LeWorldModel: Stable End-to-End Joint-Embedding Predictive Architecture from Pixels
Lucas Maes$^{*1}$ Quentin Le Lidec$^{*2}$ Damien Scieur$^{1,3}$ Yann LeCun$^{2}$ Randall Balestriero$^{4}$
$^{1}$ Mila & Université de Montréal $^{2}$ New York University $^{3}$ Samsung SAIL $^{4}$ Brown University
- Equal contribution. Correspondence to [email protected]
Abstract
Joint Embedding Predictive Architectures (JEPAs) offer a compelling framework for learning world models in compact latent spaces, yet existing methods remain fragile, relying on complex multi-term losses, exponential moving averages, pre-trained encoders, or auxiliary supervision to avoid representation collapse. In this work, we introduce LeWorldModel (LeWM), the first JEPA that trains stably end-to-end from raw pixels using only two loss terms: a next-embedding prediction loss and a regularizer enforcing Gaussian-distributed latent embeddings. This reduces tunable loss hyperparameters from six to one compared to the only existing end-to-end alternative. With 15M parameters trainable on a single GPU in a few hours, LeWM plans up to $48\times$ faster than foundation-model-based world models while remaining competitive across diverse 2D and 3D control tasks. Beyond control, we show that LeWM's latent space encodes meaningful physical structure through probing of physical quantities. Surprise evaluation confirms that the model reliably detects physically implausible events.
Executive Summary: Developing reliable AI agents that can learn and predict how the world works from raw visual inputs, like camera feeds, is crucial for advancing robotics and autonomous systems. Current methods often struggle with instability, requiring complex tweaks or pre-trained components that limit flexibility and increase costs. This is especially pressing now, as AI applications in real-world tasks—such as navigation or object manipulation—demand efficient, end-to-end learning without manual feature engineering to enable planning in imagination rather than real trials, saving time and resources in safety-critical or data-scarce settings.
This work introduces LeWorldModel (LeWM), a new architecture designed to create stable predictive models of environments directly from pixel observations and actions, without relying on rewards or task-specific guidance. It aims to demonstrate that a simple training setup can prevent common failures in similar models while supporting effective decision-making across varied 2D and 3D tasks.
The team trained LeWM on offline datasets of trajectories from environments like room navigation, block pushing, and robotic cube handling, using about 10,000 to 20,000 episodes per task over 10 training epochs. The core approach involves two neural networks: an encoder that compresses images into low-dimensional latent representations, and a predictor that forecasts the next latent state based on the current one and an action. Training uses just two loss components—a basic error measure for predictions and a regularizer to keep latents spread out like a standard Gaussian distribution—optimized jointly on a single GPU in a few hours for a 15-million-parameter model. For evaluation, they tested planning performance via model predictive control, where the model simulates action sequences to reach goals, and probed the latent space for physical insights using linear and nonlinear predictors of quantities like positions and velocities.
LeWM's key results show strong performance gains. First, it achieves up to 18% higher success rates in challenging tasks like pushing a T-shaped block compared to the prior end-to-end method (PLDM), while matching or exceeding models using large pre-trained encoders (like DINO-WM) in most cases, even without extra sensor data. Second, planning with LeWM completes in under a second—48 times faster than foundation-model alternatives—enabling near real-time control across navigation, manipulation, and locomotion in 2D and 3D. Third, the latent space reliably encodes physical details, with probing accuracies outperforming PLDM by 10-20% on metrics like object positions and agent velocities in manipulation tasks. Fourth, it detects implausible events, assigning 20-50% higher surprise scores to physical disruptions (like object teleportation) than visual changes alone, confirming intuitive physics understanding. Finally, beneficial properties emerge without extra design, such as straighter temporal paths in latents, aiding smoother predictions.
These findings mean LeWM offers a practical breakthrough for building world models that support AI agents in imagining and planning actions efficiently, cutting computational costs by orders of magnitude and reducing reliance on massive pre-training data. Unlike unstable alternatives with multiple hyperparameters, its simplicity lowers development risks and speeds deployment, potentially improving robot performance in warehouses or homes by enabling safer, faster adaptation to new scenarios. This contrasts with prior work's fragility, highlighting how targeted regularization can yield representations as rich as those from billion-parameter models but at far less expense—vital for scaling AI beyond labs.
Next steps should include integrating LeWM into robotic prototypes for pilot testing in real environments, starting with short-horizon tasks like object grasping. For broader use, explore hierarchical extensions to handle longer planning sequences, pre-training on diverse video datasets to boost low-data performance, and methods to infer actions without labels, such as inverse modeling. Decisions on adoption could weigh its speed gains against needs for custom tuning in niche domains.
While robust across tested tasks, limitations include sensitivity to dataset diversity—performance dips in overly simple settings—and short planning horizons due to error buildup in simulations. Confidence in the core results is high, backed by consistent ablations and multiple seeds showing low variance, but caution applies to untested complex or long-term scenarios where more data or hybrid approaches may be needed.
1. Introduction
Section Summary: Artificial intelligence aims to create agents that learn diverse skills from raw sensory inputs like camera pixels, without custom tweaks, using world models to predict action outcomes and plan in imagined scenarios—especially useful when learning from fixed datasets without real-world interaction. A common approach, joint embedding predictive architecture, encodes observations into a compact latent space for future predictions but often suffers from collapse, where inputs map to identical representations, and existing fixes rely on complex heuristics or pre-trained components. To address this, the authors introduce LeWorldModel, a simple end-to-end method that learns stable world models from pixels alone, requiring just one hyperparameter with guarantees against collapse, achieving strong performance in various tasks while demonstrating intuitive physical understanding in its latent space.

A central goal of artificial intelligence is to develop agents that acquire skills across diverse tasks and environments using a single, unified learning paradigm—one that operates directly from sensory inputs of its surroundings–without hand-engineered state representations or domain-specific calibration. Vision is ideally suited for this aim: cameras are inexpensive and scalable, and learning from pixels enables fully end-to-end training from raw sensory input to action [1]. World Models (WMs) are a powerful family of methods [2] that learn to predict the consequences of actions in the environment. When successful, WMs allows agents to plan and to improve themselves solely form their model of the world, i.e., in imagination space. This is particularly valuable in the offline setting, where agents must learn from fixed datasets without environment interaction—leveraging the model to generate synthetic experience and evaluate counterfactual action sequences [3, 4].
A recent popular approach for learning world models is the Joint Embedding Predictive Architecture (JEPA) [5]. Instead of attempting to model every aspect of the environment, JEPA focuses on capturing the most relevant features needed to predict future states. Concretely, JEPA learns to encode observations into a compact, low-dimensional latent space and models temporal dynamics by predicting the latent representation of future observations.
However, despite their conceptual simplicity, existing JEPA methods are highly prone to collapse. In this failure mode, the model maps all inputs to nearly identical representations to trivially satisfy the temporal prediction objective leading to unusable representations. Preventing collapse is therefore one of the central challenges in training JEPA models. Many influential works have proposed methods to address this issue. Yet, these approaches typically rely on heuristic regularization, multi-objective loss functions, external sources of information, or architectural simplifications such as pre-trained encoders. In practice, these strategies often introduce additional instability or significantly increase training complexity.
To overcome these limitations, we propose LeWorldModel (LeWM), the first method to learn a stable JEPA end-to-end from raw pixels without heuristic, principled, and simple (cf. Figure 2). Furthermore, LeWM can be trained on a single GPU, lowering the barrier to entry for research. We evaluate LeWM across a diverse set of manipulation, navigation, and locomotion tasks in both 2D and 3D environments. In addition, we probe its intuitive physical understanding through targeted probing and surprise-quantification evaluations in latent space. Overall, our key findings and contributions are:
- We propose an end-to-end JEPA method for learning a latent world model from raw pixels on a single GPU. The method relies on a simple and stable two-term objective that remains robust across architectures and hyperparameter choices, while enabling efficient logarithmic-time hyperparameter search.
- LeWM achieves strong control performance across diverse 2D and 3D tasks with a compact 15M-parameter model, surpassing existing end-to-end JEPA-based approach while remaining competitive with foundation-model-based world models at substantially lower cost, enabling planning up to $48\times$ faster.
- We evaluate physical understanding in the latent space through probing of physical quantities and a violation-of-expectation test for detecting unphysical trajectories.
2. Related Work
Section Summary: World models are AI systems that learn to predict how environments change over time from data, helping agents imagine future scenarios without needing real-world trials. Generative versions simulate visuals directly and work well in games or robotics, often using reward information, but approaches like JEPA build reward-free models in a simplified hidden space to avoid common training pitfalls and enable broader use. Planning techniques then use these models either to train policies through imagined rollouts or to make real-time decisions by optimizing actions in the hidden space during execution.
World Models aim to learn predictive models of environment dynamics from data, enabling agents to reason about future states in imagination. A prominent class of WMs consists of generative approaches that explicitly model environment dynamics in pixel space. These action-conditioned generative models act as learned simulators by producing future observations conditioned on past states and actions. Generative world models have been successfully applied to simulate existing game-like environments. For example, IRIS [3], DIAMOND [6], $\Delta$-IRIS [7], OASIS [8], and DreamerV4 [4] model environments such as Minecraft, Counter-Strike, and Crafter, improving policy sample efficiency in reinforcement learning. Other methods generate entirely new interactive simulators, e.g., Genie [9] and HunyuanWorld [10], while learned simulators have also been applied to robot policy evaluation [11]. Importantly, many generative WMs assume access to datasets containing reward signals, enabling joint modeling of dynamics and value-relevant information for downstream reinforcement learning. In contrast, we focus on the reward-free setting, corresponding to the setup considered in the JEPA line of work, which aims at learning generic, task-agnostic world models from observational data without relying on reward supervision.
JEPA is a framework for learning world models that predict the dynamic evolution of a system in a compact, low-dimensional latent space. Since their introduction by [5], JEPA methods have evolved considerably, differing mainly in their target tasks and in the strategies used to learn non-collapsing representations. One prominent line of work applies JEPA to self-supervised representation learning by predicting the latent embeddings of masked input patches. Examples include I-JEPA [12] for images, V-JEPA [13, 14] for videos, and Echo-JEPA and Brain-JEPA [15, 16] for medical data. These approaches typically employ an exponential moving average (EMA) of the target encoder together with stop-gradient (SG) updates to stabilize training and prevent representation collapse. However, the theoretical understanding of EMA and SG remains limited, as they do not in general correspond to the minimization of a well-defined objective [17]. A second line of work uses the JEPA recipe for action-conditioned latent world modeling. Some approaches rely on pretrained encoders to obtain representations [14, 18, 19, 20]. This avoids collapse but limits the expressivity of representation to the pretrained encoder used. In contrast, PLDM [21, 22] learns representations end-to-end using VICReg [23] with additional regularization terms, at the cost of known training instabilities and scalability limitations ([24]). Several works further improve stability by incorporating auxiliary signals or architectural components, such as proprioceptive inputs or action decoders [18, 19]. In this work, we propose a stable method for training end-to-end JEPAs directly from raw pixels using a simple two-term loss: a predictive objective on future embeddings and a regularization objective that enforces Gaussian-distributed embeddings ([25]).
Planning with Latent Dynamics. World Models [26] pioneered learning policies directly from compact latent representations of high-dimensional observations. Some works leverage learned latent dynamics models to train policies using reinforcement learning [27, 28, 29, 4]. In these approaches, the generative world model acts as a simulator in which trajectories are rolled out in imagination, allowing policy optimization to occur largely in imagination in latent space. Once training is complete, the policy is executed directly, and the world model is no longer required at test time.
More recent works instead perform planning directly in the latent space at test time using Model Predictive Control (MPC) [30, 31, 32, 33, 18, 22]. In contrast to imagination-based policy learning, these methods use the world model online to predict the outcomes of candidate action sequences and iteratively optimize them during execution. The model therefore remains part of the control loop at runtime, enabling adaptive decision-making but increasing computational requirements.
3. Method: LeWorldModel
Section Summary: LeWorldModel is a system designed to learn a compact representation of how environments work from videos of actions and observations, without needing rewards or specific goals. It uses a vision transformer to encode each frame into a low-dimensional "latent" state, then a transformer-based predictor to forecast the next state based on the current state and action, trained on offline data to model dynamics while avoiding trivial solutions through a regularization technique that keeps representations diverse. Once trained, this model supports planning and decision-making in new tasks by simulating future states in the latent space using a control method called model predictive control.
In this section, we introduce LeWorldModel (LeWM). We first describe the streamlined training procedure used to learn the latent world model from offline data, including the dataset, model architecture, and training objective. We then explain how the learned model can be leveraged for decision making through latent planning using model predictive control (MPC).
3.1 Learning the Latent World Model
Offline Dataset.
We consider a fully offline and reward-free setting. LeWorldModel is trained solely from unannotated trajectories of observations and actions, without access to reward signals or task specifications. This setup aligns with the JEPA line of work [18, 14], which aims to learn generic, task-agnostic world models from observational data. Our objective is not to optimize behavior for a specific task, but to learn representations that capture environment dynamics and can later be controlled or adapted to a diverse set of tasks.
The training data consists of trajectories of length $T$ composed of raw pixel observations ${\bm{o}}{1:T}$ and associated actions ${\bm{a}}{1:T}$. Trajectories are collected offline from behavior policies with no optimality requirements; they may be pseudo-expert or exploratory, as long as they sufficiently cover the environment dynamics. Additional implementation details (batch size, resolution, and sub-trajectory construction) are provided in App. Appendix D.
Model Architecture.
LeWM is built upon two components: an encoder and a predictor. The encoder maps a given frame observation ${\bm{o}}_t$ into a compact, low-dimensional latent representation ${\bm{z}}t$. The predictor models the environment dynamics in latent space by predicting the embedding of the next frame observation $\hat{{\bm{z}}}{t+1}$ given the latent embedding ${\bm{z}}_t$ and an action ${\bm{a}}_t$.
$ \begin{aligned} \text{Encoder:} \quad & {\bm{z}}t = {\rm enc}\theta({\bm{o}}t) \ \text{Predictor:} \quad & \hat{{\bm{z}}}{t+1} = {\rm pred}_\phi({\bm{z}}_t, {\bm{a}}_t) \end{aligned} \tag{LeWM} $
The encoder is implemented as a Vision Transformer (ViT) [34]. Unless otherwise specified, we use the tiny configuration ($\sim$ 5M parameters) with a patch size of 14, 12 layers, 3 attention heads, and hidden dimensions of 192. The observation embedding ${\bm{z}}_t$ is constructed from the [CLS] token embedding of the last layer, followed by a projection step. The projection step maps the [CLS] token embedding into a new representation space using a 1-layer MLP with Batch Normalization [35]. This step is necessary because the final ViT layer applies a Layer Normalization [36], which prevents our anti-collapse objective from being optimized effectively.
The predictor is a transformer with 6 layers, 16 attention heads, and 10% dropout ($\sim$ 10M parameters). Actions are incorporated into the predictor through Adaptive Layer Normalization (AdaLN) [37] applied at each layer. The AdaLN parameters are initialized to zero to stabilize training and ensure that action conditioning impacts the predictor training progressively. The predictor takes as input a history of $N$ frame representations and predicts the next frame representation auto-regressively with temporal causal masking to avoid looking at future embeddings. The predictor is also followed by a projector network with the same implementation as the one used for the encoder. All components of our world model are learned jointly using the loss described in the following paragraph.
Training Objective.
Our objective is to learn latent representations useful for predicting the future, i.e., modeling the environment dynamics. LeWorldModel training objective is the sum of two terms: a prediction loss and a regularization loss. The prediction loss $\mathcal{L}_{\rm pred}$ (teacher-forcing) computes the error between the predicted embedding of consecutive time-steps:
$ \mathcal{L}{\rm pred} \triangleq |\hat{{\bm{z}}}{t+1} - {{\bm{z}}}{t+1}|^2_2, \quad\quad \hat{{\bm{z}}}{t+1} = {\rm pred}_\phi({\bm{z}}_t, {\bm{a}}_t). $
Through the prediction loss, the encoder is incentivized to learn a predictable representation for the predictor.
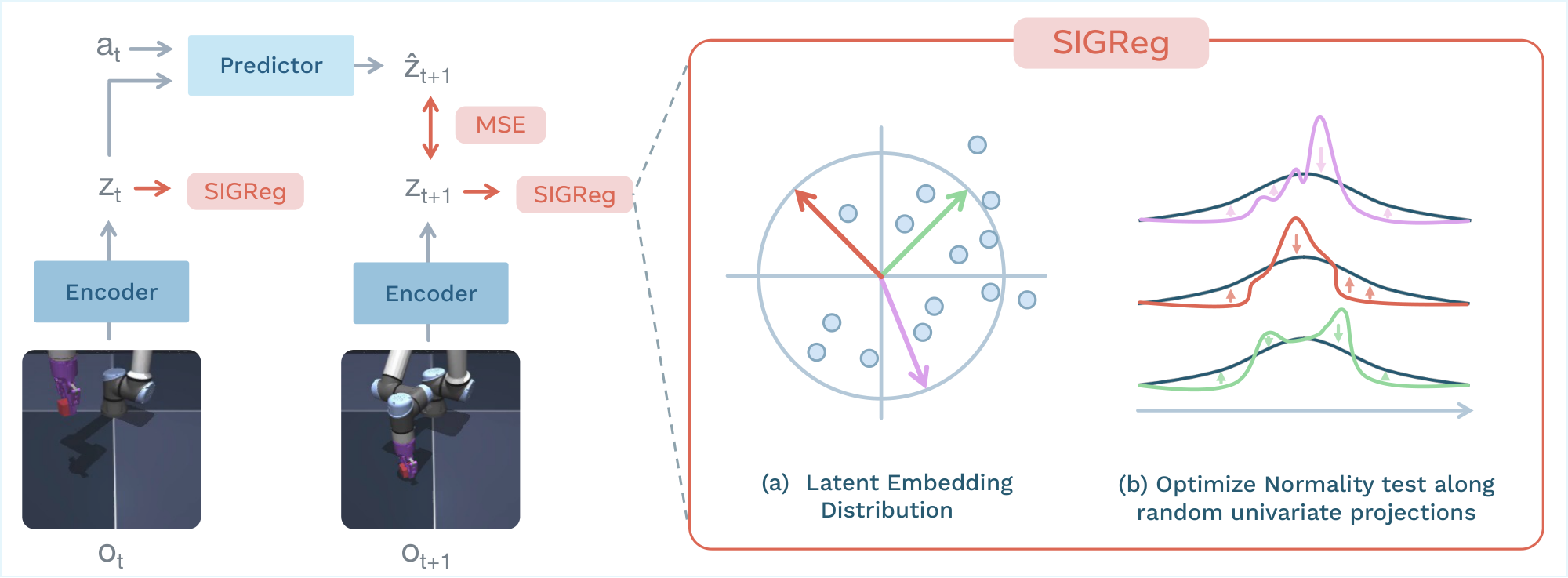
However, this loss alone leads to representation collapse, yielding a trivial solution in which the encoder maps all inputs to a constant representation. To prevent this behavior, we introduce an anti-collapse regularization term that promotes feature diversity in the embedding space. Specifically, we adopt the Sketched-Isotropic-Gaussian Regularizer (SIGReg) [25] due to its simplicity, scalability, and stability. SIGReg encourages the latent embeddings to match an isotropic Gaussian target distribution.
Let ${\bm{Z}} \in \mathbb{R}^{N \times B \times d}$ denote the tensor of latent embeddings collected over the history length $N$, the batch size $B$, and where $d$ demotes the embedding dimension. Assessing normality directly in high-dimensional spaces is challenging, as most classical normality tests are designed for univariate data and do not scale reliably with dimensionality. SIGReg circumvents this limitation by projecting embeddings onto $M$ random unit-norm directions ${\bm{u}}^{(m)} \in \mathbb{S}^{d-1}$ and optimizing the univariate Epps–Pulley [38] test statistic $T(\cdot)$ along the resulting one-dimensional projections ${\bm{h}}^{(m)} = {\bm{Z}} {\bm{u}}^{(m)}$, as illustrated in Figure 1. By the Cramér–Wold theorem [39], matching all one-dimensional marginals is equivalent to matching the full joint distribution.
$ {\rm SIGReg}({\bm{Z}}) \triangleq \frac{1}{M} \sum_{m=1}^M T({\bm{h}}^{(m)}). $
Additional details on SIGReg and the definition of the Epps–Pulley statistical test are provided in Appendix A.
The complete LeWM training objective is defined as:
$ {\mathcal{L}}{\rm LeWM} \triangleq {\mathcal{L}}{\rm pred} + \lambda, {\rm SIGReg}({\bm{Z}}). $
The method introduces only two training hyperparameters: the number of random projections $M$ used in SIGReg and the regularization weight $\lambda$. Unless otherwise specified, we use $M = 1024$ projections and $\lambda = 0.1$. In practice, we observe that the number of projections has negligible impact on downstream performance (see Section 4 and App. Appendix G), making $\lambda$ the only effective hyperparameter to tune. This greatly simplifies hyperparameter selection, as $\lambda$ can be efficiently optimized using a simple bisection search with logarithmic complexity. We do not employ stop-gradient, exponential moving averages, or additional stabilization heuristics. Gradients are propagated through all components of the loss, and all parameters are optimized jointly in an end-to-end manner, resulting in a streamlined and easy-to-implement training procedure. The training logic is summarized in Alg. Figure 5.

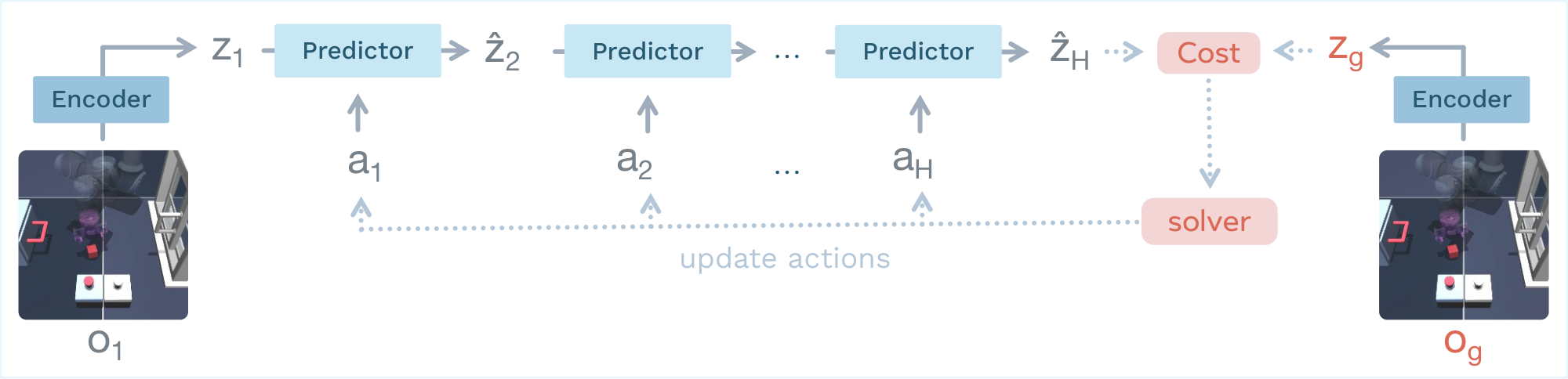
3.2 Latent Planning
At inference time, we perform trajectory optimization in our world model latent space, as illustrated in Figure 4. Given an initial observation ${\bm{o}}_1$, we initialize a candidate action sequence randomly and iteratively rollout predicted latent states up to a planning horizon $H$. The model predicts latent transitions according to
$ \hat{{\bm{z}}}{t+1} = {\rm pred}\phi(\hat{{\bm{z}}}_t, {\bm{a}}_t), \quad \hat{{\bm{z}}}1 = {\rm enc}\theta({\bm{o}}_1), $
Planning is performed by optimizing the action sequence to minimize a terminal latent goal-matching objective:
$ {\mathcal{C}}(\hat{{\bm{z}}}_H) = | \hat{{\bm{z}}}_H - {\bm{z}}_g |_2^2, \quad {\bm{z}}g = {\rm enc}\theta({\bm{o}}_g), $
where $\hat{{\bm{z}}}_H$ is the predicted latent state at the end of the rollout and ${\bm{z}}_g$ is the latent embedding of the goal observation ${\bm{o}}_g$. The world model parameters remain fixed during planning. This procedure corresponds to a finite-horizon optimal control problem:
$ {\bm{a}}^*_{1:H} = \arg\min_{{\bm{a}}_{1:H}} {\mathcal{C}}(\hat{{\bm{z}}}_H),\tag{1} $
which we solve using the Cross-Entropy Method (CEM) [40], a sampling method that iteratively selects the best plan and updates the parameters of the sampling distribution with the statistics of the best plans. The planning horizon $H$ trades off long-term lookahead against increased computational cost and model bias. In particular, auto-regressive rollouts accumulate prediction errors as the horizon grows, which can deteriorate the quality of the optimized action sequence. To mitigate this effect, we adopt a Model Predictive Control (MPC) strategy: only the first $K$ planned actions are executed before replanning from the updated observation. We provide more details on the planning strategy in Appendix D.
4. Latent Planning Performance
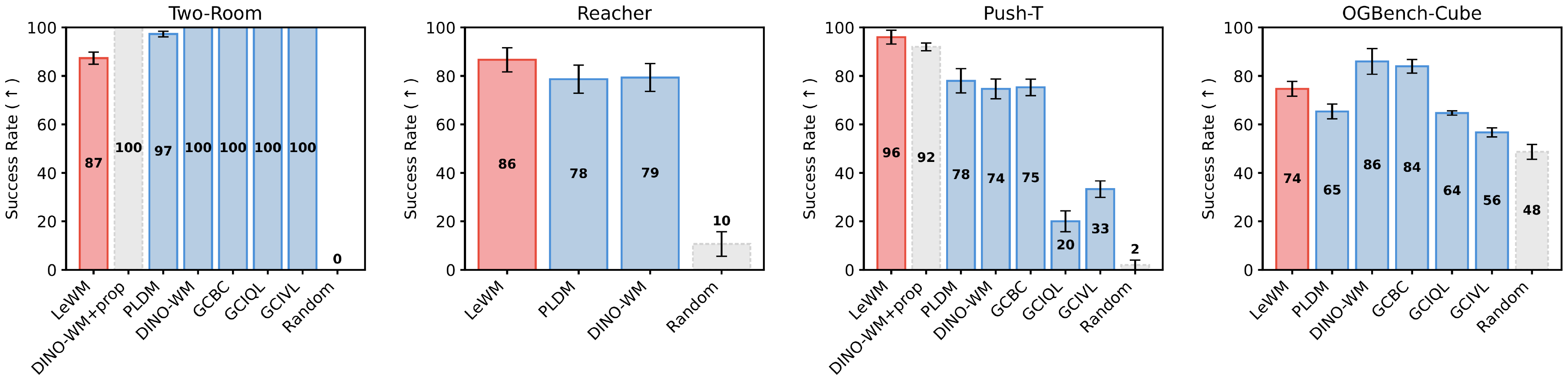
Section Summary: Researchers evaluated a new AI method called LeWM for planning tasks in various simulated environments like pushing blocks, navigating rooms, and reaching targets with robotic arms, comparing it to other advanced techniques such as PLDM and DINO-WM. LeWM showed stronger performance on challenging tasks, like an 18% higher success rate in block-pushing compared to PLDM, and it planned actions 48 times faster—often in under a second—while matching or beating competitors even without extra sensor data. Ablation tests revealed LeWM's training is stable and simple, needing just one key parameter to tune unlike more complex rivals, and it works well with different model sizes and architectures, though it struggles slightly in very basic setups.
4.1 Planning evaluation setup
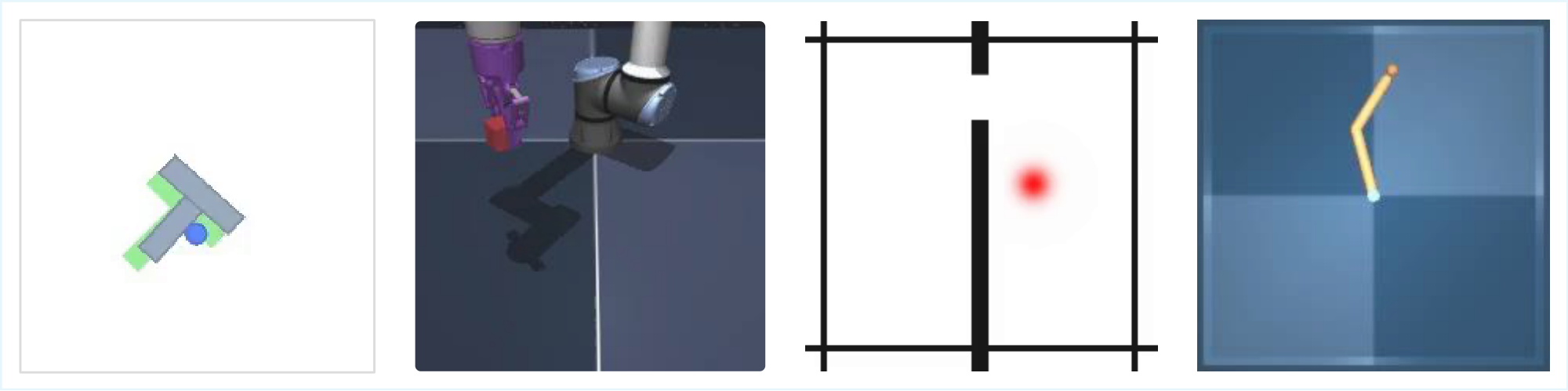
Environments.
We evaluate LeWM on a diverse set of tasks, including navigation, motion planning and manipulation, in both two- and three-dimensional environments, all illustrated in Figure 6. We provide more details on dataset generation and environments in App. Appendix E.
Baselines.
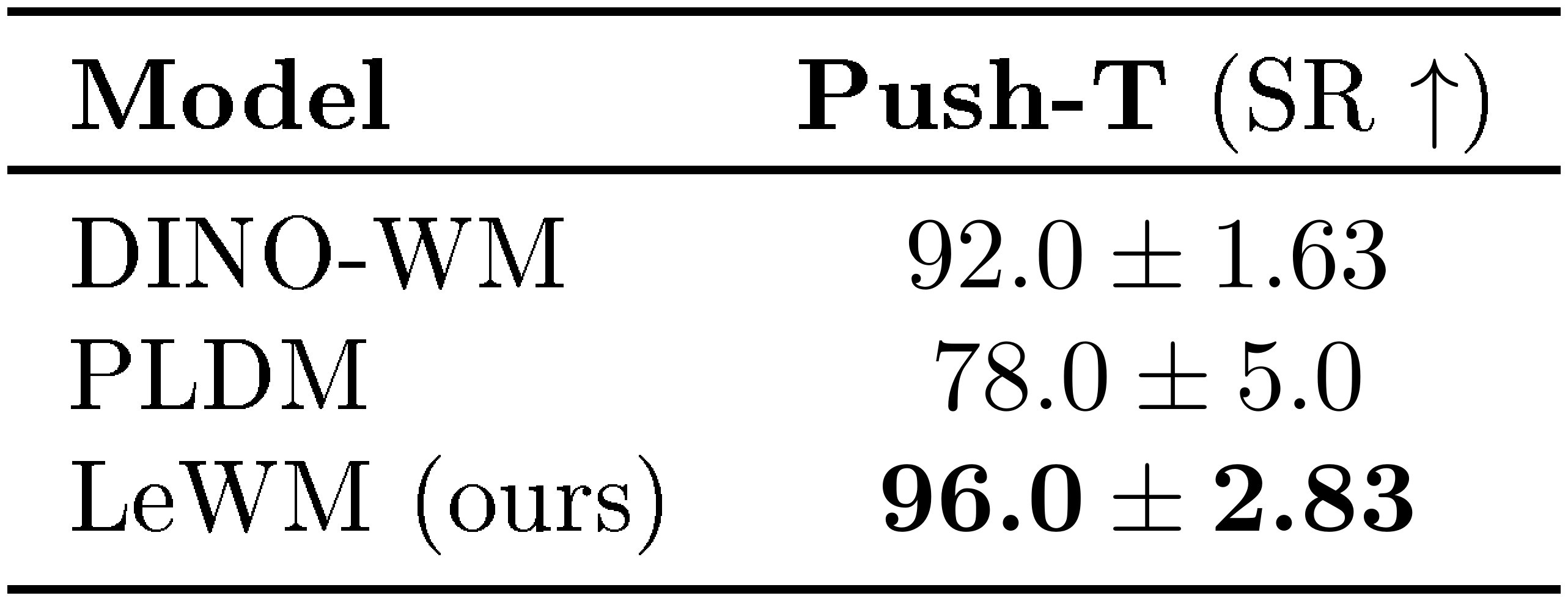
We compare the performance of LeWM against several baselines: DINO-WM and PLDM, two state-of-the-art JEPA-based methods; a goal-conditioned behavioral cloning policy (GCBC); and two goal-conditioned offline reinforcement learning algorithms, GCIVL and GCIQL. Among these baselines, PLDM is the closest to our setup, as it also learns a world model end-to-end directly from pixel observations. However, it relies on a seven-term training objective derived from the VICReg criterion, which introduces training instability and increases the complexity of hyperparameter tuning. DINO-WM, in contrast, models dynamics using DINOv2 [41] as feature encoder to mitigate representation collapse, but its original formulation additionally incorporates other modalities, such as proprioceptive inputs; for a fair comparison, unless specified otherwise, we exclude proprioceptive information from DINO-WM. Additional implementation details for the baselines (App. Appendix C) and evaluation settings (App. Appendix F.1) are provided in the appendix. For each method, we keep the hyperparameters fixed across all environments.
4.2 Towards Efficient Planning with WMs
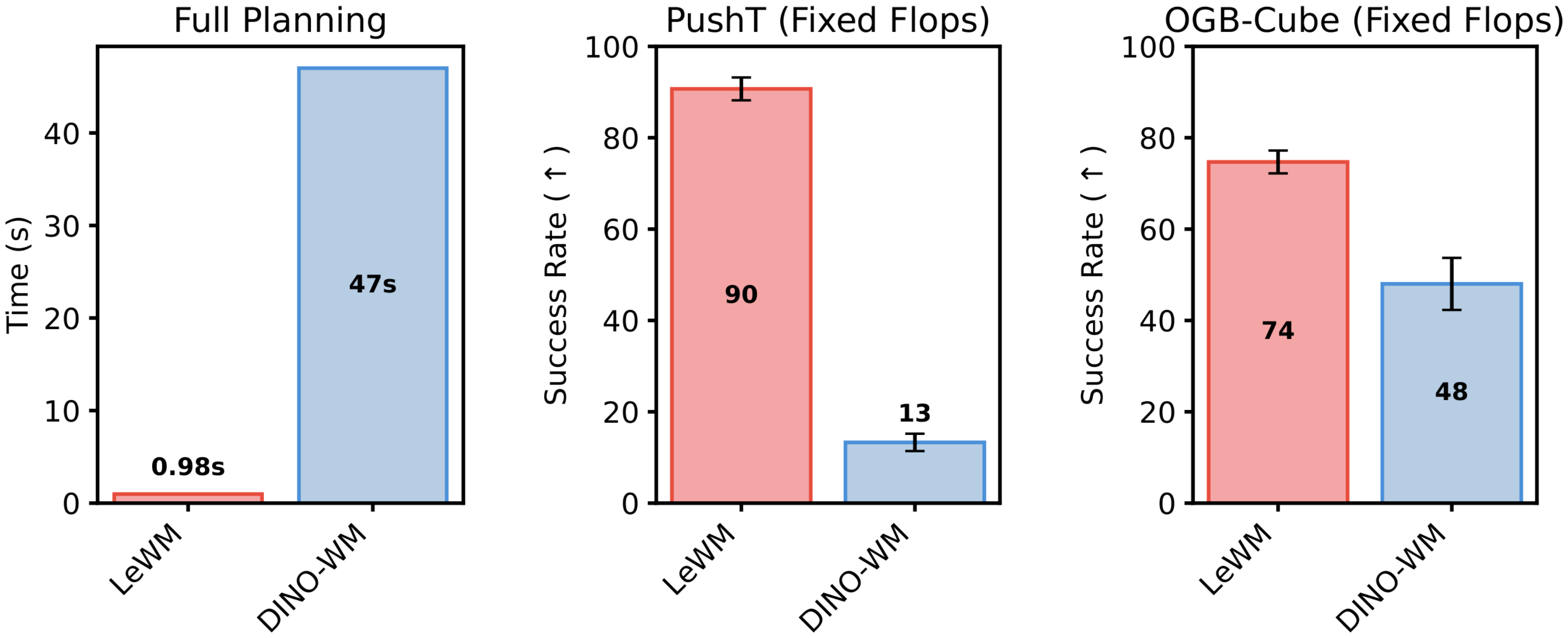
We report planning performance in Figure 7. LeWM improves over PLDM on the more challenging planning tasks, achieving an 18% higher success rate on PushT while remaining competitive with DINO-WM. Notably, on PushT, LeWM (pixels-only) surpasses DINO-WM, even when DINO-WM has access to additional proprioceptive information, demonstrating LeWM’s ability to capture underlying task-relevant quantities. Moreover, when comparing planning speedups (Figure 3), LeWM achieves a 48× faster planning time, with the full planning completing in under one second while preserving competitive performance across tasks. This planning time is consistent across environments for a fixed planning setup, narrowing gap with real-time control.
We report planning performance in Figure 7. LeWM outperforms PLDM on the more challenging planning tasks, achieving an 18% higher success rate on PushT, while remaining competitive with DINO-WM. Notably, on PushT, LeWM (pixels-only) surpasses DINO-WM even when DINO-WM has access to additional proprioceptive information, demonstrating LeWM’s ability to capture underlying task-relevant quantities. Interestingly, LeWM performs worse on the simplest environment, Two-Room. A possible explanation is that the low diversity and low intrinsic dimensionality of this dataset make it difficult for the encoder to match the isotropic Gaussian prior enforced by SIGReg in a high-dimensional latent space, which may lead to a less structured latent representation. This highlights a potential limitation of the SIGReg regularization in very low-complexity environments.
Moreover, when comparing planning speedups (Figure 3), LeWM achieves a $48\times$ faster planning time, with the full planning completing in under one second while preserving competitive performance across tasks. This planning time remains consistent across environments for a fixed planning setup, narrowing the gap toward real-time control.
4.3 Towards Stable Training of World Models
Ablations.
We perform ablations on several design choices of LeWM. First, we analyze the sensitivity of SIGReg to its internal parameters, namely the number of random projections and the number of integration knots. The performance is largely unaffected by these quantities, indicating that they do not require careful tuning. As a result, the regularization weight $\lambda$ remains the only effective hyperparameter. Since only a single hyperparameter needs to be tuned, grid search can be performed efficiently using a simple bisection strategy ($\mathcal{O}(\log n)$), whereas PLDM requires search in polynomial time ($\mathcal{O}(n^6)$). We also study the effect of the embedding dimensionality. While the representation dimension must be sufficiently large for the method to perform well, performance quickly saturates beyond a certain threshold, suggesting that the approach is robust to the precise choice of encoder capacity. Additionally, we examine the impact of the encoder architecture by replacing the default ViT encoder with a ResNet-18 backbone (Table 8). LeWM achieves competitive performance with both architectures, indicating that it is largely agnostic to the choice of vision encoder. Details on all ablations are available in App. Appendix G.
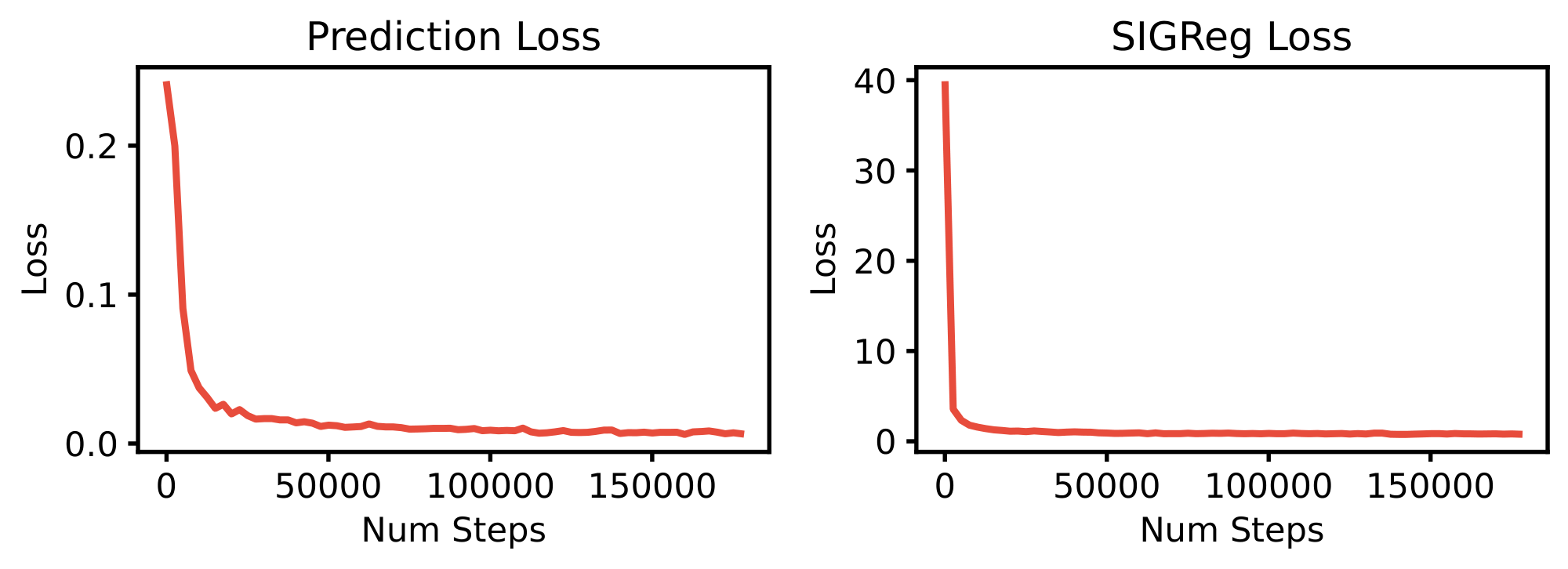
Training Curves.
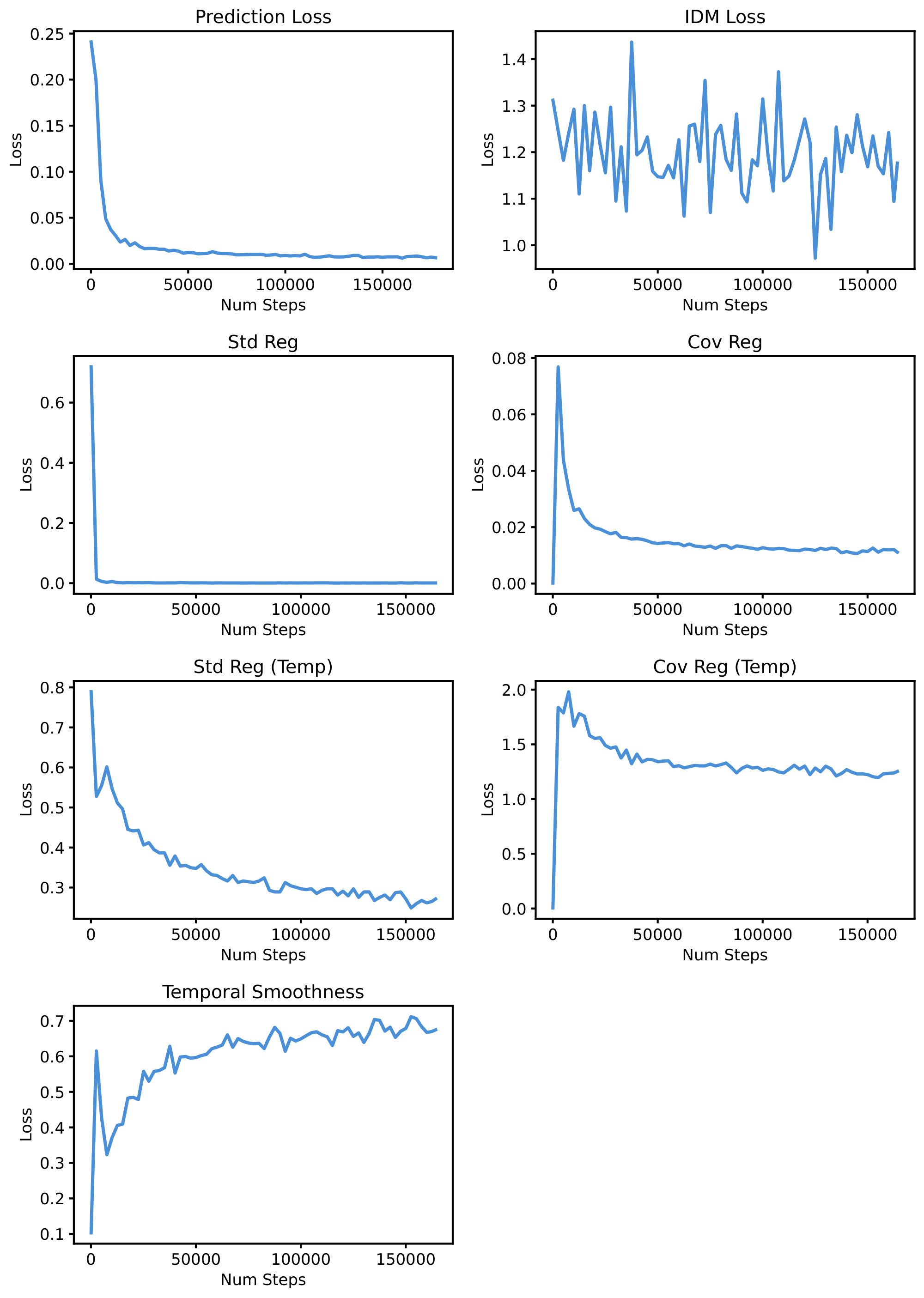
We report the training loss curves on PushT for LeWM in Figure 25 and PLDM in Figure 26. The two-term objective of LeWM exhibits smooth and monotonic convergence: the prediction loss decreases steadily while the SIGReg regularization term drops sharply in the early phase of training before plateauing, indicating that the latent distribution quickly approaches the isotropic Gaussian target. In contrast, PLDM's seven-term objective displays noisy and non-monotonic behavior across several of its loss components. These observations highlight a key advantage of LeWM: by reducing the training objective to only two well-behaved terms, the training becomes significantly more stable, removing the need to balance competing gradients from multiple regularizers.
5. Quantifying Physical Understanding in LeWM
Section Summary: This section assesses how well LeWM, a machine learning model, captures physical dynamics in its compact latent space by testing whether it can extract key physical properties like object positions from hidden representations and detect breaks in physical rules. Experiments show LeWM outperforming similar models in predicting these properties and reconstructing visual scenes, while visualizations reveal that its latent space preserves the environment's spatial layout and smooth motion paths as training advances. Additionally, the model exhibits greater surprise for physically impossible events, such as objects suddenly teleporting, compared to mere visual changes like color shifts, highlighting its sensitivity to real-world physics over superficial appearances.
In this section, we evaluate the quality of the dynamics captured by LeWM’s latent space, either by learning to extract physical quantities from latent embeddings or by measuring the world model’s ability to detect changes in physics.
5.1 Physical Structure of the Latent Space
Probing physical quantities.
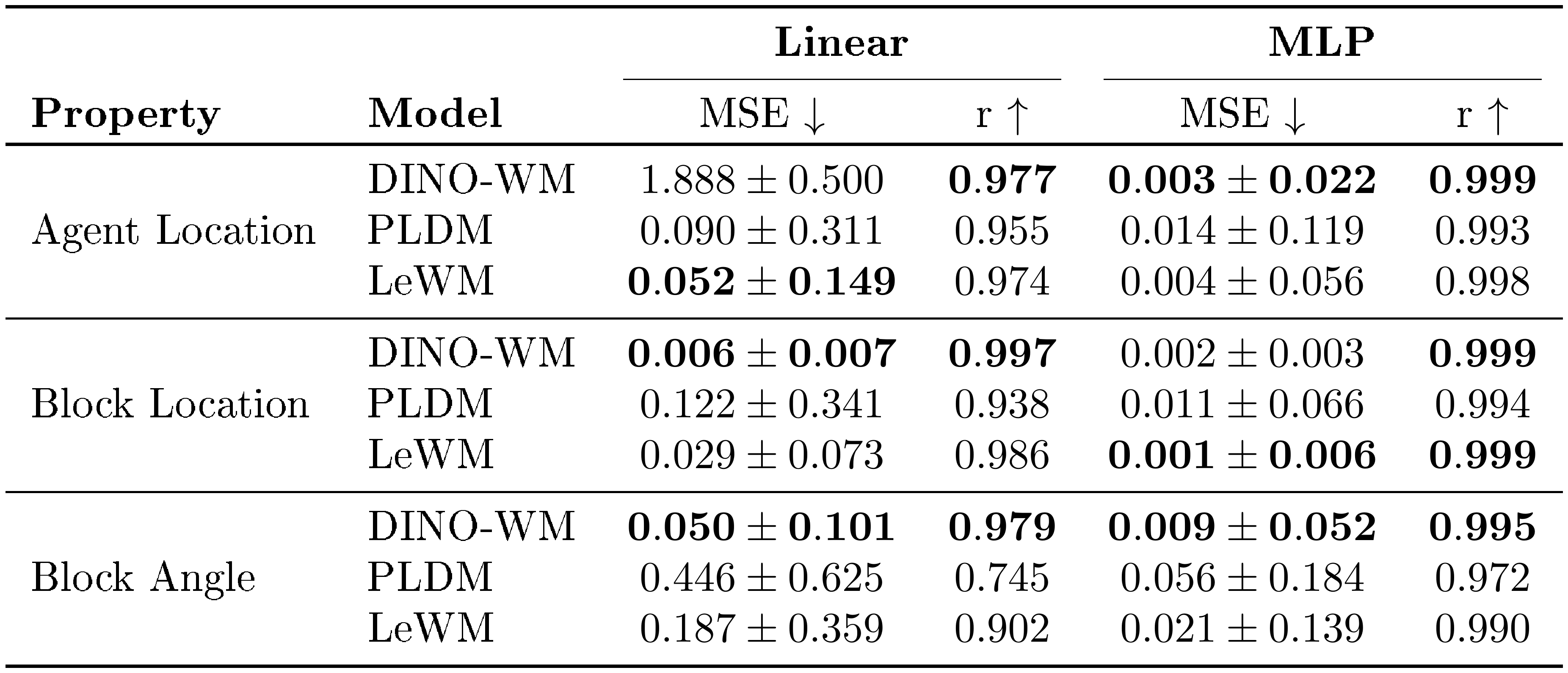
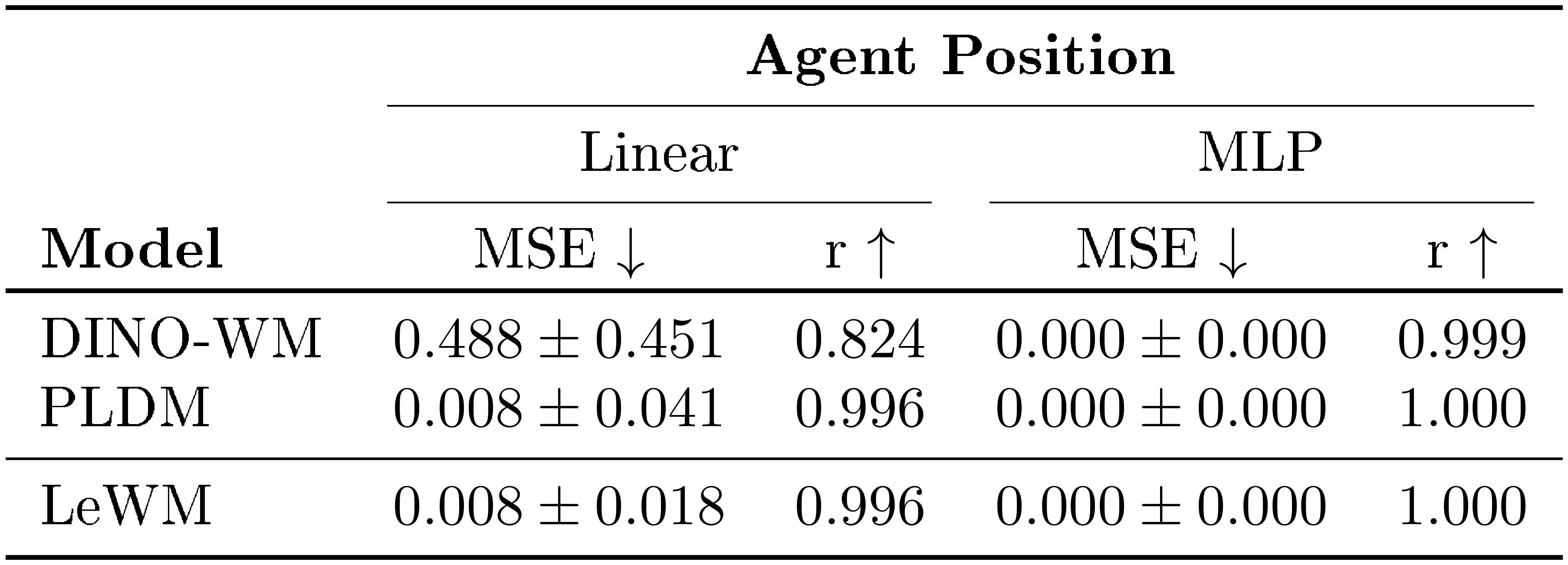
As a first measure of physical understanding, we evaluate which physical quantities are recoverable from LeWM’s latent representations. We train both linear and non-linear probes to predict physical quantities of interest from a given embedding. Results on the Push-T environment are reported in Table 1. Our method consistently outperforms PLDM while remaining competitive with representations produced by large pretrained models such as DINOv2. We provide probing results on other environments in App. Appendix F.2.
::: {caption="Table 1: Physical latent probing results on Push-T. LeWM consistently outperforms PLDM while remaining competitive with DINO-WM. The strong probing performance of DINO-WM on certain properties may stem from its foundation-model pretraining: the DINOv2 encoder is trained on two orders of magnitude more data ($\sim$ 124M images) spanning a far more diverse distribution, which likely allows it to capture some physical properties in its embeddings by default."}
:::
:::: {cols="1"}
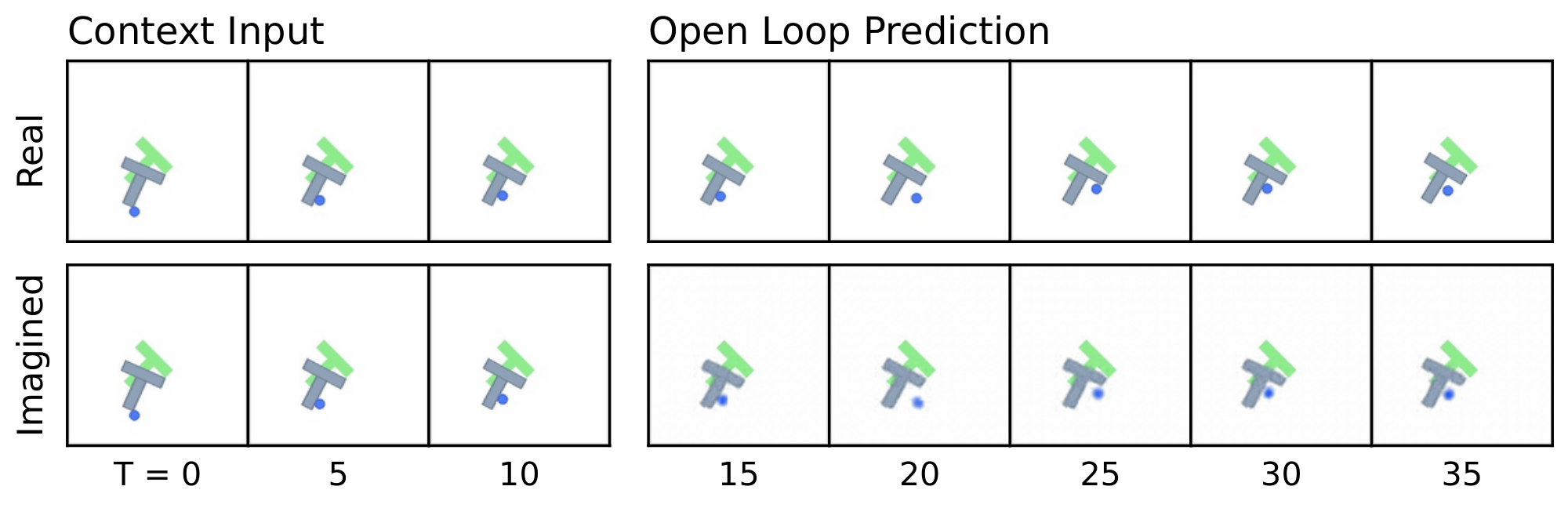
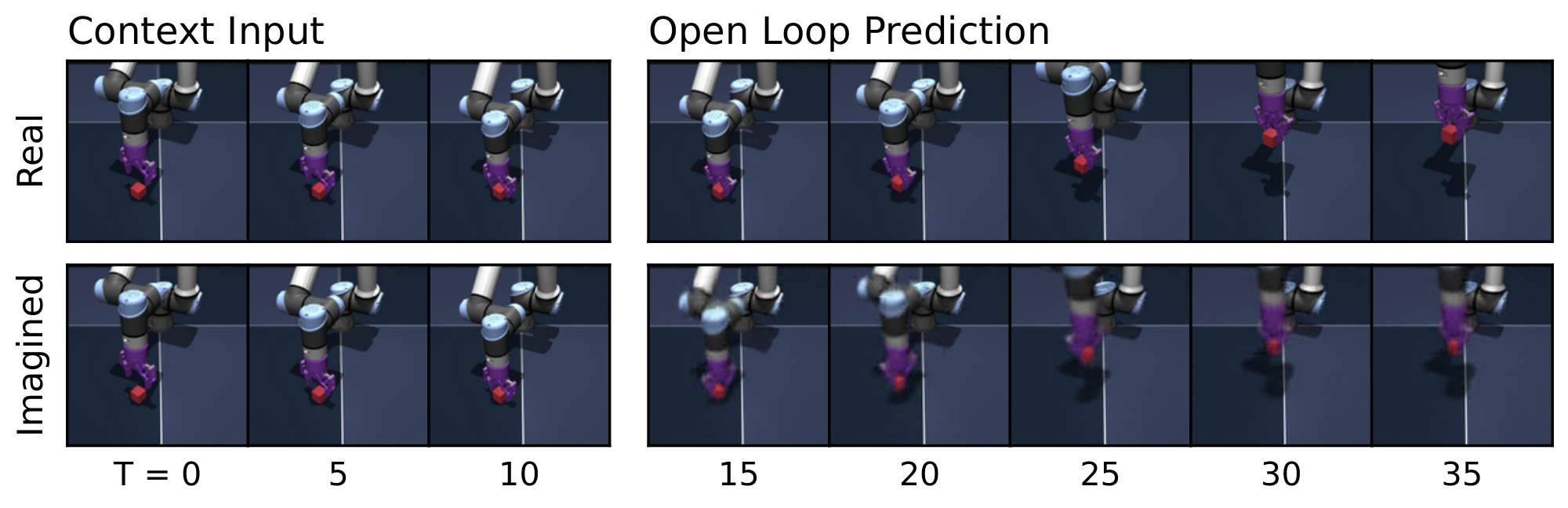
Figure 8: Predictor rollouts on PushT and OGBench-Cube. We visualize decoded latent plans produced by LeWM given a context and an action sequence. Each rollout uses three image observations as context, which are encoded into latent representations. Conditioned on the action sequence, the predictor autoregressively generates future latent states in an open-loop manner. All predicted latents are decoded into images using a decoder that was not used during training. The resulting imagined rollouts closely match the real observations, demonstrating that the latent representation effectively captures the overall scene structure and essential environment dynamics. Some finer details, however, are not fully captured by LeWM; for instance, the angle of the end-effector in OGBench-Cube. Additional rollouts are provided in Figure 15. ::::
![**Figure 12:** **Decoder visualization during training.** As training progresses, the latent representation increasingly captures the information required to reconstruct the visual scene, even though no reconstruction loss is used during training. Early in training, the decoded images correspond to slow features, a phenomenon previously reported [21].](https://ittowtnkqtyixxjxrhou.supabase.co/storage/v1/object/public/public-images/prkjvwsw/decoder_training.png)
Decoding Latent Space.
To further assess the information captured in the latent representation, we report in Figure 12 images produced by a decoder trained to reconstruct pixel observations from a single latent embedding (192 dim) during training. Although reconstruction is never used during training, the decoder is able to recover the visual scene from the learned representation, confirming that the low-dimensional and compact latent space retains sufficient information about the underlying physical state. Details on the decoder architecture are provided in App. Appendix D.
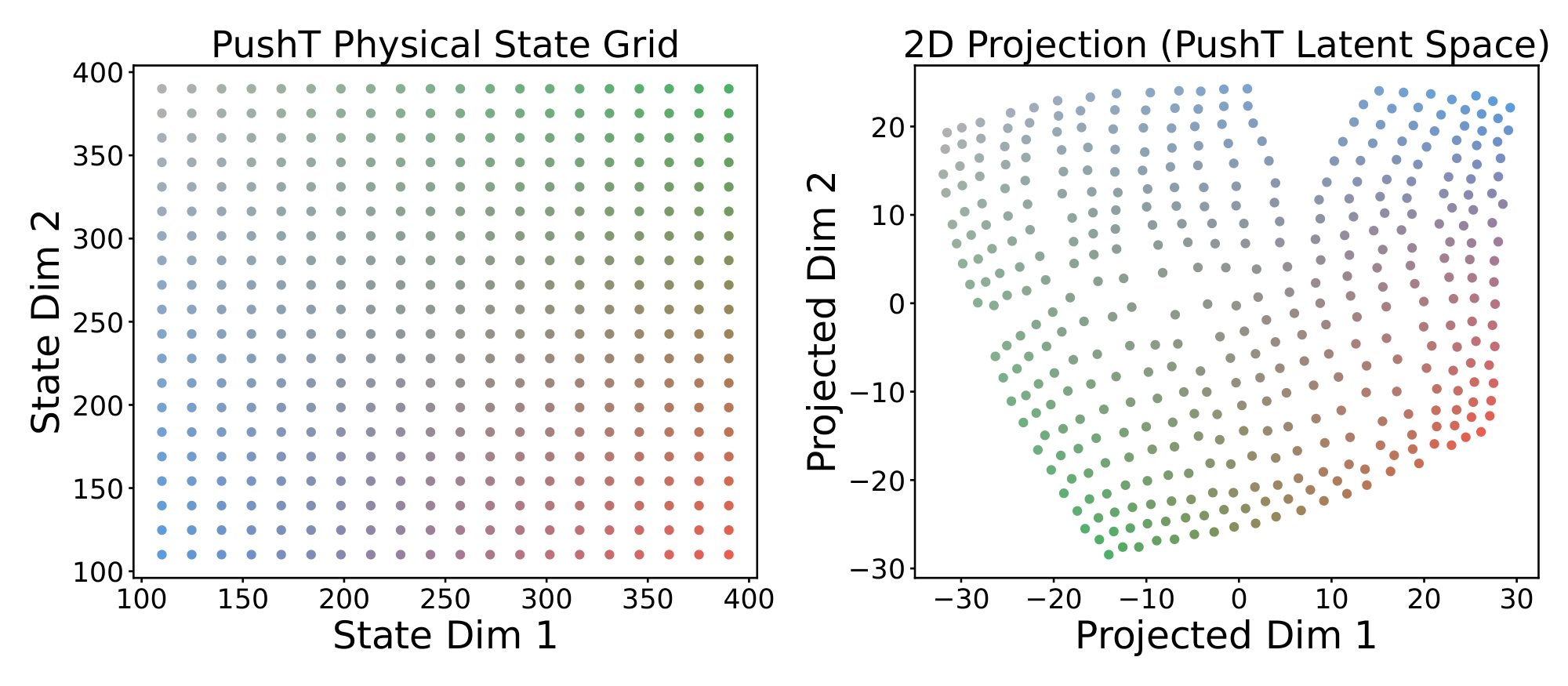
Visualizing Latent Space.
We further visualize the structure of the latent space using t-SNE. Figure 13 provides a qualitative visualization of the latent space in the PushT environment. The visualization suggests that the learned representation captures the spatial structure of the environment, preserving neighborhood relationships and relative positions in the latent space.
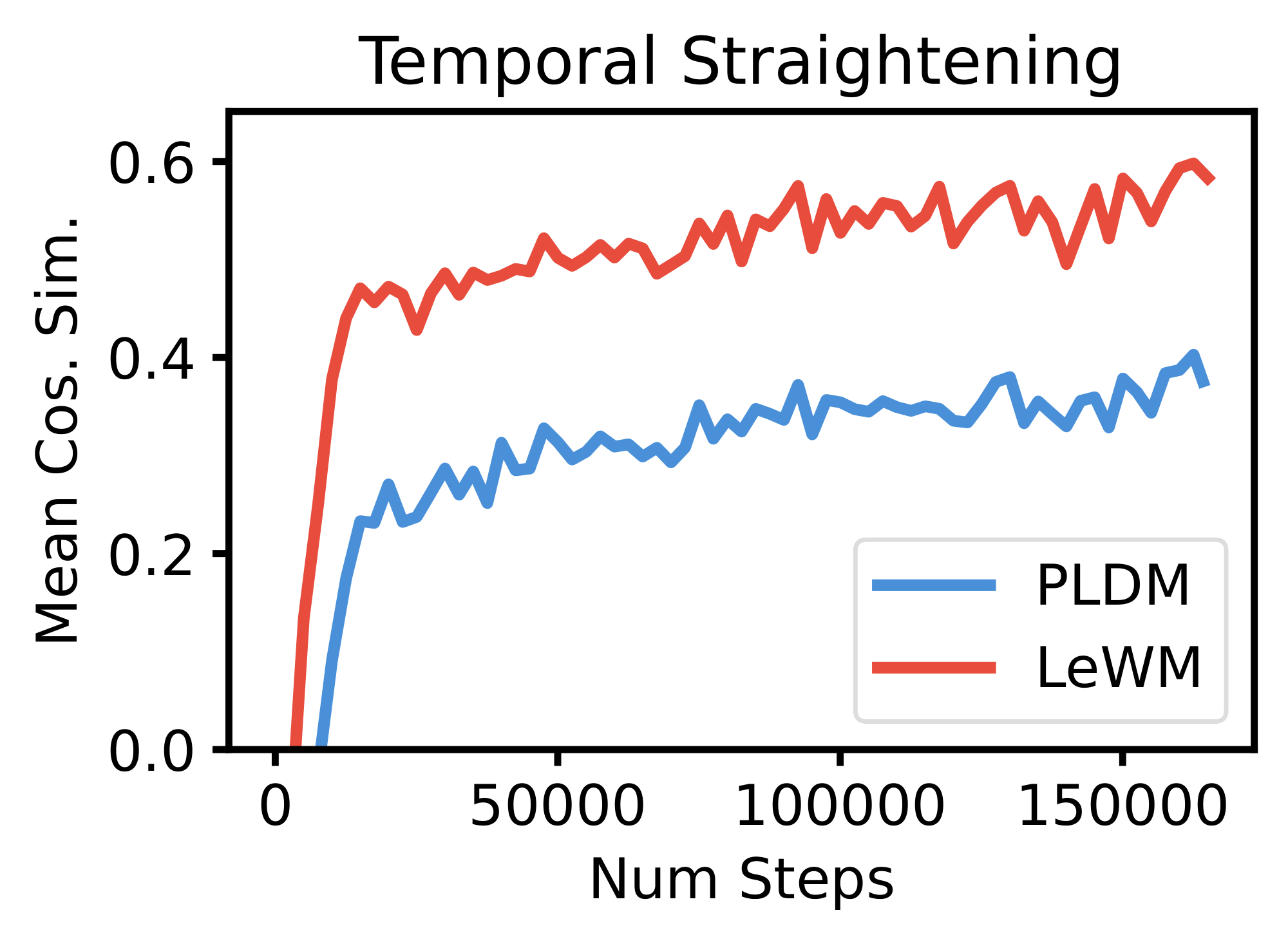
Temporal Latent Path Straightening.
Inspired by the temporal straightening hypothesis from neuroscience ([42]), we measure the cosine similarity between consecutive latent velocity vectors throughout training Equation (5). We find that LeWM's latent trajectories become increasingly straight on PushT over training as a purely emergent phenomenon, without any explicit regularization encouraging this behavior, cf. Figure 24. Remarkably, LeWM achieves higher temporal straightness than PLDM, despite PLDM employing a dedicated temporal smoothness regularization term. We detail our findings in App. Appendix H.
5.2 Violation-of-expectation Framework
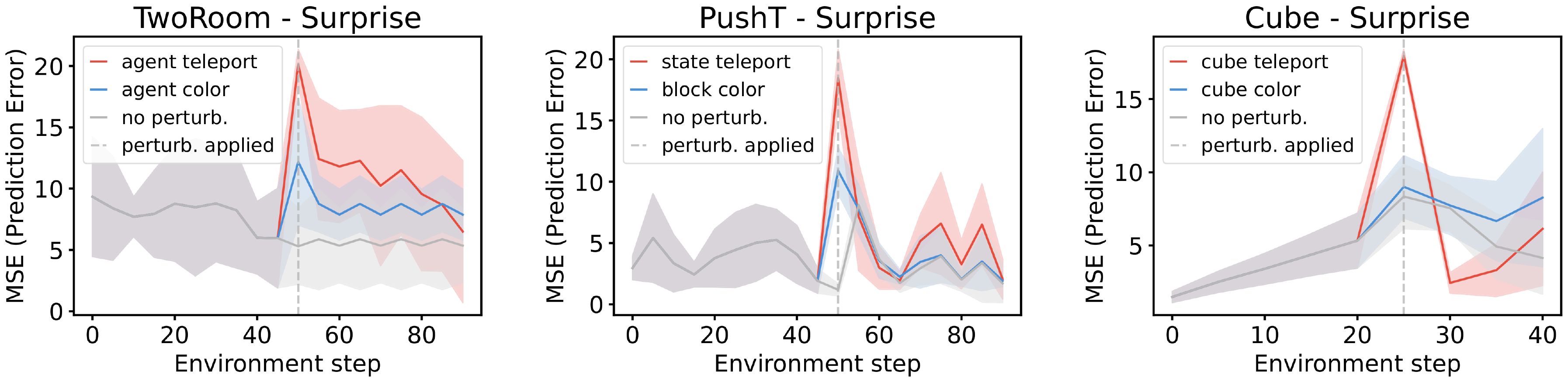
Another approach to quantifying physical understanding is the ability to detect violations of the learned world model. Inspired by the violation-of-expectation (VoE) paradigm used in developmental psychology and recently adopted in machine learning [43, 44, 45], this framework evaluates whether a model assigns higher surprise to events that contradict learned physical regularities.
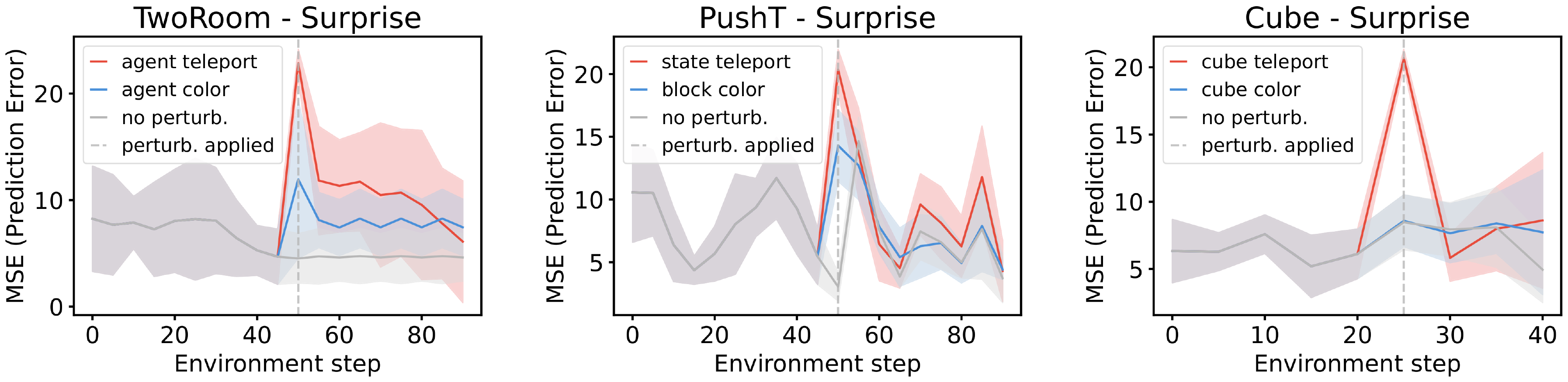
Following prior work, we quantify surprise by measuring the discrepancy between the model’s predicted future observations and the actual observed future. We evaluate this framework across three environments: TwoRoom, PushT, and OGBench Cube. For each environment, we introduce two types of perturbations. The first is a visual perturbation, where the color of an object changes abruptly during the trajectory. The second is a physical perturbation, where one or more objects are teleported to a random location, violating the expected physical continuity of the scene. Figure 14 shows that LeWM consistently assigns higher surprise to frames containing physical violations compared to their unperturbed counterparts. We provide more details on VoE in App. Appendix F.3.
6. Conclusion
Section Summary: This research introduces LeWorldModel (LeWM), a straightforward and reliable system that learns simplified representations of environments directly from pixel-based images, using an encoder to compress observations into a hidden space and a predictor to forecast how that space changes over time based on actions. In various robotic control tasks, LeWM surpasses earlier methods by requiring less data and time for training and planning, while staying stable and performing well overall, thanks to a technique that keeps the hidden representations balanced like a standard bell curve to prevent breakdowns. However, it faces challenges like limited planning for long-term tasks, dependence on high-quality interaction data that's hard to gather, and reliance on action details; future improvements could include layered modeling for longer horizons, pre-training on everyday videos for better starting points, and ways to infer actions without explicit labels.
This work introduced LeWorldModel (LeWM), a stable end-to-end method for learning latent world models of environments. LeWM is a Joint-Embedding Predictive Architecture that uses an encoder to map image observations into a latent space and a predictor that models temporal dynamics in the embedding space by predicting future embeddings conditioned on actions. Across a variety of continuous control environments and using only raw pixel inputs, LeWM outperforms previous approaches in data efficiency, planning time, training time, and stability while maintaining competitive final task performance. The stability and simplicity of training arise from explicitly encouraging latent embeddings to follow an isotropic Gaussian distribution to avoid collapse. Overall, LeWM provides a scalable alternative to existing latent world model methods, offering principled training dynamics alongside interpretable and emergent representation properties.
Limitations & Future Work.
Despite these promising results, several limitations highlight important research directions. First, planning with current latent world models remains restricted to short horizons. Hierarchical world modeling represents a promising direction to address long-horizon reasoning and planning. Second, our approach still relies on offline datasets with sufficient interaction coverage, which can be costly or difficult to collect. In particular, limited data diversity can affect the effectiveness of the SIGReg regularization in very simple environments with low intrinsic dimensionality, where matching the isotropic Gaussian prior in a high-dimensional latent space becomes challenging. Pre-training on large and diverse natural video datasets could provide strong representation priors and reduce reliance on domain-specific data. Finally, current end-to-end latent world models depend on action labels to predict future states, which can also be costly to obtain. A promising direction is to learn future action representations through inverse dynamics modeling, potentially reducing the need for explicit action annotations.
Appendix
Section Summary: The appendix describes SIGReg, a technique that aligns high-dimensional embeddings to an ideal Gaussian distribution by projecting them onto random directions and using statistical tests to measure and minimize differences, ensuring the overall distribution matches the target. It then explains the Cross-Entropy Method, an iterative optimization approach for planning action sequences in a simulated world, where it samples candidates, evaluates their costs, selects the best performers to refine the sampling distribution, and repeats until converging on an optimal plan, though it struggles with high-dimensional spaces. Finally, it outlines baseline world models like DINO-WM, which predicts future states using pre-trained features to minimize errors without full end-to-end training, and PLDM, an end-to-end predictor that adds regularization terms for variance, covariance, and temporal aspects to prevent model collapse during learning.
A. SIGReg
SIGReg proposes to match the distribution of embeddings towards the isotropic Gaussian target distribution. Achieving that match in high-dimension is gracefully done by combining two statistical components (i) Cramer-Wold theorem, and (ii) the univariate Epps-Pulley test-statistic. In short, SIGReg first produces $M$ unit-norm directions ${\bm{u}}^{(m)}$ and projects the embeddings ${\bm{Z}}$ onto them as
$ \begin{align} {\bm{h}}^{(m)}&\triangleq {\bm{Z}} {\bm{u}}^{(m)}, {\bm{u}}^{(m)}\in\mathbb{S}^{D-1}, \end{align}\tag{2} $
where the directions are sampled uniformly on the hypersphere. Then, SIGReg performs univariate distribution matching as
$ \begin{align} {\rm SIGReg}({\bm{Z}})\triangleq \frac{1}{M}\sum_{m=1}^{M}T^{(m)}, \tag{SIGReg} \end{align} $
with $T$ the univariate Epps-Pulley test-statistic
$ T^{(m)} = \int_{-\infty}^{\infty} w(t) \left|\phi_N(t; {\bm{h}}^{(m)}) - \phi_0(t)\right|^2 dt, \tag{EP} $
where the empirical characteristic function (ECF) is defined as $\phi_N(t; {\bm{h}}) = \frac{1}{N}\sum_{n=1}^N e^{it {\bm{h}}_n}$, $w$ is a weighting function, e.g., $w(t) = e^{-\frac{t^2}{2\lambda^2}}$. Lastly, because the target is an isotropic Gaussian in $\mathbb{R}^D$, the univariate projection through ${\bm{u}}^{(m)}$ makes the univariate target distribution $\phi_0$ the standard Gaussian $N(0, 1)$. By Cramér–Wold, matching all 1D marginals implies matching the joint distribution, i.e., in the asymptotic limit over $M$ we have the following weak convergence result
$ \begin{align} {\rm SIGReg}({\bm{Z}})\rightarrow 0 \iff \mathbb{P}_{\bm{Z}}\rightarrow N(0, {\bm{I}}).\tag{Cramer-Wold} \end{align} $
Practically, the integral in equation 4 employs a quadrature scheme, e.g., trapezoid with $T$ nodes uniformly distributed in $[0.2, 4]$.
B. Cross-Entropy Method
The Cross-Entropy Method (CEM) [40] is a sampling-based (zero-order) optimization algorithm. Intuitively, CEM is an iterative sampling procedure that progressively refines a plan, defined as a sequence of actions, at each iteration.
At every iteration, the algorithm samples a pool of candidate plans from a distribution, typically a Gaussian (with initial parameters $\mu=\mathbf{0}$ and $\sigma=\mathbf{I}$). Next, each candidate plan is evaluated using the world model, and a cost is associated with it. The algorithm then selects the top $k$ plans with the lowest cost, referred to as elites. These elites are used to compute statistics that update the parameters of the sampling distribution for the next iteration. Through this iterative process, the method explores the action space while gradually concentrating the sampling distribution around regions associated with lower costs. The final action plan is obtained from the mean of the sampling distribution at the last iteration.
However, in non-convex settings, there is no guarantee that the solution to which CEM converges is a global optimum. Furthermore, CEM suffers from the curse of dimensionality and becomes increasingly difficult to apply when the action space is large.
In our experiments, we use a CEM solver with $300$ sampled action sequences per iteration and perform $30$ optimization steps. At each step, the top $30$ candidates are selected as elites to update the sampling distribution. We provide the algorithm pseudo-code in Algorithm 1.
**Require:** World model $f$, planning horizon $H$, number of samples $N$, number of elites $K$, number of iterations $T$
Initialize sampling distribution parameters $\mu_0 = \mathbf{0}$, $\Sigma_0 = I$
**for** $t = 1$ to $T$ **do**
Sample $N$ candidate action sequences $\{a_{1:H}^{(i)}\}_{i=1}^N \sim \mathcal{N}(\mu_t-1, \Sigma_t-1)$
**for** $i = 1$ to $N$ **do**
Roll out $a_{1:H}^{(i)}$ in the world model $f$
Compute cost $J^{(i)}$
**end for**
Select the $K$ sequences with lowest cost (elites)
Update distribution parameters using elite set:
$\mu_t \leftarrow \frac{1}K\sum_{i \in \mathcal{E}} a_{1:H}^{(i)}$
$\Sigma_t \leftarrow \text{Var}_{i \in \mathcal{E}}\left(a_{1:H}^{(i)}\right)$
**end for**
**return** best action sequence found or first action of $\mu_T$
C. Baselines
C.1 DINO-WM
DINO world model (DINO-WM) focused on learning a predictor by leveraging DINOv2 frozen pre-trained representation to avoid collapse. Because not trained end-to-end, the loss simply is to minimize the predicted next-embedding with the ground trught next-state embedding produced by DINOv2.
$ \mathcal{L}{\text{DINO-WM}} = \frac{1}{BT} \sum_i^B \sum_t^T | \hat{{\bm{z}}}^{(i)}{t+1} - {\bm{z}}^{(i)}_{t+1} |_2^2 $
We use the same setup as the original paper ([18]) (architecture, hyper-paremeters, etc..)
C.2 PLDM
PLDM ([22]) proposed a method for learning an end-to-end joint-embedding predictive architecture (JEPA). To avoid collapse, their approach takes inspiration from the variance-invariance-covariance regularization (VICReg, [23]) with extra terms to take into account the temporality of the next state prediction. The PLDM objective is the following:
$ \mathcal{L}{\text{PLDM}} = \mathcal{L}{\text{pred}} + \alpha \mathcal{L}{\text{var}} + \beta \mathcal{L}{\text{cov}} + \gamma \mathcal{L}{\text{time-sim}} + \zeta \mathcal{L}{\text{time-var}} + \nu \mathcal{L}{\text{time-cov}} + \mu \mathcal{L}{\text{IDM}} $
where,
$ \mathcal{L}{\text{pred}} = \frac{1}{BT} \sum_i^B \sum_t^T | \hat{{\bm{z}}}^{(i)}{t+1} - {\bm{z}}^{(i)}_{t+1}|_2^2 $
$ \mathcal{L}{\text{var}} = \frac{1}{TD} \sum_t^T \sum_d^D \max\left(0, 1-\sqrt{\text{Var}({\bm{z}}^{(:)}{t, d})}+\epsilon\right) $
$ \mathcal{L}{\text{cov}} = \frac{1}{T} \sum_t^T \frac{1}{D}\sum{i\neq j}^D \left[\text{Cov}({\bm{Z}}_t)\right] _{ij} $
$ \mathcal{L}_{\text{time-sim}} = \frac{1}{BT} \sum_i^B \sum_t^T | {\bm{z}}^{(i)}t - {\bm{z}}^{(i)}{t+1}|_2^2 $
$ \mathcal{L}{\text{time-var}} = \frac{1}{BD} \sum_i^B \sum_d^D \max\left(0, 1-\sqrt{\text{Var}({\bm{z}}^{(i)}{:, d})}+\epsilon\right) $
$ \mathcal{L}{\text{time-cov}} = \frac{1}{B} \sum_b^B \frac{1}{D}\sum{i\neq j}^D \left[\text{Cov}({\bm{Z}})\right] _{ij} $
$ \mathcal{L}_{\text{IDM}} = \frac{1}{BT} \sum_i^B \sum_t^T | \hat{{\bm{a}}}^{(i)}_t - {\bm{a}}^{(i)}_t|_2^2 $
with ${\bm{z}}^{(i)}_{t} \in \mathbb{R}^{D}$ correspond to step $t \in [T]$ of trajectory $i \in [B]$ and $T$ is trajectory length and $B$ the batch size, and ${\bm{Z}}_t \in \mathbb{R}^{B \times D}$ denote the matrix whose $i$-th row is ${\bm{z}}_t^{(i)}$, i.e.,
$ {\bm{Z}}_t = \begin{bmatrix} ({\bm{z}}_t^{(1)})^\top \ \vdots \ ({\bm{z}}_t^{(B)})^\top \end{bmatrix}, $
Let $\bar{{\bm{Z}}}_t$ be the row-centered version of ${\bm{Z}}_t$:
$ \bar{{\bm{Z}}}_t = {\bm{Z}}_t - \frac{1}{B}\mathbf{1}\mathbf{1}^\top {\bm{Z}}_t . $
Then, for each time step $t$ and feature dimension $d$, the variance across the batch is
$ \mathrm{Var}({\bm{z}}^{(:)}_{t, d})
\frac{1}{B-1}\sum_{i=1}^B \left(z^{(i)}{t, d} - \frac{1}{B}\sum{i'=1}^B z^{(i')}_{t, d} \right)^2, $
and the covariance matrix across feature dimensions is
$ \mathrm{Cov}({\bm{Z}}_t)
\frac{1}{B-1}\bar{{\bm{Z}}}_t^\top \bar{{\bm{Z}}}_t \in \mathbb{R}^{D \times D}. $
Similarly, for the temporal regularization, let ${\bm{Z}}^{(i)} \in \mathbb{R}^{T \times D}$ denote the matrix whose $t$-th row is ${\bm{z}}_t^{(i)}$, and let $\bar{{\bm{Z}}}^{(i)}$ be its row-centered version:
$ \bar{{\bm{Z}}}^{(i)} = {\bm{Z}}^{(i)} - \frac{1}{T}\mathbf{1}\mathbf{1}^\top {\bm{Z}}^{(i)} . $
Then the variance across time is
$ \mathrm{Var}({\bm{z}}^{(i)}_{:, d})
\frac{1}{T-1}\sum_{t=1}^T \left(z^{(i)}{t, d} - \frac{1}{T}\sum{t'=1}^T z^{(i)}_{t', d} \right)^2, $
and the temporal covariance matrix is
$ \mathrm{Cov}({\bm{Z}}^{(i)})
\frac{1}{T-1}(\bar{{\bm{Z}}}^{(i)})^\top \bar{{\bm{Z}}}^{(i)} \in \mathbb{R}^{D \times D}. $
$\hat{{\bm{z}}}^{(i)}{t} \in \mathbb{R}^{d}$ is the predicted embedding at step $t$ for traj $i$ using the predictor. ${\bm{a}}^{(i)}{t} \in \mathbb{R}^{A}$ is the action associated to step $t$ and $\hat{{\bm{a}}}^{(i)}_{t} \in \mathbb{R}^{A}$ is the predicted action for the inverse dynamic model (IDM) $\text{idm}({\bm{z}}t, {\bm{z}}{t+1})$.
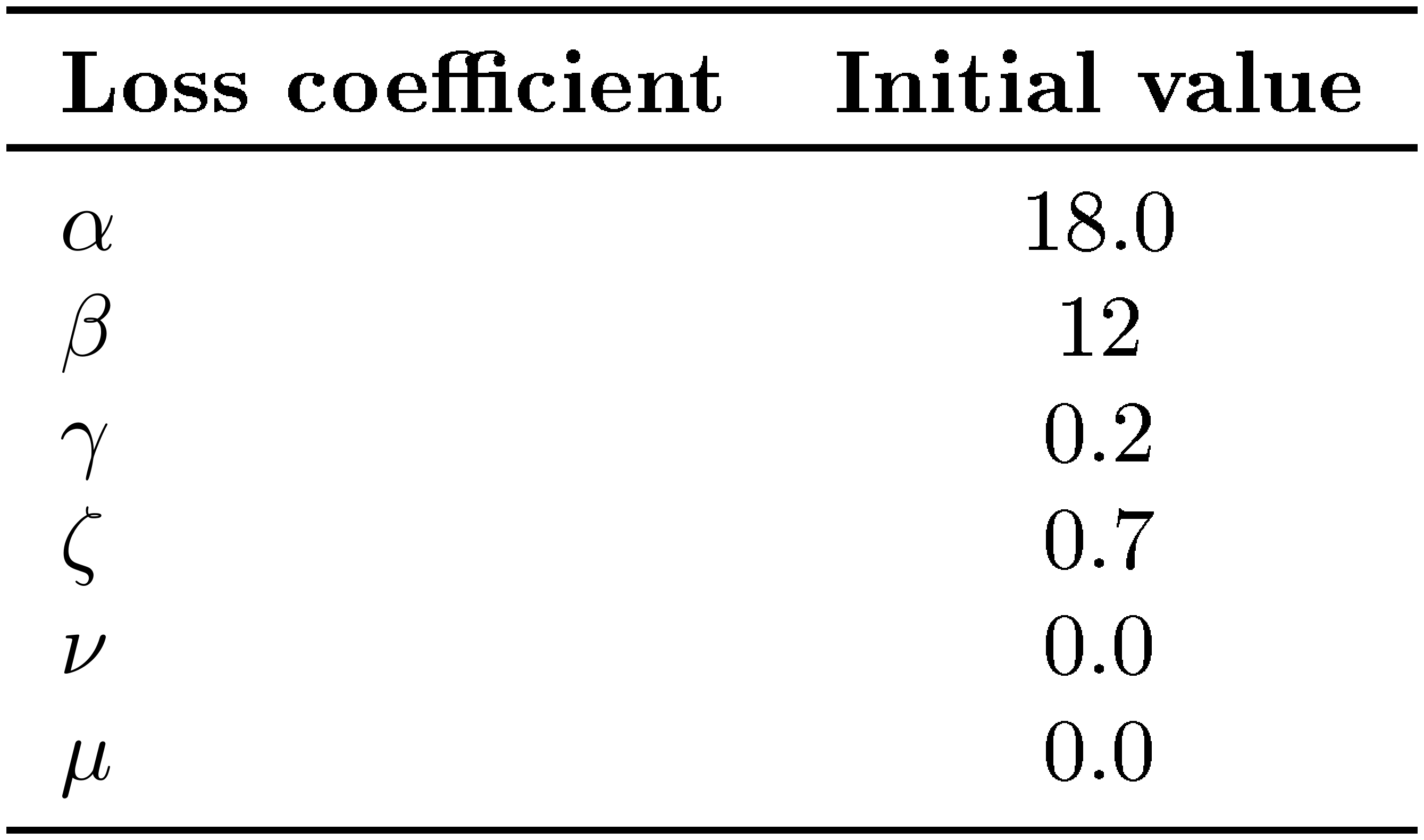
We select PLDM hyperparameters via a grid search over the loss coefficients. Since the overall objective includes six tunable weights ($\alpha$, $\beta$, $\gamma$, $\zeta$, $\nu$, $\mu$), an exhaustive search over all combinations is not tractable $(\mathcal{O}(n^6))$. Moreover, the original PLDM study reports coefficients that were extensively tuned per environment and dataset, which limits their transferability. We start from the set of hyperparameters from the config provided in their open-source codebase. We motivate this choice by mentioning that no mention of the time-var and time-cov regularization term are mentionned in the original paper. We then perform a grid search for each initial loss coefficient over 256 configurations on Push-T and keep the one performing the best on a held-out set. We report the best hyperparameters found in Table 2. We kept these coefficients fixed for all training.
::: {caption="Table 2: Best coefficient found from grid search."}
:::
C.3 GC-RL
To evaluate downstream control, we use goal-conditioned reinforcement learning (GC-RL) with offline training. In particular, we consider goal-conditioned variants of Implicit Q-Learning (IQL) and Implicit Value Learning (IVL). In both cases, observations and goals are encoded using DINOv2 patch embeddings, and policies are trained from offline datasets. Training proceeds in two phases: first learning a value function (and optionally a Q-function), followed by policy extraction via advantage-weighted regression.
GCIQL
Implicit Q-Learning (IQL) [46] is an offline reinforcement learning algorithm that avoids querying out-of-distribution actions by learning a value function via expectile regression. In the goal-conditioned setting, the algorithm learns both a Q-function $Q_\psi(s_t, a_t, g)$ and a value function $V_\theta(s_t, g)$ conditioned on a goal $g$.
The Q-function is trained with Bellman regression, bootstrapping from a target value network $V_{\bar{\theta}}$:
$ \mathcal{L}{Q} = \mathbb{E}{(s_t, a_t, s_{t+1}, g) \sim \mathcal{D}} \left[\left(Q_\psi(s_t, a_t, g) - \left(r(s_t, g) + \gamma m_t V_{\bar{\theta}}(s_{t+1}, g) \right) \right)^2 \right], $
where $m_t = 0$ if $s_t = g$ (terminal transition) and $m_t = 1$ otherwise.
The value network is trained using expectile regression against targets from the target Q-network $Q_{\bar{\psi}}$:
$ \mathcal{L}{V} = \mathbb{E}{(s_t, a_t, g) \sim \mathcal{D}} \left[L_\tau^2 \left(Q_{\bar{\psi}}(s_t, a_t, g) - V_\theta(s_t, g) \right) \right], $
where the expectile loss is defined as
$ L_\tau^2(u) = |\tau - \mathbb{1}(u < 0)| u^2 . $
The total critic loss is given by
$ \mathcal{L}_{\text{critic}} = \mathcal{L}_Q + \mathcal{L}_V . $
GCIVL
Implicit Value Learning (IVL) [47] simplifies IQL by removing the Q-function and learning the value function directly through bootstrapped targets. The value network $V_\theta(s_t, g)$ is trained via expectile regression against a target network $V_{\bar{\theta}}$:
$ \mathcal{L}{V} = \mathbb{E}{(s_t, s_{t+1}, g) \sim \mathcal{D}} \left[L_\tau^2 \left(r(s_t, g) + \gamma V_{\bar{\theta}}(s_{t+1}, g)
V_\theta(s_t, g) \right) \right]. $
As in IQL, $L_\tau^2$ denotes the asymmetric expectile loss and $\gamma$ is the discount factor.
Policy extraction.
For both GCIQL and GCIVL, the policy $\pi_\theta(s_t, g)$ is trained via advantage-weighted regression (AWR). The policy objective is
$ \mathcal{L}{\pi} = \mathbb{E}{(s_t, a_t, g) \sim \mathcal{D}} \left[\exp\left(\beta A(s_t, a_t, g)\right) | \pi_\theta(s_t, g) - a_t |_2^2 \right], $
where the advantage is computed as
$ A(s_t, a_t, g) = r(s_t, g) + \gamma V(s_{t+1}, g) - V(s_t, g), $
and $\beta$ is an inverse temperature parameter controlling the strength of advantage weighting.
C.4 GCBC
As a simple imitation learning baseline, we consider Goal-Conditioned Behavioral Cloning (GCBC) [48]. GCBC trains a goal-conditioned policy $\pi_\theta(s_t, g)$ to reproduce expert actions given the current observation $s_t$ and a goal observation $g$. In our implementation, both observations and goals are encoded using DINOv2 patch embeddings before being provided to the policy network.
The policy is trained via supervised learning on an offline dataset $\mathcal{D}$ of state-action-goal tuples. Specifically, the objective minimizes the mean squared error between the predicted action and the action taken in the dataset:
$ \mathcal{L}{\text{GCBC}} = \mathbb{E}{(s_t, a_t, g) \sim \mathcal{D}} \left[| \pi_\theta(s_t, g) - a_t |_2^2 \right], $
where $s_t$ denotes the observation embedding, $g$ the goal embedding, and $a_t$ the corresponding expert action.
D. Implementation details
We apply a frame-skip of 5, grouping consecutive actions between frames into a single action block. This choice enables computationally efficient longer-horizon predictions while maintaining informative temporal transitions. We use a batch size of 128 with sub-trajectories of size 4 corresponding to 4 frames and 4 blocks of 5 actions. Each frame is $224\times224$ pixels. All the training scripts were made with stable-pretraining [49].
Encoder Architecture.
The encoder is a Vision Transformer Tiny (ViT-Tiny) model from the Hugging Face library, using a patch size of 14.
Predictor Architecture.
The predictor is implemented as a ViT-S backbone with learned positional embeddings and causal masking over the observation history. The history length is set to 3 for the PushT and OGBench-Cube environments, and to 1 for TwoRoom. During planning, the predictor is used autoregressively to generate rollouts of future latent states.
Decoder (Visualization Only).
For visualization, we decode the [CLS] token embedding (192 dim) from the last encoder layer into an image using a lightweight transformer decoder. The [CLS] representation is first projected to a hidden dimension and used as the key and value in cross-attention. A fixed set of learnable query tokens, one for each patch of the target image, interacts with this global representation through several cross-attention layers with residual MLP blocks. For an image of size $224\times224$ with patch size $16$, this corresponds to $P=(224/16)^2=196$ learnable query tokens. The resulting patch embeddings are then linearly projected to $16 \times 16 \times 3$ pixel patches and rearranged to produce a $224 \times 224$ RGB image. This decoder is used only as a diagnostic tool to visualize what visual information is retained in the [CLS] representation.
Planning solver.
For planning, we use the Cross-Entropy Method (CEM). At each planning step, CEM samples 300 candidate action sequences and optimizes them for a maximum of 30 iterations in PushT and 10 iterations in the other environments. At each iteration, the top 30 trajectories are retained to update the sampling distribution, and the initial sampling variance is set to 1. The planning horizon is set to 5 steps, which corresponds to 25 environment timesteps due to the use of a frame skip of 5. We employ a receding-horizon Model Predictive Control (MPC) scheme with a horizon of 5, meaning that the entire optimized action sequence is executed before replanning. This configuration follows the setup used in [18].
Implementation and hardware.
All experiments are implemented using the [50] framework. Training relies on the [49] library, while evaluation is performed using PyTorch [51] and Gymnasium [52]. Both training and planning were performed on a single NVIDIA L40S GPU.
E. Environment & Dataset
- TwoRoom is a simple continuous 2D navigation task introduced by [22]. The environment consists of two rooms separated by a wall with a single door connecting them. The agent (represented as a red dot) must navigate from a random starting position in one room to a randomly sampled target location in the other room, which requires passing through the door. We collect 10, 000 episodes with an average trajectory length of 92 steps. The data are generated using a simple noisy heuristic policy that first directs the agent toward the door along a straight-line path and then toward the target location once the agent has crossed into the other room. Each world model is trained on this dataset for 10 epochs.
- PushT is a continuous 2D manipulation task in which an agent (represented as a blue dot) must push a T-shaped block to match a target configuration, with interactions restricted to pushing actions. We follow the same setup and dataset as [18], which contains 20, 000 expert episodes with an average length of 196 steps. However, we train each world model for only 10 epochs. Empirically, we observe that 10 epochs are sufficient to reach the best performance, matching the results reported in the DINO-WM paper.
- OGBench-Cube is a continuous 3D robotic manipulation task in which a robotic arm with an end-effector must pick up a cube and place it at a target location. Originally introduced by [47], we consider only the single-cube variant. We collect 10, 000 episodes, each consisting of 200 steps. The data are generated using the data-collection heuristic provided in the benchmark library. Each world model is trained on this dataset for 10 epochs.
- Reacher is a continuous control environment from the DeepMind Control Suite [53]. The task consists of controlling a two-joint robotic arm to reach a target location in a 2D plane. Following the setup used in DINO-WM, we consider the variant where success is defined by the perfect alignment of the arm joints with the target configuration required to reach the goal position. We train each world model for 10 epochs on a dataset of 10, 000 episodes, each with 200 steps. The data are collected using a Soft Actor-Critic policy.
F. Evaluation Details
:::: {cols="1"}
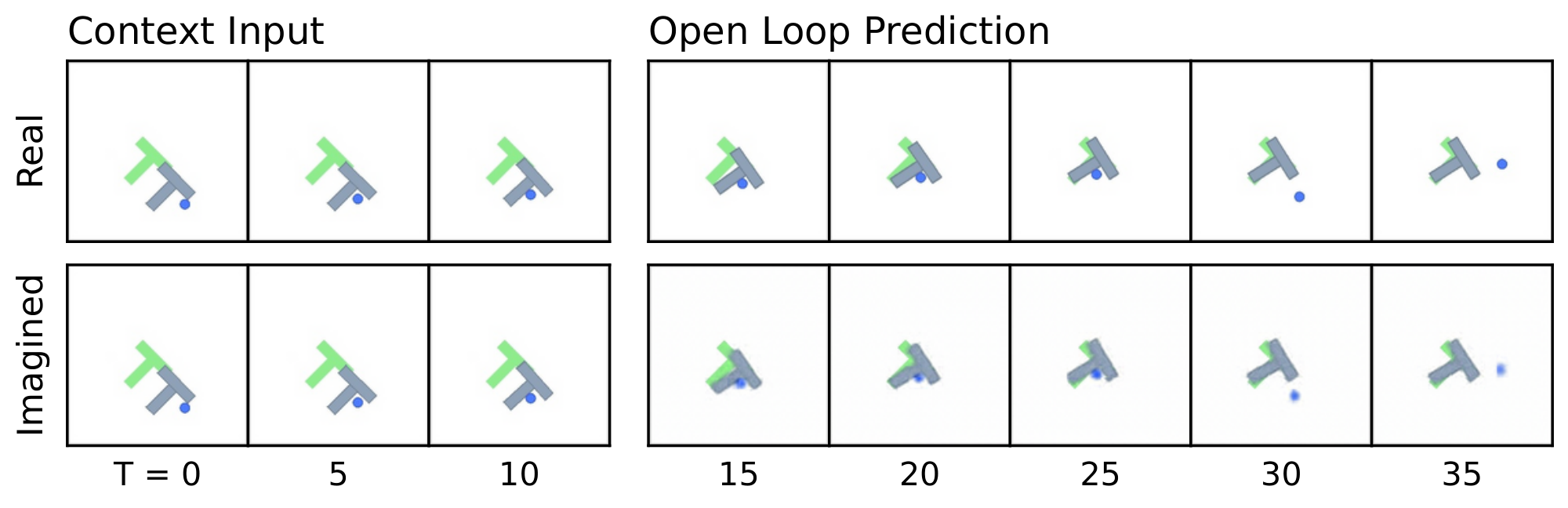
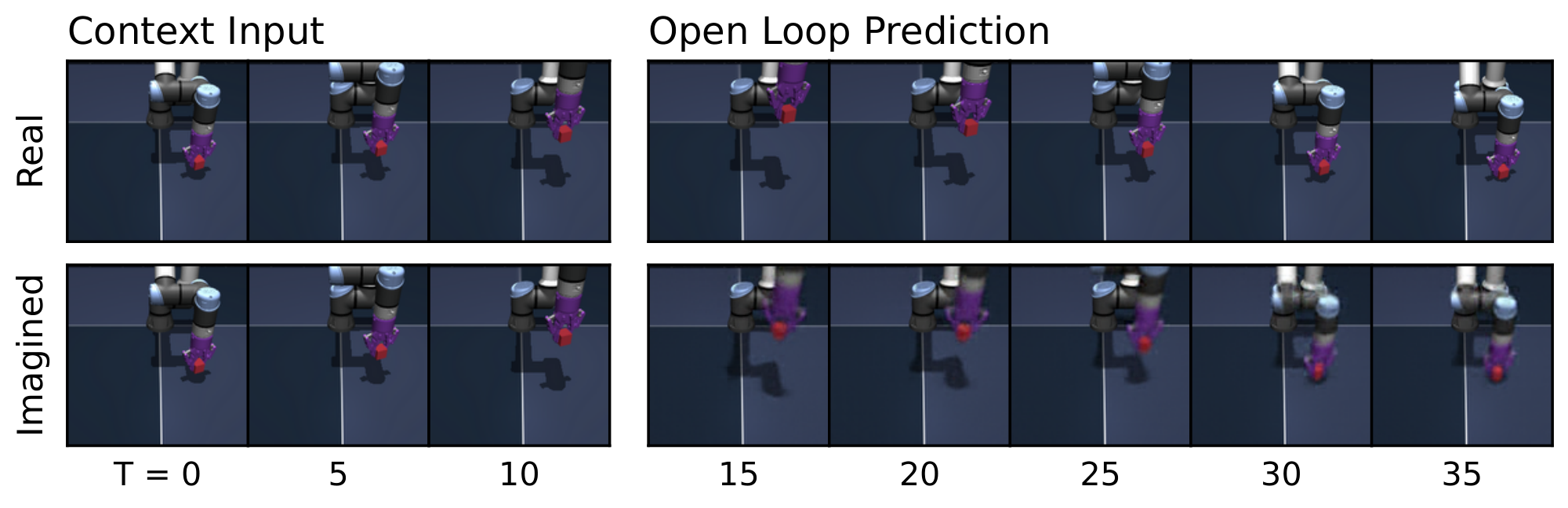
Figure 15: Additional predictor rollouts on PushT (top) and OGBench-Cube (bottom). Same setup as Figure 8: three context frames are encoded into latent representations, and the predictor autoregressively generates future latent states conditioned on the action sequence. All predictions are decoded using a decoder not used during training. On PushT, the imagined trajectory closely tracks the real one, accurately capturing both agent and block motion. On OGBench-Cube, the model preserves the overall scene layout and cube displacement but loses finer details such as end-effector orientation at longer horizons, consistent with the lower probing accuracy on rotational quantities reported in Table 4. ::::
F.1 Control
We evaluate LeWM on goal-conditioned control tasks in the three environments introduced previously. Control performance is measured using two parameters: the evaluation budget and the distance to the goal. The evaluation budget corresponds to the maximum number of actions the agent is allowed to execute in the environment. The goal distance determines how far in the future the goal state is sampled relative to the initial state. During evaluation, trajectories are sampled from the offline dataset. The initial state is chosen by randomly sampling a state from a trajectory in the dataset, while the goal state corresponds to a state occurring several timesteps later in the same trajectory. This ensures that the goal is reachable and consistent with the dataset dynamics. In TwoRoom, the evaluation budget is set to 150 steps and the goal state is sampled 100 timesteps in the future. In PushT, the evaluation budget is 50 steps and the goal is sampled 25 timesteps in the future. In OGBench-Cube and Reacher, the evaluation budget is 50 steps, and the goal is sampled 25 timesteps in the future.
F.2 Probing
We use probing to analyze the information contained in the learned latent representations across the three environments. Specifically, we train both linear and non-linear probes to predict physical quantities from the latent embeddings. Linear probes evaluate whether the information is linearly accessible in the latent space, while non-linear probes assess whether the information is present but potentially entangled.
For each probe, we report the mean squared error (MSE) and the Pearson correlation coefficient between the predicted and ground-truth quantities.
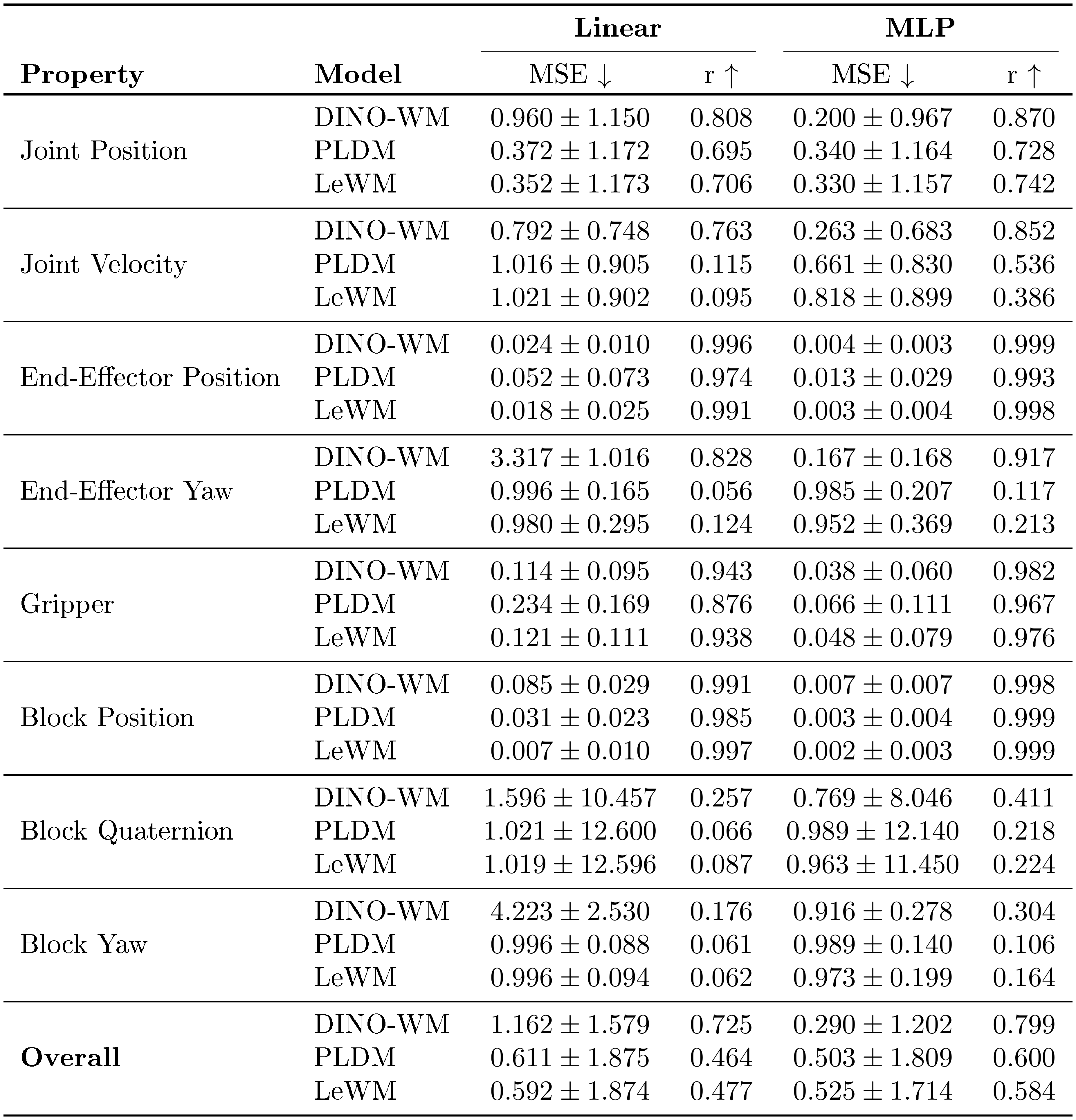
The probed variables differ across environments. In TwoRoom, we probe the 2D position of the agent (Table 3). In PushT, we probe both the state of the agent and the state of the block (Table 1). In OGBench-Cube, we probe the position of the cube and the position of the robot end-effector (Table 4).
::: {caption="Table 3: Physical Latent Probing results on TwoRoom. Although LeWM underperforms PLDM in downstream planning on this environment, it matches or outperforms PLDM across all probing metrics, and both methods substantially outperform DINO-WM on the linear probe. This suggests that the learned latent space captures the underlying physical state equally well and that the planning gap is not due to a less informative representation but rather to other factors such as the dynamics model or the planning procedure itself."}
:::
::: {caption="Table 4: Physical latent probing results on OGBench-Cube. LeWM matches or outperforms PLDM on most properties and achieves the best results on positional quantities such as block position and end-effector position. DINO-WM retains a clear advantage on dynamic and rotational properties (joint velocity, end-effector yaw), likely because such quantities benefit from the richer visual priors learned during large-scale pretraining. All three methods struggle to recover block orientation (quaternion and yaw), suggesting that fine-grained rotational information remains difficult to encode in compact latent spaces regardless of the training strategy."}
:::
F.3 Violation-of-expectation
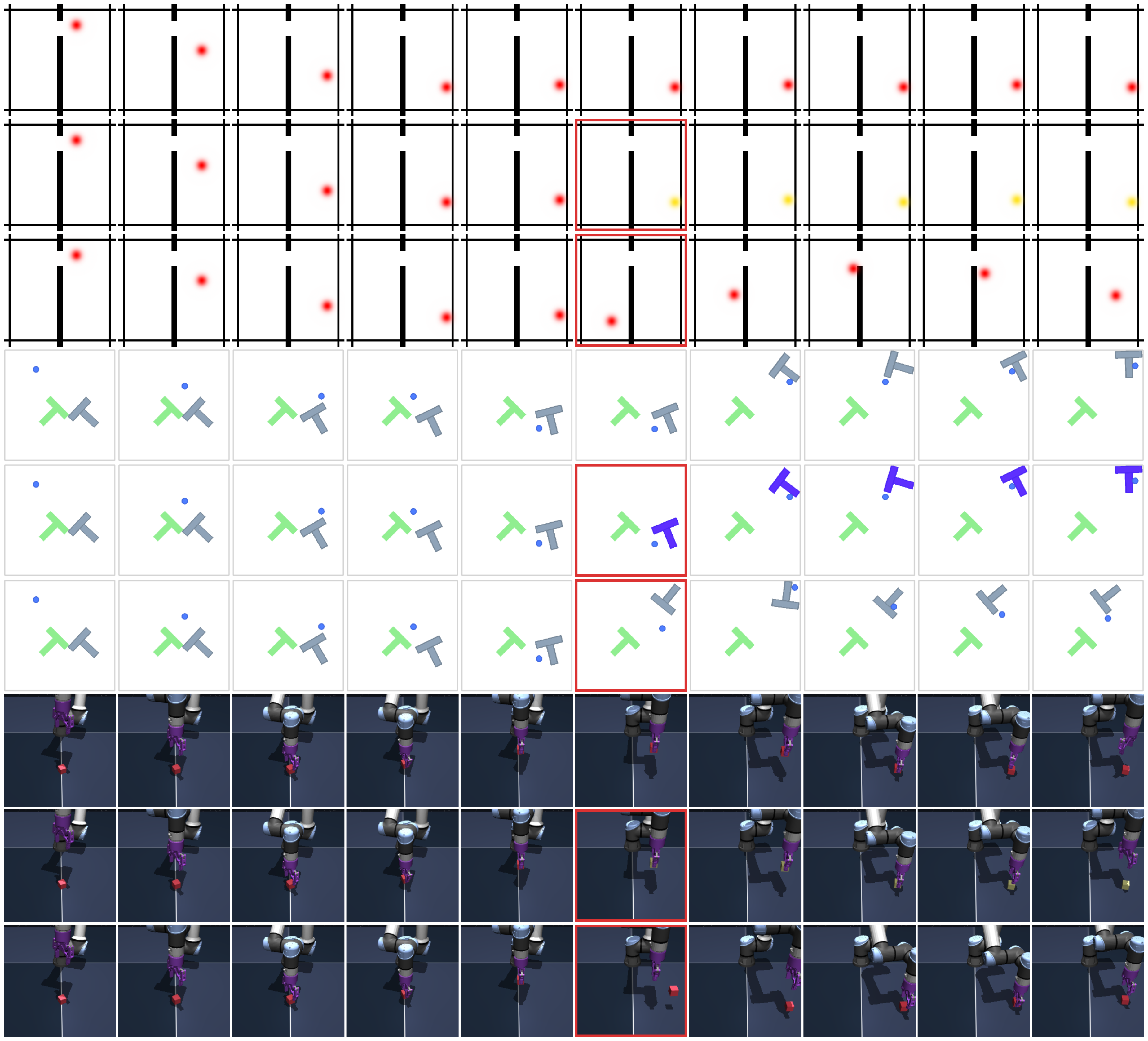
We evaluate physical understanding using the violation-of-expectation (VoE) framework across three environments. In each environment, we generate three types of trajectories: an unperturbed reference trajectory, a trajectory containing a visual perturbation, and a trajectory containing a physical perturbation. Visual perturbations correspond to abrupt color changes of an object, while physical perturbations correspond to teleporting objects to random positions, thereby violating physical continuity. Examples of trajectories are shown in Figure 19.
TwoRoom.
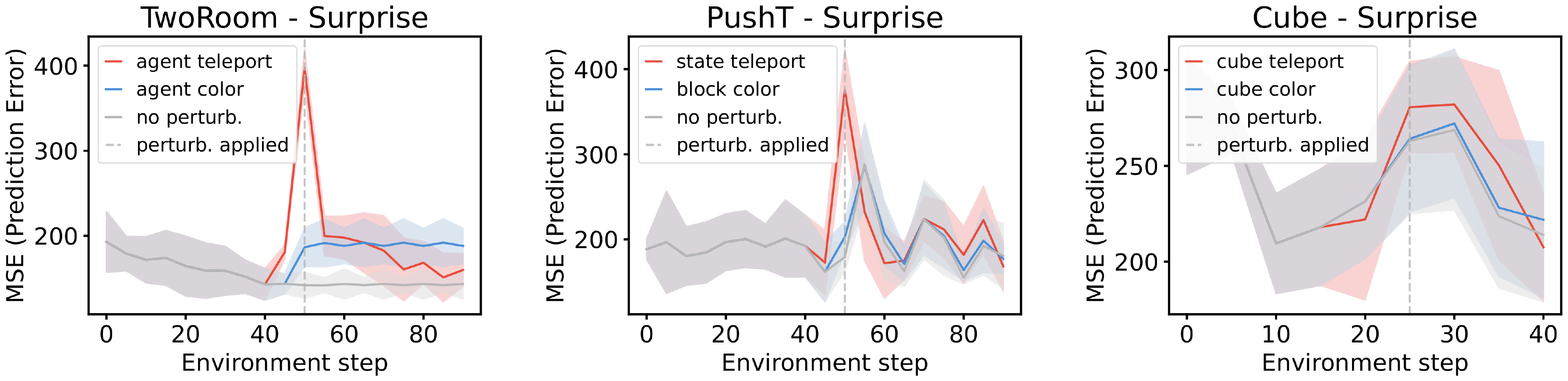
In the TwoRoom environment, the agent is controlled by an expert policy that navigates toward a goal position. We generate three trajectories: (1) an unperturbed trajectory, (2) a trajectory where the color of the agent changes midway through the episode, and (3) a trajectory where the agent is teleported to a random position at the same timestep. The resulting surprise signals for PLDM and DINO-WM are shown in the left panels of Figure 20 and Figure 21, respectively.
PushT.
In the PushT environment, the agent is controlled by a random policy biased toward interacting with the block. As before, we construct three trajectories: (1) an unperturbed trajectory, (2) a trajectory where the color of the block changes abruptly during the episode, and (3) a trajectory where both the agent and the block are teleported to random positions at the perturbation timestep. The corresponding surprise signals for PLDM and DINO-WM are shown in the center panels of Figure 20 and Figure 21.
OGBench-Cube.
In the OGBench-Cube environment, the agent follows an expert policy that picks up the cube and places it at a target position. We again consider three trajectories: (1) an unperturbed trajectory, (2) a trajectory where the cube's color changes during the episode, and (3) a trajectory where the cube is teleported to a random position midway through the trajectory. The resulting surprise signals for PLDM and DINO-WM are shown in the right panels of Figure 20 and Figure 21.
G. Ablations.
Training variance.
To assess the stability of training, we retrain the model using multiple random seeds. As shown in Table 5, the resulting performance exhibits consistently high success rates with low variance across runs, indicating that the training procedure is stable and reproducible.
::: {caption="Table 5: Training Variance. We report the mean success rate across three training seeds and the corresponding variance, evaluated over the same set of 50 trajectories on Push-T. The goal configuration is reachable within 25 steps, and we allow a planning budget of 50 steps. PLDM exhibits higher variance compared to DINO-WM and LeWM."}
:::
Embedding dimensions.
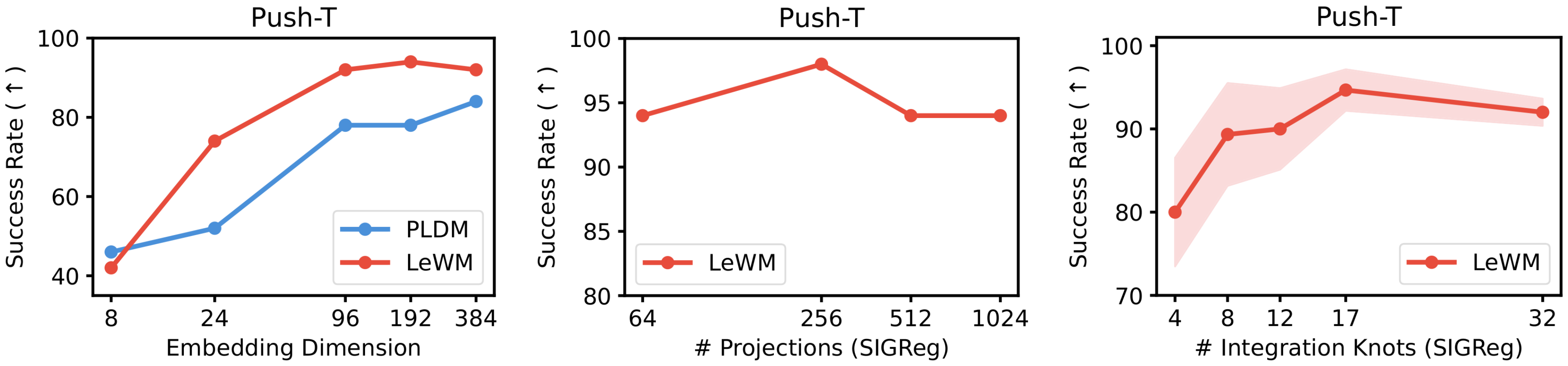
We study the impact of the embedding dimensionality on performance. As shown in Figure 22, performance drops when the embedding dimension falls below a certain threshold (around 184), while increasing the dimension beyond this value yields diminishing returns and leads to performance saturation.
Number of projections in SIGReg.
We study the impact of the number of projections used in SIGReg. As shown in Figure 22, varying the number of projections has little effect on performance in downstream control tasks. This suggests that the method is largely insensitive to this hyperparameter, and therefore it does not require careful tuning. In practice, this leaves $\lambda$ as the only effective hyperparameter to optimize.
Weight of SIGReg regularization.
We analyze the effect of the SIGReg regularization weight $\lambda$. As shown in Figure 23, the method achieves high performance across a wide range of values for $\lambda$. In particular, for $\lambda \in [0.01, 0.2]$, the success rate remains above 80%. This indicates that the approach is robust to the choice of this parameter. Moreover, since $\lambda$ is the only effective hyperparameter, it can be tuned efficiently, for instance via a simple bisection search.
![**Figure 23:** **Effect of the SIGReg regularization weight $\lambda$ on Push-T planning performance.** Success rate remains above 80% across a wide range of values ($\lambda \in [0.01, 0.2]$), peaking near $\lambda = 0.09$. Performance degrades sharply only at $\lambda = 0.5$, where the regularizer dominates the prediction loss and hinders dynamics modeling. Since $\lambda$ is the only effective hyperparameter of LeWM, the SIGReg loss coefficient is easy to tune via a simple bisection search.](https://ittowtnkqtyixxjxrhou.supabase.co/storage/v1/object/public/public-images/prkjvwsw/lambda.png)
Predictor Size.
We analyze the effect of the predictor size on performance. As shown in Table 6, the best results are obtained with a ViT-S predictor. Reducing the predictor to a ViT-T model leads to a drop in performance, while increasing the size to ViT-B does not provide additional gains and slightly degrades performance. This suggests that ViT-S offers the best trade-off between model capacity and optimization stability for this task.
::: {caption="Table 6: Effect of the predictor size on planning performance in the Push-T environment. We report the success rate (SR). The ViT-S predictor achieves the best performance."}
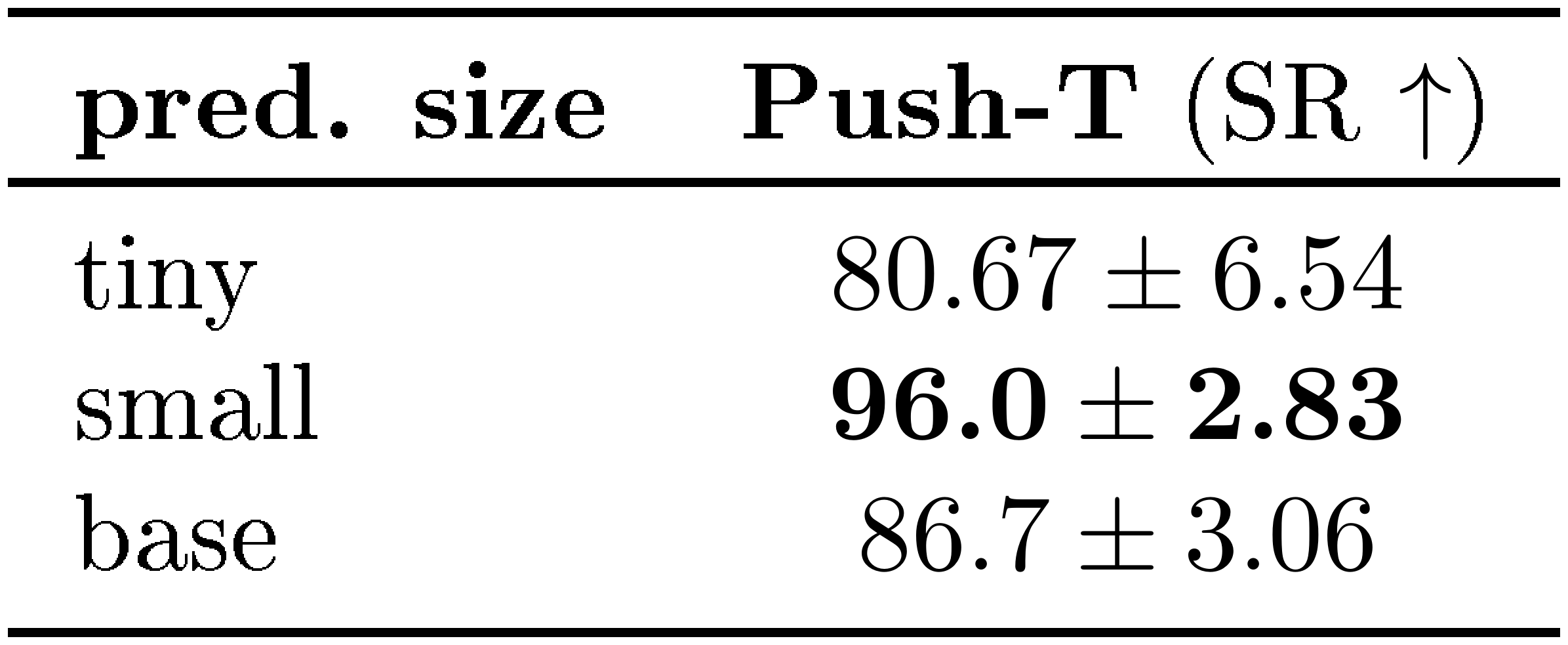
:::
Decoder.
We study the impact of adding a reconstruction loss during training. As shown in Table 7, incorporating a decoder and a reconstruction objective does not improve downstream control performance. In fact, performance slightly decreases compared to the model trained without a decoder. This suggests that the JEPA training objective already captures the information necessary for planning, while the reconstruction loss may encourage the model to encode additional visual details that are not relevant for control.
::: {caption="Table 7: Effect of adding a reconstruction loss during training. We report the success rate (SR) on the Push-T planning task. The model trained without the decoder loss achieves higher performance."}
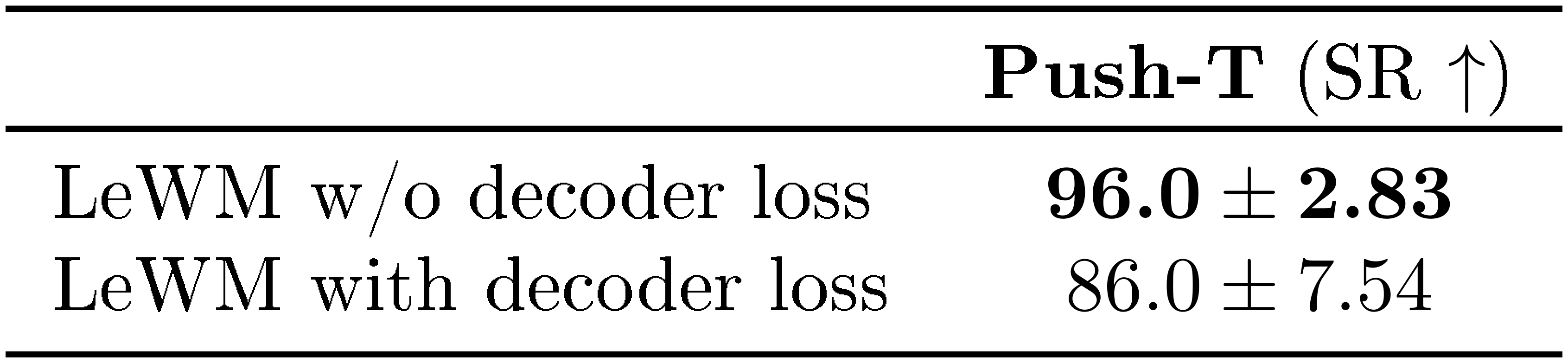
:::
Architecture.
We study the impact of encoder architecture on LeWM performance by replacing the ViT encoder with a ResNet-18 backbone. As shown in Table 8, LeWM achieves competitive performance with both architectures, suggesting that it is agnostic to the choice of vision encoder used during training, though ViT retains a modest advantage.
:Table 8: Encoder Architecture Effect. We report the success rate (SR) on the Push-T planning task. LeWM achieves competitive performance across encoder architectures, with ViT holding a slight edge.
| Push-T (SR $\uparrow$) | |
|---|---|
| LeWM ViT | $\bm{96.0} \pm \bm{2.83}$ |
| LeWM ResNet-18 | $94.0 \pm 3.27$ |
Predictor Dropout.
We analyze the effect of applying dropout in the predictor during training. As shown in Table 9, introducing a small amount of dropout significantly improves downstream control performance. In particular, a dropout rate of $0.1$ achieves the highest success rate, while both lower and higher values lead to worse performance. This suggests that moderate dropout helps regularize the predictor and improves generalization, whereas excessive dropout degrades the quality of the learned dynamics.
::: {caption="Table 9: Effect of predictor dropout during training on Push-T planning performance. We report the success rate (SR). A small amount of dropout ($p=0.1$) yields the best results."}

:::
H. Temporal Latent Path Straightening.
The temporal straightening hypothesis, introduced by [42], posits that we represent complex temporal dynamics as smooth, approximately straight trajectories in our representation spaces. This principle has since found applications beyond neuroscience: [54] leverage temporal straightness measured from DINOv2 features to discriminate AI-generated videos from real ones, demonstrating that this geometric property carries a meaningful signal about the nature of the underlying dynamics, and [55] shows it can be beneficial for planning.
During training on PushT, we record, for curiosity, the temporal straightness of LeWM's latent trajectories. Given a sequence of latent embeddings $\mathbf{z}_{1:T} \in \mathbb{R}^{B \times T \times D}$, we define the temporal velocity vectors as $\mathbf{v}t = \mathbf{z}{t+1} - \mathbf{z}_t$. The path straightening measure is defined as the mean pairwise cosine similarity between consecutive velocities:
$ \mathcal{S}{\text{straight}} = \frac{1}{B(T-2)} \sum{i=1}^{B} \sum_{t=1}^{T-2} \frac{\langle \mathbf{v}t^{(i)}, , \mathbf{v}{t+1}^{(i)} \rangle}{|\mathbf{v}t^{(i)}| , |\mathbf{v}{t+1}^{(i)}|}.\tag{5} $
A value of $\mathcal{S}_{\text{straight}}$ close to $1$ indicates that consecutive velocities are nearly collinear, meaning the latent trajectory approaches a straight line. Interestingly, we observe that temporal straightening emerges naturally over the course of training without any training term explicitly encouraging it (Figure 24).
We hypothesize that this emerges because SIGReg is applied independently at each time step but not across the temporal dimension, leaving the temporal structure unconstrained. This allows the encoder to converge toward a form of temporal collapse, where successive embeddings evolve along increasingly linear paths. Rather than being detrimental, this implicit bias appears to benefit downstream performance, as shown in Figure 7. Notably, LeWM achieves higher temporal straightness than PLDM despite having no explicit regularizer encouraging it, whereas PLDM employs a regularizer on consecutive latent states that directly promotes temporal smoothness.
I. Training Curves
We visualize several training curves comparing the optimization dynamics of LeWM (Figure 25) and PLDM (Figure 26). In contrast to PLDM, whose objective contains multiple regularization terms, LeWM uses a single regularization term in addition to the prediction loss, making the training dynamics easier to interpret and analyze.
References
[1] Levine et al. (2016). End-to-end training of deep visuomotor policies. Journal of Machine Learning Research. 17(39). pp. 1–40.
[2] Ha, David and Schmidhuber, Jürgen (2018). World models. arXiv preprint arXiv:1803.10122. 2(3).
[3] Vincent Micheli et al. (2023). Transformers are Sample-Efficient World Models. In The Eleventh International Conference on Learning Representations. https://openreview.net/forum?id=vhFu1Acb0xb.
[4] Danijar Hafner et al. (2025). Training Agents Inside of Scalable World Models. https://arxiv.org/abs/2509.24527. arXiv:2509.24527.
[5] LeCun, Yann (2022). A path towards autonomous machine intelligence version 0.9. 2, 2022-06-27. Open Review. 62(1). pp. 1–62.
[6] Eloi Alonso et al. (2024). Diffusion for World Modeling: Visual Details Matter in Atari. In The Thirty-eighth Annual Conference on Neural Information Processing Systems. https://openreview.net/forum?id=NadTwTODgC.
[7] Vincent Micheli et al. (2024). Efficient World Models with Context-Aware Tokenization. In Forty-first International Conference on Machine Learning. https://openreview.net/forum?id=BiWIERWBFX.
[8] Decart et al. (2024). Oasis: A Universe in a Transformer. https://oasis-model.github.io/.
[9] Jake Bruce et al. (2024). Genie: Generative Interactive Environments. https://arxiv.org/abs/2402.15391. arXiv:2402.15391.
[10] Team HunyuanWorld (2025). HunyuanWorld 1.0: Generating Immersive, Explorable, and Interactive 3D Worlds from Words or Pixels. arXiv preprint.
[11] Julian Quevedo et al. (2025). WorldGym: World Model as An Environment for Policy Evaluation. https://arxiv.org/abs/2506.00613. arXiv:2506.00613.
[12] Assran et al. (2023). Self-supervised learning from images with a joint-embedding predictive architecture. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 15619–15629.
[13] Bardes et al. (2023). V-jepa: Latent video prediction for visual representation learning.
[14] Assran et al. (2025). V-jepa 2: Self-supervised video models enable understanding, prediction and planning. arXiv preprint arXiv:2506.09985.
[15] Zijian Dong et al. (2024). Brain-JEPA: Brain Dynamics Foundation Model with Gradient Positioning and Spatiotemporal Masking. In The Thirty-eighth Annual Conference on Neural Information Processing Systems. https://openreview.net/forum?id=gtU2eLSAmO.
[16] Alif Munim et al. (2026). EchoJEPA: A Latent Predictive Foundation Model for Echocardiography. https://arxiv.org/abs/2602.02603. arXiv:2602.02603.
[17] Jean Ponce et al. (2026). Dual Perspectives on Non-Contrastive Self-Supervised Learning. In The Fourteenth International Conference on Learning Representations. https://openreview.net/forum?id=f5MC1G6XhB.
[18] Zhou et al. (2025). DINO-WM: World Models on Pre-trained Visual Features enable Zero-shot Planning. In Proceedings of the 42nd International Conference on Machine Learning (ICML 2025).
[19] Raktim Gautam Goswami et al. (2025). OSVI-WM: One-Shot Visual Imitation for Unseen Tasks using World-Model-Guided Trajectory Generation. https://arxiv.org/abs/2505.20425. arXiv:2505.20425.
[20] Heejeong Nam et al. (2026). Causal-JEPA: Learning World Models through Object-Level Latent Interventions. https://arxiv.org/abs/2602.11389. arXiv:2602.11389.
[21] Vlad Sobal et al. (2022). Joint Embedding Predictive Architectures Focus on Slow Features. https://arxiv.org/abs/2211.10831. arXiv:2211.10831.
[22] Vlad Sobal et al. (2025). Stress-Testing Offline Reward-Free Reinforcement Learning: A Case for Planning with Latent Dynamics Models. In 7th Robot Learning Workshop: Towards Robots with Human-Level Abilities. https://openreview.net/forum?id=jON7H6A9UU.
[23] Adrien Bardes et al. (2022). VICReg: Variance-Invariance-Covariance Regularization for Self-Supervised Learning. In International Conference on Learning Representations. https://openreview.net/forum?id=xm6YD62D1Ub.
[24] Balestriero, Randall and LeCun, Yann (2022). Contrastive and non-contrastive self-supervised learning recover global and local spectral embedding methods. Advances in Neural Information Processing Systems. 35. pp. 26671–26685.
[25] Randall Balestriero and Yann LeCun (2025). LeJEPA: Provable and Scalable Self-Supervised Learning Without the Heuristics. https://arxiv.org/abs/2511.08544. arXiv:2511.08544.
[26] Ha, David and Schmidhuber, Jürgen (2018). Recurrent world models facilitate policy evolution. Advances in neural information processing systems. 31.
[27] Danijar Hafner et al. (2020). Dream to Control: Learning Behaviors by Latent Imagination. In International Conference on Learning Representations. https://openreview.net/forum?id=S1lOTC4tDS.
[28] Hafner et al. (2020). Mastering Atari with Discrete World Models. arXiv preprint arXiv:2010.02193.
[29] Hafner et al. (2023). Mastering Diverse Domains through World Models. arXiv preprint arXiv:2301.04104.
[30] Testud et al. (1978). Model predictive heuristic control: Applications to industial processes. Automatica. 14(5). pp. 413–428.
[31] Nicklas Hansen et al. (2022). Temporal Difference Learning for Model Predictive Control. In International Conference on Machine Learning (ICML).
[32] Nicklas Hansen et al. (2024). TD-MPC2: Scalable, Robust World Models for Continuous Control. In The Twelfth International Conference on Learning Representations. https://openreview.net/forum?id=Oxh5CstDJU.
[33] Amir Bar et al. (2025). Navigation World Models. https://arxiv.org/abs/2412.03572. arXiv:2412.03572.
[34] Dosovitskiy, Alexey (2020). An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929.
[35] Sergey Ioffe and Christian Szegedy (2015). Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. https://arxiv.org/abs/1502.03167. arXiv:1502.03167.
[36] Ba et al. (2016). Layer normalization. arXiv preprint arXiv:1607.06450.
[37] Peebles, William and Xie, Saining (2023). Scalable diffusion models with transformers. In Proceedings of the IEEE/CVF international conference on computer vision. pp. 4195–4205.
[38] Epps, Thomas W and Pulley, Lawrence B (1983). A test for normality based on the empirical characteristic function. Biometrika. 70(3). pp. 723–726.
[39] Cramér, Harald and Wold, Herman (1936). Some theorems on distribution functions. Journal of the London Mathematical Society. 1(4). pp. 290–294.
[40] Rubinstein, Reuven Y and Kroese, Dirk P (2004). The cross-entropy method: a unified approach to combinatorial optimization, Monte-Carlo simulation and machine learning. Springer Science & Business Media.
[41] Maxime Oquab et al. (2024). DINOv2: Learning Robust Visual Features without Supervision. Transactions on Machine Learning Research. https://openreview.net/forum?id=a68SUt6zFt.
[42] Hénaff et al. (2019). Perceptual straightening of natural videos. Nature neuroscience. 22(6). pp. 984–991.
[43] Margoni et al. (2024). The violation-of-expectation paradigm: A conceptual overview.. Psychological Review. 131(3). pp. 716.
[44] Garrido et al. (2025). Intuitive physics understanding emerges from self-supervised pretraining on natural videos. arXiv preprint arXiv:2502.11831.
[45] Florian Bordes et al. (2025). IntPhys 2: Benchmarking Intuitive Physics Understanding In Complex Synthetic Environments. https://arxiv.org/abs/2506.09849. arXiv:2506.09849.
[46] Kostrikov et al. (2021). Offline reinforcement learning with implicit q-learning. arXiv preprint arXiv:2110.06169.
[47] Seohong Park et al. (2025). OGBench: Benchmarking Offline Goal-Conditioned RL. In The Thirteenth International Conference on Learning Representations. https://openreview.net/forum?id=M992mjgKzI.
[48] Ghosh et al. (2019). Learning to reach goals via iterated supervised learning. arXiv preprint arXiv:1912.06088.
[49] Randall Balestriero et al. (2025). stable-pretraining-v1: Foundation Model Research Made Simple. https://arxiv.org/abs/2511.19484. arXiv:2511.19484.
[50] Lucas Maes et al. (2026). stable-worldmodel-v1: Reproducible World Modeling Research and Evaluation. https://arxiv.org/abs/2602.08968. arXiv:2602.08968.
[51] Adam Paszke et al. (2019). PyTorch: An Imperative Style, High-Performance Deep Learning Library. https://arxiv.org/abs/1912.01703. arXiv:1912.01703.
[52] Towers et al. (2024). Gymnasium: A Standard Interface for Reinforcement Learning Environments. arXiv preprint arXiv:2407.17032.
[53] Tassa et al. (2018). Deepmind control suite. arXiv preprint arXiv:1801.00690.
[54] Christian Internò et al. (2025). AI-Generated Video Detection via Perceptual Straightening. In The Thirty-ninth Annual Conference on Neural Information Processing Systems. https://openreview.net/forum?id=LsmUgStXby.
[55] Wang et al. (2026). Temporal Straightening for Latent Planning. arXiv preprint arXiv:2603.12231.