Small Language Models are the Future of Agentic AI
Peter Belcak$^{1}$ Greg Heinrich$^{1}$ Shizhe Diao$^{1}$ Yonggan Fu$^{1}$ Xin Dong$^{1}$
Saurav Muralidharan$^{1}$ Yingyan Celine Lin$^{1,2}$ Pavlo Molchanov$^{1}$
[email protected]
$^{1}$ NVIDIA Research $^{2}$ Georgia Institute of Technology
Abstract
Large language models (LLMs) are often praised for exhibiting near-human performance on a wide range of tasks and valued for their ability to hold a general conversation. The rise of agentic AI systems is, however, ushering in a mass of applications in which language models perform a small number of specialized tasks repetitively and with little variation.
Here we lay out the position that small language models (SLMs) are sufficiently powerful, inherently more suitable, and necessarily more economical for many invocations in agentic systems, and are therefore the future of agentic AI. Our argumentation is grounded in the current level of capabilities exhibited by SLMs, the common architectures of agentic systems, and the economy of LM deployment. We further argue that in situations where general-purpose conversational abilities are essential, heterogeneous agentic systems (i.e., agents invoking multiple different models) are the natural choice. We discuss the potential barriers for the adoption of SLMs in agentic systems and outline a general LLM-to-SLM agent conversion algorithm.
Our position[^1], formulated as a value statement, highlights the significance of the operational and economic impact even a partial shift from LLMs to SLMs is to have on the AI agent industry. We aim to stimulate the discussion on the effective use of AI resources and hope to advance the efforts to lower the costs of AI of the present day. Calling for both contributions to and critique of our position, we commit to publishing all such correspondence at research.nvidia.com/labs/lpr/slm-agents.
[^1]: The views and positions expressed in this paper are those of the authors and do not necessarily reflect the views or positions of any entities they represent.
Executive Summary: The rapid growth of agentic AI—systems that autonomously perform tasks like planning, tool use, and decision-making—is transforming industries, with over half of large enterprises already deploying them and the market projected to reach nearly $200 billion by 2034. Yet, these systems heavily rely on large language models (LLMs), which are powerful generalists but expensive and resource-intensive to run, especially for the repetitive, narrow subtasks common in agents. This creates inefficiencies in cost, energy use, and scalability, straining the $57 billion invested in cloud infrastructure for LLM hosting and raising sustainability concerns as adoption surges.
This document evaluates the potential of small language models (SLMs)—compact AI models with under 10 billion parameters—to replace LLMs in agentic AI. It argues that SLMs are sufficiently capable, better suited, and more economical for most agent tasks, positioning them as the future of this field, while outlining how to transition existing systems.
The authors support their position through a review of recent literature on SLM performance, agent architectures, and deployment economics, drawing from benchmarks, efficiency studies, and case analyses of open-source agents. They cite examples from 2023–2025, including models like Microsoft's Phi series and NVIDIA's Nemotron, focusing on tasks relevant to agents such as reasoning, tool calling, and instruction following, without delving into new experiments.
Key findings show that modern SLMs now match or surpass older LLMs on essential agent capabilities: for instance, a 7-billion-parameter SLM like Phi-3 achieves commonsense reasoning and code generation scores comparable to 70-billion-parameter models, while running 10–30 times faster and using far less energy. In agentic systems, which break tasks into modular subtasks, SLMs handle 40–70% of LLM queries in studied frameworks like MetaGPT and Cradle, based on their repetitive nature. Economically, SLMs cut inference costs by an order of magnitude, enable quick fine-tuning on modest hardware, and support edge deployment on consumer devices, making them ideal for scalable, heterogeneous agents that invoke larger models only for complex reasoning. Agent designs naturally lend themselves to this mix, with data from interactions providing organic fuel for customizing SLMs.
These results imply a shift toward more efficient, sustainable AI deployment, potentially slashing operational costs by tens of percent for agent-heavy applications and reducing environmental impact from data centers. Unlike the current LLM-centric model, which over-relies on generalists for simple tasks, an SLM-first approach aligns resources with needs, fostering innovation by democratizing access—smaller organizations can build and adapt models without massive budgets. This challenges industry inertia but promises faster, cheaper agents that maintain performance while addressing rising infrastructure demands.
Leaders should prioritize converting agent systems to SLMs using the proposed step-by-step algorithm: profile current LLM uses, collect task-specific data, fine-tune SLMs for subtasks, and integrate them via routing logic, starting with low-risk modules. For broader impact, adopt heterogeneous designs where SLMs default for routine work and LLMs handle edge cases, balancing cost savings against occasional higher latency for generality. Pilot this in one agent framework to quantify benefits, then scale; further studies on fine-tuning datasets and real-world latency in diverse setups will refine decisions.
While SLM capabilities are well-evidenced by recent benchmarks, limitations include the need for task-specific fine-tuning data and potential gaps in highly creative or open-ended scenarios, where LLMs still excel. Adoption barriers like legacy infrastructures persist, but the authors express high confidence in SLMs for 50–70% of agent invocations, urging caution in unregulated or safety-critical domains until more validation occurs.
1. Introduction
Section Summary: AI agents powered by large language models are exploding in popularity, with over half of big tech companies using them and the market already worth billions, projected to reach nearly $200 billion by 2034. These agents rely on cloud-based LLMs to make decisions, plan actions, and handle tasks, backed by massive investments in infrastructure. This paper argues that small language models should replace large ones for agentic AI, outlining why, how to migrate, and calling for broader discussion despite current industry commitments.
The deployment of agentic artificial intelligence is on a meteoric rise. Recent surveys show that more than a half of large IT enterprises are actively using AI agents, with 21% having adopted just within the last year [1]. Aside from the users, markets also see substantial economic value in AI agents: As of late 2024, the agentic AI sector had seen more than USD 2bn in startup funding, was valued at USD 5.2bn, and was expected to grow to nearly USD 200bn by 2034 [2, 3]. Put plainly, there is a growing expectation that AI agents will play a substantial role in the modern economy.
The core components powering most modern AI agents are (very) large language models [4, 5]. It is the LLMs that provide the foundational intelligence that enables agents to make strategic decisions about when and how to use available tools, control the flow of operations needed to complete tasks, and, if necessary, to break down complex tasks into manageable subtasks and to perform reasoning for action planning and problem-solving [4, 6]. A typical AI agent then simply communicates with a chosen LLM API endpoint by making requests to centralized cloud infrastructure that hosts these models [4].
LLM API endpoints are specifically designed to serve a large volume of diverse requests using one generalist LLM. This operational model is deeply ingrained in the industry. In fact, it forms the foundation of substantial capital investment in the hosting cloud infrastructure – estimated at USD 57bn [7]. It is anticipated that this operational model will remain the cornerstone of the industry and that the large initial investment will deliver returns comparable to traditional software and internet solutions within 3-4 years [8].
In this work, we recognize the dominance of the standard operational model but verbally challenge one of its aspects, namely the custom that the agents' requests to access language intelligence are – in spite of their comparative simplicity – handled by singleton choices of generalist LLMs. We state (Section 2), argue (Section 3), and defend (Section 4) the position that the small, rather than large, language models are the future of agentic AI. We, however, recognize the business commitment and the now-legacy praxis that is the cause for the contrary state of the present (Section 5). In remedy, we provide an outline of a conversion algorithm for the migration of agentic applications from LLMs to SLMs (Section 6), and call for a wider discussion (Section 7). If needed to concretize our stance, we attach a set of short case studies estimating the potential extent of LLM-to-SLM replacement in selected popular open-source agents (Appendix B).
2. Position
Section Summary: The section argues that small language models, or SLMs, which are compact AI systems under 10 billion parameters, are sufficient, efficient, and often better suited than larger models for most tasks in AI agents, which are software systems that act autonomously to achieve goals. It criticizes the overreliance on big language models for everything, noting that agentic applications usually involve repetitive, focused subtasks where SLMs provide lower costs, faster performance, and less environmental strain. Ultimately, the authors predict SLMs will dominate the future of AI agents through modular designs that use them as the default, reserving larger models only for complex reasoning, aligning with community values for sustainable development.
2.1 Definitions
For the purpose of concretizing our position, we use the following working definitions:

We justify the wording of these definitions in Appendix A, but note that their choice has little bearing on the essence of our position. We note that as of 2025, we would be comfortable with considering most models below 10bn parameters in size to be SLMs.
We use the words agent and agentic system interchangeably, preferring the former when emphasizing the software with some agency as a whole (e.g., "as seen in popular coding agents") and the latter when highlighting the systems aspect of the agentic application as a sum of its components (e.g., "not all LMs of an agentic system are replaceable by SLMs"). For brevity, we focus on LMs as the bedrock of agentic applications and do not explicitly consider vision-language models, although we note that our position and most of our arguments readily extend to vision-language models as well.
2.2 Statement
**We contend that SLMs are

and that on the basis of V1, V2, and V3 SLMs are the future of agentic AI.**
The phrasing of our position is deliberate. In its statement, we wish to convey that the described future development is ultimately a necessary consequence of the differences between SLMs and LLMs if the natural priorities are followed. We do not make a recommendation or try to impose an obligation — we make a statement of what we see as a faithful reflection of the community's values in this context.
2.3 Elaboration
We assert that the dominance of LLMs in the design of AI agents is both excessive and misaligned with the functional demands of most agentic use cases. While LLMs offer impressive generality and conversational fluency, the majority of agentic subtasks in deployed agentic systems are repetitive, scoped, and non-conversational—calling for models that are efficient, predictable, and inexpensive. In this context, SLMs not only suffice, but are often preferable. They offer several advantages: lower latency, reduced memory and computational requirements, and significantly lower operational costs, all while maintaining adequate task performance in constrained domains.
Our position stems from a pragmatic view of language model usage patterns within agentic architectures. These systems typically decompose complex goals into modular sub-tasks, each of which can be reliably handled by specialized or fine-tuned SLMs. We argue that insisting on LLMs for all such tasks reflects a misallocation of computational resources—one that is economically inefficient and environmentally unsustainable at scale.
Moreover, in cases where general reasoning or open-domain dialogue is essential, we advocate for heterogeneous agentic systems, where SLMs are used by default and LLMs are invoked selectively and sparingly. This modular composition — combining the precision and efficiency of SLMs with the generality of LLMs — enables the construction of agents that are both cost-effective and capable.
Ultimately, we observe that shifting the paradigm from LLM-centric to SLM-first architectures represents to many not only a technical refinement but also a Humean moral ought. As the AI community grapples with rising infrastructure costs and environmental concerns, adopting and normalizing the use of SLMs in agentic workflows can play a crucial role in promoting responsible and sustainable AI deployment.
3. Position Arguments
Section Summary: The section argues that small language models (SLMs) are now powerful enough to power AI agents, matching or surpassing larger models in key skills like common-sense reasoning, tool use, and following instructions, as shown by examples such as Microsoft's Phi series and NVIDIA's Nemotron, which run much faster and more efficiently. These models can be further improved with simple tweaks like fine-tuning or added tools, making their capabilities the real limit rather than their size. Additionally, SLMs are more cost-effective for agent systems, offering quicker responses, easier customization, and simpler deployment on everyday devices compared to bulky large models.
We support V1, V2, and V3 by the following non-exclusive arguments.
3.1 SLMs are already sufficiently powerful for use in agents
Over the past few years, the capabilities of small language models have advanced significantly. Although the LM scaling laws remain observed, the scaling curve between model size and capabilities is becoming increasingly steeper, implying that the capabilities of newer small language models are much closer to those of previous large language models. Indeed, recent advances show that well-designed small language models can meet or exceed the task performance previously attributed only to much larger models.
Extensive comparisons with large models have been conducted in the individual works cited below, but not all capabilities assessed by benchmarks are essential to their deployment in the agentic context. Here we highlight their aptitude for commonsense reasoning (an indicator of basic understanding), tool calling and code generation (both indicators of the ability to correctly communicate across the model→tool/code interface; see Figure 1; [9, 10]), and instruction following (ability to correctly respond back across the code←model interface; [11]). In each case, we also quote the efficiency increase if stated by the authors.
- Microsoft Phi series. Phi-2 (2.7bn) achieves commonsense reasoning scores and code generation scores on par with 30bn models while running $\sim$ 15 $\times$ faster [12]. Phi-3 small (7bn) [13] achieves language understanding and commonsense reasoning on par with and code generation scores running up to 70bn models of the same generation.
- NVIDIA Nemotron-H family. The 2/4.8/9bn hybrid Mamba-Transformer models achieve instruction following and code-generation accuracy comparable to dense 30bn LLMs of the same generation at an order-of-magnitude fraction of the inference FLOPs [14].
- Huggingface SmolLM2 series. SmolLM2 family of compact language models with sizes ranging from 125mn to 1.7bn parameters [15] each run up in their language understanding, tool calling, and instruction following performance to 14bn contemporaries while matching 70bn models of 2 years prior.
- NVIDIA Hymba-1.5B. This Mamba-attention hybrid-head SLM demonstrates best instruction accuracy and 3.5 $\times$ greater token throughput than comparably-sized transformer models [16]. On instruction following, it outperforms larger 13bn models.
- DeepSeek-R1-Distill series. DeepSeek-R1-Distill is a family of reasoning models featuring 1.5-8bn sizes, trained on samples generated by DeepSeek-R1 [17]. They demonstrate strong commonsense reasoning capabilities. Notably, the DeepSeek-R1-Distill-Qwen-7B model outperforms large proprietary models such as Claude-3.5-Sonnet-1022 and GPT-4o-0513.
- DeepMind RETRO-7.5B: Retrieval-Enhanced Transformer (RETRO) is a 7.5bn parameter model augmented with an extensive external text database, achieving performance comparable to GPT-3 (175B) on language modeling while using 25× fewer parameters [18].
- Salesforce xLAM-2-8B. The 8bn model achieves state-of-the-art performance on tool calling despite is relatively modest size, surpassing frontier models like GPT-4o and Claude 3.5 [19].
Note that on top of competitive off-the-shelf performance, the reasoning capabilities of SLMs can be enhanced by light-weight selective finetuning [20] or at inference time with self-consistency, verifier feedback, or tool augmentation — e.g., Toolformer (6.7bn) outperforms GPT-3 (175bn) via API use [21], and 1-3bn models have rivaled 30bn+ LLMs on math problems via structured reasoning [22].
In sum, with modern training, prompting, and agentic augmentation techniques, capability — not the parameter count — is the binding constraint. SLMs now supply sufficient reasoning power for a substantial portion of agentic invocations, making them not just viable, but comparatively more suitable than LLMs for modular and scalable agentic systems.
3.2 SLMs are more economical in agentic systems
Small models provide significant benefits in cost-efficiency, adaptability, and deployment flexibility. These advantages are specifically valuable in agentic workflows where specialization and iterative refinement are critical. Section 3.1 detailed a number of efficiency comparisons of the listed SLMs to relevant LLMs. Here we draw a more encompassing picture to support A2.
- Inference efficiency. Serving a 7bn SLM is 10–30 $\times$ cheaper (in latency, energy consumption, and FLOPs) than a 70–175bn LLM, enabling real-time agentic responses at scale [23, 24, 25, 26]. Recent advances in inference operating systems such as NVIDIA Dynamo [27] explicitly provide support for high-throughput, low-latency SLM inference in both cloud and edge deployments. In addition, since SLMs require less or no parallelization across GPUs and nodes, the maintenance and operation of the serving infrastructure comes at a lower expense as well (see CA4 and A13).
- Fine-tuning agility. Parameter-efficient (e.g., LoRA [28] and DoRA [29]), low-resource [30], and full-parameter finetuning for SLMs require only a few GPU-hours, allowing behaviors to be added, fixed, or specialized overnight rather than over weeks [23].
- Edge deployment. Advances in on-device inference systems such as ChatRTX [31] demonstrate local execution of SLMs on consumer-grade GPUs, showcasing real-time, offline agentic inference with lower latency and stronger data control.
- Parameter and embedding space utilization. At the outset, LLMs appear to operate as monoliths involving a large amount of parameters representing swathes of compressed information in the production of their outputs. On a closer look, however, many of the embeddings passing through these systems are very sparse, engaging only a fraction of their parameters for any single input [32, 33] and being effectively compressible [34, 35]. That this behavior appears to be more subdued in SLMs [32, 36] suggests that SLMs may be fundamentally more efficient by the virtue of having a smaller proportion of their parameters contribute to the inference cost without a tangible effect on the output.
Modular system design. The position outlined in [37] presents a thorough argument in favor of composite agentic systems. Here we note that the approach of leveraging several models of varying sizes aligns well with the real-world heterogeneity of agentic tasks and is already slowly being incorporated into major software development frameworks [38]. Furthermore, this newly discovered sense for modularity in the context of agents allows for the easy addition of new skills and the ability to adapt to changing requirements, and is consistent with the push for modularity in language model design [39, 40, 41].
The above-mentioned "Lego-like" composition of agentic intelligence—scaling out by adding small, specialized experts instead of scaling up monolithic models—yields systems that are cheaper, faster to debug, easier to deploy, and better aligned with the operational diversity of real-world agents. When combined with tool calling, caching, and fine-grained routing, SLM-first architectures appear to offer the best path forward for cost-effective, modular, and sustainable agentic AI.
3.3 SLMs are more flexible

Due to their small size and the associated reduction in pre-training and fine-tuning costs (Section 3.2), SLMs are inherently more flexible than their large counterparts when appearing in agentic systems. As such, it becomes much more affordable and practical to train, adapt, and deploy multiple specialized expert models for different agentic routines. This efficiency enables rapid iteration and adaptation, making it feasible to address evolving user needs, including supporting new behaviors, meeting new output formatting requirements, and complying with changing local regulation in selected markets [42, 43, 44].
Democratization.
One particularly notable and desirable consequence of SLM flexibility when put in place of LLMs is the ensuing democratization of agents. When more individuals and organizations can participate in developing language models with the aim for deployment in agentic systems, the aggregate population of agents is more likely to represent a more diverse range of perspectives and societal needs. This diversity can then help with reducing the risk of systemic biases and encourage competition and innovation. With more actors entering the field to create and refine models, the field will advance more rapidly [45].
3.4 Agents expose only very narrow LM functionality
An AI agent is essentially a heavily instructed and externally choreographed gateway to a language model featuring a human-computer interface and a selection of tools that, when engaged correctly, do something of utility [42]. From this perspective, the underlying large language model that was engineered to be a powerful generalist is through a set of tediously written prompts and meticulously orchestrated context management restricted to operate within a small section of its otherwise large pallet of skills. Thus, we argue that a SLM appropriately fine-tuned for the selected prompts would suffice while having the above-mentioned benefits of increased efficiency and greater flexibility.
It could be argued back that the careful interfacing with a generalist LLM is necessary for strong performance on the narrow task because of the LLM's better understanding of the broader language and the world (AV1). This is addressed in Section 4.1.
3.5 Agentic interactions necessitate close behavioral alignment
A typical AI agent has frequent interactions with code, be it through LM tool calling or by returning output that is to be parsed by a piece of agentic code that makes the LM call [4]. It is essential for the success of these interactions that the generated tool call and the generated output conform to strict formatting requirements imposed on it by the order, typing, and nature of the tool's parameters, and the expectation of the code invoking the LM, respectively. In such cases, it becomes unnecessary for the model to handle multiple different formats (e.g. JSON/XML/Python for tool calls and XML/YAML/Markdown/Latex for output [46]), as only one would be chosen for consistency across the agentic application. It is also undesirable for the model to make the occasional hallucinatory mistake and respond in a format different from that being expected by the "code parts" of the agentic system. It is because of this that the SLM trained with a single formatting decision enforced during its post-training or encouraged through additional fine-tuning at a low cost is preferable over a general-purpose LLM in the context of AI agents.
3.6 Agentic systems are naturally heterogeneous
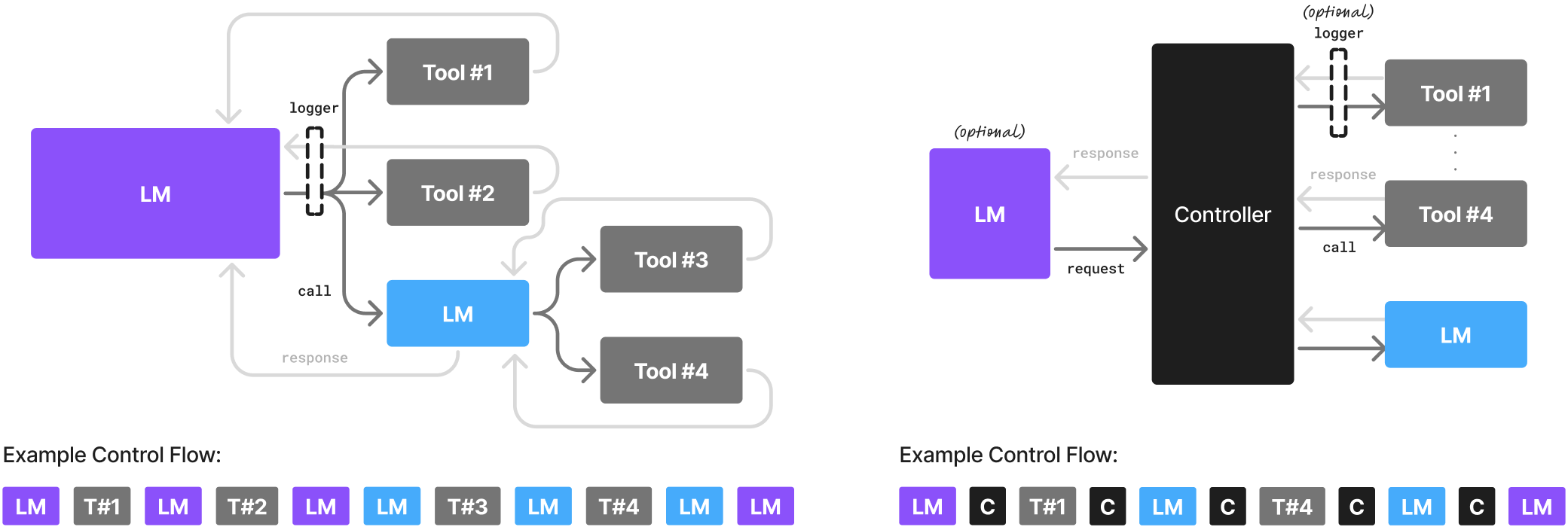
A language model can itself be a tool called by another language model. Likewise, every time the agent's code invokes a language model, it can, in principle, choose any language model. This is illustrated in Figure 1. We argue that incorporating multiple language models of different sizes and capabilities for queries or operations of different levels of complexity offers a natural way for the introduction of SLMs. In the context of Figure 1-Left, an LLM can be used for the model with the root agency, while a SLM could be used for the subordinate LM. In Figure 1-Right, all LMs could in principle be specialized SLMs: one for conversationality, another one for carrying out controller-defined language modeling tasks.
3.7 Agentic interactions are natural pathways for gathering data for future improvement
As noted in Section 3.4, invocations of tools and language models during an agentic process are often accompanied by careful prompting that focuses the language model on delivering the narrow functionality that is required at the time. Each one of these invocations is itself a natural source of data for future improvement (under the necessary assumption that no non-retainable confidential data is being processed). A listener decorating the tool/model call interface can gather specialized instruction data that can later be used to produce a fine-tune an expert SLM and lower the cost of that call in the future (see logger in Figure 1). We argue that this avenue is enabled by the architecture of agents [4] and produces high-quality organic data (that can be further post-filtered by considering the overall success of the workflow), thus making the production of expert SLMs to stand in place of LLMs a natural step in agent deployment — not just an auxiliary effort.
4. Alternative Views
Section Summary: This section explores alternative perspectives in academic and popular discussions that challenge the advantages of small language models (SLMs) over large language models (LLMs). One view argues that LLMs will always outperform SLMs on any language task due to their broader understanding, though the authors rebut this as overly narrow or complex reasoning. Another suggests LLMs remain cheaper to run through centralized operations, which the authors partially accept as case-specific but counter with emerging factors favoring SLMs, while a third posits equally viable futures for both, yet the authors believe SLMs' multiple strengths could shift the balance.
The following significant alternative views have been expressed in the academic and popular literature.
4.1 LLM generalists will always have the advantage of more general language understanding

This alternative view disputes V2 and rests on the following counter-arguments:

A conclusion can be then drawn that LLM generalist models will always retain the advantage of universally better performance on language tasks, no matter how narrowly defined, over small language models of the same generation. This to be to their advantage over SLMs when deployed in agentic applications.
Rebuttal.
The above alternative view is the most popularly cited belief against the use of SLMs, even when only a narrow language task needs to be performed [52, 53, 54, 55].
We believe that CA1 is too limited to attack V2, namely because

We also believe that CA2 is too arcane to attack V2 because

4.2 LLM inference will still be cheaper because of their centralization
It could be argued that the analysis in A2 that put forth in favor of V3 was ignorant of the wider business of AI model deployment:

Acknowledgment. We acknowledge that AV2 is a valid view, with the exact economical considerations being highly case-specific. We believe that the jury is still out on AV2, but that several factors hint that V3 might prevail:

4.3 Equally possible worlds

Acknowledgment. We acknowledge AV3 as a distinct possibility, but maintain the position that the weight of advantages described across A1, A2, A3, A4, A5, A6, and A7 can plausibily overturn the present state of affairs.
5. Barriers to Adoption
Section Summary: Even though smaller, specialized language models (SLMs) offer clear advantages for AI agents, the field keeps relying on larger, general-purpose models, largely due to practical barriers like implementation challenges, lack of awareness, and economic uncertainties. These hurdles—such as slow adoption inertia, underappreciated flexibility, and unclear cost benefits—are not inherent flaws in SLM technology but can be overcome with tools like advanced scheduling systems and growing recognition in the industry. While these issues are fading, widespread use of SLMs in agents remains unpredictable without a set timeline.
It would be prudent to ask oneself: If the A1, A2, A3, A4, A5, A6, and A7 are truly compelling, why do the ever newer generations of agents seemingly just perpetuate the status quo of using generalist LLMs?
We believe the following to be among the today's main barriers to wide-spread adoption of SLMs:

We note that B1, B2, and B3 are practical hurdles and far from being fundamental flaws of the SLM technology in the context of agentic AI. With advanced inference scheduling systems such as Dynamo [27], B1 is being reduced to a mere effect of inertia. B2 is becoming increasingly recognized in the field [16, 12], and it would be natural for B3 to fall once the economic benefits of SLM deployment in agentic applications (A2) are better known. With the inertia of B1 in particular, we do not endeavor to give a timeline for the retreat of these barriers or the popular adoption of SLMs.
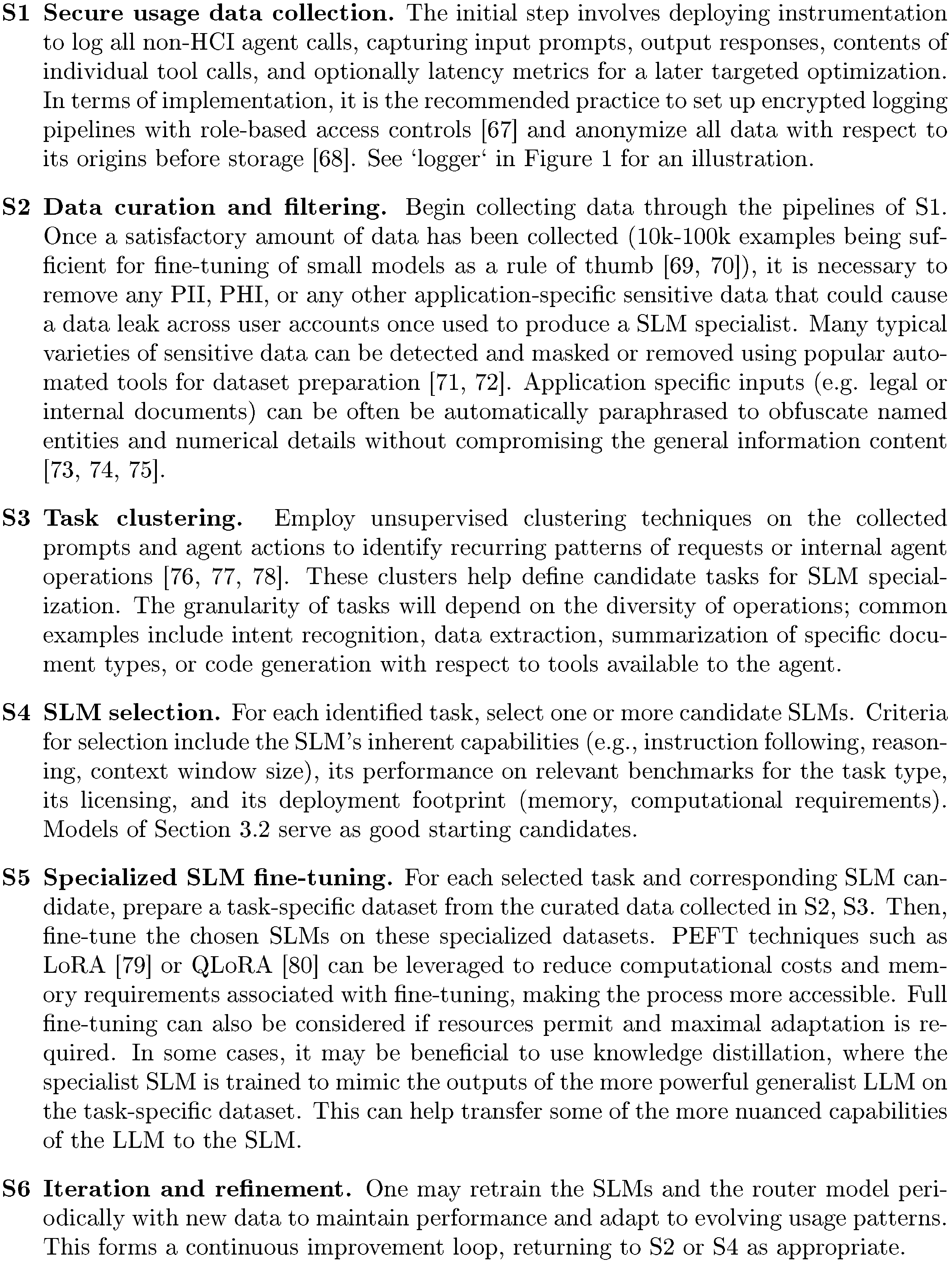
6. LLM-to-SLM Agent Conversion Algorithm
Section Summary: This section describes how AI-powered applications designed to act autonomously can transition from relying on large, general-purpose models to smaller, specialized ones at various points in their operations. It outlines a straightforward algorithm to perform this switch smoothly, ensuring minimal disruption to the overall system. The goal is to make the process painless as applications evolve toward more efficient, targeted AI components.
The very nature of agentic applications enables them to eventually switch from using LLM generalists to using SLM specialists at many of their interfaces. In the following steps, we outline an algorithm that describes one possible way to carry out the change of the underlying model painlessly.
7. Call for Discussion
Section Summary: The agentic AI industry, which involves AI systems capable of independent action, shows great potential to revolutionize white-collar jobs and other areas of work. The authors argue that reducing costs or enhancing the sustainability of AI infrastructure would speed up this change, making it crucial to investigate all possible ways to achieve those goals. They invite contributions and critiques on their views, to be sent to [email protected], and promise to publish all responses on their research website at research.nvidia.com/labs/lpr/slm-agents.
The agentic AI industry is showing the signs of a promise to have a transformative effect on white collar work and beyond.
It is the view of the authors that any expense savings or improvements on the sustainability of AI infrastructure would act as a catalyst for this transformation, and that it is thus eminently desirable to explore all options for doing so.
We therefore call for both contributions to and critique of our position, to be directed to [email protected], and commit to publishing all such correspondence at research.nvidia.com/labs/lpr/slm-agents.
Appendix
Section Summary: The appendix justifies the definitions of small language models (SLMs) by emphasizing a practical, timeless approach that focuses on their ability to run on everyday devices with low latency, aligning with goals of efficiency and real-world use, while contrasting them with large language models (LLMs) that require massive infrastructure. It explores extreme scales of intelligence—from galactic super-systems plagued by communication delays to minimal biological entities—to argue that human-like balance of capability and context best defines SLMs as agile, interactive tools. Additionally, the section presents case studies on replacing LLMs with SLMs in open-source AI agents like MetaGPT, estimating that around 60% of queries in such frameworks could be handled by SLMs for routine tasks, though complex reasoning might still need LLMs.
A. Definitions
This appendix provides two justifications for the choice of definitions in Section 2.1.
A.1 Pragmatic argument
It is desirable to have a definition of SLMs that meets three key criteria:
- Timelessness. The definition should be timeless: It should avoiding dependence on hardware-specific metrics like parameter count or FLOPs, which quickly become obsolete as technology advances—what qualifies as "small" today may be "large" tomorrow.
- Practicality. The definition is likely to have much wider generality if it is grounded in practical use, reflecting the real-world goal of deploying SLMs on widely available consumer devices, where they can serve the user in their proximity with low-latency inference.
- Motivation alignment. The definition should capture the fundamental motivation that drives the training of SLMs in the first place, which is to enable capable language models that can run on-device or within significantly constrained budgets compared to LLMs.
We find WD1 to possess all three. WD2 is then phrased to complement the set of all language models.
A.2 Limit argument
To explore the distinction between small and large language models in the context of agentic AI, let us adopt the uncompromising lens of an extremalist, for whom intelligence must be either maximally small or maximally large.
Imagine a super-intelligent system spanning galactic scales, marshaling all available matter to optimize its computations. Such a system, while theoretically capable of addressing profound questions would face insurmountable physical constraints. The speed of light limits communication, with round-trip delays across a galaxy potentially spanning tens of thousands of years [81]. This latency precludes real-time coordination, fragmenting the system into loosely coupled components rather than a unified "mind". At cosmological scales, spanning millions or billions of light-years, communication delays could approach or exceed the universe’s age of 13.8 billion years [82]. Such a system, while vast, would be impractical for human-relevant applications, its computations unfolding over eons.
Conversely, consider an infinitely small intelligent system, reduced to the minimal substrate capable of computation. Such a system, akin to the simplest biological organisms, would lack the sensors, effectors, or computational capacity to meaningfully interact with its environment. Its intelligence would be constrained to rudimentary evolution, much like early life forms that emerged 3.5 billion years ago [83]. Yet, even in nature, scale varies dramatically: living organisms range from bacteria (hundreds of nanometers) to blue whales (up to 30 meters), the heaviest ones being limited by heat dissipation due to their high volume-to-surface ratio [84]. At the cosmic scale, all terrestrial life appears microscopic, suggesting that absolute size is less critical than functional adaptability.
Hereby: Humans, often regarded as a pinnacle of intelligence, offer a useful anchor for defining SLMs and LLMs. With a brain-to-body mass ratio surpassed only by small mammals like mice [85], humans balance computational efficiency with practical embodiment. SLMs, by analogy, are systems compact enough to run on personal devices, be trained with modest human interaction, or perform constrained, verifiable tasks. LLMs, in contrast, demand datacenter-scale infrastructure, organization-level training, and extensive validation, reflecting their computational load. The extremalist perspective hints at a profound truth: intelligence is not defined by size alone but by the balance of capability, efficiency, and context. For agentic workflows, SLMs may offer agility and accessibility, while LLMs provide depth at the cost of scale.
It is because of this apparent continuum that, if pressed to provide a definition of SLMs, we choose to anchor it in characteristics of a model that can be deployed in a distributed fashion with present-day technology and be interactive enough when engaging with a human to be of utility. Proceeding in such a way, the contemporary instances of the definition will evolve as the technology underpinning these models advances, making the definition sufficiently timeless to be practical.
B. LLM-to-SLM Replacement Case Studies
This appendix assesses the potential extent of replacing large language model invocations with small language models in three popular open-source agents: MetaGPT, Open Operator, and Cradle. Each case study examines the use of LLMs, evaluates where SLMs may be viable replacements, and concludes with an estimated percentage of replaceable queries.
B.1 Case study 1: MetaGPT
Name.
MetaGPT
License.
Apache 2.0
Purpose.
MetaGPT is a multi-agent framework designed to emulate a software company. It assigns roles such as Product Manager, Architect, Engineer, and QA Engineer to collaboratively handle tasks including requirement drafting, system design, implementation, and testing.
LLM Invocations.
- Role-Based Actions. Each agent role invokes LLMs to fulfill its specialized responsibilities (e.g., coding, documentation).
- Prompt Templates. Structured prompts used for consistent outputs.
- Dynamic Intelligence. Used for planning, reasoning, and adaptation.
- Retrieval-Augmented Generation (RAG). Retrieves relevant documents to enhance generation.
Assessment for SLM Replacement.
SLMs would be well-suited for routine code generation and boilerplate tasks, as well as for producing structured responses based on predefined templates. However, they would require further fine-tuning data to reliably perform more complex tasks, such as architectural reasoning and adaptive planning or debugging, which would initially benefit from the broader contextual understanding and the generality of LLMs.
Conclusion.
In the case of MetaGPT, we estimate that about 60% of its LLM queries could be reliably handled by appropriately specialized SLMs.
B.2 Case study 2: Open Operator
Name.
Open Operator
License.
MIT License
Purpose.
Open Operator is a workflow automation agent enabling users to define behaviours of agents that can perform tasks like API calls, monitoring, and orchestration using tools and services.
LLM Invocations
- Natural Language Processing. Parses user intent.
- Decision Making. Guides execution flow.
- Content Generation. Writes summaries, reports.
Assessment for SLM Replacement
SLMs would be well-suited for tasks such as simple command parsing and routing, as well as generating messages based on predefined templates. They could be meeting their limitations when dealing with more complex tasks that would require multi-step reasoning or the ability to maintain conversation flow and context over time—areas where LLMs would continue to offer significant advantages.
Conclusion.
In the case of Open Operator, we estimate that about 40% of its LLM queries could be reliably handled by appropriately specialized SLMs.
B.3 Case study 3: Cradle
Name.
Cradle
License.
MIT License
Purpose
Cradle is designed for General Computer Control (GCC), enabling agents to operate GUI applications via screenshot input and simulated user interaction.
LLM Invocations.
- Interface Interpretation. Understands visual context.
- Task Execution Planning. Determines sequences of GUI actions.
- Error Handling. Diagnoses and reacts to unexpected software states.
Assessment for SLM Replacement
SLMs would be well-suited for handling repetitive GUI interaction workflows and the execution of pre-learned click sequences. However, they would face challenges when it comes to tasks involving dynamic GUI adaptation or unstructured error resolution, which would require a higher degree of contextual understanding typically provided by LLMs.
Conclusion
In the case of Cradle, we estimate that about 70% of its LLM queries could be reliably handled by appropriately specialized SLMs.
References
[1] Cloudera, Inc. 96% of enterprises are expanding use of ai agents, according to latest data from cloudera, April 2025. Accessed: 2025-05-08.
[2] Jeff Loucks, Gillian Crossan, Baris Sarer, China Widener, and Ariane Bucaille. Autonomous generative ai agents: Under development. Deloitte Insights, November 2024. Accessed: 2025-05-08.
[3] Market.us. Global agentic ai market size, share analysis by product type, agent role, agent system, end user, region and companies – industry segment outlook, market assessment, competition scenario, trends and forecast 2025–2034, March 2025. Accessed: 2025-05-08.
[4] Tula Masterman, Sandi Besen, Mason Sawtell, and Alex Chao. The landscape of emerging ai agent architectures for reasoning, planning, and tool calling: A survey. arXiv preprint arXiv:2404.11584, 2024.
[5] Junyu Luo, Weizhi Zhang, Ye Yuan, Yusheng Zhao, Junwei Yang, Yiyang Gu, Bohan Wu, Binqi Chen, Ziyue Qiao, Qingqing Long, et al. Large language model agent: A survey on methodology, applications and challenges. arXiv preprint arXiv:2503.21460, 2025.
[6] DAIR.AI. Llm agents, April 2024. Accessed: 2025-05-08.
[7] Colliers. 2025 data center marketplace: Balancing unprecedented opportunity with strategic risk. U.s. research report, Colliers, 2025.
[8] Morgan Stanley. Genai revenue growth and profitability, April 2025. Accessed: 2025-05-08.
[9] Fanjia Yan, Huanzhi Mao, Charlie Cheng-Jie Ji, Tianjun Zhang, Shishir G. Patil, Ion Stoica, and Joseph E. Gonzalez. Berkeley function calling leaderboard. https://gorilla.cs.berkeley.edu/blogs/8_berkeley_function_calling_leaderboard.html, 2024.
[10] Shunyu Yao, Noah Shinn, Pedram Razavi, and Karthik Narasimhan. Tau-bench: A benchmark for tool-agent-user interaction in real-world domains. arXiv preprint arXiv:2406.12045, 2024.
[11] Jeffrey Zhou, Tianjian Lu, Swaroop Mishra, Siddhartha Brahma, Sujoy Basu, Yi Luan, Denny Zhou, and Le Hou. Instruction-following evaluation for large language models. arXiv preprint arXiv:2311.07911, 2023.
[12] Mojan Javaheripi and Sébastien Bubeck. Phi-2: The surprising power of small language models, 2023. Microsoft Research Blog.
[13] Marah Abdin, Jyoti Aneja, Hany Awadalla, Ahmed Awadallah, Ammar Ahmad Awan, Nguyen Bach, Amit Bahree, Arash Bakhtiari, Jianmin Bao, Harkirat Behl, et al. Phi-3 technical report: A highly capable language model locally on your phone. arXiv preprint arXiv:2404.14219, 2024.
[14] Aaron Blakeman, Aarti Basant, Abhinav Khattar, Adithya Renduchintala, Akhiad Bercovich, Aleksander Ficek, Alexis Bjorlin, Ali Taghibakhshi, Amala Sanjay Deshmukh, Ameya Sunil Mahabaleshwarkar, et al. Nemotron-h: A family of accurate and efficient hybrid mamba-transformer models. arXiv preprint arXiv:2504.03624, 2025.
[15] Loubna Ben Allal, Anton Lozhkov, Elie Bakouch, Gabriel Martín Blázquez, Guilherme Penedo, Lewis Tunstall, Andrés Marafioti, Hynek Kydlíček, Agustín Piqueres Lajarín, Vaibhav Srivastav, Joshua Lochner, Caleb Fahlgren, Xuan-Son Nguyen, Clémentine Fourrier, Ben Burtenshaw, Hugo Larcher, Haojun Zhao, Cyril Zakka, Mathieu Morlon, Colin Raffel, Leandro von Werra, and Thomas Wolf. Smollm2: When smol goes big – data-centric training of a small language model, 2025.
[16] Xin Dong, Yonggan Fu, Shizhe Diao, Wonmin Byeon, Zijia Chen, Ameya Sunil Mahabaleshwarkar, Shih-Yang Liu, Matthijs Van Keirsbilck, Min-Hung Chen, Yoshi Suhara, et al. Hymba: A hybrid-head architecture for small language models. arXiv preprint arXiv:2411.13676, 2024.
[17] DeepSeek-AI. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning, 2025.
[18] Sebastian Borgeaud, Arthur Mensch, Jordan Hoffmann, Trevor Cai, Eliza Rutherford, Katie Millican, George van den Driessche, Bogdan Damoc, Aidan Clark, Jan Kramár, et al. Improving language models by retrieving from trillions of tokens. arXiv preprint arXiv:2112.04426, 2022.
[19] Jianguo Zhang, Tian Lan, Ming Zhu, Zuxin Liu, Thai Hoang, Shirley Kokane, Weiran Yao, Juntao Tan, Akshara Prabhakar, Haolin Chen, et al. xlam: A family of large action models to empower ai agent systems. arXiv preprint arXiv:2409.03215, 2024.
[20] Nunzio Lore, Sepehr Ilami, and Babak Heydari. Large model strategic thinking, small model efficiency: transferring theory of mind in large language models. arXiv preprint arXiv:2408.05241, 2024.
[21] Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. Toolformer: Language models can teach themselves to use tools. In Advances in Neural Information Processing Systems (NeurIPS), 2023.
[22] Xuezhi Zhou, Nathanael Schärli, Yujie Hou, Jason Wei, Denny Zhou, Quoc V. Le, and Douwe Kiela. Least-to-most prompting enables complex reasoning in small language models. arXiv preprint arXiv:2205.10625, 2022.
[23] Shreyas Subramanian, Vikram Elango, and Mecit Gungor. Small language models (slms) can still pack a punch: A survey. arXiv preprint arXiv:2501.05465, 2025.
[24] Olivia Shone. Explore ai models: Key differences between small language models and large language models, November 2024. Accessed: 2025-05-21.
[25] Invisible Technologies. How small language models can outperform llms, March 2025. Accessed: 2025-05-21.
[26] Sourabh Mehta. How much energy do llms consume? unveiling the power behind ai, July 2024. Accessed: 2025-05-21.
[27] Amr Elmeleegy et al. Introducing nvidia dynamo, a low-latency distributed inference framework for scaling reasoning ai models, March 2025. NVIDIA Technical Blog.
[28] Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. Lora: Low-rank adaptation of large language models. arxiv 2021. arXiv preprint arXiv:2106.09685, 2021.
[29] Shih-Yang Liu, Chien-Yi Wang, Hongxu Yin, Pavlo Molchanov, Yu-Chiang Frank Wang, Kwang-Ting Cheng, and Min-Hung Chen. Dora: Weight-decomposed low-rank adaptation. arXiv preprint arXiv:2402.09353, 2024.
[30] Peter Belcak, Greg Heinrich, Jan Kautz, and Pavlo Molchanov. Minifinetuning: Low-data generation domain adaptation through corrective self-distillation. arXiv preprint arXiv:2506.15702, 2025.
[31] NVIDIA. Chatrtx, 2024. NVIDIA AI Product.
[32] Yixin Song, Zeyu Mi, Haotong Xie, and Haibo Chen. Powerinfer: Fast large language model serving with a consumer-grade gpu. In Proceedings of the ACM SIGOPS 30th Symposium on Operating Systems Principles, pages 590–606, 2024.
[33] Zichang Liu, Jue Wang, Tri Dao, Tianyi Zhou, Binhang Yuan, Zhao Song, Anshumali Shrivastava, Ce Zhang, Yuandong Tian, Christopher Re, et al. Deja vu: Contextual sparsity for efficient llms at inference time. In International Conference on Machine Learning, pages 22137–22176. PMLR, 2023.
[34] Peter Belcak and Roger Wattenhofer. Tiny transformers excel at sentence compression. arXiv preprint arXiv:2410.23510, 2024.
[35] David Gu, Peter Belcak, and Roger Wattenhofer. Text compression for efficient language generation. arXiv preprint arXiv:2503.11426, 2025.
[36] Zhenliang Xue, Yixin Song, Zeyu Mi, Xinrui Zheng, Yubin Xia, and Haibo Chen. Powerinfer-2: Fast large language model inference on a smartphone. arXiv preprint arXiv:2406.06282, 2024.
[37] Erik Miehling, Karthikeyan Natesan Ramamurthy, Kush R Varshney, Matthew Riemer, Djallel Bouneffouf, John T Richards, Amit Dhurandhar, Elizabeth M Daly, Michael Hind, Prasanna Sattigeri, et al. Agentic ai needs a systems theory. arXiv preprint arXiv:2503.00237, 2025.
[38] google. GitHub - google/A2A: An open protocol enabling communication and interoperability between opaque agentic applications.
[39] Yonggan Fu, Zhongzhi Yu, Junwei Li, Jiayi Qian, Yongan Zhang, Xiangchi Yuan, Dachuan Shi, Roman Yakunin, and Yingyan Celine Lin. Amoeballm: Constructing any-shape large language models for efficient and instant deployment. In Proceedings of the 38th Annual Conference on Neural Information Processing Systems (NeurIPS 2024), 2024.
[40] Ruisi Cai, Saurav Muralidharan, Greg Heinrich, Hongxu Yin, Zhangyang Wang, Jan Kautz, and Pavlo Molchanov. Flextron: Many-in-one flexible large language model. In Proceedings of the 41st International Conference on Machine Learning (ICML 2024), 2024.
[41] Sneha Kudugunta, Aditya Kusupati, Tim Dettmers, Kaifeng Chen, Inderjit Dhillon, Yulia Tsvetkov, Hannaneh Hajishirzi, Sham Kakade, Ali Farhadi, Prateek Jain, et al. Matformer: Nested transformer for elastic inference. arXiv preprint arXiv:2310.07707, 2023.
[42] Fali Wang, Zhiwei Zhang, Xianren Zhang, Zongyu Wu, Tzuhao Mo, Qiuhao Lu, Wanjing Wang, Rui Li, Junjie Xu, Xianfeng Tang, et al. A comprehensive survey of small language models in the era of large language models: Techniques, enhancements, applications, collaboration with llms, and trustworthiness. arXiv preprint arXiv:2411.03350, 2024.
[43] Akshi Kumar. From large to small: The rise of small language models (slms) in text analytics. 2025.
[44] Brian G. Thamm. Trustworthy and secure ai: How small language models strengthen data security. Service Contractor Magazine, October 2024. Accessed: 2025-05-08.
[45] Andreas Jungherr. Artificial intelligence and democracy: A conceptual framework. Social media+ society, 9(3):20563051231186353, 2023.
[46] Meta Platforms, Inc. Model cards and prompt formats: Llama 3.3, April 2025. Accessed: 2025-05-08.
[47] Badhan Chandra Das, M Hadi Amini, and Yanzhao Wu. Security and privacy challenges of large language models: A survey. ACM Computing Surveys, 57(6):1–39, 2025.
[48] Humza Naveed, Asad Ullah Khan, Shi Qiu, Muhammad Saqib, Saeed Anwar, Muhammad Usman, Naveed Akhtar, Nick Barnes, and Ajmal Mian. A comprehensive overview of large language models. arXiv preprint arXiv:2307.06435, 2023.
[49] Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, Diego de Las Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, et al. Training compute-optimal large language models. arXiv preprint arXiv:2203.15556, 2022.
[50] Danny Hernandez, Jared Kaplan, Tom Henighan, and Sam McCandlish. Scaling laws for transfer. arXiv preprint arXiv:2102.01293, 2021.
[51] Adam Zewe. Like human brains, large language models reason about diverse data in a general way. MIT News, February 19 2025. Accessed: 2025-05-09.
[52] ABBYY. Small language models vs. large language models, November 2024. Accessed: 2025-05-09.
[53] Synergy Technical. Small language models vs. large language models, 2025. Accessed: 2025-05-09.
[54] Harrison Clarke. Large language models vs. small language models, March 2024. Accessed: 2025-05-09.
[55] Aashima. Small language models vs. llms: Finding the right fit for your needs, October 2024. Accessed: 2025-05-09.
[56] Henry Evans. Llms vs. slms: Balancing comprehensiveness and smart resource-saving, April 2025. Accessed: 2025-05-09.
[57] Aviv Kaufmann. Understanding the total cost of inferencing large language models. Technical report, Enterprise Strategy Group, April 2024. Commissioned by Dell Technologies. Accessed: 2025-05-09.
[58] Michael Chui, Bryce Hall, Helen Mayhew, Alex Singla, and Alexander Sukharevsky. The state of ai in 2022—and a half decade in review, December 2022. Accessed: 2025-05-09.
[59] Tanya Seda. Cloud llm cost model: Breakdown for mid-market businesses, 2024. Accessed: 2025-05-09.
[60] David Zier and Harry Kim. Introducing nvidia dynamo, a low-latency distributed inference framework for scaling reasoning ai models, March 2025. Accessed: 2025-05-09.
[61] NVIDIA. Nvidia dynamo: A datacenter scale distributed inference serving framework. https://github.com/ai-dynamo/dynamo, 2025. Accessed: 2025-05-09.
[62] Tobias Mann. A closer look at dynamo, nvidia's 'operating system' for ai inference, March 2025. Accessed: 2025-05-09.
[63] Kevin Zhang. A deep dive on ai inference startups, 2024. Accessed: 2025-05-09.
[64] Adyog. The economics of ai training and inference: How deepseek broke the cost curve, February 2025. Accessed: 2025-05-09.
[65] Zhenyan Lu, Xiang Li, Dongqi Cai, Rongjie Yi, Fangming Liu, Xiwen Zhang, Nicholas D Lane, and Mengwei Xu. Small language models: Survey, measurements, and insights. arXiv preprint arXiv:2409.15790, 2024.
[66] Felipe Maia Polo, Lucas Weber, Leshem Choshen, Yuekai Sun, Gongjun Xu, and Mikhail Yurochkin. tinybenchmarks: evaluating llms with fewer examples. arXiv preprint arXiv:2402.14992, 2024.
[67] Metomic. Understanding ai agents & data security, 2025. Accessed: 2025-05-13.
[68] WorkOS. Build secure ai agents, 2025. Accessed: 2025-05-13.
[69] Ishika Agarwal, Krishnateja Killamsetty, Lucian Popa, and Marina Danilevksy. Delift: Data efficient language model instruction fine tuning. arXiv preprint arXiv:2411.04425, 2024.
[70] Ning Ding, Yujia Qin, Guang Yang, Fuchao Wei, Zonghan Yang, Yusheng Su, Shengding Hu, Yulin Chen, Chi-Min Chan, Weize Chen, et al. Parameter-efficient fine-tuning of large-scale pre-trained language models. Nature Machine Intelligence, 5(3):220–235, 2023.
[71] Judith Sáinz-Pardo D'ıaz and Álvaro López Garc'ıa. An open source python library for anonymizing sensitive data. Scientific data, 11(1):1289, 2024.
[72] Lakshmi Radhakrishnan, Gundolf Schenk, Kathleen Muenzen, Boris Oskotsky, Habibeh Ashouri Choshali, Thomas Plunkett, Sharat Israni, and Atul J Butte. A certified de-identification system for all clinical text documents for information extraction at scale. JAMIA open, 6(3):ooad045, 2023.
[73] Michael Brennan, Sadia Afroz, and Rachel Greenstadt. Adversarial stylometry: Circumventing authorship recognition to preserve privacy and anonymity. ACM Transactions on Information and System Security (TISSEC), 15(3):1–22, 2012.
[74] Da Yu, Peter Kairouz, Sewoong Oh, and Zheng Xu. Privacy-preserving instructions for aligning large language models. arXiv preprint arXiv:2402.13659, 2024.
[75] Biwei Yan, Kun Li, Minghui Xu, Yueyan Dong, Yue Zhang, Zhaochun Ren, and Xiuzhen Cheng. On protecting the data privacy of large language models (llms): A survey. arXiv preprint arXiv:2403.05156, 2024.
[76] Shaohan Huang, Furu Wei, Lei Cui, Xingxing Zhang, and Ming Zhou. Unsupervised fine-tuning for text clustering. In Proceedings of the 28th international conference on computational linguistics, pages 5530–5534, 2020.
[77] Luying Liu, Jianchu Kang, Jing Yu, and Zhongliang Wang. A comparative study on unsupervised feature selection methods for text clustering. In 2005 International Conference on Natural Language Processing and Knowledge Engineering, pages 597–601. IEEE, 2005.
[78] Shizhe Diao, Yu Yang, Yonggan Fu, Xin Dong, Dan Su, Markus Kliegl, Zijia Chen, Peter Belcak, Yoshi Suhara, Hongxu Yin, et al. Climb: Clustering-based iterative data mixture bootstrapping for language model pre-training. arXiv preprint arXiv:2504.13161, 2025.
[79] Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models. ICLR, 1(2):3, 2022.
[80] Tim Dettmers, Artidoro Pagnoni, Ari Holtzman, and Luke Zettlemoyer. Qlora: Efficient finetuning of quantized llms. Advances in neural information processing systems, 36:10088–10115, 2023.
[81] Martin J Rees. Before the Beginning: Our Universe and Others. Addison-Wesley, 1997.
[82] Planck Collaboration et al. Planck 2018 results. vi. cosmological parameters. Astronomy & Astrophysics, 641:A6, 2020.
[83] J William Schopf. Microfossils of the early archean apex chert: New evidence of the antiquity of life. Science, 260(5108):640–646, 1993.
[84] Barbara A Ferguson, Timothy A Dreisbach, Catherine G Parks, Gregory M Filip, and Craig L Schmitt. Coarse-scale population structure of pathogenic armillaria species in a mixed-conifer forest in the blue mountains of northeast oregon. Canadian Journal of Forest Research, 33(4):612–623, 2003.
[85] Georgina M Mace, Paul H Harvey, and Timothy H Clutton-Brock. Brain size and ecology in small mammals. Journal of Zoology, 193(3):333–354, 1981.