Playing Atari with Deep Reinforcement Learning
Volodymyr Mnih
Koray Kavukcuoglu
David Silver
Alex Graves
Ioannis Antonoglou
Daan Wierstra
Martin Riedmiller
DeepMind Technologies
{ vlad,koray,david,alex.graves,ioannis,daan,martin.riedmiller} @ deepmind.com
Abstract
We present the first deep learning model to successfully learn control policies directly from high-dimensional sensory input using reinforcement learning. The model is a convolutional neural network, trained with a variant of Q-learning, whose input is raw pixels and whose output is a value function estimating future rewards. We apply our method to seven Atari 2600 games from the Arcade Learning Environment, with no adjustment of the architecture or learning algorithm. We find that it outperforms all previous approaches on six of the games and surpasses a human expert on three of them.
Executive Summary: This paper addresses a key challenge in artificial intelligence: teaching computer agents to make decisions in complex environments using only raw visual inputs, like pixels from a screen, without relying on human-designed features. Traditional reinforcement learning, where agents learn by trial and error to maximize rewards, has struggled with high-dimensional data such as video footage because rewards are often sparse, delayed, and the data is highly correlated. This matters now because recent progress in deep learning has revolutionized image recognition and speech processing, opening the door to more general-purpose AI that could handle real-world tasks like robotics or autonomous driving, where raw sensory data is abundant but labeling it for training is impractical.
The document sets out to demonstrate that a deep neural network can learn effective control strategies directly from pixel inputs in reinforcement learning settings. Specifically, it evaluates the model's performance on seven classic Atari 2600 video games, aiming to show it can play them at or beyond human levels without any game-specific tweaks.
The researchers developed a convolutional neural network—a type of deep learning model good at processing images—trained using a modified version of Q-learning, an algorithm that estimates the value of actions in given states to guide decisions. To handle issues like data correlation and changing behavior during learning, they introduced experience replay, which stores and randomly samples past interactions to stabilize training. The model took raw game screen pixels as input, preprocessed them simply by converting to grayscale, downsampling, and stacking four frames for a sense of motion. It was tested on the Arcade Learning Environment, a standard Atari simulator, over a period covering 10 million game frames per game, using a fixed network design and hyperparameters across all seven titles: Beam Rider, Breakout, Enduro, Pong, Q*bert, Seaquest, and Space Invaders. Rewards were clipped to +1, -1, or 0 to normalize scales, and actions were selected with some randomness for exploration.
The core results show the model, called Deep Q-Network (DQN), achieved superior performance. It outperformed prior reinforcement learning methods—such as those using hand-engineered features—on six of the seven games, with scores roughly 2-10 times higher in top cases. DQN surpassed an expert human player on three games: in Breakout, it scored 168 versus the human's 31; in Enduro, 470 versus 368; and in Pong, 20 versus -3 (where positive scores indicate wins). On Beam Rider, it came close to human levels at 4,092 versus 7,456. Weaker results appeared on Q*bert, Seaquest, and Space Invaders, where human scores were 10-40 times higher, likely due to the need for long-term planning. Overall, DQN exceeded random play by orders of magnitude and even topped evolutionary algorithms that exploit game flaws.
These findings mean deep reinforcement learning can autonomously extract useful patterns from raw visuals to master diverse tasks, bypassing the need for expert knowledge in feature design. This reduces development costs and risks in AI systems by enabling end-to-end learning, potentially speeding up applications in gaming, simulation, or safety-critical areas like self-driving cars, where performance gains could translate to better decision-making under uncertainty. Surprisingly, the approach avoided past pitfalls like training instability in deep networks, thanks to experience replay, marking a step beyond earlier limited successes like backgammon AI from the 1990s.
Next, organizations should invest in scaling this method to broader domains, such as real-world robotics or multi-agent simulations, starting with pilots on simpler physical tasks to validate generalization. Trade-offs include balancing exploration randomness (higher for robustness, lower for exploitation) against computational demands; more advanced replay sampling could prioritize key experiences for faster gains. Further analysis on unclipped rewards or longer-term strategies would strengthen decisions.
Key limitations include the simplified reward clipping, which might undervalue nuanced scoring, and the focus on Atari's stylized visuals, limiting direct applicability to messier real-world data. The fixed architecture assumes similar visual challenges across games, and results rely on simulator assumptions like finite episodes. Confidence is high for pixel-based control in structured environments like these games—evidenced by stable training and consistent outperformance—but readers should be cautious about extrapolating to open-ended or highly variable settings without additional testing.
1. Introduction
Section Summary: Learning to guide artificial agents using raw sensory inputs like video and sound has long been a tough problem in reinforcement learning, where most effective systems depend on manually designed features that can limit performance. While deep learning has revolutionized fields like image recognition by pulling insights from unprocessed data, applying it to reinforcement learning faces hurdles such as sparse and delayed rewards, correlated observations, and shifting data patterns during training. This paper shows how a convolutional neural network, trained via a modified Q-learning method with experience replay to handle those issues, can master complex Atari 2600 games directly from pixel inputs alone, outperforming prior algorithms on several titles and even beating human experts on a few.
Learning to control agents directly from high-dimensional sensory inputs like vision and speech is one of the long-standing challenges of reinforcement learning (RL). Most successful RL applications that operate on these domains have relied on hand-crafted features combined with linear value functions or policy representations. Clearly, the performance of such systems heavily relies on the quality of the feature representation.
Recent advances in deep learning have made it possible to extract high-level features from raw sensory data, leading to breakthroughs in computer vision [1, 2, 3] and speech recognition [4, 5]. These methods utilise a range of neural network architectures, including convolutional networks, multilayer perceptrons, restricted Boltzmann machines and recurrent neural networks, and have exploited both supervised and unsupervised learning. It seems natural to ask whether similar techniques could also be beneficial for RL with sensory data.
However reinforcement learning presents several challenges from a deep learning perspective. Firstly, most successful deep learning applications to date have required large amounts of hand-labelled training data. RL algorithms, on the other hand, must be able to learn from a scalar reward signal that is frequently sparse, noisy and delayed. The delay between actions and resulting rewards, which can be thousands of timesteps long, seems particularly daunting when compared to the direct association between inputs and targets found in supervised learning. Another issue is that most deep learning algorithms assume the data samples to be independent, while in reinforcement learning one typically encounters sequences of highly correlated states. Furthermore, in RL the data distribution changes as the algorithm learns new behaviours, which can be problematic for deep learning methods that assume a fixed underlying distribution.
This paper demonstrates that a convolutional neural network can overcome these challenges to learn successful control policies from raw video data in complex RL environments. The network is trained with a variant of the Q-learning [6] algorithm, with stochastic gradient descent to update the weights. To alleviate the problems of correlated data and non-stationary distributions, we use an experience replay mechanism [7] which randomly samples previous transitions, and thereby smooths the training distribution over many past behaviors.
We apply our approach to a range of Atari 2600 games implemented in The Arcade Learning Environment (ALE) [8]. Atari 2600 is a challenging RL testbed that presents agents with a high dimensional visual input ($210 \times 160$ RGB video at 60Hz) and a diverse and interesting set of tasks that were designed to be difficult for humans players. Our goal is to create a single neural network agent that is able to successfully learn to play as many of the games as possible. The network was not provided with any game-specific information or hand-designed visual features, and was not privy to the internal state of the emulator; it learned from nothing but the video input, the reward and terminal signals, and the set of possible actions—just as a human player would. Furthermore the network architecture and all hyperparameters used for training were kept constant across the games. So far the network has outperformed all previous RL algorithms on six of the seven games we have attempted and surpassed an expert human player on three of them. Figure 1 provides sample screenshots from five of the games used for training.

2. Background
Section Summary: In this setup, an AI agent plays Atari video games by selecting actions based on screen images and rewards from the game emulator, but it can't see the full internal state, so it relies on sequences of recent images and actions to understand the situation. The agent's goal is to maximize long-term rewards, discounted over time, through a framework called a Markov decision process, where strategies are learned by estimating an optimal action-value function that predicts the best future outcomes for each state-action pair. This function is approximated using neural networks trained via an iterative process based on the Bellman equation, leading to a model-free algorithm known as Q-learning that explores the game efficiently without needing a full model of the environment.
We consider tasks in which an agent interacts with an environment $\mathcal{E}$, in this case the Atari emulator, in a sequence of actions, observations and rewards. At each time-step the agent selects an action $a_t$ from the set of legal game actions, $\mathcal{A}={1, \ldots, K }$. The action is passed to the emulator and modifies its internal state and the game score. In general $\mathcal{E}$ may be stochastic. The emulator's internal state is not observed by the agent; instead it observes an image $x_t \in \mathbb{R}^d$ from the emulator, which is a vector of raw pixel values representing the current screen. In addition it receives a reward $r_t$ representing the change in game score. Note that in general the game score may depend on the whole prior sequence of actions and observations; feedback about an action may only be received after many thousands of time-steps have elapsed.
Since the agent only observes images of the current screen, the task is partially observed and many emulator states are perceptually aliased, i.e. it is impossible to fully understand the current situation from only the current screen $x_t$. We therefore consider sequences of actions and observations, $s_t = {x_1, a_1, x_2, ..., a_{t-1}, x_t}$, and learn game strategies that depend upon these sequences. All sequences in the emulator are assumed to terminate in a finite number of time-steps. This formalism gives rise to a large but finite Markov decision process (MDP) in which each sequence is a distinct state. As a result, we can apply standard reinforcement learning methods for MDPs, simply by using the complete sequence $s_t$ as the state representation at time $t$.
The goal of the agent is to interact with the emulator by selecting actions in a way that maximises future rewards. We make the standard assumption that future rewards are discounted by a factor of $\gamma$ per time-step, and define the future discounted return at time $t$ as $R_t = \sum_{t'=t}^{T} \gamma^{t'-t} r_{t'}$, where $T$ is the time-step at which the game terminates. We define the optimal action-value function $Q^*(s, a)$ as the maximum expected return achievable by following any strategy, after seeing some sequence $s$ and then taking some action $a$, $Q^*(s, a) = \max_{\pi} \mathbb{E} \left[R_t | s_t=s, a_t=a, \pi \right]$, where $\pi$ is a policy mapping sequences to actions (or distributions over actions).
The optimal action-value function obeys an important identity known as the Bellman equation. This is based on the following intuition: if the optimal value $Q^*(s', a')$ of the sequence $s'$ at the next time-step was known for all possible actions $a'$, then the optimal strategy is to select the action $a'$ maximising the expected value of $r + \gamma Q^*(s', a')$,
$ \begin{align} Q^*(s, a) &= \mathbb{E}{s' \sim \mathcal{E}} \left[r + \gamma \max{a'} Q^*(s', a') \Big| s, a \right] \end{align} $
The basic idea behind many reinforcement learning algorithms is to estimate the action-value function, by using the Bellman equation as an iterative update, $Q_{i+1}(s, a) = \mathbb{E}\left[r + \gamma \max_{a'} Q_i(s', a') | s, a \right]$. Such value iteration algorithms converge to the optimal action-value function, $Q_i \rightarrow Q^*$ as $i \rightarrow \infty$ [9]. In practice, this basic approach is totally impractical, because the action-value function is estimated separately for each sequence, without any generalisation. Instead, it is common to use a function approximator to estimate the action-value function, $Q(s, a; \theta) \approx Q^*(s, a)$. In the reinforcement learning community this is typically a linear function approximator, but sometimes a non-linear function approximator is used instead, such as a neural network. We refer to a neural network function approximator with weights $\theta$ as a Q-network. A Q-network can be trained by minimising a sequence of loss functions $L_i(\theta_i)$ that changes at each iteration $i$,
$ \begin{align} L_i\left(\theta_i\right) &= \mathbb{E}_{s, a \sim \rho(\cdot)} \left[\left(y_i - Q \left(s, a ; \theta_i \right) \right)^2 \right], \end{align}\tag{1} $
where $y_i = \mathbb{E}{s' \sim \mathcal{E}} \left[r + \gamma \max{a'} Q(s', a'; \theta_{i-1}) | s, a \right]$ is the target for iteration $i$ and $\rho(s, a)$ is a probability distribution over sequences $s$ and actions $a$ that we refer to as the behaviour distribution. The parameters from the previous iteration $\theta_{i-1}$ are held fixed when optimising the loss function $L_i\left(\theta_i\right)$. Note that the targets depend on the network weights; this is in contrast with the targets used for supervised learning, which are fixed before learning begins. Differentiating the loss function with respect to the weights we arrive at the following gradient,
$ \begin{align} \nabla_{\theta_i} L_i\left(\theta_i\right) &= \mathbb{E}{s, a \sim \rho(\cdot); s' \sim \mathcal{E}} \left[\left(r + \gamma \max{a'} Q(s', a'; \theta_{i-1}) - Q(s, a ; \theta_i) \right) \nabla_{\theta_i} Q(s, a;\theta_{i}) \right] . \end{align}\tag{2} $
Rather than computing the full expectations in the above gradient, it is often computationally expedient to optimise the loss function by stochastic gradient descent. If the weights are updated after every time-step, and the expectations are replaced by single samples from the behaviour distribution $\rho$ and the emulator $\mathcal{E}$ respectively, then we arrive at the familiar Q-learning algorithm [6].
Note that this algorithm is model-free: it solves the reinforcement learning task directly using samples from the emulator $\mathcal{E}$, without explicitly constructing an estimate of $\mathcal{E}$. It is also off-policy: it learns about the greedy strategy $a = \max_{a} Q(s, a;\theta)$, while following a behaviour distribution that ensures adequate exploration of the state space. In practice, the behaviour distribution is often selected by an $\epsilon$-greedy strategy that follows the greedy strategy with probability $1 - \epsilon$ and selects a random action with probability $\epsilon$.
3. Related Work
Section Summary: One of the earliest successes in reinforcement learning was TD-Gammon, a program that mastered backgammon through self-play and a simple neural network, but similar efforts failed in games like chess and Go, leading many to think it was unique to backgammon's random dice rolls. Challenges arose when combining reinforcement learning with complex neural networks, often causing unstable results, so researchers shifted to simpler methods before a recent revival integrated deep learning for better environment modeling and value estimation, though full nonlinear control remains tricky. Prior work like neural fitted Q-learning used batch updates on processed data for real tasks, while Atari games served as testbeds for linear approximations and evolved strategies, but none applied end-to-end learning directly from raw visuals like the current approach.
Perhaps the best-known success story of reinforcement learning is TD-gammon, a backgammon-playing program which learnt entirely by reinforcement learning and self-play, and achieved a super-human level of play [10]. TD-gammon used a model-free reinforcement learning algorithm similar to Q-learning, and approximated the value function using a multi-layer perceptron with one hidden layer[^1].
[^1]: In fact TD-Gammon approximated the state value function $V(s)$ rather than the action-value function $Q(s, a)$, and learnt on-policy directly from the self-play games
However, early attempts to follow up on TD-gammon, including applications of the same method to chess, Go and checkers were less successful. This led to a widespread belief that the TD-gammon approach was a special case that only worked in backgammon, perhaps because the stochasticity in the dice rolls helps explore the state space and also makes the value function particularly smooth [11].
Furthermore, it was shown that combining model-free reinforcement learning algorithms such as Q-learning with non-linear function approximators [12], or indeed with off-policy learning [13] could cause the Q-network to diverge. Subsequently, the majority of work in reinforcement learning focused on linear function approximators with better convergence guarantees [12].
More recently, there has been a revival of interest in combining deep learning with reinforcement learning. Deep neural networks have been used to estimate the environment $\mathcal{E}$; restricted Boltzmann machines have been used to estimate the value function [14]; or the policy [15]. In addition, the divergence issues with Q-learning have been partially addressed by gradient temporal-difference methods. These methods are proven to converge when evaluating a fixed policy with a nonlinear function approximator [16]; or when learning a control policy with linear function approximation using a restricted variant of Q-learning [17]. However, these methods have not yet been extended to nonlinear control.
Perhaps the most similar prior work to our own approach is neural fitted Q-learning (NFQ) [18]. NFQ optimises the sequence of loss functions in Equation 1, using the RPROP algorithm to update the parameters of the Q-network. However, it uses a batch update that has a computational cost per iteration that is proportional to the size of the data set, whereas we consider stochastic gradient updates that have a low constant cost per iteration and scale to large data-sets. NFQ has also been successfully applied to simple real-world control tasks using purely visual input, by first using deep autoencoders to learn a low dimensional representation of the task, and then applying NFQ to this representation [19]. In contrast our approach applies reinforcement learning end-to-end, directly from the visual inputs; as a result it may learn features that are directly relevant to discriminating action-values. Q-learning has also previously been combined with experience replay and a simple neural network [7], but again starting with a low-dimensional state rather than raw visual inputs.
The use of the Atari 2600 emulator as a reinforcement learning platform was introduced by [8], who applied standard reinforcement learning algorithms with linear function approximation and generic visual features. Subsequently, results were improved by using a larger number of features, and using tug-of-war hashing to randomly project the features into a lower-dimensional space [20]. The HyperNEAT evolutionary architecture [21] has also been applied to the Atari platform, where it was used to evolve (separately, for each distinct game) a neural network representing a strategy for that game. When trained repeatedly against deterministic sequences using the emulator's reset facility, these strategies were able to exploit design flaws in several Atari games.
4. Deep Reinforcement Learning
Section Summary: This section explores how deep neural networks, successful in fields like image and speech recognition, can enhance reinforcement learning by directly processing raw game visuals like Atari frames. It builds on early work like TD-Gammon for backgammon by introducing deep Q-learning, which uses a technique called experience replay to store and randomly sample past actions and outcomes, making training more efficient and stable by breaking correlations and avoiding unstable feedback loops. To handle raw inputs, the method preprocesses images by converting them to grayscale, downsampling, and cropping, while the network architecture outputs separate predictions for each possible action from a shared state representation.
Recent breakthroughs in computer vision and speech recognition have relied on efficiently training deep neural networks on very large training sets. The most successful approaches are trained directly from the raw inputs, using lightweight updates based on stochastic gradient descent. By feeding sufficient data into deep neural networks, it is often possible to learn better representations than handcrafted features [1]. These successes motivate our approach to reinforcement learning. Our goal is to connect a reinforcement learning algorithm to a deep neural network which operates directly on RGB images and efficiently process training data by using stochastic gradient updates.
Tesauro's TD-Gammon architecture provides a starting point for such an approach. This architecture updates the parameters of a network that estimates the value function, directly from on-policy samples of experience, $s_t, a_t, r_t, s_{t+1}, a_{t+1}$, drawn from the algorithm's interactions with the environment (or by self-play, in the case of backgammon). Since this approach was able to outperform the best human backgammon players 20 years ago, it is natural to wonder whether two decades of hardware improvements, coupled with modern deep neural network architectures and scalable RL algorithms might produce significant progress.
In contrast to TD-Gammon and similar online approaches, we utilize a technique known as experience replay [7] where we store the agent's experiences at each time-step, $e_t = (s_t, a_t, r_t, s_{t+1})$ in a data-set $\mathcal{D} = e_1, ..., e_N$, pooled over many episodes into a replay memory. During the inner loop of the algorithm, we apply Q-learning updates, or minibatch updates, to samples of experience, $e \sim \mathcal{D}$, drawn at random from the pool of stored samples. After performing experience replay, the agent selects and executes an action according to an $\epsilon$-greedy policy. Since using histories of arbitrary length as inputs to a neural network can be difficult, our Q-function instead works on fixed length representation of histories produced by a function $\phi$. The full algorithm, which we call deep Q-learning, is presented in Algorithm 1.
This approach has several advantages over standard online Q-learning [9]. First, each step of experience is potentially used in many weight updates, which allows for greater data efficiency. Second, learning directly from consecutive samples is inefficient, due to the strong correlations between the samples; randomizing the samples breaks these correlations and therefore reduces the variance of the updates. Third, when learning on-policy the current parameters determine the next data sample that the parameters are trained on. For example, if the maximizing action is to move left then the training samples will be dominated by samples from the left-hand side; if the maximizing action then switches to the right then the training distribution will also switch. It is easy to see how unwanted feedback loops may arise and the parameters could get stuck in a poor local minimum, or even diverge catastrophically [12]. By using experience replay the behavior distribution is averaged over many of its previous states, smoothing out learning and avoiding oscillations or divergence in the parameters. Note that when learning by experience replay, it is necessary to learn off-policy (because our current parameters are different to those used to generate the sample), which motivates the choice of Q-learning.
In practice, our algorithm only stores the last $N$ experience tuples in the replay memory, and samples uniformly at random from $\mathcal{D}$ when performing updates. This approach is in some respects limited since the memory buffer does not differentiate important transitions and always overwrites with recent transitions due to the finite memory size $N$. Similarly, the uniform sampling gives equal importance to all transitions in the replay memory. A more sophisticated sampling strategy might emphasize transitions from which we can learn the most, similar to prioritized sweeping [22].

4.1 Preprocessing and Model Architecture
Working directly with raw Atari frames, which are $106$ pixel images with a 128 color palette, can be computationally demanding, so we apply a basic preprocessing step aimed at reducing the input dimensionality. The raw frames are preprocessed by first converting their RGB representation to gray-scale and down-sampling it to a $19$ image. The final input representation is obtained by cropping an $1800$ region of the image that roughly captures the playing area. The final cropping stage is only required because we use the GPU implementation of 2D convolutions from [1], which expects square inputs. For the experiments in this paper, the function $920$ from Algorithm 1 applies this preprocessing to the last $\textbf{1720}$ frames of a history and stacks them to produce the input to the $1332$-function.
There are several possible ways of parameterizing $4$ using a neural network. Since $91$ maps history-action pairs to scalar estimates of their Q-value, the history and the action have been used as inputs to the neural network by some previous approaches [18, 19]. The main drawback of this type of architecture is that a separate forward pass is required to compute the Q-value of each action, resulting in a cost that scales linearly with the number of actions. We instead use an architecture in which there is a separate output unit for each possible action, and only the state representation is an input to the neural network. The outputs correspond to the predicted Q-values of the individual action for the input state. The main advantage of this type of architecture is the ability to compute Q-values for all possible actions in a given state with only a single forward pass through the network.
We now describe the exact architecture used for all seven Atari games. The input to the neural network consists is an $-16$ image produced by $1325$. The first hidden layer convolves $800$ $1145$ filters with stride $\textbf{5184}$ with the input image and applies a rectifier nonlinearity [23, 24]. The second hidden layer convolves $\textbf{225}$ $\textbf{661}$ filters with stride $\textbf{21}$, again followed by a rectifier nonlinearity. The final hidden layer is fully-connected and consists of $\textbf{4500}$ rectifier units. The output layer is a fully-connected linear layer with a single output for each valid action. The number of valid actions varied between $\textbf{1740}$ and $1075$ on the games we considered. We refer to convolutional networks trained with our approach as Deep Q-Networks (DQN).
5. Experiments
Section Summary: Researchers tested their AI approach on seven classic Atari games, using the same basic setup for learning and rewards across all, with a tweak to cap rewards at a small fixed value to make training consistent despite varying game scores. They trained the AI for 10 million game frames using a technique called RMSProp and a replay buffer, noting that while game scores fluctuated wildly during training, the AI's internal estimates of its performance improved steadily without any breakdowns. Visualizations showed the AI learning to anticipate rewards in complex scenarios like Seaquest, and the results compared favorably to other reinforcement learning methods from prior studies.
So far, we have performed experiments on seven popular ATARI games – Beam Rider, Breakout, Enduro, Pong, Q*bert, Seaquest, Space Invaders. We use the same network architecture, learning algorithm and hyperparameters settings across all seven games, showing that our approach is robust enough to work on a variety of games without incorporating game-specific information. While we evaluated our agents on the real and unmodified games, we made one change to the reward structure of the games during training only. Since the scale of scores varies greatly from game to game, we fixed all positive rewards to be $\epsilon$ and all negative rewards to be $\epsilon=0.05$, leaving $\epsilon$ rewards unchanged. Clipping the rewards in this manner limits the scale of the error derivatives and makes it easier to use the same learning rate across multiple games. At the same time, it could affect the performance of our agent since it cannot differentiate between rewards of different magnitude.
In these experiments, we used the RMSProp algorithm with minibatches of size 32. The behavior policy during training was $\epsilon=0.05$-greedy with $\epsilon$ annealed linearly from $8$ to $4$ over the first million frames, and fixed at $0.1$ thereafter. We trained for a total of $10$ million frames and used a replay memory of one million most recent frames.
Following previous approaches to playing Atari games, we also use a simple frame-skipping technique [8]. More precisely, the agent sees and selects actions on every $k^{th}$ frame instead of every frame, and its last action is repeated on skipped frames. Since running the emulator forward for one step requires much less computation than having the agent select an action, this technique allows the agent to play roughly $k$ times more games without significantly increasing the runtime. We use $k=4$ for all games except Space Invaders where we noticed that using $k=4$ makes the lasers invisible because of the period at which they blink. We used $k=3$ to make the lasers visible and this change was the only difference in hyperparameter values between any of the games.
5.1 Training and Stability
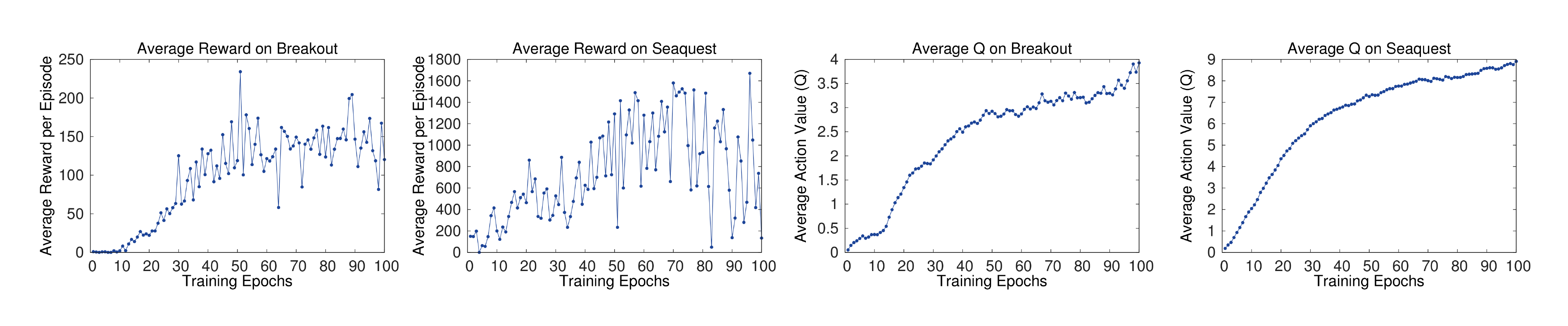
In supervised learning, one can easily track the performance of a model during training by evaluating it on the training and validation sets. In reinforcement learning, however, accurately evaluating the progress of an agent during training can be challenging. Since our evaluation metric, as suggested by [8], is the total reward the agent collects in an episode or game averaged over a number of games, we periodically compute it during training. The average total reward metric tends to be very noisy because small changes to the weights of a policy can lead to large changes in the distribution of states the policy visits . The leftmost two plots in Figure 2 show how the average total reward evolves during training on the games Seaquest and Breakout. Both averaged reward plots are indeed quite noisy, giving one the impression that the learning algorithm is not making steady progress. Another, more stable, metric is the policy's estimated action-value function $Q$, which provides an estimate of how much discounted reward the agent can obtain by following its policy from any given state. We collect a fixed set of states by running a random policy before training starts and track the average of the maximum[^2] predicted $Q$ for these states. The two rightmost plots in Figure 2 show that average predicted $Q$ increases much more smoothly than the average total reward obtained by the agent and plotting the same metrics on the other five games produces similarly smooth curves. In addition to seeing relatively smooth improvement to predicted $Q$ during training we did not experience any divergence issues in any of our experiments. This suggests that, despite lacking any theoretical convergence guarantees, our method is able to train large neural networks using a reinforcement learning signal and stochastic gradient descent in a stable manner.
[^2]: The maximum for each state is taken over the possible actions.
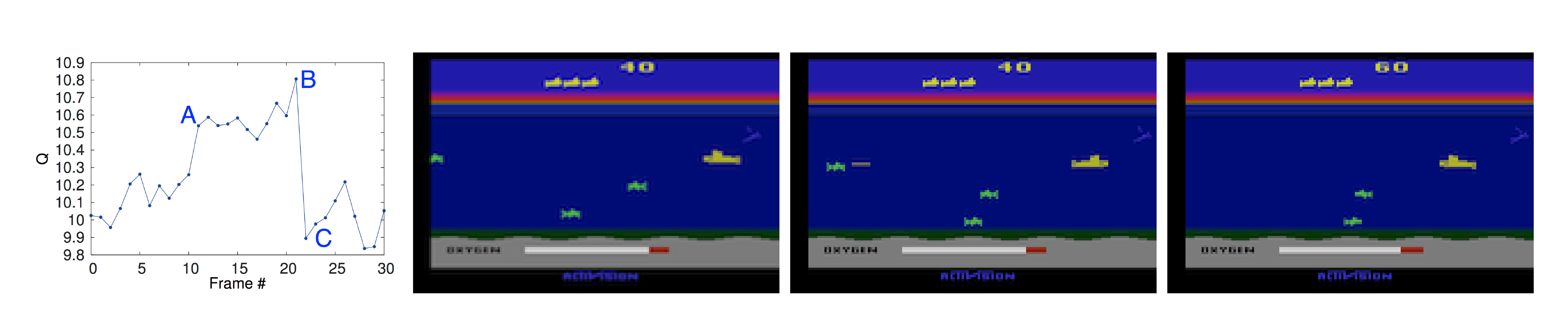
5.2 Visualizing the Value Function
Figure 3 shows a visualization of the learned value function on the game Seaquest. The figure shows that the predicted value jumps after an enemy appears on the left of the screen (point A). The agent then fires a torpedo at the enemy and the predicted value peaks as the torpedo is about to hit the enemy (point B). Finally, the value falls to roughly its original value after the enemy disappears (point C). Figure 3 demonstrates that our method is able to learn how the value function evolves for a reasonably complex sequence of events.
5.3 Main Evaluation
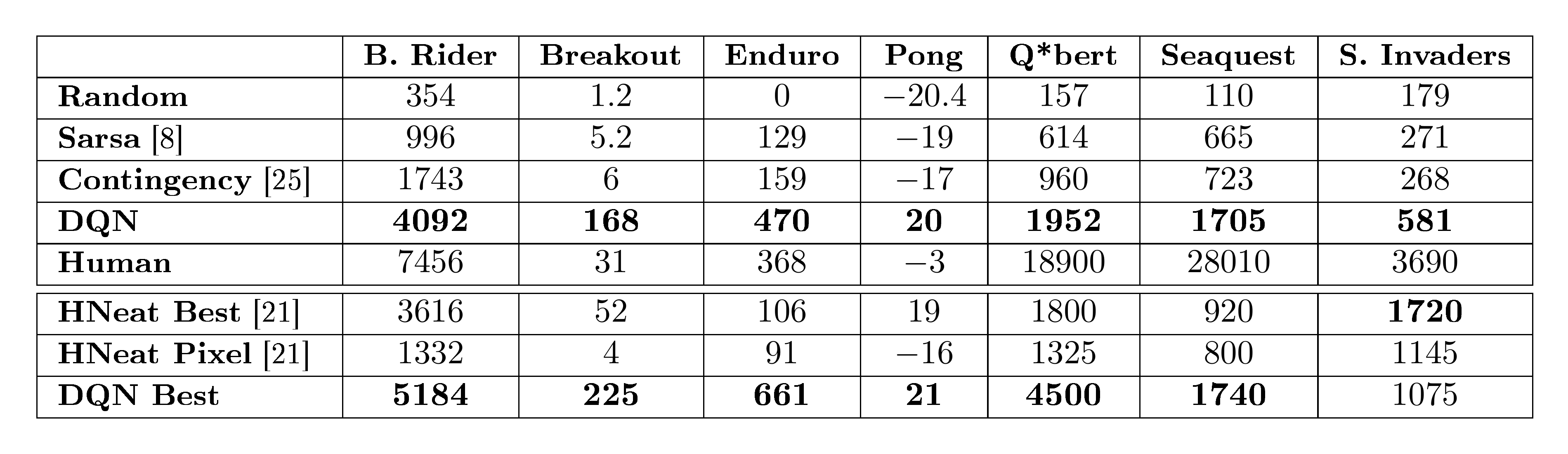
We compare our results with the best performing methods from the RL literature [8, 25]. The method labeled Sarsa used the Sarsa algorithm to learn linear policies on several different feature sets hand-engineered for the Atari task and we report the score for the best performing feature set [8]. Contingency used the same basic approach as Sarsa but augmented the feature sets with a learned representation of the parts of the screen that are under the agent's control [25]. Note that both of these methods incorporate significant prior knowledge about the visual problem by using background subtraction and treating each of the 128 colors as a separate channel. Since many of the Atari games use one distinct color for each type of object, treating each color as a separate channel can be similar to producing a separate binary map encoding the presence of each object type. In contrast, our agents only receive the raw RGB screenshots as input and must learn to detect objects on their own.
In addition to the learned agents, we also report scores for an expert human game player and a policy that selects actions uniformly at random. The human performance is the median reward achieved after around two hours of playing each game. Note that our reported human scores are much higher than the ones in Bellemare et al. [8]. For the learned methods, we follow the evaluation strategy used in Bellemare et al. [8, 26] and report the average score obtained by running an $\epsilon$-greedy policy with $\epsilon=0.05$ for a fixed number of steps. The first five rows of Table 1 show the per-game average scores on all games. Our approach (labeled DQN) outperforms the other learning methods by a substantial margin on all seven games despite incorporating almost no prior knowledge about the inputs.
::: {caption="Table 1: The upper table compares average total reward for various learning methods by running an $\epsilon$-greedy policy with $\epsilon=0.05$ for a fixed number of steps. The lower table reports results of the single best performing episode for HNeat and DQN. HNeat produces deterministic policies that always get the same score while DQN used an $\epsilon$-greedy policy with $\epsilon=0.05$."}
:::
We also include a comparison to the evolutionary policy search approach from [21] in the last three rows of Table 1. We report two sets of results for this method. The HNeat Best score reflects the results obtained by using a hand-engineered object detector algorithm that outputs the locations and types of objects on the Atari screen. The HNeat Pixel score is obtained by using the special 8 color channel representation of the Atari emulator that represents an object label map at each channel. This method relies heavily on finding a deterministic sequence of states that represents a successful exploit. It is unlikely that strategies learnt in this way will generalize to random perturbations; therefore the algorithm was only evaluated on the highest scoring single episode. In contrast, our algorithm is evaluated on $\epsilon$-greedy control sequences, and must therefore generalize across a wide variety of possible situations. Nevertheless, we show that on all the games, except Space Invaders, not only our max evaluation results (row $8$), but also our average results (row $4$) achieve better performance.
Finally, we show that our method achieves better performance than an expert human player on Breakout, Enduro and Pong and it achieves close to human performance on Beam Rider. The games Q*bert, Seaquest, Space Invaders, on which we are far from human performance, are more challenging because they require the network to find a strategy that extends over long time scales.
6. Conclusion
Section Summary: This paper introduces a new deep learning model for reinforcement learning that excels at learning tough control strategies for classic Atari 2600 video games, relying solely on raw pixel inputs from the screen. It also features an enhanced version of online Q-learning, which uses random batch updates and a replay of past experiences to make training deep networks smoother and more efficient. The approach delivered top results in six of the seven games tested, without needing tweaks to the model's structure or settings.
This paper introduced a new deep learning model for reinforcement learning, and demonstrated its ability to master difficult control policies for Atari 2600 computer games, using only raw pixels as input. We also presented a variant of online Q-learning that combines stochastic minibatch updates with experience replay memory to ease the training of deep networks for RL. Our approach gave state-of-the-art results in six of the seven games it was tested on, with no adjustment of the architecture or hyperparameters.
References
Section Summary: This references section lists key academic papers, theses, and books from the early 1990s to 2013 that shaped artificial intelligence, particularly deep learning and reinforcement learning. It includes groundbreaking works on convolutional neural networks for image classification and object detection, recurrent networks for speech recognition, and foundational reinforcement learning techniques like Q-learning and temporal difference methods applied to games such as backgammon and Atari. These citations highlight innovations in neural architectures, function approximation, and efficient learning algorithms for tasks like robotics and environmental modeling.
[1] Alex Krizhevsky, Ilya Sutskever, and Geoff Hinton. Imagenet classification with deep convolutional neural networks. In Advances in Neural Information Processing Systems 25, pages 1106–1114, 2012.
[2] Pierre Sermanet, Koray Kavukcuoglu, Soumith Chintala, and Yann LeCun. Pedestrian detection with unsupervised multi-stage feature learning. In Proc. International Conference on Computer Vision and Pattern Recognition (CVPR 2013). IEEE, 2013.
[3] Volodymyr Mnih. Machine Learning for Aerial Image Labeling. PhD thesis, University of Toronto, 2013.
[4] George E. Dahl, Dong Yu, Li Deng, and Alex Acero. Context-dependent pre-trained deep neural networks for large-vocabulary speech recognition. Audio, Speech, and Language Processing, IEEE Transactions on, 20(1):30 –42, January 2012.
[5] Alex Graves, Abdel-rahman Mohamed, and Geoffrey E. Hinton. Speech recognition with deep recurrent neural networks. In Proc. ICASSP, 2013.
[6] Christopher JCH Watkins and Peter Dayan. Q-learning. Machine learning, 8(3-4):279–292, 1992.
[7] Long-Ji Lin. Reinforcement learning for robots using neural networks. Technical report, DTIC Document, 1993.
[8] Marc G Bellemare, Yavar Naddaf, Joel Veness, and Michael Bowling. The arcade learning environment: An evaluation platform for general agents. Journal of Artificial Intelligence Research, 47:253–279, 2013.
[9] Richard Sutton and Andrew Barto. Reinforcement Learning: An Introduction. MIT Press, 1998.
[10] Gerald Tesauro. Temporal difference learning and td-gammon. Communications of the ACM, 38(3):58–68, 1995.
[11] Jordan B. Pollack and Alan D. Blair. Why did td-gammon work. In Advances in Neural Information Processing Systems 9, pages 10–16, 1996.
[12] John N Tsitsiklis and Benjamin Van Roy. An analysis of temporal-difference learning with function approximation. Automatic Control, IEEE Transactions on, 42(5):674–690, 1997.
[13] Leemon Baird. Residual algorithms: Reinforcement learning with function approximation. In Proceedings of the 12th International Conference on Machine Learning (ICML 1995), pages 30–37. Morgan Kaufmann, 1995.
[14] Brian Sallans and Geoffrey E. Hinton. Reinforcement learning with factored states and actions. Journal of Machine Learning Research, 5:1063–1088, 2004.
[15] Nicolas Heess, David Silver, and Yee Whye Teh. Actor-critic reinforcement learning with energy-based policies. In European Workshop on Reinforcement Learning, page 43, 2012.
[16] Hamid Maei, Csaba Szepesvari, Shalabh Bhatnagar, Doina Precup, David Silver, and Rich Sutton. Convergent Temporal-Difference Learning with Arbitrary Smooth Function Approximation. In Advances in Neural Information Processing Systems 22, pages 1204–1212, 2009.
[17] Hamid Maei, Csaba Szepesvári, Shalabh Bhatnagar, and Richard S. Sutton. Toward off-policy learning control with function approximation. In Proceedings of the 27th International Conference on Machine Learning (ICML 2010), pages 719–726, 2010.
[18] Martin Riedmiller. Neural fitted q iteration–first experiences with a data efficient neural reinforcement learning method. In Machine Learning: ECML 2005, pages 317–328. Springer, 2005.
[19] Sascha Lange and Martin Riedmiller. Deep auto-encoder neural networks in reinforcement learning. In Neural Networks (IJCNN), The 2010 International Joint Conference on, pages 1–8. IEEE, 2010.
[20] Marc Bellemare, Joel Veness, and Michael Bowling. Sketch-based linear value function approximation. In Advances in Neural Information Processing Systems 25, pages 2222–2230, 2012.
[21] Matthew Hausknecht, Risto Miikkulainen, and Peter Stone. A neuro-evolution approach to general atari game playing. 2013.
[22] Andrew Moore and Chris Atkeson. Prioritized sweeping: Reinforcement learning with less data and less real time. Machine Learning, 13:103–130, 1993.
[23] Kevin Jarrett, Koray Kavukcuoglu, Marc’Aurelio Ranzato, and Yann LeCun. What is the best multi-stage architecture for object recognition? In Proc. International Conference on Computer Vision and Pattern Recognition (CVPR 2009), pages 2146–2153. IEEE, 2009.
[24] Vinod Nair and Geoffrey E Hinton. Rectified linear units improve restricted boltzmann machines. In Proceedings of the 27th International Conference on Machine Learning (ICML 2010), pages 807–814, 2010.
[25] Marc G Bellemare, Joel Veness, and Michael Bowling. Investigating contingency awareness using atari 2600 games. In AAAI, 2012.
[26] Marc G. Bellemare, Joel Veness, and Michael Bowling. Bayesian learning of recursively factored environments. In Proceedings of the Thirtieth International Conference on Machine Learning (ICML 2013), pages 1211–1219, 2013.