The Topological Trouble With Transformers
Michael C. Mozer
Google DeepMind
[email protected]
Shoaib Ahmed Siddiqui
Google DeepMind
[email protected]
Rosanne Liu
Google DeepMind
[email protected]
Abstract
Transformers encode structure in sequences via an expanding contextual history. However, their purely feedforward architecture fundamentally limits dynamic state tracking. State tracking—the iterative updating of latent variables reflecting an evolving environment—involves inherently sequential dependencies that feedforward networks struggle to maintain. Consequently, feedforward models push evolving state representations deeper into their layer stack with each new input step, rendering information inaccessible in shallow layers and ultimately exhausting the model’s depth. While this depth limit can be bypassed by dynamic depth models and by explicit or latent thinking that externalizes state representations, these solutions are computationally and memory inefficient. In this article, we argue that temporally extended cognition requires refocusing from explicit thought traces to implicit activation dynamics via recurrent architectures. We introduce a taxonomy of recurrent and continuous-thought transformer architectures, categorizing them by their recurrence axis (depth versus step) and their ratio of input tokens to recurrence steps. Finally, we outline promising research directions, including enhanced state-space models and coarse-grained recurrence, to better integrate state tracking into modern foundation models.
Preprint.
Executive Summary: Transformers power today’s leading AI systems, yet they face a structural barrier when required to maintain and update an internal picture of an evolving situation over many steps. The paper examines this barrier—known as state tracking—and explains why purely feedforward designs, even with very long context windows, systematically lose or misplace critical information.
The authors set out to diagnose the topological cause of these failures and to map practical routes toward architectures that can perform ongoing state updates without exhausting model depth.
They proceed through conceptual analysis supported by published examples, failure traces from current models, and a systematic classification of recent recurrent and hybrid designs. No new large-scale experiments are presented; the work rests on architectural diagrams, logical bounds from the literature, and observed behavior in existing systems.
Three core findings stand out. First, each new input forces the current state representation deeper into the layer stack; after a modest number of steps the information becomes inaccessible to the shallow layers that generate the next output. Second, popular work-arounds—chain-of-thought prompting, looped layers, or linear state-space models—either remain depth-limited or re-introduce explicit token-level computation that is both slow and memory-intensive. Third, only recurrence that enforces sequential dependencies across input steps (rather than merely across layers) can support arbitrary, indefinitely long state tracking while still allowing substantial parallel training.
These results imply that continued scaling of today’s dominant designs will yield diminishing returns on tasks that require sustained coherence, multi-turn planning, or consistent belief maintenance. At the same time, simply bolting recurrence onto existing models risks unacceptable training cost unless new optimization techniques are adopted.
The paper therefore recommends three concrete next steps: (1) accelerate research on enhanced state-space models and gated linear attention that preserve parallel training yet exceed the expressivity of standard transformers; (2) explore coarse-grained recurrence that operates over sentences or “thought” chunks rather than individual tokens; and (3) develop staged training regimes in which recurrent mechanisms are introduced only after initial feedforward pre-training. Until such methods are validated at scale, organizations should treat long-horizon reasoning outputs from current models as provisional and maintain human oversight or external memory safeguards.
The analysis is primarily theoretical and draws on selected published cases; empirical confirmation at frontier scale remains limited. Readers should therefore view the taxonomy and recommendations as a well-reasoned research agenda rather than a finished engineering prescription.
1. Introduction
Section Summary: Progress in understanding human thought has come from viewing the brain as a dynamic system whose mental state evolves over time in response to new inputs. Recurrent neural networks were once seen as a natural fit for modeling this process, but training difficulties limited their success, whereas transformers instead keep a complete record of past information in a long context window. This article examines the drawbacks of the transformer approach and methods for overcoming them.
Progress in understanding human cognition has resulted from conceptualizing the brain as a dynamical system. In terms of its hardware, the physical brain is composed of billions of interacting neurons whose collective behavior is inherently dynamical. In terms of its function, the emergent mind can be usefully modeled as a dynamical process with a high-dimensional state, $s$, that evolves over time, modulated by external stimuli, $x$. These levels can be bridged by formalizing the state progression as $s_t= f(s_{t-1}, x_t)$, assuming discrete time $t$.
From this perspective, an ideal architecture for modeling temporally extended cognition would be a recurrent neural network (RNN), which explicitly performs such a state-update operation. In principle, gradient-based training procedures might discover the function $f$ from data such that the important input signals would be integrated into the state representation and held until later required. The appeal of RNNs was somewhat dampened in the 1990s by the inherent limitations of gradient-based training ([1, 2, 3]).
Until the transformer ([4]) came along, feedforward nets did not seem like a viable approach to replicating human thought and reasoning. The transformer, with an audaciously long context window, retains all information in its history, often postponing the selection of relevant data until required for inference ([5]). In contrast, RNNs filter information as it arrives into a bottlenecked state representation ([6]). This article is about what can go wrong with the transformer's strategy and approaches that can address its limitations.
2. State tracking
Section Summary: State tracking requires maintaining a compact, evolving summary of the current situation—often called a belief state—to support consistent reasoning and interaction over time. Transformers can retrieve earlier information from their context window but lack a built-in mechanism for iteratively updating this internal state, which produces failures such as contradicting an implied hidden number in a guessing game or abruptly shifting interpretations mid-conversation. Because information flows upward through successive layers in a feedforward manner, the architecture makes sustained, reliable state maintenance difficult even for simple cases.
Tracking the evolving world state is an essential ingredient for language understanding and reasoning, regardless of how tracking is achieved. The transformer's strategy often leverages its capacity to retrieve static, previously observed information from a context window. The attention mechanism of transformers is highly effective at retrieving past tokens ([7]). However, this lookup mechanism is conceptually distinct from the explicit maintenance of a dynamic state—the iterative, inherently sequential updating of latent variables that reflect a changing environment. The term belief state is often used to refer to this compact, sufficient summary of the knowledge an AI agent has about its environment ([8, 9]). Belief state can be a set of facts or it can be a probability distribution over possible worlds.
To illustrate, consider the game of twenty questions. Each answer to a question narrows the hypothesis space, and each subsequent question should be designed to shrink the hypothesis space further. In a game where one is asked to guess a number, if one is told that the number is larger than 50, it would make no sense to follow up it with a guess of 25. And on the flip side, if one is asked to think of a number between 1 and 100 and respond 'higher'or 'lower' to guesses, maintaining the state—the hidden number—is critical to preventing inconsistent answers. Yet, here is a trace from Gemini 3 (Fast) revealing a failure mode of models:[^1]
[^1]: This example was originally suggested by Gamal ElSayed circa 2020, still causing some modern foundation models to fail. Other models may have been trained to address this particular failure mode. [10] formally address the failure of standard models to reliably maintain a consistent hidden state over sequential interactions.

Even though the model cannot generate a random number internally, it can play the game without actually having a number in mind simply by choosing responses consistent with its previous responses. However, consistency requires tracking the valid range. Gemini 3 Thinking does generate an explicit target, but then it fails to make use of the generated target even though it is also a part of the input token stream in this case:

Beyond games, state tracking is essential to understanding the ever-changing world, the structure of arguments, and social interactions. State tracking failures in foundation models lead to loss of coherence in multi-turn conversations ([11]), inefficiency in information gathering ([12]), and breakdowns in communication and cooperation in multi-agent settings ([13, 14]).
Without proper state tracking, models flip-flop in their interpretations and fail to detect their inconsistencies, e.g., the meaning of a polysemous word ([15]):[^2]
[^2]: The example that follows was produced by Gemini 2.5 Flash in 2025. Although the model sometimes responded correctly, and newer and more powerful models are much less susceptible to this error, the example reveals a fundamental limitation of the core architecture.

In this example, the model jumps from one interpretation of bank to the other without a human-like acknowledgment of the reversal (e.g., "Oh wait, I misinterpreted. You must have been talking about a financial institution."). We consider this flip-flop a failure to track the world situation, the model's earlier responses, and the listener's expectations.
While tracking Fred's location in the above example should not be challenging, in the most general case, it is untenable for models—and people—to maintain and track probabilistic belief states over all environmental possibilities because the distributions explode in dimensionality. People adopt heuristics such as sampling (e.g., [16]), collapsing distributions into prototypical cases ([17]), or forming concrete mental models most consistent with premises ([18]), like a MAP estimate. Nonetheless, even finite-memory, deterministic state tracking can be unreliable in a transformer decoder.
We will use a schematic to explain the challenge of state tracking. In Figure 1 a, we depict the transformer with input steps shown along the horizontal axis and blocks (or layers) of the transformer along the vertical axis. Activation propagates from bottom to top (shallow to deep layers). For three selected blocks, we use color to indicate the functional connectivity of a causal transformer: activation in a block is influenced by all blocks immediately below and below to the left. In Figure 1 b, we depict the flow of state information, indicated by the green rectangles. The integration of the state representation and a new input (purple arrows) leads to a new state representation, $s_t = f(s_{t-1}, x_t)$. Because the architecture is feedforward, $s_t$ must lie deeper in the stack than $s_{t-1}$, eventually topping out of the model. Figure 2 shows examples from several recent articles matching this upward activation flow. This flow can make the integration of information over the sequence unreliable ([19, 20, 15, 12, 21, 10]).
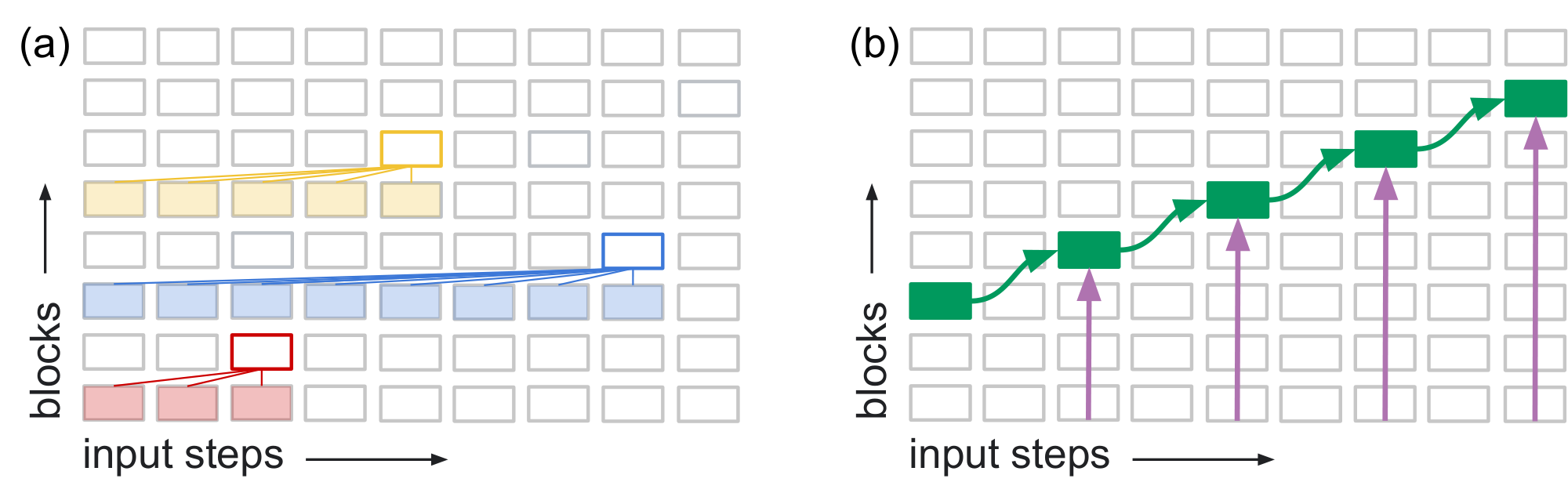
![**Figure 2:** Two examples from the literature: [22] and [23]. The details of each Figure are not critical, but in each case, the upward flow of information to deeper layers is depicted.](https://ittowtnkqtyixxjxrhou.supabase.co/storage/v1/object/public/public-images/qgktezan/ff_other_models_onerow.png)
Not every state-tracking problem requires depth linear in the number of layers. [24] prove the necessity and sufficiency of $\log n$ layers to recognize regular language strings of up to length $n$ and graph-connectivity problems with $n$ vertices. However, this proof addresses only the constructability of solutions, not their learnability.
In practice, many researchers have identified clever solutions obtained by training depth-limited models on specific finite sequence-length problems ([22, 25, 26, 27]). Essentially, when the state update function, $f$ is of a certain form, the sequence of state updates may be composed into a simpler one-step function, e.g., there exists a function $g$ computable by a transformer layer such that
$ s_t = f(\dots f(f(s_0, x_1), x_2), \dots, x_t) = g(s_0, x_1, \dots, x_t). $
Training losses have been proposed that aim to steer models toward such solutions, to the extent they exist exactly or approximately ([28, 29, 30]). However, when belief-state cascades push deeper and deeper into a network, computational limitations arise because the resulting representations are unavailable to shallower layers. To illustrate, Figure 3 depicts the processing of the bank dialog. Using a technique called Patchscopes ([31]), [15] observed that the embedding of the polysemous word 'bank' was ambiguous (i.e., a mixture of money bank vs. river bank) at shallow layers of the network, but deep in the network, the model selected the river bank interpretation. The previous sentences provided context (e.g., `took the day off work','fishing pole') to support one interpretation over the other. In the Figure, we depict this contextualization as occurring at the sixth block of the transformer stack, which means that when subsequent tokens are processed, the disambiguation is not available in blocks 1-5. [15] show that this delayed disambiguation leads to downstream errors whenever the response generation outpaces the model's internal semantic convergence, such as when the model forms its yes/no response to the question about an ATM at the bank.
![**Figure 3:** The depth of a state representation in a transformer can limit its utility for inference (adapted from [15], [15]). The input tokens are presented at the bottom, processed sequentially by the layers of the model. The symbols within the layers represent the model's internal belief state. This highlights that despite the model converging to the correct belief (river bank) deep in the network at the "bank" token, this high-level disambiguation is inaccessible to the shallower layers of subsequent tokens. Consequently, when processing the final tokens, the model defaults to superficial associations (money bank $\rightarrow$ ATM) early in the stack, resulting in an incorrect prediction at the last token position.](https://ittowtnkqtyixxjxrhou.supabase.co/storage/v1/object/public/public-images/qgktezan/racingthoughts.png)
If reasonable models make errors when the inference cascade is just two steps ([15] studied Gemma2-9B), it should be no surprise that models produce more severe failures in comprehending extended multi-agent conversations.
One solution to the depth dilemma is chain-of-thought style "thinking" where the model recasts a deep representation as one or more output tokens, which are then available to the model on its input ([32]). For ordinary, step-by-step microcognition, this solution is a cop out. Inferences that people make automatically and unconsciously and then utilize consistently, such as the selection of a polysemous word's meaning, should not require elaborated, extended cognition. Even those who disagree with this desideratum should agree that if cognition in a transformer can be shifted from explicit thought traces to implicit activation dynamics, the resulting model will be more powerful.
3. Recurrent architectures
Section Summary: Recurrent architectures overcome the inherent limits of feedforward transformers in tracking evolving state by allowing a model’s internal representation to update recursively as new inputs arrive. When transformers incorporate recurrence, the connections can be unrolled in different ways, such as looping through layers repeatedly or advancing autoregressively over input blocks. Only the forms that enforce truly sequential, non-parallel updates across time steps can support arbitrary and ongoing state tracking; simpler depth-recurrence approaches remain constrained by layer depth.
As we previously mentioned, the state tracking ability of a feedforward model is limited by model depth (e.g., [33, 34, 24]) and by the fact that effectively utilizing the state representation becomes more challenging as it shifts upwards to deeper layers ([19, 15, 12, 21]).
The alternative is a recurrent model, which is necessary to express arbitrary state dynamics, i.e., $s_t = f(s_{t-1}, x_t)$. In this section, we explore how to combine recurrence with transformers. Given the subtle yet critical differences among varieties of recurrence, they are easily conflated and mistakenly treated as equivalent. This equivalence is problematic because recurrence is not in itself sufficient for state tracking; the most popular form of recurrence is unable to track state ([35]).
Figure 4, adapted from [36], shows a simple recurrent net (left) and the net unrolled $t$ steps to form a weight-constrained feedforward net (right).
![**Figure 4:** Unrolling a three-neuron recurrent neural net (left) into its equivalent feedforward network (right). Figure adapted from [36].](https://ittowtnkqtyixxjxrhou.supabase.co/storage/v1/object/public/public-images/qgktezan/unrolling_generic_compact.png)
Unrolling the net requires making a copy of all neurons in the network for each step of recurrence. At each step, activation flows through each connection.
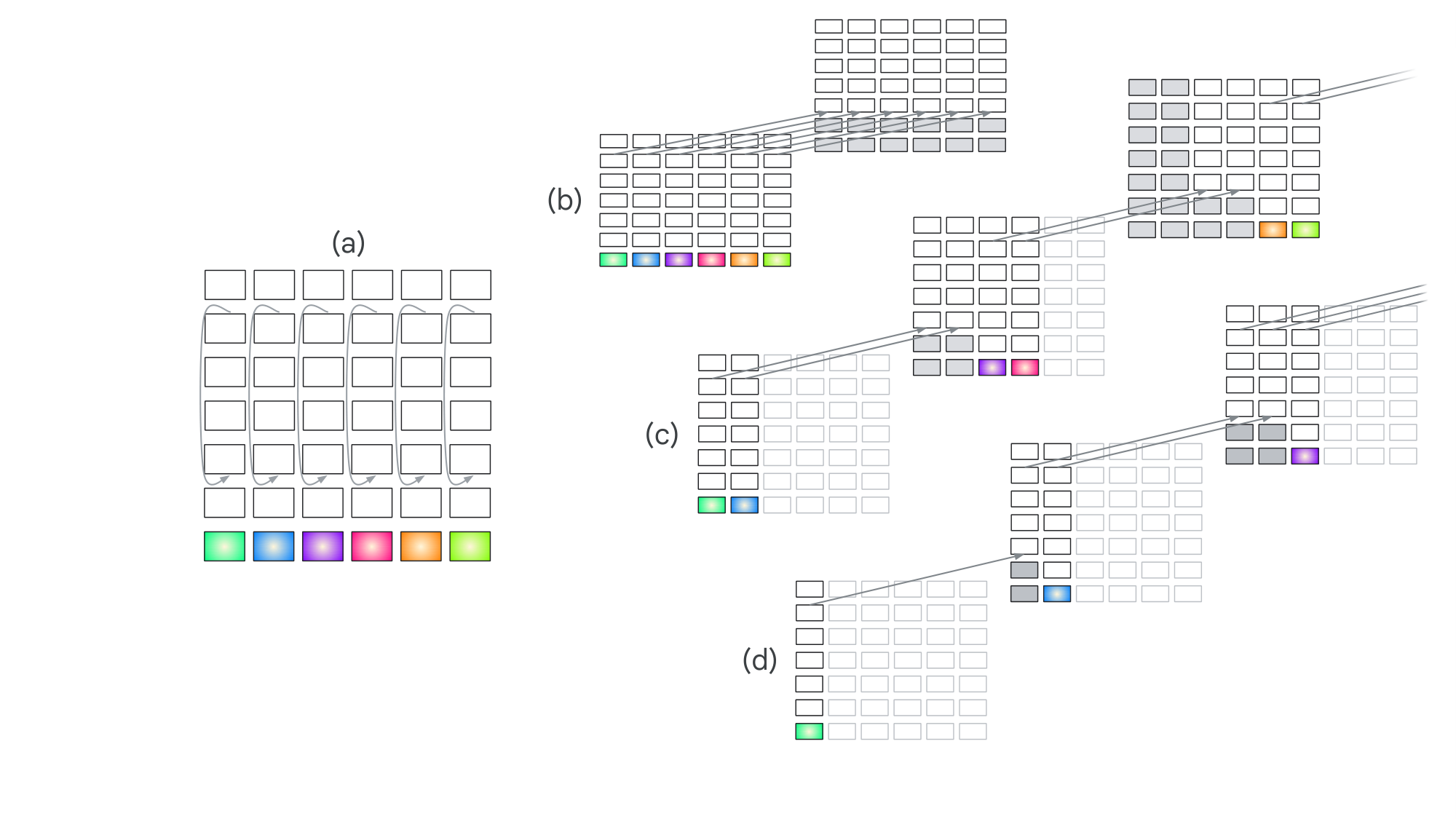
Now consider a transformer with some recurrent connections, as depicted in Figure 5 a. As before, each box denotes a transformer block and the horizontal and vertical axes correspond to input tokens and layers, respectively. The additional arrows are meant to illustrate one possible type of recurrence involving activation flow from a deep layer to a shallow layer at every input step. The nature of the activation flow is not important for our purposes; for example, the shallow layer may generate queries that allow it to cross attend to keys and values from the deep layer (e.g., [37]).
Unlike the simple RNN in Figure 4, which can be unrolled in only one way, unrolling the recurrent transformer in Figure 5 a results in ambiguity due to the fact that that the transformer architecture incorporates three distinct ordered dimensions: (1) the layers of the architecture, bottom to top (shallow to deep) in the Figure; (2) the input steps of the architecture, left to right in the Figure; and (3) autoregressive steps performed at execution. During model pretraining, an ordinary (feedforward) transformer has only a single autoregressive step because all input steps are run in parallel; and during inference, autoregressive steps are typically confounded with input steps, although multi-token prediction allows for multiple input/output steps per autoregressive step ([38]). However, recurrence allows for further decoupling. In particular, many forms of recurrence require that even when a model is trained via teacher forcing, it must still be unrolled autoregressively ([39]). This necessary sequentiality is what we mean by autoregressive unrolling, not the sequentiality that arises from token-by-token generation in a pure feedforward model.
Figure 5 b depicts a transformer unrolled in depth, sometimes referred to as a looped transformer. Depth recurrence—whether of individual layers or ranges of layers, and whether deterministic or adaptive—is a very popular and successful approach. Some methods are designed and trained to allow for inference time scaling (e.g., [40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51]); others incorporate recurrence via pretraining ([52]) or fine tuning a pretrained model ([53, 54]); and surprisingly, several operate purely as an inference-time method to improve reasoning ([55, 56, 57]).
While depth recurrence can increase the expressivity of a transformer ([58]), it does not enable indefinite state tracking; the propagation is still depth limited. To appreciate this fact, pick any layer $l$ in the lower or upper stack as the representation of $s(0)$, the state at the first stack. Then note that any $s(t+1)$, if it is to depend arbitrarily on $s(t)$ recursively, must be in a higher layer. The state representation still shifts upward due to the parallel propagation of activation across steps $t$, regardless of how deep the transformer is made to be with recurrent depth (Figure 1 b).
Indefinite tracking of state with an arbitrary state update function requires sequential dependency that precludes parallelization across the sequence length during training. Two examples of autoregressive updates are presented in Figure 5 c, d. Figure 5 c depicts a blockwise-recurrent model ([59, 60, 61, 62]) in which a subsequence of input steps is run in parallel (two in the Figure) followed by an autoregressive iteration; Figure 5 d shows a model in which one input step is presented per autoregressive step, and at step $t$, all stacks up to $t-1$ send a signal from the deep layer to the shallow layer, yielding a fully recurrent model. This model may have attractor dynamics since each layer continues to update, converging only when all previous steps have reached asymptote.
![**Figure 6:** Unrolling a latent-thought model, where the model feeds back its latent thoughts as input to the model for multiple auto-regressive steps before processing the next input token, which is marked with the blue color (e.g., [63, 64]).](https://ittowtnkqtyixxjxrhou.supabase.co/storage/v1/object/public/public-images/qgktezan/unrolling_latent_thinking.png)
Having addressed recurrence with multiple input steps per autoregressive step (Figure 5 c) and a standard one-to-one mapping (Figure 5 d), we can also consider a setup where multiple autoregressive steps are executed for each input step (Figure 6). Latent-thought models have this form (e.g., [63, 64]). Some of these models can track state, whereas others do not (e.g., [65]).
![**Figure 7:** Unrolling an SSM, where information from the previous input step at layer $l$ flows directly to the next step in the horizontal direction (e.g., [66, 67]).](https://ittowtnkqtyixxjxrhou.supabase.co/storage/v1/object/public/public-images/qgktezan/unrolling_ssm.png)
The examples of recurrence we have given all involve signal propagation from deeper layers to shallower layers, but within-layer propagation over inputs steps (Figure 7) also yields state dynamics (e.g., [66, 67]).
\begin{tabularx}{5.5cc}{|m{1.1in}|X|X|X|}
\hline
\multirow{2}{*}{\textbf{Recurrence Axis}}
& \multicolumn{3}{c|}{\textbf{Input Tokens Per Recurrence Step}} \\ \cline{2-4}
& \multicolumn{1}{c|}{\textit{Ratio gt;1$}} & \multicolumn{1}{c|}{\textit{Ratio $=1$}} & \multicolumn{1}{c|}{\textit{Ratio lt;1$}} \\ \hline
\textit{Depth} &
\tiny\RaggedRight
[Figure 5 b]
looped transformer ([68]),
universal transformer ([69]),
RINS ([43])
&
\tiny[Figure 5 d]
&
\tiny\RaggedRight
\\ \hline
\textit{Step} &
\tiny\RaggedRight
block-recurrent transformers ([59])
&
\tiny\RaggedRight
[Figure 7 b]
linear attention ([70]),
DeltaNet ([71]),
MAMBA ([67]),
canon layers ([66]),
PaTH attention ([72]),
RWKV-7 ([73]),
test-time regression ([74])
&
\tiny\RaggedRight
DeltaProduct ([75])
\\ \hline
\textit{Depth + Step} &
\tiny\RaggedRight
[Figure 5 c]
recurrent memory transformer ([76]),
RINs ([77]),
sentence gestalt ([62])
&
\tiny\RaggedRight
feedback transformer ([37])
&
\tiny\RaggedRight
[Figure 6]
COCONUT ([63]),
hierarchical reasoning model ([64]),
CYB ([65])
\\ \hline
\end{tabularx}
Table 1 attempts to lay out a taxonomy of recurrent transformer architectures that includes the cases we have considered so far. We characterize architectures along two dimensions: recurrence axis and input tokens per recurrence step. The axis can be depth alone (Figure 5 b, c, d), in step alone (Figure 7), and in both depth and step (Figure 6). The ratio of input tokens to recurrence steps can be greater than one (Figure 5 b, c), equal to one (Figure 5 d, Figure 7), or less than one (Figure 6).[^3] In cells of the taxonomy, we list some popular and representative transformer-based architectures. We omit architectures that are described as "recurrent" in the sense that processing is iterative, but that are neither recurrent in depth nor step, e.g., Transformer-XL ([78]). Being recurrent in depth and/or step is necessary for state tracking but is not sufficient. Essentially, full-fledged state tracking requires sequential dynamics during training; any model that can be entirely parallelized across the context has limitations in updating state.
[^3]: We define a `recurrence step' strictly as a sequential dependency that precludes parallelization across the sequence length during training.
While we have not shown all such architectures, we have not succeeded in identifying any examples of work that lies in the empty cells of the taxonomy. Some of these cells would be worth exploration. For example, architectures in the second row, third column, could include ones with within-layer attractor dynamics, where the model's activation may iterate to convergence before advancing to the next token. Architectures in the first row, second and third columns, are interesting because they feed activation from a deep layer to a shallow layer (once for $\text{ratio}=1$, multiple times for $\text{ratio}>1$) in a manner that—unlike the looped transformer—does allow for indefinite state propagation.
We have deliberately sidestepped the question of what a recurrent arrow signifies in terms of activation dynamics. Different models make different proposals. The arrow could indicate copying key-value cache ([79]), it could represent a source of keys and values for cross attention ([37]) or self attention ([80]), or it might represent a direct connection through a linear layer, an MLP, or an adapter such as LoRA ([81]). The coupling of step-to-step recurrence with attention—which gives neurons direct visibility to the entire step history—prevents credit assignment bottlenecks that arise when training traditional recurrent neural networks ([82, 80]).
4. Architectural limitations and workarounds
Section Summary: Transformers struggle with tasks that require tracking evolving information over time, such as planning or multi-step reasoning, because their parallel design limits the ability to maintain and update an internal state sequentially. They often compensate by converting these problems into lookups within their full context window and by using chain-of-thought reasoning to pass information forward through layers, while also representing different aspects of state separately so they can be updated independently. These workarounds can be effective but tend to waste computation on explicit intermediate steps that might otherwise be handled more efficiently through implicit updates.
[83] point to the weakness of modern massively parallel architectures on problems that are inherently sequential, problems where combinatorics make it impractical to parallelize, such as state tracking, multihop inference, and planning. Formal analyses point to bounds on serial capacity for transformers ([33]). State-space models (SSMs) are often touted as a means of state propagation, but SSMs with linear updates are no more expressive than an ordinary transformer ([35]). In contrast, chain of thought does enhance model expressivity ([84, 85]), as one would intuit: Allowing a model to talk to itself, whether in natural language or latent space, sends signals from deep in the transformer to shallow layers, thereby propagating state forward. It is no wonder that frontier models have become increasingly reliant on internal 'thinking'. However, the reliance on intermediate outputs to track micro-state may perform wasteful computation steps and unnecessarily consume the context window. Implicit activation dynamics—albeit recurrent—might be adequate to efficiently update mundane state information of the sort that people can process unconsciously and automatically. In human terms, it is fine to talk to yourself if you are reasoning through a calculus problem, but it is a bit weird to have to continually remind yourself of the relationship between two characters in a book you are reading.
Given their limitations in state tracking, why are transformers as successful as they are? The short answer is that by being able to reexamine their entire input history, they can often turn a state-tracking problem into a working memory problem, i.e., into retrieval from the context window. For example, consider the latch problem from the 1990s that required a sequence-processing model latch on to a bit of information early in a sequence and to retain it over a long time gap ([86, 87]). This problem in large part motivated LSTM but is entirely trivial for a transformer that can re-index into its input history to retrieve the early information. Transformers learn many clever strategies including this sort of lookback ([26]), associatve scans ([22]), more specialized algorithms for formal language understanding ([88, 25]), including belief updating that reflects state uncertainty ([27]). A simple illustration is the computation of parity from an input sequence of $0$ 's and $1$ 's. Instead of maintaining a parity state, the model can compute pairwise parity in the first layer of a transformer, then combine the pairs into four-bit parity in the second layer, and so forth, achieving a computation from scratch in $\log_2 n$ feedforward layers for a sequence of maximum length $n$. Such alternate and even shortcut solutions are common for transformers to develop in practice ([89]).
Another factor in the success of transformers is their support of state compositionality. State need not be—as we have depicted it in Figure 1—a monolithic representation. The representation of state can be split across embeddings and updated asynchronously for each component. For example, if the model needs to track the changing locations of two entities, those state variables can be updated independently for each entity.
5. Promising directions
Section Summary: Several emerging approaches aim to help transformers maintain and update internal state more effectively without sacrificing too much speed or scalability. Researchers are exploring enhanced state-space models that extend beyond standard attention, along with ways to add recurrence at a coarser level such as sentences rather than individual tokens. Additional ideas include specialized training to improve state tracking in ordinary feedforward models, techniques that exploit natural alignments between layers, and multi-stage training schedules that introduce recurrence only after initial parallel pretraining to keep computation manageable.
In addition to the native mechanisms that transformers have to estimate state, several emerging research directions seem particularly promising for promoting state maintenance and updating. These directions balance the need for expressivity with computational feasibility.
5.1 Enhanced State-Space Models
While most linear SSMs do not exceed the expressivity of standard transformers, Delta Net ([71]), when its eigenvalue range is extended to include negative values ([90]), maintains the highly desirable property of being trainable in parallel while simultaneously achieving greater expressivity than a standard transformer. The delta rule underlying Delta Net has inspired a range of further developments, including RWKV-7 ([73]) and PaTH attention ([72]), that also achieve state tracking beyond the capability of ordinary transformers while demonstrating competitive language modeling at scale. Similarly, other new forms of attention are being developed with sequential dependencies that promise to be more powerful in stateful tasks ([91, 92, 93]), including the notion of gated linear attention ([94]) and gated Delta Net ([95]) that, when mixed with standard transformer blocks is more powerful than either, both in theory and practice ([96]).
5.2 Approximating state tracking in feedforward transformers
Rather than incorporating recurrence, feedforward transformers can be steered to better approximate state tracking through specialized training objectives and structural priors ([28, 29, 30]). The promise is that such biases will encourage models to bolster their native lookback abilities. However, we hope that future research will take into account structured, compositional state representations.
5.3 Coarse recurrence
Introducing recurrence at a coarser granularity than individual tokens can mitigate the computational burden of token-by-token state updates. In the past, block-recurrent models have operated on this principle by compressing and passing memory forward in fixedlength chunks. A promising approach is to consider linguistic structure in identifying the chunks: [62] have modeled language as a sequence of discrete 'thoughts' by chunking at the sentence level.
5.4 Leveraging representational alignment
Variable-depth models dynamically select the number of iterations of a layer or the number of times a range of layers repeats. The fact that this approach succeeds with only fine tuning—and sometimes with no training whatsoever—suggests that the model is well predisposed to communication of representations across layers, due to the alignment resulting from the residual connections. Similarly, canon layers ([88]) leverage alignment of representations from one input step to the next. We speculate that there are additional means of leveraging this alignment.
5.5 Efficient training of recurrence
Any architecture which is capable of indefinite, arbitrary state propagation requires autoregressive processing. Autoregressive pretraining is computationally inefficient and limits parallelization ([60]). One potential solution is a multi-stage training scheme in which initial pretraining relies entirely on standard, parallelizable feedforward transformer architectures. Recurrent mechanisms are then introduced only at a later training stage. To ensure training efficiency during these subsequent recurrent stages, optimization techniques such as truncated gradient methods and—for training attractor dynamics—recurrent backpropagation ([97, 98, 99]). Methods have also been proposed to increase arithmetic intensity to obtain scaling that is near linear time in context length versus quadratic for a naive implementation ([80]).
6. Conclusions
Section Summary: The conclusions argue that transformers remain limited by their non-iterative structure, which struggles with sustained state tracking despite workarounds like explicit chain-of-thought reasoning. The authors propose moving toward implicit recurrent dynamics to achieve stronger long-term coherence and multi-step reasoning while preserving the models’ efficiency. They present their taxonomy as a roadmap for building future systems that maintain fluid, evolving internal representations over extended time scales.
Although the transformer’s feedforward design has expanded the limits of context-based retrieval, its topological structure remains fundamentally at odds with the iterative nature of state tracking. As we have argued, the current reliance on explicit natural-language-like "thought" to bypass depth limitations is an inefficient workaround for a structural deficiency. By transitioning toward implicit, recurrent activation dynamics, we can move beyond these depth-limited constraints to attain robust long-term coherence and multihop inference.
The taxonomy and research directions proposed in this article provide a roadmap for improving sequential inference dependencies without sacrificing the foundational strengths of modern models. Ultimately, bridging the gap between the transformer's parallel efficiency and the brain's inherent dynamical nature is essential. The next generation of foundation models must do more than simply re-scan the past; they must maintain a fluid, evolving representation of reality that persists across the many time scales required for temporally extended cognition.
Acknowledgments
Many thanks to Sunny Sanyal, Kazuki Irie, Kevin Murphy, Jay McClelland, and Chris Williams for helpful feedback on earlier drafts of the manuscript.
References
Section Summary: This references section compiles a wide range of academic papers, from foundational works on recurrent neural networks, long-term memory challenges, and the transformer architecture to recent studies on large language models. The cited works explore topics such as in-context learning, multi-hop reasoning, belief tracking, working memory limitations, and the internal mechanisms of modern AI systems, alongside relevant cognitive science research on human decision-making. Together they provide historical context and supporting evidence for investigations into how language models process and retain information over extended interactions.
[1] Mozer, Michael C. (1992). The induction of multiscale temporal structure. In Advances in Neural Information Processing Systems 4. pp. 275–282.
[2] Hochreiter, Sepp (1998). The vanishing gradient problem during learning recurrent neural nets and problem solutions. International Journal of Uncertainty, Fuzziness and Knowledge-Based Systems. 6(02). pp. 107–116.
[3] Hochreiter et al. (2001). Gradient flow in recurrent nets: the difficulty of learning long-term dependencies.
[4] Vaswani et al. (2017). Attention Is All You Need. In Advances in Neural Information Processing Systems. pp. 5998–6008. https://papers.nips.cc/paper/7181-attention-is-all-you-need.
[5] Meng et al. (2022). Locating and editing factual associations in gpt. Advances in neural information processing systems. 35. pp. 17359–17372.
[6] Hochreiter, Sepp and Schmidhuber, Jürgen (1997). Long short-term memory. Neural computation. 9(8). pp. 1735–1780.
[7] Olsson et al. (2022). In-context Learning and Induction Heads. Transformer Circuits Thread.
[8] Chrisman, Lonnie (1992). Reinforcement learning with perceptual aliasing: the perceptual distinctions approach. In Proceedings of the Tenth National Conference on Artificial Intelligence. pp. 183–188.
[9] Leslie Pack Kaelbling et al. (1998). Planning and acting in partially observable stochastic domains. Artificial Intelligence. 101(1). pp. 99-134. doi:https://doi.org/10.1016/S0004-3702(98)00023-X. https://www.sciencedirect.com/science/article/pii/S000437029800023X.
[10] Davide Baldelli et al. (2026). LLMs Can't Play Hangman: On the Necessity of a Private Working Memory for Language Agents. arXiv:2601.06973 [cs.CL]. https://arxiv.org/abs/2601.06973. arXiv:2601.06973.
[11] Philippe Laban et al. (2025). LLMs Get Lost In Multi-Turn Conversation. arXiv:2505.06120 [cs.CL]. https://arxiv.org/abs/2505.06120. arXiv:2505.06120.
[12] Daniel P. Sawyer et al. (2025). Exploring exploration with foundation agents in interactive environments. In NeurIPS 2025 Workshop on Embodied World Models for Decision Making. https://openreview.net/forum?id=ay2d66HWO2.
[13] Tim R. Davidson et al. (2025). The Collaboration Gap. arXiv:2511.02687 [cs.AI]. https://arxiv.org/abs/2511.02687. arXiv:2511.02687.
[14] Arpandeep Khatua et al. (2026). CooperBench: Why Coding Agents Cannot be Your Teammates Yet. https://arxiv.org/abs/2601.13295. arXiv:2601.13295.
[15] Lepori et al. (2025). Racing Thoughts: Explaining Contextualization Errors in Large Language Models. In Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). pp. 3020–3036. doi:10.18653/v1/2025.naacl-long.155. https://aclanthology.org/2025.naacl-long.155/.
[16] Vul et al. (2014). One and Done? Optimal Decisions From Very Few Samples. Cognitive Science. 38(4). pp. 599–637. doi:10.1111/cogs.12101.
[17] Tversky, Amos and Kahneman, Daniel (1971). Belief in the Law of Small Numbers. Psychological Bulletin. 76(2). pp. 105–110. doi:10.1037/h0031322.
[18] Johnson-Laird, P.N. (1983). Mental Models: Towards a Cognitive Science of Language, Inference, and Consciousness. Harvard University Press. https://books.google.com/books?id=FS3zSKAfLGMC.
[19] Biran et al. (2024). Hopping Too Late: Exploring the Limitations of Large Language Models on Multi-Hop Queries. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. pp. 14113–14130. doi:10.18653/v1/2024.emnlp-main.781. https://aclanthology.org/2024.emnlp-main.781/.
[20] Satchel Grant et al. (2025). Emergent Symbol-like Number Variables in Artificial Neural Networks. https://arxiv.org/abs/2501.06141. arXiv:2501.06141.
[21] Constantin Venhoff et al. (2025). Too Late to Recall: Explaining the Two-Hop Problem in Multimodal Knowledge Retrieval. In The Thirty-ninth Annual Conference on Neural Information Processing Systems. https://openreview.net/forum?id=qeL8fi8GS7.
[22] Belinda Z. Li et al. (2025). (How) Do Language Models Track State?. In Forty-second International Conference on Machine Learning. https://openreview.net/forum?id=8SXosAVIFH.
[23] Lindsey et al. (2025). On the Biology of a Large Language Model. Transformer Circuits Thread. https://transformer-circuits.pub/2025/attribution-graphs/biology.html.
[24] William Merrill and Ashish Sabharwal (2025). A Little Depth Goes a Long Way: The Expressive Power of Log-Depth Transformers. arXiv:2503.03961 [cs.LG]. https://arxiv.org/abs/2503.03961. arXiv:2503.03961.
[25] Mateusz Piotrowski et al. (2025). Constrained belief updates explain geometric structures in transformer representations. arXiv:2502.01954 [cs.LG]. https://arxiv.org/abs/2502.01954. arXiv:2502.01954.
[26] Nikhil Prakash et al. (2026). Language Models Use Lookbacks to Track Beliefs. In The Fourteenth International Conference on Learning Representations. https://openreview.net/forum?id=6gO6KTRMpG.
[27] Adam Shai et al. (2024). Transformers Represent Belief State Geometry in their Residual Stream. In The Thirty-eighth Annual Conference on Neural Information Processing Systems. https://openreview.net/forum?id=YIB7REL8UC.
[28] Edward S. Hu et al. (2025). The Belief State Transformer. In The Thirteenth International Conference on Learning Representations. https://openreview.net/forum?id=ThRMTCgpvo.
[29] Jayden Teoh et al. (2025). Next-Latent Prediction Transformers Learn Compact World Models. https://arxiv.org/abs/2511.05963. arXiv:2511.05963.
[30] Hai Huang et al. (2026). Semantic Tube Prediction: Beating LLM Data Efficiency with JEPA. arXiv:2602.22617 [cs.LG]. https://arxiv.org/abs/2602.22617. arXiv:2602.22617.
[31] Ghandeharioun et al. (2024). Patchscopes: a unifying framework for inspecting hidden representations of language models. In Proceedings of the 41st International Conference on Machine Learning.
[32] Wei et al. (2022). Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems. 35. pp. 24824–24837.
[33] Merrill, William and Sabharwal, Ashish (2023). The Parallelism Tradeoff: Limitations of Log-Precision Transformers. Transactions of the Association for Computational Linguistics. 11. pp. 531–545. doi:10.1162/tacl_a_00562. https://aclanthology.org/2023.tacl-1.31/.
[34] Strobl et al. (2024). What Formal Languages Can Transformers Express? A Survey. Transactions of the Association for Computational Linguistics. 12. pp. 543-561. doi:10.1162/tacl_a_00663. https://doi.org/10.1162/tacl_a_00663.
[35] William Merrill et al. (2025). The Illusion of State in State-Space Models. arXiv:2404.08819 [cs.LG]. https://arxiv.org/abs/2404.08819. arXiv:2404.08819.
[36] Rumelhart et al. (1986). Learning representations by back-propagating errors. nature. 323(6088). pp. 533–536.
[37] Angela Fan et al. (2021). Addressing Some Limitations of Transformers with Feedback Memory. arXiv:2002.09402 [cs.CL]. https://arxiv.org/abs/2002.09402. arXiv:2002.09402.
[38] Gloeckle et al. (2024). Better and faster large language models via multi-token prediction. arXiv preprint arXiv:2404.19737.
[39] Teoh et al. (2025). Next-Latent Prediction Transformers Learn Compact World Models. arXiv preprint arXiv:2511.05963.
[40] Liu Yang et al. (2024). Looped Transformers are Better at Learning Learning Algorithms. In The Twelfth International Conference on Learning Representations. https://openreview.net/forum?id=HHbRxoDTxE.
[41] Aleksandra I. Nowak et al. (2024). Towards Optimal Adapter Placement for Efficient Transfer Learning. arXiv:2410.15858 [cs.LG]. https://arxiv.org/abs/2410.15858. arXiv:2410.15858.
[42] David Raposo et al. (2024). Mixture-of-Depths: Dynamically allocating compute in transformer-based language models. arXiv:2404.02258 [cs.LG]. https://arxiv.org/abs/2404.02258. arXiv:2404.02258.
[43] Ibrahim Alabdulmohsin and Xiaohua Zhai (2025). Recursive Inference Scaling: A Winning Path to Scalable Inference in Language and Multimodal Systems. In The Thirty-ninth Annual Conference on Neural Information Processing Systems. https://openreview.net/forum?id=cLbGkINOLP.
[44] Sangmin Bae et al. (2025). Mixture-of-Recursions: Learning Dynamic Recursive Depths for Adaptive Token-Level Computation. In The Thirty-ninth Annual Conference on Neural Information Processing Systems. https://openreview.net/forum?id=QuqsEIVWIG.
[45] Yilong Chen et al. (2025). Inner Thinking Transformer: Leveraging Dynamic Depth Scaling to Foster Adaptive Internal Thinking. arXiv:2502.13842 [cs.CL]. arXiv:2502.13842.
[46] Jonas Geiping et al. (2025). Scaling up Test-Time Compute with Latent Reasoning: A Recurrent Depth Approach. In The Thirty-ninth Annual Conference on Neural Information Processing Systems. https://openreview.net/forum?id=S3GhJooWIC.
[47] Ivan Rodkin et al. (2025). Beyond Memorization: Extending Reasoning Depth with Recurrence, Memory and Test-Time Compute Scaling. arXiv:2508.16745 [cs.LG]. https://arxiv.org/abs/2508.16745. arXiv:2508.16745.
[48] Yu et al. (2025). Back Attention: Understanding and Enhancing Multi-Hop Reasoning in Large Language Models. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. pp. 11257–11272. doi:10.18653/v1/2025.emnlp-main.567. https://aclanthology.org/2025.emnlp-main.567/.
[49] Rui-Jie Zhu et al. (2025). Scaling Latent Reasoning via Looped Language Models. arXiv:2510.25741 [cs.LG]. https://arxiv.org/abs/2510.25741. arXiv:2510.25741.
[50] Boyi Zeng et al. (2026). PonderLM: Pretraining Language Models to Ponder in Continuous Space. In The Fourteenth International Conference on Learning Representations. https://openreview.net/forum?id=UrM4MNRYZm.
[51] Ahmadreza Jeddi et al. (2026). LoopFormer: Elastic-Depth Looped Transformers for Latent Reasoning via Shortcut Modulation. In The Fourteenth International Conference on Learning Representations. https://openreview.net/forum?id=RzYXb5YWBs.
[52] Sunny Sanyal (2026). Looped-GPT: Looping During Pre-training improves Generalization. https://sanyalsunny111.github.io/posts/2026-01-15-post1-looped-gpt/.
[53] Yeskendir Koishekenov et al. (2025). Encode, Think, Decode: Scaling test-time reasoning with recursive latent thoughts. arXiv:2510.07358 [cs.LG]. https://arxiv.org/abs/2510.07358. arXiv:2510.07358.
[54] Sean McLeish et al. (2025). Teaching Pretrained Language Models to Think Deeper with Retrofitted Recurrence. https://arxiv.org/abs/2511.07384. arXiv:2511.07384.
[55] Ziyue Li et al. (2025). Skip a Layer or Loop it? Test-Time Depth Adaptation of Pretrained LLMs. arXiv:2507.07996 [cs.LG]. https://arxiv.org/abs/2507.07996. arXiv:2507.07996.
[56] Lizhang Chen et al. (2026). Training-Free Looped Transformers. arXiv:2605.23872 [cs.CL]. https://arxiv.org/abs/2605.23872. arXiv:2605.23872.
[57] Ng, David Noel (2026). LLM Neuroanatomy: How I Topped the LLM Leaderboard Without Changing a Single Weight. https://dnhkng.github.io/posts/rys/.
[58] Nikunj Saunshi et al. (2025). Reasoning with Latent Thoughts: On the Power of Looped Transformers. In The Thirteenth International Conference on Learning Representations. https://openreview.net/forum?id=din0lGfZFd.
[59] Hutchins et al. (2022). Block-Recurrent Transformers. In Advances in Neural Information Processing Systems. pp. 33248–33261. https://proceedings.neurips.cc/paper_files/paper/2022/file/d6e0bbb9fc3f4c10950052ec2359355c-Paper-Conference.pdf.
[60] Alexis Chevalier et al. (2023). Adapting Language Models to Compress Contexts. arXiv:2305.14788 [cs.CL]. https://arxiv.org/abs/2305.14788. arXiv:2305.14788.
[61] Yinpeng Chen et al. (2025). MELODI: Exploring Memory Compression for Long Contexts. In The Thirteenth International Conference on Learning Representations. https://openreview.net/forum?id=TvGPP8i18S.
[62] Nasim Borazjanizadeh and James McClelland (2025). Modeling Language as a Sequence of Thoughts. arXiv:2512.25026 [cs.CL]. https://arxiv.org/abs/2512.25026. arXiv:2512.25026.
[63] Shibo Hao et al. (2025). Training Large Language Models to Reason in a Continuous Latent Space. In Second Conference on Language Modeling. https://openreview.net/forum?id=Itxz7S4Ip3.
[64] Alexia Jolicoeur-Martineau (2025). Less is More: Recursive Reasoning with Tiny Networks. arXiv:2510.04871 [cs.LG]. https://arxiv.org/abs/2510.04871. arXiv:2510.04871.
[65] Alexandre Galashov et al. (2025). Catch Your Breath: Adaptive Computation for Self-Paced Sequence Production. arXiv:2510.13879 [cs.CL]. https://arxiv.org/abs/2510.13879. arXiv:2510.13879.
[66] Zeyuan Allen-Zhu (2025). Physics of Language Models: Part 4.1, Architecture Design and the Magic of Canon Layers. arXiv:2512.17351 [cs.CL]. https://arxiv.org/abs/2512.17351. arXiv:2512.17351.
[67] Albert Gu and Tri Dao (2024). Mamba: Linear-Time Sequence Modeling with Selective State Spaces. In First Conference on Language Modeling. https://openreview.net/forum?id=tEYskw1VY2.
[68] Giannou et al. (2023). Looped transformers as programmable computers. In International Conference on Machine Learning. pp. 11398–11442.
[69] Mostafa Dehghani et al. (2019). Universal Transformers. In International Conference on Learning Representations. https://openreview.net/forum?id=HyzdRiR9Y7.
[70] Katharopoulos et al. (2020). Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention. In Proceedings of the 37th International Conference on Machine Learning. pp. 5156–5165.
[71] Imanol Schlag et al. (2021). Linear Transformers Are Secretly Fast Weight Programmers. arXiv preprint arXiv:2102.11174.
[72] Songlin Yang et al. (2025). PaTH Attention: Position Encoding via Accumulating Householder Transformations. In The Thirty-ninth Annual Conference on Neural Information Processing Systems. https://openreview.net/forum?id=ZBlHEeSvKd.
[73] Bo Peng et al. (2025). RWKV-7 "Goose" with Expressive Dynamic State Evolution. In Second Conference on Language Modeling. https://openreview.net/forum?id=ayB1PACN5j.
[74] Yu Sun et al. (2025). Learning to (Learn at Test Time): RNNs with Expressive Hidden States. In Forty-second International Conference on Machine Learning. https://openreview.net/forum?id=wXfuOj9C7L.
[75] Julien Siems et al. (2025). DeltaProduct: Improving State-Tracking in Linear RNNs via Householder Products. In The Thirty-ninth Annual Conference on Neural Information Processing Systems. https://openreview.net/forum?id=SoRiaijTGr.
[76] Bulatov et al. (2022). Recurrent Memory Transformer. In Advances in Neural Information Processing Systems. pp. 11079–11091. https://proceedings.neurips.cc/paper_files/paper/2022/file/47e288629a6996a17ce50b90a056a0e1-Paper-Conference.pdf.
[77] Allan Jabri et al. (2023). Scalable Adaptive Computation for Iterative Generation. arXiv:2212.11972 [cs.LG]. https://arxiv.org/abs/2212.11972. arXiv:2212.11972.
[78] Zihang Dai et al. (2019). Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context. arXiv:1901.02860 [cs.LG]. https://arxiv.org/abs/1901.02860. arXiv:1901.02860.
[79] Yang et al. (2024). Kvsharer: Efficient inference via layer-wise dissimilar kv cache sharing. arXiv preprint arXiv:2410.18517.
[80] Costin-Andrei Oncescu et al. (2026). The Recurrent Transformer: Greater Effective Depth and Efficient Decoding. arXiv:2604.21215 [cs.LG]. https://arxiv.org/abs/2604.21215. arXiv:2604.21215.
[81] Hu et al. (2022). Lora: Low-rank adaptation of large language models.. Iclr. 1(2). pp. 3.
[82] Ke et al. (2018). Sparse Attentive Backtracking: Temporal Credit Assignment Through Reminding. In Advances in Neural Information Processing Systems. pp. . https://proceedings.neurips.cc/paper_files/paper/2018/file/e16e74a63567ecb44ade5c87002bb1d9-Paper.pdf.
[83] Yuxi Liu et al. (2026). The Serial Scaling Hypothesis. https://arxiv.org/abs/2507.12549. arXiv:2507.12549.
[84] Zhiyuan Li et al. (2024). Chain of Thought Empowers Transformers to Solve Inherently Serial Problems. In The Twelfth International Conference on Learning Representations. https://openreview.net/forum?id=3EWTEy9MTM.
[85] William Merrill and Ashish Sabharwal (2024). The Expressive Power of Transformers with Chain of Thought. In The Twelfth International Conference on Learning Representations. https://openreview.net/forum?id=NjNGlPh8Wh.
[86] Mozer, Michael C (1991). Induction of multiscale temporal structure. Advances in neural information processing systems. 4.
[87] Bengio et al. (1994). Learning long-term dependencies with gradient descent is difficult. IEEE Transactions on Neural Networks. 5(2). pp. 157-166. doi:10.1109/72.279181.
[88] Zeyuan Allen-Zhu and Yuanzhi Li (2025). Physics of Language Models: Part 1, Learning Hierarchical Language Structures. arXiv:2305.13673 [cs.CL]. https://arxiv.org/abs/2305.13673. arXiv:2305.13673.
[89] Liu et al. (2022). Transformers learn shortcuts to automata. arXiv preprint arXiv:2210.10749.
[90] Riccardo Grazzi et al. (2025). Unlocking State-Tracking in Linear RNNs Through Negative Eigenvalues. arXiv:2411.12537 [cs.LG]. https://arxiv.org/abs/2411.12537. arXiv:2411.12537.
[91] Zhixuan Lin et al. (2025). Forgetting Transformer: Softmax Attention with a Forget Gate. In The Thirteenth International Conference on Learning Representations. https://openreview.net/forum?id=q2Lnyegkr8.
[92] Yaniv Leviathan et al. (2025). Selective Attention Improves Transformer. In The Thirteenth International Conference on Learning Representations. https://openreview.net/forum?id=v0FzmPCd1e.
[93] Beltagy et al. (2020). Longformer: The long-document transformer. arXiv preprint arXiv:2004.05150.
[94] Yang et al. (2024). Gated linear attention transformers with hardware-efficient training. In Proceedings of the 41st International Conference on Machine Learning.
[95] Songlin Yang et al. (2025). Gated Delta Networks: Improving Mamba2 with Delta Rule. In The Thirteenth International Conference on Learning Representations. https://openreview.net/forum?id=r8H7xhYPwz.
[96] Merrill et al. (2026). Olmo Hybrid: From Theory to Practice and Back. https://allenai.org/papers/olmo-hybrid.
[97] Almeida, Luis B. (1987). A Learning Rule for Asynchronous Perceptrons with Feedback in a Combinatorial Environment. In Proceedings of the IEEE First International Conference on Neural Networks. pp. 609–618.
[98] Pineda, Fernando (1987). Generalization of Back-Propagation to Recurrent Neural Networks. Physical Review Letters. 59(19). pp. 2229–2232. doi:10.1103/PhysRevLett.59.2229.
[99] Liao et al. (2018). Reviving and Improving Recurrent Back-Propagation. In Proceedings of the 35th International Conference on Machine Learning. pp. 3082–3091. https://proceedings.mlr.press/v80/liao18c.html.