Variational Flow Maps: Make Some Noise for One-Step Conditional Generation
Abbas Mammadov
Department of Statistics, University of Oxford
So Takao
California Institute of Technology
Bohan Chen
California Institute of Technology
Ricardo Baptista
University of Toronto
Morteza Mardani
NVIDIA
Yee Whye Teh
Department of Statistics, University of Oxford
Julius Berner
NVIDIA
Correspond to: Abbas Mammadov [email protected]
Keywords: Machine Learning, ICML
Abstract
Flow maps enable high-quality image generation in a single forward pass. However, unlike iterative diffusion models, their lack of an explicit sampling trajectory impedes incorporating external constraints for conditional generation and solving inverse problems. We put forth Variational Flow Maps, a framework for conditional sampling that shifts the perspective of conditioning from "guiding a sampling path", to that of "learning the proper initial noise". Specifically, given an observation, we seek to learn a noise adapter model that outputs a noise distribution, so that after mapping to the data space via flow map, the samples respect the observation and data prior. To this end, we develop a principled variational objective that jointly trains the noise adapter and the flow map, improving noise-data alignment, such that sampling from complex data posterior is achieved with a simple adapter. Experiments on various inverse problems show that VFMs produce well-calibrated conditional samples in a single (or few) steps. For ImageNet, VFM attains competitive fidelity while accelerating the sampling by orders of magnitude compared to alternative iterative diffusion/flow models. Code is available at https://github.com/abbasmammadov/VFM .
Executive Summary: Generative models, such as diffusion-based systems, have revolutionized image creation by producing high-fidelity outputs like realistic photos from noise. However, they require dozens to hundreds of iterative steps for each sample, making them computationally expensive and impractical for real-time use in areas like medical imaging, video editing, or scientific simulations. This slowness becomes especially problematic for conditional generation tasks, where outputs must align with specific constraints, such as restoring a blurred or partially obscured image—an inverse problem common in fields like astronomy and diagnostics. As AI applications scale, reducing this computational burden without sacrificing quality is urgent to enable broader adoption and lower energy costs.
This paper introduces Variational Flow Maps (VFMs), a new framework designed to achieve high-quality conditional image generation in just one or a few steps. The core idea is to adapt fast "flow maps"—neural networks that directly transform random noise into images—by learning a simple "noise adapter" that selects appropriate starting noise based on an observation, like a degraded image. Unlike traditional methods that iteratively guide the generation process, VFMs reformulate the problem in the noise space, ensuring the output respects both the constraint and the underlying data distribution.
The authors developed VFMs through a principled training approach that jointly optimizes the flow map and noise adapter using a variational objective, similar to techniques in autoencoders but tailored for flows. They tested it on a 2D toy dataset and high-resolution ImageNet images (256x256 pixels), covering inverse problems like inpainting missing regions, deblurring, and super-resolution. Training involved datasets of up to 50,000 samples, with models based on established architectures fine-tuned over 100-180 epochs on GPU clusters. Key assumptions included Gaussian noise distributions and linear forward operators for observations, ensuring computational tractability.
The main findings highlight VFMs' efficiency and effectiveness. First, on ImageNet tasks, VFMs generated samples with superior perceptual quality—measured by metrics like Fréchet Inception Distance (FID) of 33 versus 63-76 for baselines—and better distribution matching, outperforming iterative diffusion methods by capturing multimodal posteriors (e.g., diverse plausible completions for masked images). Second, sampling speed improved by orders of magnitude: one neural evaluation (about 0.03 seconds) versus 250+ steps (up to a minute) for competitors, while maintaining sharpness and diversity. Third, joint training of the components proved essential; training the adapter alone led to artifacts and poor calibration. A 2D ablation confirmed that this coupling warps the noise space to better fit complex constraints, with metrics like maximum mean discrepancy (MMD) dropping by 20-50% compared to fixed-map baselines. Finally, VFMs extended to reward alignment, fine-tuning models to favor high-reward outputs (e.g., aligned with text prompts) in under 0.5 epochs, achieving top scores on human preference benchmarks.
These results matter because they bridge the gap between fast unconditional generation and constrained real-world applications, potentially cutting inference costs by 100x and enabling on-device AI for tasks like real-time photo editing or uncertainty-aware medical scans. Unlike expectations that one-step methods sacrifice quality, VFMs deliver competitive or better fidelity, especially in perceptual metrics, while preserving uncertainty estimates crucial for decision-making in high-stakes fields. This challenges prior work reliant on slow iterations and opens doors to energy-efficient AI deployment.
Next, organizations should pilot VFMs in targeted applications, such as image restoration pipelines, integrating the open-source code for custom fine-tuning. For broader impact, extend the framework to video or audio by incorporating temporal flows, or relax the Gaussian adapter assumption with more flexible distributions to handle non-linear problems. Trade-offs include balancing speed gains against minor setup complexity for joint training.
Confidence in these findings is high for image inverse problems, backed by rigorous comparisons on standard benchmarks, though results may vary with dataset shifts. Limitations include reliance on pre-trained backbones, sensitivity to hyperparameters like the relaxation parameter (τ), and untested scalability to ultra-high resolutions or non-vision domains; further validation on diverse real-world data would strengthen applicability.
1. Introduction
Section Summary: Diffusion and flow-based methods have become the leading approach for creating high-quality generated content like images and videos, but they are slow because generating even one sample requires many sequential steps, making them impractical for real-time use. Recent efforts, such as consistency models and flow maps, aim to speed this up by enabling generation in just a few steps, yet they struggle with conditional tasks where outputs must match specific constraints, like restoring a blurry image, due to a lack of ways to guide the process. To solve this, the authors introduce Variational Flow Maps, a new framework that learns to select the right starting noise based on the given constraint, allowing fast one- or few-step generation while jointly training the core model and an adapter for better alignment between noise, data, and observations, with extensions for tasks like reward-based sampling.
Diffusion and flow-based methods have emerged as the dominant paradigm for high-fidelity generative modeling, achieving state-of-the-art results across images, audio, and video ([1, 2, 3, 4, 5, 6]). These methods can be understood from the unified perspective of interpolating between two distributions; a simple noise distribution and a complex data distribution, and learning dynamics based on ordinary or stochastic differential equations (ODE/SDEs) that transport one to the other [7]. However, these share a fundamental limitation that generating a single sample requires dozens to hundreds of sequential function evaluations, creating high computational cost for real-time applications.
To address this issue, recent research have sought to dramatically reduce this sampling cost. Consistency models ([8]), for example, learn to map any point on the flow trajectory directly to the corresponding clean data, enabling few-step generation. Despite their promise, consistency models often suffer from training instabilities and frequently require re-noising steps for multi-step sampling to correct the drift trajectory, complicating the inference process [9]. Flow maps ([10, 11]) offer an alternative framework that seeks to learn ODE flows directly, by training on the mathematical structure of such flows. For example, the state-of-the-art Mean Flow model [12] presents a particular parameterisation of flow maps based on average velocities, and trained on the so-called Eulerian condition satisfied by ODE flows.
While flow maps excel at unconditional few-steps generation, many applications require conditional generation to produce samples that satisfy external constraints. Inverse problems provide a canonical example: given a degraded observation $y = A(x) + \varepsilon$ (e.g., a blurred, masked, or noisy image), we seek to recover plausible original signals $x$ consistent with both the observation and our learned prior $p(x)$. Iterative generative models naturally accommodate such conditioning through guidance mechanisms [13, 14, 15, 16], where the trajectory is iteratively nudged toward the conditional target. Flow maps, despite their efficiency, lack this iterative refinement mechanism: once the noise vector $z$ is chosen, the generated sample $z \mapsto x$ is fixed; there is no intermediate state to guide, nor a trajectory to steer, hence there is no opportunity to incorporate measurement information during generation. This "guidance gap" has limited flow maps to unconditional settings, leaving their potential for conditional generation largely unexplored.
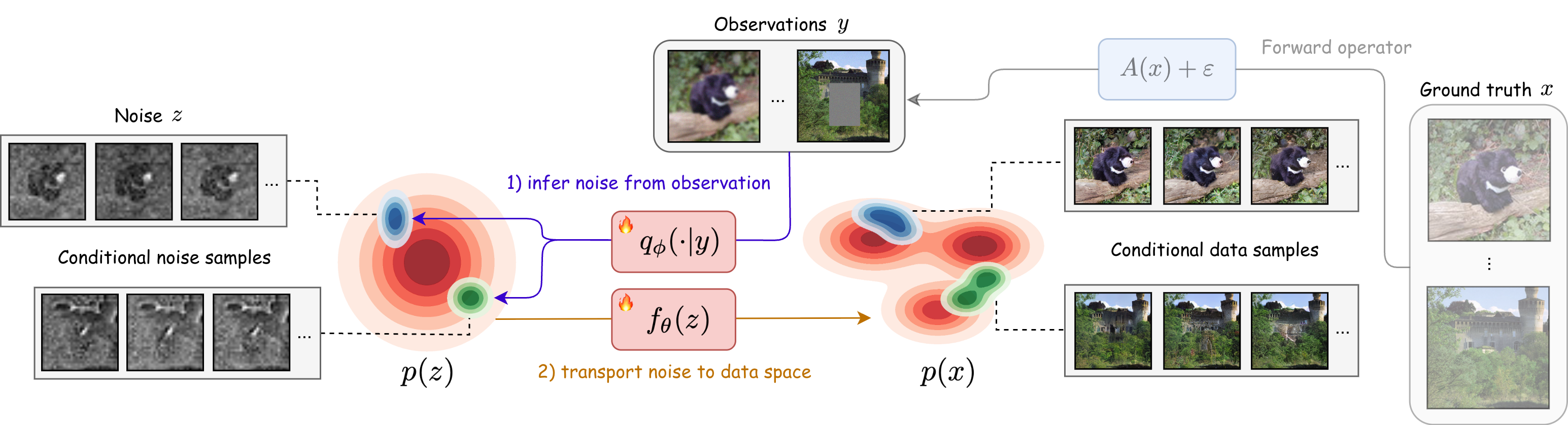
To fill this "guidance gap", we introduce Variational Flow Maps (VFMs), a framework for conditional sampling that is compatible with one/few-step generation using flow maps. Our approach is based on the following perspective: rather than steer the generation process itself, we can find the noise $z$ to generate from, as each $z$ deterministically maps to a data $x = f_\theta(z)$ (see Figure 1). Specifically, given an observation $y$, we seek to produce a distribution of $z$ 's, such that each $x = f_\theta(z)$ is a candidate data that produced $y$. Formulating this as a Bayesian inverse problem, we can derive a principled variational training objective to jointly learn the flow map $f_\theta$ and a noise adapter model $q_\phi$ that produces appropriate noise $z$ from observations $y$.
We note the resemblance to variational autoencoders (VAEs) ([17]), where $q_\phi$ plays the role of an encoder that takes $y$ to a latent $z$, and $f_\theta$ acts as a decoder from $z$ to data $x$. Our key innovation is in learning the alignment of all three variables $(x, y, z)$ simultaneously, allowing updates to $q_\phi$ to reshape the noise-to-data coupling by $f_\theta$ and vice versa. Notably, we observe that joint training can compensate for limited adapter expressivity by learning a noise-to-data coupling that makes the conditional posterior easier to represent in latent space.
Altogether, our contributions can be summarized as follows:
- We introduce Variational Flow Maps (VFMs), a new paradigm enabling one and few-step conditional generation with flow maps by learning an observation-dependent noise sampler.
- We derive a principled variational objective for joint adapter/flow map training, linking the mean flow loss to likelihood bounds.
- We demonstrate empirically and theoretically that joint training yields better noise-data coupling to fit complex posteriors in data space using simple variational posteriors in noise space.
- We extend the framework to general reward alignment, introducing a fast and scalable method that fine-tunes pre-trained flow maps to sample from reward-tilted distributions in a single step.
2. Background
Section Summary: This section provides background on key concepts in generative modeling and inference. It first explains flow-based models, which transform simple noise into realistic data using mathematical flows, and introduces flow maps as a faster way to generate samples in just a few steps without lengthy computations. It then covers inverse problems, where noisy observations are used to recover original signals through Bayesian methods relying on generative priors, and discusses variational inference, which approximates complex probability distributions via neural networks, as seen in variational autoencoders that encode and decode data efficiently.
We review essential backgrounds on flow maps for few-step generation, the Bayesian formulation of inverse problems, and variational inference with amortization.
2.1 Flow-based Generative Models and Flow Maps
Flow-based generative models learn to transport samples from a prior distribution $p_1(z) = \mathcal{N}(0, I)$ to the data distribution $p_0(x) = p_{\text{data}}(x)$ via an ODE:
$ \frac{dx_t}{dt} = v_t(x_t), \quad t \in [0, 1], $
where $v_t$ is a time-dependent velocity field. Flow matching ([5, 6, 7]) provides a training objective to learn $v_t$: given $x_0 \sim p_{\text{data}}$ and $x_1 \sim \mathcal{N}(0, I)$, we construct a linear interpolant $x_t = (1-t)x_0 + tx_1$ with conditional velocity $v_t = x_1 - x_0$. Then, $v_\theta(x_t, t) \approx v_t(x_t)$ is trained via:
$ \mathcal{L}{\text{FM}}(\theta) = \mathbb{E}{x_0, x_1, t}\left[|v_\theta(x_t, t) - (x_1 - x_0)|^2 \right]. $
At inference time, samples are generated by integrating the ODE backwards from $t=1$ to $t=0$, typically requiring 50–250 function evaluations.
To accelerate sample generation, flow maps ([10, 11]) directly learn the solution operator of the ODE, instead of the instantaneous velocity $v_t$. Denoting by $\phi_{t, s}: x_t \mapsto x_s$ the backward flow of the ODE, the two-time flow map $f_\theta(x_t, s, t)$ learns to approximate $\phi_{t, s}(x_t)$ for any $0 \leq s < t \leq 1$. This enables generation with an arbitrary number of steps chosen post-training, e.g. a single evaluation $f_\theta(x_1, 0, 1)$ produces a one-step sample, while intermediate evaluations can be composed for multi-step refinement.
One such approach to learn flow maps is mean flows ([12]), which introduce the average velocity as an alternative characterization:
$ u(x_t, r, t) := \frac{1}{t - r} \int_r^t v_s(\phi_{t, s}(x_t)) , ds. $
The average velocity satisfies $x_r = x_t - (t-r) \cdot u(x_t, r, t)$, enabling one-step generation via $x_0 = x_1 - u(x_1, 0, 1)$. Thus the corresponding flow map is given by $f_\theta(x_t, r, t) = x_t - (t-r) \cdot u_\theta(x_t, r, t)$. For simplicity, we denote the one-step flow map as $f_\theta(z) := z - u_\theta(z, 0, 1)$, mapping noise $z \sim \mathcal{N}(0, I)$ directly to data $x = f_\theta(z)$.
2.2 Inverse Problems
Inverse problem seeks to recover an unknown signal $x \in \mathbb{R}^d$ from noisy observations, given by
$ y = A(x) + \varepsilon, \quad \varepsilon \sim \mathcal{N}(0, \sigma^2 I), $
where $A: \mathbb{R}^d \to \mathbb{R}^m$ is a known forward operator and $\sigma > 0$ is the noise level. Given a prior $p(x)$ over signals, the Bayesian formulation seeks the posterior distribution:
$ p(x|y) \propto \exp\left(-\frac{|y - A(x)|^2}{2\sigma^2} \right) p(x).\tag{1} $
When $p(x)$ is defined implicitly by a generative model, guidance-based methods ([14, 16]) approximate posterior sampling by incorporating likelihood gradients $\nabla_x \log p(y|x)$ at each denoising step. While effective, these methods inherently require iterative refinement and cannot be applied to one-step flow maps.
2.3 Variational Inference and Data Amortization
Variational inference seeks to approximate an intractable posterior $p(z|x)$ with a tractable disribution $q(z|x)$ by minimizing the Kullback-Leibler (KL) divergence:
$ \text{KL}(q(z|x) | p(z|x)) := \mathbb{E}{q\phi}[\log q(z|x) - \log p(z|x)]. $
Extending this, amortized inference uses a neural network to directly predict the variational distribution from the conditioning variable $x$, rather than optimizing separately for each instance. For example, if we choose the variational family to be Gaussians with diagonal covariance, then amortized inference learns a neural network $x \mapsto (\mu_\phi(x), \sigma_\phi(x))$ with parameter $\phi$, such that $q_\phi(z|x) = \mathcal{N}(z|\mu_\phi(x), \mathtt{diag}(\sigma^2_\phi(x)))$ is close to $p(z|x)$ under the KL divergence.
A prototypical example is the Variational Autoencoder (VAE) ([17]), which learns both an encoder $q_\phi(z|x)$ and a decoder $p_\theta(x|z)$ by optimizing the VAE objective $\mathcal{L}{\text{VAE}}(\theta, \phi) = \mathbb{E}{p(x)}[\ell(\theta, \phi; x)]$, where
$ \ell(\theta, \phi; x) := -\mathbb{E}{q\phi(z|x)}[\log p_\theta(x|z)] + \text{KL}(q_\phi(z|x) | p(z)), $
is the negative evidence lower bound (ELBO), yielding $q_\phi(z | x) \approx p_\theta(z | x) \propto p_\theta(x|z)p(z)$ for any $x \sim p(x)$. Probabilistically, the VAE objective can be derived from the KL divergence between two representations of the joint distribution of $(x, z)$, i.e., $\text{KL}(q_\phi(z, x) || p_\theta(z, x))$, where $q_\phi(z, x) = q_\phi(z | x)p(x)$ and $p_\theta(z, x) = p_\theta(x | z)p(z)$. This perspective will be useful in the derivation of our loss later.
3. Variational Flow Maps (VFMs)
Section Summary: Variational Flow Maps (VFMs) offer a method for generating data in one step based on observations by reworking a complex math problem into a simpler "noise space," using a flow map to connect random noise to data and approximating the likely noise patterns with a technique similar to variational autoencoders. While a basic version of this approach falls short because it ignores important flow map structures and uses a too-simple approximation for the noise patterns, the improved strategy trains the flow map and the noise approximator together, adding a term to ensure generated data stays true to the original dataset. This joint training, supported by math showing it better captures the average expected data for any observation, avoids biases from separate training and makes the process more reliable.
Our proposed method for one-step conditional generation, which we term Variational Flow Maps (VFMs), is based on reformulating the inverse problem Equation 1 in noise space. To motivate our methodology, we begin with a simple “strawman" approach that is intuitively sound but ultimately insufficient for our task: Let $x = f_\theta(z)$ denote a pretrained flow map. Then the posterior over latent noise variables induced by the inverse problem can be written as
$ p(z|y) \propto \exp\left(-\frac{|y - A(f_\theta(z))|^2}{2\sigma^2} \right) p(z).\tag{2} $
Although the posterior Equation 2 is intractable, we can approximate it in the same spirit as VAEs. In particular, introducing a variational posterior $q_\phi(z | y) \approx p(z | y)$, we minimize the objective $\mathcal{L}{\text{VAE}}(\theta, \phi) = \mathbb{E}{p(y)}[\ell(\theta, \phi ; y)]$, where,
$ \ell(\theta, \phi ; y) := -\mathbb{E}{q\phi(z|y)}[\log p_\theta(y|z)] + \text{KL}(q_\phi(z|y) | p(z)),\tag{3} $
and $p_\theta(y | z) := \mathcal{N}(y | A(f_\theta(z)), \sigma^2 I)$, the likelihood in noise space. A key advantage of working in the noise space rather than the original data space is that the noise prior $p(z)$ is simple and tractable (commonly $\mathcal{N}(0, I)$, which we assume hereafter). Thus, imposing a conjugate variational posterior, such as $q_\phi(z|y) = \mathcal{N}(z|\mu_\phi(y), \mathtt{diag}(\sigma^2_\phi(y)))$, makes the computation of the KL term in Equation 3 tractable.
However, the objective Equation 3 has two major limitations in our setting. First, it does not impose structural properties of flow maps, such as the semi-group property ([11]), known to be crucial for learning said maps. Second, when the flow map $f_\theta$ is pretrained and held fixed, a Gaussian variational posterior $q_\phi(z|y)$ may not be expressive enough to approximate the true posterior $p(z | y)$ accurately.
Motivated by this observation, we pursue training the parameters $\theta$ and $\phi$ jointly. By adapting the map $f_\theta : z \mapsto x$ alongside learning the variational posterior $q_\phi$, we can compensate for the limited expressibility of $q_\phi(z|y)$ by reshaping the correspondence between noise and data. In the next section, we formalize this idea by deriving a modified objective that enables joint training of $(\theta, \phi)$ while explicitly incorporating additional structural constraints to the flow.
3.1 Joint Training of the Flow Map and Noise Adapter
We now propose a joint training strategy that simultaneously aligns the data variable $x$, the observation $y$, and the latent noise variable $z$. Following the probabilistic perspective underlying VAEs (see Section 2.3), we achieve this by matching the following two factorizations of $p(x, y, z)$:
$ \begin{align} q_\phi(z | y) p(y | x) p(x) \approx p_\theta(x, y | z) p(z). \end{align}\tag{4} $
For simplicity, we assume a Gaussian decoder of the form
$ \begin{align} p_\theta(x, y | z) != !\mathcal{N}(x | f_\theta(z), \tau^2 I) , \mathcal{N}(y | A(f_\theta(z)), \sigma^2 I), \end{align}\tag{5} $
where we introduce a new hyperparameter $\tau > 0$ that relaxes the correspondence between $x$ and $z$. Taking the KL divergence between the two representations in Equation 4 yields
$ \begin{align} &\text{KL}(q_\phi(z | y) p(y | x) p(x) , ||, p_\theta(x, y | z) p(z)) \ &\leq \frac{1}{2\tau^2}\mathcal{L}{\text{data}}(\theta, \phi) + \frac{1}{2\sigma^2} \mathcal{L}{\text{obs}}(\theta, \phi) + \mathcal{L}_{\text{KL}}(\phi), \nonumber \end{align}\tag{6} $
(see Appendix A.1 for details), where
$ \begin{align} \mathcal{L}{\text{data}}(\theta, \phi) &= \mathbb{E}{q_\phi(z | y) p(y | x)p(x)}\left[|x - f_\theta(z)|^2\right], \ \mathcal{L}{\text{obs}}(\theta, \phi) &= \mathbb{E}{q_\phi(z | y) p(y)}\left[|y - A(f_\theta(z))|^2\right], \ \mathcal{L}{\text{KL}}(\phi) &= \mathbb{E}{p(y)}\left[\text{KL}\left(q_\phi(z|y) , ||, p(z)\right)\right]. \end{align}\tag{7} $
We note that relative to 3, this formulation gives rise to an additional term $\mathcal{L}{\text{data}}(\theta, \phi)$ that measures closeness of the reconstructed state $f\theta(z)$ and the ground-truth data $x$, where noise $z$ is drawn from the noise adapter $q_\phi(z|y)$, with observation $y$ taken from $x$. This term couples the adapter model and flow map more tightly, encouraging the samples ${f_\theta(z)}{z \sim q{\phi}(z|y)}$ to remain consistent with data manifold.
In the following result, we identify a concrete benefit of jointly learning $f_\theta$ and $q_\phi$ to target the true posterior $p(x|y)$, under a simple Gaussian setting. While this does not claim that the distribution of samples ${f_\theta(z)}{z \sim q{\phi}(z|y)}$ matches $p(x|y)$ exactly, it shows that joint training can at least match the posterior mean for every observation $y$. This sharply contrasts with separately training $f_\theta$ and $q_\phi$, which leads to bias almost surely, even at the level of the posterior mean.
Proposition 1
Assume that $p(z) = \mathcal{N}(z | 0, I)$, $p(x) = \mathcal{N}(x | m, C)$ for some $m\in \mathbb{R}^d$ and $C \in \mathbb{R}^{d \times d}$ symmetric positive definite, $f_\theta(z) = K_\theta z + b_\theta$ and $q_\phi(z|y) = \mathcal{N}(z|\mu_\phi(y), \mathtt{diag}(\sigma^2_\phi(y)))$. Then, for any linear observation $y = Ax + \varepsilon$, we have that
- Separate Training: Training $f_\theta$ first to match $p(x)$ and then training $q_\phi$ via loss Equation 6 with $\theta$ fixed almost surely fails to match the posterior mean, i.e., $\mathbb{E}{z \sim q{\phi}(z|y)} [f_\theta(z)] \neq \mathbb{E}_{p(x|y)}[x]$.
- Joint Training: Joint optimization of $f_\theta$ and $q_\phi$ via loss Equation 6 recovers the true posterior mean $\mathbb{E}{p(x|y)}[x]$ exactly via the procedure $\mathbb{E}{z \sim q_\phi(z|y)}[f_\theta(z)]$.
Proof: See Proposition 12 in Appendix A.2.
Next, we relate the new term $\mathcal{L}_{\text{data}}(\theta, \phi)$ in Equation 6 to the mean flow loss [12], which imposes structural constraints on the flow map.
Connection to mean flows.
We briefly recall the mean flow objective from [12]. Denoting
$ \begin{align} &\mathcal{E}\theta(x, z, r, t) := (t-r) \left[u\theta(\psi_t(x, z), r, t) - \dot{\psi}_t(x, z)\right], \nonumber \ &\text{where} \quad \psi_t(x, z) := (1 - t)x + t z, 0\le r\le t\le 1, \end{align} $
is the linear interpolant between data $x$ and noise $z$, the mean flow loss is given by
$ \begin{align} &\mathbb{E}{x, z, r, t}\left[|\partial_t \mathcal{E}\theta(x, z, r, t)|^2\right] \approx \mathcal{L}{\text{MF}}(\theta) \ &, := \mathbb{E}{x, z, r, t}\left[|u_\theta(\psi_t(x, z), r, t) - \mathtt{stopgrad}(u_{\text{tgt}})|^2\right], \nonumber \end{align}\tag{8} $
where $u_{\text{tgt}} := \dot{\psi}t(x, z) - (t-r)\frac{d}{dt} u\theta(\psi_t(x, z), r, t)$ is the effective regression target. Below, we establish a direct link between this objective and the term $\mathcal{L}_{\text{data}}(\theta, \phi)$ in Equation 6.
Proposition 2
Let the noise-to-data map $f_\theta$ be defined by $f_\theta(z) := z - u_\theta(z, 0, 1)$. Then we have
$ \begin{align} |x - f_\theta(z)|^2 \leq \int^1_0 |\partial_t \mathcal{E}_\theta(x, z, 0, t)|^2 dt. \end{align} $
Proof: See Appendix A.3.
This result shows that the mean flow loss in the anchored case $r = 0$ and $t \sim U([0, 1])$ acts as an upper bound proxy to the reconstruction error $|x - f_\theta(z)|^2$ in Equation 7. This specialized setting targets direct one-step transport to $r=0$. Motivated by this connection, we opt to use the general mean flow loss Equation 8, which distributes learning over $(r, t)$ to additionally learn intermediate flow maps $f_\theta(x_t, r, t)$. While this does not ensure optimality for the one-step transport $x = f_\theta(z, 0, 1)$, in practice, it yields strong empirical performance and furthermore provides functionality for multi-step sampling (Section 3.3). Summarizing, we propose to train $(\theta, \phi)$ using the following objective:
$ \begin{align} \mathcal{L}{\theta, \phi} := \frac{1}{2\tau^2} \mathcal{L}{\text{MF}}(\theta; \phi) + \frac{1}{2\sigma^2} \mathcal{L}{\text{obs}}(\theta, \phi) + \mathcal{L}{\text{KL}}(\phi), \end{align}\tag{9} $
where the mean flow term is evaluated using $(x, z)$-pairs sampled from the joint distribution $\pi_\phi(x, z) := \int q_\phi(z | y)p(y | x)p(x) dy$, in accordance with Equation 7. This dependence induces an implicit coupling between $\theta$ and $\phi$. To promote stable optimization, we further limit the interaction to this term by replacing $\theta$ in the observation loss $\mathcal{L}{\text{obs}}$ with its exponential moving average (EMA), yielding $\mathcal{L}{\text{obs}}(\theta^-, \phi)$, where $\theta^-$ denotes the EMA of $\theta$.
Remark
Our framework can also be related to consistency model training by Proposition 6.1 in [18]. In this case, the mean flow loss in Equation 9 is replaced by an appropriate consistency loss.
Input: Observation $y$, inverse problem class $c$, time partition $1=t_0 > \cdots > t_K=0$, adapter mean and standard deviation $\mu_\phi, \sigma_\phi$, mean flow model $u_\theta$
$\epsilon \sim \mathcal{N}(0, I)$
$z \gets \mu_\phi(y, c) + \sigma_\phi(y, c)\odot \epsilon$
$x \gets z$
**for** $k=1$ to $K$ **do**
$x \gets x + (t_k - t_k-1) u_\theta(x, t_k, t_k-1)$
**end for**
Output: $x$
Input: Inverse problem classes $\mathcal{A}_1, \ldots, \mathcal{A}_C$, observation noise standard deviation $\sigma$, data misfit tolerance $\tau$, conditional noise proportion $\alpha$, learning rates $\eta_1, \eta_2$, EMA rate $\mu$, adaptive loss constants $\gamma, p$
$\theta^- \leftarrow \mathtt{stopgrad}(\theta)$
**repeat**
Sample $c \sim p(c)$, $x \sim p(x)$
Sample forward operator $A_c^\omega \in \mathcal{A}_c$
$y \leftarrow A_c^\omega x + \varepsilon, \quad \varepsilon \sim \mathcal{N}(0, \sigma^2I)$
$z \gets \mu_\phi(y, c) + \sigma_\phi(y, c)\odot \epsilon, \quad \epsilon \sim \mathcal{N}(0, I)$
$\mathcal{L}_{\text{obs}}(\phi) \leftarrow \|y - A_c^\omega(f_{\theta^-}(z, 0, 1))\|^2$
$\mathcal{L}_{\text{KL}}(\phi) \leftarrow \text{KL}\!\left(\mathcal{N}(\mu_\phi(y, c), \sigma^2_\phi(y, c)I) \,||\,\mathcal{N}(0, I)\right)$
Sample $w \sim U([0, 1])$ and $(r, t) \sim p(r, t)$
**if** $w > \alpha$ **then**
$z \sim \mathcal{N}(0, I)$
**end if**
$\mathcal{L}_{\text{MF}}(\theta; \phi) \leftarrow \mathrm{MeanFlowLoss}(x, z, r, t)$
$\mathcal{L}(\theta, \phi) \leftarrow \frac{1}{2\tau^2} \mathcal{L}_{\text{MF}}(\theta; \phi) + \frac{1}{2\sigma^2} \mathcal{L}_{\text{obs}}(\theta) + \mathcal{L}_{\text{KL}}(\phi)$
$\mathcal{L}(\theta, \phi) \leftarrow \mathcal{L}(\theta, \phi) / \mathtt{stopgrad}(\|\mathcal{L}(\theta, \phi) + \gamma\|^p)$
$\theta \leftarrow \theta - \eta_1 \nabla_{\theta} \mathcal{L}(\theta, \phi)$
$\phi \leftarrow \phi - \eta_2 \nabla_{\phi} \mathcal{L}(\theta, \phi)$
$\theta^- \leftarrow \mathtt{stopgrad}(\mu \theta^- + (1 - \mu) \theta)$
**until** convergence
3.2 Amortizing Over Multiple Inverse Problems
In many applications, one is interested not in a single inverse problem defined by a fixed forward operator $A$, but rather a family of inverse problems. To accommodate this setting, we extend our framework by amortizing inference over multiple forward operators $A_1, \ldots, A_C$. This allows for a single model to handle multiple tasks, such as denoising, inpainting, and deblurring.
To achieve this, we consider a class-conditional noise adapter $q_\phi(z | y, c) !=! \mathcal{N}(z | \mu_\phi(y, c), \mathtt{diag}(\sigma^2_\phi(y, c)))$, where $c \in {1, \ldots, C}$ is a categorical variable indicating which forward operator $A_c$ was used to generate the observation $y$. Conditioning the adapter on $c$ enables the model to adapt its posterior approximation to the specific structure of each inverse problem. We may further extend this by amortizing over inverse problem classes, where $c$ now defines a collection of inverse problems $\mathcal{A}c = {A_c^\omega}{\omega \in \Omega}$. For example, these can define a family of random masks or a distribution of blurring kernels.
3.3 Single and Multi-Step Conditional Sampling
Given a trained noise adapter $q_\phi(z|y)$ and flow map $f_\theta(z)$, samples from the data-space posterior $p(x|y)$ can be approximately generated by first sampling $z \sim q_\phi(z|y)$ and then mapping $x = f_\theta(z)$. The validity of this procedure is justified by the following result.
Proposition 3
Let the joint distribuion of $(x, y, z)$ be given by $p(x, y, z) = p_\theta(x, y | z) p(z)$, for $p_\theta(x, y | z)$ in Equation 5. Then, for any fixed observation $y$, the data-space posterior $p(x | y)$ converges weakly to the pushforward of the noise-space posterior $p(z | y)$ under the map $f_\theta$, as $\tau \rightarrow 0$.
Proof: See Appendix A.4.
The proposition states that in the limiting case $\tau \rightarrow 0$, sampling from $p(x|y)$ is equivalent in distribution to first sampling $z \sim p(z|y)$ (approximated by $q_\phi(z|y)$) and then applying $x = f_\theta(z)$. While sound in theory, we find that when $\tau \ll \sigma$, joint optimization of $(\theta, \phi)$ becomes difficult. This is likely due to the RHS distribution in Equation 4 concentrating sharply around the submanifold ${(x, y, z) : x = f_\theta(z)}$, making it nearly impossible to match using the LHS representation of Equation 4, which remains a full distribution over $(x, y, z)$. In practice, we find that using $\tau$ larger than $\sigma$ yields stable optimization and the best empirical results.
Sample quality can also be improved by considering multi-step sampling instead of single-step sampling, as described in Algorithm 1. Empirically, high-quality samples can be obtained with only a small number of steps $K$, substantially fewer than the number of integration steps required for solving a full generative ODE or SDE.
3.4 Other Training Considerations
Mixing in the unconditional loss:
We observe that training solely using the objective Equation 9 can degrade the quality of unconditional samples $x = f_\theta(z)$, with $z \sim \mathcal{N}(0, I)$. This behaviour arises because latent samples drawn from $q_\phi(z | y)$ retain structural details of $y$, and therefore are not fully representative of pure noise drawn from $\mathcal{N}(0, I)$. Thus, during training, the mean flow loss is never evaluated on pure noise, imparining the model to generate unconditional samples. To address this, we modify the computation of the mean flow loss $\mathcal{L}{\text{MF}}(\theta; \phi)$, by sampling $(x, z) \sim \pi\phi(x, z)$ with probability $\alpha$ and with remaining probablility $1-\alpha$, we sample $z \sim \mathcal{N}(0, I)$ independently of $x$.
Adaptive loss:
Similar to the mean flow training procedure of [12], we consider an adaptive loss scaling to stabilize optimization. Specifically, we use the rescaled loss $w \cdot \mathcal{L}{\theta, \phi}$, where the weight $w$ is given by $w = 1/\mathtt{stopgrad}(|\mathcal{L}{\theta, \phi} + \gamma|^p)$ for constants $\gamma, p > 0$.
We summarize the full training procedure in Algorithm 2.
4. Experiments
Section Summary: In the experiments section, researchers test their Variational Flow Matching (VFM) method on a simple 2D toy problem using a checkerboard pattern of data points, where only one coordinate is observed with added noise, comparing it to baseline approaches that either fix the core model or train it without constraints. VFM outperforms these baselines by better capturing the two-peaked uncertainty in the data while keeping samples on the intended pattern, as shown through metrics measuring prediction accuracy, uncertainty, and structure preservation, with key improvements from joint training adjustments and stabilizing techniques. The method also demonstrates strong results on real-world image tasks like filling in missing parts or sharpening blurry photos from the ImageNet dataset, producing diverse and realistic outputs that surpass existing tools.
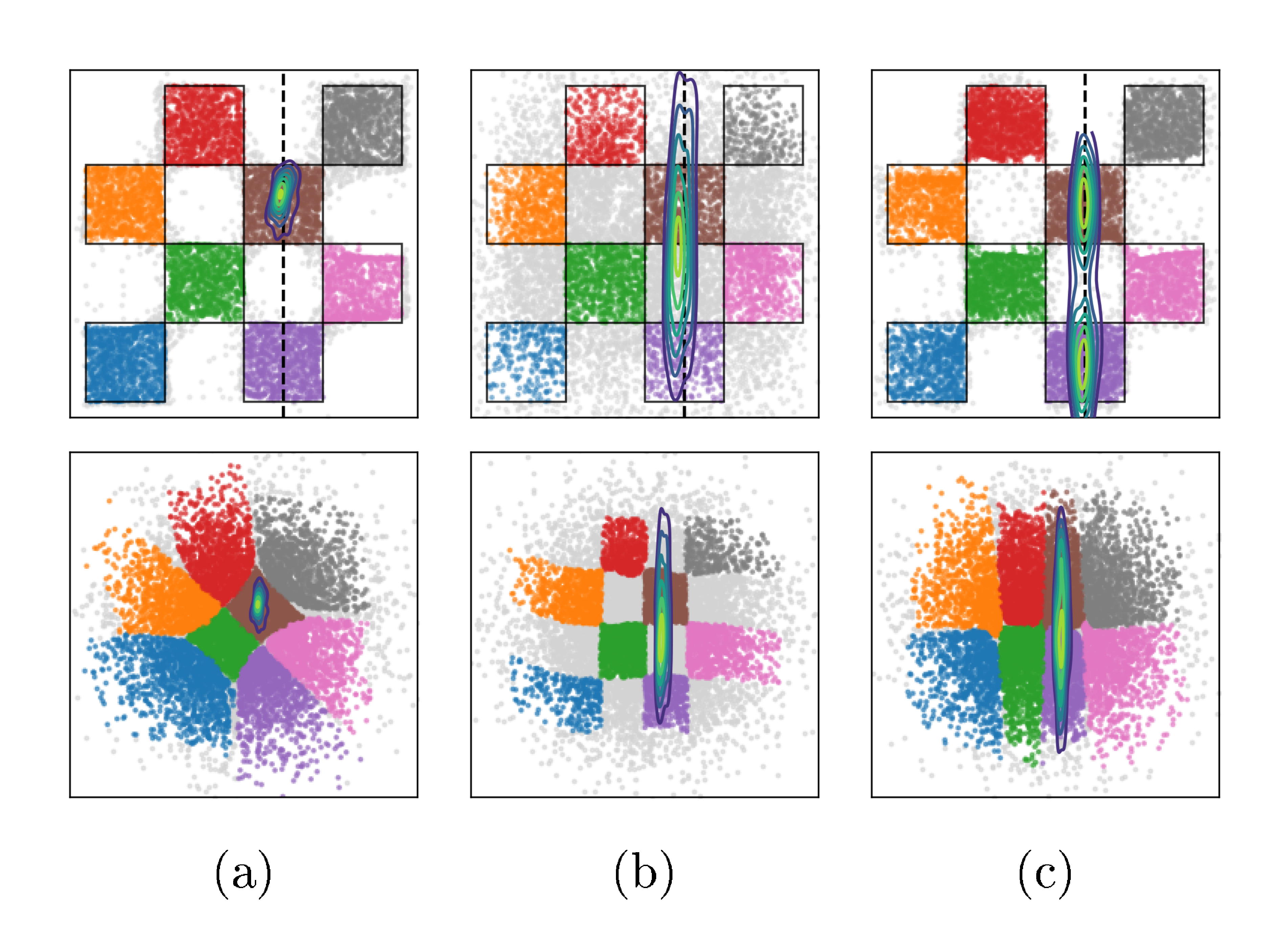

4.1 Illustration on a 2D Example
In this experiment, we illustrate the effects of jointly training $(\theta, \phi)$ on a toy 2D example, and perform ablations on key design choices in VFM. Specifically, we take $p(x)$ to be a $4\times4$ checkerboard distribution supported on $[-2, 2]\times[-2, 2]$. For the forward problem, we observe only the first coordinate, i.e. $y = Ax + \varepsilon$ with $A=\begin{pmatrix}1 & 0\end{pmatrix} $ and $ \varepsilon\sim\mathcal N(0, \sigma^2) $ with $ \sigma=0.1$. We refer the readers to Appendix B.1 for details on the experimental setup.
Baselines and evaluation metrics.
We consider two baselines: the first, frozen- $\theta$ trains only the noise adapter $q_\phi(z|y)$ via loss Equation 3 (amortized over $y$), while keeping $\theta$ fixed to a pretrained flow map. The second, unconstrained- $\theta$ , optimizes the same objective but learns $\theta$ jointly with $\phi$. These baselines are chosen to illustrate (i) the effect of joint optimization of $\theta$ and $\phi$, and (ii) the failure mode that can occur when $\theta$ is trained without the structural constraints imposed by the mean flow loss.
For model evaluation, we use the following metrics: (1) The negative log predictive density (NLPD), evaluates how well generated samples are consistent with observations $y$; (2) the continuous ranked probability score (CRPS) measures uncertainty calibration around the ground truth $x$ that generated $y$; (3) the maximum mean discrepancy (MMD) provides a sample-based distance between the true and approximate posteriors [19]; (4) the support accuracy (SACC) measures the proportion of samples $x = f_\theta(z)$ that lie on the checkerboard support. We compare MMD and SACC on both unconditional samples ${f_\theta(z)}{z \sim \mathcal{N}(0, I)}$ and conditional samples ${f\theta(z)}{z \sim q\phi(z | y)}$ to evaluate the quality of both prior and posterior approximations, respectively. For details, see Appendix B.1.3.
Ablation on the loss components.
We compare VFM against frozen- $\theta$ and unconstrained- $\theta$ to isolate the effect of the mean flow term $\mathcal{L}{\text{MF}}(\theta; \phi)$ in Equation 9; results displayed in Figure 2. The frozen- $\theta$ baseline (Figure 2a) fails to capture the bimodality of the true posterior (support in the brown and purple cells), due to the limited flexibility of $q\phi$. On the other hand, unconstrained- $\theta$ (Figure 2b) is able to sample from both brown and purple cells, however, also produces many off-manifold samples. VFM (Figure 2c, $\tau=100$, $\alpha=1$) successfully captures both modes while preserving the checkerboard pattern; joint training improves the noise-to-data coupling, while $\mathcal{L}{\text{MF}}$ pull samples towards the structured data manifold. This observation is supported by the improvements in CRPS and posterior MMD (see Figure 17 & Figure 18, Appendix), and high support accuracy comparable to the pretrained flow map used in frozen- $\theta$ . Finally, removing $\mathcal{L}{\text{KL}}(\phi)$ from Equation 9 makes training unstable, owing to the ill-posedness of the inverse problem without prior regularization.
Ablation on $\tau$ and $\alpha$.
We sweep $\tau \in [10^{-2}, 10^2]$, and report metrics using a single-step and 4-step sampler (See Figure 17 & Figure 18, Appendix). When $\tau \lesssim \sigma$, performance across metrics is generally worse than frozen- $\theta$ (Figure 20a & Figure 20b, Appendix). For $\tau \geq 1$, results improve substantially, especially CRPS and posterior MMD, while SACC and prior MMD approach the strong values already achieved by the pretrained flow used in frozen- $\theta$ . We also ablate on $\alpha$, fixing $\tau = 100$ (Figure 21, Appendix). Setting $\alpha = 0$ decouples the training of mean flow and the adapter, yielding behaviour close to frozen- $\theta$ . Increasing $\alpha$ strengthens the coupling, inducing a more pronounced warping of the latent space. In practice, $\alpha < 1$ is more stable and yields better prior fit (lower prior MMD, compare Figure 16 and Figure 16), whereas $\alpha = 1$ gives the best posterior fit (lower posterior MMD, see Figure 16 vs Figure 16, Appendix).
To EMA or not to EMA.
Finally, we examine the role of using an EMA of $\theta$ in the observation loss $\mathcal{L}{\text{obs}}(\theta, \phi)$. Without EMA, i.e., allowing $\theta$-gradients to propagate through $\mathcal{L}{\text{obs}}$, both prior and posterior support accuracy deteriorate as $\tau$ increases (orange curves in Figure 17 and Figure 18). This can be explained by the fact that in the limit $\tau \rightarrow \infty$, this pushes training toward the unconstrained- $\theta$ failure mode, leading to unstructured sample generation. This can be seen in Figure 19c, where the no-EMA variant when $\tau=100$ yields results similar to unconstrained- $\theta$ .
4.2 Image Inverse Problems
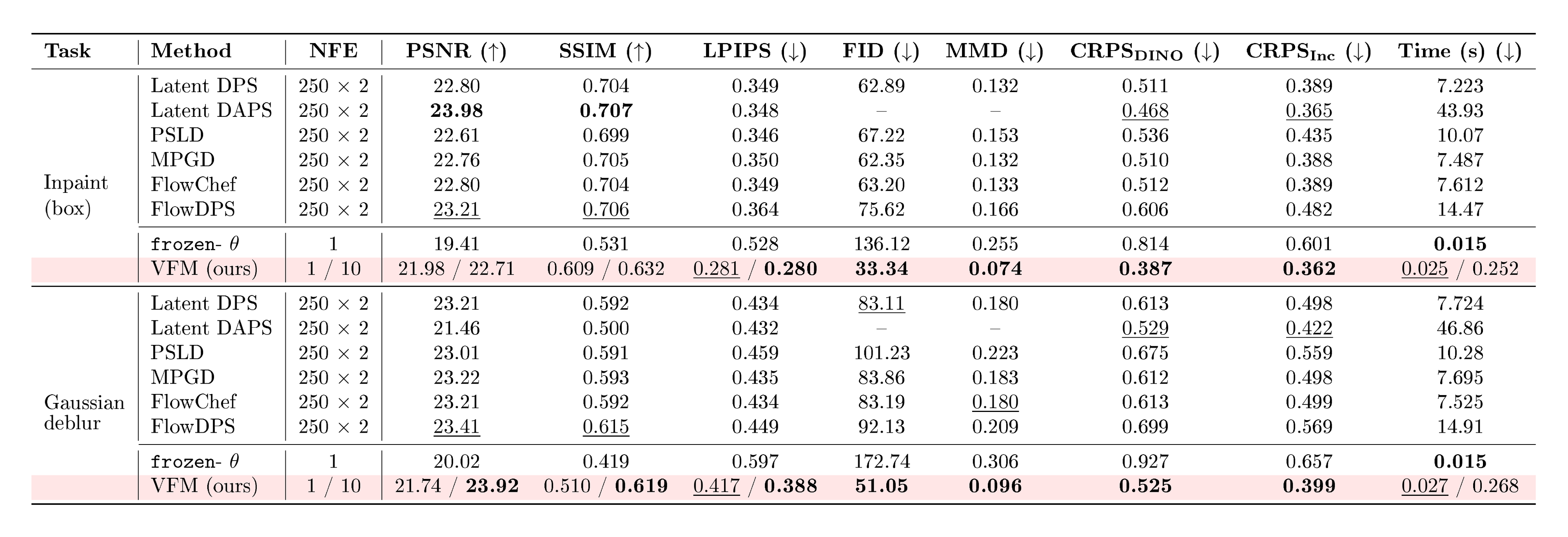
::: {caption="Table 1: Quantitative comparison on ImageNet for box inpainting and Gaussian deblurring. Best results are in bold, second best are $\underline{underlined}$. $\uparrow$ : higher is better, $\downarrow$ : lower is better. For VFM, we display results for single samples and average over 10 samples, displayed as {sample} / {average}. VFM achieves the best results on LPIPS, FID, MMD, CRPS, with a significantly reduced wall-clock time."}
:::
We evaluate VFM on standard image inverse problems using ImageNet 256 $\times$ 256, comparing against established guidance-based solvers, as well as the frozen- $\theta$ baseline considered in our earlier 2D experiment. For VFM, we amortize over the problems, as described in Section 3.2. All methods operate in the latent space of SD-VAE [20]. We provide further details of our experimental settings in Appendix B.2.
Comparison with guidance-based methods.
Table 1 reports quantitative results on box inpainting and Gaussian deblurring tasks (additional tasks are in Table 2, Appendix). For VFM, we report results for both single posterior samples and averaged estimates over 10 posterior samples, shown as {sample}/{average}. For all guidance-based baselines, we use the same flow-matching backbone (SiT-B/2) used to initialize our mean-flow model.
Across both tasks, we observe that VFM is consistently better than the baselines on distributional metrics (FID, MMD & CRPS), e.g., on box inpainting, the FIDs on the baselines range between 63–76, while we achieve an FID of 33.3. These improvements align with the qualitative results in Figure 3, where we observe that VFM exhibits notable diversity in the inpainted region, while maintaining visual sharpness. Guidance-based methods generally struggle with box-inpainting, especially when operating in latent space.
On pixel-space fidelity metrics (PSNR, SSIM), guidance methods consistently scores higher than a single VFM draw. However, both PSNR and SSIM typically reward mean behavior and thus prefer smoother results [21]. To confirm this, we observe that averaging multiple VFM samples narrows this gap and even exceeds the baselines in some instances, e.g., on Gaussian deblurring. On LPIPS, which is a feature-space perceptual similarity metric, we find that VFM is competitive even without averaging; this is consistent with LPIPS being more aligned with the perceptual quality than PSNR or SSIM [21].
We also note the significant speed advantage of VFM at inference time: we used 250 sampling steps for the guidance methods with an additional $\times 2$ cost for classifier-free guidance [22], while VFM requires only one step to achieve competitive results, as displayed. This results in around two orders of magnitude lower wall-clock time, e.g., DAPS [23] has an inference cost close to a minute; in comparison, the $\sim 0.03$ s cost of VFM is instantaneous.
Benefits of joint training.
The frozen- $\theta$ baseline, while fastest at inference time, performs poorly across all metrics, exhibiting visible artifacts and blurriness. This highlights the importance of jointly training the flow map $f_\theta$ and the adapter $q_\phi$, consistent with our observations from the 2D experiment that the flow map itself needs to adjust for the adapter to approximate the conditional distributions well. By training jointly, we observe surprisingly strong perceptual quality, despite the simple Gaussian structural assumption used in the variational posterior.
Unconditional generation.
To assess the robustness of VFM, we also evaluate unconditional generation from the trained flow map. In Figure 4, we compare the FID on 50, 000 unconditional samples generated from the flow map in VFM, against various baselines with similar architecture sizes [24, 25, 26, 27]. We fine-tune the SiT-B/2 model (trained for 80 epochs) for an additional 100 epochs. We note, however, that the baselines are trained for longer ($\sim ! 240$ epochs). Unconditional generation of VFM remains competitive, with 2-step sampling results achieving FID below 10 (see Figure 4 for visual results). To achieve this result, we emphasize the important role of the $\alpha$ parameter; we observe that the adapter's noise outputs retain some structure from the observations (see Figure 28, Appendix) and are therefore not representative of pure standard Gaussian noise. Thus, using $\alpha < 1$ is necessary to achieve good unconditional performance. In our experiments, we used $\alpha=0.5$.

4.3 General Reward Alignment via VFM Fine-Tuning

Beyond solving standard inverse problems, the Variational Flow Map presents a highly efficient framework for general reward alignment. The goal is to fine-tune a pre-trained model such that its generated samples maximize a differentiable reward function $R(x, c)$ conditioned on a context $c$, while staying close to the original data distribution. This objective effectively corresponds to sampling from a reward-tilted distribution $p_{\text{reward}}(x|c) \propto p_{\text{data}}(x) \exp(\beta R(x, c))$.
Traditional flow and diffusion reward fine-tuning methods require expensive backpropagation through iterative sampling trajectories [28, 29, 30] or rely on approximations [31, 32]. In contrast, VFM achieves this by learning an amortized noise adapter $q_\phi(z|c)$ that directly maps the condition $c$ to a high-reward region of the latent space, while simultaneously fine-tuning the flow map $f_\theta$ to decode this noise into high-quality data. We formulate this by replacing the standard observation loss with a reward maximization objective:
$ \begin{align} \mathcal{L}{reward}(\theta, \phi) = -\lambda ;\mathbb{E}{c \sim p(c), z \sim q_\phi(z | c)}\left[R(f_\theta(z), c)\right] \end{align} $
where $\lambda$ controls the reward strength. In this context, the reward $R(x, c)$ can be viewed as the (unnormalized) log-likelihood of the context $c$ (e.g., a text prompt) given the generated sample.
To the best of our knowledge, this is the first rigorous, scalable framework for fine-tuning flow maps to arbitrary differentiable rewards. In particular, the fine-tuning process is very fast and stable. Starting from a pre-trained flow map, VFM achieves strong reward alignment in under $0.5$ epochs. The resulting model enables sampling from the reward-tilted distribution in a single neural function evaluation (1 NFE). We provide qualitative results in Figure 5 and present further training and generation details in Appendix B.3.
5. Related Works
Section Summary: Previous studies have explored using diffusion-based models for variational inference to approximate data distributions given observations, but they often depend on complex tools like normalizing flows that struggle with high-resolution images, or stick to simpler Gaussian approximations in the raw data space rather than more efficient noise spaces. Other approaches handle posterior inference in noise spaces with fixed generators and added complexity, or focus on stabilizing training for unconditional models through special noise mappings, differing from the current method's simpler setup that adapts the core model for conditional tasks. Finally, techniques for one-step conditional sampling tie closely to specific model types like consistency models, limiting their flexibility compared to broader flow-based approaches.
Variational/amortized inference with diffusion-based priors has been explored in previous works: [33] explores usage of score-based prior in variational inference to approximate posteriors $p(x|y)$ in data space and [34] extends this to the amortized inference setting. However, these approaches rely on normalizing flows to ensure sufficient flexibility for the variational posterior, making scaling to high-resolution settings difficult. The work [35] on the other hand, uses a Gaussian variational posterior similar to ours, but still performs variational inference in data space.
Noise space posterior inference for arbitrary generative models has been considered in ([36]). However, their method considers a frozen generator and compensates with a more flexible noise adapter based on neural SDEs, making training significantly more complex. In comparison, VFM uses a simpler adapter and instead unfreeze the generative flow map, so the model itself can adapt to the conditional task while keeping the objective simple.
We also note the work ([18]), which introduces Variational Consistency Training (VCT) to address instability issues in consistency model training by learning data-dependent noise couplings through a variational encoder that maps data into a better-behaved latent representation. While conceptually related to our work, the goal is different: VCT is aimed at improving stability of unconditional consistency training, whereas VFM is designed to amortize posterior sampling for conditional generation.
Finally, Noise Consistency Training (NCT) [37] also targets one-step conditional sampling, but via a different construction: they consider a diffusion process in $(z, y)$-space and learns a consistency map from intermediate states to $(x, y)$. This is strongly tied to consistency models and therefore do not generalize naturally to flow maps, considered state-of-the-art in one-step generative modeling.
6. Conclusion
Section Summary: Variational Flow Maps, or VFMs, offer a new way to quickly sample from complex data distributions and fine-tune AI models for rewards using just one or a few steps, making the process much more efficient. This approach trains a special mapping tool along with an adapter that smartly guesses the best starting noise based on imperfect inputs like blurry images, category labels, or text descriptions. Looking ahead, researchers plan to improve it by incorporating more flexible noise patterns and applying it to areas like video processing to ensure smoother transitions between frames.
We proposed Variational Flow Maps (VFMs) to enable highly efficient posterior sampling and reward fine-tuning with just a single (or few) sampling steps. VFM leverages a principled variational objective to jointly train a flow map alongside an amortized noise adapter, which infers optimal initial noise from noisy observations, class labels, or text prompts. A natural next step is to relax our current Gaussian adapter assumption by using more expressive noise models, such as normalizing flows or energy-transformers [38], which can capture richer, non-Gaussian conditional structures. Another exciting direction for future research is to extend the VFM framework to other distillation methods and modalities; for instance, one could tackle video inverse problems, where latent noise evolution could be leveraged to promote temporal coherence among frames.
Impact Statement
Section Summary: The main aim is to cut down the computing power needed for generating specific outputs and sampling from probability distributions, which could speed up real-world uses in science and engineering while also lowering the energy used for running these models. As AI tools that create data become more common in everyday life, reducing these costs is a growing priority in machine learning. Variational flow maps advance this by allowing efficient, targeted sampling without any drop in quality.
The overarching goal of reducing the computational cost for conditional generation and posterior sampling has the potential not only to drive practical applications in scientific and engineering workflows that rely on fast generation of posterior samples, but also to help reduce the high energy cost for inference. This is especially valuable as generative models see widespread use in today's society; thus, the problem of lowering inference costs is an increasingly important challenge for machine learning. Variational flow maps take a step in this direction by enabling low-cost conditional sampling without sacrificing performance.
Acknowledgments
Section Summary: The authors express thanks to the Isambard-AI National AI Research Resource for providing the computing power used in their work. This resource is managed by the University of Bristol and funded by the UK government's Department for Science, Innovation and Technology through UK Research and Innovation, along with the Science and Technology Facilities Council. Further support came from a US Department of Defense fellowship awarded to Professor Andrew Stuart and a grant from the Office of Naval Research to the SciAI Center.
The authors acknowledge the use of resources provided by the Isambard-AI National AI Research Resource (AIRR) [39]. Isambard-AI is operated by the University of Bristol and is funded by the UK Government’s Department for Science, Innovation and Technology (DSIT) via UK Research and Innovation; and the Science and Technology Facilities Council [ST/AIRR/I-A-I/1023]. ST is supported by a Department of Defense Vannevar Bush Faculty Fellowship held by Prof. Andrew Stuart, and by the SciAI Center, funded by the Office of Naval Research (ONR), under Grant Number N00014-23-1-2729.
Appendix
Section Summary: The appendix outlines the theoretical underpinnings of a machine learning model involving latent variables and observations. It first derives the model's loss function by using Kullback-Leibler divergence to approximate the joint probability distribution of data, observations, and hidden variables, resulting in three key terms: one for fitting data, one for matching observations, and a regularization term to align the inferred latent distribution with a standard prior. The second part proves a key proposition in a simplified linear-Gaussian setup, demonstrating that training the model's generation and inference components together is essential for accurately recovering the true posterior distribution, while separate training often fails.
A. Theory
A.1 Derivation of the loss
We recall that the VFM objective is obtained by matching the following two representations of $p(x, y, z)$ using the KL divergence:
$ \begin{align} q_\phi(z | y) p(y | x) p(x) \approx p_\theta(x, y | z) p(z), \end{align} $
where we assumed that
$ \begin{align} p_\theta(x, y | z) = \mathcal{N}(x | f_\theta(z), \sigma^2 I) \mathcal{N}(y | A f_\theta(z), \tau^2 I). \end{align}\tag{10} $
By direct computation, this yields
$ \begin{align} &KL(q_\phi(z | y) p(y | x) p(x) || p_\theta(x, y | z) p(z)) \ &= -\int \log \frac{p_\theta(x, y | z) p(z)}{q_\phi(z | y) p(y | x) p(x)} q_\phi(z | y) p(y | x) p(x) dx dy dz \ &= -\mathbb{E}{q\phi(z | y) p(y | x)p(x)}\left[\log p_\theta(x, y|z)\right] + \mathbb{E}{p(y | x)p(x)}\left[KL\left(q\phi(z|y) || p(z)\right)\right] + \underbrace{\mathbb{E}{p(y|x) p(x)}[\log (p(y|x) p(x))]}{\leq 0} \ &\leq -\mathbb{E}{q\phi(z | y) p(y | x)p(x)}\left[\log p_\theta(x, y|z)\right] + \mathbb{E}{p(y)}\left[KL\left(q\phi(z|y) || p(z)\right)\right] \ \begin{split} &\stackrel{Equation 10}{=} -\mathbb{E}{q\phi(z | y) p(y)}\left[\log \mathcal{N}(x | f_\theta(z), \sigma^2 I) + \log \mathcal{N}(y | \mathcal{A} f_\theta(z), \tau^2 I)\right] + \mathbb{E}{p(y | x)p(x)}\left[\mathcal{KL}\left(q\phi(z|y) || p(z)\right)\right], \end{split} \end{align}\tag{11} $
where we used that $\mathbb{E}{p(y|x) p(x)}[\log (p(y|x) p(x))] \leq 0$ since this is the negative Shannon entropy of the joint distribution $H(p(x, y)) := -\mathbb{E}{p(x, y)}[\log (p(x, y))] \geq 0$. This yields
$ \begin{align} &KL(q_\phi(z | y) p(y | x) p(x) || p_\theta(x, y | z) p(z)) \leq \frac{1}{2\tau^2}\mathcal{L}{data}(\theta, \phi) + \frac{1}{2\sigma^2} \mathcal{L}{obs}(\theta, \phi) + \mathcal{L}_{KL}(\phi), \nonumber \end{align} $
where
$ \begin{align} \mathcal{L}{data}(\theta, \phi) &= \mathbb{E}{q_\phi(z | y) p(y | x)p(x)}\left[|x - f_\theta(z)|^2\right], \ \mathcal{L}{obs}(\theta, \phi) &= \mathbb{E}{q_\phi(z | y) p(y)}\left[|y - Af_\theta(z)|^2\right], \ \mathcal{L}{KL}(\phi) &= \mathbb{E}{p(y)}\left[KL\left(q_\phi(z|y) || p(z)\right)\right]. \end{align}\tag{12} $
A.2 Proof of Proposition 1
This section provides the formal proofs for Proposition 1 within a Linear-Gaussian framework. We analyze the interaction between the generative map $f_\theta$ and the variational posterior $q_\phi$ to demonstrate that joint optimization is necessary for exact posterior mean recovery under diagonal constraints. The derivation proceeds from characterizing the optimal parameters to proving the almost sure failure of separate training in Proposition 12. We conclude with Remark 13, which discusses the extension of these results to non-linear cases through the lens of Jacobian alignment and symmetry restoration.
Data and Observation Model.
We assume the ground truth data $x \in \mathbb{R}^d$ follows a Gaussian distribution:
$ \begin{align} x \sim p_{data}(x) = \mathcal{N}(x|m, C), \end{align} $
where $m \in \mathbb{R}^d$ is the data mean and $C \in \mathbb{R}^{d\times d}$ is the symmetric positive definite (SPD) covariance matrix. The observation $y \in \mathbb{R}^{d_y}$ is obtained via a linear operator $A \in \mathbb{R}^{d_y \times d}$ with additive Gaussian noise:
$ \begin{align} y = Ax + \epsilon, \quad \epsilon \sim \mathcal{N}(0, \sigma^2 I), \end{align} $
where $\sigma > 0$ is the noise level. Consequently, the marginal distribution of observations is given by
$ \begin{align} p(y) = \mathcal{N}(y|\mu_y, \Sigma_y), \quad where \mu_y = Am, \quad \Sigma_y = ACA^\top + \sigma^2 I. \end{align} $
Generative Model.
We define the generative model $f_\theta: \mathbb{R}^d \to \mathbb{R}^d$ as a linear map acting on a standard Gaussian latent variable $z$:
$ \begin{align} &z \sim p(z) = \mathcal{N}(z|0, I), \ &x = f_\theta(z) = K_\theta z + b_\theta, \end{align} $
where $\theta = {K_\theta, b_\theta}$ are the learnable parameters with $K_\theta \in \mathbb{R}^{d \times d}$ and $b_\theta \in \mathbb{R}^d$. The induced model distribution is $p_\theta(x) = \mathcal{N}(b_\theta, K_\theta K_\theta^\top)$.
Amortized Inference (Adapter).
We parameterize the variational posterior (noise adapter) $q_\phi(z|y)$ as a multivariate Gaussian distribution:
$ \begin{align} q_\phi(z|y) = \mathcal{N}(\mu_\phi(y), \Sigma_\phi(y)), \end{align} $
where $\mu_\phi: \mathbb{R}^{d_y} \to \mathbb{R}^d$ and $\Sigma_\phi: \mathbb{R}^{d_y} \to \mathbb{R}^{d\times d}$ are generally parameterized by neural networks. While one may optionally restrict $\Sigma_\phi(y)$ to be a diagonal matrix for computational efficiency.
In the following sections, we will derive the optimal solutions for $\theta = {K_\theta, b_\theta}$ and $\phi$ under the separate training and joint training paradigms, respectively.
Training Objective.
Recall that in the general framework, we minimized a joint objective consisting of a data matching term, observation matching term, and a KL divergence term:
$ \begin{split} \mathcal{L}(\theta, \phi) = &\underbrace{\mathbb{E}{y \sim p{\mathrm{data}}(y)} \mathbb{E}{z \sim q\phi(z|y)} \left[\frac{1}{2\sigma^2} | y - A f_\theta(z) |^2 \right]}{\mathcal{L}{\text{obs}}: \text{ Observation Loss}} \ &+ \underbrace{\mathbb{E}{x \sim p{\mathrm{data}}(x)} \mathbb{E}{y \sim p(y|x)} \mathbb{E}{z \sim q_\phi(z|y)} \left[\frac{1}{2\tau^2} | x - f_\theta(z) |^2 \right]}{\mathcal{L}{\text{data}}: \text{ Data Fitting Loss}}\ &+ \underbrace{\mathbb{E}{y \sim p{\mathrm{data}}(y)} \left[\mathrm{KL}(q_\phi(z|y) , ||, p(z)) \right]}{\mathcal{L}{\mathrm{KL}}: \text{ KL Loss}}. \end{split}\tag{13} $
In the linear-Gaussian theoretical analysis, the generative map $f_\theta(z) = K_\theta z + b_\theta$ is explicitly parameterized as a single-step affine transformation. Note that $\mathcal{L}{\text{data}}$ corresponds to the negative expected log-likelihood term $-\mathbb{E} \left[\log \mathcal{N}(x|f{\theta}(z), \tau^2 I) \right]$.
Definition 4: Matrix Sets and Measure
We denote the set of $d \times d$ orthogonal matrices as the orthogonal group $\mathbb{O}(d) := { Q \in \mathbb{R}^{d \times d} \mid Q^\top Q = I }$. The space $\mathbb{O}(d)$ is equipped with the unique normalized Haar measure $\nu_{\mathbb{O}(d)}$, representing the uniform distribution over the group. Furthermore, let $\mathbb{S}^d$ represent the space of $d \times d$ real symmetric matrices. The subsets of symmetric positive semi-definite (SPSD) and symmetric positive definite (SPD) matrices are denoted by $\mathbb{S}+^d := { M \in \mathbb{S}^d \mid x^\top M x \ge 0, \forall x \in \mathbb{R}^d }$ and $\mathbb{S}{++}^d := { M \in \mathbb{S}^d \mid x^\top M x > 0, \forall x \in \mathbb{R}^d \setminus {0} }$, respectively. We denote the set of $d \times d$ real diagonal matrices as $\mathbb{D}(d) := { \mathrm{diag}(d_1, \dots, d_d) \mid d_i \in \mathbb{R} }$. We denote the determinant of a square matrix $M$ by $|M|$.
Lemma 5: Optimal Generative Parameters via KL Minimization
Consider the data distribution $p_{\mathrm{data}}(x) = \mathcal{N}(m, C)$ and the induced model distribution $p_\theta(x) = \mathcal{N}(b_\theta, \Sigma_\theta)$ with $\Sigma_\theta = K_\theta K_\theta^\top$. Let $C = U \Lambda^2 U^\top$ be the eigen-decomposition of the data distribution covariance, where $U \in \mathbb{O}(d)$ and $\Lambda \in \mathbb{D}(d)$ has positive entries. The set of optimal parameters $\Theta^* := \arg\min_{\theta} \mathrm{KL}(p_{\mathrm{data}}(x) , ||, p_\theta(x))$ is given by:
$ \Theta^* = { {K_\theta, b_\theta} \mid b_\theta = m, , K_\theta = U \Lambda Q, , \forall Q \in \mathbb{O}(d) }. $
Proof: The KL divergence between two multivariate Gaussians is minimized if and only if their first and second moments match, i.e., $b_\theta = m$ and $\Sigma_\theta = C$. Substituting the parameterization $\Sigma_\theta = K_\theta K_\theta^\top$ and the eigen-decomposition of $C$, the second condition becomes $K_\theta K_\theta^\top = U \Lambda^2 U^\top = (U\Lambda)(U\Lambda)^\top$. This equality holds if and only if $K_\theta = U \Lambda Q$ for some $Q \in \mathbb{R}^{d \times d}$ such that $Q Q^\top = I$, which implies $Q \in \mathbb{O}(d)$.
Definition: Optimal Loss Value
We define the optimal loss value for any $\theta\in\Theta^*$ and any $\phi$ as:
$ \mathcal{L}\mathrm{opt} = \min{\theta\in\Theta^*, \phi} \mathcal{L}(\theta, \phi). $
Lemma 6
Consider the joint training objective $\mathcal{L}(\theta, \phi)$ in the Linear-Gaussian setting. For fixed generative parameters $\theta = {K_\theta, b_\theta}$, the optimal variational posterior $q_{\phi^*}(z|y) = \mathcal{N}(\mu^*(y), \Sigma^*(y))$ that minimizes the loss Equation 13 (under the constratint that $\Sigma(y)\in\mathbb{S}_{++}^d$) is given by:
$ \begin{align} \mu^*(y) &:= K_\phi y + b_\phi, \ \Sigma^*(y) &:= \Sigma_\phi, \end{align} $
where
$ \begin{align} \Sigma_\phi &:= \left(I_d + \frac{1}{\tau^2} K_\theta^\top K_\theta + \frac{1}{\sigma^2} K_\theta^\top A^\top A K_\theta \right)^{-1}, \tag{a} \ K_\phi &:= \Sigma_\phi K_\theta^\top \left(\frac{1}{\sigma^2} A^\top + \frac{1}{\tau^2} K \right), \tag{b} \ b_\phi &:= \Sigma_\phi K_\theta^\top \left[-\frac{1}{\sigma^2} A^\top A b_\theta + \frac{1}{\tau^2} (I_d - K A) m - \frac{1}{\tau^2} b_\theta \right], \tag{c} \end{align}\tag{14} $
and $K = C A^\top (A C A^\top + \sigma^2 I_{d_y})^{-1}$ denotes the Kalman gain matrix associated with the data distribution. In particular, this shows that the optimal covariance $\Sigma^*$ is independent of $y$, and the optimal mean $\mu^*(y)$ is an affine function of $y$
Proof: The total loss is expressed as the expectation $\mathcal{L} = \mathbb{E}{y \sim p(y)} [J(y; \mu, \Sigma)]$, where $\mu := \mu\phi(y)$ and $\Sigma := \Sigma_\phi(y)$. The pointwise objective $J(y; \mu, \Sigma)$ is
$ \begin{align} J(y; \mu, \Sigma) &= \frac{1}{2\sigma^2} \left(| y - A b_\theta - A K_\theta \mu |^2 + \mathrm{Tr}(K_\theta^\top A^\top A K_\theta \Sigma) \right) \nonumber \ &\quad + \frac{1}{2\tau^2} \left(\mathbb{E}{x|y} [| x - b\theta - K_\theta \mu |^2] + \mathrm{Tr}(K_\theta^\top K_\theta \Sigma) \right) \nonumber \ &\quad + \frac{1}{2} \left(\mathrm{Tr}(\Sigma) + |\mu|^2 - \ln |\Sigma| \right). \end{align}\tag{15} $
Differentiating $J$ with respect to $\Sigma$ yields
$ \frac{\partial J}{\partial \Sigma} = \frac{1}{2} \left(\frac{1}{\sigma^2} K_\theta^\top A^\top A K_\theta + \frac{1}{\tau^2} K_\theta^\top K_\theta + I_d \right) - \frac{1}{2} \Sigma^{-1}. $
The stationary point of this gradient corresponds to the constant optimal covariance matrix $\Sigma_\phi$ defined in Equation 14a, naturally satisfying the SPD restriction. Similarly, the gradient with respect to the variational mean $\mu$ is given by
$ \nabla_\mu J = -\frac{1}{\sigma^2} K_\theta^\top A^\top (y - A b_\theta - A K_\theta \mu) - \frac{1}{\tau^2} K_\theta^\top (\mathbb{E}[x|y] - b_\theta - K_\theta \mu) + \mu. $
Rearranging the terms for the condition $\nabla_\mu J = 0$, it follows that
$ \left(I_d + \frac{1}{\sigma^2} K_\theta^\top A^\top A K_\theta + \frac{1}{\tau^2} K_\theta^\top K_\theta \right) \mu = \frac{1}{\sigma^2} K_\theta^\top A^\top (y - A b_\theta) + \frac{1}{\tau^2} K_\theta^\top (\mathbb{E}[x|y] - b_\theta).\tag{16} $
Observing that the coefficient matrix on the left-hand side is $\Sigma_\phi^{-1}$, we obtain the expression for the optimal mean
$ \mu^*(y) = \Sigma_\phi K_\theta^\top \left[\frac{1}{\sigma^2} A^\top y - \frac{1}{\sigma^2} A^\top A b_\theta + \frac{1}{\tau^2} \mathbb{E}[x|y] - \frac{1}{\tau^2} b_\theta \right].\tag{17} $
Substituting the conditional expectation of the data distribution $\mathbb{E}[x|y] = K y + (I_d - K A) m$ into Equation 17 results in
$ \mu^*(y) = \Sigma_\phi K_\theta^\top \left(\frac{1}{\sigma^2} A^\top + \frac{1}{\tau^2} K \right) y + \Sigma_\phi K_\theta^\top \left[-\frac{1}{\sigma^2} A^\top A b_\theta + \frac{1}{\tau^2} (I_d - K A) m - \frac{1}{\tau^2} b_\theta \right].\tag{18} $
This affine structure identifies $K_\phi$ and $b_\phi$ as defined in Equation 14b and 14c.
Corollary 7
We can optimize $\phi\in\Phi$ where
$ \Phi := { (K_\phi, b_\phi, \Sigma_\phi) \mid K_\phi \in \mathbb{R}^{d \times d_y}, b_\phi \in \mathbb{R}^d, \Sigma_\phi \in \mathbb{S}^d_{++} }.\tag{19} $
Proof: The functional forms derived in Lemma 6 show that any $q_\phi$ not belonging to this parametric family is strictly sub-optimal for the joint loss $\mathcal{L}(\theta, \phi)$, thus reducing the search space to the coefficients ${K_\phi, b_\phi, \Sigma_\phi}$.
Definition: Separate Training
The separate training paradigm consists of a two-stage sequential optimization. First, the generative parameters $\theta = {K_\theta, b_\theta}$ are obtained by minimizing the unconditional KL divergence
$ \begin{align} \theta^* = \operatorname*{argmin}\theta \mathrm{KL}\left((f\theta)\sharp \mathcal{N}(0, I) , ||, p{\mathrm{data}}(x) \right), \end{align} $
which, in the linear-Gaussian case, implies $b_{\theta^*} = m$ and $K_{\theta^*} K_{\theta^*}^\top = C$. Subsequently, the variational parameters are determined by fixing $\theta^*$ and minimizing the joint objective
$ \begin{align} \phi^* = \operatorname*{argmin}_\phi \mathcal{L}(\theta^*, \phi). \end{align} $
Definition: Joint Training
The joint training paradigm optimizes $\theta$ and $\phi$ simultaneously by minimizing the regularized objective with $\alpha > 0$,
$ \begin{split} &\min_{\theta, \phi} \mathcal{L}(\theta, \phi) \ &\quad \text{s.t. }(f_\theta)\sharp \mathcal{N}(0, I) = p{\mathrm{data}}. \end{split} $
For the linear-Gaussian framework, this constraint restricts the search space of $\theta$ to the manifold
$ \Theta^* = { {K_\theta, b_\theta} \mid b_\theta = m, K_\theta K_\theta^\top = C }. $
Definition: Solution Sets
Let $\Theta^*$ be the set of optimal generative parameters from Lemma 5, and the set $\Phi$ is defined in Equation 19. We define the diagonal parameter space by restricting the covariance matrix to be diagonal, yielding
$ \Phi_{\mathbb{D}} := { (K_\phi, b_\phi, \Sigma_\phi) \in \Phi \mid \Sigma_\phi \in \mathbb{S}_{++}^d \cap \mathbb{D}(d) }. $
The solution sets for the training paradigms are defined as
$ \begin{align} \mathcal{S}^{\mathrm{sep}} &:= { (\theta^*, \phi), \theta^* \in \Theta^*\mid \phi = \operatorname*{argmin}{\phi' \in \Phi} \mathcal{L}(\theta^*, \phi') }, \ \mathcal{S}^{\mathrm{sep}}{\mathrm{diag}} &:= { (\theta^*, \phi), \theta^* \in \Theta^*\mid \phi = \operatorname*{argmin}{\phi' \in \Phi{\mathbb{D}}} \mathcal{L}(\theta^*, \phi') }, \ \mathcal{S}^{\mathrm{joint}} &:= { (\theta, \phi) \mid (\theta, \phi) = \operatorname*{argmin}{\theta' \in \Theta^*, \phi' \in \Phi} \mathcal{L}(\theta', \phi') }, \ \mathcal{S}^{\mathrm{joint}}{\mathrm{diag}} &:= { (\theta, \phi) \mid (\theta, \phi) = \operatorname*{argmin}{\theta' \in \Theta^*, \phi' \in \Phi{\mathbb{D}}} \mathcal{L}(\theta', \phi') }. \end{align} $
Lemma 8
For $Q\in\mathbb{O}(d)$ and $\theta(Q) := (U \Lambda Q, m) \in \Theta^*$, there exists a corresponding optimal parameter $\phi(Q) := (K_\phi(Q), b_\phi(Q), \Sigma_\phi(Q)) \in\Phi$ such that the joint loss Equation 13 is invariant to the choice of $Q$, i.e., $\mathcal{L}(\theta(Q), \phi(Q)) = \mathcal{L}_{\mathrm{opt}}$. In particular, we have the explicit expressions
$ \begin{align} \Sigma_\phi(Q) &:= Q^\top \left(I_d + \frac{1}{\tau^2} \Lambda^2 + \frac{1}{\sigma^2} \Lambda U^\top A^\top A U \Lambda \right)^{-1} Q, \tag{a}\ K_\phi(Q) &:= \Sigma_\phi(Q) Q^\top \Lambda U^\top \left(\frac{1}{\sigma^2} A^\top + \frac{1}{\tau^2} K \right), \tag{b}\ b_\phi(Q) &:= \Sigma_\phi(Q) Q^\top \Lambda U^\top \left[-\frac{1}{\sigma^2} A^\top A m + \frac{1}{\tau^2} (I_d - K A) m - \frac{1}{\tau^2} m \right].\tag{c} \end{align}\tag{20} $
Consequently, the solution sets for separate and joint training are
$ \begin{align} \mathcal{S}^{\mathrm{sep}} &= { (\theta(Q_{\mathrm{sep}}), \phi(Q_{\mathrm{sep}})) \mid Q_{\mathrm{sep}} \in \mathbb{O}(d) , \text{is fixed}}, \ \mathcal{S}^{\mathrm{joint}} &= { (\theta(Q), \phi(Q)) \mid \forall Q \in \mathbb{O}(d) }. \end{align} $
Proof: For a fixed $Q \in \mathbb{O}(d)$, let $K_{\theta} = U \Lambda Q$ and $b_\theta = m$. Substituting these into the optimality conditions Equation 14a–Equation 14c yields the parameterized forms of $\Sigma_\phi(Q)$, $K_\phi(Q)$, and $b_\phi(Q)$. The optimal precision matrix $P(Q) := (\Sigma_\phi(Q))^{-1}$ satisfies
$ \begin{align} P(Q) &= I_d + \frac{1}{\tau^2} Q^\top \Lambda U^\top U \Lambda Q + \frac{1}{\sigma^2} Q^\top \Lambda U^\top A^\top A U \Lambda Q \nonumber \ &= Q^\top \left(I_d + \frac{1}{\tau^2} \Lambda^2 + \frac{1}{\sigma^2} \Lambda U^\top A^\top A U \Lambda \right) Q \coloneqq Q^\top H Q, \end{align} $
where $H$ is a SPD matrix independent of $Q$ defined by
$ H \coloneqq I_d + \frac{1}{\tau^2} \Lambda^2 + \frac{1}{\sigma^2} \Lambda U^\top A^\top A U \Lambda. $
According to Lemma 6, the optimal covariance is given by Equation 20a,
$ \Sigma_\phi(Q) = Q^\top H^{-1} Q.\tag{21} $
According to equations 17 and 18, we have the optimal mean of $q_\phi(z|y)$ as
$ \mu_Q(y) = \Sigma_\phi(Q) K_\theta^\top v(y),\tag{22} $
where $v(y)$ is independent of $Q$. Specifically, by plugging the equation 22 and $K_\theta = U\Lambda Q$ into Equation 22, we know the optimal solution $K_\phi(Q)$ and $b_\phi(Q)$ as equations 20b and 20c, respectively.
Then we plug Equation 21, Equation 22 and $K_\theta = U\Lambda Q$ into the pointwise objective $J(y;\mu_Q, \Sigma_Q)$ Equation 15. All terms related to $Q$ will be canceled out because $QQ^\top = Q^\top Q = I$, reducing $J(y;\mu_Q, \Sigma_Q)$ to an expression independent of $Q$. Therefore, for every $Q \in \mathbb{O}(d)$, the pair $(\theta(Q), \phi(Q))$ achieves the global minimum $\mathcal{L}{\mathrm{opt}}$, forming the manifold $\mathcal{S}^{\mathrm{joint}}$. The separate training paradigm uniquely determines $Q{\mathrm{sep}}$ during the pre-training of the generative map, restricting the solution to a singleton.
Lemma 9
For any $(\theta, \phi) \in \mathcal{S}^{\mathrm{joint}}$, the product of the generative and variational weight matrices equals the Kalman gain $K = C A^\top (A C A^\top + \sigma^2 I_{d_y})^{-1}$, i.e., $K_\theta K_\phi = K$. Furthermore, the expected output of the generative inference process recovers the exact Bayesian posterior mean,
$ \mathbb{E}{z \sim q\phi(z|y)} [f_\theta(z)] = \mathbb{E}{p{\mathrm{data}}(x|y)} [x]. $
Specifically, this holds for the separate training where $\mathcal{S}^{\mathrm{sep}} = { (\theta(Q_{\mathrm{sep}}), \phi(Q_{\mathrm{sep}})) }\subset \mathcal{S}^\mathrm{joint}$ for a fixed $Q_{\mathrm{sep}} \in \mathbb{O}(d)$.
Proof: Substituting $\Sigma_\phi$ from Equation 14a into the expression for $K_\phi$ in Equation 14b, and applying the push-through identity $K_\theta (I_d + K_\theta^\top \mathcal{M} K_\theta)^{-1} = (I_d + K_\theta K_\theta^\top \mathcal{M})^{-1} K_\theta$ with $\mathcal{M} := \sigma^{-2} A^\top A + \tau^{-2} I_d$, we have
$ \begin{align} K_\theta K_\phi &= (I_d + C (\sigma^{-2} A^\top A + \tau^{-2} I_d))^{-1} C \left(\sigma^{-2} A^\top + \tau^{-2} K \right) \nonumber \ &= (C^{-1} + \sigma^{-2} A^\top A + \tau^{-2} I_d)^{-1} \left(\sigma^{-2} A^\top + \tau^{-2} K \right). \end{align}\tag{23} $
Using the identity of the Kalman gain, $(C^{-1} + \sigma^{-2} A^\top A) K = \sigma^{-2} A^\top$, and adding $\tau^{-2} K$ to both sides, we have
$ (C^{-1} + \sigma^{-2} A^\top A + \tau^{-2} I_d) K = \sigma^{-2} A^\top + \tau^{-2} K. $
Left-multiplying by $(C^{-1} + \sigma^{-2} A^\top A + \tau^{-2} I_d)^{-1}$ and comparing with Equation 23, we obtain $K_\theta K_\phi = K$.
Consider $\mathbb{E}{z \sim q\phi(z|y)} [f_\theta(z)] = K_\theta (K_\phi y + b_\phi) + b_\theta$. Since $b_\theta = m$ and $K_\theta K_\phi = K$, expanding $K_\theta b_\phi$ via Equation 14c yields
$ \begin{align} K_\theta b_\phi &= K_\theta \Sigma_\phi K_\theta^\top \left[-\sigma^{-2} A^\top A m + \tau^{-2} (I_d - KA) m - \tau^{-2} m \right] \nonumber \ &= -(C^{-1} + \sigma^{-2} A^\top A + \tau^{-2} I_d)^{-1} (\sigma^{-2} A^\top A + \tau^{-2} KA) m \nonumber \ &= -(C^{-1} + \sigma^{-2} A^\top A + \tau^{-2} I_d)^{-1} (\sigma^{-2} A^\top + \tau^{-2} K) Am = -KAm. \end{align} $
Therefore
$ \mathbb{E}{z \sim q\phi(z|y)} [f_\theta(z)] = Ky - KAm + m = m + K(y - Am) = \mathbb{E}{p{\mathrm{data}}(x|y)} [x]. $
Proposition 10
Assume that the observation operator $A$ and data covariance $C$ are in general position such that they are not simultaneously diagonalizable in the canonical basis. For separate training with $Q_\mathrm{sep}$ uniformly randomly sampled from $\mathbb{O}(d)$, the following properties hold:
- Sub-optimality of Separate Training: $\mathcal{S}^{\mathrm{sep}} \cap \mathcal{S}^{\mathrm{sep}}{\mathrm{diag}} = \emptyset$ a.s. w.r.t. $\nu{\mathbb{O}(d)}$ (Definition 4).
- Optimality of Joint Training: $\mathcal{S}^{\mathrm{joint}} \cap \mathcal{S}^{\mathrm{joint}}{\mathrm{diag}} \neq \emptyset$ and $\mathcal{S}^{\mathrm{joint}}{\mathrm{diag}} \subset \mathcal{S}^{\mathrm{joint}}$
Proof: For $Q\in\mathbb{O}(d)$ and $\theta(Q) \in \Theta^*$, recall from the proof in Lemma 8 by
$ P(Q) := (\Sigma_\phi^*(Q))^{-1} = Q^\top H Q, \quad \text{where} \quad H := I_d + \frac{1}{\tau^2} \Lambda^2 + \frac{1}{\sigma^2} \Lambda U^\top A^\top A U \Lambda. $
Let $\Sigma_\phi = \mathrm{diag}(\sigma_1^2, \sigma_2^2, \ldots, \sigma_d^2) \in \mathbb{D}(d)$. The covariance-dependent objective $J(\Sigma_\phi)$ according to 15 and its minimizer $\Sigma^*_{\mathrm{diag}, \phi}$ are:
$ \begin{align} J(\Sigma_\phi) &= \frac{1}{2} \sum_{i=1}^d \left(P_{ii}(Q) \sigma_{i}^2 - \ln \sigma_i^2 \right) + \text{const}, \ ^{-1} &= \mathrm{diag}(P(Q)) = \mathrm{diag}(\Sigma^*_\phi(Q)^{-1}), \end{align} $
where $\Sigma^*_\phi(Q) = P(Q)^{-1}$. The optimality gap $\Delta J(Q)$ between $\Sigma^*_{\mathrm{diag}, \phi}(Q)$ and the unconstrained $\Sigma^*_\phi(Q) = P(Q)^{-1}$ is:
$ \begin{split} \Delta J(Q) &:= J(\Sigma^*_{\mathrm{diag}, \phi}(Q)) - J(\Sigma^*_\phi(Q)) \ &= \frac{1}{2} \left(\mathrm{Tr}(P(Q) \Sigma^*_{\mathrm{diag}, \phi}(Q)) - \ln |\Sigma^*_{\mathrm{diag}, \phi}(Q)| \right) - \frac{1}{2} \left(\mathrm{Tr}(P(Q) \Sigma^*_\phi(Q)) - \ln |\Sigma^*_\phi(Q)| \right) \ &= \frac{1}{2} \left(\sum_{i=1}^d P_{ii}(Q) P_{ii}(Q)^{-1} + \ln \prod_{i=1}^d P_{ii}(Q) \right) - \frac{1}{2} \left(\mathrm{Tr}(I_d) + \ln |P(Q)| \right) \ &= \frac{1}{2} \left(d + \ln \prod_{i=1}^d P_{ii}(Q) \right) - \frac{1}{2} \left(d + \ln |P(Q)| \right) \ &= \frac{1}{2} \ln \left(\frac{\prod_{i=1}^d P_{ii}(Q)}{|P(Q)|} \right). \end{split} $
By Hadamard's inequality, $\Delta J(Q) \geq 0$ and the equality holds if and only if $P(Q) \in \mathbb{D}(d)$.
In separate training, $Q_{\mathrm{sep}}$ is fixed during pre-training and global optimality requires $P(Q_{\mathrm{sep}}) = Q_{\mathrm{sep}}^\top H Q_{\mathrm{sep}} \in \mathbb{D}(d)$. By the general position assumption of $A$ and $C$, $H = I_d + \tau^{-2} \Lambda^2 + \sigma^{-2} \Lambda U^\top A^\top A U \Lambda$ is not a diagonal matrix. The set of matrices ${Q \in \mathbb{O}(d) \mid Q^\top H Q \in \mathbb{D}(d)}$ corresponds exclusively to the orthogonal matrices whose columns are the eigenvectors of $H$. Because this forms a finite set of permutation and sign-flip matrices, it holds a measure of zero with respect to the normalized Haar measure $\nu_{\mathbb{O}(d)}$ on the continuous manifold $\mathbb{O}(d)$ (refer to the Definition 4).
According to the equality condition of the Hadamard's inequality, $P(Q_{\mathrm{sep}}) \notin \mathbb{D}(d)$ a.s., leading to $\Delta J(Q) > 0$, which implies that the optimal loss value reached by the diagonal constrained $\Sigma^*_{\mathrm{diag}, \phi}(Q)$ is bigger than $\mathcal{L}\mathrm{opt}$. According to Lemma 8, $\mathcal{S}^\mathrm{sep}$ has the optimal loss $\mathcal{L}\mathrm{opt}$. Therefore $\mathcal{S}^{\mathrm{sep}} \cap \mathcal{S}^{\mathrm{sep}}_{\mathrm{diag}} = \emptyset$.
In joint training, $Q$ is a learnable parameter optimized over $\mathbb{O}(d)$. The global minimum $\mathcal{L}{\mathrm{opt}}$ under the diagonal constraint is achieved if and only if the optimality gap vanishes, $\Delta J(Q) = 0$. By Hadamard's inequality, this condition holds if and only if $P(Q) = Q^\top H Q \in \mathbb{D}(d)$, which restricts $Q$ to the set of eigen-bases $\mathcal{V}(H) := { Q \in \mathbb{O}(d) \mid Q^\top H Q \in \mathbb{D}(d) }$. For any $Q \in \mathcal{V}(H)$, the optimal variational covariance $\Sigma^*{\phi}(Q) = P(Q)^{-1}$ inherently belongs to $\mathbb{D}(d)$. Because these specific configurations satisfy the diagonal constraint while simultaneously achieving the unconstrained global minimum, it follows that $\mathcal{S}^{\mathrm{joint}}{\mathrm{diag}} = { (\theta(Q), \phi(Q)) \mid Q \in \mathcal{V}(H) } \subset \mathcal{S}^{\mathrm{joint}}$, thereby confirming $\mathcal{S}^{\mathrm{joint}} \cap \mathcal{S}^{\mathrm{joint}}{\mathrm{diag}} \neq \emptyset$.
Lemma 11
Let $\mathbb{O}(d)$ be the orthogonal group equipped with the normalized Haar measure $\nu_{\mathbb{O}(d)}$. Let $\text{Sym}_0(d) := { M \in \mathbb{R}^{d \times d} \mid M = M^\top, \text{diag}(M) = 0 }$. Define the map $G: \mathbb{O}(d) \to \text{Sym}_0(d)$ by $G(Q) = QHQ^\top - \text{diag}(QHQ^\top)$, where $H \in \mathbb{R}^{d \times d}$ is a fixed symmetric matrix with distinct eigenvalues. Let $V \subset \mathbb{R}^{d \times d}$ be a proper subspace such that $\text{Sym}_0(d) \not\subseteq V$. Then the set
$ S := { Q \in \mathbb{O}(d) \mid G(Q) \in V } $
has measure $\nu_{\mathbb{O}(d)}(S) = 0$.
Proof: The orthogonal group $\mathbb{O}(d)$ is a compact real analytic manifold. Let $\mathfrak{so}(d) = { B \in \mathbb{R}^{d \times d} \mid B = -B^\top }$ denote its Lie algebra. The map $G$ is real analytic since its entries are polynomial functions of the elements of $Q$. Let $P_{V^\perp}$ be the projection operator onto the orthogonal complement of $V$. The condition $G(Q) \in V$ is equivalent to $f(Q) \coloneqq P_{V^\perp} G(Q) = 0$. Now, $f = P_{V^\perp} \circ G$ is a composition of a linear projection and a polynomial map, which is real analytic on the manifold. Therefore $\nu_{\mathbb{O}(d)}(S) = 0$ follows if $f$ is not identically zero on the connected components of $\mathbb{O}(d)$ by the identity theorem.
Since $H$ is symmetric with distinct eigenvalues, there exists $Q_0 \in \mathbb{O}(d)$ such that $Q_0 H Q_0^\top = \Lambda = \text{diag}(\lambda_1, \dots, \lambda_d)$, where $\lambda_i \neq \lambda_j$ for $i \neq j$. We evaluate the differential $\text{D}G(Q_0)$ by considering the variation $Q(\epsilon) = e^{\epsilon B} Q_0$ for $B \in \mathfrak{so}(d)$. The directional derivative at $Q_0$ is given by
$ \text{D}G(Q_0)[B] = [B, \Lambda] - \text{diag}([B, \Lambda]). $
For the off-diagonal entries $i \neq j$, the commutator yields $[B, \Lambda] {ij} = \sum_k (B{ik} \Lambda_{kj} - \Lambda_{ik} B_{kj}) = B_{ij}\lambda_j - \lambda_i B_{ij} = (\lambda_j - \lambda_i) B_{ij}$. For the diagonal entries, $[B, \Lambda] {ii} = B{ii}\lambda_i - \lambda_i B_{ii} = 0$, which implies $\text{diag}([B, \Lambda]) = 0$. Thus, for any $i \neq j$, we have
$ (\text{D}G(Q_0)[B]){ij} = (\lambda_j - \lambda_i) B{ij}. $
Given that ${\lambda_i}$ are pairwise distinct, for any target matrix $M \in \text{Sym}0(d)$, we can uniquely determine $B \in \mathfrak{so}(d)$ by setting $B{ij} = M_{ij} / (\lambda_j - \lambda_i)$ for $i < j$. This proves that the differential $\text{D}G(Q_0): \mathfrak{so}(d) \to \text{Sym}_0(d)$ is a linear isomorphism.
Since $\text{D}G(Q_0)$ is an isomorphism onto $\text{Sym}_0(d)$ and $\text{Sym}0(d) \not\subseteq V$, there exists $B \in \mathfrak{so}(d)$ such that $\text{D}G(Q_0)[B] \notin V$. It follows that $P{V^\perp} \text{D}G(Q_0)[B] \neq 0$, implying that $f$ is not identically zero in a neighborhood of $Q_0$. By the identity theorem for real analytic functions, the zero set $S \cap \mathbb{O}(d)^\circ$ has Haar measure zero, where $\mathbb{O}(d)^\circ$ denotes the connected component containing $Q_0$. A similar argument holds for the remaining connected component of $\mathbb{O}(d)$ since $\mathbb{O}(d)$ has two connected components, i.e. $|Q|=1$ and $|Q|=-1$.
Proposition 12: Mean Recovery Gap under Diagonal Constraint
Assuming $A$ and $C$ are in general position, the following properties hold under the diagonal constraint $\Sigma_\phi \in \mathbb{D}(d)$:
- Separate Training: For any $(\theta, \phi) \in \mathcal{S}^{\mathrm{sep}}_{\mathrm{diag}}$, the inference process fails to recover the posterior mean almost surely:
$ \mathbb{E}{z \sim q{\phi}(z|y)} [f_\theta(z)] \neq \mathbb{E}{p{\mathrm{data}}(x|y)} [x] \quad \text{a.s. w.r.t. } y \sim \mathcal{N}(Am, \Sigma_y), , , Q \sim \nu_{\mathbb{O}(d)}. $
- Joint Training: For any $(\theta, \phi) \in \mathcal{S}^{\mathrm{joint}}_{\mathrm{diag}}$, the inference process recovers the exact posterior mean:
$ \mathbb{E}{z \sim q{\phi}(z|y)} [f_\theta(z)] = \mathbb{E}{p{\mathrm{data}}(x|y)} [x]. $
Proof: Let $\text{Sym}0(d) := { M \in \mathbb{R}^{d \times d} \mid M = M^\top, \text{diag}(M) = 0 }$. The expected reconstruction is $\hat{x} = \mathbb{E}{z \sim q_{\phi}(z|y)} [f_\theta(z)]=K_\theta K_\phi y + K_\theta b_\phi + b_\theta$, while the analytical posterior mean is $\mathbb{E}[x|y] = m + K(y - Am)$. In the separate training paradigm, where $(\theta(Q_{\mathrm{sep}}), \phi(Q_{\mathrm{sep}})) \in \mathcal{S}^{\mathrm{sep}}{\mathrm{diag}}$, the rotation $Q{\mathrm{sep}}$ is fixed. Let $P := Q_{\mathrm{sep}} H Q_{\mathrm{sep}}^\top$ and denote $E := [\mathrm{diag}(P)]^{-1} P - I$. Under the diagonal constraint, the gain matrix becomes $K_{\mathrm{diag}} = K_\theta [\mathrm{diag}(P)]^{-1} K_\theta^\top (\sigma^{-2} A^\top + \tau^{-2} K)$. The recovery error simplifies to
$ \hat{x} - \mathbb{E}[x|y] = (K_{\mathrm{diag}} - K)(y - Am) = K_\theta E K_\theta^{-1} K (y - Am). $
Since $A$ and $C$ are in general position, $Q_{\mathrm{sep}}$ does not diagonalize $H$ almost surely, implying that $P$ is non-diagonal and thus $E$ is a non-zero matrix with a vanishing diagonal. In addition, this general position assumption implies that $H$ has distinct eigenvalues and that $K = C A^\top (A C A^\top + \sigma^2 I)^{-1}$ has rank $d_y$.
Now define $V := {M\in \text{Sym}0(d) \mid K\theta M K_\theta^{-1} K=0}$ as a subspace of $\mathbb{R}^{d\times d}$. Since $K_\theta$ is invertible due to $K_\theta K_\theta^\top = C$, the condition $M \in V$ is equivalent to $M (K_\theta^{-1} K) = 0$. By the general position assumption, $K$ is non-zero, meaning the matrix $K_\theta^{-1} K$ contains at least one non-zero column $w$. If $M w = 0$ for all $M \in \text{Sym}_0(d)$, then applying symmetric matrices $M$ with a single pair of off-diagonal ones (and zeros elsewhere) would force all components of $w$ to be zero, contradicting $w \neq 0$. Thus, there exists some $M \in \text{Sym}0(d)$ such that $M K\theta^{-1} K \neq 0$, ensuring that $V$ is a proper subspace of $\text{Sym}_0(d)$ (i.e., $V \subsetneq \text{Sym}_0(d)$). Therefore we can use the Lemma 11 for $H$ and $V$ to show that
$ \nu_{\mathbb{O}(d)} ({Q\in\mathbb{O}(d) | QHQ^\top - \mathrm{diag}(QHQ^\top) \in V}) = 0,\tag{24} $
To connect this with the recovery error, let $M_\mathrm{sep} = Q_{\mathrm{sep}} H Q_{\mathrm{sep}}^\top - \mathrm{diag}(Q_{\mathrm{sep}} H Q_{\mathrm{sep}}^\top)$. By definition, the error matrix $E$ satisfies $E = [\mathrm{diag}(P)]^{-1} M_\mathrm{sep}$. Because $[\mathrm{diag}(P)]^{-1}$ is an invertible diagonal matrix, the condition $K_\theta E K_\theta^{-1} K = 0$ holds if and only if $M_\mathrm{sep} K_\theta^{-1} K = 0$, which is exactly $M_\mathrm{sep} \in V$. According to 24, we have
$ \nu_{\mathbb{O}(d)} ({ Q_{\mathrm{sep}} \in \mathbb{O}(d) \mid K_\theta E K_\theta^{-1} K = 0 }) = 0. $
This ensures that for almost every $Q_{\mathrm{sep}}$ sampled from $\mathbb{O}(d)$, the linear mapping matrix $K_\theta E K_\theta^{-1} K$ is strictly non-zero. Consequently, the null space ${ y \in \mathbb{R}^{d_y} \mid K_\theta E K_\theta^{-1} K(y - Am) = 0 }$ constitutes a proper affine subspace of $\mathbb{R}^{d_y}$ with dimension strictly less than $d_y$. Since the marginal distribution $p(y) = \mathcal{N}(y|Am, \Sigma_y)$ is a non-degenerate continuous Gaussian, it assigns zero probability mass to any strictly lower-dimensional subspace. It follows directly that the recovery error $\hat{x} - \mathbb{E}[x|y] \neq 0$ almost surely with respect to the joint measure of $p(y)$ and $\nu_{\mathbb{O}(d)}$, i.e.
$ \mathbb{E}{z \sim q{\phi}(z|y)} [f_\theta(z)] \neq \mathbb{E}{p{\mathrm{data}}(x|y)} [x] \quad \text{a.s. w.r.t. } y \sim \mathcal{N}(Am, \Sigma_y), , , Q \sim \nu_{\mathbb{O}(d)}. $
For joint training, Proposition 10 establishes that $\mathcal{S}^{\mathrm{joint}}{\mathrm{diag}} \subset \mathcal{S}^{\mathrm{joint}}$. Since every pair in $\mathcal{S}^{\mathrm{joint}}$ satisfies the unconstrained optimality condition $\hat{x} = \mathbb{E}[x|y]$ by Lemma 9, the identity holds for all $(\theta, \phi) \in \mathcal{S}^{\mathrm{joint}}{\mathrm{diag}}$ for all $y \in \mathbb{R}^{d_y}$, i.e.
$ \mathbb{E}{z \sim q{\phi}(z|y)} [f_\theta(z)] = \mathbb{E}{p{\mathrm{data}}(x|y)} [x]. $
Remark 13: Coordinate Alignment and Non-linear Extensions
Proposition 10 and Proposition 12 characterize the interaction between the generative map and the amortized inference network under structural constraints. In the separate training paradigm, the fixed generative map imposes a rigid coordinate system in the latent space. Restricting the variational posterior to a diagonal covariance $\Sigma_\phi$ forces it to approximate a structurally dense precision matrix $P(Q_{\mathrm{sep}})$, which inherently induces a systematic recovery gap. Joint training resolves this limitation by optimizing the orthogonal matrix $Q \in \mathbb{O}(d)$ to align the principal axes of the posterior precision with the canonical basis of the prior. This alignment guarantees that the diagonal parameterization attains the unconstrained global minimum $\mathcal{L}_{\mathrm{opt}}$.
Furthermore, this geometric alignment property extends to non-linear generative models. During joint optimization, the generator adapts its representation such that the local geometry of the data distribution corresponds with the inductive bias of the variational distribution. By adjusting its Jacobian $\nabla_z f_\theta(z)$, the generator can approximately diagonalize the pull-back metric in the latent space, providing a mathematical justification for the deployment of factorized posterior approximations in more general inference settings.
A.3 Proof of Proposition 2
First, noting that $f_\theta(z) = z - u_\theta(z, 0, 1)$, we have
$ \begin{align} \left|x - f_\theta(z)\right|^2 = \left|x - (z - u_\theta(z, 0, 1))\right|^2= \left|u_\theta(z, 0, 1) - (z - x)\right|^2. \end{align} $
Then, by Jensen's inequality, and recalling that $\psi_{t}(x, z) := tz + (1-t)x$, we get
$ \begin{align} &\int^1_0|\partial_t \mathcal{E}\theta(x, z, 0, t)|^2 dt \ &= \int^1_0\left|\frac{d}{dt} \left[t u\theta(\psi_{t}(x, z), 0, t) - \int^t_0 \dot{\psi}{t}(x, z) ds\right]\right|^2 dt \ & \stackrel{\text{Jensen}}{\geq} \left|\int^1_0 \frac{d}{dt} \left[t u\theta(\psi_{t}(x, z), 0, t) - t (z - x) \right] dt \right|^2 \ &= \left|u_\theta(z, 0, 1) - (z - x)\right|^2. \end{align} $
Putting these together, we establish our desired bound. \blacksquare
A.4 Proof of Proposition 3
From our assumptions, we can compute
$ \begin{align} p_\tau(x | y) := \int_{\mathbb{R}^d} \mathcal{N}(x | f_\theta(z), \tau^2 I) p(z | y) d z, \end{align}\tag{25} $
where
$ \begin{align} p(z | y) := \frac{\mathcal{N}(y | Af_\theta(z), \sigma^2 I) p(z)}{\int_{\mathbb{R}^d} \mathcal{N}(y | Af_\theta(z), \sigma^2 I) p(z) dz}. \end{align} $
Denoting by $\mu^y_\tau(dx) := p_\tau(x | y)dx$ and $\nu^y(dz) := p(z | y)dz$ the posterior measures in $x$ and $z$ spaces, respectively, for any $g \in C_b(\mathbb{R}^d)$, we have
$ \begin{align} \int_{\mathbb{R}^d} g(x) \mu^y_\tau(dx) &\stackrel{Equation 25}{=} \int_{\mathbb{R}^d} \int_{\mathbb{R}^d} g(x) \mathcal{N}(x | f_\theta(z), \tau^2 I) \nu^y(dz) dx \ &\stackrel{\tau \rightarrow 0}{\longrightarrow} \int_{\mathbb{R}^d} g\big(f_\theta(z)\big) \nu^y(dz) \ &= \int_{\mathbb{R}^d} g\big(x\big) (f_\theta)_\sharp \nu^y(dx), \end{align} $
where we used the standard result that $\mathcal{N}(x | f_\theta(z), \tau^2 I)$ converges weakly to the delta measure around $f_\theta(z)$ as $\tau \rightarrow 0$ [40], and we used the dominated convergence theorem and Fubini's theorem, both justified by the bound
$ \begin{align} \left|\int_{\mathbb{R}^d} g(x) \mathcal{N}(x | f_\theta(z), \tau^2 I) dx\right| \leq |g|_\infty. \end{align} $
This proves the weak convergence of measures $\mu^y_\tau \Rightarrow (f_\theta)_\sharp \nu^y$ as $\tau \rightarrow 0$. \blacksquare
B. Experimental Details
B.1 2D Checkerboard Data
We use a 2D checkerboard distribution supported on alternating squares in $[-2, 2]^2$. To sample, we first draw $u \sim \mathrm{Unif}([0, 1]^2)$ and partition the unit square into a $4\times4$ uniform grid. Then, we accept samples that lie on one of the checkerboard cells. Finally, we center and scale via $x = 4(u-(0.5, 0.5))$, so the support lies in $[-2, 2]^2$ and each retained square has side length $1$. We used $20, 000$ samples from this distribution to train our models.
B.1.1 Model architectures
For the mean-flow network $u_\theta$, we use a SiLU MLP with six layers and width $512$. We initialize this model from a flow-matching velocity network pretrained on the checkerboard samples. The noise adapter is a smaller SiLU MLP with four layers and width $256$, trained from scratch. Each model is trained for $50{, }000$ iterations with batch size $2048$ using the AdamW optimizer with learning rate $2\times10^{-4}$ and weight decay $1 \times 10^{-4}$.
B.1.2 Problem formulation
The task in this experiment is to solve the Bayesian inverse problem
$ \begin{align} p(x | y) \propto \exp\left(-\frac{|y - Ax|^2}{2\sigma^2}\right) p(x), \end{align} $
where $p(x)$ is the 2D checkerboard distribution and the forward operator is given by $A=\begin{pmatrix}1 & 0\end{pmatrix} $, that is, observing only the first component. For the observation noise, we take $ \sigma=0.1$.
B.1.3 Metrics
To evaluate our results, we use the following metrics.
Negative log predictive density (NLPD).
Given an observation $y\in\mathbb{R}$ and posterior samples ${x^{(j)}}_{j=1}^J$ with $x^{(j)} \sim p(x | y)$, the predictive density is approximated by Monte Carlo:
$ p(y'|y) ;=; \int p(y'\mid x), p(x | y), dx ;\approx; \frac{1}{J}\sum_{j=1}^J \mathcal{N}!\big(y' | Ax^{(j)}, \ \sigma^2\big), $
where $y'$ is a fresh observation independent of $y$. We report the negative log predictive density (NLPD),
$ \mathrm{NLPD}(y'; y) ;=; -\log p(y' | y) ;\approx; -\log!\left(\frac{1}{J}\sum_{j=1}^J \mathcal{N}!\big(y' | Ax^{(j)}, \ \sigma^2\big)\right), $
which is a proper scoring rule. To sample from $p(x | y)$ approximately using VFM, we first sample $z^{(j)} \sim q_\phi(z | y)$ and then set $x^{(j)} = f_\theta(z^{(j)})$. We report the averaged NLPD over a batch ${y_b', y_b, {x_b^{(j)}}{j=1}^J}{b=1}^B$. We take $B = 10, 000$ and $J = 100$.
Continuous ranked probability score (CRPS).
Given ground-truth targets $x^\dagger \in\mathbb{R}^2$ and $J$ predictive samples ${x^{(j)}}{j=1}^J$ corresponding to an observation $y^\dagger = Ax^\dagger + \varepsilon^\dagger$ for some noise realisation $\varepsilon^\dagger$ (i.e. we take $x^{(j)} = f\theta(z^{(j)})$ for $z^{(j)} \sim q_\phi(z | y^\dagger)$), we estimate the CRPS as:
$ \mathrm{CRPS}(x^\dagger; y^\dagger) ;\approx; \frac{1}{J}\sum_{j=1}^J \bigl|x^{(j)} - x^\dagger\bigr| ;-; \frac{1}{2J^2}\sum_{j=1}^J\sum_{k=1}^J \bigl|x^{(j)} - x^{(k)}\bigr| . $
The first term measures the average distance of samples to the truth, while the second term rewards diversity. We report the averaged CRPS over a batch ${x_b^\dagger, y_b^\dagger, {x^{(j)}b}{j=1}^J}_{b=1}^B$. We take $B = 10, 000$ and $J = 100$.
Maximum mean discrepancy (MMD).
To compare two measures $\mu_P$ and $\mu_Q$, we can compute their maximum mean discrepancy, which is a distance on the space of measures, whose square is given by [19]
$ \mathrm{MMD}^2(X, Y) = \mathbb{E}[k(x, x')] + \mathbb{E}[k(y, y')] - 2, \mathbb{E}[k(x, y)], $
with $x, x'\sim \mu_P$ and $y, y'\sim \mu_Q$ i.i.d., and $k(\cdot, \cdot)$ is a choice of kernel such as the squared exponential kernel
$ k(u, v) := \exp!\left(-\frac{|u-v|_2^2}{2\ell^2}\right). $
In practice, we use the unbiased estimator:
$ \widehat{\mathrm{MMD}}^2
\frac{1}{N(N-1)}\sum_{i\neq i'} k(x^{(i)}, x^{(i')}) + \frac{1}{M(M-1)}\sum_{j\neq j'} k(y^{(j)}, y^{(j')})
\frac{2}{NM}\sum_{i=1}^N\sum_{j=1}^M k(x^{(i)}, y^{(j)}), $
For the lengthscale hyperparameter $\ell$, we choose the median heuristic computed from pairwise distances between samples. In our computations, we choose $N = M = 10, 000$ samples to compare the prior distributions and the posterior distributions. Here, our true prior distribution is the checkerboard distribution, and our approximate prior is obtained by ${f_\theta(z)}{z \sim \mathcal{N}(0, I)}$. For the true posterior, we compute it using rejection sampling (see Algorithm 3) and the approximate posterior is obtained by ${f\theta(z)}{z \sim q\phi(z | y)}$.
Input: observation $y\in\mathbb{R}$, noise $\sigma>0$, number of samples $J$, prior $p(x)$
Initialize accepted set $\mathcal{S}\gets \varnothing$
**while** $|\mathcal{S}| < J$ **do**
Propose $x \sim p(x)$
Compute $a \gets \exp\!\left(-\frac{(y - Ax)^2}{2\sigma^2}\right)$
Draw $u \sim \mathrm{Unif}(0,1)$
**if** $u < a$ **then**
Append $x$ to $\mathcal{S}$
**end if**
**end while**
Output: $\{x^{(j)}\}_{j=1}^J \gets \mathcal{S}$
Support accuracy (SACC).
We measure support accuracy as the proportion (percentage) of generated samples that fall inside one of the filled checkerboard squares. Concretely, for samples ${x^{(j)}}_{j=1}^J$, we compute
$ \mathrm{Acc}({x^{(j)}}{j=1}^J) ;=; \frac{1}{J}\sum{j=1}^J \mathbf{1}!\left[x^{(j)} \text{ lies in a checkerboard cell}\right]. $
We compute the support accuracy for both prior samples ${f_\theta(z)}{z \sim \mathcal{N}(0, I)}$ and posterior samples ${f\theta(z)}{z \sim q\phi(z | y)}$.
B.1.4 Ablation plots
- Figure 17: Ablation of VFM for all metrics with respect to the parameter $\tau$. The parameter $\alpha$ is set to $0.5$. We also display the results of the
frozen- $\theta$baseline for reference. - Figure 18: Ablation of VFM for all the metrics with respect to $\tau$. The parameter $\alpha$ is set to $1.0$. We also display the results of the
frozen- $\theta$baseline for reference. - Figure 19: Plots displaying the noise-to-data alignment in VFM with or without various modeling choices in the loss to isolate their effects on the final results. In particular, we consider: (1)
frozen- $\theta$, (2)unconstrained- $\theta$, (3) VFM with no EMA, (4) VFM without KL loss. - Figure 20: Plots displaying how the noise-to-data alignment for VFM changes with respect to $\tau$. Here, $\alpha$ is set to $1.0$.
- Figure 21: Plots displaying how the noise-to-data alignment for VFM changes with respect to $\alpha$. Here, $\tau$ is set to $100.0$.
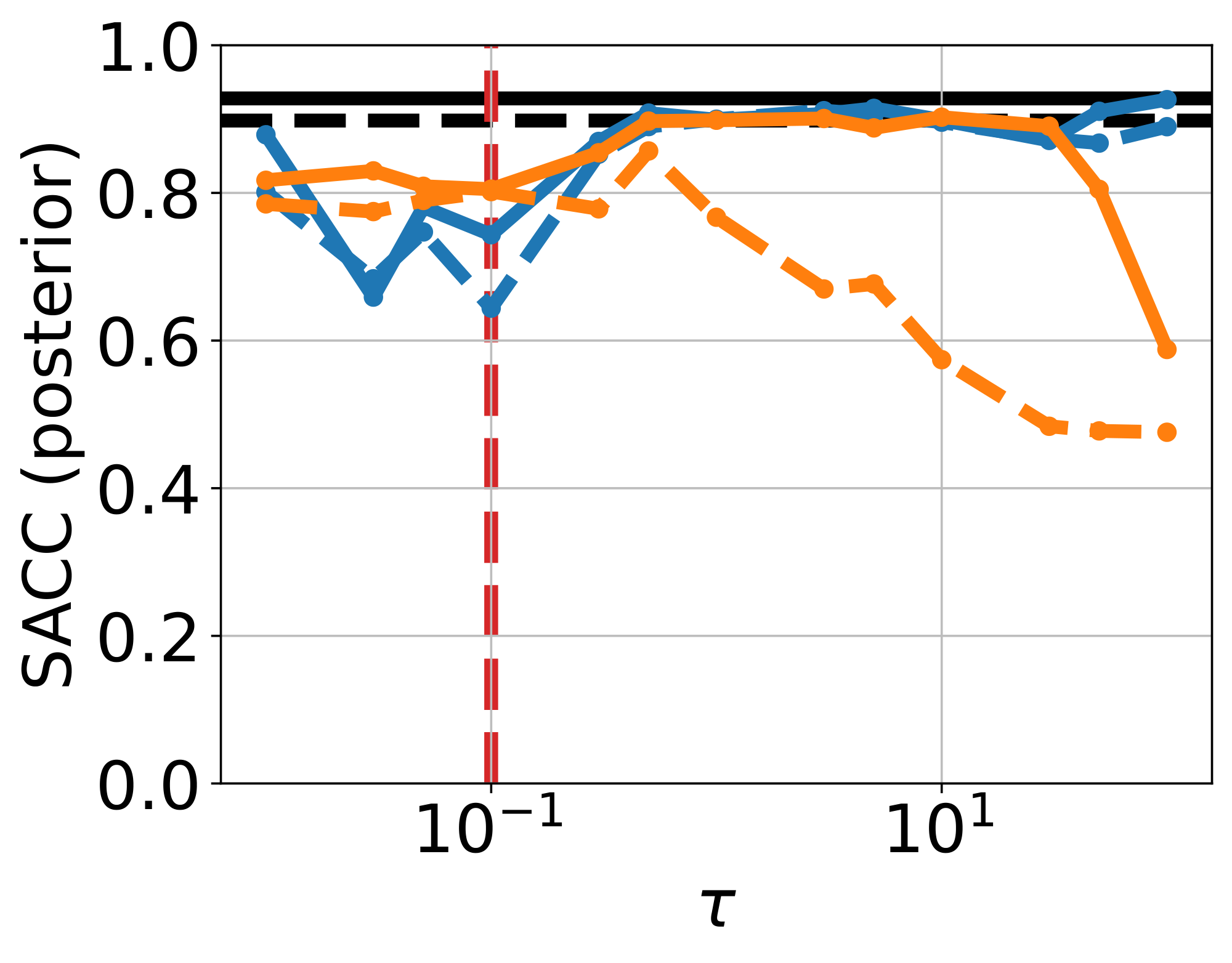
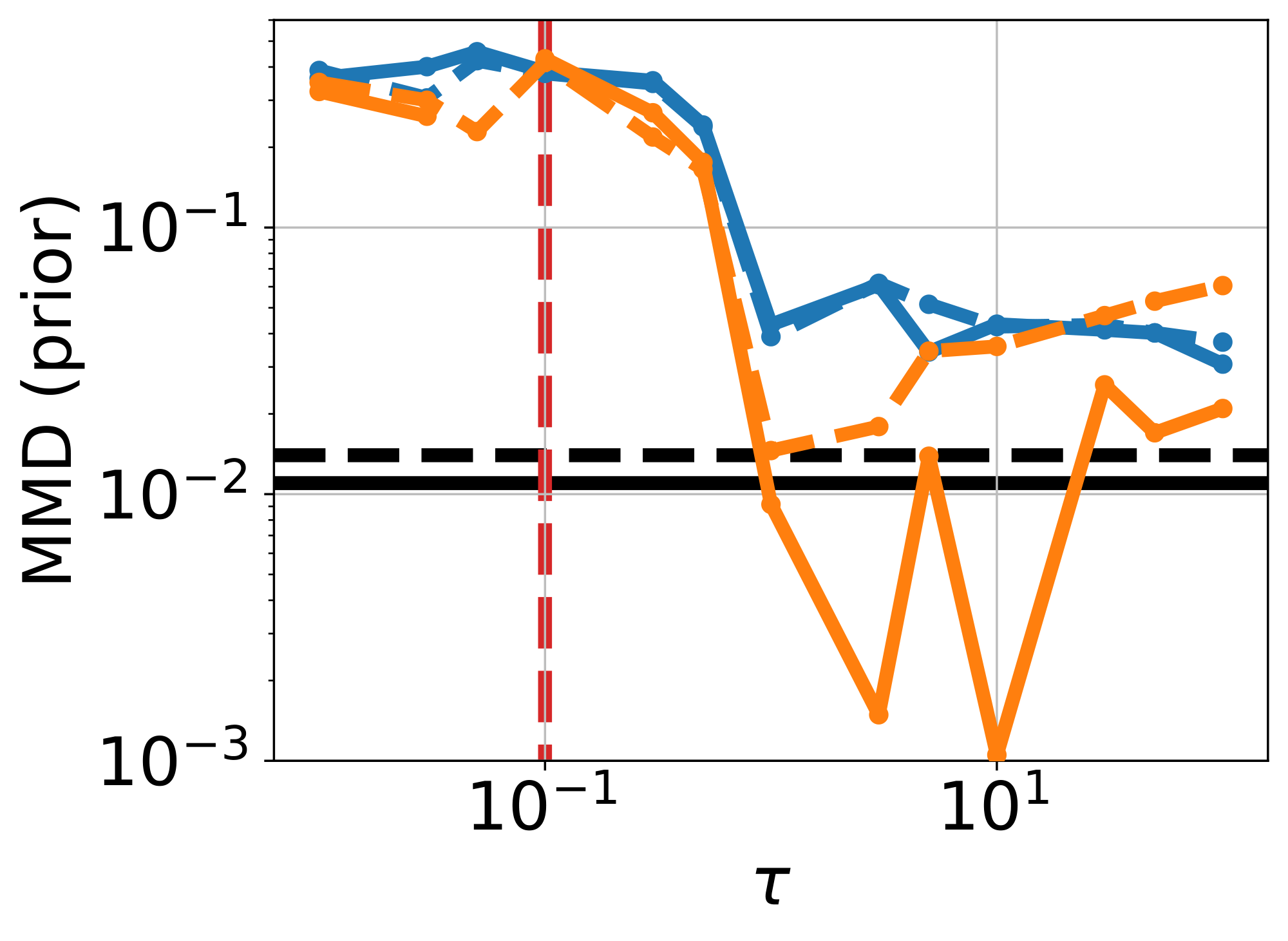
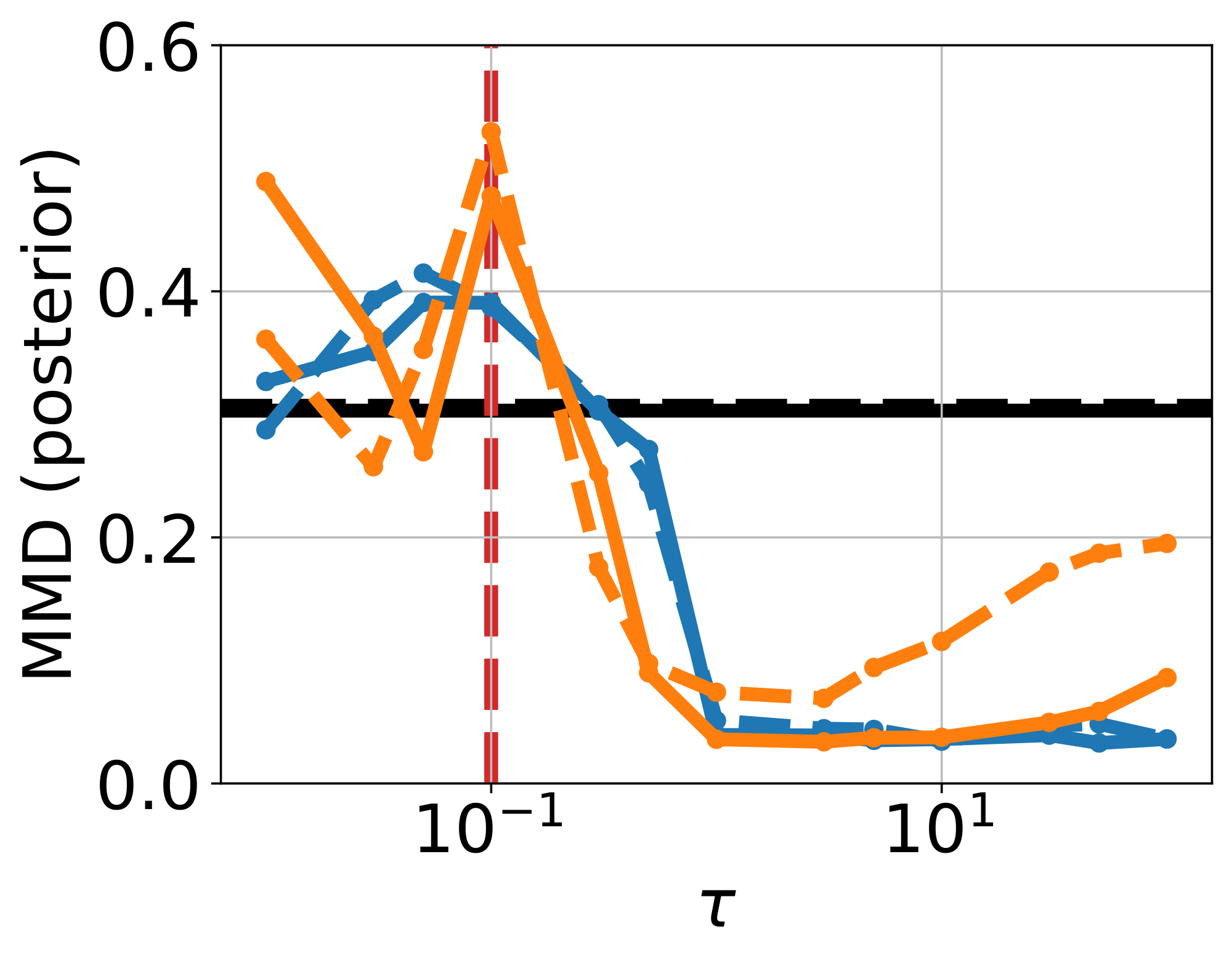
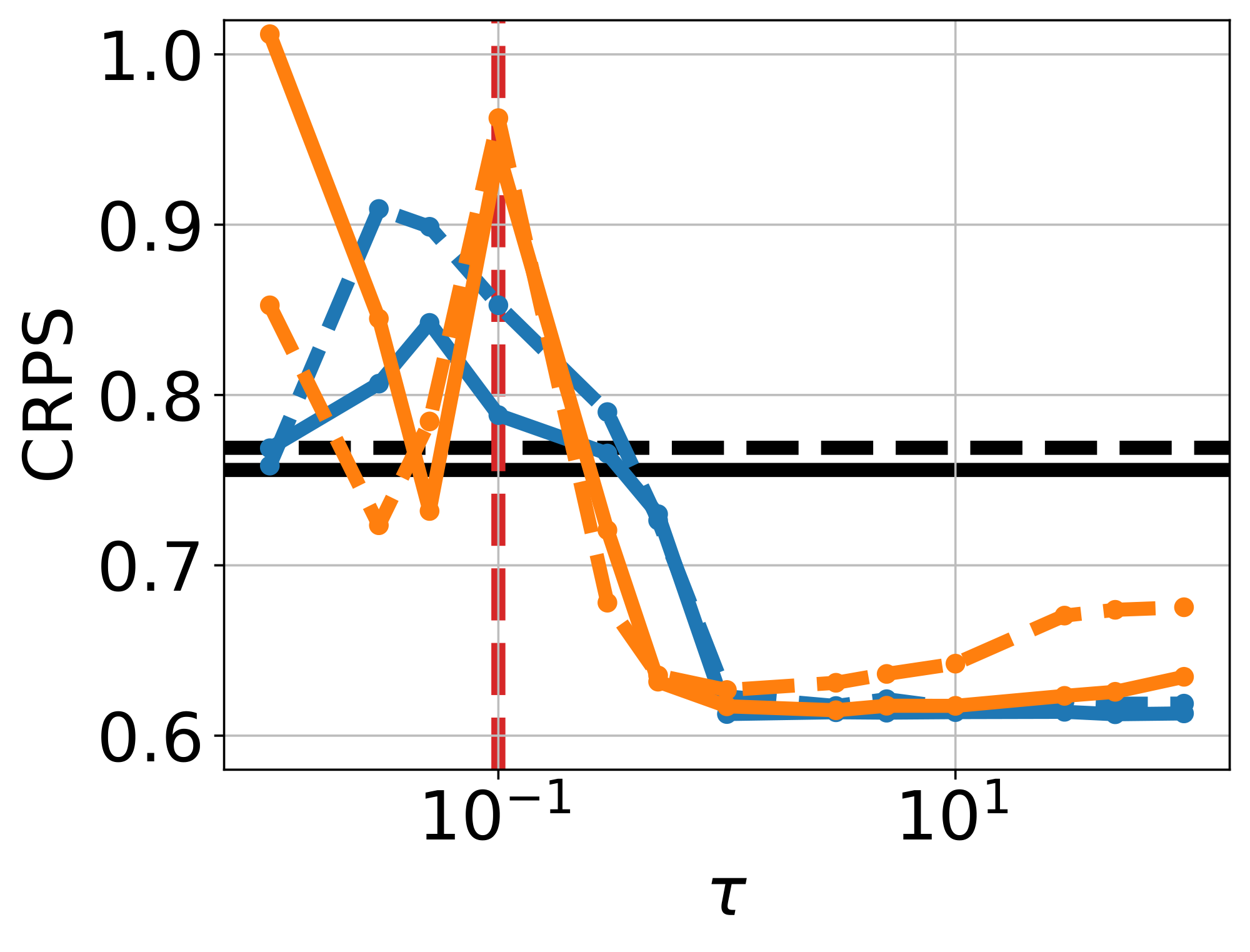
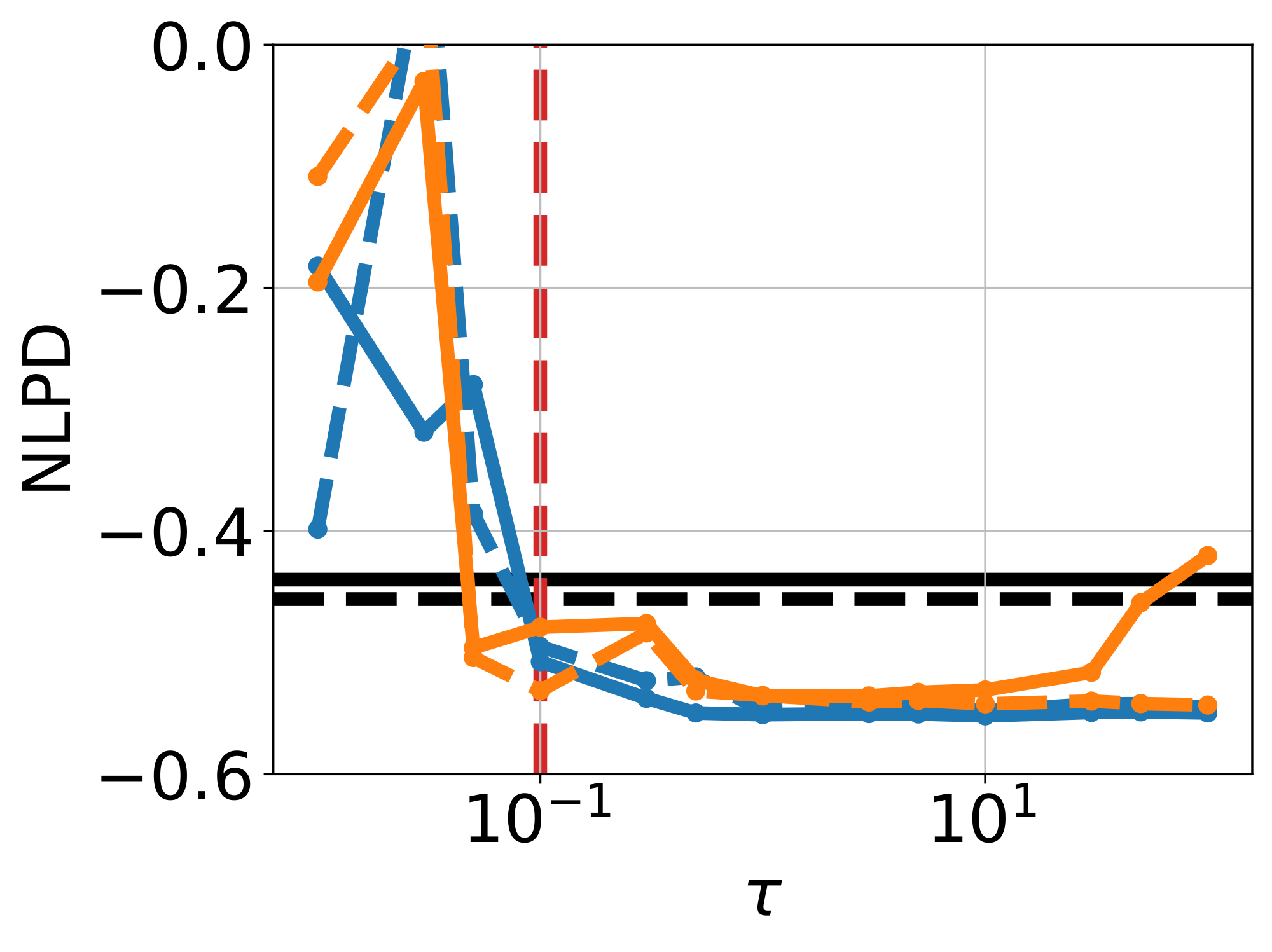

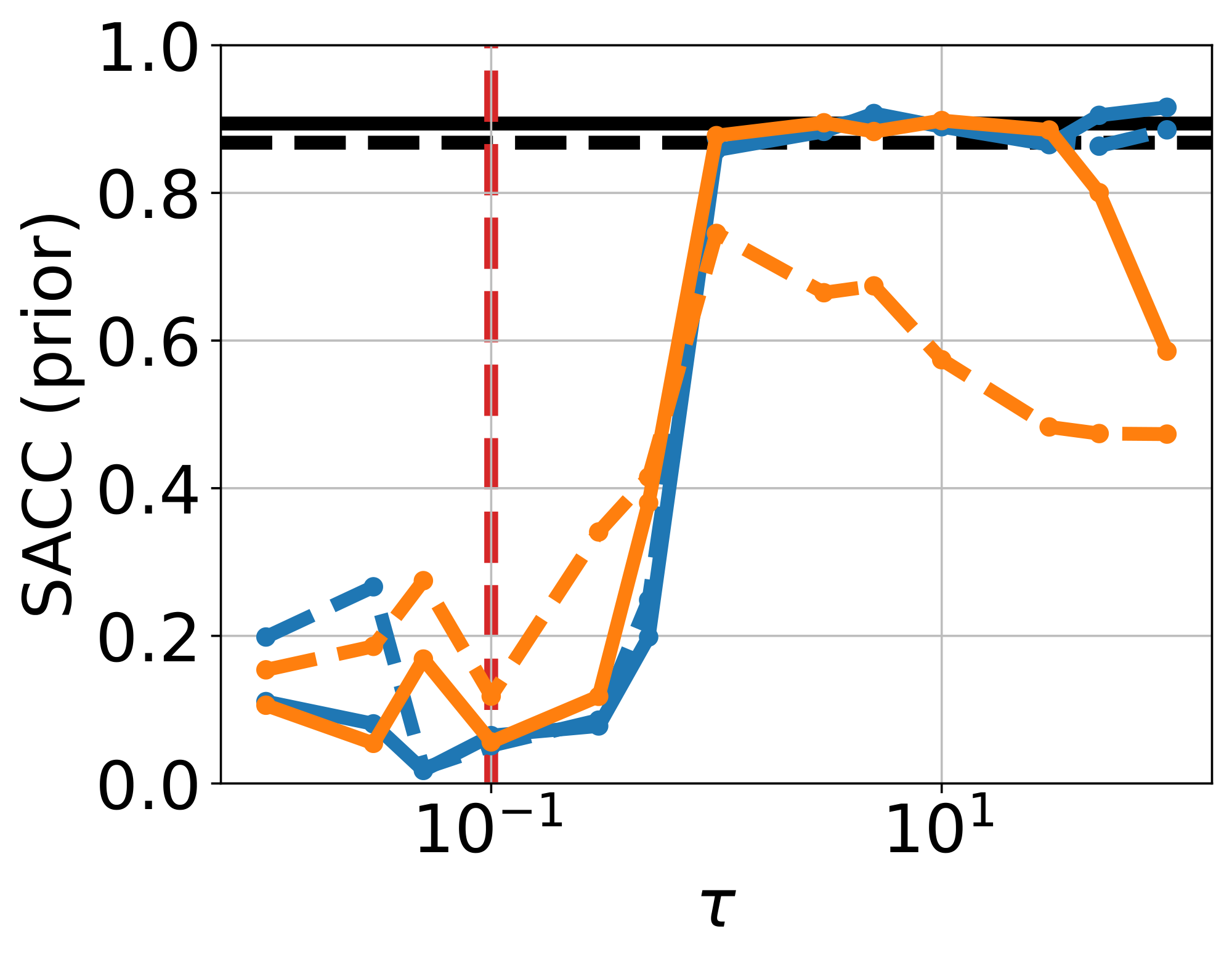
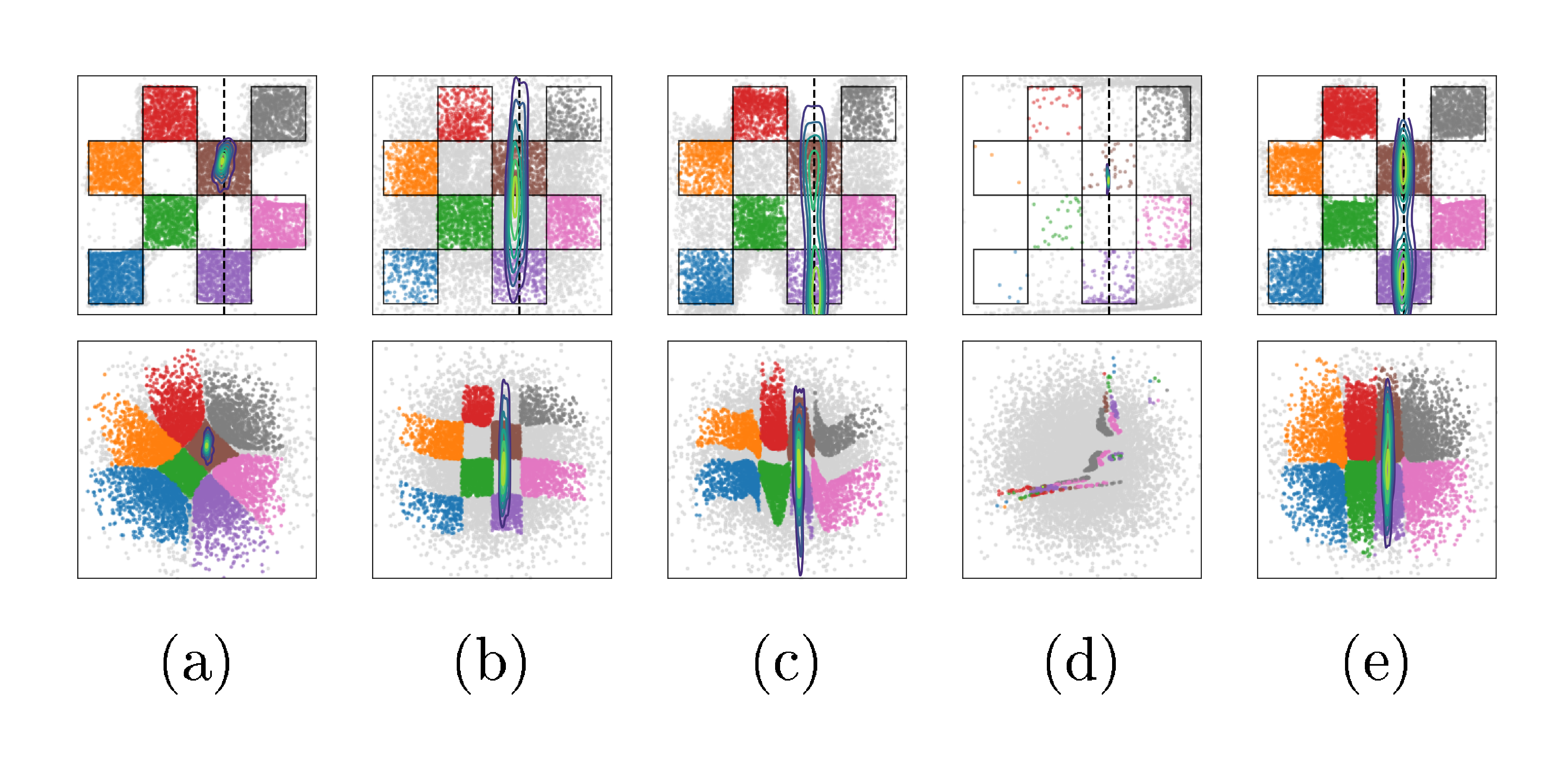
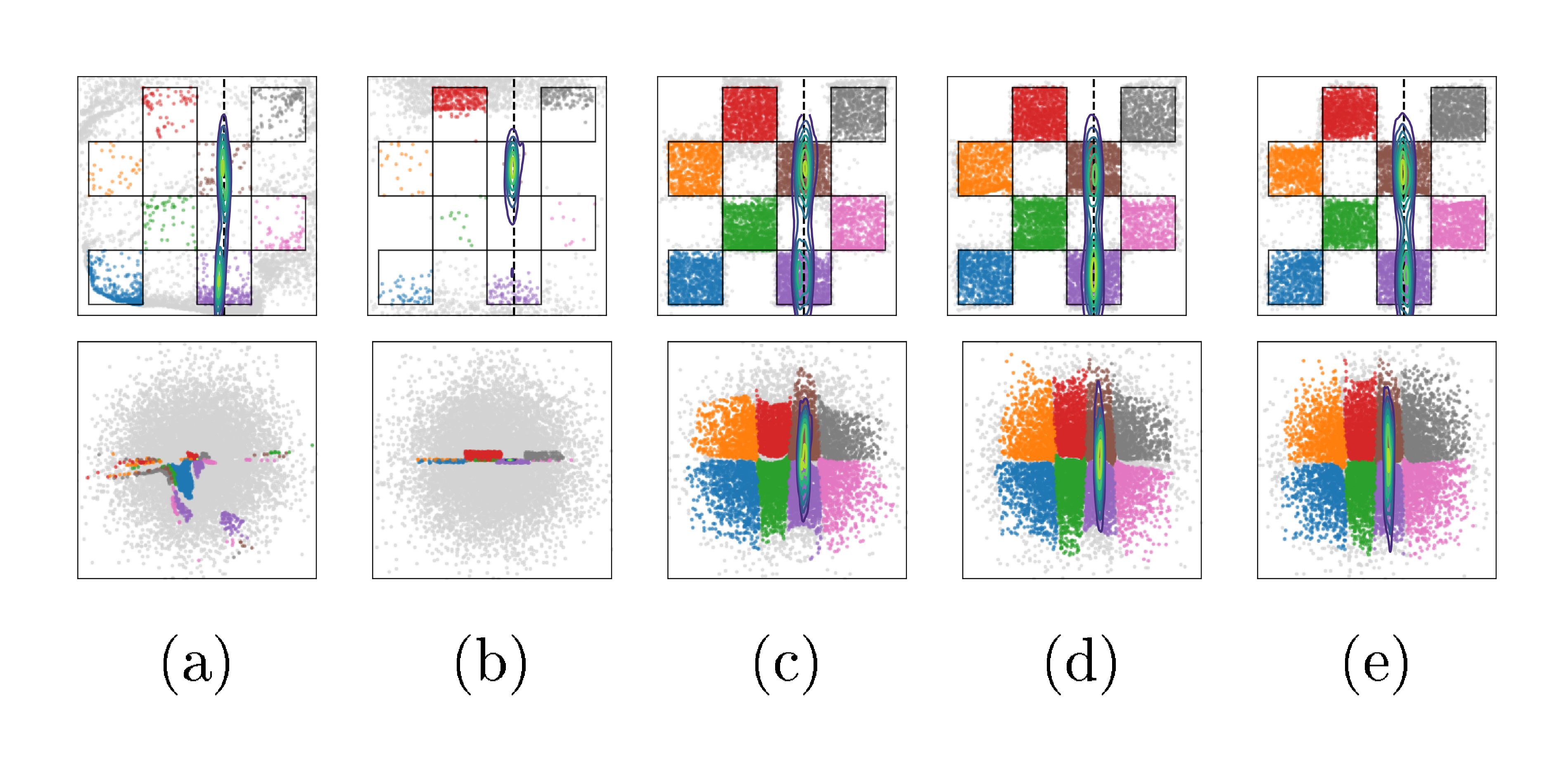
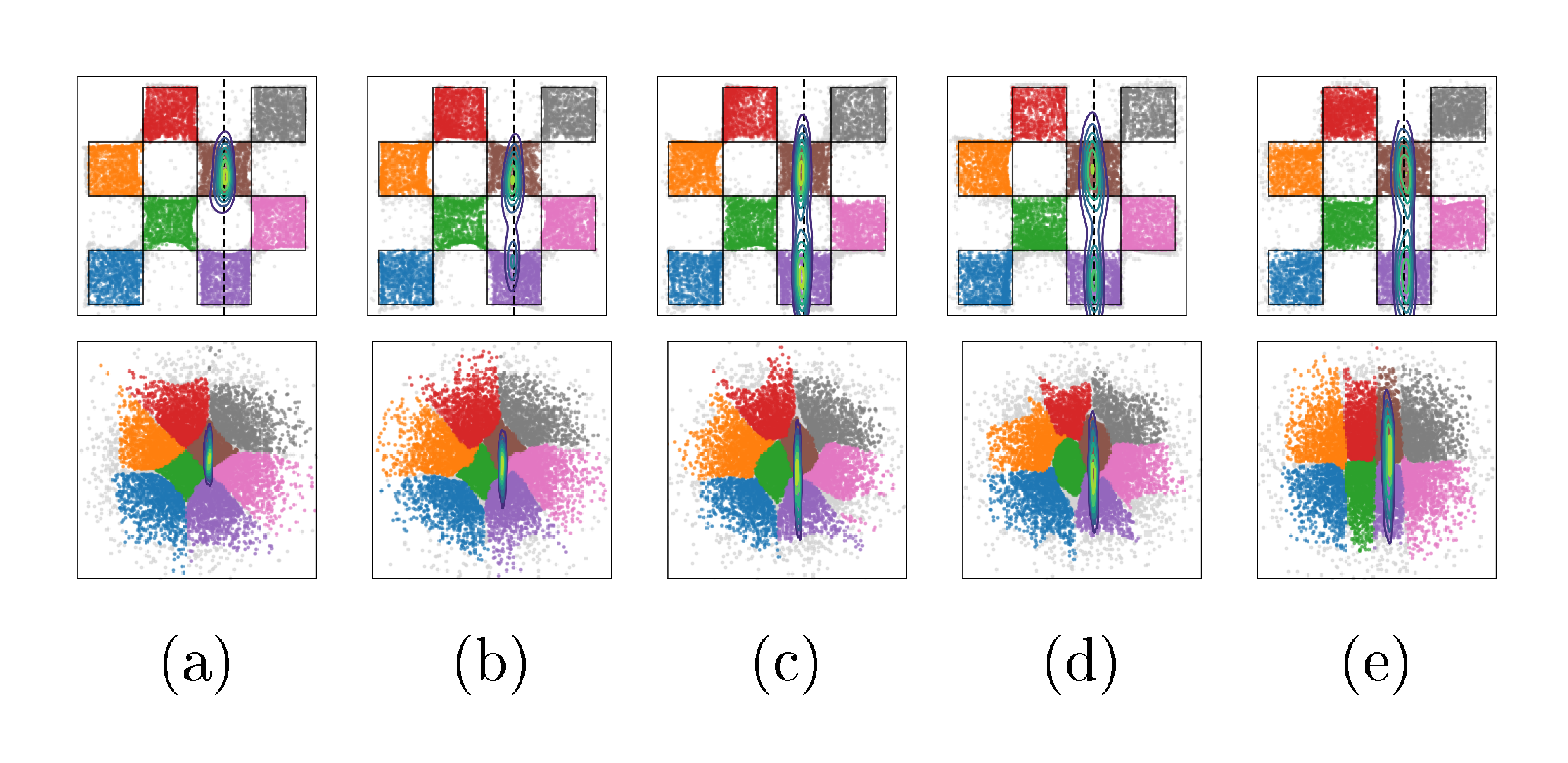
B.2 ImageNet experiment
In this section, we provide a detailed breakdown of the architectures, training objectives, and the extensive tuning process conducted for the baselines used in the ImageNet $256 \times 256$ experiments.
B.2.1 Model Architectures
Flow Map Backbone ($f_\theta$).
We employ a SiT-B/2 architecture [41] (130M parameters) initialized from a flow-matching model pre-trained for 80 epochs. Following the design of Decoupled Mean Flow (DMF) [26], we utilize decoupled encoder/decoder embeddings for the timesteps to better capture the flow dynamics. Our fine-tuning is performed for 100 epochs, making the total training process to be 180 epochs.
Noise Adapter ($q_\phi$).
To map high-dimensional observations $y$ and inverse problem classes $c$ to the latent noise distribution $q_\phi(z|y, c)$, we design a lightweight U-Net style adapter (10M parameters). The adapter is conditioned on the inverse problem class $c$ using Feature-wise Linear Modulation (FiLM) [42]. The class embedding modifies the features at multiple resolutions via affine transformations $\gamma \cdot x + \beta$. The network processes the $256 \times 256$ input observation through a series of residual blocks and downsampling layers (channel multipliers: 1, 2, 4, 4), which compresses the spatial resolution to $32 \times 32$. The final projection layer outputs the mean $\mu$ and log-variance $\log \sigma^2$ (clamped between -10.0 and 2.0) for the latent distribution, from which we sample $z$ using the reparameterization trick.
Latent space encoding.
Modern generative models often operate in a lower-dimensional latent space obtained via an autoencoder or similar compression mechanism [20]. We adopt this setting in this experiment by defining the flow map and adapter in the latent space of SD-VAE [20] rather than pixel space, and applying the forward operator to decoded samples. Measurement encoding can be incorporated directly into the adapter architecture; specifically, our U-Net-based architecture for the adapter maps the high-dimensional input observations into a lower-dimensional latent representation, which allows us to estimate the mean ($\mu$) and variance ($\sigma$) within the latent space.
Training.
For VFM training, we employ standard model guidance techniques during the flow map training phase. Following previous works [43, 26], we utilize a prefixed CFG probability to redefine the target velocity, which allows us to perform robust one-step generation during sampling. After extensive experiments and ablations on the $\tau$ parameter, we found that setting the coefficient of $\mathcal{L}_{data}$ to $1.0$ works best in practice. All training and inference were conducted using $8$ and $1$ NVIDIA GH $200$ GPUs, respectively.
B.2.2 Baselines and Tuning
We compare VFM against a comprehensive suite of guidance-based solvers. A major challenge in this comparison is the high sensitivity of these methods to hyperparameters. To ensure a fair comparison, we performed an exhaustive hyperparameter sweep for every baseline, task, and backbone. We found that most inference-time methods require significant per-task tuning, which makes them computationally burdensome compared to the one-step nature of VFM.
Unless otherwise stated, all baselines use 250 ODE steps. To maximize their performance, we also applied Classifier-Free Guidance (CFG) with a scale of 2.0, which we found empirically boosts results across methods, even those that do not originally prescribe it.
Latent DPS [14].
We extend Diffusion Posterior Sampling (DPS) to the latent flow matching setting. Through extensive sweeping, we identified a novel gradient scaling technique that provided the best stability. We normalize the likelihood gradient update to have a magnitude of 1, i.e., using a step size of $1/||\nabla_z \log p(y|z)||$.
Latent DAPS [23].
We implemented DAPS in the latent flow matching space, strictly following the original paper's settings. This involves 5 ODE rollout steps followed by 50 annealing steps and 50 Langevin steps, which makes the optimization extremely slow.
PSLD [44]
Our implementation follows the original paper. We tuned the coefficients and found the optimal values to match the original recommendations, where DPS and gluing coefficients are chosen to be 1.0 and 0.1, respectively.
MPGD [45].
We extended Manifold Preserving Guidance (MPGD) to flow matching, which approximates the Jacobian as identity. We utilized DDIM-type deterministic velocity maps and, similar to DPS, found that a gradient scaling of $1/||\nabla||$ yielded the best performance.
FlowChef [46].
We followed the exact implementation from the original paper. After heavy tuning, we found that it behaved similarly to MPGD and performed best with the $1/||\nabla||$ gradient scaling.
FlowDPS [47].
We followed the official implementation. Tuning revealed that a larger step size coefficient of $10.0/||\nabla||$ was optimal. We adhered to the original protocol of repeating the update 3 times per ODE iteration. Importantly, we disabled the stochasticity parameter as it was found to degrade performance, instead we relied on deterministic velocity updates.
B.2.3 Metrics and Evaluation
We evaluate performance using two distinct categories of metrics:
Pixel-Space Fidelity (PSNR/SSIM).
While we report these standard metrics, we note that inference-time optimization methods (like DPS) tend to produce smooth estimates that maximize these scores by converging toward the conditional mean. This often results in a loss of high-frequency texture and realistic detail [21].
Semantic and Distributional Fidelity (LPIPS, FID, MMD, CRPS).
To assess whether the model captures the true posterior distribution rather than just the mean, we prioritize metrics in embedding space. We evaluate methods by using standard LPIPS and FID by using 1024 reconstructions from the validation set of ImageNet. We further evaluate Maximum Mean Discrepancy (MMD) metric in the embedding space of Inception network (used also in FID). This measures the distance between the true and approximate posterior distributions in the semantic space. To evaluate the generation quality along with its diversity (which is very important in posterior sampling and uncertainty quantification), we also use the Continuous Ranked Probability Score (CRPS) scoring rule. It assesses the calibration and coverage of the posterior. We compute this in the embedding spaces of both Inception and DINO models to ensure semantic consistency. Refer to Appendix B.1.3 for further details on the computation of MMD and CRPS.
We evaluate PSNR, SSIM, LPIPS, FID, and MMD on the randomly selected 1024 samples from the validation set of the ImageNet dataset. As for CRPS metric, we generate 10 different reconstructions of 128 samples from validation set. We follow this recipe for all the baselines and our VFM experiments, except for Latent DAPS, where, due to the slower generation we only generated 128 samples instead of 1024 (all the rest of the settings are followed as stated above).
Our results show that while baselines may achieve high PSNR/SSIM due to mean-seeking behavior, VFM significantly outperforms them on distributional metrics (FID, MMD, CRPS), which indicates superior perceptual quality and a more accurate approximation of the complex posterior. We also observe that generating multiple samples through VFM in 1-step and then taking the average smoothes the reconstructions, which achieves competitive or better PSNR/SSIM values as well.
Projection trick
Measurement space projection is very common to improve the pixel-wise metrics (PSNR/SSIM) in guidance world. In most of the methods (also gluing term in PSLD), it is common to use projection to guide the samples further towards measurement space [44, 13, 48]. Specifically, given that we have a generation $z_0$ and observation $y$, we can project generated samples by applying $\hat z_0 = \mathcal{E}(A^Ty + (I-A^TA)\mathcal{D}(z_0))$, where $\mathcal{E}$ and $\mathcal{D}$ denotes encoder and decoder, respectively. We found this useful in inpainting and gaussian debluring tasks, where the 1-step output of VFM is corrected by this formula.
B.2.4 Inverse Problems and Evaluation Setup
We evaluate VFM and all baselines on a diverse set of standard linear inverse problems frequently used in the literature. Our VFM model was trained jointly to handle denoising, random inpainting, box inpainting, super-resolution, Gaussian deblurring, and motion deblurring via the amortized conditioning mechanism described in Section 3.2.
For quantitative evaluation, we focus on the structurally challenging tasks (inpainting, super-resolution, and deblurring) and omit pure denoising. To ensure a rigorous and fair comparison, all baselines utilize the exact same pre-trained SiT-B/2 backbone that was used to initialize VFM. This strictly isolates the performance differences to the sampling method (iterative guidance vs. one-step VFM) rather than the generative prior quality. Consequently, the reported numbers for VFM can serve as a reliable reference for future benchmarking on the SiT-B/2 architecture. We also followed the best practices from SiT-B/2 unconditional sampling to get the best results.
The specific forward operators for the evaluated tasks are defined as follows. For random inpainting, we apply a random noise mask where the occlusion probability is sampled uniformly from the interval $(0.3, 0.7)$ for each image. In the case of box inpainting, we utilize a rectangular mask with a random location and aspect ratio, where the height and width are sampled independently from the interval $(32, 128)$. Super-resolution (x4) is implemented by downsampling the input image by a factor of 4 using bicubic interpolation. Finally, for the deblurring tasks, we employ a $61 \times 61$ kernel size, using a standard deviation of $\sigma=3.0$ for Gaussian deblurring and an intensity value of $0.5$ for motion deblurring. Additionally, for all inverse problems, the measurements are further corrupted by additive Gaussian noise with a standard deviation of $\sigma=0.05$.
::: {caption="Table 2: Quantitative comparison on ImageNet for various inverse problems. Best results are in bold, second best are $\underline{underlined}$. $\uparrow$ : higher is better, $\downarrow$ : lower is better."}
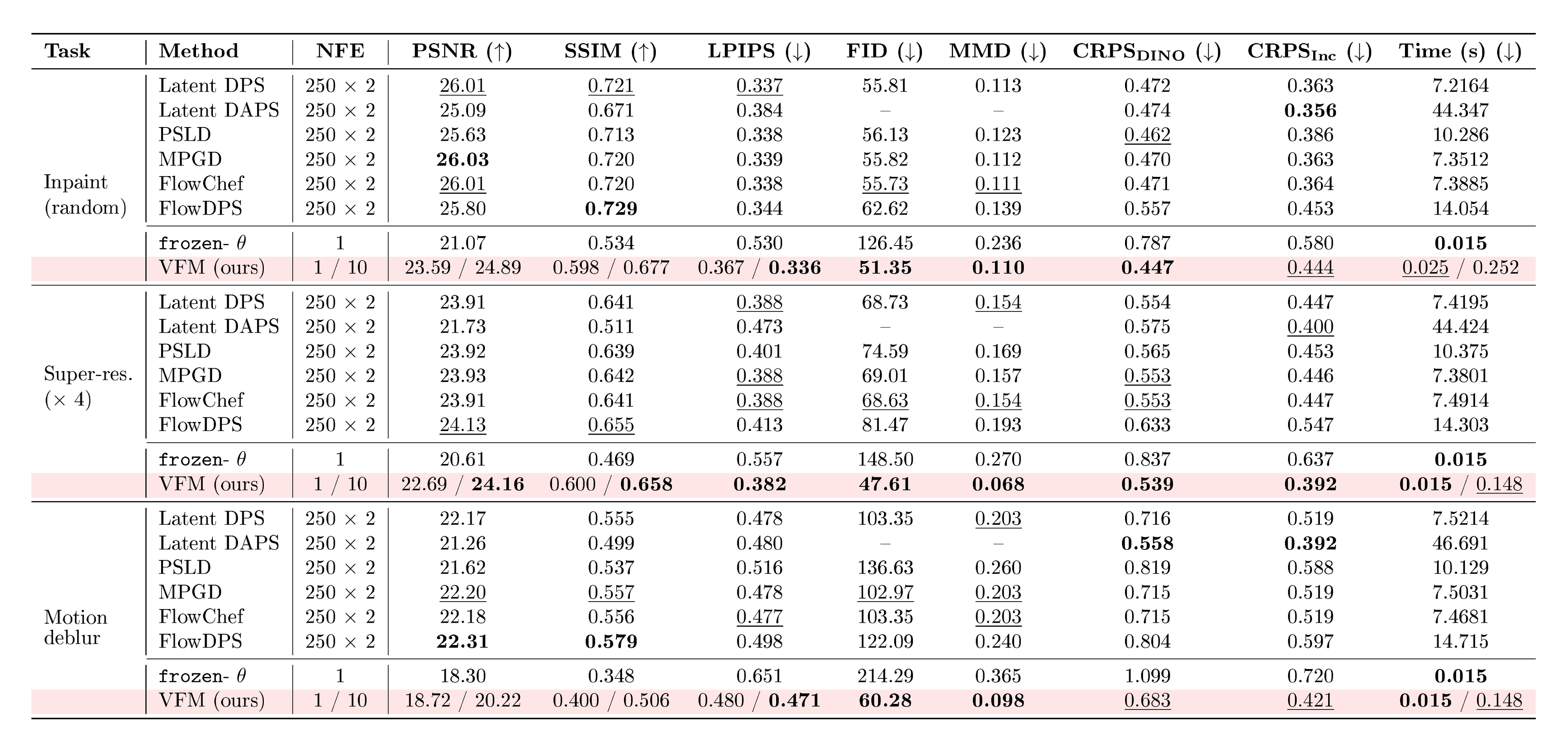
:::
B.3 General Reward Alignment with VFM
In Figure 5, we introduced Variational Flow Maps for general reward alignment. Given a base data distribution $p_{data}(x)$ and a differentiable reward model $R(x, c)$ conditioned on context $c$ (e.g., a class label or text prompt), the goal of reward alignment is to sample from the reward-tilted distribution:
$ \begin{align} p_\text{reward}(x|c) \propto p_\text{data}(x) \exp(\beta R(x, c)), \end{align} $
where $\beta>0$ is a temperature parameter controlling the strength of the reward. In the context of a flow map $x=f_\theta(z)$, this target data distribution induces a corresponding target posterior in the latent noise space:
$ \begin{align} p(z|c) \propto p(z) \exp(\beta R(f_\theta(z), c)). \end{align} $
In the reward-alignment setting, there is no standard structural degradation $y = A(x)+\varepsilon$. However, reward maximization can still be naturally cast as an inverse problem. In this view, the context $c$ (e.g., a text prompt) takes the place of the observation. Probabilistically, we treat the evaluated reward $R(\cdot, c)$ as the (unnormalized) log-likelihood of this context given the generated sample. Substituting the standard inverse problem observation loss $-\frac{1}{2\sigma^2}|y - A(f_\theta(z))|^2$ with this reward-based log-likelihood $\lambda R(f_\theta(z), c)$ naturally yields the objective:
$ \begin{align} \mathcal{L}(\theta, \phi) = - \lambda , \mathbb{E}{c \sim p(c), z \sim q\phi(z|c)}[R(f_\theta(z), c)] + \mathcal{L}\text{KL}(\phi) + \frac{1}{2\tau^2}\mathcal{L}\text{data}(\theta; \phi). \end{align} $
Motivation. Crucially, this fine-tuning objective is a principled Variational Inference (VI) formulation derived directly from the Evidence Lower Bound (ELBO). At its global optimum, it recovers the true reward-tilted distribution $p_\text{reward}(x|c)$. The $-\lambda R(f_\theta(z), c)$ term corresponds to maximizing the expected log-likelihood of the ideal observation, pushing the adapter to find, and the flow map to decode, regions of high reward. The $\mathcal{L}\text{KL}$ term matches the variational posterior to the prior $p(z)$, preventing the latent space from collapsing to a single deterministic point. Finally, the $\mathcal{L}\text{data}$ term ensures that the generator $f_\theta$ remains a valid transport map anchored to the true data manifold. By minimizing this principled objective, the framework naturally prevents the generator from collapsing into an adversarial state purely to cheat the reward model.
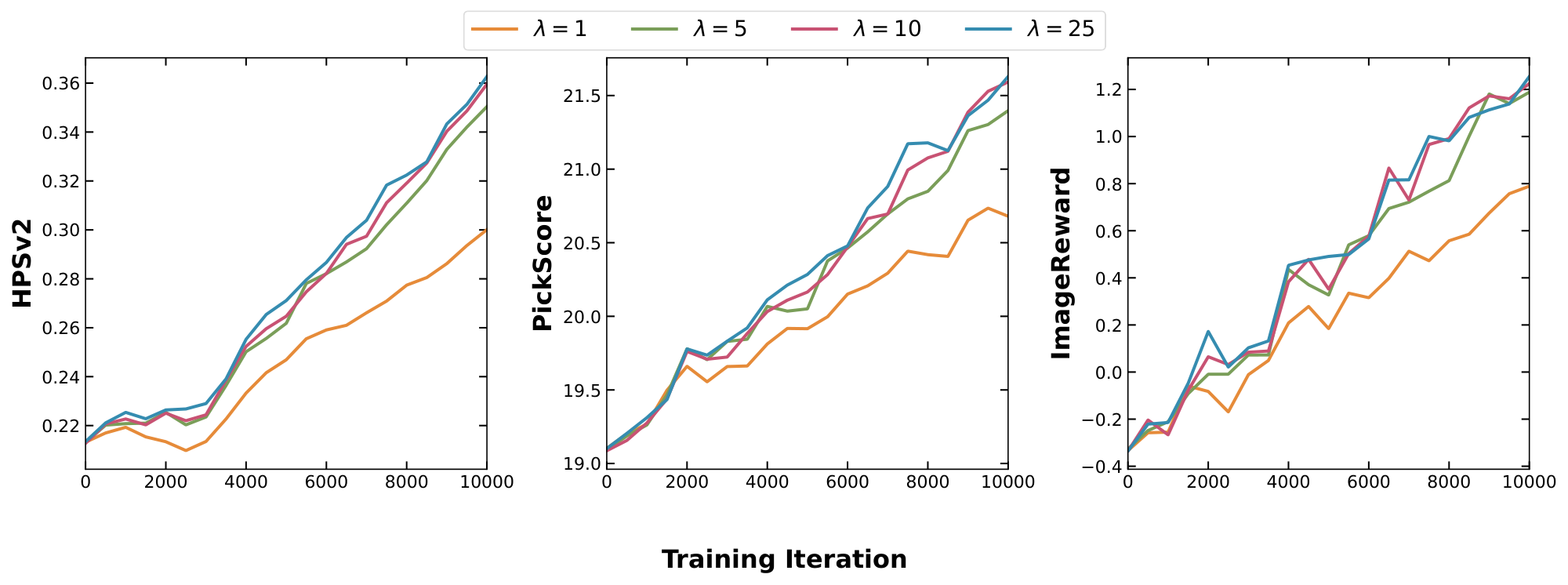
Fine-tuning setup. We use the same adapter architecture as in the original VFM training, but instead of degraded observations, we map a fixed, learned spatial latent grid to $(\mu, \sigma)$ conditioned on the class label. In standard VFM training, an adaptive scaling function is applied to the entire loss to stabilize gradients. Since $-\lambda R(f_\theta(z), c)$ can take large negative values, applying this normalization to the full reward objective distorts gradient magnitudes unpredictably. We therefore apply adaptive normalization only to the flow-related terms during reward alignment tasks. Next, because we explicitly want to tilt the flow map toward high-reward regions, we pass gradients through the active trainable model during the reward loss calculation. This contrasts with standard VFM, which uses the EMA model to prevent the flow map from being updated by the observation loss. Following the reward alignment setup in Meta Flow Maps (MFM) [49], we use HPSv2 [50] during the fine-tuning stage. The adapter is amortized over all $1, 000$ classes of ImageNet, and the reward is calculated using a fixed prompt "A high-resolution, high-quality photograph of a class_name" as utilized in MFM. Finally, we initialize VFM with the large DMF-XL/2+ model [26] and fine-tune for $10, 000$ iterations with a batch size of $64$ (corresponding to $\sim!0.5$ epochs and taking only $6$ hours). The rest of the VFM training follows the standard procedure and parameter choices described throughout the paper.
Multi-step observation. We observe that one-step samples achieve the highest reward scores under the fine-tuned model, whereas multi-step samples tend to regress toward the unconditional ImageNet distribution. We attribute this to two factors. First, the reward loss is evaluated directly on the one-step map $z \to f_\theta(z)$. Second, unlike standard VFM training, we evaluate the reward loss through the active flow map rather than the EMA model. This explicitly tilts the model's one-step predictions, while its intermediate vector fields remain largely anchored to the unconditional data distribution. This discrepancy pulls multi-step trajectories back toward the base ImageNet data manifold. A natural remedy, computing the reward on a short $K$-step rollout (e.g., $K=3$) during training, would propagate the reward signal into the intermediate velocity field and is left as future work.
Evaluation. In addition to training with the HPSv2 reward, we evaluate the reward scores of VFM outputs during training based on various alignment metrics, including HPSv2 [50], PickScore [51], and ImageReward [52]. Figure 22 shows the reward score progression throughout training, calculated every $500$ steps and averaged over $64$ random generations. While we explore the effects of varying the reward strength $\lambda$, we find that a default value of $\lambda=1$ achieves strong performance without the need for extensive hyperparameter tuning. As shown, VFM consistently boosts the reward across all alignment metrics.
B.4 Additional Results
In this section, we present a comprehensive set of qualitative results on ImageNet $256 \times 256$ to further validate the effectiveness of Variational Flow Maps.
Qualitative Comparisons. Figure 23, Figure 24, Figure 25, Figure 26, Figure 27 provide side-by-side comparisons of VFM against seven state-of-the-art baselines across five distinct inverse problems. In all cases, VFM produces sharp, coherent, and consistent samples in a single forward pass, whereas baselines often exhibit artifacts or require hundreds of function evaluations to achieve comparable fidelity.
Uncertainty Quantification. A key advantage of VFM is its ability to learn a proper posterior distribution rather than collapsing to a single mode. In Figure 29, we visualize the pixel-wise mean and standard deviation computed from multiple posterior samples (10 samples). The uncertainty maps clearly highlight that VFM localizes variance in ambiguous regions (e.g., occluded areas or fine details lost to blur), which provides valuable information about the posterior that is typically infeasible to extract with slow or mode-collapsing baselines.
Structured Noise ("Make Some Noise"). Figure 28 visualizes the internal operation of the noise adapter $q_\phi(z|y)$. We display the predicted latent mean $\mu$, the standard deviation $\sigma$, and the resulting reparameterized noise samples $z$. We observe strong structural patterns in the learned noise, which indicates that the adapter actively aligns the latent space to the data manifold. This validates our core premise: by "learning the proper noise" via optimization, we bridge the guidance gap without requiring iterative steering.
Diversity and Mode Coverage. In Figure 31 and Figure 32, we examine diverse generation scenarios. While the baselines frequently fail or collapse to a single (often incorrect) solution, VFM successfully generates diverse, high-quality samples that are all consistent with the measurements. We observe that greater ill-posedness naturally leads to higher diversity in our generations, confirming that the model captures the multimodal nature of the posterior.
Unconditional Generation. Figure 30 presents additional curated unconditional samples generated by the trained flow map. It further highlights the generative quality of our backbone model.
Reward Alignment. Figure 33 provides additional uncurated samples generated by the fine-tuned flow map. VFM consistently samples from the target reward-tilted distribution. Furthermore, Figure 34 illustrates the evolution of generated images across different fine-tuning iterations using fixed latent seeds, which highlights the rapid and stable adaptation of the model.





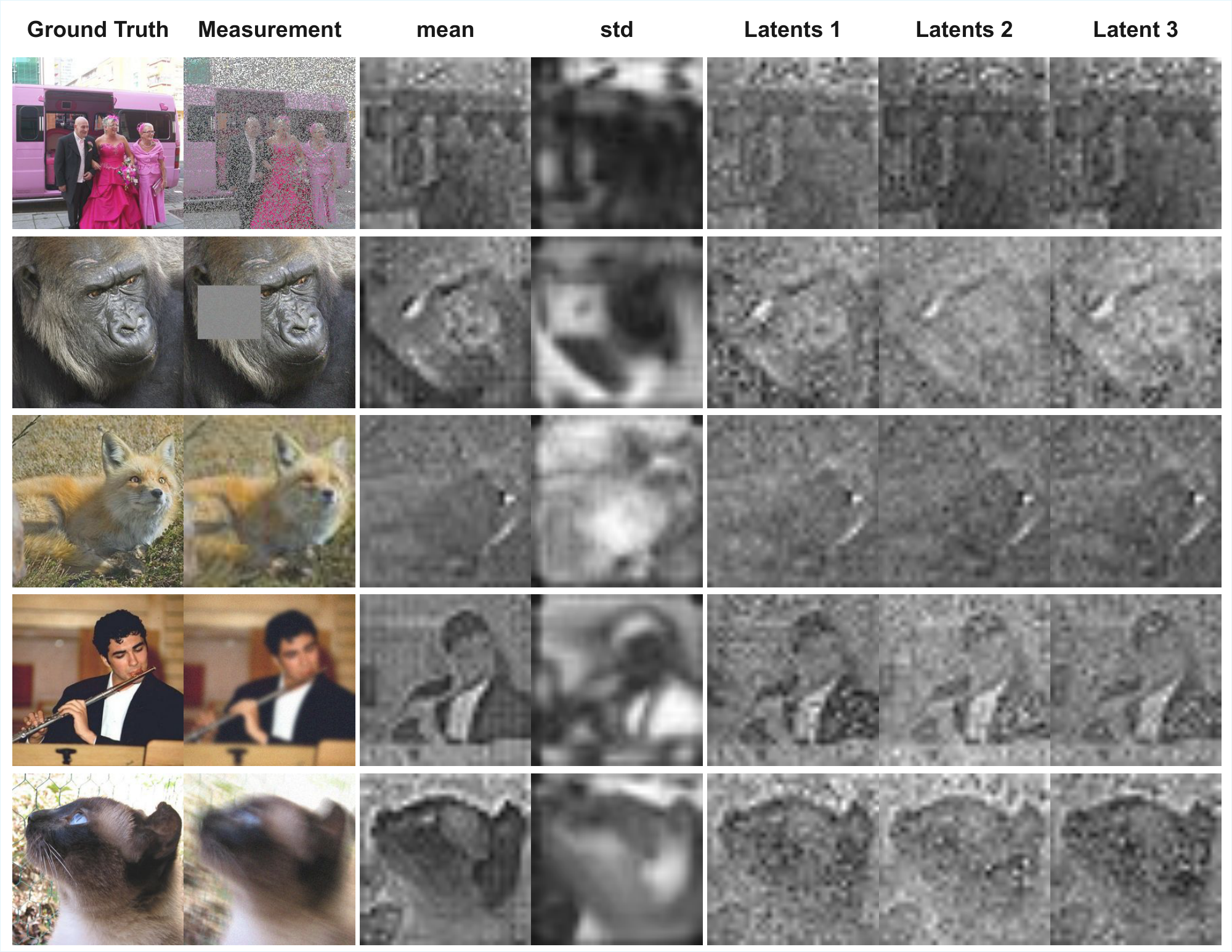






References
[1] Ho et al. (2020). Denoising diffusion probabilistic models. In Advances in neural information processing systems. pp. 6840–6851.
[2] Song, Yang and Ermon, Stefano (2020). Generative Modeling by Estimating Gradients of the Data Distribution. arXiv:1907.05600.
[3] Jascha Sohl-Dickstein et al. (2015). Deep Unsupervised Learning using Nonequilibrium Thermodynamics. arXiv:1503.03585.
[4] Tero Karras et al. (2022). Elucidating the Design Space of Diffusion-Based Generative Models. arXiv:2206.00364.
[5] Lipman et al. (2022). Flow Matching for Generative Modeling. In The Eleventh International Conference on Learning Representations.
[6] Liu et al. (2022). Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow. In The Eleventh International Conference on Learning Representations.
[7] Albergo et al. (2023). Stochastic interpolants: A unifying framework for flows and diffusions. arXiv preprint arXiv:2303.08797.
[8] Song et al. (2023). Consistency Models. arXiv:2303.01469.
[9] Geng et al. (2024). Consistency Models Made Easy. arXiv:2406.14548.
[10] Boffi et al. (2024). Flow Map Matching: A unifying framework for consistency models. arXiv:2406.07507.
[11] Nicholas M. Boffi et al. (2025). How to build a consistency model: Learning flow maps via self-distillation. https://arxiv.org/abs/2505.18825.
[12] Zhengyang Geng et al. (2025). Mean Flows for One-step Generative Modeling. https://arxiv.org/abs/2505.13447.
[13] Chung et al. (2022). Improving diffusion models for inverse problems using manifold constraints. Advances in Neural Information Processing Systems. 35. pp. 25683–25696.
[14] Hyungjin Chung et al. (2024). Diffusion Posterior Sampling for General Noisy Inverse Problems. https://arxiv.org/abs/2209.14687.
[15] Kawar et al. (2022). Denoising diffusion restoration models. Advances in neural information processing systems. 35. pp. 23593–23606.
[16] Jiaming Song et al. (2023). Pseudoinverse-Guided Diffusion Models for Inverse Problems. In International Conference on Learning Representations. https://openreview.net/forum?id=9_gsMA8MRKQ.
[17] Kingma, Diederik P and Welling, Max (2013). Auto-encoding variational bayes. arXiv preprint arXiv:1312.6114.
[18] Silvestri et al. (2025). Training consistency models with variational noise coupling. arXiv preprint arXiv:2502.18197.
[19] Gretton et al. (2012). A kernel two-sample test. The journal of machine learning research. 13(1). pp. 723–773.
[20] Rombach et al. (2022). High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 10684–10695.
[21] Zhang et al. (2018). The unreasonable effectiveness of deep features as a perceptual metric. In Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 586–595.
[22] Ho, Jonathan and Salimans, Tim (2022). Classifier-free diffusion guidance. arXiv preprint arXiv:2207.12598.
[23] Zhang et al. (2025). Improving diffusion inverse problem solving with decoupled noise annealing. In Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 20895–20905.
[24] Song, Yang and Dhariwal, Prafulla (2023). Improved Techniques for Training Consistency Models. arXiv:2310.14189.
[25] Kevin Frans et al. (2025). One Step Diffusion via Shortcut Models. https://arxiv.org/abs/2410.12557.
[26] Lee et al. (2025). Decoupled meanflow: Turning flow models into flow maps for accelerated sampling. arXiv preprint arXiv:2510.24474.
[27] Linqi Zhou et al. (2025). Inductive Moment Matching. arXiv:2503.07565.
[28] Alexander Denker et al. (2025). DEFT: Efficient Fine-Tuning of Diffusion Models by Learning the Generalised $h$-transform. https://arxiv.org/abs/2406.01781.
[29] Carles Domingo-Enrich et al. (2025). Adjoint Matching: Fine-tuning Flow and Diffusion Generative Models with Memoryless Stochastic Optimal Control. https://arxiv.org/abs/2409.08861.
[30] Siddarth Venkatraman et al. (2025). Amortizing intractable inference in diffusion models for vision, language, and control. https://arxiv.org/abs/2405.20971.
[31] Kevin Clark et al. (2024). Directly Fine-Tuning Diffusion Models on Differentiable Rewards. https://arxiv.org/abs/2309.17400.
[32] Jaemoo Choi et al. (2026). Rethinking the Design Space of Reinforcement Learning for Diffusion Models: On the Importance of Likelihood Estimation Beyond Loss Design. https://arxiv.org/abs/2602.04663.
[33] Feng et al. (2023). Score-based diffusion models as principled priors for inverse imaging. In Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 10520–10531.
[34] Mammadov et al. (2024). Amortized posterior sampling with diffusion prior distillation. arXiv preprint arXiv:2407.17907.
[35] Mardani et al. (2023). A variational perspective on solving inverse problems with diffusion models. arXiv preprint arXiv:2305.04391.
[36] Venkatraman et al. (2025). Outsourced diffusion sampling: Efficient posterior inference in latent spaces of generative models. arXiv preprint arXiv:2502.06999.
[37] Luo et al. (2025). Noise Consistency Training: A Native Approach for One-Step Generator in Learning Additional Controls. arXiv preprint arXiv:2506.19741.
[38] Hoover et al. (2023). Energy transformer. Advances in neural information processing systems. 36. pp. 27532–27559.
[39] Simon McIntosh-Smith et al. (2024). Isambard-AI: a leadership class supercomputer optimised specifically for Artificial Intelligence. https://arxiv.org/abs/2410.11199.
[40] Billingsley, Patrick (2013). Convergence of probability measures. John Wiley & Sons.
[41] Ma et al. (2024). SiT: Exploring Flow and Diffusion-based Generative Models with Scalable Interpolant Transformers. arXiv:2401.08740.
[42] Ethan Perez et al. (2017). FiLM: Visual Reasoning with a General Conditioning Layer. https://arxiv.org/abs/1709.07871.
[43] Tang et al. (2025). Diffusion models without classifier-free guidance. arXiv preprint arXiv:2502.12154.
[44] Rout et al. (2023). Solving linear inverse problems provably via posterior sampling with latent diffusion models. Advances in Neural Information Processing Systems. 36. pp. 49960–49990.
[45] Yutong He et al. (2023). Manifold Preserving Guided Diffusion. https://arxiv.org/abs/2311.16424.
[46] Patel et al. (2025). FlowChef: Steering of Rectified Flow Models for Controlled Generations. In Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 15308–15318.
[47] Kim et al. (2025). FlowDPS: Flow-driven posterior sampling for inverse problems. arXiv preprint arXiv:2503.08136.
[48] Wang et al. (2022). Zero-shot image restoration using denoising diffusion null-space model. arXiv preprint arXiv:2212.00490.
[49] Peter Potaptchik et al. (2026). Meta Flow Maps enable scalable reward alignment. https://arxiv.org/abs/2601.14430.
[50] Xiaoshi Wu et al. (2023). Human Preference Score v2: A Solid Benchmark for Evaluating Human Preferences of Text-to-Image Synthesis. https://arxiv.org/abs/2306.09341.
[51] Yuval Kirstain et al. (2023). Pick-a-Pic: An Open Dataset of User Preferences for Text-to-Image Generation. https://arxiv.org/abs/2305.01569.
[52] Jiazheng Xu et al. (2023). ImageReward: Learning and Evaluating Human Preferences for Text-to-Image Generation. https://arxiv.org/abs/2304.05977.