Qwen-Image-VAE-2.0 Technical Report
Qwen Team
https://github.com/alibaba/OmniDoc-TokenBench
Abstract
We present Qwen-Image-VAE-2.0, a suite of high-compression Variational Autoencoders (VAEs) that achieve significant advances in both reconstruction fidelity and diffusability. To address the reconstruction bottlenecks of high compression, we adopt an improved architecture featuring Global Skip Connections (GSC) and expanded latent channels. Moreover, we scale training to billions of images and incorporate a synthetic rendering engine to improve performance in text-rich scenarios. To tackle the convergence challenges of high-dimensional latent space, we implement an enhanced semantic alignment strategy to make the latent space highly amenable to diffusion modeling. To optimize computational efficiency, we leverage an asymmetric and attention-free encoder-decoder backbone to minimize encoding overhead. We present a comprehensive evaluation of Qwen-Image-VAE-2.0 on public reconstruction benchmarks. To evaluate performance in text-rich scenarios, we propose OmniDoc-TokenBench, a new benchmark comprising a diverse collection of real-world documents coupled with specialized OCR-based evaluation metrics. Qwen-Image-VAE-2.0 achieves state-of-the-art reconstruction performance, demonstrating exceptional capabilities in both general domains and text-rich scenarios at high compression ratio. Furthermore, downstream DiT experiments reveal our models possess superior diffusability, significantly accelerating convergence compared to existing high-compression baselines. These establish Qwen-Image-VAE-2.0 as a leading model with high compression, superior reconstruction, and exceptional diffusability.
Executive Summary: Qwen-Image-VAE-2.0 introduces a family of image autoencoders that compress visual data far more aggressively than prior standards while preserving fine detail and remaining easy for downstream generators to use. The work targets a core tension in modern image synthesis: higher spatial compression cuts the computational cost of training large diffusion models on high-resolution images, yet it routinely destroys reconstruction quality and slows generator convergence, especially on text-heavy content.
The team set out to break this trade-off. They built two compression levels (16× and 32×) using an asymmetric, attention-free architecture, global skip connections to retain high-frequency detail, expanded latent channels to offset information loss, and a two-part training regimen that combines massive-scale data with targeted semantic alignment to pretrained vision features. They also created OmniDoc-TokenBench, a new test set of roughly 3,000 real documents, to measure text legibility through OCR rather than pixel metrics alone.
On standard ImageNet and FFHQ benchmarks the new models achieve state-of-the-art reconstruction at their respective compression ratios; the strongest f16 variant even exceeds several established f8 models on structural similarity. On the document benchmark the same models reach normalized edit distances above 0.85–0.96, preserving readable text where competing high-compression approaches drop to 0.15–0.57. When the resulting latents drive a diffusion transformer, convergence is faster and final image quality higher than existing high-compression baselines, despite the larger channel counts.
These outcomes matter because they allow native high-resolution generation pipelines to run with substantially fewer tokens and lower memory use, without the usual penalties in visual fidelity or training time. The gains are large enough to shift cost-performance curves for production text-to-image or video systems that must handle both natural scenes and dense typography.
Organizations should evaluate Qwen-Image-VAE-2.0 as a drop-in replacement for f8 or lower-compression encoders in new high-resolution generators. A practical next step is to integrate the f16c128 variant into an end-to-end diffusion pipeline and run targeted scaling or fine-tuning experiments before broader deployment. Further work on even higher resolutions and additional modalities would strengthen the case for production use.
The results rest on large, curated training data and specific alignment choices; performance could vary under markedly different data distributions or weaker downstream training regimes. Overall is high for the reported settings and benchmarks.
1. Introduction
Section Summary: Latent Diffusion Models rely on VAEs to compress images into a compact space for efficient generation, but raising the compression ratio for high-resolution work creates a difficult trade-off between visual quality, detail preservation, and how well the compressed data works with diffusion models. The new Qwen-Image-VAE-2.0 series addresses this with an improved architecture that includes global skip connections and higher-dimensional latents, plus massive training on billions of images and specially prepared text-rich documents. These changes deliver strong reconstruction of fine details, especially text, while semantic alignment techniques ensure the resulting latents still allow fast and effective training of downstream diffusion models.
Latent Diffusion Models (LDMs) have become the dominant paradigm in image synthesis ([1, 2, 3, 4, 5, 6]). These models typically employ a Variational Autoencoder (VAE) to project images into a compressed latent space for efficient diffusion modeling, where a widely adopted spatial compression ratio is 8 (denoted as $f8$). However, as the industry shifts toward native high-resolution synthesis, this standard ratio faces significant computational bottlenecks. Increasing the spatial compression ratio has thus become essential for computational efficiency, as the complexity of modern Diffusion Transformers (DiTs) ([7]) scales quadratically with the number of latent tokens. Over the past few years, several advances have been achieved in this field, demonstrating the significant potential of high-compression VAEs ([8, 9, 10, 11]).
Despite these advances, a critical challenge exists: the inevitable trade-off between high compression ratio, reconstruction fidelity, and diffusability ([12]). Specifically, higher compression ratios often lead to severe degradation in reconstruction quality, particularly in text-rich scenarios where fine-grained detail is lost. While increasing the latent channel dimension can mitigate this information bottleneck, it frequently results in an over-complex and unstructured latent distribution, which significantly hinders the convergence and generative performance of downstream diffusion models ([13, 14]).
In this work, we introduce Qwen-Image-VAE-2.0, a series of high-compression image VAEs ($f16$ & $f32$), designed to overcome these challenges through improved architecture, comprehensive data engineering, and enhanced training strategy.
To address the challenge of reconstruction fidelity in high-compression regimes, we adopt an improved VAE architecture with Global Skip Connection (GSC), which establishes a global shortcut from pixels to latents, preserving fine-grained detail. Moreover, our design incorporates a higher latent dimensionality to alleviate the information bottleneck inherent in high-compression scenarios. On the data front, we scale our training corpus to billions of images and curate a specialized document collection (including academic papers, posters, slides, web pages, etc.) to enhance the reconstruction of text-rich images. Furthermore, we develop a synthetic pipeline that renders documents to provide dense supervisory signals for character-level reconstruction. Through these advancements, Qwen-Image-VAE-2.0 achieves state-of-the-art reconstruction performance, especially in text-rich scenarios, despite its high compression ratio. To address the challenge of diffusability brought by high compression ratio and expanded latent dimension, we demonstrate that semantic alignment with intermediate features of DINOv2 ([15]) can effectively accelerate DiT convergence. Furthermore, we adopt a staged semantic alignment paradigm that transitions from strict semantic alignment to a balanced optimization of reconstruction and generation. Leveraging these techniques, Qwen-Image-VAE-2.0 achieves superior diffusability compared to existing high-compression VAEs, despite its large channel dimension.
To ensure computational efficiency, we leverage an asymmetric architecture that features a lightweight encoder to minimize encoding overhead during diffusion training. Additionally, we utilize an attention-free backbone to maintain high throughput even with ultra-high-resolution inputs.
We conduct a comprehensive evaluation to validate the performance of Qwen-Image-VAE-2.0, focusing on two key aspects: reconstruction fidelity and latent space diffusability. For reconstruction fidelity, we evaluate it across general reconstruction tasks and introduce OmniDoc-TokenBench, a benchmark specifically targeting challenging scenarios like real-world text-rich document reconstruction. For latent space diffusability, we also perform extensive downstream DiT experiments to empirically verify it. The results demonstrate that Qwen-Image-VAE-2.0 not only achieves superior reconstruction fidelity, especially in text-rich scenarios despite high compression ratios, but also exhibits excellent latent space compatibility, facilitating rapid DiT convergence even with large latent dimension.
The key contributions of Qwen-Image-VAE-2.0 can be summarized as follows:
- High-Compression VAE: We introduce a suite of $f16$ and $f32$ image VAEs, providing a robust solution for efficient and native high-resolution image generation.
- Superior Reconstruction Performance: Qwen-Image-VAE-2.0 achieves state-of-the-art reconstruction performance across multiple benchmarks. It maintains exceptional legibility in text-rich scenarios where traditional high-compression models typically fail.
- Enhanced Latent Diffusability: Through a refined semantic alignment strategy, we demonstrate that large-channel VAEs can achieve excellent diffusability. This provides a promising solution to the tripartite trade-off between compression ratio, reconstruction fidelity, and diffusability.
2. Model
Section Summary: The Qwen-Image-VAE-2.0 is a specialized variational autoencoder designed to compress images much more aggressively than typical models, using spatial compression factors of 16 or 32 rather than the standard 8. To offset the resulting loss of fine detail, the design increases the number of channels in the latent representation and introduces a global skip connection that directly routes high-frequency pixel information past the early downsampling layers. The model further improves efficiency and scalability by relying on an attention-free convolutional backbone and an asymmetric encoder-decoder pair, with a lightweight encoder for fast latent extraction and a heavier decoder for high-quality reconstruction.
In this section, we present the detailed design and architectural innovations of Qwen-Image-VAE-2.0.
2.1 Design Principle: High Compression VAE with Large Channel
To optimize the training efficiency of downstream DiTs, we prioritize a higher spatial compression ratio. Given an input image $I \in \mathbb{R}^{H \times W \times 3}$, the VAE maps it to a latent representation $z \in \mathbb{R}^{\frac{H}{f} \times \frac{W}{f} \times C}$, where $f$ denotes the spatial compression ratio and $C$ represents the channel dimension. This results in a sequence length of $L = HW/f^2$ for the DiT. Since DiT's computational complexity scales quadratically with sequence length ([16]), the computation overhead of $\mathcal{O}(L^2)=\mathcal{O}(H^2W^2/{f^4})$ presents a significant bottleneck in high-resolution image generation.
To alleviate this, we move beyond the conventional $f8$ paradigm ([1, 2, 17]), adopting higher compression ratios of $f16$ and $f32$ to significantly reduce DiT training costs. While high spatial compression ratio $f$ promises training efficiency, it inevitably constrains the information capacity of the latent space, often resulting in the loss of fine-grained structural detail. To mitigate this, we rely on the principle that reconstruction fidelity is largely governed by the total information bottleneck $N(z)={CHW}/{f^2}$ ([9]). By increasing the channel dimension $C$, we compensate for the spatial information loss incurred by high compression ratio $f$. Notably, channel expansion does not compromise DiT training efficiency: during training, the DiT first projects latents into a fixed hidden dimension via a linear layer, ensuring that the computational complexity remains nearly invariant to channel dimension.
2.2 Model Architecture
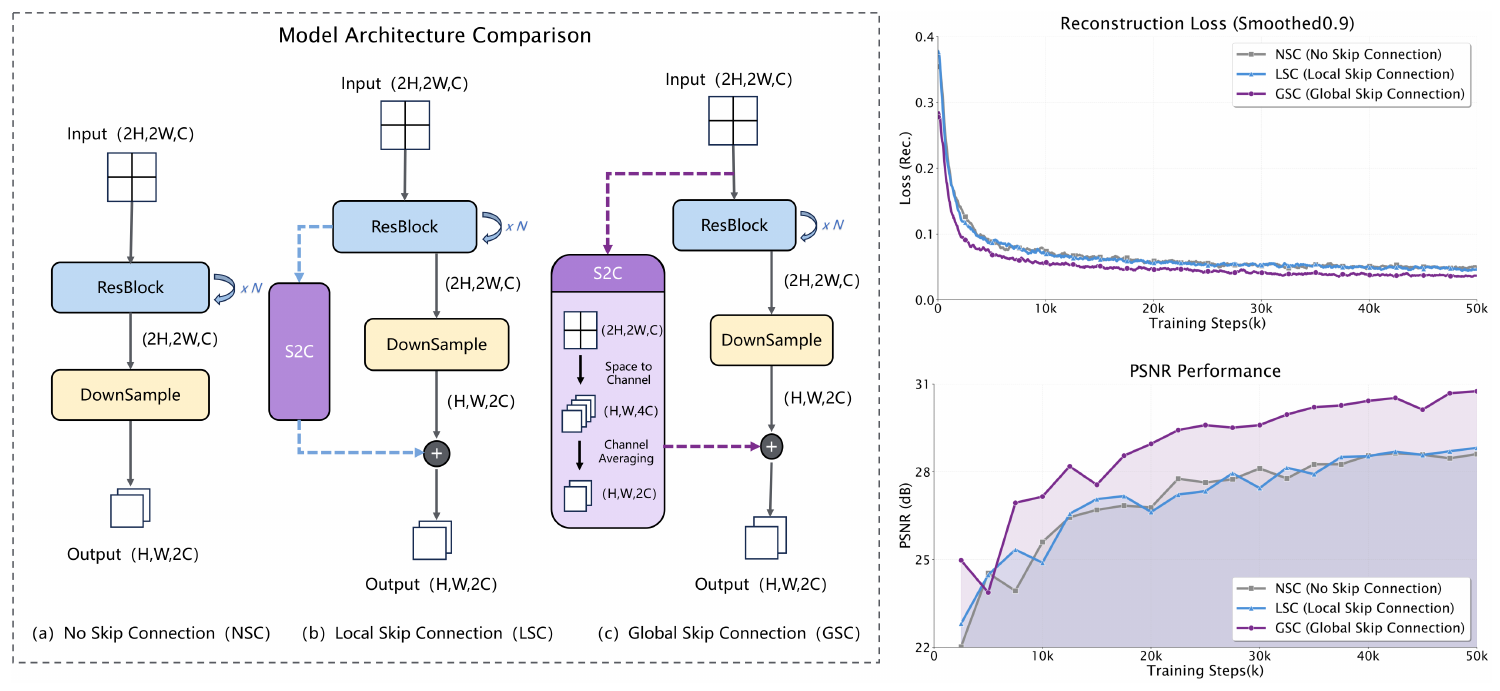
Global Skip Connection (GSC).
A primary challenge in high-compression VAEs is the preservation of fine-grained detail during the aggressive downsampling process. The encoder, particularly its non-parametric downsampling layers, often struggles to retain high-frequency information from the original image, leading to optimization difficulties and blurry reconstructions ([9]). To alleviate this information loss, we introduce the Global Skip Connection (GSC).
The GSC establishes a direct residual path that bypasses the initial downsampling stage, feeding pixel-level information directly into the deeper latent space. As illustrated in Figure 1, we implement this by employing a space-to-channel operation followed by reshaping, which effectively "folds" spatial information from the input image into the channel dimension.
To validate the efficacy of this design, we conducted an ablation study comparing three configurations: No Skip Connection (NSC), Local Skip Connection (LSC), and Global Skip Connection (GSC). Experiments on an f16c64 model trained from scratch demonstrate that the GSC significantly accelerates convergence by providing the network with high-frequency signal from the input. Based on these findings, we integrate the GSC across the entire Qwen-Image-VAE-2.0 series.
Attention-Free Backbone.
For an input of sequence length $N$, the computational complexity of self-attention is $\mathcal{O}(N^2)$, whereas that of convolution with a kernel size $k$ is $\mathcal{O}(N \cdot k^2)$. This quadratic scaling with pixels creates a significant throughput bottleneck for high-resolution image processing. Moreover, the activation memory required for self-attention also scales as $\mathcal{O}(N^2)$, imposing a severe memory constraint during training. In addition, we observed no significant performance degradation when removing attention modules. Consequently, we adopt an attention-free backbone for the entire Qwen-Image-VAE-2.0 series to ensure both training efficiency and scalability.
Encoder-Decoder Asymmetry.
We adopt an asymmetric architecture to balance encoding speed with reconstruction quality. By employing a lightweight encoder, we streamline the latent extraction process, effectively reducing training latency for the downstream DiT. Meanwhile, the heavyweight decoder guarantees high-fidelity reconstruction and the preservation of intricate image detail.
2.3 Model Configurations
The detailed configurations of the Qwen-Image-VAE-2.0 series are summarized in Table 1.
::: {caption="Table 1: Configurations of Qwen-Image-VAE-2.0 suite. $d_{enc}$ and $d_{dec}$ denote the first projected hidden dimensions of the encoder and decoder. $n_{\text{layer}}$ denotes the number of layers."}

:::
3. Data
Section Summary: The section explains how the authors built massive training datasets to help a VAE model learn high-quality image reconstruction, especially for text. They scaled up to billions of real-world images across many categories, then used filters to remove blurry or low-resolution examples and added large numbers of text-rich documents such as papers and slides collected via OCR. To further strengthen text handling, they also created synthetic images by rendering English and Chinese characters of varying sizes onto complex real backgrounds, producing varied levels of difficulty suited to different compression rates.
3.1 Data Collection
Scaling Data to Billion Scale.
To ensure robust generalization across diverse domains, we scale the VAE training corpus to encompass billions of images. This large-scale dataset covers a wide spectrum of visual content, spanning various categories, resolutions and aspect ratios. However, data at this scale inevitably contains noise like edge blur and compression artifacts, which impedes model's ability to learn high-frequency detail. To mitigate this, we employ clarity and blur filters to prune low-quality samples, ensuring that the VAE is supervised by high-fidelity signals.
Text-Rich Image Collection.
To address the reconstruction bottleneck in text-rich scenarios, we adopt a two-fold strategy. First, we leverage an OCR filter to identify and prioritize samples with high character density from extensive real-world datasets. Second, we curate a specialized document corpus, which includes screenshots of academic papers, presentation slides, posters, and complex web pages. By training on these real-world text-rich images, our models learn to prioritize the preservation of sharp edges of characters and semantic structures, enabling legible text reconstruction that is challenging for high compression VAEs.
3.2 Data Synthesis
To further enhance character-level reconstruction, we develop a synthetic pipeline that renders text documents into images. Our pipeline supports both alphabetic (English) and logographic (Chinese) languages, accounting for their distinct stroke densities and complexities. Crucially, we observed models trained on background-free synthetic data (e.g., black text on white backgrounds) generalize poorly to real-world images where text is often overlaid on complex textures. To bridge this gap, we implement background-contained synthesis, where text is rendered onto backgrounds randomly sampled from general-domain images. Moreover, to adapt different compression settings, we construct synthetic datasets of varying difficulty by rendering characters ranging from 5 to 20 pixels. This multi-granularity supervision forces the VAE to capture fine detail, ensuring legibility even at $f32$ compression.
4. Training
Section Summary: The training process for this image VAE relies on a straightforward combination of pixel-level reconstruction loss, perceptual loss, and a custom semantic alignment loss that matches the model's internal representations to those from a pretrained DINOv2 encoder. The authors deliberately omit the usual KL divergence and adversarial terms, finding that these constraints reduce reconstruction quality and training stability while slowing progress on later generative tasks. They train progressively across multiple stages that increase resolution up to 2K while varying aspect ratios, selecting middle-layer features from the semantic encoder and aligning them through simple margin-based similarity objectives.
4.1 Training Loss
The training objective of our image VAE is designed to be simple yet effective. Unlike traditional VAE frameworks that introduce distributional priors and adversarial paradigms, our training process focuses on high-fidelity reconstruction and semantic alignment of the latent space.
The total training loss $\mathcal{L}_{total}$ is formulated as:
$ \mathcal{L}{total} = \mathcal{L}{recon} + \lambda_{lpips} \mathcal{L}{lpips} + \lambda{align} \mathcal{L}_{align}, $
where $\mathcal{L}{recon}$ is the pixel-level $L_1$ reconstruction loss, and $\mathcal{L}{lpips}$ denotes the perceptual loss ([18]) weighted by $\lambda_{lpips}$. To improve the "diffusability" of the latent space, we incorporate a semantic alignment loss $\mathcal{L}_{align}$ which aligns latents to semantic counterparts extracted from pretrained encoders (detailed in Section 4.2). This ensures that the latent space captures more generation-friendly features.
Our empirical findings suggest that two common practices in VAE training (KL regularization and adversarial training) can be removed to achieve better performance and training stability.
Removing KL Loss for Enhanced Semantic Alignment.
We remove the Kullback-Leibler (KL) divergence loss as it inherently restricts latent capacity and compromises reconstruction fidelity. More importantly, we observe that the KL penalty acts as a competing constraint to our semantic alignment objective. Given that target semantic features are not necessarily Gaussian-distributed, forcing the model to satisfy both a normal prior and a semantic manifold leads to suboptimal alignment, which ultimately delays the convergence of the downstream DiT. By removing this constraint, we achieve a more flexible latent space that is better suited for generative tasks.
Removing GAN Loss for Training Stability and Efficiency.
While GAN loss ([19]) are conventionally used to sharpen visual detail, we find them unnecessary when the training budget is sufficiently large. Given extensive data and iterations, the combination of $\mathcal{L}{recon}$ and $\mathcal{L}{lpips}$ is capable of producing high-quality and sharp reconstructions. Eliminating the discriminator not only simplifies the optimization landscape, but also improves training stability and accelerates the overall training process.
In summary, by breaking the conventional reliance on KL loss and GAN loss, we demonstrate the feasibility and effectiveness of a simplified training objective, providing insights for future VAEs.
4.2 Semantic Alignment
Inspired by [13], we introduce a semantic alignment loss to strike a delicate balance between low-level detail preservation and high-level semantics, thereby making the latent space more generation-friendly.
Selection of Semantic Encoder.
Through extensive ablation studies comparing various pretrained vision encoders (including DINOv2 ([15]), DINOv3 ([20]), MAE ([21]), and PE-Spatial ([22])), we find that DINOv2 consistently outperforms other candidates in providing generation-friendly semantic priors. Consequently, we select DINOv2-L features as our default semantic guidance.
Selection of Aligned Layer.
We observe that the choice of encoder layer affects the alignment results. While conventional approaches often utilize the final layer, we find that middle layer of these encoders offer smoother spatial maps that are easier to align with, yielding more generation-friendly latent space. Furthermore, we find that naively combining features from different layers introduces unnecessary noise that corrupts the alignment signal. Consequently, we align the VAE latent with a single, optimally selected middle layer, rather than relying on the final output or multi-layer fusion.
Specifically, given a target image, we first extract the semantic feature map $f \in \mathbb{R}^{h \times w \times c}$ using the pretrained semantic encoder, where $h$ and $w$ denote the spatial resolution and $c$ is the feature dimension. Then, we project the VAE latent $z$ into the same dimensionality through a learnable linear transformation, $z' = Wz$, where $W$ is a trainable projection matrix. Let $\mathcal{P} = {(i, j) \mid 1 \le i \le h, ; 1 \le j \le w}$ denote the set of spatial positions, where $|\mathcal{P}| = N = hw$. For each position $p \in \mathcal{P}$, we denote by $f_p \in \mathbb{R}^{c}$ and $z'_p \in \mathbb{R}^{c}$ the semantic feature and projected latent feature at position $p$, respectively.
The alignment objective consists of two complementary components: (1) a Marginal Cosine Similarity Loss $\mathcal{L}{mcos}$ with margin $m{cos}$ which aligns the direction of VAE latents with target semantics, and (2) a Marginal Distance Matrix Similarity Loss $\mathcal{L}{mdms}$ with margin $m{dist}$, which preserves the relative spatial layout. The core alignment objectives are formulated as:
$ \begin{aligned} \mathcal{L}{mcos}(z', f) &= \frac{1}{N} \sum{p \in \mathcal{P}} ReLU \left(1 - \cos(z'p, f_p) - m{cos}\right), \ \mathcal{L}{mdms}(z', f) &= \frac{1}{N^2} \sum{p \in \mathcal{P}} \sum_{q \in \mathcal{P}} ReLU \left(\left| \cos(z'p, z'q) - \cos(f_p, f_q) \right| - m{dist} \right), \ \mathcal{L}{align}(z, f) &= \mathcal{L}{mcos}(z', f) + \mathcal{L}{mdms}(z', f), \end{aligned} $
where $\mathcal{P}$ denotes the set of spatial positions and $N=hw$ is the total number of elements.
4.3 Training Strategy
We employ a multi-stage training paradigm designed to progressively improve spatial resolution, refine textual rendering, and ensure robust semantic alignment.
Enhancing Resolution: From Low Resolution to High Resolution.
To facilitate stable training, we adopt a curriculum-based resolution strategy, starting from low-resolution foundations and progressively scaling up to 2K. Throughout this progression, we incorporate a diverse spectrum of aspect ratios to enhance the model's geometric robustness, ensuring the VAE maintains structural integrity across various image compositions without distortion. This progressive upscaling allows the model to first learn basic structures and then capture finer detail and textures.
Integrating Textual Rendering: From Non-text to Text.
To master high-fidelity text reconstruction, we employ a multi-stage data infusion strategy. We start with general-domain images to accelerate initial convergence. Subsequently, we progressively incorporate real-world text-rich samples to address the challenges of complex character recognition. In the final phase, we introduce synthetic text data across varying difficulty levels to refine character precision. As general textures and character detail require different reconstruction focuses, we maintain a balanced ratio between these two types of data to ensure high quality for both.
Calibrating Semantic Alignment: From Strict Alignment to Balanced Reconstruction.
At the beginning of training, we apply strict semantic alignment using a strict margin ($m_{cos}$ and $m_{dist}$). We found that strong alignment at the early stage significantly helps the diffusability of the latent space. As the training progresses, we gradually loose the alignment margins. This allows the model to strike a better balance between maintaining semantic consistency and achieving high-quality pixel-level reconstruction.
5. OmniDoc-TokenBench
Section Summary: OmniDoc-TokenBench is a new dataset of roughly 3,000 text-heavy document images drawn from books, slides, papers, newspapers, and similar sources in both English and Chinese. It was built from an existing document collection by cropping text blocks to a controlled character size, filtering for suitable text density, removing near-duplicates, and performing manual checks to ensure quality. The benchmark evaluates reconstruction quality with ordinary image metrics plus a text-focused score that runs OCR on both the original and rebuilt images and measures how much the recognized text differs, avoiding errors that arise when comparing against manual annotations.
5.1 Motivation
Standard reconstruction benchmarks such as ImageNet ([23]) and FFHQ ([24]) consist predominantly of natural photographs with negligible textual content, making them ill-suited for evaluating text-rich image reconstruction. Conventional pixel-level metrics (PSNR, SSIM) are inherently insensitive to text legibility, as minor stroke distortions may lead to a negligible decrease in conventional evaluation metrics yet render characters unrecognizable. While TokBench ([25]) introduces OCR-based reconstruction evaluation, its data is drawn from scene text datasets where text instances are sparse and character sizes are insufficiently small, making it inadequate for benchmarking reconstruction capability in text-rich scenarios.
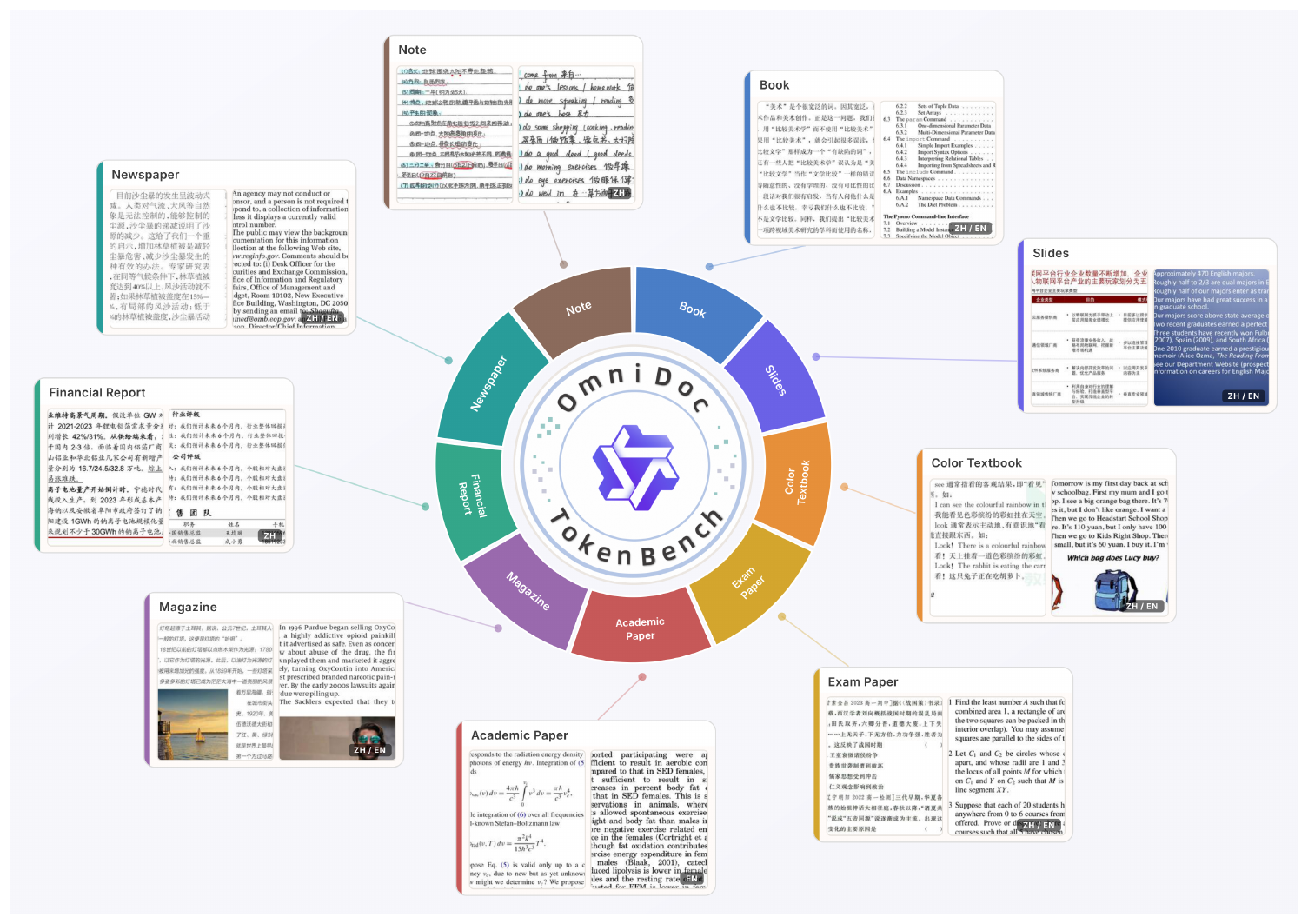
To address these limitations, we propose OmniDoc-TokenBench (Figure 2), a curated benchmark of ${\sim}$ 3K text-rich document images spanning nine categories—book, slides, color textbook, exam paper, academic paper, magazine, financial report, newspaper, and note—covering both alphabetic (English) and logographic (Chinese) text. We perform full-page OCR on both the original and reconstructed images and compute Normalized Edit Distance (NED) ([26, 27]) between their OCR outputs, directly measuring page-level document readability without requiring word-level bounding box annotations. This annotation-free design also facilitates easy scaling to new document types.
5.2 Benchmark Construction
OmniDoc-TokenBench is derived from OmniDocBench ([28]), a document parsing dataset offering fine-grained layout annotations and text-level ground truth across diverse sources. We construct the benchmark through a four-stage pipeline:
Text block extraction and font normalization.
Specifically, we first crop a region from the top-left corner of each text block and then resize it to $256!\times!256$ pixels so that each character occupies approximately $f_{\text{ref}}!\times!f_{\text{ref}}$ pixels. We set $f_{\text{ref}}!=!16$ for Chinese and $f_{\text{ref}}!=!10$ for English. These reference sizes are chosen empirically to provide a meaningful evaluation regime: the resulting inputs remain challenging for VAE reconstruction, especially in preserving fine stroke details, while standard OCR models still maintain high recognition accuracy.
Content filtering.
We apply PP-OCRv5 ([29]) to each sample, and retain only samples whose total count of recognized characters fall within $[200, 600]$ (Chinese) or $[300, 600]$ (English), ensuring sufficient textual density for reliable metric computation while excluding overly sparse or dense samples.
Deduplication.
We compute character-level $n$-gram overlap ($n!=!3$ for Chinese, $n!=!5$ for English) between samples from the same source page and across the same document category. Pairs exceeding overlap thresholds of $0.2$ (intra-page) or $0.3$ (intra-category) are considered duplicates, among each overlapping group, only the sample with the highest character count is retained.
Human inspection.
To ensure data quality, we manually prune samples that are blurred, visually redundant, or contain significant blank regions. The final benchmark maintains a roughly balanced distribution between Chinese and English text.
5.3 Evaluation Methodology
Beyond standard reconstruction metrics (PSNR ([30]), SSIM ([31]), LPIPS ([18]), FID ([32])), we employ NED as the primary text-fidelity metric. A key design choice is using the OCR output of the original image as reference rather than the ground-truth annotations. Since OCR models introduce systematic errors even on clean inputs (e.g., confusing visually similar characters such as "rn" vs. " $m'')$, comparing against annotations would falsely attribute such errors to the VAEs. By applying the same OCR model to both images, these biases largely cancel in the edit distance computation, isolating degradation caused solely by reconstruction.
Concretely, for each image $I_i$ in the benchmark, we apply PP-OCRv5 independently to the original image and its VAE reconstruction, yielding text strings $s_{\mathrm{gt}}^{(i)}$ and $s_{\mathrm{recon}}^{(i)}$, respectively. The benchmark-level NED is defined as:
$ NED = \frac{1}{N}\sum_{i=1}^{N}\left(1 - \frac{d_{edit}!\bigl(s_{gt}^{(i)}, , s_{recon}^{(i)}\bigr)}{\max!\bigl(|s_{gt}^{(i)}|, , |s_{recon}^{(i)}|\bigr)}\right),\tag{1} $
where $d_{\mathrm{edit}}(\cdot, \cdot)$ denotes the Levenshtein distance, $N$ is the total number of benchmark images, and $|\cdot|$ denotes the string length. Each term measures character-level agreement for a single image, averaging over the benchmark yields a robust global estimate of text reconstruction fidelity.
6. Experiments
Section Summary: The researchers tested their Qwen-Image-VAE-2.0 models on standard image datasets such as ImageNet and FFHQ to measure reconstruction quality at different compression levels. Using metrics like PSNR and SSIM, they found that the new models outperformed or matched leading alternatives, with a highly compressed version performing comparably to less efficient ones used in current systems. They also evaluated performance on text-rich images and generation tasks, confirming strong results across the board.
\begin{tabular}{llccccccc}
\toprule
\multirow{2}{*}{\textbf{Baseline}} & \multirow{2}{*}{\textbf{Setting}} & \multicolumn{2}{c}{\textbf{Generation(w/o CFG)}} & \multicolumn{2}{c}{\textbf{Recon@Imagenet}} & \multicolumn{2}{c}{\textbf{Recon@FFHQ}} \\
\cmidrule(lr){3-4} \cmidrule(lr){5-6} \cmidrule(lr){7-8}
& & IS $\uparrow$ & gFID $\downarrow$ & PSNR $\uparrow$ & SSIM $\uparrow$ & PSNR $\uparrow$ & SSIM $\uparrow$ \\
\midrule
\rowcolor{gray!8} \multicolumn{8}{l}{\textit{ViT-backone AutoEncoders}} \\
VTP-Large ([33]) & f16c64 & 146.22 & 5.25 & 26.88 & 0.7718 & 16.52 & 0.3129 \\
RAE-DINOv2-B ([34]) & f16c768 & 139.80 & 6.64 & 19.24 & 0.5025 & -- & -- \\
RAE-SigLIP2-B ([34]) & f16c768 & 103.24 & 11.58 & 19.71 & 0.5279 & -- & -- \\
\midrule
\rowcolor{gray!8} \multicolumn{8}{l}{\textit{f8 Compression VAEs}} \\
FLUX.1-dev ([2]) & f8c16 & 54.64 & 25.41 & 32.84 & 0.9155 & 38.14 & 0.9574 \\
HunyuanVideo ([35]) & f8c16 & 63.57 & 21.29 & 33.21 & 0.9143 & 39.85 & 0.9607 \\
Qwen-Image ([3]) & f8c16 & 73.52 & 17.68 & 33.42 & 0.9159 & 38.75 & 0.9512 \\
Wan2.1 ([17]) & f8c16 & 78.60 & 16.25 & 31.29 & 0.8870 & 38.16 & 0.9456 \\
Cosmos-0.1-CI8x8 ([10]) & f8c16 & 52.89 & 26.02 & 32.33 & 0.9024 & 39.16 & 0.9546 \\
\midrule
\rowcolor{gray!8} \multicolumn{8}{l}{\textit{f16 Compression VAEs}} \\
Cosmos-0.1-CI16x16 ([10]) & f16c16 & 85.14 & 15.21 & 25.13 & 0.7015 & 30.91 & 0.8285 \\
HunyuanVideo-1.5 ([36]) & f16c32 & 69.59 & 19.08 & 31.18 & 0.8710 & 37.30 & 0.9336 \\
HunyuanImage-3.0 ([37]) & f16c32 & 73.84 & 17.87 & 31.08 & 0.8655 & 36.85 & 0.9260 \\
VAVAE ([13]) & f16c32 & \textbf{129.80} & \textbf{6.03} & 27.75 & 0.7986 & 32.84 & 0.8752 \\
Wan2.2 ([17]) & f16c48 & 79.55 & 15.65 & 31.30 & 0.8784 & 37.75 & 0.9386 \\
Stepvideo-T2V ([38]) & f16c64 & 45.18 & 33.53 & 31.54 & 0.8973 & 37.46 & 0.9451 \\
FLUX.2-dev ([39]) & f16c128 & 91.53 & 10.61 & 34.34 & 0.9358 & 40.36 & 0.9676 \\
\rowcolor{blue!5} \textbf{Qwen-Image-VAE-2.0-f16c64} & f16c64 & $\underline{102.76}$ & $\underline{9.52}$ & 32.72 & 0.9086 & 39.14 & 0.9541 \\
\rowcolor{blue!5} \textbf{Qwen-Image-VAE-2.0-f16c128} & f16c128 & 92.42 & 10.29 & \textbf{35.90} & \textbf{0.9519} & \textbf{43.10} & \textbf{0.9795} \\
\midrule
\rowcolor{gray!8} \multicolumn{8}{l}{\textit{f32 Compression VAEs}} \\
DC-AE-sana ([9]) & f32c32 & $\underline{75.73}$ & $\underline{16.88}$ & 24.82 & 0.6897 & 31.35 & 0.8303 \\
HunyuanImage-2.1 ([40]) & f32c64 & 47.96 & 33.32 & 28.67 & 0.8199 & 35.30 & 0.9110 \\
LTX-Video ([8]) & f32c128 & 33.48 & 44.94 & 29.57 & 0.8329 & 35.56 & 0.9051 \\
LTX-2 ([41]) & f32c128 & 42.57 & 38.19 & 26.06 & 0.7925 & 33.63 & 0.9058 \\
\rowcolor{blue!5} \textbf{Qwen-Image-VAE-2.0-f32c128} & f32c128 & \textbf{81.23} & \textbf{15.05} & $\underline{29.69}$ & $\underline{0.8423}$ & $\underline{35.91}$ & $\underline{0.9177}$ \\
\rowcolor{blue!5} \textbf{Qwen-Image-VAE-2.0-f32c192} & f32c192 & 72.31 & 18.33 & \textbf{31.13} & \textbf{0.8785} & \textbf{37.52} & \textbf{0.9381} \\
\bottomrule
\end{tabular}
6.1 Quantitative Results
6.1.1 Performance of Reconstruction
We evaluate the reconstruction performance of Qwen-Image-VAE-2.0 on two standard benchmarks: ImageNet ([23]) and FFHQ([24]). Specifically, we evaluate low-resolution (256p) general-domain performance on ImageNet and high-resolution (1K) performance on FFHQ, using the Peak Signal-to-Noise Ratio (PSNR) and the Structural Similarity Index Measure (SSIM) as our quality metrics. As demonstrated in Table 2, Qwen-Image-VAE-2.0 achieves state-of-the-art reconstruction fidelity within its corresponding compression tiers ($f16$ and $f32$). Notably, our $f32c192$ VAE performs comparably to established $f8$ VAEs (e.g., Wan2.1), despite operating at a $4\times$ compression factor. This superior performance in reconstruction is largely attributable to our refined VAE architecture, expanded channel dimensions, and extensive training regimen.
\begin{tabular}{llccccc}
\toprule
\textbf{Model} & \textbf{Setting} & \textbf{SSIM}\, $\uparrow$ & \textbf{PSNR}\, $\uparrow$ & \textbf{LPIPS}\, $\downarrow$ & \textbf{FID}\, $\downarrow$ & \textbf{NED}\, $\uparrow$ \\
\midrule
\rowcolor{gray!8} \multicolumn{7}{l}{\textit{ViT-backbone AutoEncoders}} \\
RAE-DINOv2-B ([34]) & f16c768 & 0.3261 & 14.32 & 0.2290 & 18.21 & 0.0392 \\
RAE-SigLIP2-B ([34]) & f16c768 & 0.3871 & 14.36 & 0.1972 & 11.49 & 0.0483 \\
VTP-Large ([33]) & f16c64 & \textbf{0.7185} & \textbf{18.11} & \textbf{0.1046} & \textbf{3.94} & \textbf{0.4170} \\
\midrule
\rowcolor{gray!8} \multicolumn{7}{l}{\textit{f8 Compression VAEs}} \\
Wan2.1 ([17]) & f8c16 & 0.8282 & 20.54 & 0.0679 & 4.57 & 0.8021 \\
Cosmos-0.1-CI8x8 ([10]) & f8c16 & 0.9057 & 24.29 & 0.0464 & 2.89 & 0.9033 \\
Qwen-Image ([3]) & f8c16 & 0.8998 & 24.94 & 0.0519 & 4.48 & 0.9073 \\
HunyuanVideo ([35]) & f8c16 & 0.9227 & 25.26 & 0.0434 & 2.03 & 0.9266 \\
FLUX.1-dev ([2]) & f8c16 & \textbf{0.9364} & \textbf{26.24} & \textbf{0.0246} & \textbf{0.55} & \textbf{0.9546} \\
\midrule
\rowcolor{gray!8} \multicolumn{7}{l}{\textit{f16 Compression VAEs}} \\
Cosmos-0.1-CI16x16 ([10]) & f16c16 & 0.5460 & 15.55 & 0.1349 & 7.78 & 0.1547 \\
VAVAE ([13]) & f16c32 & 0.6905 & 17.50 & 0.0974 & 4.45 & 0.3488 \\
HunyuanVideo-1.5 ([36]) & f16c32 & 0.8422 & 21.49 & 0.0839 & 4.67 & 0.6938 \\
HunyuanImage-3.0 ([37]) & f16c32 & 0.8672 & 22.66 & 0.0650 & 3.49 & 0.7753 \\
Wan2.2 ([17]) & f16c48 & 0.8577 & 21.67 & 0.0525 & 3.05 & 0.8310 \\
Stepvideo-T2V ([38]) & f16c64 & 0.8970 & 23.69 & 0.0650 & 6.02 & 0.8838 \\
\rowcolor{blue!5} \textbf{Qwen-Image-VAE-2.0-f16c64} & f16c64 & 0.9279 & 26.00 & 0.0382 & 1.94 & 0.9244 \\
FLUX.2-dev ([39]) & f16c128 & 0.9544 & 27.72 & 0.0216 & \textbf{0.73} & 0.9535 \\
\rowcolor{blue!5} \textbf{Qwen-Image-VAE-2.0-f16c128} & f16c128 & \textbf{0.9706} & \textbf{30.45} & \textbf{0.0167} & 0.79 & \textbf{0.9617} \\
\midrule
\rowcolor{gray!8} \multicolumn{7}{l}{\textit{f32 Compression VAEs}} \\
DC-AE-sana ([9]) & f32c32 & 0.5259 & 15.62 & 0.1441 & 7.26 & 0.0692 \\
LTX-2 ([41]) & f32c128 & 0.7354 & 18.41 & 0.1192 & 9.94 & 0.3569 \\
HunyuanImage-2.1 ([40]) & f32c64 & 0.7805 & 19.85 & 0.0957 & 5.19 & 0.4895 \\
LTX-Video ([8]) & f32c128 & 0.8055 & 20.92 & 0.1190 & 17.10 & 0.5651 \\
\rowcolor{blue!5} \textbf{Qwen-Image-VAE-2.0-f32c128} & f32c128 & 0.8442 & 22.13 & 0.0642 & 3.36 & 0.7065 \\
\rowcolor{blue!5} \textbf{Qwen-Image-VAE-2.0-f32c192} & f32c192 & \textbf{0.8908} & \textbf{23.84} & \textbf{0.0497} & \textbf{1.98} & \textbf{0.8555} \\
\bottomrule
\end{tabular}
6.1.2 Performance of Text Rendering
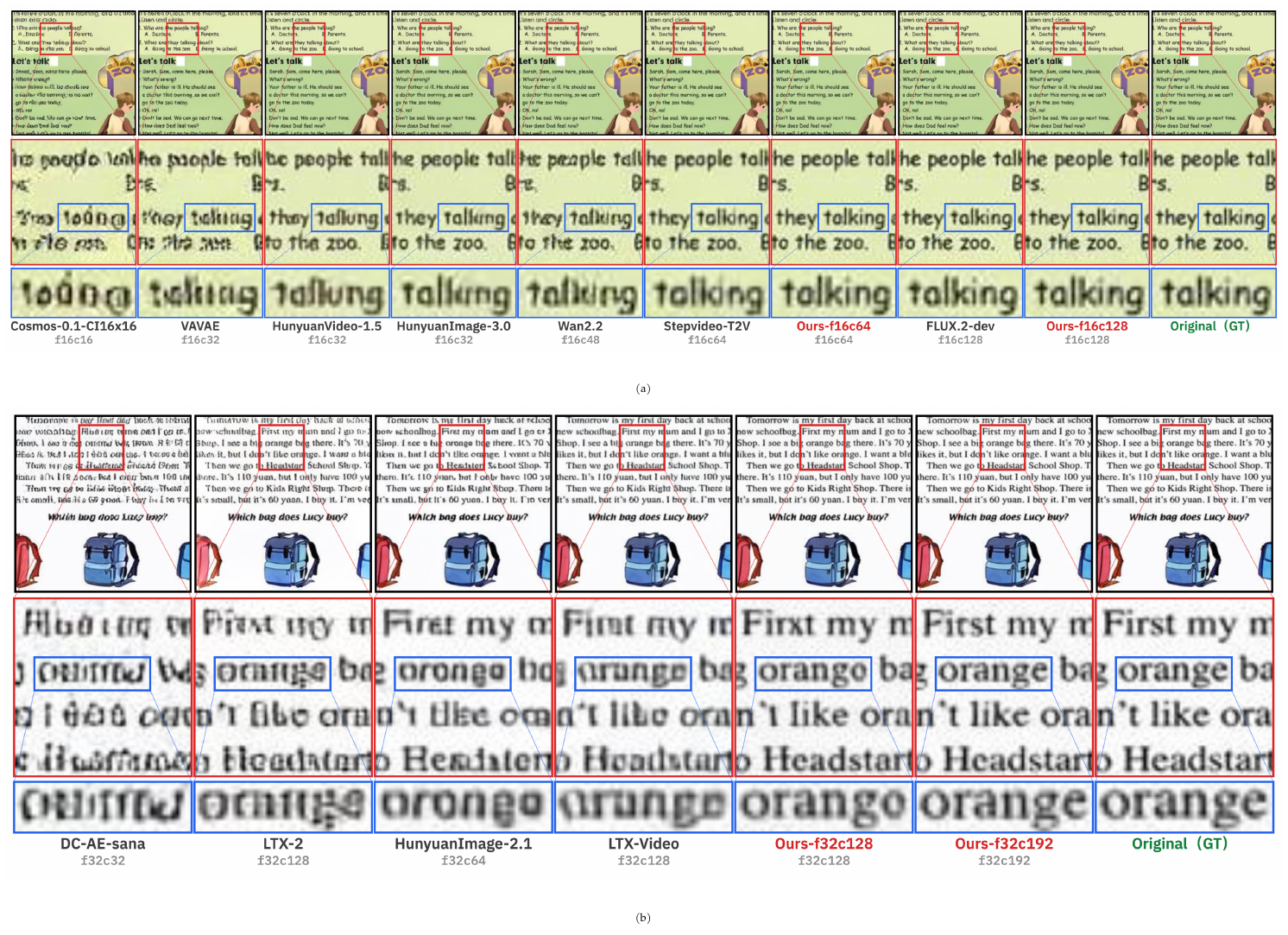
To assess reconstruction fidelity in challenging text-rich scenarios, we evaluate all models on OmniDoc-TokenBench (§ 5), reporting both traditional pixel-based metrics and the proposed OCR-based NED metric. We compute NED on raw OCR outputs without text normalization, while minor spacing artifacts from OCR may inflate edit distance, the evaluation pipeline is applied consistently across all models ensuring fair comparison. Results are summarized in Table 3, with qualitative comparisons in Figure 3.
Traditional Reconstruction Metrics.
Our high-compression VAEs ($f16$ and $f32$ settings) achieve state-of-the-art pixel-level reconstruction, outperforming all competing methods at the same compression ratios. Notably, Qwen-Image-VAE-2.0-f16c128 attains an SSIM of 0.9706 and PSNR of 30.45 dB, surpassing the best $f8$ baseline (FLUX.1-dev at 0.9364 / 26.24 dB) despite $2\times$ higher spatial compression. Even our lighter f16c64 variant surpasses most $f8$ baselines (SSIM 0.9279 vs. HunyuanVideo's 0.9227), demonstrating strong efficiency at moderate channel budgets. Under extreme $f32$ compression where existing methods degrade catastrophically (SSIM as low as 0.5259), our f32c192 achieves 0.8908 SSIM with FID 1.98—outperforming all $f32$ competitors by substantial margins.
NED for Text Fidelity.
Traditional pixel metrics are inherently insensitive to character-level legibility. A single-character reconstruction error such as "orange" $\to$ "orango" incurs negligible PSNR loss (<0.5 dB) yet reduces NED by 16.7%, exposing the semantic corruption that pixel metrics might miss. The NED metric directly measures text preservation by comparing recognized character sequences between original and reconstructed images.
In the $f16$ VAEs, baseline performance varies dramatically: Cosmos-0.1-CI16x16 collapses to NED 0.1547 (${\sim}$ 85% character loss), while others range 0.35–0.88, all below $f8$ state-of-the-art. Our Qwen-Image-VAE-2.0-f16c64 achieves 0.9244, competitive with leading $f8$ methods. Most remarkably, Qwen-Image-VAE-2.0-f16c128 reaches 0.9617, surpassing all evaluated $f8$ VAEs including FLUX.1-dev (0.9546). To the best of our knowledge, this is the first $f16$ autoencoder to achieve text fidelity exceeding $f8$ VAEs.
The $f32$ VAEs further validate our advantage. While competing models exhibit near-total text destruction (NED: 0.07–0.57), our Qwen-Image-VAE-2.0-f32c192 achieves 0.8555, surpassing multiple $f16$ baselines. This cross-compression superiority stems directly from our comprehensive data engineering incorporating diverse text-rich documents and synthetic rendering pipelines.
Correlation Analysis.
We observe an imperfect correlation between pixel metrics and text fidelity. In $f16$, Stepvideo-T2V achieves notably higher NED than HunyuanImage-3.0 (0.8838 vs. 0.7753) despite modest SSIM differences (0.8970 vs. 0.8672); in $f32$, LTX-Video outperforms HunyuanImage-2.1 in NED (0.5651 vs. 0.4895) despite worse FID (17.10 vs. 5.19). These discrepancies validate NED as a necessary complementary metric for text reconstruction evaluation.
6.1.3 Performance of Diffusability
To empirically validate the diffusability of our learned latent space, we evaluate downstream generative performance by training SiT ([42]) on the ImageNet 256 $\times$ 256 dataset. We strictly adhere to the codebase and default hyperparameter settings of [43], reporting generation quality at 80 epochs via the Inception Score (IS) ([44]) and generative FID (gFID). Specifically, we employed the SiT-XL/2 architecture for the $f8$ compression setting, and the SiT-XL/1 architecture for the $f16$ and $f32$ settings. Since higher-dimensional latent space often require larger optimal Classifier-Free Guidance (CFG) ([45]) scales, and the evaluated VAEs possess varying dimensions, we report only the results without guidance to ensure a fair comparison. As shown in Table 2, Qwen-Image-VAE-2.0 demonstrates superior latent space diffusability, consistently outperforming existing high-compression baselines in overall generation quality. Despite their large latent dimensions, our models facilitate rapid DiT convergence. This exceptional diffusability effectively resolves the traditional tripartite trade-off and is primarily driven by our improved semantic alignment strategy and staged alignment paradigm.
6.2 Qualitative Results
6.2.1 Text Rendering
Figure 3 visualizes qualitative reconstruction results across different compression ratios. At $f16$ VAEs (Figure 3a), the degradation gap widens dramatically. Weaker baselines show severe character blurring, stroke merging, and inter-character ghosting—Cosmos-0.1-CI16x16 ([10]) exhibits near-complete text collapse. In contrast, our Qwen-Image-VAE-2.0-f16c128 preserves crisp character boundaries, accurate inter-character spacing, and fine stroke detail.

For $f32$ VAEs (Figure 3b), competing models reduce text to fragmented noise patterns where individual characters become unrecognizable. Our Qwen-Image-VAE-2.0-f32c192 uniquely retains clearly distinguishable character forms and recognizable word boundaries, consistent with its substantially higher NED scores and validating the effectiveness of our architecture under extreme compression constraints.
6.2.2 Diffusability
Figure 4 illustrates selected ImageNet samples generated by SiT-XL, serving as a visual validation of the latent space's semantic coherence and fine-grained detail. To demonstrate cross-scale consistency, samples are generated at $256\times256$ for $f16$ VAEs and $512\times512$ for $f32$ VAEs using a further-trained SiT-XL with classifier-free guidance, following our quantitative training protocol. Across $f16$ and $f32$ compression ratios, the generations maintain high visual fidelity without structural degradation.
6.2.3 Large-scale Text-to-Image Validation
The successful integration of Qwen-Image-VAE-2.0[^1] into the Qwen-Image-2.0 ([6]) further validates the diffusability of our latent space at a foundation-model scale. Operating within this large-scale text-to-image pipeline, our compressed representations readily support complex open-vocabulary conditioning and intricate compositional constraints. The resulting generations consistently demonstrate Qwen-Image-2.0’s core capabilities through precise text rendering and refined photorealistic textures across diverse semantic contexts. This large-scale deployment demonstrates that our latent space preserves the structural stability and information fidelity required for demanding synthesis tasks, thereby confirming the scalability and robustness of our alignment paradigm in advanced generative systems.
[^1]: The VAE integrated into Qwen-Image-2.0 is an intermediate variant derived from the methodological framework established in this work.
7. Conclusion
Section Summary: The paper presents Qwen-Image-VAE-2.0, a family of highly compressed image models designed to support native high-resolution synthesis while balancing compression, detail preservation, and ease of use in generative systems. It achieves this through an improved network architecture with skip connections, training on billions of images plus synthetic text data, and alignment techniques that keep the compressed representations suitable for downstream diffusion models. The result is a practical, efficient foundation that maintains strong visual and textual fidelity, as shown on standard benchmarks.
In this paper, we introduce Qwen-Image-VAE-2.0, a suite of high-compression image VAEs ($f16$ and $f32$) designed to overcome the long-standing bottlenecks in native high-resolution image synthesis. Our work demonstrates a clear technical path to resolving the fundamental tripartite trade-off between high compression ratio, reconstruction fidelity, and downstream diffusability: by leveraging expanded latent channel dimensions to compensate for spatial information loss caused by high compression, while simultaneously applying advanced semantic alignment techniques to ensure the latent space remains suitable for diffusion modeling. To achieve state-of-the-art reconstruction fidelity in high-compression regimes, we adopt an improved VAE architecture featuring Global Skip Connections (GSC), establishing a direct path for fine-grained detail recovery. This is bolstered by a comprehensive data strategy where we scale the training corpus to billions of images and utilize a specialized synthetic document-rendering pipeline to ensure the legibility of dense text—a traditional failure point for high-compression models. To address the challenge of diffusability inherent in high-dimensional latent space, we introduce an improved semantic alignment strategy. By aligning latent representations with middle-layer feature of DINOv2, we significantly accelerate the convergence of downstream DiT. Finally, to ensure practical utility, we implement a light-encoder paradigm and an attention-free backbone, maintaining high throughput and minimal encoding overhead even at ultra-high resolutions. Extensive evaluations on public benchmarks and OmniDoc-TokenBench demonstrate that Qwen-Image-VAE-2.0 not only preserves exceptional structural and textual integrity but also facilitates efficient generative modeling. These models provide a robust foundation for the next generation of visual synthesis systems, marking a significant milestone in efficient image generation.
8. Authors
Section Summary: This section lists the many contributors responsible for the research or project being described. It names two dozen individuals, from Zekai Zhang and Deqing Li through Zikai Zhou, and notes that several share equal credit for the work while one serves as the main contact. The listing simply credits everyone involved without further detail on their specific roles.
Contributors: Zekai Zhang $^{\text{}}$, Deqing Li $^{\text{}}$, Kuan Cao $^{\text{}}$, Yujia Wu $^{\text{}}$, Chenfei Wu $^{\dagger}$, Yu Wu, Liang Peng, Hao Meng, Jiahao Li, Jie Zhang, Kaiyuan Gao, Kun Yan, Lihan Jiang, Ningyuan Tang, Shengming Yin, Tianhe Wu, Xiao Xu, Xiaoyue Chen, Yan Shu, Yanran Zhang, Yilei Chen, Yixian Xu, Yuxiang Chen, Zhendong Wang, Zihao Liu, Zikai Zhou, Yiliang Gu, Yi Wang, Xiaoxiao Xu, Lin Qu
$^{\text{*}}$ Equal contribution.
$^{\dagger}$Corresponding Author.
References
Section Summary: The references section provides a bibliography of around three dozen sources, mainly peer-reviewed papers, arXiv preprints, and technical reports that underpin the document’s discussion of image and video generation technologies. These citations focus on neural network methods such as diffusion models, transformers, autoencoders, and evaluation metrics for visual quality. They range from foundational studies published in 2017 to the most recent work appearing in 2026.
[1] Rombach et al. (2022). High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 10684–10695.
[2] Black Forest Labs (2024). FLUX. https://github.com/black-forest-labs/flux.
[3] Wu et al. (2025). Qwen-image technical report. arXiv preprint arXiv:2508.02324.
[4] Esser et al. (2024). Scaling rectified flow transformers for high-resolution image synthesis. In Forty-first international conference on machine learning.
[5] Gao et al. (2025). Seedream 3.0 technical report. arXiv preprint arXiv:2504.11346.
[6] Bing Zhao et al. (2026). Qwen-Image-2.0 Technical Report. https://arxiv.org/abs/2605.10730. arXiv:2605.10730.
[7] Peebles, William and Xie, Saining (2023). Scalable diffusion models with transformers. In Proceedings of the IEEE/CVF international conference on computer vision. pp. 4195–4205.
[8] HaCohen et al. (2024). Ltx-video: Realtime video latent diffusion. arXiv preprint arXiv:2501.00103.
[9] Chen et al. (2024). Deep Compression Autoencoder for Efficient High-Resolution Diffusion Models. In The Thirteenth International Conference on Learning Representations.
[10] Agarwal et al. (2025). Cosmos world foundation model platform for physical ai. arXiv preprint arXiv:2501.03575.
[11] Chen et al. (2025). Dc-ae 1.5: Accelerating diffusion model convergence with structured latent space. In Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 19628–19637.
[12] Skorokhodov et al. (2025). Improving the Diffusability of Autoencoders. In Forty-second International Conference on Machine Learning.
[13] Yao et al. (2025). Reconstruction vs. generation: Taming optimization dilemma in latent diffusion models. In Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 15703–15712.
[14] Qiu et al. (2025). Image tokenizer needs post-training. arXiv preprint arXiv:2509.12474.
[15] Oquab et al. (2023). Dinov2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193.
[16] Vaswani et al. (2017). Attention is all you need. Advances in neural information processing systems. 30.
[17] Wan et al. (2025). Wan: Open and advanced large-scale video generative models. arXiv preprint arXiv:2503.20314.
[18] Zhang et al. (2018). The unreasonable effectiveness of deep features as a perceptual metric. In Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 586–595.
[19] Isola et al. (2017). Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 1125–1134.
[20] Siméoni et al. (2025). Dinov3. arXiv preprint arXiv:2508.10104.
[21] He et al. (2022). Masked autoencoders are scalable vision learners. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 16000–16009.
[22] Bolya et al. (2025). Perception encoder: The best visual embeddings are not at the output of the network. arXiv preprint arXiv:2504.13181.
[23] Deng et al. (2009). Imagenet: A large-scale hierarchical image database. In 2009 IEEE conference on computer vision and pattern recognition. pp. 248–255.
[24] Tero Karras et al. (2018). A Style-Based Generator Architecture for Generative Adversarial Networks. 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 4396-4405. https://api.semanticscholar.org/CorpusID:54482423.
[25] Junfeng Wu et al. (2025). TokBench: Evaluating Your Visual Tokenizer before Visual Generation. ArXiv. abs/2505.18142. https://api.semanticscholar.org/CorpusID:278886218.
[26] Xi Liu et al. (2019). ICDAR 2019 Robust Reading Challenge on Reading Chinese Text on Signboard. 2019 International Conference on Document Analysis and Recognition (ICDAR). pp. 1577-1581. https://api.semanticscholar.org/CorpusID:209439793.
[27] Andrés Marzal and Enrique Vidal (1993). Computation of Normalized Edit Distance and Applications. IEEE Trans. Pattern Anal. Mach. Intell.. 15. pp. 926-932. https://api.semanticscholar.org/CorpusID:14851115.
[28] Linke Ouyang et al. (2024). OmniDocBench: Benchmarking Diverse PDF Document Parsing with Comprehensive Annotations. 2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 24838-24848. https://api.semanticscholar.org/CorpusID:274609934.
[29] Cheng Cui et al. (2025). PaddleOCR 3.0 Technical Report. https://arxiv.org/abs/2507.05595. arXiv:2507.05595.
[30] Hore, Alain and Ziou, Djemel (2010). Image quality metrics: PSNR vs. SSIM. In 2010 20th international conference on pattern recognition. pp. 2366–2369.
[31] Wang et al. (2004). Image quality assessment: from error visibility to structural similarity. IEEE transactions on image processing. 13(4). pp. 600–612.
[32] Heusel et al. (2017). Gans trained by a two time-scale update rule converge to a local nash equilibrium. Advances in neural information processing systems. 30.
[33] Yao et al. (2025). Towards Scalable Pre-training of Visual Tokenizers for Generation. arXiv preprint arXiv:2512.13687.
[34] Zheng et al. (2025). Diffusion transformers with representation autoencoders. arXiv preprint arXiv:2510.11690.
[35] Kong et al. (2024). Hunyuanvideo: A systematic framework for large video generative models. arXiv preprint arXiv:2412.03603.
[36] Wu et al. (2025). Hunyuanvideo 1.5 technical report. arXiv preprint arXiv:2511.18870.
[37] Cao et al. (2025). Hunyuanimage 3.0 technical report. arXiv preprint arXiv:2509.23951.
[38] Ma et al. (2025). Step-video-t2v technical report: The practice, challenges, and future of video foundation model. arXiv preprint arXiv:2502.10248.
[39] Black Forest Labs (2025). FLUX.2: Frontier Visual Intelligence. https://bfl.ai/blog/flux-2.
[40] Tencent Hunyuan Team (2025). HunyuanImage 2.1: An Efficient Diffusion Model for High-Resolution (2K) Text-to-Image Generation. https://github.com/Tencent-Hunyuan/HunyuanImage-2.1.
[41] HaCohen et al. (2026). LTX-2: Efficient Joint Audio-Visual Foundation Model. arXiv preprint arXiv:2601.03233.
[42] Ma et al. (2024). Sit: Exploring flow and diffusion-based generative models with scalable interpolant transformers. In European Conference on Computer Vision. pp. 23–40.
[43] Leng et al. (2025). Repa-e: Unlocking vae for end-to-end tuning of latent diffusion transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 18262–18272.
[44] Salimans et al. (2016). Improved techniques for training gans. Advances in neural information processing systems. 29.
[45] Ho, Jonathan and Salimans, Tim (2022). Classifier-free diffusion guidance. arXiv preprint arXiv:2207.12598.