Direct Preference Optimization: Your Language Model is Secretly a Reward Model
Rafael Rafailov$^{*\dagger}$
Archit Sharma$^{*\dagger}$
Eric Mitchell$^{*\dagger}$
Stefano Ermon$^{\dagger\ddagger}$
Christopher D. Manning$^{\dagger}$
Chelsea Finn$^{\dagger}$
$^{\dagger}$ Stanford University $^{\ddagger}$ CZ Biohub
{rafailov,architsh,eric.mitchell}@cs.stanford.edu
Abstract
While large-scale unsupervised language models (LMs) learn broad world knowledge and some reasoning skills, achieving precise control of their behavior is difficult due to the completely unsupervised nature of their training. Existing methods for gaining such steerability collect human labels of the relative quality of model generations and fine-tune the unsupervised LM to align with these preferences, often with reinforcement learning from human feedback (RLHF). However, RLHF is a complex and often unstable procedure, first fitting a reward model that reflects the human preferences, and then fine-tuning the large unsupervised LM using reinforcement learning to maximize this estimated reward without drifting too far from the original model. In this paper we introduce a new parameterization of the reward model in RLHF that enables extraction of the corresponding optimal policy in closed form, allowing us to solve the standard RLHF problem with only a simple classification loss. The resulting algorithm, which we call Direct Preference Optimization (DPO), is stable, performant, and computationally lightweight, eliminating the need for sampling from the LM during fine-tuning or performing significant hyperparameter tuning. Our experiments show that DPO can fine-tune LMs to align with human preferences as well as or better than existing methods. Notably, fine-tuning with DPO exceeds PPO-based RLHF in ability to control sentiment of generations, and matches or improves response quality in summarization and single-turn dialogue while being substantially simpler to implement and train.
Executive Summary: Large language models (LMs) have advanced rapidly, enabling tasks like text generation and conversation with impressive capabilities derived from vast, unsupervised training data. However, this broad training often leads to unpredictable or undesirable outputs, such as biased responses, factual errors, or unhelpful tones, making it challenging to ensure models behave safely, reliably, and in line with human values. As LMs increasingly power real-world applications—from chatbots to content tools—aligning them with human preferences has become urgent to mitigate risks like misinformation or harm, while enhancing performance in areas like summarization and dialogue.
This paper aims to simplify the process of fine-tuning LMs to match human preferences, proposing a method called Direct Preference Optimization (DPO) that avoids the complexities of traditional approaches like reinforcement learning from human feedback (RLHF).
The authors developed DPO by reparameterizing the underlying math of preference alignment, allowing direct optimization of the LM's policy using a straightforward classification loss—essentially treating the model as an implicit reward evaluator. They tested it on datasets from sentiment control (using movie reviews), summarization (Reddit posts), and single-turn dialogue (user queries), drawing from human-labeled preferences totaling tens of thousands of examples. Experiments involved models up to 6 billion parameters, with baselines like RLHF using proximal policy optimization (PPO) and supervised fine-tuning, evaluated over training periods of hours to days on standard hardware.
Key findings highlight DPO's strengths. First, DPO achieved the highest rewards while keeping divergence from the base model low, outperforming PPO—even when PPO had access to perfect reward signals—by 20-30% in efficiency on sentiment tasks. Second, in summarization, DPO reached a 61% win rate against human references (evaluated by GPT-4 as a human proxy), surpassing PPO's 57% and exceeding the best-of-128 sampling baseline, with quicker convergence in under 10 epochs. Third, for dialogue, DPO was the only efficient method to improve beyond preferred responses, hitting up to 55% win rates while maintaining stability across sampling temperatures from 0 to 1.0. Fourth, DPO generalized well to new data distributions, like news articles, outperforming PPO by 5-10% in win rates. Finally, it required minimal hyperparameter tuning, often converging with a single value for the regularization parameter.
These results mean DPO streamlines alignment, cutting training time and costs by eliminating RL's need for iterative sampling and multiple model fittings—potentially reducing compute by half or more compared to PPO. It lowers risks of training instability, enabling safer, more controllable LMs without sacrificing quality, and differs from prior work by proving RLHF's objectives can be met exactly without reinforcement learning. This could accelerate deployment in industries like customer service or education, where helpful, unbiased responses directly impact user trust and outcomes.
Leaders should prioritize DPO for future LM fine-tuning projects, integrating it into pipelines for preference-based tasks to boost efficiency and reliability. For immediate adoption, start with off-the-shelf models like GPT-J, using existing preference datasets; trade-offs include slightly higher sensitivity to data quality versus PPO's robustness to noise, but DPO's simplicity offsets this. Next steps involve piloting DPO on domain-specific data (e.g., legal or medical queries) and scaling to larger models beyond 6 billion parameters. Further research should explore self-generated preferences and long-form generation to confirm broader applicability.
While the experiments provide strong evidence—validated by human studies showing GPT-4 evaluations align with people about 60-70% of the time—limitations include reliance on pairwise preferences, which may not capture nuanced rankings, and tests limited to English text up to 6B parameters. Confidence is high for the evaluated tasks, but caution is advised for untested domains; additional pilots could address data gaps.
1. Introduction
Section Summary: Large language models trained on vast human-generated data develop impressive abilities but often include undesirable traits from that diverse content, making it essential to guide them toward safe and high-quality behaviors without amplifying flaws. Traditional approaches use reinforcement learning to align these models with human preferences, but this process is complex and computationally expensive, involving reward modeling and iterative sampling. The paper introduces Direct Preference Optimization (DPO), a simpler method that directly fine-tunes models using a basic classification objective to match preferences, achieving similar results to reinforcement learning on tasks like summarization and dialogue without the added complexity.
Large unsupervised language models (LMs) trained on very large datasets acquire surprising capabilities ([1, 2, 3, 4]). However, these models are trained on data generated by humans with a wide variety of goals, priorities, and skillsets. Some of these goals and skillsets may not be desirable to imitate; for example, while we may want our AI coding assistant to understand common programming mistakes in order to correct them, nevertheless, when generating code, we would like to bias our model toward the (potentially rare) high-quality coding ability present in its training data. Similarly, we might want our language model to be aware of a common misconception believed by 50% of people, but we certainly do not want the model to claim this misconception to be true in 50% of queries about it! In other words, selecting the model's desired responses and behavior from its very wide knowledge and abilities is crucial to building AI systems that are safe, performant, and controllable ([5]). While existing methods typically steer LMs to match human preferences using reinforcement learning (RL), we will show that the RL-based objective used by existing methods can be optimized exactly with a simple binary cross-entropy objective, greatly simplifying the preference learning pipeline.
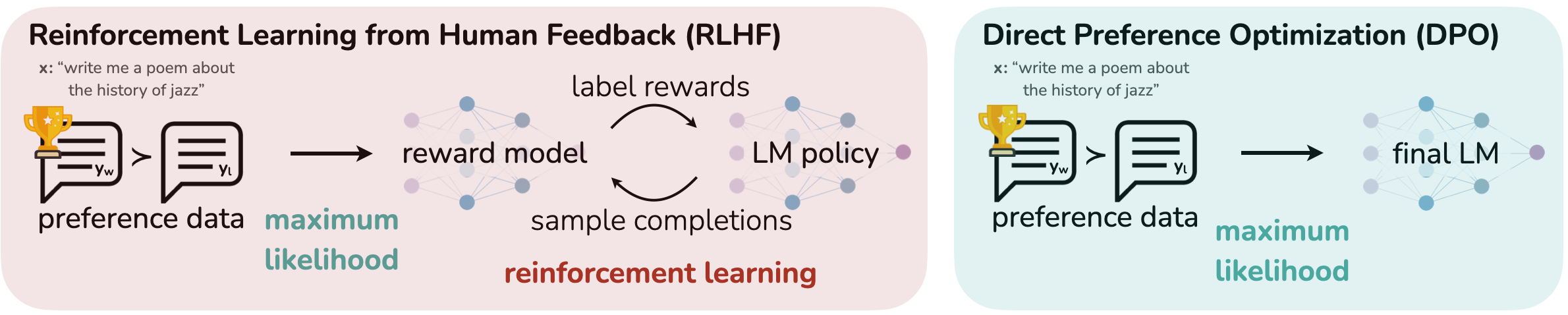
At a high level, existing methods instill the desired behaviors into a language model using curated sets of human preferences representing the types of behaviors that humans find safe and helpful. This preference learning stage occurs after an initial stage of large-scale unsupervised pre-training on a large text dataset. While the most straightforward approach to preference learning is supervised fine-tuning on human demonstrations of high quality responses, the most successful class of methods is reinforcement learning from human (or AI) feedback (RLHF/RLAIF; ([6, 7])). RLHF methods fit a reward model to a dataset of human preferences and then use RL to optimize a language model policy to produce responses assigned high reward without drifting excessively far from the original model. While RLHF produces models with impressive conversational and coding abilities, the RLHF pipeline is considerably more complex than supervised learning, involving training multiple LMs and sampling from the LM policy in the loop of training, incurring significant computational costs.
In this paper, we show how to directly optimize a language model to adhere to human preferences, without explicit reward modeling or reinforcement learning. We propose Direct Preference Optimization (DPO), an algorithm that implicitly optimizes the same objective as existing RLHF algorithms (reward maximization with a KL-divergence constraint) but is simple to implement and straightforward to train. Intuitively, the DPO update increases the relative log probability of preferred to dispreferred responses, but it incorporates a dynamic, per-example importance weight that prevents the model degeneration that we find occurs with a naive probability ratio objective. Like existing algorithms, DPO relies on a theoretical preference model (such as the Bradley-Terry model; [8]) that measures how well a given reward function aligns with empirical preference data. However, while existing methods use the preference model to define a preference loss to train a reward model and then train a policy that optimizes the learned reward model, DPO uses a change of variables to define the preference loss as a function of the policy directly. Given a dataset of human preferences over model responses, DPO can therefore optimize a policy using a simple binary cross entropy objective, producing the optimal policy to an implicit reward function fit to the preference data.
Our main contribution is Direct Preference Optimization (DPO), a simple RL-free algorithm for training language models from preferences. Our experiments show that DPO is at least as effective as existing methods, including PPO-based RLHF, for learning from preferences in tasks such as sentiment modulation, summarization, and dialogue, using language models with up to 6B parameters.
2. Related Work
Section Summary: Large language models trained on vast amounts of text can perform basic tasks without specific examples, but they improve significantly when fine-tuned using human instructions and preferences, which help them better follow user requests in areas like translation, summarization, and storytelling. This process often involves creating a reward system from human comparisons of responses and then using reinforcement learning to adjust the model, though some approaches generate extra training data with AI under light human guidance to boost safety. Beyond language tasks, similar ideas appear in bandit and reinforcement learning fields, where preferences replace rewards, but most methods first estimate an underlying score before optimizing behavior, unlike this work's direct, reward-free policy learning from fixed preference data.
Self-supervised language models of increasing scale learn to complete some tasks zero-shot ([9]) or with few-shot prompts ([10, 11, 1]). However, their performance on downstream tasks and alignment with user intent can be significantly improved by fine-tuning on datasets of instructions and human-written completions ([12, 13, 14, 15]). This 'instruction-tuning' procedure enables LLMs to generalize to instructions outside of the instruction-tuning set and generally increase their usability ([14]). Despite the success of instruction tuning, relative human judgments of response quality are often easier to collect than expert demonstrations, and thus subsequent works have fine-tuned LLMs with datasets of human preferences, improving proficiency in translation ([16]), summarization ([17, 18]), story-telling ([18]), and instruction-following ([5, 19]). These methods first optimize a neural network reward function for compatibility with the dataset of preferences under a preference model such as the Bradley-Terry model ([8]), then fine-tune a language model to maximize the given reward using reinforcement learning algorithms, commonly REINFORCE ([20]), proximal policy optimization (PPO; [21]), or variants ([19]). A closely-related line of work leverages LLMs fine-tuned for instruction following with human feedback to generate additional synthetic preference data for targeted attributes such as safety or harmlessness ([7]), using only weak supervision from humans in the form of a text rubric for the LLM's annotations. These methods represent a convergence of two bodies of work: one body of work on training language models with reinforcement learning for a variety of objectives ([22, 23, 24]) and another body of work on general methods for learning from human preferences ([6, 25]). Despite the appeal of using relative human preferences, fine-tuning large language models with reinforcement learning remains a major practical challenge; this work provides a theoretically-justified approach to optimizing relative preferences without RL.
Outside of the context of language, learning policies from preferences has been studied in both bandit and reinforcement learning settings, and several approaches have been proposed. Contextual bandit learning using preferences or rankings of actions, rather than rewards, is known as a contextual dueling bandit (CDB; [26, 27]). In the absence of absolute rewards, theoretical analysis of CDBs substitutes the notion of an optimal policy with a von Neumann winner, a policy whose expected win rate against any other policy is at least 50% ([27]). However, in the CDB setting, preference labels are given online, while in learning from human preferences, we typically learn from a fixed batch of offline preference-annotated action pairs ([28]). Similarly, preference-based RL (PbRL) learns from binary preferences generated by an unknown 'scoring' function rather than rewards ([29, 30]). Various algorithms for PbRL exist, including methods that can reuse off-policy preference data, but generally involve first explicitly estimating the latent scoring function (i.e. the reward model) and subsequently optimizing it ([31, 29, 6, 32, 25]). We instead present a single stage policy learning approach that directly optimizes a policy to satisfy preferences.
3. Preliminaries
Section Summary: The RLHF process for training language models typically involves three main stages. First, supervised fine-tuning adapts a pre-trained model on high-quality data for specific tasks like conversation or summarization, creating an initial improved version. Next, the model generates pairs of responses to prompts, humans rank their preferences to train a reward model that predicts which outputs are better, and finally, reinforcement learning optimizes the model to produce higher-reward responses while staying close to the original to avoid losing helpful behaviors.
We review the RLHF pipeline in [18] (and later ([17, 33, 5])). It usually includes three phases: 1) supervised fine-tuning (SFT); 2) preference sampling and reward learning and 3) RL optimization.
SFT: RLHF typically begins by fine-tuning a pre-trained LM with supervised learning on high-quality data for the downstream task(s) of interest (dialogue, summarization, etc.), to obtain a model $\pi^\text{SFT}$.
Reward Modelling Phase: In the second phase the SFT model is prompted with prompts $x$ to produce pairs of answers $(y_1, y_2)\sim \pi^\text{SFT}(y \mid x)$. These are then presented to human labelers who express preferences for one answer, denoted as $y_w\succ y_l \mid x$ where $y_w$ and $y_l$ denotes the preferred and dispreferred completion amongst $(y_1, y_2)$ respectively. The preferences are assumed to be generated by some latent reward model $r^*(y, x)$, which we do not have access to. There are a number of approaches used to model preferences, the Bradley-Terry (BT) [8] model being a popular choice (although more general Plackett-Luce ranking models ([34, 35]) are also compatible with the framework if we have access to several ranked answers). The BT model stipulates that the human preference distribution $p^*$ can be written as:
$ p^*(y_1\succ y_2 \mid x)=\frac{\exp\left(r^*(x, y_1)\right)}{\exp\left(r^*(x, y_1)\right) + \exp\left(r^*(x, y_2)\right)}.\tag{1} $
Assuming access to a static dataset of comparisons $\mathcal{D}=\bigl{x^{(i)}, y_w^{(i)}, y_l^{(i)}\bigr}{i=1}^N$ sampled from $p^*$, we can parametrize a reward model $r{\phi}(x, y)$ and estimate the parameters via maximum likelihood. Framing the problem as a binary classification we have the negative log-likelihood loss:
$ \mathcal{L}R(r{\phi}, \mathcal{D}) = -\mathbb{E}{(x, y_w, y_l)\sim \mathcal{D}}\bigl[\log \sigma(r{\phi}(x, y_w)- r_{\phi}(x, y_l))\bigr]\tag{2} $
where $\sigma$ is the logistic function. In the context of LMs, the network $r_{\phi}(x, y)$ is often initialized from the SFT model $\pi^\text{SFT}(y \mid x)$ with the addition of a linear layer on top of the final transformer layer that produces a single scalar prediction for the reward value [18]. To ensure a reward function with lower variance, prior works normalize the rewards, such that $\mathbb{E}{x, y\sim \mathcal{D}}\left[r\phi(x, y)\right] = 0$ for all $x$.
RL Fine-Tuning Phase: During the RL phase, the learned reward function is used to provide feedback to the language model. Following prior works ([36, 37]), the optimization is formulated as
$ \max_{\pi_{\theta}} \mathbb{E}{x\sim \mathcal{D}, y\sim \pi{\theta}(y \mid x)}\bigl[r_{\phi}(x, y)\bigr] - \beta\mathbb{D}{\textrm{KL}}\bigl[\pi{\theta}(y\mid x)\mid \mid \pi_\text{ref}(y\mid x)\bigr],\tag{3} $
where $\beta$ is a parameter controlling the deviation from the base reference policy $\pi_\text{ref}$, namely the initial SFT model $\pi^\text{SFT}$. In practice, the language model policy $\pi_\theta$ is also initialized to $\pi^\text{SFT}$. The added constraint is important, as it prevents the model from deviating too far from the distribution on which the reward model is accurate, as well as maintaining the generation diversity and preventing mode-collapse to single high-reward answers. Due to the discrete nature of language generation, this objective is not differentiable and is typically optimized with reinforcement learning. The standard approach ([18, 17, 33, 5]) has been to construct the reward function ${r(x, y) = r_{\phi}(x, y) -\beta (\log \pi_{\theta}(y\mid x) - \log \pi_\text{ref}(y\mid x))}$, and maximize using PPO [21].
4. Direct Preference Optimization
Section Summary: Direct Preference Optimization offers a streamlined way to fine-tune large language models using human feedback, bypassing the complex steps of traditional methods that first learn a reward model and then apply reinforcement learning. Instead, it cleverly reparameterizes the reward function so that the model's policy—essentially its way of generating responses—can be optimized directly through a simple loss function based on preferences, drawing from the Bradley-Terry model to compare preferred and dispreferred outputs. This approach implicitly embeds the reward within the policy itself, making training more efficient by boosting good responses and downplaying poor ones, weighted by how mistaken the current model is.
Motivated by the challenges of applying reinforcement learning algorithms on large-scale problems such as fine-tuning language models, our goal is to derive a simple approach for policy optimization using preferences directly. Unlike prior RLHF methods, which learn a reward and then optimize it via RL, our approach leverages a particular choice of reward model parameterization that enables extraction of its optimal policy in closed form, without an RL training loop. As we will describe next in detail, our key insight is to leverage an analytical mapping from reward functions to optimal policies, which enables us to transform a loss function over reward functions into a loss function over policies. This change-of-variables approach avoids fitting an explicit, standalone reward model, while still optimizing under existing models of human preferences, such as the Bradley-Terry model. In essence, the policy network represents both the language model and the (implicit) reward.
Deriving the DPO objective. We start with the same RL objective as prior work, Equation 3, under a general reward function $r$. Following prior work ([38, 39, 40, 41]), it is straightforward to show that the optimal solution to the KL-constrained reward maximization objective in Equation 3 takes the form:
$ \pi_r(y\mid x) = \frac{1}{Z(x)}\pi_\text{ref}(y\mid x)\exp\left(\frac{1}{\beta}r(x, y)\right),\tag{4} $
where $Z(x) =\sum_{y}\pi_\text{ref}(y\mid x)\exp\left(\frac{1}{\beta}r(x, y)\right)$ is the partition function. See Appendix A.1 for a complete derivation. Even if we use the MLE estimate $r_{\phi}$ of the ground-truth reward function $r^*$, it is still expensive to estimate the partition function $Z(x)$ ([40, 41]), which makes this representation hard to utilize in practice. However, we can rearrange Equation 4 to express the reward function in terms of its corresponding optimal policy $\pi_r$, the reference policy $\pi_\text{ref}$, and the unknown partition function $Z(\cdot)$. Specifically, we first take the logarithm of both sides of Equation 4 and then with some algebra we obtain:
$ r(x, y) =\beta \log \frac{\pi_r(y\mid x)}{\pi_\text{ref}(y\mid x)} + \beta \log Z(x).\tag{5} $
We can apply this reparameterization to the ground-truth reward $r^*$ and corresponding optimal model $\pi^*$. Fortunately, the Bradley-Terry model depends only on the difference of rewards between two completions, i.e., ${p^*(y_1 \succ y_2 \mid x) = \sigma(r^*(x, y_1) - r^*(x, y_2))}$. Substituting the reparameterization in Equation 5 for $r^*(x, y)$ into the preference model Equation 1, the partition function cancels, and we can express the human preference probability in terms of only the optimal policy $\pi^*$ and reference policy $\pi_\text{ref}$. Thus, the optimal RLHF policy $\pi^*$ under the Bradley-Terry model satisfies the preference model:
$ p^*(y_1\succ y_2 \mid x)=\frac{1}{1 + \exp\left(\beta \log \frac{\pi^*(y_2\mid x)}{\pi_\text{ref}(y_2\mid x)} - \beta \log \frac{\pi^*(y_1\mid x)}{\pi_\text{ref}(y_1\mid x)}\right)}\tag{6} $
The derivation is in Appendix A.2. While Equation 6 uses the Bradley-Terry model, we can similarly derive expressions under the more general Plackett-Luce models ([34, 35]), shown in Appendix A.3.
Now that we have the probability of human preference data in terms of the optimal policy rather than the reward model, we can formulate a maximum likelihood objective for a parametrized policy $\pi_\theta$. Analogous to the reward modeling approach (i.e. Equation 2), our policy objective becomes:
$ \mathcal{L}\text{DPO}(\pi{\theta}; \pi_\text{ref}) = -\mathbb{E}{(x, y_w, y_l)\sim \mathcal{D}}\left[\log \sigma \left(\beta \log \frac{\pi{\theta}(y_w\mid x)}{\pi_\text{ref}(y_w\mid x)} - \beta \log \frac{\pi_{\theta}(y_l\mid x)}{\pi_\text{ref}(y_l\mid x)}\right)\right].\tag{7} $
This way, we fit an implicit reward using an alternative parameterization, whose optimal policy is simply $\pi_\theta$. Moreover, since our procedure is equivalent to fitting a reparametrized Bradley-Terry model, it enjoys certain theoretical properties, such as consistencies under suitable assumption of the preference data distribution [42]. In Section 5, we further discuss theoretical properties of DPO in relation to other works.
What does the DPO update do? For a mechanistic understanding of DPO, it is useful to analyze the gradient of the loss function $\mathcal{L}_\text{DPO}$. The gradient with respect to the parameters $\theta$ can be written as:
$ \begin{split} \nabla_\theta \mathcal{L}\text{DPO}(\pi\theta; \pi_\text{ref}) = \ -\beta\mathbb{E}{(x, y_w, y_l) \sim \mathcal{D}} \bigg[\underbrace{\sigma(\hat{r}\theta(x, y_l) - \hat{r}\theta (x, y_w))}\text{higher weight when reward estimate is wrong}\bigg[\underbrace{\nabla_\theta\log \pi(y_w \mid x)}\text{increase likelihood of $y_w$} - \underbrace{\nabla\theta\log\pi(y_l \mid x)}_\text{decrease likelihood of $y_l$}\bigg]\bigg], \end{split}\tag{8} $
where $\hat{r}\theta(x, y) = \beta \log \frac{\pi\theta(y \mid x)}{\pi_\text{ref}(y \mid x)}$ is the reward implicitly defined by the language model $\pi_\theta$ and reference model $\pi_\text{ref}$ (more in Section 5). Intuitively, the gradient of the loss function $\mathcal{L}\text{DPO}$ increases the likelihood of the preferred completions $y_w$ and decreases the likelihood of dispreferred completions $y_l$. Importantly, the examples are weighed by how much higher the implicit reward model $\hat{r}\theta$ rates the dispreferred completions, scaled by $\beta$, i.e, how incorrectly the implicit reward model orders the completions, accounting for the strength of the KL constraint. Our experiments suggest the importance of this weighting, as a naïve version of this method without the weighting coefficient can cause the language model to degenerate (Appendix Table 3).
DPO outline. The general DPO pipeline is as follows: 1) Sample completions $y_1, y_2 \sim \pi_\text{ref}(\cdot \mid x)$ for every prompt $x$, label with human preferences to construct the offline dataset of preferences $\mathcal{D} = {x^{(i)}, y_w^{(i)}, y_l)^{(i)}}{i=1}^N$ and 2) optimize the language model $\pi\theta$ to minimize $\mathcal{L}\text{DPO}$ for the given $\pi\text{ref}$ and $\mathcal{D}$ and desired $\beta$. In practice, one would like to reuse preference datasets publicly available, rather than generating samples and gathering human preferences. Since the preference datasets are sampled using $\pi^\text{SFT}$, we initialize $\pi_\text{ref} = \pi^\text{SFT}$ whenever available. However, when $\pi^\text{SFT}$ is not available, we initialize $\pi_\text{ref}$ by maximizing likelihood of preferred completions ${(x, y_w)}$, that is, ${\pi_\text{ref} = \operatorname{arg, max}{\pi}\mathbb{E}{x, y_w \sim \mathcal{D}}\left[\log \pi(y_w \mid x)\right]}$. This procedure helps mitigate the distribution shift between the true reference distribution which is unavailable, and $\pi_\text{ref}$ used by DPO. Further details related to the implementation and hyperparameters can be found in Appendix B.
5. Theoretical Analysis of DPO
Section Summary: This section explores the theoretical foundations of the Direct Preference Optimization (DPO) method, showing how it simplifies training language models by skipping the need for a separate reward model and reinforcement learning steps, instead using a single optimization goal based on preferences. It proves that DPO's approach reparameterizes rewards in a way that captures all possible preference patterns without losing generality, ensuring the resulting model aligns perfectly with optimal behavior under common preference models like Bradley-Terry. Additionally, it highlights DPO's stability advantages over traditional actor-critic techniques like PPO, which can become unstable during reinforcement learning from human feedback due to issues in estimating values and policies.
In this section, we give further interpretation of the DPO method, provide theoretical backing, and relate advantages of DPO to issues with actor critic algorithms used for RLHF (such as PPO [21]).
5.1 Your Language Model Is Secretly a Reward Model
DPO is able to bypass both fitting an explicit reward and performing RL to learn the policy using a single maximum likelihood objective. Note the optimization objective Equation 5 is equivalent to a Bradley-Terry model with a reward parameterization $r^*(x, y) = \beta \log\frac{\pi^*_\theta(y \mid x)}{\pi_\text{ref}(y \mid x)}$ and we optimize our parametric model $\pi_{\theta}$, equivalently to the reward model optimization in Equation 2 under the change of variables. In this section we will build the theory behind this reparameterization, show that it does not constrain the class of learned reward models, and allows for the exact recovery of the optimal policy. We begin with by defining an equivalence relation between reward functions.
########## {caption="Definition"}
We say that two reward functions $r(x, y)$ and $r'(x, y)$ are equivalent iff ${r(x, y)-r'(x, y) = f(x)}$ for some function $f$.
It is easy to see that this is indeed an equivalence relation, which partitions the set of reward functions into classes. We can state the following two lemmas:
########## {caption="Lemma 1"}
Under the Plackett-Luce, and in particular the Bradley-Terry, preference framework, two reward functions from the same class induce the same preference distribution.
########## {caption="Lemma 2"}
Two reward functions from the same equivalence class induce the same optimal policy under the constrained RL problem.
The proofs are straightforward and we defer them to Appendix A.5. The first lemma is a well-known under-specification issue with the Plackett-Luce family of models [34]. Due to this under-specification, we usually have to impose additional identifiability constraints to achieve any guarantees on the MLE estimates from Equation 2 [42]. The second lemma states that all reward functions from the same class yield the same optimal policy, hence for our final objective, we are only interested in recovering an arbitrary reward function from the optimal class. We prove the following Theorem in Appendix A.6:
########## {caption="Theorem 3"}
Under mild assumptions, all reward classes consistent with the Plackett-Luce (and Bradley-Terry in particular) models can be represented with the reparameterization ${r(x, y) = \beta \log \frac{\pi(y\mid x)}{\pi_\text{ref}(y\mid x)}}$ for some model $\pi(y\mid x)$ and a given reference model $\pi_\text{ref}(y \mid x)$.
Consider any reward function $r(x, y)$, which induces a corresponding optimal model $\pi_r(y \mid x)$, specified by Equation 4. We will show that a reward function from the equivalence class of $r$ can be represented using the reparameterization given above. We define the projection $f$ as
$ f(r; \pi_\text{ref}, \beta)(x, y) = r(x, y) - \beta\log\sum_{y}\pi_\text{ref}(y\mid x)\exp\left(\frac{1}{\beta}r(x, y)\right) $
The operator $f$ simply normalizes the reward function with the logarithm of the partition function of $\pi_r$. Since the added normalization term is only a function of the prefix $x$, $f(r; \pi_\text{ref}, \beta)(x, y) $ is a reward function in the equivalence class of $r(x, y)$. Finally, replacing $r$ with the RHS of Equation 5 (which holds for any reward function), we have $f(r; \pi_\text{ref}, \beta)(x, y) = \beta \log \frac{\pi_r(y\mid x)}{\pi_\text{ref}(y\mid x)}$. That is, the projection $f$ produces a member of the equivalence class of $r$ with the desired form, and we do not lose any generality in our reward model from the proposed reparameterization. We can alternatively view Theorem 3 as specifying exactly which reward function within each equivalence class the DPO reparameterization selects, that is, the reward function satisfying:
$ \sum_{y}\underbrace{\pi_\text{ref}(y\mid x)\exp\left(\frac{1}{\beta}r(x, y)\right)}_{=\pi(y\mid x)\text{, using Theorem 3 reparam.}} = 1,\tag{9} $
i.e., $\pi(y\mid x)$ is a valid distribution (probabilities are positive and sum to 1). However, following Equation 4, we can see that Equation 9 is the partition function of the optimal policy induced by the reward function $r(x, y)$. The key insight of the DPO algorithm is that we can impose certain constraints on the under-constrained Plackett-Luce (and Bradley-Terry in particular) family of preference models, such that we preserve the class of representable reward models, but explicitly make the optimal policy in Equation 4 analytically tractable for all prompts $x$.
5.2 Instability of Actor-Critic Algorithms
We can also use our framework to diagnose instabilities with standard actor-critic algorithms used for the RLHF, such as PPO. We follow the RLHF pipeline and focus on the RL fine-tuning step outlined in Section 3. We can draw connections to the control as inference framework [43] for the constrained RL problem outlined in Equation 3. We assume a parameterized model $\pi_{\theta}(y\mid x)$ and minimize $\mathbb{D}{\text{KL}}[\pi{\theta}(y|x) \mid \mid \pi^*(y\mid x)]$ where $\pi^*$ is the optimal policy from Equation 7 induced by the reward function $r_{\phi}(y, x)$. With some algebra this leads to the optimization objective:
$ \max_{\pi_{\theta}}\mathbb{E}{\pi{\theta}(y\mid x)}\bigg[\underbrace{r_{\phi}(x, y) -\beta\log\sum_{y}\pi_\text{ref}(y\mid x)\exp\left(\frac{1}{\beta}r_{\phi}(x, y)\right)}{f(r{\phi}, \pi_\text{ref}, \beta)} - \underbrace{\beta\log\frac{\pi_{\theta}(y\mid x)}{\pi_\text{ref}(y\mid x)}}_{\text{KL}}\bigg]\tag{10} $
This is the same objective optimized in prior works ([18, 17, 33, 5]) using the DPO-equivalent reward for the reward class of $r_{\phi}$. In this setting, we can interpret the normalization term in $f(r_{\phi}, \pi_\text{ref}, \beta)$ as the soft value function of the reference policy $\pi_\text{ref}$. While this term does not affect the optimal solution, without it, the policy gradient of the objective could have high variance, making learning unstable. We can accommodate for the normalization term using a learned value function, but that can also be difficult to optimize. Alternatively, prior works have normalized rewards using a human completion baseline, essentially a single sample Monte-Carlo estimate of the normalizing term. In contrast the DPO reparameterization yields a reward function that does not require any baselines.
6. Experiments
Section Summary: This section tests how well Direct Preference Optimization (DPO) trains AI language models to generate preferred text outputs based on human likes and dislikes, comparing it to methods like PPO in controlled scenarios and tougher real-world tasks. It covers three tasks: generating positive movie reviews, summarizing Reddit posts, and creating helpful responses to user queries in dialogues. DPO matches or outperforms baselines, showing strong results with minimal adjustments, evaluated through reward efficiency, divergence from starting models, and win rates judged by GPT-4 against human preferences.
In this section, we empirically evaluate DPO's ability to train policies directly from preferences. First, in a well-controlled text-generation setting, we ask: how efficiently does DPO trade off maximizing reward and minimizing KL-divergence with the reference policy, compared to common preference learning algorithms such as PPO? Next, we evaluate DPO's performance on larger models and more difficult RLHF tasks, including summarization and dialogue. We find that with almost no tuning of hyperparameters, DPO tends to perform as well or better than strong baselines like RLHF with PPO as well as returning the best of $N$ sampled trajectories under a learned reward function. Before presenting these results, we describe the experimental set-up; additional details are in Appendix C.
Tasks. Our experiments explore three different open-ended text generation tasks. For all experiments, algorithms learn a policy from a dataset of preferences $\mathcal{D}=\bigl{x^{(i)}, y_w^{(i)}, y_l^{(i)}\bigr}_{i=1}^N$. In controlled sentiment generation, $x$ is a prefix of a movie review from the IMDb dataset [44], and the policy must generate $y$ with positive sentiment. In order to perform a controlled evaluation, for this experiment we generate preference pairs over generations using a pre-trained sentiment classifier, where $p(\text{positive}\mid x, y_w)>p(\text{positive}\mid x, y_l)$. For SFT, we fine-tune GPT-2-large until convergence on reviews from the train split of the IMDB dataset (further details in Appendix C.1). In summarization, $x$ is a forum post from Reddit; the policy must generate a summary $y$ of the main points in the post. Following prior work, we use the Reddit TL;DR summarization dataset ([45]) along with human preferences gathered by [17]. We use an SFT model fine-tuned on human-written forum post summaries^1 with the TRLX ([46]) framework for RLHF. The human preference dataset was gathered by [17] on samples from a different, but similarly-trained, SFT model. Finally, in single-turn dialogue, $x$ is a human query, which may be anything from a question about astrophysics to a request for relationship advice. A policy must produce an engaging and helpful response $y$ to a user's query; we use the Anthropic Helpful and Harmless dialogue dataset ([33]), containing 170k dialogues between a human and an automated assistant. Each transcript ends with a pair of responses generated by a large (although unknown) language model along with a preference label denoting the human-preferred response. In this setting, no pre-trained SFT model is available; we therefore fine-tune an off-the-shelf language model on only the preferred completions to form the SFT model.
:::: {cols="2"}
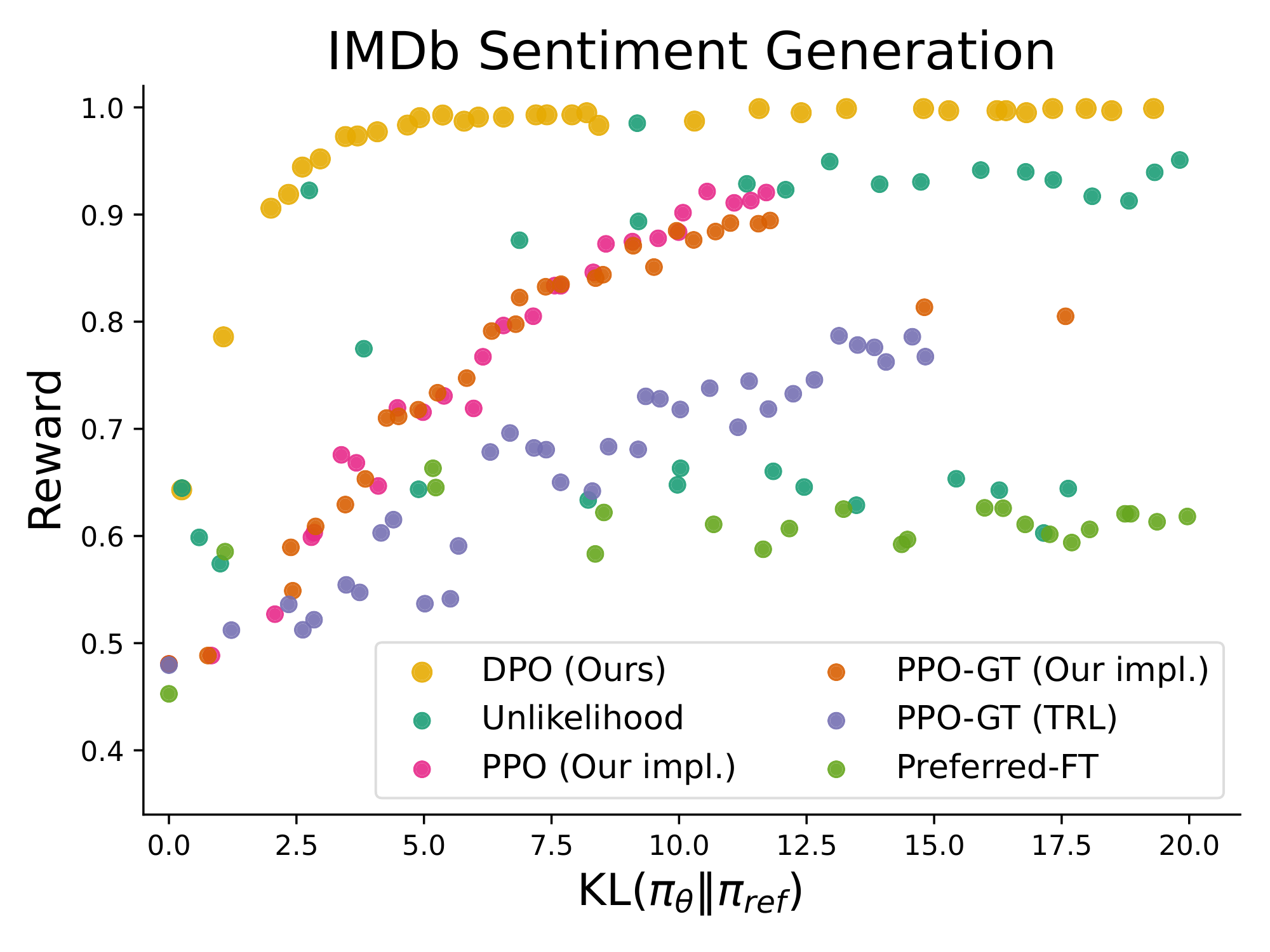
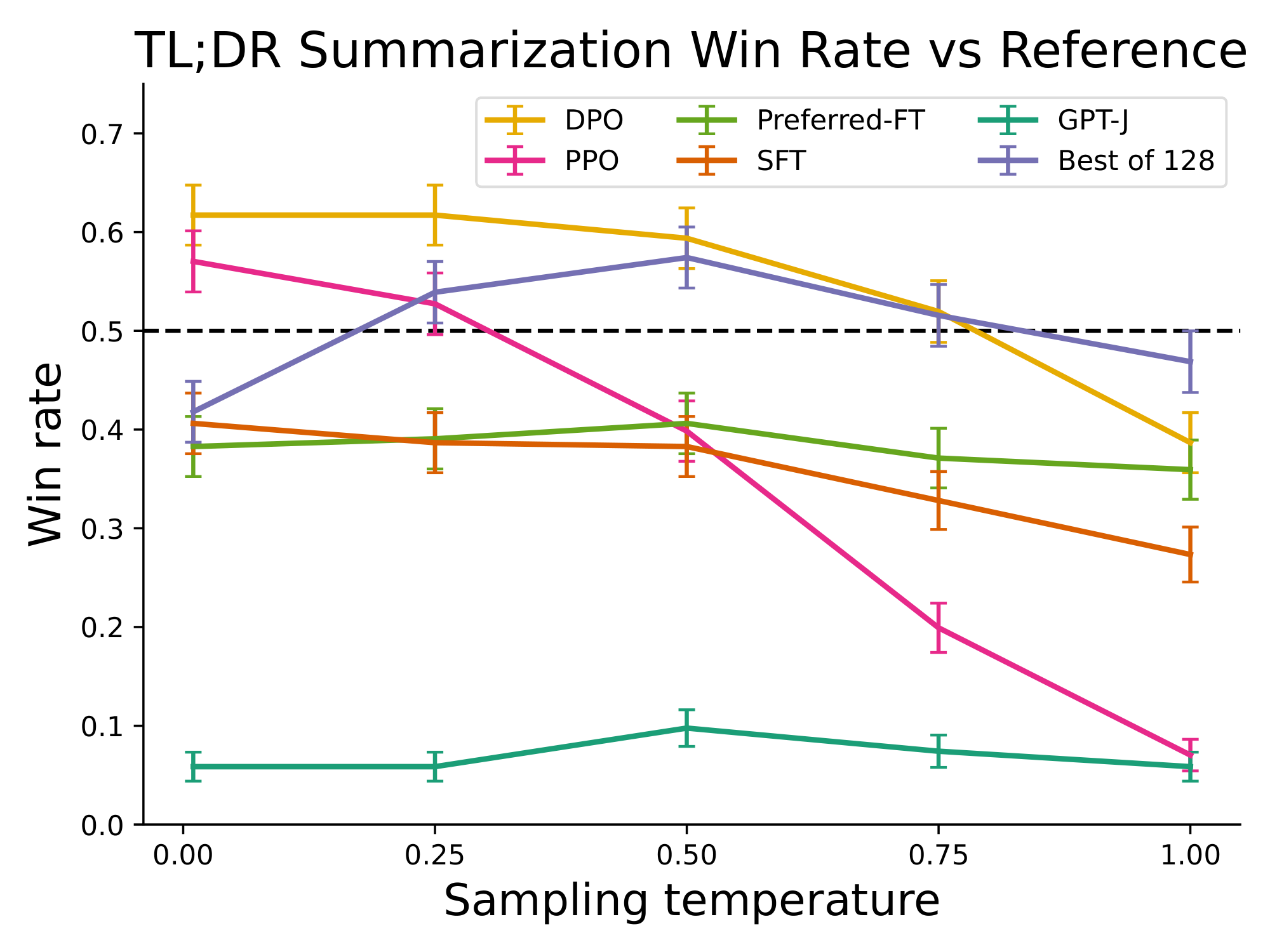
Figure 2: Left. The frontier of expected reward vs KL to the reference policy. DPO provides the highest expected reward for all KL values, demonstrating the quality of the optimization. Right. TL;DR summarization win rates vs. human-written summaries, using GPT-4 as evaluator. DPO exceeds PPO's best-case performance on summarization, while being more robust to changes in the sampling temperature. ::::
Evaluation. Our experiments use two different approaches to evaluation. In order to analyze the effectiveness of each algorithm in optimizing the constrained reward maximization objective, in the controlled sentiment generation setting we evaluate each algorithm by its frontier of achieved reward and KL-divergence from the reference policy; this frontier is computable because we have acccess to the ground-truth reward function (a sentiment classifier). However, in the real world, the ground truth reward function is not known; therefore, we evaluate algorithms with their win rate against a baseline policy, using GPT-4 as a proxy for human evaluation of summary quality and response helpfulness in the summarization and single-turn dialogue settings, respectively. For summarization, we use reference summaries in the test set as the baseline; for dialogue, we use the preferred response in the test dataset as the baseline. While existing studies suggest LMs can be better automated evaluators than existing metrics ([47]), we conduct a human study to justify our usage of GPT-4 for evaluation in Section 6.4. We find GPT-4 judgments correlate strongly with humans, with human agreement with GPT-4 typically similar or higher than inter-human annotator agreement.
Methods. In addition to DPO, we evaluate several existing approaches to training language models to adhere to human preferences. Most simply, we explore zero-shot prompting with GPT-J ([48]) in the summarization task and 2-shot prompting with Pythia-2.8B ([49]) in the dialogue task. In addition, we evaluate the SFT model as well as Preferred-FT, which is a model fine-tuned with supervised learning on the chosen completion $y_w$ from either the SFT model (in controlled sentiment and summarization) or a generic LM (in single-turn dialogue). Another pseudo-supervised method is Unlikelihood ([50]), which simply optimizes the policy to maximize the probability assigned to $y_w$ and minimize the probability assigned to $y_l$; we use an optional coefficient $\alpha\in[0, 1]$ on the 'unlikelihood' term. We also consider PPO ([21]) using a reward function learned from the preference data and PPO-GT, which is an oracle that learns from the ground truth reward function available in the controlled sentiment setting. In our sentiment experiments, we use two implementations of PPO-GT, one of-the-shelf version [46] as well as a modified version that normalizes rewards and further tunes hyperparameters to improve performance (we also use these modifications when running 'normal' PPO with learned rewards). Finally, we consider the Best of $N$ baseline, sampling $N$ responses from the SFT model (or Preferred-FT in dialogue) and returning the highest-scoring response according to a reward function learned from the preference dataset. This high-performing method decouples the quality of the reward model from the PPO optimization, but is computationally impractical even for moderate $N$ as it requires sampling $N$ completions for every query at test time.
6.1 How well can DPO optimize the RLHF objective?
:::: {cols="2"}
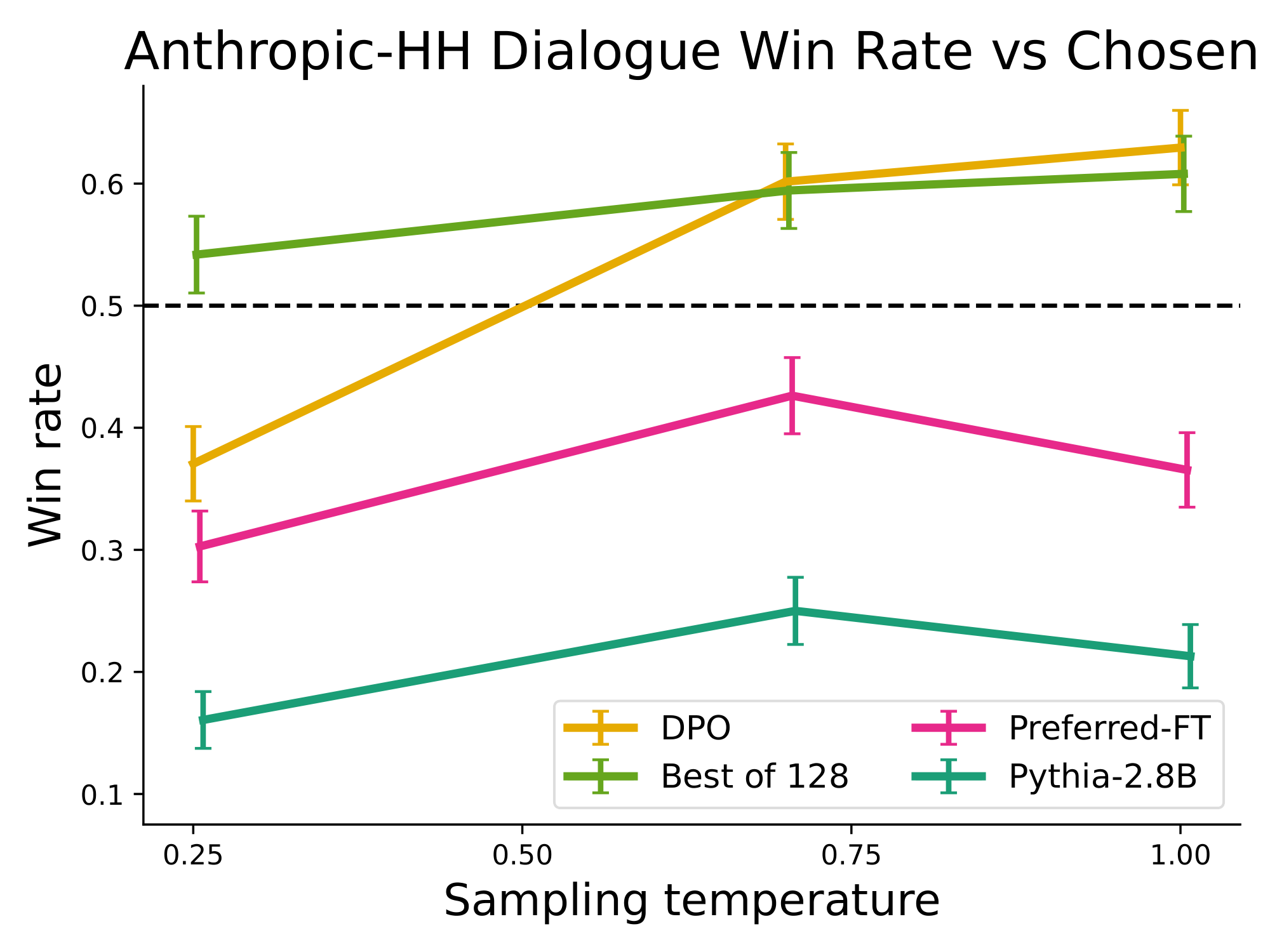
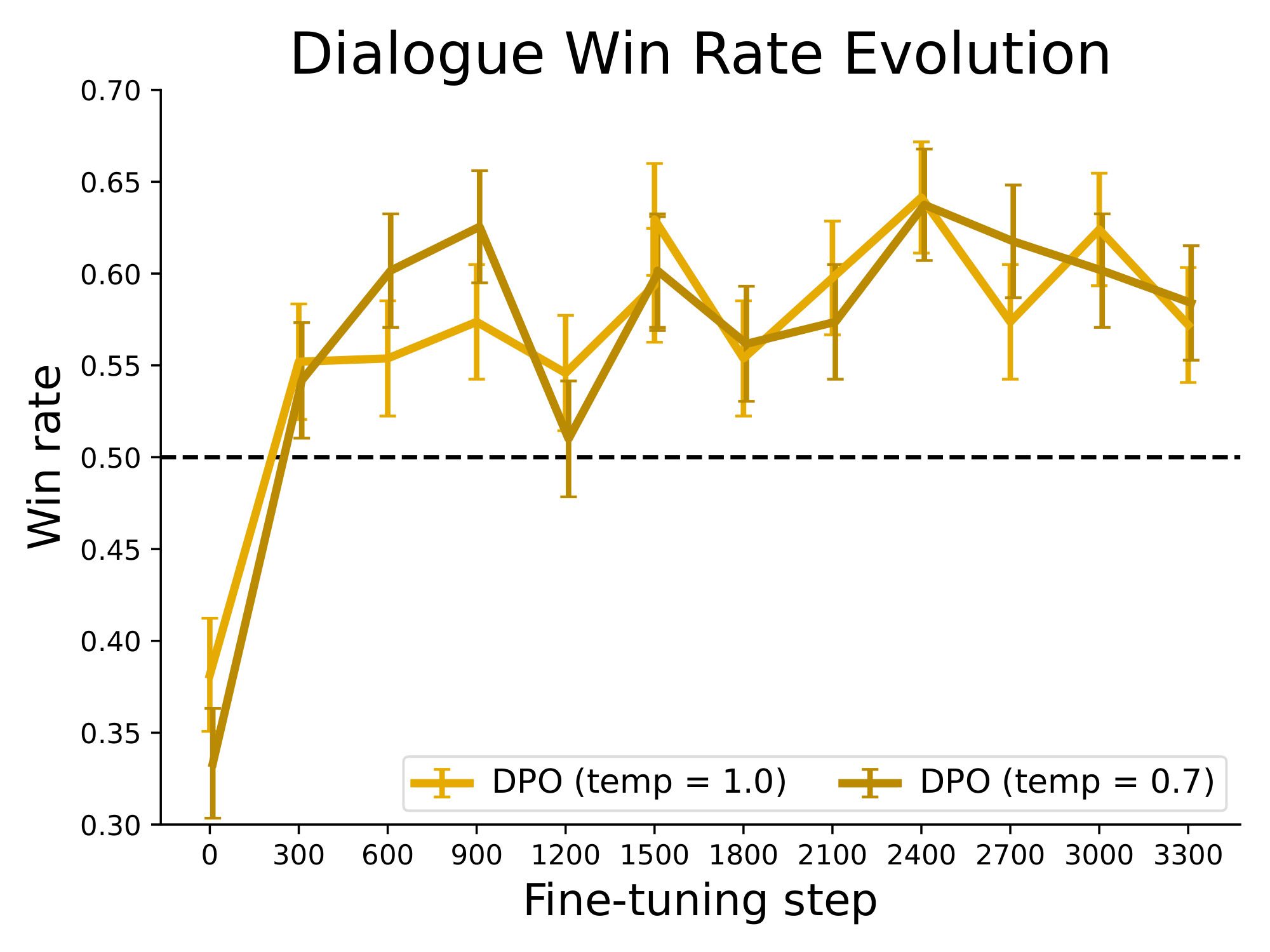
Figure 6: Left. Win rates computed by GPT-4 for Anthropic-HH one-step dialogue; DPO is the only method that improves over chosen summaries in the Anthropic-HH test set. Right. Win rates for different sampling temperatures over the course of training. DPO's improvement over the dataset labels is fairly stable over the course of training for different sampling temperatures. ::::
The KL-constrained reward maximization objective used in typical RLHF algorithms balances exploitation of reward while restricting the policy from deviating far from the reference policy. Therefore, when comparing algorithms, we must take into account both reward achieved as well as the KL discrepancy; achieving slightly higher reward but with much higher KL is not necessarily desirable. Figure 2 shows the reward-KL frontier for various algorithms in the sentiment setting. We execute multiple training runs for each algorithm, using a different hyperparameter for policy conservativeness in each run (target KL $\in{3, 6, 9, 12}$ for PPO, $\beta \in {0.05, 0.1, 1, 5}$, $\alpha\in{0.05, 0.1, 0.5, 1}$ for unlikelihood, random seeds for preferred-FT). This sweep includes 22 runs in total. After each 100 training steps until convergence, we evaluate each policy on a set of test prompts, computing the average reward under the true reward function as well as the average sequence-level KL[^2] with the reference policy $\text{KL}\left(\pi\mid \mid \pi_\text{ref}\right)$. We find that DPO produces by far the most efficient frontier, achieving the highest reward while still achieving low KL. This result is particularly notable for multiple reasons. First, DPO and PPO optimize the same objective, but DPO is notably more efficient; DPO's reward/KL tradeoff strictly dominates PPO. Second, DPO achieves a better frontier than PPO, even when PPO can access ground truth rewards (PPO-GT).
[^2]: That is, the sum of the per-timestep KL-divergences.
6.2 Can DPO scale to real preference datasets?
Next, we evaluate fine-tuning performance of DPO on summarization and single-turn dialogue. For summarization, automatic evaluation metrics such as ROUGE can be poorly correlated with human preferences ([17]), and prior work has found that fine-tuning LMs using PPO on human preferences to provide more effective summaries. We evaluate different methods by sampling completions on the test split of TL;DR summarization dataset, and computing the average win rate against reference completions in the test set. The completions for all methods are sampled at temperatures varying from 0.0 to 1.0, and the win rates are shown in Figure 2 (right). DPO, PPO and Preferred-FT all fine-tune the same GPT-J SFT model^3. We find that DPO has a win rate of approximately 61% at a temperature of 0.0, exceeding the performance of PPO at 57% at its optimal sampling temperature of 0.0. DPO also achieves a higher maximum win rate compared to the best of $N$ baseline. We note that we did not meaningfully tune DPO's $\beta$ hyperparameter, so these results may underestimate DPO's potential. Moreover, we find DPO to be much more robust to the sampling temperature than PPO, the performance of which can degrade to that of the base GPT-J model at high temperatures. Preferred-FT does not improve significantly over the SFT model. We also compare DPO and PPO head-to-head in human evaluations in Section 6.4, where DPO samples at temperature 0.25 were preferred 58% times over PPO samples at temperature 0.
On single-turn dialogue, we evaluate the different methods on the subset of the test split of the Anthropic HH dataset ([33]) with one step of human-assistant interaction. GPT-4 evaluations use the preferred completions on the test as the reference to compute the win rate for different methods. As there is no standard SFT model for this task, we start with a pre-trained Pythia-2.8B, use Preferred-FT to train a reference model on the chosen completions such that completions are within distribution of the model, and then train using DPO. We also compare against the best of 128 Preferred-FT completions (we found the Best of $N$ baseline plateaus at 128 completions for this task; see Appendix Figure 10) and a 2-shot prompted version of the Pythia-2.8B base model, finding DPO performs as well or better for the best-performing temperatures for each method. We also evaluate an RLHF model trained with PPO on the Anthropic HH dataset ^4 from a well-known source ^5, but are unable to find a prompt or sampling temperature that gives performance better than the base Pythia-2.8B model. Based on our results from TL;DR and the fact that both methods optimize the same reward function, we consider Best of 128 a rough proxy for PPO-level performance. Overall, DPO is the only computationally efficient method that improves over the preferred completions in the Anthropic HH dataset, and provides similar or better performance to the computationally demanding Best of 128 baseline. Finally, Figure 6 shows that DPO converges to its best performance relatively quickly.
6.3 Generalization to a new input distribution
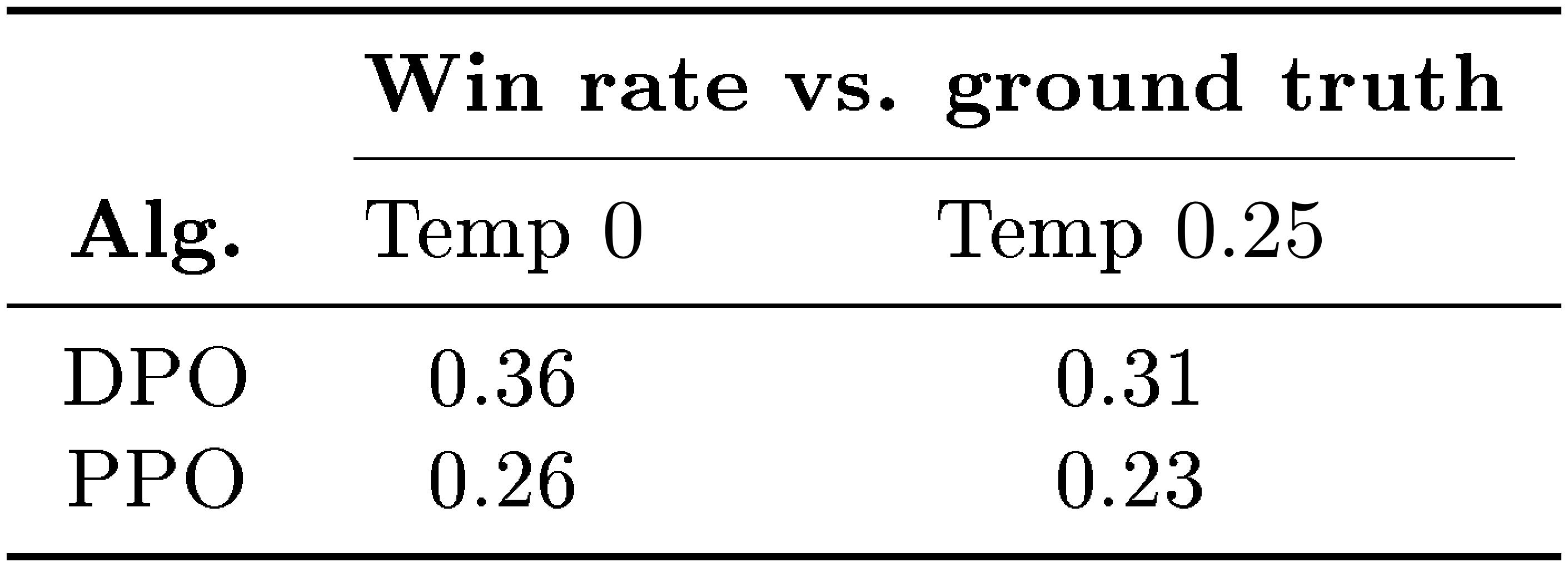
::: {caption="Table 1: GPT-4 win rates vs. ground truth summaries for out-of-distribution CNN/DailyMail input articles."}
:::
To further compare the performance of PPO and DPO under distribution shifts, we evaluate the PPO and DPO policies from our Reddit TL;DR summarization experiment on a different distribution, news articles in the test split of the CNN/DailyMail dataset ([51]), using the best sampling temperatures from TL;DR (0 and 0.25). The results are presented in Table 1. We computed the GPT-4 win rate against the ground-truth summaries in the datasets, using the same GPT-4 (C) prompt we used for Reddit TL;DR, but replacing the words "forum post" with "news article". For this new distribution, DPO continues to outperform the PPO policy by a significant margin. This experiment provides initial evidence that DPO policies can generalize similarly well to PPO policies, even though DPO does not use the additional unlabeled Reddit TL;DR prompts that PPO uses.
6.4 Validating GPT-4 judgments with human judgments
We conduct a human study to verify the reliability of GPT-4's judgments, using the results of the TL;DR summarization experiment and two different GPT-4 prompts. The GPT-4 (S) (simple) prompt simply asks for which summary better-summarizes the important information in the post. The GPT-4 (C) (concise) prompt also asks for which summary is more concise; we evaluate this prompt because we find that GPT-4 prefers longer, more repetitive summaries than humans do with the GPT-4 (S) prompt. See Appendix C.2 for the complete prompts. We perform three comparisons, using the highest (DPO, temp. 0.25), the lowest (PPO, temp. 1.0), and a
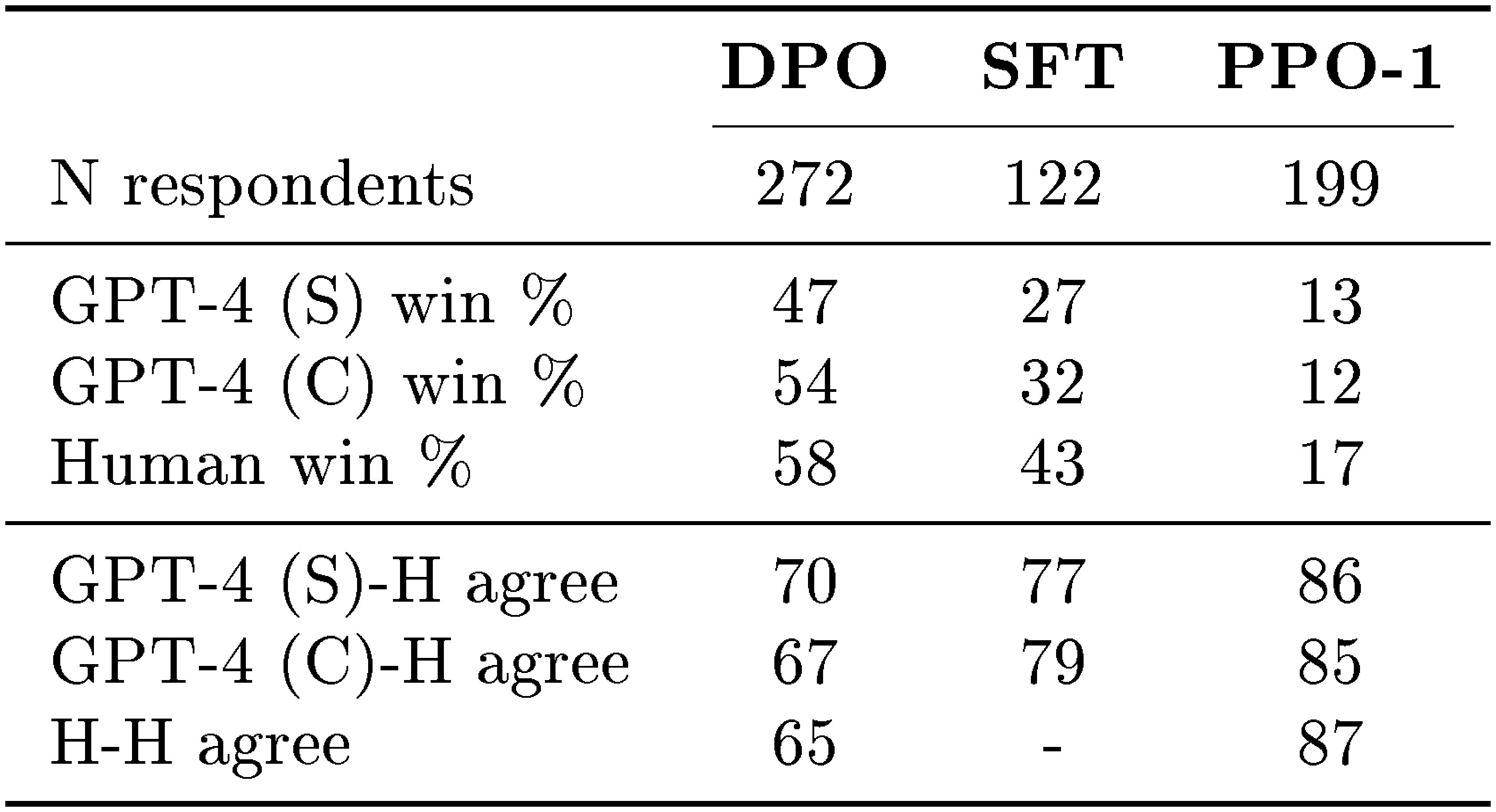
::: {caption="Comparing human and GPT-4 win rates and per-judgment agreement on TL;DR summarization samples. Humans agree with GPT-4 about as much as they agree with each other. Each experiment compares a summary from the stated method with a summary from PPO with temperature 0."}
:::
middle-performing (SFT, temp. 0.25) method with the aim of covering a diversity of sample qualities; all three methods are compared against greedily-sampled PPO (its best-performing temperature). We find that with both prompts, GPT-4 tends to agree with humans about as often as humans agree with each other, suggesting that GPT-4 is a reasonable proxy for human evaluations (due to limited human raters, we only collect multiple human judgments for the DPO and PPO-1 comparisons). Overall, the GPT-4 (C) prompt generally provides win rates more representative of humans; we therefore use this prompt for the main results in Section 6.2. For additional details about the human study, including the web interface presented to raters and the list of human volunteers, see Appendix D.3.
7. Discussion
Section Summary: This section highlights DPO as a straightforward method for training language models to align with human preferences using a simple loss function, bypassing the need for complex reinforcement learning and matching or surpassing traditional approaches like PPO with minimal adjustments. It lowers the hurdles for creating preference-aligned models, but notes limitations such as questions about how well DPO handles new situations compared to reward-based methods and potential over-optimization issues. Future research could explore scaling DPO to massive models, improving automated evaluations, using unlabeled data, and extending it to other types of generative AI beyond text.
Learning from preferences is a powerful, scalable framework for training capable, aligned language models. We have introduced DPO, a simple training paradigm for training language models from preferences without reinforcement learning. Rather than coercing the preference learning problem into a standard RL setting in order to use off-the-shelf RL algorithms, DPO identifies a mapping between language model policies and reward functions that enables training a language model to satisfy human preferences directly, with a simple cross-entropy loss, without reinforcement learning or loss of generality. With virtually no tuning of hyperparameters, DPO performs similarly or better than existing RLHF algorithms, including those based on PPO; DPO thus meaningfully reduces the barrier to training more language models from human preferences.
Limitations & Future Work. Our results raise several important questions for future work. How does the DPO policy generalize out of distribution, compared with learning from an explicit reward function? Our initial results suggest that DPO policies can generalize similarly to PPO-based models, but more comprehensive study is needed. For example, can training with self-labeling from the DPO policy similarly make effective use of unlabeled prompts? On another front, how does reward over-optimization manifest in the direct preference optimization setting, and is the slight decrease in performance in Figure 6-right an instance of it? Additionally, while we evaluate models up to 6B parameters, exploration of scaling DPO to state-of-the-art models orders of magnitude larger is an exciting direction for future work. Regarding evaluations, we find that the win rates computed by GPT-4 are impacted by the prompt; future work may study the best way to elicit high-quality judgments from automated systems. Finally, many possible applications of DPO exist beyond training language models from human preferences, including training generative models in other modalities.
Acknowledgements
Section Summary: The acknowledgements highlight funding and support for the research from various sources. One author, EM, received a Knight-Hennessy Graduate Fellowship, while CF and CM are fellows of CIFAR. Additional backing came from Stanford's Accelerator for Learning and Institute for Human-Centered Artificial Intelligence through a seed grant on generative AI for education, compute resources from the Stanford Center for Research on Foundation Models, and a U.S. Office of Naval Research grant.
EM gratefully acknowledges funding from a Knight-Hennessy Graduate Fellowship. CF and CM are CIFAR Fellows. This work was supported in part by the Stanford Accelerator for Learning (SAL) and Stanford Institute for Human-Centered Artificial Intelligence (HAI) Generative AI for the Future of Learning seed grant program. The Stanford Center for Research on Foundation Models (CRFM) provided part of the compute resources used for the experiments in this work. This work was supported in part by ONR grant N00014-20-1-2675.
Appendix
Section Summary: The appendix begins by detailing the contributions of each author to the research, including idea generation, experiment design, implementation, training, evaluation, and writing. It then provides mathematical derivations for key aspects of the paper's method, starting with the optimal policy under a KL-constrained reward maximization objective, which shows how a policy balances rewards against deviation from a reference model. Further sections derive the Direct Preference Optimization (DPO) objective using the Bradley-Terry model for pairwise preferences and extend it to the Plackett-Luce model for broader rankings.
Author Contributions
All authors provided valuable contributions to designing, analyzing, and iterating on experiments, writing and editing the paper, and generally managing the project’s progress.
RR proposed using autoregressive reward models in discussions with EM; derived the DPO objective; proved the theoretical properties of the algorithm and wrote the relevant sections and appendices. He also suggested and helped with organizing experiments and contributed some of the PPO and reward learning baselines.
AS initiated the discussion on using weighted regression methods as an alternative to PPO; initiated project-related organization, wrote initial analysis connecting DPO with weighted regression and unlikelihood; design and iterations of DPO + baseline implementations, initial exploratory experiments for DPO; substantial experiment organization and design (datasets, baselines, evaluation); led model training and evaluation for controlled sentiment generation and summarization; design iterations for GPT-4 evaluation (particularly summarization); substantial writing contributions to abstract, prelims/method and experiments; editing contributions to other sections.
EM provided input on early discussions on learning autoregressive reward functions; wrote the first implementation of DPO and ran the first DPO experiments; trained the large-scale (summarization and dialogue) DPO models used in paper experiments; conducted initial GPT-4 win rate evaluations and set up related infrastructure; recruited participants for, conducted, and analyzed results from the human study; wrote the abstract, introduction, related work, discussion, and most of experiments; and assisted with editing the rest of the paper.
CF, CM, & SE supervised the research, suggested ideas and experiments, and assisted in writing the paper.
A. Mathematical Derivations
A.1 Deriving the Optimum of the KL-Constrained Reward Maximization Objective
In this appendix, we will derive Equation 4. Analogously to 3, we optimize the following objective:
$ \max_{\pi} \mathbb{E}{x\sim \mathcal{D}, y\sim \pi}\bigl[r(x, y)\bigr] - \beta\mathbb{D}{\textrm{KL}}\bigl[\pi(y|x)|| \pi_\text{ref}(y|x)\bigr] $
under any reward function $r(x, y)$, reference model $\pi_\text{ref}$ and a general non-parametric policy class. We now have:
$ \begin{align} \max_{\pi} \mathbb{E}{x\sim \mathcal{D}, y\sim \pi}&\bigl[r(x, y)\bigr] - \beta\mathbb{D}{\textrm{KL}}\bigl[\pi(y|x)\mid\mid \pi_\text{ref}(y|x)\bigr] \nonumber\ &=\max_{\pi} \mathbb{E}{x\sim \mathcal{D}}\mathbb{E}{y\sim \pi(y|x)}\left[r(x, y) - \beta\log\frac{\pi(y|x)}{\pi_\text{ref}(y|x)}\right] \nonumber\&= \min_{\pi} \mathbb{E}{x\sim \mathcal{D}}\mathbb{E}{y\sim \pi(y|x)}\left[\log\frac{\pi(y|x)}{\pi_\text{ref}(y|x)} - \frac{1}{\beta}r(x, y)\right] \nonumber\ &= \min_{\pi} \mathbb{E}{x\sim \mathcal{D}}\mathbb{E}{y\sim \pi(y|x)}\left[\log\frac{\pi(y|x)}{\frac{1}{Z(x)}\pi_\text{ref}(y|x)\exp\left(\frac{1}{\beta}r(x, y)\right)} - \log Z(x)\right] \end{align}\tag{11} $
where we have partition function:
$ Z(x) = \sum_{y}\pi_\text{ref}(y|x)\exp\left(\frac{1}{\beta}r(x, y)\right). $
Note that the partition function is a function of only $x$ and the reference policy $\pi_\text{ref}$, but does not depend on the policy $\pi$. We can now define
$ \pi^*(y|x) = \frac{1}{Z(x)}\pi_\text{ref}(y|x)\exp\left(\frac{1}{\beta}r(x, y)\right), $
which is a valid probability distribution as $\pi^*(y|x)\geq 0$ for all $y$ and $\sum_{y}\pi^*(y|x)=1$. Since $Z(x)$ is not a function of $y$, we can then re-organize the final objective in Eq Equation 11 as:
$ \begin{align} \min_{\pi} \mathbb{E}{x\sim \mathcal{D}}\left[\mathbb{E}{y\sim \pi(y|x)}\left[\log\frac{\pi(y|x)}{\pi^*(y|x)}\right] - \log Z(x)\right]=\ \min_{\pi}\mathbb{E}{x\sim\mathcal{D}}\left[\mathbb{D}{\text{KL}}(\pi(y|x)\mid\mid\pi^*(y|x)) - \log Z(x)\right] \end{align} $
Now, since $Z(x)$ does not depend on $\pi$, the minimum is achieved by the policy that minimizes the first KL term. Gibbs' inequality tells us that the KL-divergence is minimized at 0 if and only if the two distributions are identical. Hence we have the optimal solution:
$ \pi(y|x)= \pi^*(y|x) = \frac{1}{Z(x)}\pi_\text{ref}(y|x)\exp\left(\frac{1}{\beta}r(x, y)\right) $
for all $x\in\mathcal{D}$. This completes the derivation.
A.2 Deriving the DPO Objective Under the Bradley-Terry Model
It is straightforward to derive the DPO objective under the Bradley-Terry preference model as we have
$ p^*(y_1\succ y_2|x)=\frac{\exp\left(r^*(x, y_1)\right)}{\exp\left(r^*(x, y_1)\right) + \exp\left(r^*(x, y_2)\right)}\tag{12} $
In Section 4 we showed that we can express the (unavailable) ground-truth reward through its corresponding optimal policy:
$ r^*(x, y) =\beta \log \frac{\pi^*(y|x)}{\pi_\text{ref}(y|x)} + \beta \log Z(x)\tag{13} $
Substituting Equation 13 into Equation 12 we obtain:
$ \begin{align*} p^*(y_1\succ y_2|x)&=\frac{\exp\left(\beta \log \frac{\pi^*(y_1|x)}{\pi_\text{ref}(y_1|x)} + \beta \log Z(x)\right)}{\exp\left(\beta \log \frac{\pi^*(y_1|x)}{\pi_\text{ref}(y_1|x)} + \beta \log Z(x)\right) + \exp\left(\beta \log \frac{\pi^*(y_2|x)}{\pi_\text{ref}(y_2|x)} + \beta \log Z(x)\right)}\ &= \frac{1}{1+\exp\left(\beta \log \frac{\pi^*(y_2|x)}{\pi_\text{ref}(y_2|x)}-\beta \log \frac{\pi^*(y_1|x)}{\pi_\text{ref}(y_1|x)}\right)} \&= \sigma\left(\beta \log \frac{\pi^*(y_1|x)}{\pi_\text{ref}(y_1|x)} - \beta \log \frac{\pi^*(y_2|x)}{\pi_\text{ref}(y_2|x)}\right). \end{align*} $
The last line is the per-instance loss in Equation 7.
A.3 Deriving the DPO Objective Under the Plackett-Luce Model
The Plackett-Luce model ([34, 35]) is a generalization of the Bradley-Terry model over rankings (rather than just pair-wise comparisons). Similar to to the Bradley-Terry model, it stipulates that when presented with a set of possible choices, people prefer a choice with probability proportional to the value of some latent reward function for that choice. In our context, when presented with a prompt $x$ and a set of $K$ answers $y_1, \ldots, y_K$ a user would output a permutation $\tau:[K]\to[K]$, giving their ranking of the answers. The Plackett-Luce model stipulates that
$ p^*(\tau| y_1, \ldots, y_K, x)= \prod_{k=1}^{K}\frac{\exp(r^*(x, y_{\tau(k)}))}{\sum_{j=k}^{K}\exp(r^*(x, y_{\tau(j)}))}\tag{14} $
Notice that when $K=2$, Equation 14 reduces to the Bradley-Terry model. However, for the general Plackett-Luce model, we can still utilize the results of Equation 5 and substitute the reward function parameterized by its optimal policy. Similarly to Appendix A.2, the normalization constant $Z(x)$ cancels out and we're left with:
$ p^*(\tau| y_1, \ldots, y_K, x)= \prod_{k=1}^{K}\frac{\exp\left(\beta \log \frac{\pi^*(y_{\tau(k)}|x)}{\pi_\text{ref}(y_{\tau(k)}|x)}\right)}{\sum_{j=k}^{K}\exp\left(\beta \log \frac{\pi^*(y_{\tau(j)}|x)}{\pi_\text{ref}(y_{\tau(j)}|x)}\right)} $
Similarly to the approach of Section 4, if we have access to a dataset $\mathcal{D} = {\tau^{(i)}, y_1^{(i)}, \ldots, y_K^{(i)}, x^{(i)}}_{i=1}^N$ of prompts and user-specified rankings, we can use a parameterized model and optimize this objective with maximum-likelihood.:
$ \mathcal{L}{\text{DPO}}(\pi{\theta}, \pi_\text{ref}) = -\mathbb{E}{\tau, y_1, \ldots, y_K, x\sim\mathcal{D}}\left[\log \prod{k=1}^{K}\frac{\exp\left(\beta \log \frac{\pi_{\theta}(y_{\tau(k)}|x)}{\pi_\text{ref}(y_{\tau(k)}|x)}\right)}{\sum_{j=k}^{K}\exp\left(\beta \log \frac{\pi_{\theta}(y_{\tau(j)}|x)}{\pi_\text{ref}(y_{\tau(j)}|x)}\right)}\right] $
A.4 Deriving the Gradient of the DPO Objective
In this section we derive the gradient of the DPO objective:
$ \begin{align} \nabla_{\theta}\mathcal{L}\text{DPO}(\pi{\theta}; \pi_\text{ref}) = -\nabla_{\theta}\mathbb{E}{(x, y_w, y_l)\sim \mathcal{D}}\left[\log \sigma \left(\beta \log \frac{\pi{\theta}(y_l|x)}{\pi_\text{ref}(y_l|x)} - \beta \log \frac{\pi_{\theta}(y_w|x)}{\pi_\text{ref}(y_w|x)}\right)\right] \end{align}\tag{15} $
We can rewrite the RHS of Equation 15 as
$ \begin{align} \nabla_{\theta}\mathcal{L}\text{DPO}(\pi{\theta}; \pi_\text{ref}) =-\mathbb{E}{(x, y_w, y_l)\sim \mathcal{D}}\left[\frac{\sigma'\left(u\right)}{\sigma \left(u\right)}\nabla{\theta}\left(u\right)\right], \end{align} $
where $u = \beta \log \frac{\pi_{\theta}(y_l|x)}{\pi_\text{ref}(y_l|x)} - \beta \log \frac{\pi_{\theta}(y_w|x)}{\pi_\text{ref}(y_w|x)}$.
Using the properties of sigmoid function $\sigma'(x) = \sigma(x)(1-\sigma(x))$ and $\sigma(-x) = 1-\sigma(x)$, we obtain the final gradient
$ \begin{split} \nabla_{\theta}\mathcal{L}\text{DPO}(\pi{\theta}; \pi_\text{ref}) = \ -\mathbb{E}{(x, y_w, y_l) \sim \mathcal{D}} \bigg[\beta\sigma \left(\beta \log \frac{\pi{\theta}(y_w|x)}{\pi_\text{ref}(y_w|x)} - \beta \log \frac{\pi_{\theta}(y_l|x)}{\pi_\text{ref}(y_l|x)}\right)\bigg[\nabla_\theta\log \pi(y_w \mid x) - \nabla_\theta\log\pi(y_l \mid x)\bigg]\bigg], \end{split} $
After using the reward substitution of $\hat{r}\theta(x, y) = \beta \log \frac{\pi\theta(y \mid x)}{\pi_\text{ref}(y \mid x)}$ we obtain the final form of the gradient from Section 4.
A.5 Proof of Lemma 1 and 2
In this section, we will prove the two lemmas from Section 5.
Lemma 1 Restated. Under the Plackett-Luce preference framework, and in particular the Bradley-Terry framework, two reward functions from the same equivalence class induce the same preference distribution.
Proof: We say that two reward functions $r(x, y)$ and $r'(x, y)$ are from the same equivalence class if $r'(x, y) = r(x, y) + f(x)$ for some function $f$. We consider the general Plackett-Luce (with the Bradley-Terry model a special case for $K=2$) and denote the probability distribution over rankings induced by a particular reward function $r(x, y)$ as $p_r$. For any prompt $x$, answers $y_1, \ldots, y_K$ and ranking $\tau$ we have:
$ \begin{align*} p_{r'}(\tau| y_1, \ldots, y_K, x) &= \prod_{k=1}^{K}\frac{\exp(r'(x, y_{\tau(k)}))}{\sum_{j=k}^{K}\exp(r'(x, y_{\tau(j)}))} \ &= \prod_{k=1}^{K}\frac{\exp(r(x, y_{\tau(k)}) + f(x))}{\sum_{j=k}^{K}\exp(r(x, y_{\tau(j)})+f(x))} \ &= \prod_{k=1}^{K}\frac{\exp(f(x))\exp(r(x, y_{\tau(k)}))}{\exp(f(x))\sum_{j=k}^{K}\exp(r(x, y_{\tau(j)}))} \ &= \prod_{k=1}^{K}\frac{\exp(r(x, y_{\tau(k)}))}{\sum_{j=k}^{K}\exp(r(x, y_{\tau(j)}))} \ &= p_{r}(\tau| y_1, \ldots, y_K, x), \end{align*} $
which completes the proof.
Lemma 2 Restated. Two reward functions from the same equivalence class induce the same optimal policy under the constrained RL problem.
Proof: Let us consider two reward functions from the same class, such that $r'(x, y)=r(x, y)+f(x)$ and, let us denote as $\pi_r$ and $\pi_{r'}$ the corresponding optimal policies. By Equation 4, for all $x, y$ we have
$ \begin{align*} \pi_{r'}(y|x) &= \frac{1}{\sum_{y}\pi_\text{ref}(y|x)\exp\left(\frac{1}{\beta}r'(x, y)\right)}\pi_\text{ref}(y|x)\exp\left(\frac{1}{\beta}r'(x, y)\right) \ &= \frac{1}{\sum_{y}\pi_\text{ref}(y|x)\exp\left(\frac{1}{\beta}(r(x, y) + f(x))\right)}\pi_\text{ref}(y|x)\exp\left(\frac{1}{\beta}(r(x, y)+f(x))\right) \ &= \frac{1}{\exp\left(\frac{1}{\beta}f(x)\right)\sum_{y}\pi_\text{ref}(y|x)\exp\left(\frac{1}{\beta}r(x, y)\right)}\pi_\text{ref}(y|x)\exp\left(\frac{1}{\beta}r(x, y)\right)\exp\left(\frac{1}{\beta}f(x)\right) \ &= \frac{1}{\sum_{y}\pi_\text{ref}(y|x)\exp\left(\frac{1}{\beta}r(x, y)\right)}\pi_\text{ref}(y|x)\exp\left(\frac{1}{\beta}r(x, y)\right) \ &= \pi_r(y|x), \end{align*} $
which completes the proof.
A.6 Proof of Theorem 1
In this section, we will expand on the results of Theorem 3.
Theorem 1 Restated. Assume, we have a reference model, such that $\pi_\text{ref}(y|x)>0$ for all pairs of prompts $x$ and answers $y$ and a parameter $\beta>0$. All reward equivalence classes, as defined in Section 5 can be represented with the reparameterization $r(x, y) = \beta \log \frac{\pi(y|x)}{\pi_\text{ref}(y|x)}$ for some model $\pi(y|x)$.
Proof: Consider any reward function $r(x, y)$, which induces an optimal model $\pi_r(y|x)$ under the KL-constrained RL problem, with solution given by Equation 4. Following Equation 5, when we log-linearize both sides we obtain:
$ r(x, y) =\beta \log \frac{\pi_r(y|x)}{\pi_\text{ref}(y|x)} + \beta \log Z(x) $
where $Z(x) =\sum_{y}\pi_\text{ref}(y|x)\exp\left(\frac{1}{\beta}r(x, y)\right)$ (notice that $Z(x)$ also depends on the reward function $r$). Using the operator $r'(x, y) = f(r, \pi_\text{ref}, \beta)(x, y) = r(x, y) - \beta \log Z(x)$, we see that this new reward function is within the equivalence class of $r$ and, we have:
$ r'(x, y) =\beta \log \frac{\pi_r(y|x)}{\pi_\text{ref}(y|x)} $
which completes the proof.
We can further expand on these results. We can see that if $r$ and $r'$ are two reward functions in the same class, then
$ f(r, \pi_\text{ref}, \beta)(x, y)= \beta \log \frac{\pi_r(y|x)}{\pi_\text{ref}(y|x)}= \beta \log \frac{\pi_r'(y|x)}{\pi_\text{ref}(y|x)} = f(r', \pi_\text{ref}, \beta)(x, y) $
where the second equality follows from Lemma 2. We have proven that the operator $f$ maps all reward functions from a particular equivalence class to the same reward function. Next, we show that for every equivalence class of reward functions, the reward function that has the reparameterization outlined in Theorem 3 is unique.
########## {caption="Proposition 4"}
Assume, we have a reference model, such that $\pi_\text{ref}(y|x)>0$ for all pairs of prompts $x$ and answers $y$ and a parameter $\beta>0$. Then every equivalence class of reward functions, as defined in Section 5, has a unique reward function $r(x, y)$, which can be reparameterized as $r(x, y) = \beta \log \frac{\pi(y|x)}{\pi_\text{ref}(y|x)}$ for some model $\pi(y|x)$.
Proof: We will proceed using proof by contradiction. Assume we have two reward functions from the same class, such that $r'(x, y) = r(x, y) + f(x)$. Moreover, assume that $r'(x, y) = \beta \log \frac{\pi'(y|x)}{\pi_\text{ref}(y|x)}$ for some model $\pi'(y|x)$ and $r(x, y) = \beta \log \frac{\pi(y|x)}{\pi_\text{ref}(y|x)}$ for some model $\pi(y|x)$, such that $\pi\neq\pi'$. We then have
$ r'(x, y) = r(x, y) + f(x) = \beta \log \frac{\pi(y|x)}{\pi_\text{ref}(y|x)} + f(x) = \beta \log \frac{\pi(y|x)\exp(\frac{1}{\beta} f(x))}{\pi_\text{ref}(y|x)}=\beta \log \frac{\pi'(y|x)}{\pi_\text{ref}(y|x)} $
for all prompts $x$ and completions $y$. Then we must have $\pi(y|x)\exp(\frac{1}{\beta} f(x)) = \pi'(y|x)$. Since these are distributions, summing over $y$ on both sides, we obtain that $\exp(\frac{1}{\beta} f(x)) = 1$ and since $\beta>0$, we must have $f(x)=0$ for all $x$. Therefore $r(x, y) = r'(x, y)$. This completes the proof.
We have now shown that every reward class has a unique reward function that can be represented as outlined in Theorem 3, which is given by $f(r, \pi_\text{ref}, \beta)$ for any reward function in that class.
B. DPO Implementation Details and Hyperparameters
DPO is relatively straightforward to implement; PyTorch code for the DPO loss is provided below:
import torch.nn.functional as F
def dpo_loss(pi_logps, ref_logps, yw_idxs, yl_idxs, beta):
"""
pi_logps: policy logprobs, shape (B,)
ref_logps: reference model logprobs, shape (B,)
yw_idxs: preferred completion indices in [0, B-1], shape (T,)
yl_idxs: dispreferred completion indices in [0, B-1], shape (T,)
beta: temperature controlling strength of KL penalty
Each pair of (yw_idxs[i], yl_idxs[i]) represents the
indices of a single preference pair.
"""
pi_yw_logps, pi_yl_logps = pi_logps[yw_idxs], pi_logps[yl_idxs]
ref_yw_logps, ref_yl_logps = ref_logps[yw_idxs], ref_logps[yl_idxs]
pi_logratios = pi_yw_logps - pi_yl_logps
ref_logratios = ref_yw_logps - ref_yl_logps
losses = -F.logsigmoid(beta * (pi_logratios - ref_logratios))
rewards = beta * (pi_logps - ref_logps).detach()
return losses, rewards
Unless noted otherwise, we use a $\beta = 0.1$, batch size of 64 and the RMSprop optimizer with a learning rate of 1e-6 by default. We linearly warmup the learning rate from 0 to 1e-6 over 150 steps. For TL;DR summarization, we use $\beta=0.5$, while rest of the parameters remain the same.
C. Further Details on the Experimental Set-Up
In this section, we include additional details relevant to our experimental design.
C.1 IMDb Sentiment Experiment and Baseline Details
The prompts are prefixes from the IMDB dataset of length 2-8 tokens. We use the pre-trained sentiment classifier siebert/sentiment-roberta-large-english as a ground-truth reward model and gpt2-large as a base model. We use these larger models as we found the default ones to generate low-quality text and rewards to be somewhat inaccurate. We first use supervised fine-tuning on a subset of the IMDB data for 1 epoch. We then use this model to sample 4 completions for 25000 prefixes and create 6 preference pairs for each prefix using the ground-truth reward model. The RLHF reward model is initialized from the gpt2-large model and trained for 3 epochs on the preference datasets, and we take the checkpoint with the highest validation set accuracy. The "TRL" run uses the hyper-parameters in the TRL library. Our implementation uses larger batch samples of 1024 per PPO step.
C.2 GPT-4 prompts for computing summarization and dialogue win rates
A key component of our experimental setup is GPT-4 win rate judgments. In this section, we include the prompts used to generate win rates for the summarization and dialogue experiments. We use gpt-4-0314 for all our experiments. The order of summaries or responses are randomly chosen for every evaluation.
Summarization GPT-4 win rate prompt (S).
Which of the following summaries does a better job of summarizing the most \
important points in the given forum post?
Post:
<post>
Summary A:
<Summary A>
Summary B:
<Summary B>
FIRST provide a one-sentence comparison of the two summaries, explaining which \
you prefer and why. SECOND, on a new line, state only "A" or "B" to indicate your \
choice. Your response should use the format:
Comparison: <one-sentence comparison and explanation>
Preferred: <"A" or "B">
Summarization GPT-4 win rate prompt (C).
Which of the following summaries does a better job of summarizing the most \
important points in the given forum post, without including unimportant or \
irrelevant details? A good summary is both precise and concise.
Post:
<post>
Summary A:
<Summary A>
Summary B:
<Summary B>
FIRST provide a one-sentence comparison of the two summaries, explaining which \
you prefer and why. SECOND, on a new line, state only "A" or "B" to indicate your \
choice. Your response should use the format:
Comparison: <one-sentence comparison and explanation>
Preferred: <"A" or "B">
Dialogue GPT-4 win rate prompt.
For the following query to a chatbot, which response is more helpful?
Query: <the user query>
Response A:
<either the test method or baseline>
Response B:
<the other response>
FIRST provide a one-sentence comparison of the two responses and explain \
which you feel is more helpful. SECOND, on a new line, state only "A" or \
"B" to indicate which response is more helpful. Your response should use \
the format:
Comparison: <one-sentence comparison and explanation>
More helpful: <"A" or "B">
C.3 Unlikelihood baseline
While we include the unlikelihood baseline ([50]) (simply maximizing $\log p(y_w|x)$, the log probability of the preferred response, while minimizing $\log p(y_l|x)$, the log probability of the dispreferred response) in our sentiment experiments, we do not include it as a baseline in either the summarization or dialogue experiment because it produces generally meaningless responses, which we believe is a result of unconstrained likelihood minimization.
::: {caption="Table 3: Unlikelihood samples from TL;DR prompts sampled at temperature 1.0. In general, we find unlikelihood fails to generate meaningful responses for more complex problems such as summarization and dialogue."}

:::
D. Additional Empirical Results
D.1 Performance of Best of $N$ baseline for Various $N$
We find that the Best of $N$ baseline is a strong (although computationally expensive, requiring sampling many times) baseline in our experiments. We include an evaluation of the Best of $N$ baseline for various $N$ for the Anthropic-HH dialogue and TL;DR summarization; the results are shown in Figure 10.
:::: {cols="2"}
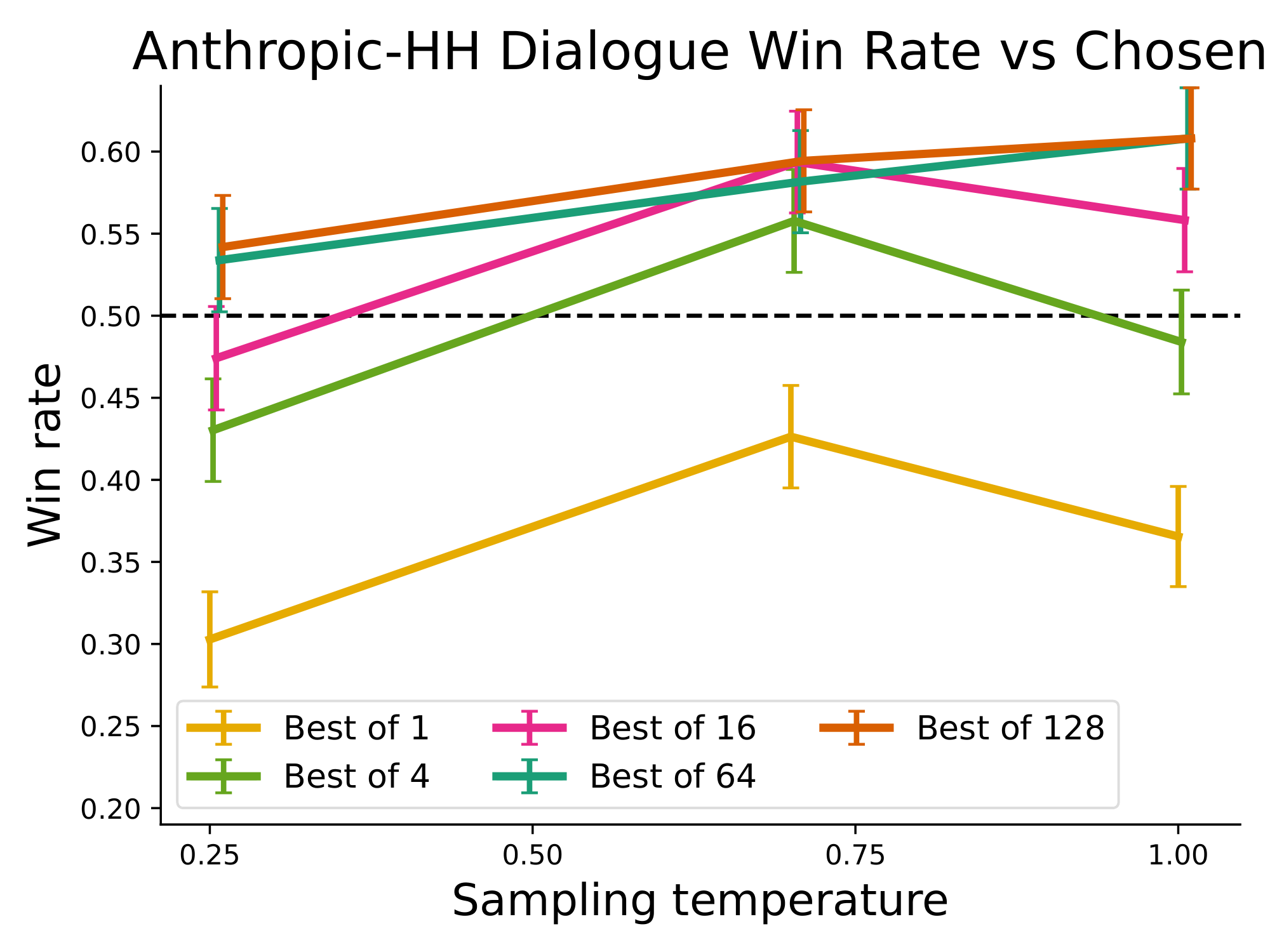
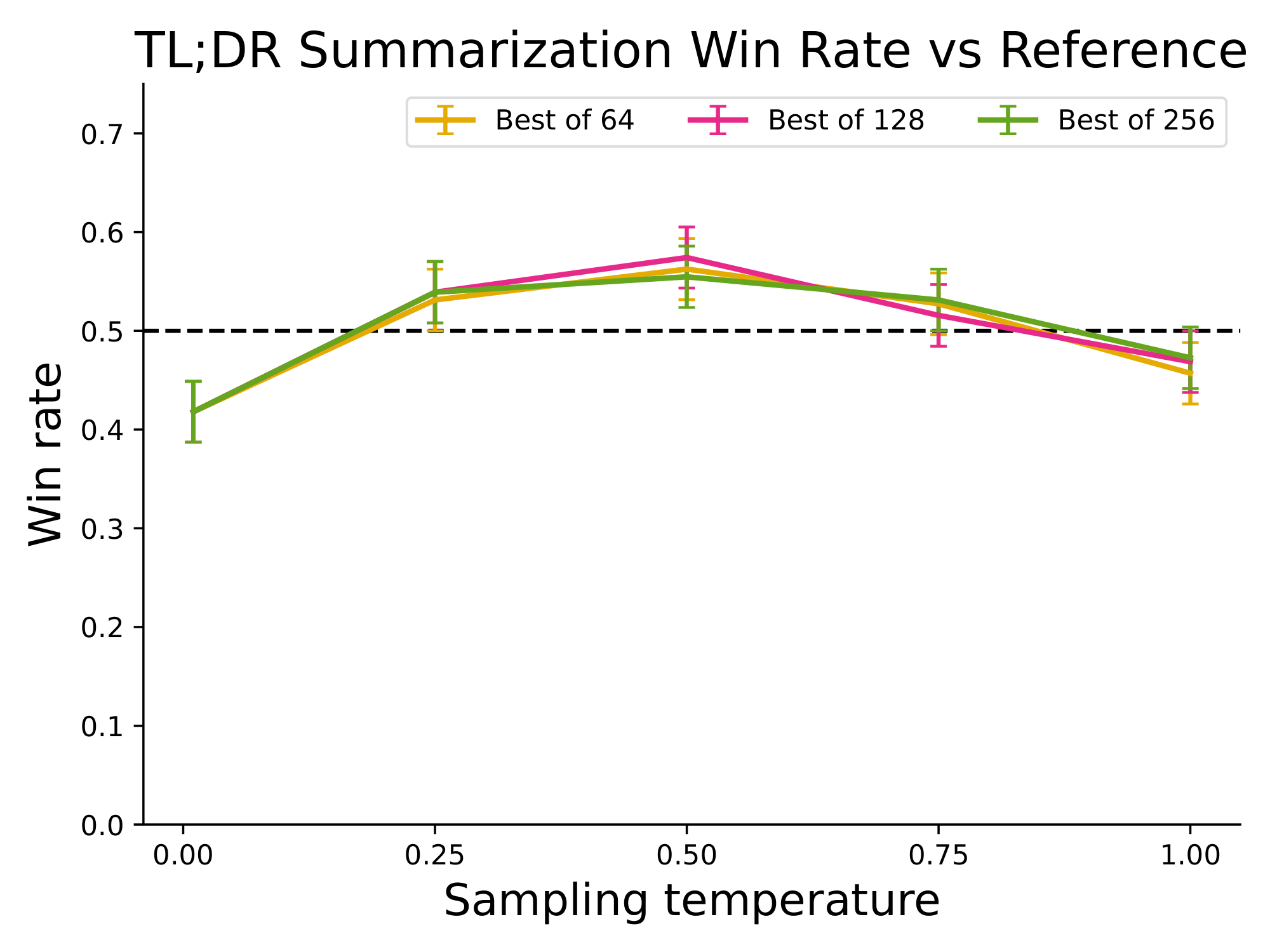
Figure 10: Best of $N$ baseline for $N={1, 4, 16, 64, 128}$. Performance plateaus after roughly 64-128 samples. ::::
D.2 Sample Responses and GPT-4 Judgments
In this section, we present examples of comparisons between DPO and the baseline (PPO temp 0. for summarization, and the ground truth chosen response for dialogue). See Table 4-Table 6 for summarization examples, and Table 7-Table 10 for dialogue examples.
::: {caption="Table 4: Sample summaries to a post from the TL;DR test set. DPO sample generated with a temperature 0.25; PPO sample generated at a temperature of 0. The order in which summaries are presented in randomized when evaluating with GPT-4, so the order in the Judgment may not correspond to the order in the table. For clarity, post-hoc annotations are included in bold, formatted as [annotation]. These annotations are not part of the model generations."}

:::
::: {caption="Table 5: Sample summaries to a post from the TL;DR test set. DPO sample generated with a temperature 0.25; PPO sample generated at a temperature of 0. The order in which summaries are presented in randomized when evaluating with GPT-4, so the order in the Judgment may not correspond to the order in the table. For clarity, post-hoc annotations are included in bold, formatted as [annotation]. These annotations are not part of the model generations."}

:::
::: {caption="Table 6: Sample summaries to a post from the TL;DR test set. DPO sample generated with a temperature 0.25; PPO sample generated at a temperature of 0. The order in which summaries are presented in randomized when evaluating with GPT-4, so the order in the Judgment may not correspond to the order in the table. For clarity, post-hoc annotations are included in bold, formatted as [annotation]. These annotations are not part of the model generations."}

:::
::: {caption="Table 7: GPT-4 chooses DPO over GT. Sample responses to a prompt from the Anthropic-HH test set. DPO sample generated with temperature 0.7; GT is the chosen completion in the dataset of preferences. For clarity, post-hoc annotations are included in bold, formatted as [annotation]. These annotations are not part of the model generations."}

:::
::: {caption="Table 8: GPT-4 chooses DPO over GT. Sample responses to a prompt from the Anthropic-HH test set. DPO sample generated with temperature 1.0; GT is the chosen completion in the dataset of preferences. For clarity, post-hoc annotations are included in bold, formatted as [annotation]. These annotations are not part of the model generations."}

:::
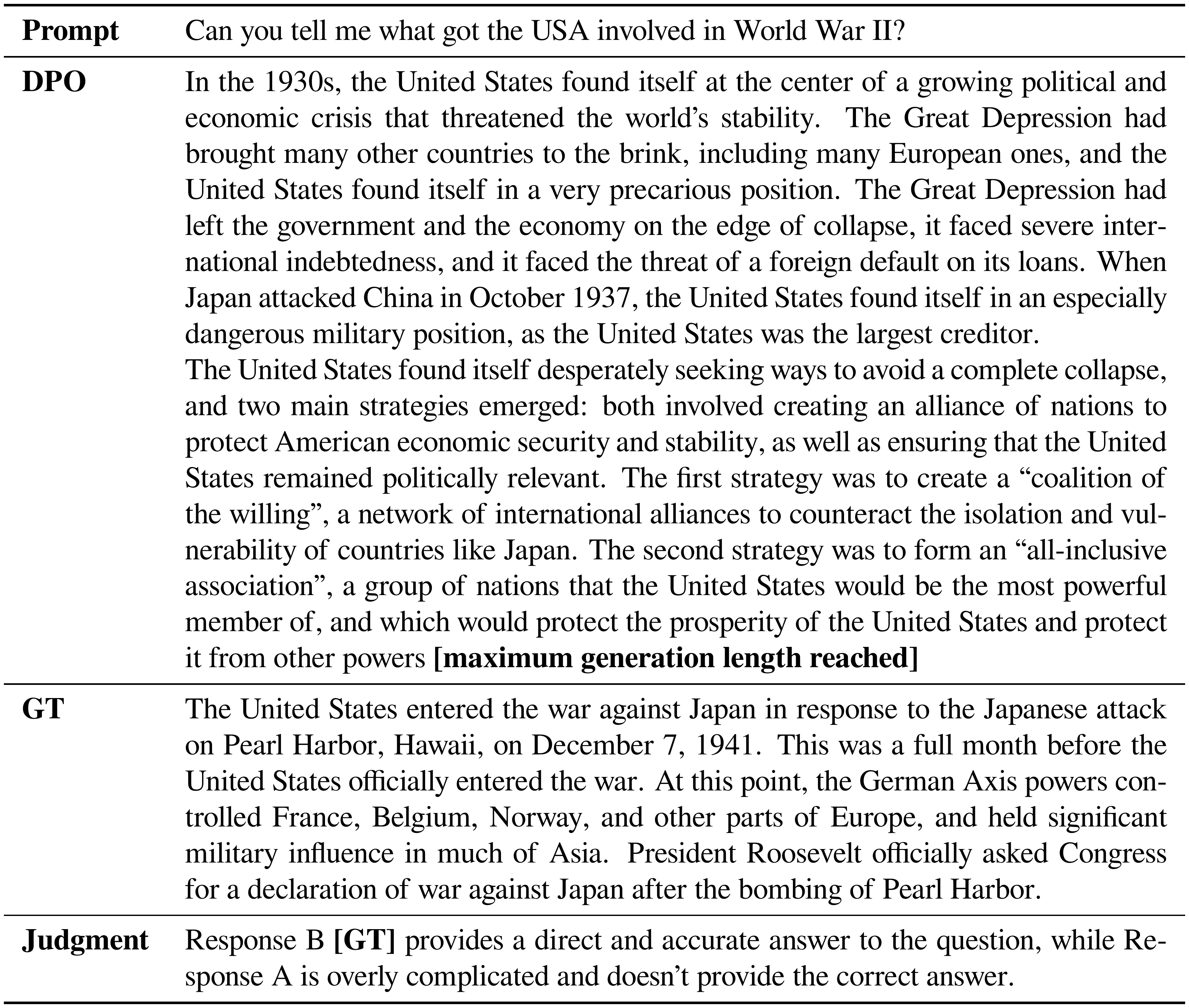
::: {caption="Table 9: GPT-4 chooses GT over DPO. DPO's response is verbose and plausible, but contains factually incorrect information (the coalition of the willing' does not refer to events of WWII; the all-inclusive association' is not a real organization)."}
:::
::: {caption="Table 10: GPT-4 chooses GT over DPO. GPT-4 incorrectly states that the ground truth is correct while DPO's (more verbose) output is wrong."}

:::
D.3 Human study details

In order to validate the usage of GPT-4 for computing win rates, our human study collects human preference data for several matchups in the TL;DR summarization setting. We select three different algorithmic matchups, evaluating DPO (temp. 0.25), SFT (temp. 0.25), and PPO (temp 1.0) compared to the reference algorithm PPO (temp 0.). By selecting matchups for three unique algorithms as well as algorithms with a wide range of win rates vs the reference, we capture the similarity of human and GPT-4 win rates across the response quality spectrum. We sample 150 random comparisons of DPO vs PPO-0 and 100 random comparisons PPO-1 vs PPO-0, assigning two humans to each comparison, producing 275 judgments for DPO-PPO[^6] and 200 judgments for PPO-PPO. We sample 125 SFT comparisons, assigning a single human to each. We ignore judgments that humans labeled as ties (which amount to only about 1% of judgments), and measure the raw agreement percentage between human A and human B (for comparisons where we have two human annotators, i.e., not SFT) as well as between each human and GPT-4.
[^6]: One volunteer did not respond for the DPO-PPO comparison.
Participants.
We have 25 volunteer human raters in total, each comparing 25 summaries (one volunteer completed the survey late and was not included in the final analysis, but is listed here). The raters were Stanford students (from undergrad through Ph.D.), or recent Stanford graduates or visitors, with a STEM (mainly CS) focus. See Figure 14 for a screenshot of the survey interface. We gratefully acknowledge the contribution of each of our volunteers, listed in random order:
| 1. Gordon Chi | 2. Virginia Adams | 3. Max Du | 4. Kaili Huang |
|---|---|---|---|
| 5. Ben Prystawski | 6. Ioanna Vavelidou | 7. Victor Kolev | 8. Karel D'Oosterlinck |
| 9. Ananth Agarwal | 10. Tyler Lum | 11. Mike Hardy | 12. Niveditha Iyer |
| 13. Helena Vasconcelos | 14. Katherine Li | 15. Chenchen Gu | 16. Moritz Stephan |
| 17. Swee Kiat Lim | 18. Ethan Chi | 19. Kaien Yang | 20. Ryan Chi |
| 21. Joy Yun | 22. Abhay Singhal | 23. Siyan Li | 24. Amelia Hardy |
| 25. Zhengxuan Wu |
References
[1] A. Chowdhery, S. Narang, J. Devlin, M. Bosma, G. Mishra, A. Roberts, P. Barham, H. W. Chung, C. Sutton, S. Gehrmann, et al. Palm: Scaling language modeling with pathways. arXiv preprint arXiv:2204.02311, 2022.
[2] T. Brown, B. Mann, N. Ryder, M. Subbiah, J. D. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell, et al. Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901, 2020b.
[3] H. Touvron, T. Lavril, G. Izacard, X. Martinet, M.-A. Lachaux, T. Lacroix, B. Rozière, N. Goyal, E. Hambro, F. Azhar, et al. Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971, 2023.
[4] S. Bubeck, V. Chandrasekaran, R. Eldan, J. Gehrke, E. Horvitz, E. Kamar, P. Lee, Y. T. Lee, Y. Li, S. Lundberg, H. Nori, H. Palangi, M. T. Ribeiro, and Y. Zhang. Sparks of artificial general intelligence: Early experiments with GPT-4, 2023. arXiv preprint arXiv:2303.12712.
[5] L. Ouyang, J. Wu, X. Jiang, D. Almeida, C. Wainwright, P. Mishkin, C. Zhang, S. Agarwal, K. Slama, A. Ray, J. Schulman, J. Hilton, F. Kelton, L. Miller, M. Simens, A. Askell, P. Welinder, P. F. Christiano, J. Leike, and R. Lowe. Training language models to follow instructions with human feedback. In S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh, editors, Advances in Neural Information Processing Systems, volume 35, pages 27730–27744. Curran Associates, Inc., 2022. URL https://proceedings.neurips.cc/paper_files/paper/2022/file/b1efde53be364a73914f58805a001731-Paper-Conference.pdf.
[6] P. F. Christiano, J. Leike, T. Brown, M. Martic, S. Legg, and D. Amodei. Deep reinforcement learning from human preferences. In I. Guyon, U. V. Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Garnett, editors, Advances in Neural Information Processing Systems, volume 30. Curran Associates, Inc., 2017. URL https://proceedings.neurips.cc/paper_files/paper/2017/file/d5e2c0adad503c91f91df240d0cd4e49-Paper.pdf.
[7] Y. Bai, S. Kadavath, S. Kundu, A. Askell, J. Kernion, A. Jones, A. Chen, A. Goldie, A. Mirhoseini, C. McKinnon, C. Chen, C. Olsson, C. Olah, D. Hernandez, D. Drain, D. Ganguli, D. Li, E. Tran-Johnson, E. Perez, J. Kerr, J. Mueller, J. Ladish, J. Landau, K. Ndousse, K. Lukosuite, L. Lovitt, M. Sellitto, N. Elhage, N. Schiefer, N. Mercado, N. DasSarma, R. Lasenby, R. Larson, S. Ringer, S. Johnston, S. Kravec, S. E. Showk, S. Fort, T. Lanham, T. Telleen-Lawton, T. Conerly, T. Henighan, T. Hume, S. R. Bowman, Z. Hatfield-Dodds, B. Mann, D. Amodei, N. Joseph, S. McCandlish, T. Brown, and J. Kaplan. Constitutional ai: Harmlessness from ai feedback, 2022b.
[8] R. A. Bradley and M. E. Terry. Rank analysis of incomplete block designs: I. the method of paired comparisons. Biometrika, 39(3/4):324–345, 1952. doi:https://doi.org/10.2307/2334029.
[9] A. Radford, J. Wu, R. Child, D. Luan, D. Amodei, and I. Sutskever. Language models are unsupervised multitask learners, 2019. Ms., OpenAI.
[10] T. Brown, B. Mann, N. Ryder, M. Subbiah, J. D. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell, S. Agarwal, A. Herbert-Voss, G. Krueger, T. Henighan, R. Child, A. Ramesh, D. Ziegler, J. Wu, C. Winter, C. Hesse, M. Chen, E. Sigler, M. Litwin, S. Gray, B. Chess, J. Clark, C. Berner, S. McCandlish, A. Radford, I. Sutskever, and D. Amodei. Language models are few-shot learners. In H. Larochelle, M. Ranzato, R. Hadsell, M. Balcan, and H. Lin, editors, Advances in Neural Information Processing Systems, volume 33, pages 1877–1901. Curran Associates, Inc., 2020a. URL https://proceedings.neurips.cc/paper_files/paper/2020/file/1457c0d6bfcb4967418bfb8ac142f64a-Paper.pdf.
[11] D. Narayanan, M. Shoeybi, J. Casper, P. LeGresley, M. Patwary, V. Korthikanti, D. Vainbrand, P. Kashinkunti, J. Bernauer, B. Catanzaro, A. Phanishayee, and M. Zaharia. Efficient large-scale language model training on gpu clusters using megatron-lm. In Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, SC '21, New York, NY, USA, 2021. Association for Computing Machinery. ISBN 9781450384421. doi:10.1145/3458817.3476209. URL https://doi.org/10.1145/3458817.3476209.
[12] S. Mishra, D. Khashabi, C. Baral, and H. Hajishirzi. Cross-task generalization via natural language crowdsourcing instructions. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 3470–3487, Dublin, Ireland, May 2022. Association for Computational Linguistics. doi:10.18653/v1/2022.acl-long.244. URL https://aclanthology.org/2022.acl-long.244.
[13] V. Sanh, A. Webson, C. Raffel, S. Bach, L. Sutawika, Z. Alyafeai, A. Chaffin, A. Stiegler, A. Raja, M. Dey, M. S. Bari, C. Xu, U. Thakker, S. S. Sharma, E. Szczechla, T. Kim, G. Chhablani, N. Nayak, D. Datta, J. Chang, M. T.-J. Jiang, H. Wang, M. Manica, S. Shen, Z. X. Yong, H. Pandey, R. Bawden, T. Wang, T. Neeraj, J. Rozen, A. Sharma, A. Santilli, T. Fevry, J. A. Fries, R. Teehan, T. L. Scao, S. Biderman, L. Gao, T. Wolf, and A. M. Rush. Multitask prompted training enables zero-shot task generalization. In International Conference on Learning Representations, 2022. URL https://openreview.net/forum?id=9Vrb9D0WI4.
[14] H. W. Chung, L. Hou, S. Longpre, B. Zoph, Y. Tay, W. Fedus, Y. Li, X. Wang, M. Dehghani, S. Brahma, A. Webson, S. S. Gu, Z. Dai, M. Suzgun, X. Chen, A. Chowdhery, A. Castro-Ros, M. Pellat, K. Robinson, D. Valter, S. Narang, G. Mishra, A. Yu, V. Zhao, Y. Huang, A. Dai, H. Yu, S. Petrov, E. H. Chi, J. Dean, J. Devlin, A. Roberts, D. Zhou, Q. V. Le, and J. Wei. Scaling instruction-finetuned language models, 2022.
[15] R. Thoppilan, D. D. Freitas, J. Hall, N. Shazeer, A. Kulshreshtha, H.-T. Cheng, A. Jin, T. Bos, L. Baker, Y. Du, Y. Li, H. Lee, H. S. Zheng, A. Ghafouri, M. Menegali, Y. Huang, M. Krikun, D. Lepikhin, J. Qin, D. Chen, Y. Xu, Z. Chen, A. Roberts, M. Bosma, V. Zhao, Y. Zhou, C.-C. Chang, I. Krivokon, W. Rusch, M. Pickett, P. Srinivasan, L. Man, K. Meier-Hellstern, M. R. Morris, T. Doshi, R. D. Santos, T. Duke, J. Soraker, B. Zevenbergen, V. Prabhakaran, M. Diaz, B. Hutchinson, K. Olson, A. Molina, E. Hoffman-John, J. Lee, L. Aroyo, R. Rajakumar, A. Butryna, M. Lamm, V. Kuzmina, J. Fenton, A. Cohen, R. Bernstein, R. Kurzweil, B. Aguera-Arcas, C. Cui, M. Croak, E. Chi, and Q. Le. Lamda: Language models for dialog applications, 2022.
[16] J. Kreutzer, J. Uyheng, and S. Riezler. Reliability and learnability of human bandit feedback for sequence-to-sequence reinforcement learning. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1777–1788, Melbourne, Australia, July 2018. Association for Computational Linguistics. doi:10.18653/v1/P18-1165. URL https://aclanthology.org/P18-1165.
[17] N. Stiennon, L. Ouyang, J. Wu, D. M. Ziegler, R. Lowe, C. Voss, A. Radford, D. Amodei, and P. Christiano. Learning to summarize from human feedback, 2022.
[18] D. M. Ziegler, N. Stiennon, J. Wu, T. B. Brown, A. Radford, D. Amodei, P. Christiano, and G. Irving. Fine-tuning language models from human preferences, 2020.
[19] R. Ramamurthy, P. Ammanabrolu, K. Brantley, J. Hessel, R. Sifa, C. Bauckhage, H. Hajishirzi, and Y. Choi. Is reinforcement learning (not) for natural language processing: Benchmarks, baselines, and building blocks for natural language policy optimization. In The Eleventh International Conference on Learning Representations, 2023. URL https://openreview.net/forum?id=8aHzds2uUyB.
[20] R. J. Williams. Simple statistical gradient-following algorithms for connectionist reinforcement learning. Mach. Learn., 8(3–4):229–256, may 1992. ISSN 0885-6125. doi:10.1007/BF00992696. URL https://doi.org/10.1007/BF00992696.
[21] J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov. Proximal policy optimization algorithms, 2017.
[22] M. Ranzato, S. Chopra, M. Auli, and W. Zaremba. Sequence level training with recurrent neural networks. CoRR, abs/1511.06732, 2015.
[23] R. Paulus, C. Xiong, and R. Socher. A deep reinforced model for abstractive summarization. In International Conference on Learning Representations, 2018. URL https://openreview.net/forum?id=HkAClQgA-.
[24] Y. Wu and B. Hu. Learning to extract coherent summary via deep reinforcement learning. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence and Thirtieth Innovative Applications of Artificial Intelligence Conference and Eighth AAAI Symposium on Educational Advances in Artificial Intelligence, AAAI'18/IAAI'18/EAAI'18. AAAI Press, 2018. ISBN 978-1-57735-800-8.
[25] A. Kupcsik, D. Hsu, and W. S. Lee. Learning Dynamic Robot-to-Human Object Handover from Human Feedback, pages 161–176. Springer International Publishing, 01 2018. ISBN 978-3-319-51531-1. doi:10.1007/978-3-319-51532-8_10.
[26] Y. Yue, J. Broder, R. Kleinberg, and T. Joachims. The k-armed dueling bandits problem. Journal of Computer and System Sciences, 78(5):1538–1556, 2012. ISSN 0022-0000. doi:https://doi.org/10.1016/j.jcss.2011.12.028. URL https://www.sciencedirect.com/science/article/pii/S0022000012000281. JCSS Special Issue: Cloud Computing 2011.
[27] M. Dudík, K. Hofmann, R. E. Schapire, A. Slivkins, and M. Zoghi. Contextual dueling bandits. In P. Grünwald, E. Hazan, and S. Kale, editors, Proceedings of The 28th Conference on Learning Theory, volume 40 of Proceedings of Machine Learning Research, pages 563–587, Paris, France, 03–06 Jul 2015. PMLR. URL https://proceedings.mlr.press/v40/Dudik15.html.
[28] X. Yan, C. Luo, C. L. A. Clarke, N. Craswell, E. M. Voorhees, and P. Castells. Human preferences as dueling bandits. In Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR '22, page 567–577, New York, NY, USA, 2022. Association for Computing Machinery. ISBN 9781450387323. doi:10.1145/3477495.3531991. URL https://doi.org/10.1145/3477495.3531991.
[29] R. Busa-Fekete, B. Szörényi, P. Weng, W. Cheng, and E. Hüllermeier. Preference-based reinforcement learning: evolutionary direct policy search using a preference-based racing algorithm. Machine Learning, 97(3):327–351, July 2014. doi:10.1007/s10994-014-5458-8. URL https://doi.org/10.1007/s10994-014-5458-8.
[30] A. Saha, A. Pacchiano, and J. Lee. Dueling rl: Reinforcement learning with trajectory preferences. In F. Ruiz, J. Dy, and J.-W. van de Meent, editors, Proceedings of The 26th International Conference on Artificial Intelligence and Statistics, volume 206 of Proceedings of Machine Learning Research, pages 6263–6289. PMLR, 25–27 Apr 2023. URL https://proceedings.mlr.press/v206/saha23a.html.
[31] A. Jain, B. Wojcik, T. Joachims, and A. Saxena. Learning trajectory preferences for manipulators via iterative improvement. In C. Burges, L. Bottou, M. Welling, Z. Ghahramani, and K. Weinberger, editors, Advances in Neural Information Processing Systems, volume 26. Curran Associates, Inc., 2013. URL https://proceedings.neurips.cc/paper_files/paper/2013/file/c058f544c737782deacefa532d9add4c-Paper.pdf.
[32] D. Sadigh, A. D. Dragan, S. Sastry, and S. A. Seshia. Active preference-based learning of reward functions. In Robotics: Science and Systems (RSS), 2017.
[33] Y. Bai, A. Jones, K. Ndousse, A. Askell, A. Chen, N. DasSarma, D. Drain, S. Fort, D. Ganguli, T. Henighan, N. Joseph, S. Kadavath, J. Kernion, T. Conerly, S. El-Showk, N. Elhage, Z. Hatfield-Dodds, D. Hernandez, T. Hume, S. Johnston, S. Kravec, L. Lovitt, N. Nanda, C. Olsson, D. Amodei, T. Brown, J. Clark, S. McCandlish, C. Olah, B. Mann, and J. Kaplan. Training a helpful and harmless assistant with reinforcement learning from human feedback, 2022a.
[34] R. L. Plackett. The analysis of permutations. Journal of the Royal Statistical Society. Series C (Applied Statistics), 24(2):193–202, 1975. doi:https://doi.org/10.2307/2346567.
[35] R. D. Luce. Individual choice behavior: A theoretical analysis. Courier Corporation, 2012.
[36] N. Jaques, S. Gu, D. Bahdanau, J. M. Hernández-Lobato, R. E. Turner, and D. Eck. Sequence tutor: Conservative fine-tuning of sequence generation models with kl-control. In International Conference on Machine Learning, pages 1645–1654. PMLR, 2017.
[37] N. Jaques, J. H. Shen, A. Ghandeharioun, C. Ferguson, A. Lapedriza, N. Jones, S. S. Gu, and R. Picard. Human-centric dialog training via offline reinforcement learning. arXiv preprint arXiv:2010.05848, 2020.
[38] J. Peters and S. Schaal. Reinforcement learning by reward-weighted regression for operational space control. In Proceedings of the 24th international conference on Machine learning, pages 745–750, 2007.
[39] X. B. Peng, A. Kumar, G. Zhang, and S. Levine. Advantage-weighted regression: Simple and scalable off-policy reinforcement learning. arXiv preprint arXiv:1910.00177, 2019.
[40] T. Korbak, H. Elsahar, G. Kruszewski, and M. Dymetman. On reinforcement learning and distribution matching for fine-tuning language models with no catastrophic forgetting. In S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh, editors, Advances in Neural Information Processing Systems, volume 35, pages 16203–16220. Curran Associates, Inc., 2022. URL https://proceedings.neurips.cc/paper_files/paper/2022/file/67496dfa96afddab795530cc7c69b57a-Paper-Conference.pdf.
[41] D. Go, T. Korbak, G. Kruszewski, J. Rozen, N. Ryu, and M. Dymetman. Aligning language models with preferences through f-divergence minimization. In Proceedings of the 40th International Conference on Machine Learning, ICML'23. JMLR.org, 2023.
[42] H. Bong and A. Rinaldo. Generalized results for the existence and consistency of the MLE in the Bradley-Terry-Luce model. International Conference on Machine Learning, 2022. arXiv:2110.11487.
[43] S. Levine. Reinforcement learning and control as probabilistic inference: Tutorial and review, 2018.
[44] A. L. Maas, R. E. Daly, P. T. Pham, D. Huang, A. Y. Ng, and C. Potts. Learning word vectors for sentiment analysis. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies, pages 142–150, Portland, Oregon, USA, June 2011. Association for Computational Linguistics. URL http://www.aclweb.org/anthology/P11-1015.
[45] M. Völske, M. Potthast, S. Syed, and B. Stein. TL;DR: Mining Reddit to learn automatic summarization. In Proceedings of the Workshop on New Frontiers in Summarization, pages 59–63, Copenhagen, Denmark, Sept. 2017. Association for Computational Linguistics. doi:10.18653/v1/W17-4508. URL https://aclanthology.org/W17-4508.
[46] L. von Werra, J. Tow, reciprocated, S. Matiana, A. Havrilla, cat state, L. Castricato, Alan, D. V. Phung, A. Thakur, A. Bukhtiyarov, aaronrmm, F. Milo, Daniel, D. King, D. Shin, E. Kim, J. Wei, M. Romero, N. Pochinkov, O. Sanseviero, R. Adithyan, S. Siu, T. Simonini, V. Blagojevic, X. Song, Z. Witten, alexandremuzio, and crumb. CarperAI/trlx: v0.6.0: LLaMa (Alpaca), Benchmark Util, T5 ILQL, Tests, Mar. 2023. URL https://doi.org/10.5281/zenodo.7790115.
[47] Y. Chen, R. Wang, H. Jiang, S. Shi, and R.-L. Xu. Exploring the use of large language models for reference-free text quality evaluation: A preliminary empirical study. ArXiv, abs/2304.00723, 2023.
[48] B. Wang and A. Komatsuzaki. GPT-J-6B: A 6 Billion Parameter Autoregressive Language Model. https://github.com/kingoflolz/mesh-transformer-jax, May 2021.
[49] S. Biderman, H. Schoelkopf, Q. Anthony, H. Bradley, K. O'Brien, E. Hallahan, M. A. Khan, S. Purohit, U. S. Prashanth, E. Raff, A. Skowron, L. Sutawika, and O. van der Wal. Pythia: A suite for analyzing large language models across training and scaling, 2023.
[50] S. Welleck, I. Kulikov, S. Roller, E. Dinan, K. Cho, and J. Weston. Neural text generation with unlikelihood training. arXiv preprint arXiv:1908.04319, 2019.
[51] R. Nallapati, B. Zhou, C. dos Santos, Ç. Gulçehre, and B. Xiang. Abstractive text summarization using sequence-to-sequence RNNs and beyond. In Proceedings of the 20th SIGNLL Conference on Computational Natural Language Learning, pages 280–290, Berlin, Germany, Aug. 2016. Association for Computational Linguistics. doi:10.18653/v1/K16-1028. URL https://aclanthology.org/K16-1028.