daVinci-Dev: Agent-native Mid-training for Software Engineering
Ji Zeng$^{2,3}$, Dayuan Fu$^{1,3}$, Tiantian Mi$^{1,3}$, Yumin Zhuang$^{2,3}$, Yaxing Huang$^{3}$, Xuefeng Li$^{1,2,3}$, Lyumanshan Ye$^{3}$, Muhang Xie$^{1,3}$, Qishuo Hua$^{2,3}$, Zhen Huang$^{1,3}$, Mohan Jiang$^{1,2,3}$, Hanning Wang$^{1,3}$, Jifan Lin$^{2,3}$, Yang Xiao$^{3}$, Jie Sun$^{1,3}$, Yunze Wu$^{2,3}$, Pengfei Liu $^{\text{†}}$ $^{1,2,3}$
$^{\text{1}}$ SII
$^{\text{2}}$ SJTU
$^{\text{3}}$ GAIR
$^{\text{†}}$ Corresponding author.
Abstract
Recently, the frontier of Large Language Model (LLM) capabilities has shifted from single-turn code generation to agentic software engineering—a paradigm where models autonomously navigate, edit, and test complex repositories. While post-training methods have become the de facto approach for code agents, agentic mid-training—mid-training (MT) on large-scale data that mirrors authentic agentic workflows—remains critically underexplored due to substantial resource requirements, despite offering a more scalable path to instilling foundational agentic behaviors than relying solely on expensive reinforcement learning. A central challenge in realizing effective agentic mid-training is the distribution mismatch between static training data and the dynamic, feedback-rich environment of real development. To address this, we present a systematic study of agentic mid-training, establishing both the data synthesis principles and training methodology for effective agent development at scale. Central to our approach is agent-native data—supervision comprising two complementary types of trajectories: contextually-native trajectories that preserve the complete information flow an agent experiences, offering broad coverage and diversity; and environmentally-native trajectories collected from executable repositories where observations stem from actual tool invocations and test executions, providing depth and interaction authenticity. We verify the model’s agentic capabilities on SWE-Bench Verified. We demonstrate our superiority over the previous open software engineering mid-training recipe $\textsc{Kimi-Dev}$ under two post-training settings with an aligned base model and agentic scaffold, while using less than half mid-training tokens (73.1B). Besides relative advantage, our best performing 32B and 72B models achieve 56.1% and 58.5% resolution rates, respectively, which are state-of-the-art among open training recipes using agentic scaffolds under their model sizes, despite starting from non-coder Qwen2.5-Base base models. Beyond these agentic capabilities, we also observe performance gains on general code generation and scientific benchmarks. We plan to open-source a significant portion of our datasets, recipes, and model checkpoints—resources representing substantial computational investment typically unavailable to the broader community—to facilitate further research in this underexplored paradigm.
1. Introduction
The capabilities of code-generating large language models have rapidly expanded from synthesizing isolated functions ([1, 2]) to tackling repository-level software engineering tasks ([3]). This shift toward agentic software engineering ([3, 4, 5]) reflects the demands of real-world development, where resolving issues requires code agents to autonomously and iteratively navigate complex codebases, understand cross-file dependencies, apply edits, and validate changes through test execution. The dominant approach to building such code agents has centered on post-training: supervised fine-tuning (SFT) on curated trajectories ([6, 7]) followed by reinforcement learning (RL) from execution feedback ([8]). While effective, the quantity and diversity are limited for the repositories that can be used in this paradigm. Due to the unclear instructions in the repositories' README files and the resource limitation (e.g., GPUs), the number of repositories that can be transformed into executable environments is limited. Moreover, in most cases, only correct trajectories can be used in training, but high-quality agentic trajectories generated by expert human annotators are expensive to collect, while the sophisticated agent systems can only solve a small subset of issues, so most environments will also be filtered before the training process ([9]). Such a flaw constrains the learning dynamics and degrades performance during SFT or RL training. More fundamentally, post-training is constrained by the base model's intrinsic capacities, and certain agentic reasoning abilities may not be learnable through post-training alone ([10]).
This raises a natural question: Can we instill foundational agentic behaviors earlier in the training pipeline, during mid-training? Mid-training (MT) on domain-specific data has proven transformative for specializing LLMs to domains like mathematics ([11, 12]) and code ([7]). For agentic software engineering, mid-training offers a compelling value proposition: by exposing base models to massive-scale data that mirrors agentic iterations—file navigation, contextual edits, tool invocations, test-driven iterations—we can build stronger foundations that subsequent post-training can refine more efficiently. Yet despite this potential, agentic mid-training remains critically underexplored. Existing mid-training or pre-training efforts for code models ([7]) predominantly adopt a factorized approach: synthesizing isolated samples for atomic capabilities such as localization and editing, without the procedural context that an agent would encounter before exercising these capabilities.
In effect, we argue that existing MT data is not agent-native: it does not preserve the action–observation loop structure that governs real development. We therefore identify the core challenge as a distribution mismatch between conventional training data and the dynamic reality of agentic deployment. Consider a typical GitHub Pull Request: while the commit history reveals what files were changed, it obscures how a developer (or agent) discovered those files, what context they examined before editing, and how test feedback shaped subsequent revisions. Training on such static snapshots—even at massive scale—leaves models unprepared for the sequential, interactive nature of real development workflows. An agent should not just learn to navigate to the right location, retrieve relevant context, generate correct edits, apply changes, and run unit tests separately, but should coordinate these skills into a coherent, iterative problem-solving loop, where feedback from each step informs the next action.
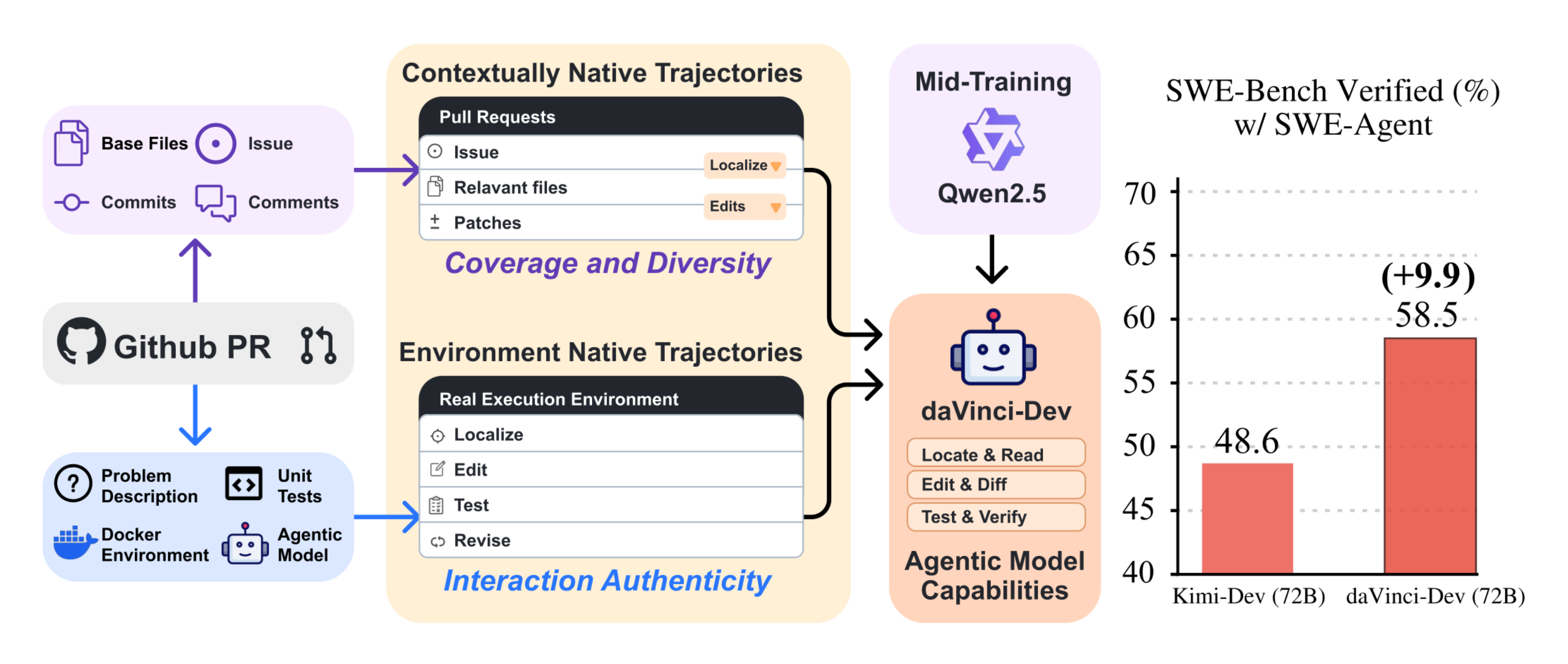
To bridge this gap, we present the first systematic study of agentic mid-training for software engineering at scale. Our central thesis is that effective agentic mid-training requires large-scale and diverse agent-native data—supervision that preserves the complete information flow and environmental dynamics an agent experiences during deployment. We formalize this through two complementary trajectory types:
- Contextually-native trajectories: This type of trajectory emphasizes coverage and diversity. Any supervision instance that preserves the structure of a realistic engineering process can be included, regardless of whether it was produced through live execution, ensuring broad source repository coverage and diversity. Supervision is organized around full task-level action sequences, bundling localization steps (e.g., identifying relevant files) together with modification steps (e.g., applying edits). Edit actions can be conducted multiple times with interleaved textual reasoning to reflect a coherent software development process. This allows the dataset to capture a wide variety of valid contextual patterns and operational permutations.
- Environmentally-native trajectories: This type of trajectory prioritizes interaction authenticity while also considering quantity. Only trajectories generated through actual interactions with a real development environment are eligible for inclusion. These trajectories record genuine observations—tool invocations, test executions, runtime errors, and scaffold system feedback—rather than simulated or retrospectively constructed observations. We do not apply any filter strategy, so that the quantity of such trajectories can be much larger than the ones in the SFT stage. This exposes models to the dynamic feedback loops inherent in real development.
We materialize these principles through a large-scale data synthesis effort that leverages different elements from GitHub Pull Requests to construct two complementary data types, as illustrated in Figure 1. First, we curate a 68.6B-token contextually-native trajectories ($ \mathcal{D}^{\mathrm{ctx}}{}$) using base files and commits, carefully reconstructing the procedural process behind each code change: which context the developer likely examined (related issue and base file content), and how they iteratively refined their solution (temporal commits). This transforms static diffs into contextually-rich trajectories that preserve the natural coupling between navigation and editing, providing broad coverage and diversity across repositories and languages. Second, we construct 3.1B-token environmentally-native trajectories ($ \mathcal{D}^{\mathrm{env}}{}$) from PR-derived software engineering tasks using their Docker environments and unit tests, generating agentic rollouts where our agent interacts with real build systems, test suites, and linters, collecting observations from actual tool outputs. This provides depth and authenticity through genuine execution feedback that cannot be retrospectively reconstructed.
Evaluating our models on SWE-Bench Verified, we surpass the previous state-of-the-art open MT recipe, $\textsc{Kimi-Dev}$, under two post-training settings with an aligned base model and agentic scaffold while reducing the mid-training corpus size by over 50% (73.1B vs $\sim$ 150B tokens). Our best performing 32B and 72B models reach resolution rates of 56.1% and 58.5%, respectively. These scores represent the highest performance among open training recipes using agentic scaffolds for their respective model sizes, a significant feat given our initialization from Qwen2.5-Base models instead of newer or code-focused base models. Beyond agentic workflows, this regimen also confers broad benefits, improving performance on scientific and general code generation tasks as detailed in Table 3.
To conclude, we make the following contributions:
- We formulate agentic mid-training and introduce agent-native data as supervision that preserves the information flow of real software engineering. We build large-scale agent-native corpora from public software development traces, including a 68.6B-token contextually-native corpus and a 3.1B-token set of environmentally-native rollouts, and provide a practical training recipe that leverages them.
- We demonstrate consistent gains on agentic software engineering brought by our agentic mid-training recipe across post-training schemes and model sizes, and provide analysis of robustness, scalability, and generalization. We plan to release the data construction code, training configurations, and a substantial portion of the resulting artifacts (e.g., curated datasets and checkpoints) where permitted.
2. Background and Problem Setup
2.1 Agentic Software Engineering Tasks
We formalize an agentic software engineering task as a tuple $(\mathcal{R}, q, \mathcal{E})$, where $\mathcal{R}$ is a repository state, $q$ is a natural language problem description (e.g., bug report, issue), and $\mathcal{E}$ is an evaluation oracle (typically a test suite). Unlike single-turn generation where all necessary context is provided upfront, agentic tasks require multi-step interaction. At each step $t$, the agent selects an action based on the conversation history and receives an observation from an observation generator:
$ \begin{align*} a_t &\sim \pi_\theta(a \mid h_{t-1}, q) \quad (action selection) \ o_t &\sim Obs(a_t, \mathcal{R}) \quad (observation) \end{align*} $
where $h_{t-1} = {(a_1, o_1), \ldots, (a_{t-1}, o_{t-1})}$ accumulates prior interactions.
Actions correspond to tool calls such as searching for files, reading code, applying edits, or running tests, while observations return concrete outputs like file contents, compiler errors, or test results. This interaction is necessary because the agent initially does not know which parts of the codebase (potentially thousands of files) are relevant to the issue, and must iteratively refine its solution based on feedback from the evaluation oracle.
While the exact sequence varies by task complexity, a typical development workflow follows the pattern: localize (identifying relevant files) $\rightarrow$ read (understanding code context) $\rightarrow$ edit (applying modifications) $\rightarrow$ test (validating changes) $\rightarrow$ revise (refining based on feedback). This structure reflects common agent implementations ([6]) and mirrors natural software development practices, though agents may repeat or interleave these steps as needed.

This complete sequence is an agent trajectory $\tau = (q, \mathcal{R}, {(a_i, o_i)}_{i=1}^T, y)$, where $y \in {0, 1}$ indicates whether the trajectory is successful under its supervision source.
2.2 The Distribution Mismatch Problem
As formalized in Section 2.1, agentic software engineering requires multi-step interaction. However, traditional training data predominantly consists of static, completed artifacts that bear no resemblance to this interactive process (Figure 2 a). Models are exposed to final outcomes—complete code files, merged commits, finished implementations—without the sequential action-observation pairs $(a_t, o_t)$ that agents experience at deployment. This creates a critical distribution mismatch: training data shows what was ultimately produced, but deployment requires agents to learn how to construct solutions through the dynamic workflow of localization, reading, editing, testing, and revision.
Moreover, even when workflow structure is preserved, training data typically shows only successful final states, omitting the validation failures, error messages, and iterative refinements that emerge from actual environment interaction. Models trained on such incomplete supervision must learn to orchestrate complete workflows and respond to execution feedback during post-training, rather than internalizing these coordination patterns as foundational behaviors.
3. Agent-Native Data: Design and Synthesis
To address the distribution mismatch between static training data and interactive deployment, we construct agent-native data—supervision that preserves the complete action-observation trajectories and environmental feedback agents experience during real problem-solving. Specifically, we construct two complementary types of agent-native trajectories: contextually-native trajectories, which reconstruct complete workflows from GitHub Pull Requests to preserve the full development context, and environmentally-native trajectories, which capture authentic execution feedback through agent rollouts in real executable environments. The combination ensures both breadth (diverse workflow patterns at scale) and depth (authentic execution dynamics), addressing the distribution mismatch from complementary angles.
3.1 Contextually-Native Trajectories
3.1.1 Design Rationale
To construct contextually-native trajectories, we leverage GitHub Pull Requests (PRs) as the base data source. PRs naturally connect problem specifications (issues) to solutions (code changes) with validation signals (tests, reviews), making them well-suited for reconstructing development workflows. The key design principle is bundling complete context: rather than factorizing PRs into independent localization and editing tasks ([7]) (Figure 2 b), we keep all relevant information together—issue description, relevant repository files, and modifications—in a single training sample. This preserves the causal flow agents experience at deployment, where editing decisions must be conditioned on the context gathered during localization.
3.1.2 Construction Pipeline
Data Sources.
We construct contextually-native trajectories from two complementary subsets: $ \mathcal{D}^{\mathrm{ctx}}{\text{gen}}$ ("general") provides broad coverage of software engineering patterns across diverse languages and frameworks by drawing from highly-starred repositories, while $ \mathcal{D}^{\mathrm{ctx}}{\text{py}}$ ("Python") ensures strong alignment with software engineering benchmarks (e.g., SWE-Bench Verified) through focused coverage of Python development. The two subsets partially overlap in Python repositories but serve complementary purposes: $ \mathcal{D}^{\mathrm{ctx}}{\text{gen}}$ establishes cross-language understanding, while $ \mathcal{D}^{\mathrm{ctx}}{\text{py}}$ ensures alignment with target evaluation tasks.
Collection.
We collect pull requests through GitHub REST[^1] and GraphQL APIs[^2]. For each repository, we obtain pull request metadata and selectively query additional endpoints for detailed content, including linked issue descriptions (if exist), relevant file contents at the base commit, and the full commit sequence with corresponding diffs. We determine relevant files deterministically by querying the net diff between base and head commits. To ensure correctness, we align file contents and patches with the parent of the first PR commit, rather than using the base commit recorded in PR metadata, which may not reflect the actual codebase state when the PR was created.
[^1]: REST API: https://docs.github.com/en/rest
[^2]: GraphQL API: https://docs.github.com/en/graphql
Filtering.
We apply multi-level filtering criteria to ensure data quality while maintaining coverage. (1) At the repository level, $ \mathcal{D}^{\mathrm{ctx}}{\text{gen}}$ selects from the top 10, 000 most-starred repositories across all languages[^3]. $ \mathcal{D}^{\mathrm{ctx}}{\text{py}}$ focuses on public Python repositories (language=Python in metadata API) with at least 5 stars and not archived. The relaxed star threshold for $ \mathcal{D}^{\mathrm{ctx}}{\text{py}}$ balances repository diversity with quality standards. (2) At the pull request level, both subsets retain only merged PRs and exclude bot-created PRs. For $ \mathcal{D}^{\mathrm{ctx}}{\text{py}}$, we additionally require modifications to be done only in Python source or documentation files, with the number of changed Python files between 1 and 5. Six million out of thirteen million pull requests pass the $ \mathcal{D}^{\mathrm{ctx}}_{\text{py}}$ pull request level filters. These constraints ensure focused, manageable tasks suitable for agent learning.
[^3]: In the future, we will scale our approach to more repositories.
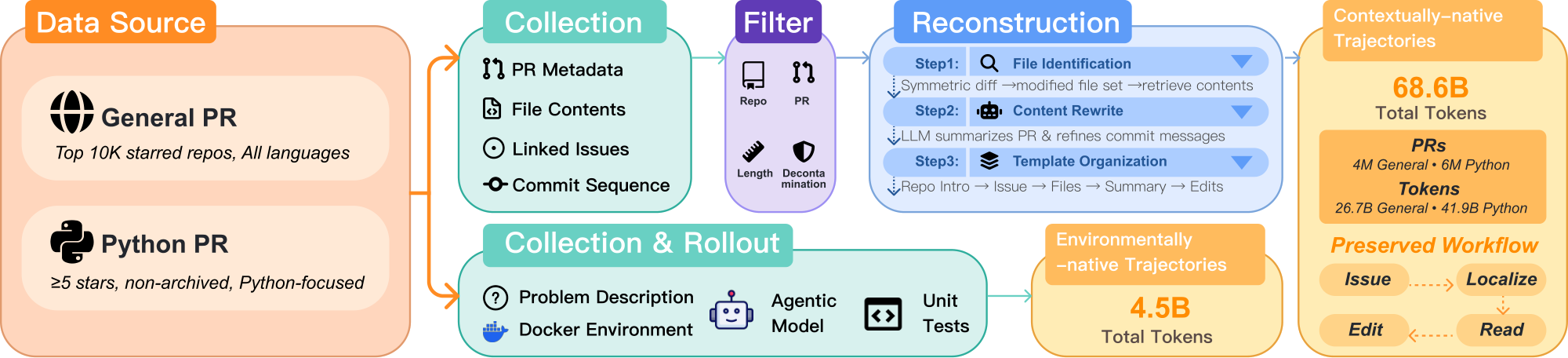
Reconstruction.
For each filtered PR, we reconstruct an agent-native training sample through the following process: (1) Content enhancement. We use Qwen3-235B-A22B-Instruct-2507 ([13]) to generate two types of enhancements. First, we create a concise summary of the overall PR that captures its intent and main changes. Second, since some commit messages are terse or uninformative (e.g., "fix", "update"), we refine them into more descriptive summaries that explain what each commit accomplishes. Detailed prompts are provided in Appendix B. (2) Relevant file identification. We identify relevant files through reverse engineering: analyzing symmetric diffs across all commits to extract the set of modified files, then retrieving their complete contents at the base commit. (3) Template organization. We organize all extracted information into clearly delineated sections: Repository Context, Issue (when available), Pull Request, Relevant Files Found (complete file contents), LLM-generated Summary, and Edits. The Edits section contains the code modifications: for PRs with multiple commits, we concatenate them in temporal order, with each refined commit message followed by its associated code changes. The two subsets use different structural formats: $ \mathcal{D}^{\mathrm{ctx}}{\text{gen}}$ adopts XML-like tags with traditional patch diffs and additionally includes developer comments and reviews, while $ \mathcal{D}^{\mathrm{ctx}}{\text{py}}$ uses Markdown structure with search-and-replace blocks that more directly represent agent editing actions. See Appendix C for detailed format specifications and examples.
This organization mirrors the workflow: relevant file paths simulates the "localize" phase, file contents represent the "read" phase, edits represent the "edit" phase, and LLM-generated contents serve as textual reasoning in between.
We apply standard post-processing to ensure training efficiency and evaluation integrity. For length filtering, we discard samples exceeding 32k tokens, which retains over 90% of Python pull requests while improving training efficiency. For decontamination, we remove all pull requests from repositories included in SWE-Bench Verified to prevent data leakage and ensure fair evaluation.
3.1.3 Corpus Statistics
After applying the pipeline described, we obtain two complementary subsets. The general subset $ \mathcal{D}^{\mathrm{ctx}}{\text{gen}}$ (26.7B tokens) provides broad software engineering coverage across diverse languages and tooling patterns, drawn from 4 million PRs in the top 10, 000 most-starred repositories. The Python subset $ \mathcal{D}^{\mathrm{ctx}}{\text{py}}$ (41.9B tokens), comprising 6 million PRs from $7.4 \times 10^5$ repositories, focuses on Python development to ensure alignment with benchmarks. Together, $ \mathcal{D}^{\mathrm{ctx}}{} = \mathcal{D}^{\mathrm{ctx}}{\text{gen}} \cup \mathcal{D}^{\mathrm{ctx}}_{\text{py}}$ contains 68.6B tokens of contextually-native trajectories and preserves complete development workflows across diverse repositories and scenarios.
3.2 Environmentally-Native Trajectories
Notation. We denote the environmentally-native dataset as $ \mathcal{D}^{\mathrm{env}}{}$, consisting of trajectories $ \tau^{\mathrm{env}}$. We further split it into $ \mathcal{D}^{\mathrm{env}}{\text{pass}}$ and $ \mathcal{D}^{\mathrm{env}}_{\text{fail}}$ based on the final test outcome.
3.2.1 Design Rationale
While contextually-native trajectories provide agent-like structure, they lack agent-like dynamics: the model never observes the iterative feedback loop (edit $\rightarrow$ test $\rightarrow$ revise) that characterizes real agentic coding in practice. To close this gap, we curate environmentally-native trajectories—collected by running a capable agent in real executable development environments with authentic test feedback.
Our approach contrasts with trajectories in simulated or synthetic environments ([7]) where codebase navigation is read-only or test execution is unavailable during rollout. While such approaches produce trajectories with agentic format, they lack agentic feedback—the model never observes how its edits affect test outcomes or how error messages guide revisions. Environmentally-native trajectories preserve this critical feedback loop by recording actual agent-environment interactions: tool invocations, test executions, and the resulting observations (test outputs, error messages, runtime feedback).
3.2.2 Construction Pipeline
In order to ensure authenticity, we choose to derive executable environments from real GitHub pull requests, rather than artificially constructed ones. Therefore, we construct our agentic rollout environments following the methodology established in $\textsc{SWE-rebench}$ ([4]). We build a Docker image for each task that reproduces the repository state at a specific commit, alongside unit tests from the actual codebase, and infrastructure to execute tool calls (file edits, shell commands, test runs). Then we deploy GLM-4.6 ([14]) within the $\textsc{SWE-Agent}$ framework ([6]). For each task, we generate up to 4 rollouts, recording the complete action-observation sequences: the agent's actions and the environment's responses (file contents, search results, test outcomes, error messages).
After discarding trajectories exceeding 128k tokens, we classify the remaining trajectories based on final test outcomes into passing trajectories (all tests pass) and non-passing trajectories (tests fail). Both types provide valuable learning signals: passing trajectories demonstrate complete problem-solving cycles, while non-passing trajectories capture realistic debugging scenarios with error feedback.
3.2.3 Corpus Statistics
After filtering, we obtain two types of environmentally-native trajectories: $1.85 \times 10^{4}$ passing trajectories $ \mathcal{D}^{\mathrm{env}}{\text{pass}}$ (0.7B tokens) where all tests pass, and $5.55 \times 10^{4}$ non-passing trajectories $ \mathcal{D}^{\mathrm{env}}{\text{fail}}$ (2.4B tokens) with test failures, totaling approximately $7.4 \times 10^{4}$ trajectories and 3.1B tokens. The corpus features the authentic execution feedback—test results, runtime errors and iterative refinements that complement the workflow structure learned from PR data.
4. Experiments
4.1 Training Pipeline Terminology
We clarify our position within the standard LLM development pipeline:
Pre-training.
Large-scale next-token prediction on diverse corpora.
Mid-training (MT).
An intermediate stage that shifts capability distribution by training on curated domain data at scale ([12]). Unlike fine-tuning (which teaches specific behaviors), mid-training operates at the knowledge level.
Post-training.
Supervised fine-tuning (SFT) on demonstrations and/or reinforcement learning.
4.2 Experimental Setup
Base model.
Unless otherwise specified, we start from base model Qwen2.5-72B-Base and Qwen2.5-32B-Base.
Evaluation.
We evaluate on SWE-Bench Verified using $\textsc{SWE-Agent}$ (temperature 0, 128k context and 100 steps) and report Pass@1, averaged across 4 runs. We manually fix a small number of test cases where the provided ground truth patch cannot pass due to various reasons.
Training stages.
We consider two stages: (i) mid-training (MT) on large-scale unlabeled corpora (PR data and/or trajectories), and (ii) supervised fine-tuning (SFT) on agentic trajectories. The training configuration is detailed in § A.
Data components.
We use three main data sources. For compactness in tables, we denote datasets with symbols (defined in Section 2.1):
For contextually-native trajectories ($ \mathcal{D}^{\mathrm{ctx}}_{}$), we transform GitHub pull requests into the structured format described in § 3.1. In this setting, we use two subsets:
- $ \mathcal{D}^{\mathrm{ctx}}_{\text{py}}$ (41.9B): a Python-focused subset for alignment with software engineering benchmarks.
- $ \mathcal{D}^{\mathrm{ctx}}_{\text{gen}}$ (26.7B): a general subset drawn from most-starred repositories across all languages.
- $ \mathcal{D}^{\mathrm{ctx}}{}$ (68.6B): $ \mathcal{D}^{\mathrm{ctx}}{\text{gen}} \cup \mathcal{D}^{\mathrm{ctx}}_{\text{py}}$.
For environmentally-native trajectories ($ \mathcal{D}^{\mathrm{env}}{}$), we collect rollouts by running $\textsc{SWE-Agent}$ with
GLM-4.6in executable Docker environments derived from real GitHub pull requests, forming $ \mathcal{D}^{\mathrm{env}}{}$ (3.1B raw tokens; $\sim$ 4.5B effective tokens). We upsample $ \mathcal{D}^{\mathrm{env}}_{\text{pass}}$ by $3\times$ during training.For data to activate the model after mid-training, we may use:
- $ \mathcal{D}^{\mathrm{env}}{\text{pass}}$ (0.7B): subset of $ \mathcal{D}^{\mathrm{env}}{}$ that pass the unit tests
- $ \mathcal{D}^{\text{SWE-smith}}_{}$ (0.11B tokens): a public set of $\textsc{SWE-Agent}$ trajectories released by [6] (mostly generated with Claude 3.7 Sonnet), which we use as an external SFT baseline.
Baselines.
For Kimi-Dev comparisons, we quote results from [7] where applicable, and match our SFT dataset $ \mathcal{D}^{\text{SWE-smith}}{}$ and parameters (§ A) close to theirs. For experiments requiring downstream SFT on $ \mathcal{D}^{\mathrm{env}}{\text{pass}}$ (Table 1), we utilize the official Kimi-Dev-72B checkpoint as the starting point, as their pre-RL mid-training checkpoint is not publicly available.
4.3 Mid-Training Provides Robust Gains
```latextable {caption="**Table 1:** Ablations and mid-training comparisons on SWE-Bench Verified (SWE-V). Our agentic mid-training on contextually-native trajectories ($ \mathcal{D}^{\mathrm{ctx}}{}$) and environmentally-native trajectories ($ \mathcal{D}^{\mathrm{env}}{}$) consistently improves downstream performance, and is competitive with or surpasses prior mid-training recipes. All results use $\textsc{SWE-Agent}$ for evaluation. \textsuperscript{$\dagger$}Trained and tested using our infrastructure. \textsuperscript{$\ddagger$}Estimated from Figure 5 in [7]."}
\begin{tabular}{l c c c c} \toprule \textbf{Model / Variant} & \makecell{\textbf{Mid-training}\\textbf{Data}} & \makecell{\textbf{Post-training}\\textbf{Data}} & \makecell{\textbf{Post-training}\\textbf{Method}} & \textbf{SWE-V} \ \midrule
\multicolumn{5}{l}{\textit{Qwen 2.5 32B Series}} \ \rowcolor{tableblue!25} Baseline (Weak SFT)\textsuperscript{\textdagger} & - & $ \mathcal{D}^{\text{SWE-smith}}{}$ & SFT & 34.8 \ \rowcolor{tableblue!25} Baseline (Strong SFT)\textsuperscript{\textdagger} & - & $ \mathcal{D}^{\mathrm{env}}{\text{pass}}$ & SFT & 53.0 \ \rowcolor{tableorange!60} Ours (Weak SFT) & $ \mathcal{D}^{\mathrm{ctx}}{}$ & $ \mathcal{D}^{\text{SWE-smith}}{}$ & SFT & 39.5 \ \rowcolor{tableorange!60} Ours (Strong SFT) & $ \mathcal{D}^{\mathrm{ctx}}{}$ & $ \mathcal{D}^{\mathrm{env}}{\text{pass}}$ & SFT & 54.1 \ \rowcolor{tableorange!60} \textbf{Ours (daVinci-Dev-32B)} & \textbf{$ \mathcal{D}^{\mathrm{ctx}}{}+ \mathcal{D}^{\mathrm{env}}{}$} & \textbf{$ \mathcal{D}^{\mathrm{env}}_{\text{pass}}$} & \textbf{SFT} & \textbf{56.1} \ \addlinespace[2pt]
\midrule \multicolumn{5}{l}{\textit{Qwen 2.5 72B Series}} \ \rowcolor{tableblue!30} Baseline (Weak SFT)\textsuperscript{\textdagger} & - & $ \mathcal{D}^{\text{SWE-smith}}{}$ & SFT & 38.0 \ \rowcolor{tableblue!30} Baseline (Strong SFT)\textsuperscript{\textdagger} & - & $ \mathcal{D}^{\mathrm{env}}{\text{pass}}$ & SFT & 56.6 \ \rowcolor{tableblue!30} Kimi-Dev ([7]) & $\mathcal{D}^{\text{AgentlessMT}}{}$ & $\mathcal{D}^{\text{SWE-smith}}{}$ & SFT & $\approx$ 46.0\textsuperscript{\textdaggerdbl} \ \rowcolor{tableblue!30} Kimi-Dev ([7]) & $\mathcal{D}^{\text{AgentlessMT}}{}$ & $\mathcal{D}^{\text{AgentlessRL}}{}$ + $\mathcal{D}^{\text{SWE-smith}}{}$ & SFT+RL & 48.6 \ \rowcolor{tableblue!30} Kimi-Dev ([7])\textsuperscript{\textdagger} & $\mathcal{D}^{\text{AgentlessMT}}{}$ & $\mathcal{D}^{\text{AgentlessRL}}{}$ + $\mathcal{D}^{\mathrm{env}}{\text{pass}}$ & SFT+RL & 56.2 \ \rowcolor{tableorange!60} Ours (Weak SFT) & $ \mathcal{D}^{\mathrm{ctx}}{}$ & $ \mathcal{D}^{\text{SWE-smith}}{}$ & SFT & 46.4 \ \rowcolor{tableorange!60} Ours (Strong SFT) & $ \mathcal{D}^{\mathrm{ctx}}{}$ & $ \mathcal{D}^{\mathrm{env}}{\text{pass}}$ & SFT & 58.2 \ \rowcolor{tableorange!60} \textbf{Ours (daVinci-Dev-72B)} & \textbf{$ \mathcal{D}^{\mathrm{ctx}}{}+ \mathcal{D}^{\mathrm{env}}{}$} & \textbf{$ \mathcal{D}^{\mathrm{env}}_{\text{pass}}$} & \textbf{SFT} & \textbf{58.5} \ \bottomrule \end{tabular}
Our most important finding is that agent-native mid-training improves performance even when strong trajectory SFT already yields competitive results. For robustness we also validate this across two SFT regimes and against the strongest prior MT recipe (with best effort). The comparison results are shown in Table 1.
**Robustness across SFT regimes.**
On the 72B model, our MT consistently boosts performance. With weak SFT, we improve from 38.0\% to 46.4\% with only $ \mathcal{D}^{\mathrm{ctx}}_{}$ MT, matching the Kimi-Dev baseline despite using fewer than half the tokens (68.6B vs. 150B) and no synthetic reasoning data. With strong SFT, we reach **58.2\%** with only $ \mathcal{D}^{\mathrm{ctx}}_{}$ MT, outperforming the RL-tuned Kimi-Dev checkpoint and SFT-only baseline. This indicates that our contextually-native representation—bundling file context and edits—successfully bridges the gap between pre-training and agentic fine-tuning. With $ \mathcal{D}^{\mathrm{ctx}}_{}+ \mathcal{D}^{\mathrm{env}}_{}$ MT, our performance further increases to our strongest result **58.5\%**, showing that adding environmentally-native trajectories to MT enables the model to internalize the dynamics of the execution environment.
**Robustness across scales.**
The benefits of our MT recipes transfer effectively from 72B to the smaller 32B model. On the 32B scale, $ \mathcal{D}^{\mathrm{ctx}}_{}$ MT improves the weak SFT baseline by 4.7\% and the strong SFT baseline by 1.1\%, and $ \mathcal{D}^{\mathrm{ctx}}_{}+ \mathcal{D}^{\mathrm{env}}_{}$ MT continues to deliver the best performance **56.1\%**, 3.1\% above the strong SFT baseline. This confirms that the effectiveness of contextually-native trajectories and environmentally native trajectories is not specific to a single model capacity.
### 4.4 Comparison with Open Recipes
```latextable {caption="**Table 2:** Comparison with representative methods on `SWE-Bench Verified` (SWE-V). We include representative works with agentic scaffolds."}
\begin{tabular}{l c c c c c}
\toprule
\textbf{Model} & \makecell{\textbf{Base}\\\textbf{or Inst.}} & \makecell{\textbf{Mid-}\\\textbf{training}} & \makecell{\textbf{Post-training}\\\textbf{Method}} & \textbf{Scaffold} & \textbf{SWE-V} \\
\midrule
\multicolumn{6}{l}{\textit{Qwen 2.5 32B Coder Series}} \\
R2EGym-Agent ([15]) & Base & No & SFT & R2E-Gym & 34.4 \\
Openhands-LM ([16]) & Inst. & No & SFT & OpenHands & 37.2 \\
SWE-Agent-LM ([6]) & Inst. & No & SFT & SWE-Agent & 40.2 \\
SWE-Mirror-LM ([17]) & Inst. & No & SFT & MOpenHands & 52.2 \\
Skywork-SWE ([18]) & Inst. & No & SFT & OpenHands & 38.0 \\
SWE-Dev ([19]) & Inst. & No & SFT+RL & OpenHands & 36.6 \\
\midrule
\multicolumn{6}{l}{\textit{Qwen 3 32B Series}} \\
DeepSWE-Preview ([20]) & Inst. & No & RL & OpenHands & 42.2 \\
FrogBoss ([21]) & Inst. & No & SFT & SWE Agent & 54.6 \\
SWE-Lego-Qwen3-32B ([22]) & Inst. & No & SFT & OpenHands & 52.6 \\
\midrule
\multicolumn{6}{l}{\textit{Qwen 2.5 32B Series}} \\
\textbf{daVinci-Dev-32B (Ours)} & \textbf{Base} & \textbf{Yes} & \textbf{SFT} & \textbf{SWE-Agent} & \textbf{56.1} \\
\midrule
\multicolumn{6}{l}{\textit{Qwen 2.5 72B Series}} \\
Kimi-Dev ([7]) & Base & Yes & SFT+RL & SWE-Agent & 48.6 \\
\textbf{daVinci-Dev-72B (Ours)} & \textbf{Base} & \textbf{Yes} & \textbf{SFT} & \textbf{SWE-Agent} & \textbf{58.5} \\
\bottomrule
\end{tabular}
We compare our full recipe against representative open methods on SWE-Bench Verified based on the Qwen2.5 model family and use agentic scaffolds. Table 2 presents the results.
Results.
Within the 72B scale, our daVinci-Dev-72B achieves 58.5%, surpassing 48.6% for Kimi-Dev using the same base model and agentic scaffold. At 32B scale, daVinci-Dev-32B achieves 56.1%, which is state-of-the-art among open training recipes at this scale using agentic scaffolds, despite the fact that prior work uses Qwen2.5-Coder-32B series or Qwen3-32B while our method starts from non-coder Qwen2.5-32B-Base.
4.5 Generalization Beyond SWE Tasks
\begin{tabular}{l ccc ccc}
\toprule
& \multicolumn{3}{c}{\textbf{Qwen2.5-32B}} & \multicolumn{3}{c}{\textbf{Qwen2.5-72B}} \\
\cmidrule(lr){2-4} \cmidrule(lr){5-7}
\textbf{Benchmark} & \textbf{Base} & \textbf{MT Mix} & \textbf{$\Delta$} & \textbf{Base} & \textbf{MT Mix} & \textbf{$\Delta$} \\
\midrule
\multicolumn{7}{l}{\textit{Scientific Benchmarks}} \\
GPQA-Main & 38.17 & 38.84 & +0.67 & 43.30 & 44.87 & +1.57 \\
SuperGPQA & 33.85 & 35.94 & +2.09 & 37.76 & 39.27 & +1.51 \\
SciBench & 18.46 & 20.49 & +2.03 & 19.33 & 19.77 & +0.44 \\
\midrule
\multicolumn{7}{l}{\textit{Code Benchmarks}} \\
HumanEval & 58.16 & 81.42 & +23.26 & 64.27 & 76.73 & +12.46 \\
EvalPlus & 50.13 & 71.31 & +21.18 & 56.04 & 69.45 & +13.41 \\
DS-1000 & 12.2 & 21.2 & +9.0 & 21.4 & 24.7 & +3.3 \\
\bottomrule
\end{tabular}
While our agentic mid-training is specialized for software engineering, we investigate whether the agentic capabilities acquired from processing Pull Requests and execution trajectories transfer to broader domains requiring complex logic. We focus our evaluation on two distinct categories: standard code generation and rigorous scientific reasoning. In this experiment we choose a clean single stage MT recipe with $ \mathcal{D}^{\mathrm{ctx}}{\text{py}}$ + $ \mathcal{D}^{\mathrm{env}}{}$ as dataset.
As reported in Table 3, our model demonstrates strong generalization performance, consistently surpassing the base models across both 32B and 72B scales. In code generation, we observe substantial gains on HumanEval ([23]) and EvalPlus ([24]) (after decontamination following XCoder ([25])), confirming that our data improves fundamental coding proficiency. More notably, we observe transfer learning to scientific benchmarks such as GPQA ([26]) and SciBench ([27]). These tasks, which demand expert-level domain knowledge and multi-step reasoning, benefit from the decision-making patterns inherent in our agentic mid-training. This suggests that the logic required for autonomous software engineering fosters fundamental reasoning skills that generalize beyond code.
5. Analysis
In this section, we analyze the factors contributing to the effectiveness of agentic mid-training. We first examine the efficiency and information density of contextually-native data, then explore the synergistic relationship between our two data types, and finally discuss the scalability of this paradigm.
5.1 High Information Density and Efficiency
A key advantage of our approach is token efficiency. Kimi-Dev's recipe involves 70B tokens directly derived from PR plus 20B synthetic trajectory/CoT tokens upsampled 4 times, totaling $\sim$ 150B tokens. In contrast, our 68.6B tokens $ \mathcal{D}^{\mathrm{ctx}}{}$ MT stage consistently outperforms Kimi-Dev as shown in Section 4.3, and performance further grows with additional 4.5B effective tokens $ \mathcal{D}^{\mathrm{env}}{}$ added to MT training stage. This efficiency stems from our contextually-native representation being closer to software engineering agent's test distribution compared to factorized approaches, and our environmentally-native trajectories being more authentic than simulated trajectories.
5.2 Synergy: contextually-native data amplifies trajectory learning
While environmentally-native trajectories provide the correct format for agentic interaction, we find they are insufficient for generalization when used in isolation. Table 4 presents an ablation study on the composition of MT data across both 32B and 72B model scales.
\begin{tabular}{l c c c c}
\toprule
& & & \multicolumn{2}{c}{\textbf{SWE-Verified}} \\
\textbf{MT Data Composition} & \textbf{Tokens} & \textbf{SFT Data} & \textbf{32B Base} & \textbf{72B Base} \\
\midrule
\multicolumn{5}{l}{\textit{Ablation: Trajectories vs. PR (Zero-shot / No SFT)}} \\
$ \mathcal{D}^{\mathrm{env}}_{}$ & 4.5B & -- & 43.7 & 47.1 \\
$ \mathcal{D}^{\mathrm{env}}_{}$ + $ \mathcal{D}^{\mathrm{ctx}}_{\text{py}}$ & 46.4B & -- & \textbf{49.9} & \textbf{54.8} \\
\midrule
\multicolumn{5}{l}{\textit{Impact of MT Composition on SFT}} \\
$ \mathcal{D}^{\mathrm{ctx}}_{\text{py}}$ & 41.9B & $ \mathcal{D}^{\mathrm{env}}_{\text{pass}}$ & 52.9 & 56.5 \\
$ \mathcal{D}^{\mathrm{env}}_{}$ + $ \mathcal{D}^{\mathrm{ctx}}_{\text{py}}$ & 46.4B & $ \mathcal{D}^{\mathrm{env}}_{\text{pass}}$ & \textbf{53.6} & \textbf{57.8} \\
$ \mathcal{D}^{\mathrm{env}}_{}$ + $ \mathcal{D}^{\mathrm{ctx}}_{}$ & 73.1B & $ \mathcal{D}^{\mathrm{env}}_{\text{pass}}$ & \textbf{56.1} & \textbf{58.5} \\
\bottomrule
\end{tabular}
Trajectories require PR grounding.
In the zero-shot setting (top section), training on environmentally-native trajectories alone yields 47.1% (72B). However, mixing in the Python contextually-native subset $ \mathcal{D}^{\mathrm{ctx}}_{\text{py}}$ boosts performance to 54.8%—a significant +7.7% gain. This suggests that while environmentally-native trajectories teach the model how to interact with the environment, contextually-native data provides the necessary knowledge and code modification diversity required to solve complex issues.
Mid-training on trajectories aids SFT.
A key question in agent training is whether "double-dipping"—training on trajectories during MT and then fine-tuning on them during SFT—provides value. Comparing the first two rows of the SFT section (Table 4), we observe a consistent improvement when trajectories are included in MT. For the 72B model, adding trajectories to the MT mix improves the final SFT score from 56.5% to 57.8%. This indicates that mid-training allows the model to internalize the dynamics of the execution environment more deeply than SFT alone, creating a better initialization for the final alignment stage. Finally, our strongest result, 58.5% (72B) and 56.1% (32B) comes from scaling the contextually-native foundation from $ \mathcal{D}^{\mathrm{ctx}}{\text{py}}$ (41.9B) to the full $ \mathcal{D}^{\mathrm{ctx}}{}$ (68.6B). This demonstrates that while mixing trajectories into MT is beneficial, the sheer scale and diversity of contextually-native supervision remain the dominant factors in model performance.
5.3 Scalability: from raw PRs to executable tasks
Our approach is scalable along two axes: data availability and empirical performance scaling.
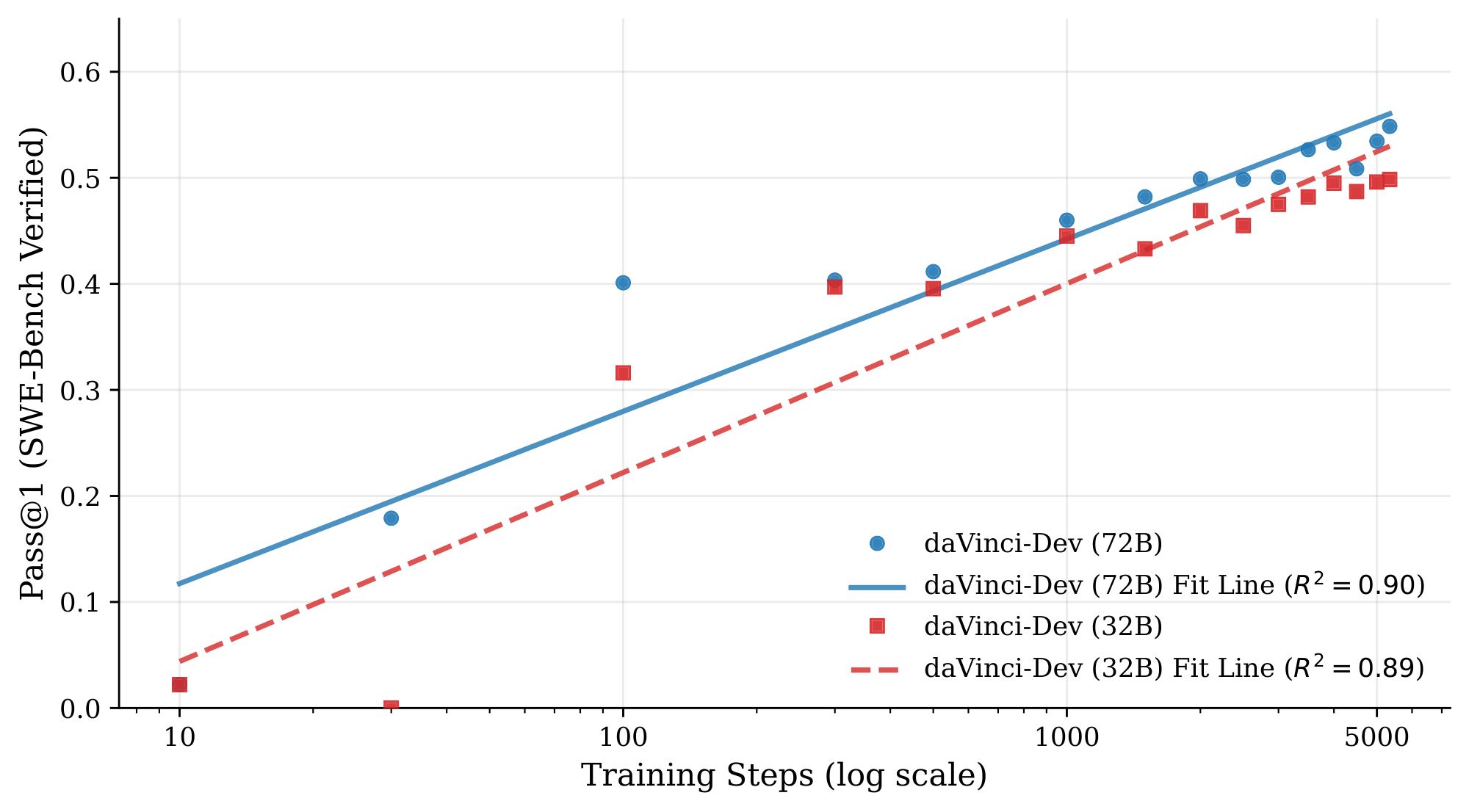
Empirical Scaling.
Beyond the theoretical abundance of data, we verify that our model effectively converts additional compute and training steps into performance gains. Figure 4 illustrates the learning curves of both Qwen2.5-72B and Qwen2.5-32B during the MT stage on the $ \mathcal{D}^{\mathrm{ctx}}{\text{py}}$ + $ \mathcal{D}^{\mathrm{env}}{}$ mixture. We observe a robust log-linear relationship between training steps and Pass@1 performance for both model sizes ($R^2 \approx 0.90$). Specifically, the 72B model climbs to 54.9%, while the 32B model follows a parallel trajectory to reach 49.9%. Notably, we select the $ \mathcal{D}^{\mathrm{ctx}}{\text{py}}$ + $ \mathcal{D}^{\mathrm{env}}{}$ mixture as training dataset in this experiment because only when $ \mathcal{D}^{\mathrm{env}}_{}$ is added can the models achieve zero-shot agentic capabilities (without SFT) directly from mid-training, and that we train the model using only one stage Appendix A.1. The consistent monotonic upward trends, suggests that performance has not saturated. This indicates that further scaling would yield continued improvements.
Scaling PR data.
The Python-focused subset $ \mathcal{D}^{\mathrm{ctx}}{\text{py}}$ is built from $\sim 1.3 \times 10^{7}$ pull requests (before filtering) in $\sim 7.4\times 10^{5}$ repositories while the multi-language subset $ \mathcal{D}^{\mathrm{ctx}}{\text{gen}}$ only utilize the $1 \times 10^4$ most starred repositories. However, our survey indicates there are $\sim 3 \times 10^{8}$ pull requests in $\sim 10^{9}$ public repositories, suggesting substantial headroom to scale the corpus by expanding language coverage and relaxing filters.
Scaling executable supervision.
Recent advances in environment construction ([4]) demonstrate that PR-derived data can be automatically transformed into deeper supervision: executable tasks with Docker environments and unit tests, constructed via a fully automated pipeline. Conceptually, this is a more processed form of PR data than our raw PR corpora. Because verification is test-based and environments are executable, scaling increases not only quantity but also authenticity: each additional task comes with real environment feedback rather than synthetic traces. Importantly, $\textsc{SWE-rebench}$ builds its public dataset from 3, 468 Python repositories and reports 21, 336 validated tasks, suggesting substantial headroom for scaling as repository coverage expands. This supports a long-term path where raw PR mining provides breadth, while rebench-style processing provides depth and verifiability for agent training.
6. Limitations
Data privacy and attribution.
We did not explicitly remove developer identifiers from PR text in the general subset $ \mathcal{D}^{\mathrm{ctx}}_{\text{gen}}$, which may raise privacy concerns and could lead to memorization of contributor names.
Evaluation sensitivity.
Some results depend on a patched evaluation harness that fixes a small number of benchmark issues. This introduces an additional source of variance.
Scope.
We focus on a single base model family and a single benchmark. Extending to other model families and more real-world agentic tasks ([28, 29, 5]) is left for future work.
7. Related Work
Mid-training
Recent work increasingly positions mid-training as a critical bridge between large-scale pre-training and post-training. Rather than transitioning directly from noisy, web-scale corpora to SFT or RL, mid-training introduces higher-quality, task-structured, or instruction-oriented data at later stages of training, often paired with learning-rate annealing ([30, 31, 32]). For example, OctoThinker ([12]) argues that mid-training can substantially improve both the sample efficiency and the achievable performance ceiling of subsequent RL by stabilizing internal representations and encouraging reasoning-friendly behaviors. Despite these advances, existing studies provide only limited insight into agentic mid-training data. For example, although Kimi-Dev ([7]) incorporates data such as file retrieval and file editing during mid-training, these behaviors are treated in isolation and do not constitute a coherent, end-to-end agentic process. In contrast to prior work, this paper introduces Agent-Native Mid-Training, a paradigm that treats agentic behavior as a first-class training objective. We systematically design and construct mid-training data that reflects complete agentic processes and release both the construction methodology and the resulting datasets to the community.
Agentic training
Agentic training builds upon prior work, SFT and RL. Early agents were predominantly trained by sampling trajectories in specific environments using closed-source large models, followed by applying SFT to distill the collected data into smaller, task-specialized models ([33, 34, 35, 36]). SWE-smith ([6]), BugPilot ([21]), SWE-rebench ([37]), and SWE-Factory ([38]) use these ideas to create datasets in the domain of code agents. With the introduction of GRPO ([39, 40]), recent work has increasingly focused on training agents capable of multi-step reasoning, tool usage, and explicit interaction with external environments ([8, 41, 42]). Despite a growing body of research on agentic post-training, systematic studies of agentic mid-training remain notably scarce. Since mid-training can gain more diverse data than the post-training stage, exploring its role and potential benefits becomes important.
Data synthesis
Early approaches to synthetic data primarily focused on recombining and rewriting large-scale corpora and using reject-sampling to get the final data ([43]). As the demand for data scale and coverage increased, persona-driven synthesis was introduced ([44, 45]), enabling a systematic expansion of the task space beyond naturally occurring data. More recently, with the rise of agent-oriented research, synthetic data has shifted from text-level generation to the synthesis of agentic processes. Through interaction within synthetic environments ([40, 8, 37]), models actively generate data containing decision-making trajectories, feedback loops, and long-horizon dependencies. In this paper, synthetic data for mid-training has become an emerging trend. Mid-training synthesis emphasizes agentic data to shape intermediate representations, serving as a critical bridge between pre-training and post-training.
8. Conclusion
In this work, we demonstrated that the agentic coding capabilities of large language models can be substantially enhanced through a rigorous data-centric strategy leveraging GitHub pull requests and executable interaction trajectories. By constructing a unified training recipe that combines 68.6B tokens of context-rich PR data with high-quality, verified rollouts collected in executable environments, we obtained a daVinci-Dev-72B with strong performance on SWE-Bench Verified (58.5%), surpassing recent baselines such as Kimi-Dev.
Across experiments, the key driver is agent-native data—agent-native PR supervision (context-complete samples) plus environmentally-native trajectories (executable, test-verified rollouts).
Our analysis highlights two critical insights. First, the structural representation of PR data is paramount; keeping relevant file contents and commit edits together provides a cohesive supervision signal that mirrors the "localize-read-edit" loop of code agents, proving more effective than decomposing PRs into isolated subtasks. Second, not all agentic trajectories are equal. We showed that training on executable, test-verified passing trajectories yields significantly higher gains than training on static or simulated traces. The synergy between these data sources—using PRs to establish general software engineering priors and verified trajectories to specialize agentic behavior—offers a highly token-efficient path to strong performance.
Looking forward, these results suggest a scalable paradigm for future code agent development. With the vast availability of public repositories and the increasing feasibility of automated environment verification, there is substantial headroom to expand this approach to broader language ecosystems and more complex software maintenance tasks. As the field shifts from single-turn code generation to autonomous engineering, bridging the gap between static historical data and dynamic execution environments will be essential.
Acknowledgments
We express our gratitude to Haoyang Zou, Zengzhi Wang, and Fan Zhou for their constructive feedback and stimulating discussions. We are also grateful to Liming Liu for his guidance and advice.
Appendix
A. Training Details
A.1 Dataset Components and Staging
PR MT Staging.
Our $ \mathcal{D}^{\mathrm{ctx}}{}$ (68.6B) training was conducted in two sequential stages rather than a single mix. We first trained on the general subset $ \mathcal{D}^{\mathrm{ctx}}{\text{gen}}$ (26.7B tokens) to establish a broad software engineering baseline. We then performed mid-training (MT) on the Python subset $ \mathcal{D}^{\mathrm{ctx}}{\text{py}}$ (41.9B tokens) to specialize the model on agent-native, Python-centric patterns. Our $ \mathcal{D}^{\mathrm{ctx}}{}$ + $ \mathcal{D}^{\mathrm{env}}{}$ (73.1B) was also conducted in two sequential stages where the first stage is the general subset $ \mathcal{D}^{\mathrm{ctx}}{\text{gen}}$ (26.7B tokens) and the second stage is the other two datasets.
SFT Configuration.
For all SFT experiments involving our $ \mathcal{D}^{\mathrm{env}}{\text{pass}}$ or $ \mathcal{D}^{\text{SWE-smith}}{}$ datasets, we trained for 5 epochs.
A.2 Hyperparameters
We provide the key hyperparameters used for Mid-training (MT) and Supervised Fine-tuning (SFT) below.
MT Hyperparameters.
We use a global batch size of 1024 samples and a peak learning rate of $8 \times 10^{-5}$. The learning rate schedule utilizes a warmup ratio of 0.05 (5% of total training steps), followed by cosine decay until all samples are consumed once (1 epoch). No loss mask is applied during MT.
SFT Hyperparameters.
We use a global batch size of 128 samples and a peak learning rate of $1 \times 10^{-5}$. The learning rate schedule utilizes a warmup ratio of 0.10 (10% of total training steps), followed by cosine decay until all samples are consumed once per epoch. A standard loss mask is applied to user and tool tokens during SFT.
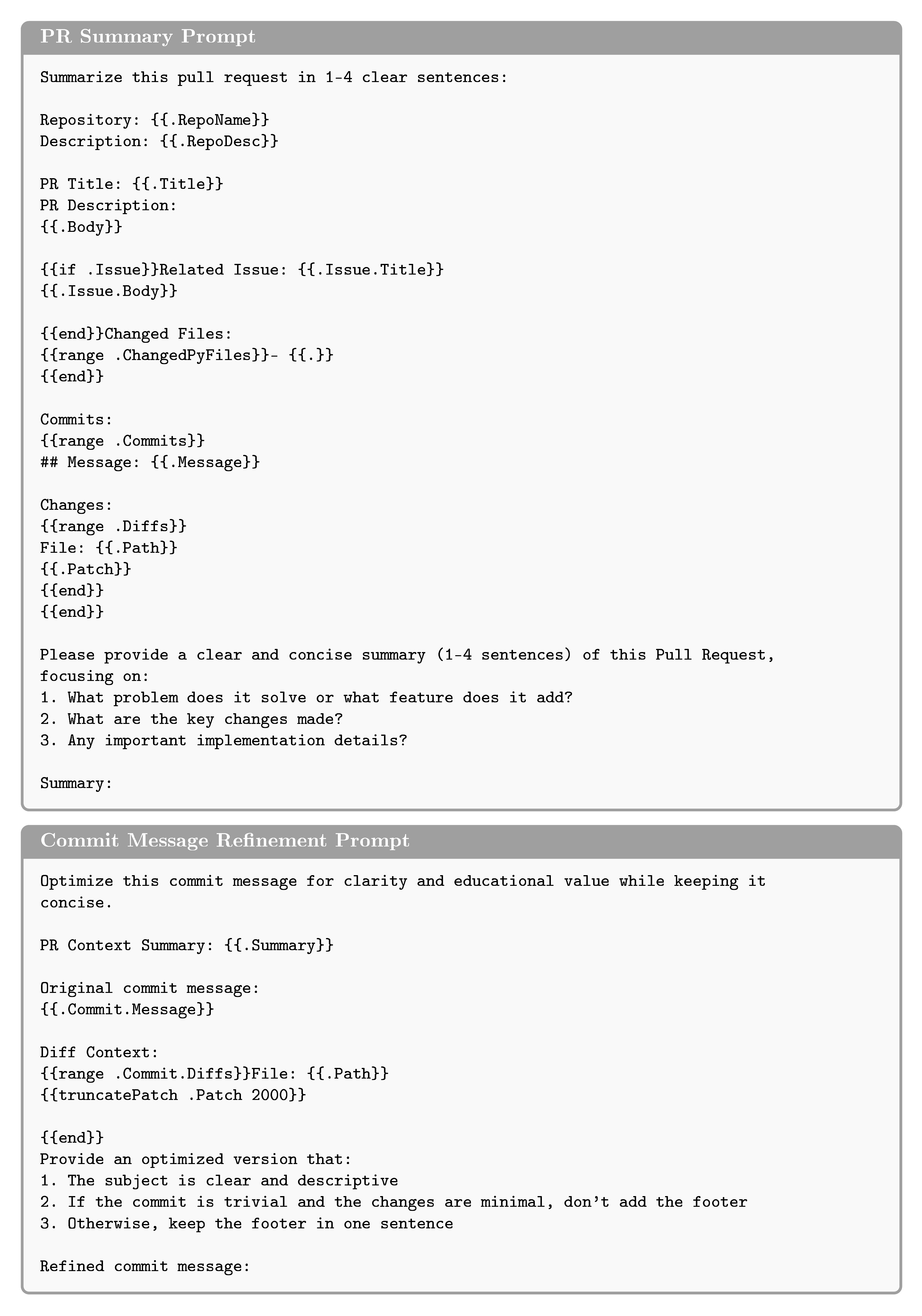
B. LLM prompts used for PR rendering
During context enrichment (Section 3.1), we optionally call an LLM to (i) generate a concise pull-request summary and (ii) normalize/optimize commit messages for readability. We use Qwen3-235B-A22b-Instruct-2507 with fixed output budgets (512 tokens for PR summaries; 256 tokens for commit-message refinement).
C. Dataset Formats
We include the templates for two types of data in the contextually-native dataset: (i) the General PR format, and (ii) the Python PR agentic format.
The General PR format uses XML-like tags similar to The Stack v2 ([46]) and includes rich interaction history (comments and reviews). Events related to a pull requests are concatenated in chronological order. Different from The Stack v2, we always include relevant file content and grouped review comments threads. This corpus is sourced from top-starred repositories without the 1–5 Python-file constraint.

The Python PR format uses a Markdown structure and represents edits in a search-and-replace action space. It includes an LLM-generated PR summary after presenting all related files (simulating a overall planning and reasoning phase in an agentic workflow) and enhanced commit messages (simulating textual reasoning before action). Edits are rewritten from git diff format to search-replace format used in many agentic scaffolds. The # Issue section is omitted if no linked issue is found.

D. Benchmark decontamination
In our training dataset we take measures to remove samples related to the SWE-Bench Verified benchmark as detailed in Section 3.1. For the HumanEval and EvalPlus benchmarks, we follow the decontamination procedure of XCoder ([25]). Concretely, for each benchmark instance we form the reference text by concatenating the prompt and canonical solution, tokenize it, and compute the set of unique $n$-grams ($n=13$). We then scan the tokenized training corpus and, for every training sample, compute its set of unique 13-grams and the overlap with each benchmark instance. Similarity is measured as a leakage ratio:
$ \mathrm{leakage_ratio}(e, x) ;=; \frac{\left|G_e \cap G_x\right|}{\left|G_e\right|}, $
where $G_e$ is the set of unique 13-grams in the benchmark instance and $G_x$ is the set of unique 13-grams in a training sample. For each benchmark instance, we take the maximum leakage ratio over all training samples as its contamination score.
We manually selected the contamination threshold as $\tau=0.10$ based on case studies of high-overlap matches. Using this criterion, we identified 24 contaminated HumanEval instances, which were removed from evaluation.
References
[1] Jain et al. (2024). Livecodebench: Holistic and contamination free evaluation of large language models for code. arXiv preprint arXiv:2403.07974.
[2] Wang et al. (2024). How do your code llms perform? empowering code instruction tuning with really good data. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. pp. 14027–14043.
[3] Jimenez et al. (2023). Swe-bench: Can language models resolve real-world github issues?. arXiv preprint arXiv:2310.06770.
[4] Ibragim Badertdinov et al. (2025). SWE-rebench: An Automated Pipeline for Task Collection and Decontaminated Evaluation of Software Engineering Agents. https://arxiv.org/abs/2505.20411.
[5] Wu et al. (2025). InnovatorBench: Evaluating Agents' Ability to Conduct Innovative LLM Research. arXiv preprint arXiv:2510.27598.
[6] John Yang et al. (2025). SWE-smith: Scaling Data for Software Engineering Agents. https://arxiv.org/abs/2504.21798.
[7] Zonghan Yang et al. (2025). Kimi-Dev: Agentless Training as Skill Prior for SWE-Agents. https://arxiv.org/abs/2509.23045.
[8] Team et al. (2025). Kimi k2: Open agentic intelligence. arXiv preprint arXiv:2507.20534.
[9] Qiying Yu et al. (2025). DAPO: An Open-Source LLM Reinforcement Learning System at Scale. https://arxiv.org/abs/2503.14476.
[10] Ye et al. (2025). Limo: Less is more for reasoning. arXiv preprint arXiv:2502.03387.
[11] Aitor Lewkowycz et al. (2022). Solving Quantitative Reasoning Problems with Language Models. https://arxiv.org/abs/2206.14858.
[12] Zengzhi Wang et al. (2025). OctoThinker: Mid-training Incentivizes Reinforcement Learning Scaling. https://arxiv.org/abs/2506.20512.
[13] Yang et al. (2025). Qwen3 technical report. arXiv preprint arXiv:2505.09388.
[14] 5 Team et al. (2025). GLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models. https://arxiv.org/abs/2508.06471.
[15] Naman Jain et al. (2025). R2E-Gym: Procedural Environments and Hybrid Verifiers for Scaling Open-Weights SWE Agents. https://arxiv.org/abs/2504.07164.
[16] Xingyao Wang et al. (2025). OpenHands: An Open Platform for AI Software Developers as Generalist Agents. In The Thirteenth International Conference on Learning Representations. https://openreview.net/forum?id=OJd3ayDDoF.
[17] Junhao Wang et al. (2025). SWE-Mirror: Scaling Issue-Resolving Datasets by Mirroring Issues Across Repositories. https://arxiv.org/abs/2509.08724.
[18] Liang Zeng et al. (2025). Skywork-SWE: Unveiling Data Scaling Laws for Software Engineering in LLMs. https://arxiv.org/abs/2506.19290.
[19] Haoran Wang et al. (2025). SWE-Dev: Building Software Engineering Agents with Training and Inference Scaling. https://arxiv.org/abs/2506.07636.
[20] Luo et al. (2025). DeepSWE: Training a Fully Open-sourced, State-of-the-Art Coding Agent by Scaling RL. Blog post. https://www.all-hands.dev/blog/deepswe.
[21] Atharv Sonwane et al. (2025). BugPilot: Complex Bug Generation for Efficient Learning of SWE Skills. https://arxiv.org/abs/2510.19898.
[22] Chaofan Tao et al. (2026). SWE-Lego: Pushing the Limits of Supervised Fine-tuning for Software Issue Resolving. https://arxiv.org/abs/2601.01426.
[23] Mark Chen et al. (2021). Evaluating Large Language Models Trained on Code.
[24] Liu et al. (2023). Is Your Code Generated by ChatGPT Really Correct? Rigorous Evaluation of Large Language Models for Code Generation. In Thirty-seventh Conference on Neural Information Processing Systems. https://openreview.net/forum?id=1qvx610Cu7.
[25] Yejie Wang et al. (2024). How Do Your Code LLMs Perform? Empowering Code Instruction Tuning with High-Quality Data. https://arxiv.org/abs/2409.03810.
[26] David Rein et al. (2023). GPQA: A Graduate-Level Google-Proof Q&A Benchmark. https://arxiv.org/abs/2311.12022.
[27] Xiaoxuan Wang et al. (2024). SciBench: Evaluating College-Level Scientific Problem-Solving Abilities of Large Language Models. https://arxiv.org/abs/2307.10635.
[28] Li et al. (2026). AgencyBench: Benchmarking the Frontiers of Autonomous Agents in 1M-Token Real-World Contexts. arXiv preprint arXiv:2601.11044.
[29] Tianze Xu et al. (2025). ResearcherBench: Evaluating Deep AI Research Systems on the Frontiers of Scientific Inquiry. https://arxiv.org/abs/2507.16280.
[30] Kaixiang Mo et al. (2025). Mid-Training of Large Language Models: A Survey. https://arxiv.org/abs/2510.06826.
[31] Charlie Zhang et al. (2025). On the Interplay of Pre-Training, Mid-Training, and RL on Reasoning Language Models. https://arxiv.org/abs/2512.07783.
[32] Chengying Tu et al. (2025). A Survey on LLM Mid-Training. https://arxiv.org/abs/2510.23081.
[33] Zeng et al. (2024). AgentTuning: Enabling Generalized Agent Abilities for LLMs. In Findings of the Association for Computational Linguistics: ACL 2024. pp. 3053–3077. doi:10.18653/v1/2024.findings-acl.181. https://aclanthology.org/2024.findings-acl.181/.
[34] Zehui Chen et al. (2024). Agent-FLAN: Designing Data and Methods of Effective Agent Tuning for Large Language Models. https://arxiv.org/abs/2403.12881.
[35] Zhiheng Xi et al. (2024). AgentGym: Evolving Large Language Model-based Agents across Diverse Environments. https://arxiv.org/abs/2406.04151.
[36] Dayuan Fu et al. (2025). Interaction as Intelligence Part II: Asynchronous Human-Agent Rollout for Long-Horizon Task Training. https://arxiv.org/abs/2510.27630.
[37] Ibragim Badertdinov et al. (2025). SWE-rebench: An Automated Pipeline for Task Collection and Decontaminated Evaluation of Software Engineering Agents. https://arxiv.org/abs/2505.20411.
[38] Lianghong Guo et al. (2026). SWE-Factory: Your Automated Factory for Issue Resolution Training Data and Evaluation Benchmarks. https://arxiv.org/abs/2506.10954.
[39] Zhihong Shao et al. (2024). DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models. https://arxiv.org/abs/2402.03300.
[40] Liu et al. (2025). Deepseek-v3. 2: Pushing the frontier of open large language models. arXiv preprint arXiv:2512.02556.
[41] Yuxiang Zheng et al. (2025). DeepResearcher: Scaling Deep Research via Reinforcement Learning in Real-world Environments. https://arxiv.org/abs/2504.03160.
[42] Xuefeng Li et al. (2025). ToRL: Scaling Tool-Integrated RL. https://arxiv.org/abs/2503.23383.
[43] Zheng Yuan et al. (2023). Scaling Relationship on Learning Mathematical Reasoning with Large Language Models.
[44] Tao Ge et al. (2025). Scaling Synthetic Data Creation with 1,000,000,000 Personas. https://arxiv.org/abs/2406.20094.
[45] Fu et al. (2025). Agentrefine: Enhancing agent generalization through refinement tuning. arXiv preprint arXiv:2501.01702.
[46] Anton Lozhkov et al. (2024). StarCoder 2 and The Stack v2: The Next Generation. https://arxiv.org/abs/2402.19173.