Prioritized Experience Replay
Tom Schaul, John Quan, Ioannis Antonoglou and David Silver
Google DeepMind
{schaul,johnquan,ioannisa,davidsilver}@google.com
Abstract
Experience replay lets online reinforcement learning agents remember and reuse experiences from the past. In prior work, experience transitions were uniformly sampled from a replay memory. However, this approach simply replays transitions at the same frequency that they were originally experienced, regardless of their significance. In this paper we develop a framework for prioritizing experience, so as to replay important transitions more frequently, and therefore learn more efficiently. We use prioritized experience replay in Deep Q-Networks (DQN), a reinforcement learning algorithm that achieved human-level performance across many Atari games. DQN with prioritized experience replay achieves a new state-of-the-art, outperforming DQN with uniform replay on 41 out of 49 games.
Executive Summary: Reinforcement learning (RL) systems, which train artificial agents to make decisions by trial and error, often face challenges in environments with sparse rewards or rare useful events, such as navigating complex games. Traditional RL agents using experience replay store past interactions and reuse them randomly, but this treats all experiences equally, ignoring their potential value. This inefficiency slows learning and limits performance, especially as RL scales to real-world applications like robotics or game AI, where gathering data is costly.
This paper aimed to evaluate a new approach called prioritized experience replay, which selects past experiences for reuse based on their likely contribution to learning, and to demonstrate its impact on RL efficiency.
The authors built on Deep Q-Networks (DQN), an RL method that previously reached human-level play on Atari 2600 video games. They modified DQN's replay mechanism to prioritize experiences using the temporal-difference (TD) error—a measure of prediction surprise. Two variants were developed: one proportional to error magnitude and another rank-based to handle outliers. To address biases from non-uniform sampling, they applied importance sampling corrections that anneal over time. Experiments used a replay memory holding the last 1 million transitions from 49 to 57 Atari games, with training over 200 million frames per game. They compared results to uniform replay baselines, including the prior state-of-the-art Double DQN, across single runs without game-specific tuning.
The key findings show prioritized replay substantially boosts performance. First, it outperformed uniform replay on 41 of 49 games, raising the median score from 48% to 106% of human level when added to original DQN. Second, combined with Double DQN, it set a new state-of-the-art, increasing the median score from 111% to 128% across 57 games and the mean from 418% to 551%, with gains on hard games like River Raid and Seaquest reaching human parity for the first time. Third, learning speed doubled, with agents matching baseline performance in 38-47% less training time. Fourth, both prioritization variants were robust and complementary to other DQN improvements, though proportional prioritization edged out in some games and rank-based in others. Finally, a simple test on imbalanced supervised learning (digit classification) confirmed the method's broader potential, nearly closing the performance gap without prior knowledge of imbalances.
These results mean RL agents can learn more from limited data by focusing on informative experiences, reducing reliance on expensive interactions with environments. This lowers costs and risks in applications like autonomous systems, where rare events (e.g., collisions) must be handled efficiently. Unlike expectations of uniform replay's sufficiency, prioritization reveals untapped efficiency, especially in sparse-reward settings, and aligns with neuroscience evidence of selective memory replay. It does not overhaul DQN but enhances it, suggesting synergies with future RL advances.
Adopt prioritized experience replay in DQN-based systems for faster convergence and higher scores, starting with the rank-based variant for its robustness to noise. For implementation, reduce the learning rate by a factor of four and tune prioritization strength (alpha around 0.6-0.7). Next, integrate it with exploration strategies using replay counts as feedback signals, and test on non-Atari domains like robotics. If off-policy data is available, hybridize with importance ratios for further gains. A pilot on a target task would validate transferability.
Limitations include reliance on fixed replay memory contents (storage decisions were not optimized) and focus on near-deterministic environments; noisy or partially observable settings may need adjusted prioritization proxies. Confidence is high for Atari-scale RL, with consistent speed-ups across diverse games, but caution applies to vastly different tasks without additional validation.
1 Introduction
Section Summary: Online reinforcement learning agents learn by updating their strategies from a continuous flow of experiences, but basic methods often discard data after one use, leading to unreliable updates from correlated information and loss of valuable rare events. Experience replay solves this by storing past experiences in memory and randomly sampling them for repeated use, as shown in the Deep Q-Network, which stabilized deep neural network training and made learning more efficient by swapping scarce real-world interactions for extra computation and storage. This paper advances the idea by prioritizing replay of experiences that promise the most learning progress, based on their surprise or error levels, using techniques to maintain variety and correct biases, resulting in quicker and top-performing results on classic video games like Atari.
Online reinforcement learning (RL) agents incrementally update their parameters (of the policy, value function or model) while they observe a stream of experience. In their simplest form, they discard incoming data immediately, after a single update. Two issues with this are (a) strongly correlated updates that break the i.i.d. assumption of many popular stochastic gradient-based algorithms, and (b) the rapid forgetting of possibly rare experiences that would be useful later on.
Experience replay ([1]) addresses both of these issues: with experience stored in a replay memory, it becomes possible to break the temporal correlations by mixing more and less recent experience for the updates, and rare experience will be used for more than just a single update. This was demonstrated in the Deep Q-Network (DQN) algorithm ([2, 3]), which stabilized the training of a value function, represented by a deep neural network, by using experience replay. Specifically, DQN used a large sliding window replay memory, sampled from it uniformly at random, and revisited each transition [^1] eight times on average. In general, experience replay can reduce the amount of experience required to learn, and replace it with more computation and more memory – which are often cheaper resources than the RL agent's interactions with its environment.
[^1]: A transition is the atomic unit of interaction in RL, in our case a tuple of (state $S_{t-1}$, action $A_{t-1}$, reward $R_{t}$, discount $\gamma_{t}$, next state $S_{t}$). We choose this for simplicity, but most of the arguments in this paper also hold for a coarser ways of chunking experience, e.g. into sequences or episodes.
In this paper, we investigate how prioritizing which transitions are replayed can make experience replay more efficient and effective than if all transitions are replayed uniformly. The key idea is that an RL agent can learn more effectively from some transitions than from others. Transitions may be more or less surprising, redundant, or task-relevant. Some transitions may not be immediately useful to the agent, but might become so when the agent competence increases ([4]). Experience replay liberates online learning agents from processing transitions in the exact order they are experienced. Prioritized replay further liberates agents from considering transitions with the same frequency that they are experienced.
In particular, we propose to more frequently replay transitions with high expected learning progress, as measured by the magnitude of their temporal-difference (TD) error. This prioritization can lead to a loss of diversity, which we alleviate with stochastic prioritization, and introduce bias, which we correct with importance sampling. Our resulting algorithms are robust and scalable, which we demonstrate on the Atari 2600 benchmark suite, where we obtain faster learning and state-of-the-art performance.
2 Background
Section Summary: Neuroscience research shows that rodents' brains replay past experiences in the hippocampus, especially those linked to rewards or significant surprises, during rest or sleep. In reinforcement learning, techniques like prioritized sweeping use prediction errors to focus updates efficiently, and similar ideas have guided exploration, feature selection, and handling unbalanced data in machine learning, as seen in methods for replaying experiences based on errors or rewards. For Atari games, deep reinforcement learning approaches such as deep Q-networks and Double DQN represent the leading methods, with recent innovations also boosting performance.
Numerous neuroscience studies have identified evidence of experience replay in the hippocampus of rodents, suggesting that sequences of prior experience are replayed, either during awake resting or sleep. Sequences associated with rewards appear to be replayed more frequently ([5, 6, 7]). Experiences with high magnitude TD error also appear to be replayed more often ([8, 9]).
It is well-known that planning algorithms such as value iteration can be made more efficient by prioritizing updates in an appropriate order. Prioritized sweeping ([10, 11]) selects which state to update next, prioritized according to the change in value, if that update was executed. The TD error provides one way to measure these priorities ([12]). Our approach uses a similar prioritization method, but for model-free RL rather than model-based planning. Furthermore, we use a stochastic prioritization that is more robust when learning a function approximator from samples.
TD-errors have also been used as a prioritization mechanism for determining where to focus resources, for example when choosing where to explore ([13]) or which features to select ([14, 15]).
In supervised learning, there are numerous techniques to deal with imbalanced datasets when class identities are known, including re-sampling, under-sampling and over-sampling techniques, possibly combined with ensemble methods (for a review, see [16]). A recent paper introduced a form of re-sampling in the context of deep RL with experience replay ([17]); the method separates experience into two buckets, one for positive and one for negative rewards, and then picks a fixed fraction from each to replay. This is only applicable in domains that (unlike ours) have a natural notion of 'positive/negative' experience. Furthermore, [18] introduced a form of non-uniform sampling based on error, with an importance sampling correction, which led to a 3x speed-up on MNIST digit classification.
There have been several proposed methods for playing Atari with deep reinforcement learning, including deep Q-networks (DQN) ([2, 3, 19, 20, 21, 22]), and the Double DQN algorithm ([23]), which is the current published state-of-the-art. Simultaneously with our work, an architectural innovation that separates advantages from the value function (see the co-submission by [24]) has also led to substantial improvements on the Atari benchmark.
3 Prioritized Replay
Section Summary: This section explores how to make better use of stored experiences in reinforcement learning by prioritizing which ones to replay for training, rather than picking them randomly, to speed up learning in challenging environments. It uses a simple example called the "Blind Cliffwalk," where rewards are extremely rare and hidden among many failures, showing that random replay takes exponentially longer than smart selection, like using an ideal "oracle" that picks the most helpful experiences. The proposed solution prioritizes based on the TD error—a measure of how surprising or informative an experience is—which dramatically reduces the number of steps needed to learn effectively, as demonstrated in experiments.
Using a replay memory leads to design choices at two levels: which experiences to store, and which experiences to replay (and how to do so). This paper addresses only the latter: making the most effective use of the replay memory for learning, assuming that its contents are outside of our control (but see also Section 6).
3.1 A Motivating Example
:::: {cols="2"}
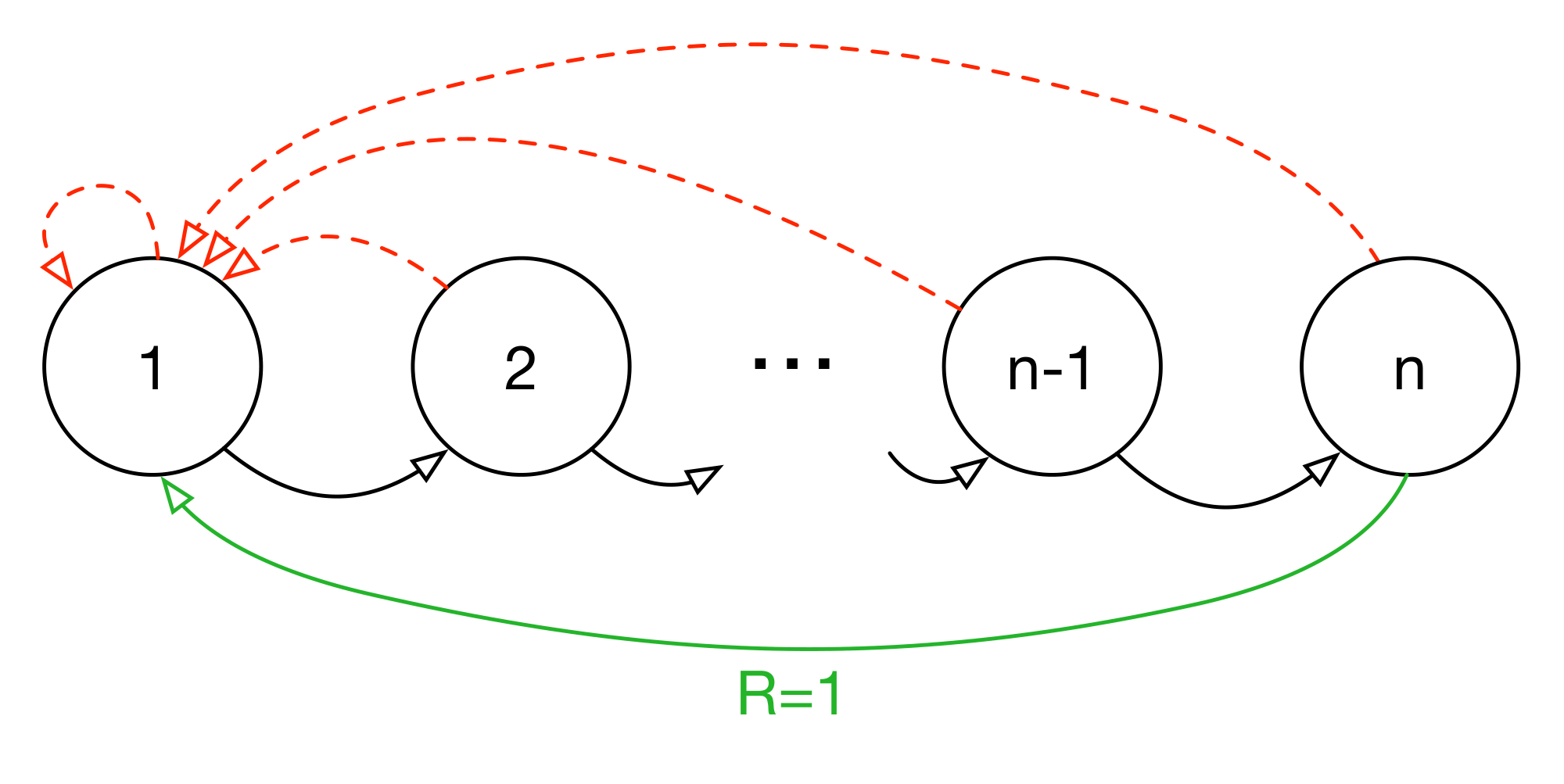
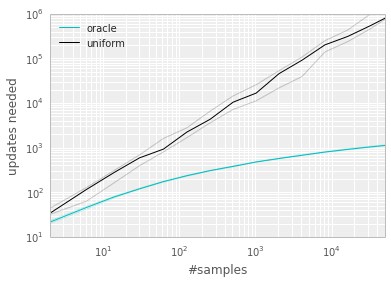
Figure 1: Left: Illustration of the 'Blind Cliffwalk' example domain: there are two actions, a 'right' and a 'wrong' one, and the episode is terminated whenever the agent takes the 'wrong' action (dashed red arrows). Taking the 'right' action progresses through a sequence of $n$ states (black arrows), at the end of which lies a final reward of $1$ (green arrow); reward is $0$ elsewhere. We chose a representation such that generalizing over what action is 'right' is not possible. Right: Median number of learning steps required to learn the value function as a function of the size of the total number of transitions in the replay memory. Note the log-log scale, which highlights the exponential speed-up from replaying with an oracle (bright blue), compared to uniform replay (black); faint lines are min/max values from 10 independent runs. ::::
To understand the potential gains of prioritization, we introduce an artificial 'Blind Cliffwalk' environment (described in Figure 1, left) that exemplifies the challenge of exploration when rewards are rare. With only $n$ states, the environment requires an exponential number of random steps until the first non-zero reward; to be precise, the chance that a random sequence of actions will lead to the reward is $2^{-n}$. Furthermore, the most relevant transitions (from rare successes) are hidden in a mass of highly redundant failure cases (similar to a bipedal robot falling over repeatedly, before it discovers how to walk).
We use this example to highlight the difference between the learning times of two agents. Both agents perform Q-learning updates on transitions drawn from the same replay memory. The first agent replays transitions uniformly at random, while the second agent invokes an oracle to prioritize transitions. This oracle greedily selects the transition that maximally reduces the global loss in its current state (in hindsight, after the parameter update). For the details of the setup, see Appendix B.1. Figure 1 (right) shows that picking the transitions in a good order can lead to exponential speed-ups over uniform choice. Such an oracle is of course not realistic, yet the large gap motivates our search for a practical approach that improves on uniform random replay.
3.2 Prioritizing with TD-error
The central component of prioritized replay is the criterion by which the importance of each transition is measured. One idealised criterion would be the amount the RL agent can learn from a transition in its current state (expected learning progress). While this measure is not directly accessible, a reasonable proxy is the magnitude of a transition's TD error $\delta$, which indicates how 'surprising' or unexpected the transition is: specifically, how far the value is from its next-step bootstrap estimate ([11]). This is particularly suitable for incremental, online RL algorithms, such as SARSA or Q-learning, that already compute the TD-error and update the parameters in proportion to $\delta$. The TD-error can be a poor estimate in some circumstances as well, e.g. when rewards are noisy; see Appendix A for a discussion of alternatives.
To demonstrate the potential effectiveness of prioritizing replay by TD error, we compare the uniform and oracle baselines in the Blind Cliffwalk to a 'greedy TD-error prioritization' algorithm. This algorithm stores the last encountered TD error along with each transition in the replay memory. The transition with the largest absolute TD error is replayed from the memory. A Q-learning update is applied to this transition, which updates the weights in proportion to the TD error. New transitions arrive without a known TD-error, so we put them at maximal priority in order to guarantee that all experience is seen at least once. Figure 2 (left), shows that this algorithm results in a substantial reduction in the effort required to solve the Blind Cliffwalk task. [^2]
[^2]: Note that a random (or optimistic) initialization of the Q-values is necessary with greedy prioritization. If initializing with zero instead, unrewarded transitions would appear to have zero error initially, be placed at the bottom of the queue, and not be revisited until the error on other transitions drops below numerical precision.
Implementation: To scale to large memory sizes $N$, we use a binary heap data structure for the priority queue, for which finding the maximum priority transition when sampling is $O(1)$ and updating priorities (with the new TD-error after a learning step) is $O(\log N)$. See Appendix B.2.1 for more details.
:::: {cols="2"}
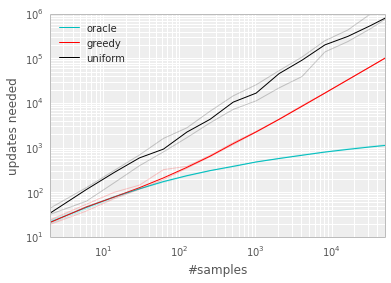
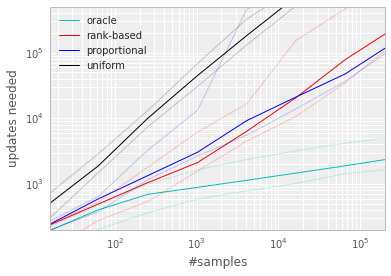
Figure 2: Median number of updates required for Q-learning to learn the value function on the Blind Cliffwalk example, as a function of the total number of transitions (only a single one of which was successful and saw the non-zero reward). Faint lines are min/max values from 10 random initializations. Black is uniform random replay, cyan uses the hindsight-oracle to select transitions, red and blue use prioritized replay (rank-based and proportional respectively). The results differ by multiple orders of magnitude, thus the need for a log-log plot. In both subplots it is evident that replaying experience in the right order makes an enormous difference to the number of updates required. See Appendix B.1 for details. Left: Tabular representation, greedy prioritization. Right: Linear function approximation, both variants of stochastic prioritization. ::::
3.3 Stochastic Prioritization
However, greedy TD-error prioritization has several issues. First, to avoid expensive sweeps over the entire replay memory, TD errors are only updated for the transitions that are replayed. One consequence is that transitions that have a low TD error on first visit may not be replayed for a long time (which means effectively never with a sliding window replay memory). Further, it is sensitive to noise spikes (e.g. when rewards are stochastic), which can be exacerbated by bootstrapping, where approximation errors appear as another source of noise. Finally, greedy prioritization focuses on a small subset of the experience: errors shrink slowly, especially when using function approximation, meaning that the initially high error transitions get replayed frequently. This lack of diversity that makes the system prone to over-fitting.
To overcome these issues, we introduce a stochastic sampling method that interpolates between pure greedy prioritization and uniform random sampling. We ensure that the probability of being sampled is monotonic in a transition's priority, while guaranteeing a non-zero probability even for the lowest-priority transition. Concretely, we define the probability of sampling transition $i$ as
$ P(i) = \frac{p_i^{\alpha}}{\sum_k p_k^{\alpha}}\tag{1} $
where $p_i > 0$ is the priority of transition $i$. The exponent $\alpha$ determines how much prioritization is used, with $\alpha = 0$ corresponding to the uniform case.
The first variant we consider is the direct, proportional prioritization where $p_i = |\delta_i| + \epsilon$, where $\epsilon$ is a small positive constant that prevents the edge-case of transitions not being revisited once their error is zero. The second variant is an indirect, rank-based prioritization where $p_i = \frac{1}{\text{rank}(i)}$, where $\text{rank}(i)$ is the rank of transition $i$ when the replay memory is sorted according to $|\delta_i|$. In this case, $P$ becomes a power-law distribution with exponent $\alpha$. Both distributions are monotonic in $|\delta|$, but the latter is likely to be more robust, as it is insensitive to outliers. Both variants of stochastic prioritization lead to large speed-ups over the uniform baseline on the Cliffwalk task, as shown on Figure 2 (right).
Implementation: To efficiently sample from distribution (1), the complexity cannot depend on $N$. For the rank-based variant, we can approximate the cumulative density function with a piecewise linear function with $k$ segments of equal probability. The segment boundaries can be precomputed (they change only when $N$ or $\alpha$ change). At runtime, we sample a segment, and then sample uniformly among the transitions within it. This works particularly well in conjunction with a minibatch-based learning algorithm: choose $k$ to be the size of the minibatch, and sample exactly one transition from each segment – this is a form of stratified sampling that has the added advantage of balancing out the minibatch (there will always be exactly one transition with high magnitude $\delta$, one with medium magnitude, etc). The proportional variant is different, also admits an efficient implementation based on a 'sum-tree' data structure (where every node is the sum of its children, with the priorities as the leaf nodes), which can be efficiently updated and sampled from. See Appendix B.2.1 for more additional details.
3.4 Annealing the Bias
The estimation of the expected value with stochastic updates relies on those updates corresponding to the same distribution as its expectation. Prioritized replay introduces bias because it changes this distribution in an uncontrolled fashion, and therefore changes the solution that the estimates will converge to (even if the policy and state distribution are fixed). We can correct this bias by using importance-sampling (IS) weights
$ w_i = \left(\frac{1}{N} \cdot \frac{1}{P(i)}\right)^{\beta} $
that fully compensates for the non-uniform probabilities $P(i)$ if $\beta = 1$. These weights can be folded into the Q-learning update by using $w_i\delta_i$ instead of $\delta_i$ (this is thus weighted IS, not ordinary IS, see e.g. [25]). For stability reasons, we always normalize weights by $1/\max_i w_i$ so that they only scale the update downwards.
In typical reinforcement learning scenarios, the unbiased nature of the updates is most important near convergence at the end of training, as the process is highly non-stationary anyway, due to changing policies, state distributions and bootstrap targets; we hypothesize that a small bias can be ignored in this context (see also Figure 12 in the appendix for a case study of full IS correction on Atari). We therefore exploit the flexibility of annealing the amount of importance-sampling correction over time, by defining a schedule on the exponent $\beta$ that reaches $1$ only at the end of learning. In practice, we linearly anneal $\beta$ from its initial value $\beta_0$ to $1$. Note that the choice of this hyperparameter interacts with choice of prioritization exponent $\alpha$; increasing both simultaneously prioritizes sampling more aggressively at the same time as correcting for it more strongly.
Importance sampling has another benefit when combined with prioritized replay in the context of non-linear function approximation (e.g. deep neural networks): here large steps can be very disruptive, because the first-order approximation of the gradient is only reliable locally, and have to be prevented with a smaller global step-size. In our approach instead, prioritization makes sure high-error transitions are seen many times, while the IS correction reduces the gradient magnitudes (and thus the effective step size in parameter space), and allowing the algorithm follow the curvature of highly non-linear optimization landscapes because the Taylor expansion is constantly re-approximated.
We combine our prioritized replay algorithm into a full-scale reinforcement learning agent, based on the state-of-the-art Double DQN algorithm. Our principal modification is to replace the uniform random sampling used by Double DQN with our stochastic prioritization and importance sampling methods (see Algorithm 1).
**Input:** minibatch $k$, step-size $\eta$, replay period $K$ and size $N$, exponents $\alpha$ and $\beta$, budget $T$.
1: Initialize replay memory $\mathcal{H} = \emptyset$, $\Delta = 0$, $p_1 = 1$
2: Observe $S_0$ and choose $A_0 \sim \pi_\theta(S_0)$
3: **for** $t = 1$ **to** $T$ **do**
4: Observe $S_t, R_t, \gamma_t$
5: Store transition $(S_{t-1}, A_{t-1}, R_t, \gamma_t, S_t)$ in $\mathcal{H}$ with maximal priority $p_t = \max_{i<t} p_i$
6: **if** $t \equiv 0 \mod K$ **then**
7: **for** $j = 1$ **to** $k$ **do**
8: Sample transition $j \sim P(j) = p_j^\alpha / \sum_i p_i^\alpha$
9: Compute importance-sampling weight $w_j = (N \cdot P(j))^{-\beta} / \max_i w_i$
10: Compute TD-error $\delta_j = R_j + \gamma_j Q_{\text{target}}(S_j, \arg\max_a Q(S_j, a)) - Q(S_{j-1}, A_{j-1})$
11: Update transition priority $p_j \leftarrow |\delta_j|$
12: Accumulate weight-change $\Delta \leftarrow \Delta + w_j \cdot \delta_j \cdot \nabla_\theta Q(S_{j-1}, A_{j-1})$
13: **end for**
14: Update weights $\theta \leftarrow \theta + \eta \cdot \Delta$, reset $\Delta = 0$
15: From time to time copy weights into target network $\theta_{\text{target}} \leftarrow \theta$
16: **end if**
17: Choose action $A_t \sim \pi_\theta(S_t)$
18: **end for**
4 Atari Experiments
Section Summary: Researchers tested a technique called prioritized replay, which focuses on replaying the most informative past experiences, in the challenging Atari video game benchmarks, using baseline algorithms like DQN and Double DQN that normally sample experiences randomly. They made only small tweaks to learning rates and other settings, then compared rank-based and proportional versions of prioritized sampling across many games. The results showed big improvements in performance on most games, with learning happening about twice as fast and reaching state-of-the-art levels, including human-like play on several titles.
With all these concepts in place, we now investigate to what extent replay with such prioritized sampling can improve performance in realistic problem domains. For this, we chose the collection of Atari benchmarks ([26]) with their end-to-end RL from vision setup, because they are popular and contain diverse sets of challenges, including delayed credit assignment, partial observability, and difficult function approximation ([3, 23]). Our hypothesis is that prioritized replay is generally useful, so that it will make learning with experience replay more efficient without requiring careful problem-specific hyperparameter tuning.
We consider two baseline algorithms that use uniform experience replay, namely the version of the DQN algorithm from the Nature paper ([3]), and its recent extension Double DQN ([23]) that substantially improved the state-of-the-art by reducing the over-estimation bias with Double Q-learning ([27]). Throughout this paper we use the tuned version of the Double DQN algorithm. For this paper, the most relevant component of these baselines is the replay mechanism: all experienced transitions are stored in a sliding window memory that retains the last $10^6$ transitions. The algorithm processes minibatches of 32 transitions sampled uniformly from the memory. One minibatch update is done for each 4 new transitions entering the memory, so all experience is replayed 8 times on average. Rewards and TD-errors are clipped to fall within $[-1, 1]$ for stability reasons.
We use the identical neural network architecture, learning algorithm, replay memory and evaluation setup as for the baselines (see Appendix B.2). The only difference is the mechanism for sampling transitions from the replay memory, with is now done according to Algorithm 1 instead of uniformly. We compare the baselines to both variants of prioritized replay (rank-based and proportional).
Only a single hyperparameter adjustment was necessary compared to the baseline: Given that prioritized replay picks high-error transitions more often, the typical gradient magnitudes are larger, so we reduced the step-size $\eta$ by a factor 4 compared to the (Double) DQN setup. For the $\alpha$ and $\beta_0$ hyperparameters that are introduced by prioritization, we did a coarse grid search (evaluated on a subset of 8 games), and found the sweet spot to be $\alpha = 0.7$, $\beta_0 = 0.5$ for the rank-based variant and $\alpha = 0.6$, $\beta_0 = 0.4$ for the proportional variant. These choices are trading off aggressiveness with robustness, but it is easy to revert to a behavior closer to the baseline by reducing $\alpha$ and/or increasing $\beta$.
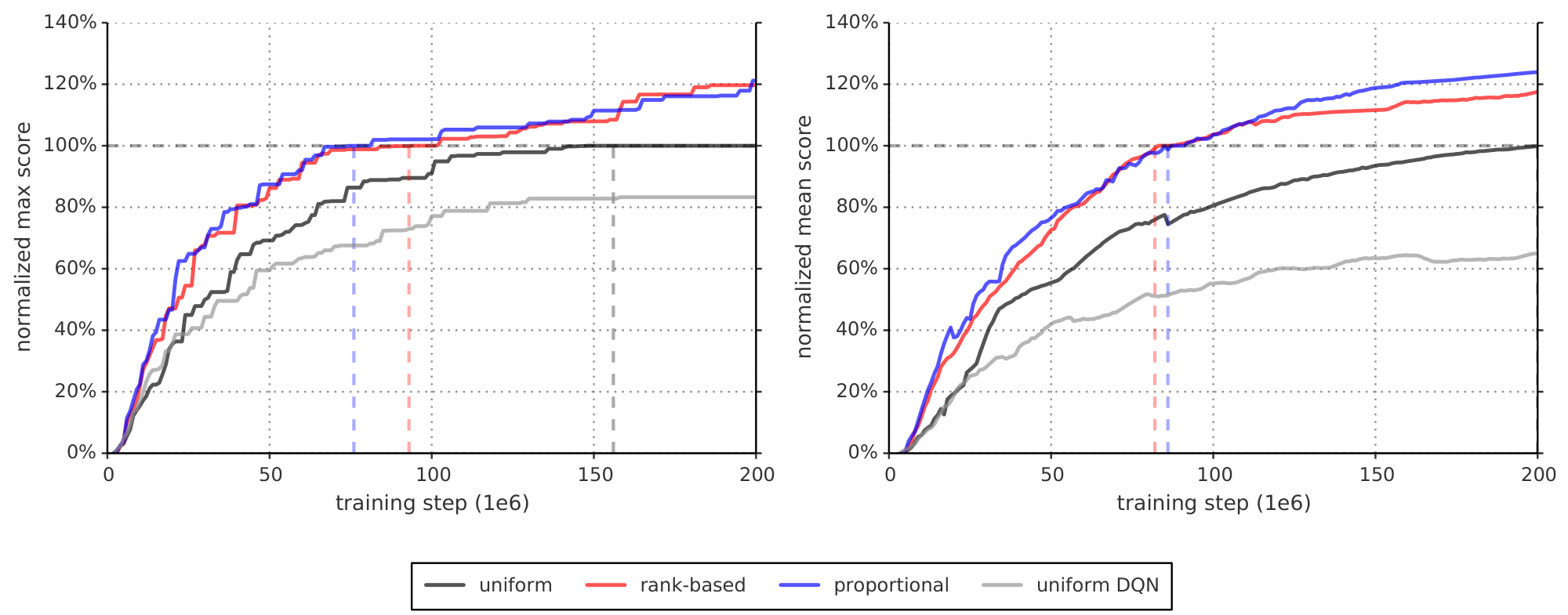
We produce the results by running each variant with a single hyperparameter setting across all games, as was done for the baselines. Our main evaluation metric is the quality of the best policy, in terms of average score per episode, given start states sampled from human traces (as introduced in [21] and used in [23], which requires more robustness and generalization as the agent cannot rely on repeating a single memorized trajectory). These results are summarized in Table 1 and Figure 3, but full results and raw scores can be found in Table 7 and Table 6 in the Appendix. A secondary metric is the learning speed, which we summarize on Figure 4, with more detailed learning curves on Figure 7 and Figure 8.
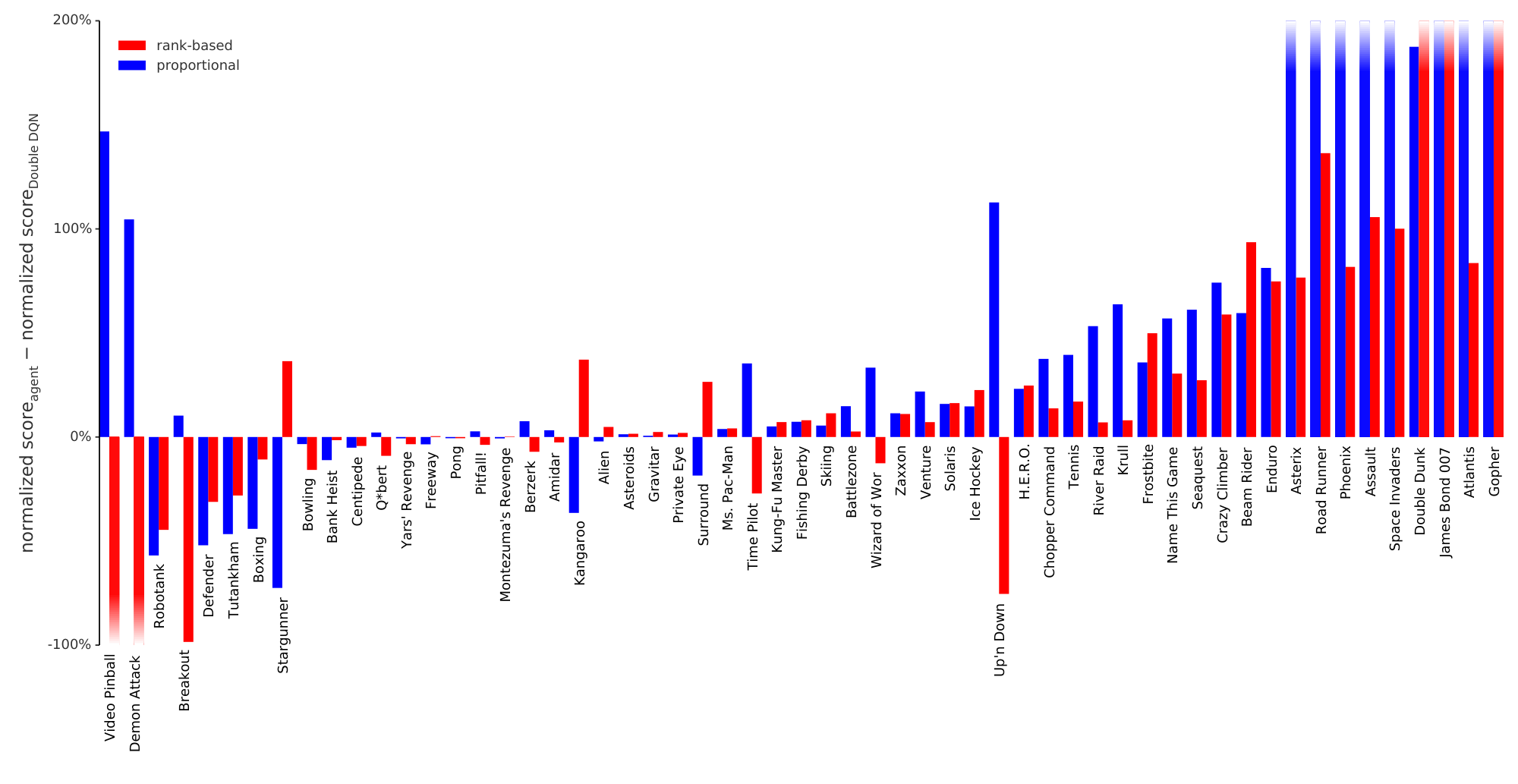
:::
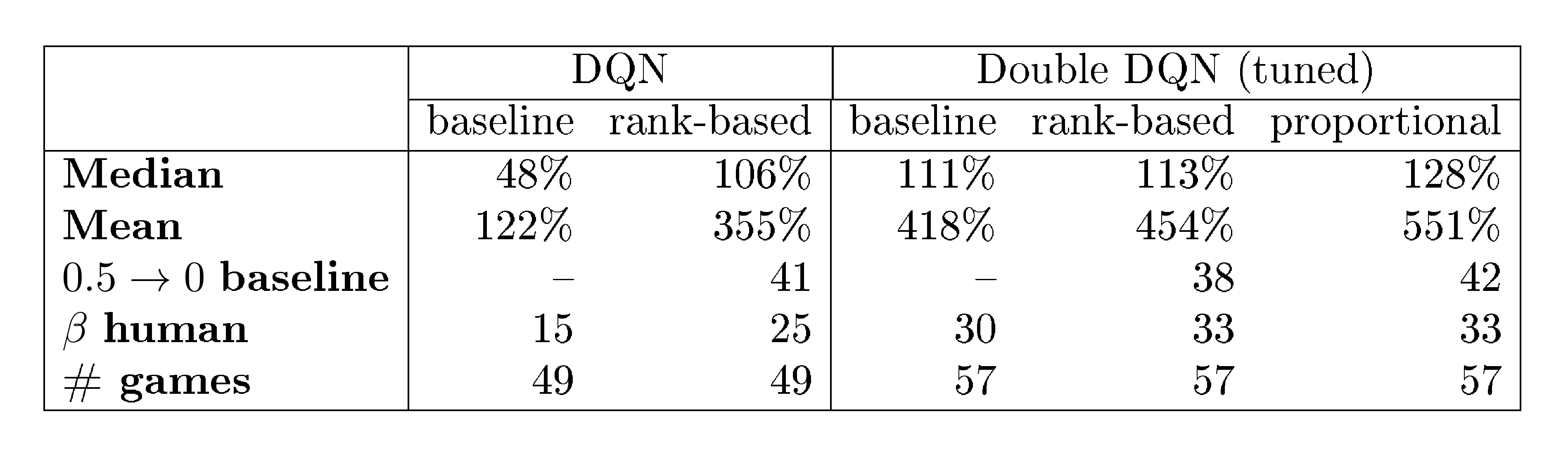
Table 1: Summary of normalized scores. See Table 6 in the appendix for full results.
:::
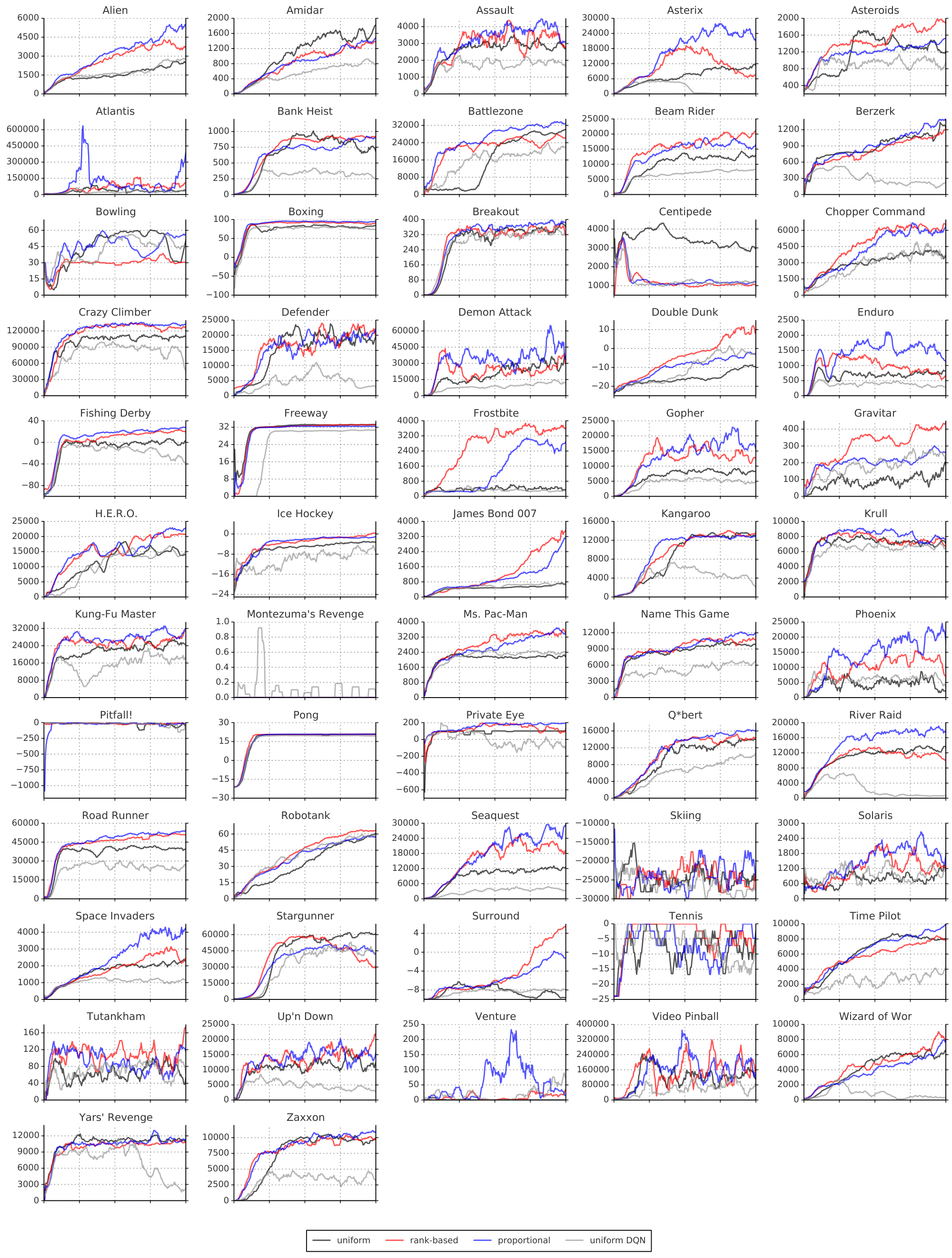
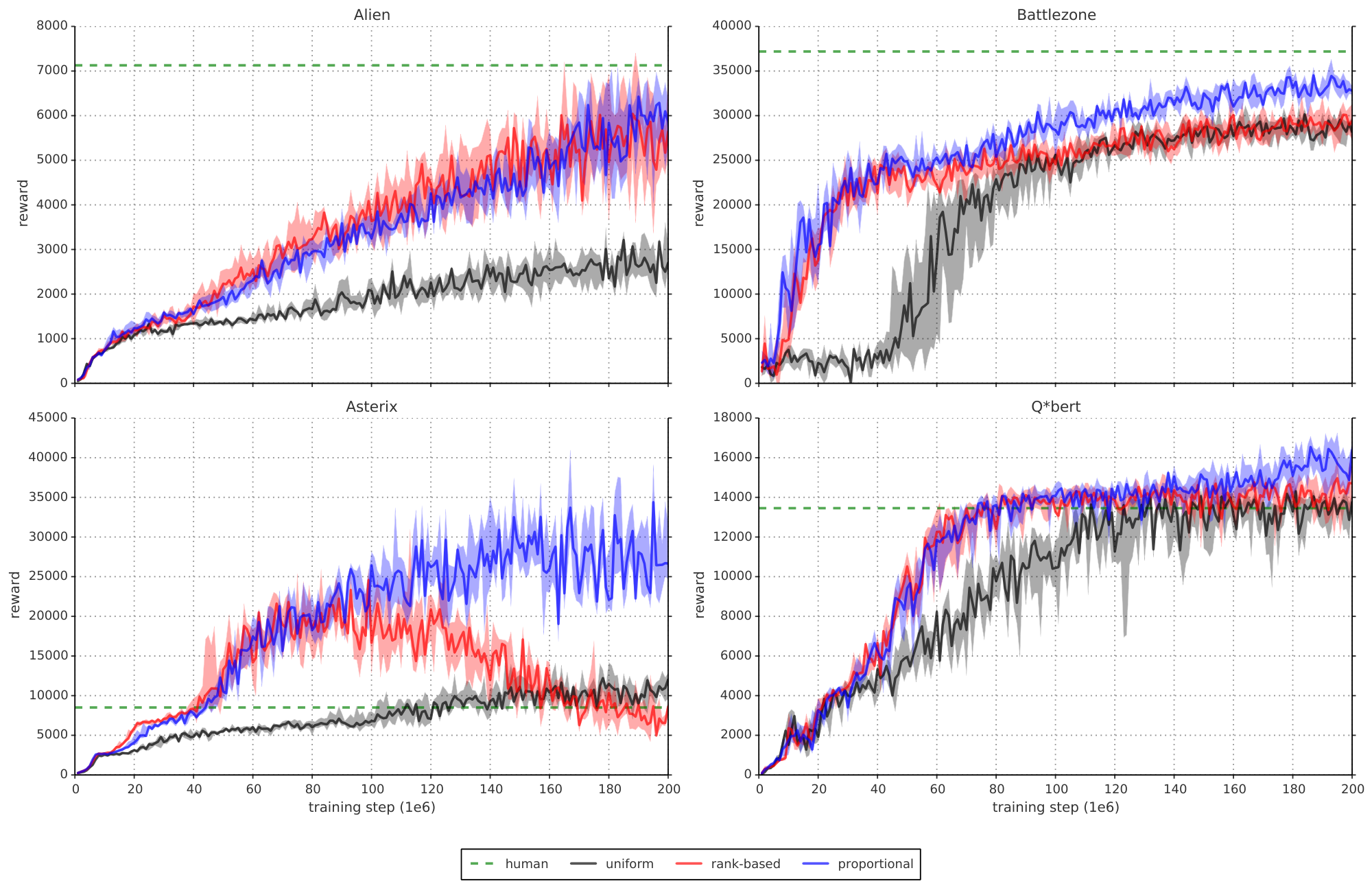
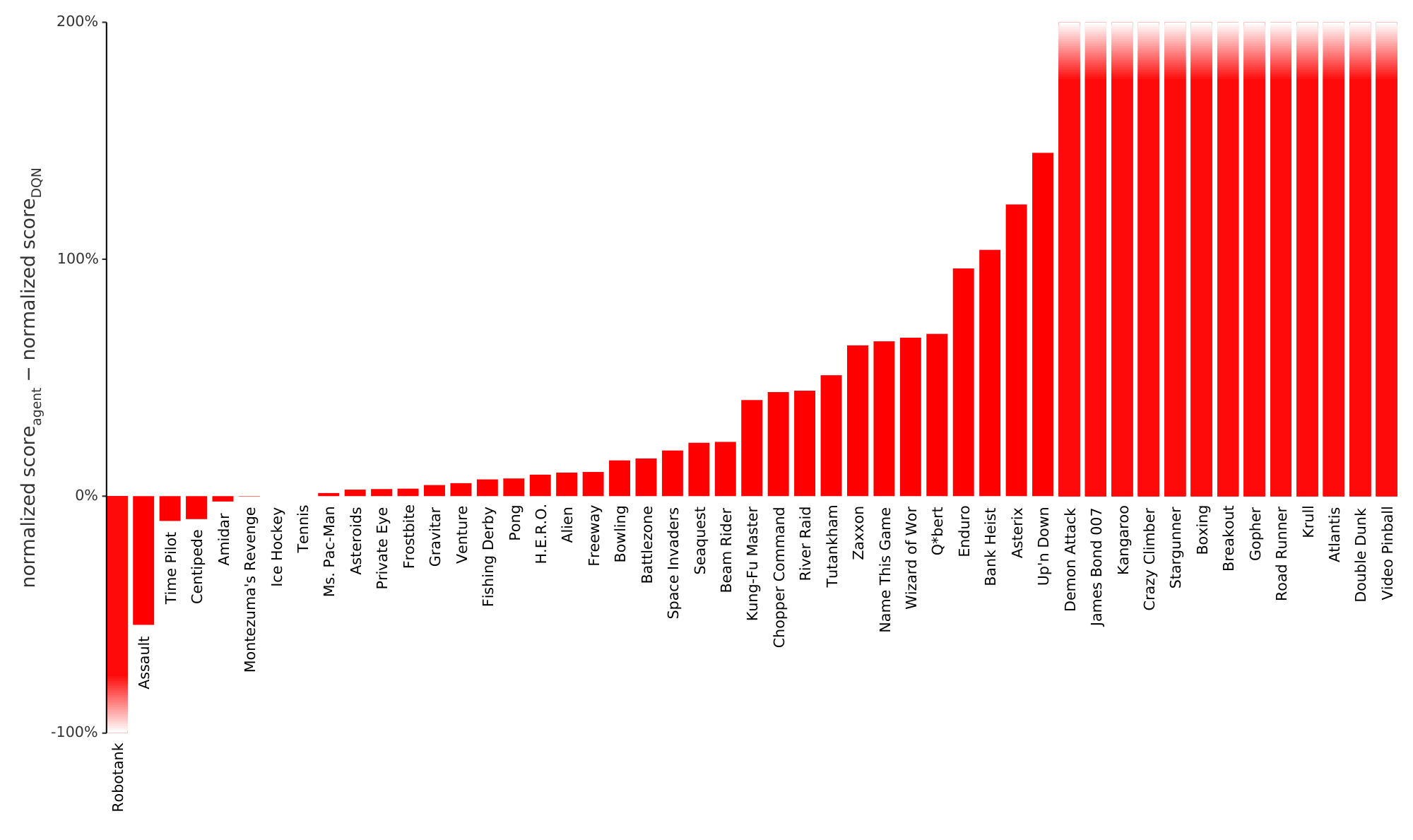
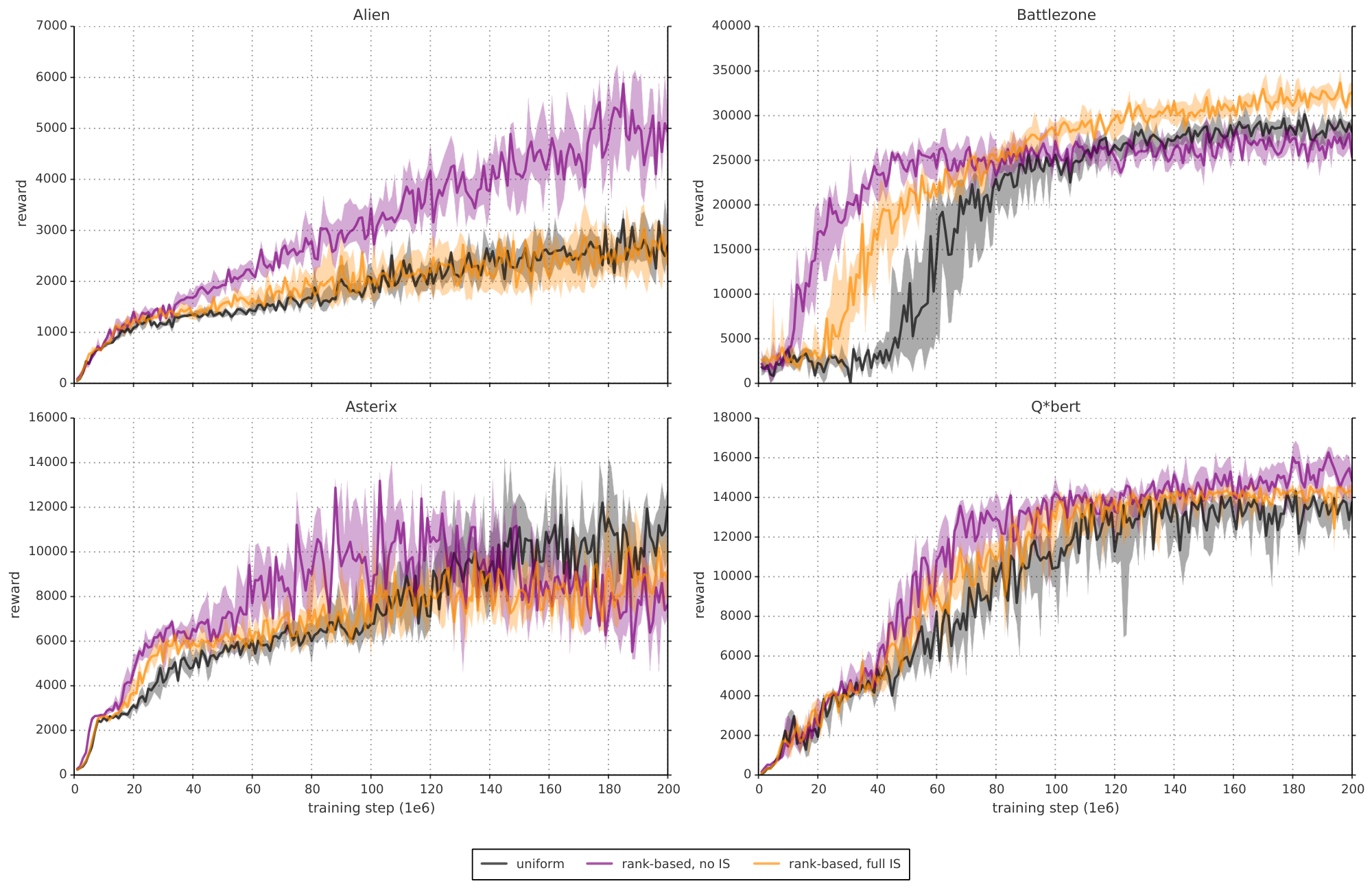
We find that adding prioritized replay to DQN leads to a substantial improvement in score on 41 out of 49 games (compare columns 2 and 3 of Table 6 or Figure 9 in the appendix), with the median normalized performance across 49 games increasing from $0.5 \rightarrow 1$ to $0.4 \rightarrow 1$. Furthermore, we find that the boost from prioritized experience replay is complementary to the one from introducing Double Q-learning into DQN: performance increases another notch, leading to the current state-of-the-art on the Atari benchmark (see Figure 3). Compared to Double DQN, the median performance across 57 games increased from $\eta$ to $\eta_{\text{baseline}} / 4$, and the mean performance from $\eta_{\text{baseline}} / 4$ to $\eta_{\text{baseline}} / 4$ bringing additional games such as River Raid, Seaquest and Surround to a human level for the first time, and making large jumps on others (e.g. Gopher, James Bond 007 or Space Invaders). Note that mean performance is not a very reliable metric because a single game (Video Pinball) has a dominant contribution. Prioritizing replay gives a performance boost on almost all games, and on aggregate, learning is twice as fast (see Figure 4 and Figure 8). The learning curves on Figure 7 illustrate that while the two variants of prioritization usually lead to similar results, there are games where one of them remains close to the Double DQN baseline while the other one leads to a big boost, for example Double Dunk or Surround for the rank-based variant, and Alien, Asterix, Enduro, Phoenix or Space Invaders for the proportional variant. Another observation from the learning curves is that compared to the uniform baseline, prioritization is effective at reducing the delay until performance gets off the ground in games that otherwise suffer from such a delay, such as Battlezone, Zaxxon or Frostbite.
5 Discussion
Section Summary: The study compares two methods for prioritizing training samples in reinforcement learning—rank-based and proportional—and finds they perform similarly in practice, despite expectations that rank-based would be more robust to outliers, thanks to techniques like clipping that normalize errors and lead to heavy-tailed error distributions over time. It also reveals that many experiences in the replay buffer are either never used or replayed long after collection, with uniform sampling favoring outdated data, but prioritized replay counters this by emphasizing unseen and recent samples with higher errors. Additionally, the authors hypothesize that in deep neural networks, this prioritization shifts focus toward improving weak state representations, aiding in distinguishing similar observations if the network has sufficient capacity.
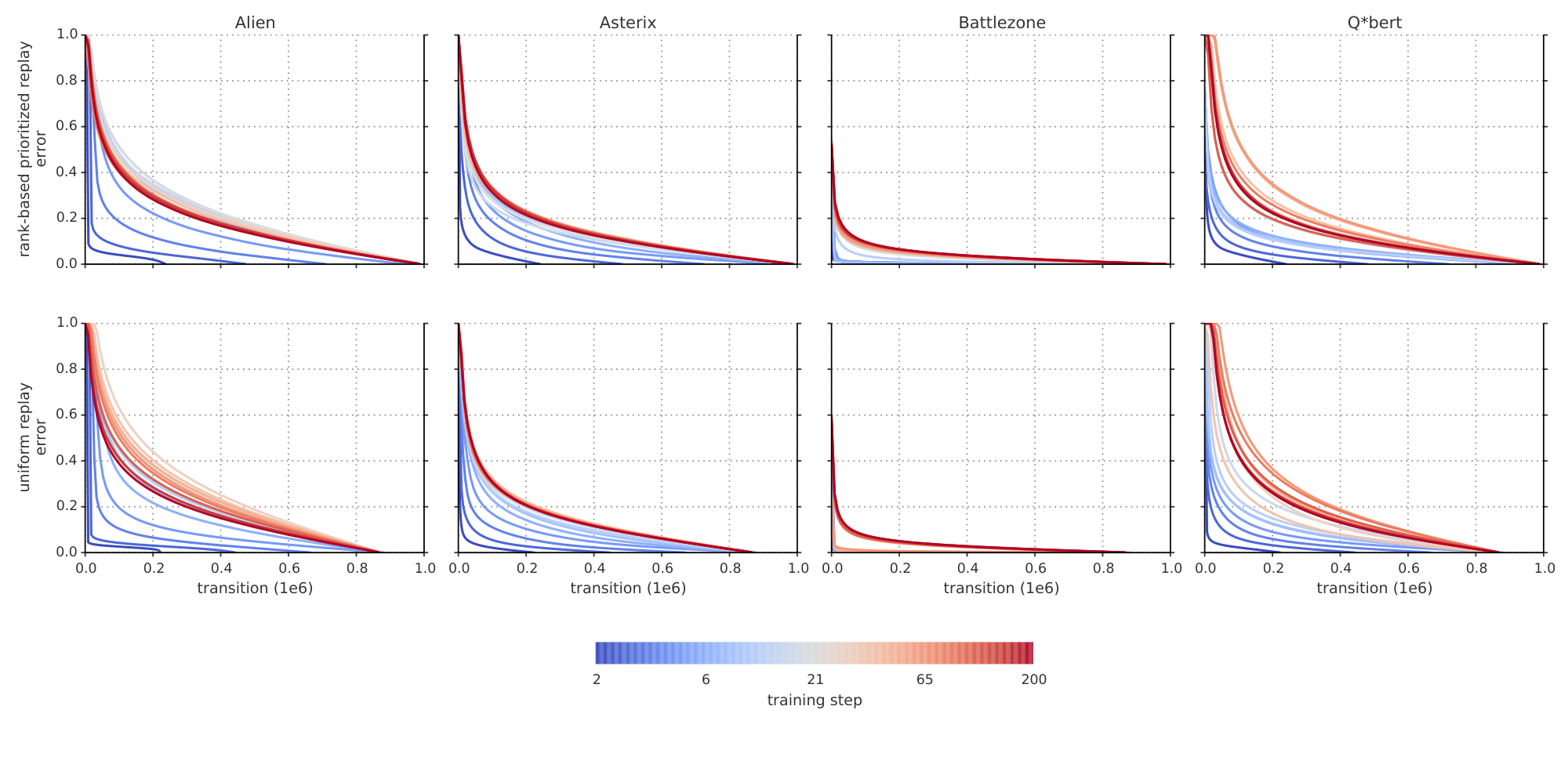
In the head-to-head comparison between rank-based prioritization and proportional prioritization, we expected the rank-based variant to be more robust because it is not affected by outliers nor error magnitudes. Furthermore, its heavy-tail property also guarantees that samples will be diverse, and the stratified sampling from partitions of different errors will keep the total minibatch gradient at a stable magnitude throughout training. On the other hand, the ranks make the algorithm blind to the relative error scales, which could incur a performance drop when there is structure in the distribution of errors to be exploited, such as in sparse reward scenarios. Perhaps surprisingly, both variants perform similarly in practice; we suspect this is due to the heavy use of clipping (of rewards and TD-errors) in the DQN algorithm, which removes outliers. Monitoring the distribution of TD-errors as a function of time for a number of games (see Figure 10 in the appendix), and found that it becomes close to a heavy-tailed distribution as learning progresses, while still differing substantially across games; this empirically validates the form of Equation 1. Figure 11, in the appendix, shows how this distribution interacts with Equation 1 to produce the effective replay probabilities.
While doing this analysis, we stumbled upon another phenomenon (obvious in retrospect), namely that some fraction of the visited transitions are never replayed before they drop out of the sliding window memory, and many more are replayed for the first time only long after they are encountered. Also, uniform sampling is implicitly biased toward out-of-date transitions that were generated by a policy that has typically seen hundreds of thousands of updates since. Prioritized replay with its bonus for unseen transitions directly corrects the first of these issues, and also tends to help with the second one, as more recent transitions tend to have larger error – this is because old transitions will have had more opportunities to have them corrected, and because novel data tends to be less well predicted by the value function.
We hypothesize that deep neural networks interact with prioritized replay in another interesting way. When we distinguish learning the value given a representation (i.e., the top layers) from learning an improved representation (i.e., the bottom layers), then transitions for which the representation is good will quickly reduce their error and then be replayed much less, increasing the learning focus on others where the representation is poor, thus putting more resources into distinguishing aliased states – if the observations and network capacity allow for it.
6 Extensions
Section Summary: The section explores ways to extend prioritized replay techniques beyond their original use in reinforcement learning. In supervised learning, it adapts the method to focus on hard or rare examples in imbalanced datasets, as shown in an experiment with a skewed version of the MNIST digit recognition task, where it boosts performance and reduces overfitting without needing prior knowledge of the imbalance. It also discusses applications to off-policy training by combining priorities with importance sampling, using replay feedback to refine exploration strategies, and managing memory storage by prioritizing useful experiences while discarding redundant ones, potentially incorporating data from planners or human experts.
Prioritized Supervised Learning: The analogous approach to prioritized replay in the context of supervised learning is to sample non-uniformly from the dataset, each sample using a priority based on its last-seen error. This can help focus the learning on those samples that can still be learned from, devoting additional resources to the (hard) boundary cases, somewhat similarly to boosting ([16]). Furthermore, if the dataset is imbalanced, we hypothesize that samples from the rare classes will be sampled disproportionately often, because their errors shrink less fast, and the chosen samples from the common classes will be those nearest to the decision boundaries, leading to an effect similar to hard negative mining ([28]). To check whether these intuitions hold, we conducted a preliminary experiment on a class-imbalanced variant of the classical MNIST digit classification problem ([29]), where we removed 99% of the samples for digits 0, 1, 2, 3, 4 in the training set, while leaving the test/validation sets untouched (i.e., those retain class balance). We compare two scenarios: in the informed case, we reweight the errors of the impoverished classes artificially (by a factor 100), in the uninformed scenario, we provide no hint that the test distribution will differ from the training distribution. See Appendix B.3 for the details of the convolutional neural network training setup. Prioritized sampling (uninformed, with $\alpha = 1$, $\beta = 0$) outperforms the uninformed uniform baseline, and approaches the performance of the informed uniform baseline in terms of generalization (see Figure 5); again, prioritized training is also faster in terms of learning speed.
:::: {cols="2"}
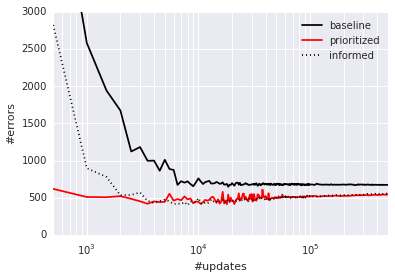
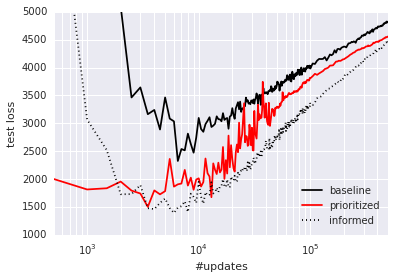
Figure 5: Classification errors as a function of supervised learning updates on severely class-imbalanced MNIST. Prioritized sampling improves performance, leading to comparable errors on the test set, and approaching the imbalance-informed performance (median of 3 random initializations). Left: Number of misclassified test set samples. Right: Test set loss, highlighting overfitting. ::::
Off-policy Replay: Two standard approaches to off-policy RL are rejection sampling and using importance sampling ratios $\rho$ to correct for how likely a transition would have been on-policy. Our approach contains analogues to both these approaches, the replay probability $P$ and the IS-correction $w$. It appears therefore natural to apply it to off-policy RL, if transitions are available in a replay memory. In particular, we recover weighted IS with $w = \rho$, $\alpha = 0$, $\beta = 1$ and rejection sampling with $p = \min(1; \rho)$, $\alpha = 1$, $\beta = 0$, in the proportional variant. Our experiments indicate that intermediate variants, possibly with annealing or ranking, could be more useful in practice – especially when IS ratios introduce high variance, i.e., when the policy of interest differs substantially from the behavior policy in some states. Of course, off-policy correction is complementary to our prioritization based on expected learning progress, and the same framework can be used for a hybrid prioritization by defining $p = \rho \cdot |\delta|$, or some other sensible trade-off based on both $\rho$ and $\delta$.
Feedback for Exploration: An interesting side-effect of prioritized replay is that the total number $M_i$ that a transition will end up being replayed varies widely, and this gives a rough indication of how useful it was to the agent. This potentially valuable signal can be fed back to the exploration strategy that generates the transitions. For example, we could sample exploration hyperparameters (such as the fraction of random actions $\epsilon$, the Boltzmann temperature, or the amount of of intrinsic reward to mix in) from a parametrized distribution at the beginning of each episode, monitor the usefulness of the experience via $M_i$, and update the distribution toward generating more useful experience. Or, in a parallel system like the Gorila agent ([21]), it could guide resource allocation between a collection of concurrent but heterogeneous 'actors', each with different exploration hyperparameters.
Prioritized Memories: Considerations that help determine which transitions to replay are likely to also be relevant for determining which memories to store and when to erase them (e.g. when it becomes likely that they will never be replayed anymore). An explicit control over which memories to keep or erase can help reduce the required total memory size, because it reduces redundancy (frequently visited transitions will have low error, so many of them will be dropped), while automatically adjusting for what has been learned already (dropping many of the 'easy' transitions) and biasing the contents of the memory to where the errors remain high. This is a non-trivial aspect, because memory requirements for DQN are currently dominated by the size of the replay memory, no longer by the size of the neural network. Erasing is a more final decision than reducing the replay probability, thus an even stronger emphasis of diversity may be necessary, for example by tracking the age of each transitions and using it to modulate the priority in such a way as to preserve sufficient old experience to prevent cycles (related to 'hall of fame' ideas in multi-agent literature, [30]). The priority mechanism is also flexible enough to permit integrating experience from other sources, such as from a planner or from human expert trajectories ([19]), since knowing the source can be used to modulate each transition's priority, e.g. in such a way as to preserve a sufficient fraction of external experience in memory.
7 Conclusion
Section Summary: This paper presents prioritized replay, a technique that improves the efficiency of experience replay in machine learning by focusing on more important past experiences. Researchers explored different versions of this method, created versions that work with huge data sets, and discovered it doubles the speed of learning while achieving top results on Atari video games. The work also suggests future adaptations, such as for handling uneven data classes in standard supervised learning.
This paper introduced prioritized replay, a method that can make learning from experience replay more efficient. We studied a couple of variants, devised implementations that scale to large replay memories, and found that prioritized replay speeds up learning by a factor 2 and leads to a new state-of-the-art of performance on the Atari benchmark. We laid out further variants and extensions that hold promise, namely for class-imbalanced supervised learning.
Acknowledgments
We thank our Deepmind colleagues, in particular Hado van Hasselt, Joseph Modayil, Nicolas Heess, Marc Bellemare, Razvan Pascanu, Dharshan Kumaran, Daan Wierstra, Arthur Guez, Charles Blundell, Alex Pritzel, Alex Graves, Balaji Lakshminarayanan, Ziyu Wang, Nando de Freitas, Remi Munos and Geoff Hinton for insightful discussions and feedback.
A Prioritization Variants
Section Summary: This section explores alternative ways to prioritize which past experiences to replay in reinforcement learning algorithms, beyond just using the size of prediction errors, since those can overlook randomness, unlearnable patterns, or data limitations. Options include tracking changes in error trends over time, focusing on how much replay alters the model's weights, favoring positive surprises over negative ones as they might signal more useful insights, basing priorities on full episode outcomes rather than single steps, adding bonuses for rarely seen or outdated experiences to maintain variety, and boosting the priority of actions leading into newly learned states to propagate knowledge backward. While some ideas draw from brain studies in animals and show promise for diverse environments, early tests were mixed, often depending on the simplicity of the setups used.
The absolute TD-error is only one possible proxy for the ideal priority measure of expected learning progress. While it captures the scale of potential improvement, it ignores inherent stochasticity in rewards or transitions, as well as possible limitations from partial observability or FA capacity; in other words, it is problematic when there are unlearnable transitions. In that case, its derivative – which could be approximated by the difference between a transition's current $\epsilon$ and the $\eta_{\text{baseline}}, \eta_{\text{baseline}} / 2, \eta_{\text{baseline}} / 4, \eta_{\text{baseline}} / 8$ when it was last replayed [^3] – may be more useful. This measure is less immediately available, however, and is influenced by whatever was replayed in the meanwhile, which increases its variance. In preliminary experiments, we found it did not outperform $\alpha$, but this may say more about the class of (near-deterministic) environments we investigated, than about the measure itself.
[^3]: Of course, more robust approximations would be a function of the history of all encountered $\eta_{\text{baseline}} = 0.00025$ values. In particular, one could imagine an RProp-style update ([31]) to priorities that increase the priority while the signs match, and reduce it whenever consecutive errors (for the same transition) differ in sign.
An orthogonal variant is to consider the norm of the weight-change induced by replaying a transition – this can be effective if the underlying optimizer employs adaptive step-sizes that reduce gradients in high-noise directions ([32, 33]), thus placing the burden of distinguishing between learnable and unlearnable transitions on the optimizer.
It is possible to modulate prioritization by not treating positive TD-errors the same than negative ones; we can for example invoke the Anna Karenina principle ([34]), interpreted to mean that there are many ways in which a transition can be less good than expected, but only one in which can be better, to introduce an asymmetry and prioritize positive TD-errors more than negative ones of equal magnitude, because the former are more likely to be informative. Such an asymmetry in replay frequency was also observed in rat studies ([8]). Again, our preliminary experiments with such variants were inconclusive.
The evidence from neuroscience suggest that a prioritization based on episodic return rather than expected learning progress may be useful too [5, 6, 7]. For this case, we could boost the replay probabilities of entire episodes, instead of transitions, or boost individual transitions by their observed return-to-go (or even their value estimates).
For the issue of preserving sufficient diversity (to prevent overfitting, premature convergence or impoverished representations), there are alternative solutions to our choice of introducing stochasticity, for example, the priorities could be modulated by a novelty measure in observation space. Nothing prevents a hybrid approach where some fraction of the elements (of each minibatch) are sampled according to one priority measure and the rest according to another one, introducing additional diversity. An orthogonal idea is to increase priorities of transitions that have not been replayed for a while, by introducing an explicit staleness bonus that guarantees that every transition is revisited from time to time, with that chance increasing at the same rate as its last-seen TD-error becomes stale. In the simple case where this bonus grows linearly with time, this can be implemented at no additional cost by subtracting a quantity proportional to the global step-count from the new priority on any update. [^4]
[^4]: If bootstrapping is used with policy iteration, such that the target values come from separate network (as is the case for DQN), then there is a large increase in uncertainty about the priorities when the target network is updated in the outer iteration. At these points, the staleness bonus is increased in proportion to the number of individual (low-level) updates that happened in-between.
In the particular case of RL with bootstrapping from value functions, it is possible to exploit the sequential structure of the replay memory using the following intuition: a transition that led to a large amount of learning (about its outgoing state) has the potential to change the bootstrapping target for all transitions leading into that state, and thus there is more to be learned about these. Of course we know at least one of these, namely the historic predecessor transition, and so boosting its priority makes it more likely to be revisited soon. Similarly to eligibility traces, this lets information trickle backward from a future outcome to the value estimates of the actions and states that led to it. In practice, we add $0.5 \rightarrow 0$ of the current transition to predecessor transition's priority, but only if the predecessor transition is not a terminal one. This idea is related to 'reverse replay' observed in rodents [7], and to a recent extension of prioritized sweeping ([12]).
B Experimental Details
Section Summary: In the Blind Cliffwalk experiments, researchers used a basic Q-learning approach to train AI agents on a grid world with varying numbers of states from 2 to 16, representing Q-values with either simple tables or linear models, and filling a replay memory by simulating all possible action sequences to ensure comprehensive experience data. For the Atari games, they optimized prioritized replay memory handling for a million transitions by implementing efficient data structures like binary heaps for rank-based sampling and sum-trees for proportional prioritization, which added only minor runtime overhead. Hyperparameters such as prioritization weights, learning rates, and annealing schedules were carefully tuned across select games to improve performance over standard DQN baselines.
B.1 Blind Cliffwalk
For the Blind Cliffwalk experiments (Section 3.1 and following), we use a straight-forward Q-learning ([35]) setup. The Q-values are represented using either a tabular look-up table, or a linear function approximator, in both cases represented $Q(s, a) := \theta^\top \phi(s, a)$. For each transition, we compute its TD-error using:
$ \begin{align} \delta_t & := & R_t + \gamma_t \max_a Q(S_{t}, a) - Q(S_{t-1}, A_{t-1}) \end{align}\tag{2} $
and update the parameters using stochastic gradient ascent:
$ \begin{align} \theta & \leftarrow & \theta + \eta \cdot \delta_t \cdot \nabla_{\theta} Q\bigr|{S{t-1}, A_{t-1}} = \theta + \eta \cdot \delta_t \cdot \phi(S_{t-1}, A_{t-1}) \end{align}\tag{3} $
For the linear FA case we use a very simple encoding of state as a 1-hot vector (as for tabular), but concatenated with a constant bias feature of value 1. To make generalization across actions impossible, we alternate which action is 'right' and which one is 'wrong' for each state. All elements are initialized with small values near zero, $0.5 \rightarrow 1$.
We vary the size of the problem (number of states $n$) from 2 to 16. The discount factor is set to $\gamma = 1 - \frac{1}{n}$ which keeps values on approximately the same scale independently of $n$. This allows us to used a fixed step-size of $\eta = \frac{1}{4}$ in all experiments.
The replay memory is filled by exhaustively executing all $2^n$ possible sequences of actions until termination (in random order). This guarantees that exactly one sequence will succeed and hit the final reward, and all others will fail with zero reward. The replay memory contains all the relevant experience (the total number of transitions is $2^{n+1} - 2$), at the frequency that it would be encountered when acting online with a random behavior policy. Given this, we can in principle learn until convergence by just increasing the amount of computation; here, convergence is defined as a mean-squared error (MSE) between the Q-value estimates and the ground truth below $10^{-3}$.
B.2 Atari Experiments
B.2.1 Implementation Details
Prioritizing using a replay memory with $N = 10^6$ transitions introduced some performance challenges. Here we describe a number of things we did to minimize additional run-time and memory overhead, extending the discussion in Section 3.
Rank-based prioritization
Early experiments with Atari showed that maintaining a sorted data structure of $10^6$ transitions with constantly changing TD-errors dominated running time. Our final solution was to store transitions in a priority queue implemented with an array-based binary heap. The heap array was then directly used as an approximation of a sorted array, which is infrequently sorted once every $10^6$ steps to prevent the heap becoming too unbalanced. This is an unconventional use of a binary heap, however our tests on smaller environments showed learning was unaffected compared to using a perfectly sorted array. This is likely due to the last-seen TD-error only being a proxy for the usefulness of a transition and our use of stochastic prioritized sampling. A small improvement in running time came from avoiding excessive recalculation of partitions for the sampling distribution. We reused the same partition for values of $N$ that are close together and by updating $\alpha$ and $\beta$ infrequently. Our final implementation for rank-based prioritization produced an additional 2%-4% increase in running time and negligible additional memory usage. This could be reduced further in a number of ways, e.g. with a more efficient heap implementation, but it was good enough for our experiments.
Proportional prioritization
The 'sum-tree' data structure used here is very similar in spirit to the array representation of a binary heap. However, instead of the usual heap property, the value of a parent node is the sum of its children. Leaf nodes store the transition priorities and the internal nodes are intermediate sums, with the parent node containing the sum over all priorities, $p_{\text{total}}$. This provides a efficient way of calculating the cumulative sum of priorities, allowing $O(\log N)$ updates and sampling. To sample a minibatch of size $k$, the range $[0, p_{\text{total}}]$ is divided equally into $k$ ranges. Next, a value is uniformly sampled from each range. Finally the transitions that correspond to each of these sampled values are retrieved from the tree. Overhead is similar to rank-based prioritization.
As mentioned in Section 3.4, whenever importance sampling is used, all weights $w_i$ were scaled so that $\max_i w_i = 1$. We found that this worked better in practice as it kept all weights within a reasonable range, avoiding the possibility of extremely large updates. It is worth mentioning that this normalization interacts with annealing on $\beta$: as $\beta$ approaches 1, the normalization constant grows, which reduces the effective average update in a similar way to annealing the step-size $\eta$.
B.2.2 Hyperparameters
Throughout this paper our baseline was DQN and the tuned version of Double DQN. We tuned hyperparameters over a subset of Atari games: Breakout, Pong, Ms. Pac-Man, Q*bert, Alien, Battlezone, Asterix. Table 2 lists the values tried and Table 3 lists the chosen parameters.
:Table 2: Hyperparameters considered in experiments. Here $\eta_{\text{baseline}} = 0.00025$.
| Hyperparameter | Range of values |
|---|---|
| $\alpha$ | 0, 0.4, 0.5, 0.6, 0.7, 0.8 |
| $\beta$ | 0, 0.4, 0.5, 0.6, 1 |
| $\eta$ | $\eta_{\text{baseline}}, \eta_{\text{baseline}} / 2, \eta_{\text{baseline}} / 4, \eta_{\text{baseline}} / 8$ |
:::

Table 3: Chosen hyperparameters for prioritized variants of DQN. Arrows indicate linear annealing, where the limiting value is reached at the end of training. Note the rank-based variant with DQN as the baseline is an early version without IS. Here, the bias introduced by prioritized replay was instead corrected by annealing $\alpha$ to zero.
:::
B.2.3 Evaluation
We evaluate our agents using the human starts evaluation method described in ([23]). Human starts evaluation uses start states sampled randomly from human traces. The test evaluation that agents periodically undergo during training uses start states that are randomized by doing a random number of no-ops at the beginning of each episode. Human starts evaluation averages the score over 100 evaluations of 30 minutes of game time. All learning curve plots show scores under the test evaluation and were generated using the same code base, with the same random seed initializations.
Table 4 and Table 5 show evaluation method differences and the $\epsilon$ used in the $\epsilon$-greedy policy for each agent during evaluation. The agent evaluated with the human starts evaluation is the best agent found during training as in ([23]).
:Table 4: Evaluation method comparison.
| Evaluation method | Frames | Emulator time | Number of evaluations | Agent start point |
|---|---|---|---|---|
| Human starts | 108, 000 | 30 mins | 100 | human starts |
| Test | 500, 000 | 139 mins | 1 | up to 30 random no-ops |
:::

Table 5: The $\epsilon$ used in the $\epsilon$-greedy policy for each agent, for each evaluation method.
:::
Normalized score is calculated as in ([23]):
$ \text{score}\text{normalized} = \frac{\text{score}\text{agent} - \text{score}\text{random}}{\left|\text{score}\text{human} - \text{score}_\text{random}\right|}\tag{4} $
Note the absolute value of the denominator is taken. This only affects Video Pinball where the random score is higher than the human score. Combined with a high agent score, Video Pinball has a large effect on the mean normalized score. We continue to use this so our normalized scores are comparable.
B.3 Class-imbalanced MNIST
B.3.1 Dataset Setup
In our supervised learning setting we modified MNIST to obtain a new training dataset with a significant label imbalance. This new dataset was obtained by considering a small subset of the samples that correspond to the first 5 digits (0, 1, 2, 3, 4) and all of the samples that correspond to the remaining 5 labels (5, 6, 7, 8, 9). For each of the first 5 digits we randomly sampled 1% of the available examples, i.e., 1% of the available 0s, 1% of the available 1s etc. In the resulting dataset there are examples of all 10 different classes but it is highly imbalanced since there are 100 times more examples that correspond to the 5, 6, 7, 8, 9 classes than to the 0, 1, 2, 3, 4 ones. In all our experiments we used the original MNIST test dataset without removing any samples.
B.3.2 Training Setup
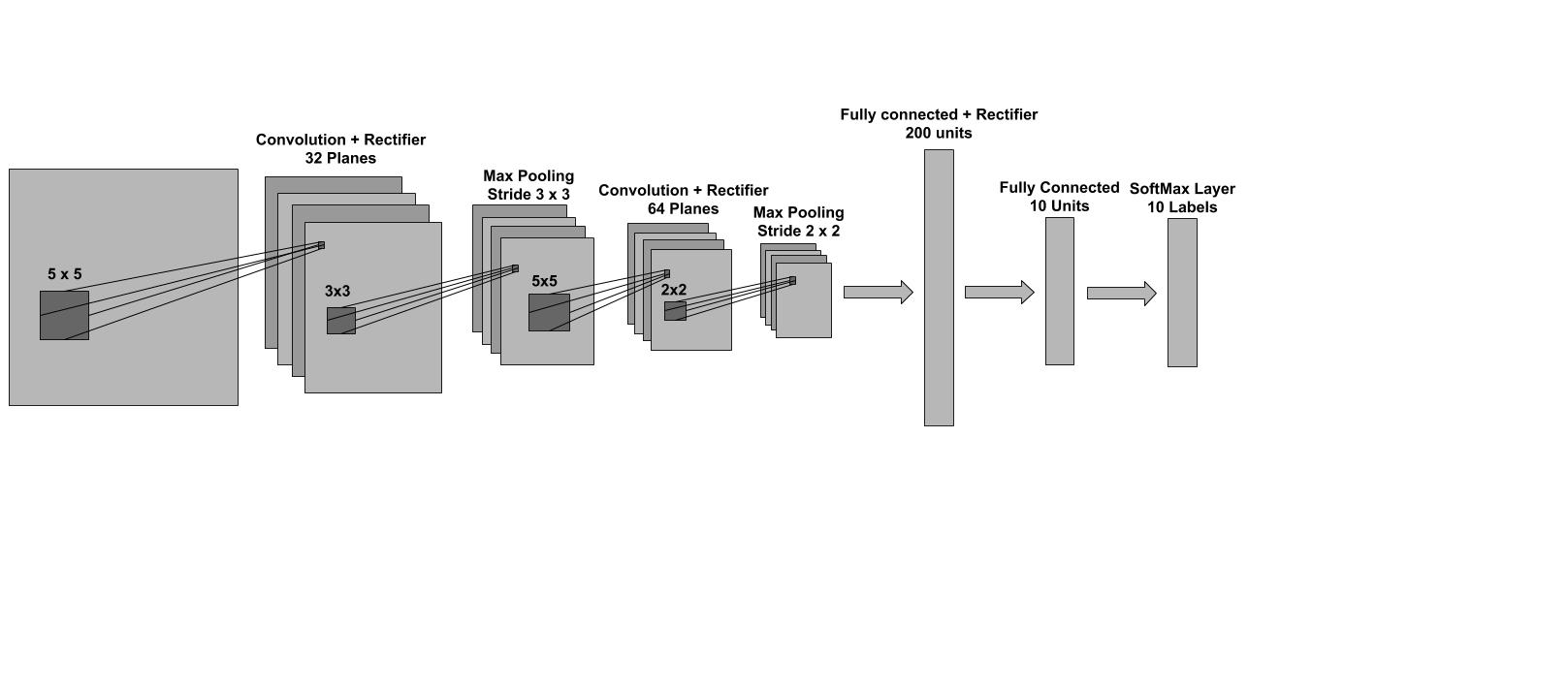
In our experiments we used a 4 layer feed-forward neural network with an architecture similar to that of LeNet5 ([36]). This is a 2 layer convolutional neural network followed by 2 fully connected layers at the top. Each convolutional layer is comprised of a pure convolution followed by a rectifier non-linearity and a subsampling max pooling operation. The two fully-connected layers in the network are also separated by a rectifier non-linearity. The last layer is a softmax which is used to obtain a normalized distribution over the possible labels. The complete architecture is shown in Figure 6, and is implemented using Torch7 ([37]). The model was trained using stochastic gradient descent with no momentum and a minibatch of size 60. In all our experiments we considered 6 different step-sizes (0.3, 0.1, 0.03, 0.01, 0.003 and 0.001) and for each case presented in this work, we selected the step-size that lead to the best (balanced) validation performance. We used the negative log-likelihood loss criterion and we ran experiments with both the weighted and unweighted version of the loss. In the weighted case the loss of the examples that correspond to the first 5 digits (0, 1, 2, 3, 4) was scaled by a factor of a 100 to accommodate the label imbalance in the training set described above.

:::
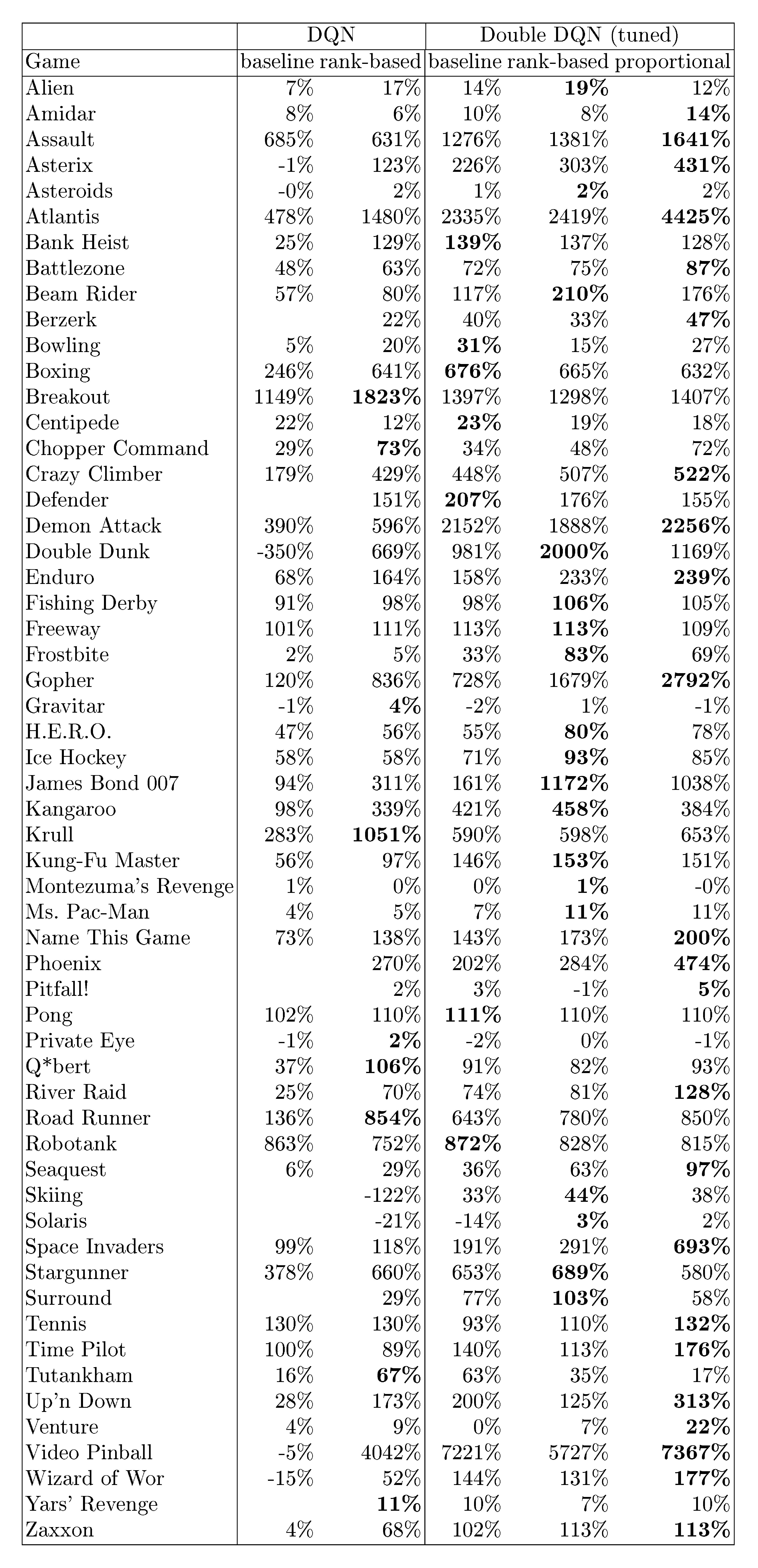
Table 6: Normalized scores on 57 Atari games (random is $0%$, human is $100%$), from a single training run each, using human starts evaluation (see Appendix B.2.3). Baselines are from [23], see Equation 4 for how normalized scores are calculated.
:::
:::
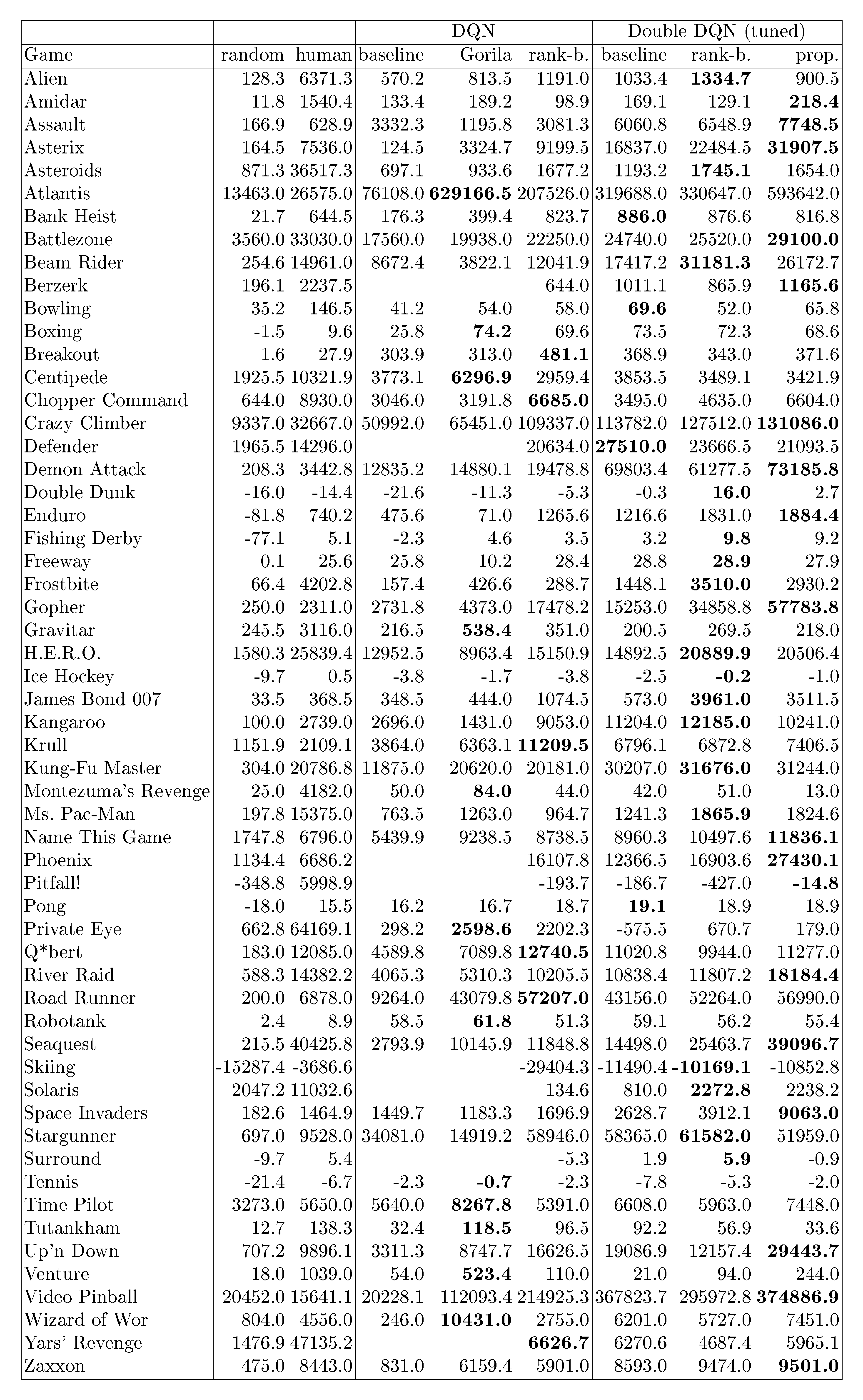
Table 7: Raw scores obtained on the original 49 Atari games plus 8 additional games where available, evaluated on human starts. Human, random, DQN and tuned Double DQN scores are from [23]. Note that the Gorila results from [21] used much more data and computation, but the other methods are more directly comparable to each other in this respect.
:::
References
Section Summary: This references section lists academic papers and studies primarily focused on reinforcement learning and artificial intelligence, including foundational works on self-improving agents, deep learning for playing Atari games, and techniques for exploration and planning in AI systems. It also draws from neuroscience research on memory replay in the brain's hippocampus and how rewards influence neural reactivation, bridging biological insights with computational methods. Additional entries cover practical implementations, such as prioritized sweeping algorithms and evaluation platforms for AI agents in simulated environments.
[1] Lin, Long-Ji. Self-improving reactive agents based on reinforcement learning, planning and teaching. Machine learning, 8(3-4):293–321, 1992.
[2] Mnih, Volodymyr, Kavukcuoglu, Koray, Silver, David, Graves, Alex, Antonoglou, Ioannis, Wierstra, Daan, and Riedmiller, Martin. Playing atari with deep reinforcement learning. arXiv preprint arXiv:1312.5602, 2013.
[3] Mnih, Volodymyr, Kavukcuoglu, Koray, Silver, David, Rusu, Andrei A, Veness, Joel, Bellemare, Marc G, Graves, Alex, Riedmiller, Martin, Fidjeland, Andreas K, Ostrovski, Georg, Petersen, Stig, Beattie, Charles, Sadik, Amir, Antonoglou, Ioannis, King, Helen, Kumaran, Dharshan, Wierstra, Daan, Legg, Shane, and Hassabis, Demis. Human-level control through deep reinforcement learning. Nature, 518(7540):529–533, 2015.
[4] Schmidhuber, Jürgen. Curious model-building control systems. In Neural Networks, 1991. 1991 IEEE International Joint Conference on, pp.\ 1458–1463. IEEE, 1991.
[5] Atherton, Laura A, Dupret, David, and Mellor, Jack R. Memory trace replay: the shaping of memory consolidation by neuromodulation. Trends in neurosciences, 38(9):560–570, 2015.
[6] Ólafsdóttir, H Freyja, Barry, Caswell, Saleem, Aman B, Hassabis, Demis, and Spiers, Hugo J. Hippocampal place cells construct reward related sequences through unexplored space. Elife, 4:e06063, 2015.
[7] Foster, David J and Wilson, Matthew A. Reverse replay of behavioural sequences in hippocampal place cells during the awake state. Nature, 440(7084):680–683, 2006.
[8] Singer, Annabelle C and Frank, Loren M. Rewarded outcomes enhance reactivation of experience in the hippocampus. Neuron, 64(6):910–921, 2009.
[9] McNamara, Colin G, Tejero-Cantero, Álvaro, Trouche, Stéphanie, Campo-Urriza, Natalia, and Dupret, David. Dopaminergic neurons promote hippocampal reactivation and spatial memory persistence. Nature neuroscience, 2014.
[10] Moore, Andrew W and Atkeson, Christopher G. Prioritized sweeping: Reinforcement learning with less data and less time. Machine Learning, 13(1):103–130, 1993.
[11] Andre, David, Friedman, Nir, and Parr, Ronald. Generalized prioritized sweeping. In Advances in Neural Information Processing Systems. Citeseer, 1998.
[12] van Seijen, Harm and Sutton, Richard. Planning by prioritized sweeping with small backups. In Proceedings of The 30th International Conference on Machine Learning, pp.\ 361–369, 2013.
[13] White, Adam, Modayil, Joseph, and Sutton, Richard S. Surprise and curiosity for big data robotics. In Workshops at the Twenty-Eighth AAAI Conference on Artificial Intelligence, 2014.
[14] Geramifard, Alborz, Doshi, Finale, Redding, Joshua, Roy, Nicholas, and How, Jonathan. Online discovery of feature dependencies. In Proceedings of the 28th International Conference on Machine Learning (ICML-11), pp.\ 881–888, 2011.
[15] Sun, Yi, Ring, Mark, Schmidhuber, Jürgen, and Gomez, Faustino J. Incremental basis construction from temporal difference error. In Proceedings of the 28th International Conference on Machine Learning (ICML-11), pp.\ 481–488, 2011.
[16] Galar, Mikel, Fernandez, Alberto, Barrenechea, Edurne, Bustince, Humberto, and Herrera, Francisco. A review on ensembles for the class imbalance problem: bagging-, boosting-, and hybrid-based approaches. Systems, Man, and Cybernetics, Part C: Applications and Reviews, IEEE Transactions on, 42(4):463–484, 2012.
[17] Narasimhan, Karthik, Kulkarni, Tejas, and Barzilay, Regina. Language understanding for text-based games using deep reinforcement learning. In Conference on Empirical Methods in Natural Language Processing (EMNLP), 2015.
[18] Hinton, Geoffrey E. To recognize shapes, first learn to generate images. Progress in brain research, 165:535–547, 2007.
[19] Guo, Xiaoxiao, Singh, Satinder, Lee, Honglak, Lewis, Richard L, and Wang, Xiaoshi. Deep Learning for Real-Time Atari Game Play Using Offline Monte-Carlo Tree Search Planning. In Ghahramani, Z., Welling, M., Cortes, C., Lawrence, N.D., and Weinberger, K.Q. (eds.), Advances in Neural Information Processing Systems 27, pp.\ 3338–3346. Curran Associates, Inc., 2014.
[20] Stadie, Bradly C, Levine, Sergey, and Abbeel, Pieter. Incentivizing exploration in reinforcement learning with deep predictive models. arXiv preprint arXiv:1507.00814, 2015.
[21] Nair, Arun, Srinivasan, Praveen, Blackwell, Sam, Alcicek, Cagdas, Fearon, Rory, Maria, Alessandro De, Panneershelvam, Vedavyas, Suleyman, Mustafa, Beattie, Charles, Petersen, Stig, Legg, Shane, Mnih, Volodymyr, Kavukcuoglu, Koray, and Silver, David. Massively parallel methods for deep reinforcement learning. arXiv preprint arXiv:1507.04296, 2015.
[22] Bellemare, Marc G., Ostrovski, Georg, Guez, Arthur, Thomas, Philip S., and Munos, Rémi. Increasing the action gap: New operators for reinforcement learning. In Proceedings of the AAAI Conference on Artificial Intelligence, 2016. URL http://arxiv.org/abs/1512.04860.
[23] van Hasselt, Hado, Guez, Arthur, and Silver, David. Deep Reinforcement Learning with Double Q-learning. In Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence, 2016. URL http://arxiv.org/abs/1509.06461.
[24] Wang, Z., de Freitas, N., and Lanctot, M. Dueling network architectures for deep reinforcement learning. Technical report, 2015. URL http://arxiv.org/abs/1511.06581.
[25] Mahmood, A Rupam, van Hasselt, Hado P, and Sutton, Richard S. Weighted importance sampling for off-policy learning with linear function approximation. In Advances in Neural Information Processing Systems, pp.\ 3014–3022, 2014.
[26] Bellemare, Marc G, Naddaf, Yavar, Veness, Joel, and Bowling, Michael. The arcade learning environment: An evaluation platform for general agents. arXiv preprint arXiv:1207.4708, 2012.
[27] van Hasselt, Hado. Double Q-learning. In Advances in Neural Information Processing Systems, pp.\ 2613–2621, 2010.
[28] Felzenszwalb, Pedro, McAllester, David, and Ramanan, Deva. A discriminatively trained, multiscale, deformable part model. In Computer Vision and Pattern Recognition, 2008. CVPR 2008. IEEE Conference on, pp.\ 1–8. IEEE, 2008.
[29] LeCun, Yann, Cortes, Corinna, and Burges, Christopher JC. The MNIST database of handwritten digits, 1998.
[30] Rosin, Christopher D and Belew, Richard K. New methods for competitive coevolution. Evolutionary Computation, 5(1):1–29, 1997.
[31] Riedmiller, Martin. Rprop-description and implementation details. 1994.
[32] Schaul, Tom, Zhang, Sixin, and Lecun, Yann. No more pesky learning rates. In Proceedings of the 30th International Conference on Machine Learning (ICML-13), pp.\ 343–351, 2013.
[33] Kingma, Diederik P. and Ba, Jimmy. Adam: A method for stochastic optimization. CoRR, abs/1412.6980, 2014.
[34] Diamond, Jared. Zebras and the Anna Karenina principle. Natural History, 103:4–4, 1994.
[35] Watkins, Christopher JCH and Dayan, Peter. Q-learning. Machine learning, 8(3-4):279–292, 1992.
[36] Lecun, Y., Bottou, L., Bengio, Y., and Haffner, P. Gradient-based learning applied to document recognition. Proceedings of the IEEE, 86(11):2278–2324, Nov 1998. ISSN 0018-9219. doi:10.1109/5.726791.
[37] Collobert, Ronan, Kavukcuoglu, Koray, and Farabet, Clément. Torch7: A matlab-like environment for machine learning. In BigLearn, NIPS Workshop, number EPFL-CONF-192376, 2011.