Detecting overfitting in Neural Networks during long-horizon grokking using Random Matrix Theory
Hari K. Prakash
University of California San Diego
Data Science and Engineering
[email protected]
Charles H. Martin
Calculation Consulting
San Francisco, CA, USA
[email protected]
Abstract
Training Neural Networks (NNs) without overfitting is difficult; detecting that overfitting is difficult as well. We present a novel Random Matrix Theory method that detects the onset of overfitting in deep learning models without access to train or test data. For each model layer, we randomize each weight matrix element-wise, $\mathbf{W} \rightarrow \mathbf{W}^{\mathrm{rand}}$, fit the shuffled matrix’s empirical spectral distribution with a Marchenko-Pastur distribution, and identify large outliers that violate self-averaging. We call these outliers Correlation Traps. During the onset of overfitting, which we call the "anti-grokking" phase in long-horizon grokking, Correlation Traps form and grow in number and scale as test accuracy decreases while train accuracy remains high. Traps may be benign or may harm generalization; we provide an empirical approach to distinguish between them by passing random data through the trained model and evaluating the JS divergence of output logits. Our findings show that anti-grokking is an additional grokking phase with high train accuracy and decreasing test accuracy, structurally distinct from pre-grokking through its Correlation Traps. More broadly, we find that some foundation-scale LLMs exhibit the same Correlation Traps, indicating potentially harmful overfitting.
Preprint.
Executive Summary: Neural networks, the core of modern AI systems, often overfit their training data, meaning they memorize specifics rather than learning general rules that work on new inputs. This is a growing concern for open-weight models, like those released by companies for public use, which serve as bases for custom applications. Without access to the original training or test data, users struggle to tell if a model is robust or brittle—performing well on seen examples but failing on unseen ones. Detecting overfitting directly from a model's weights is vital now, as millions of such models are shared online, and regulators seek ways to assess AI safety without proprietary data.
This document evaluates a new method to spot overfitting signatures in neural network weights alone, using "grokking"—a phenomenon where models delay generalization—as a test case. Grokking involves training far beyond initial memorization to see if models lose their learned rules under prolonged optimization. The goal is to distinguish true overfitting from early learning struggles, helping users pick reliable models.
The authors analyzed three standard setups: a simple multilayer perceptron (MLP) on a small set of handwritten digits (MNIST), a small transformer on modular arithmetic problems, and a GPT-style model on synthetic reasoning tasks. They trained each for up to 10 million steps, far longer than usual, to induce overfitting. Without using any data, they shuffled elements in each layer's weight matrix to break learned patterns, then applied random matrix theory—a statistical tool for matrix behavior—to fit the resulting spectrum to a baseline distribution (Marchenko-Pastur law). Outliers beyond this baseline, called Correlation Traps, signal non-random structures hinting at overfitting. They used the open-source WeightWatcher tool for this, focusing on trap counts per layer across phases, and tested trap impacts via a data-free ablation (replacing traps with random vectors and measuring output changes using Jensen-Shannon divergence, or JSD).
The key findings reveal a three-phase learning pattern across all setups. First, pre-grokking: training accuracy climbs to near-perfect while test accuracy stays low, but traps remain near zero, indicating the model hasn't generalized yet. Second, grokking: test accuracy surges to high levels (over 95% in most cases) with still few or no traps, showing a stable generalizing solution. Third, anti-grokking: after grokking, test accuracy drops sharply (by 20-40% in experiments) despite perfect training accuracy, as traps emerge and multiply—rising from zero to dozens per layer. Weight decay, a common regularizer, cut trap numbers by half and limited accuracy drops to under 10%. Traps split into harmful (altering outputs significantly, worsening generalization) and benign (little effect), identifiable via JSD scores; harmful ones correlated with brittle behavior like over-relying on input noise rather than patterns. Finally, screening two large open-weight language models (20 billion and 120 billion parameters) uncovered hundreds of traps per layer, far above baselines.
These results mean overfitting can strike even after a model achieves strong generalization if training continues unchecked, creating hidden risks in seemingly solid checkpoints. Unlike pre-grokking, which looks similar on accuracy metrics but lacks traps, anti-grokking embeds data-specific correlations that boost training fit but erode real-world performance—potentially hiking error rates on new tasks by 30% or more. This challenges the view that grokking signals the end of training; instead, it highlights a "post-generalization" failure mode. For stakeholders, it matters for costs (wasted compute on flawed models), risks (unreliable AI in critical uses like reasoning), and compliance (auditing without data). The trap method offers a lightweight, data-free check, outperforming simple norm measures.
To act, integrate trap detection into training pipelines: monitor counts during long runs and apply weight decay or early stopping if traps exceed thresholds (e.g., 5-10 per layer). For fine-tuning, screen base models and ablate harmful traps before adaptation. Options include full retraining (high effort, best reliability) versus targeted regularization (faster, but risks over-correction). Further work is essential: pilot suppression techniques like trap-specific penalties on diverse architectures and datasets, and validate against real-world tasks beyond these benchmarks.
While robust in controlled experiments (consistent across seeds and shuffles), limitations include reliance on just three setups, so results may not generalize to all models or optimizers. Large-model traps suggest issues but require task-specific tests to confirm harm—avoid over-relying on counts alone. Confidence is high for detecting anti-grokking in similar scenarios, but use cautiously for broad safety judgments.
1. Introduction
Section Summary: Open-weight AI models are widely used, but it's hard to tell if they've been properly trained or just overfit to their training data, especially without access to the training details. To address this, researchers study "grokking," where models first memorize training data without generalizing, then suddenly improve on new data, but prolonged training can lead to "anti-grokking," a phase of harmful overfitting that looks similar to the early stage from accuracy scores alone. They introduce "Correlation Traps," a method to spot overfitting signatures directly in the model's weights by detecting unusual patterns in the layers, which reliably signals this decline in three tested setups, including large language models.
Open-weight models are increasingly used as foundations for downstream systems, but it is often unclear whether a checkpoint is robustly trained or overfit to its training distribution. Users may have access to the weights and a model card, but not to the training data, held-out losses, optimizer state, or long-horizon checkpoint history. As a result, two models can look similar from the outside while differing sharply in whether their weights encode useful structure or brittle, data-specific correlations. This motivates a basic question: can we detect signatures of overfitting directly from the weights of a trained model, without having access to the training or any test data?
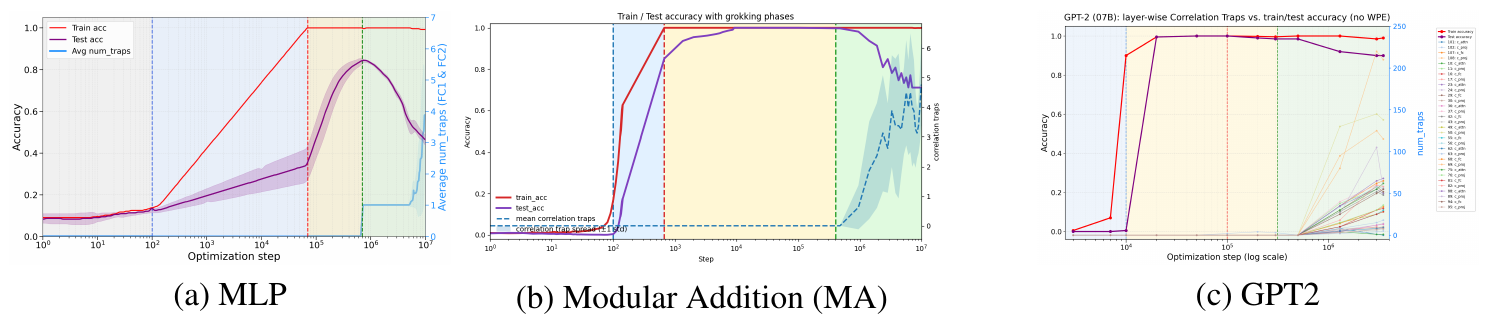
Because such histories are usually unavailable for open-weight checkpoints, we first study a setting where the relevant dynamics are visible and overfitting can be readily induced with long-horizon training: grokking. In grokking, training accuracy reaches near perfection while test accuracy stays near chance for many optimization steps, before abruptly improving ([1]). Grokking has been studied across several architectures and tasks, including algorithmic tasks such as modular addition, computer vision models, and GPT-style transformers ([2, 3]). We extend this view to the long-horizon after grokking, where long-horizon training can drive the model into a classical overfitting phase. We call this post-generalization regime anti-grokking.
Our setup lets us compare three phases of learning: pre-grokking, grokking, and anti-grokking. Pre-grokking and anti-grokking can look deceptively similar from train and test accuracy alone: in both regimes, training accuracy is high while held-out accuracy is poor. But they are structurally different. Pre-grokking occurs before the model has found a generalizing solution; anti-grokking occurs after such a solution has been found and then lost. In comparing different phases, this makes long-horizon grokking an excellent case for studying harmful overfitting.
To detect this post-grokking overfitting structure, we introduce Correlation Traps. Correlation Traps are outliers to the (self-averaging) Random Matrix Theory (RMT) description of the layer weight matrices. For each layer, we shuffle the weights entry-wise, $\mathbf{W}\rightarrow\mathbf{W}^{\rm rand}$, fit the eigenvalue spectrum of the covariance matrix $\mathbf{X}^{\rm rand}=\frac{1}{N}(\mathbf{W}^{\rm rand})^\top\mathbf{W}^{\rm rand}$ to a Marchenko-Pastur (MP) bulk, and count outliers far beyond the MP edge. The key observation is that while both pre-grokking and anti-grokking can look similar, only anti-grokking exhibits Correlation Traps.
Figure 1 shows the phenomenon in three controlled settings: an MNIST MLP, a transformer trained on Modular Addition (MA), and a GPT2 transformer trained for long-horizon grokking ([3]). In all three cases, training separates into three phases. During pre-grokking, training accuracy increases while test accuracy remains low. During grokking, test accuracy improves and the model reaches a high-generalization solution. During anti-grokking, test accuracy falls despite sustained near-perfect training accuracy. Across all three tasks, the trap signal tracks this late divergence: trap counts are low while generalization improves and increase as test accuracy declines.
These results indicate that Correlation Traps reveal the onset of this overfitting phase in a well-studied grokking setting where standard train/test curves alone would not distinguish it from pre-grokking.
Our Contributions.
- We define Correlation Traps as outliers to the MP/TW right-edge in shuffled layer spectra.
- We show the onset of traps tracks anti-grokking in MLP, MA, and GPT2-style runs.
- We link traps to non-self-averaging through localization and condensation.
- We distinguish between harmful and benign traps using JSD-based behavioral testing.
- We screen GPT-OSS 20B/120B checkpoints with layer-wise trap profiles.
Most importantly, however, we argue that Correlation Traps can be used to detect signatures of potentially harmful overfitting in open-source, foundation-scale models from just the weights.
2. Related Work
Section Summary: Researchers have studied "grokking," a phenomenon where AI models suddenly generalize well after initially memorizing training data, but this work explores what happens much later in training, when models that have already grokked can start overfitting and perform worse on new data. The authors build on techniques from random matrix theory to analyze the internal weight structures of neural networks, identifying unusual patterns called Correlation Traps that signal potential overfitting during prolonged training. These traps relate to ideas from statistical physics, where overfitting arises from unstable, sample-specific patterns rather than reliable rules, similar to disordered states in physical systems.
Grokking and long-horizon generalization.
Grokking was introduced by Power et al. ([1]) as delayed generalization after training accuracy has already saturated. Subsequent work has studied grokking in algorithmic and mechanistic settings, including modular arithmetic, MLPs, and Transformer models ([4, 2, 5, 3]). Most of this literature focuses on the transition from memorization to generalization: the model first fits the training set, then later discovers a rule that generalizes. Our focus is the long-horizon regime after this transition, where a model that has already grokked can lose held-out performance (and overfit its training data) after extended training.
Random-matrix diagnostics of neural-network weights.
Our diagnostic builds on spectral approaches to neural-network weight matrices, especially Random Matrix Theory (RMT) and the WeightWatcher framework ([6, 7, 8, 9]). Prior spectral diagnostics use heavy-tailed structure of the correlated (unrandomized) layer weight matrices $\mathbf{W}$, and related metrics to characterize trained networks. We analyze the spectral properties of the randomized $\mathbf{W}$, and look for large eigenvalues $(\lambda_{trap})$ that deviate from the Random Matrix Theory (RMT) Marchenko-Pastur (MP) baseline. We call these outliers Correlation Traps, and track them through extended training, connecting them to overfitting in the anti-grokking phase. We note that Correlation Traps were first proposed in [7].
Self-averaging and overfitting.
Our overfitting criterion connects to statistical-mechanics accounts of glassy learning, where poor generalization reflects sample-specific structure rather than a single stable rule ([10, 11, 12, 13, 14]). The MP law gives a self-averaging baseline for randomized layer spectra, and Correlation Traps violate that baseline. Such traps can support a non-self-averaging generalization error such as through localization, where a small coordinate set retains $O(1)$ variance under subsampling, or through condensation, where a dominant spectral mode carries macroscopic variance.[^1]In either case, the presence of traps aligns with classic notions of overfitting that occur in the spin-glass-like phase(s) of simple statistical mechanics models of NNs.
[^1]: The corresponding physics analogies are Anderson localization, Bose–Einstein condensation, and the Curie–Weiss mean-field model of magnetization ([15, 16, 17, 18]).
3. WeightWatcher, Random Matrix Theory, and Correlation Traps
Section Summary: The WeightWatcher tool applies ideas from random matrix theory to analyze the inner workings of neural network layers by studying the distribution of their eigenvalues, which reveal patterns in the weights. For random weights, this distribution follows a predictable shape called the Marchenko-Pastur law, indicating balanced, self-averaging behavior without dominant directions. To spot problems like overfitting, the tool shuffles the weight entries to create a randomized version and looks for outlier eigenvalues beyond the expected edges, termed "Correlation Traps," which signal hidden correlations that can lead to training failures.
The open-source WeightWatcher tool (WeightWatcher) implements several random-matrix-based analyses of neural-network layers [6]. Here, it is used to examine the individual layer spectral densities using techniques adapted from Random Matrix Theory (RMT), and rigorously established by Statistical Mechanics and extensive experimental observations.
3.1 The Marchenko-Pastur (MP) self-averaging baseline
For a layer weight matrix $\mathbf{W}\in\mathbb{R}^{N\times M}$, define the layer covariance
$ \mathbf{X} := \frac{1}{N}\mathbf{W}^{\top}\mathbf{W} \in \mathbb{R}^{M\times M}.\tag{1} $
Let ${\lambda_i}_{i=1}^{M}$ be the eigenvalues of $\mathbf{X}$. The empirical spectral density (ESD) is
$ \rho_{\mathrm{emp}}(\lambda) := \frac{1}{M}\sum_{i=1}^{M}\delta(\lambda-\lambda_i).\tag{2} $
If the entries of $\mathbf{W}$ are i.i.d. and well behaved, then in the limit $N, M\to\infty$, with $Q=N/M\ge 1$ fixed, $\rho_{\mathrm{emp}}(\lambda)$ converges to the Marchenko–Pastur density [19].
$ \rho_{\mathrm{MP}}(\lambda)
\frac{Q}{2\pi\sigma^2} \frac{\sqrt{(\lambda_+-\lambda)(\lambda-\lambda_-)}}{\lambda} \mathbf{1}{[\lambda-, \lambda_+]}(\lambda),\tag{3} $
with edges
$ \lambda_{\pm}
\sigma^2\left(1\pm Q^{-1/2}\right)^2.\tag{4} $
At finite $N$, the right edge $\lambda_+$ lives within the scale of the Tracy-Widom (TW) fluctuations.
Also, and importantly, the MP singular and/or eigenvectors $\mathbf{v}$ are delocalized with randomly distributed components. That is, we may expect $|v_j|^2 \sim \tfrac{1}{M}$ up to fluctuations.
The MP bulk is consistent with self-averaging behavior. In the large- $N$ limit, the ESD concentrates onto the deterministic MP law,
$ \rho_{\mathrm{emp}}(\lambda);\to;\rho_{\mathrm{MP}}(\lambda), \quad N, M\to\infty, ; Q=\tfrac{N}{M}\ \text{fixed}. $
Large spectral outliers represent non-self-averaging structure: a small number of directions dominate the statistics. Observables that depend on these directions fail to concentrate. This is the crux of our analysis: such outliers $(\lambda_{trap}, \mathbf{v}_{trap})$ can be detected directly from the weight matrices and indicate that the layer has developed structured, non-random correlations associated with overfitting.
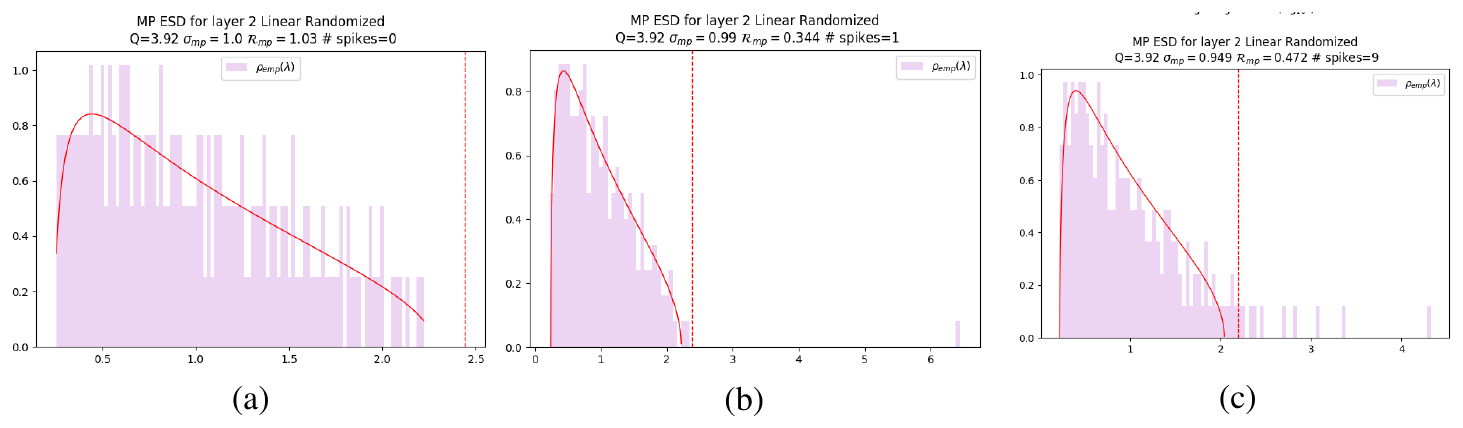
3.2 Entry-wise shuffling and Correlation Traps
Recognizing that RMT requires the elements of a matrix to be i.i.d. and well-behaved (i.e., not too heavy tailed), to apply RMT faithfully, we randomize the weight matrix elementwise, and form
$ \mathbf{W} \mapsto \mathbf{W}^{rand} .;;\tag{5} $
Under the randomized null, the entries of $\mathbf{W}^{\mathrm{rand}}$ should be effectively uncorrelated, so the ESD of $\mathbf{X}^{\mathrm{rand}}=\tfrac{1}{N}(\mathbf{W}^{\mathrm{rand}})^{\top}\mathbf{W}^{\mathrm{rand}}$ should be well fit by an MP distribution if the model is well-trained. Also, the singular vectors of $\mathbf{W}^{\mathrm{rand}}$ (and eigenvectors of $\mathbf{X}^{\mathrm{rand}}$) will be delocalized. [^2].
[^2]: The bulk MP vector components $v_{i}$ will follow a Porter–Thomas distribution [20, 21]
Figure 2 shows this diagnostic. In a well-behaved layer, the randomized ESD follows the fitted MP bulk and no large right-edge outliers appear; see Figure 2(a). During anti-grokking, however, the randomized spectrum develops separated spikes well beyond the MP edge; see Figure 2(b, c). These spikes are structural outliers that survive entry-wise shuffling (and frequently localize).
We call these outliers Correlation Traps. If $\lambda_{trap}$ is an eigenvalue of $\mathbf{X}^{\mathrm{rand}}$ and $\lambda_+^{\mathrm{MP}}$ is the fitted MP right edge, then a trap is an eigenvalue that lies significantly beyond the right MP edge:
$ \text{Correlation Trap:} \qquad \lambda_{trap}
\lambda_+^{MP} + \Delta_{TW}\tag{6} $
where $\Delta_{\mathrm{TW}}$ denotes the scale of finite-size Tracy-Widom fluctuations.
By the Baik–Ben Arous–Péché (BBP) theory, an eigenvalue that separates beyond the TW edge is a structural outlier [22]. This is why the MP fit provides the randomized null for our diagnostic. Moreover, the resulting outliers are similar in spirit to the strong aligned directions emphasized by Li and Sonthalia [23] which induce catastrophic failure.
Our setting is nonparametric and implemented as a practical diagnostic, and does not distinguish the specific mechanisms that may be inducing what appears to be non-self-averaging/failure-of-concentration. Also, some traps are harmful, other benign. Later, we show how to distinguish between harmful and benign traps, again without needing any test or training data, in a given model.
: Table 1: Trap-detection algorithm. Full procedure used to compute trap-count curves.
| Step | Procedure |
|---|---|
| 1 | Take a trained layer $\mathbf{W} \in \mathbb{R}^{N \times M}$ at a saved checkpoint. |
| 2 | Shuffle the entries $W_{ij}$ elementwise to form $\mathbf{W}^{\mathrm{rand}}$. |
| 3 | Run SVD($\mathbf{W}^{\mathrm{rand}}$), form the eigenvalue density, $\rho_{emp}(\lambda)$ (or ESD) |
| 4 | Fit the ESD $\rho_{emp}(\lambda)$ to the Marchenko–Pastur (MP) law. |
| 5 | Identify eigenvalues $\lambda_{trap} > \lambda_{+}^{\mathrm{MP}} + \Delta_{\mathrm{TW}}$; these are Correlation Traps |
The WeightWatcher tool detects Correlation Traps automatically, as outlined in Table 1.
4. Traps as Signs of Non-Self-Averaging: Localization and Condensation
Section Summary: In statistics and machine learning, self-averaging means that as data grows, measurements become more reliable with shrinking random fluctuations. However, "traps" in data correlations can disrupt this by causing non-self-averaging through two main issues: localization, where the problem concentrates in just a few specific features or parameters, limiting the averaging effect; or condensation, where one dominant spectral component overwhelms the rest, even if spread out, leading to outsized variance. These traps signal potential risks to model performance, but their actual harm varies and requires further testing to assess.
Self-averaging is the statistical-mechanics analogue of concentration. An observable $A_N$ self-averages when its relative fluctuations vanish, for example when
$ \frac{\operatorname{Var}(A_N)}{\mathbb{E}[A_N]^2} \longrightarrow 0 .\tag{7} $
For the empirical risk $R_n$, one defines the variance and covariance:
$ R_n = \frac{1}{n}\sum_{i=1}^n L_i, \qquad \operatorname{Var}(R_n)
\frac{1}{n^2}\mathbf{1}^{\top}\Sigma_n\mathbf{1}, \quad (\Sigma_n)_{ij}=\operatorname{Cov}(L_i, L_j).\tag{8} $
Concentration requires that the covariance has no macroscopic, sample-specific mode(s). More generally, define a covariance-like matrix $C$ with eigendecomposition
$ C = \sum_{\alpha} \lambda_{\alpha} v_{\alpha}v_{\alpha}^{\top}. $
Let $A_b$ be some linearized observable with sensitivity vector $b$. Write the variance of $A_b$ as
$ \operatorname{Var}(A_b)
b^{\top} C b
\sum_{\alpha} \lambda_{\alpha} \langle b, v_{\alpha}\rangle^2 .\tag{9} $
A trap is therefore dangerous when one term in this sum remains macroscopic. A failure to concentrate can happen in at least two different ways: localization and/or condensation.
Geometric localization.
A trap mode may be localized in coordinates. For a normalized eigenvector $v\in\mathbb{R}^M$, this means that its squared mass is concentrated on a small set $S$:
$ \sum_{i\in S} v_i^2 \approx 1, \qquad |S|\ll M . $
The corresponding variance component $\lambda vv^{\top}$ is then carried by a small effective support. If an observable $(A_b)$ has non-negligible projection on this support, then it is not averaging over many comparable coordinates, so its fluctuations need not decay at the usual rate.
In practical terms, this means the trap is highly localized, and frequently contains a significant fraction of the top $5%$ mass of $W_{ij}$. We examined the localization of traps and found that they provide only limited predictive signal for harmful traps, with the relationship varying across experiments. [^3]
[^3]: This is analogous to Anderson localization: an eigenmode is spatially or coordinate-localized, so the relevant variance is supported on only a few degrees of freedom.
Spectral condensation.
A trap may also be diffuse in coordinates but dominant in spectrum. Suppose one eigenvalue $\lambda_{\rm max}$ is much larger than the rest. Then the variance contribution
$ \lambda_{\rm max} \langle b, v_1\rangle^2 $
can dominate Equation 9, even when $v_1$ is spread across many coordinates. In this case self-averaging fails not because the mode is geometrically sparse (i.e. the trap is highly localized), but because variance has condensed into a single large spectral degree of freedom.[^4]
[^4]: This resembles the Curie-Weiss model, which has a matrix $(J/N)\mathbf{1}\mathbf{1}^{\top}$ with one large eigenvalue and a perfectly delocalized eigenvector $\mathbf{1}/\sqrt{N}$. Similarly, a Bose condensate occupies one spectral mode that can remain spatially diffuse.
Correlation Traps can exhibit localization, condensation, or a mixture of both. The MP violation indicates non-self-averaging structure, but it is not a sign rule: localized traps and diffuse spectral spikes can each be useful, harmful, or benign. Their effect on generalization must therefore be determined either by intervention and/or the data-free JSD diagnostic ablation test described below.
5. Empirical Results: Correlation Traps Track Anti-Grokking
Section Summary: Researchers examined three machine learning benchmarks—a simple neural network on handwritten digits, a transformer for modular arithmetic, and a larger model for composing synthetic facts—and found that after models initially memorize training data and then generalize well in a "grokking" phase, continued training leads to a new "anti-grokking" phase where test performance drops sharply while training accuracy stays high. In all cases, a measure called correlation traps, which detect non-random patterns in the model's weights, remains near zero during memorization and grokking but spikes precisely when anti-grokking begins, indicating overfitting. Adding weight decay reduces these traps and the performance drop, and experiments altering weight scales confirm the traps specifically track this overfitting phase rather than just overall model growth.
We study three standard grokking benchmarks, denoted MLP, MA, and GPT2. The first, MLP, is a fully connected depth-3 ReLU MLP trained on a balanced MNIST subset containing 100 examples from each class, for a total of 1,000 training points. The network has width $M=200$ in each hidden layer and is trained with AdamW, MSE loss on one-hot targets, and learning rate $\text{lr}=5\times 10^{-4}$ for up to $10^7$ optimization steps. The main runs use WD=0, and we include a control with WD=0.01 to measure the effect of weight decay. Full hyperparameters appear in Appendix A.
The second benchmark, MA, is a small one-layer transformer trained on the modular-addition task $\mathbf{x}+\mathbf{y}\bmod P$. We again train far beyond the point at which the model first generalizes. Architecture details, phase summaries, and per-layer trap counts appear in Appendix A.3. Pre-grokking, grokking, and anti-grokking are descriptive phase labels tied to the observed train/test trajectories.
The third benchmark, GPT2, follows the synthetic composition task of GrokkedTransformer - Wang et al. ([3]). It uses a synthetic knowledge graph with atomic one-hop facts $(h, r, t)$, queried as $(h, r)\mapsto t$, and latent composition rules that produce inferred two-hop facts. For instance, atomic facts $(h, r_1, m)$ and $(m, r_2, t)$ imply the inferred query $(h, r_1, r_2)\mapsto t$. Following the original setup, atomic facts are split into $\mathrm{atomic}{\mathrm{ID}}$ and $\mathrm{atomic}{\mathrm{OOD}}$. Training includes all atomic facts plus a random subset of inferred facts derived only from $\mathrm{atomic}{\mathrm{ID}}$, denoted $\mathrm{train_inferred}{\mathrm{ID}}$, and a hold-out set, $\mathrm{test_inferred}_{\mathrm{ID}}$. Thus, "test’’ measures in-distribution compositional generalization over unseen inferred facts from the same atomic pool. See Appendix A.4 for more details.
The supplemental material (See Appendix F) contains the corresponding training and analysis code.
5.1 MLP: a third phase after grokking
Figure 1(a) shows the full long-horizon trajectory for the MLP trained on the MNIST subset. The run exhibits the familiar pre-grokking $\to$ grokking transition: training accuracy saturates rapidly, test accuracy improves much later, and the model reaches a high-generalization regime around $10^6$ steps. Continued optimization reveals a third phase. After grokking, test accuracy drops substantially again while training accuracy remains essentially perfect. Likewise, as shown in Figure 3, the test loss reaches a minimum at some point. This is the regime (green) we call anti-grokking.
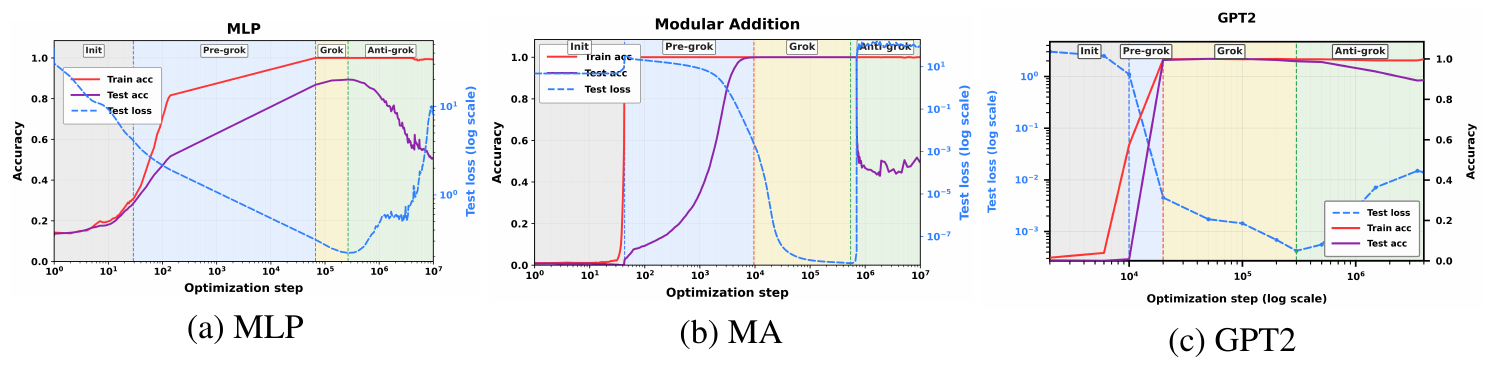
Trap count separates this regime from the earlier phases. During pre-grokking, when the model has already fit the training set but has not yet generalized, the average number of detected traps is effectively zero. During grokking, trap count remains near zero. It is only when late-stage anti-grokking begins that trap count rises sharply. This is exactly what one would expect if the traps are measuring departure from a self-averaging random baseline rather than mere scale growth.
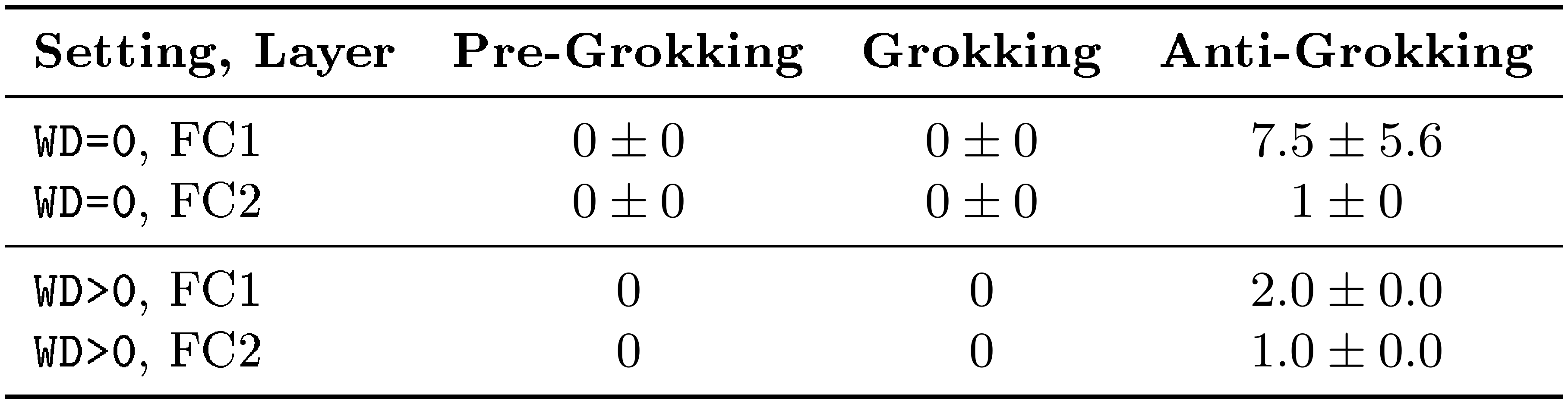
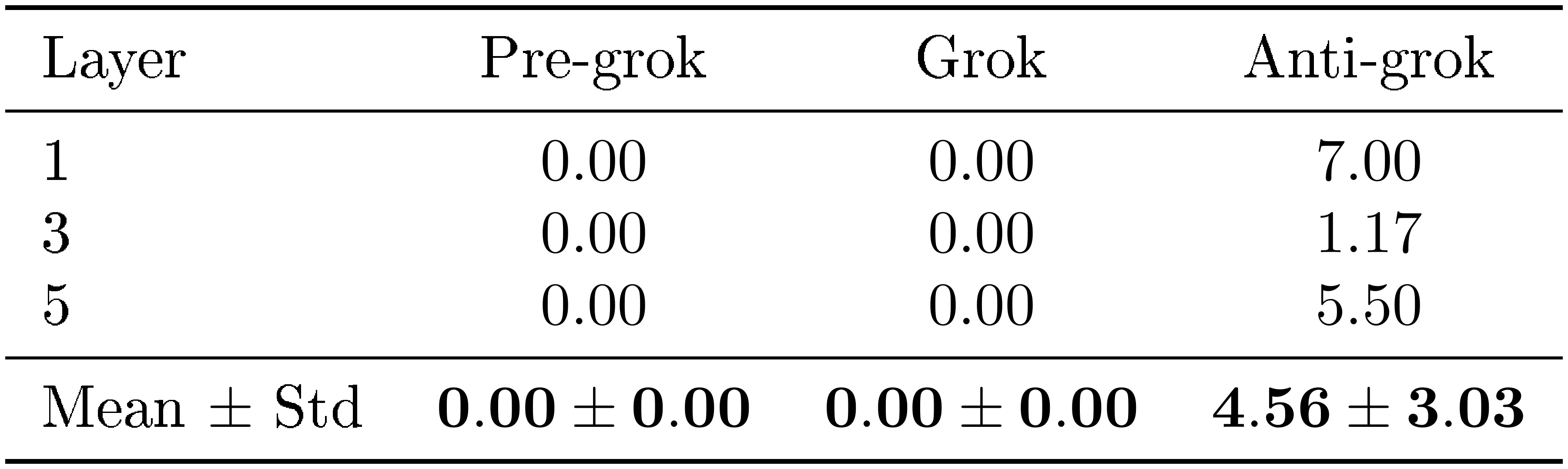
Table 3 makes the phase separation explicit. In both the no-weight-decay setting (WD=0) and the weight-decay control (WD>0), traps are absent during pre-grokking and grokking and appear only in anti-grokking. The no-weight-decay run exhibits both a larger trap count and a more severe drop in test accuracy, suggesting that trap count reflects not only onset but also severity.
5.2 GPT2: the same pattern in a larger architecture
We also study a GPT2 model designed specifically to induce grokking ([3]), now trained for a very long-horizon to also induce anti-grokking. The same three-phase structure appears in this very different benchmark. Figure 1(c) shows training and test accuracy for the GPT2 transformer together with trap count, this time for each layer. As in the MLP, the model first memorizes, then generalizes, and later experiences a substantial degradation in test-accuracy under continued optimization while (mostly) preserving perfect training accuracy. The appearance of Correlation Traps is also very well correlated with the minimum of the test loss, as shown in Figure 3
5.3 Weight decay suppresses anti-grokking (trap growth & overfitting)
A useful control is the MLP run with nonzero weight decay. Weight decay does not eliminate the three phases entirely, but it reduces both the number of traps and the extent of the late-stage test degradation (Appendix A.2; Table 3). This matters for two reasons. First, it shows that anti-grokking is not merely an artifact of the phase definitions: when optimization is regularized, the structural signature is weaker and so is the degradation. Second, it supports the non-self-averaging interpretation; it is not just that the weights are smaller, but that the Correlation Traps are suppressed.
5.4 Additional validation: perturbation study
Appendix C runs a perturbation experiment with the goal of ruling out a simpler explanation: that trap counts are only tracking the overall size of the weights. We perturb the checkpoints in a way that changes the global weight scale, so norm-based quantities move across training phases. Even under this perturbation, the shuffled-spectrum trap count remains near zero in pre-grokking and grokking, and becomes nonzero only in anti-grokking. Thus, Correlation Traps are not merely a proxy for increasing global weight norm; they are phase-specific and indicative of overfitting.
6. Trap Classification by a JSD Diagnostic Ablation Test
Section Summary: Researchers use a method called the JSD diagnostic ablation test to figure out which "traps" in neural network models are truly harmful by replacing a trap with a random substitute and measuring how much this changes the model's predictions on random inputs, using a metric known as Jensen-Shannon divergence. A high score on this test indicates a harmful trap that significantly alters the model's behavior and affects its accuracy on real tasks, while a low score points to a benign trap with little impact. Experiments on different models, like those for math problems and language tasks, show that this score reliably predicts whether removing a trap improves or worsens performance, helping to distinguish dangerous from harmless ones within each model.
Random Matrix Theory (RMT) lets us detect Correlation Traps, but we also want to know how harmful traps really are; to do this, we define a data-free JSD diagnostic ablation test which can quantify the importance of a trap. Let $M_{\theta}$ denote the original model and $M_{\theta\setminus k}$ the model after replacing trap $k$ with a suitable random vector. Define the temperature-scaled output distributions
$ p_\theta(\mathbf{x};T)=\operatorname{softmax}!\left(z_\theta(\mathbf{x})/T\right), \qquad p_{\theta\setminus k}(\mathbf{x};T)
\operatorname{softmax}!\left(z_{\theta\setminus k}(\mathbf{x})/T\right). $
Given probe inputs $\mathbf{x}_p$, define the trap-removal score
$ J_k(T)
\mathbb{E}{\mathbf{x}p} !\left[D{JS} !\left(p\theta(\mathbf{x}p;T) , \middle|, p{\theta\setminus k}(\mathbf{x}_p;T) \right) \right].\tag{10} $
Here $z_\theta(\mathbf{x})$ and $z_{\theta\setminus k}(\mathbf{x})$ are the original and trap-removed logits, and $D_{JS}$ denotes the Jensen–Shannon divergence (a symmetric, smoothed version of the KL divergence).
For modular addition and GPT-style models, the probe distribution is random-token sequences. For the MLP, random tokens are not meaningful, so probes are Gaussian inputs matched to a preset mean and standard deviation. $J_k(T)$ measures how important a trap is: large $J_k(T)$ means removing the trap significantly changes the model outputs even on random input data $\mathbf{x}_p$.
To identify a trap as harmful or benign in our experiments, we replace it with a suitable random vector and compute the change ($\Delta$) in test error. The classification is:
- Harmful trap: replacement changes logits and improves or hurts the test accuracy.
- Benign trap: replacement has a negligible effect on the test accuracy.
Ablating most traps either causes the $\Delta$ (change in) test accuracy to fall even more when removed / replaced, as well as degrade the training accuracy, or has a very small, sometimes positive effect on one or both.
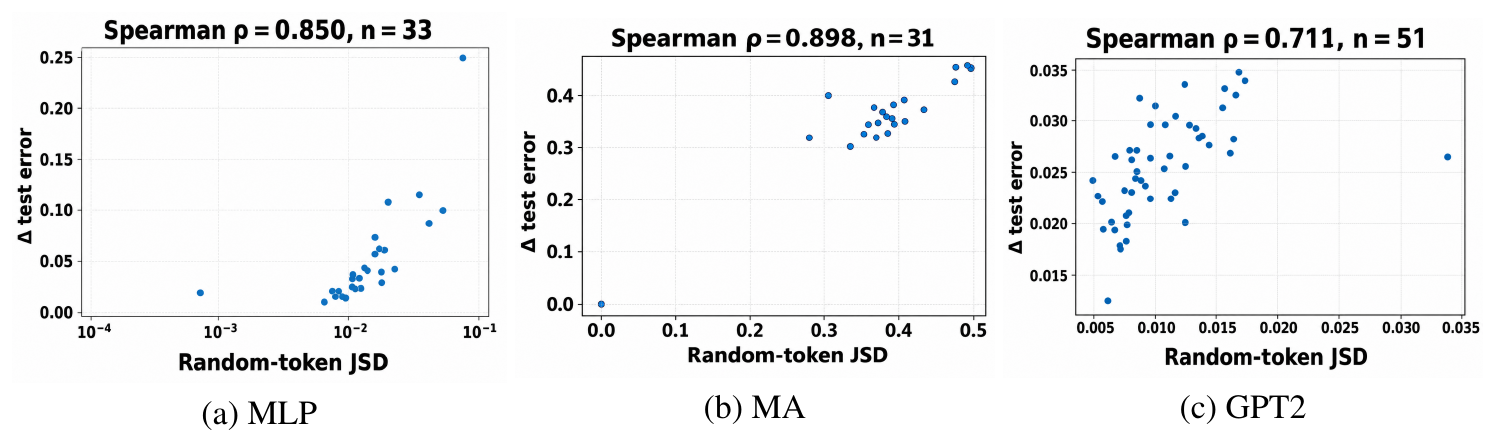
Figure 4 shows the JSD behavioral diagnostic for the three experiments. For MLP and MA, we evaluate the first, middle, and final anti-grokking checkpoints. For GPT2, we analyze a representative layer from the first anti-grokking checkpoint ($1.5\times10^6$ steps). Within a given trained model, the trap-removal score $J_k(T=1)$ closely tracks the downstream performance change induced by trap ablation. The absolute scale depends on the model and trap strength, so JSD is best interpreted as a within-model measure of trap activity, distinguishing between relatively benign vs. harmful traps.
7. Broader implications for frontier-scale models
Section Summary: Researchers tested a tool called the shuffled-spectrum diagnostic on two large AI models from OpenAI, named gpt-oss-20b and gpt-oss-120b, to detect something called Correlation Traps in each layer of the models. The results, shown in a figure, revealed many of these traps across the layers. Overall, this indicates that Correlation Traps could help spot harmful overfitting in massive AI systems, suggesting that these advanced language models might be memorizing their training data in ways that could cause problems.
To motivate the broader relevance of Correlation Traps, we applied the same shuffled-spectrum diagnostic to two open-weight reasoning models released by OpenAI, gpt-oss-20b and gpt-oss-120b [24, 25]. Figure 5 reports the number of detected Correlation Traps per layer.
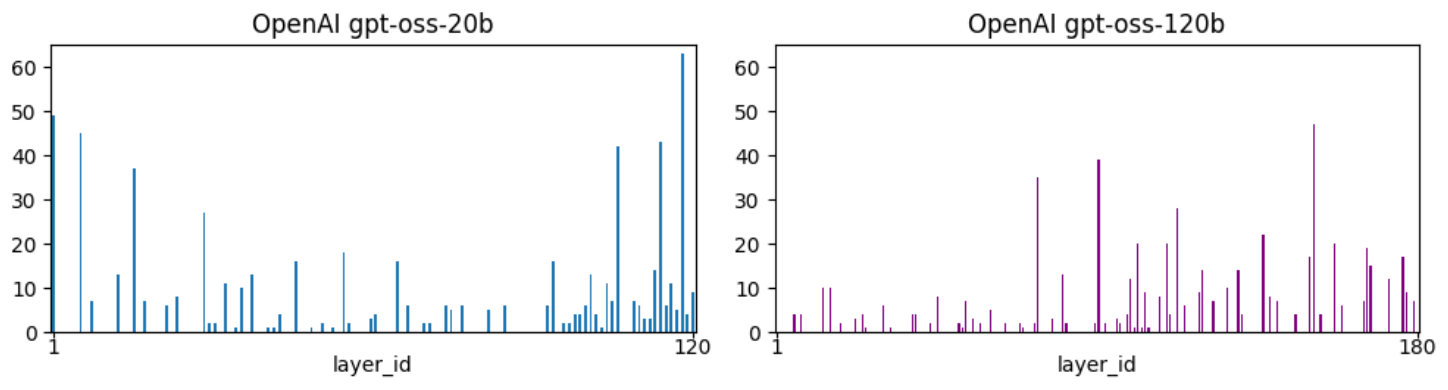
Taken together, these observations suggest that Correlation Traps may provide a practical spectral diagnostic for identifying potentially harmful overfitting structures in frontier-scale foundation models. More broadly, the large number of traps in Figure 5 suggests that foundation-scale LLMs may be inadvertently overfitting their training data in potentially harmful ways.
8. Conclusion
Section Summary: The conclusion highlights that while machine learning models can initially learn general rules that work well on new data—a process called grokking—they may later lose this ability through continued training, a phenomenon termed "anti-grokking," where performance on unseen data drops but fits the training data perfectly. This failure is signaled by "Correlation Traps," which are unusual patterns in the model's internal weight structures, detectable through a simple analysis of the weights alone without needing data or extra training details. These traps reveal harmful overfitting across various model types, from image classifiers to language models, and offer a practical way to screen large AI systems for potential issues, though not all overfitting creates them.
The main lesson is that grokking is not always the end of training. A model can first learn a rule that generalizes, and then lose that generalization under continued optimization. We call this late-stage failure mode anti-grokking: specifically, post-generalization, test accuracy degrades, while training accuracy remains high. Across MNIST MLP, Modular Addition (MA), and GPT2-style grokking experiments, this transition is marked by the appearance of outliers $(\lambda_{trap})$ in the eigenspectrum of one or more randomized, layer-wise weight matrices. We call these outliers Correlation Traps.
The term Correlation Trap is operational. We call these outliers Correlation Traps because they identify latent structures that appear to "trap" the correlations, causing the model to overfit its data, reducing the test accuracy of the model, but not (necessarily) the training accuracy. And as the overfitting gets worse, more traps appear. Moreover, removing them can even hurt the model's test (and training) accuracy, apparently removing the correlations the model had learned.
Correlation Traps reveal a structural difference between two superficially similar regimes. In both pre-grokking and anti-grokking, training accuracy can be high while test accuracy is poor. But the weight spectra are different. During pre-grokking, trap counts remain near zero. During successful grokking, they also remain absent or nearly absent. They appear only during anti-grokking; thus, traps do not merely detect memorization, low test accuracy, or high training accuracy. They detect overfitting that arises during anti-grokking.
The diagnostic is simple and weight-only. It does not require training data, test data, gradients, optimizer state, or access to the training pipeline. It only requires a checkpoint. For each layer, we shuffle the weight matrix entry-wise, form the randomized covariance spectrum, fit a Marchenko–Pastur (MP) bulk, and count right-edge outliers beyond the fitted MP/TW edge. The MP/TW law provides a self-averaging baseline. A Correlation Trap is a separated spectral mode that violates this baseline, and may be harmful or benign.
The self-averaging interpretation explains why these modes matter. A trap can disrupt concentration in two ways: geometric localization and/or spectral concentration. In either case, trap-aligned observables like the test error can become non-self-averaging when the trap overlaps significantly with the model's generalizing layer eigen-components. This gives at least two concrete mechanisms by which a spectral anomaly in the weights can become a behavioral failure mode.
We can distinguish harmful from benign traps using a data-free empirical check, called the JSD trap ablation test. We replace the trap with a random vector, pass probe inputs through the original and ablated models, and measure the Jensen-Shannon divergence between their output distributions. A large JSD means removing the trap significantly changes the model outputs even on random input data, indicative of the effect on real inputs. The trap is harmful if replacement changes the test accuracy, and benign if it has little-to-no effect.
The MLP case study shows what a harmful trap can look like mechanistically. In anti-grokking, mapped first-layer trap directions become prototype-like in pixel space, and intervening on the trap changes the confusion structure. The model still classifies the finite training set correctly, but on trap-affected test examples its behavior increasingly depends on flattened-vector amplitude and prototype statistics, such as $\Vert x\Vert_2$, rather than the correlated two-dimensional digit pattern. This gives one concrete example of how a model can remain perfectly fit to its training data while losing the correlation-based rule that supported generalization.
The same trap-onset signature is not specific to image MLPs. Modular Addition provides an algorithmic transformer setting where trap counts remain near zero before and during grokking and rise during anti-grokking. The GPT2-style experiment shows the same long-horizon pattern in a transformer language-model architecture. Together, these experiments show that Correlation Traps recur across the model families and task types studied here: dense image classifiers, algorithmic transformers, and GPT-style sequence models.
The frontier-scale screening experiment points to a practical use case. Some large open-weight LLM checkpoints exhibit a large number of traps. These profiles do not by themselves prove harmful overfitting in those models, but they are suggestive of potential problems. For foundation-model training, trap counts could serve as a checkpoint-level warning signal. For fine-tuning, they may help identify base-model layers whose behavior should be tested before adaptation.
We do not claim that every form of overfitting must produce Correlation Traps. The claim here is sharper: in long-horizon grokking, trap onset tracks anti-grokking while pre-grokking provides the trap-free negative control. Using the JSD diagnostic trap ablation test, traps can be identified as harmful or benign for a given model. These results suggest some forms of harmful overfitting leave detectable signatures in the layer weight matrices of seemingly well-trained models. The next step is to use this diagnostic during training and fine-tuning, and to test whether harmful Correlation Traps can be suppressed, removed, or regularized without damaging useful learned structure.
9. Limitations
Section Summary: This study draws its evidence from just three specific training setups, like a simple image classifier and a language model style, which clearly show different phases of learning but don't cover all possible model designs, data types, or random variations. While results from larger open models suggest these "correlation traps" happen there too, they only screen for issues rather than prove real harm, and the biggest danger is misusing trap counts as a simple pass-fail grade for model quality or safety without deeper checks. On the positive side, it helps people sift through millions of free models to find ones less likely to overfit their training data and better for real tasks, and it offers regulators a neutral tool to assess safety without accessing private information.
Our controlled evidence comes from three long-horizon grokking settings: an MNIST MLP, modular addition (MA), and a GPT2-style training trajectory. These experiments expose the pre-grokking, grokking, and anti-grokking phases clearly, but they do not exhaust the space of architectures, optimizers, datasets, losses, or seeds. The GPT-OSS results show that Correlation Traps also occur in large open-weight models, but those results are screening evidence only; they do not by themselves establish harmful behavior. The main risk is over-interpretation: trap counts should not be used as universal model-quality or safety scores without additional probe-based and task-based evaluations.
Potential societal impacts.
There are over a million open-source model weights available to download, but many of them, however, have no doubt overfit their training data. This study lets users select for models that have fewer signatures of overfitting and potentially better suited to the desired tasks. Moreover, with the calls for regulation of foundation-scale models, Correlation Traps can provide regulatory bodies one unbiased way to gauge of model safety, and without needing access to proprietary, secure, or even any available data.
Appendix
Section Summary: This appendix outlines the experimental setups for training a simple multi-layer neural network on a small set of handwritten digit images, using specific settings like a three-layer structure and no regularization to study long-term training behaviors over millions of steps. It includes a comparison showing that adding slight regularization reduces unusual patterns in the model's weights and limits performance drops. Additional tests on a basic math task with a small transformer and a language model on synthetic fact-composition data reveal similar weight anomalies appearing only in late training phases, coinciding with declining accuracy on new examples.
A. Experimental Setup and Additional Notes: MLP, MA, and GPT2
A.1 MLP Experimental Setup
We train a Multi-Layer Perceptron (MLP) on a subset of the MNIST dataset using the hyperparameters in Table 2. The training subset is constructed by randomly selecting 100 samples from each of the 10 MNIST classes, yielding a balanced dataset of 1,000 unique training points. The primary long-horizon runs were performed on a single NVIDIA Quadro P2000 GPU and the main $10^7$-step MLP experiment took approximately 11 hours; a considerable fraction of the wall-clock time is due to checkpointing and saving measurements for later analysis.
: Table 2: MLP experimental hyperparameters used in the study.
| Parameter | Value |
|---|---|
| Network Architecture | Fully Connected MLP |
| Depth | 3 Linear layers (Input $\to$ Hidden1 $\to$ Hidden2 $\to$ Output) |
| Width | 200 hidden units per hidden layer |
| Activation Function | ReLU |
| Input Layer Size | 784 (flattened MNIST image $28\times 28$) |
| Output Layer Size | 10 |
| Weight Initialization | Default PyTorch (Kaiming Uniform for weights), parameters scaled by 8.0 |
| Bias Initialization | Default PyTorch (Uniform), then scaled by 8.0 |
| Dataset | MNIST |
| Training Points | 1, 000 (100 per class, stratified random sampling) |
| Test Points | Standard MNIST test set (10, 000 samples) |
| Batch Size | 200 |
| Loss Function | MSE with one-hot encoded targets |
| Optimizer | AdamW |
| Learning Rate (LR) | $5\times 10^{-4}$ |
| Weight Decay (WD) | 0.0 (main results), 0.01 (control experiment) |
| AdamW $\beta_1$ | 0.9 |
| AdamW $\beta_2$ | 0.999 |
| AdamW $\epsilon$ | $10^{-8}$ |
| Optimization Steps | $10^7$ |
| Data Type (PyTorch) | torch.float64 |
| Random Seed | 0 |
| Software Framework | PyTorch |
| WeightWatcher Version | v0.7.5.5 [6] |
Note on weight decay.
The primary results in the main paper were obtained with weight decay explicitly set to 0. This isolates the long-horizon optimization dynamics from explicit norm regularization. Runs with nonzero weight decay (WD=0.01) were performed for comparison and exhibit substantially weaker trap growth and milder loss of generalization.
A.2 MLP Control Experiment with Weight Decay
::: {caption="Table 3: Average number of Correlation Traps in MLP with and without Weight Decay (WD). Trap counts for FC1 and FC2 at representative checkpoints at the right edge of each phase: pre-grokking ($\sim 10^5$ steps), grokking ($10^6$), and anti-grokking ($10^7$). Adding weight decay suppresses trap growth and late-stage collapse, but does not eliminate overfitting entirely."}
:::
The weight-decay control uses the same architecture, data, and optimizer as the main MLP experiment, but with WD=0.01. The central observation is that weight decay suppresses trap growth. As Table 3 shows, anti-grokking under WD>0 still exhibits traps, but fewer than in the WD=0 case, and the associated degradation in test accuracy is much smaller. This supports the interpretation that weight decay mitigates the structural anomalies detected by the shuffled-spectrum diagnostic.
A.3 Modular Addition (MA) Experiment
We additionally evaluate the shuffled-spectrum diagnostic on a modular-addition task with a small one-layer transformer.
Model architecture.
| Hyper-parameter | Value |
|---|---|
| Layers | 1 |
| Model dimension $d_{\mathrm{model}}$ | 128 |
| MLP hidden size $d_{\mathrm{mlp}}$ | 512 |
| Heads $\times$ head dim | $4\times 32$ |
| Context length $n_{\mathrm{ctx}}$ | 3 |
| Activation | ReLU |
| LayerNorm disabled | use_ln=False |
| Vocabulary size | 114 ($=$ equals_token+1) |
: Table 4: Modular Addition phase summary. Train and test accuracy (mean $\pm$ std) across sampled checkpoints in each phase.
| Phase | Train Acc. (mean $\pm$ std) | Test Acc. (mean $\pm$ std) |
|---|---|---|
| Pre-grok | $1.0\pm0.0$ | $0.40\pm0.28$ |
| Grok | $1.0\pm0.0$ | $0.97\pm0.02$ |
| Anti-grok | $1.0\pm0.0$ | $0.68\pm0.11$ |
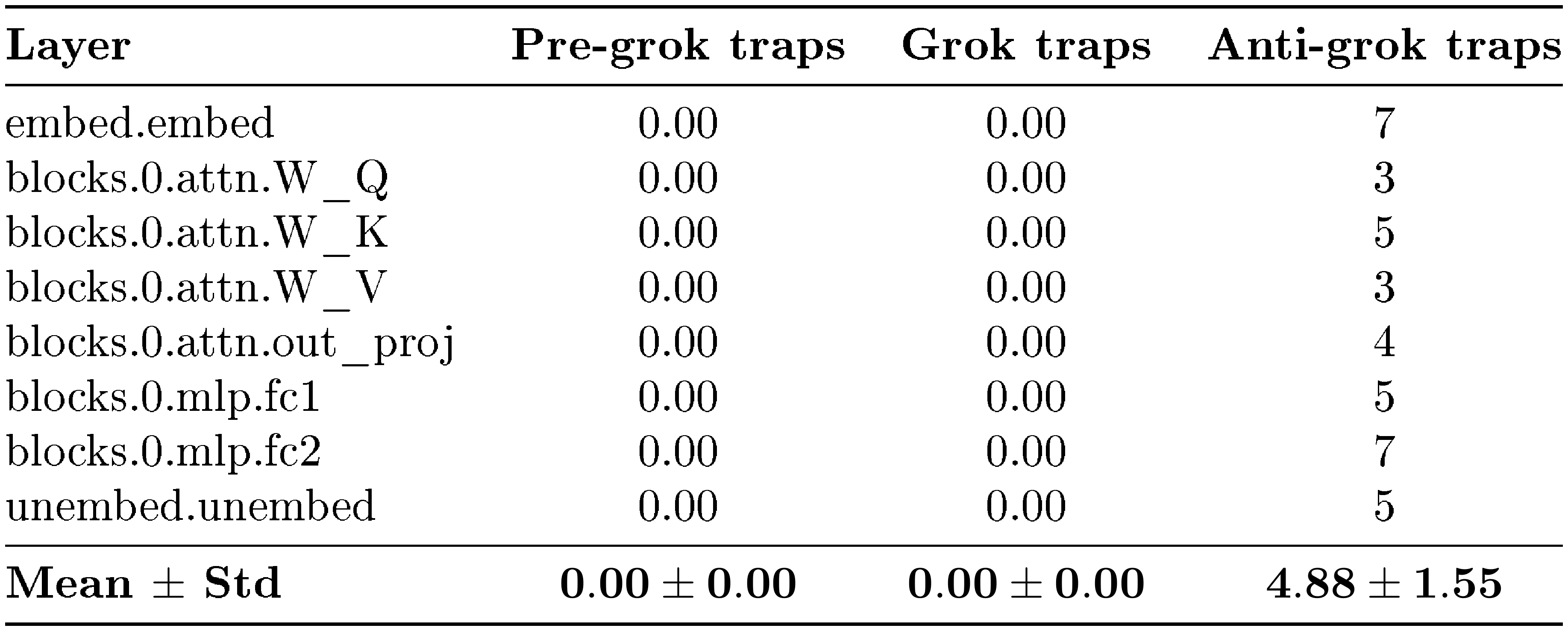
::: {caption="Table 5: Modular Addition trap counts. Number of shuffled-spectrum outliers detected by WeightWatcher in each layer and phase."}
:::
Trap counts are effectively zero in pre-grokking and grokking and rise sharply across many layers in anti-grokking. This reproduces the same qualitative signature observed in the MLP: trap-free shuffled spectra in the first two phases and numerous shuffled-spectrum outliers during late-stage collapse.
A.4 GPT2 Experimental Setup
We evaluate the shuffled-spectrum diagnostic on the synthetic composition benchmark from GrokkedTransformer ([3]). The task is generated from a random knowledge graph of atomic one-hop facts and latent two-hop composition rules. Table 6 summarizes the dataset construction, Table 7 defines the evaluation splits, and Table 8 lists the training and analysis configuration.
: Table 6: GPT2 synthetic composition dataset. The benchmark is generated from a random knowledge graph with atomic facts $(h, r, t)$, queried as $(h, r)\mapsto t$, and inferred two-hop queries $(h, r_1, r_2)\mapsto t$ induced by pairs of atomic facts $(h, r_1, m)$ and $(m, r_2, t)$.
| Dataset parameter | Value |
|---|---|
| Dataset variant | composition.2000.200.12.6 |
| Number of entities | $2000$ |
| Number of relations | $200$ |
| Atomic outgoing facts per entity | $20$ |
| Atomic fact form | $(h, r, t)$ |
| Atomic query form | $(h, r)\mapsto t$ |
| Composition rule | $(h, r_1, m), (m, r_2, t) \Rightarrow (h, r_1, r_2)\mapsto t$ |
| Atomic partition | $\mathrm{atomic}{\mathrm{ID}} \cup \mathrm{atomic}{\mathrm{OOD}}$ |
| OOD atomic fraction | Approximately $5%$ |
| Training inferred downsampling | $12.6 \times \vert{}\mathrm{atomic}_{\mathrm{ID}}\vert{}$ |
: Table 7: GPT2 train/test split definitions. The main grokking curve treats $\mathrm{train_inferred}{\mathrm{ID}}$ as the training curve and $\mathrm{test_inferred}{\mathrm{ID}}$ as the test curve. The OOD inferred split is reserved as a stronger systematicity diagnostic.
| Split | Included in training? | Role in evaluation |
|---|---|---|
| $\mathrm{id_atomic}$ | Yes | ID atomic memorization/control accuracy |
| $\mathrm{ood_atomic}$ | Yes | OOD atomic memorization/control accuracy |
| $\mathrm{train_inferred}_{\mathrm{ID}}$ | Yes | Main "train" curve for inferred facts |
| $\mathrm{test_inferred}_{\mathrm{ID}}$ | No | Main "test" curve for ID compositional generalization |
| $\mathrm{test_inferred}_{\mathrm{OOD}}$ | No | Stronger systematicity diagnostic |
The training set contains all atomic facts, both ID and OOD, together with a random subset of inferred facts deduced only from $\mathrm{atomic}{\mathrm{ID}}$. Therefore, the primary train/test comparison measures in-distribution compositional generalization: the model must apply the learned latent composition rule to unseen inferred facts drawn from the same atomic pool used to generate the training compositions. We report $\mathrm{test_inferred}{\mathrm{OOD}}$ separately, since it probes generalization to inferred facts involving the held-out atomic pool rather than the main grokking transition.
: Table 8: GPT2 model, training, and evaluation configuration. The model is an 8-layer GPT2-style decoder-only transformer initialized from scratch and trained with the GrokkedTransformer training code.
| Hyper-parameter | Value |
|---|---|
| Architecture | GPT2-style decoder-only transformer |
| Initialization | From scratch |
| Number of layers | $8$ |
| Vocabulary | Synthetic entity, relation, and answer-delimiter tokens added |
| Maximum sequence length | $10$ |
| Batch size | $512$ |
| Optimizer | AdamW |
| Learning rate | $10^{-4}$ |
| Weight decay | $0.001$ |
| Schedule | Constant schedule with warmup |
| Precision | Mixed precision |
| Training steps | $1.5\times 10^6$ |
| Checkpointing | Checkpoints saved throughout training |
| Evaluation protocol | Exact-match generation |
| Correctness criterion | Generated answer token matches target before closing delimiter |
| Reported accuracies | $\mathrm{id_atomic}$, $\mathrm{ood_atomic}$, $\mathrm{train_inferred}{\mathrm{ID}}$, $\mathrm{test_inferred}{\mathrm{ID}}$, $\mathrm{test_inferred}_{\mathrm{OOD}}$ |
For spectral and ablation analyses, we run WeightWatcher on the transformer block matrices and exclude the positional embedding layer wpe. This exclusion avoids treating the positional embedding table as a standard learned linear map in the layerwise trap analysis.
: Table 9: GPT2 spectral-analysis convention. WeightWatcher is applied to learned transformer block matrices, with positional embeddings excluded from the layerwise trap count.
| Analysis choice | Convention |
|---|---|
| Diagnostic | Shuffled-spectrum outlier detection with WeightWatcher |
| Included modules | Transformer block matrices |
| Excluded module | Positional embedding layer wpe |
| Reason for exclusion | wpe is an embedding table, not a standard learned linear map |
| Layerwise output | Trap counts per analyzed transformer matrix |
B. Mechanistic Case Study on Anti-Grokking in the MLP Experiment
The randomized trap itself is only a diagnostic of atypical amplitude disorder. To interpret the failure mode, we map the trap mode back to the original unshuffled layer coordinates using the WeightWatcher procedure summarized below and visualized in Figure 7. In other words, the trap tells us that a particular direction has moved into an overfit sector of weight space; the prototype-like structure appears when that direction is expressed back in the coordinates of the original layer.
B.1 Localized leading directions induce norm-based prototype collapse
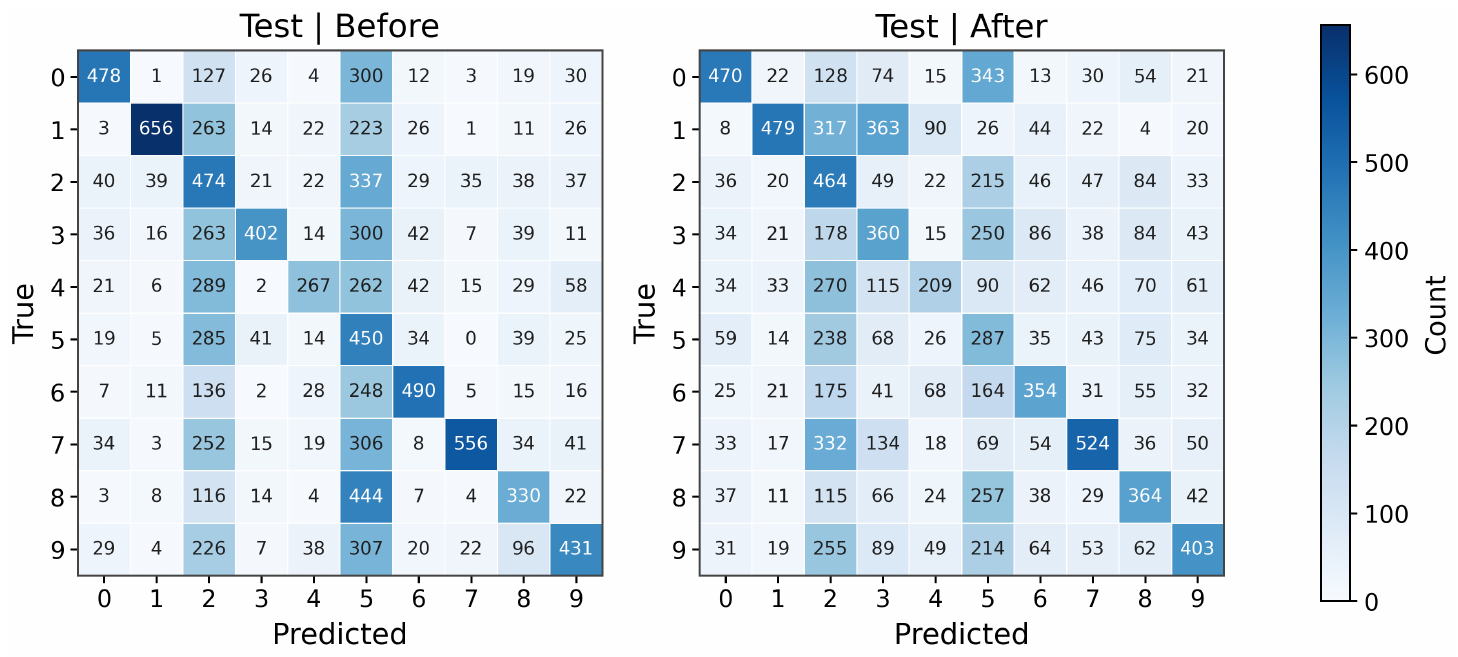
Figure 6 shows that the anti-grokking MLP no longer uses stable digit geometry in the usual sense. On original MNIST, the confusion matrix remains structured, but when each image is independently pixel-shuffled, the same network collapses most predictions into a small number of classes, especially class $5$. This means the classifier is not simply recognizing spatial digit templates. Instead, it is responding to low-order global statistics that survive shuffling, most notably the overall input scale.
To isolate this effect, we next remove digit structure entirely and probe the model with matched Gaussian inputs whose mean and variance match the MNIST input distribution. These inputs contain no class information and no coherent strokes, yet the model again predicts almost exclusively class $5$, with nearly constant confidence. Thus, the late-stage classifier has developed a degenerate decision rule in which prediction is strongly controlled by $|\mathbf{x}|_2$-like input magnitude rather than semantic digit shape. This supports the interpretation in Figure 7: localized leading directions become prototype-like but uncorrelated with the true task. They can preserve perfect training accuracy while inducing brittle, norm-sensitive behavior on perturbed or data-free probes.
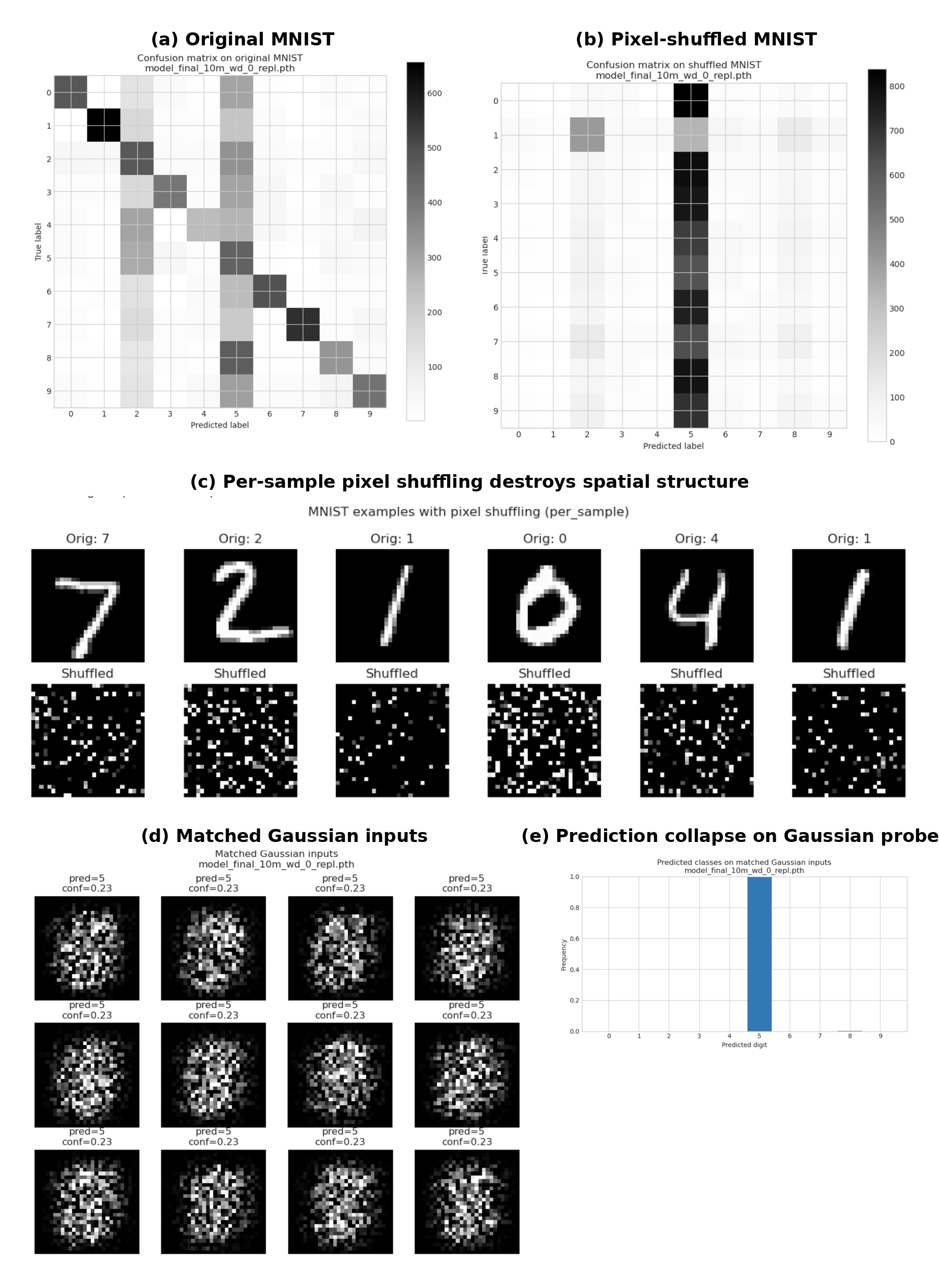
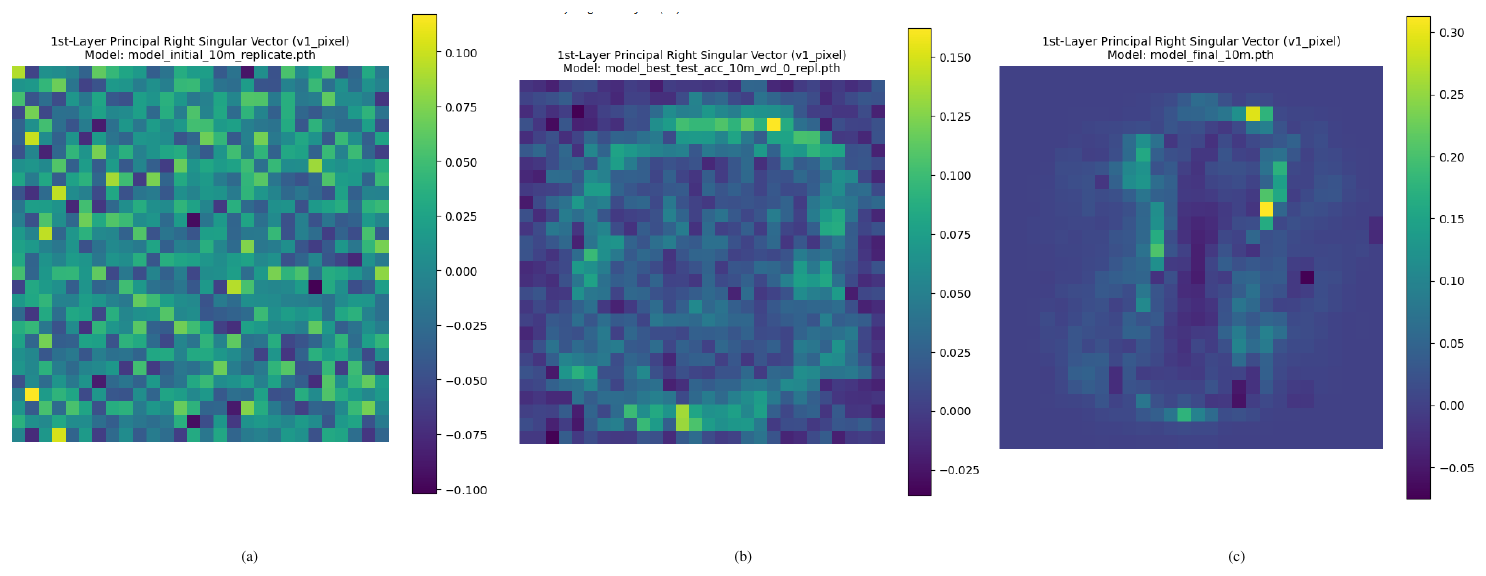
This is the sense in which the trap diagnoses harmful overfitting without being the learned pattern itself. The shuffled trap says that the randomized layer has become atypical. When we pull that mode back into the original layer, we see which direction in the true weight matrix has condensed into an overfit prototype, but based solely on the statistical properties of the test instance elements $x^{test}_{i, j}$, such as the test instance norm $\Vert\mathbf{x}^{test}\Vert_2$, and not their correlated pattern structure.
B.2 Intervening on the trap direction changes behavior
Figure 8 shows that this structural interpretation is not merely visual. In the anti-grokking regime, an FC1 trap biases many test examples toward a prototype class. Replacing that trap direction with a matched random vector changes the confusion structure and weakens the prototype bias. This is important: it shows that the overfit sector identified through the trap is behaviorally active.
B.3 Traps recur under continued optimization
When a localized trap is removed, it typically reappears under continued training. The same data, objective, and optimizer continue to favor that condensed direction. This recurrence is consistent with the idea that the trap is an emergent finite-size instability of the long-horizon optimization dynamics rather than a static artifact of one checkpoint.
B.4 Leading Eigenvectors, Receptive Fields, and Structural Outliers
For a weight matrix $\mathbf{W}\in\mathbb{R}^{N\times M}$, write
$ \mathbf{X}(\mathbf{W}) := \frac{1}{N}\mathbf{W}^\top \mathbf{W}, \qquad \lambda_{\max}(\mathbf{W}) := \lambda_{\max}\bigl(\mathbf{X}(\mathbf{W})\bigr). $
If $\mathbf{W}=U\boldsymbol{\Sigma} \mathbf{V}^\top$ is the thin SVD, then the eigenpairs of $\mathbf{X}(\mathbf{W})$ are $(\sigma_k^2/N, \mathbf{v}_k)$, so the leading right singular vector identifies the dominant direction in the input space of the layer. In the MLP, this makes the first-layer leading vector directly visualizable in pixel coordinates.
Figure 10 shows that anti-grokking introduces visibly extreme coordinates into the weight distributions of all three layers. This supports the idea that the late-stage trapped regime is associated with large-magnitude perturbations, not just diffuse reshaping of the bulk.
Figure 9 further sharpens the mechanism. Rows of $\mathbf{W}1$ selected by leading-vector localization evolve from noise-like patterns to digit-like receptive fields in anti-grokking. This is consistent with the picture developed in the main text: harmful traps are associated with sharply localized prototype directions. In the notation of the paper, these same rows correspond to large $\mathcal{O}{l}!\left(\mathbf{v}_k\right)$ values when the mapped trap direction is projected onto the dominant eigenvectors of $\mathbf{X}(\mathbf{W}_1)$.

B.5 Is the distribution of weights in anti-grokking simply very heavy-tailed?
If overfitting is driven by atypically large entries, one could imagine inspecting the largest weights directly. In practice this is unsatisfactory. A threshold on the largest entries is necessarily ad hoc, depends on scale and architecture, and cannot distinguish diffuse large-weight growth from a genuinely condensed harmful mode. Direct tail fitting is also problematic. The element histogram can look roughly Laplacian in one regime, power-law-like in another, and often shows finite-size crossovers or mixture behavior rather than a clean single exponent. Standard procedures require choosing quantiles or cutoffs, and with millions of squared elements even brute-force fitting can be numerically unstable and conceptually ambiguous.
Instead we use the MP law as a nonparametric self-averaging baseline for the entry-wise randomized layer. The question becomes simple: after the learned arrangement is destroyed, how far does the randomized spectrum still sit outside the MP bulk? This turns the detection problem into one of atypical spectral mass rather than unstable histogram fitting. The MP null is not only a statement about eigenvalues. In the random-matrix regime the eigenvalue density concentrates into a deterministic bulk and the associated eigenvectors are mostly delocalized and look random uniform. A shuffled layer that develops a separated right-edge eigenvalue or a visibly localized top vector has therefore departed from that null. In this sense, good MP fits are empirical evidence of self-averaging for the randomized layer, and strong deviations from the fit are qualitative evidence of non-self-averaging.
The point is not that $\mathbf{W}_{ij}$ must follow a very heavy-tailed law. Empirically the entries can look roughly Laplacian, power-law-like with exponent $\alpha\gtrsim2$, or like a finite-size mixture. Our theory therefore uses replacement-compatible probes of the learned trap vectors rather than a single asymptotic tail model. The mechanism does not require exponent
lt;2$, and the observed traps are often driven by several large or moderately large entries rather than one extraordinary coordinate.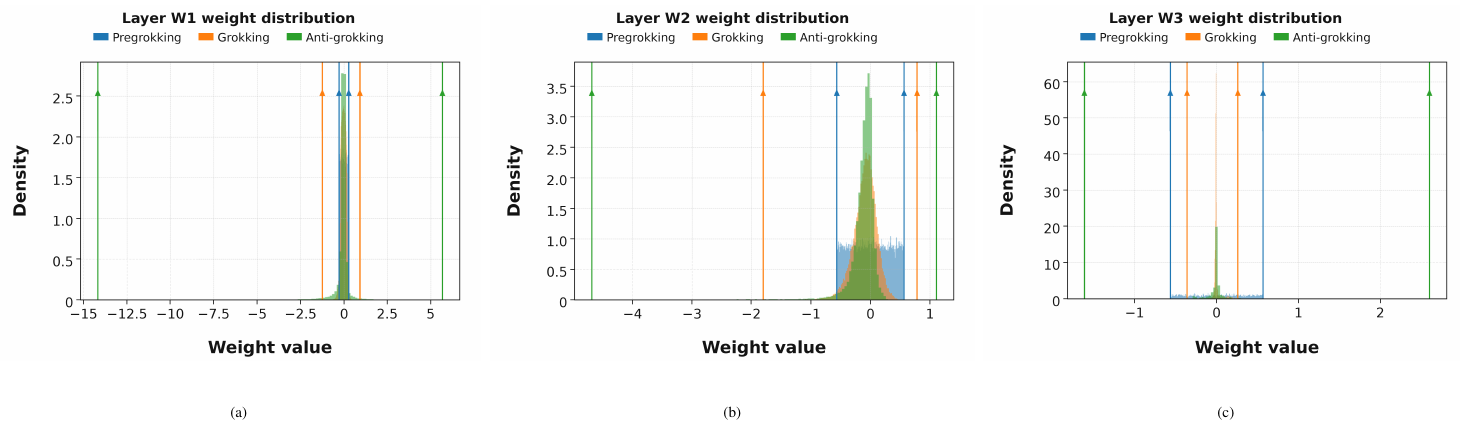
C. MLP Perturbation Study
Do Traps Simply Reflect the Scale of the Weights?
As an additional robustness check, we want to eliminate the possibility that trap counts are merely tracking the scale of the weights. We evaluate the number of traps on a perturbed version of the MLP checkpoints. The perturbation changes the overall scale of the weights, so global norm-based quantities move across training phases. Even under this perturbation, trap counts remain near zero in pre-grokking and grokking, and become nonzero only in anti-grokking.
Protocol and phase definitions.
For this study we use phase boundaries pre-grok ($10^2$ – $5\times10^4$ steps), grok ($5\times10^4$ – $5\times10^5$ steps), and anti-grok (
gt;5\times10^5$ steps). The reported statistics are mean $\pm$ std over sampled checkpoints within each phase.: Table 10: Accuracy by phase under perturbation.
| Phase | Train Accuracy (mean $\pm$ std) | Test Accuracy (mean $\pm$ std) |
|---|---|---|
| Pre-grok | $0.7298 \pm 0.0408$ | $0.4926 \pm 0.0187$ |
| Grok | $1.0000 \pm 0.0000$ | $0.8879 \pm 0.0051$ |
| Anti-grok | $1.0000 \pm 0.0000$ | $0.6184 \pm 0.1086$ |
: Table 11: Global $\ell_2$ norm by phase under perturbation.
| Phase | WeightNorm (mean $\pm$ std) |
|---|---|
| Pre-grok | $17.52 \pm 0.00$ |
| Grok | $16.80 \pm 0.22$ |
| Anti-grok | $27.64 \pm 8.39$ |
::: {caption="Table 12: Layer-wise trap statistic by phase under perturbation."}
:::
The same pattern reappears: trap counts remain zero during pre-grokking and grokking and rise only in anti-grokking, whereas the global $\ell_2$ norm changes throughout and does not by itself distinguish the phases.
D. Self-averaging, concentration, and why MP is the right null
D.1 Statistical-mechanics language versus statistical concentration
Self-averaging is always a property of an observable, not of a matrix in the abstract. In statistical mechanics one usually studies sample-to-sample fluctuations of macroscopic quantities such as free-energy density, magnetization, or overlap. In statistics and learning theory the same idea appears as concentration of measure: an observable $A_N$ self-averages if $A_N-\mathbb{E}A_N\to 0$ in probability, and a sufficient $L^2$ criterion is $\mathrm{Var}(A_N)\to 0$. Non-self-averaging means that order-one fluctuations persist even when the nominal system size is large. In such a case, any potential bound on the relevant observable will fail because the observable fails to concentrate.
Historical statistical-mechanics view.
The spin-glass interpretation of neural-network overfitting is older than modern concentration language. The Hopfield and Amit–Gutfreund–Sompolinsky models already showed in the 1980s that associative memories develop a glassy phase with many metastable, sample-specific states once interference from stored patterns becomes strong enough [10, 11]. The Gardner program then turned this into a geometric theory of learning constraints: one studies the volume of interactions compatible with many patterns, and the overconstrained regime is naturally described by a glassy landscape rather than a single clean retrieval state [12]. By the 1990s, statistical-mechanics analyses of learning and regularization were already interpreting poor generalization and overfitting as movement into such glassy, sample-dependent states, with weight decay or early stopping acting as ways of keeping the system away from that regime [13, 14].
Modern concentration-theoretic view.
The present paper uses the same qualitative picture but states it in modern probabilistic language. Instead of replicas or order parameters for the full disorder ensemble, we ask whether explicit observables concentrate. For an observable $A_N$, self-averaging means variance collapse and concentration; non-self-averaging means that variance stays order one and concentration inequalities cannot improve with dimension. This reformulation does not change the story. It only isolates the precise observables for which the glassy behavior is visible.
This observable-specific viewpoint matters here. A shuffled weight matrix can have well-behaved bulk averages and still have non-self-averaging edge observables. That is exactly the deep-learning analogue of the statistical-mechanics distinction between an ordinary disordered phase and a spin-glass phase: bulk summaries may look innocuous while a small set of frozen, sample-specific directions continues to dominate the behavior. The present paper therefore makes an intentionally narrow claim. We do not say that an entire layer is non-self-averaging in every statistic. We say that Correlation Traps have the potential to make the generalization error non-self-averaging and therefore fail to concentrate.
D.2 Why MP is the appropriate randomized baseline
For covariance-type random matrices with independent, well-behaved entries, the empirical spectral density concentrates around the Marchenko–Pastur law. This is the random-matrix version of a law of large numbers for eigenvalues. The null also carries a vector statement: the singular/eigenvectors are delocalized and effectively random-looking rather than concentrated on a tiny set of coordinates. From this perspective, an MP fit is empirical evidence that the shuffled layer is behaving like a self-averaging disorder ensemble.
The relevant right-edge benchmark is not the fitted bulk edge alone but the bulk edge together with Tracy–Widom-scale edge fluctuations. The Baik–Ben Arous–Péché transition then provides the conceptual interpretation: once an eigenvalue cleanly separates past that edge scale, it should no longer be viewed as an ordinary random fluctuation but as a structural outlier. That is exactly how Correlation Traps are used in the main paper.
D.3 Why moderate tails and multi-entry structure are enough
The actual diagnostic is implemented as an entry-wise shuffle of the learned multiset of entries. The appendix states the proof for without-replacement coordinate probes, matching this finite-population view, and then notes that the with-replacement analogue gives the same dichotomy up to constants. The scientific point does not depend on the sampling convention. The same benign-versus-harmful distinction persists: what matters is localization of the trap vectors and spectral size of the associated outliers, not the choice of sampling convention.
Likewise, the mechanism does not require extremely heavy tails or a sub-Gaussian element law. A single very large entry is one sufficient route to an outlier, but it is not the generic practical one. In the anti-grokking checkpoints we more often see a small collection of large or moderately large ${W}{ij}$ values whose combined squared mass produces a localized trap direction after randomization. This is why the empirical distribution of the weights, $\rho(W{i, j})$, can be fit to a Laplacian or power-law-like with PL exponent $\ge 2$, or like a crossover between the two while still producing large traps.
E. Robustness to random seeds and shuffle randomization
This appendix records the compact robustness summaries that support two paper-level claims: the three-phase anti-grokking trajectory is not a single-run artifact, and the shuffled-spectrum diagnostic is not driven by one lucky permutation. These checks use the same benchmarks and checkpoints already analyzed in the main paper. Their role is technical rather than conceptual: they confirm that the story is unchanged under modest seed-to-seed and shuffle-to-shuffle variation.
E.1 Phase stability across random seeds
Table 13 summarizes qualitative robustness observations across the seed runs analyzed for this study. The point is not that every seed collapses at exactly the same step, but that the qualitative ordering of the phases is unchanged: pre-grokking remains trap-free, grokking remains trap-free or nearly so, and anti-grokking still begins only after successful generalization and still coincides with the onset of clearly nonzero trap counts.
: Table 13: Qualitative robustness across random seeds. The exact onset step of anti-grokking varies modestly across seeds, but the qualitative three-phase structure and the trapped-versus-untrapped separation remain unchanged.
| Phase | Observed behavior across seeds | Interpretation |
|---|---|---|
| Pre-grokking | Train accuracy rises while test accuracy remains low; trap counts remain approximately zero | Stable trap-free regime |
| Grokking | Test accuracy improves sharply; shuffled spectra remain MP-like with few or no traps | Stable generalization regime |
| Anti-grokking | Test accuracy declines under continued optimization while trap counts become clearly nonzero | Stable trapped overfitting regime |
E.2 Stability across repeated entry-wise randomizations
Because the diagnostic shuffles each layer entry-wise, the exact trap count can vary slightly from one shuffle to the next. Table 14 records the paper-level conclusion needed for the main claim. In the trap-free phases, repeated shuffles may create microscopic variation around zero but do not create phase ambiguity. In anti-grokking, the count fluctuates slightly across shuffles but remains clearly nonzero, so the separation between the earlier phases and the collapse phase is unchanged.
: Table 14: Qualitative robustness to repeated randomization. Repeating the entry-wise shuffle changes the exact trap count slightly, but it does not change the phase separation, the number of observed traps to a material degree, or the interpretation of the diagnostic.
| Phase | Effect of repeating the shuffle | Interpretation |
|---|---|---|
| Pre-grokking | Occasional microscopic variation around zero detected traps | Remains trap-free at the paper level |
| Grokking | Same qualitative behavior as pre-grokking; no stable right-edge outliers appear | Remains trap-free or nearly trap-free |
| Anti-grokking | Trap count fluctuates slightly across shuffles but remains clearly nonzero for the same checkpoint | Phase separation unchanged; the anomaly is structural rather than a one-shuffle artifact |
These robustness summaries should be read as technical support for the main claim, not as a second contribution. They show that the anti-grokking phase transition and the trapped-versus-untrapped distinction are stable features of the training dynamics rather than artifacts of one seed or one randomization.
F. Reproducibility artifacts
The supplemental material accompanying this submission includes an anonymized artifact bundle for reproducing the main experiments. The release contains: (i) training scripts for the MLP and modular-addition benchmarks, including the exact hyperparameter settings used in the paper; (ii) analysis scripts for the shuffled-spectrum trap counts, KS tests, and figure generation; (iii) checkpoints or scripts to regenerate representative checkpoints for the phase-level analyses; and (iv) a short README specifying the software environment, package versions, and example commands for reproducing the main tables and figures. The datasets and core analysis tool used in the paper are public: MNIST is used for the MLP benchmark, and trap analysis is performed with the open-source WeightWatcher package [6]. This artifact bundle is intended to make the paper reproducible end-to-end.
G. Assets, licenses, and attribution
The paper uses only existing public assets. The MLP benchmark uses MNIST, whose commonly distributed dataset license is Creative Commons Attribution-Share Alike 3.0. The shuffled-spectrum analysis uses the open-source WeightWatcher package, version v0.7.5.5, distributed under the Apache License 2.0. The exploratory frontier-model analysis uses the public gpt-oss-20b and gpt-oss-120b open-weight releases, which are made available under the Apache License 2.0 and the corresponding OpenAI usage policy. We do not introduce a new dataset.
References
Section Summary: This references section lists scholarly works and tools related to understanding how neural networks learn and generalize, starting with recent papers on "grokking," a phenomenon where models suddenly improve after initial struggles on simple tasks. It includes studies on deep learning theories, statistical mechanics applied to networks, and foundational physics concepts like random matrices that influence modern AI research. The list ends with resources from OpenAI on new open-source language models, accessed in early 2026.
[1] Alethea Power et al. (2022). Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets. https://arxiv.org/abs/2201.02177. arXiv:2201.02177.
[2] Neel Nanda et al. (2023). Progress measures for grokking via mechanistic interpretability. https://arxiv.org/abs/2301.05217. arXiv:2301.05217.
[3] Wang et al. (2024). Grokked Transformers are Implicit Reasoners: A Mechanistic Journey to the Edge of Generalization. In The Thirty-eighth Annual Conference on Neural Information Processing Systems. https://arxiv.org/pdf/2405.15071.
[4] Liu et al. (2022). Towards Understanding Grokking: An Effective Theory of Representation Learning. In Advances in Neural Information Processing Systems. pp. 34651–34663. https://arxiv.org/abs/2205.10343.
[5] Lee et al. (2024). Grokfast: Accelerated Grokking by Amplifying Slow Gradients. https://arxiv.org/abs/2405.20233. arXiv:2405.20233.
[6] Charles H. Martin (2018-2024). WeightWatcher: Analyze Deep Learning Models without Training or Data. https://github.com/CalculatedContent/WeightWatcher. Version 0.7.5.5 used in this study. Accessed May 12, 2025.
[7] Martin, Charles H. and Hinrichs, Christopher (2025). SETOL: A Semi-Empirical Theory of (Deep) Learning. arXiv preprint arXiv:2507.17912. https://arxiv.org/abs/2507.17912.
[8] Martin, Charles H. and Mahoney, Michael W. (2021). Implicit Self-Regularization in Deep Neural Networks: Evidence from Random Matrix Theory and Implications for Learning. Journal of Machine Learning Research. 22(1). pp. 1–73. http://jmlr.org/papers/v22/20-410.html.
[9] Martin et al. (2021). Predicting trends in the quality of state-of-the-art neural networks without access to training or testing data. Nature Communications. 12. pp. 4122. doi:10.1038/s41467-021-24025-8. https://doi.org/10.1038/s41467-021-24025-8.
[10] Hopfield, John J. (1982). Neural networks and physical systems with emergent collective computational abilities. Proceedings of the National Academy of Sciences. 79(8). pp. 2554–2558. doi:10.1073/pnas.79.8.2554.
[11] Amit et al. (1985). Spin-glass models of neural networks. Physical Review A. 32(2). pp. 1007–1018. doi:10.1103/PhysRevA.32.1007.
[12] Gardner, E. (1988). The Space of Interactions in Neural Network Models. Journal of Physics A: Mathematical and General. 21(1). pp. 257–270. doi:10.1088/0305-4470/21/1/030.
[13] Seung et al. (1992). Statistical Mechanics of Learning from Examples. Physical Review A. 45(8). pp. 6056–6091. doi:10.1103/PhysRevA.45.6056.
[14] Bös, Siegfried (1998). Statistical Mechanics Approach to Early Stopping and Weight Decay. Physical Review E. 58(1). pp. 833–847. doi:10.1103/PhysRevE.58.833.
[15] Anderson, Philip W. (1958). Absence of diffusion in certain random lattices. Physical Review. 109(5). pp. 1492–1505. doi:10.1103/PhysRev.109.1492.
[16] Bose, Satyendra Nath (1924). Plancks Gesetz und Lichtquantenhypothese. Zeitschrift für Physik. 26(1). pp. 178–181. doi:10.1007/BF01327326.
[17] Einstein, Albert (1925). Quantentheorie des einatomigen idealen Gases. Sitzungsberichte der Preussischen Akademie der Wissenschaften. pp. 3–14.
[18] Weiss, Pierre (1907). L'hypothèse du champ moléculaire et la propriété ferromagnétique. Journal de Physique Théorique et Appliquée. 6(1). pp. 661–690. doi:10.1051/jphystap:019070060066100.
[19] Vladimir A. Marchenko and Leonid Andreevich Pastur (1967). Distribution of eigenvalues for some sets of random matrices. Matematicheskii Sbornik. 72(114)(4). pp. 507–536.
[20] Porter, C. E. and Thomas, R. G. (1956). Fluctuations of nuclear reaction widths. Physical Review. 104(2). pp. 483–491.
[21] Potters, Marc and Bouchaud, Jean-Philippe (2021). A First Course in Random Matrix Theory: For Physicists, Engineers and Data Scientists. Cambridge University Press.
[22] Baik et al. (2005). Phase transition of the largest eigenvalue for nonnull complex sample covariance matrices. The Annals of Probability. 33(5). pp. 1643–1697.
[23] Li, Jiping and Sonthalia, Rishi (2025). Risk Phase Transitions in Spiked Regression: Alignment Driven Benign and Catastrophic Overfitting. arXiv preprint arXiv:2510.01414.
[24] OpenAI (2025). Introducing gpt-oss. https://openai.com/index/introducing-gpt-oss/. Accessed: 2026-03-28.
[25] OpenAI (2025). gpt-oss-120b & gpt-oss-20b Model Card. https://openai.com/index/gpt-oss-model-card/. Accessed: 2026-03-28.