DeepSeek-OCR 2: Visual Causal Flow
Haoran Wei, Yaofeng Sun, Yukun Li DeepSeek-AI
Abstract
We present DeepSeek-OCR 2 to investigate the feasibility of a novel encoder—DeepEncoder V2—capable of dynamically reordering visual tokens upon image semantics. Conventional vision-language models (VLMs) invariably process visual tokens in a rigid raster-scan order (top-left to bottom-right) with fixed positional encoding when fed into LLMs. However, this contradicts human visual perception, which follows flexible yet semantically coherent scanning patterns driven by inherent logical structures. Particularly for images with complex layouts, human vision exhibits causally-informed sequential processing. Inspired by this cognitive mechanism, DeepEncoder V2 is designed to endow the encoder with causal reasoning capabilities, enabling it to intelligently reorder visual tokens prior to LLM-based content interpretation. This work explores a novel paradigm: whether 2D image understanding can be effectively achieved through two-cascaded 1D causal reasoning structures, thereby offering a new architectural approach with the potential to achieve genuine 2D reasoning. Codes and model weights are publicly accessible at http://github.com/deepseek-ai/DeepSeek-OCR-2.
Executive Summary: DeepSeek-OCR 2 addresses a key challenge in artificial intelligence: how vision-language models, which combine image processing with language understanding, handle complex documents like reports, forms, and tables. Traditional models scan images in a fixed left-to-right, top-to-bottom order, much like reading text, but this ignores the natural way humans view images—focusing on meaningful elements in a logical, sequential flow based on content. This mismatch leads to errors in tasks such as optical character recognition (OCR), where accurate interpretation of layouts, formulas, and tables is essential. With AI increasingly used for automating document analysis in business, research, and data processing, improving these models is urgent to boost efficiency, reduce costs, and enable reliable applications like extracting information from PDFs or scanned files.
The document introduces DeepSeek-OCR 2, an upgraded version of the earlier DeepSeek-OCR model, designed to better capture this human-like visual flow. It evaluates a new encoder component, called DeepEncoder V2, which reorders visual information semantically rather than spatially, while keeping the overall model efficient for real-world use.
To build and test this, the researchers redesigned the encoder by replacing a standard vision component with a compact language model architecture. This setup uses two types of attention: full visibility among image patches (like peripheral vision) and sequential processing for special query tokens that reorder the patches based on content logic (like focused reading). They trained the model in three stages—initial feature learning, query refinement, and decoder tuning—on a mix of OCR datasets (80% of training) and general images, totaling over 100 million image-text pairs. Training occurred across resolutions up to 1024x1024 pixels on high-performance hardware, limiting visual tokens fed to the language decoder to 256–1120 per image to balance speed and detail. Evaluation focused on the OmniDocBench benchmark, which tests document parsing across 1,355 diverse pages in English and Chinese.
The core results highlight substantial gains. First, DeepSeek-OCR 2 scored 91.09% overall accuracy on OmniDocBench, a 3.73 percentage point increase over the previous DeepSeek-OCR under similar training conditions. Second, it excelled in reading order accuracy, cutting the edit distance error measure from 0.085 to 0.057, showing stronger logical sequencing of document elements. Third, in production settings without ground truth labels, it reduced repetition errors—unwanted duplicate outputs—from 6.25% to 4.17% on user-submitted images and from 3.69% to 2.88% on batch PDF processing. Fourth, it outperformed Google's Gemini-3 Pro in document parsing edit distance (0.100 versus 0.115) while using a comparable token budget, proving efficient compression without losing quality. Finally, across nine document types like academic papers and magazines, it consistently improved reading order, though text recognition varied.
These findings mean DeepSeek-OCR 2 processes documents more like humans, leading to fewer errors in extracting and ordering content. This enhances performance in AI pipelines, cutting risks of misinterpretation that could affect decisions in finance, legal reviews, or research. Unlike prior models that stuck to rigid scans, the causal flow design aligns visual and language processing better, potentially speeding up tasks while maintaining low computational costs—vital for scalable deployment. The improvements exceed expectations for token-limited setups, suggesting broader potential beyond documents.
Leaders should deploy DeepSeek-OCR 2 in production for online OCR services and data generation pipelines, as it delivers immediate quality boosts with minimal changes. For further gains, increase local image crops to handle text-dense documents like newspapers, and expand training data for underrepresented types. Explore pilots for general image reasoning or integrating audio and text modalities into the same encoder. If aiming for wider adoption, weigh scaling queries for multi-step visual analysis against added compute needs.
While the results show high confidence in document OCR improvements, limitations include sparse training data for niche formats (e.g., only 250,000 newspaper samples) and a token cap that may limit ultra-dense pages. Readers should be cautious extrapolating to non-document visuals without additional testing, but the benchmark and production metrics provide solid evidence for current applications.
1. Introduction
Section Summary: Human vision processes images through focused fixations that build on each other based on meaning, unlike the rigid left-to-right scanning used in many AI vision models, which overlooks natural logical flows in things like documents. To fix this, the authors introduce DeepSeek-OCR 2, featuring a new encoder called DeepEncoder V2 that uses a small language model and special "causal flow tokens" to reorder visual information more like how eyes naturally refocus, while keeping processing efficient for tasks like reading complex layouts, formulas, and tables. This design boosts performance by about 3.7% on document benchmarks and opens doors to unified AI handling of images, audio, and text.
The human visual system closely mirrors transformer-based vision encoders [1, 2]: foveal fixations function as visual tokens, locally sharp yet globally aware. However, unlike existing encoders that rigidly scan tokens from top-left to bottom-right, human vision follows a causally-driven flow guided by semantic understanding. Consider tracing a spiral—our eye movements follow inherent logic where each subsequent fixation causally depends on previous ones. By analogy, visual tokens in models should be selectively processed with ordering highly contingent on visual semantics rather than spatial coordinates.
This insight motivates us to fundamentally reconsider the architectural design of vision-language models (VLMs), particularly the encoder component. LLMs are inherently trained on 1D sequential data, while images are 2D structures. Directly flattening image patches in a predefined raster-scan order introduces unwarranted inductive bias that ignores semantic relationships. To address this, we present DeepSeek-OCR 2 with a novel encoder design—DeepEncoder V2—to advance toward more human-like visual encoding. Following DeepSeek-OCR [3], we adopt document reading as our primary experimental testbed. Documents present rich challenges including complex layout orders, intricate formulas, and tables. These structured elements inherently carry causal visual logic, demanding sophisticated reasoning capabilities that make document OCR an ideal platform for validating our approach.
Our main contributions are threefold:
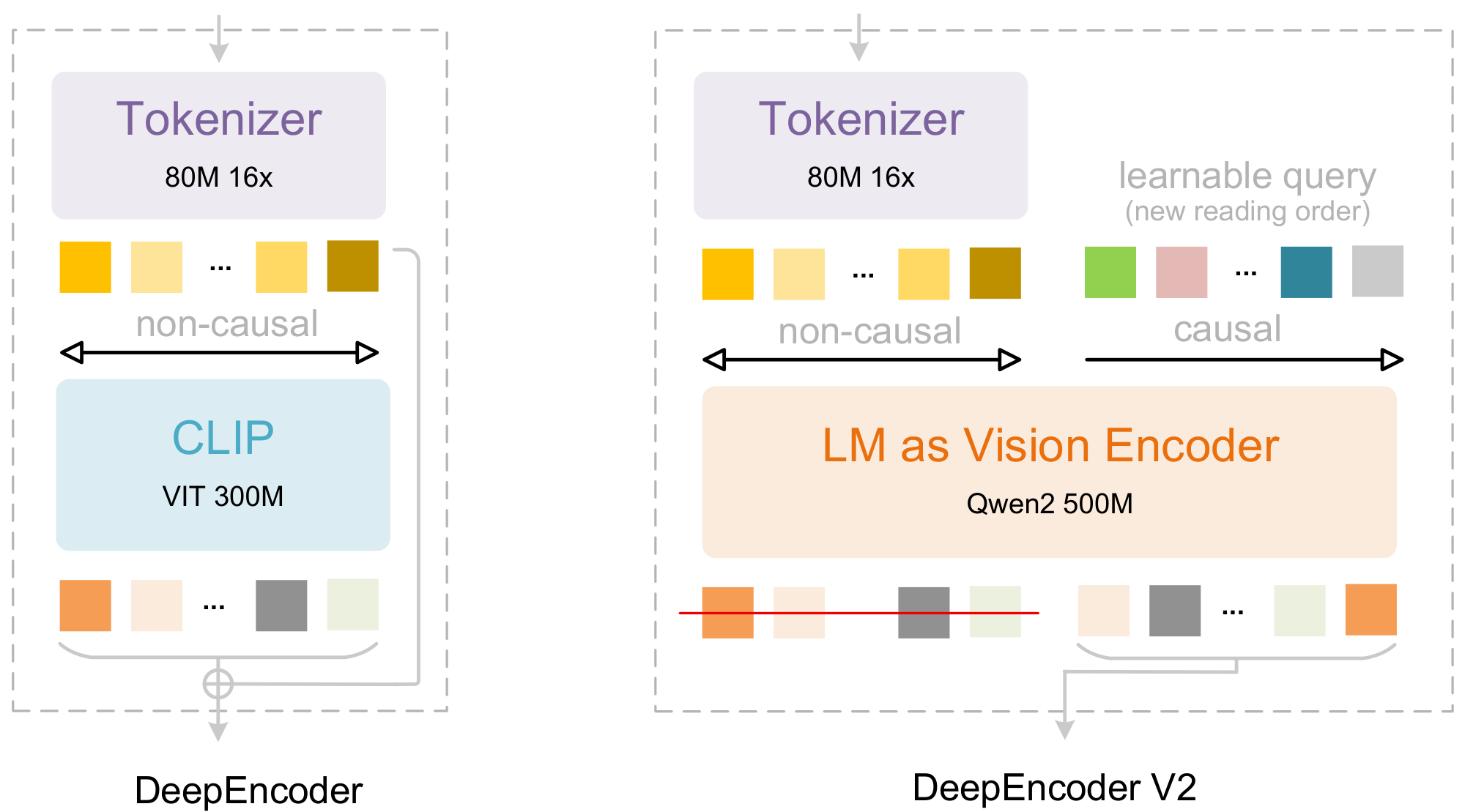
First, we present DeepEncoder V2, featuring several key innovations: (1) we replace the CLIP [4] component in DeepEncoder [3] with a compact LLM [5] architecture, as illustrated in Figure 1, to achieve visual causal flow; (2) to enable parallelized processing, we introduce learnable queries [6], termed causal flow tokens, with visual tokens prepended as a prefix—through a customized attention mask, visual tokens maintain global receptive fields, while causal flow tokens can obtain visual token reordering ability; (3) we maintain equal cardinality between causal and visual tokens (with redundancy such as padding and borders) to provide sufficient capacity for re-fixation; (4) only the causal flow tokens—the latter half of the encoder outputs—are fed to the LLM [7] decoder, enabling cascade causal-aware visual understanding.
Second, leveraging DeepEncoder V2, we present DeepSeek-OCR 2, which preserves the image compression ratio and decoding efficiency of DeepSeek-OCR while achieving substantial performance improvements. We constrain visual tokens fed to the LLM between 256 and 1120. The lower bound (256) corresponds to DeepSeek-OCR's tokenization of 1024×1024 images, while the upper bound (1120) matches Gemini-3 pro's [8] maximum visual token budget. This design positions DeepSeek-OCR 2 as both a novel VLM architecture for research exploration and a practical tool for generating high-quality training data for LLM pretraining.
Finally, we provide preliminary validation for employing language model architectures as VLM encoders—a promising pathway toward unified omni-modal encoding. This framework enables feature extraction and token compression across diverse modalities (images, audio, text [9]) by simply configuring modality-specific learnable queries. Crucially, it naturally succeeds to advanced infrastructure optimizations from the LLM community, including Mixture-of-Experts (MoE) architectures, efficient attention mechanisms [10], and so on.
In summary, we propose DeepEncoder V2 for DeepSeek-OCR 2, employing specialized attention mechanisms to effectively model the causal visual flow of document reading. Compared to the DeepSeek-OCR baseline, DeepSeek-OCR 2 achieves 3.73% performance gains on OmniDocBench v1.5 [11] and yields considerable advances in visual reading logic.
![**Figure 2:** This figure shows two computer vision models with parallelized queries: DETR's decoder [6] for object detection and BLIP2's Q-former [12] for visual token compression. Both employ bidirectional self-attention among queries.](https://ittowtnkqtyixxjxrhou.supabase.co/storage/v1/object/public/public-images/999fynhn/3.png)
2. Related Works
Section Summary: The section reviews key advancements in using transformer-based methods for object detection and multimodal AI. It begins by explaining how DETR revolutionized detection by introducing parallel learnable queries that efficiently process visual features through attention mechanisms, a design now standard in similar systems. It then discusses projectors in vision-language models, like the Q-former in BLIP-2, which compress visual data into a form large language models can understand using similar query techniques, and highlights how pretrained language models serve as strong starting points for building multimodal systems in vision and speech.
2.1 Parallelized Queries in Decoder
DETR [6] pioneered the integration of transformer architecture into object detection, fundamentally breaking away from traditional detection paradigms [13, 14]. To overcome the efficiency limitations of serial decoding in transformer blocks, DETR introduced preset parallelized learnable queries—a set of 100 object queries that encode object priors such as shape and position through training. These queries interact with feature maps [15] via cross-attention mechanisms, while simultaneously engaging in bidirectional information exchange among themselves through self-attention. DETR established a foundational paradigm that enables transformers to handle parallelized tokens. The object query design has since become the de facto standard architectural component in subsequent transformer-based detection methods [16, 17].
2.2 Parallelized Queries in Projector
In recent years, vision-language models [12, 18, 19, 20] have developed rapidly, with architectures converging toward the encoder-projector-LLM paradigm. The projector aligns visual tokens with the LLM's embedding space, serving as a critical bridge that enables LLMs to understand visual content. Q-former, introduced in BLIP-2 [12], exemplifies an effective projector design that employs learnable queries for visual token compression. Adopting a BERT-like [21] architecture and drawing inspiration from DETR's object queries [6], Q-former utilizes 32 learnable queries that interact with hundreds of CLIP [4] visual tokens through cross-attention. These compressed query representations are subsequently fed into the LLM, achieving effective mapping from visual to language space. The success of Q-former demonstrates that parallelized learnable queries are effective not only for feature decoding in detection tasks but also for token compression in multimodal alignment.
2.3 LLM-based Multimodal Initialization
LLMs trained on large-scale internet data have proven effective as initialization for multimodal models. Pang et al. [22] demonstrated that frozen LLM transformer layers enhance visual discriminative tasks. Moreover, encoder-free or lightweight-encoder models such as Fuyu [23] and Chameleon [24] in vision, as well as VALL-E [25] in speech, further validate the potential of LLM pretrained weights for multimodal initialization.
3. Methodology
Section Summary: DeepSeek-OCR 2 builds on its predecessor's encoder-decoder structure, where the encoder turns images into visual tokens and the decoder generates text based on those tokens and prompts, but it upgrades the encoder to DeepEncoder V2 for better handling of complex visual layouts like tables and forms. DeepEncoder V2 uses a vision tokenizer to compress image details and a small language model with a special attention system that combines full-view awareness for visuals with step-by-step causal reasoning through added query tokens, which reorder the visuals in a more natural, semantic way. To adapt to different image sizes, it applies a multi-crop approach with global and local image sections, producing between 256 and 1120 tokens to feed into the decoder without overwhelming the system.
3.1 Architecture
As shown in Figure 3, DeepSeek-OCR 2 inherits the overall architecture of DeepSeek-OCR, which consists of an encoder and a decoder. The encoder discretizes images into visual tokens, while the decoder generates outputs conditioned on these visual tokens and text prompts. The key distinction lies in the encoder: we upgrade DeepEncoder to DeepEncoder V2, which retains all capabilities of its predecessor while introducing causal reasoning through a novel architectural design. We elaborate on the details of DeepSeek-OCR 2 in the following sections.
3.2 DeepEncoder V2
The vanilla encoder serves as an important component that extracts and compresses image features through attention mechanisms, where each token attends to all others, achieving full-image receptive fields analogous to human foveal and peripheral vision. However, flattening 2D image patches into a 1D sequence imposes a rigid ordering bias through text-oriented positional encodings (e.g., RoPE [26]). This contradicts natural visual reading patterns, especially non-linear layouts in optical texts, forms and tables.
3.2.1 Vision tokenizer
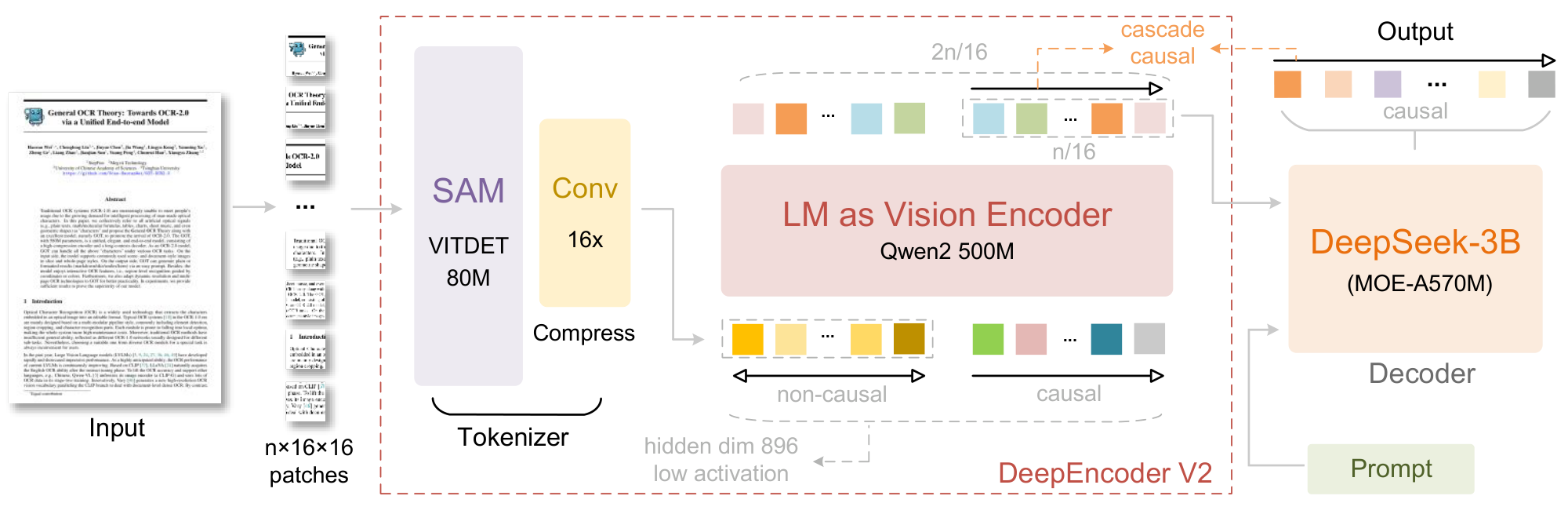
The first component of DeepEncoder V2 is a vision tokenizer. Following DeepEncoder, we employ an architecture combining an 80M-parameter SAM-base [27] along with two convolutional layers [20]. The output dimension of the final convolutional layer is reduced from 1024 in DeepEncoder to 896 to align with the subsequent pipeline. Note that this compression-based tokenizer is not mandatory and can be replaced with simple patch embedding. We retain it because it achieves 16 $\times$ token compression [28, 29, 30, 31] through window attention with minimal parameters, significantly reducing both computational cost and activation memory for the subsequent global attention module. Moreover, its parameter count (80M) remains comparable to the typical 100M parameters used for text input embeddings in LLMs.
3.2.2 Language model as vision encoder
In DeepEncoder, a CLIP ViT follows the vision tokenizer to compress visual knowledge. DeepEncoder V2 redesigns this component into an LLM-style architecture with a dual-stream attention mechanism. Visual tokens utilize bidirectional attention to preserve CLIP's global modeling capability, while newly introduced causal flow queries employ causal attention. These learnable queries are appended after visual tokens as a suffix, where each query attends to all visual tokens and preceding queries. By maintaining equal cardinality between queries and visual tokens, this design imposes semantic ordering and distilling on visual features without altering token count. Finally, only the causal query outputs are fed to the LLM decoder.
We instantiate this architecture using Qwen2-0.5B [5], whose 500M parameters are comparable to CLIP ViT (300M) without introducing excessive computational overhead. The decoder-only architecture with prefix-concatenation of visual tokens proves crucial: extra experiments with cross-attention in an mBART-style [32] encoder-decoder structure fail to converge. We hypothesize this failure stems from insufficient visual token interaction when isolated in a separate encoder. In contrast, the prefix design keeps visual tokens active throughout all layers, fostering effective visual information exchange with causal queries.
This architecture actually establishes two-stage cascade causal reasoning: the encoder semantically reorders visual tokens through learnable queries, while the LLM decoder performs autoregressive reasoning over the ordered sequence. Unlike vanilla encoders that impose rigid spatial ordering through positional encodings, our causally-ordered queries adapt to smooth visual semantics while naturally aligning with the LLM's unidirectional attention pattern. This design may bridge the gap between 2D spatial structure and 1D causal language modeling.
3.2.3 Causal flow query
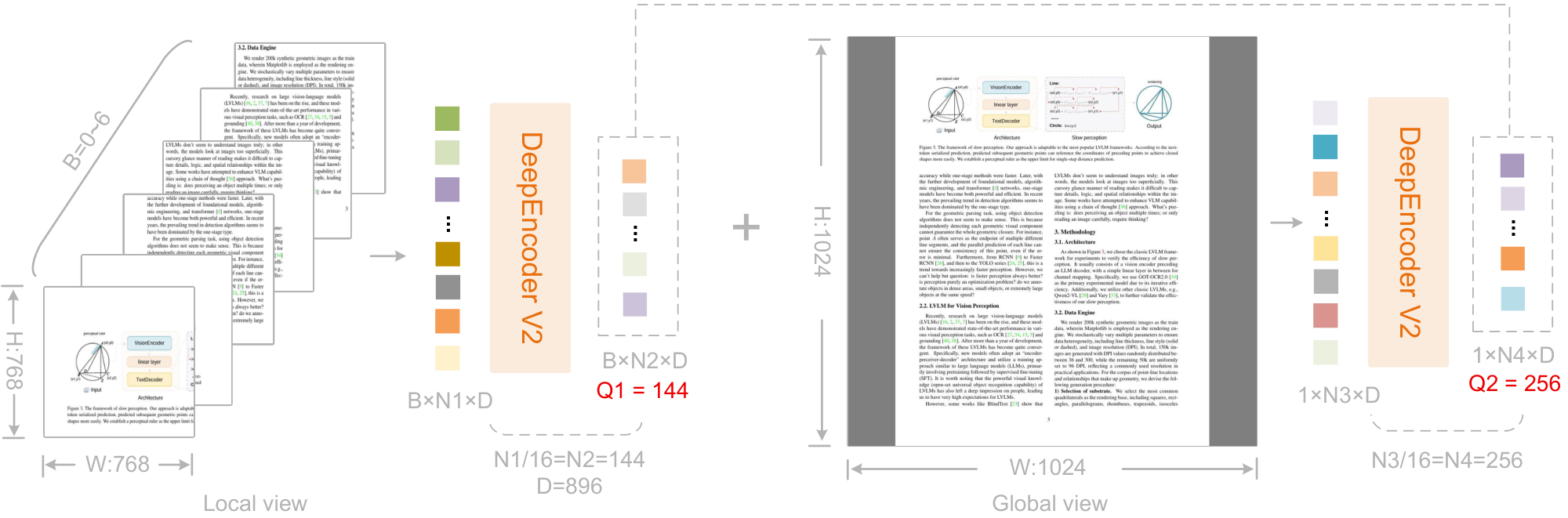
As aforementioned, the number of causal query tokens equals the number of visual tokens, computed as $\frac{W \times H}{16^2 \times 16}$, where $W$ and $H$ denote the width and height of the image input to the encoder. To avoid maintaining multiple query sets for different resolutions, we adopt a multi-crop strategy with fixed query configurations at predefined resolutions.
Specifically, the global view uses a resolution of $1024 \times 1024$, corresponding to 256 query embeddings denoted as $\text{query}{\text{global}}$. Local crops adopt a resolution of $768 \times 768$, with the number of crops $k$ ranging from 0 to 6 (no cropping is applied when both image dimensions are smaller than 768). All local views share a unified set of 144 query embeddings, denoted as $\text{query}{\text{local}}$. Therefore, the total number of reordered visual tokens fed to the LLM is $k \times 144 + 256$, ranging from $[256, 1120]$. This maximum token count (1120) is lower than DeepSeek-OCR's 1156 (Gundam mode) and matches Gemini-3-Pro's maximum visual token budget.
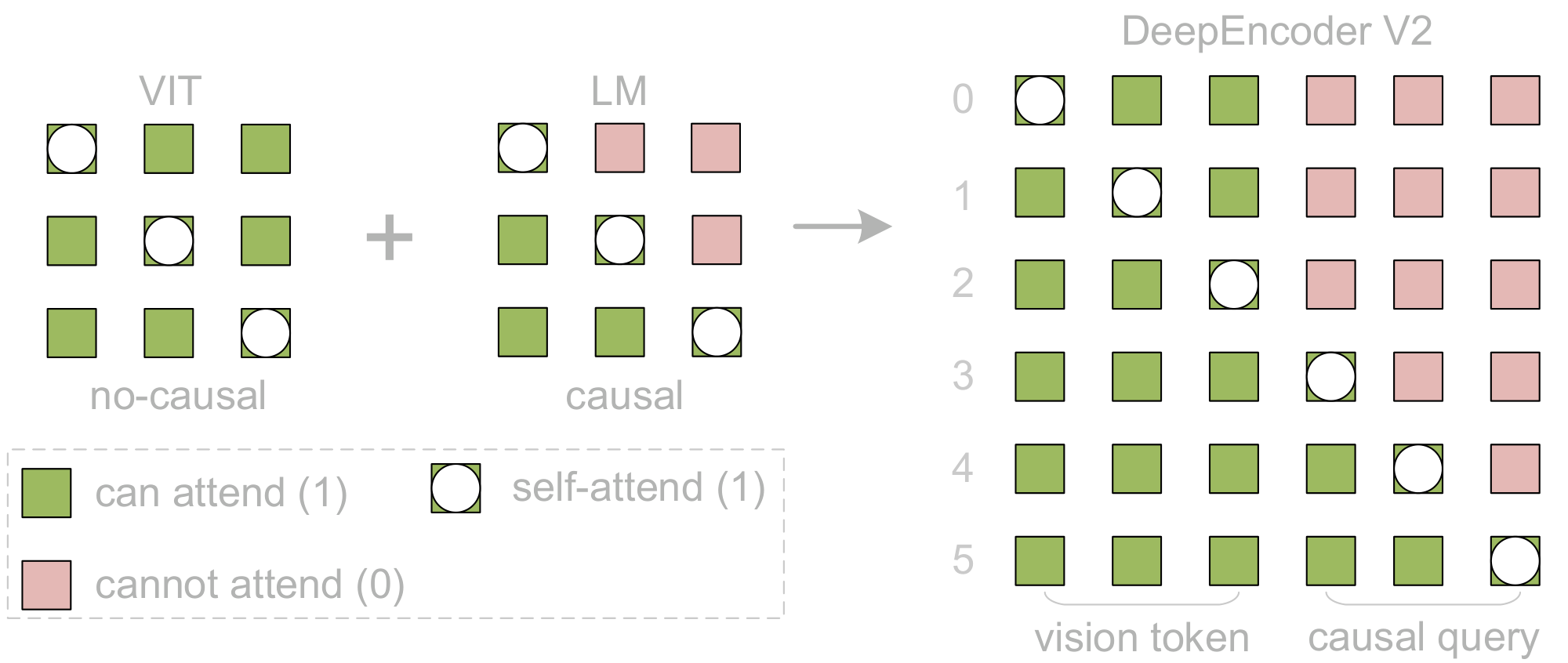
3.2.4 Attention mask
To better illustrate the attention mechanism of DeepEncoder V2, we visualize the attention mask in Figure 5. The attention mask is composed of two distinct regions. The left region applies bidirectional attention (similar to ViT) to original visual tokens, allowing full token-to-token visibility. The right region employs causal attention (triangular mask, identical to decoder-only LLMs) for causal flow tokens, where each token attends only to previous tokens. These two components are concatenated along the sequence dimension to construct DeepEncoder V2's attention mask (M), as follows:
$ M = \begin{bmatrix} \mathbf{1}{m \times m} & \mathbf{0}{m \times n} \ \mathbf{1}_{n \times m} & \text{LowerTri}(n) \end{bmatrix}, \quad \text{where } n = m\tag{1} $
where $n$ is the number of causal query tokens, $m$ represents vanilla visual tokens number, and $\text{LowerTri}$ denotes a lower triangular matrix (with ones on and below the diagonal, zeros above).
3.3 DeepSeek-MoE Decoder
Since DeepSeek-OCR 2 primarily focuses on encoder improvements, we do not upgrade the decoder component. Following this design principle, we retain DeepSeek-OCR's decoder $-$ a 3B-parameter MoE structure with about 500M active parameters. The core forward pass of DeepSeek-OCR 2 can be formulated as:
$ \mathbf{O} = \mathcal{D}\left(\pi_Q\left(\mathcal{T}^L\left(\mathcal{E}(\mathbf{I}) \oplus \mathbf{Q}_0; \mathbf{M}\right)\right)\right)\tag{2} $
where $\mathbf{I} \in \mathbb{R}^{H \times W \times 3}$ is the input image, $\mathcal{E}$ is the vision tokenizer mapping images to $m$ visual tokens $\mathbf{V} \in \mathbb{R}^{m \times d}$, $\mathbf{Q}0 \in \mathbb{R}^{n \times d}$ are learnable causal query embeddings, $\oplus$ denotes sequence concatenation, $\mathcal{T}^L$ represents an $L$-layer Transformer with masked attention, $\mathbf{M} \in {0, 1}^{2n \times 2n}$ is the block causal attention mask defined in Equation 1, $\pi_Q$ is the projection operator that extracts the last $n$ tokens (i.e., $\mathbf{Z} = \mathbf{X}{m+1:m+n}$), $\mathcal{D}$ is the language decoder, and $\mathbf{O} \in \mathbb{R}^{n \times |\mathcal{V}|}$ is the output logits over LLM vocabulary.
4. Experimental Settings
Section Summary: DeepSeek-OCR 2 builds on its predecessor's data sources, using mostly OCR-focused materials with adjustments like more balanced sampling of text, formulas, and tables, plus simplified labels for similar layout elements to improve accuracy. The model undergoes three training stages: first pretraining the encoder to handle image features and token organization; next, enhancing query processing by fine-tuning the encoder and decoder together on varied image sizes; and finally, specializing the decoder alone while freezing the encoder to process data faster on powerful GPU setups. This setup allows efficient training on millions of image-text pairs over several iterations with optimized learning rates.
4.1 Data Engine
DeepSeek-OCR 2 employs the same data sources as DeepSeek-OCR, comprising OCR 1.0, OCR 2.0 [33, 34, 35], and general vision data [3], with OCR data constituting 80% of the training mixture. We also introduce two modifications: (1) a more balanced sampling strategy for OCR 1.0 data, partitioning pages by content type (text, formulas, tables) with a 3:1:1 ratio, and (2) label refinement for layout detection by merging semantically similar categories (e.g., unifying "figure caption" and "figure title"). Given these minimal differences, we consider DeepSeek-OCR a valid baseline for comparison.
4.2 Training Pipelines
We train DeepSeek-OCR 2 in three stages: (1) encoder pretraining, (2) query enhancement, and (3) decoder specialization. The stage-1 enables the vision tokenizer and LLM-style encoder to acquire fundamental capabilities in feature extraction, token compression, and token reordering capabilities. The stage-2 further strengthens the token reordering capability of the encoder while enhancing visual knowledge compression. The stage-3 freezes the encoder parameters and optimizes only the decoder, enabling higher data throughput under the same FLOPs.
4.2.1 Training DeepEncoder V2
Following DeepSeek-OCR and Vary [20], we train DeepEncoder V2 using a language modeling objective, coupling the encoder with a lightweight decoder [36] for joint optimization via next token prediction. We employ two dataloaders at resolutions of 768 $\times$ 768 and 1024 $\times$ 1024. The vision tokenizer is initialized from DeepEncoder, and the LLM-like encoder from Qwen2-0.5B-base [5]. After pretraining, only the encoder parameters are retained for subsequent stages. We use the AdamW [37] optimizer with cosine learning rate decay from 1e-4 to 1e-6, training on 160 A100 GPUs (20 nodes $\times$ 8 GPUs) with batch size 640 for 40k iterations (with sequence packing at 8K length, about 100M image-text pair samples).
4.2.2 Query enhancement
After DeepEncoder V2 pretraining, we integrate it with DeepSeek-3B-A500M [7, 38] as our final pipeline. We freeze the visual tokenizer (SAM-conv structure) while jointly optimizing the LLM encoder and LLM decoder to enhance query representations. At this stage, we unify the two resolutions into a single dataloader via multi-crop strategy. We adopt 4-stage pipeline parallelism: vision tokenizer (PP0), LLM-style encoder (PP1), and DeepSeek-LLM layers (6 layers per stage on PP2-3). With 160 GPUs (40GB/per-GPU), we configure 40 data parallel replicas (4 GPUs per replica) and train with global batch size 1280 using the same optimizer and learning rate decay from 5e-5 to 1e-6 over 15k iterations.
4.2.3 Continue-training LLM
To rapidly consume training data, we freeze all DeepEncoder V2 parameters in this stage and only update the DeepSeek-LLM parameters. This stage accelerates training (more than doubles the training speed under the same global batch size) while helping the LLM better understand DeepEncoder V2's reordered visual tokens. Continuing from stage-2, we perform another learning rate decay from 1e-6 to 5e-8 training for 20k iterations in this stage.
::: {caption="Table 1: Comprehensive evaluation of document reading on OmniDocBench v1.5. V-token$^{max}$ represents the maximum number of visual tokens used per page in this benchmark. R-order denotes reading order. Except for DeepSeek OCR and DeepSeek OCR 2, all other model results in this table are sourced from the OmniDocBench repository."}
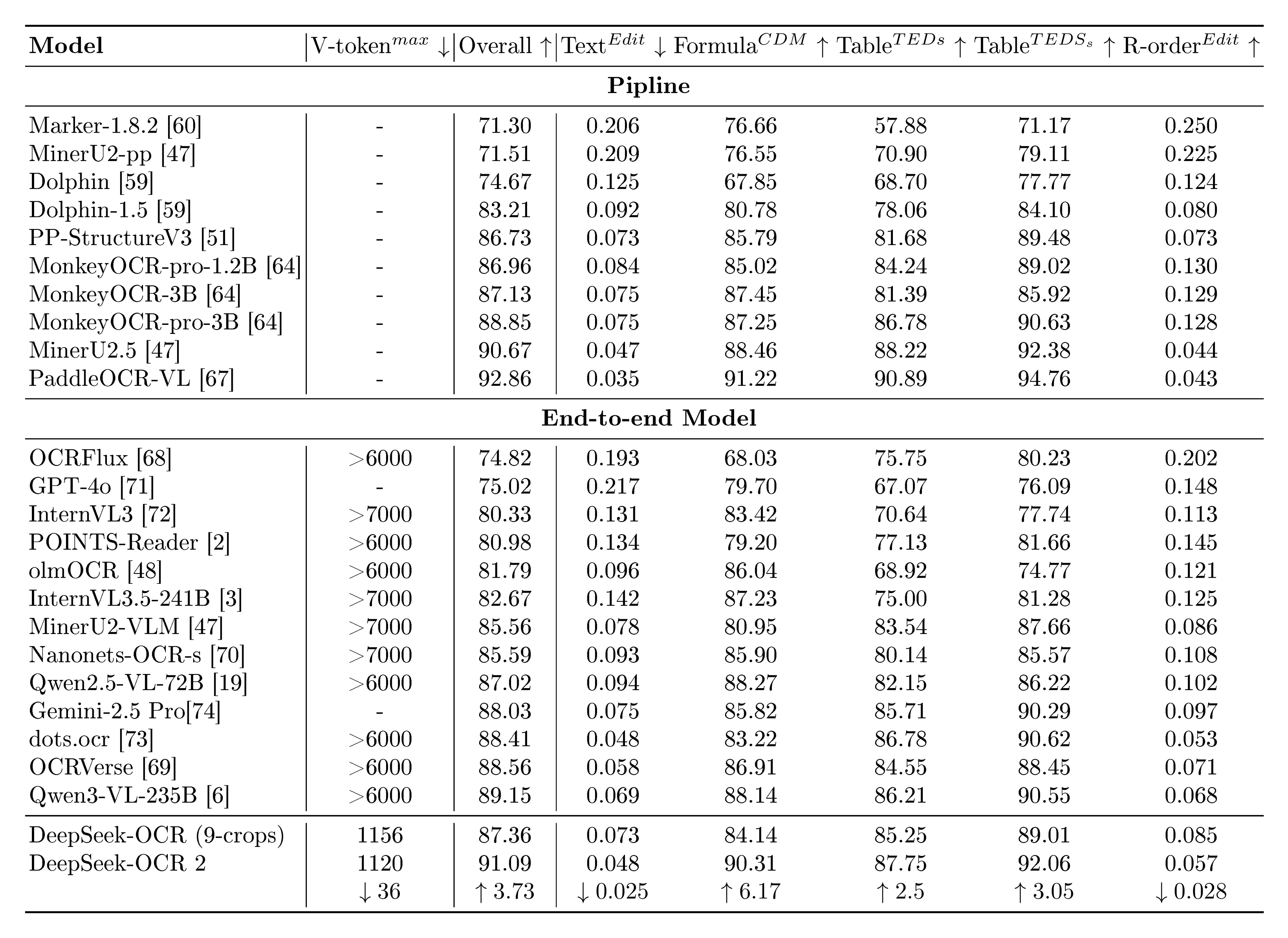
:::
5. Evaluation
Section Summary: DeepSeek-OCR 2 was evaluated using the OmniDocBench v1.5 benchmark, which tests OCR performance on over 1,300 diverse document pages in English and Chinese across nine categories like magazines and academic papers. The model achieved a strong 91.09% score with efficient use of visual tokens, outperforming its predecessor by 3.73% and showing better accuracy in reading order and document parsing compared to rivals like Gemini-3 Pro. While it has room for improvement in text-heavy formats like newspapers due to data and token limits, it demonstrated practical gains in real-world use, reducing errors in online image processing and PDF batch handling.
We select OmniDocBench v1.5 [11] as our primary benchmark for evaluation. This benchmark comprises 1, 355 document pages spanning 9 major categories (including magazines, academic papers, research reports, and so on) in both Chinese and English. With its diverse test samples and robust evaluation criteria, OmniDocBench provides an effective framework for validating the performance of DeepSeek-OCR 2, particularly the effectiveness of DeepEncoder V2.
5.1 Main Results
As shown in Table 1, DeepSeek-OCR 2 achieves advanced performance of 91.09% while using the smallest upper limit of visual tokens (V-token$^{max}$). Compared to the DeepSeek-OCR baseline, it demonstrates a 3.73% improvement under similar train data sources, validating the effectiveness of our newly designed architecture. Beyond the overall improvement, the Edit Distance (ED) for reading order (R-order) has also significantly decreased (from 0.085 to 0.057), indicating that the new DeepEncoder V2 can effectively select and arrange initial visual tokens based on image information. As illustrated in Table 2, DeepSeek-OCR 2 (0.100) achieves lower ED in document parsing compared to Gemini-3 Pro (0.115) under a similar visual token budget (1120), further demonstrating that our new model maintains high compression rates of visual tokens while ensuring superior performance, with exceptionally high potential.
::: {caption="Table 2: Edit Distances for different categories of document-elements in OmniDocBench v1.5. V-token$^{max}$ denotes the lowest maximum number of visual tokens."}

:::
5.2 Improvement Headroom
We conduct a detailed performance comparison between DeepSeek-OCR and DeepSeek-OCR 2 across 9 document types and found that DeepSeek-OCR 2 still has considerable room for improvement, as shown in Table 3. For text recognition Edit Distance (ED), DeepSeek-OCR 2 outperforms DeepSeek-OCR in most cases, but there are also notable weaknesses, such as newspapers, where it performs
gt;0.13$ ED. We believe there are two main reasons: (1) the lower upper limit of visual tokens may affect the recognition of text-super-rich newspapers, which can be simply addressed in the future by increasing the number of local crops; (2) insufficient newspaper data $-$ our training data contains only 250k relevant samples, which is inadequate for training DeepEncoder V2 for this class. Of course, for the reading order (R-order) metric, DeepSeek-OCR 2 consistently outperforms DeepSeek-OCR across the board, further validating the effectiveness of our visual causal flow encoder design.::: {caption="Table 3: Detailed comparison between DeepSeek-OCR 2 and DeepSeek-OCR across 9 document types. R-order denotes reading order. All metrics are Edit Distances, where lower is better."}
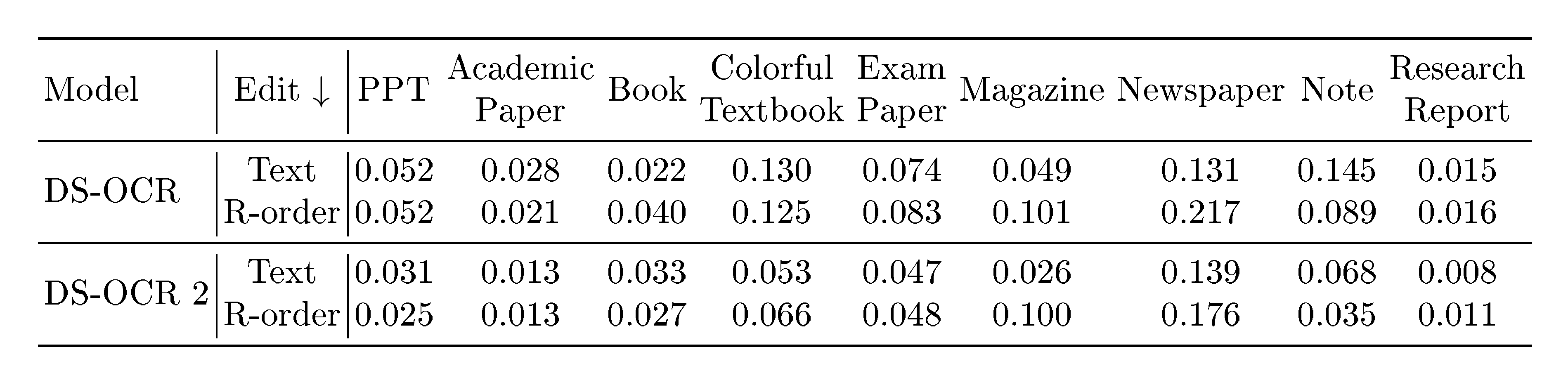
:::
::: {caption="Table 4: Production performance comparison between DeepSeek-OCR and DeepSeek-OCR 2. For OCR models serving LLM pipelines, ground truth is not accessible in production environments. Therefore, Repetition rate constitutes the primary observable quality metric."}

:::
5.3 Practical Readiness
DeepSeek-OCR serves two primary production use cases: an online OCR service that reads image/documents for DeepSeek-LLMs, and a pretraining data pipeline that performs batch PDF processing. We compare the production performance between DeepSeek-OCR 2 and DeepSeek-OCR. Since ground truth is unavailable in production environments, we focus primarily on repetition rate as our key metric. As shown in Table 4, DeepSeek-OCR 2 demonstrates markedly improved practical readiness compared to its predecessor (DeepSeek-OCR), reducing the repetition rate from 6.25% to 4.17% for online user-log images, and from 3.69% to 2.88% for PDF data production. These results further validate the effectiveness of the DeepSeek-OCR 2 architecture, particularly its logical visual comprehension capabilities.
6. Discussion and Future Works
Section Summary: DeepSeek-OCR 2 introduces a new approach using a language model-like encoder and decoder to break down two-dimensional visual reasoning into simpler one-dimensional steps, where the encoder reorders visual information and the decoder handles tasks based on that order, potentially leading to more authentic 2D understanding, though further refinements like longer sequences for repeated checks are needed. The model's encoder also shows promise for handling multiple types of data, such as text, speech, and images, through a shared framework with custom prompts for each, building on earlier optical compression efforts. Future work will focus on improving this architecture for broader visual reasoning and integrating more data types.
6.1 Towards Genuine 2D Reasoning
DeepSeek-OCR 2 presents a novel architectural paradigm with an LLM-style encoder cascaded with an LLM decoder. This cascade of two 1D causal reasoners holds promise for genuine 2D reasoning: the encoder performs reading logic reasoning (causally reordering visual information through query tokens), while the decoder executes visual task reasoning over these causally-ordered representations. Decomposing 2D understanding into two complementary/orthogonal 1D causal reasoning subtasks may represent a breakthrough toward genuine 2D reasoning. Of course, achieving this goal remains a long journey. For instance, to enable multiple re-examinations and multi-hop reordering of visual content, we may need substantially longer causal flow tokens than the original visual token sequence. We will continue to refine this architecture and explore its effectiveness on general visual reasoning tasks in future work.
6.2 Towards Native Multimodality
DeepEncoder V2 provides initial validation of the LLM-style encoder's viability for visual tasks. More importantly, this architecture enjoys the potential to evolve into a unified omni-modal encoder: a single encoder with shared $Wk, Wv$ projections, attention mechanisms, and FFNs can process multiple modalities through modality-specific learnable query embeddings. Such an encoder could compress text, extract speech features, and reorganize visual content within the same parameter space, differing only in the learned weights of their query embeddings. DeepSeek-OCR's optical compression represents an initial exploration toward native multimodality, while we believe DeepSeek-OCR 2's LLM-style encoder architecture marks our further step in this direction. We will also continue exploring the integration of additional modalities through this shared encoder framework in the future.
7. Conclusion
Section Summary: This report introduces DeepSeek-OCR 2, an enhanced version of DeepSeek-OCR that preserves efficient compression of visual data while delivering clear performance gains. The upgrade relies on DeepEncoder V2, which blends forward-and-backward and step-by-step attention techniques to build a deeper understanding of images, improving the system's ability to read and reason about visual content like text in documents. Though extracting text from visuals is a practical application in modern AI, it's only a piece of the puzzle in overall image comprehension, and the developers aim to evolve this technology for broader, more intelligent handling of diverse visual tasks.
In this technical report, we present DeepSeek-OCR 2, a significant upgrade to DeepSeek-OCR, that maintains high visual token compression while achieving meaningfully performance improvements. This advancement is powered by the newly proposed DeepEncoder V2, which implicitly distills causal understanding of the visual world through the integration of both bidirectional and causal attention mechanisms, leading to causal reasoning capabilities in the vision encoder and, consequently, marked lifts in visual reading logic.
While optical text reading, particularly document parsing, represents one of the most practical vision tasks in the LLM era, it constitutes only a small part of the broader visual understanding landscape. Looking ahead, we will refine and adapt this architecture to more diverse scenarios, seeking deeper toward a more comprehensive vision of multimodal intelligence.
References
Section Summary: This section provides a bibliography of key research papers and preprints in artificial intelligence, focusing on advancements in image recognition, vision-language models, and object detection techniques. It cites works from 2015 to 2026, including influential studies on transformers for handling images at various scales, efficient language models like DeepSeek and Qwen, and tools for tasks such as OCR and document understanding. These references draw from sources like arXiv, NeurIPS, and CVPR, highlighting innovations that blend visual and textual data processing.
[1] Dosovitskiy, Alexey (2020). An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929.
[2] Dehghani et al. (2023). Patch n' Pack: NaViT, a Vision Transformer for any Aspect Ratio and Resolution. Advances in Neural Information Processing Systems. 36. pp. 3632–3656.
[3] Wei et al. (2025). Deepseek-ocr: Contexts optical compression. arXiv preprint arXiv:2510.18234.
[4] Radford et al. (2021). Learning transferable visual models from natural language supervision. In International conference on machine learning. pp. 8748–8763.
[5] Wang et al. (2024). Qwen2-vl: Enhancing vision-language model's perception of the world at any resolution. arXiv preprint arXiv:2409.12191.
[6] Carion et al. (2020). End-to-end object detection with transformers. In European conference on computer vision. pp. 213–229.
[7] Liu et al. (2024). Deepseek-v2: A strong, economical, and efficient mixture-of-experts language model. arXiv preprint arXiv:2405.04434.
[8] Team et al. (2023). Gemini: a family of highly capable multimodal models. arXiv preprint arXiv:2312.11805.
[9] Liu, Fanfan and Qiu, Haibo (2025). Context cascade compression: Exploring the upper limits of text compression. arXiv preprint arXiv:2511.15244.
[10] Liu et al. (2025). Deepseek-v3. 2: Pushing the frontier of open large language models. arXiv preprint arXiv:2512.02556.
[11] Ouyang et al. (2025). Omnidocbench: Benchmarking diverse pdf document parsing with comprehensive annotations. In Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 24838–24848.
[12] Li et al. (2023). Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. In International conference on machine learning. pp. 19730–19742.
[13] Ren et al. (2015). Faster r-cnn: Towards real-time object detection with region proposal networks. In Advances in neural information processing systems. pp. 91–99.
[14] Redmon, Joseph and Farhadi, Ali (2017). YOLO9000: better, faster, stronger. In Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 7263–7271.
[15] He et al. (2016). Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 770–778.
[16] Zhu et al. (2020). Deformable detr: Deformable transformers for end-to-end object detection. arXiv preprint arXiv:2010.04159.
[17] Liu et al. (2021). WB-DETR: Transformer-Based Detector Without Backbone. In Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 2979–2987.
[18] Bai et al. (2023). Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond. arXiv preprint arXiv:2308.12966.
[19] Bai et al. (2025). Qwen2.5-VL Technical Report. arXiv preprint arXiv:2502.13923.
[20] Wei et al. (2024). Vary: Scaling up the vision vocabulary for large vision-language model. In European Conference on Computer Vision. pp. 408–424.
[21] Devlin et al. (2019). Bert: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers). pp. 4171–4186.
[22] Pang et al. (2023). Frozen transformers in language models are effective visual encoder layers. arXiv preprint arXiv:2310.12973.
[23] Adept (2023). Fuyu-8B. https://huggingface.co/adept/fuyu-8b.
[24] Chameleon Team (2024). Chameleon: Mixed-Modal Early-Fusion Foundation Models. arXiv preprint arXiv:2405.09818.
[25] Wang et al. (2023). Neural Codec Language Models are Zero-Shot Text to Speech Synthesizers. arXiv preprint arXiv:2301.02111.
[26] Su et al. (2021). RoFormer: Enhanced Transformer with Rotary Position Embedding. arXiv preprint arXiv:2104.09864.
[27] Kirillov et al. (2023). Segment anything. arXiv preprint arXiv:2304.02643.
[28] Wei et al. (2024). General ocr theory: Towards ocr-2.0 via a unified end-to-end model. arXiv preprint arXiv:2409.01704.
[29] Wang et al. (2025). Step-3 is Large yet Affordable: Model-system Co-design for Cost-effective Decoding. arXiv preprint arXiv:2507.19427.
[30] Wei et al. (2024). Small language model meets with reinforced vision vocabulary. arXiv preprint arXiv:2401.12503.
[31] Huang et al. (2026). STEP3-VL-10B Technical Report. arXiv preprint arXiv:2601.09668.
[32] Liu et al. (2020). Multilingual denoising pre-training for neural machine translation. Transactions of the Association for Computational Linguistics. 8. pp. 726–742.
[33] Chen et al. (2024). Onechart: Purify the chart structural extraction via one auxiliary token. In Proceedings of the 32nd ACM International Conference on Multimedia. pp. 147–155.
[34] Wei et al. (2024). Slow Perception: Let's Perceive Geometric Figures Step-by-step. arXiv preprint arXiv:2412.20631.
[35] Liu et al. (2024). Focus Anywhere for Fine-grained Multi-page Document Understanding. arXiv preprint arXiv:2405.14295.
[36] Iyer et al. (2022). OPT-IML: Scaling Language Model Instruction Meta Learning through the Lens of Generalization. arXiv preprint arXiv:2212.12017.
[37] Ilya Loshchilov and Frank Hutter (2019). Decoupled Weight Decay Regularization. In ICLR.
[38] Liu et al. (2024). Deepseek-v3 technical report. arXiv preprint arXiv:2412.19437.