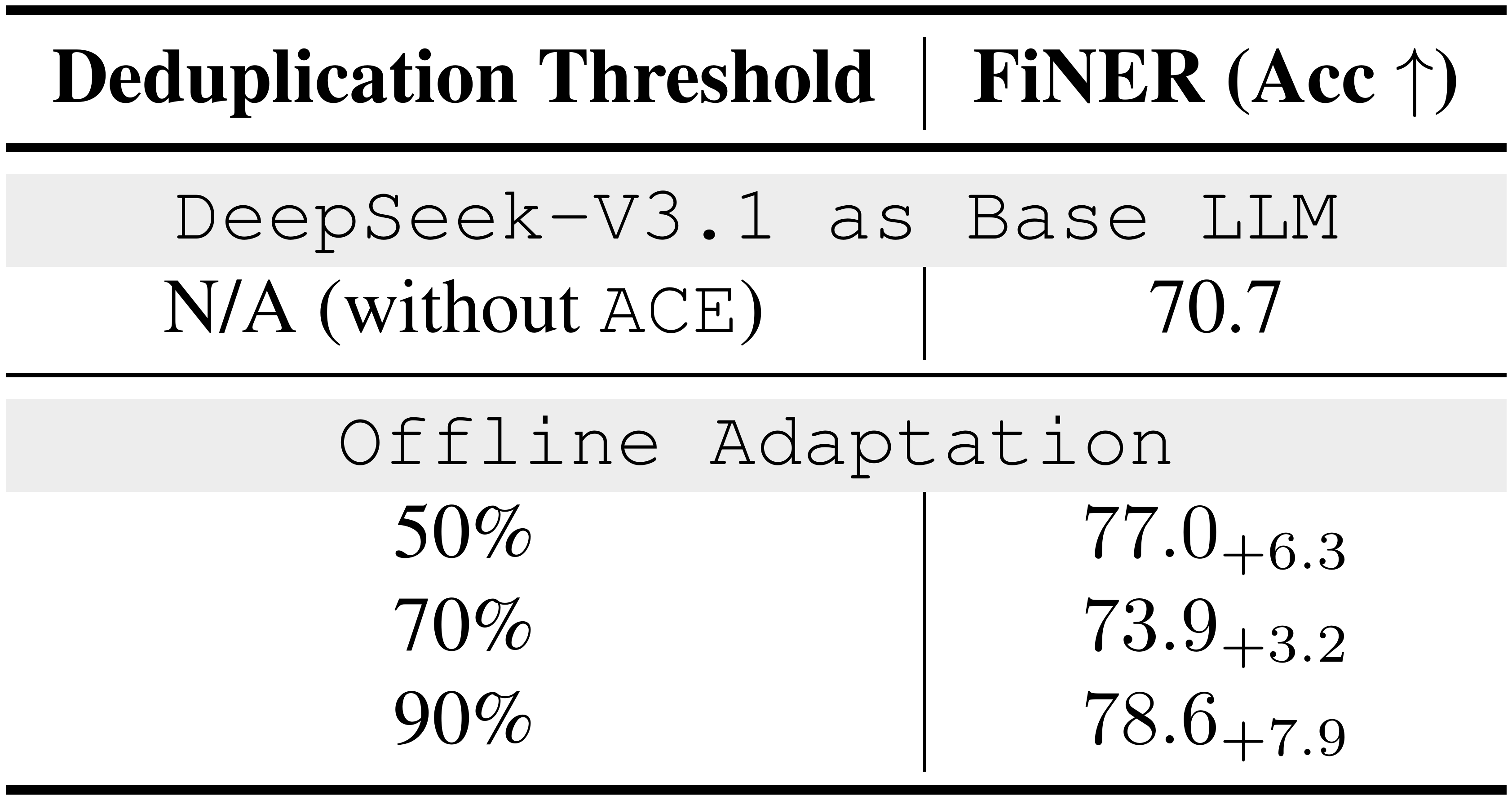
Deduplication Threshold
This controls how aggressively newly extracted insights are merged with existing entries. On FiNER, performance changes only mildly across the tested range, suggesting $\textsc{ACE}$ is robust to moderate variation in dedup aggressiveness.
::: {caption="Table 20: Effect of Deduplication Threshold (FiNER, DeepSeek-V3.1)."}
:::
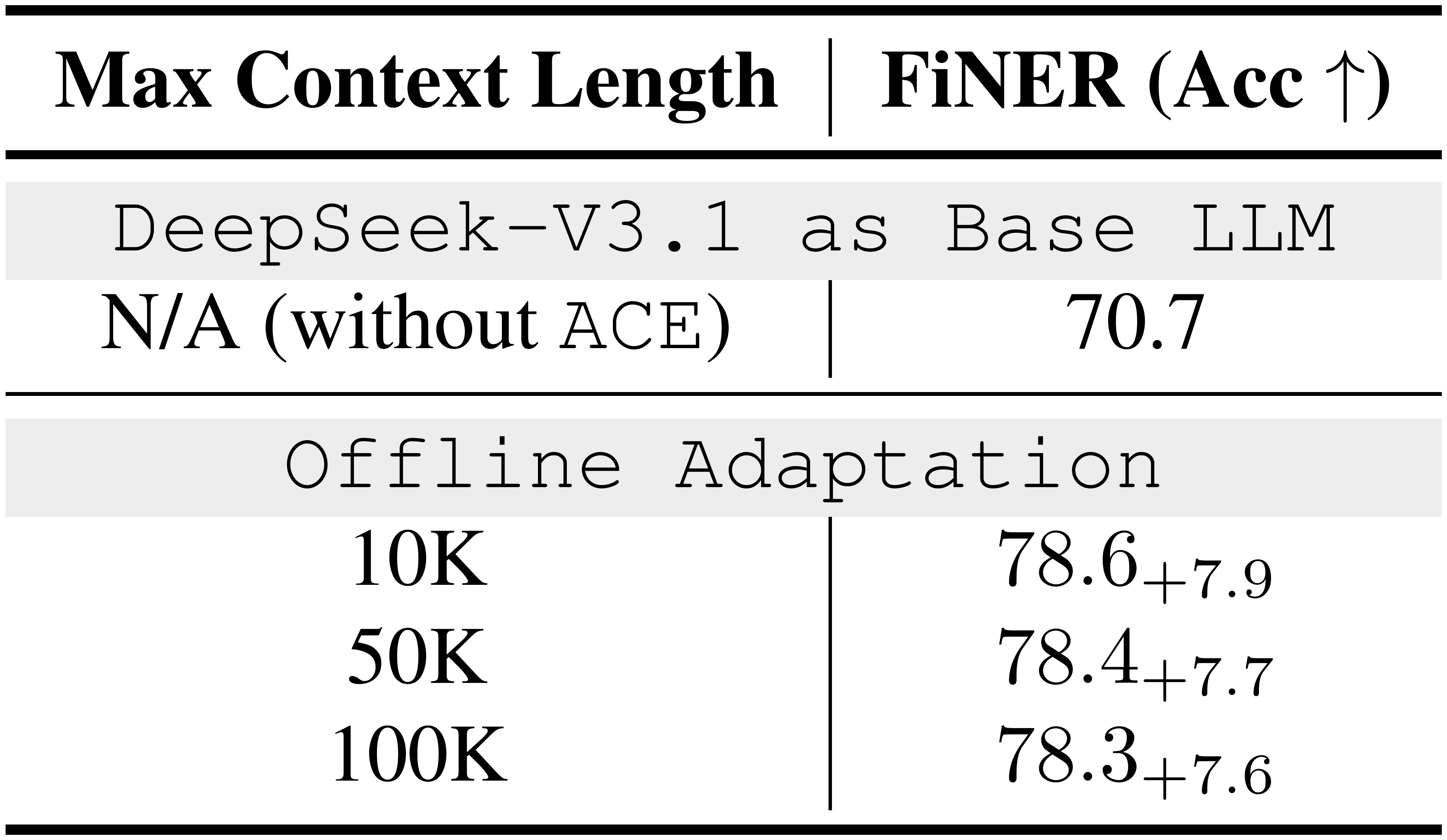
Pruning Trigger (Maximum Context Length)
This threshold determines when $\textsc{ACE}$ merges and prunes older or low-utility entries to prevent unbounded growth. It balances (1) retaining enough accumulated context to improve learning from experience and (2) keeping the context compact to reduce cost and limit noise. On FiNER, performance is stable from 10K to 100K tokens, indicating $\textsc{ACE}$ does not require finely tuned length thresholds; pruning mainly removes stale or harmful fragments while preserving core reusable strategies.
::: {caption="Table 21: Effect of Pruning Trigger (FiNER, DeepSeek-V3.1)."}
:::
Overall, $\textsc{ACE}$ is not highly sensitive to these hyperparameters: reasonable choices (*e.g., * 3-5 reflection rounds, 50-90% dedup threshold, and 10K-100K pruning triggers) consistently yield strong performance.
B. Extended Related Work
B.1 Agent Memory
A growing body of work explores how agents can accumulate experience from past trajectories and leverage external (often non-parametric) memory to guide future actions. AgentFly ([68]) presents an extensible framework where memory evolves continuously as agents solve tasks, enabling scalable reinforcement learning and long-horizon reasoning across diverse environments. AWM (Agent Workflow Memory) ([69]) induces reusable workflows, *i.e., * structured routines distilled from past trajectories, and selectively injects them into memory to improve efficiency and generalization in web navigation benchmarks. A-MEM ([7]) introduces a dynamically organized memory system inspired by the Zettelkasten method: each stored memory is annotated with structured attributes (*e.g., * tags, keywords, contextual descriptions) and automatically linked to relevant past entries, while existing entries are updated to integrate new knowledge, yielding adaptive and context-aware retrieval. Agentic Plan Caching ([70]) instead focuses on cost efficiency by extracting reusable plan templates from agent trajectories and caching them for fast execution at test time.
Together, these works demonstrate the value of external memory for improving adaptability, efficiency, and generalization in LLM agents. Our work differs by tackling the broader challenge of context adaptation, which spans not only agent memory but also system prompts, factual evidence, and other inputs underpinning AI systems. We further highlight two fundamental limitations of existing adaptation methods: brevity bias and context collapse; and show that addressing them is essential for robustness, reliability, and scalability beyond raw task performance. Accordingly, our evaluation considers not only accuracy but also cost, latency, and scalability.
C. Extended Discussions
C.1 ACE vs. GEPA
Scope and Objective Both GEPA and ACE improve model or agent behavior by adapting context at test time (rather than updating model weights), but they are designed for different forms of adaptation. GEPA treats adaptation as prompt evolution: it iteratively proposes and selects improved instruction prompts using rollout trajectories and reflective feedback, aiming to maximize a task evaluator under a rollout budget. ACE targets settings where performance depends on accumulating and preserving many granular, reusable insights over long horizons. For multi-turn agents (*e.g., * AppWorld), the model must retain step-by-step procedures and tool-use rules across an interaction. For domain-specific and knowledge-intensive benchmarks (*e.g., * FiNER, Formula), accuracy depends on keeping many specific rules, edge cases, and domain concepts that are difficult to compress into a single instruction prompt without losing detail.
Update Mechanism and Representation GEPA updates context by generating and selecting new prompt variants in an evolutionary loop, where each candidate is a full prompt optimized end-to-end. ACE instead represents context as a structured, itemized Playbook and applies incremental delta updates: the Curator writes only the new insight, and we merge it into the Playbook with simple deterministic logic. This avoids repeated full-prompt rewrites, helps keep earlier rules stable over long runs, and enables fine-grained bookkeeping (*e.g., * de-duplication, targeted refinement, and tracking which entries helped or harmed accuracy).
C.2 ACE vs. Dynamic Cheatsheet (DC)
Scope and Objective Both DC and ACE collect reusable insights at test time, but they are aimed at different settings. DC is mainly evaluated on single-turn reasoning benchmarks (*e.g., * AIME, Game-of-24, GPQA) where each query is independent. In this regime, improvements often come from saving short, reusable heuristics and executable artifacts (*e.g., * code snippets) that help on later problems. ACE focuses on settings where the details and high-fidelity guidenace need to stick around. For multi-turn agents (*e.g., * AppWorld), the model must remember step-by-step procedures and tool-use rules across an interaction. For domain-specific and knowledge-intensive benchmarks (*e.g., * FiNER, Formula), accuracy depends on keeping many specific rules, edge cases, and domain concepts, which are hard to compress without losing information.
Update Mechanism DC updates its memory by rewriting the cheatsheet as a whole, either by regenerating the full cheatsheet each step (DC-CU) or by writing a new summary from retrieved examples (DC-RS). With repeated full rewrites, the model tends to shorten and compress what was written before. This can cause context collapse, which means that useful domain-specific details get dropped over time or disappear suddenly (§ 2.2). ACE avoids full rewrites by using incremental delta updates. The Curator only writes the new insight, and we merge it into a structured and itemized Playbook with simple deterministic logic. This keeps earlier rules stable over long runs and also makes it easier to track which items helped, remove duplicates, and refine entries. In our ablations (§ 4.6), removing delta updates leads to a large drop on AppWorld (-11.7% TGC and -27.8% SGC on test-normal), showing that delta updates are a core part of our method.
D. AppWorld Leaderboard Snapshot (09/2025)
E. The Use of Large Language Models (LLMs)
This work focuses on developing algorithms and system frameworks for effective context adaptation in large language models (LLMs). Accordingly, our experiments employ LLMs for the empirical evaluation of the proposed methods. For paper preparation, we used LLMs only to polish writing (*e.g., * correcting grammatical errors), and not to generate new text from scratch.
F. Prompts







References
[1] Yao et al. (2023). ReAct: Synergizing Reasoning and Acting in Language Models. In International Conference on Learning Representations (ICLR).
[2] Yang et al. (2024). SWE-agent: Agent-Computer Interfaces Enable Automated Software Engineering. Advances in Neural Information Processing Systems (NeurIPS).
[3] Zaharia et al. (2024). The Shift from Models to Compound AI Systems. https://bair.berkeley.edu/blog/2024/02/18/compound-ai-systems/.
[4] Opsahl-Ong et al. (2024). Optimizing Instructions and Demonstrations for Multi-Stage Language Model Programs. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing (EMNLP). pp. 9340–9366.
[5] Agrawal et al. (2025). GEPA: Reflective Prompt Evolution Can Outperform Reinforcement Learning. arXiv preprint arXiv:2507.19457.
[6] Suzgun et al. (2025). Dynamic Cheatsheet: Test-Time Learning with Adaptive Memory. arXiv preprint arXiv:2504.07952.
[7] Xu et al. (2025). A-Mem: Agentic Memory for LLM Agents. Advances in neural information processing systems (NeurIPS).
[8] Asai et al. (2024). Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection. In The Twelfth International Conference on Learning Representations (ICLR).
[9] Wei et al. (2022). Chain-of-Thought Prompting Elicits Reasoning in Large Language Models. Advances in neural information processing systems (NeurIPS). 35. pp. 24824–24837.
[10] Wang et al. (2023). Self-Consistency Improves Chain of Thought Reasoning in Language Models. In The Eleventh International Conference on Learning Representations (ICLR).
[11] Lewis et al. (2020). Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. Advances in neural information processing systems (NeurIPS).
[12] Borgeaud et al. (2022). Improving Language Models by Retrieving from Trillions of Tokens. In International Conference on Machine Learning (ICML). pp. 2206–2240.
[13] Khot et al. (2023). Decomposed Prompting: A Modular Approach for Solving Complex Tasks. In International Conference on Learning Representations (ICLR).
[14] Peng et al. (2024). YaRN: Efficient Context Window Extension of Large Language Models. In The Twelfth International Conference on Learning Representations (ICLR).
[15] Gim et al. (2024). Prompt Cache: Modular Attention Reuse for Low-Latency Inference. Proceedings of Machine Learning and Systems (MLSys). 6. pp. 325–338.
[16] Yao et al. (2025). *CacheBlend: Fast Large Language Model Serving for RAG with Cached Knowledge Fusion *. In Proceedings of the Twentieth European Conference on Computer Systems (EuroSys). pp. 94–109.
[17] Gao et al. (2025). The Prompt Alchemist: Automated LLM-Tailored Prompt Optimization for Test Case Generation. arXiv preprint arXiv:2501.01329.
[18] Trivedi et al. (2024). AppWorld: A Controllable World of Apps and People for Benchmarking Interactive Coding Agents. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). pp. 16022–16076.
[19] Patil et al. (2024). Gorilla: Large Language Model Connected with Massive APIs. Advances in Neural Information Processing Systems (NeurIPS).
[20] Zhang et al. (2024). Caravan: Practical Online Learning of In-Network ML Models with Labeling Agents. In 18th USENIX Symposium on Operating Systems Design and Implementation (OSDI). pp. 325–345.
[21] Ye et al. (2023). Generating Data for Symbolic Language with Large Language Models. In Proceedings of the 2023 conference on empirical methods in natural language processing (EMNLP). pp. 8418–8443.
[22] Genghan Zhang et al. (2025). Adaptive Self-Improvement LLM Agentic System for ML Library Development. In Forty-second International Conference on Machine Learning (ICML).
[23] Zhang et al. (2025). AccelOpt: A Self-Improving LLM Agentic System for AI Accelerator Kernel Optimization. arXiv preprint arXiv:2511.15915.
[24] Mang et al. (2025). FrontierCS: Evolving Challenges for Evolving Intelligence. arXiv preprint arXiv:2512.15699.
[25] Loukas et al. (2022). FiNER: Financial Numeric Entity Recognition for XBRL Tagging. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). pp. 4419–4431.
[26] Guha et al. (2023). LegalBench: A Collaboratively Built Benchmark for Measuring Legal Reasoning in Large Language Models. Advances in neural information processing systems (NeurIPS).
[27] Wang et al. (2025). FinLoRA: Benchmarking LoRA Methods for Fine-Tuning LLMs on Financial Datasets. arXiv preprint arXiv:2505.19819.
[28] Jiang et al. (2025). Putting It All into Context: Simplifying Agents with LCLMs. arXiv preprint arXiv:2505.08120.
[29] Chung et al. (2025). Is Long Context All You Need? Leveraging LLM's Extended Context for NL2SQL. Proceedings of the VLDB Endowment. 18(8). pp. 2735–2747.
[30] Chen et al. (2025). Flora: Effortless Context Construction to Arbitrary Length and Scale. arXiv preprint arXiv:2507.19786.
[31] Mao et al. (2024). LIFT: Improving Long Context Understanding Through Long Input Fine-Tuning. arXiv preprint arXiv:2412.13626.
[32] Liu et al. (2025). SelfElicit: Your Language Model Secretly Knows Where is the Relevant Evidence. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). pp. 9153–9173.
[33] AppWorld. Leaderboard. https://appworld.dev/leaderboard. Accessed: 09/2025.
[34] Marreed et al. (2025). Towards Enterprise-Ready Computer Using Generalist Agent. arXiv preprint arXiv:2503.01861.
[35] Shinn et al. (2023). Reflexion: Language Agents with Verbal Reinforcement Learning. Advances in Neural Information Processing Systems (NeurIPS).
[36] Yuksekgonul et al. (2025). Optimizing Generative AI by Backpropagating Language Model Feedback. Nature. 639(8055). pp. 609–616.
[37] Krause et al. (2019). Dynamic Evaluation of Transformer Language Models. arXiv preprint arXiv:1904.08378.
[38] Wu et al. (2024). StreamBench: Towards Benchmarking Continuous Improvement of Language Agents. Advances in Neural Information Processing Systems (NeurIPS).
[39] Fansi Tchango et al. (2022). DDXPlus: A New Dataset For Automatic Medical Diagnosis. Advances in neural information processing systems (NeurIPS).
[40] Li et al. (2023). Can LLM Already Serve as A Database Interface? A BIg Bench for Large-Scale Database Grounded Text-to-SQLs. Advances in Neural Information Processing Systems (NeurIPS).
[41] OpenAI (2024). GPT‑4o mini: Advancing Cost-Efficient Intelligence. https://openai.com/index/gpt-4o-mini-advancing-cost-efficient-intelligence/.
[42] Zheng et al. (2023). Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena. Advances in neural information processing systems (NeurIPS). 36. pp. 46595–46623.
[43] Agarwal et al. (2024). Many-Shot In-Context Learning. Advances in Neural Information Processing Systems (NeurIPS). 37. pp. 76930–76966.
[44] DSPy. dspy.MIPROv2: Multiprompt Instruction PRoposal Optimizer Version 2. https://dspy.ai/api/optimizers/MIPROv2/. Accessed: 09/2025.
[45] DSPy. dspy.GEPA: Reflective Prompt Optimizer. https://dspy.ai/api/optimizers/GEPA/overview/. Accessed: 09/2025.
[46] Mirac Suzgun et al.. Dynamic Cheatsheet: Test-Time Learning with Adaptive Memory. https://github.com/suzgunmirac/dynamic-cheatsheet. Accessed: 09/2025.
[47] Liu et al. (2024). DeepSeek-V3 Technical Report. arXiv preprint arXiv:2412.19437.
[48] Liu et al. (2024). KIVI: A Tuning-Free Asymmetric 2bit Quantization for KV Cache. In International Conference on Machine Learning (ICML).
[49] Liu et al. (2024). CacheGen: KV Cache Compression and Streaming for Fast Large Language Model Serving. In Proceedings of the ACM SIGCOMM 2024 Conference. pp. 38–56.
[50] Lee et al. (2024). InfiniGen: Efficient Generative Inference of Large Language Models with Dynamic KV Cache Management. In 18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24). pp. 155–172.
[51] Li et al. (2025). Continuum: Efficient and Robust Multi-Turn LLM Agent Scheduling with KV Cache Time-to-Live. arXiv preprint arXiv:2511.02230.
[52] Koh et al. (2021). WILDS: A Benchmark of in-the-Wild Distribution Shifts. In International conference on machine learning (ICML).
[53] Gulrajani, Ishaan and Lopez-Paz, David (2021). In Search of Lost Domain Generalization. In International Conference on Learning Representations (ICLR).
[54] Pan, Sinno Jialin and Yang, Qiang (2010). A Survey on Transfer Learning. IEEE Transactions on Knowledge and Data Engineering. 22(10). pp. 1345–1359.
[55] Hutchinson et al. (2017). Overcoming Data Scarcity with Transfer Learning. arXiv preprint arXiv:1711.05099.
[56] Zhuang et al. (2019). A Comprehensive Survey on Transfer Learning. arXiv:1911.02685.
[57] Brown et al. (2020). Language Models are Few-Shot Learners. Advances in Neural Information Processing Systems (NeurIPS). 33. pp. 1877–1901.
[58] Lester et al. (2021). The Power of Scale for Parameter-Efficient Prompt Tuning. In Proceedings of the 2021 conference on empirical methods in natural language processing (EMNLP). pp. 3045–3059.
[59] Li, Xiang Lisa and Liang, Percy (2021). Prefix-Tuning: Optimizing Continuous Prompts for Generation. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). pp. 4582–4597.
[60] Hu et al. (2022). LoRA: Low-Rank Adaptation of Large Language Models. In The Tenth International Conference on Learning Representations (ICLR).
[61] Cao, Yinzhi and Yang, Junfeng (2015). Towards Making Systems Forget with Machine Unlearning. In IEEE Symposium on Security and Privacy (IEEE S&P).
[62] Bourtoule et al. (2021). Machine Unlearning. In IEEE Symposium on Security and Privacy (IEEE S&P).
[63] Liu et al. (2025). Rethinking Machine Unlearning for Large Language Models. Nature Machine Intelligence. 7(2). pp. 181–194.
[64] (2016). General Data Protection Regulation (GDPR) Article 17: Right to Erasure. EU Regulation 2016/679.
[65] (2018). California Consumer Privacy Act, Civil Code §1798.105: Right to Delete. State of California Civil Code.
[66] Yang et al. (2018). HotpotQA: A Dataset for Diverse, Explainable Multi-hop Question Answering. In Proceedings of the 2018 conference on empirical methods in natural language processing (EMNLP). pp. 2369–2380.
[67] Zhou et al. (2024). Defending Jailbreak Prompts via In-Context Adversarial Game. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing (EMNLP). pp. 20084–20105.
[68] Zhou et al. (2025). AgentFly: Fine-tuning LLM Agents without Fine-tuning LLMs. arXiv preprint arXiv:2508.16153.
[69] Zora Zhiruo Wang et al. (2025). Agent Workflow Memory. In Forty-second International Conference on Machine Learning (ICML).
[70] Qizheng Zhang et al. (2025). Agentic Plan Caching: Test-Time Memory for Fast and Cost-Efficient LLM Agents. In The Thirty-ninth Annual Conference on Neural Information Processing Systems (NeurIPS).