Can LLMs Clean Up Your Mess? A Survey of Application-Ready Data Preparation with LLMs
Wei Zhou, Jun Zhou, Haoyu Wang, Zhenghao Li, Qikang He, Shaokun Han, Guoliang Li,
Xuanhe Zhou, Yeye He, Chunwei Liu, Zirui Tang, Bin Wang, Shen Tang, Kai Zuo, Yuyu Luo,
Zhenzhe Zheng, Conghui He, Jingren Zhou, Fan Wu
\faGithub Awesome-Data-LLM: https://github.com/weAIDB/awesome-data-llm
${}^{*}$ Wei Zhou, Jun Zhou, Haoyu Wang, Zhenghao Li, Qikang He, Shaokun Han, Xuanhe Zhou, Zhenzhe Zheng, and Fan Wu are with Shanghai Jiao Tong University, Shanghai, China. Guoliang Li is with Tsinghua University, Beijing, China. Yeye He is with Microsoft Research. Chunwei Liu is with MIT CSAIL, USA. Bin Wang and Conghui He are with Shanghai AI Laboratory. Shen Tang and Kai Zuo are with Xiaohongshu Inc. Yuyu Luo is with the Hong Kong University of Science and Technology (Guangzhou), China. Jingren Zhou is with Alibaba Group. ${}^{†}$ Corresponding author: Xuanhe Zhou ([email protected]).
Keywords: Data Preparation, Data Cleaning, Data Integration, Data Enrichment, LLMs, Agents
Abstract
Data preparation aims to denoise raw datasets, uncover cross-dataset relationships, and extract valuable insights from them, which is essential for a wide range of data-centric applications. Driven by (i) rising demands for application-ready data (e.g., for analytics, visualization, decision-making), (ii) increasingly powerful LLM techniques, and (iii) the emergence of infrastructures that facilitate flexible agent construction (e.g., using Databricks Unity Catalog), LLM-enhanced methods are rapidly becoming a transformative and potentially dominant paradigm for data preparation.
By investigating hundreds of recent literature works, this paper presents a systematic review of this evolving landscape, focusing on the use of LLM techniques to prepare data for diverse downstream tasks. First, we characterize the fundamental paradigm shift, from rule-based, model-specific pipelines to prompt-driven, context-aware, and agentic preparation workflows. Next, we introduce a task-centric taxonomy that organizes the field into three major tasks: data cleaning (e.g., standardization, error processing, imputation), data integration (e.g., entity matching, schema matching), and data enrichment (e.g., data annotation, profiling). For each task, we survey representative techniques, and highlight their respective strengths (e.g., improved generalization, semantic understanding) and limitations (e.g., the prohibitive cost of scaling LLMs, persistent hallucinations even in advanced agents, the mismatch between advanced methods and weak evaluation). Moreover, we analyze commonly used datasets and evaluation metrics (the empirical part). Finally, we discuss open research challenges and outline a forward-looking roadmap that emphasizes scalable LLM-data systems, principled designs for reliable agentic workflows, and robust evaluation protocols.
1. Introduction
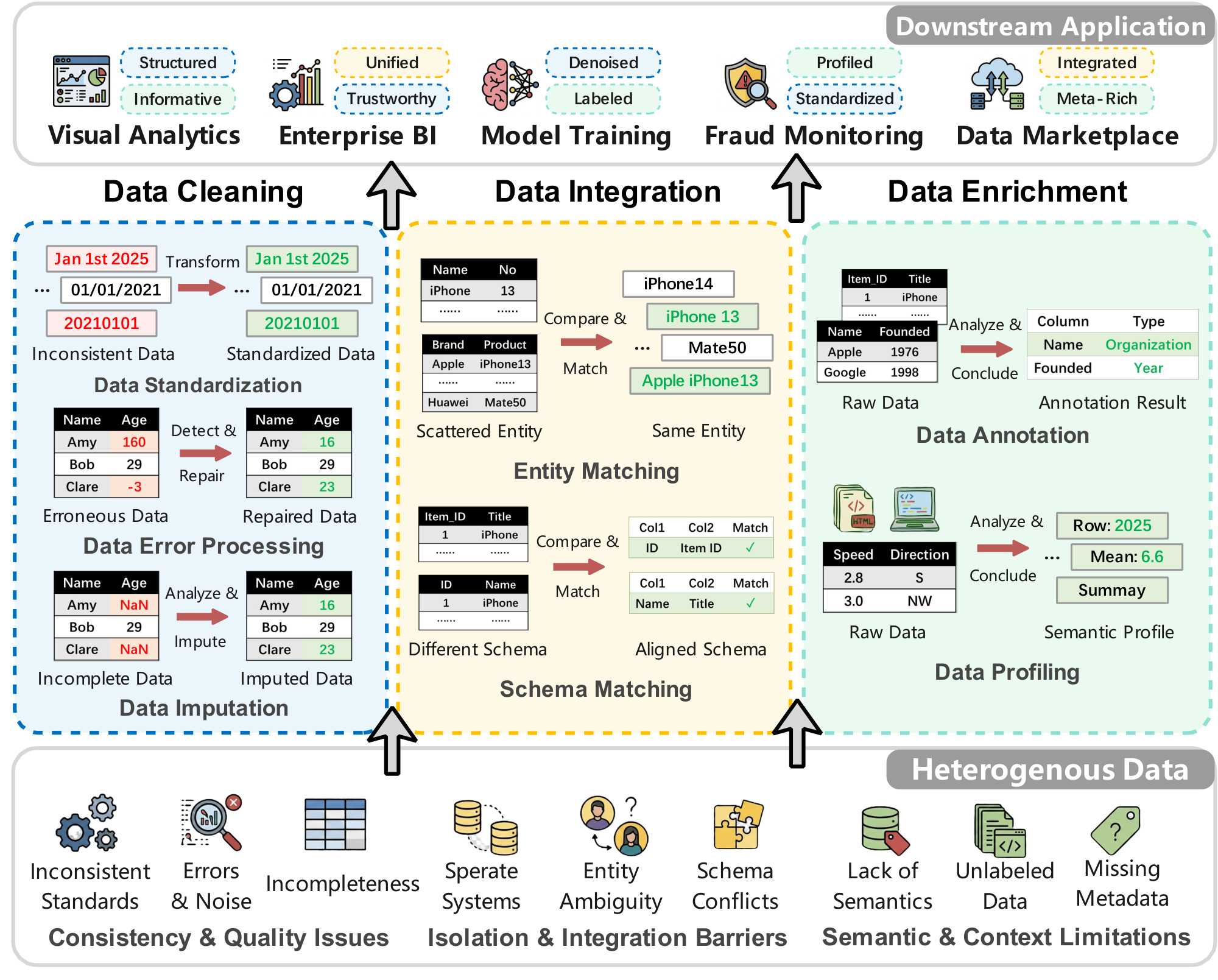
Data preparation refers to the process of transforming raw datasets into high-quality ones (e.g., trustworthy and comprehensive) by denoising corrupted inputs, identifying cross-dataset relationships, and extracting meaningful insights. Despite its foundational role in downstream applications such as business intelligence (BI) analytics [1, 2], machine learning (ML) model training [3, 4], and data sharing [5, 6], data preparation remains a critical bottleneck in real scenarios. For instance, an estimated 20%–30% of enterprise revenue is lost due to data inefficiencies [7]. As illustrated in Figure 1, real-world data inefficiencies primarily arise from three sources: (1) Consistency & Quality Issues (e.g., non-standard formats, noise, and incompleteness); (2) Isolation & Integration Barriers (e.g., disparate systems, entity ambiguity, and schema conflicts); and (3) Semantic & Context Limitations (e.g., missing metadata and unlabeled data). To these challenges, data preparation [8, 9] involves three main tasks: Data Cleaning, Data Integration, and Data Enrichment, which transform raw inputs into unified, reliable, and enriched datasets. As the volume and heterogeneity of data continue to surge (e.g., global data volume is forecast to triple from 2025 to 2029 [10]), the imperative for effective data preparation has never been greater. However, traditional data preparation methods rely heavily on static rules [11, 12], manual interventions, or narrowly scoped models [13, 14], motivating the need for more intelligent, adaptive solutions.
1.1 Limitations of Traditional Data Preparation
As discussed above, traditional preparation techniques, ranging from heuristic rule-based systems [15, 16, 12] to domain-specific machine-learning models [17, 18, 13, 14], face several fundamental limitations.
$\bullet$ (Limitation ❶) High Manual Effort and Expertise Dependence. Traditional data preparation methods largely depend on fixed rules and domain-specific configurations, such as regular expressions and validation constraints [19, 20]. This reliance demands substantial manual effort and specialized expert knowledge, introducing significant development and maintenance barriers. For instance, data standardization typically requires complex, handcrafted scripts (e.g., user-defined functions) or manual constraints (e.g., date formatting rules) [11, 21]. Similarly, data error processing pipelines often rely on fixed detect-then-correct workflows defined by manually crafted rules, which are not only labor-intensive to maintain but also prone to introducing new errors (e.g., incorrectly repaired values) during correction [22].
$\bullet$ (Limitation ❷) Limited Semantic Awareness in Preparation Enforcement. Conventional rule-based approaches predominantly rely on statistical patterns (e.g., computing missing value percentages) or syntactic matching, which fundamentally limit their ability to accurately identify complex inconsistencies that require semantic reasoning. For example, in data integration, traditional similarity-based matching techniques struggle to resolve semantic ambiguities (such as abbreviations, synonyms, or domain-specific terminology) due to the lack of commonsense or domain-specific knowledge [23]. Moreover, keyword-based search mechanisms in data enrichment frequently fail to capture user intent, creating a semantic gap that leaves relevant datasets undiscovered [24, 25].
$\bullet$ (Limitation ❸) Poor Generalization across Diverse Preparation Tasks and Data Modalities. Traditional deep learning models typically require specialized feature engineering [14] or domain-specific training [13], which severely restricts their generalizability across diverse domains and data modalities. For example, fine-tuned entity-matching models exhibit significant performance degradation when applied to out-of-distribution entities [26]. Similarly, supervised data annotation models struggle to perform well on data from underrepresented subgroups or domains with limited labeled examples [27, 28]. Furthermore, methods designed for structured tabular data often fail to effectively process semi-structured text or other modalities [29], limiting their applicability in heterogeneous data environments.
$\bullet$ (Limitation ❹) Preparation Reliance on Labeled Data and Limited Knowledge Integration. Small-model-based approaches typically require large volumes of high-quality and accurately labeled examples, which can be expensive to obtain at scale [30]. For instance, in data annotation, the prohibitively high cost of expert labeling limits the scale of reliable datasets, whereas crowdsourced alternatives often exhibit unstable quality [31]. Moreover, existing methods often lack the flexibility to integrate diverse contexts. For example, general retrieval-based systems [24] face challenges in effectively integrating structured table data with unstructured free-text context.
1.2 LLM-Enhanced Data Preparation: Driving Forces And Opportunities
To overcome these limitations, recent advances in large language models (LLMs) have catalyzed a paradigm shift in data preparation [32, 33]. This transformation is fueled by three converging forces. First, the increasing demand for application-ready data, which is essential for scenarios such as personalizing customer experiences [34] and enabling real-time analytics. Second, the methodological shift from static, rule-based pipelines to LLM agent frameworks that can autonomously plan (e.g., interpret ambiguous data patterns), execute (e.g., adapt to heterogeneous formats), and reflect on data preparation actions. Third, infrastructure advances that support flexible and cost-effective LLM technique usage, such as the API integrations for LLM agent construction in Databricks Unity Catalog [35] and the proliferation of open-source LLMs.
By leveraging generative capabilities, semantic reasoning, and extensive pretraining, $\textsc{LLMs}$ introduce a paradigm shift that offers opportunities in four aspects.
$\bullet$ (Opportunity ❶) From Manual Preparation to Instruction-Driven and Agentic Automation. To address the high manual effort and expertise dependence in data preparation, LLM-enhanced techniques facilitate natural-language interactions and automated workflow generation [36, 19]. For instance, in data cleaning, users can directly define transformation logic using textual prompts rather than writing complex user-defined functions [11]. Moreover, advanced data cleaning frameworks (e.g., Clean Agent [36], AutoDCWorkflow [19]) have integrated LLM-enhanced agents to orchestrate cleaning workflows, in which agents plan and execute pipelines by identifying quality issues and invoking external tools to achieve effective data cleaning with minimal human intervention.
$\bullet$ (Opportunity ❷) Semantic Reasoning for Consistent Preparation Enforcement. Unlike traditional methods that rely on syntactic similarity or heuristics, LLM-enhanced approaches incorporate semantic reasoning into preparation workflows [20, 22]. For example, in data integration, LLMs utilize pretrained semantic knowledge to resolve ambiguities of abbreviations, synonyms, and domain-specific terminology [23]. In data enrichment, LLMs infer semantic column groups and generate human-aligned dataset descriptions, enabling more accurate dataset understanding and enrichment beyond keyword-based or statistical profiling [37, 38].
$\bullet$ (Opportunity ❸) From Domain-Specific Preparation Training to Cross-Modal Generalization. LLM-enhanced techniques reduce reliance on domain-specific feature engineering and task-specific training, demonstrating strong adaptability across data modalities [39]. For example, in data cleaning, LLMs handle heterogeneous schemas and formats by following instructions via few-shot, similarity-based in-context prompting without fine-tuning [40]. For tabular data integration, specialized encoders (e.g., TableGPT2 [41]) bridge the modality gap between tabular structures and textual queries, ensuring robust performance without extensive domain-specific feature engineering.
$\bullet$ (Opportunity ❹) Knowledge-Augmented Preparation with Minimal Labeling. LLMs alleviate the need for large volumes of high-quality labels by exploiting pretrained knowledge and dynamically integrating external context [42]. For example, in entity matching, some methods incorporate external domain knowledge (e.g., from Wikidata) and structured pseudo-code into prompts to reduce reliance on task-specific training pairs [43]. In data cleaning and data enrichment, Retrieval-Augmented Generation (RAG) based frameworks retrieve relevant external information from data lakes, enabling accurate value restoration and metadata generation without requiring fully observed training data [44, 25].
1.3 Contributions and Differences with Existing Surveys
We comprehensively review recent advances in LLM-enhanced application-ready data preparation (e.g., for decision-making, analytics, or other applications) with a focused scope. Instead of covering all possible preparation tasks, we concentrate on three core tasks that appear most in existing studies [8, 9] and real-world pipelines [45] (i.e., data cleaning, data integration, and data enrichment in Figure 2). Within this scope, we present a task-centered taxonomy, summarize representative methods and their technical characteristics, and discuss open problems and future research directions.
• Data Cleaning. Targeting the Consistency & Quality Issues in Figure 1, this task aims to produce standardized and denoised data. We focus on three main subtasks: (1) Data Standardization, which transforms diverse representations into unified formats using specific prompts [11, 21] or agents that automatically generate cleaning workflows [36, 19]; (2) Data Error Processing, which detects and repairs erroneous values (e.g., spelling mistakes, invalid values, outlier values) through direct LLM prompting [46, 37, 20], methods that add context to the model [40, 47], or fine-tuning models for specific error types [20]; and (3) Data Imputation, which fills missing values using clear instructions and retrieval-augmented generation to find relevant information [44].
• Data Integration. Addressing the Isolation & Integration Barriers in Figure 1, this task aims to identify and combine related data from different sources. We review two core subtasks: (1) Entity Matching, which links records referring to the same real-world entity using structured prompts [26, 48], sometimes supported by code-based reasoning [43]; and (2) Schema Matching, which matches columns or attributes between datasets using direct prompting [49], RAG techniques with multiple models [50], knowledge graph-based methods [23], or agent-based systems that plan the matching process [51, 52].
• Data Enrichment. Focusing on the Semantic & Context Limitations, this task augments datasets with semantic insights. We cover two key subtasks: (1) Data Annotation, which assigns data labels or types using various prompting strategies [53, 54, 28], supported by retrieval-based [55] and LLM-generated context [24]; and (2) Data Profiling, which generates semantic profiles and summaries (e.g., metadata) using task-specific prompts [38, 56], often enhanced with external context via retrieval-augmented generation [25].
:::
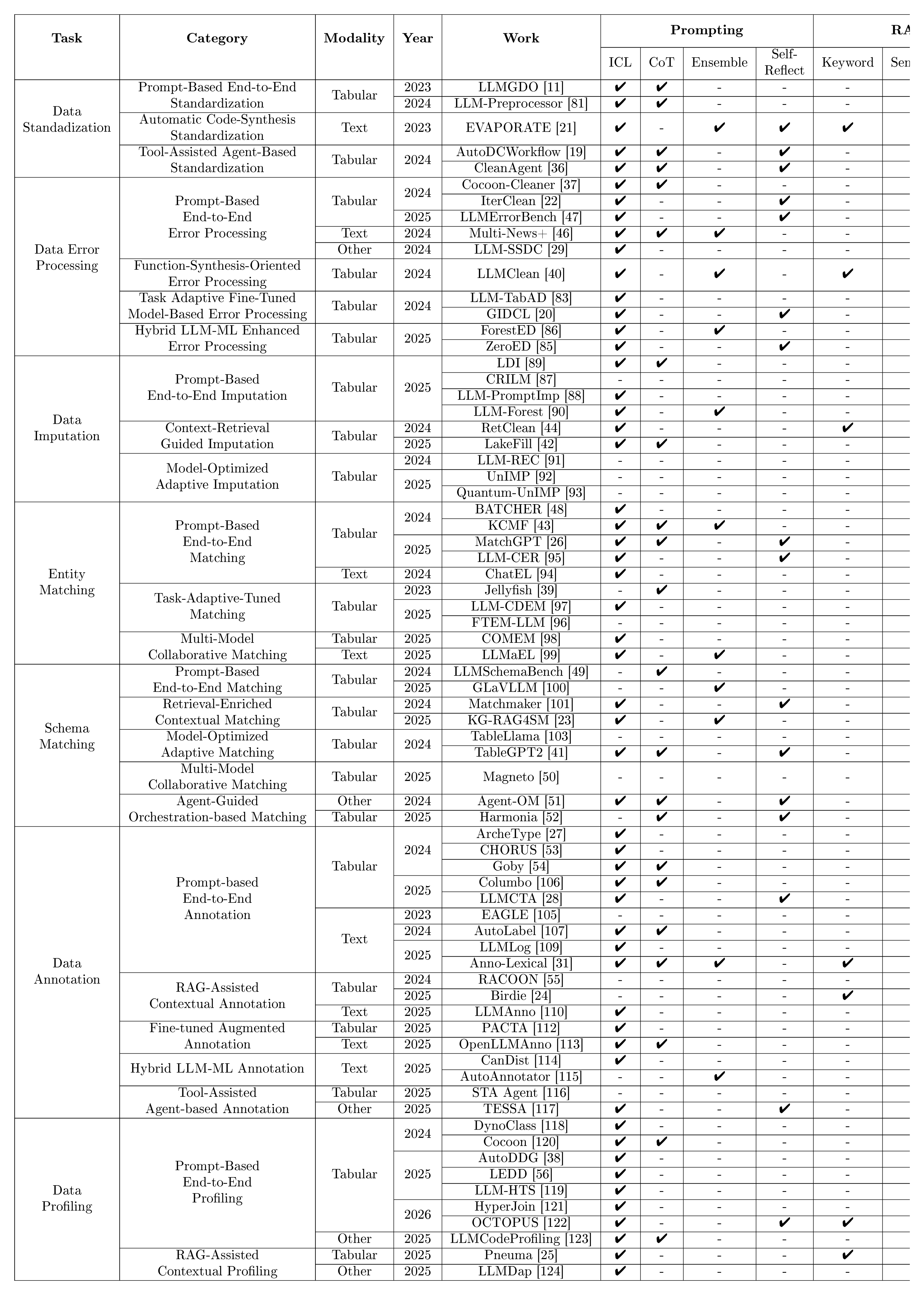
Table 1: Technique Overview of $\textsc{LLM}$-Enhanced $\textsc{Data Preparation}$ Methods.
:::
Compared with existing $\textsc{LLM}$ and data preparation surveys [57, 58, 59, 32, 60, 61, 33, 62, 63, 64], our survey differs in several significant aspects.
$\bullet$ Holistic vs. Limited Task Scope. We provide a comprehensive review of three fundamental data preparation tasks (cleaning, integration, enrichment) across diverse data modalities, including table and text. In contrast, existing surveys typically limit their scope to specific tasks [65, 57] or only the tabular modality [33, 62]
$\bullet$ Systematic Taxonomy vs. Coarse or Narrow Method Category. We propose a unified taxonomy that systematically organizes existing $\textsc{LLM}$ -enhanced methods by underlying techniques, including prompt-based and $\textsc{LLM}$ agent-based frameworks. In contrast, prior surveys either classifies works using coarse, general categories [8] or limit their focus to specific methods, such as agent-based systems [9].
$\bullet$ Paradigm Shift Summary vs. Static Description. We systematically examine how data preparation has evolved from rule-based systems to LLM agent frameworks, summarizing the corresponding advantages and limitations. In contrast, prior studies [8] present works individually, offering limited analysis of paradigm shifts and little discussion of the field's evolution.
$\bullet$ Emerging Challenges and Roadmap vs. Conventional Perspectives. We summarize challenges in the LLM era, including inference costs, hallucinations, and cross-modal consistency, and outline a forward-looking roadmap. This distinguishes our work from existing surveys that focus primarily on typical issues (e.g., scalability) or offer generic conclusions, providing guidance for the next-generation data preparation.
Moreover, we have the following observations on the evolution of methodology across data preparation tasks.
$\bullet$ Shift Toward Cost-Efficient Hybrid Methods. Recent work moves beyond exclusive reliance on LLM inference and instead adopts hybrid approaches. Among them, LLMs either generate executable preparation programs or transfer their reasoning capabilities to smaller language models (SLMs), thereby reducing execution cost and improving scalability.
$\bullet$ Reduced Emphasis on Task-Specific Fine-Tuning. The focus has shifted away from maintaining heavily fine-tuned, task-specific LLMs toward methods that optimize other aspects, such as the input construction. Techniques such as retrieval augmentation and structured serialization are used to adapt general-purpose models to new tasks, enabling greater flexibility and lower maintenance overhead.
$\bullet$ Limited Attempts of Agentic Implementations. Although agent-based orchestration supports more autonomous data preparation workflows, relatively few systems have been fully studied and implemented in practice. This gap indicates that reliable and robust agentic deployment remains to be explored.
$\bullet$ Task-Specific Methodology Difference. Data cleaning employs a hybrid LLM-ML approach for accurate error detection and repair; data integration emphasizes multi-model collaboration to scale matching and alignment; and data enrichment integrates retrieval-augmented and hybrid prompting techniques to enhance the semantic understanding of data and metadata.
$\bullet$ Cross-Modal Generalization with Unified Representations. Recent methods increasingly support multiple data modalities within a single architecture. By using shared semantic representations, these methods process tables, text, and other data uniformly, reducing the reliance on modality-specific feature engineering.
2. Data Preparation: Definition and Scope
In this section, we provide a clear definition of three fundamental data preparation tasks, including Data Cleaning to remove errors and inconsistencies from raw data, Data Integration to combine and harmonize data from multiple sources, and Data Enrichment to identify patterns, relationships, and knowledge that support informed decisions.
Data Cleaning aims to convert corrupted or low-quality data within a dataset into a trustworthy form suitable for downstream tasks (e.g., statistical analysis). It involves tasks such as fixing typographical errors, resolving formatting inconsistencies, and handling violations of data dependencies. Recent $\textsc{LLM}$ -enhanced studies primarily focus on three critical tasks including data standardization, data error detection and correction of data errors, and data imputation.
$\bullet$ (1) Data Standardization [66, 67] aims to transform heterogeneous, inconsistent, or non-conforming data into a unified representation that satisfies predefined consistency requirements. Formally, given a dataset $\mathcal{D}$ and consistency criteria $\mathcal{C}$, it applies or learns a standardization function $f_{std}$ such that the output dataset $\mathcal{D}{std}=f{std}(\mathcal{D}, \mathcal{C})$ satisfies $\mathcal{C}$. Typical tasks include format normalization (e.g., converting dates from "7th April 2021" to "20210407"), case normalization (e.g., "SCHOOL" to "school"), and symbol or delimiter cleanup (e.g., removing redundant separators "1000 ." to obtain "1000"). $\textsc{LLM}$ -enhanced methods leverage context-aware prompting and reasoning-driven code synthesis to produce automated, semantically consistent transformations, reducing reliance on manual pattern definition and improving generalization across heterogeneous data formats.
$\bullet$ (2) Data Error Processing [15, 68, 69] refers to the two-stage process of detecting erroneous values and subsequently repairing them to restore data reliability. Formally, given a dataset $\mathcal{D}$ and a set of error types $\mathcal{K}$, an detection function $f_{id}(\mathcal{D}, \mathcal{K})$ identifies an error set $\mathcal{D}{err}$, after which a repair function $f{fix}$ produces a refined dataset $\mathcal{D}{fix} = f{fix}(\mathcal{D}, \mathcal{D}{err})$ such that $f{id}(\mathcal{D}_{fix}, \mathcal{K}) = \emptyset$ . Typical tasks include identifying data irregularities (e.g., constraint violations) and performing data corrections (e.g., resolving encoding errors) to uphold data correctness. $\textsc{LLM}$ -enhanced techniques employ hybrid LLM–ML architectures and executable code generation to deliver accurate, scalable error identification and correction, thereby lowering dependence on hand-crafted rules and boosting adaptability across varied, noisy datasets.
$\bullet$ (3) Data Imputation [70, 71, 160] refers to the task of detecting missing data entries and estimating plausible values for them, with the goal of restoring a dataset’s structural completeness and logical coherence. More formally, given a dataset $\mathcal{D}$ containing missing entries, the objective is to learn or apply an imputation function $f_{imp}$ that yields a completed dataset $\mathcal{D}{imp} = f{imp}(\mathcal{D})$, in which all previously missing entries are filled with inferred, plausible values. Typical tasks include predicting absent columns based on correlated attributes (e.g., deducing a missing city from a phone area code) or exploiting auxiliary sources (e.g., inferring missing product attributes using relevant tuples from a data lake). $\textsc{LLM}$ -enhanced approaches use semantic reasoning and external knowledge to generate accurate, context-aware replacements, lessening dependence on fully observed training data and enhancing generalization across heterogeneous datasets.
Data Integration aims to align elements across diverse datasets so that they can be accessed and analyzed in a unified, consistent manner. Instead of exhaustively enumerating all integration task, this survey focuses on entity matching and schema matching, as these are key steps in real-world data integration workflows and have received the most attention in recent LLM-based research.
$\bullet$ (1) Entity Matching [72, 73] refers to the task of deciding whether two records correspond to the same real-world entity, facilitating data alignment within a single dataset or across multiple datasets. More formally, given two collections $R_1$ and $R_2$ and a record pair $(r_1, r_2)$ with $r_1 \in R_1$ and $r_2 \in R_2$, the objective is to estimate and assign a score to the likelihood that the two records describe the same entity. Typical subtasks include mapping product listings across different e-commerce sites (e.g., associating the same item on Amazon and eBay) and detecting duplicate customer entries. $\textsc{LLM}$ -enhanced entity matching leverages structured prompting and collaboration among multiple models to deliver robust and interpretable matching, reducing dependence on task-specific training and enhancing generalization across diverse schemas.
$\bullet$ (2) Schema Matching [74, 75, 76] aims to identify semantic correspondences between columns or tables across heterogeneous schemas, thereby supporting integrated data access and analysis. Formally, given a source schema $S_s$ and a target schema $S_t$, each represented as a collection of tables with their respective column sets, the goal is to learn a mapping function $f_{sm}$ that maps every source column $A_s$ to a semantically equivalent target column $A_t$ (or to $\emptyset$ if no suitable counterpart exists). Common subtasks involve matching columns whose names with synonymous meanings (e.g., linking price in one table with cost in another) and detecting correspondences between tables (e.g., aligning CustomerInfo with ClientDetails). $\textsc{LLM}$ -enhanced schema matching leverages prompt-based reasoning, retrieval-augmented information, and multi-agent coordination to handle semantic ambiguity and structural variation, thereby lowering reliance on hand-crafted rules and improving alignment quality across heterogeneous domains.
{Data Enrichment} focuses on augmenting datasets by adding semantic labels and descriptive metadata, or by discovering complementary datasets that increase their value for downstream tasks (e.g., data analysis). It involves subtasks such as classifying column types and producing dataset-level descriptions. This survey concentrates on data annotation and data profiling, which represent the predominant enrichment operations in existing LLM-enhanced studies.
$\bullet$ (1) Data Annotation [77, 78] aims to attach semantic or structural labels to elements in raw data so that they can be understood and utilized by downstream applications. Formally, given a dataset $\mathcal{D}$, the objective is to define a labeling function $f_{ann}$ that maps each data element to one or more labels in $\mathcal{L}$, such as its semantic role or data type. Typical subtasks include semantic column-type annotation (e.g., identifying a column as CustomerID or birthDate), table-class detection (e.g., determining that a table is an Enterprise Sales Record), and cell entity annotation (e.g., linking the cell Apple to the entity Apple_Inc). $\textsc{LLM}$ -enhanced annotation leverages instruction-based prompting, retrieval-augmented context, and fine-tuning to deliver precise, scalable, and domain-sensitive labeling, substantially decreasing manual workload and reducing manual effort and mitigating hallucination compared to traditional task-specific models.
$\bullet$ (2) Data Profiling [79, 80] refers to the task of systematically analyzing a dataset to derive its structural, statistical, and semantic properties, as well as identifying associations with relevant datasets, thereby producing rich metadata that facilitates data comprehension and quality evaluation. Formally, for a dataset $\mathcal{D}$, a profiling function $f_{pro}$ generates a metadata collection $\mathcal{M}={m_1, \ldots, m_k}$, where each metadata element $m_i$ encodes characteristics such as distributional statistics, structural regularities, semantic categories, or connections to semantically related datasets. Common subtasks include semantic metadata generation (e.g., summarizing the contents of tables and assigning domain-aware descriptions to columns) and structural relationship extraction (e.g., clustering related columns and inferring hierarchical dependencies). $\textsc{LLM}$ -enhanced profiling combines prompt-based analysis, retrieval-augmented contextualization, and layered semantic reasoning to yield accurate, interpretable metadata that improves data exploration, enables quality assurance, and offers a reliable foundation for downstream applications.
Unlike data preparation pipelines designed specifically for training, fine-tuning, or directly prompting $\textsc{LLMs}$ themselves [8], this survey focuses on $\textsc{LLM}$ -enhanced data preparation methods that aim to refine the quality, consistency, and semantic coherence of data used in downstream analytical and machine-learning applications, as summarized in Table 1.
3. LLM for Data Cleaning
Traditional data cleaning methods rely on rigid rules and constraints (e.g., ZIP code validation), which demand substantial manual effort and domain expertise (e.g., schema knowledge in financial data) [19, 20]. Moreover, they often require task-specific training, which limits their generalization across different scenarios [21]. Recent studies show that $\textsc{LLMs}$ can address these limitations by reducing manual and programming effort (e.g., offering natural language interfaces), and supporting the seamless integration of domain knowledge for the following tasks.
Data Standardization. Data standardization refers to transforming heterogeneous or non-uniform values into a unified format, enabling dependable analysis and efficient downstream processing. Existing $\textsc{LLM}$ -enhanced standardization techniques can be classified into three main categories.
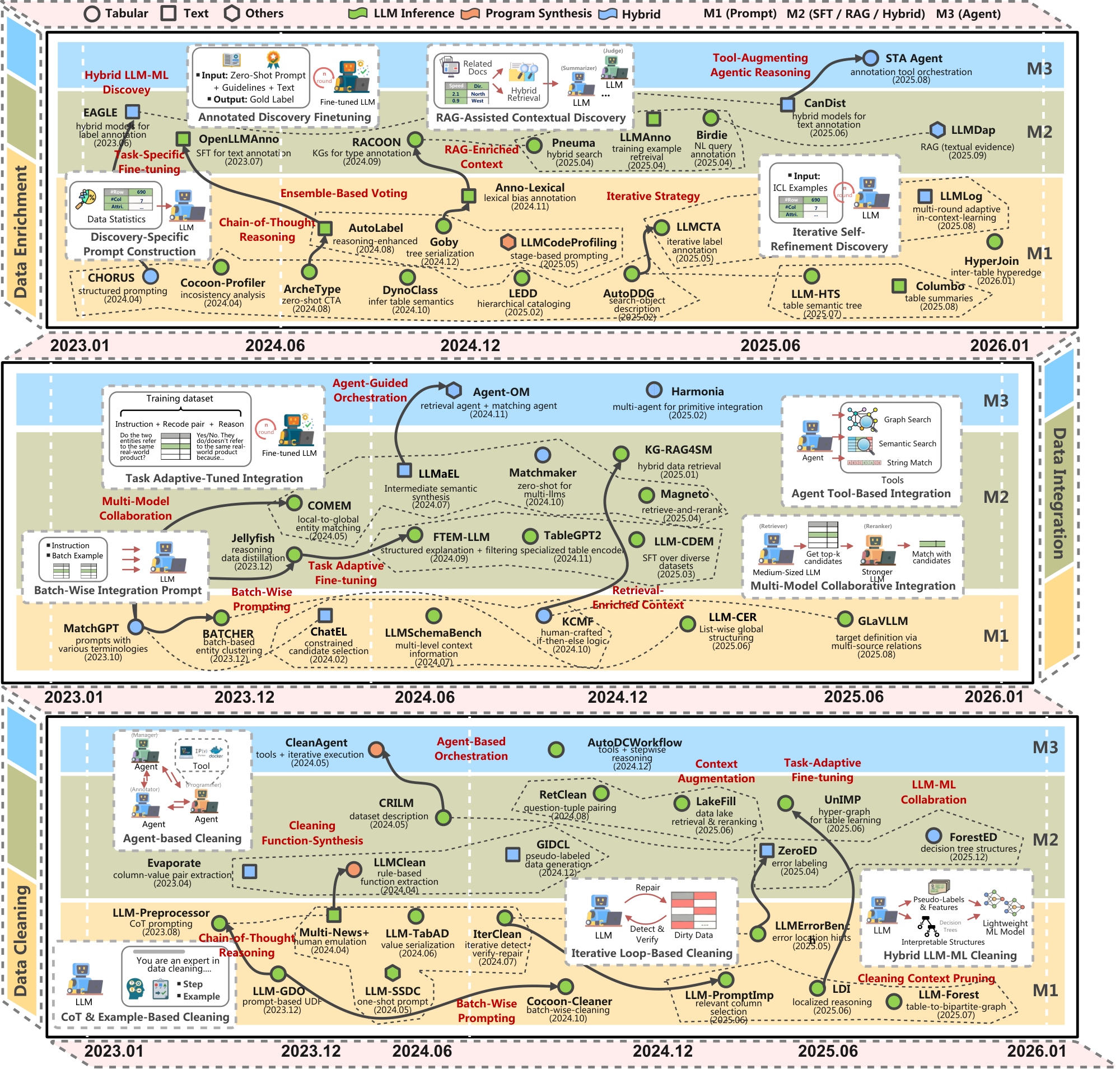
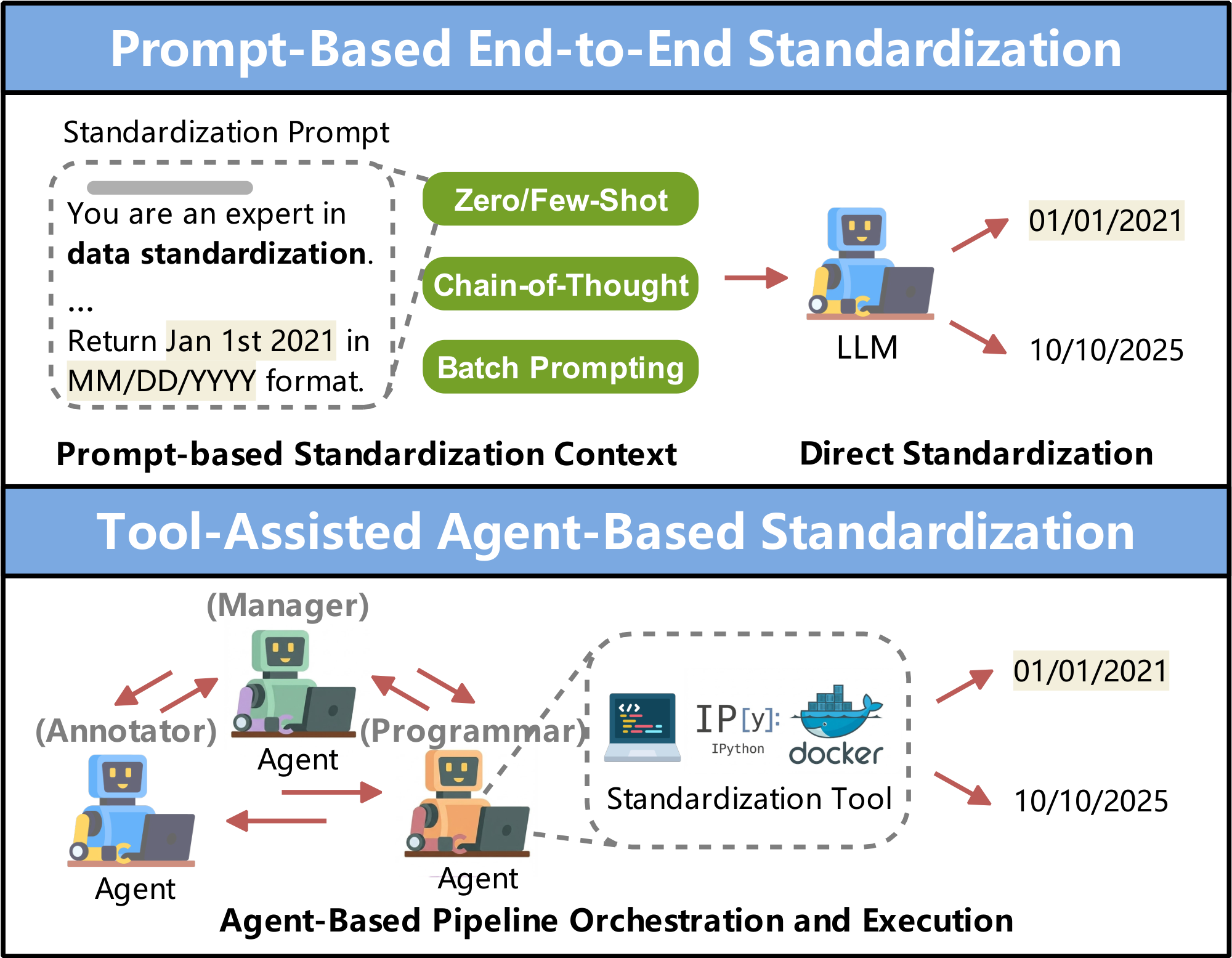
❶ Prompt-Based End-to-End Standardization. As shown in Figure 3, this method uses structured prompts that specify detailed standardization rules (e.g., normalization criteria) or provide stepwise reasoning instructions, guiding $\textsc{LLMs}$ to generate data outputs in a standardized format.
$\bullet$ Instruction-Guided Standardization Prompting. This category relies on manually crafted prompts, together with in-context or labeled standardization examples, to guide $\textsc{LLMs}$ in performing data standardization across diverse tasks. For instance, LLM-GDO [11] employs user-specified prompts with parameterized templates to encode data standardization rules as textual instructions (e.g., "convert dates into YYYYMMDD") and to substitute user-defined functions (e.g., executable formatting code implementations).
$\bullet$ Reasoning-Enhanced Batch Standardization Prompting. This category leverages step-wise reasoning and batch-wise processing prompting to enhance both the standardization robustness and efficiency. For instance, LLM-Preprocessor [57] proposes a unified prompting framework that tackles hallucinations, domain shifts, and computational costs through: (1) zero-shot Chain-of-Thought prompting, which elicits step-by-step reasoning to first verify the correct target column and then to guide $\textsc{LLMs}$ in producing the standardized output; and (2) batch-wise prompting, which feeds multiple items into a single prompt so they can be processed simultaneously.
❷ Automatic Code-Synthesis Standardization. This approach standardizes data by instructing $\textsc{LLMs}$ to generate executable code that performs the standardization. The generated code is then executed to ensure uniform data handling and improve efficiency. For instance, Evaporate [21] prompts $\textsc{LLMs}$ to produce code that derives structured representations from semi-structured documents; results from multiple candidate functions are then combined to boost accuracy while preserving low computational overhead.
❸ Tool-Assisted Agent-Based Standardization. As shown in Figure 3, this approach overcomes the challenges of complex prompt design by employing $\textsc{LLM}$ agents to coordinate and execute standardization pipelines. For instance, CleanAgent [36] maps specific standardization operations with domain-specific APIs, and relies on agents to execute a standardization pipeline, which involves generating API calls (e.g., clean_date(df, "Admission Date", "MM/DD/YYYY")) and executing them iteratively. Similarly, AutoDCWorkflow [19] leverages $\textsc{LLM}$ agents to assemble pipelines and carry out stepwise reasoning to locate relevant columns, evaluate data quality, and apply appropriate operations (e.g., upper() and trim()), while leveraging tools such as OpenRefine [12] for execution and feedback.
Discussion.
(1) Prompt-Based Standardization for Heterogeneous Modalities. This paradigm leverages structured instructions and in-context examples to flexibly convert diverse inputs into a unified format, enabling rapid, training-free deployment [21]. Nonetheless, its dependence on direct $\textsc{LLM}$ inference leads to high token consumption and constrains scalability for large-scale or frequently repeated tasks. (2) Code-Based Standardization for Scalable Execution. This paradigm enhances efficiency by using reusable transformation functions with fixed execution cost, making it well-suited for processing large datasets [21, 81]. However, it is vulnerable to errors because $\textsc{LLMs}$ may produce faulty code, requiring the aggregation of multiple candidate functions to maintain reliability. (3) Agentic-Based Standardization for Automated Pipelines. This paradigm constructs automated pipelines by translating natural-language specifications into executable workflows, thereby increasing usability and transparency [11, 36, 19]. However, coordinating numerous tools and APIs introduces additional maintenance overhead and can increase latency relative to direct prompt-based approaches.
Data Error Processing. Given a data item, data error processing typically involves two stages: detecting errors and then correcting them. Common error types include typographical mistakes (typos), anomalous numeric values, and violations of data dependencies. Existing approaches to error processing can generally be grouped into four major categories.
❶ Prompt-Based End-to-End Error Processing. This approach relies on structured prompts that describe explicit error detection and correction instructions, organize processing steps into iterative workflows, or incorporate illustrative examples and reasoning guidance, to instruct $\textsc{LLMs}$ to identify and repair data errors directly.
$\bullet$ Instruction-Based Processing Prompting. This category pairs explicit prompting instructions with serialized tabular rows to guide $\textsc{LLMs}$ in performing error detection and correction. For instance, Cocoon-Cleaner [37] uses batch-style prompting by serializing sampled values from each column (e.g., 1,000 entries per column) and grouping them by their corresponding subject column. It allows $\textsc{LLMs}$ to iteratively identify and fix issues such as typos and inconsistent formats, with minimal supervision (e.g., five labeled tuples).
$\bullet$ Workflow-Based Iterative Processing Prompting. This category encompasses iterative, multi-step processing workflows (e.g., the detect–verify–repair loop), in which $\textsc{LLM}$ repeatedly executes, evaluates, and refines processing operations. For instance, LLMErrorBench [47] guides $\textsc{LLMs}$ through an iterative sequence of dataset examination, targeted correction (e.g., value substitution), and automated quality evaluation, using prompts enriched with contextual cues such as error locations. To address newly introduced errors and the dependence on rigid, predefined rules in sequential pipelines, IterClean [22] introduces an integrated prompting framework in which $\textsc{LLMs}$ simultaneously serve as error detector, self-verifier, and data repairer within a continuous feedback loop.
$\bullet$ Example- and Reasoning-Enhanced Processing Prompting. This category incorporates few-shot examples and explicit reasoning steps into error-handling pipelines. For instance, $\text{Multi-News}^{+}$ [46] employs Chain-of-Thought prompting in conjunction with majority voting and self-consistency verification, thereby mimicking human decision-making to enhance both the accuracy and interpretability of noisy document classification. To alleviate the need for manually crafting intricate parsing rules for semi-structured data errors, LLM-SSDC [29] recasts the problem as a text correction task, using a one-shot prompt that includes general instructions and a single input-output example. This allows $\textsc{LLMs}$ to automatically fix structural misplacements (e.g., relocating paragraph indices from a <content> tag to a <num> tag).
❷ Function-Synthesis-Oriented Error Processing. To address the scalability of manually crafting rules, this approach leverages $\textsc{LLMs}$ to synthesize executable processing functions that explicitly encode table semantics and data dependencies. For instance, LLMClean [40] instructs $\textsc{LLMs}$ to derive a collection of ontological functional dependencies (OFDs) from the dataset schema, the data, and a domain ontology, which together define validation rules within a context model. Each OFD represents a concrete rule, such as ZipCode $\rightarrow$ City in a postal ontology. These OFDs are subsequently used to detect errors (e.g., inconsistent values) and to steer iterative data repair via integrated tools such as Baran [161].
❸ Task-Adaptive Fine-Tuned Error Processing. As shown in Figure 4, this method fine-tunes $\textsc{LLMs}$ to learn dataset-specific error patterns that are hard to capture via prompting alone, leveraging synthetic noise or contextual augmentation to enhance both error detection and correction performance.
$\bullet$ Synthetic Noise-Augmented Fine-Tuning. This category fine-tunes $\textsc{LLMs}$ using synthetic datasets augmented with different noises, such as Gaussian or multinomial, to learn error detection. For instance, LLM-TabAD [83] adapts base $\textsc{LLMs}$ (e.g., Llama 2 [84]) for error detection by constructing synthetic datasets where each example is a small batch of rows together with the indices of the abnormal rows. Continuous columns in the rows are drawn from a mixture of a narrow Gaussian (normal values) and a wide Gaussian (anomalous extremes), while categorical columns are sampled from two multinomial distributions with different probability patterns. Each batch is then serialized into a natural-language description, and the $\textsc{LLM}$ is fine-tuned to predict the anomaly row indices.
$\bullet$ LLM-Based Context Augmentation Fine-Tuning. In this category, $\textsc{LLMs}$ are fine-tuned using prompts that are enriched with additional contextual information, such as serialized neighboring cells and retrieved similar examples. As an illustration, GIDCL [20] constructs fine-tuning data by combining labeled tuples with pseudo-labeled tuples produced via $\textsc{LLM}$ -based augmentation. Each training instance is represented as a context-enriched prompt that includes: (1) an instruction (e.g., "Correct the ProviderID to a valid numeric format"), (2) a serialized erroneous cell along with its row and column context (e.g., ```< COL> ProviderID< VAL> 1x1303...'''), (3) in-context learning examples (e.g., "bxrmxngham $\rightarrow$ birmingham"), and (4) retrieval-augmented examples drawn from the same cluster (e.g., clean tuples obtained via $k$-means).
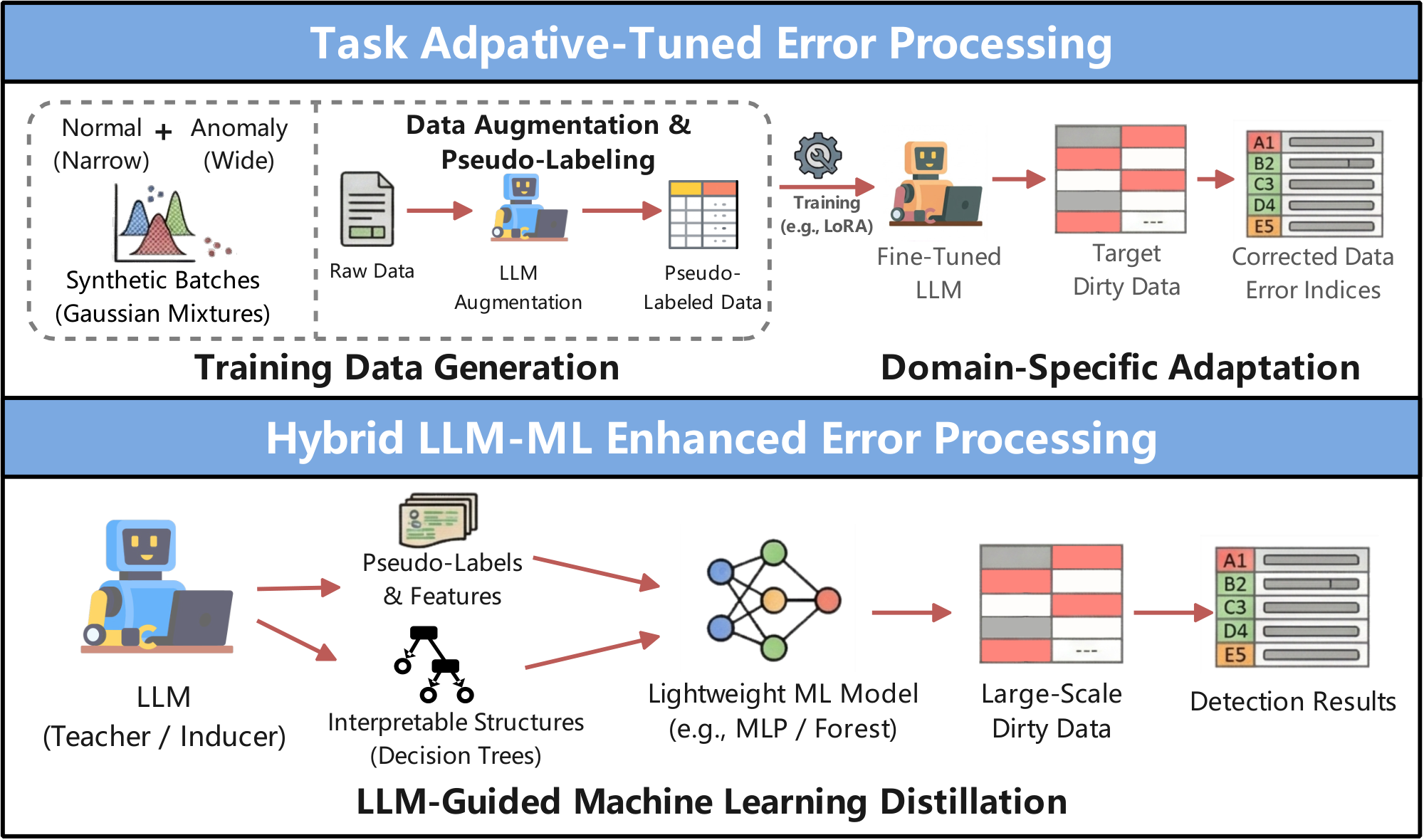
❹ Hybrid LLM-ML Enhanced Error Processing. As shown in Figure 4, this approach integrates $\textsc{LLMs}$ with machine learning models to strike a balance between accuracy and computational efficiency in handling errors. In practical deployments, $\textsc{LLMs}$ are either employed to create labeled datasets that train ML models, or to derive structural representations that guide ML-based error processing.
$\bullet$ LLM-Labeled ML Processing Training. In this category, $\textsc{LLM}$ is employed as a data labeler to create pseudo-labels and synthetic examples of correctly identified errors, which are then used to train a lightweight ML model that serves as an efficient detector. As an illustrative instance, ZeroED [85] uses $\textsc{LLMs}$ to annotate features and subsequently trains a lightweight ML classifier (e.g., an MLP) for end-to-end error detection. The training dataset is obtained via a zero-shot pipeline: representative values are first chosen through clustering, then labeled by the $\textsc{LLM}$ , and these labels are propagated to nearby values. The dataset is further enriched with $\textsc{LLM}$ -generated synthetic corruptions (e.g., substituting valid ages with impossible values such as 999) to better capture rare error patterns.
$\bullet$ LLM-Induced Structure for ML Processing. In this category, $\textsc{LLM}$ is employed as a logical blueprint to construct interpretable error-detection programs, which are later run and combined by machine-learning models. As an illustration, to enhance both explainability and robustness in data processing, ForestED [86] restructures the processing pipeline by leveraging the $\textsc{LLM}$ to produce transparent decision structures (e.g., trees whose nodes apply rule-based format or range checks, along with relational nodes that encode cross-column dependencies), while downstream ML models execute and aggregate these structures to generate the final predictions.
Discussion. (1) Prompt-Based Processing for End-to-End Workflows. This approach reframes error processing as a generative modeling problem through data serialization [29, 46], and couples decomposed pipelines with iterative verification loops to ensure robust reasoning [37, 22, 47]. However, direct $\textsc{LLM}$ inference remains constrained by token limits when operating on large tables, and iterative self-correction cycles can compound hallucinations or introduce new errors. (2) Function-Synthesis Processing for Automatic Rule Discovery. This paradigm leverages $\textsc{LLMs}$ to autonomously identify hidden dependencies and synthesize explicit, executable cleaning routines directly from raw data [40].
However, deriving strict validation rules from already corrupted inputs risks overfitting to noise, causing the $\textsc{LLM}$ to synthesize invalid rules that effectively encode errors as valid rules. (3) Task-Adaptive Error Processing for Domain Specificity. This strategy addresses the text–table modality discrepancy by fine-tuning $\textsc{LLMs}$ on synthetic noise or context-enriched datasets to capture complex, dataset-specific error patterns [83, 20]. Nonetheless, it requires a significant "cold start" investment to curate or generate sufficiently high-quality training data. (4) Hybrid $\textsc{LLM}$ -ML Error Processing for Scalable Detection. This approach uses $\textsc{LLMs}$ to produce pseudo-labels [85] or to derive interpretable decision structures [86] that guide lightweight, scalable ML classifiers. However, the ultimate detection performance is tightly constrained by both the fidelity of the initial $\textsc{LLM}$ -generated labels and the capabilities of the induced models.
Data Imputation. For a data record that contains missing entries (e.g., null values), data imputation aims to estimate these unknown values using the surrounding contextual information. Existing $\textsc{LLM}$ -enhanced approaches can be grouped into three main categories.
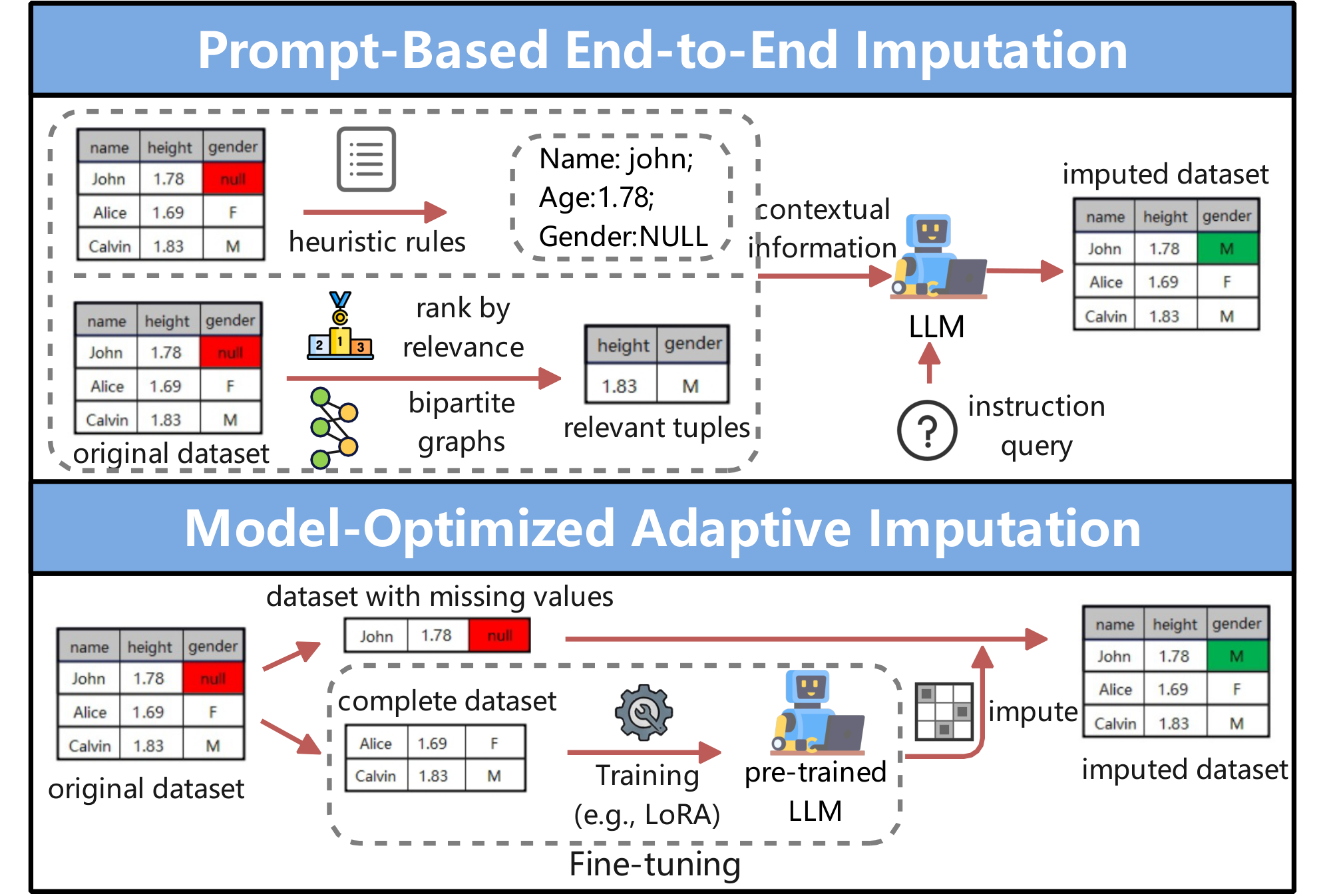
❶ Prompt-Based End-to-End Imputation. As shown in Figure 5, this approach uses structured prompts to direct $\textsc{LLMs}$ to fill in missing values in a single step. Existing methods either arranges imputation prompts via heuristic formatting schemes or selectively augments prompts with relevant context.
$\bullet$ Heuristic-Structured Imputation Prompting. This category organizes imputation prompts using heuristic rules that aim to optimize the formatting of instructions for missing value imputation. For instance, CRILM [87] employs rule-based prompt design by converting feature names into natural language phrases (e.g., turning alcohol into "alcohol content"), retaining the observed values (e.g., 12.47), and adding domain-specific context (e.g., wine). These components are then combined into explicit natural language statements such as "The alcohol content in the wine is 12.47". The resulting descriptions are supplied as prompts to $\textsc{LLMs}$ , along with detailed instructions for producing descriptions for the missing values.
$\bullet$ Selective Imputation Context Prompting. This category focuses on including only the most relevant information in the imputation context, thereby reducing redundancy and token usage. For instance, LLM-PromptImp [88] refines the context by choosing the columns that are most relevant to the target missing attribute, where relevance is determined using correlation metrics (e.g., Pearson correlation, Cramer's V, and $\eta$ correlation) tailored to different data types. LDI [89] narrows the imputation context by first detecting columns that exhibit explicit dependency relationships with the target column, and then selecting a small number of representative tuples whose values are among the top-$k$ most similar to the incomplete tuple, measured by the normalized length of the longest common substring across these dependent columns. $\textsc{LLM}$ -Forest [90] enables selective construction of the imputation context by converting tabular data into hierarchically merged bipartite information graphs and then retrieving neighboring nodes that are both correlated and diverse for tuples containing missing entries.
❷ Context-Retrieval Guided Imputation. This approach enables $\textsc{LLMs}$ to handle previously unseen, domain-specific, or private datasets by dynamically enriching the input with supplemental context retrieved from external sources. For instance, RetClean [44] builds an index over a data lake using both syntactic and semantic retrieval, selects a pool of candidate tuples, reranks them with a learned ranking model, and then presents the dirty tuple together with the top-$k$ retrieved tuples to $\textsc{LLMs}$ for imputation. Similarly, LakeFill [42] adopts a two-stage retriever–reranker architecture: an initial vector-based retriever assembles a broad candidate set from the data lake, followed by a reranker that filters this down to a small set of highly relevant tuples that form the imputation context.
❸ Model-Optimized Adaptive Imputation. As shown in Figure 5, this approach improves imputation quality by adjusting either the $\textsc{LLM}$ 's training procedure or its architecture to better capture complex relationships in mixed-type tabular data.
$\bullet$ Adaptive Model Fine-Tuning Optimization. This category improves imputation by fine-tuning $\textsc{LLMs}$ on task-specific datasets through parameter-efficient methods. For example, LLM-REC [91] adopts a data-partitioned fine-tuning framework that divides the dataset into complete and incomplete portions. It then leverages the complete portion to partially fine-tune the $\textsc{LLM}$ using LoRA, thereby enabling the model to impute missing values based on the observed data.
$\bullet$ Module-Augmented Architecture Optimization. This class of methods incorporates dedicated modules into $\textsc{LLMs}$ to model structural or feature-level dependencies that standard $\textsc{LLMs}$ may overlook. For instance, UnIMP [92] augments the $\textsc{LLM}$ with two lightweight components that capture interactions among numerical, categorical, and textual cells: (1) a high-order message-passing module that aggregates both local and global relational information, and (2) an attention-based fusion module that merges these features with prompt embeddings prior to decoding the final imputed values. Building on UnIMP, Quantum-UnIMP [93] adds a quantum feature-encoding module that maps mixed-type inputs into classical vectors used to parameterize an Instantaneous Quantum Polynomial (IQP) circuit. The resulting quantum embeddings serve as the initial node representations in the UnIMP hypergraph.
Discussion. (1) Prompt-Based Imputation for Balanced Efficiency. This line of work leverages structured prompts and targeted context removal to reduce token consumption while mitigating class imbalance [88]. However, aggressive pruning can omit subtle cross-column relationships that are crucial for inferring missing values in complex, high-dimensional tables. (2) Retrieval-Guided Imputation for Verifiable Privacy. This paradigm relies on RAG to ground imputation in external data lakes, enabling explicit source attribution and secure, on-premise deployment [44]. However, its performance is tightly constrained by the coverage and fidelity of relevant tuples in the data lake, and retrieval noise can further impair imputation accuracy. (3) Model-Optimized Imputation for Structural Complexity. This strategy incorporates tailored architectural components or incremental training schemes to model global and local dependencies in heterogeneous, mixed-type datasets [92]. Nonetheless, these specialized components introduce additional architectural complexity and higher computational costs compared to standard, general-purpose $\textsc{LLMs}$.
4. LLM for Data Integration
Traditional integration methods often struggle with semantic ambiguities and inconsistencies, especially in complex settings where domain-specific knowledge is unavailable [23]. Moreover, pretrained language models generally demand substantial task-specific training data and often suffer from performance degradation when dealing with out-of-distribution entities [26]. By contrast, recent work has demonstrated that $\textsc{LLMs}$ exhibit strong semantic understanding, allowing them to detect relationships across datasets and integrate domain knowledge, thereby achieving robust generalization across a wide range of integration tasks.
Entity Matching. Entity matching aims to decide whether a pair of data records corresponds to the same real-world entity. Existing $\textsc{LLM}$ -enhanced approaches can be broadly grouped into three main categories.
❶ Prompt-Based End-to-End Matching. This approach relies on structured prompts to guide $\textsc{LLMs}$ in performing entity matching directly. Existing methods either include explicit guidance via detailed instructions and in-context examples or organize candidate tuples into batches to enhance efficiency.
$\bullet$ Guidance-Driven In-Context Matching Prompting. This category enhances entity matching through carefully structured in-context guidance, including strategically selected demonstrations, expert-defined logical rules, and multi-step prompting pipelines. For example, MatchGPT [26] prepares guidance by selecting in-context demonstrations via various strategies (e.g., similarity-based vs. manual) and automatically generating textual matching rules from handwritten examples. ChatEL [94] further follows the guidance of a multi-step pipeline to first retrieve candidates, then generate task-oriented auxiliary descriptions, and finally perform instruction-guided multiple-choice selection to identify matches. To mitigate hallucination and reliance on the $\textsc{LLM}$ 's internal knowledge, KcMF [43] incorporates expert-designed pseudo-code of if-then-else logic enriched with external domain knowledge, and employs an ensemble voting mechanism to aggregate multi-source outputs.
$\bullet$ Batch-Clustering Matching Prompting. This category enhances matching efficiency by packing multiple entities or entity pairs into a single prompt, allowing $\textsc{LLMs}$ to jointly reason about them. For instance, BATCHER [48] groups multiple entity pairs into one prompt via a greedy, cover-based selection strategy that clusters pairs exhibiting similar matching semantics (e.g., relying on the same matching rules or patterns). Similarly, LLM-CER [95] employs a list-wise prompting approach that processes a batch of tuples at once, using in-context examples to cluster related entities in a single pass and thereby lowering the cost associated with sequential pairwise matching.
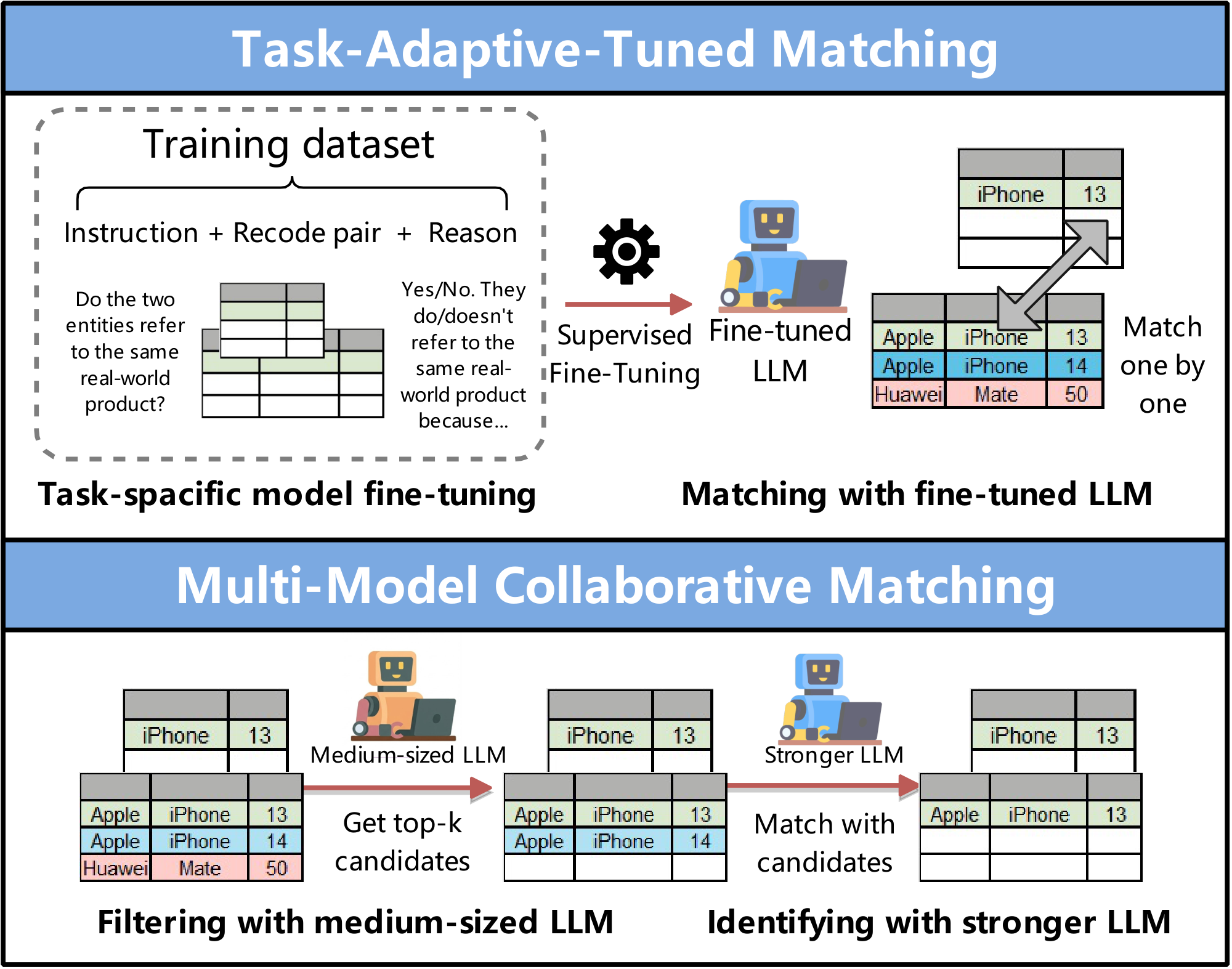
❷ Task-Adaptive-Tuned Matching. As shown in Figure 6, this approach fine-tunes $\textsc{LLMs}$ for entity matching using task-specific supervision, either by distilling reasoning traces from stronger models or by improving training data quality to enhance matching adaptability and generalization.
$\bullet$ Reasoning-Distilled Matching Tuning. This category fine-tunes local small $\textsc{LLMs}$ using Chain-of-Thought traces distilled from larger models. For example, Jellyfish [39] performs parameter-efficient instruction tuning on small models (ranging 7B-13B) using reasoning traces (derived from CoT prompting over serialized data) distilled from a larger mixture-of-experts $\textsc{LLM}$ (e.g., Mixtral-8x7B) to improve reasoning consistency and task transferability.
$\bullet$ Data-Centric Matching Tuning. This category optimizes the fine-tuning process by improving the quality of training data via enriched information. For example, FTEM-LLM [96] adds clear explanations to the training data that describe why two items are the same or different (e.g., comparing specific columns). It also cleans the data by removing mislabeled examples and generating hard negatives via embedding-space neighbor selection. Similarly, LLM-CDEM [97] demonstrates that data-centric strategies (e.g., Anymatch [159] uses an AutoML-based strategy to identify and add hard examples to the training set, and uses attribute-level augmentation to increase the training set's granularity), which focus on improving training data quality, significantly outperform model-centric approaches in achieving robust cross-domain generalization.
❸ Multi-Model Collaborative Matching. As shown in Figure 6, this approach enhances entity matching by coordinating multiple models to exploit their complementary strengths. For instance, COMEM [98] proposes $\textsc{LLM}$ collaboration in a combined local and global matching strategy, where a medium-sized $\textsc{LLM}$ (3B-11B) ranks top-$k$ candidates via bubble sort to mitigate position bias and context-length dependency, and a stronger $\textsc{LLM}$ (e.g., GPT-4o) refines these candidates by modeling inter-tuple interactions to ensure globally consistent and accurate matching. To effectively resolve long-tail entity ambiguity and maintain computational efficiency, LLMaEL [99] leverages $\textsc{LLMs}$ as context augmenters to generate entity descriptions as additional input for small entity matching models. The augmented context is integrated via concatenation, fine-tuning, or ensemble methods to guide small entity matching models to produce accurate results.
Discussion. (1) Prompt-Based Matching for End-to-End Resolution. This approach utilizes structured guidance (e.g., logical rules, multi-step pipelines) [26, 94, 43] and batching strategies [48, 95] to perform matching directly, facilitating explainable decisions and improved efficiency. However, reliance on the $\textsc{LLMs}$ ' internal knowledge makes it sensitive to input phrasing and incurs significant token costs for large-scale candidate lists. (2) Task-Adaptive Matching for Robust Adaptation. This approach bridges the gap between security and generalization by fine-tuning local models [39] or prioritizing data-centric training strategies to handle unseen schemas [96, 97]. However, it faces a significant "cold start" challenge, requiring high-quality, diverse training data to prevent overfitting or performance regression on out-of-distribution domains. (3) Multi-Model Collaborative Matching for Scalable Consistency. This approach leverages lightweight rankers for preliminary blocking [98] or context augmentation [99] to address position bias and global consistency violations. However, the pipeline's overall accuracy is strictly bounded by the recall of the preliminary blocking stage, as early filtering errors cannot be recovered by the $\textsc{LLM}$.
Schema Matching. The objective of schema matching is to identify correspondences between elements across different database schemas (e.g., matching column names such as "employee ID" and "staff number"). Existing $\textsc{LLM}$ -enhanced approaches can be divided into five categories.
❶ Prompt-Based End-to-End Matching. This approach uses structured prompts to enable $\textsc{LLMs}$ to perform schema matching without explicit code implementations. For example, LLMSchemaBench [49] designs prompts for different tasks across varying contexts and adopts prompting patterns such as persona specification (e.g., instructing $\textsc{LLMs}$ to act as a schema matcher), match-criteria definition, Chain-of-Thought reasoning instructions, and structured output formats. GLaVLLM [100] further optimizes matching prompts by three strategies: (1) it improves output consistency by applying symmetric transformations to the input schemas and aggregating multiple outputs; (2) it increases matching expressiveness through structured prompting and rule decomposition, supporting complex matching patterns such as "Global-and-Local-as-View", where multiple source relations jointly define multiple target relations; and (3) it reduces token usage by filtering tasks based on data types and grouping similar tasks before prompting $\textsc{LLMs}$ .
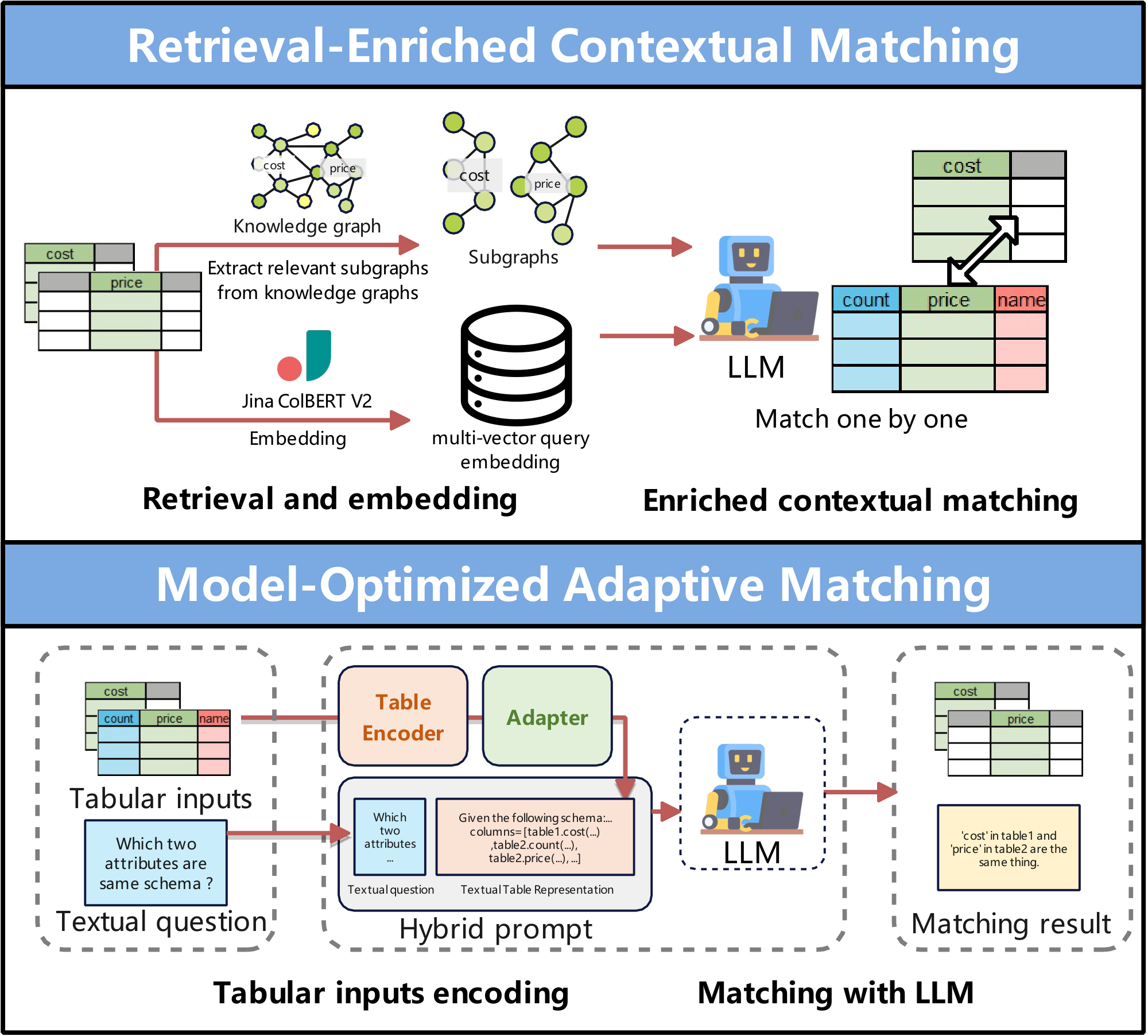
❷ Retrieval-Enriched Contextual Matching. As shown in Figure 7, this approach improves schema matching by augmenting $\textsc{LLM}$ inputs with context obtained from external retrieval components. For instance, Matchmaker [101] integrates pretrained retrieval models (such as ColBERTv2 [102]) with $\textsc{LLMs}$ by encoding columns at the token level for vector-based semantic retrieval, and then using an $\textsc{LLM}$ to score and rank the retrieved candidates. KG-RAG4SM [23] extends this idea by employing multiple retrieval strategies, including vector-based, graph traversal, and query-driven search—to extract relevant subgraphs from knowledge graphs, which are then ranked and injected into $\textsc{LLM}$ prompts to provide richer context for matching.
❸ Model-Optimized Adaptive Matching. As shown in Figure 7, this approach enhances matching effectiveness through modality-aware fine-tuning, complemented by specialized module designs. For example, TableLlama [103] applies instruction tuning over a wide range of table-centric tasks, allowing the model to learn alignment strategies and column semantics implicitly, without changing its core architecture. Building on this, TableGPT2 [41] adopts an architecture-augmented optimization scheme by incorporating a two-dimensional table encoder that generates permutation-invariant representations, thereby enhancing the stability and accuracy of cross-table column alignment and candidate match ranking.
❹ Multi-Model Collaborative Matching. This approach improves schema matching by coordinating multiple models with complementary capabilities. For example, Magneto [50] adopts a retrieve-and-rerank framework in which small pre-trained language models first produce candidate match rankings for each input column, and $\textsc{LLMs}$ subsequently refine these candidates through reranking to achieve higher matching accuracy and efficiency.
❺ Agent-Guided Orchestration-Based Matching. In this paradigm, $\textsc{LLM}$ agents are used to manage and coordinate the entire schema matching pipeline. Existing methods either designate distinct agents to handle and carry out specific matching subtasks or depend on agent-based planning mechanisms to orchestrate a set of predefined tools.
$\bullet$ Role-Based Matching Orchestration. In this category, the workflow is partitioned into specialized agents, each responsible for different operations. For instance, Agent-OM [51] uses two $\textsc{LLM}$ agents (a Retrieval Agent and a Matching Agent) to coordinate the matching process, breaking tasks down via Chain-of-Thought prompting, calling specialized tools (such as syntactic, lexical, and semantic retrievers and matchers), and relying on a hybrid memory architecture (relational + vector database) for storage and retrieval.
$\bullet$ Tool-Planning Matching Orchestration. This category uses $\textsc{LLM}$ agents to coordinate predefined tools through dynamic planning to solve complex matching problems. For example, Harmonia [52] employs $\textsc{LLM}$ agents to orchestrate and integrate a set of predefined data integration tools (i.e., modular algorithms tailored to specific matching subtasks, such as top_matches for retrieving the top-$k$ most suitable candidates), and complements them with on-demand code generation when the available tools are inadequate. At the same time, it incorporates mechanisms such as ReAct [104] for joint reasoning and action planning, interactive user feedback for correcting errors, and declarative pipeline specifications to guarantee reproducibility.
Discussion. (1) Prompt-Based Matching for Stable Alignment. This paradigm employs one-to-many comparisons and symmetric transformations to promote consistency and reduce sensitivity to inputs constrained by privacy [49, 100]. However, when it relies exclusively on metadata, the model is unable to interpret semantically opaque column names, and its exhaustive verification strategy leads to prohibitive token consumption for large schemas. (2) Retrieval-Enriched Matching for Hallucination Resistance. This approach grounds the alignment in verifiable semantic subgraphs by retrieving contextual information from external knowledge graphs [23]. However, its performance can be constrained by the domain coverage of the external knowledge source and the added retrieval overhead (e.g., graph traversal). (3) Model-Optimized Matching for Structural Semantics. This approach integrates specialized architectural components (e.g., table encoders) or task-oriented fine-tuning to encode table-specific alignment regularities [103, 41]. However, it relocates the bottleneck to training data acquisition, demanding high-quality or large-scale datasets to achieve robust generalization across heterogeneous domains. (4) Multi-Model Matching for Cost-Efficient Scale. This paradigm relies on $\textsc{LLMs}$ to generate training instances for lightweight scorers, forming a scalable filter-then-rank pipeline [50]. However, the ultimate matching quality is tightly constrained by the fidelity of the synthetic training data and the loss of reasoning capability transferred to the smaller model. (5) Agent-Guided Matching for Autonomous Workflows. This approach leverages chain-based reasoning and self-refinement strategies to coordinate complex, multi-stage alignment procedures [51]. However, the complex orchestration of tools and iterative reasoning cycles can introduce additional latency and maintenance overhead compared with static $\textsc{LLMs}$.
5. LLM for Data Enrichment
Existing data enrichment techniques suffer from two main drawbacks. First, they limited interactions between queries and tables [24]. Second, many such methods depend strongly on large labeled corpora, are brittle under distribution shifts, and do not generalize well to rare or highly specialized domains [27, 28]. Recent studies have shown that $\textsc{LLMs}$ can mitigate these issues by producing high-quality metadata, enhancing the contextual information of datasets, and enabling natural language interfaces for performing enrichment tasks.
Data Annotation. Data annotation is the process of assigning semantic or structural labels to data instances, such as identifying column types (e.g., Manufacturer or birthDate in the DBPedia ontology). Recent $\textsc{LLM}$ -enhanced methods typically can be divided into five main categories.
❶ Prompt-Based End-to-End Annotation. This approach utilizes carefully crafted prompts to guide $\textsc{LLMs}$ in performing diverse annotation tasks. It involves methods that supply explicit annotation guidelines and contextual information, while also leveraging reasoning and iterative self-refinement to improve annotation accuracy.
$\bullet$ Instruction-Guided Annotation Prompting. This category uses structured prompts with explicit instructions to guide $\textsc{LLMs}$ in performing data annotation tasks. For example, CHORUS [53] designs prompts that combine correct annotation demonstrations, serialized data samples, metadata, domain knowledge, and output formatting guidance. Similarly, EAGLE [105] employs task-specific prompts to selectively label critical or uncertain samples (identified via prediction disagreement), combining zero-shot $\textsc{LLM}$ annotation with active learning to enhance generalization in low-data settings. ArcheType [27] adopts a column-at-once serialization strategy that includes only representative column samples for zero-shot column type annotation. To handle abbreviated column names, Columbo [106] defines prompt instructions over three modules: (1) a summarizer module generates concise group and table summaries from context to provide annotation guidance, (2) a generator module expands tokenized column names into meaningful phrases, and (3) a reviser module evaluates and refines the consistency of these expanded phrases.
$\bullet$ Reasoning-Enhanced Iterative Annotation Prompting. This category enhances annotation quality by using structured prompts that guide models through step-by-step reasoning and iterative self-assessment to produce more accurate labels. For example, Goby [54] applies tree-structured serialization and Chain-of-Thought prompting for enterprise column type annotation. AutoLabel [107] performs automated text annotation on representative samples (selected via DBSCAN [108] clustering and stratified sampling) using domain-optimized CoT reasoning templates that decompose complex labeling tasks into stepwise instructions (e.g., "First classify entity types, then assess confidence levels"), while a human feedback loop iteratively validates low-confidence outputs. Anno-lexical [31] further adopts a majority voting mechanism that aggregates annotations from multiple open-source $\textsc{LLMs}$ to enhance annotation robustness and reduce bias. LLMCTA [28] produces and iteratively improves label definitions using prompt-driven methods, such as self-refinement (progressively enhancing definitions by learning from errors) and self-correction (a two-stage process involving a separate reviewer model). LLMLog [109] tackles ambiguity in log template generation via multi-round annotation, leveraging self-evaluation metrics like prediction confidence to identify uncertain or representative logs, and repeatedly updating in-context examples to refine prompt instructions and boost annotation accuracy.
❷ RAG-Assisted Contextual Annotation. This approach enriches $\textsc{LLM}$ prompts to enhance annotation by retrieving relevant context, either from semantically similar examples or from external knowledge graphs.
$\bullet$ Semantic-Based Annotation Example Retrieval. This category enhances annotation accuracy by retrieving semantically relevant examples to enrich the prompt context. For instance, LLMAnno [110] addresses the inefficiency of manually selecting examples for large-scale named entity recognition (e.g., annotating 10, 000 resumes) by retrieving the most relevant training examples and constructing context-enriched prompts for $\textsc{LLMs}$ . Experiments show that retrieval based on appropriate embeddings (e.g., text-embedding-3-large [111]) outperforms zero-shot and in-context learning across multiple $\textsc{LLMs}$ (7B-70B parameters) and datasets.
$\bullet$ Graph-Based Annotation Knowledge Retrieval. This category enhances annotation by retrieving relevant entity triples from external knowledge graphs to enrich the prompt context. For example, RACOON [55] extracts entity-related knowledge (e.g., labels and triples) from a knowledge graph, converting it into concise contextual representations, and incorporating it into prompts to enhance semantic type annotation accuracy.
❸ Fine-Tuned Augmented Annotation. This approach improves annotation in specialized domains by fine-tuning $\textsc{LLMs}$ on task-specific datasets. For example, PACTA [82] combines low-rank adaptation with prompt augmentation, decomposing prompts into reusable patterns and training across diverse contexts to reduce prompt sensitivity in column type annotation. OpenLLMAnno [113] demonstrates that fine-tuned local $\textsc{LLMs}$ (e.g., Llama 2, FLAN-T5) outperform proprietary models like GPT-3.5 in specialized text annotation tasks, achieving substantial accuracy gains even with a small number of labeled samples (e.g., 12.4% improvement with 100 samples for FLAN-T5-XL).
❹ Hybrid LLM-ML Annotation. As shown in Figure 8, this approach combines $\textsc{LLMs}$ with ML models to improve annotation accuracy and robustness through knowledge distillation and collaborative orchestration. For instance, CanDist [114] employs a distillation-based framework where $\textsc{LLMs}$ uses task-specific prompts to generate multiple candidate annotations, and SLMs (e.g., RoBERTa-Base) then distill and filter them. A distribution refinement mechanism updates the SLM's distribution, gradually correcting false positives and improving robustness to noisy data. AutoAnnotator [115] uses two-layer collaboration: (1) $\textsc{LLMs}$ act as meta-controllers, selecting suitable SLMs, generating annotation, and verifying hard samples, while (2) SLMs perform bulk annotation, produce high-confidence labels via majority voting, and iteratively fine-tune on $\textsc{LLM}$ -verified hard samples to enhance generalization.
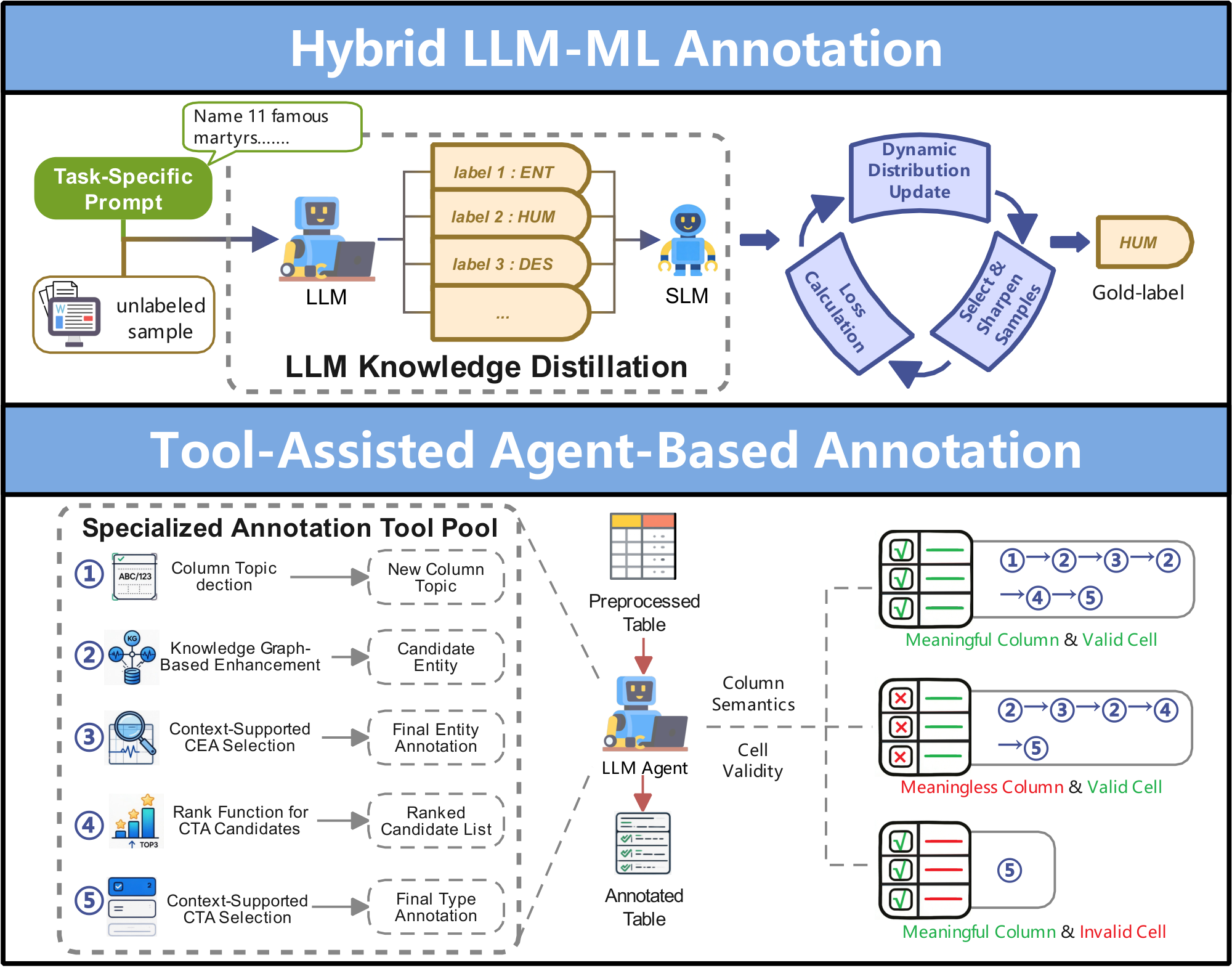
❺ Tool-Assisted Agent-Based Annotation. As shown in Figure 8, this approach uses $\textsc{LLM}$ agents augmented with specialized tools to handle complex annotation tasks. For example, STA Agent [116] leverages a ReAct-based $\textsc{LLM}$ agent for semantic table annotation, combining preprocessing (e.g., spelling correction, abbreviation expansion) with tools for column topic detection, knowledge graph enrichment, and context-aware selection, while reducing redundant outputs via Levenshtein distance. TESSA [117] employs a multi-agent system for cross-domain time series annotation, integrating general and domain-specific agents with a multi-modal feature extraction toolbox for intra- and inter-variable analysis and a reviewer module to ensure consistent and accurate annotations.
Discussion. (1) Prompt-Based Annotation for Complex Reasoning. This approach uses structured prompts to capture iterative feedback [28, 53] or multi-step reasoning [54, 106], progressively refining annotation guidelines to clarify ambiguous schemas. However, the reliance on lengthy, complex instructions and repeated interactions might lead to high token consumption and latency. (2) Retrieval-Enriched Annotation for Factual Accuracy. This approach fetches context from external knowledge bases to ground annotations in verifiable information, enabling more reliable handling of specialized domains where the model's internal knowledge may be obsolete [55, 110]. However, its accuracy is tightly constrained by the reliability of the external resources and by noise from irrelevant or low-quality retrieved content. (3) Fine-Tuned Annotation for Domain Specificity. This approach adapts open-source models for specific domains (e.g., law, politics) via parameter-efficient fine-tuning, reaching high accuracy with lower deployment costs [113]. However, this merely shifts the primary bottleneck to data acquisition, since it requires extensive, high-quality instruction data to avoid overfitting. (4) Hybrid LLM-ML Annotation for Scalable Deployment. This approach trains lightweight ML models on weighted label distributions generated by $\textsc{LLMs}$, ensuring cost-effective inference [114]. However, the ML model's performance is fundamentally limited by the $\textsc{LLMs}$ 's upper bound, and the distillation step often results in a loss of the reasoning depth required for subtle edge cases. (5) Agent-Based Annotation for Tool-Assisted Tasks. This approach uses autonomous agents that call external tools (e.g., search engines) for resolving hard-to-label entities [116]. However, the sequential use of multiple tools might introduce significant delays, making it impractical for real-time or high-volume annotation.
Data Profiling.
Data profiling involves characterizing a given dataset by generating additional information (e.g., dataset descriptions, schema summaries, or hierarchical organization) or associating relevant datasets that enrich its structural and semantic understanding. Recent $\textsc{LLM}$ -enhanced methods can be classified into two categories.
❶ Prompt-Based End-to-End Profiling. As shown in Figure 9, this approach uses carefully designed prompts to guide $\textsc{LLMs}$ in profiling datasets, combining explicit instructions or constraints with few-shot examples and reasoning to handle complex, heterogeneous, and structured data effectively.
$\bullet$ Instruction and Constraint-Based Profiling Prompting. This category guides dataset profiling by incorporating explicit instructions or usage constraints in prompts to cover various aspects of the data. For example, AutoDDG [38] instructs $\textsc{LLMs}$ to generate both user-oriented and search-optimized descriptions based on dataset content and intended usage. LEDD [56] employs prompts with task-specific instructions for data lake profiling, including summarizing clusters into hierarchical categories and refining natural language queries for semantic search. DynoClass [118] specifies instructions in the prompt to synthesize detailed table descriptions from sampled rows and existing documentation, integrating them into a coherent global hierarchy. LLM-HTS [119] instructs $\textsc{LLMs}$ to infer open-set semantic types for tables and columns, which are then used to build hierarchical semantic trees via embedding-based clustering. Cocoon-Profiler [120] describes instructions at three levels: (1) table-level prompts constrain summarization using initial rows and documentation, (2) schema-level prompts guide hierarchical column grouping in JSON format, and (3) column-level prompts generate descriptions based on example rows and global context. HyperJoin [121] instructs $\textsc{LLMs}$ to create semantically equivalent column name variants using table context and naming conventions, producing structured JSON outputs to construct inter-table hyperedges. OCTOPUS [122] specifies strict constraints in the prompts to output only column names separated by specific delimiters and a SQL sketch, enabling lightweight entity-aware profiling.
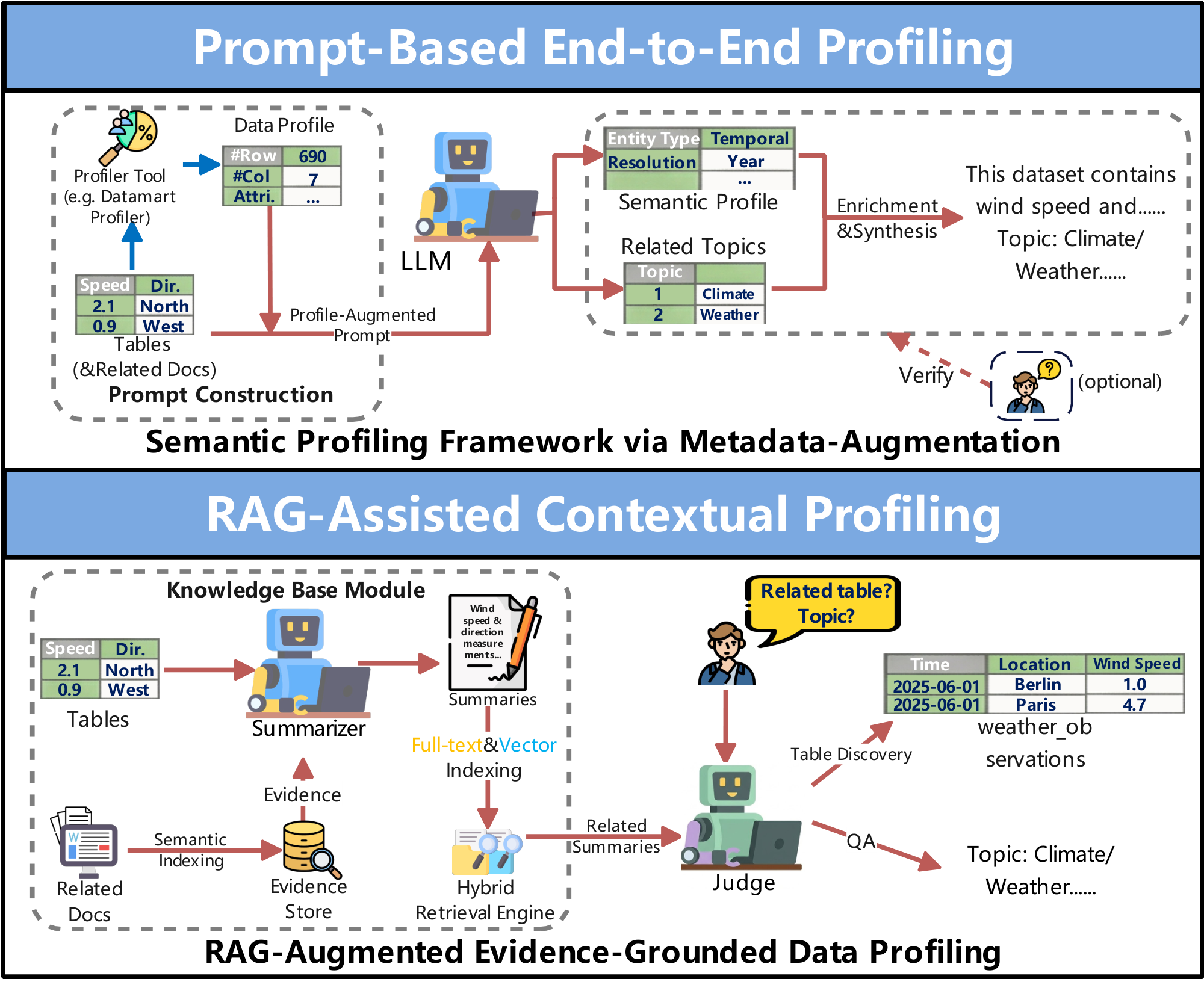
$\bullet$ Example and Reasoning-Enhanced Profiling Prompting. This category combines few-shot example prompts with Chain-of-Thought (CoT) reasoning to support structured profiling of complex and heterogeneous data. For instance, LLMCodeProfiling [123] uses a two-stage, prompt-based framework for cross-language code profiling. In the syntactic abstraction stage, few-shot CoT prompts demonstrate how abstract syntax tree (AST) nodes from different languages can be converted into a unified tabular representation, guiding the $\textsc{LLM}$ to infer deterministic mappings that align language-specific constructs to a common schema. In the semantic assignment stage, instructional classification prompts direct the $\textsc{LLM}$ to assign imported packages to functional categories (e.g., labeling scikit-learn as "machine learning").
❷ RAG-Assisted Contextual Profiling. As shown in Figure 9, this approach combines multiple retrieval techniques with $\textsc{LLM}$ reasoning to improve profiling accuracy and consistency, especially when metadata is sparse or incomplete. For example, LLMDap [124] employs vector search to gather relevant textual evidence, including scientific articles, documentation, and metadata fragments, to generate semantically consistent dataset-level profiles (e.g., dataset descriptions, variable definitions, and structured metadata). Pneuma [25] integrates hybrid retrieval methods, such as full-text and vector search, to identify relevant tables from databases or data lakes, using $\textsc{LLMs}$ to generate semantic column descriptions and to refine and rerank the retrieved results.
Discussion. (1) Prompt-Based Profiling for Descriptive Summarization. This approach integrates structural and statistical metadata into prompts to generate faithful dataset descriptions, overcoming context window limits [38]. However, relying solely on summary statistics is a lossy compression, potentially causing the model to miss fine-grained semantic anomalies hidden in the raw data. (2) Iterative Profiling for Hierarchical Structure. This approach utilizes $\textsc{LLM}$ -driven clustering and summarization to build hierarchical views of data lakes, enabling semantic search across disparate tables [56]. However, the iterative abstraction process risks accumulating information loss, resulting in vague or generic descriptions at higher levels of the hierarchy. (3) Hybrid Profiling for Quality Assurance. This approach augments statistical profiling with $\textsc{LLM}$ -driven reasoning and human verification to identify complex structural anomalies and disguised missing values [37]. However, the reliance on human-in-the-loop intervention creates a scalability bottleneck, making it unsuitable for fully automated, real-time data pipelines. (4) Retrieval-Enriched Profiling for Contextual Grounding. This approach retrieves external context (e.g., similar tables or text) to ground the generation of evidence-based schema descriptions [25, 124]. However, the final profiling accuracy is strictly bounded by the relevance of the retrieved corpus, where noisy or outdated external context can induce hallucinations.
6. Evaluation
6.1 Data Preparation Datasets
:::
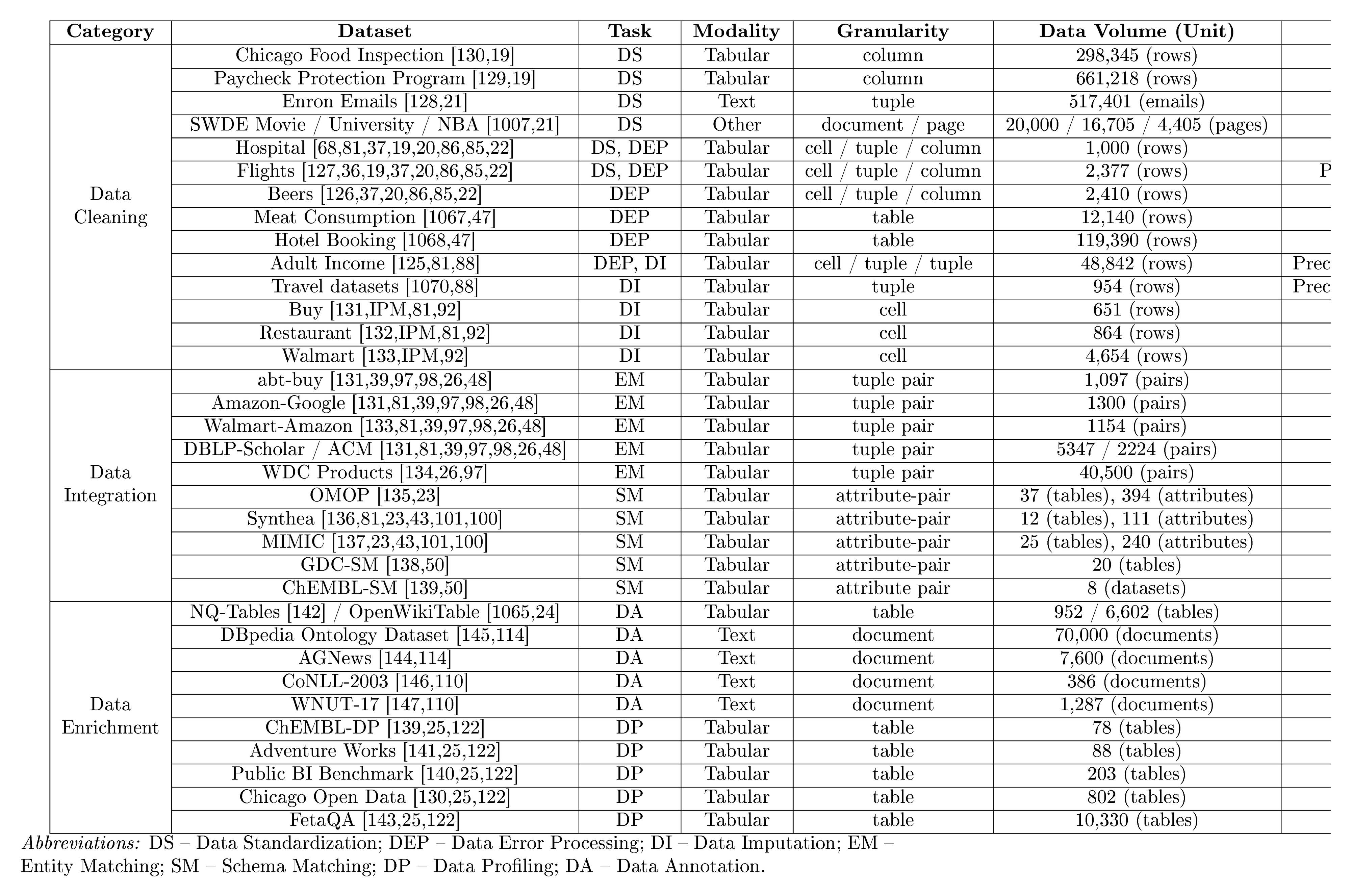
Table 2: Summary of Representative $\textsc{Data Preparation}$ Datasets.
:::
To support a systematic evaluation of $\textsc{LLM}$ -enhanced data preparation, we summarize representative datasets in Table 2, providing detailed information across multiple dimensions, including category, task, modality, granularity, data volume, and evaluation metrics. It allows researchers to compare and select benchmarks tailored to their specific use cases. For instance, we present a granularity-driven perspective below that groups benchmarks by their fundamental processing unit (i.e., records, schemas, or entire objects).
(1) Record-Level. This category treats individual tuples, cells, or tuple pairs as the analysis unit. It covers most data cleaning, error processing, data imputation, and entity matching tasks, including detecting erroneous values, standardizing attributes, imputing missing cells, and identifying coreference across records. Representative tuple-level benchmarks include Adult Income [125], Hospital [68], Beers [126], Flights [127], and text-based datasets such as Enron Emails [128]. Column-level benchmarks include the Paycheck Protection Program [129] and Chicago Food Inspection [130]. Cell-level benchmarks include Buy [131], Restaurant [132], and Walmart [133]. Conversely, tuple-pair benchmarks, including abt-buy [131], Amazon–Google [131], Walmart–Amazon [133], DBLP–Scholar [131], DBLP–ACM [131], and WDC Products [134], focus on pairwise comparisons across heterogeneous sources for record-level alignment.
(2) Schema-Level. This category focuses on attribute pairs or schema elements, aiming to align columns and conceptual entities across heterogeneous schemas. The challenge shifts from validating individual values to matching semantic meanings and structural roles. Benchmarks such as OMOP [135], Synthea [136], and MIMIC [137] focus on clinical attribute alignment. Moreover, datasets such as GDC-SM [138] and ChEMBL-SM [139] evaluate cross-source attribute alignment within complex scientific and biomedical schemas.
(3) Object-Level. This category deals with entire tables or documents as the fundamental processing unit. Unlike record- or schema-level tasks, these benchmarks require reasoning over global structure and broader context. Table-level datasets supporting data profiling and annotation include Public BI [140], Adventure Works [141], ChEMBL-DP [139], Chicago Open Data [130], NQ-Tables [142], and FetaQA [143]. Document-level benchmarks, such as AGNews [144], DBpedia [145], CoNLL-2003 [146], and WNUT-17 [147], require combining evidence across full texts for semantic grounding and annotation.
6.2 Data Preparation Metrics
In real deployments, data preparation methods are evaluated across multiple dimensions. Therefore, we organize evaluation metrics in Table 2 by the aspects they measure, including correctness, robustness, ranking quality, and semantic consistency, rather than only by the tasks.
❶ Preparation Correctness Assessment. This category evaluates the correctness of preparation methods by measuring how accurately they process target data elements relative to ground-truth references.
$\bullet$ Operation Precision. These metrics quantify the reliability of predictions from preparation methods. For example, (1) Accuracy [148] measures the proportion of correctly classified elements across relevant and irrelevant elements, commonly used in classification tasks such as error identification in data error processing. (2) Precision [148] measures the fraction of correctly identified matches or errors among all elements flagged by the method, reflecting output reliability in tasks like entity or schema matching. (3) F1-score [148] extends precision to penalize both incorrect identifications and missed detections within a single measure, making it suitable for applications where both erroneous outputs and overlooked cases are significant.
$\bullet$ Operation Coverage. These metrics reflect whether preparation methods comprehensively address all required elements. For example, (1) Recall [148] measures the proportion of correctly identified matches or errors among all ground-truth elements, reflecting a method's ability to avoid missed detections in tasks such as entity matching. (2) Matching Rate [131] quantifies the proportion of target elements that are successfully aligned to a valid representation, commonly used in tasks such as entity matching.
❷ Preparation Robustness Assessment. This category evaluates the stability and reliability of preparation methods over diverse datasets. These metrics measure how consistently a method maintains its effectiveness across varying data distributions and structural complexity. For example, (1) ROC [149] characterizes the trade-off between correctly identifying target elements (e.g., valid matches) and incorrectly flagging non-target elements as the decision threshold varies, providing a global view of method behavior in tasks such as data error processing. (2) AUC [149] summarizes this behavior into a single measure that reflects a method's ability to distinguish relevant from irrelevant elements across all thresholds and is commonly used in tasks such as data error processing.
❸ Enrichment and Ranking Quality Assessment. This category evaluates the quality of preparation methods by measuring how effectively they retrieve and prioritize relevant information over ground-truth results.
$\bullet$ Retrieval Ranking Quality. These metrics assess the relevance of top-ranked candidates in retrieval-based preparation tasks. For example, (1) P@k [150] measures the fraction of queries where a correct result is found within the top-$k$ elements, reflecting retrieval utility in data profiling. (2) MRR [150] measures the average rank position of the first correct result across queries, indicating how quickly relevant elements are placed at the top of the list.
$\bullet$ Enrichment Completeness. These metrics measure how comprehensively preparation methods find all relevant information during data enrichment. For example, (1) Recall@GT [150] measures the fraction of correctly identified elements among the top-$k$ results, where $k$ is the total number of true elements, assessing coverage in tasks such as entity or schema matching. (2) $1-\alpha$ [151] measures the fraction of data elements for which the correct label is present in the set of candidates, evaluating label coverage in tasks such as data annotation. (3) Hit Rate [150] measures the fraction of search queries that return at least one correct result, evaluating basic retrieval success in tasks such as data annotation.
❹ Semantic Preservation Assessment. This category evaluates the ability of preparation methods to preserve semantic meaning in the generated outputs. These metrics measure how consistently a method maintains semantics between its outputs and the reference content. For example, (1) ROUGE [152] assesses semantic consistency at the lexical level by measuring $n$-gram overlap between the output and the reference text, commonly used to evaluate whether the outputs retain key terms in tasks such as data standardization. (2) Cosine Similarity [153] measures semantic alignment in an embedding space by comparing vector representations of the generated and reference texts with a continuous measure in tasks such as data profiling.
7. Challenges and Future Directions
7.1 Data Cleaning
❶ Global-Aware and Semantically Flexible Cleaning. Most existing prompt-based cleaning methods operate on restrictive local contexts, such as individual rows or small batches [81, 37]. While retrieval-augmented methods expand this scope by fetching external evidence [44, 42], they remain centered on instance-level context and cannot capture dataset-level properties (e.g., uniqueness constraints or aggregate correlations) essential for issues requiring holistic views. Future work should explore hybrid systems that integrate $\textsc{LLMs}$ with external analysis engines capable of providing global statistics and constraints, enabling joint reasoning over local instances and dataset-level signals while preserving the semantic flexibility.
❷ Robust and Error-Controlled Cleaning. Agent-based data cleaning mimics human-style workflows and can improve cleaning coverage [36, 19], but current systems lack effective safeguards against error accumulation and hallucinated cleaning. Although recent general-purpose frameworks introduce uncertainty estimation [154] and self-correction strategies [155] to improve agent reliability, these techniques are mostly heuristic and cannot be directly applied to data cleaning tasks that require strict correctness guarantees. An important open direction is to design uncertainty-aware agent-based cleaning frameworks that use conservative decision strategies, formal validation mechanisms, and explicit risk control, allowing systems to balance cleaning coverage with measurable error risk and move toward provably robust cleaning pipelines.
❹ Efficient and Scalable Collaborative Cleaning. Prompt-based data cleaning methods struggle to scale to large tables due to context limits [47, 85], while agent-based workflows often incur high computational cost and latency [36]. Although smaller, locally deployable models and federated learning frameworks enable privacy-preserving cleaning deployments [156], existing systems lack principled strategies for coordinating models with different capabilities. An important future direction is to design hierarchical cleaning frameworks that assign routine cleaning tasks to small local models and reserve $\textsc{LLMs}$ for complex reasoning, combined with efficient table partitioning and selective context management to reduce cost and latency without sacrificing cleaning quality.
7.2 Data Integration
❶ Universal and Cross-Domain Integration. Recent structure-aware matching methods [157] and cross-dataset integration studies [97] have shown encouraging results, but they generally assume the presence of reasonably informative schemas. In practice, many integration scenarios involve extreme heterogeneity, including unclear or abbreviated attribute names, substantial structural mismatches (e.g., nested data mapped to flat tables), and datasets with little or no usable metadata. These conditions remain difficult for current methods to handle reliably. An key future direction is to develop techniques that rely less on schema descriptions and prompts, and instead infer semantic correspondences directly from data instances (e.g., value distributions and co-occurrence patterns), enabling robust integration even when schema information is missing or misleading.
❷ Universal Integration in Diverse Realistic Datasets. Despite recent progress, $\textsc{LLM}$ -enhanced integration methods often require curated examples [26, 94] or domain-specific fine-tuning [39, 96] to achieve high performance. Although zero-shot cross-domain integration has received increasing attention [158], it remains limited in realistic integration with varying schema design, value formats, or domain-specific semantics. Thus, building a single matcher that can reliably transfer integration behaviors across diverse datasets remains a major challenge. We should explore research in meta-learning and synthetic data generation to create universal integration models that generalize to new domains without requiring expensive, domain-specific training data.
❸ Rule-Constrained and Globally Valid Integration. Recent in-context clustering methods [48] for entity matching can efficiently enforce simple global properties, such as transitivity, during matching [95, 43]. In practice, however, data integration often requires satisfying more complex and domain-specific constraints, including multi-entity relationships, temporal ordering, and business rules. These constraints are difficult to express and enforce using prompt-based approaches. An important future direction is to augment $\textsc{LLM}$ -based integration pipelines with explicit reasoning components, such as constraint solvers and graph-based inference modules, that can be invoked by $\textsc{LLM}$ agents to ensure that integration results respect complex, domain-specific constraints.
7.3 Data Enrichment
❶ Interactive Human-in-the-Loop Enrichment. Fully automated data enrichment is often impractical, especially when enrichment decisions are ambiguous or domain dependent [38, 124]. In practice, effective workflows require close collaboration between human experts and $\textsc{LLM}$ -enhanced systems. However, most existing methods are designed for one-shot automation and provide limited support for interactive refinement, where users can guide decisions, verify results, and correct errors during the enrichment process. We need to develop novel interactive frameworks where $\textsc{LLMs}$ can explain their reasoning, solicit feedback on ambiguous cases, and incrementally refine enrichment tasks based on human guidance, treating the user as a core component of the system.
❷ Multi-Aspect and Open-Ended Enrichment. Evaluating $\textsc{LLM}$ -enhanced data enrichment remains challenging in two aspects. First, enrichment often involves multiple aspects, such as annotating column types [53, 28], expanding textual descriptions [38, 56], which are difficult to assess with a single task-level metric. Second, many enrichment outputs are free-form text, where quality cannot be judged using simple binary or precision-based measures. As a result, existing benchmark is largely designed for structured or closed-form tasks and fail to reflect the quality and usefulness of real-world enrichment results. A key future direction is to develop standardized enrichment benchmarks that support multi-aspect evaluation and richer assessment criteria, combining automatic metrics with reference-based, model-based, or human-in-the-loop evaluation to better capture enrichment quality, usefulness, and cost in realistic scenarios.
❸ Faithful and Evidence-Grounded Enrichment. Generative data enrichment using $\textsc{LLMs}$ can produce fluent but unsupported outputs, such as inferred constraints, textual summaries, or data profiles, particularly when the input data is noisy or incomplete [54, 122]. Although retrieval-augmented generation provides useful grounding mechanisms [110, 55, 25], existing approaches are primarily designed for structured tables and do not directly meet the needs of unstructured data enrichment. As a result, enriched content often lacks clear links to the data or knowledge sources that justify it. An important future direction is to design faithfulness-aware enrichment methods in which every generated output is explicitly grounded in verifiable evidence, such as supporting data samples, query execution results, or cited external knowledge, so that enriched information is both useful and trustworthy.
8. Conclusion
In this survey, we present a task-centric review of recent advances in $\textsc{LLM}$ -enhanced data preparation, covering data cleaning, data integration, and data enrichment. We systematically analyze how $\textsc{LLMs}$ reshape traditional data preparation workflows by enabling capabilities such as instruction-driven automation, semantic-aware reasoning, cross-domain generalization, and knowledge-augmented processing. Through a unified taxonomy, we organize representative methods, distill their design principles, and discuss the limitations of existing $\textsc{LLM}$ -enhanced methods. We also summarize representative datasets and metrics to facilitate comprehensive evaluations of these methods. Finally, we identify open challenges and outline future research directions.
References
[1] Neeli, Sethu Sesha Synam (2021). Ensuring Data Quality: A Critical Aspect of Business Intelligence Success. International Journal of Leading Research Publication. 2(9). pp. 1–7. doi:10.5281/zenodo.15360192. https://doi.org/10.5281/zenodo.15360192.
[2] Ali, Rizwan and Darmawan, Didit (2023). Big Data Management Optimization for Managerial Decision Making and Business Strategy. Journal of Social Science Studies. 3(2). pp. 139–144. https://jos3journals.id/index.php/jos3/article/view/263.
[3] Prasad, Aditya Nandan (2024). Introduction to Data Governance for Machine Learning Systems: Fundamental Principles, Critical Practices, and Future Trends. Apress. doi:10.1007/979-8-8688-1023-7. https://doi.org/10.1007/979-8-8688-1023-7.
[4] Jason Hausenloy et al. (2024). Towards Data Governance of Frontier AI Models. CoRR. abs/2412.03824.
[5] Guan, Jian (2026). Data Sharing Governance and Management Framework. doi:10.1007/978-981-95-2806-6_2. https://doi.org/10.1007/978-981-95-2806-6_2.
[6] Davis et al. (2025). Establishing data governance for sharing and access to real-world data: a case study. JAMIA Open. 8(3). pp. ooaf041. doi:10.1093/jamiaopen/ooaf041. https://doi.org/10.1093/jamiaopen/ooaf041.
[7] Ramon Chen (2025). The Hidden Cost of Poor Data Quality & Governance: ADM Turns Risk Into Revenue. Online. Acceldata Blog. Accessed: 2026-01-05.
[8] Xuanhe Zhou et al. (2025). A Survey of LLM x DATA. CoRR. abs/2505.18458.
[9] Yizhang Zhu et al. (2025). A Survey of Data Agents: Emerging Paradigm or Overstated Hype?. CoRR. abs/2510.23587.
[10] Statista (2025). Worldwide Data Created, Captured, Copied, and Consumed. Online. Statista. Accessed: 2026-01-05.
[11] (2023). LLMs with User-defined Prompts as Generic Data Operators for Reliable Data Processing. In IEEE Big Data. pp. 3144–3148.
[12] OpenRefine Community. OpenRefine: A power tool for working with messy data. https://openrefine.org. Accessed: 2025-11-05.
[13] Yuliang Li et al. (2020). Deep Entity Matching with Pre-Trained Language Models. Proc. VLDB Endow.. 14(1). pp. 50–60. doi:10.14778/3421424.3421431. http://www.vldb.org/pvldb/vol14/p50-li.pdf.
[14] Xiang Deng et al. (2020). TURL: Table Understanding through Representation Learning. Proc. VLDB Endow.. 14(3). pp. 307–319.
[15] Philip Bohannon et al. (2007). Conditional Functional Dependencies for Data Cleaning. In ICDE. pp. 746–755.
[16] Michele Dallachiesa et al. (2013). NADEEF: a commodity data cleaning system. In SIGMOD Conference. pp. 541–552.
[17] Muhammad Ebraheem et al. (2018). Distributed Representations of Tuples for Entity Resolution. Proc. VLDB Endow.. 11(11). pp. 1454–1467.
[18] Saravanan Thirumuruganathan et al. (2021). Deep Learning for Blocking in Entity Matching: A Design Space Exploration. Proc. VLDB Endow.. 14(11). pp. 2459–2472.
[19] Lan Li et al. (2024). AutoDCWorkflow: LLM-based Data Cleaning Workflow Auto-Generation and Benchmark. CoRR. abs/2412.06724.
[20] Mengyi Yan et al. (2024). GIDCL: A Graph-Enhanced Interpretable Data Cleaning Framework with Large Language Models. Proc. ACM Manag. Data. 2(6). pp. 236:1–236:29.
[21] (2023). Language Models Enable Simple Systems for Generating Structured Views of Heterogeneous Data Lakes. Proc. VLDB Endow.. 17(2). pp. 92–105.
[22] Wei Ni et al. (2024). IterClean: An Iterative Data Cleaning Framework with Large Language Models. In ACM TUR-C.
[23] (2025). Knowledge Graph-based Retrieval-Augmented Generation for Schema Matching. CoRR. abs/2501.08686.
[24] Yuxiang Guo et al. (2025). BIRDIE: Natural Language-Driven Table Discovery Using Differentiable Search Index. Proc. VLDB Endow.. 18(7). pp. 2070–2083.
[25] Muhammad Imam Luthfi Balaka et al. (2025). Pneuma: Leveraging LLMs for Tabular Data Representation and Retrieval in an End-to-End System. Proc. ACM Manag. Data. 3(3). pp. 200:1–200:28.
[26] Ralph Peeters et al. (2025). Entity Matching using Large Language Models. In EDBT. pp. 529–541.
[27] Benjamin Feuer et al. (2024). ArcheType: A Novel Framework for Open-Source Column Type Annotation using Large Language Models. Proc. VLDB Endow.. 17(9). pp. 2279–2292.
[28] Keti Korini and Christian Bizer (2025). Evaluating Knowledge Generation and Self-refinement Strategies for LLM-Based Column Type Annotation. In ADBIS. pp. 111–127.
[29] (2024). Cleaning Semi-Structured Errors in Open Data Using Large Language Models. In SDS. pp. 258–261.
[30] Jianhong Tu et al. (2023). Unicorn: A Unified Multi-tasking Model for Supporting Matching Tasks in Data Integration. Proc. ACM Manag. Data. 1(1). pp. 84:1–84:26.
[31] (2025). The Promises and Pitfalls of LLM Annotations in Dataset Labeling: a Case Study on Media Bias Detection. In NAACL (Findings). pp. 1370–1386.
[32] Wang et al. (2025). Large Language Models for Data Science: A Survey. https://openreview.net/forum?id=PiBQUGagoi. Under review at ACL Rolling Review.
[33] Mengshi Chen et al. (2025). Empowering Tabular Data Preparation with Language Models: Why and How?. CoRR. abs/2508.01556.
[34] Manish Sood and Venkat Venkatraman (2025). Is Your Enterprise Data Strategy Ready for the Age of Intelligence?. Sponsored Content, Harvard Business Review. https://hbr.org/sponsored/2025/09/is-your-enterprise-data-strategy-ready-for-the-age-of-intelligence.
[35] Archika Dogra et al. (2025). Introducing New Governance Capabilities to Scale AI Agents with Confidence: Unified Governance Across Models, Tools, and Data. Online. Databricks Blog. Accessed: 2026-01-05.
[36] Danrui Qi and Jiannan Wang (2024). CleanAgent: Automating Data Standardization with LLM-based Agents. CoRR. abs/2403.08291.
[37] Shuo Zhang et al. (2025). Data Cleaning Using Large Language Models. In ICDEW. pp. 28–32.
[38] (2025). AutoDDG: Automated Dataset Description Generation using Large Language Models. CoRR. abs/2502.01050.
[39] Haochen Zhang et al. (2023). Jellyfish: A Large Language Model for Data Preprocessing. CoRR. abs/2312.01678.
[40] Fabian Biester et al. (2024). LLMClean: Context-Aware Tabular Data Cleaning via LLM-Generated OFDs. In ADBIS. pp. 68–78.
[41] Aofeng Su et al. (2024). TableGPT2: A Large Multimodal Model with Tabular Data Integration. CoRR. abs/2411.02059.
[42] Chenyu Yang et al. (2025). Data Imputation with Limited Data Redundancy Using Data Lakes. Proc. VLDB Endow.. 18(10). pp. 3354–3367. doi:10.14778/3748191.3748200.
[43] Yongqin Xu et al. (2024). KcMF: A Knowledge-compliant Framework for Schema and Entity Matching with Fine-tuning-free LLMs. CoRR. abs/2410.12480.
[44] Mohamed Y. Eltabakh et al. (2024). RetClean: Retrieval-Based Tabular Data Cleaning Using LLMs and Data Lakes. Proc. VLDB Endow.. 17(12). pp. 4421–4424.
[45] Mazhar Hameed and Felix Naumann (2020). Data Preparation: A Survey of Commercial Tools. SIGMOD Rec.. 49(3). pp. 18–29.
[46] Juhwan Choi et al. (2024). Multi-News+: Cost-efficient Dataset Cleansing via LLM-based Data Annotation. In EMNLP. pp. 15–29.
[47] Tommaso Bendinelli et al. (2025). Exploring LLM Agents for Cleaning Tabular Machine Learning Datasets. CoRR. abs/2503.06664.
[48] Meihao Fan et al. (2024). Cost-Effective In-Context Learning for Entity Resolution: A Design Space Exploration. In ICDE. pp. 3696–3709.
[49] Marcel Parciak et al. (2024). Schema Matching with Large Language Models: an Experimental Study. In VLDB Workshops.
[50] (2025). Magneto: Combining Small and Large Language Models for Schema Matching. Proc. VLDB Endow.. 18(8). pp. 2681–2694.
[51] Zhangcheng Qiang et al. (2024). Agent-OM: Leveraging LLM Agents for Ontology Matching. Proc. VLDB Endow.. 18(3). pp. 516–529.
[52] (2025). Interactive Data Harmonization with LLM Agents. CoRR. abs/2502.07132.
[53] Moe Kayali et al. (2024). CHORUS: Foundation Models for Unified Data Discovery and Exploration. Proc. VLDB Endow.. 17(8). pp. 2104–2114.
[54] (2024). Mind the Data Gap: Bridging LLMs to Enterprise Data Integration. CoRR. abs/2412.20331.
[55] Linxi Wei et al. (2024). RACOON: An LLM-based Framework for Retrieval-Augmented Column Type Annotation with a Knowledge Graph. CoRR. abs/2409.14556.
[56] Qi An et al. (2025). LEDD: Large Language Model-Empowered Data Discovery in Data Lakes. CoRR. abs/2502.15182.
[57] Zhen Tan et al. (2024). Large Language Models for Data Annotation and Synthesis: A Survey. In EMNLP. pp. 930–957.
[58] Bosheng Ding et al. (2024). Data Augmentation using LLMs: Data Perspectives, Learning Paradigms and Challenges. In ACL (Findings). pp. 1679–1705.
[59] Cheng et al. (2025). A survey on table mining with large language models: Challenges, advancements and prospects. Authorea Preprints.
[60] Zhen Qin et al. (2025). The Synergy Between Data and Multi-Modal Large Language Models: A Survey From Co-Development Perspective. IEEE Trans. Pattern Anal. Mach. Intell.. 47(10). pp. 8415–8434.
[61] Mihai Nadas et al. (2025). Synthetic Data Generation Using Large Language Models: Advances in Text and Code. IEEE Access. 13. pp. 134615–134633. doi:10.1109/ACCESS.2025.3589503. https://doi.org/10.1109/ACCESS.2025.3589503.
[62] Ruxue Shi et al. (2025). A Comprehensive Survey of Synthetic Tabular Data Generation. CoRR. abs/2504.16506.
[63] Juyong Jiang et al. (2024). A Survey on Large Language Models for Code Generation. CoRR. abs/2406.00515. doi:10.48550/ARXIV.2406.00515. https://doi.org/10.48550/arXiv.2406.00515.
[64] Lin Long et al. (2024). On LLMs-Driven Synthetic Data Generation, Curation, and Evaluation: A Survey. In ACL (Findings). pp. 11065–11082.
[65] Mohammad Hossein Moslemi et al. (2025). Heterogeneity in Entity Matching: A Survey and Experimental Analysis. CoRR. abs/2508.08076. doi:10.48550/ARXIV.2508.08076. https://doi.org/10.48550/arXiv.2508.08076.
[66] Erhard Rahm and Hong Hai Do (2000). Data Cleaning: Problems and Current Approaches. IEEE Data Eng. Bull.. 23(4). pp. 3–13.
[67] (1998). Real-world Data is Dirty: Data Cleansing and The Merge/Purge Problem. Data Min. Knowl. Discov.. 2(1). pp. 9–37.
[68] Xu Chu et al. (2013). Holistic data cleaning: Putting violations into context. In ICDE. pp. 458–469.
[69] Wenfei Fan and Floris Geerts (2012). Foundations of Data Quality Management. Morgan & Claypool Publishers.
[70] Roderick J. Little and Donald B. Rubin (2019). Statistical Analysis with Missing Data. Wiley. doi:10.1002/9781119482260.
[71] Joseph L. Schafer and John W. Graham (2002). Missing Data: Our View of the State of the Art. Psychological Methods. 7(2). pp. 147–177. doi:10.1093/biomet/63.3.581. https://doi.org/10.1093/biomet/63.3.581.
[72] Ivan P. Fellegi and Alan B. Sunter (1969). A Theory for Record Linkage. Journal of the American Statistical Association. 64(328). pp. 1183–1210.
[73] Ahmed K. Elmagarmid et al. (2007). Duplicate Record Detection: A Survey. IEEE Trans. Knowl. Data Eng.. 19(1). pp. 1–16.
[74] Erhard Rahm and Philip A. Bernstein (2001). A survey of approaches to automatic schema matching. VLDB J.. 10(4). pp. 334–350.
[75] AnHai Doan et al. (2001). Reconciling Schemas of Disparate Data Sources: A Machine-Learning Approach. In SIGMOD Conference. pp. 509–520.
[76] Jayant Madhavan et al. (2001). Generic Schema Matching with Cupid. In VLDB. pp. 49–58.
[77] Girija Limaye et al. (2010). Annotating and Searching Web Tables Using Entities, Types and Relationships. Proc. VLDB Endow.. 3(1). pp. 1338–1347.
[78] (2019). Sherlock: A Deep Learning Approach to Semantic Data Type Detection. In KDD. pp. 1500–1508.
[79] Ziawasch Abedjan et al. (2015). Profiling relational data: a survey. VLDB J.. 24(4). pp. 557–581.
[80] (1999). TANE: An Efficient Algorithm for Discovering Functional and Approximate Dependencies. Comput. J.. 42(2). pp. 100–111.
[81] Haochen Zhang et al. (2024). Large Language Models as Data Preprocessors. In VLDB Workshops.
[82] Mohammad Mahdavi et al. (2019). Raha: A Configuration-Free Error Detection System. In SIGMOD Conference. pp. 865–882.
[83] Aodong Li et al. (2024). Anomaly Detection of Tabular Data Using LLMs. CoRR. abs/2406.16308.
[84] (2023). Llama 2: Open Foundation and Fine-Tuned Chat Models. CoRR. abs/2307.09288. doi:10.48550/ARXIV.2307.09288. https://doi.org/10.48550/arXiv.2307.09288.
[85] Wei Ni et al. (2025). ZeroED: Hybrid Zero-Shot Error Detection Through Large Language Model Reasoning. In ICDE. pp. 3126–3139.
[86] Wang et al. (2025). Ensembling LLM-Induced Decision Trees for Explainable and Robust Error Detection. arXiv preprint arXiv:2512.07246.
[87] Ahatsham Hayat and Mohammad Rashedul Hasan (2025). A Context-Aware Approach for Enhancing Data Imputation with Pre-trained Language Models. In COLING. pp. 5668–5685.
[88] Shreenidhi Srinivasan and Lydia Manikonda (2025). Does Prompt Design Impact Quality of Data Imputation by LLMs?. CoRR. abs/2506.04172.
[89] Omidvartehrani, Soroush and Rafiei, Davood (2025). LDI: Localized Data Imputation for Text-Rich Tables. arXiv preprint arXiv:2506.16616.
[90] Xinrui He et al. (2025). LLM-Forest: Ensemble Learning of LLMs with Graph-Augmented Prompts for Data Imputation. In ACL (Findings). pp. 6921–6936.
[91] Zhicheng Ding et al. (2024). Data Imputation using Large Language Model to Accelerate Recommendation System. arXiv preprint arXiv:2407.10078.
[92] Jianmin Wang et al. (2025). On LLM-Enhanced Mixed-Type Data Imputation with High-Order Message Passing. Proc. VLDB Endow.. 18(10). pp. 3421–3434.
[93] Hossein Jamali (2025). Quantum-Accelerated Neural Imputation with Large Language Models (LLMs). CoRR. abs/2507.08255.
[94] Yifan Ding et al. (2024). ChatEL: Entity Linking with Chatbots. In LREC/COLING. pp. 3086–3097.
[95] Jiajie Fu et al. (2025). In-context Clustering-based Entity Resolution with Large Language Models: A Design Space Exploration. Proc. ACM Manag. Data. 3(4). pp. 252:1–252:28.
[96] Qian Ruan et al. (2025). Fine-tuning large language models with contrastive margin ranking loss for selective entity matching in product data integration. Adv. Eng. Informatics. 67. pp. 103538.
[97] Zeyu Zhang et al. (2025). A Deep Dive Into Cross-Dataset Entity Matching with Large and Small Language Models. In EDBT. pp. 922–934.
[98] Tianshu Wang et al. (2025). Match, Compare, or Select? An Investigation of Large Language Models for Entity Matching. In COLING. pp. 96–109.
[99] Amy Xin et al. (2025). LLMAEL: Large Language Models are Good Context Augmenters for Entity Linking. In CIKM. pp. 3550–3559.
[100] Christopher Buss et al. (2025). Towards Scalable Schema Mapping using Large Language Models. CoRR. abs/2505.24716.
[101] Nabeel Seedat and Mihaela van der Schaar (2024). Matchmaker: Self-Improving Large Language Model Programs for Schema Matching. CoRR. abs/2410.24105.
[102] Omar Khattab and Matei Zaharia (2020). ColBERT: Efficient and Effective Passage Search via Contextualized Late Interaction over BERT. In SIGIR. pp. 39–48.
[103] Tianshu Zhang et al. (2024). TableLlama: Towards Open Large Generalist Models for Tables. In NAACL-HLT. pp. 6024–6044.
[104] Shunyu Yao et al. (2023). ReAct: Synergizing Reasoning and Acting in Language Models. In ICLR.
[105] Parikshit Bansal and Amit Sharma (2023). Large Language Models as Annotators: Enhancing Generalization of NLP Models at Minimal Cost. CoRR. abs/2306.15766.
[106] Ting Cai et al. (2025). Columbo: Expanding Abbreviated Column Names for Tabular Data Using Large Language Models. CoRR. abs/2508.09403.
[107] Xuran Ming et al. (2024). AutoLabel: Automated Textual Data Annotation Method Based on Active Learning and Large Language Model. In KSEM (4). pp. 400–411.
[108] (2017). DBSCAN Revisited, Revisited: Why and How You Should (Still) Use DBSCAN. ACM Trans. Database Syst.. 42(3). pp. 19:1–19:21.
[109] Fei Teng et al. (2025). LLMLog: Advanced Log Template Generation via LLM-driven Multi-Round Annotation. Proc. VLDB Endow.. 18(9). pp. 3134–3148.
[110] Muhammad Uzair-Ul-Haq et al. (2025). LLMs as Data Annotators: How Close Are We to Human Performance. CoRR. abs/2504.15022.
[111] OpenAI (2024). Embeddings. https://platform.openai.com/docs/guides/embeddings. Accessed: 2024-07-20. https://platform.openai.com/docs/guides/embeddings.
[113] (2025). Open-source LLMs for text annotation: a practical guide for model setting and fine-tuning. J. Comput. Soc. Sci.. 8(1). pp. 17.
[114] Mingxuan Xia et al. (2025). Prompt Candidates, then Distill: A Teacher-Student Framework for LLM-driven Data Annotation. In ACL (1). pp. 2750–2770.
[115] Yao Lu et al. (2025). From LLM-anation to LLM-orchestrator: Coordinating Small Models for Data Labeling. CoRR. abs/2506.16393.
[116] Yilin Geng et al. (2025). An LLM Agent-Based Complex Semantic Table Annotation Approach. In ADMA (2). pp. 223–238.
[117] Minhua Lin et al. (2024). Decoding Time Series with LLMs: A Multi-Agent Framework for Cross-Domain Annotation. CoRR. abs/2410.17462.
[118] Haonan Wang et al. (2024). DynoClass: A Dynamic Table-Class Detection System Without the Need for Predefined Ontologies. In TRL @ NeurIPS 2024. https://openreview.net/forum?id=r45TbawHl8.
[119] Grace Fan and Juliana Freire (2025). Hierarchical Table Semantics for Exploratory Table Discovery. In HILDA@SIGMOD. pp. 5:1–5:7.
[120] Zezhou Huang and Eugene Wu (2024). Cocoon: Semantic Table Profiling Using Large Language Models. In HILDA@SIGMOD. pp. 1–7.
[121] Liu et al. (2026). HyperJoin: LLM-augmented Hypergraph Link Prediction for Joinable Table Discovery. arXiv preprint arXiv:2601.01015.
[122] Li, Wen-Zhi and Galhotra, Sainyam (2026). Octopus: A Lightweight Entity-Aware System for Multi-Table Data Discovery and Cell-Level Retrieval. arXiv preprint arXiv:2601.02304.
[123] Pankaj Thorat et al. (2025). LLM-Aided Customizable Profiling of Code Data Based On Programming Language Concepts. CoRR. abs/2503.15571.
[124] Jiang et al. (2025). LLMDap: LLM-based Data Profiling and Sharing. In VLDB 2025 Workshop: 3rd Data EConomy Workshop (DEC).
[125] wenruliu (2016). Adult Income Dataset. https://www.kaggle.com/datasets/wenruliu/adult-income-dataset. Kaggle dataset, Accessed: 2026-01-14.
[126] Jean-NicholasHould (2017). Craft Beers Dataset. https://www.kaggle.com/nickhould/craft-cans. Kaggle dataset, Accessed: 2026-01-14.
[127] Li et al. (2012). Truth finding on the deep web: is the problem solved?. Proc. VLDB Endow.. 6(2). pp. 97–108. doi:10.14778/2535568.2448943. https://doi.org/10.14778/2535568.2448943.
[128] Bryan Klimt and Yiming Yang (2004). Introducing the Enron Corpus. In CEAS.
[129] U.S. Small Business Administration (2021). PPP FOIA. https://data.sba.gov/dataset/ppp-foia. [Data set]. Accessed: 2026-01-14. https://data.sba.gov/dataset/ppp-foia.
[130] Chicago Open Data Portal.
[131] (2010). Evaluation of entity resolution approaches on real-world match problems. Proc. VLDB Endow.. 3(1). pp. 484–493.
[132] University of Texas at Austin Machine Learning Research Group (2003). Duplicate Detection, Record Linkage, and Identity Uncertainty: Datasets. https://www.cs.utexas.edu/~ml/riddle/data.html. Last modified: August 25, 2003. https://www.cs.utexas.edu/~ml/riddle/data.html.
[133] Ryan A. Rossi and Nesreen K. Ahmed (2015). The Network Data Repository with Interactive Graph Analytics and Visualization. https://sites.google.com/site/anhaidgroup/useful-stuff/the-magellan-data-repository.
[134] Ralph Peeters et al. (2024). WDC Products: A Multi-Dimensional Entity Matching Benchmark. In EDBT. pp. 22–33.
[135] (2015). Observational Health Data Sciences and Informatics (OHDSI): Opportunities for Observational Researchers. In MedInfo. pp. 574–578.
[136] Jason A. Walonoski et al. (2018). Synthea: An approach, method, and software mechanism for generating synthetic patients and the synthetic electronic health care record. J. Am. Medical Informatics Assoc.. 25(3). pp. 230–238.
[137] Johnson et al. (2018). The MIMIC Code Repository: enabling reproducibility in critical care research. Journal of the American Medical Informatics Association. 25(1). pp. 32–39.
[138] (2025). GDC-SM: The GDC Schema Matching Benchmark (Version 1.0). https://doi.org/10.5281/zenodo.14963588. Accessed: 2026-01-15..
[139] (2012). ChEMBL: a large-scale bioactivity database for drug discovery. Nucleic Acids Res.. 40(Database-Issue). pp. 1100–1107.
[140] Public BI Benchmark.
[141] AdventureWorks (2026). Adventure Works Sample Databases. https://learn.microsoft.com/en-us/sql/samples/adventureworks-install-configure. Accessed: 2026-01-14.
[142] (2020). TaPas: Weakly Supervised Table Parsing via Pre-training. In ACL. pp. 4320–4333.
[143] Linyong Nan et al. (2021). FeTaQA: Free-form Table Question Answering. CoRR. abs/2104.00369.
[144] Xiang Zhang et al. (2015). Character-level Convolutional Networks for Text Classification. In NIPS. pp. 649–657.
[145] (2015). DBpedia - A large-scale, multilingual knowledge base extracted from Wikipedia. Semantic Web. 6(2). pp. 167–195.
[146] Erik F. Tjong Kim Sang and Fien De Meulder (2003). Introduction to the CoNLL-2003 Shared Task: Language-Independent Named Entity Recognition. In CoNLL. pp. 142–147.
[147] Leon Derczynski et al. (2017). Results of the WNUT2017 Shared Task on Novel and Emerging Entity Recognition. In NUT@EMNLP. pp. 140–147.
[148] Van Rijsbergen, C.J. (1979). Information Retrieval. Butterworths.
[149] Tom Fawcett (2006). An Introduction to ROC Analysis. Pattern Recognit. Lett.. 27(8). pp. 861–874.
[150] Manning et al. (2008). Introduction to Information Retrieval. Cambridge University Press.
[151] Shuo He et al. (2024). Candidate Label Set Pruning: A Data-centric Perspective for Deep Partial-label Learning. In The 12th International Conference on Learning Representations (ICLR).
[152] Lin, Chin-Yew (2004). Rouge: A Package for Automatic Evaluation of Summaries. In in Text Summarization Branches Out. ACL. pp. 74–81.
[153] Gerard Salton et al. (1975). A Vector Space Model for Automatic Indexing. Commun. ACM. 18(11). pp. 613–620.
[154] Qiwei Zhao et al. (2025). Uncertainty Propagation on LLM Agent. In ACL (1). pp. 6064–6073.
[155] Sri Vatsa Vuddanti et al. (2025). PALADIN: Self-Correcting Language Model Agents to Cure Tool-Failure Cases. CoRR. abs/2509.25238.
[156] Weirui Kuang et al. (2024). FederatedScope-LLM: A Comprehensive Package for Fine-tuning Large Language Models in Federated Learning. In KDD. pp. 5260–5271.
[157] Marcel Parciak et al. (2025). LLM-Matcher: A Name-Based Schema Matching Tool using Large Language Models. In SIGMOD Conference Companion. pp. 203–206.
[158] (2025). ZeroNER: Fueling Zero-Shot Named Entity Recognition via Entity Type Descriptions. In ACL (Findings). pp. 15594–15616. [159] Z. Zhang, P. Groth, I. Calixto, and S. Schelter (2024). "Anymatch - efficient zero-shot entity matching with a small language model". CoRR. abs/2409.04073.
[160] D. B. Rubin (1976). "Inference and missing data". Biometrika. 63(3). pp. 581–592.
[161] M. Mahdavi et al. (2019). "Raha: A configuration-free error detection system". In SIGMOD Conference. pp. 865–882.