Omnilingual MT: Machine Translation for {1,600} Languages
Omnilingual MT Team, Belen Alastruey$^{\dagger}$, Niyati Bafna$^{\dagger}$, Andrea Caciolai$^{\dagger}$, Kevin Heffernan$^{\dagger}$, Artyom Kozhevnikov$^{\dagger}$, Christophe Ropers$^{\dagger}$, Eduardo Sánchez$^{\dagger}$, Charles-Eric Saint-James$^{\dagger}$, Ioannis Tsiamas$^{\dagger}$, Chierh Cheng$^{\S}$, Joe Chuang$^{\S}$, Paul-Ambroise Duquenne$^{\S}$, Mark Duppenthaler$^{\S}$, Nate Ekberg$^{\S}$, Cynthia Gao$^{\S}$, Pere Lluís Huguet Cabot$^{\S}$, João Maria Janeiro$^{\S}$, Jean Maillard$^{\S}$, Gabriel Mejia Gonzalez$^{\S}$, Holger Schwenk$^{\S}$, Edan Toledo$^{\S}$, Arina Turkatenko$^{\S}$, Albert Ventayol-Boada$^{\S}$, Rashel Moritz$^{\ddagger}$, Alexandre Mourachko$^{\ddagger}$, Surya Parimi$^{\ddagger}$, Mary Williamson$^{\ddagger}$, Shireen Yates$^{\ddagger}$, David Dale$^{\perp}$, Marta R. Costa-jussà$^{\perp}$
FAIR at Meta
$^{\dagger}$ Core Contributors, alphabetical order
$^{\S}$ Other Contributors, alphabetical order
$^{\ddagger}$ Project Management, alphabetical order
$^{\perp}$ Technical Leadership, alphabetical order
Abstract
Advances made through No Language Left Behind (NLLB) have demonstrated that high-quality machine translation (MT) scale to 200 languages. Later Large Language Models (LLMs) have been adopted for MT, increasing in quality but not necessarily extending language coverage. Current systems remain constrained by limited coverage and a persistent generation bottleneck: while cross-lingual transfer enables models to somehow understand many undersupported languages, they often cannot generate them reliably, leaving most of the world’s 7,000 languages—especially endangered and marginalized ones—outside the reach of modern MT. Early explorations in extreme scaling offered promising proofs of concept but did not yield sustained solutions. We present Omnilingual Machine Translation (OMT), the first MT system supporting more than 1,600 languages. This scale is enabled by a comprehensive data strategy that integrates large public multilingual corpora with newly created datasets, including manually curated MeDLEY bitext, synthetic backtranslation, and mining, substantially expanding coverage across long-tail languages, domains, and registers. To ensure both reliable and expansive evaluation, we combined standard metrics with a suite of evaluation artifacts: BLASER 3 quality estimation model (reference-free), OmniTOX toxicity classifier, BOUQuET dataset (a newly created, largest-to-date multilingual evaluation collection built from scratch and manually extended across a wide range of linguistic families), and Met- BOUQuET dataset (faithful multilingual quality estimation at scale). We explore two ways of specializing an LLM for machine translation: as a decoder-only model ($\textsc{OMT-LLaMA}$) or as a module in an encoder–decoder architecture ($\textsc{OMT-NLLB}$). The former consists of a model built on $\textsc{LLaMA3}$, with multilingual continual pretraining and retrieval-augmented translation for inference-time adaptation. The latter is a model built on top of a multilingual aligned space ($\textsc{OmniSONAR}$, itself also based on $\textsc{LLaMA3}$), and introduces a training methodology that can exploit non-parallel data, allowing us to incorporate the decoder-only continuous pretraining data into the training of an encoder–decoder architecture. Notably, all our 1B to 8B parameter models match or exceed the MT performance of a 70B LLM baseline, revealing a clear specialization advantage and enabling strong translation quality in low-compute settings. Moreover, our evaluation of English-to- 1,600 translations further shows that while baseline models can interpret undersupported languages, they frequently fail to generate them with meaningful fidelity; $\textsc{OMT-LLaMA}$ models substantially expand the set of languages for which coherent generation is feasible. Additionally, OMT models improve in cross-lingual transfer, being close to solving the “understanding” part of the puzzle in MT for the 1,600 evaluated. Beyond strong out-of-the-box performance, we find that finetuning and retrieval-augmented generation offer additional pathways to improve quality for the given subset of languages when targeted data or domain knowledge is available. Our leaderboard and main humanly created evaluation datasets (BOUQuET and Met- BOUQuET) are dynamically evolving towards Omnilinguality and freely available.
Leaderboard and Available Evaluation: https://huggingface.co/spaces/facebook/bouquet
Correspondence: Marta R. Costa-jussà at mailto:[email protected], David Dale at mailto:[email protected]
Executive Summary: The rapid growth of machine translation (MT) has improved communication across languages, but current systems cover only about 200 languages effectively, leaving the vast majority of the world's 7,000 languages—particularly endangered and marginalized ones—out of reach. This gap persists despite advances in large language models (LLMs), which boost quality for major languages but fail to expand coverage reliably. A key issue is the "generation bottleneck": models can often understand low-resource languages through cross-lingual transfer but struggle to produce coherent output in them. With global diversity under threat from language loss, addressing this now is crucial to promote inclusion, support cultural preservation, and enable equitable access to technology in education, policy, and everyday communication.
This document introduces Omnilingual Machine Translation (OMT), a family of MT systems designed to support more than 1,600 languages—the broadest coverage to date. The work evaluates two approaches to specialize LLMs for translation: a decoder-only model (OMT-LLaMA) and an encoder-decoder model (OMT-NLLB), aiming to achieve high quality across diverse languages while overcoming data scarcity and evaluation challenges.
The team assembled one of the largest multilingual corpora by integrating public sources like Common Crawl and Bible translations with new datasets, including manually curated parallel texts (MeDLEY for 109 low-resource languages) and synthetic data from backtranslation and mining to fill gaps in underrepresented domains and registers. They extended model vocabularies to 256,000 tokens for better handling of rare scripts. For OMT-LLaMA, based on LLaMA3 (1B to 8B parameters), they applied continual pretraining on mixed monolingual and parallel data, followed by supervised fine-tuning, reinforcement learning, and retrieval-augmented generation for adaptation. OMT-NLLB, a 3B-parameter model, used a cross-lingually aligned encoder (OmniSONAR) with a novel training method to incorporate non-parallel data via autoencoding, then transitioned to full encoder-decoder attention on parallel data. Evaluation combined standard metrics like ChrF++ with new tools: a reference-free quality estimator (BLASER 3), toxicity detector (OmniTOX), and datasets (BOUQuET for diverse domains in 275+ languages; Met-BOUQuET for metric benchmarking across 161 directions), plus a human protocol (XSTS+R+P) assessing semantics, register, and context. Data spanned 2023–2025, with samples up to millions of sentences per source, assuming cross-lingual transfer aids low-resource cases.
The analysis reveals five key findings. First, OMT expands effective coverage: models now "understand" over 400 languages (doubling prior benchmarks of 200) and provide non-trivial performance from/to 1,600 and 1,200 languages, respectively, outperforming baselines like NLLB and LLMs by wide margins on new state-of-the-art results for most. Second, smaller specialized models (1B–8B parameters) match or exceed a 70B LLM baseline, showing that targeted design yields better efficiency-performance trade-offs than sheer scale. Third, OMT overcomes the generation bottleneck, enabling coherent output for many previously unsupported languages—e.g., English-to-1,560 Bible translations show baselines interpret but fail to generate meaningfully, while OMT succeeds for far more. Fourth, new evaluation tools like BLASER 3 correlate strongly (Spearman ρ up to 0.70) with human judgments across 119 languages, outperforming prior metrics by 8–12% on low-resource pairs, with adjustments for language detection boosting reliability. Fifth, techniques like finetuning and retrieval-augmented generation improve targeted subsets by 5–10% when extra data is available.
These results mean OMT makes high-quality translation feasible for billions in low-resource communities, reducing risks of cultural erasure and enhancing safety by detecting toxicity across languages. Unlike expectations of endless scaling, it highlights specialization's edge, cutting compute costs by 90% for comparable performance and aiding low-resource deployment. This shifts MT from elite languages to global equity, impacting compliance in international policy and performance in cross-cultural tools, though it differs from past work by prioritizing generation over mere understanding.
Leaders should prioritize adopting OMT models—freely released with datasets and a leaderboard—for applications like global chat or content localization, opting for smaller variants in resource-limited settings. Trade-offs include decoder-only for flexibility (e.g., integrating reasoning) versus encoder-decoder for efficiency in pure translation. Next steps: Cascade with speech recognition for omnilingual speech-to-text; finetune for specific domains; invest in pilots for endangered languages. Further analysis on zero-resource cases and more human evaluations are needed before full-scale decisions.
While robust across 1,600+ languages, limitations include Bible data contamination in evaluations and gaps in monolingual corpora for ultra-rare languages, potentially inflating scores by 5–10%. Assumptions like cross-lingual transfer hold for most but falter in isolated families. Confidence is high in coverage gains (validated on diverse benchmarks) but moderate for zero-resource output—use cautiously there, relying on human checks.
1. Introduction
Section Summary: The No Language Left Behind project advanced machine translation to cover 200 languages effectively, but it highlighted major gaps for the world's 7,000 languages, especially rare and low-resource ones, where models can understand but struggle to generate text reliably due to limited data. This work introduces Omnilingual Machine Translation, a new system that supports over 1,600 languages—the widest coverage yet—by building massive, diverse datasets with human and synthetic inputs, and using specialized large language models in two architectures that expand vocabulary and improve performance. These models double the number of well-handled languages to over 400, outperform rivals on thousands more, show that targeted designs beat massive general-purpose models for efficiency, and pave the way for broader multilingual AI tools beyond just translation.
The recent success of No Language Left Behind (NLLB) ([1]) marked a turning point in multilingual translation. By demonstrating that high-quality MT could be extended to 200 languages, NLLB reshaped the research landscape and set a new standard for linguistic inclusion. It catalyzed new data pipelines, evaluation frameworks, and community partnerships that continue to benefit the entire field—including the work we present here. But NLLB also revealed a deeper asymmetry in multilingual MT. Modern models can often recognize or interpret long-tail languages through cross-lingual transfer, yet they struggle to produce them reliably. This generation bottleneck is compounded by a static, training-time definition of coverage: languages with little or no data simply never enter the system. Together, these constraints leave most of the world’s 7, 000 languages—especially endangered and underdocumented ones—effectively outside the reach of current MT technology. Early attempts to explore extreme scaling, such as Google’s Massively Multilingual Translation project ([2]), demonstrated the feasibility of reaching toward 1, 000 languages, but these efforts did not evolve into sustained work, and progress toward broader global coverage has stalled. However, notable progress has been made towards improving quality for top priority languages with decoder-only architectures (Large Language Models, LLMs) e.g. ([3, 4, 5]).
In this work, we introduce Omnilingual Machine Translation (Omnilingual MT), a family of multilingual translation systems that extend support to more than 1, 600 languages, the broadest coverage of any benchmarked MT system to date. To start, our data efforts included assembling and curating one of the largest and most diverse multilingual corpora to date, drawing from prior massive collections while substantially expanding coverage through new human-curated and synthetic data pipelines. More specifically, we integrated material from large-scale public sources and augmented them with newly created resources—including manually curated seed datasets and synthetic backtranslation—to address long-tail gaps in domains, registers, and under-documented languages.
Omnilingual MT explores two complementary ways of specializing LLMs for translation: as a standalone decoder-only model and as a block within an encoder–decoder architecture. In the first approach, we extend $\textsc{LLaMA3}$ –based decoder-only models with a multilingual continual-pretraining recipe and retrieval-augmented translation for inference-time adaptation. In the second approach, we employ a cross-lingually aligned encoder ($\textsc{OmniSONAR}$ ([6]) built itself on top of $\textsc{LLaMA3}$) to build an encoder–decoder architecture that maintains the size of the original NLLB model while expanding its language coverage through a novel training methodology that exploits non-parallel data, reusing the continual-pretraining data from the decoder-only model. Both approaches share an expanded 256K-token vocabulary and improved pre-tokenization for underserved scripts, enabling large-scale language expansion to cover over 1, 000 languages.
To ensure both reliable and expansive evaluation, we combined standard metrics such as MetricX and ChrF with a suite of evaluation artifacts developed for this effort. These include BLASER 3 quality estimation model (reference-free), OmniTOX toxicity classier, BOUQuET dataset (a newly created, largest-to-date multilingual evaluation collection built from scratch and manually extended across a wide range of linguistic families), and Met- BOUQuET dataset (which provides faithful multilingual quality estimation at scale).
Omnilingual MT expands the number of languages that modern models "understand sufficiently well" twofold, from about 200 to over 400 languages. Moreover, it offers non-trivial performance when translating from 1, 600 and into about 1, 200 languages, outperforming all competitive translation systems by a large margin and establishing new (and often first) state-of-the-art (SOTA) results for the majority of these 1, 600 languages.
Notably, we show that specialized MT models offer superior efficiency–performance tradeoffs compared to general-purpose LLMs. More specifically, our 1B to 8B parameter models match or exceed the MT performance of a 70B-parameter LLM baseline, revealing a clear Pareto advantage: specialization, not scale, is perhaps a more reliable path to high-quality multilingual translation. This efficiency extends the practical reach of the model, enabling strong MT performance in real-world, low-compute contexts. In addition, our systematic evaluation of Omnilingual MT on English-to- 1, 560 Bible translations reveals a striking pattern: many baseline models can interpret undersupported languages, yet they often fail to generate them with even remote similarity to the target. Omnilingual MT substantially widens the set of languages for which coherent generation is possible, reinforcing the central claim of this work—that large-scale MT coverage requires not only cross-lingual understanding but robust language generation, which current baselines do not reliably provide. Beyond strong out-of-the-box performance, we analyze how targeted techniques, such as finetuning and retrieval-augmented generation, can further boost translation quality for individual languages. With this, Omnilingual MT not only provides broad coverage but also offers flexible pathways for further improving performance when additional data or domain knowledge is available.
Although Omnilingual MT is primarily designed for translation, we consider it as a general-purpose multilingual base model. Its architecture can be further trained to build multilingual LLMs, enabling future research that integrates translation, reasoning, dialog, and multimodal capabilities in thousands of languages. Moreover, with the recent release of Omnilingual ASR ([7]), Omnilingual MT can be cascaded with large-scale speech recognition to produce speech-to-text translation systems operating at a scale previously unattainable. The Omnilingual MT recipes for building models with unprecedented language support can in principle be reproduced on top of diverse base language models, and we hope that they will inspire communities, researchers, and practitioners to build systems that evolve alongside the world’s languages.
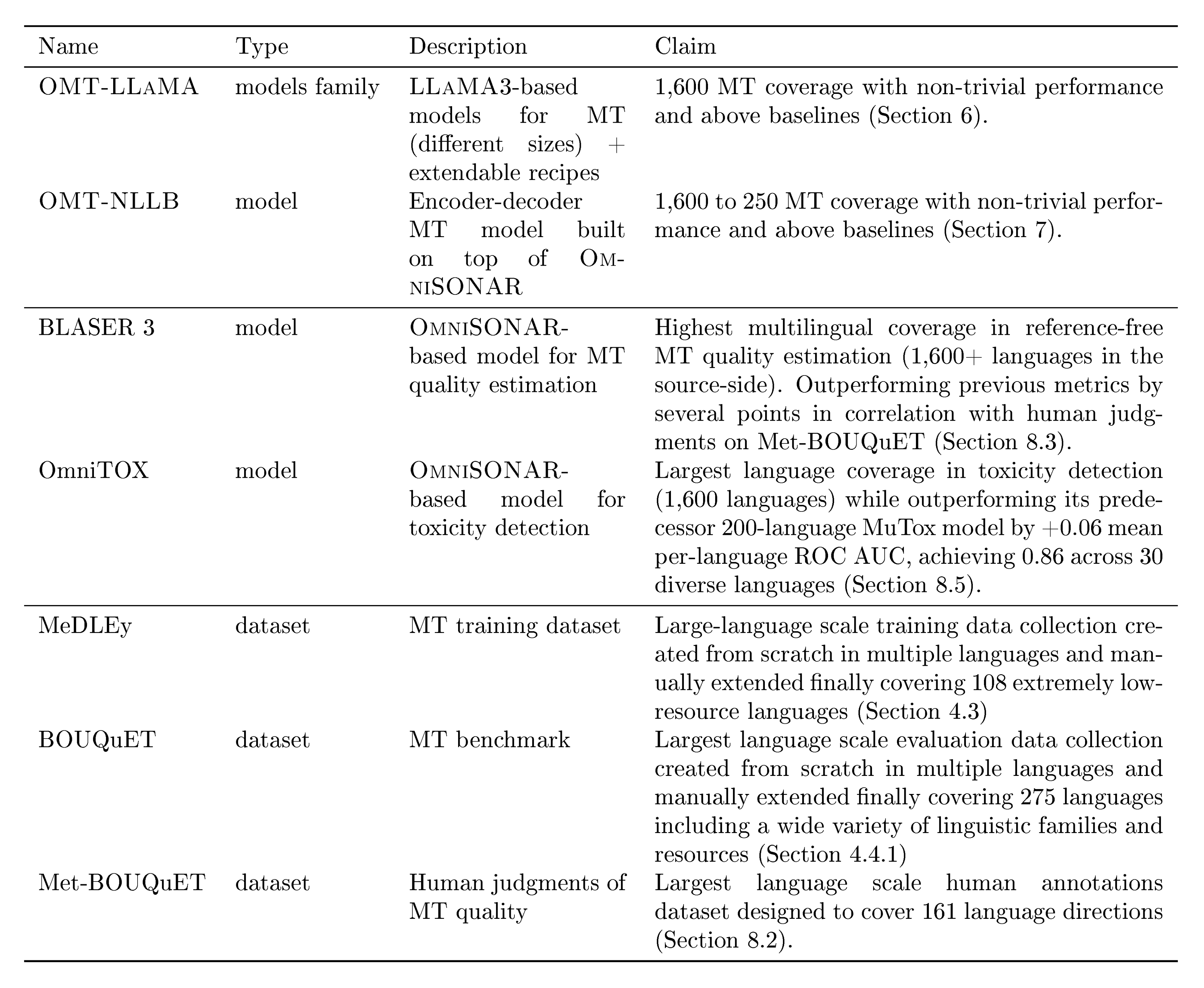
The main claims of our line of work are outlined in Table 1. Our translation models are built on top of freely available models. BOUQuET and Met-BOUQuET and the adjacent leaderboard are freely available^1.
::: {caption="Table 1: A summary of the corresponding claims of our line of work."}
:::
2. Expanding Machine Translation
Section Summary: Recent advances in machine translation, such as the NLLB model, have made high-quality translations possible for around 200 languages, challenging the old idea that adding more languages lowers overall performance and inspiring new data tools and standards. However, these systems still leave most of the world's 7,000 languages out, especially endangered ones, with models often understanding low-resource languages but struggling to produce accurate outputs in them. Efforts to expand coverage to 1,000 or more languages face hurdles like linguistic diversity, uneven data availability, and unreliable evaluation methods, calling for smarter ways to build adaptable, efficient systems that better represent global diversity.
Recent advances in multilingual MT have demonstrated that high-quality translation can extend far beyond high-resource languages. Most notably, the trajectory is best represented by NLLB ([1]), which demonstrated that it is possible to deliver strong translation quality for 200 languages, setting a new standard for linguistic inclusion. More specifically, NLLB illustrated that the long-standing curse of multilinguality-the tendency for quality to degrade as the number of languages increases—was not an insurmountable barrier. Through large-scale data curation, targeted architecture choices, and multilingual optimization strategies, NLLB achieved both breadth and quality, overturning the assumption that scaling coverage inevitably sacrifices performance. Since the release of NLLB, the work has reshaped the multilingual MT ecosystem in several ways, including establishing FLoRes-200 as the de facto evaluation standard, catalyzing new data pipelines across academia and industry, and enabling dozens of downstream models, fine-tuning efforts, and community adaptation projects that continue to rely on its multilingual backbone.
Despite the impact of this effort, NLLB and other projects in this current landscape continue to leave the vast majority of the world’s 7, 000 languages, especially endangered or marginalized, largely absent from technological representation. As a result, coverage plateaus at roughly the same frontier across systems. Compounding this issue, many models exhibit cross-lingual understanding of underserved languages through transfer, yet consistently fail to generate them with meaningful fidelity, revealing a generation bottleneck that further limits practical support for long-tail languages.
That said, several projects have started to explore scaling MT beyond the 200-language ceiling. Google’s Massively Multilingual Translation work investigated models covering up to 1, 000 languages, offering an early proof of concept that extreme multilingual scaling was technically possible ([2]). These efforts demonstrated that multilingual transfer can be leveraged even in very low-resource conditions. However, they did not yield sustained, or extensible systems, and none produced a practical path for continual expansion. Subsequent multilingual MT systems, including large decoder-only LLMs, mostly reporting MT quality improvements on top priority languages, have also increased language coverage indirectly. Their big-scale pretraining exposes them to a broader, if uneven, range of languages than purpose-built MT systems, allowing them to exhibit surprising zero-shot and few-shot translation abilities. Improvements in reasoning, instruction-following, and cross-lingual representations have also provided new avenues for multilingual transfer. Yet these gains remain dominated by high-resource languages, and large LLMs remain inefficient MT systems—often requiring tens of billions of parameters to match the MT performance of much smaller specialized models (see Section 9).
The expansion of MT is compounded by other problems. Long-tail languages, for one, bring substantial linguistic diversity ranging from rich morphological systems and agglutinative patterns to unique orthographic and script traditions—with available written data often distributed across different formats and community contexts ([8]). These linguistic and sociocultural features expose the brittleness of closed-coverage systems: adding a language requires far more than acquiring data; it requires modeling choices that account for typological diversity and social context. Furthermore, while large-scale multilingual corpora—including Bible-based datasets, Gatitos ([9]) and SMOL ([10]) with parallel texts, and large-scale web datasets like FineWeb2 ([11]) or HPLT 3.0 ([12])—have expanded the availability of multilingual training text, these corpora exhibit systematic gaps. They disproportionately represent formal registers, religious domains, and well-documented language families while underrepresenting dialect variation, colloquial styles, and many of the world’s marginalized languages. As a result, increasing dataset size does not reliably translate into broader or more equitable coverage. However, recent work using synthetic data ([13]), bitext mining, and multilingual transfer ([12]) has proven to be helpful in extending coverage.
In addition, large-scale evaluation remains a major bottleneck for multilingual MT. FLoRes+ ([14]), and the Aya benchmark ([15]) provide high-quality evaluation for hundreds of languages, but none provide coverage beyond 200–300 languages (there are few recent exceptions to this ([16])) . Reference-based metrics also struggle at scale: BLEU and ChrF++ fail to capture meaning adequacy, while reference-free metrics such as COMET, BLASER 3 and MetricX require careful calibration and validation in typologically diverse languages (see metric cards in Appendix C). Without reliable evaluation for long-tail languages, progress becomes difficult to measure and even harder to compare across systems. This problem becomes acute when scaling to 1, 000+ languages, where many systems can produce outputs that appear fluent yet remain unintelligible or unrelated to the target language, making generation accuracy particularly challenging to assess. The field requires multilingual quality-estimation frameworks that scale to thousands of languages while preserving metric fidelity.
Taken together, these limitations highlight that progress in massively multilingual MT now depends less on marginal model improvements than on rethinking how systems can grow, adapt, and represent the world’s linguistic diversity. What is needed is not only broader coverage but deeper support—models that can generate underserved languages robustly, operate efficiently at smaller scales, and provide reliable evaluation mechanisms for long-tail settings. Our goal is to operationalize this shift. Rather than building another large model centered on high-resource performance, we design Omnilingual MT to address the structural challenges of extreme coverage: data scarcity, typological diversity, long-tailed language generation, efficiency–performance tradeoffs, and the absence of evaluation frameworks for 1, 600+ languages.
This perspective also motivates how we organize the remainder of the paper. In Section 3, we move from the structural challenges outlined above to the linguistic realities of scaling to 1, 600+ languages. This section is specially relevant to inform about the concept of language; and related language features such as what does it take to qualify as pivot language, relevance of context, how to determine resource-levels.
Section 4 presents the data contributions in this work with special focus on under-represented languages. This section reports several well-known directions to expand data for pretraining MT models. Additionally, it reports more innovative diverse and representative post-training and evaluation datasets.
The three subsequent sections—Section 5, Section 6, and Section 7—describe the translation model architectures that we propose. We report several ablations to motivate our modeling decisions.
Next, Section 8 is dedicated to the contributions that we make towards expanding the MT metrics to Omnilinguality. We propose a variation of human evaluation protocol (XSTS+R+P) to better represent languages outside of English, build the largest human annotations collection on language coverage on MT quality (Met- BOUQuET), propose the largest multilingual MT quality metric (BLASER 3), and the largest multilingual toxicity detector (OmniTOX).
Section 9 reports the final results of our MT models evaluation focusing on answering questions such as language coverage and relative performance to external baselines.
The final sections focus on key features of the MT adoption problem space. Section 9.1.4 demonstrates how our smaller models achieve performance improvements over, or parity with, larger models. Section 10 addresses the growing trend of researchers fine-tuning NLLB for machine translation in their languages and adapting smaller $\textsc{LLaMA}$ models to various language-specific tasks, including translation. Building on this momentum, we demonstrate that our models are architecturally designed to facilitate such extensions and adaptations. The findings presented in this paper underscore the importance of continued investment in specialized models to enhance translation quality and expand language coverage in MT. Finally, Section 11 summarizes the conclusions and discusses the social impact of our work.
3. Languages
Section Summary: The section explains how languages are identified and referenced using standardized codes like ISO 639-3 for languages and ISO 15924 for writing systems, allowing for precise distinctions such as different scripts for Mandarin Chinese, while noting that classifications can be debated and that counts often include unique language-script combinations. It highlights the uneven global distribution of language speakers, with over half the world's population relying on the top 20 languages and the rest spread across thousands of others in a long-tail pattern, many of which are underserved due to limited access to technologies like machine translation. To address quality issues in training data and evaluations for these underserved languages, the authors discuss challenges like finding proficient translators amid generational language shifts and propose using pivot languages—high-resource ones familiar to speakers, such as Spanish for certain Indigenous languages—along with providing contextual details to improve translation workflows.
3.1 Referring to languages
In the absence of a strict scientific definition of what constitutes a language, we arbitrarily started considering as language candidates, and referring to those candidates as languages, those linguistic entities—or languoids, following [17]—that have been assigned their own ISO 639-3 codes.
We acknowledge that language classification in general, and the attribution of ISO 639-3 codes in particular, is a complex process, subject to limitations and disagreements, and not always aligned with how native speakers themselves conceptualize their languages. To allow for greater granularity when warranted, ISO 639-3 codes can be complemented with Glottolog languoid codes ([18]).
Additionally, as some languages can typically be written using more than a single writing system, all languages supported by our model are associated with the relevant ISO 15924 script code. For example, we use cmn_Hant to denote Mandarin Chinese written in traditional Han script and cmn_Hans for the same language written in simplified Han script. When counting languages throughout this paper, we typically count the distinct combinations of the language and the writing system, identified by the pair of ISO 639-3 and ISO 15924 codes.
Finally, the use of the phrases long-tail languages and underserved languages also needs further defining. There are over 7, 000 languages used in the world today used by over 8 billion human beings. The number of users is not evenly distributed among those languages, far from it. It is estimated ([19]) that slightly less than half of the world's population uses as their native languages (or L1) one of the 20 most used languages, which means that the other half uses as their L1 one of the remaining 7, 000+ languages. The same authors[^2] estimate that 88% of the world's population use as their L1 or L2 one of the 200 most used languages. Overall, we can see that the distribution of L1 users per language is quasi-zipfian, and therefore displays a conspicuous long tail (hence, our use of the phrase long-tail languages). It is not uncommon for many of the long-tail languages to be considered underserved, as defined in the following section.
[^2]: https://www.ethnologue.com/insights/ethnologue200/, last accessed 2026-02-18
3.2 Quality translations from or into underserved languages
In this section we discuss the main impediments to the creation of high-quality training or evaluation data that could partially offset the lack of existing data for underserved languages, and present non-English-centric solutions as an alternative to existing translation workflows. We use the phrase underserved languages as a synecdoche referring to communities of language users who do not have access to the full gamut of language technologies—and more specifically here to machine translation—in their respective native languages. The language technology industry often refers to those languages as low-resource languages because of the small amount of available data. We discuss resource-level classification at greater length in the next section, as this kind of classification carries some degree of arbitrariness that warrants further explanations.
The problem of low-quality translations into or out of underserved languages can be approached from at least two angles: training data and evaluation. On the training data front, mitigation strategies for observed quality issues entail creating additional parallel data; this is most often done by commissioning translations into underserved languages. From the standpoint of evaluation, quality issues can stem from the lack of evaluation datasets or the lack of useful human evaluation annotations. The common denominator to training data and evaluation shortcomings is the difficulty faced by the research community to commission high-quality work from proficient translators or bilingual speakers.
Determining pivot languages
Receiving high-quality work products from proficient translators or bilingual speakers implies, firstly, having access to said speakers and, secondly, creating optimal conditions for quality work. When it comes to underserved languages, it is important to consider that the vast majority of those languages score high on the intergenerational disruption scale [^3]. High disruption typically occurs when different generations of speakers become geographically estranged due to drastic changes in labor and macroeconomic settings (e.g., when a country's economy shifts its primary source of production from the primary sector to the secondary or tertiary sector). Corollary to this shift is a massive displacement of younger generations from rural areas to urban business and higher education centers. As a result, the linguistic profiles of those generations become differentiated. The older generations are proficient native speakers of the underserved language and, in most cases, proficient second-language speakers of an official language of the country where they reside. The younger generations are native or near-native proficient speakers of the official language and of a business or research lingua franca (more often than not, English) but they are not as proficient in the underserved language. For the above reasons, pairing underserved languages with English in human translation work is not always the optimal solution. Alternatively, we also need to provide for the pairing of underserved languages with high-resource languages at which native speakers are proficient. In this project, we refer to those alternate high-resource languages as pivot languages (e.g., Spanish used as a pivot language for translations into or out of Mískito [miq], or K'iche' [quc]).
[^3]: For additional information on language disruption and disruption scoring, please see [20].
Providing contextual information
Even when English is a possible—or the only available—pivot option, its lack of explicit grammatical markings is a constant reminder that sentences rarely speak for themselves, and that translators need a good amount of contextual information to produce quality translations, especially when moving away from the formal textual domain and closer to the conversational domain. For example, one of the many differences between those two domains is a shift from a predominance of unspecified third grammatical persons to first and second grammatical persons (often in the singular). In English, the pronouns I and you do not provide any intrinsic information about grammatical gender; in fact, you does not even provide any distinctive information about grammatical number, which is not complemented either by any form of verbal or adjectival inflection. This causes ambiguities that translators cannot resolve on their own, which in turn may lead to mistranslations that are not due to lack of proficiency but rather lack of relevant information. The same is true of information about language register and formality. In the conversational domain, English provides very few formality markers, and identifying language register markers may require a very high level of proficiency, which is only accessible to translators with extensive cultural experience. To mitigate these problems, we first ensured that all sentences to be translated be included in a paragraph (or what would be the equivalent of a paragraph in speech). We also provided translators with additional information about the following: the overall domain in which the paragraphs are most likely to be found, the protagonists depicted or referred to in the paragraphs, the language register most likely to be used in such situations, and the overall tone of the paragraphs (if any specific tones were to be conveyed).
3.3 Resource levels
Historically, languages in MT have typically been classified as either high-resource or low-resource (e.g., see WMT evaluations ([21, 22])). This classification facilitates the analysis of MT performance in highly multilingual and massively multilingual settings, among other applications.
The definition of low-resource languages is somewhat arbitrary, or at the very least, highly dynamic, as additional resources may be created at any time. More broadly in NLP, this classification is based on the availability of corpora, dictionaries, grammars, and overall research attention. One widely used definition in the field of MT originates from the NLLB work ([1]), in which the authors differentiate between high- and low-resource languages based on the amount of parallel data available for each language (with "documents" predominantly consisting of single sentences). Specifically, the threshold is set at 1 million parallel documents, above which a language is considered high-resource.
We want to revisit this definition because we are dealing with a much larger amount of languages than NLLB; and works with similar amount of languages ([23]) do not provide an explicit definition; we want to optimize for this definition to correlate with MT quality; and given the large amount of languages that we are covering, we want to further fine-grain our language resource classification by splitting low resource languages into low and extremely low resource, and by distinguishing high- and medium-resourced languages.
Based on our experiments (see Figure 1), we confirm a correlation between translation quality and the amount of parallel documents available. A clear shift in translation quality is observed for languages with more than 1 million parallel documents, which, following the NLLB convention, we establish as the threshold for the "low-resource" designation. An additional qualitative change is observed at approximately 40K parallel documents: this corresponds to a corpus size comparable to that of the Bible, supplemented by at least one additional source of parallel training data.
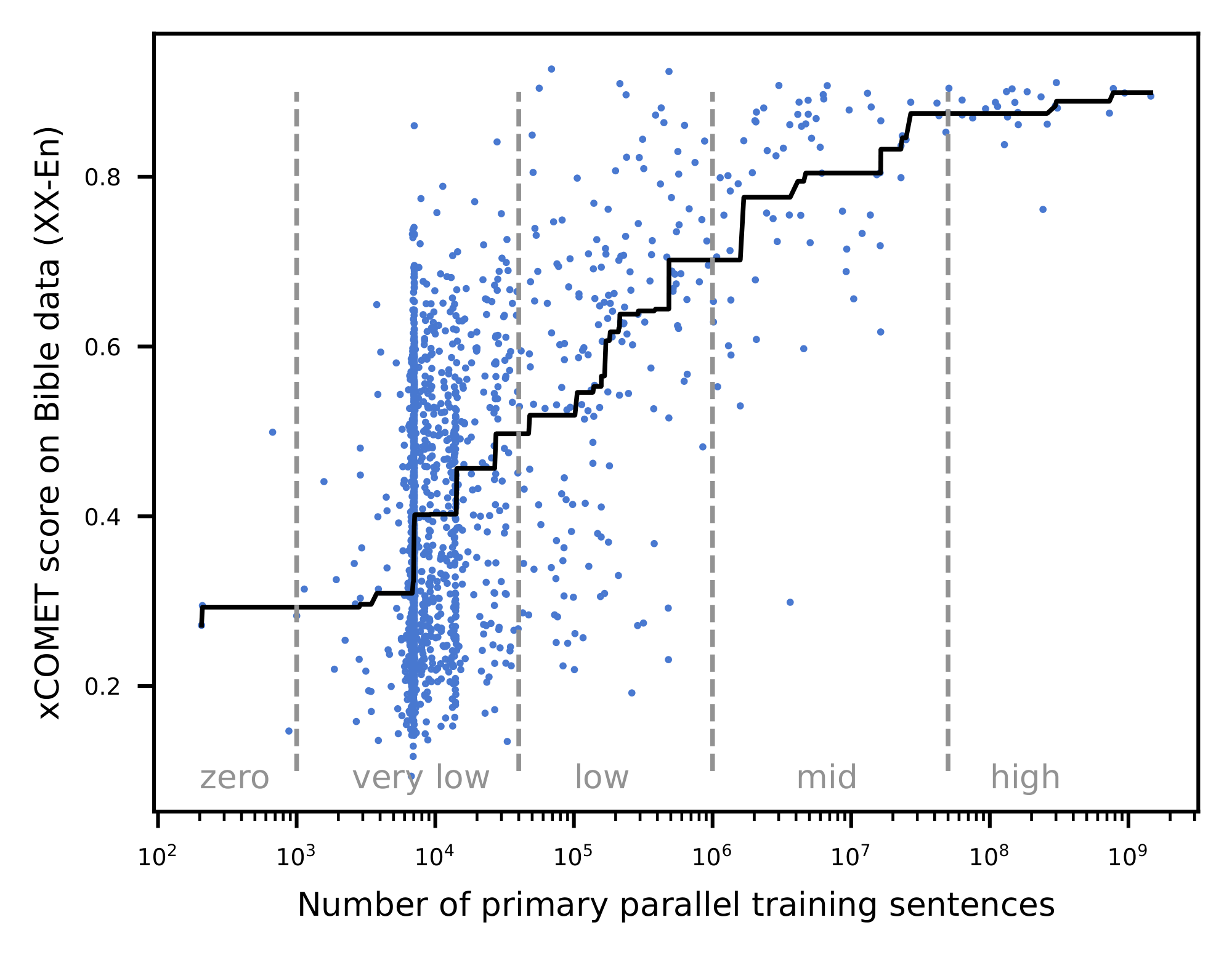
Therefore, the final classification relies on parallel documents available, with a language considered high resource if we have more than 50M document pairs (for such languages, MT quality of most systems is predictably high), mid resource above 1M, low resource if we have parallel documents between 40K and 1M, extremely low resource if we have between 40K and 1K parallel documents, and zero-resource below 1K (mostly to indicate that their training data size is much lower than even a typical Bible translation or a seed corpus, often represented only by a few sentences in a multilingual resource like Tatoeba). See the graph with distribution of languages per resource bucket in Figure 2.
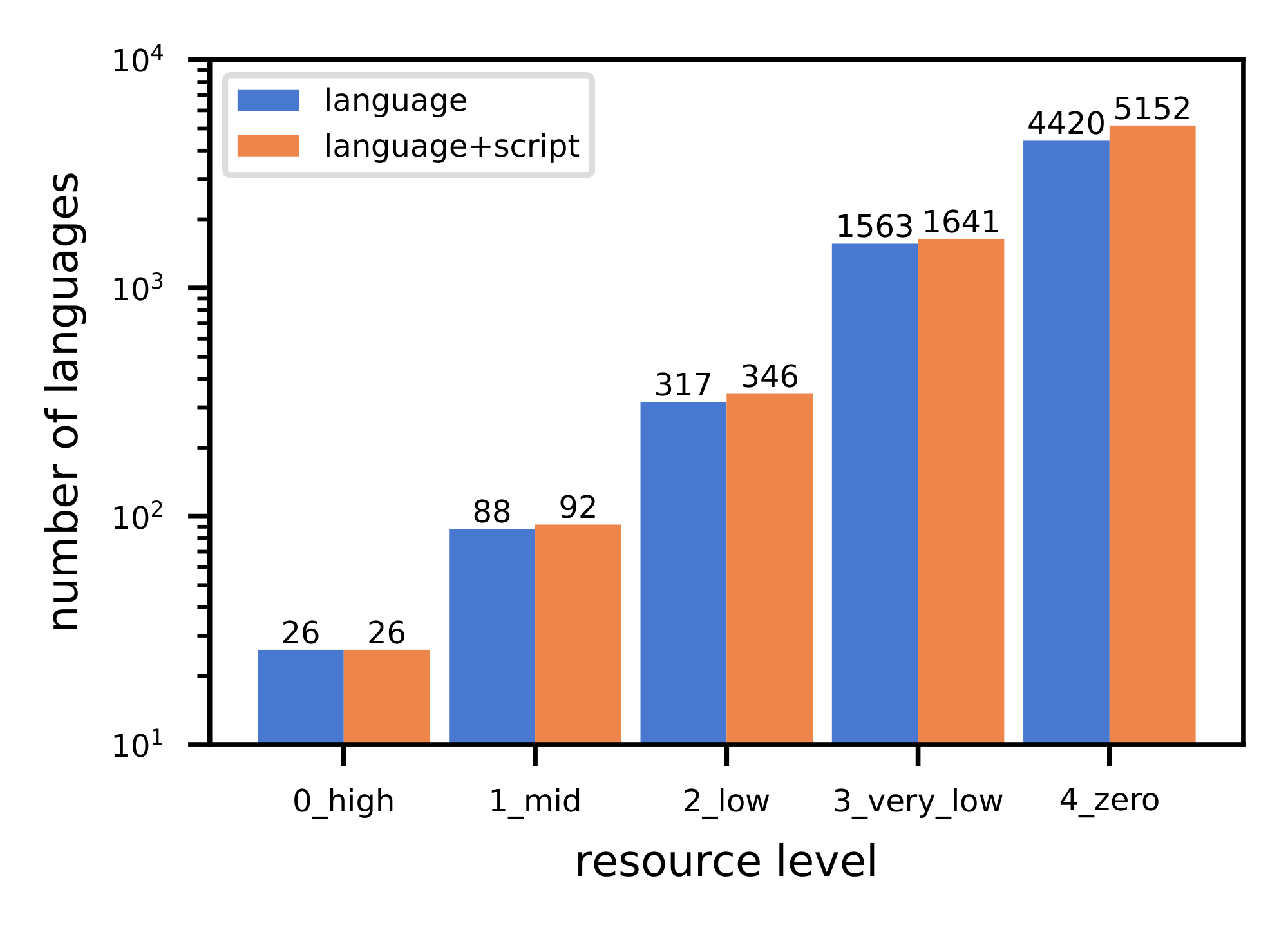
This definition comes with some limitations. Most anomalies come from languages with less than 1k parallel documents on which we observe equally high translation quality. By doing a manual inspection on those languages, we could hypothesize that this bucket contains languages which are highly similar to other high resource languages and benefit from positive knowledge transfer. Another anomaly, but much more rare, is low-performing languages in the bucket of languages with more than 1M documents. In this case, again, by manual analysis we could hypothesize that there are languages for which we have extremely low quality data or very narrow domain distribution of it. Or, complimentary, rare scripts that are not well represented by the tokenizer and as a consequence low quality MT performance. Finally, sometimes we misattribute the available training data to other languages, due to loosely defined language boundaries (e.g. some data for a dialectal Arabic language could be identified simply with the ara_Arab code, pointing to the Arabic macro-language without specifying the language).
3.4 Describing languages in prompts
When prompting both $\textsc{OMT-LLaMA}$ models and instruction-following external baselines to translate, the precise format of describing the target language may affect the generation results. Different organizations prefer different language code formats, and to ensure interoperability of our prompts between diverse models, we opted for natural-language descriptions of the language varieties.
Our template for language names includes the language name itself, followed by optional brackets with the script, locale, or a dialect: for example, spa_Latn becomes "Spanish", cmn_Hans becomes "Mandarin Chinese (Simplified script)", eng_Latn-GB turns into "English (a variety from United Kingdom)", and twi_Latn_akua1239, into "Twi (Akuapem dialect)". We omit the script description for the languages that are "well-known" (using inclusion into FLORES-200 as a criterion) and that are expected to be using one single script in an overwhelming majority of scenarios.
For mapping the codes of languages, scripts and locales into their English names, we mostly rely on the Langcodes package, ^4, which in turn relies on the IANA language tag registry. For referring to dialects, we use their names from the Glottolog database[^5], but employ them only for disambiguating otherwise identical language varieties in FLoRes+.
[^5]: From the languoids table in https://glottolog.org/meta/downloads; currently we are using version 4.8.
4. Creating High-Quality Datasets
Section Summary: High-quality data is essential for building effective translation systems across thousands of languages, so this section emphasizes curating and selecting reliable sources for training and evaluation. For training through continual pretraining, the team uses diverse multilingual resources like filtered Common Crawl datasets covering over 2,000 languages, Bible translations for alignment, dictionaries such as Panlex, and sentence collections like Tatoeba, along with specialized parallel texts. To address gaps in underrepresented languages and topics, they also create new monolingual and aligned datasets from web sources, synthetic generations, and manual efforts, while relying on Bible subsets and benchmarks like FLoRes+ for evaluation.
Access to high quality data is crucial to develop a high quality translation system. We give special focus to creating, selecting, and curating high-quality data for thousands of languages both for training and evaluation. In this section, regarding training, we mainly discuss continual pretraining (CPT) data, while main data for postraining is directly discussed in the corresponding section (Section 6.3). For CPT, we leverage mainly datasets in Table 2 and presented in Section 4.1. For evaluation, we rely on a subset of the Bible (Section 4.4.2) and several standard ones—e.g., FLoRes+ ([1]).
Beyond this, and to compensate for existing limitations in the existing data such as lack of long-tail languages, domains, registers and others, we curate new training datasets, both monolingual (inspired by [11] and [24]) and aligned (manual MeDLEy, parallel data inspired by [1], Section 4.3, and synthetic data, Section 4.2) as well as the BOUQuET evaluation dataset (Section 4.4.1).
4.1 Main CPT Training Data Collection
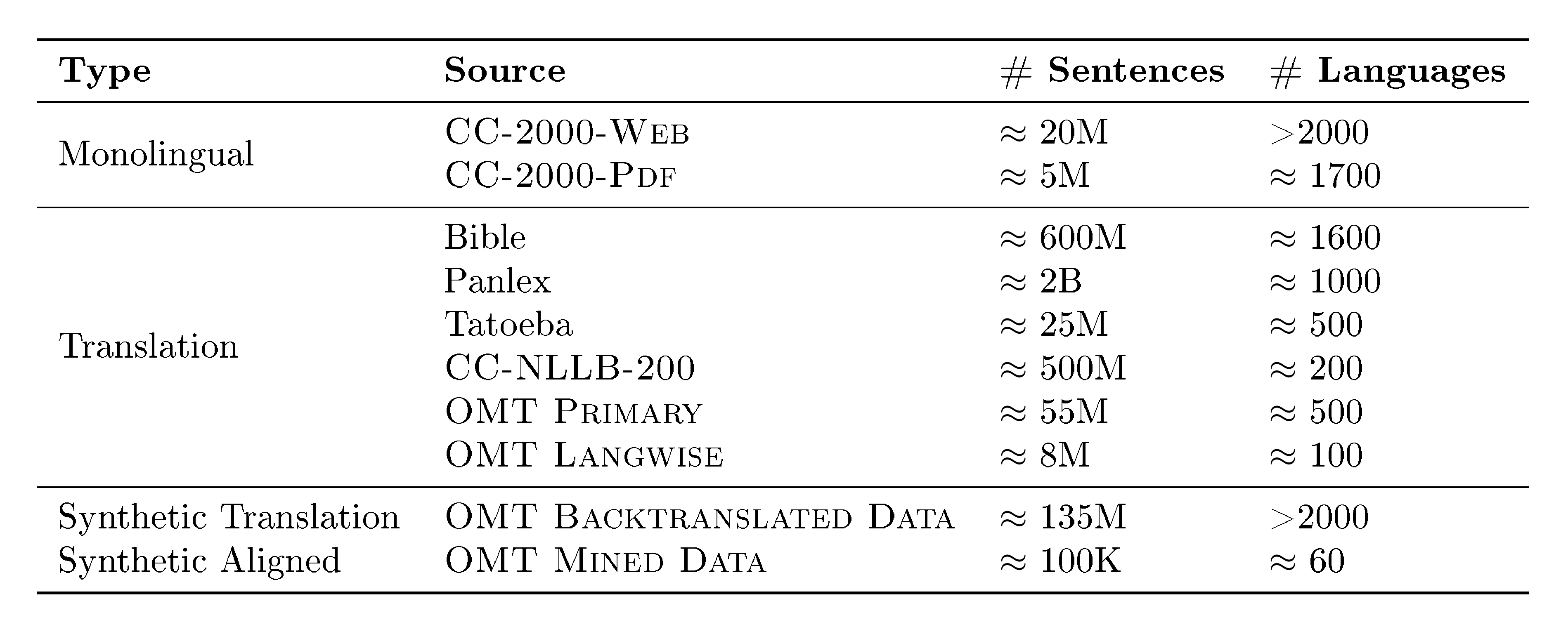
As follows, we mention and briefly categorize some highly multilingual text resources of various kinds: parallel and non-parallel, word-, sentence-, and document-level. Additionally, Table 2 summarises the main sources and volumes used to train our systems.
::: {caption="Table 2: A summary of the main sources and volumes (in number of sentences) used for CPT as detailed in Section 6.2."}
:::
Monolingual Datasets
We collect and curate two massively monolingual corpora, starting from snapshots of Common Crawl, ^6 inspired by the methodology and motivated by the results of [11] and [24]. We apply filters based on original URLs to discard low-quality pages, resulting in a URL-filtered version of Common Crawl. From this we create two datasets, that we refer to as $\textsc{CC-2000-Web}$ and $\textsc{CC-2000-Pdf}$, that collectively contain monolingual textual data sourced from web-pages or PDF documents spanning more than 2000 identifiable languages, as per the GlotLID model ([25]). Since our scope is continual pretraining (not full pretraining) and gathering more data for lower resource languages, we assign a fixed budget of at most 50 thousands documents per language, randomly sampling from the upstream corpora.
Bible texts
are used as one of the main parallel dataset for language analysis, for training and evaluation of MT systems. The Bible has the large language coverage (over 2000 languages) and many Bible translations are publicly available under permissive licenses. Finally, the Bible books are explicitly segmented into chapters and verses which are always preserved during translation, so aligning the translated text across the languages is trivial. Due to these reasons, Bible has already been used as the primary training set in several research works ([26, 7, 27, 28]). Additionally, we use the Bible to do part of our evaluation in order to have a reference-based benchmarking with large language coverage. We suggest using the Gospel by John as the test set, because the Gospels are the most translated from the Bible books, and John is considered to be the most different from the other Gospels. Training the Bible data has its caveats: its domain coverage is very limited, and language is often very old and formal. While training a model to understand such language might be alright, generating it would result in very unnatural style and various translation errors. Evaluating with the Bible shares the caviat of narrow domain and adds the contamination issue. We accept these risks and still use Bible both for training and evaluating, but we mitigate them using other sources (as explained in this section). We compile our Bible dataset from multiple sources[^7]
[^7]: With the prevailing majority of texts being downloaded using the eBible tool: https://github.com/BibleNLP/ebible.
Panlex
is a project collecting various dictionaries in a unified format^8. A processed dump of its database has 1012 languages containing at least 1, 000 entries, as well as over 6000 languages with at least one entry. This makes it probably the most multilingual publicly available dictionary.
Tatoeba
([29]) is a dataset of aprox 400 languages and 11M sententences. Overall, it is a large, open‑source collection of example sentences and their translations, built collaboratively by volunteers around the world. Its main goals are to provide a freely available multilingual resource for language learning, research, and the development of natural‑language‑processing tools.
$\textsc{CC-NLLB-200}$
We aim at building a system that improves upon NLLB-200 ([1]), at least retaining the performance on the 202 language varieties it covered. As a consequence, we apply the same URL filtering as we used to create $\textsc{CC-2000-Web}$ and $\textsc{CC-2000-Pdf}$ to a mixture of primary and mined datasets roughly reproducing the original data composition used to train NLLB-200 models, which we refer to as $\textsc{CC-NLLB-200}$.
$\textsc{OMT Primary}$
is a group of several massively multilingual datasets, some of which we describe as follows. SMOL ([10]) dataset includes sentences and small documents manually translated from English into 100+ languages. The docs are present both fully and by individual sentence pairs 2.4M rows. This dataset includes Gatitos ([9]), which is a dataset of 4000 words and short phrases translated from English into 173 low-resourced languages. BPCC ([30]) is a collection of various human-translated and mined texts in Indic languages, parallel with English. KreyolMT ([31]) contains bitexts for 41 Creole languages from all over the world. The dataset from the AmericasNLP shared task ([32]) represents 14 diverse Indigenous languages of the Americas. AfroLingu-MT ([33]) covers 46 African languages.
$\textsc{OMT Langwise}$
This dataset groups a set of less multilingual datasets, usually focused on a single low-resourced language or a group of related languages. A few examples of this compilation include ZenaMT ([34]) focused on Ligurian language, the Feriji dataset ([35]) for Zarma, and a dataset from [36] covering 6 low-resourced Finno-Ugric languages.
LTPP
Part of our training data mix constituted an extremely valuable parallel data from the Language Technology Partnership Program^9 which was launched with the purpose of expanding the support of underserved languages in AI models. Specifically, the compilation of parallel data from LTPP that we were able to use comprises 18 sources of various sizes and about 1.4M sentence pairs in total.
Limitations
Although we did a relevant effort to collect data, we are not exhaustive and detailed on its description and this inhibits replicability of our training, which is mitigated by the fact that we are sharing the model. More importantly, our current version of the model still misses many relevant sources.
4.2 Synthetic Data for CPT
For a significant portion of the languages we aim to support with our MT systems, there simply is no parallel data available, beside the Bible, and for some of them, not even the Bible has been translated yet[^10] or is not available for MT use. However, for several of them, publicly available monolingual corpora do exist and can be leveraged to generate synthetic parallel data via backtranslation and bitext mining, resulting in $\textsc{OMT Backtranslated Data}$ and $\textsc{OMT Mined Data}$.
[^10]: Bible translations statistics
4.2.1 Backtranslation
Motivation and related work
Backtranslation has become a standard technique to do data‑augmentation strategies for MT by translating monolingual target‑language data back into the source language ([37]). Since then, there have been several works exploring variations of this strategy. Edunov et al. [38] showed that iterative back‑translation, where the augmented data are repeatedly re‑translated, yields further gains and helps the model learn more robust representations. Subsequent work has extended the technique to low‑resource settings. [39] proposed copying monolingual sentences directly into the training data. [40] demonstrated that multilingual back‑translation can simultaneously improve translation across many language pairs by sharing a single encoder‑decoder architecture. [1] focused on efficiently in massively multilingual settings and they used a combination of neural and statistical MT translated data similarly to ([41]). More recently, ([13]) propose to use LLM‑based technique that generates topic‑diverse data in multiple low‑resource languages (LRLs) and back‑translate the resulting data. Several studies have investigated how to best filter ([42]) back‑translated sentences. Recently, the approach has even been proved useful in speech translation ([43]).
Methodology
To produce backtranslation data we mainly rely on the two massively monolingual datasets obtained from Common Crawl: $\textsc{CC-2000-Web}$ and $\textsc{CC-2000-Pdf}$. Furthermore, to increase domain diversity of our backtranslation data mix, we also rely on $\textsc{DCLM-Edu}$ ([44]) for educational-level forward-translated (out of English) data.
The backtranslation pipeline we build extracts clean monolingual texts from the monolingual corpora above, produces source- or target-side translations, and estimates the translation quality of the resulting synthetic bitext. Several of these steps are model-based, including but not limited to the translation step itself.
The first step consists of text segmentation, for which we use a fine-tuned version ([6]) of the $\textsc{sat-12l-sm}$ model ([45]), trained to predict the probability of a newline occurring at a given point in the text. Both sentence and paragraph boundaries can be obtained directly by tweaking the decision threshold. However, we find that resorting to heuristics to further refine these splits, e.g. re-splitting sentences deemed too long into smaller units, is beneficial.
After extracting textual units, the following step aims at removing noisy monolingual samples, i.e. units that are either too short or too long, and those for which we struggle to identify the language with enough certainty. For the language identification task we resort to $\textsc{GlotLID}$ ([46]), supporting 1, 880 languages at the time of writing. Empirically we find that $\textsc{GlotLID}$ top-1 score aligns well with human judgement on sample quality, with texts falling below certain thresholds either containing artifacts (e.g. HTML tags) or otherwise appearing as nonsensical text. We also find that this threshold is language-dependent, with a negative correlation between resourcefulness of the language and the average $\textsc{GlotLID}$ score of positive samples, when tested on annotated data. This suggests that, in line with intuition, texts in lower-resource languages are not just harder to translate but also to identify. We generalize this by calibrating $\textsc{GlotLID}$ scores on the aligned Bible, and define language-dependent thresholds for rejecting samples. This helps balance the competing objectives of keeping more data and rejecting lower quality samples.
For the translation step, we rely on two base MT systems: $\textsc{NLLB}$ ([1]) and $\textsc{LLaMA}$ 3 ([47]). The former is used as-is with no further fine-tuning to translate out of (or into) the 200 languages it supports, while the latter is used with no restriction, taking the best CPT and FT 8b model we were able to produce thus far. Notably, this model has been trained on both monolingual texts sampled from $\textsc{CC-2000-Web}$ itself and bitext from the Bible belonging to more than 1, 700 languages. This is crucial since the base model has not been explicitly optimized for tasks (e.g. translation) in languages, present in the original pre-training corpora, but beyond 8 high resource languages. Given the more demanding nature of producing translations with $\textsc{LLaMA}$ compared to $\textsc{NLLB}$, and that we already have data for languages covered by $\textsc{NLLB}$, we only run the former on a stratified sample of the monolingual corpora, down-sampling languages already supported by $\textsc{NLLB}$.
Finally, we estimate translation quality of the produced synthetic bitext with a mixture of model-based and model-free signals. For the model-based signals we rely on omnilingual latent space ($\textsc{OmniSONAR}$) similarity of source and target text ([6]). We find that other model-free signals such as unique character ratio are helpful to complement the model-based ones, as they are strong predictors of particular failure cases, e.g. repetition issues or MT systems producing translations that are just a copy of the source text.
Ablations
We run a series of ablations to understand how to effectively filter the produced data and incorporate it along other non-synthetic pre-existing corpora during continual pre-training.
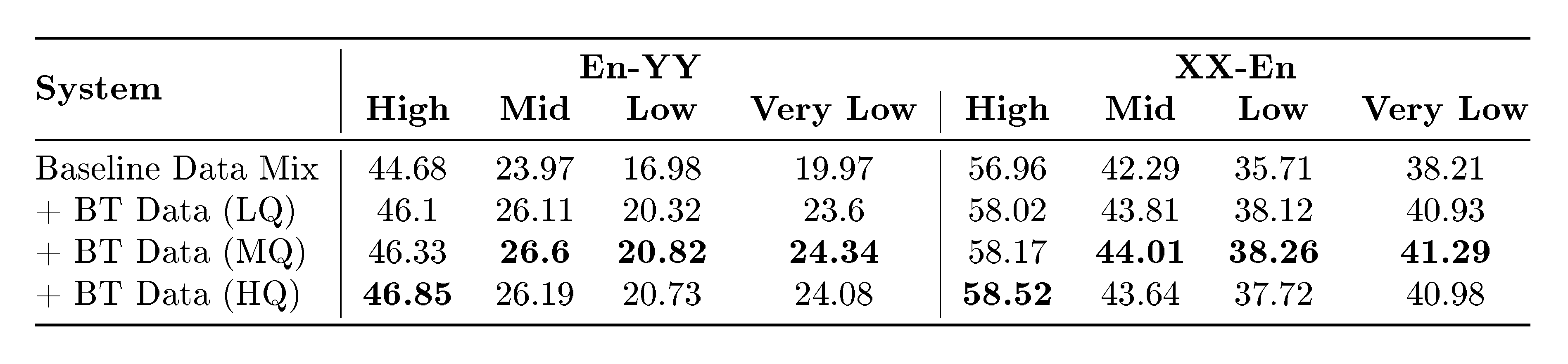
First, we study the downstream effect of filtering the backtranslation data according to cosine similarity of the translation in $\textsc{OmniSONAR}$ space. We first naively calibrate $\textsc{OmniSONAR}$ scores on the Bible development set, assuming perfectly uniform similarity estimation across languages, and find the mean latent space cosine similarity between aligned sentences: $\mu_{sim}$. Then, we define three thresholds, one standard deviation below ($LQ := \mu_{sim} - \sigma_{sim}$), at the mean ($MQ:= \mu_{sim}$) and above the mean ($HQ:= \mu_{sim} + \sigma_{sim}$). Then, we run an ablation training $\textsc{LLaMA}$ 3.2 3B Instruct on a stratified sample of $\textsc{CC-2000-Web}$, producing backtranslation data and then filtering according to these thresholds. We evaluate on FLoRes+, measuring translation quality over different language buckets (see Section 4.4) and comparing against a baseline fine-tuned on the same data mix but without backtranslation data. The results, summarized in Table 3, indicate that a uniform filtering strategy across language groups yield the best results, although filtering more aggressively on high-resource languages can yield even better results.
::: {caption="Table 3: ChrF++ when evaluating MT systems trained with different backtranslation data mixes."}
:::
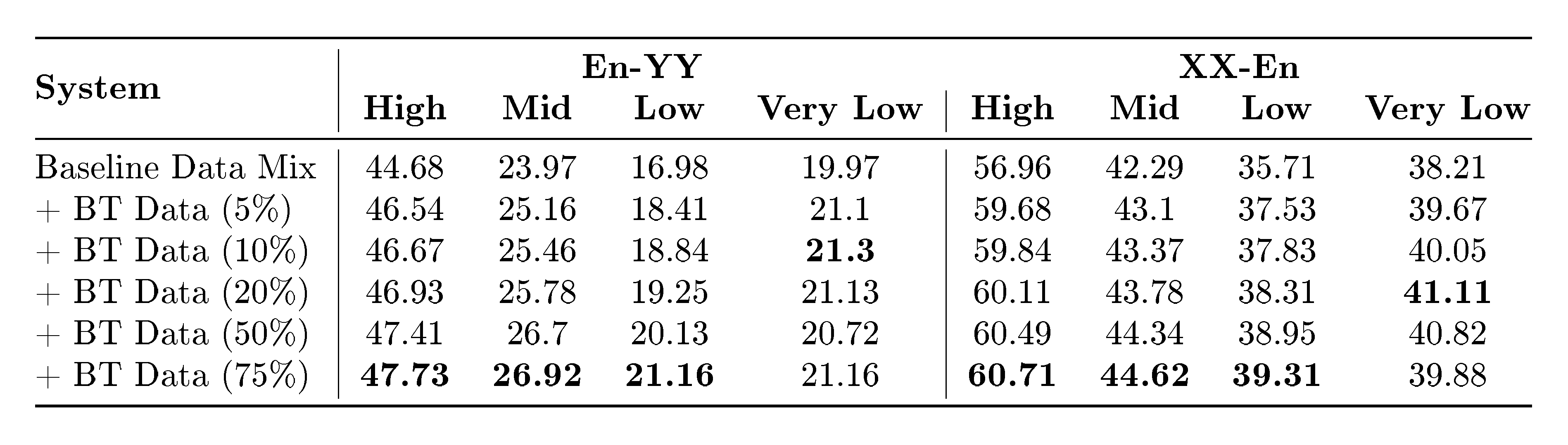
Second, after establishing a filtering strategy, we investigate the effect that mixing backtranslation data in different proportions along with pre-existing training corpora has on the downstream MT system performance. Given a fixed token budget for a training batch, we allocate $x%$ of those tokens to examples sampled from backtranslation data, exploring a range of $5%$ (ratio of 1:19 with respect to natural bitext) up to $75%$ (ratio of 3:1 with respect to natural bitext). The results reported in Table 4 show how the optimal performance for lower-resource languages is achieved when maintaining a ratio of 1:9 or 1:4 with natural bitext, as performance increases up to that point and then starts decreasing again. On the other hand, all the other buckets see increased performance as we increase the amount of backtranslation data.
::: {caption="Table 4: ChrF++ when evaluating MT systems trained with different backtranslation data mixes."}
:::
Dataset statistics
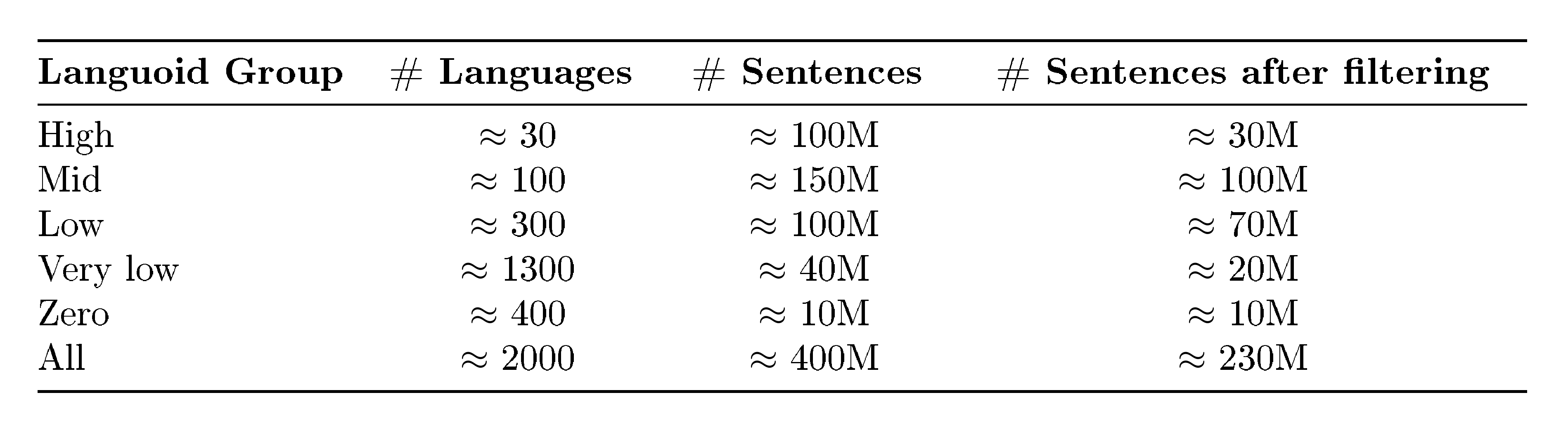
In Table 5 we summarize the resulting dataset obtained with the methodology outlined above. The dataset contains roughly 270 million sentences spanning more than 2, 000 languoids, that we divide in three buckets: high resource and low resource indicate languoids that were described as such in [1], while very low resource indicate any languoid not included among the ones supported by $\textsc{NLLB}$. The stratified sampling by languoid group at the source results in an artificially balanced distribution, with high resource languoids taking up 38% of the unfiltered data, low resource languoids taking up 35% and very low resource languoids the remaining 23%. The progressively more relaxed filtering strategy leads to a final distribution where 51% of the data is taken up by sentences belonging to low resource languoids, 26% belonging to very low resource languoids, and 23% belonging to high resource languoids.
::: {caption="Table 5: Statistics about resulting backtranslation data."}
:::
4.2.2 Bitext Mining
Motivation and related work
Complementary to backtranslation, bitext mining is another method for data augmentation which expands parallel corpora by automatically aligning pairs of text spans with semantic equivalence from collections of monolingual text. In order to find semantic equivalence, early works such as [48] attempted to find parallel text at the document level by examining an article's macro information such as the metadata and overall structure. Later works have applied more focus on the textual content within articles, leveraging methods such as bag-of-words ([49]) or Jaccard similarity ([50]). With the advances of representation learning, more recent approaches have begun to employ the use of embedding spaces by encoding texts and applying distance metrics within the space to determine similarity, moving beyond the surface-form structure. Works such as [51] and [52] used bilingual embedding spaces. However, a drawback to this approach is that custom embedding spaces are needed for each possible language pair, limiting the permissibility to scale. Alternatively, encoding texts with a massively multilingual embedding space allows for any possible pair to be encoded and subsequently mined, and has become the adopted backbone for many large-scale mining approaches ([53, 54, 55]). Generally, within this setting there are two main approaches: global mining and hierarchical mining. The latter focuses on first finding potential document pairs using methods such as URL matching, and then limiting the mining scope within each document pair only. Examples of such approaches are the European ParaCrawl project ([56, 57]). Alternatively global mining disregards any potential document pair as a first filtering step, and instead considers all possible text pairs across available sources of monolingual corpora ([58, 59]). This approach has yielded considerable success in supplementing existing parallel data for translation systems ([1, 42]).
Methodology
We adopt the global mining approach in this work. For our source of non-English monolingual corpora, we used $\textsc{CC-2000-Web}$ and FineWeb-Edu ([60]) as our source of English articles. We also considered $\textsc{DCLM-Edu}$ as an option for English texts. However, as $\textsc{DCLM-Edu}$ contains less articles than Fineweb-Edu, and given that the likelihood of a possible alignment increases as a function of the dataset size, we opted for the latter. We begin by first pre-processing our monoglingual data using the same sentence segmentation and LID methods as our backtranslation pipeline (see Section 4.2.1). Subsequently, we encode the resulting data into the massively multilingual $\textsc{OmniSONAR}$ embedding space. In order to help accelerate our approach, we use the FAISS library to perform quantization over our representations, and enable fast KNN search ([61]). We first train our quantizers on a sample of 50M embeddings for each language using product quantization ([62]), and then populate each FAISS index with all available quantized data. For our KNN search we set the number of neighbours fixed to $k = 3$, and to apply our approach at scale we leverage the stopes mining library^11 ([63]).
Ablation
In order to measure the effect of our resulting mined data, we performed a controlled ablation experiment. We choose the LLaMA3.2 3B Instruct model, and continuously pretrain it with two different data mixtures: one without the mined alignments, and a second supplemented with the mined data. In order to control for possible confounding variables, we fix the effective batch size, number of training steps, and all other hyperparameters for both models. Similar to our backtranslation ablations, we evaluate performance with the FLoRes+ benchmark using the metric ChrF++. Results are shown below in Table 6. Overall, we see improvements when adding in mined alignments to the data mixture showing the effectiveness across both high and low-resource settings. For example, langoids such as Greek and Turkish both see good relative improvements of 2.95% (47.4 $\rightarrow$ 48.8) and 2.74% (43.7 $\rightarrow$ 44.9) respectively. Similarly, we observe a 5.12% relative increase for the low-resource langoid N'Ko (13.00 $\rightarrow$ 13.67).
::: {caption="Table 6: ChrF++ on FLoRes+ when evaluating MT systems continuously pretrained with and without mined data, split by whether English is the target or the source language and by the resource level of the other language."}

:::
4.2.3 Conclusions and limitations
The synthetic data we produce plays an important role in boosting MT system performance for lower-resource languages. Here, we briefly discuss some limitations and potential future work to further improve the impact of synthetic data.
We work from a limited collection of Common Crawl snapshots, that cover only a portion of the human spoken languages. Furthermore, since we rely on resource-hungry models and algorithms for both backtranslation and mining, scaling up the approaches is expensive and we limit the production of synthetic data to stratified samples of those snapshots. A more thorough investigation of the relationship between synthetic data quantity and downstream MT performance might reveal scaling laws that can be used to take more informed sampling decisions.
The backtranslation approach we employ could be improved both in the generation and filtering phase. In the generation phase, previous work (e.g. [64, 65]) often employ backtranslation in an iterative fashion, using a base system to backtranslate monolingual data, using the synthetic bitext to build a system better than the base one, then using the new system to produce higher quality synthetic data, and repeating the cycle for a number of steps. In the filtering phase, we could complement latent space similarity metrics with LLM-as-a-judge approaches similar to [66]; if the base model is itself a LLM, we could investigate the ability of the model to effectively score its own translations, and the interference between this ability and translation ability as CPT on new backtranslated data progresses.
The mining approach could be significantly scaled up by considering alignment with pivot languages beyond English. For instance, aligning languages within the same family or group such as Spanish and Portuguese can enhance cross-lingual transfer by leveraging their structural and lexical similarities. This strategy not only facilitates more effective knowledge transfer between related languages but also helps to reduce the model's bias toward English-centric data, promoting greater linguistic diversity and inclusivity in multilingual applications.
4.3 Seed Data for Post-Training: MeDLEy
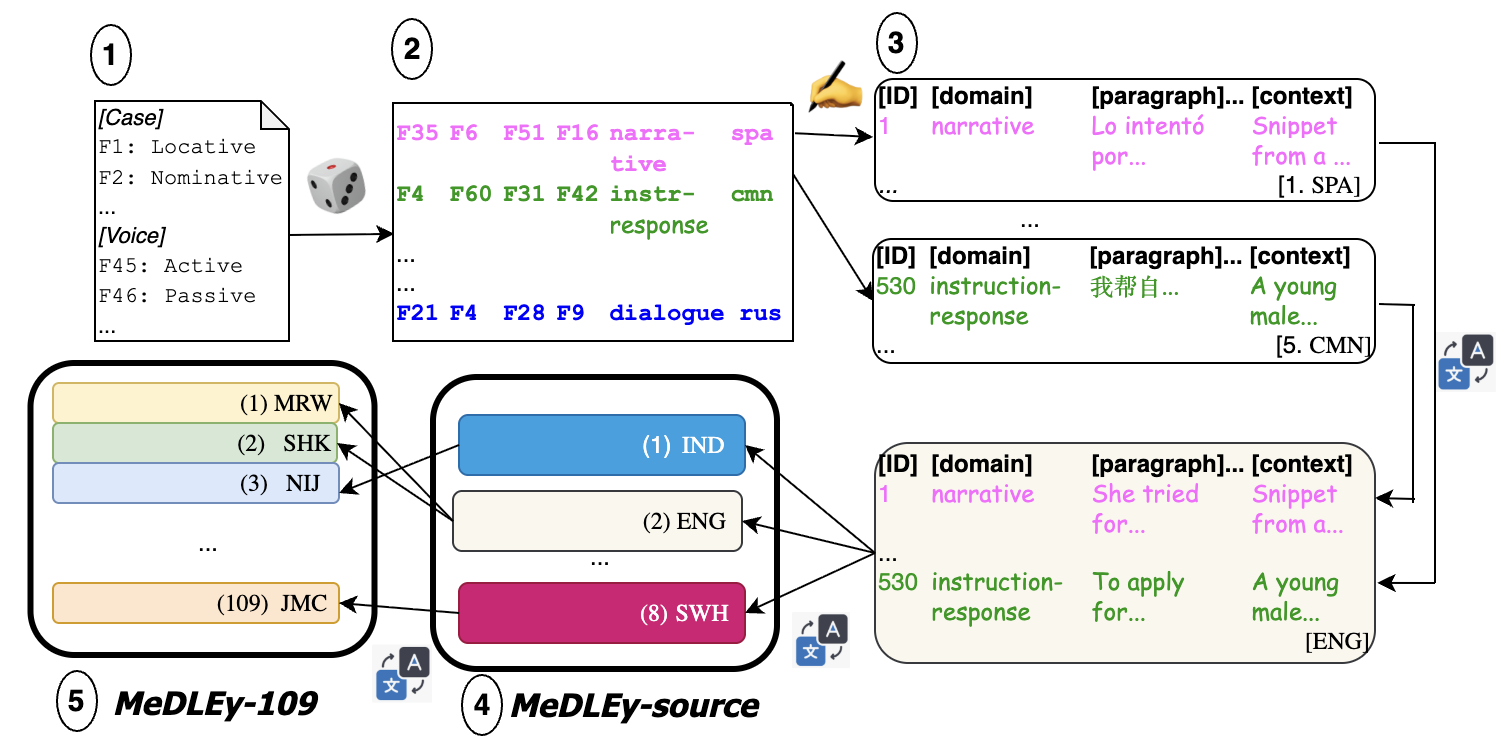
In this section we present MeDLEy, a multicentric, multiway, domain-diverse, linguistically-diverse, and easy-to-translate seed dataset. MeDLEy is a large scale data collection effort covering 109 LRLs. It MeDLEy-source and MeDLEy- 109. MeDLEy-source consists of $605$ manually constructed paragraphs with roughly $2200$ sentences and $34K$ words (counted in English). It is multicentric: source paragraphs are written in five source languages, thus including styles and cultural perspectives as well as topical subjects from a few different cultures. Each paragraph is accompanied with notes on any additional context required for its translation. It is then manually multiway parallelized across 8 pivot languages, increasing its accessibility to bilingual communities around the world. It is domain-diverse and grammatically diverse: it covers 5 domains and provides coverage to 61 cross-linguistic functional grammatical features that aim to cover a broad range of grammatical features in any arbitrary language that the dataset may be translated to. Further, we ensure that it is easy to translate: i.e., that it uses accessible, jargon-free language for lay community translators. MeDLEy- 109 provides professional translations of the dataset into 109 low-resource languages, as can be seen in Table 50. More details can be found in Appendix A, with examples from the dataset in Appendix A.7.
4.3.1 Motivation and related work
It is infeasible to manually curate data for LRLs at a large scale. Previous work emphasizes quality over quantity in the context of data collection for low-resource languages ([67, 68, 69]), and previous efforts seek to curate a small high-quality set of examples in these languages ([1, 10]). Such a "seed" dataset has various uses, such as training LID systems that can be used for data mining ([46]), or providing high-quality examples for few-shot learning strategies ([70, 71]). Importantly, while high-quality MT systems in both directions typically require training data at a much larger scale, seed datasets can be used to train models to translate into English with reasonable quality, which can then be used for bootstrapping synthetic bitext and better MT systems using monolingual data in LRLs ([37, 1]).
While there exist web-crawled monolingual and parallel datasets with low-resource languages such as $\textsc{MADLAD}$ ([72]), $\textsc{Glot500}$ ([73]), and $\textsc{NLLB}$ ([1]), these may be noisy and of unclear quality due to the scarcity of high-quality LRL content on the web ([74]) as well as LID quality issues for LRLs ([46]). There have been manual data collection efforts focusing on particular language groups, such as Masakhane ([75]), Turkish Interlingua ([76]), Kreyol-MT ([31]), HinDialect ([77]), as well as efforts for particular languages, such as Bhojpuri ([78]), Yoruba ([79, 80]), Quechua ([81]), among many others. $\textsc{NLLB}$-Seed is a highly-multilingual, professionally-translated parallel dataset, containing 6000 sentences from the Wikipedia domain translated into 44 languages ([1]). However, the most comparable effort to MeDLEy, in terms of scale, in collecting high-quality, professionally-translated parallel datasets is $\textsc{SMOL}$ suite ([10]). It consists of the $\textsc{SmolSent}$ and $\textsc{SmolDoc}$ datasets. The former consists of sentence-level source samples selected from web-crawled data translated into 88 language pairs, focusing on covering common English words. The latter consists of automatically generated source documents designed to cover a diverse range of topics and then translated into 109 languages. MeDLEy covers 92 languages not present in $\textsc{SMOL}$ or $\textsc{NLLB}$-Seed, contributing to the language coverage of existing datasets. MeDLEy also differs significantly in design considerations from the above, and it is the first such effort to focus on the coverage of grammatical phenomena in an arbitrary target language.
4.3.2 Approach
The goal of MeDLEy is to provide a bitext corpus that is domain-diverse and grammatically diverse in a large number of included languages. Given that a seed dataset is limited in size, it becomes crucial to include diverse and representative examples in it, so as to gain as much information as possible about the language. In this work, we focus on grammatical and domain diversity. The knowledge of a language's grammar is crucial to navigating the translation of basic situations into or out of that language. In order for an MT system to be flexible across various registers, domains, and sociopragmatic situations, it needs to be exposed to a variety of grammatical mechanisms used in those conditions.
What is grammar?
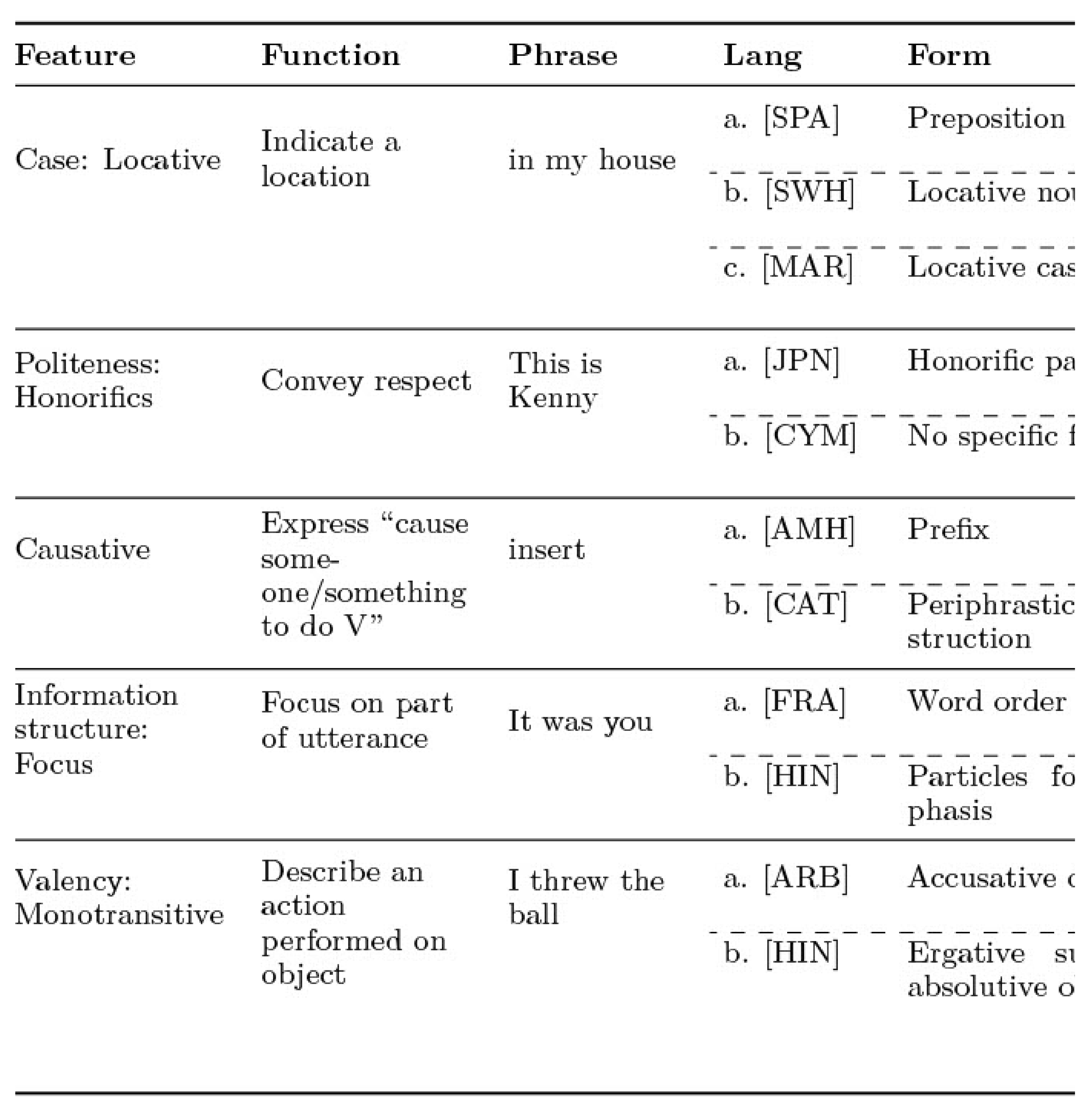
A language uses its grammar to systematically express certain kinds of information (for example, case is a grammatical mechanism used to express information about the role of a noun). In this work, we call the underlying meaning of a grammatical mechanism a grammatical function, and the actual shape of the grammatical mechanism used in the language the grammatical form. We show examples of functions and their forms in various languages in Table 7. Note that, as these examples show, these function-form pairs may be at all levels of linguistic structure, including morphology, syntax, and information structure. To refer to particular functions in this paper, we use canonical names associated with them for convenience. We refer to these as grammatical features. We construct our grammar schema in terms of these features.
Cross-linguistic variation
It is important to stress that languages vary extensively in terms of a) the set of forms they use to codify grammatical functions, b) in the manner of codification of a function (i.e. what form a particular function takes), and c) the mapping between form and function. First, the set of grammatical forms found in each language are not the same. For example, while some languages have honorifics to convey esteem or respect to address their interlocutors, other languages may not use any grammatical mechanism for this at all. Secondly, the same grammatical function may be codified into different grammatical mechanisms depending on the language, as in the example of the locative case (see Table 7). Finally, forms and functions often follow many-to-many relationships across languages. For example, the same feature can cover slightly different functions in two languages despite each having forms that share a core meaning with the other: English allows the so-called present continuous to express future events, while Spanish does not (1).
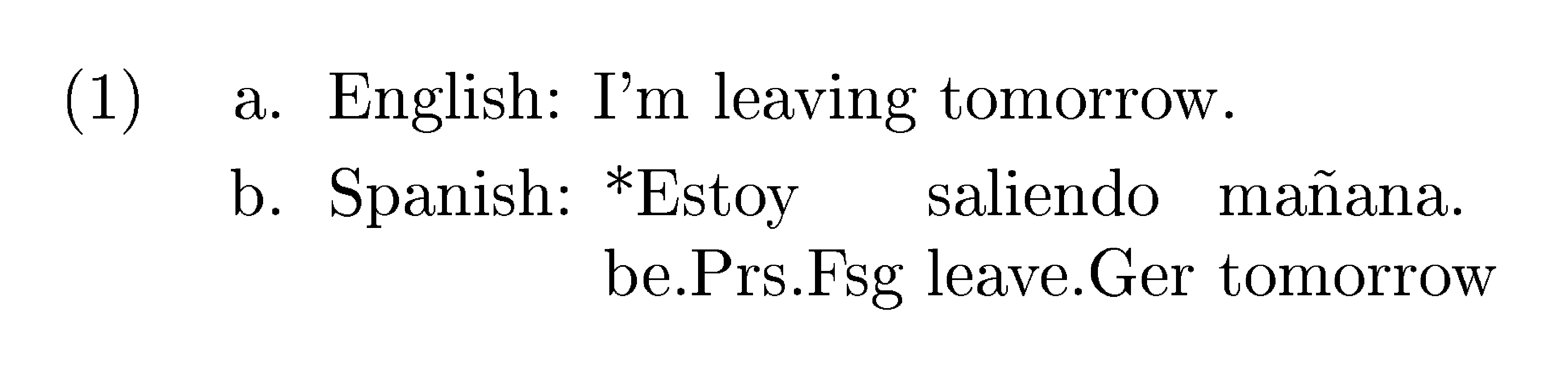
Building a grammatically-diverse corpus
::: {caption="Table 7: Examples of grammatical features and their associated functions or meanings, with various language dependent forms (specific mechanisms used to express that feature)."}
:::
Despite these differences, many grammatical functions codified in grammars tend to be shared across languages. For example, most languages have ways to differentiate which participants perform the action of an event and which ones experience it, the time at which an event occurred, how many referents there are, or whether an event is conditional upon another event taking place, to name a few.
Thus, achieving coverage over grammatical functions is a reasonable proxy for achieving coverage of grammatical phenomena at different levels of linguistic structure in a particular language. These grammatical functions can be enumerated up to a required degree of fine-grainedness at all linguistic levels with broad cross-linguistic coverage. Also note that, broadly speaking, most functions can be expressed in any language, regardless of the grammar of that language. For example, even though Spanish and English don't have a case system, it is certainly possible to express location in these languages akin to the Marathi locative case (see Table 7). Since the function is likely to be retained across translation, we can construct a source corpus that has high coverage over our grammatical features (in any source language), and expect that when it is translated into an arbitrary language, it will cover many grammatical phenomena in that language. For example, when we translate the English phrase "in my house" to Marathi, we gain coverage of the locative case in Marathi. We do not expect that each grammatical feature will be realized in the same manner across languages. However, we do expect that in many cases, the function associated with a feature will be manifested in some manner in a text or its context regardless of the language of the text. This allows us to build a grammatically-diverse source corpus that achieves broad grammatical coverage when translated into arbitrary target languages. This forms our cross-linguistic framework of grammatical diversity.
Dataset construction
Here we summarize the dataset construction process. The creation process involves: (1) curating a list of cross-linguistic grammatical features, as described above; (2) selecting domains (informative, dialogue, casual, narrative, and instruction-response) and source languages (English, Mandarin, Russian, Spanish, and German); (3) having expert native-speaker linguists craft natural, accessible source paragraphs based on templates combining grammatical features and domains, along with contextual notes; (4) translating these source paragraphs into eight pivot languages (English, Mandarin, Hindi, Indonesian, Modern Standard Arabic, Swahili, Spanish, and French) chosen to represent common L2 languages of low-resource language communities; and (5) commissioning professional translations from these pivots into numerous low-resource target languages selected for translator availability, prior coverage gaps, and language family diversity, resulting in grammatically diverse parallel text for underrepresented languages. See the list of grammatical features used, annotator guidelines, and more details about our approach in Appendix A.1 and Appendix A.2.
Grammatical features transfer and retention
Given the aim of covering naturally rarer features in our dataset, we compare the entropy of grammatical feature distributions in our dataset versus other seed datasets, across 9 categories (e.g. tense, formality). We find that MeDLEy shows the highest entropy in 5 out of 9 categories, indicating that MeDLEy often has higher proportions of rarer features in a paradigm. Furthermore, given our assumptions of feature transfer via translation during the creation of MeDLEy, we measure the extent of feature transfer and the extent to which features are preserved across translation hops. We thus conduct a qualitative feature transfer analysis looking both at single-hop and 2-hop translations. We find that most morphosyntactic features have transfer rates above 50%, and interestingly, forms that do not surface in a target translation can resurface in next hop from that language, indicating that grammatical diversity is preserved in a language-dependent manner via translation. The grammatical feature distribution as well as feature retention analyses are detailed in Appendix A.8.
4.3.3 Experiments
MeDLEy may have several uses given its grammatical feature coverage and n-way parallel nature. We demonstrate its general utility for fine-tuning MT models for LRLs.
Experiment Setup
In particular, we perform a Token-controlled comparison and also measure Absolute and combined gains for models fine-tuned on MeDLEy versus other datasets. On the former, given that larger datasets are more expensive to annotate, we compare randomly sampled equally-sized training subsets of MeDLEy and baseline datasets in terms of number of tokens for a fair comparison, using the size of the smallest dataset as the token budget. For the latter, we report absolute gains from training on the entire dataset. We also look at additive gains from combining seed datasets, which may help inform decisions about language coverage in future seed datasets.
We evaluate the performance of the fine-tuned models on FLoRes+([1]) and BOUQuET ([82]), considering 5 languages that are in the intersection of all the datasets. In particular, we experiment with $\textsc{NLLB-200-3.3B}$ ^12 as a representative of sequence-to-sequence (seq2seq) models ([1]), and $\textsc{LLaMA-3.1-8B-Instruct}$ ^13 representing LLM-based MT, and fine-tune them to obtain language-specific checkpoints, considering into- and out-of-English separately. More precise details about the experiments setup can be found in Appendix A.10.
Experiment Results
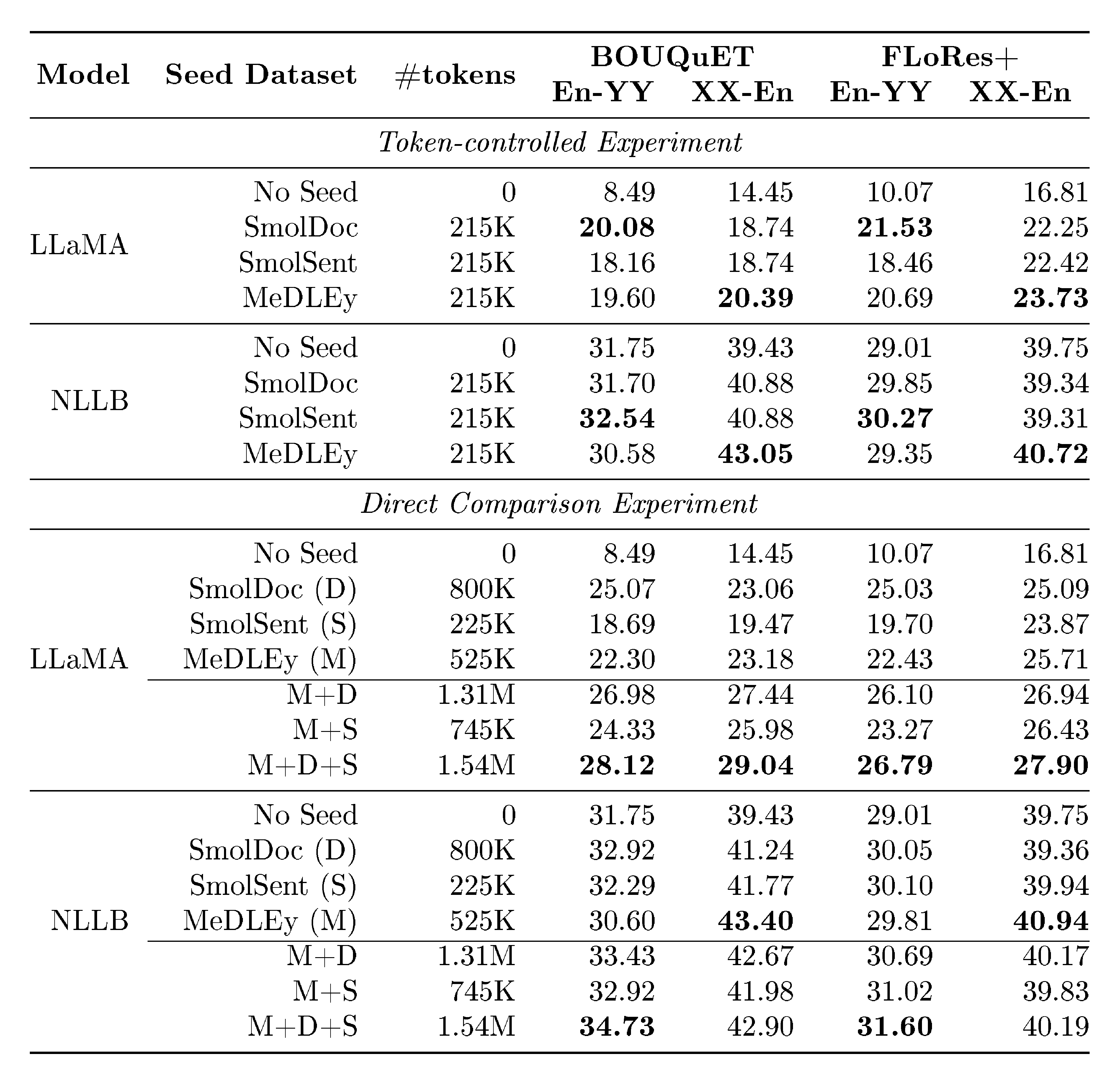
::: {caption="Table 8: Token-controlled and Direct comparison: reporting number of $\textsc{LLaMA}$ tokens on involved languages (Bambara, Mossi, Wolof, Yoruba, and Ganda, for both evaluation datasets) and ChrF++ numbers."}
:::
The overall results of our experiments are reported in Table 8. A more detailed breakdown of these results can be found in Appendix A.11. We see that MeDLEy matches or outperforms baseline datasets in the token-controlled setting, and shows gains in the into-English direction, while adding MeDLEy to existing datasets yield generally modest gains. We also show similar findings on a comparison on $\textsc{NLLB}$-Seed on a separate set of intersection languages[^14], see Table 46. We confirm these trends over various other MT evaluation metrics such as xCOMET and MetricX ([83, 84]), see Figure 25. This supports a major application of seed datasets, i.e., synthetic data generation from monolingual LRL data via better xx-en systems as discussed in Section 4.3.1.
[^14]: In addition, we also show that $\textsc{NLLB}$-Seed contains a high proportion of difficult-to-translate texts potentially due to technical or obscure terminology (54% as compared to 10.41%), which may hinder lay community translators.
4.3.4 Conclusions and limitations
MeDLEy has been a large scale MT training data collection effort across 109 low-resource languages, culminated in a multi-centric, domain-diverse, and multi-way parallel seed dataset, that showed both a broader grammatical diversity and a larger impact when used to fine-tune MT models, compared to other pre-existing seed datasets. Indeed, MeDLEy proved to be an essential component of our post-training recipe, as can be seen in Section 6.3. Nevertheless, the iterative nature of the data collection effort impacted the scope of the experiments we could perform with the dataset, both in isolation and as part of the broader MT recipe; furthermore, we identify several limitations that we mention below.
The grammatical coverage of MeDLEy is limited by both budget constraints and by intrinsically language-specific source-side grammatical functions, that may not reliable transfer into target languages. As a consequence, MeDLEy targets common, cross-lingual, function-oriented features rather than language-specific phenomena. Furthermore, the lack of labeled evaluation data in low-resource languages prevents us from performing more fine-grained evaluations, at the level of single grammatical phenomena. Finally, as both translation and quality assurance mainly relies on external vendors for low resource languages, inaccurate translations may occur more frequently in these languages than in higher resource ones, where in-house expertise allows further quality checks.
4.4 Evaluation Data
MT evaluation has been driven by a series of publicly available test collections that enable reproducible comparison of systems. The Workshop on Machine Translation (WMT) series introduced large, community‑curated benchmarks that have become the de‑facto standard for both automatic and human evaluation [22, 85]. Alternative efforts have focused on multilingual, low‑resource, and cross‑domain evaluation. FLORES benchmarks extended evaluation to 200 languages, providing expert‑translated reference sentences for a curated set of English sentences ([1]). In this work, we report results with our proposed datasets (BOUQuET, which has been manually created from scratch, and a subset of the Bible that we explicitly reserved for evaluation) described in this section, and exisiting ones like FLoRes+ ([86]), which covers 220+ languages, in 3 domains (wikipedia, travel guides and news). The complete list of evaluation datasets is summarised in Table 9.
4.4.1 BOUQuET
Description
To evaluate translation systems that purport to be massively multilingual or omnilingual, we need a multi-way parallel evaluation dataset. Prior to BOUQuET, such datasets as those derived from FLoRes-101 ([14]) and FLORES-200 ([1]) (e.g. 2M-FLoRes ([87]), or FLoRes+ ([86])) existed but came with various shortcomings in that they represented a narrow selection of domains and registers, were prone to contamination ([88]) due mainly to automatic construction, and proved difficult to translate accurately because of their English-centric nature or their lack of helpful context needed by translators (e.g., context about grammatical gender when referring to human beings only mentioned by proper nouns or titles). Some of this context could have been inferred through paragraph-level parsing if there were not missing metadata on existing paragraph structures.
With the introduction of BOUQuET, we aim to address the above limitations and progress towards a more culturally-diverse MT evaluation ([89]). BOUQuET was created (as opposed to crawled or mined) from scratch in eight non-English languages[^15] by linguists, who provided gold-standard English translations, contextual information, as well as register labels to facilitate accurate translations into a large number of languages. The sentences that compose BOUQuET are all part of clearly delineated paragraphs of various lengths, and they represent eight domains that are not represented in FLoRes-derived datasets. The construction and evaluation of BOUQuET are described in further detail in ([82]).
[^15]: arz_Arab, cmn_Hans, deu_Latn, fra_Latn, hin_Deva, ind_Latn, rus_Cyrl, and spa_Latn
Expansion Analysis
BOUQuET started early 2025, with 9 pivot languages, since then it has been expanded through vendors, partnering (Mozilla Common Voice^16) and the open-initiative^17. To date of this paper, BOUQuET is available in 275 languages (see Appendix D) covering 56 distinct language families and 33 scripts. 18 languages have been totally translated through community efforts (16 by Mozilla Common Voice and 2 through the BOUQuET open-initiative) and the rest have been commissioned through vendors. Regarding pivots, we learned that some pivot languages (French, Indonesian, Swahili, Spanish) appear to ease resourcing and translation more than others (German, Hindi); vendors that rely exclusively on English deliver translations of lower quality, drive up costs, and fail to deliver a significant amount of work we commission. Figure 4 details the pivots that were used for each language.
4.4.2 Bible Evaluation Partition
In order to have validation/evaluation signals, we suggest keeping some data from the highest multilingual sources aside. From the Bible, we suggest using the Gospel by John as the test set, because the Gospels are the most translated from the Bible books, and John is considered to be the most different from the other Gospels. The Gospel of John still contains about 30% of verses that have a high semantic overlap with other books (such as "If you will ask anything in my name, I will do it." in John vs "All things, whatever you ask in prayer, believing, you will receive." in Matthew). This benchmark is multi-way parallel and it allows to compare performance across languages and systems. The content and partitioning of our Bible dataset are the same as in ([26, 7])
A clear limitation of these datasets is the training contamination (since models are likely to have ingested the entire Bible). However, these are the best efforts to have a validation signal for the long-tail of languages in our process to constructing Omnilingual datasets (BOUQuET) and Omnilingual quality estimation metrics (BLASER 3, see Section 8.3).
4.4.3 Benchmarks Specialization
Why use more than one evaluation dataset? The Bible benchmark is used for providing direct evidence on 1561 language varieties, albeit a single domain. FLoRes+[^18] and BOUQuET provide a more varied coverage of domains in languages of different resource levels, with BOUQuET including a rich representation of extremely low-resourced languages. Languages and resources of several of these datasets are reported in Table 50. For ablations, we also define two subsets of FLoRes+, that we call FLoRes-HRL and FLoRes-Hard. FLoRes-HRL consists of a selection of 54 languages chosen to represent higher resource languages, in accordance with the definition provided in ([1]). FLoRes-Hard consists of a selection of 20 languages chosen to represent lower resource languages with particularly low performance from baseline MT systems.[^19]
[^18]: In all evaluations throughout the paper, we use version 2.1 of FLoRes+, corresponding to its state in early 2025. Unless otherwise specified, we use its devtest split, which has a slightly different set of languages from the dev split.
[^19]: The codes of the selected languages are ayr_Latn, brx_Deva, chv_Cyrl, dar_Cyrl, dgo_Deva, dik_Latn, dzo_Tibt, gom_Deva, knc_Arab, mhr_Cyrl, min_Arab, mos_Latn, myv_Cyrl, nqo_Nkoo, nus_Latn, quy_Latn, sat_Olck, taq_Tfng, tyv_Cyrl, vmw_Latn. For selection, we prioritized the languages added to FLoRes+ by the community, as well as languages from the FLORES-200 list representing diverse language families and scripts. For experiments with FLoRes-Hard, we are using the dev split, as some of its languages are not included in devtest.
::: {caption="Table 9: Number of language varieties, grouped by resource level (as per Section 3.3) in each of the benchmark datasets, and the number of domains covered by them. The line "All benchmarks" counts the union of all language codes in the three individual benchmarks, and the following line counts only unique ISO 639-3 codes, ignoring the variation in scripts, locales, or dialects."}
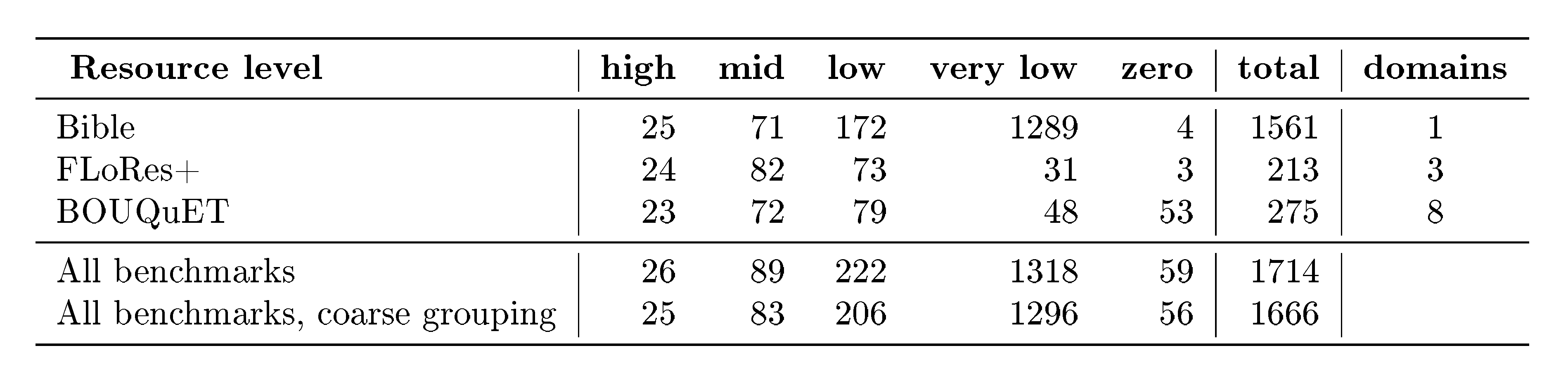
:::
As Table 9 demonstrates, our three evaluation benchmarks collectively cover over 1, 700 language varieties, or over 1, 600 unique languages, if we abstract away from the more fine-grained varieties differentiated by scripts, regions, or dialects.
5. Translation Modeling Overview
Section Summary: This section explains the motivations for advanced translation models that work across hundreds of languages, highlighting how traditional encoder-decoder systems like NLLB have scaled up, while newer large language models show promise but often underperform on rare languages unless specialized, such as through fine-tuning or hybrid architectures explored here. The authors propose two main strategies: directly adapting decoder-only models for translation or creating encoder-decoder versions from them. To support this, they extend the vocabulary and tokenization of models like LLaMA3 to better handle diverse languages, using techniques like continued byte-pair encoding on balanced multilingual data to reduce token needs and improve efficiency and performance.
5.1 Motivation and Approaches
Related Work
The modeling advances that enable massively multilingual MT can be grouped into mainly encoder-decoder architectures and large‑scale decoder-only language‑model based approaches. Early work showed that a single Transformer encoder–decoder can handle many language pairs by conditioning the decoder on a language identifier [90]. This paradigm was scaled to hundreds of languages with NLLB ([1]). The recent surge of large language models (LLMs) has opened a new modeling direction. [91] evaluate eight state‑of‑the‑art LLMs on a suite of 100+ languages and find that, while LLMs can acquire translation ability with few examples, they still lag behind dedicated multilingual translation systems on low‑resource pairs. Specialised LLMs to MT e.g. TowerLLM ([3]) has shown the validity of certain recipes and motivation for specialization.
Our approaches
In this work, we investigate how to specialize general-purpose decoder-only LLMs for the translation task, and we investigate two distinct architectural approaches. The first approach involves directly fine-tuning the LLM for translation tasks while maintaining its original decoder-only architecture. The second alternative is to build an encoder-decoder Transformer model derived from the LLM for both its encoder and its decoder. In this work, we explore both of these strategies in Section 6 and Section 7.
5.2 Vocabulary Extension and Tokenization
A critical prerequisite for omnilingual translation is ensuring adequate vocabulary coverage across all languages. Since Llama's original tokenizer was optimized for a limited set of languages, applying it directly to multilingual translation would result in suboptimal tokenization for many language pairs. We therefore begin by describing our approach to vocabulary extension and tokenizer adaptation.
Related work
Recent research has tackled the “vocabulary bottleneck" that limits the performance of large language models on low‑resource languages. One line of work introduces VEEF‑Multi‑LLM ([92]), expands the token set with Byte‑Level Byte‑Pair Encoding, then fine‑tunes only a small set of extra embeddings. Another promising direction is the Efficient and Effective Vocabulary Expansion method, which freezes most of the original embeddings and initializes new ones via subword‑level interpolation, enabling rapid adaptation to languages like Korean with just a few billion training tokens ([93]). A broader survey of vocabulary‑centric techniques highlights adapter‑based approaches, lexical‑level curriculum learning, and even zero‑shot expansion showing that modest data can still yield noticeable gains across many typologically diverse languages ([94]). In co-occurrence to this work, [6], in the context of learning an Omnilingual multilingual embedding space, disentangle the challenge of learning a new vocabulary representation from the challenge of learning new languages. The authors minimize the MSE loss between the student and teacher $\textsc{OmniSONAR}$ sentence embeddings using monolingual sentences for the base languages.
We reuse two tokenizers from [6] (one for the encoder and one for the decoder side of $\textsc{OMT-NLLB}$) and build a third one (for $\textsc{OMT-LLaMA}$) using the same methodology. The $\textsc{OMT-NLLB}$ input tokenizer is trained from scratch for over 1.5K languages, while the $\textsc{OMT-NLLB}$ output tokenizer extends the $\textsc{LLaMA3}$ tokenizer vocabulary for 200 languages. The $\textsc{OMT-LLaMA}$ takes a middle ground between the two: it retains the original $\textsc{LLaMA3}$ tokenizer vocabulary but extends it with extra tokens for 1.5K languages. All three tokenizers have the resulting vocabulary size of 256K tokens.
Methodology
We chose to modify the default BPE $\textsc{LLaMA3}$ tokenizer to increase the granularity of its subword tokens for the long tail of languages distribution. We achieved it by two means:
- Adjust the pre-tokenization regular expression (the rule for splitting text into "words") by making it more friendly to languages that use rare writing systems or a lot of diacritic characters.
- Increase the vocabulary of the tokenizer from 128K to 256K tokens by continued BPE merging.
These two measures lead to decreased fertility (number of tokens per text) of the tokenizer, especially languages with non-Latin scripts. Improved fertility always results in higher throughput of training and inference (because the same number of tokens now covers a larger length of text), and usually (but not always) results in better translation performance — because the model spends less of its capacity on reconstructing the meaning of a word from its subwords.
To extend the tokenizer vocabulary, we implemented a byte-pair encoding "continued training" algorithm by sequentially merging the most frequently occurring consecutive pairs of tokens within a word. The word frequencies were computed with a balanced sample from the parallel training data in all our languages and from the $\textsc{CC-2000-Web}$ dataset of web documents (in equal proportions). As weights for balancing, we used the total number of characters in the texts, and we applied unimax sampling over the languages, squashing the proportions of the first 126 languages to uniform and upsampling the rest at most x100 (on top of this, we manually increased the weights for some languages with underrepresented scripts, such as Greek or Korean, to adjust the resulting tokenizer fertilities). For some languages, the bottleneck of tokenization fertility has been not in the vocabulary itself but in the pre-tokenization word splitting regular expression, so we extended it with additional Unicode ranges and with a pattern for matching diacritic marks within a word. As a result of these operations, the extended tokenizer achieved the average fertility of 44.8 tokens per sentence over the 212 languages in the FLORES+ dataset, as opposed to 80.7 tokens in the original $\textsc{LLaMA3}$ tokenizer.
When initializing representations for newly added tokens, we first tokenize them using the original tokenizer and then subsequently compute the average of the corresponding token embeddings ([95, 96]).
Ablation
In order to measure the effects of our extended tokenizer, we perform a controlled ablation experiment. We choose the $\textsc{LLaMA3}$.2 1B Instruct model as a baseline, and then extend the vocabulary from 128K to 256K tokens. Both models were continuously pre-trained for 30K steps on the same data mixture with identical hyperparameters. Results are shown in Table 10. Overall, we observe a relative ChrF++ improvement of 26% (17.8 $\rightarrow$ 22.5) for out-of-English and 7% (35.9 $\rightarrow$ 38.7) for into-English on FLoRes+, with tangible improvements across all language resource levels.
::: {caption="Table 10: ChrF++ when evaluating MT systems continuously pretrained with and without our extended 256K tokenizer."}

:::
6. Decoder-only Modeling
Section Summary: This section describes a translation model built on the LLaMA3 language model, starting with an 8-billion-parameter version and smaller 1- and 3-billion-parameter variants adapted for multilingual use by updating their tokenizers. The model undergoes continual pretraining on monolingual texts and parallel translation pairs to learn language associations and improve translation skills, using prompts that specify languages and running for thousands of steps on powerful GPUs with a specialized optimizer. Post-training then refines the model through supervised fine-tuning on diverse instruction and translation datasets to restore interactive abilities and boost translation quality, followed by reinforcement learning that rewards better outputs for even stronger performance.
In this section, we present the proposed translation model built on top of $\textsc{LLaMA3}$. The development of this model consists of the following phases: Continual PreTraining (CPT) and Post-training. Additionally, we explore Retrieval Augmented Translation (RAG).
6.1 Base models
The main $\textsc{OMT-LLaMA}$ model is based on the LLaMA 3.1 8B Instruct model^20, inheriting its architecture and parameters. The only architectural change that it underwent was replacing its tokenizer with a more multilingual one and extending the input and output token embedding matrices accordingly, as described in the previous section. In all subsequent sections, we refer by default as " $\textsc{OMT-LLaMA}$ " to the result of further training this 8B model.
In addition, we experiment with scaling the model size down to enable training and inference in more resource-constrained environments or simply at a lower cost. For this purpose, we create smaller models following the same recipe: 1B and 3B models. We initialize them with LLaMA 3.2 1B Instruct and LLaMA 3.2 3B Instruct, respectively, and carry out the same vocabulary extension procedure as for the main, 8B model. The smaller models also undergo the same training process as the main one, outlined in the following subsections.
6.2 Continued Pretraining
Inspired by the related work of specialised MT models e.g. Tower ([3]), we include two tasks in our Continual PreTraining (CPT): language modeling with monolingual documents, and translation with parallel documents.
In practice, our dataloader samples batches from multiple sources. Long monolingual documents are wrapped; short documents are packed together to fill the maximum sequence length. We sample from the streams of tokens from different sources proportionally to their weights described in Table 2.
Before each monolingual document, we insert the name of the language, to teach the model to associate languages with names. For each translation pair, we use a simplified translation prompt indicating the source and target languages as follows:
Translate source-sentence from source-language into target-language: target-sentence
Training Configuration
We continuously pretrain our base models for up to 50, 000 steps, distributed across a cluster of 256 NVIDIA A100 GPUs. For model variants necessitating vocabulary adaptation, we precede the main pretraining phase with a dedicated warmup stage. This warmup consists of 10, 000 steps executed on 80 NVIDIA A100 GPUs, during which all model parameters are held fixed except for the token embedding matrix and the output projection layer, which remain trainable to facilitate efficient vocabulary integration. All training procedures utilize the AdamW optimizer, configured with a base learning rate of $\eta = 5 \times 10^{-5}$, $\beta_1 = 0.9$, $\beta_2 = 0.95$, and weight decay $\lambda = 0.1$. The maximum input sequence length is set to 8, 192 tokens for all training runs. During the vocabulary adaptation warmup phase, we employ an elevated learning rate of $\eta = 2 \times 10^{-4}$ to accelerate convergence of the newly introduced parameters.
6.3 Post-training
Post-training is used to recover and enhance instruction-following behavior after continued pretraining (CPT), while further specializing the model for high-quality machine translation. We apply supervised fine-tuning (SFT) and reinforcement learning (RL), and analyze their respective contributions relative to the CPT model.
6.3.1 Supervised Fine-Tuning
We fine-tune the CPT model on a mixture of instruction-following and machine translation data. The objective of supervised fine-tuning (SFT) is twofold: (i) to restore instruction-following capabilities that may be degraded during CPT, and (ii) to bias the model toward producing high-quality translations across a wide range of language pairs.
Training Data
Our base fine-tuning dataset ($\textsc{OMT-base-FTdata}$) contains $\approx$ 600k multilingual instruction-tuning examples covering 10 languages (English, Portuguese, Spanish, French, German, Dutch, Italian, Korean, Chinese, Russian). The dataset covers general conversational instruction-following (42%), machine translation (25%), machine translation evaluation (22%), automatic post-editing (6%), and other language-related tasks such as named entity recognition and paraphrasing. The data is predominantly English (53%), with substantial mixed-language content (18%, largely English combined with code). All examples are formatted as instruction–response pairs.
To extend the language coverage of the base fine-tuning dataset, we format the SMOL and MeDLEy translation datasets with diverse translation prompts. In the training mix, we weigh the three datasets in the 3:1:1 proportion.
Training Configuration
We optimize using AdamW ([97]) with learning rate $\eta = 1 \times 10^{-6}$, $\beta_1 = 0.9$, $\beta_2 = 0.95$, and weight decay $\lambda = 0.1$. We use a cosine annealing schedule with 1, 000 warmup steps and a final learning rate scale of 0.2. Training runs for 10, 000 steps with a maximum sequence length of 8, 192 tokens, validating every 100 steps.
Training employs Fully Sharded Data Parallel (FSDP) with FP32 gradient reduction and layer-wise activation checkpointing. All examples are formatted using the $\textsc{LLaMA3}$ chat template ([98]).
6.3.2 Reinforcement Learning
We further apply reinforcement learning (RL) to improve translation quality beyond SFT. Initial experiments using Group Relative Policy Optimization (GRPO) with lexical rewards such as ChrF++ and BLEU revealed that dataset curation was critical: narrowly templated instruction data led to in-distribution improvements but poor generalization. Using the $\textsc{OMT-base-FTdata}$ subset, which exhibits substantial instruction diversity, enabled stable and generalizable gains.
Consistent with MT-R1-Zero ([99]), we use a reward that averages normalized ChrF++ and BLEU scores and adopt a direct translation setup without explicit reasoning tokens. While reasoning-based approaches such as DeepTrans ([100]) show strong results for literary translation, reliably eliciting such behavior remains an open challenge.
Applying RL on top of SFT checkpoints introduces optimization difficulties due to low entropy and vanishing gradients under standard GRPO ([101]). To address this, we adopt Decoupled Clip and Dynamic Sampling Policy Optimization (DAPO) with larger group sizes ($N=64$). DAPO preserves exploration through asymmetric clipping and ensures non-zero gradient signals via dynamic sampling. We reintroduce KL regularization to constrain deviation from the SFT checkpoint and do not apply overlong reward shaping. The final reward objective is a balanced 50/50 combination of ChrF++ and MetricX.
6.3.3 Results
For some datasets, we report results both on the full evaluation set and on a subset of language directions corresponding to those explicitly used during supervised fine-tuning and reinforcement learning. We refer to this subset as SFT langs. Results are summarized in Table 11.
::: {caption="Table 11: Machine translation performance (xCOMET) after post-training. We compare the CPT model (CP4), supervised fine-tuning (SFT), and further reinforcement learning with DAPO. BOUQuET is evaluated at the sentence (s) and paragraph (p) level. We evaluate both in FLoRes+ and FLoRes-Hard (h)."}

:::
Effects of Supervised Fine-Tuning
Supervised fine-tuning yields consistent improvements over CPT across all evaluated benchmarks. On BOUQuET, SFT improves most directions, particularly paragraph-level translation into English (from 0.527 to 0.549) and sentence-level translation into English (from 0.725 to 0.732), while remaining largely neutral for English-to-other directions.
On FLoRes+, SFT produces small but consistent improvements on the hardest subsets, increasing $\rightarrow$ en$_{(hard)}$from 0.376 to 0.382. On the full evaluation set, SFT improves all directions, with especially large gains for English-to-other languages (from 0.609 to 0.656). On the SFT language subset, SFT further improves translation quality (e.g., $\rightarrow$ en from 0.703 to 0.706), reflecting targeted specialization on languages seen during post-training.
Effects of Reinforcement Learning
Reinforcement learning provides consistent additional improvements over SFT, though with smaller magnitude. On BOUQuET, RL further improves most directions, notably sentence-level translation into English (from 0.732 to 0.741) and paragraph-level translation into English (from 0.549 to 0.555).
On FLoRes+, RL yields clear gains on harder subsets, improving $\rightarrow$ en$_{(hard)}$from 0.382 to 0.393. Gains are observed both on the full evaluation set (e.g., $\rightarrow$ en from 0.685 to 0.689) and on the SFT language subset (e.g., $\rightarrow$ en from 0.706 to 0.708), indicating that RL refines translation quality without overfitting to the languages used during post-training. Importantly, RL does not degrade performance in any evaluated direction.
6.4 Retrieval-Augmented Translation
Motivation, related work and use cases
Retrieval-augmented LLM systems become more and more popular, and using them for translation enables adaptation to new languages and domains without retraining. RAG ([102]) has been successfully extended to MT appending retrieved source‑target pairs to the input on low‑resource language pairs ([103]). RAG is specially relevant for faster quality assessment of collected or generated translation data; continuous integration of new curated and domain specific translation examples into a retrieval database; and allowing the adaptation of closed LLM systems that cannot be finetuned.
6.4.1 Algorithm Overview
For retrieval-augmented translation, we query a database of parallel texts for the sources similar to the current source text to be translated, and insert the retrieved source-translation pairs as few-shot examples into the translation prompt.
Our database for the RAG translation system consists of all parallel data sources from different translation directions and domains, as described in Section 4.1. The source texts are indexed for both full text search (FTS) and vectorial search (VS). We also index several of scalar bi-text quality signals to allow a fast filtering during the retrieval. For the vectorial search we are using $\textsc{OmniSONAR}$ text embeddings, which exist for all considered languages.
To maximize good matching chances and to generate more diverse retrieved examples, we use not only an entire input text but also split it into smaller text chunks. More concretely, we first apply sentence-based level segmentation, and then we split sentences into ngrams of words of a certain size so that the total number of text chunks remain reasonable (usually between 5 and 30). Then, for each text chunk we query similar bi-text examples based on cosine similarity ($cossim$) and BM25-based^21 score similarity (up 64 examples at most for each strategy). For each query above, we also apply some filtering based on the quality signals that can remove up $30%$ of the original samples depending on the translation direction. Technically speaking, we are using Lance binary format^22 with all indexing functionalities and all queries are executed in parallel.
After the retrieval phase, all candidate examples are merged together. They are next deduplicated and reranked based on a linear mixture of $cossim$, BM25 and quality scores. We additionally optimize for the word level recall (so that the union of words from top candidates covers the maximum of words in the original input text). We keep up to 80 examples (going beyond that showed only negligible improvement).
If the number of samples in RAG database is small or zero for a given direction, we can use an extra candidate generation strategy. Since $\textsc{OmniSONAR}$ representations are language-agnostic, we use source text embedding to find the most similar examples directly among all target examples (this subset can be large especially for higher resource languages). We keep only the examples where $cossim > 0.7$ and we say that these matching examples are actual translations (on-the-fly mining).
6.4.2 Experiments and Results
Experimental framework.
To understand the effect of retrieval, we added RAG examples in the prompts of 3 baseline models: $\textsc{LLaMA3}$.1-8B, $\textsc{LLaMA3}$.3-70B and $\textsc{OMT-LLaMA}$-8B. We run an evaluation on a subset of 56 directions from BOUQuET for which we have some data to build RAG system. In particular, among these directions, 31 directions have more than 30K RAG samples and 25 directions have less than 30k of them. Note that for the directions where there are no available samples we rely purely on-the-fly mining strategy.
::: {caption="Table 12: Average performance metrics by system and level over 56 directions from the BOUQuET dataset. In parentheses, differences from applying RAG with the same system"}
:::
Results.
Table 12 presents the evaluation metrics averaged over directions with a breakdown by evaluation level (sentence or paragraph) and number of available RAG examples.
As for averaged results, we note that RAG enabled models consistently improve over baseline model in all automatic metrics. We see that the absolute gains are stronger if RAG systems have a large number of available examples. From the same perspective, the gain on sentence level translations is stronger than on paragraph (specially for smaller models) probably because most of our database example data is at sentence (or even word) level and finding good matches for the paragraph is more difficult. Note that all 3 models manifest a similar tendency in the gain for different metrics.
7. Encoder-Decoder Modeling
Section Summary: This section describes a translation model called OMT-NLLB, a compact 3-billion-parameter system based on the encoder-decoder Transformer architecture, designed to translate from 1,600 source languages to 250 target languages without relying solely on scarce parallel training data. It builds on a multilingual tool called OmniSONAR, which aligns sentences across languages into a shared space, allowing the model to train its decoder on both parallel data for direct translation and abundant monolingual text through a reconstruction task that boosts performance in low-resource languages. To improve efficiency, the approach eliminates a restrictive single-vector summary between encoder and decoder, shifting to detailed token-by-token connections via a two-phase training process that starts with decoder adaptation and ends with full model fine-tuning on parallel data.
In this section, we focus on an alternative translation modeling architecture to the one presented in previous section. We use the well-known encoder–decoder Transformer architecture that has been classically used for the MT task ([1]). Concretely, we train a compact 3B-parameter Transformer model, namely $\textsc{OMT - No Language Left Behind}$ ($\textsc{OMT-NLLB}$), that can translate from 1, 600 source languages into 250 target languages.
A known limitation of standard sequence-to-sequence training for MT is the need for parallel data, to train the system in a supervised way. To bypass this limitation, we propose a new training strategy, described in Figure 5.
Our method builds on top of $\textsc{OmniSONAR}$, a multilingual model that maps sentences in 1600 languages into a shared representation space. In this space, equivalent sentences in different languages are mapped to the same (or very similar) sentence embeddings. $\textsc{OmniSONAR}$ is paired with a multilingual decoder that can decode text from the representation space in 200 target languages, via cross-attention on pooled representations. Taken together, the $\textsc{OmniSONAR}$ encoder and decoder already define a translation system operating through a single cross-lingual sentence embedding.
We leverage the cross-lingual alignment property to exploit both parallel and non-parallel data. In a first stage, we keep the cross-lingually aligned encoder fixed and train a decoder on a mixture of: (1) standard parallel MT data, and (2) monolingual data via an auto-encoding objective. For the auto-encoding task, the encoder maps a monolingual sentence into the shared $\textsc{OmniSONAR}$ space, and the decoder is trained to reconstruct the same sentence in the same language. This allows us to substantially increase the amount of training data, especially for low-resource languages where parallel corpora are scarce but monolingual text is widely available. As a result, the decoder becomes stronger and more robust across languages, since it is exposed to much more linguistic variation than it would see from parallel data alone.
A key limitation of this setup, however, is the bottleneck representation between encoder and decoder. The original $\textsc{OmniSONAR}$ architecture relies on a pooled sentence-level representation: the encoder compresses the input sequence into a single vector, which is then fed to the decoder. While this design is well-suited to building a shared cross-lingual space, it restricts the amount of fine-grained information that can be passed from the encoder to the decoder, and it prevents the model from fully exploiting token-level cross-attention as in standard Transformer-based MT.
To address this, the second key idea of our method is to remove this bottleneck and move from cross-attention on sentence-level pooled representations to token-level encoder-decoder attention. After the initial stage that exploits the aligned $\textsc{OmniSONAR}$ space, we connect the encoder and decoder through standard cross-attention over the full sequence of encoder hidden states. Since the removal of the bottleneck breaks the original alignment in the shared embedding space, the following training stages operate only on parallel translation data. We then apply a two-stage training procedure in this non-pooled setup.
First, we perform a decoder warm-up phase, where only the decoder parameters (including cross-attention layers) are updated, while the encoder remains frozen. This step allows the decoder to adapt its cross-attention to reading full token sequences instead of a single pooled vector, and stabilizes training when transitioning away from the sentence-level bottleneck.
In the second phase, we fine-tune the entire model end-to-end on parallel data, jointly updating encoder and decoder. This final stage enables the model to fully exploit token-level interactions while retaining the benefits of the initial training on large amounts of monolingual data through the cross-lingual encoder.
Overall, our approach combines the strengths of a cross-lingually aligned encoder with the flexibility of a standard encoder-decoder Transformer. It allows us to train with non-parallel data via auto-encoding in the initial stage, and then to recover a powerful sequence-to-sequence MT model without the representational bottleneck imposed by a single sentence embedding. Furthermore, the resulting system remains compact, with only 3B parameters, since it preserves the original size of the $\textsc{OmniSONAR}$ encoder–decoder architecture.
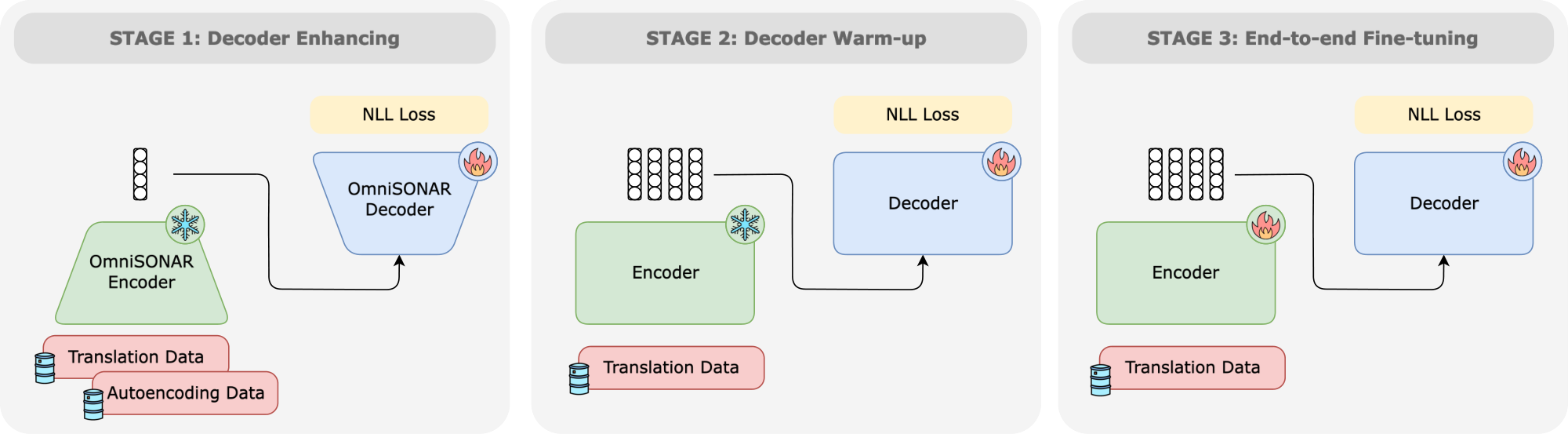
7.1 Leveraging an Aligned Encoder for Enhanced Decoder Training
Training Data.
For the first stage of our experiments, we use the data described in Table 2, which was curated for continual pretraining of our decoder-only model. We leverage the bilingual parallel data from this collection to train our model for translation using traditional supervised learning. Additionally, we incorporate the monolingual non-parallel data to train the model with an autoencoding objective.
Experimental Framework.
For our first experiments we employ the $\textsc{OmniSONAR}$ codebase, keeping its original architecture but keeping the encoder frozen. We initialize our encoder and decoder using the ones from the $\textsc{OmniSONAR}$ model. In our experiments, we set the training objective to Negative Log Likelihood in the Machine Translation and Autoencoding tasks. The batch size per GPU is set to 6k tokens per batch, and the models were trained on 16 nodes, of 8 A100 GPUs each. We utilize the AdamW optimizer ([97]). The learning rate is set to 0.001, and this first stage takes a total of 40k steps, including a learning rate warmup in the first 200.
Results.
We evaluate our approach both with and without the autoencoding (AE) objective to assess its contribution. As shown in Table 13, our first-stage training shows that leveraging the cross-lingually aligned encoder for enhanced decoder training is effective.
The Decoder Enhancing MT variant, trained exclusively on parallel translation data while keeping the encoder frozen, shows improvements over the baseline $\textsc{OmniSONAR}$ model. Furthermore, the Decoder Enhancing MT+AE experiment demonstrates larger performance improvements. By incorporating monolingual data through the autoencoding objective, the decoder is exposed to more linguistic diversity and becomes more robust across languages. These results confirm that exploiting monolingual data via the cross-lingually aligned $\textsc{OmniSONAR}$ encoder provides an enhancement to decoder quality.
To understand if these gains are consistent, we further analyze performance specifically on languages for which we added substantial amounts of autoencoding data in Stage 1. Figure 6 shows the performance of both Decoder Enhancing MT+AE and Decoder Enhancing MT models by language. We can see that the trend clearly shows that AE data improved the performance of those languages where it was added. In particular, the performance increased in 105 out of the 114 languages where AE data was added, with an average improvement of 5.20 chrF++ points. This confirms our hypothesis that autoencoding data is valuable for low-resource languages where parallel corpora are limited. However, we observe that the performance improvement of the overall model increases less than the performance of these specific languages, showing signs of the well-known Curse of Mulilinguality ([104, 105, 106]).
7.2 Decoder Warm-up for Token-Level Cross-Attention
Training Data.
In the second stage of our experiments, we train the model exclusively on the bilingual parallel data described in Table 2, removing the monolingual non-parallel data and its associated autoencoding component.
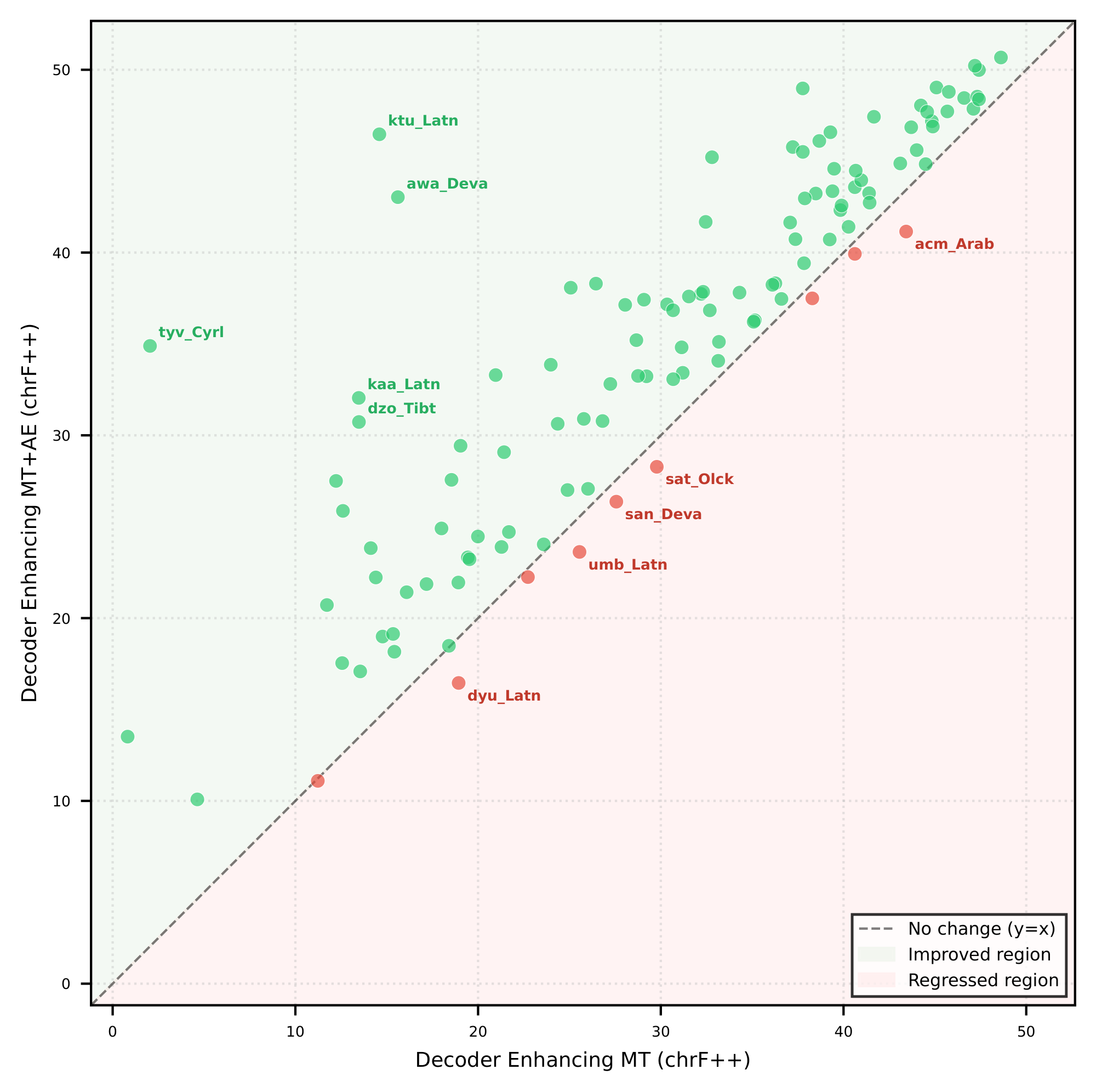
Experimental Framework.
For the second stage of our experiments we employ the $\textsc{OmniSONAR}$ codebase, still keeping the encoder frozen but adding a custom adaptation to remove the original bottleneck. We initialize our model using the original $\textsc{OmniSONAR}$ encoder and the enhanced decoder we obtained in the previous stage training with both translation and autoencoding data. We set the training objective to Negative Log Likelihood in only the Machine Translation task. The rest of the training setup remains the same as the one used during the Decoder Enhancing step.
Results.
The decoder warm-up stage, which removes the sentence-level pooling bottleneck and introduces token-level cross-attention, yields further improvements across all benchmarks, as shown in model Decoder Warm-up in Table 13. By allowing the decoder to attend to the full sequence of encoder hidden states rather than a single pooled vector, the model can access fine-grained, token-level information that was previously lost in the bottleneck. Importantly, this warm-up phase, where only decoder parameters are updated, allows the model to adapt its cross-attention mechanism to reading full sequences without destabilizing the encoder representations. We observe that skipping this step causes training instabilities (exploding gradients) in the third training stage. Therefore, this warmup proves to be helpful in transitioning from the pooled to the non-pooled architecture, obtaining consistent gains over the Decoder Enhancing MT + AE baseline and making it possible to perform the final fine-tuning.
7.3 End-to-End Parallel Fine-Tuning
Training Data.
In the final stage of our experiments, we maintain the same training configuration as in the previous step, continuing to use only the bilingual parallel data described in Table 2
Experimental Framework.
For the last step of our training we employ our adapted $\textsc{OmniSONAR}$ codebase to remove the bottleneck, but we unfreeze the whole system. We initialize the model using the original $\textsc{OmniSONAR}$ encoder and the warmed-up enhanced decoder obtained in the end of the second stage. We set the training objective to Negative Log Likelihood in only the Machine Translation task, and we utilize the AdamW optimizer setting the learning rate is set to 0.0004. This last stage takes a total of 100k steps, including a learning rate warmup in the first 200. The rest of the training setup remains the same as the one used during the previous training stages.
Final Results.
The final $\textsc{OMT-NLLB}$ model, after the end-to-end fine-tuning stage where both encoder and decoder are jointly updated on parallel data, produces the overall strongest results, as reported in Table 13. By unfreezing the encoder, the model can now fully optimize the token-level interactions between encoder and decoder, adapting the encoder representations specifically for the translation task rather than relying solely on the pre-trained $\textsc{OmniSONAR}$ alignment. Compared to the original $\textsc{OmniSONAR}$ baseline and the following proposed training steps, our final model achieves notable improvements across all evaluation sets.
Overall, these results demonstrate that our three-stage training strategy successfully combines the benefits of cross-lingual alignment, monolingual data exploitation through autoencoding, and token-level encoder-decoder attention. The final $\textsc{OMT-NLLB}$ model achieves substantial improvements over the $\textsc{OmniSONAR}$ baseline while maintaining the same compact 3B parameter size, making it both effective and efficient for multilingual machine translation.
::: {caption="Table 13: Results of our proposed model on each training step of the proposed methodology compared to the original $\textsc{OmniSONAR}$ "}
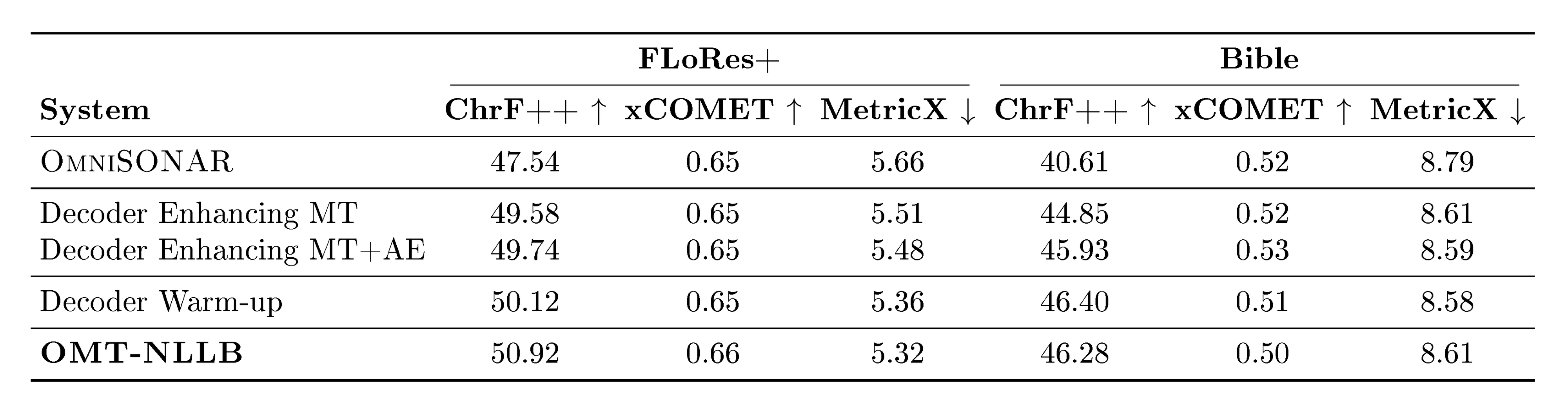
:::
8. Proposed Evaluation Metrics and Dataset
Section Summary: This section outlines key advancements in evaluating machine translation models for many languages, addressing the unreliability of existing automated metrics, especially for less common ones, and the lack of ways to measure those metrics' accuracy. The authors introduce an improved human evaluation method called XSTS+R+P, which builds on a prior approach to assess translation faithfulness while also considering elements like language style and context across paragraphs, and they created the largest-ever dataset of such human judgments, named Met-BOUQuET. They also developed a new multilingual metric called BLASER 3 and used the dataset to test various metrics, showing how well they perform across a wide range of languages.
Model evaluation constitutes a key contribution of the Omnilingual MT effort. The primary challenge we encounter is the limited reliability of current automatic metrics for long-tail languages, compounded by the lack of a robust methodology to assess metric quality in this context. In this section, we describe our contributions toward advancing Omnilingual MT evaluation. We present a variation of the previously established human evaluation protocol XSTS ([107]); the human annotations collected using this protocol, which constitute the largest dataset of human annotations in terms of language coverage, Met- BOUQuET; and the largest multilingually trained MT metric, BLASER 3. Finally, this section includes a comprehensive benchmarking of MT metrics using Met- BOUQuET, including our proposed BLASER 3, enabling us to quantify the reliability of several MT metrics across a broad representation of languages and language pairs.
8.1 Human Evaluation Protocol: XSTS+R+P
MT human evaluation is the most relevant way of comparing system performance but it is not free of challenges. Human evaluation is expensive, slow (or even unfeasible if annotators are not available) and its quality is highly dependent on the human evaluation protocol. In our case, we want a human evaluation that is easy enough to scale to a large number of languages, but still compatible with omnilinguality, by for example taking aspects as register, which is highly relevant across cultures, and context, which can reduce relevant ambiguities.
Related Work
Existing protocols include Direct Assessment (DA) ([108]), one of the simplest protocols that simply uses a single continuous rating scale of quality. Then, XSTS ([107]) which assesses the faithfulness of translations in a 5-likert scale and focuses on semantic similarity. Multidimensional Quality Metric (MQM) ([109]) which is one of the most complex ones because it annotates each error span with its severity level and the error type selected from seven high-level error type dimensions. And most recently, Error Span Annotation (ESA) ([110]) combines the continuous rating of DA with the high-level error severity span marking of MQM, without specifying error types. While MQM is by far the most complete and specific, which may cover most aspects of language varieties, it is quite complex and expensive. However, since we are aiming at omnilinguality, it is highly relevant that the protocol does not sacrifice sensitivity to omnilingual aspects of translation, avoiding covering only English-centric errors.
XSTS+R+P
Among the existing human evaluation protocols–DA, MQM, ESA, XSTS—we prioritized a well-documented protocol with an associated calibration method, which focuses on semantic equivalence rather than on error analysis. The XSTS protocol best meets these initial requirements. It offers higher inter-annotator agreement than DA, as shown in ([107]), and is easier to implement at omnilingual scale, where finding the expertise necessary to master MQM can prove challenging. However, using XSTS in its original formulation would preclude taking full advantage of two central aspects of the central evaluation dataset of our work (BOUQuET, Section 4.4.1): its language register diversity, and its paragraph-based design. To meet our full requirements, while building on XSTS, our proposed protocol, XSTS+R+P, specifies scoring criteria for two additional situations. First, it takes into account elements of pragmatics by indicating how annotators should rate register (R) discrepancies at the sentence level. Second, it provides annotators with a means to downgrade the rating of a translation that is semantically equivalent at the sentence level but causes confusion when considered at the paragraph (P) level (e.g., that is inconsistent in degree of formality, verb conjugation, or grammatical gender attribution with other sentences of the same paragraph). Detailed guidelines with examples are available in Appendix B.
Annotation and Calibrations Process
We commissioned XSTS+R+P language annotations across different vendors and checked all the deliveries we received. Each delivery contained three parts: the calibration file which had twenty annotations, the file with source-to-target annotations and the file with the opposite language direction. To ensure the quality of all those deliveries, we established a validation process which had three main steps. During the first step, we checked the calibration: we compared how well the ratings we received were aligned with the references we had prepared. We also studied all the comments left by the raters to ensure they were following the guidelines. For the most part, the comments proved to be relevant and showcased good understanding of the guidelines. However, in some cases we had to emphasize that the goal of the protocol was to only evaluate semantic similarity, not translation style and quality. During the second step, we studied the main part of the delivery (by bidirectional pairs) focusing on the paragraphs where the raters showed the most misalignment. We automatically highlighted the paragraphs where the deviation between the scores of different raters was equal or more than 2 (for example, one rater gave a sentence a score of 5, whereas another one gave it a score of 3). We looked at how many such rows there were: most deliveries had around 2% of rows showing annotation misalignment, and if this parameter was significantly higher than 3%, we sent the delivery back for rework. The common reasons which caused misalignment included, above all, different interpretation of the guidelines and edge cases, such as code-mixing and the presence of loan words in the target sentence. Finally, we spot-checked some of the rows manually to the best of our ability, especially if the misalignment for the row was apparent. We utilized machine translation where possible and checked if the rating was compliant with the guidelines we provided. We checked around 10% of all items that way.
To complement the manual validation process, we implemented automated checks across all language directions. For each direction, we computed pairwise exact match rates between annotators to detect potential duplication of annotations, and analyzed per-annotator score distributions using divergence metrics (Jensen-Shannon Divergence, Wasserstein Distance) and item-level statistics (Mean Absolute Error, bias, Spearman correlation) to identify outliers. Annotators flagged by these checks were manually reviewed, and deliveries with confirmed issues were returned to the vendor for rework.
Final score.
The sentence‑level consensus is the median of the three annotator ratings. Paragraph‑level scores are computed as the harmonic mean of the sentence‑level consensus values, chosen for its greater sensitivity to low‑scoring sentences than the arithmetic mean.
Protocol comparison
For protocol comparison we choose 7 language pairs and annotated 1358 BOUQuET sentences (dev and test partitions) on each pair (English-Russian, English-Spanish, English-Korean, English-Romanized Hindi, Hungarian-Czech, German-Croatian, French-Kinhasa Lingala). Linguistic considerations for pairs included: dominant word order, use of registers, number of grammatical genders and number of pairs with English. We controlled our protocol with the initial XSTS, for similarity, and RSQM, a simplified version of the MQM protocol.
Score Distribution
Figure 7 shows the distributions of scores for the three protocols. We notice that the distribution of XSTS+R+P is similar to XSTS' but slightly less concentrated on the upper end. This hints at XSTS+R+P's improved ability to provide additional nuance in the evaluation of translations. We also show the distribution of RSQM scores, projected within the same range as XSTS+R+P and XSTS. RSQM exhibits a distinctively skewed distribution, with a significant concentration on higher scores. To compare RSQM scores (range [0, 100]) with XSTS+R+P scores (range [1, 5]), we define RSQM_{rnd} as a linear projection of RSQM onto the [1, 5] scale, rounded to the nearest integer:
$ \text{RSQM}_{\text{rnd}} = \text{round}\left(0.04 \times \text{RSQM} + 1 \right) $
Computing the correlation, we see that XSTS+R+P is strongly and positively correlated with XSTS (0.65) and RSQM (0.62) on terms of Kendall's Tau.
Inter-Annotator Agreement
Table 14 shows the inter-annotator agreement (IAA) calculated with Krippendorf α using the squared distance penalty. Our inter-annotator agreement results are broadly consistent with, and in several cases exceed, values reported in the literature for comparable translation evaluation frameworks [111] and [107]. Crucially, our proposed XSTS+R+P protocol achieves a substantially higher mean Krippendorff's α of 0.80, representing a marked improvement over both our baseline protocols and the agreement levels typically reported in the translation evaluation literature. These findings indicate that XSTS+R+P provides a more reliable and reproducible framework for cross-lingual translation quality assessment.
::: {caption="Table 14: Inter-annotator agreement (IAA) for different language directions, calculated with Krippendorf α using the squared distance penalty. Best results in bold."}
:::
Differences between Protocols
Using BOUQuET sentences gives us the unique opportunity to compare the differences between XSTS+R+P and XSTS protocols across domains but also across three functional areas of register: connectedness, preparedness, and social differential. See Figure 5 in [82] for deeper explanation of register. We observe that, for the same translations, the average absolute difference in scores between protocols varies according to the social differential present in the sentence. As expected, translations where the speaker addresses someone of higher social status (lower-to-higher social differential) are penalized most by XSTS+R+P compared to XSTS, while those where the speaker addresses someone of lower status (higher-to-lower social differential) receive the least penalty. Additionally, we find a clear trend: as the length of the source segment increases, the penalty imposed by XSTS+R+P also grows. Overall, XSTS+R+P scores tend to diverge (decrease relative to XSTS) as both the context size and the social differential increase.
8.2 Met- BOUQuET
Motivation
While making Machine Translation (MT) more and more massively multilingual, MT metrics have to continue evolving to meet the needs of the field. Met- BOUQuET is contributing towards this end by presenting a highly multilingual, multi-way parallel annotation dataset and benchmark for MT evaluation metrics and quality estimation. This dataset is designed in two different rounds with complimentary rationales. The first round rationale was to collect a variety of systems outputs to optimise for a variety of translation errors and diverse quality annotations. The second round was designed to a selection of our best decoder-only systems ($\textsc{OMT-LLaMA}$) to strongest external baseline systems (following automatic evaluation). The language selection optimised for language and language direction coverage. Annotations were done based on XSTS+R+P (Section 8.1).
Related work
While WMT competitions ([22]) provide a powerful arena to evaluate MT metrics, the dataset developed there has its own challenges. Originally, the metric evaluation benchmark was designed to evaluate MT systems and not metrics themselves. This means that covered languages are not necessarily representative enough to cover linguistic families. Additionally, competitions' rules vary year to year, meaning that collections that are derived from them have some mismatches such as several protocols and close to random collection of languages. However, there are indeed other collections that have been created and designed for the purpose of metric evaluation which do not have these challenges but are more limited in size. This includes MLQE-DA-PE ([112]) and the Indic collection ([113]). Rarely, the existing datasets share the same source sentences across several source languages which some exceptions e.g. NLLB ([1]), with the aim of making the dataset the closest to multi-way parallel that it can be. Note that we cannot aim at having fully multi-way parallel dataset because the MT outputs differ for each language pair translation. The motivation for close to-multi-way parallel, hereinafter we will avoid "close" for simplicity, is the same as in for MT evaluation which is comparing the performance across languages.
BOUQuET Dataset selection Round 1
Additional motivations to construct an MT metric evaluation data set is the need to do it in one of the latest MT evaluation sets BOUQuET [82], described in Section 4.4.1. BOUQuET in addition to being highly multilingual and constantly expanding through its online contribution tool^23, it has other interesting characteristics, which are relevant for building a MT metrics dataset including diversity of domains and registers and non-English-centric data, among others. For this round, we use the dev (564 sentences) and test (854 sentences) partitions of BOUQuET.
BOUQuET Dataset selection Round 2
Again, we evaluate the outputs on the BOUQuET dataset. Differently from Round 1, we prioritise the test partition (854 sentences), to optimize the annotations budget that we have with more language pairs evaluated and two outputs per source sentence. The second round was intended as a part of evaluation study of the $\textsc{OMT-LLaMA}$ models (see Section 9.2), so for each translation, we annotated the translations from one OMT-based system (either $\textsc{OMT-LLaMA}$ or a system based on Omnilingual MT retrieval-augmented translation) and from one external baseline system.
Language selection Round 1 and 2
Met- BOUQuET covers a diversity in language directions. The criteria to choose those language directions are mainly guided by the languages available in BOUQuET (see Table 6 in ([82])) that cover a wide range of high and extremely low resource languages representing a wide variety of language families and geographical regions. To choose language pairs, and the complete list of language pairs is reported in Table 50, we are motivated by:
- Language pairs need to have a source language available in Bouquet.
- Optimize for a large number of languages evaluated, do not limit to having bidirectional pairs so that we can include languages that are not in BOUQuET as target languages.
- Optimize for non-English pairs and use pivot languages instead, to follow the BOUQuET non-English-centric criteria
- Include a variability of likely-zero-shot languages so that we are able to study what should be the lowest performing languages.
- Include a variability of internal priority languages.
- Include languages available in MeDLEy, so that we can explore its effectiveness in likely-zero-shot languages and low-resource languages.
- Do final selection to optimize for a diverse range of language families and language scripts.
Specifically, we end up covering 104 language directions in Round 1 and 57 language directions, mostly complimentary to Round 1, in Round 2. In total, Met-BOUQuET currently covers 161 language directions and 119 unique language varieties.
Pairs were formed based on known or likely patterns of bilingualism between source and target languages due to geographical adjacency (including pairings of subnational languages with a regional lingua franca or a national language of wider/official communication).
MT Systems and Outputs Considered Round 1
We aim to cover a variety of errors and also provide a diversity of scores. The WMT data provide a large number of systems, but this is not the case for other benchmarks MLQE-PE ([112]), IndicMT ([113]) and NLLB data ([1]). In our case, we prioritize a variety of open systems which cover a wide range of languages. We include a variation of open systems and early variations of $\textsc{OMT-LLaMA}$, all of them reported in Table 15. For each source sentence and translation direction, we sampled exactly one output translation, trying to balance the representation of various levels of translation quality and the diversity of systems. Exact details on the selection of MT outputs can be found on Appendix B.
MT Systems and Outputs Considered Round 2
For each direction, we evaluate two main systems of interest to compare: the strongest external baseline (one of Gemma-3 27B, MADLAD-400-MT-10B, Aya-101 13B, Aya-Expanse 8B, EuroLLM 9B) and the strongest of several $\textsc{OMT-LLaMA}$-based systems ($\textsc{OMT-LLaMA}$ 8B with or without RAG examples, and in a few cases, vanilla $\textsc{LLaMA3}$ 70B with the Omnilingual MT RAG examples). To select the two candidate systems for each direction, we use the dev split of BOUQuET and a combination of automated metrics: the average of normalized BLASER 3 (reported in Section 8.3 and MetricX scores and, when references are available, ChrF++ scores. See Table 15 for a summary of system selection and outputs considered as well as the goal and setup of each Round.
::: {caption="Table 15: Summary of MT Systems (not including small variants of each), Selection Methodology and setup and goals of Round 1 and Round 2"}
:::
Statistics Round 1
Following the XSTS+R+P protocol, we collect 1358 sentence annotations (318 paragraphs) which correspond to the BOUQuET dev and test partitions[^24] for 53 languages and 104 language directions from 31 different MT systems.
[^24]: Note that the [82] paper reports incorrectly the number of test sentences (10 sentences more than it has)
Statistics Round 2
In this round, we collect annotations of 854 sentences translated in 57 directions between 80 unique languages, with each sentence translated by two systems. We use stronger MT systems and do not perform adversarial sampling, unlike in the first round, but we also choose more challenging translation directions.[^25] As a result, the distribution of XSTS+R+P scores in the two rounds is roughly the same, with the average score of 3.0 and about 30% of the scores in the "very low" and "very high" areas each.
[^25]: For several translation directions with extremely low-resourced source or target languages, we had to cancel the annotation after receiving over 80% of lowest score in the first annotation batch, indicating that both systems fail to produce even minimally meaningful translations. They were therefore excluded from Round 2.
Preference annotations as a by-product
Because each sentence in Round 2 has been translated in each target language twice, the resulting annotated dataset can be viewed as a dataset of human preferences (induced from the human labels indirectly, because the alternative translations were not shown to the annotators side-by-side). Out of the $\approx 49K$ annotated translation pairs, 57% have different consensus scores and therefore express a preference.
Available annotations.
The complete Met-BOUQuET is available as part of BOUQuET effort.[^26] The data includes both rounds of XSTS+R+P annotations, as well as the experimental annotations of a subset of Round 1 data with XSTS and RSQM protocols that were used in Section 8.1. Comparison to other datasets as well as details on score distribution are reported on Appendix B showing that Met- BOUQuET uniquely contains 73% of directions without English (118 directions).
[^26]: See https://huggingface.co/datasets/facebook/bouquet. Note that Met-BOUQuET similarly to BOUQuET, is dynamic and we are constantly extending it new languages.
8.3 BLASER 3
State-of-the-art reference-free quality estimation (QE) metrics, like xCOMET ([114]) and MetricX-24 ([84]), despite being powerful, have several limitations. Specifically: (1) they are not multilingual enough, being trained on a handful of directions; (2) they have limited zero-shot cross-lingual generation power to unseen languages, since the base encoders XLM-R ([115]) or mT5 ([116]) are fully finetuned; and (3) they can only handle a single evaluation protocol, [^27] MQM ([117]), restricting generalization and limiting training resources. Given these constraints, they are not ideal candidates for evaluating omnilingual translation. Thus, we take a first step towards omnilingual QE, by proposing BLASER 3, a highly multilingual and multi-protocol metric build. Like its predecessor ([118]), it is build on top of cross-lingual embeddings from SONAR ([119]), where now we use $\textsc{OmniSONAR}$ ([6]), unlocking the potential to generalize to thousands of languages. To further push the multilinguality capacity of our proposed QE model, we train it with multi-task learning on several evaluation protocols, and on a mix of real and synthetic data, covering hundreds of directions.
[^27]: DA scores are used during pre-training, or converted to the MQM scale during finetuning.
8.3.1 Related Work
Reference‑free quality estimation (QE) aims to predict translation quality without relying on a human reference. Over the past decade the field has moved from simple lexical proxies to deep contextual models that can be deployed at runtime. Learnable Surface‑Form Metrics train a model on human‑rated QE data using shallow features (e.g. QuEst ([120]) and QT21 ([121])). Neural Sentence‑Embedding metrics embed source and hypothesis sentences in a shared semantic space and compute a similarity score e.g. COMET ([122]), SentSim ([123]), PRISM ([124]). Zero‑Shot and Prompt‑Based Methods leverage large language models (LLMs) without any task‑specific fine‑tuning e.g. InstructScore ([125]), GPT‑QE ([126]). Finally, Hybrid and Ensemble metrics combine the strengths of different reference‑free signals e.g. QE‑Ensemble ([127]), e.g. OpenKi ([128]). Overall, reference‑free metrics have progressed from hand‑crafted feature sets to end‑to‑end neural regressors and, most recently, to zero‑shot LLM prompts.
8.3.2 Methodology
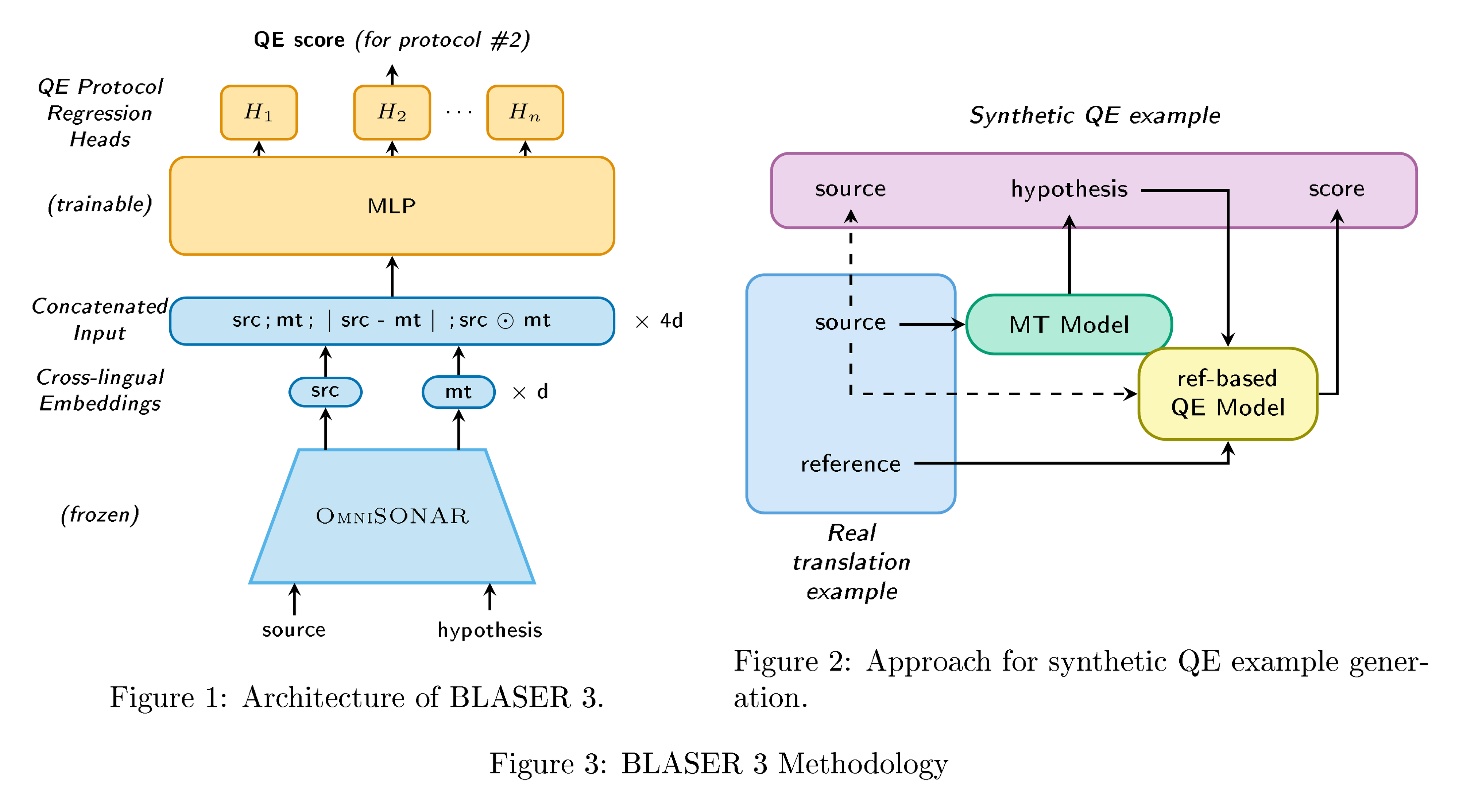
Task
QE data are triplets of (src^{(x)}, mt^{(y)}, $s^{(i)})$, where src^{(x)} is the source text in language x, mt^{(y)} is the translation hypothesis text in language y, and $s^{(i)} \in \mathbb{R}$ is the human annotation score for the pair (src^{(x)}, mt^{(y)}), according to an evaluation protocol i (e.g. MQM, XSTS). The task of reference-free QE aims to learn a model to predict $s^{(i)}$ given the pair (src^{(x)}, mt^{(y)}).
Architecture
The architecture of BLASER 3 is illustrated in Figure 8a. We use (frozen) $\textsc{OmniSONAR}$ to extract cross-lingual embeddings $\mathbf{e}^\text{src}, \mathbf{e}^\text{mt} \in \mathbb{R}^{d_s}$ for the source and hypothesis, where $d_s$ is the dimensionality of the $\textsc{OmniSONAR}$ embedding space. The two individual embeddings, together with two element-wise interaction embeddings, are concatenated to obtain obtain $\mathbf{e}^\text{input} \in \mathbb{R}^{4d_s}$ as in:
$ \mathbf{e}^\text{input} = \mathbf{e}^\text{src}; \mathbf{e}^\text{mt}; |\mathbf{e}^\text{src} - \mathbf{e}^\text{mt}|; \mathbf{e}^\text{src} \odot \mathbf{e}^\text{mt}, $
where ; denotes horizontal concatenation, and $\odot$ denotes element-wise multiplication. The input $\mathbf{e}^\text{input}$ is passed through a two-layer MLP [4 $d_s\rightarrow d_h \rightarrow d_o]$ to obtain an output embedding $\mathbf{c} \in \mathbb{R}^{d_o}$. According to the protocol of each example, the output embedding is routed through the corresponding regression head Head_i, which is a linear layer $d_o \rightarrow 1$ that predicts the QE score $\hat{s}^{(i)} \in \mathbb{R}$. The MLP and protocol head parameters are optimized with an MSE loss: $\mathcal{L}_\text{mse} = ||s^{(i)} - \hat{s}^{(i)}||^2$.
Synthetic Examples
QE datasets are not very multilingual nor diverse, usually covering a couple of directions and domains ([129, 130]), with some exceptions specifically for the XSTS protocol [1]. Although our model can take advantage of multiple data sources due to its multi-tasking nature, ideally we would like to cover more languages, for which there is no QE data availability. Thus, we propose a synthetic data generation pipeline using MT models and reference-based QE (Figure 8b). We use a large corpus of translation data, which are tuples of (src^{(x)}, ref^{(y)}). For each example, we translate the source with K MT models, to obtain a set of hypotheses {mt^{(y)}k}{k=1}^K in language y. We then use a reference-based QE model, that takes as input a triplet of (src^{(x)}, ref^{(y)}, mt^{(y)}_k) to label it with a score $\bar{s}_k$. Finally, we disregard the reference that was used to label this example, and use the triples of {src^{(x)}, mt^{(y)}_k, $\bar{s}k$}{k=1}^K as training examples for BLASER 3. The motivation is that we can obtain examples of diverse quality due to the multiple MT models used, and can be labeled reliably using the reference of the example, which we then discard. Our methodology here is akin to distilling a reference-based QE model into a reference-free one.
8.3.3 Experimental Setup
Data
Our training data is comprised from several different datasets, covering in total 6 protocols (DA, ESA, MQM, SQM, XSTS, XSTS+R+P) and 204 unique directions, amounting to 1.6M examples. We use a variety of data including, but not limited to, IndicMT-Eval ([113]), DA data from MLQE-PQ ([112]) and XSTS data from BLASER 2 ([118]). Finally, we allocate 15 paragraphs of the development set of the XSTS+R+P data of Met-BOUQuET[^28] for training (around 80 %), while the rest is used for validation during training. We evaluate our models primarily on the test set of Met-BOUQuET. The statistics of the training and test data are available on Table 16.
[^28]: Using 77 annotated directions from Round 1 that were already available at the moment of BLASER 3 experiments; the other 25 directions of Round 1 Met-BOUQuET are not included in this section.
For each protocol we aggregate duplicate examples (same source-hypothesis) by averaging their scores. To minimize cross-contamination, we explicitly remove all training examples where the tuple source-hypothesis also appears in our validation/test sets. All scores are normalized to 0-1 scale, by applying min-max normalization with according to the ranges for each protocol (e.g. 0-100 for DA, 1-5 for XSTS). MQM is scaled with a different formula to make the normalized score more uniform (1-(score/25)^{0.5}).
::: {caption="Table 16: Training data statistics by protocol, and combined. Examples are in thousands."}
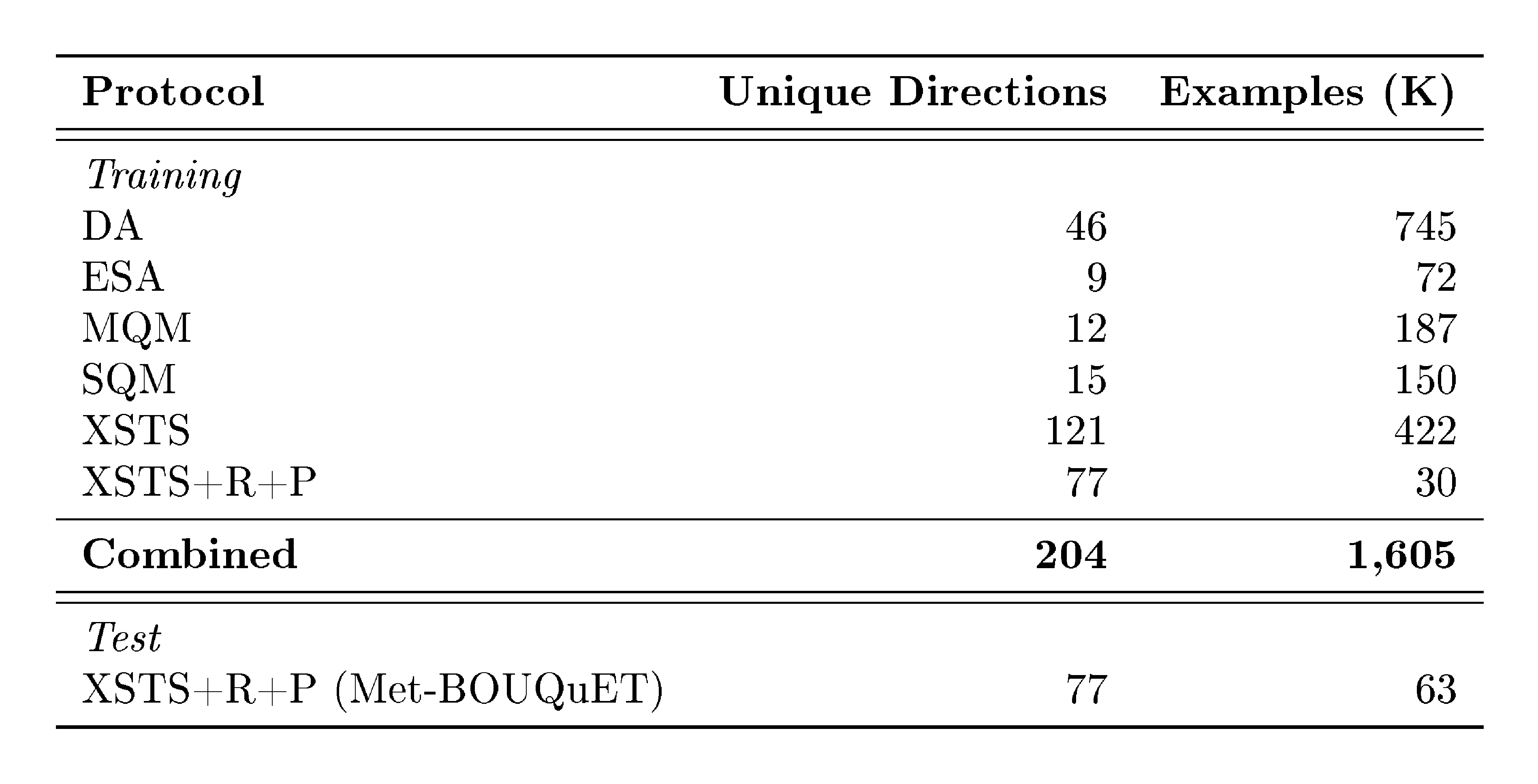
:::
Synthetic Data
We sample 2M translation examples from our MT training data covering aRound 100 directions, tailored around the Met-BOUQuET directions.[^29] We translate the source text with 5 different MT models: 2 variants of $\textsc{OmniSONAR}$ ([6]), NLLB-3B ([1]), Madlad-10B ([72]), and Gemma3-27B ([5]). We use the reference-based MetricX-24 to label the examples, thus resulting in 10M synthetic QE examples.
[^29]: In the future we plan to extend to all possible directions for which we have translation data.
Architecture & Training
The embeddings from $\textsc{OmniSONAR}$ have dimensionality $d_s=1024$, and thus the input to the MLP has dimensionality 4d=4096. For the MLP we use $d_h=2048$ and $d_o=256$, with GeLU activations ([131]). We have in total 7 QE regression heads, one for each of the 6 protocols, plus a separate one for the synthetic data. Since scores are normalized to 0-1 scale, we apply a sigmoid function to the regression logits. The total parameters of the model are 9M. We train with AdamW (0.9, 0.98) ([97]) using a base learning rate of 1e-3, and a cosine annealing scheduler. We use a batch size of 1024 examples, and train for 40k steps. Dropout is set to 0.1 in input/output and 0.3 in the MLP. Training takes only 90 minutes on a single A100 GPU (using pre-extracted $\textsc{OmniSONAR}$ embeddings).
Evaluation
We use Spearman's rank correlation coefficient $\rho$ as our main evaluation metric. We pick the best checkpoint according to Met-BOUQuET validation performance using the XSTS+R+P head and report results in Met-BOUQuET test, using their corresponding regression heads.
8.3.4 Results
On Table 17, we compare our proposed method BLASER 3, with its predecessor BLASER 2 ([118]), and two strong QE models from the literature, xCOMET-XL^30 [114] and MetricX-24^31 [84] on the test sets of Met-BOUQuET. For Met-BOUQuET we report results on all the directions, and additionally on three subsets, depending on the use of English in source or target.
Our results show that BLASER 3 surpasses previous models on multilingual QE on Met-BOUQuET, on average achieving gains of +0.08 compared to MetricX-24, and +0.12 compared to xCOMET-XL. By specifically looking into the direction with non-English source (X $\rightarrow$ Eng) and non-English target (Eng $\rightarrow Y)$, we see that the improvements of BLASER 3 can be attributed to better performance on the source-side. We hypothesize that cross-lingual generalization from the omnilingual embedding space is particularly strong on the source-side of QE, since it contains proper sentences. Contrary, the target-side of QE, naturally contains errors, making generalization from $\textsc{OmniSONAR}$ embeddings more difficult. Finally, our ablations show that using synthetic data is helpful, thus indicating that scaling-up domain/language coverage through synthetic data can lead to further improvements.
::: {caption="Table 17: Spearman's $\rho (\uparrow)$ on the Met-BOUQuET (XSTS+R+P) test set. X indicates non-English source languages, and Y indicates non-English target languages. In bold is the best among the proposed BLASER 3 and the three baselines. In parenthesis is the number of pairs in each group (note that we use a subset of Met-BOUQuET from r1 annotations, available at the time of experimentation)."}
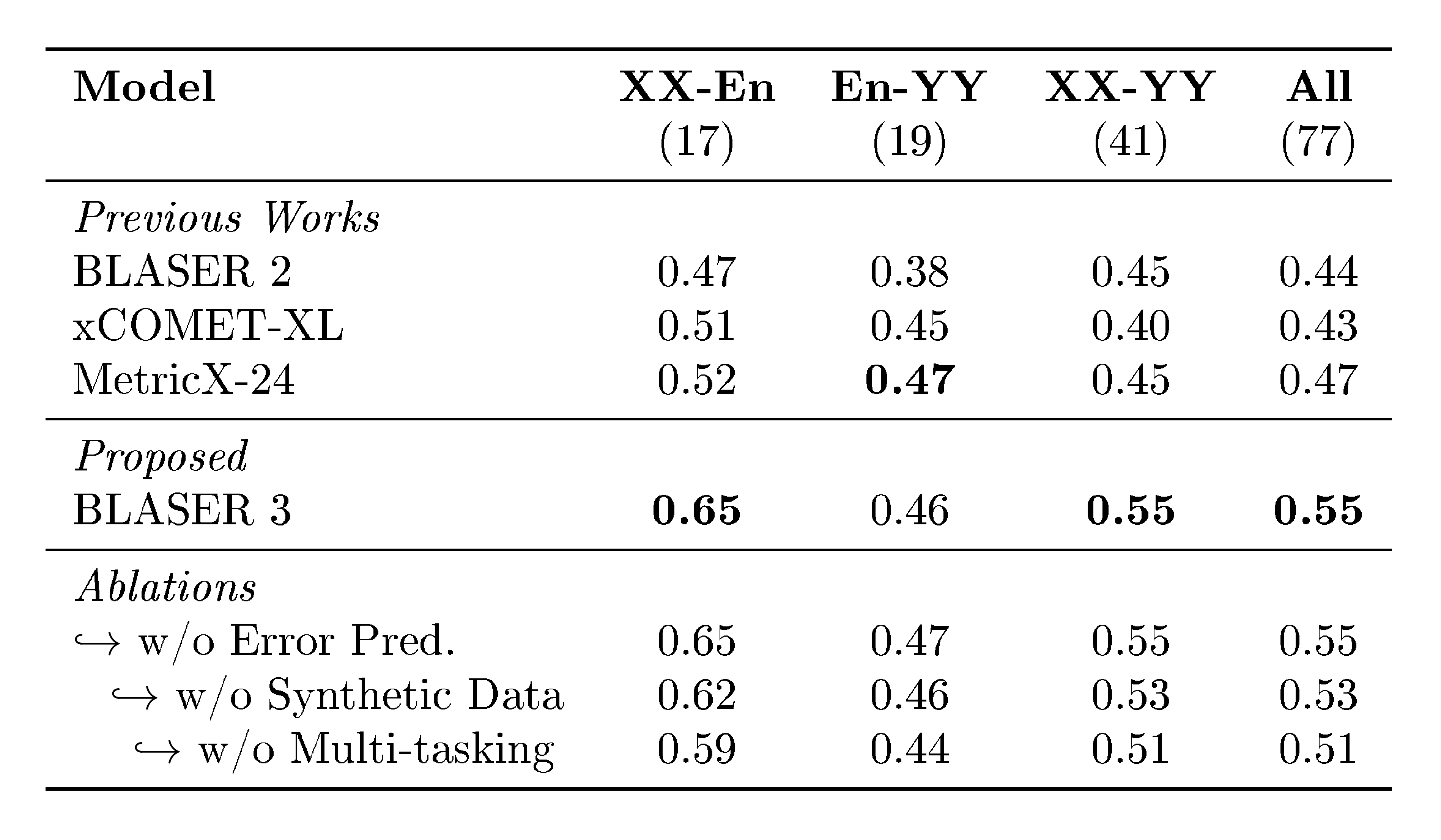
:::
8.4 Metrics Benchmarking
8.4.1 Automatic analysis
Besides training and evaluating BLASER 3, we take advantage of the Met-BOUQuET dataset to benchmark a wider set of popular and traditional MT metrics[^32]. Consistently with Section 8.3, we evaluate each metric by the average of its Spearman correlations with human XSTS+R+P scores in each translation direction of the Met-BOUQuET test set[^33]. We evaluate a set of lexical-based metrics (BLEU ([132]), ChrF++ ([133]), METEOR ([134])), a set of model-based (BLASER 2 ([118]), BLEURT ([135]), COMETKiWi ([136]), MetricX ([84]), SONAR ([119]) and $\textsc{OmniSONAR}$ ([6]), xCOMET ([114])) available and the newly proposed BLASER 3 in previous section.[^34] For SONAR and $\textsc{OmniSONAR}$, we are using cosine similarity of the translation embedding and source/reference embedding. For consistency between the reference-based and reference-free metrics, we drop the translation directions for which the reference translations are not yet available. Results are presented in Table 18.
[^32]: We are not adding in our benchmarking LLM-based metrics since there is not an standard metric of this type and it would require an extensive amount of work on experimenting with prompt and models that we leave for further work.
[^33]: note that for BLEU and ChrF++, we are using their sentence-level versions
[^34]: We did not include any LLM-based metrics, because the space of the models, prompt templates, and decision strategies is too large to explore in this small section. We defer this to future work.
::: {caption="Table 18: Mean per-direction Spearman's $\rho$ on the test set of Met-BOUQuET (XSTS+R+P) for several popular metrics, depending on whether they compare the translation with source, reference, or both, and whether they are adjusted with the GlotLID score. The best metric for each setting is in boldface."}
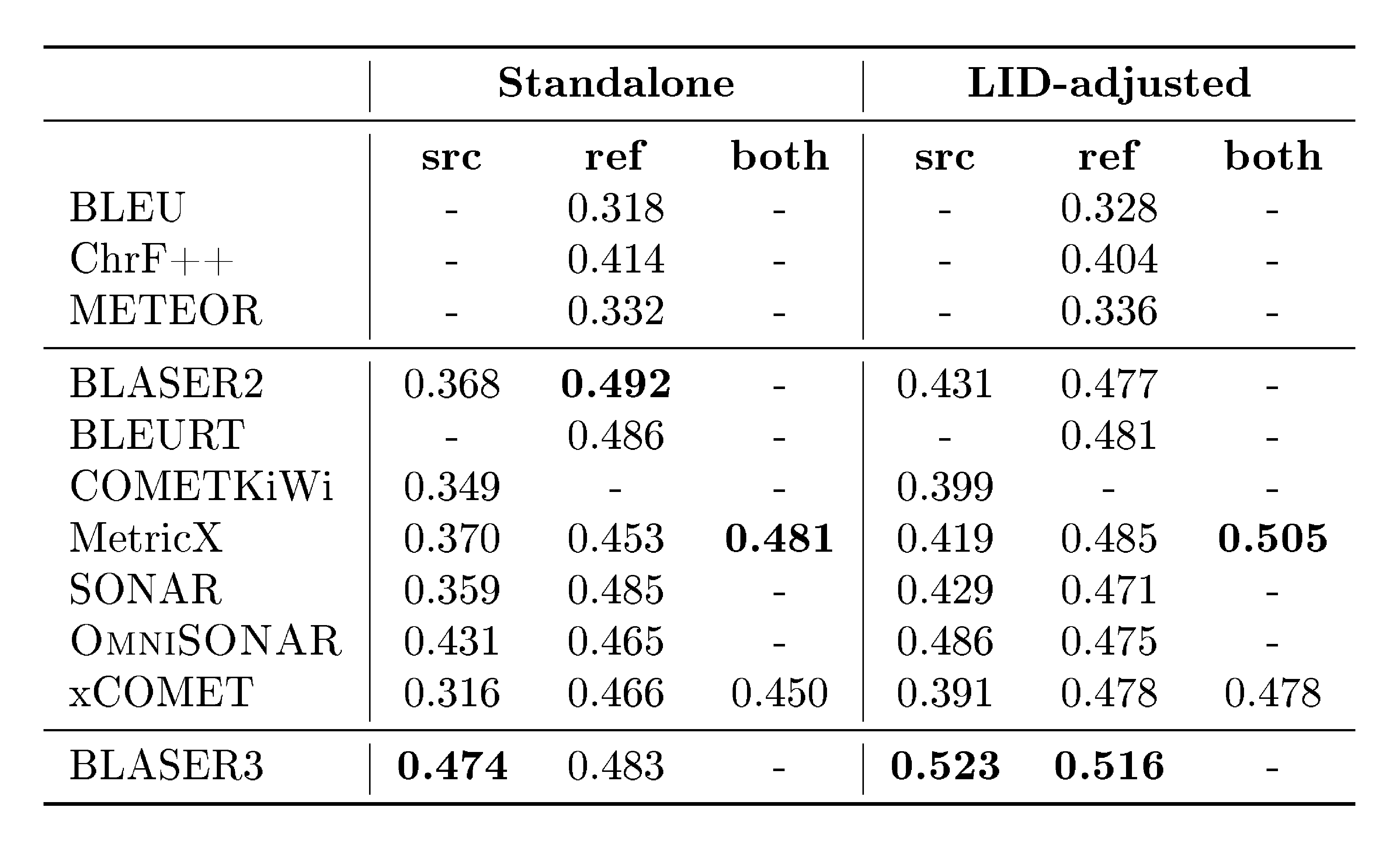
:::
One question addressed by this benchmark is about the role of source and reference information for translation evaluation. Consistently with the results of the WMT25 evaluation campaign ([137]), we find that for metrics capable of using the source and the reference simultaneously, their combination typically works better than the source or the reference alone (except for the case of xCOMET without LID correction, where adding the sources actually hurts the performance).
Another issue, also reported by [137], is that automatic metrics often cannot detect translations into a wrong target language (which is a catastrophic error), even despite seeing a reference in the correct language. We addressed this issue by multiplying each metric by the confidence of a GlotLID v3 model ([25]) that the translation is in the target language.[^35] The right half of Table 18 shows that this adjustment is highly beneficial for all reference-free metrics, as well as for the majority of model-based metrics that use reference.
[^35]: To make it work, the base metric has to be put on a scale where 0 corresponds to the worst quality and some positive number corresponds to the best quality. MetricX violates this requirement, so before multiplying we rescaled it with a formula MetricX_{adjusted}=1-(MetricX/25)^{0.5} which makes its scale comparable to the one of xCOMET.
Based on the above comparison, we recommend three strongest model-based metrics for evaluating the quality of highly multilingual translation: reference-free BLASER 3 with LID adjustment, and, in case translation references are available, the versions of MetricX and xCOMET that use both source and reference and are also adjusted with LID.
To understand how these comparisons depend on the difficulty of the source and target languages, we grouped all Met-BOUQuET languages in two buckets: "high" (all "truly high resource" languages with at least 50M primary parallel sentences, as per our definition in Section 3.3) and "low" (all other languages), and grouped our 144 directions accordingly, with 4 groups by source and target resource levels of roughly similar sizes. Table 19 reports the results grouped by the combination of translation directions. Low-resourced languages make the automatic evaluation more difficult on the source and especially on the target side. BLASER 3 turns out to be competitive for each group of directions, outperforming, on average, every other metric in each group. Comparing the metrics' signatures makes intuitive sense: LID adjustment improves the evaluation for translation into lower-resourced languages (where out-of-target translations usually occur), and reference-based metrics clearly outperform reference-free ones either when translating form a low-resourced languages to a high-resourced one (so that comparison to the high-resourced reference is easier than to the low-resourced source) or when evaluating translation into low-resourced languages without LID adjustment (when comparison with references can partially compensate for the lack of off-target detection). These results confirm the need to invest in improving metrics, hinting at more urgency to evaluate probably fluency of low-resource languages.
::: {caption="Table 19: Mean per-direction Spearman's $\rho$ on the test set of Met-BOUQuET, aggregated per group of translation directions. Top part: for each metric, we report the best correlation over the metric signatures (whether to use source, reference, and LID adjustment). Bottom part: for each signature, we report the best score over different metrics."}
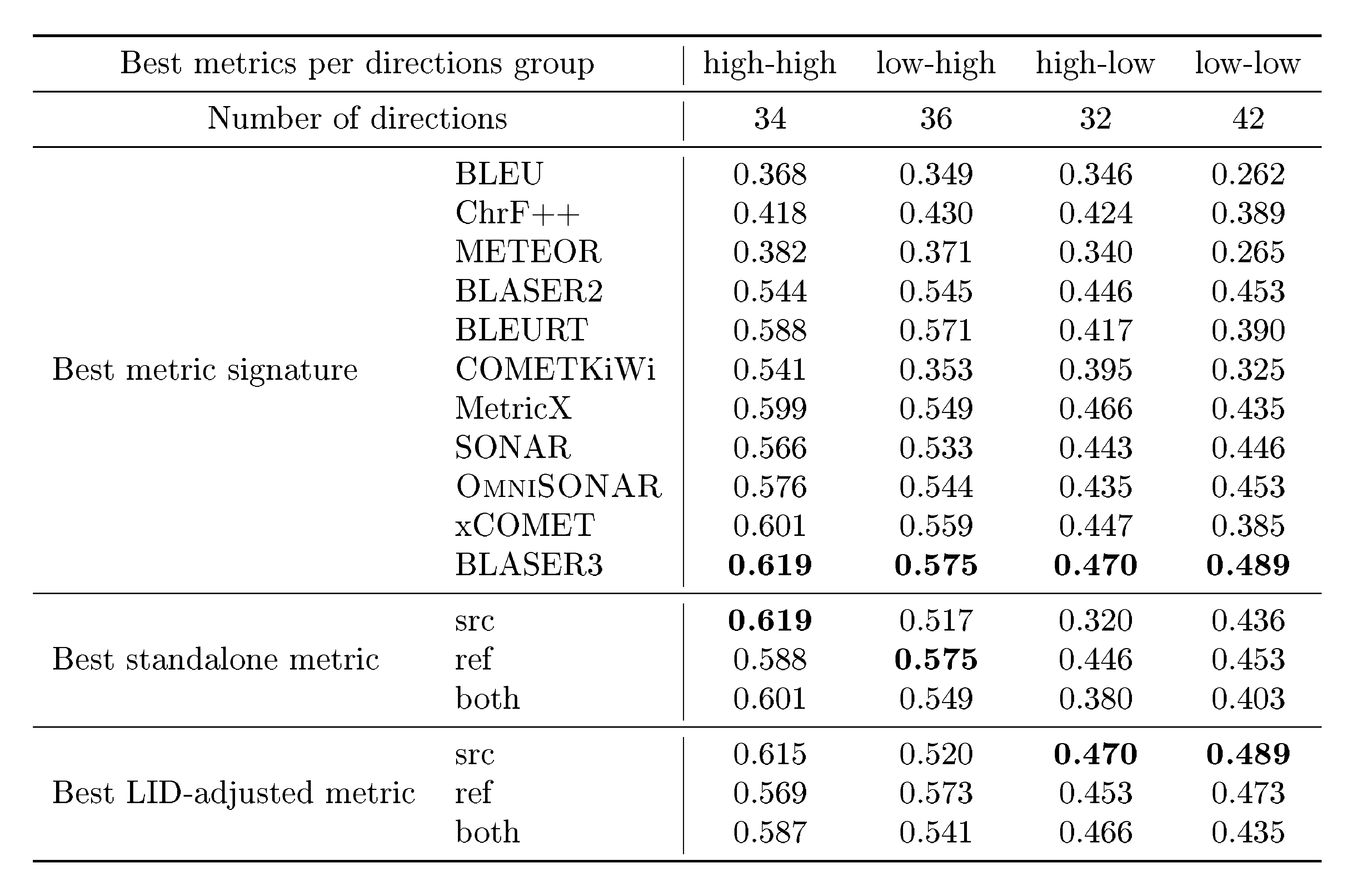
:::
Examples of translation directions with the lowest correlations include French to Zarma, English to Plains Cree, and English to Egyptian Arabic. The first two simply contain very few good translations, and the third direction, while containing a substantial proportion of semantically similar translations, often includes penalties for translating into Modern Standard Arabic instead of Egyptian Arabic and for problems with fluency, which all automatic metrics fail to reflect. For a future generation of automatic quality metrics for translation, it would probably make sense to build some language identification capabilities directly into them.
8.4.2 Manual analysis: automatic metrics vs human judgment
Using a subset of Round 1 annotations, we performed a side-by-side analysis of translation quality, where we looked at how the automatic metrics matched human judgment (or not). Overall, automatic metrics correlate rather well with human judgment, but they are not good at capturing: paragraph-level discrepancies; the relative importance of salient words; language register discrepancies.
We want to find out where the biggest translation errors come from and how these evaluations compare to automatic metrics. We chose four language pairs (Swedish to English, English to Swedish, Italian to Romanian, Romanian to Italian) according to our internal capabilities.
In most cases, the automatic metrics align with human judgment. It is especially apparent in such cases as obvious hallucinations and the opposite meaning of the target text. LID metrics successfully judge the presence of the wrong language in the translation. However, there are additional factors that automatic tools cannot take into account. Primarily, these tools cannot work on the paragraph level, which results in inaccurate judgment when the context is needed for correct translation.
Secondly, automatic metrics do not always judge what words are key words in a sentence in the same way as a human does. Often, when only the key word is mistranslated (which leads to a completely different meaning and low human score) automatic metrics score the sentence significantly higher than expected, since “almost everything” in the sentence is correct.
Interestingly, when translating out of English, register problems are much more obvious.
::: {caption="Table 20: Examples where automated metrics and human judgment do not align"}
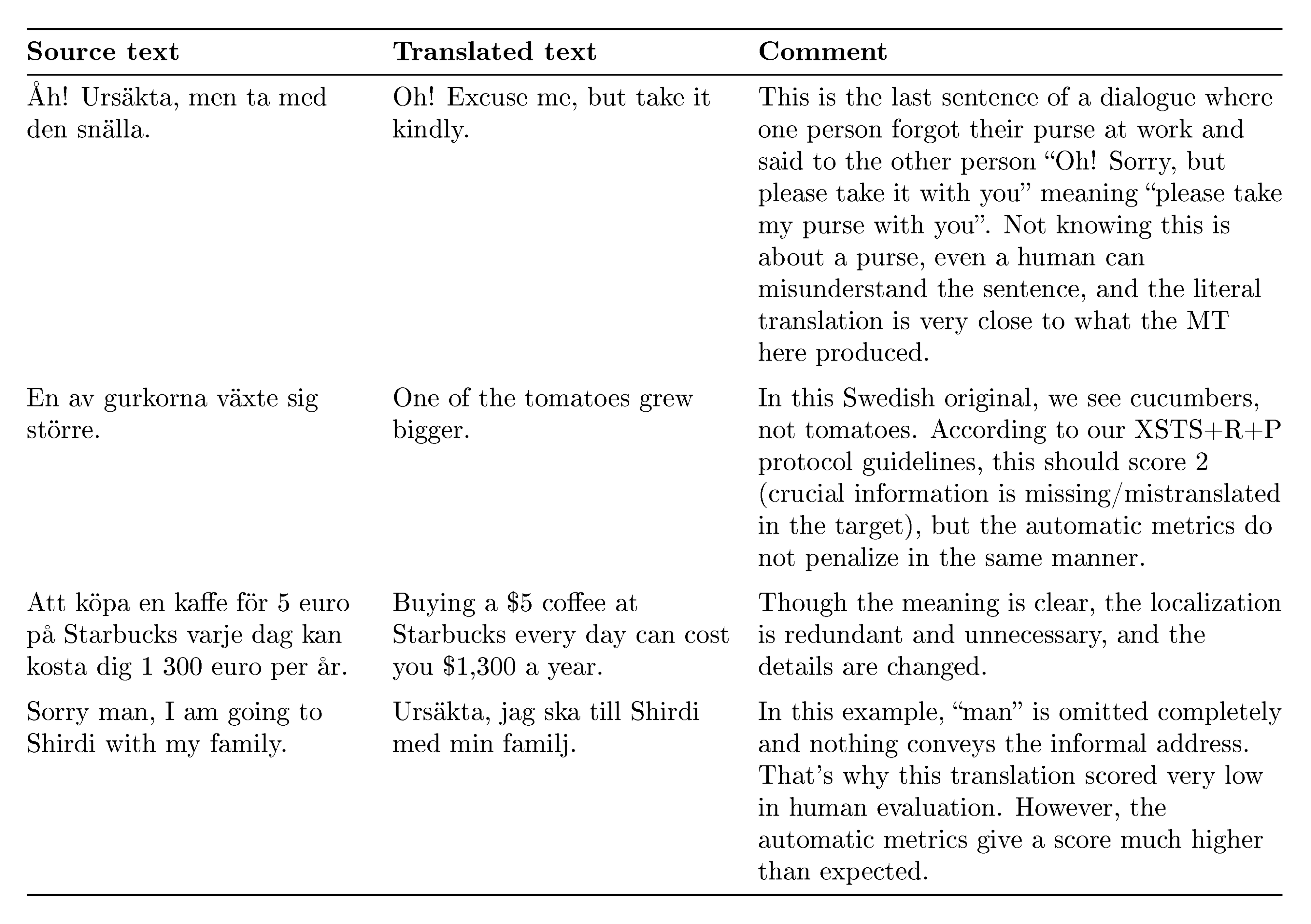
:::
All in all, it is clear that register and paragraph coherence represent challenges to automatic metrics. Besides that, these metrics tend to give higher scores to literal translation, which is not necessarily representative of how the translation should work.
8.5 OmniTOX
To define toxicity we refer to previous works ([1, 42]) that consider toxicity as instances of profanity or language that may incite hate, violence or abuse against an individual or a group (such as a religion, race or gender). When detecting toxicity in MT, it is important to report toxicity unbalances between the source (or input) and the MT output. Toxicity unbalances can be of two kinds: deleted toxicity, where the output contains fewer toxic items than the source, and added toxicity, where the output contains more toxic items than the source. While both cases are critical, we focus here on added toxicity, following prior work by [1] and [42]. It has been our experience that consumers of MT regard added toxicity as more problematic than deleted toxicity, as exemplified in real situations ([138]).
There are many works in multilingual toxicity detection in NLP—e.g., [139]—and even going beyond multilingual toxicity detection in explainability and interpretability ([140]). However, there is a limited number of toxicity detectors that scale to the long-tail of languages; e.g., ETOX ([141]) and MuTox ([142]), both covering 200 languages.
In this section we describe OmniTOX, a new toxicity classifier serving 1, 600 languages. OmniTOX achieves a mean per-language ROC AUC of 0.86, outperforming the previous state-of-the-art MuTox (0.80) by +0.06 points. In particular, OmniTOX shows strong zero-shot capabilities, when trained exclusively on English and Spanish, it achieves 0.82 mean per-language ROC AUC across 30 evaluation languages.
8.5.1 Methodology
Overview
OmniTOX is a direct successor to MuTox ([142]), designed to extend multilingual toxicity detection from 200 to 1600+ languages. Rather than introducing architectural complexity, we focus on upgrading the underlying representation space: replacing SONAR embeddings with $\textsc{OmniSONAR}$.
Task
Toxicity detection data are tuples of (sent^{(x)}, y), where sent^{(x)} is a sentence in language x, and y $\in$ 0, 1 is the binary toxicity label (0 for non-toxic, 1 for toxic). The task of toxicity detection aims to learn a classifier f that predicts $\hat{y} = f(\text{sent}^{(x)})$.
Architecture
Following MuTox ([142]), we employ a simple MLP classifier on top of cross-lingual sentence embeddings. The key difference is the underlying encoder: we replace SONAR (200 languages) with $\textsc{OmniSONAR}$ (1600+ languages) ([6]), which provides stronger multilingual representations and broader language coverage. We use (frozen) $\textsc{OmniSONAR}$ to extract cross-lingual embeddings e $\in \mathbb{R}^{d_s}$ for each input sentence, where $d_s$ is the dimensionality of the $\textsc{OmniSONAR}$ embedding space. The embedding e is passed through a two-layer MLP [$d_s \rightarrow d_1 \rightarrow d_2 \rightarrow 1]$ to obtain the toxicity prediction:
$ h_1 = \text{ReLU}(W_1 e + b_1), \quad h_2 = \text{ReLU}(W_2 h_1 + b_2), \quad \hat{y} = \sigma(W_3 h_2 + b_3), $
where $W_1 \in \mathbb{R}^{d_1 \times d_s}, W_2 \in \mathbb{R}^{d_2 \times d_1}, W_3 \in \mathbb{R}^{1 \times d_2}$ are learnable weight matrices, $b_1, b_2, b_3$ are bias terms, and $\sigma$ denotes the sigmoid function. During training, we apply dropout (p=0.4) after each hidden layer for regularization.
The MLP parameters are optimized with binary cross-entropy loss:
$ \mathcal{L}_{\text{BCE}} = -\left[y \log \hat{y} + (1-y) \log(1-\hat{y})\right]. $
Using a simple classifier on top of powerful cross-lingual embeddings is a deliberate design choice that facilitates zero-shot cross-lingual transfer, allowing the model to generalize to languages unseen during training.
8.5.2 Experimental Setup
Data
Our training data is comprised of a subset of the MuTox dataset ([142]), covering 30 languages with varying resource levels. We maintain the original data partitions: 'train' for model training, 'dev' for validation and hyperparameter tuning, and 'devtest' for final evaluation. To ensure data integrity, we exclude instances without explicit partition assignments. The dataset statistics are presented in Table 21. English and Spanish serve as high-resource anchor languages, comprising approximately 40% of the training data (12, 906 and 10, 716 examples, respectively). The remaining 28 languages contain between 887–1, 476 training examples each. This imbalanced distribution allows us to evaluate both supervised performance on well-resourced languages and cross-lingual transfer to lower-resource languages. The full list of languages is provided in the MuTox paper ([142]).
::: {caption="Table 21: Training and evaluation data statistics for OmniTOX. We use a subset of the MuTox dataset covering 30 languages across three partitions."}
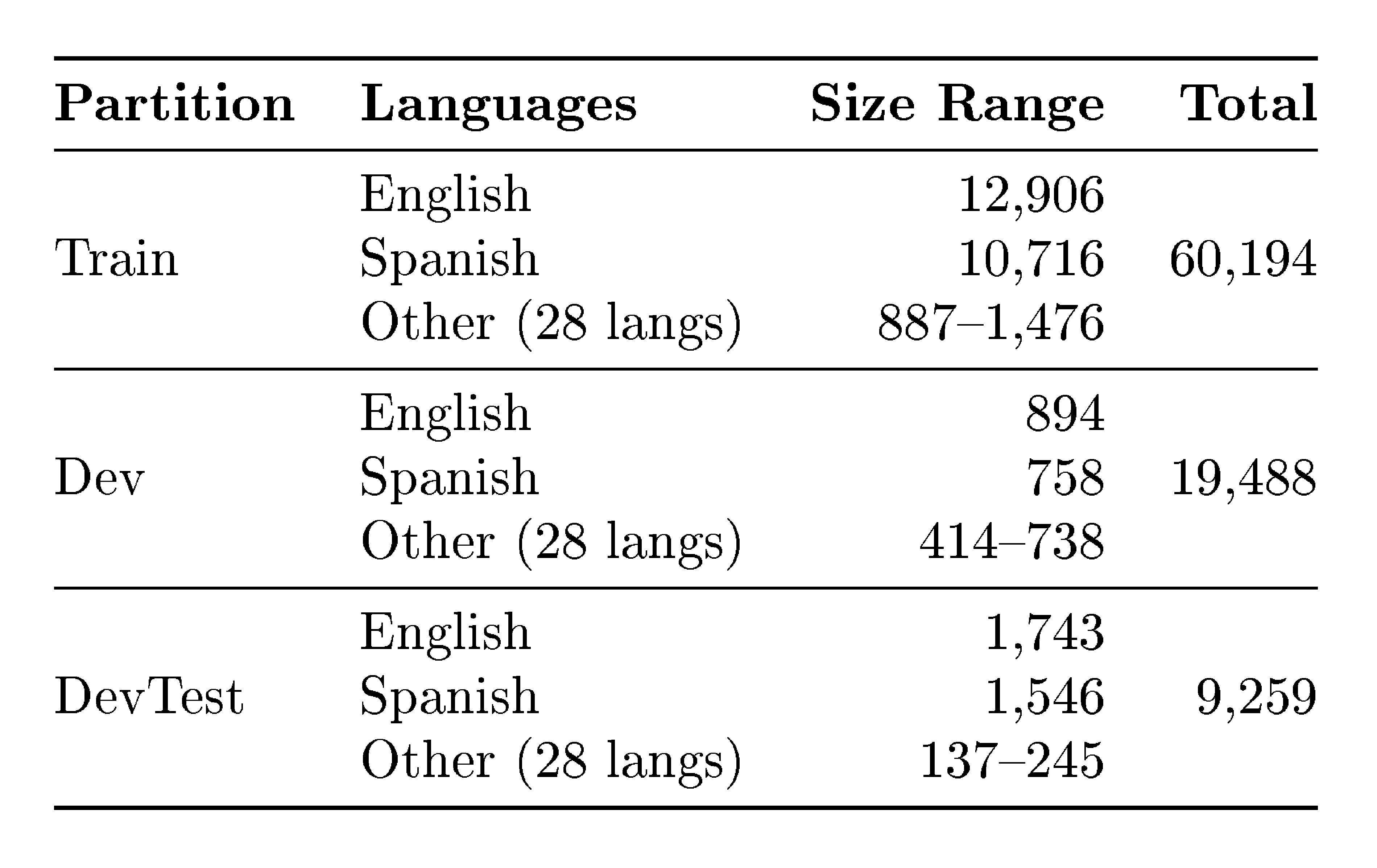
:::
Architecture & Training
The embeddings from $\textsc{OmniSONAR}$ have dimensionality $d_s = 1024$, serving as input to the MLP. For the MLP, we use $d_1 = 512$ and $d_2 = 128$, with ReLU activations. The total number of trainable parameters is approximately 590K. We train with Adam using a base learning rate of 1e-3, weight decay of 1e-3, and a CosineAnnealingLR scheduler. We use a batch size of 32 and train for 30 epochs. Dropout is set to 0.4 for regularization, and gradient clipping is applied at 5. We select the best checkpoint according to development set performance. Training takes approximately 5 minutes on an NVIDIA Quadro GV100 GPU (using pre-extracted $\textsc{OmniSONAR}$ embeddings).
Baselines
Our experimental design isolates the contribution of $\textsc{OmniSONAR}$ embeddings through controlled comparisons. We compare against MuTox ([142]), the previous state-of-the-art multilingual toxicity detector built on SONAR embeddings covering 200 languages. To disentangle the effects of the embedding space from classifier optimization, we train two additional models:
- Baseline: Uses $\textsc{OmniSONAR}$ embeddings with MuTox's original classifier architecture and hyperparameters. Comparing MuTox vs Baseline isolates the impact of upgrading from SONAR to $\textsc{OmniSONAR}$, holding the classifier constant.
- Baseline ZS: Identical to Baseline but trained exclusively on English and Spanish data, then evaluated on all 30 languages. This tests the zero-shot cross-lingual transfer capabilities enabled by $\textsc{OmniSONAR}$ embeddings. Comparison of Baseline ZS versus OmniTOX shows the differences from classifier optimization (architecture, dropout, weight decay, learning rate tuning).
Evaluation Metrics
We use the Receiver Operating Characteristic Area Under the Curve (ROC AUC) as our primary evaluation metric. ROC AUC quantifies the classifier's ability to distinguish between toxic and non-toxic classes across all possible classification thresholds, providing a threshold-agnostic measure of ranking quality. We report: (1) overall ROC AUC computed on the aggregated DevTest set with 95% confidence intervals via bootstrap resampling (1000 iterations); (2) mean ROC AUC averaged across individual languages; and (3) per-language ROC AUC range to assess cross-lingual consistency. This evaluation framework allows for subsequent threshold tuning tailored to specific use cases, potentially at the language level.
8.5.3 Results
Table 22 presents the performance comparison between OmniTOX, our baseline variants, and MuTox on the DevTest partition across 30 languages. We report overall ROC AUC on the aggregated test set, mean ROC AUC averaged across individual languages, and the per-language performance range. Figure 9 provides a detailed per-language breakdown.
Our results show that OmniTOX achieves an overall ROC AUC of 0.845, outperforming MuTox by +0.058 points. More importantly, our controlled experiments reveal that the majority of this improvement stems from upgrading the embedding space rather than classifier optimization.
Impact of Embedding Upgrade
Comparing MuTox to Baseline, which differ only in the underlying encoder (SONAR vs $\textsc{OmniSONAR}$) while using identical classifier architecture and hyperparameters, we observe a gain of +0.052 ROC AUC. This accounts for 90% of the total improvement over MuTox, validating our hypothesis that representation quality is the primary driver of cross-lingual toxicity detection performance. We attribute this to $\textsc{OmniSONAR}$ 's improved cross-lingual alignment and broader language coverage, which yields more semantically coherent embeddings across diverse languages.
Impact of Classifier Optimization
Comparing Baseline to OmniTOX, which differ only in classifier architecture and hyperparameters, we observe a modest additional gain of +0.006 ROC AUC. This confirms our design philosophy: when embeddings are sufficiently powerful, a simple classifier suffices, and architectural complexity yields diminishing returns.
Zero-Shot Cross-Lingual Transfer
Remarkably, Baseline ZS, trained exclusively on English and Spanish, achieves 0.793 overall ROC AUC, outperforming MuTox (0.787) despite using 28 fewer training languages. This demonstrates the exceptional zero-shot transfer capabilities of $\textsc{OmniSONAR}$ embeddings. The mean per-language ROC AUC of 0.821 for Baseline ZS compared to 0.798 for MuTox further confirms that $\textsc{OmniSONAR}$ 's cross-lingual alignment enables effective generalization to unseen languages without explicit supervision.
Cross-Lingual Consistency
As shown in Figure 9, OmniTOX achieves consistent improvements across the language spectrum. The per-language ROC AUC ranges from 0.664 to 0.972, with OmniTOX outperforming MuTox on 28 of 30 languages. The mean per-language ROC AUC improves from 0.798 (MuTox) to 0.860 (OmniTOX), a gain of +0.062 points.
::: {caption="Table 22: Performance comparison on the DevTest partition (30 languages). Overall ROC AUC: computed on the aggregated test set with 95% confidence intervals via bootstrap resampling (1000 iterations). Mean per Lang.: average of individual language ROC AUCs. Range per Lang.: minimum and maximum ROC AUC across languages. Baseline uses $\textsc{OmniSONAR}$ embeddings with MuTox hyperparameters; Baseline ZS is trained only on English and Spanish. Best results in bold."}
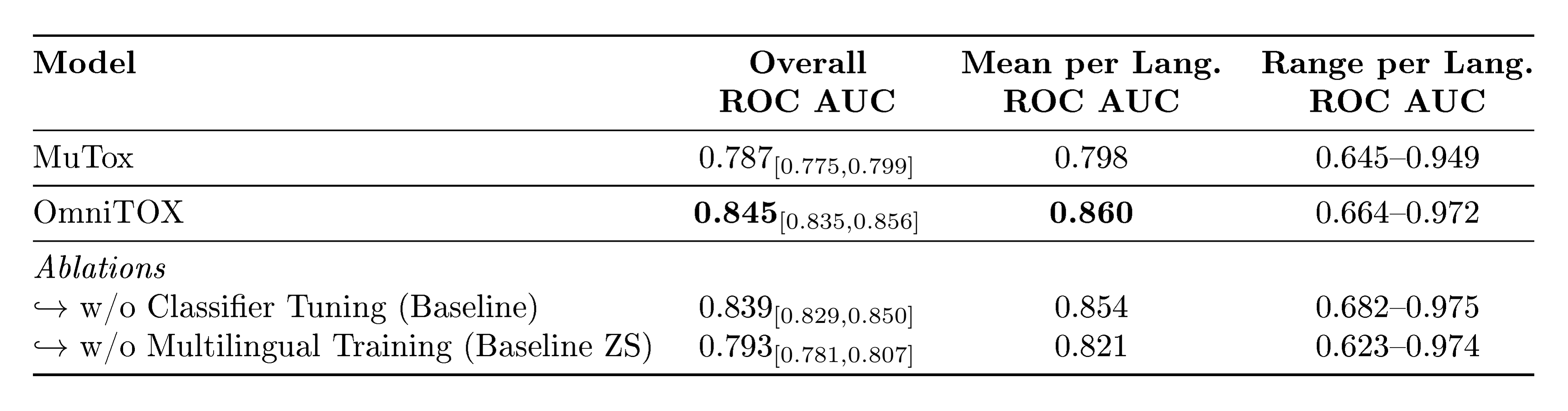
:::
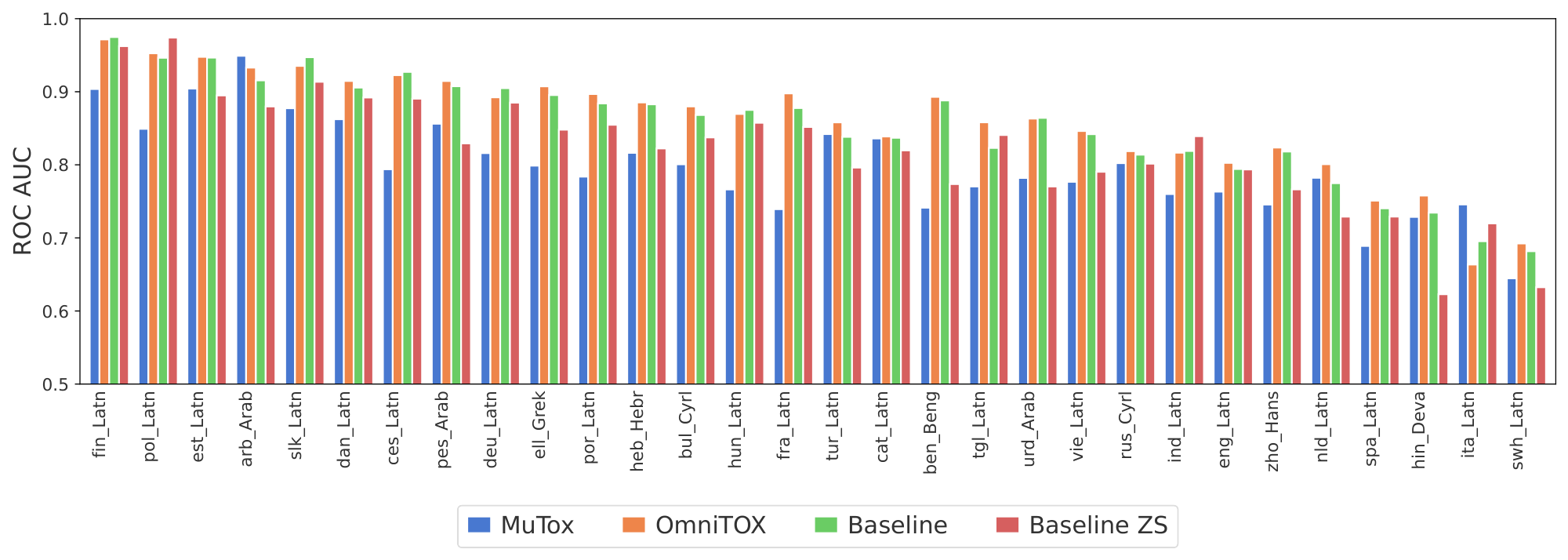
Summary
Our experiments confirm that OmniTOX's improvements over MuTox are primarily driven by the upgrade from SONAR to $\textsc{OmniSONAR}$ embeddings. The strong zero-shot performance of Baseline ZS suggests that $\textsc{OmniSONAR}$ 's cross-lingual representations can generalize effectively to the 1600+ languages beyond our 30 training languages, enabling truly omnilingual toxicity detection.
Limitations
Our work has several limitations that suggest directions for future research. Embedding Space Dependence
OmniTOX inherits both the strengths and weaknesses of $\textsc{OmniSONAR}$. While $\textsc{OmniSONAR}$ provides broad language coverage, its representations may be weaker for languages with limited pre-training data. Additionally, $\textsc{OmniSONAR}$ was not explicitly trained to preserve toxicity-related semantic distinctions, which may limit fine-grained toxicity detection in some languages.
Limited Language Evaluation
Although $\textsc{OmniSONAR}$ supports 1600+ languages, we evaluated OmniTOX on only 30 languages due to the availability of annotated data. Performance on the remaining 1570+ languages relies entirely on zero-shot transfer, which remains unvalidated. Furthermore, our training data is imbalanced: English and Spanish comprise approximately 40% of examples, potentially biasing the model toward Western toxicity norms.
Annotation Subjectivity
Toxicity perception is inherently subjective and culturally dependent ([142]). Our training data may reflect annotator biases toward certain toxicity patterns, and culturally-specific forms of toxicity may be underrepresented.
Task Scope
OmniTOX performs sentence-level binary classification, which has two implications: (1) context-dependent toxicity spanning multiple sentences may be missed, and (2) the binary output does not capture toxicity severity or type (e.g., hate speech vs. profanity). These limitations may affect downstream applications requiring fine-grained toxicity analysis.
9. MT Results
Section Summary: This section evaluates the translation performance and any increase in toxicity from the study's final decoder-only and encoder-decoder models using standard datasets like BOUQuET and FLoRes+, focusing on metrics such as ChrF++ and BLASER 3 to measure accuracy across languages of varying resource levels. The OMT models prove highly competitive against baselines, especially for translating into or from low- and mid-resourced languages, often outperforming systems like Tower+ in those scenarios. It also compares non-English language pairs, showing consistent rankings across directions and highlighting strengths in culturally proximate pairings.
This section reports evaluations of general translation quality and added toxicity for our final decoder-only and encoder-decoder models presented in previous sections.
9.1 Automatic evaluation of translation quality
9.1.1 Evaluation framework
We report results on evaluation datasets presented in Section 4.4 which includes Bible, BOUQuET, and FLoRes+. Throughout the paper, we have been presenting MT results with metrics that are reported in Appendix C. In particular, these metrics include lexical-based (BLEU [132], ChrF++ [133]) and model-based (XCOMET [114], MetricX ([84])). In this section, and based on findings from Section 8.4, we present results with a subset of them, and a newly proposed reference-free and model-based metric, BLASER 3 (Section 8.3). We complement MetricX, xCOMET, and BLASER 3 with LID to compensate for off-target mistakes of the metrics (as motivated in Section 8.4). As baseline systems, we report a variety of models of different sizes reported in Table 23.
::: {caption="Table 23: Proposed and external MT systems evaluated throughout this section and classified as General or Specialised (on MT)."}
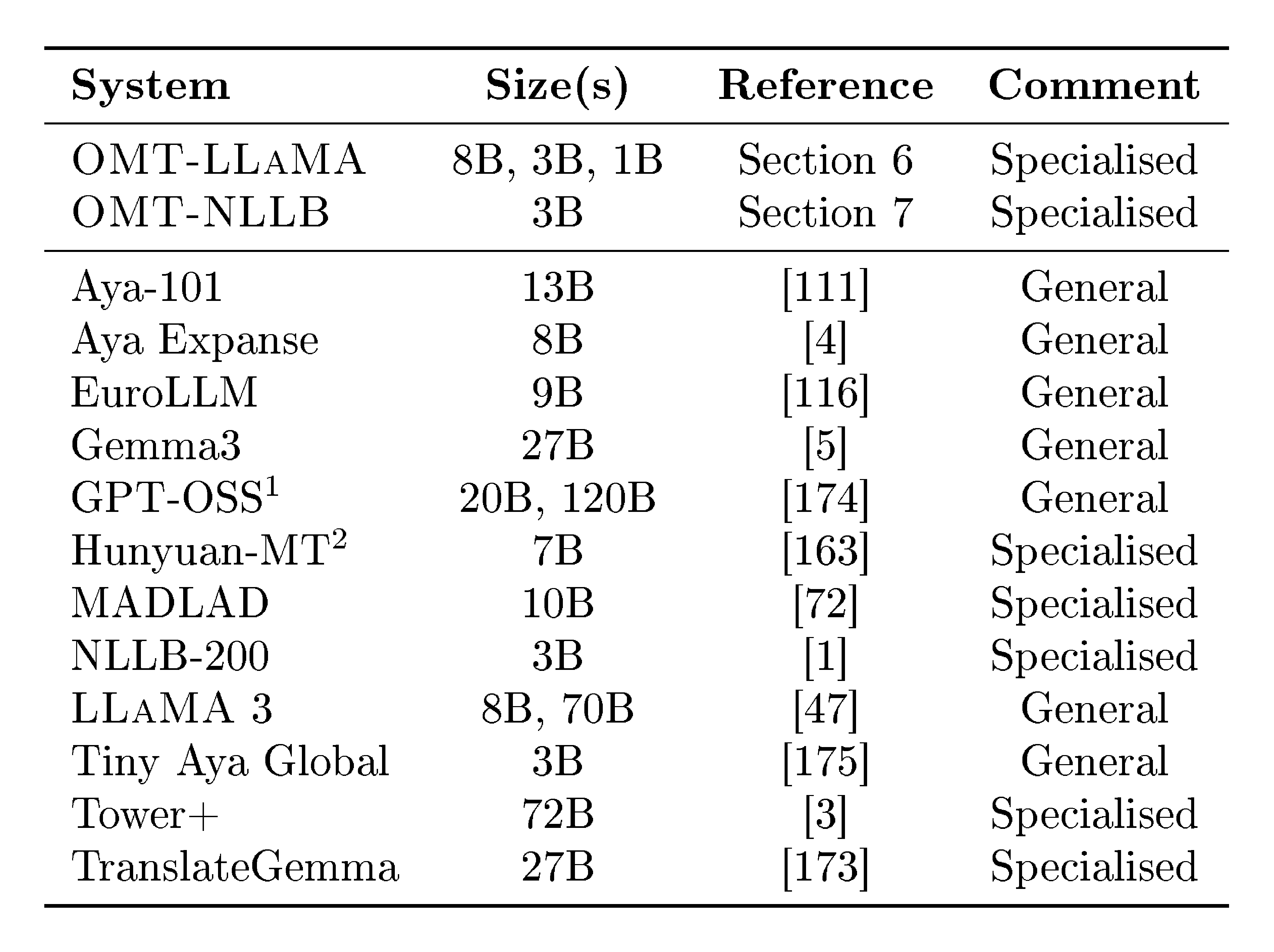
:::
Some of these translation models come with a pre-defined translation prompt template (e.g. NLLB, MADLAD, TranslateGemma) which we had only to tweak to either extend the set of supported languages or to replace an unsupported language code with the "most similar" supported language.[^36] With most of the other models, we use the same minimalist prompt template (with the language names as described in Section 3.4):
[^36]: In many cases, this amounts to simply replacing language tags with nearly-equivalent ones, e.g. for NLLB-200, we replaced cmn_Hans with zho_Hans, where the former means "Mandarin Chinese" and the latter simply "Chinese" (still implying Mandarin). However, for very low-resourced languages not supported for $\textsc{OMT-NLLB}$, NLLB-200, or MADLAD, we had to substitute them with one language from the model's supported set, selected by genealogical proximity or, in its absence, by geographical one.
```
Translate the following text from {source language} into {target language}.
Please write only its translation to {target language}, without any additional comments.
Make sure that your response is a translation to {target language} and not the original text.
{source language}: {source text}
{target language}:
```
Box 1: Prompt template for translation with instruction-following models
For $\textsc{OMT-LLaMA}$ models, we did not include the additional instructions (lines 2 and 3) into the prompt because these models are already trained to produce concise translations, unless explicitly requested otherwise.
9.1.2 Evaluating with standard benchmarks
Performance on BOUQuET by the language resource level
Table 24 reports ChrF++ results on BOUQuET dataset by language resource level defined as in Section 3 and Section 4.4.3. OMT models (both $\textsc{OMT-LLaMA}$ and $\textsc{OMT-NLLB}$) are very competitive for into-English translation from languages of any resource group. For translation into high- and mid-resourced languages, $\textsc{OMT-NLLB}$ is preferable, on average, while $\textsc{OMT-LLaMA}$ shines for translation into low- and very-low-resourced languages (note that some of the lower-resourced BOUQuET languages are not officially supported by $\textsc{OMT-NLLB}$ on the output side).
::: {caption="Table 24: Translation performance on BOUQuET (ChrF++) by the non-English language resource level."}
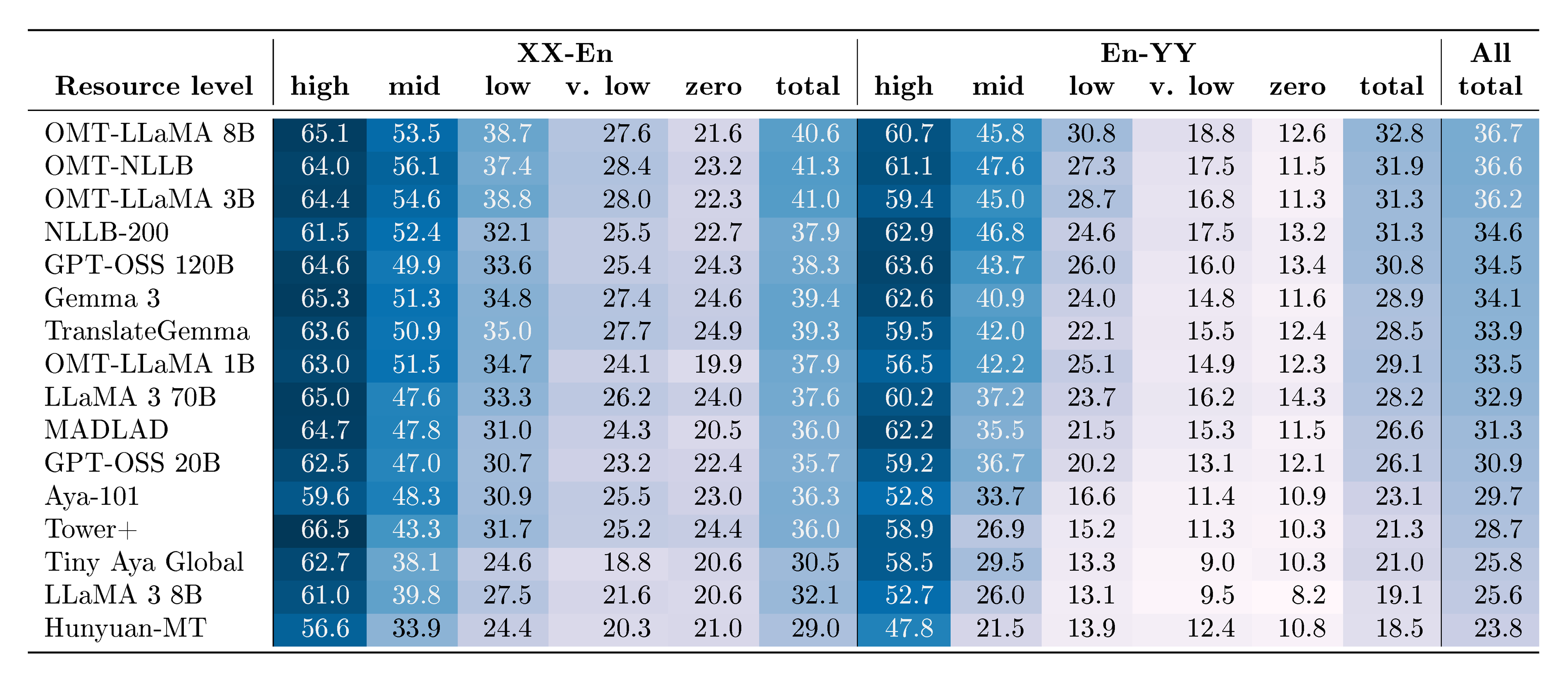
:::
Performance on FLoRes+
To corroborate our BOUQuET evaluation results, we report similar evaluation numbers based on FLoRes+ in Table 25. Similarly to BOUQuET, on FLoRes+, OMT systems perform comparably to strong baselines like Tower+ for translation between high-resource languages and English, and outperform them by a significant margin when it comes to mid- and low-resourced languages.
::: {caption="Table 25: Translation performance on FLoRes+ (ChrF++) by the non-English language resource level."}
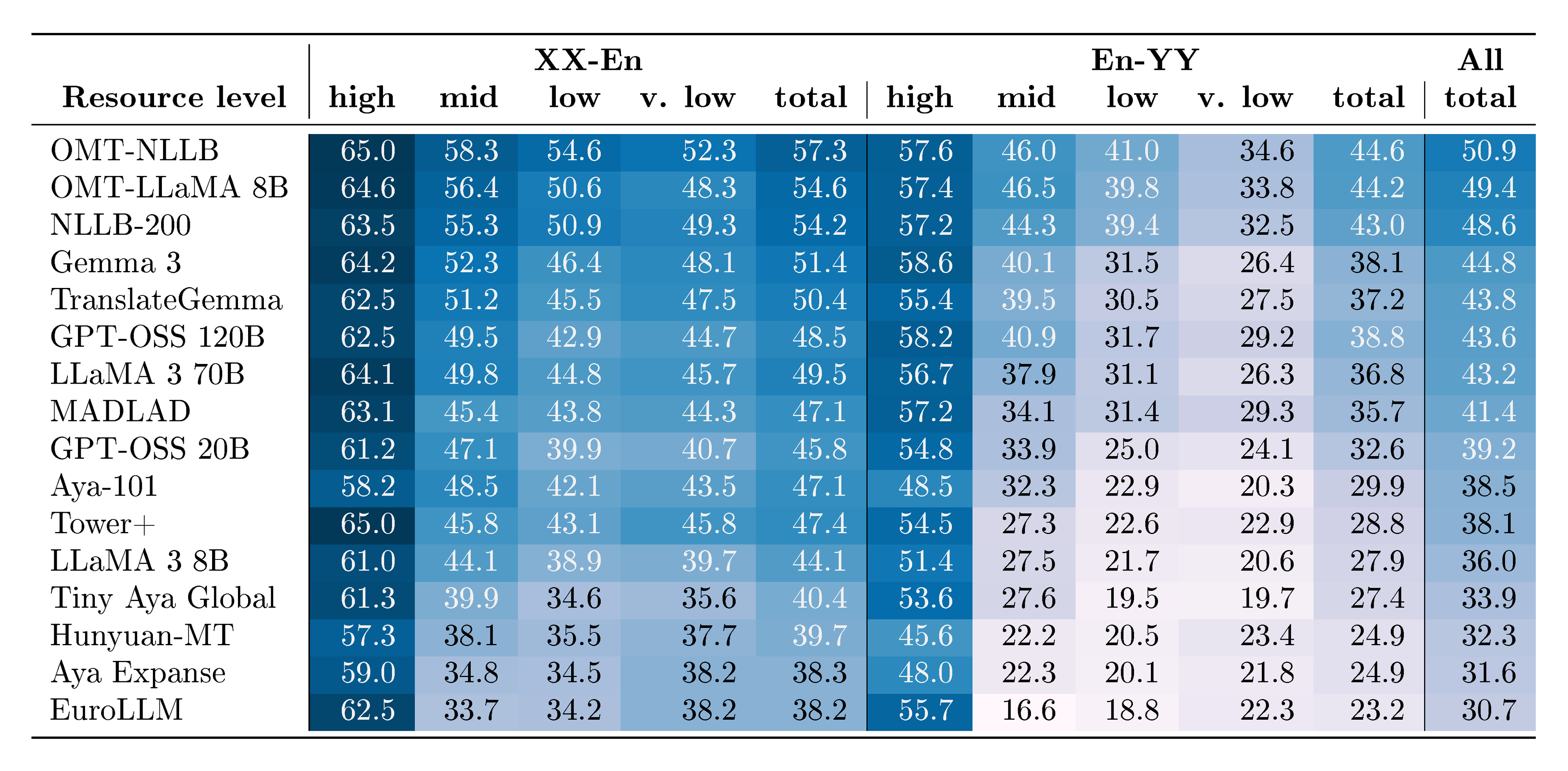
:::
Relative comparison of non-English centric performance.
For each BOUQuET non-English language, we select at least one other high- or mid-resource non-English "proxy language" based on their geographical and cultural proximity (see Section 3). Most usually, it amounts to pairing a lower-resourced language with a high-resource language spoken in the same country (majority language or a local lingua franca): for example, Spanish gets paired with Catalan and Basque languages spoken in Spain, as well as with many native American languages from Spanish-speaking countries such as Mexico. Each pair is evaluated in both directions.[^37] We evaluate how different systems compare on this set of directions, as well as how the $\textsc{OMT-LLaMA}$ 8B performance for each language depends on whether it is paired with English or not.
[^37]: This results in 514 distinct non-English-centric directions: less than two times 274 (the number of non-English languages in BOUQuET), because some high- or mid-resourced languages are paired to each other symmetrically, reducing the total number of unordered pairs.
We compare the systems ranking in different types of directions in Table 26. The two metrics we report (reference-based ChrF++ and reference-free BLASER 3 + glotlid combination) mostly agree with each other, and most systems are ranked similarly regardless of the direction. One interesting outlier is NLLB-200 which ranks relatively high in En-YY directions compared to other systems, which is probably a sign that all other systems (including the OMT ones) are still underinvesting into generation of diverse languages.
::: {caption="Table 26: Systems ranking on BOUQuET depending on the direction type."}
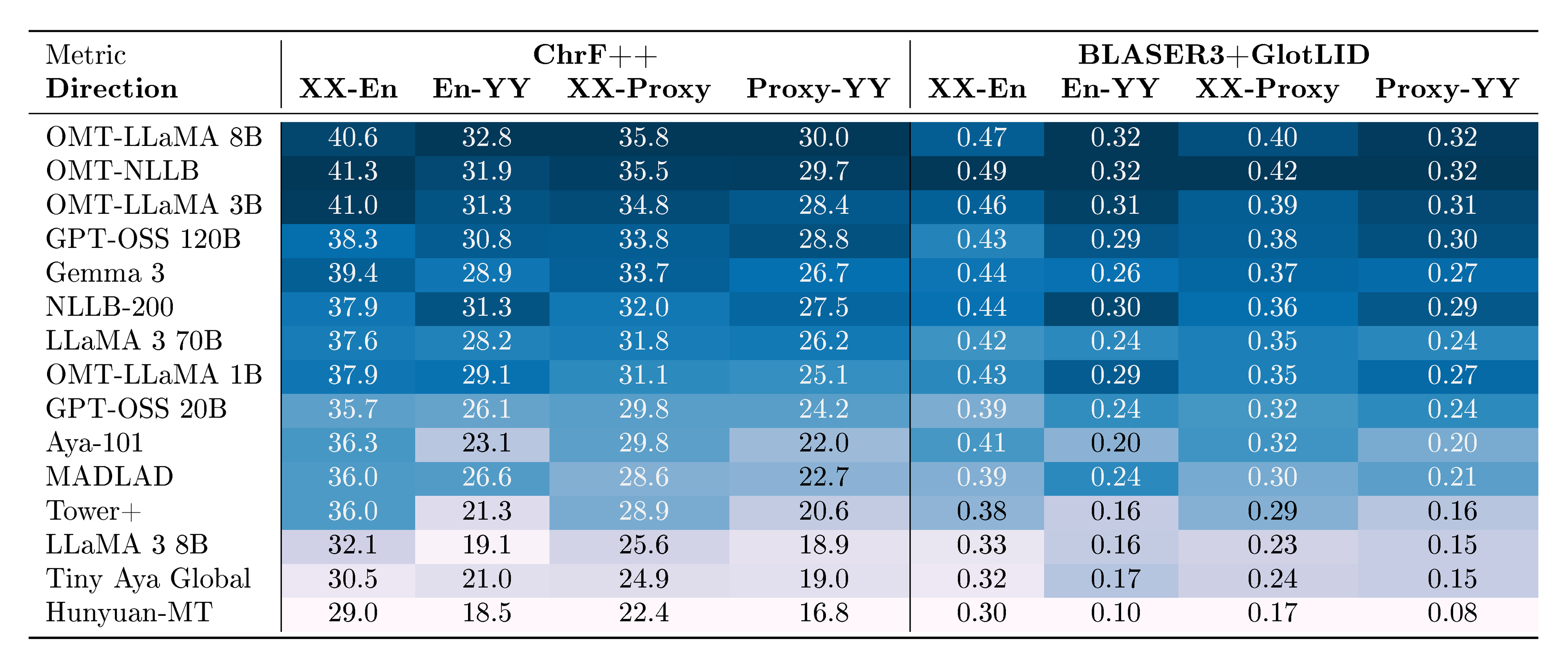
:::
To evaluate the role of the proxy languages, for each non-English source language, we compare the quality of translating it with $\textsc{OMT-LLaMA}$ 8B into English and into its non-English proxy language. We do similarly for the target languages paired with either English or non-English sources. The results are presented in Figure 10. For out-of-a-language translation into either English or a non-English language (left pane), a large part of the distribution is below the diagonal: translation into a non-English language is often harder than into English.[^38]. But for into-a-language translation out of either English or non-English languages (right pane), the distribution is mostly diagonal, indicating that the source language does not affect difficulty as much. In other words, the difficulty of non-English-centric pairs for $\textsc{OMT-LLaMA}$ is more often driven by a non-English target than by a non-English source language.
[^38]: There is a cluster of exceptions, though: some directions like Amis-Chinese, Aguaruna-Spanish, Baatonum-French look better than their into-English equivalents, either because these language pairs have more training data, or simply because of the bias in the evaluation metrics, which are generally not intended for comparisons between different target languages and might be less exigent for non-English target languages.
For a non-negligible proportion of languages, quality from and into non-English language is quite high, which back-up the idea that is worth to explore non-English translations. Further research is needed on how to pair languages and experimenting with them.
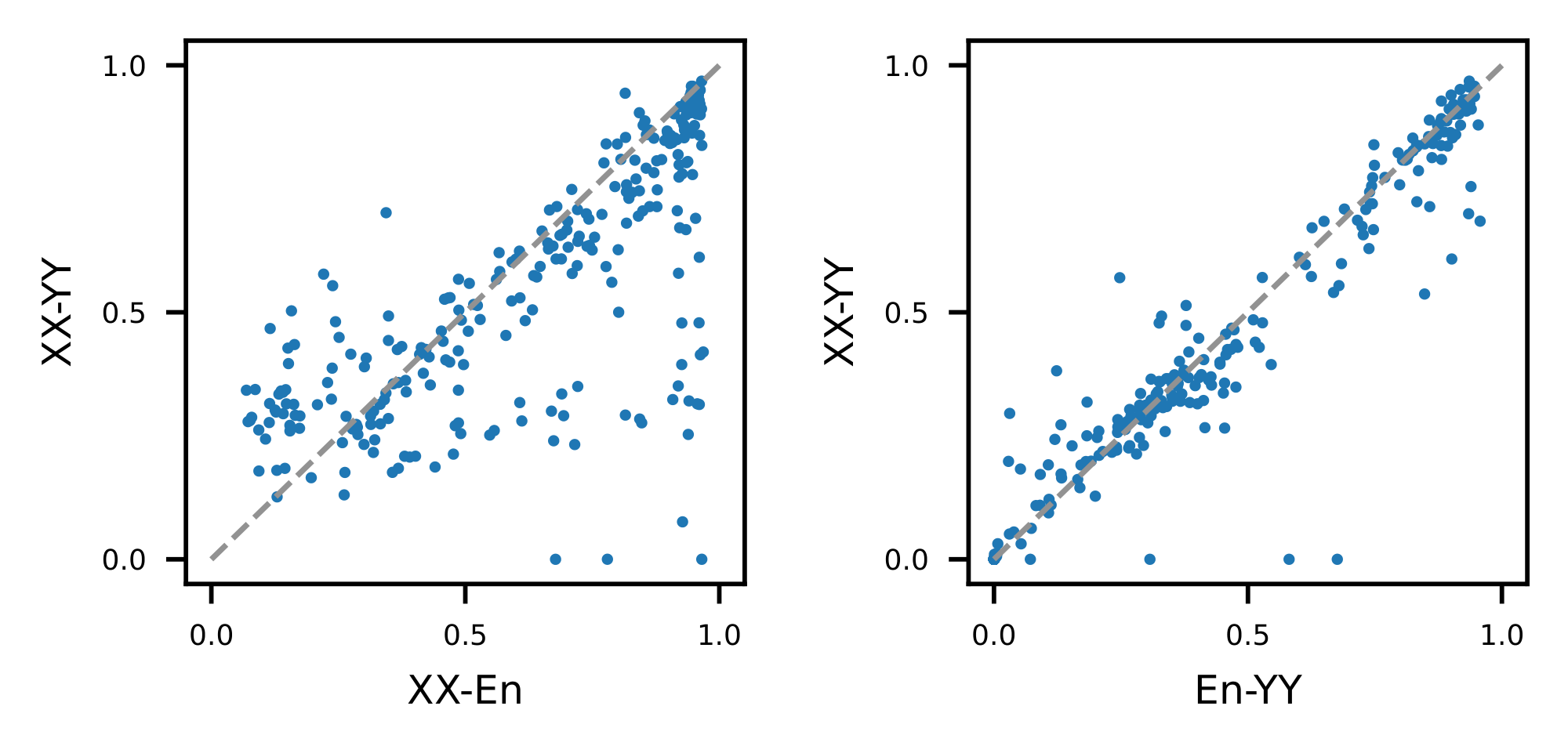
9.1.3 Evaluating long-tail understanding and generation
Relative Performance on language understanding in the long tail
We compare our models to open models included in Table 23. Figure 11 shows how the OMT models understand the longtail of languages compared to baseline systems on the Bible evaluation benchmark (test split) in terms of ChrF++ and xCOMET for XX-En. The number of languages where $\textsc{OMT-LLaMA}$ 8B strictly outperforms all the baselines in the Bible is 1045 (which is approximately 2/3 of the languages). Furthermore, our 3B model $\textsc{OMT-NLLB}$ consistently outperforms all baselines in the 1, 600 evaluated languages. When testing on MetricX and BLASER 3, we obtain similar results.
:::: {cols="1"}
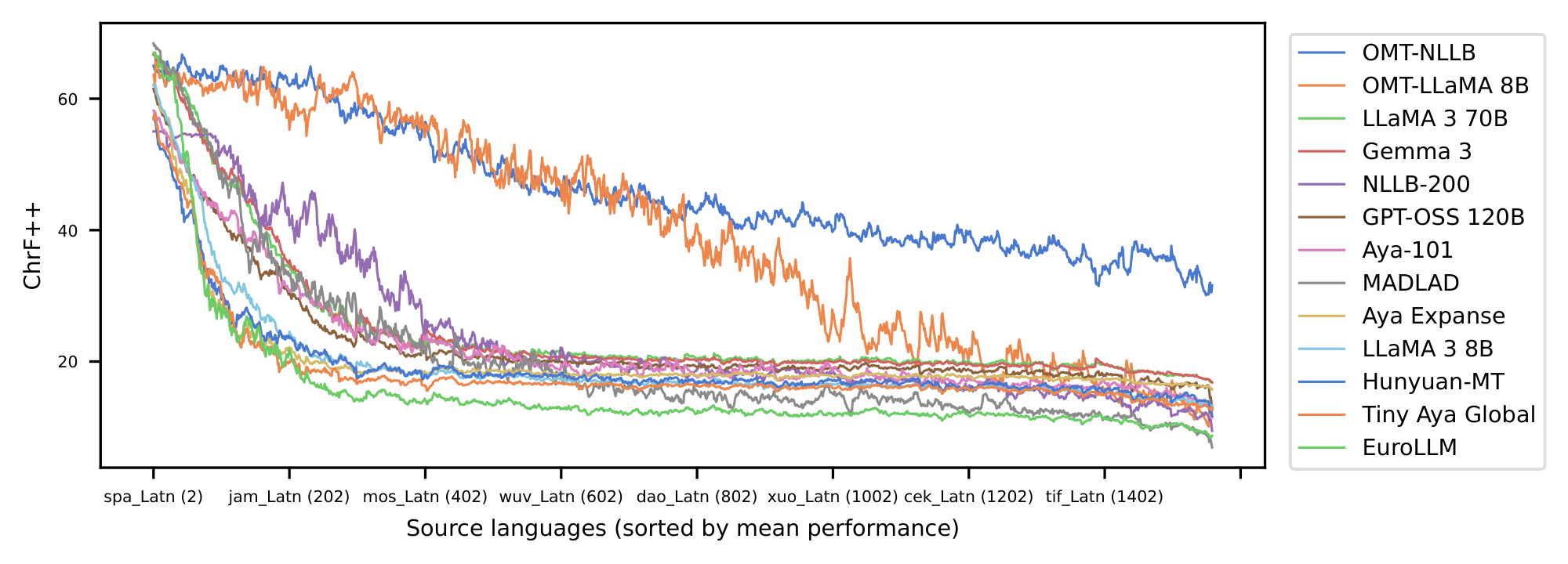
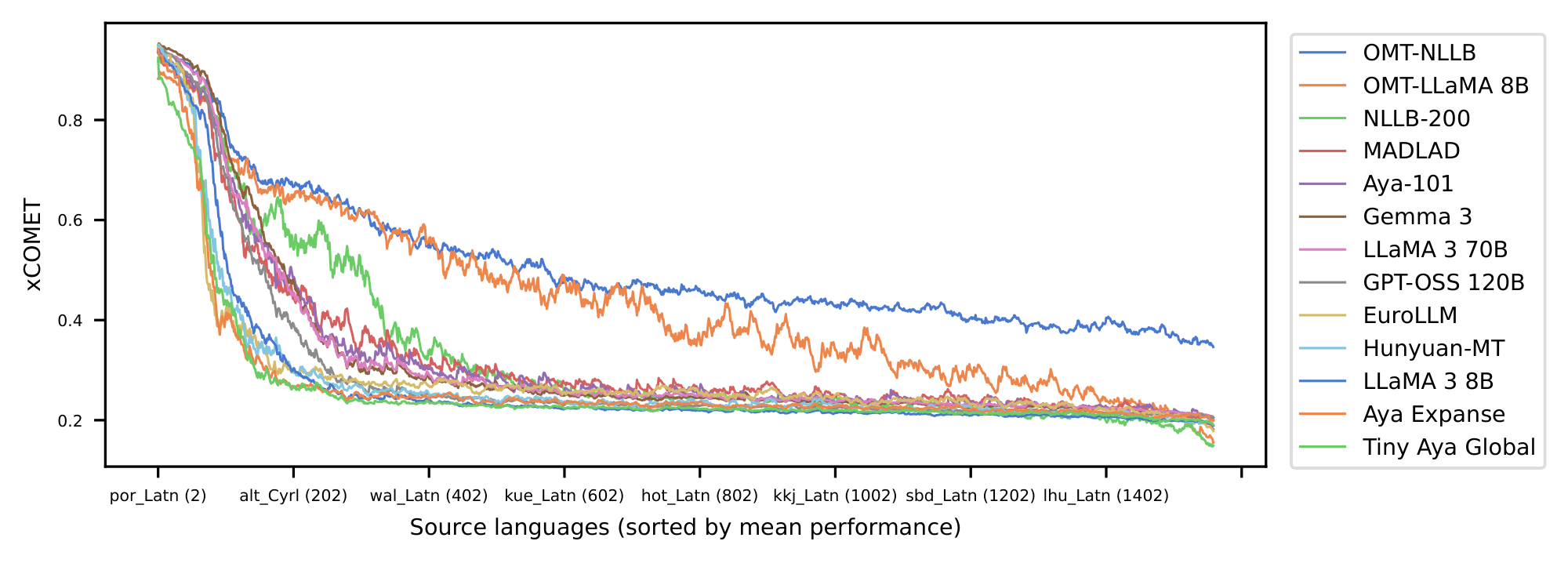
Figure 11: Relative performance in terms of ChrF++ (top) and XCOMET (bottom) of OMT models in understanding the longtail in the Bible domain compared to external baselines. Languages sorted by average performance of the models; curves smoothed with exponential moving average. ::::
Languages passing the quality bar on understanding the long tail
Beyond the relative performance of models in understanding hundreds of languages, we seek to determine how many languages the OMT models understand "well enough" in absolute terms. We define a passing quality threshold as an average XSTS+R+P score above 2.5. Based on the definition of XSTS+R+P scores (see Section 8.1), this roughly means that the system is capable of conveying the core meaning of a sentence in the majority of cases. We rely on MetricX (reference-based) to estimate whether a translation meets this criterion. The primary motivation for using MetricX is that it is a well-established external metric that effectively leverages both target and reference translations. Furthermore, unlike BLASER 3, it is not based on $\textsc{OmniSONAR}$, thereby avoiding potential bias toward the $\textsc{OMT-NLLB}$ model, which shares the same encoder. We apply a monotonic regression over Met- BOUQuET (restricted to the XX-En directions for direct compatibility with the Bible evaluation setup) to map between MetricX and XSTS+R+P scores (see Figure 14).
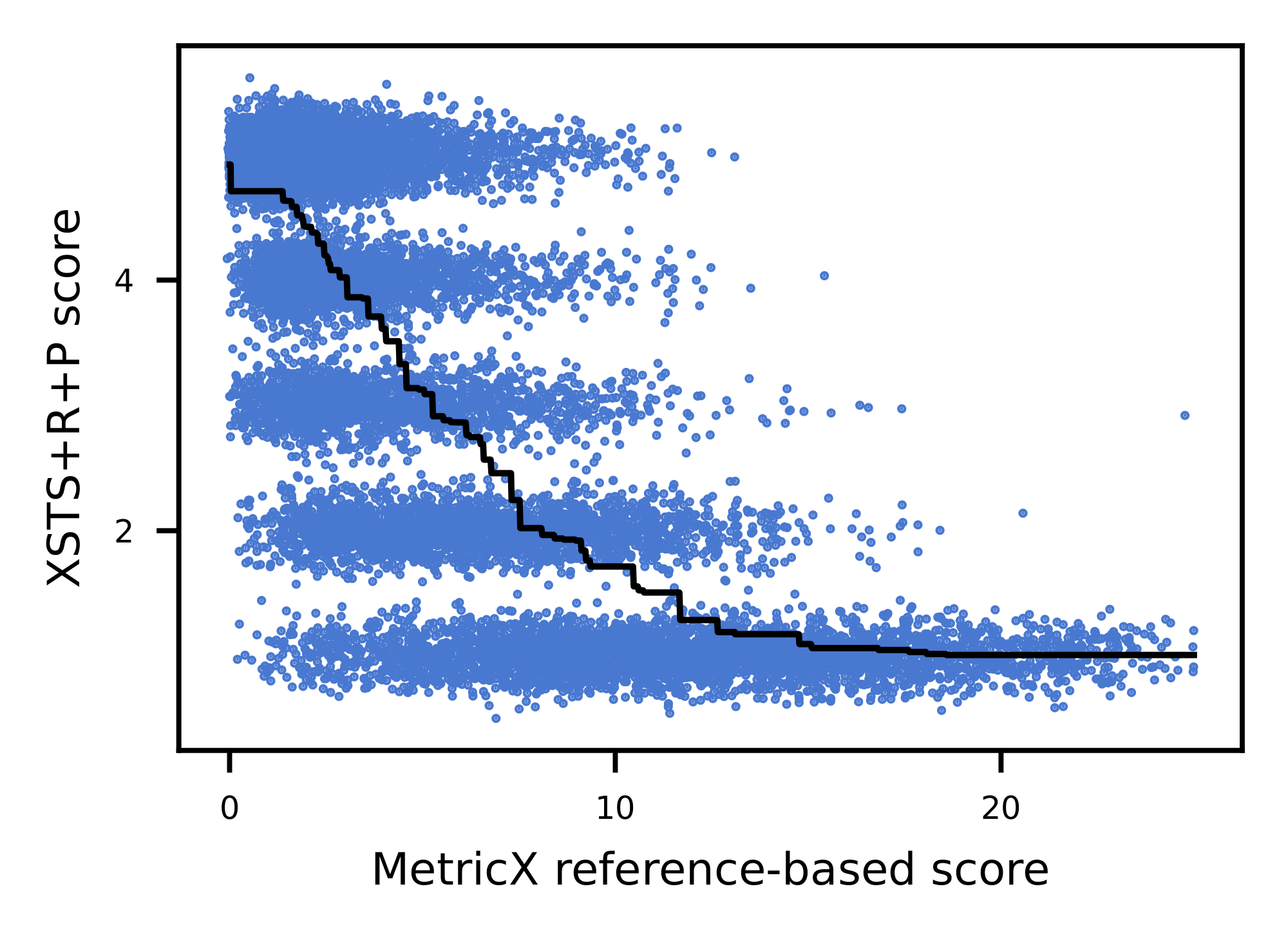
We use the Bible benchmark (comprising 1, 560 languages) to estimate the average XSTS+R+P score using the MetricX proxy for each source language translated into English. The right panel of Figure 15 presents the results of this extrapolation for $\textsc{OMT-LLaMA}$, $\textsc{OMT-NLLB}$, and NLLB-200 as a baseline. All three models cover approximately the same number of Bible languages (around 130) at the "good" quality threshold of at least 3.5 extrapolated XSTS+R+P points on average. However, the number of Bible languages for which the "passable" quality threshold of 2.5 points is exceeded is substantially larger for the OMT models: 440 languages for the $\textsc{OMT-LLaMA}$ 8B model and 416 languages for $\textsc{OMT-NLLB}$ —nearly double the 221 varieties for which NLLB-200 surpasses this threshold. We therefore conclude that, while we remain far from completely "solving" machine translation for the long tail of languages, the OMT models double the number of reasonably well-understood source languages compared to previous massively multilingual models.
Relative Performance on generating the long tail of languages
For reference evaluation, we use the Bible and translate the English part into 1, 560 languages; report ChrF++ and LID-adjusted BLASER 3, MetricX (rescaled to 0-1), and xCOMET scores. Results are shown in Figure 16.
For all baseline models and all scores, the quality becomes near-random-level at about 300-400 languages, while for OMT models, it holds for about $\approx 1, 200$ languages. On the first 150 languages (the intersection of the NLLB-200 set with Bible), the $\textsc{OMT-LLaMA}$ model sometimes underperforms compared to $\textsc{OMT-NLLB}$ and NLLB-200. However, $\textsc{OMT-NLLB}$ nearly always outperforms NLLB-200.
Some limitations of this experiment include that none of our automatic metrics are capable of adequately evaluating the grammaticality/fluency/naturalness of translations into long-tail languages, so we cannot say for sure, for how many languages our translations are “good enough”, without extensive human evaluation results (which are reported for Round 2 of Met-BOUQuET in Section 9.2). Also, we had to adjust all scores (except ChrF++) by LID, because all models tend to generate outputs in the wrong language. Finally, we admit that we did not do thorough prompt-engineering to ensure that all the long-tail target languages are correctly identified by each of the baseline models, and there might be a room for improvement by using better instructions and/or few-shot examples with the baseline models.
:::: {cols="1"}
Figure 16: Relative performance in terms of ChrF++ (top) and LID-adjusted BLASER 3 (bottom) of OMT models in generating the longtail in the Bible domain compared to external baselines. ::::
9.1.4 Comparing across model sizes and architectures
Size vs performance
Given that Omnilingual MT models come in different sizes, it is interesting to explore the size-performance tradeoff. Figure 19 displays the interaction of model size (in billions of parameters) and translation quality (ChrF++) on the BOUQuET dataset (all resource levels, translation into and from Englihs) for $\textsc{OMT-LLaMA}$ and for several other open model families. Across all size categories, the OMT models are outperforming the baseline models of the corresponding size.
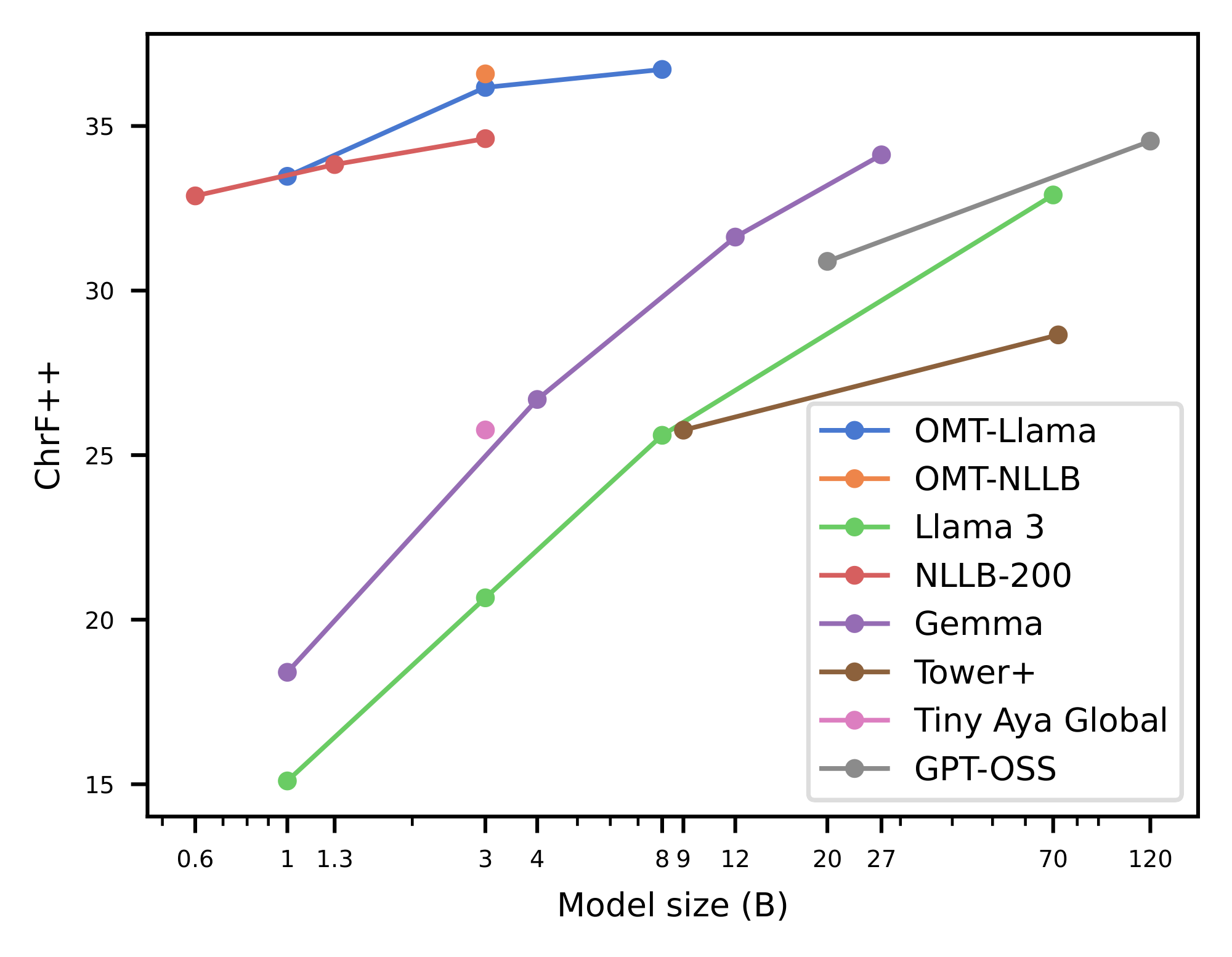
$\textsc{OMT-LLaMA}$ downscaling effect on languages
To see which languages contribute most to the differences in $\textsc{OMT-LLaMA}$ generation and understanding at three different model scales, we plot the per-language LID-adjusted BLASER 3 performance in Figure 20. The results look qualitatively similar for XX-En and En-YY directions. The 1B model slightly underperforms compared to the larger variants for most languages, but especially for the hardest ones, perhaps because the smaller number of parameters prevents it from learning as efficiently from very low-resourced data or from generalizing to languages never seen in the traning data.
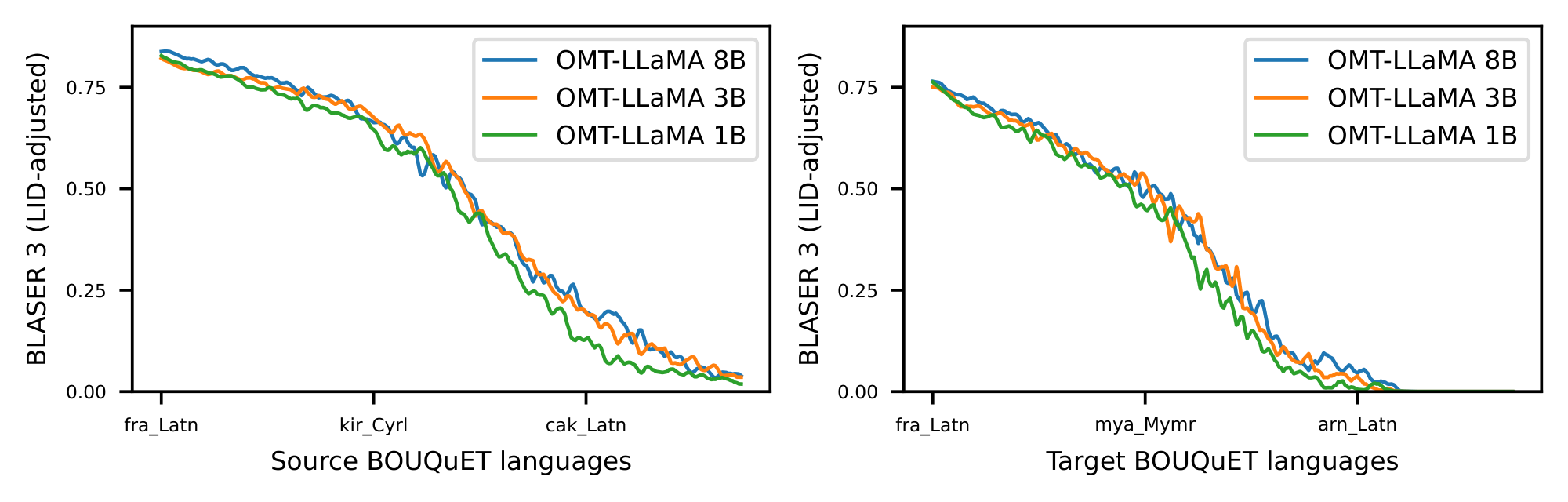
$\textsc{OMT-LLaMA}$ vs $\textsc{OMT-NLLB}$
These models share several key characteristics, including language coverage, massively multilingual tokenization, training data, extensibility, and a common LLaMA 3 backbone. However, they differ in certain respects, as detailed in Table 27. Most notably, $\textsc{OMT-LLaMA}$ models have been instruction-finetuned and therefore are compatible with diverse translation instructions, such as using few-shot prompts, either static or retrieved from a database based on the source text. The $\textsc{OMT-NLLB}$ model has not been trained to support any instructions apart from basic translation, although in principle it can be fine-tuned this way.
::: {caption="Table 27: List of features comparing $\textsc{OMT-LLaMA}$ vs $\textsc{OMT-NLLB}$ models presented in this paper."}

:::
As demonstrated in the previous subsections, the Omnilingual MT models also exhibit variation in relative performance across the translation directions they support. On the input side, $\textsc{OMT-NLLB}$ is the best model when it comes to translating from low- and zero-resourced languages, whereas $\textsc{OMT-LLaMA}$ seems to be competitive for translation from more high-resourced ones. On the output side, the trend is opposite: $\textsc{OMT-NLLB}$ is capable of generating "only" 250 languages, compared to over 1000 languages with $\textsc{OMT-LLaMA}$, but for many high- and mid-resourced languages, its generation quality is superior.
Further experimental evidence would be required to identify the main factors driving the difference in performance between $\textsc{OMT-LLaMA}$ and $\textsc{OMT-NLLB}$ on the set of translation directions that they both support. Those differences might stem from the architecture (separating the encoder and decoder modules seems to benefit cross-lingual generalization on the input side), the training tasks (with language modeling as a secondary task for $\textsc{OMT-LLaMA}$ and reconstruction, for $\textsc{OMT-NLLB}$, inducing different competences), the composition of the training data (more imbalanced across languages for $\textsc{OMT-LLaMA}$ than for $\textsc{OMT-NLLB}$), or even simply the "intensity" of training (how much the language competences are retained from the base model or acquired during continual training) — or a combination of these factors. In future research, a more principled set of experiments could shed more light on the effects of each of these choices.
9.2 Human Evaluation
Our human evaluation analysis corresponds to the Met-BOUQuET Round 2 annotations. Details of the data and systems evaluated are in Section 8.2 when describing Round 2. In short, we compare a variety of $\textsc{OMT-LLaMA}$ systems to the strongest baseline in terms of automatic evaluation in the test partition of BOUQuET. The set of languages is given in Table 50 specified as Met-BOUQuET r2 and the annotation protocol is XSTS+R+P described in Section 8.1.
::: {caption="Table 28: Average results of Met-BOUQuET Round 2 annotations: $\textsc{OMT-LLaMA}$ win rate, $\textsc{OMT-LLaMA}$ and baseline mean score and number of directions for each. "Win rate" is defined as the proportion of directions with the average scores for $\textsc{OMT-LLaMA}$ higher than for the baseline system."}
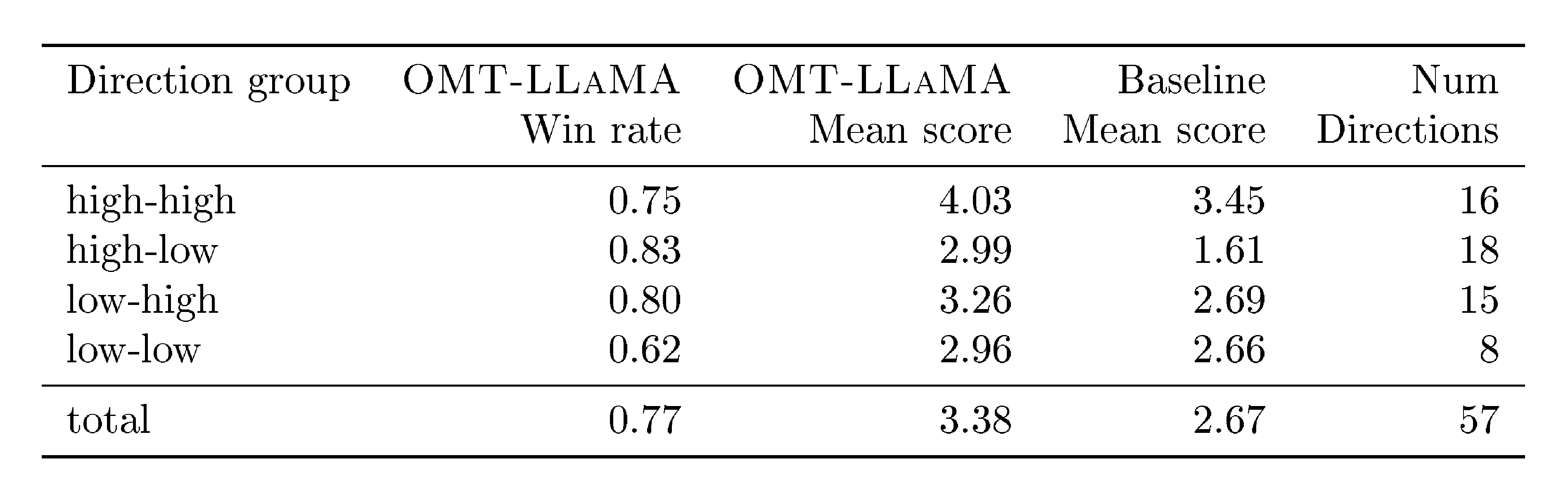
:::
The currently available annotation results cover 57 directions composed of 80 unique language varieties. Of these 57 directions, in 44 (77%), the $\textsc{OMT-LLaMA}$ system outperforms the baseline, according to the mean XSTS+R+P score. Figure 21 and Table 28 report these results, aggregated by translation direction resource levels (with "high" standing for high- and mid-resource languages, i.e. the ones with at least 1M of primary parallel sentences, and "low" standing for low- and very-low-resource languages).
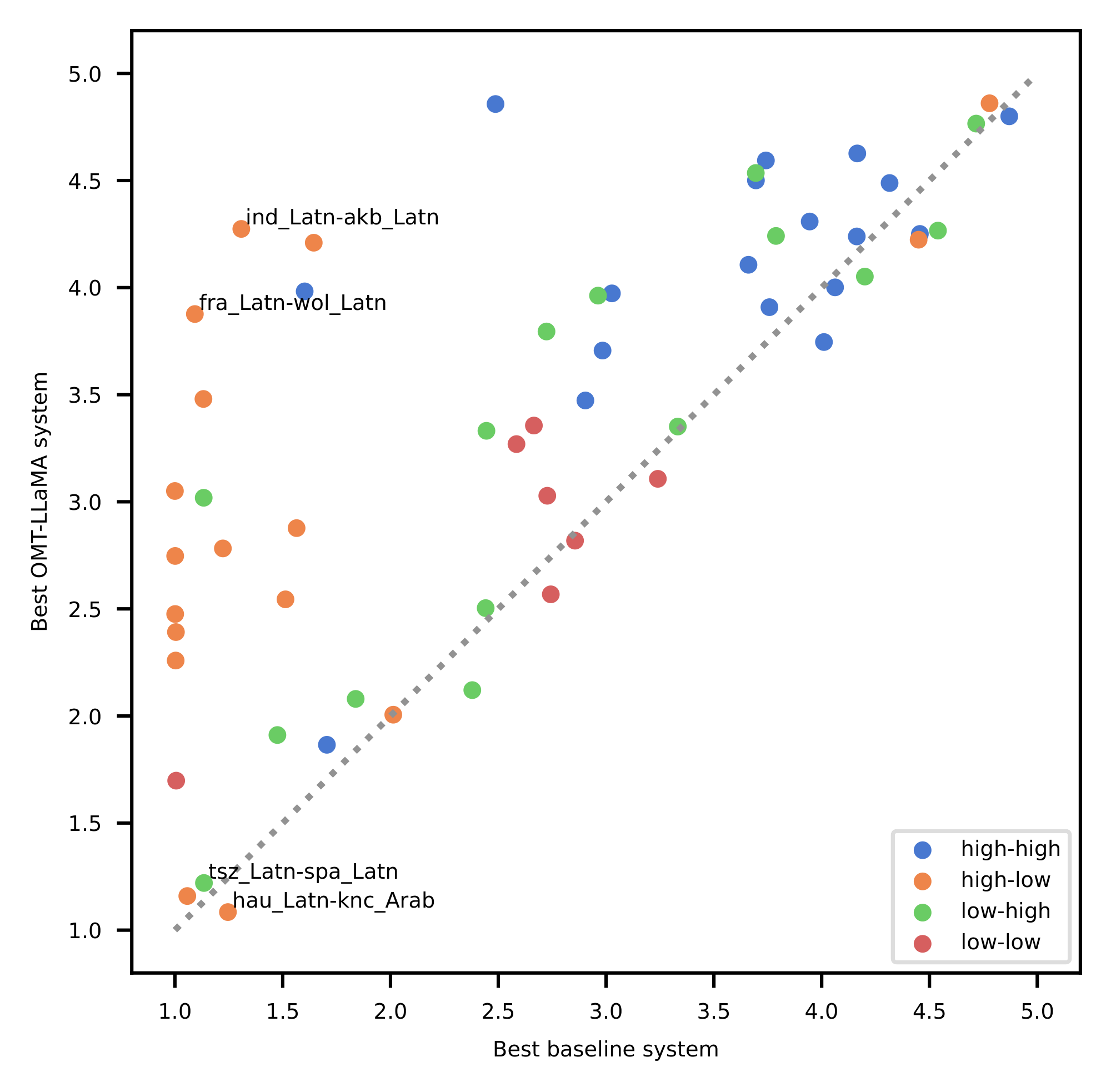
The largest improvements of $\textsc{OMT-LLaMA}$ over the baseline systems, in agreement with the automatic evaluation results, are observed when translating from higher-resourced to lower-resourced languages: while the baseline systems often struggle to produce meaningful translations, OMT models generate a significant proportion of least moderate-quality translations. But overall, $\textsc{OMT-LLaMA}$ is outperforming the baselines in each group of directions, and in no directions it lags behind the baseline by more than 0.3 XSTS+R+P points on average.
The three directions where both $\textsc{OMT-LLaMA}$ and the baseline systems produce the majority of minimal scores are Hausa to Central Kanuri (Arabic script), Spanish to Tzotzil, and Purepecha to Spanish. Some directions with the largest Omnilingual MT gains include Indonesian to Batak Angkola, between French and Wolof, and Spanish to Alacatlatzala Mixtec.
Overall, this manual annotation campaign demonstrates the significant progress that Omnilingual MT made in challenging language pairs but shows that much more progress is yet to follow: the evolution from the average score from 2.67 (baseline) to 3.38 (OMT) represents a qualitative jump from "useless" to "useful" for many of the directions, but it is only halfway to the "really good" score of 4 and the "perfect" score of 5.
9.3 Added Toxicity Automatic Evaluation
Added toxicity definition and experimental framework
Using OmniTOX, we benchmark $\textsc{OMT-LLaMA}$ and $\textsc{OMT-NLLB}$ for added toxicity comparing against Gemma-3-27B and NLLB-200-3B as baselines. We define added toxicity as the increase in toxicity between the source text and its translation, quantified through the difference in OmniTOX logits.
Language debiasing
To mitigate inherent language-level biases in the classifier, we establish per-language baselines using the BOUQuET dataset, which contains professionally crafted, non-toxic sentences across a comprehensive set of languages. For each language l, we compute the mean logit $\mu_l = \mathbb{E}[z \mid \text{language} = l]$ from both source and target texts in BOUQuET. Each raw logit z is then debiased as $z_{\text{debiased}} = z - \mu_l$.
Added toxicity computation
For a translation pair, added toxicity ($\Delta)$ is computed as the difference between debiased logits:
$ \Delta = z_{\text{tgt}}^{\text{debiased}} - z_{\text{src}}^{\text{debiased}} $
where $z_{\text{src}}^{\text{debiased}}$ and $z_{\text{tgt}}^{\text{debiased}}$ are the debiased logits for the source and target texts, respectively. When either language lacks a baseline (i.e., is not represented in BOUQuET), we use raw logits for both source and target to ensure consistent comparisons.
Threshold calibration
We calibrate flagging thresholds using BOUQuET to achieve an approximate 5% False Positive Rate (FPR). Specifically, we compute the 95th percentile of the $\Delta$ distribution. To account for variation across translation directions, we compute per-direction thresholds $\tau_{l_s \rightarrow l_t}$ for each direction available in BOUQuET. For the other directions, we fall back to a global threshold $\tau_{\text{global}}$ computed across all BOUQuET translation pairs.
Flagging criterion
A translation is flagged for added toxicity if it satisfies two conditions:
$ \Delta > \tau \quad \text{and} \quad p_{\text{tgt}} > 0.20 $
where $\tau$ is the per-direction threshold $\tau_{l_s \rightarrow l_t}$ when available, or the global threshold $\tau_{\text{global}}$ otherwise. The probability constraint ($p_{\text{tgt}} = \sigma(z_{\text{tgt}}) > 0.20)$ filters out false positives arising from minor fluctuations at low toxicity levels, where small logit changes can produce disproportionately large relative differences.
Results
Table 29 shows the average added toxicity and flagging rates across 207 languages available in BOUQuET at the time of this experiment. Overall, none of the evaluated systems exhibit meaningful added toxicity, with flagging rates remaining below 1.5% across all configurations. This suggests that both our systems and the external baselines reliably preserve the toxicity profile of source texts during translation. Note that similarly to FLoRes+, BOUQuET may be limited for triggering added toxicity, and in the future, we can consider using more adequate datasets e.g. ([143]).
We observe a directional asymmetry that correlates with model architecture. Encoder-decoder models (NLLB-200-3B and $\textsc{OMT-NLLB}$) show slightly higher added toxicity for X $\rightarrow$ Eng translations, whereas decoder-only LLMs (Gemma-3-27B and $\textsc{OMT-LLaMA}$) exhibit the opposite pattern, with marginally higher values for Eng $\rightarrow X$. While the absolute differences are small, this consistency across architectures suggests a systematic effect that may warrant further investigation.
::: {caption="Table 29: Average Added Toxicity and Flagging Rate (%) on BOUQuET dataset for 207 languages."}
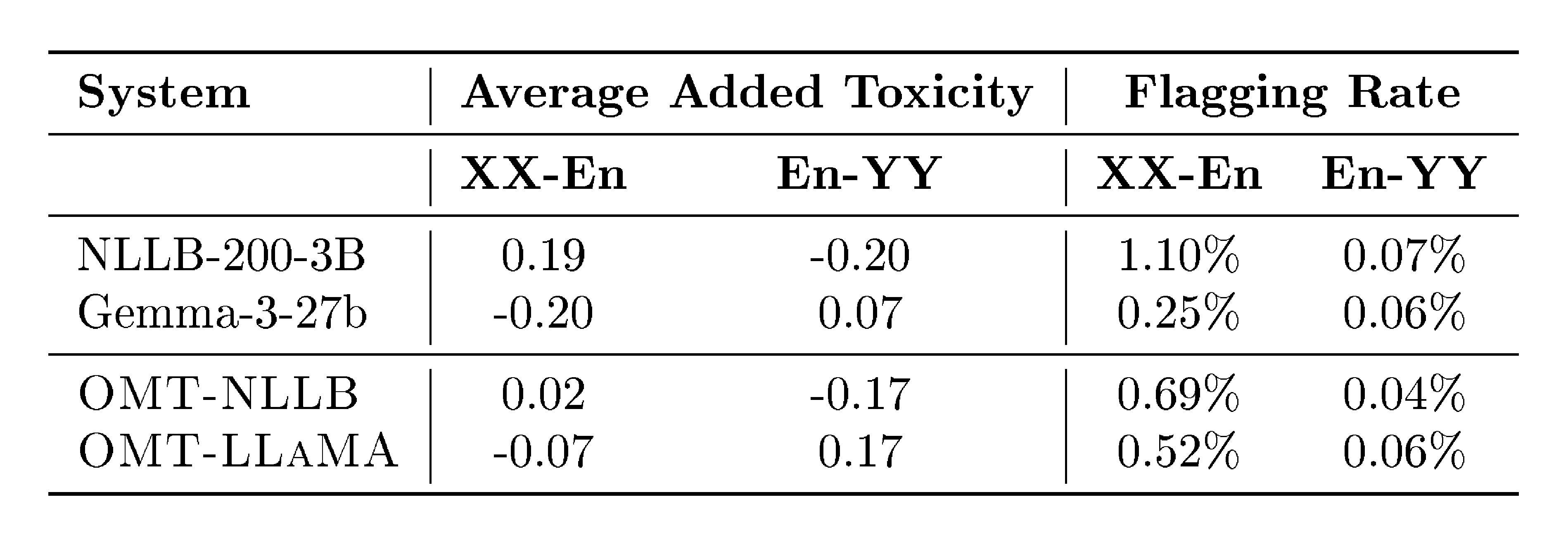
:::
10. Extensibility of $\textsc{OMT-LLaMA}$
Section Summary: Researchers exploring the OMT-LLaMA AI model, designed for translating many languages, tested ways to improve its performance on 25 challenging, low-resource languages by using targeted training data through fine-tuning or retrieval-augmented generation, a method that pulls in relevant examples during translation. Fine-tuning boosted translations from English into these languages but sometimes weakened the reverse, while retrieval-augmented generation consistently enhanced both directions, especially when combined with fine-tuning. Overall, these approaches complement each other, with the pre-trained OMT-LLaMA outperforming a basic language model even after adaptations, making it ideal for customizing translations for specific language pairs.
Motivation
An omnilingual model, by definition, intends to provide support for any language. In many practical use cases, however, MT models are applied to a limited subset of language pairs and optimized for improved translation quality for that subset. In this section, we select several difficult languages and explore how the $\textsc{OMT-LLaMA}$ models could be extended for their improved support using additional data. We consider two approaches of feeding this focused data to models: via fine-tuning (already described in Section 6.3.1) and through retrieval-augmented translation (explored in Section 6.4).
Languages
For extension experiments, we selected the languages among those for which the $\textsc{OMT-LLaMA}$ model demonstrated low performance on BOUQuET (mostly low- and very-low-resourced ones), either in understanding or in generation, with the additional criterion of being included in the version of MeDLEy available at the time of the experiment.[^39] In addition, we selected 5 mid-resourced moderately difficult BOUQuET languages[^40]. We tune the systems of this section for translation of these 25 languages into and out of English.
[^39]: These languages are azb_Arab, bam_Latn, dik_Latn, fuv_Latn, kam_Latn, kmb_Latn, lug_Latn, mam_Latn, miq_Latn, mos_Latn, pcm_Latn, sba_Latn, shn_Mymr, tsz_Latn, tzh_Latn, umb_Latn, vmw_Latn, wol_Latn, yor_Latn, yua_Latn.
[^40]: gaz_Latn, lin_Latn, mya_Mymr, swh_Latn, tir_Ethi
Data
For the selected 25 languages, for both fine-tuning and retrieval, we use a subset of primary (non-synthetic) parallel data already described in Section 4.1. The number of parallel examples (mostly sentences, but also words in case of Panlex and paragraphs in case of MeDLEy) per language ranges from 300K (Swahili) to 11K (Ngambay). Note that because a large part of the data comes from massively parallel sources (such as the Bible or MeDLEy), the same English texts often appear multiple times in it, paired with different languages.
Experimental setup
We use the above data for addapting models to translation of specific languages in two ways: via fine-tuning and via retrieval-augmented translation. We compare two models as the base model for fine-tuning and direct translation:
- LLaMA-base: the original LLaMA 3.1 8B Instruct model without any modifications;
- $\textsc{OMT-LLaMA}$: the 8B version of $\textsc{OMT-LLaMA}$ that underwent the standard Omnilingual MT continual pretraining (as described in Section 6.2) and then was fine-tuned only with the $\textsc{OMT-base-FTdata}$ dataset (which does not include the low-resourced languages) to isolate the effect of massively multilingual fine-tuning data.
For all the baselines and the models fine-tuned in this section, we evaluate retrieval-augmented translation as well as standard translation with the minimalistic prompt. We report ChrF++ and LID-augmented BLASER 3 scores on the BOUQuET dataset (sentence-level part).
::: {caption="Table 30: Results of extending the $\textsc{OMT-LLaMA}$ and LLaMA-base models via focused fine-tuning, retrieval augmentation, or both. Reported on the dev split of BOUQuET, for 20 hard languages and 5 mid-resourced languages."}
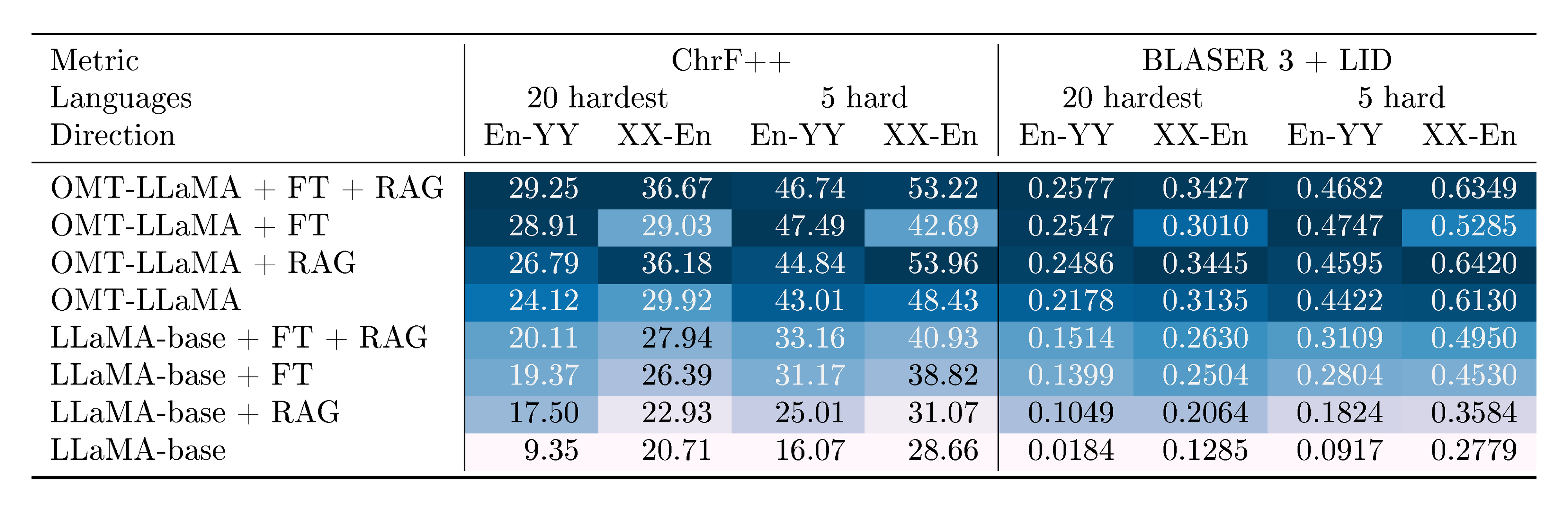
:::
Fine-tuning
As a base fine-tuning experiment, we mix the parallel data described above (all 25 languages from and into English) with $\textsc{OMT-base-FTdata}$ (in equal proportion) and fine-tune each of the three baseline models with the same hyperparameters as in Section 6.3.1. As Table 30 shows, fine-tuning on average improves out-of-English results, but is detrimental for into-English translation. We hypothesize that it is the same effect as observed in the SMOL paper ([10]), with the model degenerating after training on repetitive English outputs.
RAG
We use a simplified version of the retrieval algorithm described in Section 6.4, with TF-IDF matching of words only (without extra retrieval with embeddings or on-the-fly mining). As Table 30 shows, RAG almost always leads to improvement both of the baseline model and of the fine-tuned models (despite the latter have been exposed to the same data during fine-tuning), with the only exception of translation into the 5 mid-resourced languages.
Comparison with LLaMA-base
The results of applying focused fine-tuning and RAG to the base LLaMA 3 model are mostly qualitatively similar to those obtained for $\textsc{OMT-LLaMA}$: finetuning is crucial for reaching good En-YY translation, whereas RAG is sufficient for reaping a large part of the improvements in XX-En results, and the positive effects of these two techniques add up. One difference between LLaMA-base and $\textsc{OMT-LLaMA}$ is that the former doesn't exhibit the negative effects of fine-tuning on XX-En translation, maybe simply because of the low base effect. But, crucially, even after applying a combination of instruction fine-tuning and RAG translation, the base LLaMA model does not outperform the unadapted $\textsc{OMT-LLaMA}$ model, highlighting that $\textsc{OMT-LLaMA}$ is a strongly preferable base model for adaptation into a translation model specialized on certain language pairs.
Conclusions
Both fine-tuning and RAG, when applied to a focused set of languages, yield improved translation performance, enabling targeted customization of the $\textsc{OMT-LLaMA}$ model. The two techniques are complementary: fine-tuning is particularly effective for translation into challenging languages, while RAG is essential for enhancing translation quality from these languages.
11. Conclusion
Section Summary: Omnilingual machine translation reimagines how translation systems are designed, trained, and tested to cover over a thousand languages, using innovative data strategies that blend vast public resources with new ones like MeDLEy and BOUQuET to fill gaps in underrepresented languages, varieties, and topics. The models, including efficient decoder-only and encoder-decoder versions, deliver strong improvements in translation quality for well-supported languages and provide the first reliable systems for hundreds of emerging ones, while smaller models outperform much larger language models in low-resource settings. Ultimately, this work highlights the need for early focus on multilingual data and training to enable true inclusivity, offers public tools for further research, and inspires ongoing innovations in translation, language models, and speech systems.
Omnilingual MT demonstrates that scaling multilingual translation is not simply a matter of increasing the number of supported languages, but of rethinking how MT systems are built, trained, and evaluated. Expanding from 200 to more than one thousand languages required coordinated advances across every layer of the pipeline. Our data strategy — combining massive public corpora with newly created resources such as MeDLEy and BOUQuET bitext, deliberate data creation targeting linguistic varieties, domains, and registers that existing corpora overlook—allows us to improve translation generation quality and more meaningfully evaluate long-tail coverage. Our modeling strategy — based on pretrained language models with extended tokenizer vocabulary — encompassed 2 distinct architectures. Our decoder-only models ($\textsc{OMT-LLaMA}$) introduce only minimal changes to the architecture and training scheme of standard language models that are necessary to support over a thousand languages. Our encoder-decoder ($\textsc{OMT-NLLB}$) model introduces a novel three-stage training strategy that effectively exploits non-parallel data to achieve substantial quality improvements.
Omnilingual MT models deliver strong, consistent gains for broad-coverage languages, and provides the first non-trivial MT for hundreds of emerging-support languages where no usable systems previously existed. Our evaluation efforts further show that our 1B to 8B parameter specialized MT models can match or exceed the MT performance of a 70B LLM, offering a clear Pareto improvement and enabling high-quality translation in low-compute real-world settings. Our English-to- 1, 600 evaluation additionally reveals a consistent failure mode in existing systems: while many models can interpret undersupported languages, they frequently cannot generate them with meaningful fidelity. Omnilingual MT dramatically improves in cross-lingual transfer, being close to solving the "understanding" part of the puzzle in MT; and it substantially expands the set of languages for which coherent generation is feasible, underscoring the central bottleneck for genuine large-scale language coverage: robust generation in under-resourced languages. We also show that targeted techniques such as finetuning and retrieval-augmented generation can yield further quality improvements in our models when additional data in the languages and domains of interest is available.
Our experiments show that post-training techniques targeting multilingual extension of models do not compensate the lack of large improvements obtained by embracing massively multilingual training data and vocabulary in the earlier stages of training. Therefore, our findings should motivate model researchers and developers interested in boosting multilingual tasks performance to gather high-quality massively multilingual data and train models that are highly multilingual by design and are well equipped to extend their support to any additional language, if necessary.
Taken together, Omnilingual MT positions large-scale inclusion as an ongoing technical and scientific challenge — one that demands continued investment in data creation, architecture design, evaluation methodology, and under-resourced-language generation capabilities. By pairing broad coverage with efficient specialization and flexible avenues for improvement, Omnilingual MT provides inspiration for future research and applications across translation, multilingual LLM development, and speech-to-text systems. Ultimately, setting a baseline for 1, 600 languages is therefore not a terminus but an encouragement to sustained innovation in pursuit of genuinely inclusive language technology.
Our key dataset for massively multilingual evaluation of machine translation, BOUQuET (including its Met- BOUQuET extension with human judgments of translation quality) is publicly available, enabling researchers from anywhere to reproduce our evaluation results. Moreover, we hope that our MeDLEy detailed guidelines can be used to create more high-quality and diverse data. Finally, we encourage the scientific community to use our $\textsc{OMT-LLaMA}$, $\textsc{OMT-NLLB}$, BLASER 3 and OmniTOX recipes to develop and release yet other radically inclusive foundational models for machine translation, evaluation, and general-purpose massively multilingual language processing.
12. Contribution Statements
Section Summary: This section acknowledges the dedicated contributions of the Omnilingual MT team, fueled by a deep passion for multilingual technology, though words can't fully capture their emotional commitment. It highlights roles across key areas: data efforts led by individuals like Niyati Bafna on the MeDLEy dataset and Holger Schwenk on large-scale mining; modeling advancements driven by Belen Alastruey on the OMT-NLLB system and others on training, scaling, and post-training experiments; evaluation work including quality checks by Arina Turkatenko and tool development by Mark Duppenthaler for datasets like BOUQuET. Project management and technical leadership were overseen by figures such as Mary Williamson for strategy and co-leads David Dale and Marta R. Costa-jussà for overall direction and engineering coordination.
We outline the contributions of each member of Omnilingual MT. However, there are no possible words to describe the emotional dedication stemming from the multilingual passion that characterizes this team.
Data
Niyati Bafna - designed and led efforts on MeDLEy
Andrea Caciolai - led experiments on backtranslation, contributed to the creation of MeDLEy and led its experiments, supported $\textsc{OMT-NLLB}$ data curation
Jean Maillard - managed linguistic partnerships and community engagement, coordinating with language communities and external organizations
Holger Schwenk - inspired large scale data mining
Modeling
Belen Alastruey - led, designed and drove efforts for $\textsc{OMT-NLLB}$
Pere Lluís Huguet Cabot, João Maria Janeiro - contributed to the training of $\textsc{OMT-NLLB}$
Paul-Ambroise Duquenne - contributed to the technical supervision of $\textsc{OMT-NLLB}$
Kevin Heffernan - drove CPT experiments, parallel mining, contributed to model scaling, vocabulary extension
Artyom Kozhevnikov - drove retrieval-augmented translation experiments
Eduardo Sánchez - designed and drove efforts on $\textsc{OMT-LLaMA}$ post-training
Edan Toledo - contributed to post-training experiments, implementing the RL stage
Ioannis Tsiamas - spearheaded the development of BLASER 3 and engineered data pipelines for CPT
Evaluation
Chierh Cheng, Joe Chuang, Gabriel Mejia Gonzalez - insured the quality of manual translations and annotations
Mark Duppenthaler - developed the online BOUQuET collection tool
Nate Ekberg, Cynthia Gao - drove relationships with language service providers
Christophe Ropers - led the linguistic team and data creation efforts across MeDLEy, BOUQuET, Met- BOUQuET and XSTS+R+P
Charles-Eric Saint-James - developed OmniTOX and added toxicity analysis, built data pipelines and ran data validation for Met-BOUQuET
Arina Turkatenko - led extensive analysis on the quality of manual translations and annotations
Albert Ventayol-Boada - led linguistic efforts and feature retention analysis in MeDLEy, led language selection across projects, and contributed to translation quality and error analyses
Project management
Rashel Moritz - Technical Program Manager, coordinated the Language Technology Partnership Program
Alexandre Mourachko - Research Manager, helped with the overall direction, strategy and resourcing plan and supported data efforts
Surya Parimi - Technical Program Manager, supported data efforts
Shireen Yates - Product Manager, helped with the overall direction and strategy
Mary Williamson - Research director, helped with overall direction and strategy
Technical leadership
David Dale - co-technical lead, devised the continual pretraining framework, led the direction of the family of models strategy, coordinated engineering efforts across the team
Marta R. Costa-jussà - co-technical lead, led the overall direction for evaluation, main driver on BOUQuET, Met- BOUQuET, BLASER 3, OmniTOX, XSTS+R+P
Acknowledgements
Section Summary: The authors express gratitude to Mikel Artetxe for his ongoing support and collaboration in brainstorming ideas for the model's development, to Sebastian Ruder for his helpful feedback on early versions of the paper, and to Anaelia Ovalle for engaging discussions and help with experiments exploring ways to enhance the model with more autonomous features. They also thank Luke Zettlemoyer for his advice on the overall project direction. Finally, they appreciate the contributions and enthusiasm from participants in the Language Technology Partnership Program's workshops, as well as those involved in the BOUQuET open-source initiative.
We extend our thanks to Mikel Artetxe for his continued support and partnering while brainstorming modeling directions. We thank Sebastian Ruder for his feedback on early drafts of the paper. We thank Anaelia Ovalle for the discussions and her involvement on exploration experiments on agentic extensions of the model. We thank Luke Zettlemoyer for his guidance and feedback on the project strategy. Finally, we thank all the participants of the Language Technology Partnership Program, for their contributions and keen interest in our workshops as well as the contributors to the BOUQuET open-initiative.
Appendix
Section Summary: MeDLEy is a diverse collection of parallel texts designed to cover various subjects and grammatical structures across many languages, making it easy for non-experts to add more languages through simple translations. The creation process starts with listing key grammatical features and selecting domains like conversations, stories, and instructions, then uses templates to generate natural paragraphs in five source languages, which are translated step-by-step into eight pivot languages and finally into 109 low-resource languages by professionals. This involved two batches of data production, refining features from 61 across 18 categories to ensure they work well in different contexts, with random combinations in templates to promote variety while avoiding awkward mixes.
A. MeDLEy details
A.1 More details on the approach
The goal of MeDLEy is to provide a bitext corpus that is domain-diverse and grammatically diverse in a large number of included languages. Further, we would like for lay people of various language communities to be able to extend the dataset to their native language in the future via simple translation, while maintaining this property. Our approach therefore does not rely on linguistic expertise in specific target languages. Instead, we formulate a framework of grammatical diversity which is transferrable via translation (cf. Section 4.3.2), and craft MeDLEy-source with domain and grammatical diversity in mind. Here are the steps involved in creating MeDLEy, as depicted in Figure 3.
- Feature enumeration We curate a list of broad grammatical categories of interest, with associated features per category. Features are chosen to be representative of known cross-linguistic grammatical phenomena. See the list of features in Appendix A.3.
- 2a. Domain selection We choose the following 5 domains: informative, dialogue, casual, narrative, and instruction-response. Notably, we include data in the style of user instructions and large language model (LLM) responses, given the increasing practice of and need for translating instruction fine-tuning datasets into LRLs in the era of LLMs ([144, 15]).
- 2b. Source language selection We choose 5 source languages, in which paragraphs are crafted: English, Mandarin, Russian, Spanish, and German, based on team's linguistic proficiency.
- 2c. Template generation We create linguistic templates, consisting of constrained combinations of grammatical features and a domain for each paragraph. We assign each template to a source language uniformly at random.
- 3a. Creation of grammatically-diverse, domain-diverse source paragraphs, with accompanying context Expert native speaker linguists craft source paragraphs given the set of templates assigned to each source language, within the associated domain for a template, and exhibiting the listed grammatical features. We prioritize naturalness, and avoid highly specialized or technical jargon for the sake of accessibility. This results in a set of multi-centric, domain-diverse, easy-to-translate, and grammatically diverse source paragraphs. Each source paragraph is accompanied by notes regarding its context, which may provide additional relevant information. Notes may specify the gender or age of the referents involved, or the surrounding context of a conversation, since these may become relevant for translations into some languages.
- 3b. Quality checks and iteration We check the created paragraphs for naturalness and the feasibility of including various features, and iterate on the feature list and annotation instructions. The process is repeated with the refined guidelines.
- 4a. Pivot selection We select 8 pivot languages: English, Mandarin, Hindi, Indonesian, Modern Standard Arabic, Swahili, Spanish, and French. This selection was done with the goal of covering common L2 languages spoken by LRL communities around the world, and as per the availability of professional translators in these languages.
- 4b. N-way parallelization The source paragraphs, including context notes, created in the 5 source languages are then manually n-way parallellized across the 8 pivot languages. This is done in two stages: firstly, all source paragraphs are translated into English. The resulting English dataset is then translated into all the pivot languages. Additionally, the contextual information is transcreated into all the pivot languages (e.g., information about grammatical gender of participants is added or removed based how readily available it is in the pivot translation). This forms MeDLEy-source.
- 5a. Selection of LRL target languages We then select 109 LRL target languages, based on availability of professional translators, previous coverage in open source initiatives, and language family representativeness. See the list of languages pertaining to MeDLEy in Table 50.
- 5b. Translation into LRLs Finally, we commissioned professional translations of MeDLEy-source into the above LRLs. Translators worked out of the pivot language of their choice. This results in grammatical diverse bitext in our target languages. See guidelines and annotator details for creation and translation in Appendix A.4 and Appendix A.5.
A.2 More details on data creation
Data creation was done in two major batches of 254 and 352 paragraphs respectively, with procedural refinements in Batch 2 based on feedback from linguists from Batch 1 creation process.
Feature enumeration
As per Section 4.3.2, we are interested in common cross-linguistic grammatical features. Each feature is associated with a meaning that can be cued in any language, regardless of its typology. We chose 18 grammatical categories and 61 features across them. Of these, 2 features were dropped in Batch 2 due to lack of generalized transfer in translation. See Table 31 for a list of features and associated functions.
Template generation
Each template consists of a random combination of k features such that each feature occurs at least N=45 times over all templates. Each feature category may be represented at most twice in a single template. Each template is then assigned a domain, a source language, and a number of sentences between 2-5, uniformly at random. The number of sentences per paragraph is to ensure variation in the length of paragraphs and avoid length artifacts.
We received feedback about the low compatibility of some features with certain domains for Batch 1, so we added constraints to disallow such combinations for Batch 2. E.g., we disallowed dialogue-relevant features such as Inclusive/exclusive distinction for templates with narrative, informative, or literary domain. We also decreased the maximum number of times a feature could appear in a template from 2 to 1. Finally, while k was set to 5 for Batch 1, we reduced it to 4 for Batch 2, to increase the ease of creation of naturalistic paragraphs for the linguists.
Sentence-level alignments
We did not require the translators to provide one-to-one sentence translations in order to preserve naturalness of the document-level translations. However, some translation models may require aligned sentence pairs to train. Therefore, we segment the paragraphs into sentences and align them across languages automatically after dataset creation, and provide this annotation alongside with other metadata for optional use. See Appendix A.6 for more details.
A.3 Features
We list all the grammatical features that we use in corpus creation as described in Appendix A.1 in Table 31. Of these, middle voice and suppletion were dropped in Batch 2.
\begin{longtable}{@{}p{0.2\textwidth} p{0.3\textwidth} p{0.4\textwidth}@{}}
\midrule
\endfirsthead
\bottomrule
\endlastfoot
Case marking & Nominative case & Marks subject of a clause \\
& Accusative case & Marks patient or theme \\
& Genitive case & Marks possession \\
& Dative case & Marks recipient or experiencer \\
& Locative or spatial case & Marks location \\
& Instrumental or comitative case & Marks means, tool, or companion \\
\midrule
Number marking & Singular & Marks one entity \\
& Plural & Marks more than one entity \\
& Dual & Marks two entities \\
\midrule
Tense marking & Present tense & Marks current time relative to moment of speaking \\
& Past tense & Marks previous time relative to moment of speaking \\
& Future tense & Marks propsective time relative to moment of speaking \\
\midrule
Aspect marking & Perfective aspect & Marks completed event \\
& Imperfective or progressive aspect & Marks ongoing or incomplete event \\
& Habitual aspect & Marks repeated or customary events \\
& Perfect aspect & Marks event as complete at the time of reference \\
\midrule
Mood marking & Indicative mood & Marks statements \\
& Imperative mood & Marks commands or requests \\
& Conditional or subjunctive mood & Expresses hypotheticals or counterfactual events \\
\midrule
Evidentiality marking & Evidential marker (direct, reported, inferred) & Marks source of information \\
\midrule
Politeness \& honorifics & Formal or polite form & Marks respect or social distance \\
& Informal or casual form & Marks familiarity or solidarity \\
& Honorifics or self-humbling used & Marks status of others or self-lowering status \\
\midrule
Voice marking & Active voice & Subject is the agent, doer or experiencer \\
& Passive voice & Subject is the patient, theme or recipient \\
& Middle voice & Subject is both the agent and the patient \\
& Causative construction & Marks a causer acting on a causee to do something \\
\midrule
Valency & Impersonal & No explicit participants \\
& Intransitive & One-participant event \\
& Monotransitive used & Two-participant event \\
& Ditransitive & Three-participant event \\
& Intransitive + transitive sequence & Sequence of events involving differing valencies \\
\midrule
Negation marking & Clause-level negation & Marks a negated proposition \\
& Negative polarity item & Marks affirmation or negation in a licensing environment \\
& Double or emphatic negation present & Reinforces or intensifies negation \\
\midrule
Questions & Polar question & Elicits yes/no answers \\
& Wh-question & Elicits specific information \\
& Tag, echo or rhetorical question & Elicits agreement, clarification or does not elicit a response \\
\midrule
Subordination & Relative clause & Modifies a nominal referent \\
& Complement clause present & Modifies a verb phrase \\
& Adverbial clause present & Adds information about time, reason, condition, etc. \\
\midrule
Information structure & Topic marking present & Marks what the utterance is about \\
& Focus marking present & Marks new or contrastive information \\
\midrule
Anaphora \& coreference & Personal pronoun & Refers to an aforementioned participants in discourse \\
& Reflexive/Reciprocal pronoun & Refers to a participant acting upon itself \\
& Null subject or argument & Referent is understood by not overt \\
\midrule
Pronouns \& persons & Inclusive/exclusive distinction & Marks inclusion/exclusion of addressee in first person plural forms \\
& Deictic pronoun & Marks space and time relative to the context of the utterance and the speaker \\
& Placeholder & Syntactically-integrated filler word to denote a forgotten word or one that the speaker is unsure about \\
\midrule
Coordination & Conjunction & Joins clauses or phrases (e.g., and) \\
& Disjunction & Marks alternatives in a clause or phrase (e.g., or) \\
\midrule
Morphosyntactic constructions & Serial verb construction & Single event encoded with 2+ verbs \\
& Productive compound & Word with more than one stem which follows most common patterns of word formation \\
& Suppletion & Displays distinct roots in different grammatical environments \\
\midrule
Emphasis & Lexical intensifier (e.g., ``very'') & Marks additional emotional context to a modified entity \\
& Focus particle (e.g., ``only'', ``even'') & Marks arrowed or restricted scope \\
& Emphatic pronoun & Reinforces referent identity \\
& Cleft and pseudo-cleft & Emphasizes focus of one or more constitutents with subordination \\
& Exclamative construction & Expresses heightened emotion \\
& Repetition for emphasis & Reinforces meaning through duplication \\
& Marked word order & Highlights information structure or emphasis \\
\end{longtable}
A.4 Guidelines for linguists and translators
We crafted two sets of guidelines: one for writing the source paragraphs in various languages for MeDLEy-source, and one for the commissioned translations of MeDLEy-source into various target languages.
Guidelines for source paragraph creation
We held a session with the linguists to explain our goals and expectations for the source paragraph creation. We also provided a document explaining the same. In particular, this contained:
- Basic instructions explaining the domains, templates, and features: for each template, we asked linguists to craft a paragraph in the assigned domain that contained at least one example of each of the template features. We asked that the paragraph roughly containing the suggested number of sentences.
- We emphasized naturalness as a first priority. The linguists were allowed to drop features when including them led to unnaturalness. Similarly, it was acceptable to add sentences if required to accommodate the listed features in a natural way. This resulted in 21 dropped feature instances over all templates (of a total of 2500+ instances). 50 features are covered 45 times over the dataset, 9 features are covered between 38-44 times, and 2 features were dropped after the first batch due to poor generalizability (Appendix A.1).
- Linguists were also requested to provide any additional context (in English), including any relevant details about the text that would not be readily obvious from the content of the text itself, such as the broader context of the utterance or the genders of the mentioned human referents. This information was collected to inform text translations and consistency across several language translations.
- We also provided a checklist for additional phenomena to include across all translations. For example, we asked linguists to include at least 5 examples of lexical phenomena such as slang, acronyms, and filler words. We also asked them to include examples with human referents of various genders to avoid a gender-biased corpus. For the full checklist see Table 32.
::: {caption="Table 32: A global checklist for linguists to include over all source paragraphs for a single source language."}

:::
Guidelines for post-editors and translators
The above source paragraphs were manually translated into English by the same person that created them in the original pivot language. We then used these English translations to prepare automatic translations of all source paragraphs into each target pivot language. These translations were manually post-edited by professional translators, who also transcreated the contextual information. By "transcreated" we mean that the information was not merely translated into the target, but also adapted. The process of adaptation involves removing information that might no longer apply to the target language, as well as adding information that might be lost in the translation process.
For example, English "we" is ambiguous in English, as it can have two different readings: "you and I" (inclusive) and "I and somebody else but not you" (exclusive). Where English has one form with two meanings, Indonesian has two different forms: kita for inclusive, and kami for exclusive. If the translation makes clear what the reading is, translators were informed to delete information about inclusivity in the transcreation process. Conversely, where English has male and female third person singular pronouns (he/she), Indonesian only has one (dia). If the contextual information does not readily indicate the gender of a participant because it is obvious in the source but that information does copy over into the target, then translators were instructed to add that information in the transcreation process (e.g., "the third person singular is male"; "Sam is female"; "the character is female"). Thus, that process ensures that any translations out of target match the original text regardless of the language it was crafted in. The result is MeDLEy-source.
A.5 Annotator details
MeDLEy-source was translated into 109 target languages by professional translators. We commissioned the translations through third-party vendors, which resourced native-level speakers in our list of target low-resource languages who also had a level of proficiency in the source language equivalent to CEFR C2. Translators were able to choose the pivot language to translate from (i.e., English, French, Hindi, Indonesian, Mandarin, Russian, Spanish, and Swahili). Translators were provided instructions to pay heed to the contextual information of each paragraph, ensuring that translations were semantically adequate as well as contextually appropriate. We expressly forbade the use of AI or any automatic machine translation tools in the translation process.
Translations were checked for format and quality both on the vendor's side and by us. Checks included preservation of new lines and paragraph boundaries, digits (where applicable and sensible), emojis, quotes in reported speech, and mark-up style tags in angular brackets. Vendors were compensated at market rates.
A.6 Sentence-level annotations
By construction, MeDLEy is multiway parallel at the paragraph level, but we provide additional sentence-level segmentation aligned across all languages, so that the dataset can be viewed as parallel sentences for any pair of languages. The process of extracting this segmentation is described below.
Given a pair of aligned source (in a pivot language) and target paragraphs, we use a neural sentence boundary detector, SaT ([145]), to get character-level sentence boundary probabilities for both. To align the sentence boundaries across languages, we use SONAR-based multilingual text encoder ([146]) to extract contextualized cross-lingual representations of subword tokens. The words are not aligned across languages in a one-to-one or monotonic way, but we expect this to be the case for sentences (or sentence-like structures), so we compute a forced monotonic alignment path across the token representations of two languages using a dynamic time warping algorithm and use this alignment to compare potential locations of sentence boundaries in two languages. The token alignment algorithm chooses a strictly monotonic path (with each token aligned to at most one other token) that maximizes the sum of adjusted cosine similarities of token representations.
Concretely, let $\mathbf{X} \in \mathbb{R}^{m \times d}$ and $\mathbf{Y} \in \mathbb{R}^{n \times d}$ be the SONAR token embeddings for the source and target paragraphs, respectively, and let
$ S_{ij} ;=; \cos(\mathbf{X}_i, \mathbf{Y}_j) $
be the pairwise cosine similarity matrix. We then compute a dynamic-programming table $\mathbf{C} \in \mathbb{R}^{m \times n}$ of cumulative scores
$ C_{ij} ;=; \max\Bigl{ S_{ij} + C_{i-1, j-1}, ; C_{i-1, j}, ; C_{i, j-1} \Bigr}, $
with appropriate boundary conditions, and backtrack from (m, n) to (0, 0) to obtain an optimal monotonic alignment path
$ \mathcal{A}^{\text{src}\rightarrow\text{tgt}} ;=; \bigl{(i_k, j_k)\bigr}_{k=1}^{K}. $
We perform the same procedure in the reverse direction, using $S^\top$, to obtain
$ \mathcal{A}^{\text{tgt}\rightarrow\text{src}} ;=; \bigl{(i'_k, j'k)\bigr}{k=1}^{K'}, $
where K is the number of tokens of the source paragraph and $K'$ of the target paragraph. Then, we take the intersection $\mathcal{A} = \mathcal{A}^{\text{src}\rightarrow\text{tgt}} \cap \mathcal{A}^{\text{tgt}\rightarrow\text{src}}$ as a set of high-confidence alignment links. The resulting sparse mapping is then densified by linear interpolation to define a total, approximately monotonic mapping from source token indices to target token indices and vice versa.
On the source side, we treat SaT’s character-level probabilities as primary, with the intuition that the SaT probabilities will be more reliable for higher resource pivot languages, and detect peaks to define a set of source character boundaries, which we map to source tokens to obtain token boundaries that we project to the target side via the dense token alignment $\mathcal{A}$, yielding candidate target token boundaries.
Finally, we refine the candidate target sentence boundaries at the character level. For each projected target token boundary, we consider a small character window around the token span and generate a set of candidate split positions with high SaT probability. For each candidate, we compute a combined score
$ \text{score} ;=; \lambda_{\text{prob}} \cdot p_{\text{tgt}} ;+; \lambda_{\text{sim}} \cdot s_{\text{bi}}, $
where $\times$ is the normalized SaT boundary probability (with an additional bonus for candidates following sentence-final punctuation), and $\times$ is a bidirectional semantic similarity term that compares (i) the current source sentence to the candidate left target segment, and (ii) the remaining source text to the candidate right target segment using SONAR sentence embeddings and cosine similarity. The best-scoring candidate in each window is selected as the final target character boundary. This procedure produces a 1:1 sequence of aligned source–target sentence segments with boundaries that are jointly supported by monolingual boundary probabilities, cross-lingual token alignment, and sentence-level semantic similarity.
In post-processing, we optionally enforce length constraints by merging very short aligned sentence pairs and splitting very long ones. When the number of detected boundaries differs between source and target, we either (i) add missing boundaries on the side with fewer sentences by projecting and refining peaks from the other side, or (ii) remove the lowest-confidence boundaries on the side with more sentences, ensuring that the final alignment consists of well-formed, semantically corresponding sentence pairs.
Due to imperfections in sentence boundary detection, cross-lingual token alignment, and the intrinsic variability of human translation (e.g., sentence splits/merges or reorderings), the resulting automatic sentence alignment is not guaranteed to be perfect. To help users identify potentially mismatched or noisy pairs, we provide, for each aligned sentence pair, automatically computed diagnostic scores.
- Split confidence. For each language side, we evaluate how confident the SaT model is at the chosen sentence boundaries. For every split position, we look up the SaT boundary probability at the corresponding character and aggregate these values, reporting the mean and minimum confidence as well as the list of per-split confidences.
- Length ratios. To detect structurally implausible alignments, we compute, for each aligned sentence pair, the ratio between the longer and the shorter sentence length (in characters). From these ratios we report the mean, maximum, and the full list of per-pair ratios. Very large ratios may indicate over- or under-segmentation on one side or missing content in the translation.
- Semantic similarity. Finally, we measure semantic adequacy of each sentence pair using the same SONAR encoder. For every aligned source–target sentence pair, we compute cosine similarity between their sentence embeddings and report the list of per-pair similarities, their mean and minimum values, and a count of pairs whose similarity falls below a certain threshold (by default, 0.7). Low similarity scores highlight pairs that are likely mistranslated, misaligned, or otherwise noisy.
These validation scores are not used to modify the alignment itself, but they provide a convenient way to automatically flag questionable sentence pairs. In downstream applications, they can be used to filter out low-quality alignments (e.g., by discarding pairs with low boundary confidence, extreme length ratios, or low semantic similarity) or to prioritize them for manual inspection.
A.7 Examples from our dataset
In Table 33 we report some examples from our dataset, detailing the template used to craft the original text, the context surrounding the text, useful for accurate professional translations, the English translation, the text of the dataset entry in the translated language, and the route taken to obtain the translation, i.e. the sequence of translation steps from the original text language to the final text language.
::: {caption="Table 33: Examples from our dataset. We can see the feature template used to craft the original text, the original text itself and its language, the domain it belongs to, the english translation of the original text, the text of the dataset entry, the language it has been translated to, and the route used to obtain this translation. For instance spa_Latn $\times$ eng_Latn $\times$ ind_Latn $\times$ akb_Latn means that the text was originally created in Spanish, then translated into English, then into Indonesian, and finally into Batak."}

:::
A.8 Grammatical feature analyses
A.8.1 Feature distribution analysis
::: {caption="Table 34: Entropy over paradigm distributions over features for different datasets (bold indicates highest value per paradigm)."}
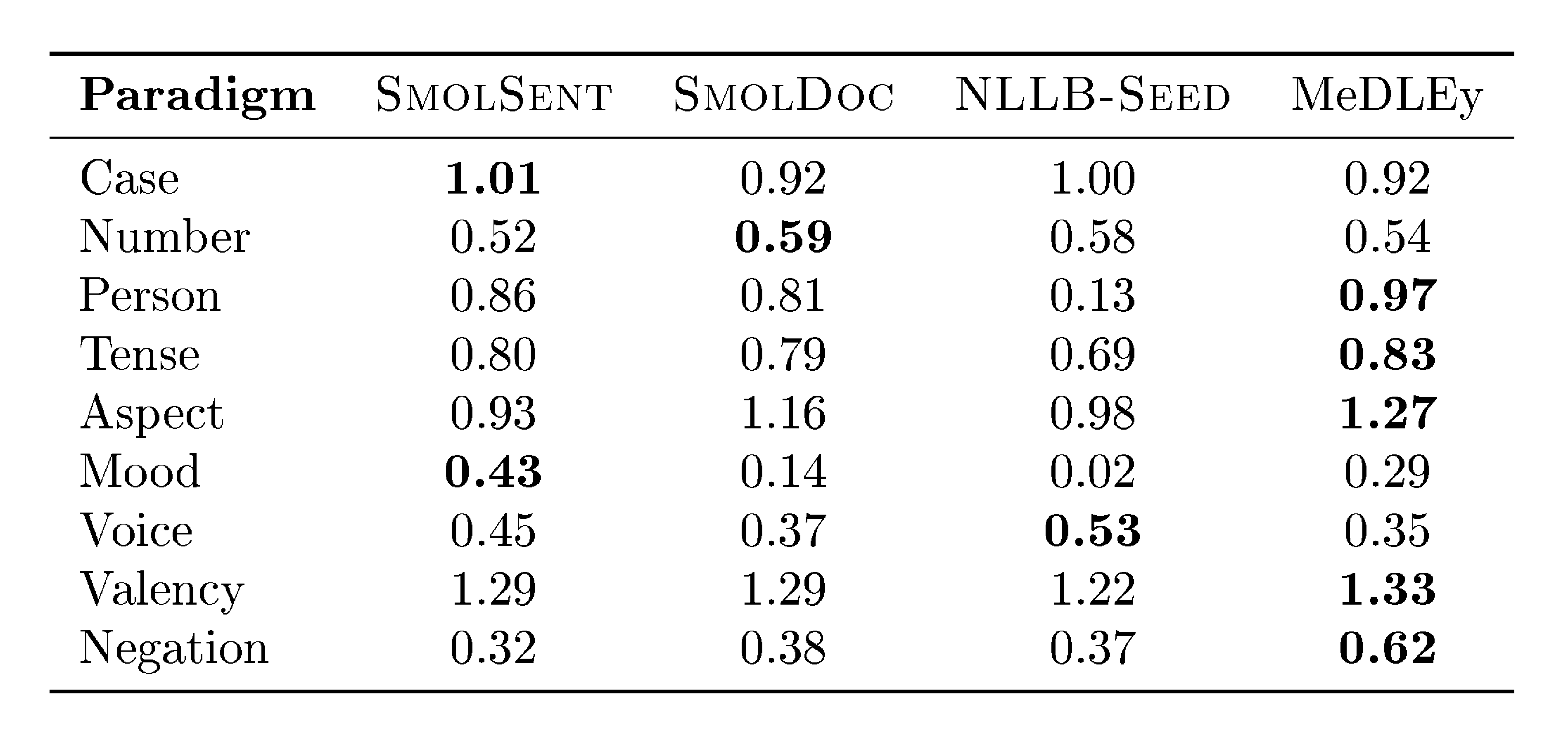
:::
::: {caption="Table 35: Feature distributions per paradigm and dataset. Cell values are proportions of that feature given the paradigm."}
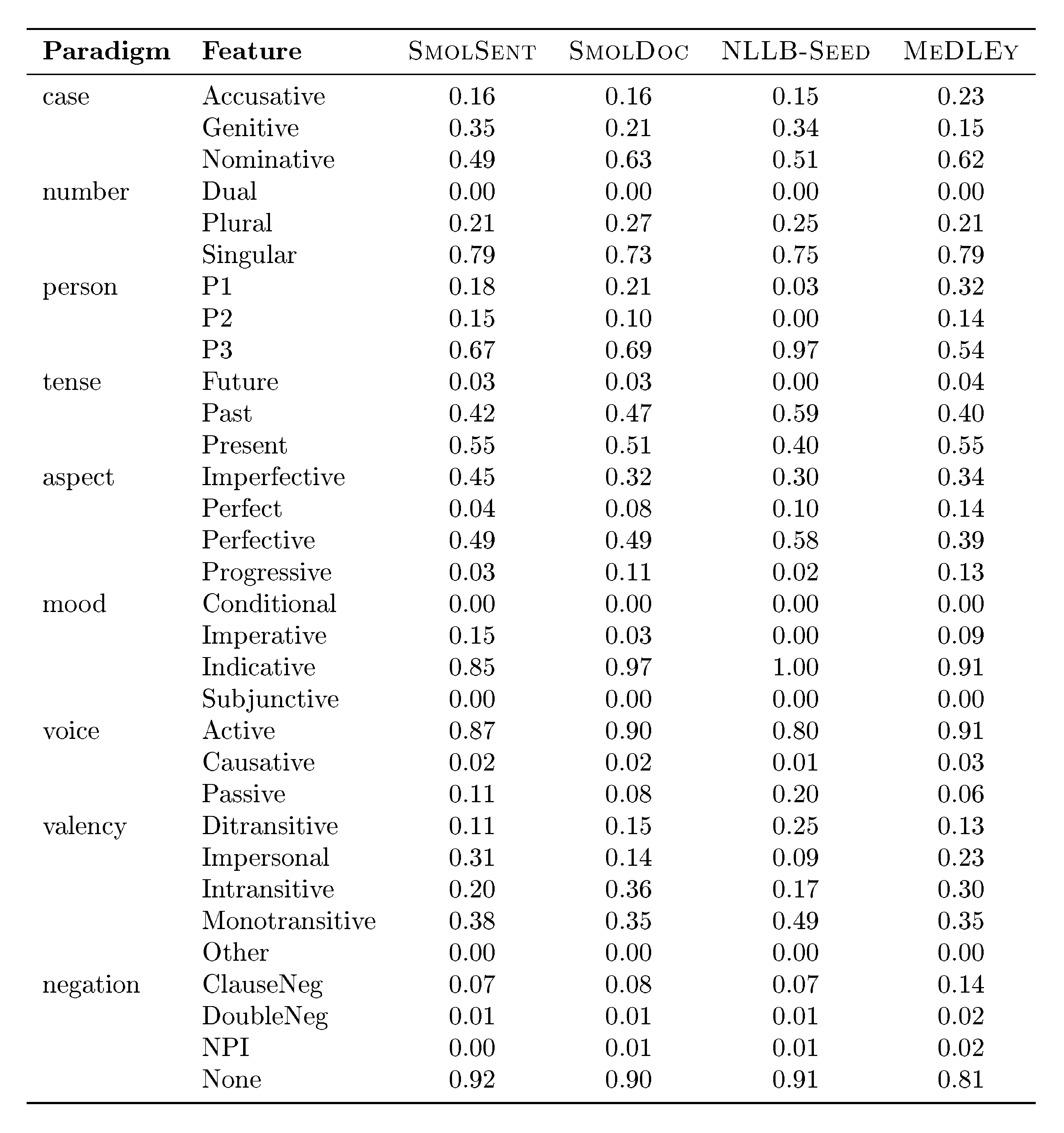
:::
Given the aim of covering naturally rarer features in our dataset, we compare grammatical feature distributions in our dataset versus others. We look at several paradigms such as tense, aspect, formality, among others, and look at the entropy of the distribution over various features in each paradigm in each dataset for English (see Table 34. See Table 35 for the full distributions over features.). We label features automatically using a Stanza parser ([147]) as well as some heuristics in cases where Stanza annotation was not rich enough for the target feature.[^41] A higher entropy signals a more balanced distribution over the paradigm.
[^41]: We are limited to languages that lie in the intersection of our considered datasets, for which we also have parsers and linguistic expertise. English was the only such language.
We find that $\textsc{NLLB}$-Seed, which is Wikipedia domain text, unsurprisingly shows high concentrations of past tense, indicative mood, third person features (low entropies for tense, mood, and person). The other datasets are more balanced, with MeDLEy showing the highest entropy in 5 of 9 categories. MeDLEy often has higher proportions of rarer features in a paradigm, such as first person text, the perfect aspect, or clausal negation.
We also automatically translated $\textsc{SmolSent}$ and $\textsc{NLLB}$-Seed to Hindi and repeated this analysis. Note that the translations produced as a result may affect our findings. We find that for Hindi, as for English, $\textsc{NLLB}$-Seed shows distributions representative of Wikipedia, e.g. almost no second person pronouns, no informal pronouns, only indicative mood. $\textsc{SmolSent}$ and MeDLEy are more diverse, with the latter often showing the highest distribution entropy (i.e. most diversity). For example, it has a more balanced distribution over tense, verbal valencies, as well as negation types. See Table 36 for a list of studied features for Hindi, and Table 37 for the entropies of the paradigm distributions.
::: {caption="Table 36: Feature types contained in each paradigm for Hindi case study."}
:::
::: {caption="Table 37: Entropy of feature paradigms for Hindi across datasets (bold indicates highest entropy per paradigm)."}
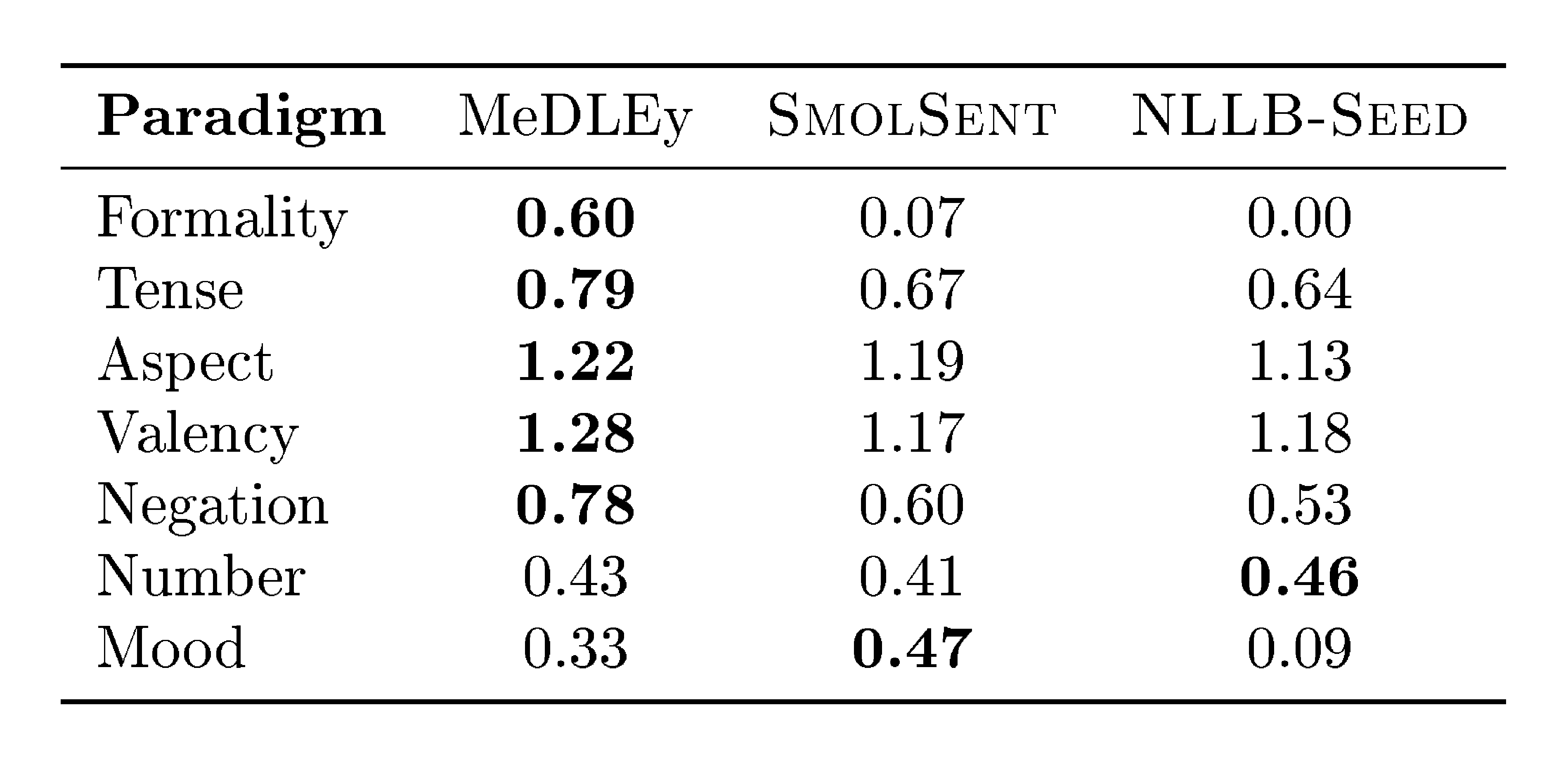
:::
A.8.2 Feature retention study
::: {caption="Table 38: Percentage of transferred feature for 10 features, starting with Spanish or Russian as source languages, and for 1 or 2 hops."}
:::
We are also interested in measuring the extent of feature transfer with our approach: i.e., the extent to which we can cue a feature in a source language (regardless of its typology) via its underlying function and have the target form in an arbitrary target surface when the text is translated to that language. To study the retention of features across translation, we analyzed 10 features in the 120 paragraphs originally created in Russian and Spanish, their translations into English, and their 2-hop translations into Spanish and Russian (i.e., the Russian-to-English-to-Spanish and Spanish-to-English-to-Russian translations). The features included: dative and instrumental case, past tense, passive voice, imperative mood, ditransitive constructions, marked word order, compound words, lexical intensifiers, and evidentiality. These features were chosen to target different levels of linguistic structure, from morphology to morphosyntax, to information structure. Evidentiality was included to investigate a known feature that is not overtly marked morphosyntactically in either pivot language but rather through various lexical choices.
We are also interested in whether these features are preserved across translation hops; thus, we also look at feature transfer for the same paragraphs created via 2-hop translation in our pipeline (Spanish-English-Russian and vice versa).
Results and summary of findings
See Table 38 for this analysis. Broadly, we find that most morphosyntactic features have decent transfer rates ($\times$), with the exception of marked word order. Crucially, we find that forms that are "lost" (i.e. do not surface in a target translation) can resurface in next hop from that language. For example, although marked word order is lost in the Russian-to-English translation, some instances of marked word order resurface in Spanish with the 2-hop Russian-English-Spanish translation. Such resurfacing likely occurs because both Spanish and Russian share pragmatic uses of word order that are utterance dependent and, thus, are not dependent on the form not appearing in English.[^42]
[^42]: This loss and resurfacing of marked word order is not entirely surprising, since English has 1) more rigid word order and 2) fewer available patterns of marked word order than both Russian and Spanish. However, our approach shows that even when English lacks some forms, they can still be cued into a target translation of out English.
Analysis in more detail
The results show that the most robust feature is the imperative, which is always copied both in 1- and 2-hop translations. All three languages have mechanisms to convey commands and requests (as most, if not all, languages), therefore the close mapping is to be expected. Overall, features that are prototypically marked as verbal morphology (i.e., past tense, passive voice, imperative mood) have the highest retention rates. The slightly lower retention for passives out of Spanish are due to two factors: the so-called Spanish "pasiva refleja" does not have a clear equivalent in English and is hard to recover in Russian (1), and some passive readings in Spanish and English can be expressed with marked word order in Russian (2).

The preservation of case shows many idiosyncrasies, which is to be expected considering that Russian does have morphological case, while English and Spanish only have remnants of a case system. For Spanish and English, the notion of "instrumental" case is restricted to uses of the preposition "con" and "with", respectively; but in Russian this case can also mark agents in passive constructions or attributes in copular or copular-like constructions, which do not elicit these prepositions in English or Spanish. Similarly, dative case in Spanish in pronominal verbs or the so-called "ethic dative" constructions may not always have clear equivalents in English or Russian.

The examples above show that features may be lost in the first hop, as in (1) and (1). However, they can also redistribute to other rare features of interest, like marked word order in (2) and instrumental case in (2). Additionally, features that are lost in the first hop can reappear in the second, as shown in (1-2), in which post-verbal subjects (i.e., "a car", "two dogs", "several rumors") are attested in the 2-hop in Spanish and Russian but not in the 1-hop in English.

Taken together, the results from the qualitative analysis suggests that 1) some features will naturally be lost in the translation process into LRLs, since languages differ in terms of the forms and functions they codify in their grammars; 2) some features that are lost in the translation process can cue other, equally-rare linguistic features; and 3) some features that do not appear in a translation hop can resurface in a subsequent hop, especially if the two languages share a similar use of that feature (even if the intermediary language does not).
A.9 More details on datasets and language statistics
Here we provide statistics about the datasets and language we leverage to conduct our experiments. We experiment on into English and out of English directions, considering five low resource languages: Bambara, Ganda, Mossi, Wolof, Yoruba[^43]. These are the languages for which all the seed datasets we evaluate, and the evaluation datasets, contain examples. Note that given the different nature of the three seed datasets, number of examples and number of tokens vary across them, as can be seen in Figure 22. In particular, MeDLEy tends to have longer examples, while SmolSent and SmolDoc tend to have shorter sequences, in terms of number of tokens, see Figure 23. Furthermore, SmolDoc is much larger than the other two as can be seen in Figure 24. These discrepancies motivated as to perform the token-controlled experiments, sampling from the three sources while sticking to a per-language shared fixed budget of tokens, determined by the seed dataset containing the least number of tokens for that language.
[^43]: bam_Latn, lug_Latn, mos_Latn, wol_Latn, yor_Latn
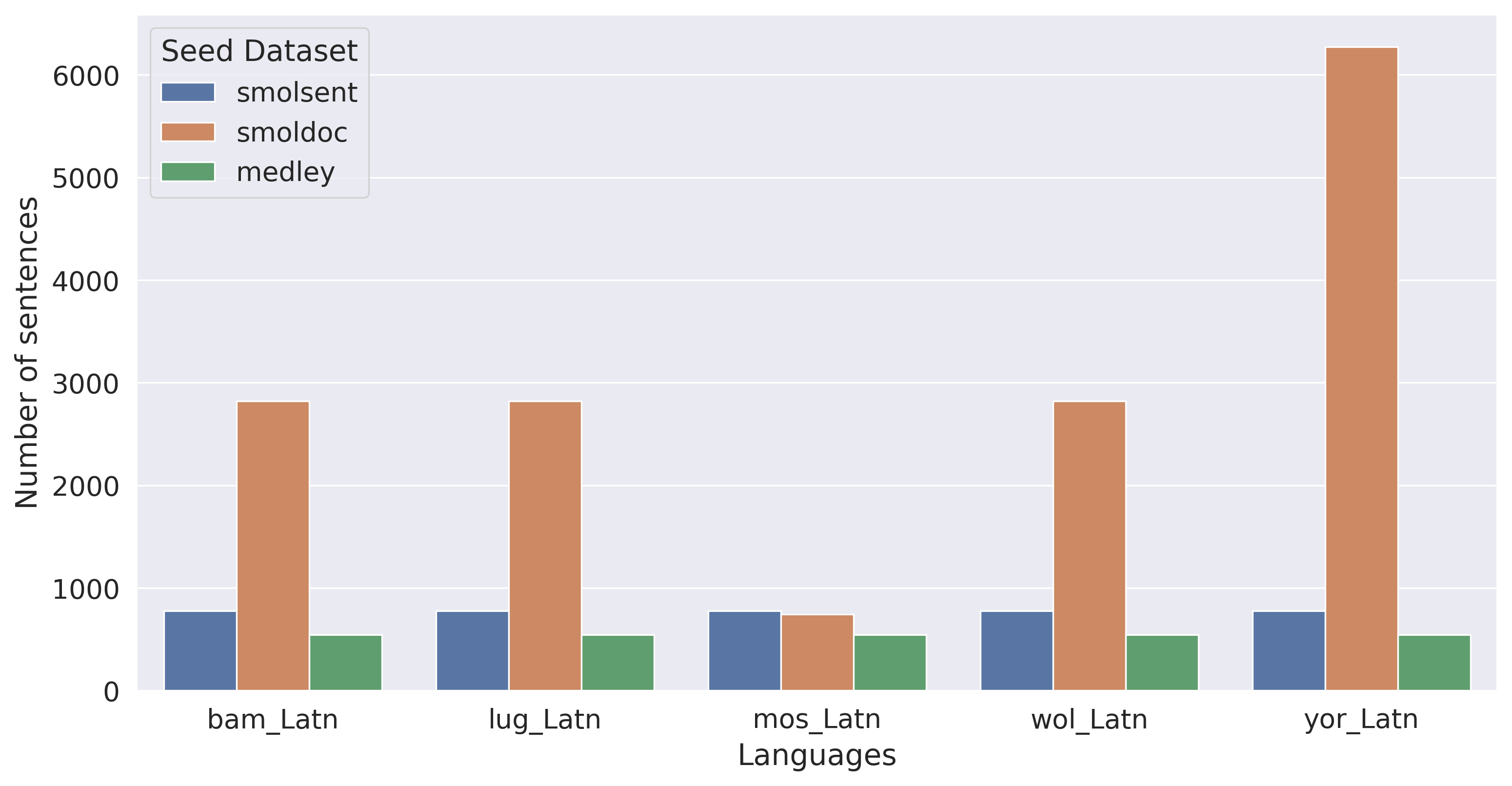
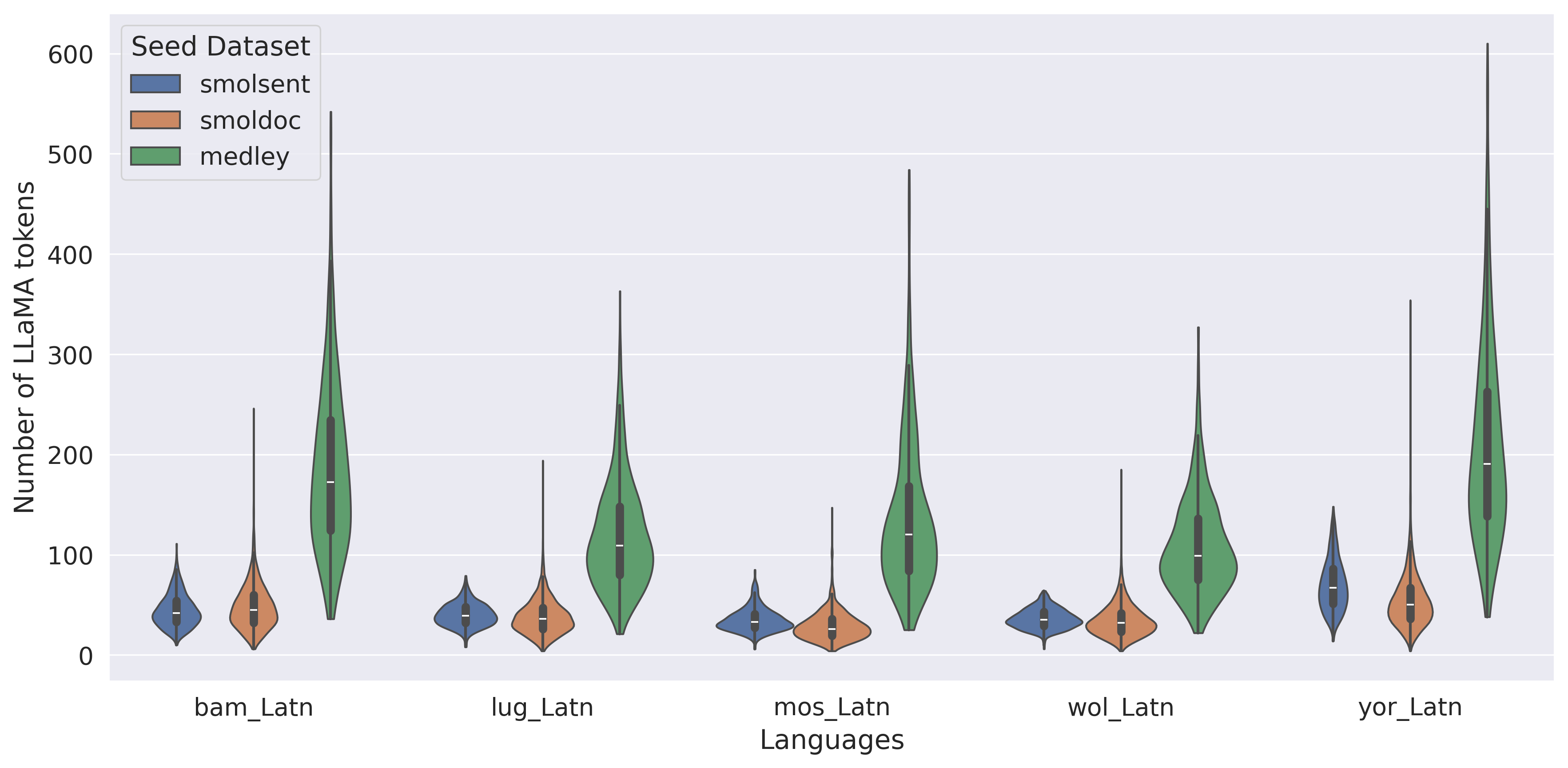
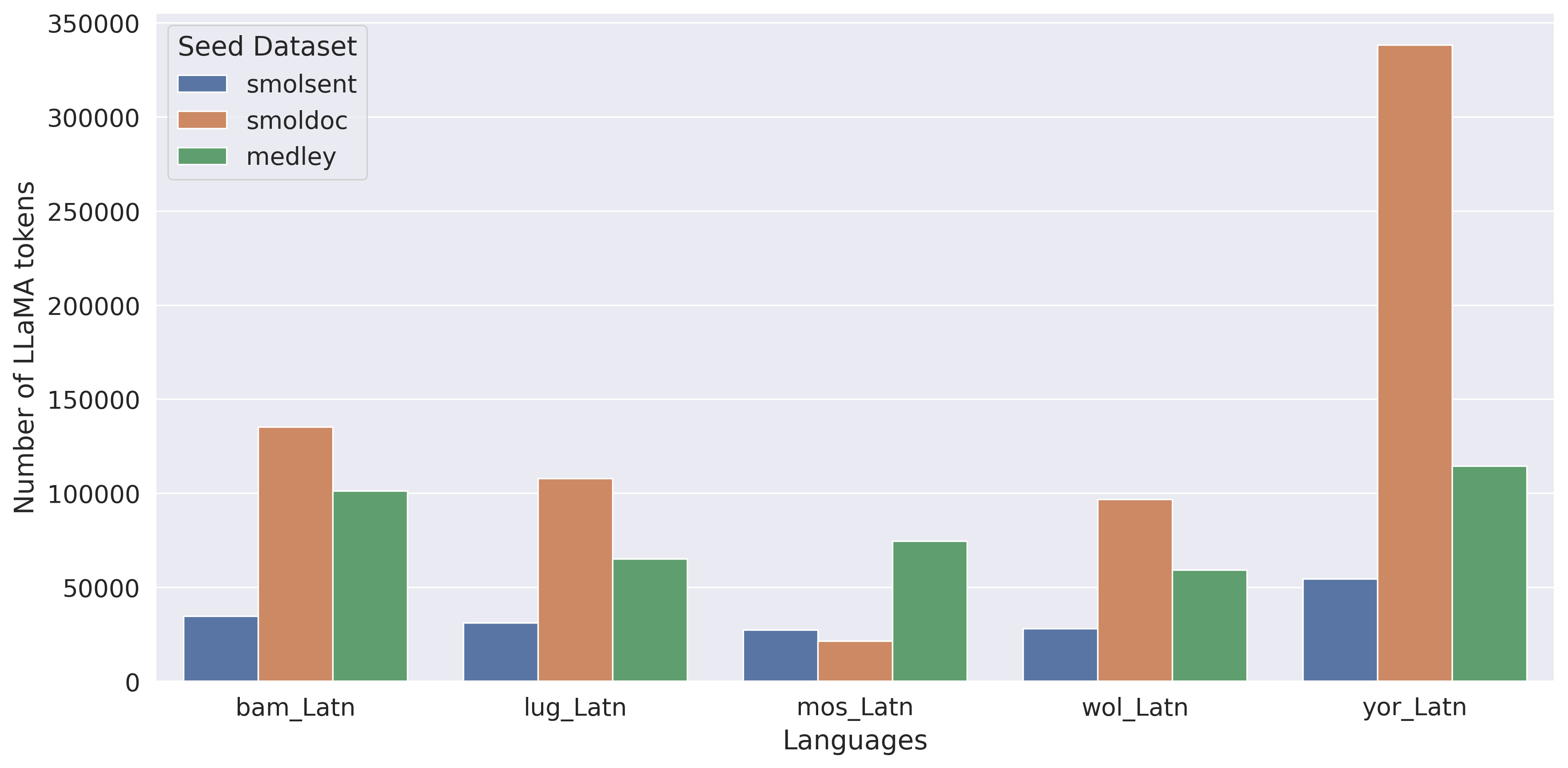
A.10 More details on the experimental setup
We experiment with two popular MT paradigms: $\textsc{NLLB-200-3.3B}$ ^44 as a representative of sequence-to-sequence (seq2seq) models ([1]), and $\textsc{LLaMA-3.1-8B-Instruct}$ ^45 representing LLM-based MT, or autoregressive decoder-only instruction-following models ([47]). For $\textsc{NLLB}$, tokenized source text is fed to the model, with appropriate delimiting language tags, and translations are obtained via beam search decoding, whereas for $\textsc{LLaMA}$, we use a minimal prompt template instructing the model to translate from source to target taken from [148].
We consider into-English and out-of-English directions per language, and fine-tune and evaluate models for each language pair and direction separately. We train both models in a supervised way by maximizing the log-likelihood of the target sequence given the source, with teacher forcing. We train for a fixed number of epochs, monitoring the model performance on a held-out validation set to pick the best checkpoint. For training $\textsc{NLLB}$, we use the same hyperparameters reported in [1] for various fine-tuning experiments, while for $\textsc{LLaMA}$ we adopt a similar setup to [10]. For $\textsc{NLLB}$, we dynamically pad tokenized source sequences to the longest in the batch. For $\textsc{LLaMA}$, we apply packing, merging tokenized prompts together when possible to minimize padding.
We experiment with 5 languages that are covered by these baseline datasets, MeDLEy- 109, as well as our evaluation datasets: Bambara, Mossi, Wolof, Yoruba, and Ganda. Since $\textsc{SmolDoc}$ samples can range to over several thousand tokens, we break it into sentence-level chunks with the provided sentence alignments in accordance with [10]. See Appendix A.9 for training dataset statistics.
We perform supervised fine-tuning leveraging "labelled" datasets, i.e. bitext corpora (the seed datasets), in which each example in these datasets is a piece of text (source text), of known language (source language), along with its translation (target text) in a give language (target language). We then work with datasets $\times$ where $\times$ is a representation of the source language, $\times$ is a representation of target language, $\times$ is a representation of the source text, and $\times$ is a representation of the target text. These representations differ slighly across the two models used to solve the task. For NLLB, we encode them as can be seen in Box 2, since the NLLB tokenizer reserves special tokens for representing language codes of the supported languages. Note that all of the languages we evaluate on are (technically) supported by NLLB, meaning that the tokenizer has a reserved language code token for them. For LLaMa, given prior work ([47]) highlighting the good performance of instruction-following LLMs at translation tasks, we perform instruction fine-tuning, with a very simple prompt template and task description, as can be seen in Box 2.
```
Source: <{source language code}> {source text} </s> <pad> ... <pad>
Target: <{target language code}> {target text} </s> <pad> ... <pad>
```
Box 2: Example encoding of a translation pair for fine-tuning NLLB
```
Translate the following text from {source language} into {target language}.
{source language}: {source text}
{target language}:
```
Box 3: Prompt template for fine-tuning LLaMa
All fine-tuning experiments and subsequent evaluations are conducted on A100 GPUs^46, using the HuggingFace transformers ([149]) implementations. The models are efficiently fine-tuned using mixed precision training ([150]), with dynamic padding for NLLB (padding to the longest sequence in the batch) for NLLB, and using packing^47, FlashAttention-2 ([151]) and FSDP[^48] for LLaMa, using the AdamW optimizer ([97]). Sequences longer than the model max length are truncated from the left (keeping the source language code for conditioning) for NLLB, while from the right for LLaMa. All training hyperparameters are detailed in Table 39.
[^48]: Fully Sharded Data Parallel
::: {caption="Table 39: Training Hyperparameters"}
:::
Then, to efficiently produce inference results from the resulting checkpoints for evaluation, we leverage ctranslate2 ([152]) for NLLB and vLLM ([153]) for LLaMa. All inference hyperparameters are listed in Table 40.
::: {caption="Table 40: Inference hyperparameters"}
:::
A.11 More details on the experiment results
We observe the benefits of any seed data over the no-seed baseline, especially for $\textsc{LLaMA}$. This is true to a lesser extent for $\textsc{NLLB}$, which has already been fine-tuned for these languages.[^49] $\textsc{NLLB}$ shows higher baseline and fine-tuned performance across the board, highlighting that smaller sequence-to-sequence models are still state-of-the-art for low-resource MT as compared to LLM-based MT in accordance with previous findings ([154, 155]).
[^49]: Note that MeDLEy covers 79 languages that are not supported by $\textsc{NLLB}$, for which we can expect higher gains over the baseline. However, we lack the evaluation resources in these languages to demonstrate this.
We see that MeDLEy matches or outperforms baseline datasets in the token-controlled, and shows gains in the into-English direction. We also show similar findings on a comparison on $\textsc{NLLB}$-Seed on a separate set of intersection languages in Appendix A.11.[^50] We confirm these trends over various other MT evaluation metrics such as xCOMET and MetricX ([83, 84]), among others, reported in Appendix A.11. This supports a major application of seed datasets, i.e., synthetic data generation from monolingual LRL data via better xx-en systems as discussed in Section 4.3.1.
[^50]: In addition, we also show that $\textsc{NLLB}$-Seed contains a high proportion of difficult-to-translate texts potentially due to technical or obscure terminology (54% as compared to 10.41%), which may hinder lay community translators.
We observe some improvements from adding MeDLEy to existing seed datasets. However, these are generally small, indicating the challenges of making significant improvements for LRLs via manual collection of data at the scale of a few thousands of sentences. Note that MeDLEy contains 92 languages not covered by $\textsc{SMOL}$.
We note that regardless of the seed dataset used, scores remain low in general, especially in the en-xx direction. Given that scaling up data collection is infeasible for this range of languages, one possible takeaway from this is that standard supervised fine-tuning-based approaches may not be sufficient for language learning in this data regime. Current literature already investigates various creative ways of using structured information about a language to boost LLM performance for unseen or very low-resource language ([156, 157, 158, 159, 160]); future work in this direction may further investigate the most efficient usage of a seed dataset to augment these methods. Our dataset, in focusing on the controlled and principled coverage of grammatical features, opens up possibilities for future research in more efficient language learning.
Summary results
Beside chrF++ score we also report xCOMET ([83]) and MetricX ([84]) as they are usually better correlated with human judgement and thus can provide a more practical measure of translation quality, see Table 41 for token-controlled and Table 42 for direct comparison results. Furthermore, we report Spearman rank correlation between the metric we report in the main manuscript, namely chrF++, and a selection of other widely used evaluation metrics, namely BLASER ([161]), BLEU ([132]), BLEURT ([135]), METEOR ([162]), MetricX ([84]), TER ([163]), xCOMET ([83]), see Figure 25.
::: {caption="Table 41: Average translation performance when fine-tuning on token-controlled seed datasets."}
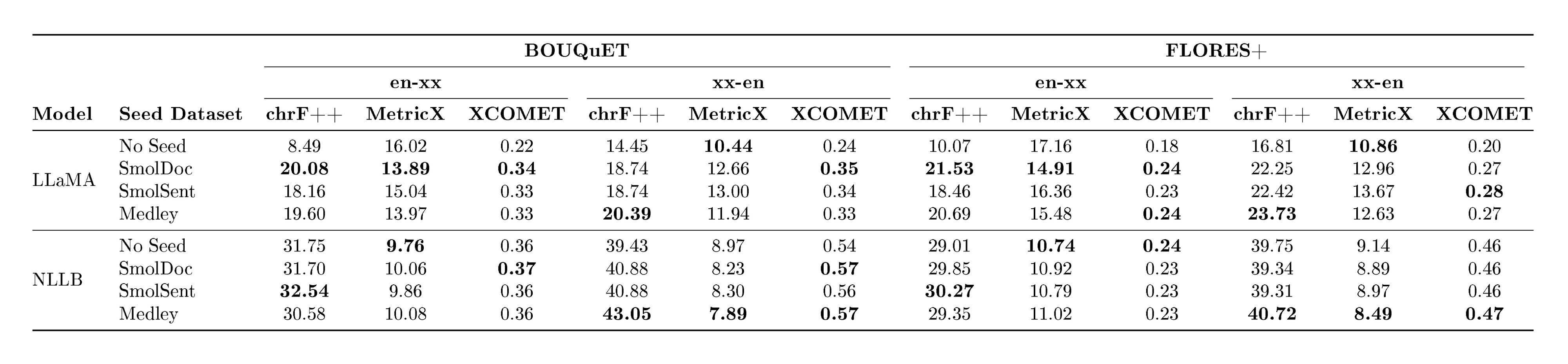
:::
::: {caption="Table 42: Average translation performance when fine-tuning on seed datasets and their combination."}
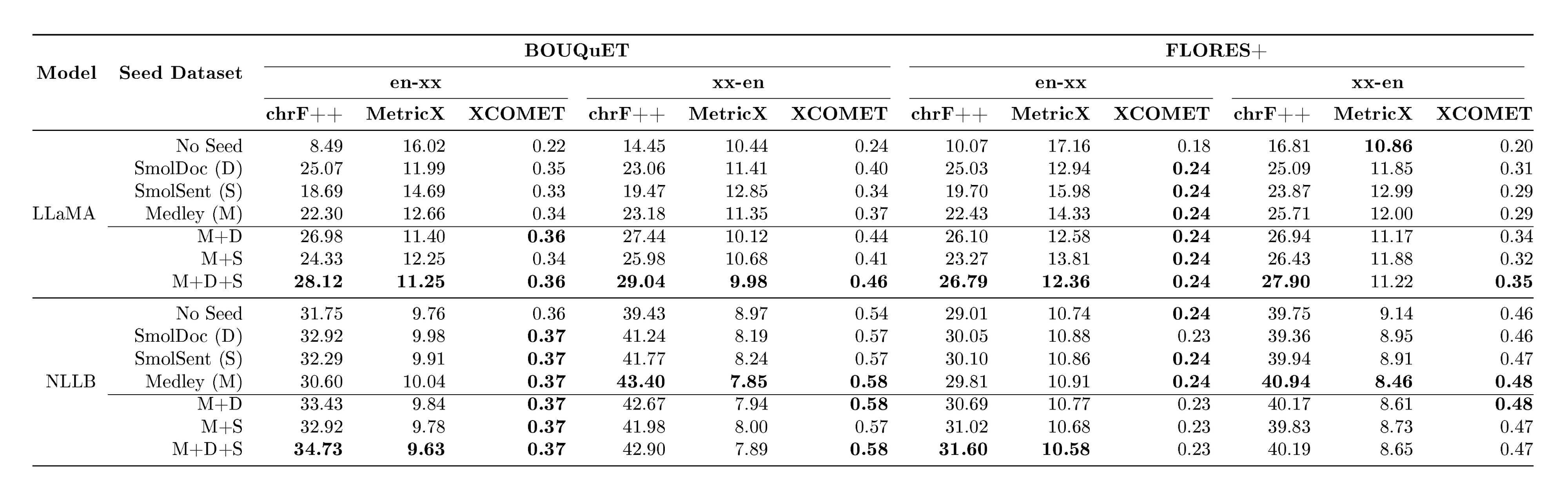
:::
Language-wise breakdowns
Here we report the same as above but with aggregating per-language, see Table 43 for token-controlled and Table 44 for direct comparison.
::: {caption="Table 43: Per-language translation performance when fine-tuning on token-controlled seed datasets."}
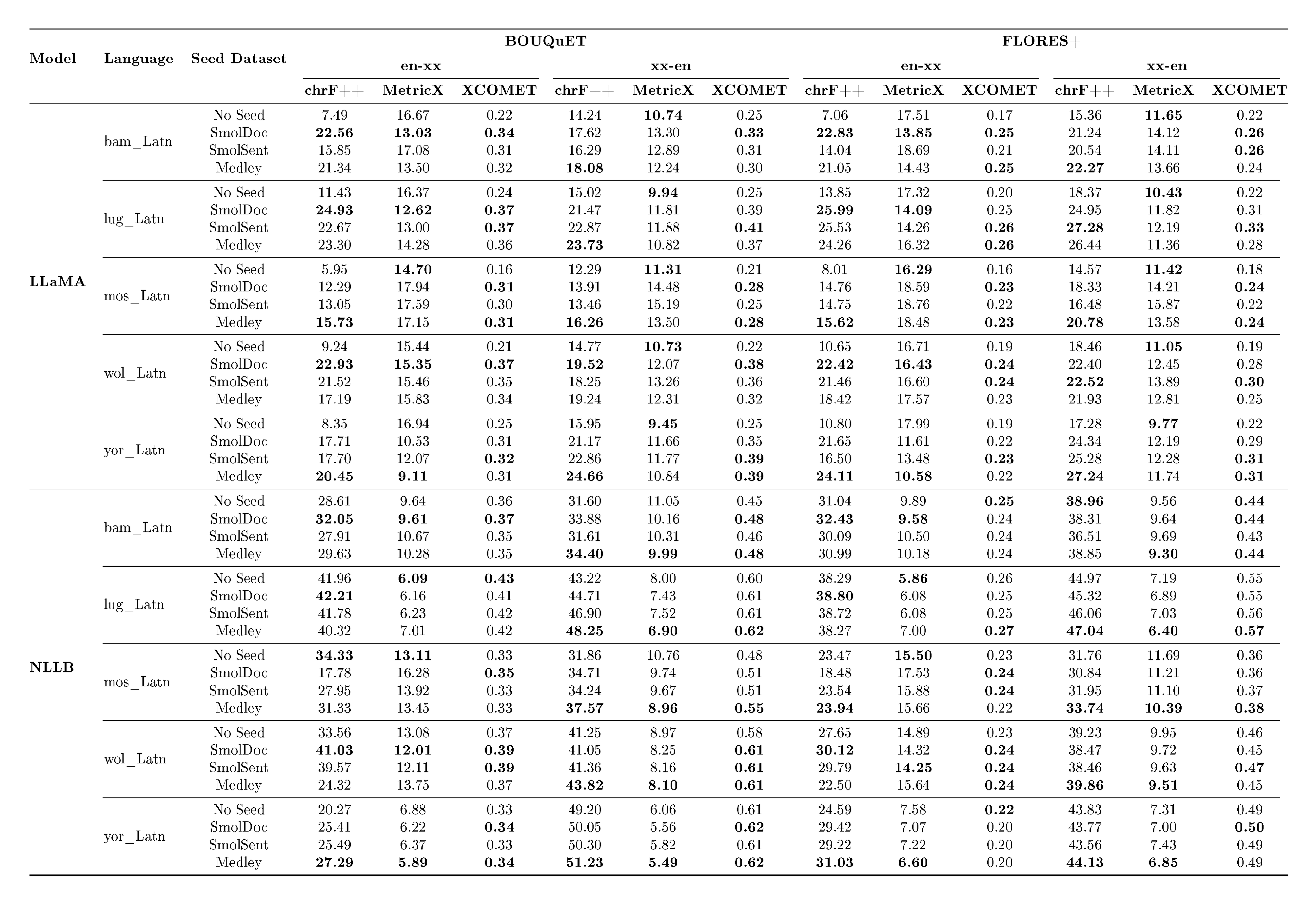
:::
::: {caption="Table 44: Per-language translation performance when fine-tuning on seed datasets and their combinations."}
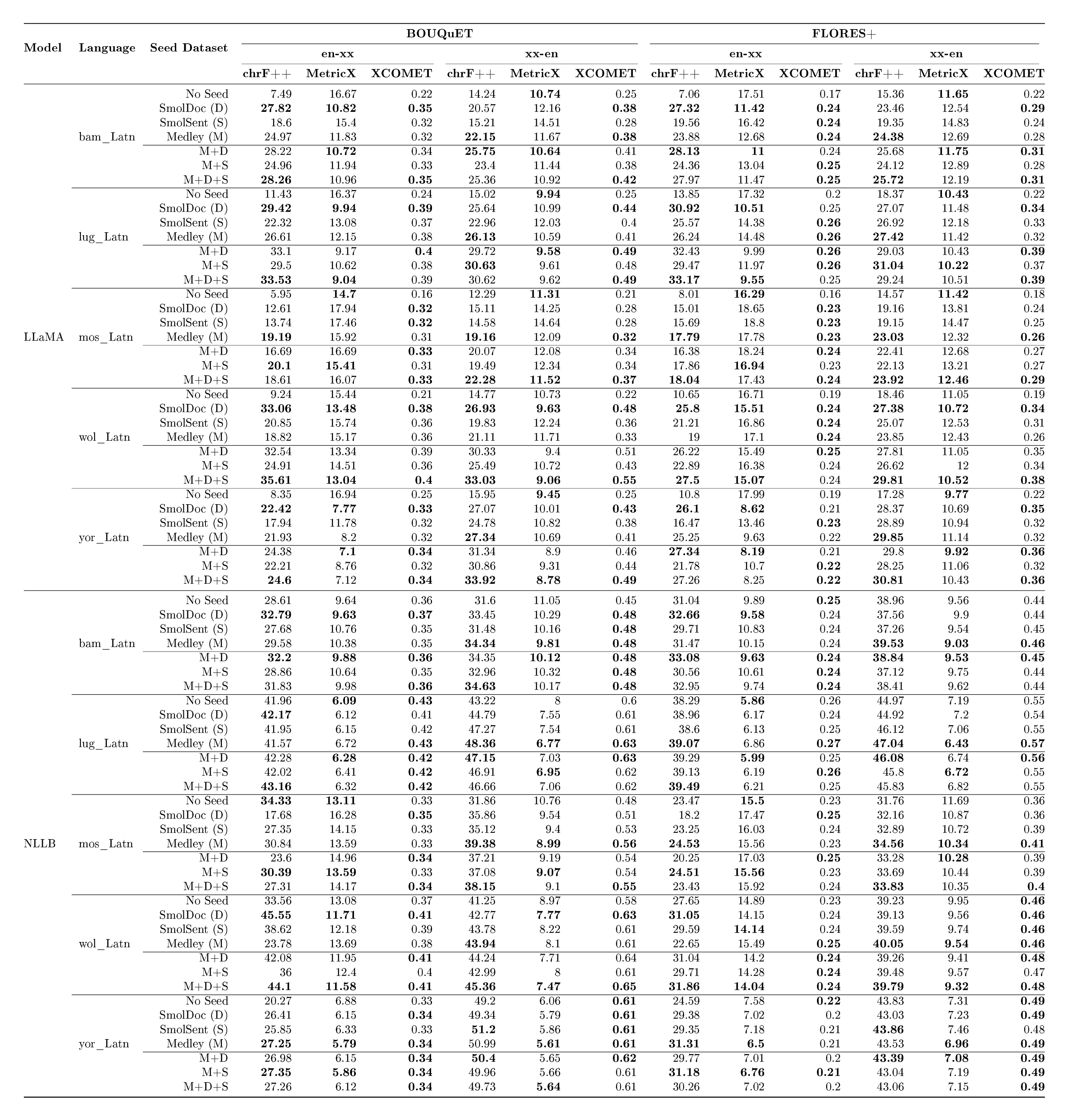
:::
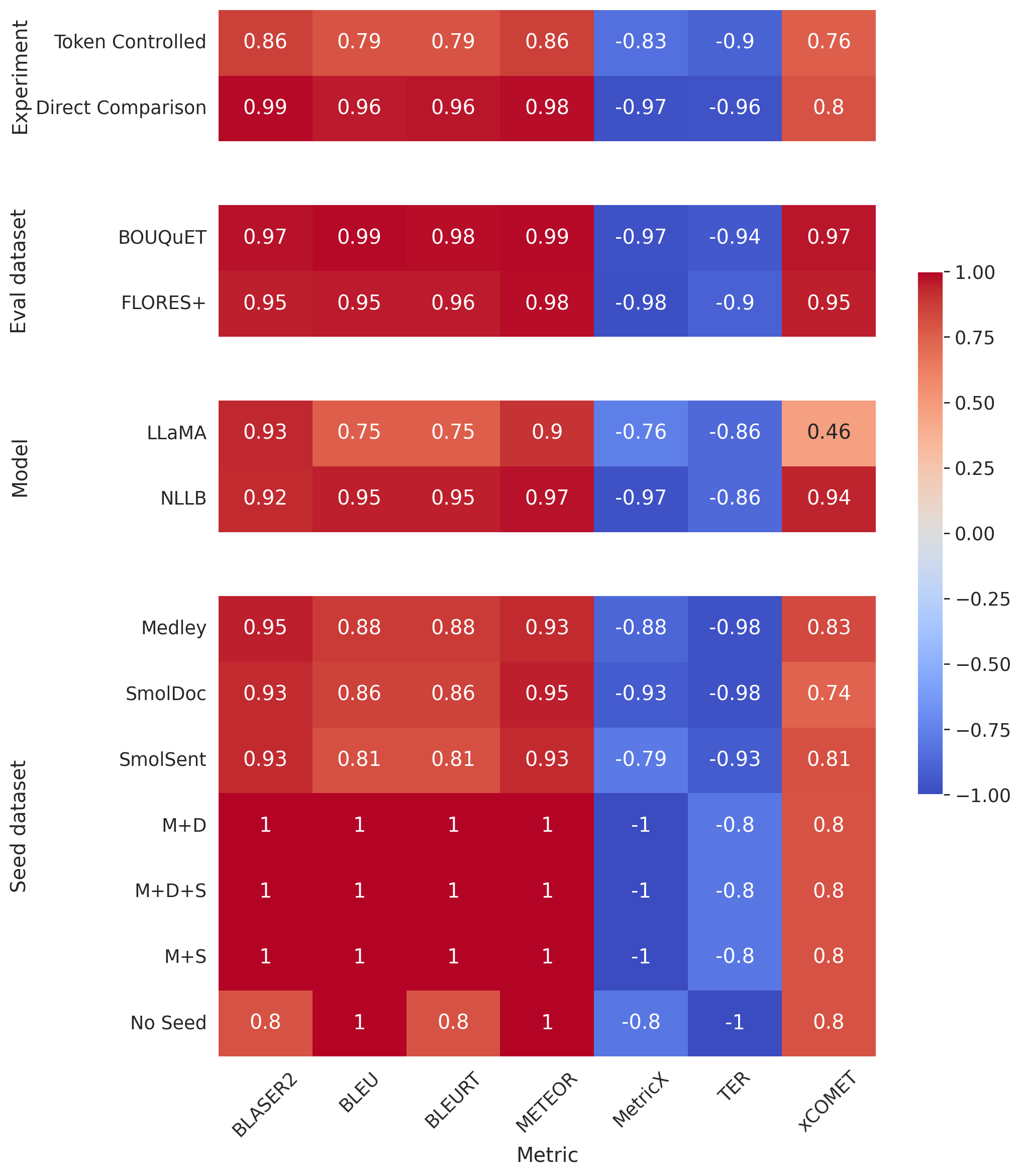
Domain-wise breakdown
We evaluate our models also at the domain-level, leveraging the domain-split provided by BOUQuET, and report results in Table 45.
::: {caption="Table 45: Per-domain BOUQuET evaluation results comparing models fine-tuned on token-controlled version of the seed datasets."}
:::
Comparison with $\textsc{NLLB}$-Seed
While $\textsc{NLLB}$-Seed does not cover 4 of 5 of our evaluation languages in Section 4.3.3, at the time of writing it has $\times$ low-resource languages languages in common with MeDLEy and our evaluation datasets: Bambara, Dinka and Fulfulde (bam_Latn, dik_Latn, fuv_Latn). We fine-tune, evaluate and compare the two with the same token-controlled methodology, and report the results of the comparison for those languages in Table 46 and Table 47. Note that there are significant differences between $\textsc{NLLB}$-Seed and our dataset. The former is single-domain English-centric data selected across a variety of topics, whereas MeDLEy is multicentric and multiway, and contains human-written source sentences over 5 domains. The Wikipedia domain has been observed to contain obscure and specialized terms that are difficult for language translators to work with ([164, 165]) and may not necessarily add general utility to an MT system trained on such a corpus. We also perform our difficulty analysis , and find that $\textsc{NLLB}$-Seed contains a very high percentage of texts that are labeled C1 or C2 (54.1%) as compared to MeDLEy (10.4%) or $\textsc{SMOL-sent}$ (9.7%).
::: {caption="Table 46: Average translation performance comparing $\textsc{NLLB}$-Seed and MeDLEy ."}
:::
::: {caption="Table 47: Per-language translation performance comparing $\textsc{NLLB}$-Seed and MeDLEy ."}
:::
B. Met- BOUQuET details
B.1 XSTS+R+P
Goal
The goal is to assess the degree of meaning correspondence/equivalence between a translation request and the translation of the requested paragraph. The scores will be aggregated to estimate an average semantic correspondence between languages in the dataset.
You will need to read the source and the target, compare them sentence by sentence and assign a score to each sentence. An automatic formula will then calculate the resulting score for the whole paragraph. You will be asked not to only compare the semantic meaning, but also the register of the paragraphs.
Rating guidelines
Notes:
- The examples you will now see are phrase or sentence-based for simplicity purposes. You will work with longer paragraphs.
- Please ignore minor typos and grammatical errors if they do not affect your understanding of the texts.
- Please ignore capitalization and punctuation differences if they do not affect your understanding.
[1]
The source paragraph and its translation are not semantically equivalent, share very little detail, and may be about different topics.
Example A (different topics)
Text 1. (English): Train station
Text 2. (Spanish): Restaurante vegano (Vegan restaurant)
Example B (false equivalents)
Text 1. When I get home, I always lock the door. It gives me peace of mind.
Text 2. Cuando llego a casa siempre loqueo la puerta. Me da tranquilidad.
Example C (very little overlap and unrelated entities)
Text 1. Open museums
Text 2. Centros comerciales abiertos (Open malls)
Example D (indecipherable on one side or the other)
Text 1. lorbo lorbo lorl room
Text 2. Habitación doble (double room)
Example E (untranslated text)
Text 1. Should you have any questions, please let me know.
Text 2. Si tiene cualquier duda, please let me know.
Example F (hallucinations)
Text 1. Thank you for joining us today. We’re so happy you’re here.
Text 2. Gracias por acompañarnos hoy. Nos alegra mucho que estéis aquí. Esta noche la vamos a recordar toda la vida. (We will remember this night for the rest of our lives).
[2]
The source paragraph and its translation share some details, but are not equivalent. Some important information related to the primary subject/verb/object differs or is missing, which alters the intent or meaning of the paragraph. Alternatively, the register differs so much that this translation will be a big mistake. A significant change in register will always score no more than 2 points.
Example A (opposite polarity)
Text 1. Flight to London
Text 2. Vuelo desde Londres (Flight from London)
Example B (non-equivalent numbers)
Text 1. Two rooms for three people
Text 2. Tres habitaciones para dos personas (Three rooms for two people)
Example C (substitution/change in named entity)
Text 1. Flight to Valencia
Text 2. Vuelo a Valladolid (Flight to Valladolid)
Example D (different meaning due to word order)
Text 1. I like pizza
Text 2. Yo gusto a la pizza (Pizza likes me)
Example E (equivalent constructions with different meanings)
Text 1. The bus is arriving at 2.
Text 2. El autobús está llegando a las 2.
**Explanation:**Spanish present progressive cannot be used to refer to the future
Example F (missing salient information)
Text 1. Vegan Italian restaurant
Text 2. Restaurante italiano (Italian restaurant)
Example G (omitted relevant chunks)
Text 1. The company's new product (a flask with temperature regulation) is expected to be a success.
Text 2. Se espera que el nuevo producto de la empresa sea un éxito.
Example H (register difference)
Text 1. What’s up, dude?
Text 2. ¿Cómo se encuentra, señor? (How are you, sir?)
[3]
The two paragraphs are mostly equivalent, but some unimportant details can differ. There cannot be any significant conflicts in intent, meaning or register between the sentences, no matter how long the sentences are.
Example A (omitted non-critical information, but no contradictory info introduced)
Text 1. Table for 3 adults
Text 2. Mesa para 3 (Table for 3)
Example B (unit of measurement differences)
Text 1. I want 2 pounds of cheese.
Text 2. Quería 1 kg de queso. (I wanted 1kg of cheese.)
Example C (minor verb tense differences)
Text 1. When he arrived at the station, the train had already left.
Text 2. Cuando llegue a la estación, el tren ya se habrá ido. (When he arrives at the station, the train will have already left.)
Example D (small, non-conflicting differences \textbf{in meaning)}
Text 1. I love running.
Text 2. Me gusta correr. (I like running.)
Example E (non-critical information added)
Text 1. Photos of the trip
Text 2. Fotos de mi viaje (Photos of my trip)
Example F (non-equivalent constructions)
Text 1. The president finally signed the new education bill yesterday at noon.
Text 2. La nueva ley de educación finalmente fue firmada por el presidente ayer al mediodía. (The new education bill was finally signed by the president yesterday at noon.)
Example G (inconsistent register)
Text 1. First, you will need to purchase all the painting supplies you need. Then, film and tape everything that is not to be painted.
Text 2. Primero, tendrás que comprar todo lo que necesitas para pintar. Luego proteja con film y cinta de pintor todo lo que no deba ser pintado.
Explanation:“proteja” is a formal second person imperative form (“usted”), but the verb in the previous sentence (“tendrás”) uses an informal second person form (“tú”).
Example H (inconsistent target)
Text 1. It’s pretty flashy, but remember that you have to wash it often.
Text 2. Es bien chido, pero acordate que tienes que lavarlo frecuentemente.
**Explanation:**The translation mixes lexical and/or grammatical forms from different varieties/dialects (“bien chido” is broadly Mexican, “acordate” is broadly Rioplatense and “tienes” is from a non-voseo variety like European Spanish).
[4]
The two paragraphs are paraphrases of each other. Their meanings are near-equivalent, with no major differences or information missing. There can only be minor differences in meaning due to differences in expression (e.g., formality level, style, emphasis, potential implication, idioms, common metaphors). For single word texts, there might be multiple meanings depending on the context they would be used in, but the one presented is still correct.
Example A
Text 1. This is great
Text 2. Esto es la leche (Lit: This is the milk)
Explanation: “Esto es la leche” is an idiom, “this is great” is not.
Example B
Text 1. The day that comes after the day of today
Text 2. Mañana (Tomorrow)
Explanation: Differences in phrasing, text 1 is oddly phrased and more verbose than text2.
Example C
Text 1. Bird
Text 2. Pajarito (birdie)
Explanation: Different level of formality (“Birdie” vs “bird”).
[5]
The two paragraphs are exactly and completely equivalent in meaning and usage expression (e.g., formality level, style, emphasis, potential implication, idioms, common metaphors). In other words, nuance is completely preserved and there is a faithful correspondence. Fidelity is also preserved.
Example A
Text 1. I am so happy.
Text 2. Estoy lleno de felicidad (I am filled with happiness).
Example B
Text 1. Hi friends
Text 2. Hola chicos (Hello guys)
Example C
Text 1. Hello, how are you
Text 2. Hola cómo estás (Hello how are you)
Pilot
To validate the XSTS+R+P protocol, we designed a pilot consisting of 210 sentence pairs organized in 50 paragraphs in two high resource languages (i.e., 105 Russian-to-Spanish pairs, and 105 Spanish-to-Russian). Similar to XSTS, annotators were asked to rate each Russian-Spanish sentence pair on a scale from 1 to 5 based on how equivalent they were, with 1 being not semantically equivalent and 5 being completely equivalent in meaning and usage expression. Meaning is broadly construed here, that is, it includes both lexical and grammatical meaning (i.e., the semantics of grammatical constructions, formality levels, style, emphasis, etc.). Unlike XSTS, however, annotators were asked to consider each sentence in the context of the paragraphs they were in, as well as any additional information provided about the paragraphs’ source, genre, and communicative goal. Finally, annotators provided comments for their rating decisions. The pilot results show that annotators were able to rate sentences considering register and paragraph information, although they tended to point out lexical mistranslations at a higher rate. We attribute this tendency to a smaller pool of examples involving grammatical non-equivalent meaning in our guidelines (e.g., identical lexical items with alternate active-passive sentences). This was corrected in the guidelines for the final evaluation.
B.2 Detailed Selection of MT outputs Met- BOUQuET Round 1
For the entire set of development and test sentences from BOUQuET (1358), we select only one translation output among the different systems. We optimitze for a variety of quality (in order to have a wide range of scores) and a variety of systems (in order to have a wide range of error types typical for different systems). We use variations of the same selection algorithm for very strong translation directions (when we had to oversample bad translations to provide some signal for QE) and directions with very poor quality (where bad translations should be undersampled). This resulted in the following implementation:
Step1. For every translation direction, we have the outputs of several candidate systems (3 to 24) and for each sentence output, we have 4 translation scores (ChrF++ [133], Blaser 2.0-QE [118], either WMT23-Cometkiwi-da-xl [136] or xCOMET-XL [114], MetricX-24-hybrid-xl-v2p6 [84]). The systems are selected so that they always include a Llama-based system and NLLB (if it supports the target language), and several other systems with the best translations according to any of the scores above (at least one system per score, at most 4 systems if they are "good" according to this score; the systems selected by different scores may overlap).
Step2. For each translation direction and unique source text, we select at most one translation from the ones that are “probably good enough” (MetricX $\times$ 5, Blaser-QE $\times$ 3, ChrF++ $\times$ 10); if several systems provide good translations for a source, the system is chosen randomly. We keep such translations for at most 50% of all volume per direction.
Step3. 10% translations per direction (or more, if at the previous step less than 50% were selected) are chosen by the best values of each metric for each system. 25% translations are selected by the worst values for each metric for each system.
Step4. The rest is selected randomly, with a slight upsampling of the systems that have been underrepresented before.
B.3 Comparison to other MT metrics evaluation datasets
::: {caption="Table 48: Summary of key attributes of MT metrics evaluation datasets, including language coverage, source sentences, systems evaluated, and domains. Statistics are reported only for datasets with available evaluation scores."}
:::
Table 48 compares to other datasets that have been used to evaluate MT metrics. It includes MLQE [112]; IndicMT Eval [113], AmericasNLP (Task3) [32], NLLB [1].
Table 48 summarizes key characteristics of each dataset, including: Evaluation protocol used to score translations; number of languages covered (as source or target); Number of language pairs (source–target combinations); Number of source sentences for which translations are available; Number of translation systems used; Number of domains represented in the dataset.
Most existing datasets use different sets of source sentences for different language directions. Notable exceptions are the AmericasNLP 2025 Task 3 and IndicMT Eval datasets, which employ the same set of source sentences (in Spanish and English, respectively) in all translation directions. However, these datasets are limited in their multilingual scope as they maintain parallelism only within a single source language.
In contrast, Met- BOUQuET is designed to maximize both parallelism and multilinguality. By assigning a unique identifier to each source paragraph and sentence, regardless of the source language, it enables true cross-lingual comparisons across a wide range of languages and translation directions. This approach supports parallel evaluation while also facilitating comprehensive multilingual benchmarking.
It is also relevant noting that Met- BOUQuET Round 1 uniquely contains 100% of bidirectional pairs and 60% of directions without English (62 directions), and Met- BOUQuET Round 1 + 2 includes a total of 118 directions without English, only followed by NLLB with 20 directions without English.
Additionally, Met- BOUQuET inherits advantages from BOUQuET (as discussed in Section 4.4.1) by offering detailed domain, register and linguistic annotations for all sentences [82] and information about the specific MT system that produced the output. Although it covers a single target output, it is the only dataset reviewed that provides such comprehensive metadata, enabling more granular and fine-grained performance benchmarking.
Score Distribution.
Figure 26 (top) reports the histogram of the XSTS+R+P consensus scores (median) across English and non-English directions for Met- BOUQuET Round 1. We observe that pairs involving English tend to have higher scores than non-English pairs. Non-English pairs feature a higher number of very poor translations (XSTS+R+P of 1). Figure 26 (bottom) shows the XSTS+R+P average score across source and target languages. While for this round we aimed for a uniform score distribution, the cases further from this goal are low-resource languages such as Plains Cree (crk_Cans) and Ngambay (sba_Latn).
:::: {cols="1"}
Figure 26: For Met- BOUQuET Round 1: Top, XSTS+R+P consensus scores histogram across English and non-English directions; Bottom, XSTS+R+P consensus averages across source and target languages. ::::
:::: {cols="1"}
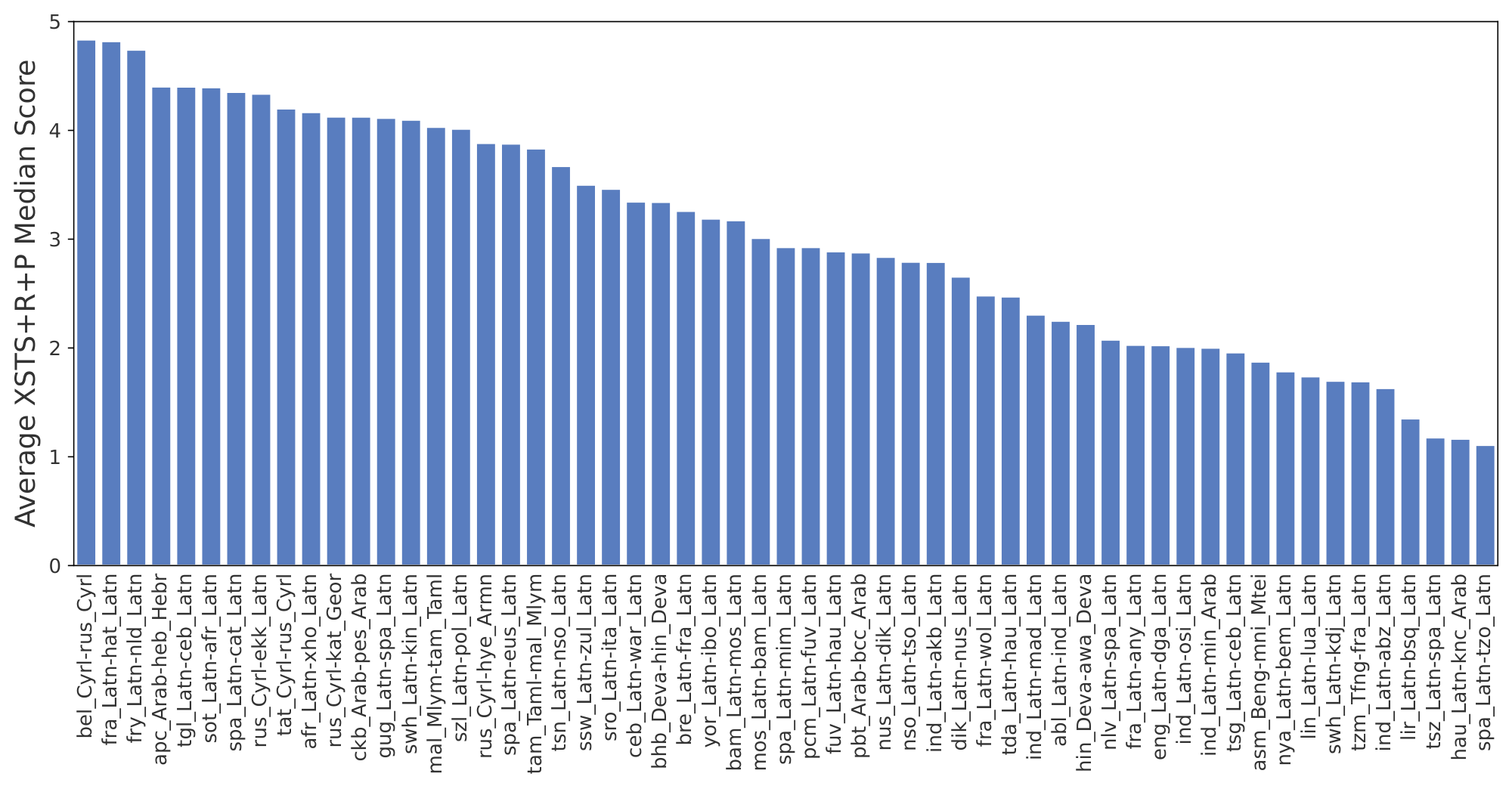
Figure 29: For Met- BOUQuET Round 2: Top, XSTS+R+P consensus scores histogram; Bottom, XSTS+R+P consensus averages across directions. ::::
C. Cards
::: {caption="Table 49: Automatic and human evaluation metrics/protocols used in this work."}
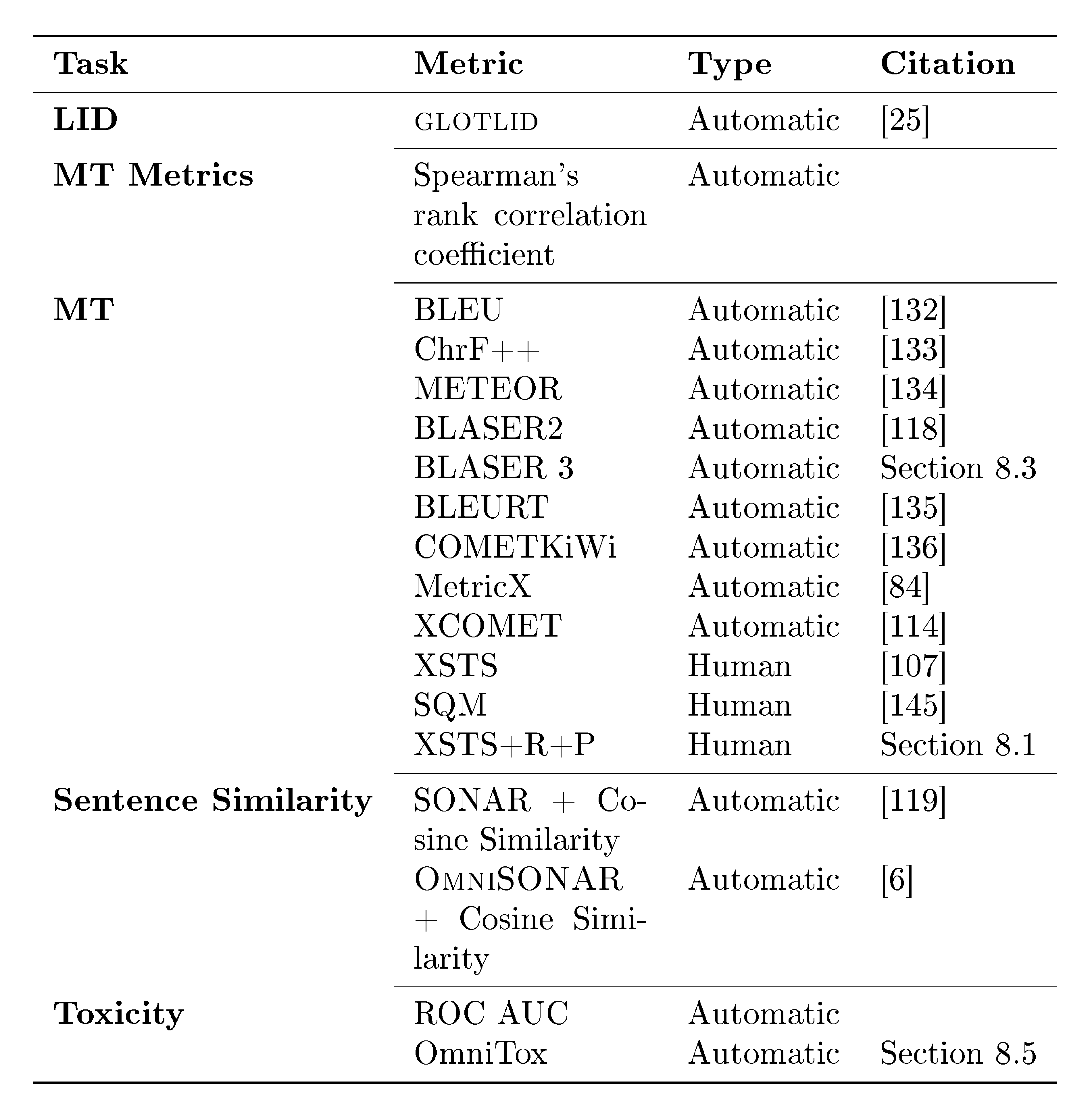
:::
D. Languages at a glance
\begin{longtable}{ccccccc}
\midrule
\endfirsthead
\toprule
\textbf{ISO 639-3} & \textbf{ISO 15924} &\textbf{Language family} &\textbf{BOUQuET} & \textbf{MeDLEy} & \textbf{met- BOUQuET}& \textbf{FLoRes+}\\
\midrule
aar & Latn & Afro-Asiatic & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; (R1) & $\times$ \\ abl & Latn & Austronesian & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; (R2) & $\times$ \\ abz & Arab & Timor-Alor-Pantar & $\times$ & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; (R2) & $\times$ \\ ace & Arab & Austronesian & $\times$ & $\times$ & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ ace & Latn & Austronesian & $\times$ & $\times$ & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ acm & Arab & Afro-Asiatic & $\times$ & $\times$ & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ acq & Arab & Afro-Asiatic & $\times$ & $\times$ & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ aeb & Arab & Afro-Asiatic & $\times$ & $\times$ & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ afr & Latn & Indo-European & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; (R2) & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ agr & Latn & Chicham & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; (R1) & $\times$ \\ ahk & Thai & Sino-Tibetan & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ \\ aiq & Arab & Indo-European & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & $\times$ \\ akb & Latn & Austronesian & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; (R2) & $\times$ \\ als & Latn & Indo-European & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ amh & Ethi & Afro-Asiatic & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ ami & Latn & Austronesian & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; (R1) & $\times$ \\ ane & Latn & Austronesian & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & $\times$ \\ any & Latn & Atlantic-Congo & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; (R2) & $\times$ \\ apc & Arab & Afro-Asiatic & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; (R2) & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ arb & Arab & Afro-Asiatic & $\times$ & $\times$ & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ arb & Latn & Afro-Asiatic & $\times$ & $\times$ & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ arg & Latn & Indo-European & $\times$ & $\times$ & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ arh & Latn & Chibchan & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & $\times$ \\ arn & Latn & Araucanian & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & $\times$ \\ ars & Arab & Afro-Asiatic & $\times$ & $\times$ & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ ary & Arab & Afro-Asiatic & $\times$ & $\times$ & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ arz & Arab & Afro-Asiatic & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; (R1) & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ arz & Latn & Afro-Asiatic & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; (R1) & $\times$ \\ asm & Beng & Indo-European & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; (R2) & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ ast & Latn & Indo-European & $\times$ & $\times$ & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ ati & Latn & Atlantic-Congo & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ \\ awa & Deva & Indo-European & $\times$ & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; (R2) & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ ayr & Latn & Aymaran & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ ayz & Latn & Maybratic & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & $\times$ \\ azb & Arab & Turkic & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ azj & Latn & Turkic & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ azm & Latn & Otomanguean & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & $\times$ \\ azz & Latn & Uto-Aztecan & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ \\ bak & Cyrl & Turkic & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ bam & Latn & Mande & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; (R2) & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ ban & Latn & Austronesian & $\times$ & $\times$ & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ bas & Latn & Atlantic-Congo & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & $\times$ \\ bba & Latn & Atlantic-Congo & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ \\ bbc & Latn & Austronesian & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ \\ bcc & Arab & Indo-European & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; (R2) & $\times$ \\ bel & Cyrl & Indo-European & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; (R2) & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ bem & Latn & Atlantic-Congo & $\times$ & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; (R2) & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ ben & Beng & Indo-European & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; (R1, R2) & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ ben & Latn & Indo-European & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & $\times$ \\ bfa & Latn & Nilotic & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ \\ bft & Arab & Sino-Tibetan & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & $\times$ \\ bhb & Deva & Indo-European & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; (R2) & $\times$ \\ bho & Deva & Indo-European & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ bib & Latn & Mande & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ \\ bjn & Arab & Austronesian & $\times$ & $\times$ & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ bjn & Latn & Austronesian & $\times$ & $\times$ & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ blt & Latn & Tai-Kadai & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ \\ bod & Tibt & Sino-Tibetan & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ bom & Latn & Atlantic-Congo & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ \\ bos & Latn & Indo-European & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ bre & Latn & Indo-European & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; (R2) & $\times$ \\ brh & Arab & Dravidian & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & $\times$ \\ brx & Deva & Sino-Tibetan & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ bsh & Arab & Indo-European & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & $\times$ \\ bsk & Arab & Burushaski & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & $\times$ \\ bsq & Latn & Kru & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; (R2) & $\times$ \\ bug & Latn & Austronesian & $\times$ & $\times$ & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ bul & Cyrl & Indo-European & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ cak & Latn & Mayan & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & $\times$ \\ cat & Latn & Indo-European & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; (R2) & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ ceb & Latn & Austronesian & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; (R2) & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ ces & Latn & Indo-European & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; (R1) & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ che & Cyrl & Nakh-Daghestanian & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & $\times$ \\ chr & Cher & Iroquoian & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & $\times$ \\ chv & Cyrl & Turkic & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ cja & Arab & Austronesian & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & $\times$ \\ cjk & Latn & Atlantic-Congo & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ ckb & Arab & Indo-European & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; (R2) & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ ckl & Latn & Afro-Asiatic & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & $\times$ \\ cmn & Hans & Sino-Tibetan & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; (R1) & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ cmn & Hant & Sino-Tibetan & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; (R1) & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ crh & Latn & Turkic & $\times$ & $\times$ & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ crk & Cans & Algic & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; (R1) & $\times$ \\ crk & Latn & Algic & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & $\times$ \\ cux & Latn & Otomanguean & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & $\times$ \\ cym & Latn & Indo-European & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ dan & Latn & Indo-European & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ daq & Deva & Dravidian & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & $\times$ \\ dar & Cyrl & Nakh-Daghestanian & $\times$ & $\times$ & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ deu & Latn & Indo-European & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; (R1) & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ dga & Latn & Atlantic-Congo & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; (R2) & $\times$ \\ dgo & Deva & Indo-European & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\
dik & Latn & Nilotic & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; (R2) & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\
diq & Latn & Indo-European & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & $\times$ \\ div & Thaa & Indo-European & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & $\times$ \\ djc & Latn & Dajuic & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & $\times$ \\ dje & Latn & Songhay & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; (R1) & $\times$ \\ dnj & Latn & Mande & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ \\ dtm & Latn & Dogon & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & $\times$ \\ dts & Latn & Dogon & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & $\times$ \\ dua & Latn & Atlantic-Congo & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & $\times$ \\ dyu & Latn & Mande & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ dzo & Tibt & Sino-Tibetan & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ ekk & Latn & Uralic & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; (R2) & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ ell & Grek & Indo-European & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; (R1) & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ enb & Latn & Nilotic & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & $\times$ \\ eng & Latn & Indo-European & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; (R1, R2) & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ enl & Latn & Lengua-Mascoy & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & $\times$ \\ epo & Latn & Esperanto & $\times$ & $\times$ & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ eto & Latn & Atlantic-Congo & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & $\times$ \\ eus & Latn & Basque & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; (R2) & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ ewe & Latn & Atlantic-Congo & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ ewo & Latn & Atlantic-Congo & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & $\times$ \\ fao & Latn & Indo-European & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ fia & Copt & Nubian & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & $\times$ \\ fij & Latn & Austronesian & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ fil & Latn & Austronesian & $\times$ & $\times$ & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ fin & Latn & Uralic & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ fon & Latn & Atlantic-Congo & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\
fra & Latn & Indo-European & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; (R1, R2) & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\
fry & Latn & Indo-European & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; (R2) & $\times$ \\ fuc & Latn & Atlantic-Congo & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & $\times$ \\ fur & Latn & Indo-European & $\times$ & $\times$ & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\
fuv & Latn & Atlantic-Congo & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; (R2) & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\
fvr & Latn & Furan & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & $\times$ \\ gax & Latn & Afro-Asiatic & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & $\times$ \\ gaz & Latn & Afro-Asiatic & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; (R1) & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ gil & Latn & Austronesian & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; (R1) & $\times$ \\ gkp & Latn & Mande & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & $\times$ \\ gla & Latn & Indo-European & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ gle & Latn & Indo-European & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ glg & Latn & Indo-European & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ gom & Deva & Indo-European & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ gor & Latn & Austronesian & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ \\ grt & Latn & Sino-Tibetan & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ \\ guc & Latn & Arawakan & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; (R1) & $\times$ \\ gug & Latn & Tupian & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; (R2) & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ guj & Gujr & Indo-European & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ guz & Latn & Atlantic-Congo & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & $\times$ \\ gxx & Latn & Kru & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & $\times$ \\ hat & Latn & Indo-European & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; (R2) & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ hau & Latn & Afro-Asiatic & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; (R2) & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ heb & Hebr & Afro-Asiatic & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; (R2) & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ heh & Latn & Atlantic-Congo & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ \\ hig & Latn & Afro-Asiatic & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ \\ hin & Deva & Indo-European & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; (R1, R2) & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ hin & Latn & Indo-European & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; (R1) & $\times$ \\ hne & Deva & Indo-European & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ hrv & Latn & Indo-European & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; (R1) & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ hun & Latn & Uralic & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; (R1) & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ hve & Latn & Huavean & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & $\times$ \\ hye & Armn & Indo-European & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; (R2) & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ ibo & Latn & Atlantic-Congo & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; (R2) & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ ijc & Latn & Ijoid & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & $\times$ \\ ilo & Latn & Austronesian & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\
ind & Latn & Austronesian & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; (R1, R2) & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\
irk & Latn & Afro-Asiatic & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ \\ isl & Latn & Indo-European & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ ita & Latn & Indo-European & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; (R1, R2) & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ jav & Latn & Austronesian & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; (R1) & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ jmc & Latn & Atlantic-Congo & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ \\ jnj & Latn & Ta-Ne-Omotic & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & $\times$ \\ jpn & Jpan & Japonic & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; (R1) & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ kaa & Cyrl & Turkic & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; (R1) & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ kab & Latn & Afro-Asiatic & $\times$ & $\times$ & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ kac & Latn & Sino-Tibetan & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ kai & Latn & Afro-Asiatic & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & $\times$ \\ kal & Latn & Eskimo-Aleut & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; (R1) & $\times$ \\ kam & Latn & Atlantic-Congo & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ kan & Knda & Dravidian & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ kas & Arab & Indo-European & $\times$ & $\times$ & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ kas & Deva & Indo-European & $\times$ & $\times$ & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ kat & Geor & Kartvelian & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; (R2) & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ kaz & Cyrl & Turkic & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ kbp & Latn & Atlantic-Congo & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ kde & Latn & Atlantic-Congo & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ \\ kdj & Latn & Nilotic & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; (R2) & $\times$ \\ kea & Latn & Indo-European & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ kek & Latn & Mayan & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ \\ khk & Cyrl & Mongolic-Khitan & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ khm & Khmr & Austroasiatic & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; (R1) & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ khq & Latn & Songhay & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & $\times$ \\ khw & Latn & Indo-European & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & $\times$ \\ kik & Latn & Atlantic-Congo & $\times$ & $\times$ & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ kin & Latn & Atlantic-Congo & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; (R2) & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ kir & Cyrl & Turkic & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ kls & Arab & Indo-European & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & $\times$ \\ kmb & Latn & Atlantic-Congo & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ kmr & Latn & Indo-European & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ knc & Arab & Saharan & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; (R2) & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ knc & Latn & Saharan & $\times$ & $\times$ & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ knw & Latn & Kxa & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & $\times$ \\ kor & Kore & Koreanic & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; (R1) & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ krt & Latn & Saharan & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & $\times$ \\ kru & Deva & Dravidian & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; (R1) & $\times$ \\ ksf & Latn & Atlantic-Congo & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & $\times$ \\ ktu & Latn & Atlantic-Congo & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ kuj & Latn & Atlantic-Congo & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & $\times$ \\ kus & Latn & Atlantic-Congo & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ \\ kwy & Latn & Atlantic-congo & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & $\times$ \\ kxp & Arab & Indo-European & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & $\times$ \\ lao & Laoo & Tai-Kadai & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ led & Latn & Central Sudanic & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & $\times$ \\ lgg & Latn & Central Sudanic & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ \\ lia & Latn & Atlantic-Congo & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ \\ lij & Latn & Indo-European & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; (R1) & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ lim & Latn & Indo-European & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ lin & Latn & Atlantic-Congo & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; (R1, R2) & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ lir & Latn & Pidgin & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; (R2) & $\times$ \\ lit & Latn & Indo-European & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ lld & Latn & Indo-European & $\times$ & $\times$ & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ lmo & Latn & Indo-European & $\times$ & $\times$ & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ loa & Latn & North Halmahera & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & $\times$ \\ loh & Latn & Surmic & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & $\times$ \\ lon & Latn & Atlantic-Congo & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ \\ ltg & Latn & Indo-European & $\times$ & $\times$ & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ ltz & Latn & Indo-European & $\times$ & $\times$ & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ lua & Latn & Atlantic-Congo & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; (R2) & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ lug & Latn & Atlantic-Congo & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ luo & Latn & Nilotic & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; (R2) & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ lus & Latn & Sino-Tibetan & $\times$ & $\times$ & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ lvs & Latn & Indo-European & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ mad & Latn & Austronesian & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; (R2) & $\times$ \\ maf & Latn & Afro-Asiatic & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & $\times$ \\ mag & Deva & Indo-European & $\times$ & $\times$ & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ mah & Latn & Austronesian & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ \\ mai & Deva & Indo-European & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ mak & Latn & Austronesian & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ \\ mal & Mlym & Dravidian & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; (R2) & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ mam & Latn & Mayan & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ \\ mar & Deva & Indo-European & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; (R2) & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ mas & Latn & Nilotic & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & $\times$ \\ men & Latn & Mande & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ \\ mey & Latn & Afro-Asiatic & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & $\times$ \\ mfe & Latn & Indo-European & $\times$ & $\times$ & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ mhr & Cyrl & Uralic & $\times$ & $\times$ & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ mie & Latn & Otomanguean & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & $\times$ \\ mim & Latn & Otomanguean & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; (R2) & $\times$ \\ min & Arab & Austronesian & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; (R2) & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ min & Latn & Austronesian & $\times$ & $\times$ & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ mio & Latn & Otomanguean & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ \\ miq & Latn & Misumalpan & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ \\ mkd & Cyrl & Indo-European & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ mlt & Latn & Afro-Asiatic & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ mni & Beng & Sino-Tibetan & $\times$ & $\times$ & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ mni & Mtei & Sino-Tibetan & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; (R2) & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\
mos & Latn & Atlantic-Congo & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; (R2) & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\
mri & Latn & Austronesian & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ mrw & Latn & Austronesian & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ \\ mtq & Latn & Austroasiatic & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & $\times$ \\ mya & Mymr & Sino-Tibetan & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; (R1) & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ myv & Cyrl & Uralic & $\times$ & $\times$ & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ myx & Latn & Atlantic-Congo & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ \\ mzl & Latn & Mixe-Zoque & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & $\times$ \\ mzm & Latn & Atlantic-Congo & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ \\ naq & Latn & Khoe-Kwadi & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & $\times$ \\ nga & Latn & Atlantic-Congo & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ \\ ngl & Latn & Atlantic-Congo & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ \\ ngu & Latn & Uto-Aztecan & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ \\ nhe & Latn & Uto-Aztecan & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & $\times$ \\ nia & Latn & Austronesian & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ \\ nij & Latn & Austronesian & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ \\ nim & Latn & Atlantic-Congo & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ \\ nld & Latn & Indo-European & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; (R1, R2) & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ nlv & Latn & Uto-Aztecan & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; (R2) & $\times$ \\ nno & Latn & Indo-European & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ nob & Latn & Indo-European & $\times$ & $\times$ & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ npi & Deva & Indo-European & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; (R2) & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ nqo & Nkoo & N'Ko & $\times$ & $\times$ & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ nso & Latn & Atlantic-Congo & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; (R2) & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ nuj & Latn & Atlantic-Congo & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ \\ nus & Latn & Nilotic & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; (R2) & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ nya & Latn & Atlantic-Congo & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ nyy & Latn & Atlantic-Congo & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ \\ oci & Latn & Indo-European & $\times$ & $\times$ & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ ory & Orya & Indo-European & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ osi & Latn & Austronesian & $\times$ & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; (R2) & $\times$ \\ pag & Latn & Austronesian & $\times$ & $\times$ & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ pam & Latn & Austronesian & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ \\ pan & Guru & Indo-European & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ pap & Latn & Indo-European & $\times$ & $\times$ & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ pbs & Latn & Otomanguean & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & $\times$ \\ pbt & Arab & Indo-European & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; (R2) & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ pcm & Latn & Indo-European & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; (R2) & $\times$ \\ pes & Arab & Indo-European & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; (R1, R2) & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ plt & Latn & Austronesian & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ pol & Latn & Indo-European & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; (R1, R2) & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ por & Latn & Indo-European & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; (R1) & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ prs & Arab & Indo-European & $\times$ & $\times$ & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ quc & Latn & Mayan & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ \\ quh & Latn & Quechuan & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & $\times$ \\ quy & Latn & Quechuan & $\times$ & $\times$ & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ quz & Latn & Quechuan & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & $\times$ \\ rhg & Rohg & Indo-European & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ \\ rim & Latn & Atlantic-Congo & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ \\ rmy & Latn & Indo-European & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ \\ rob & Latn & Austronesian & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & $\times$ \\ roh & Latn & Indo-European & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & $\times$ \\ ron & Latn & Indo-European & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; (R1) & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ run & Latn & Atlantic-Congo & $\times$ & $\times$ & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ rus & Cyrl & Indo-European & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; (R1, R2) & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ sag & Latn & Atlantic-Congo & $\times$ & $\times$ & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ san & Deva & Indo-European & $\times$ & $\times$ & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ sat & Olck & Austroasiatic & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ sba & Latn & Central Sudanic & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; (R1) & $\times$ \\ scn & Latn & Indo-European & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ sgc & Latn & Nilotic & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & $\times$ \\ shk & Latn & Nilotic & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ \\ shn & Mymr & Tai-Kadai & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ sif & Latn & Siamou & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & $\times$ \\ sin & Sinh & Indo-European & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ skr & Arab & Indo-European & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & $\times$ \\ slk & Latn & Indo-European & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ slv & Latn & Indo-European & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ sme & Latn & Uralic & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & $\times$ \\ smo & Latn & Austronesian & $\times$ & $\times$ & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ sna & Latn & Atlantic-congo & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ snd & Arab & Indo-European & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ snd & Deva & Indo-European & $\times$ & $\times$ & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ som & Latn & Afro-Asiatic & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ sot & Latn & Atlantic-Congo & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; (R2) & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\
spa & Latn & Indo-European & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; (R1, R2) & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\
sro & Latn & Indo-European & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & $\times$ \\ srd & Latn & Indo-European & $\times$ & $\times$ & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ srp & Cyrl & Indo-European & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ ssw & Latn & Atlantic-Congo & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; (R2) & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ sun & Latn & Austronesian & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ swe & Latn & Indo-European & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; (R1) & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\
swh & Latn & Atlantic-Congo & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; (R1, R2) & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\
syl & Beng & Indo-European & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ \\ szl & Latn & Indo-European & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; (R2) & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ taj & Deva & Sino-Tibetan & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ \\ tam & Latn & Dravidian & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & $\times$ \\ tam & Taml & Dravidian & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; (R2) & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ taq & Latn & Afro-Asiatic & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ taq & Tfng & Afro-Asiatic & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ tat & Cyrl & Turkic & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; (R2) & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ tda & Latn & Songhay & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; (R2) & $\times$ \\ tel & Latn & Dravidian & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ tel & Telu & Dravidian & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & $\times$ \\ tem & Latn & Atlantic-Congo & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ \\ teo & Latn & Nilotic & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ \\ tgk & Cyrl & Indo-European & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ tgl & Latn & Austronesian & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; (R1, R2) & $\times$ \\ tha & Thai & Tai-Kadai & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; (R1) & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\
tir & Ethi & Afro-Asiatic & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; (R1) & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\
toc & Latn & Totonacan & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & $\times$ \\ tpi & Latn & Indo-European & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ tpl & Latn & Otomanguean & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & $\times$ \\ tsg & Latn & Austronesian & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; (R2) & $\times$ \\ tsn & Latn & Atlantic-Congo & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; (R2) & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ tso & Latn & Atlantic-Congo & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; (R2) & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ tsz & Latn & Tarascan & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ tui & Latn & Atlantic-Congo & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & $\times$ \\ tuk & Latn & Turkic & $\times$ & $\times$ & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ tum & Latn & Atlantic-Congo & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ tur & Latn & Turkic & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; (R1) & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ twi & Latn & Atlantic-Congo & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ tyv & Cyrl & Turkic & $\times$ & $\times$ & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ tzh & Latn & Mayan & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ \\ tzm & Tfng & Afro-Asiatic & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; (R2) & $\times$ \\ tzo & Latn & Mayan & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; (R2) & $\times$ \\ uig & Arab & Turkic & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ ukr & Cyrl & Indo-European & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; (R1) & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ umb & Latn & Atlantic-Congo & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ urd & Arab & Indo-European & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; (R1) & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ urd & Latn & Indo-European & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & $\times$ \\ uzn & Latn & Turkic & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ uzs & Arab & Turkic & $\times$ & $\times$ & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ vec & Latn & Indo-European & $\times$ & $\times$ & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ ven & Latn & Atlantic-congo & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & $\times$ \\ vie & Latn & Austroasiatic & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; (R1) & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ wlv & Latn & Mataguayan & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & $\times$ \\ vmw & Latn & Atlantic-Congo& \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ war & Latn & Aystronesian & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; (R2) & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\
wol & Latn & Atlantic-Congo& \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; (R2) & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\
wsg & Deva & Dravidian & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ \\ wuu & Hans & Sino-Tibetan & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ xho & Latn & Atlantic-Congo & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; (R2) & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ xon & Latn & Atlantic-congo & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ \\ xsr & Deva & Sino-Tibetan & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ \\ xuu & Latn & Khoe-Kwadi & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & $\times$ \\ yao & Latn & Atlantic-Congo & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ \\ ybb & Latn & Atlantic-Congo & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ \\ ydd & Hebr & Indo-European & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ ydg & Arab & Indo-European & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & $\times$ \\ yor & Latn & Atlantic-Congo & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; (R1, R2) & $\times$ \\ yua & Latn & Mayan & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ \\ yue & Hant & Sino-Tibetan & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & $\times$ \\ zai & Latn & Otomanguean & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ & $\times$ \\ zgh & Tfng & Afro-Asiatic & $\times$ & $\times$ & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ zsm & Latn & Austronesian & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; (R1) & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\ zne & Latn & Atlantic-Congo & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & $\times$ \\ zul & Latn & Atlantic-Congo & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; & $\times$ & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; (R2) & \tikz\fill[scale=0.4](0, .35) -- (.25, 0) -- (1, .7) -- (.25, .15) -- cycle; \\
\bottomrule
\end{longtable}
References
[1] NLLB Team et al. (2024). Scaling neural machine translation to 200 languages. Nature. 630(8018). pp. 841–846. doi:10.1038/s41586-024-07335-x. https://doi.org/10.1038/s41586-024-07335-x.
[2] Siddhant et al. (2022). Towards the next 1000 languages in multilingual machine translation: Exploring the synergy between supervised and self-supervised learning. arXiv preprint arXiv:2201.03110.
[3] Duarte M. Alves et al. (2024). Tower: An Open Multilingual Large Language Model for Translation-Related Tasks.
[4] John Dang et al. (2024). Aya Expanse: Combining Research Breakthroughs for a New Multilingual Frontier. https://arxiv.org/abs/2412.04261.
[5] Gemma Team et al. (2025). Gemma 3 Technical Report. https://arxiv.org/abs/2503.19786.
[6] Omnilingual SONAR Team et al. (2026). Omnilingual SONAR: Cross-Lingual and Cross-Modal Sentence Embeddings Bridging Massively Multilingual Text and Speech. https://arxiv.org/abs/2603.16606.
[7] Omnilingual ASR Team et al. (2025). Omnilingual ASR: Open-Source Multilingual Speech Recognition for 1600+ Languages. https://arxiv.org/abs/2511.09690.
[8] Magueresse et al. (2020). Low-resource languages: A review of past work and future challenges. arXiv preprint arXiv:2006.07264.
[9] Jones et al. (2023). "GATITOS: Using a New Multilingual Lexicon for Low-resource Machine Translation". In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. pp. 371–405. doi:10.18653/v1/2023.emnlp-main.26. https://aclanthology.org/2023.emnlp-main.26/.
[10] Isaac Caswell et al. (2025). SMOL: Professionally translated parallel data for 115 under-represented languages. https://arxiv.org/abs/2502.12301.
[11] Guilherme Penedo et al. (2025). FineWeb2: One Pipeline to Scale Them All – Adapting Pre-Training Data Processing to Every Language. https://arxiv.org/abs/2506.20920.
[12] Stephan Oepen et al. (2025). HPLT 3.0: Very Large-Scale Multilingual Resources for LLM and MT. Mono- and Bi-lingual Data, Multilingual Evaluation, and Pre-Trained Models. https://arxiv.org/abs/2511.01066.
[13] Armel Zebaze et al. (2025). TopXGen: Topic-Diverse Parallel Data Generation for Low-Resource Machine Translation. https://arxiv.org/abs/2508.08680.
[14] Goyal et al. (2022). The flores-101 evaluation benchmark for low-resource and multilingual machine translation. Transactions of the Association for Computational Linguistics. 10. pp. 522–538.
[15] Singh et al. (2024). Aya Dataset: An Open-Access Collection for Multilingual Instruction Tuning. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). pp. 11521–11567. doi:10.18653/v1/2024.acl-long.620. https://aclanthology.org/2024.acl-long.620/.
[16] Emily Chang and Niyati Bafna (2025). ChiKhaPo: A Large-Scale Multilingual Benchmark for Evaluating Lexical Comprehension and Generation in Large Language Models. https://arxiv.org/abs/2510.16928.
[17] Jeff Good and Calvin Hendryx-Parker (2006). Modeling contested categorization in linguistic databases. In Proceedings of the EMELD 2006 Workshop on Digital Language Documentation: Tools and standards: The state of the art.
[18] Harald Hammarström et al. (2024). Glottolog 5.1.. https://glottolog.org/.
[19] SIL International (2025). Ethnologue: Languages of the World. Twenty-eighth edition.. Last accessed 2026-02-18. https://www.ethnologue.com/insights/how-many-languages/.
[20] Lewis, M. Paul and Simons, Gary F. (2010). Assessing endangerment: expanding Fishman’s GIDS. Revue roumaine de linguistique. 55(2). pp. 103–120.
[21] Kocmi et al. (2024). Findings of the WMT24 General Machine Translation Shared Task: The LLM Era Is Here but MT Is Not Solved Yet. In Proceedings of the Ninth Conference on Machine Translation. pp. 1–46. doi:10.18653/v1/2024.wmt-1.1. https://aclanthology.org/2024.wmt-1.1/.
[22] Kocmi et al. (2025). Findings of the WMT25 General Machine Translation Shared Task: Time to Stop Evaluating on Easy Test Sets. In Proceedings of the Tenth Conference on Machine Translation. pp. 355–413. https://aclanthology.org/2025.wmt-1.22/.
[23] Ankur Bapna et al. (2022). Building Machine Translation Systems for the Next Thousand Languages. https://arxiv.org/abs/2205.03983.
[24] Hynek Kydl'ıček et al. (2025). FinePDFs. https://huggingface.co/datasets/HuggingFaceFW/finepdfs.
[25] Kargaran et al. (2023). GlotLID: Language Identification for Low-Resource Languages. In Findings of the Association for Computational Linguistics: EMNLP 2023. pp. 6155–6218. doi:10.18653/v1/2023.findings-emnlp.410. https://aclanthology.org/2023.findings-emnlp.410/.
[26] Pratap et al. (2024). Scaling speech technology to 1,000+ languages. J. Mach. Learn. Res.. 25(1).
[27] Ma et al. (2025). Taxi1500: A Dataset for Multilingual Text Classification in 1500 Languages. In Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 2: Short Papers). pp. 414–439. doi:10.18653/v1/2025.naacl-short.36. https://aclanthology.org/2025.naacl-short.36/.
[28] Janeiro et al. (2025). MEXMA: Token-level objectives improve sentence representations. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). pp. 23960–23995. doi:10.18653/v1/2025.acl-long.1168. https://aclanthology.org/2025.acl-long.1168/.
[29] Jörg Tiedemann (2012). Parallel Data, Tools and Interfaces in OPUS. In Proceedings of the Eight International Conference on Language Resources and Evaluation (LREC'12).
[30] Jay Gala et al. (2023). IndicTrans2: Towards High-Quality and Accessible Machine Translation Models for all 22 Scheduled Indian Languages. Transactions on Machine Learning Research. https://openreview.net/forum?id=vfT4YuzAYA.
[31] Robinson et al. (2024). Kreyòl-MT: Building MT for Latin American, Caribbean and Colonial African Creole Languages. In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). pp. 3083–3110.
[32] De Gibert et al. (2025). Findings of the AmericasNLP 2025 Shared Tasks on Machine Translation, Creation of Educational Material, and Translation Metrics for Indigenous Languages of the Americas. In Proceedings of the Fifth Workshop on NLP for Indigenous Languages of the Americas (AmericasNLP). pp. 134–152. doi:10.18653/v1/2025.americasnlp-1.16. https://aclanthology.org/2025.americasnlp-1.16/.
[33] Elmadany et al. (2024). Toucan: Many-to-Many Translation for 150 African Language Pairs. In Findings of the Association for Computational Linguistics: ACL 2024. pp. 13189–13206. doi:10.18653/v1/2024.findings-acl.781. https://aclanthology.org/2024.findings-acl.781/.
[34] Haberland et al. (2024). Italian-Ligurian Machine Translation in Its Cultural Context. In Proceedings of the 3rd Annual Meeting of the Special Interest Group on Under-resourced Languages @ LREC-COLING 2024. https://aclanthology.org/2024.sigul-1.21.
[35] Alfari et al. (2023). Feriji: A French-Zarma Parallel Corpus, Glossary & Translator. https://github.com/27-GROUP/Feriji.
[36] Yankovskaya et al. (2023). Machine Translation for Low-resource Finno-Ugric Languages. In Proceedings of the 24th Nordic Conference on Computational Linguistics (NoDaLiDa). pp. 762–771. https://aclanthology.org/2023.nodalida-1.77/.
[37] Sennrich et al. (2016). Improving Neural Machine Translation Models with Monolingual Data. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). pp. 86–96. doi:10.18653/v1/P16-1009. https://aclanthology.org/P16-1009/.
[38] Edunov et al. (2018). Understanding Back-Translation at Scale. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. pp. 489–500. doi:10.18653/v1/D18-1045. https://aclanthology.org/D18-1045/.
[39] Currey et al. (2017). Copied Monolingual Data Improves Neural Machine Translation. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics.
[40] Liu et al. (2020). Multilingual Denoising Pre-training for Neural Machine Translation. Transactions of the Association for Computational Linguistics. 8. pp. 726–742. doi:10.1162/tacl_a_00343. https://aclanthology.org/2020.tacl-1.47/.
[41] Soto et al. (2020). Selecting Backtranslated Data from Multiple Sources for Improved Neural Machine Translation. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. pp. 3898–3908. doi:10.18653/v1/2020.acl-main.359. https://aclanthology.org/2020.acl-main.359/.
[42] Seamless-Communication (2025). Joint speech and text machine translation for up to 100 languages. Nature. 637. pp. 587–593. doi:10.1038/s41586-024-08359-z.
[43] Wang et al. (2025). From Tens of Hours to Tens of Thousands: Scaling Back-Translation for Speech Recognition. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. pp. 12461–12475. https://aclanthology.org/2025.emnlp-main.629/.
[44] Loubna Ben Allal et al. (2025). SmolLM2: When Smol Goes Big – Data-Centric Training of a Small Language Model. https://arxiv.org/abs/2502.02737.
[45] Frohmann et al. (2024). Segment any text: A universal approach for robust, efficient and adaptable sentence segmentation. arXiv preprint arXiv:2406.16678.
[46] Kargaran et al. (2023). GlotLID: Language Identification for Low-Resource Languages. In The 2023 Conference on Empirical Methods in Natural Language Processing. https://openreview.net/forum?id=dl4e3EBz5j.
[47] Grattafiori et al. (2024). The llama 3 herd of models. arXiv preprint arXiv:2407.21783.
[48] Resnik, Philip (1999). Mining the web for bilingual text. In Proceedings of the 37th annual meeting of the association for computational linguistics. pp. 527–534.
[49] Buck, Christian and Koehn, Philipp (2016). Findings of the wmt 2016 bilingual document alignment shared task. In Proceedings of the First Conference on Machine Translation: Volume 2, Shared Task Papers. pp. 554–563.
[50] Azpeitia et al. (2017). Weighted set-theoretic alignment of comparable sentences. In Proceedings of the 10th workshop on building and using comparable corpora. pp. 41–45.
[51] Hassan et al. (2018). Achieving human parity on automatic chinese to english news translation. arXiv preprint arXiv:1803.05567.
[52] Yang et al. (2019). Improving multilingual sentence embedding using bi-directional dual encoder with additive margin softmax. arXiv preprint arXiv:1902.08564.
[53] Sanjay Suryanarayanan et al. (2025). Pralekha: Cross-Lingual Document Alignment for Indic Languages. https://arxiv.org/abs/2411.19096.
[54] Ramesh et al. (2022). Samanantar: The largest publicly available parallel corpora collection for 11 indic languages. Transactions of the Association for Computational Linguistics. 10. pp. 145–162.
[55] Artetxe, Mikel and Schwenk, Holger (2019). Margin-based parallel corpus mining with multilingual sentence embeddings. In Proceedings of the 57th annual meeting of the Association for Computational Linguistics. pp. 3197–3203.
[56] Bañón et al. (2020). ParaCrawl: Web-scale acquisition of parallel corpora. In Proceedings of the 58th annual meeting of the association for computational linguistics. pp. 4555–4567.
[57] Al Ghussin et al. (2023). Exploring paracrawl for document-level neural machine translation. In Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics. pp. 1304–1310.
[58] Schwenk et al. (2021). CCMatrix: Mining billions of high-quality parallel sentences on the web. In Proceedings of the 59th annual meeting of the association for computational linguistics and the 11th international joint conference on natural language processing (volume 1: long papers). pp. 6490–6500.
[59] Schwenk et al. (2021). Wikimatrix: Mining 135m parallel sentences in 1620 language pairs from wikipedia. In Proceedings of the 16th conference of the European Chapter of the Association for Computational Linguistics: Main volume. pp. 1351–1361.
[60] Lozhkov et al. (2024). FineWeb-Edu: the Finest Collection of Educational Content. doi:10.57967/hf/2497. https://huggingface.co/datasets/HuggingFaceFW/fineweb-edu.
[61] Johnson et al. (2019). Billion-scale similarity search with GPUs. IEEE Transactions on Big Data. 7(3). pp. 535–547.
[62] Jegou et al. (2010). Product quantization for nearest neighbor search. IEEE transactions on pattern analysis and machine intelligence. 33(1). pp. 117–128.
[63] Andrews et al. (2022). stopes-Modular Machine Translation Pipelines. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing: System Demonstrations. pp. 258–265.
[64] Hoang et al. (2018). Iterative back-translation for neural machine translation. In Proceedings of the 2nd workshop on neural machine translation and generation. pp. 18–24.
[65] Brimacombe, Benjamin and Zhou, Jiawei (2023). Quick back-translation for unsupervised machine translation. arXiv preprint arXiv:2312.00912.
[66] Kocmi, Tom and Federmann, Christian (2023). GEMBA-MQM: Detecting translation quality error spans with GPT-4. arXiv preprint arXiv:2310.13988.
[67] Yu et al. (2022). Beyond Counting Datasets: A Survey of Multilingual Dataset Construction and Necessary Resources. In Findings of the Association for Computational Linguistics: EMNLP 2022. pp. 3725–3743. doi:10.18653/v1/2022.findings-emnlp.273. https://aclanthology.org/2022.findings-emnlp.273/.
[68] de Gibert et al. (2022). Quality versus quantity: Building catalan-english mt resources. In Proceedings of the 1st Annual Meeting of the ELRA/ISCA Special Interest Group on Under-Resourced Languages. pp. 59–69.
[69] Talukdar et al. (2023). Influence of Data Quality and Quantity on Assamese-Bodo Neural Machine Translation. In 2023 14th International Conference on Computing Communication and Networking Technologies (ICCCNT). pp. 1–5.
[70] Lin et al. (2022). Few-shot Learning with Multilingual Generative Language Models. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing. pp. 9019–9052. doi:10.18653/v1/2022.emnlp-main.616. https://aclanthology.org/2022.emnlp-main.616/.
[71] Garcia et al. (2023). The Unreasonable Effectiveness of Few-shot Learning for Machine Translation. In Proceedings of the 40th International Conference on Machine Learning. pp. 10867–10878. https://proceedings.mlr.press/v202/garcia23a.html.
[72] Kudugunta et al. (2023). Madlad-400: A multilingual and document-level large audited dataset. Advances in Neural Information Processing Systems. 36. pp. 67284–67296.
[73] Imani et al. (2023). Glot500: Scaling Multilingual Corpora and Language Models to 500 Languages. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). pp. 1082–1117.
[74] Kreutzer et al. (2022). Quality at a Glance: An Audit of Web-Crawled Multilingual Datasets. Transactions of the Association for Computational Linguistics. 10. pp. 50–72. http://dx.doi.org/10.1162/tacl_a_00447.
[75] Nekoto et al. (2020). Participatory research for low-resourced machine translation: A case study in african languages. In Findings of the Association for Computational Linguistics: EMNLP 2020. pp. 2144–2160.
[76] Mirzakhalov et al. (2021). A Large-Scale Study of Machine Translation in Turkic Languages. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. pp. 5876–5890. doi:10.18653/v1/2021.emnlp-main.475. https://aclanthology.org/2021.emnlp-main.475/.
[77] Bafna et al. (2022). Combining Noisy Semantic Signals with Orthographic Cues: Cognate Induction for the Indic Dialect Continuum. In Proceedings of the 26th Conference on Computational Natural Language Learning (CoNLL). pp. 110–131. doi:10.18653/v1/2022.conll-1.9. https://aclanthology.org/2022.conll-1.9/.
[78] Kumar et al. (2023). Machine translation by projecting text into the same phonetic-orthographic space using a common encoding. Sādhanā. 48(4). pp. 238.
[79] Adelani et al. (2021). The Effect of Domain and Diacritics in Yoruba–English Neural Machine Translation. In Proceedings of Machine Translation Summit XVIII: Research Track. pp. 61–75. https://aclanthology.org/2021.mtsummit-research.6/.
[80] Akpobi, Maro (2025). Yankari: Monolingual Yoruba Dataset. In Proceedings of the Sixth Workshop on African Natural Language Processing (AfricaNLP 2025). pp. 1–6. doi:10.18653/v1/2025.africanlp-1.1. https://aclanthology.org/2025.africanlp-1.1/.
[81] Ahmed et al. (2023). Enhancing Spanish-Quechua Machine Translation with Pre-Trained Models and Diverse Data Sources: LCT-EHU at AmericasNLP Shared Task. In Proceedings of the Workshop on Natural Language Processing for Indigenous Languages of the Americas (AmericasNLP). pp. 156–162. doi:10.18653/v1/2023.americasnlp-1.16. https://aclanthology.org/2023.americasnlp-1.16/.
[82] The Omnilingual MT Team et al. (2025). BOUQuET: dataset, Benchmark and Open initiative for Universal Quality Evaluation in Translation. https://arxiv.org/abs/2502.04314.
[83] Guerreiro et al. (2024). xcomet: Transparent machine translation evaluation through fine-grained error detection. Transactions of the Association for Computational Linguistics. 12. pp. 979–995.
[84] Juraska et al. (2024). MetricX-24: The Google Submission to the WMT 2024 Metrics Shared Task. In Proceedings of the Ninth Conference on Machine Translation. pp. 492–504. doi:10.18653/v1/2024.wmt-1.35. https://aclanthology.org/2024.wmt-1.35/.
[85] Deutsch et al. (2025). WMT24++: Expanding the Language Coverage of WMT24 to 55 Languages & Dialects. In Findings of the Association for Computational Linguistics: ACL 2025. pp. 12257–12284. doi:10.18653/v1/2025.findings-acl.634. https://aclanthology.org/2025.findings-acl.634/.
[86] Maillard et al. (2024). Findings of the WMT 2024 Shared Task of the Open Language Data Initiative. In Proceedings of the Ninth Conference on Machine Translation. pp. 110–117. doi:10.18653/v1/2024.wmt-1.4. https://aclanthology.org/2024.wmt-1.4/.
[87] Costa-jussà et al. (2024). 2m-belebele: Highly multilingual speech and american sign language comprehension dataset. arXiv preprint arXiv:2412.08274.
[88] Sainz et al. (2023). NLP Evaluation in trouble: On the Need to Measure LLM Data Contamination for each Benchmark. In Findings of the Association for Computational Linguistics: EMNLP 2023. pp. 10776–10787. doi:10.18653/v1/2023.findings-emnlp.722. https://aclanthology.org/2023.findings-emnlp.722/.
[89] Oh et al. (2025). Culture is Everywhere: A Call for Intentionally Cultural Evaluation. In Findings of the Association for Computational Linguistics: EMNLP 2025. pp. 19156–19168. https://aclanthology.org/2025.findings-emnlp.1043/.
[90] Melvin Johnson et al. (2017). Google's Multilingual Neural Machine Translation System: Enabling Zero-Shot Translation. Transactions of the Association for Computational Linguistics. 5. pp. 339–351. doi:10.1162/tacl_a_00065.
[91] Wenhao Zhu et al. (2024). Multilingual Machine Translation with Large Language Models: Empirical Results and Analysis. In Findings of the Association for Computational Linguistics: NAACL 2024. pp. 2765–2781. doi:10.18653/v1/2024.findings-naacl.176. https://aclanthology.org/2024.findings-naacl.176/.
[92] Sha et al. (2025). VEEF-Multi-LLM: Effective Vocabulary Expansion and Parameter Efficient Finetuning Towards Multilingual Large Language Models. In Proceedings of the 31st International Conference on Computational Linguistics. pp. 7963–7981. https://aclanthology.org/2025.coling-main.533/.
[93] Seungduk Kim et al. (2024). Efficient and Effective Vocabulary Expansion Towards Multilingual Large Language Models. https://arxiv.org/abs/2402.14714.
[94] David Spuler (2025). Vocabulary Expansion Survey. https://www.aussieai.com/research/vocab-expansion.
[95] Gee et al. (2022). Fast vocabulary transfer for language model compression. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing: Industry Track. pp. 409–416.
[96] Moroni et al. (2025). Optimizing LLMs for Italian: Reducing token fertility and enhancing efficiency through vocabulary adaptation. In Findings of the Association for Computational Linguistics: NAACL 2025. pp. 6646–6660.
[97] Ilya Loshchilov and Frank Hutter (2019). Decoupled Weight Decay Regularization. https://arxiv.org/abs/1711.05101.
[98] AI@Meta (2024). Llama 3 Model Card. https://github.com/meta-llama/llama3/blob/main/MODEL_CARD.md.
[99] Zhaopeng Feng et al. (2025). MT-R1-Zero: Advancing LLM-based Machine Translation via R1-Zero-like Reinforcement Learning. https://arxiv.org/abs/2504.10160.
[100] Jiaan Wang et al. (2025). DeepTrans: Deep Reasoning Translation via Reinforcement Learning. https://arxiv.org/abs/2504.10187.
[101] Qiying Yu et al. (2025). DAPO: An Open-Source LLM Reinforcement Learning System at Scale. https://arxiv.org/abs/2503.14476.
[102] Patrick Lewis et al. (2020). Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. Advances in Neural Information Processing Systems. 33. pp. 9459–9474.
[103] Harsha Vardhan et al. (2022). Low resource retrieval augmented adaptive neural machine translation. https://www.amazon.science/publications/low-resource-retrieval-augmented-adaptive-neural-machine-translation.
[104] Aharoni et al. (2019). Massively Multilingual Neural Machine Translation. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). pp. 3874–3884. doi:10.18653/v1/N19-1388. https://aclanthology.org/N19-1388/.
[105] Pfeiffer et al. (2022). Lifting the Curse of Multilinguality by Pre-training Modular Transformers. In Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. pp. 3479–3495. doi:10.18653/v1/2022.naacl-main.255. https://aclanthology.org/2022.naacl-main.255/.
[106] Belen Alastruey et al. (2025). Interference Matrix: Quantifying Cross-Lingual Interference in Transformer Encoders. https://arxiv.org/abs/2508.02256.
[107] Licht et al. (2022). Consistent Human Evaluation of Machine Translation across Language Pairs. In Proceedings of the 15th biennial conference of the Association for Machine Translation in the Americas (Volume 1: Research Track). pp. 309–321. https://aclanthology.org/2022.amta-research.24/.
[108] Graham et al. (2013). Continuous Measurement Scales in Human Evaluation of Machine Translation. In Proceedings of the 7th Linguistic Annotation Workshop and Interoperability with Discourse. pp. 33–41. https://aclanthology.org/W13-2305/.
[109] Arle Lommel et al. (2024). The Multi-Range Theory of Translation Quality Measurement: MQM scoring models and Statistical Quality Control. https://arxiv.org/abs/2405.16969.
[110] Kocmi et al. (2024). Error Span Annotation: A Balanced Approach for Human Evaluation of Machine Translation. In Proceedings of the Ninth Conference on Machine Translation. pp. 1440–1453. doi:10.18653/v1/2024.wmt-1.131. https://aclanthology.org/2024.wmt-1.131/.
[111] Song et al. (2025). Enhancing Human Evaluation in Machine Translation with Comparative Judgement. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). pp. 20536–20551. doi:10.18653/v1/2025.acl-long.1002. https://aclanthology.org/2025.acl-long.1002/.
[112] Fomicheva et al. (2022). MLQE-PE: A Multilingual Quality Estimation and Post-Editing Dataset. In Proceedings of the Thirteenth Language Resources and Evaluation Conference. pp. 4963–4974. https://aclanthology.org/2022.lrec-1.530/.
[113] Sai B et al. (2023). IndicMT Eval: A Dataset to Meta-Evaluate Machine Translation Metrics for Indian Languages. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). pp. 14210–14228. doi:10.18653/v1/2023.acl-long.795. https://aclanthology.org/2023.acl-long.795/.
[114] Guerreiro et al. (2024). xcomet: Transparent Machine Translation Evaluation through Fine-grained Error Detection. Transactions of the Association for Computational Linguistics. 12. pp. 979–995. doi:10.1162/tacl_a_00683. https://aclanthology.org/2024.tacl-1.54/.
[115] Conneau et al. (2020). Unsupervised cross-lingual representation learning at scale. In Proceedings of the 58th annual meeting of the association for computational linguistics. pp. 8440–8451.
[116] Xue et al. (2021). mT5: A Massively Multilingual Pre-trained Text-to-Text Transformer. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. pp. 483–498. doi:10.18653/v1/2021.naacl-main.41. https://aclanthology.org/2021.naacl-main.41/.
[117] Lommel et al. (2013). Multidimensional quality metrics: a flexible system for assessing translation quality. In Proceedings of Translating and the Computer 35. https://aclanthology.org/2013.tc-1.6/.
[118] Dale, David and Costa-jussà, Marta R. (2024). BLASER 2.0: a metric for evaluation and quality estimation of massively multilingual speech and text translation. In Findings of the Association for Computational Linguistics: EMNLP 2024. pp. 16075–16085. doi:10.18653/v1/2024.findings-emnlp.943. https://aclanthology.org/2024.findings-emnlp.943/.
[119] Paul-Ambroise Duquenne et al. (2023). SONAR: Sentence-Level Multimodal and Language-Agnostic Representations. https://arxiv.org/abs/2308.11466.
[120] Specia et al. (2013). QuEst – A Translation Quality Estimation Framework. In Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics. pp. 123–128.
[121] Rei et al. (2021). QT21: A New Benchmark for Quality Estimation. In Proceedings of the Sixth Conference on Machine Translation (WMT). pp. 345–355.
[122] Rei et al. (2020). COMET: A Neural Framework for MT Evaluation. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). pp. 3165–3175.
[123] Rei et al. (2022). SentSim: Sentence‑Level Similarity for MT Evaluation. In Proceedings of the Seventh Conference on Machine Translation (WMT). pp. 123–133.
[124] Thompson et al. (2020). PRISM: A Reference‑Free Metric for Machine Translation. In Proceedings of the Fifth Conference on Machine Translation (WMT). pp. 456–466.
[125] Lu et al. (2023). InstructScore: Evaluating Translation Quality via Instruction Following. arXiv preprint arXiv:2305.14282.
[126] Kumar et al. (2023). GPT‑QE: Zero‑Shot Quality Estimation with Large Language Models. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics. pp. 789–796.
[127] Fernandes et al. (2023). Ensemble Methods for Machine Translation Quality Estimation. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics. pp. 567–574.
[128] Liu et al. (2021). OpenKi: An Open‑Source Toolkit for Quality Estimation. Journal of Machine Translation. 35(2). pp. 123–138.
[129] Blain et al. (2023). Findings of the WMT 2023 Shared Task on Quality Estimation. In Proceedings of the Eighth Conference on Machine Translation. pp. 629–653. doi:10.18653/v1/2023.wmt-1.52. https://aclanthology.org/2023.wmt-1.52/.
[130] Zerva et al. (2024). Findings of the Quality Estimation Shared Task at WMT 2024: Are LLMs Closing the Gap in QE?. In Proceedings of the Ninth Conference on Machine Translation. pp. 82–109. doi:10.18653/v1/2024.wmt-1.3. https://aclanthology.org/2024.wmt-1.3/.
[131] Dan Hendrycks and Kevin Gimpel (2016). Bridging Nonlinearities and Stochastic Regularizers with Gaussian Error Linear Units. CoRR. abs/1606.08415. http://arxiv.org/abs/1606.08415.
[132] Papineni et al. (2002). BLEU: a Method for Automatic Evaluation of Machine Translation. Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics. pp. 311–318. https://aclanthology.org/P02-1040.
[133] Popović, Maja (2015). chrF: character n-gram F-score for automatic MT evaluation. Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing. pp. 392–395. https://aclanthology.org/D15-1047.
[134] Satanjeev Banerjee and Alon Lavie (2005). METEOR: An Automatic Metric for MT Evaluation with Improved Correlation with Human Judgments. Proceedings of the ACL Workshop on Intrinsic and Extrinsic Evaluation Measures for Machine Translation and/or Summarization. pp. 65–72. https://aclanthology.org/W05-0908.
[135] Thibault Sellam et al. (2020). BLEURT: Learning Robust Metrics for Machine Translation Evaluation. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. pp. 1281–1292. doi:10.18653/v1/2020.acl-main.116. https://aclanthology.org/2020.acl-main.116.
[136] Rei et al. (2022). CometKiwi: IST-Unbabel 2022 Submission for the Quality Estimation Shared Task. In Proceedings of the Seventh Conference on Machine Translation (WMT). pp. 634–645. https://aclanthology.org/2022.wmt-1.60/.
[137] Lavie et al. (2025). Findings of the WMT25 Shared Task on Automated Translation Evaluation Systems: Linguistic Diversity is Challenging and References Still Help. In Proceedings of the Tenth Conference on Machine Translation. pp. 436–483. doi:10.18653/v1/2025.wmt-1.24. https://aclanthology.org/2025.wmt-1.24/.
[138] García Gilabert et al. (2024). ReSeTOX: Re-learning attention weights for toxicity mitigation in machine translation. In Proceedings of the 25th Annual Conference of the European Association for Machine Translation (Volume 1). pp. 37–58. https://aclanthology.org/2024.eamt-1.8/.
[139] Ian Kivlichan et al. (2020). Jigsaw Multilingual Toxic Comment Classification. Kaggle. https://kaggle.com/competitions/jigsaw-multilingual-toxic-comment-classification.
[140] Dementieva et al. (2025). Multilingual and Explainable Text Detoxification with Parallel Corpora. In Proceedings of the 31st International Conference on Computational Linguistics. pp. 7998–8025. https://aclanthology.org/2025.coling-main.535/.
[141] Costa-jussà et al. (2023). Toxicity in Multilingual Machine Translation at Scale. In Findings of the Association for Computational Linguistics: EMNLP 2023. pp. 9570–9586. doi:10.18653/v1/2023.findings-emnlp.642. https://aclanthology.org/2023.findings-emnlp.642/.
[142] Costa-jussà et al. (2024). MuTox: Universal MUltilingual Audio-based TOXicity Dataset and Zero-shot Detector. In Findings of the Association for Computational Linguistics: ACL 2024. pp. 5725–5734. doi:10.18653/v1/2024.findings-acl.340. https://aclanthology.org/2024.findings-acl.340/.
[143] Tan et al. (2025). Towards Massive Multilingual Holistic Bias. In Proceedings of the 6th Workshop on Gender Bias in Natural Language Processing (GeBNLP). pp. 403–426. doi:10.18653/v1/2025.gebnlp-1.35. https://aclanthology.org/2025.gebnlp-1.35/.
[144] Upadhayay, Bibek and Behzadan, Vahid (2023). Taco: Enhancing cross-lingual transfer for low-resource languages in llms through translation-assisted chain-of-thought processes. arXiv preprint arXiv:2311.10797.
[145] Frohmann et al. (2024). Segment Any Text: A Universal Approach for Robust, Efficient and Adaptable Sentence Segmentation. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. pp. 11908–11941. doi:10.18653/v1/2024.emnlp-main.665. https://aclanthology.org/2024.emnlp-main.665/.
[146] Paul-Ambroise Duquenne et al. (2023). SONAR: Sentence-Level Multimodal and Language-Agnostic Representations. https://arxiv.org/abs/2308.11466.
[147] Qi et al. (2020). Stanza: A Python Natural Language Processing Toolkit for Many Human Languages. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics: System Demonstrations. pp. 101–108. doi:10.18653/v1/2020.acl-demos.14. https://aclanthology.org/2020.acl-demos.14/.
[148] Alves et al. (2024). Tower: An open multilingual large language model for translation-related tasks. arXiv preprint arXiv:2402.17733.
[149] Thomas Wolf et al. (2020). HuggingFace's Transformers: State-of-the-art Natural Language Processing.
[150] Micikevicius et al. (2017). Mixed precision training. arXiv preprint arXiv:1710.03740.
[151] Dao, Tri (2023). Flashattention-2: Faster attention with better parallelism and work partitioning. arXiv preprint arXiv:2307.08691.
[152] Klein et al. (2020). Efficient and high-quality neural machine translation with OpenNMT. In Proceedings of the fourth workshop on neural generation and translation. pp. 211–217.
[153] Kwon et al. (2023). Efficient memory management for large language model serving with pagedattention. In Proceedings of the 29th symposium on operating systems principles. pp. 611–626.
[154] Stap, David and Araabi, Ali (2023). ChatGPT is not a good indigenous translator. In Proceedings of the Workshop on Natural Language Processing for Indigenous Languages of the Americas (AmericasNLP). pp. 163–167. doi:10.18653/v1/2023.americasnlp-1.17. https://aclanthology.org/2023.americasnlp-1.17/.
[155] Scalvini et al. (2025). Rethinking Low-Resource MT: The Surprising Effectiveness of Fine-Tuned Multilingual Models in the LLM Age. In Proceedings of the Joint 25th Nordic Conference on Computational Linguistics and 11th Baltic Conference on Human Language Technologies (NoDaLiDa/Baltic-HLT 2025). pp. 609–621. https://aclanthology.org/2025.nodalida-1.62/.
[156] Tanzer et al. (2023). A benchmark for learning to translate a new language from one grammar book. arXiv preprint arXiv:2309.16575.
[157] Kornilov, Albert and Shavrina, Tatiana (2024). From mteb to mtob: Retrieval-augmented classification for descriptive grammars. arXiv preprint arXiv:2411.15577.
[158] Zhang et al. (2024). Hire a linguist!: Learning endangered languages in LLMs with in-context linguistic descriptions. In Findings of the Association for Computational Linguistics ACL 2024. pp. 15654–15669.
[159] Hus, Jonathan and Anastasopoulos, Antonios (2024). Back to school: Translation using grammar books. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. pp. 20207–20219.
[160] Hus et al. (2025). Machine translation using grammar materials for llm post-correction. In Proceedings of the Fifth Workshop on NLP for Indigenous Languages of the Americas (AmericasNLP). pp. 92–99.
[161] Dale, David and Costa-jussà, Marta R (2024). Blaser 2.0: a metric for evaluation and quality estimation of massively multilingual speech and text translation. In Findings of the Association for Computational Linguistics: EMNLP 2024. pp. 16075–16085.
[162] Banerjee, Satanjeev and Lavie, Alon (2005). METEOR: An automatic metric for MT evaluation with improved correlation with human judgments. In Proceedings of the acl workshop on intrinsic and extrinsic evaluation measures for machine translation and/or summarization. pp. 65–72.
[163] Snover et al. (2006). A Study of Translation Edit Rate with Targeted Human Annotation. In Proceedings of the 7th Conference of the Association for Machine Translation in the Americas. pp. 223–231.
[164] Taguchi et al. (2025). Languages Still Left Behind: Toward a Better Multilingual Machine Translation Benchmark. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. pp. 20142–20154.
[165] Jumashev et al. (2025). The Kyrgyz Seed Dataset Submission to the WMT25 Open Language Data Initiative Shared Task. In Proceedings of the Tenth Conference on Machine Translation. pp. 1088–1102. doi:10.18653/v1/2025.wmt-1.84. https://aclanthology.org/2025.wmt-1.84/.