Sakana Fugu Technical Report
Fugu Team
Sakana AI $^{1}$
Abstract
The capabilities of frontier Large Language Models (LLMs) continue to advance, with different providers increasingly specializing in distinct domains. This raises a natural next objective: how to combine the individual specializations of various LLMs into a collectively intelligent system. To this end, we report the development of Sakana Fugu, a family of orchestrator models that harness and amplify the capabilities of an LLM agent team. Fugu models are themselves language models trained to understand user queries and dynamically devise agentic scaffolds to solve them. Through these adaptive scaffolds, Fugu accesses performance beyond any individual LLM agent, achieving state-of-the-art results compared to other publicly accessible models across a range of challenging tasks, including SWE-Bench Pro, Terminal Bench, LiveCodeBench, GPQA-Diamond, Humanity's Last Exam, and CharXiv Reasoning. We release two models: FUGU, which balances performance with latency for everyday use, and FUGU-ULTRA, which prioritizes answer quality on the hardest problems. We describe our training paradigm, which encompasses large-scale fine-tuning, evolutionary algorithms, and reinforcement learning approaches, along with the infrastructure and core design principles that turn these methods into a production system. We hope this report encourages further research into multi-agent systems and dynamic, query-adaptive agentic scaffolds as a path toward the next frontier of AI capabilities, accessed through collective intelligence. https://sakana.ai/fugu
$^{1}$ Please cite this work as "Sakana AI (2026)". Full authorship and contributions appear at the end of the document.
Executive Summary: Sakana Fugu is a family of language-model orchestrators developed by Sakana AI to combine the specialized strengths of multiple frontier LLMs into a single, adaptive system rather than relying on any one model. Frontier models now show clear domain and task-specific strengths—such as GPT-series models in mathematical planning and Claude-series models in software engineering and debugging—yet no single model consistently leads across all areas. At the same time, agentic scaffolds that add tools, feedback, and iteration have proven essential to turning raw model capability into reliable performance. The report therefore addresses how to learn orchestration itself so that complementary models can be assembled on a per-query basis without hand-designed workflows or parameter access.
The document presents two production-oriented models. Fugu is a latency-aware router that selects one worker per input after supervised fine-tuning and evolutionary optimization. Fugu-Ultra uses reinforcement learning to generate full multi-step agentic workflows, including tree topologies, debate, and function-calling coordination, while maintaining shared yet isolated memory across agents. Both are evaluated on established benchmarks (SWE-Bench Pro, Terminal Bench 2.1, GPQA-Diamond, LiveCodeBench, Humanity’s Last Exam, CharXiv Reasoning) plus expert-designed tasks in autonomous ML optimization, classical Japanese text reconstruction, CAD generation, blindfold chess, and sequential trading.
Fugu-Ultra establishes new state-of-the-art results among publicly accessible systems on the hardest tasks, improving 5–6 % relative to the next-best single frontier model on the two primary coding benchmarks and surpassing the strongest individual worker on scientific reasoning. Fugu matches or exceeds the best single-model baselines while keeping latency comparable to a direct frontier call. Across domains the orchestrators exhibit fine-grained, query-adaptive routing that matches known model specializations and dynamically assembles useful coordination patterns such as builder–debugger alternation or specialist aggregation. On non-benchmark tasks the same models produce measurably stronger outcomes—lower validation loss in autonomous pipeline optimization, higher reading-order recovery on expert-annotated historical documents, and mechanically sound CAD mechanisms—while frontier baselines frequently fail to complete the same workflows.
These results indicate that learned orchestration constitutes a practical scaling axis complementary to increasing model size. Because Fugu composes models at the behavioral level, new workers can be added without retraining, provider or privacy constraints can be enforced at deployment time, and capability gains accrue from coordination rather than solely from larger training runs. The approach therefore distributes frontier-level performance more broadly and supports modular, compliance-aware deployments.
The immediate next steps are to incorporate newly released frontier models into the worker pool, expose configuration options that let organizations restrict model selection, and conduct larger-scale user studies on long-horizon production workflows. Further investment in richer shared memory mechanisms and automated discovery of coordination topologies would strengthen the approach for the most demanding multi-turn tasks.
The primary limitations are dependence on the underlying worker pool for raw capability, higher latency for Fugu-Ultra on complex queries, and the need for continued evaluation as new single models appear. Results are based on current frontier checkpoints and may shift as those models evolve; all claims are therefore bounded by the specific evaluation harnesses and time period reported.
1. Introduction
Section Summary: Frontier AI models are advancing rapidly and showing increasingly specialized strengths in areas like math, coding, and security, raising the idea that future progress may come from intelligently combining multiple models rather than relying on any single one. The introduction presents Sakana Fugu, a family of smaller models trained to act as orchestrators that dynamically choose and coordinate teams of powerful frontier agents, either routing each query to the single best worker or assembling multi-agent workflows for harder tasks. This approach seeks to deliver frontier-level performance more efficiently and modularly while offering greater flexibility and accessibility than training ever-larger individual models.
Frontier Large Language Models (LLMs) now approach or match expert-level performance across a wide range of domains ([1, 2, 3, 4, 5]). For example, Gemini-3-Deep-Think recently achieved gold-medal performance at the International Mathematical Olympiad ([1]), GPT-5.5 disproved an 80-year-old Erdős conjecture in combinatorial geometry ([3]), and Claude-Mythos uncovered numerous zero-day vulnerabilities in OpenBSD and FreeBSD ([6]). Yet as frontier capabilities advance, we also observe increasingly differentiated model specializations at multiple levels of granularity. At the domain level, past GPT-series models often displayed state-of-the-art performance on mathematical reasoning tasks ([3, 7]), while Opus-series models have specialized in software engineering and cybersecurity ([6, 8]). Within a single domain, the differences can be even more fine-grained: in competitive coding, Gemini-3.1-Pro can be particularly effective at directly implementing known algorithms, while GPT-series models can often excel at planning and combining multiple algorithmic ideas to solve the hardest problems ([9]). These observations suggest that the next frontier may not be achieved by any single model alone, but by systems that can identify, combine, and amplify the complementary strengths of many models. A system that can engineer software like the strongest coding model, reason mathematically like the strongest theorem-proving model, and dynamically decide when each specialization is needed would provide a natural path toward expanding frontier performance through collective intelligence.
At the same time, recent improvements in LLM performance have been driven not only by advances in the underlying models but also by agentic scaffolds that treat the LLM as one component within a larger system ([10]). Such scaffolds augment autoregressive generation with structured prompting ([11, 12, 13]), external tool use and function calling ([14, 15]), environment feedback, and memory management ([16]). This is especially visible in software engineering, where Claude Code and other modern agentic scaffolds can shape the model's interaction trajectory, supply continuous environment feedback, and turn raw model capability into an iterative agentic workflow ([17]). These developments suggest that capability should be understood not only as a property of the model, but also as a property of the scaffold through which the model acts.
The growing range of language models with diverse capabilities and the impact of domain-specific agentic scaffolds motivate the development of systems that can orchestrate collective intelligence: dynamically choosing which models to involve, how they should communicate, use tools and interact with the environment, and when their outputs should be synthesized. We view this kind of model orchestration as a new complementary scaling axis beyond ever larger and expensive language models. If successful, this direction could make frontier-level capability more efficient, more modular, and more broadly accessible.
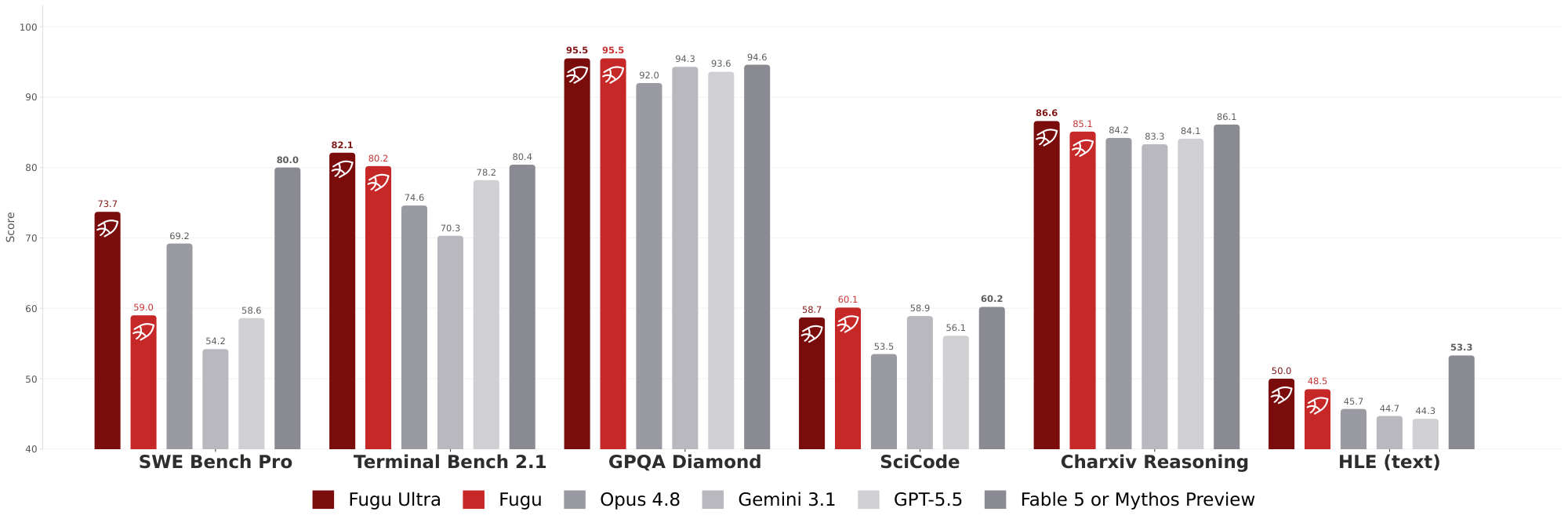
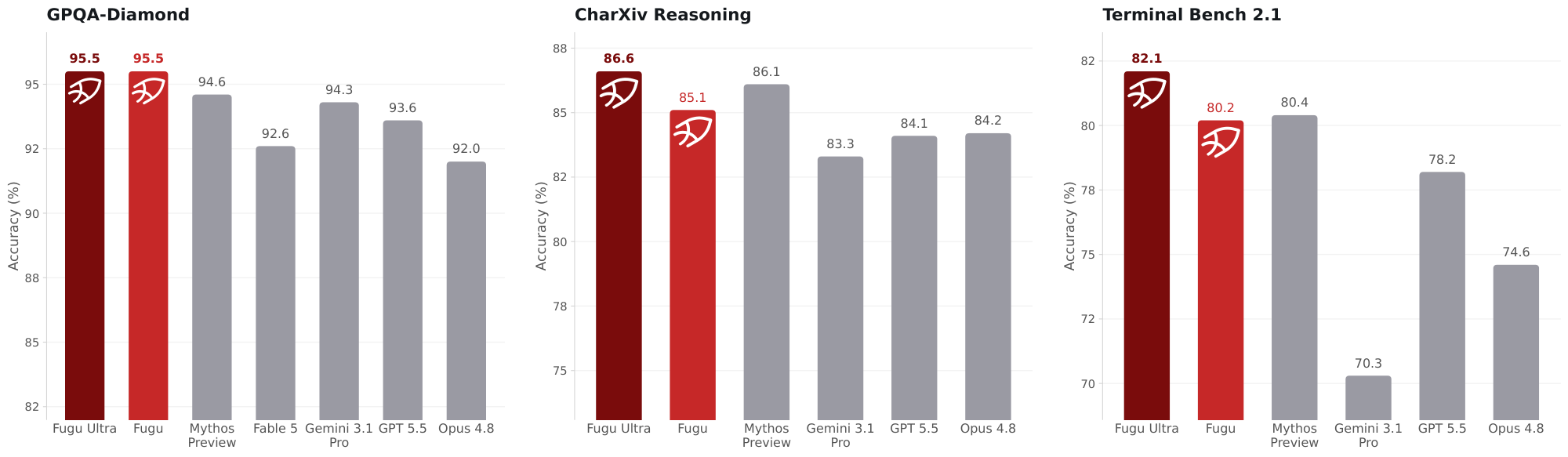
In this technical report, we detail the development of Sakana Fugu, our system harnessing the benefits of collective intelligence to realize this vision. Sakana Fugu is a family of language models trained to adaptively and dynamically orchestrate a team of more powerful frontier agent workers. In our initial release, we make two variants available to the public, targeting different operating points. $\textsc{Fugu}$ is optimized for speed, selecting a single worker per input so that its latency is comparable to a direct call to a frontier model, while still routing each query to the most capable agent for that input. Despite this efficiency, $\textsc{Fugu}$ matches and in many cases surpasses best-in-class performance across tasks. $\textsc{Fugu-Ultra}$ is optimized for performance, composing workflows of multiple agents per input. It therefore trades additional latency for higher quality and is intended for the most complex tasks that benefit from combining multiple specializations. Figure 1 compares Sakana Fugu with frontier models on popular benchmarks. Our Fugu models surpass publicly accessible frontier models and are shoulder-to-shoulder with Fable 5 and Mythos Preview in various rigorous engineering, scientific, and reasoning benchmarks while delivering frontier capability without the risk of export controls. See Section 4 for more results.
Beyond raw performance, we believe learned orchestration carries broader implications. If capability can be amplified by composing existing models rather than only by training larger ones, then progress in AI need not depend solely on access to the largest training runs. Orchestration offers a more modular and accessible path, in which improvements arise from how models are selected, coordinated, and combined, and in which newly released models can be incorporated into the worker pool as they appear. This composability also gives users meaningful control over the system. For example, agent pools can be configured to favor particular providers, exclude specific models, or respect data, privacy, and compliance constraints, without retraining. More speculatively, treating orchestration as a first-class scaling axis may have economic and geopolitical consequences, distributing the benefits of frontier AI more broadly across organizations and regions rather than concentrating them in those able to train the largest models. We offer Fugu as a first step in this direction, and hope it encourages further research into collective intelligence as a path toward the next frontier of AI capabilities.
2. Related Work
Section Summary: The section reviews prior research on coordinating multiple large language models to achieve stronger results than any one model alone, typically through fixed communication patterns or routing systems, and on building agent scaffolds that prompt models to reason, use tools, and reflect iteratively. It also examines model-merging techniques that combine capabilities either by averaging parameters or by routing internal activations, noting that these approaches usually require access to open model weights and cannot easily handle closed frontier systems. Sakana Fugu is positioned as an extension of these ideas that hides the coordination behind a single trained interface and dynamically generates its own orchestration plans at inference time rather than relying on hand-designed or external scaffolds.
LLM Collective Intelligence. Collective intelligence studies how groups of relatively limited individuals can, through interaction, produce behavior that exceeds the capability of any single member ([18, 19]). This perspective has recently become increasingly relevant for LLMs, as frontier models from different providers exhibit complementary strengths and weaknesses. A growing body of work therefore studies how to coordinate groups of LLM agents through communication protocols, voting mechanisms, routing policies, and learned collaboration structures ([20, 21, 22, 23, 24, 25, 26]). Recent multi-agent LLM systems often rely on hand-designed collaboration patterns: for example, [20] and [21] orchestrate multiple agents across successive discussion or reasoning rounds, using fixed interaction structures to improve final answers. Other works move toward learned or adaptive coordination. [23] and [25] learn representations that map queries to suitable agents or topologies, [24] treats collaboration as a learnable graph, and [26] learns a router that directs each query to a single best-matched agent.
Sakana Fugu follows this line of work in treating intelligence as an emergent property of coordinated model collectives. However, our goal differs from that of many prior multi-agent systems in two respects. First, rather than exposing a multi-agent workflow that users must design, tune, or operate, Sakana Fugu presents the collective as a single model interface. Second, rather than relying solely on fixed communication patterns or single-step routing, Fugu models are themselves trained orchestrators that can adaptively decide how to use an agent pool for each query. In this sense, Sakana Fugu aims to make collective intelligence not only a research paradigm for studying LLM collaboration, but also a practical model interface for accessing complementary model capabilities.
Agentic Scaffolds. To elevate LLMs from autoregressive chatbots into action-taking agents, a large body of work has developed agentic scaffolds that elicit reasoning, planning, reflection, and tool use from an underlying model. A first line of work shapes the model's reasoning through prompting and decoding strategies, including chain-of-thought prompting ([11]), self-consistency ([27]), and structured search over reasoning paths such as Tree of Thoughts ([28]). A second line interleaves reasoning with acting, allowing the model to plan, call tools, and incorporate observations: ReAct couples reasoning traces with actions ([12]), while Toolformer and subsequent work equip models with external tools and function calling ([15, 14]). A third line adds feedback and iteration, where models critique and revise their own outputs through self-reflection ([13, 29]) or by incorporating signals from an external environment. Together with growing support for long-horizon memory ([16]), these components transform a static model into a capable agent.
These ideas have also been consolidated into production harnesses that wrap frontier models in rich interactive environments. In software engineering, for example, systems such as Claude Code and Codex manage repository context, tool use, code execution, editing loops, and environment feedback, often contributing substantially to end-to-end performance beyond the raw model call itself ([30, 17]). These systems demonstrate that the practical capability of an LLM depends critically on the scaffold through which it interacts with the task environment. However, such harnesses are typically designed for a specific class of tasks and expose the scaffold as an external system around the model. Sakana Fugu takes a different approach, in which the scaffold is generated by a trained orchestrator at inference time. Rather than applying a fixed interaction pattern or relying on a task-specific harness, Fugu dynamically decides how to reason about each request, which frontier agents to involve, how they should communicate, and how their outputs should be synthesized into a final answer.
Model Merging. Another line of work studies how to combine the capabilities of multiple models through model merging. At the parameter level, early approaches use static recipes such as weight averaging, model soups, or task-balanced interpolation to integrate capabilities across domains with minimal additional computation ([31]). More recent work introduces optimization-based merging, for example evolutionary search over "merging recipes" showing that learned strategies can outperform hand-designed ones and yield stronger generalization ([32]). Other methods improve the reliability of parameter-space fusion by resolving task conflicts, sparsifying parameter updates, or preserving directions important to individual models ([33, 34]). However, because parameter-space merging operates directly on weights, it requires access to model parameters and typically assumes architectural or representational compatibility. This confines its applicability largely to open-source checkpoints and makes it unsuitable for composing the closed-source frontier models that currently define much of the state of the art.
A complementary family of methods composes models in the data-flow or representation space. Instead of averaging all weights, these approaches stitch layers, mix blocks, route hidden states, or construct hybrid architectures from existing components ([35, 32]). Such methods relax some constraints of full parameter merging and can combine capabilities at a more modular level, but they still generally require internal access to model activations, layers, or architectures. They therefore cannot be generally applied to heterogeneous API-only systems, where models may differ in architecture, provider, context interface, latency, cost, and availability.
Sakana Fugu can be viewed as a macro-level analogue of model merging. Rather than merging weights or stitching layers, it composes model capabilities at the behavioral level, treating frontier models as black-box agents and learning how to route, coordinate, verify, and synthesize their outputs. In this sense, Fugu performs a form of functional model composition wherein it aims to preserve and amplify the complementary specializations of different models without requiring parameter access or architectural compatibility. This macro-level perspective allows Fugu to incorporate closed-source frontier models, heterogeneous providers, and user-specific constraints, while still pursuing the central goal of model merging so that it combines multiple specialized models into a stronger collective system.
3. Sakana Fugu
Section Summary: Sakana Fugu is a system that uses a single orchestrator model to manage and coordinate multiple specialized AI language models behind the scenes, so users experience it as if they are simply calling one model. The orchestrator decides which models to activate for a given query, how to assign them tasks or roles, how to combine their results, and when to produce a final answer. The family includes two versions: a faster one tuned for everyday interactive use with good speed and quality, and an ultra version that invests more computation for higher accuracy at the expense of added delay.
Sakana Fugu is a family of learned orchestrators that expose a multi-agent system through a single model interface. Given a user query, a Fugu model constructs an agentic scaffold over a pool of frontier LLM workers, deciding which workers to involve, what instructions or roles to assign, how intermediate outputs should be combined or verified, and when to synthesize the final answer. The user interacts with Fugu as if calling a single model, while internally the system can route, delegate, and coordinate across multiple specialized agents. We release two variants targeting different points on the quality-latency frontier. $\textsc{Fugu}$ balances strong performance with low latency, making it suitable for everyday interactive use and configurable deployment constraints. $\textsc{Fugu-Ultra}$ prioritizes answer quality, using deeper orchestration over a larger worker pool at the cost of additional latency.
3.1 $\textsc{Fugu}$: Balancing Performance and Latency
$\textsc{Fugu}$ is the latency-aware variant of Sakana Fugu, designed for interactive and everyday workloads where response time matters alongside answer quality. It builds on Trinity ([36]), but scales and adapts the learned-orchestration idea to a production setting in which the orchestrator must make fast, reliable routing decisions under reasonable latency and must be optimized not only for single-step performance but also for multi-turn end-to-end interactive tasks common in real-world use.
3.1.1 Parametrization
$\textsc{Fugu}$ 's orchestrator is designed as a fast decision module over a pool of frontier worker models. Fugu uses a pre-trained language model as its backbone and coordinates the worker pool based on its own hidden states. We provide a high-level illustration of this process in Figure 2.
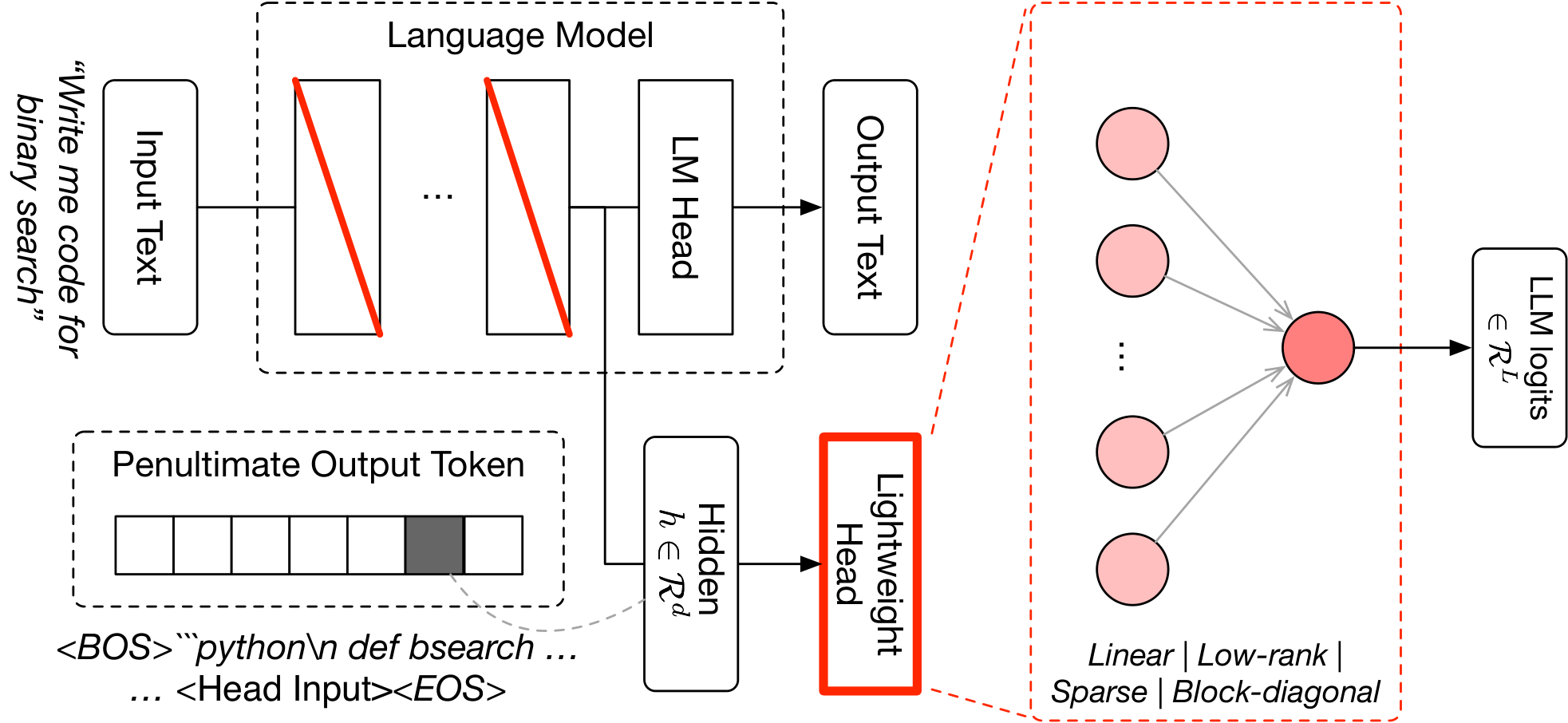
Concretely, given a pool of $L$ worker models, we attach a lightweight prediction head after the final hidden layer of the orchestrator backbone. For a hidden state $h \in \mathbb{R}^d$, the head outputs $L$ logits that score which worker model should be selected for the input. Unlike Trinity, which additionally assigns one of several roles to the selected model, $\textsc{Fugu}$ always dispatches the query to the selected model as a worker. Removing role assignment narrows the coordination space to model selection alone, which keeps the orchestration decision simple and minimizes the latency overhead of the orchestrator.
To improve the representation used by this lightweight head without full fine-tuning, we adapt a small subset of the backbone parameters using singular-value fine-tuning, following recent work on efficient adaptation ([37]). For selected weight matrices in the orchestrator backbone, we decompose the matrix and train only the singular-value scales, keeping the orthogonal components fixed. Together with the lightweight prediction head, this yields an extremely small trainable parameter set while still allowing the orchestrator representation to effectively adapt to the routing problem.
A key design choice is that $\textsc{Fugu}$ uses the orchestrator's logits rather than its generated text. Since prompting and task execution are delegated to the selected frontier worker model, the orchestrator only needs to produce a worker-selection decision. This makes inference substantially cheaper: the system can compute a hidden state at an early token position, apply the selection head, and immediately dispatch the query to the selected worker, without the expensive autoregressive decoding process. This decision-only parametrization is central to $\textsc{Fugu}$ 's latency profile and also makes evolutionary optimization practical, as described in the following subsection.
3.1.2 Supervised Fine-tuning on Single-Step Tasks
We train $\textsc{Fugu}$ in two stages, starting with large-scale supervised fine-tuning (SFT). For this stage, we assemble a large collection of single-step tasks spanning coding, mathematics, reasoning, language understanding, and numerous agentic scenarios. Each question $q_i$ in this collection $\mathcal{D}$ is verifiable and has a ground-truth solution $s_i$.
To construct training labels, we run every worker model $\mathcal{M}_j$ where $j =1 \cdot s K$ in the pool on $q_i$ for $n$ repetitions and measure each model's performance by comparing with $s_i$, yielding for each model a set of candidate solutions ${o^{\mathcal{M}_j}_1, o^{\mathcal{M}_j}_2, ..., o^{\mathcal{M}_j}_n }$ and a corresponding reward set ${r^{\mathcal{M}_j}_1, r^{\mathcal{M}_j}_2, ..., r^{\mathcal{M}j}n}$. These rewards induce a ranking over the worker pool, from the model best suited to the problem to the least suited. We summarize for each model $j$ the performance on $q_i$ by the average of its rewards, $\bar{r}{i, j} ;=; \frac{1}{n}\sum{k=1}^{n} r^{\mathcal{M}_j}k, $ and collect these scores into a vector $\mathbf{s}i = (\bar{r}{i, 1}, \dots, \bar{r}{i, K})$.
Rather than discarding the reward magnitudes by supervising on the hard ranking alone, we convert the scores into a soft target distribution over workers via a softmax transform,
$ p_i(j) ;=; \frac{\exp(\bar{r}{i, j}/\tau)}{\sum{j'=1}^{K} \exp(\bar{r}_{i, j'}/\tau)},\tag{1} $
with temperature $\tau$. We use this distribution as supervision, training both the lightweight selection head and the singular-value scales in the orchestrator backbone to minimize:
$ \mathcal{L}_{\mathrm{SFT}}(\theta)
\frac{1}{|\mathcal{D}|} \sum_{i=1}^{|\mathcal{D}|} \mathbb{D}{KL}!\left(p_i(\cdot) , |, \pi{\theta}(\cdot \mid q_i) \right),\tag{2} $
Learning from a soft performance distribution, rather than classifying a single best label, gives the orchestrator a richer training signal and makes its selection more robust when several workers are similarly capable. Because supervision is derived directly from measured worker performance and does not require generation from the orchestrator itself, this stage provides an efficient and stable initialization for the subsequent evolutionary optimization stage.
3.1.3 Applying Evolutionary Strategies on End-to-end Tasks
After supervised fine-tuning on single-step tasks, we further optimize $\textsc{Fugu}$ with evolutionary strategies on end-to-end tasks. While single-step tasks provide clean correctness signals and broad coverage across domains, they do not fully capture how models are used in real interactive systems. We therefore collect real-world multi-turn trajectories from different coding-assistant environments like Claude Code, Codex, and OpenCode, and construct end-to-end tasks that involve repository context, iterative editing, tool calls, execution feedback, and final task completion. This stage expands the training distribution from static questions to agentic workflows that better reflect production usage. Formally, for an end-to-end task $q_i$ drawn from a collection $\mathcal{E}$, the orchestrator interacts with the harness over a sequence of turns. Let $s_t$ denote the interaction state at turn $t$, i.e., the task together with the transcript of prior turns, tool calls, and execution feedback. At each turn, $\textsc{Fugu}$ computes a hidden state $h(s_t)$ and selects a worker $a_t \sim \pi_{\theta}(\cdot \mid s_t)$ with $\pi_{\theta}(a \mid s) \propto \exp!\big(f_{\theta}(h(s))_a\big)$, yielding a trajectory $\tau = (s_0, a_0, s_1, a_1, \dots, s_T)$ of horizon $T \le B$, where $B$ is a fixed turn budget. A terminal reward $R(\tau) \in {0, 1}$ records whether the task is ultimately completed.
These end-to-end trajectories also reveal differences between agents that are not visible from performance scores alone. Some models may be strong at high-level reasoning or proposing implementation plans, but less reliable when operating tools, editing files, or reacting to environment feedback. Others may be less impressive on standalone reasoning benchmarks but more robust inside an interactive coding harness. Training on these trajectories therefore helps $\textsc{Fugu}$ learn a more practical notion of worker capability, one that accounts not only for answer quality in isolation, but also for how well each worker performs when embedded in a scaffold with tools and feedback.
For this stage, we use sep-CMA-ES, following the optimization approach of Trinity. Concretely, we directly maximize the expected terminal reward of the orchestrator,
$ J(\theta) ;:=; \mathbb{E}{\tau \sim \pi{\theta}}!\big[R(\tau)\big],\tag{3} $
over end-to-end task outcomes. sep-CMA-ES maintains a parent parameter vector $\theta_t$, a step size $\sigma_t$, and a diagonal covariance $D_t$, and at each iteration samples a population of $\lambda$ candidates,
$ \theta^{(k)} ;=; \theta_t + \sigma_t, D_t, z^{(k)}, \qquad z^{(k)} \sim \mathcal{N}(0, I), \quad k = 1, \dots, \lambda.\tag{4} $
Each candidate's fitness $J(\theta^{(k)})$ is estimated by averaging the terminal reward over replicated end-to-end runs, and the top- $\mu$ candidates are recombined via fitness-weighted averaging to form the next parent,
$ \theta_{t+1} ;=; \theta_t + \sigma_t, D_t \sum_{j=1}^{\mu} w_j, z_{j:\lambda},\tag{5} $
where $z_{j:\lambda}$ is the perturbation of the $j$-th best candidate under the fitness ranking and ${w_j}_{j=1}^{\mu}$ are the recombination weights. Evolutionary optimization is well suited here because the SFT stage already places the orchestrator parameters in a strong region of the search space, allowing the evolutionary search to refine routing behavior at a finer granularity ([38]). It also lets us optimize end-to-end task outcomes directly, including sparse or noisy success signals, without constructing reliable ranking labels for complex multi-turn trajectories. Empirically, we find this stage to be substantially more stable than supervised fine-tuning on the additional end-to-end tasks and better suited to settings where correctness depends on the full interaction between the worker model, the harness, tools, and environment feedback.
3.2 $\textsc{Fugu-Ultra}$: Prioritizing Performance
$\textsc{Fugu-Ultra}$ prioritizes unlocking the maximum capability from an LLM agent team and is designed for the most complex user workloads, where absolute answer quality takes precedence. $\textsc{Fugu-Ultra}$ builds on the Conductor ([39]), adding novel extensions to accommodate long-horizon function-calling and multi-agent workflows through adaptive agent memory.
3.2.1 Conducting an Orchestra of Models
We begin with a brief overview of the Conductor framework powering $\textsc{Fugu-Ultra}$ before detailing the extensions to accommodate multi-agent function calling and shared memory. The Conductor framework leverages reinforcement learning for training a language model to prompt-engineer and coordinate a set of powerful LLM agents. The Conductor outputs full agentic workflows as natural language that divide an input task, allocate arbitrary subtasks, and define targeted communication strategies to best make use of the agents' complementary capabilities.
The Conductor task. The Conductor's objective is to solve tasks indirectly by designing agentic workflows specific to any input question $q_i$. Each agentic workflow is defined as a sequence of workflow steps whose final output is returned as the actual Conductor response $o_i$. Each step specifies a string with a natural-language subtask, an integer id corresponding to the assigned worker agent responsible for performing that subtask, and an access list indexing which subtask solutions from the previous steps to include in the worker's context. This design lets the Conductor freely craft tailored subtasks and communication strategies across its workers, allowing the specification of agentic workflows ranging from simple best-of-N and sequential chain-like topologies to arbitrary parallelizable tree-structured approaches, harnessing the individual strengths and synergies of its highly-specialized agents.
Workflow execution and learning dynamics. Each agentic workflow the Conductor outputs is executed by prompting the specified worker agent with their assigned subtask. In each workflow step, the worker's context includes the sequence of previous subtasks and corresponding responses defined in the access list. Analogously to the traditional RL framework, the reward $r_i$ for each response from the Conductor model is determined by two progressive conditions:
- The Conductor format condition, setting $r_i$ to 0 for responses from which the lists of subtasks, worker agents, and access lists cannot be parsed.
- The Conductor correctness condition, setting $r_i$ to 1 if the final output from executing a well-formatted agentic workflow $o_i$ matches the solution $s_i$ and to $0.5$ otherwise.
We trained $\textsc{Fugu-Ultra}$ with GRPO ([40]):
$ J(\theta)= \mathbb{E}{q\sim D, , {o}^G_1\sim\pi\theta(\cdot\mid q)} \left[\frac{1}{G}\sum_{i=1}^G \Big(\min!\big(r_i A_i, ; \mathrm{clip}(r_i, , 1-\epsilon, , 1+\epsilon), A_i \big) -\beta, \mathbb{D}{\mathrm{KL}}(\pi\theta, |, \pi_{\text{ref}}) \Big) \right],\tag{6} $
using the grouped completions to compute a Monte-Carlo advantage function ([41]):
$ A_i=\frac{r_i-\mathrm{mean}({r_1, \dots, r_G})}{\mathrm{std}({r_1, \dots, r_G})},\tag{7} $
where $r_i$ is our specific Conductor reward. The Conductor framework also allows specifying the orchestrator itself as a worker agent, further extending the range and complexity of possible coordination topologies.
Training $\textsc{Fugu-Ultra}$ with this recipe, we observe the emergence of problem decompositions and prompt-engineered subtasks that leverage the differing strengths and skills of each agent in the team, alongside communication topologies that leverage both independent work and agent-to-agent collaboration according to the task requirements.
3.2.2 Function Calling Agentic Workflows
Function calling within a multi-agent workflow poses a unique additional challenge in terms of orchestration memory. For a generic, single-agent system, the function call loop ([42, 43, 44]) requires no additional persistent memory on the part of the agent, since the message transcript carries the full context and there is only one possible recipient to receive that context.
In our $\textsc{Fugu-Ultra}$ system, however, any agent may make a function call at any time. Thus, to honor the function call loop and enable any agent to interact freely with the user environment, the system must therefore retain which agent emitted every call, along with where that agent sits in the overall Conductor workflow, such that each agent's function call loop is correctly routed to the corresponding agent and the inter-agent communication topology is maintained. This therefore requires our orchestrator to track the Conductor's workflow state containing the selected models, communication topology, and assigned subtasks for the corresponding user query throughout a user-agent interaction.
Intra-workflow agent isolation.
In order to fully leverage the differing specialties of the agent team, we isolate each agent's function calling trajectory from one another. This intra-workflow isolation is necessary to prevent orchestration collapse, whereby the first agent to interact with the environment sets the trajectory for all future agents, leading to redundant contributions from future agents as they are steered to follow the path initialized by the first agent. That is, an agent observes the actions and outputs of another agent only through the access list, as proscribed by $\textsc{Fugu-Ultra}$, otherwise observing a transcript history preserving only their own actions. This prevents conditioning subsequent agents' solution trajectories on the work done by previous agents, allowing each agent full freedom to determine its own solution path as instructed by the subtask assigned to it by our model.
Persistent shared memory.
While intra-workflow isolation is necessary to prevent orchestration collapse, complete isolation from all function calling over a multi-turn conversation history is likewise suboptimal. This is because agents must retain some memory of their interactions with the environment in order to not make redundant, repeated tool calls to rediscover the same artifacts and accrue the necessary background context to solve the required task. To resolve this tension, we permit inter-workflow shared memory across agents, which allows agents to observe tool calling from previous workflows. Thus, we grant agents full memory over the ongoing state of a multi-turn conversation, which provides the required background context to each agent, while isolating the agents from one another within the current workflow, but for the context determined necessary by $\textsc{Fugu-Ultra}$ 's designated communication topology described by the access list.
3.2.3 Training Setup
To train $\textsc{Fugu-Ultra}$, we scale the Conductor's reinforcement learning approach starting from a pre-trained checkpoint of a regular language model. Ultra is instructed to design agentic workflows of up to 5 steps using a diverse pool of frontier LLMs that includes Gemini-3.1-Pro ([45]), Claude-Opus-4.8 ([46]), and GPT-5.5 ([47]). For multi-turn tasks, any agent is permitted unlimited interaction with the user environment. We train using our Conductor reward detailed in Section 3.2.1 with GRPO and without any KL divergence penalty.
Our training dataset is a mixture of both publicly available data and expert-designed end-to-end environments simulating real agent-user interactions. These end-to-end tasks were also used in the development of our previous model (Section 3.1.3) and help expose different kinds of real-world specializations across agents, such as expertise in math, science, engineering, factual knowledge and recall, numerous tool-usage scenarios, conversational dialog, multi-turn context retention, and planning. Large-scale training on these tasks produces substantial gains in $\textsc{Fugu-Ultra}$, boosting its ability to discern the expertise and skills across the worker pool and how to optimally combine them.
4. Capabilities
Section Summary: This section evaluates the capabilities of Sakana Fugu models through standardized benchmarks covering coding, scientific reasoning, and other skills, as well as custom tasks designed to reflect realistic uses. It shows that Fugu achieves top results by intelligently orchestrating multiple leading AI models like Claude and GPT, often surpassing the performance of any single one through adaptive coordination. The analysis also examines how Fugu adjusts its strategies across domains and identifies effective ways to organize agent teams.
In this section, we report the capabilities of Sakana Fugu, as measured by performance on a diverse set of challenging benchmarks (Section 4.1), as well as expert-designed tasks (Section 4.3), which were hand-crafted to be representative of real and challenging use cases for Sakana Fugu. We additionally analyze the orchestration adaptivity of Sakana Fugu across domains (Section 4.2), before concluding with findings on optimal coordination strategies and agent topologies (Section 4.4).
4.1 Benchmark Performance
We first evaluate Sakana Fugu on a broad suite of standardized benchmarks designed to measure core agentic capabilities under reproducible conditions. These benchmarks cover tasks requiring reasoning, tool use, coding, long-horizon problem solving, and domain-specific expertise, providing a quantitative view of Fugu's performance relative to frontier baselines.
4.1.1 Evaluation setup
We tested the capabilities of the Sakana Fugu models on contemporary, challenging benchmarks unseen by our models during training to evaluate their generalization capabilities. For agentic coding and software engineering, we use SWE Bench Pro ([48]) and Terminal Bench 2.1 ([49]). To best expose the underlying capabilities of Fugu, we use minimal evaluation harnesses such as Mini-SWE-agent ([50]) and Terminus 2 ([51]). To evaluate scientific knowledge, we used GPQA Diamond ([52]), the set of diamond difficulty questions on natural science taken from the Graduate-level Google-proof Q&A benchmark. For multidisciplinary reasoning, we used Humanity's Last Exam ([53]), including multimodal samples, and evaluated without tools. To evaluate competitive programming, we used the latest available split of LiveCodeBench ([54]) (problems taken from January through April 2025) and the latest publicly available and gradable split of LiveCodeBench Pro ([9]) (problems taken from quarter 2 of 2025). For additional coding evaluation with scientific application, we used SciCode ([55]) with background provided. For multimodal graphical understanding, we used Charxiv Reasoning ([56]), and for conversational dialog, we used $\tau^3$ Banking with GPT-5.2 as the user simulator. Finally, for long context retrieval and reasoning, we used needle-in-a-haystack MRCRv2 ([57]) and long document information retrieval benchmark Long Context Reasoning ([58]). See Appendix A for further details on benchmark evaluation configuration.
Sakana Fugu models orchestrate a large pool of diverse models that includes state-of-the-art (SOTA) frontier LLMs such as Gemini-3.1-Pro ([45]), Claude-Opus-4.8 ([46]), and GPT-5.5 ([47]). Therefore, to assess Fugu's ability to harness and amplify the skills of its individual workers, we evaluate Fugu against these same models, with the same maximum reasoning effort configured.
::: {caption="Table 1: Model Card. Fugu models, through intelligent orchestration of leading frontier models, harness and amplify their differing skillsets to achieve new SOTA capabilities. Best scores are in bold and second-best are underlined. Baseline scores are provider-reported wherever available. Additional details in Appendix A."}
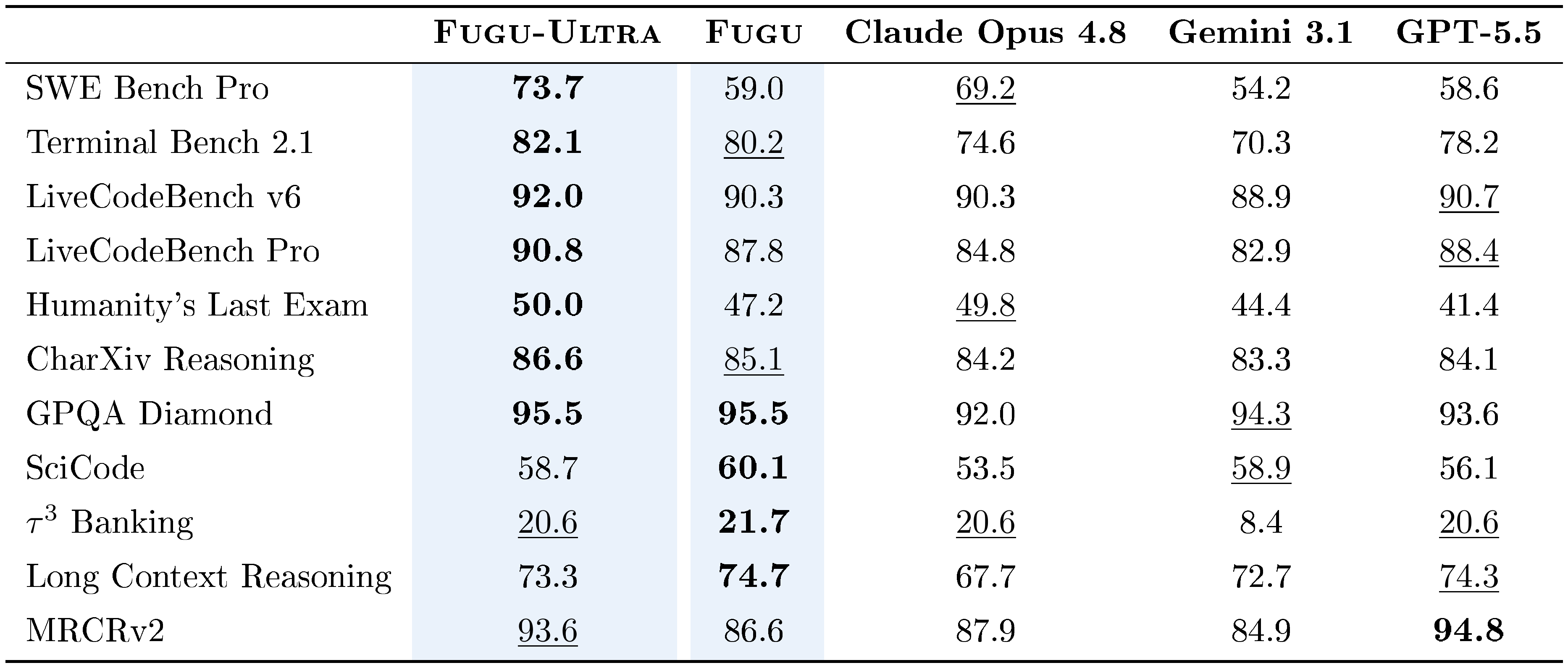
:::
4.1.2 Agentic Coding
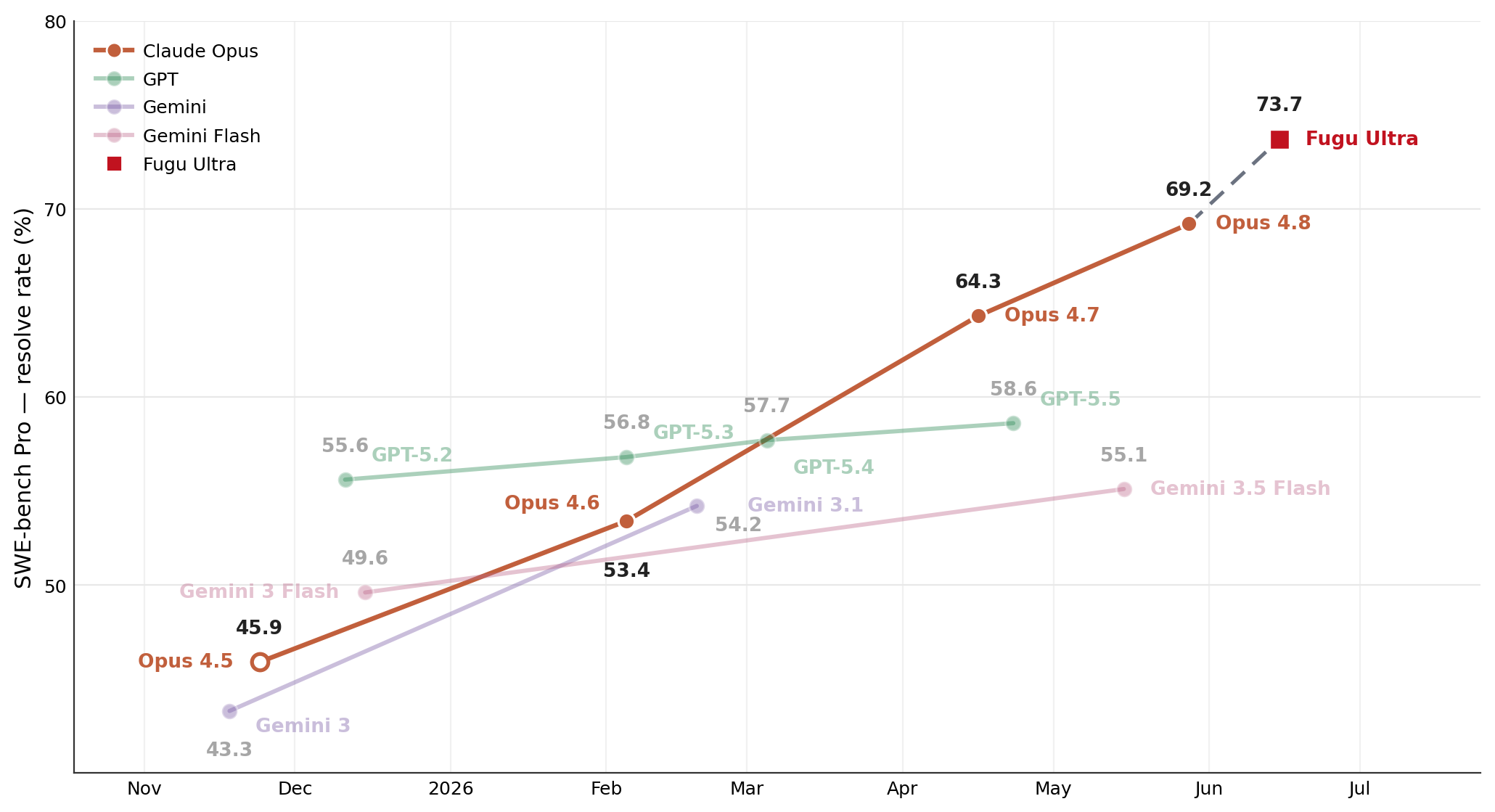
We find that $\textsc{Fugu-Ultra}$ excels in agentic coding and software engineering, achieving state-of-the-art performance in both SWE Bench Pro and Terminal Bench 2.1, with a substantial leap forward in performance across both benchmarks. The gains in both benchmarks, both in the range of 5-6% relative to the next best performer, are consistent with entire generational improvements across these frontier providers, as shown in Figure 3.
We additionally note that excelling across both benchmarks illustrates $\textsc{Fugu-Ultra}$ 's fine-grained adaptivity, achieving and surpassing individual SOTA models in our agentic coding tasks, outperforming Claude-Opus in SWE Bench Pro and GPT in Terminal Bench. This demonstrates $\textsc{Fugu-Ultra}$ successfully learns the granular capabilities of the agent team, including how they differ and how they can be optimally combined, to excel itself as an effective agent beyond the best of its individual workers.
$\textsc{Fugu}$ 's performance in Terminal Bench additionally reveals how per-step adaptivity can yield optimal performance. Despite $\textsc{Fugu}$ only selecting one model for each input, we find that $\textsc{Fugu}$ can also substantially outperform the state-of-the-art GPT-5.5 in this task. Analyzing the trajectories, we find $\textsc{Fugu}$ alternates between GPT-5.5 and Claude-Opus-4.8 throughout the progression of the solution, calling in Claude-Opus-4.8 at particular, critical debugging points. Additional qualitative analysis on optimal trajectories is found in Section 4.4.
4.1.3 Scientific Reasoning
We additionally find that Sakana $\textsc{Fugu}$ models excel in scientific reasoning, with both $\textsc{Fugu}$ and $\textsc{Fugu-Ultra}$ achieving SOTA performance in GPQA-Diamond. These results consolidate our models'ability to discern scientific expertise from their agent pool and indeed surpass the best-in-class performance of Gemini-3.1-Pro through selectively drawing on the complementary skillsets of additional models. A consistent pattern we observed was that our models recognized GPT's dominance in math and physics and applied GPT in targeted settings where mathematical computation was required. This fine-grained adaption to draw on GPT's mathematical expertise allowed our Fugu models to attain new levels of performance in scientific reasoning.
Sakana Fugu models also exhibit such marked performance gains in scientific reasoning, even surpassing the Mythos Preview and Fable 5 ([59]) model class, which is not publicly available (see Figure 4). Such a finding offers additional evidence of one of our central motivations for training Sakana Fugu, which is that intelligent orchestration ought to be an additional axis to scale performance without scaling training compute. Through targeted selection and application of existing frontier models, our models attain performance beyond both generational upgrades and even entire model classes.
4.2 Domain Adaptivity
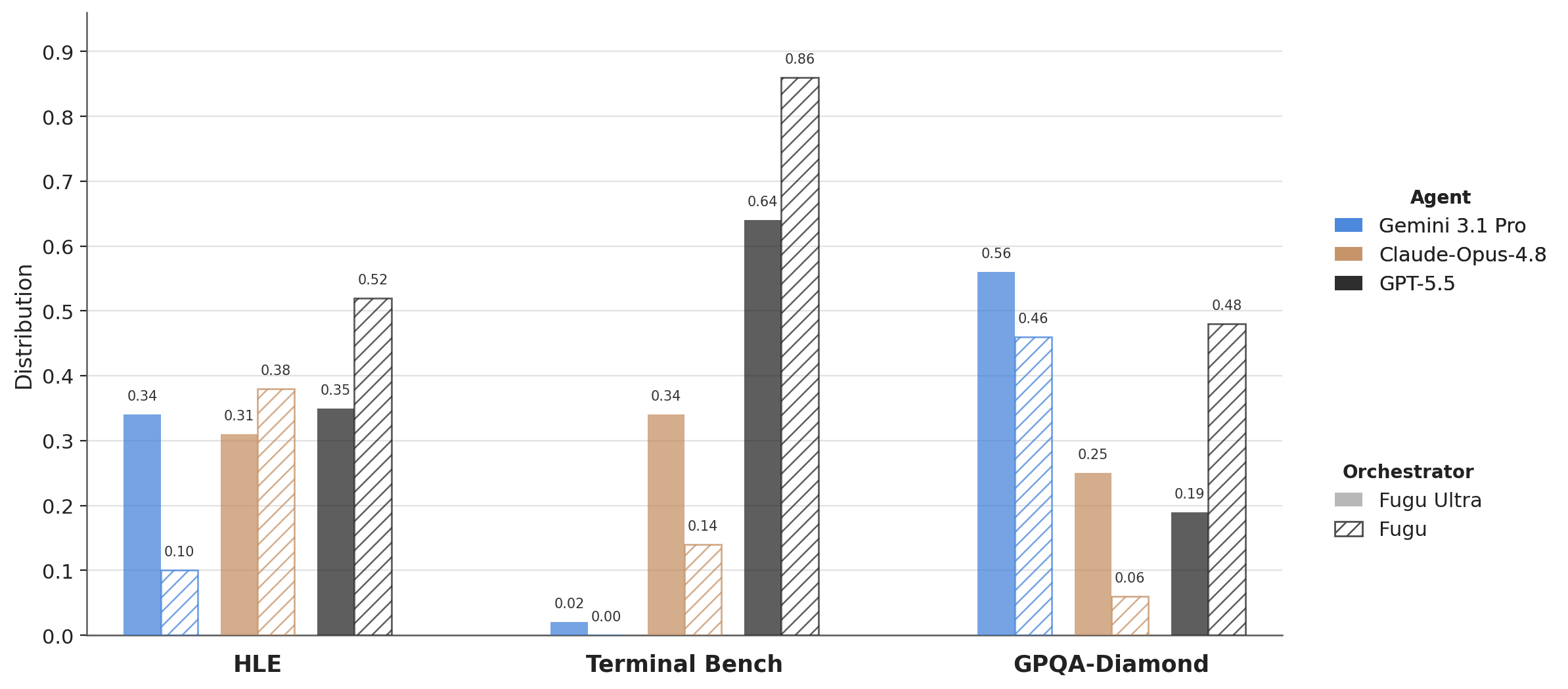
We view adaptivity as a hallmark feature of an intelligent orchestrator. Throughout our evaluations, we find that Fugu models show consistent and varied adaptivity across their routing distributions, demonstrating the capability of our models to accurately learn the differing skills across the model team and then deploy these models according to those specializations.
Across domains, we observe deployed distributions agreeing with our SOTA capability priors. For example, in Figure 5, we observe the agent distribution peaks on GPT-5.5 in Terminal Bench for both $\textsc{Fugu}$ and $\textsc{Fugu Ultra}$, for which GPT-5.5 exhibits SOTA performance. Likewise, in GPQA-Diamond, where Gemini-3.1-Pro is the leading model, both Fugu models focus their orchestration around Gemini. In Humanity's Last Exam, which is by nature multidisciplinary, we observe ahighly balanced distribution over the three agents in $\textsc{Fugu-Ultra}$. Per-category, however, we observe that math questions are predominantly handled by GPT-5.5, again echoing widespread findings on GPT's expertise in math. Likewise, chemistry and biology questions are predominantly routed to Gemini, mirroring its SOTA scientific capabilities.
4.3 Performance Beyond Benchmarks
To complement aggregate benchmark scores, we evaluate Sakana Fugu on qualitative, end-to-end tasks that stress real agentic behavior such as long-horizon research, program synthesis, optimization, CAD generation, among others. In these examples we compare Sakana Fugu models against three frontier baselines, namely Gemini 3.1 Pro (high), Opus 4.8 (max), and GPT 5.5 (xhigh). We anonymize these baselines as Model A, Model B, and Model C in the descriptions, and we intentionally vary the mapping across examples to keep the discussion focused on behavioral differences rather than model identity or brand-specific expectations. To ensure fair comparisons, we use identical settings for all the models in each experiment, so that any differences reflect model behavior rather than differences in tooling or orchestration infrastructure. As an AI research lab, we show three research related examples in this section, and present more results in Appendix B.
4.3.1 Autonomous LLM Training Optimization on AutoResearch
We evaluate whether $\textsc{Fugu-Ultra}$ can improve autonomous ML research workflows relative to strong single-model agents. The task is drawn from AutoResearch ([60]): an agent iteratively edits a small GPT training pipeline, executes each proposed change, and retains modifications that reduce validation bits-per-byte (BPB; lower is better). This benchmark is well suited to our setting because success depends not on a single coding step, but on sustained exploration of optimizer settings, batching, architecture scale, and schedule choices over many sequential experiments.
All systems use the same AutoResearch scaffold, dataset, evaluation protocol, and per-experiment compute budget on a single H100 GPU. Each agent is run for 123 autonomous experiments (${\sim}$ 14 hours total wall-clock time per seed). We compare $\textsc{Fugu-Ultra}$ against three frontier-model baselines, denoted Model A, Model B, and Model C, each evaluated with maximum reasoning effort. Each system is evaluated over three independent random seeds. The only methodological difference beyond the shared scaffold is the agent backend: the baselines are single frontier models acting alone, whereas $\textsc{Fugu-Ultra}$ orchestrates multiple strong models within a unified research loop.
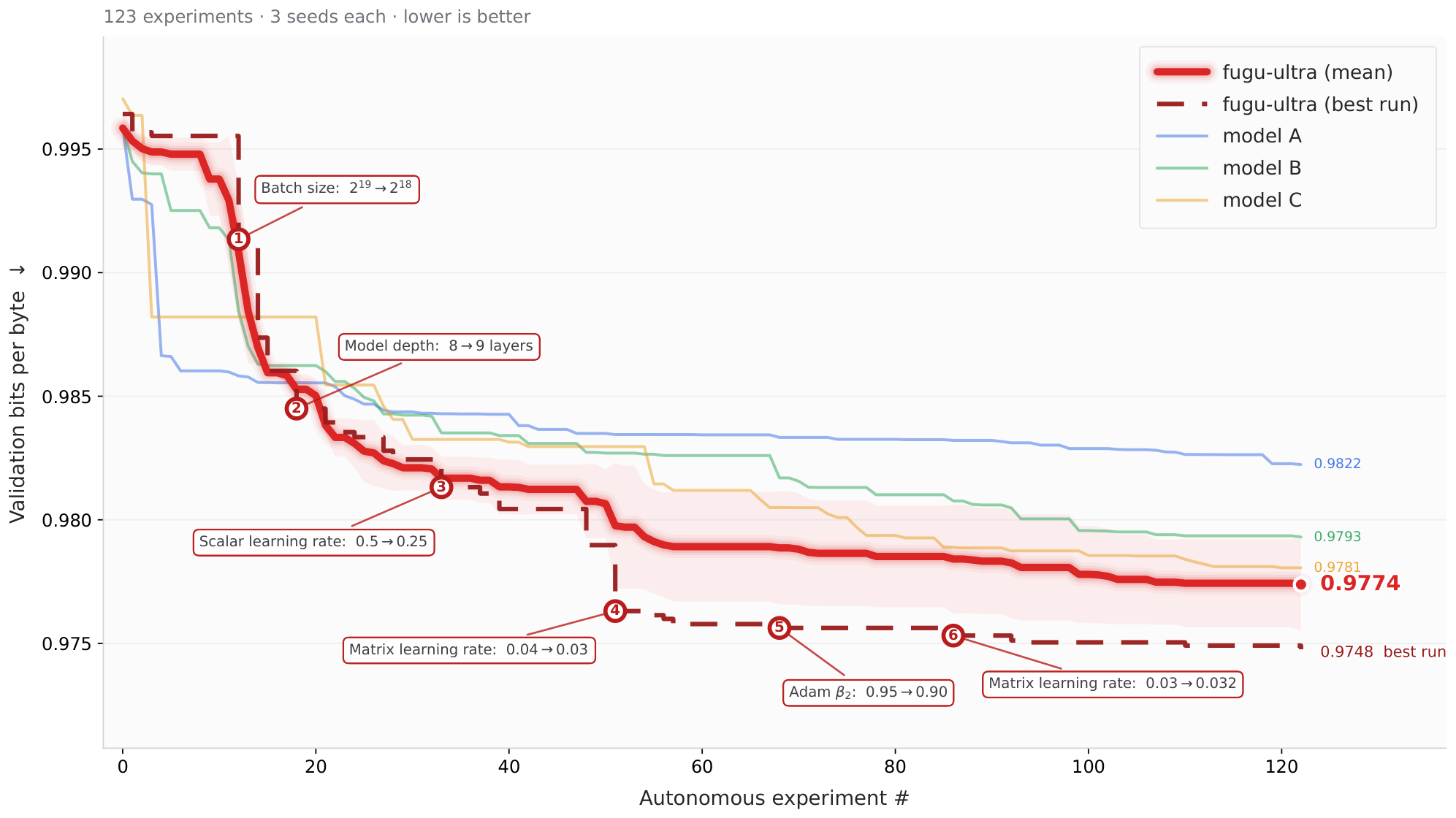
Figure 6 summarizes the optimization trajectories. Solid lines report the mean best validation BPB across seeds (shaded bands: $\pm 1$ standard deviation); the dashed line shows the best single-seed run for $\textsc{Fugu-Ultra}$ only. Baseline trajectories are shown as mean $\pm$ std so the figure emphasizes cross-seed trends without cluttering the plot with four additional best-run curves. Table 2 reports the corresponding endpoint numbers for all systems, including each baseline's best single-seed result.
\begin{tabular}{lcc}
\toprule
Agent & Mean best val. BPB & Best single-seed run \\
\midrule
\textsc{Fugu-Ultra} & 0.9774 $\pm$ 0.0019 & \textbf{0.9748} \\
Model C & 0.9781 $\pm$ 0.0011 & 0.9766 \\
Model B & 0.9793 $\pm$ 0.0025 & 0.9758 \\
Model A & 0.9822 $\pm$ 0.0017 & 0.9799 \\
\bottomrule
\end{tabular}
At the end of the 123-experiment budget, $\textsc{Fugu-Ultra}$ achieves the lowest mean validation BPB (0.9774 $\pm$ 0.0019), outperforming Model C (0.9781 $\pm$ 0.0011), Model B (0.9793 $\pm$ 0.0025), and Model A (0.9822 $\pm$ 0.0017). On best single-seed runs (Table 2), $\textsc{Fugu-Ultra}$ reaches 0.9748 BPB, compared with 0.9766 (Model C), 0.9758 (Model B), and 0.9799 (Model A), corresponding to absolute gains of 0.0018, 0.0010, and 0.0051 BPB, respectively. These gains are modest in absolute magnitude, as expected for a highly optimized training pipeline, but they are consistent across both mean and best-run metrics and persist throughout the optimization process rather than emerging at a single checkpoint.
Two patterns are especially informative. First, $\textsc{Fugu-Ultra}$ is competitive early in the run and pulls ahead after mid-training, suggesting that orchestration is most valuable once the search space shifts from coarse configuration changes to finer optimizer and schedule tuning. Second, although Model B attains a strong best-seed result, its higher cross-seed variance in Table 2 indicates less reliable optimization; $\textsc{Fugu-Ultra}$ improves both peak performance and consistency. Taken together, these results provide an initial demonstration that multi-model orchestration can outperform any individual frontier agent on an agentic training-optimization benchmark, supporting the broader claim that $\textsc{Fugu-Ultra}$ is effective for autonomous ML research workflows.
4.3.2 Classical Japanese Letter Reading Order
Recovering the reading order of classical Japanese kana letters (kana-shōsoku) remains an open problem, with no established method and no public benchmark. To our knowledge no dataset for this task exists; we therefore construct our own, 25 pages hand-annotated by a domain expert, for this experiment. Unlike printed or even ordinary handwritten text, these letters are composed in the chirashigaki ("scattered writing") style: the characters are deliberately spread across the page at varying sizes and positions. Recovering the reading order is a task that even trained readers of classical Japanese find demanding. This is exactly the regime where data-driven learning does not apply, not because a learned model would be weak, but because the training data does not, and cannot readily, exist.

: Table 3: Reading-order recovery on 25 expert-annotated kana letters; mean NED over all pages (higher is better; a seed heuristic scores $0.116$). Every model is improved by the same beam search, so the result tracks the model driving it: $\textsc{Fugu-Ultra}$ is best, ahead of every frontier baseline, though the strongest frontier (Model A) is competitive. A third frontier model did not complete the search at high effort. Models A and B are anonymized frontier baselines.
| Model | Mean NED |
|---|---|
| Fugu-Ultra | 0.776 |
| Model A | 0.642 |
| Fugu | 0.473 |
| Model B | 0.449 |
| Model C | No completed run |
| Baseline | 0.116 |
A domain expert can nonetheless state the rules they read by: characters are grouped by relative size, separated into distinct vertical blocks. The hard part is turning this tacit, qualitative rule set into a working algorithm. We test whether $\textsc{Fugu}$ models can perform that translation directly. Rather than train a model, $\textsc{Fugu}$ writes a reading-order predictor (a function over the detected character bounding boxes that returns their reading order) and improves it through test-time scaling. In this case we used beam search: at each iteration the model proposes new predictor variants, each is executed and scored, and the best are carried forward and mutated again over many rounds. The objective is normalized edit distance (NED) against the annotated reading order.
The same beam search drives every model, and the outcome tracks the model driving it (Table 3). Across all 25 pages, $\textsc{Fugu-Ultra}$ produces the best predictor, with a mean NED of 0.776, ahead of every frontier baseline. The strongest frontier baseline reaches 0.642, $\textsc{Fugu}$ 0.473, and the weaker frontier baseline 0.449 (a seed heuristic scores 0.116). Figure 7 shows one page on which $\textsc{Fugu-Ultra}$ follows the expert's traversal across the scattered characters while the frontier predictors do not. With the search held fixed, $\textsc{Fugu-Ultra}$ is the strongest engine, ahead of every frontier model, on a task where the model, not the search, sets the ceiling.
4.3.3 CAD Generation
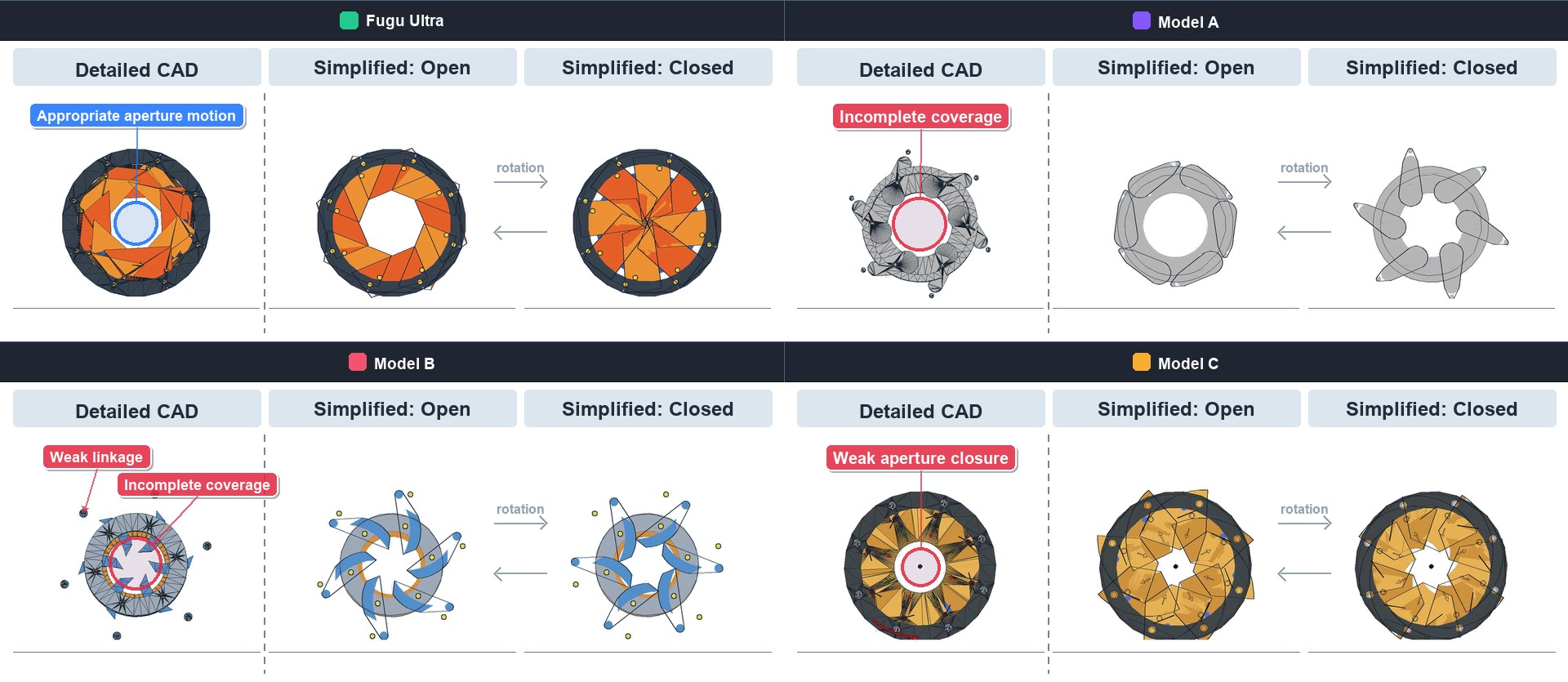
In this experiment, we evaluate how well each model can generate CAD with a working mechanism from a text instruction. We chose a mechanical iris, the mechanism used in a camera aperture. This task requires more than a static circular part. The model must produce several blades, outer pins, a rotating ring, and a central opening whose geometry stays consistent as the iris opens and closes. Each model generated its design in Codex using the CAD skill ([61]), and we qualitatively evaluated the resulting STEP files. To check the dynamic behavior, we added a rule-based open-close animation driven by the blade pin positions.
Figure 8 shows the CAD view and the simplified view in both the open and closed states. $\textsc{Fugu-Ultra}$ generated a structure in which each blade rotates around its outer pin and smoothly widens or narrows the central opening. The other models were less complete as iris mechanisms: their blades did not fully cover the center, their outer links were mechanically weak, or the opening did not close far enough. We note that the results can vary with the prompt and across trials, but $\textsc{Fugu-Ultra}$ consistently produced qualitatively strong results.
4.4 Optimal Strategies and Topologies
We conclude with findings on performant orchestrative strategies, demonstrating granular application of agent expertise to achieve the high performance reported throughout this section.
Debate and aggregation.
A core benefit of $\textsc{Fugu-Ultra}$ 's dynamic workflows is that $\textsc{Fugu-Ultra}$ can produce any coordination topology describable in natural language on a per-question basis. In knowledge-intensive domains, multi-round debate and tree topologies are powerful strategies to maximize the collective knowledge from an agent team. We find that such strategies indeed arise in domains requiring niche or specialized factual knowledge. For instance, in Humanity's Last Exam, when $\textsc{Fugu-Ultra}$ was tasked to determine the outcome of a specific game state in Heroes of Might & Magic III – a question testing both knowledge and application of game mechanics with precise trivia knowledge – $\textsc{Fugu-Ultra}$ produced a tree structure with Gemini-3.1-Pro at the head of the tree tasked to synthesize two independent attempts. Usage of Gemini as the aggregator made use of Gemini's SOTA performance in niche factual recall, however, further noteworthy, $\textsc{Fugu-Ultra}$ also used a second instance of Gemini alongside GPT in the two leaf positions to attempt the problem independently. In this task, both leaf-agents produced partially correct answers, with Gemini incorrectly inferring a base defense statistic and GPT incorrectly applying a game-mechanical rule, however the Gemini-as-aggregator correctly identified the partial correctness in either answer and synthesized a fully correct answer. In a second example, when tasked to compute the Crowley–Nordström invariant of the Calabi–Yau link defined by a given weighted-homogeneous polynomial, $\textsc{Fugu-Ultra}$, leveraged the mathematical expertise of GPT at the root of the tree with both Gemini and Opus at leaf positions. Here, GPT-as-aggregator resolved a disagreement between Gemini and Opus over a single integer in the solution by rederiving the spectral numbers from the spectral generating function, locating the exact error and crux of the question's difficulty, and solving the question.
These simple examples are revealing in two ways. First, once again, we observe granular adaptivity on a per-question basis, with $\textsc{Fugu-Ultra}$ utilizing tree-like topologies in both tasks while adapting its aggregator between Gemini for a trivia-heavy task and GPT for a math-heavy task, leveraging their individual expertise in the key aggregation role. Second, dynamic adaptation of an aggregator role is precisely the kind of adaptation unavailable to existing multi-agent systems ([62, 63]), which necessitate a fixed model to always act as a final synthesizer, regardless of whether that model is suitable for the task or not. Such systems are thereby bottlenecked by that rigidity, and typically struggle to surpass the performance of the aggregator for tasks outside of the aggregator's expertise. $\textsc{Fugu-Ultra}$ 's adaptivity sidesteps this issue, and is key to unlocking the capabilities discussed throughout this section.
Build and debug.
In multi-turn agentic tasks, one performant strategy we observe is GPT being deployed as a builder, making use of its impressive performance in agentic coding, with Opus being deployed at crucial moments to reverify quality and expose vulnerabilities, making use of Opus'expertise in debugging. When $\textsc{Fugu-Ultra}$ was tasked to build a PyPI server hosting a vectorops package in Terminal Bench 2.1, $\textsc{Fugu-Ultra}$ first deployed GPT-5.5 to build the server and confirm the server's reachability after it finished. After GPT finished the build, Opus was then deployed to enumerate all concrete risks in the GPT's implementation, for which Opus noticed 1) GPT used a plain static http.server rather than a pypiserver, 2) the hand-built wheel was built via zipfile, which was fragile and 3) GPT had failed to properly manage the Debian-slim environment, which would lead to several commands failing. Noticing these issues, Opus then discovered GPT's reachability check was erroneous and had come from an orphaned http.server. Relaying these findings back to GPT enabled GPT to complete the build successfully.
For $\textsc{Fugu}$, we similarly observe select application of Opus's debugging expertise to expose and correct vulnerabilities in GPT's build. In Terminal Bench 2.1's merge-diff-arc-agi-task, $\textsc{Fugu}$ allowed GPT to build out the scaffold, fetch the two bundles into the branches, and perform the merge in algo.py. At the point GPT recieved the merge conflict back from the environment, $\textsc{Fugu}$ then swapped in Opus, which then both rechecked the scaffold and resolved the merge initiated by GPT, which then revealed the required input-output mapping as originating from neither branch, prompting Opus to then correctly infer the solution from first principles. This per-step alternation between GPT-as-builder and then Opus-as-debugger was critical to allowing $\textsc{Fugu}$ to access performance beyond either model through merging their fine-grained and complementary capabilities.
In other agentic coding tasks, we observe $\textsc{Fugu-Ultra}$ alternating Opus into the lead engineer role with GPT probing for weaknesses and offering alternate perspectives. One example of this was during $\textsc{Fugu-Ultra}$ 's solution to a gravitational/teleport instance in SWE Bench Pro, where the model needs to resolve a failed validation error code when a user adds an additional OTP device. $\textsc{Fugu-Ultra}$ deployed Opus to understand the issue and propose a fix, to which Opus tracked the server registration and validation all the way into the TOTP library itself, ultimately leading to a dead end. At this point, $\textsc{Fugu-Ultra}$ then called GPT to re-examine the issue from a clean slate, to which GPT noticed the issue was not a server-side issue at all but a client-side concurrency bug, for which the server error was merely a symptom of a larger, structural bug. GPT then relayed this information back to Opus which duly changed course and identified the proper fix, which was to introduce a single, shared ContextReader to prevent the concurrency bug.
Bringing in a specialist.
Another strategy we observed delivering strong performance was the select usage of additional models when highly specific knowledge was required. To take another example from Terminal Bench 2.1, an interesting instance of this was during $\textsc{Fugu-Ultra}$ 's solution to the feal-differential-cryptanalysis problem. In this problem, the model is tasked to write an attack that recovers a key from a FEAL-like encryption function. Making use of Opus-4.8's expertise in cybersecurity and software engineering, $\textsc{Fugu-Ultra}$ started the task with Opus building a first-pass chosen-plaintext attack. After Opus was satisfied with its attack, $\textsc{Fugu-Ultra}$ then made use of GPT-5.5's mathematical expertise, tasking it to act specifically as a math specialist to re-derive the entire attack from first principles, and in particular trace through the cipher bit-by-bit to derive the differential constant necessary for the attack to succeed and recover the required round subkey. This example illustrates $\textsc{Fugu-Ultra}$ 's ability to recognize the need to combine cross-domain expertise, drawing on cybersecurity, engineering, and math, and efficiently leverage that expertise from within its agent team to solve complex, multi-disciplinary problems.
5. Conclusions
Section Summary: Sakana Fugu is a family of models that act as intelligent coordinators, directing specialized AI systems to handle tasks through adaptive, multi-step workflows rather than relying on any single model. One version emphasizes quick, balanced responses for everyday use, while an Ultra edition prioritizes maximum quality on difficult reasoning or coding problems. The work shows that learning how to combine existing frontier models can expand capabilities in flexible ways and will grow more valuable as new models appear.
We present Sakana Fugu, a family of learned LLM orchestrators that expose multi-agent intelligence through a single model interface. Motivated by the complementary specializations of frontier models and the growing importance of agentic scaffolds, Fugu models learn to construct query-adaptive workflows over a pool of expert LLM workers. We introduced two variants: $\textsc{Fugu}$, which balances performance and latency for everyday interactive use, and $\textsc{Fugu-Ultra}$, which prioritizes answer quality for difficult multi-step tasks. Building on the Trinity and Conductor frameworks, and extending them with production-oriented design choices, Sakana Fugu demonstrates that model orchestration can serve as a practical scaling axis for frontier AI capabilities. Our evaluations and early user experiences suggest that learned coordination can achieve strong performance on challenging coding, reasoning, and agentic tasks while providing a simple interface to a complex multi-agent system.
Looking ahead, we believe learned orchestration will become increasingly important as the ecosystem of frontier models continues to diversify. Because Sakana Fugu composes models at the behavioral level rather than the parameter level, it can incorporate new worker models as they become available, adapt to different user constraints, and support a wider range of deployment and privacy requirements. More broadly, Sakana Fugu points toward a view of AI progress in which capabilities arise not only from scaling individual models but also from learning how specialized models can collaborate. We hope this report encourages further research into collective intelligence, query-adaptive scaffolds, and production-ready multi-agent systems.
Acknowledgments
Section Summary: The authors express gratitude to their colleagues at Sakana AI for regularly using the Fugu models in their work and offering ongoing feedback that helped refine the system. They also thank outside early adopters, whose reports of problems, ideas for improvements, and real-world testing proved especially valuable in making Sakana Fugu better.
We thank all Sakana AI members who adopted Fugu models in their daily workflows and helped shape the system through continuous feedback. We are also deeply grateful to our external early users, whose detailed bug reports, thoughtful suggestions, and demanding real-world use cases were invaluable in improving Sakana Fugu.
6. Authors List and Technical Contributions
Section Summary: The section lists all team members in alphabetical order by first name and notes that, as a small group, most people contributed across many different tasks rather than being limited to one role. It identifies Yujin Tang as the team and project lead, names several core contributors who worked on the model and on infrastructure, and lists additional contributors who provided further support. Only the main areas of contribution are highlighted.
Team members are listed alphabetically by their first name. As a small team, contributions naturally spanned many areas, and most members helped well beyond any single role. We list only the main contributions here.
Team & Project Lead: Yujin Tang
Core Contributors (model): Edoardo Cetin, Jinglue Xu, Qi Sun, Stefan Nielsen, Vincent Richard
Core Contributors (infrastructure): Haruto Goda, Iaroslav Tymchenko, Nhan Nguyen
Contributors: Hyunin Lee, Mari Ashiga, Shashank Kotyan, So Kuroki, Tarin Clanuwat
Appendix
Section Summary: The appendix describes the precise setups, software versions, resource limits, and scoring rules applied when testing models on a wide range of benchmarks, from software-engineering and coding challenges to science, math, and long-context retrieval tasks. It explains adjustments made to avoid errors, ensure fair comparisons with provider-reported baselines, and handle edge cases such as missing tools or outdated packages. A follow-up experiment shows that the Fugu models, unlike most frontier baselines, could generate reliable, near-optimal Rubik’s-cube-solving code in a single attempt.
etocdepthtag.tocmtappendix etocsettagdepthmtchapternone etocsettagdepthmtappendixsubsection
A. Additional Evaluation Configuration Details
SWE Bench Pro.
We set the max turns to 1000, effectively disabling any turn cap and allowing the model to work until completion. We report results using Mini-Swe-Agent. We additionally tested our model through EvalScope's default configuration (v1.8.1) with resource limit set to 32GB RAM, 4 CPU, and using the toolcalling harness, and found consistent results. All baseline results are provider-reported.
Terminal Bench 2.1.
Results are obtained using the latest EvalScope(v 1.8.1) default configuration with 500 max turns. We use the Terminus 2 harness and use either provider-reported results (when results are available for Terminus 2) or the Terminal Bench leaderboard from tbench.ai.
LiveCodeBench v6.
We run the evaluation using the most up-to-date split, January-April 2025, which consists of 175 questions. We patched EvalScope's execution utility to add a buffer attribute to sys.stdin, allowing models to read input via sys.stdin.buffer.read(). This prevents legitimate solutions raising attribute errors. We ran all baselines with five retries.
LiveCodeBench Pro.
We run the evaluation text-only and without tools. Occasional LiveCodeBench Pro samples include image URLs in the footnotes, however we choose not to pass any web fetch tools to the models to allow them to fetch these URLs, relying only on the problem description in the main body of the problem. We use the 2025 quarter 2 split, which is the most recent publicly available and gradable split. We run all baselines with five retries on timeouts or max token exhaustion.
Humanity's Last Exam.
We run the evaluation with the full 2500 samples, including multimodal samples, and without providing tools to the models. All baseline results are either provider-reported or collected from Artificial Analysis.
CharXiv Reasoning.
We use gpt-4o as the LLM judge. All baseline results are provider-reported, with the exception of Opus-4.8, which was self-computed.
GPQA-Diamond.
We use the default configuration in EvalScope (v1.8.1). All baseline results are provider-reported.
SciCode.
We follow the Artificial Analysis implementation, using Inspect AI's default implementation with background provided, and report the final score as the resolve rate over the canonical 288 subproblems. We found that certain SciCode test cases can fail legitimate solutions due to outdated package versioning, requiring us to version bump numpy, scipy, and sympy. All baseline results are taken from Artificial Analysis's official leaderboard.
$\tau^3$ Banking.
We follow the default configuration from $\tau^3$-bench banking setting, with all tool available for information retrieval, reporting pass@4 accuracy with GPT-5.2 (low) as the user simulator. All baseline results are taken from the official $\tau$-bench leaderboard.
Long Context Reasoning.
We follow the default setup as in Artificial Analysis ([58]) with zero few shot examples, using Qwen3 235B A22B 2507 Non-Reasoning as an equality checker and a two hour timeout setting. All baseline results are taken from Artificial Analysis's leaderboard.
MRCR v2.
We run the benchmark using the standard 8-needle retrieval up to 128k context length. All baseline results are provider-reported.
References to Mythos / Fable 5 and Mythos preview results are collected from official Anthropic-reported material wherever possible, and from official leaderboards and third-party services (such as tbench.ai, Artificial Analysis, and Benchmarklist) when Anthropic-provided scores are unavailable.
B. More Experiments
B.1 One-shot Rubik's Cube Solver
We test whether a model can synthesize a correct, near-optimal combinatorial solver from scratch in a single attempt. Each model is prompted once to write a function solve(facelet) that returns a WCA move string, restricted to the Python standard library (no off-the-shelf cube-solving package), so the model must implement both the cube model and the search itself. The emitted code is executed on a frozen, held-out set of 300 scrambled cubes and checked by an independent cube engine; because solving runs as local CPU, no further model tokens are spent at evaluation time. Beyond the shared scaffold, this task carries an absolute quality reference: God's number is 20, giving an absolute upper bound on optimal solution length, and we report solve rate, mean solution length in the half-turn metric (HTM), and mean solver runtime per cube.
: Table 4: Rubik's cube solver synthesis on 300 held-out scrambles. Both $\textsc{Fugu}$ models and one frontier baseline (Model A) solve every cube; the other two frontier baselines crash before solving a single one. $\textsc{Fugu-Ultra}$ produces the shortest solutions of any model (mean 19.72 HTM, optimal $=20$) and never returns a longer solution than Model A on any cube; $\textsc{Fugu}$ trades about one extra move for a far faster solver (1.9 s per cube, roughly 35 × faster than the deep solvers' $\sim$ 70 s). HTM, half-turn metric; "mean time" is the solver's per-cube runtime.
| Model | Solve rate | Mean HTM | Mean time |
|---|---|---|---|
| Fugu-Ultra | 300/300 | 19.72 | 72.6 s |
| Model A | 300/300 | 19.76 | 67.2 s |
| Fugu | 300/300 | 21.15 | 1.9 s |
| Model B | 0/300 | — | — |
| Model C | 0/300 | — | — |
The decisive result is the reliability of the synthesized code (Table 4). Both Fugu models, $\textsc{Fugu}$ and $\textsc{Fugu-Ultra}$, produced solvers that ran and solved every cube. Among the three frontier baselines, one (Model A) also solved every cube, but the other two shipped solvers that crashed before solving a single cube. Producing a solver that actually runs is exactly where two of the three frontier baselines fail and where both $\textsc{Fugu}$ models do not.
On solution length, $\textsc{Fugu-Ultra}$ is the strongest model: it produces the shortest solutions of any model (mean 19.72 HTM, within one move of the optimal bound of 20, and ahead of Model A's 19.76), and on no cube does it return a longer solution than Model A (7 wins, 293 ties, 0 losses across all 300 cubes). $\textsc{Fugu}$ trades about one extra move (21.15 HTM) for a far faster solver, solving each cube in 1.9, s, roughly 35x faster than the deep solvers' 70, s. Both $\textsc{Fugu}$ models achieve this while solving every cube, exactly where two of the three frontier baselines fail to run at all.
B.2 Blindfold Chess Gameplay
Blindfold chess is a stress test for one specific ability: to hold a complex, changing state in mind, and to think about it for a long time. Each model is given a fixed opening as a list of moves (never as a board in ASCII or FEN string) and continues from there entirely from memory. On each turn, it receives only the opponent's last move in coordinate notation and must return its own, within a single continuous session. We do not provide a list of legal moves available, and models are expected to find one on its own. In addition, no external record is maintained in the conversation history. We expect the model to track the entire position on its own by internally maintaining a record of every capture, castle, and promotion over a game that may span dozens of moves. It is important to note that in a game of chess, a single forgotten or misplaced piece is typically sufficient to lose.
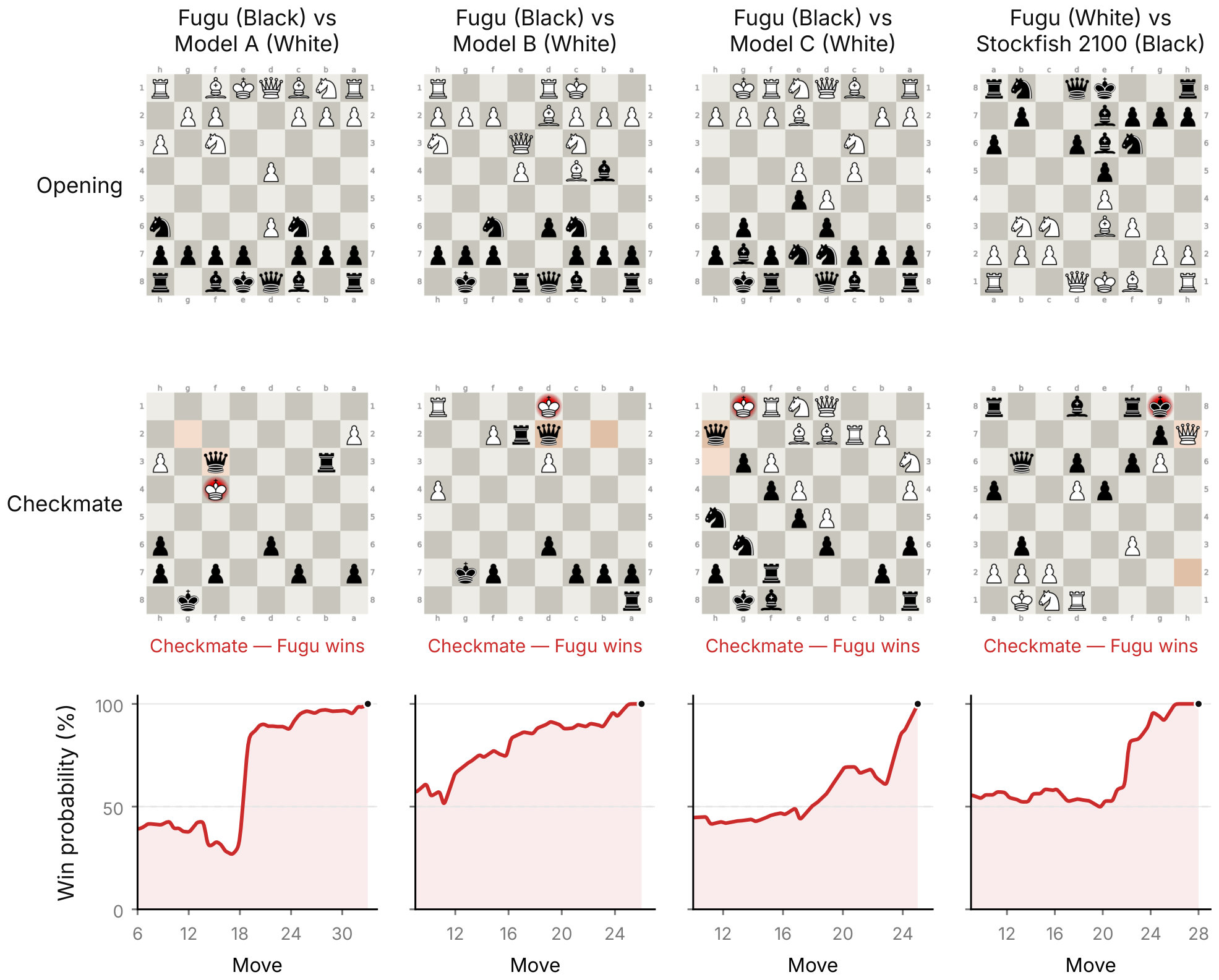
We run the same protocol against the three frontier baselines Model A, Model B, Model C and against Stockfish 18 ([64]), whose playing strength we cap to an expert ${\sim}2100$ Elo [^1]. Figure 9 shows four representative games: $\textsc{Fugu}$ against each frontier baseline and against an expert-strength Stockfish (2100-Elo), each with its opening, its final checkmate, and the win-probability curve between them. We provide a complete move history of the games in Appendix C. The central observation is that $\textsc{Fugu}$ sustains accurate play over the course of a full game. In all four games, it commits no blunders and no mistakes (only occasional minor inaccuracies) under the engine's labeling, whereas each opponent commits at least one mistake or blunder, which proves decisive. Its mean average centipawn loss (ACPL) is accordingly lower than its opponent's in every game (${\approx}, 18$ – $30$ for $\textsc{Fugu}$ versus ${\approx}, 46$ – $72$ for the opponents).
[^1]: Win probabilities and per-move quality labels are obtained from a Stockfish 18 analysis at search depth 8 with 10 principal variations; the engine's centipawn score is mapped to a win percentage through the Lichess win percentage logistic ([65]), and the move labels (best, excellent, good, inaccuracy, mistake, blunder) follow standard centipawn-loss thresholds. As an opponent, Stockfish 18 has its playing strength limited to the stated Elo through the built-in UCI strength limiter of the engine.
The most demanding case is the 2100-Elo Stockfish against which $\textsc{Fugu}$ (as White) plays a game that the engine's own analysis finds entirely free of inaccuracies. The win-probability trajectories further indicate that these are not one-sided games, against Model A, $\textsc{Fugu}$ enters the agent-played phase at a slight disadvantage and recovers to a winning position rather than converting a pre-existing opening advantage. We present these as illustrative examples rather than as an estimate of the win rate. The main objective of this experiment is to isolate the capability of the models to do accurate calculation over a long horizon without an external record of state and to show that $\textsc{Fugu}$ maintains it consistently across opponents.
Reproducibility. Every game uses the same two prompt templates, reproduced in Listing 1. A one-time setup prompt names the side to move and gives the opening as a list of coordinate moves, from then on, each turn sends only the opponent's latest move, in the same session, so the board is never restated. The task does not use an agentic scaffold; every model is queried directly through its bare API under an identical prompt and harness, so the measurement reflects the underlying model rather than the surrounding tooling.
## Setup prompt (sent once, on the first turn)
> **Section Summary**: The setup prompt instructs an AI to take on the role of the black player in a chess game that is already underway. It supplies the full sequence of moves made by both sides up to that point, using standard chess notation, and ends by asking what black should play next. This message is delivered only once, at the very beginning of the interaction, to establish the game context.
You are playing a chess game and you are playing with black pieces. Current move history is 1. e2e4 e7e5 2. d2d4 e5d4 3. d1d4 b8c6 4. d4e3 g8f6 5. b1c3 f8b4 6. c1d2 e8g8 7. e1c1 f8e8 8. f1c4 d7d6 9. g1h3. What is your move?
## Per-move prompt (every later turn, same session): opponent's move in UCI only
> **Section Summary**: The section illustrates a per-move prompting approach used in ongoing chess sessions, where the opponent's latest move is supplied solely in compact UCI format such as “c1e3” to continue play without restating prior context. It then describes a separate online stock-trading benchmark that evaluates agents on a single anonymized equity over 50 weeks, with no look-ahead access to future prices; each model begins with $10,000, observes only historical weekly data plus its own portfolio state, and must choose buy/hold/sell actions plus position size after every step. Results show one model, Fugu-Ultra, achieving the highest mean return (+19.43 %) while the others stayed below +15 %, followed by full move-by-move records of several blindfold chess games.
c1e3
B.3 Online Sequential Stock Trading
We ask whether agents can trade profitably online, where future information is unavailable and each decision permanently shapes the portfolio [^2]. The method extends the next-action prediction paradigm, studied in sequential recommendation ([66]) and agentic recommendation ([67]), into an agentic trading task requiring the agent to both anticipate future dynamics and commit to irreversible decisions. Built on the Apple Inc. Stock Price Dataset from Kaggle ([68]), the experiment follows the causal, no-look-ahead principle of LSTM-based financial prediction ([69]). But where such work uses batch walk-forward evaluation, we adopt a fully online, per-step setting: the agent observes only past prices for a single asset (STOCK_X), commits to an action, and sees the true next value only afterward, before acting again with accumulated feedback. We disable web search in addition to anonymizing and normalizing the data into weekly observations, so performance reflects genuine reasoning rather than memorized ticker knowledge.
[^2]: This benchmark uses a single anonymized equity over one historical 50-week window and is intended to compare sequential, no-look-ahead decision-making rather than to establish generalizable trading performance. Results may not transfer to other assets, time periods, or live markets.
Each agent begins with \10, 000 and proceeds through an identical 50-week pipeline. At every step it observes only current and past weekly market data (opening, high, low, and closing prices, volume, 1/4/12-week returns, 4/12/26-week moving averages, 12-week volatility, and 26-week drawdown), together with its current portfolio state and its own prior feedback. Each agent maintains a persistent memory log it updates after each step, and chooses both a direction (buy, hold, or sell) and a sizing (25%, 50%, or 100% of available cash or held shares). After each action the next week's price is revealed and the portfolio is marked to market, so the agent must continually revise its strategy from realized outcomes rather than peeking ahead. All frontier models are run under this identical setup, with the same prompts, action space, and evaluation harness, to ensure a fair comparison.
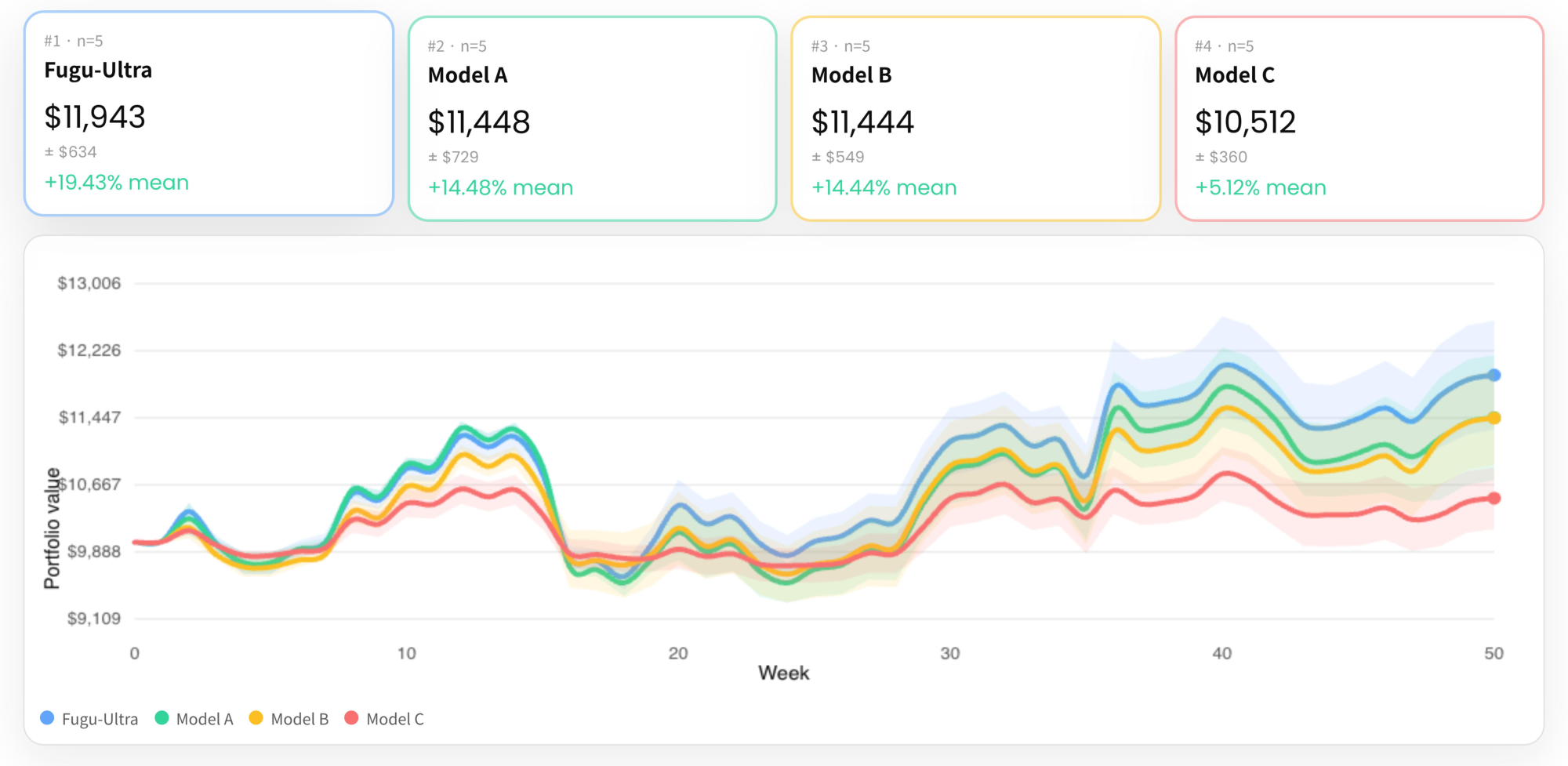
Across five runs of the identical 50-week pipeline, $\textsc{Fugu-Ultra}$ produced the strongest result, growing the portfolio to \11,943.22 ± \633.86 (+19.43% mean return), while the other frontier models reached their return less than +15%. As shown in Figure 10, $\textsc{Fugu-Ultra}$ compounds gains more effectively over the sequence, whereas the other frontier models stay their trades less strategic. The gap suggests that $\textsc{Fugu-Ultra}$ is better at translating noisy market signals into well-timed, appropriately-sized trades and at adapting its position from week-to-week feedback, rather than defaulting to passive or overly conservative behavior.
C. Blindfold Chess: Full Game Records
For reproducibility, we give the complete move record (standard algebraic notation) and the final board position (FEN) for each of the four games in Figure 9. Each record is split into the fixed opening (the shared book sequence, supplied to both models as a list of moves) and the subsequent blindfold play (generated move-by-move from memory, with no board or legal-move list shown).
$\textsc{Fugu}$ (Black) vs Model A (White).
Result: 0–1 ($\textsc{Fugu}$ wins).
--- Opening (fixed book moves, given to both models) ---
1. e4 Nc6 2. Nf3 Nf6 3. e5 Ng4 4. d4 d6 5. h3 Nh6 6. exd6
--- Blindfold play (from memory; no board or legal moves shown) ---
6... exd6 7. Bxh6 gxh6 8. Nc3 Bg7 9. Bb5 O-O 10. O-O Bd7 11. Re1 Re8 12. Rxe8+ Qxe8 13. Bxc6 Bxc6 14. d5 Bxc3 15. dxc6 Bxb2 16. Rb1 Ba3 17. cxb7 Rb8 18. Qd3 Bc5 19. Qa3 Bxa3 20. Rb3 Bc5 21. c3 Qe6 22. Nd4 Bxd4 23. cxd4 Qe1+ 24. Kh2 Qxf2 25. Rb2 Qxb2 26. Kg3 Qxd4 27. Kf3 Rxb7 28. Kg3 Qe5+ 29. Kf3 Qf5+ 30. Kg3 Qg5+ 31. Kf3 Rb3+ 32. Ke4 Qxg2+ 33. Kf4 Qf3# 0-1
Final FEN: 6k1/p1p2p1p/3p3p/8/5K2/1r3q1P/P7/8 w - - 2 34
$\textsc{Fugu}$ (Black) vs Model B (White).
Result: 0–1 ($\textsc{Fugu}$ wins).
--- Opening (fixed book moves, given to both models) ---
1. e4 e5 2. d4 exd4 3. Qxd4 Nc6 4. Qe3 Nf6 5. Nc3 Bb4 6. Bd2 O-O 7. O-O-O Re8 8. Bc4 d6 9. Nh3
--- Blindfold play (from memory; no board or legal moves shown) ---
9... Bxc3 10. Bxc3 Nxe4 11. Qf4 Nxc3 12. bxc3 Be6 13. Bd3 Ne5 14. g4 Bxg4 15. Rdg1 Nxd3+ 16. cxd3 Bxh3 17. Qg3 Qf6 18. Qxh3 Qxc3+ 19. Kd1 Qa1+ 20. Kd2 Qxa2+ 21. Kd1 Qb1+ 22. Kd2 Qb2+ 23. Kd1 Re2 24. Qxh7+ Kxh7 25. Rxg7+ Kxg7 26. h4 Qd2# 0-1
Final FEN: r7/ppp2pk1/3p4/8/7P/3P4/3qrP2/3K3R w - - 1 27
$\textsc{Fugu}$ (Black) vs Model C (White).
Result: 0–1 ($\textsc{Fugu}$ wins).
--- Opening (fixed book moves, given to both models) ---
1. d4 Nf6 2. c4 g6 3. Nc3 Bg7 4. e4 d6 5. Nf3 O-O 6. Be2 e5 7. O-O Nc6 8. d5 Ne7 9. Ne1 Nd7
--- Blindfold play (from memory; no board or legal moves shown) ---
10. Be3 f5 11. f3 f4 12. Bf2 g5 13. Nd3 Nf6 14. c5 Ng6 15. cxd6 cxd6 16. Rc1 Rf7 17. Nb5 Bf8 18. a4 g4 19. Rc2 g3 20. Be1 Nh5 21. h3 a6 22. Na3 Bxh3 23. gxh3 Qd7 24. Bd2 Qxh3 25. Ne1 Qh2# 0-1
Final FEN: r4bk1/1p3r1p/p2p2n1/3Pp2n/P3Pp2/N4Pp1/1PRBB2q/3QNRK1 w - - 2 26
$\textsc{Fugu}$ (White) vs Stockfish 2100 (Black).
Result: 1–0 ($\textsc{Fugu}$ wins).
--- Opening (fixed book moves, given to both models) ---
1. e4 c5 2. Nf3 d6 3. d4 cxd4 4. Nxd4 Nf6 5. Nc3 a6 6. Be3 e5 7. Nb3 Be6 8. f3 Be7
--- Blindfold play (from memory; no board or legal moves shown) ---
9. Qd2 O-O 10. O-O-O b5 11. g4 Qc7 12. h4 Nbd7 13. g5 Nh5 14. Kb1 Ng3 15. Rg1 b4 16. Nd5 Bxd5 17. exd5 Nxf1 18. Rgxf1 a5 19. Nc1 f6 20. g6 hxg6 21. Rg1 g5 22. hxg5 Nb6 23. Bxb6 Qxb6 24. g6 Bd8 25. Rh1 b3 26. Rh8+ Kxh8 27. Qh2+ Kg8 28. Qh7# 1-0
Final FEN: r2b1rk1/6pQ/1q1p1pP1/p2Pp3/8/1p3P2/PPP5/1KNR4 b - - 3 28
References
Section Summary: This references section compiles citations to recent research papers, technical reports, and blog posts primarily from 2022 to 2026 on advanced AI systems. The sources cover topics such as large language models achieving expert-level performance in mathematics, science, and coding, along with methods for improving reasoning, multi-agent collaboration, and tool use. They include benchmarks for evaluating AI on real-world tasks as well as surveys and technical tools related to model development and optimization.
[1] Luong, Thang and Lockhart, Edward (2025). Advanced Version of Gemini with Deep Think Officially Achieves Gold-Medal Standard at the International Mathematical Olympiad. Google DeepMind Blog, https://deepmind.google/blog/advanced-version-of-gemini-with-deep-think-officially-achieves-gold-medal-standard-at-the-international-mathematical-olympiad/. Accessed: 2026-06-12.
[2] Anthropic (2026). Making Claude a Chemist. https://www.anthropic.com/research/making-claude-a-chemist. Accessed: 2026-06-12.
[3] OpenAI (2026). An OpenAI Model Has Disproved a Central Conjecture in Discrete Geometry. https://openai.com/index/model-disproves-discrete-geometry-conjecture/. Accessed: 2026-06-12.
[4] Patwardhan et al. (2025). GDPval: Evaluating AI Model Performance on Real-World Economically Valuable Tasks. OpenAI. https://arxiv.org/abs/2510.04374. arXiv:2510.04374.
[5] Nori et al. (2025). Sequential Diagnosis with Language Models. Microsoft AI. https://arxiv.org/abs/2506.22405. arXiv:2506.22405.
[6] Carlini et al. (2026). Assessing Claude Mythos Preview's Cybersecurity Capabilities. Anthropic Frontier Red Team, https://red.anthropic.com/2026/mythos-preview. Accessed: 2026-06-12.
[7] Glazer et al. (2024). FrontierMath: A Benchmark for Evaluating Advanced Mathematical Reasoning in AI. arXiv preprint arXiv:2411.04872.
[8] Carlos E Jimenez et al. (2024). SWE-bench: Can Language Models Resolve Real-world Github Issues?. In The Twelfth International Conference on Learning Representations. https://openreview.net/forum?id=VTF8yNQM66.
[9] Zheng et al. (2026). Livecodebench pro: How do olympiad medalists judge llms in competitive programming?. Advances in Neural Information Processing Systems. 38.
[10] Hu et al. (2025). Automated design of agentic systems. In International Conference on Learning Representations. pp. 21344–21377.
[11] Wei et al. (2022). Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems. 35. pp. 24824–24837.
[12] Yao et al. (2022). React: Synergizing reasoning and acting in language models. arXiv preprint arXiv:2210.03629.
[13] Madaan et al. (2023). Self-refine: Iterative refinement with self-feedback. Advances in Neural Information Processing Systems. 36. pp. 46534–46594.
[14] Qu et al. (2025). Tool learning with large language models: A survey. Frontiers of Computer Science. 19(8). pp. 198343.
[15] Schick et al. (2024). Toolformer: Language models can teach themselves to use tools. Advances in Neural Information Processing Systems. 36.
[16] Zhang et al. (2025). A survey on the memory mechanism of large language model-based agents. ACM Transactions on Information Systems. 43(6). pp. 1–47.
[17] Anthropic (2026). Claude Code: Agentic coding tool for the terminal. https://github.com/anthropics/claude-code. Version 2.1.88.
[18] Ha, David and Tang, Yujin (2022). Collective intelligence for deep learning: A survey of recent developments. Collective Intelligence. 1(1). pp. 26339137221114874.
[19] Jiang et al. (2025). A Comprehensive Survey of LLM-Driven Collective Intelligence: Past, Present, and Future.
[20] Du et al. (2023). Improving factuality and reasoning in language models through multiagent debate. In Forty-first International Conference on Machine Learning.
[21] Wang et al. (2024). Mixture-of-agents enhances large language model capabilities. arXiv preprint arXiv:2406.04692.
[22] Dang et al. (2025). Multi-Agent Collaboration via Evolving Orchestration. arXiv preprint arXiv:2505.19591.
[23] Guha et al. (2024). Smoothie: Label free language model routing. Advances in Neural Information Processing Systems. 37. pp. 127645–127672.
[24] Zhuge et al. (2024). Gptswarm: Language agents as optimizable graphs. In Forty-first International Conference on Machine Learning.
[25] Yue et al. (2025). Masrouter: Learning to route llms for multi-agent systems. arXiv preprint arXiv:2502.11133.
[26] Chen et al. (2024). Routerdc: Query-based router by dual contrastive learning for assembling large language models. Advances in Neural Information Processing Systems. 37. pp. 66305–66328.
[27] Wang et al. (2022). Self-consistency improves chain of thought reasoning in language models. arXiv preprint arXiv:2203.11171.
[28] Yao et al. (2023). Tree of thoughts: Deliberate problem solving with large language models. Advances in neural information processing systems. 36. pp. 11809–11822.
[29] Noah Shinn et al. (2023). Reflexion: language agents with verbal reinforcement learning. In Thirty-seventh Conference on Neural Information Processing Systems. https://openreview.net/forum?id=vAElhFcKW6.
[30] OpenAI (2026). Codex CLI: Lightweight coding agent that runs in your terminal. https://github.com/openai/codex. Version 0.135.0.
[31] Goddard et al. (2024). Arcee's MergeKit: A Toolkit for Merging Large Language Models. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing: Industry Track. pp. 477–485. doi:10.18653/v1/2024.emnlp-industry.36. https://aclanthology.org/2024.emnlp-industry.36/.
[32] Akiba et al. (2025). Evolutionary optimization of model merging recipes. Nature Machine Intelligence. 7(2). pp. 195–204.
[33] Yadav et al. (2023). Ties-merging: Resolving interference when merging models. Advances in Neural Information Processing Systems. 36. pp. 7093–7115.
[34] Yu et al. (2024). Language models are super mario: Absorbing abilities from homologous models as a free lunch. In Forty-first International Conference on Machine Learning.
[35] Bansal et al. (2021). Revisiting model stitching to compare neural representations. Advances in neural information processing systems. 34. pp. 225–236.
[36] Xu et al. (2025). TRINITY: An Evolved LLM Coordinator. arXiv preprint arXiv:2512.04695.
[37] Qi Sun et al. (2025). Transformer-Squared: Self-adaptive LLMs. In The Thirteenth International Conference on Learning Representations. https://openreview.net/forum?id=dh4t9qmcvK.
[38] Risi et al. (2026). Neuroevolution: Harnessing creativity in ai agent design. MIT Press.
[39] Nielsen et al. (2025). Learning to Orchestrate Agents in Natural Language with the Conductor. arXiv preprint arXiv:2512.04388.
[40] Shao et al. (2024). Deepseekmath: Pushing the limits of mathematical reasoning in open language models, 2024. URL https://arxiv. org/abs/2402.03300. 2(3). pp. 5.
[41] Sutton et al. (1999). Policy gradient methods for reinforcement learning with function approximation. Advances in neural information processing systems. 12.
[42] Anthropic (2026). Tool Use with Claude. Claude Developer Platform Documentation, https://platform.claude.com/docs/en/agents-and-tools/tool-use/overview. Accessed: 2026-06-12.
[43] OpenAI (2026). Function Calling. OpenAI API Documentation, https://developers.openai.com/api/docs/guides/function-calling. Accessed: 2026-06-12.
[44] Model Context Protocol (2026). What Is the Model Context Protocol (MCP)?. Model Context Protocol Documentation, https://modelcontextprotocol.io/docs/getting-started/intro. Accessed: 2026-06-12.
[45] Google DeepMind (2026). Gemini 3.1 Pro Model Card. https://deepmind.google/models/model-cards/gemini-3-1-pro/. Results reported as of February 2026. Accessed June 16, 2026.
[46] Anthropic (2026). Claude Opus 4.8 System Card. https://www-cdn.anthropic.com/0b4915911bb0d19eca5b5ee635c80fef830a37ea/Claude%20Opus%204.8%20System%20Card.pdf. Published May 28, 2026. Accessed June 16, 2026.
[47] OpenAI (2026). GPT-5.5 System Card. https://openai.com/index/gpt-5-5-system-card/. Published April 23, 2026; updated April 24, 2026. Accessed June 16, 2026.
[48] Deng et al. (2025). Swe-bench pro: Can ai agents solve long-horizon software engineering tasks?. arXiv preprint arXiv:2509.16941.
[49] Mike A. Merrill et al. (2026). Terminal-Bench: Benchmarking Agents on Hard, Realistic Tasks in Command Line Interfaces. https://arxiv.org/abs/2601.11868. arXiv:2601.11868.
[50] SWE-agent Contributors (2026). mini-swe-agent: The Minimal AI Software Engineering Agent. https://github.com/SWE-agent/mini-swe-agent. Version 2; accessed 2026-06-12.
[51] Laude Institute (2026). Terminus-2: Harbor's Reference Agent Implementation. Harbor Framework Documentation, https://www.harborframework.com/docs/agents/terminus-2. Accessed: 2026-06-12.
[52] Rein et al. (2024). Gpqa: A graduate-level google-proof q&a benchmark. In First Conference on Language Modeling.
[53] Phan et al. (2025). Humanity's last exam. arXiv preprint arXiv:2501.14249.
[54] Jain et al. (2024). Livecodebench: Holistic and contamination free evaluation of large language models for code. arXiv preprint arXiv:2403.07974.
[55] Tian et al. (2024). Scicode: A research coding benchmark curated by scientists. Advances in Neural Information Processing Systems. 37. pp. 30624–30650.
[56] Wang et al. (2024). Charxiv: Charting gaps in realistic chart understanding in multimodal llms. Advances in Neural Information Processing Systems. 37. pp. 113569–113697.
[57] Vodrahalli et al. (2024). Michelangelo: Long context evaluations beyond haystacks via latent structure queries. arXiv preprint arXiv:2409.12640.
[58] Artificial Analysis Team (2025). Artificial Analysis Long Context Reasoning Benchmark(LCR).
[59] Anthropic (2026). Claude Fable 5 & Claude Mythos 5 System Card. https://www-cdn.anthropic.com/d00db56fa754a1b115b6dd7cb2e3c342ee809620.pdf. Published June 9, 2026. Accessed June 16, 2026.
[60] Andrej Karpathy (2026). AutoResearch. https://github.com/karpathy/autoresearch. GitHub repository.
[61] Fitzgerald, Jake and others (2026). CAD SKILLS. https://github.com/earthtojake/text-to-cad.
[62] Junlin Wang et al. (2025). Mixture-of-Agents Enhances Large Language Model Capabilities. In The Thirteenth International Conference on Learning Representations. https://openreview.net/forum?id=h0ZfDIrj7T.
[63] OpenRouter, Inc. (2026). OpenRouter: Fusion. https://openrouter.ai/openrouter/fusion. Multi-model deliberation router. Accessed June 16, 2026.
[64] The Stockfish Developers (2025). Stockfish 18. Open-source UCI chess engine. https://stockfishchess.org. Version 18.
[65] Lichess (2023). Accuracy and Win%: How move quality is evaluated. https://lichess.org/page/accuracy.
[66] Wang-Cheng Kang and Julian McAuley (2018). Self-Attentive Sequential Recommendation. In Proceedings of the 2018 IEEE International Conference on Data Mining (ICDM). pp. 197–206. doi:10.1109/ICDM.2018.00035.
[67] Zhenrui Yue et al. (2026). Retrieval Augmented Conversational Recommendation with Reinforcement Learning. https://arxiv.org/abs/2604.04457. arXiv:2604.04457.
[68] meetnagadia (2022). Apple Stock Price from 1980-2021. Kaggle dataset. Accessed: 2026-06-16. https://www.kaggle.com/datasets/meetnagadia/apple-stock-price-from-19802021/data.
[69] Thomas Fischer and Christopher Krauss (2018). Deep learning with long short-term memory networks for financial market predictions. European Journal of Operational Research. 270(2). pp. 654-669. doi:https://doi.org/10.1016/j.ejor.2017.11.054. https://www.sciencedirect.com/science/article/pii/S0377221717310652.