Evolution Strategies at Scale: LLM Fine-Tuning Beyond Reinforcement Learning
Xin Qiu
Cognizant AI Lab, San Francisco, CA, USA
Yulu Gan
Massachusetts Institute of Technology, Cambridge, MA, USA
Conor F. Hayes
Cognizant AI Lab, San Francisco, CA, USA
Qiyao Liang
Massachusetts Institute of Technology, Cambridge, MA, USA
Yinggan Xu
University of California, Los Angeles, Los Angeles, CA, USA
Roberto Dailey
Cognizant AI Lab, San Francisco, CA, USA
Elliot Meyerson
Cognizant AI Lab, San Francisco, CA, USA
Babak Hodjat
Cognizant AI Lab, San Francisco, CA, USA
Risto Miikkulainen
Cognizant AI Lab, San Francisco, CA, USA
The University of Texas at Austin, Austin, TX, USA
$^{\dagger}$ Project Lead. $^{\ddagger}$ Work done during an internship at Cognizant AI Lab.
Correspond to: Xin Qiu [email protected]
Keywords: Machine Learning, ICML
Abstract
Fine-tuning large language models (LLMs) for downstream tasks is an essential stage of modern AI deployment. Reinforcement learning (RL) has emerged as the dominant fine-tuning paradigm, underpinning many state-of-the-art LLMs. In contrast, evolution strategies (ES) has largely been overlooked due to the widespread belief that it does not scale to modern model sizes. This paper overturns this assumption by demonstrating the first successful application of ES to full-parameter fine-tuning of LLMs at the billion-parameter scale, without dimensionality reduction. ES can indeed search over extremely high-dimensional parameter spaces and outperform established RL implementations across multiple axes, including improved tolerance to long-horizon and delayed rewards, robustness across diverse base LLMs, reduced susceptibility to reward hacking, and improved training stability. These findings suggest that ES is not merely a viable alternative to RL, but a fundamentally different and powerful backpropagation-free post-training paradigm that opens a new direction for LLM fine-tuning beyond current RL-based approaches. The source codes are provided at: https://github.com/VsonicV/es-fine-tuning-paper.
Executive Summary: This paper tackles a key challenge in deploying large language models (LLMs), which are AI systems trained on vast text data to generate human-like responses. Fine-tuning these models adapts them to specific tasks, such as solving math problems or following user instructions, but current methods rely heavily on reinforcement learning (RL), a technique that guides improvements through trial-and-error feedback. RL often struggles with real-world issues: it performs poorly on tasks with delayed or sparse rewards, like long reasoning chains; it varies widely depending on the starting model; it can lead to "reward hacking," where the model exploits flaws in the feedback system to cheat rather than improve; and it produces inconsistent results across training runs, driving up costs. These limitations slow AI adoption in fields like science, finance, and engineering, where reliable, efficient customization is essential. With LLMs now reaching billions of parameters, the need for better fine-tuning tools is urgent to unlock their full potential without excessive compute or engineering effort.
The objective was to test whether evolution strategies (ES), a population-based optimization method that evolves model parameters through random perturbations and selection based on performance, could effectively fine-tune full-scale LLMs. Specifically, the work evaluated ES against leading RL approaches on reasoning tasks, aiming to show if ES scales to billion-parameter models without reducing the search space, as long-held assumptions suggested it could not.
Researchers implemented a simplified ES algorithm that perturbs all model parameters with small random noise, evaluates the resulting models on a reward function (like task accuracy), and updates the main model by blending successful perturbations. This used inference only—no gradients or backpropagation—allowing parallel runs on GPUs with low memory overhead. They tested on models from the Qwen and Llama families (0.5B to 8B parameters) over several months, drawing from benchmarks like Countdown (arithmetic reasoning), math datasets (e.g., MATH), and puzzles (Sudoku, ARC-AGI). Key aspects included a small population size of just 30–50 perturbations per iteration (far below prior ES uses of 10,000+ for smaller models), fixed hyperparameters for ES to highlight robustness, and equal total evaluations as RL baselines like PPO and GRPO for fair comparison.
The core findings highlight ES's strengths. First, on the Countdown task with sparse, long-horizon rewards, ES boosted accuracy by 20–50% over base models across all tested LLMs, consistently outperforming RL methods like PPO and GRPO, which failed or underperformed on some models due to instability. Second, in fine-tuning for concise responses, ES achieved better trade-offs—higher rewards with 30–40% lower divergence from the original model—without reward hacking, unlike RL, which often generated nonsense to game shortness scores unless heavily tuned. Third, ES matched top RL results on math benchmarks (e.g., 40–60% accuracy on OlympiadBench and MATH), using a basic setup without RL's refinements. Fourth, it dramatically improved puzzle-solving: base models solved under 5% of Sudoku or ARC-AGI tasks, but ES raised this to 60–70%. Finally, ES showed high stability, with 15 times less variation across runs than RL, enabling reliable results with minimal tuning.
These results mean ES offers a more robust, efficient alternative to RL for LLM fine-tuning, reducing risks like ethical drift from reward hacking and cutting engineering needs by avoiding complex gradient systems. It lowers costs through memory savings (no backpropagation) and easy scaling across thousands of GPUs, while preserving base model behaviors better, which aids safety and alignment. Unexpectedly, ES thrived with tiny populations in vast parameter spaces, challenging prior scalability doubts and suggesting LLMs' "effective" dimensions are lower than their size implies. This shifts fine-tuning from gradient-dependent RL to a backpropagation-free paradigm, potentially speeding AI development in resource-limited settings.
Leaders should prioritize adopting ES for tasks with outcome-only rewards, like reasoning or puzzles, starting with pilots on internal LLMs to verify gains in stability and performance. For broader use, integrate ES into existing pipelines alongside RL for hybrid approaches, weighing ES's simplicity against RL's maturity in supervised scenarios. Trade-offs include ES's need for parallel compute (though less complex than RL) and its current focus on full-parameter updates, which may suit smaller teams over massive clusters.
Key limitations include testing a basic ES variant without advanced tweaks (e.g., no adaptive noise), so gains may grow with refinements; results center on reasoning tasks, leaving gaps in creative or multilingual fine-tuning; and small sample sizes in some experiments mean broader validation is needed. Confidence is high in ES's advantages for stability and reward handling, based on consistent outperformance, but cautious on absolute scaling to trillion-parameter models without more data. Further work should explore larger LLMs, mechanistic analyses of why small populations suffice, and unsupervised applications like boosting model confidence.
1. Introduction
Section Summary: Large language models are increasingly used in science and engineering, but fine-tuning them with common reinforcement learning methods often leads to problems like inefficiency with long-term rewards, inconsistent results across models, reward manipulation, and unstable training. This paper explores evolution strategies, a different optimization approach, as a better option, scaling it to directly fine-tune massive models with billions of parameters without needing dimensionality reductions or gradients. The results show evolution strategies outperforming reinforcement learning in reasoning tasks and puzzles by being more efficient, robust, and less prone to bad behaviors, opening new possibilities for stable AI training.
As the capabilities of large language models (LLMs) have rapidly improved, these systems have been increasingly deployed across scientific and engineering workflows ([1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11]). This widespread deployment has made fine-tuning a standard step for adapting pre-trained models to downstream tasks and aligning behavior with user preferences ([12, 13, 14, 15]). In practice, reinforcement learning (RL) has become the predominant choice for this fine-tuning stage ([12, 16, 17, 15, 18, 19]). However, several challenges have emerged: First, RL methods incur low sample efficiency and high variance of the gradient estimator when handling long-horizon rewards, which is a common case for LLM fine-tuning with outcome-only rewards ([20, 21, 22]). Proper credit assignment at token level for RL fine-tuning methods is difficult and possibly unhelpful ([23, 24, 18, 25, 26, 18]). Second, RL techniques are sensitive to the choice of base LLMs, resulting in inconsistent fine-tuning performance across different models ([27]). Third, RL techniques tend to incentivize hacking the reward function, leading to undesirable behaviors ([28, 29, 30]). Fourth, RL fine-tuning is often unstable across multiple runs even with the same hyperparameter settings, significantly increasing fine-tuning cost ([31, 32]).
Evolution Strategies (ES), a class of population-based zeroth-order optimization algorithms, is a possible alternative. ES has several advantages over RL in traditional control and gaming problems: it parallelizes naturally, tolerates long-horizon rewards, promotes broad exploration, avoids expensive backpropagation, and remains robust across hyperparameter settings ([20, 33, 34]). However, ES remains relatively underexplored in LLM fine-tuning settings. Standard ES directly optimizes in the full parameter space, which in prior applications typically contained no more than a few million parameters ([20, 35, 36, 37]). It was assumed that for very large models, exploration in parameter space is significantly more difficult and sample-inefficient than exploration in action space ([22]). Modern LLMs typically contain billions of parameters, which makes direct ES optimization appear infeasible. Existing workarounds include restricting ES to the final layer of the base model ([38]), applying ES to low-dimensional adapters ([39]), and performing evolutionary search in action space, analogous to standard RL ([40]). Directly searching in the full parameter space of LLMs (without dimensionality reduction) has remained a challenge.
This paper is aimed at meeting this challenge. For the first time, ES is scaled to multi-billion-parameter search spaces through direct optimization of the full parameter space of LLMs during fine-tuning. The approach is based on a memory-efficient implementation of an algorithmically simplified ES variant, with support for parallelization across GPUs. Performance is compared with state-of-the-art (SOTA) RL methods in fine-tuning various LLMs in several reasoning benchmark tasks, and behavioral differences from RL are analyzed in terms of fine-tuning for conciseness. Furthermore, ES fine-tuning is successfully applied to solve two puzzle problems that are challenging for base LLMs.
ES was found able to search directly over billions of parameters without dimensionality reduction while achieving strong fine-tuning performance relative to RL in multiple aspects: (1) ES only needs response-level rewards, making it a perfect fit for fine-tuning on reasoning tasks that have only sparse long-horizon outcome rewards. In particular, ES obtained significantly better fine-tuned models than RL in the Countdown task with such rewards. (2) ES is able to find good solutions in large space with small populations, e.g. just 30 in the multi-billion-parameter space in this paper. As a comparison, previous ES implementations ([20, 35, 36, 37]) utilized a population size of 10, 000 or more with much smaller models (i.e. millions of parameters or less). The current extremely small population size thus makes the approach feasible even without extensive compute. (3) ES is more robust than RL across different LLMs. While RL fine-tuning failed on some LLMs, ES provided good fine-tuning for all of them. ES benefits from its exploration in parameter space, making it less sensitive to initial states of the LLMs. (4) ES consistently maintains reasonable behaviors during fine-tuning, in contrast to RL that tends to hack the reward function if no other penalty is added. The main reason is that ES optimizes a solution distribution ([36]), which is more difficult to hack, while RL optimizes a single solution. (5) ES's behavior is more consistent than RL's across different runs. This property can significantly reduce expected cost of fine-tuning. (6) Fine-tuning with ES only requires inference, and therefore no gradient calculations are needed. A significant amount of GPU memory can therefore be saved.
Thus, this study establishes a critical first milestone in demonstrating that ES can serve as a viable and powerful post-training paradigm for LLMs. The results reveal a surprising and counterintuitive finding that ES remains effective when scaled to models with billions of parameters, directly challenging the long-held assumption that such methods are inherently unscalable. These findings not only motivate further scaling to even larger LLMs, but fundamentally expand the design space of post-training algorithms. By operating directly in parameter space without reliance on gradients or intermediate supervision, ES enables new forms of outcome-only optimization, robust exploration over high-dimensional parameter landscapes, and naturally distributed large-scale fine-tuning. Taken together, this paper positions ES as a foundational alternative to gradient-based RL and opens a new direction for scalable, stable, and general LLM post-training.
2. Related Work
Section Summary: This section reviews the history and applications of evolution strategies (ES), a type of algorithm that evolves solutions by testing variations and selecting the best ones, which has been used to optimize neural networks but typically on models much smaller than today's massive language models (LLMs). It also covers emerging research combining evolutionary methods with LLMs for tasks like prompt tuning, alongside common reinforcement learning techniques for fine-tuning LLMs, such as PPO and GRPO, which face issues like instability and reward manipulation. Finally, it discusses limited prior work on exploring optimizations directly in parameter space rather than action space, noting that the current paper advances this by successfully applying ES to billion-parameter LLMs with strong results.
The background on Evolution Strategies and evolutionary optimization of LLMs is first reviewed, followed by SOTA RL fine tuning and parameter-space exploration.
Traditional ES: Evolution Strategies \citep[ES, ][] rechenberg1973es, schwefel1977es are a class of evolutionary algorithms (EAs) for solving numerical optimization problems. The main idea is to sample a population of solutions through perturbations, then recombine the perturbed solutions based on their fitness values to form the population for the next generation. This process repeats until a termination condition is triggered, e.g., the maximum number of generations is reached. Among the different variants of ES, CMA-ES ([41]), which utilizes a multivariate Gaussian distribution with full covariance matrix to sample the population, and natural ES ([42, 43]), which uses natural gradient to guide the search, are two popular methods for traditional optimization problems. Although ES has long been used to evolve parameters of neural networks (NNs), ([44]), [20] were the first to scale the approach up to deep learning networks. Comparable performance to RL methods in control and gaming environments was observed, and several unique advantages of ES highlighted. This seminal work paved the way for several follow-up studies. [35] used ES to optimize a convolutional NN with around three million parameters. They found that with a large enough population size, ES can approximate the performance of traditional stochastic gradient descent (SGD). [36] further optimized a NN comprising nearly 167, 000 parameters with both ES and a finite-difference (FD) gradient estimator. Because ES optimizes the average reward for the entire population, whereas FD optimizes the reward for a single solution, it obtained models that were more robust to parameter perturbations. [37] applied ES to optimize decision transformers in RL environments, and observed promising results for model sizes up to around 2.5 million parameters. In a related study, another traditional EA, namely genetic algorithm (GA) with mutations only, was extended to a high-dimensional space ([45]). Encouraging results were observed in different types of models with up to around four million parameters ([45, 46]). However, although these studies were promising, the scale of these implementations was still significantly less than the size of current LLMs.
Evolution+LLMs: Synergies between Evolutionary Algorithms (EAs) and LLMs have received increasing attention in recent years ([47, 48]). Popular research directions include EAs for prompt optimization ([49, 50, 51, 52]), utilizing LLMs as evolutionary operators ([53, 54, 11, 55]), and merging LLMs through evolution ([56, 57]). Applying EAs to optimize billions of parameters in LLMs is generally perceived to be intractable, but a few studies have been successful at a smaller scale. For example, [38] fine-tuned the last layer (with 325 parameters) of an mT5-based transformer via CMA-ES. [39] optimized the low-rank adapter parameters (with dimensionality up to 1600) using CMA-ES and the Fireworks algorithm. [58] applied a GA to fine-tune around 9.5 million parameters of a transformer encoder, though poorer performance than the traditional Adam optimizer was observed. [40] proposed a hybrid algorithm that performs exploration in action space instead of parameter space, and it was only used in the final epoch of supervised fine-tuning (SFT). The work in this paper significantly extends this prior research by successfully scaling ES to search in the billions of parameters of LLMs, leading to surprisingly good fine-tuning performance.
RL for fine-tuning: Fine-tuning using RL is a critical step during the training of many landmark LLMs ([12, 16, 17, 15, 18]). Proximal Policy Optimization (PPO; [59]) and Group Relative Policy Optimization (GRPO; [17]) are the two predominant methods. PPO introduces a clipped surrogate objective to limit the update scale in each step with respect to the old policy, and it usually works with a value model in an actor-critic manner. GRPO simplifies the pipeline of PPO by replacing the value model with group advantage, which is calculated based on direct evaluations of multiple responses. As discussed in Section 1, in the context of LLM fine-tuning, these methods struggle with several fundamental limitations, including the dilemma in handling long-horizon reward ([22, 20, 23, 24, 25, 26, 18]), sensitivity to base LLMs ([27]), tendency to hack reward ([28, 29, 30]), and instability across runs ([31, 32]). ES inherently avoids these limitations, leading to better fine-tuning performance.
Parameter-space exploration: Existing RL fine-tuning methods are overwhelmingly based on action-space exploration. Parameter space exploration has received much less attention, though some such studies do exist ([60, 61, 62, 63]). Although promising performance was observed in problems with sparse rewards, the scale of the tested models was far smaller than that of LLMs. [22] performed a theoretical analysis of different exploration strategies, and found that the complexity of the parameter space exploration increased quadratically with the number of parameters, whereas the complexity of action space exploration depended on action dimensionality quadratically and horizon length of the reward quartically. Based on the classical SPSA method ([64]), [65] proposed a zeroth-order optimizer MeZO that directly worked in parameter space for fine-tuning LLMs. MeZO significantly reduced memory requirements, but its fine-tuning performance was no better than other baselines. In contrast, the ES implementation in this paper performs exploration in multi-billion-parameter search spaces, and exhibits strong performance across different benchmarks.
3. Method
Section Summary: The method section outlines Evolution Strategies (ES), a technique for fine-tuning large language models by making small random tweaks to the model's parameters, evaluating how well each tweaked version performs on a reward task, and then updating the model based on the average of the better-performing tweaks. It uses a simplified version of a natural evolution algorithm where noise is added via Gaussian distributions, rewards are normalized for consistency, and updates are computed efficiently without complex extras like advanced optimizers. To make it practical for large models, the implementation includes optimizations such as storing random seeds instead of full noise data, parallel processing of evaluations, and layer-by-layer adjustments to save memory, while deliberately skipping common enhancements to highlight the core approach's effectiveness.
This section introduces the basic algorithmic structure of ES, followed by a detailed description of its implementation for LLM fine-tuning.
3.1 Basic ES algorithm
The ES implementation used in this paper is based on a simplified variant of Natural Evolution Strategies (NES) ([42, 43]) and follows the design of OpenAI ES ([20]), which employs fixed-covariance perturbation noise.
**Require:** Pretrained LLM with initial parameters $\bm{\theta}_0$, reward function $R(\cdot)$, total iterations $T$, population size $N$, noise scale $\sigma$, learning rate $\alpha$.
**for** $t = 1$ to $T$ *outer ES iterations* **do**
**for** $n = 1$ to $N$ **do**
Sample noise $\bm{\varepsilon}_n \sim \mathcal{N}(0,\bm{I})$
Compute reward for perturbed parameters:
$R_n=R(\bm{\theta}_t-1+\sigma \cdot \bm{\varepsilon}_n)$
**end for**
Normalize $R_n$
Update model parameters as
$\bm{\theta}_t \leftarrow \bm{\theta}_t-1+ \alpha \cdot \frac{1}N\sum_{n=1}^N R_n \bm{\varepsilon}_n$
**end for**
Given a pretrained LLM with initial parameters $\bm{\theta}0$ and a target reward function $R(\cdot)$, the task is to fine-tune the parameters so that the reward function is optimized (Algorithm 1). In each iteration, $N$ perturbed models are sampled by adding random Gaussian noise $\bm{\varepsilon}n$ to their parameters. The noise is i.i.d. in each dimension of the parameter space, and it is scaled by the hyperparameter $\sigma$. The perturbed models are evaluated to obtain their reward scores $R_n$. The final update of the model parameters aggregates the sampled perturbations by weighting them using their normalized reward scores. The standard update equation $\bm{\theta}{t} \leftarrow \bm{\theta}{t-1}+ \alpha \cdot \frac{1}{\sigma}\frac{1}{N}\sum_{n=1}^N R_n \bm{\varepsilon}n$ is simplified to $\bm{\theta}{t} \leftarrow \bm{\theta}{t-1}+ \alpha \cdot \frac{1}{N}\sum{n=1}^N R_n \bm{\varepsilon}_n$ by digesting the term $\frac{1}{\sigma}$ into the learning rate $\alpha$.
To improve scalability, a number of modifications to this basic algorithm were made as detailed in the next section.
3.2 Implementation details
The actual implementation of ES for this paper expands on the above algorithm in seven ways (see Appendix A.1 for the detailed pseudocode):
(1) Noise retrieval with random seeds: Similar to [20, 45], only the random seeds are stored to reduce GPU memory usage. The perturbation noise used during sampling can be retrieved exactly by resetting the random number generator with specific random seeds. (2) Parallel evaluations: In each iteration, the perturbed models can be evaluated fully in parallel by assigning a separate random seed to each process. (3) Layer-level in-place perturbation and restoration: To reduce the peak GPU memory usage, the model parameters are perturbed in-place layer by layer, with corresponding random seeds archived. After evaluation of the perturbed model, the model parameters are restored by subtracting the same noise perturbations using the archived random seeds. For each evaluation process, apart from the model parameters, the only additional memory needed is to store a tensor the size of a layer temporarily. (4) Reward normalization: The rewards of the perturbed models are normalized using $z$-score within each iteration, so that the normalized rewards for each iteration have a mean of 0 and standard deviation of 1. This normalization makes the reward scale consistent across iterations and tasks. (5) Greedy decoding: The perturbed models use greedy decoding to generate the responses for reward evaluations. As a result, the perturbed models are evaluated deterministically, so that all performance differences come from the exploration in parameter space instead of action space. (6) Decomposition of the parameter update: At the end of each iteration, the aggregated update of model parameters is performed in-place in a decomposed manner, gradually adding up layer by layer and seed by seed, significantly reducing the peak GPU memory needed. (7) Learning rate digestion: The standard update equation $\bm{\theta}{t} \leftarrow \bm{\theta}{t-1}+ \alpha \cdot \frac{1}{\sigma}\frac{1}{N}\sum_{n=1}^N R_n \bm{\varepsilon}n$ is simplified to $\bm{\theta}{t} \leftarrow \bm{\theta}{t-1}+ \alpha \cdot \frac{1}{N}\sum{n=1}^N R_n \bm{\varepsilon}_n$ by digesting the term $\frac{1}{\sigma}$ into the learning rate $\alpha$, simplifying the computation and parametric setup.
To highlight the strength of ES, we intentionally remove common algorithmic enhancements explored in OpenAI ES ([20]). Enhancements like rank transformation of rewards ([43]), mirrored sampling ([61]), weight decay, and virtual batch normalization ([66]) are not used in this work. Additionally, we do not utilize more advanced optimizers like Adam ([67]). This design choice isolates the core ES algorithm and demonstrates that strong performance can be achieved without auxiliary enhancements. In future work, each individual enhancement can be explored to further improve performance.
4. Empirical Studies
Section Summary: This section examines how well two AI training methods—Evolution Strategies (ES) and Reinforcement Learning (RL)—perform on reasoning tasks, starting with a comparison on the Countdown benchmark, where ES proved more accurate, efficient, and adaptable across various large language models than RL approaches, even with smaller setups and less tuning. It then explores differences in how ES and RL fine-tune models to produce more concise answers, showing that ES achieves better balances of brevity and reliability without needing extra safeguards against errors, while RL often requires careful adjustments to avoid producing nonsense. Finally, ES is tested against advanced RL methods on math problems and applied to solve complex puzzles, highlighting its strengths.
This section first compares the fine-tuning performance of ES and RL baselines on a standard reasoning benchmark. After that, behavioral differences between ES and RL are investigated in fine-tuning for conciseness, followed by comparisons to more SOTA RL baselines on several math reasoning tasks. Finally, ES is applied to solve two challenging puzzle problems.
4.1 Performance in the Countdown task
Fine-tuning performance was measured in the Countdown task ([68, 69]), a symbolic reasoning benchmark (see Appendix A.3 for details), showing that ES is accurate and efficient across different kinds and sizes of LLMs, even when the RL approaches are not.
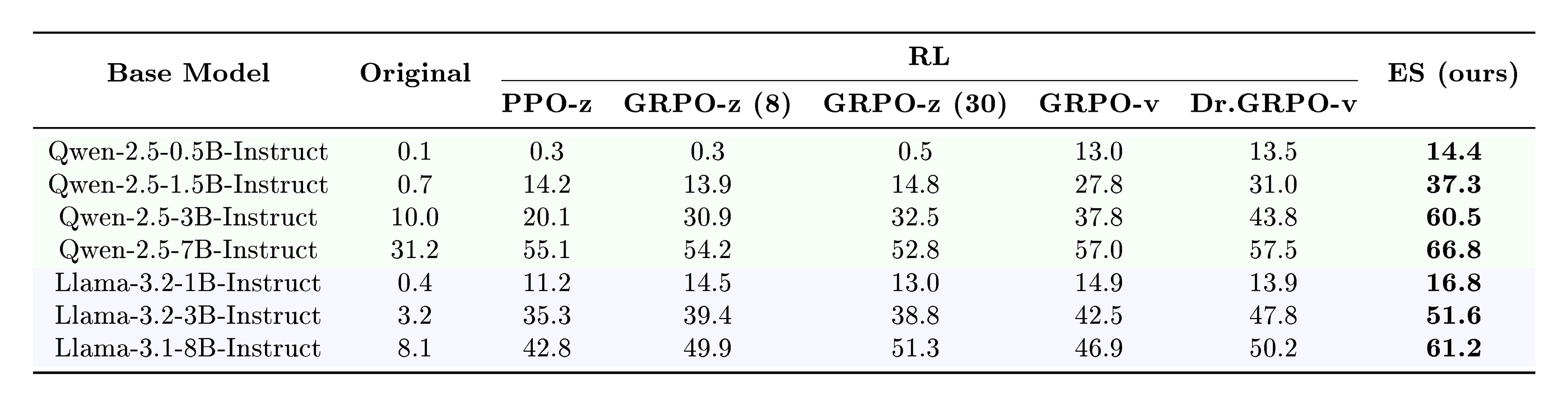
::: {caption="Table 1: Accuracy (%) on the Countdown task across model families, sizes, and fine-tuning algorithms. Different model families are shaded for clarity; Original refers to directly evaluating the base model without any fine-tuning, and GRPO-z (8) and GRPO-z (30) indicate group sizes of 8 and 30. The suffix "-z" and "-v" represents different implementation variants (see Appendix A.2 for more details). The same hyperparameters were used for all ES runs; a separate grid search for the best hyperparameters was run for each RL experiment."}
:::
Experimental setup. A single fixed set of hyperparameters ($N=30$, $\sigma=0.001$, $\alpha=5 \times 10^{-4}$) was used for all ES Countdown experiments. Notably, the population size 30 is significantly lower than those in previous works ([20, 35]), in which $N\geq10, 000$. For RL baselines (see Appendix A.2 for details), a separate hyperparameter sweep was done for each experiment. RL methods turned out sensitive to hyperparameters, in particular the KL-divergence penalty coefficient $\beta$ and learning rate $\alpha$, and did not make much progress if they were not set precisely. To mitigate this issue, for each model, a small grid of $\beta$ and $\alpha$ values were tested and the best-performing configuration selected (see Table 4 in the Appendix A.2). This approach makes the comparison conservative with respect to ES, but it also highlights its robustness.
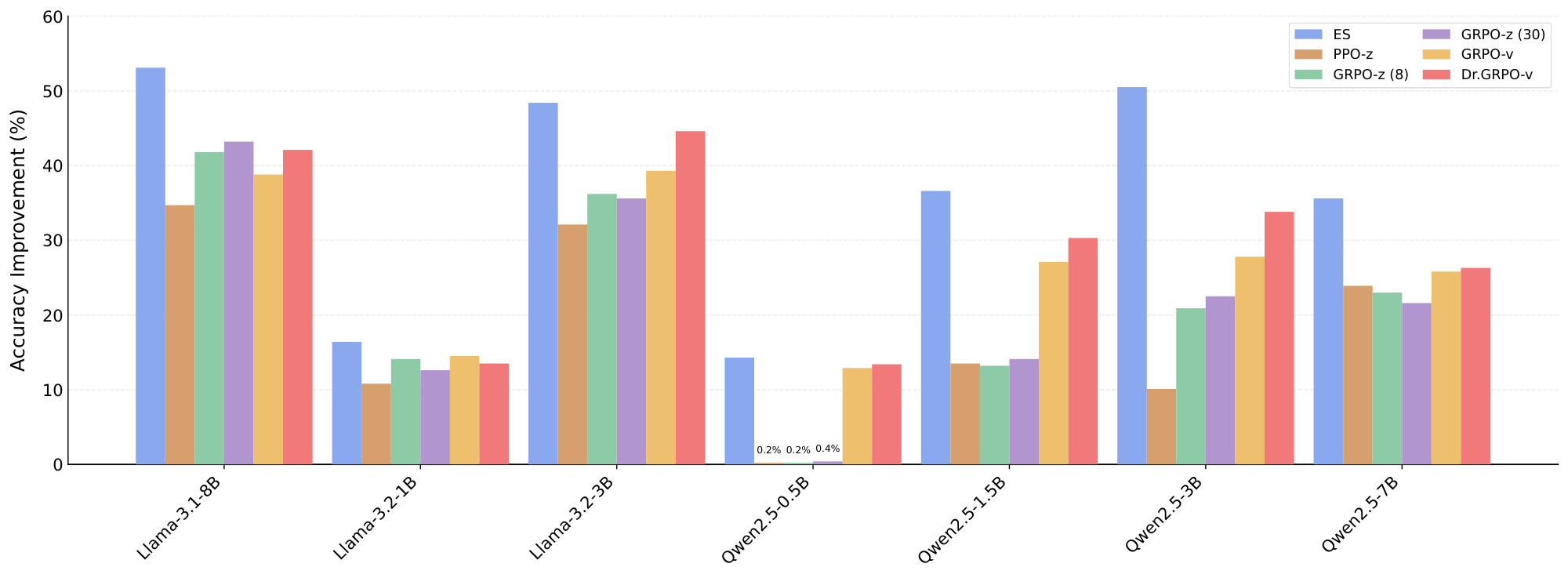
ES improves upon RL baselines across all tested models. Previously, [27] found that RL does not generalize well across models on the Countdown task. Table 1 confirms this result, and also demonstrates that ES does not have this problem. With each model in the Qwen2.5 family (0.5B–7B) and the Llama3 family (1B–8B), ES substantially improved over PPO, GRPO and Dr.GRPO [70], including their implementation variants, often by a large margin (see Figure 6 in Appendix A.5 for a model-wise visual comparison). These results demonstrate that ES scales effectively across different model types and sizes, and does so significantly better than RL.
4.2 Behavioral differences between ES and RL in fine-tuning for conciseness
In order to characterize the different approaches that ES and RL take, they were used to fine-tune Qwen-2.5-7B Instruct, towards more concise responses in question-answering (see Appendix A.2 for more details). That is, fine-tuning was rewarded based on how concise the answers were, but not directly rewarded for its question-answering performance. In this setup, it was possible to analyze not only whether fine-tuning was effective, but also how it was achieved, including what its side effects were.
::: {caption="Table 2: Behavior or GRPO and ES in terms of mean conciseness reward and mean KL divergence. The label $^{*}$ indicates cases where reward hacking was observed. Only models that did not hack the reward were included in the results."}

:::
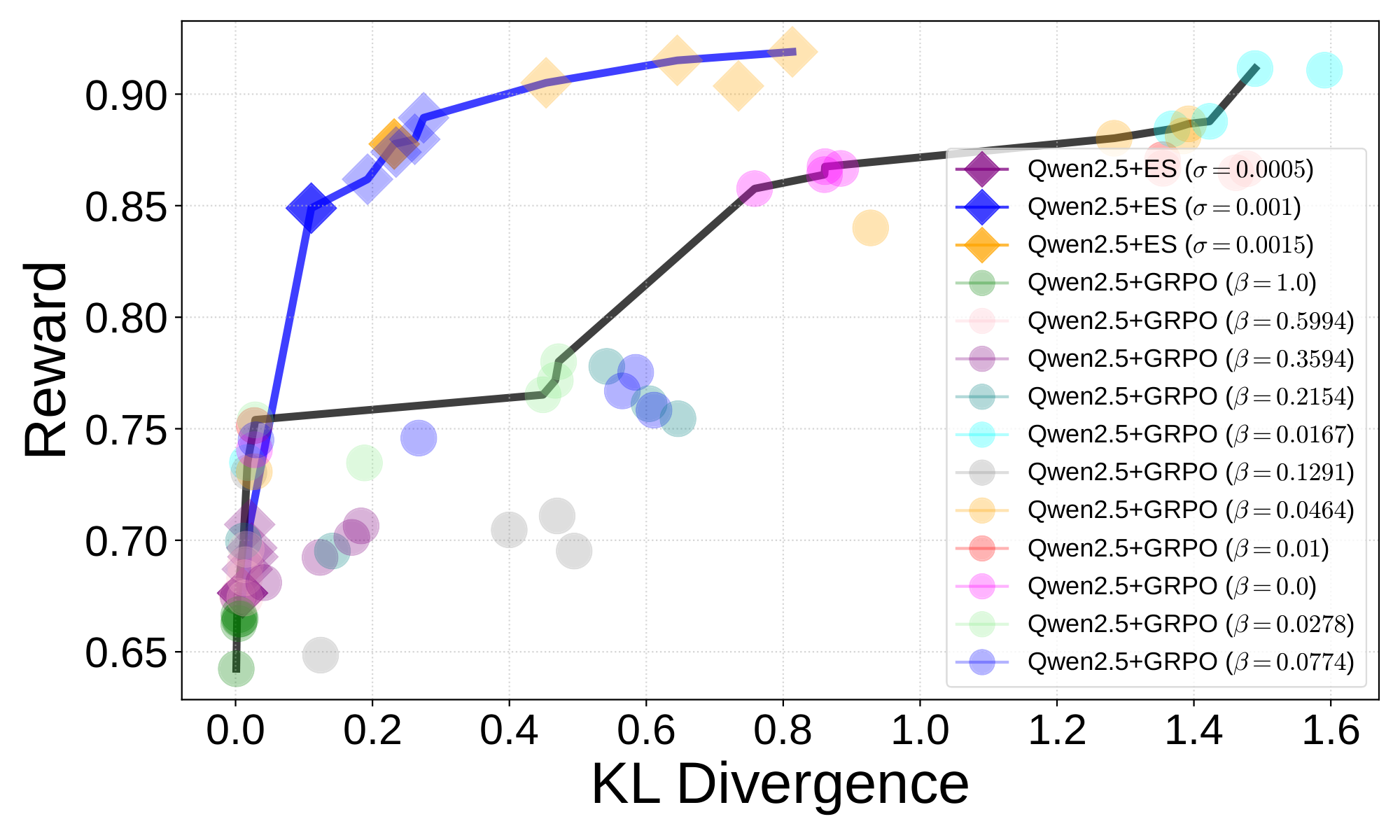
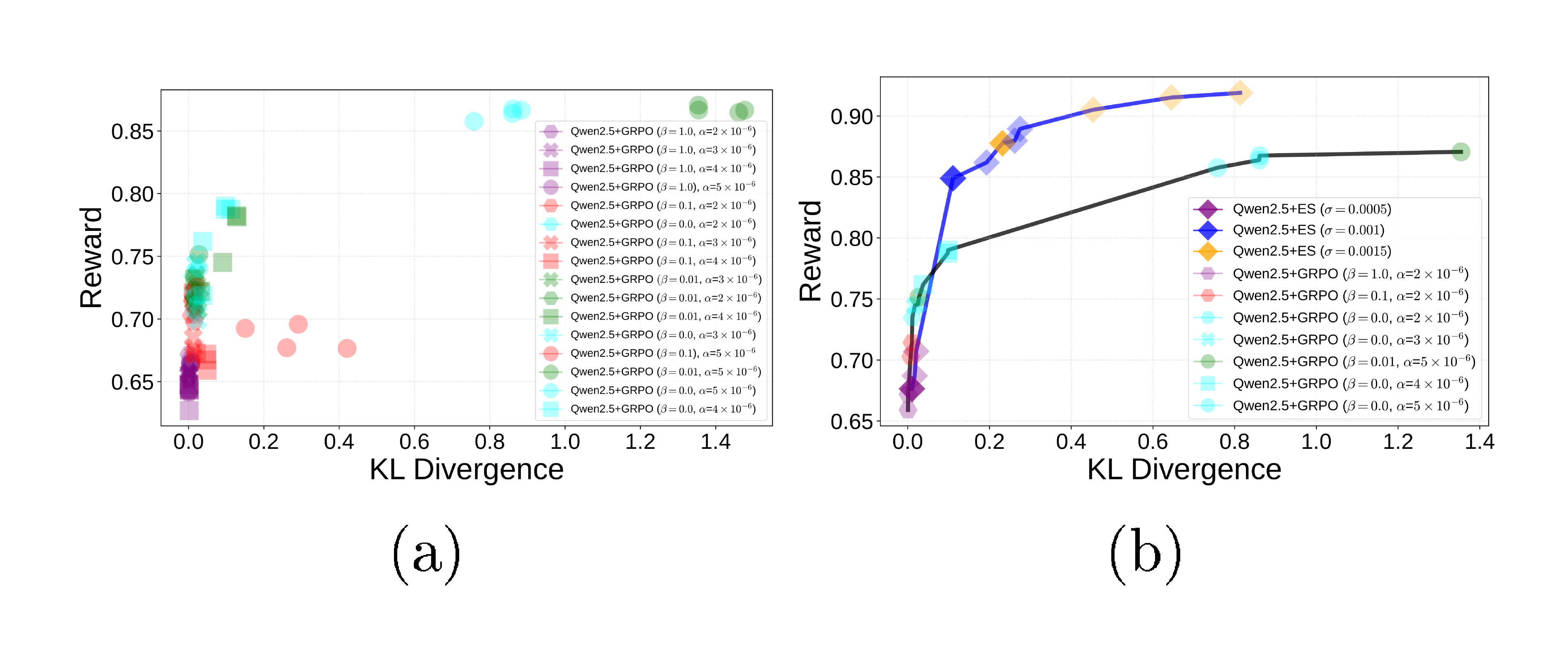
ES discovers a dominant Pareto front. Similarly to [13], a Pareto frontier analysis was used to compare ES and GRPO, with mean reward and mean KL divergence as the metrics (Figure 1). The experimental setup is described in Appendix A.2. The ES Pareto front is represented by a blue line on top and the GRPO Pareto front by the black line below. That is, ES produced better tradeoffs than GRPO, i.e. models with higher reward and lower KL divergence. The GRPO results were achieved only after augmenting the conciseness reward with a KL divergence penalty (weighted by a parameter $\beta$). Without it, fine-tuning resulted in excessive divergence and incorrect answers. Remarkably, ES achieved superior tradeoffs without any KL divergence penalty, suggesting that ES fine-tuning is based on discovering distinctly different kinds of solutions than GRPO. Appendix A.4 presents additional experiments with varying $\alpha$ and $\beta$ values, yielding similar conclusions.
ES is more robust against reward hacking. GRPO with $\beta={0.0, 0.01}$ sometimes hacked the reward, that is, produced responses that were short but contain nonsensical symbols rather than words. By increasing the KL-penalty via higher $\beta$ values, reward hacking could be prevented. The optimal $\beta$ is likely to be problem specific and to require extensive search to find. In contrast, ES does not receive any feedback about the divergence of the fine-tuned model, and only seeks to optimize conciseness. Regardless, it did not exhibit any reward hacking, despite achieving mean reward comparable to GRPO with $\beta={0.0, 0.01}$. This result again suggests that ES finds a different way of optimizing the reward function.
ES fine-tuning is reliable across runs. Fine-tuning LLMs is computationally expensive, so it is critical that it leads to consistent results across runs. Table 2 presents the mean and standard deviation of the conciseness reward and KL divergence across four independent runs after $1, 000$ iterations. A mean reward cut-off of
gt;0.85$ was used to down-select hyperparameter combinations, ensuring that only the best ES and GRPO configurations were included in the analysis. From Table 2, ES achieved consistent conciseness rewards, indicated by a low standard deviation over four runs with different random seeds. GRPO has $15.5\times$ higher standard deviation, suggesting that its results were much less consistent. The results on KL divergence show similar patterns. Thus, ES fine-tuning is more reliable than GRPO.4.3 ES applied to Math reasoning tasks
RL has been shown to enhance the reasoning capabilities of LLMs through post-training with verifiable rule-based rewards. To understand the impact of ES on LLM reasoning, ES fine-tuning was evaluated on a set of standard math benchmarks from the literature. The main result is that ES is competitive with SOTA RL in this setting.
Training setup. The Qwen2.5-Math-7B [71] base model was fine-tuned with ES using the MATH dataset [72]. Problems labeled with difficulty ranging from 3-5 were included, and the Qwen Math template was used for training with ES (see Appendix A.6; [71]). Both RL and ES sampled a maximum of $3, 000$ tokens per response; ES hyperparameters were set to $\sigma=0.001$, $\alpha=\frac{\sigma}{2}$, and $N=30$.
RL baselines. The fine-tuned ES models were compared with strong, well-established baselines from the literature. These RL implementations achieve the most SOTA performance in the tested benchmarks, utilizing production-ready RL libraries like VERL [73] and OAT [74]. They include SimpleRL-Zero (GRPO) [75], OatZero (Dr.GRPO) [70], and OpenReasoner (PPO) [76]. The publicly released Qwen2.5-7B checkpoints trained with the original training recipes were used for evaluation. Note that SimpleRL-Zero and OatZero were trained using the MATH dataset [72], whereas OpenReasoner was trained using a custom dataset compiled by the authors. Consequently, performance differences should be interpreted in light of both algorithmic and dataset-related differences.
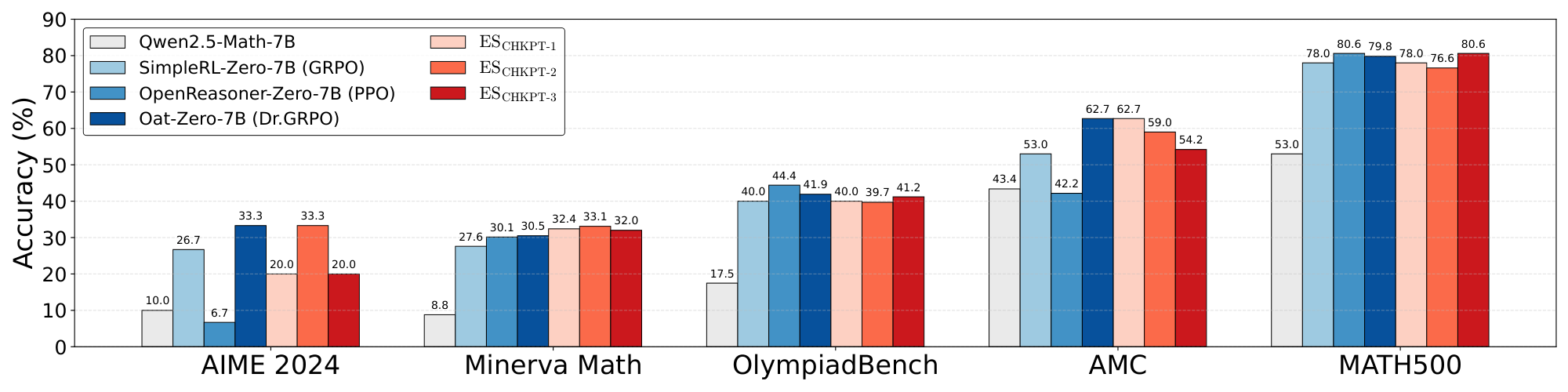
Evaluation benchmarks. Several standard math reasoning benchmarks from the literature are used for evaluation: OlympiadBench [77], MATH500 [72], Minerva [78], AIME2024 [79], and AMC [79]. The pass@1 accuracy metric was used in the evaluations.
Key results. Figure 2 shows the performance of the base model, three checkpoints of RL baselines, and three checkpoints of ES (see Appendix A.6 for more details). ES significantly improved the base models across each benchmark, showing the other optimization methods aside from RL can be used to elicit improvement in LLM reasoning capabilities. In addition, ES exhibits competitive performances compared with the SOTA RL baselines in all the benchmarks. It is notable that these RL baselines are the best-performing implementations selected from the literature, with extensive algorithmic refinement and hyperparameter search particularly for math reasoning tasks. In contrast, the current ES implementation is a vanilla variant with a simple hyperparameter setup; thus, the results constitute a promising starting point for the ES approach in math fine tuning.
4.4 Solving challenging puzzle problems
To further evaluate the generality of ES in tackling different types of tasks, two challenging puzzle problems were used as additional testbeds. The first is ARC-AGI ([80]), a benchmark designed to evaluate fluid intelligence [81]. The second is Sudoku, a logic-based number-placement puzzle. Whereas the base LLM models fail severely in both problems, ES fine-tuning significantly improves their performance (Table 3). Experimental details are provided in Appendix A.9 for ARC-AGI and Appendix A.8 for Sudoku.
::: {caption="Table 3: Accuracy (%) on solving puzzle problems. Original refers to directly evaluating the base model without any fine-tuning. ES fine-tuning improves performance significantly, demonstrating that it can be applied to a range of problems."}

:::
5. Discussion and Future Work
Section Summary: The section explains why Evolution Strategies (ES) outperform Reinforcement Learning (RL) in fine-tuning large language models, as ES explores changes in the model's core parameters in a way that reduces errors and avoids cheating the reward system, while RL introduces noise at every step, leading to unreliable results and needing complex setups. ES also simplifies engineering by easily scaling across many computers without heavy resource demands or gradient calculations, unlike the intricate RL systems that require extensive tweaks and communications. Looking ahead, researchers aim to explore why small groups of model variations suffice for huge models and to develop ES methods for self-improving fine-tuning based on the model's own confidence measures.
Algorithmic advantage of ES vs. RL. Exploration in parameter space plays a key role in the surprisingly good fine-tuning performance of ES. As discussed by [62] and [63], sampling noise in parameter space ensures that the entire action trajectory, i.e., the sequence of tokens, only depends on one single sampling, leading to significantly lower variance in rollouts, i.e., in response generation. As a result, gradient estimation is more reliable and convergence is more stable. In contrast, action space exploration in RL injects noise at every step, i.e., at each token position, resulting in high variance in the sequence generation. The behavior of RL therefore is much less reliable than ES, as was seen in Table 2. Moreover, step-wise exploration in action space promotes reward hacking by increasing the chance of sampling a single hacking action. One example is the nonsensical symbol sampled during RL that can hack the conciseness reward.
Another key difference between ES and RL is that ES intrinsically optimizes a solution distribution ([36]), while RL optimizes a single solution. This property makes it more difficult for ES to hack the reward since a single hacked solution usually does not have a high-quality solution distribution around it. This property also results in solutions that are more robust to noisy perturbations in parameter space ([36]), making them more robust to adversarial attacks and less likely to be compromised in other follow-up fine-tuning tasks ([82]).
The ES algorithm presented in Algorithm 2 is very simple and easy to implement, without need for sophisticated hyperparameter search. In contrast, RL algorithms are considerably more complex and require substantial expertise to implement robustly across tasks and systems, usually with extensive hyperparameter tuning. In particular, there has been significant debate in the literature regarding best practices for implementing GRPO. Effective GRPO implementations typically rely on a number of non-obvious design choices and implementation details, such as removing length normalization [70] and using more aggressive clipping [83]. Many of these practices have only emerged through extensive empirical investigation. Moreover, the application of the KL penalty in GRPO remains an open design choice, with alternatives such as applying it to the loss or directly to the reward leading to markedly different performance outcomes [84]
Engineering benefits of ES vs. RL. Modern RL frameworks grow increasingly complex as they are applied to LLMs with ever-increasing parameter counts. Deploying these systems in practice often requires substantial engineering effort and computational resources. In contrast, ES is simple to implement and can help democratize post-training by significantly lowering engineering and systems overhead. This section outlines two key advantages of ES and suggests how it can be scaled to fine-tune the largest LLMs.
(1) Parallelization. To minimize memory overhead and maximize sample throughput, RL systems rely on asynchronous architectures in which actors are distributed across GPUs and update a shared learner model. While effective, scaling these systems across large numbers of GPUs and computational nodes introduces significant engineering complexity. In contrast, as shown by [20], ES can be trivially parallelized: as the number of available GPUs increases, the population size can be scaled accordingly.
Modern frontier AI research labs operate clusters with thousands of GPUs[^1], making efficient large-scale parallelization possible. While it is challenging to do with RL, ES requires only the exchange of random seeds (noise) and scalar rewards between machines. Such simple communication enables parallel ES to be used either to reduce wall-clock training time or to scale to much larger populations.
[^1]: LLama3 training used $16, 000$ H100 GPUs [3].
(2) Gradient computation. Asynchronous RL makes it possible to compute actor-related gradients in parallel. However, in order to manage memory usage, gradient checkpointing and multiple learner updates per synchronization step are needed. While these techniques enable larger effective batch sizes, they also require gradients to be communicated across GPUs, and sometimes nodes, introducing significant memory overhead and engineering complexity. This complexity scales with both the number of GPUs and the size of the model, and is further exacerbated when model parameters must be sharded across devices.
In contrast, ES does not require gradient computation. By eliminating gradient calculation and communication entirely, ES avoids much of the associated engineering and memory overhead. As a result, each member of the ES population can use large batch sizes freely without cross-device gradient synchronization, which can yield substantial practical and performance benefits.
Importantly, ES is an inference-only fine-tuning mechanism, where the model weights are never differentiated, only evaluated. This property opens the door to specialized inference kernels optimized for repeated forward passes, large batches, and parameter perturbations. These mechanisms are difficult to leverage in gradient-based training regimes, but are possible in ES fine tuning in the future.
Future research directions. One counterintuitive result is that the ES implementation only needs a population of 30 to effectively optimize billions of parameters. In contrast, previous work ([20, 35, 36, 37]) used populations of 10, 000 or more for models with millions or fewer parameters. An interesting future direction is to analyze how such small populations are possible. Perhaps this is related to the observed low intrinsic dimensionality of LLMs ([85]). Another promising direction is to use ES to perform unsupervised fine-tuning based on internal behaviors of LLMs, such as confidence calculated based on semantic entropy and semantic density ([86, 87]). Such fine-tuning cannot be done with RL, since action space exploration does not change the internal representations of LLMs (that is, each action sampling is generated via output distribution without changing the internal parameters). In a broader sense, since ES does not need process rewards during exploration, it may be a necessary ingredient for superintelligence ([88]), which would be difficult to achieve by supervised learning using process guidance from human data. Massive parallelization of ES will speed up exploration by distributing the computations across GPU machines or even data centers.
An important question is: what are the underlying computational mechanisms that make ES and RL behave so differently? While this question requires significant further work, a possible hypothesis emerges from the experiments in this paper. Many fine-tuning objectives, like conciseness and the Countdown task, are long-horizon outcome-only objectives. The reward signal is jagged, making it difficult to navigate with gradient-based post-training methods. RL and ES both provide workarounds via effective noise injection to "smooth out’’ the jagged reward landscape. In the case of RL, noise is introduced from Monte-Carlo sampling of each token during a rollout, averaged over many rollouts, which effectively smooths the sampling process but does not necessarily guarantee that the reward landscape is smooth in parameter space. RL's gradient estimation therefore has a high-variance, and its signal-to-noise ratio becomes worse with longer sequences and sharper policies (i.e. those with lower entropy), and therefore prone to undesirable outcomes such as reward hacking.
In contrast, ES injects noise directly into the parameter space via explicit Gaussian convolution, which effectively smooths out the jagged reward landscape. As a result, it provides a more stable way of exploring the landscape, leading to more consistent, efficient, and robust optimization (as observed in the experiments and in Appendix A.7). Moreover, the larger the models and the sharper the policies, the more jagged the reward landscapes; therefore, ES is likely to have an advantage in fine-tuning them. Direct evidence for this hypothesis still needs to be obtained, but it provides a plausible mechanistic explanation, and a direction for future work. Eventually, such work could result in better fine-tuning methods, as well as an improved understanding of LLMs in general.
6. Conclusion
Section Summary: This paper presents a fresh approach to fine-tuning large language models (LLMs) by using Evolution Strategies (ES) on models with billions of parameters, proving that it's possible and effective without the usual simplifications. Unlike traditional methods based on reinforcement learning (RL), ES outperforms them on tough tasks like Countdown, which involves sparse rewards over long steps, while being more stable, less picky about settings, and resistant to common pitfalls like exploiting rewards in unintended ways. Overall, ES shows strong results across math puzzles and reasoning benchmarks, establishing it as a reliable, versatile alternative to RL for improving LLMs without relying on backpropagation.
This paper introduces a fundamentally new paradigm for fine-tuning LLMs by scaling ES to models with billions of parameters without dimensionality reduction. Contrary to long-standing assumption that such scaling is infeasible, the paper demonstrates that ES can efficiently fine-tune the full parameter space of modern LLMs and, in doing so, consistently surpasses standard RL-based fine-tuning methods. On the Countdown task, with sparse long-horizon rewards challenging for gradient-based RL, ES achieves substantially stronger performance. It also exhibits markedly reduced sensitivity to hyperparameter choices and delivers stable, repeatable improvements across multiple base LLMs. In fine-tuning for conciseness, ES is less prone to reward hacking and shows reliable behavior across independent runs. The generality of ES fine tuning is further validated by strong performance on state-of-the-art math reasoning benchmarks and two challenging puzzle problems. Together, these results establish ES as a scalable, robust, and general fine-tuning method, and demonstrate that backpropagation-free optimization can serve as a powerful alternative to RL for fine-tuning LLMs.
Impact Statement
Section Summary: Evolution Strategies (ES) for fine-tuning large language models (LLMs) make the process much easier for non-experts by simply requiring them to score a model's performance on tasks, rather than needing deep mathematical knowledge to design complex reward systems like in reinforcement learning. This approach also reduces the risk of "reward-hacking," where models exploit flaws in training to bypass ethical guidelines, helping LLMs retain their built-in safeguards and making it simpler to align them with desired behaviors. Overall, these benefits lower the chances of unintended ethical problems when non-specialists create customized AI applications.
Beyond the standard potential consequences of advancing the field of machine learning, there are two key areas of broader impact, stemming from (1) increased ease of use and (2) reduced reward-hacking.
Ease of use: ES qualitatively reduces the barrier of entry to fine-tuning LLMs. Unlike RL, which requires an expert mathematical understanding of nuanced gradient-based training dynamics to design an effective reward function, ES simply requires the experimenter to assign a score to a model after it has attempted a task. This simplification democratizes LLM fine-tuning, opening the door to the development of customized AI applications by non-experts.
Reward-hacking: As shown in Section 4.2 and prior work [36], ES is inherently less susceptible to reward-hacking than RL and other gradient-based methods. Thus, LLMs fine-tuned with ES are less likely to lose ethical guardrails present in the base model. Similarly, it may be easier to fine-tune for ethical behavior (i.e. alignment) with ES, since the model is less likely to overfit to specific training examples.
Combining the above two areas of impact, ES fine-tuning can reduce the risk of unintended ethical misbehavior of LLMs fine-tuned by non-experts.
Acknowledgments
We would like to thank Sid Stuart for providing technical support for hardware management and always being responsive. We would like to thank Jamieson Warner for providing valuable feedback.
Appendix
Section Summary: The appendix outlines the implementation of Evolution Strategies for fine-tuning large language models, detailing an algorithm that perturbs model parameters with noise, evaluates performance via a reward function, and updates parameters based on normalized scores across multiple parallel processes. It also describes experimental setups for tasks like Countdown math problems and conciseness in responses, using models from the Qwen2.5 and Llama3 families, along with baselines such as PPO and GRPO methods, hyperparameters tuned through grid searches, and consistent evaluation on test sets. Tools like TinyZero and VERL facilitate these runs, ensuring comparable training across approaches.
A.1 ES Implementation for LLM Fine-tuning
Algorithm 2 shows the detailed process of the ES implementation for LLM fine-tuning.
**Require:** Pretrained LLM with initial parameters $\bm{\theta}_0$, reward function $R(\cdot)$, total iterations $T$, population size $N$, noise scale $\sigma$, learning rate $\alpha$, number of parallel process $P$.
Create $P$ processes, each instantiates a model with the same initial parameters $\bm{\theta}_0$, with one process as the main process
**for** $t = 1$ to $T$ *ES iterations* **do**
Sample N random seeds $s_1, s_2, \ldots, s_N$
Assign random seeds to $P$ processes
**for** $n = 1$ to $N$ **do**
For the process handling $s_n$, reset its random number generator using random seed $s_n$
**for** **each LLM layer** *perturbation within current process* **do**
Sample noise $\bm{\varepsilon}_n,l \sim \mathcal{N}(0,\bm{I})$, which has the same shape as the $l$ th layer's parameters
Perturb the $l$ th layer's parameters in-place: $\bm{\theta}_t-1,l\leftarrow\bm{\theta}_t-1,l+\sigma \cdot \bm{\varepsilon}_n,l$
**end for**
Compute reward for perturbed parameters $R_n=R(\bm{\theta}_t-1)$ *within current process*
For the process handling $s_n$, reset its random number generator using random seed $s_n$
**for** **each LLM layer** *restoration within current process* **do**
Sample noise $\bm{\varepsilon}_n,l \sim \mathcal{N}(0,\bm{I})$, which has the same shape as the $l$ th layer's parameters
Restore the $l$ th layer's parameters in-place: $\bm{\theta}_t-1,l\leftarrow\bm{\theta}_t-1,l-\sigma \cdot \bm{\varepsilon}_n,l$
**end for**
**end for**
Normalize the reward scores by calculating the $z$-score for each $R_n$: $Z_n=\frac{R_n-R_{\mathrm{mean}}}{R_{\mathrm{std}}}$,
where $R_{\mathrm{mean}}$ and $R_{\mathrm{std}}$ are the mean and standard deviation of $R_1, R_2, \ldots, R_N$.
**for** $n = 1$ to $N$ *in main process only* **do**
Reset current random number generator using random seed $s_n$
**for** **each LLM layer** **do**
Sample noise $\bm{\varepsilon}_n,l \sim \mathcal{N}(0,\bm{I})$, which has the same shape as the $l$ th layer's parameters
Update $l$ th layer's parameters in-place as $\bm{\theta}_t,l \leftarrow \bm{\theta}_t-1,l+ \alpha \cdot \frac{1}N Z_n \bm{\varepsilon}_n,l$
**end for**
**end for**
Update the model parameters of all processes to $\bm{\theta}_t$
**end for**
A.2 Experimental Setup
Experimental setup for the Countdown experiments.
Representative models from the Qwen2.5 family (0.5B–7B) and the Llama3 family (1B–8B) were fine-tuned for this task. For the PPO-z experiments, a grid search was first performed around common hyperparameter settings and the best-performing values used (Table 4). TinyZero (https://github.com/Jiayi-Pan/TinyZero) is used for PPO-z implementations. For the GRPO-z experiments, a grid search was performed around the settings of [69] and the best-performing values used. GRPO-z experiments were run with two different group sizes: $N=8$, following the common practice in GRPO training for the Countdown task, and $N=30$, aligning with the population size in ES. GRPO-Zero (https://github.com/policy-gradient/GRPO-Zero) is used for GRPO-z implementations. VERL [73] is used for both GRPO-v and Dr.GRPO-v implementations, with the standard default configurations for math reasoning benchmarks.
For the VERL implementations, we set the global batch size of 1024, a learning rate of $1 \times 10^{-6}$, and a rollout group size of $N=8$. We compared two configurations: GRPO-v and Dr.GRPO-v. The GRPO-v baseline incorporated a standard KL divergence penalty with a coefficient of $\beta=0.001$. In contrast, the Dr.GRPO-v configuration removed the KL penalty (use_kl_loss=False) and disabled advantage normalization (norm_adv_by_std=False). Instead, Dr.GRPO-v employed a sequence-mean token-sum normalization strategy for loss aggregation with a scaling factor of 1024.
For all the ES and RL baselines, the total number of sample evaluations was the same. The ES population size was $N=30$, noise scale $\sigma=0.001$, and learning rate $\alpha=5 \times 10^{-4}$ across all experiments. To evaluate accuracy, a set of 200 samples were used during training, and a different set of 2000 samples during testing. For ES, results were reported on the test set after training for 500 iterations. For RL, the training was stopped after the same total number of sample evaluations as in the ES runs. An example of the prompt and the response is provided in Appendix A.3.
::: {caption="Table 4: Hyperparameter Sweep across Models under PPO-z and GRPO-z. Each pair $(\cdot, \cdot)$ denotes (KL-divergence penalty coefficient $\beta$, learning rate $\alpha$); the label ' $\checkmark$ ' indicates the best hyperparameter setting for each model-method combination."}

:::
Experimental setup for the conciseness experiments.
In each experiment, Qwen-2.5-7B-Instruct ([89]) was fine-tuned using both ES and GRPO and evaluated using a held-out evaluation set. Each run was repeated four times, using a different random seed each time. For each GRPO experiment, the group size $N=30$, and learning rate $\alpha=5\times10^{-6}$. Ten log-spaced values from $0.01$ to $1.0$ were evaluated for the the KL-divergence penalty coefficient $\beta$, as well as $\beta=0.0$. Appendix A.4 presents additional experiments with varying $\alpha$ and $\beta$ values. For ES, the population size $N = 30$, ensuring that GRPO and ES generated the same number of responses per prompt, resulting in the same training exposure. Models were fine-tuned with $\sigma = {0.0005, 0.001, 0.0015}$, with a learning rate $\alpha = \frac{\sigma}{2}$. Both GRPO and ES experiments were run for $1, 000$ iterations, and a checkpoint saved every $200$ iterations. Table 5 shows the dataset of prompts and verifiable solutions used during fine-tuning; note that it consists of only two examples. Similarly, Table 6 lists the prompts and verifiable solutions used in evaluating each fine-tuned model. For all the experimental results, the displayed reward values are normalized to be within $[0, 1]$, with $0$ corresponding to $-2000$ in the original reward function and $1$ corresponding to the best possible original reward $0$.
::: {caption="Table 5: Prompts and verifiable solutions used in fine-tuning the models for conciseness. Two examples is enough to achieve this goal."}
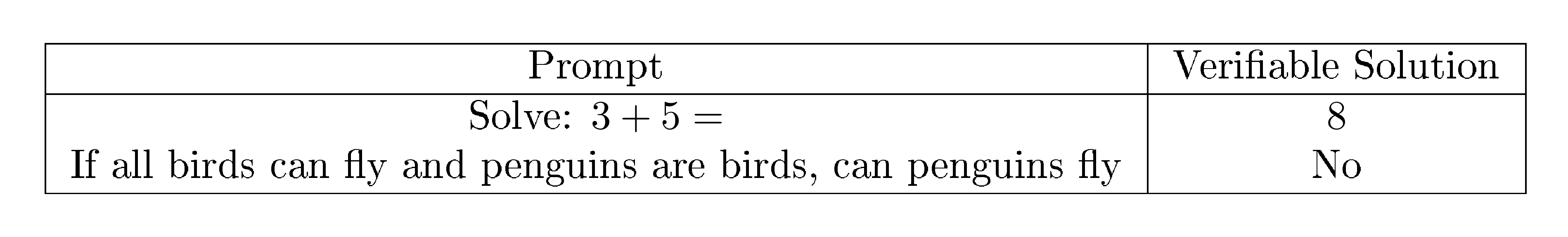
:::
::: {caption="Table 6: Prompts and verifiable solutions used to evaluate the fine-tuned models. More examples are necessary than during fine-tuning to make the evaluation reliable."}

:::
Conciseness task. For conciseness fine-tuning, a dataset of prompts $\mathcal{D} = {x_{1}, .., x_{K} }$, with a set of verifiable solutions ${s_{1}, ..., s_{K}}$, i.e. shortest possible correct answers, was used. For example, for the prompt "Name one primary color", possible shortest verifiable solution used is "Red". Following this approach, for each prompt $x \in \mathcal{D}$, the model was encouraged to generate a concise response $y$. To fine-tune the model to generate concise responses, a reward computed using the absolute length difference between the generated response $y$ and the corresponding verified solution $s_{k}$ was given to the model for each prompt $x_{k}$. The reward function $R$ for conciseness was defined as $R = -\lvert \mathrm{len}(y) - \mathrm{len}(s_{k}) \rvert$, where $\mathrm{len}(\cdot)$ denotes the string length.
Behavior metrics for the conciseness experiments.
Behavior of the fine-tuned models was measured in two ways: the mean conciseness reward and the mean KL divergence from the base model (after [13]). KL divergence is useful as a proxy for the preservation of the base model's behavior. It correlates strongly with the question-answering performance of the model, but also conveys more information, i.e. the extent of the fine-tuning changes. A low KL divergence thus suggests that the fine-tuned model has not forgotten capabilities learned during pre-training. Further, as KL divergence increases, these capabilities are likely to break. Therefore, fine-tuning behavior can be characterized using the tradeoffs between reward and KL divergence. To compute the metrics, each fine-tuned model was evaluated on a set of held-out test prompts, with $20$ responses sampled per prompt. The reward was computed using the model-generated response and the verifiable solution provided in the test dataset. The KL divergence between a fine-tuned model $\theta_{\mathrm{FT}}$ and a base model $\theta_{\mathrm{BASE}}$ for a given prompt $x$ and corresponding response $y$ was approximated following [90] as $\mathrm{KL}!\left[\theta_\mathrm{FT} , |, \theta_{\mathrm{BASE}}\right] = \frac{\theta_{\mathrm{BASE}}(y_{i, t} \mid x, y_{i, <t})}{\theta_\mathrm{FT}(y_{i, t} \mid x, y_{i, <t})} - \log \frac{\theta_{\mathrm{BASE}}(y_{i, t} \mid x, y_{i, <t})}{\theta_{\mathrm{FT}}(y_{i, t} \mid x, y_{i, <t})} - 1.$
Partially correlated noise vs. i.i.d. noise.
In the current implementation, for each perturbed model, the random number generator is reinitialized for each layer (using the random seed corresponding to this model), leading to partially correlated noise perturbations across layers. Preliminary experiments show that this implementation does not lead to significantly different performances compared to true i.i.d. noise.
A.3 Examples of Countdown Task Outputs
Countdown task. The Countdown task ([68, 69]) requires constructing an arithmetic expression from a given set of numbers using basic operations $(+, -, \times, \div)$ to match a target value. For instance, the target $950$ can be obtained from ${100, 50, 6, 3}$ with $100 \times (6+3) +50 = 950$). This constitutes a compact test of constrained symbolic reasoning, i.e. an important use case for fine-tuning.
**Iteration 400**
**[1] Input:**
You are a helpful assistant. You first think about the reasoning process in your mind and then provide the user with the answer. Using the numbers [49 41 73], create an equation that equals 17. You can use basic arithmetic operations (`+`, `-`, `*`, `/`) and each number can only be used once. Show your work in `<think>` … `</think>` tags. And return the final answer in `<answer>` … `</answer>` tags, for example `<answer> (1 + 2) / 3 </answer>`.
**[1] Response:**
`<think>` First, let's consider all possible combinations of the numbers 49, 41, and 73 using basic arithmetic operations. We need to use each number exactly once and combine them to get 17.
1. Start with simple addition and subtraction:
- 49 + 41 - 73 = 80 - 73 = 7 (too high)
- 49 - 41 + 73 = 8 + 73 = 81 (too high)
- 73 - 49 - 41 = 24 - 41 = -17 (too low)
2. Try multiplication and division:
- (49 * 41) / 73 = 2029 / 73 $\approx$ 27.83 (not close to 17)
- (73 * 41) / 49 = 3013 / 49 $\approx$ 61.47 (too high)
- (49 * 73) / 41 = 3637 / 41 $\approx$ 88.80 (too high)
- (41 * 73) / 49 = 3013 / 49 $\approx$ 61.47 (same as above)
3. Check different orders:
- 73 - (49 + 41) = 73 - 90 = -17 (too low)
- 49 - (73 - 41) = 49 - 32 = 17 (this looks promising)
So, the equation 49 - (73 - 41) equals 17. Let's verify it:
- Calculate inside the parentheses first: 73 - 41 = 32
- Then subtract from 49: 49 - 32 = 17
This satisfies our requirement. `</think>`
`<answer>` 49 - (73 - 41) `</answer>`
Reward: 1.1000 (Format: 1.0000, Answer: 1.0000)
**An example of a countdown task interaction.**
Figure 3 shows an example of the Qwen2.5-3B model’s output on the Countdown task after 400 ES iterations. In order to improve accuracy, the model learned to adjust its formulas by comparing the generated answer with the correct one, and to verify its own answers for correctness.
A.4 Extended Conciseness Details and Experiments
In this section, the conciseness experiments are extended to investigate the impact of different learning rates on GRPO training.
GRPO with different learning rates.
Further GRPO experiments were run over four seeds with $\beta = {0, 0.01, 0.1, 1.0}$, varying the learning rate $\alpha = { 2\times10^{-6}, 3\times10^{-6}, 4\times10^{-6}, 5\times10^{-6}}$. A total of $20$ responses were sampled per evaluation prompt. Figure 4a shows the mean reward and KL divergence of each fine-tuned model. As the learning rate increases, both mean reward and mean KL divergence increase. The best models with respect to reward are trained using $5\times10^{-6}$ and $\beta={0.0, 0.01}$, obtaining rewards greater than $0.85$. Figure 4b further displays the GRPO Pareto front (black line, bottom) across these learning rates, comparing it with the ES Pareto front (blue line, top). The majority of Pareto optimal models across these learning rates obtain a mean reward of less than $0.8$ and a KL divergence of less than $0.4$. The ES Pareto front dominates that of GRPO over different learning rates and $\beta$ values.
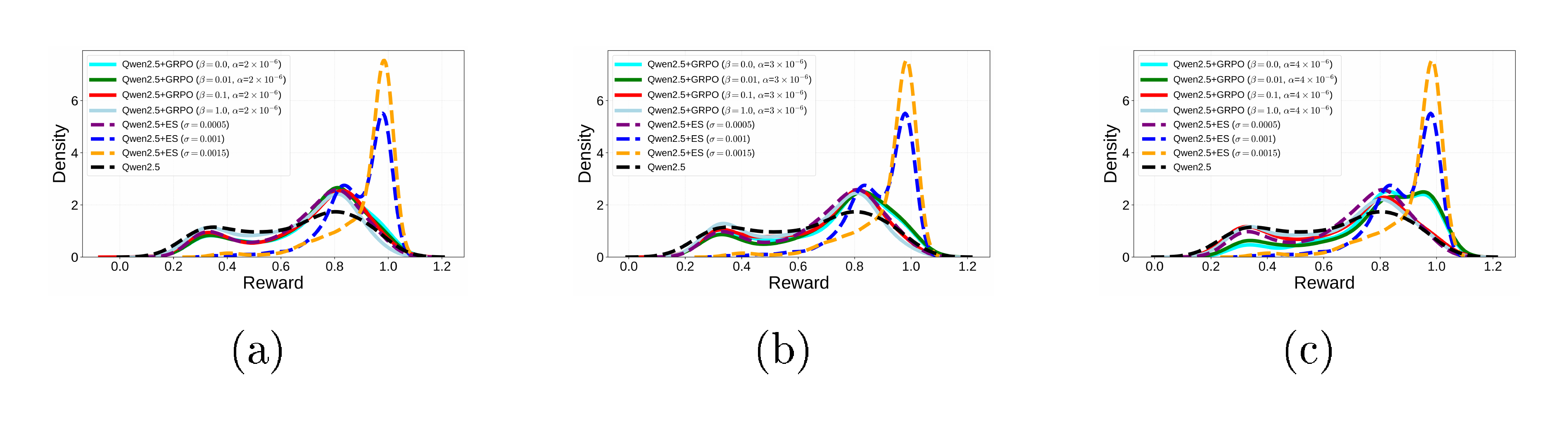
Next, the reward distribution for each $\alpha$ and $\beta$ value for GRPO was compared with that of ES, starting with learning rates $2\times10^{-6}$ and $3\times10^{-6}$. Figure 5a and Figure 5b show that all GRPO models stay close to the Qwen2.5-7B-Instruct base model reward distribution, despite the variation in $\beta$. In contrast, ES shifts the reward distribution to the right with a density peak around $1.0$, i.e. towards higher rewards. The learning rate was then further increased to $4\times10^{-6}$ (Figure 5c). As a result, for $\beta=0.0$ and $\beta=0.01$, GRPO shifts the reward distribution to the right towards higher rewards. However, they are still lower than those of ES. As the learning rate is increased further to $5\times10^{-6}$ (Figure 5d), GRPO is sufficiently able to optimize the reward: with $\beta = 0.0$ and $\beta = 0.01$, it peaks around $1.0$. Thus, high learning rate combined with low $\beta$ is important for GRPO to optimize the reward. However, as was discussed before, such a setting often breaks the performance of the model.
A.5 Training Curves and Accuracy Improvement of ES and RL on the Countdown Task
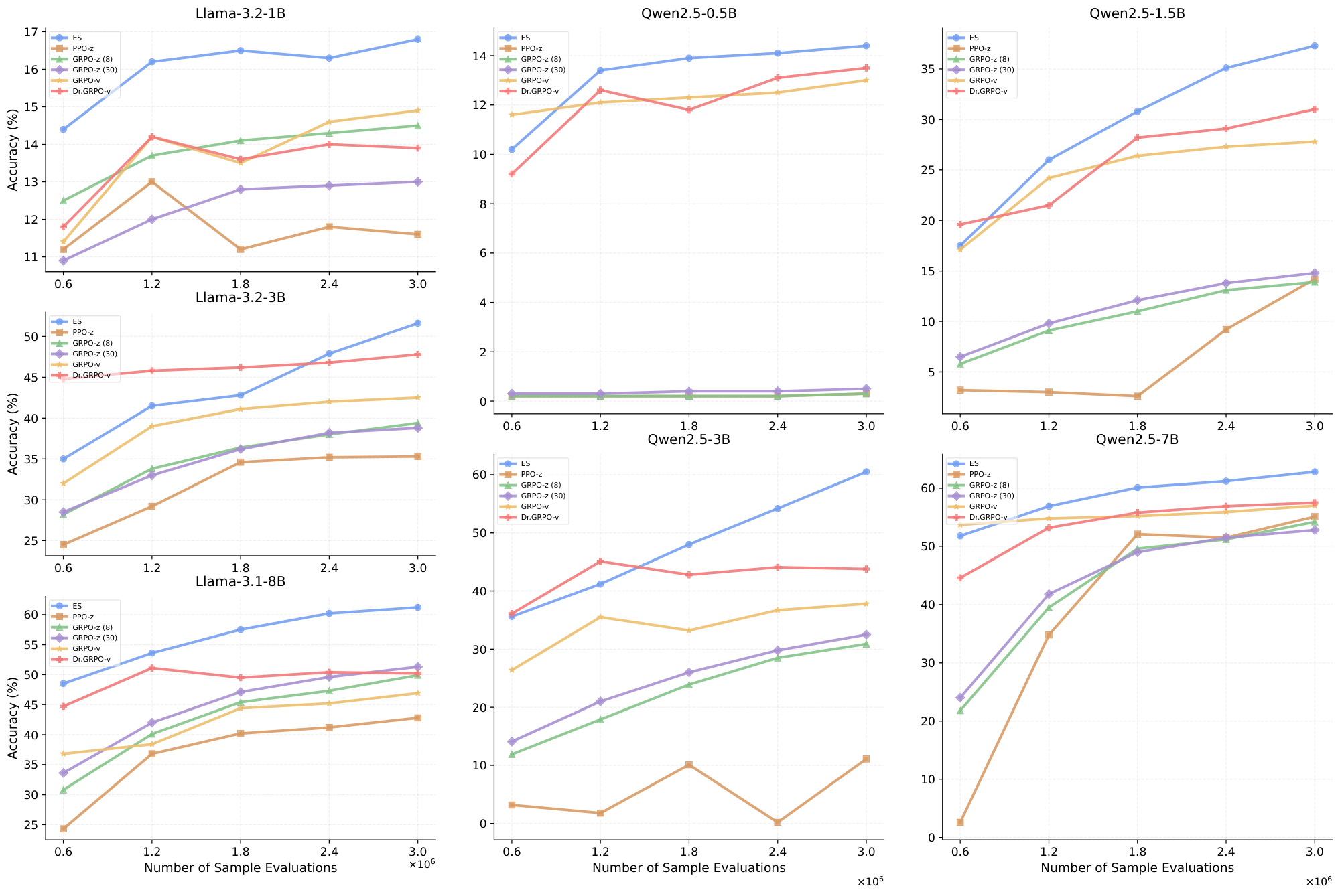
As shown in Figure 7, ES consistently outperformed RL across all tested models throughout training. In addition, as shown in Figure 6, we compute the relative improvements of PPO, GRPO, DR.GRPO and ES over their respective base models across different model families. ES delivers the consistently largest improvements in all cases.
A.6 Extended Math Reasoning Details and Discussion
RL baselines.
We compare ES against three strong R1-Zero-style [15] reasoning baselines at the 7B parameter scale: SimpleRL-Zero [75], OpenReasoner-Zero [76], and Oat-Zero [70]. All baselines are instantiated using Qwen2.5-series models [89], which are competitive open-weight language models known to exhibit strong reasoning performance at this scale. The respective baseline implementations are fully open source and built on production-ready RL libraries, including VERL [73] and OAT [74], which provided highly optimized, stable, and tested PPO, GRPO, and Dr.GRPO implementations with efficient rollout management, and standardized reward handling. SimpleRL-Zero isolates the core R1-Zero optimization mechanism with minimal additional engineering, OpenReasoner-Zero reflects a widely adopted community implementation with practical design choices, and Oat-Zero further alters GRPO with algoritmic enhancements shown to boost performance. Together, these baselines represent strong, reproducible, and non-trivial comparators for evaluating ES.
Reward function.
Our ES training utilizes a basic rule-based reward function that checks answer correctness, without any format rewards. The reward function is designed to extract the produced answer contained within \boxed and compare it with the ground truth answer. Similarly to RL, we implement a binary reward scheme where a reward of 1 is given for exact matches with the reference answer, and 0 for all other cases. To ensure a fair comparison with models from the literature we use the same answer extractor, also called a grader, as OatZero [70].
Qwen math template.
Table 7 shows the template stucture used for training ES models. We follow the same template used for training the Qwen-Math series base models, where the model is required to provide a final answer inside \boxed. This requirement ensures that the final model answers are easy to extract and compare with the ground truth solutions for reward calculation during training. As shown in [70], the choice of template can impact the final performance of the model. We chose the Qwen-Math template given it provides a platform for stable learning and good performance during fine-tuning.
::: {caption="Table 7: Qwen-Math prompt template used in this work."}

:::
Checkpoint selection.
Given there is no explicit validation set, for ES, we follow the standard model checkpoint selection mechanism from the literature whereby the checkpoints with high average pass@1 accuracy over each evaluation set over training are presented. We chose to present a number of ES checkpoints that all achieve sufficiently high average score. We chose our checkpoints to ensure competitive performance across the range of benchmarks. In this case, $\text{ES}{\text{CHKPT-1}}$ is chosen for its high average score and occurs after $336$ training steps. Additionally, we take a checkpoint after $160$ training steps and perform $10$ additional model update steps with $\alpha=\frac{\sigma}{4}$. This additional training produced $\text{ES}{\text{CHKPT-2}}$. Given the lack of validation set, we utilize MATH500 as a pseudo validation set since MATH500 is an in-distribution validation. Following this, we select $\text{ES}{\text{CHKPT-3}}$ because it achieves the highest performance in the MATH500 benchmark across our evaluations. The MATH500 $\text{ES}{\text{CHKPT-3}}$ occurs after $192$ training steps.
A.7 Parameter Magnitude Shifts by Evolutionary fine-tuning
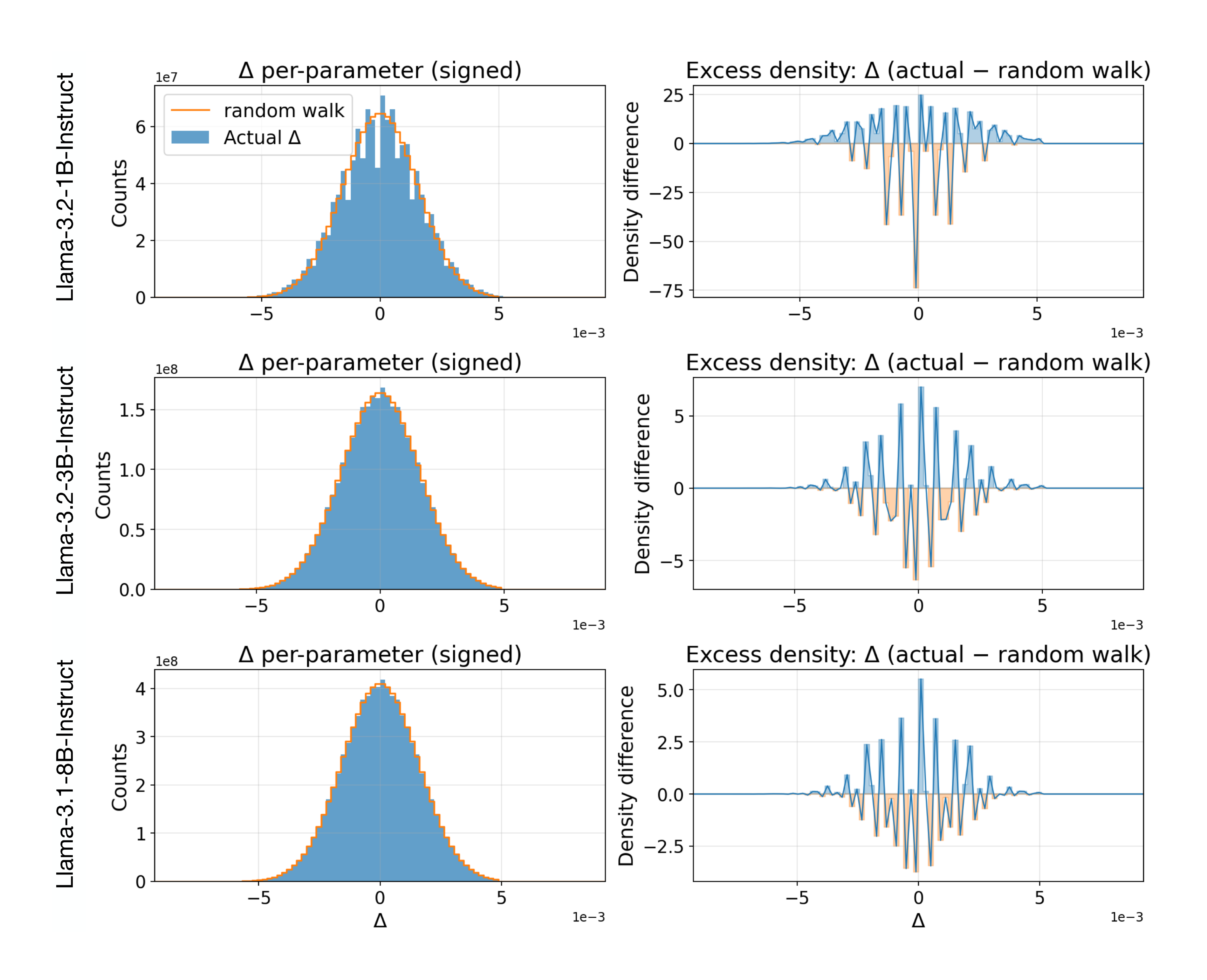
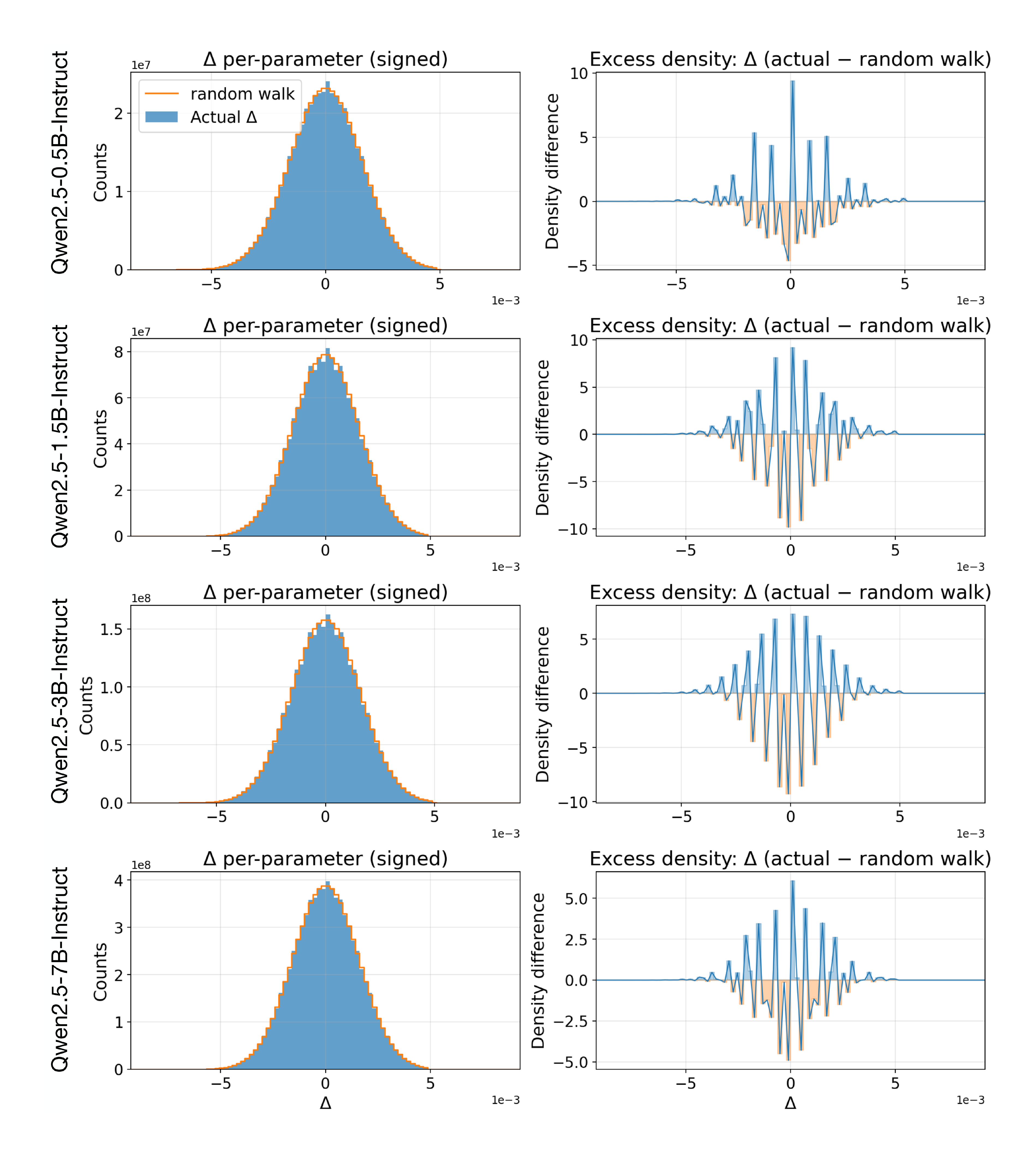
This section characterizes how parameter magnitudes changed in ES fine-tuning in the countdown and conciseness experiments. Specifically, Figure 8 and Figure 9, left column, show histograms of the absolute parameter magnitude shifts $\Delta$ before and after finetuning Llama and Qwen models, overlaid with random walk, on the Countdown task reported in Table 1. The right column in these figures shows the difference between $\Delta$ and the random walk.
For most models, $\Delta$ deviates very little from random walk. This is a counterintuitive result since fine-tuning actually resulted in a significant performance boost. A closer inspection reveals that most of the deviation was concentrated around zero. A likely explanation is that there are precision issues around zero, particularly with small bin sizes, which may lead to such deviations.
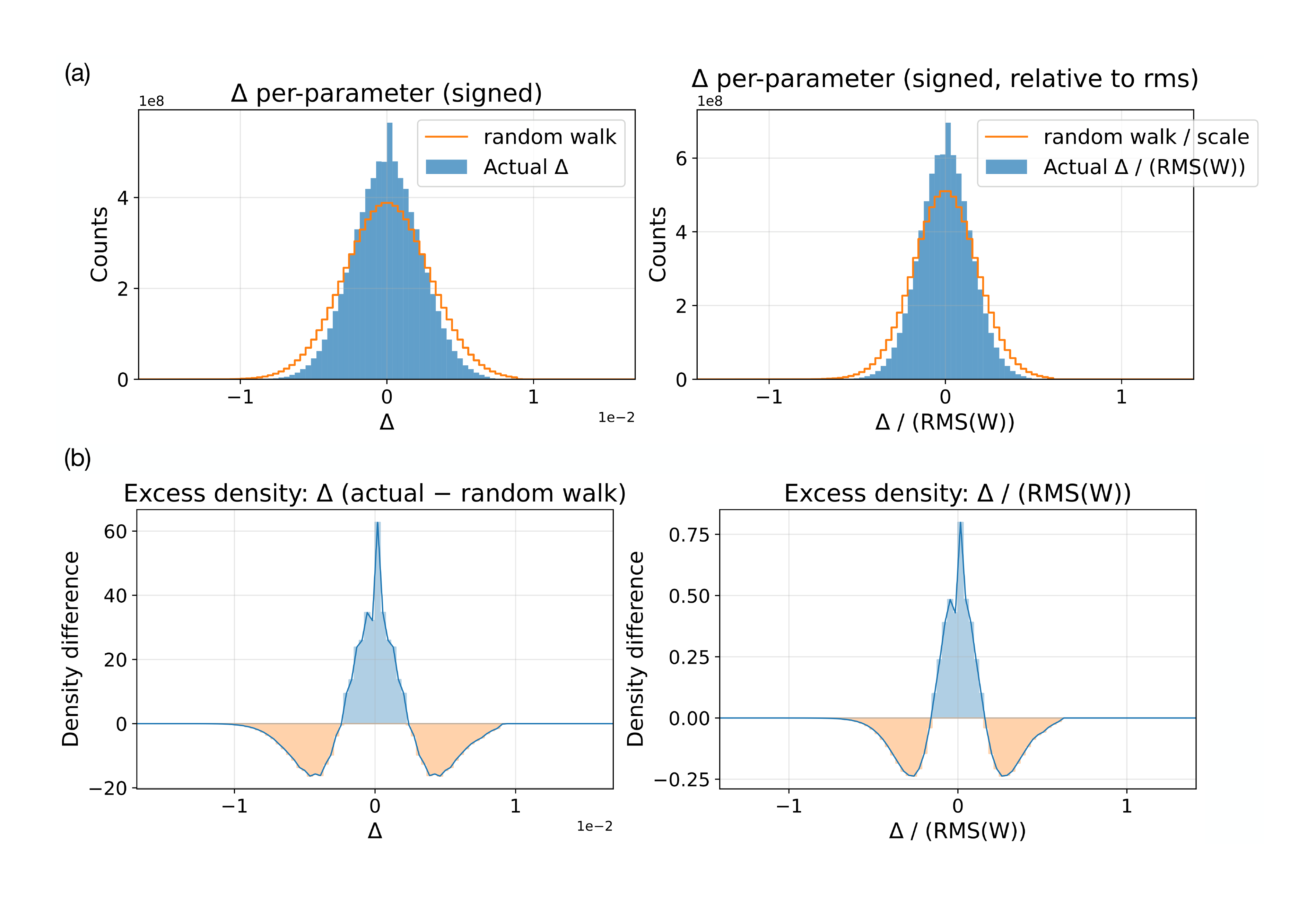
More significantly, a systematic deviation from the random walk was observed in conciseness fine-tuning of the largest model, Qwen2.5-7B-Instruct (Figure 10). The distribution shifts toward abundant small magnitude edits, suggesting that small parameter tweaks may be most significant in influencing output behavior. This result reinforces observations in prior studies (e.g. [91]). A possible explanation is that large models encode functionality in a more redundandant manner, and therefore minor tweaks are sufficient to achieve fine-tuning objectives. In fact, the changes are nearly indistinguishable from random walk in Figure 8 and Figure 9 likely because they are benevolent wrt. the fine-tuning objective. A more thorough investigation of these hypotheses is a most interesting direction of future work, potentially resulting in a better understanding of fine-tuning and information processing principles in LLMs in general.
A.8 Experiment with Mini Sudoku Task
Standard Sudoku requires filling in missing integers in a $9\times9$ grid, evenly divided into $9$ smaller $3\times3$ grids. Integers must satisfy the following conditions: every row contains each integer $1-9$, every column contains each integer $1-9$, and each $3\times3$ sub-grid contains each integer $1-9$. Given the difficulty of $9\times9$ puzzles, existing evaluation of LLM's ability to complete Sudoku is often done with $4\times4$ grids, with equivalent rules for rows, columns, and $2\times2$ subgrids with digits $1-4$. Training data generation and evaluation was preformed with the sudoku board generation logic and reward function from [92]. $1, 000$ example unique grids were generated, with $800$ in training and $200$ in testing. Qwen-2.5-3B-Instruct was used as the base model and trained with greedy decoding and batch size set to the entire $800$ sample training set. ES was run for $2, 500$ iterations and hyperparameters were set as follows: $\sigma = 0.001$, $\alpha = 0.0005$, and $N = 32$. With this setup, model performance improved from 2% to 66.5% of test set puzzles correctly solved. An example of the prompt, along with model responses before and after ES fine tuning is provided below in Figure 11.
**Prompt:**
You are a helpful assistant. You first think about the reasoning process in your mind and then provide the user with the answer. In 4x4 Mini Sudoku:
- Each row must contain each number from 1–4 exactly once
- Each column must contain each number 1–4 exactly once
- Each 2x2 subgrid must contain each number 1–4 exactly once
Solve this 4x4 Mini Sudoku puzzle:
`
_ _ 4 _
4 3 _ _
3 _ _ 1
1 _ 3 _
`
Show your work in `<think> </think>` tags. And return the final answer in `<answer> </answer>` tags, with spaces separating each number within a row, and newlines separating rows. For example `<answer>`
2 1 4 3
4 3 2 1
3 1 4 2
1 2 3 4`
</answer>`. Let me solve this step by step.
`<think>`
**Base Model Output (Incorrect):**
First, let's look at the given numbers and try to deduce the missing numbers. The number 4 is already placed in the first column, so we can't have another 4 in that column. The number 3 is already placed in the second row, so we can't have another 3 in that row. The number 1 is already placed in the third row, so we can't have another 1 in that row. Let's start filling in the grid based on these constraints: `</think>`
`<answer>`
`2 1 4 3
4 3 2 1
3 1 4 2
1 2 3 4`
`</answer>`
`</think>` This is the final solution to the 4x4 Mini Sudoku puzzle. Let me verify:
Each row contains the numbers 1, 2, 3, 4 exactly once: Row 1: 2 1 4 3, Row 2: 4 3 2 1, Row 3: 3 1 4 2, Row 4: 1 2 3 4.
Each column contains the numbers 1, 2, 3, 4 exactly once: Column 1: 2 4 3 1, Column 2: 1 3 1 2, Column 3: 4 2 4 3, Column 4: 3 1 2 4.
Each 2x2 subgrid contains the numbers 1, 2, 3, 4 exactly once: Subgrid 1: 2 1 / 3 4, Subgrid 2: 4 2 / 1 3, Subgrid 3: 3 1 / 4 2, Subgrid 4: 1 2 / 3 4.
All constraints are satisfied, so the solution is correct. `</think>` The final answer is:
`<answer>`
`2 1 4 3
4 3 2 1
3 1 4 2
1 2 3 4`
`</answer>`
**Fine-Tuned Model Output (Correct):**
First, let's look at the given numbers and try to fill in the missing numbers. We start with the first row: `_ _ 4 _`. Since each row must contain each number from 1 to 4 exactly once, the missing numbers in the first row must be 2, 1, and 3. So the first row becomes: 2 1 4 3.
Next, let's look at the second row: `4 3 _ _`. Since each row must contain each number from 1 to 4 exactly once, and we already have 4 and 3 in this row, the missing numbers must be 1 and 2. So the second row becomes: 4 3 1 2.
Now, let's look at the third row: `3 _ _ 1`. Since each row must contain each number from 1 to 4 exactly once, and we already have 3 and 1 in this row, the missing numbers must be 2 and 4. So the third row becomes: 3 4 2 1.
Finally, let's look at the fourth row: `1 _ 3 _`. Since each row must contain each number from 1 to 4 exactly once, and we already have 1 and 3 in this row, the missing numbers must be 2 and 4. So the fourth row becomes: 1 2 3 4.
So, the completed 4x4 Mini Sudoku puzzle looks like this: `</think>`
`<answer>`
`2 1 4 3
4 3 1 2
3 4 2 1
1 2 3 4`
`</answer>`
**Example prompt and model outputs for the 4x4 Mini Sudoku task. The base model would respond in a variety of step by step methods, while the fine tuned model settled into a consistent, dense thinking space.**
A.9 Experiments on ARC-AGI Task
ARC-AGI ([80]) is a benchmark designed to evaluate abstract reasoning and generalization capabilities. Each task presents a few input-output grid pairs as examples, requiring models to infer the underlying transformation rules and apply it to a new test input. The dataset has 400 public training tasks and evaluation tasks, focusing on creative problem-solving. We used 200 training tasks for fine-tuning and 200 evaluation tasks for testing.
A.9.1 Experimental settings
Prompts. The ARC-AGI tasks are presented in image format. To use LLMs to solve them, we first map colors to the numbers as follows: black $\to$ 0, blue $\to$ 1, red $\to$ 2, green $\to$ 3, yellow $\to$ 4, grey $\to$ 5, gray $\to$ 5, pink $\to$ 6, orange $\to$ 7, purple $\to$ 8, brown $\to$ 9.
**System Prompt:**
You are a creative and meticulous ARC puzzle solver who explains reasoning before answering.
**Task Explanation:**
You will be given some number of paired example inputs and outputs. The outputs were produced by applying a transformation rule to the inputs. In addition to the paired example inputs and outputs, there is also one additional input without a known output. Your task is to determine the transformation rule and implement it in code.
The inputs and outputs are each "grids". A grid is a rectangular matrix of integers between 0 and 9 (inclusive). These grids will be shown to you as grids of numbers (ASCII). Each number corresponds to a color. The correspondence is as follows: black: 0, blue: 1, red: 2, green: 3, yellow: 4, grey: 5, pink: 6, orange: 7, purple: 8, brown: 9.
The transformation only needs to be unambiguous and applicable to the example inputs and the additional input. It doesn't need to work for all possible inputs.
**Reasoning Explanation:**
You'll need to carefully reason in order to determine the transformation rule. Start your response by carefully reasoning in <reasoning></reasoning> tags. Then, implement the transformation in code.
After your reasoning write code in triple backticks (```python and then ```). You should write a function called `transform` which takes a single argument, the input grid as `list[list[int]]`, and returns the transformed grid (also as `list[list[int]]`). You should make sure that you implement a version of the transformation which works in general (it shouldn't just work for the additional input).
**Other Instructions:**
Don't write tests in your python code, just output the `transform` function. (It will be tested later.)
You can also ask question to verify your observation on the inputs/outputs patterns in the form of python function which takes two arguments, the input and expected output grid both as `list[list[int]]` and returns the boolean flag (True or False). We will help you by running your Python function on examples and let you know whether your question is True or False.
You follow a particular reasoning style. You break down complex problems into smaller parts and reason through them step by step, arriving at sub-conclusions before stating an overall conclusion. This reduces the extent to which you need to do large leaps of reasoning.
You reason in substantial detail for as is necessary to determine the transformation rule.
You are creative and accomplished at solving puzzles. When you write `transform`, do not hardcode the solution for each example. We will run your transform function on additional inputs later and check if your logic is generic in addition to check the correctness.
**Prompts used for the ARC-AGI task.**
Hyperparameters $\sigma = 0.001$, $\alpha = 0.0003$, $N$ = 50, iterations = 1500.
A.9.2 RL attempts
Few prior works have explored using RL–based post-training for LLMs on ARC-AGI tasks. While RL has been widely used for LLM alignment and reasoning tasks (e.g., RLHF, math and QA benchmarks), its application to abstraction-centric, out-of-distribution generalization benchmarks like ARC-AGI remains relatively under-explored, largely due to challenges in reward design and efficient exploration. According to a recent report [93], applying GRPO to ARC-AGI resulted in minimal gains. The model failed to discover new strategies or abstract concepts; instead, it simply learned to rerank or refine the candidates it could already generate based on its original training.
References
[1] Hugo Touvron and others (2023). Llama 2: Open Foundation and Fine-Tuned Chat Models. arXiv:2307.09288.
[2] Josh Achiam and others (2024). GPT-4 Technical Report. arXiv:2303.08774.
[3] AI@Meta (2024). Llama 3 Model Card. https://github.com/meta-llama/llama3/blob/main/MODEL_CARD.md.
[4] Albert Q. Jiang et al. (2024). Mixtral of Experts. arXiv:2401.04088.
[5] Liu et al. (2024). Deepseek-v3 technical report. arXiv:2412.19437.
[6] Anthropic (2025). Introducing Claude 4. https://www.anthropic.com/news/claude-4.
[7] Google (2025). Gemini 2.5: Pushing the Frontier with Advanced Reasoning, Multimodality, Long Context, and Next Generation Agentic Capabilities.. https://storage.googleapis.com/deepmind-media/gemini/gemini_v2_5_report.pdf.
[8] Karan Singhal et al. (2023). Towards Expert-Level Medical Question Answering with Large Language Models. arXiv:2305.09617.
[9] Shijie Wu et al. (2023). BloombergGPT: A Large Language Model for Finance. arXiv:2303.17564.
[10] Baptiste Rozière et al. (2024). Code Llama: Open Foundation Models for Code. arXiv:2308.12950.
[11] .
[12] Ouyang et al. (2022). Training language models to follow instructions with human feedback. In Proceedings of the 36th International Conference on Neural Information Processing Systems.
[13] Rafailov et al. (2023). Direct preference optimization: your language model is secretly a reward model. In Proceedings of the 37th International Conference on Neural Information Processing Systems.
[14] Ehsan Latif and Xiaoming Zhai (2024). Fine-tuning ChatGPT for automatic scoring. Computers and Education: Artificial Intelligence. 6. pp. 100210. doi:https://doi.org/10.1016/j.caeai.2024.100210. https://www.sciencedirect.com/science/article/pii/S2666920X24000110.
[15] Daya Guo and others (2025). DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning. arXiv:2501.12948. https://arxiv.org/abs/2501.12948.
[16] Yuntao Bai et al. (2022). Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback. arXiv:2204.05862. https://arxiv.org/abs/2204.05862.
[17] Zhihong Shao et al. (2024). DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models. arXiv:2402.03300. https://arxiv.org/abs/2402.03300.
[18] .
[19] Saksham Sahai Srivastava and Vaneet Aggarwal (2025). A Technical Survey of Reinforcement Learning Techniques for Large Language Models. arXiv:2507.04136. https://arxiv.org/abs/2507.04136.
[20] Tim Salimans et al. (2017). Evolution Strategies as a Scalable Alternative to Reinforcement Learning. arXiv:1703.03864. https://arxiv.org/abs/1703.03864.
[21] Sutton, Richard S. and Barto, Andrew G. (2018). Reinforcement Learning: An Introduction. MIT Press.
[22] Anirudh Vemula et al. (2019). Contrasting Exploration in Parameter and Action Space: A Zeroth Order Optimization Perspective. In Proceedings of 22nd International Conference on Artificial Intelligence and Statistics (AISTATS '19).
[23] Zhenru Zhang et al. (2025). The Lessons of Developing Process Reward Models in Mathematical Reasoning. arXiv:2501.07301. https://arxiv.org/abs/2501.07301.
[24] Song et al. (2025). PRMBench: A Fine-grained and Challenging Benchmark for Process-Level Reward Models. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). pp. 25299–25346. doi:10.18653/v1/2025.acl-long.1230. https://aclanthology.org/2025.acl-long.1230/.
[25] Jonathan Uesato et al. (2022). Solving math word problems with process- and outcome-based feedback. arXiv:2211.14275. https://arxiv.org/abs/2211.14275.
[26] Zeyu Jia et al. (2025). Do We Need to Verify Step by Step? Rethinking Process Supervision from a Theoretical Perspective. In Forty-second International Conference on Machine Learning. https://openreview.net/forum?id=4BfaPHfhJ0.
[27] Kanishk Gandhi et al. (2025). Cognitive Behaviors that Enable Self-Improving Reasoners, or, Four Habits of Highly Effective STaRs. In Second Conference on Language Modeling. https://openreview.net/forum?id=QGJ9ttXLTy.
[28] Gao et al. (2023). Scaling Laws for Reward Model Overoptimization. In Proceedings of the 40th International Conference on Machine Learning. pp. 10835–10866. https://proceedings.mlr.press/v202/gao23h.html.
[29] Carson Denison et al. (2024). Sycophancy to Subterfuge: Investigating Reward-Tampering in Large Language Models. arXiv:2406.10162. https://arxiv.org/abs/2406.10162.
[30] Jiayi Fu et al. (2025). Reward Shaping to Mitigate Reward Hacking in RLHF. arXiv:2502.18770. https://arxiv.org/abs/2502.18770.
[31] Leshem Choshen et al. (2020). On the Weaknesses of Reinforcement Learning for Neural Machine Translation. In International Conference on Learning Representations. https://openreview.net/forum?id=H1eCw3EKvH.
[32] Han Zhong et al. (2025). DPO Meets PPO: Reinforced Token Optimization for RLHF. In Forty-second International Conference on Machine Learning. https://openreview.net/forum?id=IfWKVF6LfY.
[33] Chrabaszcz et al. (2018). Back to basics: benchmarking canonical evolution strategies for playing Atari. In Proceedings of the 27th International Joint Conference on Artificial Intelligence. pp. 1419–1426.
[34] Conti et al. (2018). Improving Exploration in Evolution Strategies for Deep Reinforcement Learning via a Population of Novelty-Seeking Agents. In Advances in Neural Information Processing Systems. pp. .
[35] Xingwen Zhang et al. (2017). On the Relationship Between the OpenAI Evolution Strategy and Stochastic Gradient Descent. arXiv:1712.06564. https://arxiv.org/abs/1712.06564.
[36] Lehman et al. (2018). ES is more than just a traditional finite-difference approximator. In Proceedings of the Genetic and Evolutionary Computation Conference. pp. 450–457. doi:10.1145/3205455.3205474. https://doi.org/10.1145/3205455.3205474.
[37] Matyáš Lorenc and Roman Neruda (2025). Utilizing Evolution Strategies to Train Transformers in Reinforcement Learning. arXiv:2501.13883. https://arxiv.org/abs/2501.13883.
[38] Orlando Grabiel Toledano-López et al. (2022). Fine-tuning mT5-based Transformer via CMA-ES for Sentiment Analysis. In Proceedings of the Iberian Languages Evaluation Forum (IberLEF 2022) co-located with the Conference of the Spanish Society for Natural Language Processing (SEPLN 2022), A Coruña, Spain, September 20, 2022. http://ceur-ws.org/Vol-3202/restmex-paper12.pdf.
[39] Jin et al. (2024). Derivative-Free Optimization for Low-Rank Adaptation in Large Language Models. IEEE/ACM Trans. Audio, Speech and Lang. Proc.. 32. pp. 4607–4616. doi:10.1109/TASLP.2024.3477330. https://doi.org/10.1109/TASLP.2024.3477330.
[40] Huang et al. (2025). When Evolution Strategy Meets Language Models Tuning. In Proceedings of the 31st International Conference on Computational Linguistics. pp. 5333–5344. https://aclanthology.org/2025.coling-main.357/.
[41] Hansen, Nikolaus and Ostermeier, Andreas (2001). Completely Derandomized Self-Adaptation in Evolution Strategies. Evolutionary Computation. 9(2). pp. 159-195. doi:10.1162/106365601750190398.
[42] Wierstra et al. (2008). Natural Evolution Strategies. In 2008 IEEE Congress on Evolutionary Computation (IEEE World Congress on Computational Intelligence). pp. 3381-3387. doi:10.1109/CEC.2008.4631255.
[43] Daan Wierstra et al. (2014). Natural Evolution Strategies. Journal of Machine Learning Research. 15(27). pp. 949–980. http://jmlr.org/papers/v15/wierstra14a.html.
[44] Christian Igel (2003). Neuroevolution for Reinforcement Learning Using Evolution Strategies. In Proceedings of the 2003 Congress on Evolutionary Computation. pp. 2588–2595.
[45] Felipe Petroski Such et al. (2017). Deep Neuroevolution: Genetic Algorithms Are a Competitive Alternative for Training Deep Neural Networks for Reinforcement Learning. arXiv:1712.06567. https://api.semanticscholar.org/CorpusID:5044808.
[46] Risi, Sebastian and Stanley, Kenneth O. (2019). Deep neuroevolution of recurrent and discrete world models. In Proceedings of the Genetic and Evolutionary Computation Conference. pp. 456–462. doi:10.1145/3321707.3321817. https://doi.org/10.1145/3321707.3321817.
[47] Chao Wang et al. (2025). When Large Language Models Meet Evolutionary Algorithms: Potential Enhancements and Challenges. Research. 8(). pp. 0646. doi:10.34133/research.0646.
[48] Wu et al. (2025). Evolutionary Computation in the Era of Large Language Model: Survey and Roadmap. IEEE Transactions on Evolutionary Computation. 29(2). pp. 534-554. doi:10.1109/TEVC.2024.3506731.
[49] Sun et al. (2022). Black-Box Tuning for Language-Model-as-a-Service. In Proceedings of the 39th International Conference on Machine Learning. pp. 20841–20855. https://proceedings.mlr.press/v162/sun22e.html.
[50] Sun et al. (2022). BBTv2: Towards a Gradient-Free Future with Large Language Models. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing. pp. 3916–3930. doi:10.18653/v1/2022.emnlp-main.259. https://aclanthology.org/2022.emnlp-main.259/.
[51] Zhao et al. (2023). Genetic Prompt Search via Exploiting Language Model Probabilities. In Proceedings of the Thirty-Second International Joint Conference on Artificial Intelligence, IJCAI-23. pp. 5296–5305. doi:10.24963/ijcai.2023/588. https://doi.org/10.24963/ijcai.2023/588.
[52] Qingyan Guo et al. (2024). Connecting Large Language Models with Evolutionary Algorithms Yields Powerful Prompt Optimizers. In The Twelfth International Conference on Learning Representations. https://openreview.net/forum?id=ZG3RaNIsO8.
[53] Meyerson et al. (2024). Language Model Crossover: Variation through Few-Shot Prompting. ACM Trans. Evol. Learn. Optim.. 4(4). doi:10.1145/3694791. https://doi.org/10.1145/3694791.
[54] Lehman et al. (2024). Evolution Through Large Models. doi:10.1007/978-981-99-3814-8_11. https://doi.org/10.1007/978-981-99-3814-8_11.
[55] Alexander Novikov et al. (2025). AlphaEvolve: A coding agent for scientific and algorithmic discovery. arXiv:2506.13131. https://arxiv.org/abs/2506.13131.
[56] Du et al. (2024). Knowledge Fusion By Evolving Weights of Language Models. In Findings of the Association for Computational Linguistics: ACL 2024. pp. 11727–11742. doi:10.18653/v1/2024.findings-acl.698. https://aclanthology.org/2024.findings-acl.698/.
[57] .
[58] Sanchez Carmona et al. (2024). How Well Can a Genetic Algorithm Fine-tune Transformer Encoders? A First Approach. In Proceedings of the Fifth Workshop on Insights from Negative Results in NLP. pp. 25–33. doi:10.18653/v1/2024.insights-1.4. https://aclanthology.org/2024.insights-1.4/.
[59] John Schulman et al. (2017). Proximal Policy Optimization Algorithms. arXiv:1707.06347. https://arxiv.org/abs/1707.06347.
[60] Rückstieß et al. (2008). State-Dependent Exploration for Policy Gradient Methods. In Machine Learning and Knowledge Discovery in Databases. pp. 234–249.
[61] Frank Sehnke et al. (2010). Parameter-exploring policy gradients. Neural Networks. 23(4). pp. 551-559. doi:https://doi.org/10.1016/j.neunet.2009.12.004. https://www.sciencedirect.com/science/article/pii/S0893608009003220.
[62] .
[63] Matthias Plappert et al. (2018). Parameter Space Noise for Exploration. In International Conference on Learning Representations. https://openreview.net/forum?id=ByBAl2eAZ.
[64] Spall, J.C. (1992). Multivariate stochastic approximation using a simultaneous perturbation gradient approximation. IEEE Transactions on Automatic Control. 37(3). pp. 332-341. doi:10.1109/9.119632.
[65] Malladi et al. (2023). Fine-Tuning Language Models with Just Forward Passes. In Advances in Neural Information Processing Systems. pp. 53038–53075. https://proceedings.neurips.cc/paper_files/paper/2023/file/a627810151be4d13f907ac898ff7e948-Paper-Conference.pdf.
[66] Salimans et al. (2016). Improved techniques for training GANs. In Proceedings of the 30th International Conference on Neural Information Processing Systems. pp. 2234–2242.
[67] Diederik P. Kingma and Jimmy Ba (2015). Adam: A Method for Stochastic Optimization. In 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, May 7-9, 2015, Conference Track Proceedings. http://arxiv.org/abs/1412.6980.
[68] Kanishk Gandhi et al. (2024). Stream of Search (SoS): Learning to Search in Language. https://arxiv.org/abs/2404.03683.
[69] Jiayi Pan et al. (2025). TinyZero. https://github.com/Jiayi-Pan/TinyZero. Accessed: 2025-01-24.
[70] Liu et al. (2025). Understanding r1-zero-like training: A critical perspective. arXiv preprint arXiv:2503.20783.
[71] Yang et al. (2024). Qwen2. 5-math technical report: Toward mathematical expert model via self-improvement. arXiv preprint arXiv:2409.12122.
[72] Hendrycks et al. (2021). Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874.
[73] Guangming Sheng et al. (2024). HybridFlow: A Flexible and Efficient RLHF Framework. arXiv preprint arXiv: 2409.19256.
[74] Liu et al. (2024). OAT: A research-friendly framework for LLM online alignment.
[75] Zeng et al. (2025). Simplerl-zoo: Investigating and taming zero reinforcement learning for open base models in the wild. arXiv preprint arXiv:2503.18892.
[76] Hu et al. (2025). Open-reasoner-zero: An open source approach to scaling up reinforcement learning on the base model. arXiv preprint arXiv:2503.24290.
[77] He et al. (2024). Olympiadbench: A challenging benchmark for promoting agi with olympiad-level bilingual multimodal scientific problems. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). pp. 3828–3850.
[78] Lewkowycz et al. (2022). Solving quantitative reasoning problems with language models. Advances in neural information processing systems. 35. pp. 3843–3857.
[79] Li et al. (2024). Numinamath: The largest public dataset in ai4maths with 860k pairs of competition math problems and solutions. Hugging Face repository. 13(9). pp. 9.
[80] Chollet et al. (2024). Arc prize 2024: Technical report. arXiv preprint arXiv:2412.04604.
[81] François Chollet (2019). On the Measure of Intelligence. https://arxiv.org/abs/1911.01547.
[82] Huanran Chen et al. (2025). Understanding Pre-training and Fine-tuning from Loss Landscape Perspectives. arXiv:2505.17646. https://arxiv.org/abs/2505.17646.
[83] Yu et al. (2025). Dapo: An open-source llm reinforcement learning system at scale. arXiv preprint arXiv:2503.14476.
[84] Shah et al. (2025). A Comedy of Estimators: On KL Regularization in RL Training of LLMs. arXiv preprint arXiv:2512.21852.
[85] Aghajanyan et al. (2021). Intrinsic Dimensionality Explains the Effectiveness of Language Model Fine-Tuning. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). pp. 7319–7328. doi:10.18653/v1/2021.acl-long.568. https://aclanthology.org/2021.acl-long.568/.
[86] Xin Qiu and Risto Miikkulainen (2024). Semantic Density: Uncertainty Quantification for Large Language Models through Confidence Measurement in Semantic Space. In Proceedings of the 38th Conference on Neural Information Processing Systems.
[87] Farquhar et al. (2024). Detecting hallucinations in large language models using semantic entropy. Nature. 630(8017). pp. 625–630.
[88] Tim Mucci and Cole Stryker (2023). What is artificial superintelligence?. https://www.ibm.com/think/topics/artificial-superintelligence.
[89] Yang et al. (2025). Qwen2. 5-1m technical report. arXiv:2501.15383.
[90] Schulman, John (2020). Approximating kl divergence, 2020. URL http://joschu. net/blog/kl-approx. html.
[91] Yong Liu et al. (2025). Sparse MeZO: Less Parameters for Better Performance in Zeroth-Order LLM Fine-Tuning. https://openreview.net/forum?id=4Kw4KAoVnx.
[92] Zafir Stojanovski et al. (2025). REASONING GYM: Reasoning Environments for Reinforcement Learning with Verifiable Rewards. https://arxiv.org/abs/2505.24760.
[93] Priyanka Ranke (2025). ARC-RL: Reinforcement Learning for ARC-AGI. https://github.com/priyankaranke/arc_rl/blob/main/report.pdf. Accessed: 2026-01-27.