Efficient Rectification of Neuro-Symbolic Reasoning Inconsistencies by Abductive Reflection
Wen-Chao Hu$^{1,2}$, Wang-Zhou Dai$^{1,3}$, Yuan Jiang$^{1,2}$, Zhi-Hua Zhou$^{1,2}$
$^{1}$National Key Laboratory for Novel Software Technology, Nanjing University, China
$^{2}$School of Artificial Intelligence, Nanjing University, China
$^{3}$School of Intelligence Science and Technology, Nanjing University, China
{huwc, daiwz, jiangy, zhouzh}@lamda.nju.edu.cn
Abstract
Neuro-Symbolic (NeSy) AI could be regarded as an analogy to human dual-process cognition, modeling the intuitive System 1 with neural networks and the algorithmic System 2 with symbolic reasoning. However, for complex learning targets, NeSy systems often generate outputs inconsistent with domain knowledge and it is challenging to rectify them. Inspired by the human Cognitive Reflection, which promptly detects errors in our intuitive response and revises them by invoking the System 2 reasoning, we propose to improve NeSy systems by introducing Abductive Reflection (ABL-Refl) based on the Abductive Learning (ABL) framework. ABL-Refl leverages domain knowledge to abduce a reflection vector during training, which can then flag potential errors in the neural network outputs and invoke abduction to rectify them and generate consistent outputs during inference. ABL-Refl is highly efficient in contrast to previous ABL implementations. Experiments show that ABL-Refl outperforms state-of-the-art NeSy methods, achieving excellent accuracy with fewer training resources and enhanced efficiency.
Executive Summary: Neuro-symbolic artificial intelligence (NeSy AI) combines the quick, pattern-based thinking of neural networks with the logical, rule-based reasoning of symbolic systems, much like how humans balance intuition and deliberation. However, in complex tasks such as puzzle-solving or optimization problems, neural networks often produce outputs that clash with established domain rules, leading to unreliable results. Fixing these inconsistencies traditionally requires heavy computation, limiting NeSy AI's use in real-world applications like text generation, biological modeling, or decision support systems where accuracy and speed are critical. This issue is pressing now as AI systems grow more ambitious, demanding methods that ensure logical consistency without sacrificing efficiency.
This document introduces Abductive Reflection (ABL-Refl), an enhancement to the Abductive Learning framework, to detect and correct errors in neural network outputs using domain knowledge. It aims to demonstrate that ABL-Refl can achieve higher accuracy in reasoning tasks while using fewer resources than existing NeSy methods.
The authors developed ABL-Refl by adding a "reflection vector" to neural networks, which flags potential errors in initial outputs and directs symbolic solvers to fix only those spots, drawing on domain rules like puzzle constraints or mathematical definitions. They tested it through experiments on standard benchmarks: solving Sudoku puzzles (both text-based and image-based versions) using datasets from Kaggle and prior studies, and finding maximum cliques in graphs from the TUDataset collection. These involved thousands of examples, with neural networks processing inputs and solvers like MiniSAT or Gurobi handling corrections. Training used a mix of labeled and unlabeled data over 100 epochs, repeated five times on typical server hardware, assuming access to clear domain rules but no extra synthetic data.
Key findings highlight ABL-Refl's strengths. First, it reached 97% accuracy on text Sudoku, about 20-25% higher than top baselines like recurrent relational networks (73%) or logic-constrained methods (77%), with training time around 110 minutes—similar to or less than competitors' 115-174 minutes. Second, it cut labeled data needs sharply, hitting 95% accuracy with just 10% of standard training samples (2,000 instead of 20,000), enabling use in data-scarce settings. Third, it sped symbolic reasoning by narrowing focus: abduction time dropped 15-70% compared to pure solvers (e.g., 32 seconds versus 106 on logic puzzles; 0.2 seconds versus 0.23 on simpler rules), with overall inference under 0.3 seconds per case. Fourth, on image Sudoku, accuracy climbed to 94% (with pretraining), tripling baselines at 64-68%. Fifth, for graph optimization, it achieved 98-99% approximation ratios—near perfect—versus 78-96% for leading neural methods, even on large graphs with thousands of nodes.
These results mean NeSy AI can now handle intricate reasoning more reliably and affordably, reducing risks of flawed outputs in high-stakes areas like planning or diagnostics, while cutting costs through less data and faster processing. Unlike prior approaches that approximate logic and lose precision or grind through exhaustive searches, ABL-Refl keeps full symbolic power intact, efficiently mimicking human error-checking. This outperforms expectations from earlier Abductive Learning, which bogged down on scale, making it viable for broader deployment.
Leaders should prioritize integrating ABL-Refl into NeSy pipelines for tasks needing rule adherence, starting with pilots in optimization or puzzle-like problems. Options include tuning the reflection threshold for speed (higher retains more neural output, trading slight accuracy for 10-20% faster runs) versus precision. Further work is essential: test on real applications like enhancing large language models for trustworthy text or judicial analysis, gather more diverse datasets, and scale to ultra-large inputs.
While robust across benchmarks, limitations include reliance on well-defined domain rules and potential slowdowns on massive graphs without hardware upgrades; reflection training assumes solver compatibility. Confidence is high in efficiency gains and accuracy boosts, backed by consistent repeats, but caution applies to untested domains where rules are fuzzy.
1. Introduction
Section Summary: Human decision-making relies on two mental systems: a fast, intuitive one for quick responses and a slower, logical one for careful reasoning, a pattern mirrored in neuro-symbolic AI where neural networks handle rapid pattern recognition and symbolic methods apply domain knowledge to fix inconsistencies. While approaches like abductive learning bridge machine learning and logic effectively, they often lose full symbolic precision or require computationally intensive optimizations that limit scalability. To address this, the authors introduce Abductive Reflection, an efficient enhancement inspired by human cognitive reflection, which uses a simple vector to detect errors in neural outputs and guide targeted symbolic fixes, leading to higher accuracy and speed in tasks like solving Sudoku puzzles and graph optimizations with minimal training resources.
Human decision-making is generally recognized as an interaction between two systems: System 1 quickly generates an intuitive response, and System 2 engages in further algorithmic and slow reasoning [1,2]. In Neuro-Symbolic (NeSy) Artificial Intelligence (AI), neural networks often resemble System 1 for rapid pattern recognition, and symbolic reasoning mirrors System 2 to leverage domain knowledge and handle complex problems thoughtfully, yet in a slower and more controlled way [3]. Like human System 1 reasoning, when facing complicated tasks, neural networks often produce unreliable outputs which cause inconsistencies with domain knowledge. These inconsistencies can then be reconciled with the help of the symbolic reasoning counterpart [4].
To achieve the above process, some methods relax symbolic domain knowledge as neural network constraints [5,6], some attempt to approximate logical calculus using distributed representations within neural networks [7]. However, a loss of full symbolic reasoning ability often occurs during these relaxation or approximation, hampering the ability of generating reliable output.
Abductive Learning (ABL) [8,9] is a framework for bridging machine learning and logical reasoning while preserving full expressive power in each side. In ABL, the machine learning component first converts raw data into primitive symbolic outputs. These outputs can be utilized by the symbolic reasoning component, which leverages domain knowledge and performs abduction to generate a revised, more reliable output. However, previous implementations of ABL require a highly discrete combinatorial consistency optimization before applying abduction, and this optimization has high complexity which encumbers, thereby severely limiting the efficiency and applicability to large-scale scenarios.
Human reasoning naturally exploits both sides efficiently, a hypothetical model for this process is called Cognitive Reflection, where the fast System 1 thinking is called to quickly generate an approximate over-all solution, and then seamlessly hands the complicated parts to System 2 [1]. The key to this process is the reflection mechanism, which promptly detects which part in the intuitive response may contain inconsistencies with domain knowledge and invokes System 2 to rectify them. This reflection typically positively associates with System 2 capabilities, as both are closely linked to an individual's mastery of domain knowledge [10]. Following the reflection, the process of the step-by-step formal reasoning becomes less complex: With a largely reduced search space, deriving the correct solution for System 2 becomes straightforward.
Inspired by this phenomenon, we propose a general enhancement, Abductive Reflection (ABL-Refl). Based on ABL framework, ABL-Refl preserves full expressive power of neural networks and symbolic reasoning, while replacing the time-consuming consistency optimization with the reflection mechanism, thereby significantly improves efficiency and applicability. Specifically, in ABL-Refl, a reflection vector is concurrently generated with the neural network intuitive output, which flags potential errors in the output and invokes symbolic reasoning to perform abduction, thereby rectifying these errors and generating a new output that is more consistent with domain knowledge. During model training, the training information for the reflection derives from domain knowledge. In essence, the reflection vector is abduced from domain knowledge and serves as an attention mechanism for narrowing the problem space of symbolic reasoning. The reflection can be trained unsupervisedly, requiring only the same amount of domain knowledge as state-of-the-art NeSy systems without generating extra training data.
We validate the effectiveness of ABL-Refl in solving Sudoku NeSy benchmarks in both symbolic and visual forms. Compared to previous NeSy methods, ABL-Refl performs significantly better, achieving higher reasoning accuracy efficiently with fewer training resources. We also compare our method to symbolic solvers, and show that the reduced search space in ABL-Refl improves the reasoning efficiency. Further experiments on solving combinatorial optimization on graphs validate that ABL-Refl can handle diverse types of data in varied dimensions, and exploit knowledge base in different forms.
2. Related Work
Section Summary: Recent research has advanced the integration of neural networks with symbolic reasoning, using techniques like fuzzy logic or softened constraints to blend machine learning with logic, though these often reduce the reliability of results. Specialized models such as DeepProbLog and NeurASP interpret neural outputs as symbolic distributions before applying solvers, which is computationally expensive, while Abductive Learning seeks a balanced fusion of learning and reasoning but struggles with complex optimizations. Other approaches focus on predicting errors and applying targeted reasoning in limited domains like math, and unlike methods requiring pre-built datasets, the current work automatically generates corrections during training.
Recently, there has been notable progress in enhancing neural networks with reliable symbolic reasoning. Some methods use differentiable fuzzy logic [11,12] or relax symbolic domain knowledge as constraints for neural network training [5,6,13,14], while others learn constraints within neural networks by approximating logic reasoning with distributed representations [15,16,7]. These models tend to soften the requirements in symbolic reasoning, impacting the reliability of output generation. Models like DeepProbLog [17] and NeurASP [18] interpret the neural network output as a distribution over symbols and then apply a symbolic solver, incurring substantial computational costs. Abductive Learning (ABL) [8,9] attempts to integrate machine learning and logical reasoning in a balanced and mutually supporting way. It features an easy-to-use open-source toolkit [19] with many practical applications [20,21,22,23]. However, the consistency optimization is with high complexity.
Another category of work related to our study also follows a similar process of prediction, error identification, and reasoning [24,25,26]. These methods are usually constrained in a narrow scope of domain knowledge, confined to specific mathematical problems or are bounded within a minimal world model.
Cornelio el al. \shortcite{cornelio2023learning} generates a selection module to identify errors requiring symbolic reasoning rectification. In constrast to their approach which requires the preparation of a large synthetic dataset in advance, our approach automatically abduces the reflection vector during model training.
3. Abductive Reflection
Section Summary: This section outlines a method for generating reliable outputs from raw data using a neural network to produce an initial guess and a knowledge base to ensure the results follow logical rules, like solving Sudoku or generating consistent text. Traditional Abductive Learning fixes errors in the network's output by first identifying inconsistencies and then using symbolic reasoning, but this error-detection step is slow and impractical for large datasets. To solve this, the proposed Abductive Reflection approach adds a "reflection" layer to the network that quickly flags potential errors, making the whole process faster and more efficient.
This section presents problem setting and the Abductive Reflection (ABL-Refl) method.
3.1 Problem Setting
The main task of this paper is as follows: The input is raw data $\boldsymbol{x}$, which can be in either symbolic or sub-symbolic form, and the target output is $\boldsymbol{y}=\left[y_1, y_2, \dots, y_n\right]$, with each $y_i$ being a symbol from a set $\mathcal{Y}$ that contains all possible output symbols. We assume two key components at our disposal: neural network $f$ and domain knowledge base $\mathcal{KB}$. $f$ can directly map $\boldsymbol{x}$ to $\boldsymbol{y}$, and $\mathcal{KB}$ holds constraints between the symbols in $\boldsymbol{y}$. $\mathcal{KB}$ can assume various forms, including propositional logic, first-order logic, mathematical or physical equations, etc., and can perform symbolic reasoning operations by exploiting the corresponding symbolic solver. The output $\boldsymbol{y}$ should adhere to the constraints in $\mathcal{KB}$, otherwise it will inevitably contain errors that lead to inconsistencies with the domain knowledge and incorrect reasoning results.
This problem type has broad applications. For example, it can be used to solve Sudoku puzzles, where the output $\boldsymbol{{y}}$ consists of $n=81$ symbols from the set $\mathcal{Y}={1, 2, \dots, 9}$, and the constraints in $\mathcal{KB}$ are the rules of Sudoku. It can also be applied in deploying generative models for text generation, gene prediction, mathematical problem-solving, etc., producing outputs that adhere to intricate commonsense, biological, or mathematical logics in $\mathcal{KB}$.
3.2 Brief Introduction to Abductive Learning
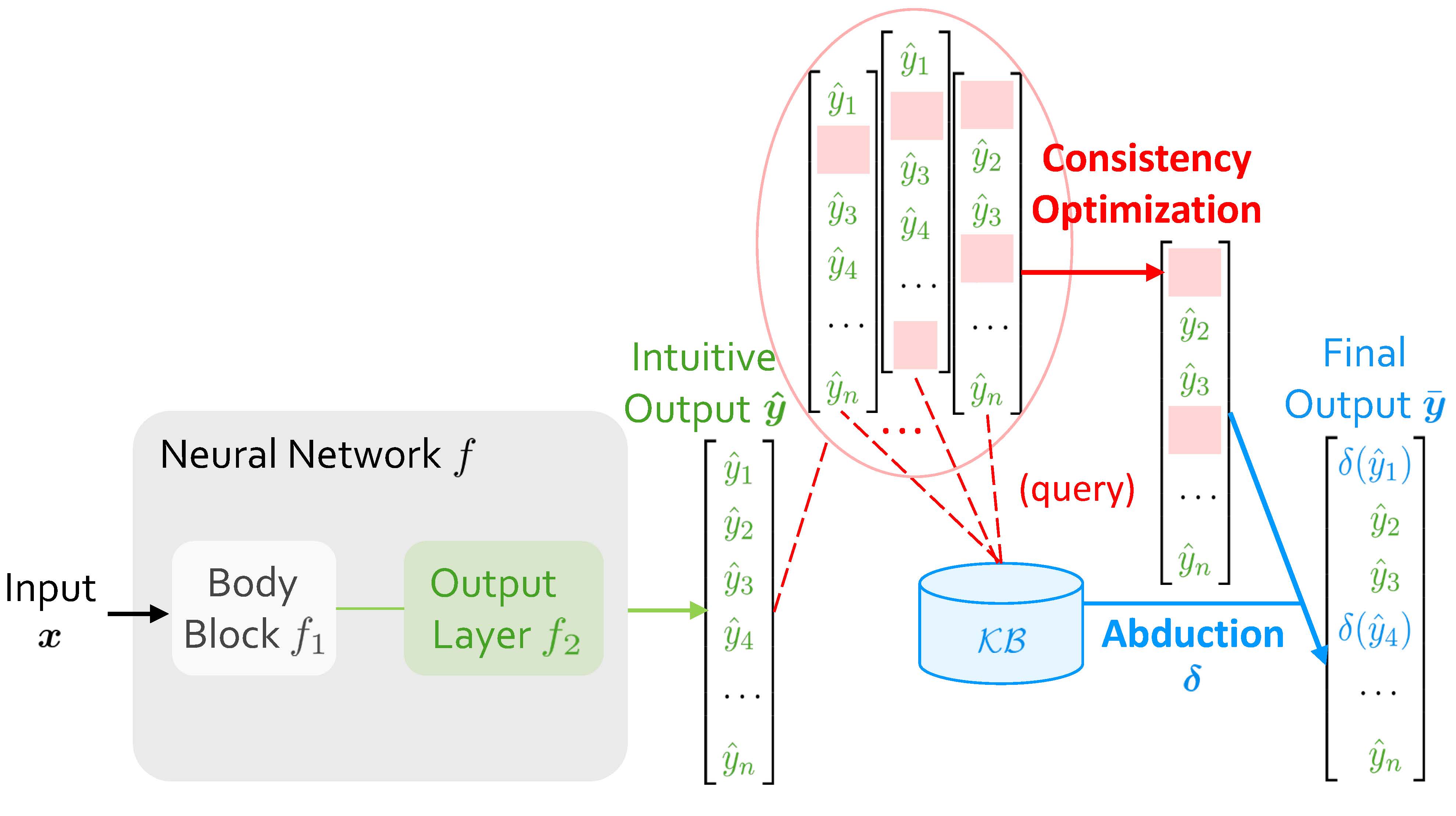
When Abductive Learning (ABL) receives an input $\boldsymbol{x}$, it initially employs $f$ to map $\boldsymbol{x}$ into an intuitive output $\boldsymbol{\hat{y}} = \left[\hat{y}_1, \hat{y}_2, \dots, \hat{y}_n\right]$. When $f$ is under-trained, $\boldsymbol{\hat{y}}$ might contain errors leading to inconsistencies with $\mathcal{KB}$. ABL then tries to rectify them, and obtains a revised $\boldsymbol{\bar{y}}$. As shown in Figure 1, the final output, $\boldsymbol{\bar{y}}$, consists of two parts: the green part retains the results from neural network, and the blue part is the modified result obtained by abduction, a basic form of symbolic reasoning that seeks plausible explanations for observations based on $\mathcal{KB}$.
Specifically, the process of obtaining $\boldsymbol{\bar{y}}$ can be divided into two sequential steps. The first step, consistency optimization, determines which positions in $\boldsymbol{\hat{y}}$ include elements that contain errors causing inconsistencies, so that performing abduction at these positions will yield a $\boldsymbol{\bar{y}}$ consistent with $\mathcal{KB}$. Essentially, this process is pinpointing propositions (or ground atoms, etc.) which have incorrect truth assignments, and most neuro-symbolic tasks can be formalized into this form. Once these positions are determined, the second step is rectifying by abduction, which then becomes easy for $\mathcal{KB}$ and its corresponding symbolic solver.
Challenge.
In previous ABL, consistency optimization has always been a computational bottleneck. It operates as an external module using zeroth-order optimization methods, independent from both $f$ and $\mathcal{KB}$ [27,9]. For each time of inference, it involves repetitively selecting various possible positions and querying the $\mathcal{KB}$ to see if a consistent result can be inferred. Each query involves an invocation of $\mathcal{KB}$ for slow symbolic reasoning. Also, since it is a complex combinatorial problem with a highly discrete nature, the number of such queries required escalates exponentially as data scale increases. This large number leads to a marked increase in time consumption, hence confines the applicability of ABL to only small datasets, usually those with output dimension $n$ less than 10.
3.3 Architecture
To address the challenges above, we propose Abductive Reflection (ABL-Refl). In this section, we will provide a detailed description of its architecture.
Let's first revisit the role of the neural network $f$ when we map the input to symbols from the set $\mathcal{Y}$. Typically, the raw data is first passed through the body block of the network, denoted by $f_1$, resulting in a high-dimensional embedding which encapsulates a wealth of feature information of the raw data. The form of $f_1$ varies, including structures like recurrent layers, graph convolution layers, or Transformers, etc. The result of $f_1$ is subsequently passed into several layers, usually linear layers, denoted by $f_2$, to obtain the intuitive output: $\boldsymbol{\hat{y}}=\text{argmax}(f_2(f_1(\boldsymbol{x})))\in\mathcal{Y}^n$.
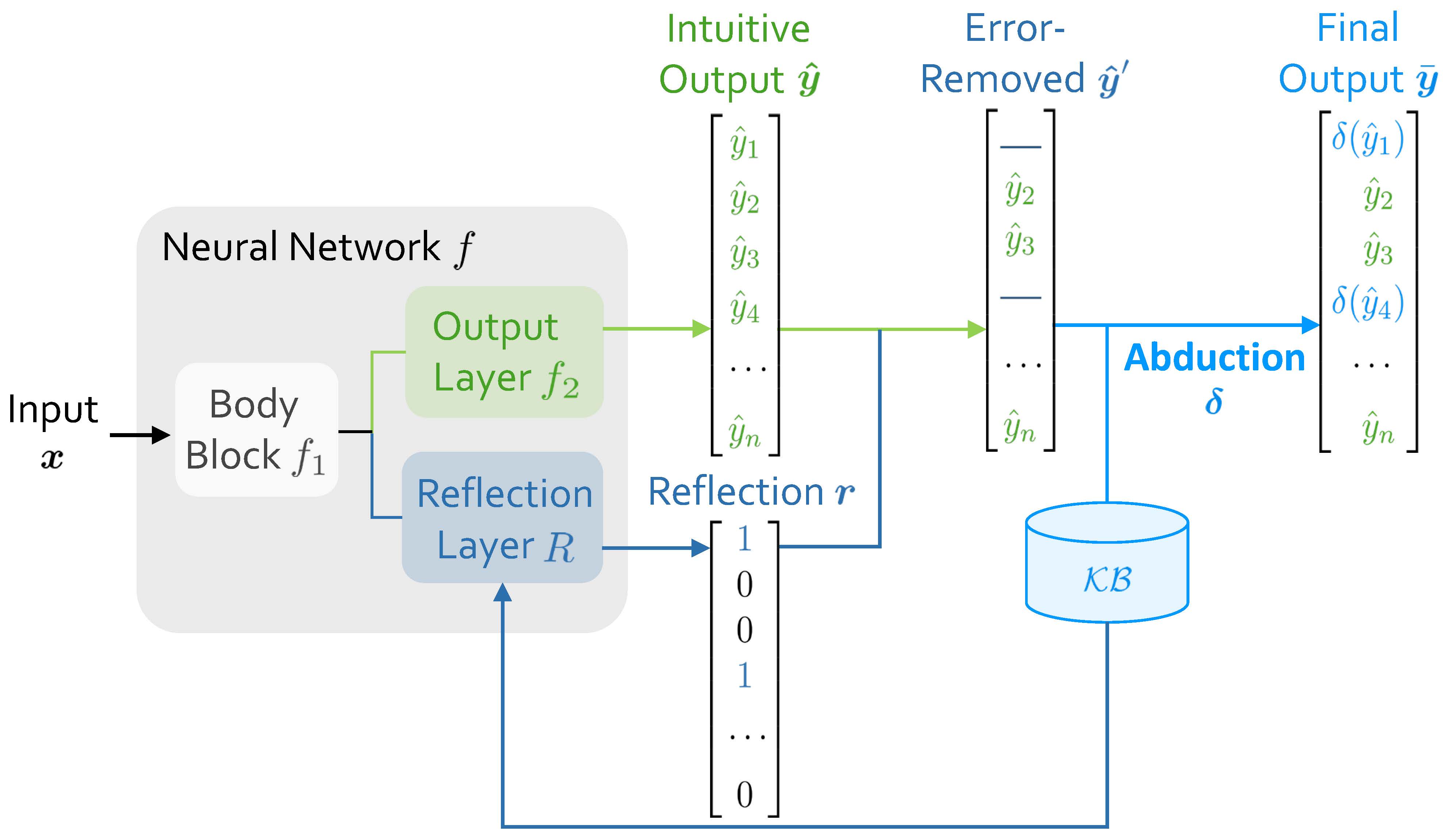
Besides the structure described above, as shown in Figure 2, our architecture further incorporates a reflection layer $R$ after the body block $f_1$, generating a reflection vector: $\boldsymbol{r}=\text{argmax}(R(f_1(\boldsymbol{x})))\in {0, 1}^n$. The reflection layer $R$ and reflection vector $\boldsymbol{r}$ together constitute the reflection mechanism. This vector $\boldsymbol{r}$ has the same dimensionality $n$ as the intuitive output $\boldsymbol{\hat{y}}$, and each element, $r_i$, acts as a binary classifier to indicate whether the corresponding element $\hat{y}_i$ is an error leading to inconsistencies with $\mathcal{KB}$ (flagged as 1 for an error, and 0 otherwise). The reflection vector $\boldsymbol{r}$ is generated concurrently with the intuitive response during inference, resonating with human cognition where cognitive reflection typically forms right upon generation of an intuitive response [1].
With the initial intuitive output $\boldsymbol{\hat{y}}$ and the corresponding reflection vector $\boldsymbol{r}$, we seamlessly obtain the error-removed output $\hat{\boldsymbol{y}}^\prime$: In $\hat{\boldsymbol{y}}^\prime$, elements flagged as error by $\boldsymbol{r}$ are removed and left as blanks, while the rest are retained. Subsequently, $\mathcal{KB}$ applies abduction to fill in these blanks, thereby generating an output $\boldsymbol{\bar{y}}$ that is consistent with $\mathcal{KB}$. That is:
$ \bar{y}_i=\begin{cases}\quad!!;\hat{y}_i, &r_i=0\ \delta(\hat{y}_i), &r_i=1\end{cases}\quad i=1, 2, \dots, n\tag{1} $
where $\delta$ denotes abduction. We treat $\boldsymbol{\bar{y}}= \left[\bar{y}_1, \bar{y}_2, \dots, \bar{y}_n\right]$ as the final output.
During model training, the reflection is abduced from $\mathcal{KB}$ by directly leveraging information from domain knowledge (discussed later in Section 3.4). It can be seen as an attention mechanism generated from neural networks, which can help quickly focus symbolic reasoning specifically on areas it identifies as errors, hence largely narrowing the problem space of deliberate symbolic reasoning [28].
Benefits.
Compared to previous ABL implementations, ABL-Refl replaces the zeroth-order consistency optimization module with the reflection mechanism to address the computational bottleneck. In this way, the need for a substantial number of querying $\mathcal{KB}$ is mitigated: After promptly pinpointing inconsistencies in System 1 output, regardless of the data scale, only a single invocation of $\mathcal{KB}$ is required to obtain a rectified and more consistent output.
Another thing worth noticing is that, in the architecture, the reflection layer directly connects to the body block, which helps leveraging information from the embeddings and linking more closely with the raw data. Therefore, the reflection vector $\boldsymbol{r}$ establishes a more direct and tighter bridge between raw data and domain knowledge.
3.4 Training Paradigm
In this section, we will discuss how to train the ABL-Refl method, especially the reflection in it.
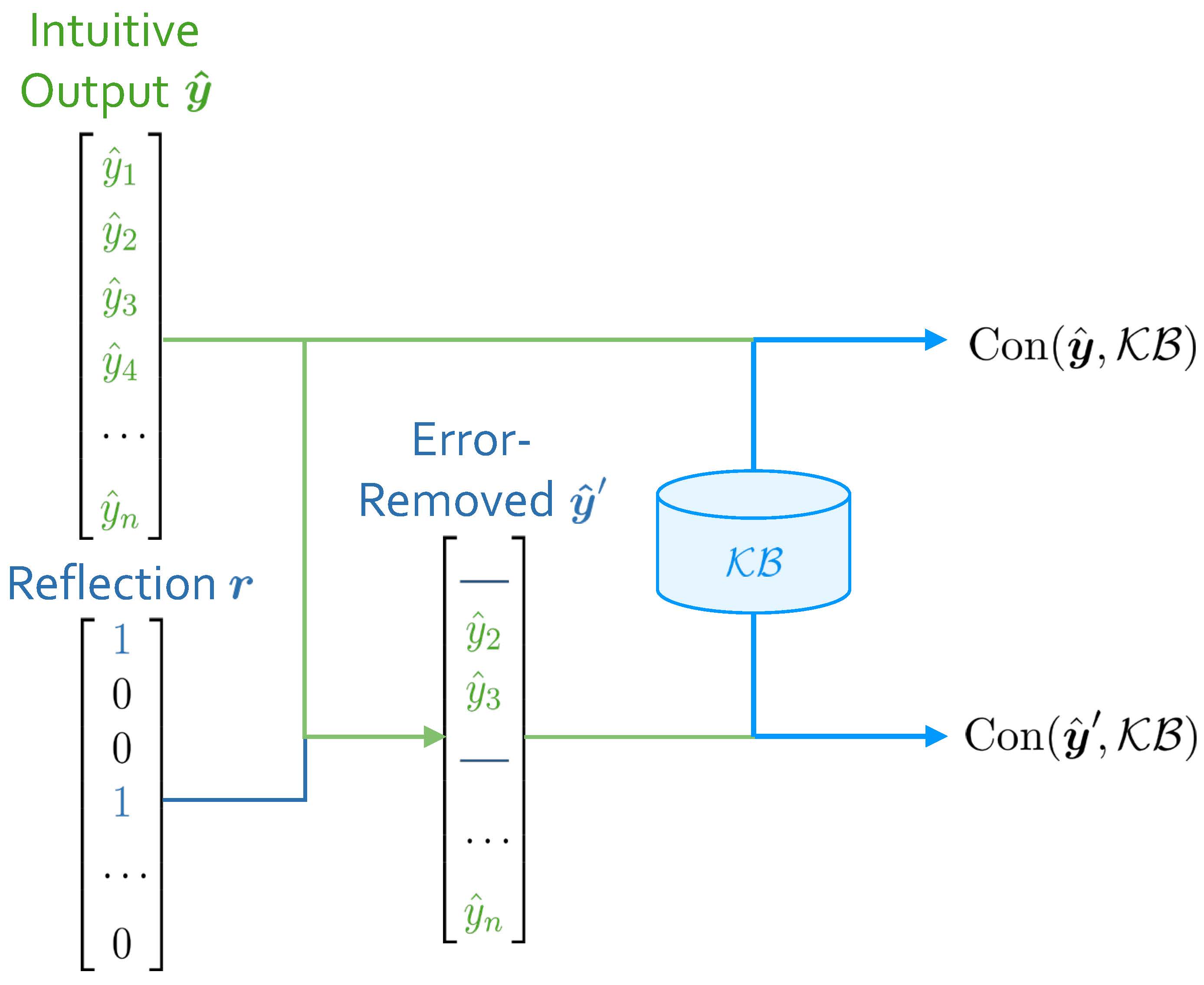
In ABL-Refl, when each input $\boldsymbol{x}$ is processed by the neural network, we obtain the intuitive output $\boldsymbol{\hat{y}}$ and the reflection vector $\boldsymbol{r}$, and subsequently obtain the error-removed (by $\boldsymbol{r}$) output $\boldsymbol{\hat{y}}^\prime$. With $\boldsymbol{\hat{y}}$ and $\boldsymbol{\hat{y}}^\prime$, we can measure their consistency with $\mathcal{KB}$, respectively. We denote these consistency measurements as $\text{Con}(\boldsymbol{\hat{y}}, \mathcal{KB})$ and $\text{Con}(\boldsymbol{\hat{y}}^\prime, \mathcal{KB})$, as shown in Figure 3. For a simplest example, if all elements in $\boldsymbol{\hat{y}}$ (or $\boldsymbol{\hat{y}}^\prime$) adhere to constraints in $\mathcal{KB}$, the consistency measurement is 1; otherwise, it is 0.
Consequently, the improvement in consistency measurement after reflection, as denoted by
$ \Delta\text{Con}_{\boldsymbol{r}}(\boldsymbol{\hat{y}})=\text{Con}(\boldsymbol{\hat{y}}', \mathcal{KB}) - \text{Con}(\boldsymbol{\hat{y}}, \mathcal{KB}) $
naturally indicates the effectiveness of the reflection vector: A higher value of it signifies that reflection $\boldsymbol{r}$ can more effectively detect inconsistencies within $\boldsymbol{\hat{y}}$. Our training goal is to guide the neural network's parameters towards generating reflections that can maximize this value. Given that $\Delta\text{Con}{\boldsymbol{r}}(\boldsymbol{\hat{y}})$ is usually a discrete value, we employ the REINFORCE algorithm to achieve this goal [29], which optimizes the policy (implicitly defined by neural network $f$) through maximizing a specified reward — in this case, $\Delta\text{Con}{\boldsymbol{r}}(\boldsymbol{\hat{y}})$. This process leads to the following consistency loss:
$ L_{con}(\boldsymbol{x})=-\Delta\text{Con}{\boldsymbol{r}}(\boldsymbol{\hat{y}})\cdot\nabla\theta\log f_\theta\left(\boldsymbol{\hat{y}}, \boldsymbol{r}\mid\boldsymbol{x}\right)\tag{2} $
where $\theta$ are parameters of neural network $f$.
Additionally, given that the time abduction required often escalates with problem size, we want to invoke it judiciously during inference, applying it only when it is truly necessary. Therefore, we aim to avoid the reflection vector from flagging too many elements in $\boldsymbol{\hat{y}}$ as error. To achieve this, we then introduce a reflection size loss:
$ L_{size}(\boldsymbol{x})=\Phi!\left(C-\frac{1}{n}\sum_{i=1}^n \left(1-R\left(f_1(\boldsymbol{x})\right)_i\right)\right)\tag{3} $
where $\Phi(a)\triangleq \max(0, a)^2$ and $C$ is a hyperparameter ranging between 0 and 1. When $C$ is set at a higher value, the reflection vector tends to retain a greater number of intuitive output elements instead of flagging them as error and delegating to abduction.
In addition to the above-mentioned training methods, using labeled data, we employ data-driven supervised training methods similar to common neural network training paradigm. The loss function in this process, e.g., cross-entropy loss, is denoted by $L_{labeled}(\boldsymbol{x}, \boldsymbol{y})$.
Therefore, combining all the training loss, the total loss for ABL-Refl is represented as follows:
$ \begin{aligned} \mathcal{L}&=\frac{1}{|D_l|}\sum_{(\boldsymbol{x}, \boldsymbol{y})\in D_l} L_{labeled}(\boldsymbol{x}, \boldsymbol{y})\ &+\frac{1}{|D_l\cup D_u|}\sum_{\boldsymbol{x}\in D_l\cup D_u}(\alpha L_{con}(\boldsymbol{x}) + \beta L_{size}(\boldsymbol{x})) \end{aligned}\tag{4} $
where $\alpha$ and $\beta$ are hyperparameters, $D_l={(\boldsymbol{x}_1, \boldsymbol{y}_1), (\boldsymbol{x}_2, \boldsymbol{y}_2), \dots}$ are the labeled datasets and $D_u={\boldsymbol{x}_1, \boldsymbol{x}_2, \dots}$ are the unlabeled datasets.
Note that neither $L_{con}$ nor $L_{size}$, which are loss functions specifically related to the reflection, incorporate information from the data label. Instead, we leverage training information directly from $\mathcal{KB}$ to train the reflection. Also, despite sharing the prior feature layers, the output layer $f_2$ and reflection layer $R$ utilize different training information, thereby decoupling the objectives of intuitive problem-solving and inconsistency reflection.
4. Experiments
Section Summary: The experiments section tests the ABL-Refl method, a neuro-symbolic approach combining neural networks with logical reasoning, on challenging tasks like solving Sudoku puzzles and optimizing complex graph problems to check its effectiveness, efficiency, and versatility. In the Sudoku tests using symbolic numbers, ABL-Refl outperforms baseline methods like recurrent networks and SATNet, achieving 97% accuracy on test puzzles while using fewer training epochs and comparable computation time overall. These results suggest ABL-Refl excels at complex reasoning, reduces resource needs, accelerates problem-solving by narrowing options, and applies broadly to various data types, with further tests planned for image-based inputs and other hard problems.
In this section, we will conduct several experiments. First, we will test our method on the NeSy benchmark task of solving Sudoku to comprehensively verify its effectiveness. Next, we will change the Sudoku input from symbols to images, which requires integrating and simultaneous reasoning with both sub-symbolic and symbolic elements, representing one of the most challenging tasks in this field. Finally, we will tackle NP-hard combinatorial optimization problems on graphs, using a knowledge base of only mathematical definitions, to demonstrate our method's versatility. Through these experiments, we aim to answer the following questions:
- Q1 Compared to existing neuro-symbolic learning methods, can ABL-Refl achieve better performance in tasks requiring complex reasoning?
- Q2 Can ABL-Refl reduce the training resources required?
- Q3 Can ABL-Refl narrow the problem space for symbolic reasoning to achieve acceleration?
- Q4 Does ABL-Refl possess the capability for broad application, such as handling diverse data scenarios or various forms of domain knowledge?
All experiments are performed on a server with Intel Xeon Gold 6226R CPU and Tesla A100 GPU. In our experiments, we simply set hyperparameters $\alpha$ and $\beta$ in Equation 4 to 1, since adjusting them does not have a noticeable impact on the results. For the hyperparameter $C$ in Equation 3, we set it to 0.8, and have provided discussions in Appendix C, demonstrating that setting it to a value within a broad moderate range (e.g., 0.6-0.9) would always be a recommended choice. All experiments are repeated 5 times.
4.1 Solving Sudoku
Dataset and Setting.
This task aims to solve a 9 $\times$ 9 Sudoku: Given 81 digits of 0-9 (where 0 represents a blank space) in a 9 $\times$ 9 board, we aim to find a solution $\boldsymbol{y}\in{1, 2, \dots, 9}^{81}$ that adhere to the Sudoku rules: no duplicate numbers are allowed in any row, column, or 3 $\times$ 3 subgrid. In this section, we first consider inputs in symbolic form, $\boldsymbol{x}\in{0, 1, \dots, 9}^{81}$, and use datasets from a publicly available Kaggle site [30].
For the neural network $f$, we use a simple graph neural network (GNN): the body block $f_1$ consists of one embedding layer and eight iterations of message-passing layers, resulting in a 128-dimensional embedding for each number, and then connects to both a linear output layer $f_2$ to obtain the intuitive output $\hat{\boldsymbol{y}}$ and a linear reflection layer $R$ to obtain the reflection vector ${\boldsymbol{r}}$. We use the cross-entropy loss as $L_{labeled}$. For the domain knowledge base $\mathcal{KB}$, it contains the Sudoku rules mentioned above. We express $\mathcal{KB}$ in the form of propositional logic and utilize the MiniSAT solver [31], an open-source SAT solver, as the symbolic solver to leverage $\mathcal{KB}$ and perform abduction.
For the consistency measurement, we define it as follows: one point is awarded for each row, each column and each 3 $\times$ 3 subgrid with no duplicate numbers, additionally, ten points are awarded if the entire board has no inconsistencies with $\mathcal{KB}$. In this way, it is entirely based on $\mathcal{KB}$. Notice that we deviated from the 1 or 0 measurement example setup mentioned in Section 3.4 to avoid a predominance of zero values in $\Delta\text{Con}_{\boldsymbol{r}}(\boldsymbol{\hat{y}})$ of Equation 2, facilitating effective training with the REINFORCE algorithm. Similar considerations are applied in subsequent experiments.
Compared Methods and Results.
We compare ABL-Refl with the following baseline methods: 1) Recurrent Relational Network (RRN) [32], a pure neural network method, 2) CL-STE [6], a representative method of logic-based regularized loss, and 3) SATNet [7]. A detailed description of these methods is provided in Appendix A. We also report the result for Simple GNN, which is the very same neural network used in our setting, yet directly treats the intuitive output $\hat{\boldsymbol{y}}$ as the final output.
\begin{tabular}{lccc}
\toprule
\multicolumn{1}{c}{\textbf{Method}} &
\textbf{\begin{tabular}[c]{@{}c@{}}Training\\ Time (min)\end{tabular}} & \textbf{\begin{tabular}[c]{@{}c@{}}Inference\\ Time (s)\end{tabular}}
& \textbf{\begin{tabular}[c]{@{}c@{}}Inference\\ Accuracy\end{tabular}} \\
\midrule
RRN & 114.8\scriptsize{ $\pm$ 7.8} & 0.19\scriptsize{ $\pm$ 0.01} & 73.1\scriptsize{ $\pm$ 1.2} \\
CL-STE & 173.6\scriptsize{ $\pm$ 9.9} & 0.19\scriptsize{ $\pm$ 0.02} & 76.5\scriptsize{ $\pm$ 1.8} \\
SATNet & 140.3\scriptsize{ $\pm$ 6.8} & 0.11\scriptsize{ $\pm$ 0.01} & 74.1\scriptsize{ $\pm$ 0.4} \\
\textbf{ABL-Refl} & \textbf{109.8\scriptsize{ $\pm$ 10.8}} & 0.22\scriptsize{ $\pm$ 0.02} & \textbf{97.4\scriptsize{ $\pm$ 0.3}} \\
\midrule
Simple GNN & 29.7\scriptsize{ $\pm$ 2.6} & 0.02\scriptsize{ $\pm$ 0.00} & 55.6\scriptsize{ $\pm$ 0.3} \\
\bottomrule
\end{tabular}
We report the training time (for a total of 100 epochs using 20K training data), inference time (on 1K test data) and accuracy (the percentage of completely accurate Sudoku solution boards on test data) in Table 1. We may see that our method outperforms the baselines significantly, improving by over 20% while maintaining a comparable inference time. This suggests an answer to Q1: ABL-Refl can achieve better reasoning performance. This improvement is primarily due to the use of abduction to rectify the neural network's output during inference.
Furthermore, our method reaches high accuracy in only a few epochs (training curve is shown in Appendix B), significantly reducing training time. Even considering under identical training epochs, our total training time is less than baseline methods, despite involving a time-consuming symbolic solver. This partly stems from the neural network in our approach being less complex than those in baseline methods while achieving high accuracy. Overall, this suggests an answer to Q2: ABL-Refl can reduce the training time required.
We also attempt to reduce the amount of labeled data, removing labels from 50%, 75%, and 90% of the training data. We record the inference accuracy in Table 2. It can be observed that even with only 2K labeled training data, our method still achieves far better accuracy than the baseline methods with 20K labeled training data. This suggests an answer to Q2 from another aspect: ABL-Refl can reduce the labeled training data required.
:Table 2: Inference accuracy on solving Sudoku after reducing the amount of labeled data.
| Labeled Data | Unlabeled Data | Inference Accuracy |
|---|---|---|
| 20K | 0 | 97.4{ $\pm$ 0.3} |
| 10K | 10K | 96.3{ $\pm$ 0.3} |
| 5K | 15K | 95.8{ $\pm$ 0.6} |
| 2K | 18K | 94.7{ $\pm$ 0.8} |
Comparing to Symbolic Solvers.
\begin{tabular}{cclcccc}
\toprule
\multicolumn{1}{c}{\multirow{2}{*}{ $\boldsymbol{\mathcal{KB}}$ \textbf{Form}}} & \multicolumn{1}{c}{\multirow{2}{*}{\textbf{Solver}}} & \multicolumn{1}{c}{\multirow{2}{*}{\textbf{Method}}} & \multirow{2}{*}{\textbf{\begin{tabular}[c]{@{}c@{}}Inference\\ Accuracy\end{tabular}}} & \multicolumn{3}{c}{\textbf{Inference Time (s)}} \\
\cmidrule(r){5-7}
& & & & \textbf{NN Time} & \textbf{Abduction Time} & \textbf{Overall Time} \\
\midrule
\multirow{2}{*}{\begin{tabular}[c]{@{}c@{}}Propositional\\ logic\end{tabular}} & \multirow{2}{*}{MiniSAT} & Solver only & 100\scriptsize{ $\pm$ 0} & - & 0.227\scriptsize{ $\pm$ 0.024} & 0.227\scriptsize{ $\pm$ 0.024} \\
\cmidrule(r){3-7}
& & \textbf{ABL-Refl} & 97.4\scriptsize{ $\pm$ 0.3} & 0.021\scriptsize{ $\pm$ 0.004} & \textbf{0.196\scriptsize{ $\pm$ 0.015}} & \textbf{0.217\scriptsize{ $\pm$ 0.019}} \\
\midrule
\multirow{2}{*}{\begin{tabular}[c]{@{}c@{}}First-order\\ logic\end{tabular}} & \multirow{2}{*}{\begin{tabular}[c]{@{}c@{}}Prolog with\\ CLP(FD)\end{tabular}} & Solver only & 100\scriptsize{ $\pm$ 0} & - & 105.81\scriptsize{ $\pm$ 5.62} & 105.81\scriptsize{ $\pm$ 5.62} \\
\cmidrule(r){3-7}
& & \textbf{ABL-Refl} & 97.4\scriptsize{ $\pm$ 0.3} & 0.021\scriptsize{ $\pm$ 0.004} & \textbf{31.86\scriptsize{ $\pm$ 1.88}} & \textbf{31.88\scriptsize{ $\pm$ 1.89}} \\
\bottomrule
\end{tabular}
We next compare our method with merely employing symbolic solvers from scratch, to demonstrate its capability in accelerating symbolic reasoning. We perform inference on 1K test data and record the accuracy and time in Table 3. The inference time for our method includes the combined duration for data processing through both the neural network (NN time) and symbolic reasoning (abduction time).
As observed in the former two lines, our method achieves a notable acceleration in the abduction process, consequently decreasing the overall inference time, with only a minor compromise in accuracy. This efficiency gain is due to the fact that in ABL-Refl, after quickly generating an intuition through the neural network, abduction only needs to focus on areas identified as necessary by the reflection vector, whereas using only symbolic solvers requires abduction to reason through all blanks in a Sudoku puzzle. Overall, this suggests an answer to Q3: ABL-Refl can quickly generate the reflection, thereby reducing the symbolic reasoning search space and enhancing reasoning efficiency.
We also compared with Prolog with CLP(FD) [33] solver, by expressing the same $\mathcal{KB}$ with a first-order constraint logic program. As shown in the table, we observe a significant reduction in abduction time and overall inference time, which puts another evidence to our previous answer to Q3, and also suggests an answer to Q4: ABL-Refl can effectively utilize the two most commonly used forms in symbolic knowledge representation, propositional logic and first-order logic.
4.2 Solving Visual Sudoku
Dataset and Setting.
In this section, we modify the input from 81 symbolic digits to 81 MNIST images (handwritten digits of 0-9). We use the dataset provided in SATNet [7] and use 9K Sudoku boards for training and 1K for testing.
In order to process image data, we first pass each image through a LeNet convolutional neural network (CNN) [34] to obtain the probability of each digit. The rest of our setting follows from that described in Section 4.1.
Compared Methods and Results.
We compare ABL-Refl with SATNet, as both methods allow for end-to-end training from visual inputs. We report the results in Table 4 and the training curve in Appendix B. Compared to SATNet, ABL-Refl shows notable improvement in reasoning accuracy within only a few training epochs. We then consider pretraining the CNN in advance using self-supervised learning methods [35] and find that this can further improve accuracy. Overall, the results further suggest positive answers to Q1 and Q2.
We also compare with CNN+Solver: each image is first mapped to symbolic form by a fully trained CNN (with 99.6% accuracy on the MNIST dataset) and then directly fed into the symbolic solver to fill in the blanks and derive the final output. In such scenarios, the problem space for the symbolic solver includes all the Sudoku blanks, and additionally, since the symbolic solver cannot revise errors from CNN, any inaccuracies in CNN's output could lead the symbolic solver to crash (i.e., output no solution). Consequently, inference accuracy and time are adversely affected. This confirms the positive answer to Q3.
Finally, an overview of Sections 4.1 and Section 4.2 also suggests an answer to Q4: ABL-Refl is capable of handling both symbolic and sub-symbolic forms of input data.
\begin{tabular}{lccc}
\toprule
\multicolumn{1}{c}{\textbf{Method}} & \textbf{\begin{tabular}[c]{@{}c@{}}Inference\\ Time (s)\end{tabular}} &
\textbf{\begin{tabular}[c]{@{}c@{}}Inference\\ Accuracy\end{tabular}} \\
\midrule
SATNet & 0.12\scriptsize{ $\pm$ 0.01} & 63.5\scriptsize{ $\pm$ 2.2} \\
CNN+Solver & 0.23\scriptsize{ $\pm$ 0.02} & 67.8\scriptsize{ $\pm$ 4.2} \\
\textbf{ABL-Refl} & 0.22\scriptsize{ $\pm$ 0.02} & \textbf{77.8\scriptsize{ $\pm$ 5.8}} \\
\textbf{ABL-Refl} \small{(with pretrained CNN)} & 0.22\scriptsize{ $\pm$ 0.02} & \textbf{93.5\scriptsize{ $\pm$ 3.2}} \\
\bottomrule
\end{tabular}
4.3 Solving Combinatorial Optimization Problems on Graphs
In this section, we will further expand the application domain of our method. We apply ABL-Refl to solving combinatorial optimization problems on graphs. We conduct the experiment on finding the maximum clique in this section, and provide an additional experiment in Appendix E.
Dataset and Setting.
In this task, we are given a graph $G=(V, E)$ with $|V|=n$ nodes, and aim to output $\boldsymbol{y}\in{0, 1}^n$, where each index corresponds to a node, and the set of indices assigned the value of 1 collectively constitute the maximum clique. Note that this problem is a challenging NP-hard problem with extensive applications in real-life scenarios, and is generally considered challenging for neural networks [36].
We use several datasets from the TUDatasets [37], with their basic information shown in Table 5. We use 80% of the data for training and 20% for testing.
In our method, the body layer $f_1$ consists of a single GAT layer [38] and 16 gated graph convolution layers [39], and the output layer $f_2$ and reflection layer $R$ are both linear layers. We use binary cross-entropy loss as $L_{labeled}$. The domain knowledge base $\mathcal{KB}$ expresses the mathematical definition of maximum clique, i.e., every pair of vertices in the output set should be connected by an edge. We use Gurobi solver, an efficient mixed-integer program solver, to perform abduction. We define the consistency measurement as follows: one point is awarded for each pair of vertices if they are not connected by an edge; additionally, the size of the output set multiplied by 10 is added if the output set is indeed a clique.
\begin{tabular}{lcccc}
\toprule
\multicolumn{1}{c}{\multirow{2}{*}{\textbf{Method}}} & \multicolumn{4}{c}{\textbf{Dataset \footnotesize{(Graph nums./Avg. nodes per graph/Avg. edges per graph)}}} \\
\cmidrule{2-5}
\multicolumn{1}{c}{} & ENZYMES\footnotesize{ (600/33/62)} & PROTEINS\footnotesize{ (1113/39/73)} & IMDB-Binary\footnotesize{ (1000/19/97)} & COLLAB\footnotesize{ (5000/74/2457)} \\
\midrule
Erdos & 0.883\scriptsize{ $\pm$ 0.156} & 0.905\scriptsize{ $\pm$ 0.133} & 0.936\scriptsize{ $\pm$ 0.175} & 0.852\scriptsize{ $\pm$ 0.212} \\
Neural SFE & 0.933\scriptsize{ $\pm$ 0.148} & 0.926\scriptsize{ $\pm$ 0.165} & 0.961\scriptsize{ $\pm$ 0.143} & 0.781\scriptsize{ $\pm$ 0.316} \\
\textbf{ABL-Refl} & \textbf{0.991\scriptsize{ $\pm$ 0.017}} & \textbf{0.985\scriptsize{ $\pm$ 0.020}} & \textbf{0.979\scriptsize{ $\pm$ 0.029}} & \textbf{0.982\scriptsize{ $\pm$ 0.015}} \\
\bottomrule
\end{tabular}
Compared Methods and Results.
We compare our methods with the following baselines: 1) Erdos [40], 2) Neural SFE [41], both leading methods for solving graph combinatorial problems. Their detailed descriptions are provided in Appendix A.
We report the approximation ratios in Table 5. The approximation ratio, indicating the result set size relative to the actual maximum set size, is better when closer to 1. We may observe that our method outperforms the baseline methods, achieving near-perfect results on all datasets. This confirms the positive answer to Q1. Also, as the scale of the data increases, our method maintains a high level of accuracy, showing a more pronounced improvement compared to baseline methods. This suggests an answer to Q4: ABL-Refl is capable of handling scalable data scenarios, even in high-dimensional settings that are challenging for previous methods. Finally, an overview of this section provides another aspect to Q4: ABL-Refl can utilize a wide range of $\mathcal{KB}$, not limited to logical expressions but can also operate effectively with just the basic mathematical formulations.
5. Effects of Reflection Mechanism
Section Summary: The section analyzes the reflection mechanism in the ABL-Refl system, which uses domain knowledge to spot and fix errors in neural network outputs through focused symbolic reasoning, like an attention guide in a hybrid neural-symbolic pipeline for tasks such as solving visual Sudoku puzzles. It compares ABL-Refl to other approaches—ABL, which struggles with slow consistency checks on large datasets; NN Confidence, which poorly detects errors by relying on neural network self-doubt alone; and NASR, a trained module that needs extra data and time—showing ABL-Refl achieves the highest error recall rate of over 99%, the fastest processing at 0.22 seconds per example, and top accuracy of 93.5% on test data without these drawbacks. This superior performance stems from ABL-Refl's integrated, efficient design that avoids massive searches or separate training, allowing real-time error correction tied directly to the neural network's inner workings.
This section provides a further analysis on the reflection mechanism. In ABL-Refl, the reflection is abduced from domain knowledge, and acts as an efficient attention mechanism to direct the focus for symbolic search. This reflection is the key in our method to accomplish the NeSy reasoning rectification pipeline, i.e., a pipeline that detects errors in neural networks and then invokes symbolic reasoning to rectify these positions. To corroborate the effectiveness of the reflection, we conduct direct comparison with other methods that achieve the same pipeline:
- ABL, minimizing the inconsistency of intuitive output and knowledge base with an external zeroth-order consistency optimization module, as detailed in Section 3.2;
- NN Confidence, retaining intuitive output with the top 80% confidence from the neural network result (other retain thresholds are explored in Appendix D) and passing the remaining into symbolic reasoning;
- NASR [42], using a Transformer-based external selection module to detect error, and the module is trained on a large synthetic dataset in advance.
We compare them on the solving visual Sudoku task in Section 4.2. For a fair comparison, all methods employ the same neural network, $\mathcal{KB}$ and MiniSAT solver setup. We report the recall (the percentage of errors from neural networks that can be identified), inference time and accuracy (on 1K test data) in Table 6. Note that ``recall" directly evaluates the effectiveness of the detection module itself. The following analysis examines the results:
- The consistency optimization in ABL faces significant efficiency challenges due to the large data scale (output dimension $n=81$). In such scenarios, the potential rectifications can reach up to $2^{81}$, resulting in an overwhelmingly large search space for consistency optimization. Also, as an external module, its only way of interacting with $\mathcal{KB}$ is to treat it as a black box and repetitively submit queries for consistency evaluation. As a result, it may require more than $10^9$ queries to identify errors for each Sudoku example, resulting in several hours to complete inference on 1K test data.
- NN Confidence performs poorly in identifying outputs with errors. Since the pure data-driven neural network training does not explicitly incorporate $\mathcal{KB}$ information, a low confidence from it does not necessarily indicate an inconsistency with the domain knowledge. This subsequently results in the frequent crashing in symbolic solver, therefore hampering the overall inference time and accuracy. This result parallels human cognitive reflection abilities, which do not show much positive correlation with System 1 intuition [43]. To further illustrate this point, we provide additional analysis, including a case study, in Appendix D.
- Our method also outperforms NASR, and notably, without the need of a synthetic dataset. This could be due to the fact that NASR's error-selection module is trained independently from other components, and operates sequentially and separately during inference. Therefore, it can only rely on information from the output label, in contrast to our method, which can leverage information directly from the body block of neural network, establishing a deeper connection with the raw data. Additionally, in NASR, traversing the separate selection module takes additional time, whereas in ABL-Refl, the reflection is generated concurrently with the neural network output, avoiding efficiency loss.
\begin{tabular}{lccc}
\toprule
\multicolumn{1}{c}{\textbf{Method}} & \textbf{Recall} & \textbf{\begin{tabular}[c]{@{}c@{}}Inference\\ Time (s)\end{tabular}} &
\textbf{\begin{tabular}[c]{@{}c@{}}Inference\\ Accuracy\end{tabular}} \\
\midrule
ABL & \multicolumn{1}{l}{Timeout} & \multicolumn{1}{l}{Timeout} & \multicolumn{1}{l}{\;Timeout} \\
NN Confidence & 82.64\scriptsize{ $\pm$ 2.78} & 0.24\scriptsize{ $\pm$ 0.03} & 64.3\scriptsize{ $\pm$ 6.2} \\
NASR & 95.86\scriptsize{ $\pm$ 0.96} & 0.26\scriptsize{ $\pm$ 0.02} & 82.7\scriptsize{ $\pm$ 4.4} \\
\textbf{ABL-Refl} & \textbf{99.04\scriptsize{ $\pm$ 0.85}} & \textbf{0.22\scriptsize{ $\pm$ 0.02}} & \textbf{93.5\scriptsize{ $\pm$ 3.2}} \\
\bottomrule
\end{tabular}
6. Conclusion
Section Summary: This paper introduces Abductive Reflection, or ABL-Refl, a method that uses expert knowledge to detect errors in neural network results and then applies focused logical reasoning to a smaller set of possibilities, making the process more efficient. Tests show it beats other similar approaches by delivering high accuracy with less training effort and faster thinking overall, while keeping the strengths of both machine learning and logic intact. Looking ahead, it could improve large language models by spotting mistakes in their outputs and using symbolic reasoning to make them more reliable.
In this paper, we present Abductive Reflection (ABL-Refl). It leverages domain knowledge to abduce a reflection vector, which flags potential errors in neural network outputs and then invokes abduction, serving as an attention mechanism for symbolic reasoning to focus on a much smaller problem space. Experiments show that ABL-Refl significantly outperforms other NeSy methods, achieving excellent reasoning accuracy with fewer training resources, and has successfully enhanced reasoning efficiency.
ABL-Refl preserves the integrity of both machine learning and logical reasoning with superior inference speed and high versatility. Therefore, it has the potential for broad application. In the future, it can be applied to large language models [44] to help identify errors within their outputs, and subsequently exploit symbolic reasoning to enhance their trustworthiness and reliability.
Acknowledgments
This research was supported by the NSFC (62176117, 62206124) and Jiangsu Science Foundation Leading-edge Technology Program (BK20232003).
Appendix
Section Summary: The appendix provides supplementary details on the baseline methods compared in the study's experiments, including neural network approaches like Recurrent Relational Network and CL-STE for solving Sudoku puzzles, which generally outperform other logic-infused methods in accuracy and speed, while graph optimization baselines like Erdos and Neural SFE are used for combinatorial tasks. It also includes training curves showing that the proposed method achieves high accuracy on Sudoku and visual Sudoku problems in just a few epochs, far quicker than baselines. Finally, it discusses the hyperparameter C, typically set at 0.8, demonstrating through extended results that varying it (e.g., to 0.7 or 0.9) still yields superior performance for the method, with lower values allowing more solver corrections to boost reasoning accuracy.
A. Comparison Methods
In this section, we will provide a brief supplementary introduction to the compared baseline methods used in experiments.
A.1 Solving Sudoku
In the solving Sudoku experiment (Section 4.1 and Section 4.2), we have compared our method with the following baselines:
- Recurrent Relational Network (RRN) [32], a state-of-the-art pure neural network method tailored for this problem;
- CL-STE [6], injecting logical knowledge (defined in the same way as our $\mathcal{KB}$) as neural network constraints during the training of RRN;
- SATNet [7], incorporating a differentiable MaxSAT solver into the neural network to perform reasoning.
Note that CL-STE is a representative method of logic-based regularized loss, relaxing symbolic logic as neural network loss. Additionally, among these methods, CL-STE stands out in both accuracy and efficiency (partly because it prevents constructing complex SDDs, unlike other methods including semantic loss [5]).
Other lines of methods generally underperform above baselines in scenarios where $n$ (the scale of $\boldsymbol{y}$) is high. For instance, ABL faces the challenge where consistency optimization needs to choose among exponential query candidates, resulting in runtimes thousands of times longer than other methods, as seen in Section 5. Take two other representative NeSy methods as examples: DeepProbLog [17] involves substantial computational costs, taking days to complete solving Sudoku; NeurASP [18] also performs slow and lags in accuracy, as shown in Yang et al. \shortcite{yang2022injecting}.
A.2 Solving Combinatorial Optimization on Graphs
In the solving combinatorial optimization on graphs experiment (Section 4.3 and Appendix E), we have compared our method with the following baselines:
- Erdos [40], optimizing set functions using a neural network parametrizing a distribution over sets;
- Neural SFE [41], optimizing set functions by extending them onto high-dimensional continuous domains.
In this experiment, the above methods use the same body block graph neural network as our method.
B. Training Curve
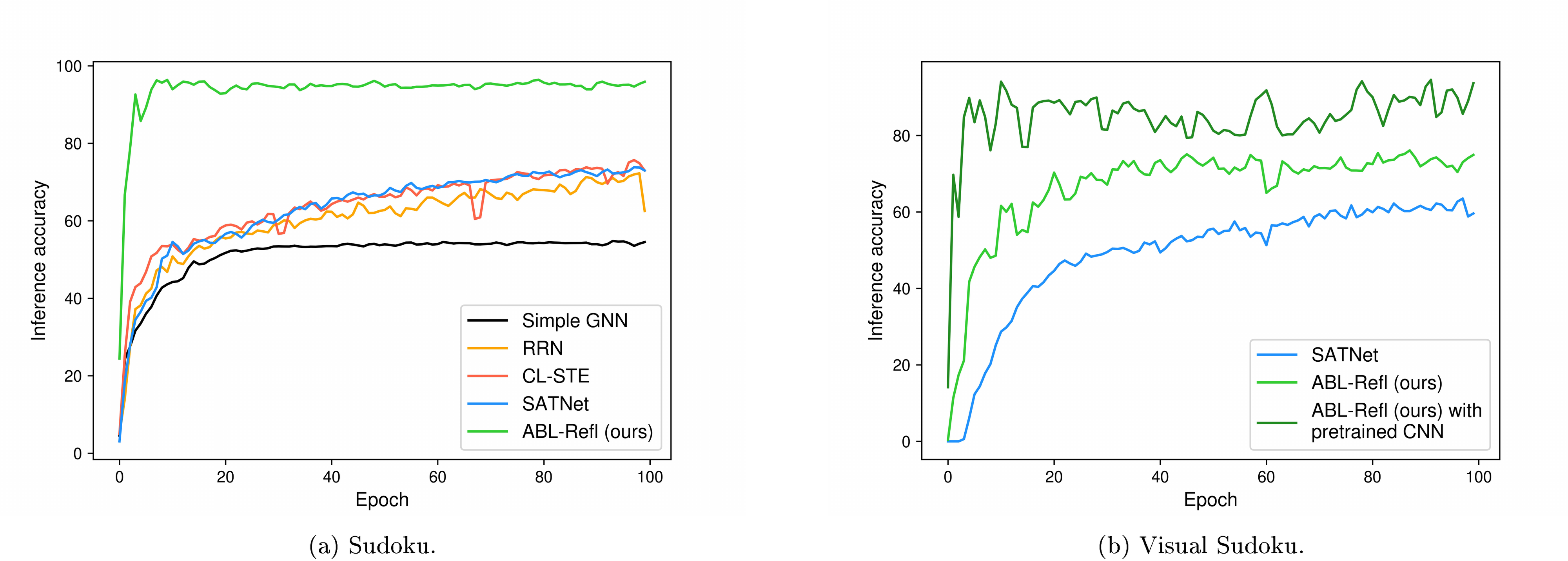
In this section, we will report the training curve in the experiments on solving Sudoku (Section 4.1) and visual Sudoku (Section 4.2). The respective training curves for each scenario are shown in Figures 4a and Figure 4b, with the horizontal axis representing training epochs and the vertical axis representing inference accuracy. We may see that our method achieves high accuracy within just a few epochs, significantly reducing training time compared to other baseline methods.
C. Discussion on Hyperparameter $C$
In this section, we will discuss the effect of the hyperparameter $C$. Previous experiments in Sections 4 and Section 5, $C$ was consistently set to 0.8, and we will now explore adjustments. We report the extended results in Tables 7 and Table 8. It is shown that when $C$ is set within a wide range, ABL-Refl uniformly outperforms the baseline methods.
Intuitively, as mentioned in Section Figure 3, setting $C$ lower delegates more elements to the solver for correction, thereby often enhancing reasoning accuracy. The results in Tables 7 and Table 8 have also demonstrated this point.
\begin{tabular}{lcccc}
\toprule
\multicolumn{1}{c}{\textbf{Experiment}} & \multicolumn{2}{c}{\textbf{Method}} & \multicolumn{1}{c}{\textbf{Inference Time (s)}} & \multicolumn{1}{c}{\textbf{Inference Accuracy}} \\
\midrule
\multirow{7}{*}{Sudoku} & \multicolumn{2}{l}{Simple GNN} & 0.02\scriptsize{ $\pm$ 0.00} & 55.6\scriptsize{ $\pm$ 0.3} \\
& \multicolumn{2}{l}{RNN} & 0.19\scriptsize{ $\pm$ 0.01} & 73.1\scriptsize{ $\pm$ 1.2} \\
& \multicolumn{2}{l}{CL-STE} & 0.19\scriptsize{ $\pm$ 0.02} & 76.5\scriptsize{ $\pm$ 1.8} \\
& \multicolumn{2}{l}{SATNet} & 0.11\scriptsize{ $\pm$ 0.01} & 74.1\scriptsize{ $\pm$ 0.4} \\
\cmidrule{2-5}
& \multirow{3}{*}{\textbf{ABL-Refl}} & $C=0.7$ & 0.24\scriptsize{ $\pm$ 0.02} & \textbf{99.1\scriptsize{ $\pm$ 0.2}} \\
& & $C=0.8$ & 0.22\scriptsize{ $\pm$ 0.02} & \textbf{97.4\scriptsize{ $\pm$ 0.3}} \\
& & $C=0.9$ & 0.21\scriptsize{ $\pm$ 0.02} & \textbf{96.6\scriptsize{ $\pm$ 0.5}} \\
\midrule
\multicolumn{1}{l}{} & \multicolumn{2}{l}{SATNet} & 0.12\scriptsize{ $\pm$ 0.01} & 63.5\scriptsize{ $\pm$ 2.2} \\
\multicolumn{1}{l}{\multirow{5}{*}{Visual Sudoku}} & \multicolumn{2}{l}{CNN+Solver} & 0.23\scriptsize{ $\pm$ 0.02} & 67.8\scriptsize{ $\pm$ 4.2} \\
\cmidrule{2-5}
\multicolumn{1}{l}{} & \multirow{3}{*}{\textbf{ABL-Refl}} & $C=0.7$ & 0.24\scriptsize{ $\pm$ 0.02} & \textbf{95.9\scriptsize{ $\pm$ 2.8}} \\
\multicolumn{1}{l}{} & & $C=0.8$ & 0.22\scriptsize{ $\pm$ 0.02} & \textbf{93.5\scriptsize{ $\pm$ 3.2}} \\
\multicolumn{1}{l}{} & & $C=0.9$ & 0.21\scriptsize{ $\pm$ 0.02} & \textbf{90.6\scriptsize{ $\pm$ 4.2}} \\
\bottomrule
\end{tabular}
\begin{tabular}{lccccc}
\toprule
\multicolumn{2}{c}{\multirow{2}{*}{\textbf{Method}}} & \multicolumn{4}{c}{\textbf{Dataset }} \\
\cmidrule{3-6}
\multicolumn{2}{c}{} & ENZYMES & PROTEINS & IMDB-Binary & COLLAB \\
\midrule
\multicolumn{2}{l}{Erdos} & 0.883\scriptsize{ $\pm$ 0.156} & 0.905\scriptsize{ $\pm$ 0.133} & 0.936\scriptsize{ $\pm$ 0.175} & 0.852\scriptsize{ $\pm$ 0.212} \\
\multicolumn{2}{l}{Neural SFE} & 0.933\scriptsize{ $\pm$ 0.148} & 0.926\scriptsize{ $\pm$ 0.165} & 0.961\scriptsize{ $\pm$ 0.143} & 0.781\scriptsize{ $\pm$ 0.316} \\
\midrule
\multirow{3}{*}{\textbf{ABL-Refl}} & $C=0.7$ & \textbf{0.992\scriptsize{ $\pm$ 0.012}} & \textbf{0.988\scriptsize{ $\pm$ 0.019}} & \textbf{0.984\scriptsize{ $\pm$ 0.026}} & \textbf{0.986\scriptsize{ $\pm$ 0.016}} \\
& $C=0.8$ & \textbf{0.991\scriptsize{ $\pm$ 0.017}} & \textbf{0.985\scriptsize{ $\pm$ 0.020}} & \textbf{0.979\scriptsize{ $\pm$ 0.029}} & \textbf{0.982\scriptsize{ $\pm$ 0.015}} \\
& $C=0.9$ & \textbf{0.982\scriptsize{ $\pm$ 0.023}} & \textbf{0.975\scriptsize{ $\pm$ 0.021}} & \textbf{0.968\scriptsize{ $\pm$ 0.035}} & \textbf{0.971\scriptsize{ $\pm$ 0.021}} \\
\bottomrule
\end{tabular}
However, setting $C$ to more extreme lower values, while potentially further enhancing reasoning accuracy, will face the risk of weakening the reflection in accelerating reasoning, since more elements are delegated to symbolic reasoning. Therefore, we do not recommend excessively lowering $C$. For this effect of $C$ in computational efficiency, we have also conducted experimental evaluation: The runtime after adjusting $C$ are reported in Table 9. It can be seen that setting $C$ to a higher value can further narrow the search space for symbolic reasoning, thereby offering a more substantial efficiency improvement. (On the contrary, setting $C$ to a more extreme high value would essentially rely merely on the neural network's intuitive output, rendering the reflection vector ineffective; hence, such settings are not considered.)
\begin{tabular}{cclccccc}
\toprule
\multicolumn{1}{c}{\multirow{2}{*}{ $\boldsymbol{\mathcal{KB}}$ \textbf{Form}}} & \multicolumn{1}{c}{\multirow{2}{*}{\textbf{Solver}}} & \multicolumn{2}{c}{\multirow{2}{*}{\textbf{Method}}} & \multirow{2}{*}{\textbf{\begin{tabular}[c]{@{}c@{}}Inference\\ Accuracy\end{tabular}}} & \multicolumn{3}{c}{\textbf{Inference Time (s)}} \\
\cmidrule(r){6-8}
& & & & & \textbf{NN Time} & \textbf{Abduction Time} & \textbf{Overall Time} \\
\midrule
\multirow{4}{*}{\begin{tabular}[c]{@{}c@{}}Propositional\\ logic\end{tabular}} & \multirow{4}{*}{MiniSAT} & \multicolumn{2}{l}{Solver only} & 100\scriptsize{ $\pm$ 0} & - & 0.227\scriptsize{ $\pm$ 0.024} & 0.227\scriptsize{ $\pm$ 0.024} \\
\cmidrule(r){3-8}
& & \multirow{3}{*}{\textbf{ABL-Refl}} & $C=0.7$ & 99.1\scriptsize{ $\pm$ 0.2} & & 0.218\scriptsize{ $\pm$ 0.019} & 0.239\scriptsize{ $\pm$ 0.023} \\
& & & $C=0.8$ & 97.4\scriptsize{ $\pm$ 0.3} & 0.021\scriptsize{ $\pm$ 0.004} & \textbf{0.196\scriptsize{ $\pm$ 0.015}} & \textbf{0.217\scriptsize{ $\pm$ 0.019}} \\
& & & $C=0.9$ & 96.6\scriptsize{ $\pm$ 0.5} & & \textbf{0.185\scriptsize{ $\pm$ 0.017}} & \textbf{0.206\scriptsize{ $\pm$ 0.021}} \\
\midrule
\multirow{4}{*}{\begin{tabular}[c]{@{}c@{}}First-order\\ logic\end{tabular}} & \multirow{4}{*}{\begin{tabular}[c]{@{}c@{}}Prolog with\\ CLP(FD)\end{tabular}} & \multicolumn{2}{l}{Solver only} & 100\scriptsize{ $\pm$ 0} & - & 105.81\scriptsize{ $\pm$ 5.62} & 105.81\scriptsize{ $\pm$ 5.62} \\
\cmidrule(r){3-8}
& & \multirow{3}{*}{\textbf{ABL-Refl}} & $C=0.7$ & 99.1\scriptsize{ $\pm$ 0.2} & & \textbf{68.59\scriptsize{ $\pm$ 3.31}} & \textbf{68.61\scriptsize{ $\pm$ 3.31}} \\
& & & $C=0.8$ & 97.4\scriptsize{ $\pm$ 0.3} & 0.021\scriptsize{ $\pm$ 0.004} & \textbf{31.86\scriptsize{ $\pm$ 1.88}} & \textbf{31.88\scriptsize{ $\pm$ 1.89}} \\
& & & $C=0.9$ & 96.6\scriptsize{ $\pm$ 0.5} & & \textbf{20.47\scriptsize{ $\pm$ 1.23}} & \textbf{20.49\scriptsize{ $\pm$ 1.23}} \\
\bottomrule
\end{tabular}
In summary, to utilize the reflection vector’s role in bridging neural network outputs and symbolic reasoning, setting $C$ within a moderate range is advised. Experimental evidence suggests that within this broad range, e.g., 0.6-0.9, the specific value of $C$ actually does not significantly impact outcomes; it is merely a balance between accuracy and computation time.
D. More Discussion on Comparison with Neural Network Confidence
The core idea of ABL-Refl is to identify areas in the neural network’s intuitive output where inconsistencies with knowledge are most likely to occur. Thus, a straightforward approach might seem to be letting the neural network itself highlight errors, i.e., treating elements with low confidence values from the neural network result as potential errors. However, Section 5 have proven that such a naive approach significantly underperforms our method. This is because neural networks cannot explicitly utilize symbolic knowledge during training, making it challenging to establish a correlation between confidence levels and inconsistencies with knowledge.
To illustrate this more clearly, we now demonstrate a case study in the solving Sudoku experiment: Figures 5a-Figure 5b below depict a Sudoku problem and its correct solution. Figure 5c shows the intuitive output obtained from the GNN, where several numbers marked in red are incorrect. Figures 5d and Figure 5e display the results using NN confidence and the reflection vector, respectively, with identified potential error positions in blue.
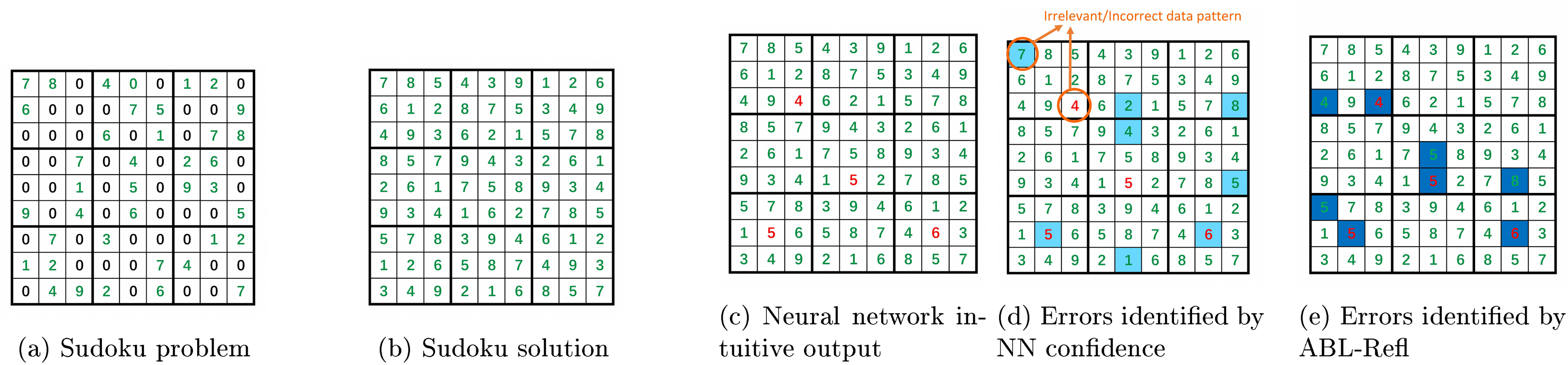
It can be seen that the errors marked by the reflection vector generally correspond to the constraints in $\mathcal{KB}$, containing duplicate numbers either in a row, column, or subgrid. In contrast, errors identified by NN confidence are difficult to align with such knowledge. Take the incorrect identification of the first row, first column as an example, after examining the dataset, we find that there are some of the Sudoku solutions with a number 4" in the third row, third column and a number 7" in the first row, first column at the same time. These irrelevant yet common data patterns likely lead the neural network to erroneously learn during training. Hence, when an error occurs in the third row and third column, the confidence in the first row and first column also drops. This case study highlights that pure data-driven networks cannot explicitly utilize KB knowledge: during training, they only have access to data labels, not the logical principles behind the data. Consequently, due to factors like learning incorrect data patterns or overfitting to noise, confidence values often misalign with the compatibility with domain knowledge, leading them become unreliable to identify errors. In contrast, the training information for the reflection vector is directly derived from the $\mathcal{KB}$.
Furthermore, as discussed in Appendix C, in ABL-Refl, adjusting the hyperparameter $C$, as a soft margin, can help determine how much of the neural network's output is retained. In Section 5, corresponding to $C=0.8$, the neural network's output with top 80% confidence was retained. We will now test adjusting this threshold of retaining neural network's output. We report the results in Table 10. As can be seen, regardless of the threshold value, our method consistently outperforms NN confidence.
\begin{tabular}{clcc}
\toprule
\textbf{Retain Threshold} & \multicolumn{1}{c}{\textbf{Method}} & \multicolumn{1}{c}{\textbf{Recall}} & \multicolumn{1}{c}{\textbf{Inference Accuracy}} \\
\midrule
\multirow{2}{*}{60\%} & NN Confidence & 93.18\scriptsize{ $\pm$ 2.34} & 77.2\scriptsize{ $\pm$ 5.5} \\
& \textbf{ABL-Refl} ($C=0.6$) & \textbf{99.31\scriptsize{ $\pm$ 0.84}} & \textbf{95.8\scriptsize{ $\pm$ 2.8}} \\
\midrule
\multirow{2}{*}{70\%} & NN Confidence & 88.60\scriptsize{ $\pm$ 2.66} & 70.1\scriptsize{ $\pm$ 5.7} \\
& \textbf{ABL-Refl} ($C=0.7$) & \textbf{99.25\scriptsize{ $\pm$ 0.84}} & \textbf{94.5\scriptsize{ $\pm$ 2.9}} \\
\midrule
\multirow{2}{*}{80\%} & NN Confidence & 82.64\scriptsize{ $\pm$ 2.78} & 64.3\scriptsize{ $\pm$ 6.2} \\
& \textbf{ABL-Refl} ($C=0.8$) & \textbf{99.04\scriptsize{ $\pm$ 0.85}} & \textbf{93.5\scriptsize{ $\pm$ 3.2}} \\
\midrule
\multirow{2}{*}{90\%} & NN Confidence & 71.05\scriptsize{ $\pm$ 3.01} & 52.1\scriptsize{ $\pm$ 6.2} \\
& \textbf{ABL-Refl} ($C=0.9$) & \textbf{98.86\scriptsize{ $\pm$ 0.89}} & \textbf{91.2\scriptsize{ $\pm$ 3.5}} \\
\bottomrule
\end{tabular}
E. Additional Experiment on Solving Combinatorial Optimization Problems on Graphs
In this section, we present an additional experiment on solving combinatorial optimization problems on graphs, finding the maximum independent set. In this experiment, we will demonstrate how our method can easily extend across varied reasoning scenarios.
Dataset and Settings.
The input is the same as in Section 4.3 for solving the maximum clique, given a graph $G=(V, E)$ with $|V|=n$ nodes, but in this section, we aim for the output $\boldsymbol{y}\in{0, 1}^n$ where the set of value 1 collectively constitutes the maximum independent set. While the two problems share similarities, they exhibit distinct reasoning capabilities: cliques rely on high homophily, whereas an independent set demonstrates significant heterophily. Generally, it is challenging for graph neural networks to simultaneously handle both scenarios effectively.
We utilize the same structure of graph neural networks as in Section 4.3. For the reasoning part, we continue to use Gurobi as the symbolic solver, and $\mathcal{KB}$ remains the basic mathematical definition of an independent set, i.e., no two nodes are connected by an edge. For consistency measurement, we adopt a similar definition in Section 4.3 as follows: one point is awarded for each pair of vertices if they are not connected by an edge; additionally, if the output set is indeed an independent set, the size of the output set multiplied by 10 is added. We may see that although the nature of the reasoning becomes entirely opposite compared to solving the maximum clique, we are able to flexibly transition to the new scenario with minimal changes.
Results.
We report the results in Table 11. We may see that our method significantly outperforms compared methods. Additionally, when compared to the results in Table 8, it can be observed that the performance of other baselines has declined when switching from finding maximum cliques to this task of finding maximum independent set. However, the performance of ABL-Refl has remained near perfect.
\begin{tabular}{llcccc}
\toprule
\multicolumn{2}{c}{\multirow{2}{*}{\textbf{Method}}} & \multicolumn{4}{c}{\textbf{Dataset}} \\
\cmidrule{3-6}
& & ENZYMES & PROTEINS & IMDB-Binary & COLLAB \\
\midrule
\multicolumn{2}{l}{Erdos} & 0.821\scriptsize{ $\pm$ 0.125} & 0.903\scriptsize{ $\pm$ 0.114} & 0.515\scriptsize{ $\pm$ 0.310} & 0.886\scriptsize{ $\pm$ 0.198} \\
\multicolumn{2}{l}{Neural SFE} & 0.775\scriptsize{ $\pm$ 0.155} & 0.729\scriptsize{ $\pm$ 0.205} & 0.679\scriptsize{ $\pm$ 0.287} & 0.392\scriptsize{ $\pm$ 0.253} \\
\midrule
\multirow{3}{*}{\textbf{ABL-Refl}} & $C=0.7$ & \textbf{0.989\scriptsize{ $\pm$ 0.022}} & \textbf{0.958\scriptsize{ $\pm$ 0.029}} & \textbf{0.964\scriptsize{ $\pm$ 0.026}} & \textbf{0.987\scriptsize{ $\pm$ 0.016}} \\
& $C=0.8$ & \textbf{0.986\scriptsize{ $\pm$ 0.026}} & \textbf{0.954\scriptsize{ $\pm$ 0.053}} & \textbf{0.960\scriptsize{ $\pm$ 0.037}} & \textbf{0.985\scriptsize{ $\pm$ 0.016}} \\
& $C=0.9$ & \textbf{0.980\scriptsize{ $\pm$ 0.025}} & \textbf{0.942\scriptsize{ $\pm$ 0.051}} & \textbf{0.952\scriptsize{ $\pm$ 0.021}} & \textbf{0.975\scriptsize{ $\pm$ 0.021}} \\
\bottomrule
\end{tabular}
References
[1] Frederick, Shane (2005). Cognitive reflection and decision making. Journal of Economic perspectives. 19(4). pp. 25–42.
[2] Kahneman, Daniel (2011). Thinking, fast and slow. macmillan.
[3] Bengio, Yoshua (2019). From system 1 deep learning to system 2 deep learning. In Neural Information Processing Systems.
[4] Hitzler, Pascal (2022). Neuro-symbolic artificial intelligence: The state of the art. IOS Press.
[5] Xu et al. (2018). A semantic loss function for deep learning with symbolic knowledge. In International conference on machine learning. pp. 5502–5511.
[6] Yang et al. (2022). Injecting logical constraints into neural networks via straight-through estimators. In International Conference on Machine Learning. pp. 25096–25122.
[7] Wang et al. (2019). Satnet: Bridging deep learning and logical reasoning using a differentiable satisfiability solver. In International Conference on Machine Learning. pp. 6545–6554.
[8] Zhou, Zhi-Hua (2019). Abductive learning: towards bridging machine learning and logical reasoning. Science China Information Sciences. 62. pp. 1–3.
[9] Zhou, Zhi-Hua and Huang, Yu-Xuan (2022). Abductive Learning.
[10] Sinayev, Aleksandr and Peters, Ellen (2015). Cognitive reflection vs. calculation in decision making. Frontiers in psychology. 6. pp. 532.
[11] Serafini, Luciano and Garcez, Artur d'Avila (2016). Logic tensor networks: Deep learning and logical reasoning from data and knowledge. arXiv preprint arXiv:1606.04422.
[12] Marra et al. (2020). Integrating learning and reasoning with deep logic models. In Machine Learning and Knowledge Discovery in Databases. pp. 517–532.
[13] Hoernle et al. (2022). Multiplexnet: Towards fully satisfied logical constraints in neural networks. In Proceedings of the AAAI Conference on Artificial Intelligence. pp. 5700–5709.
[14] Ahmed et al. (2022). Neuro-symbolic entropy regularization. In Uncertainty in Artificial Intelligence. pp. 43–53.
[15] Amos, Brandon and Kolter, J Zico (2017). Optnet: Differentiable optimization as a layer in neural networks. In International Conference on Machine Learning. pp. 136–145.
[16] Selsam et al. (2018). Learning a SAT solver from single-bit supervision. arXiv preprint arXiv:1802.03685.
[17] Manhaeve et al. (2018). Deepproblog: Neural probabilistic logic programming. advances in neural information processing systems. 31.
[18] Yang et al. (2020). Neurasp: Embracing neural networks into answer set programming. In 29th International Joint Conference on Artificial Intelligence.
[19] Huang et al. (2024). ABLkit: A Python Toolkit for Abductive Learning. Frontiers of Computer Science, pp. to appear.
[20] Huang et al. (2020). Semi-Supervised Abductive Learning and Its Application to Theft Judicial Sentencing. In Proceedings of the 20th IEEE International Conference on Data Mining (ICDM'20). pp. 1070–1075.
[21] Cai et al. (2021). Abductive Learning with Ground Knowledge Base. In Proceedings of the 30th International Joint Conference on Artificial Intelligence (IJCAI'21). pp. 1815–1821.
[22] Wang et al. (2021). Tac-Valuer: Knowledge-based Stroke Evaluation in Table Tennis. In Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD'21). pp. 3688–3696.
[23] Gao et al. (2024). Knowledge-Enhanced Historical Document Segmentation and Recognition. In Proceedings of the 38th AAAI Conference on Artificial Intelligence (AAAI'24). pp. 8409–8416.
[24] Nair et al. (2020). Solving mixed integer programs using neural networks. arXiv preprint arXiv:2012.13349.
[25] Nye et al. (2021). Improving coherence and consistency in neural sequence models with dual-system, neuro-symbolic reasoning. Advances in Neural Information Processing Systems. 34. pp. 25192–25204.
[26] Han et al. (2023). A GNN-Guided Predict-and-Search Framework for Mixed-Integer Linear Programming. arXiv preprint arXiv:2302.05636.
[27] Dai et al. (2019). Bridging machine learning and logical reasoning by abductive learning. Advances in Neural Information Processing Systems. 32.
[28] Zhang et al. (2020). NLocalSAT: Boosting local search with solution prediction. arXiv preprint arXiv:2001.09398.
[29] Williams, Ronald J (1992). Simple statistical gradient-following algorithms for connectionist reinforcement learning. Reinforcement learning. pp. 5–32.
[30] Vopani (2019). 9 Million Sudoku Puzzles and Solutions. https://www.kaggle.com/datasets/rohanrao/sudoku Accessed: 2024-08-01.
[31] Sörensson, Niklas (2010). Minisat 2.2 and minisat++ 1.1. A short description in SAT Race.
[32] Palm et al. (2018). Recurrent relational networks. Advances in neural information processing systems. 31.
[33] Triska, Markus (2012). The finite domain constraint solver of SWI-Prolog. In Functional and Logic Programming: 11th International Symposium. pp. 307–316.
[34] LeCun et al. (1998). Gradient-based learning applied to document recognition. Proceedings of the IEEE. 86(11). pp. 2278–2324.
[35] Chen et al. (2020). A simple framework for contrastive learning of visual representations. In International conference on machine learning. pp. 1597–1607.
[36] Zhang et al. (2023). Rethinking the expressive power of gnns via graph biconnectivity. arXiv preprint arXiv:2301.09505.
[37] Morris et al. (2020). Tudataset: A collection of benchmark datasets for learning with graphs. arXiv preprint arXiv:2007.08663.
[38] (2017). Graph attention networks. arXiv preprint arXiv:1710.10903.
[39] Li et al. (2015). Gated graph sequence neural networks. arXiv preprint arXiv:1511.05493.
[40] Karalias, Nikolaos and Loukas, Andreas (2020). Erdos goes neural: an unsupervised learning framework for combinatorial optimization on graphs. Advances in Neural Information Processing Systems. 33. pp. 6659–6672.
[41] Karalias et al. (2022). Neural Set Function Extensions: Learning with Discrete Functions in High Dimensions. arXiv preprint arXiv:2208.04055.
[42] Cornelio et al. (2023). Learning where and when to reason in neuro-symbolic inference. In The Eleventh International Conference on Learning Representations.
[43] Pennycook et al. (2016). Is the cognitive reflection test a measure of both reflection and intuition?. Behavior research methods. 48. pp. 341–348.
[44] Mialon et al. (2023). GAIA: a benchmark for General AI Assistants. arXiv preprint arXiv:2311.12983.