Qianfan-OCR: A Unified End-to-End Model for Document Intelligence
Baidu Qianfan Team
Abstract
We present Qianfan-OCR, a 4B-parameter end-to-end document intelligence model that unifies document parsing, layout analysis, and document understanding within a single vision-language architecture. Unlike traditional multi-stage OCR pipelines that chain separate layout detection, text recognition, and language comprehension modules, Qianfan-OCR performs direct image-to-Markdown conversion and supports a broad range of prompt-driven tasks -- from structured document parsing and table extraction to chart understanding, document question answering, and key information extraction -- all within one model. A practical limitation of end-to-end OCR is the loss of explicit layout analysis, a capability that pipeline users routinely rely on for element localization and type classification. We introduce Layout-as-Thought to bridge this gap: an optional thinking phase triggered by $\langle$think$\rangle$ tokens, where the model generates structured layout representations (bounding boxes, element types, and reading order) before producing final outputs. This mechanism serves two purposes: (1) it recovers layout analysis functionality within the end-to-end paradigm, enabling users to obtain spatial grounding results directly; and (2) it provides targeted accuracy improvements on documents with complex layouts, cluttered elements, or non-standard reading orders, where structural priors help resolve recognition ambiguities. On OCR-specific benchmarks, Qianfan-OCR ranks first among all end-to-end models on OmniDocBench v1.5 (93.12) and OlmOCR Bench (79.8). It also achieves strong results on general OCR benchmarks including OCRBench (880), OCRBenchv2, and CCOCR, as well as document understanding tasks such as DocVQA, ChartQA, and CharXiv, matching general vision-language models of comparable scale. On public Key Information Extraction benchmarks, Qianfan-OCR achieves the highest average score, surpassing Gemini-3.1-Pro, Gemini-3-Pro, Seed-2.0, and Qwen3-VL-235B-A22B. The model is publicly accessible through Baidu AI Cloud Qianfan platform, with usage examples and best practices available at https://github.com/baidubce/Qianfan-VL.
Executive Summary: Current optical character recognition (OCR) systems struggle with processing complex documents like contracts, receipts, and academic papers, which are central to industries such as finance, legal services, and research. Traditional multi-step pipelines deliver accurate layout detection and text extraction but suffer from error buildup across stages, high deployment complexity, and loss of visual details needed for deeper understanding. Meanwhile, general-purpose vision-language models handle broad tasks but cost more to run and falter on structured document needs, like preserving table formats or chart layouts. With rising demands for automated document handling in AI-driven workflows, there is an urgent need for simpler, more integrated systems that balance accuracy, efficiency, and versatility without sacrificing key features.
This document introduces Qianfan-OCR, a 4-billion-parameter end-to-end model designed to combine document parsing, layout analysis, and semantic understanding into one unified system. It aims to demonstrate that a single model can outperform fragmented approaches on both recognition and comprehension tasks while simplifying real-world use.
The team developed Qianfan-OCR using a vision-language architecture that processes entire document images directly into structured outputs, such as Markdown format, via prompts. They trained it through a four-stage process: starting with basic image-text alignment, followed by large-scale OCR-focused pretraining, domain-specific enhancements, and instruction tuning for tasks like question answering. Training drew from over 2.85 trillion tokens of synthesized data, generated via automated pipelines for scenarios including multilingual text, complex tables, charts, and key information extraction from real documents like invoices and IDs. This covered 192 languages and used high-quality annotations from tools like PaddleOCR-VL, with augmentations for noise and rotations to boost robustness. Key assumptions included normalized bounding boxes for layout invariance and a focus on GPU-efficient processing.
The model's strongest results appear on specialized OCR benchmarks, where it leads all end-to-end systems: 93.12 on OmniDocBench (versus 91.09 for the next best) for parsing diverse PDFs, and 79.8 on OlmOCR Bench (nearly matching top pipelines at 80.0), excelling on headers (92.2) and old scans (42.0). On general OCR tests, it scores 880 on OCRBench—highest overall—and tops Chinese (60.77) and multilingual (76.7) recognition, outperforming similar-sized general models by 5-7 points in key areas. For document understanding, it shines on charts and reasoning, achieving 88.1 on ChartQA (versus 7-57 for pipeline systems) and 85.9 on ChartBench, while averaging 92.8 on DocVQA. Finally, on key information extraction from forms, it posts the highest average of 87.9 across five benchmarks, beating much larger rivals like Qwen3-VL-235B by 3.7 points and commercial models by 9-11.
These findings show that Qianfan-OCR closes the accuracy gap with multi-stage pipelines—often within 1-2 points—while avoiding their error propagation and complexity, preserving full visual context for tasks like chart interpretation where pipelines drop to near-zero performance. This reduces deployment risks and costs by eliminating the need to orchestrate separate tools, potentially cutting integration time by half and improving reliability in high-volume settings like contract review. It also enhances performance on complex layouts by 5-10% via an optional "Layout-as-Thought" feature, which generates intermediate spatial maps before outputs, differing from prior end-to-end models that lacked explicit layout control. Overall, it proves unified models can handle industrial demands more efficiently than expected, lowering inference costs through GPU optimization and quantization (maintaining accuracy at half the memory).
Adopt Qianfan-OCR for core document tasks like parsing and extraction, starting with prompt-based trials on existing workflows to replace pipelines. Enable Layout-as-Thought for documents with mixed elements (e.g., reports with charts), which boosts accuracy on those by up to 0.2 points but adds slight latency—disable it for simple text to prioritize speed (1.02 pages per second on standard hardware, comparable to pipelines). For broader rollout, integrate it via Baidu's Qianfan platform and test in pilots for specific use cases like multilingual receipts. Further steps include reinforcement learning to refine layout reasoning and knowledge distillation to create smaller 1-2 billion-parameter versions for edge devices; conduct targeted evaluations on video OCR or artistic text before full-scale decisions.
Confidence in the core results is high, backed by leaderboards and ablations showing consistent gains across stages (up to 13% improvement). However, limitations include untested Layout-as-Thought on non-parsing tasks and weaker handling of edge cases like curved 3D text, so users should validate on their data and avoid over-relying on it for stylized handwriting without additional fine-tuning.
1. Introduction
Section Summary: Current OCR systems struggle with balancing low cost, high accuracy, and versatile capabilities, as traditional pipelines require cumbersome preprocessing for varied documents, specialized models introduce errors between stages, and general vision-language models are expensive and weak on structured tasks like parsing layouts. Industrial applications often rely on chaining multiple models for tasks such as document retrieval or key information extraction, which raises costs and complicates deployment. Qianfan-OCR, a unified 4-billion-parameter end-to-end model, overcomes these issues by integrating layout analysis, text recognition, and semantic understanding into one system, featuring an optional "thinking" phase for explicit layout details and excelling in both OCR accuracy and advanced comprehension, as shown in top benchmark performances.
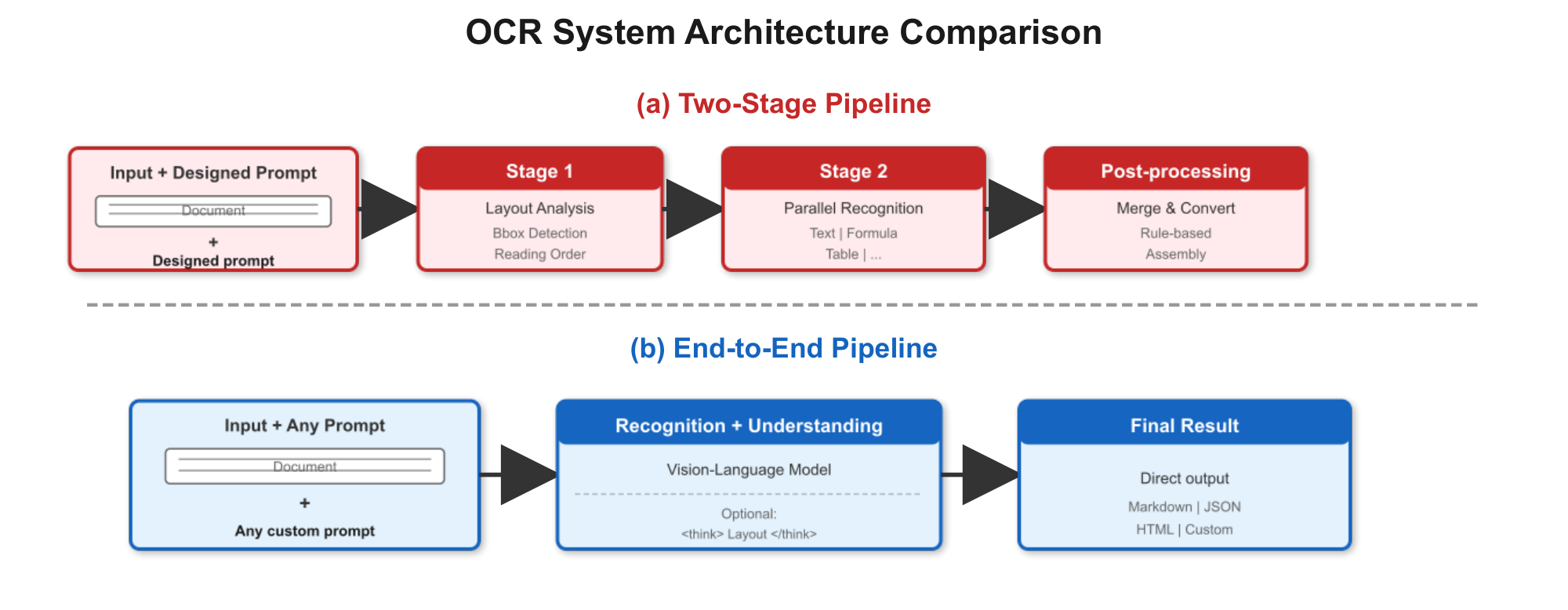
Current OCR systems face a three-way trade-off between cost, accuracy, and capability. Traditional OCR pipelines based on small specialized models offer low inference cost and high throughput, but require complex multi-stage preprocessing and postprocessing to handle diverse document layouts. Specialized OCR large models ([1, 2, 3, 4]) improve accuracy through two-stage architectures – layout detection followed by element-wise recognition – but introduce deployment complexity, inter-stage error propagation, and irreversible loss of visual context during text extraction. General vision-language models ([5, 6]) offer broad multimodal capabilities but incur higher inference costs and underperform specialized systems on structured document parsing tasks requiring precise layout preservation.
In practice, industrial OCR applications – document retrieval with chunking and indexing, contract review, key information extraction from receipts and certificates – often chain detection models, OCR models, and separate LLMs for downstream understanding. This fragmented approach increases deployment cost, limits end-to-end optimization, and requires careful orchestration of heterogeneous components.
We introduce Qianfan-OCR, a 4B-parameter unified end-to-end model that addresses these limitations with three key designs:
End-to-End Architecture: Qianfan-OCR integrates layout analysis, text recognition, and semantic understanding into a single vision-language model, eliminating inter-stage error propagation and enabling joint optimization across all tasks. The end-to-end design allows the model to retain full visual context throughout processing – spatial relationships, chart structures, and formatting that pipeline systems discard during text extraction. For tasks that do not require explicit layout analysis (e.g., simple document transcription or scene text recognition), the model directly outputs results without mandatory layout preprocessing.
Layout-as-Thought: A practical limitation of end-to-end OCR is the loss of explicit layout analysis – a capability that pipeline systems inherently provide through dedicated detection modules. Layout-as-Thought recovers this within the end-to-end paradigm: an optional thinking phase triggered by $\langle$ think $\rangle$ tokens, where the model generates bounding boxes, element types, and reading order before producing final outputs. This serves two purposes: (1) functional – users obtain structured layout results (element localization, type classification, spatial grounding) directly from an end-to-end model, bridging a key functionality gap relative to pipeline systems; (2) enhancement – the explicit structural priors help resolve ambiguities in documents with cluttered elements, complex multi-column layouts, or non-standard reading orders. For well-structured documents where the model already performs well, the layout phase is unnecessary; it targets the subset of challenging cases where structural reasoning provides measurable gains.
Unified OCR and Understanding: Beyond conventional OCR tasks (document parsing, handwriting recognition, table extraction), Qianfan-OCR handles cognitively demanding tasks including chart understanding, document question answering, and key information extraction – tasks requiring both precise text perception and semantic reasoning. Traditional OCR models lack comprehension capabilities, limiting them to character-level extraction; general VLMs possess reasoning abilities but underperform on structured parsing. Qianfan-OCR bridges this divide, combining OCR-specialist-level accuracy with document understanding capabilities in a single model controllable through prompts.
2. Related Work
Section Summary: This section reviews three main approaches in optical character recognition (OCR) technology and explains how Qianfan-OCR fits among them. Pipeline systems break down document analysis into separate steps like layout detection and text recognition, offering clear layout details but prone to errors that build up across stages, while Qianfan-OCR combines these into one smooth process using a technique called Layout-as-Thought to avoid those issues. End-to-end models and general vision-language models handle documents directly but often lack detailed layout control and can be less efficient or accurate for structured tasks, whereas Qianfan-OCR achieves expert-level precision with added flexibility for custom prompts and layout insights.
We review three technical routes in OCR and position Qianfan-OCR relative to each.
Pipeline OCR Systems. Pipeline systems [7] decompose document parsing into layout detection, element-wise recognition, and rule-based assembly. Recent systems such as PaddleOCR-VL [3], MonkeyOCR, and MinerU 2.5 pair lightweight detection models with VLM-based recognizers, achieving strong accuracy with modular efficiency. Their key advantage is explicit layout analysis output (bounding boxes, element types), but they suffer from inter-stage error propagation and irreversible loss of visual context during text extraction. Qianfan-OCR recovers the layout analysis capability through Layout-as-Thought while avoiding the pipeline's cascading error problem.
End-to-End OCR Models. End-to-end approaches directly map document images to structured outputs. Nougat [8] demonstrated feasibility on academic papers; GOT-OCR 2.0 [1] broadened format support (Markdown, LaTeX, TikZ) at 580M parameters; DeepSeek-OCR [2] introduced context optical compression for efficiency; olmOCR [4] scaled SFT-based training on large-scale web documents, while its successor olmOCR 2 further introduced GRPO reinforcement learning with unit-test rewards. More recently, Dolphin v2 proposed analyze-then-parse, and Logics-Parsing and Infinity-Parser explored layout-aware RL for structure prediction. These models primarily focus on recognition accuracy or efficiency but lack explicit layout analysis output – a functionality gap that Qianfan-OCR's Layout-as-Thought addresses. Qianfan-OCR relies on supervised fine-tuning with high-quality layout annotations, a complementary paradigm that future work could augment with reinforcement learning.
General Vision-Language Models. Large VLMs such as Qwen-VL [9, 10], InternVL [6, 11], and Gemini exhibit OCR capabilities as a byproduct of broad multimodal training, but are not optimized for structured document parsing: they incur higher inference costs, lack fine-grained layout control, and underperform specialized systems on structure-sensitive metrics (e.g., table TEDS, reading order accuracy). Qianfan-OCR targets OCR-specialist-level accuracy at comparable inference cost to these models, while additionally supporting explicit layout analysis and prompt-driven task control.
3. Model Architecture and Training Data
Section Summary: Qianfan-OCR uses a multimodal architecture that combines a vision encoder to process high-resolution images by breaking them into patches, a simple adapter to connect visual data to text, and a language model backbone for generating and reasoning about content like documents. This setup allows the system to handle detailed tasks such as reading fine text and understanding layouts efficiently on standard hardware. For training, the model relies on large-scale data created through automated pipelines that synthesize diverse examples for document parsing, key information extraction, complex tables, charts, formulas, and multilingual text recognition, including techniques to improve accuracy and robustness like filtering noisy data and adding intermediate reasoning steps.
3.1 Architecture Overview
Qianfan-OCR adopts the multimodal bridging architecture from Qianfan-VL ([12]), consisting of three core components: a vision encoder for flexible visual encoding, a lightweight projection adapter for cross-modal alignment, and a language model backbone for text generation and reasoning. The overall architecture is illustrated in Figure 3(b).
Vision Encoder. The vision encoder employs Qianfan-ViT, pretrained as part of the Qianfan-VL framework ([12]). It adopts the AnyResolution design that dynamically tiles input images into 448 $\times$ 448 patches, supporting variable-resolution inputs up to 4K. This is critical for OCR tasks where documents contain dense text, small fonts, and complex layouts that require high-resolution processing. The encoder consists of 24 Transformer layers with 1024 hidden dimensions, 16 attention heads, and a 14 $\times$ 14 patch size, producing 256 visual tokens per tile. With a maximum of 16 tiles, the encoder can represent a single document image with up to 4, 096 visual tokens, providing sufficient spatial resolution for fine-grained character recognition.
Language Model Backbone. We adopt Qwen3-4B ([10]) as the language model backbone. The model has 4.0B total parameters (3.6B non-embedding), 36 layers, 2560 hidden dimensions, and a 32K native context window (extendable to 131K via YaRN). This scale strikes a balance between reasoning capability and deployment efficiency – large enough for complex document understanding and layout reasoning, yet practical for single-GPU serving in production. The model uses Grouped-Query Attention (GQA) ([13]) with 32 query heads and 8 KV heads, reducing KV cache memory by 4 $\times$ compared to standard multi-head attention while maintaining generation quality. RMSNorm ([14]) is used for layer normalization, improving training stability.
Cross-Modal Adapter. A lightweight two-layer MLP with GELU activation bridges the vision encoder and the language model, projecting visual features from the encoder's representation space (1024 dimensions) into the language model's embedding space (2560 dimensions). This simple design minimizes adapter parameters while ensuring effective cross-modal alignment. During Stage 1 training, only the adapter is trained with a higher learning rate for fast alignment, while subsequent stages perform full-parameter training.
3.2 Large-Scale Data Synthesis Pipelines
We develop six data synthesis pipelines covering document parsing, key information extraction, complex tables, chart understanding, formula recognition, and multilingual OCR.
Document Parsing Data Synthesis: We construct an automated pipeline that converts document images into structured Markdown using PaddleOCR-VL ([3]) for layout detection and content recognition, with bbox coordinates normalized to [0, 999] for resolution invariance. Tables are converted to HTML via OTSL intermediate format, and formulas are wrapped in $ blocks. Automatic filtering removes repetitive or extreme-length samples, and image-level augmentations (compression, flipping, blur) improve robustness.
A key design choice is the layout label system. We compare PaddleOCR-VL and MinerU 2.5 along label granularity and detection accuracy. The main difference lies in body text labels: PaddleOCR-VL provides fine-grained categories (text, vertical_text, paragraph_title, doc_title, abstract, content, reference, reference_content, aside_text), while MinerU 2.5 uses coarser labels (text, title, list, aside_text). Finer granularity directly benefits downstream tasks – e.g., distinguishing abstract from content supports structured extraction from papers, and separating reference enables clean bibliography parsing. We also evaluate both systems on a multi-type document layout benchmark, where PaddleOCR-VL achieves consistently higher detection accuracy. We therefore adopt PaddleOCR-VL's label system and use it as the annotation engine. Our final taxonomy contains 25 categories in four groups: text elements (12 labels), headers/footers (4), figures/tables (6), and formulas (3).
Layout-as-Thought Data Construction: We construct training data where the model generates structured layout analysis within <think> tokens before final output, listing bbox coordinates, element labels, and content summaries as intermediate reasoning enclosed in <layout>...</layout> tags. Users activate this by appending <think> tokens to queries. The layout phase focuses model attention on relevant document regions before generation, improving performance on documents requiring spatial reasoning (complex layouts, multi-column text, interleaved figures).
Key Information Extraction (KIE): For KIE tasks, we construct datasets for two scenarios: complete extraction ("what you see is what you get") and targeted extraction (user-specified keys). To address hallucination in teacher models, we combine open-source data with small model pre-annotations for multi-model collaborative labeling. We implement semantic generalization for keys across different regions and formats, constructing multiple synonymous descriptions for the same field. The pipeline includes quality enhancement through direction correction and image enhancement for low-resolution inputs, hard rule filtering using business logic (e.g., verifying "unit price × quantity = total"), and difficult sample mining for long sequences with 5+ detail rows and dense text documents. Sample distribution is rebalanced based on task difficulty to enhance stability in extreme scenarios.
Complex Tables: We combine programmatic synthesis with real document extraction. The programmatic pipeline randomly generates tables with 3-20 rows/columns supporting random cell merging, populates content via Faker library or LLMs covering diverse data types, randomly samples from 50+ professional CSS themes, renders via Jinja2 and KaTeX engines, and applies geometric transformations, color perturbations, and blur augmentations. For real document tables, we use internal parsing tools to detect and extract table regions, parse with both PaddleOCR-VL and internal table models, convert both outputs to HTML, and perform consistency validation to filter samples with significant structural or content differences, ensuring reliable annotations while preserving real document layout and noise characteristics.
Chart Understanding: We build an automated synthesis pipeline based on arXiv LaTeX sources (2022-present). The pipeline systematically extracts Figure code blocks through rule parsing, re-renders using TexLive engine to obtain lossless vector images, leverages caption parameters as ground truth, and uses VLMs to generate detailed visual descriptions capturing visual encoding, statistical features, spatial layout, and fine-grained distribution characteristics. We categorize 11 mainstream chart types and construct "metadata + visual description" driven synthesis. Custom reasoning tasks are designed for different chart types: trend analysis for line charts, correlation and distribution features for scatter plots, outlier detection for box plots. This pipeline synthesizes over 300, 000 high-accuracy, diverse multimodal instruction-tuning samples.
Multilingual OCR Data Construction: To extend language coverage to 192 languages, we adopt a reverse synthesis approach starting from the HPLT multilingual corpus. The pipeline performs text-font renderability filtering using fonttools character set validation, then renders document images with differentiated handling for different writing systems (Latin, Cyrillic, Arabic, South Asian, Southeast Asian, Han). Key features include automatic RTL text direction detection, Arabic character reshaping, and word-level line breaking. Diverse typesetting variations (font size, column layout, margins, spacing, texture backgrounds) are randomized to approximate real document distributions.
Document Image Augmentation: We employ two augmentation pipelines: one for OCR tasks (allowing mild geometric perturbations) and one for layout parsing tasks (preserving geometric consistency). Both apply three noise stages: (1) text noise (broken strokes, ink bleeding, character misalignment), (2) background noise (texture, color drift, watermarks), and (3) imaging noise (blur, moiré, shadows, exposure variation). Additionally, rotation augmentation (90\textdegree, 180\textdegree, 270\textdegree, and $\pm$ 15\textdegree) significantly improves performance on KIE and table recognition tasks where documents frequently appear in non-standard orientations.
Through these specialized synthesis pipelines, we generate large-scale, high-quality training data covering diverse OCR scenarios, providing comprehensive data support for Qianfan-OCR's multi-stage progressive training.
4. Training Recipe
Section Summary: Qianfan-OCR's training follows a multi-stage approach borrowed from Qianfan-VL, progressing from basic vision-language alignment to advanced OCR skills across four phases: initial alignment with simple image-text pairs, foundational OCR development using vast specialized datasets, targeted enhancements for complex domains like tables and charts, and final tuning with diverse instruction-based tasks to boost reasoning. This method prioritizes OCR-focused data mixtures throughout, such as documents, handwriting, and multilingual text, to build robust document intelligence while avoiding loss of general abilities. The process runs efficiently on over 1,000 specialized chips, completing in about a week with quick iterations for optimization, and ablation tests confirm that the full staged recipe significantly improves OCR performance over simpler alternatives.
Qianfan-OCR adopts the proven multi-stage progressive training methodology from Qianfan-VL ([12]), which systematically builds model capabilities from basic cross-modal alignment through advanced reasoning tasks. The key adaptation for OCR scenarios lies in the data mixture composition, where we significantly enhance OCR-specific domains while maintaining the overall training framework. The training pipeline consists of four stages with carefully designed data distributions optimized for document intelligence.
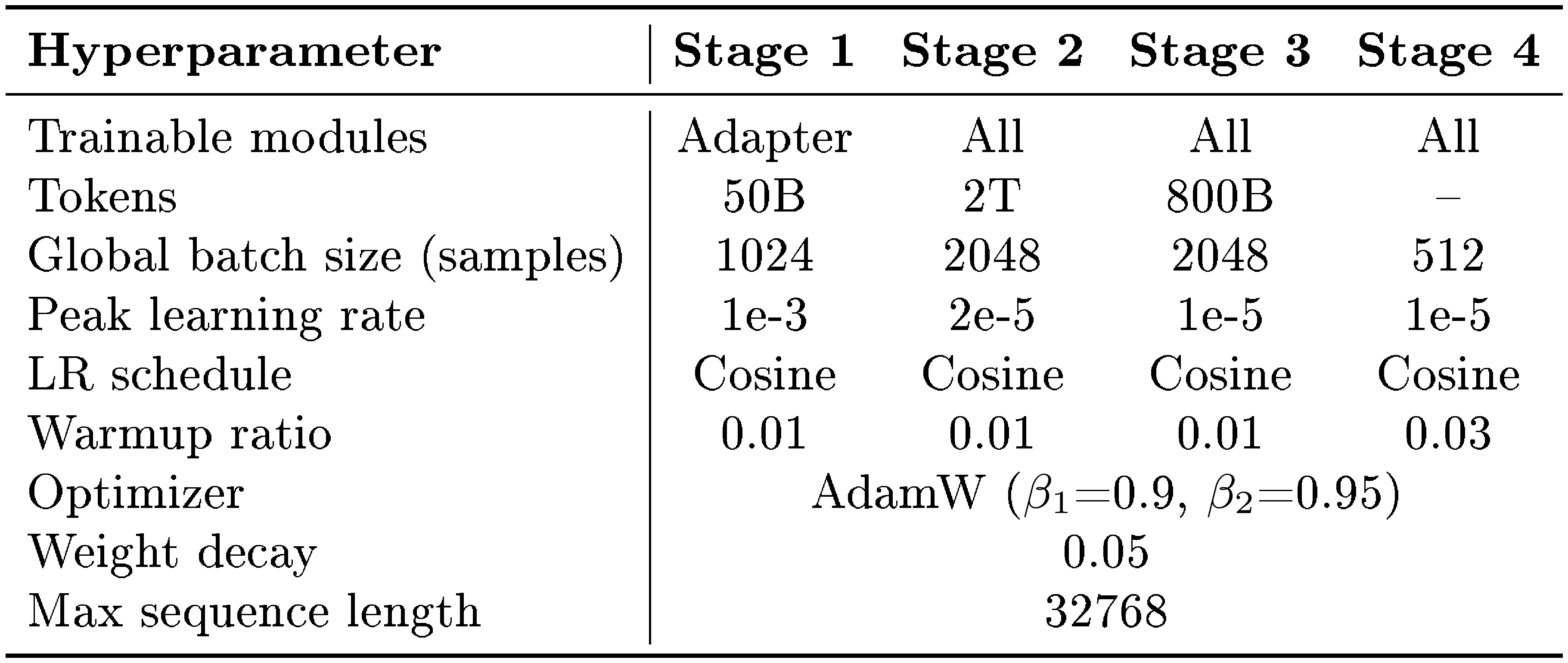
Stage 1: Cross-Modal Alignment (50B tokens) – Establishes fundamental vision-language alignment with adapter-only training, using basic image-caption pairs and simple OCR tasks to ensure stable initialization.
Stage 2: Foundational OCR Training (2T tokens) – Develops comprehensive OCR capabilities through full parameter training with OCR-heavy data mixture: Document OCR (45%), Scene OCR (25%), Caption (15%), and Specialized OCR tasks including handwriting, formulas, tables, and multilingual text (15%).
Stage 3: Domain-Specific Enhancement (800B tokens) – Implements targeted enhancement for enterprise-critical OCR domains with balanced mixture: Complex Tables (22%), Formula Recognition (20%), Chart Understanding (18%), Information Extraction (18%), Multilingual OCR (12%), and Document Understanding (10%). Maintains 70% domain-specific data and 30% general data to enhance specialization while preventing catastrophic forgetting.
Stage 4: Instruction Tuning and Reasoning Enhancement (millions of instruction samples) – Covers a comprehensive set of document intelligence tasks including document parsing, layout analysis, handwriting recognition, scene text recognition, formula recognition, table recognition, multi-page document parsing, chart QA, document QA, and complex table QA. The instruction data is constructed through three complementary strategies: (1) Public data curation: we collect publicly available OCR-related training datasets and perform instruction rewriting and generalization using DeepSeek models to diversify prompt styles and task formulations; (2) Reverse synthesis: for tasks amenable to reverse generation (e.g., tables, exam papers), we construct large-scale QA pairs by generating questions conditioned on structured ground-truth content; (3) Chart data mining: we extract chart-figure pairs from a large corpus of academic papers via their LaTeX source code and generate chart understanding QA pairs grounded in the original source, significantly enhancing chart comprehension capabilities. All instruction data undergoes systematic prompt generalization and rewriting to improve robustness to diverse user instructions.
The critical differentiator from general VLM training lies in the OCR-centric data composition throughout all stages, with particular emphasis on document parsing, table/chart understanding, and information extraction tasks. Detailed data synthesis pipelines for each domain are described in Section 3.
Training Infrastructure and Iteration Strategy. All training is conducted on 1, 024 Baidu Kunlun P800 chips using 3D parallelism (data, tensor, and pipeline parallelism with communication-computation overlap), processing over 2.85T tokens across all stages. In practice, Stages 1 and 2 are trained once to establish a stable foundation checkpoint, while Stages 3 and 4 are iterated multiple times to explore different domain-specific data mixtures, sampling ratios, and instruction tuning configurations. Since Stages 3 and 4 account for a smaller token budget (800B + instruction tuning vs. 2T for Stage 2), each iteration completes quickly. The full four-stage pipeline completes within a week, and Stage 3/4 iterations take approximately one day each, supporting systematic ablation and optimization of OCR-specific training recipes.
4.1 Hyperparameters
Table 1 summarizes the key hyperparameters for each training stage.
::: {caption="Table 1: Training hyperparameters for each stage. Stage 1 trains only the adapter with a higher learning rate for fast alignment. Stages 2–4 use full-parameter training with lower learning rates."}
:::
4.2 Ablation Study: Multi-Stage Training Effectiveness
Prior to training the 4B Qianfan-OCR model, we conduct low-cost ablation studies on Qianfan-VL-8B – a model from the same architectural family that has undergone large-scale general-purpose continual pretraining – to systematically validate our multi-stage training recipe. Starting from a Stage 1 (adapter-only alignment) checkpoint, we evaluate the contribution of each subsequent training stage to OCR performance. All configurations employ full-parameter training, which prior Qianfan-VL experiments have confirmed to be essential for effective domain transfer. Results are summarized in Table 2.
: Table 2: Ablation study on multi-stage training effectiveness using Qianfan-VL-8B. "OCR" denotes domain-specific OCR data, "General" denotes general-purpose data, and "OCR + General" denotes a 1:1 mixture. Stage 4 is instruction tuning with a fixed set of alignment samples across all configurations. Average accuracy is computed over multiple OCR benchmarks.
| Stage 1 | Stage 2 | Stage 3 | Stage 4 | AVG |
|---|---|---|---|---|
| ✓ | – | – | ✓ | 71.37 |
| ✓ | – | OCR | ✓ | 75.97 |
| ✓ | – | OCR + General | ✓ | 80.07 |
| ✓ | General | – | ✓ | 83.47 |
| ✓ | General | OCR | ✓ | 84.09 |
| ✓ | General | OCR + General | ✓ | 84.39 |
Stage 2 (foundational pretraining) is essential. Skipping Stage 2 and proceeding directly from Stage 1 to domain-specific Stage 3 training yields significantly lower performance. Even the best Stage 3-only configuration (OCR + General mixture, 80.07%) falls substantially short of Stage 2 followed by Stage 4 alone (83.47%), indicating that large-scale general-purpose pretraining provides a critical capability foundation that cannot be substituted by domain-specific data alone.
Domain-specific enhancement benefits from general data mixing. In Stage 3, a 1:1 mixture of OCR-specific and general-purpose data (80.07%) consistently outperforms pure OCR data (75.97%), suggesting that maintaining general capability during domain specialization acts as an effective regularizer and prevents overfitting to narrow OCR patterns. The same trend holds when Stage 2 is included: OCR + General in Stage 3 (84.39%) outperforms OCR-only Stage 3 (84.09%).
The complete pipeline achieves optimal performance. The full four-stage configuration (Stage 1 $\rightarrow$ Stage 2 General $\rightarrow$ Stage 3 OCR+General $\rightarrow$ Stage 4) achieves the highest accuracy of 84.39%, representing a +13.02% absolute improvement over the Stage 1+4 baseline. Notably, this configuration also surpasses Qwen2.5-VL-7B (79.30%) by +5.09%, despite the latter being a strong general-purpose VLM. In practice, we keep the Stage 4 data volume fixed and incorporate all additional domain-specific data augmentation into Stage 3, which proves to be the most effective strategy for scaling OCR capabilities without compromising the general abilities established in Stage 2.
These findings, obtained at relatively low cost on the 8B model, directly motivated the training recipe adopted for the 4B Qianfan-OCR. The consistency of improvements across training stages suggests that this progressive recipe generalizes across model scales within the same architectural family.
5. Evaluation Framework
Section Summary: The evaluation framework for Qianfan-OCR tests its abilities in optical character recognition (OCR) and deeper document understanding through four main areas. It uses specialized benchmarks to check accuracy on tasks like parsing PDFs, handling multilingual text, and processing large documents, plus general tests for everyday scenarios involving handwriting, formulas, and scene text. The framework also evaluates comprehension and reasoning on visual content like charts and forms, extracts key information from real-world documents such as receipts and invoices, and compares the model's end-to-end approach against traditional step-by-step systems combining separate OCR and language tools.
To comprehensively assess Qianfan-OCR's capabilities across the spectrum from specialized OCR to document understanding, we employ a multi-dimensional evaluation framework spanning four key categories:
Specialized OCR Model Benchmarks: We evaluate OCR-specific capabilities using benchmarks designed for specialized document parsing systems: Omni-Doc-Bench v1.5 ([15]) for diverse PDF document parsing, OLMOCRBench ([16]) for end-to-end document OCR evaluation, CCOCR for multilingual OCR recognition across diverse scripts, and BigDocs ([17]) for large-scale document processing tasks. These benchmarks assess the model's ability to achieve recognition accuracy competitive with specialized OCR systems.
General OCR Capability Benchmarks: To evaluate general-purpose optical character recognition across diverse scenarios, we use OCRBench ([18]) and OCRBench v2, comprehensive benchmarks covering scene text, document text, handwriting recognition, formula recognition, and multilingual text across various real-world conditions. These evaluations ensure the model maintains robust OCR performance beyond specialized document parsing scenarios.
Document Understanding Benchmarks: We assess document comprehension and reasoning capabilities using a diverse set of understanding-oriented benchmarks: TextVQA ([19]) for scene text question answering, DocVQA ([20]) for document visual question answering, CharXiv document question (CharXiv_DQ) and reasoning question (CharXiv_RQ) tasks ([21]) for academic document understanding, ChartQA ([22]) and ChartQAPro ([23]) for chart interpretation, and ChartBench for comprehensive chart reasoning evaluation. These benchmarks evaluate the model's ability to perform high-level semantic understanding and reasoning over visual document content, including complex table analysis and chart interpretation.
Key Information Extraction (KIE): We evaluate KIE capabilities across five public benchmarks: OCRBench KIE ([18]) (structured field extraction from receipts, invoices, and forms), OCRBenchv2 KIE in both English and Chinese (cross-lingual extraction across diverse document templates), CCOCR KIE (Chinese document field extraction including ID cards, business licenses, and financial documents), and Nanonets KIE (real-world invoice and receipt parsing, measured by F1 score). All scores are normalized to a 0–100 scale. Since specialized OCR models lack native KIE capabilities, we compare against commercial large models (Gemini-3.1-Pro, Gemini-3-Pro, Seed-2.0) and open-source VLMs (Qwen3-4B-VL, Qwen3-VL-235B-A22B).
Comparative Evaluation Against Pipeline Systems: To fairly compare against traditional OCR-then-LLM approaches, we establish baseline systems that combine specialized OCR models with language models of comparable parameter count to Qianfan-OCR. This comparative evaluation on understanding benchmarks isolates the architectural effects from parameter count differences, providing controlled evidence for the trade-offs between end-to-end and pipeline approaches.
6. Experimental Results
Section Summary: The researchers tested their Qianfan-OCR model on various benchmarks for optical character recognition, including specialized tests like OlmOCR and OmniDocBench, where it achieved top scores among end-to-end models, such as 79.8 on OlmOCR and 93.12 on OmniDocBench, often rivaling or surpassing traditional pipeline systems that handle layout and text separately. They compared it to both specialized OCR tools and general vision-language models, using standard metrics and sometimes combining OCR outputs with a language model for broader tasks like document understanding. An optional "thinking mode" that reasons about document layouts slightly lowered overall performance but improved results on complex pages with mixed elements like text, tables, and formulas, while slowing things down on simpler documents.
We conduct comprehensive evaluations across OCR-specific benchmarks, general OCR benchmarks, and document understanding tasks. Our evaluation framework is primarily based on VLMEvalKit ([24]) with modifications tailored to different benchmark requirements.
Evaluation Methodology. For OCR-specific benchmarks, we follow official metrics or adopt results from recent publications. Specifically, we reference metrics from the OmniDocBench official leaderboard ([15]), DeepSeek-OCR v2 ([25]), and PaddleOCR-VL 1.5 ([26]) papers. For benchmarks with official evaluation scripts (e.g., OmniDocBench v1.5), we directly reuse their implementations.
Model Categorization. We categorize comparison models based on their architectural paradigms:
- Pipeline OCR Systems: Models that perform layout analysis first, followed by parallel text recognition (e.g., PaddleOCR-VL, MonkeyOCR series, Dolphin series).
- End-to-end Models: Vision-language models that directly process images through prompts without separate detection stages, including both specialized OCR models (e.g., MinerU2.5, Dotsocr, DeepSeek-OCR) and general VLMs (e.g., Qwen3-VL, GPT-4o, Gemini).
Benchmark-Specific Considerations. For general OCR benchmarks (OCRBench, OCRBenchv2, CCOCR-multilan), we compute metrics using VLMEvalKit. Since specialized OCR models typically do not report these metrics, we integrate their OCR outputs in our evaluation environment. Note that these benchmarks include not only pure OCR recognition but also understanding and key information extraction (KIE) tasks, where specialized OCR models generally underperform. For document understanding tasks, specialized OCR models cannot directly complete such tasks (metrics approach zero). To simulate real-world usage scenarios, we employ a two-stage pipeline: first using specialized OCR models for text extraction, then feeding the extracted text to Qwen3-4B LLM for answer generation.
6.1 OCR-Specific Benchmarks
::: {caption="Table 3: Detailed performance on OlmOCR Bench across document categories. Models are categorized into Pipeline (two-stage) and End-to-end architectures. Best results in each section are in bold."}
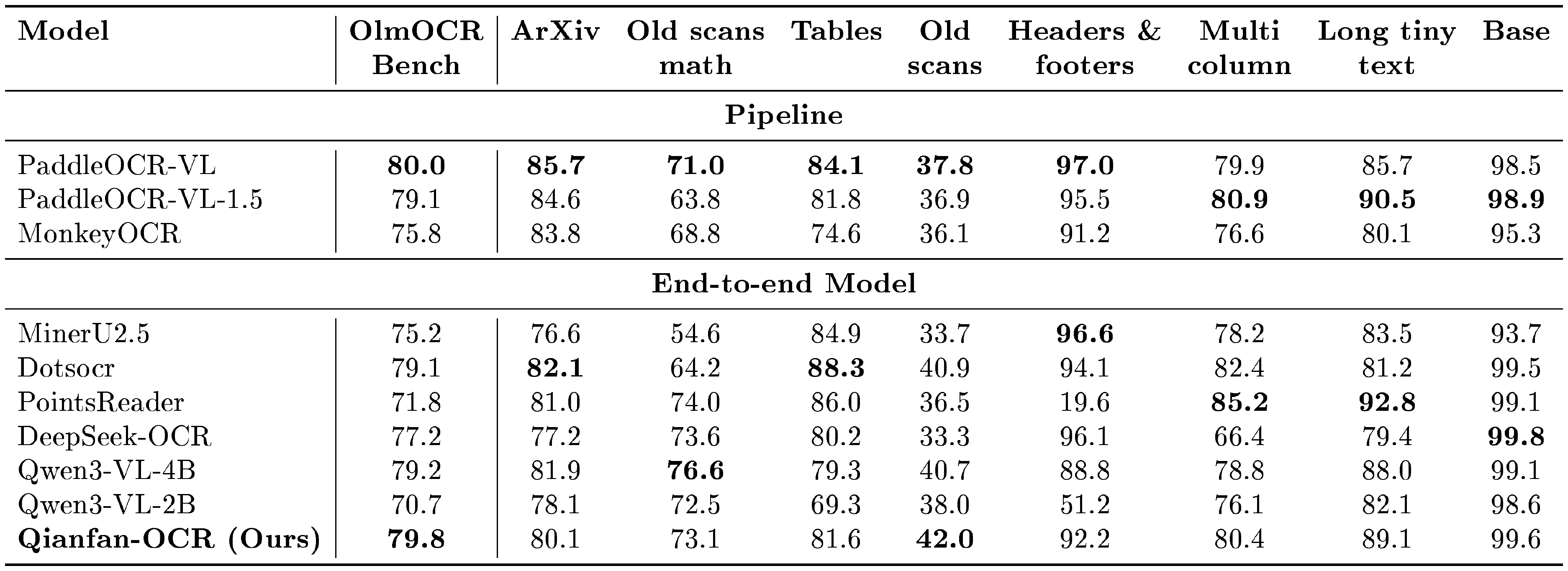
:::
Table 3 presents detailed performance on OlmOCR Bench across document categories. Qianfan-OCR achieves the highest overall score (79.8) among end-to-end models, competitive with the top pipeline system PaddleOCR-VL (80.0), with strong scores on Base (99.6), Headers & footers (92.2), and Old scans (42.0, best among end-to-end).
::: {caption="Table 4: Performance comparison on OmniDocBench. Models are categorized into Pipeline (two-stage) and End-to-end architectures. $\uparrow$ indicates higher is better, $\downarrow$ indicates lower is better. Best results in each section are in bold. Data source: https://github.com/opendatalab/OmniDocBench"}
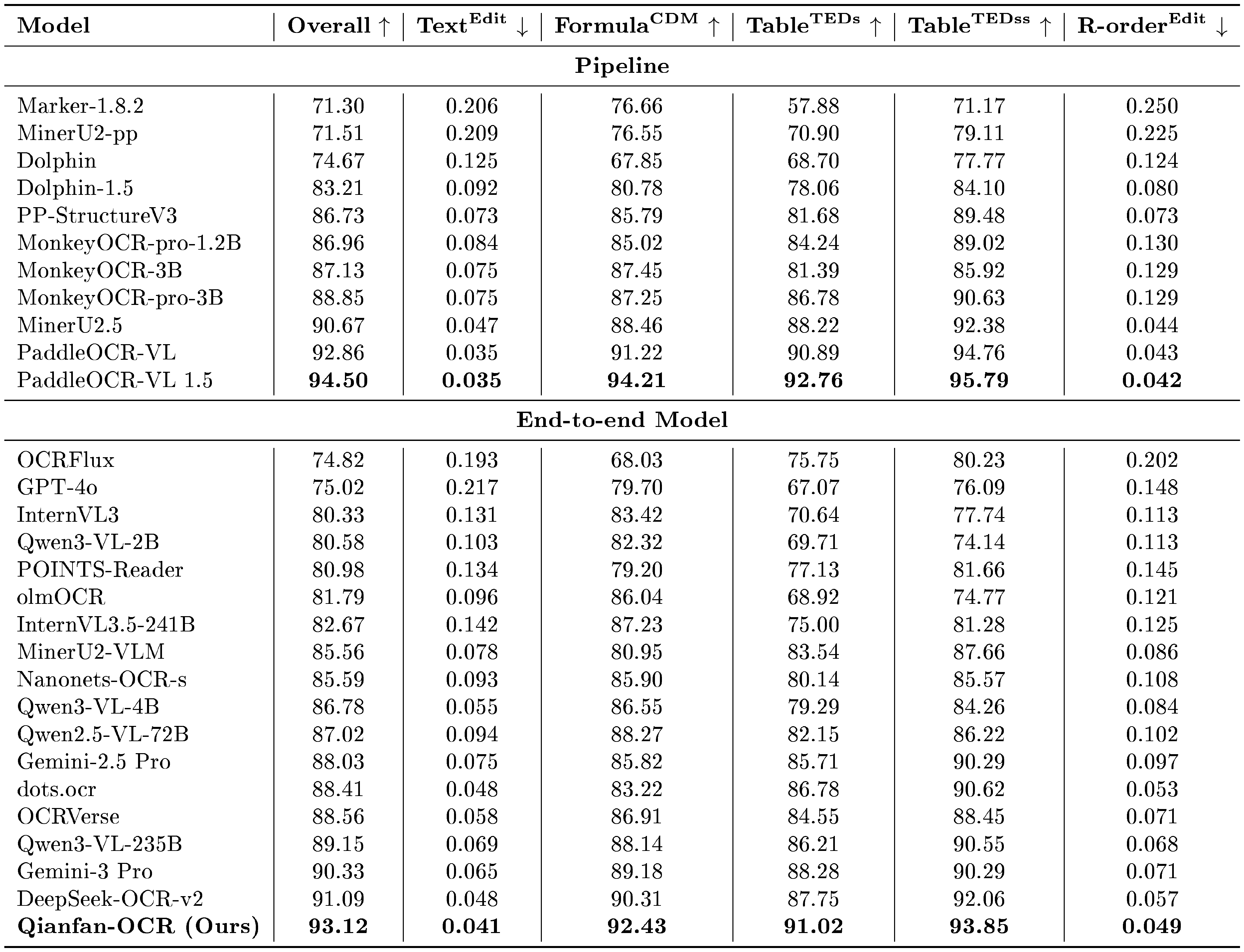
:::
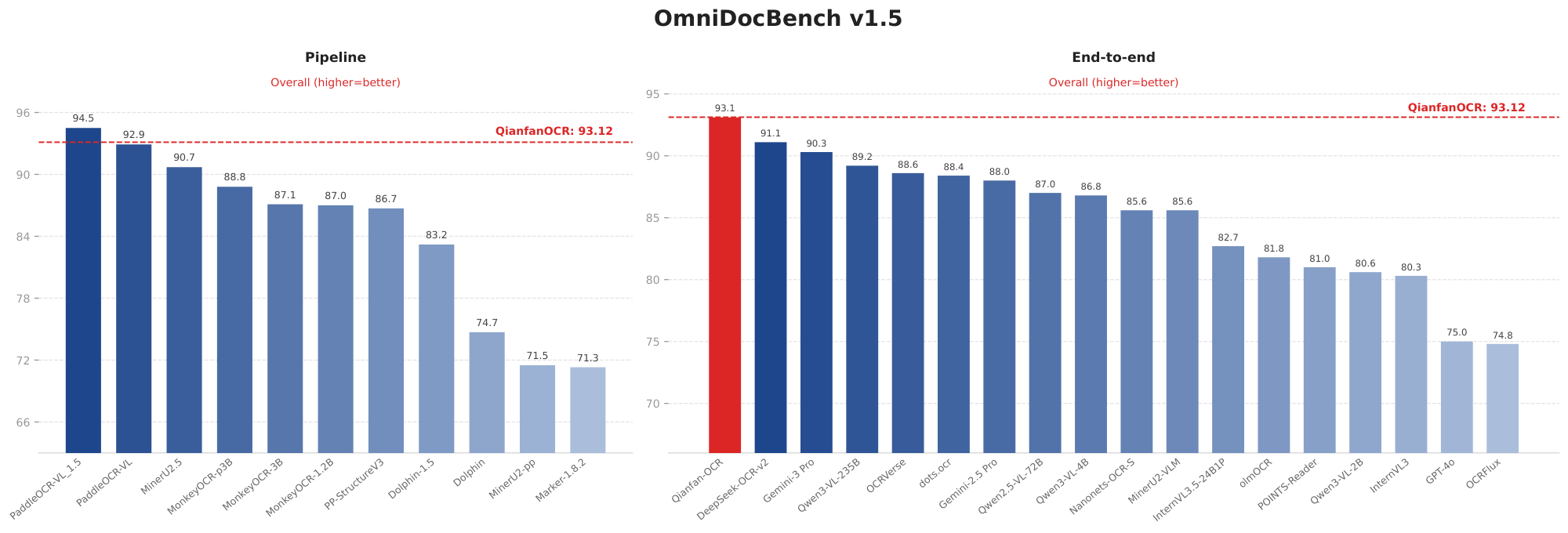
Table 4 presents results on OmniDocBench v1.5. Among end-to-end models, Qianfan-OCR achieves the highest overall score of 93.12, surpassing DeepSeek-OCR-v2 (91.09), Gemini-3 Pro (90.33), and all other end-to-end models across every sub-metric. Notably, Qianfan-OCR also outperforms several pipeline systems including MinerU2.5 (90.67) and MonkeyOCR-pro-3B (88.85), narrowing the gap with the top pipeline system PaddleOCR-VL 1.5 (94.50).
Analysis of Layout-as-Thought (Thinking Mode). We additionally evaluate Qianfan-OCR with the Layout-as-Thought mechanism enabled at inference time (denoted Qianfan-OCR-think). Compared to the default mode, the thinking variant achieves an overall score of 92.64 vs. 93.12, with per-metric results: Text $^{\text{Edit}}$ 0.052 vs. 0.041, Formula $^{\text{CDM}}$ 91.92 vs. 92.43, Table $^{\text{TEDs}}$ 91.21 vs. 91.02, Table $^{\text{TEDss}}$ 94.03 vs. 93.85, and R-order $^{\text{Edit}}$ 0.051 vs. 0.049. While the aggregate score is slightly lower, the thinking variant shows improvements on table-related metrics (Table $^{\text{TEDs}}$: +0.19, Table $^{\text{TEDss}}$: +0.18). More importantly, per-sample analysis reveals that Layout-as-Thought provides targeted benefits on structurally complex documents but can be counterproductive on simpler ones.
To investigate this, we sort all OmniDocBench v1.5 samples by their layout label entropy in descending order and plot the cumulative score as samples are progressively included (Figure 4). Layout label entropy measures the diversity of element types (text, table, formula, figure, etc.) on each page – higher entropy indicates more heterogeneous layouts.
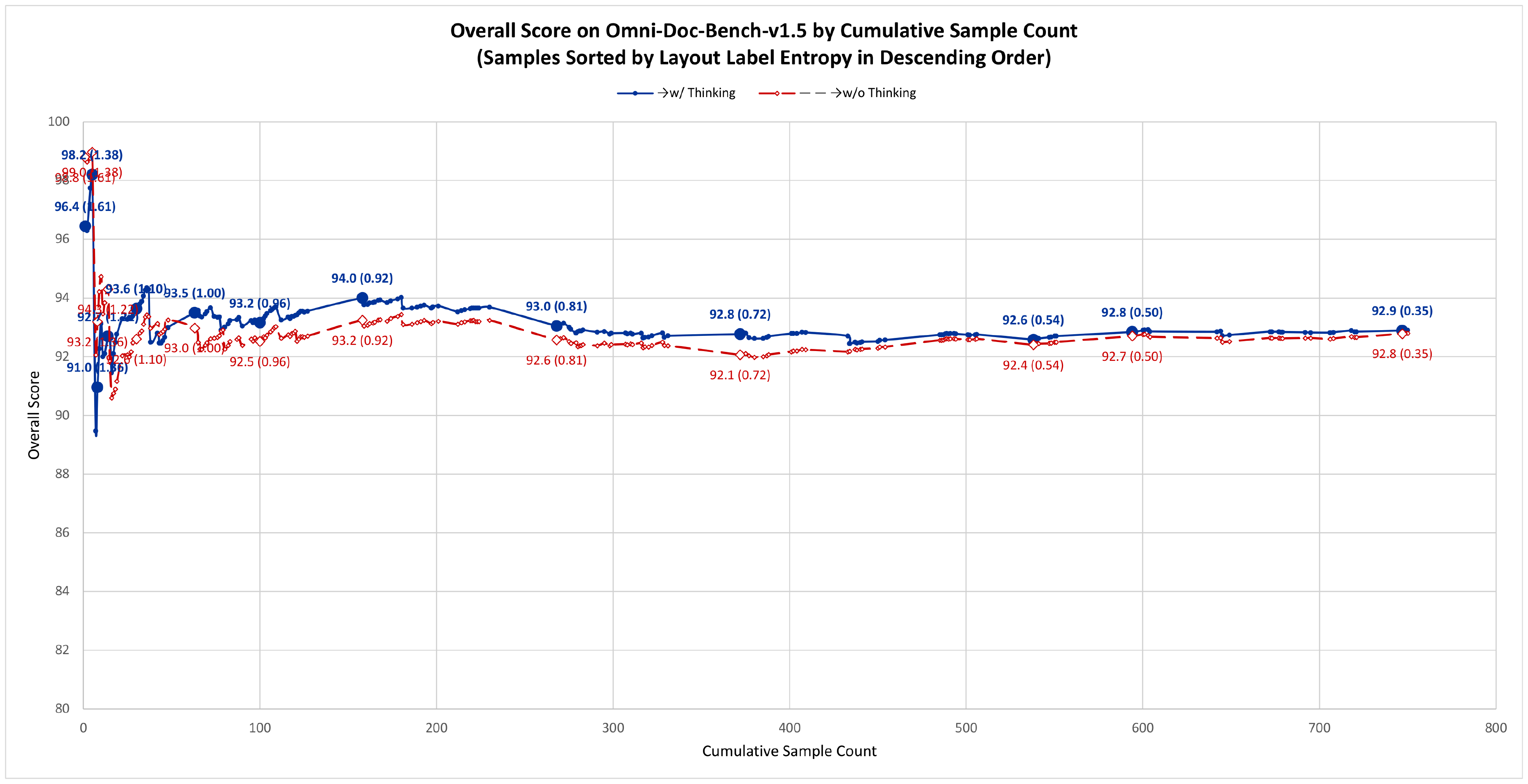
The results reveal a clear pattern: in the high-entropy region (left portion of the curve), where documents contain diverse element types such as mixed text, formulas, tables, and figures, enabling thinking provides a consistent score advantage. As lower-entropy samples are progressively included – documents with more homogeneous layouts (e.g., pure text pages) – the gap narrows and eventually reverses, with the no-think mode achieving a higher cumulative total. This indicates that Layout-as-Thought introduces unnecessary overhead on structurally simple documents, where explicit layout reasoning provides no additional benefit and may even interfere with direct recognition.
In practice, users should decide whether to enable the thinking mode based on the layout complexity of their target documents: for heterogeneous pages with mixed element types (exam papers, technical reports, newspapers), enabling thinking improves accuracy; for homogeneous documents (single-column text, simple forms), disabling thinking yields better results with lower latency.
Illustrative Example. Figure 5 presents a concrete example of Layout-as-Thought on a math exam paper with mixed content (text, formulas, geometric diagrams, and multi-column layout). When the <think> token is activated, the model first generates a structured layout analysis enumerating each document element in reading order:
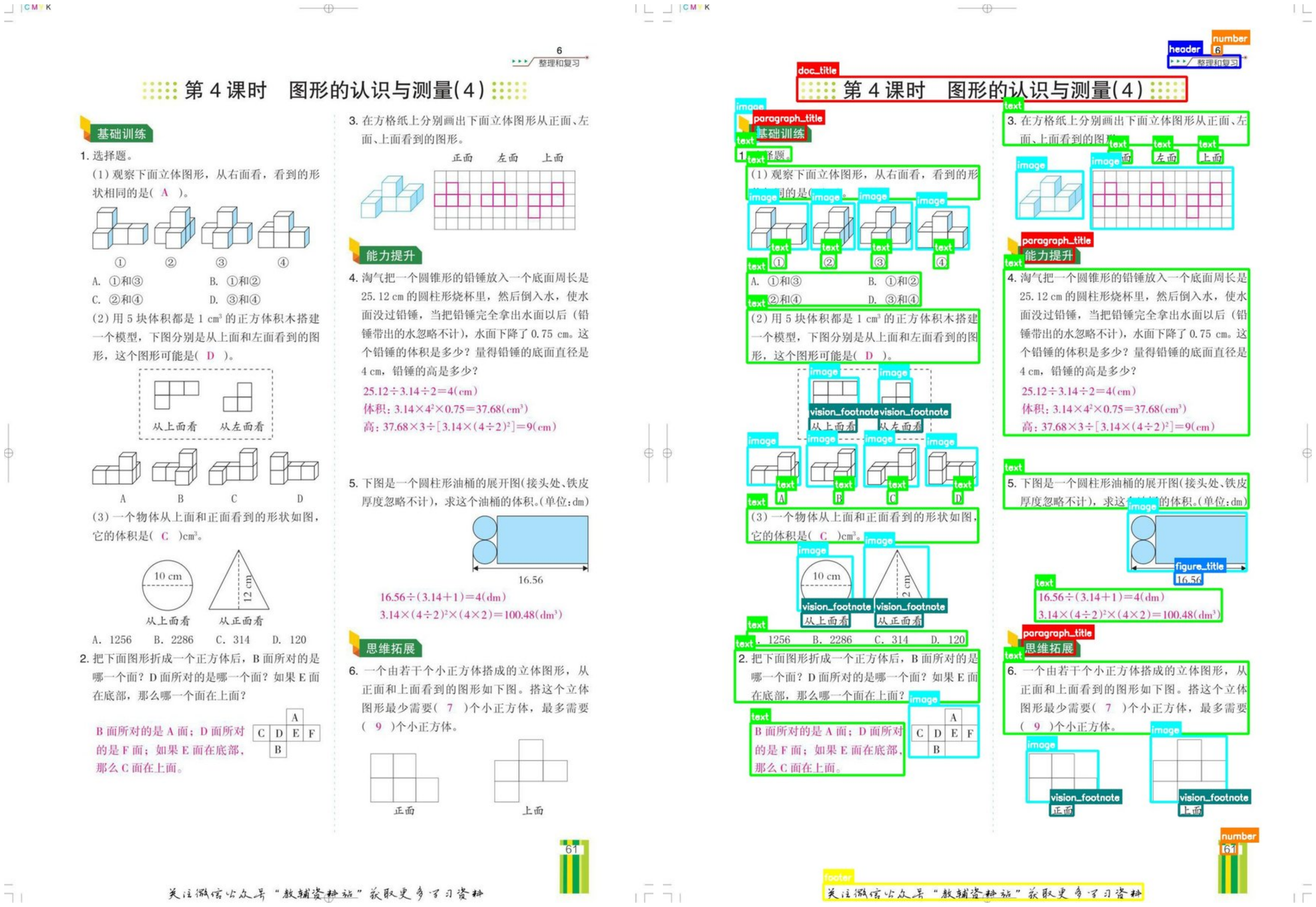
<think>
<box>[[<COORD_779>,<COORD_057>,<COORD_890>,<COORD_071>]]</box>
<label>header</label>
<brief>Section title indicating review and organization</brief>
<box>[[<COORD_207>,<COORD_081>,<COORD_808>,<COORD_108>]]</box>
<label>doc_title</label>
<brief>Lesson title: Graphical Recognition and Measurement (4)</brief>
<box>[[<COORD_139>,<COORD_134>,<COORD_221>,<COORD_151>]]</box>
<label>paragraph_title</label>
<brief>Subsection title: Basic Training</brief>
<box>[[<COORD_129>,<COORD_180>,<COORD_488>,<COORD_217>]]</box>
<label>text</label>
<brief>Asks to identify shapes seen from the right side...</brief>
<box>[[<COORD_132>,<COORD_222>,<COORD_224>,<COORD_273>]]</box>
<label>image</label>
<brief>A 3D arrangement of white cubes with light blue edges...</brief>
... (60+ layout elements in reading order)
</think>
Each entry contains three fields: a <box> with normalized bounding box coordinates, a <label> indicating the element type (from 25 layout categories including text, image, paragraph_title, display_formula, table, vision_footnote, etc.), and a <brief> providing a concise content summary for text-type elements. The model then generates the final OCR response conditioned on this structured layout reasoning.
Coordinate Special Tokens. All bounding box coordinates are normalized to [0, 999] and represented as dedicated special tokens <COORD_0> through <COORD_999>. These tokens are introduced during Stage 3 continued pretraining alongside layout analysis data, enabling the model to learn spatial representations efficiently. Compared to encoding coordinates as plain digit sequences (e.g., "779" requires 3 tokens), each coordinate consumes only a single token, reducing the thinking output length by approximately 50% and substantially decreasing inference latency for the layout reasoning phase. This compact representation is critical for practical deployment, as complex documents may contain 60+ layout elements in a single page.
How Layout-as-Thought Guides Response Generation. The structured thinking output benefits the final response in two key ways: (1) Element-type-aware generation: by explicitly identifying element categories (formula, table, image, text), the model applies appropriate rendering formats in the response – wrapping mathematical content in $ ... $ blocks, converting table structures to HTML, and inserting image placeholders at correct positions; (2) Reading-order-guided sequencing: the thinking phase enumerates elements following the natural reading order of the document (handling multi-column layouts, interleaved figures, and footnotes), providing an explicit ordering signal that the response generation can follow to produce correctly sequenced output.
6.2 General OCR Benchmarks
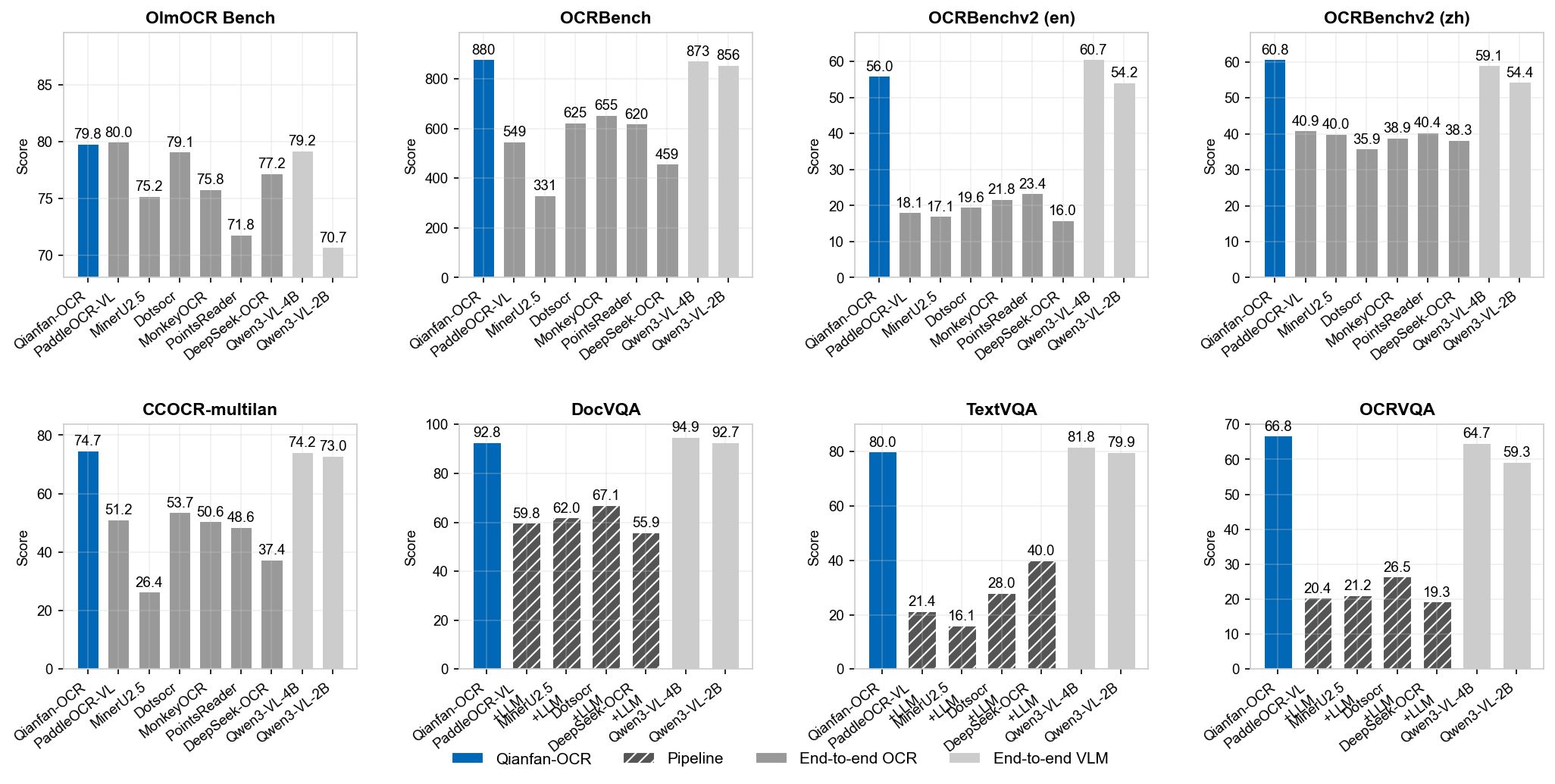
Table 5 shows performance on general OCR benchmarks covering diverse scenarios including scene text, documents, handwriting, and multilingual text. Qianfan-OCR achieves the highest OCRBench score (880) among all models and demonstrates strong performance on OCRBenchv2 (56.0 en / 60.77 zh), CCOCR-multilan (76.7), and CCOCR-overall (79.3). Compared with the similarly-sized general-purpose VLM Qwen3-VL-4B, Qianfan-OCR surpasses it on OCRBench (880 vs. 873) while showing a modest gap on OCRBenchv2 en (56.0 vs. 60.68), and leading on both CCOCR metrics (76.7 vs. 74.2 multilan, 79.3 vs. 76.5 overall). This trade-off is expected: Qianfan-OCR prioritizes specialized OCR capabilities (OmniDocBench 93.12, OlmOCR 79.8, both ranking first among all end-to-end models) while retaining competitive general performance without significant degradation.
: Table 5: Performance on general OCR benchmarks. Qianfan-OCR achieves competitive scores while maintaining strong understanding capabilities (Table 6).
| Model | OCRBench | OCRBenchv2 (en/zh) | CCOCR-multilan | CCOCR-overall |
|---|---|---|---|---|
| Qianfan-OCR (Ours) | 880 | 56.0 / 60.77 | 76.7 | 79.3 |
| PaddleOCR-VL | 549 | 18.15 / 40.86 | 45.5 | 29.1 |
| MinerU2.5 | 331 | 17.09 / 40.03 | 43.2 | 24.4 |
| Dotsocr | 625 | 19.59 / 35.94 | 47.2 | 34.6 |
| MonkeyOCR | 655 | 21.78 / 38.91 | 43.8 | 35.2 |
| PointsReader | 620 | 23.40 / 40.39 | 43.5 | 35.0 |
| DeepSeek-OCR | 459 | 15.98 / 38.31 | 32.5 | 27.6 |
| Qwen3-VL-4B | 873 | 60.68 / 59.13 | 74.2 | 76.5 |
| Qwen3-VL-2B | 856 | 54.18 / 54.41 | 73.0 | 71.5 |
Notable observations:
- OCRBench: Qianfan-OCR scores 880, surpassing Qwen3-VL-4B (873) and ranking first among all models
- OCRBenchv2: Qwen3-VL-4B leads on English (60.68 vs. 56.0), while Qianfan-OCR achieves the best Chinese text recognition (60.77), significantly outperforming all specialized OCR models on both languages
- CCOCR: Qianfan-OCR leads on both CCOCR-multilan (76.7 vs. 74.2) and CCOCR-overall (79.3 vs. 76.5) over Qwen3-VL-4B, demonstrating strong multilingual and comprehensive OCR capabilities
6.3 Document Understanding Benchmarks
Document understanding benchmarks evaluate the model's ability to perform visual question answering, chart interpretation, and reasoning tasks requiring both accurate text perception and semantic comprehension.
Table 6 compares end-to-end models with two-stage OCR+LLM systems, where specialized OCR models first extract text and Qwen3-4B then generates answers from the extracted text.
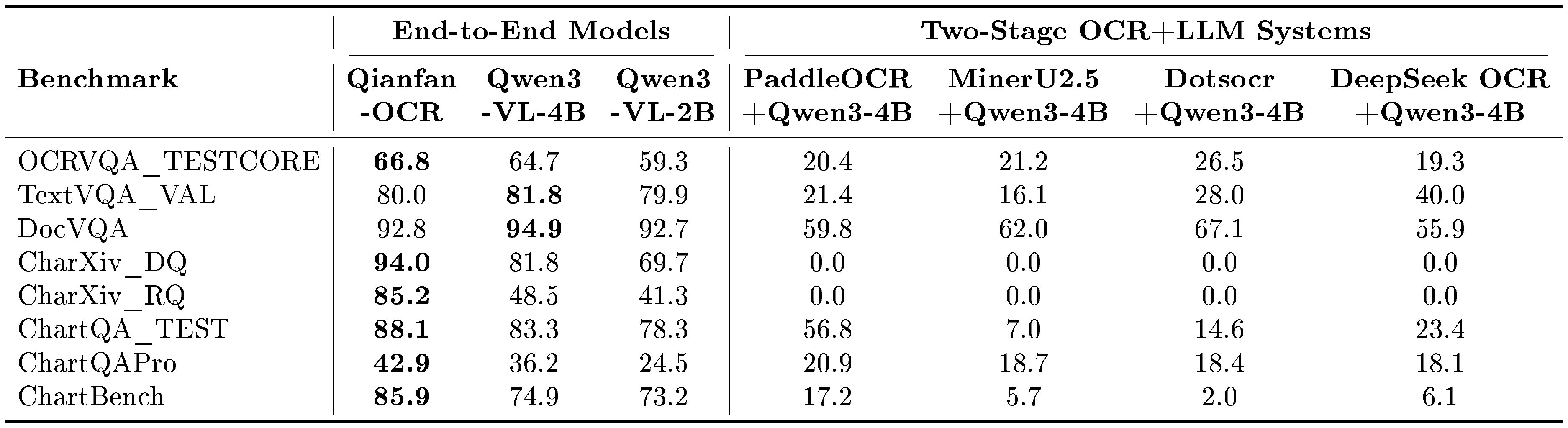
::: {caption="Table 6: End-to-end models vs. two-stage OCR+LLM systems on document understanding benchmarks. Two-stage systems use Qwen3-4B as the downstream LLM. Best end-to-end results in bold."}
:::
Qianfan-OCR achieves the best scores on six out of eight benchmarks, with particular strength on chart and academic reasoning tasks: CharXiv_DQ (94.0), CharXiv_RQ (85.2), ChartQA (88.1), ChartQAPro (42.9), ChartBench (85.9), and OCRVQA (66.8). On general document understanding benchmarks, Qwen3-VL-4B outperforms Qianfan-OCR on DocVQA (94.9 vs. 92.8) and TextVQA (81.8 vs. 80.0). This gap is consistent with the trend observed in Section 6.2: as a model designed for specialized OCR tasks, Qianfan-OCR accepts modest performance differences on general understanding benchmarks relative to same-size general VLMs, while achieving substantially stronger results on domain-specific OCR benchmarks (OmniDocBench, OlmOCR) and chart-related tasks where structural visual reasoning is critical.
The most striking result is the complete failure of all two-stage systems on CharXiv (0.0 on both DQ and RQ), where chart structures, axis relationships, and data point positions – discarded during text extraction – are essential for answering. The degradation extends to other chart benchmarks (ChartQA: 7.0–56.8 vs. 88.1; ChartBench: 2.0–17.2 vs. 85.9) and even text-heavy tasks like DocVQA (55.9–67.1 vs. 92.8–94.9), confirming that spatial and layout context provides value beyond what plain text can capture.
6.4 Key Information Extraction Benchmarks
We evaluate KIE performance on five public benchmarks as described in Section 5. Since specialized OCR models lack native KIE capabilities, we compare Qianfan-OCR with commercial models (Gemini-3.1-Pro, Gemini-3-Pro, Seed-2.0) and open-source models (Qwen3-4B-VL, Qwen3-VL-235B-A22B).
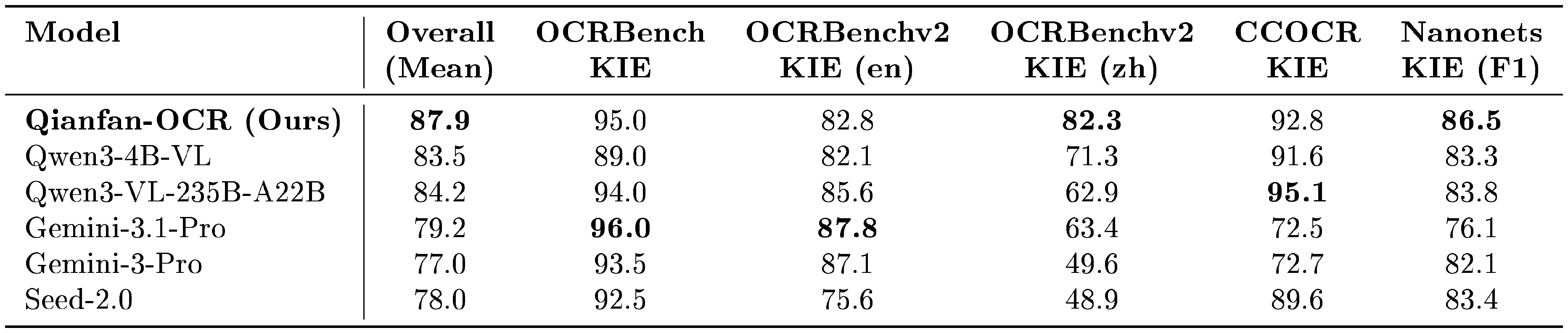
::: {caption="Table 7: Performance comparison on Key Information Extraction (KIE) benchmarks (normalized scores). Qianfan-OCR achieves the highest overall mean score of 87.9 across five public KIE benchmarks, outperforming both state-of-the-art commercial models and similarly-sized open-source models."}
:::
As shown in Table 7, Qianfan-OCR achieves the highest overall mean score of 87.9 across five public KIE benchmarks, outperforming the similarly-sized Qwen3-4B-VL (83.5) by 4.4 points, the much larger Qwen3-VL-235B-A22B (84.2) by 3.7 points, and commercial large models by approximately 9–11 points. Qianfan-OCR leads on OCRBenchv2 KIE Chinese (82.3) and Nanonets KIE F1 (86.5), demonstrating strong advantages on Chinese document extraction and real-world evaluation scenarios. Notably, even Qwen3-VL-235B-A22B with over 50 $\times$ more activated parameters achieves a lower overall score, primarily due to weak Chinese KIE performance (62.9 on OCRBenchv2 KIE zh). The Gemini-3 series achieves strong results on English KIE tasks (Gemini-3.1-Pro: OCRBench KIE 96.0, OCRBenchv2 KIE en 87.8), but drops sharply on Chinese benchmarks (OCRBenchv2 KIE zh: 63.4 and 49.6), indicating limited multilingual generalization. Seed-2.0 shows relatively weaker performance on OCRBenchv2 KIE tasks (en 75.6, zh 48.9) compared to other models. These results validate the effectiveness of Qianfan-OCR's end-to-end architecture for spatial reasoning and field association tasks across both Chinese and English scenarios.
6.5 Inference Throughput
Beyond accuracy, inference throughput is a critical factor for production deployment. Since two-stage pipeline systems (e.g., PaddleOCR-VL) involve heterogeneous components beyond the language model (layout detection, element-wise recognition, post-processing), raw model throughput alone is not a meaningful comparison metric. We therefore adopt pages per second (PPS) – the number of complete document pages parsed per second – as a holistic throughput measure that captures end-to-end system efficiency. All benchmarks are conducted on the OmniDocBench v1.5 dataset using a single NVIDIA A100 GPU with vLLM 0.10.2, consistent with the inference framework version reported in the PaddleOCR-VL technical report.
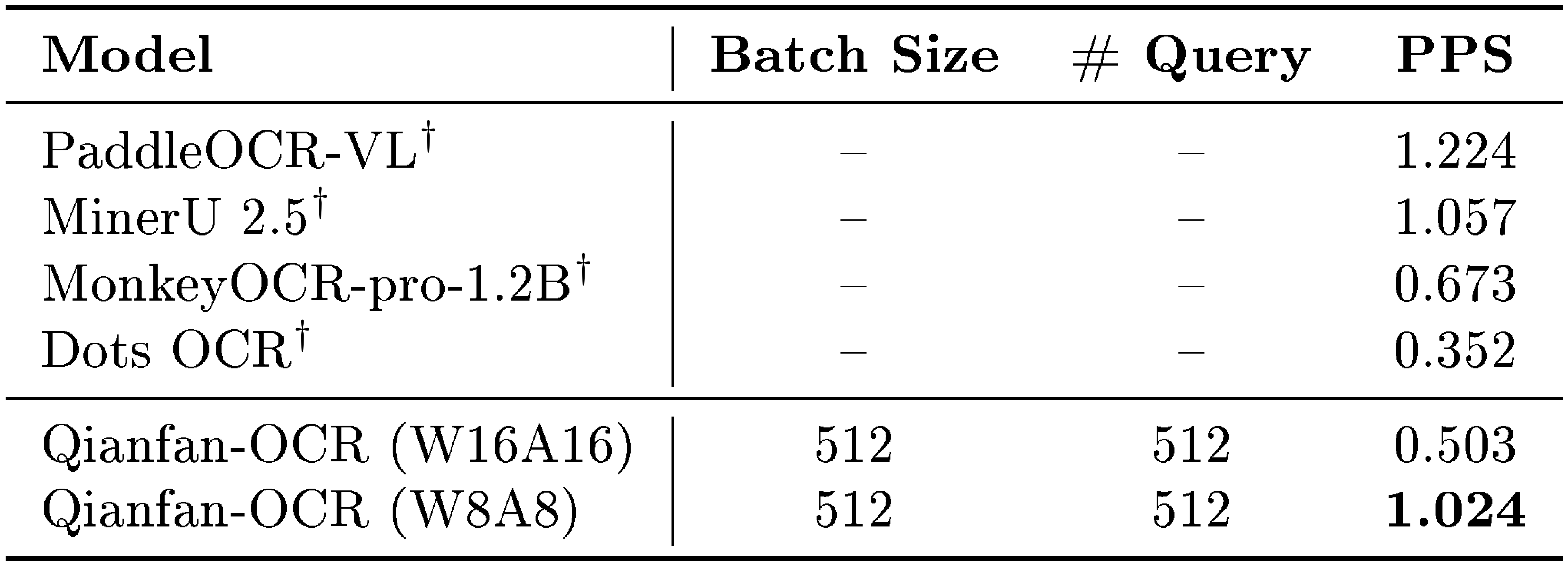
::: {caption="Table 8: Inference throughput comparison measured in pages per second (PPS) on OmniDocBench v1.5 with a single A100 GPU. $^{\dagger}$Results from PaddleOCR-VL technical report."}
:::
As shown in Table 8, despite having a 4B-parameter language model backbone – substantially larger than the detection and recognition modules in pipeline systems – Qianfan-OCR with W8A8 quantization achieves 1.024 PPS, comparable to PaddleOCR-VL (1.224 PPS) and exceeding MonkeyOCR-pro-1.2B (0.673 PPS) and Dots OCR (0.352 PPS).
This competitive throughput is attributable to two architectural advantages of the end-to-end approach:
- GPU-centric computation: Two-stage pipeline systems rely on CPU-based layout analysis (detection, NMS, rule-based assembly) as a prerequisite for GPU-based recognition. Under high concurrency, the CPU stage becomes a bottleneck that throttles GPU utilization – a problem that worsens with more powerful GPUs. Qianfan-OCR processes entire pages through the GPU with minimal CPU involvement, avoiding this bottleneck entirely.
- Efficient batching: End-to-end models accept whole-page images that can be resized to uniform dimensions, enabling large-batch GPU inference with well-aligned memory access patterns. In contrast, pipeline systems process variable numbers of cropped regions per page, leading to irregular batch sizes and fragmented GPU utilization.
- Lower deployment complexity: Pipeline systems such as PaddleOCR-VL require asynchronous orchestration of data loading, layout analysis, and LLM inference stages, demanding careful tuning of per-stage concurrency, queue depths, and resource allocation to achieve optimal throughput. Qianfan-OCR reduces this to a standard single-model serving problem (e.g., a single vLLM instance), significantly lowering deployment effort and performance tuning cost.
With AWQ quantization at W8A8 precision, Qianfan-OCR achieves a 2 $\times$ speedup over the W16A16 baseline (1.024 vs. 0.503 PPS) with negligible accuracy degradation, making it a practical choice for high-throughput document processing pipelines.
7. Limitations and Future Work
Section Summary: Qianfan-OCR, an early effort in unified document intelligence, faces several key limitations, including a rigid layout analysis tool that's only tested for basic document parsing and hasn't been explored for tasks like extracting key info or understanding charts. Future improvements could involve making layout reasoning more flexible through techniques like reinforcement learning, pushing end-to-end performance to rival traditional step-by-step systems, and shrinking the model's size for use on everyday devices via methods like distillation. It also struggles with video text, curved 3D writing, and artistic handwriting, opening paths to broaden its capabilities.
Qianfan-OCR represents an early exploration of unified end-to-end document intelligence with several limitations that warrant further investigation.
Layout-as-Thought. The current Layout-as-Thought mechanism has only been validated on OmniDocBench v1.5 for document parsing, where it shows targeted benefits on structurally complex pages. Its effectiveness on other tasks – such as key information extraction, document QA, and chart understanding – remains unexplored. The current implementation generates layout bounding boxes, labels, and brief text descriptions in a relatively rigid format via supervised fine-tuning. Future work should integrate these layout elements more naturally into the reasoning process, allowing the model to flexibly invoke spatial reasoning when needed rather than producing a fixed-format layout dump. Reinforcement learning is a promising direction to achieve this: by optimizing layout generation based on downstream task rewards, the model can learn to produce task-adaptive layout reasoning that selectively emphasizes relevant structural information, ultimately strengthening reasoning capabilities across diverse document intelligence scenarios.
Performance Ceiling. As a pioneering attempt at end-to-end OCR, the ultimate performance ceiling of purely end-to-end architectures remains an open question – future work should systematically explore architectural innovations, training strategies, and data scaling laws to determine whether end-to-end models can fully match or surpass heavily optimized pipeline systems.
Deployment Efficiency. Although W8A8 quantization enables competitive throughput on GPU (Section 6.5), Qianfan-OCR's 4B parameter footprint limits deployment in resource-constrained environments such as edge devices and CPU-only servers – future work should explore knowledge distillation and pruning to develop compact variants (1B–2B parameters) suitable for broader deployment scenarios. Beyond these core challenges, Qianfan-OCR exhibits limitations in video OCR, 3D text on curved surfaces, and highly stylized artistic handwriting, presenting promising directions for extending the unified architecture.
8. Conclusion
Section Summary: Qianfan-OCR is a powerful AI model with 4 billion parameters that handles text reading, document layout analysis, and meaning understanding all in one seamless system, combining vision and language processing. It achieves top performance on key benchmarks, outperforming traditional step-by-step systems in accuracy, especially through a new "Layout-as-Thought" feature that lets it reason about document structure when needed, while showing that simpler text-only approaches fail badly on tasks involving visuals like charts. Overall, keeping visual details intact throughout processing proves much better for smart document tasks, and the model is freely available on Baidu's AI Cloud platform via GitHub.
We present Qianfan-OCR, a 4B-parameter end-to-end model that unifies text recognition, layout analysis, and semantic understanding within a single vision-language architecture. Our key contributions include: (1) achieving state-of-the-art results among end-to-end models on OmniDocBench v1.5 and OlmOCR Bench, demonstrating that end-to-end architectures can be competitive with pipeline systems on recognition accuracy; (2) introducing Layout-as-Thought, a mechanism that integrates layout reasoning as optional chain-of-thought, enabling the model to dynamically invoke structural analysis for complex documents; (3) providing empirical evidence that two-stage OCR+LLM pipelines degrade substantially on tasks requiring spatial and visual reasoning, with zero accuracy on chart interpretation benchmarks where layout information is essential.
These results suggest that for document intelligence tasks requiring joint visual and textual understanding, preserving visual context throughout the processing pipeline offers significant advantages over text-only intermediate representations.
The model is publicly accessible through Baidu AI Cloud Qianfan platform at https://github.com/baidubce/Qianfan-VL.
Acknowledgments
Section Summary: The authors express thanks to the Baidu AI Cloud team for providing infrastructure support, along with the Baige and Kunlun teams for help with AI infrastructure, and all those who contributed to the QianFan platform. They are particularly grateful to the operations, storage, and network teams for ensuring the stability of the P800 clusters. Special recognition goes to the annotation teams and quality assurance engineers for their careful work in validating data.
We thank the Baidu AI Cloud team for infrastructure support, the Baige and Kunlun teams for AI infrastructure assistance, and all contributors to the QianFan platform. We are deeply grateful to the operations, storage, and network teams for maintaining the stability of the P800 clusters. Special thanks to our annotation teams and quality assurance engineers for their meticulous work in data validation.
Contributors
Section Summary: The "Contributors" section highlights the key individuals involved in the project, starting with six core contributors: Daxiang Dong, Mingming Zheng, Dong Xu, Chunhua Luo, Bairong Zhuang, and Yuxuan Li. It then lists eleven additional contributors, including Ruoyun He, Haoran Wang, Wenyu Zhang, Wenbo Wang, Yicheng Wang, Xue Xiong, Ayong Zheng, Xiaoying Zuo, Ziwei Ou, Jingnan Gu, and Quanhao Guo. The section concludes by recognizing three project sponsors: Jianmin Wu, Dawei Yin, and Dou Shen.
Core Contributors
Daxiang Dong, Mingming Zheng, Dong Xu, Chunhua Luo, Bairong Zhuang, Yuxuan Li
Contributors
Ruoyun He, Haoran Wang, Wenyu Zhang, Wenbo Wang, Yicheng Wang, Xue Xiong, Ayong Zheng, Xiaoying Zuo, Ziwei Ou, Jingnan Gu, Quanhao Guo
Project Sponsors
Jianmin Wu, Dawei Yin, Dou Shen
References
Section Summary: This references section lists about two dozen recent academic papers and preprints, mainly from 2023 to 2026, focusing on advancements in optical character recognition (OCR) and vision-language models for parsing documents like PDFs. It includes works on unified OCR models, compact vision-language systems for multilingual tasks, and tools for understanding academic and visual content such as charts and code. The citations also cover benchmarks and datasets for evaluating these technologies, highlighting ongoing efforts to improve AI's ability to read and interpret complex visual texts.
[1] Wei et al. (2024). General OCR Theory: Towards OCR-2.0 via a Unified End-to-end Model. arXiv preprint arXiv:2409.01704.
[2] Wei et al. (2025). DeepSeek-OCR: Contexts Optical Compression. arXiv preprint arXiv:2510.18234.
[3] Cui et al. (2025). PaddleOCR-VL: Boosting Multilingual Document Parsing via a 0.9B Ultra-Compact Vision-Language Model. arXiv preprint arXiv:2510.14528.
[4] Poznanski et al. (2025). olmOCR: Unlocking Trillions of Tokens in PDFs with Vision Language Models. arXiv preprint arXiv:2502.18443.
[5] Liu et al. (2024). Visual instruction tuning. Advances in neural information processing systems. 36.
[6] Chen et al. (2024). Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks. arXiv preprint arXiv:2312.14238.
[7] Cui et al. (2025). Paddleocr 3.0 technical report. arXiv preprint arXiv:2507.05595.
[8] Blecher et al. (2023). Nougat: Neural optical understanding for academic documents. arXiv preprint arXiv:2308.13418.
[9] Bai et al. (2023). Qwen-vl: A versatile vision-language model for understanding, localization, text reading, and beyond. arXiv preprint arXiv:2308.12966.
[10] Bai et al. (2025). Qwen2. 5-vl technical report. arXiv preprint arXiv:2502.13923.
[11] Zhu et al. (2025). Internvl3: Exploring advanced training and test-time recipes for open-source multimodal models. arXiv preprint arXiv:2504.10479.
[12] Daxiang Dong et al. (2025). Qianfan-VL: Domain-Enhanced Universal Vision-Language Models. https://arxiv.org/abs/2509.18189. arXiv:2509.18189.
[13] Ainslie et al. (2023). GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints. arXiv preprint arXiv:2305.13245.
[14] Zhang, Biao and Sennrich, Rico (2019). Root mean square layer normalization. In Advances in Neural Information Processing Systems.
[15] Ouyang et al. (2024). OmniDocBench: Benchmarking Diverse PDF Document Parsing with Comprehensive Annotations. arXiv preprint arXiv:2412.07626.
[16] AllenAI (2024). olmOCR-Bench: A Comprehensive OCR Evaluation Benchmark. https://huggingface.co/datasets/allenai/olmOCR-bench.
[17] Rodriguez et al. (2024). Bigdocs: An open dataset for training multimodal models on document and code tasks. arXiv preprint arXiv:2412.04626.
[18] Chen et al. (2024). OCRBench: On the Hidden Mystery of OCR in Large Multimodal Models. arXiv preprint arXiv:2305.07895.
[19] Singh et al. (2019). Towards vqa models that can read. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 8317–8326.
[20] Mathew et al. (2021). Docvqa: A dataset for vqa on document images. In Proceedings of the IEEE/CVF winter conference on applications of computer vision. pp. 2200–2209.
[21] Wang et al. (2024). CharXiv: Charting Gaps in Realistic Chart Understanding in Multimodal LLMs. arXiv preprint arXiv:2406.18521.
[22] Masry et al. (2022). Chartqa: A benchmark for question answering about charts with visual and logical reasoning. arXiv preprint arXiv:2203.10244.
[23] Masry et al. (2025). ChartQAPro: A more diverse and challenging benchmark for chart question answering. arXiv preprint arXiv:2504.05506.
[24] Duan et al. (2024). Vlmevalkit: An open-source toolkit for evaluating large multi-modality models. In Proceedings of the 32nd ACM International Conference on Multimedia. pp. 11198–11201.
[25] Haoran Wei et al. (2026). DeepSeek-OCR 2: Visual Causal Flow. https://arxiv.org/abs/2601.20552. arXiv:2601.20552.
[26] Cheng Cui et al. (2026). PaddleOCR-VL-1.5: Towards a Multi-Task 0.9B VLM for Robust In-the-Wild Document Parsing. https://arxiv.org/abs/2601.21957. arXiv:2601.21957.