Making Text Embedders Few-Shot Learners
Chaofan Li $^{1,2,}$, MingHao Qin $^{1,3,}$, Shitao Xiao $^{1}$, Jianlyu Chen $^{1,4}$, Kun Luo $^{1,3}$, Yingxia Shao $^{2}$, Defu Lian $^{4}$, Zheng Liu $^{1\dagger}$
1: Beijing Academy of Artificial Intelligence
2: Beijing University of Posts and Telecommunications
3: Chinese Academy of Sciences
4: University of Science and Technology of China
{cfli, shaoyx}@bupt.edu.cn [email protected]
[email protected] [email protected]
[email protected] {luokun695, zhengliu1026}@gmail.com
$^{*}$ Co-first authors
$^{\dagger}$ Corresponding author
Abstract
Large language models (LLMs) with decoder-only architectures demonstrate remarkable in-context learning (ICL) capabilities. This feature enables them to effectively handle both familiar and novel tasks by utilizing examples provided within their input context. Recognizing the potential of this capability, we propose leveraging the ICL feature in LLMs to enhance the process of text embedding generation. To this end, we introduce a novel model bge-en-icl, which employs few-shot examples to produce high-quality text embeddings. Our approach integrates task-related examples directly into the query side, resulting in significant improvements across various tasks. Additionally, we have investigated how to effectively utilize LLMs as embedding models, including various attention mechanisms, pooling methods, etc. Our findings suggest that retaining the original framework often yields the best results, underscoring that simplicity is best. Experimental results on the MTEB and AIR-Bench benchmarks demonstrate that our approach sets new state-of-the-art (SOTA) performance. Our model, code and dataset are freely available at https://github.com/FlagOpen/FlagEmbedding.
Executive Summary: Text embeddings—vector representations that capture the meaning of text—are essential for applications like search engines, recommendation systems, and question answering. However, existing models based on large language models (LLMs) often falter on unfamiliar tasks or instructions, limiting their real-world flexibility. This is a pressing issue as AI systems increasingly handle diverse, evolving queries in global contexts, where retraining for every new scenario is costly and inefficient.
This document introduces bge-en-icl, a new embedding model that harnesses in-context learning (ICL)—the ability of LLMs to adapt via examples in prompts—to generate more versatile text representations. The goal was to evaluate whether adding few-shot examples to queries during training and use could boost embedding quality without major architectural changes, while testing optimal ways to adapt LLMs for this purpose.
The researchers fine-tuned the open-source Mistral-7B LLM using contrastive learning on public datasets covering retrieval, classification, and clustering tasks, spanning sources like MSMARCO and SQuAD. Training involved one epoch with low-rank adaptation for efficiency, incorporating 0 to 5 randomized in-batch examples per query to build ICL skills without harming zero-shot performance. Evaluations used the MTEB benchmark (56 English tasks) and AIR-Bench (retrieval-focused, out-of-domain data), comparing zero-shot (no examples) and few-shot scenarios over recent periods.
Key findings show bge-en-icl achieves state-of-the-art results in few-shot settings: 66.08 average on MTEB (1.41 points above baselines like GritLM), with gains of 1-4 points in classification and clustering. On AIR-Bench, it improved question-answering retrieval by 1.43 points and long-document recall by 1.08 points versus zero-shot. Using in-batch examples preserved zero-shot scores (slight 0.16-point drop) while enabling few-shot boosts of up to 3.96 points. Simpler setups—retaining causal attention and last-token pooling—outperformed bidirectional modifications or mean pooling, yielding 1-2 point edges. A companion multilingual model, bge-multilingual-gemma2, set new highs on MIRACL (74.1 nDCG@10 across 18 languages) and French/Polish benchmarks (70+ averages), while a lightweight reranker enhanced retrieval by 5-10 points on BEIR with 60% fewer operations.
These results mean embedding models can now adapt dynamically to new tasks via prompts, improving accuracy in unseen domains by 2-4% without retraining, which cuts costs and speeds deployment in search or multilingual apps. Unlike prior work focused on complex tweaks, this emphasizes simplicity, aligning with LLMs' strengths and avoiding performance mismatches. The multilingual advances address global needs, where English-centric models lag, potentially raising retrieval effectiveness by 10-15% in non-English settings.
Leaders should integrate bge-en-icl or the multilingual variant into systems requiring flexible embeddings, starting with few-shot prompts for high-stakes retrieval. For the lightweight reranker, pilot it in production pipelines to balance speed and accuracy, trading minor score drops (1-2 points) for efficiency gains. Further work could extend ICL to the multilingual model and test on proprietary data; a pilot with real user queries would confirm scalability.
Limitations include reliance on public datasets, which may understate full-data overfitting risks, and primary focus on English (multilingual is preliminary). Confidence is high in few-shot superiority based on benchmark consistency, but zero-shot results match rather than exceed leaders—exercise caution for no-example scenarios and validate with domain-specific data.
1. Introduction
Section Summary: Text embeddings are numerical representations that capture the meaning and context of words and sentences, making them essential for tasks like searching information, classifying text, or answering questions in natural language processing. Recent large language models have improved these embeddings, but they still falter with unfamiliar instructions or complex retrieval, so researchers propose using in-context learning—providing examples right in the input prompt—to make embeddings more flexible and effective across different scenarios. Their approach, which keeps the model simple without major changes, achieves top performance on key benchmarks and includes open-source models for English, multilingual use, and a lightweight tool for reranking.
Text embeddings are vector representations that capture the semantic and contextual meaning of natural language text. They play a pivotal role in natural language processing (NLP) tasks, facilitating a wide range of applications such as information retrieval, text classification, item recommendation, and question answering ([1, 2, 3]). Pre-trained bidirectional encoder and encoder-decoder architectures have been widely adopted as backbone models for embedding model, owing to their effectiveness in producing high-quality vector embeddings for text thanks to their extensive pre-training ([4, 5]).
Recent advancements in LLMs have significantly shifted the focus towards embedding models that rely primarily on decoder-only architectures ([6, 7, 8]). These LLM-based embedding models have demonstrated remarkable improvements in in-domain accuracy and generalization, particularly when trained using supervised learning approaches ([8]). However, despite these advances, embedding models still struggle to follow unseen task instructions and execute complex retrieval tasks [9, 10]. This limitation stems from a mismatch between the relatively narrow range of instructions encountered during training and the broader variety of real-world text embedding tasks.
In-context learning (ICL) is a core capability of LLMs, enabling them to incorporate task-specific examples directly into input prompts to generate desired outputs ([11, 12, 13]). The scope of ICL extends beyond tasks seen during training; it enables LLMs to generalize to new and complex tasks by learning patterns from the provided examples. This allows LLMs to adapt dynamically to novel tasks without additional training, making them highly applicable to large-scale, real-world scenarios ([14, 15, 16]).
Recognizing the robust ICL abilities of LLMs, in this study, we propose to generate more adaptable text embeddings with ICL strategy. Specifically, we guide the model by including task-specific examples directly within the query prompt. By doing so, we leverage the ICL capabilities of LLMs to produce embeddings that are not only more relevant to the specific domain but also more generalizable across various contexts.
Moreover, LLMs are predominantly utilized for text generation tasks, and adapting them for embedding representation tasks requires specific fine-tuning strategies. Recent studies have introduced various approaches, including the generation of high-quality training data through LLMs ([8]), modifications to attention mechanisms, and changes in pooling methods ([6, 7]). Following previous works ([17, 18]), we investigate how to effectively utilize LLMs as embedding models by modifying various architectures, e.g., bidirectional attention, meaning pooling, etc. Our experimental findings indicate that in the ICL scenario, making complex modifications to the models does not lead to significant improvements. Surprisingly, the best results are obtained using the original, unmodified architecture. By employing only the ICL strategy, our model bge-en-icl achieves state-of-the-art (SOTA) results on both the MTEB and AIR-Bench benchmarks. We have also released a multi-language embedding model bge-multilingual-gemma2 and a lightweight reranker bge-reranker-v2.5-gemma2-lightweight. The lightweight reranker also serves as the teacher model for training embedding models through distillation. Further details are provided in Appendix C and Appendix D.
In summary, the key contributions of our work are as follows:
- We propose bge-en-icl, which incorporate few-shot examples into the query side to enhance the query embeddings. This integration leverages the in-context learning (ICL) capabilities of large language models (LLMs) in text embedding tasks.
- We rethink and explore how to effectively utilize LLMs as embedding models by evaluating various attention mechanisms, pooling methods, and the incorporation of passage prompts. Our findings highlight that simplicity is best; simply combining ICL capabilities with embedding models can achieve excellent performance.
- In contrast to other leading models on the MTEB benchmark, we provide open access to our model checkpoint, dataset, and training scripts.
2. Related Work
Section Summary: Text embedding, a key technique in information retrieval for tasks like web search and question answering, involves converting queries and documents into numerical vectors that can be compared for similarity, with recent advances building on powerful pre-trained language models like BERT and T5 that outperform older methods. Researchers have increasingly turned to large language models (LLMs) as the core of these systems, with projects like Repllama and Llama2Vec fine-tuning them for better retrieval performance, while others like E5-mistral use synthetic data or unsupervised approaches such as LLM2Vec to create versatile embeddings for both search and other tasks. Although these efforts yield strong results, they often overlook LLMs' built-in ability to learn from examples in context, which the authors' model exploits to achieve top performance without extra customization.
Text embedding is a critical research direction in the field of information retrieval, with wide-ranging applications including web search, question answering, and dialogue systems. The fundamental principle involves encoding both queries and documents into embedding vectors within the same latent space. By calculating similarity scores between these vectors, effective retrieval is achieved. In recent years, numerous studies have leveraged pre-trained language models such as BERT ([19]), T5 ([20]), and RoBERTa ([21]) as the backbone for embedding models. These models have consistently demonstrated superior performance compared to traditional sparse retrieval methods.
The capability of the backbone is a crucial determinant in the effectiveness of retrieval systems. ([22]) have demonstrated that performance improves with increased scale and extensive pre-training. Currently, numerous studies have explored the effectiveness of utilizing LLMs as backbone encoders for text embedding tasks.
Repllama ([6]) fine-tuned Llama-2 to serve as both a dense retriever and a reranker, demonstrating the effectiveness of applying large language models (LLMs) in text embedding tasks. To further align LLMs with text embedding tasks, Llama2Vec ([7]) introduced two pretraining tasks specifically designed to enhance the model's performance in such tasks, which led to significant improvements on the BEIR benchmark. E5-mistral and Gecko ([8, 23]) advanced the training of LLM-based embedding models through the use of synthetic data, markedly boosting their performance across a diverse range of retrieval and non-retrieval tasks. NV-Embed ([24]) innovatively proposed a latent attention layer to replace conventional pooling methods and implemented a two-stage training strategy to address the challenge of false negatives in non-retrieval tasks. This model has shown strong performance in both retrieval and non-retrieval domains. Additionally, GRIT ([17]) successfully integrated text embedding and generation within a single LLM, achieving performance levels on par with specialized models focused solely on either embedding or generation. In the exploration of LLMs as embedding models from an unsupervised perspective, LLM2Vec ([18]) presented a novel unsupervised method to transform decoder-only LLMs into embedding models. This approach demonstrated significant potential for modifying LLM backbone encoders to perform retrieval without any supervision. Similarly, PromptReps ([25]) leveraged chat-based LLMs aligned with human preferences to generate high-quality dense representations in an unsupervised manner.
The LLM-based embedding models mentioned above exhibit commendable performance across both retrieval and non-retrieval tasks. However, much of the existing work has disproportionately focused on altering model architectures, thereby neglecting the intrinsic capabilities of LLMs. Even models like GritLM, which integrate generation and embedding functionalities, fail to fully exploit the potential ICL capabilities of LLMs within the embedding process. By leveraging the innate ICL capabilities of LLMs, embedding models can be more versatile and adapt to diverse scenarios without necessitating additional fine-tuning. Our model not only achieves SOTA results on the MTEB and AIR-Bench benchmarks but also effectively utilizes the inherent strengths of LLMs across tasks.
3. Methology
Section Summary: Researchers propose enhancing embedding models, which convert text into numerical representations for tasks like search, by using in-context learning from large language models. This involves adding task instructions and a few example query-response pairs to new queries before encoding them, then training the model with a contrastive loss to better match relevant texts while using the model's built-in one-way attention mechanism and end-of-sequence tokens for representations. Their method avoids past issues with following instructions and aims to boost adaptability across various real-world scenarios without harming the model's core abilities.
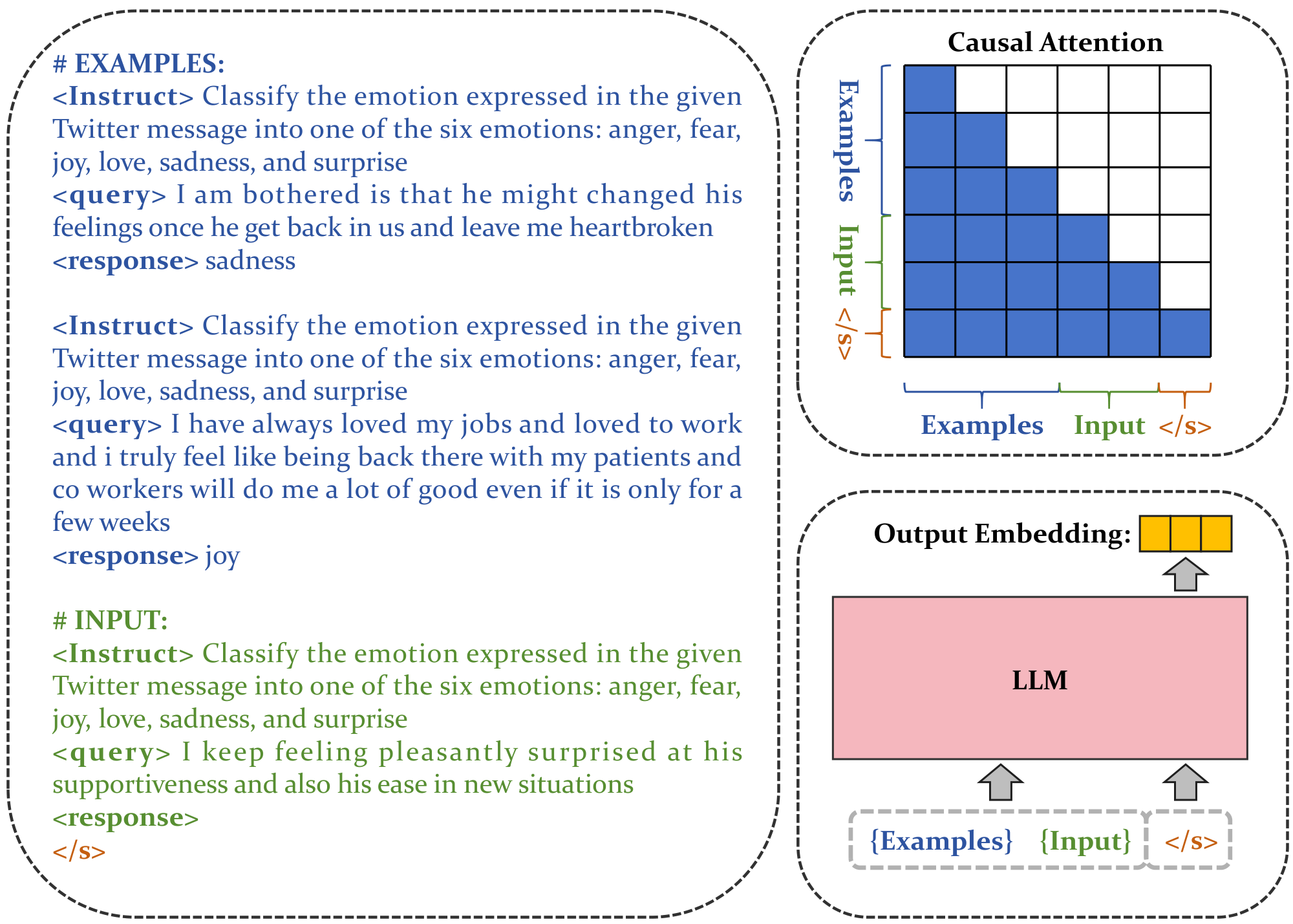
3.1 In-Context Learning for Embedding Models
Previous embedding models often involve directly inputting the query into the model to generate target embeddings. However, this method struggles to handle tasks with different intents, limiting the model's adaptability and generalization capabilities. To address this, researchers have introduced task instructions ([26]) appended to queries, enabling a single embedding model to generalize across tasks in various domains by altering the instructions.
Despite these advances, studies such as [9, 10] reveal that embedding models have a limited ability to follow unseen embedding task instructions and conduct complex retrieval tasks. This limitation arises from a gap between the limited diversity of instructions seen during training and the vast range of real-world scenarios. Inspired by the ability of LLMs to generalize to unseen tasks through in-context learning (ICL), we explore whether embedding models can be enhanced by leveraging ICL, thereby significantly improving their generalization and versatility across diverse embedding tasks with various user intents.
In this work, we demonstrate the potential of embedding models to benefit from ICL through few-shot contrastive training. Consider a query-passage pair $(\mathrm{q}_i, \mathrm{p}_i)$ in an embedding task. We first construct an example template as follows:
$ \langle \text{Instruct} \rangle {\text{task_definition}} \newline \langle \text{query} \rangle {q_i} \newline \langle \text{response} \rangle {p_i} $
Here, "task_definition" represents the description of the specific embedding task. This example template is applied to new input queries for each embedding task (Figure 1). For a relevant query-passage pair $(\mathrm{q}^+, \mathrm{p}^+)$, the modified query $\mathrm{q}^+_{\mathrm{exp}}$ is constructed as follows:
$ {\text{example 1}} ... {\text{example n}} \langle \text{Instruct} \rangle {\text{task_definition}} \newline \langle \text{query} \rangle {q^+} \newline \langle \text{response} \rangle $
All modified queries and passages in the corpus are encoded using the same LLM to obtain their embedding representations. Specifically, we append an [EOS] token to the end of the input modified queries and passages, feeding them into the LLM to obtain embeddings $(\mathrm{h}{\mathrm{q}^+{\mathrm{exp}}}, \mathrm{h}_{\mathrm{p^+}})$ by extracting the final layer's [EOS] vector. We employ the standard InfoNCE ([27]) loss function $\mathrm{L}$, utilizing both in-batch negatives and hard negatives for training: \
$ \mathrm{L} = - \log \frac{\exp(\mathrm{s}(\mathrm{q}^+{\mathrm{exp}}, \mathrm{p}i^+))}{ \exp(\mathrm{s}(\mathrm{q}^+{\mathrm{exp}}, \mathrm{p}i^+)) + \sum\limits{j} \exp(\mathrm{s}(\mathrm{q}^+{\mathrm{exp}}, \mathrm{p}_j^-))}\tag{1} $
$\mathrm{p}_j^-$ denotes the set of negative passages, and $\mathrm{s}(\mathrm{q}, \mathrm{p})$ is the scoring function between the query and passage. In this work, we adopt a temperature-scaled cosine similarity function defined as:
$ \mathrm{s}(\mathrm{q}, \mathrm{p}) = \frac{1}{\tau} \cos(\mathrm{h}_q, \mathrm{h}_p) $
where $\tau$ is a temperature hyperparameter, which is fixed at 0.02 during training.
3.2 Representation Method
The attention mechanism in LLM-based embedding models is typically unidirectional, aligned with the next-token prediction task fundamental to their pre-training ([28]).
However, recent studies indicate that unidirectional attention may limit the model's capacity for representation learning. Evidence suggests that bidirectional attention is more effective at integrating contextual information, resulting in improved performance on certain tasks. For example, LLM2Vec ([18]) introduces an additional training phase with a masked token prediction task, preconditioning the model for bidirectional attention. Approaches such as NV-Embed ([24]) and GritLM ([17]) replace unidirectional attention with bidirectional attention during the embedding training phase, often employing mean pooling or more sophisticated latent attention layers to obtain representations for queries and passages.
Despite these advances, we argue that incorporating bidirectional attention during embedding fine-tuning creates a mismatch with the model's pre-training design, potentially undermining its in-context learning and generative properties. To address the trade-off between enhancing embedding representations for specific tasks and preserving the model's inherent generative properties for deep semantic pattern understanding, our approach retains the unidirectional attention mechanism, consistent with the majority of existing embedding methods.
We use the [EOS] token's output embedding as the vector representation for queries and passages, positioning it at the end of inputs to capture both semantic and ICL patterns through causal attention mechanisms, thereby aligning with the foundational pretraining methodology of LLMs. Specifically, given the tokenized input sequence $\mathrm{T}$: $\mathrm{[BOS]}$, $\mathrm{t}_1$, ..., $\mathrm{t}_N$ is sent into the LLM (Figure 1):
$ \mathrm{h}_t = \mathrm{LLM}(\mathrm{T})[\mathrm{EOS}] $
The text embedding is taken from the output embedding of the special token $\mathrm{[EOS]}$.
3.3 ICL-based Instruction-Tuning
While previous works ([8, 24]) have proposed the training method of instruction-tuning, which incorporates a large number of task-specific instructions during the training process, enabling the model to adapt to various downstream retrieval tasks based on different instructions, it is not applicable to the ICL strategy. As demonstrated by GRIT ([17]), directly supplying few-shot examples when generating embeddings can actually degrade model performance.
To incorporate ICL capabilities into models, we need to modify the conventional instruction tuning strategy. Our approach involves integrating ICL abilities during the training phase. Specifically, we provide task-relevant examples to the query throughout the training process, allowing the model to develop ICL capabilities as it learns.
Recognizing the risk of compromising zero-shot capabilities if examples are consistently provided during training, we propose a dynamic training process. In each training step, queries are supplied with a variable number of few-shot examples, ranging from zero to n, determined by a sampling function. This approach maintains a balance between developing ICL abilities and preserving zero-shot performance.
To further enhance the model's ICL capabilities, we introduce an innovative technique for examples selection. By incorporating in-batch pairs as few-shot examples, we train the model to better differentiate between examples and inputs, aims to improve the model's ability to generate reliable embeddings based on the provided examples.
4. Experimentens
Section Summary: This section explores experiments testing the effectiveness of a training method called in-context learning for large language models used in creating text embeddings, focusing on how well it works in scenarios with no examples (zero-shot) or a few examples (few-shot). Researchers use the Mistral-7B model as a base, train it on public and expanded datasets covering tasks like retrieval, classification, and clustering, and evaluate performance on benchmarks such as MTEB and AIR-Bench. The results show the model, named bge-en-icl, performs strongly, especially in few-shot settings where it outperforms others and adapts well to new tasks, demonstrating the value of incorporating example prompts during training.
In this section, we examine the effectiveness of the ICL training pipeline and reconsider the training methodologies for LLM-based embedding models.
- RQ 1: What is the effectiveness of the ICL training strategy for both zero-shot and few-shot learning scenarios?
- RQ 2: How does the ICL training strategy impact performance compared to traditional training methods?
- RQ 3: How does the integration of in-batch examples affect the performance of the ICL training strategy.
- RQ 4: What are the implications of replacing a causal attention mask with a bidirectional attention mask within the framework of LLMs?
- RQ 5: What is the impact of various representation strategies, including last token pooling and mean pooling, on model performance?
- RQ 6: Do passage-based prompts enhance performance in the ICL training strategy?
4.1 setup
LLM. Following E5-Mistral ([8]), SFR, and NV-Embedder ([24]), we have adopted Mistral-7B ([29]) as the backbone for our framework.
Evaluation. We evaluate the performance of our model on MTEB ([30]) and AIR-Bench. MTEB is a comprehensive benchmark designed to evaluate the performance of text embedding models. AIR-Bench is dedicated to the evaluation of retrieval performance, its testing data is automatically generated by large language models without human intervention.
Training Data. To ensure a fair comparison, we use the same public datasets from E5-Mistral ([8]), which includes ELI5 ([31]), HotpotQA ([32]), FEVER ([33]), MIRACL ([34]), MSMARCO passage and document ranking ([35]), NQ ([1]), NLI ([5]), SQuAD ([1]), TriviaQA ([1]), Quora Duplicate Questions ([36]), MrTyDi ([37]), DuReader ([38]), and T2Ranking ([39]), all of which are also used for LLM2Vec ([18]).
However, methods that typically perform exceptionally well, such as NV-Embedder ([24]) and SFR, often require more training data. Additionally, some of these methods, such as GTE-Qwen2 ([40]), do not disclose their sources of training data. In response, we have developed an enhanced version of our model that leverages a more comprehensive dataset, which includes the following training sets:
- Retrieval: ELI5, HotpotQA, FEVER, MSMARCO passage and document ranking, NQ, NLI, SQuAD, TriviaQA, Quora Duplicate Questions, Arguana ([41]), and FiQA ([42]).
- Reranking: SciDocsRR ([43]) and StackOverFlowDupQuestions ([44]).
- Classification: AmazonReviews-Classification ([45]), AmazonCounterfactual-Classification ([46]), Banking77-Classification ([47]), Emotion-Classification ([48]), TweetSentimentExtraction-Classification ([49]), MTOPIntent-Classification ([50]), IMDB-Classification ([51]), ToxicConversations-Classification ([52]).
- Clustering: Arxiv/Biorxiv/Medrxiv/Reddit/StackExchange-Clustering-S2S/P2P, TwentyNewsgroups-Clustering ([53]).
- STS: STS12 ([54]), STS22 ([55]), STS-Benchmark ([56]).
Training Detail. We fine-tune the Mistral-7B model using a contrastive loss and conduct the process over a single epoch. For efficient fine-tuning, we employ Low-Rank Adaptation (LoRA) ([57]), setting the LoRA rank to 64 and the LoRA alpha to 32, with a learning rate of 1e-4. For retrieval tasks, we use in-batch negatives, a strategy not adopted for other tasks. Each dataset incorporates 7 hard negatives. The batch size is set to 512 for retrieval tasks and 256 for other types of tasks. We maintain consistency by using the same dataset throughout one training step, and the maximum sequence length is set at 512 tokens. To distill the score from reranker in retrieval tasks, we use the bge-reranker model as the teacher. For in-context learning training, we implement a randomized sampling method. For each query, we select between 0 to 5 examples from the in-batch training data. The maximum allowable lengths for example queries and documents are set to 256 tokens each, and the combined length for a query with examples is set at 2048 tokens.
Evaluation. We evaluate the performance of our model under both zero-shot and few-shot conditions. In the few-shot scenario, a consistent set of in-context examples is applied to each query. The examples utilized for evaluation are sourced from training datasets. In cases where training datasets are unavailable, examples are generated using ChatGPT.
4.2 Main Results
::: {caption="Table 1: Top MTEB leaderboard models as of August 27, 2024."}
:::
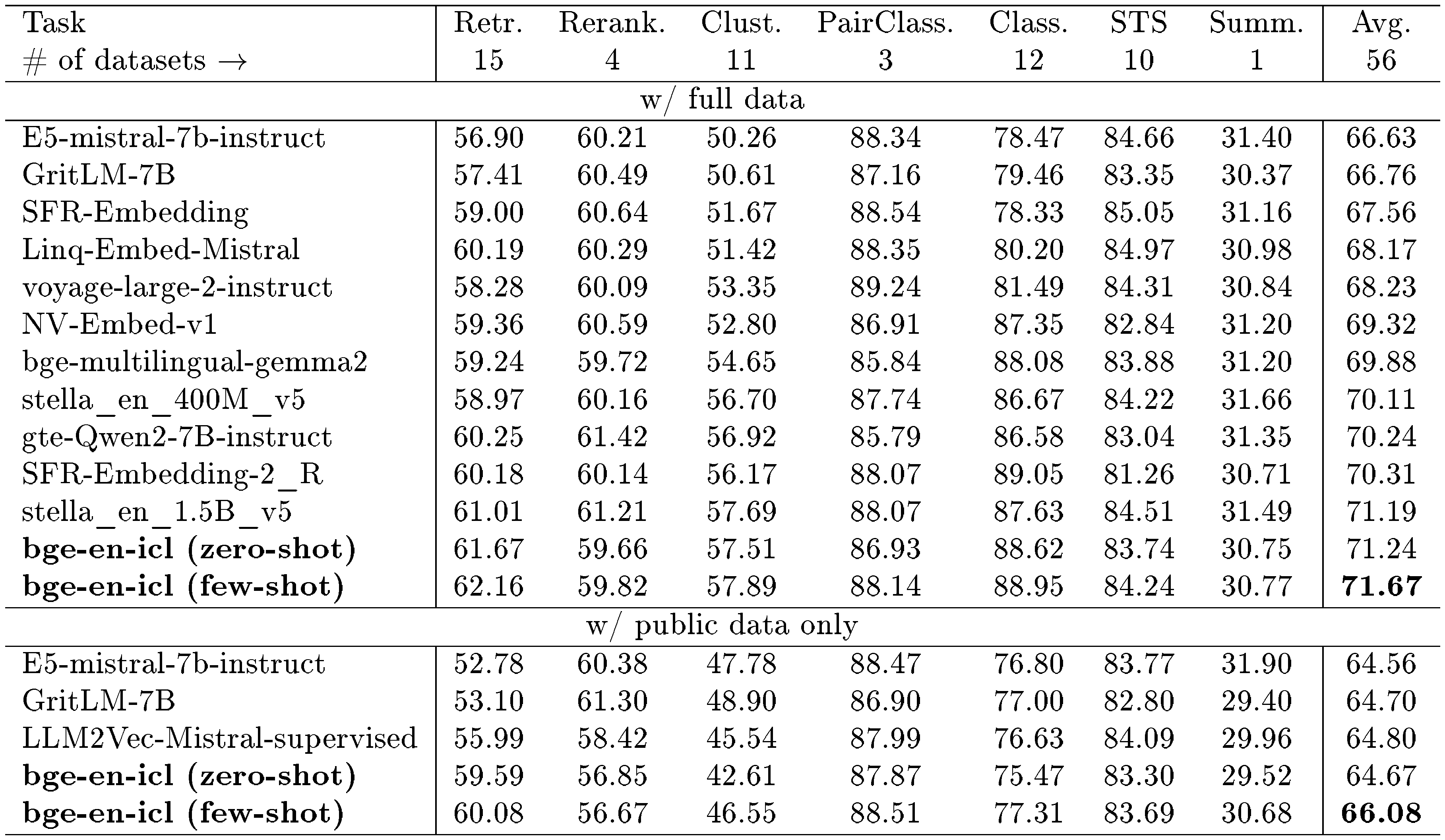
MTEB. Table 1 presents the performance of our model, bge-en-icl, evaluated on the MTEB benchmark. This evaluation contrasts the results obtained from using the full dataset with those obtained from using only the public dataset. When leveraging the full dataset, our model demonstrates strong capabilities in both zero-shot and few-shot settings, achieving SOTA results in few-shot scenarios. However, it is important to note that the use of full datasets may introduce inconsistencies, as different models often rely on varying datasets. Notably, many of these models do not disclose the specific datasets they use, leading to potential unfair comparisons.
For a fairer comparison and to better understand the impact of in-context learning, we conducts an evaluation using only the public dataset. Under these constraints, our model's performance in the zero-shot scenario is on par with, or slightly below, that of other models such as LLM2Vec and GritLM. However, in the few-shot settings, our model show significant enhancements (↑1.41), particularly in the classification and clustering tasks that were not part of the training data. These improvements underscore the potential advantages of in-context learning, emphasizing its efficacy in adapting to tasks beyond the direct scope of initial training parameters. Furthermore, in contrast to training exclusively with public datasets, the utilization of full training data effectively familiarizes the model with these datasets. As a result, the model's ability to generalize effectively is compromised, leading to only a modest improvement in few-shot settings (↑0.43).
::: {caption="Table 2: QA (en, nDCG@10) performance on AIR-Bench 24.04."}
:::
::: {caption="Table 3: Long-Doc (en, Recall@10) performance on AIR-Bench 24.04."}
:::
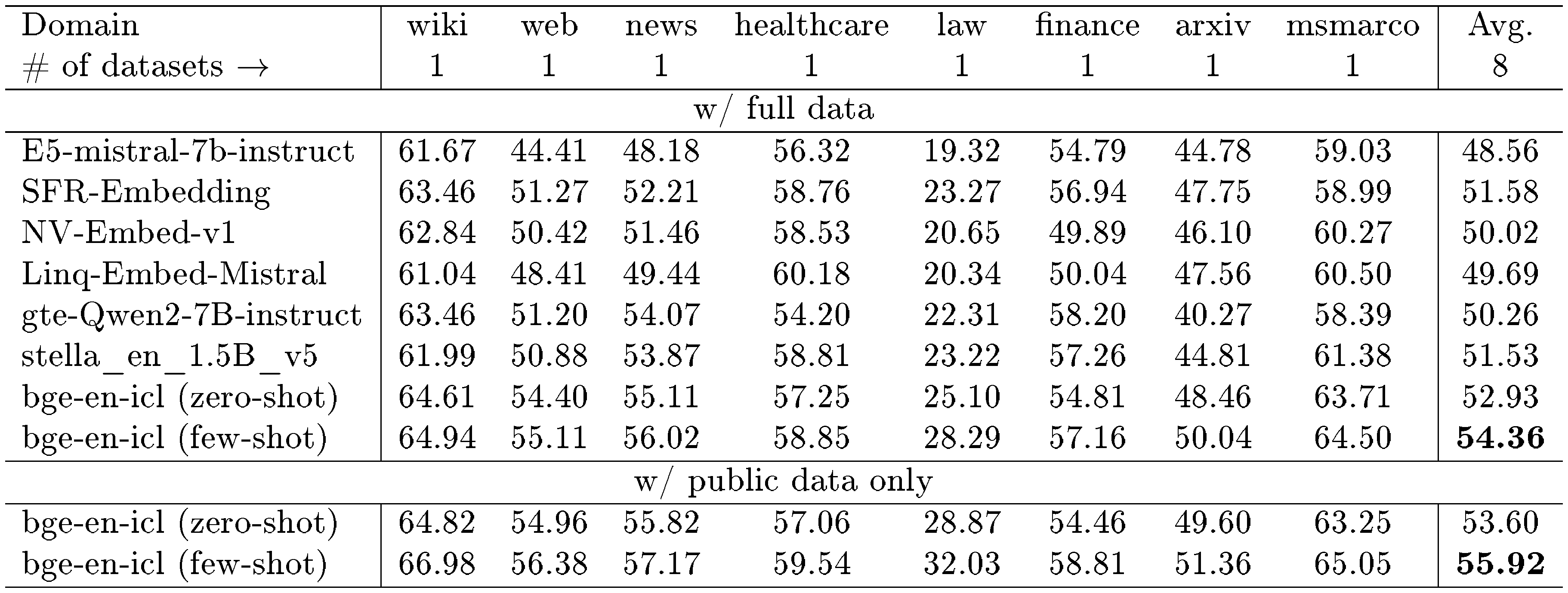
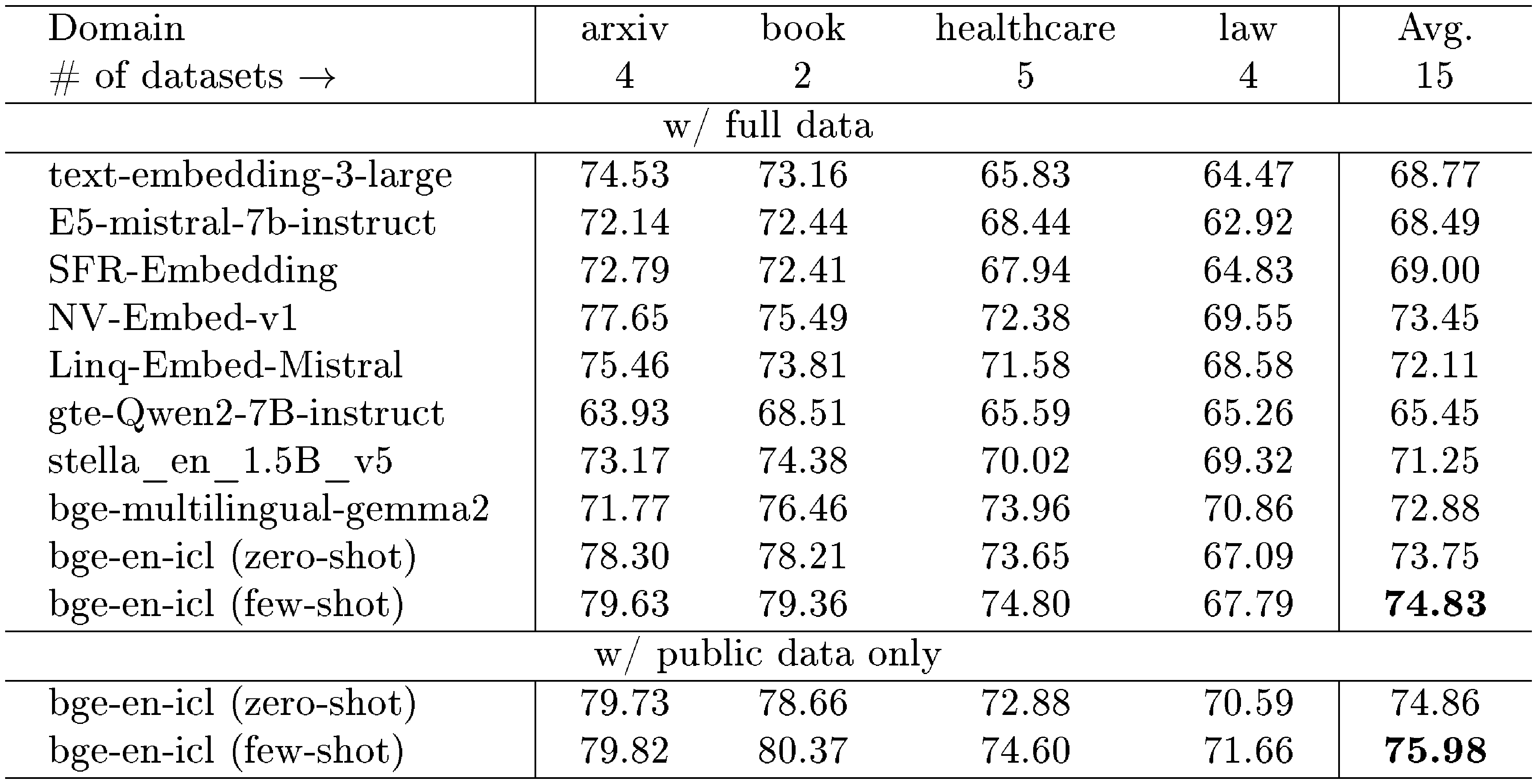
AIR-Bench. The performance of our model is also evaluated using the AIR-Bench dataset. As illustrated in Table 2 and Table 3, the model demonstrates superior performance compared to prior models in both zero-shot and few-shot scenarios, excelling across qa and long-doc tasks. Notably, there is no overlap between the training dataset and the evaluation data for these tasks, highlighting the robustness of the model in scenarios with limited prior exposure. In the few-shot setting, the model exhibits significant improvements over the zero-shot scenario, achieving gains of 1.43 points in the qa task and 1.08 points in the long-doc task. This improvement underscores the efficacy of in-context learning in enhancing the model's generalization capabilities.
However, when the model is trained exclusively using public data, it achieves better results compared to training with the full dataset. This could be attributed to the presence of an excessive amount of MTEB-related data, such as clustering and classification, within the full dataset. Such data might introduce the risk of overfitting, thereby potentially hampering the model's generalization performance on the AIR-Bench dataset.
4.3 In-context Learning
::: {caption="Table 4: Evaluation of various ICL strategies on the MTEB Benchmark."}
:::
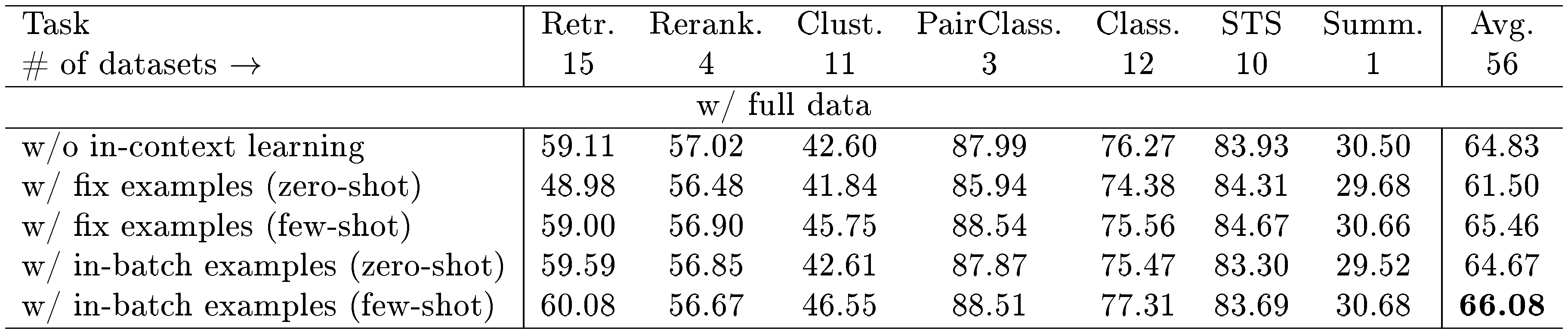
To evaluate the impact of the ICL strategy, we conduct a series of ablation studies using the MTEB benchmark. In these studies, we compare the performance of models fine-tuned with the ICL strategy against those fine-tuned without it. Specifically, for ICL training, we employ two distinct training approaches: fixed examples and in-batch examples. In the fixed examples approach, each task was trained using three predetermined examples.
In Table 4, we present various results from our experiment. When the model is trained without ICL strategy, its average performance is 64.83. This performance is comparable to GritLM ([17]), LLM2Vec ([18]), etc. When fixed examples are used during ICL training, there is a significant decline in zero-shot evaluation performance, with a decrease of 3.33 points. This decline is attributed to the model's consistent exposure to specific training examples, which can impair its zero-shot capabilities. On the other hand, in few-shot scenarios, the model demonstrates improved performance, exceeding zero-shot results by 3.96 points and surpassing models trained without ICL by 0.63 points. This also confirms the effectiveness of the ICL strategy.
Meanwhile, the use of in-batch examples, where training may involve zero examples, has preserved the zero-shot capability of the model. There is a modest decrease of 0.16 points compared to the model trained without ICL. Notably, in few-shot scenarios, the performance of the model employing in-batch examples rises to 66.08 (↑1.25), indicating a robust improvement. Furthermore, when compared with the model utilizing fixed examples, the model trained with in-batch examples displays superior performance in tasks that diverge significantly from the training data, such as classification and clustering tasks.
4.4 Attention
::: {caption="Table 5: Results of different attention and pooling mechanisms on the MTEB Benchmark."}
:::
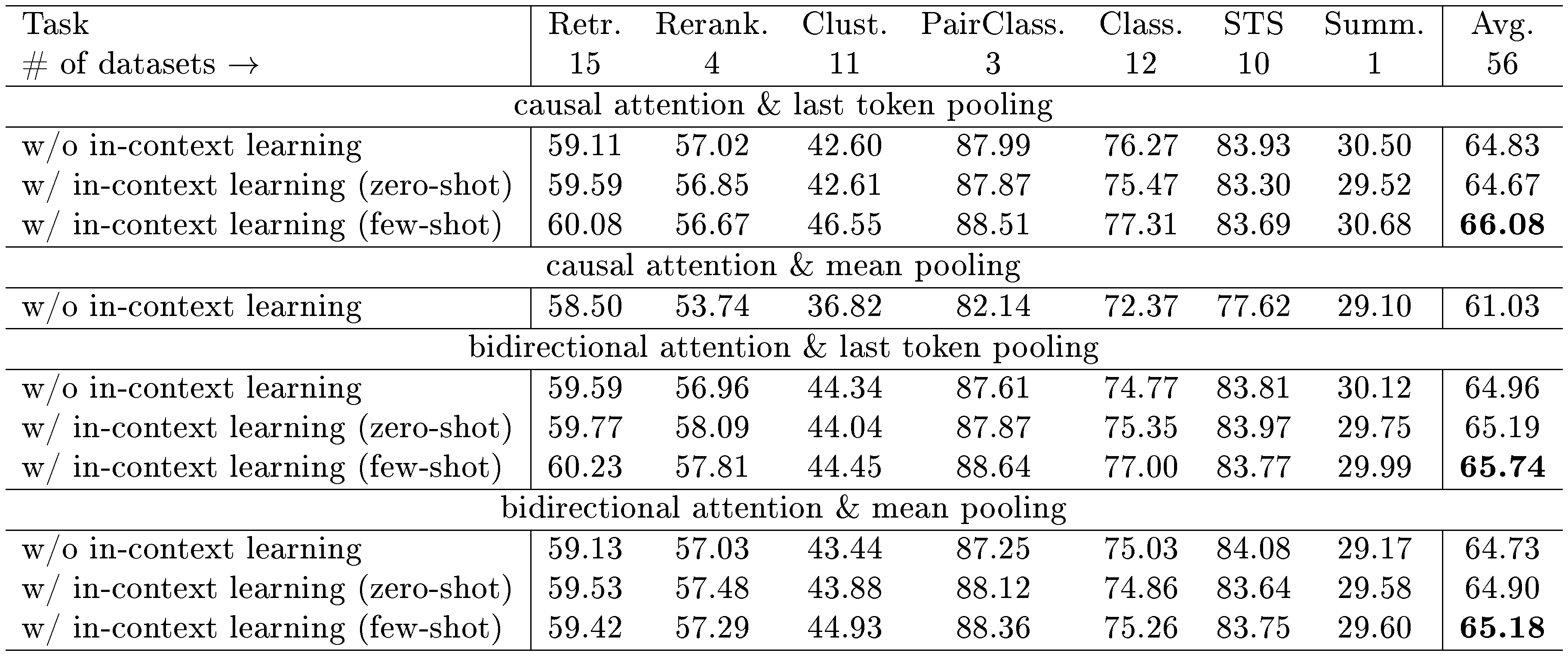
Recent studies have explored modifying causal attention in LLMs to adopt bidirectional attention and employ mean pooling for embedding generation. Notably, models such as GritLM ([17]), NV-Embed ([24]), and LLM2Vec ([18]) have utilized these techniques with considerable experimental success. Motivated by these advancements, we explore the potential benefits of implementing bidirectional attention in the ICL scenario. Specifically, we investigate the impacts of various attention and pooling mechanisms, including causal and bidirectional attention, coupled with last token pooling and mean pooling. In a causal attention framework, each token is limited to accessing only preceding tokens' information and not the subsequent ones. Consequently, employing mean pooling tends to yield suboptimal results because of this restriction. We find that the model could not be trained effectively under the ICL setting. Therefore, only results from experiments without ICL are presented in this specific configuration.
Table 5 presents our experimental setup and results in both non-ICL and ICL scenarios. It demonstrates that in non-ICL scenarios, most methods yield consistent performance, aside from the combination of causal attention with mean pooling. In contrast, within ICL scenarios, the integration of causal attention and last token pooling emerges as the superior approach. This configuration appears to resonate with the competencies fostered during the initial training phase of the model, suggesting a strong alignment with the foundational strategies employed during pre-training. Moreover, shifting from causal attention to bidirectional attention does not result in significant improvements, and mean pooling is not necessary for the implementation of bidirectional attention.
Additionally, configurations utilizing bidirectional attention paired with last token pooling are notably effective, excelling in both non-ICL and zero-shot scenarios. This configuration’s performance is also pronounced in few-shot reranking tasks, highlighting its adaptability and potential applicability across various demands.
4.5 Prompt
:Table 6: Comparative results of different prompts on the MTEB benchmark.
| Task | Retr. | Rerank. | Clust. | PairClass. | Class. | STS | Summ. | Avg. |
|---|---|---|---|---|---|---|---|---|
| # of datasets $\rightarrow$ | 15 | 4 | 11 | 3 | 12 | 10 | 1 | 56 |
| w/o passage prompt (zero-shot) | 59.59 | 56.85 | 42.61 | 87.87 | 75.47 | 83.30 | 29.52 | 64.67 |
| w/o passage prompt (few-shot) | 60.08 | 56.67 | 46.55 | 88.51 | 77.31 | 83.69 | 30.68 | 66.08 |
| w/ passage prompt (zero-shot) | 59.50 | 46.84 | 39.57 | 81.25 | 71.41 | 80.38 | 30.26 | 61.61 |
| w/ passage prompt (few-shot) | 59.93 | 46.39 | 39.40 | 82.25 | 72.00 | 79.81 | 30.97 | 61.74 |
Recently, most LLM-based embedding models have incorporated instruction-based prompts on the query side. However, there has been limited investigation into the efficacy of utilizing prompts on the passage side. To address this gap, our study introduces and explores the use of prompts on the passage side. The specific prompt employed in our study is as follows:
$ {\text{passage}} \newline \text{Summarize the above passage: } $
Table 6 presents the results obtained using passage prompts. The results demonstrate that the integration of passage prompts leads to a significant decline in performance across all tasks except retrieval. This indicates that further exploration and experimentation are needed when employing prompts at the passage level.
5. Conclusion
Section Summary: This paper examines how large language models can use in-context learning—a way of guiding the model with examples in prompts—to create text embeddings, testing features like attention mechanisms, pooling techniques, and special prompts for passages. The authors recommend sticking with the model's original design and simply tweaking the query prompts to incorporate this learning style into search processes, without any structural changes. Though straightforward, this method performs exceptionally well on standard benchmarks for text evaluation and retrieval tasks.
In this paper, we explore the utilization of in-context learning (ICL) derived from large language models (LLMs) for generating text embeddings and investigate various methods of LLMs as embedding models. Specifically, we examine the integration of attention mechanisms, different pooling methods, and passage prompts. We advocate for maintaining the model's original architecture while embedding in-context learning capabilities into the dense retrieval process. Our approach necessitates no modifications to the model's architecture; instead, it involves altering the prompt on the query side to include in-context learning features in the embedding generation task. Despite its simplicity, our method proves highly effective on the MTEB and AIR-Bench benchmarks.
Appendix
Section Summary: The appendix offers additional details on the research, starting with the instructions used for evaluating models on the MTEB and AIR-Bench benchmarks, followed by comprehensive MTEB results including performance scores across dozens of datasets for the bge-en-icl model in zero-shot and few-shot settings. It then describes the development of a new multilingual embedding model, bge-multilingual-gemma2, built on the Gemma-2-9b language model and trained on English, Chinese, and multilingual datasets using efficient techniques like LoRA and contrastive loss. This initial version achieves strong results on benchmarks such as MIRACL, FR-MTEB, PL-MTEB, and C-MTEB, though it has not yet explored in-context learning capabilities.
A. Instruction
::: {caption="Table 7: The instruction we used on the MTEB and AIR-Bench benchmarks."}

:::
B. Detailed MTEB Results
::: {caption="Table 8: MTEB results with full data."}
:::
:Table 9: MTEB results with public data only.
| Dataset | bge-en-icl (zero-shot) | bge-en-icl (few-shot) |
|---|---|---|
| ArguAna | 55.81 | 55.41 |
| ClimateFEVER | 45.17 | 45.14 |
| CQADupStack | 46.03 | 46.46 |
| DBPEDIA | 50.79 | 51.14 |
| FEVER | 91.96 | 92.42 |
| FiQA2018 | 58.49 | 58.15 |
| HotpotQA | 84.34 | 84.68 |
| MSMARCO | 46.52 | 46.56 |
| NFCorpus | 40.16 | 40.96 |
| Natural Question | 73.56 | 74.01 |
| QuoraRetrieval | 90.79 | 90.89 |
| SCIDOCS | 20.56 | 20.87 |
| SciFact | 78.10 | 79.65 |
| Touche2020 | 33.64 | 34.93 |
| TREC-COVID | 77.89 | 79.95 |
| BIOSSES | 86.80 | 87.49 |
| SICK-R | 83.83 | 83.69 |
| STS12 | 77.80 | 78.39 |
| STS13 | 84.90 | 85.62 |
| STS14 | 82.53 | 82.62 |
| STS15 | 88.33 | 88.52 |
| STS16 | 86.14 | 86.44 |
| STS17 | 91.65 | 91.79 |
| STS22 | 63.79 | 64.83 |
| STSBenchmark | 87.27 | 87.52 |
| SummEval | 29.52 | 30.68 |
| SprintDuplicateQuestions | 94.79 | 96.09 |
| TwitterSemEval2015 | 81.53 | 82.04 |
| TwitterURLCorpus | 87.30 | 87.39 |
| AmazonCounterfactual | 80.78 | 83.36 |
| AmazonPolarity | 88.57 | 92.69 |
| AmazonReviews | 47.55 | 49.85 |
| Banking77 | 87.57 | 88.70 |
| Emotion | 54.29 | 54.24 |
| Imdb | 81.14 | 84.96 |
| MassiveIntent | 78.54 | 79.24 |
| MassiveScenario | 79.27 | 82.00 |
| MTOPDomain | 95.57 | 96.61 |
| MTOPIntent | 85.32 | 88.19 |
| ToxicConversations | 63.58 | 64.68 |
| TweetSentimentExtraction | 63.47 | 63.16 |
| Arxiv-P2P | 47.22 | 48.97 |
| Arxiv-S2S | 42.87 | 45.35 |
| Biorxiv-P2P | 33.17 | 38.37 |
| Biorxiv-S2S | 35.00 | 37.05 |
| Medrxiv-P2P | 28.74 | 30.24 |
| Medrxiv-S2S | 28.10 | 31.45 |
| 53.83 | 59.14 | |
| Reddit-P2P | 64.40 | 65.51 |
| StackExchange | 57.50 | 68.61 |
| StackExchange-P2P | 34.21 | 36.01 |
| TwentyNewsgroups | 43.65 | 51.40 |
| AskUbuntuDupQuestions | 63.71 | 62.96 |
| MindSmallRerank | 27.90 | 27.90 |
| SciDocsRR | 84.31 | 84.24 |
| StackOverflowDupQuestions | 51.48 | 51.56 |
| MTEB Average (56) | 64.67 | 66.08 |
C. Multilingual Embedding Model
Considering that the LLM-based multilingual embedding models are still relatively scare, we further train a LLM-based multilingual embedding model, bge-multilingual-gemma2, on a diverse range of languages and tasks. It is noted that bge-multilingual-gemma2 is just our initial attempt, and we have not explored the in-context learning (ICL) capabilities of bge-multilingual-gemma2. The exploration of ICL capabilities in the multilingual embedding models is probably a future research topic. However, in our experiment, the new multilingual embedding model has already achieved excellent performance on multiple embedding benchmarks, and especially led to new state-of-the-art results on several multilingual benchmarks.
C.1 Setup
LLM. XLM-RoBERTa ([58]) demonstrated that the larger vocabulary size were beneficial for improving the multilingual capability of language models. Therefore, we employ Gemma-2-9b ([59]) as the backbone for the new multilingual embedding model, considering that the vocabulary size of Gemma-2-9b is 256K, which is larger than the vocabulary size of other LLMs, such as Qwen2 ([60]) or Llama 3 ([61]).
Dataset. In addition to MTEB ([30]) and AIR-Bench ^1, we also evaluate the multilingual capability of bge-multilingual-gemma2 on MIRACL ([34]), FR-MTEB ([62]), PL-MTEB ([63]) and C-MTEB ([64]).
Training Data. For the Engilsh training data, we use most of the datasets used by bge-en-icl. For the Chinese training data, in addition to the datasets used by BGE-M3 ([65]), more datasets in retrieval, classification, and clustering tasks are included. For the multilingual training data, we still use the two multilingual datasets used by BGE-M3. The full training data used by bge-multilingual-gemma2 includes:
- English: The English datasets (refer to Section 4.1) used by bge-en-icl are employed, except for the MSMARCO document ranking dataset.
- Chinese: The Chinese datasets used by BGE-M3 ([65]) are employed. The retrieval datasets including the three domain-specific datasets in Multi-CPR ([66]), the classification datasets including AmazonReviews-Classification ([45]) and MultilingualSentiment-Classification ([67]), and the clustering datasets including CSL-Clustering-S2S/P2P2 ([68]) are addtionally employed.
- Multilingual: Two multilingual retrieval datasets including MIRACL ([34]) and Mr.TyDi ([37]) are employed.
Training Detail. We fine-tune the Gemma-2-9b model using a contrastive loss and conduct the process over a single epoch. For efficient fine-tuning, we employ Low-Rank Adaptation (LoRA) ([57]), setting the LoRA rank to 64 and the LoRA alpha to 32, with a learning rate of 1e-4. We use in-batch negatives only for retrieval tasks, where each dataset incorporates 7 hard negatives. For the retrieval tasks and the other tasks, we set the batch size to 512 and 256, respectively. We consistently use the same dataset throughout one step, and the maximum sequence length remains capped at 512 tokens. Meanwhile, we use bge-reranker as the teacher to distill our model in retrieval tasks.
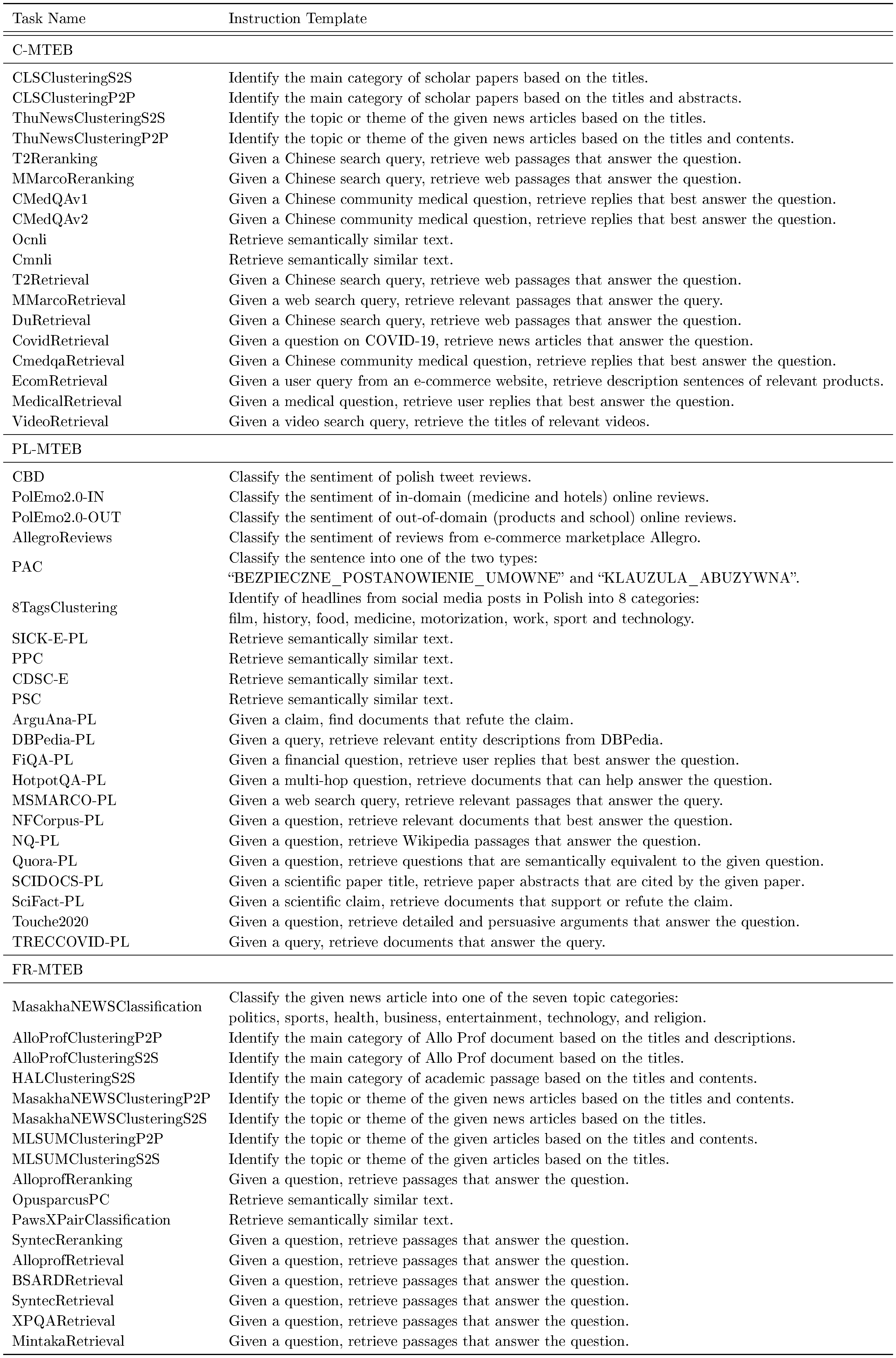
Evaluation. On the MTEB benchmark, the instructions used by bge-multilingual-gemma2 are consistent with the instructions used by bge-en-icl, which are shown in Table 7. The instructions used by bge-multilingual-gemma2 on the C-MTEB, PL-MTEB and FR-MTEB benchmarks are available in Table 16. On the MIRACL benchmark, we use the same instruction for all 18 languages: "Given a question, retrieve Wikipedia passages that answer the question.". On the AIR-Bench benchmark, for the sake of simplicity, we also use the same instruction for all datasets: "Given a question, retrieve passages that answer the question.".
C.2 Main Results
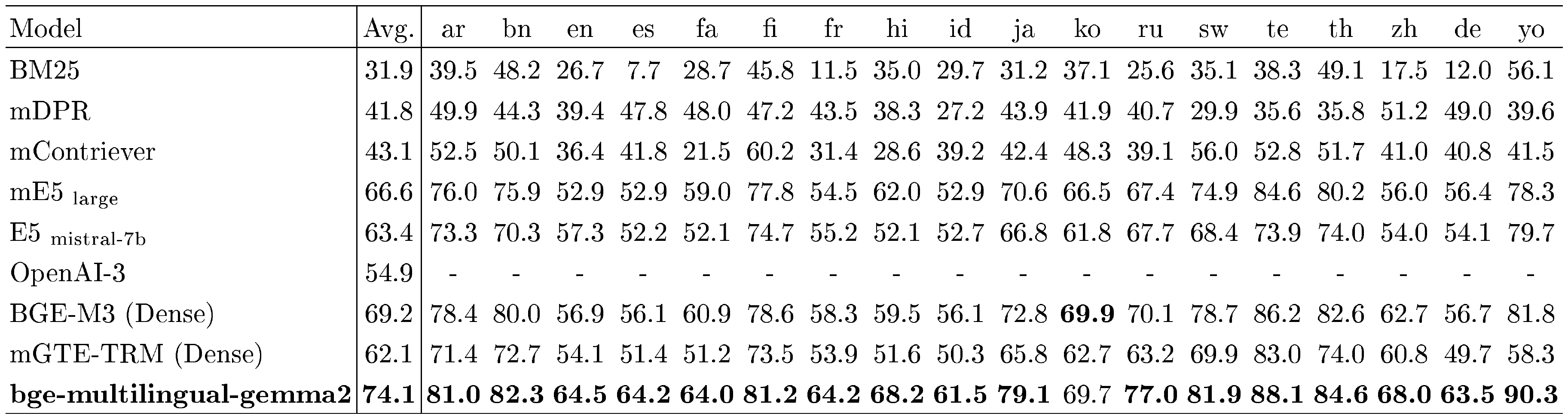
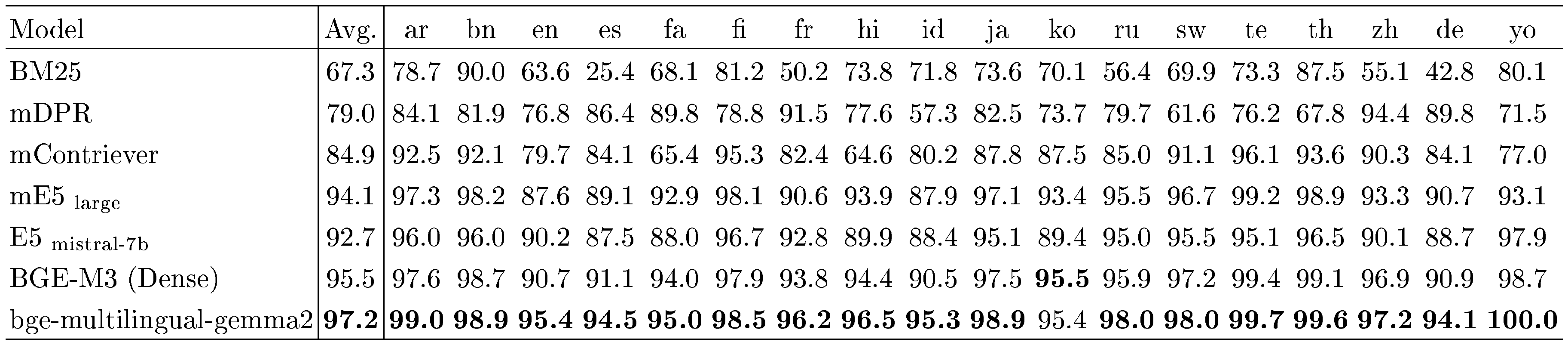
MIRACL. Following BGE-M3 ([65]), we evaluate the multilingual retrieval performance with MIRACL ([34]). We cite most of the results reported in the Table 1 of BGE-M3's paper. It should be noted that the results of BM25 are lower than the results reported in MIRACL's paper, as the BM25 tested in BGE-M3's paper used the same tokenizer with BGE-M3. We also include another recent work mGTE ([69]) as one of the baseline models.
As shown in Table 10, our model bge-multilingual-gemma2 achieves the state-of-the-art (SOTA) performance in all 18 languages. The overall performance of bge-multilingual-gemma2 is 74.1, which is far ahead of the performance of the previous best model BGE-M3 (Dense), indicating the excellent multilingual retrieval capability of bge-multilingual-gemma2. The results of Recall@100 are available in Table 11.
::: {caption="Table 10: Multi-lingual retrieval performance on the MIRACL ([34]) dev set (measured by nDCG@10)."}
:::
::: {caption="Table 11: Multi-lingual retrieval performance on the MIRACL ([34]) dev set (measured by Recall@100)."}
:::
FR-MTEB & PL-MTEB & C-MTEB. We further evaluate our model on FR-MTEB ([62]), PL-MTEB ([63]) and C-MTEB ([64]) benchmarks. FR-MTEB consists of 26 datasets in 6 different tasks, PL-MTEB consists of 26 datasets in 5 different tasks, and C-MTEB consists of 35 datasets in 6 different tasks. We use the API provided by MTEB ^2 to perform evaluation.
The results shown in Table 12, Table 13 and Table 14 are all available in the MTEB leaderboard ^3. We can observe that bge-multilingual-gemma2 leads to new SOTA performances on both FR-MTEB and PL-MTEB benchmarks, and especially achieves very excellent results in the retrieval tasks (Retr.). On the C-MTEB benchmark, bge-multilingual-gemma2 surpasses most of the baseline models, such as e5-mistral-7b-instruct, bge-large-zh-v1.5, etc. However, its overall performance on C-MTEB benchmark is still slightly worse than gte-Qwen2-7B-instruct, which can be attributed to Gemma-2's Chinese proficiency being worse than that of Qwen2.
:Table 12: Results on the FR-MTEB ([62]) benchmark (26 datasets in the French subset). Please refer to Table 17 for the scores of bge-multilingual-gemma2 per dataset.
| Task | Retr. | Rerank. | Clust. | PairClass. | Class. | STS | Summ. | Avg. |
|---|---|---|---|---|---|---|---|---|
| # of datasets $\rightarrow$ | 5 | 2 | 7 | 2 | 6 | 3 | 1 | 26 |
| mistral-embed | 46.81 | 80.46 | 44.74 | 77.32 | 68.61 | 79.56 | 31.47 | 59.41 |
| gte-multilingual-base | 52.97 | 76.47 | 41.66 | 79.46 | 68.72 | 81.36 | 29.74 | 59.79 |
| voyage-multilingual-2 | 54.56 | 82.59 | 46.57 | 78.66 | 68.56 | 80.13 | 29.96 | 61.65 |
| gte-Qwen2-1.5B-instruct | 52.56 | 83.76 | 55.01 | 86.88 | 78.02 | 81.26 | 30.5 | 66.6 |
| gte-Qwen2-7B-instruct | 55.65 | 78.7 | 55.56 | 90.43 | 81.76 | 82.31 | 31.45 | 68.25 |
| bge-multilingual-gemma2 | 63.47 | 85.22 | 56.48 | 85.07 | 81.62 | 82.59 | 31.26 | 70.08 |
:Table 13: Results on the PL-MTEB ([63]) benchmark (26 datasets in the Polish subset). Please refer to Table 17 for the scores of bge-multilingual-gemma2 per dataset.
| Task | Retr. | Clust. | PairClass. | Class. | STS | Avg. |
|---|---|---|---|---|---|---|
| # of datasets $\rightarrow$ | 11 | 1 | 4 | 7 | 3 | 26 |
| gte-multilingual-base | 46.40 | 33.67 | 85.45 | 60.15 | 68.92 | 58.22 |
| multilingual-e5-large | 48.98 | 33.88 | 85.50 | 63.82 | 66.91 | 60.08 |
| mmlw-roberta-large | 52.71 | 31.16 | 89.13 | 66.39 | 70.59 | 63.23 |
| gte-Qwen2-1.5B-instruct | 51.88 | 44.59 | 84.87 | 72.29 | 68.12 | 64.04 |
| gte-Qwen2-7B-instruct | 54.69 | 51.36 | 88.48 | 77.84 | 70.86 | 67.86 |
| bge-multilingual-gemma2 | 59.41 | 50.29 | 89.62 | 77.99 | 70.64 | 70.00 |
:Table 14: Results on the C-MTEB ([64]) benchmark (35 datasets in the Chinese subset). Please refer to Table 17 for the scores of bge-multilingual-gemma2 per dataset.
| Task | Retr. | Rerank. | Clust. | PairClass. | Class. | STS | Avg. |
|---|---|---|---|---|---|---|---|
| # of datasets $\rightarrow$ | 8 | 4 | 4 | 2 | 9 | 8 | 35 |
| multilingual-e5-large | 63.66 | 56.00 | 48.23 | 69.89 | 67.34 | 48.29 | 58.81 |
| e5-mistral-7b-instruct | 61.75 | 61.86 | 52.30 | 72.19 | 70.17 | 50.22 | 60.81 |
| gte-multilingual-base | 71.95 | 68.17 | 47.48 | 78.34 | 64.27 | 52.73 | 62.72 |
| bge-large-zh-v1.5 | 70.46 | 65.84 | 48.99 | 81.6 | 69.13 | 56.25 | 64.53 |
| gte-Qwen2-1.5B-instruct | 71.86 | 68.21 | 54.61 | 86.91 | 71.12 | 60.96 | 67.65 |
| gte-Qwen2-7B-instruct | 76.03 | 68.92 | 66.06 | 87.48 | 75.09 | 65.33 | 72.05 |
| bge-multilingual-gemma2 | 73.73 | 68.28 | 59.3 | 86.67 | 74.11 | 56.87 | 68.44 |
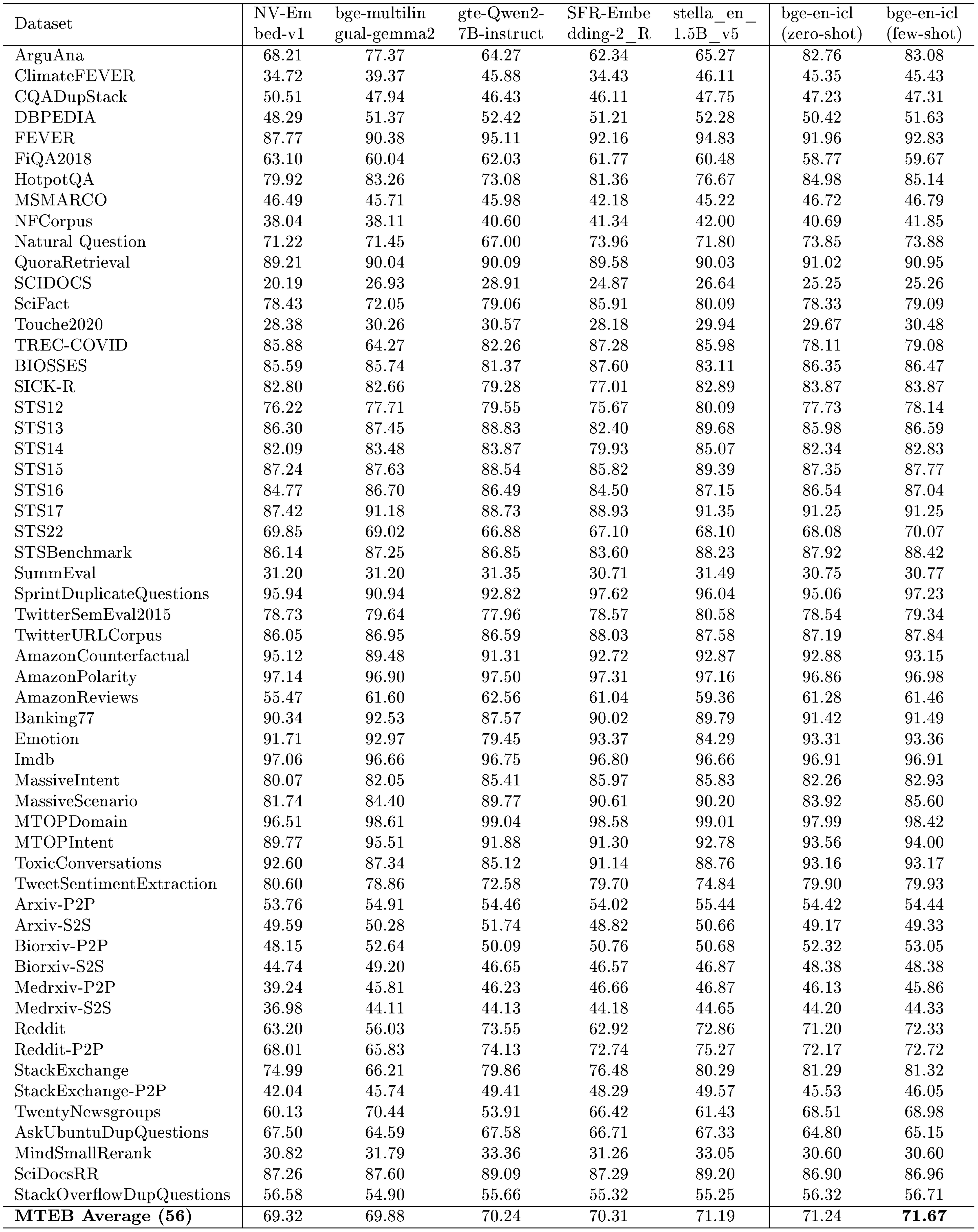
MTEB. The evaluation results of bge-multilingual-gemma2 on the MTEB benchmark are available in Table 1. The detailed results for each dataset are available in Table 8. We can also observe that bge-multilingual-gemma2 achieves good performance on the MTEB benchmark.
AIR-Bench. For the QA task in AIR-Bench, we perform evaluation on all of the 13 datasets in 24.04 version, which consists of 8 English datasets and 5 Chinese datasets. For the Long-Doc task in AIR-Bench, we perform evaluation on all of the 15 datasets in 24.04 version, which are all English datasets. As shown in Table 15 and Table 3, bge-multilingual-gemma2 also achieves excellent performance in the out-of-distribution (OOD) evaluation on AIR-Bench, which indicates that our model has excellent generalization ability.
:Table 15: QA (en & zh, nDCG@10) performance on AIR-Bench 24.04.
| Domain | wiki | web | news | healthcare | law | finance | arxiv | msmarco | Avg. |
|---|---|---|---|---|---|---|---|---|---|
| # of datasets $\rightarrow$ | 2 | 2 | 2 | 2 | 1 | 2 | 1 | 1 | 13 |
| bge-m3 (Dense) | 61.42 | 48.86 | 44.40 | 45.74 | 26.68 | 41.85 | 40.76 | 54.40 | 46.65 |
| multilingual-e5-large | 57.16 | 42.91 | 41.61 | 42.18 | 19.66 | 37.38 | 36.93 | 54.44 | 42.58 |
| e5-mistral-7b-instruct | 58.82 | 45.18 | 42.08 | 46.06 | 19.32 | 40.45 | 44.78 | 59.03 | 45.26 |
| gte-Qwen2-1.5B-instruct | 55.04 | 42.95 | 37.30 | 44.50 | 11.95 | 40.24 | 32.06 | 49.74 | 41.06 |
| gte-Qwen2-7B-instruct | 64.95 | 51.59 | 48.55 | 46.51 | 22.31 | 42.42 | 40.27 | 58.39 | 48.38 |
| bge-multilingual-gemma2 | 65.50 | 51.81 | 47.46 | 44.68 | 22.58 | 40.45 | 23.28 | 63.14 | 46.83 |
::: {caption="Table 16: The additional instruction we used on the C-MTEB, PL-MTEB and FR-MTEB benchmarks. These instructions are adopted from gte-Qwen2-7B-instruct ([40]). To ensure sentence completeness, we add a period at the end."}
:::
::: {caption="Table 17: Results of bge-multilingual-gemma2 for each dataset in the FR-MTEB, PL-MTEB and C-MTEB benchmarks."}

:::
D. Lightweight Re-ranker
We have also introduced a lightweight version of the reranker, which incorporates both depth and width compression techniques. Specifically, depth compression is implemented on a layerwise method, allowing for the selective adjustment of the number of layers according to the desired output. Regarding width compression, it is configured to execute token compression at predetermined layers, whereby $n$ tokens are merged into a single token.
For the input template, we use the following format:
$ \text{A:} {\text{query}} \newline \text{B:} {\text{passage}} \newline {\text{prompt}} $
where the prompt inquires about the relationship between A and B, e.g., Predict whether passage B contains an answer to query A. And we use the logits of Yes as our reranking score.
Considering the depth compression generates output scores at each layer, we extract the linear layer connected to the logits for the Yes prediction in the language model head. This extracted linear layer is then appended to each layer, allowing every layer to compute a reranking score.
D.1 Setup
LLM. Our objective is to develop a multilingual version of the lightweight reranker. Considering the extensive vocabulary necessitated by multilingual support, we employ Gemma-2-9b ([59]) as the backbone for our reranker.
Dataset. We evaluate the performance of our reranker bge-reranker-v2.5-gemma-lightweight on BEIR ([70]) and MIRACL ([34]). The BEIR benchmark encompasses a variety of text retrieval tasks across multiple domains, while MIRACL serves as a significant dataset for multilingual evaluation, featuring 18 distinct languages.
Training Data. To enhance the multilingual capabilities and retrieval performance of the Reranker, we utilize the BGE-M3 dataset ([65]), along with Arguana, HotpotQA, and FEVER, for the training process.
Training Detail. The reranker is trained using contrastive loss. Furthermore, LoRA is employed for fine-tuning, where the LoRA rank is set to 64 and the LoRA alpha is set to 32, accompanied by a learning rate of 1e-4. During the training process, a batch size of 128 is utilized, and 15 hard negatives are assigned to each query. At the same time, the training of the reranker employs self-distillation, wherein the final layer serves as the teacher for preceding layers. Throughout this training process, KL divergence loss is utilized. During training, we randomly select a width compression strategy and train all depth compression strategies. Regarding depth compression, we support outputs from 8 to 42 layers. Regarding width compression, we support compression ratios of 1, 2, 4, and 8, and support width compression at 8, 16, 24, 32, and 40 layers. During the training process, we utilized four types of prompts: query to passage, query to query, passage to passage, and argument to counter-argument. The specific application of these prompts was dependent on the type of dataset used, as shown in Table 18.
Evaluation. On the BEIR benchmark, we rerank the top-100 retrieval results of bge-large-en-v1.5 and E5-mistral-7b-instruct. On the MIRACL dataset, we rerank the top-100 retrieval results of bge-m3 (dense). The instructions for evaluation are shown in Table 19.
:Table 18: The training instructions we used for reranker.
| Task Type | Instruction Template |
|---|---|
| query to passage | Predict whether passage B contains an answer to query A. |
| query to query | Predict whether queries A and B are asking the same thing. |
| passage to passage | Predict whether passages A and B have the same meaning. |
| argument to counter-argument | Predict whether argument A and counterargument B express contradictory opinions. |
::: {caption="Table 19: The instructions we used for the BEIR benchmark and MIRACL dataset for reranker."}

:::
D.2 Main Results
::: {caption="Table 20: The performance of various rerankers on BEIR benchmark (based on bge-large-en-v1.5)."}
:::
::: {caption="Table 21: The performance of various rerankers on BEIR benchmark (based on E5-mistral-7b-insturct)."}
:::
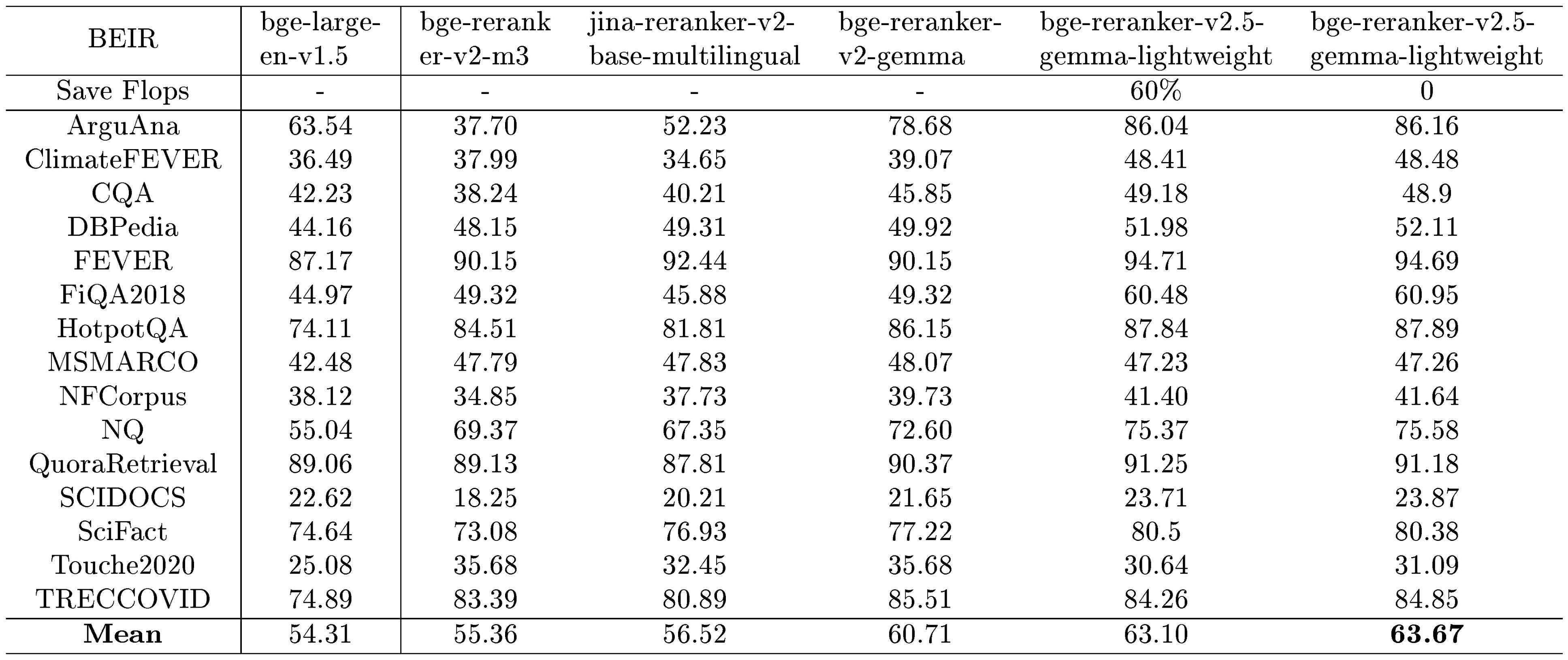
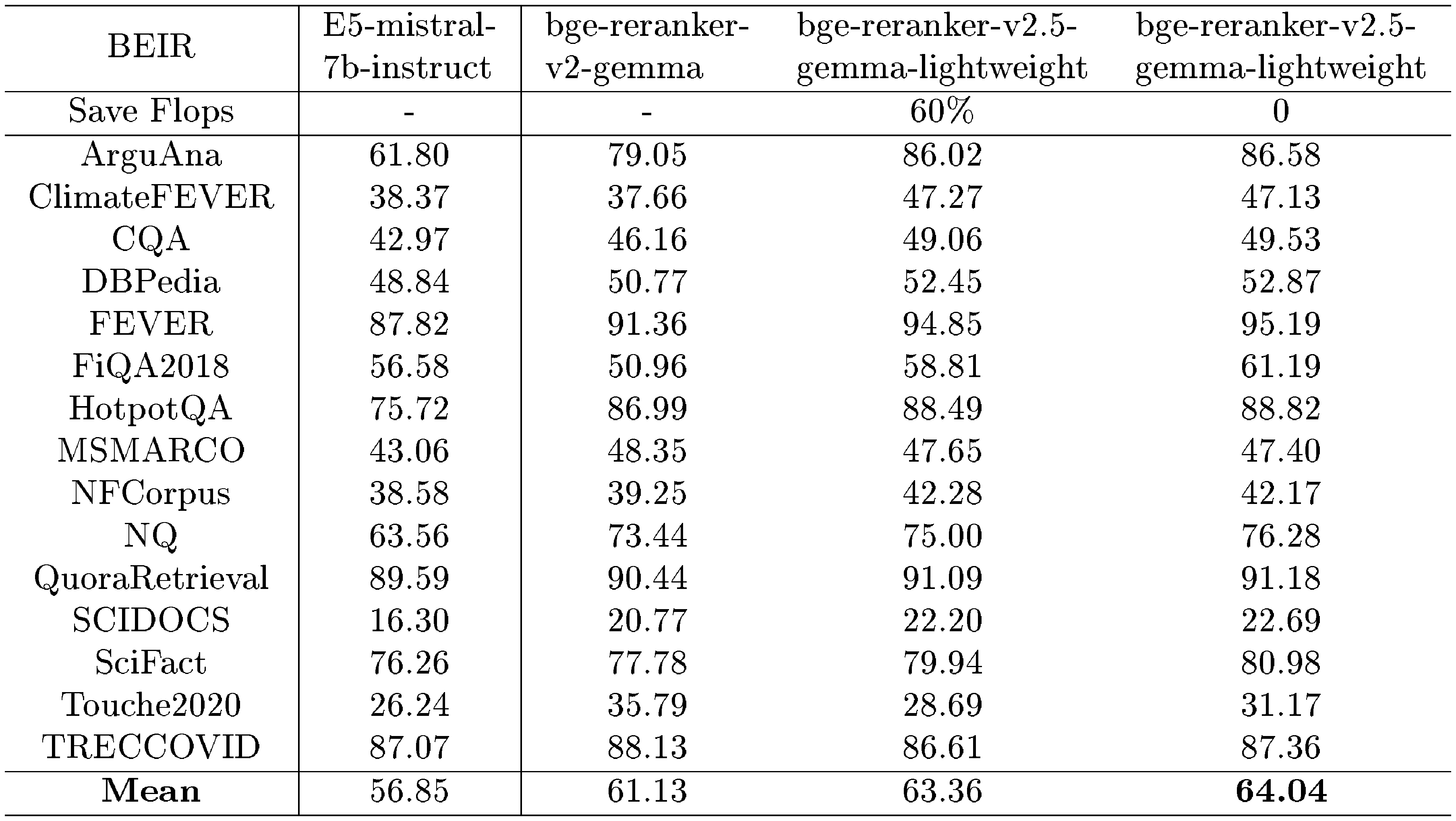
BEIR. We rerank the retrieval results from the BEIR dataset using two models, bge-large-en-v1.5 and E5-Mistral-7b-Instruct, and we rerank top-100 retrieval results from these models. We conduct both a comprehensive evaluation and a lightweight evaluation. In the lightweight evaluation, we select a compression ratio of 2, a width compression factor of 8, and a depth of the output layer set to 25. This configuration results in a 60% FLOPs.
Table 20 and Table 21 present the evaluation results for the BEIR benchmark. It indicates that bge-reranker-v2.5-gemma2-lightweight records exceptional performance in enhancing both bge-large-en-v1.5 and E5-Mistral-7b-Instruct retrieval outcomes. Furthermore, there exists a positive correlation between the initial retrieval quality and the subsequent reranking performance, when reranking the retrieval results from E5-Mistral-Instruct, our reranker achieves improved performance. Additionally, the implementation of the lightweight model variant results in only a marginal decline in performance while achieving a significant reduction in FLOPs.
::: {caption="Table 22: Comparison of MIRACL dev nDCG@10 scores across various rerankers (based on bge-m3 (Dense))."}
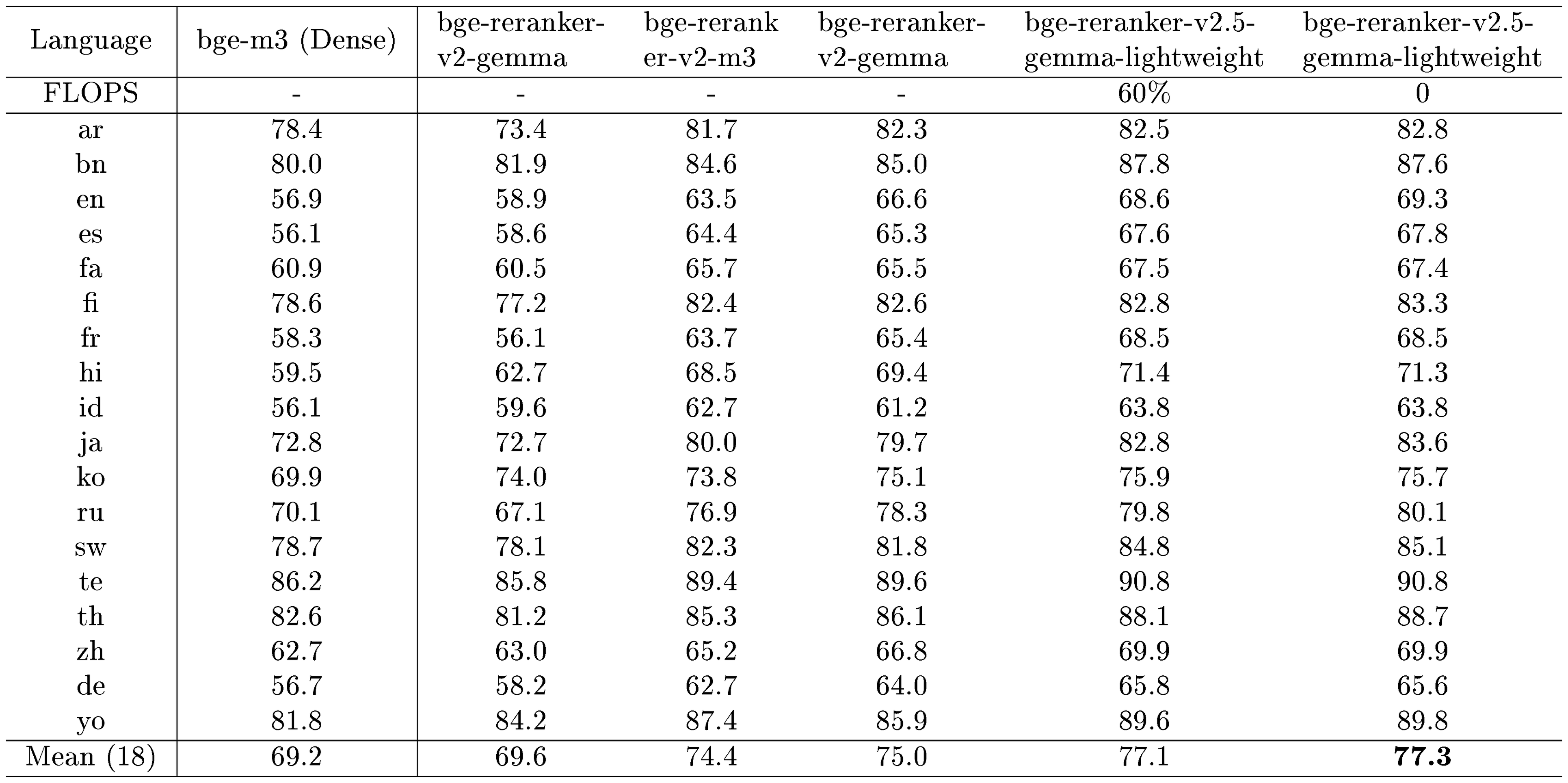
:::
MIRACL. We further evaluate the multilingual capabilities of the reranker using the MIRACL dataset, with the results presented in Table 22. The reranking is conducted based on the top 100 retrieval results obtained from the bge-m3 (dense) model. The reranker demonstrates a significant improvement in retrieval accuracy across each dataset and outperforms other multilingual rerankers. Notably, compared to monolingual (English) retrieval, the multilingual retrieval experienced minimal negative effects from model lightweighting, essentially maintaining the original performance of the model.
References
[1] Karpukhin et al. (2020). Dense passage retrieval for open-domain question answering. arXiv preprint arXiv:2004.04906.
[2] Xiong et al. (2020). Approximate nearest neighbor negative contrastive learning for dense text retrieval. arXiv preprint arXiv:2007.00808.
[3] Lu et al. (2020). Twinbert: Distilling knowledge to twin-structured compressed bert models for large-scale retrieval. In Proceedings of the 29th ACM International Conference on Information & Knowledge Management. pp. 2645–2652.
[4] Xiao et al. (2022). RetroMAE: Pre-training retrieval-oriented language models via masked auto-encoder. arXiv preprint arXiv:2205.12035.
[5] Gao et al. (2021). Simcse: Simple contrastive learning of sentence embeddings. arXiv preprint arXiv:2104.08821.
[6] Ma et al. (2023). Fine-tuning llama for multi-stage text retrieval. arXiv preprint arXiv:2310.08319.
[7] Li et al. (2024). Llama2Vec: Unsupervised Adaptation of Large Language Models for Dense Retrieval. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). pp. 3490–3500.
[8] Wang et al. (2023). Improving text embeddings with large language models. arXiv preprint arXiv:2401.00368.
[9] Su et al. (2024). BRIGHT: A Realistic and Challenging Benchmark for Reasoning-Intensive Retrieval. arXiv preprint arXiv:2407.12883.
[10] Weller et al. (2024). FollowIR: Evaluating and Teaching Information Retrieval Models to Follow Instructions. arXiv preprint arXiv:2403.15246.
[11] Radford et al. (2019). Language models are unsupervised multitask learners. OpenAI blog. 1(8). pp. 9.
[12] Brown, Tom B (2020). Language models are few-shot learners. arXiv preprint arXiv:2005.14165.
[13] Gao et al. (2020). Making pre-trained language models better few-shot learners. arXiv preprint arXiv:2012.15723.
[14] Wei et al. (2022). Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems. 35. pp. 24824–24837.
[15] Yao et al. (2022). React: Synergizing reasoning and acting in language models. arXiv preprint arXiv:2210.03629.
[16] Dong et al. (2022). A survey on in-context learning. arXiv preprint arXiv:2301.00234.
[17] Muennighoff et al. (2024). Generative representational instruction tuning. arXiv preprint arXiv:2402.09906.
[18] BehnamGhader et al. (2024). Llm2vec: Large language models are secretly powerful text encoders. arXiv preprint arXiv:2404.05961.
[19] Devlin, Jacob (2018). Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805.
[20] Raffel et al. (2020). Exploring the limits of transfer learning with a unified text-to-text transformer. Journal of machine learning research. 21(140). pp. 1–67.
[21] Liu, Yinhan (2019). Roberta: A robustly optimized bert pretraining approach. arXiv preprint arXiv:1907.11692.
[22] Luo et al. (2024). Large Language Models as Foundations for Next-Gen Dense Retrieval: A Comprehensive Empirical Assessment. arXiv preprint arXiv:2408.12194.
[23] Lee et al. (2024). Gecko: Versatile text embeddings distilled from large language models. arXiv preprint arXiv:2403.20327.
[24] Lee et al. (2024). NV-Embed: Improved Techniques for Training LLMs as Generalist Embedding Models. arXiv preprint arXiv:2405.17428.
[25] Zhuang et al. (2024). PromptReps: Prompting Large Language Models to Generate Dense and Sparse Representations for Zero-Shot Document Retrieval. arXiv preprint arXiv:2404.18424.
[26] Su et al. (2022). One embedder, any task: Instruction-finetuned text embeddings. arXiv preprint arXiv:2212.09741.
[27] Izacard et al. (2021). Unsupervised dense information retrieval with contrastive learning. arXiv preprint arXiv:2112.09118.
[28] Touvron et al. (2023). Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971.
[29] Jiang et al. (2023). Mistral 7B. arXiv preprint arXiv:2310.06825.
[30] Muennighoff et al. (2022). MTEB: Massive text embedding benchmark. arXiv preprint arXiv:2210.07316.
[31] Fan et al. (2019). ELI5: Long form question answering. arXiv preprint arXiv:1907.09190.
[32] Yang et al. (2018). HotpotQA: A dataset for diverse, explainable multi-hop question answering. arXiv preprint arXiv:1809.09600.
[33] Thorne et al. (2018). FEVER: a large-scale dataset for fact extraction and VERification. arXiv preprint arXiv:1803.05355.
[34] Zhang et al. (2023). Miracl: A multilingual retrieval dataset covering 18 diverse languages. Transactions of the Association for Computational Linguistics. 11. pp. 1114–1131.
[35] Nguyen et al. (2016). Ms marco: A human-generated machine reading comprehension dataset.
[36] DataCanary et al. (2017). Quora Question Pairs. https://kaggle.com/competitions/quora-question-pairs.
[37] Zhang et al. (2021). Mr. TyDi: A multi-lingual benchmark for dense retrieval. arXiv preprint arXiv:2108.08787.
[38] Qiu et al. (2022). Dureader_retrieval: A large-scale chinese benchmark for passage retrieval from web search engine. arXiv preprint arXiv:2203.10232.
[39] Xie et al. (2023). T2ranking: A large-scale chinese benchmark for passage ranking. In Proceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval. pp. 2681–2690.
[40] Li et al. (2023). Towards general text embeddings with multi-stage contrastive learning. arXiv preprint arXiv:2308.03281.
[41] Wachsmuth et al. (2018). Retrieval of the best counterargument without prior topic knowledge. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). pp. 241–251.
[42] Maia et al. (2018). Www'18 open challenge: financial opinion mining and question answering. In Companion proceedings of the the web conference 2018. pp. 1941–1942.
[43] Cohan et al. (2020). Specter: Document-level representation learning using citation-informed transformers. arXiv preprint arXiv:2004.07180.
[44] Liu et al. (2018). Linkso: a dataset for learning to retrieve similar question answer pairs on software development forums. In Proceedings of the 4th ACM SIGSOFT International Workshop on NLP for Software Engineering. pp. 2–5.
[45] McAuley, Julian and Leskovec, Jure (2013). Hidden factors and hidden topics: understanding rating dimensions with review text. In Proceedings of the 7th ACM conference on Recommender systems. pp. 165–172.
[46] O'Neill et al. (2021). I Wish I Would Have Loved This One, But I Didn't–A Multilingual Dataset for Counterfactual Detection in Product Reviews. arXiv preprint arXiv:2104.06893.
[47] Casanueva et al. (2020). Efficient intent detection with dual sentence encoders. arXiv preprint arXiv:2003.04807.
[48] Saravia et al. (2018). CARER: Contextualized affect representations for emotion recognition. In Proceedings of the 2018 conference on empirical methods in natural language processing. pp. 3687–3697.
[49] Maggie, Phil Culliton, Wei Chen (2020). Tweet Sentiment Extraction. https://kaggle.com/competitions/tweet-sentiment-extraction.
[50] Li et al. (2020). MTOP: A comprehensive multilingual task-oriented semantic parsing benchmark. arXiv preprint arXiv:2008.09335.
[51] Maas et al. (2011). Learning word vectors for sentiment analysis. In Proceedings of the 49th annual meeting of the association for computational linguistics: Human language technologies. pp. 142–150.
[52] C.J. Adams et al. (2019). Jigsaw Unintended Bias in Toxicity Classification. https://kaggle.com/competitions/jigsaw-unintended-bias-in-toxicity-classification.
[53] Lang, Ken (1995). Newsweeder: Learning to filter netnews.
[54] Agirre et al. (2012). SemEval-2012 task 6: A pilot on semantic textual similarity. In SEM 2012: The First Joint Conference on Lexical and Computational Semantics–Volume 1: Proceedings of the main conference and the shared task, and Volume 2: Proceedings of the Sixth International Workshop on Semantic Evaluation (SemEval 2012)*. Association for Computational Linguistics. URL http://www. aclweb. org/anthology/S12-1051.
[55] Chen et al. (2022). SemEval-2022 Task 8: Multilingual news article similarity.
[56] Cer et al. (2017). Semeval-2017 task 1: Semantic textual similarity-multilingual and cross-lingual focused evaluation. arXiv preprint arXiv:1708.00055.
[57] Hu et al. (2021). Lora: Low-rank adaptation of large language models. arXiv preprint arXiv:2106.09685.
[58] Conneau et al. (2020). Unsupervised Cross-lingual Representation Learning at Scale. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. pp. 8440–8451. doi:10.18653/v1/2020.acl-main.747. https://aclanthology.org/2020.acl-main.747.
[59] Team et al. (2024). Gemma 2: Improving open language models at a practical size. arXiv preprint arXiv:2408.00118.
[60] An Yang et al. (2024). Qwen2 Technical Report. arXiv preprint arXiv:2407.10671.
[61] Abhimanyu Dubey et al. (2024). The Llama 3 Herd of Models. arXiv preprint arXiv:2407.21783.
[62] Mathieu Ciancone et al. (2024). MTEB-French: Resources for French Sentence Embedding Evaluation and Analysis. arXiv preprint arXiv:2405.20468.
[63] Rafał Poświata et al. (2024). PL-MTEB: Polish Massive Text Embedding Benchmark. arXiv preprint arXiv:2405.10138.
[64] Xiao et al. (2024). C-Pack: Packed Resources For General Chinese Embeddings. In Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval. pp. 641–649.
[65] Chen et al. (2024). Bge m3-embedding: Multi-lingual, multi-functionality, multi-granularity text embeddings through self-knowledge distillation. arXiv preprint arXiv:2402.03216.
[66] Long et al. (2022). Multi-CPR: A Multi Domain Chinese Dataset for Passage Retrieval. In Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval. pp. 3046–3056. doi:10.1145/3477495.3531736. https://doi.org/10.1145/3477495.3531736.
[67] Mollanorozy et al. (2023). Cross-lingual Transfer Learning with Persian. In Proceedings of the 5th Workshop on Research in Computational Linguistic Typology and Multilingual NLP. pp. 89–95. doi:10.18653/v1/2023.sigtyp-1.9. https://aclanthology.org/2023.sigtyp-1.9.
[68] Yudong et al. (2022). CSL: A Large-scale Chinese Scientific Literature Dataset. arXiv preprint arXiv:2209.05034.
[69] Xin Zhang et al. (2024). mGTE: Generalized Long-Context Text Representation and Reranking Models for Multilingual Text Retrieval.
[70] Thakur et al. (2021). Beir: A heterogenous benchmark for zero-shot evaluation of information retrieval models. arXiv preprint arXiv:2104.08663.