BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models
1) Executive overview
Researchers developed BLIP-2, a vision-language model that trains efficiently by using frozen pre-trained image encoders and large language models. A small trainable module called Q-Former bridges the gap between image and text data in two training stages. This approach achieves top performance on tasks like visual question answering, image captioning, and image-text retrieval, while using far fewer trainable parameters than rivals.2) Why this work matters
Vision-language models power applications like image search, captioning, and chatbots with visuals, but training them from scratch costs massive compute. BLIP-2 cuts costs by reusing existing models, speeds development, and unlocks new abilities like following text instructions for image tasks without extra training. It lowers barriers for teams building AI that mixes vision and language.3) What we did (methods)
Teams froze strong image encoders (like ViT variants) and language models (like OPT or FlanT5). They trained only Q-Former, a 188-million-parameter transformer with 32 learnable queries. Stage 1 aligned images and text using contrastive learning, text generation from images, and matching on 129 million image-text pairs. Stage 2 connected Q-Former outputs as prompts to frozen language models for generative training. They tested on zero-shot and fine-tuned tasks.4) Key results
BLIP-2 topped zero-shot visual question answering at 65% accuracy on VQAv2, beating Flamingo-80B (56.3%) with 54 times fewer trainable parameters. It led image captioning scores (CIDEr 121.6 on NoCaps) and image-text retrieval (97.6% recall@1 on Flickr). Fine-tuned, it matched or beat leaders on these tasks. Training the largest version took under 9 days on one machine with four GPUs.5) Interpretation of findings
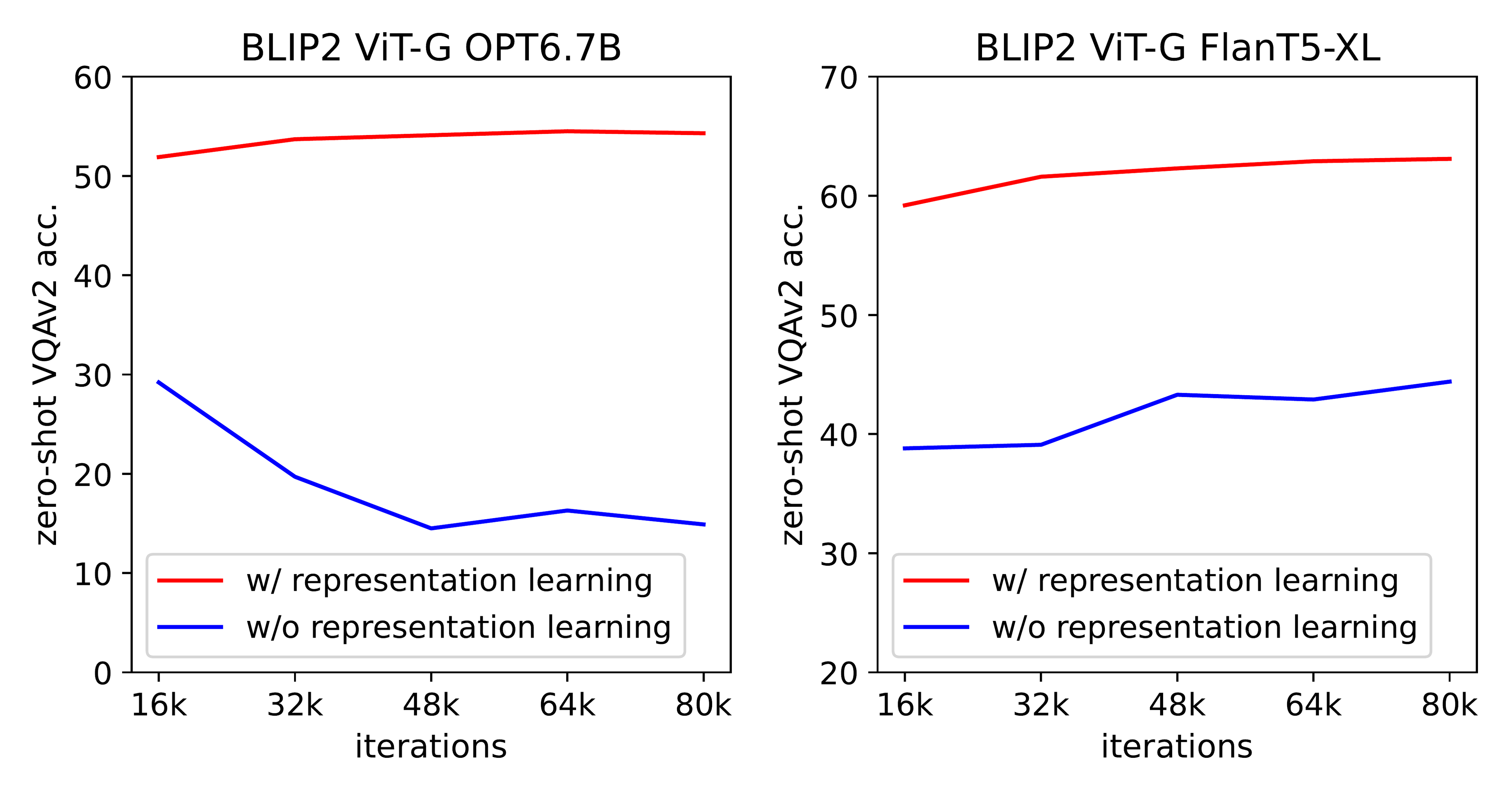
Stronger frozen image encoders or language models boosted results, showing BLIP-2 scales with unimodal advances. The first training stage proved essential; skipping it dropped performance sharply due to poor image-text alignment. Gains cut compute needs and risks of retraining giants, improving efficiency and safety by avoiding full retrains. It outperformed end-to-end methods despite less data and params, signaling a shift to modular training.6) Recommendations and next steps
Adopt BLIP-2 for vision-language projects to save compute and gain strong baselines. Pair it with top frozen models like newer ViTs or language models for quick wins. For production, fine-tune on task data while freezing language parts. Test larger datasets with multiple image-text pairs per sample to add few-shot learning. Run pilots on real apps like visual assistants before full rollout.7) Limitations and confidence
Frozen models limit adaptation to new data and inherit language model biases or outdated knowledge. No in-context learning from few-shot examples in tests. High confidence in reported benchmarks (reproduced state-of-the-art across tasks); caution on open-world knowledge tasks like OK-VQA where larger rivals edged ahead.Salesforce Research
https://github.com/salesforce/LAVIS/tree/main/projects/blip2
Abstract
In this section, the escalating computational cost of vision-language pre-training from end-to-end training of massive models poses a major barrier, prompting BLIP-2 as a generic, efficient alternative that leverages frozen pre-trained image encoders and large language models. It bridges the modality gap via a lightweight Querying Transformer pre-trained in two stages—first for vision-language representation learning from the image encoder, then for vision-to-language generation from the language model—achieving state-of-the-art results across vision-language tasks with far fewer trainable parameters, such as outperforming Flamingo80B by 8.7% on zero-shot VQAv2 using 54 times fewer parameters, while unlocking zero-shot image-to-text generation that follows natural language instructions.
1. Introduction
In this section, vision-language pre-training incurs prohibitive computation costs from end-to-end training of massive models, which BLIP-2 addresses through a generic, efficient strategy bootstrapping from frozen pre-trained image encoders and large language models via a lightweight Querying Transformer pre-trained in two stages to bridge the modality gap. The first stage extracts text-relevant visual representations from the image encoder, while the second aligns them for generative learning with the language model. As a result, BLIP-2 achieves state-of-the-art performance on visual question answering, captioning, and retrieval—outperforming Flamingo by 8.7% on zero-shot VQAv2 with 54× fewer trainable parameters—enables prompted zero-shot image-to-text generation for capabilities like visual reasoning, and flexibly harnesses advancing unimodal models.
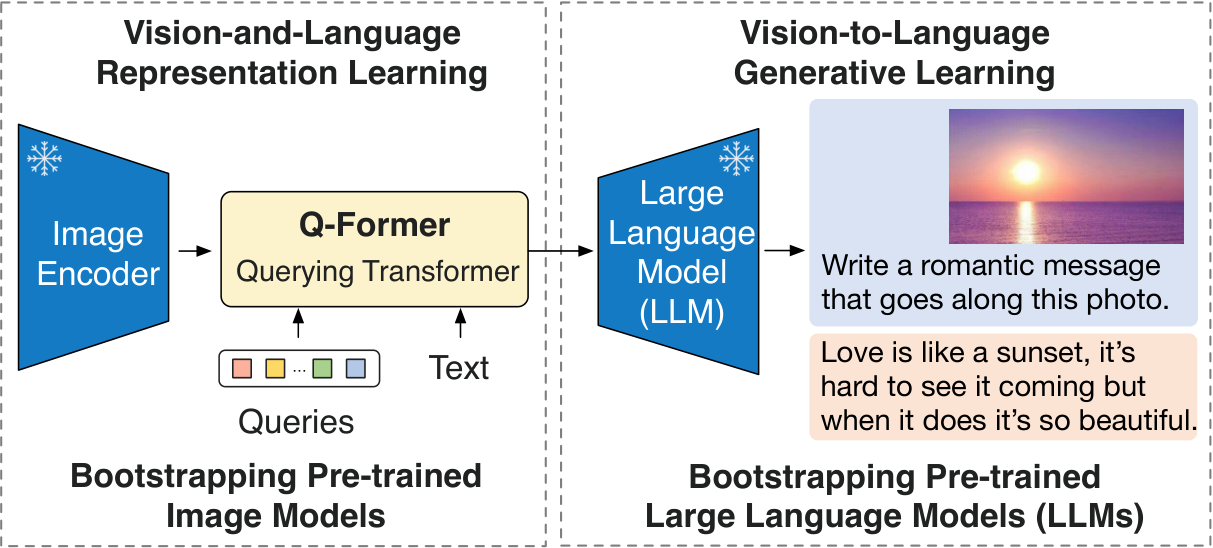
- BLIP-2 effectively leverages both frozen pre-trained image models and language models. We bridge the modality gap using a Q-Former pre-trained in two-stages: representation learning stage and generative learning stage. BLIP-2 achieves state-of-the-art performance on various vision-language tasks including visual question answering, image captioning, and image-text retrieval.
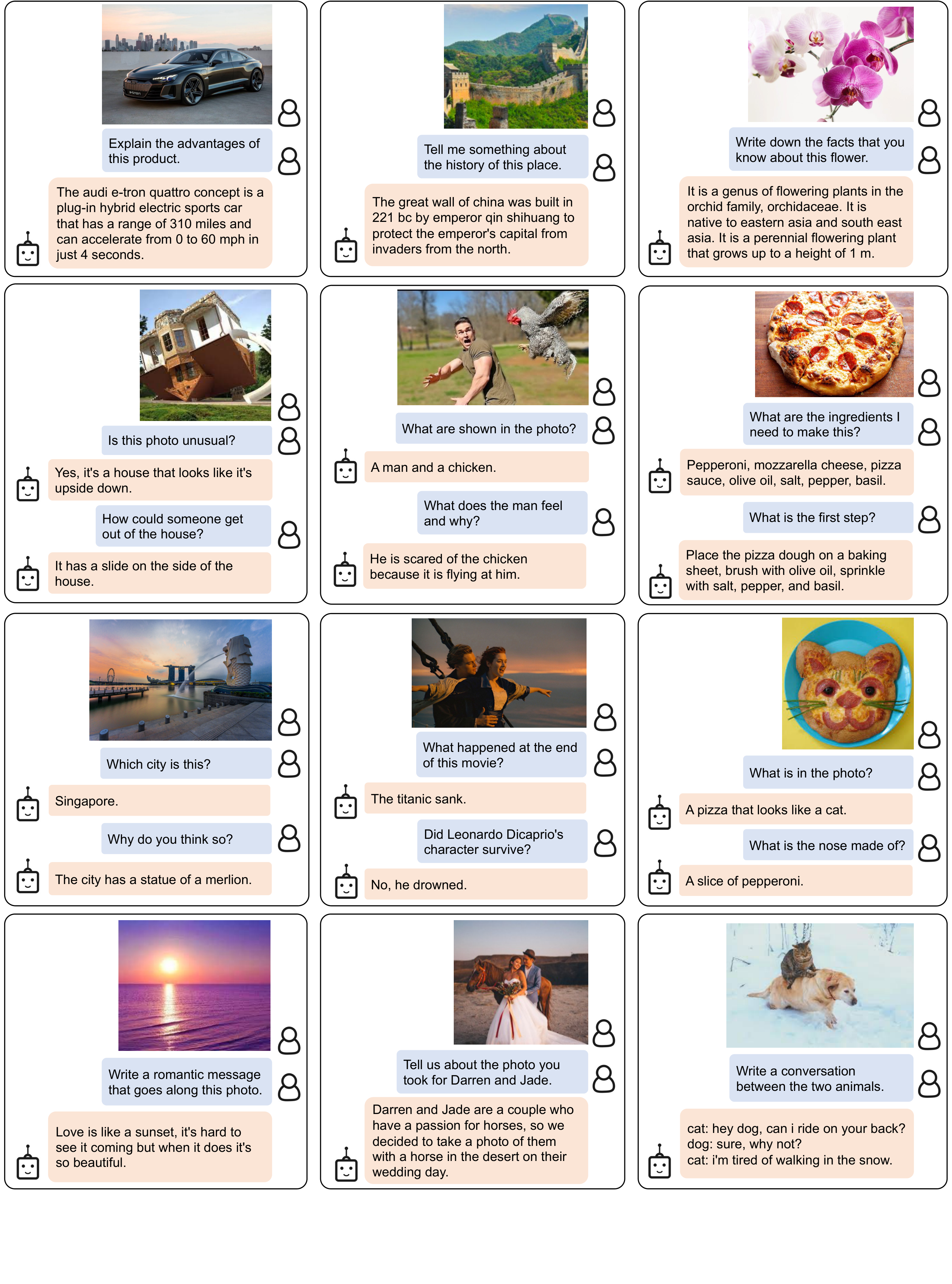
- Powered by LLMs (e.g. OPT [8], FlanT5 [9]), BLIP-2 can be prompted to perform zero-shot image-to-text generation that follows natural language instructions, which enables emerging capabilities such as visual knowledge reasoning, visual conversation, etc. (see Figure 4 for examples).
- Due to the use of frozen unimodal models and a lightweight Q-Former, BLIP-2 is more compute-efficient than existing state-of-the-arts. For example, BLIP-2 outperforms Flamingo [5] by 8.7% on zero-shot VQAv2, while using 54×\times× fewer trainable parameters. Furthermore, our results show that BLIP-2 is a generic method that can harvest more advanced unimodal models for better VLP performance.
2. Related Work
In this section, vision-language pre-training grapples with escalating compute costs from end-to-end training of massive models on vast datasets, limiting flexibility with off-the-shelf unimodal models. End-to-end approaches rely on architectures like dual-encoders or unified transformers with objectives such as contrastive learning and masked modeling, while modular methods freeze either image encoders—as in LiT for CLIP pre-training—or language models, like Frozen's finetuned image encoder soft prompts or Flamingo's inserted cross-attention layers trained on billions of pairs, both hinged on language modeling loss yet challenged by visual-text alignment. BLIP-2 differentiates by seamlessly leveraging both frozen image encoders and LLMs, delivering superior performance across vision-language tasks at drastically reduced computational expense.
2.1. End-to-end Vision-Language Pre-training
2.2. Modular Vision-Language Pre-training
3. Method
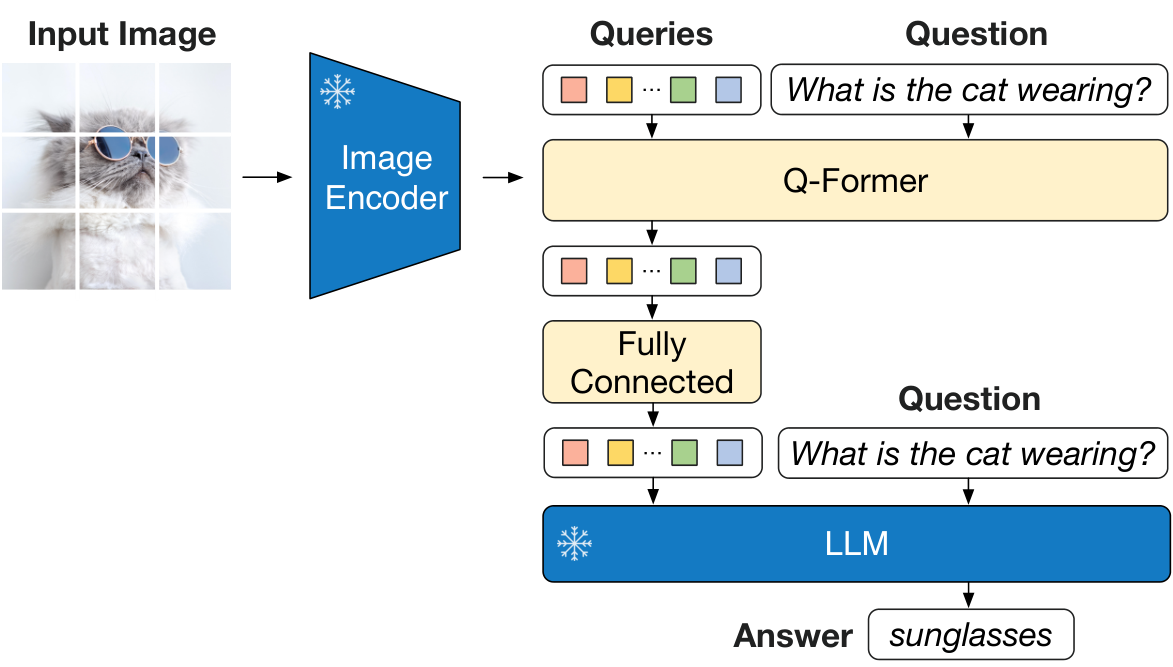
In this section, bridging the modality gap between frozen pre-trained image encoders and large language models poses a key challenge for efficient vision-language pre-training. BLIP-2 addresses it with a lightweight Querying Transformer (Q-Former) featuring learnable queries that extract compact, text-relevant visual features via cross-attention, acting as an information bottleneck. Pre-training unfolds in two stages: first, joint optimization of image-text contrastive, grounded text generation, and matching losses on image-text pairs to align representations; second, connecting Q-Former outputs as soft visual prompts to a frozen LLM for generative learning via language modeling. This yields a compute-efficient framework trainable on modest hardware, enabling strong downstream performance while freezing massive unimodal backbones.
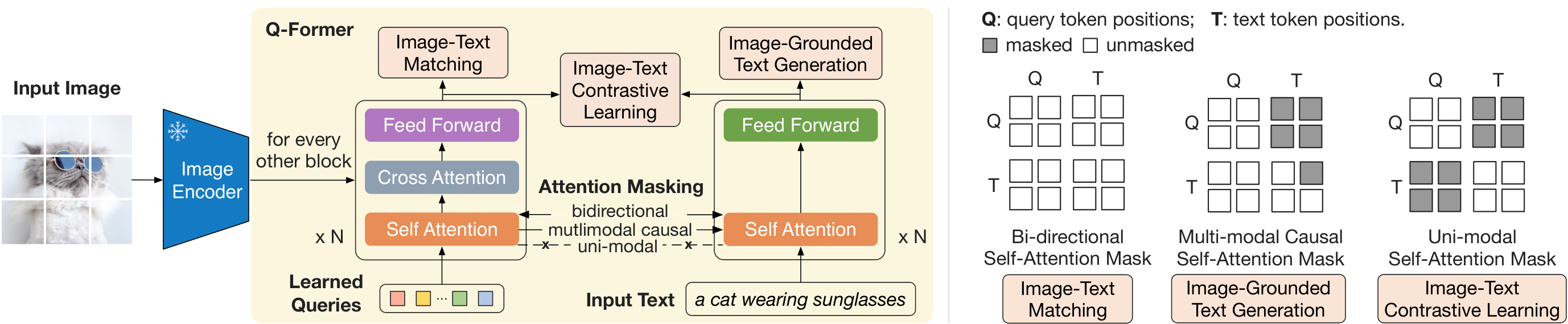
3.1. Model Architecture
3.2. Bootstrap Vision-Language Representation Learning from a Frozen Image Encoder
[CLS] token. Since ZZZ contains multiple output embeddings (one from each query), we first compute the pairwise similarity between each query output and ttt, and then select the highest one as the image-text similarity. To avoid information leak, we employ a unimodal self-attention mask, where the queries and text are not allowed to see each other. Due to the use of a frozen image encoder, we can fit more samples per GPU compared to end-to-end methods. Therefore, we use in-batch negatives instead of the momentum queue in BLIP.[CLS] token with a new [DEC] token as the first text token to signal the decoding task.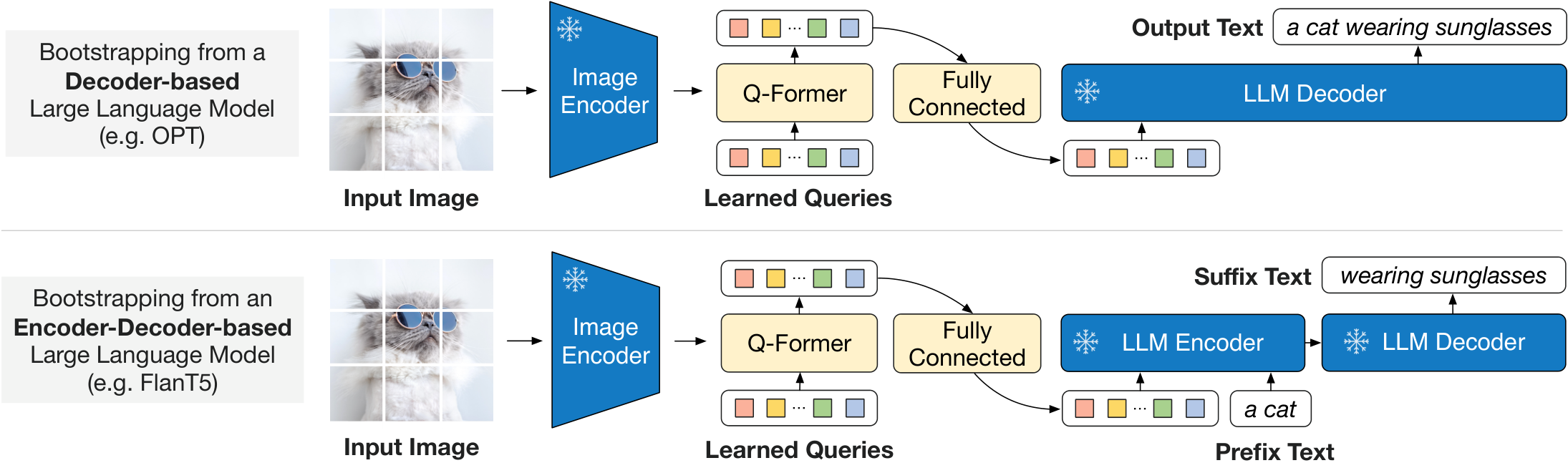
3.3. Bootstrap Vision-to-Language Generative Learning from a Frozen LLM
3.4. Model Pre-training
4. Experiment
In this section, experiments validate BLIP-2's superiority on zero-shot and fine-tuned vision-language tasks like VQA, captioning, and retrieval. By bridging frozen state-of-the-art image encoders (ViT-L/g) and LLMs (OPT/FlanT5) via Q-Former, it leverages representation learning to align modalities efficiently, preventing catastrophic forgetting in generative pre-training. BLIP-2 achieves top zero-shot VQAv2 (65.0%), NoCaps CIDEr (121.6), and Flickr retrieval (97.6% TR@1), surpassing Flamingo and others with 54x fewer trainable parameters (188M), while fine-tuning yields SOTA among generation models and confirms ITG loss enhances alignment even for retrieval.
4.1. Instructed Zero-shot Image-to-Text Generation
4.2. Image Captioning
4.3. Visual Question Answering
4.4. Image-Text Retrieval
5. Limitation
In this section, BLIP-2 falters in in-context learning for VQA because its pre-training uses single image-text pairs per sample, failing to capture correlations across multiples unlike Flamingo’s interleaved M3W dataset, prompting plans for a similar resource. Image-to-text generation yields poor results from LLM knowledge gaps, erroneous reasoning paths, or outdated image info, while frozen components inherit risks like offensive language, social biases, and data leaks. Mitigation relies on instructional prompts or filtered datasets to curb harms.
6. Conclusion
In this section, vision-language pre-training demands efficiency amid surging model sizes; BLIP-2 tackles this via a generic, compute-efficient paradigm that bridges frozen pre-trained image encoders and large language models with minimal trainable parameters. This yields state-of-the-art results across diverse vision-language tasks while unlocking emerging zero-shot instructed image-to-text generation. Ultimately, BLIP-2 advances the path to multimodal conversational AI agents.

References
In this section, the references compile foundational and cutting-edge works tackling vision-language integration, from early contrastive models like CLIP and ALIGN to generative paradigms in Flamingo, OFA, and BLIP that fuse image encoders with frozen LLMs via lightweight bridges like Q-Former. Spanning dual-encoder alignment, fusion strategies, and datasets such as COCO, Visual Genome, and LAION, they highlight scalable pre-training with noisy supervision, momentum distillation, and task unification. This synthesis grounds BLIP-2's parameter-efficient pre-training, enabling state-of-the-art zero-shot generalization and multimodal capabilities across captioning, VQA, and retrieval.