QJL: 1-Bit Quantized JL Transform for KV Cache Quantization with Zero Overhead
Amir Zandieh
Independent Researcher
[email protected]
Majid Daliri
New York University
[email protected]
Insu Han$^*$
Adobe Research
[email protected]
July 19, 2024
$^*$ Work done while at Yale University.
Abstract
Serving LLMs requires substantial memory due to the storage requirements of Key-Value (KV) embeddings in the KV cache, which grows with sequence length. An effective approach to compress KV cache is quantization. However, traditional quantization methods face significant memory overhead due to the need to store quantization constants (at least a zero point and a scale) in full precision per data block. Depending on the block size, this overhead can add 1 or 2 bits per quantized number. We introduce QJL, a new quantization approach that consists of a Johnson-Lindenstrauss (JL) transform followed by sign-bit quantization. In contrast to existing methods, QJL eliminates memory overheads by removing the need for storing quantization constants. We propose an asymmetric estimator for the inner product of two vectors and demonstrate that applying QJL to one vector and a standard JL transform without quantization to the other provides an unbiased estimator with minimal distortion. We have developed an efficient implementation of the QJL sketch and its corresponding inner product estimator, incorporating a lightweight CUDA kernel for optimized computation. When applied across various LLMs and NLP tasks to quantize the KV cache to only 3 bits, QJL demonstrates a more than fivefold reduction in KV cache memory usage without compromising accuracy, all while achieving faster runtime. Codes are available at https://github.com/amirzandieh/QJL.
Executive Summary: Large language models (LLMs) power applications like chatbots, image generation, and coding assistants, but their deployment faces a major hurdle: the key-value (KV) cache, which stores embeddings from previous tokens, consumes vast amounts of memory as sequences lengthen. This cache grows linearly with input size, straining GPU resources, slowing inference speeds, and limiting the ability to handle long contexts—critical for tasks like summarizing documents or answering multi-turn questions. With millions of users demanding low-latency responses, reducing KV cache memory without losing model accuracy has become urgent to cut costs and scale services.
This document introduces QJL, a novel quantization technique, to compress the KV cache efficiently. The goal is to evaluate and demonstrate a method that shrinks memory use dramatically while preserving the model's performance in natural language processing tasks, outperforming existing approaches that incur extra storage costs for calibration data.
The authors developed QJL by combining a random projection technique—known as the Johnson-Lindenstrauss transform—with simple sign-bit quantization on key embeddings. They project keys into a lower-dimensional space using a random matrix, then reduce each projected value to a single bit (positive or negative sign), storing only these bits plus the key's norm. For accurate attention scores, they use a specialized estimator to compute inner products between the current query (kept full precision) and quantized keys, ensuring unbiased results with low distortion. Values in the cache receive straightforward per-token quantization to a few bits. To handle larger values in deeper model layers, they separate and quantize outlier channels with extra bits. The method assumes bounded embedding sizes, typical in LLMs, and was implemented with custom CUDA kernels for GPU efficiency. Experiments ran on models like Llama-2 (7 billion parameters) and Llama-3 (8 billion parameters), using datasets from LongBench for long-context tasks and LM-eval for standard ones, with sequences up to 32,000 tokens, over a recent period on A100 GPUs.
Key results show QJL quantizes the KV cache to just 3 bits per original floating-point number—versus 16 bits in the baseline—cutting memory use by over five times, or about 81% overall. This holds across layers without accuracy loss: on long-context question-answering tasks like NarrativeQA and Qasper from LongBench, QJL matched or exceeded the full-precision baseline's F1 scores and beat competitors like KIVI and KVQuant. For shorter tasks such as HellaSwag or MMLU, accuracy stayed comparable to the original, sometimes slightly better. Runtime improved too: prompt encoding and token generation were as fast as or faster than the baseline for sequences over 1,000 tokens, with no slowdown from overhead, unlike other methods that added 1-2 bits per value for calibration.
These findings mean QJL enables LLMs to process much longer inputs on existing hardware, reducing inference costs by minimizing memory bandwidth and GPU idle time, while maintaining output quality for real-world uses like extended conversations or analysis. It addresses a flaw in prior quantization by eliminating extra storage for scales and offsets, avoiding up to 20% wasted space in comparisons. Surprisingly, the 1-bit core performs as well as higher-bit alternatives, thanks to mathematical guarantees on distortion, making it more reliable than data-tuned methods that falter on unseen inputs.
Leaders should prioritize integrating QJL into LLM serving pipelines, starting with open models like Llama, to deploy longer-context capabilities without hardware upgrades. For production, test it on proprietary systems, balancing the fixed 3-bit setup against rare cases needing more bits for outliers. Further steps include broader pilots on diverse tasks and models, plus full CUDA optimization to boost speed by another 10-20%. If scaling to extreme lengths (over 100,000 tokens), validate norm assumptions.
While QJL's proofs and tests build high confidence in its low-distortion claims for tested setups, limitations include reliance on detecting outliers during prompts (adding minor preprocessing) and untested edge cases like highly variable norms across model architectures. Results may vary on non-standard LLMs, so caution applies until more diverse evaluations confirm generalizability.
1 Introduction
Section Summary: Large language models have become incredibly powerful for tasks like chatbots, image generation, and coding assistance, thanks to their underlying Transformer architecture, but they face big challenges when generating text for many users at once, especially due to the massive memory needed to store key-value caches for long sequences. Existing solutions, such as reducing attention heads, pruning tokens, or quantizing data to fewer bits, often require model retraining or add extra memory overhead from storing calibration values. This paper proposes QJL, a simple sketching method that uses random projections and sign-bit quantization on key embeddings to cut memory use dramatically without losing accuracy, no tuning needed, and zero extra overhead.
Large language models (LLMs) have garnered significant attention and demonstrated remarkable success in recent years. Their applications span various domains, including chatbot systems [1, 2] to text-to-image [3, 4, 5], text-to-video synthesis [6], coding assistant [7] and even multimodal domain across text, audio, image, and video [8]. The Transformer architecture with self-attention mechanism [9] is at the heart of these LLMs as it enables capturing intrinsic pairwise correlations across tokens in the input sequence. The ability of LLMs grows along with their model size [10], which leads to computational challenges in terms of huge memory consumption.
Deploying auto-regressive transformers during the generation phase is costly because commercial AI models must simultaneously serve millions of end users while meeting strict latency requirements. One significant challenge is the substantial memory needed to store all previously generated key-value (KV) embeddings in cache to avoid recomputations. This has become a major memory and speed bottleneck, especially for long context lengths. Additionally, the GPU must load the entire KV cache from its main memory to shared memory for each token generated, resulting in low arithmetic intensity and leaving most GPU threads idle. Therefore, reducing the KV cache size while maintaining accuracy is crucial.
There are several approaches to address this challenge. One method involves reducing the number of heads in the KV cache using multi-query attention [11] and multi-group attention [12], but these require fine-tuning the pre-trained models or training from scratch. Another line of work tries to reduce the KV cache size by pruning or evicting unimportant tokens [13, 14, 15, 16]. Additionally, some recent works tackle the issue from a system perspective, such as offloading [17] or using virtual memory and paging techniques in the attention mechanism [18].
A simple yet effective approach is to quantize the floating-point numbers (FPN) in the KV cache using fewer bits. Several quantization methods have been proposed specifically for the KV cache [19, 20, 21, 22, 23]. Most recently, KIVI [24] and KVQuant [25] proposed per-channel quantization for the key cache to achieve better performance. However, all existing quantization methods for the KV cache face significant "memory overhead" issues. Specifically, all these methods group the data into blocks, either channel-wise or token-wise, and calculate and store quantization constants (at least a zero point and a scale) for each group. Depending on the group size, this overhead can add approximately 1 or 2 additional bits per quantized number, which results in significant computational overhead. In this work, our goal is to develop an efficient, data-oblivious quantization method, referred to as a sketching technique. This method, which we call QJL, does not need to be tuned by or adapted to the input data with significantly less overhead than prior works, without any loss in performance.
:::: {cols="1"}
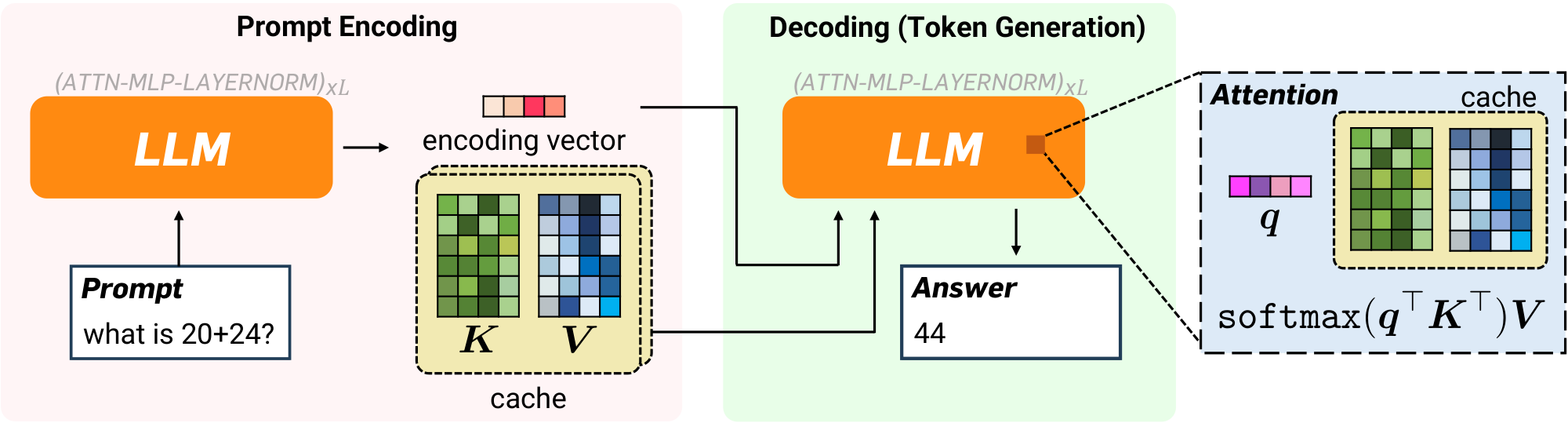
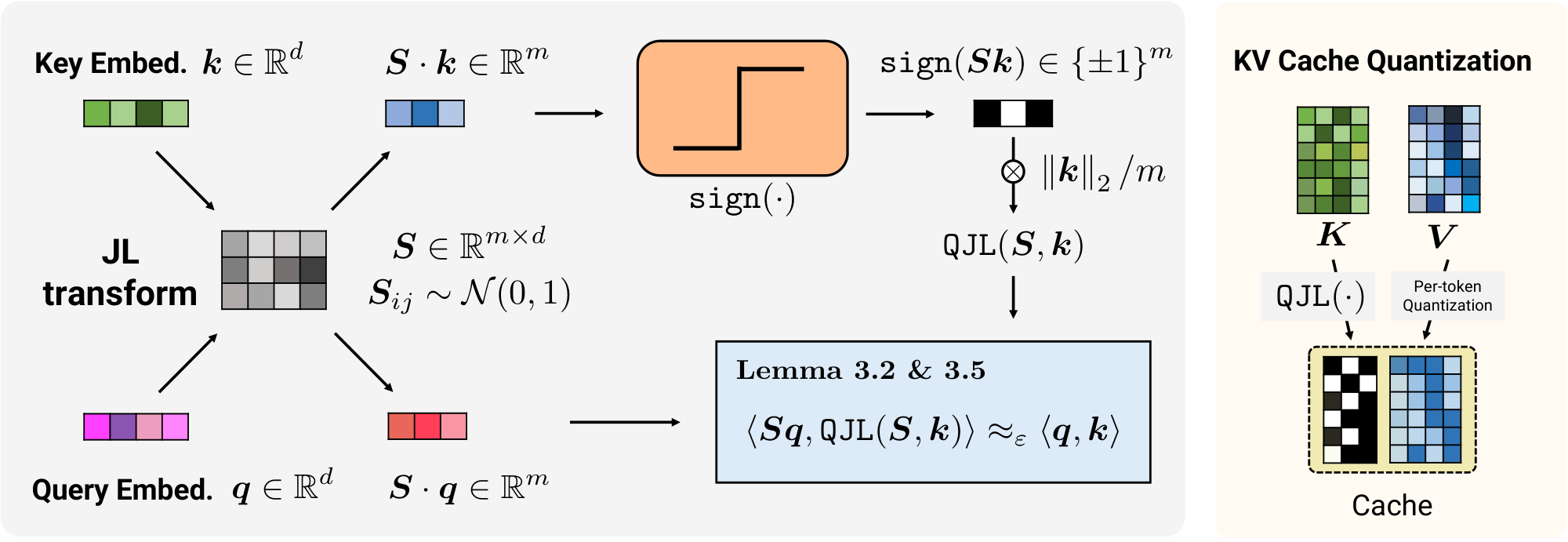
Figure 1: Overview of the KV cache quantization via Quantized JL (QJL) transform ::::
1.1 Overview of Contributions
The decoding phase in the attention mechanism involves the following computations: (1) computing attention scores by applying the softmax function to the inner product between the current query embedding and all previously generated keys, and (2) multiplying the attention scores with all previously generated values. To make the attention score calculations in step (1) more memory efficient, we quantize the keys in the cache. We introduce a quantization scheme for key embeddings, named QJL, leveraging randomized sketching techniques. Alongside, we develop a high-accuracy estimator for the inner product of query/key pairs, crucial for mitigating errors amplified by the softmax operation in attention score calculations.
Firstly, we revisit a fundamental concept in numerical linear algebra: applying a Johnson-Lindenstrauss (JL) transform, i.e., a random Gaussian projection, to a pair of vectors and then computing the inner product of the projected vectors provides an unbiased and low-distortion estimator for their original inner product [26]. To address the key cache quantization problem, our aim is to quantize the result after applying the JL transform to a key embedding, ideally to just a single bit. Surprisingly, we prove that by applying the JL transform to a key embedding and then quantizing the result to a single bit (the sign bit), while applying the same JL transform to the query embedding without quantization, we still obtain an unbiased estimator of their inner product (see Lemma 2). Moreover, the distortion of this estimator is small and comparable to that of the standard JL transform (see Lemma 5). In Theorem 6, we demonstrate that the proposed inner product estimator based on QJL achieves a relative distortion of $1\pm\varepsilon$ on the final attention scores. Notably, the number of required bits for representing quantized keys is independent of the embedding dimension and scales logarithmically with the context length, using a fixed number of bits per token.
Thus the QJL sketch combines a JL transform—a random Gaussian projection—with quantization to the sign bit. An overview of this approach is illustrated in Figure 1. Unlike previous methods, the QJL sketch can quantize vectors with zero overhead because it does not require grouping the data and storing quantization constants (zeros and scales) per group. Furthermore, this is a data-oblivious algorithm that does not rely on specific input, requires no tuning, and can be easily parallelized and applied in real-time.
The value cache quantization used to make step (2) memory efficient is known to be a straightforward task, and a standard token-wise quantization is very effective and efficient in practice, as observed in prior work [24, 25]. Hence, we follow the same approach for the value therein.
Furthermore, we analyzed the distribution of outliers in large language models (LLMs). We observed that while there are no significant outliers in the initial layers, certain fixed key embedding channels (coordinates) in the deeper layers exhibit considerably larger magnitudes (see Figure 2). To address this, we identify these outlier channels during the prompt phase and simply apply two independent copies of our quantizer to the outliers and inliers separately.
The QJL transform and its accompanying inner product estimator are highly efficient and GPU-friendly algorithms. In particular, we provide a lightweight CUDA kernel for their efficient computation. We apply QJL and our inner product estimator to compress the KV cache in several LLMs, including Llama-2 [27] and its fine-tuned models by long sequence [28], under various NLP tasks. Our results show that quantizing the KV cache to only 3 bits per FPN results in no accuracy drop compared to the exact model with 16 bits per FPN while reducing cache memory usage by over fivefold and increasing the generation speed significantly for long contexts. For example, our proposed quantization shows better F1 scores on long-range question-answering tasks from LongBench [29] (a collection of long-context datasets) compared to the recent KV cache quantization methods, while minimizing memory overheads.
2 Preliminaries: Token Generation in Attention
Section Summary: When AI language models generate text one word at a time, they use a process called attention to weigh the importance of previous words, relying on stored representations known as key and value embeddings to avoid repeating calculations. These embeddings for all prior tokens must be kept in memory, which demands significant space and processing time, especially for lengthy inputs, as computing the attention involves checking similarities across everything so far. To address this, the section outlines the underlying math and proposes compressing the storage by simplifying or quantizing these embeddings.
Deploying auto-regressive language models for inference involves performing attention decoding in an online setting, where key and value embeddings from each transformer layer are cached in memory to remove redundant computations. The model sequentially uses and updates the KV cache to generate the next token, one at a time.
More precisely, in every phase of token generation, the stream of tokens is represented by a triplet of vectors called by the query, key, and value embeddings, respectively. Let ${\bm q}_i, {\bm k}_i, {\bm v}_i \in \mathbb{R}^d$ be the triplet at $i$-th generation phase and $n$ be the total number of tokens in the stream so far either in the prompt encoding (prefill) or the generation (decoding) phase. Then, the attention output in $n$-th generation phase can be written as
$ {\bm o}{n} = \sum{i \in [n]} {\tt Score}(i) \cdot {\bm v}_i,\tag{1} $
where ${\tt Score} \in \mathbb{R}^n$ is the vector of attention scores defined as:
$ {\tt Score} :={\tt softmax}\left([\langle {\bm q}_n, {\bm k}_1 \rangle, \langle {\bm q}_n, {\bm k}_2 \rangle, \ldots \langle {\bm q}_n, {\bm k}_n \rangle] \right).\tag{2} $
The output embedding ${\bm o}n$ will be used for computing the next tokens in the stream ${\bm q}{n+1}, {\bm k}{n+1}, {\bm v}{n+1}$ unless the generation phase terminates. Observe that to compute output ${\bm o}_n$, one needs to store all previous key and value embeddings ${{\bm k}_i, {\bm v}i}{i\in[n]}$ and keeping them in full precision requires significant memory for long-context inputs. The time complexity to compete Equation 2 is $O(nd)$ due to the computation of $n$ inner products. Additionally, the inference speed is also impacted by the KV cache size, as the KV cache must be loaded from GPU main memory for every token generated, resulting in low arithmetic intensity and underutilization of GPU cores [30]. In this work, we focus on compressing the KV cache by quantizing tokens, thereby reducing the memory required to store each key or value embedding in the cache.
3 Quantized Johnson-Lindenstrauss (QJL) Transform
Section Summary: To save memory when storing key-value caches in machine learning models, researchers propose transforming embedding vectors with a random projection technique called the Johnson-Lindenstrauss transform, which preserves the important inner products between queries and keys, followed by quantization to just a single sign bit for extreme compression. This creates a 1-bit version they call the Quantized Johnson-Lindenstrauss (QJL) transform, which applies the projection only to keys while keeping queries unquantized, allowing an asymmetric estimator to accurately approximate the original inner products. They prove this estimator is unbiased, meaning its average value over random projections exactly matches the true inner product, making it reliable for practical use.
Our goal is to save memory space for storing the KV cache while the inner product between query and key remains undistorted. To achieve this, we first transform the embedding vectors using a random projection that preserves the inner products, acting as a preconditioning step, and then quantize the result. Specifically, we project the input vectors onto a random subspace by applying the Johnson-Lindenstrauss (JL) transform [31], which amounts to multiplying by a random Gaussian matrix. The inner product of the resulting vectors after applying this projection provides an unbiased and low-distortion estimator for the inner product of the original vectors [26]. We introduce a 1-bit Johnson-Lindenstrauss transform, comprising a JL transformation followed by quantization to a single sign bit, and demonstrate its ability to offer an unbiased and low-distortion inner product estimator. We complement our binary quantizer by developing an unbiased estimator for the inner product of the quantized vector with any arbitrary vector. This inner product estimator is asymmetric, as one of the vectors is quantized to a single bit while the other remains unquantized, making it well-suited for the KV cache mechanism. The Quantized Johnson-Lindenstrauss (QJL) transformation, acting as a 1-bit quantizer, alongside our proposed estimator, is formally defined in the following definition:
Definition 1: QJL and inner product estimator
For any positive integers $d, m$, let ${\bm S} \in \mathbb{R}^{m \times d}$ be a JL transform matrix, i.e., entries of ${\bm S}$ are i.i.d. samples from the zero mean and unit variance Normal distribution. The QJL is a mapping function $\mathcal{H}_S: \mathbb{R}^d \to {-1, +1}^m$ defined as:
$ \mathcal{H}_S({\bm k}) := {\tt sign}({\bm S} {\bm k}) ; \text{ for any } {\bm k} \in \mathbb{R}^d. $
Furthermore, for any pair of vectors ${\bm k}, {\bm q} \in \mathbb{R}^d$ the estimator for their inner product $\langle {\bm q}, {\bm k} \rangle$ based on the aforementioned quantizer is defined as:
$ \operatorname{{\tt Prod_{QJL}}}({\bm q}, {\bm k}) := \frac{\sqrt{\pi/2}}{m} \cdot | {\bm k} |_2 \cdot \langle {\bm S} {\bm q}, \mathcal{H}_S({\bm k}) \rangle.\tag{3} $
Now, we show that the inner product estimator $\operatorname{{\tt Prod_{QJL}}}({\bm q}, {\bm k})$, exactly like the inner product of JL-transformed vectors without quantization to sign bit, is an unbiased estimator. The crucial point to note is that if we applied QJL to both vectors ${\bm q}$ and ${\bm k}$ in Equation 3, we would obtain an unbiased estimator for the angle between these vectors, as shown in [32]. However, to estimate the inner product one needs to apply the cosine function on top of the angle estimator, which results in a biased estimation. Thus, to achieve an unbiased inner product estimator, it is necessary to asymmetrically apply quantization to the JL transform of only one of the vectors ${\bm q}$ and ${\bm k}$.
Lemma 2: Inner product estimator $\operatorname{{\tt Prod_{QJL}}}$ is unbiased
For any vectors ${\bm q}, {\bm k} \in \mathbb{R}^d$ the expected value of the estimator $\operatorname{{\tt Prod_{QJL}}}({\bm q}, {\bm k})$ defined in Equation 3 is:
$ \mathop{{\mathbb{E}}}{{\bm S}} [\operatorname{{\tt Prod{QJL}}}({\bm q}, {\bm k})] = \langle {\bm q}, {\bm k} \rangle, $
where the expectation is over the randomness of the JL matrix ${\bm S}$ in Definition 1.
Proof: Let ${\bm s}_1, {\bm s}_2, \ldots {\bm s}_m$ denote the rows of the JL matrix ${\bm S}$. Additionally, let us decompose ${\bm q}$ to its projection onto the vector ${\bm k}$ and its orthogonal component, i.e., ${\bm q}^{\perp k} := {\bm q} - \frac{\langle {\bm q}, {\bm k} \rangle}{| {\bm k}|_2^2} \cdot {\bm k} $. We can write,
$ \begin{align*} \operatorname{{\tt Prod_{QJL}}}({\bm q}, {\bm k}) &= \frac{\sqrt{\pi/2}}{m} \sum_{i\in[m]} | {\bm k} |_2 \cdot {\bm s}_i^\top {\bm q} \cdot {\tt sign}({\bm s}i^\top {\bm k}) \ &= \frac{\sqrt{\pi/2}}{m} \sum{i\in[m]} \frac{\langle {\bm q}, {\bm k} \rangle}{| {\bm k}|_2} \cdot {\bm s}_i^\top {\bm k} \cdot {\tt sign}({\bm s}_i^\top {\bm k}) + | {\bm k} |_2 \cdot {\bm s}_i^\top {\bm q}^{\perp k} \cdot {\tt sign}({\bm s}i^\top {\bm k}) \ &= \frac{\sqrt{\pi/2}}{m} \sum{i\in[m]} \frac{\langle {\bm q}, {\bm k} \rangle}{| {\bm k}|_2} \cdot | {\bm s}_i^\top {\bm k}| + | {\bm k} |_2 \cdot {\bm s}_i^\top {\bm q}^{\perp k} \cdot {\tt sign}({\bm s}_i^\top {\bm k}). \end{align*} $
Since ${\bm s}_i$ 's have identical distributions, we have:
$ \begin{align*} \mathop{{\mathbb{E}}}{{\bm S}} [\operatorname{{\tt Prod{QJL}}}({\bm q}, {\bm k})] = \sqrt{\pi/2} \left(\frac{\langle {\bm q}, {\bm k} \rangle}{| {\bm k}|_2} \cdot \mathop{{\mathbb{E}}}\left[| {\bm s}_1^\top {\bm k} | \right] + | {\bm k} |_2 \cdot \mathop{{\mathbb{E}}}\left[{\bm s}_1^\top {\bm q}^{\perp k} \cdot {\tt sign}({\bm s}_1^\top {\bm k})\right] \right). \end{align*} $
To calculate the above expectation let us define variables $x := {\bm s}_1^\top {\bm k}$ and $y := {\bm s}_1^\top {\bm q}^{\perp k}$. Note that $x$ and $y$ are both zero-mean Gaussian random variables and because $\langle {\bm q}^{\perp k}, {\bm k} \rangle = 0$. By the following Fact 3, $x$ and $y$ are independent.
Fact 3
If ${\bm x} \in \mathbb{R}^d$ is a vector of i.i.d. zero-mean normal entries with variance $\sigma^2$ and $A \in \mathbb{R}^{m \times d}$ is a matrix, then ${\bm A}\cdot {\bm x}$ is a normal random variable with mean zero and covariance matrix $\sigma^2 \cdot {\bm A} {\bm A}^\top$.
This implies that the second expectation term above is zero because $\mathop{{\mathbb{E}}}\left[{\bm s}_1^\top {\bm q}^{\perp k} \cdot {\tt sign}({\bm s}_1^\top {\bm k})\right] = \mathop{{\mathbb{E}}}[y \cdot {\tt sign}(x)] = \mathop{{\mathbb{E}}}[y] \cdot \mathop{{\mathbb{E}}} [{\tt sign}(x)] = 0$. Furthermore, $x$ is a Gaussian random variable with mean zero and variance $| {\bm k} |_2^2$. Therefore, we have
$ \begin{align*} \mathop{{\mathbb{E}}}{{\bm S}} [\operatorname{{\tt Prod{QJL}}}({\bm q}, {\bm k})] = \sqrt{\pi/2} \cdot \frac{\langle {\bm q}, {\bm k} \rangle}{| {\bm k}|_2} \cdot \mathop{{\mathbb{E}}}_x \left[| x | \right] = \langle {\bm q}, {\bm k} \rangle. \end{align*} $
where the equality comes from the following Fact 4:
Fact 4: Moments of Normal Random Variable
If $x$ is a normal random variable with zero mean and variance $\sigma^2$, then for any integer $\ell$, the $\ell$-th moment of $x$ is $\mathop{{\mathbb{E}}} \left[|x|^\ell \right] = \sigma^\ell \cdot 2^{\ell/2} \Gamma((\ell+1)/2) / \sqrt{\pi}$.
This completes the proof of Lemma 2.
Now we show that the inner product estimator $\operatorname{{\tt Prod_{QJL}}}$ in Definition 1, just like the estimators based on the standard JL transform, has a bounded distortion with high probability.
Lemma 5: Distortion of inner product estimator $\operatorname{{\tt Prod_{QJL}}}$
For any vectors ${\bm q}, {\bm k} \in \mathbb{R}^d$ if the estimator $\operatorname{{\tt Prod_{QJL}}}({\bm q}, {\bm k})$ is defined as in Equation 3 for QJL with dimension $m \ge \frac{4}{3} \cdot \frac{1 + \varepsilon}{\varepsilon^2}\log \frac{2}{\delta}$, then:
$ \Pr_{{\bm S}} \left[\left| \operatorname{{\tt Prod_{QJL}}}({\bm q}, {\bm k}) - \langle {\bm q}, {\bm k} \rangle \right| > \varepsilon | {\bm q}|_2| {\bm k}|_2 \right] \le \delta, $
where the probability is over the randomness of the JL matrix ${\bm S}$ in Definition 1.
Proof: First note that, letting ${\bm s}_1, {\bm s}_2, \ldots {\bm s}_m$ denote the rows of the JL transform matrix $S$, we have:
$ \operatorname{{\tt Prod_{QJL}}}({\bm q}, {\bm k}) = \frac{1}{m} \sum_{i\in[m]} \sqrt{\pi/2} \cdot | {\bm k} |_2 \cdot {\bm s}_i^\top {\bm q} \cdot {\tt sign}({\bm s}_i^\top {\bm k}). $
Since ${\bm s}_i$ 's are i.i.d. the above is indeed the average of $m$ i.i.d. estimators defined as $z_i := \sqrt{\pi/2} \cdot | {\bm k} |_2 \cdot {\bm s}_i^\top {\bm q} \cdot {\tt sign}({\bm s}_i^\top {\bm k})$ for $i \in [m]$. Let us now calculate the $\ell$-th moment of $z_i$ using Fact 4:
$ \mathop{{\mathbb{E}}} \left[|z_i|^\ell \right] = \left(\sqrt{\pi/2} \cdot | {\bm k} |_2\right)^\ell \cdot \mathop{{\mathbb{E}}} \left[| {\bm s}_i^\top {\bm q}|^\ell \right] = \left(\sqrt{\pi} \cdot | {\bm k} |_2 | {\bm q} |_2 \right)^\ell \cdot \frac{\Gamma((\ell+1)/2)}{\sqrt{\pi}},\tag{4} $
where the second equality above follows because ${\bm s}_i^\top {\bm q}$ is a Gaussian random variable with mean zero and variance $| {\bm q}|_2^2$ along with Fact 4. Now we can prove the result by invoking the unbiasedness of the estimator, Lemma 2, along with an appropriate version of Bernstein inequality and using the moment bounds in Equation 4. More specifically, our moment calculation in Equation 4 implies:
$ \mathop{{\mathbb{E}}} \left[|z_i|^\ell \right] = \mathop{{\mathbb{E}}} \left[|z_i|^2 \right] \cdot \left(\sqrt{\pi} | {\bm k} |_2 | {\bm q} |_2 \right)^{\ell-2} \cdot \frac{\Gamma((\ell+1)/2)}{\Gamma(3/2)} \le \mathop{{\mathbb{E}}} \left[|z_i|^2 \right] \cdot \left(\frac{2}{3} \cdot | {\bm k} |_2 | {\bm q} |_2 \right)^{\ell-2} \cdot \frac{\ell!}{2} $
Therefore, by invoking a proper version of the Bernstein inequality, for instance Corollary 2.11 from [33], we have the following:
$ \Pr_{{\bm S}} \left[\left| \operatorname{{\tt Prod_{QJL}}}({\bm q}, {\bm k}) - \langle {\bm q}, {\bm k} \rangle \right| > t \right] \le 2\exp\left(-\frac{3}{4} \cdot \frac{m t^2}{ | {\bm k} |_2^2 | {\bm q} |_2^2 + | {\bm k} |_2 | {\bm q} |_2 \cdot t } \right). $
If we set $t = \varepsilon | {\bm q}|_2| {\bm k}|_2$ the above simplifies to:
$ \Pr_{{\bm S}} \left[\left| \operatorname{{\tt Prod_{QJL}}}({\bm q}, {\bm k}) - \langle {\bm q}, {\bm k} \rangle \right| > \varepsilon | {\bm q}|_2| {\bm k}|_2 \right] \le 2\exp\left(-\frac{3}{4} \cdot \frac{m \varepsilon^2}{1 + \varepsilon} \right). $
Therefore if $m \ge \frac{4}{3} \cdot \frac{1 + \varepsilon}{\varepsilon^2}\log \frac{2}{\delta}$ the error bound follows. This completes the proof of Lemma 5.
Note that the distortion bound in Lemma 5 has remarkably small constants, even smaller than those of the original unquintized JL transform. This indicates that quantizing one of the vectors to just a single sign bit does not result in any loss of accuracy. We use these properties of QJL and our inner product estimator to prove the final approximation bound on our KV cache quantizer.
3.1 Key Cache Quantization via QJL
The key cache is used in the computation of attention scores as shown in Equation 2. To calculate these scores, we need to compute the inner products of the current query embedding with all key embeddings in the cache. We design a quantization scheme that allows for a low-distortion estimate of the inner products between an arbitrary query and all keys in the cache. In this section, we develop a practical algorithm with provable guarantees based on QJL and the inner product estimator defined in Definition 1.
**Input:** Stream of key tokens ${\bm k}_1, {\bm k}_2, \ldots \in \mathbb{R}^d$, integer $m$
1: Draw a random sketch ${\bm S} \in \mathbb{R}^{m \times d}$ with i.i.d. entries ${\bm S}_{i,j} \sim \mathcal{N}(0, 1)$ as per Definition 1
2: **repeat**
3: Compute $\tilde{{\bm k}}_i \gets {\tt sign}\left( {\bm S} {\bm k}_i \right)$ and $\nu_i \gets \left\| {\bm k}_i \right\|_2$
4: **store** the quantized vector $\tilde{{\bm k}}_i$ and the key norm $\nu_i$ in the cache
5: **until** token stream ends
**Procedure** EstimateScores(${\bm q}_n$)
6: Compute inner product estimators $\widetilde{{\bf qK}}(j) \gets \frac{\sqrt{\pi/2}}{m} \cdot \nu_i \cdot \langle {\bm S} {\bm q}_n, \tilde{{\bm k}}_j \rangle$ for every $j \in [n]$
7: $\widetilde{\tt Score} \gets {\tt softmax}\left( \widetilde{{\bf qK}} \right)$
**return** $\widetilde{\tt Score}$
The quantization scheme presented in Algorithm 1 applies QJL, defined in Definition 1, to each key embedding, mapping them to binary vectors and storing the results in the key cache. We show in the following theorem that the attention scores calculated by Algorithm 1 have very small $(1\pm \varepsilon)$ relative distortion with high probability:
Theorem 6: Distortion bound on QJL key cache quantizer
For any sequence of key tokens ${\bm k}_1, \ldots {\bm k}_n \in {\mathbf{R}}^d$ and any integer $m$, Algorithm 1 stores binary vectors $\tilde{{\bm k}}_1, \ldots \tilde{{\bm k}}n \in {-1, +1}^m$ along with scalar values $\nu_1, \ldots \nu_n$ in the cache. If the key embeddings have bounded norm $\max{i \in [n]} \left| {\bm k}_i \right|_2 \le r$ and $m \ge 2 r^2\varepsilon^{-2} \log n$, then for any query embedding ${\bm q}_n \in {\mathbf{R}}^d$ with bounded norm $\left| {\bm q}_n \right|_2 \le r$ the output of the procedure EstimateScores(${\bm q}_n$) satisfies the following with probability $1-\frac{1}{{\tt poly}(n)}$ sinultaneously for all $i \in [n]$:
$ \left| \widetilde{\tt Score}(i) - {\tt Score}(i) \right| \le 3\varepsilon \cdot {\tt Score}(i), $
where ${\tt Score}$ is the vector of attention scores defined in Equation 2.
Proof: The proof is by invoking Lemma 5 and a union bound. For every $j \in [n]$ the estimator $\widetilde{{\bf qK}}(j)$ computed in line 6 of Algorithm 1 is in fact equal to the inner product estimator $\widetilde{{\bf qK}}(j) = \operatorname{{\tt Prod_{QJL}}}({\bm q}_n, {\bm k}_j)$ as defined in Equation 3. Thus by Lemma 5 we have the following with probability at least $1 - \frac{1}{n^{3/(2+2\varepsilon)}}$:
$ \left| \widetilde{{\bf qK}}(j) - \langle {\bm q}_n, {\bm k}_j \rangle \right| \le \frac{\varepsilon}{r^2} \cdot | {\bm q}_n|_2| {\bm k}_j|_2 \le \varepsilon, $
where the second inequality follows from the preconditions of the theorem regarding the boundedness of the norms of the query and key embeddings. By union bound, the above inequality holds simultaneously for all $j \in [n]$ with high probability in $n$. Thus after applying the softmax function in line 7 of Algorithm 1 we get that with high probability in $n$:
$ \widetilde{\tt Score}(i) \in e^{\pm 2 \varepsilon} \cdot {\tt Score}(i) \in (1 \pm 3 \varepsilon) \cdot {\tt Score}(i). $
This completes the proof of Theorem 6.
This theorem shows that if the query and key embeddings have constant norms, as is common in practical scenarios, we can quantize each key embedding such that only $m \approx \varepsilon^{-2} \log n$ bits are needed to store each key token. This is independent of the embedding dimension of the tokens and scales only logarithmically with the sequence length.
3.2 Value Cache Quantization
We quantize the value cache using a standard quantization method, i.e., normalizing each token's entries and then rounding each entry to a few-bit integer representation. This approach aligns with prior work, which has shown that standard token-wise quantization is highly effective for the value cache and results in a minimal accuracy drop [24, 25].
4 Experiments
Section Summary: This section tests the algorithm's performance on a powerful GPU, using custom software to compress and process data in AI models, with plans to speed it up further. It discusses handling unusual large values in the model's data, especially in later stages, by analyzing patterns and using a special compression technique for accuracy, and notes that a refined mathematical step improves results. Benchmarks on long-text tasks show the new method outperforming similar compression approaches in question-answering accuracy while keeping generation times efficient.
In this section, we validate the empirical performance of our algorithm. All experiments are conducted under a single A100 GPU with 80GB memory. We implement two main CUDA kernels for our core primitives: one for quantizing embedding vectors using various floating point data types such as bfloat16, FP16, and FP32, and the other for computing the inner product of an arbitrary embedding vector with all quantized vectors in the cache. The algorithm's wrapper is implemented in PyTorch, handling all the housekeeping tasks. We plan to complete implementation in the CUDA for future work, which will further accelerate our algorithm.
4.1 Practical Consideration
Outliers.
As reported in recent works e.g., KIVI [24], KVQuant [25], key embeddings typically contain outliers exhibiting a distinct pattern. Specifically, certain coordinates of key embeddings display relatively large magnitudes. To further investigate these observations, we analyze the distribution of the magnitudes of key embedding coordinates across different layers. Firstly, we observe that there are no significant outliers in the initial attention layers. However, in the deeper layers, certain fixed coordinates of key embeddings consistently exhibit large magnitudes, and this pattern persists within these channels across all tokens. The distribution of outliers across different layers for the Llama-2 model is plotted in Figure 2. It is evident that in the initial layers, outliers are rare, but as we approach the final layers, their frequency and impact increase significantly. Secondly, the outliers show a persistent pattern in specific fixed coordinates of the key embeddings. This observation aligns with previous findings that certain fixed embedding coordinates exhibit larger outliers [34, 35, 24, 25].
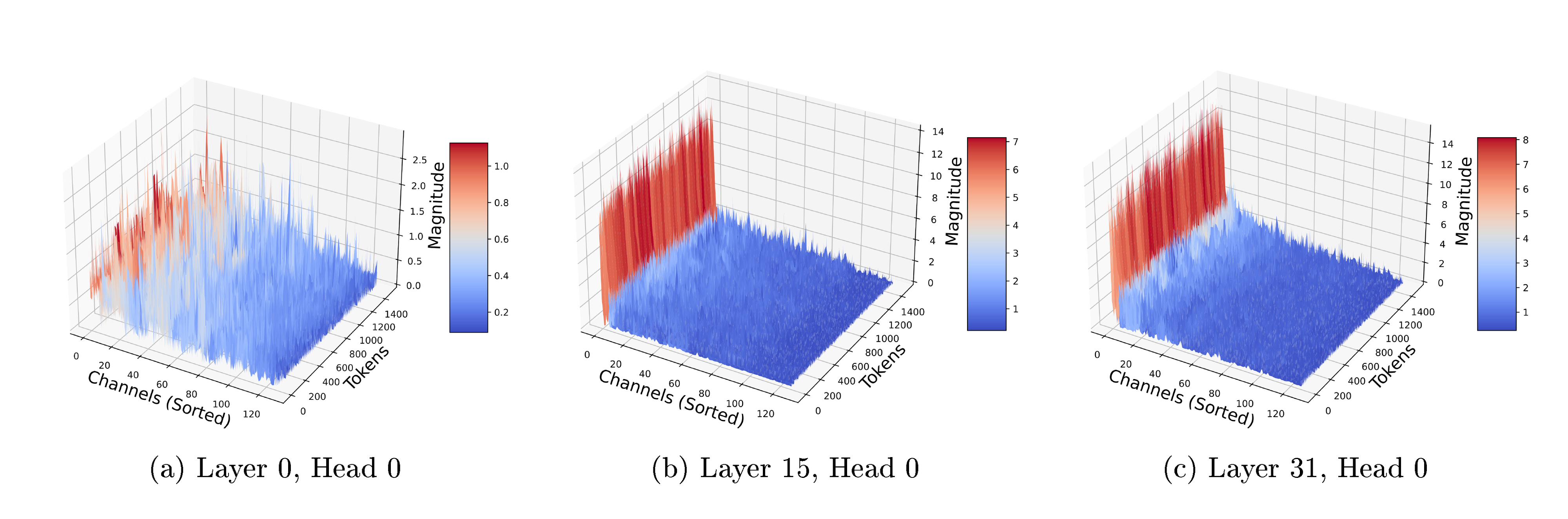
As demonstrated in Theorem 6, the distortion on the attention scores is directly proportional to the norms of the embeddings. Therefore, capturing these outlier coordinates is essential, as their large magnitudes contribute significantly to the norms of key embeddings. By identifying and isolating these outlier channels, we can reduce the norm of the key embeddings and, consequently, significantly decrease the final distortion. Next, we quantize the outliers using an independent instance of our QJL quantizer but with a lower compression rate, utilizing more bits to accurately represent each outlier coordinate.
Orthogonalized JL transform.
We observed that orthogonalizing the rows of the JL matrix $S$ in Definition 1 almost always improves the performance of our QJL quantizer. This finding aligns with previous work on various applications of the JL transform, such as random Fourier features [36] and locality sensitive hashing [37]. Consequently, in our implementation and all experiments, we first generate a random JL matrix $S$ with i.i.d. Gaussian entries and then orthogonalize its rows using QR decomposition. We then use this orthogonalized matrix in our QJL quantizer, as described in Algorithm 1.
4.2 End-to-end text generation
Next we benchmark our method on LongBench [29], a benchmark of long-range context on various tasks. We choose the base model as longchat-7b-v1.5-32k [28] (fine-tuned Llama-2 with 7B parameter with 16{, }384 context length) and apply following quantization methods to this model; KIVI [24], KVQuant [19] and our proposed quantization via QJL. Each floating-point number (FPN) in the base model is represented by 16 bits, and we choose proper hyper-parameters of KIVI and QJL so that their bits per FPN become 3. For KVQuant, we follow the default setting which holds its bits per FPN as 4.3. To validate the quality of those quantized models, we benchmark them on $6$ question-answer datasets from LongBench [29], and we set the maximum sequence length to 31{, }500. We follow the same approach of prompting and evaluating to evaluate the prediction of the model from the original repository. Table 1 summarizes the results. Our proposed QJL achieves the highest F1 score within the quantization methods for NarrativeQA, Qasper and 2WikiMultiQA.
:::
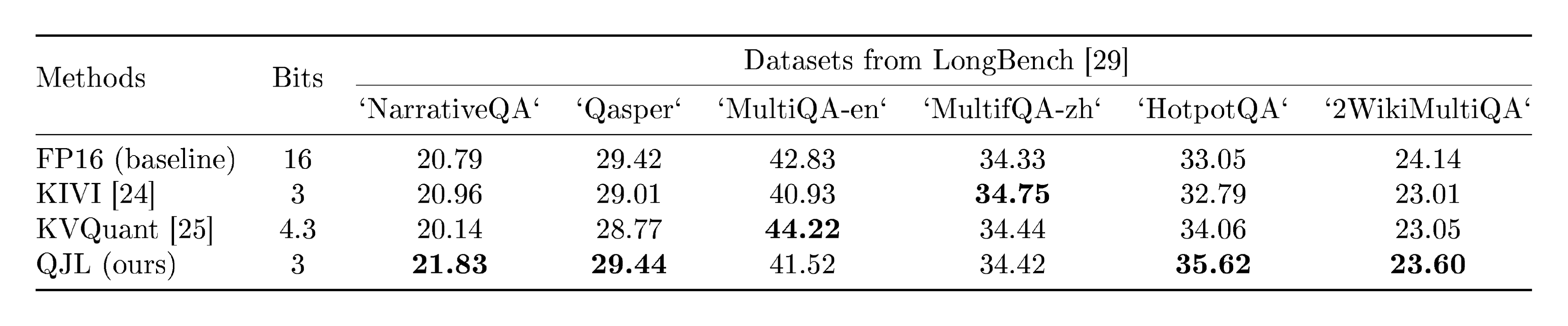
Table 1: Evaluation (F1 scores) of various quantization methods on long-context question-answering datasets from LongBench [29]. We set bits per floating-point number (FPN) to 3. Bold indicates the highest scores within quantization methods.
:::
:::
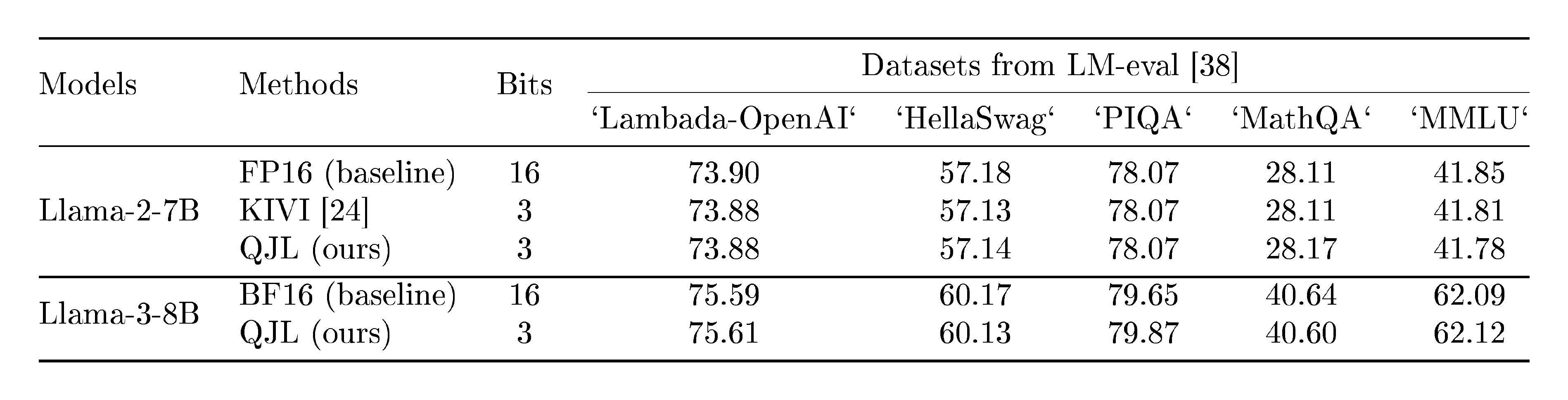
Table 2: Evaluation (accuracy) of various quantization methods on regular length datasets from LM-eval [38]. These comparisons are not typically based on long-context length; however, as evident, even in these cases, our QJL with 3 bits per FPN performs comparably to the baseline with 16 bits per FPN.
:::
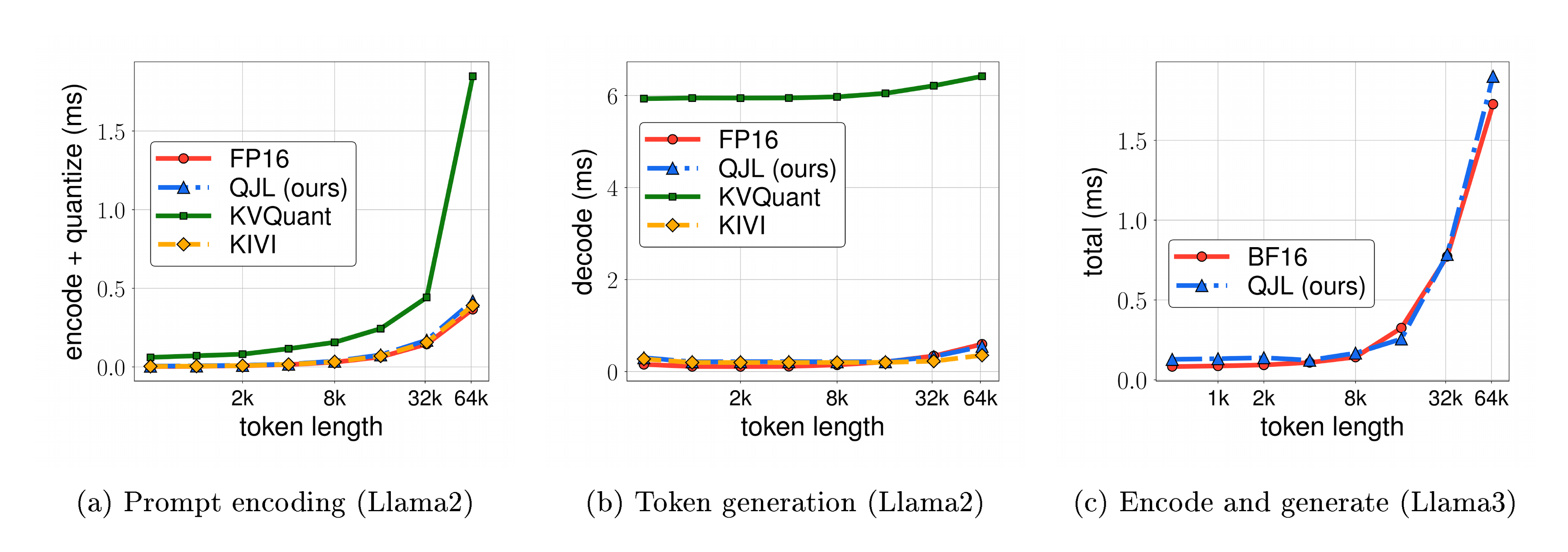
Although KVQuant performs better than other methods for MultiQA-en dataset, it requires a huge amount of preprocessing which leads to slow runtime. To validate this, we additionally report runtime of prompt encoding, KV cache quantization, and decoding (token generation) in a single attention layer. Figure 3 shows the wall-clock time to encode a prompt and quantize the KV cache, generate 128 tokens for llama2 model, and generate 64 tokens for llama3 model using different quantization methods in a single attention layer of these models. Note that QJL is the only method that can quantize Llama3, as our kernels support grouped query attention and BF16 data type. we observe the same speed for Llama3 as the exact method for generation. The input sequence lengths vary between 1k to 128k. As shown in Figure 3, KVQuant runs slower than other methods during both prompt encoding and decoding phases. On the other hand, both KIVI and our QJL with 3 bits per FPN show marginal runtime overhead compared to the exact baseline during prompting but reduce KV cache memory usage by at least a factor of 5.
We additionally test our method on datasets Lambada-OpenAI, HellaSwag, PIQA, MathQA, and MMLU, which have shorter sequence lengths. We benchmark our method using LM-eval [38] framework to ensure a thorough evaluation across various metrics. We evaluate quantization methods with accuracy across Llama-2-7B [27] and Llama-3-8B [39] models. Note that KIVI only supports a half-precision floating point, whereas our method can be used for any precision format type. This makes it unable to run KIVI on the Llama-3 model.
As a results, QJL can significantly reduce memory usage by utilizing only 3 bits per FPN, compared to the 16 bits per FPN in the baseline, achieving around an 81% reduction in memory. We observe that this efficiency does not compromise performance significantly. Across all datasets, our method's accuracy is generally comparable to the baseline, with slight variations. In Table 2, our QJL on the Llama-3-8B performs on average about slightly better than the baseline across all datasets.
References
Section Summary: This references section compiles a wide range of sources on artificial intelligence advancements, including technical reports on major language models like GPT-4 and Claude, as well as tools for generating images and videos such as DALL-E, Midjourney, and Sora. It features foundational papers on transformer technology, which powers many modern AI systems, and explores how these models can be scaled up for better performance. Additionally, the list highlights recent research on making large AI models more efficient, through methods like compressing data storage and optimizing memory use during processing.
[1] Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report. arXiv preprint arXiv:2303.08774, 2023.
[2] Antropic. claude, 2024. https://www.anthropic.com/news/claude-3-family.
[3] Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, and Mark Chen. Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:2204.06125, 2022.
[4] Adobe FireFly, 2023. https://firefly.adobe.com/.
[5] Midjourney, 2022. https://www.midjourney.com/home.
[6] OpenAI. Sora: Creating video from text, 2024. https://openai.com/index/sora/.
[7] Microsoft Copilot, 2023. https://github.com/features/copilot.
[8] OpenAI. Introducing gpt-4o, 2024. https://openai.com/index/hello-gpt-4o/.
[9] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need. 2017.
[10] Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. Scaling laws for neural language models. arXiv preprint arXiv:2001.08361, 2020.
[11] Noam Shazeer. Fast transformer decoding: One write-head is all you need. arXiv preprint arXiv:1911.02150, 2019.
[12] Joshua Ainslie, James Lee-Thorp, Michiel de Jong, Yury Zemlyanskiy, Federico Lebron, and Sumit Sanghai. Gqa: Training generalized multi-query transformer models from multi-head checkpoints. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 4895–4901, 2023.
[13] Zhenyu Zhang, Ying Sheng, Tianyi Zhou, Tianlong Chen, Lianmin Zheng, Ruisi Cai, Zhao Song, Yuandong Tian, Christopher Ré, Clark Barrett, et al. H2o: Heavy-hitter oracle for efficient generative inference of large language models. Advances in Neural Information Processing Systems, 36, 2024.
[14] Zichang Liu, Aditya Desai, Fangshuo Liao, Weitao Wang, Victor Xie, Zhaozhuo Xu, Anastasios Kyrillidis, and Anshumali Shrivastava. Scissorhands: Exploiting the persistence of importance hypothesis for llm kv cache compression at test time. Advances in Neural Information Processing Systems, 36, 2024.
[15] Guangxuan Xiao, Yuandong Tian, Beidi Chen, Song Han, and Mike Lewis. Efficient streaming language models with attention sinks. arXiv preprint arXiv:2309.17453, 2023.
[16] Amir Zandieh, Insu Han, Vahab Mirrokni, and Amin Karbasi. Subgen: Token generation in sublinear time and memory. arXiv preprint arXiv:2402.06082, 2024.
[17] Ying Sheng, Lianmin Zheng, Binhang Yuan, Zhuohan Li, Max Ryabinin, Beidi Chen, Percy Liang, Christopher Ré, Ion Stoica, and Ce Zhang. Flexgen: High-throughput generative inference of large language models with a single gpu. In International Conference on Machine Learning, pages 31094–31116. PMLR, 2023.
[18] Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with pagedattention. In Proceedings of the 29th Symposium on Operating Systems Principles, pages 611–626, 2023.
[19] Yuxuan Yue, Zhihang Yuan, Haojie Duanmu, Sifan Zhou, Jianlong Wu, and Liqiang Nie. Wkvquant: Quantizing weight and key/value cache for large language models gains more. arXiv preprint arXiv:2402.12065, 2024.
[20] June Yong Yang, Byeongwook Kim, Jeongin Bae, Beomseok Kwon, Gunho Park, Eunho Yang, Se Jung Kwon, and Dongsoo Lee. No token left behind: Reliable kv cache compression via importance-aware mixed precision quantization. arXiv preprint arXiv:2402.18096, 2024.
[21] Shichen Dong, Wen Cheng, Jiayu Qin, and Wei Wang. Qaq: Quality adaptive quantization for llm kv cache. arXiv preprint arXiv:2403.04643, 2024.
[22] Hao Kang, Qingru Zhang, Souvik Kundu, Geonhwa Jeong, Zaoxing Liu, Tushar Krishna, and Tuo Zhao. Gear: An efficient kv cache compression recipefor near-lossless generative inference of llm. arXiv preprint arXiv:2403.05527, 2024.
[23] Tianyi Zhang, Jonah Yi, Zhaozhuo Xu, and Anshumali Shrivastava. Kv cache is 1 bit per channel: Efficient large language model inference with coupled quantization. arXiv preprint arXiv:2405.03917, 2024.
[24] Zirui Liu, Jiayi Yuan, Hongye Jin, Shaochen Zhong, Zhaozhuo Xu, Vladimir Braverman, Beidi Chen, and Xia Hu. Kivi: A tuning-free asymmetric 2bit quantization for kv cache. arXiv preprint arXiv:2402.02750, 2024.
[25] Coleman Hooper, Sehoon Kim, Hiva Mohammadzadeh, Michael W Mahoney, Yakun Sophia Shao, Kurt Keutzer, and Amir Gholami. KVQuant: Towards 10 Million Context Length LLM Inference with KV Cache Quantization. arXiv preprint arXiv:2401.18079, 2024.
[26] Sanjoy Dasgupta and Anupam Gupta. An elementary proof of a theorem of johnson and lindenstrauss. Random Structures & Algorithms, 22(1):60–65, 2003.
[27] Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288, 2023.
[28] Dacheng Li, Rulin Shao, Anze Xie, Ying Sheng, Lianmin Zheng, Joseph Gonzalez, Ion Stoica, Xuezhe Ma, and Hao Zhang. How long can open-source llms truly promise on context length?, 2023. https://huggingface.co/lmsys/longchat-7b-v1.5-32k.
[29] Yushi Bai, Xin Lv, Jiajie Zhang, Hongchang Lyu, Jiankai Tang, Zhidian Huang, Zhengxiao Du, Xiao Liu, Aohan Zeng, Lei Hou, Yuxiao Dong, Jie Tang, and Juanzi Li. Longbench: A bilingual, multitask benchmark for long context understanding. arXiv preprint arXiv:2308.14508, 2023.
[30] Reiner Pope, Sholto Douglas, Aakanksha Chowdhery, Jacob Devlin, James Bradbury, Jonathan Heek, Kefan Xiao, Shivani Agrawal, and Jeff Dean. Efficiently scaling transformer inference. Proceedings of Machine Learning and Systems, 5, 2023.
[31] William B Johnson, Joram Lindenstrauss, and Gideon Schechtman. Extensions of Lipschitz maps into Banach spaces. Israel Journal of Mathematics.
[32] Moses S Charikar. Similarity estimation techniques from rounding algorithms. In Proceedings of the thiry-fourth annual ACM symposium on Theory of computing, pages 380–388, 2002.
[33] Stéphane Boucheron, Gábor Lugosi, and Olivier Bousquet. Concentration inequalities. In Summer school on machine learning, pages 208–240. Springer, 2003.
[34] Tim Dettmers, Mike Lewis, Younes Belkada, and Luke Zettlemoyer. Gpt3. int8 (): 8-bit matrix multiplication for transformers at scale. Advances in Neural Information Processing Systems, 35:30318–30332, 2022.
[35] Ji Lin, Jiaming Tang, Haotian Tang, Shang Yang, Xingyu Dang, and Song Han. Awq: Activation-aware weight quantization for llm compression and acceleration. arXiv preprint arXiv:2306.00978, 2023.
[36] Felix Xinnan X Yu, Ananda Theertha Suresh, Krzysztof M Choromanski, Daniel N Holtmann-Rice, and Sanjiv Kumar. Orthogonal random features. Advances in neural information processing systems, 29, 2016.
[37] Jianqiu Ji, Jianmin Li, Shuicheng Yan, Bo Zhang, and Qi Tian. Super-bit locality-sensitive hashing. Advances in neural information processing systems, 25, 2012.
[38] Leo Gao, Jonathan Tow, Baber Abbasi, Stella Biderman, Sid Black, Anthony DiPofi, Charles Foster, Laurence Golding, Jeffrey Hsu, Alain Le Noac'h, Haonan Li, Kyle McDonell, Niklas Muennighoff, Chris Ociepa, Jason Phang, Laria Reynolds, Hailey Schoelkopf, Aviya Skowron, Lintang Sutawika, Eric Tang, Anish Thite, Ben Wang, Kevin Wang, and Andy Zou. A framework for few-shot language model evaluation, 2023. https://github.com/EleutherAI/lm-evaluation-harness.
[39] Llama3, 2024. https://github.com/meta-llama/llama3.