CoA-VLA: Improving Vision-Language-Action Models via Visual-Textual Chain-of-Affordance
# Executive Summary
Purpose and context
This research addresses a critical gap in robot learning: current Vision-Language-Action (VLA) models struggle with complex, multi-step manipulation tasks because they lack explicit reasoning capabilities. While these models can learn from large datasets, they often fail when tasks require understanding *what* to manipulate, *how* to grasp it, *where* to place it, and *how* to move safely. The work introduces Chain-of-Affordance (CoA-VLA), a new approach that teaches robots to reason through these decisions step-by-step before acting, similar to how OpenAI's O1 model uses reasoning chains to solve complex problems in language tasks.
What was done
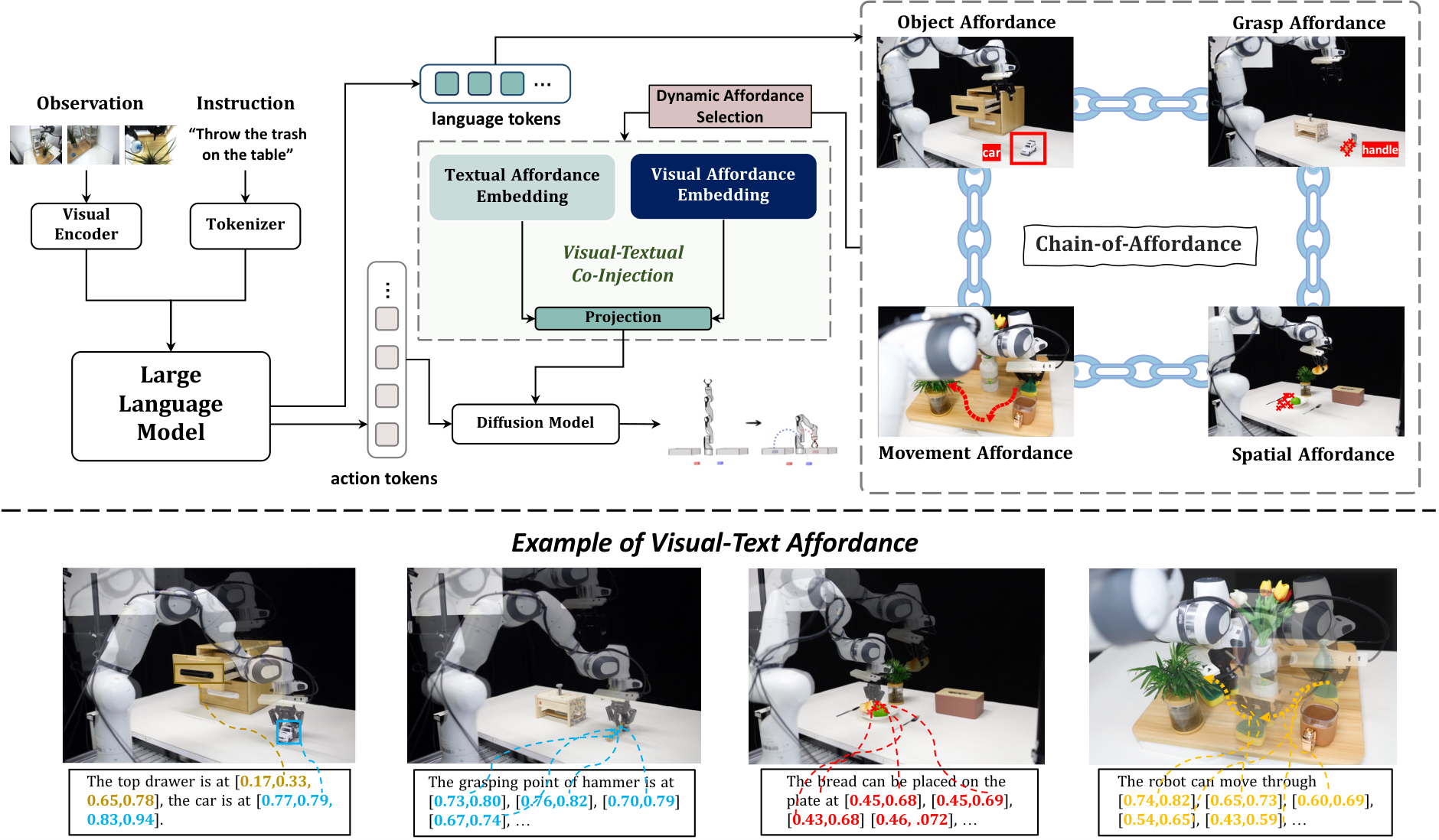
The team developed CoA-VLA by enhancing an existing robot foundation model (DiffusionVLA) with four types of structured reasoning called "affordances": object affordance (identifying what to manipulate and where it is), grasp affordance (determining the best grip point), spatial affordance (finding safe placement locations), and movement affordance (planning collision-free paths). These affordances are represented in two formats—textual descriptions and visual overlays on camera images—and integrated into the robot's decision-making process through a new visual-language co-injection module. To train the system efficiently, the researchers built an automated pipeline using AI tools (GPT-4o, SAM, Grounding DINO, CoTracker, RoboPoint) to generate large-scale affordance annotations from robot demonstration data, avoiding costly manual labeling.
Key findings
CoA-VLA substantially outperformed state-of-the-art robot models in both simulation and real-world tests. On seven real-world manipulation tasks using a Franka robot arm, CoA-VLA achieved an 85.5% average success rate in standard conditions, compared to 76.6% for the baseline DiffusionVLA and 54.9% for OpenVLA—despite using a smaller model and less training data. When tested under challenging visual conditions (distractors, varied lighting, cluttered backgrounds), CoA-VLA's advantage widened to 57.1% success versus 44.4% for DiffusionVLA and 22.2% for OpenVLA. In the LIBERO simulation benchmark across 40 tasks, CoA-VLA reached 79.8% average success, exceeding OpenVLA's 76.5%. The model demonstrated strong generalization to novel scenarios: it successfully identified free space on crowded plates, avoided unexpected obstacles during motion, and grasped objects in unfamiliar orientations not seen during training.
What the results mean
These results demonstrate that explicit affordance-based reasoning significantly improves robot reliability and adaptability, particularly in unstructured or changing environments. The performance gains translate to fewer task failures, reduced risk of collisions and damage, and better handling of real-world variability—all critical for deploying robots outside controlled laboratory settings. The success with visual generalization suggests the approach reduces the need for extensive retraining when environments change, potentially lowering deployment costs and accelerating robot system updates. The ability to reason about spatial constraints and movement paths also directly addresses safety concerns in human-shared spaces.
Recommendations and next steps
Organizations developing or deploying robot manipulation systems should consider integrating affordance-based reasoning into their VLA architectures, particularly for applications requiring robust performance in variable environments (warehouses, kitchens, medical facilities, field operations). For immediate adoption, focus on tasks where spatial reasoning and obstacle avoidance are critical. The automated affordance annotation pipeline should be scaled to additional robot datasets to expand the training base. Further development should investigate extending the affordance types to handle tool use, deformable objects, and multi-robot coordination. Before full production deployment, conduct pilot studies in target operational environments to validate the 6× inference speed improvement from dynamic affordance selection and confirm safety margins in human-robot interaction scenarios.
Limitations and confidence
The model still fails on extreme object orientations (e.g., hammers positioned horizontally), indicating limits to generalization from the training distribution. All real-world tests used a single robot platform (Franka arm) with specific camera configurations; performance on different hardware requires validation. The simulation results, while promising, reflect a domain with less environmental complexity than many real applications. Training data came primarily from the Droid dataset supplemented by 692 task-specific demonstrations; substantially different task domains may require additional data collection. The automated affordance annotation pipeline depends on the accuracy of third-party vision models, which may introduce errors. Confidence is high that the approach improves over baselines in the tested scenarios, but moderate regarding performance in significantly different environments or with different robot morphologies until further validation is completed.
Chengmeng Li1,⋆{}^{1,\star}1,⋆, Ran Cheng2{}^{2}2, Yaxin Peng1,†,⋆{}^{1,\dagger,\star}1,†,⋆, Yan Peng1{}^{1}1, Feifei Feng2{}^{2}2
1^{1}1Shanghai University, 2^{2}2Midea Group, 3^{3}3East China Normal University
- Co-first author, † Corresponding Author, ⋆\star⋆ Core Contributor
Abstract
In this section, the authors address whether robot models can improve performance in complex, multi-task environments by incorporating reasoning chains similar to OpenAI's O1 model, which uses extensive reasoning to solve difficult problems. They introduce Chain-of-Affordance (CoA-VLA), a novel approach that scales robot foundation models by integrating sequential reasoning through four types of affordances: object affordance identifies what to manipulate and its location, grasp affordance determines the optimal grasping point, spatial affordance finds the best placement space, and movement affordance plans collision-free trajectories. Each affordance is represented in both visual and textual formats, integrated into the policy network through a vision-language co-injection module that provides essential contextual information during action inference. Experiments demonstrate that CoA-VLA outperforms state-of-the-art models like OpenVLA and Octo across various tasks while exhibiting strong generalization to unseen object poses, free space identification, and obstacle avoidance in novel environments.
1. Introduction
In this section, the authors address how recent Vision-Language-Action models have improved robot policy learning through internet-scale data but remain limited by their reliance on external LLMs or VLMs for high-level planning, preventing them from developing implicit reasoning capabilities. Inspired by OpenAI's O1 model, which demonstrated that extensive reasoning chains enhance performance on complex tasks, they propose Chain-of-Affordance (CoA-VLA) to enable self-driven reasoning in robotics. The approach introduces four sequential affordance types—object, grasp, spatial, and movement—that guide robots through progressive decision-making: identifying what to manipulate, how to grasp it, where to place it, and which collision-free path to follow. These affordances are presented in both text-based and image-based formats and integrated through a novel visual-language co-injection module. Experiments on simulated benchmarks and real-world tasks demonstrate that CoA-VLA outperforms state-of-the-art models while exhibiting strong generalization to unseen poses, obstacles, and novel environments.
-
Object affordance. When a user provides vague instructions, the robot should be capable of identifying the target object for interaction and its location within the view.
-
Grasp affordance. It involves the robot assessing the object's most appropriate points or surfaces to enable secure and stable handling.
-
Spatial affordance. The robot needs to identify a set of coordinates that satisfy relationships described in language, such as free space for placement.
-
Movement affordance. Identifying a trajectory for the robot to move without collision is crucial in the real world to avoid catastrophic damage.
2. Related Works
In this section, the authors position their work within two research threads: affordance in robotics and reasoning for language and control. Affordance in robotics refers to the functional and spatial properties of objects that guide manipulation, traditionally represented through part segmentation, keypoints, dense features, or predictions from vision-language models for grasping and placement tasks. Meanwhile, reasoning approaches like chain-of-thought prompting have empowered large language models to solve complex problems by breaking them into steps, and recent robotics research has applied this by using LLMs and VLMs as high-level planners that decompose tasks into sub-goals or movement instructions for low-level execution. The authors distinguish their contribution by introducing a unified affordance taxonomy with four types—object, grasp, spatial, and movement—represented in both textual and visual formats, integrated through a dynamic selection mechanism that adaptively prioritizes task-relevant affordances at each timestep, achieving computationally efficient reasoning with improved robustness to environmental ambiguities.
3. Preliminary on Vision-Language-Action Models
In this section, Vision-Language-Action models are introduced as the foundation for chain-of-affordance policies, where a pre-trained vision-language model is fine-tuned to predict robot actions conditioned on image observations, task instructions, and reasoning. VLAs fall into two categories: autoregressive models that treat actions as discrete tokens and predict them sequentially like language generation, and diffusion-based VLAs that use policy heads such as diffusion models or flow matching to output continuous actions. The work builds specifically on DiVLA, which combines the Qwen2-VL vision-language model with a diffusion head for action prediction. This preliminary establishes the baseline architecture that will be enhanced by incorporating affordance-based reasoning, enabling the robot to explicitly reason about object manipulation, grasping points, spatial relationships, and movement trajectories before executing actions, thereby improving generalization and robustness in complex manipulation tasks.
4. Methodology
In this section, the authors tackle the challenge of enhancing robot policy learning by introducing Chain-of-Affordance (CoA), a structured reasoning framework that guides action prediction through four sequential affordance types: object affordance (identifying what to manipulate and its location), grasp affordance (determining optimal grasping points), spatial affordance (finding suitable placement coordinates), and movement affordance (planning collision-free trajectories). These affordances are represented in two complementary formats—textual descriptions and visual overlays on observation images—which are integrated into the policy network through a novel visual-language co-injection module that fuses both modalities using Vision Transformer encoders, Transformer blocks, and FiLM conditioning layers. To avoid computational overhead, a dynamic affordance selection mechanism leverages proprioceptive data to adaptively choose only task-relevant affordances at each timestep. The methodology also includes an automated pipeline using GPT-4o, Grounding DINOv2, SAM, RoboPoint, and CoTracker to generate large-scale chain-of-affordance annotations, enabling scalable training without extensive human labeling.
4.1 Definition of Chain-of-Affordance

4.2 Formatting of Visual-Textual Chain-of-Affordance
4.3 Generating Chain-of-Affordance Data
5. Experiments
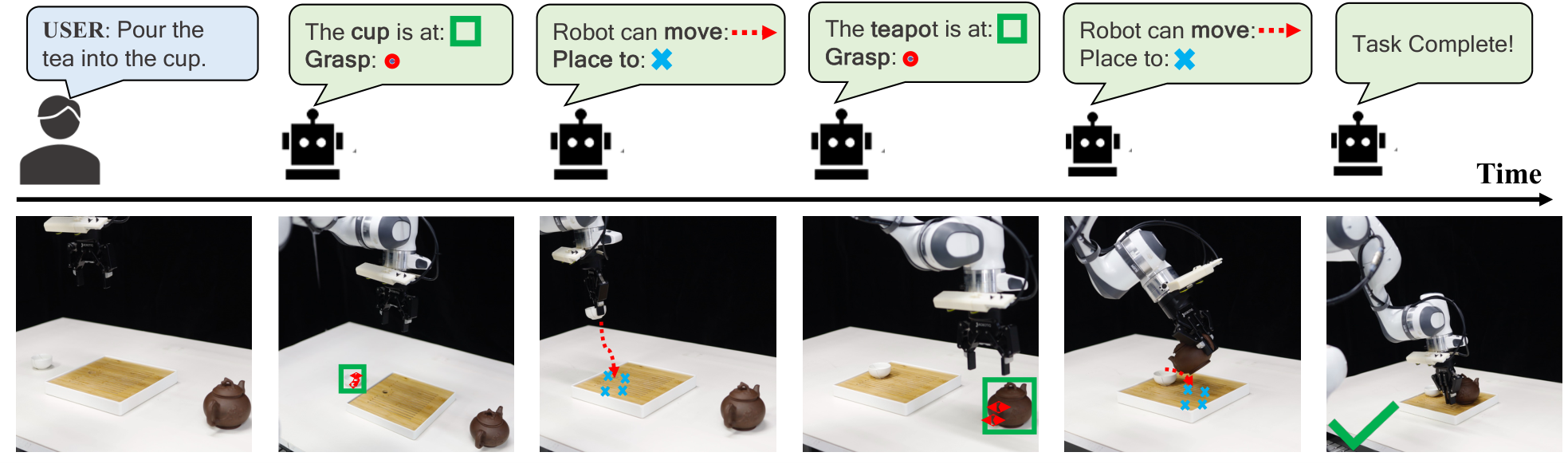
In this section, the authors evaluate CoA-VLA's performance through real-world robot experiments and simulation benchmarks to determine whether integrating chain-of-affordance reasoning improves policy learning compared to baseline vision-language-action models. Using a Franka robot arm across seven challenging manipulation tasks, CoA-VLA achieves 85.54% success rate in-distribution and 57.14% under visual generalization conditions, substantially outperforming OpenVLA, Octo, and DiffusionVLA despite having a smaller model size and less pre-training data. On the LIBERO simulation benchmark spanning four task suites, CoA-VLA attains 79.8% average success rate, exceeding OpenVLA by 3.3%. Critically, the method demonstrates superior spatial reasoning by identifying free placement areas and robust obstacle avoidance through movement affordance integration, completing all tested scenarios where baselines largely failed. These results confirm that explicit affordance reasoning—spanning object, grasp, spatial, and movement dimensions—significantly enhances generalization, safety, and task completion in complex robotic manipulation.
5.1 Evaluation on Real Robot
5.2 Evaluation on Simulation

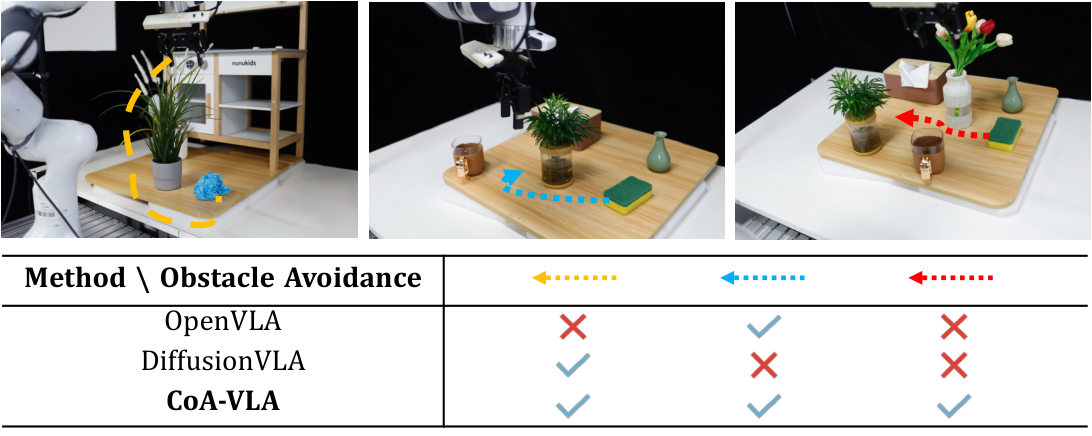
5.3 More Experiments
6. Conclusion
In this section, the authors establish that explicit reasoning is crucial for language models to manage complex tasks and introduce CoA-VLA, a reasoning-aware foundation model for robotics that centers on four interdependent affordances: object, grasp, spatial, and movement. The model structures these affordances as a chain where the robot sequentially identifies the target object and location, determines the appropriate grasp, decides on placement, and plans navigation accordingly. By representing this chain of affordances through intermediate language and image outputs that feed into the policy model, CoA-VLA demonstrates superior performance compared to baseline methods on real-world robotic tasks. The model exhibits strong generalization capabilities in complex environments, successfully handling challenges such as grasping objects in unfamiliar orientations, avoiding obstacles, and adapting to varied spatial configurations. This approach offers a novel perspective on designing reasoning chains to enhance embodied control in robotic systems.
Acknowledegments
In this section, the authors acknowledge the financial support that enabled this research work. The project received funding from two primary sources in China: the National Science Foundation of China under grant number 12471501, and the Sci-Tech Innovation Initiative administered by the Science and Technology Commission of Shanghai Municipality under grant number 24ZR1419000. These funding mechanisms provided the necessary resources to develop and evaluate CoA-VLA, the Chain-of-Affordance Vision-Language-Action model for robotic manipulation tasks. The acknowledgment recognizes the critical role of institutional support in advancing research at the intersection of robotics, computer vision, and language models, particularly for conducting extensive real-world experiments with robotic hardware and developing novel reasoning frameworks that enhance robot foundation models' ability to generalize across diverse manipulation scenarios.
Supplementary Material
Purpose and context
Vision-Language-Action (VLA) models enable robots to learn manipulation policies from visual observations and language instructions. Current VLA models often rely on external large language models for high-level planning, limiting their ability to develop internal reasoning capabilities. This work introduces Chain-of-Affordance (CoA-VLA), a method that teaches robot models to reason about affordances—the actionable properties of objects and environments—before executing actions. The goal is to improve task performance, generalization to new scenarios, and safety in complex manipulation tasks.
What was done
We developed CoA-VLA by extending an existing VLA model (DiffusionVLA) with structured reasoning about four types of affordances: object affordance (what to manipulate and where it is), grasp affordance (how to grip the object), spatial affordance (where to place it), and movement affordance (collision-free trajectories). The model generates these affordances in two formats—natural language descriptions and visual overlays on camera images—and integrates both into policy learning through a novel visual-textual co-injection module. To reduce computational cost, we implemented dynamic affordance selection, which adaptively chooses only the relevant affordances at each timestep based on the robot's proprioceptive state. We created training data by developing an automated pipeline that uses GPT-4o, object detection models (Grounding DINOv2, SAM), spatial reasoning models (RoboPoint), and motion tracking (CoTracker) to generate affordance annotations at scale.
Main findings
CoA-VLA substantially outperformed state-of-the-art robot models in both simulated and real-world experiments. On seven real-world manipulation tasks using a Franka robot arm, CoA-VLA achieved an 85.5% success rate in standard conditions, exceeding OpenVLA by 30.7 percentage points and the base DiffusionVLA model by 8.9 points. Under visually challenging conditions with distractors and varied lighting, CoA-VLA maintained a 57.1% success rate compared to 44.4% for DiffusionVLA and 22.2% for OpenVLA. In simulation benchmarks (LIBERO), CoA-VLA reached 79.8% average success rate across four task suites, outperforming OpenVLA by 3.3 points. The model demonstrated strong generalization: it successfully identified free space for object placement, avoided obstacles by planning collision-free paths, and grasped objects in previously unseen orientations. Ablation studies confirmed that both visual and textual affordances contribute to performance, with textual affordances having stronger influence, and that dynamic affordance selection maintains accuracy while increasing inference speed sixfold.
What the findings mean
These results show that explicit affordance reasoning significantly improves robot manipulation performance and robustness without requiring larger models or more pre-training data. The improvements are particularly pronounced in challenging scenarios involving visual clutter, obstacles, and ambiguous placement locations—situations where cost of failure is high and safety is critical. The model's ability to generalize to unseen object poses and dynamically avoid obstacles reduces the need for exhaustive training data covering every possible scenario, potentially lowering deployment costs and training time. The computational efficiency gain from dynamic affordance selection makes the approach practical for real-time robotic control at 6Hz compared to 1Hz when using all affordances indiscriminately.
Recommendations and next steps
Deploy CoA-VLA for manipulation tasks where spatial reasoning, obstacle avoidance, and adaptability to visual variation are critical, particularly in unstructured environments with changing object configurations. For new task domains, use the automated affordance annotation pipeline to generate training data efficiently rather than relying on manual labeling. Consider CoA-VLA when model size and inference speed are constraints, as it achieves strong performance with smaller model size than alternatives like OpenVLA. Before broader deployment, evaluate the model on additional long-horizon tasks and test failure modes when objects are positioned in extreme orientations (e.g., horizontally), as current results show limitations in these cases. Future work should explore extending the affordance taxonomy to additional manipulation primitives and testing on mobile manipulation platforms beyond fixed-arm setups.
Limitations and confidence
The real-world evaluation covered seven tasks with 692 training demonstrations plus external data; performance may vary on task types not represented in this set. The model struggles with object grasps when handles are oriented horizontally relative to the robot, indicating limits to pose generalization. Simulation results are based on the LIBERO benchmark's specific task distribution and may not fully predict performance in other simulated or real environments. The automated affordance annotation pipeline depends on the accuracy of underlying models (GPT-4o, SAM, etc.), which may introduce noise in training data. Confidence is high that CoA-VLA provides meaningful improvements over baseline VLA models in the tested scenarios, moderate confidence that similar gains will transfer to related manipulation tasks, and lower confidence for task domains substantially different from those evaluated (e.g., deformable object manipulation, bimanual tasks).
6.1. Video Demo

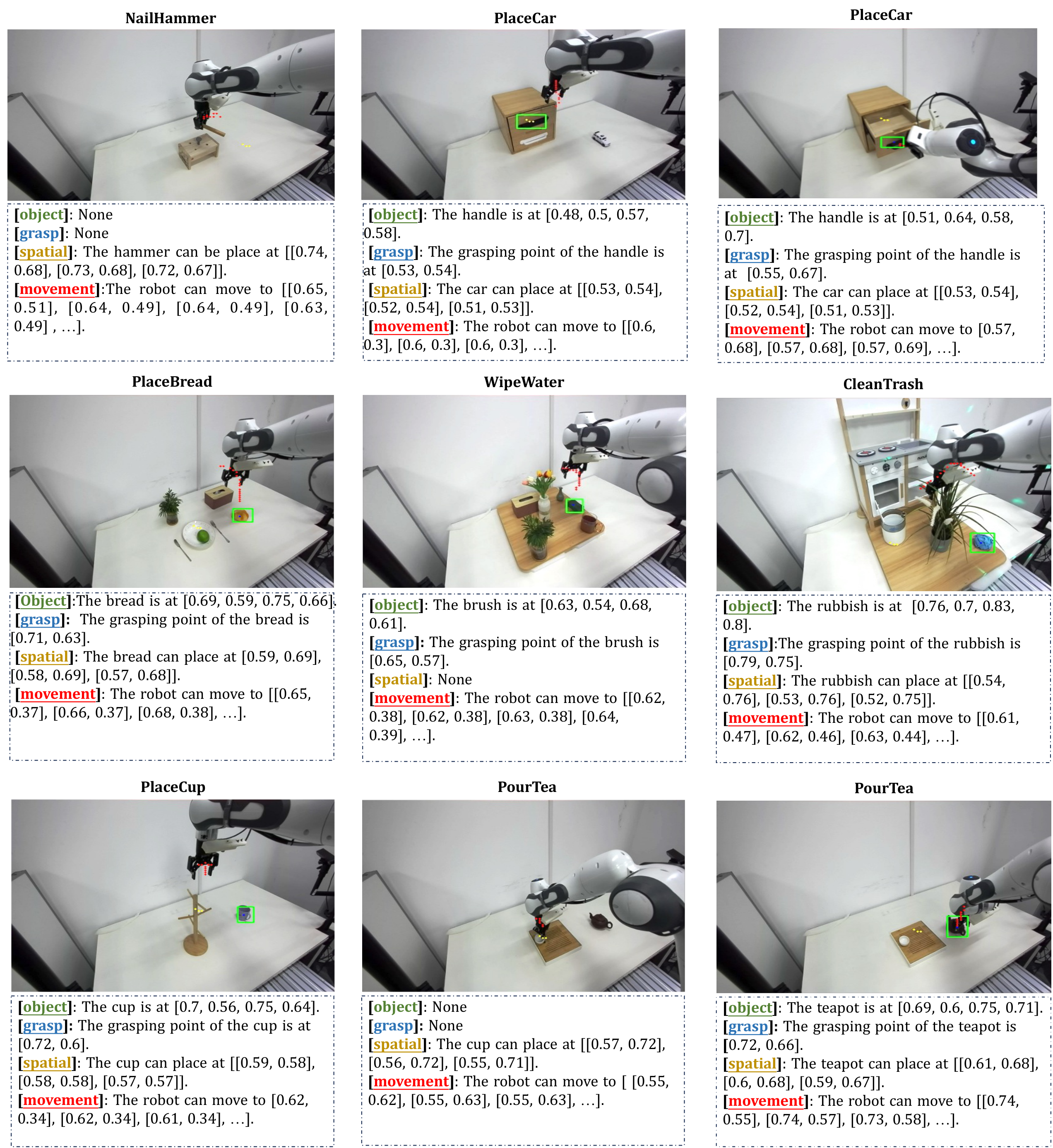
6.2. Evaluation Tasks
- PlaceCar. We randomly place the toy car on the right side of the drawer. The model is asked to pick up the toy car, put it into the drawer, and eventually close the drawer. This is a long-horizon task that requires multiple steps of action.
- PlaceBread. The model needs to pick up the bread and place it on an empty spot on the plate, avoiding placing it on the fruit. The bread is randomly placed on the table. The model needs to pick up the bread and place it on the empty spot on the plate.
- NailHammer. We evaluate the model's proficiency in utilizing tools effectively by assessing its ability to perform a sequence of precise actions with a hammer. The model must first identify the correct grasp point on the hammer, ensuring a stable and ergonomic grip suitable for controlled operation. It must then carefully pick up the hammer without causing it to topple or disturb its surroundings. Once the hammer is securely held, the model is tasked with driving a nail into a designated spot with precision.
- PourTea. In this task, the robot is required to perform a sequence of actions involving a tea cup and a teapot. First, the robot must place the tea cup onto the tea tray. Next, it needs to pick up the teapot and pour tea into the teacup. Both the tea cup and the teapot are randomly positioned within a defined range on the table. A key aspect of the task is the robot's ability to accurately grasp the teapot by its stem. To ensure consistency during data collection, the tea pot's stem is always oriented facing the robot, simplifying the grasping process while still challenging the model's precision and manipulation skills.
- CleanTrash. In this task, the robot is required to perform a sequence of actions to clean up trash on a table. The task has two distinct scenarios. In the first scenario, with no obstacles, the robot must identify and pick up the randomly placed trash, then deposit it into the trash bin. The trash items are distributed across the table in a random manner. In the second scenario, a flower pot is placed on the table as an obstacle. The robot must avoid colliding with the flower pot while picking up the trash and placing it into the trash bin. The trash's location remains random, and the robot must navigate carefully to avoid knocking over the flower pot during the cleanup process. A key aspect of this task is the robot's ability to accurately avoid the flower pot while maintaining efficiency in picking up and discarding the trash.
- WiperWater In this task, the robot is required to clean up water from a table by using a sponge. The sponge is placed on the right side of the table, and the robot must pick it up and use it to wipe the water from the surface, moving from right to left. During this process, the robot must avoid any objects placed on the table, such as vases, cups, boxes, and other items. A key challenge in this task is the robot's ability to manipulate the sponge effectively while navigating around the obstacles without causing any collisions, ensuring that the entire table is cleaned efficiently. The robot's precision in both grasping the sponge and avoiding the table items is critical for completing the task successfully.
- HangCup In this task, the robot is required to pick up cups that are randomly scattered on the table and hang them on a cup rack. The robot must handle the cups carefully to avoid damaging them and ensure that the rack is not disturbed or knocked over during the process. The task challenges the robot's precision in both grasping the cups and placing them securely on the rack while maintaining stability in the environment. Successful completion relies on careful manipulation and accurate placement.
6.3. Details for Real Robot Experiments
6.4. Details for LIBERO Simulation
7. More Experiments
In this section, the authors investigate the individual contributions of visual and textual affordances, the computational efficiency of dynamic affordance selection, and the model's ability to generalize to unseen object orientations. Ablation studies on LIBERO demonstrate that both visual and textual affordances are critical for performance, with textual affordances showing stronger influence due to their capacity to encode task-specific semantics like "graspable" or "pour-able." Dynamic affordance selection proves essential, as using all affordances indiscriminately introduces optimization noise and reduces inference speed by six times compared to the selective approach. Finally, evaluation on novel object poses reveals that CoA-VLA successfully grasps hammers and teapots in unfamiliar orientations not seen during training, significantly outperforming OpenVLA, though all models fail when objects are positioned horizontally, indicating that grasp affordance substantially enhances generalization to varied spatial configurations despite remaining limitations.
7.1. Ablation Study on Visual-Textual Affordance

7.2. Ablation Study on Dynamic Affordance Selection
7.3. Generalization to Unseen Object Pose
References
In this section, the references catalog the foundational and state-of-the-art works underpinning vision-language-action models and robotic manipulation research. The citations span several key areas: diffusion-based policy learning methods like DiffusionVLA and Diffusion Policy that enable visuomotor control through action diffusion; large-scale vision-language-action models such as OpenVLA, RT-2, and Octo that leverage web-scale data for generalist robotic policies; affordance-based approaches including grasp prediction networks like AnyGrasp and Contact-GraspNet, as well as spatial and relational affordance frameworks; reasoning techniques borrowed from large language models, particularly chain-of-thought and tree-of-thought prompting methods; benchmark datasets and tasks like LIBERO for evaluating imitation learning; and foundational computer vision tools such as Segment Anything, CoTracker, and Grounding DINO for perception. Together, these works establish the technical foundation for integrating affordance reasoning, multimodal perception, and policy learning to advance robotic manipulation capabilities across diverse, real-world scenarios.