MEMO: Memory as a Model
Ryan Wei Heng Quek$^{1,2,3,4,}$, Sanghyuk Lee$^{5,6,7,}$, Alfred Wei Lun Leong$^{4,8,}$, Arun Verma$^{9,}$ $^{\dagger}$, Alok Prakash$^{9}$, Nancy F. Chen$^{3}$, Bryan Kian Hsiang Low$^{1,2,4,9}$, Daniela Rus$^{7,9}$, Armando Solar-Lezama$^{7,9}$
$^{1}$ Institute of Data Science, National University of Singapore, Singapore
$^{2}$ Integrative Sciences and Engineering Programme, NUSGS, Singapore
$^{3}$ Agency for Science, Technology, Research (A*STAR), Singapore
$^{4}$ Department of Computer Science, National University of Singapore, Singapore
$^{5}$ University of Tokyo, Japan
$^{6}$ Liquid AI, USA
$^{7}$ CSAIL, Massachusetts Institute of Technology, USA
$^{8}$ AI Singapore
$^{9}$ Singapore-MIT Alliance for Research and Technology Centre, Singapore
[email protected] [email protected] [email protected] [email protected] [email protected] [email protected] [email protected] [email protected] [email protected]
$^{*}$ Equal contributions and $^{\dagger}$ Corresponding author.
Abstract
Large language models (LLMs) achieve strong performance across a wide range of tasks, but remain frozen after pretraining until subsequent updates. Many real-world applications require timely, domain-specific information, motivating the need for efficient mechanisms to incorporate new knowledge. In this paper, we introduce MEMO (Memory as a Model), a modular framework that encodes new knowledge into a dedicated MEMORY model while keeping the LLM parameters unchanged. Compared to existing methods, MEMO offers several advantages: (a) it captures complex cross-document relationships, (b) it is robust to retrieval noise, (c) it avoids catastrophic forgetting in the LLM, (d) it does not require access to the LLM's weights or output logits, enabling plug-and-play integration with both open and proprietary closed-source LLMs, and (e) its retrieval cost is independent of corpus size at inference time. Our experimental results on three benchmarks, BrowseComp-Plus, NarrativeQA, and MuSiQue, show that MEMO achieves strong performance compared to existing methods across diverse settings.
Executive Summary: MEMO (Memory as a Model) is a modular framework that lets organizations keep large language models (LLMs) frozen while adding up-to-date or domain-specific knowledge through a small, dedicated Memory model. The approach addresses a practical problem: after pretraining, LLMs remain static until expensive retraining occurs, yet many applications need timely facts that the base model does not reliably hold.
The work evaluates whether a separate Memory model, trained once on synthesized “reflections” of a target corpus, can capture single-document facts and cross-document relationships, then supply that knowledge at inference time through structured queries from any Executive LLM (open- or closed-source). The evaluation uses three benchmarks—BrowseComp-Plus, NarrativeQA, and MuSiQue—together with controlled noise ablations, Memory-model size and architecture tests, and a model-merging experiment for incremental corpus arrival.
The framework first runs a five-step synthesis pipeline (fact extraction, consolidation, verification, entity surfacing, and cross-document synthesis) to turn raw documents into self-contained question–answer pairs. A smaller LLM (1.5 B–14 B parameters) is then fine-tuned on these pairs so that it internalizes the knowledge parametrically. At inference, the Executive model decomposes user queries into targeted sub-questions, obtains compact natural-language answers from the Memory model in three sequential stages, and synthesizes a final response. Retrieval cost stays constant regardless of corpus size, and no access to the Executive model’s weights or logits is required.
Across the three benchmarks, MEMO matches or exceeds strong retrieval and parametric baselines when paired with capable Executive models, with the largest gains (12–27 percentage points) on NarrativeQA and MuSiQue. Accuracy remains stable as distractor documents are added, while retrieval baselines drop several points. Larger Memory models improve results, yet performance stays robust across different model families. Model merging reduces cumulative training compute by roughly one-third for two successive corpora while still beating retrieval methods, at the cost of a measurable accuracy gap versus full retraining.
These outcomes indicate that organizations can add or refresh knowledge without retraining the main LLM, without incurring growing retrieval latency, and without risking catastrophic forgetting or losing compatibility with proprietary models. The approach is therefore attractive for high-stakes domains that demand both accuracy and auditability of updates.
For immediate deployment, practitioners should adopt the current data-synthesis and three-stage inference pipeline when the corpus is moderately sized and performance with a capable Executive model meets requirements. When new corpora arrive frequently, model merging offers a practical first step; full retraining on the union remains an option only when accuracy margins justify the quadratic cost. Further work is warranted to lower synthesis cost, test scaling limits of the Memory model on larger corpora, and refine merging methods that narrow the accuracy gap. Results should be interpreted with the caveat that all reported figures come from three specific benchmarks and moderate corpus sizes; behavior on very large or highly technical corpora is not yet characterized.
1. Introduction
Section Summary: Large language models excel at many tasks but cannot easily update their knowledge after initial training, creating problems for applications needing current or specialized information. Existing approaches to adding knowledge either retrieve external data at runtime with limited context, retrain the model at high cost and risk of forgetting, or compress information into forms that cannot transfer between different models. MeMo addresses these issues by training a dedicated Memory model on synthesized question-answer pairs that capture cross-document relationships, then letting a separate Executive model query it through targeted sub-questions to produce accurate answers without retraining or altering the original LLM.
Large language models (LLMs) have demonstrated remarkable capabilities across diverse tasks ([1, 2, 3]). Despite their successes, these models are effectively frozen for extended periods after pretraining ([4]) until subsequent updates, causing their pretrained knowledge to become increasingly outdated as the world evolves. For applications that require up-to-date ([5, 6]) or domain-specific ([7, 8]) knowledge, this dependence on static knowledge presents a fundamental architectural limitation ([9, 10]). Retraining is a natural solution but remains prohibitively expensive at modern scales ([11]), motivating the need for an efficient mechanism to integrate new external knowledge into LLMs without full retraining.
Existing methods for integrating new knowledge into LLMs fall into three categories. textcircled1 Non-parametric methods retrieve relevant information from an external store at inference time via lexical ([12]), dense ([13]), or graph-based retrievers ([14, 15, 16, 17]), before incorporating it through in-context learning ([18, 19]). However, these methods are constrained by limited context windows and struggle to synthesize cross-document relationships when relevant information is distributed across multiple documents ([20, 21]). textcircled2 Parametric methods internalize knowledge directly into model parameters via continual pretraining ([22]) or fine-tuning ([23, 24, 25]) on the target corpus directly. While effective, they are computationally expensive, prone to catastrophic forgetting ([26]), and tend to memorize training distributions rather than acquire transferable knowledge, limiting generalization to unseen queries ([27]). textcircled3 Latent memory methods ([28, 29, 30, 31]) compress knowledge into soft tokens or other model-specific representations, but suffer from representation coupling: the memory is tightly bound to the specific model used to produce these representations, limiting transferability across LLMs.
We introduce $\textsc{MeMo}$ (Memory as a Model), a modular framework where a dedicated $\textsc{Memory}$ model is trained on new knowledge, and an $\textsc{Executive}$ model retrieves relevant information from the $\textsc{Memory}$ model at inference time via targeted sub-queries and then reasons over the retrieved information to respond to user queries. $\textsc{MeMo}$ combines the complementary strengths of the three paradigms above while mitigating their individual limitations. Like the non-parametric methods, it is able to leverage off-the-shelf frontier models unchanged by separating the memory from the reasoning model; it shares with the parametric methods the ability to internalize knowledge in model parameters, and it shares the benefits of a compact, queryable memory artifact with latent memory methods. As a result, $\textsc{MeMo}$ offers the following advantages: (a) it captures complex cross-document relationships, (b) it is robust to retrieval noise, (c) it avoids catastrophic forgetting by keeping the $\textsc{Executive}$ model parameters unchanged, (d) it does not require access to the $\textsc{Executive}$ model’s weights or output logits, enabling plug-and-play integration with both open and proprietary LLMs, and (e) its retrieval cost is independent of corpus size at inference time due to the fixed size of the $\textsc{Memory}$ model. However, designing $\textsc{MeMo}$ to comprehensively capture cross-document relationships during training while accurately answering arbitrary queries at inference time introduces two key challenges, which we outline below and address them with novel methods.
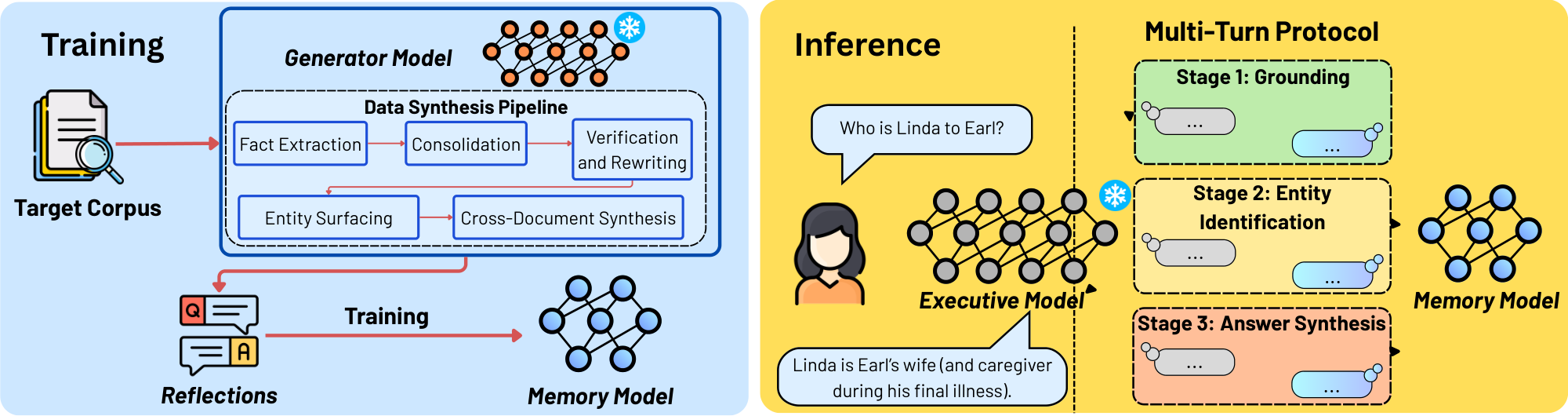
textcircled1 Training $\textsc{Memory}$ model. A core challenge in the $\textsc{Memory}$ model is ensuring it can accurately answer diverse, unseen queries at inference time, including those requiring cross-document reasoning and long-context understanding. A natural approach is to train directly on the raw corpus using standard data augmentation techniques such as paraphrasing ([32, 33, 34]), additional sampling of generated QA pairs ([35, 36]), or targeted gap-filling, where the model identifies and completes missing knowledge from the corpus ([37, 38]). However, these approaches fail to consolidate related facts into compositional representations necessary for robust generalization to unseen queries ([27]). With this challenge in mind, we design a novel five-step data synthesis pipeline guided by a $\textsc{Generator}$ model (Section 4.1) that distills the corpus into a question–answer (QA) dataset of reflections: compositional representations that expose underlying corpus knowledge under diverse query variations (illustrated in Figure 1 (left) and details in Section 4.1). We train $\textsc{Memory}$ model on the synthesized reflection QA dataset via supervised fine-tuning (see Section 4.2), enabling $\textsc{Memory}$ model to capture more complex, cross-document relationships and compositional structure than retrieval-based methods.
textcircled2 Querying $\textsc{Memory}$ model. At inference time, complex or compositional queries often require multi-step reasoning and aggregation of information across multiple documents. Naively querying $\textsc{Memory}$ model via single-turn or unstructured multi-turn interactions fails to reliably retrieve the knowledge required to answer such queries. To address this, we design a three-stage inference pipeline in which $\textsc{Executive}$ model queries and retrieves information from $\textsc{Memory}$ model via a structured multi-turn protocol, decomposing complex user queries into targeted sub-queries that align with the shared reflection interface (illustrated in Figure 1 (right) and more details are in Section 4.4). Unlike retrieval-based methods, this approach incurs retrieval cost independent of corpus size and is robust to retrieval noise (see Section 5.2). Crucially, because $\textsc{MeMo}$ treats $\textsc{Executive}$ model as a black box and does not access its weights, gradients, or output logits, it supports plug-and-play integration with any LLM, including both open and proprietary closed-source models.
Our method is guided by a single design principle: reflections, corpus-derived structures that require no knowledge of future queries, yet naturally serve as the precise interface through which any query can access the underlying corpus without ever observing it directly. During training, the $\textsc{Memory}$ model internalizes these reflections; $\textsc{Executive}$ model retrieves relevant knowledge through targeted sub-queries at inference time. Building on the challenges outlined above and the methods proposed to address them, we summarize the key contributions of this paper as follows:
- Novel data synthesis pipeline. We propose a five-step data synthesis pipeline that uses a $\textsc{Generator}$ model, an LLM that may be the same as or smaller than $\textsc{Executive}$ model, to distill a target corpus into reflections, enabling a dedicated $\textsc{Memory}$ model to internalize knowledge in compositional forms that capture more complex cross-document relationships and generalize robustly to diverse, unseen query variations at inference time (see Section 4.1 and Section 4.2).
- Structured multi-turn protocol. We introduce a structured multi-turn protocol that systematically decomposes complex queries into targeted sub-queries aligned with the shared reflection interface. The protocol supports plug-and-play integration with any arbitrary LLM, including proprietary closed-source LLMs, and has retrieval cost independent of corpus size (see Section 4.4).
- Empirical validation. We evaluate $\textsc{MeMo}$ on BrowseComp-Plus, NarrativeQA, and MuSiQue, demonstrating strong performance against both parametric and non-parametric baselines. We further empirically validate $\textsc{MeMo}$ 's robustness to retrieval noise (see Section 5).
2. Related Work
Section Summary: Existing approaches to equipping large language models with new or updated knowledge fall into three broad categories, each with notable drawbacks. Non-parametric techniques such as in-context learning and retrieval-augmented generation add information at inference time without changing model weights, yet they incur high computational costs, suffer from sensitivity to irrelevant retrieved content, and struggle to synthesize information spread across many documents. Parametric methods incorporate knowledge through continued training or fine-tuning, but they risk overwriting earlier knowledge, demand substantial compute, and cannot be applied to closed-source models, while latent-memory methods that compress knowledge into compact internal representations remain tightly coupled to particular model architectures and thus lack broad compatibility.
Non-parametric methods. Non-parametric alternatives ([12, 13, 17]) avoid parameter updates entirely, instead, supplying new knowledge at inference time. In particular, in-context learning (ICL) ([18, 19]) inserts relevant knowledge directly into the prompt, avoiding catastrophic forgetting. However, ICL scales poorly with increasing context length: the computational cost of autoregressive generation ([39]) leads to substantial token overhead and inference latency as the knowledge base grows ([40]), and even explicitly long-context models exhibit significant performance degradation as context length increases ([41, 42]). Retrieval-augmented generation (RAG) ([14, 15, 16, 17]) addresses this scalability bottleneck by selectively retrieving relevant chunks of knowledge at inference time. However, RAG systems are highly sensitive to retrieval noise ([43]), where irrelevant or misleading passages substantially degrade generation quality ([44, 45]). In addition, RAG systems often struggle to reason over complex cross-document dependencies ([20]), as they lack robust mechanisms for synthesizing information that is distributed across multiple chunks or a large corpus ([21]).
Parametric methods. Existing post-training approaches, such as continual pretraining on new corpora ([22, 46]) or supervised fine-tuning (SFT) on curated instruction data ([23, 24, 25]), attempt to address this limitation by incorporating new knowledge into LLMs during post-training. While conceptually straightforward, these parametric methods often suffer from catastrophic forgetting, whereby adaptation to newly observed knowledge degrades previously acquired knowledge, learned capabilities ([26, 47, 48]), and safety alignment learned during LLM post-training ([49]). In addition, the scale of modern LLMs makes frequent fine-tuning computationally expensive ([50, 51]), and fine-tuning is often infeasible for proprietary, closed-source models ([52]), substantially limiting the practicality of parametric methods in real-world, large-scale applications.
Latent memory methods. Another approach to storing knowledge is via compressed latent representations, which lie between non-parametric retrieval and fully parametric methods. Context compression techniques such as AutoCompressor ([28]), Gist tokens ([29]), and ICAE ([30]) encode knowledge into compact soft tokens prepended at inference, reducing ICL token overhead without discarding information. However, these representations are tightly coupled to the encoder and cannot be consumed by other model families, limiting compatibility with black-box LLMs. Similarly, recurrent-state models ([53, 54]) and nearest-neighbor memory methods such as Memorizing Transformers ([55]) and $k$ NN-LM ([56]) rely on model-specific representations or architectures, preventing post hoc use with pretrained LLMs. Although Memory Decoder ([57]) is a plug-and-play pretrained memory module that integrates without modifying model parameters, it is limited to architectures sharing a common tokenizer, enabling reuse only within this subset. The core limitation of these methods is representation coupling: latent memory is inseparable from the model that produces it. In contrast, $\textsc{MeMo}$ allows a plug-and-play integration with any LLM, including closed-source models.
\begin{tabular}{|l|c|c|c|c|c|c|}
\hline \textbf{Methods}
& \makecell{\textbf{Frozen}\\\textbf{base LLM}}
& \makecell{\textbf{No}\\\textbf{retrieval index}}
& \makecell{\textbf{Black-box}\\\textbf{compatible}}
& \makecell{\textbf{No catastrophic}\\\textbf{forgetting}}
& \makecell{\textbf{Constant-size}\\\textbf{memory}}
& \makecell{\textbf{Cross-LLM}\\\textbf{transferable}} \\
\hline
\textbf{Non-parametric} {\small(RAG, ICL)} & \checkmark & $\times$ & \checkmark & \checkmark & $\times$ & \checkmark\tablefootnote{We assume a fixed, task-agnostic embedding model decoupled from the \textsc{Executive} model for RAG, enabling the retrieval index to be reused across models. For ICL, prompts are assumed to be raw-text-based, free of model-specific formatting.} \\
\textbf{Parametric} {\small(CPT, SFT)} & $\times$ & \checkmark & $\times$ & $\times$ & \checkmark & $\times$ \\
\textbf{Latent memory} {\small(AutoCompressor, Gist, ICAE)} & \checkmark & \checkmark & $\times$ & \checkmark & $\times$ & $\times$ \\
\textbf{{\textsc{MeMo}} (Ours)} & \checkmark & \checkmark & \checkmark & \checkmark & \checkmark & \checkmark \\
\hline
\end{tabular}
3. Preliminaries
Section Summary: The section outlines a setup where a frozen large language model, accessible only through prompts, must be augmented with knowledge from a target collection of documents it cannot reliably recall on its own. This goal is formalized as finding a representation of the documents together with an inference-time procedure that combines them with the fixed model to maximize correct answers on related queries, without altering the model's parameters. Standard solutions such as stuffing documents into prompts, retrieving passages on demand, or fine-tuning the model itself are contrasted with the proposed approach of training a compact auxiliary memory model.
Problem setting. Let $\mathcal{M}\theta$ denote a large language model with frozen parameters $\theta \in \mathbb{R}^p$, pretrained on a corpus $\mathcal{D}{\text{pre}}$. We treat $\mathcal{M}\theta$ as a conditional distribution that maps a prompt $x$ to a response $\mathcal{M}\theta(x)$, and assume only black-box access; in particular, $\mathcal{M}\theta$ may be either a white-box model or a closed-source model accessed via API. Let $\mathcal{D} = {d_1, \ldots, d_N}$ denote a target corpus of $N$ documents containing knowledge that $\mathcal{M}\theta$ cannot reliably recall[^1]. Let $\mathcal{Q}$ be a set of queries, each $q \in \mathcal{Q}$ associated with a ground-truth answer $a^\star(q)$ and a set of supporting documents $\mathcal{S}(q) \subseteq \mathcal{D}$. Note that $\mathcal{S}(q)$ is a theoretical construct used to characterize query complexity.
[^1]: We do not assume $\mathcal{D}$ is disjoint from $\mathcal{D}{\text{pre}}$, as training data is rarely disclosed by model providers. A document is considered effectively absent from $\mathcal{M}\theta$ 's knowledge if the model fails to answer questions grounded in it, either because it never appeared in $\mathcal{D}_{\text{pre}}$ or because the training process was insufficient to retain it. For more information, refer to Appendix I.
Knowledge integration mechanism. A knowledge integration mechanism is a pair $(\Phi, f)$, where $\Phi$ maps the corpus to a representation $\mathcal{K} \doteq \Phi(\mathcal{D})$ and $f$ combines $\mathcal{K}$ with $\mathcal{M}\theta$ at inference to produce responses $f(\mathcal{M}\theta, \mathcal{K}, q)$. We formalize the goal as follows.
########## {caption="Definition 1: Knowledge Integration Problem"}
Given a frozen model $\mathcal{M}\theta$ and a target corpus $\mathcal{D}$, find a mechanism $(\Phi, f)$ that maximizes $\mathbb{E}{q \sim \mathcal{Q}}\bigl[\mathbb{P}\left{f(\mathcal{M}_\theta, \Phi(\mathcal{D}), q) = a^\star(q)\right}\bigr]$ without modifying $\theta$.
Existing approaches. Existing methods differ in their choice of $(\Phi, f)$. ICL sets $\mathcal{K} = \mathcal{D}$ and $f(\mathcal{M}\theta, \mathcal{K}, q) = \mathcal{M}\theta([\mathcal{D}; q])$, i.e., appending the corpus directly to the prompt. RAG constructs $\mathcal{K}$ as a retrieval index and defines $f$ to retrieve a subset $\hat{\mathcal{S}} \subseteq \mathcal{D}$ before passing $[\hat{\mathcal{S}}; q]$ to $\mathcal{M}\theta$. Fine-tuning sets $\mathcal{K} = \emptyset$ and $f = \mathcal{M}{\theta'}$, where $\theta'$ is obtained by updating $\theta$ on $\mathcal{D}$. In contrast, $\textsc{MeMo}$ defines $\mathcal{K}$ as the parameters of a small, dedicated $\textsc{Memory}$ model $\mathcal{M}\varphi$ with $\varphi \ll \theta$, trained on a reflection QA dataset derived from $\mathcal{D}$, and queried by a frozen $\textsc{Executive}$ model $\mathcal{M}\theta$ at inference time. Table 1 summarizes how these paradigms compare across desirable properties.
4. MeMo: Memory as a Model
Section Summary: MeMo tackles the challenge of integrating external knowledge by pairing a frozen Executive model, which handles reasoning and user queries, with a trainable Memory model whose parameters are updated to encode information from a target document collection. The approach runs in two stages: first a training phase that builds the Memory model from the corpus, and then an inference phase in which the Executive model consults the Memory model to answer questions. To prepare suitable training data, the system runs a five-step synthesis pipeline that extracts facts, merges related items, verifies self-contained QA pairs, surfaces entities from multiple angles, and creates cross-document questions, all without embedding document identifiers.
$\textsc{MeMo}$ addresses the knowledge integration problem (Def. Definition 1) through two components: a frozen model $\mathcal{M}\theta$ ($\textsc{Executive}$ model), which handles reasoning and responds to user queries, and a $\textsc{Memory}$ model $\mathcal{M}\varphi$, which is trained to encode knowledge in its parameters from a target corpus $\mathcal{D}$. Our pipeline operates in two phases: (i) a training phase that constructs $\textsc{Memory}$ model from $\mathcal{D}$, and (ii) an inference phase in which $\textsc{Executive}$ model queries and retrieves information from $\textsc{Memory}$ model to answer knowledge-intensive questions (see Section 4.1, Section 4.2, and Section 4.4).
4.1 Data Synthesis Pipeline
Given a corpus of documents $\mathcal{D}$, our objective in the data generation process is to construct a reflection QA dataset $\mathcal{Q}{\text{final}}$ that captures both single-document facts and cross-document relationships. This process is driven by a $\textsc{Generator}$ model $\mathcal{M}{\text{gen}}$ and proceeds through five steps, as summarized in Algorithm 1 and illustrated in Figure 1: (1) fact extraction from raw documents, (2) consolidation of redundant or overlapping information, (3) verification and rewriting to ensure correctness and clarity, (4) entity surfacing to explicitly represent key entities, and (5) cross-document synthesis to integrate evidence across the corpus. Importantly, no document identifiers or watermarks are embedded in the generated QA pairs at any step, preventing $\textsc{Memory}$ model from exploiting shortcut signals during evaluation.
**Require:** Corpus D, generator M(gen), document groups G = (G₁, …, G(R)) with G(i) ⊆ D
Q(final) ← ∅
**for all** document d ∈ D **do**
C ← Chunk(d) ▷ Segment into chunks
Q(ver)(d) ← ∅
**for all** chunk c ∈ C **do**
Q(dir), Q(indir) ← M(gen)(c) ▷ Step 1: Direct and indirect extraction
Q(raw) ← Q(dir) ∪ Q(indir) ▷ Step 2a: Merge direct and indirect
Q(mrg) ← M(gen)(Q(raw)) ▷ Step 2b: Consolidate related pairs
Q(con) ← Q(raw) ∪ Q(mrg) ▷ Step 2c: Full merge set
Q(ver) ← M(gen)(Q(con), c) ▷ Step 3: Verify self-containment; rewrite or discard
Q(ver)(d) ← Q(ver)(d) ∪ Q(ver)
**end for**
Q(ent)(d) ← M(gen)(Q(ver)(d)) ▷ Step 4: Entity-surfacing pairs
Q(final) ← Q(final) ∪ Q(ver)(d) ∪ Q(ent)(d)
**end for**
**for all** G(i) ∈ G **do**
Q(cross) ← M(gen)(∪_{d ∈ G(i)} (Q(ver)(d) ∪ Q(ent)(d))) ▷ Step 5: Cross-document synthesis
Q(final) ← Q(final) ∪ Q(cross)
**end for**
**return** Q(final)
Step 1: Fact extraction. Each document $d \in \mathcal{D}$ is segmented into chunks $C$, where each chunk corresponds either to an entire document or to a contiguous segment of a longer document. For each chunk, $\mathcal{M}{\text{gen}}$ performs two parallel extraction processes: direct extraction, which captures explicitly stated facts (producing $\mathcal{Q}{\text{dir}}$), and indirect extraction, which targets inferred or synthesized information beyond the surface text (producing $\mathcal{Q}_{\text{indir}}$). This dual extraction process ensures that both factual recall and inferential reasoning are represented in the training signal for $\textsc{Memory}$ model.
Step 2: Consolidation. The $\textsc{Generator}$ model $\mathcal{M}{\text{gen}}$ consolidates $\mathcal{Q}{\text{dir}} \cup \mathcal{Q}{\text{indir}}$ by identifying QA pairs that share a common underlying context (such as entity, time period, or relationship type) and combining them into QA pairs that encompass multiple facts, denoted $\mathcal{Q}{\text{mrg}}$. This merging process produces training instances that require integrating multiple facts within the same contextual chunk, going beyond single-fact question answering pairs. The synthesized QA pairs are subsequently unified with the original sets to form the consolidated dataset $\mathcal{Q}{\text{con}} = \mathcal{Q}{\text{dir}} \cup \mathcal{Q}{\text{indir}} \cup \mathcal{Q}{\text{mrg}}$.
Step 3: Verification and rewriting. Each QA pair in $\mathcal{Q}{\text{con}}$ is evaluated for self-containment by $\mathcal{M}{\text{gen}}$, i.e., whether it can be fully understood and correctly answered in isolation, without access to the source chunk. Common failure modes include unresolved pronouns (e.g., "What did they propose?") and implicit references (e.g., "As noted in the above table…"). Non-self-contained QA pairs are rewritten by $\mathcal{M}{\text{gen}}$ using the source chunk $C$ as context; QA pairs that remain ambiguous after rewriting are discarded. This check-and-rewrite procedure yields the verified set $\mathcal{Q}{\text{ver}}$, a set of QA pairs that can be used as training examples without access to the source chunk.
Step 4: Entity surfacing. For each named entity in $\mathcal{Q}{\text{ver}}$, $\mathcal{M}{\text{gen}}$ generates a set of entity-surfacing QA pairs in which the question encodes the entity’s attributes and relationships (including connections to other named entities) and the answer reveals its identity. Facts about each entity are aggregated across all QA pairs within the chunk prior to generation, enabling the integration and composition of information from multiple source pairs. Questions are generated at varying levels of complexity, ranging from single-fact to multi-fact queries. These pairs, denoted $\mathcal{Q}_{\text{ent}}$, aim to mitigate the reversal curse ([58, 59]) by training $\textsc{Memory}$ model to infer entities from indirect or partially specified descriptions. This capability supports the entity identification turn at inference time (Section 4.4).
Step 5: Cross-document synthesis. The final step operates over pre-defined document groups $\mathcal{G} = {G_1, \ldots, G_R}$, where chunks within each group $G_i$ are topically related. Such groups arise naturally, for example, when a large document is segmented into chunks (forming a single group) or from human-provided labels. For each group $G_i$, $\mathcal{M}{\text{gen}}$ is provided with both the verified pairs $\mathcal{Q}{\text{ver}}^{d}$ and the entity-surfacing pairs $\mathcal{Q}_{\text{ent}}^{d}$ for all $d \in G_i$ from all member documents and identifies two types of cross-document connections:
- Converging clues: multiple documents provide complementary facts about the same entity, which together enable its identification.
- Parallel properties: different entities across documents share a common attribute or role, enabling comparative and analogical reasoning.
Both types yield QA pairs with support size $\mathcal{S}(q) > 1$ (Section 3), directly targeting the cross-document synthesis objective. The final dataset is $\mathcal{Q}{\text{final}} = \mathcal{Q}{\text{ver}} \cup \mathcal{Q}{\text{ent}} \cup \mathcal{Q}{\text{cross}}$, which collectively captures self-contained, entity-centric, and cross-document reflections for training $\textsc{Memory}$ model. Ablations of the pipeline design are presented in Appendix E.
4.2 Training the $\textsc{Memory}$ model
Given $\mathcal{Q}_{\text{final}}$, $\textsc{Memory}$ model is trained via supervised fine-tuning to map questions directly to answers without access to source documents at inference time. $\textsc{Memory}$ model is initialized from a small pretrained language model, substantially smaller than $\textsc{Executive}$ model (e.g., 1.5B vs. 32B parameters), and optimized by minimizing the next-token prediction loss over answer tokens only.
$ \mathcal{L}(\varphi) ;=; -!!!\sum_{(q_i, , a_i), \in, \mathcal{Q}{\text{final}}};; \sum{t=1}^{|a_i|} \log \mathcal{M}_\varphi!\left(a_i^{(t)} ;\middle|; q_i, , a_i^{(1:t-1)}\right). $
Conditioning only on the question and preceding answer tokens, and never on source documents, forces $\textsc{Memory}$ model to internalize knowledge parametrically rather than rely on copying from retrieved context. This constitutes a key distinction from RAG-based readers: at inference time, $\textsc{Memory}$ model generates answers solely from its internalized parametric knowledge, without access to any external corpus. Further details on hyperparameter choices are provided in Appendix F and training paradigms (full SFT vs. LoRA) are provided in Appendix O.
4.3 Continual Knowledge Integration via Model Merging
A practical desideratum of any knowledge integration system is the ability to incorporate new corpora incrementally without retraining on or rebuilding from all previously ingested sources. For parametric models, integrating new knowledge typically requires retraining on the union of all observed corpora, a cost that grows prohibitively with the number of sources. In contrast, non-parametric systems such as knowledge graphs and vector databases support efficient incremental updates. We explore model merging ([60]) as an approach to close this gap for parametric models. Model merging aims to preserve knowledge from multiple sources without requiring joint training on their union, by combining $K$ $\textsc{Memory}$ model models, each trained independently on a distinct corpus, into a single model.
Continual knowledge integration. Let ${\mathcal{D}1, \dots, \mathcal{D}K}$ be a collection of pairwise disjoint target corpora. For each corpus $\mathcal{D}i$, we generate a reflection QA dataset $\mathcal{Q}^{(i)}{\text{final}}$ (Section 4.1) and train a corresponding $\textsc{Memory}$ model $\mathcal{M}{\varphi_i}$ via SFT (Section 4.2), initializing all $K$ models from the same pretrained base $\mathcal{M}{\varphi_0}$. We define the task vector for $\mathcal{D}_i$ as $\tau_i ;{=}; \varphi_i - \varphi_0$, capturing the parametric shift induced by training on $\mathcal{D}_i$ alone. The merged $\textsc{Memory}$ model is then obtained as
$ \varphi_{\text{merged}} ;{=}; \mathrm{Merge}(\varphi_0, , {\tau_i}_{i=1}^{K};, \Theta), $
where $\Theta$ denotes method-specific hyperparameters (e.g., merging coefficients, sparsification densities). We discuss alternative merging methods and their respective limitations in Appendix H.
4.4 Inference-Time Integration
At inference time, $\textsc{Executive}$ model queries and retrieves information from $\textsc{Memory}$ model through a structured multi-turn protocol, with $\textsc{Executive}$ model treating $\textsc{Memory}$ model as an external knowledge oracle. The pipeline has three sequential stages, each designed to progressively improve the likelihood of producing a correct final answer, as illustrated in Figure 1 (right). Each stage utilizes distinct prompts, sampling temperatures and independent budgets to control the number of interactions between $\textsc{Executive}$ model and $\textsc{Memory}$ model.
Stage 1: Grounding. Given a query $q$, $\textsc{Executive}$ model decomposes it into a set of atomic, clue-probing sub-questions ${q_1', \ldots, q_J'}$, where each sub-question targets a single identifying constraint in $q$, and $J$ is adaptively determined by $\textsc{Executive}$ model. The $\textsc{Memory}$ model answers each sub-question independently, without shared context, producing grounding responses ${m_1, \ldots, m_J}$. These responses draw on $\textsc{Memory}$ model's parametric knowledge to provide additional contextual grounding for subsequent interactions in the later stages.
Stage 2: Entity identification. Using the grounding responses as context, $\textsc{Executive}$ model iteratively narrows a set of candidate entities by issuing targeted follow-up sub-queries to $\textsc{Memory}$ model across multiple interactions. This process continues until $\textsc{Executive}$ model converges on a single entity $e^\star$ or the stage budget is exhausted. If no candidates are identified, Stage 3 is skipped and $\textsc{Executive}$ model synthesizes a final answer from the grounding responses alone. This stage leverages $\textsc{Memory}$ model's training on the entity-surfacing QA pairs $\mathcal{Q}_{\text{ent}}$ (Section 4.1).
Stage 3: Answer seeking and synthesis. Conditioned on the identified entity $e^\star$, $\textsc{Executive}$ model queries $\textsc{Memory}$ model for additional supporting facts through targeted follow-up questions. Once sufficient evidence is gathered, or the stage budget is exhausted, $\textsc{Executive}$ model synthesizes the accumulated responses into a final answer:
$ \hat{a} ;=; \mathcal{M}\theta!\bigl(q, ; {m_j}{j=1}^J, ; e^\star, ; m_{\text{seek}}\bigr). $
Notably, the $\textsc{Memory}$ model responses $m_j$ and $m_{\text{seek}}$ are compact natural-language snippets whose lengths are independent of the corpus size, ensuring constant-time inference. As all interactions with $\mathcal{M}_\theta$ occur through its input–output interface, $\textsc{MeMo}$ remains fully compatible with black-box $\textsc{Executive}$ models, including proprietary APIs, without requiring access to internal parameters. For full implementation details, refer to Appendix J and the supplementary materials.
5. Experiments
Section Summary: The experiments evaluate MeMo on three knowledge-intensive benchmarks—BrowseComp-Plus, NarrativeQA, and MuSiQue—by training a memory model on generated long-context data and pairing it at inference with executive models of varying strength, while comparing against lexical, dense, graph-based, and parametric retrieval baselines. Results show MeMo outperforming the baselines on NarrativeQA and MuSiQue across both executives and remaining competitive on BrowseComp-Plus, with clear gains when a stronger executive model is substituted, underscoring its ability to capture cross-document reasoning that retrieval methods miss. Additional tests confirm plug-and-play compatibility and support for continual model merging without retraining.
Datasets. We evaluate $\textsc{MeMo}$ on three knowledge-intensive benchmarks. BrowseComp-Plus ([61]) is a deep-research benchmark requiring multi-hop, multi-document retrieval and reasoning; we filter non-English instances with LangDetect ([62]), sample 300 questions, and pair each question's evidence documents with an equal number of negative documents, [^2] yielding 3, 541 documents in total. NarrativeQA ([63]) tests discourse understanding over long documents such as books and movie scripts; we use 293 questions across 10[^3] documents. MuSiQue ([64]) requires composing 2–4 reasoning steps across multiple Wikipedia paragraphs; we use 1, 000 questions and construct the target corpus following the same procedure as for BrowseComp-Plus, yielding 5, 296 documents. Further details are in Appendix D; datasets and code are in the supplementary materials.
[^2]: BrowseComp-Plus and MuSiQue provide annotations of gold (correct), evidence (supporting), and negative (distractor) documents. Gold documents are a subset of the evidence documents.
[^3]: We follow HippoRAG2 and evaluate on 10 such documents from the NarrativeQA validation split (294 questions); one duplicate is removed for consistency.
Baselines. We compare $\textsc{MeMo}$ against four baselines: BM25 ([12]) (lexical retrieval), NV-Embed-V2 ([13]) (dense retrieval), HippoRAG2 ([17]) (graph-based RAG, state-of-the-art), and Cartridges ([65]) (a trained KV-cache loaded onto $\textsc{Executive}$ model at inference; the closest existing parametric baseline to $\textsc{MeMo}$). Newer methods exist ([28, 66]) but typically require white-box access to $\textsc{Executive}$ model and are therefore not directly comparable. We additionally include Perfect Retrieval as an empirical upper bound, where $\textsc{Executive}$ model receives exclusively the evidence documents in context ([18]). Retrieval baselines use top- $k{=}9$ with adaptive backoff: reducing $k$ progressively until the retrieved context fits $\textsc{Executive}$ model's context window.
Implementation and evaluation. (a) Data generation. We use Qwen2.5-32B-Instruct ([67]) as the $\textsc{Generator}$ model, served via vLLM ([68]) with YaRN RoPE scaling ([69, 70]) to support a 131K-token context window during long-context generation. (b) Training. We train $\textsc{Memory}$ model, which is initialized from Qwen2.5-14B-Instruct for 3 epochs with fused AdamW ([71]) and DeepSpeed 2 ([72]) at learning rate $2{\times}10^{-5}$; full hyperparameters are provided in Appendix F. (c) Evaluation. We instantiate $\textsc{Executive}$ model with either Qwen2.5-32B-Instruct or Gemini-3-Flash ([73]) to evaluate the same trained $\textsc{Memory}$ model across models of varying reasoning capability; both models have minimal prior knowledge of the evaluation datasets (Appendix I). $\textsc{Executive}$ model queries $\textsc{Memory}$ model through the multi-turn protocol described in Section 4.4. We report binary accuracy judged by Gemini-2.5-Flash-Lite ([74]) via DeepEval ([75]), as mean $\pm$ standard deviation over three runs for Qwen2.5-32B-Instruct and a single run for Gemini-3.0-Flash. (d) Continual integration. For the model-merging experiment (Section 5.5), we partition NarrativeQA into two pairwise-disjoint subsets ($K{=}2$, with $\sim$ 640k QA pairs each), SFT a separate Qwen2.5-14B-Instruct $\textsc{Memory}$ model on each, and sweep six merging methods at three densities (yielding 14 configurations total).
5.1 Experimental results
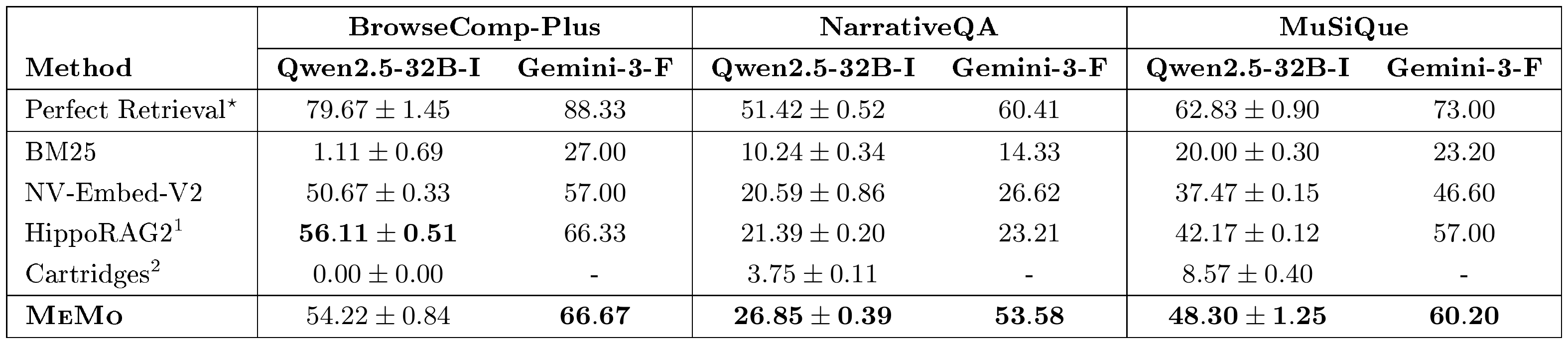
$\textsc{MeMo}$ achieves strong performance across benchmarks. As shown in Table 2, $\textsc{MeMo}$ consistently outperforms all baselines on NarrativeQA and MuSiQue across both $\textsc{Executive}$ models. On NarrativeQA, the most challenging benchmark (Appendix I), $\textsc{MeMo}$ achieves $26.85%$ with Qwen2.5-32B-Instruct and $53.58%$ with Gemini-3-Flash, substantially surpassing all baselines. This is notable: NarrativeQA requires reasoning over long passages with complex connections, where retrieval-based methods are constrained by context windows and struggle to synthesize information across long documents; $\textsc{MeMo}$ instead captures these connections via reflections during training and retrieves them through its multi-turn protocol at inference. The same trend holds on MuSiQue, where $\textsc{MeMo}$ achieves $48.30%$ and $58.70%$, respectively, outperforming baselines that struggle with multi-hop reasoning across independently retrieved passages. On BrowseComp-Plus, $\textsc{MeMo}$ leads with Gemini-3-Flash ($66.67%$) and remains competitive with Qwen2.5-32B-Instruct ($54.22%$, narrowly trailing HippoRAG2's $56.11%$). This gap reflects BrowseComp-Plus's nature: its answers are absent from $\textsc{Executive}$ model's parametric knowledge (Appendix I), making direct access to evidence documents especially valuable and favoring retrieval methods that pass raw documents to $\textsc{Executive}$ model.
::: {caption="Table 2: Accuracy (%) on BrowseComp-Plus, NarrativeQA, and MuSiQue under two Executive models: Qwen2.5-32B-Instruct (Qwen2.5-32B-I) and Gemini-3-Flash (Gemini-3-F). Bold values indicate the best result in each column, excluding Perfect Retrieval. MeMo uses Qwen2.5-14B-Instruct as Memory model, and results are reported at the best training epoch. ^*Perfect Retrieval represents an empirical upper bound."}
:::
$\textsc{MeMo}$ supports plug-and-play integration. Across the three benchmarks, $\textsc{MeMo}$ consistently achieves higher performance when paired with a more capable $\textsc{Executive}$ model (Gemini-3-Flash): switching from Qwen2.5-32B-Instruct to Gemini-3-Flash yields gains of 12.45%, 26.73%, 11.90% on BrowseComp-Plus, NarrativeQA and MuSiQue, respectively. This demonstrates that $\textsc{MeMo}$ can be trained once with a weaker $\textsc{Generator}$ model, and seamlessly paired with any LLM at inference, including proprietary models such as Gemini-3-Flash. This plug-and-play capability allows $\textsc{MeMo}$ to directly leverage state-of-the-art models without any additional training or overhead.
5.2 Ablation on the amount of noise for the dataset
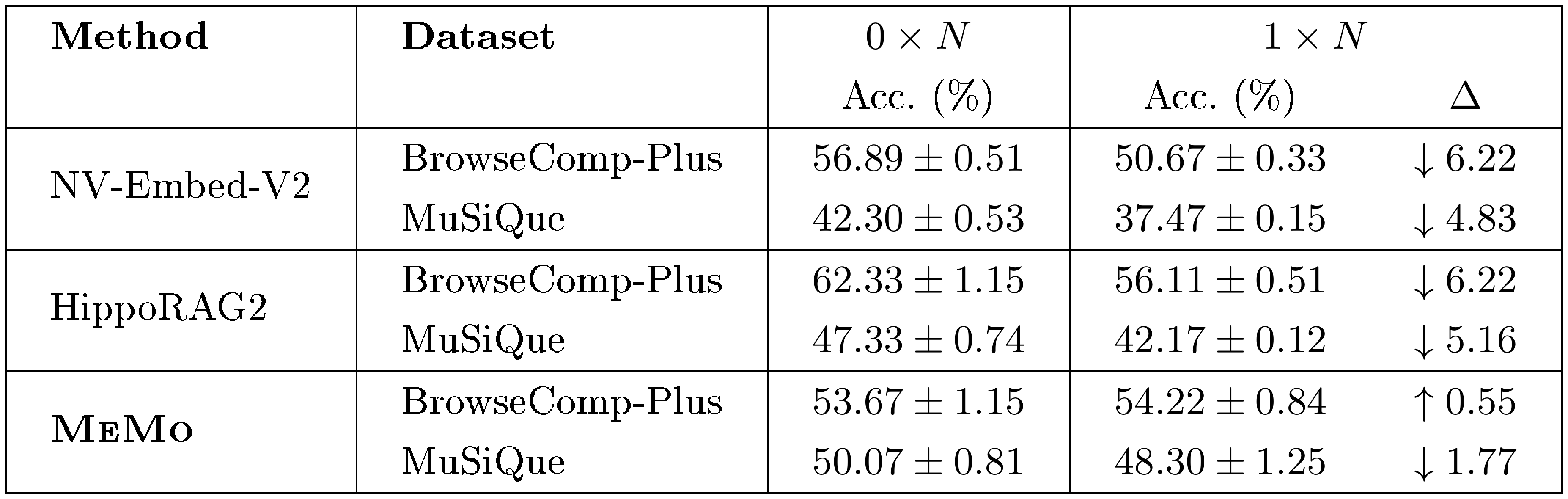
::: {caption="Table 3: Accuracy (%) on BrowseComp-Plus and MuSiQue with Qwen2.5-32B-Instruct as Executive model. MeMo results are based on Qwen2.5-14B-Instruct and reported at the best training epoch. N = $N_e$vidence^dataset denotes the number of ground-truth evidence documents in the corpus; column headers indicate the number of additional negative (distractor) documents added, as a multiple of N. Delta denotes accuracy difference (%) compared to 0N."}
:::
We investigate the robustness of $\textsc{MeMo}$ against two strong retrieval-based baselines, NV-Embed-V2 and HippoRAG2, under increasing levels of retrieval noise, controlled by varying the number of negative (distractor) documents added to the target corpus as a multiple of the total number of ground-truth evidence documents in each dataset ($N_\text{evidence}^\text{dataset} = 1{,}775$ for BrowseComp-Plus and $N_\text{evidence}^\text{dataset} = 2{,}648$ for MuSiQue). The datasets used throughout this paper (detailed in Appendix D) correspond to a ratio of 1 $\times N_\text{evidence}^\text{dataset}$; we additionally evaluate at ratio 0 $\times N_\text{evidence}^\text{dataset}$ (no distractors) as an idealized noise-free reference to isolate the effect of distractors.
Results in Table 3 demonstrate that retrieval-based methods exhibit pronounced sensitivity to noise. Both NV-Embed-V2 and HippoRAG2 suffer drops of up to 6.22% on BrowseComp-Plus and up to 5.16% on MuSiQue when scaling from $0\times N$ to $1\times N$, confirming that these systems struggle to filter irrelevant documents under realistic corpus conditions. In contrast, $\textsc{MeMo}$ maintains stable performance across both benchmarks, with a marginal improvement of 0.55% on BrowseComp-Plus and a decline of only 1.77% on MuSiQue, both within one standard deviation, demonstrating that $\textsc{MeMo}$ is robust to increasing retrieval noise. We attribute this robustness to $\textsc{MeMo}$ 's design: despite being trained on a corpus containing negative documents, $\textsc{Memory}$ model provides more precise information to $\textsc{Executive}$ model's sub-queries than direct document retrieval. Additional analysis of performance degradation in retrieval-based methods is provided in Appendix L.
5.3 Ablation on $\textsc{Memory}$ model size
We investigate how the size of $\textsc{Memory}$ model affects downstream task performance by comparing models of 1.5B and 14B parameters in the Qwen2.5 family. Implementation details are provided in Appendix M. Results in Table 4 show a consistent positive scaling trend: larger $\textsc{Memory}$ models yield improved performance across all benchmarks and $\textsc{Executive}$ models. However, the results also show that a stronger $\textsc{Executive}$ model reasoning capability modulates this gap non-uniformly across tasks: the performance difference between $\textsc{Memory}$ model sizes widens for NarrativeQA but shrinks for BrowseComp-Plus and MuSiQue. This suggests that the interaction between $\textsc{Executive}$ model reasoning capability and $\textsc{Memory}$ model size is task-dependent.
::: {caption="Table 4: Ablation on Memory model size within the Qwen2.5 family. Bold results indicate best performing results in the column."}

:::
5.4 Ablation on $\textsc{Memory}$ model family
We investigate whether the choice of $\textsc{Memory}$ model family affects performance by comparing three models of similar parameter scale ($\sim$ 1–2B) but distinct architectures and pretraining lineages: Qwen2.5-1.5B-Instruct ([67]), Gemma3-1B-IT ([76]), and LFM2.5-1.2B-Instruct ([77]). Implementation details are provided in Appendix N. Results in Table 5 show that $\textsc{MeMo}$ performance is largely robust to the choice of $\textsc{Memory}$ model architecture, demonstrating that the framework is not sensitive to the specific pretraining lineage of $\textsc{Memory}$ model at similar parameter scale, and that the parametric knowledge compression induced by our training procedure generalizes across diverse model families.
::: {caption="Table 5: Ablation across Memory models at similar parameter scales (∼ 1–2B). Bold results indicate best performing results in the column."}

:::
5.5 Continual integration via model merging
We test the streaming-update scenario described in Section 4.2 on NarrativeQA, comparing model merging against full retraining of $\textsc{Memory}$ model on the union of both subsets when the second arrives. Of the 14 sweep configurations (see Table 12, Appendix H), we report TIES ([78]) at $\rho{=}0.3$ in the main paper, the top-performing one. Letting $X$ and $Y$ denote the SFT cost on each subset alone (cost scales approximately linearly with the number of QA pairs, so the union costs $X{+}Y$), cumulative compute across the two arrivals is $X{+}Y$ for merging versus $X{+}(X{+}Y)$ for full retraining.
\begin{tabular}{|l|c|cc|cc|}
\hline
\textbf{Method} & \textbf{Cumulative compute}
& \multicolumn{2}{c|}{\textbf{Qwen2.5-32B-I}}
& \multicolumn{2}{c|}{\textbf{Gemini-3-F}} \\
& (8 $\times$ H100 GPU-h) & Acc. (\%) & $\Delta$ & Acc. (\%) & $\Delta$ \\
\hline
Full retrain ($X{+}(X{+}Y)$)
& $\approx 72$ h
& $\mathbf{26.85 \pm 0.39}$ & ---
& $\mathbf{53.58}$ & --- \\
Merge-TIES ($\rho{=}0.3$, $X{+}Y$)
& $\approx 48$ h
& $15.81 \pm 0.39$ & ${\downarrow 11.04}$
& $34.47$ & ${\downarrow 19.11}$ \\
\hline
\end{tabular}
Merging cuts compute by $\mathbf{33%}$ at $K{=}2$, with widening returns at scale. As reported in Table 6, the full-retrain baseline incurs $X{+}(X{+}Y) \approx 72$ GPU-hours of cumulative compute, while merging accumulates only $X{+}Y \approx 48$ GPU-hours — a $33%$ reduction (Figure 2). The gap widens with $K$: under the same per-corpus cost, merging scales as $\Theta(K)$ while full retraining scales as $\Theta(K^2)$, yielding a $5.5{\times}$ saving at $K{=}10$ ($240$ vs. $1{,}320$ GPU-hours).
Merging trades a measurable accuracy gap for the compute saving, but still beats retrieval. Merge-TIES ($\rho{=}0.3$) trails the full-retrain $\textsc{Memory}$ model by $11.0$ % under Qwen2.5-32B-Instruct and $19.1$ % under Gemini-3-Flash (Table 6); across the full 14-configuration sweep, accuracy ranges from $7.85%$ (SLERP, worst) to $15.81%$ (TIES, best), shown in Figure 2. Despite this gap, the merged $\textsc{Memory}$ model still outperforms every retrieval baseline (BM25, NV-Embed-V2, HippoRAG2, Cartridges; see Table 2) on NarrativeQA, indicating that even an aggressively-cheaper merging procedure preserves most of $\textsc{MeMo}$ 's qualitative advantage over retrieval-based approaches. TIES and DARE-Linear at $\rho{=}0.3$ dominate the sweep, suggesting that aggressive sparsification combined with sign-conflict resolution is the most reliable merging recipe in this regime.
6. Conclusion
Section Summary: The paper presents MeMo, a modular system that lets large language models absorb new or specialized information through a separate memory component trained on crafted question-answer data, rather than altering the main model itself. This design sidesteps common drawbacks of other approaches, such as limits on handling long or scattered source material and the high cost or instability of full retraining, while enabling easy updates and plug-and-play use with both open and commercial models. Tests show it outperforms prior methods on multiple benchmarks, though challenges remain around training expense and scaling to larger data collections.
We introduced $\textsc{MeMo}$, a modular framework for integrating updated or domain-specific knowledge into LLMs via a $\textsc{Memory}$ model trained on a synthesized reflection QA dataset. $\textsc{MeMo}$ addresses key limitations of existing methods: it bypasses context constraints and limited cross-document reasoning in retrieval-based approaches, avoids costly and brittle parametric updates (including catastrophic forgetting), and removes representation coupling in latent memory methods. Its core components are a data synthesis pipeline capturing explicit facts and implicit relationships, and a multi-turn inference protocol that decomposes complex queries into targeted sub-queries for desired information retrieval from the memory model. While $\textsc{MeMo}$ demonstrates strong performance, it has limitations regarding training cost, evaluation scope, and the capacity of $\textsc{Memory}$ model to scale with corpus size (see Appendix B). Empirically, $\textsc{MeMo}$ outperforms strong baselines across diverse benchmarks. It also provides a scalable pathway for knowledge integration, supporting efficient updates and plug-and-play deployment with both open and proprietary closed-source LLMs. Future work includes more efficient memory construction, extensions to dynamic corpora, and tighter coordination between the $\textsc{Executive}$ model and $\textsc{Memory}$ model. We view $\textsc{MeMo}$ (Memory as a Model) as a promising foundation for more flexible, updatable, and knowledge-aware AI systems.
Appendix
Section Summary: The appendix discusses the broader effects of the MeMo system, which improves how large language models absorb specialized knowledge from large document collections without needing direct access to the models themselves, while also noting risks around misuse for spreading misinformation and challenges in tracing information sources. It outlines key limitations such as high upfront training costs for new datasets and the fact that performance depends on the capacity of the memory model and may vary across different fields or document types. The section also describes planned future improvements around efficiency, chunking methods, and scaling, along with details on how the authors prepared and processed the specific datasets used in their experiments.
A. Impact statement
$\textsc{MeMo}$ advances the ability of LLMs to internalize knowledge over large, domain-specific corpora without requiring access to model weights, lowering the barrier for deploying capable AI systems in knowledge-intensive domains such as law, medicine, and scientific research. By enabling plug-and-play integration with any LLM, including proprietary models, $\textsc{MeMo}$ democratizes access to powerful knowledge integration capabilities that would otherwise require significant computational resources or white-box model access. At the same time, this accessibility introduces dual-use concerns, as the same capability that enables beneficial applications could be used to internalize misinformation, proprietary data without authorization, or harmful content at scale. Additionally, as $\textsc{MeMo}$ reduces reliance on explicit retrieval, it may obscure the provenance of retrieved information, making it harder to attribute the sources underlying a model's responses. We encourage future work to investigate attribution mechanisms and access controls for memory-based systems, and urge practitioners to carefully consider the nature of the documents used to train $\textsc{Memory}$ model.
B. Limitations
$\textsc{MeMo}$ incurs an upfront training cost for each new corpus, and performance may vary across domains, document types, or LLM families beyond those covered in our experiments. Furthermore, the performance of $\textsc{MeMo}$ is inherently bounded by the representational capacity of $\textsc{Memory}$ model to internalize the target corpus. Although our experiments do not reveal clear signs that $\textsc{Memory}$ model has reached its capacity limit, we hypothesize that sufficiently large or information-dense corpora will exceed what a fixed-size $\textsc{Memory}$ model can correctly compress and represent.
C. Future work
We outline several directions for future work. The data generation pipeline is computationally expensive, with Step 5 in Algorithm 1 scaling quadratically at $O(k \cdot C^2 \cdot Q^2)$, and reducing this cost remains an open problem. A systematic evaluation of chunking strategies and their associated tradeoffs (Appendix D) is likewise an open direction. On the training side, scaling $\textsc{Memory}$ model with corpus size and developing more effective model merging strategies for reducing per-corpus training costs (Section 5.5) are promising directions. Other post-training methods such as Reinforcement Learning ([79]) have also shown to be effective in improving model task performance ([80]), and applying such methods to $\textsc{Memory}$ model training warrants future investigation.
LoRA configurations better suited to specific architectures, including per-architecture tuning of rank and learning rate, also warrant further investigation (Appendix O). Finally, a more systematic study of the interaction between $\textsc{Executive}$ model reasoning capability and $\textsc{Memory}$ model model size (Section 5.3), as well as the optimal interaction budget at each stage and $\textsc{Executive}$ model selection (Appendix J.2), are other promising future directions.
D. Preparation of datasets
Corpus construction. Extending from our description in Section 5, we distinguish between two types of documents[^4]: evidence documents, which contain information relevant to answering a given question, and negative documents, which are irrelevant and serve as noise. For BrowseComp-Plus, we used $1{,}775$ unique evidence documents and $1{,}766$ unique negative documents (after removal of non-English documents), yielding $3{,}541$ documents in total. For MuSiQue, we used $2{,}648$ documents for each of the evidence and negative documents, yielding $5{,}296$ documents in total. NarrativeQA does not have negative documents.
[^4]: Note that for BrowseComp-Plus, the gold documents are a subset of the evidence documents.
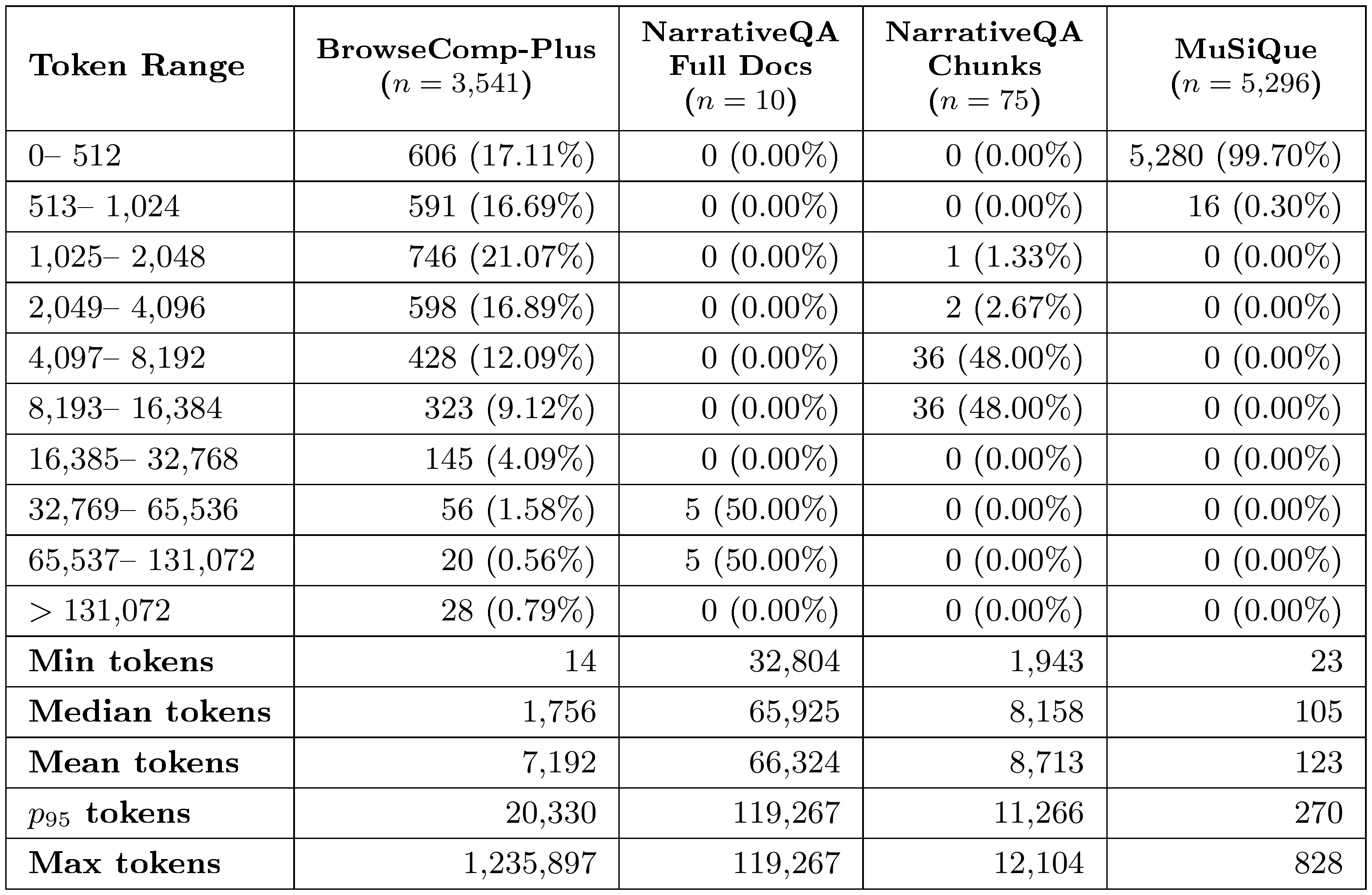
Chunking strategy. As shown in Table 7, NarrativeQA full documents span the $32{,}769$ – $131{,}072$ token range with a median length of $65{,}925$ tokens, reflecting the long-form nature of the source novels. Processing such documents without chunking risks reduced coverage of extractable QA pairs in Step 1 of Algorithm 1, as attention quality is known to deteriorate over longer contexts ([42]). We therefore chunk NarrativeQA documents using a fixed sliding window of $6{,}400$ words with a $640$-word overlap ($10%$ overlap ratio), yielding $75$ chunks concentrated in the $4{,}097$ – $16{,}384$ token range and accounting for $96%$ of all chunks, with a median group size of $7$ per document as shown in Table 8. Unlike NarrativeQA, MuSiQue documents are compact with $99.70%$ falling below $512$ tokens, and each MuSiQue document is treated as a single chunk.
::: {caption="Table 7: Token length distribution across corpora at the chunk level, where n represents the total number of individual chunks processed by Algorithm 1. Each entry reflects the token count of a single text chunk. Statistics for NarrativeQA are reported before and after chunking."}
:::
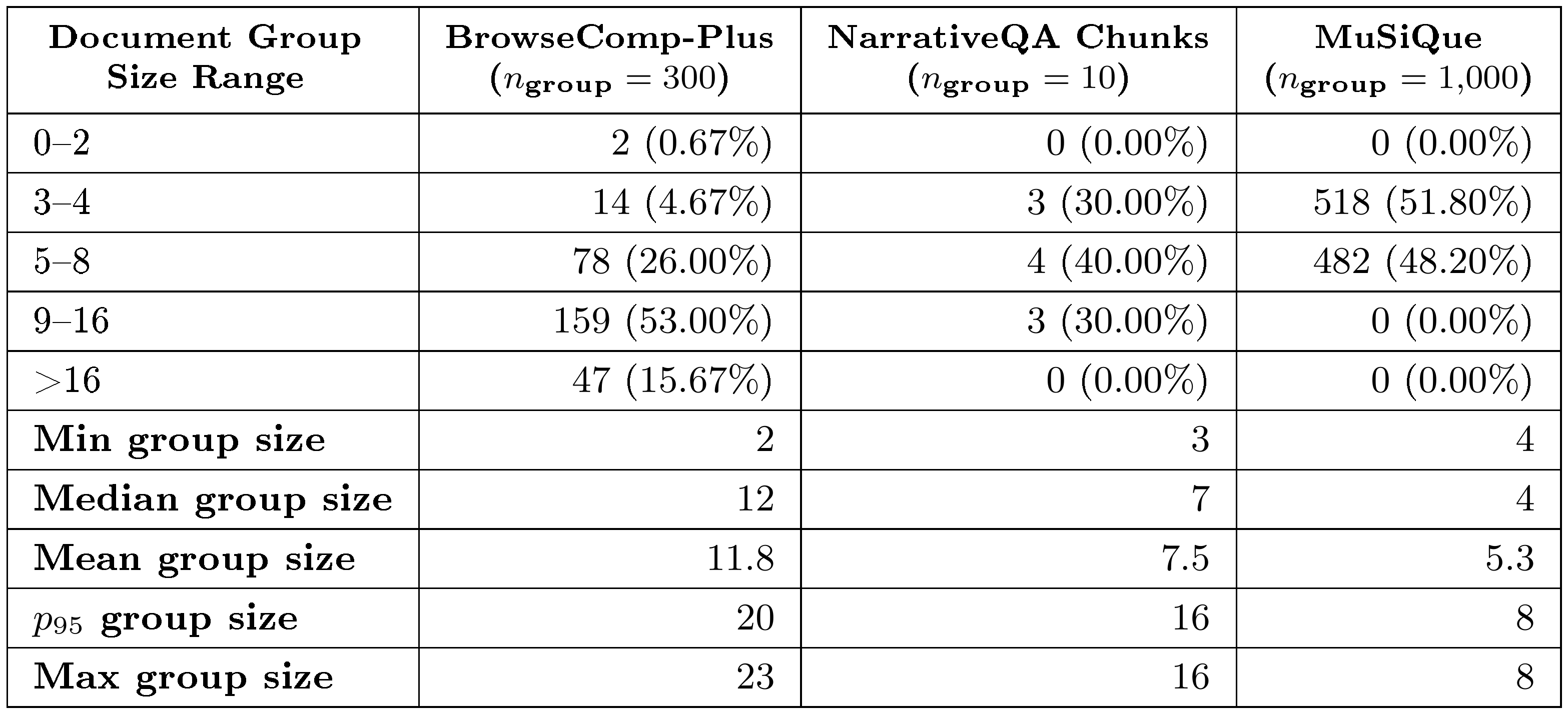
::: {caption="Table 8: Distribution of document group sizes across datasets, where group size denotes the number of chunks associated with a single question or document. For BrowseComp-Plus and MuSiQue, each question is associated with a subset of chunks drawn from the corpus, and group size represents the number of chunks per question. For NarrativeQA, each subset of chunks is derived from the original document used for multiple questions, and group size represents the number of chunks per document."}
:::
BrowseComp-Plus documents are also treated as a single chunk. The time complexity of Step 5 in Algorithm 1 is $O(k \cdot C^2 \cdot Q^2)$, where $k = n_{\text{group}}$ is the number of groups, $C = |G_i|$ is the number of participating chunks per group, and $Q = \bar{Q}_i$ is the average number of QA pairs extracted per chunk. Since chunking increases $C$, pipeline costs at Step 5 scale quadratically as the number of chunks per group increases. Given that only $2.93%$ of BrowseComp-Plus documents exceed $32{,}768$ tokens, the majority of documents fit within a single chunk, making the cost of chunking difficult to justify. We therefore opted against chunking in favor of lower pipeline cost, and leave a systematic evaluation of chunking strategies and related tradeoffs to future work.
Subset selection of negative documents. We include only a subset of negative documents for BrowseComp-Plus and MuSiQue due to computational constraints arising from the quadratic scaling of Step 5. As reported in Table 8, BrowseComp-Plus currently has a mean group size of $11.8$ and a maximum of $23$, while MuSiQue has a mean group size of $5.3$ and a maximum of $8$. Incorporating all available negative documents, which average $78$ per question (up to $197$) for BrowseComp-Plus and $17$ per question (up to $18$) for MuSiQue, would cause the group size to increase substantially. Given the quadratic dependence on $C$ in Step 5, this would result in a prohibitive increase in pipeline cost for BrowseComp-Plus ($k = 300$) and MuSiQue ($k = 1{,}000$). Hence, we opted to only include up to $N_\text{evidence}^\text{dataset}$ number of negative documents for each question in the corpus.
E. Discussion on steps in data generation pipeline
E.1 Ablation of data synthesis steps
We experiment with the data generation pipeline to show the importance of each step. We perform a leave-one-out (LOO) ablation for each step of data synthesis and train the model on the synthesized QA pairs generated. Results are reported in Table 9 on the NarrativeQA and MuSiQue datasets using Qwen2.5-32B-Instruct as the $\textsc{Executive}$ model and Qwen2.5-1.5B-Instruct as the $\textsc{Memory}$ model.
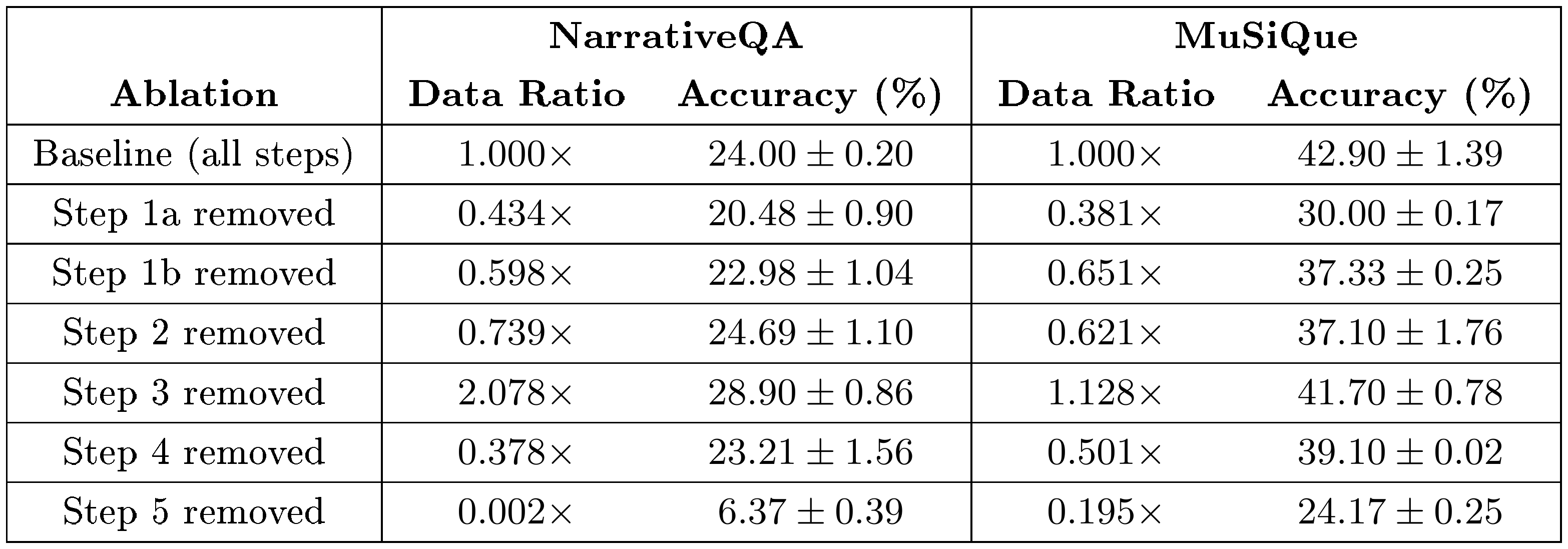
::: {caption="Table 9: LOO ablation accuracy at best performing Qwen2.5-1.5B-Instruct epoch across datasets. Data ratio indicates the number of QA pairs retained relative to the baseline. For each step removed, the Qwen2.5-1.5B-Instruct was retrained, and we report the mean ± std. dev. over 3 runs at the same training epoch as the baseline."}
:::
Step 5 (Cross-document synthesis) is the most critical component of the pipeline. Its removal causes accuracy to collapse to $6.37%$ and $24.17%$ on NarrativeQA and MuSiQue respectively, against baseline scores of $24.00%$ and $42.90%$, accompanied by a near-total loss of training data ($0.002\times$ and $0.195\times$ retention). As described in Section 4.1, Step 5 enables cross-document synthesis where $\mathcal{M}{\text{gen}}$ constructs $\mathcal{Q}{\text{cross}}$ pairs spanning inter-document connections and cross-chunk connections within a single long document, making it the dominant source of training pairs in $\mathcal{Q}_{\text{final}}$ and directly targeting the multi-source synthesis objective central to both benchmarks.
An interesting anomaly arises with Step 2 and Step 3, where their removal does not consistently hurt performance and improves accuracy on NarrativeQA. Step 2 merges related QA pairs from a single document chunk into multi-fact questions by identifying commonalities such as shared entities, overlapping time periods, and sequential events. For MuSiQue, these commonalities reflect genuine knowledge relationships that directly resemble the multi-hop factual reasoning the benchmark evaluates, such that removing Step 2 eliminates a large fraction of useful training pairs, leading to a drop in accuracy from $42.90%$ to $37.10%$. For NarrativeQA, however, the same consolidation patterns operate on superficial narrative co-occurrences rather than meaningful knowledge relationships. The predominant commonality categories are event or scene groupings that NarrativeQA does not evaluate, and entity co-occurrence patterns that are trivially satisfied given the pervasive presence of central characters across scenes. Removing Step 2 eliminates these low-quality pairs, leading to the marginal accuracy improvement from $24.00%$ to $24.69%$.
Removing Step 3 retains more data than the baseline ($2.078\times$ and $1.100\times$ for NarrativeQA and MuSiQue respectively), yet the effect on performance diverges. For MuSiQue, performance drops from $42.90%$ to $41.78%$, whereas for NarrativeQA, performance improves from $24.00%$ to $28.90%$. Step 3 applies a self-containment filter that rewrites or discards pairs whose questions cannot be understood without access to the source chunk. For MuSiQue, violations are predominantly localized and shallow, making them amenable to filtering; the proposed filter effectively identifies and removes defective pairs. For NarrativeQA, long-form narrative text frequently contains pronouns and temporal references that span many paragraphs, which are structural features of the domain rather than fixable defects. This causes the rewriting loop to introduce substitute unrelated content and corrupt the pairs produced by earlier steps. Removing Step 3 for NarrativeQA therefore avoids this domain-induced corruption and retains the original pairs intact, explaining both the data retention ratio increase and the accuracy improvement. This suggests that Step 3 is most beneficial when applied to domains where self-containment violations are well-defined and resolvable.
The remaining steps follow a consistent trend: removing Step 1a, Step 1b, or Step 4 reduces both data volume and accuracy across both datasets, confirming that each step contributes a distinct and meaningful role to the final training corpus quality.
E.2 Additional steps considered but excluded
Three additional steps were considered but ultimately excluded from the pipeline. These include paraphrasing ([81]), increasing the number of sampling trials at Step 1 of Algorithm 1, and a targeted fill whereby $\mathcal{M}_{\text{gen}}$ reviews the generated QA pairs and rewrites them to incorporate additional missed information. Paraphrasing was excluded as the scale of generated pairs already provides sufficient coverage ($\approx$ 600k–1.6M across the three datasets, see Table 11), and the potential gains were outweighed by the additional computational overhead. Increasing sampling trials proved unreliable, as additional trials did not consistently extract facts that the initial pass had failed to extract. The targeted fill similarly offered limited gains, where appending the existing QA pairs as context to prompt a revision only lengthens the context when the model had already failed to extract a fact from the original chunk, likely exacerbating attention further degradation over long inputs ([42]) and making retrieval of relevant information less reliable at inference time.
F. $\textsc{Memory}$ model hyperparameter settings
Training was conducted on H100 and H200 GPUs using the hyperparameter settings reported in Table 10. The effective batch size for each dataset is summarized in Table 11.
: Table 10: $\textsc{Memory}$ model SFT Training Configuration
| Parameter | Value |
|---|---|
| Optimizer | Fused AdamW |
| Gradient checkpointing | True |
| Learning rate (LR) | 2 × 10⁻⁵ |
| Num of Training epochs | 3 |
| LR scheduler type | Constant with warmup |
| Warmup ratio | 0.05 |
| Weight decay | 0.01 |
| Max gradient norm | 1.0 |
| Max sequence length | 8096 |
| Precision | BF16 |
| Attention implementation | Flash Attention 2 |
\begin{tabular}{|l|c|c|c|}
\hline
\textbf{Dataset} & \textbf{Target Num of Questions} & \textbf{Num of QA Pairs} & \textbf{Effective Batch Size} \\
\hline
BrowseComp-Plus & $300$ & $1{,}639{,}995$ & $512$ \\
\hline
NarrativeQA & $293$ & $1{,}276{,}676$ & $512$ \\
\hline
NarrativeQA.1 & $146$ & $635{,}009$ & $256$ \\
\hline
NarrativeQA.2 & $147$ & $641{,}667$ & $256$ \\
\hline
MuSiQue & $1{,}000$ & $664{,}762$ & $256$ \\
\hline
\end{tabular}
G. Compute resources
All experiments were conducted using NVIDIA H200 GPUs. We report computational cost in GPU-hours.
Data generation.
Generating the full reflection dataset for BrowseComp-Plus, NarrativeQA, and MuSiQue took approximately 240, 200, and 150 GPU-hours respectively.
Training.
$\textsc{Memory}$ model (Qwen2.5-14B-Instruct) training for a single run BrowseComp-Plus, NarrativeQA, and MuSiQue took approximately 180, 150, 90 GPU-hours.
H. Model training discussion
We considered three training paradigms: CPT, SFT, and LoRA-based SFT. CPT was excluded as it risks degrading instruction-following capability ([82]), which is critical for downstream QA evaluation. Full SFT was selected as it directly optimizes for the target task while preserving alignment ([23]). LoRA-based SFT serves as a parameter-efficient alternative and we include a comparison to these training methods in Appendix O.
Model merging targets the practical streaming setting in which new corpora arrive over time and $\textsc{Memory}$ model must continually integrate them. Retraining $\textsc{Memory}$ model from scratch on the union of all observed corpora is the natural baseline but quickly becomes prohibitive at scale, since its cost grows with the cumulative corpus size. Model merging instead trains a separate $\textsc{Memory}$ model on each new corpus and combines it with the existing model in parameter space, so the cost of each update scales only with the size of the new corpus rather than the entire history. This decoupling comes at a measurable accuracy cost relative to full retraining, which we quantify in Figure 2. We assume the corpora to be merged are pairwise disjoint.
H.1 Model merging
Merging methods. We consider the following methods, all of which produce $\varphi_{\text{merged}}$ without ever training on $\mathcal{D}_1 \cup \dots \cup \mathcal{D}_K$:
- Linear merging ([83]) computes a weighted sum of task vectors: $\varphi_{\text{merged}} = \varphi_0 + \sum_{i=1}^{K} \lambda_i \tau_i$, where $\lambda_i > 0$ are merging coefficients.
- SLERP ([84]) interpolates between two task vectors along the unit sphere, preserving their magnitudes: $\varphi_{\text{merged}} = \varphi_0 + \mathrm{SLERP}(\tau_1, \tau_2;, t)$, with $t \in [0, 1]$ controlling the interpolation factor.
- Task arithmetic ([85]) adds task vectors directly without further processing, recovering linear merging as a special case with uniform $\lambda_i$.
- TIES ([78]) resolves interference among task vectors before summation by (i) trimming each $\tau_i$ to its top- $\rho$ fraction of largest-magnitude entries, (ii) electing a sign at each coordinate by magnitude-weighted majority vote, and (iii) disjoint-merging only the entries that agree with the elected sign.
- DARE ([86]) sparsifies each task vector by randomly dropping a fraction $1 - \rho$ of its entries and rescaling the survivors by $1 / \rho$ to preserve expected magnitude, before linear merging.
- DARE-TIES ([86]) combines DARE-style stochastic sparsification with TIES sign-conflict resolution, retaining the diversity of random dropout while filtering out conflicting updates.
Avoiding catastrophic forgetting. Because no individual $\textsc{Memory}$ model $\mathcal{M}_{\varphi_i}$ is ever fine-tuned on another corpus' data, model merging cannot induce the kind of distributional interference that drives catastrophic forgetting in sequential fine-tuning ([26]). Knowledge from each corpus is preserved within its own task vector $\tau_i$, and conflicts between task vectors are addressed at merge time via the methods above rather than during gradient updates.
Scalability. When a new corpus $\mathcal{D}{K+1}$ arrives, we train auxiliary model $\mathcal{M}{\varphi_{K+1}}$ on its reflection QA dataset, derive $\tau_{K+1}$, and re-merge in $\mathcal{O}(1)$ additional cost relative to the full collection. This enables modular, plug-and-play integration over a continuous stream of disjoint knowledge sources, unlike retraining from scratch on $\bigcup_i \mathcal{D}_i$, which scales linearly with the cumulative corpus size.
Inference. The merged $\textsc{Memory}$ model is queried identically to a single-corpus $\textsc{Memory}$ model via the structured multi-turn protocol described in Section 4.4. Because merging operates entirely in parameter space and produces a model with the same architecture and interface as $\mathcal{M}_{\varphi_0}$, it inherits the plug-and-play property of $\textsc{MeMo}$ without requiring changes to the $\textsc{Executive}$ model or the inference protocol. Importantly, the $\textsc{Executive}$ model queries a single merged $\textsc{Memory}$ model at inference rather than dispatching across $K$ separate per-corpus $\textsc{Memory}$ models, keeping the multi-turn retrieval pipeline unchanged regardless of how many corpora have been integrated.
Procedure. For our experiments we partition NarrativeQA into two pairwise-disjoint subsets, NarrativeQA.1 and NarrativeQA.2, of $\sim$ 640k reflection QA pairs each. Each subset is used to fine-tune an independent $\textsc{Memory}$ model from the same Qwen2.5-14B-Instruct base via SFT for $3$ epochs, producing $\mathcal{M}{\varphi_1}$ and $\mathcal{M}{\varphi_2}$ at SFT costs of $X$ and $Y$ GPU-hours, respectively (each is $\approx 24$ GPU-hours on 8 $\times$ H100; full-retrain on the union NarrativeQA.1 $\cup$ NarrativeQA.2 costs $X{+}Y \approx 48$ GPU-hours by linear scaling). We evaluate every saved checkpoint of each run on the held-out NarrativeQA evaluation set and select the best-performing checkpoint per subset; the corresponding task vectors $\tau_1$ and $\tau_2$ are the inputs to the merging step. We then sweep all six merging methods listed above (Linear, Task arithmetic, SLERP, TIES, DARE, DARE-TIES) at three sparsification densities $\rho \in {0.3, 0.5, 0.7}$ (or three interpolation factors $t \in {0.3, 0.5, 0.7}$ for SLERP), giving $14$ merged- $\textsc{Memory}$ model configurations in total. Each configuration is evaluated on NarrativeQA with Qwen2.5-32B-Instruct as $\textsc{Executive}$ model (mean $\pm$ std over 3 runs). The configuration that we report in the Section 5 as Merge-TIES is the best of the sweep (TIES with $\rho{=}0.3$).
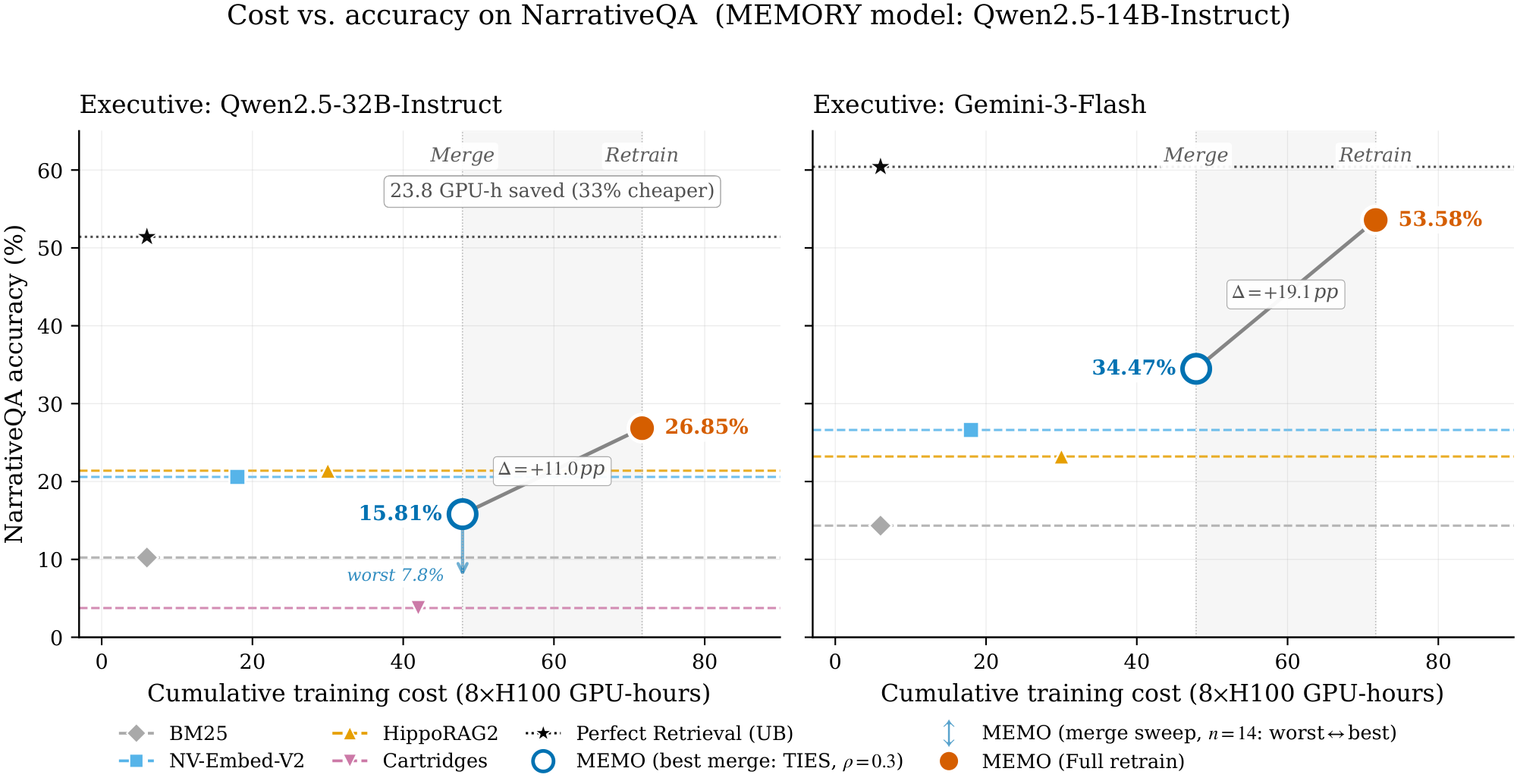
Results. A single SFT run consumes $\approx 24$ GPU-hours on 8 $\times$ H100; after two arrivals, full retraining incurs $X{+}(X{+}Y){=}72$ GPU-hours of cumulative compute, whereas merging accumulates only $X{+}Y{=}48$ GPU-hours — a 33% reduction (Figure 2). The asymptotic gap widens with $K$: under the same per-corpus cost, merging scales as $\Theta(K)$ while full retraining scales as $\Theta(K^2)$, yielding a $5.5{\times}$ saving at $K{=}10$ ($240$ vs. $1{,}320$ GPU-hours). On accuracy, Merge-TIES ($\rho{=}0.3$) trails full retraining by $11.0$ % with Qwen2.5-32B-Instruct as $\textsc{Executive}$ model ($15.81%$ vs. $26.85%$) and by $19.1$ % with Gemini-3-Flash ($34.47%$ vs. $53.58%$), placing the merged $\textsc{Memory}$ model below the union-retrained $\textsc{Memory}$ model but above every retrieval baseline. The full per-method sweep is reported in Table 12: TIES ($\rho{=}0.3$) and DARE-Linear ($\rho{=}0.3$) lead at $15.81%$ and $15.47%$ respectively, while SLERP ($t{=}0.5$) is the worst configuration at $7.85%$. The pattern across families suggests that aggressive sparsification at low $\rho$ paired with sign-conflict resolution (TIES, DARE-Linear) is the most reliable merging recipe in this regime. These results confirm the predicted compute–accuracy trade-off: merging recovers most of $\textsc{Memory}$ model's headroom over retrieval methods at substantially lower cumulative cost.
\begin{tabular}{|l|c|c|}
\hline
\textbf{Method family} & \textbf{Hyperparameter} & \textbf{Accuracy (\%)} \\
\hline
Linear & --- & $11.60 \pm 1.02$ \\
Task arithmetic & --- & $12.74 \pm 1.75$ \\
\hline
\multirow{3}{*}{SLERP} & $t=0.3$ & $11.60 \pm 2.24$ \\
& $t=0.5$ & $\phantom{0}7.85 \pm 1.71$ \\
& $t=0.7$ & $11.60 \pm 2.13$ \\
\hline
\multirow{3}{*}{TIES} & $\rho=0.3$ & $\mathbf{15.81 \pm 0.39}$ \\
& $\rho=0.5$ & $12.17 \pm 1.94$ \\
& $\rho=0.7$ & $12.06 \pm 2.58$ \\
\hline
\multirow{3}{*}{DARE-Linear} & $\rho=0.3$ & $15.47 \pm 0.79$ \\
& $\rho=0.5$ & $\phantom{0}9.78 \pm 1.20$ \\
& $\rho=0.7$ & $13.65 \pm 2.08$ \\
\hline
\multirow{3}{*}{DARE-TIES} & $\rho=0.3$ & $11.72 \pm 0.52$ \\
& $\rho=0.5$ & $12.97 \pm 1.23$ \\
& $\rho=0.7$ & $11.04 \pm 1.20$ \\
\hline
\end{tabular}
I. Validating evaluation dataset suitability
::: caption="Table 13: Performance gap between no context and perfect retrieval across datasets and Executive models."

:::
To assess the suitability of the evaluation datasets for $\textsc{Executive}$ model and whether the $\textsc{Executive}$ model has memorized answers from training data, we evaluate performance both without any context (No Context) and with evidence documents provided (Perfect Retrieval), the latter serving as an empirical upper-bound that assumes perfect retrieval of relevant documents.
As shown in Table 13, the large disparity in performance between No Context and Perfect Retrieval confirms that these datasets require access to evidence documents to achieve correct answers, validating their suitability for evaluating $\textsc{MeMo}$.
Unsurprisingly, MuSiQue yields the highest No Context scores, as its Wikipedia-grounded questions fall within models' parametric knowledge. NarrativeQA proves most challenging as it achieves the lowest Perfect Retrieval scores across both $\textsc{Executive}$ models, reflecting the demand for careful reasoning over full-length books and movie scripts. BrowseComp-Plus yields the largest disparity between No Context and Perfect Retrieval, with near-zero No Context performance but strong recovery when evidence documents are provided.
These findings confirm that $\textsc{Executive}$ model heavily relies on evidence documents across all three datasets to perform well. MuSiQue tests multi-hop factual reasoning where parametric knowledge provides partial signals, NarrativeQA tests narrative comprehension that remains challenging even with perfect context, and BrowseComp-Plus tests the ability to exploit retrieved documents for facts otherwise entirely inaccessible to the model.
J. Evaluation details
J.1 Implementation details
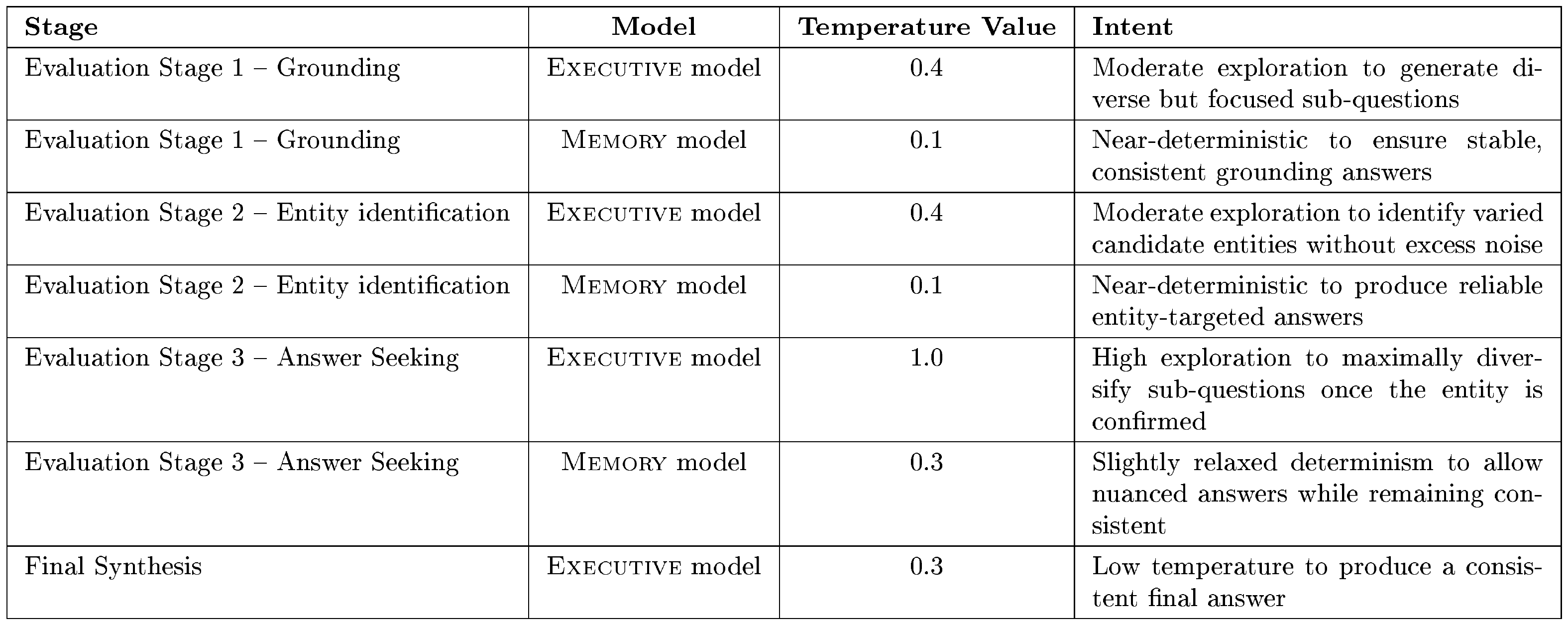
The current temperature settings are described in Table 14. Stage 1 only has a budget of $1$ interaction, Stage 2 has a budget of $7$ interactions, Stage 3 has a budget of $8$ interactions.
::: caption="Table 14: Temperature Configuration of each Stage from Section 4.4"
:::
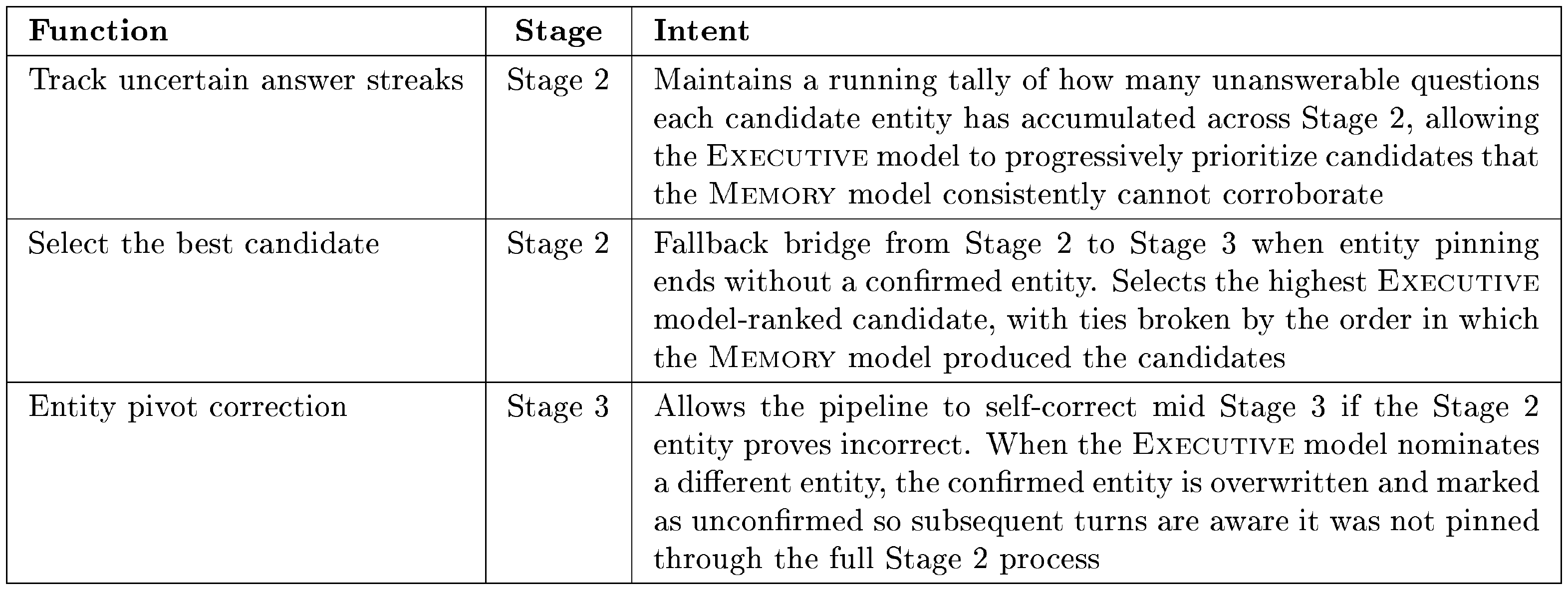
::: caption="Table 15: Helper Functions for Stage 2 and 3 of the Evaluation Pipeline"
:::
Beyond what is described in Section 4.4, there are additional helper functions that help manage failure modes across Stage 2 and Stage 3. Within Stage 2, the uncertain answer streak tracker is called at the start of every entity-pinning interaction and its output is passed directly into the entity-pinning prompt, giving the $\textsc{Executive}$ model a live view of which candidates the $\textsc{Memory}$ model has repeatedly failed to corroborate. This allows the $\textsc{Executive}$ model to continuously re-rank and prune the candidate pool as evidence accumulates. When Stage 2 concludes without a confirmed entity, either because the $\textsc{Executive}$ model explicitly exhausts its options or the interaction budget is reached, the best candidate selector acts as the bridge into Stage 3 by returning the top-ranked candidate. In cases where multiple candidates share the highest rank, the first candidate in the order produced by $\textsc{Executive}$ model is selected. In both cases, the downstream Stage 3 prompt is informed of whether the entity was formally confirmed or merely a best guess. Finally, if Stage 3 reveals that the Stage 2 entity was incorrect due to persistent $\textsc{Memory}$ model failures, the entity pivot mechanism allows the $\textsc{Executive}$ model to nominate a replacement entity mid-stage. The confirmed entity is then overwritten and marked as unconfirmed, ensuring subsequent stages treat it with appropriate uncertainty rather than the confidence of a fully pinned entity.
J.2 Ablations on evaluation setup
To justify our structured multi-turn evaluation design, we compare against two baselines: a single-turn setup and an unstructured multi-turn setup; in both cases, the same trained $\textsc{Memory}$ model is used and $\textsc{Executive}$ model is held fixed. Results are reported in Table 16.
::: {caption="Table 16: MeMo accuracy results with Qwen2.5-32B-Instruct as Executive model and Qwen2.5-14B-Instruct as Memory model across evaluation setups. The best performing epoch was used in comparison across all 3 setups, with mean ± std. dev. reported across 3 runs. Bold results indicate best performing results in the column."}
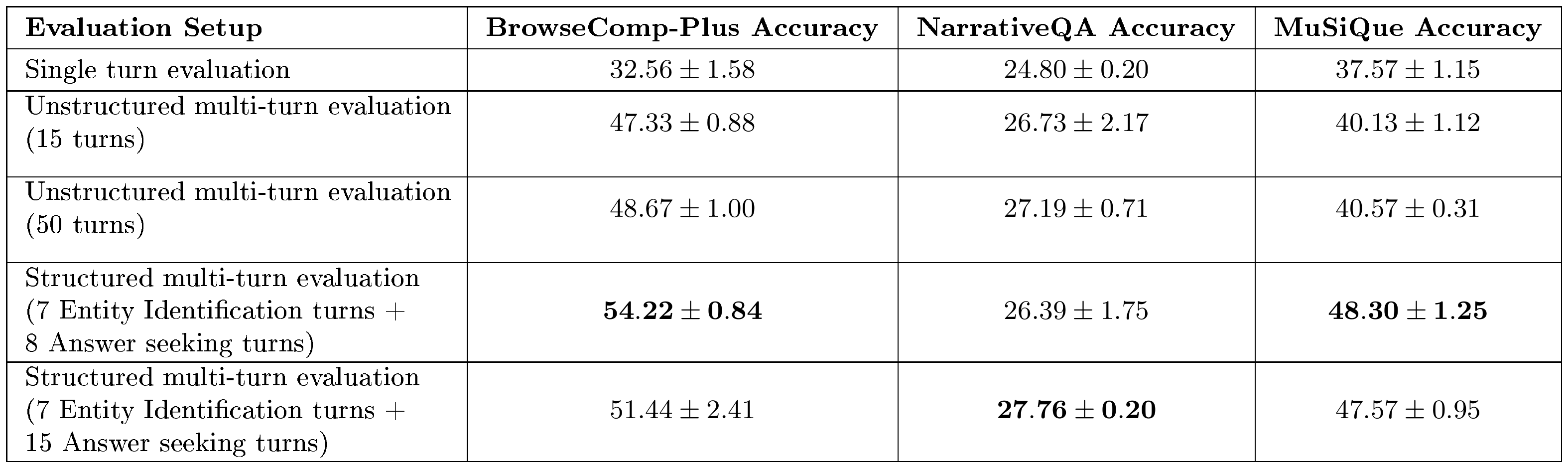
:::
In a single-turn interaction, $\textsc{Executive}$ model first determines whether the question requires external memory retrieval, and if so, decomposes it into a set of sub-questions (Stage 1, Section 4.4) and poses them all simultaneously to $\textsc{Memory}$ model. $\textsc{Memory}$ model responds to each sub-question independently, and responses indicating uncertainty are discarded before the remaining answers are passed to $\textsc{Executive}$ model for final synthesis. This design requires $\textsc{Executive}$ model to commit to its full sub-question set before observing any responses, preventing it from reformulating uninformative queries, following up on answers that introduce new candidate entities, or correcting retrievals that are incomplete, contradictory, or anchored to the wrong entity. This is a fundamental limitation that is reflected in its consistently lowest performance across all three datasets (Table 16).
A natural extension of the single-turn setting is an unstructured multi-turn interaction, where $\textsc{Executive}$ model examines the responses from $\textsc{Memory}$ model and decides whether sufficient information has been gathered, or whether additional retrieval rounds are needed (Stage 3, Section 4.4). In this setting, $\textsc{Executive}$ model is presented with the full history of question-answer pairs and prompted to either synthesize a final answer or generate a new batch of sub-questions targeting remaining gaps, repeating for up to $T$ interactions. While iterative retrieval yields clear improvements over the single-turn baseline, performance plateaus quickly when increasing from 15 to 50 interactions ($47.33 \pm 0.88$ to $48.67 \pm 1.00$ on BrowseComp-Plus, $26.73 \pm 2.17$ to $27.19 \pm 0.71$ on NarrativeQA, and $40.13 \pm 1.12$ to $40.57 \pm 0.31$ on MuSiQue), suggesting that iterative retrieval alone is insufficient.
The structured multi-turn setup (see Section 4.4 and Appendix J.1) outperforms the unstructured multi-turn baseline, with 8 answer-seeking interactions achieving the strongest overall performance for BrowseComp-Plus and MuSiQue. This is consistent with the expectation that explicit entity identification is well-suited to the multi-hop reasoning demands of these datasets. NarrativeQA, which tests discourse understanding over long documents, has the unstructured 15- and 50-interaction baselines ($26.73 \pm 2.17$ and $27.19 \pm 0.71$) initially outperform the structured setup with 8 answer-seeking interactions ($26.39 \pm 1.75$). Inference logs indicate that $\textsc{Executive}$ model rarely utilizes the entity identification stage on NarrativeQA, likely because its questions are less reliant on resolving specific entities. Consequently, the fixed-entity identification budget effectively reduces the number of available answer-seeking interactions compared to unstructured baselines. Increasing the answer-seeking budget to 15 interactions recovers this gap, with NarrativeQA reaching $27.76 \pm 0.20$, surpassing both unstructured baselines. We hypothesize that this could be due to additional answer-seeking interactions continuing to surface useful signals without the risk of entity drift or state corruption that compound in open-domain multi-hop settings.
Unlike NarrativeQA, structured entity identification and state tracking in BrowseComp-Plus and MuSiQue introduce sensitivity to error accumulation as the number of answer-seeking interactions increases beyond the optimal budget. Additional interactions increase the risk of erroneous $\textsc{Memory}$ model responses corrupting the known facts state, and provide more opportunities for $\textsc{Executive}$ model to commit to an incorrect intermediate entity via the entity pivot correction helper (Table 15). Furthermore, more interactions dilute the correct signal with potentially incorrect answers at the final synthesis stage. These failure modes are partly a function of the reasoning capability of $\textsc{Executive}$ model, as structured state maintenance demands strong in-context reasoning to accurately track entities and avoid premature entity commitment. Corroborating this, we observe in Table 2 that a stronger reasoning model as $\textsc{Executive}$ model yields improved performance when paired with the same $\textsc{Memory}$ model, suggesting that these failure modes can be mitigated by scaling the reasoning capability of $\textsc{Executive}$ model.
The stage budget used in our experiments was selected without systematic tuning, and alternative settings may yield similar performance with greater token efficiency. We therefore leave a systematic study of the optimal interaction budget and $\textsc{Executive}$ model selection as future work.
K. Discussion on number of training epochs
From Figure 3, Figure 4, and Figure 5, we observe that additional training epochs do not consistently improve accuracy, as peak performance for most $\textsc{Memory}$ model occurs at epoch 2 with marginal gains or mild regression thereafter. We attribute the early saturation and subsequent regression to overfitting on the SFT corpus, which exhibits substantial lexical overlap across steps by design, as later steps are derived from earlier ones Algorithm 1. To quantify this lexical overlap, we compute the lossless compression ratio of the combined QA text across all steps for each dataset by extracting all question and answer strings, concatenating them into a single text corpus, and applying gzip compression at maximum level (compression level 9), where the compression ratio is defined as the ratio of the original text size to the compressed size.
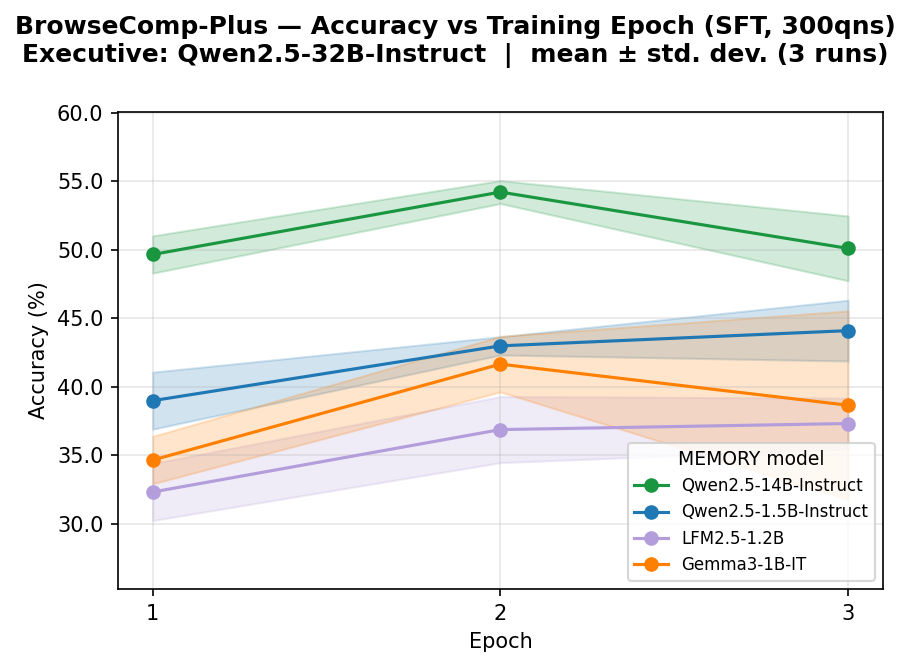
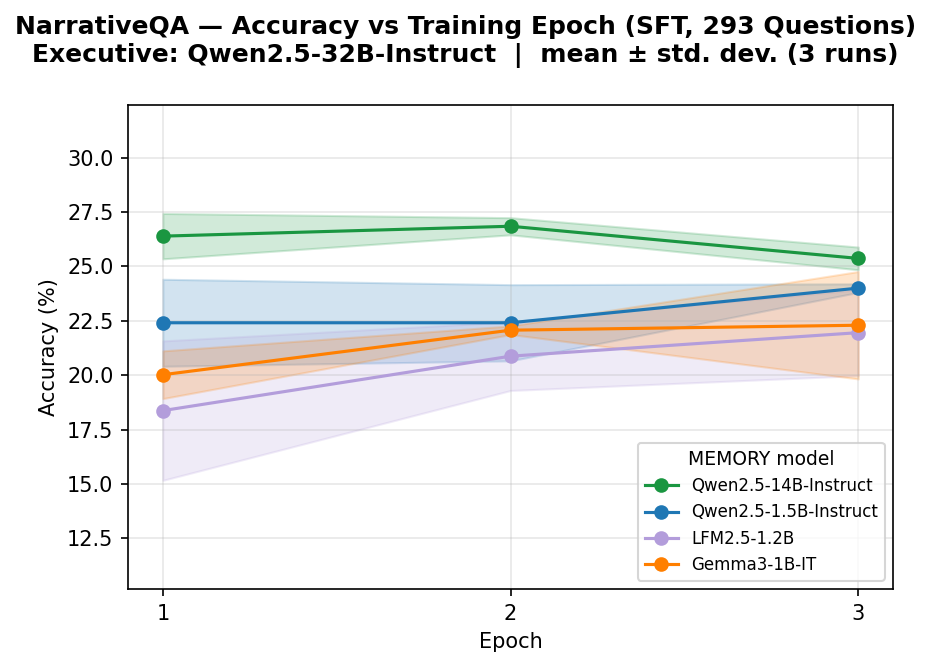
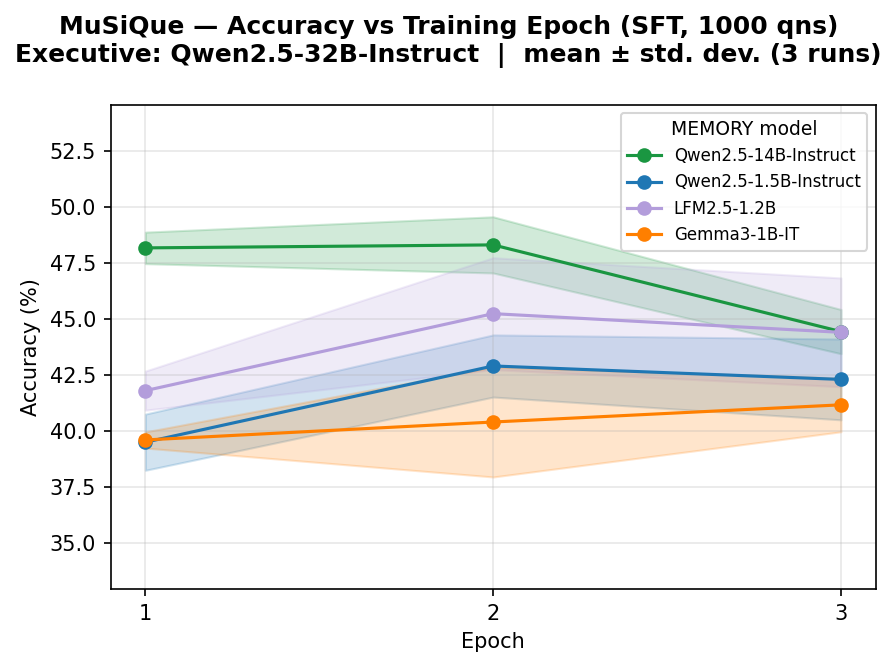
BrowseComp-Plus ($1{,}639{,}995$ pairs) achieves a ratio of $5.80\times$ ($82.8%$ savings), MuSiQue ($664{,}762$ pairs) achieves $7.03\times$ ($85.8%$ savings), and NarrativeQA ($1{,}276{,}676$ pairs) achieves $5.45\times$ ($81.7%$ savings), indicating substantial lexical overlap within each dataset. We note that compression ratio captures lexical overlap only, and semantic diversity across QA pairs may remain higher, as each step targets distinct reasoning operations ranging from direct fact extraction to cross-document synthesis (see Algorithm 1), which is consistent with the impact of removing Step 5 (see Appendix E).
L. Performance degradation of retrieval-based methods with increasing noise
::: {caption="Table 17: Accuracy (%) on BrowseComp-Plus and MuSiQue with Qwen2.5-32B-Instruct as Executive model. MeMo results are based on Qwen2.5-14B-Instruct and reported at the best training epoch. N is the number of evidence documents present in the target corpus. Delta denotes accuracy difference (%) compared to 0N."}
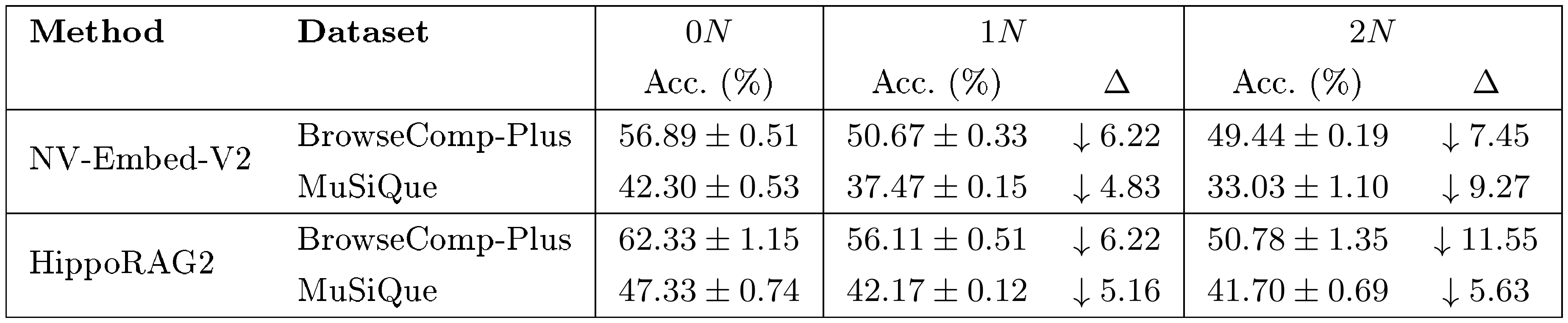
:::
Table 17 reports the performance of two retrieval-based baselines (NV-Embed-V2 and HippoRAG2) under increasing retrieval noise. Both methods degrade monotonically as noise increases, confirming their susceptibility to irrelevant documents. The degradation is most severe for HippoRAG2 on BrowseComp-Plus, which drops 11.55% from $0N$ to $2N$, and for NV-Embed-V2 on MuSiQue, which drops 9.27% over the same range. Notably, even a single negative document per evidence document ($1N$) causes substantial drops of up to 6.22% for both methods on BrowseComp-Plus, suggesting that retrieval-based methods are extremely sensitive to noisy retrieval settings.
M. Ablation on $\textsc{Memory}$ model size
Both Qwen2.5-1.5B-Instruct and Qwen2.5-14B-Instruct $\textsc{Memory}$ s are trained on the same QA dataset generated by the $\textsc{Generator}$ model (Qwen2.5-32B-Instruct) under training settings described in Appendix F. Each $\textsc{Memory}$ model is evaluated using Qwen2.5-32B-Instruct and Gemini-3-Flash as the $\textsc{Executive}$ model.
N. Ablation on $\textsc{Memory}$ model family
Each $\textsc{Memory}$ model is trained on the same QA dataset generated by $\textsc{Generator}$ model (Qwen2.5-32B-Instruct) and evaluated using Qwen2.5-32B-Instruct and Gemini-3-Flash as $\textsc{Executive}$ model. Notably, while Qwen2.5-1.5B-Instruct and Gemma3-1B-IT are based on standard transformer architectures, LFM2.5-1.2B-Instruct adopts a hybrid architecture combining state-space convolution with transformer attention blocks, thereby providing a broader test of $\textsc{Memory}$ model across diverse model designs. These models are trained on the same training settings in Appendix F, with Gemma3-1B-IT using eager attention during training instead of Flash Attention 2.
O. Comparison between full SFT and LoRA
We train all models using LoRA ([87]) applied to the attention and feed-forward projection layers: q_proj, k_proj, v_proj, o_proj, gate_proj, up_proj, and down_proj. The general LoRA configuration is summarised in Table 18, with model-specific rank and scaling settings reported in Table 19. All remaining training hyperparameters follow Table 10, and per-dataset batch sizes are given in Table 11.
: Table 18: LoRA Specific Training Configuration. All other parameters are the same as those in Table 10.
| Parameter | Value |
|---|---|
| Target modules | q_proj, k_proj, v_proj, o_proj, |
gate_proj, up_proj, down_proj |
|
| LoRA dropout | 0.05 |
| Bias | None |
| Learning rate | 2 × 10⁻⁴ |
: Table 19: Model-Specific LoRA Configuration.
| Model | Size | LoRA rank | LoRA alpha | Trainable params |
|---|---|---|---|---|
| LFM2.5-1.2B-Instruct | 1.2B | 8 | 16 | 6.1M (0.41%) |
| Gemma3-1B-IT | 1B | 8 | 16 | 6.6M (0.65%) |
| Qwen2.5-1.5B-Instruct | 1.5B | 8 | 16 | 9.2M (0.60%) |
| Qwen2.5-14B-Instruct | 14B | 16 | 32 | 68.8M (0.47%) |
::: {caption="Table 20: Ablation on LoRA vs Full SFT training across all Memory models, evaluated with Qwen2.5-32B-Instruct as Executive model. All results are mean ± std. dev. over 3 runs. Bold results indicate best performing results in the column."}

:::
The notably poor LoRA performance of LFM2.5-1.2B-Instruct can be attributed to its hybrid convolution–attention architecture, which differs from the standard transformer models in our evaluation. Following the LFM2 architecture ([77]), LFM2.5-1.2B-Instruct consists of $16$ layers — $6$ grouped-query attention (GQA) blocks (at indices ${2, 5, 8, 10, 12, 14}$) interleaved with $10$ short-range LIV convolution (ShortConv) blocks ([77]). Crucially, the LFM2 attention output projection is named out_proj (rather than o_proj) and its SwiGLU MLP uses w1/w3/w2 (rather than gate_proj/up_proj/down_proj), while the ShortConv blocks expose their own in_proj and out_proj layers. A LoRA configuration targeting the standard Llama-family module names therefore adapts only a strict subset of the projections that exist in LFM2.5, leaving the remainder frozen. The result is $6.1$ M trainable parameters ($0.41%$ of total), disproportionately low given the model size and below our target of ${\sim}0.5%$. The rank $r=8$ was kept fixed across all sub-2B models for a controlled comparison; in retrospect, this penalises LFM2.5-1.2B-Instruct due to its architectural mismatch with the standard Llama-style target set.
Furthermore, the $10$ ShortConv blocks which handle the bulk of the model's local feature extraction and the SwiGLU MLPs attached to every block remain entirely unadapted under standard LoRA targeting, severely limiting the adapter's ability to shift the model's behaviour. As shown in Table 20, the large performance gap between LoRA and Full SFT confirms that the model is capable of learning the task when all parameters are updated.
Future work could explore LoRA configurations better suited to this architecture: targeting the LFM2-specific module names (out_proj, w1, w3, w2) alongside the ShortConv projections (in_proj, out_proj), as well as tuning the rank and learning rate per architecture rather than holding them fixed across families for the controlled comparison reported here.
---
References
Section Summary: This section consists of a numbered bibliography listing dozens of academic papers and surveys on large language models and related AI techniques. The entries cite works on topics such as model training, knowledge retrieval, context handling, and performance limitations, drawn mainly from arXiv preprints along with proceedings from conferences like NeurIPS, ACL, and EMNLP. Most references include authors, titles, publication years, and links or page details.
[1] Kojima et al. (2023). Large Language Models are Zero-Shot Reasoners. arXiv:2205.11916.
[2] Zhao et al. (2023). A Survey of Large Language Models. arXiv:2303.18223.
[3] Jiang et al. (2026). A Survey on Large Language Models for Code Generation. ACM Transactions on Software Engineering and Methodology.
[4] Xu et al. (2024). Knowledge Conflicts for LLMs: A Survey. arXiv:2403.08319.
[5] Jeffrey Cheng et al. (2024). Dated Data: Tracing Knowledge Cutoffs in Large Language Models. arXiv:2403.12958.
[6] Jungo Kasai et al. (2024). RealTime QA: What's the Answer Right Now?. arXiv:2207.13332.
[7] Karan Singhal et al. (2022). Large Language Models Encode Clinical Knowledge. arXiv:2212.13138. https://arxiv.org/abs/2212.13138.
[8] Shijie Wu et al. (2023). BloombergGPT: A Large Language Model for Finance. arXiv:2303.17564.
[9] Patrick Lewis et al. (2021). Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. arXiv:2005.11401.
[10] Nikhil Kandpal et al. (2023). Large Language Models Struggle to Learn Long-Tail Knowledge. arXiv:2211.08411.
[11] Wu et al. (2022). Sustainable AI: Environmental Implications, Challenges and Opportunities. In Proc. MLSys. pp. 795–813.
[12] Robertson, Stephen E. and Walker, Steve (1994). Some Simple Effective Approximations to the 2-Poisson Model for Probabilistic Weighted Retrieval. In Proc. SIGIR.
[13] Lee et al. (2024). NV-Embed: Improved Techniques for Training LLMs as Generalist Embedding Models. arXiv:2405.17428.
[14] Lewis et al. (2020). Retrieval-augmented generation for knowledge-intensive nlp tasks. In Proc. NeurIPS. pp. 9459–9474.
[15] Edge et al. (2024). From Local to Global: A Graph RAG Approach to Query-Focused Summarization. arXiv:2404.16130.
[16] Gutiérrez et al. (2024). Hipporag: Neurobiologically inspired long-term memory for large language models. In Proc. NeurIPS. pp. 59532–59569.
[17] Gutiérrez et al. (2025). From RAG to Memory: Non-Parametric Continual Learning for Large Language Models. In Proc. ICML.
[18] Brown et al. (2020). Language Models are Few-Shot Learners. In Proc. NeurIPS. pp. 1877–1901.
[19] Dong et al. (2024). A Survey on In-Context Learning. In Proc. EMNLP.
[20] Tang, Yixuan and Yang, Yi (2024). MultiHop-RAG: Benchmarking Retrieval-Augmented Generation for Multi-Hop Queries. arXiv:2401.15391.
[21] Lin et al. (2025). Optimizing Multi-Hop Document Retrieval Through Intermediate Representations. arXiv:2503.04796.
[22] Ke et al. (2023). Continual Pre-Training of Language Models. arXiv:2302.03241.
[23] Ouyang et al. (2022). Training Language Models to Follow Instructions with Human Feedback. In Proc. NeurIPS.
[24] Wang et al. (2023). Self-instruct: Aligning language models with self-generated instructions. In Proc. ACL. pp. 13484–13508.
[25] Chung et al. (2024). Scaling instruction-finetuned language models. Journal of Machine Learning Research. pp. 1–53.
[26] Luo et al. (2025). An Empirical Study of Catastrophic Forgetting in Large Language Models During Continual Fine-Tuning. arXiv:2308.08747.
[27] Chu et al. (2025). Sft memorizes, rl generalizes: A comparative study of foundation model post-training. arXiv:2501.17161.
[28] Chevalier et al. (2023). Adapting Language Models to Compress Contexts. In Proc. EMNLP.
[29] Mu et al. (2023). Learning to Compress Prompts with Gist Tokens. In Proc. NeurIPS.
[30] Ge et al. (2024). In-context Autoencoder for Context Compression in a Large Language Model. In Proc. ICLR.
[31] Guibin Zhang et al. (2026). MemGen: Weaving Generative Latent Memory for Self-Evolving Agents. In Proc. ICLR.
[32] Li et al. (2022). Data augmentation approaches in natural language processing: A survey. AI Open. pp. 71–90.
[33] Chen et al. (2023). An empirical survey of data augmentation for limited data learning in nlp. Transactions of the Association for Computational Linguistics. pp. 191–211.
[34] Allen-Zhu, Zeyuan and Li, Yuanzhi (2024). Physics of language models: part 3.1, knowledge storage and extraction. In Proc. ICML. pp. 1067–1077.
[35] Alberti et al. (2019). Synthetic QA corpora generation with roundtrip consistency. In Proc. ACL. pp. 6168–6173.
[36] Puri et al. (2020). Training question answering models from synthetic data. In Proc. EMNLP. pp. 5811–5826.
[37] Feng et al. (2024). Don’t hallucinate, abstain: Identifying llm knowledge gaps via multi-llm collaboration. In Proc. ACL. pp. 14664–14690.
[38] Jie et al. (2024). Self-training large language models through knowledge detection. In Proc. EMNLP Findings. pp. 15033–15045.
[39] Vaswani et al. (2017). Attention Is All You Need. In Proc. NeurIPS.
[40] Gelada et al. (2025). Scaling Context Requires Rethinking Attention. arXiv:2507.04239.
[41] Liu et al. (2024). Lost in the Middle: How Language Models Use Long Contexts. Transactions of the Association for Computational Linguistics. 12. pp. 157–173.
[42] Hsieh et al. (2024). RULER: Whattextquoterights the Real Context Size of Your Long-Context Language Models?. In Proc. COLM.
[43] Cuconasu et al. (2024). The Power of Noise: Redefining Retrieval for RAG Systems. In Proc. SIGIR.
[44] Liu et al. (2026). Tackling the Inherent Difficulty of Noise Filtering in RAG. arXiv:2601.01896.
[45] Zhang et al. (2026). Understanding the relationship between prompts and response uncertainty in large language models. In Proc. ACL Findings.
[46] Sun et al. (2020). ERNIE 2.0: A Continual Pre-Training Framework for Language Understanding. In Proc. AAAI.
[47] Li, Zhizhong and Hoiem, Derek (2018). Learning without Forgetting. IEEE Transactions on Pattern Analysis and Machine Intelligence. 40(12). pp. 2935–2947.
[48] Harmon et al. (2025). Mapping Post-Training Forgetting in Language Models at Scale. arXiv:2510.17776.
[49] Qi et al. (2024). Fine-tuning Aligned Language Models Compromises Safety, Even When Users Do Not Intend To!. In Proc. ICLR.
[50] Zhang et al. (2023). Dissecting the Runtime Performance of the Training, Fine-Tuning, and Inference of Large Language Models. arXiv:2311.03687.
[51] Xia et al. (2024). Understanding the Performance and Estimating the Cost of LLM Fine-Tuning. In Proc. IISWC.
[52] Manchanda et al. (2025). The Open Source Advantage in Large Language Models (LLMs). arXiv:2412.12004.
[53] Gu, Albert and Dao, Tri (2023). Mamba: Linear-Time Sequence Modeling with Selective State Spaces. arXiv:2312.00752.
[54] Sun et al. (2023). Retentive Network: A Successor to Transformer for Large Language Models. arXiv:2307.08621.
[55] Wu et al. (2022). Memorizing Transformers. In Proc. ICLR.
[56] Khandelwal et al. (2020). Generalization through Memorization: Nearest Neighbor Language Models. In Proc. ICLR.
[57] Cao et al. (2025). Memory decoder: A pretrained, plug-and-play memory for large language models. arXiv:2508.09874.
[58] Berglund et al. (2023). The Reversal Curse: LLMs trained on" A is B" fail to learn" B is A". arXiv:2309.12288.
[59] Allen-Zhu, Zeyuan and Li, Yuanzhi (2023). Physics of language models: Part 3.2, knowledge manipulation. arXiv:2309.14402.
[60] Yang et al. (2024). Model Merging in LLMs, MLLMs, and Beyond: Methods, Theories, Applications, and Opportunities. ACM Computing Surveys.
[61] Zijian Chen et al. (2025). BrowseComp-Plus: A More Fair and Transparent Evaluation Benchmark of Deep-Research Agent. arXiv:2508.06600.
[62] Danilák, Michal (2021). langdetect. https://github.com/Mimino666/langdetect.
[63] Kočiskỳ et al. (2018). The NarrativeQA Reading Comprehension Challenge. Transactions of the Association for Computational Linguistics. pp. 317–328.
[64] Harsh Trivedi et al. (2022). MuSiQue: Multihop Questions via Single-hop Question Composition. arXiv:2108.00573.
[65] Eyuboglu et al. (2025). Cartridges: Lightweight and General-Purpose Long Context Representations via Self-Study. arXiv:2506.06266.
[66] Jiaqi Cao et al. (2025). Memory Decoder: A Pretrained, Plug-and-Play Memory for Large Language Models. arXiv:2508.09874.
[67] Yang et al. (2025). Qwen2.5 Technical Report. arXiv:2412.15115.
[68] Woosuk Kwon et al. (2023). Efficient Memory Management for Large Language Model Serving with PagedAttention. arXiv:2309.06180.
[69] Su et al. (2024). RoFormer: Enhanced transformer with rotary position embedding. Neurocomputing. pp. 127063.
[70] Peng et al. (2024). YaRN: Efficient Context Window Extension of Large Language Models. In Proc. ICLR.
[71] Loshchilov, Ilya and Hutter, Frank (2017). Decoupled weight decay regularization. arXiv:1711.05101.
[72] Rajbhandari et al. (2020). Zero: Memory optimizations toward training trillion parameter models. In SC20: international conference for high performance computing, networking, storage and analysis. pp. 1–16.
[73] Google DeepMind (2025). Gemini 3 Flash Model Card. https://storage.googleapis.com/deepmind-media/Model-Cards/Gemini-3-Flash-Model-Card.pdf.
[74] Gheorghe Comanici et al. (2025). Gemini 2.5: Pushing the Frontier with Advanced Reasoning, Multimodality, Long Context, and Next Generation Agentic Capabilities. arXiv:2507.06261.
[75] Ip, Jeffrey and Vongthongsri, Kritin (2025). deepeval. https://github.com/confident-ai/deepeval.
[76] Gemma Team et al. (2025). Gemma 3 Technical Report. arXiv:2503.19786.
[77] Amini et al. (2025). LFM2 Technical Report. arXiv:2511.23404.
[78] Yadav et al. (2023). Ties-merging: Resolving interference when merging models. In Proc. NeurIPS.
[79] Sutton et al. (1998). Reinforcement learning: An introduction. MIT press Cambridge.
[80] Lambert et al. (2024). Tulu 3: Pushing frontiers in open language model post-training. arXiv preprint arXiv:2411.15124.
[81] Ovadia et al. (2024). Fine-tuning or retrieval? comparing knowledge injection in llms. In Proc. EMNLP. pp. 237–250.
[82] Wu et al. (2024). Continual learning for large language models: A survey. arXiv:2402.01364.
[83] Wortsman et al. (2022). Model soups: averaging weights of multiple fine-tuned models improves accuracy without increasing inference time. In Proc. ICML. pp. 23965–23998.
[84] Shoemake, Ken (1985). Animating rotation with quaternion curves. In Proc. SIGGRAPH. pp. 245–254.
[85] Ilharco et al. (2023). Editing models with task arithmetic. In Proc. ICLR.
[86] Yu et al. (2024). Language models are super mario: Absorbing abilities from homologous models as a free lunch. In Proc. ICML.
[87] Hu et al. (2022). LoRA: Low-Rank Adaptation of Large Language Models. In Proc. ICLR.