Visual Instruction Tuning
1) Purpose
Researchers aimed to create an open-source AI model that understands images and text together and follows user instructions, like a visual assistant. Current vision models handle fixed tasks but lack flexibility to adapt to varied instructions. Large language models excel at text instructions, so the work extends this idea to vision-language tasks. This matters now due to recent successes in text-based chatbots and the need for general-purpose multimodal AI.2) Approach
The team used GPT-4 to generate 158,000 instruction-following examples from public images, covering chats, descriptions, and reasoning. They linked a pre-trained image encoder (CLIP) to an open language model (Vicuna) with a simple projection layer. Training occurred in two stages: first align image features to text on 595,000 filtered image-text pairs; then fine-tune end-to-end on the new data for chat or science questions.3) Key results
- LLaVA matched behaviors of proprietary GPT-4 on unseen images in visual chats, outperforming rivals like BLIP-2 and OpenFlamingo. - On a new benchmark with COCO images, it scored 85% relative to GPT-4 using ground-truth image details. - On diverse real-world images, it reached 67% relative score, far above competitors (BLIP-2 at 38%, OpenFlamingo at 19%). - Alone, it hit 91% accuracy on ScienceQA questions; combined with GPT-4 as a judge, it set a new record of 92.5%.4) Interpretation
Results show instruction tuning works for vision-language tasks, enabling the model to follow specific prompts rather than just describe images. It handles complex reasoning, counts objects, and links visuals to knowledge. Open-sourcing data, code, and models speeds research. Training finishes in hours on standard hardware, making it accessible.5) What the findings mean
Strong results boost performance on chat and question-answering tasks, cutting need for proprietary tools like GPT-4. This lowers costs for developers and shortens timelines to deploy visual assistants. Safety improves with built-in filters for harmful text or images, though risks like biases persist from base models. It outperforms prior open models, signaling a shift to instruction-tuned multimodal AI.6) Recommendations and next steps
Use LLaVA as a base for visual chatbots or QA systems; fine-tune on domain data for specific needs. Explore ensembling with GPT-4 for top accuracy. Next, scale to larger models or datasets, test on more benchmarks, and refine for real-world apps like navigation or editing. If building production systems, run pilots on user tasks first.7) Limitations and confidence
Limited training data may miss edge cases; model can hallucinate details or inherit biases from CLIP and Vicuna. Evaluation relies partly on GPT-4 judging, which assumes its reliability. High confidence in benchmark gains and chat demos; caution on novel domains or high-stakes use without more tests.Abstract
1 Introduction
In this section, humans' multimodal interaction via vision and language inspires the quest for a general-purpose AI assistant that follows diverse real-world instructions, yet current vision models remain task-specific with fixed interfaces, while language-only LLMs excel at instruction-following but ignore visuals. Visual instruction-tuning bridges this gap by using GPT-4 to generate vision-language data from image-text pairs, powering LLaVA—a large multimodal model that connects CLIP's visual encoder to Vicuna's LLM and fine-tunes end-to-end. This yields impressive chat abilities rivaling GPT-4, state-of-the-art Science QA accuracy via ensembling, new benchmarks like LLaVA-Bench, and open-sourced data, models, and demos to advance the field.
- Multimodal instruction-following data. One key challenge is the lack of vision-language instruction-following data. We present a data reformation perspective and pipeline to convert image-text pairs into an appropriate instruction-following format, using ChatGPT/GPT-4.
- Large multimodal models. We develop a large multimodal model (LMM), by connecting the open-set visual encoder of CLIP ([5]) with the language decoder Vicuna [29], and fine-tuning end-to-end on our generated instructional vision-language data. Our empirical study validates the effectiveness of using generated data for LMM instruction-tuning, and suggests practical tips for building a general-purpose instruction-following visual agent. When ensembled with GPT-4, our approach achieves SoTA on the Science QA [31] multimodal reasoning dataset.
- Multimodal instruction-following benchmark. We present LLaVA-Bench with two challenging benchmarks, with a diverse selection of paired images, instructions and detailed annotations.
- Open-source. We release the following assets to the public: the generated multimodal instruction data, the codebase, the model checkpoints, and a visual chat demo.
2 Related Work
In this section, developing multimodal instruction-following agents remains fragmented, split between end-to-end models for narrow tasks like navigation or image editing and LLM-orchestrated systems like Visual ChatGPT. Instruction tuning, proven in NLP to boost LLMs' zero-shot generalization via explicit human-like directives, inspires vision-language extension, yet prior large multimodal models such as Flamingo, BLIP-2, OpenFlamingo, and LLaMA-Adapter—trained mainly on image-text pairs—lack targeted vision-language instruction data, yielding weaker multimodal than language-only performance. The paper bridges this void through visual instruction tuning, distinct from parameter-efficient visual prompt tuning, to enhance broad instruction adherence.
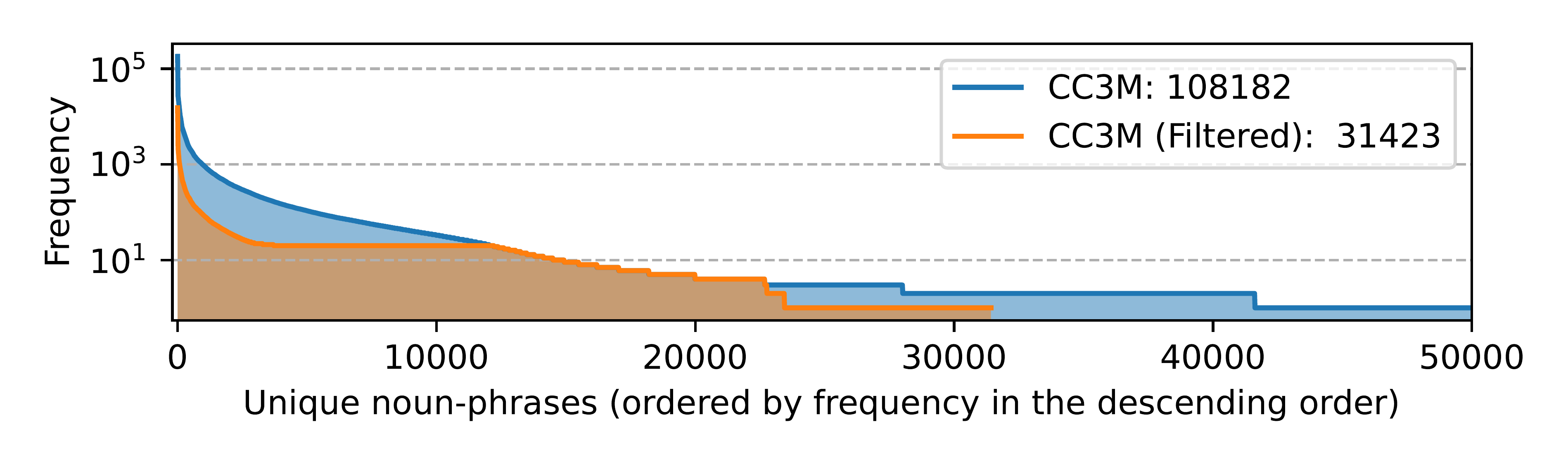
In this section, the challenge of curating balanced, diverse image-text data for multimodal pre-training is tackled through varied prompting strategies and dataset filtering. Brief and detailed image descriptions are generated using lists of natural-language-equivalent instructions (Tables 11–12) to enrich captions via GPT models. For CC3M, noun-phrases are extracted with Spacy, rare ones (frequency <3) discarded, and captions iteratively added starting from lowest-frequency phrases, capping subsets at 100 for high-frequency ones to prioritize tail concepts. This yields a 595K-pair subset with superior coverage of low-frequency concepts versus the original, as visualized in noun-phrase frequency statistics.
3 GPT-assisted Visual Instruction Data Generation
In this section, the scarcity of multimodal instruction-following data despite abundant image-text pairs poses a key challenge for training visual assistants. To address it, GPT-4 is prompted with symbolic representations—captions and bounding boxes from COCO images—to generate diverse instruction-response pairs via in-context learning from seed examples, yielding three types: conversations probing objects, actions, and positions; detailed descriptions curated from targeted question lists; and complex reasoning requiring step-by-step logic. This pipeline produces 158K unique language-image samples (58K conversations, 23K descriptions, 77K reasoning), with ablations confirming GPT-4's superiority over ChatGPT for high-quality outputs like spatial reasoning.

- Conversation. We design a conversation between the assistant and a person asking questions about this photo. The answers are in a tone as if the assistant is seeing the image and answering the question. A diverse set of questions are asked about the visual content of the image, including the object types, counting the objects, object actions, object locations, relative positions between objects. Only questions that have definite answers are considered. Please see Appendix for the detailed prompt.
- Detailed description. To include a rich and comprehensive description for an image, we create a list of questions with such an intent. We prompt GPT-4 then curate the list (see detailed prompts and curation process in Appendix). For each image, we randomly sample one question from the list to ask GPT-4 to generate the detailed description.
- Complex reasoning. The above two types focus on the visual content itself, based on which we further create in-depth reasoning questions. The answers typically require a step-by-step reasoning process by following rigorous logic.
4 Visual Instruction Tuning
In this section, visual instruction tuning tackles the challenge of linking a pre-trained vision encoder and large language model to enable general-purpose multimodal instruction-following. It connects CLIP ViT-L/14 visual features—extracted as grid representations—to Vicuna's word embedding space via a simple trainable linear projection layer, producing visual tokens inserted into multi-turn conversation sequences, with images randomly placed before or after the first question prompt. Training uses a two-stage process: initial pre-training on 595K filtered CC3M image-caption pairs aligns features by optimizing only the projection while freezing encoders; subsequent end-to-end fine-tuning optimizes the projection and LLM on 158K generated instruction data for chatbot dialogues or Science QA tasks, yielding models with strong zero-shot generalization to visual reasoning and chat.
In this section, visual instruction tuning addresses the challenge of integrating a pre-trained vision encoder with a large language model to enable effective multimodal instruction-following. It employs a simple linear projection layer to map CLIP ViT-L/14 image features into the Vicuna LLM's word embedding space, forming visual tokens for autoregressive training on multi-turn conversation sequences. A two-stage process first aligns features via pre-training solely on the projection matrix using filtered CC3M captions, then fine-tunes the projection and LLM end-to-end: for a multimodal chatbot on 158K diverse instruction data with uniform sampling of conversation, descriptions, and reasoning; for Science QA as single-turn tasks combining question, context, reasoning, and answers. This lightweight approach yields general-purpose visual assistants excelling in chat and reasoning.
4 Visual Instruction Tuning
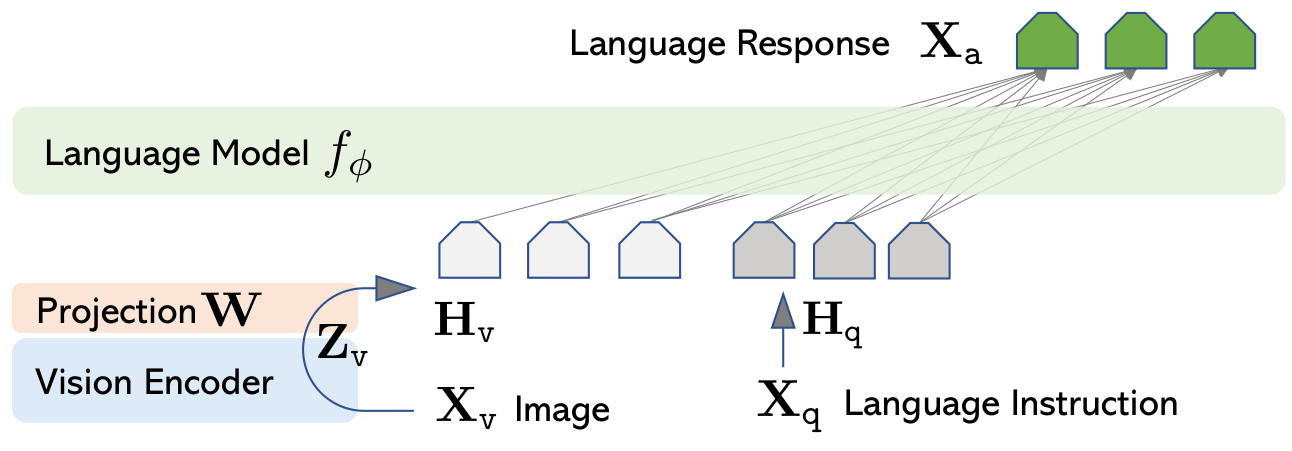
4.2 Training

<STOP> for better readability. For LLaVA model training, we consider a two-stage instruction-tuning procedure.- Multimodal Chatbot. We develop a Chatbot by fine-tuning on the 158K language-image instruction-following data in Section 3. Among the three types of responses, conversation is multi-turn while the other two are single-turn. They are uniformly sampled in training.
- Science QA. We study our method on the ScienceQA benchmark [31], the first large-scale multimodal science question dataset that annotates the answers with detailed lectures and explanations. Each question is provided a context in the form of natural language or an image. The assistant provides the reasoning process in natural language and selects the answer among multiple choices. For training in Equation 2, we organize the data as a single turn conversation, the question & context as Xinstruct\mathbf{X}_{\text{instruct}}Xinstruct, and reasoning & answer as Xa\mathbf{X}_{\text{a}}Xa.
5 Experiments
In this section, experiments rigorously assess LLaVA's instruction-following and visual reasoning in multimodal chatbot and ScienceQA settings, using two-stage tuning on filtered CC3M pairs and 158K GPT-generated instruction data with Vicuna LLM and projected CLIP features. Qualitative demos rival GPT-4 on complex prompts, outperforming BLIP-2 and OpenFlamingo by focusing on user intent over mere description. GPT-4-judged LLaVA-Bench yields 85% relative score on COCO tasks and 67% in-the-wild, with all data types optimal. ScienceQA accuracy reaches 90.92%, and GPT-4 ensembling as judge sets new state-of-the-art at 92.53%. Ablations validate pre-training for alignment, larger scale, penultimate CLIP features, and reasoning-first for faster convergence, underscoring visual instruction tuning's efficacy.

5.1 Multimodal Chatbot

5.2 ScienceQA
text-davinci-002) with and without chain-of-thought (CoT), LLaMA-Adapter ([56]), as well as multimodal chain-of-thought (MM-CoT) [62], which is the current SoTA method on this dataset. For more baseline numbers, please see [31].
6 Conclusion
In this section, visual instruction tuning tackles the challenge of enabling multimodal models to follow human intent across diverse visual tasks. An automatic pipeline generates high-quality language-image instruction-following data, powering the training of LLaVA, which delivers state-of-the-art accuracy on ScienceQA after fine-tuning and excels in visual chat with multimodal data. The work introduces the first benchmark for multimodal instruction-following, marks an initial focus on real-life applications with extended academic results in [63], and aims to inspire future development of advanced multimodal models.
A Broader Impact
In this section, LLaVA's release as a general-purpose visual assistant entails benefits like advancing research and applications alongside risks such as malicious inputs, hallucinations, biases inherited from CLIP and LLaMA/Vicuna, high energy demands at scale, and complex evaluations needing finer hallucination and visual understanding metrics. Mitigations employ OpenAI text filters and NSFW image blockers. Ultimately, community-driven investigation outweighs harms, spurring mitigation strategies, innovation, and responsible vision-language foundation model progress.
B More Results
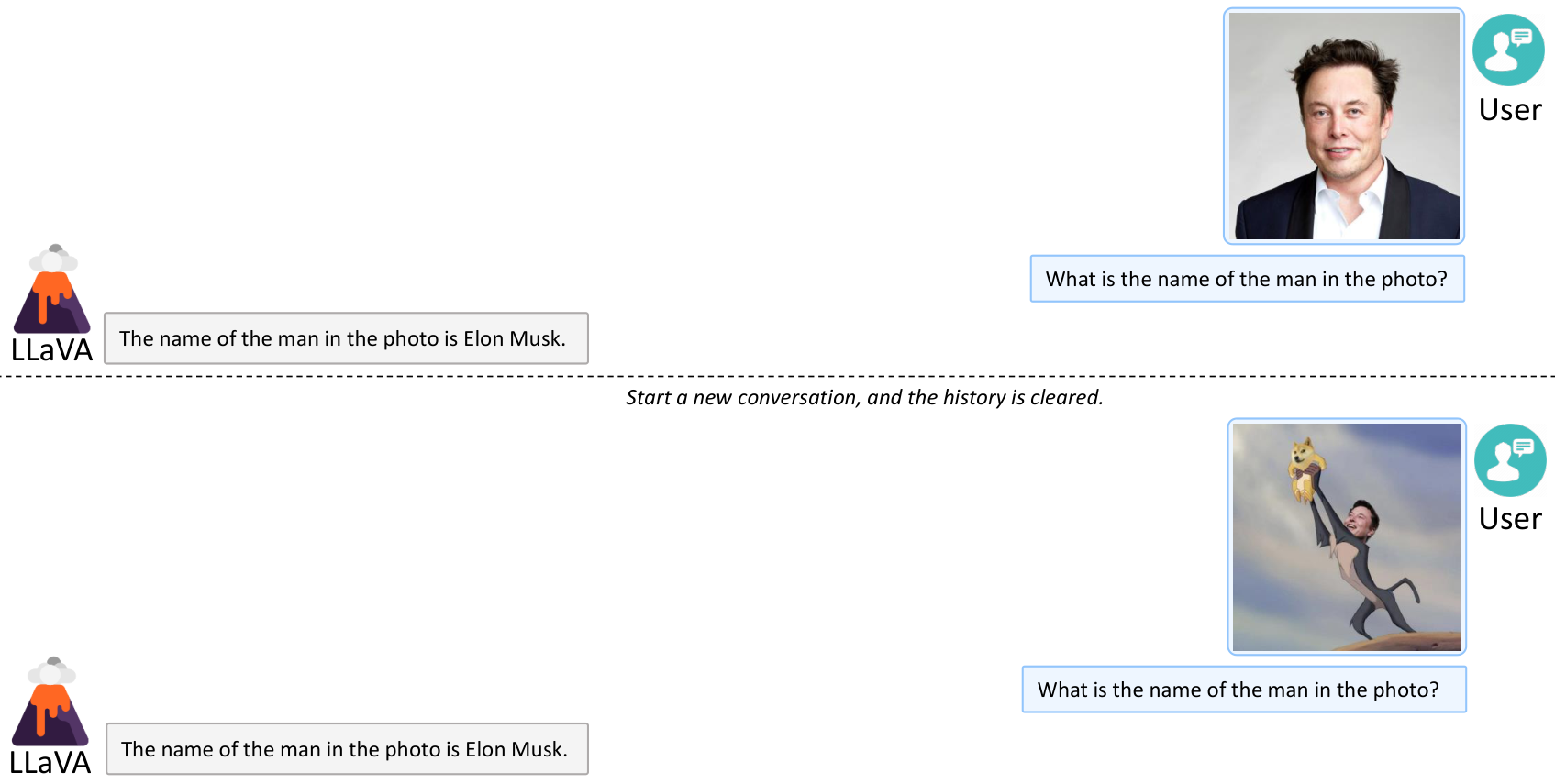
In this section, additional qualitative results reveal LLaVA's emergent behaviors and untapped potential beyond its training data. Through examples like generating functional HTML/JS/CSS code from sketches, delivering detailed conversational responses to visual prompts, linking images to pretrained textual knowledge, recognizing unseen figures such as Elon Musk in headshots and memes, and performing strong OCR on rare training instances, LLaVA showcases generalization powered by CLIP's visual encoding and LLaMA/Vicuna's language capabilities. These findings, illustrated across tables and figures, affirm LLaVA's versatility for diverse applications while calling for future probes into underlying mechanisms to foster more robust, bias-reduced vision-language models.

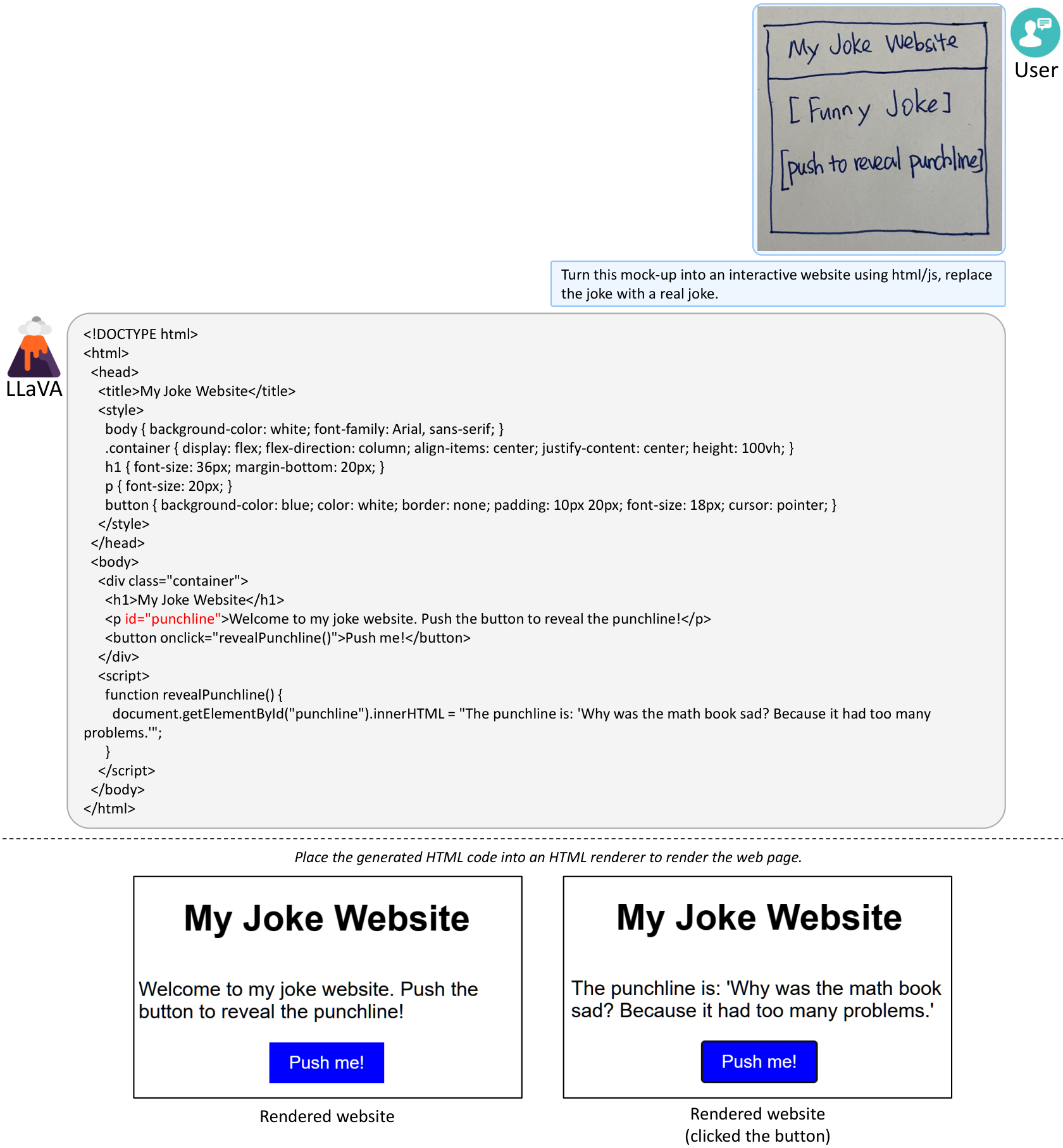
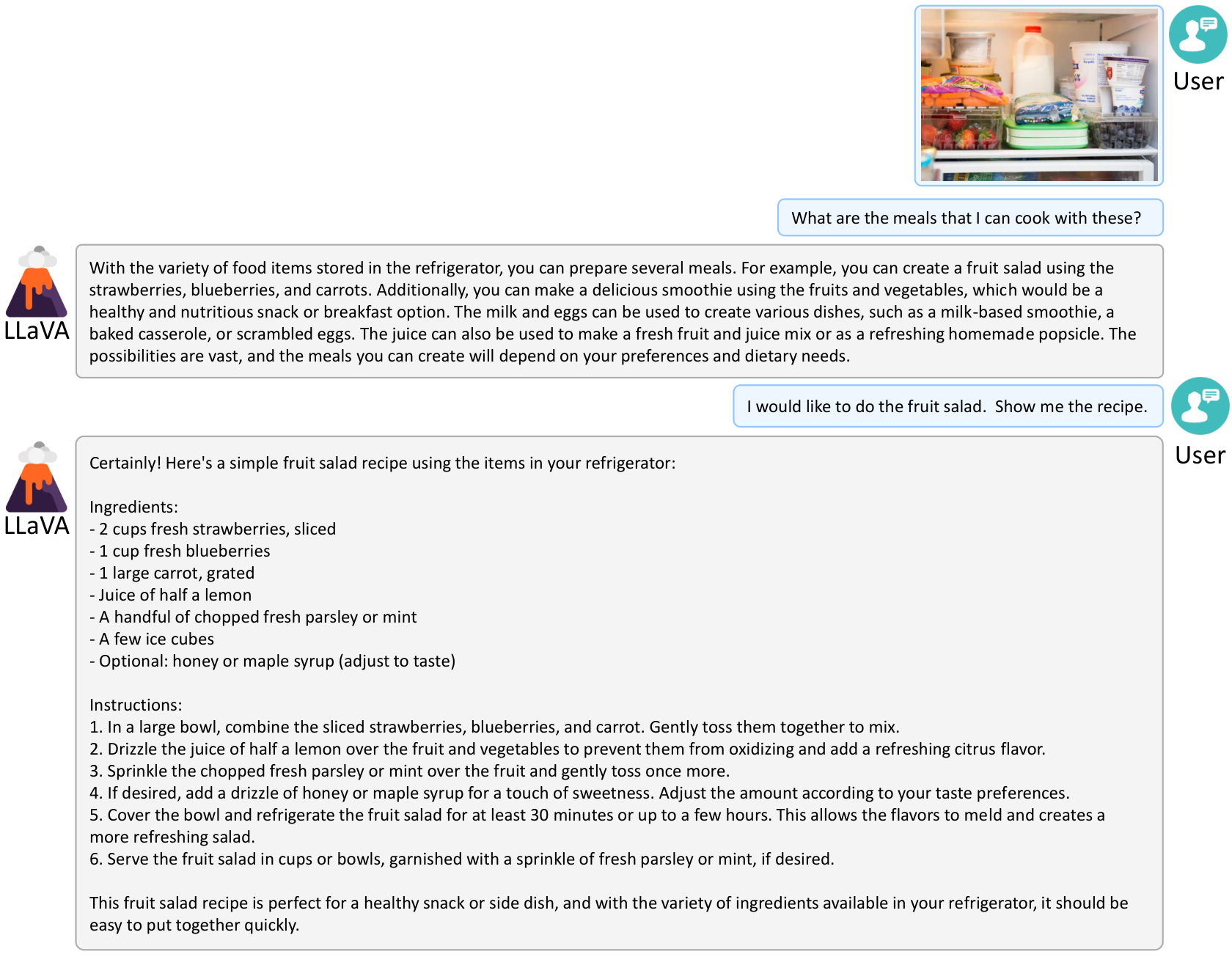
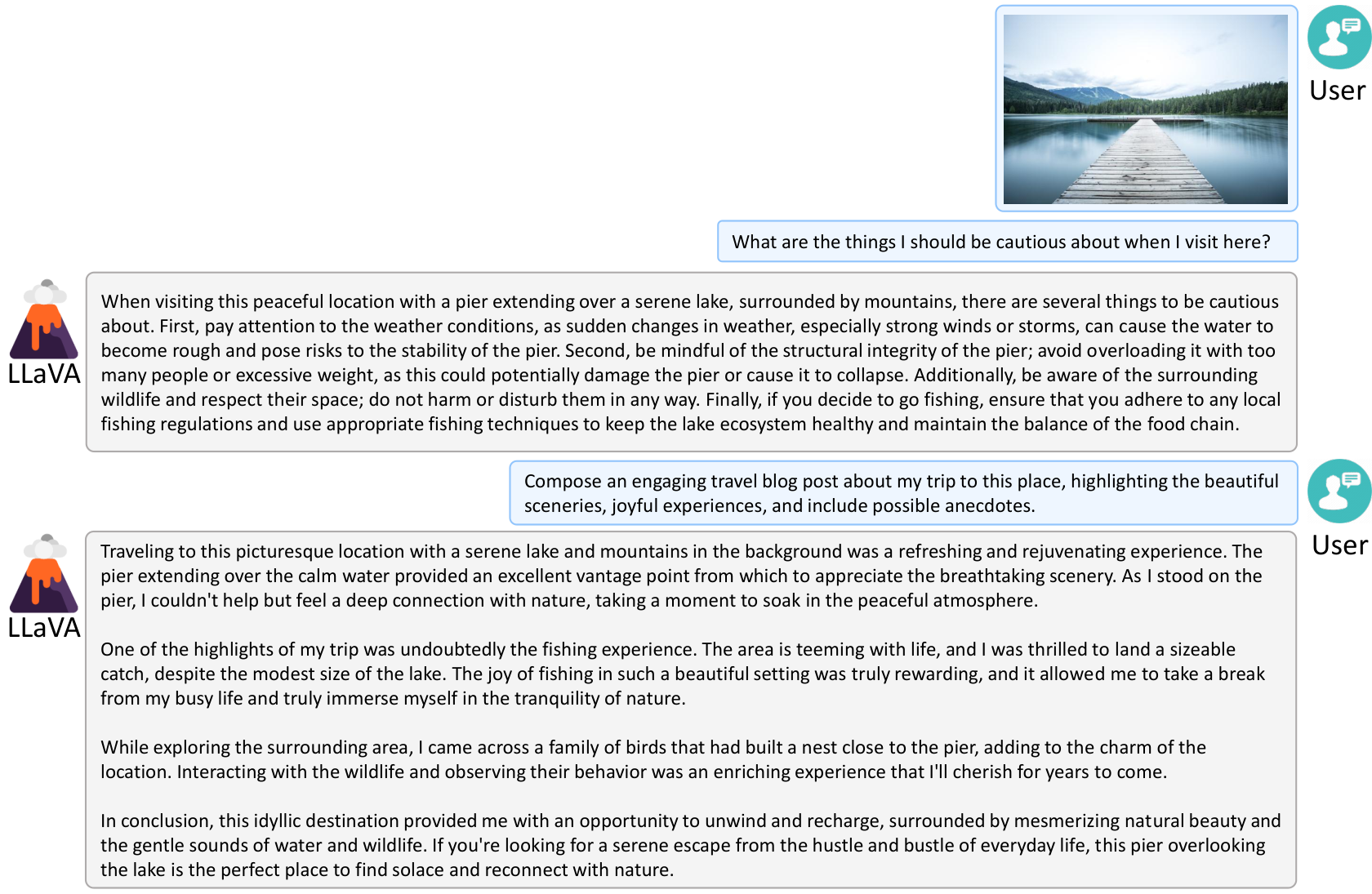



C Training Details
In this section, efficient training of LLaVA balances multimodal alignment with instruction-following on modest hardware. Pre-training on the filtered CC-595K subset runs one epoch at learning rate 2e-3 and batch size 128, followed by fine-tuning on LLaVA-Instruct-158K for three epochs at 2e-5 learning rate and batch size 32, employing Adam optimization without weight decay, cosine scheduling with 3% warmup, FSDP, gradient checkpointing, BF16, and TF32 for memory and precision efficiency. Conducted on eight A100 GPUs, pre-training finishes in 4 hours, instruction fine-tuning in 10 hours, and ScienceQA fine-tuning in 4 hours, enabling rapid iteration toward state-of-the-art performance.
D Assets
In this section, the LLaVA project addresses reproducibility by uploading essential assets to an anonymized GitHub repository. It includes source code, README, web demo instructions, GPT-4 prompts with few-shot examples, the LLaVA-Instruct-158K dataset, LLaVA-Bench evaluations on COCO and in-the-wild images, and 25GB compressed model checkpoints. Exceeding GitHub LFS limits, checkpoints await public release or reviewer requests. This comprehensive sharing accelerates multimodal research and enables direct extension of visual instruction tuning.
- Source Code: link
- README: link
- Instructions to launch the demo: link
- All prompts and few shot examples for querying GPT-4: link
- LLaVA-Instruct-158K: link
- LLaVA-Bench: COCO, In-The-Wild
- Model checkpoints. The size of the model checkpoints after compression is 25GB, which exceeds the 5GB limit of GitHub LFS (Large File Storage). We'll release the checkpoint to the public, or upon request with reviewers for this submission.
E Data

Unable to load figure
Multi-image figure could not be rendered

F Prompts
In this section, prompts enable text-only GPT-4/ChatGPT to generate multimodal instruction-following data from image contexts like captions and bounding boxes, bypassing direct image input. Table 13 details the construction process using few-shot in-context learning—drawing examples from fewshot_samples to form final messages that elicit responses such as conversations—while Tables 14 and 15 illustrate full examples of contexts prompting detailed descriptions, complex reasoning, and dialogues. This streamlined approach yields diverse, structured data like LLaVA-Instruct-158K, powering effective visual instruction tuning without visual encoders during generation.




References
In this section, the references compile 63 pivotal works addressing the challenge of integrating vision and language in foundation models to create capable multimodal assistants. Core contributions span transferable visual models like CLIP, large language models such as LLaMA and Vicuna, instruction-tuning paradigms from Alpaca to GPT-4, and datasets including CC3M, LAION-5B, and COCO, alongside benchmarks for reasoning, navigation, and generation. This synthesis reveals rapid evolution toward efficient, aligned vision-language systems, enabling emergent abilities like OCR and generalization in models like LLaVA while highlighting paths to mitigate biases and hallucinations.