Why Diffusion Models Don’t Memorize: The Role of Implicit Dynamical Regularization in Training
Tony Bonnaire, LPENS, Université PSL, Paris, [email protected]
Raphaël Urfin, LPENS, Université PSL, Paris, [email protected]
Giulio Biroli, LPENS, Université PSL, Paris, [email protected]
Marc Mézard, Department of Computing Sciences, Bocconi University, Milano, [email protected]
Equal contribution.
Abstract
Diffusion models have achieved remarkable success across a wide range of generative tasks. A key challenge is understanding the mechanisms that prevent their memorization of training data and allow generalization. In this work, we investigate the role of the training dynamics in the transition from generalization to memorization. Through extensive experiments and theoretical analysis, we identify two distinct timescales: an early time at which models begin to generate high-quality samples, and a later time beyond which memorization emerges. Crucially, we find that increases linearly with the training set size , while remains constant. This creates a growing window of training times with where models generalize effectively, despite showing strong memorization if training continues beyond it. It is only when becomes larger than a model-dependent threshold that overfitting disappears at infinite training times. These findings reveal a form of implicit dynamical regularization in the training dynamics, which allow to avoid memorization even in highly overparameterized settings. Our results are supported by numerical experiments with standard U-Net architectures on realistic and synthetic datasets, and by a theoretical analysis using a tractable random features model studied in the high-dimensional limit.
1. Introduction
Diffusion Models [DMs, 1, 2, 3, 4] achieve state-of-the-art performance in a wide variety of AI tasks such as the generation of images [5], audios [6], videos [7], and scientific data [8, 9]. This class of generative models, inspired by out-of-equilibrium thermodynamics [1], corresponds to a two-stage process: the first one, called forward, gradually adds noise to a data, whereas the second one, called backward, generates new data by denoising Gaussian white noise samples. In DMs, the reverse process typically involves solving a stochastic differential equation (SDE) with a force field called score. However, it is also possible to define a deterministic transport through an ordinary differential equation (ODE), treating the score as a velocity field, an approach that is for instance followed in flow matching [10].
Understanding the generalization properties of score-based generative methods is a central issue in machine learning, and a particularly important question is how memorization of the training set is avoided in practice. A model without regularization achieving zero training loss only learns the empirical score, and is bound to reproduce samples of the training dataset at the end of the backward process. This memorization regime [11, 12] is empirically observed when the training set is small and disappears when it increases beyond a model-dependent threshold [13]. Understanding the mechanisms controlling this change of regimes from memorization to generalization is a central challenge for both theory and applications. Model regularization and inductive biases imposed by the network architecture were shown to play a role [14, 15], as well as a dynamical regularization due to the finiteness of the learning rate [16]. However, the regime shift described above is consistently observed even in models where all these regularization mechanisms are present. This suggests that the core mechanism behind the transition from memorization to generalization lies elsewhere. In this work, we demonstrate -- first through numerical experiments, and then via the theoretical analysis of a simplified model -- that this transition is driven by an implicit dynamical bias towards generalizing solutions emerging in the training, which allows to avoid the memorization phase.
💭 Click to ask about this figure
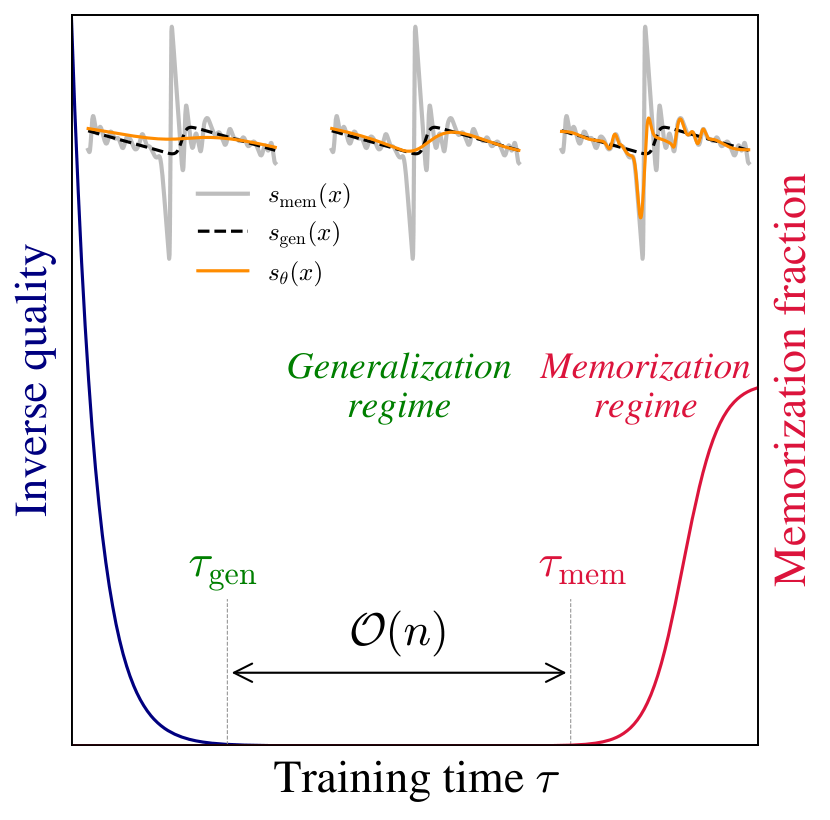
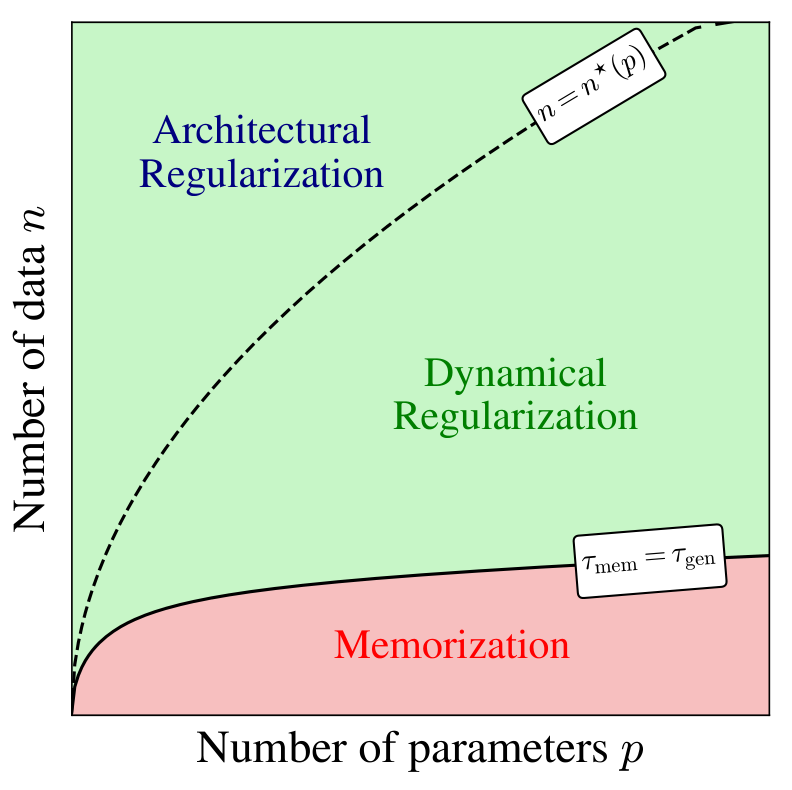
Contributions and theoretical picture. We investigate the dynamics of score learning using gradient descent, both numerically and analytically, and study the generation properties of the score depending on the time at which the training is stopped. The theoretical picture built from our results and combining several findings from the recent literature is illustrated in Figure 1. The two main parameters are the size of the training set and the expressivity of the class of score functions on which one trains the model, characterized by a number of parameters ; when both and are large one can identify three main regimes. Given , if is larger than (which depends on the training set and on the class of scores), the score model is not expressive enough to represent the empirical score associated to data, and instead provides a smooth interpolation, approximately independent of the training set. In this regime, even with a very large training time , memorization does not occur because the model is regularized by its architecture and the finite number of parameters. When the model is expressive enough to memorize, and two timescales emerge during training: one, , is the minimum training time required to achieve high-quality data generation; the second, , signals when further training induces memorization, and causes the model to increasingly reproduce the training samples (left panel). The first timescale, , is found independent of , whereas the second, , grows approximately linearly with , thus opening a large window of training times during which the model generalizes if early stopped when .
Our results shows that implicit dynamical regularization in training plays a crucial role in score-based generative models, substantially enlarging the generalization regime (see right panel of Figure 1), and hence allowing to avoid memorization even in highly overparameterized settings. We find that the key mechanism behind the widening gap between and is the irregularity of the empirical score at low noise level and large . In this regime the models used to approximate the score provide a smooth interpolation that remains stable for a long period of training times and closely approximates the population score, a behavior likely rooted in the spectral bias of neural networks [18]. Only at very long training times do the dynamics converge to the low lying minimum corresponding to the empirical score, leading to memorization (as illustrated in the one-dimensional examples in the left panel of Figure 1).
The theoretical picture described above is based on our numerical and analytical results, and builds up on previous works, in particular numerical analysis characterizing the memorization--generalization transition [19, 20], analytical works on memorization of DMs [17, 14, 13], and studies on the spectral bias of deep neural networks [18]. Our numerical experiments use a class of scores based on a realistic U-Net [21] trained on downscaled images of the CelebA dataset [22]. By varying and , we measure the evolution of the sample quality (through FID) and the fraction of memorization during learning, which support the theoretical scenario presented in Figure 1. Additional experimental results on synthetic data are provided in Supplemental Material (SM, Sects. Appendix A and Appendix B). On the analytical side, we focus on a class of scores constructed from random features and simplified models of data, following [17]. In this setting, the timescales of training dynamics correspond directly to the inverse eigenvalues of the random feature correlation matrix. Leveraging tools from random matrix theory, we compute the spectrum in the limit of large datasets, high-dimensional data, and overparameterized models. This analysis reveals, in a fully tractable way, how the theoretical picture of Figure 1 emerges within the random feature framework.
Related works. - The memorization transition in DMs has been the subject of several recent empirical investigations [23, 24, 25] which have demonstrated that state-of-the-art image DMs -- including Stable Diffusion and DALL·E -- can reproduce a non-negligible portion of their training data, indicating a form of memorization. Several additional works [19, 20] examined how this phenomenon is influenced by factors such as data distribution, model configuration, and training procedure, and provide a strong basis for the numerical part of our work.
-
A series of theoretical studies in the high-dimensional regime have analyzed the memorization--generalization transition during the generative dynamics under the empirical score assumption [12, 26, 27], showing how trajectories are attracted to the training samples. Within this high-dimensional framework, [28, 29, 30, 17] study the score learning for various model classes. In particular, [17] uses a Random Feature Neural Network [31]. The authors compute the asymptotic training and test losses for and relate it to memorization.The theoretical part of our work generalizes this approach to study the role of training dynamics and early stopping in the memorization--generalization transition.
-
Recent works have also uncovered complementary sources of implicit regularization explaining how DMs avoid memorization. Architectural biases and limited network capacity were for instance shown to constrain memorization in [14, 13], and finiteness of the learning rate prevents the model from learning the empirical score in [16]. Also related to our analysis, [32] provides general bounds showing the beneficial role of early stopping the training dynamics to enhance generalization for finitely supported target distributions, as well as a study of its effect for one-dimensional gaussian mixtures.
-
Finally, previous studies on supervised learning [18, 33], and more recently on DMs [34], have shown that deep neural networks display a frequency-dependent learning speed, and hence a learning bias towards low frequency functions.This fact plays an important role in the results we present since the empirical score contains a low frequency part that is close to the population score, and a high-frequency part that is dataset-dependent. To the best of our knowledge, the training time to learn the high-frequency part and hence memorize, that we find to scale with , has not been studied from this perspective in the context of score-based generative methods.
Setting: generative diffusion and score learning. Standard DMs define a transport from a target distribution in to a Gaussian white noise through a forward process defined as an Ornstein-Uhlenbeck (OU) stochastic differential equation (SDE):
where is square root of two times a Wiener process. Generation is performed by time-reversing the SDE Equation 1 using the score function ,
where is the probability density at time along the forward process, and the noise is also the square root of two times a Wiener process. As shown in the seminal works [35, 36], can be obtained by minimizing the score matching loss
where . In practice, the optimization problem is restricted to a parametrized class of functions defined, for example, by a neural network with parameters . The expectation over is replaced by the empirical average over the training set ( iid samples drawn from ),
where . The loss in (Equation 4) can be minimized with standard optimizers, such as stochastic gradient descent [SGD, 37] or Adam [38]. In practice, a single model conditioned on the diffusion time is trained by integrating (Equation 4) over time [39]. The solution of the minimization of Equation 4 is the so-called empirical score (e.g. [12, 11]), defined as , with
This solution is known to inevitably recreate samples of the training set at the end of the generative process (i.e., it perfectly memorizes), unless grows exponentially with the dimension [12]. However, this is not the case in many practical applications where memorization is only observed for relatively small values of , and disappears well before becomes exponentially large in . The empirical minimization performed in practice, within a given class of models and a given minimization procedure, does not drive the optimization to the global minimum of Equation 4, but instead to a smoother estimate of the score that is independent of the training set with good generalization properties [13], as the global minimum of Equation 3 would do. Understanding how it is possible, and in particular the role played by the training dynamics to avoid memorization, is the central aim of the present work.
2. Generalization and memorization during training of diffusion models
💭 Click to ask about this figure
Data & architecture. We conduct our experiments on the CelebA face dataset [22], which we convert to grayscale downsampled images of size , and vary the training set size from 128 up to 32768. Our score model has a U-Net architecture [21] with three resolution levels and a base channel width of with multipliers 1, 2 and 3 respectively. All our networks are DDPMs [2] trained to predict the injected noise at diffusion time using SGD with momentum at fixed batch size . The models are all conditioned on , i.e. a single model approximates the score at all times, and make use of a standard sinusoidal position embedding [40] that is added to the features of each resolution. More details about the numerical setup can be found in SM (Appendix A).
Evaluation metrics. To study the transition from generalization to memorization during training, we monitor the loss Equation 4 during training using a fixed diffusion time . At various numbers of SGD updates , we compute the loss on all training examples (training loss) and on a held-out test set of 2048 images (test loss). To characterize the score obtained after a training time , we assess the originality and quality of samples by generating 10K samples using a DDIM accelerated sampling [41]. We compute (i) the Fréchet-Inception Distance [FID, 42] against 10K test samples which we use to identify the generalization time ; and (ii) the fraction of memorized generated samples granting access to , the memorization time. Following previous numerical studies [20, 19], a generated sample is considered memorized if
where and are the nearest and second nearest neighbors of in the training set in the sense. In what follows, we choose to work with [20, 19], but we checked that varying to or does not impact the claims about the scaling. Error bars in the figures correspond to twice the standard deviation over 5 different test sets for FIDs, and 5 noise realizations for and . For , we report the 95% CIs on the mean evaluated with 1, 000 bootstrap samples.
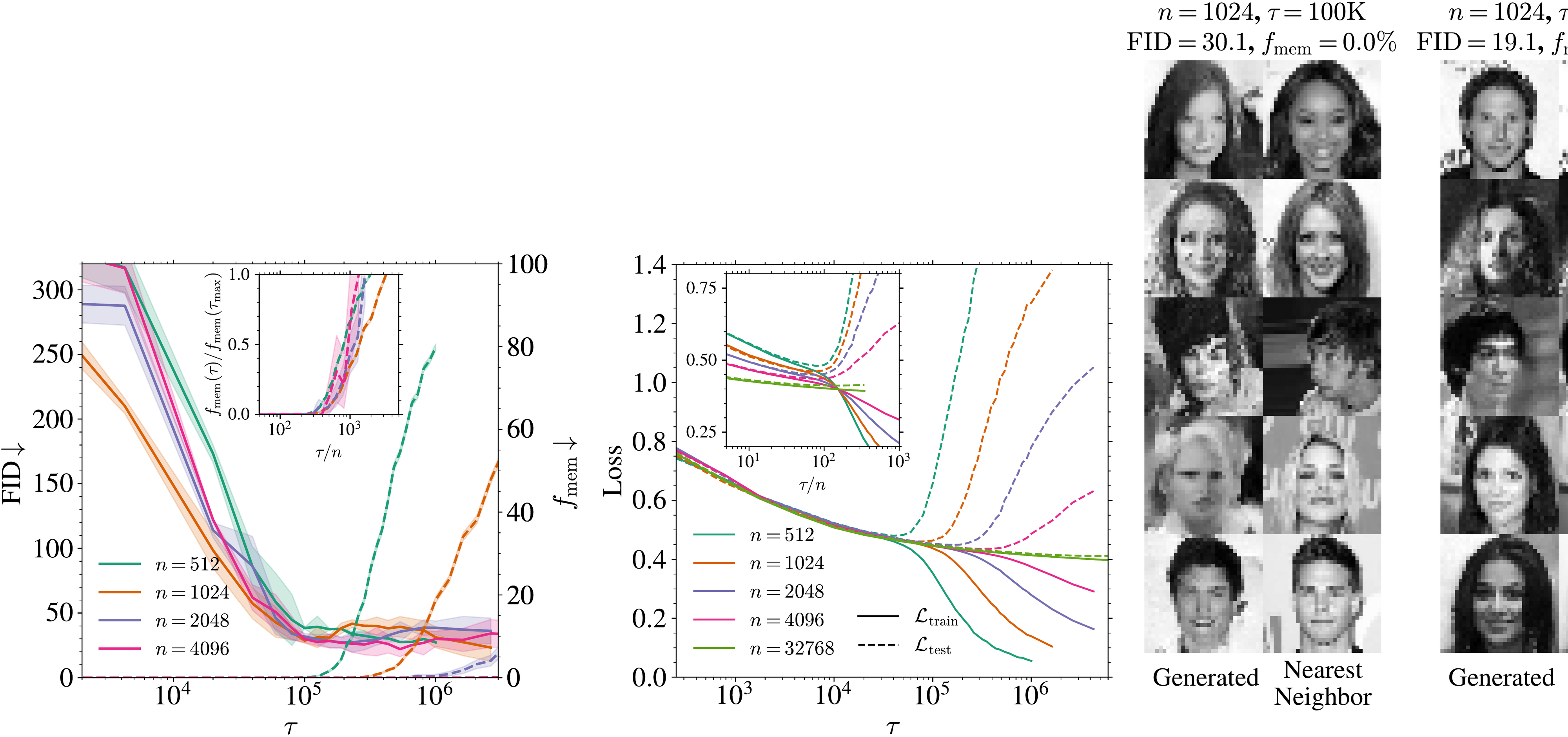
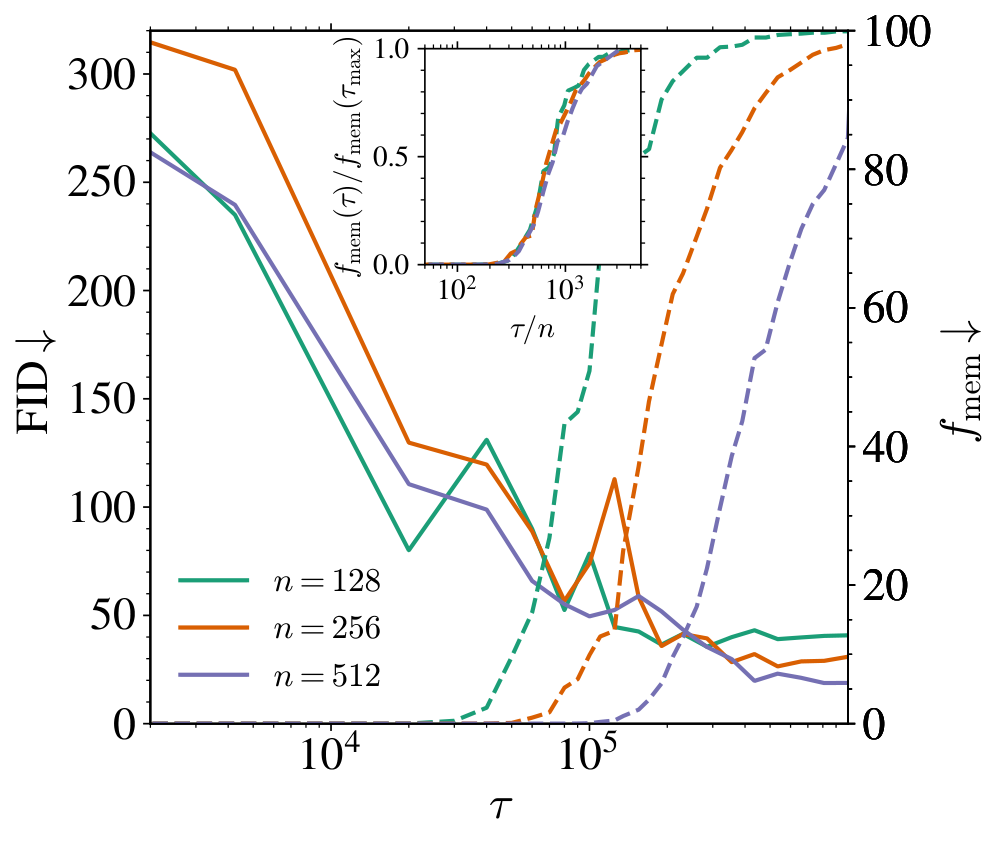
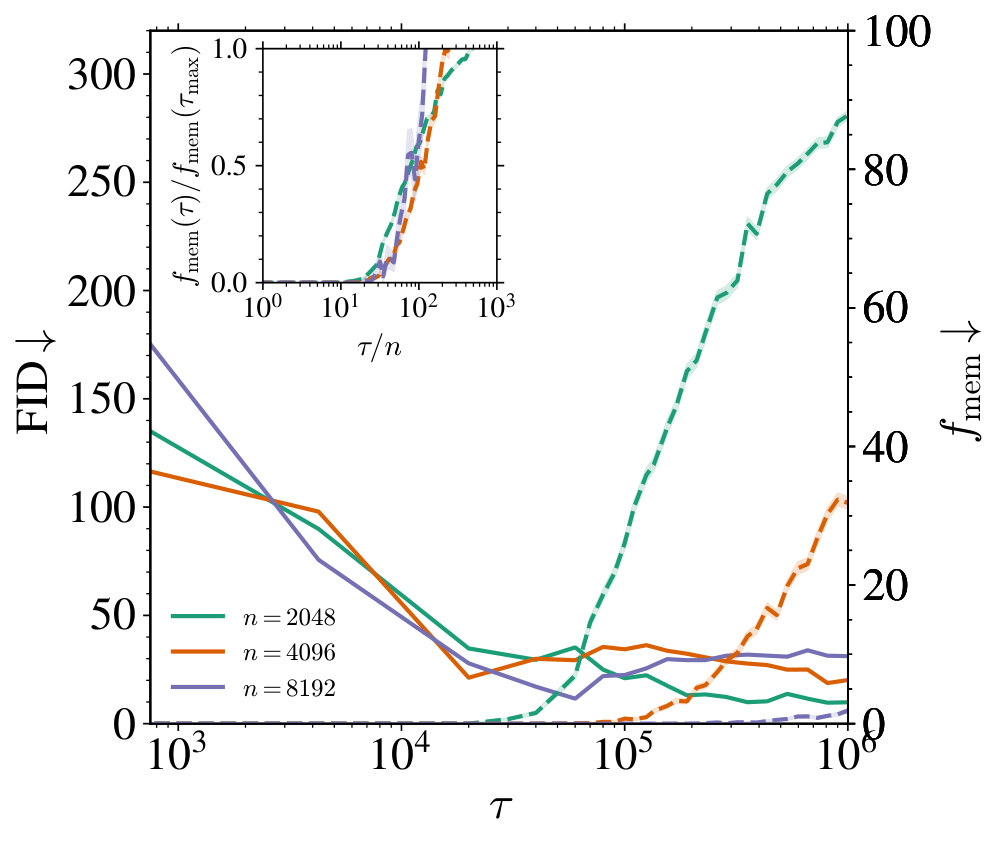
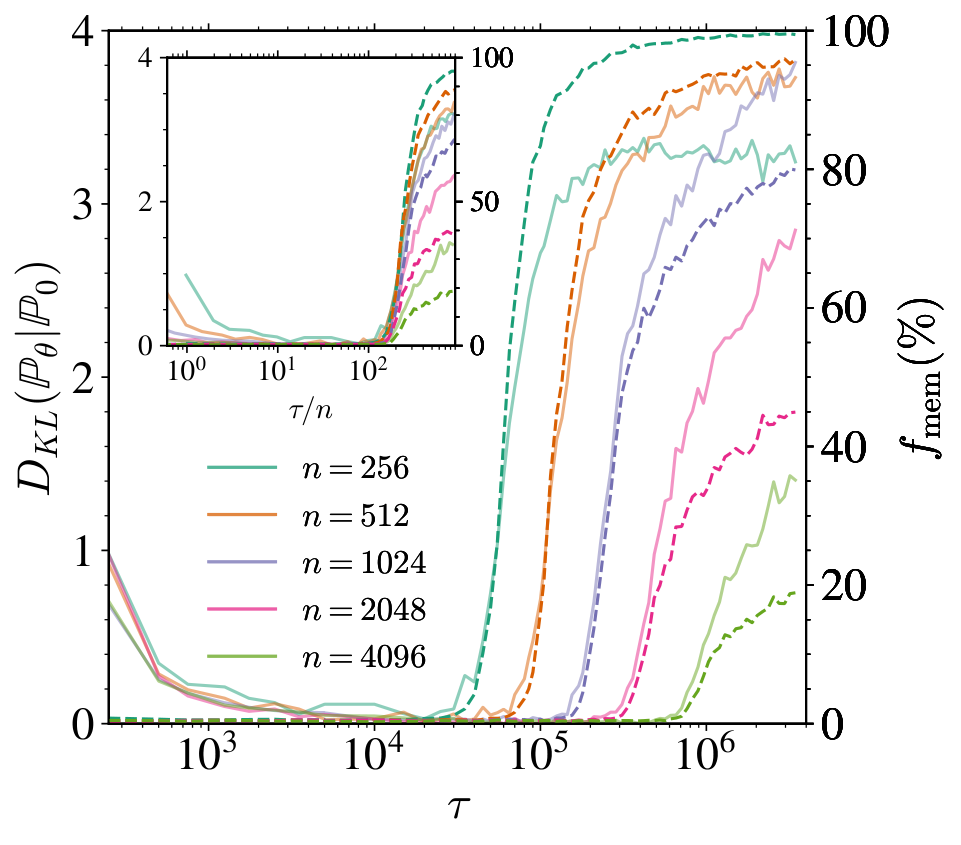
Role of training set size on the learning dynamics. At fixed model capacity (, base width ), we investigate how the training set size impacts the previous metrics. In the left panel of Figure 2, we first report the FID (solid lines) and (dashed lines) for various . All trainings dynamics exhibit two phases. First, the FID quickly decreases to reach a minimum value on a timescale ( K) that does not depend on . In the right panel, the generated samples at K clearly differ from their nearest neighbors in the training set, indicating that the model generalizes correctly. Beyond this time, the FID remains flat. is zero until a later time after which it increases, clearly signaling the entrance into a memorization regime, as illustrated by the generated samples in the right-most panel of Figure 2, very close to their nearest neighbors. Both the transition time and the value of the final fraction (with being one to four million SGD steps) vary with . The inset plot shows the normalized memorization fraction against the rescaled time , making all curves collapse and increase at around , showing that , and demonstrating the existence of a generalization window for that widens linearly with , as illustrated in the left panel of Figure 1.
As highlighted in the introduction, memorization in DMs is ultimately driven by the overfitting of the empirical score . The evolution of and at fixed are shown in the middle panel of Figure 2 for ranging from 512 to 32768. Initially, the two losses remain nearly indistinguishable, indicating that the learned score does not depend on the training set. Beyond a critical time, continues to decrease while increases, leading to a nonzero generalization loss whose magnitude depends on . As increases, this critical time also increases and, eventually, the training and test loss gap shrinks: for , the test loss remains close to the training loss, even after 11 million SGD steps. The inset shows the evolution of both losses with , demonstrating that the overfitting time scales linearly with the training set size , just like identified in the left panel. Moreover, there is a consistent lag between the overfitting time and at fixed , reflecting the additional training required for the model to overfit the empirical score sufficiently to reproduce the training samples, and therefore to impact the memorization fraction.
Memorization is not due to data repetition. We must stress that this delayed memorization with is not due to the mere repetition of training samples, as a first intuition could suggest. In SM Sects. Appendix A and Appendix B, we show that full-batch updates still yield . In other words, even if at fixed all models have processed each sample equally often, larger consistently postpone memorization. This confirms that memorization in DMs is driven by a fundamental -dependent change in the loss landscape -- not by a sample repetition during training.
💭 Click to ask about this figure
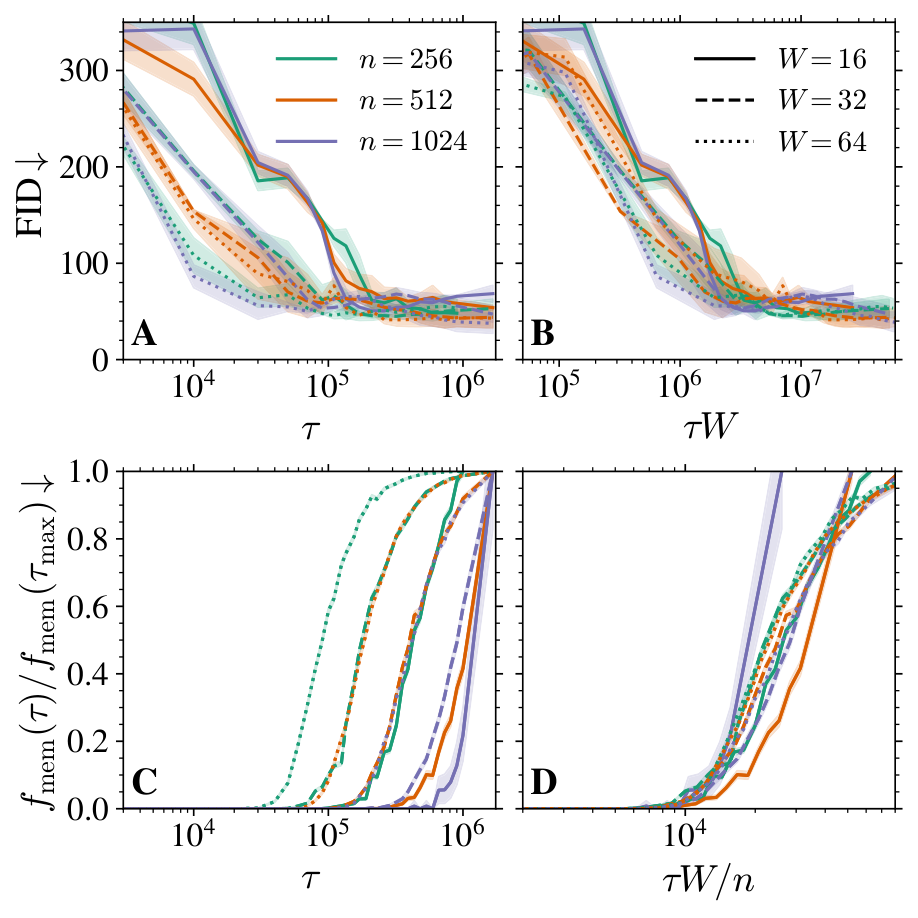
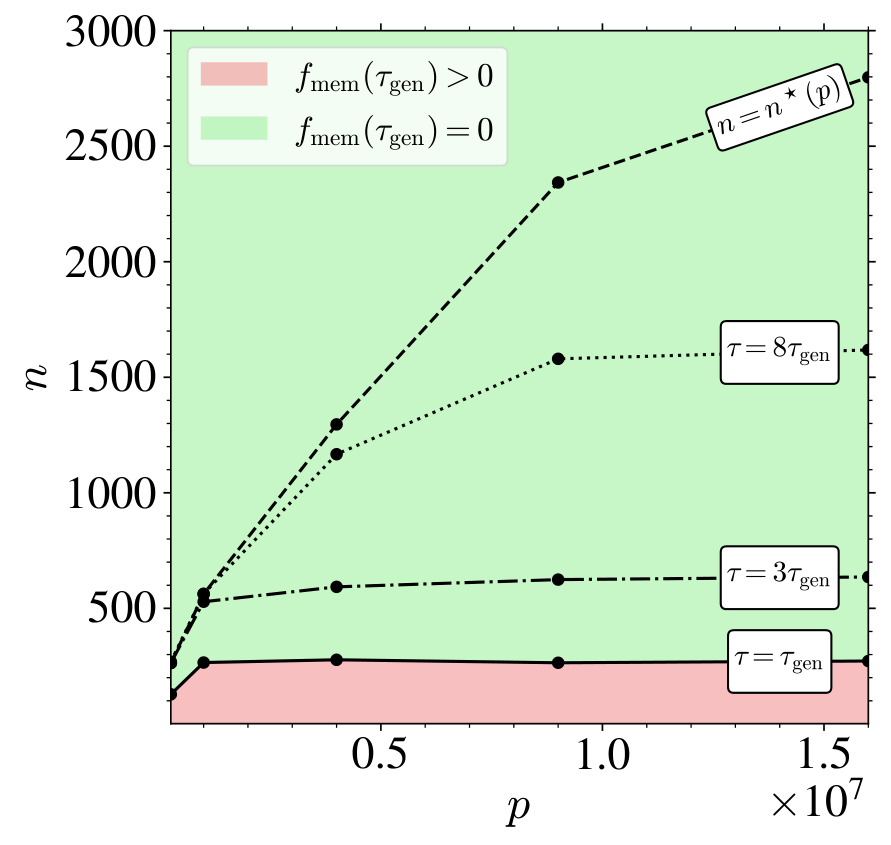
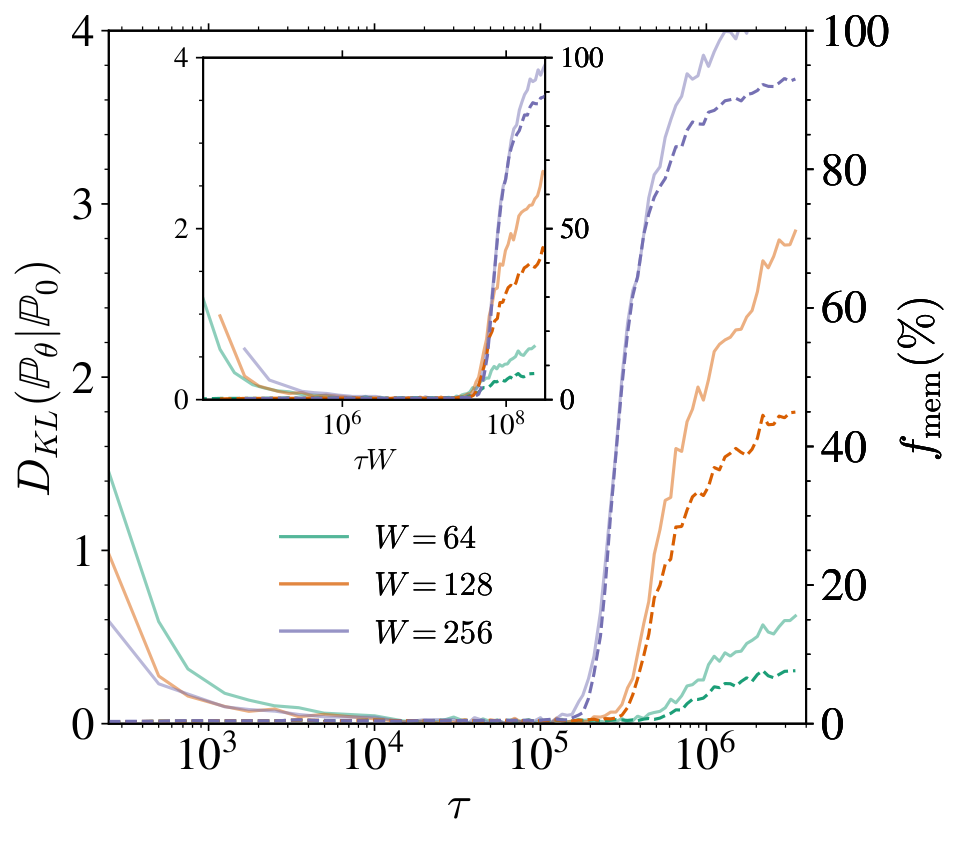
Effect of the model capacity. To study more precisely the role of the model capacity on the memorization--generalization transition, we vary the number of parameters by changing the U-Nets base width , resulting in a total of parameters. In the left panel of Figure 3, we plot both the FID (top row) and the normalized memorization fraction (bottom row) as functions of for several width and training set sizes . Panels A and C demonstrate that higher-capacity networks (larger ) achieve high-quality generation and begin to memorize earlier than smaller ones. Panels B and D show that the two characteristic timescales simply scale as and . In particular, this implies that, for , the critical training set size at which is approximately independent of (at least on the limited values of we focused on). When , the interval opens up, so that early stopping within this window yields high quality samples without memorization. In the right panel of Figure 3, we display this boundary (solid line) in the plane by fixing the training time to , that we identify numerically using the collapse of all FIDs at around (see panel B), and computing the smallest such that . The resulting solid curve delineates two regimes: below the curve, memorization already starts at ; above the curve, the models generalize perfectly under early stopping. We repeat this experiment for and , showing saturation to larger and larger as increases. Eventually, for , we expect these successive boundaries to converge to the architectural regularization threshold , i.e. the point beyond which the network avoids memorization because it is not expressive enough, as found in [17] and highlighted in the right panel of Figure 1. In order to estimate , we measure for a given the largest yielding . The curve approaches for large . We therefore estimate by measuring the asymptotic values of , which in practice is reached already at M updates for the values of we focus on.
3. Training dynamics of a Random Features Network
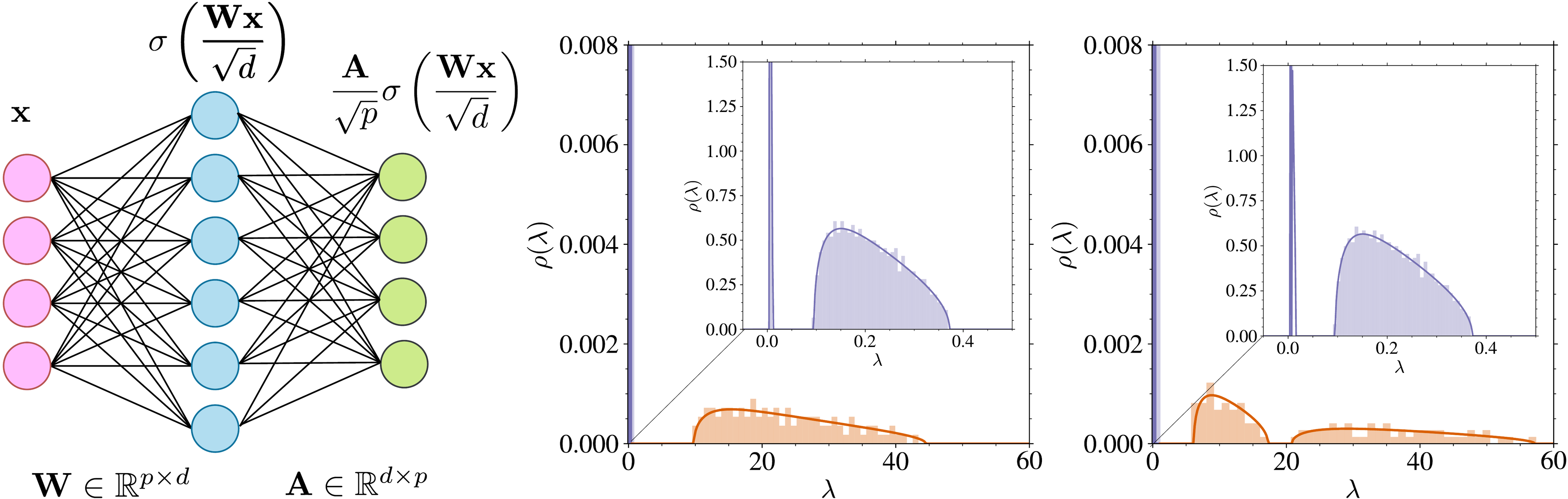
Notations. We use bold symbols for vectors and matrices. The norm of a vector is denoted by . We write to mean that in the limit , there exists a constant such that . Setting. We study analytically a model introduced in [17], where the data lie in dimensions. We parametrize the score with a Random Features Neural Network [RFNN, 31]
An RFNN, illustrated in Figure 4 (left), is a two-layer neural-network whose first layer weights () are drawn from a Gaussian distribution and remain frozen while the second layer weights () are learned during training. This model has already served as theoretical framework for studying several behaviors of deep neural network such as the double descent phenomenon [43, 44]. is an element-wise non-linear activation function. We consider a training set of iid samples for and we focus on the high-dimensional limit with the ratios kept fixed. We study the training dynamics associated to the minimization of the empirical score matching loss defined in (Equation 4) at a fixed diffusion time . This is a simplification compared to practical methods, which use a single model for all . It has been already studied in previous theoretical works [28, 17]. The loss (Equation 4) is rescaled by a factor in order to ensure a finite limit at large . We also study the evolution of the test loss evaluated on test points and the distance to the exact score ,
where the expectations are computed over and . The generalization loss, defined as , indicates the degree of overfitting in the model while the distance to the exact score measures the quality of the generation as it is an upper bound on the Kullback–Leibler divergence between the target and generated distributions [45, 46]. The weights are updated via gradient descent
where is the learning rate. In the high-dimensional limit, as the learning rate , and after rescaling time as , the discrete-time dynamics converges to the following continuous-time gradient flow:
with
💭 Click to ask about this figure
Assumptions. For our analytical results to hold, we make the following mathematical assumptions which are standard when studying Random Features [47, 48, 49] namely (i) the activation function admits a Hermite polynomial expansion ; and (ii) the data distribution has sub-Gaussian tails and a covariance with bounded spectrum. We assume that the empirical distribution of eigenvalues of converges weakly in the high dimensional limit to a deterministic density and that converges to a finite limit (for a more precise mathematical statement see SM Appendix C.3). Moreover, we make additional assumptions that are not essential to the proofs but which simplify the analysis: (iii) the activation function verifies ; and (iv) the second layer is initialized with zero weights . In numerical applications, unless specified, we use and .
![**Figure 5:** **Evolution of the training and test losses for the RFNN.** (A) Distance to the true score $\mathcal{E}_\mathrm{score}$ against training time $\tau$ for $\psi_n=4, 8, 16, 32$, $\psi_p=64, t=0.1$ and $d=100$. In the inset, the training time is rescaled by $\tau_\mathrm{mem}=\psi_p/\Delta_t\lambda_\mathrm{min}$. (B) Training (solid) and test (dashed) losses for various $\psi_n$. The inset shows both losses rescaled by $\tau_\mathrm{mem}$. (C) Heatmaps of $\mathcal{L}_\mathrm{gen}$ for $\tau=10^{3}$ (top) and $\tau=10^4$ (bottom) as a function of $\psi_n$ and $\psi_p$. All the curves use Pytorch [50] gradient descent. More numerical details can be found in SM Section D.](https://ittowtnkqtyixxjxrhou.supabase.co/storage/v1/object/public/public-images/zajbagrd/complex_fig_99643b8ecb8c.png)
💭 Click to ask about this figure
Emergence of the two timescales during training. We first show in Figure 5 that the behavior of training and test losses in the RF model mirrors the one found in realistic cases in Section 2, with a separation of timescales and which increases with . Equation (Equation 10) is linear in and hence it can be solved exactly (see SM). The timescales of the training dynamics are given by the inverse eigenvalues of the matrix . Building on the Gaussian Equivalence Principle [GEP, 51, 48, 52] and the theory of linear pencils [53], [17] ([17]) derive a coupled system of equations characterizing the Stieltjes transform of the eigenvalue density of for isotropic Gaussian data that lie in a -dimensional subspace with and . We offer an alternative derivation presented in SM for general variance using the replica method [54] -- a heuristic method from the statistical physics of disordered systems -- yielding the more compact formulation for obtaining the spectrum stated in Theorem 1. Before stating the theorem, we introduce
where , and the expectation is over the random variables which are independent standard Gaussian .
Theorem 1
Let , and , with . Let
Then and satisfy the following set of three equations:
The eigenvalue distribution of , , can then be obtained using the Sokhotski–Plemelj inversion formula .
We now focus on the asymptotic regime , typical for strongly over‑parameterized models trained on large data sets. In this limit, the spectrum of can be described analytically by the following Theorem 2.
Theorem 2: Informal
Let denote the spectral density of .
- Regime I (overparametrized): .
- Regime II (underparametrized): .
where is an atomless measure with support
and coincides with the asymptotic eigenvalue bulk density of the population covariance ; is independent of and its support is on the scale .
The eigenvectors associated with leave both training and test losses unchanged and are therefore irrelevant. In the limit , the supports of and are respectively on the scales and , i.e. they are well separated.
The proofs of both theorems are shown in SM (Appendix C). We recall that training timescales are directly related to eigenvalues via the relation . Theorem 2 therefore demonstrates the emergence of the two training timescales and in the overparametrized regime of the RFNN model. They are respectively associated to the measures and , which are well separated in regime I, for , as shown in Figure 4.
Generalization: The timescale on which the first relaxation takes place is associated to the formation of the generalization regime. It is related to the bulk and is or order . This regime only depends on the population covariance of the data and is independent of the specific realization of the dataset. On this timescale, which is of order one, both the training and test losses decrease. The generalization loss is zero, and tends to a value that we find to scale as with numerically (see Figure 5).
Memorization: The timescale , on which the second stage of the dynamics takes place, is associated to overfitting and memorization. It is related to the bulk , and scales as , where is the left edge of . In the overparameterized regime , becomes large and of order , thus implying a scaling of with . On this timescale, the training loss decreases while the test loss increases, converging to their respective asymptotic values as computed in [17]. Figure 5 indeed shows that all training and test curves separate, correspondingly the generalization loss increases, at a time that scales with , as shown in the inset.
As increases, the asymptotic () generalization loss decreases, indicating a reduced overfitting. For , although some overfitting remains (i.e., ), the value of is sensibly reduced, and the model is no longer expressive enough to memorize the training data, as shown in [17]. This regime corresponds to the Architectural Regularization phase in Figure 1. We show in Figure 5 (panel C) how the generalization loss varies in the plane depending on the time at which training is stopped. In agreement with the above results, we find that the generalization--memorization transition line depends on and moves upward for larger values of , similarly to the numerical results exposed in Figure 3 and the illustration in Figure 1.
4. Conclusions
We have shown that the training dynamics of neural network-based score functions display a form of implicit regularization that prevents memorization even in highly overparameterized diffusion models. Specifically, we have identified two well-separated timescales in the learning: , at which models begins to generate high-quality, novel samples, and , beyond which they start to memorize the training data. The gap between these timescales grows with the size of the training set, leading to a broad window where early stopped models generate novel samples of high-quality. We have demonstrated that this phenomenon happens in realistic settings, for controlled synthetic data, and in analytically tractable models. Although our analysis focuses on DMs, the underlying score‑learning mechanism we uncover is common to all score‑based generative models such as stochastic interpolants [55] or flow matching [10]; we therefore expect our results to generalize to this broader class.
Limitations and future works. - While we derived our results under SGD optimization, most DMs are trained in practice with Adam [38]. In SM Sects. Appendix A and Appendix D, we show that the two key timescales still arise using Adam, although with much fewer optimization steps. Studying how different optimizers shift these timescales would be valuable for practical usage.
- All experiments in Section 2 are conducted with unconditional DMs. We additionally verify in SM Sect. B, using a toy Gaussian mixture dataset and classifier-free guidance [56], that the same scaling of with holds in the conditional settings. Understanding precisely how the absolute timescales and depend on the conditioning remains an open question.
- Our numerical experiments cover a range of between 1M and 16M. Exploring a wider range is essential to map the full phase diagram sketched in Figure 1 and understand the precise effect of expressivity on dynamical regularization.
- Finally, our theoretical analysis rely on well-controlled data and score models that reproduce the core effects. Extending these analytical frameworks to richer data distributions (such as Gaussian mixtures or data from the hidden manifold model) and to structured architectures would be valuable to further characterize the implicit dynamical regularization of training score-functions. In particular investigating how heavy-tailed data distribution [57] affect the picture described here could be valuable.
- Although DMs trained on large and diverse datasets likely avoid the memorization regime we study here, some industrial models were shown to exhibit partial memorization [23, 24]. Our results provide practical guidelines (early-stopping, control the network capacity) to train DMs robustly and hence avoid memorization, which can be especially helpful in data-scarce domains (e.g., physical sciences).
Acknowledgments
The authors thank Valentin De Bortoli for initial motivating discussions on memorization--generalization transitions. RU thanks Beatrice Achilli, Jérome Garnier-Brun, Carlo Lucibello and Enrico Ventura for insightful discussions. RU is grateful to Bocconi University for its hospitality during his stay, during which part of this work was conducted. This work was performed using HPC resources from GENCI-IDRIS (Grant 2025-AD011016319). GB acknowledges support from the French government under the management of the Agence Nationale PR[AI] RIE-PSAI (ANR-23-IACL-0008). MM acknowledges the support of the PNRR-PE-AI FAIR project funded by the NextGeneration EU program. After completing this work, we became aware that A. Favero, A. Sclocchi, and M. Wyart [58] had also been investigating the memorization--generalization transition from a similar perspective.
Appendix
This document provides detailed derivations and additional experiments supporting the main text (MT). In Appendix A, we give details about the numerical experiments carried out in Section 2. In Appendix B we provide additional numerical experiments on simplified score and data models. Appendix C gives formal proofs of the main theorems of Section 3. Finally, Appendix D exposes more details on the numerical experiments of Section 3.
A. Numerical experiments on CelebA
A.1 Details on the numerical setup
Dataset. All numerical experiments in Section 2 of the MT use the CelebA face dataset [22]. We center-crop each RGB image to pixels and convert to grayscale images in order to accelerate the training of our Diffusion Models (DMs). To precisely control the samples seen by a model, no data augmentation is applied, and we vary the training set size in the window . Examples of training samples are shown in the left-most block of Figure 6.
Architecture. As commonly done in DDPMs implementations [e.g., 2, 4], the network approximating the score function is a U-Net [21] made of three resolution levels, each containing two residual blocks with channel multipliers respectively. We apply attention to the two coarsest resolutions, and embed the diffusion time via sinusoidal position embedding [40]. The base channel width varies from to depending on the experiment, resulting in a total of to million trainable parameters.
Time reparameterization. Compared to the framework presented in the MT, the DDPMs we train make use of a time reparameterization of the forward and backward processes with a variance schedule , where is the time horizon given as a number of steps, fixed to 1000 in our experiments. The variance is evolving linearly from to . A sample at time , denoted , can be expressed from as the following interpolation
where , and is a standard and centered Gaussian noise. This is a reparameterization of the Ornstein-Uhlenbeck process from Equation 1 defined through time in the MT, with
Training. All DMs are trained with Stochastic Gradient Descent (SGD) at fixed learning rate , fixed momentum and batch size . We focus on SGD to facilitate the analysis of time scaling, avoiding problems that may cause alternative adaptive optimization schemes like Adam [38]. We train each model for at least 2M SGD steps, sometimes more for large values of displaying memorization only later. We do not employ exponential moving average or learning-rate warm-up.
Generation. To accelerate sampling while preserving FID, we employ the DDIM sampler of [41] ([41]) which replaces the Markovian reverse SDE with a deterministic, non-Markovian update. Given a trained denoiser , we iterate for
with . During training, we generate at 40 milestones a set of 10, 000 samples to assess generalization and memorization. Examples of samples obtained from a model trained on samples with base width are shown in the middle and right blocks from Figure 6 for two training times, K and M. At K the model generalizes () and achieve a test FID of 35.1. After too much training, memorization sets in and, by M steps, nearly half the generated samples reproduce training images ().
Statistical evaluation. FIDs [42] are computed1 using 10, 000 generated samples and 10, 000 test samples, averaged over 5 independent runs with disjoint test sets. Error bars in the MT denote twice the standard deviation. Training and test losses are estimated similarly over 5 repeated evaluation on training samples and 2048 test samples, and give negligible confidence intervals. For the memorization fraction , we report the standard error on the mean obtained via bootstrap resampling of the 10, 000 generated samples. We also verified that the scaling in the memorization time is insensitive to the choice of the threshold used to define in Equation 6 by testing larger and lower values.
Using the pytorch-fid Python package.
Computing resources. Most trainings were performed on Nvidia H100 GPUs (80GB of memory). A typical run of 2M steps takes approximately 50 hours on two GPUs and vary with the model size (defined through its base width ). In total, we train 18 distinct models for the several configurations of the MT. The longest training ( and in Figure 2) ran for 11M steps. The generation of samples over 40 training times takes around an additional hour per model on the same hardware support.

💭 Click to ask about this figure
💭 Click to ask about this figure
A.2 Batch-size effect: repetition vs. memorization
All the experiments in the MT use a fixed batch size , and in Sect Section 2 we emphasize that the observed scaling of cannot be explained by repetition over training samples. To validate this statement, the left panel of Figure 7 shows FID and memorization fraction curves when we train the models with full-batch updates () for . At any fixed , every sample has been seen exactly times. Yet continues to grow linearly with , as shown in the inset. This demonstrates that larger datasets reshape the loss landscape -- requiring proportionally more updates to overfit -- rather than simply increasing memorization through repeated exposure of training samples.
A.3 What about Adam?
We conclude this section by repeating our analysis at fixed using the Adam optimizer [38] instead of SGD with momentum. The learning rate is , gradient averages take values , and batch size . We keep all other settings and evaluation metrics as above. As shown in the right panel of Figure 7, Adam yields the same two-phase training dynamics with first a generalization regime with and good performances (small FID), and later a memorization phase at , as shown in the inset. The only difference is that both and occur after much fewer steps compared to SGD. This also points out that the emergence of the two well-separated timescales and their scaling is a fundamental property of the loss landscape.
B. Generalization--memorization transition in the Gaussian Mixture Model
The aim of this section is to show our results hold for other data distributions than natural images, and alternative score model that U-Net architectures.
B.1 Settings
Data distribution. We focus on data iid sampled from a -dimensional Gaussian Mixture Model (GMM) made of two balanced Gaussians centered on with unit covariance, i.e.,
In what follows, we choose to work with , with . In this controlled setup, the generalization score can be computed analytically from and reads
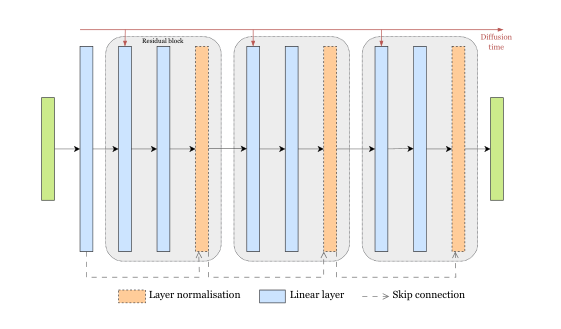
Score model. The denoise is implemented as a lightweight residual multi-layer neural network (see Figure 8): an input layer projecting , followed by three identical residual blocks and an output layer projecting back to . Each block consists of two fully connected layers of width , a skip connection, and a layer normalization. We encode the diffusion time via sinusoidal position embedding and add it to the first feature of each block. The total number of parameter in the network is . For , and , the reference setting of this section, this yields trainable parameters.
💭 Click to ask about this figure
Training and computing resources. Unless otherwise specified, we train every model of this section with SGD at fixed learning rate and momentum using full-batch updates for , running for up to 4M updates. All experiments are executed on an Nvidia RTX 2080 Ti, with the largest requiring around 10 hours to complete.
Generalization and memorization metrics. In addition to the memorization fraction , we exploit this controlled setting where we know the true data distribution to directly measure how closely it matches the generated distribution via the Kullback-Leibler (KL) divergence
The cross-entropy term is easy to estimate using Monte Carlo,
where are samples drawn from the model with parameters at training time . Estimating the negative entropy term is more challenging, since DMs only give access to the score function and not the underlying probability distribution . We can however employ time integration to express it as a function of the score only,
with
This expression assumes that the model learns an accurate representation of the score function. It is noteworthy to mention that samples are generated using standard Euler-Maruyama discretization of the backward process Equation 2 of the MT over timesteps.
B.2 Scaling of and with and
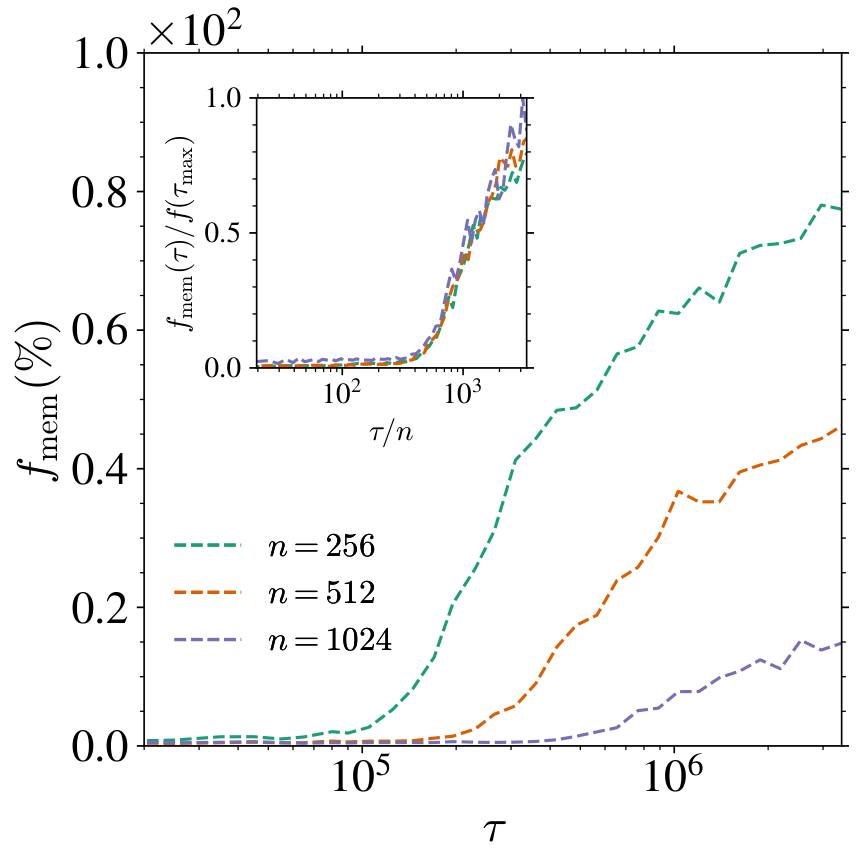
In Figure 9, the left panel shows how the KL divergence and memorization fraction evolve with training time for different training set sizes at fixed width , while the right panel fixes and varies . In both cases, we observe two distinct phases. First, the KL divergence decreases to near zero on a timescale independent of during which the model fully generalizes (). Beyond , both and begin to rise at a time that scales linearly with , as highlighted by the inset of the left panel. In contrast, scales with , as shown in the inset of the right panel. While the precise dependence of with remains inconclusive in this setting and require a more careful analysis, these results on the GMM mirror the main findings of the MT: the training dynamics of DMs unfolds first in a generalization phase and only later -- at -- memorization begins.
💭 Click to ask about this figure
B.3 Discussion on conditional diffusion models
Conditional generation aims to sample from distributions of the form , where denotes a conditioning variable such as a class label, a text embedding, or any other contextual information. DMs can naturally be extended to this setting using for instance classifier-free guidance [56]. Although conditioning often improves sample quality in practice, memorization effects have also been observed in models trained conditionally [25, 59, 60]. Our analysis does not rely on the model being unconditional since these variables typically enter the model as additional inputs and we expect our result to hold in this setting as well. To investigate it, we train a classifier-free guidance model to generate sample from our Gaussian mixture conditionally on the class label, and compute the memorized fraction as a function of that we report in Figure 10. In the inset, when rescaling the training time by , the curves for all collapse perfectly, confirming that the phenomenon persists in the conditional setting. For more complex datasets, and may in fact depend on the conditioning variable and intermediate regimes could exist where certain classes have already entered the generalization (or memorization) phase while others have not yet.
💭 Click to ask about this figure
C. Proofs of the analytical results
In the following we provide the mathematical arguments and the proofs for the statement in the MT. The section using the replica method is not mathematically rigorous but uses a well established method of theoretical physics, which has been already shown to provide correct results in several cases. The final result is rigorous, since it can alternatively be obtained from the rigorous free random matrix approach of [17], as shown in Appendix C.4.
C.1 Notations
We recall here the notations used throughout Section 3 of the MT and Appendix C of the SM.
Unless specified, all the expectation values are taken for standard Gaussian variables. We will denote
the matrix whose columns are the data point vectors and likewise we decompose as
where denotes the th row of .
We recall the definitions of the matrices and
C.2 Closed form of the learning dynamics
Proposition 3
Let be the solution of the gradient flow (Equation 10) defined in the MT with initial conditions , then
with
Proof: We expand the square in the training loss
and compute the gradient
Solving this ordinary differential equation yields the desired result. Consequently, the timescales of the dynamics of is determined by the inverse of the eigenvalues of .
C.3 Gaussian Equivalence Principle
As explained in [47, 48, 49], the Gaussian Equivalence Principle which applies in the high dimensional setting considered here establishes an equivalence between the spectral properties of the original model and those of a Gaussian covariate model in which the nonlinear activation function is replaced by a linear term and a nonlinear term that acting as noise,
where are constants that depend on the distribution of the data and on the activation function whose formula we recall
The expectation function are with respect to and . The Gaussian Equivalence Principle (GEP) holds if the distribution of the vector verifies
- (i) has sub-Gaussian tails: there exists a constant such that for all and each entry ,
- (ii) The data covariance matrix is bounded: there exists a constant independent of such that and where denotes the spectral norm of .
In this section, we outline the derivation of the Gaussian Equivalence Principle (GEP) for the matrices and under arbitrary input covariance. This generalizes the approach developed in [17], which considered only the case of data drawn from . A more rigorous approach, which would consist in following [52], is left for future works. We will make use of the Mehler kernel formula [61] which states that for a test function defined on ,
where the expectation on the left-hand side is taken over jointly Gaussian random variables and with zero mean, unit variance, and correlation , while on the right-hand side the expectation is taken over independent standard Gaussian variables. denotes the -th Hermite polynomial. We recall some useful properties of the Hermite polynomials [62]:
- They form an orthogonal base of .
- The first Hermite polynomials are .
Lemma 4: Gaussian Equivalence Principle for
In the limit with and with a dataset sampled from a distribution which verifies assumptions (i) and (ii) with , the matrix
has the same spectrum as its Gaussian equivalent
where
is a matrix whose columns are sampled according to and has gaussian entries independent of and .
Proof: For the sake of clarity, in this proof we explicitly make the covariance of the data appear by writing the data points are written as where the vectors have variance 1. Let us focus on the element of in position
where repeated indices mean that there is a hidden sum. We introduce the random variable . In the high dimensional limit it converges to a Gaussian random variable by the Central Limit Theorem (since the tails of the data distribution are sub-Gaussian). If , the diagonal terms concentrate with respect to the data points and we can thus replace the sum by an average
The finite corrections can be discarded because they cannot change the spectrum of . can be taken Gaussian with mean 0 and covariance hence
If , we denote . For now we consider and the fixed and look at . We use the Mehler Kernel formula for the random variables and that have correlation
We truncate at order since the corrections are order .
by neglecting corrections and where the law of can be considered Gaussian with zero mean correlation . The coefficient in front of is therefore
Denote . We now focus on
We use the GEP on
with and . Hence the truncated expansion yields for
Now we need to deal with the diagonal term. We need to substract
The Gaussian equivalent of reads
with .
Lemma (GEP for ).
Let
where the expectation value is taken . Then the GEP of reads
where and are defined in Appendix C.1.
Proof: For a vector sampled from , the are asymptotically Gaussian with 0 mean, variance and correlation . We apply Mehler Kernel formula to
where the expectation on and is standard Gaussian. We keep only terms at order . If we keep the terms up to order .
For we cannot truncate because all terms are . Hence the diagonals terms are asymptotically
Taking care of the diagonal terms, the Gaussian Equivalent matrix reads
where .
Building on the GEP of , we prove the following lemma on the scaling of the eigenvalues in the bulk.
Lemma 5: Scaling of the bulk of
We assume that is positive definite and that the spectral norm stays . In the high dimensional limit , the spectrum of is asymptotically equal to
where is an atomless measure whose support is of order .
Proof: Since and and , the spectrum admits a Dirac mass at with weight . For the order of magnitude of the eigenvalues in the bulk, let us first observe that the bulk of is the same as the one of . We can bound the spectral norm of the product by the product of the spectral norms
since we assumed that and since is given by the Marchenko-Pastur law [63]. To bound the norm from below we use the following inequality
Since is positive definite, the bound is also of order . This concludes that the support of the bulk is of order .
Lemma (GEP for and ).
Let
They can be replaced by their Gaussian Equivalence Principle in the train and test losses.
Proof: The two matrices only differ element-wise by quantity of order and therefore have the same Gaussian Equivalent matrix. We focus on . Introduce the random variable . Its has 0 mean, covariance and correlation with . We apply the Mehler Kernel formula
C.4 Proof of Theorem 1
We recall the Theorem 1 of the MT.
Theorem 6
Let , and , with . Let
Then and satisfy the following set of three equations:
The eigenvalue distribution of , , can then be obtained using the Sokhotski–Plemelj inversion formula .
We first show that the equations of the Stieltjes transform of found in Ref. [17] with linear pencils [53] in the case i.e. can be reduced to the equations of Theorem 1 with our definitions of and . The equations of [17] read
with and auxiliary variables. We make the following change of variables . The second equations relates to and
Injecting this into the second equations gives the second equation of Theorem 1. The fourth equation gives
Injecting this into the first equation gives
After some massaging we find back the first equation of Theorem 1.
We now prove Theorem 1 using a replica computation, inspired by the calculation done in Ref. [44].
Proof: Our goal is to compute the Stieltjes transform of the matrix .
The so-called replica trick consists of replacing the by . Applying this identity, we obtain
where as usual with replica computations we have inverted the order of the limits and . We define the partition function as
We replace by its Gaussian equivalent proved in Lemma 4 and write the partition function for an arbitrary integer
We first perform the computation for integer values of , and then analytically continue the result to the limit . To compute the expectation over , , and , we need the following standard result from Gaussian integration
where is a square matrix and a vector. Averaging over the data set. The dataset dependence enters through
We introduce for each replica a Fourier transform of the delta function by using the auxiliary variables as2
Throughout the computation, we discard non-exponential prefactors, as they give subleading contributions.
In the following, we do the change of variable with a dimensional Gaussian random variable with unit variance.
Denote and , then
where repeated indices mean that there is an implicit summation. Averaging over . The terms that depend on are
with
We are left with
Averaging over the random features . only appears through .
We end up with
Averaging over the . We can integrate with respect to . The only terms that appear with it are
Denote and , then the integral is of the form
This gives
Introducing the order parameters. We define the order parameters as and . To enforce these constraints, we use the following delta function representations
We also introduce .
The integration over and gives
We need to combine and ,
Then for , we can introduce the density of eigenvalues of
We end up with
where the action reads
In the high dimensional limit, the partition function is dominated by the saddle point. By derivating with respect to we get
which yields
As a sanity check, if , differentiation with respect to and yields
and we find back the same action as before. RS Ansatz. As before we introduce a RS ansatz for all the the matrices and moreover suppose that only the diagonal terms are non vanishing i.e. they are of the form . This ansatz yields
Let us differentiate with respect to the 5 variables
Hence the saddle point equations read
Finally, we observe that the solution to the saddle point equations corresponds to the Stieltjes transform of .
C.5 Proof of Theorem 2
We recall Theorem 2 of the MT.
Theorem 7: Informal
Let denote the spectral density of .
- Regime I (overparametrized): .
- Regime II (underparametrized): .
where is a atomless measure with support
and coincides with the asymptotic eigenvalue bulk density of the population covariance ; is independent of and its support is on the scale .
The eigenvectors associated with leave both training and test losses unchanged and are therefore irrelevant. In the limit , the supports of and are respectively on the scales and , i.e. they are well separated.
We now proceed to prove Theorem 2.
Proof: Delta peak. We first account for the delta peak in the spectrum. We use the Gaussian equivalence for computed in Lemma 4. Let be the th column of and the th row of . Suppose a vector lies in the kernel of all these
then . These are linear constraints on a vector of size hence there are non trivial solutions for . Hence a delta‐peak at appears as soon as . Next, we extract its weight. Recall that the Stieltjes transform satisfies
and a point mass of weight at contributes as . Meanwhile
remain finite in that limit, since the corresponding eigenvectors satisfy . We substitute this Ansatz into the equations of Theorem 1. The first equation reads
and simplifies to
It readily gives
Thus the point mass at has weight , in agreement with the counting of degrees of freedom presented above.
Finally, one checks that these isolated eigenvalues do not contribute to the train and test losses. After expanding the square they read
The terms that appear in the loss are of the form and . The trace can be decomposed on the basis of eigenvectors of . The eigenvectors associated with the delta peak satisfy . Looking at the expression of the matrix , one can easily see that, for initial conditions , one has and the subspace corresponding to these isolated eigenvalues does not contribute to the loss.
First bulk. Using the expression for and we make the following Ansatz in the large limit:
In this limit the saddle point equations becomes at leading order in
We can focus only on the last equation on only. This is a quadratic polynomial in . If its discriminant is negative then the solutions are imaginary and thus the density of eigenvalues is non-zero. The edge of the bulk are where the discriminant vanishes
It vanishes for
which are the edges of the first bulk . We have checked this result, and hence validated the Ansatz solving numerically the equations on . Interestingly at leading order the expression of the first bulk is independent of .
Second Bulk. We scale and . The equations on and lead to
This yields the following equation on
We denote the shifted variable . This yields
We decompose the integral
By plugging this back in the equation we find
We do the change of variable . This yields
An integration by parts give that . We thus realize that the integral is over the eigenvalue distribution of ,
We recognize the Bai-Silverstein equations [64, 65] for the eigenvalue density of the matrix
which is the population version of and is thus independent of . Lemma 5 concludes on the order of the eigenvalues in the bulk of .
C.6 Dynamics on the fast timescales
In the following we denote for a matrix ,
the operator norm and
the Frobenius norm. Before deriving the fast‐time behavior, we need the following lemma.
Lemma 8
The operator norm of satisfies
when .
Proof: On the one hand,
and on the other hand,
We also note the identities and .
We can bound its operator norm
where are constants independent of . We bound each of the three terms on the right hand side. We will use the fact that for a symmetric matrix, the operator norm is equal to its largest eigenvalue.
First term.
We observe that and have the same eigenvalues up to the multiplicity of 03. We then use the sub-multiplicativity of the operator norm
They both have the same moments owing to the cyclicity of the trace.
We can do the same operation by introducing with with standard Gaussian entries,
Among our assumptions, we had . The spectrum of is the Marchenko-Pastur law whose largest eigenvalue is of order while for it is order . The bound reads
Second term.
We observe that the spectrum of is Marchenko-Pastur and thus its largest eigenvalue is order yielding
Third term.
We first bound the operator norm by the Frobenius norm.
We expand the square
The Central Limit Theorem yields
hence
Putting all the contributions together yields
Proposition (Informal).
On timescales , both the train and test losses satisfy
Proof: According to the spectral analysis of conducted previously, there are two bulks in the spectrum that contribute to the dynamics: a first bulk with eigenvalues of order and a second bulk with eigenvalues of order in the limit. Hence, in the regime , if is in the second bulk and is if is in the first bulk. We remind the expressions of the train and test loss
and use the expression of in Proposition 3 that we expand on the basis of eigenvectors of .
where means that the eigenvalue belongs to the second bulk. We also have that and have the same GEP and they thus cancel each other when computing the generalization loss . It reads
We then use Lemma 8 --- which states that the operator norm of in the subspace spanned by the eigenvectors of the second bulk is bounded by --- to bound ,
We also used the fact that the sums contain terms --- the only terms that matter are the diagonal ones --- and that the eigenvalues scale as . The bound yield that vanishes asymptotically in the large number of data and large number of parameters regime. Therefore, on the fast timescale we find . Let us now focus on
There are values in the sum and the eigenvalues of and are both order hence the sum divided by is a positive quantity thus in this training time regime, , we obtain:
D. Numerical experiments for Random Features
Details on the numerical experiments. All the numerical experiments for the RFNN were conducted using and unless specified. At each step, the gradient of the loss was computed using the full batch of data points. The train loss was estimated by adding noise to each data point times. The test loss was computed by drawing new points from the data distribution and noising each one times. The error on the score was evaluated by drawing 10, 000 points from the noisy distribution .
Effect of .
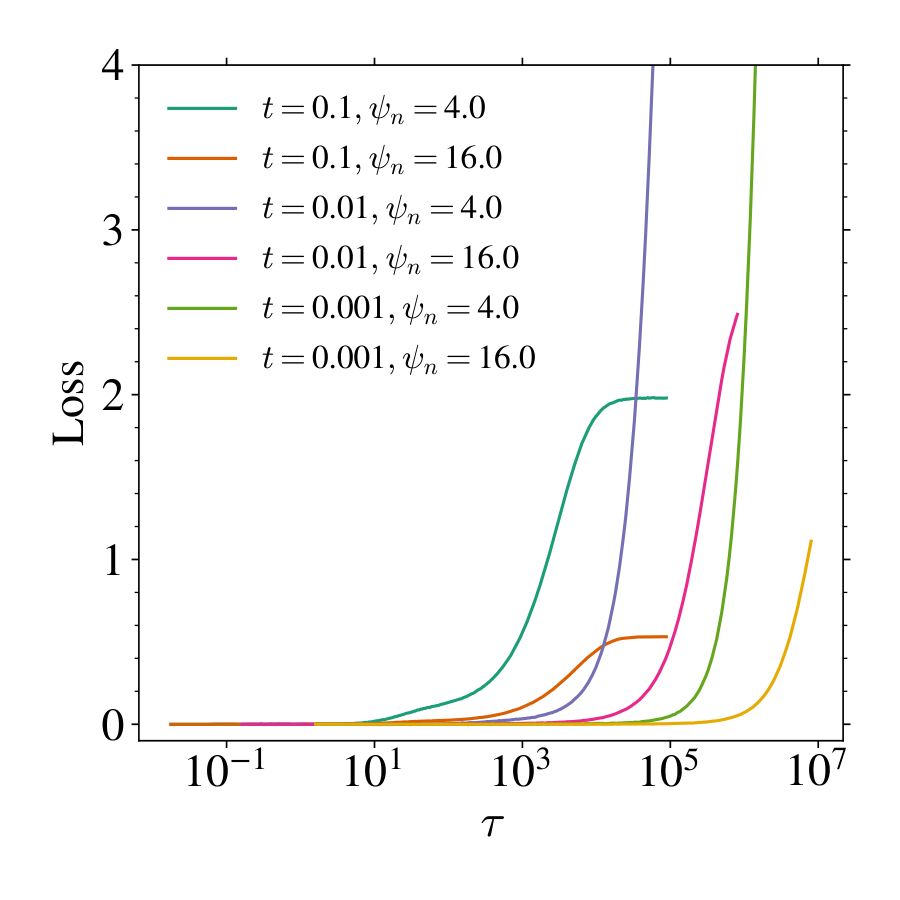
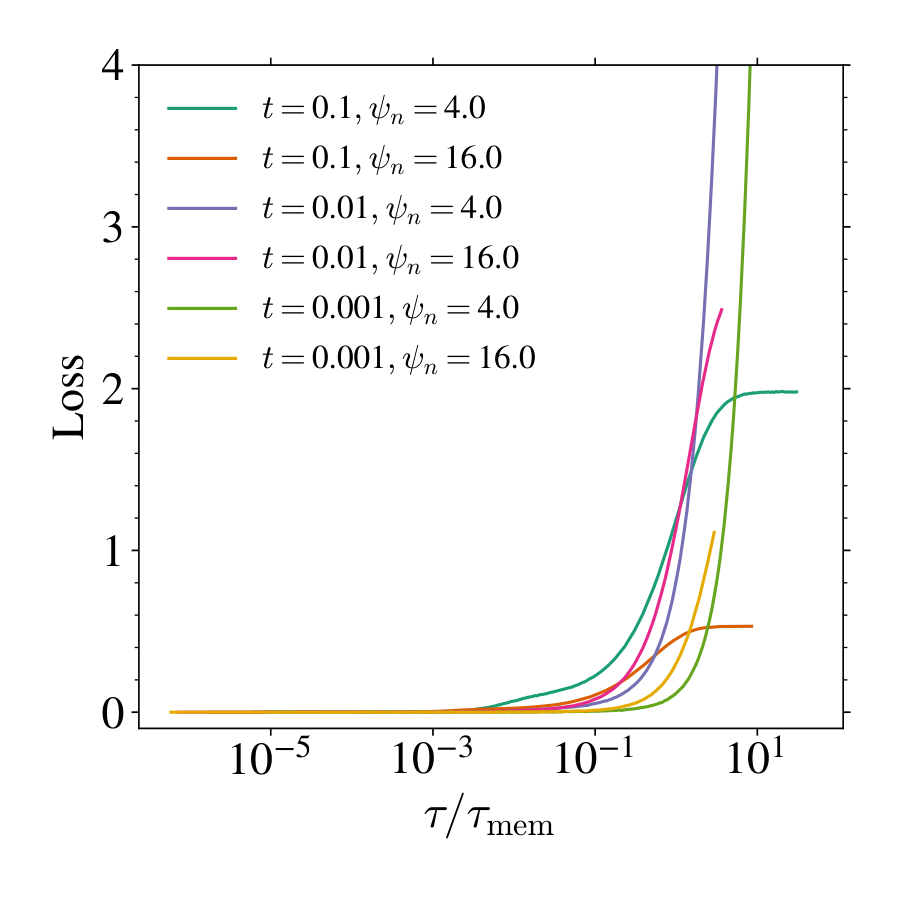
💭 Click to ask about this figure
We present plots for different diffusion times in Figure 11 and show that the rescaling of the training times by also makes the loss curves collapse. Of particular interest is the behavior of , and more specifically the ratio , at small . Recall that
In the overparameterized regime , this ratio is independent of since and . However, when , a nontrivial scaling emerges: since , it follows that
implying that the two timescales become increasingly separated. It is unclear whether this behavior is related to specific properties of the learned score function, and is related to the approach of the interpolation threshold. We leave this question for future investigation.
Experiments with . In Figure 12, we present train and test loss curves for . We see that our prediction of the timescale of memorization computed in the MT holds for general data variance.
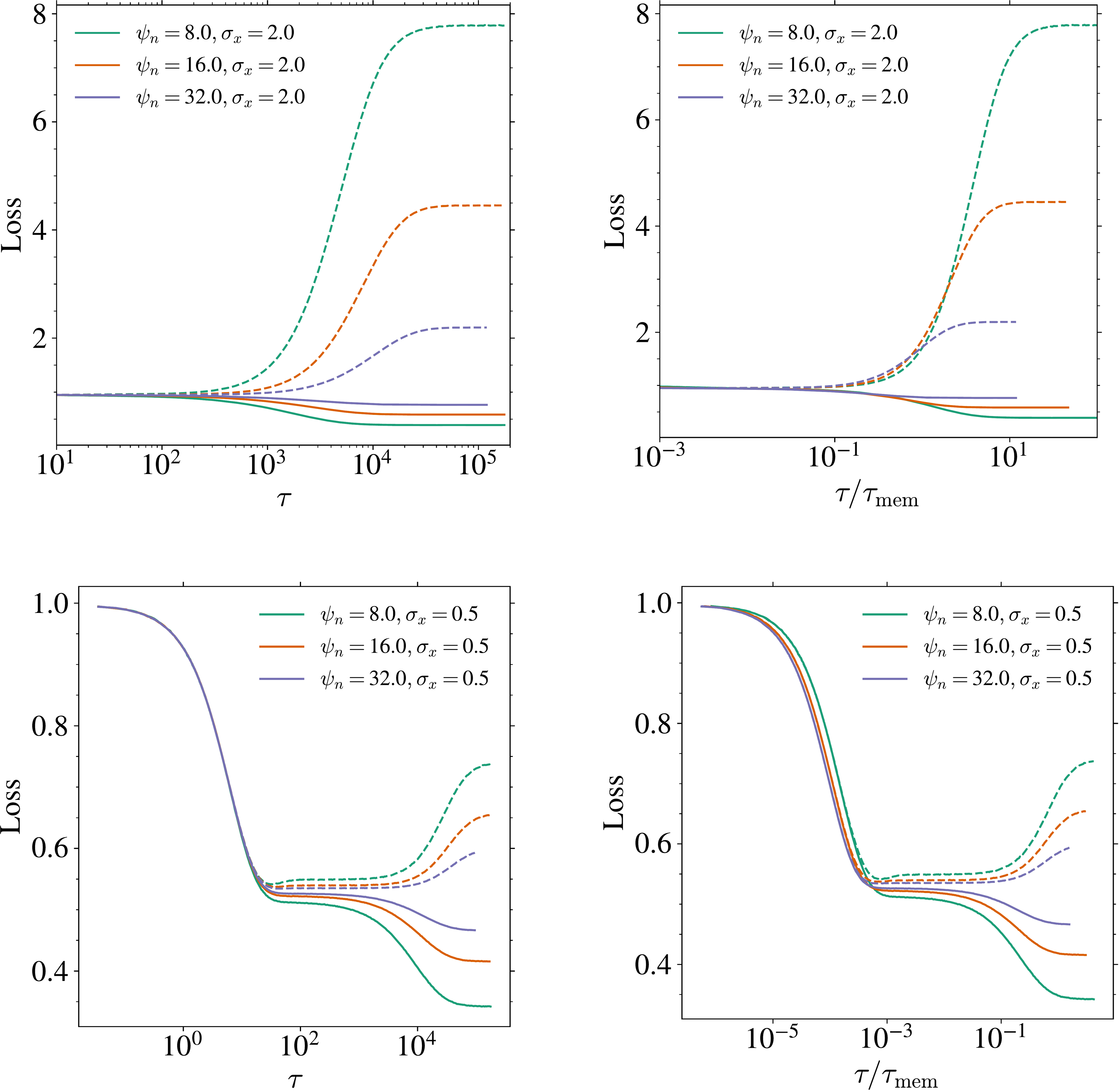
💭 Click to ask about this figure
Scaling of with . In the RF model, the error with respect to the true score, as defined in the main text,
serves as a measure of the generalization capability of the generative process. As shown in [45], the Kullback–Leibler divergence between the true data distribution and the generated distribution can be upper bounded
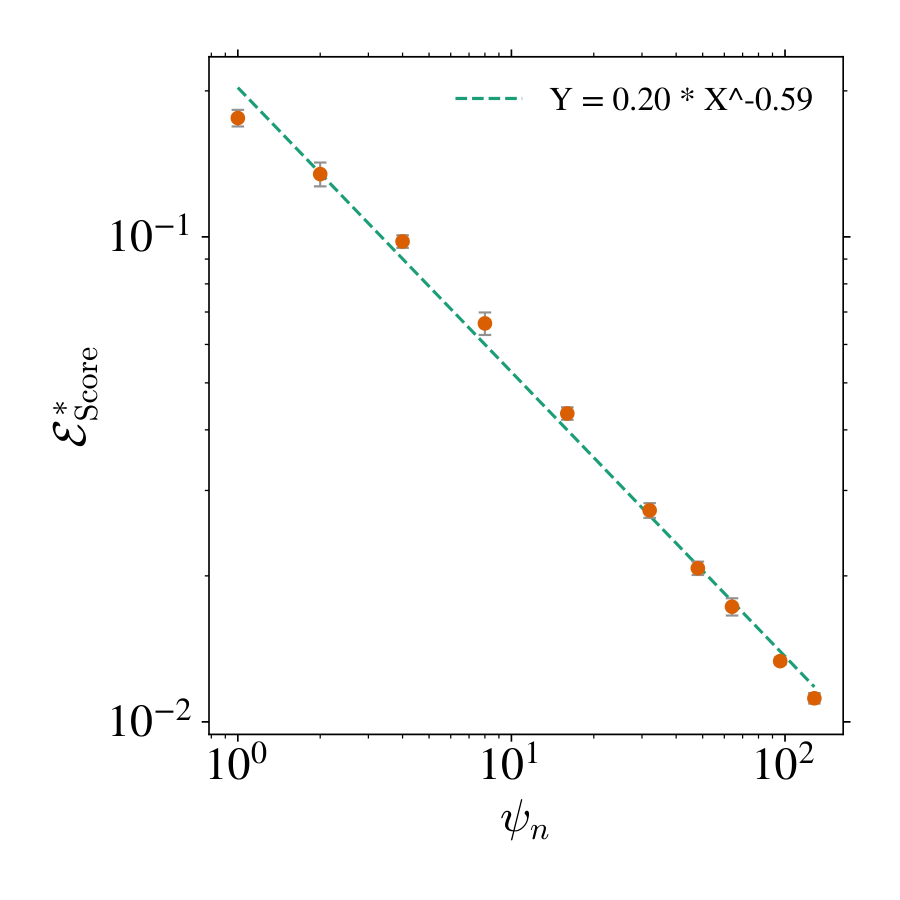
where the integral is taken over all estimations of the parameter matrix at all diffusion times . This bound assumes that the reverse dynamics are integrated exactly, starting from infinite time. In practical settings, however, one typically relies on an approximate scheme and initiates the reverse process at a large but finite time . A generalization of this bound under such conditions can be found in [46]. We have numerically investigate the behaviour of on Figure 13. On the fast timescale , it decreases until a minimal value that depends only on with a power-law with . We leave for future work performing an accurate numerical estimate of and a developing a theory for it.
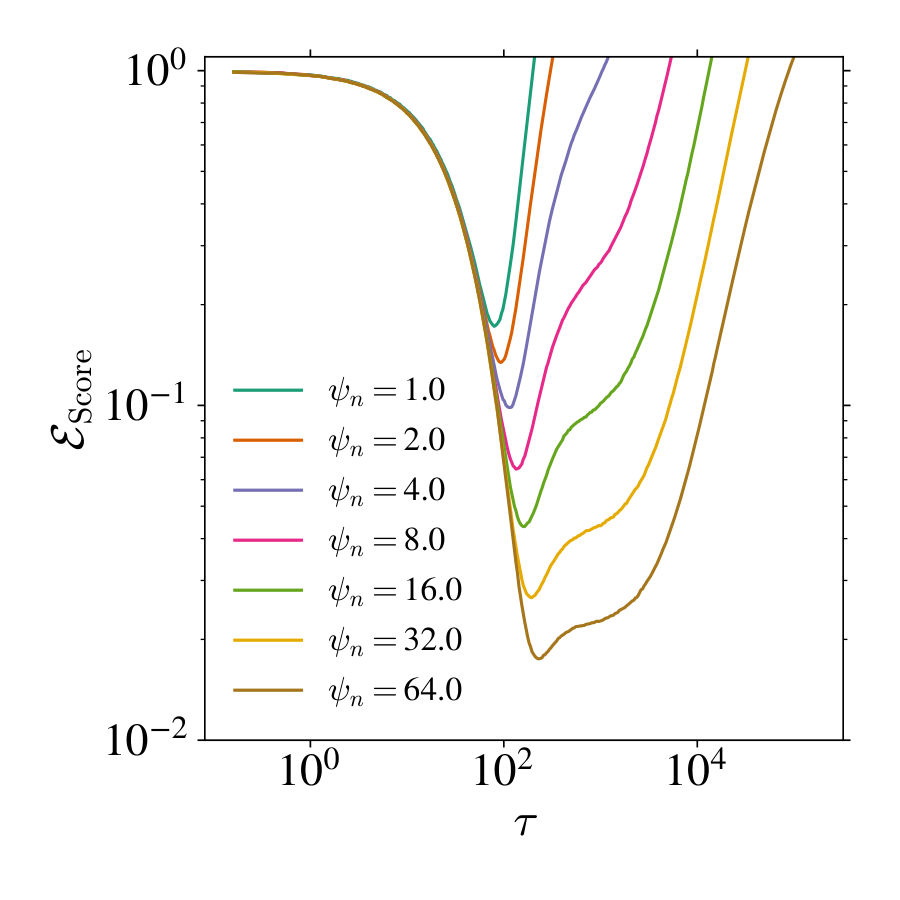
💭 Click to ask about this figure
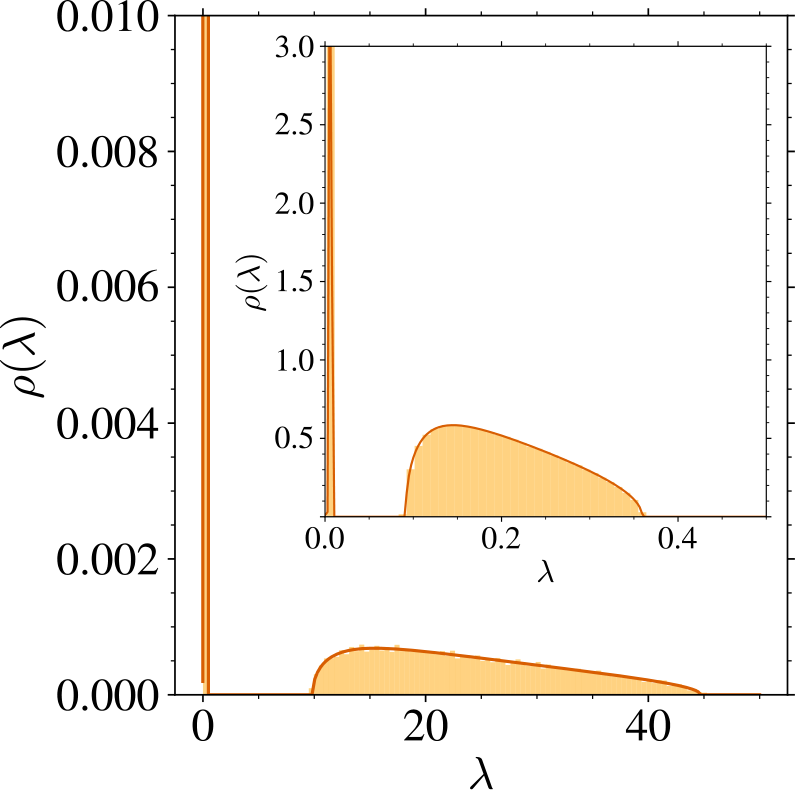
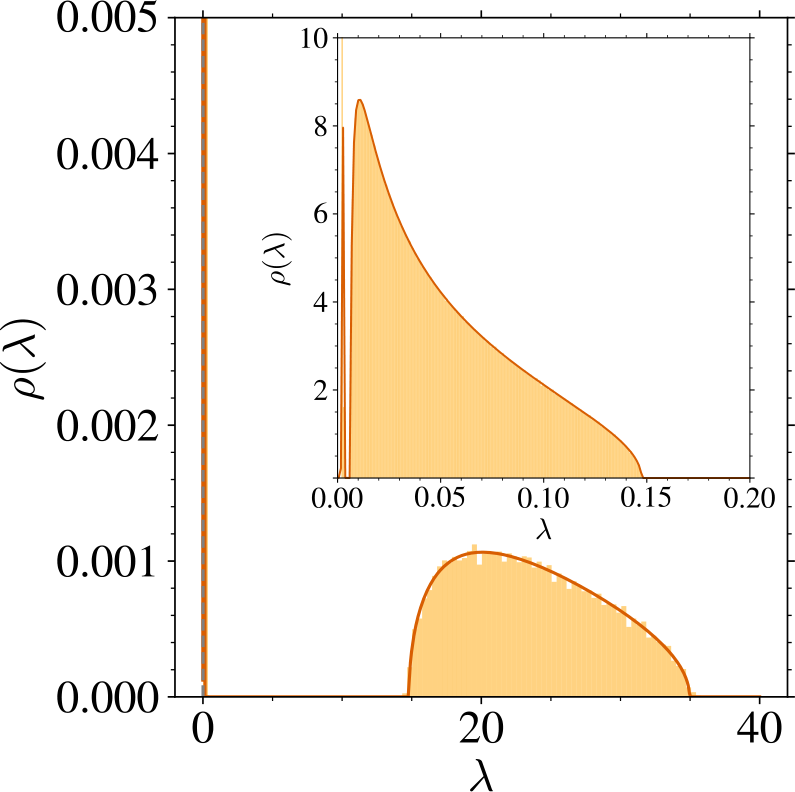
Spectrum of U. In Figure 14, we compare the solutions of the equations of Theorem 1 to the histogram of finite size realizations of .
💭 Click to ask about this figure
Effect of Adam optimization. Numerical experiments with RFNN on Gaussian data show that the linear scaling of the memorization time with holds also for the Adam optimizer as shown in Figure 15.
![**Figure 15:** **Adam.** Train loss (solid line) and test loss (dotted line) at $t=0.01, d=100, \psi_p=64$ for several $\psi_n$ with the Pytorch [50] implementation of Adam. The inset shows the effect of a rescaling of the training time by $n$.](https://ittowtnkqtyixxjxrhou.supabase.co/storage/v1/object/public/public-images/zajbagrd/Psi_p_64_d_100_t_001_Adam.png)
💭 Click to ask about this figure
References
[1] Sohl-Dickstein, J., Weiss, E., Maheswaranathan, N., and Ganguli, S. (2015). Deep unsupervised learning using nonequilibrium thermodynamics. In Bach, F. and Blei, D., editors, Proceedings of the 32nd International Conference on Machine Learning, volume 37 of Proceedings of Machine Learning Research, pages 2256–2265, Lille, France. PMLR.
[2] Ho, J., Jain, A., and Abbeel, P. (2020). Denoising diffusion probabilistic models.
[3] Song, Y. and Ermon, S. (2019). Generative modeling by estimating gradients of the data distribution. In Wallach, H., Larochelle, H., Beygelzimer, A., d\textquotesingle Alché-Buc, F., Fox, E., and Garnett, R., editors, Advances in Neural Information Processing Systems, volume 32. Curran Associates, Inc.
[4] Song, Y., Sohl-Dickstein, J., Kingma, D. P., Kumar, A., Ermon, S., and Poole, B. (2021b). Score-based generative modeling through stochastic differential equations.
[5] Rombach, R., Blattmann, A., Lorenz, D., Esser, P., and Ommer, B. (2021). High-resolution image synthesis with latent diffusion models.
[6] Zhang, C., Zhang, C., Zheng, S., Zhang, M., Qamar, M., Bae, S.-H., and Kweon, I. S. (2023). A survey on audio diffusion models: Text to speech synthesis and enhancement in generative ai.
[7] Liu, Y., Zhang, K., Li, Y., Yan, Z., Gao, C., Chen, R., Yuan, Z., Huang, Y., Sun, H., Gao, J., He, L., and Sun, L. (2024). Sora: A review on background, technology, limitations, and opportunities of large vision models.
[8] Li, T., Biferale, L., Bonaccorso, F., and et al. (2024b). Synthetic lagrangian turbulence by generative diffusion models. Nat Mach Intell, 6:393–403.
[9] Price, I., Sanchez-Gonzalez, A., Alet, F., and et al. (2025). Probabilistic weather forecasting with machine learning. Nature, 637:84–90.
[10] Lipman, Y., Chen, R. T. Q., Ben-Hamu, H., Nickel, M., and Le, M. (2023). Flow matching for generative modeling. In The Eleventh International Conference on Learning Representations.
[11] Li, S., Chen, S., and Li, Q. (2024a). A good score does not lead to a good generative model.
[12] Biroli, G., Bonnaire, T., de Bortoli, V., and Mézard, M. (2024). Dynamical regimes of diffusion models. Nature Communications, 15(9957). Open access.
[13] Kadkhodaie, Z., Guth, F., Simoncelli, E. P., and Mallat, S. (2024). Generalization in diffusion models arises from geometry-adaptive harmonic representations. In The Twelfth International Conference on Learning Representations.
[14] Kamb, M. and Ganguli, S. (2024). An analytic theory of creativity in convolutional diffusion models.
[15] Shah, K., Kalavasis, A., Klivans, A. R., and Daras, G. (2025). Does generation require memorization? creative diffusion models using ambient diffusion.
[16] Wu, Y.-H., Marion, P., Biau, G., and Boyer, C. (2025). Taking a big step: Large learning rates in denoising score matching prevent memorization.
[17] George, A. J., Veiga, R., and Macris, N. (2025). Denoising score matching with random features: Insights on diffusion models from precise learning curves.
[18] Rahaman, N., Baratin, A., Arpit, D., Draxler, F., Lin, M., Hamprecht, F., Bengio, Y., and Courville, A. (2019). On the spectral bias of neural networks. In International conference on machine learning, pages 5301–5310. PMLR.
[19] Gu, X., Du, C., Pang, T., Li, C., Lin, M., and Wang, Y. (2023). On memorization in diffusion models.
[20] Yoon, T., Choi, J. Y., Kwon, S., and Ryu, E. K. (2023). Diffusion probabilistic models generalize when they fail to memorize. In ICML 2023 Workshop on Structured Probabilistic Inference & Generative Modeling.
[21] Ronneberger, O., Fischer, P., and Brox, T. (2015). U-net: Convolutional networks for biomedical image segmentation. In Navab, N., Hornegger, J., Wells, W. M., and Frangi, A. F., editors, Medical Image Computing and Computer-Assisted Intervention – MICCAI 2015, pages 234–241, Cham. Springer International Publishing.
[22] Liu, Z., Luo, P., Wang, X., and Tang, X. (2015). Deep learning face attributes in the wild. In Proceedings of International Conference on Computer Vision (ICCV).
[23] Carlini, N., Hayes, J., Nasr, M., Jagielski, M., Sehwag, V., Tramèr, F., Balle, B., Ippolito, D., and Wallace, E. (2023). Extracting training data from diffusion models. In Proceedings of the 32nd USENIX Conference on Security Symposium, SEC '23, USA. USENIX Association.
[24] Somepalli, G., Singla, V., Goldblum, M., Geiping, J., and Goldstein, T. (2023a). Diffusion art or digital forgery? investigating data replication in diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition.
[25] Somepalli, G., Singla, V., Goldblum, M., Geiping, J., and Goldstein, T. (2023b). Understanding and mitigating copying in diffusion models. Advances in Neural Information Processing Systems, 36:47783–47803.
[26] Achilli, B., Ventura, E., Silvestri, G., Pham, B., Raya, G., Krotov, D., Lucibello, C., and Ambrogioni, L. (2024). Losing dimensions: Geometric memorization in generative diffusion.
[27] Ventura, E., Achilli, B., Silvestri, G., Lucibello, C., and Ambrogioni, L. (2025). Manifolds, random matrices and spectral gaps: The geometric phases of generative diffusion.
[28] Cui, H., Krzakala, F., Vanden-Eijnden, E., and Zdeborova, L. (2024). Analysis of learning a flow-based generative model from limited sample complexity. In The Twelfth International Conference on Learning Representations.
[29] Cui, H., Pehlevan, C., and Lu, Y. M. (2025). A precise asymptotic analysis of learning diffusion models: theory and insights.
[30] Wang, P., Zhang, H., Zhang, Z., Chen, S., Ma, Y., and Qu, Q. (2024). Diffusion models learn low-dimensional distributions via subspace clustering.
[31] Rahimi, A. and Recht, B. (2007). Random features for large-scale kernel machines. In Platt, J., Koller, D., Singer, Y., and Roweis, S., editors, Advances in Neural Information Processing Systems, volume 20. Curran Associates, Inc.
[32] Li, P., Li, Z., Zhang, H., and Bian, J. (2025). On the generalization properties of diffusion models.
[33] Zhi-Qin John Xu, Z.-Q. J. X., Yaoyu Zhang, Y. Z., Tao Luo, T. L., Yanyang Xiao, Y. X., and Zheng Ma, Z. M. (2020). Frequency principle: Fourier analysis sheds light on deep neural networks. Communications in Computational Physics, 28(5):1746–1767.
[34] Wang, B. (2025). An analytical theory of power law spectral bias in the learning dynamics of diffusion models.
[35] Hyvärinen, A. (2005). Estimation of non-normalized statistical models by score matching. Journal of Machine Learning Research, 6(24):695–709.
[36] Vincent, P. (2011). A connection between score matching and denoising autoencoders. Neural Computation, 23(7):1661–1674.
[37] Robbins, H. and Monro, S. (1951). A stochastic approximation method. The annals of mathematical statistics, pages 400–407.
[38] Kingma, D. P. and Ba, J. (2015). Adam: A method for stochastic optimization. In Bengio, Y. and LeCun, Y., editors, ICLR (Poster).
[39] Karras, T., Aittala, M., Aila, T., and Laine, S. (2022). Elucidating the design space of diffusion-based generative models.
[40] Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, L. u., and Polosukhin, I. (2017). Attention is all you need. In Guyon, I., Luxburg, U. V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., and Garnett, R., editors, Advances in Neural Information Processing Systems, volume 30. Curran Associates, Inc.
[41] Song, J., Meng, C., and Ermon, S. (2022). Denoising diffusion implicit models.
[42] Heusel, M., Ramsauer, H., Unterthiner, T., Nessler, B., and Hochreiter, S. (2017). Gans trained by a two time-scale update rule converge to a local nash equilibrium.
[43] Mei, S., Misiakiewicz, T., and Montanari, A. (2019). Mean-field theory of two-layers neural networks: dimension-free bounds and kernel limit. In Beygelzimer, A. and Hsu, D., editors, Proceedings of the Thirty-Second Conference on Learning Theory, volume 99 of Proceedings of Machine Learning Research, pages 2388–2464. PMLR.
[44] D'Ascoli, S., Refinetti, M., Biroli, G., and Krzakala, F. (2020). Double trouble in double descent: Bias and variance(s) in the lazy regime. In III, H. D. and Singh, A., editors, Proceedings of the 37th International Conference on Machine Learning, volume 119 of Proceedings of Machine Learning Research, pages 2280–2290. PMLR.
[45] Song, Y., Durkan, C., Murray, I., and Ermon, S. (2021a). Maximum likelihood training of score-based diffusion models.
[46] Bortoli, V. D. (2022). Convergence of denoising diffusion models under the manifold hypothesis. Transactions on Machine Learning Research. Expert Certification.
[47] Péché, S. (2019). A note on the pennington-worah distribution. Electronic Communications in Probability, 24:1–7.
[48] Goldt, S., Loureiro, B., Reeves, G., Krzakala, F., Mézard, M., and Zdeborová, L. (2021). The gaussian equivalence of generative models for learning with shallow neural networks.
[49] Hu, H. and Lu, Y. M. (2023). Universality laws for high-dimensional learning with random features. IEEE Transactions on Information Theory, 69(3):1932–1964.
[50] Paszke, A., Gross, S., Massa, F., Lerer, A., Bradbury, J., Chanan, G., Killeen, T., Lin, Z., Gimelshein, N., Antiga, L., Desmaison, A., Kopf, A., Yang, E., DeVito, Z., Raison, M., Tejani, A., Chilamkurthy, S., Steiner, B., Fang, L., Bai, J., and Chintala, S. (2019). Pytorch: An imperative style, high-performance deep learning library. In Advances in Neural Information Processing Systems, volume 32, pages 8024–8035. Curran Associates, Inc.
[51] Gerace, F., Loureiro, B., Krzakala, F., Mezard, M., and Zdeborova, L. (2020). Generalisation error in learning with random features and the hidden manifold model. In III, H. D. and Singh, A., editors, Proceedings of the 37th International Conference on Machine Learning, volume 119 of Proceedings of Machine Learning Research, pages 3452–3462. PMLR.
[52] Mei, S. and Montanari, A. (2020). The generalization error of random features regression: Precise asymptotics and double descent curve.
[53] Bodin, A. P. M. (2024). Random Matrix Methods for High-Dimensional Machine Learning Models. Phd thesis, École Polytechnique Fédérale de Lausanne (EPFL), Lausanne, Switzerland.
[54] Mézard, M., Parisi, G., and Virasoro, M. A. (1987). Spin Glass Theory and Beyond: An Introduction to the Replica Method and Its Applications, volume 9 of Lecture Notes in Physics. World Scientific Publishing Company, Singapore.
[55] Albergo, M. S., Boffi, N. M., and Vanden-Eijnden, E. (2023). Stochastic interpolants: A unifying framework for flows and diffusions.
[56] Ho, J. and Salimans, T. (2022). Classifier-free diffusion guidance.
[57] Adomaityte, U., Defilippis, L., Loureiro, B., and Sicuro, G. (2024). High-dimensional robust regression under heavy-tailed data: asymptotics and universality. Journal of Statistical Mechanics: Theory and Experiment, 2024(11):114002.
[58] Favero, A., Sclocchi, A., and Wyart, M. (2025). Bigger isn't always memorizing: Early stopping overparameterized diffusion models.
[59] Wen, Y., Liu, Y., Chen, C., and Lyu, L. (2024). Detecting, explaining, and mitigating memorization in diffusion models.
[60] Chen, C., Liu, D., and Xu, C. (2024). Towards memorization-free diffusion models.
[61] Kibble, W. F. (1945). An extension of a theorem of mehler’s on hermite polynomials. Mathematical Proceedings of the Cambridge Philosophical Society, 41(1):12–15.
[62] Bach, F. (2023). Polynomial magic iii: Hermite polynomials. https://francisbach.com/hermite-polynomials/ Accessed: 2025-10-09.
[63] Potters, M. and Bouchaud, J.-P. (2020). A First Course in Random Matrix Theory: for Physicists, Engineers and Data Scientists. Cambridge University Press.
[64] Silverstein, J. and Bai, Z. (1995). On the empirical distribution of eigenvalues of a class of large dimensional random matrices. Journal of Multivariate Analysis, 54(2):175–192.
[65] Bai, Z. and Zhou, W. (2008). Large sample covariance matrices without independence structures in columns. Statistica Sinica, 18(2):425–442.