AI Co-Mathematician: Accelerating Mathematicians with Agentic AI
Daniel Zheng$^{1}$, Ingrid von Glehn$^{1}$, Yori Zwols$^{1}$, Iuliya Beloshapka$^{1}$, Lars Buesing$^{1}$, Daniel M.~Roy$^{1}$, Martin Wattenberg$^{1}$, Bogdan Georgiev$^{1}$, Tatiana Schmidt$^{1}$, Andrew Cowie$^{1}$, Fernanda Viegas$^{1}$, Dimitri Kanevsky$^{1}$, Vineet Kahlon$^{2}$, Hartmut Maennel$^{1}$, Sophia Alj$^{1}$, George Holland$^{1}$, Alex Davies$^{1}$, Pushmeet Kohli$^{1}$
$^{1}$ Google Research
$^{2}$ Google
Abstract
We introduce the AI co-mathematician, a workbench for mathematicians to interactively leverage AI agents to pursue open-ended research. The AI co-mathematician is optimized to provide holistic support for the exploratory and iterative reality of mathematical workflows, including ideation, literature search, computational exploration, theorem proving and theory building. By providing an asynchronous, stateful workspace that manages uncertainty, refines user intent, tracks failed hypotheses, and outputs native mathematical artifacts, the system mirrors human collaborative workflows. In early tests, the AI co-mathematician helped researchers solve open problems, identify new research directions, and uncover overlooked literature references. Besides demonstrating a highly interactive paradigm for AI-assisted mathematical discovery, the AI co-mathematician also achieves state of the art results on hard problem-solving benchmarks, including scoring 48% on FrontierMath Tier 4, a new high score among all AI systems evaluated.
Correspondence: [email protected], [email protected]
Executive Summary: Mathematics research involves a messy, iterative process of exploring ideas, testing hypotheses, searching literature, and building proofs, but current AI tools often handle only isolated tasks like solving equations or generating code. This leaves mathematicians to manually connect the dots, slowing discovery in fields critical to science, technology, and innovation—such as algorithms, cryptography, and physics modeling. With AI models now matching human performance on many math problems, the real bottleneck has shifted to supporting end-to-end workflows, much like how AI coding tools have transformed software development. Addressing this gap is urgent as AI advances could unlock faster breakthroughs in unsolved problems that underpin global challenges.
This document introduces the AI co-mathematician, an interactive workbench designed to assist mathematicians by orchestrating AI agents in a collaborative research environment. It aims to demonstrate how such a system can handle the full spectrum of math work—from brainstorming and literature reviews to computations and proof drafting—while keeping humans in the loop for steering and validation.
The team at Google Research built the system using off-the-shelf Gemini language models, without custom training. At its core is a stateful workspace that tracks project progress over time, with a hierarchy of AI agents: a top-level coordinator assigns tasks to specialized sub-agents for parallel streams like literature searches or code development, all sharing files and messages. Key features include interactive goal-setting with users, built-in reviews to catch errors, hard rules to prevent shortcuts or hallucinations, and outputs in standard math formats like LaTeX documents. Development drew from observations of real math practices and tests with a small group of professional mathematicians over several months. No advanced specialized AI engines were integrated yet, but the design allows for future additions.
The system's early tests revealed strong results. First, it enabled mathematicians to resolve open problems: one user solved a long-standing question from the Kourovka Notebook in topology by steering agents through flawed drafts to a complete proof, incorporating their expertise to fill gaps. Another proved two conjectures on Stirling coefficients in symmetric power representations, generating computational evidence and inductive formulas where prior tools failed. A third resolved a technical lemma in Hamiltonian systems, producing an elegant proof after literature synthesis. Second, on an internal benchmark of 100 research-level math problems, it solved more cases than base Gemini models alone, leveraging tools like code execution and searches to handle complex reductions, such as turning tiling problems into solvable logic puzzles. Third, it set a new record on the challenging FrontierMath Tier 4 benchmark, solving 48% of 48 extreme research-like problems—about 2.5 times better than the base model and higher than any prior AI system—by running extended agent workflows without human input.
These findings show the AI co-mathematician can meaningfully speed up math discovery by acting as a tireless collaborator that manages routine tasks, uncovers insights, and documents failures transparently, reducing the time researchers spend on dead ends or literature hunts. This matters because it could cut timelines for breakthroughs in high-stakes areas like optimization algorithms or theoretical physics, boosting efficiency without replacing human creativity. Unlike expectations of fully autonomous AI, the results highlight the value of human-AI interplay, where users familiar with a domain achieve the best outcomes, differing from past tools that prioritized solo solving and often hit walls on nuanced exploration.
Next steps should include expanding access beyond the limited prototype to more mathematicians, integrating cutting-edge engines like AlphaProof for formal verification or AlphaEvolve for searches to enhance reliability on hard tasks. Organizations should pilot the tool in research teams, prioritizing training on effective prompting to maximize gains. If scaling compute proves costly, trade-offs might involve shorter runs for routine work versus longer ones for deep dives. Further analysis of user feedback is needed to refine interfaces and benchmarks that better measure interactive collaboration, rather than just final answers.
Confidence in benchmark results is high, given blind external evaluations and clear outperformance, but real-world use varies: it shines for exploratory tasks in familiar areas yet struggles with highly novel or compute-heavy problems. Limitations include reliance on informal proofs prone to subtle errors, higher resource demands than simple chat AIs, and risks like over-reliance on AI outputs without verification. Data gaps exist for long-term impacts, so readers should approach deployment cautiously, starting with supervised applications.
1. Introduction
Section Summary: Mathematics research involves a hidden, iterative process of exploration, testing ideas, and revising proofs, far beyond the polished publications that appear publicly. Recent AI developments have boosted areas like automated reasoning, algorithm discovery, and formal proofs, but they fall short in supporting the long-term, collaborative workflows that mathematicians use to manage uncertainty, synthesize information, and track evolving hypotheses. To address this, the introduction proposes the AI co-mathematician, an interactive workbench powered by advanced language models that acts like a collaborative partner, orchestrating AI agents to assist in open-ended research while integrating with existing tools to speed up genuine discoveries.
Mathematics research is a multi-dimensional, complex, highly iterative process. While the publication record is built almost entirely on polished, rigorous proofs, a mathematician's day-to-day work has long been understood to involve activities traditionally concealed from public view ([1, 2, 3]). Beneath the final formalism lies a deeply exploratory process, where initial intuitions are tested, counter-examples are discovered, and both core definitions and proofs are subjected to continuous cycles of refutation and revision.
Recent years have seen an explosion of capabilities in AI-for-mathematics, rapidly expanding the field across several distinct dimensions. In the realm of autonomous mathematical reasoning, building on early systems like Minerva ([4]) and the vast body of subsequent work ([5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16]), the field has now advanced to breakthroughs like the autonomous research system Aletheia ([17]). In the realm of exploratory search, AlphaEvolve ([18, 19]) and systems it has inspired ([20, 21, 22]) allow researchers to uncover novel algorithms and structures through continuous, steerable evolutionary runs. In the realm of formalized mathematics, AlphaProof ([23]), related systems ([24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36]), and interactive environments such as Aristotle ([37]) have deeply integrated reinforcement learning and language models into verified mathematics and open-source proof assistants. Meanwhile, the inference-scaling models currently powering commercial chat interfaces have already brought immense problem-solving power directly into the hands of mathematicians.
Yet first-hand experience with these systems reveals that a critical dimension of mathematical research remains under-supported: the orchestration of these capabilities into a long-term, stateful, collaborative workflow. Day-to-day mathematics is rarely a sequence of isolated queries or computer-assisted proofs; it involves managing uncertainty, synthesizing disparate literature, drafting and revising intermediate artifacts, and tracking complex, branching hypotheses over days or weeks.
Because standard chat interfaces are inherently transient and specialized engines lack broader context, researchers must act as the manual connective tissue between conversational brainstorming, formal provers, and computational scripts. While software developers increasingly rely on AI-powered coding environments to provide this exact kind of orchestration, those tools are fundamentally optimized for the lifecycle of code, not the unique abstractions, proofs, and artifacts of mathematics. To truly accelerate discovery, we believe the next phase of AI-for-mathematics must focus on this missing dimension of orchestration, natively supporting the full, messy reality of mathematical activities.
To understand how to build a native environment for these activities, we can look deeper into the field of software engineering. Recent advancements (for example, Google Antigravity ([38]), Claude Code ([39]), and OpenAI Codex ([40])) have demonstrated the transformative potential of efficient interactive collaboration between humans and agentic AI systems. One of the reasons behind the success of these systems is that pre-existing software engineering practices embody the paradigms necessary to capture and accelerate iterative exploration. Informal software specifications such as design documents allow agents to work autonomously for long periods of time whilst remaining on a predefined path, and continuous testing pipelines provide an automated flow for verification, while version control seamlessly tracks and maintains the evolving state of a project in a manner familiar to human professionals. In contrast, almost none of the analogous activities in the everyday work of a mathematician are routinely automated.
To establish this missing agentic flow for mathematics, we introduce the AI co-mathematician, a workbench for mathematicians to interactively leverage AI agents to pursue open-ended research, based on the latest Gemini language models.
The AI co-mathematician provides a stateful, interactive workspace where a project coordinator agent delegates complex tasks across parallel workstreams, allowing the user to direct and interact with an evolving research process, rather than waiting for end-to-end autonomous execution. As with other agentic systems, the AI co-mathematician is a harness designed to be used with standard, commercially available language models, and does not rely on any custom model behavior or training.
Importantly, the AI co-mathematician is designed to complement existing frontier approaches rather than replace them. By establishing this stateful architecture, we pave the way for powerful underlying engines—whether autonomous reasoners like AlphaProof and Aletheia, or evolutionary iterators like AlphaEvolve—to be deployed dynamically within the human researcher's interactive loop. While the AI co-mathematician itself is currently subject to a limited initial release, our goal is to develop future products that grant much broader access to this interactive paradigm.
In the remainder of this paper, we detail the philosophy and architecture behind the AI co-mathematician, and share early results. Section 2 outlines our core design principles for interactive, AI-assisted mathematics. Section 3 grounds these principles in practice through a concrete walkthrough, highlighting the programmatic constraints and adversarial review loops that prevent the system from taking the easy path on intractable problems, and the parallel workstreams which enable multi-faceted research. Section 4 discusses evaluation strategies for interactive mathematical agents such as the AI co-mathematician. Section 5 presents early qualitative results, demonstrating how practicing mathematicians have used the system to steer open-ended research and generate verifiable insights. Section 6 evaluates the system's performance on static problem-solving benchmarks, providing a baseline measurement of its underlying capabilities. Section 7 describes challenges and limitations we encountered in developing the AI co-mathematician. Finally, we conclude by outlining our vision for the next era of AI-assisted mathematics.
2. Design Principles for AI-Assisted Mathematics
Section Summary: The main goal of designing AI for mathematics is to help human mathematicians in their work, recognizing that math is a social activity focused on building human knowledge rather than just creating formal proofs. These AI tools are designed to fit into real mathematical practices by drawing on historical insights and lessons from past systems, like those at Google, while accounting for AI's current abilities and limitations. The approach follows seven key principles to make the AI a true partner in mathematical discovery.
The overriding goal of our design is to support human mathematicians in their own work. As [41] famously argued, mathematics is fundamentally a social enterprise aimed at advancing human understanding, rather than merely a machine for generating formal proofs. To genuinely accelerate mathematicians, AI tools must integrate into this human-centric reality. To this end, the AI co-mathematician is built to capture the enduring aspects of professional mathematical workflows, while pragmatically navigating the current strengths and weaknesses of AI reasoning. Our design is grounded in both historical accounts of mathematical practice and our experience observing and improving previous systems for mathematical discovery, especially those developed at Google. We relied on seven core principles to guide this design:

3. AI co-mathematician in practice: a walkthrough
Section Summary: This section walks through a sample session where an AI co-mathematician helps a researcher tackle an open problem in computational geometry, specifically proving upper limits on the size of a "sofa" shape that can navigate right-angle corners. The AI operates through a shared workspace managed by a hierarchy of agents, starting with a top-level coordinator that engages the user in dialogue to refine and approve project goals, avoiding the need for a perfectly crafted initial prompt. Once goals are set, the coordinator delegates tasks to parallel workstreams, each led by a sub-agent that conducts actions like literature searches or queries, producing incremental reports to track progress without overwhelming the user.
To demonstrate how our design principles manifest in practice, we walk through a representative session with the co-mathematician prototype.
In this scenario, a mathematician explores an open problem in computational geometry: proving upper bounds on the area of a "sofa" that can move around both left- and right-handed right-angle corners. This is a variant of a problem first introduced by [44], with the lower bound explored in recent work on applying AlphaEvolve to mathematical optimization problems ([45]).
Rather than functioning as a standard conversational chatbot, the system provides an associated "workspace" where all information for the project is stored. This workspace is operated on by a hierarchy of agents, which write their work to a shared file system and communicate via an internal messaging system. The user provides input and discusses their thoughts with the top-level project coordinator agent, which delegates work to other agents further down the chain, and so on. Much like in human organizations, we observed it to be important for the functioning of the group to have lines of communication and clear escalation pathways available to the agents, to use when they run into issues. See Figure 1 for an approximate diagram of the agent organization.
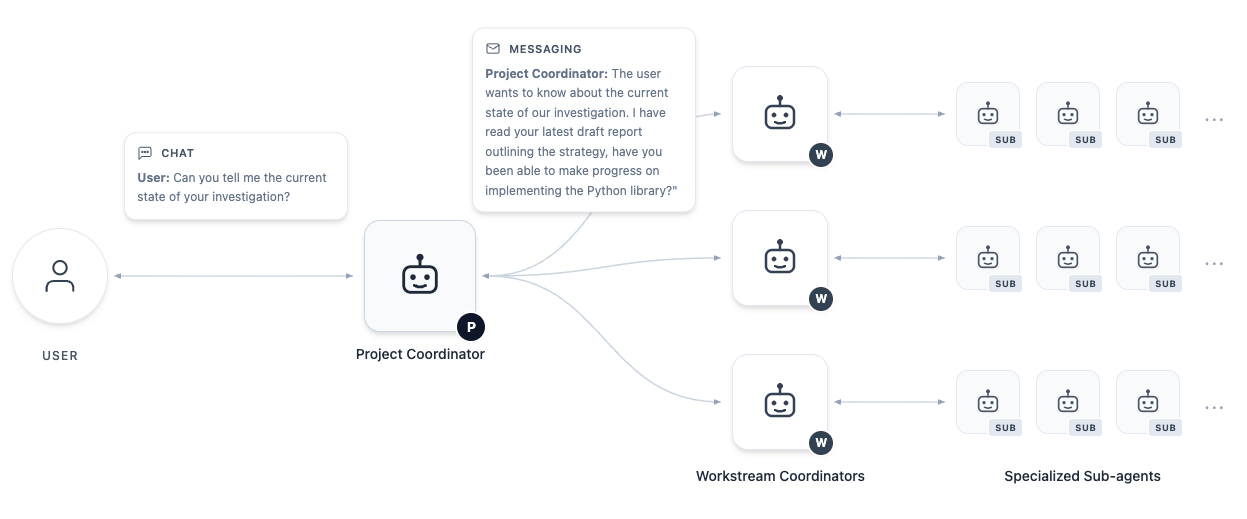
3.1 Initial Exploration

A standard zero-shot LLM requires the user to front-load a perfect prompt. Reflecting our principle to support the iterative refinement of intent, the AI co-mathematician begins with an interactive on-boarding phase designed to help the user formalize their intent.
In this example, the user initiates the session by uploading a recent paper ([45]) and some context into the chat interface: "I'd like to set up a project to see if we can prove some upper bounds on the variants of the moving sofa problem discussed in this paper."
The top-level project coordinator agent does not immediately start working on a solution. Instead, it opens a dialogue and acts as a sounding board, replying in the chat: "From the text, Baek has already proved that Gerver's lower bound is sharp for the classic sofa problem. However, the upper bounds for the other two variants are still open: $\ldots{}$ Would you like to focus on one in particular, or both? And are you aiming to prove that a specific lower bound is sharp, or simply establish any new, rigorous upper bound?"
Once the user clarifies, the project coordinator agent formalizes its understanding of the project's central question and high-level goals and presents them to the user. After reading these proposals in detail, the user requests changes to the wording of the goals, and the project coordinator updates them. At this point the user formally approves the goals, allowing the project coordinator to move on to the next phase of the project (Figure 2). By treating the initial interaction as a dialogue, the system ensures that downstream resources are directed toward the mathematician's actual, refined intent.
3.2 Branching the Research
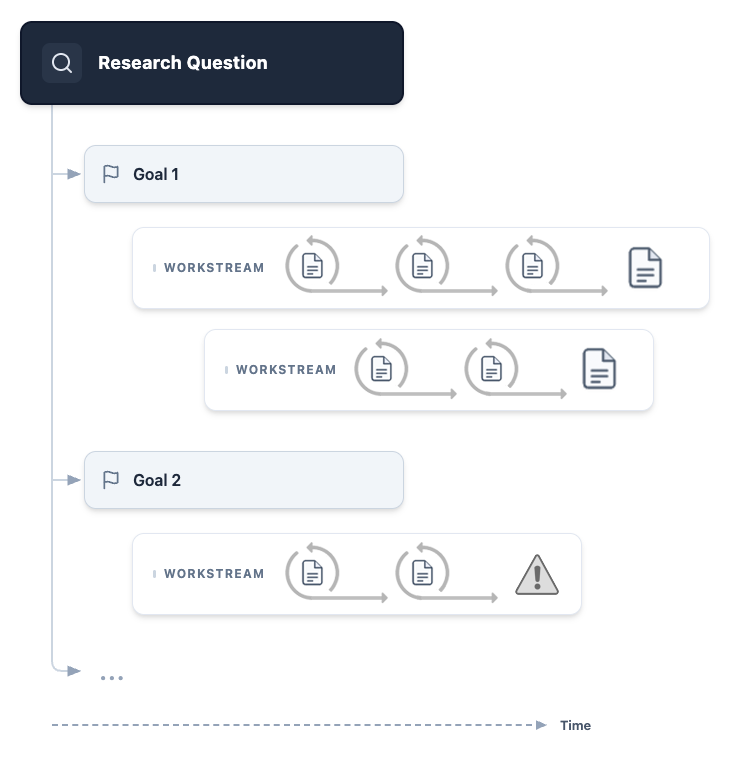
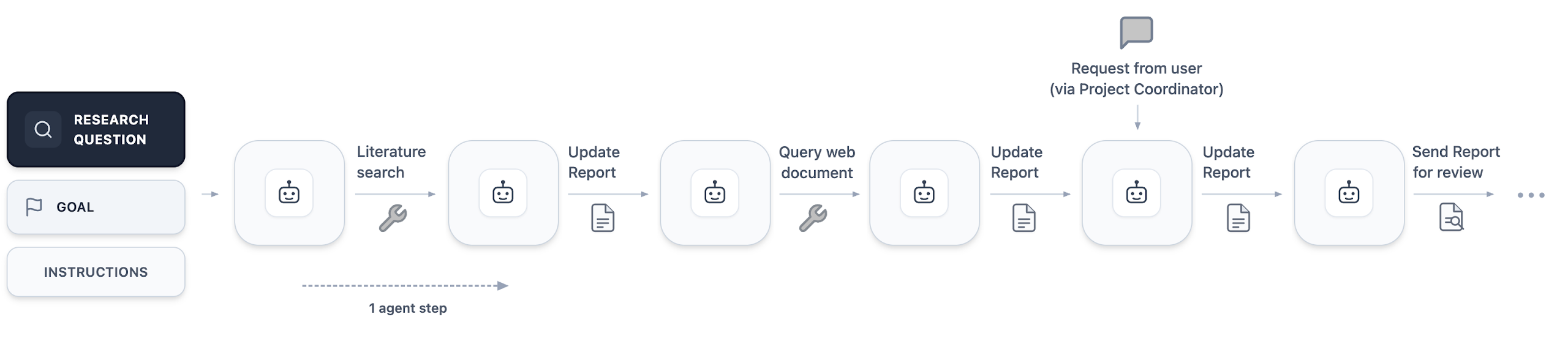
With the goals defined, the system manages the user's cognitive load via progressive disclosure: the project coordinator agent delegates work to parallel workstreams, each associated with one of the pre-approved goals, and managed by its own workstream coordinator agent (Figure 3). As input, the workstream coordinator receives the statements of the approved research question and the selected Goal, along with any specific instructions which the project coordinator chooses to provide. Each coordinator performs a linear sequences of actions, which may include delegating to specialized sub-agents (Figure 4). The diverse nature of these workstreams highlights the system's capacity to embrace mathematics beyond proofs. Currently, our specialized sub-agents are based on standard LLM calls (including Gemini Deep Think) and do not make use of advanced research systems such as AlphaEvolve, AlphaProof or Aletheia, but we illustrate the points in the process where they would naturally add value.
Here we describe a scenario where the project coordinator agent starts one workstream for each goal, but it is also possible to have multiple workstreams defined per goal, or for goals to remain unpopulated with workstreams until work they depend on has been completed.
Goal 1: Literature Review: A workstream coordinator agent delegates to a specialized literature review sub-agent. Utilizing our computationally intensive search tool, it discovers the key papers containing the machinery used for previous upper bounds in the sofa problem. With pointers to important references, it queries them directly using specific web and literature access tools, to identify the exact statements and proofs of key results.
Goal 2: Computational Framework: Another workstream coordinator agent tackles the task of designing the required computational framework. Based on strategies observed in prior literature, the workstream coordinator agent first designs the high-level logic for the computational framework, using a sub-agent creation tool to dispatch Gemini Deep Think to prove that this could give a rigorous upper bound as required. Once this is proven, it uses another sub-agent creation tool to create a coding agent, instructing it to implement the required Python library with associated tests and demonstration cases. As each of these agents gives status updates, the workstream coordinator agent asynchronously updates the user-facing workstream report with details of the proofs and provides links to the key code files.
All proofs in the existing system are purely informal, but the possibility of adding a formal prover such as AlphaProof would allow for increased confidence in the correctness of proofs, for those that are able to be stated and proved with existing formal mathematics libraries. Alternatively, using a stronger informal proving system such as Aletheia would add considerable power to the system, at an associated computational cost.
Goal 3: Execute the Search: The final branch-and-bound search is executed in a further workstream, created by the project coordinator agent after the computational framework workstream has successfully completed. The shared file system allows this workstream coordinator agent to import the library developed in the previous workstream, and it now uses a parallel code execution tool to scale up the search beyond a single script. Parallel code execution requests are run on separate cloud machines, avoiding the burden for the user to set up or access a local cluster. The results of the search are collated into a single file which is attached to the workstream report, with summary information and conclusions written up into the main text.
In the current prototype, such computational searches are executed as a combination of standard agent primitives, but the addition of evolutionary search algorithms such as AlphaEvolve would provide a supercharged engine for such optimization and search routines.
3.3 Interactive Steering and Hard Constraints
When tasked with solving difficult research problems, standard AI agents often find invalid shortcuts, hallucinate lemmas, hand-wave details, and claim success prematurely. One of the defining technical features of the AI co-mathematician is the application of hard programmatic constraints to prevent these failure modes, combined with active human steering by the user.
During the computational exploration, if the search space explodes, the naive backtracking approach initially proposed may fail. In this situation, the coding sub-agent is bound by strict rules: it cannot mark code as finished until its tests pass and a reviewer agent accepts the validity of the code and golden values in the tests. Because the reviewer agent repeatedly rejects the failing code, the workstream coordinator agent is blocked. Rather than silently restarting, the system preserves this failed exploration as a durable record in the shared file system, which the project coordinator reads.
Forced to manage and disclose its uncertainty, the project coordinator agent surfaces an alert to the user and explicitly asks for help in the chat: "Our initial implementation of the search is not efficient enough to find the result that we need, and there aren't many other examples in the literature. Do you have a mathematical intuition for a better pruning strategy we can apply? More details on the current approach can be found in the following document."
Crucially, the user is not locked out while agents work. Via the chat interface, the user reads the project coordinator's update and actively steers the project, sending a message to suggest a topological pruning heuristic, and directing the coordinator to create additional workstreams to investigate new bounding strategies while the current work is ongoing.
3.4 The Final Output
After the user steers the system past the computational bottleneck, the workstreams conclude their specific goals. However, the final output is not a transient chat message. Each workstream coordinator agent is responsible for producing, as its main output, a compiled and reviewed LaTeX write-up, which is displayed prominently to the user when they open the workstream.
In order to produce natural mathematical artifacts, we require the coordinators to meet specific criteria in these write-ups:

4. The Evaluation of Interactive Mathematical Agents
Section Summary: Traditionally, the success of AI in mathematics has been judged by how well it solves static problems on benchmarks like IMO ProofBench or GSM8K, but now that advanced AIs can match expert humans in raw problem-solving, the focus is shifting to other skills that mimic real mathematical workflows, such as fact-finding or spotting errors in proofs. While some benchmarks exist for these auxiliary tasks in competition math, none yet cover professional research, making it crucial to develop measurements that address the uneven "jagged frontier" of AI capabilities and better align with human collaboration. Ultimately, these interactive AI systems should be evaluated as tools assisting mathematicians in real-time, with evidence drawn first from actual user experiences and then from standalone performance tests.
Historically, AI-for-mathematics progress has been measured against static problem-solving benchmarks. Today, the field relies heavily on such benchmarks, including IMO ProofBench ([46]), FrontierMath ([47]), and PutnamBench ([48]), and their predecessors MATH ([49]) and GSM8K ([50]) were highly influential in measuring early LLM progress.
However, with frontier systems now demonstrably performing at or above the level of expert humans at raw problem-solving ability (e.g., [51, 52]), we believe the incremental value of improving this ability is reducing, and that progress in AI-assisted mathematics is now at least partially bottlenecked on other capabilities that reflect the broader workflows of professional mathematicians.
This implies, firstly, that AI systems should be measured against a wider array of tasks. Benchmarks such as DeepSearchQA ([53]) for general purpose fact-finding, and Hard2Verify ([54]) for mistake-finding in competition-mathematics proofs, measure capabilities with exact analogues in the mathematical research process. But to our knowledge no similar benchmarks have been developed for the setting of professional research mathematics. Clear measurements of these auxiliary capabilities (and improvements against them!) will become increasingly important as AI systems improve, to reduce the severity of the "jagged frontier" ([55]) and the associated impedance mismatch between human-driven and AI-driven mathematics.
And yet more importantly, we believe that AI-for-mathematics systems should be considered as human-in-the-loop by default, and advancements and achievements measured accordingly. This echoes our design principle that the foremost purpose of our system is to assist mathematicians with their work, not to achieve success independently of them. With this framing in mind, we first present results which have arisen from mathematicians directly using the AI co-mathematician (Section 5), followed by measurements of the AI co-mathematician's static problem-solving performance (Section 6).
5. Early Results with Mathematicians
Section Summary: Researchers have provided access to an AI tool designed to assist mathematicians with their work, allowing a small group of professionals to integrate it into tasks like reviewing literature, running experiments, and developing proofs across various math fields. In one case, mathematician M. Lackenby used the AI to solve a longstanding open problem in group theory by collaborating iteratively with it, where the tool drafted arguments, identified errors, and helped refine a complete proof after his input. Another user, G. Bérczi, fed the AI detailed background on conjectures about Stirling coefficients, resulting in proofs for two of them along with supporting computations, though overall feedback from users varies, highlighting both successes and areas for improvement.
As part of our efforts to make interactive tools more widely available, we have given access to the AI co-mathematician to a small number of professional mathematicians to use for their own research. The wide range of use cases that early users have explored with the AI co-mathematician reflects its broad applicability and integration into standard research workflows. The AI co-mathematician has served as a functional aid in instances such as navigating disparate literatures, performing numerical experimentation, and obtaining proofs across several domains in mathematics. In the remainder of this section, we showcase several use cases illustrating the system's current utility, obtained by recent users in our limited release. It should be stated that whilst many users have had successful interactions with the AI co-mathematician leading to novel discoveries, there has been a range of feedback and satisfaction with the tool, and other users have found it less effective for their work. We discuss some of the challenges in Section 7, and we hope to use the experiences and feedback from these mathematicians to inform future benchmarking and development directions.
Notably, all results showcased here were produced independently by mathematicians using the tool directly, without any supervision or intervention from GDM researchers.
5.1 Case Study: A Kourovka Problem
An early user, M. Lackenby, used AI co-mathematician to investigate several problems in topology and group theory. His work led to a resolution of an open question (Problem 21.10 from the Kourovka Notebook).[^1] Lackenby's process in this case illustrates the value of a "mathematician-in-the-loop" style of interaction.
[^1]: The problem asks whether every finite group admits a so-called "just finite presentation, " i.e., a finite presentation where removing any relation results in an infinite group. The answer turned out to be affirmative.
Lackenby began by simply typing in the problem statement; the system confirmed the meaning and then created two independent workstreams, one attempting to prove the result, the other to disprove it. The first result to come back was a "proof" that the system itself marked as incorrect—a workstream had written up an argument, but then a reviewer agent had found a flaw. However, when looking at the paper, Lackenby realized that despite this gap, it contained what he called a "really, really clever proof strategy." Furthermore, when he read the reviewer's critique of the proof, he realized, "Hang on a second, I know how to fill that gap."
He pointed out a way to correct the argument, and the system was able to write up a complete and correct proof. Finally, Lackenby downloaded the document and applied his own revisions—generalizing the result and adding examples—before uploading it again and asking the project coordinator to create a workstream for a final review. It did so, spotting two minor issues in the paper that he fixed for the final copy.
A lesson from this case is that the back-and-forth between AI and mathematician was crucial to the resolution of the problem. To Lackenby, this suggests "the system works best when the user is familiar with the area." While one might see this as a limitation, he adds, "What's the point in getting it to solve a problem that I have no idea about?"
Agent Actions
Behind the scenes, the coordinator agent for the workstream:
- Created a coding sub-agent to perform a computational search for non-just-finite presentations, which succeeded in finding two examples.
- Analyzed these and performed literature searches to identify relevant theory to their constructions, leading to a general method of producing non-just-finite presentations.
- Noted that this did not negatively resolve the conjecture (as groups may have multiple presentations, and finding one non-just-finite presentation does not imply that none of them are just-finite), but decided to conclude its workstream here with a sharper conjecture based on this argument, and sent the report for review.
- Opened a back-and-forth discussion with reviewer agents as part of the review process. During this, one of the reviewer agents spotted a method that could be used to prove the conjecture in the positive direction.
- Agreed with the reviewer and pivoted the workstream to writing up this method. After further reviews, this led to the draft which Lackenby augmented to complete the proof.
5.2 Case Study: Stirling Coefficients
Another early user, G. Bérczi, approached the AI co-mathematician by initially tackling a problem concerning the behavior of Stirling coefficients for symmetric power representations. Specifically, the conjectures hypothesized that in a certain binomial expansion, the coefficients are not only strictly positive but also form a log-concave sequence.
To initiate the project, Bérczi prepared a brief note introducing the topic, the background of the conjectures, and known methods. This primer also included suggested directions derived from his prior experiments with other systems, such as AlphaEvolve. While AlphaEvolve had failed to resolve the higher-index cases, it had hinted at a possible direction to recover an inductive formula for the coefficients. Bérczi included this in his document, which he uploaded as part of the initial project formulation discussion. This style of providing deep, rich background on the problem, which Bérczi referred to as "structured posing of questions, " was one that he had found effective with other AI systems.
In response to Bérczi's question, the AI co-mathematician established proofs (currently in detailed human review) for two of the conjectures in separate workstreams. It additionally provided detailed computational evidence for its claims as well as for investigations into the unproven conjectures. Bérczi noted that the design of the system helped in various ways. Not only was it easy to follow the "green ticks" checking off tasks, but more importantly, a marginal comment in the finished document alerted him to a key insight, which he was able to ask about in the chat interface. Nonetheless, he pointed out that collaborating with AI systems requires some skill, saying "It's not trivial how to use this now" and suggested that "It will make a big difference between mathematicians, how they use these models."
Agent Actions
Two key workstreams provided claimed proofs of the conjectures. To illustrate the workflow, in the first workstream, the coordinator agent:
- Created a coding sub-agent to perform an initial computational enumeration of expansions, to an extent that was reasonable to run in a few minutes.
- Observed from the results that the conjecture as stated was false for $n = 1, 2$, but appeared to hold for larger $n$, and further that its original proof strategy was invalid.
- Used a Gemini Deep Think sub-agent to propose a new proof strategy for the updated conjecture. It did so successfully, convincing the workstream coordinator agent and subsequently the reviewer agent.
5.3 Case Study: A
Lemma in Hamiltonian Systems
A third early user of the AI co-mathematician, S. Rezchikov, posed a recent technical subproblem that he had come across in his research, on the topic of the existence of perturbations of a specific class of Hamiltonian diffeomorphism with certain convenient properties.
Using the system, Rezchikov discussed the problem with the project coordinator agent and provided supplementary papers which contained results relevant to the problem statement, until agreement was reached on the precise definition of the task, and a workstream created in order to attempt to solve it. The write-up produced by the workstream included a key lemma with an elegant proof, that withstood careful checking, and essentially resolved the question posed by Rezchikov. Again, Rezchikov noted that other AI systems had failed to prove the result given the same prompt, though without multiple sampling attempts and controlled conditions it is hard to draw conclusions from such individual experiments.
Rezchikov made two other observations which shed light on the value of the system. One was about exploration of an approach which did not seem to work: here the added value was that the system let him reach a dead end faster than otherwise. As he put it, "I could have easily spent a week dreaming about what was there, but instead I just moved on." Separately, he noted that the quality of correct proofs seemed comparatively high: "I would rank, aesthetically, its general style of proofs as the best one of any models I've gotten to use."
This gives an illustration of how the AI co-mathematician can help mathematics researchers explore ideas in a manner that integrates naturally into their typical exploratory research workflows.
Agent Actions
In this case, the workstream coordinator agent:
- Performed a literature review using the specialized tool, into commonly used techniques and pitfalls for the problem in question, which highlighted a few key properties to be aware of in addition to those provided by Rezchikov.
- Made specific follow-up literature queries to understand the precise nature of these points.
- Passed the problem statement and the key pieces of context to Gemini Deep Think, which produced the proof, including the key lemma, which was then written up into the report.
6. Problem-Solving Benchmark Results
Section Summary: The section explains how researchers adapted their AI co-mathematician, which normally works interactively with users on math problems, into a standalone mode that solves challenges autonomously within set time limits to better fit standard benchmarks. On an internal test of 100 advanced math problems, the AI outperformed basic versions of the Gemini model by leveraging tools like code libraries, literature searches, and multi-step planning to correct errors and find solutions. It also set a new record on the tough FrontierMath benchmark, solving nearly half of 48 challenging research-level problems, compared to just 19% for the underlying Gemini model.
Having made a case for broader measurements of abilities, we acknowledge that problem-solving benchmarks are currently the best available objective measures of AI systems' performance in mathematics. In this section, we discuss our attempts to measure the AI co-mathematician's performance using such benchmarks.
As the AI co-mathematician is designed to communicate results via long-form reports and ask questions of the user when stuck, we developed a custom mode where the system is not able to receive external input beyond that of an initial question, and returns a single final answer in the user chat panel. The main differences implemented for this mode are:
Bypassing of the initial problem-definition conversation, with the assumption that all the required information is present in the problem statement.
Hard-coding of a single project goal to "solve the problem".
The introduction of a fixed time limit, after which the project coordinator agent is required to give a final answer, if it has not already. This was set to 24 hours for internal evaluations and 48 hours for FrontierMath.
Most problem attempts finish well within this time limit, but for hard problems without human intervention the system occasionally continues beyond this, especially in cases where it struggles to produce a clean solution.
As a long-running agentic system, compared to base models which are typically evaluated on these tasks the AI co-mathematician uses a correspondingly larger amount of compute. However, though there are no explicit inference limits in the AI co-mathematician solution attempts, the system was developed to be efficient enough to serve to many external users. We observe that each attempt uses a broadly comparable number of model and tool calls to a long AI-assisted software engineering session, matching its primary use case as an interactive agentic tool.
6.1 Internal Research Mathematics Evaluation
We tested the AI co-mathematician on an internal benchmark consisting of 100 unleaked, research-level mathematics problems with code-checkable answers, sourced from professional mathematicians.
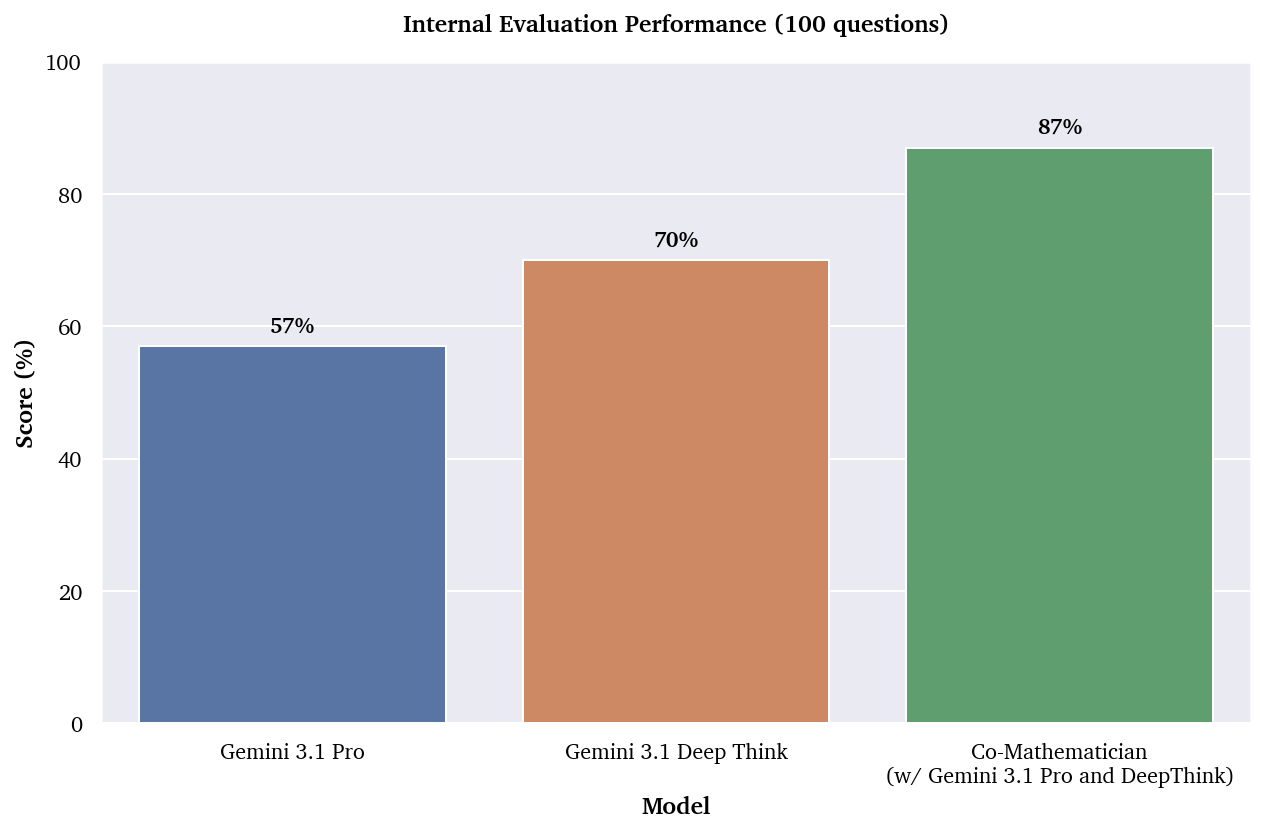
On these benchmarks, the AI co-mathematician significantly outperforms a single call to the Gemini 3.1 Pro model, and a single call to the Gemini Deep Think system (Figure 5). As discussed, the AI co-mathematician also uses a larger amount of compute: indeed, many of the internal agents underlying the AI co-mathematician are built on Gemini 3.1 Pro, and the prover agent can utilize Gemini Deep Think.
Analyzing specific examples, we see the benefits of various features of the AI co-mathematician.
In one question relating to geometric tilings, we see that the AI co-mathematician successfully reduces the core of the question to a Boolean satisfiability (SAT) problem, which it solves using the PySAT library. Several non-trivial adaptations were required to the core problem to make this framing work—this form of solution clearly favors a system which has a persistent file system and agentic code-writing abilities. Whilst the evaluation harness for other models allows code to be executed, developing and testing more complex libraries is difficult for them to achieve. Both Gemini 3.1 Pro and Gemini Deep Think attempt a purely theoretical solution to this problem, which in this case is a far harder task.
In a problem on representation theory, the AI co-mathematician uses its literature search tools to correctly retrieve exact theorem statements from relevant papers, and apply them to solve the task. The other models attempt to apply more general theorems; though these are relevant to the subject area, without literature access to check precise statements they aren't able to correctly match the theorem conditions to the assumptions present in the problem.
In a combinatorics problem with both a theoretical and computational aspect, we see the AI co-mathematician cleanly separates its work into multiple workstreams, refining the theoretical foundation for the solution separately from the development of code. In the theoretical workstream, multiple logical errors and inconsistencies (similar to those made by the other models) were pointed out by the reviewers running spot-checks, and were eventually corrected for the final workstream report, allowing the project coordinator to neatly assemble the pieces to give a correct solution.
6.2 FrontierMath
A natural comparison is the external FrontierMath benchmark ([47]). Epoch AI tested the AI co-mathematician on Tier 4 of the benchmark, in the final-answer mode described above. In the words of Epoch AI, "This extreme tier consists of 50 problems crafted as short-term research projects by professors and postdocs. They are designed to surpass Tier 3 in difficulty, with some potentially remaining unsolved by AI for decades". Frontier models and systems from all major providers are regularly tested on the FrontierMath benchmark.[^2]
[^2]: Latest results and leaderboards can be viewed at https://epoch.ai/frontiermath/tiers-1-4?tier=Tier+4.
The evaluation was conducted blind, with Epoch AI having direct access to the AI co-mathematician UI and entering the problems and retrieving the answers themselves, without the system developers seeing the problems or observing the state of the project workspaces during the evaluation.
The AI co-mathematician achieved a new high score on this benchmark, correctly solving 23 problems out of 48, once the two public sample problems are excluded, an accuracy of 48%. Notably, this is a significant increase over the Gemini 3.1 Pro base model which achieved 19% accuracy and which the AI co-mathematician is based on, showing our parallel investigation branches, enforced review cycles and tool implementations lead to improved outcomes on problem-solving tasks. The problems solved correctly included three problems which had not been solved by any previously evaluated system, though the AI co-mathematician also failed to solve two problems which had been previously solved by at least one system.
An important difference versus prior evaluations is that FrontierMath evaluations are generally executed with a standard agentic harness developed by Epoch AI.[^3] This offers access to a Python interpreter but also places a hard limit on the number of tokens used in the agent trajectory (to the extent that these are accounted for in the associated model API). In our setup however, we only use our own tool implementations and place no limit on the number of model calls or tokens generated. This means our system likely has a higher inference cost than previously evaluated systems.
[^3]: A notable exception: Gemini 2.5 Deep Think was also evaluated via the web UI without an additional harness ([56]).
7. Challenges and Limitations
Section Summary: Although the AI co-mathematician highlights the promise of interactive AI tools for math work, the developers ran into several hurdles in building a system that's truly practical and helpful. Bringing powerful, self-acting AI into the world of mathematics also introduces some risks that need careful handling. Looking ahead, the broader math community will have to address larger, ongoing challenges to make this technology work well.
While the AI co-mathematician demonstrates the potential of interactive AI workflows, we encountered several difficulties in making such a system genuinely useful.

Further, the introduction of highly capable, agentic systems into the mathematical ecosystem carries some risk. Moving forward, the community must navigate several systemic challenges:

8. Conclusion
Section Summary: While AI has achieved impressive feats on math benchmarks, matching or exceeding human performance, this alone isn't enough to speed up scientific discovery, which involves messy, iterative processes full of unproven ideas and teamwork. The AI co-mathematician acts as a complete workspace that mirrors human research habits, managing uncertainties, documenting everything from failures to refinements, and enabling true collaboration, as early users have already solved open problems and discovered new proofs. To unlock its potential, the AI community must create better evaluation methods that assess interactive exploration and uncertainty handling, rather than just fast answers to set puzzles.
The AI community has recently passed multiple technical milestones, demonstrating human-level and superhuman performance across a variety of mathematical benchmarks. If we want to genuinely accelerate scientific discovery, however, solving static, well-defined problems is only part of the solution. The frontier of mathematical research is not a linear conversation or a series of disconnected puzzles; it is a messy, overlapping, highly iterative process defined by unproven intuition, branching hypotheses, and complex human collaboration.
The AI co-mathematician is designed to meet researchers where they are. Rather than reducing AI to an isolated oracle or a simple verification pipeline, the system acts as a holistic workspace. By managing the life cycle of uncertainty, mirroring human workflows through hierarchical delegation, and grounding its output in native mathematical artifacts, it elevates powerful base models into natural collaborators. Through hard programmatic constraints and the continuous maintenance of a living "working paper, " the system ensures that the full research journey—the failed tests, the literature synthesized, and the continuous refinement of an idea—is captured, audited, and explicitly communicated to the user. As demonstrated by early users resolving open problems and finding novel proofs, this bidirectional exchange allows humans to effectively steer AI past difficult bottlenecks.
Realizing the full potential of this paradigm, however, requires a shift in how the AI community measures success. While these benchmarks are excellent at evaluating a model's ability to generate a final answer to a curated problem, they do not capture the full scope of frontier research. They are not designed to measure a system's ability to interactively prune a hypothesis tree, synthesize niche literature, or appropriately halt and disclose uncertainty when scaling fails.
If we want to build systems that act as true co-mathematicians, we must develop complementary evaluation frameworks that measure collaborative efficacy, stateful exploration, and the rigorous management of uncertainty. The next revolution in AI-assisted mathematics will not just be defined by which model can synthesize the right answer the fastest, but by which system can most effectively help human researchers navigate the unknown.
Acknowledgments
Section Summary: The acknowledgments section expresses gratitude to numerous individuals and teams for their contributions to the report and prototype system, including reviews, improvements to deployment and reliability, advice on partnerships, legal counsel, communications strategy, dataset maintenance, UI enhancements, code reviews, and coordination of evaluations. It also thanks a wide array of mathematicians, testers, and early users for providing detailed feedback, testing the system, and collaborating on mathematical performance, workflows, and interface design, along with support for distribution, compute resources, and engineering. Special appreciation is given to the Institute for Advanced Study at Princeton for hosting a workshop and to Gemini 3.1 Pro for assisting in drafting text, proofreading, and creating figures.
We would like to thank:
Edward Lockhart, Allison Woodruff, Juanita Bawagan, Uchechi Okereke, Thang Luong for reviewing this report.
Anna Trostanetski, Andrey Petrov, Matin Akhlaghinia, Victoria Johnston, Nick Dietrich for their help in improving the deployment setup and reliability of the prototype system.
Mariana Felix, Francesca Pietra for advising on externalization and partnerships.
Uchechi Okereke, Gemma Gibbs for legal counsel.
Adriana Lara, Armin Senoner, Danielle Breen, Duncan Smith, Juanita Bawagan for advising on communications strategy and naming.
Henryk Michalewski for maintaining the internal dataset of research mathematics problems.
Greg Burnham (Epoch AI) for coordinating the FrontierMath evaluation.
Ellen Jiang for UI advice and improvements.
Victoria Johnston, Doug Fritz, Felix Riedel for frontend code reviews.
Sébastien Racaniere, Romu Elie for communicating with early testers and members of the mathematical community and feeding back insights and requests from them.
Richard Bamler, Johannes Bausch, Mehdi Bennani, Gergely Bérczi, David Berghaus, Otis Chodosh, Bennett Chow, Maria Chudnovsky, Romu Elie, Sergey Galkin, Javier Gómez-Serrano, Matt Harvey, Amaury Hayat, Marcus Hutter, Ray Jiang, Ayush Khaitan, Alex Kontorovich, Robin Kothari, Marc Lackenby, Tor Lattimore, Igor Makhlin, Johan Martens, Alex Matthews, Stanislav Nikolov, Georg Ostrovski, Stan Palasek, Sébastien Racaniere, Danylo Radchenko, Johannes Ruf, Julian Salazar, Simone Severini, Phiala Shanahan, Iain Smears, Elahe Vedadi, Adam Zsolt Wagner, for testing the system and providing feedback.
Javier Gómez-Serrano and Terence Tao for early testing and feedback on the literature search capabilities.
Nada Baessa, Bruno Vergara Biggio, Semon Rezchikov for in-depth testing, checking of outputs, detailed feedback, feature requests.
Allison Woodruff, Patrick Gage Kelley for help with interviewing early users and collating feedback.
Marc Lackenby for feedback on the mathematical performance of the system, input into the workflow and interface design, and deep mathematical collaboration.
JD Velasquez, Yunhan Xu for advising on distribution and product viewpoints.
Victor Martin, Stig Petersen, Petko Yotov, Hamish Tomlinson, Sam Blackwell for sourcing compute and assisting with model serving.
Sam Blackwell for engineering support and advice.
Stig Petersen for technical reviewing.
The IAS at Princeton for hosting a joint workshop last year, at which many of these topics were discussed.
Gemini 3.1 Pro was used at various stages in the preparation of this manuscript, for drafting portions of the main text, proofreading human-written sections, and producing and iterating on figures and diagrams.
Contributions
Section Summary: Y.Z. led the design of the initial system prototype, with Y.Z., I.V.G., D.Z., I.B., L.B., and A.D. handling ongoing development of the core system and user interface, alongside research improvements and inputs from others like V.K., M.W., and D.K. for testing and UI elements, while F.V. contributed to the visual design, T.S. built the access route for external users, and S.A. defined the requirements for that. The team, including I.V.G., Y.Z., D.Z., I.B., L.B., A.C., T.S., D.M.R., and H.M., maintained the system, prepared it for evaluations, coordinated efforts through B.G., D.Z., I.V.G., and G.H., developed the overall strategy via A.D. and D.Z., and saw supervision from A.D. and P.K.; D.M.R., M.W., and D.Z. wrote the paper with inputs from others, and F.V., M.W., D.Z., and D.M.R. created the diagrams.
Y.Z. designed the initial prototype of the system. Y.Z., I.V.G., D.Z., I.B., L.B., A.D. continued development of the core system and user interface and performed research on improving capabilities, with input from V.K. on research ideas. M.W., D.K. provided input and testing throughout prototype iterations. M.W. designed key elements of the user interface and workflow, F.V. designed the visual language and further UI elements. T.S. developed the route for external users to access the system. S.A. developed the system requirements for externalization. I.V.G., Y.Z., D.Z., I.B., L.B., A.C., T.S. maintained the system for external users. Y.Z., I.V.G., D.Z., I.B., L.B., D.M.R., H.M. prepared the system for internal and external evaluations. D.M.R., M.W., D.Z. wrote the paper, with input from I.V.G., Y.Z., A.D., B.G., F.V. F.V., M.W., D.Z., D.M.R. created the diagrams. B.G. coordinated the external user community. D.Z., I.V.G., and G.H. coordinated the team. A.D. and D.Z. developed the overall strategy. A.D. and P.K. supervised the research program.
References
Section Summary: This references section compiles a diverse bibliography of books, academic papers, and online resources focused on mathematical reasoning, proofs, and the growing role of artificial intelligence in scientific discovery. It features foundational texts from thinkers like George Pólya and Imre Lakatos on induction and the logic of mathematical progress, alongside modern studies on AI language models such as Galactica and Llemma that tackle quantitative problems and theorem proving. The list spans mid-20th-century classics to forward-looking works projected into 2026, including tools like Lean Copilot and evolutionary coding agents that automate math and research tasks.
[1] George Pólya (1954). Induction and Analogy in Mathematics: Vol. 1 of Mathematics and Plausible Reasoning.
[2] I. Lakatos (1976). Proofs and Refutations: The Logic of Mathematical Discovery.
[3] Epstein et al. (1992). About This Journal. Experimental Mathematics. 1(1).
[4] Lewkowycz et al. (2022). Solving Quantitative Reasoning Problems with Language Models. arXiv:2206.14858.
[5] Taylor et al. (2022). Galactica: A Large Language Model for Science. arXiv:2211.09085.
[6] Azerbayev et al. (2024). Llemma: An Open Language Model For Mathematics. In International Conference on Learning Representations (ICLR). arXiv:2310.10631.
[7] Yue et al. (2024). MAmmoTH: Building Math Generalist Models through Hybrid Instruction Tuning. In International Conference on Learning Representations (ICLR). arXiv:2309.05653.
[8] Shao et al. (2024). DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models. arXiv:2402.03300.
[9] (2024). Mathstral 7B. https://huggingface.co/mistralai/mathstral-7B-v0.1.
[10] Yang et al. (2024). Qwen2.5-Math Technical Report: Toward Mathematical Expert Model via Self-Improvement. arXiv:2409.12122.
[11] Lu et al. (2024). The AI Scientist: Towards Fully Automated Open-Ended Scientific Discovery. arXiv:2408.06292.
[12] Thang Luong and Vahab Mirrokni (2025). Accelerating mathematical and scientific discovery with Gemini Deep Think. https://deepmind.google/blog/accelerating-mathematical-and-scientific-discovery-with-gemini-deep-think/.
[13] He et al. (2025). Skywork Open Reasoner 1 Technical Report. arXiv:2505.22312.
[14] Yamada et al. (2025). The AI Scientist-v2: Workshop-Level Automated Scientific Discovery via Agentic Tree Search. arXiv:2504.08066.
[15] Liu et al. (2026). Scientific Algorithm Discovery by Augmenting AlphaEvolve with Deep Research. In International Conference on Learning Representations (ICLR). arXiv:2510.06056.
[16] Zimmer et al. (2026). The Agentic Researcher: A Practical Guide to AI-Assisted Research in Mathematics and Machine Learning. arXiv:2603.15914.
[17] Feng et al. (2026). Towards Autonomous Mathematics Research. arXiv:2602.10177.
[18] Romera-Paredes et al. (2024). Mathematical discoveries from program search with large language models. Nature. 625. pp. 468– 475. doi:10.1038/s41586-023-06924-6.
[19] Novikov et al. (2025). AlphaEvolve: A coding agent for scientific and algorithmic discovery. arXiv:2506.13131.
[20] Cemri et al. (2026). AdaEvolve: Adaptive LLM Driven Zeroth-Order Optimization. arXiv:2602.20133.
[21] Asankhaya Sharma (2025). OpenEvolve: an open-source evolutionary coding agent. https://github.com/algorithmicsuperintelligence/openevolve.
[22] Lange et al. (2026). ShinkaEvolve: Towards Open-Ended And Sample-Efficient Program Evolution. In International Conference on Learning Representations (ICLR). arXiv:2509.19349.
[23] Hubert et al. (2025). Olympiad-level formal mathematical reasoning with reinforcement learning. Nature. doi:10.1038/s41586-025-09833-y.
[24] Song et al. (2024). Lean Copilot: A Framework for Running LLM Inference Natively in Lean. arXiv:2404.12534.
[25] Wang et al. (2024). LEGO-Prover: Neural Theorem Proving with Growing Libraries. In International Conference on Learning Representations (ICLR).
[26] Ren et al. (2025). DeepSeek-Prover-V2: Advancing Formal Mathematical Reasoning via Reinforcement Learning for Subgoal Decomposition. arXiv:2504.21801.
[27] Lin et al. (2026). Goedel-Prover-V2: Scaling Formal Theorem Proving with Scaffolded Data Synthesis and Self-Correction. In International Conference on Learning Representations (ICLR). arXiv:2508.03613.
[28] Li et al. (2025). In International Conference on Learning Representations (ICLR).
[29] Chen et al. (2025). Seed-Prover 1.5: Mastering Undergraduate-Level Theorem Proving via Learning from Experience. arXiv:2512.17260.
[30] Wang et al. (2025). Kimina-Prover Preview: Towards large formal reasoning models with reinforcement learning. arXiv:2504.11354.
[31] Hariharan et al. (2026). A Milestone in Formalization: The Sphere Packing Problem in Dimension 8. arXiv:2604.23468.
[32] Li et al. (2024). HunyuanProver: A Scalable Data Synthesis Framework and Guided Tree Search for Automated Theorem Proving. arXiv:2412.20735.
[33] Jana et al. (2025). ProofBridge: Auto-Formalization of Natural Language Proofs in Lean via Joint Embeddings. In International Conference on Learning Representations (ICLR).
[34] Chen et al. (2026). Parity of $k$-differentials in genus zero and one. arXiv:2602.03722.
[35] Liu et al. (2026). Numina-Lean-Agent: An Open and General Agentic Reasoning System for Formal Mathematics. arXiv:2601.14027.
[36] Tredici et al. (2025). Ax-Prover: Agentic LEAN Proving with LLMs and MCP-based Verifiers. ICLR 2026 Conference Desk Rejected Submission / Preprint.
[37] Achim et al. (2025). Aristotle: IMO-level Automated Theorem Proving. arXiv:2510.01346.
[38] (2025). Google Antigravity. https://antigravity.google/. Accessed: 2026-04-27.
[39] (2025). Claude Code. https://www.anthropic.com/product/claude-code. Accessed: 2026-04-27.
[40] (2021). OpenAI Codex. https://openai.com/index/introducing-codex/. Accessed: 2026-04-27.
[41] William P. Thurston (1994). On Proof and Progress in Mathematics. Bulletin of the American Mathematical Society. 30(2). pp. 161– 177. doi:10.1090/S0273-0979-1994-00502-6.
[42] Hilary Putnam (1975). What Is Mathematical Truth?.
[43] Joseph Warren Dauben (1979). Georg Cantor: His Mathematics and Philosophy of the Infinite.
[44] Leo Moser (1966). Moving furniture through a hallway. SIAM Review. 8(3). pp. 381.
[45] Georgiev et al. (2025). Mathematical Exploration and Discovery at Scale. arXiv:2511.02864.
[46] Luong et al. (2025). Towards Robust Mathematical Reasoning. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. arXiv:2511.01846.
[47] Glazer et al. (2024). FrontierMath: A Benchmark for Evaluating Advanced Mathematical Reasoning in AI. arXiv:2411.04872.
[48] Tsoukalas et al. (2024). PutnamBench: Evaluating Neural Theorem-Provers on the Putnam Mathematical Competition. arXiv:2407.11214.
[49] Hendrycks et al. (2021). Measuring Mathematical Problem Solving With the MATH Dataset. Advances in Neural Information Processing Systems. 34. pp. 29157– 29169.
[50] Cobbe et al. (2021). Training Verifiers to Solve Math Word Problems. arXiv:2110.14168.
[51] Thang Luong and Edward Lockhart (2025). Advanced version of Gemini with Deep Think officially achieves gold-medal standard at the International Mathematical Olympiad. https://deepmind.google/blog/advanced-version-of-gemini-with-deep-think-officially-achieves-gold-medal-standard-at-the-international-mathematical-olympiad/. Google DeepMind Blog.
[52] Abouzaid et al. (2026). First Proof. arXiv:2602.05192.
[53] Gupta et al. (2026). DeepSearchQA: Bridging the Comprehensiveness Gap for Deep Research Agents. arXiv:2601.20975.
[54] Pandit et al. (2025). Hard2Verify: A Step-Level Verification Benchmark for Open-Ended Frontier Math. arXiv:2510.13744.
[55] Dell'Acqua et al. (2026). Navigating the Jagged Technological Frontier: Field Experimental Evidence of the Effects of Artificial Intelligence on Knowledge Worker Productivity and Quality. Organization Science. 37(2). pp. 403– 423. doi:10.1287/orsc.2025.21838.
[56] (2025). Evaluating Gemini 2.5 Deep Think's math capabilities. https://epoch.ai/blog/deep-think-math. Accessed: 2026-05-05.
[57] Alex Kontorovich (2025). The Shape of Math To Come. arXiv:2510.15924.
[58] Dang et al. (2026). Escaping the Cognitive Well: Efficient Competition Math with Off-the-Shelf Models. arXiv:2602.16793.
[59] (2025). Read smarter, not harder, with Lumi. https://medium.com/people-ai-research/read-smarter-not-harder-with-lumi-6a1a8210ccc7. Accessed: 2026-04-23.