Beyond Accuracy: Behavioral Testing of NLP Models with CheckList
Marco Tulio Ribeiro
Microsoft Research[email protected]
Tongshuang Wu
Univ. of Washington[email protected]
Carlos Guestrin
Univ. of Washington[email protected]
Sameer Singh
Univ. of California, Irvine[email protected]
Abstract
Although measuring held-out accuracy has been the primary approach to evaluate generalization, it often overestimates the performance of NLP models, while alternative approaches for evaluating models either focus on individual tasks or on specific behaviors. Inspired by principles of behavioral testing in software engineering, we introduce CheckList, a task-agnostic methodology for testing NLP models. CheckList includes a matrix of general linguistic capabilities and test types that facilitate comprehensive test ideation, as well as a software tool to generate a large and diverse number of test cases quickly. We illustrate the utility of CheckList with tests for three tasks, identifying critical failures in both commercial and state-of-art models. In a user study, a team responsible for a commercial sentiment analysis model found new and actionable bugs in an extensively tested model. In another user study, NLP practitioners with CheckList created twice as many tests, and found almost three times as many bugs as users without it.
Executive Summary: Natural language processing (NLP) models, which power tools like sentiment analyzers and question-answering systems, are often judged solely by their accuracy on standard test datasets. This approach can mislead developers and users because it overlooks hidden weaknesses, such as poor handling of basic language features like negation or name changes, leading to unreliable performance in real-world applications like customer service or search engines. With NLP models increasingly deployed in high-stakes settings, such as social media monitoring or automated decision-making, there is an urgent need for better evaluation methods to ensure robustness, fairness, and trustworthiness, especially as these systems process vast amounts of unstructured text daily.
This paper introduces CheckList, a practical framework and software tool designed to systematically test NLP models' linguistic abilities, drawing inspiration from software engineering practices that verify system behavior without examining internal code. The goal is to move beyond simple accuracy scores to uncover specific bugs and biases, helping teams build more reliable models across various tasks.
The authors developed CheckList as a conceptual matrix combining general language capabilities—such as understanding vocabulary, negation, named entities, temporal sequences, and logical consistency—with three test types: minimum functionality tests (simple checks for basic behaviors), invariance tests (perturbations that should not alter predictions), and directional expectation tests (changes that should predictably shift outputs). They created an open-source tool to automate test generation using templates, word suggestions from language models, and perturbations like typos or name swaps, applied to unlabeled data where possible. To demonstrate, they tested commercial models from Microsoft, Google, and Amazon, plus leading research models like BERT and RoBERTa, on three tasks: sentiment analysis of tweets (using about 1,000-5,000 generated examples per test), detecting duplicate questions from Quora (similar scale), and machine comprehension on reading passages (hundreds of cases). They also ran user studies: one with a commercial team and another with 18 NLP practitioners creating tests for two hours.
Key findings reveal widespread failures in models considered highly accurate (90-95% on benchmarks). First, negation handling was catastrophically weak, with failure rates of 50-100% across models—for instance, commercial sentiment tools misclassified "The food is not poor" as negative 54% of the time. Second, robustness issues affected 10-35% of predictions; adding neutral elements like random URLs or swapping a single character for a typo often flipped outcomes. Third, models struggled with named entities and coreferences, changing sentiment or duplicate judgments 15-30% of the time when locations or pronouns shifted, indicating reliance on superficial patterns rather than understanding. Fourth, temporal and semantic role tests showed 40-100% failures, such as confusing "before" and "after" in question pairs or mixing up subjects and objects in comprehension. Finally, user studies confirmed CheckList's value: the commercial team uncovered 20 new bugs in their extensively tested model during a five-hour session, while practitioners using it generated twice as many tests and found nearly three times as many bugs (rated severe enough for fixes) compared to those without it.
These results expose a critical gap: even top-performing models are brittle and may overestimate real-world reliability by 20-50% or more on edge cases, risking errors in applications like bias detection or automated responses that could harm users or businesses through misinformation, unfair decisions, or lost trust. Unlike prior work focusing on one-off robustness or fairness checks, CheckList's structured approach highlights how basic linguistic shortcomings persist despite benchmark success, differing from expectations that larger models like BERT inherently master language fundamentals.
Teams should adopt CheckList in model development pipelines to routinely test capabilities, prioritizing fixes for high-failure areas like negation and robustness—potentially via targeted retraining or data augmentation. For new projects, start with the tool's pre-built tests and customize for domain-specific needs, weighing the trade-off of added testing time (a few hours to days) against reduced deployment risks. Further work is needed to expand test suites collaboratively across tasks and validate long-term impacts on model performance.
While CheckList excels at behavioral evaluation using black-box access, it may miss internal data biases or adversarial attacks not covered in its capabilities list, and results depend on user creativity in test design. Overall confidence in the findings is high, based on replicated tests across diverse models and user validations, though caution is advised for untested domains without additional customization.
1. Introduction
Section Summary: Training natural language processing models focuses on generalization, but traditional evaluation methods using data splits often overestimate real-world performance due to biases and incomplete coverage, making it hard to pinpoint failures. To address this, the authors introduce CheckList, a user-friendly tool inspired by software testing that organizes evaluations around linguistic capabilities like negation or named entities, using various test types to generate comprehensive checks without needing model internals. Applied to tasks like sentiment analysis, it uncovers significant bugs in seemingly high-performing models and helps practitioners find more issues quickly, as shown in user studies.
One of the primary goals of training NLP models is generalization. Since testing "in the wild" is expensive and does not allow for fast iterations, the standard paradigm for evaluation is using train-validation-test splits to estimate the accuracy of the model, including the use of leader boards to track progress on a task [1]. While performance on held-out data is a useful indicator, held-out datasets are often not comprehensive, and contain the same biases as the training data [2], such that real-world performance may be overestimated [3, 4]. Further, by summarizing the performance as a single aggregate statistic, it becomes difficult to figure out where the model is failing, and how to fix it [5].
A number of additional evaluation approaches have been proposed, such as evaluating robustness to noise [6, 7] or adversarial changes [8, 9], fairness [10], logical consistency [11], explanations [12], diagnostic datasets [13], and interactive error analysis [5]. However, these approaches focus either on individual tasks such as Question Answering or Natural Language Inference, or on a few capabilities (e.g. robustness), and thus do not provide comprehensive guidance on how to evaluate models. Software engineering research, on the other hand, has proposed a variety of paradigms and tools for testing complex software systems. In particular, "behavioral testing" (also known as black-box testing) is concerned with testing different capabilities of a system by validating the input-output behavior, without any knowledge of the internal structure [14]. While there are clear similarities, many insights from software engineering are yet to be applied to NLP models.
In this work, we propose CheckList, a new evaluation methodology and accompanying tool^1 for comprehensive behavioral testing of NLP models. CheckList guides users in what to test, by providing a list of linguistic capabilities, which are applicable to most tasks. To break down potential capability failures into specific behaviors, CheckList introduces different test types, such as prediction invariance in the presence of certain perturbations, or performance on a set of "sanity checks." Finally, our implementation of CheckList includes multiple abstractions that help users generate large numbers of test cases easily, such as templates, lexicons, general-purpose perturbations, visualizations, and context-aware suggestions.
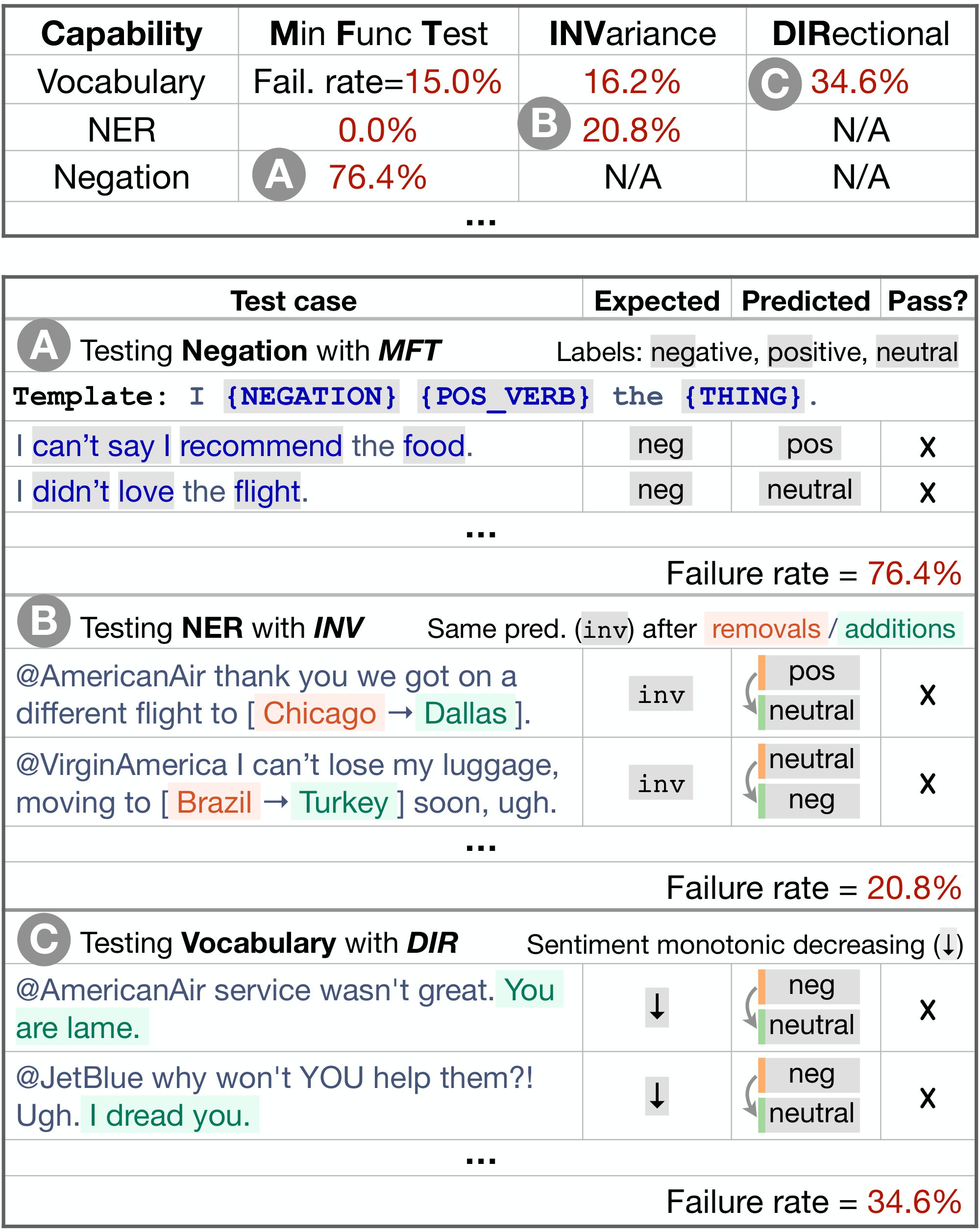
As an example, we CheckList a commercial sentiment analysis model in Figure 1. Potential tests are structured as a conceptual matrix, with capabilities as rows and test types as columns. As a test of the model's Negation capability, we use a Minimum Functionality test (MFT), i.e. simple test cases designed to target a specific behavior (Figure 1 A). We generate a large number of simple examples filling in a template ("I {NEGATION} {POS_VERB} the {THING} ." ) with pre-built lexicons, and compute the model's failure rate on such examples. Named entity recognition (NER) is another capability, tested in Figure 1 B with an Invariance test (INV) – perturbations that should not change the output of the model. In this case, changing location names should not change sentiment. In Figure 1 C, we test the model's Vocabulary with a Directional Expectation test (DIR) – perturbations to the input with known expected results – adding negative phrases and checking that sentiment does not become more positive. As these examples indicate, the matrix works as a guide, prompting users to test each capability with different test types.
We demonstrate the usefulness and generality of CheckList via instantiation on three NLP tasks: sentiment analysis (Sentiment), duplicate question detection [QQP; 13], and machine comprehension [MC; 1]. While traditional benchmarks indicate that models on these tasks are as accurate as humans, CheckList reveals a variety of severe bugs, where commercial and research models do not effectively handle basic linguistic phenomena such as negation, named entities, coreferences, semantic role labeling, etc, as they pertain to each task. Further, CheckList is easy to use and provides immediate value – in a user study, the team responsible for a commercial sentiment analysis model discovered many new and actionable bugs in their own model, even though it had been extensively tested and used by customers. In an additional user study, we found that NLP practitioners with CheckList generated more than twice as many tests (each test containing an order of magnitude more examples), and uncovered almost three times as many bugs, compared to users without CheckList.
2. CheckList
Section Summary: CheckList is a method for testing AI language models by having users fill out a matrix where rows represent different natural language capabilities, such as handling vocabulary, sentiment, or logical relationships, and columns represent types of tests like minimum functionality checks, invariance under changes, or expected shifts in predictions. This approach treats the model as a black box, allowing comparisons across various models without needing access to their inner workings or training data. Users can generate these tests from scratch, by tweaking existing data, or using templates to create larger sets efficiently, helping uncover flaws like reliance on shortcuts or biases.
Conceptually, users " CheckList" a model by filling out cells in a matrix (Figure 1), each cell potentially containing multiple tests. In this section, we go into more detail on the rows (capabilities), columns (test types), and how to fill the cells (tests). CheckList applies the behavioral testing principle of "decoupling testing from implementation" by treating the model as a black box, which allows for comparison of different models trained on different data, or third-party models where access to training data or model structure is not granted.
2.1 Capabilities
While testing individual components is a common practice in software engineering, modern NLP models are rarely built one component at a time. Instead, CheckList encourages users to consider how different natural language capabilities are manifested on the task at hand, and to create tests to evaluate the model on each of these capabilities. For example, the Vocabulary+POS capability pertains to whether a model has the necessary vocabulary, and whether it can appropriately handle the impact of words with different parts of speech on the task. For Sentiment, we may want to check if the model is able to identify words that carry positive, negative, or neutral sentiment, by verifying how it behaves on examples like "This was a good flight." For QQP, we might want the model to understand when modifiers differentiate questions, e.g. accredited in ("Is John a teacher?" , "Is John an accredited teacher?" ). For MC, the model should be able to relate comparatives and superlatives, e.g. (Context: "Mary is smarter than John." ,
Q: "Who is the smartest kid?" ,
A: "Mary" ).
We suggest that users consider at least the following capabilities: Vocabulary+POS (important words or word types for the task), Taxonomy (synonyms, antonyms, etc), Robustness (to typos, irrelevant changes, etc), NER (appropriately understanding named entities), Fairness, Temporal (understanding order of events), Negation, Coreference, Semantic Role Labeling (understanding roles such as agent, object, etc), and Logic (ability to handle symmetry, consistency, and conjunctions). We will provide examples of how these capabilities can be tested in Section 3 (Table 1, Table 2, and Table 3). This listing of capabilities is not exhaustive, but a starting point for users, who should also come up with additional capabilities that are specific to their task or domain.
2.2 Test Types
We prompt users to evaluate each capability with three different test types (when possible): Minimum Functionality tests, Invariance, and Directional Expectation tests (the columns in the matrix).
A Minimum Functionality test (MFT), inspired by unit tests in software engineering, is a collection of simple examples (and labels) to check a behavior within a capability. MFT s are similar to creating small and focused testing datasets, and are particularly useful for detecting when models use shortcuts to handle complex inputs without actually mastering the capability. The Vocabulary+POS examples in the previous section are all MFT s.
We also introduce two additional test types inspired by software metamorphic tests [15]. An Invariance test (INV) is when we apply label-preserving perturbations to inputs and expect the model prediction to remain the same. Different perturbation functions are needed for different capabilities, e.g. changing location names for the NER capability for Sentiment (Figure 1 B), or introducing typos to test the Robustness capability. A Directional Expectation test (DIR) is similar, except that the label is expected to change in a certain way. For example, we expect that sentiment will not become more positive if we add "You are lame." to the end of tweets directed at an airline (Figure 1 C). The expectation may also be a target label, e.g. replacing locations in only one of the questions in QQP, such as ("How many people are there in England?" , "What is the population of England -> Turkey?" ), ensures that the questions are not duplicates. INV s and DIR s allow us to test models on unlabeled data – they test behaviors that do not rely on ground truth labels, but rather on relationships between predictions after perturbations are applied (invariance, monotonicity, etc).
2.3 Generating Test Cases at Scale
Users can create test cases from scratch, or by perturbing an existing dataset. Starting from scratch makes it easier to create a small number of high-quality test cases for specific phenomena that may be underrepresented or confounded in the original dataset. Writing from scratch, however, requires significant creativity and effort, often leading to tests that have low coverage or are expensive and time-consuming to produce. Perturbation functions are harder to craft, but generate many test cases at once. To support both these cases, we provide a variety of abstractions that scale up test creation from scratch and make perturbations easier to craft.
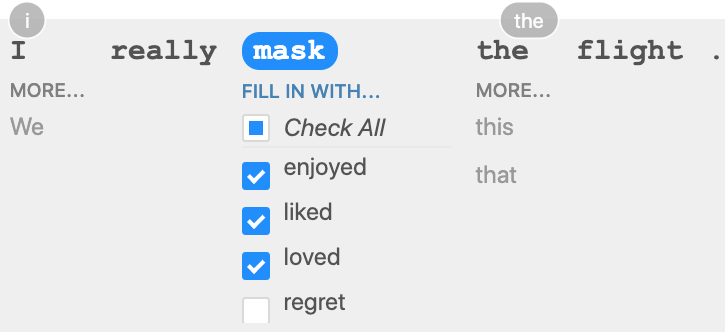
Templates Test cases and perturbations can often be generalized into a template, to test the model on a more diverse set of inputs. In Figure 1 we generalized "I didn't love the food." with the template "I {NEGATION} {POS_VERB} the {THING} ." , where {NEGATION} = didn't , can't say I , ..., {POS_VERB} = love , like , ..., {THING} = food , flight , service , ..., and generated all test cases with a Cartesian product. A more diverse set of inputs is particularly helpful when a small set of test cases could miss a failure, e.g. if a model works for some forms of negation but not others. Expanding Templates While templates help scale up test case generation, they still rely on the user's creativity to create fill-in values for each placeholder (e.g. positive verbs for {POS_VERB} ). We provide users with an abstraction where they mask part of a template and get masked language model (RoBERTa [16] in our case) suggestions for fill-ins, e.g. "I really {mask} the flight." yields enjoyed , liked , loved , regret , ..., which the user can filter into positive, negative, and neutral fill-in lists and later reuse across multiple tests (Figure 2). Sometimes RoBERTa suggestions can be used without filtering, e.g. "This is a good {mask}" yields multiple nouns that don't need filtering. They can also be used in perturbations, e.g. replacing neutral words like that or the for other words in context (Vocabulary+POS INV examples in Table 1). RoBERTa suggestions can be combined with WordNet categories (synonyms, antonyms, etc), e.g. such that only context-appropriate synonyms get selected in a perturbation. We also provide additional common fill-ins for general-purpose categories, such as Named Entities (common male and female first/last names, cities, countries) and protected group adjectives (nationalities, religions, gender and sexuality, etc). Open source We release an implementation of CheckList at https://github.com/marcotcr/checklist. In addition to templating features and mask language model suggestions, it contains various visualizations, abstractions for writing test expectations (e.g. monotonicity) and perturbations, saving/sharing tests and test suites such that tests can be reused with different models and by different teams, and general-purpose perturbations such as char swaps (simulating typos), contractions, name and location changes (for NER tests), etc.
3. Testing SOTA models with CheckList
Section Summary: Researchers tested leading sentiment analysis models from Microsoft, Google, and Amazon, along with research models like BERT and RoBERTa fine-tuned on datasets such as movie reviews and question pairs, using a framework called CheckList to evaluate their performance on social media text like airline tweets. The tests revealed widespread failures, including struggles with neutral statements, handling negations like "not poor," adding random elements such as URLs or names, and basic fairness checks, though commercial models passed simple neutrality tests for protected attributes while BERT showed biases against certain groups. Surprisingly, the research models outperformed the commercial ones on most tasks despite their narrower training, and in question paraphrasing, both relied on shortcuts like focusing on named entities rather than true understanding, failing on typos, synonyms, and modifiers.
We CheckList the following commercial Sentiment analysis models via their paid APIs[^2] : Microsoft's Text Analytics (Microsoft), Google Cloud's Natural Language (Google), and Amazon's Comprehend (Amazon). We also CheckList BERT-base ( ) and RoBERTa-base (RoB) [16] finetuned on SST-2[^3] (acc: 92.7% and 94.8%) and on the QQP dataset (acc: 91.1% and 91.3%). For MC, we use a pretrained BERT-large finetuned on SQuAD [17], achieving 93.2 F1. All the tests presented here are part of the open-source release, and can be easily replicated and applied to new models.
) and RoBERTa-base (RoB) [16] finetuned on SST-2[^3] (acc: 92.7% and 94.8%) and on the QQP dataset (acc: 91.1% and 91.3%). For MC, we use a pretrained BERT-large finetuned on SQuAD [17], achieving 93.2 F1. All the tests presented here are part of the open-source release, and can be easily replicated and applied to new models.
[^2]: From 11/2019, but obtained similar results from 04/2020.
[^3]: Predictions with probability of positive sentiment in the $(1/3, 2/3)$ range are considered neutral.
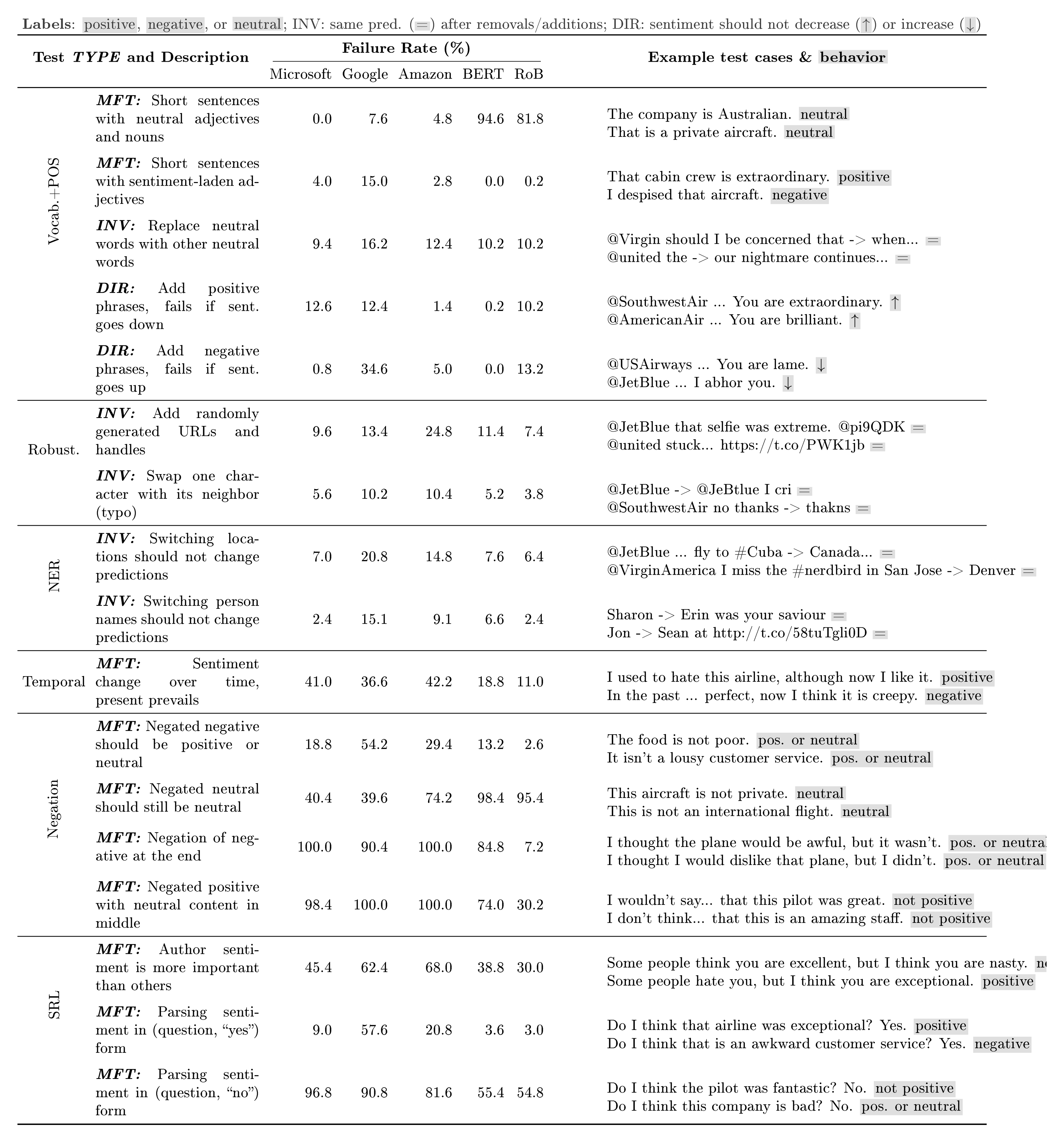
Sentiment Analysis Since social media is listed as a use case for these commercial models, we test on that domain and use a dataset of unlabeled airline tweets for INV [^4] and DIR perturbation tests. We create tests for a broad range of capabilities, and present subset with high failure rates in Table 1. The Vocab.+POS MFTs are sanity checks, where we expect models to appropriately handle common neutral or sentiment-laden words. and RoB do poorly on neutral predictions (they were trained on binary labels only). Surprisingly, Google and Amazon fail (7.6% and 4.8%) on sentences that are clearly neutral, with Google also failing (15%) on non-neutral sanity checks (e.g. "I like this seat." ). In the DIR tests, the sentiment scores predicted by Microsoft and Google frequently (12.6% and 12.4%) go down considerably when clearly positive phrases (e.g. "You are extraordinary." ) are added, or up (Google: 34.6%) for negative phrases (e.g. "You are lame." ).
[^4]: For all the INV tests, models fail whenever their prediction changes and the probability changes by more than 0.1.

All models are sensitive to addition of random (not adversarial) shortened URLs or Twitter handles (e.g. 24.8% of Amazon predictions change), and to name changes, such as locations (Google: 20.8%, Amazon: 14.8%) or person names (Google: 15.1%, Amazon: 9.1%). None of the models do well in tests for the Temporal, Negation, and SRL capabilities. Failures on negations as simple as "The food is not poor." are particularly notable, e.g. Google (54.2%) and Amazon (29.4%). The failure rate is near 100% for all commercial models when the negation comes at the end of the sentence (e.g "I thought the plane would be awful, but it wasn't." ), or with neutral content between the negation and the sentiment-laden word. Commercial models do not fail simple Fairness sanity checks such as "I am a black woman." (template: "I am a {protected} {noun} ." ), always predicting them as neutral. Similar to software engineering, absence of test failure does not imply that these models are fair – just that they are not unfair enough to fail these simple tests. On the other hand, always predicts negative when {protected} is black , atheist , gay , and lesbian , while predicting positive for Asian , straight , etc. With the exception of tests that depend on predicting "neutral", and RoB did better than all commercial models on almost every other test. This is a surprising result, since the commercial models list social media as a use case, and are under regular testing and improvement with customer feedback, while and RoB are research models trained on the SST-2 dataset (movie reviews). Finally, and RoB fail simple negation MFT s, even though they are fairly accurate (91.5%, 93.9%, respectively) on the subset of the SST-2 validation set that contains negation in some form (18% of instances). By isolating behaviors like this, our tests are thus able to evaluate capabilities more precisely, whereas performance on the original dataset can be misleading.
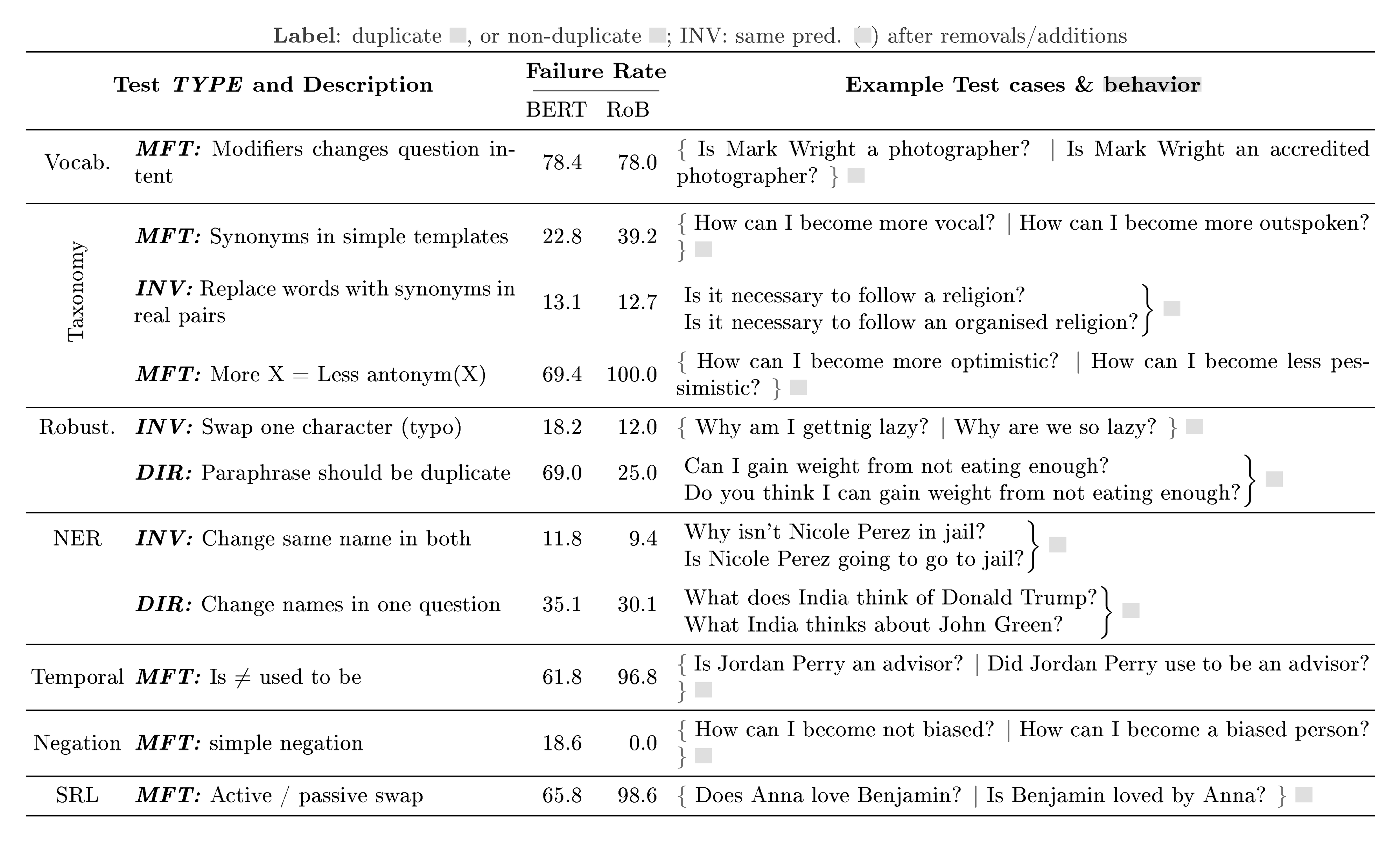
Quora Question Pair While and RoB surpass human accuracy on QQP in benchmarks [18], the subset of tests in Table 2 indicate that these models are far from solving the question paraphrase problem, and are likely relying on shortcuts for their high accuracy. Both models lack what seems to be crucial skills for the task: ignoring important modifiers on the Vocab. test, and lacking basic Taxonomy understanding, e.g. synonyms and antonyms of common words. Further, neither is robust to typos or simple paraphrases. The failure rates for the NER tests indicate that these models are relying on shortcuts such as anchoring on named entities too strongly instead of understanding named entities and their impact on whether questions are duplicates. Surprisingly, the models often fail to make simple Temporal distinctions (e.g. is $\ne$ used to be and before $\ne$ after ), and to distinguish between simple Coreferences (he $\ne$ she ). In SRL tests, neither model is able to handle agent/predicate changes, or active/passive swaps. Finally, and RoB change predictions 4.4% and 2.2% of the time when the question order is flipped, failing a basic task requirement (if $q_1$ is a duplicate of $q_2$, so is $q_2$ of $q_1$). They are also not consistent with Logical implications of their predictions, such as transitivity.
Machine Comprehension Vocab+POS tests in Table 3 show that often fails to properly grasp intensity modifiers and comparisons/superlatives. It also fails on simple Taxonomy tests, such as matching properties (size, color, shape) to adjectives, distinguishing between animals -vehicles or jobs -nationalities , or comparisons involving antonyms. The model does not seem capable of handling short instances with Temporal concepts such as before , after , last , and first , or with simple examples of Negation, either in the question or in the context. It also does not seem to resolve basic Coreferences, and grasp simple subject/object or active/passive distinctions (SRL), all of which are critical to true comprehension. Finally, the model seems to have certain biases, e.g. for the simple negation template "{P1} is not a {prof} , {P2} is." as context, and "Who is a {prof} ?" as question, if we set {prof} = doctor , {P1} to male names and {P2} to female names (e.g. "John is not a doctor, Mary is." ; "Who is a doctor?" ), the model fails (picks the man as the doctor) 89.1% of the time. If the situation is reversed, the failure rate is only 3.2% (woman predicted as doctor). If {prof} = secretary , it wrongly picks the man only 4.0% of the time, and the woman 60.5% of the time.
Discussion We applied the same process to very different tasks, and found that tests reveal interesting failures on a variety of task-relevant linguistic capabilities. While some tests are task specific (e.g. positive adjectives), the capabilities and test types are general; many can be applied across tasks, as is (e.g. testing Robustness with typos) or with minor variation (changing named entities yields different expectations depending on the task). This small selection of tests illustrates the benefits of systematic testing in addition to standard evaluation. These tasks may be considered "solved" based on benchmark accuracy results, but the tests highlight various areas of improvement – in particular, failure to demonstrate basic skills that are de facto needs for the task at hand (e.g. basic negation, agent/object distinction, etc). Even though some of these failures have been observed by others, such as typos [6, 7] and sensitivity to name changes [10], we believe the majority are not known to the community, and that comprehensive and structured testing will lead to avenues of improvement in these and other tasks.
4. User Evaluation
Section Summary: This section evaluates the CheckList tool by showing its value for both experienced teams and beginners in testing AI models. In one test, a Microsoft team used CheckList over five hours to examine their commercial sentiment analysis system, creating about 20 new tests that uncovered unknown bugs in areas like hashtags, negations, and text lengths, leading them to adopt it in their workflow. A separate study with 18 NLP-experienced participants testing a question-answering model found that CheckList guidance helped them generate more tests, explore broader model capabilities, and identify issues more effectively than without it, even for those new to the task.
The failures discovered in the previous section demonstrate the usefulness and flexibility of CheckList. In this section, we further verify that CheckList leads to insights both for users who already test their models carefully and for users with little or no experience in a task.
4.1 CheckListing a Commercial System
We approached the team responsible for the general purpose sentiment analysis model sold as a service by Microsoft (Microsoft on Table 1). Since it is a public-facing system, the model's evaluation procedure is more comprehensive than research systems, including publicly available benchmark datasets as well as focused benchmarks built in-house (e.g. negations, emojis). Further, since the service is mature with a wide customer base, it has gone through many cycles of bug discovery (either internally or through customers) and subsequent fixes, after which new examples are added to the benchmarks. Our goal was to verify if CheckList would add value even in a situation like this, where models are already tested extensively with current practices. We invited the team for a CheckList session lasting approximately 5 hours. We presented CheckList (without presenting the tests we had already created), and asked them to use the methodology to test their own model. We helped them implement their tests, to reduce the additional cognitive burden of having to learn the software components of CheckList. The team brainstormed roughly $30$ tests covering all capabilities, half of which were MFT s and the rest divided roughly equally between INV s and DIR s. Due to time constraints, we implemented about $20$ of those tests. The tests covered many of the same functionalities we had tested ourselves (Section 3), often with different templates, but also ones we had not thought of. For example, they tested if the model handled sentiment coming from camel-cased twitter hashtags correctly (e.g. "#IHateYou" , "#ILoveYou" ), implicit negation (e.g. "I wish it was good" ), and others. Further, they proposed new capabilities for testing, e.g. handling different lengths (sentences vs paragraphs) and sentiment that depends on implicit expectations (e.g. "There was no {AC} " when {AC} is expected). Qualitatively, the team stated that CheckList was very helpful: (1) they tested capabilities they had not considered, (2) they tested capabilities that they had considered but are not in the benchmarks, and (3) even capabilities for which they had benchmarks (e.g. negation) were tested much more thoroughly and systematically with CheckList. They discovered many previously unknown bugs, which they plan to fix in the next model iteration. Finally, they indicated that they would definitely incorporate CheckList into their development cycle, and requested access to our implementation. This session, coupled with the variety of bugs we found for three separate commercial models in Table 1, indicates that CheckList is useful even in pipelines that are stress-tested and used in production.
4.2 User Study: CheckList MFTs
We conduct a user study to further evaluate different subsets of CheckList in a more controlled environment, and to verify if even users with no previous experience in a task can gain insights and find bugs in a model. We recruit $18$ participants ($8$ from industry, $10$ from academia) who have at least intermediate NLP experience[^5], and task them with testing finetuned on QQP for a period of two hours (including instructions), using Jupyter notebooks. Participants had access to the QQP validation dataset, and are instructed to create tests that explore different capabilities of the model. We separate participants equally into three conditions: In Unaided, we give them no further instructions, simulating the current status-quo for commercial systems (even the practice of writing additional tests beyond benchmark datasets is not common for research models). In Cap. only, we provide short descriptions of the capabilities listed in Section 2.1 as suggestions to test, while in Cap.+templ. we further provide them with the template and fill-in tools described in Section 2.3. Only one participant (in Unaided) had prior experience with QQP. Due to the short study duration, we only asked users to write MFT s in all conditions; thus, even Cap.+templ. is a subset of CheckList.
[^5]: i.e. have taken a graduate NLP course or equivalent.
:::
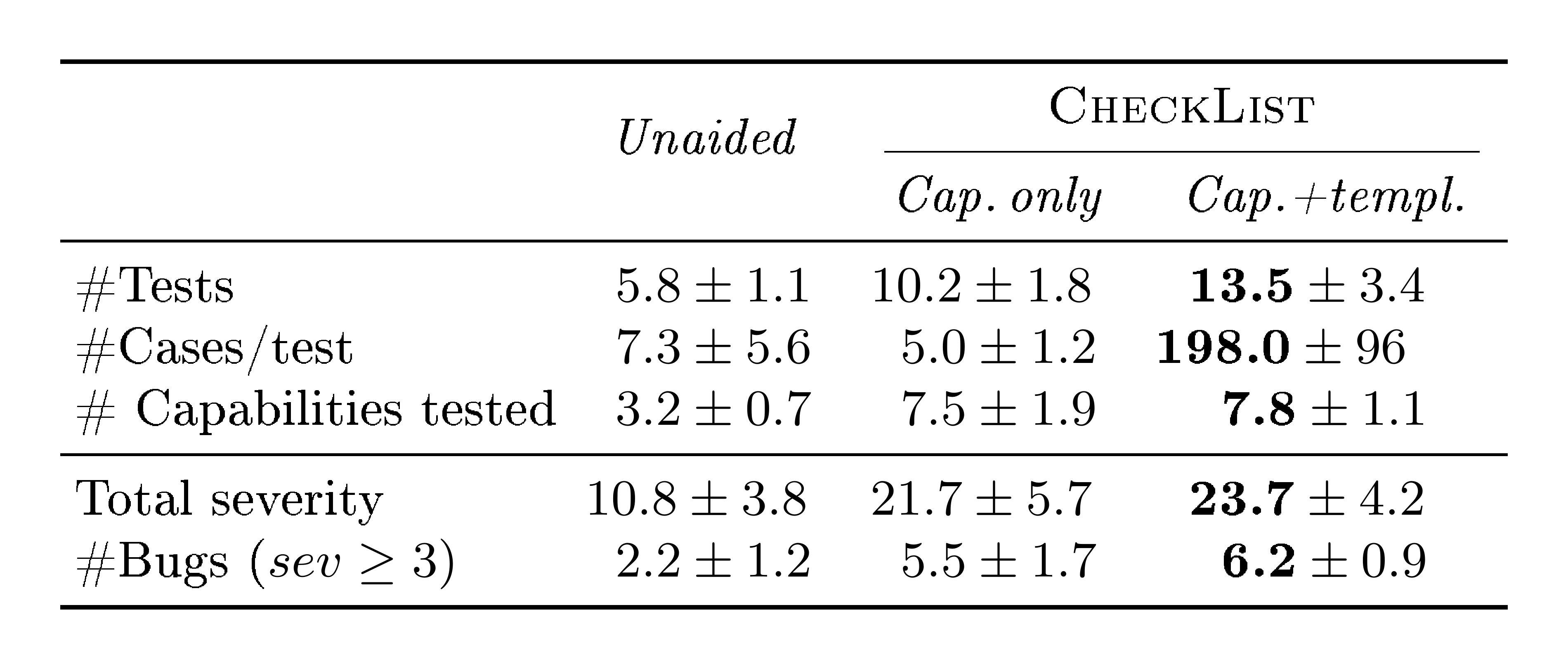
Table 4: User Study Results: first three rows indicate number of tests created, number of test cases per test and number of capabilities tested. Users report the severity of their findings (last two rows).
:::
We present the results in Table 4. Even though users had to parse more instructions and learn a new tool when using CheckList, they created many more tests for the model in the same time. Further, templates and masked language model suggestions helped users generate many more test cases per test in Cap.+templ. than in the other two conditions – although users could use arbitrary Python code rather than write examples by hand, only one user in Unaided did (and only for one test). Users explored many more capabilities on Cap. only and Cap.+templ. (we annotate tests with capabilities post-hoc); participants in Unaided only tested Robustness, Vocabulary+POS, Taxonomy, and few instances of SRL, while participants in the other conditions covered all capabilities. Users in Cap. only and Cap.+templ. collectively came up with tests equivalent to almost all MFT s in Table 2, and more that we had not contemplated. Users in Unaided and Cap. only often did not find more bugs because they lacked test case variety even when testing the right concepts (e.g. negation). At the end of the experiment, we ask users to evaluate the severity of the failures they observe on each particular test, on a 5 point scale[^6]. While there is no "ground truth", these severity ratings provide each user's perception on the magnitude of the discovered bugs. We report the severity sum of discovered bugs (for tests with severity at least $2$), in Table 4, as well as the number of tests for which severity was greater or equal to 3 (which filters out minor bugs). We note that users with CheckList (Cap. only and Cap.+templ.) discovered much more severe problems in the model (measured by total severity or # bugs) than users in the control condition (Unaided). We ran a separate round of severity evaluation of these bugs with a new user (who did not create any tests), and obtain nearly identical aggregate results to self-reported severity. The study results are encouraging: with a subset of CheckList, users without prior experience are able to find significant bugs in a SOTA model in only $2$ hours. Further, when asked to rate different aspects of CheckList (on a scale of 1-5), users indicated the testing session helped them learn more about the model ($4.7 \pm 0.5$), capabilities helped them test the model more thoroughly ($4.5 \pm 0.4$), and so did templates ($4.3 \pm 1.1$).
[^6]: 1 (not a bug), 2 (minor bug), 3 (bug worth investigating and fixing), 4 (severe bug, model may not be fit for production), and 5 (no model with this bug should be in production).
5. Related Work
Section Summary: Researchers have used challenge datasets to test specific language skills in AI models, offering precise control but often limited in scale and realism, and mostly focused on tasks like natural language inference; CheckList builds on this by combining controlled examples with tests on real data to spot bugs even in straightforward cases, as shown in quick user studies that uncovered serious flaws in sentiment analysis and question-answering models. Probes that analyze hidden layers of deep learning models reveal linguistic insights but fail to show how well the full model performs on actual tasks, such as named entity recognition in fine-tuned versions of BERT, where accuracy drops sharply. While CheckList organizes and expands on existing methods like perturbations for checking consistency or robustness, it is limited to behavioral evaluations and cannot address issues like data errors, biases, or security vulnerabilities.
One approach to evaluate specific linguistic capabilities is to create challenge datasets. [19] note benefits of this approach, such as systematic control over data, as well as drawbacks, such as small scale and lack of resemblance to "real" data. Further, they note that the majority of challenge sets are for Natural Language Inference. We do not aim for CheckList to replace challenge or benchmark datasets, but to complement them. We believe CheckList maintains many of the benefits of challenge sets while mitigating their drawbacks: authoring examples from scratch with templates provides systematic control, while perturbation-based INV and DIR tests allow for testing behavior in unlabeled, naturally-occurring data. While many challenge sets focus on extreme or difficult cases [20], MFT s also focus on what should be easy cases given a capability, uncovering severe bugs. Finally, the user study demonstrates that CheckList can be used effectively for a variety of tasks with low effort: users created a complete test suite for sentiment analysis in a day, and MFT s for QQP in two hours, both revealing previously unknown, severe bugs.
With the increase in popularity of end-to-end deep models, the community has turned to "probes", where a probing model for linguistic phenomena of interest (e.g. NER) is trained on intermediate representations of the encoder [21, 22]. Along similar lines, previous work on word embeddings looked for correlations between properties of the embeddings and downstream task performance [23, 24]. While interesting as analysis methods, these do not give users an understanding of how a fine-tuned (or end-to-end) model can handle linguistic phenomena for the end-task. For example, while [21] found that very accurate NER models can be trained using BERT (96.7%), we show BERT finetuned on QQP or SST-2 displays severe NER issues.
There are existing perturbation techniques meant to evaluate specific behavioral capabilities of NLP models such as logical consistency [11] and robustness to noise [6], name changes [10], or adversaries [8]. CheckList provides a framework for such techniques to systematically evaluate these alongside a variety of other capabilities. However, CheckList cannot be directly used for non-behavioral issues such as data versioning problems [25], labeling errors, annotator biases [26], worst-case security issues [27], or lack of interpretability [12].
6. Conclusion
Section Summary: Although accuracy on standard benchmarks is helpful, it's not enough to fully evaluate natural language processing models, so the authors introduce CheckList, a flexible testing method inspired by software engineering that checks specific model abilities across different test types and works for any model or task. This approach uncovers major issues in top-performing models and even commercial systems, showing it works well alongside existing evaluation tools. User studies confirm CheckList is simple for both experts and newcomers to use, with its open-source tests and tools enabling collaborative creation of more thorough, reusable evaluations that go beyond basic accuracy measures.
While useful, accuracy on benchmarks is not sufficient for evaluating NLP models. Adopting principles from behavioral testing in software engineering, we propose CheckList, a model-agnostic and task-agnostic testing methodology that tests individual capabilities of the model using three different test types. To illustrate its utility, we highlight significant problems at multiple levels in the conceptual NLP pipeline for models that have "solved" existing benchmarks on three different tasks. Further, CheckList reveals critical bugs in commercial systems developed by large software companies, indicating that it complements current practices well. Tests created with CheckList can be applied to any model, making it easy to incorporate in current benchmarks or evaluation pipelines.
Our user studies indicate that CheckList is easy to learn and use, and helpful both for expert users who have tested their models at length as well as for practitioners with little experience in a task. The tests presented in this paper are part of CheckList's open source release, and can easily be incorporated into existing benchmarks. More importantly, the abstractions and tools in CheckList can be used to collectively create more exhaustive test suites for a variety of tasks. Since many tests can be applied across tasks as is (e.g. typos) or with minor variations (e.g. changing names), we expect that collaborative test creation will result in evaluation of NLP models that is much more robust and detailed, beyond just accuracy on held-out data. CheckList is open source, and available at https://github.com/marcotcr/checklist.
Acknowledgments
Section Summary: The acknowledgments section expresses gratitude to Sara Ribeiro, Scott Lundberg, Matt Gardner, Julian Michael, and Ece Kamar for their valuable discussions and feedback on the work. It also notes that Sameer received partial funding from the National Science Foundation under award number IIS-1756023. Additionally, support came from the DARPA MCS program through a contract with the United States Office of Naval Research, numbered N660011924033.
We would like to thank Sara Ribeiro, Scott Lundberg, Matt Gardner, Julian Michael, and Ece Kamar for helpful discussions and feedback. Sameer was funded in part by the NSF award #IIS-1756023, and in part by the DARPA MCS program under Contract No. N660011924033 with the United States Office of Naval Research.
References
Section Summary: This references section lists over two dozen academic papers and resources focused on natural language processing (NLP) and machine learning, including datasets for testing question-answering systems, methods for evaluating model robustness against errors or biases, and tools for explaining AI predictions. It covers topics like adversarial examples to debug models, benchmarks such as GLUE for language understanding, and techniques from software testing applied to AI, such as black-box and metamorphic testing. The citations span conferences, journals, and preprints from 1995 to 2019, highlighting foundational and recent advances in making AI systems more reliable and interpretable.
[1] Pranav Rajpurkar, Jian Zhang, Konstantin Lopyrev, and Percy Liang. 2016. Squad: 100,000+ questions for machine comprehension of text. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, pages 2383–2392.
[2] Pranav Rajpurkar, Robin Jia, and Percy Liang. 2018. Know what you don{'}t know: Unanswerable questions for {SQ}u{AD}. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pages 784–789, Melbourne, Australia. Association for Computational Linguistics.
[3] Kayur Patel, James Fogarty, James A Landay, and Beverly Harrison. 2008. Investigating statistical machine learning as a tool for software development. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, pages 667–676. ACM.
[4] Benjamin Recht, Rebecca Roelofs, Ludwig Schmidt, and Vaishaal Shankar. 2019. Do imagenet classifiers generalize to imagenet? In International Conference on Machine Learning, pages 5389–5400.
[5] Tongshuang Wu, Marco Tulio Ribeiro, Jeffrey Heer, and Daniel S Weld. 2019. Errudite: Scalable, reproducible, and testable error analysis. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 747–763.
[6] Yonatan Belinkov and Yonatan Bisk. 2018. Synthetic and natural noise both break neural machine translation. In International Conference on Learning Representations.
[7] Barbara Rychalska, Dominika Basaj, Alicja Gosiewska, and Przemysław Biecek. 2019. Models in the wild: On corruption robustness of neural nlp systems. In International Conference on Neural Information Processing, pages 235–247. Springer.
[8] Marco Tulio Ribeiro, Sameer Singh, and Carlos Guestrin. 2018. Semantically equivalent adversarial rules for debugging nlp models. In Association for Computational Linguistics (ACL).
[9] Mohit Iyyer, John Wieting, Kevin Gimpel, and Luke Zettlemoyer. 2018. Adversarial example generation with syntactically controlled paraphrase networks. In Proceedings of NAACL-HLT, pages 1875–1885.
[10] Vinodkumar Prabhakaran, Ben Hutchinson, and Margaret Mitchell. 2019. Perturbation sensitivity analysis to detect unintended model biases. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 5740–5745, Hong Kong, China. Association for Computational Linguistics.
[11] Marco Tulio Ribeiro, Carlos Guestrin, and Sameer Singh. 2019. Are red roses red? evaluating consistency of question-answering models. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 6174–6184.
[12] Marco Tulio Ribeiro, Sameer Singh, and Carlos Guestrin. 2016. Why should i trust you?: Explaining the predictions of any classifier. In Proceedings of the 22nd ACM SIGKDD international conference on knowledge discovery and data mining, pages 1135–1144. ACM.
[13] Alex Wang, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy, and Samuel R. Bowman. 2019b. {GLUE}: A multi-task benchmark and analysis platform for natural language understanding. In International Conference on Learning Representations.
[14] Boris Beizer. 1995. Black-box Testing: Techniques for Functional Testing of Software and Systems. John Wiley & Sons, Inc., New York, NY, USA.
[15] Sergio Segura, Gordon Fraser, Ana B Sanchez, and Antonio Ruiz-Cortés. 2016. A survey on metamorphic testing. IEEE Transactions on software engineering, 42(9):805–824.
[16] Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. 2019. Roberta: A robustly optimized bert pretraining approach. arXiv preprint arXiv:1907.11692.
[17] Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pierric Cistac, Tim Rault, R'emi Louf, Morgan Funtowicz, and Jamie Brew. 2019. Huggingface's transformers: State-of-the-art natural language processing. ArXiv, abs/1910.03771.
[18] Alex Wang, Yada Pruksachatkun, Nikita Nangia, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy, and Samuel Bowman. 2019a. Superglue: A stickier benchmark for general-purpose language understanding systems. In Advances in Neural Information Processing Systems, pages 3261–3275.
[19] Yonatan Belinkov and James Glass. 2019. Analysis methods in neural language processing: A survey. Transactions of the Association for Computational Linguistics, 7:49–72.
[20] Aakanksha Naik, Abhilasha Ravichander, Norman Sadeh, Carolyn Rose, and Graham Neubig. 2018. Stress Test Evaluation for Natural Language Inference. In International Conference on Computational Linguistics (COLING).
[21] Ian Tenney, Dipanjan Das, and Ellie Pavlick. 2019. {BERT} rediscovers the classical {NLP} pipeline. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 4593–4601, Florence, Italy. Association for Computational Linguistics.
[22] Najoung Kim, Roma Patel, Adam Poliak, Patrick Xia, Alex Wang, Tom McCoy, Ian Tenney, Alexis Ross, Tal Linzen, Benjamin Van Durme, et al. 2019. Probing what different nlp tasks teach machines about function word comprehension. In Proceedings of the Eighth Joint Conference on Lexical and Computational Semantics ( SEM 2019)*, pages 235–249.
[23] Yulia Tsvetkov, Manaal Faruqui, and Chris Dyer. 2016. Correlation-based intrinsic evaluation of word vector representations. In Proceedings of the 1st Workshop on Evaluating Vector-Space Representations for NLP, pages 111–115, Berlin, Germany. Association for Computational Linguistics.
[24] Anna Rogers, Shashwath Hosur Ananthakrishna, and Anna Rumshisky. 2018. What{'}s in your embedding, and how it predicts task performance. In Proceedings of the 27th International Conference on Computational Linguistics, pages 2690–2703, Santa Fe, New Mexico, USA. Association for Computational Linguistics.
[25] Saleema Amershi, Andrew Begel, Christian Bird, Rob DeLine, Harald Gall, Ece Kamar, Nachi Nagappan, Besmira Nushi, and Tom Zimmermann. 2019. Software engineering for machine learning: A case study. In International Conference on Software Engineering (ICSE 2019) - Software Engineering in Practice track. IEEE Computer Society.
[26] Mor Geva, Yoav Goldberg, and Jonathan Berant. 2019. Are we modeling the task or the annotator? an investigation of annotator bias in natural language understanding datasets. In Empirical Methods in Natural Language Processing (EMNLP), pages 1161–1166.
[27] Eric Wallace, Shi Feng, Nikhil Kandpal, Matt Gardner, and Sameer Singh. 2019. Universal adversarial triggers for attacking and analyzing nlp. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 2153–2162.