Memory Caching: RNNs with Growing Memory
Ali Behrouz $^{1,2, \dagger}$ Zeman Li $^{1,3}$ Yuan Deng $^{1}$ Peilin Zhong $^{1}$ Meisam Razaviyayn $^{1,3}$ Vahab Mirrokni $^{1}$
$^{1}$ Google Research
$^{2}$ Cornell University
$^{3}$ USC
$^{\dagger}$ Correspondence: [email protected]
Abstract
Transformers have been established as the de-facto backbones for most recent advances in sequence modeling, mainly due to their growing memory capacity that scales with the context length. While plausible for retrieval tasks, it causes quadratic complexity and so has motivated recent studies to explore viable subquadratic recurrent alternatives. Despite showing promising preliminary results in diverse domains, such recurrent architectures underperform Transformers in recall-intensive tasks, often attributed to their fixed-size memory. In this paper, we introduce Memory Caching ($\textsc{MC}$), a simple yet effective technique that enhances recurrent models by caching checkpoints of their memory states (a.k.a. hidden states). $\textsc{MC}$ allows the effective memory capacity of RNNs to grow with sequence length, offering a flexible trade-off that interpolates between the fixed memory (i.e., $\mathcal{O}(L)$ complexity) of RNNs and the growing memory (i.e., $\mathcal{O}(L^2)$ complexity) of Transformers. We propose four variants of MC, including gated aggregation and sparse selective mechanisms, and discuss their implications on both linear and deep memory modules. Our experimental results on language modeling, and long-context understanding tasks show that $\textsc{MC}$ enhances the performance of recurrent models, supporting its effectiveness. The results of in-context recall tasks indicate that while Transformers achieve the best accuracy, our MC variants show competitive performance, close the gap with Transformers, and performs better than state-of-the-art recurrent models.
Executive Summary: Modern AI models for processing text and sequences, like Transformers, excel at handling long inputs but suffer from high computational costs that grow quadratically with sequence length, making them inefficient for very long contexts such as extended documents or conversations. This limits their use in real-world applications needing quick processing of large data volumes. In contrast, recurrent neural networks (RNNs) process sequences efficiently with fixed memory but often forget earlier information, underperforming on tasks requiring recall of distant details. With growing demands for AI to manage longer contexts in areas like search, reasoning, and content generation, there is an urgent need for models that balance efficiency and memory capacity.
This paper introduces Memory Caching (MC), a technique to boost RNNs by allowing their memory to grow controllably with sequence length, bridging the gap between RNNs and Transformers. The goal is to evaluate whether MC can improve RNN performance on language tasks without the full efficiency drawbacks of Transformers.
The authors developed MC by dividing input sequences into segments, compressing each into a memory state, and caching these states for later use. They then aggregate cached memories with the current one using simple methods like adding them with gates that weigh relevance (Gated Residual Memory, or GRM) or averaging parameters (Memory Soup), and a sparse version that selects only the most relevant caches (Sparse Selective Caching, or SSC) to save resources. They tested four MC variants on three RNN types—Linear Attention, Deep Linear Attention, and Titans—across language modeling and long-context tasks. Models with 760 million to 1.3 billion parameters were trained on 30 billion to 100 billion tokens from web text datasets like FineWeb over context lengths up to 32,000 tokens, with segment sizes from 16 to 512 tokens. Key assumptions included uniform or logarithmic segmentation to control complexity, focusing on causal processing for text generation.
The core findings highlight MC's effectiveness. First, MC-enhanced RNNs consistently outperformed baseline RNNs by 0.8 percentage points on average in downstream tasks like commonsense reasoning and question answering, and reduced perplexity (a measure of prediction error) by about 5-10% in language modeling. Second, on recall-intensive benchmarks like Needle-in-a-Haystack—where models retrieve a specific detail from long text—MC variants succeeded 10-20% more often than plain RNNs and beat logarithmic attention methods, especially beyond 8,000 tokens. Third, in in-context retrieval tasks from datasets like Natural Questions and SQuAD, MC closed the performance gap with Transformers to within 5-10%, surpassing state-of-the-art RNNs while using far less computation. Fourth, GRM and SSC proved most robust, with constant-size segments outperforming logarithmic ones by enabling better recall. Finally, MC offered a tunable complexity of O(NL), where N is the number of segments, yielding 2-5 times faster training throughput than Transformers for sequences over 16,000 tokens, with minimal added overhead for RNNs.
These results mean MC makes RNNs more practical for long-context AI applications, improving accuracy in retrieval and reasoning while cutting costs—vital for scaling models in resource-constrained settings like mobile devices or real-time search. Unlike expectations that deep memories alone would suffice, MC shows that simple caching and selective access unlock RNN potential, outperforming hybrids without their complexity. This reduces risks of information loss in long inputs, enhances safety in tasks like fact-checking, and shortens development timelines by leveraging existing RNNs.
Leaders should integrate MC into RNN-based systems, starting with GRM or SSC variants for tasks needing long recall, as they provide the best trade-off of performance and speed. For production, pilot MC on specific use cases like document summarization, tuning segment size to balance accuracy and latency—smaller segments boost recall but raise costs by 20-50%. Further work is needed to scale to billion-parameter models and test in non-text domains like video; additional analysis on diverse datasets would strengthen decisions.
While experiments used standard academic setups, limitations include focus on English text and moderate scales, potentially underestimating gains or issues in multilingual or massive deployments. Assumptions about segment relevance may falter in noisy data. Confidence is high in the observed improvements for tested scenarios, but caution is advised for untested extremes like sequences over 100,000 tokens, where more validation is required.
1. Introduction
Section Summary: Transformers have driven major progress in machine learning by using an attention mechanism that acts like an expanding memory, but this comes at the cost of high computational demands that grow quadratically with input length. To address this, researchers have revived recurrent neural networks, which efficiently compress past data into a fixed memory but struggle with long sequences because they inevitably forget earlier information. The paper introduces Memory Caching, a technique that lets recurrent models expand their memory by saving snapshots of compressed states along the way, blending the efficiency of these networks with the recall power of transformers through innovative ways to blend and select past memories, as shown in tests on language and retrieval tasks.
Transformers ([1]) are the foundation of recent advances in machine learning across diverse domains ([2, 3, 4]). This success often is attributed to their ability to learn at scale ([5]) and in-context ([6]), both of which are the byproduct of their primary building block–attention module–that acts as an associative memory with growing capacity ([7, 8, 9]). While effective for many retrieval tasks ([10]), this growing memory incurs quadratic complexity and high inference-time memory usage (KV-caching). This has motivated the development of sub-quadratic architectures that aim to improve efficiency while maintaining performance ([11, 12, 13]).
In particular, recurrent neural networks that aim to compress the past data into their memory state, maintaining a fixed size over the entire input sequence, have regained attention in recent years ([14, 15, 16, 17]). Despite showing promising results in diverse short-context language modeling ([18]) and other sequence modeling tasks such as video data ([19]), the fixed-memory state of such recurrent architectures is the bottleneck to unleash their actual power. The foundation of these architectures is based on recurrence and data compression, which, with careful design, can result in highly efficient and expressive learning algorithms ([20, 21]). However, their fixed capacity to compress a growing sequence forces them to forget past information, which is a critical bottleneck, specifically in recall-intensive and long-context tasks ([10, 22]).
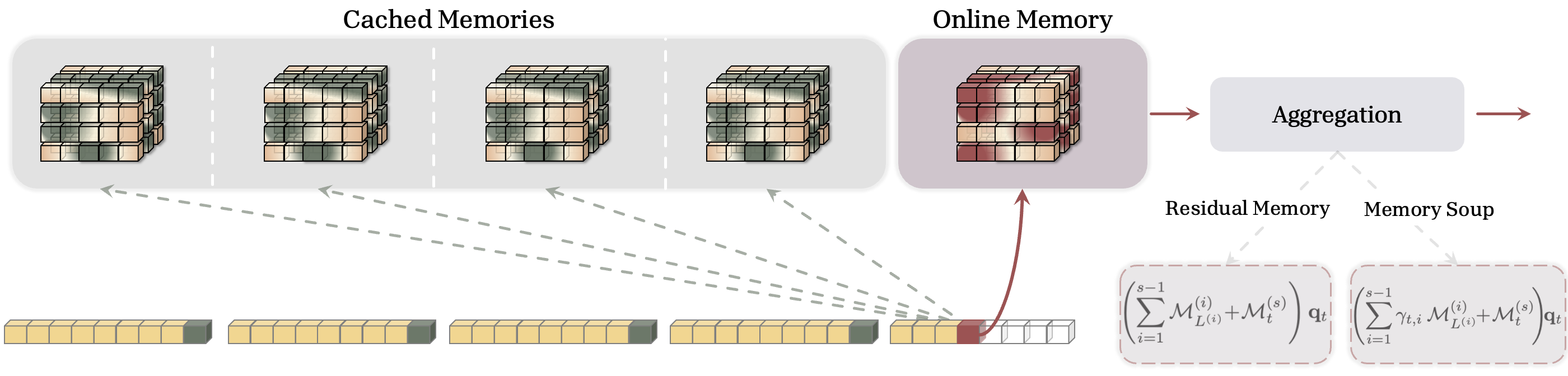
Contributions. We introduce Memory Caching ($\textsc{MC}$), a general technique that allows the effective memory of recurrent models to grow with sequence length by caching checkpoints of the memory states (see Figure 1). MC provides a flexible middle ground interpolating between standard recurrence and attention, offering a controllable complexity of $\mathcal{O}(NL)$. This allows for flexible interpolation between the $\mathcal{O}(L)$ complexity of RNNs and the $\mathcal{O}(L^2)$ complexity of Transformers. Our contributions are threefold:
- The MC Framework: We propose segmenting the sequence and caching the compressed memory state of each segment, allowing the model to directly access compressed information from the entire history.
- Novel Aggregation Strategies: We introduce four methods to utilize these cached memories: (i, ii) (Gated) Residual Memory, which uses residual connections and a novel context-aware gating mechanism; (iii) Memory Soup, inspired by weight souping, which averages the parameters of cached memory modules (distinct for non-linear memories); and (iv) Sparse Selective Caching (SSC), which uses a Mixture-of-Experts style router to select only the most contextually relevant cached memories for efficient aggregation.
- Empirical Validation: As a proof of concept, we demonstrate the effectiveness of MC on three architectures of Linear Attention (LA) ([14]), deep memory module Titans ([17]) and Sliding Window Linear Attention (SWLA), and Deep Linear Attention (DLA) ([23]), across language modeling, long-context, and retrieval tasks, showing that MC enhances performance and extends the effective context length of RNNs.
2. Preliminaries and Background
Section Summary: This section provides essential background on attention mechanisms in AI models like Transformers, starting with standard attention, which lets a model focus on relevant parts of input data by weighing past elements but requires heavy computation for long sequences. It then introduces linear attention, a more efficient version that uses a simpler mathematical kernel to maintain a compact memory of past information, reducing the workload. Finally, it explores how these models can be seen as dynamically learning and memorizing patterns during processing, framing the upcoming Memory Caching approach as a way to save optimization states for better long-term recall.
In this section, we review necessary background and establish notations. Particularly, we review the concepts of attention and its linear variants, followed by a discussion on parametric in-context learning and nested learning paradigm ([9, 24]), which we build Memory Caching on.
Notations. We use bold lowercase (resp. uppercase) letters for vectors (resp. matrices) and use subscript $t$ to refer to the state of the entities correspond to time $t$. Throughout, we let $x \in \mathbb{R}^{L \times d_{\text{in}}}$ be the input, $\mathcal{M}t$ be the state of memory $\mathcal{M}(\cdot)$ at time $t$, $\mathbf{K}$ be the keys, $\mathbf{V}$ be the values, $\mathbf{Q}$ be the query matrices, and $L$ denote the sequence length. We focus on MLP-based architectures for memory with $\mathcal{L}{\mathcal{M}} \geq 1$ layers. Notably, this formulation includes linear matrix-valued memory modules when $\mathcal{L}{\mathcal{M}} = 1$. When it is needed, we parameterize the memory module $\mathcal{M}(\cdot)$ with $\boldsymbol{\theta}{\mathcal{M}} := {W_1, \dots, W_{\mathcal{L}_{\mathcal{M}}}, \dots }$, which at least includes the parameters of linear layers in the MLP.
Attention. Attention ([1]) is the primary building block of Transformers that acts as their associative memory ([25, 9, 26]). Given input $x \in \mathbb{R}^{L \times d_{\text{in}}}$, causal attention computes output $\mathbf{y} \in \mathbb{R}^{L \times d_{\text{in}}}$ over input dependent key, value, and query matrices $\mathbf{Q} = x \mathbf{W}{\mathbf{Q}}, \mathbf{K} = x \mathbf{W}{\mathbf{K}}, : \text{and}:: \mathbf{V} = x \mathbf{W}_{\mathbf{V}}$ as:
$ \begin{align} &\mathbf{y}i = \sum{t = 1}^{i} \frac{ \exp\left(\mathbf{q}_i^{\top} \mathbf{k}t\right) \mathbf{v}t }{\sum{\ell = 1}^{i} \exp\left(\mathbf{q}i^{\top} \mathbf{k}{\ell}\right)} = \frac{1}{Z_i} \sum{t = 1}^{i} \exp\left(\mathbf{q}_i^{\top} \mathbf{k}_t\right) \mathbf{v}_t, \end{align}\tag{1} $
where $\mathbf{W}{\mathbf{Q}}, \mathbf{W}{\mathbf{K}}, $ and $\mathbf{W}{\mathbf{V}} \in \mathbb{R}^{d{\text{in}} \times d_{\text{in}}}$ are learnable parameters, and $Z_i = {\sum_{\ell = 1}^{i} \exp\left(\mathbf{q}i^{\top} \mathbf{k}{\ell}\right)}$ is the normalization term. Attention requires $\mathcal{O}(L^2)$ operations due to the need to access all past tokens.
Linear Attention. Linear attention ([14]) and its variants ([27, 28, 29]) improves efficiency of attention by replacing the $\exp(\cdot)$ operator in Equation 1 with a separable kernel $\phi(\cdot)$, resulting in an efficient recurrent formulation:
$ \begin{align} &\mathbf{y}i = \sum{t = 1}^{i} \frac{ \phi\left(\mathbf{q}_i\right)^{\top} \phi\left(\mathbf{k}_t\right) \mathbf{v}t }{\sum{\ell = 1}^{i} \phi\left(\mathbf{q}i \right)^{\top} \phi \left(\mathbf{k}{\ell}\right)} = \frac{1}{Z_i} : \mathcal{M}_i \phi\left(\mathbf{q}_i\right):, \end{align}\tag{2} $
where $\mathcal{M}t !=! \mathcal{M}{t-1} + \mathbf{v}_t \phi\left(\mathbf{k}_t\right)^{\top} $ acts as the fixed-size memory ([14]).
Test-time Memorization and Nested Learning Perspective. A recent unifying framework interprets the update rule of sequence models—including both attention and modern RNNs—as a dynamic in-context learning/memorization process with different objectives ([9, 24]). In this view, the model acts as an associative memory that actively learns the mapping between input tokens (keys and values). This memorization is achieved by optimizing an internal objective, often formalized as an $L_2$ regression problem ([26]) or with a general objective of "attentional bias" ([9, 24]). This perspective frames the memory state as a dynamic entity optimized during the forward pass. Particularly, in the simplest form of Miras framework ([9]), associative memory $\mathcal{M}(\cdot)$ aims to learn a mapping between keys ${{\bm{k}}t}{t = 1}^{L}$ and values ${{\bm{v}}t}{t = 1}^{L}$ based on an objective (called "attentional bias"):
$ \begin{align} \mathcal{M}{t+1} = \arg \min{\mathcal{M}} :: \mathcal{L}\left(\mathcal{M}({\bm{k}}_t); {\bm{v}}t \right) + \texttt{Ret} \left(\mathcal{M}; \mathcal{M}{t} \right), \end{align}\tag{3} $
where objective $\mathcal{L}(\cdot)$ measures the quality of mapping and $\texttt{Ret} \left(\mathcal{M}; \mathcal{M}_{t} \right)$ keeps the new solution close to the last state of the memory. For particular choices of attentional bias, one can recover well-known architectures: For example, letting $\mathcal{L}\left(\mathcal{M}({\bm{k}}_t); {\bm{v}}_t \right) = \langle \mathcal{M}({\bm{k}}_t), {\bm{v}}_t \rangle$ and $\mathcal{M}(\cdot) \in \mathbb{R}^{d \times d}$, recovers unnormalized linear attention architecture ([14]). We leverage this view by introducing Memory Caching, where cached states serve as checkpoints of this optimization process, enhancing the model's ability to retrieve information across long sequences.
3. Recurrent Neural Networks with Memory Caching
Section Summary: Recurrent neural networks (RNNs) struggle with long sequences because their fixed memory size causes overflow and poor performance, while attention mechanisms store everything from the past at a high computational cost that grows quadratically. To bridge this gap, the proposed Memory Caching approach divides the input sequence into manageable segments, updates a memory state for each one like in an RNN, and saves the final memory from earlier segments to allow scalable growth without excessive expense. Outputs are computed by combining the current segment's memory with these cached ones, either through simple addition or gated weighting that selectively emphasizes relevant past information based on the current input.
RNNs maintain a fixed-size memory to compress the input sequence. As sequences grow long, this leads to memory overflow and performance degradation. Conversely, attention caches all past tokens, resulting in a growing memory but quadratic cost. We propose Memory Caching ($\textsc{MC}$) to cache intermediate memory states, providing a middle ground where the model's memory can grow with arbitrary scale. This allows computational costs to interpolate between $\mathcal{O}(L)$ (similar to RNNs) and $\mathcal{O}(L^2)$ (similar to Transformers). To this end, given a sequence of tokens $x \in \mathbb{R}^{L \times d_{\text{in}}}$, we split the sequence into segments $S^{(1)}, \dots, S^{(N)}$ with size $L^{(1)}, \dots, L^{(N)}$ and use memories $\mathcal{M}^{(1)}, \dots, \mathcal{M}^{(N)}$ to compress the segments. The memory update rule or the recurrence for memory corresponds to $s$-th segment is:
$ \begin{align} \nonumber & {\bm{k}}t = x_t W{{\bm{k}}}, \qquad {\bm{v}}t = x_t W{{\bm{v}}}, \qquad {\bm{q}}t = x_t W{{\bm{q}}}, \ & \mathcal{M}^{(s)}t = f\left(\mathcal{M}^{(s)}{t-1}; {\bm{k}}_t, {\bm{v}}_t \right), \qquad \text{where} \quad 1 \leq t \leq L^{(s)} :, \end{align}\tag{4} $
where $f(\cdot)$ is the learning update rule (e.g., $f\left(\mathcal{M}^{(s)}_{t-1}; {\bm{k}}_t, {\bm{v}}t \right) = \mathcal{M}^{(s)}{t-1} + {\bm{v}}t {\bm{k}}t^{\top}$ for linear attention ([14])). Using the above formulation, after updating the memories, we cache their last state in each segment (i.e., ${\mathcal{M}^{(s)}{L^{(s)}}}{s = 1}^{T}$ where $T$ is the index of the current segment, $x_t \in S^{(T)}$). Standard RNNs compute the output using only the current memory state: $\mathbf{y}_t = \mathcal{M}_t({\bm{q}}_t)$. In contrast, our formulation uses all cached memories alongside the current memory (online memory) to compute the output for query ${\bm{q}}_t$. Given an arbitrary aggregation function, $\texttt{Agg}(\cdot; \cdot; \cdot)$, the output is:
$ \begin{align} \mathbf{y}_ t = \texttt{Agg}\left({\mathcal{M}^{(1)}{L^{(1)}} (\cdot), \dots, \mathcal{M}^{(s-1)}{L^{(s-1)}} (\cdot)}; \mathcal{M}^{(s)}_{t} (\cdot); \mathbf{q}_t\right), \end{align} $
where $s$ is the indices of the current segment. Note that for $1 \leq i \leq s$, the term $\mathcal{M}^{(i)}_{L^{(i)}} (\mathbf{q}_t)$ provides us with the corresponding information to query ${\bm{q}}_t$ in segment $i$. In the following sections, we present different effective choices of $\texttt{Agg}(\cdot; \cdot; \cdot)$ function to incorporate the past information into the computation of the current output and increasing the effective memory capacity of the model.
3.1 Residual Memory
We begin with the simplest $\texttt{Agg}(\cdot; \cdot; \cdot)$ operator: a summation, acting as a residual connection across memory states. In this case, given keys, values, and queries (see Equation 4) and segments $S^{(1)}, \dots, S^{(N)}$, we define the memory update and output computation at time $t$ in segment $s$ as:
$ \begin{align} \tag{a} & \mathcal{M}^{(s)}t = f\left(\mathcal{M}^{(s)}{t-1}; {\bm{k}}_t, {\bm{v}}_t \right), \qquad \text{where} \quad 1 \leq t \leq L^{(s)} :, \ \tag{b} &\mathbf{y}_t = \underset{\text{Online Memory}}{\underbrace{\mathcal{M}^{(s)}t (\mathbf{q}t)}} :: + :: \underset{\text{Cached Memories}}{\underbrace{\sum{i = 1}^{s-1} \mathcal{M}^{(i)}{L^{(i)}} (\mathbf{q}_t)}} : . \end{align}\tag{5} $
The critical change in memory caching is how the output is computed. In fact, for retrieval of the memory, the model uses forward passes over both the current memory (called online memory) and the cached memories for input query ${\bm{q}}_t$.
Gated Residual Memory (GRM). When the memory module is strictly linear (i.e., $\mathcal{M}$ is a matrix), the Residual Memory formulation Equation (5b) mathematically collapses into a standard fixed-size memory, as the cached memories can be pre-summed (c.f. Equation 9b below). However, in practice, our experimental results show that even this simple formulation can enhance the power of recurrent models (see Section 5). The main reason is even a simple residual memory acts as a retention operator that enhance access to the long past. A further limitation of the residual approach is that it treats all cached memories equally, ignoring their relevance to the query ${\bm{q}}_t$. To enable selective retrieval, we introduce input-dependent gating. Given input $x_t$ in segment $s$, we define parameters $0 \leq \gamma^{(1)}t, \dots, \gamma{t}^{(s)} \leq 1$ be input-dependent parameters and reformulate the output as:
$ \begin{align} & \mathcal{M}^{(s)}t = f\left(\mathcal{M}^{(s)}{t-1}; {\bm{k}}_t, {\bm{v}}_t \right), ; \text{for} ; 1 \leq t \leq L^{(s)}, \ &\mathbf{y}_t = \gamma_t^{(s)} \mathcal{M}^{(s)}t (\mathbf{q}t) :: + :: \sum{i = 1}^{s-1} \gamma_t^{(i)} \mathcal{M}^{(i)}{L^{(i)}} (\mathbf{q}_t) \end{align}\tag{6} $
Here, parameters $\gamma^{(i)}{t}$ modulate the contribution of each segment to the output. When $\gamma^{(i)}{t} \rightarrow 1$ (resp. $\gamma^{(i)}_{t} \rightarrow 0$), $i$-th segment has more (resp. less) contribution to the output. Due to these input dependent parameters, the above formulation cannot be pre-computed before this token and also cannot be reused for next tokens/segments. Therefore, contrary to the previous variant, it does not collapse into the fixed-size memory case (even in the linear memory case) and so requires to be recomputed for every token and needs caching memory states. A simple choice of parametrization for $\gamma^{(i)}_t$ s is to define them as linear projection of input $x_t$ (similar to projections for keys, values, and queries). With this parametrization, however, $\gamma^{(i)}_t$ acts as a position-based filtering/focus, meaning that the context of $x_t$ only determines how much the $i$-th segment's memory (based on the position) contributes, no matter what its context is. To overcome this issue, we suggests making $\gamma^{(i)}_t$ as a function of both $x_t$ and $i$-th segment $S^{(i)}$, incorporating both of their contexts and how similar they are. To this end, we introduce a connector parameter ${\bm{u}}_t$ as the linear projection of input, and define $\gamma^{(i)}_t$ as the similarity of ${\bm{u}}_t$ and $i$-th segment $S^{(i)}$:
$ \begin{align} \gamma^{(i)}_t = \langle {\bm{u}}_t, :\texttt{MeanPooling}(S^{(i)}) \rangle \qquad \text{where} :: {\bm{u}}t = x_t W{{\bm{u}}} :. \end{align}\tag{7} $
Here, $\texttt{MeanPooling}(\cdot)$ provides a simple representation of segment's context as the mean of all tokens. It, however, can be replaced by any other pooling process. In practice, we also normalize $\gamma^{(i)}_t$ using softmax $(\cdot)$. As an alternative parameterization, we can use ${\bm{u}}_t = {\bm{q}}_t$. When $\gamma^{(i)}_t$ s are constant, then GRM is equivalent to residual memory variant.
Example. To better illustrate the above formulations and as an illustrative example, we let $f\left(\mathcal{M}^{(s)}_{t-1}; {\bm{k}}t, {\bm{v}}t \right) = \mathcal{M}^{(s)}{t-1} - \nabla \langle \mathcal{M}^{(s)}{t-1}({\bm{k}}_t), {\bm{v}}_t \rangle$, where memory $\mathcal{M}(\cdot)$ is an arbitrary feedforward layer (e.g., MLP or gated MLP layers). This general form is equivalent to Deep Linear Attention (DLA) ([23]) and when the memory is a matrix (i.e., MLP with one layer) it is equivalent to the linear attention ([14]). Using residual memory caching on DLA results in a model with update and retrieval rules of:
$ \begin{align} \mathcal{M}^{(s)}t = \mathcal{M}^{(s)}{t-1} - \nabla \langle \mathcal{M}^{(s)}_{t-1}({\bm{k}}_t), {\bm{v}}_t \rangle, \qquad \mathbf{y}_t = \mathcal{M}^{(s)}t (\mathbf{q}t) :: + :: \sum{i = 1}^{s-1} \mathcal{M}^{(i)}{L^{(i)}} (\mathbf{q}_t) : . \end{align}\tag{8} $
When using a linear matrix-valued memory (i.e., linear attention), Equation 8 can be simplified to:
$ \begin{align} \tag{a} & \mathcal{M}^{(s)}t = \mathcal{M}^{(s)}{t-1} + {\bm{v}}_t {\bm{k}}_t^{\top}, \ &\mathbf{y}_t = \mathcal{M}^{(s)}t \mathbf{q}t :: + :: \sum{i = 1}^{s-1} \mathcal{M}^{(i)}{L^{(i)}} \mathbf{q}t = \left(\mathcal{M}^{(s)}t : + : \sum{i = 1}^{s-1} \mathcal{M}^{(i)}{L^{(i)}} \right) \mathbf{q}_t :. \tag{b} \end{align}\tag{9} $
Memory Complexity. In the retrieval process, we use the current memory (online memory) and the cached memories of all previous segments and so given a fixed training sequence length, the number of cached memories is a function of segment lengths. While the memory update process has not changed and so requires $\mathcal{O}(L)$ operation, the retrieval process requires forward pass over all cached memory and so needs $\mathcal{O}(N)$ operations per token. This brings the complexity of the model to $\mathcal{O}(NL)$, where $1 \leq N \leq L$. Note that when $N = 1$ (only one segment), we do not need to cache any memory state, resulting in a simple recurrent memory model. When $N = L$, it means that each token is treated as a separate segment and so the memory state for all past tokens are cached. This closely matches the intuition behind the power of attention. In fact, attention by caching all past tokens, provide a direct access to each part of the sequence, enhancing the retrieval ability.
3.2 Memory Soup
Viewing the recurrence as a meta-learning process where memory states are checkpoints, we introduce the Memory Soup variant, inspired by [30]. The core idea is to combine the memory states (parameters) into a single data-dependent memory for retrieval. Similar to the previous variant, we use $\mathcal{M}^{(i)}{L^{(i)}}$ to refer to the cached memory corresponds to $i$-th segment and parameterize it with $\boldsymbol{\theta}{\mathcal{M}^{(i)}_{L^{(i)}}} := {W^{(i)}1, \dots, W^{(i)}{c}}$. Note that the architecture of memory is unchanged and so $c$ (the number of parameters) is the same for all memory states. Accordingly, the memory update and retrieval process for memory caching is defined as:
$ \begin{align} & \mathcal{M}^{(s)}t = f\left(\mathcal{M}^{(s)}{t-1}; {\bm{k}}_t, {\bm{v}}_t \right), ; \text{for} ; 1 \leq t \leq L^{(s)} :, \ &\mathbf{y}t = \mathcal{M}^{*}{t}({\bm{q}}_t) :, \end{align}\tag{10} $
where $\mathcal{M}^{}t$ is parametrized as: $ \boldsymbol{\theta}{\mathcal{M}^{}t} := \left{\sum{i = 1}^{s} \gamma_t^{(i)} W^{(i)}1, \dots, \sum{i = 1}^{s} \gamma_t^{(i)} W^{(i)}_{c}\right}.$ Therefore, each token has its own memory for retrieval that also depends on the input-data and can change. In fact, one can interpret the above process as a memory system that each token, builds its own memory to retrieve corresponding information from. Note that here $\gamma_t^{(i)}$ parameters are defined with the same process as Equation 7.
When the memory module $\mathcal{M}$ is linear, Memory Soup is mathematically equivalent to GRM Equation (6). This is because souping the weights and then applying the query is identical to applying the query to individual memories and then ensembling the outputs, due to the linearity of the operation. The distinction becomes crucial when using deep or non-linear memory modules (e.g., DLA or Titans). In these cases, the equivalence breaks down. Memory Soup constructs a new, input-dependent memory module $\mathcal{M}_{t}^{*}$ by interpolating the parameters themselves, effectively creating a specialized non-linear retrieval function tailored for that specific timestep.
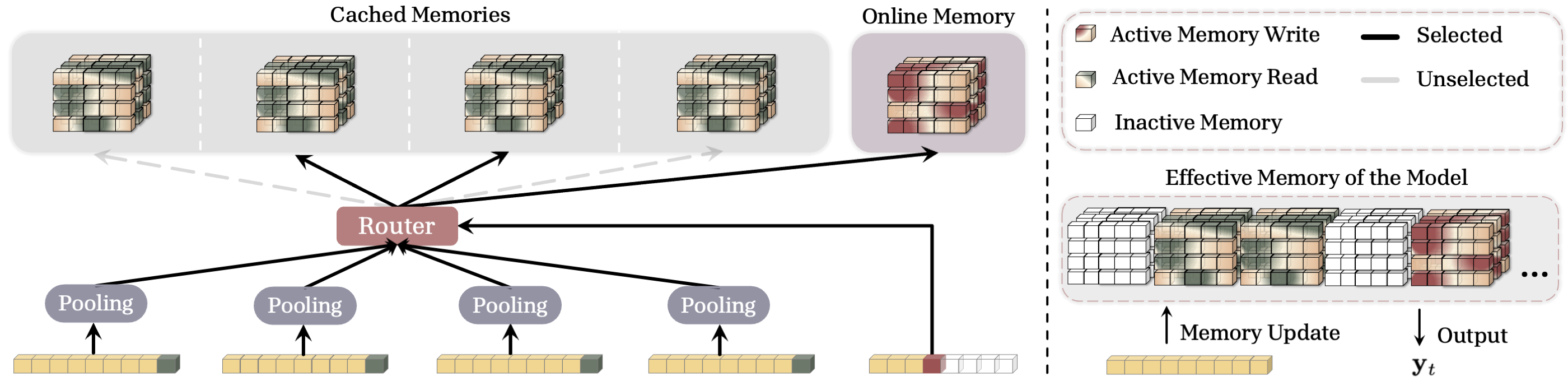
3.3 Sparse Selective Caching (SSC) of Memories
The previous variants attend to all past cached memories, which can cause significant memory overhead for ultra-long sequences. We introduce Sparse Selective Caching (SSC), where each token contextually selects a subset of cached memories, improving efficiency. To this end, inspired by Mixture of Experts (MoEs) ([31]), we use a router that based on the token and its similarity to the context of each segment choose a subset of cached memories. For each segment $S^{(i)}$, following Equation 7, we let $\texttt{MeanPooling}(S^{(i)}) = \sum_{j \in S^{(i)}} {\bm{k}}_{j}$, and define the relevance score of each segment $S^{(i)}$ to query $x_t$ as:
$ \begin{align} \mathbf{r}_t^{(i)} = \langle {\bm{u}}_t, : \texttt{MeanPooling}(S^{(i)}) \rangle, \qquad \text{where} :: {\bm{u}}t = x_t W{{\bm{u}}} :. \end{align} $
Given relevance scores, the router chooses $k$ of the cached memories with highest relevance, i.e., $\mathcal{R}_t = \arg \texttt{Top-k}({\mathbf{r}t^{(i)}}{i = 1}^{s-1})$, as well as the current online memory for retrieval. Given selected memories, the retrieval process is the same as previous variants but using only selected memories:
$ \begin{align} \nonumber & \mathcal{M}^{(s)}t = f\left(\mathcal{M}^{(s)}{t-1}; {\bm{k}}_t, {\bm{v}}_t \right), \qquad \text{where} \quad 1 \leq t \leq L^{(s)} :, \ &\mathbf{y}_t = \gamma_t^{(s)} \mathcal{M}^{(s)}_t (\mathbf{q}t) :: + :: \sum{i \in \mathcal{R}t} \gamma_t^{(i)} \mathcal{M}^{(i)}{L^{(i)}} (\mathbf{q}_t) : . \end{align}\tag{11} $
In this formulation, $\texttt{MeanPooling}(S^{(i)})$ of each segment can be pre-computed and so computing the relevance score as well as choosing Top-k segments for each token are simply parallelizable. Also, such computations do not require to store the state of the cached memories in the accelerators (i.e., GPUs, TPUs, etc.). Therefore, this process only requires loading the "selected" memories for each token and so can enhance memory consumption during both training and inference.
Effective Memory. One interesting interpretation of SSC is to see it as a sparse unified memory module. We illustrate this in Figure 2 (Right). One can see SSC as a model with growing memory, where for each token activates a subset of parameters for memory write operation (storing the token), and a larger subset of parameters for retrieval. This formulation allows the memory to (1) store information without any interfering with past memories, and (2) efficiently and adaptively retrieve information. The segment size, here, determines the size of the blocks in the unified memory that become active together.
3.4 Caching Checkpoints or Independent Compressors?
Revisiting the general formulation of the memory caching in Equation 4, there is a design choice that if we cache the checkpoints of a single memory, or we use a set of independent memory modules to compress the information each segment. That is, there are two perspectives:
(1) From the optimization point of view (i.e., Equation 3), we are training an associative memory and the tokens in the sequence are the training data samples. Accordingly, to avoid forgetting past knowledge, we cache the checkpoints of the memory through training (optimization process). In this formulation, for each $s = 0, \cdots, N$, we have $\mathcal{M}0^{(s)}(\cdot) = \mathcal{M}{L^{(s-1)}}^{(s-1)}(\cdot)$, meaning that memory, in each segment, starts from its last state in the previous segment.
(2) From the compression perspective, when we cache a memory of a past segment, we want it to be a compressed representative of the information in that segment. Therefore, the forward pass $\mathcal{M}_{L^{(s)}}^{(s)}({\bm{q}}_t)$ represents the corresponding information to ${\bm{q}}_t$ in $s$-th segment. To avoid interference of memories in different segments, we use independent memories for each segment, meaning that for segment $s$, the memory starts from an initial point $\mathcal{M}0^{(s)}(\cdot)$ that is independent of $\mathcal{M}{L^{(s-1)}}^{(s-1)}(\cdot)$.
In practice, we observe that each of these two choices has its own (dis)advantageous (see Section 5.6).
4. Discussion and Proof of Concept
Section Summary: This section explores how memory caching techniques can enhance linear and deep memory modules in neural networks, starting with a simple linear case where caching past data mimics advanced attention mechanisms like gated global attention, which helps process sequences more effectively. It highlights potential pitfalls, such as oversimplifications that might weaken performance, and examines hybrid models that combine recurrent memories with attention layers to boost efficiency and recall in tasks like language processing. As proof of concept, the authors analyze these setups to show equivalences and inspire more powerful architectures that improve memory capacity without full global attention's computational cost.
In this section we discuss the implication of using memory caching technique for linear and deep memory modules, and discuss the models we use as a proof of concept in our evaluations.
4.1 Implication of Memory Caching on Linear and Deep Memory Modules
Linear Memory. Let us start with a simple but extreme case, where the segment size is 1 and also the recurrent memory is a vector-valued value-less memory module[^1]. In this setup, each token $x_t \in \mathbb{R}^{d}$ is considered as a segment and so the memory state only stores this token: i.e.,
[^1]: Value-less memory module are associative memories whose mapping only depends on the keys. See [9, 24] for the details.
$ \begin{align} \mathcal{M}^{(t)}1 = \underset{\mathbf{b}{\mathbf{K}}}{\underbrace{\mathcal{M}^{(t)}0}} + {\bm{k}}t = \mathbf{b}{\mathbf{K}} + x_t\mathbf{W}{\mathbf{K}}, \end{align} $
where $\mathcal{M}^{(t)}_0$ acts as a bias term for the projection of input $x_t$ to key ${\bm{k}}_t$. Next, applying memory caching on this formulation results in:
$ \begin{align} \mathbf{y}t = \sum{i = 1}^{t} \gamma_t^{(i)} \mathcal{M}^{(i)}{1} (\mathbf{q}t) = \sum{i = 1}^{t}\underset{\gamma_t^{(i)}}{\underbrace{\frac{ \exp\left({\bm{u}}t^{\top} {\bm{k}}i\right)}{\sum{\ell = 1}^{i} \exp\left({\bm{u}}t^{\top} {\bm{k}}{\ell}\right)}}} ::::::\underset{\mathcal{M}^{(i)}{1}}{\underbrace{\left(\mathbf{b}{\mathbf{K}} + x_i\mathbf{W}_{\mathbf{K}} \right)}} :: {\bm{q}}_t :: . \end{align} $
Given the fact that ${\bm{q}}_t$ is a free parameter and a function of input, one can re-parametrize the above formulation by letting $\mathcal{M}_1^{(i)} = {\bm{v}}_i'$:
$ \begin{align} \mathbf{y}t = \left(\sum{i = 1}^{t}{\frac{ \exp\left({\bm{u}}_t^{\top} {\bm{k}}i\right)}{\sum{\ell = 1}^{i} \exp\left({\bm{u}}t^{\top} {\bm{k}}{\ell}\right)}} : {\bm{v}}i' \right) :\otimes :\sigma\left(x_t \mathbf{W}{\mathbf{Q}} \right), \end{align} $
which is equivalent to gated global attention block–an enhanced variant of attention, where the output is gated with a linear projection of the input. Therefore, setting segment lengths equal to one and using a value-less vector-valued recurrent memory with memory caching, recover the gated global softmax attention block. This re-discovery, however, is based on the simplest design choices in the memory caching, which motivates designing architectures that are more powerful in principle. This design can be extended to more complex formulations of global attention with clear motivations. For example, the above formulation caches the direct value of token projection, meaning that each token is stored in a value-less memory module. One, however, can extend the above formulation by using a more expressive memory update: e.g., using linear attention ([14]).
The linearity of the memory and/or a simple retrieval process using multiplication (i.e., letting $\mathbf{y}_t = \mathcal{M}_t {\bm{q}}_t$), however, can cause unwanted simplification, resulting in collapsing the design or sub-optimal performance. For example, earlier in the paper, we discussed how memory fusion technique can collapse into (gated) residual memory variant for linear memories, while these two methods providing different solutions for deep memory modules. As an another example, in linear memory configuration, one can interpret retrieval process by ${\bm{q}}t = x_t \mathbf{W}{\mathbf{Q}}$ as a gating architecture that is multiplied by the compressed context (i.e., linear memory). In this viewpoint, one can simplify the process by removing the gating and so set ${\bm{q}}_t = \mathbf{1} \in \mathbb{R}^{d}$. We refer to such modules as compressors.
Recently, hybrid models–i.e., architectures with interleaved global attention and memory-bounded modules (i.e., RNNs, sliding window attention, etc.)–have gained popularity, mainly due to their robust performance in recall intensive tasks while improving efficiency of pure global attention-based models. In particular, let us consider a compressor layer with a vector-valued recurrent memory, followed by a global attention block. Given $x_t$ as the input, the first block is computed as:
$ \begin{align} & {\bm{q}}_t = \mathbf{1}, \qquad\qquad\qquad: {\bm{k}}t = x_t \mathbf{W}{\mathbf{K}}, \qquad\qquad\qquad: {\bm{v}}t = x_t \mathbf{W}{\mathbf{V}} \ & \mathcal{M}t = f\left(\mathcal{M}{t-1}; {\bm{k}}_t, {\bm{v}}_t \right), ::\quad \mathbf{y}_t = \mathcal{M}_t \end{align} $
Next, this output is considered as the input of the next block and the final output of the layer is computed as (we disregard normalizations for the sake of clarity):
$ \begin{align} {\bm{q}}^{(\texttt{attn})}_t = \mathbf{y}t \mathbf{W}^{(\texttt{attn})}{\mathbf{Q}}, \quad\qquad\quad: & {\bm{k}}^{(\texttt{attn})}_t = \mathbf{y}t \mathbf{W}^{(\texttt{attn})}{\mathbf{K}}, \quad\qquad\quad: {\bm{v}}^{(\texttt{attn})}_t = \mathbf{y}t \mathbf{W}^{(\texttt{attn})}{\mathbf{V}} \ \mathbf{o}t = \sum{i = 1}^{t}&{\frac{ \exp\left({\bm{q}}^{(\texttt{attn})}_t {\bm{k}}^{(\texttt{attn})}i\right)}{\sum{\ell = 1}^{i} \exp\left({\bm{q}}^{(\texttt{attn})^{\top}}t {\bm{k}}^{(\texttt{attn})}{\ell}\right)}} {\bm{v}}^{(\texttt{attn})}_i \end{align}\tag{12} $
Note that $\mathbf{y}_t = \mathcal{M}_t$, and so, interestingly, the above formulation is equivalent to the memory caching with segment size of 1, when we cache memory checkpoints instead of using independent memories (see Section 3.4). This viewpoint not only provides a reason for why a famous recipe of hybrid models should work (because it can enhances the effective memory capacity of the recurrent model), but it also motivates designing more powerful variants by seeing attention as a module that enforces caching past inputs. Note that the above explanation demonstrates an equivalency only for an oversimplified version, and with considering normalization and feed-forward layers the modeling expressivity of both cases can be different. The above discussion, however, supports the power of memory caching technique and motivates going beyond ${\bm{q}}_t = \mathbf{1}$. The case where ${\bm{q}}t = x_t \mathbf{W}{\mathbf{Q}}$, memory caching can result in an ad-hoc attention, where the input sequence to attention block is different for each query ${\bm{q}}_t$. That is, instead of fully pre-determined sequence of tokens as the input of attention block in hybrid variants (i.e., outputs of the last memory layer, $\mathbf{y}_t$), memory caching allows the model to build its own input sequence based on the query ${\bm{q}}t$ (i.e., ${\mathcal{M}{L^{(i)}}^{(i)}({\bm{q}}t)}{i = 1}^{s}$).
Deep Memory. Contrary to the above, memory caching with deep memory results in a new class of architectures with no overlap with their hybrid variants. Let us revisit the initial example we used for linear memory modules. We let memory $\mathcal{M}(\cdot)$ be a 2-layer MLP, and each token $x_t \in \mathbb{R}^{d}$ be a segment (i.e., segment size is 1 and so each memory only stores one token): i.e.,
$ \begin{align} \mathcal{M}^{(t)}_1 = {\mathcal{M}^{(t)}0} - \eta_t \nabla \mathcal{L}(\mathcal{M}^{(t)}{0}; {\bm{k}}_t, {\bm{v}}_t). \end{align} $
This has two implications: (i) Now, each token is represented by a tensor rather than a matrix or vector. Therefore, a token is no longer represented by a constant vector and given the query ${\bm{q}}t$ the context and representation of token $x_i$ can be different (i.e., $\mathcal{M}{1}^{(i)}({\bm{q}}t)$); (ii) The initial point or bias term $\mathcal{M}{0}^{(i)}$, which encodes general knowledge, is a neural network. Therefore, its effect on retrieval process of different queries (i.e., $\mathcal{M}_{1}^{(i)}({\bm{q}}_t)$) is not the same.
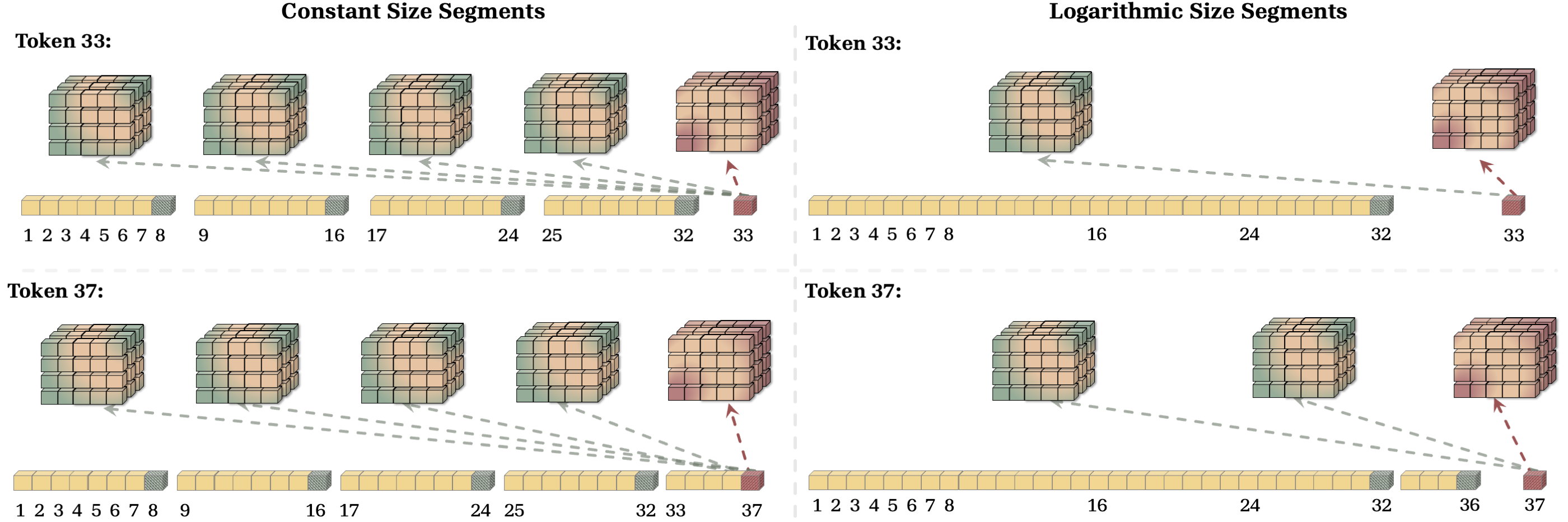
4.2 The Effect of Segmentation on Capacity and Complexity
One of the critical design choices in memory caching is the segmentation of the sequence. Intuitively, segment lengths provides a trade-off between the level of compression and computational cost: E.g., (1) As discussed earlier, Transformers can be seen as memory caching with segment size of 1, meaning that each token itself is cached (no compression, high computational cost of $\mathcal{O}(L^2)$); (2) An RNN module is the extreme case of memory caching, where the entire sequence is considered as a segment and only a single online memory is cached (full compression, constant computational cost per token, $\mathcal{O}(L)$).
In more details, for a token $x_t$, let us split the sequence into segments $S^{(1)}, \dots, S^{(N)}$ with size $L^{(1)}, \dots, L^{(N)}$ and use memories $\mathcal{M}^{(1)}, \dots, \mathcal{M}^{(N)}$ to compress the segments. The compression process for each segment is linear with respect to the segment size, i.e., $\mathcal{O}(L^{(i)})$. Therefore, the memory update operation has a cost of $\mathcal{O}(\sum_{i = 1}^{N} L^{(i)}) = \mathcal{O}(L)$ and the retrieval process requires forward pass over all past cached memories (one memory per segment). Therefore, assuming forward pass of memory requires $\mathcal{O}(p)$ operations, the computation cost per token would be $\mathcal{O}(p \times N)$. Therefore, the total cost for memory caching is $\mathcal{O}(L + p \times N \times L)$. Note that $N$, here, is the function of segmentation. As a example, if segments have equal lengths with size $C = \frac{L}{N} \geq 2$, then the computational cost is $\mathcal{O}(p \times \frac{L^2}{C})$, similar to Transformers but with a smaller constant term (i.e., better efficiency). Another example is to split the sequence logarithmically: i.e., writing $L$ in the binary format, and then let $L^{(i)}$ be the corresponding power of 2 to the indices of non-zero elements. Figure 3 (Left) shows an example of this segmentation. For a sequence length of $37 = (100101)_2$, this segmentation uses three segments with lengths $L^{(1)} = 32$, $L^{(2)} = 4$, and $L^{(3)} = 1$. Therefore, in this formulation, the maximum value of $N$ is $\log_2(L)$ and so the computational complexity is $\mathcal{O} (p \times L \log(L))$.
As discussed earlier, the segmentation provides a trade-off between the level of compression (recall performance) and computational cost. Figure 3 illustrates this trade-off by an example of constant-size and logarithmic segmentation. As discussed above, the time complexity of these methods are $\mathcal{O}(\frac{L^2}{C})$ and $\mathcal{O} (L \log(L))$, respectively, which makes the logarithmic segmentation more efficient. On the other hand, however, logarithmic segmentation provides a significantly less resolution for long past tokens, limiting its ability in recall-intensive tasks.
4.3 Memory Caching for Titans and Linear Attention Variants
As discussed earlier in the paper, the memory caching technique is applicable to any arbitrary recurrent update rule and potentially can enhance their effective context length. As a proof of concept, we use use memory caching on the update rule of Sliding Window Linear Attention (SWLA) and Deep Linear Attention (DLA) ([23]), Linear Attention ([14]), and Titans ([17]).
Sliding Window Linear Attention. Recently, [23] introduced Sliding Window Linear Attention (SWLA), in which the memory updates its weights based on a set of $c \geq 1$ past tokens (contrary to the online RNNs, where the memory is updated solely based on the last token). More specifically, given a memory module $\mathcal{M}(\cdot)$ and keys, values, and queries, ${({\bm{k}}_t, {\bm{v}}_t, {\bm{q}}t)}{t=1}^{L}$, the update and retrieval rules are defined as:
$ \begin{align} & \mathcal{M}t = \alpha_t : \mathcal{M}{t-1} : + \sum_{i = t - c + 1}^{t} \beta_{i}^{(t)} {\bm{v}}{i} {\bm{k}}{i}^{\top}, \ &\mathbf{y}_t = \mathcal{M}_t {\bm{q}}_t, \end{align} $
When $c=1$, the design collapses to the simple linear attention (online linear RNN) and its gated variants ([14, 16, 32]). As a proof of concept, we use memory caching on SWLA with $c = 2$, resulting in a recurrence and retrieval of:
$ \begin{align} & \mathcal{M}t^{(s)} = \alpha_t : \mathcal{M}{t-1}^{(s)} : + \left(\beta_{t} {\bm{v}}{t-1} {\bm{k}}{t-1}^{\top} + \lambda_{t} {\bm{v}}{t} {\bm{k}}{t}^{\top} \right), \ &\mathbf{y}_t = \gamma_t^{(s)} \mathcal{M}^{(s)}t {\bm{q}}t :: + :: \sum{i = 1}^{s-1} \gamma_t^{(i)} \mathcal{M}^{(i)}{L^{(i)}} {\bm{q}}_t. \end{align} $
Note that, as discussed earlier, since SWLA is a linear memory module, both GRM and Memory Soup variants result in the same formulation.
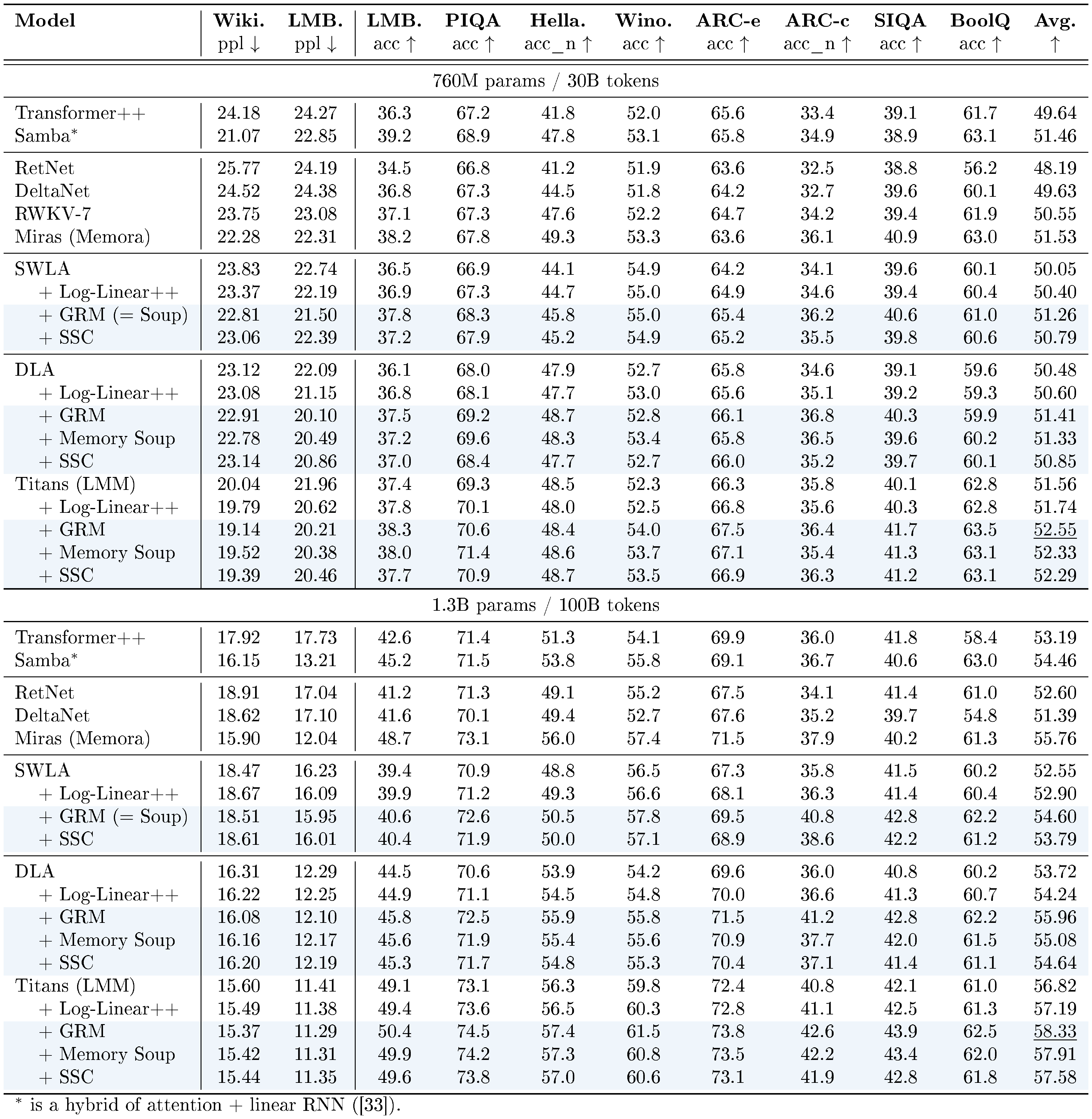
::: {caption="Table 1: Performance of models on language modeling and common-sense reasoning tasks."}
:::
Deep Linear Attention. DLA uses the same update rule as linear attention (i.e., Hebbian rule), but with a deep memory module. That is, given a memory module $\mathcal{M}(\cdot)$ and keys, values, and queries, ${({\bm{k}}_t, {\bm{v}}_t, {\bm{q}}t)}{t=1}^{L}$, the update and retrieval rules are defined as:
$ \begin{align} & \mathcal{M}{t} = \mathcal{M}{t-1} - \eta_{t} \nabla \mathcal{L}\left(\mathcal{M}_{t-1}; {\bm{k}}_t, {\bm{v}}_t \right), \ &\mathbf{y}_t = \mathcal{M}_t({\bm{q}}_t), \end{align} $
where the attentional bias objective is defined as $\mathcal{L}\left(\mathcal{M}_{t-1}; {\bm{k}}_t, {\bm{v}}t\right) = - \langle \mathcal{M}{t-1}({\bm{k}}_t), {\bm{v}}_t \rangle$. Using memory caching (GRM variant), the update and retrieval process for DLA are defined as:
$ \begin{align} \tag{a} & \mathcal{M}^{(s)}t = \mathcal{M}^{(s)}{t-1} - \eta_t \nabla \mathcal{L}\left(\mathcal{M}^{(s)}_{t-1}; {\bm{k}}_t, {\bm{v}}_t \right), ; \text{for} ; 1 \leq t \leq L^{(s)}, \ \tag{b} &\mathbf{y}_t = \gamma_t^{(s)} \mathcal{M}^{(s)}t (\mathbf{q}t) :: + :: \sum{i = 1}^{s-1} \gamma_t^{(i)} \mathcal{M}^{(i)}{L^{(i)}} (\mathbf{q}_t). \end{align}\tag{13} $
Similarly, we can replace Equation 10 or 11 with the update rule of DLA (similar to 13a) to derive other memory caching variants. Note that when memory module $\mathcal{M}(\cdot)$ is a matrix, then the above formulation is equivalent to the linear attention ([14]).
Titans. In Titans, compared to DLA, both attentional bias objective as well as the internal optimizer are different. More specifically, given a memory module $\mathcal{M}(\cdot)$ and keys, values, and queries, ${({\bm{k}}_t, {\bm{v}}_t, {\bm{q}}t)}{t=1}^{L}$, the update and retrieval rules of Titans are defined as:
$ \begin{align} \tag{a} & \mathcal{M}{t} = \alpha_t : \mathcal{M}{t-1} - \mathcal{S}t, \ \tag{b} &\mathcal{S}{t} = \beta_t : \mathcal{S}{t-1} - \eta{t} \nabla \mathcal{L}\left(\mathcal{M}_{t-1}; {\bm{k}}_t, {\bm{v}}_t \right), \ &\mathbf{y}_t = \mathcal{M}_t({\bm{q}}_t), \end{align}\tag{14} $
where the attentional bias objective is defined as $\mathcal{L}\left(\mathcal{M}_{t-1}; {\bm{k}}_t, {\bm{v}}t\right) = | \mathcal{M}{t-1}({\bm{k}}_t) - {\bm{v}}_t |^2_2$. With $\textsc{MC}$, while the memory update operation for each segment is the same as Equation 14a and 14b, the retrieval process for Titans with memory caching is defined the same as Equation 13b.
Log-Linear++ Variant. Recently, [34] take advantage of structured matrix formulation of linear RNNs and design log-linear attention, a hierarchical algorithm based on Fenwick tree structure ([35]) that allows a logarithmically growing set of hidden states. We aim to use log-linear attention as the baseline in our experiments to show the effect of segmentation on the efficiency and retrieval performance. Its formulation, however, suffer from the positional bias and lack of context-dependency in retrieval process that we discussed in Section 3.1. For the sake of fair comparison, we improve Log-linear formulation, denoted as Log-Linear++ in our experiments, by reformulating it as a variant of memory caching with GRM and logartithmic-size set of segments. The segmentation process is the same as the process describe in Section 4.2. The other components are kept unchanged, the same as our memory caching variants.
Memory Caching as Post Training. Memory caching can also be applied after pre-training of the model, where at inference, we cache the state of the memory after each segment (e.g., training sequence length). For decoding, we use moving average of the past cached memory without learnable weights. In our experimental results, we observe that even this simple technique can enhance the length extrapolation capability of recurrent models significantly.
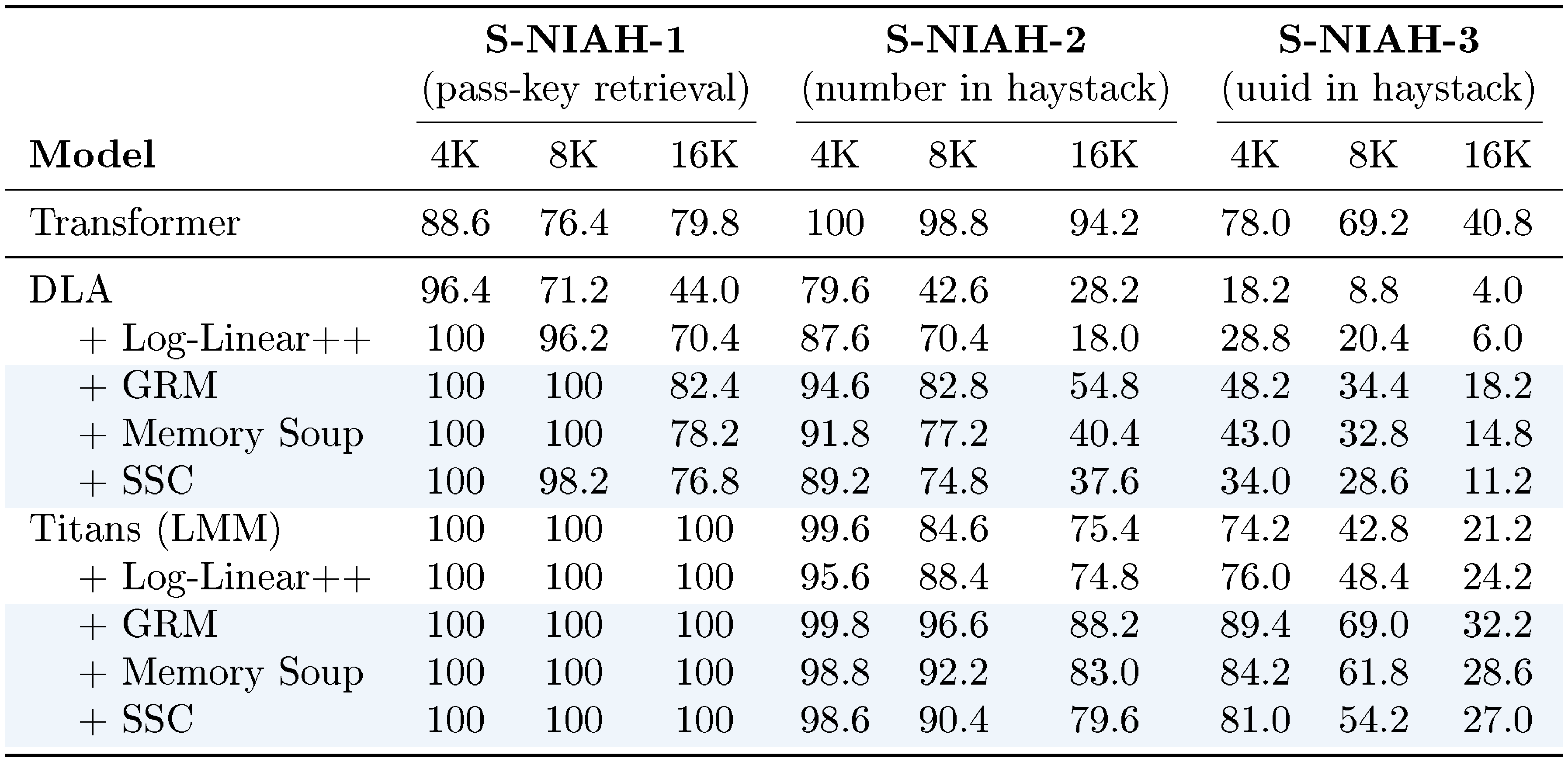
::: {caption="Table 2: Needle-In-A-Haystack experiments with three levels of difficulty: single-needle tasks—S-NIAH-1 (passkey retrieval), S-NIAH-2 (numerical needle), and S-NIAH-3 (UUID-based needle)."}
:::
5. Experiments
Section Summary: Researchers tested a technique called memory caching to boost the performance of AI language models on tasks like predicting text, understanding common sense, finding specific details in long documents, and recalling information from examples. They trained models of various sizes on large text datasets with different context lengths, comparing versions with and without caching against standard approaches like Transformers. Across benchmarks, caching consistently improved results for recurrent models, closing the gap with Transformers by providing more effective memory management, especially for long sequences, with design choices like gating and segmentation all contributing positively.
Next, we evaluate the effectiveness of memory caching in improving the performance of models on language modeling, commonsense reasoning, needle in haystack, and in-context recall tasks.
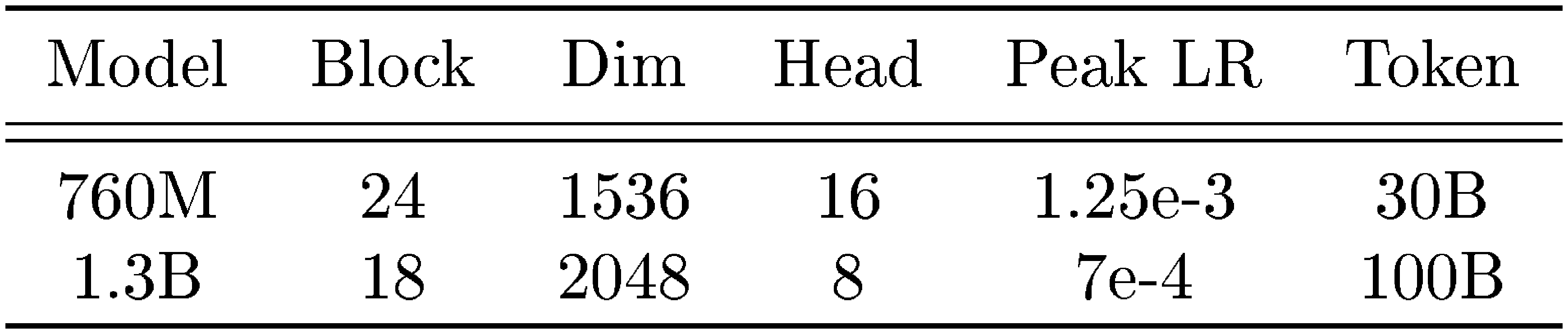
Experimental Setup. In our experimental evaluations, we mostly follow [34]. We train our models with training context window of size ${\text{2K, 4K, 8K, 16K, 32K}}$ and segment lengths ranging from ${\text{16, 32, 64, 128, 256, 512}}$ tokens using a mixture of FineWeb dataset ([36]) and Long-Data-Collections ([37]). In language modeling and common-sense reasoning tasks (Table 1), the default model is trained with context length of 4K and segment length of 256. We use model size of 760M, and 1.3B parameters and train them on 30B and 100B tokens sampled from the FineWeb dataset ([36]). Perplexity is measured on held-out validation data. As for the downstream tasks, we evaluate trained models on Wikitext ([38]), LMB ([39]), PIQA ([40]), HellaSwag ([41]), WinoGrande ([42]), ARC-easy (ARC-e) and ARC-challenge (ARC-c) ([43]), SIQA ([44]), and BoolQ ([45]). In other downstream tasks such as Needle-in-a-haystack, in-context retrieval, and LongBench, we train the models with 16K context length to better distinguish the performance of the models on short and long context. Additional details about the experimental setups and other used datasets are in Appendix B.
5.1 Language Modeling
We start with common academic-scale language modeling. The results of SWLA, DLA, and Titans with and without memory caching are reported in Table 1. There are three observations: (1) Comparing DLA, Titans, and SWLA with their enhanced version with memory caching, we observe that all memory caching variants provides consistent improvements on different downstream tasks, and also on average over their baseline. This shows the importance of memory caching to further enhance memory bounded models. (2) As discussed earlier, memory caching can be seen as a hybrid of (sparse) attention with recurrent models. Comparing memory caching enhanced models and attention-based models (i.e., hybrid and Transformers), memory caching provides a more powerful solution to the problem of limited memory in recurrent models. Particularly, Titans + MC and DLA + MC achieves +0.8% performance gain over the Titans. (3) Comparing MC's constant size segmentation and Log-Linear++ method, we observed that constant size segmentation variants provide better results. Furthermore, GRM and then SSC achieves better results among our provided methods. We attribute this performance gain to larger effective memory size that MC provides for the model.
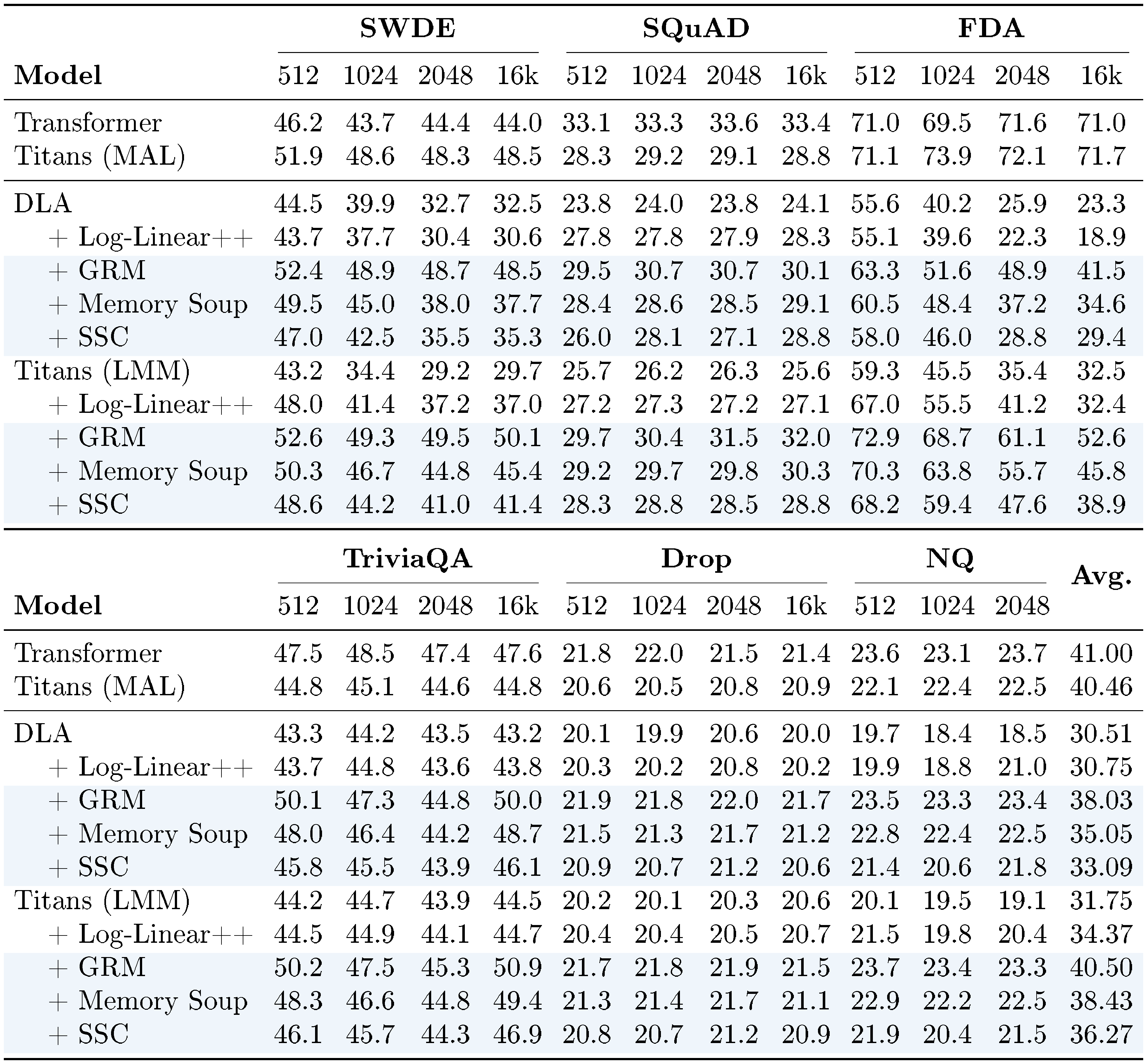
::: {caption="Table 3: Accuracy on retrieval tasks w/ input truncated to different lengths."}
:::
5.2 Needle-In-A-Haystack Tasks
We evaluate the impact of MC on long-context retrieval using Needle-in-a-Haystack (NIAH) tasks (Table 2). MC-enhanced DLA and Titans consistently outperform the base models. Furthermore, MC variants outperform the Log-Linear approach, especially at longer contexts. Log-Linear struggles because it forces a single memory to compress very large initial segments (e.g., 8K tokens in a 16K sequence), whereas $\textsc{MC}$ distributes the compression load more effectively.
5.3 In-context Retrieval Tasks
In-context recall tasks are among the most challenging benchmarks for recurrent neural networks. In this section, we follow [10] and perform experiments on SWDE ([46]), NQ ([47]), DROP ([48]), FDA ([49]), SQUAD ([50]), and TQA ([51]) to evaluate and compare the performance of $\textsc{MC}$-enhanced variants with baselines and Transformers. The results are reported in Table 3. While Transformers still achieve the best results in in-context recall tasks, our $\textsc{MC}$ variants show competitive performance, close the gap with Transformers, and performs better than state-of-the-art recurrent models. We again attribute this performance to larger memory capacity that scales with sequence length.
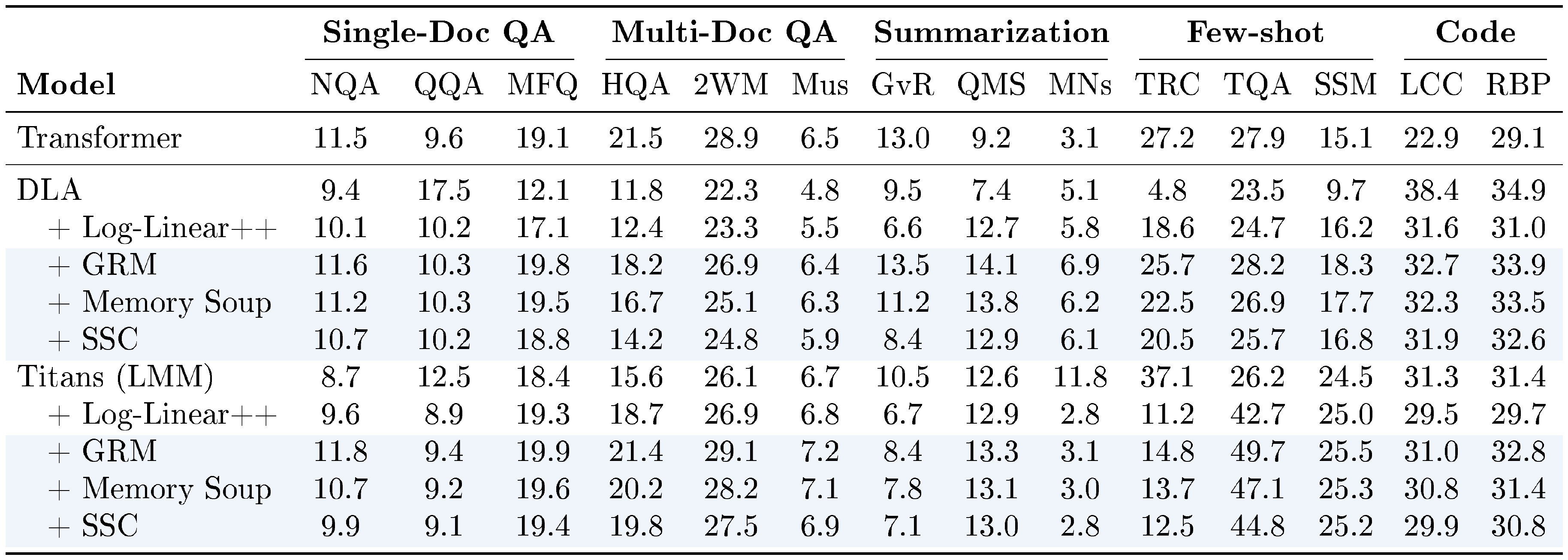
::: {caption="Table 4: Accuracy on LongBench tasks ([52]): NarrativeQA, QasperQA, MultiFieldQA, HotpotQA, 2WikiMultiQA, Musique, GovReport, QMSum, MultiNews, TREC, TriviaQA, SamSum, LCC, and RepoBench-P."}
:::
5.4 Long Context Understanding Tasks
We perform experiences on long-context understanding tasks using LongBench ([52]). The results are reported in Table 4. All $\textsc{MC}$-enhanced variants provide performance gains compared to their base RNNs, again attributed to their increased memory capacity.
:::: {cols="2"}
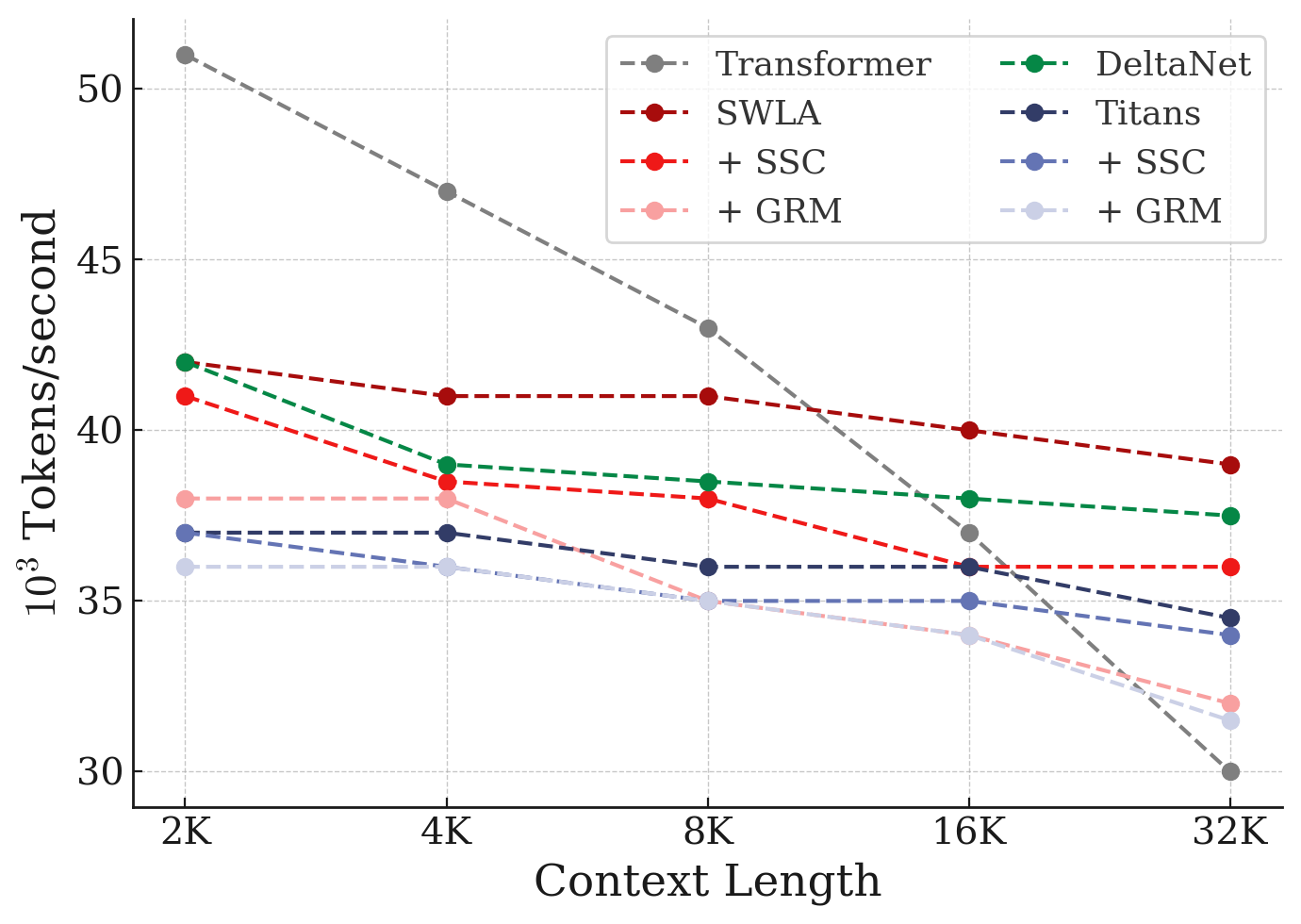
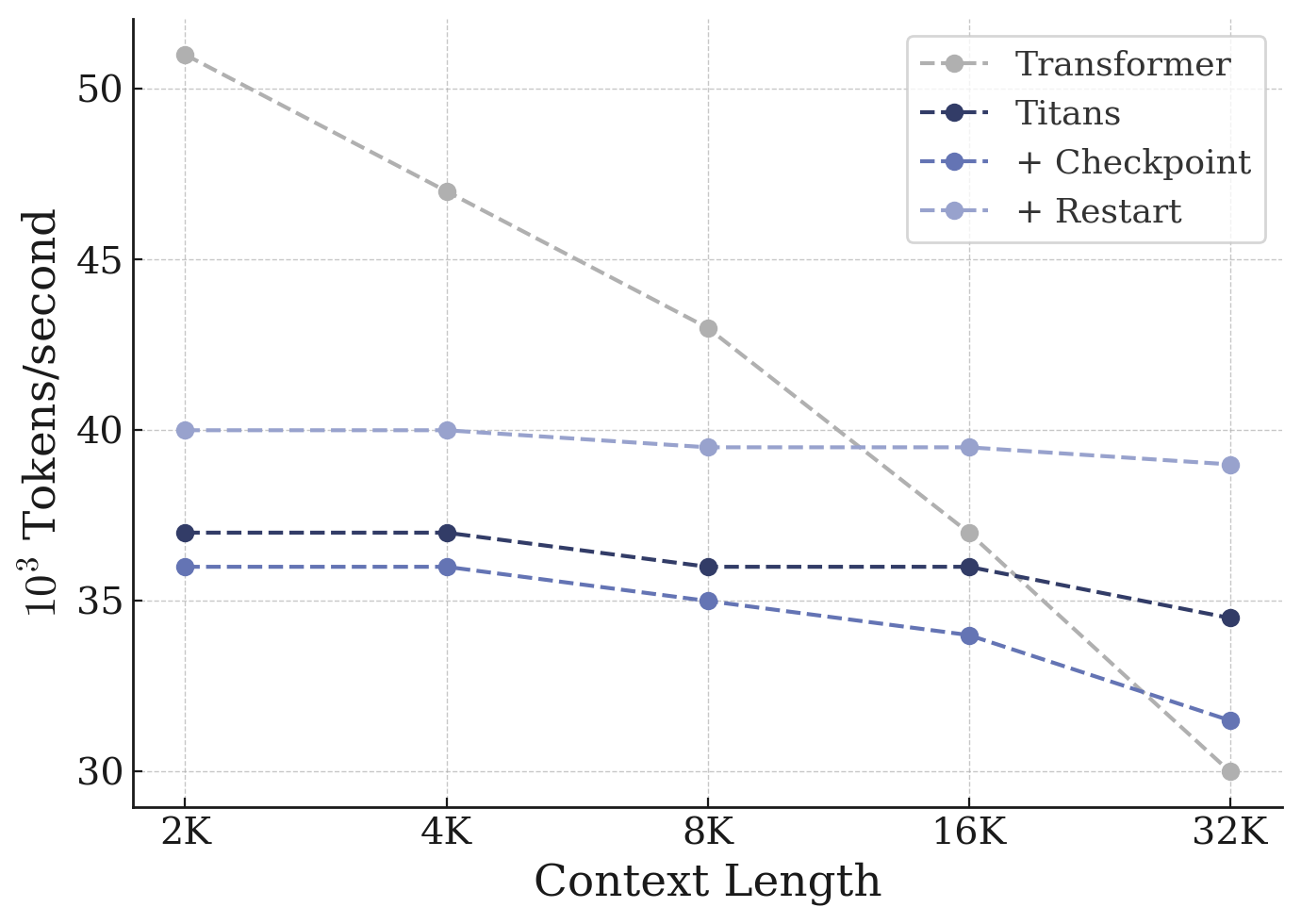
Figure 4: Training throughput comparison of memory caching variants and baselines. ::::
Average accuracy on MQAR over 5 seeds.
\begin{tabular}{l c c c}
\toprule
\multirow{2}{*}{Model} & Language Modeling & C.S. Reasoning & Retrieval\\
& ppl $\downarrow$ & acc $\uparrow$ & acc $\uparrow$ \\
\midrule
\midrule
Titans (GRM) & 13.3 & 58.3 & 40.5\\
\:\: - Context-dependent & 13.4 & 57.4 & 33.0 \\
\:\: - Gating & 13.5 & 56.9 & 32.4 \\
\:\: - Linear Memory & 13.7 & 56.3 & 34.5 \\
\:\: - Shared ${\bm{u}}$ and ${\bm{q}}$ & 00.0 & 00.0 & 00.0 \\
\midrule
Titans (SSC) & 13.4 & 57.6 & 36.3\\
\:\: - Context-dependent & 13.4 & 57.1 & 32.6 \\
\:\: - Gating & 13.5 & 56.8 & 31.9 \\
\:\: - Linear Memory & 13.8 & 56.8 & 33.4 \\
\:\: - Shared ${\bm{u}}$ and ${\bm{q}}$ & 00.0 & 00.0 & 00.0 \\
\toprule
\end{tabular}
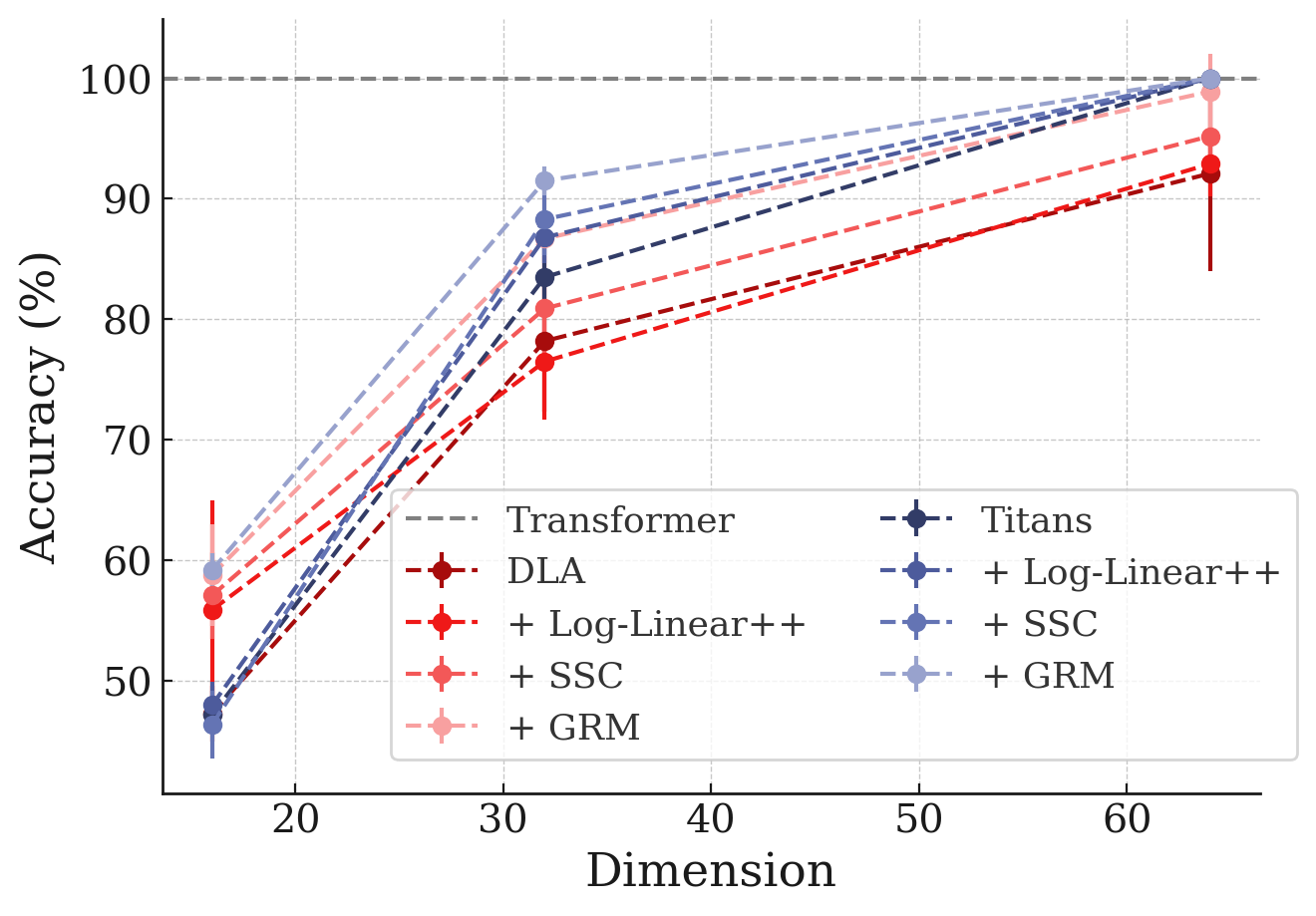
5.5 Multi-Query Associative Recall (MQAR)
In this section, we evaluate the performance of $\textsc{MC}$-enhanced variants in Multi-Query Associative Recall (MQAR) task ([53]). The results are reported in Figure 9. Our models show good performance compared to their base RNNs also the state-of-the-art recurrent models, achieving the best performance per dimension value compared to state-of-the-art models such as Atlas ([23]).
5.6 Ablation Studies
Next, we evaluate the effect of design choices in the MC framework. The first choice is wether $\gamma$ should be the function of only input or also the context of blocks. The results are reported in Table 5. This design choice has shown significant improvement on average. The second design is to remove the gating. Note that without gating, the design collapses into residual memory. The results show even this simple design can enhance the performance of the models. Finally, in the third design, we use a linear memory module. Surprisingly, using memory caching results in more robustness of the performance with respect to the memory architecture and expressivity.
5.7 Efficiency
Finally, we evaluate the training throughput of our variants with baselines. The results are reported in Figure 4. Our $\textsc{MC}$ variants provide a middle ground between Transformers and RNNs, and they become extremely efficient compared to Transformers, when increasing the context length. These results indicate that our SSC variant has the best of both worlds and while performs on par or better compared to other variants in the diverse downstream tasks that we discussed earlier, they also add minimal overhead compare to their original base RNN variant. Furthermore, they show significantly better efficiency in longer sequences.
6. Conclusion
Section Summary: This paper introduces Memory Caching, a straightforward method for recurrent neural networks that stores parts of the memory state, enabling later tokens in a sequence to directly access relevant earlier ones. Experiments demonstrate that it outperforms some standard approaches while keeping the model intentionally simple to highlight the core idea. Looking ahead, more advanced ways to select and manage this cached memory could boost performance even further.
In this paper, we present Memory Caching (MC), a simple technique applicable to all recurrent neural networks, that caches a subset of memory state, allowing subsequent tokens directly attend to its past relevant tokens. Our experiments show improvements over a subset of baselines. A lot of choices in this paper have been made to keep the resulting model as simple as possible, better showing the effect of memory caching idea. However, in future work, more expressive pooling or routing mechanism can be used to further enhance the performance.
Appendix
Section Summary: Researchers have developed linear memory modules as efficient alternatives to traditional Transformers, which struggle with complexity and long contexts, by incorporating recurrent computations, forget gates, and updates like the delta rule to speed up training and inference while maintaining strong performance. Deep memory modules further enhance these systems by boosting memory capacity and refining learning rules, such as through fast-weight programming, higher-order attention, and architectures like Hope-attention that integrate dynamic components for better long-term understanding. This work builds on foundational ideas from fast weight programs, meta-learning techniques like Hebbian learning, and Hopfield networks, which treat neural layers as associative memories for storing and retrieving key-value pairs.
A. Related Work
Linear Memory Modules. Recent efforts have focused on alleviating the quadratic complexity, context-length limitations, and limited expressive power of Transformers in solving complex problems, which have motivated the development of efficient recurrent alternatives that offer faster inference and training ([54]). More specifically, [14] show that with replacing softmax with a separable kernel in the computation of the attention results in linear attention formulation that admits recurrence computation. Building on this insight several studies has focused on improving the performance of linear attention and closing the gap with quadratic Transformers. To this end, RetNet ([16]), RWKV ([28]), Lightning Attention ([32]), and S5 ([55]) introduced forget gate mechanisms into the formulation of linear attention. Later, other studies adapted these formulations for tasks that require more selective forgetting by making the existing forget gate in linear attention architectures input-dependent ([29, 56]). In parallel, [27] presented DeltaNet, an alternative learning update for the recurrence of the recurrent neural networks based on the Delta-rule, to improve the memory management of linear attention models. Later, several studies designed different algorithms to train Delta update rule ([57, 58, 59]). Furthermore, building upon these existing techniques–ranging from forget gate, learning algorithms, and training algorithm designs–and by combining them, different variants of linear attention modules have been designed in the recent years ([60, 57, 60, 61, 59]). More recently, [62] enhanced delta-rule models by applying multiple updates per token, yielding more expressive state-tracking capabilities. Beyond linear recurrent models, several works investigate RNNs with non-linear recurrence but with linear matrix-valued memory ([63, 20, 64, 9, 23, 65, 66, 67, 68, 69]), with emphasis on accelerating their training ([68, 64, 65]).
Deep Memory Modules. Another line of research has focused on enhancing the capacity of the memory modules and also improving their learning update rules. [58] presented TTT layer, a fast-weight program ([70]) that updated its weight based on $L_2$-regression loss. [58] discussed how attention and simple linear attention are an instances of TTT layer, but put other recurrent neural networks outside of TTT layers, mainly due to the fact that they cannot accurately be recovered using inner $L_2$-regression loss, which is the definition of TTT layers. Titans ([17]) suggest incorporating more complex optimization algorithms and replace gradient descent with them. As a proof of concept the Titans use gradient descent with momentum and weight decay to optimize the inner $L_2$-regression loss. Building upon the formulation of TTT layers (i.e., optimizing inner $L_2$-regression loss), [26] show that how one can approximate $L_2$-regression loss and so approximately recover other modern recurrent neural networks. Based on this insight, [26] presented a higher-order attention variant with higher-expressive power than standard softmax attention. Concurrently, [9] presented "test-time memorization (TTM)" framework, where accurately recover architectures based on the concept of associative memory that internally learn the mapping based on an arbitrary objective. In fact, contrary to TTT layers ([58]), which restrict the inner model to $L_2$-regression loss, TTM suggest designing architectures based on the concept of associative memory with four design choices: (1) The architecture of the memory; (2) The internal objective; (3) The internal retention gate; and (4) the internal optimization algorithm.
Following this direction, and the fact that the choice of new objectives and optimization algorithms for the inner-loop can result in developing more expressive architectures ([9]), there have been a new generation of architectures by varying the internal objective. Moneta and Yaad replaces $L_2$-regression loss with $L_p$ and Huber loss, respectively. Atlas ([23]) incorporates Omega learning rule, where instead of updating the memory with respect to the last token, it updates the memory with respect to a local context of past data. It further suggested using Muon ([71]) as the internal optimization. [72] replaces $L_2$-regression loss with a dot-product similarity and suggested using large chunk-size for more efficient training. Recently, to further improve the long-term memory of machine learning models, [24] presented Continuum Memory System (CMS) that suggests instead of replacing attention blocks, one can replace one single static MLP blocks in Transformers with multiple MLP blocks each of which are updated by its own frequency in an end-to-end manner based on the task at hand (the same way as MLP blocks). This architecture– sequence of Attention with multiple dynamic MLP blocks– is called Hope-attention, and has shown better long-context understanding than simple Transformers.
Fast Weight Programs and Meta Learning. The view of linear layers as key-value associative memory systems dates back to Hopfield networks ([73]). This idea was later extended through the development of fast weight programmers, in which dynamic fast programs are integrated into recurrent neural networks to function as writable memory stores ([27, 70, 74]). Among the learning paradigms for such systems, Hebbian learning ([75]) and the delta rule ([76]) have been most prominent. Both rules have been extensively studied in the literature ([77, 70, 78, 27, 15, 57, 60]).
Hopfield Networks. Our formulation builds on the broad concept of associative memory, where the goal is to learn mappings between keys and values. Seminal work by [73] introduced Hopfield Networks as one of the earliest neural architectures explicitly based on associative memory, formalized through the minimization of an energy function for storing key-value pairs. While classical Hopfield networks have seen reduced applicability due to limitations in vector-valued memory capacity and the structure of their energy function, recent studies have sought to enhance their capacity through various approaches ([79, 80, 81]). In particular, extensions of their energy functions with exponential kernels have been explored ([81, 82]). Moreover, connections between modern Hopfield networks and Transformer architectures have been actively investigated ([7, 83]).
Efficient Attention Mechanisms. In addition to recurrent architectures, recent work has proposed using structured matrices to improve the efficiency of token and channel mixing layers. For example, Butterfly matrices ([84]), Monarch matrices ([85]), and Block Tensor-Train matrices ([86]) provide compact yet expressive parameterizations that reduce the computational burden of dense projections. Other approaches design sparse or hybrid attention mechanisms, such as sliding-window attention or models that combine localized recurrence with selective long-range connections ([87, 10, 88]).
Another family of approaches reduces the quadratic complexity of attention to nearly log-linear time. Classical examples include Reformer ([89]), which uses locality-sensitive hashing to cluster queries and keys, and LogSparse Transformer ([90]) and Informer ([91]), which rely on structured sparsity patterns for efficiency in long-sequence and time-series tasks. Subsequent work has introduced more elaborate designs, such as multi-resolution attention ([92]), which progressively refines attention scores from coarse to fine levels, and Fast Multipole Attention ([93]), which adapts the fast multipole method for scalable long-range interactions. Another group of studies focused on block or token-wise sparse attention modules. More specifically, [94] presented MoBA, which suggest chunking the sequence and performing MoE on the sequence dimension. Not only this design is based on attention module, but it also has a fundamental difference with our MoE, where the computation of attention is ad-hoc for each block and token. Here, memory states are pre-computed and there is no need for ad-hoc computation. Recently, [34] introduce Log-Linear Attention, a framework that augments linear attention with a logarithmically growing set of hidden states organized via Fenwick tree partitioning. This design achieves $\mathcal{O}(L \log L)$ training complexity and $\mathcal{O}(\log L)$ decoding memory, while preserving hardware-efficient parallelization.
::: {caption="Table 6: Architectural Details."}
:::
B. Experimental Details
In our experimental setup we follow recent studies on recurrent models ([60, 17, 9, 72, 34]), we use Wikitext ([38]), LMB ([39]), PIQA ([40]), HellaSwag ([41]), WinoGrande ([42]), ARC-easy (ARC-e) and ARC-challenge (ARC-c) ([43]), SIQA ([44]), and BoolQ ([45]). In the training, we use a vocabulary size of 32K and use training length of 4K-32K tokens. We employ AdamW optimizer with learning rate of $4e$- $4$ with cosine annealing schedule with batch size of 0.5M tokens, and weight decay of $0.1$. For the memory architecture, unless state otherwise, we use an MLP with $2$ layers with expansion factor of 4 and GELU activation function ([95]). We also use residual connections and layer norm at the end of each chunk: $\mathcal{M}(x) = x + W_1 \sigma(W_2 x)$.
References
[1] Vaswani et al. (2017). Attention is All you Need. In Advances in Neural Information Processing Systems. pp. . https://proceedings.neurips.cc/paper_files/paper/2017/file/3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf.
[2] Jumper et al. (2021). Highly accurate protein structure prediction with AlphaFold. nature. 596(7873). pp. 583–589.
[3] Alexey Dosovitskiy et al. (2021). An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. In International Conference on Learning Representations. https://openreview.net/forum?id=YicbFdNTTy.
[4] Comanici et al. (2025). Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities. arXiv preprint arXiv:2507.06261.
[5] Kaplan et al. (2020). Scaling laws for neural language models. arXiv preprint arXiv:2001.08361.
[6] Brown et al. (2020). Language models are few-shot learners. Advances in neural information processing systems. 33. pp. 1877–1901.
[7] Hubert Ramsauer et al. (2021). Hopfield Networks is All You Need. In International Conference on Learning Representations. https://openreview.net/forum?id=tL89RnzIiCd.
[8] Bietti et al. (2024). Birth of a transformer: A memory viewpoint. Advances in Neural Information Processing Systems. 36.
[9] Ali Behrouz et al. (2026). It's All Connected: A Journey Through Test-Time Memorization, Attentional Bias, Retention, and Online Optimization. In The Fourteenth International Conference on Learning Representations. https://openreview.net/forum?id=gZyEJ2kMow.
[10] Simran Arora et al. (2024). Simple linear attention language models balance the recall-throughput tradeoff. In Forty-first International Conference on Machine Learning. https://openreview.net/forum?id=e93ffDcpH3.
[11] Dai et al. (2019). Transformer-XL: Attentive Language Models beyond a Fixed-Length Context. In ACL (1). pp. 2978-2988.
[12] Child et al. (2019). Generating long sequences with sparse transformers. arXiv preprint arXiv:1904.10509.
[13] Poli et al. (2023). Hyena hierarchy: Towards larger convolutional language models. In International Conference on Machine Learning. pp. 28043–28078.
[14] Katharopoulos et al. (2020). Transformers are rnns: Fast autoregressive transformers with linear attention. In International conference on machine learning. pp. 5156–5165.
[15] Irie et al. (2021). Going beyond linear transformers with recurrent fast weight programmers. Advances in neural information processing systems. 34. pp. 7703–7717.
[16] Sun et al. (2023). Retentive network: A successor to transformer for large language models. arXiv preprint arXiv:2307.08621.
[17] Ali Behrouz et al. (2025). Titans: Learning to Memorize at Test Time. In The Thirty-ninth Annual Conference on Neural Information Processing Systems. https://openreview.net/forum?id=8GjSf9Rh7Z.
[18] Irie et al. (2022). A modern self-referential weight matrix that learns to modify itself. In International Conference on Machine Learning. pp. 9660–9677.
[19] Young-Jae Park et al. (2025). VideoTitans: Scalable Video Prediction with Integrated Short- and Long-term Memory. In The Thirty-ninth Annual Conference on Neural Information Processing Systems. https://openreview.net/forum?id=86enCXORIV.
[20] William Merrill et al. (2024). The Illusion of State in State-Space Models. In Forty-first International Conference on Machine Learning. https://openreview.net/forum?id=QZgo9JZpLq.
[21] Yuzhen Huang et al. (2024). Compression Represents Intelligence Linearly. In First Conference on Language Modeling. https://openreview.net/forum?id=SHMj84U5SH.
[22] Yuri Kuratov et al. (2024). BABILong: Testing the Limits of LLMs with Long Context Reasoning-in-a-Haystack. In The Thirty-eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track. https://openreview.net/forum?id=u7m2CG84BQ.
[23] Behrouz et al. (2025). Atlas: Learning to optimally memorize the context at test time. arXiv preprint arXiv:2505.23735.
[24] Ali Behrouz et al. (2025). Nested Learning: The Illusion of Deep Learning Architectures. In The Thirty-ninth Annual Conference on Neural Information Processing Systems. https://openreview.net/forum?id=nbMeRvNb7A.
[25] Bietti et al. (2023). Birth of a transformer: A memory viewpoint. Advances in Neural Information Processing Systems. 36. pp. 1560–1588.
[26] Wang et al. (2025). Test-time regression: a unifying framework for designing sequence models with associative memory. arXiv preprint arXiv:2501.12352.
[27] Schlag et al. (2021). Linear transformers are secretly fast weight programmers. In International Conference on Machine Learning. pp. 9355–9366.
[28] Bo Peng et al. (2023). RWKV: Reinventing RNNs for the Transformer Era. In The 2023 Conference on Empirical Methods in Natural Language Processing. https://openreview.net/forum?id=7SaXczaBpG.
[29] Songlin Yang et al. (2024). Gated Linear Attention Transformers with Hardware-Efficient Training. In Forty-first International Conference on Machine Learning. https://openreview.net/forum?id=ia5XvxFUJT.
[30] Wortsman et al. (2022). Model soups: averaging weights of multiple fine-tuned models improves accuracy without increasing inference time. In International conference on machine learning. pp. 23965–23998.
[31] Noam Shazeer et al. (2017). Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer. In International Conference on Learning Representations. https://openreview.net/forum?id=B1ckMDqlg.
[32] Li et al. (2025). Minimax-01: Scaling foundation models with lightning attention. arXiv preprint arXiv:2501.08313.
[33] Ren et al. (2024). Samba: Simple Hybrid State Space Models for Efficient Unlimited Context Language Modeling. arXiv preprint arXiv:2406.07522.
[34] Guo et al. (2025). Log-linear attention. arXiv preprint arXiv:2506.04761.
[35] Fenwick, Peter M (1994). A new data structure for cumulative frequency tables. Software: Practice and experience. 24(3). pp. 327–336.
[36] Penedo et al. (2024). The fineweb datasets: Decanting the web for the finest text data at scale. Advances in Neural Information Processing Systems. 37. pp. 30811–30849.
[37] Together AI (2024). Long Data Collections. https://huggingface.co/datasets/togethercomputer/Long-Data-Collections.
[38] Stephen Merity et al. (2017). Pointer Sentinel Mixture Models. In International Conference on Learning Representations. https://openreview.net/forum?id=Byj72udxe.
[39] Paperno et al. (2016). The LAMBADA dataset: Word prediction requiring a broad discourse context. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). pp. 1525–1534. doi:10.18653/v1/P16-1144. https://aclanthology.org/P16-1144/.
[40] Bisk et al. (2020). Piqa: Reasoning about physical commonsense in natural language. In Proceedings of the AAAI conference on artificial intelligence. pp. 7432–7439.
[41] Zellers et al. (2019). HellaSwag: Can a Machine Really Finish Your Sentence?. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. pp. 4791–4800. doi:10.18653/v1/P19-1472. https://aclanthology.org/P19-1472/.
[42] Sakaguchi et al. (2021). Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM. 64(9). pp. 99–106.
[43] Clark et al. (2018). Think you have solved question answering? try arc, the ai2 reasoning challenge. arXiv preprint arXiv:1803.05457.
[44] Sap et al. (2019). Social IQa: Commonsense Reasoning about Social Interactions. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). pp. 4463–4473. doi:10.18653/v1/D19-1454. https://aclanthology.org/D19-1454/.
[45] Clark et al. (2019). BoolQ: Exploring the Surprising Difficulty of Natural Yes/No Questions. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). pp. 2924–2936. doi:10.18653/v1/N19-1300. https://aclanthology.org/N19-1300/.
[46] Lockard et al. (2019). Openceres: When open information extraction meets the semi-structured web. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). pp. 3047–3056.
[47] Kwiatkowski et al. (2019). Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics. 7. pp. 453–466.
[48] Dua et al. (2019). DROP: A reading comprehension benchmark requiring discrete reasoning over paragraphs. arXiv preprint arXiv:1903.00161.
[49] Arora et al. (2023). Language models enable simple systems for generating structured views of heterogeneous data lakes. arXiv preprint arXiv:2304.09433.
[50] Rajpurkar et al. (2016). Squad: 100,000+ questions for machine comprehension of text. arXiv preprint arXiv:1606.05250.
[51] Kembhavi et al. (2017). Are you smarter than a sixth grader? textbook question answering for multimodal machine comprehension. In Proceedings of the IEEE Conference on Computer Vision and Pattern recognition. pp. 4999–5007.
[52] Yushi Bai et al. (2024). LongBench: A Bilingual, Multitask Benchmark for Long Context Understanding. In ACL (1). pp. 3119-3137. https://aclanthology.org/2024.acl-long.172.
[53] Simran Arora et al. (2024). Zoology: Measuring and Improving Recall in Efficient Language Models. In The Twelfth International Conference on Learning Representations. https://openreview.net/forum?id=LY3ukUANko.
[54] Tiezzi et al. (2024). On the resurgence of recurrent models for long sequences: Survey and research opportunities in the transformer era. arXiv preprint arXiv:2402.08132.
[55] Jimmy T.H. Smith et al. (2023). Simplified State Space Layers for Sequence Modeling. In The Eleventh International Conference on Learning Representations. https://openreview.net/forum?id=Ai8Hw3AXqks.
[56] Peng et al. (2024). Eagle and finch: Rwkv with matrix-valued states and dynamic recurrence. arXiv preprint arXiv:2404.05892.
[57] Yang et al. (2024). Parallelizing linear transformers with the delta rule over sequence length. Advances in Neural Information Processing Systems. 37. pp. 115491–115522.
[58] Sun et al. (2024). Learning to (learn at test time): Rnns with expressive hidden states. arXiv preprint arXiv:2407.04620.
[59] Liu et al. (2024). Longhorn: State space models are amortized online learners. arXiv preprint arXiv:2407.14207.
[60] Yang et al. (2024). Gated Delta Networks: Improving Mamba2 with Delta Rule. arXiv preprint arXiv:2412.06464.
[61] Allen-Zhu, Zeyuan. Physics of Language Models: Part 4.1, Architecture Design and the Magic of Canon Layers. In The Thirty-ninth Annual Conference on Neural Information Processing Systems.
[62] Siems et al. (2025). DeltaProduct: Increasing the Expressivity of DeltaNet Through Products of Householders. arXiv preprint arXiv:2502.10297.
[63] Csordás et al. (2024). Recurrent Neural Networks Learn to Store and Generate Sequences using Non-Linear Representations. In Proceedings of the 7th BlackboxNLP Workshop: Analyzing and Interpreting Neural Networks for NLP. pp. 248–262.
[64] Yi Heng Lim et al. (2024). Parallelizing non-linear sequential models over the sequence length. In The Twelfth International Conference on Learning Representations. https://openreview.net/forum?id=E34AlVLN0v.
[65] Schöne et al. (2025). Implicit Language Models are RNNs: Balancing Parallelization and Expressivity. arXiv preprint arXiv:2502.07827.
[66] Karami , M. and Mirrokni, V. (2025). Lattice: Learning to Efficiently Compress the Memory.
[67] Von Oswald et al. (2023). Uncovering mesa-optimization algorithms in transformers. arXiv preprint arXiv:2309.05858.
[68] Gonzalez et al. (2024). Towards scalable and stable parallelization of nonlinear rnns. Advances in Neural Information Processing Systems. 37. pp. 5817–5849.
[69] Jiaxi Hu et al. (2025). Improving Bilinear RNN with Closed-loop Control. In The Thirty-ninth Annual Conference on Neural Information Processing Systems. https://openreview.net/forum?id=jlJaRXDzCE.
[70] Schmidhuber, Juergen (1992). Learning to control fast-weight memories: An alternative to recurrent nets. Accepted for publication in. Neural Computation.
[71] Jordan et al. (2024). Muon: An optimizer for hidden layers in neural networks, 2024b. URL https://kellerjordan. github. io/posts/muon.
[72] Zhang et al. (2025). Test-time training done right. arXiv preprint arXiv:2505.23884.
[73] Hopfield, John J (1982). Neural networks and physical systems with emergent collective computational abilities.. Proceedings of the national academy of sciences. 79(8). pp. 2554–2558.
[74] Schmidhuber, Juergen (1993). Reducing the ratio between learning complexity and number of time varying variables in fully recurrent nets. In ICANN’93: Proceedings of the International Conference on Artificial Neural Networks Amsterdam, The Netherlands 13–16 September 1993 3. pp. 460–463.
[75] Hebb, Donald Olding (2005). The organization of behavior: A neuropsychological theory. Psychology press.
[76] Prados, DL and Kak, SC (1989). Neural network capacity using delta rule. Electronics Letters. 25(3). pp. 197–199.
[77] Munkhdalai, Tsendsuren and Yu, Hong (2017). Neural semantic encoders. In Proceedings of the conference. Association for Computational Linguistics. Meeting. pp. 397.
[78] Munkhdalai et al. (2019). Metalearned neural memory. Advances in Neural Information Processing Systems. 32.
[79] Krotov, Dmitry (2021). Hierarchical associative memory. arXiv preprint arXiv:2107.06446.
[80] Li et al. (2024). On the expressive power of modern hopfield networks. arXiv preprint arXiv:2412.05562.
[81] Krotov, Dmitry and Hopfield, John J (2016). Dense associative memory for pattern recognition. Advances in neural information processing systems. 29.
[82] Lucibello, Carlo and Mézard, Marc (2024). Exponential capacity of dense associative memories. Physical Review Letters. 132(7). pp. 077301.
[83] Hu et al. (2024). Provably optimal memory capacity for modern hopfield models: Transformer-compatible dense associative memories as spherical codes. arXiv preprint arXiv:2410.23126.
[84] Dao et al. (2019). Learning fast algorithms for linear transforms using butterfly factorizations. In International conference on machine learning. pp. 1517–1527.
[85] Dao et al. (2022). Monarch: Expressive structured matrices for efficient and accurate training. In International Conference on Machine Learning. pp. 4690–4721.
[86] Qiu et al. (2024). Compute better spent: Replacing dense layers with structured matrices. arXiv preprint arXiv:2406.06248.
[87] Nguyen et al. (2021). Fmmformer: Efficient and flexible transformer via decomposed near-field and far-field attention. Advances in neural information processing systems. 34. pp. 29449–29463.
[88] Munkhdalai et al. (2024). Leave no context behind: Efficient infinite context transformers with infini-attention. arXiv preprint arXiv:2404.07143.
[89] Kitaev et al. (2020). Reformer: The efficient transformer. arXiv preprint arXiv:2001.04451.
[90] Li et al. (2019). Enhancing the locality and breaking the memory bottleneck of transformer on time series forecasting. Advances in neural information processing systems. 32.
[91] Zhou et al. (2021). Informer: Beyond efficient transformer for long sequence time-series forecasting. In Proceedings of the AAAI conference on artificial intelligence. pp. 11106–11115.
[92] Zeng et al. (2022). Multi resolution analysis (mra) for approximate self-attention. In International conference on machine learning. pp. 25955–25972.
[93] Kang et al. (2023). Fast multipole attention: A divide-and-conquer attention mechanism for long sequences. arXiv preprint arXiv:2310.11960.
[94] Enzhe Lu et al. (2025). MoBA: Mixture of Block Attention for Long-Context LLMs. In The Thirty-ninth Annual Conference on Neural Information Processing Systems. https://openreview.net/forum?id=RlqYCpTu1P.
[95] Hendrycks, Dan and Gimpel, Kevin (2016). Gaussian error linear units (gelus). arXiv preprint arXiv:1606.08415.