Towards Automating Scientific Review with Google's Paper Assistant Tool
RAJESH JAYARAM
Google Research, USA
DREW TYLER
Google Research, USA
DAVID WOODRUFF
Google Research & Carnegie Mellon University, USA
CORINNA CORTES
Google Research, USA
YOSSI MATIAS
Google Research, USA
VAHAB MIRROKNI
Google Research, USA
VINCENT COHEN-ADDAD
Google Research, USA
Abstract
Artificial intelligence is driving a revolution in scientific discovery, accelerating everything from hypothesis generation to mathematical theorem proving. However, this rapid acceleration is creating a systemic challenge: traditional human peer review cannot scale to match the influx of AI-assisted science. Ultimately, to resolve this tension, we must also deploy AI to accelerate the verification and review process itself. To frame the discussion around this transition, we propose a taxonomy consisting of four progressive levels of AI-human collaboration in scientific evaluation, and discuss various trade-offs involved with each.
As a step toward this future, we introduce the Paper Assistant Tool (PAT), an agentic AI framework built for deep scientific review and verification. PAT ingests full scientific manuscripts and produces a comprehensive evaluation, checking theoretical results, validating experiments, suggesting improvements, and identifying potential flaws. By utilizing inference scaling techniques, PAT is able to identify deeper issues than a single model call alone, achieving a 34% improvement over zero-shot recall on mathematical errors in the SPOT benchmark. Pilot deployments of PAT as a pre-submission tool for authors at two major Computer Science conferences—STOC and ICML—demonstrate its ability to identify critical errors and suggest substantive improvements to research papers. By catching errors early, PAT eases the cognitive burden placed on referees, while preserving their control over the outcomes of the review process.
Corresponding authors: Rajesh Jayaram ([email protected]) and Vincent Cohen-Addad ([email protected]).
© 2026 Google LLC. All rights reserved.
Executive Summary: The rapid growth of AI-assisted research has driven explosive increases in submissions to computer science conferences, with combined totals for ICLR, ICML, and NeurIPS rising from roughly 17,000 in 2020 to an estimated 74,000 in 2026. Human peer review cannot keep pace, especially for line-by-line verification of proofs and experiments in mathematics and theoretical computer science. This document addresses the resulting validation bottleneck by developing an automated tool and framing how AI might integrate into the review process over time.
The authors created the Paper Assistant Tool (PAT), an agentic system built on Gemini models that ingests full papers, segments them by topic, allocates extra compute to dense sections, and runs coordinated deep-review agents before synthesizing a grounded report. They evaluated PAT on 26 retracted or corrected math and computer science papers containing known proof or equation errors, then deployed it as a free pre-submission service for authors at the STOC 2026 and ICML 2026 conferences, reviewing more than 4,700 manuscripts.
PAT detected 89.7 percent of the known errors—34 percentage points higher than a single zero-shot model call. In the conference pilots, 92–97 percent of surveyed authors said they would use the tool again; 11.6 percent of STOC authors and 35.4 percent of ICML authors reported that PAT identified substantive theoretical gaps requiring more than an hour to fix; and 31 percent of ICML authors ran additional experiments prompted by the feedback. Authors also noted improvements in clarity and the discovery of subtle but consequential typos that human reviewers often miss.
These results show that inference-scaled review systems can already catch errors before submission and measurably raise paper quality without removing human control. Scaled adoption would reduce the cognitive load on referees, lower the chance that flawed work enters the literature, and free experts to focus on novelty and significance rather than mechanical verification.
The authors therefore recommend that conferences continue offering PAT-style tools to authors in the near term while developing clear policies for reviewer use. They further propose phased movement toward higher-autonomy roles in which AI produces supporting reviews under human oversight, alongside continued work to reduce hallucinations, improve PDF parsing, and ensure equitable access. Longer-term exploration of fully automated repositories should proceed only after rigorous accuracy comparisons with human review.
The main limitations are that roughly one-third of authors still found some feedback ungrounded and that current models can hallucinate citations or misread proofs; the reported gains therefore reflect a specific implementation and benchmark rather than a universal guarantee.
1. Introduction: The Scientific Validation Bottleneck
Section Summary: The rapid rise of AI tools has enabled an explosion of generated scientific papers, but human experts cannot keep up with the painstaking work of verifying their accuracy and spotting errors, creating a growing bottleneck in peer review. Submission volumes to major AI conferences have surged dramatically in recent years, with evidence suggesting that a substantial share of new papers now involve AI assistance. To help ease this strain, the authors created the Paper Assistant Tool for automated error detection in math and computer science papers and tested it with conference organizers, while also outlining broader ways AI might support the review process.
The rapid advancement of Large Language Models (LLMs) has sparked a revolution in automated scientific discovery. Models can now generate complex code, infer patterns from massive datasets, and even assist in proving mathematical theorems. However, the Scientific Method requires rigorously validating these outputs, not just generating them. As AI-assisted scientific output explodes, the academic community faces the challenge of verifying these results and detecting underlying errors. While human verification remains the ideal, the cognitive labor required will not scale to keep pace with automated generation.
This validation bottleneck is particularly acute in scientific peer review, which is entirely unequipped to handle the influx of new papers. In technical fields such as mathematics and theoretical computer science (TCS), comprehensive review requires line-by-line verification of dense proofs, which can take a human reviewer days to accomplish. Perhaps the most extreme example is found in AI conferences themselves. While submission rates to AI venues were growing prior to 2023 ([1]), they exploded following the widespread availability of generative AI. As shown in Table 1, the total submissions to three flagship AI conferences have soared over the past three years. While we cannot definitively attribute this trajectory to AI, there is compelling evidence supporting it: as early as 2024, at least 17.5% of computer science abstracts on arXiv carried evidence of AI generation ([2]), a figure that reaches up to 40% in specific biomedical subcorpora ([3]). Undoubtedly, these figures are much higher today. Given this unprecedented volume, there is significant interest in exploring how AI itself can aid in unburdening the peer review system.
While recent advances in reasoning models have shown remarkable promise in scientific problem-solving, comparatively less work has been done to optimize systems for error detection and manuscript review. To address this challenge, we developed the Paper Assistant Tool (PAT), a verification and review agent that utilizes deep inference scaling techniques to identify flaws and suggest improvements in scientific papers. We specialized PAT for mathematics and computer science papers, with the particular aim of addressing the extreme submission rate at AI conferences.
To explore how empowering authors with systems like PAT can help improve the overall quality of papers, we partnered with STOC and ICML—two major computer science conferences—to freely provide PAT to authors prior to submission [4, 5]. The reaction from the community was highly positive. In Section 3, we discuss these pilots and their outcomes. Given the positive community reaction, we plan to continue improving PAT, enabling the tool to take on more influential roles within the peer review process.
Motivated by these developments and our experience with building PAT, we believe it is necessary to bring further structure to the discussion surrounding AI in science. In Section 4 we propose a taxonomy of roles for AI integration in peer review, and explore the trade-offs of each approach. By categorizing these modes of AI usage, we aim to foster a more transparent and informed discussion within the scientific community. This discussion carries significant weight, as future policy changes could shift the power of publication decisions, which have career ramifications, from human experts to AI agents.
: Table 1: Submissions to Flagship AI Conferences (2020–2026).
| Year | ICLR | ICML | NeurIPS | Combined Sum | YoY Increase |
|---|---|---|---|---|---|
| 2020 | 2, 594 ([1]) | 4, 990 ([1]) | 9, 467 ([1]) | 17, 051 | – |
| 2021 | 3, 014 ([1]) | 5, 513 ([1]) | 9, 122 ([1]) | 17, 649 | +3.51% |
| 2022 | 3, 422 ([1]) | 5, 630 ([1]) | 10, 411 ([1]) | 19, 463 | +10.28% |
| 2023 | 4, 955 ([1]) | 6, 538 ([1]) | 12, 345 ([1]) | 23, 838 | +22.48% |
| 2024 | 7, 304 ([1]) | 9, 653 ([1]) | 15, 671 ([1]) | 32, 628 | +36.87% |
| 2025 | 11, 672 ([1]) | 12, 107 ([1]) | 21, 575 ([6]) | 45, 354 | +39.00% |
| 2026 | 19, 809 ([1]) | 24, 371 ([7]) | 29, 703 (est.) | 73, 883 (est.) | +62.90% (est.) |
2. The Paper Assistant Tool: Automating the Scientific Verification Process
Section Summary: The Paper Assistant Tool (PAT) is an AI system built on advanced language models that automatically reviews scientific papers for objective mathematical or logical errors rather than offering subjective opinions or rankings. It improves on simple single-pass or repeated independent reviews by first dividing a paper into overlapping logical segments, then dynamically assigning more computing effort to complex sections and deploying specialized review agents that analyze each segment while seeing the full manuscript for context. A final synthesis agent combines the findings and cross-checks them against external sources to reduce false alarms before producing a concise error report.
In this section we introduce PAT, an agentic paper reviewing and validation system powered by Gemini Deep Think [8]. PAT utilizes inference-scaling techniques to increase the probability that a critical error is found within a given manuscript. PAT has been specialized for the detection of mathematical and logical errors, as well as comprehensive feedback and analysis of Computer Science papers. This specialization is especially motivated by the explosion of new papers in Machine Learning conferences. Currently, PAT does not produce subjective assessments or rankings of papers, and instead focuses on identifying objective errors and suggesting potential improvements.
Design Considerations.
To motivate our design choices, first we consider basic alternatives. The obvious baseline is a single inference call to a language model with the full paper given as input. While simple and not totally ineffective given today's models, this approach is limited by the effective context window of the model to perform deep analysis of the entire paper. Verifying complex mathematical claims requires generating a large number of "thinking tokens, " which can easily exceed a single model's context capacity.
To ameliorate this, one could call the model many times independently (Pass@k) and attempt to synthesize the outputs into a single report. This approach has two fundamental issues. First, while Pass@k scaling increases recall compared to a single generation, it also significantly degrades precision. Models are prone to hallucination; an actor using a review agent must check statements made to ensure their validity. If a model outputs 10 potential issues per pass, and has a 10% chance of finding a critical issue per pass, running it 10 times forces a human to sift through $\sim$ 100 proposed issues just to find one valid, critical error. Second, Pass@k scaling does not fully address the context limitations: without orchestration, independent model calls might spend their context budgets on the same sections of a paper, leaving other sections under-validated.
The PAT Pipeline.
PAT is designed to specifically resolve both of the prior limitations. PAT employs a "segmenter"agent to break each paper into segments, each of which is a set of pages which share a logical theme (e.g., experiments, theory, methodology, etc.). The segments can be overlapping and non-contiguous. The segmenter agent then dynamically allocates a compute budget to each segment based on the information density and complexity of that segment. This allows PAT to allocate more compute to the most challenging parts of the paper, and save compute for easier manuscripts.
Next, specialized Deep Review agents (powered by either an advanced version of Gemini Deep Think or another proprietary inference-scaling pipeline) verify the contents of each segment. While each review agent focuses on verifying a subset of the manuscript, it is provided with the full paper as context. Finally, PAT deploys a synthesis agent to combine the reports from each segment's deep review. The synthesis agent utilizes Google search as an extra check for hallucinations (e.g. non-existent papers or theorems), before assembling the final review. The flow of the PAT pipeline is illustrated in Figure 1.
This orchestration explicitly addresses the previously discussed limitations of single-generation and Pass@k scaling. Dividing the paper into logical segments allows models to focus deeply on their assigned section without spending too many thinking tokens on other parts of the paper, making it far more likely that they remain within their context budget. Further, by utilizing the Deep Review Agent, PAT ensures that the model calls within each segment are coordinated. This allows for deeper and more efficient review of each section, which is further improved by the dynamic budgeting mechanism. Finally, the synthesis agent counteracts the precision degradation typical of Pass@k scaling via grounding and deduplication.
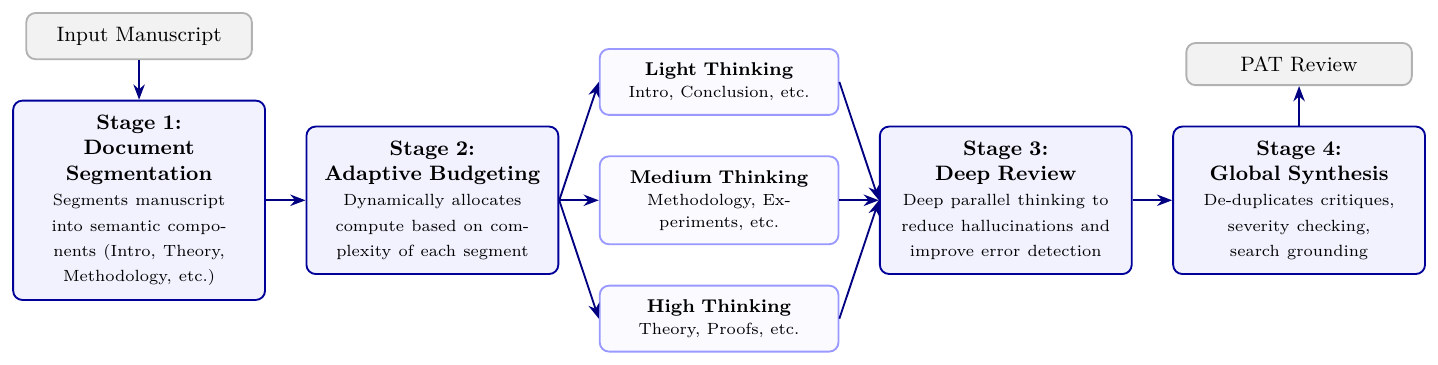
2.1 Case Study: Verification of Retracted Papers in the SPOT Benchmark
One of the primary aims of PAT is to find technical errors in full-length scientific manuscripts. Thus, it is useful to attempt to quantify the gains delivered compared with out of the box LLM calls. Towards this end, we evaluate the real-world utility of PAT on organic, human-authored errors, using the SPOT benchmark [9], which compiles manuscripts containing verified mistakes that led to subsequent errata or retractions. SPOT contains a variety of errors and typos across various literature categories, and is heavily dominated by multi-modal errors such as figure duplication. In order to isolate clearly verifiable errors and test the deep reasoning benefits of PAT, we filtered the SPOT benchmark for papers in the Mathematics and Computer Science categories containing "Equation / proof" errors. This yields an evaluation subset of 26 papers with 29 errors.
For each paper in the benchmark, we run our reviewing pipeline (either PAT or a single model generation) to generate a detailed error report. Following the evaluation protocol in the SPOT paper, we utilized an automated LLM-based grader to evaluate whether each report contains the ground truth error. While the SPOT paper utilized a strict grader which requires exact keyword matches with the ground truth for a correct score, we use a specialized grader that reasons to determine whether an issue in the reviewer is logically equivalent to the ground truth error. Thus, our numbers are not directly comparable to those reported in the SPOT paper. To guarantee grading reliability, a human reviewer among the authors audited each grade from the autograder to ensure alignment.
: Table 2: Verification Accuracy on the Math/CS Equation and Proof Error Subset of the SPOT Dataset.
| Verification Method | Detection Accuracy (%) |
|---|---|
| Original SPOT SOTA ([9]) | 21.1% |
| Gemini 3.1 Pro [10] (Zero-Shot) | 55.2% |
| PAT (Gemini 3.1 Pro) | 89.7% |
The results of this case study, presented in Table 2, demonstrate already that modern foundation models, even without inference scaling, perform strongly at the task of scientific error detection, with Gemini 3.1 Pro [10] achieving over $50%$ error recall over the dataset. This demonstrates a significant leap forward compared to the findings in the original SPOT paper ([9]), which can be attributed both to the newer generation of models and our logic-aware grader which correctly grades mathematically equivalent descriptions of an error. This rapid improvement suggests that even zero-shot AI pipelines are now useful scientific tools.
PAT, on the other hand, significantly outperforms single model generation, achieves a $34%$ gain improvement and increasing recall to $89.7%$. This illustrates the clear performance gains achieved by specialized inference-scaling pipelines. In particular, zero-shot models are more likely to accept complex mathematical claims without critically scrutinizing them. For example, in a paper on dual Banach spaces [11], the zero-shot baseline accepted a false complete contractivity claim for real linear maps between complex minimal operator spaces. PAT, however, refused to accept this claim at face value; instead, it constructed a concrete counterexample, exposing a fatal gap that invalidates the main theorem.
This performance carries a strong implication: were arXiv to implement an automated, single LLM call to review each submitted paper, more than half of the errors in these retracted papers would have been caught prior to submission. Had the authors utilized PAT, nearly all of them would have caught the error. Untracked errors propagating through the literature pose a serious problem for the development of science. The performance of models on these error detection tasks, therefore, makes a strong case for their incorporation into multiple stages of the scientific publication process. One could even imagine such a system being directly incorporated into arXiv, allowing for immediate feedback and error identification for submitted manuscripts.
3. PAT Experimental Programs at STOC and ICML
Section Summary: In late 2025 and early 2026, the PAT AI review system partnered with the STOC and ICML conferences to give authors voluntary pre-submission feedback on their papers, checking for mathematical errors in theory submissions and for issues like weak experiments or missing comparisons in machine-learning work. Powered by an advanced Gemini model, the system processed more than 4,700 manuscripts across both events, with feedback offered only to authors rather than conference reviewers. Surveys and comments showed strong approval, as most authors said the reports improved clarity, caught meaningful mistakes that would otherwise have gone unnoticed, and in many cases prompted new experiments or major revisions.
In an effort to empower the academic community with PAT's enhanced reviewing capabilities, we partnered with several high profile conferences over the last year. Specifically, in November 2025, we partnered with the Symposium on the Theory of Computing (STOC, a premier theoretical computer science conference), and in January 2026 we partnered with the International Conference on Machine Learning (ICML, a premier machine learning conference).[^1]
[^1]: Announcements can be found in the blog posts [4, 5]
For these pilot programs, we provided only the authors with access to a PAT review, run once on their manuscript, several days to weeks prior to the final submission deadline. The goal was to provide valuable pre-submission feedback, allowing authors to address potential errors and shortcomings of their work, thereby improving their paper and the overall submission pool. As we will discuss in Section 4, the usage of PAT in these pilot programs falls into the category Role 1: Tool for Authors; in other words, PAT was only offered to authors, and not utilized within the formal peer review process.
The initial deployment of PAT during the STOC 2026 pilot program was optimized specifically for the math-heavy papers submitted to TCS venues. This pipeline focused purely on mathematical rigor, using deep parallel thinking to find logical errors in proofs. For the ICML program, we needed to generalize PAT to handle the significantly more varied forms of manuscripts submitted to machine learning conferences. This expanded system allows PAT to provide detailed critiques of experimental frameworks, spot confounding factors, and point out missing comparisons and experiments. This generalized system is the one presented in Section 2. Both deployments were powered under the hood by an advanced version of Gemini 2.5 Deep Think. Between the two conferences, over 4, 700 submissions were reviewed by the PAT system.
: Table 3: Comparative Survey Results: STOC vs. ICML Pilot Programs
| Survey Question | STOC Cohort ($n=124$) | ICML Cohort ($n=733$) |
|---|---|---|
| Would use PAT Again | 97% | 92.1% |
| Improved Paper Clarity or Readability | 85.1% | 87.0% |
| Believe PAT has Education Value | 75.2% | 83.9% |
| Very or Mostly Helpful | 92.7 % | 90.7 % |
| Feedback Mostly or All Grounded | 55.8% | 64.8% |
| Identified Substantive Theory Gaps | 11.6% | 35.4% |
| Ran New Experiments | – | 31% |
3.1 Quantitative Author Feedback for PAT Experimental Programs
Author feedback on the tool for both STOC and ICML was largely positive (Table 3). For both programs, the vast majority of authors indicated that they would want to use PAT again for future papers, and that PAT improved the clarity and readability of their papers. Similarly, over $90%$ said that the feedback was either Very or Mostly helpful. Importantly, given that hallucinations and misunderstandings are key failure points of AI-assisted reviewing, we view the fact that over half found the feedback mostly or all grounded (factual) to be a strong positive result.
However, the two most significant results were responses to the final two questions in Table 3. We asked authors if PAT identified significant errors in theoretical results, requiring them to spend more than an hour to fix. For STOC, one in ten authors agreed, which is arguably a high statistic given that proofs in submissions to STOC are rarely checked in their entirety, thus it is likely that these errors would have otherwise gone unnoticed. Surprisingly, PAT found significant theory errors in more than one in three ICML respondents'papers. This uptick is likely caused by the fact that ICML is not a theory conference, and therefore submissions may adhere to a lower level of mathematical rigor. Importantly for a machine learning conference, $31%$ of ICML respondents said that they ran totally new experiments as a result of PAT's review—a significant finding given the time investment required of these authors. This demonstrates PAT's ability to suggest significant improvements to papers in addition to detecting errors.
3.2 Qualitative Author Feedback for PAT Experimental Programs
Further evidence for PAT's efficacy comes from the large swath of qualitative feedback provided by authors. The tool demonstrated a capacity to uncover subtle flaws that frequently elude human expert detection. Several specific cases include:
- (The Fatal Algorithm Bug): "It found a critical bug in a way we were applying a tool... an embarrassingly simple bug that evaded us for months. Luckily we were able to fix it but it meant we had to completely change and add 7-8 pages worth of technical content."
- (Invalid Proof): "Contradiction in the Analysis of the Unbounded Time Regime... The proof was invalid and we fixed that after AI found it. The lemma itself is a simple fact but nevertheless we still need a correct proof."
Overall, the qualitative responses to PAT have been highly positive. Authors from the STOC program were generally surprised by the level of mathematical rigor that PAT is able to assess and critique.
"The [..] set of comments were simply mind-blowing! It pointed out a subtle though fatal bug in my algorithm, which I managed to fix on time!" — Vijay Vazirani, Distinguished Professor, University of California Irvine
"I found the tool very helpful, especially for long papers... the tool caught a pretty significant error, leading to the rewriting of an important claim." — Hung Le, Associate Professor, UMass Amherst
"It spotted a technical error that was easily fixable but still took me two hours to write down." — Jason Li, Assistant Professor, Carnegie Mellon University
Even for papers that did not have critical errors to detect, PAT frequently found "mathematically significant typos", meaning typos or small errors that significantly degrade rigor and readability. Examples included missing absolute value signs, inequalities pointing in the wrong direction, overloaded notation, and off-by-one errors. Feedback from the ICML cohort strongly reinforced PAT's utility for finding such errors.
Despite these positive outcomes, pilot testing also highlighted several limitations. The most frequently reported challenges were: (1) date hallucinations and outdated knowledge cutoffs, (2) PDF parsing issues, and (3) falsely claiming a proof or argument is incorrect due to failures in reasoning or model misunderstandings. We have addressed first two issues by better search tooling and parsing. The third issue is a product of any LLM based system, and we are actively addressing it via improvements to PAT's reasoning capabilities.
4. Categorization of Roles of AI Automation in Peer Review
Section Summary: The section outlines how AI is increasingly involved in scientific writing and peer review and proposes a four-role taxonomy, modeled on levels of vehicle autonomy, to clarify the extent of its use in the review process. In the lower roles, AI acts as a supportive tool for authors or reviewers, who retain full responsibility, while higher roles allow AI to generate full reviews or even make final acceptance decisions with varying degrees of human oversight. The authors weigh the potential gains in speed, rigor, and reduced reviewer burden against risks such as hallucinations, obscured weaknesses, and inconsistent outcomes, stressing the need for explicit policies to guide responsible adoption.
AI has already begun to play a significant role in both the process of writing and reviewing scientific papers. A recent study by Pangram [12] found that 21% of ICLR 2026 Reviews were fully AI-generated, despite being a violation of conference policies. Given the rapid improvement of models and the burden of reviewing papers, this number will surely continue to grow. Thus, the best path forward may be to agree on principled and safe policies for AI usage in peer review. A positive example in this direction was the AAAI-26 AI Review Pilot ([13]), where a specialized pipeline was deployed to generate a clearly identified LLM review for every main-track submission. We believe this was only the beginning of what will be a significant change in peer review.
To aid in discussions around AI usage in peer review, we propose an explicit taxonomy of four "roles" which AI can enact within this process, and discuss the potential benefits and harms of each. Our taxonomy parallels both the SAE Levels of Vehicle Autonomy, as well as the levels of autonomy for mathematical research presented in [14]. For instance, given sufficient evidence that AI tools are better than humans at reviewing scientific papers, would organizers be willing to allow them to make conference acceptance decisions? Such decisions carry hefty consequences for both science and for authors’ personal careers. A primary goal in delineating these roles of AI usage is so that their merits can be assessed against each other.
Role 1: AI as a Tool for Authors.
In this role, AI is used purely as a tool for authors in the preparation of their final manuscripts before submission to a publication venue. This level encapsulates the usage of PAT in the pilot programs at STOC and ICML. AI tools may catch bugs in the work, suggest improvements, or automate experiments and coding tasks. However, authors ultimately are fully responsible for their work; Role 1 is not considered to be automation of the paper writing process. While utilizing AI in Role 1 may improve the overall rigor of papers by catching bugs early, it may introduce the counter-intuitive drawback of hiding the more obvious issues, making papers look superficially stronger. Consequently, human reviewers may have to exert additional effort to separate the truly strong papers from those which have been well disguised by AI tools.
Role 2: AI as a Tool for Reviewers.
Here, AI is used by reviewers in a similar capacity as it was used by authors in Role 1. AI tools can be called and interacted with to understand the paper, point out potential flaws, and produce draft reviews. However, the final review is again the full responsibility of the human reviewer. While Role 2 speeds up the initial stages of reviewing a paper, AI models may introduce hallucinated critiques of the paper, requiring the reviewer to shift their attention from verifying the paper to verifying the AI-generated review. Additionally, reviewers are still tasked with identifying issues which may not have been found by the AI. Without a coherent LLM-usage policy at a given venue, reviewers may hide their usage of AI tools, and double down on incorrect AI-generated points to protect their professional authority during a rebuttal phase. Thus, a successful deployment of Role 2 AI requires a thought-out submission policy, which may allow reviewers to use AI tools but also allow authors to flag points in the review as hallucinated and in need of further review.
Role 3: AI as a Supporting Reviewer.
In Role 3, an AI agent generates a full-length review following the same procedures that a human reviewer would. The agent would not see other human reviews prior to submitting its review, and vice versa. An AI acting in Role 3 provides only an objective assessment of the paper, such as validation of proofs or experimental designs, for a human to later review. To allow for subjective assessments, we additionally define Role 3.5: AI as a Supporting Reviewer with Ratings where the AI also provides a subjective assessment, such as a rating or acceptance recommendation, of the paper for a human to judge thereafter.
Employing Role 3 & 3.5 shifts the role of the human from a reviewer, who makes recommendations, to Area Chair (AC) who makes decisions. In the most extreme instantiation of this role, all reviews would be AI-generated, and a human AC would only study the reviews and decide whether to accept. On the less extreme side, one could have, for instance, only 2 out of 4 reviews generated by AI systems. Either case results in less demand for human review-hours, which will be a tremendously helpful in reviewing the surge of new AI-accelerated submissions. However, this can also significantly increase the chance of hallucinations affecting acceptance decisions. AI reviewers must be assessed in their accuracy when compared to human reviewers, who are also prone to errors and lapses of judgment.
Role 4: Total AI Automation of Peer Review
In the future, it is plausible that AI review systems could eventually achieve a level of consistency and precision that outperforms traditional human review in practice, opening the door for a more automated process. For example, a NeurIPS 2021 experiment [15], replicating an earlier study from 2014 [16], routed $10%$ of submissions through two independent review committees and found a $23%$ inconsistency rate in acceptance decisions. Given the overall $22.7%$ acceptance rate, purely random selection would yield an inconsistency rate of $35%$. Thus, the fraction of inconsistent human recommendations is closer to the random baseline than it is to 0. Much of the noise was driven by borderline papers (where ACs had lower confidence in the decision); excluding borderline cases, the inconsistency rate drops to 16%.
To operationalize this concept in a lower-stakes environment, one could imagine an arXiv-like repository ("AIrXiv") that hosts only papers vetted by a specialized AI agent. Submissions could undergo multiple stages of automated review, incorporating interactive rebuttals and itemized point-by-point resolutions. Papers that survive many rounds of review would earn a high confidence rating within the system. This interactive, automated pipeline would enable rapid, continual improvement of papers concurrent with their evaluation, ultimately elevating the overall quality of the papers on the repository. Furthermore, this framework could establish a novel publication tier—one more prestigious than a standard preprint but less so than a traditional human-reviewed venue—thereby bypassing bottlenecks in the publication system while still providing a measure of achievement to the author.
Aside from the risks inherited from earlier roles, Role 4 may raise less obvious risks such as a reduction in diversity of opinion due to AI reviewers potentially holding only centralized viewpoints, resulting in a dampening of intellectual debate. Such debate is crucial to the academic tradition, especially in non-technical fields such as the humanities, and must be protected when considering more automated systems.
5. Conclusion and Future Outlook
Section Summary: The rapid growth in computer science conference submissions has strained traditional peer review, prompting the creation of an AI tool called PAT that spots major flaws in papers and suggests fixes, as shown in tests at conferences like STOC and ICML. While this system now serves mainly as a helper for authors and reviewers, future versions could take on greater roles, such as acting as a supporting reviewer or even enabling fully automated publishing systems, with similar AI mentors appearing in education. Human experts must still provide final oversight to preserve accountability, avoid complacency or bias, and ensure fair access to these tools.
The exponential surge in submissions to computer science conferences has pushed the traditional peer review infrastructure to its breaking point. To address this, we introduced the Paper Assistant Tool (PAT), an agentic reviewing pipeline that utilizes inference scaling to detect deep theoretical, logical, and empirical flaws in scientific papers, and suggest substantive improvements. Pilot deployments at major conferences like STOC and ICML demonstrated PAT's ability to uncover critical errors that had evaded human experts, proving that automated verification can meaningfully alleviate the reviewing bottleneck.
The success of PAT represents a critical milestone in the taxonomy of AI integration within the scientific process. Currently, systems like PAT can operate successfully within Role 1 (Tool for Authors) and Role 2 (Tool for Reviewers), acting as powerful tools at the disposal of humans. By automating logical validation, human reviewers are liberated to focus their limited bandwidth on deep conceptual novelty and elegance.
Moving forward, the academic community must carefully navigate the transition toward higher levels of AI agency. As the underlying agents improve, we anticipate a gradual shift toward Role 3 (Supporting Reviewer), where AI operates as a technical reviewer under the supervision of human ACs. As these systems further mature, the paradigm may even evolve toward Role 4 (Total AI Automation), unlocking alternative publication ecosystems like automated repositories that bypass traditional peer review entirely. In this scenario, AI would assume increasing responsibility alongside human academics for upholding the Scientific Method, acting as both an accelerator of scientific generation as well as a validator thereof. Beyond peer review, we believe these systems can also be influential in education. Specifically, a natural role of AI for Students will likely emerge, where AI agents are deployed as technical mentors for students, further empowering the next generation of scientific minds.
However, while AI tools may accelerate validation, ultimately the scientific community remains responsible for the integrity of its own work. Thus, as peer review evolves, human editors will become increasingly essential in safeguarding scientific rigor. Additionally, delineating clear lines of accountability—where algorithmic assessment ends and human judgment begins—will be a critical, open challenge for the academic community. Beyond accountability, the academic community must guard against cognitive complacency (e.g. the deskilling of human reviewers) and ensure equitable access to the compute infrastructure required for these tools. Furthermore, automation may introduce systemic vulnerabilities, such as algorithmic biases and the risk of authors adversarially gaming review agents. Only by addressing these challenges can we safeguard the integrity of the peer review process as we transition toward an automated scientific ecosystem.
References
Section Summary: The references section compiles a list of academic papers, preprints, blog posts, and online announcements that examine how artificial intelligence tools are influencing scientific writing, peer review, and conference processes. Many entries discuss experiments with AI assistants at events like ICML, NeurIPS, and STOC, along with studies measuring AI-generated text in publications and reviews. Others report on consistency checks in peer review or efforts to verify automated research contributions.
[1] Yang et al. (2025). Paper Copilot: Tracking the Evolution of Peer Review in AI Conferences. arXiv preprint arXiv:2510.13201. https://arxiv.org/abs/2510.13201.
[2] Liang et al. (2024). Mapping the Increasing Use of LLMs in Scientific Papers. arXiv preprint arXiv:2404.01268. https://arxiv.org/abs/2404.01268.
[3] Kobak et al. (2025). Delving into LLM-assisted writing in biomedical publications through excess vocabulary. Science Advances. 11(27). pp. eadt3813. doi:10.1126/sciadv.adt3813. https://doi.org/10.1126/sciadv.adt3813.
[4] Cohen-Addad, Vincent and Woodruff, David (2025). Gemini provides automated feedback for theoretical computer scientists at STOC 2026. Google Research Blog. Accessed: May 2026. https://research.google/blog/gemini-provides-automated-feedback-for-theoretical-computer-scientists-at-stoc-2026/.
[5] Jayaram et al. (2026). ICML Experimental Program using Google's Paper Assistant Tool (PAT). ICML Blog. https://blog.icml.cc/2026/01/14/icml-experimental-program-using-googles-paper-assistant-tool-pat/.
[6] NeurIPS Program Committee Chairs (2025). Reflections on the 2025 Review Process from the Program Committee Chairs. https://blog.neurips.cc/2025/09/30/reflections-on-the-2025-review-process-from-the-program-committee-chairs/.
[7] @icmlconf (2026). Post on X. X (formerly Twitter). Accessed May 21, 2026. https://x.com/icmlconf/status/2016954655599735289?lang=en.
[8] Deep Think Team (2025). Try deep think in the gemini app. https://blog.google/products/gemini/gemini-2-5-deep-think/.
[9] Son et al. (2025). When ai co-scientists fail: Spot-a benchmark for automated verification of scientific research. arXiv preprint arXiv:2505.11855.
[10] Google Cloud (2026). Gemini 3.1 Pro on Vertex AI. https://cloud.google.com/vertex-ai.
[11] Blecher, David P. (2024). A missing theorem on dual spaces. arXiv preprint arXiv:2405.01133.
[12] Pangram Labs (2025). Pangram Predicts 21% of ICLR Reviews are AI-Generated. Pangram Labs Blog. Accessed: May 2026. https://www.pangram.com/blog/pangram-predicts-21-of-iclr-reviews-are-ai-generated.
[13] Biswas et al. (2026). AI-Assisted Peer Review at Scale: The AAAI-26 AI Review Pilot. arXiv preprint arXiv:2604.13940.
[14] Feng et al. (2026). Towards autonomous mathematics research. arXiv preprint arXiv:2602.10177.
[15] Beygelzimer et al. (2021). The NeurIPS 2021 Consistency Experiment. NeurIPS Blog. https://blog.neurips.cc/2021/12/08/the-neurips-2021-consistency-experiment/.
[16] Cortes, Corinna and Lawrence, Neil D (2021). Inconsistency in conference peer review: Revisiting the 2014 neurips experiment. arXiv preprint arXiv:2109.09774.