Dive into Claude Code: The Design Space of Today's and Future AI Agent Systems
Jiacheng Liu$^{1}$, Xiaohan Zhao$^{1}$, Xinyi Shang$^{1, 2}$, Zhiqiang Shen$^{1, \dagger}$
$^{1}$ VILA Lab, Mohamed bin Zayed University of Artificial Intelligence
$^{2}$ University College London
$^{\dagger}$ Corresponding author
Abstract
Claude Code is an agentic coding tool that can run shell commands, edit files, and call external services on behalf of the user. This study describes its comprehensive architecture by analyzing the publicly available TypeScript source code$^{a}$ and further comparing it with OpenClaw, an independent open-source AI agent system that answers many of the same design questions from a different deployment context. Our analysis identifies five human values, philosophies, and needs that motivate the architecture (human decision authority, safety and security, reliable execution, capability amplification, and contextual adaptability) and traces them through thirteen design principles to specific implementation choices. The core of the system is a simple while-loop that calls the model, runs tools, and repeats. Most of the code, however, lives in the systems around this loop: a permission system with seven modes and an ML-based classifier, a five-layer compaction pipeline for context management, four extensibility mechanisms (MCP, plugins, skills, and hooks), a subagent delegation and orchestration mechanism, and append-oriented session storage. A comparison with OpenClaw, a multi-channel personal assistant gateway, shows that the same recurring design questions produce different architectural answers when the deployment context changes: from per-action safety evaluation to perimeter-level access control, from a single CLI loop to an embedded runtime within a gateway control plane, and from context-window extensions to gateway-wide capability registration. We finally identify six open design directions for future agent systems, grounded in recent empirical, architectural, and policy literature. Our GitHub is available at: https://github.com/VILA-Lab/Dive-into-Claude-Code.
[^1]: v2.1.88, link. Disclaimer: All materials used in this work are obtained from publicly available online sources. We have not used any private, confidential, or unauthorized materials, and we do not intend to infringe any copyright or intellectual property rights. The original intellectual property rights to the source code belong to Anthropic.
Correspondence: Zhiqiang Shen (mailto:[email protected])
Executive Summary: The rise of AI-assisted software development has shifted from simple code suggestions to fully agentic systems that autonomously plan, execute, and iterate on tasks like debugging or refactoring. Tools like Claude Code, developed by Anthropic, represent this evolution by allowing AI to run commands, edit files, and interact with external services on a user's behalf. However, while such systems promise to boost productivity, their internal architectures remain opaque, limiting developers' ability to build safer, more effective agents. This lack of insight is especially pressing now, as AI agents enter production workflows, raising questions about safety, reliability, and long-term impacts on human skills amid growing adoption in engineering teams.
This document sets out to map the architecture of Claude Code through a detailed analysis of its source code, identify the human-centered values and principles driving its design, compare it with an open-source alternative called OpenClaw, and highlight open challenges for future AI agent systems. The goal is to provide a blueprint for how production-grade agents balance autonomy with control, informed by real implementation choices.
The analysis draws from a reverse-engineering of Claude Code's publicly available TypeScript source code (version 2.1.88), covering about 500,000 lines across 1,800 files, supplemented by Anthropic's official documentation and community insights. It traces key subsystems without running the code, focusing on high-level structures like the agent loop and safety layers. A side-by-side comparison with OpenClaw, a multi-channel personal AI gateway, examines six design dimensions such as trust models and extensibility, using its open-source code for contrast. The study assumes a deployment context of developer machines with bounded computational resources, emphasizing credibility through direct file references and avoidance of unverified inferences.
The most important findings center on Claude Code's core design: a simple iterative loop where the AI model proposes actions and the surrounding "harness" executes them, comprising just 1.6% decision logic and 98.4% operational infrastructure. This reflects five guiding human values—prioritizing user control, protecting against harm, ensuring dependable outputs, amplifying what users can achieve, and adapting to specific contexts—which translate into 13 principles like deny-first safety and progressive context management. Key implementations include a seven-layer permission system that blocks risky actions by default (with users approving 93% of prompts, prompting automated classifiers to reduce fatigue), a five-stage pipeline that compresses conversation history to fit the AI's limited memory window (up to 1 million tokens, but often pressured by verbose outputs), four extensibility options (from low-cost hooks to high-integration external servers) that let users customize without bloating the system, isolated subagents for task delegation (e.g., one explores code while another verifies), and append-only storage for auditable session histories. In contrast, OpenClaw, designed for persistent multi-app assistance, favors gateway-wide controls over per-action checks, shared memory across channels, and plugin registries that extend the entire system rather than single sessions—showing how context shapes choices, with Claude Code enabling 27% more ambitious tasks per internal surveys.
These findings mean AI agents like Claude Code excel at short-term task acceleration, enabling new workflows without heavy planning frameworks, but they trade off global awareness for local efficiency—potentially leading to duplicated code or overlooked conventions due to memory limits. Safety layers reduce risks like unauthorized file changes, yet shared performance constraints (e.g., token costs) could weaken them under load, as seen in documented vulnerabilities. Compared to expectations of rigid orchestration in other tools, Claude Code's model-trusting approach amplifies capabilities cost-effectively but highlights a gap: it boosts immediate output (e.g., 20-40% longer sessions over time) at possible risk to long-term developer comprehension, with studies showing AI users scoring 17% lower on code understanding tests and contributing to rising code complexity by 40%.
Leaders should prioritize investments in harness infrastructure—such as layered safety and compaction tools—over complex decision scaffolds, as these yield reliable gains with capable models. For next steps, conduct pilot evaluations of Claude Code in teams to measure outcomes like error rates and skill retention, then prototype enhancements like cross-session memory for better continuity and evaluation hooks to catch "silent" failures (78% of AI issues per industry reports). Explore governance integrations for compliance with emerging rules like the EU AI Act, weighing trade-offs between proactive agents (boosting completion by 12-18%) and user control. If results confirm comprehension risks, design features that promote human oversight, such as comprehension checks during delegation.
While the analysis confidently maps the architecture (verified against code), uncertainties include build variations from feature flags and untested runtime behaviors, plus a focus on one system that may not generalize. Readers should verify with live deployments before decisions, treating this as a strong foundation rather than exhaustive proof.
1. Introduction
Section Summary: AI-assisted software development has progressed from simple autocomplete tools like GitHub Copilot to advanced agentic systems like Anthropic's Claude Code, which can independently plan, execute tasks, and iterate on code changes using an "agentic loop." This study examines Claude Code's architecture through its source code to reveal how it handles key challenges in safety, context management, extensibility, and more, drawing on design principles inspired by human values and highlighting new workflows that enable tasks engineers might not otherwise attempt. By contrasting it with the open-source OpenClaw system and identifying open questions for future agents, the work aims to guide the creation of more capable and principled AI tools.
AI-assisted software development has evolved from autocomplete-style tools such as GitHub Copilot ([1]), through IDE-integrated assistants like Cursor ([2]), to fully agentic systems that autonomously plan multi-step modifications, execute shell commands, read and write files, and iterate on their own outputs. Claude Code ([3]) is an agentic coding tool released by Anthropic ([4]). Its official documentation describes an "agentic loop" that plans and executes actions toward accomplishing a goal and can call tools, evaluate results, and continue until the task is done ^2. This shift from suggestion to autonomous action introduces architectural requirements that have no counterpart in completion-based tools. These requirements define a design space, a set of recurring questions spanning topics such as safety, context management, extensibility, and delegation that every coding agent must navigate. This study uses source-level analysis of Claude Code to show how one production system answers these questions.
Despite growing adoption, Anthropic publishes user-facing documentation for Claude Code but not detailed architectural descriptions. This study uses source code analysis to describe architectural design decisions. Anthropic's internal survey of 132 engineers and researchers ([5]) reports that about 27% of Claude Code-assisted tasks were work that would not have been attempted without the tool, suggesting that the architecture enables qualitatively new workflows rather than merely accelerating existing ones.
In this work, we first identify five human values/philosophies and thirteen design principles that motivate the architecture (Section 2), then organize the analysis in three parts:
- Design-space analysis. We identify recurring design questions (where reasoning lives, how the iteration loop is structured, what safety posture to adopt, how the extension surface is partitioned, how context is managed, how work is delegated across subagents, and how sessions persist) and analyze Claude Code's answers through a 7-component high-level structure and a 5-layer subsystem architecture, tracing each choice to specific source files (Section 3). The analysis aims to build a deep understanding of the system mechanism, with the goal of informing the design of better and more powerful agent systems.
- Architectural contrast with OpenClaw. Beyond analyzing Claude Code itself, we also compare its design philosophy with that of open-source agent system OpenClaw ([6]), a multi-channel personal assistant gateway, across six design dimensions to show how the same recurring questions produce different answers under different deployment contexts (Section 10), in order to highlight both the common principles and the key differences between commercial and open-source software. This comparison helps reveal how deployment setting, product goals, safety requirements, and user assumptions shape architectural choices in different ways. By examining where these systems converge and where they diverge, our study aims to provide useful guidance and practical insights for the design of future, more capable agent systems.
- Open directions for future agent systems. Building on the design-space analysis and the OpenClaw contrast, Section 12 identifies six open directions spanning the observability-evaluation gap, cross-session persistence, harness boundary evolution, horizon scaling, governance, and the evaluative lens, each drawing on empirical, architectural, and policy literature. Used as an evaluative lens, our study also reveals an open question: while the Claude Code agent system substantially amplifies the short-term capabilities of programmers and end users, it offers limited mechanisms that explicitly support long-term human improvement, deeper understanding, and sustained codebase coherence.
The core agent loop is a while-true cycle with state management. The surrounding subsystems for safety, extensibility, context management, delegation, and persistence make up the bulk of the implementation. Source-level analysis[^3] allows us to identify design choices, subsystem boundaries, and implementation trade-offs directly from the system itself rather than inferring them solely from product descriptions.
[^3]: Our analysis is grounded primarily in the source code, supplemented by official Anthropic documentation and selected community analysis, Appendix B details the evidence base and methodology.
Running example.
To keep the architecture concrete, we trace the task "Fix the failing test in auth.test.ts" through Section 3, Section 4, Section 5, Section 6, Figure 6, Section 8, and Section 9. This example illustrates how a seemingly simple user request activates multiple architectural layers, including tool invocation, permission checks, context selection, iterative repair, delegation, and session persistence.
Paper organization.
Section 2 identifies the human values and design principles that motivate the architecture. Section 3 introduces the high-level architecture and the design questions it answers. Section 4, Section 5, Section 6, Figure 6, Section 8, and Section 9 each analyze a major subsystem's design choices. Section 10 contrasts the analysis with OpenClaw, Section 11 provides discussion, and Section 12 surveys open questions for future agent systems. Section 13 and Section 14 then cover related work and conclusions. Appendix B describes the evidence base and methodology.
2. Design Philosophies, Design Principles and Architectural Motivations
Section Summary: This section explores the human-centered motivations behind Claude Code's architecture, highlighting five core values: keeping ultimate decision-making in human hands for informed control, ensuring safety and privacy to protect against risks even during lapses, delivering reliable and verifiable execution that aligns with user intent over time, amplifying human capabilities to enable new kinds of work with minimal effort, and adapting flexibly to individual user contexts as trust builds. These values guide thirteen design principles that address common challenges in building coding agents, such as balancing autonomy with oversight. The principles contrast with alternatives like rigid rule-based systems or isolated execution environments, setting the stage for deeper analysis of specific features in later sections.
Production coding agents are built by humans, for humans, and the architectural decisions they embed reflect what their creators believe matters. This section identifies the human values that motivate Claude Code's design, traces them through recurring design principles, and frames the design-space questions that organize the analysis in Section 3, Section 4, Section 5, Section 6, Figure 6, Section 8, and Section 9.
Anthropic's framework for safe agents states a central tension: "Agents must be able to work autonomously; their independent operation is exactly what makes them valuable. But humans should retain control over how their goals are pursued" ([7]). Claude's Constitution resolves this not through rigid decision procedures but by cultivating "good judgment and sound values that can be applied contextually" ([8]). These commitments, together with empirical findings about how developers actually use the tool ([5, 9]), point to five human values that shape the architecture.
2.1 Five Values and Philosophies
Human Decision Authority.
The human retains ultimate decision authority over what the system does, organized through a principal hierarchy (Anthropic, then operators, then users) that formalizes who holds authority over what ([8]). The system is designed so that humans can exercise informed control: they can observe actions in real time, approve or reject proposed operations, interrupt compatible in-progress operations, and audit after the fact. When Anthropic found that users approve 93% of permission prompts ([10]), the response was not to add more warnings but to restructure the problem: defined boundaries (sandboxing, auto-mode classifiers) within which the agent can work freely, rather than per-action approvals that users stop reviewing once habituated ([11]).
Safety, Security, and Privacy.
The system protects humans, their code, their data, and their infrastructure from harm, even when the human is inattentive or makes mistakes. This is distinct from Human Decision Authority: where authority is about the human's power to choose, safety is about the system's obligation to protect even when that power lapses. Anthropic's safe-agents framework separately identifies securing agent interactions and protecting privacy across extended interactions as core commitments ([7]). The auto-mode threat model ([10]) explicitly targets four risk categories: overeager behavior, honest mistakes, prompt injection, and model misalignment.
Reliable Execution.
The agent does what the human actually meant, stays coherent over time, and supports verifying its work before declaring success. This value spans both single-turn correctness (did it interpret the request faithfully?) and long-horizon dependability (does it remain coherent across context window boundaries, session resumption, and multi-agent delegation?). Anthropic's product documentation ([12]) describes a three-phase loop that the agent repeats until the task is complete: gather context, take action, and verify results. The agent design guidance ([13]) further emphasizes that "ground truth from the environment" at each step assesses progress. The harness-design guidance ([14]) likewise notes that "agents tend to respond by confidently praising the work, " even when quality is mediocre, motivating separation of generation from evaluation.
Capability Amplification.
The system materially increases what the human can accomplish per unit of effort and cost. Anthropic's internal survey ([5]), discussed in Section 1, suggests that the architecture enables qualitatively new workflows, not merely faster existing ones: approximately 27% of tasks represented work that would not otherwise have been attempted. The system is described by its creators as "a Unix utility rather than a traditional product, " built from the smallest building blocks that are "useful, understandable, and extensible" ([15]). The architecture invests in deterministic infrastructure (context management, tool routing, recovery) rather than decision scaffolding (explicit planners or state graphs), on the premise that increasingly capable models benefit more from a rich operational environment than from frameworks that constrain their choices.
Contextual Adaptability.
The system fits the user's specific context (their project, tools, conventions, and skill level) and the relationship improves over time. The extension architecture (CLAUDE.md, skills, MCP, hooks, plugins) provides configurability at multiple levels of context cost (Section 6 and Figure 6). Longitudinal data ([9]) shows that the human-agent relationship evolves: auto-approve rates increase from approximately 20% at fewer than 50 sessions to over 40% by 750 sessions. This pattern, described as autonomy that is "co-constructed by the model, the user, and the product, " means the system is designed for trust trajectories rather than fixed trust states. MCP's donation to the Linux Foundation's Agentic AI Foundation ([16]) reflects the ecosystem dimension of this value.
2.2 Design Principles
These values are operationalized through thirteen design principles, each answering a recurring question that production coding agents must resolve. Table 1 summarizes the principles; subsequent sections (Section 3–Section 9) trace each through specific implementation choices.
::: {caption="Table 1: Design principles, the values they serve, and the design-space question each answers. Principles map to multiple values; implementations appear in the sections indicated."}
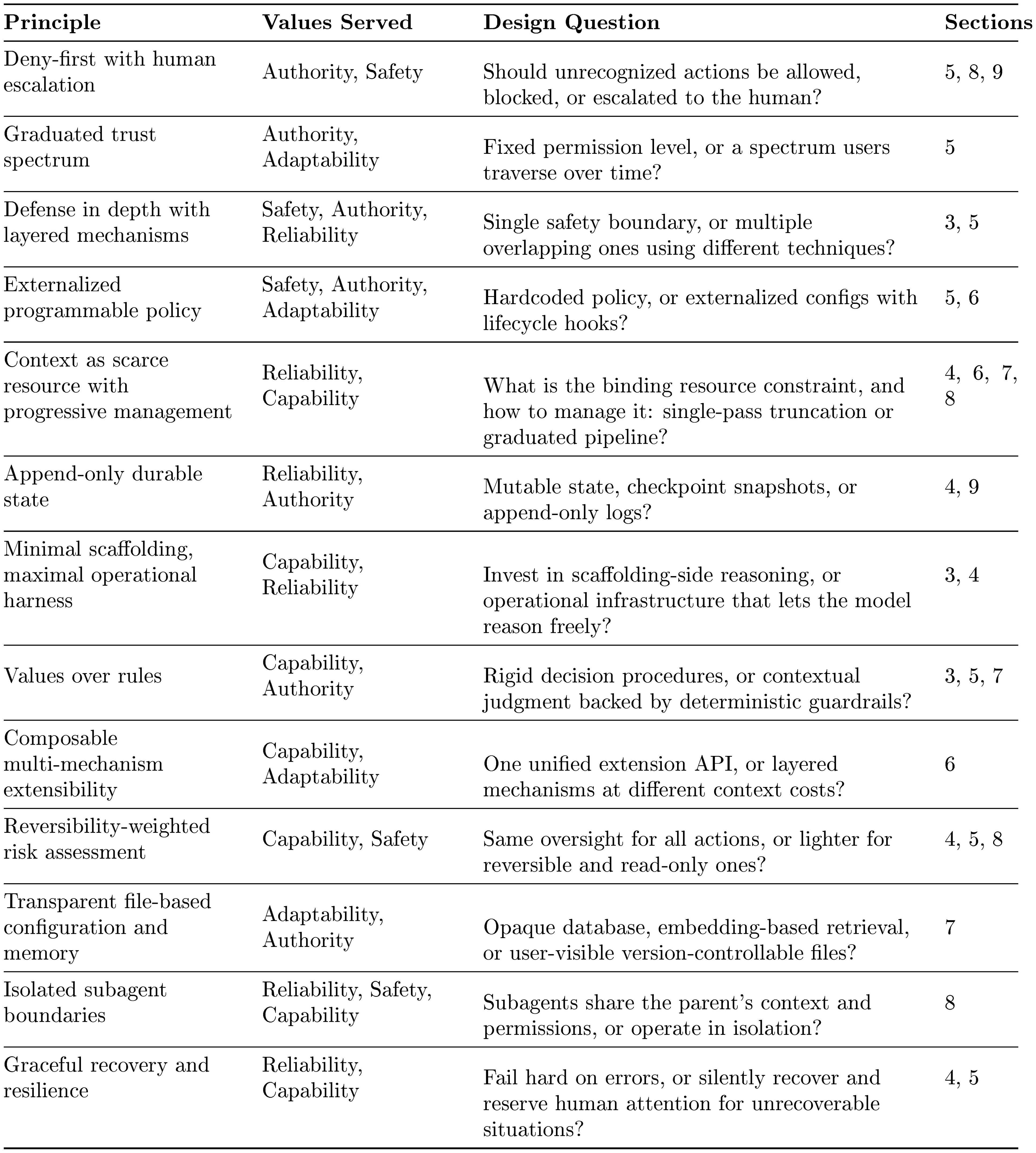
:::
These principles can be read against three major alternative design families. First, rule-based orchestration: frameworks such as LangGraph ([17]) encode decision logic as explicit state graphs with typed edges, choosing scaffolding over minimal harness. Second, container-isolated execution: SWE-Agent and OpenHands ([18, 19]) rely on Docker isolation rather than layered policy enforcement. Third, version-control-as-safety: tools like Aider ([20]) use Git rollback as the primary safety mechanism rather than deny-first evaluation. Claude Code's principle set is distinctive in combining minimal decision scaffolding with layered policy enforcement, values-based judgment with deny-first defaults, and progressive context management with composable extensibility.
2.3 From Values to Architecture
Each value traces through its principles to specific architectural decisions:
- Human Decision Authority motivates deny-first evaluation, the graduated trust spectrum, append-only state (auditable history), externalized programmable policy, and values-over-rules (Section 5, Section 9, Section 6, and Figure 6).
- Safety, Security, and Privacy motivates defense in depth, deny-first defaults, reversibility-weighted assessment, externalized policy, and isolated subagent boundaries (Section 5 and Section 8).
- Reliable Execution motivates context-as-scarce-resource, append-only durable state, graceful recovery, isolated subagent boundaries, and defense in depth (Section 4, Figure 6, Section 8, and Section 9).
- Capability Amplification motivates minimal scaffolding, composable extensibility, reversibility-weighted risk, context management, and graceful recovery (Section 4, Section 6, and Section 5).
- Contextual Adaptability motivates transparent file-based memory, composable extensibility, the graduated trust spectrum, and externalized programmable policy (Figure 6, Section 6, and Section 5).
These mappings also reveal what the architecture does not do: it does not impose explicit planning graphs on the model's reasoning, does not provide a single unified extension mechanism, and does not restore all session-scoped trust-related state across resume. These absences are consistent with the principle set above.
2.4 An Evaluative Lens: Long-term Capability Preservation
The five values above describe what the architecture is designed to serve. This paper also applies a sixth concern, whether the architecture preserves long-term human capability, as an evaluative lens. This concern is real: Anthropic's own study of 132 engineers and researchers ([5]) documents a "paradox of supervision" in which overreliance on AI risks atrophying the skills needed to supervise it, and independent research ([21]) finds that developers in AI-assisted conditions score 17% lower on comprehension tests. However, this concern is not prominently reflected as a design driver in the architecture or in Anthropic's stated design values. We therefore treat it not as a co-equal value but as a cross-cutting concern: a question applied across all five values in Section 11, asking whether short-term amplification comes at the cost of long-term human understanding, codebase coherence, and the developer pipeline.
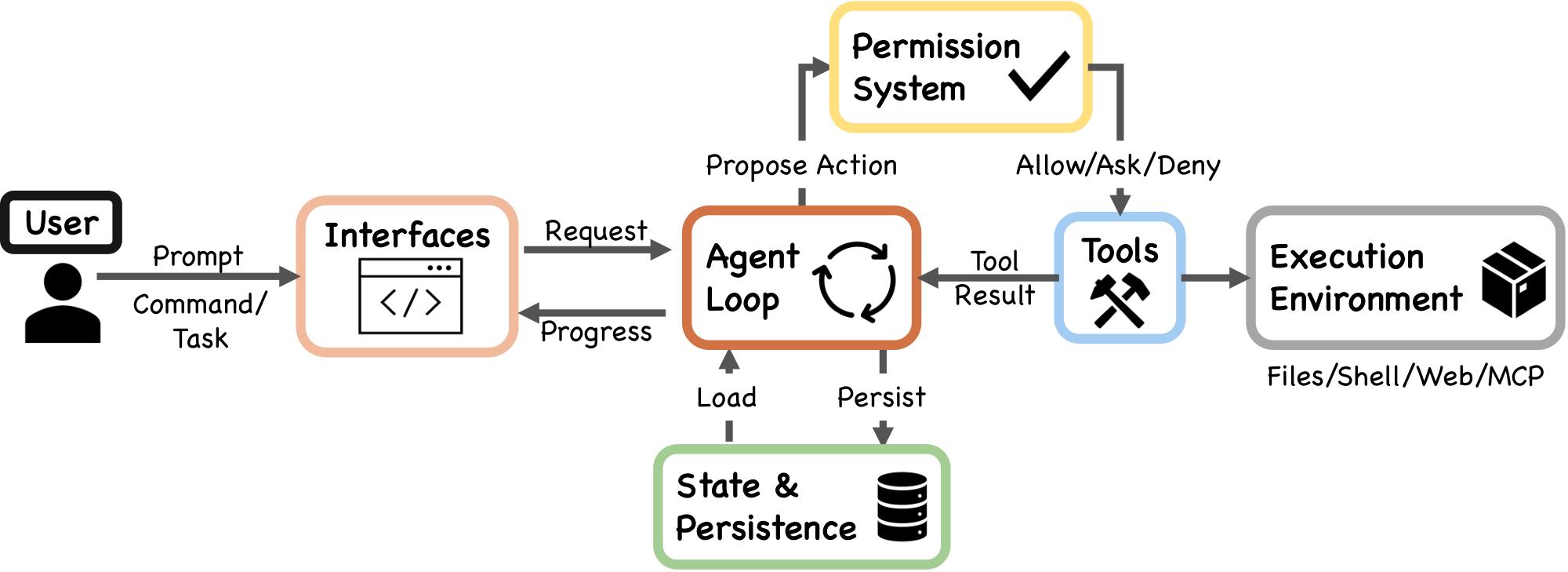
3. Architecture Overview
Section Summary: Claude Code's architecture addresses key design challenges in building production coding agents, such as where reasoning occurs, how many execution systems to use, safety approaches, and primary resource limits. In this setup, the AI model handles reasoning and suggests actions through structured requests, while a secure harness executes them after permission checks, using a single unified loop for all interfaces to ensure consistency and security. The system emphasizes a deny-first safety model with multiple protective layers, treats the AI's context window as the main bottleneck managed by various compression techniques, and illustrates these choices through a running example of fixing a failing test file.
Building a production coding agent requires answering several recurring design questions: where should reasoning live, how many execution engines are needed, what safety posture to adopt, and what resource to treat as the binding constraint. Claude Code's architecture can be read as one set of answers to these questions. At the implementation level, the system has seven components connected by a main data flow: a user submits a prompt through one of several interfaces, which feeds into a shared agent loop. The agent loop assembles context, calls the Claude model, receives responses that may include tool-use requests, routes those requests through a permission system, and dispatches approved actions to concrete tools that interact with the execution environment. Throughout this process, state and persistence mechanisms record the conversation transcript, manage session identity, and support resume, fork, and rewind operations.
3.1 Design Questions and Running Example
The description is organized around four design questions that recur across production coding agents, each grounding one or more of the design principles identified in Table 1. Each question is introduced here with Claude Code's answer, a note on plausible alternatives, and then demonstrated progressively through Section 4, Section 5, Section 6, Figure 6, Section 8, and Section 9.
Where does reasoning live?
In Claude Code, the model reasons about what to do; the harness is responsible for executing actions. The model emits tool_use blocks as part of its response, and the harness parses them, checks permissions, dispatches them to tool implementations, and collects results (query.ts). The model never directly accesses the filesystem, runs shell commands, or makes network requests. This separation has a security consequence: because reasoning and enforcement occupy separate code paths, a compromised or adversarially manipulated model cannot override the sandboxing, permission checks, or deny-first rules implemented in the harness. The model's only interface to the outside world is the structured tool_use protocol, which the harness validates before execution. Community analysis of the extracted source estimates that only about 1.6% of Claude Code's codebase constitutes AI decision logic, with the remaining 98.4% being operational infrastructure, a ratio that illustrates how thin the core agent reasoning layer is. Alternative designs invest more heavily in scaffolding-side reasoning: Devin maintains explicit planning and task-tracking structures, while LangGraph ([17]) routes control flow through developer-defined state graphs.
How many execution engines?
Claude Code uses a single queryLoop() function that executes regardless of whether the user is interacting through an interactive terminal, a headless CLI invocation, the Agent SDK, or an IDE integration (query.ts). Only the rendering and user-interaction layer varies. Other systems use mode-specific engines: for example, an IDE integration may follow a different code path than a CLI tool, trading uniformity for surface-specific optimization.
What is the default safety posture?
Claude Code's default safety posture is deny-first with human escalation: deny rules override ask rules override allow rules, and unrecognized actions are escalated to the user rather than allowed silently (permissions.ts). Multiple independent safety layers (permission rules, PreToolUse hooks, the auto-mode classifier when enabled, and optional shell sandboxing) apply in parallel, so any one can block an action (Section 5). This combines the deny-first with human escalation and defense in depth with layered mechanisms principles from Table 1. Alternative approaches shift the trust boundary elsewhere: SWE-Agent and OpenHands ([18, 19]) rely on container-based isolation to contain arbitrary execution, while Aider ([20]) uses git-based rollback as its primary safety net.
What is the binding resource constraint?
In Claude Code, the context window (200K for older models, 1M for the Claude 4.6 series) is the binding resource constraint. Five distinct context-reduction strategies execute before every model call (query.ts), and several other subsystem decisions (lazy loading of instructions, deferred tool schemas, summary-only subagent returns) exist to limit context consumption (Figure 6). The five-layer pipeline exists because no single compaction strategy addresses all types of context pressure. Budget reduction targets individual tool outputs that overflow size limits. Snip handles temporal depth. Microcompact reacts to cache overhead. Context collapse manages very long histories. Auto-compact performs semantic compression as a last resort. Each layer operates at a different cost-benefit tradeoff, and earlier, cheaper layers run before costlier ones. Alternative architectures treat other resources as the primary bottleneck, for instance compute budget (limiting the number of model calls or tool invocations) or working memory (maintaining an explicit scratchpad rather than relying on the conversation history).
Running example.
To ground these principles, we thread a single task through Section 3, Section 4, Section 5, Section 6, Figure 6, Section 8, and Section 9: "Fix the failing test in auth.test.ts." In this section the user submits the prompt through one of Claude Code's interfaces. Subsequent sections trace the request through the query loop, permission gate, tool pool, context window, subagent delegation, and session persistence.
3.2 High-Level System Structure
The seven-component model (Figure 1) maps directly to source files:
- User: Submits prompts, approves permissions, reviews output.
- Interfaces: Interactive CLI, headless CLI (
claude -p), Agent SDK, and IDE/Desktop/Browser. All surfaces feed the same loop. - Agent loop: The iterative cycle of model call, tool dispatch, and result collection, implemented as the
queryLoop()async generator inquery.ts. - Permission system: Deny-first rule evaluation (
permissions.ts), the auto-mode ML classifier, and hook-based interception (types/hooks.ts). - Tools: Up to 54 built-in tools (19 unconditional, 35 conditional on feature flags and user type) assembled via
assembleToolPool()(tools.ts), merged with MCP-provided tools. Plugins contribute indirectly through MCP servers and the skill/command registry. - State & persistence: Mostly append-only JSONL session transcripts (
sessionStorage.ts), global prompt history (history.ts), and subagent sidechain files. - Execution environment: Shell execution with optional sandboxing (
shouldUseSandbox.ts), filesystem operations, web fetching, MCP server connections, and remote execution.
The data flow follows a left-to-right spine: the user submits a request through an interface, which enters the agent loop. The loop proposes actions to the permission system; approved actions reach tools, which interact with the execution environment and return tool_result messages back to the loop. State and persistence sit alongside the loop, recording transcripts and loading prior session data.
The application entry point main() in main.tsx initializes security settings (including NoDefaultCurrentDirectoryInExePath to prevent Windows PATH hijacking), registers signal handlers for graceful shutdown, and dispatches to the appropriate execution mode.
3.3 Layered Subsystem Decomposition
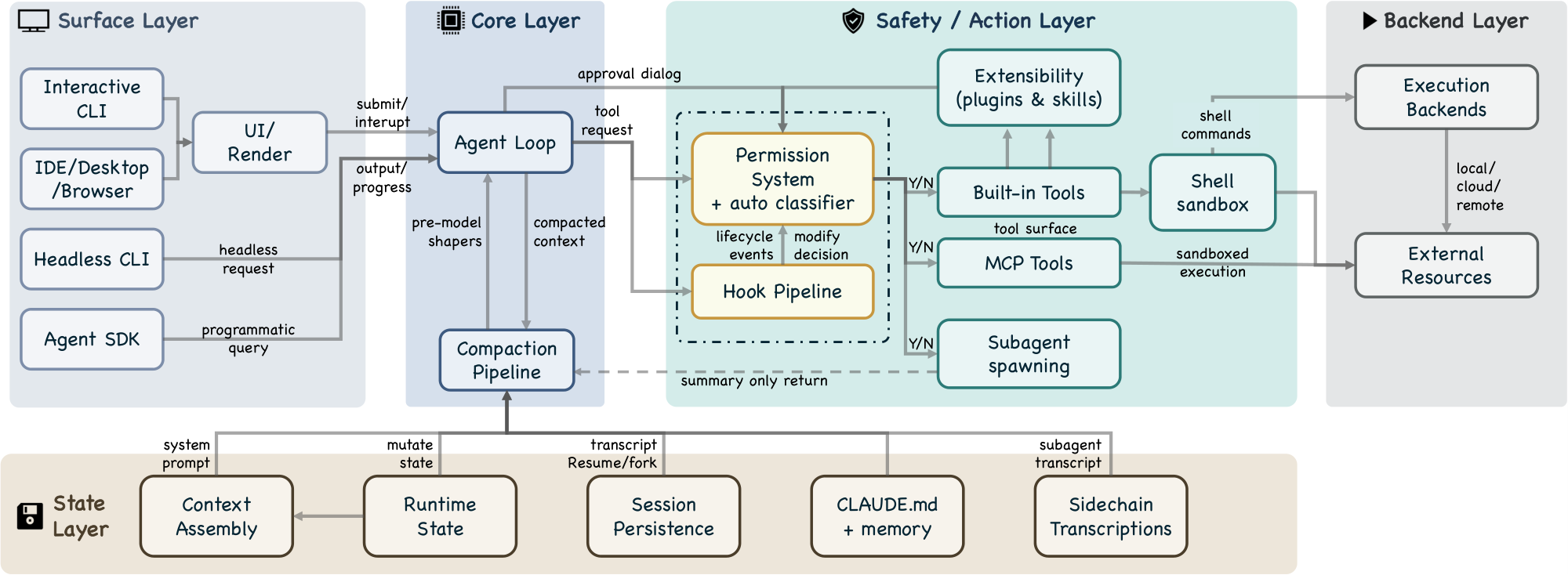
The five-layer decomposition (Figure 3) expands the seven-component model into a finer-grained view, mapping each layer to specific source directories.
Surface layer (entry points and rendering).
The src/entrypoints/ directory contains startup paths, including the SDK entry with coreTypes.ts, controlSchemas.ts, and coreSchemas.ts. The src/screens/ directory composes full-screen layouts, and src/components/ provides terminal UI building blocks via the ink framework. The interactive CLI launches a terminal UI with real-time streaming, permission dialogs, and progress indicators. The headless CLI (claude -p) creates a QueryEngine instance for single-shot processing. The Agent SDK emits typed events via async generators.
Core layer (agent loop, compaction pipeline).
The queryLoop() async generator (query.ts) implements the iterative agent loop, consuming assembled context from the state layer and dispatching tool requests to the safety/action layer. Before every model call, a compaction pipeline of five sequential shapers (query.ts:365–453) manages context pressure: budget reduction, snip, microcompact, context collapse, and auto-compact (Section 4.3 and Section 7.3).
Safety/action layer (permission system, hooks, extensibility, tools, sandbox, subagents).
The permission system (permissions.ts) implements deny-first rule evaluation with up to seven permission modes (if also counting internal-only bubble and feature-gated auto) (types/permissions.ts) and an integrated auto-mode ML classifier (yoloClassifier.ts) that provides a two-stage fast-filter and chain-of-thought evaluation of tool safety (Section 5). A hook pipeline spanning 27 event types (coreTypes.ts; output schemas in types/hooks.ts) can block, rewrite, or annotate tool requests; of these, 5 are safety-related while the remaining 22 serve lifecycle and orchestration purposes (Section 6). An extensibility subsystem allows plugins and skills to register tools and hooks into the runtime. Tool pool assembly via assembleToolPool() (tools.ts) merges built-in and MCP-provided tools. Approved shell commands pass through a shell sandbox (shouldUseSandbox.ts) that restricts filesystem and network access independently of the permission system. Subagent spawning via AgentTool (AgentTool.tsx, runAgent.ts) is dispatched through the same buildTool() factory as all other tools, re-entering the queryLoop() with an isolated context window and returning only a summary to the parent (Section 8).
State layer (context assembly, runtime state, persistence, memory, sidechains).
Context assembly is a memoized state loader, not a routing hub: getSystemContext() (context.ts) computes session-level system context including git status, and getUserContext() (context.ts) loads the CLAUDE.md hierarchy and current date. Both are cached for reuse: system context is appended to the system prompt, while user context is added as a user-context message. The src/state/ directory manages runtime application state. Session transcripts are stored as mostly append-only JSONL files at project-specific paths (sessionStorage.ts). The CLAUDE.md + memory subsystem provides a four-level instruction hierarchy (claudemd.ts) from managed settings to directory-specific files, plus auto-memory entries that Claude writes during conversations (Section 7.2). Sidechain transcripts (sessionStorage.ts:247) store each subagent's conversation in a separate file, preventing subagent content from inflating the parent context (Section 8.3). Global prompt history is maintained in history.jsonl (history.ts). Resume and fork operations reconstruct session state from transcripts (conversationRecovery.ts).
Backend layer (execution backends, external resources).
Shell command execution with optional sandboxing (BashTool.tsx, PowerShellTool.tsx), remote execution support (src/remote/), MCP server connections across multiple transport variants including stdio, SSE, HTTP, WebSocket, SDK, and IDE-specific adapters (services/mcp/client.ts), and 42 tool subdirectories in src/tools/ implement concrete tool logic.
3.4 QueryEngine: A Clarification
The class documentation at QueryEngine.ts states: "QueryEngine owns the query lifecycle and session state for a conversation. It extracts the core logic from ask() into a standalone class that can be used by both the headless/SDK path and (in a future phase) the REPL." The class is a conversation wrapper for non-interactive surfaces, not the engine itself. Its constructor accepts a QueryEngineConfig with initial messages, an abort controller, a file-state cache, and other per-conversation state. Its submitMessage() method is an async generator that orchestrates a single turn. The shared query path lives in query() (query.ts), which wraps an internal queryLoop(); QueryEngine delegates to query().
This distinction matters architecturally: the interactive CLI also calls query(), bypassing QueryEngine entirely. The shared code path is the loop function, not the engine class.
3.5 Permission and Safety Layers
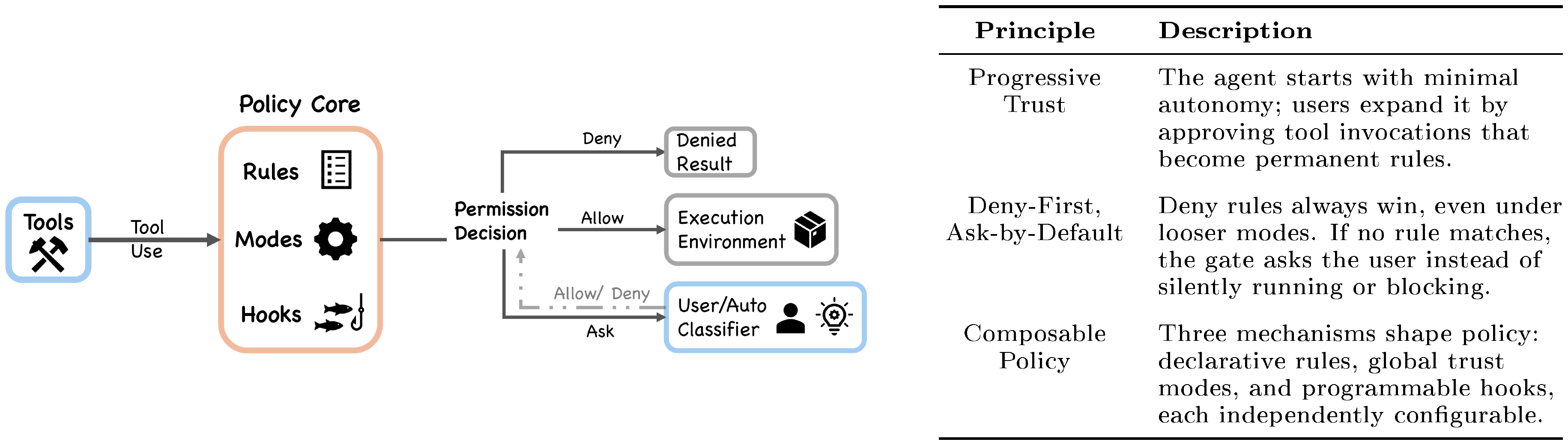
The safety-by-default principle is implemented through seven independent layers. A request must pass through all applicable layers, and any single layer can block it:
- Tool pre-filtering (
tools.ts): Blanket-denied tools are removed from the model's view before any call, preventing the model from attempting to invoke them. - Deny-first rule evaluation (
permissions.ts): Deny rules always take precedence over allow rules, even when the allow rule is more specific. - Permission mode constraints (
types/permissions.ts): The active mode determines baseline handling for requests matching no explicit rule. - Auto-mode classifier: An ML-based classifier evaluates tool safety, potentially denying requests the rule system would allow.
- Shell sandboxing (
shouldUseSandbox.ts): Approved shell commands may still execute inside a sandbox restricting filesystem and network access. - Not restoring permissions on resume (
conversationRecovery.ts): Session-scoped permissions are not restored on resume or fork. - Hook-based interception (
types/hooks.ts): PreToolUse hooks can modify permission decisions; PermissionRequest hooks can resolve decisions asynchronously alongside the user dialog (or before it, in coordinator mode).
These layers are described in detail in Section 5.
3.6 Context as Bottleneck: Beyond Compaction
Beyond the five-layer compaction pipeline (detailed in Figure 6), several other subsystem decisions reflect the context-as-bottleneck constraint:
- CLAUDE.md lazy loading: The base CLAUDE.md hierarchy is loaded at session start, but additional nested-directory instruction files and conditional rules are loaded only when the agent reads files in those directories, preventing unused instructions from consuming context.
- Deferred tool schemas: When ToolSearch is enabled, some tools include only their names in the initial context; full schemas are loaded on demand.
- Subagent summary-only return: Subagents return only summary text to the parent, not their full conversation history (Section 8).
- Per-tool-result budget: Individual tool results are capped at a configurable size, preventing a single verbose output from consuming disproportionate context.
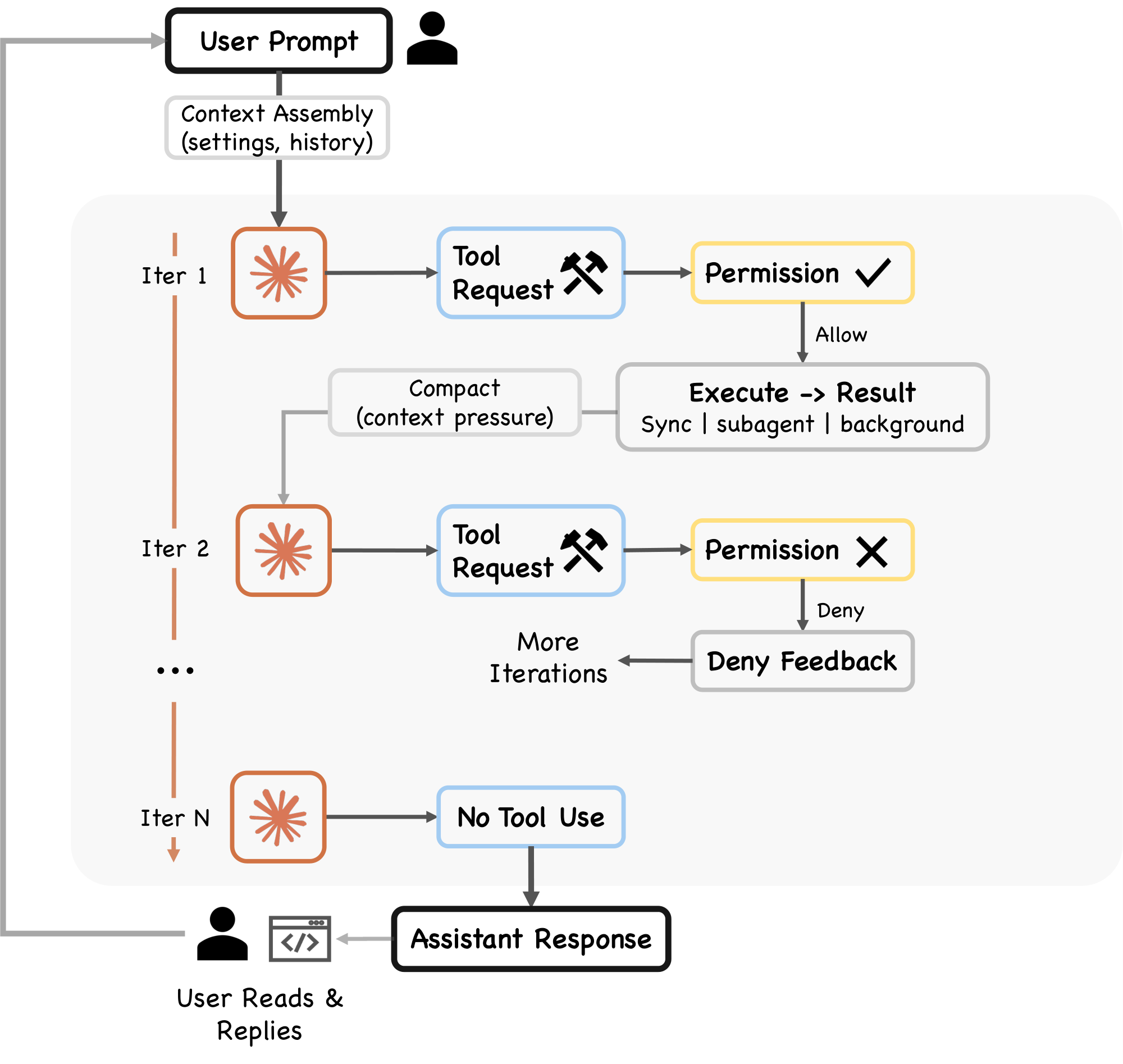
4. Turn Execution: The Agentic Query Loop
Section Summary: When a user submits a coding task like fixing a failing test, Claude Code processes it through a reactive loop that mimics a simple while-loop, allowing the AI to reason, call tools, and iterate until the task is resolved. Each loop turn follows a fixed sequence: it assembles conversation history and context, queries the model for responses that may include tool requests, executes those tools in a streaming manner for efficiency while ensuring safe concurrency, and adds results back into the loop until no more tools are needed. This design emphasizes keeping context lean through compaction and summaries, enabling quick recovery from errors while prioritizing simplicity over complex branching paths.
When the user submits "Fix the failing test in auth.test.ts, " the input enters a reactive loop, one of several possible orchestration patterns for coding agents. This section examines Claude Code's choice of a simple while-loop architecture and traces one turn of that loop end-to-end, illustrating three design principles from Table 1: minimal scaffolding with maximal operational harness, context as scarce resource with progressive management, and graceful recovery and resilience.
4.1 The Query Pipeline
Each turn follows a fixed sequence (Figure 2, query.ts):
- Settings resolution. The
queryLoop()function destructures immutable parameters including the system prompt, user context, permission callback, and model configuration. - Mutable state initialization. A single
Stateobject stores all mutable state across iterations, including messages, tool context, compaction tracking, and recovery counters. The loop's sevencontinuepoints (the "continue sites") each overwrite this object in one whole-object assignment rather than mutating fields individually. - Context assembly. The function
getMessagesAfterCompactBoundary()retrieves messages from the last compact boundary forward, ensuring that compacted content is represented by its summary rather than the original messages. - Pre-model context shapers. Five shapers execute sequentially (Section 4.3).
- Model call. A
for awaitloop overdeps.callModel()streams the model's response, passing assembled messages (with user context prepended), the full system prompt, thinking configuration, the available tool set, an abort signal, the current model specification, and additional options including fast-mode settings, effort value, and fallback model. - Tool-use dispatch. If the response contains
tool_useblocks, they flow to the tool orchestration layer (Section 4.2). - Permission gate. Each tool request passes through the permission system (Section 5).
- Tool execution and result collection. Tool results are added to the conversation as
tool_resultmessages, and the loop continues. - Stop condition. If the response contains no
tool_useblocks (text only), the turn is complete.
The queryLoop() function is defined as an AsyncGenerator, yielding StreamEvent, RequestStartEvent, Message, TombstoneMessage, and ToolUseSummaryMessage events as it progresses. This generator-based design enables streaming output to the UI layer while maintaining a single synchronous control flow within the loop.
Claude Code's reactive loop follows the ReAct pattern ([22]): the model generates reasoning and tool invocations, the harness executes actions, and results feed the next iteration. Alternative orchestration patterns include explicit graph-based routing ([17]), where control flow is defined as a state machine with typed edges, and tree-search methods ([23]) that explore multiple action trajectories before committing. Anthropic's own documentation ([13]) identifies five composable workflow patterns (prompt chaining, routing, parallelization, orchestrator-workers, and evaluator-optimizer) of which Claude Code primarily uses the orchestrator-workers pattern for subagent delegation (Section 8) while keeping the core loop reactive. The reactive design trades search completeness for simplicity and latency: each turn commits to one action sequence without backtracking.
4.2 Tool Dispatch and Streaming Execution
When the model response contains tool_use blocks, the system chooses between two execution paths. The primary path uses StreamingToolExecutor, which begins executing tools as they stream in from the model response, reducing latency for multi-tool responses. The fallback path uses runTools() in toolOrchestration.ts, which iterates over partitions produced by partitionToolCalls(). Both paths classify tools as concurrent-safe or exclusive. Read-only operations can execute in parallel, while state-modifying operations like shell commands are serialized.
The StreamingToolExecutor (StreamingToolExecutor.ts) manages concurrent execution with two coordination mechanisms:
- Sibling abort controller. Fires when any Bash tool errors, immediately terminating other in-flight subprocesses rather than letting them run to completion.
- Progress-available signal. Wakes up the
getRemainingResults()consumer when new output is ready.
Results are buffered and emitted in the order tools were received, so output order stays the same even when tools run in parallel. This is important because the model expects tool results in the same order as its tool-use requests. This concurrent-read, serial-write execution model occupies a middle ground between fully serial dispatch and more aggressive speculative approaches such as PASTE ([24]), which speculatively pre-executes predicted future tool calls while the model is still generating, hiding tool latency through speculation.
The tool result collection phase iterates over updates from either the streaming executor or the synchronous runTools() generator. Each update may carry a tool result, an attachment, or a progress event. A special check detects hook_stopped_continuation attachments: if a PostToolUse hook signals that the turn should not continue, a shouldPreventContinuation flag is set. Results are normalized for the Anthropic API via normalizeMessagesForAPI(), filtering to keep only user-type messages.
4.3 Pre-Model Context Shapers
Five context shapers execute sequentially in query.ts before every model call, each operating on the messagesForQuery array. The five shapers run in sequence, with earlier steps applying lighter reductions before later steps apply broader compaction.
Budget reduction.
(applyToolResultBudget()). Enforces per-message size limits on tool results, replacing oversized outputs with content references. Exempt tools (those where maxResultSizeChars is not finite) retain their full output. Content replacements are persisted for agent and session query sources to enable reconstruction on resume. Budget reduction runs before microcompact because microcompact operates purely by tool_use_id and never inspects content; the two compose cleanly.
Snip.
(snipCompactIfNeeded(), gated by HISTORY_SNIP). A lightweight trim that removes older history segments, returning {messages, tokensFreed, boundaryMessage}. The snipTokensFreed value is plumbed to auto-compact because the main token counter derives context size from the usage field on the most recent assistant message, and that message survives snip with its pre-snip input_tokens still attached; snip's savings are therefore invisible to the counter unless passed through explicitly.
Microcompact.
Fine-grained compression that always runs a time-based path and optionally a cache-aware path (gated by CACHED_MICROCOMPACT). When the cached path is enabled, boundary messages are deferred until after the API response so they can use actual cache_deleted_input_tokens rather than estimates. Returns {messages, compactionInfo} where compactionInfo may include pendingCacheEdits.
Context collapse.
Gated by CONTEXT_COLLAPSE. A read-time projection over the conversation history. The source comments explain: "Nothing is yielded; the collapsed view is a read-time projection over the REPL's full history. Summary messages live in the collapse store, not the REPL array. This is what makes collapses persist across turns." Unlike the other shapers, context collapse does not mutate the REPL's stored history; it replaces the messagesForQuery array with a projected view via applyCollapsesIfNeeded(), so the model sees the collapsed version while the full history remains available for reconstruction.
Auto-compact.
The fifth shaper, triggering a full model-generated summary via compactConversation() in compact.ts. This function executes PreCompact hooks, creates a summary request using getCompactPrompt(), and calls the model to produce a compressed summary. The result feeds into buildPostCompactMessages() (compact.ts). Auto-compact fires only when the context still exceeds the pressure threshold after all four previous shapers have run.
4.4 Recovery Mechanisms
The query loop implements several recovery mechanisms for edge cases:
- Max output tokens escalation: When the response hits the output token cap, the system can retry with an escalated limit, subject to a GrowthBook flag and the absence of an existing override or environment-variable cap. Up to three recovery attempts are allowed per turn (
MAX_OUTPUT_TOKENS_RECOVERY_LIMIT = 3). - Reactive compaction (gated by
REACTIVE_COMPACT): When the context is near capacity, reactive compact summarizes just enough to free space. ThehasAttemptedReactiveCompactflag ensures this fires at most once per turn. - Prompt-too-long handling: If the API returns a
prompt_too_longerror, the loop first attempts context-collapse overflow recovery and reactive compaction. Only after these fail does it terminate withreason: 'prompt_too_long'. - Streaming fallback: The
onStreamingFallbackcallback handles streaming API issues, allowing the loop to retry with a different strategy. - Fallback model: The
fallbackModelparameter enables switching to an alternative model if the primary model fails.
4.5 Stop Conditions
Multiple conditions can terminate the loop:
- No tool use: The model produces only text content (the primary stop condition).
- Max turns: The configurable
maxTurnslimit is reached. - Context overflow: The API returns
prompt_too_long. - Hook intervention: A PostToolUse hook sets
hook_stopped_continuation. - Explicit abort: The
abortControllersignal fires.
The turn pipeline determines how tool requests are orchestrated and recovered. The next section examines the gate that determines whether each request is permitted to execute at all.
5. Tool Authorization and Control Boundaries
Section Summary: Claude Code ensures safe tool use in coding tasks by following a deny-first approach, where tools like running code commands must pass multiple safety checks and often require user approval rather than being allowed automatically. This system includes seven permission modes that range from strict planning with full human oversight to more autonomous options with automated evaluations, all built on layered defenses like pre-filtering denied tools, rule checks, and hooks to prevent misuse even if users approve requests without close attention. The design addresses the problem of users habitually clicking yes to prompts, maintaining independent safeguards through sandboxing and reversible actions to minimize risks.
Production coding agents adopt different safety architectures: layered policy enforcement, OS-level sandboxing, or version-control-based rollback. Claude Code combines the first two, implementing four design principles from Table 1: deny-first with human escalation, graduated trust spectrum, defense in depth with layered mechanisms, and reversibility-weighted risk assessment.
When Claude decides to execute a tool (for example, running npm test via BashTool to reproduce the auth test failure), the request enters the permission pipeline shown in Figure 4. Every tool invocation passes through the permission system, and the default behavior is to deny or ask rather than allow silently. This default is motivated by a documented behavioral pattern: Anthropic's auto-mode analysis ([10]) found that users approve approximately 93% of permission prompts, indicating that approval fatigue renders interactive confirmation behaviorally unreliable as a sole safety mechanism. Because users habitually approve without careful review, the system must maintain safety independently of human vigilance. This motivates the architectural commitment to deny-first evaluation, blanket-deny pre-filtering, and sandboxing as independent layers that operate regardless of user attentiveness.
5.1 Permission Modes and Rule Evaluation
Seven permission modes exist across the type definitions (5 external modes at types/permissions.ts; auto added conditionally; bubble in the type union):
plan: The model must create a plan; execution proceeds only after user approval.default: Standard interactive use. Most operations require user approval.acceptEdits: Edits within the working directory and certain filesystem shell commands (mkdir, rmdir, touch, rm, mv, cp, sed) are auto-approved; other shell commands require approval.auto: An ML-based classifier evaluates requests that do not pass fast-path checks (gated byTRANSCRIPT_CLASSIFIER).dontAsk: No prompting, but deny rules are still enforced.bypassPermissions: Skips most permission prompts, but safety-critical checks and bypass-immune rules still apply.bubble: Internal-only mode for subagent permission escalation to the parent terminal.
The five externally visible modes (acceptEdits, bypassPermissions, default, dontAsk, plan) are defined in the EXTERNAL_PERMISSION_MODES array. The auto mode is conditionally included only when the TRANSCRIPT_CLASSIFIER feature flag is active. The bubble mode exists in the type union but not in either mode array; it is used internally for subagent permission escalation (Section 8).
Permission rules are evaluated in deny-first order (permissions.ts). The toolMatchesRule() function checks deny rules first: a deny rule always takes precedence over an allow rule, even when the allow rule is more specific. A broad deny ("deny all shell commands") cannot be overridden by a narrow allow ("allow npm test"). The rule system supports tool-level matching (by tool name) and content-level matching (matching specific tool input patterns, such as Bash(prefix:npm)).
The seven modes span a graduated autonomy spectrum, from plan (user approves all plans before execution) through default and acceptEdits to bypassPermissions (minimal prompting). This gradient reflects a recurring design tension: as autonomy increases, the system must shift from interactive approval to automated safety checks. Other agent systems resolve this tension differently. SWE-Agent and OpenHands ([18, 19]) use Docker container isolation, sandboxing the agent's entire execution environment rather than evaluating individual tool invocations. Aider ([20]) relies on Git as a safety net, making all changes reversible through version control. Claude Code's approach layers multiple policy-enforcement mechanisms on top of optional container sandboxing, trading simplicity for fine-grained control over individual actions.
5.2 The Authorization Pipeline
The full authorization pipeline proceeds through several stages:
Pre-filtering.
Before any tool request reaches runtime evaluation, filterToolsByDenyRules() (tools.ts) strips blanket-denied tools from the model's view entirely at tool pool assembly time. The documentation states: "Uses the same matcher as the runtime permission check, so MCP server-prefix rules like mcp__server strip all tools from that server before the model sees them." This prevents the model from attempting to invoke forbidden tools, so the model does not waste calls on them.
PreToolUse hook.
Registered hooks fire as part of the permission pipeline. A PreToolUse hook can return a permissionDecision to deny or ask, or an updatedInput that modifies the tool's input parameters (types/hooks.ts). A hook allow does not bypass subsequent rule-based denies or safety checks. In the interactive path, the user dialog is queued first and hooks run asynchronously; coordinator and similar background-agent paths await automated checks before showing the dialog.
Rule evaluation.
The deny-first rule engine evaluates the request. MCP tools are matched by their fully qualified mcp__server__tool name, and server-level rules match all tools from that server.
Permission handler.
The handler in useCanUseTool.tsx branches into one of four paths based on runtime context:
- Coordinator: For multi-agent coordination mode. Attempts automated resolution (classifier, hooks, rules) before falling back to user interaction.
- Swarm worker: Handles worker agents in a multi-agent swarm with their own resolution logic.
- Speculative classifier: When
BASH_CLASSIFIERis enabled and the tool is BashTool, a speculative classifier races a pre-started classification result against a timeout. If the classifier returns with high confidence, the tool is approved instantly without user interaction. - Interactive: The fallback path. Presents the standard user approval dialog through the terminal UI.
In coordinator and some background paths, automated resolution is attempted before user interaction. In the standard interactive path, the dialog can appear first while hooks or classifier checks continue in parallel. When the classifier or a deny rule blocks an action, the system treats the denial as a routing signal rather than a hard stop: the model receives the denial reason, revises its approach, and attempts a safer alternative in the next loop iteration. The PermissionDenied hook event (Section 6) enables external code to observe and respond to these denials programmatically. This recovery-oriented design means that permission enforcement shapes the agent's behavior rather than simply halting it.
5.3 Auto-Mode Classifier and Hook Lifecycle
The auto-mode classifier (yoloClassifier.ts) participates in permission decisions when enabled. When TRANSCRIPT_CLASSIFIER is enabled, the classifier loads three prompt resources:
- A base system prompt.
- An external permissions template.
- For Anthropic-internal users, a separate internal template.
The classifier evaluates the proposed tool invocation against the conversation transcript and the permission template, producing an allow, deny, or request for manual approval. The function isUsingExternalPermissions() checks USER_TYPE and a forceExternalPermissions config flag to select the appropriate template.
Of the 27 hook events defined in the source (coreTypes.ts), five participate directly in the permission flow, each with a specific Zod-validated output schema (types/hooks.ts):
- PreToolUse: Can return
permissionDecision(deny or ask, but allow does not bypass subsequent checks),permissionDecisionReason, andupdatedInput(modify parameters). - PostToolUse: Can inject
additionalContextand, for MCP tools, returnupdatedMCPToolOutputto modify results before they enter the context. - PostToolUseFailure: Can inject
additionalContextfor error-specific guidance. - PermissionDenied: Can provide
retryguidance after auto-mode denials. - PermissionRequest: Can return a
decisionofallowordeny. In coordinator and similar paths, this can resolve before the user dialog. In the standard interactive path, it can also run alongside the dialog.
For non-MCP tools, the tool_result is emitted before the PostToolUse hook fires. For MCP tools, the result is delayed until after post hooks have run, enabling updatedMCPToolOutput to take effect.
5.4 Shell Sandboxing
Shell sandboxing provides an additional layer of protection for Bash and PowerShell commands (shouldUseSandbox.ts). The shouldUseSandbox() function checks whether sandboxing is globally enabled, whether the invocation has opted out, and whether the command matches any exclusion patterns.
When active, the sandbox provides filesystem and network isolation independent of the application-level permission model. A command can be permission-approved but still sandboxed, or permission-denied and never reach the sandbox check. The two systems operate on different axes: authorization versus isolation.
The layered safety architecture rests on an independence assumption: if one layer fails, others catch the violation. However, several layers share common performance constraints. Security researchers ([25]) have documented that commands with more than 50 subcommands fall back to a single generic approval prompt instead of running per-subcommand deny-rule checks, because per-subcommand parsing caused UI freezes. This example demonstrates that defense-in-depth can degrade when its layers share failure modes, a structural tension between safety and performance analyzed further in Section 11.3.
The permission pipeline governs whether a tool request executes. The next section examines what determines which tools exist in the first place: the extensibility architecture that assembles the model's action surface.
6. Extensibility: MCP, Plugins, Skills, and Hooks
Section Summary: Claude Code extends its functionality through four main mechanisms—MCP servers, plugins, skills, and hooks—that allow users to add custom tools, instructions, and behaviors at different stages of the agent's operation. MCP servers connect external resources like databases, plugins bundle and distribute various components for broad enhancements, skills provide domain-specific guidance such as custom code linting, and hooks intercept events to modify actions like tool execution or permissions. These approaches follow design principles of flexible, layered extensibility and programmable policies, balancing power with the limits of the AI's context window.
A recurring design question for coding agents is how to structure the extension surface: a single unified mechanism, a small number of specialized mechanisms, or a layered stack with different context costs. The analysis here illustrates two design principles from Table 1: composable multi-mechanism extensibility and externalized programmable policy. Returning to the running example, once Claude is trying to repair auth.test.ts and the earlier npm test request has been mediated by the permission system (Section 5), the next question is what extension-enabled action surface is available for the repair. When a turn begins in Claude Code, the model sees not just built-in tools like BashTool and FileReadTool, but also database query tools from an MCP server, a custom lint skill from .claude/skills/, and tools contributed by an installed plugin. These arrive through four mechanisms that extend the agent at different points of the loop: MCP servers provide external tool integration, plugins package and distribute bundles of components, skills inject domain-specific instructions, and hooks intercept the tool execution lifecycle. Anthropic's documentation ([12]) presents a broader view that includes CLAUDE.md (Figure 6) and subagents (Section 8) alongside the four mechanisms analyzed here. We treat CLAUDE.md and subagents in their own sections because they operate in different subsystems (context construction and delegation, respectively), but the context-cost ordering is architecturally significant: it reveals how each extension point trades off expressiveness against the bounded context window.
6.1 Four Extension Mechanisms

The mechanisms are implemented in distinct source directories (Figure 5) and serve different integration patterns:
MCP servers.
The Model Context Protocol is the primary external tool integration path. MCP servers are configured from multiple scopes: project, user, local, and enterprise, with additional plugin and claude.ai servers merged at runtime (services/mcp/config.ts). The MCP client (services/mcp/client.ts) supports multiple transport types: stdio, SSE, HTTP, WebSocket, SDK, plus IDE-specific variants (sse-ide, ws-ide) and an internal claudeai-proxy. Each connected server contributes tool definitions as MCPTool objects. Dedicated built-in tools ListMcpResourcesTool and ReadMcpResourceTool provide access to MCP resources.
Plugins.
Plugins serve a dual role: they are both a packaging format and a distribution mechanism. The PluginManifestSchema (utils/plugins/schemas.ts) accepts ten component types: commands, agents, skills, hooks, MCP servers, LSP servers, output styles, channels, settings, and user configuration. The plugin loader (utils/plugins/pluginLoader.ts) validates manifests and routes each component to its respective registry: commands and skills surface through the SkillTool meta-tool, agents appear in definitions consumed by AgentTool, hooks merge into the hook registry, MCP and LSP servers fold into their standard configurations, and output styles modify response formatting. A single plugin package can therefore extend Claude Code across multiple component types simultaneously, making plugins the primary distribution vehicle for third-party extensions.
Skills.
Each skill is defined by a SKILL.md file with YAML frontmatter. The parseSkillFrontmatterFields() function (loadSkillsDir.ts) parses 15+ fields including display name, description, allowed tools (granting the skill access to additional tools), argument hints, model overrides, execution context ('fork' for isolated execution), associated agent definitions, effort levels, and shell configuration. Skills can define their own hooks, which register dynamically on invocation. Bundled skills are registered in-memory at startup. When invoked, the SkillTool meta-tool injects the skill's instructions into the context.
Hooks.
The source code defines 27 hook events spanning tool authorization (PreToolUse, PostToolUse, PostToolUseFailure, PermissionRequest, PermissionDenied), session lifecycle (SessionStart, SessionEnd, Setup, Stop, StopFailure), user interaction (UserPromptSubmit, Elicitation, ElicitationResult), subagent coordination (SubagentStart, SubagentStop, TeammateIdle, TaskCreated, TaskCompleted), context management (PreCompact, PostCompact, InstructionsLoaded, ConfigChange), workspace events (CwdChanged, FileChanged, WorktreeCreate, WorktreeRemove), and notifications (coreTypes.ts, coreSchemas.ts). Of these, 15 have event-specific output schemas with rich fields supporting permission decisions, context injection, input modification, MCP result transformation, and retry control (types/hooks.ts). Persisted hook commands configured via settings and plugins use four command types: shell commands (type: command), LLM prompt hooks (type: prompt), HTTP hooks (type: http), and agentic verifier hooks (type: agent) (schemas/hooks.ts). The runtime additionally supports non-persistable callback hooks (type: callback) used by the SDK and internal instrumentation (types/hooks.ts). Hook sources include settings.json, plugins, and managed policy at startup; skill hooks register dynamically on invocation (utils/hooks.ts). The five tool-authorization events are detailed in Section 5.3.
6.2 Tool Pool Assembly
The assembleToolPool() function at tools.ts is documented as "the single source of truth for combining built-in tools with MCP tools." The assembly follows a five-step pipeline:
- Base tool enumeration.
getAllBaseTools()(tools.ts) returns an array of up to 54 tools: 19 are always included (such asBashTool,FileReadTool,AgentTool,SkillTool), and 35 more are conditionally included based on feature flags, environment variables, and user type. Anthropic-internal users get additional internal tools. Worktree mode enablesEnterWorktreeToolandExitWorktreeTool. Agent swarms enable team tools. When embedded search tools are available in the Bun binary, dedicatedGlobToolandGrepToolare omitted. - Mode filtering.
getTools()(tools.ts) applies mode-specific filtering. InCLAUDE_CODE_SIMPLEmode, only Bash, Read, and Edit are available (orREPLToolin the REPL branch; plus coordinator tools if applicable). Each tool'sisEnabled()method is called for runtime availability checks. - Deny rule pre-filtering.
filterToolsByDenyRules()(tools.ts) strips blanket-denied tools from the model's view before any call. - MCP tool integration. MCP tools from
appState.mcp.toolsare filtered by deny rules and merged with built-in tools. - Deduplication. Tools are deduplicated by name, with built-in tools taking precedence over MCP tools.
Both REPL.tsx (via the useMergedTools hook) and AgentTool.tsx (when building the worker tool set) invoke this function, ensuring consistent assembly across all execution paths. At request time, deferred tools may be hidden from the model's context until explicitly queried via ToolSearch (tools.ts).
Agent-based extension (custom agent definitions via .claude/agents/*.md and plugin-contributed agents) is covered in Section 8, because agents differ fundamentally from the four mechanisms above: they create new, isolated context windows rather than extending the current one.
6.3 Why Four Mechanisms?
Given that each additional extension mechanism increases the surface area developers must learn, a natural question is why Claude Code uses four distinct mechanisms rather than consolidating into one or two. The answer lies in the observation that different kinds of extensibility impose different costs on the context window, and a single mechanism cannot span the full range from zero-context lifecycle hooks to schema-heavy tool servers without forcing unnecessary trade-offs on extension authors.
:Table 2: What each extension mechanism uniquely provides. Context cost refers to how much of the bounded context window the mechanism consumes when active.
| Mechanism | Unique Capability | Context Cost | Insertion Point |
|---|---|---|---|
| MCP servers | External service integration (multi-transport) | High (tool schemas) | model():tool pool |
| Plugins | Multi-component packaging + distribution | Medium (varies) | All three points |
| Skills | Domain-specific instructions + meta-tool invocation | Low (descriptions only) | assemble():context injection |
| Hooks | Lifecycle interception + event-driven automation | Zero by default | execute():pre/post tool |
As Table 2 summarizes, each mechanism trades deployment complexity for a different kind of extensibility. MCP servers provide runtime tool integration (the model gains new callable tools) at the cost of server management overhead and context budget consumed by tool schemas. Skills shape how the agent thinks (not just what tools it has) at minimal context cost, since only frontmatter descriptions (not full content) stay in the prompt. Hooks provide cross-cutting lifecycle control (blocking, rewriting, or annotating tool calls) with no context footprint by default, though hooks can opt into injecting additional context. Plugins bundle any combination of the other three into distributable packages, acting as the packaging and distribution layer rather than a distinct runtime primitive. The graduated context-cost ordering (zero for hooks, low for skills, medium for plugins, high for MCP) means that cheap extensions can scale widely without exhausting the context window, while expensive ones are reserved for cases that genuinely require new tool surfaces.
Some agent frameworks provide a single extension mechanism, typically a tool-only API where all customization arrives as additional callable tools. Others use two tiers, separating tools from configuration or instruction injection. Claude Code's four-mechanism approach can accommodate a broader range of extension patterns, from zero-context event handlers to full external service integrations, but it increases the learning curve developers face when deciding which mechanism to use for a given integration task.
7. Context Construction and Memory
Section Summary: This section explains how the AI agent, called Claude Code, builds and manages its limited context window to handle ongoing tasks, treating context as a precious resource that needs careful organization and summarization to avoid overload. It draws from various sources like system prompts, environment details, conversation history, tool results, and special instruction files called CLAUDE.md, which are organized in a clear hierarchy from global user settings to project-specific rules for easy reading and editing. Unlike more complex systems using databases or hidden searches, this approach prioritizes transparency with plain text files, allowing users to inspect, change, and version-control what the agent remembers and follows.
How an agent manages its context window and persists user instructions is a central design choice, with different systems choosing between file-based transparency, database-backed retrieval, and opaque learned representations. The design choices here implement two principles from Table 1: context as scarce resource with progressive management and transparent file-based configuration and memory.
By this point in the running example, the task has accumulated state: the original request, the npm test permission outcome, the tool pool assembled in Section 6, and any file reads or command outputs gathered so far. This section asks how that growing state is packed into Claude Code's bounded context window before the next model call.
Before the model is called, the agent loop assembles a context window from the tool pool (Section 6), CLAUDE.md files, auto memory, and conversation history. The following subsections cover the assembly order, the CLAUDE.md hierarchy, and the multi-step compaction pipeline.
7.1 Context Window Assembly
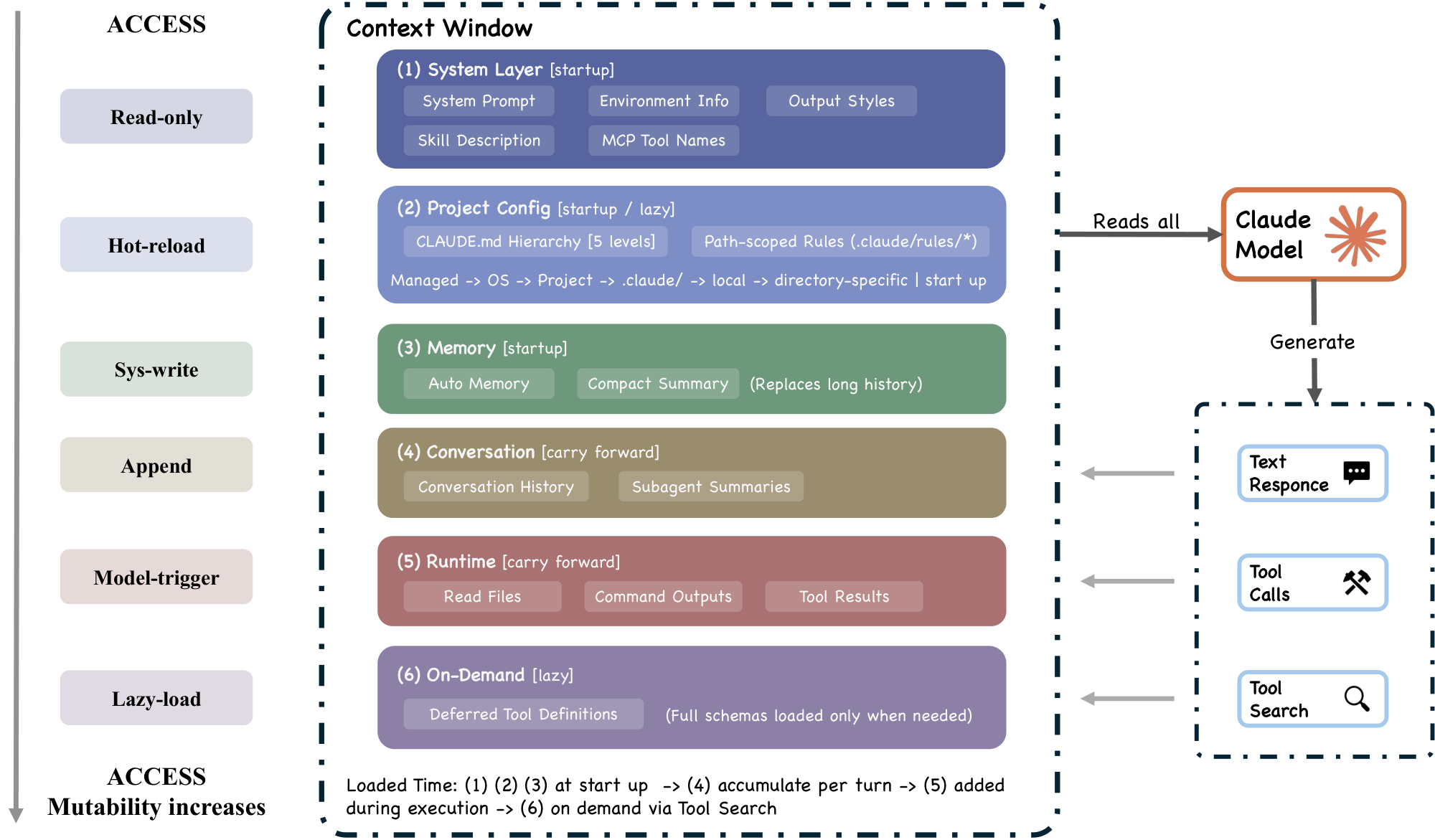
The context window (Figure 6) is assembled from the following sources, some at initial assembly and others injected late during the turn:
- System prompt, incorporating output style modifications and any
–append-system-promptflag content. - Environment info via
getSystemContext()(context.ts): git status (skipped in remote mode or when git instructions are disabled) and an optional cache-breaking injection for internal builds (gated byBREAK_CACHE_COMMAND). Memoized once per session. - CLAUDE.md hierarchy via
getUserContext()(context.ts): four-level instruction file hierarchy (Section 7.2). Also memoized. - Path-scoped rules: conditional and directory-matched rules that load lazily when the agent reads files in matching directories.
- Auto memory: contextually relevant memory entries prefetched asynchronously.
- Tool metadata: skill descriptions, MCP tool names, and deferred tool definitions (via ToolSearch, on demand).
- Conversation history: carried forward, subject to compaction.
- Tool results: file reads, command outputs, subagent summaries.
- Compact summaries: replacing older history segments.
The system prompt assembly at query.ts combines system context with the base prompt via asSystemPrompt(appendSystemContext(systemPrompt, systemContext))(). User context (CLAUDE.md and date) is prepended to the message array via prependUserContext(). This separation means CLAUDE.md content occupies a different structural position in the API request than the system prompt, potentially affecting model attention patterns.
Several context sources are injected late, after the main window is constructed: relevant-memory prefetch (query.ts), MCP instructions deltas (only new or changed server instructions), agent listing deltas, and background agent task notifications. The context window is therefore not static at assembly time but can grow during the turn.
7.2 CLAUDE.md Hierarchy and Auto Memory
A design principle shapes the memory system: stored context should be inspectable and editable by the user. CLAUDE.md files are plain-text Markdown rather than structured configuration or opaque database entries. This transparency choice trades expressiveness for auditability: users can read, edit, version-control, and delete any instruction the agent sees ([26]). Alternative memory architectures illustrate the trade-off. Retrieval-augmented approaches use embedding-based lookup to surface relevant prior context, gaining flexibility at the cost of inspectability: the user cannot easily see or edit what the retrieval system considers relevant. Database-backed memory offers structured querying but requires additional infrastructure and is opaque to version control. Claude Code's file-based approach makes every instruction the agent sees directly readable, editable, and committable alongside the codebase. The system does not use embeddings or a vector similarity index for memory retrieval; instead it uses an LLM-based scan of memory-file headers to select up to five relevant files on demand, surfacing them at file granularity rather than entry granularity. Embedding-based systems can retrieve individual entries more selectively, at the cost of inspectability and the infrastructure needed to maintain an index.
CLAUDE.md files follow a multi-level loading hierarchy. The source header (claudemd.ts) defines four memory types:
- Managed memory (e.g.
/etc/claude-code/CLAUDE.mdon Linux): OS-level policy for all users. - User memory (
/.claude/CLAUDE.md): private global instructions. - Project memory (
CLAUDE.md,.claude/CLAUDE.md, and.claude/rules/*.mdin project roots): instructions checked into the codebase. - Local memory (
CLAUDE.local.mdin project roots): gitignored, for private project-specific instructions.
File discovery traverses from the current directory up to root, checking for all project and local memory files in each directory. Files closer to the current directory have higher priority (loaded later).
Files load in "reverse order of priority": later-loaded files receive more model attention. For root-to-CWD directories, unconditional rules from .claude/rules/*.md load eagerly at startup. For nested directories below CWD, even unconditional rules are loaded lazily when the agent reads files in matching directories. This means the model's instruction set can evolve during a conversation as new parts of the codebase are explored.
CLAUDE.md content is delivered as user context (a user message), not as system prompt content (context.ts). This architectural choice has a significant implication: because CLAUDE.md content is delivered as conversational context rather than system-level instructions, model compliance with these instructions is probabilistic rather than guaranteed. Permission rules evaluated in deny-first order (Section 5) provide the deterministic enforcement layer. This creates a deliberate separation between guidance (CLAUDE.md, probabilistic) and enforcement (permission rules, deterministic). The function calls setCachedClaudeMdContent() to cache the loaded content for the auto-mode classifier, to avoid an import cycle between the CLAUDE.md loader and the permission system.
Memory files support an nclude directive for modular instruction sets (processMemoryFile() at claudemd.ts). Syntax variants include @path, @./relative, @ /home, and @/absolute. The directive works in leaf text nodes only (not inside code blocks). In the implementation, the including file is pushed first and included files are appended after it, circular references are prevented by tracking processed paths, and non-existent files are silently ignored.
7.3 Compaction Pipeline
The five-layer compaction pipeline (Section 4.3) implements the "context as bottleneck" principle through graduated compression (query.ts). Rather than a single strategy, Claude Code applies five layers in sequence, each with increasing aggressiveness (three are gated by feature flags; budget reduction is always active, while auto-compact is user-configurable). This graduated approach contrasts with simpler alternatives: many agent frameworks use single-pass truncation (dropping the oldest messages) or a single summarization step. The graduated design reflects a lazy-degradation principle: apply the least disruptive compression first, escalating only when cheaper strategies prove insufficient. The cost of this approach is complexity. Five interacting compression layers, several gated by feature flags, create behavior that is difficult for users to fully predict. Auto-compact produces a visible summary in the transcript, and microcompact emits a boundary marker, but context collapse operates without user-visible output. Simpler single-pass approaches sacrifice information but are easier to reason about.
- Budget reduction (always active): per-tool-result size limits.
- Snip (
HISTORY_SNIP): lightweight older-history trimming. - Microcompact (
CACHED_MICROCOMPACT): fine-grained cache-aware compression. - Context collapse (
CONTEXT_COLLAPSE): read-time virtual projection over history. - Auto-compact (enabled by default, can be disabled): full model-generated summary.
The buildPostCompactMessages() function (compact.ts) returns the following compacted output structure: [boundaryMarker, ...summaryMessages, ...messagesToKeep, ...attachments, ...hookResults]. The boundary marker is annotated with preserved-segment metadata via annotateBoundaryWithPreservedSegment(), recording headUuid, anchorUuid, and tailUuid to enable read-time chain patching. This mostly-append design means compaction never modifies or deletes previously written transcript lines; it only appends new boundary and summary events.
The compaction function compactConversation() (compact.ts) includes several design choices. Pre-compact hooks fire first, allowing hook-injected custom instructions. A GrowthBook feature flag controls whether the compaction path reuses the main conversation's prompt cache (a code comment documents a January 2026 experiment: "false path is 98% cache miss, costs $\sim$ 0.76% of fleet cache_creation"). After compaction, attachment builders re-announce runtime state (plans, skills, and async agents) from live app state, since compaction discards prior attachment messages but not the underlying state.
Context isolation becomes more critical when the system delegates work to subagents, each operating in its own bounded context window.
8. Subagent Delegation and Orchestration
Section Summary: Claude Code uses a delegation system to break down coding tasks by sending subtasks to specialized subagents, which operate in isolated environments to ensure safety and focus, following principles like restricting tools and requiring human approval for risky actions. The Agent tool handles this by routing work to built-in subagents for tasks like exploring code, planning, or verifying tests, or to custom ones defined by users, all configurable with their own permissions, tools, and isolation settings. This approach provides flexible boundaries, such as separate file copies via Git worktrees or remote execution, balancing autonomy with control without needing extra infrastructure like containers.
Multi-agent orchestration is a key design dimension for coding agents, with choices spanning parent-child hierarchies, peer-based conversation frameworks ([27]), and graph-structured workflow engines ([17]). Claude Code's delegation architecture implements the isolated subagent boundaries principle from Table 1, together with aspects of deny-first with human escalation (permission override) and reversibility-weighted risk assessment (subagent tool restrictions).
When Claude determines that the auth test fix requires first exploring the authentication module's structure, it can delegate this exploration to a subagent. The delegation mechanism is the Agent tool (AgentTool.tsx), with Task retained as a legacy alias. The model invokes Agent with a structured input including the delegation prompt, an optional subagent type, and configuration for isolation mode, permission overrides, and working directory.
8.1 The Agent Tool and Delegation Criteria
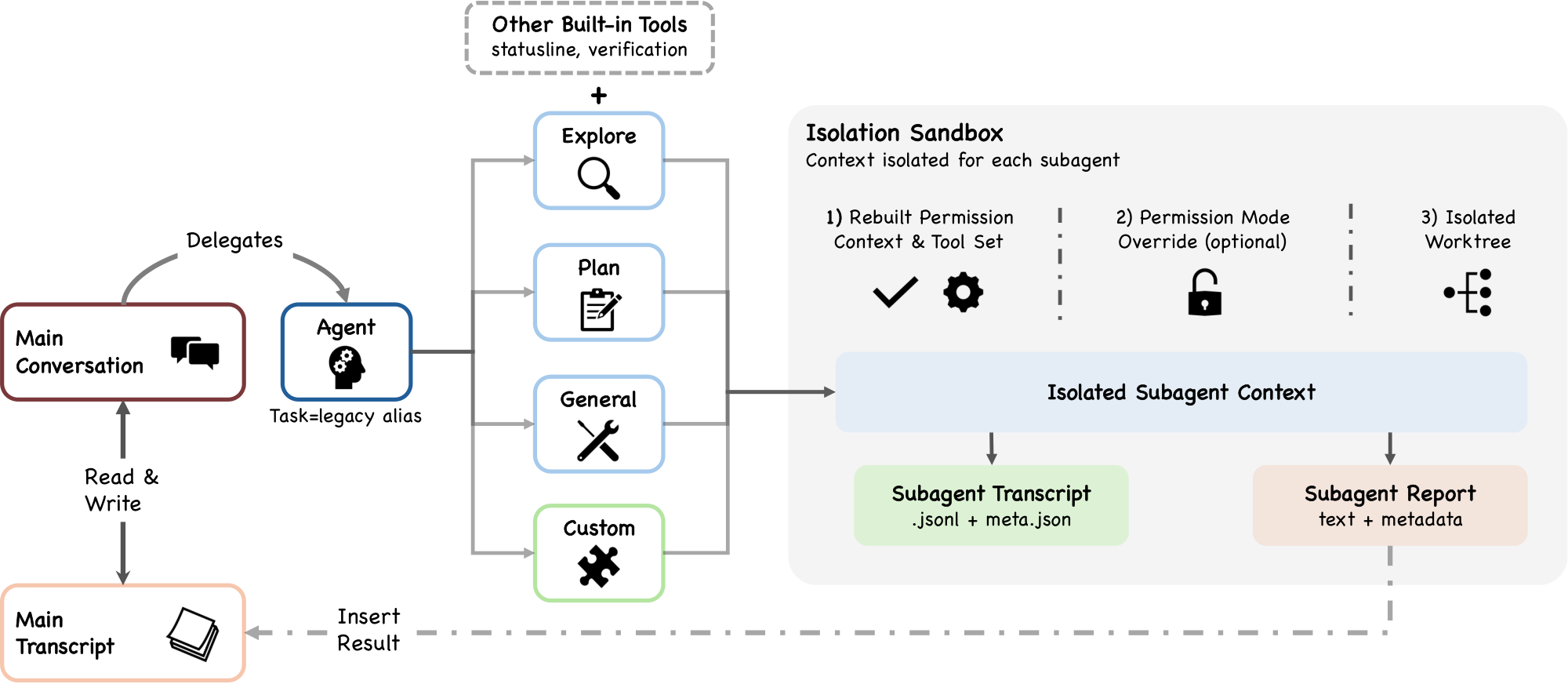
The Agent tool input schema (Figure 7) uses feature-gated fields, omitting optional parameters when their backing features are disabled. The isolation field offers ['worktree', 'remote'] for internal users and ['worktree'] for external users, determined at build time. The cwd field is gated by a feature flag. The run_in_background field is omitted when background tasks are disabled or when fork-subagent mode is enabled.
Claude Code provides up to six built-in subagent types, depending on feature flags and entrypoint:
- Explore: primarily read/search-oriented investigation, with write and edit tools in its deny-list.
- Plan: creates structured plans; execution proceeds through the standard permission model.
- General-purpose: broadly capable, used when explicitly requested (note: omitting the type may route to the fork-subagent path instead).
- Claude Code Guide: onboarding and documentation assistance, with its own
permissionModeoverride. - Verification: runs validation checks (test suites, linting).
- Statusline-setup: specialized for terminal status line configuration.
Beyond built-ins, users define custom subagents via .claude/agents/*.md files, and plugins contribute agent definitions via loadPluginAgents.ts. The markdown body of each file serves as the agent's system prompt, and YAML frontmatter specifies configuration fields including description, tools (allowlist), disallowedTools, model, effort, permissionMode, mcpServers, hooks, maxTurns, skills, memory scope, background flag, and isolation mode. JSON-formatted agent definitions support the same fields plus prompt as an explicit field (loadAgentsDir.ts). This means a custom agent can be a fully configured, isolated sub-system with its own tools, model, permissions, hooks, memory scope, and isolation mode. AgentTool sits alongside SkillTool in the base tool pool as a meta-tool that dispatches to these definitions, but the two differ fundamentally: SkillTool injects instructions into the current context window, while AgentTool spawns a new, isolated one. The tradeoff is that most subagent invocations require a self-contained prompt, because the default path does not inherit the parent's conversation history (the fork-subagent path is an exception). Conversation-based frameworks that share full transcript histories avoid this cost but risk context explosion as the number of agents grows.
8.2 Isolation Architecture
Subagent isolation supports multiple modes (AgentTool.tsx):
- Worktree: Creates a temporary git worktree, giving the subagent its own copy of the repository to modify without affecting the parent's working tree.
- Remote (internal-only): Launches in a remote Claude Code Remote environment, always running in the background.
- In-process (default): Shares the filesystem with the parent but operates in an isolated conversation context.
The permission override logic for subagents (runAgent.ts) involves several specific rules. When a subagent defines a permissionMode, the override is applied unless the parent is already in bypassPermissions, acceptEdits, or auto mode, since those modes always take precedence because they represent explicit user decisions about the safety/autonomy trade-off. For async agents, the system determines whether to avoid prompts through a cascade: explicit canShowPermissionPrompts first, then bubble mode (always show, since they escalate to the parent terminal), then the default (sync agents show prompts, async agents do not). Background agents that can show prompts set awaitAutomatedChecksBeforeDialog: true, ensuring the classifier and hooks resolve before interrupting the user.
These isolation modes occupy different points in a design space. Container-based isolation (used by SWE-Agent and OpenHands ([18, 19])) provides stronger resource boundaries but requires container infrastructure. Context-only isolation (used by conversation-based frameworks like AutoGen ([27])) shares the filesystem but separates conversation histories. Claude Code's worktree-based isolation provides filesystem-level separation with zero external dependencies, leveraging Git's built-in mechanism rather than introducing container orchestration.
When allowedTools is explicitly provided to runAgent() (runAgent.ts), a two-tier permission scoping model applies. SDK-level permissions from --allowedTools are preserved: "explicit permissions from the SDK consumer that should apply to all agents." But session-level rules are replaced with the subagent's declared allowedTools. When allowedTools is not provided (the common AgentTool path), the parent's session-level rules are inherited without replacement.
8.3 Sidechain Transcripts
Each subagent writes its own transcript as a separate .jsonl file with a .meta.json metadata file (sessionStorage.ts, runAgent.ts). This sidechain design means subagent histories are preserved for debugging and auditing but do not inflate the parent's session file. Only the subagent's final response text and metadata return to the parent conversation context; the full subagent history never enters the parent's context window, respecting the "context as bottleneck" principle.
The runAgent() function accepts 21 parameters covering agent definition, prompts, permissions, tools, model settings, isolation, and callbacks.
The summary-only return model is a deliberate context-conservation choice: conversation-based frameworks that share full transcript histories between agents risk context explosion as the number of agents grows. Even isolated-context parallelism carries substantial cost. Claude Code's agent teams consume approximately 7 $\times$ the tokens of a standard session in plan mode ([28]), which makes summary-only return more critical when subagents are also in isolated contexts.
For multi-instance coordination in agent teams, the harness uses file locking rather than a message broker or distributed coordination service ([28]). Tasks are claimed from a shared list via lock-file-based mutual exclusion, with lock files stored at predictable filesystem paths. This trades throughput for two properties: zero-dependency deployment (no external infrastructure required) and full debuggability (any agent's state can be inspected by reading plain-text JSON files).
9. Session Persistence and Recovery
Section Summary: Session persistence in coding agents like Claude Code ensures that conversations and changes can be saved and reloaded reliably, using simple append-only log files instead of complex databases for better transparency and ease of use. These logs store messages, tool results, and metadata in project-specific JSONL files, along with separate records for user prompt history and subagent activities, allowing the system to rebuild sessions when resuming or forking without losing the main conversation flow. However, session permissions are kept only in temporary memory and must be re-granted each time for safety, preventing outdated trust from carrying over, while special markers help maintain the structure during compaction and recovery.
Session persistence in coding agents involves a design choice between append-only logs, structured databases, checkpoint-based snapshots, and stateless architectures, each with different trade-offs in auditability, query power, and deployment complexity. Claude Code's persistence design implements the append-only durable state principle from Table 1. Session-scoped permissions live in memory only and are not serialized to the transcript, so resume rebuilds the permission context from CLI args and disk settings; requests the rebuilt context does not recognize fall back to deny-first prompting.
By the time the auth-test task reaches this section, the session contains the original prompt, tool invocations and results, compact boundaries, and the subagent summary from exploring the authentication module (Section 8). This section asks which of those artifacts are durably recorded and what can be recovered later without carrying forward the session's old permission grants.
Claude Code's persistence mechanisms write the conversation (messages, tool results, and compact boundaries) to disk as events occur.
9.1 Transcript Model
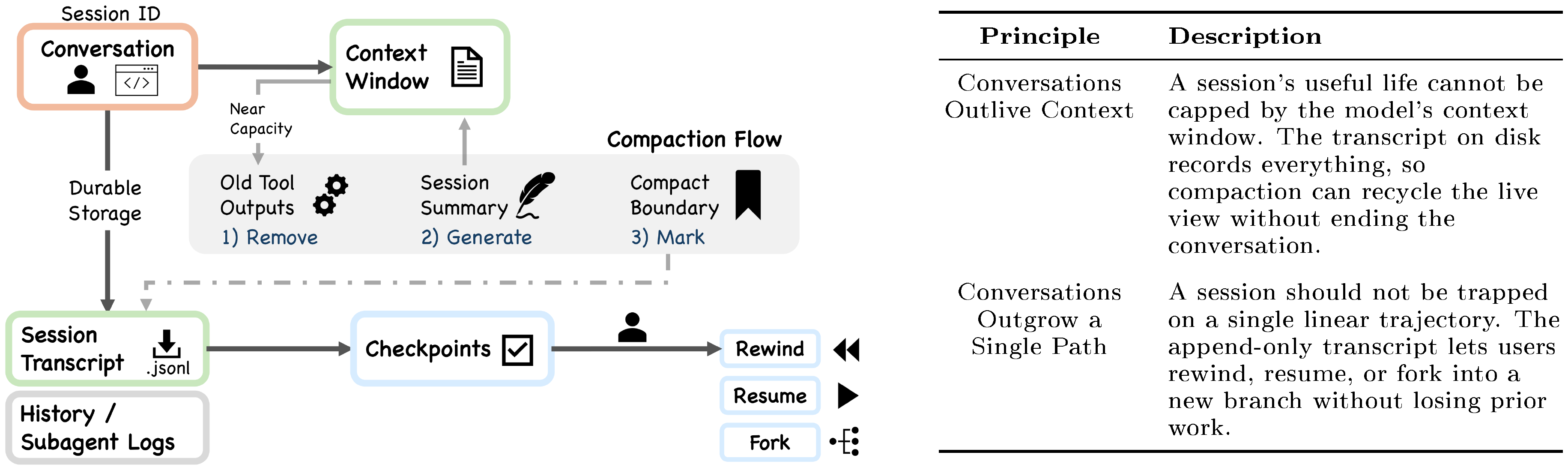
Session transcripts are stored as mostly append-only JSONL files at a project-specific path (with explicit cleanup rewrites as an exception) (Figure 8). The getTranscriptPath() function (sessionStorage.ts) computes this as join(projectDir, ${getSessionId()}.jsonl), where projectDir is determined by first checking getSessionProjectDir() (set by switchSession() during resume/branch) and falling back to getProjectDir(getOriginalCwd())().
Three persistence channels operate independently:
- Session transcripts: Conversation records including user, assistant, attachment, and system messages, plus compaction and other metadata events. Project-scoped, one file per session.
- Global prompt history: User prompts only, stored in
history.jsonlat the Claude configuration home directory (history.ts). ThemakeHistoryReader()generator yields entries in reverse order viareadLinesReverse(), supporting Up-arrow and ctrl+r navigation. - Subagent sidechains: Separate
.jsonl+.meta.jsonfiles per subagent (Section 8.3).
Session transcripts store several kinds of events beyond simple messages, including compaction markers, file-history snapshots, attribution snapshots, and content-replacement records. The append-only JSONL format is a deliberate choice favoring auditability and simplicity over query power. Every event is human-readable, version-controllable, and reconstructable without specialized tooling. Database-backed alternatives would enable richer queries over session history but introduce deployment dependencies and reduce transparency.
The session identity system pairs sessionId with sessionProjectDir, set together during resume or branch. The transcript path must use the same project directory that was active when messages were written, to avoid hooks looking in the wrong directory.
9.2 Resume, Fork, and Not Restoring Permissions
The --resume flag rebuilds the conversation by replaying the transcript (conversationRecovery.ts). Fork creates a new session from an existing one (commands/branch/branch.ts). However, resume and fork do not restore session-scoped permissions; users must grant them again in the new session. This is a deliberate safety-conservative design choice: sessions are treated as isolated trust domains. Restoring previously granted permissions on resume would create a convenience benefit but risk carrying stale trust decisions into a changed context. The architecture opts for re-granting over implicit persistence, accepting user friction as the cost of maintaining the safety invariant that trust is always established in the current session.
The compact_boundary marker is carefully designed to work with persistence. The annotateBoundaryWithPreservedSegment() function (compact.ts) records headUuid, anchorUuid, and tailUuid in the boundary event. These UUIDs enable the session loader to patch the message chain at read time: preserved messages keep their original parentUuids on disk, and the loader uses boundary metadata to link them correctly. This mostly-append design means compaction never modifies or deletes previously written transcript lines.
The "checkpoints" in Claude Code are file-history checkpoints for --rewind-files, stored at /.claude/file-history/<sessionId>/. These are file-level snapshots for reverting filesystem changes, not a generic checkpoint store.
The preceding sections have documented Claude Code's answers to recurring design questions. The next section contrasts Claude Code's design choices with those of an architecturally independent AI agent system.
10. Comparative Analysis: Claude Code and OpenClaw
Section Summary: This section compares Claude Code, a command-line tool for AI-assisted coding tied to a single project repository, with OpenClaw, an open-source system that acts as a persistent hub connecting AI agents to various messaging apps like WhatsApp and Slack across devices. While both address similar design challenges in AI agent systems—such as security, tool use, and extensions—they arrive at different solutions due to their contrasting scopes: Claude Code focuses on short-lived, developer-centric sessions, whereas OpenClaw emphasizes ongoing, multi-channel personal assistance. The analysis across six key dimensions, summarized in a table, illustrates how shifting deployment contexts leads to varied architectural choices, highlighting the two systems' complementary potential, like integrating Claude Code into OpenClaw.
The preceding sections documented Claude Code's answers to recurring design questions about loop architecture, safety, extensibility, context management, delegation, and persistence. To calibrate these findings, this section compares Claude Code with OpenClaw, an independent open-source AI agent system that answers many of the same design questions from a fundamentally different starting point. OpenClaw is a local-first WebSocket gateway that connects roughly two dozen messaging surfaces (WhatsApp, Telegram, Slack, Discord, Signal, and others) to an embedded agent runtime, with companion apps on macOS, iOS, and Android ([6]). Where Claude Code is a CLI coding harness bound to a single repository session, OpenClaw is a persistent control plane for multi-channel personal assistance. The two systems occupy different regions of the agent design space. The value of the comparison lies in showing how the same recurring questions produce different architectural answers when the deployment context changes.
10.1 Six Comparison Dimensions
Table 3 summarizes the comparison across six dimensions. Each dimension corresponds to a design question that both systems must answer.
::: {caption="Table 3: Architectural comparison: Claude Code vs. OpenClaw across six design dimensions. Each row captures a recurring design question and the different answers the two systems provide."}
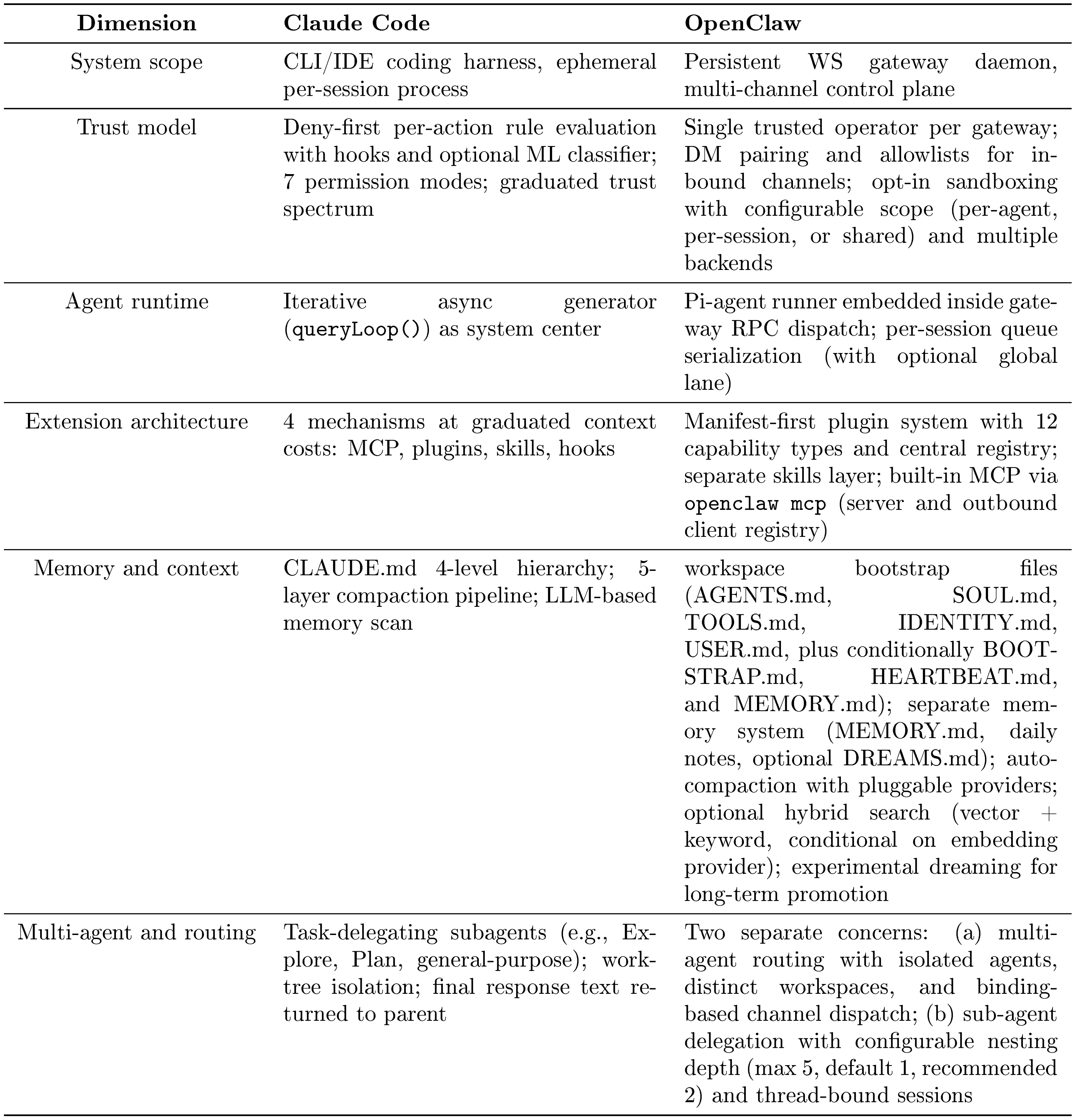
:::
System scope and deployment model.
Claude Code runs as an ephemeral CLI process bound to a single repository. Each session starts and ends with the terminal. OpenClaw runs as a persistent daemon (default port 18789, loopback-only) that owns all messaging surface connections and coordinates clients, tools, and device nodes over a typed WebSocket protocol. This difference in system scope is the most fundamental architectural divergence: it determines how every other design question is framed. A compositional relationship also exists: OpenClaw can host Claude Code, OpenAI Codex, and Gemini CLI as external coding harnesses through its ACP (Agent Client Protocol) integration, making the two systems stackable rather than purely alternative.
Trust model and security architecture.
The systems address different threat models. Claude Code assumes an untrusted model operating within a trusted developer's machine: the deny-first permission system (Section 5) evaluates every tool invocation, the ML classifier provides automated safety assessment, and seven permission modes create a graduated autonomy spectrum. OpenClaw assumes a single trusted operator per gateway instance. Its security architecture begins with identity and access control (DM pairing codes, sender allowlists, gateway authentication) rather than per-action safety classification. Tool policy uses configurable allow/deny lists per agent rather than a centralized classifier. Sandboxing is available as an opt-in feature with multiple backends (Docker, SSH, or OpenShell) and configurable scope (per-agent, per-session, or shared); a non-main mode can sandbox all non-main sessions when enabled, though sandboxing is not active by default. The OpenClaw security documentation explicitly states that hostile multi-tenant isolation on a shared gateway is not a supported security boundary. This difference reflects a design choice about where the trust boundary sits: Claude Code places it between the model and the execution environment; OpenClaw places it at the gateway perimeter.
Agent runtime and tool orchestration.
Both systems implement agentic loops, but these loops occupy different positions in their respective architectures. In Claude Code, the queryLoop() async generator (Section 4) is the system's center: all interfaces feed into it, and it directly manages context assembly, model calls, tool dispatch, and recovery. In OpenClaw, the agent runtime (an embedded Pi-agent core) sits inside a larger gateway dispatch layer. The gateway's agent RPC validates parameters, resolves sessions, and returns immediately; the embedded runner then executes the agentic loop while emitting lifecycle and stream events back through the gateway protocol. Runs are serialized through per-session queues and an optional global lane, preventing tool and session races across the multi-channel surface. Both systems follow the ReAct pattern ([22]), but OpenClaw's loop is a component within a control plane rather than the control plane itself.
Extension architecture.
Claude Code's four extension mechanisms (MCP, plugins, skills, hooks) are organized by context cost (Section 6): hooks consume zero context, skills consume low context, and MCP servers consume high context. All four extend a single agent's context window and tool surface. OpenClaw uses a manifest-first plugin system with four architectural layers (discovery, enablement, runtime loading, surface consumption) and twelve capability types including text inference, speech, media understanding, image/music/video generation, web search, and messaging channels. Plugins register capabilities into a central registry; the gateway reads the registry to expose tools, channels, provider setup, hooks, HTTP routes, CLI commands, and services. OpenClaw also has a separate skills layer with multiple sources (workspace, project-level, personal, managed, bundled, and extra directories, with workspace skills taking highest precedence) plus a public registry (ClawHub) and supports MCP through built-in openclaw mcp commands (server and outbound client registry). The key architectural difference is that Claude Code's extensions modify one agent's action surface, while OpenClaw's plugins extend the gateway's capability surface across all agents.
Memory, context, and knowledge management.
Both systems use transparent file-based memory rather than opaque databases. Claude Code loads a four-level CLAUDE.md hierarchy and manages context pressure through a five-layer compaction pipeline (Figure 6). Memory retrieval uses an LLM-based scan of file headers. OpenClaw injects workspace bootstrap files into the system prompt at session start: five core files (AGENTS.md, SOUL.md, TOOLS.md, IDENTITY.md, USER.md) plus conditionally BOOTSTRAP.md, HEARTBEAT.md, and MEMORY.md, with large files truncated. Separately, the memory system manages three file types: MEMORY.md for long-term durable facts, date-stamped daily notes (memory/YYYY-MM-DD.md), and an optional DREAMS.md for dreaming sweep summaries. When an embedding provider is configured, memory search uses hybrid retrieval combining vector similarity with keyword matching. An experimental dreaming system performs background consolidation, scoring candidates and promoting only qualified items from short-term recall into long-term memory. Before compaction, OpenClaw automatically reminds the agent to save important notes to memory files, preventing context loss. Both systems share the design commitment to user-visible, editable memory. OpenClaw invests more heavily in structured long-term memory promotion (dreaming, daily notes, memory search), while Claude Code invests more in graduated context compression (five layers with cache awareness). OpenClaw also supports pluggable compaction providers and session pruning, but its compaction pipeline is less graduated than Claude Code's five-layer system.
Multi-agent architecture and routing.
This dimension reveals the starkest architectural difference. Claude Code's multi-agent model is task delegation: the parent spawns subagents (Explore, Plan, general-purpose, and custom types) that operate in isolated context windows with restricted tool sets and return summary-only results (Section 8). Worktree isolation provides filesystem-level separation. OpenClaw separates two distinct concerns. First, multi-agent routing: a single gateway can host multiple fully isolated agents, each with its own workspace, authentication profiles, session store, and model configuration, routed to specific channels or senders via deterministic binding rules. Second, sub-agent delegation: within a single agent, background runs can be spawned with configurable nesting depth (maximum 5, default 1, recommended 2), thread-bound sessions on supported channels, and configurable tool policy by depth. OpenClaw's project vision explicitly rejects agent-hierarchy frameworks as a default architecture. The distinction matters because Claude Code's subagents are subordinate workers within one user's coding session, while OpenClaw's multi-agent routing creates genuinely independent agent instances serving different users or purposes through different channels.
10.2 What the Contrast Reveals
The comparison surfaces three observations about the design space of AI agent systems.
First, the recurring design questions identified in Section 3.1 (where reasoning lives, what safety posture to adopt, how to manage context, how to structure extensibility) apply beyond coding agents. OpenClaw answers every one of these questions, but from the starting point of a multi-channel personal assistant rather than a repository-bound coding tool. The questions are stable; the answers vary with deployment context.
Second, the systems make opposite bets on several dimensions. Claude Code invests in graduated per-action safety evaluation; OpenClaw invests in perimeter-level identity and access control. Claude Code treats the agent loop as the architectural center; OpenClaw treats the gateway control plane as the center and embeds the agent loop as one component. Claude Code's extensions modify a single context window; OpenClaw's plugins extend a shared gateway surface. These inversions are not arbitrary: they follow from the different trust models and deployment topologies.
Third, the compositional relationship between the two systems is architecturally significant. OpenClaw can host Claude Code as an external coding harness via ACP, meaning the two systems are composable rather than exclusive alternatives. This suggests that the design space of AI agents is not a flat taxonomy but a layered one, where gateway-level systems and task-level harnesses can compose.
11. Discussion
Section Summary: This discussion section synthesizes how Claude Code, an AI coding tool, addresses key design challenges in areas like safety, extensibility, and context management, revealing a unified philosophy that prioritizes robust operational infrastructure over rigid decision-making structures to give the AI model broad autonomy. It highlights how this approach invests heavily in deterministic systems—like permission controls and recovery mechanisms—that support the model's judgments, contrasting with more constraining frameworks in other AI agents and suggesting a path toward operating-system-like designs for future tools. The analysis also explores tensions between core values such as safety and autonomy, along with broader trade-offs and evidence from studies indicating potential long-term risks to developers' skills from over-reliance on AI assistance.
The analysis in the preceding sections documented how Claude Code answers recurring design questions about loop architecture, safety posture, extensibility, context management, delegation, and persistence. Each answer reflects a position in a design space with real alternatives and measurable trade-offs. This section examines what those answers reveal when read together: the design philosophy they reflect (Section 11.1), the value tensions they create (Section 11.2), the architectural trade-offs they entail (Section 11.3), the empirical predictions they generate (Section 11.4), and the cross-cutting commitments that recur across subsystems (Section 11.7). The five-value framework from Section 2.1 serves as the organizing lens throughout.
11.1 Design Philosophy
The values and design principles introduced in Section 2 predict an architecture that invests in operational infrastructure rather than decision scaffolding. The implementation confirms this: the architecture documented in Section 3, Section 4, Section 5, Section 6, Figure 6, Section 8, and Section 9 is overwhelmingly deterministic infrastructure (permission gates, tool routing, context management, recovery logic), with the LLM invoked as a stateless completion endpoint. An estimated 1.6% of the codebase constitutes decision logic, the remaining 98.4% is the operational harness. This ratio is not accidental.
The design principles documented in Section 2.2 underpin this approach: the harness creates conditions under which the model can decide well, rather than constraining its choices.
This design runs counter to the dominant pattern in agent engineering, where frameworks such as LangGraph route model outputs through explicit graph nodes with typed edges, and systems like Devin pair multi-step planners with heavy operational infrastructure. Claude Code instead gives the model maximum decision latitude within a rich operational harness. The engineering complexity exists not to constrain the model's decisions but to enable them. This layered architecture, where the model reasons and the harness enforces, raises the question of whether agentic coding tools are converging toward operating-system-like abstractions in which the core loop serves as the kernel and everything else constitutes the OS.
The design gains additional significance as frontier models converge in practical capability for coding tasks: the quality of the surrounding operational harness becomes the principal differentiator, validating an architecture that invests in infrastructure over decision scaffolding. For agent builders, the implication is that investing in deterministic infrastructure such as context management, safety layering, and recovery mechanisms may yield greater reliability gains than adding planning scaffolding around increasingly capable models.
Taken together, the preceding sections show that production coding agents face recurring design choices: where reasoning lives relative to the harness, how the iteration loop is structured, what safety posture to adopt by default, how the extension surface is partitioned, how context is assembled and compressed, how subagents are delegated and orchestrated, and how sessions persist across boundaries. Claude Code's answers to these questions form a coherent design point that privileges model autonomy within a rich operational harness.
This philosophy assumes that rich deterministic infrastructure can adequately support unconstrained model judgment. The following subsections examine where this assumption is tested.
11.2 Value Tensions
The five values identified in Section 2.1 generate tensions where pursuing one value constrains another (Table 4). These tensions are not design failures; they are structural consequences of pursuing multiple values simultaneously. We report the tensions with the strongest supporting evidence, not the full combinatorial set.
::: {caption="Table 4: Tensions between values, with supporting evidence. Each tension demonstrates that the two values capture genuinely distinct concerns."}
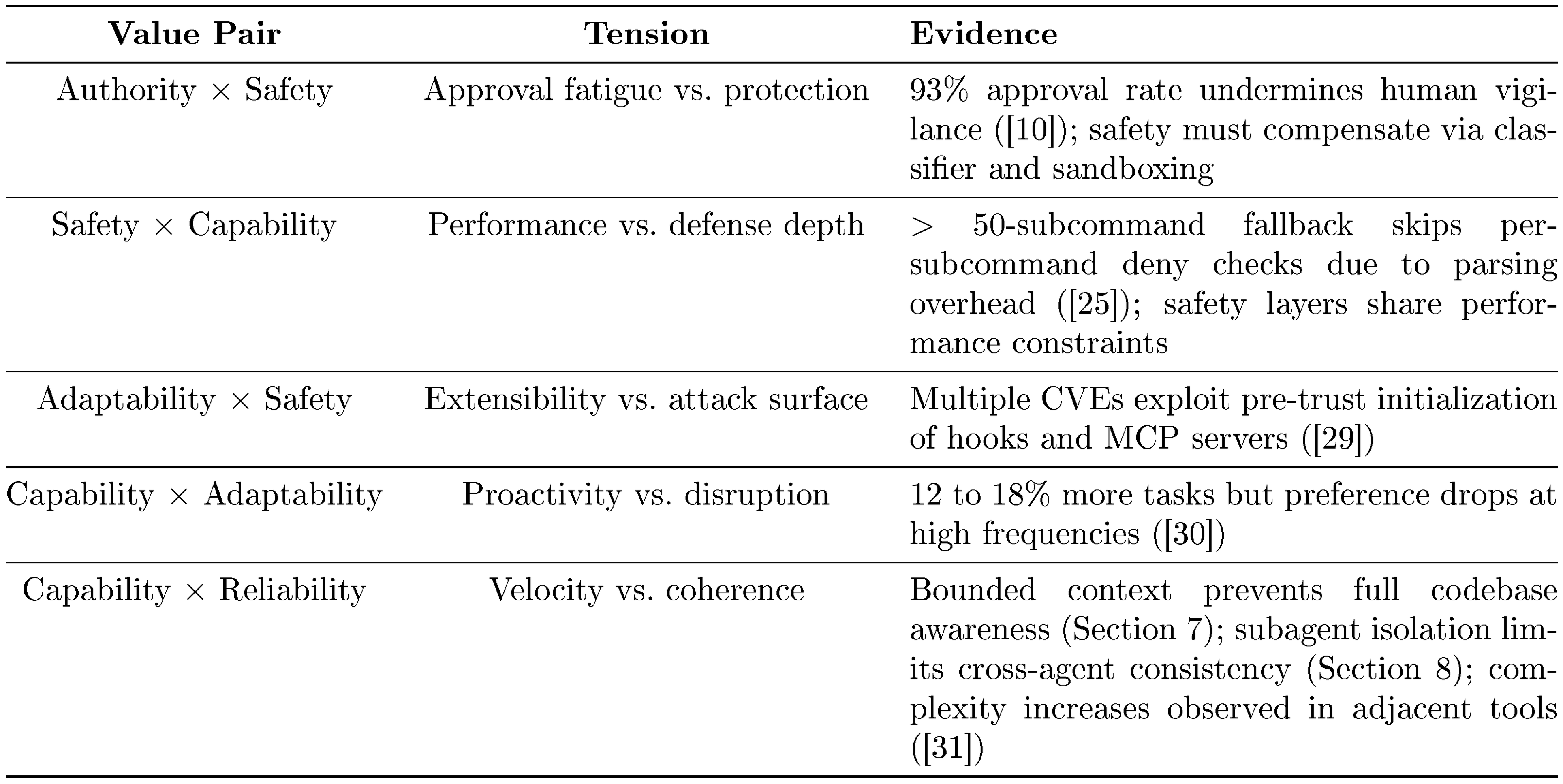
:::
Two additional tensions surface through the evaluative lens of long-term capability preservation (Section 2.4). A randomized controlled trial of 16 experienced developers across 246 tasks ([32]) found that AI tools made developers 19% slower, despite a perceived 20% improvement. A causal analysis of Cursor adoption across 807 repositories ([31]) found that code complexity increased by 40.7%. An EEG study of 54 participants ([33]) found that LLM users showed weakened neural connectivity that persisted after AI was removed. Researchers have proposed protocols for measuring cognitive offloading in AI-assisted programming, motivated by concerns that students using AI produce applications without understanding the underlying logic ([34]). These findings, combined with a 25% decline in entry-level tech hiring between 2023 and 2024 ([35]), suggest that the tension between capability amplification and long-term sustainability extends beyond individual productivity to the broader developer pipeline. This evidence motivates the evaluative lens but does not target Claude Code's architecture specifically; it applies to any agent system with bounded context and tool-use loops.
11.3 Architectural Trade-offs
The tensions in Table 4 manifest as concrete architectural trade-offs in four areas. The long-term sustainability concerns documented in the evaluative lens paragraph above surface in the empirical predictions of Section 11.4.
Safety vs. autonomy.
The permission modes (five always present, plus auto when the classifier feature flag is active, and the internal bubble mode) create a gradient from plan (user approves all plans) through default, acceptEdits, auto (ML classifier), dontAsk, to bypassPermissions (skips most prompts but safety-critical checks remain). The progression represents a monotonically decreasing safety gradient with increasing autonomy. Not restoring permissions on resume reflects a deliberate choice to err toward safety: security state does not persist implicitly across session boundaries.
The safety-autonomy gradient is shaped not only by architectural design but by user behavior. Anthropic's auto-mode analysis ([10]) found that users approve approximately 93% of permission prompts, indicating that approval fatigue renders interactive confirmation behaviorally unreliable. Longitudinal usage data ([9]) shows that auto-approve rates increase from approximately 20% at fewer than 50 sessions to over 40% by 750 sessions, with substantial increases in session duration. These patterns suggest that the gradient is navigated not by deliberate mode selection but by gradual habituation. Sandboxing reduced the frequency of permission prompts by an estimated 84% ([11]), reframing the problem as a human-factors concern: the architectural response to unreliable human approval is to reduce the number of decisions humans must make.
More fundamentally, the defense-in-depth architecture described in Section 5 rests on an independence assumption: if one safety layer fails, others catch the violation. But Claude Code's safety layers share common performance and economic constraints. The auto-mode classifier is a separate LLM call with direct token cost. The bashSecurity.ts module performs sequential AST-based checks with parsing latency. The deny-first rule evaluation operates on command structure. When performance pressure pushes toward reducing these costs, layers can degrade simultaneously. Security researchers ([25]) have documented that commands with more than 50 subcommands fall back to a single generic approval prompt instead of running per-subcommand deny-rule checks, because per-subcommand parsing caused UI freezes, demonstrating that defense-in-depth fails when the independence assumption is violated.
This tension is structural. Any LLM-based agent system that uses the model itself for safety evaluation faces it. The relevant evaluation criterion is not whether any individual layer can be bypassed, but how many independent layers must fail simultaneously and whether they share failure modes.
Permission model under adversarial conditions.
Independent security research provides empirical validation of the permission architecture, specifically by revealing a temporal ordering property not captured in Figure 4. Two independently verified vulnerabilities share a root cause in pre-trust initialization ordering: code executing during project initialization (hooks, MCP server connections, and settings file resolution) runs before the interactive trust dialog is presented to the user[^4]. This pre-trust execution window falls outside the deny-first evaluation pipeline (permissions.ts), creating a structurally privileged phase where the safety guarantees documented in Section 5 do not yet apply.
[^4]: The two pre-trust ordering vulnerabilities are CVE-2025-59536 (CVSS 8.7) and CVE-2026-21852 (CVSS 5.3) ([29]), discovered by Check Point Research. CVE-2025-54794 and CVE-2025-54795 ([36]) exploit path validation and command parsing flaws elsewhere in the permission pipeline, separately. All four were patched within weeks of disclosure.
This pattern reveals that the permission pipeline depicts a spatial ordering of safety checks but does not capture the temporal dimension: specifically, when during session initialization each mechanism becomes active. The initialization sequence (extension loading, then trust dialog, then permission enforcement) creates a window where the extensibility architecture (Section 6) operates before the safety architecture (Section 5) is fully engaged. This finding refines the extensibility-versus-simplicity tension by adding a security dimension: extensibility creates attack surface not only through combinatorial complexity but through initialization ordering.
Context efficiency vs. transparency.
The five-layer compaction pipeline achieves effective context management, but compression is largely invisible to the user. When budget reduction replaces a long tool output with a reference, when context collapse substitutes messages with a summary (described in the source as "a read-time projection over the REPL's full history"), or when snip trims older history, the user has no easy way to inspect what was lost. The cache-aware behavior of microcompact adds further opacity, as compression decisions are influenced by prompt caching in ways not visible to the user.
Simplicity vs. extensibility.
The four extension mechanisms enable rich customization but create combinatorial interactions. A plugin contributes a PreToolUse hook that modifies tool inputs. The auto-mode classifier reads cached CLAUDE.md content. Path-scoped rules load lazily when new directories are read, potentially changing classifier behavior mid-conversation. The permission handler's four branches interact with the hook pipeline at multiple points. These cross-cutting concerns create emergent behaviors difficult to predict from any single configuration file.
11.4 Empirical Predictions and Early Signals
The architectural properties documented in this paper generate testable predictions about code quality outcomes not derivable from the source code alone. The bounded context window (Figure 6) prevents the agent from maintaining simultaneous awareness of the full codebase: the five-layer compaction pipeline preserves useful information but introduces lossy compression at each stage. This makes it architecturally predicted that agent-generated code will exhibit higher rates of pattern duplication and convention violation than code produced with full codebase visibility. Subagent isolation (Section 8), where each subagent operates in its own context window with an independently assembled tool pool, compounds the effect: parallel agents can independently re-implement solutions that already exist elsewhere. The design philosophy of Section 11.1 trusts the model to make good local decisions, but good local decisions can produce poor global outcomes when the model lacks global context.
Published empirical work on architecturally similar tools provides data consistent with these predictions. A causal analysis of Cursor adoption across 807 repositories ([31]) found a statistically significant increase in code complexity, with an initial velocity spike that dissipated to baseline by month three; rising complexity was associated with a proportional decrease in future development velocity, suggesting that the gains are self-cancelling[^5]. A large-scale audit of 304, 000 AI-authored commits across 6, 275 repositories ([37]) found measurable technical debt, with approximately one-quarter of AI-introduced issues persisting to the latest revision and security-related issues persisting at a substantially higher rate. While these studies target adjacent systems, the architectural parallels (bounded context, tool-use loops, single-pass generation) suggest the findings are relevant to the design analyzed here.
[^5]: Complexity +40.7% ($p < 0.001$); velocity spike +281% in month one, baseline by month three.
Claude Code's context management pipeline is specifically designed to mitigate these effects: graduated compression preserves the most recent and most relevant context, cache-aware compaction avoids invalidating prompt caches during compression, read-time projection maintains full history for reconstruction while presenting a compressed view to the model, and subagent summary isolation prevents exploratory noise from accumulating in the parent context. Whether these mechanisms are sufficient to overcome the structural limitations of bounded context is a directly measurable empirical question that the source-level analysis in this paper cannot resolve.
11.5 Limitations
Beyond the methodological limitations in Appendix B.3, several analytical constraints apply. The memoized context assembly functions (getSystemContext() and getUserContext() both use lodash memoize at context.ts) mean that git status and CLAUDE.md content are cached rather than recomputed on every turn. Dynamic changes during a conversation may not be reflected immediately, though compaction can clear caches and lazy-loaded path-scoped rules provide a partial counter-mechanism.
Feature flags create build-time variability. In a build where TRANSCRIPT_CLASSIFIER is false, the entire auto-mode classifier is eliminated. Feature-gated modules use dynamic require() rather than static import (e.g., query.ts for context collapse), because feature() only works in if/ternary conditions due to a bun:bundle tree-shaking constraint. Different build targets may produce functionally different applications.
11.6 Emerging Directions
Several aspects of the implementation relate to broader design questions. Longer context windows would reduce compaction pressure, potentially simplifying the graduated pipeline. Multi-modal tools (screenshots, diagrams, UI previews) would expand the tool surface and create new context challenges. Formal verification of permission properties (for example, proving that deny rules always take precedence, that sandboxed commands cannot escape isolation, or that resumed sessions cannot inherit stale permissions) would provide stronger safety guarantees.
Architectural decoupling.
The tightly coupled local architecture analyzed here is one point on a spectrum that is already evolving. Anthropic's own Managed Agents work ([38]) describes virtualizing the components of an agent (session, harness, sandbox) so that "each became an interface that made few assumptions about the others, and each could fail or be replaced independently", drawing an explicit analogy to how operating systems virtualized hardware into processes and files. The Harness Design essay ([14]) makes a similar point from a different angle, observing that "the space of interesting harness combinations doesn't shrink as models improve"; instead, "it moves". The architecture documented in this paper should therefore be read as a snapshot of a co-evolving system rather than a fixed optimum.
Memory as a first-class subsystem.
The memory survey of [39] argues that agent memory is becoming a distinct cognitive substrate rather than a side effect of context window management, and identifies automated memory management, RL-driven memory, and trustworthy memory (privacy, explainability, and hallucination robustness) as open frontiers. Claude Code today exposes the factual tier (CLAUDE.md, auto memory) and the working tier (the conversation window); the experiential tier (accumulated, automatically curated playbooks of strategies learned from past sessions) is the natural next step, and the context-engineering literature ([40]) has started to provide mechanisms for that accumulation.
Observability and silent failure.
Industry surveys suggest that the dominant failure mode of deployed agents is not crashes but silent mistakes. Bessemer's 2026 infrastructure report ([41]) estimates that "78% of AI failures are invisible", while LangChain's 1,340-respondent state-of-agent-engineering survey ([42]) identifies quality, not cost, as the top barrier to production use and finds a wide gap between observability (nearly 89% adoption) and offline evaluation (52.4%). The architecture analyzed here gives operators visibility into tool calls, hooks, and session transcripts; closing the evaluation gap likely requires additional scaffolding (generator-evaluator separation, sprint contracts, and post-hoc checks of the kind discussed in [14]) rather than model improvements alone.
Governance.
Broader governance trends will constrain the design space as agents become more autonomous. The International AI Safety Report ([43]) warns that "AI agents pose heightened risks because they act autonomously, making it harder for humans to intervene before failures cause harm, " and the MIT AI Agent Index ([44]) finds that only 13.3% of indexed agentic systems publish agent-specific safety cards. Emerging regulatory frameworks, notably the EU AI Act (fully applicable August 2026) and evolving copyright jurisprudence around AI-generated code, may impose external constraints on logging, transparency, and human oversight that shape how coding agent architectures evolve.
Proactive architectures.
The feature-gated KAIROS system illustrates how this architecture may evolve beyond reactive tool use. KAIROS implements a persistent background agent with tick-based heartbeats: when no user messages are pending, the system injects periodic <tick> prompts, and the model decides whether to act or sleep. The design directly addresses a documented tension: proactive AI assistants increase task completion by 12 to 18% but reduce user preference at high frequencies ([30]). KAIROS resolves this through terminal focus awareness (maximizing autonomous action when the user is away, increasing collaboration when present) and economic throttling via SleepTool (each wake-up costs an API call; the prompt cache expires after five minutes of inactivity, making sleep/wake an explicit cost optimization). This binding of proactivity to both user presence and token economics is uncommon among production agent systems, though KAIROS cannot be confirmed as active in production builds.
11.7 Recurring Design Choices
Reading the six subsystem analyses together reveals three cross-cutting design commitments that recur across otherwise independent components.
Graduated layering over monolithic mechanisms.
Safety, context management, and extensibility all use graduated stacks of independent mechanisms rather than single integrated solutions. The permission architecture layers seven stages from tool pre-filtering through deny-first rules, permission modes, the auto-mode classifier, shell sandboxing, non-restoration on resume, and hook interception. Context management layers five compaction stages, lazy-loaded CLAUDE.md files, deferred tool schemas, and summary-only subagent returns. Extensibility layers four mechanisms (MCP servers, plugins, skills, and hooks) at different context costs (Section 6). In each case, the design trades simplicity and debuggability for defense in depth, accepting that the interaction between layers can produce emergent behaviors difficult to predict from any single configuration.
Append-only designs that favor auditability over query power.
Session transcripts are append-only JSONL files with read-time chain patching; permissions are not restored across session boundaries; context compaction applies read-time projections over a full history rather than destructive edits. This commitment recurs because it preserves the ability to resume, fork, and audit sessions without modifying previously written state. The cost is that richer structured queries ("show me all tool calls that modified file X across sessions") require post-hoc reconstruction rather than direct lookup.
Model judgment within a deterministic harness.
Across all subsystems, the architecture trusts the model's judgment within a rich deterministic harness rather than constraining its choices. The estimated 1.6% decision-logic ratio captures this quantitatively: the harness creates conditions (tool routing, permission enforcement, context assembly, recovery logic) under which the model can decide well. Hierarchical permissions preserve safety invariants across agent boundaries, and assembleToolPool() merges built-in and MCP tools into a single unified interface, but the model retains full latitude over which tools to invoke and in what order. The trade-off is that good local decisions can produce poor global outcomes when bounded context prevents global awareness, as the empirical predictions of Section 11.4 document.
12. Future Directions
Section Summary: This section explores future challenges in AI agent architecture by posing six open questions that build on the document's core framework, addressing areas like safety, reliability, and capabilities. It examines issues such as detecting silent failures through better observability tools in the system harness, maintaining agent memory and human relationships across multiple sessions, and expanding where, when, and with whom agents operate as models advance. These questions are framed as decisions on whether, how, or which mechanisms to adopt, drawing from emerging research to guide further development without prescribing specific solutions.
Section 11 read the architecture documented in Section 3, Section 4, Section 5, Section 6, Figure 6, Section 8, and Section 9 as a coherent design point and surfaced the tensions, trade-offs, and near-horizon directions that design point implies. This section steps beyond the architecture itself to record six open questions that Section 11.6 partially names and that a growing external literature has sharpened enough to state concretely. The six span the paper's five-value framework (Section 2.1) and its evaluative lens (Section 2.4): external governance constraints on the Authority hierarchy (Section 12.5); the observability–evaluation gap on the Safety side (Section 12.1); cross-session persistence of state and relationship on the Reliability side (Section 12.2); four extensions of the Capability frontier (Section 12.3); horizon scaling as a distinct axis of Reliable Execution beyond cross-session continuity (Section 12.4); and the evaluative lens of Section 2.4 reframed as a design question rather than a diagnostic one (Section 12.6). Consistent with Section 11.6's framing, each question is posed in the form whether/how/which; specific mechanism choices are named when the cited sources name them and left open otherwise.
12.1 Silent Failure and the Observability–Evaluation Gap
Whether the observability–evaluation adoption gap reported in Section 11.6 reflects a missing tooling layer, a missing evaluation interface inside the harness, or a model-capability ceiling is not resolved by the sources cited there. How the silent-mistake failure mode noted in that paragraph should be surfaced is therefore an architectural question for the harness rather than a capability question for the model. Recent empirical work characterises the gap at several resolutions. [45] catalogue fourteen failure modes spanning system-design issues, inter-agent misalignment, and task verification; [46] build a benchmark of agent trajectories specifically for anomaly detection in traces; [47] expose consistency gaps via the $\text{pass}^k$ metric (the probability that all $k$ independent trials succeed); and [48] argue that current agent benchmarks lack holdouts and cost controls, limiting what observability can actually diagnose.
Against the permission pipeline and tool-orchestration layers analysed in Section 5 and Section 4, two architectural questions remain open. First, whether the scaffolding the paper cites from [14] (generator–evaluator separation, sprint contracts, post-hoc checks, building on [49]'s self-refine pattern) belongs inside the harness (e.g., as additional hook events alongside the 27 documented in Section 6) or outside it as a separate evaluation layer is not settled by the cited sources. Second, whether the existing hook pipeline of Section 6 can host such scaffolding within its current context-cost envelope is a further open question. The observation that closing this gap "likely requires additional scaffolding $\ldots$ rather than model improvements alone" (Section 11.6) locates the open work at the harness layer.
12.2 Persistence: Memory and Longitudinal Colleague Relationships
Whether agent state and the human–agent working relationship should persist across sessions, and in what form, is treated by the paper at two distinct layers today. Figure 6 documents the four-level CLAUDE.md hierarchy and auto memory; Section 9 documents mostly-append-only JSONL transcripts (with explicit cleanup rewrites as an exception) whose session-scoped permissions resume does not restore. What belongs between these two layers (durable state that is neither a static instruction nor a single session's transcript) is an open design question. [39] and [40], already cited in Section 11.6, motivate an accumulating layer. [50] reframes the LLM as an operating system with paged memory; [51] builds a production-oriented memory store that survives restarts, while [52] proposes a research agentic-memory design; [53] captures reusable procedural traces; [54] accumulates self-reflection traces via verbal reinforcement across attempts; and surveys by [55] and [56] map candidate mechanisms.
The same persistence question recurs on the human side. Section 11.6 already cites longitudinal autonomy evidence ([5], [9]); [57]'s field experiment with 776 Procter & Gamble professionals, together with longitudinal and organisational studies of Copilot rollouts ([58]) and AI-teamwork trajectories ([59]), report shifts in human–AI work dynamics as collaboration accumulates. [60] illustrates an embodied agent that accumulates a skill library across tasks; [61] frames the human–AI working relationship as co-intelligence.
Whether a single substrate can carry both a user's personal instruction hierarchy and a shared organisational context while preserving the file-based transparency of CLAUDE.md that Figure 6 documents is an open architectural question. How session-scoped permissions interact with such a substrate, without reintroducing the resume-restoration concern that Section 9 closes as a deliberate safety choice, is a further open question.
12.3 Harness Boundary Evolution: Where, When, What, and with Whom the Agent Acts
Section 11.6 cites [14]'s observation that "the space of interesting harness combinations doesn't shrink as models improve; it moves." Whether that movement will be most pronounced in where the harness runs, when it acts, what it acts on, or with whom it coordinates is not resolved by the source-level analysis in Section 3, Section 4, Section 5, Section 6, Figure 6, Section 8, and Section 9. Each of the four has an active research literature that the paper touches only in passing.
Where.
[38]'s Managed Agents design virtualizes session, harness, and sandbox into independently replaceable interfaces, extending the virtual-memory analogy that [50] applies to context-window management and that [62] popularizes more broadly; [63] treats the harness itself as a compile target.
When.
Section 11.6 already introduces KAIROS as a feature-gated illustration, motivated by the $+12%$ – $18%$ task-pass gain that [30] report and the sharp preference penalty (47% vs. 80–90%) restricted to the high-frequency Persistent Suggest variant. [64], [65], and [66] extend the proactivity design space across programming and ambient-interface settings; [67] and [68] introduce benchmarks and training regimes aimed at sharpening it, and [69] surveys the broader landscape.
What.
Vision-language-action work extends the harness beyond textual tool returns: [70] and [71] train VLA policies that execute physical actions, and [72] grounds plans in robot affordances; industry systems such as [73] and [74] push similar ideas into humanoid control. These systems face the reversibility-weighted risk principle (Table 1) at a cost asymmetry that the principle names but does not quantify for non-textual actions. With whom. Role-differentiated multi-agent systems ([75], [76], [77], [78]) compose agents with distinct responsibilities; multi-agent debate ([79, 80]) and graph-structured workflows ([81]) explore alternatives to the parent/subagent pattern of Section 8; [82] surveys this space.
Whether a single harness architecture can span all four extensions, or whether the "harness combinations" [14] describes will fragment into specialised stacks, is an open design question. The when-extension directly continues the Capability-versus-Adaptability tension in Table 4. The with-whom-extension partially maps onto Capability-versus-Reliability but raises cross-agent consistency concerns that Table 4 does not itself cover. The where- and what-extensions raise further questions the paper's current subsystem boundaries do not cover: which governance obligations attach when harness components become hosted services (Section 12.5), and how reversibility-weighted risk (Table 1) scales to physical rather than textual effects. How these extensions compose across axes, rather than within any one, is not something the paper's single-subsystem analyses can resolve.
12.4 Horizon Scaling: From Session to Scientific Program
Section 2.1 defines Reliable Execution as spanning "both single-turn correctness and long-horizon dependability." How the architecture documented in Section 3, Section 4, Figure 6, Section 8, and Section 9 (whose primary units are the turn, the session, and the sub-agent) continues to support long-horizon dependability as autonomous work extends beyond a single session is an open question. A growing literature targets this regime. [83] present an end-to-end autonomous research pipeline producing draft manuscripts; [84] provide an independent SIGIR Forum evaluation of that pipeline, characterising what "autonomous research" currently delivers and where it falls short. [85] develop a multi-agent hypothesis-generation system that runs across days rather than turns, and [86] pursue algorithmic discovery over timescales that previously took human experts weeks. [87]'s METR study measures the task duration at which frontier agents succeed with fixed reliability (the 50%-time horizon) and how that horizon has evolved across model generations, giving an empirical frame for this scaling question.
Against the paper's analysis, long-horizon deployment tests whether the context-management pipeline of Figure 6, the last-assistant-text return policy of Section 8, and the append-only persistence of Section 9 remain sufficient when sessions compose into multi-session programs. Section 11.4 already frames this as "a directly measurable empirical question" that source-level analysis cannot resolve. Horizon scaling restates that question at the scale of weeks: whether the harness layer alone closes the gap, whether a cross-session memory substrate (Section 12.2) is required, or whether horizon-scale work demands coordination primitives beyond session, sub-agent, and memory, is not something the paper's session-scoped analyses can settle.
12.5 Governance and Oversight at Scale
Emerging AI regulation adds an external constraint on the architectures that implement the Authority hierarchy of Anthropic, operators, and users documented in Section 2.1. Which logging, transparency, and human-oversight affordances coding-agent architectures should expose under that external constraint remains an open design question. The European Commission's GPAI Code of Practice ([88]) and implementation guidelines ([89]) detail the general-purpose AI obligations that accompany the EU AI Act's full applicability in August 2026; the MIT AI Agent Index ([44]) and the International AI Safety Report ([43]), already cited in Section 11.6, motivate the disclosure and oversight side of this constraint. The Bartz v. Anthropic ruling ([90]) adds an input-side constraint on training-data sourcing (lawful acquisition of copyrighted works), distinct from the output-side copyright questions about AI-generated code that emerging cases address separately. An OECD report on AI governance frameworks ([91]) and an early analysis of compliance obligations for agent providers by [92] sketch what regulator-facing interfaces might look like without prescribing specifics.
Read against the permission pipeline analyzed in Section 5, two properties of the current architecture are open under this constraint. First, the deny-first evaluation the paper documents is internally auditable through session transcripts (Section 9) but not yet externally auditable in the forms that emerging frameworks such as the GPAI Code of Practice ([88]) contemplate. Second, whether the values-over-rules principle, which the paper pairs with deterministic guardrails, admits the kind of explicit rule articulation that compliance review may call for is a further open question. Both properties lie within the harness rather than the model, which is where future architectures may need to expose new interfaces.
12.6 The Evaluative Lens Revisited: Long-Term Human Capability
Section 2.4 introduces long-term human-capability preservation as an analytical lens rather than a co-equal design value; Section 11.2 and Section 11.4 extend the lens with external evidence (perceived-versus-measured productivity, comprehension loss, complexity accrual, technical-debt persistence, neural-connectivity persistence, early-career hiring decline), and Section 14 pivots: "Future systems could treat that sustainability gap as a first-class design problem, not a downstream evaluation metric." Whether that pivot is possible, and what architectural mechanisms a first-class treatment would require, is the last of the open questions this section records.
Two sub-questions separate the measurement gap from the design gap. First, whether the empirical claims that motivate the lens are measurable at session granularity. The existing citations operate at session to multi-month scales ([32]'s 16-developer RCT, [21]'s comprehension-test comparison, [33]'s EEG study, [31]'s 807-repository causal analysis, [37]'s 304,000-commit audit, [35]'s hiring series), but the harness documented in Section 3, Section 4, and Figure 6 exposes no per-session signal for comprehension or convention drift. Related work on programmer interaction modes ([93]) and AI-induced code-security regressions ([94]) sketches session-granularity measurement, and [34] proposes a protocol for session-level cognitive-offloading probes. Second, whether architecture can respond to such measurements once they exist (an analogue of the generator–evaluator separation ([14]) applied to the human loop, comprehension-preserving surfaces, or mechanisms not yet named) is the design-gap Problem 14 poses. The paper takes no position on which mechanism class is appropriate, and whether the harness documented here is even the right locus for that action (as opposed to the IDE, the organisation, or the human development loop) is a question the architectural analysis cannot adjudicate; the related work surveyed in Section 13 and the sustainability pivot of Section 14 mark where this paper leaves the question.
13. Related Work
Section Summary: This section reviews existing AI coding tools by categorizing them based on their level of independence, from simple code suggestions in editors like GitHub Copilot to fully autonomous systems like Devin that operate with little human input, positioning Claude Code as a balanced tool with interactive features and safety checks. It explores common design patterns in agent architectures, such as the ReAct loop for reasoning and action, multi-agent coordination, and strategies for managing context through compaction and memory hierarchies to handle large amounts of information efficiently. Additionally, it discusses safety measures in these tools, including approval processes, isolation techniques like sandboxes, and recovery options, highlighting how Claude Code integrates permissions and verification to balance autonomy with control.
13.1 Coding Agent Taxonomy
AI coding tools can be organized by the degree of autonomous action they support (Table 5). Inline completion tools such as GitHub Copilot ([1]) suggest code fragments within the editor without autonomous action. Chat-integrated products including Cursor and Windsurf add conversational interaction and multi-file edits but remain coupled to the IDE environment. Agentic CLI tools, including Claude Code, OpenAI's Codex CLI, and Aider ([20]), operate from the command line and can autonomously execute shell commands, read and write files, and iterate on outputs within a single request. Fully autonomous systems like Devin, SWE-Agent ([18]), and OpenHands ([19]) aim for minimal human supervision, often in sandboxed cloud environments.
::: {caption="Table 5: AI coding tool categories by degree of autonomous action."}
:::
Claude Code shares features with higher-autonomy agents (auto-mode classifier, background agent execution, remote environments) but retains interactive approval by default. Evaluation benchmarks such as SWE-Bench ([95]) and HumanEval ([1]) have driven much of the academic focus on coding agents. This paper examines Claude Code's internal architecture from source code.
13.2 Agent Architecture Patterns
Claude Code's core loop follows the ReAct pattern ([22]): the model generates reasoning and tool invocations, the harness executes actions, and results feed the next iteration. Toolformer ([96]) demonstrated that language models can learn to use tools; Claude Code uses up to 54 built-in tools and a layered permission system. The broader design space has been mapped by several surveys. [97] offered the now-standard decomposition into planning, memory, and tool use, and [98] catalogued early autonomous-agent work. [99] frames the field around three recurring trade-offs (autonomy vs. controllability, latency vs. accuracy, capability vs. reliability) that recur throughout our analysis, and [100] casts agent design itself as a search problem over components, algorithms, and evaluation functions. This paper characterizes one specific point in that space.
Multi-agent orchestration frameworks such as AutoGen ([27]), LangChain, and CrewAI provide conversation-based agent coordination. Claude Code's subagent delegation (Section 8) includes permission override precedence, two-level permission scoping, and separate transcript files for each subagent. LATS ([23]) unifies reasoning, acting, and planning in a tree-search framework; Claude Code's plan permission mode implements a simpler plan-then-execute approach.
Practitioner writing has converged on a handful of recurring patterns that Claude Code's architecture instantiates. Anthropic's own "Building Effective Agents" ([13]) distinguishes agents from workflows and argues for simple composable patterns over heavy frameworks. [101] synthesizes seven patterns observed in production systems, including giving agents filesystem and shell access as a general-purpose action layer, and discovering actions on demand rather than loading every tool schema upfront. [102] observes that Claude Code's planning tool is "basically a no-op" whose value lies in keeping the agent on track rather than in performing any external computation. [103] argues that authority is the element academic frameworks most often leave out, calling trust "the most overlooked element" in production agent design, a gap the permission analysis in Section 5 attempts to close. [104] makes the compound-error concern concrete: at 95% per-step accuracy, a 100-step task succeeds only 0.6% of the time, which motivates the per-step verification patterns we trace in Section 4 and Section 5.
Context management.
Table 6 presents a design-space taxonomy of context management approaches. Claude Code's five-layer compaction pipeline applies multiple strategies at different granularities before escalating, with cache-aware compression and virtual-view-on-read semantics. [40] characterizes two failure modes that this design mitigates (summarization that drops domain details, and detail loss from iterative context rewriting), and instead proposes treating context as an "evolving playbook" that accumulates strategies over time. Claude Code's approach is consistent with that framing, since the CLAUDE.md hierarchy accumulates structured instructions rather than repeatedly summarizing them. [39] distinguishes context engineering from agent memory: context engineering handles transient assembly, while memory covers persistent factual knowledge and experiential traces. Claude Code's architecture separates the two in the same way, pairing a compaction pipeline with a file-based memory hierarchy.
::: {caption="Table 6: Design space of context management approaches in LLM-based tools."}
:::
Safety and permissions.
Production coding agents adopt safety architectures that vary along three axes: approval model (per-action prompting, classifier-mediated automation, or no prompting with post-hoc review), isolation boundary (OS-level container, filesystem sandbox, permission-scoped tool pool, or none), and recovery mechanism (version-control rollback, session-scoped permission reset, or checkpoint-based rewind). SWE-Agent and OpenHands ([18, 19]) rely primarily on Docker container isolation, providing environment-level sandboxing that constrains all agent actions. Codex CLI supports sandbox modes and approval policies for shell commands. Aider ([20]) uses Git as its primary safety mechanism, making all changes reversible through version control. Claude Code combines per-action deny-first rules, an ML-based classifier for automated approval, optional shell sandboxing, and session-scoped permission non-restoration, layering multiple mechanisms rather than relying on a single isolation boundary.
Protocols and extensibility.
The Model Context Protocol that Claude Code uses as its primary external tool integration has become a de facto standard with a substantial ecosystem and a corresponding attack surface. [105] catalogues thousands of community-developed MCP servers across 26 major directories and organizes MCP-specific threats into four attacker categories and sixteen scenarios, including tool poisoning, rug pulls, and cross-server shadowing. The permission and deny-rule machinery analyzed in Section 5 and the pre-filtering step in Section 6.2 can be read as the runtime side of the mitigations that survey calls for.
Software architecture.
Layered architecture patterns ([106]) inform our five-layer decomposition. Role-based access control models ([107]) provide theory for the permission mode system. Browser sandboxing ([108]) is a similar per-process isolation approach. Multi-agent system theory ([109]) helps explain subagent delegation.
Positioning.
Prior work on coding agents has focused on benchmarks (how well agents solve tasks), frameworks (how to compose agents), and products (what users can do). This paper contributes a source-grounded design-space analysis of a production coding agent, using source-level analysis and architectural comparison to surface design choices and trade-offs. It draws on the software architecture case study tradition ([106]) but applies it to an LLM-based agent by systematically identifying design questions, mapping alternatives, and contrasting Claude Code's choices with those of OpenClaw, an independent AI agent system operating from a different deployment context.
14. Conclusion
Section Summary: This paper explains that advanced coding AI agents, like those used in real-world software development, can be analyzed through key design choices about how reasoning, execution, safety, and other features are balanced. Claude Code represents one thoughtful approach, granting the AI significant independence in tasks while wrapping it in a strict, reliable framework to handle permissions, tools, context management, and recovery, all aligned with principles that emphasize human control, safety, and adaptability. Comparing it to OpenClaw reveals diverse solutions to the same challenges—such as tight per-action checks versus broader access controls—and suggests that future agent designs should focus less on boosting AI autonomy and more on ensuring long-term human oversight and sustainable development practices.
This paper shows that production coding agents can be understood as answers to a recurring set of design questions: where reasoning sits relative to the harness, how execution, safety, extensibility, context, delegation, and persistence are organized, and which trade-offs those choices encode. Claude Code occupies a clear design point within that space. It gives the model broad local autonomy while surrounding it with a dense deterministic harness for permissioning, tool routing, context compaction, extensibility, and session recovery. Read through the five values and thirteen design principles identified in Section 2, these choices are coherent rather than ad hoc: the system consistently prioritizes human decision authority, safety, reliable execution, capability amplification, and contextual adaptability.
The OpenClaw comparison sharpens the main architectural finding by showing that the same design questions recur in different agent systems but produce different answers. Where Claude Code invests in per-action safety classification and graduated context compression within a CLI harness, OpenClaw invests in perimeter-level access control and structured long-term memory within a multi-channel gateway. The two systems can even compose: OpenClaw hosts Claude Code as an external harness via ACP. For agent builders, the most consequential open question is therefore not how to add more autonomy, but how to preserve human capability over time. As the evaluative lens in Section 2.4, the analysis in Section 11, and the open questions surveyed in Section 12 document, the architecture provides limited mechanisms that explicitly preserve long-term human understanding, codebase coherence, or the developer pipeline. Future systems could treat that sustainability gap as a first-class design problem, not a downstream evaluation metric.
Appendix
Section Summary: This appendix outlines the structure of a TypeScript package for an AI coding tool, detailing its main directories, key files like the entry point and query engine, and how tools and commands are organized with varying availability based on modes and features. It also maps dependencies across files to show how components interact without circular issues. Additionally, it explains the study's evidence from official docs, code analysis, and inferences, along with the method of tracing design choices through a framework of values like safety and adaptability, while noting limitations from relying on a single code version and reverse-engineering.
A. Package Structure
This appendix shows what each part of the TypeScript package does at runtime.
A.1 Directory-to-Responsibility Map
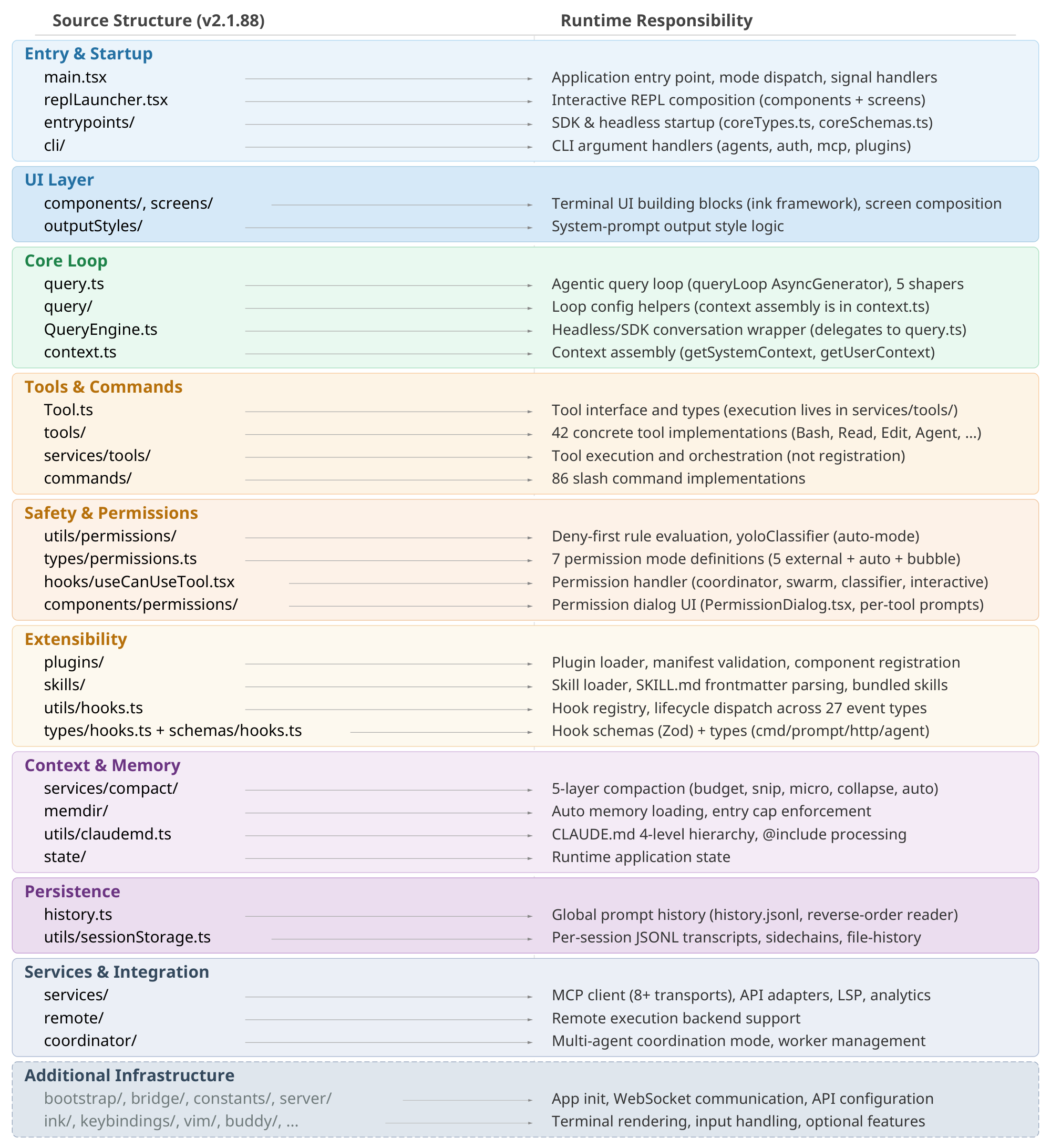
The package (Figure 9) is organized around a src/ directory. Table 7 lists the key files that form the main subsystems.
:Table 7: Key files by approximate size and runtime responsibility.
| File | Size | Responsibility |
|---|---|---|
main.tsx |
804KB | Entry point, mode dispatch, setup |
query.ts |
68KB | Core agent loop, 5 context shapers |
QueryEngine.ts |
47KB | SDK/headless conversation wrapper |
Tool.ts |
30KB | Tool interface, types, utilities |
history.ts |
14KB | Global prompt history |
mcp/client.ts |
Large | MCP client (8+ transport variants) |
compact.ts |
Large | Compaction engine |
AgentTool.tsx |
Large | Agent tool, subagent dispatch |
runAgent.ts |
Large | 21-parameter agent lifecycle |
The tools/ directory contains approximately 42 subdirectories implementing tools, with the corresponding schema, description, permission requirements, and execution logic. The commands/ directory contains approximately 86 slash command subdirectories.
Key service directories include services/tools/ (StreamingToolExecutor, toolOrchestration, toolExecution), services/compact/ (compaction engine), and services/mcp/ (MCP client and configuration). The permission infrastructure spans utils/permissions/ (rule evaluation, classifier), hooks/useCanUseTool.tsx (permission handler), types/permissions.ts (mode definitions), and types/hooks.ts (event schemas).
A structural quirk: query.ts (file) and query/ (directory) coexist. The file contains the main query loop; the directory houses helper modules for loop configuration and context assembly.
A.2 Conditional Tool Availability
The getAllBaseTools() function (tools.ts) constructs different tool sets depending on mode, build, environment, and feature flags (Table 8). The model may see as few as 3 tools in simple mode (Bash, Read, Edit) or 40+ tools in a full internal build with all features enabled.
::: {caption="Table 8: Conditional tool availability categories."}
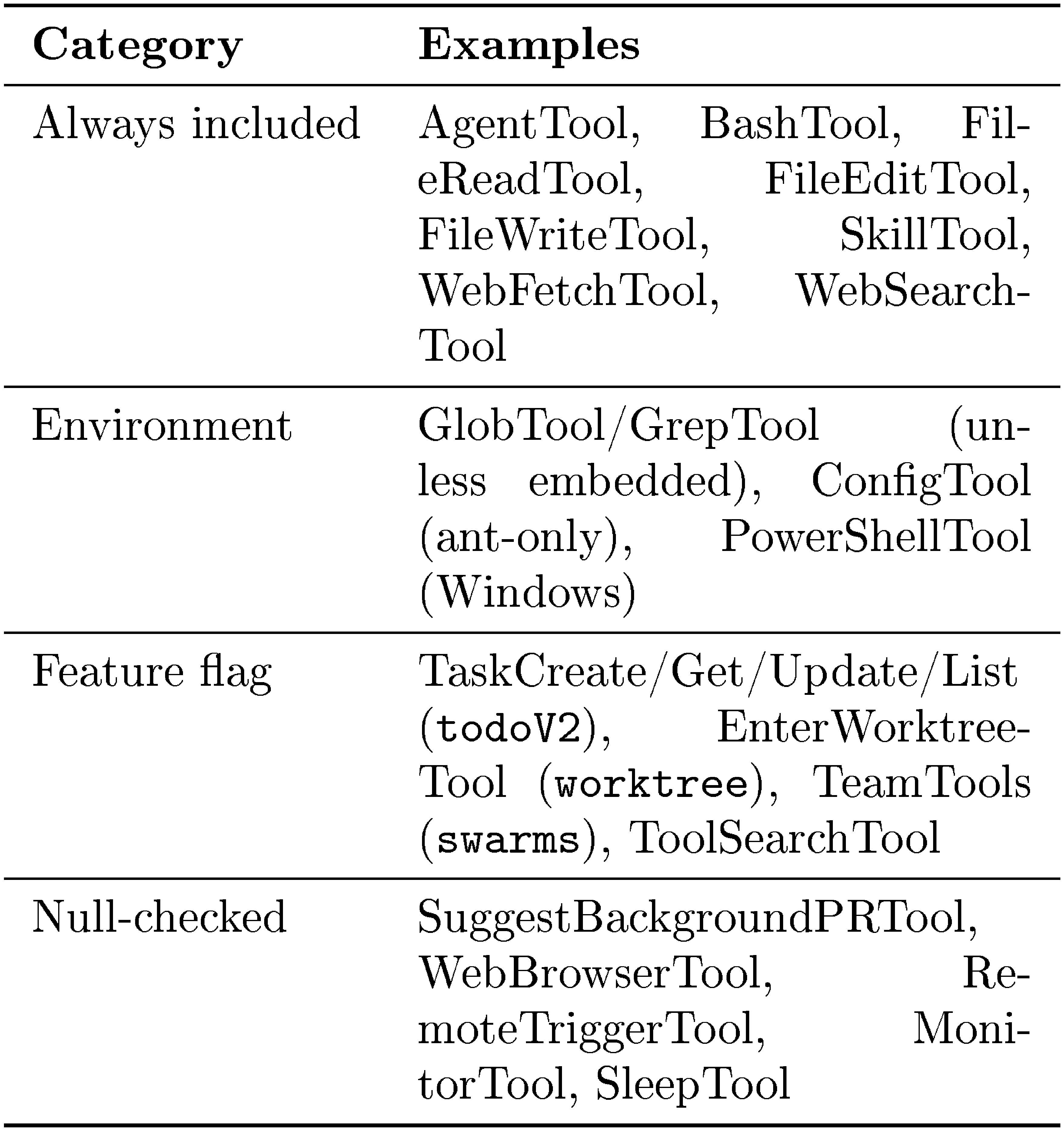
:::
A.3 Cross-File Dependencies
The import graph includes the following dependency structure. QueryEngine.ts delegates to query.ts for turn execution. query.ts imports from services/tools/ (StreamingToolExecutor, runTools) and services/compact/ (autoCompact, buildPostCompactMessages). QueryEngine.ts imports from memdir/ for memory and prompt assembly. The code explicitly avoids circular imports: types/permissions.ts was extracted to break import cycles, and setCachedClaudeMdContent() in context.ts avoids a cycle through the permissions/filesystem path.
B. Evidence Base and Methodology
This appendix describes the evidence sources, the analytic procedure, and the epistemological constraints of this study.
B.1 Evidence Base and Evidence Tiers
Claims in this paper are grounded at three evidence tiers:
- $\textsc{Tier A}$ (product-documented): Claims drawn from official Anthropic documentation and engineering publications. These establish product intent but may not reflect internal implementation.
- $\textsc{Tier B}$ (code-verified): Claims citing specific files and functions in the extracted TypeScript codebase (v2.1.88, obtained from a publicly available npm package extraction). This is the strongest evidence tier.
- $\textsc{Tier C}$ (reconstructed): Claims derived from community analysis, OpenClaw structural comparison, or inference from code patterns. These are stated with hedging language.
The source corpus comprises approximately 1, 884 files totaling roughly 512K lines of TypeScript. OpenClaw is used for calibration rather than ground truth.
B.2 Design-Space Analytic Procedure
Design questions were identified by examining each subsystem for recurring choice points where alternative designs exist in other production agents. Claude Code's answers to each question were traced through specific source files and function implementations ($\textsc{Tier B}$ evidence). The five-value framework (human decision authority, safety, security, and privacy, reliable execution, capability amplification, and contextual adaptability) was identified from official documentation and creator statements ($\textsc{Tier A}$), then traced through thirteen design principles to architectural decisions. Long-term capability preservation is treated separately as an evaluative lens rather than a design value, because it is not prominently reflected as a design driver in the architecture or in Anthropic's stated values (Section 2.4). Token economics serves as a cross-cutting constraint that bounds all five values simultaneously, revealing how individual subsystem choices interact under shared resource pressure.
B.3 Limitations
- Static snapshot. Analysis reflects one version (v2.1.88). Feature flags (e.g.,
TRANSCRIPT_CLASSIFIER,CONTEXT_COLLAPSE) create build-time variability; different build targets may produce functionally different applications. - Reverse-engineering epistemology. Source code reveals implemented structure, control flow, dependencies, and feature gates. It cannot confirm design intent, enabled production flags, runtime prevalence, or unshipped behavior.
- Single-system analysis. Findings describe Claude Code's design space, not the entire design space of coding agents. Generalizations are bounded.
- OpenClaw snapshot. The OpenClaw analysis reflects a specific development state and may not represent its current capabilities.
References
[1] Chen et al. (2021). Evaluating large language models trained on code. arXiv preprint arXiv:2107.03374.
[2] Cursor (2026). Cursor: The Best Way to Code with AI. https://cursor.com/. Official product website. Accessed April 12, 2026..
[3] Anthropic (2026). Claude Code Overview. https://code.claude.com/docs. Official Claude Code documentation. Accessed April 12, 2026..
[4] Anthropic (2026). Anthropic on GitHub. https://github.com/anthropics. Verified GitHub organization page. Accessed April 12, 2026..
[5] Saffron Huang et al. (2025). How AI Is Transforming Work at Anthropic. Anthropic Research Blog, https://anthropic.com/research/how-ai-is-transforming-work-at-anthropic.
[6] Peter Steinberger and OpenClaw Contributors (2026). OpenClaw: Personal AI Assistant. https://github.com/openclaw/openclaw. Open-source multi-channel AI assistant gateway. MIT License..
[7] Anthropic (2025). Our Framework for Developing Safe and Trustworthy Agents. https://www.anthropic.com/news/our-framework-for-developing-safe-and-trustworthy-agents.
[8] Anthropic (2026). Claude's Constitution. https://anthropic.com/constitution.
[9] Miles McCain et al. (2026). Measuring AI Agent Autonomy in Practice. Anthropic Research Blog, https://anthropic.com/research/measuring-agent-autonomy.
[10] John Hughes (2026). Claude Code Auto Mode: A Safer Way to Skip Permissions. Anthropic Engineering, https://www.anthropic.com/engineering/claude-code-auto-mode.
[11] David Dworken and Oliver Weller-Davies (2025). Beyond Permission Prompts: Making Claude Code More Secure and Autonomous. Anthropic Engineering, https://www.anthropic.com/engineering/claude-code-sandboxing.
[12] Anthropic (2026). How Claude Code Works. https://code.claude.com/docs/en/how-claude-code-works.
[13] Erik Schluntz and Barry Zhang (2024). Building effective agents. Anthropic Research, https://www.anthropic.com/research/building-effective-agents.
[14] Prithvi Rajasekaran (2026). Harness Design for Long-Running Application Development. Anthropic Engineering Blog, https://anthropic.com/engineering/harness-design-long-running-apps.
[15] Boris Cherny and Cat Wu (2025). Claude Code: Anthropic's Agent in Your Terminal. Latent Space podcast, https://www.latent.space/p/claude-code.
[16] The Linux Foundation (2025). Linux Foundation Announces the Formation of the Agentic AI Foundation (AAIF), Anchored by New Project Contributions Including Model Context Protocol (MCP), goose and AGENTS.md. Linux Foundation Press Release. https://www.linuxfoundation.org/press/linux-foundation-announces-the-formation-of-the-agentic-ai-foundation.
[17] LangChain, Inc. (2024). LangGraph: Build Resilient Language Agents as Graphs. GitHub repository. https://github.com/langchain-ai/langgraph.
[18] Yang et al. (2024). Swe-agent: Agent-computer interfaces enable automated software engineering. Advances in Neural Information Processing Systems. 37. pp. 50528–50652.
[19] Wang et al. (2024). Openhands: An open platform for ai software developers as generalist agents. arXiv preprint arXiv:2407.16741.
[20] Paul Gauthier (2024). Aider: AI Pair Programming in Your Terminal. Open-source software, https://aider.chat. https://github.com/Aider-AI/aider.
[21] Shen, Judy Hanwen and Tamkin, Alex (2026). How AI impacts skill formation. arXiv preprint arXiv:2601.20245.
[22] Yao et al. (2022). React: Synergizing reasoning and acting in language models. In The eleventh international conference on learning representations.
[23] Zhou et al. (2023). Language agent tree search unifies reasoning acting and planning in language models. arXiv preprint arXiv:2310.04406.
[24] Sui et al. (2026). Act While Thinking: Accelerating LLM Agents via Pattern-Aware Speculative Tool Execution. arXiv preprint arXiv:2603.18897.
[25] Adversa.ai (2026). Critical Claude Code Vulnerability: Deny Rules Silently Bypassed Because Security Checks Cost Too Many Tokens. https://adversa.ai/blog/claude-code-security-bypass-deny-rules-disabled/.
[26] MindStudio Team (2026). What Is the Anthropic Claude Code Source Code Leak? Three-Layer Memory Architecture Explained. https://www.mindstudio.ai/blog/claude-code-source-leak-three-layer-memory-architecture.
[27] Wu et al. (2024). Autogen: Enabling next-gen LLM applications via multi-agent conversations. In First conference on language modeling.
[28] Anthropic (2025). Orchestrate Teams of Claude Code Sessions. https://code.claude.com/docs/en/agent-teams.
[29] Aviv Donenfeld and Oded Vanunu (2026). Caught in the Hook: RCE and API Token Exfiltration Through Claude Code Project Files. https://research.checkpoint.com/2026/rce-and-api-token-exfiltration-through-claude-code-project-files-cve-2025-59536/. CVE-2025-59536 (CVSS 8.7), CVE-2026-21852 (CVSS 5.3).
[30] Chen et al. (2025). Need help? designing proactive ai assistants for programming. In Proceedings of the 2025 CHI Conference on Human Factors in Computing Systems. pp. 1–18.
[31] He et al. (2025). Speed at the Cost of Quality: How Cursor AI Increases Short-Term Velocity and Long-Term Complexity in Open-Source Projects. arXiv preprint arXiv:2511.04427.
[32] Becker et al. (2025). Measuring the impact of early-2025 AI on experienced open-source developer productivity. arXiv preprint arXiv:2507.09089.
[33] Kosmyna et al. (2025). Your brain on ChatGPT: Accumulation of cognitive debt when using an AI assistant for essay writing task. arXiv preprint arXiv:2506.08872. 4.
[34] Aiersilan, Aizierjiang (2026). The Vibe-Check Protocol: Quantifying Cognitive Offloading in AI Programming. arXiv preprint arXiv:2601.02410.
[35] Rak, Gwendolyn (2025). How to Stay Ahead of AI as an Early-Career Engineer. IEEE Spectrum. https://spectrum.ieee.org/ai-effect-entry-level-jobs.
[36] Elad Beber (2025). InversePrompt: Turning Claude Against Itself, One Prompt at a Time. https://cymulate.com/blog/cve-2025-547954-54795-claude-inverseprompt/. CVE-2025-54794, CVE-2025-54795; updated April 6, 2026.
[37] Liu et al. (2026). Debt Behind the AI Boom: A Large-Scale Empirical Study of AI-Generated Code in the Wild. arXiv preprint arXiv:2603.28592.
[38] Lance Martin et al. (2026). Scaling Managed Agents: Decoupling the Brain from the Hands. Anthropic Engineering Blog, https://www.anthropic.com/engineering/managed-agents.
[39] Hu et al. (2025). Memory in the age of ai agents. arXiv preprint arXiv:2512.13564.
[40] Zhang et al. (2025). Agentic context engineering: Evolving contexts for self-improving language models. arXiv preprint arXiv:2510.04618.
[41] Janelle Teng Wade et al. (2026). AI Infrastructure Roadmap: Five Frontiers for 2026. Bessemer Venture Partners, https://www.bvp.com/atlas/ai-infrastructure-roadmap-five-frontiers-for-2026.
[42] LangChain (2026). State of Agent Engineering. https://www.langchain.com/state-of-agent-engineering. Survey of 1,340 respondents conducted Nov-Dec 2025.
[43] Bengio et al. (2026). International ai safety report 2026. arXiv preprint arXiv:2602.21012.
[44] Staufer et al. (2026). The 2025 AI Agent Index: Documenting Technical and Safety Features of Deployed Agentic AI Systems. arXiv preprint arXiv:2602.17753.
[45] Cemri et al. (2025). Why do multi-agent llm systems fail?. arXiv preprint arXiv:2503.13657.
[46] Pathak et al. (2025). Detecting Silent Failures in Multi-Agentic AI Trajectories. arXiv preprint arXiv:2511.04032.
[47] Yao et al. (2024). $\tau$-bench: A Benchmark for Tool-Agent-User Interaction in Real-World Domains. arXiv preprint arXiv:2406.12045.
[48] Kapoor et al. (2024). Ai agents that matter. arXiv preprint arXiv:2407.01502.
[49] Madaan et al. (2023). Self-refine: Iterative refinement with self-feedback. Advances in neural information processing systems. 36. pp. 46534–46594.
[50] Packer et al. (2023). MemGPT: towards LLMs as operating systems..
[51] Chhikara et al. (2025). Mem0: Building production-ready ai agents with scalable long-term memory. arXiv preprint arXiv:2504.19413.
[52] Xu et al. (2025). A-mem: Agentic memory for llm agents. arXiv preprint arXiv:2502.12110.
[53] Wang et al. (2024). Agent workflow memory. arXiv preprint arXiv:2409.07429.
[54] Shinn et al. (2023). Reflexion: Language agents with verbal reinforcement learning. Advances in neural information processing systems. 36. pp. 8634–8652.
[55] Zhang et al. (2025). A survey on the memory mechanism of large language model-based agents. ACM Transactions on Information Systems. 43(6). pp. 1–47.
[56] Huang et al. (2026). Rethinking Memory Mechanisms of Foundation Agents in the Second Half. arXiv preprint arXiv:2602.06052.
[57] Dell'Acqua et al. (2025). The cybernetic teammate: A field experiment on generative AI reshaping teamwork and expertise.
[58] Stray et al. (2025). Developer Productivity With and Without GitHub Copilot: A Longitudinal Mixed-Methods Case Study. arXiv preprint arXiv:2509.20353.
[59] Xiao et al. (2025). AI Hasn't Fixed Teamwork, But It Shifted Collaborative Culture: A Longitudinal Study in a Project-Based Software Development Organization (2023-2025). arXiv preprint arXiv:2509.10956.
[60] Wang et al. (2023). Voyager: An open-ended embodied agent with large language models. arXiv preprint arXiv:2305.16291.
[61] Mollick, Ethan (2024). Co-intelligence: Living and working with AI. Penguin.
[62] Karpathy, Andrej (2023). [1hr Talk] Intro to Large Language Models. YouTube talk, https://www.youtube.com/watch?v=zjkBMFhNj_g. November 2023; popularizes the LLM-as-OS framing..
[63] Khattab et al. (2023). Dspy: Compiling declarative language model calls into self-improving pipelines. arXiv preprint arXiv:2310.03714.
[64] Liu et al. (2025). Proactive conversational agents with inner thoughts. In Proceedings of the 2025 CHI Conference on Human Factors in Computing Systems. pp. 1–19.
[65] Pu et al. (2025). Assistance or disruption? exploring and evaluating the design and trade-offs of proactive ai programming support. In Proceedings of the 2025 CHI conference on human factors in computing systems. pp. 1–21.
[66] Lee et al. (2025). Sensible agent: A framework for unobtrusive interaction with proactive ar agents. In Proceedings of the 38th Annual ACM Symposium on User Interface Software and Technology. pp. 1–22.
[67] Pasternak et al. (2025). Beyond reactivity: Measuring proactive problem solving in llm agents. arXiv preprint arXiv:2510.19771.
[68] Sun et al. (2025). Training proactive and personalized llm agents. arXiv preprint arXiv:2511.02208.
[69] Deng et al. (2025). Proactive conversational ai: A comprehensive survey of advancements and opportunities. ACM Transactions on Information Systems. 43(3). pp. 1–45.
[70] Brohan et al. (2024). Rt-2: Vision-language-action models transfer web knowledge to robotic control, 2023. URL https://arxiv. org/abs/2307.15818. 1. pp. 2.
[71] Black et al. (2024). $\pi_0$: A Vision-Language-Action Flow Model for General Robot Control. arXiv preprint arXiv:2410.24164.
[72] Ahn et al. (2022). Do as i can, not as i say: Grounding language in robotic affordances. arXiv preprint arXiv:2204.01691.
[73] Figure AI (2025). Helix: A Vision-Language-Action Model for Generalist Humanoid Control. https://www.figure.ai/news/helix. Figure AI technical blog..
[74] Bjorck et al. (2025). Gr00t n1: An open foundation model for generalist humanoid robots. arXiv preprint arXiv:2503.14734.
[75] Hong et al. (2023). MetaGPT: Meta programming for a multi-agent collaborative framework. In The twelfth international conference on learning representations.
[76] Li et al. (2023). Camel: Communicative agents for" mind" exploration of large language model society. Advances in neural information processing systems. 36. pp. 51991–52008.
[77] Chen et al. (2023). Agentverse: Facilitating multi-agent collaboration and exploring emergent behaviors. In The Twelfth International Conference on Learning Representations.
[78] Qian et al. (2024). Chatdev: Communicative agents for software development. In Proceedings of the 62nd annual meeting of the association for computational linguistics (volume 1: Long papers). pp. 15174–15186.
[79] Du et al. (2024). Improving factuality and reasoning in language models through multiagent debate. In Forty-first international conference on machine learning.
[80] Liang et al. (2024). Encouraging divergent thinking in large language models through multi-agent debate. In Proceedings of the 2024 conference on empirical methods in natural language processing. pp. 17889–17904.
[81] Zhuge et al. (2024). Gptswarm: Language agents as optimizable graphs. In Forty-first International Conference on Machine Learning.
[82] Guo et al. (2024). Large language model based multi-agents: A survey of progress and challenges. arXiv preprint arXiv:2402.01680.
[83] Lu et al. (2024). The ai scientist: Towards fully automated open-ended scientific discovery. arXiv preprint arXiv:2408.06292.
[84] Beel et al. (2025). Evaluating Sakana's AI Scientist: Bold Claims, Mixed Results, and a Promising Future?. In ACM SIGIR Forum. pp. 1–20.
[85] Gottweis et al. (2025). Towards an AI co-scientist. arXiv preprint arXiv:2502.18864.
[86] Novikov et al. (2025). Alphaevolve: A coding agent for scientific and algorithmic discovery. arXiv preprint arXiv:2506.13131.
[87] Kwa et al.. Measuring AI Ability to Complete Long Software Tasks. In The Thirty-ninth Annual Conference on Neural Information Processing Systems.
[88] European Commission (2025). General-Purpose AI Code of Practice. https://digital-strategy.ec.europa.eu/en/policies/contents-code-gpai. Official EU Commission publication, 10 July 2025..
[89] European Commission (2025). Guidelines on the Scope of Obligations for Providers of General-Purpose AI Models Under the AI Act. https://digital-strategy.ec.europa.eu/en/library/guidelines-scope-obligations-providers-general-purpose-ai-models-under-ai-act. Official EU Commission guideline document..
[90] (2025). Bartz v. Anthropic PBC, No. 3:24-cv-05417-WHA. U.S. District Court for the Northern District of California, Order on Motion for Summary Judgment (June 23, 2025), Alsup, J. Court docket: https://www.courtlistener.com/docket/69058235/bartz-v-anthropic-pbc/.
[91] OECD (2025). Governing with Artificial Intelligence: The State of Play and Way Forward in Core Government Functions. https://www.oecd.org/en/publications/governing-with-artificial-intelligence_795de142-en/full-report.html. Official OECD Public Governance Committee report, 18 September 2025..
[92] Nannini et al. (2026). AI Agents Under EU Law. arXiv preprint arXiv:2604.04604.
[93] Barke et al. (2023). Grounded copilot: How programmers interact with code-generating models. Proceedings of the ACM on Programming Languages. 7(OOPSLA1). pp. 85–111.
[94] Perry et al. (2023). Do users write more insecure code with ai assistants?. In Proceedings of the 2023 ACM SIGSAC conference on computer and communications security. pp. 2785–2799.
[95] Jimenez et al. (2023). Swe-bench: Can language models resolve real-world github issues?. arXiv preprint arXiv:2310.06770.
[96] Schick et al. (2023). Toolformer: Language models can teach themselves to use tools. Advances in neural information processing systems. 36. pp. 68539–68551.
[97] Lilian Weng (2023). LLM-Powered Autonomous Agents. https://lilianweng.github.io/posts/2023-06-23-agent/.
[98] Wang et al. (2024). A survey on large language model based autonomous agents. Frontiers of Computer Science. 18(6). pp. 186345.
[99] Xu, Bin (2026). AI Agent Systems: Architectures, Applications, and Evaluation. arXiv preprint arXiv:2601.01743.
[100] Hu et al. (2024). Automated design of agentic systems. arXiv preprint arXiv:2408.08435.
[101] Lance Martin (2026). Agent Design Patterns. https://rlancemartin.github.io/2026/01/09/agent_design/.
[102] Harrison Chase (2025). Deep Agents. LangChain Blog, https://blog.langchain.com/deep-agents/.
[103] Shawn Wang (2025). Agent Engineering. Latent Space, https://www.latent.space/p/agent.
[104] Chip Huyen (2025). Agents. https://huyenchip.com/2025/01/07/agents.html.
[105] Hou et al. (2025). Model context protocol (mcp): Landscape, security threats, and future research directions. ACM Transactions on Software Engineering and Methodology.
[106] Garlan et al. (1993). An introduction to software architecture.. Advances in software engineering and knowledge engineering. 1(3.4).
[107] Sandhu et al. (2002). Role-based access control models. Computer. 29(2). pp. 38–47.
[108] Reis, Charles and Gribble, Steven D (2009). Isolating web programs in modern browser architectures. In Proceedings of the 4th ACM European conference on Computer systems. pp. 219–232.
[109] Wooldridge, Michael (2009). An introduction to multiagent systems. John Wiley & Sons.