1000 Layer Networks for Self-Supervised RL: Scaling Depth Can Enable New Goal-Reaching Capabilities
Purpose and Context
Reinforcement learning (RL) has lagged behind other areas of machine learning in scaling model size. While language and vision models routinely use hundreds of layers and achieve breakthrough performance through scale, RL methods typically rely on shallow networks of only 2 to 5 layers. This research investigates whether scaling network depth can unlock similar performance gains in RL, particularly in self-supervised settings where agents must learn without demonstrations or reward functions.
Approach
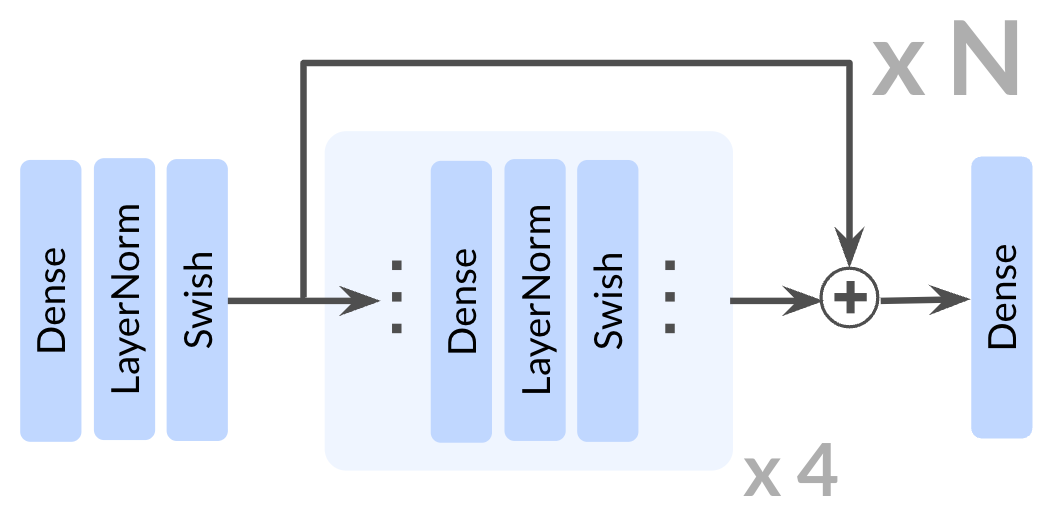
The study used contrastive reinforcement learning (CRL), a self-supervised method where agents learn to reach goals through exploration alone. Networks were scaled from the standard 4 layers up to 1024 layers—over 100 times deeper than typical RL architectures. To stabilize training at these depths, the team incorporated residual connections, layer normalization, and Swish activation functions. Experiments spanned ten tasks including locomotion (humanoid and ant agents), navigation through mazes, and robotic arm manipulation. Training used GPU-accelerated environments to generate sufficient data for deep networks.
Key Findings
Increasing network depth produced dramatic performance improvements:
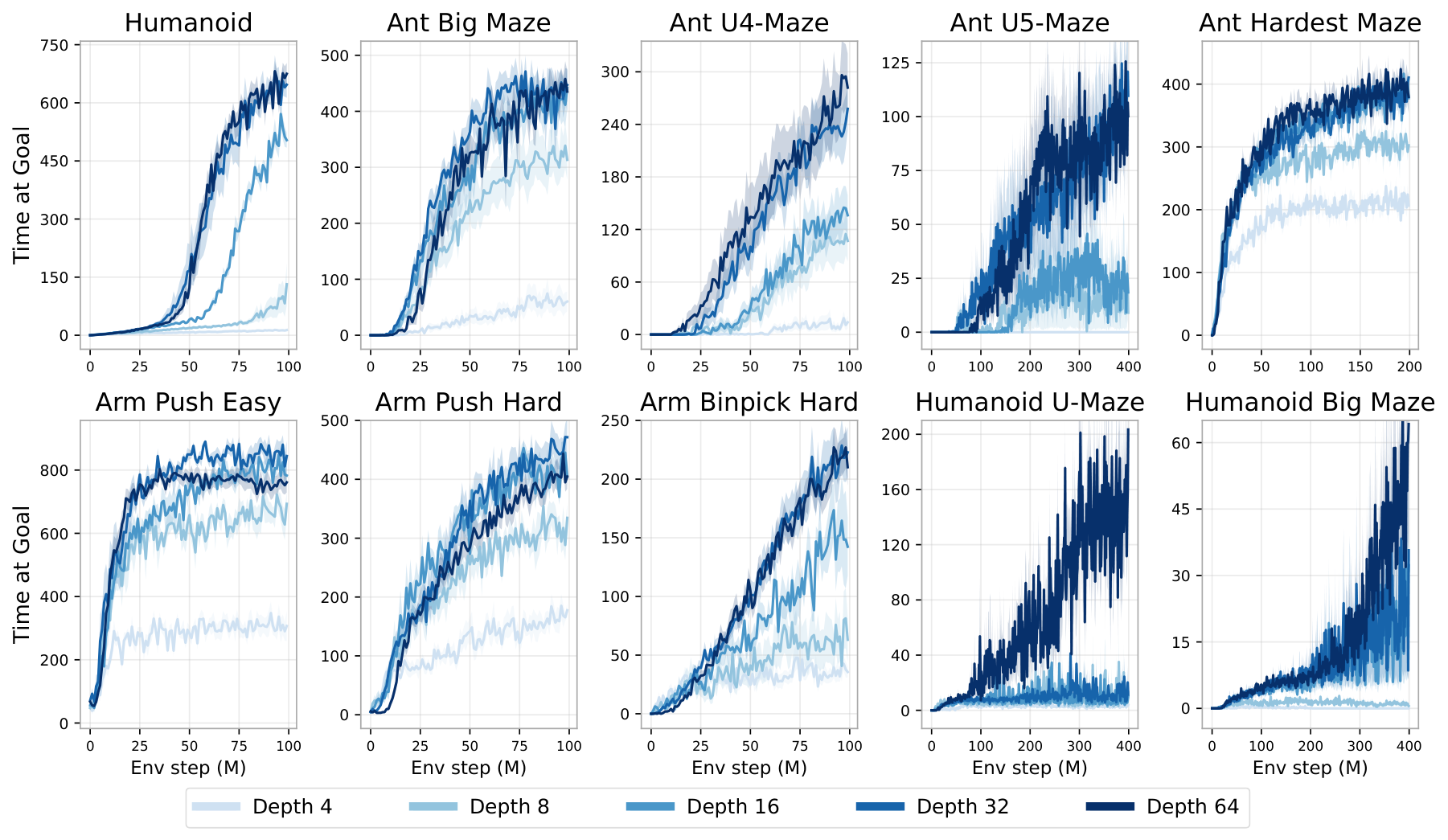
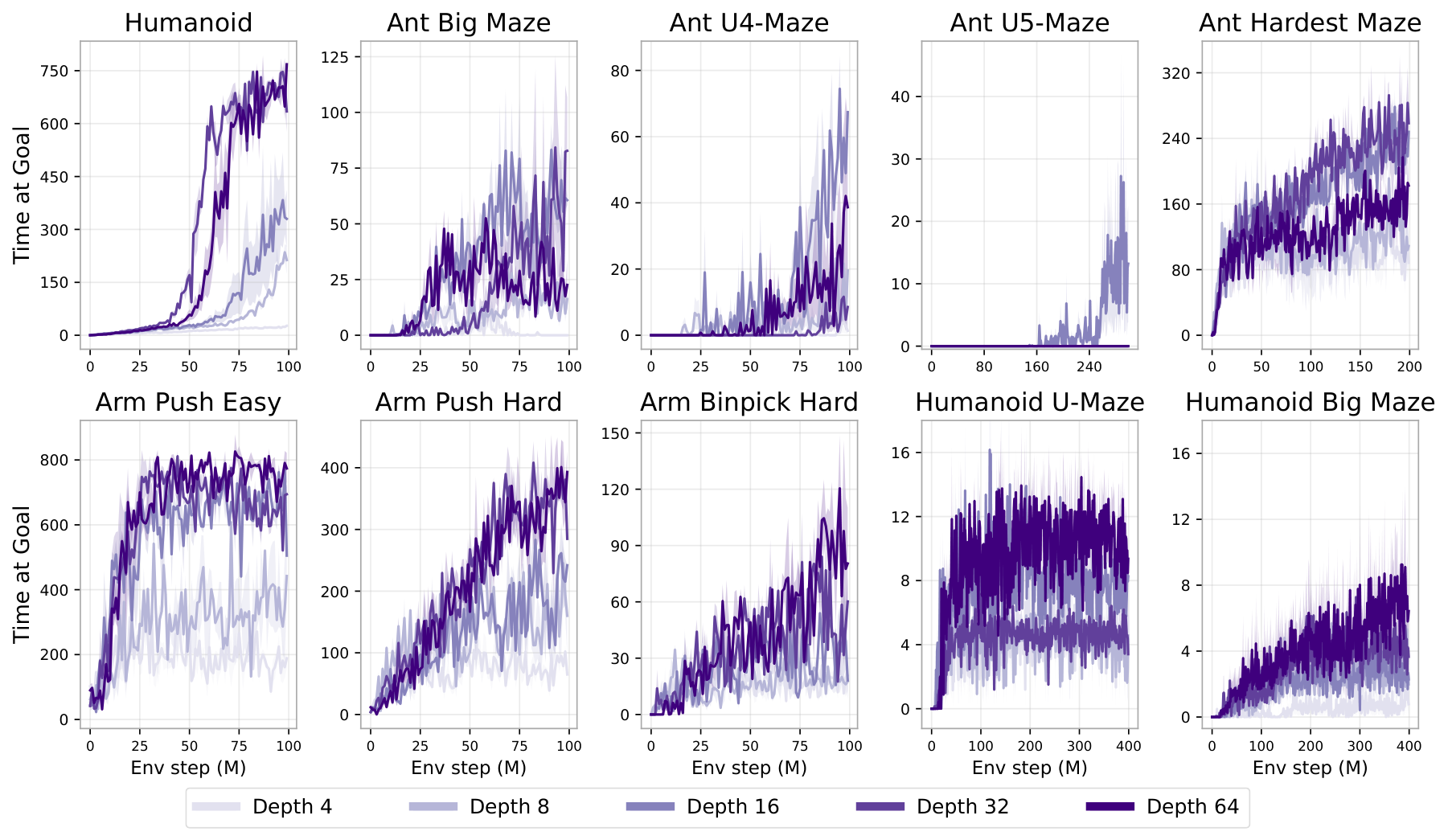
- Performance gains ranged from 2× to over 50× compared to standard 4-layer networks, depending on the task - The deepest humanoid tasks benefited most, with 50× improvements and qualitatively new behaviors emerging at specific depth thresholds - Performance often jumped discontinuously at critical depths rather than improving smoothly (for example, at 8 layers for Ant Big Maze, 64 layers for Humanoid U-Maze) - The scaled approach outperformed all standard goal-reaching baselines in 8 of 10 environments
Depth scaling proved more effective than width scaling. Simply doubling the network depth from 4 to 8 layers (holding width constant) outperformed networks made much wider while keeping depth at 4. Depth scaling also required fewer parameters for the same performance.
New capabilities emerged at greater depths. In humanoid tasks, 4-layer networks produced crude behaviors like falling toward the goal. At 16 layers, agents learned to walk upright. At 256 layers, agents developed acrobatic maneuvers including vaulting over walls and worming through obstacles—behaviors never before documented in goal-conditioned RL.
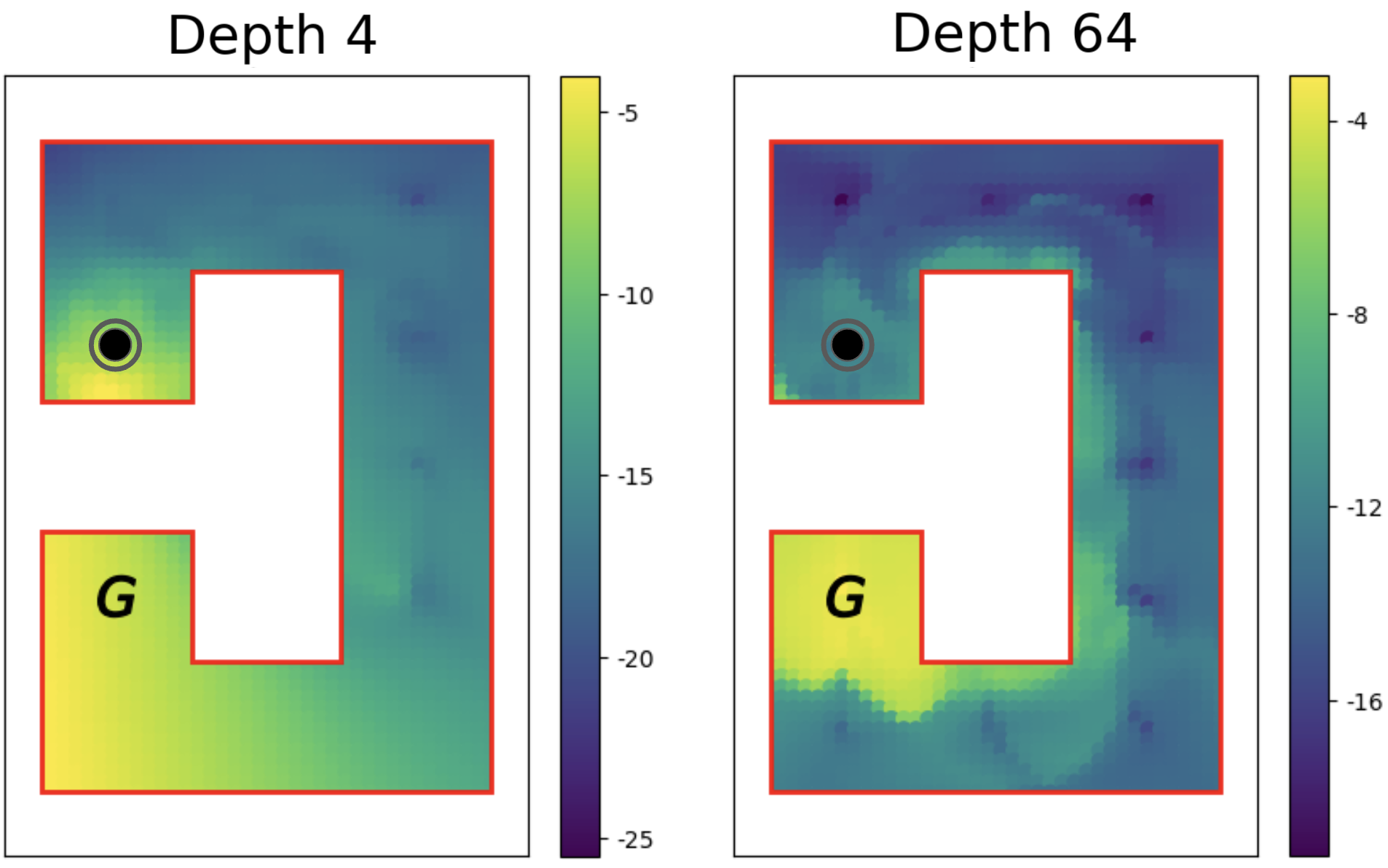
Deeper networks learned richer representations of the environment. Analysis showed that deep networks allocated more representational capacity to critical state regions and better captured environment topology, enabling them to navigate complex mazes where shallow networks failed.
What This Means
These results challenge the conventional wisdom that RL cannot benefit from depth scaling like other domains. The work demonstrates that with the right algorithmic and architectural choices—specifically self-supervised learning combined with residual networks—RL can achieve the kind of scaling benefits seen in language and vision.
The emergence of qualitatively new behaviors at specific depth thresholds mirrors "emergent capabilities" observed in large language models, suggesting RL may follow similar scaling laws. This has implications for cost-performance tradeoffs: depth scaling is parameter-efficient, so achieving better performance through depth rather than width reduces memory requirements and potentially computational costs.
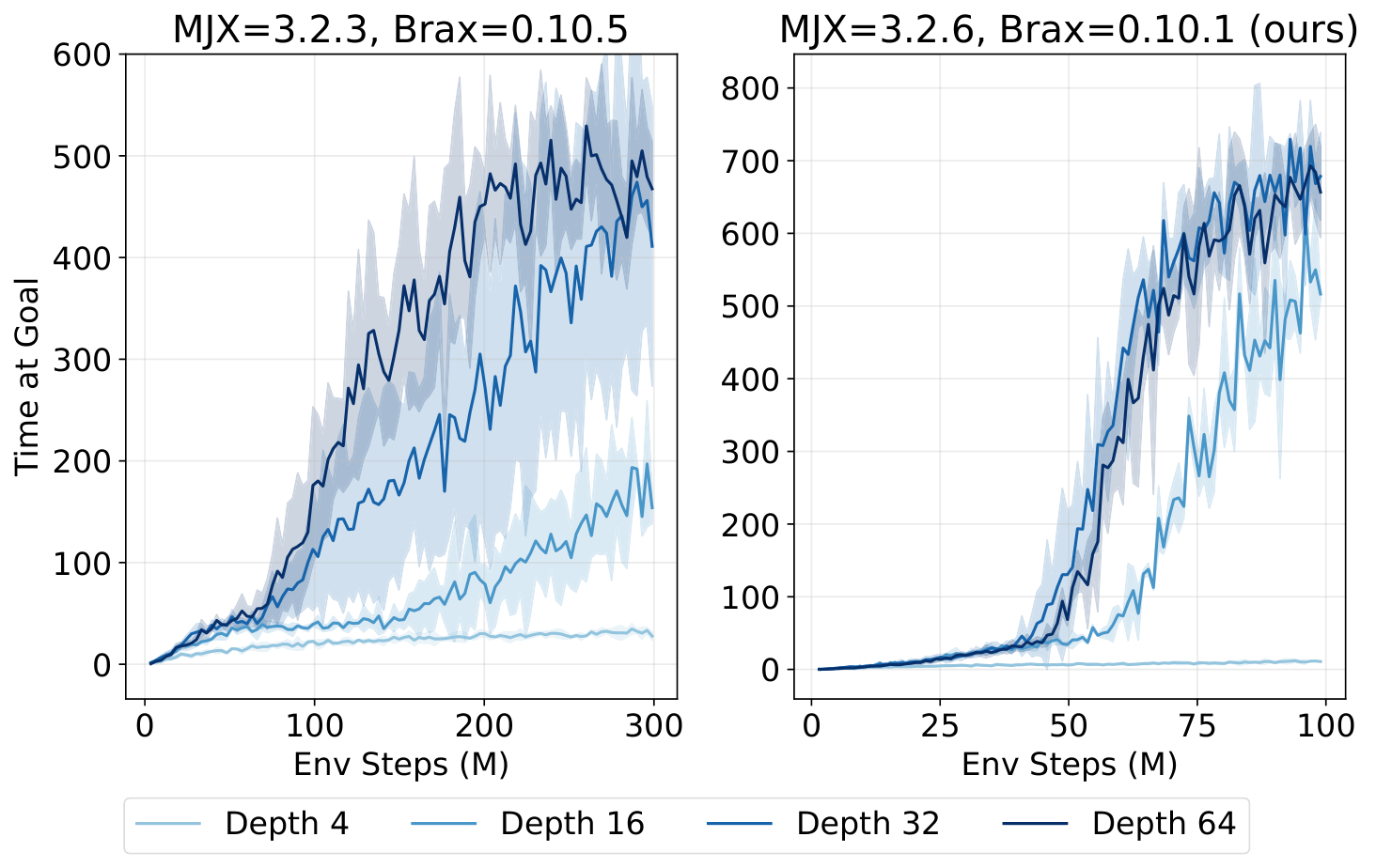
However, the benefits come with increased training time. Wall-clock time scales approximately linearly with depth beyond a certain point. For the deepest networks (1024 layers), training required over 130 hours compared to 3 hours for 4-layer networks.
Limitations and Confidence
The scaling benefits did not transfer to offline settings where the agent learns from a fixed dataset rather than active exploration. Preliminary experiments with offline goal-conditioned RL showed no improvement or degradation with increased depth, indicating the approach is specific to online learning scenarios.
The study focused on one self-supervised algorithm (CRL). While experiments with other algorithms showed mixed results—no benefit for temporal difference methods, some benefit for behavioral cloning on simple tasks—the generality of depth scaling across RL methods remains unclear.
Results are based on simulated environments. Real-world robotic applications may face additional challenges not captured in simulation, and the computational costs may be prohibitive for resource-constrained deployments.
Recommendations and Next Steps
Organizations working on goal-reaching RL should consider depth as the primary scaling axis rather than width, particularly for complex tasks with high-dimensional observations. For tasks where small networks already achieve some success, depth scaling may yield marginal benefits; focus scaling efforts on the most challenging problems where standard approaches fail.
Before deploying in production, conduct pilot studies to verify that scaling benefits transfer to your specific domain and task complexity. Monitor wall-clock training time carefully, as computational costs increase substantially with depth.
For research teams, priority next steps include: investigating distributed training approaches to manage computational costs at scale; testing whether techniques like pruning and distillation can reduce inference costs while preserving deep network benefits; and determining which other self-supervised RL algorithms can benefit from depth scaling. Understanding why depth scaling fails in offline settings is critical for broader applicability.
The work provides building blocks for scalable RL but should be viewed as an early step. Achieving the full potential of scaling in RL will likely require discovering additional components beyond those identified here.
Warsaw University of Technology,
Tooploox, IDEAS Research Institute
Abstract
1. Introduction
In this section, the authors address why scaling model size in reinforcement learning has not achieved the transformative breakthroughs seen in language and vision domains, where deep networks with hundreds of layers are commonplace while typical RL models use only 2-5 layers. They argue that the conventional wisdom of using RL merely for finetuning large self-supervised models misses the potential of self-supervised RL methods that can explore and learn without rewards or demonstrations. The authors propose integrating self-supervised RL—specifically contrastive RL—with GPU-accelerated frameworks, architectural techniques like residual connections and layer normalization, and dramatically increased network depth up to 1024 layers. This combination of building blocks enables RL to scale effectively along the depth dimension, achieving performance improvements of 2× to 50× across locomotion and manipulation tasks, with critical depth thresholds triggering the emergence of qualitatively distinct, previously unseen behaviors.
- Empirical Scalability: We observe a significant performance increase, more than 20×20\times20× in half of the environments and out-performing other standard goal-conditioned baselines. These performances gains correspond to qualitatively distinct policies that emerge with scale.
- Scaling Depth in Network Architecture: While many prior RL works have primarily focused on increasing network width, they often report limited or even negative returns when expanding depth ([10, 9]). In contrast, our approach unlocks the ability to scale along the axis of depth, yielding performance improvements that surpass those from scaling width alone (see Section 4).
- Empirical Analysis: We conduct an extensive analysis of the key components in our scaling approach, uncovering critical factors and offering new insights.
2. Related Work
In this section, the authors contextualize their work within the broader challenge of scaling reinforcement learning, noting that while NLP and computer vision have achieved transformative breakthroughs through self-supervised learning and deep architectures, RL has lagged behind due to obstacles like parameter underutilization, plasticity loss, data sparsity, and training instabilities. Most existing scaling efforts in RL remain confined to specific domains such as imitation learning or discrete action spaces, with recent work primarily focusing on increasing network width rather than depth, typically employing only four MLP layers and reporting limited gains from additional depth. The authors position their approach as distinct by successfully scaling network depth up to 1024 layers, leveraging contrastive RL's InfoNCE objective—a generalization of cross-entropy loss that frames RL as classifying trajectory membership. This classification-based formulation, echoing successful scaling principles in NLP, emerges as a potential fundamental building block for scalable reinforcement learning.
3. Preliminaries
In this section, the mathematical foundation for goal-conditioned reinforcement learning and contrastive RL is established to frame the scaling experiments. A goal-conditioned MDP extends standard RL by having agents learn to reach arbitrary commanded goals, where the reward function reflects the probability of reaching a specified goal state in the next timestep. The contrastive RL algorithm solves this problem through an actor-critic framework, using an InfoNCE objective to train a critic that learns embeddings distinguishing same-trajectory state-action-goal tuples from random negatives, effectively casting the RL problem as classification. The policy is then trained to maximize this critic's output. Residual connections are incorporated into the architecture to enable gradient flow through deep networks by adding learned residual transformations to input representations rather than learning entirely new mappings, creating shortcut paths that preserve useful features from earlier layers and stabilize training of the 1000-layer networks central to this work.
4. Experiments
In this section, the authors investigate whether scaling network depth can unlock substantial performance gains in self-supervised reinforcement learning using contrastive RL (CRL). They demonstrate that increasing depth from the typical 4 layers to 64, 256, or even 1024 layers yields 2× to 50× performance improvements across locomotion, navigation, and manipulation tasks, with performance jumps occurring at critical depth thresholds that correspond to qualitatively distinct emergent behaviors. Depth scaling proves more effective than width scaling, particularly as observation dimensionality increases, and enables the network to leverage larger batch sizes. The improvements arise from a synergistic combination of enhanced exploration and greater representational capacity: deeper networks learn richer contrastive representations that capture environment topology, allocate more capacity to goal-relevant states, and exhibit partial experience stitching for generalization. However, these benefits depend critically on the CRL algorithm itself, as traditional TD methods and offline settings show minimal gains from depth scaling.
4.1 Experimental Setup
4.2 Scaling Depth in Contrastive RL
4.3 Emergent Policies Through Depth

4.4 What Matters for CRL Scaling
![**Figure 4:** **Scaling network width vs. depth**. Here, we reflect findings from previous works ([10, 9]) which suggest that increasing network width can enhance performance. However, in contrast to prior work, our method is able to scale depth, yielding more impactful performance gains. For instance, in the Humanoid environment, raising the width to 2048 (depth=4) fails to match the performance achieved by simply doubling the depth to 8 (width=256). The comparative advantage of scaling depth is more pronounced as the observational dimensionality increases.](https://ittowtnkqtyixxjxrhou.supabase.co/storage/v1/object/public/public-images/behfx7gf/pareto.png)
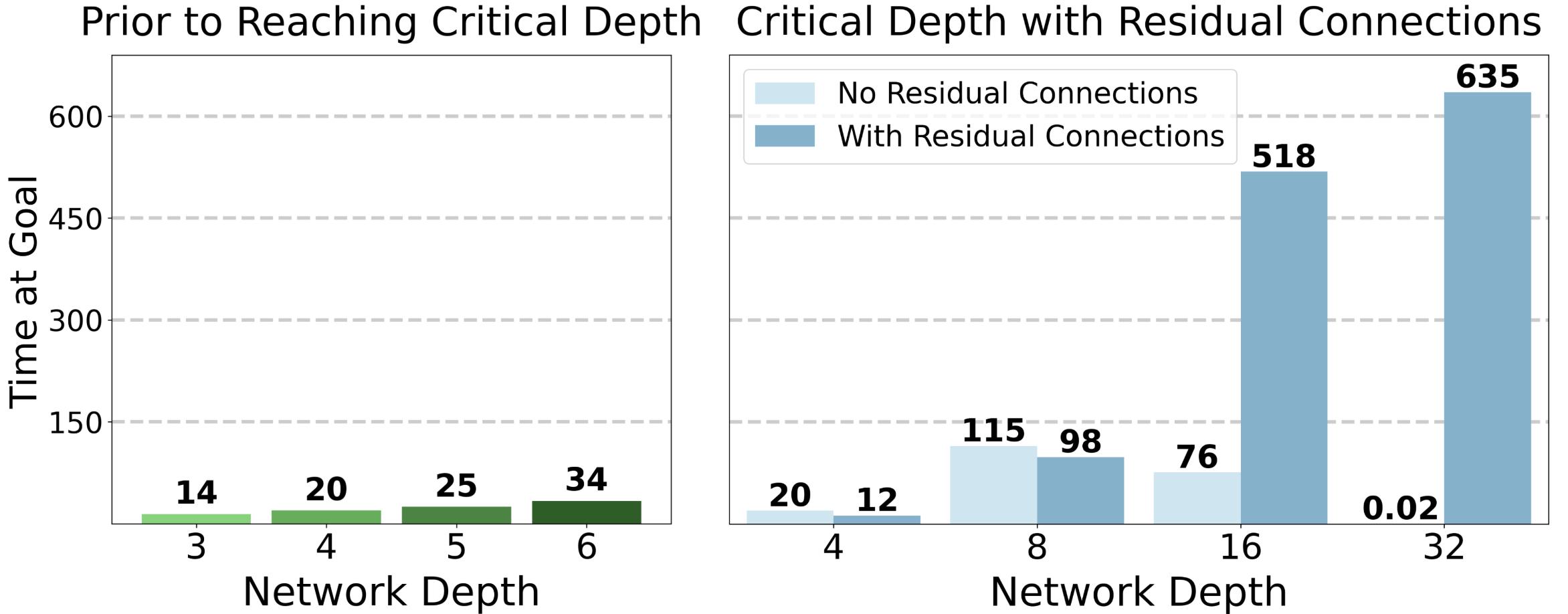
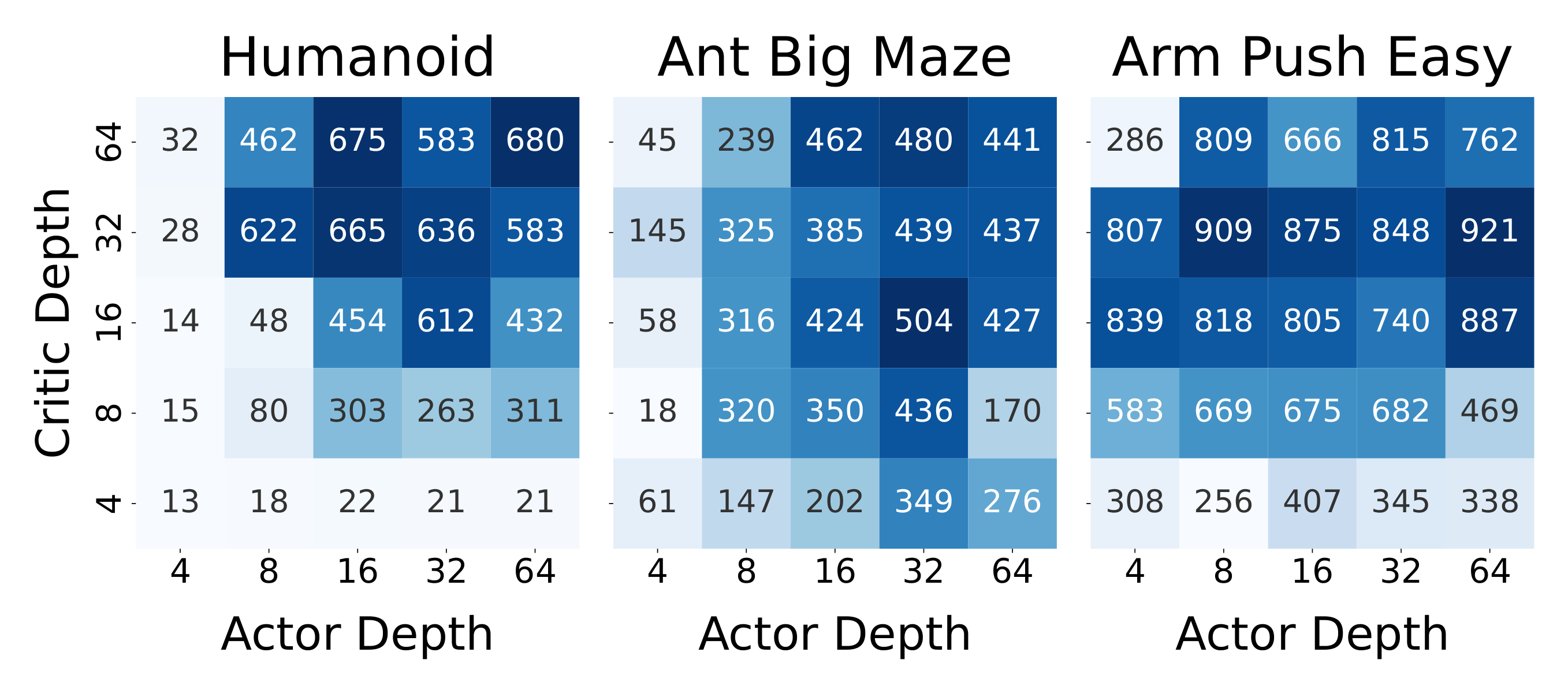
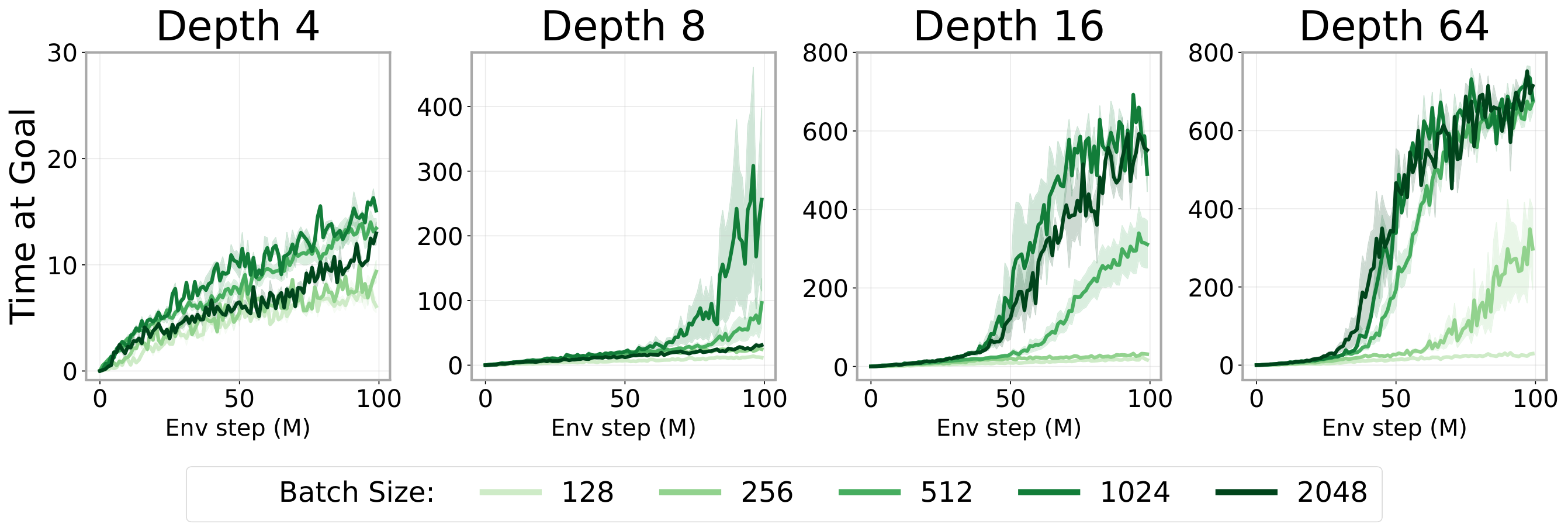
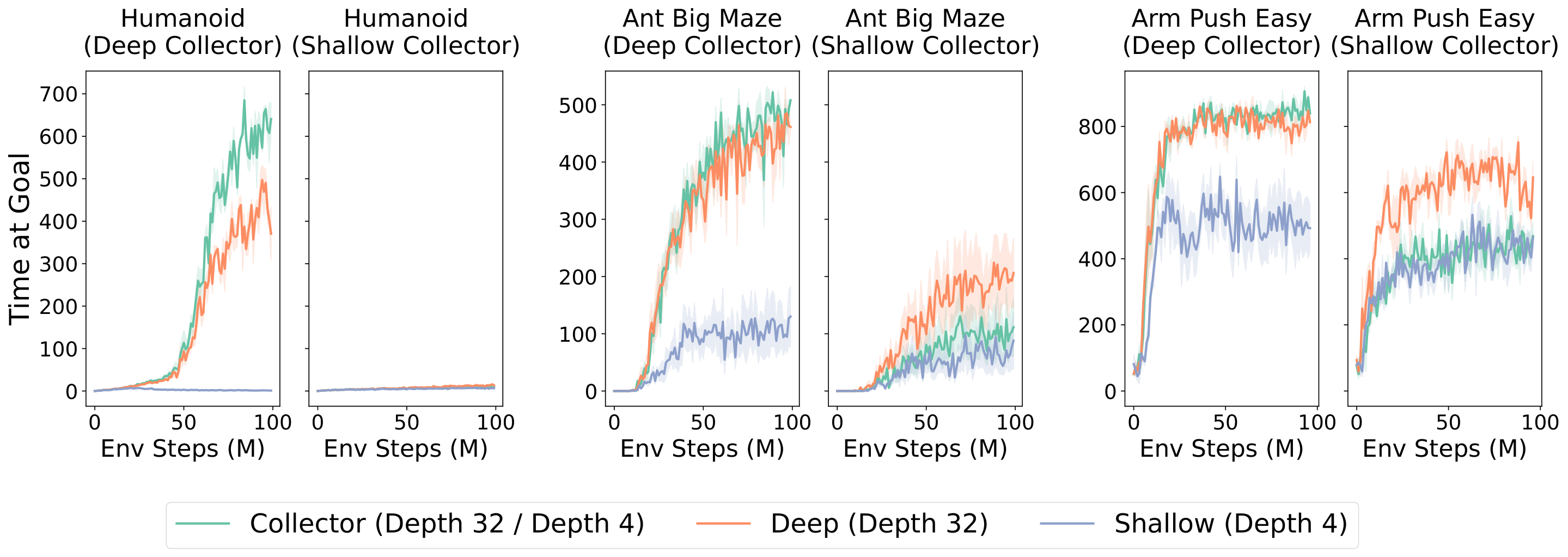
4.5 Why Scaling Happens
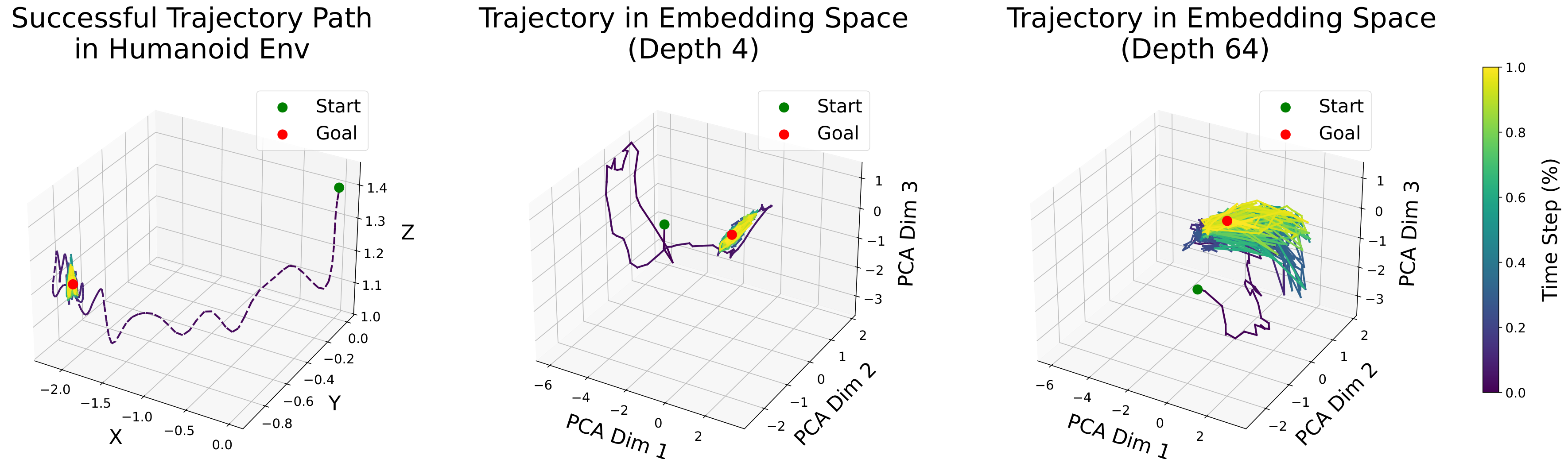
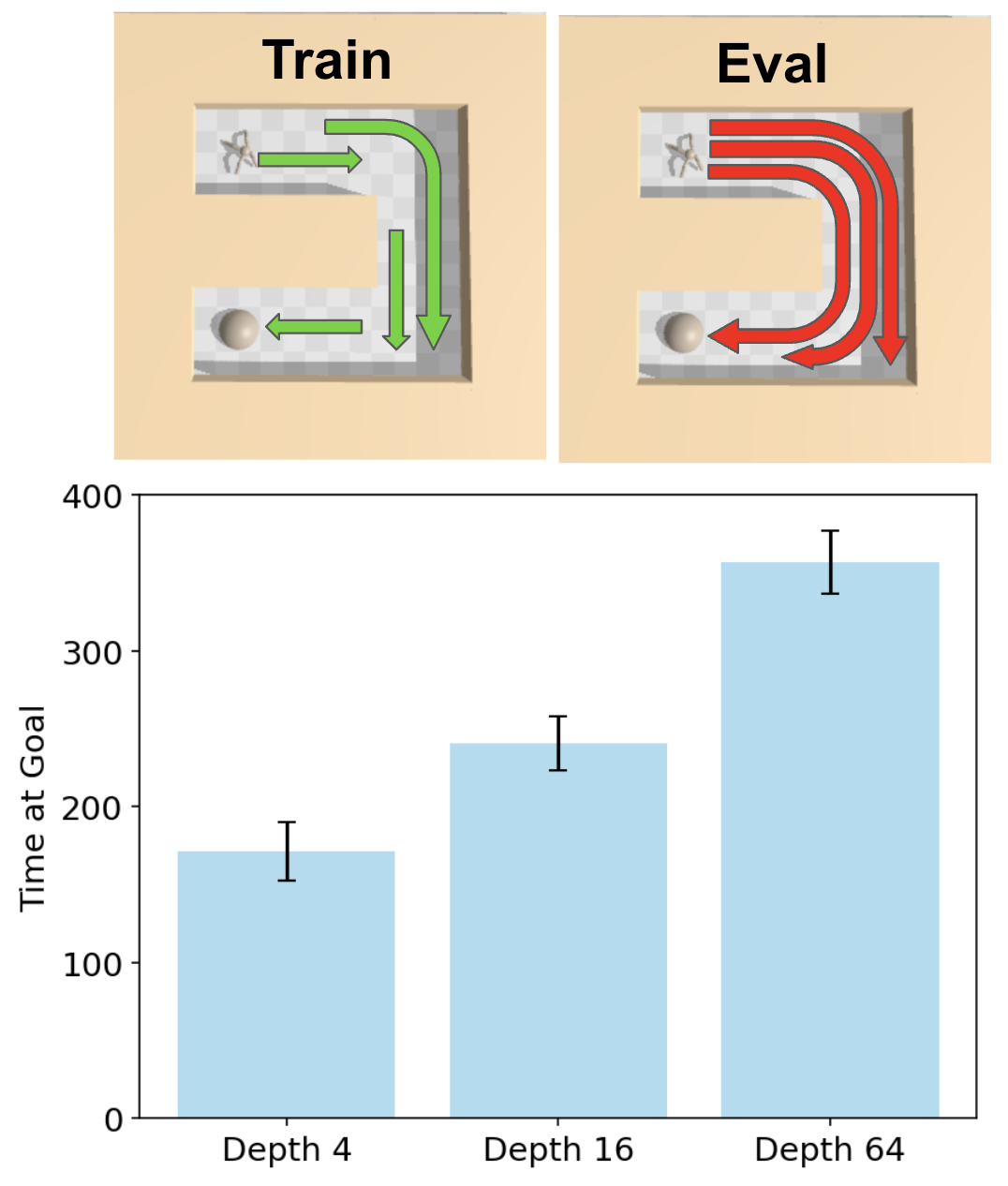
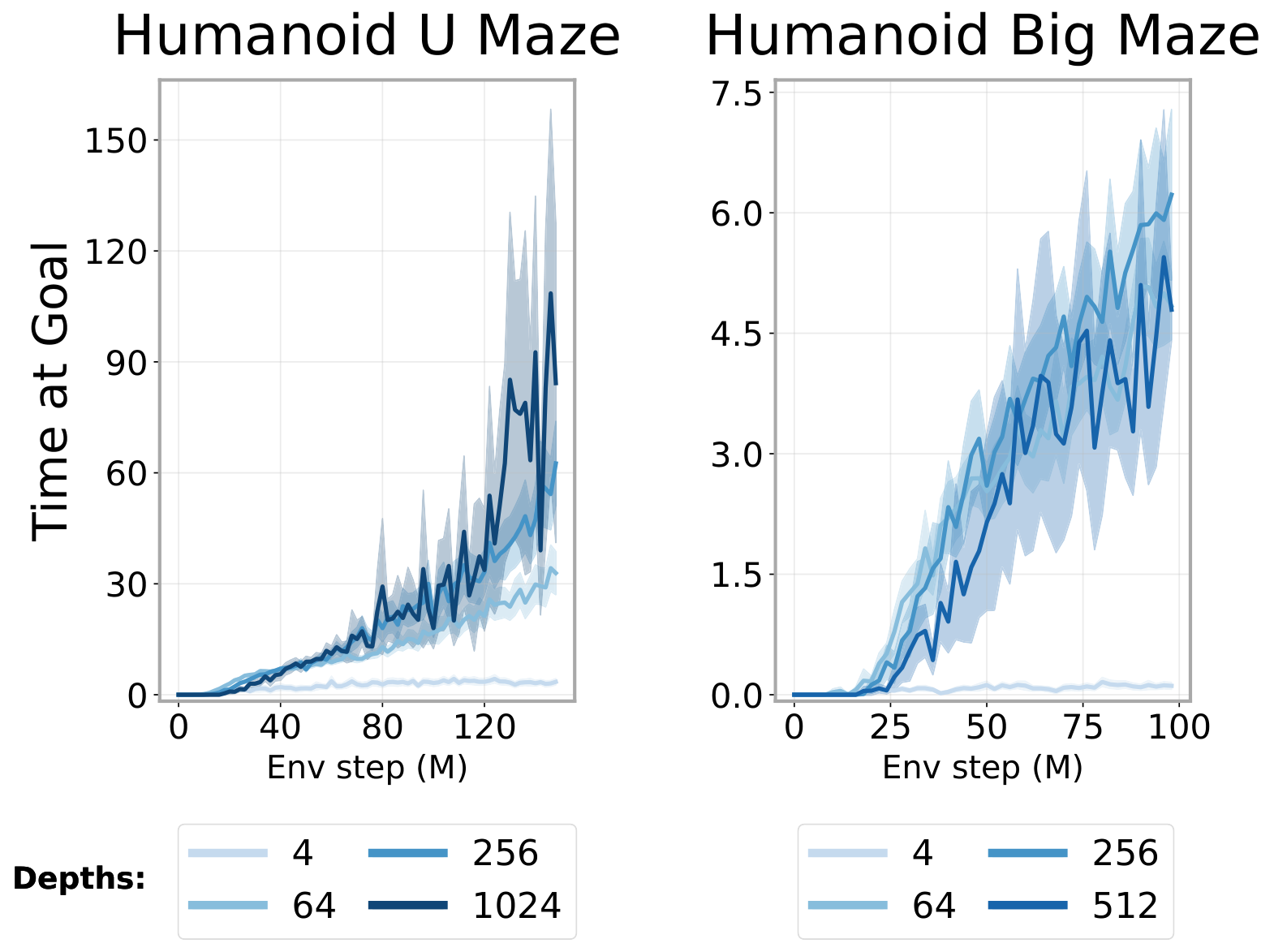
4.6 Does Depth Scaling Improve Offline Contrastive RL?
5. Conclusion
In this section, the authors argue that emergent capabilities from scale have driven much of the success in vision and language models, yet a critical question remains: where does the data come from? Unlike supervised learning, reinforcement learning methods inherently address this by jointly optimizing both the model and the data collection process through exploration. Determining effective ways to build RL systems that demonstrate emergent capabilities may be important for transforming the field into one that trains its own large models. By integrating key components for scaling up RL into a single approach, the work shows that model performance consistently improves as scale increases in complex tasks. Additionally, deep models exhibit qualitatively better behaviors which might be interpreted as implicitly acquired skills necessary to reach the goal, suggesting that this work represents a step towards building RL systems with emergent capabilities at scale.
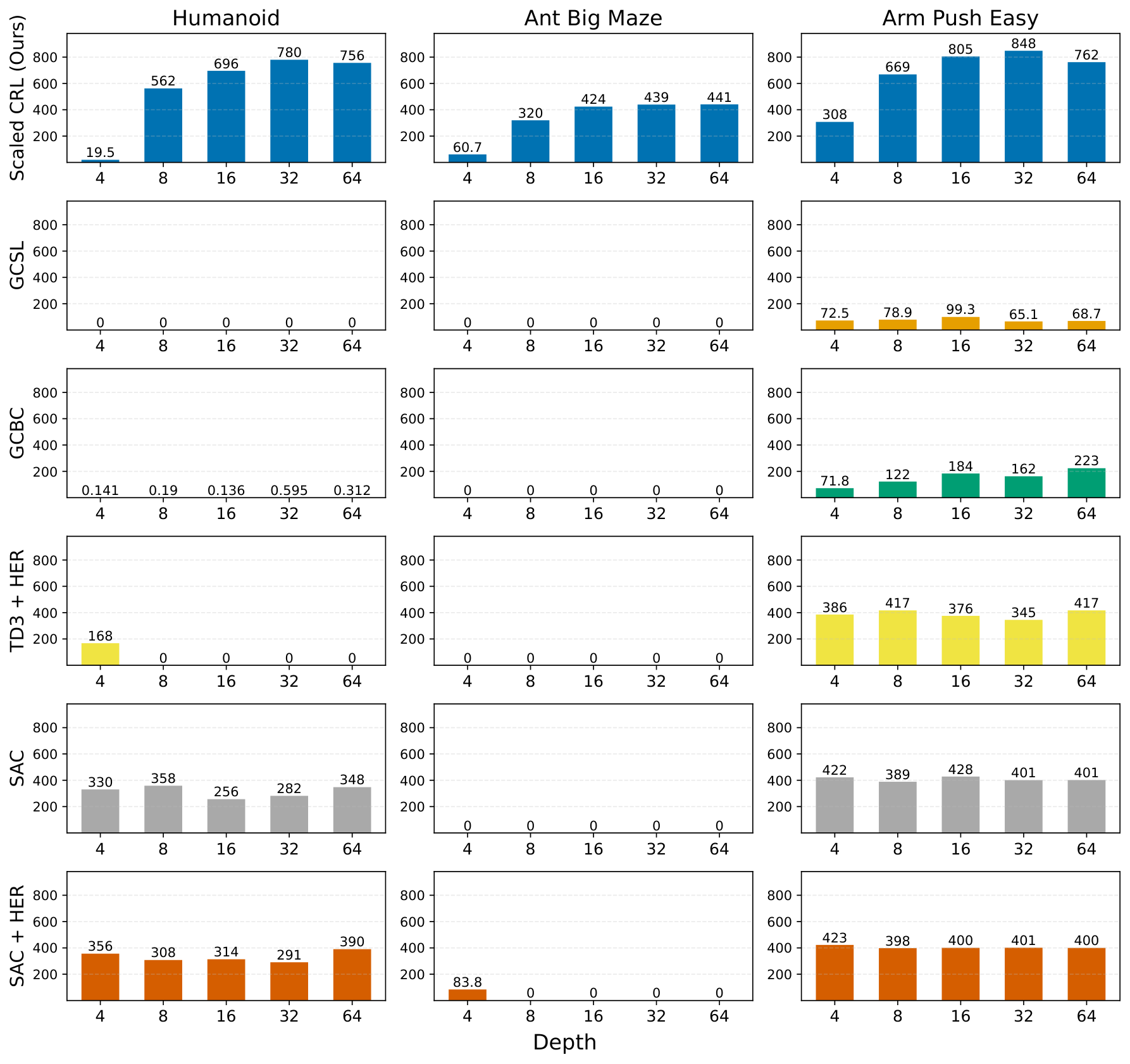
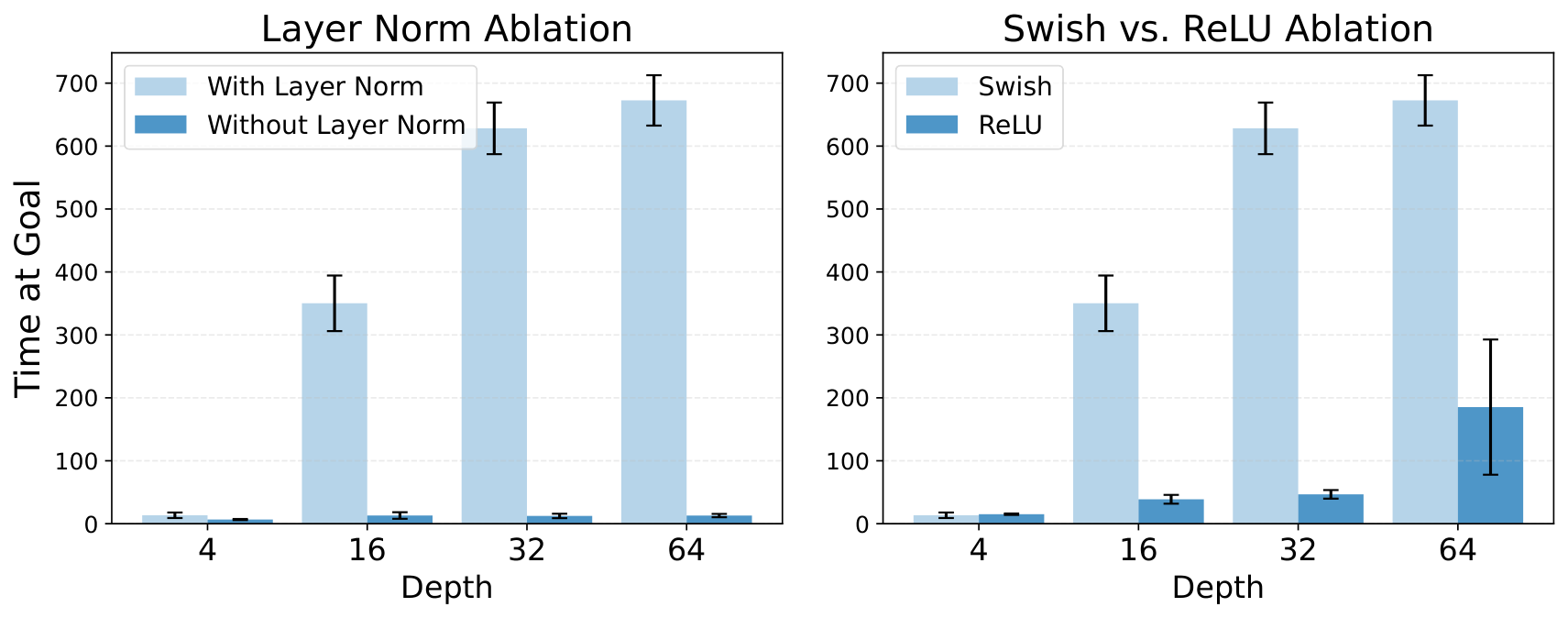
In this section, scaled contrastive reinforcement learning (CRL) demonstrates state-of-the-art performance in online goal-conditioned RL, outperforming baseline methods like SAC, TD3+HER, GCSL, and GCBC across eight of ten environments, while depth scaling proves ineffective for these baseline algorithms beyond four layers. Architectural components including residual connections, layer normalization, and Swish activations are essential for enabling depth scaling, with hyperspherical normalization further improving sample efficiency. The scaling benefits extend to quasimetric architectures and offline goal-conditioned behavioral cloning, though offline CRL scaling remains challenging. Residual activation norms decrease in deeper layers as expected, and wall-clock time increases approximately linearly with depth, yet the scaled approach often reaches superior performance faster than baselines. The experiments use the JaxGCRL benchmark with environments spanning locomotion, navigation, and manipulation tasks, demonstrating that combining self-supervised contrastive learning with deep residual architectures unlocks parameter scaling in reinforcement learning.
Appendix
A. Additional Experiments
A.1 Scaled CRL Outperforms All Other Baselines on 8 out of 10 Environments
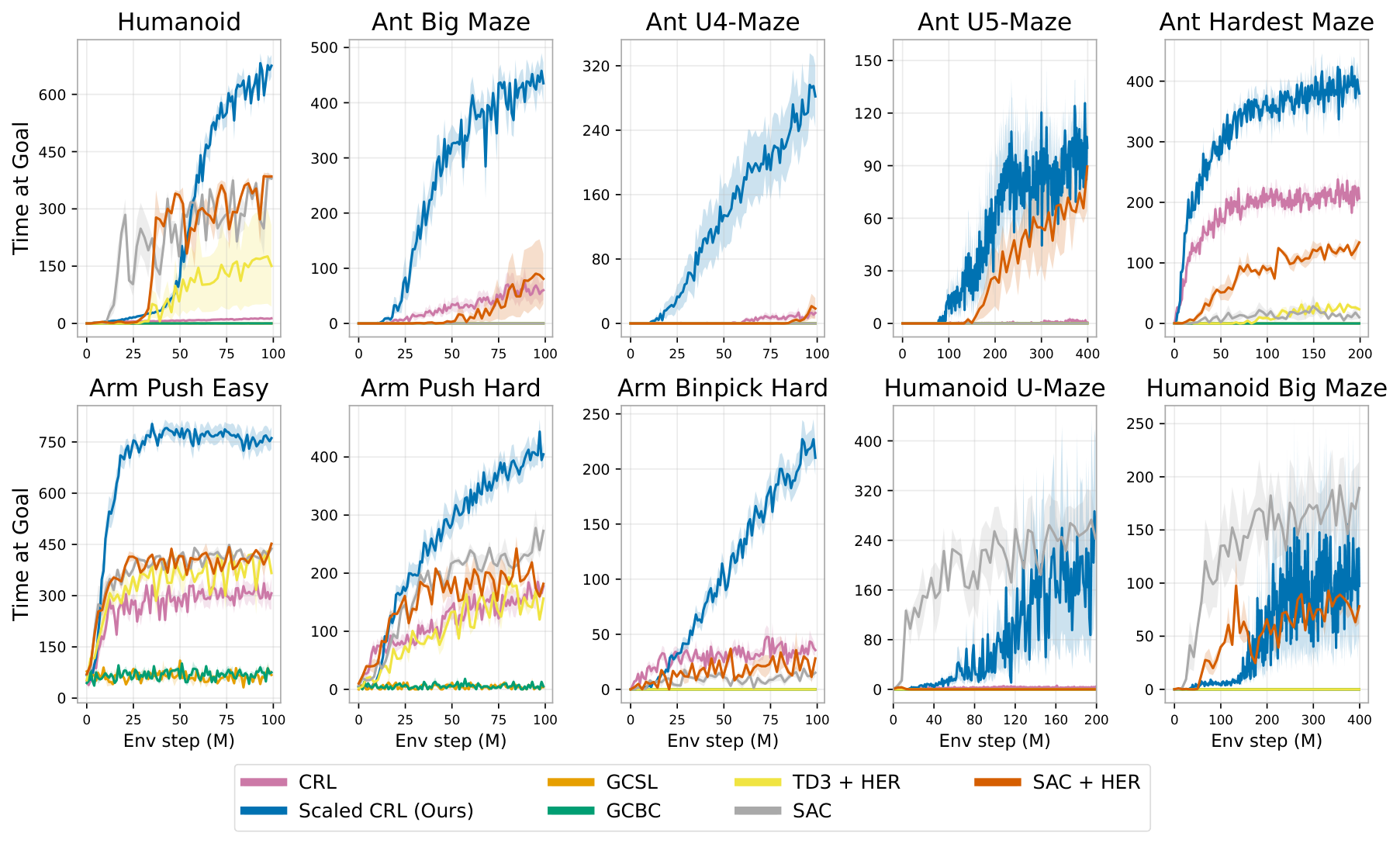
A.2 The CRL Algorithm is Key: Depth Scaling is Not Effective on Other Baselines
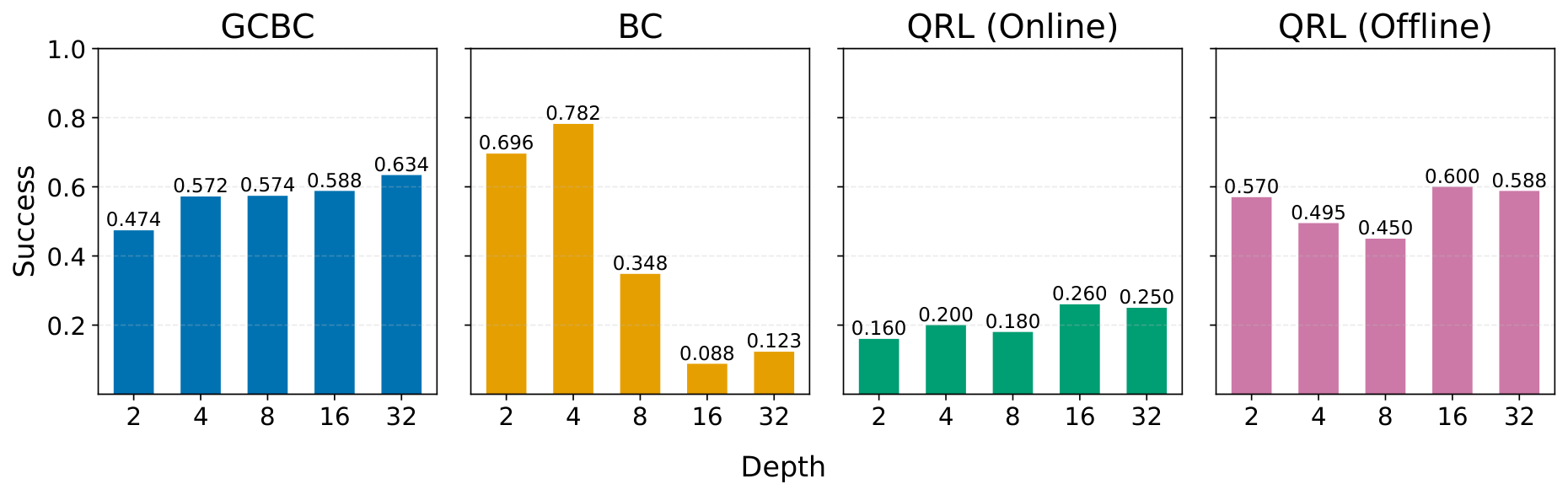
A.3 Additional Scaling Experiments: Offline GCBC, BC, and QRL
A.4 Can Depth Scaling also be Effective for Quasimetric Architectures?
A.5 Additional Architectural Ablations: Layer Norm and Swish Activation
A.6 Can We Integrate Novel Architectural Innovations from the Emerging RL Scaling Literature?

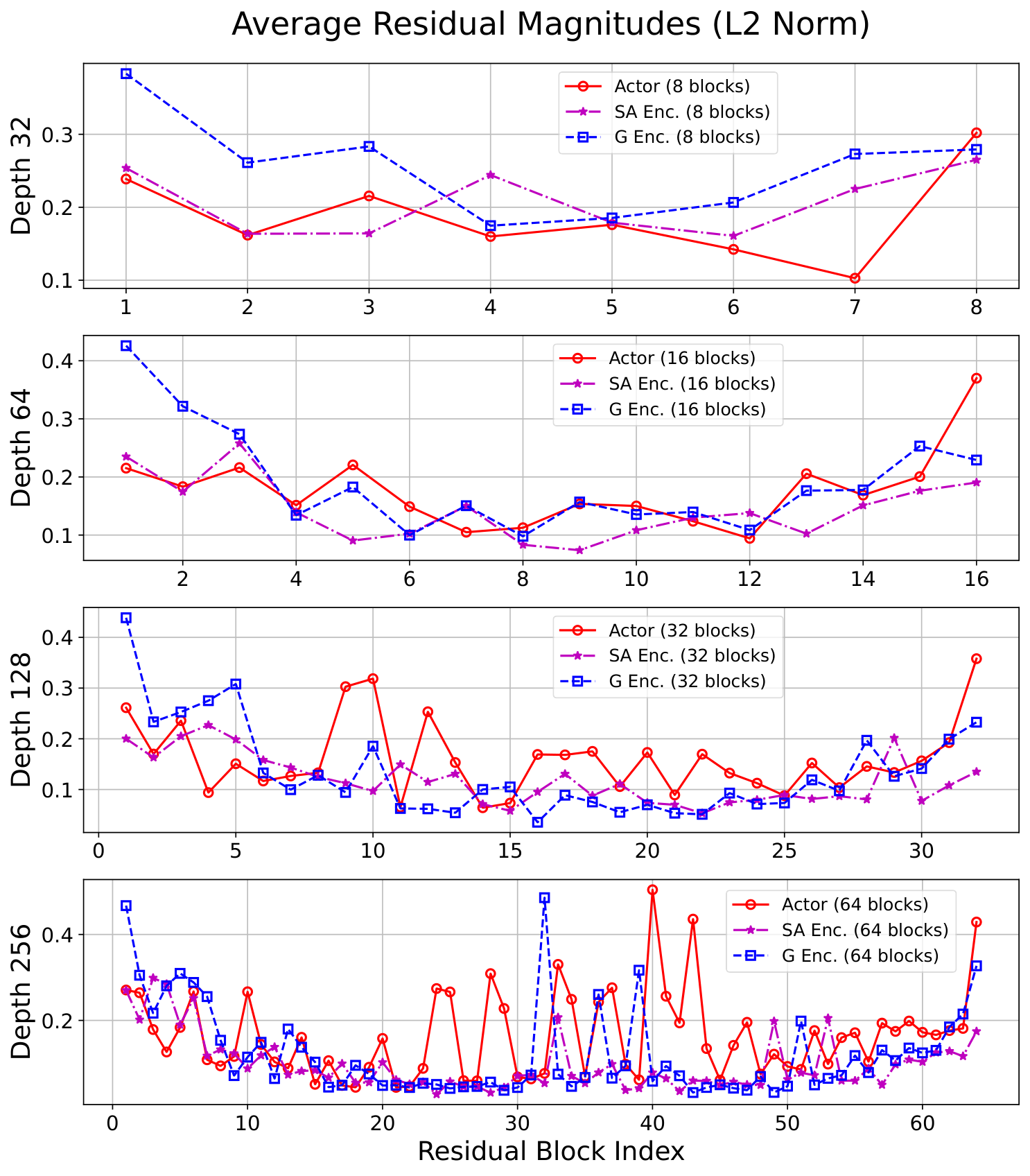
A.7 Residuals Norms in Deep Networks
A.8 Scaling Depth for Offline Goal-conditioned RL
![**Figure 18:** To evaluate the scalability of our method in the offline setting, we scaled model depth on OGBench ([62]). In two out of three environments, performance drastically declined as depth scaled from 4 to 64, while a slight improvement was seen on antmaze-medium-stitch-v0. Successfully adapting our method to scale offline GCRL is an important direction for future work.](https://ittowtnkqtyixxjxrhou.supabase.co/storage/v1/object/public/public-images/behfx7gf/offline_scaling.png)
B. Experimental Details
B.1 Environment Setup and Hyperparameters
![**Figure 19:** The scaling results of this paper are demonstrated on the JaxGCRL benchmark, showing that they replicate across a diverse range of locomotion, navigation, and manipulation tasks. These tasks are set in the online goal-conditioned setting where there are no auxiliary rewards or demonstrations. Figure taken from ([25]).](https://ittowtnkqtyixxjxrhou.supabase.co/storage/v1/object/public/public-images/behfx7gf/jaxgcrl.png)
ant_big_maze, ant_hardest_maze, arm_binpick_hard, arm_push_easy, arm_push_hard, humanoid, humanoid_big_maze, humanoid_u_maze, ant_u4_maze, ant_u5_maze.