Next-Latent Prediction Transformers Learn Compact World Models
Jayden Teoh$^{*}$
Microsoft Research
Manan Tomar
Microsoft Research
Kwangjun Ahn
Microsoft Research
Edward S. Hu
Microsoft Research
Tim Pearce
Microsoft Research
Pratyusha Sharma
Microsoft Research
Akshay Krishnamurthy
Microsoft Research
Riashat Islam
Microsoft Research
Alex Lamb
Microsoft Research
John Langford
Microsoft Research
$^{*}$ Correspondence to: [email protected]
Abstract
Transformers replace recurrence with a memory that grows with sequence length and self-attention that enables ad-hoc lookups over past tokens. Consequently, they lack an inherent incentive to compress history into compact latent states with consistent transition rules. This often leads to learning solutions that generalize poorly. We introduce Next-Latent Prediction (NextLat), which extends standard next-token training with self-supervised predictions in the latent space. Specifically, NextLat trains a transformer to learn latent representations that are predictive of the next latent state given the next token. Theoretically, we show that these latents provably converge towards belief states, compressed information about the history necessary to predict the future. This simple auxiliary objective injects a recurrent inductive bias into transformers while leaving their architecture, parallel training efficiency, and inference unchanged. NextLat effectively encourages transformers to form compact internal world models with coherent belief states and transition dynamics—crucial properties not guaranteed by standard next-token prediction alone. Empirically, across benchmarks in world modeling, reasoning, planning, and language modeling, NextLat demonstrates significant gains over standard next-token prediction and other baselines in downstream accuracy, representation compression, and lookahead planning. Furthermore, NextLat enables variable-length self-speculative decoding, accelerating inference by up to 3.3× in language modeling. NextLat offers a simple yet effective paradigm for learning compact, predictive representations in transformers that generalize better. Our code is available at https://github.com/JaydenTeoh/NextLat.
Executive Summary: Transformers have achieved strong results across language, reasoning, and planning tasks but rely on next-token prediction alone during training. This objective provides no built-in pressure to compress history into compact internal states, so models often learn brittle, task-specific shortcuts that generalize poorly outside the training distribution. The issue matters now because transformers are increasingly used for long-horizon reasoning and planning where coherent internal models of the world are essential.
This paper introduces Next-Latent Prediction (NextLat), an auxiliary training objective that augments standard next-token prediction with self-supervised forecasts of the model’s own future latent representations. A lightweight dynamics model is trained to predict the transformer’s next hidden state given only the current state and the next token. The method requires no change to the transformer architecture, its parallel training procedure, or its inference path.
Across four domains the approach yields three main results. First, on a Manhattan street-map reconstruction task the model produces visibly coherent internal maps and raises out-of-distribution trajectory validity and sequence-compression scores over strong baselines. Second, on combinatorial reasoning (Countdown) and lookahead planning (Path-Star graphs) NextLat improves solve rates by more than 35 % at short supervision horizons while preserving next-token accuracy. Third, in 1.3-billion-parameter language-model pretraining it matches or slightly exceeds baseline perplexity while enabling variable-length self-speculative decoding that reaches 3.3× inference speedup.
These gains indicate that latent-space supervision induces more predictive and compact internal representations than token-level objectives alone. Because the dynamics model is cheap to run, the method extracts richer gradient signals per sequence and supports longer speculative drafts at inference time without extra parameters. In practice this translates into better data efficiency during training and lower latency at deployment.
The authors recommend adopting NextLat as a drop-in addition to next-token training whenever downstream tasks require planning or generalization. Practitioners should start with a one-step latent prediction horizon and a modest loss weight, then increase the horizon only if inference speedup is a primary goal. Further work is needed to test larger models, richer latent dynamics architectures, and post-training application to already-trained transformers.
The main limitations are reliance on small-scale ablations for the precise loss formulation and the use of simple MLPs for the dynamics model. Results on language-model benchmarks remain modest, so gains at frontier scale are not yet confirmed.
1. Introduction
Section Summary: Transformers achieve strong predictive performance through flexible memory and attention mechanisms, yet this comes at the cost of learning complex shortcuts that fit training data without forming compact, generalizable representations of history. The paper introduces Next-Latent Prediction (NextLat), an auxiliary training objective that encourages the model to encode past tokens into compact latent summaries so that a lightweight dynamics model can forecast future states from the current summary and next token alone. This addition preserves the transformer’s parallel training and inference speed while yielding richer learning signals, more coherent internal world models, and practical gains such as faster speculative decoding.
Ptolemy's geocentric model was able to accurately predict observations of the solar system from Earth's viewpoint, yet it was structurally convoluted: at times implying that the Moon came twice as close to Earth as other times. It was later supplanted by Copernicus’s simpler, more compact heliocentric model, which provided accurate predictions that generalized beyond Earth’s perspective. In learning theory, it is well known that simpler explanations of training observations tend to generalize better ([1, 2]).
Modern transformers ([3]) stand in contrast to this principle. By replacing recurrence with a memory that scales with sequence length and self-attention that enables flexible lookups over past tokens, they achieve exceptional parallelization and predictive power. Yet, this very capability removes any inherent pressure to compress history into compact latent representations with consistent update rules. As a result, transformers often learn complex, task-specific shortcuts that fit the training data well but generalize poorly ([4, 5, 6, 7]). How can we encourage transformers to form simpler, more principled explanations that avoid such shortcuts? A natural approach is to reinstate a key property of recurrent models: the ability to learn compact world models that channel future prediction through compressed representations of the past. We will show that this inductive bias can be reintroduced while also retaining the parallel training efficiency of transformers.
In this paper, we introduce Next-Latent Prediction (NextLat), which extends the standard next-token prediction objective with self-supervised predictions in latent space. NextLat jointly trains a transformer and a latent dynamics model: the transformer learns to encode past tokens into compact latent summaries such that the dynamics model can predict the transformer’s next latent state given only the current latent state and the next token (i.e., the "action"). This objective encourages the transformer to form a compact internal world model with coherent recurrent-like dynamics, while avoiding the sequential processing overhead of recurrent architectures. Importantly, NextLat leaves the transformer’s architecture, inference procedure, and parallel training efficiency unchanged, adding only a lightweight auxiliary loss on latent representations during training. By augmenting sparse one-hot token targets with dense latent-state supervision, NextLat provides richer learning signals and improves data efficiency compared to next-token prediction and other token-level supervision methods. Our approach is inspired by the self-predictive learning paradigm in reinforcement learning (RL), a family of algorithms that learn representations by minimizing the prediction error of their own future latent states ([8, 9]).
Beyond representation learning, latent dynamics also provides an inference advantage: future states can be recursively predicted directly in latent space without invoking the main transformer. This recursive multi-step lookahead using the lightweight dynamics model enables variable-length self-speculative decoding: the model can speculate a flexible number of future tokens and accelerate inference without requiring separate multi-token prediction heads.
The core contributions of this paper are threefold. First, we establish a theoretical foundation showing that NextLat provably shapes transformer representations into belief states—compact summaries of past information sufficient for predicting future observations. Such representations are important for planning and generalization, yet are not guaranteed to emerge from next-token prediction alone. Second, we present a practical implementation of NextLat that preserves the transformer’s architecture, inference procedure, and parallel training efficiency. Finally, we empirically demonstrate NextLat’s effectiveness across diverse domains spanning world modeling, reasoning, planning, and language modeling. Our results show that NextLat improves representation compactness, lookahead planning, and downstream accuracy over standard next-token prediction and other baselines. In language modeling, NextLat achieves up to $3.3\times$ faster inference through variable-length self-speculative decoding. Together, these results position NextLat as an efficient framework for learning compact, predictive, and generalizable representations in transformers.
2. Related Work
Section Summary: This section reviews prior research on self-supervised learning methods that build predictive representations from unlabeled data, along with ideas from reinforcement learning about compressing histories into compact “belief states” or world models that forecast future observations. It notes that while these approaches have advanced planning and control in other domains, language models have largely relied on next-token prediction, leaving latent-space dynamics and efficient history compression underexplored. The authors position their method as filling these gaps by learning evolving latent representations that support richer prediction and faster inference without extra models or paired data.
We are motivated by a long line of prior works in representation learning for prediction and control. Of close interest are self-supervised learning methods, belief states for decision making, and world models.
Self-Supervised Learning.
Self-supervised learning (SSL) is a framework for learning from unlabeled data, where a model generates its own supervisory signals from the structure of raw inputs. Across modalities such as vision, audio, and time series, SSL has proven highly effective for pretraining useful features, enabling downstream transfer that rivals, or even surpasses, models trained on labeled data ([10, 11, 12]). There are several approaches to SSL. Our method falls under self-predictive representation learning, which jointly learns latent representations and a transition function that models how these representations evolve over a sequence. Self-prediction has driven state-of-the-art advances in RL ([13, 14, 15, 16, 17]). However, latent-space SSL remains underexplored in language modeling. A recent effort, LLM-JEPA ([18]), minimizes distances between embeddings of paired text–code data, but relies on manually curated pairs and therefore does not generalize to raw text. In contrast, our method introduces a fully self-supervised latent prediction objective requiring no paired data, making it broadly applicable for training transformers across arbitrary sequence modeling domains and data sources.
Belief States.
In both sequence modeling and RL, models must reason over long histories of observations. To mitigate this curse of dimensionality, prior work focuses on compressing history into latent representations that capture all information necessary for future prediction. In RL, this latent summary is formalized by [19] as a belief state, defined as: "a sufficient statistic for the past history … no additional data about its past actions or observations would supply any further information about the current state of the world". In stochastic control, the same notion of sufficient statistics appears as "information state" ([20]). The idea of sufficient statistics is also key to learning state abstractions in RL ([21]). While recurrent neural networks naturally enforce such compression, transformers have no such constraint—their internal state, or memory, grows linearly with sequence length. Recently, Belief State Transformers (BST; ([22])) extended the notion of belief states to transformers, and demonstrated benefits in planning tasks. Compared to BST, NextLat learns belief states without requiring a separate transformer and is much more computationally efficient. We compare these methods further in Section 5.
World Models.
Loosely, a world model is an internal predictive model of how the world works, with varying interpretations across cognitive science ([23, 24]), neuroscience ([25, 26]), control theory ([27, 28]) and reinforcement learning ([29, 30, 31]). Whether transformer language models implicitly learn world models remains a debate; some studies report emergent world understanding ([32, 33, 34]), while others find incoherent world structure ([35, 36]). However, successful world modeling approaches such as MuZero ([37]) for achieving superhuman performance in video and board games, Dreamer ([38, 39, 40]) for model-based RL, and Genie ([41]) for interactive video generation share a common principle: they learn a latent dynamics model that takes a latent state (an encoding of past observations), an action, and predicts the next latent state. Yet, learning such latent dynamics for transformer-based language modeling remains underexplored. NextLat addresses this gap by explicitly learning a latent dynamics model that governs how the transformer's latent states evolve given new tokens (i.e., "actions"), enabling the transformer to learn compact latent abstractions of the world with consistent dynamics.
Beyond Next-Token Prediction.
In the domain of language modeling, a growing body of work has highlighted the myopic nature of the next-token prediction objective, which limits the model's capability in downstream tasks such as planning and reasoning ([42, 43]). Recent works have also found improvements from richer supervision signals that predict further into the future ([44, 45, 22, 46]). However, these approaches operate predominantly in the token space. NextLat takes a different approach: it shifts prediction into the latent space, enforcing coherent dynamics over the model’s latent representations rather than its token outputs. As we discuss later in Section 3.1, this latent-space supervision provides richer gradient signals than token-level supervision.
Speculative Decoding.
Speculative decoding ([47, 48]) accelerates inference by using a lightweight draft model to propose multiple tokens, which are then verified in parallel by a target model. Closely related, [49, 50] train a draft model on top of a frozen language model to predict its high-level latent features. Unlike our approach, this is done post-hoc, whereas we study latent prediction as a pretraining objective to directly shape representations. Moreover, their draft model relies on full attention over past features and therefore does not learn belief states, i.e., compact summaries of past tokens. Self-speculative decoding removes the need for a separate draft model by having a single model act as both draft and verifier. A common implementation uses the multi-token prediction (MTP) objective, where the model is trained to predict multiple future tokens that can be verified in parallel ([44]). However, MTP operates in token space and is therefore typically constrained to a fixed speculative horizon determined during training. In contrast, NextLat learns a latent dynamics model that can be recursively composed in latent space, enabling variable-length self-speculative decoding and faster inference.
3. Methodology: Next-Latent Prediction
Section Summary: The methodology introduces next-latent prediction as a straightforward way for transformers to build compact internal representations, called belief states, that summarize everything needed from past tokens to forecast the future. It works by jointly training the model both to predict the next token from its hidden states and to anticipate its own next hidden state via an auxiliary dynamics model, which forces those states to act as sufficient statistics rather than relying on scattered lookups. This extra supervision in latent space supplies richer, more forward-looking training signals than token prediction alone, improving data efficiency.
In this section, we introduce a simple, yet powerful, method for learning belief states in transformers via next-latent prediction (or more specifically, via next-hidden state prediction[^1]). We begin by defining belief states in sequence modeling.
[^1]: In the sequence modeling literature, intermediate latent representations are often referred to as "hidden states". To disambiguate, we use the term "latent state" to broadly refer to learned representations within the transformer's residual stream, and "hidden state" to refer to a subset of this representation—specifically, the final layer’s output at each time step (i.e., the pre-logit activations).
########## {caption="Definition 1: Belief states in sequence modeling"}
Let $X_{1:T}$ denote a token sequence $X_1, \dots, X_T$. A random variable $\mathbf{b}t = g(X{1:t})$ is a belief state for the history $X_{1:t}$ if, for every bounded measurable function $f$ of the future,
$ \mathbb{E}[f(X_{t+1:T}) \mid \mathbf{b}t] = \mathbb{E}[f(X{t+1:T}) \mid X_{1:t}] \quad \text{a.s.} $
Equivalently, $\mathbf{b}t$ is a sufficient statistic ([20]) of the history $X{1:t}$ for predicting the future tokens, i.e., from which we can sample from the distribution $\mathbb{P}(X_{t+1:T}\mid X_{1:t})$. Next, we describe how next-latent prediction enables transformers to learn belief states and improves data efficiency.
3.1 Why Next-Latent Prediction?
Here we analyze an idealized next-latent prediction transformer which successfully optimizes both next-token prediction and next-latent prediction with respect to an underlying data distribution.
########## {caption="Theorem 2"}
Consider the joint learning of three components:
- a transformer with parameters $\theta$ that produces hidden states $\mathbf{h}_t$ at each time step $t$,
- an output head $p_\theta$ modeling the next-token distribution, and
- a latent dynamics model $p_\psi$ modeling the transition dynamics of the transformer’s hidden states.
If NextLat successfully optimizes the following objectives:
$ \begin{aligned} \textbf{(Next-Token Consistency):} \quad &p_\theta(X_{t+1}\mid \mathbf{h}t) =\mathbb{P}(X{t+1}\mid X_{1:t}), \quad\text{(a)} \ \textbf{(Transition Consistency):} \quad &p_\psi(\mathbf{h}{t+1} \mid \mathbf{h}t, X{t+1}) = \mathbb{P}(\mathbf{h}{t+1} \mid X_{1:t+1}), \quad\text{(b)} \end{aligned}\tag{1} $
then $\mathbf{h}t$ must be a belief state for the sequence $X{1:t}$. Note that the right-hand side of Equation 1b is the transition law induced by the transformer's weights[^2].
[^2]: We adopt a probabilistic formulation to retain generality with respect to stochastic transformer models, e.g. [51].
Proof Sketch. A formal proof by backward induction is provided in Appendix B. Intuitively, optimizing for next-token Equation (1a) and transition Equation (1b) consistency ensures existence of measurable maps, i.e., $p_\theta$ and $p_\psi$, that allow recursive decoding of future tokens from $\mathbf{h}_t$:
$ \begin{aligned} \mathbf{h}t &\xrightarrow[\text{decode token}]{p\theta} X_{t+1} \xrightarrow[\text{update state}]{p_\psi} \mathbf{h}{t+1} \xrightarrow[\text{decode token}]{p\theta} X_{t+2} \xrightarrow[\text{update state}]{p_\psi} \mathbf{h}{t+2} ;\cdot s; \xrightarrow[]{p\theta} X_T. \end{aligned} $
For these maps to exist, and be learned, $\mathbf{h}_t$ must jointly optimize toward a belief state—a sufficient statistic for the history to predict the future.
Remark. Optimizing only next-token consistency (i.e., Equation 1a) in standard autoregressive transformers does not guarantee that $\mathbf{h}_t$ forms a belief state (see Theorem 3 in [22]). Intuitively, self-attention enables ad-hoc lookup of past tokens, so there is no pressure to compress all necessary information about the past into compact latent summaries at every time step.
Better Data Efficiency.
A distinctive feature of NextLat is the richness of its learning signal. In prior methods that supervise in token space (see Figure 1), the learning signal is only anchored to the next token, or multiple tokens. NextLat additionally supervises in latent space. Specifically, the model is trained to predict its own next hidden state $\mathbf{h}{t+1}$, which parameterizes the full predictive distribution over $X{t+2}$. This shifts supervision from individual one-hot token labels to distribution-level alignment. Moreover, because the latent dynamics compose recursively—each latent is trained to predict the next— $\mathbf{h}{t+1}$ implicitly carries information about future states $\mathbf{h}{t+2}, \mathbf{h}_{t+3}, \dots$. As a result, NextLat not only provides learning signals that are dense in the vocabulary space, but also propagates information about future tokens into earlier representations. By augmenting sparse one-hot targets with dense latent-state supervision, NextLat extracts more learning signal from each training sequence, leading to improved data efficiency.
3.2 Learning to Predict Next-Latent States
We now describe the practical implementation of NextLat, which augments standard next-token prediction with a self-supervised predictions in the latent space. Our NextLat implementation operates primarily on the hidden states (i.e., the final-layer outputs) as they provide compact, fixed-dimensional vectors through which gradients can be propagated through the entire transformer efficiently. As usual, we optimize the transformer and output head for next-token prediction Equation (1a) using the cross-entropy loss:
$ \mathcal{L}\text{next-token}(\theta) = \mathbb{E}{t < T} \big[- \log p_\theta (X_{t+1} \mid \mathbf{h}_{t}) \big]. $
NextLat additionally enforces transition consistency Equation (1b) of the hidden states by introducing a latent dynamics model $p_\psi$ that predicts the next hidden state $\mathbf{h}{t+1}$ directly from $(\mathbf{h}t, X{t+1})$. For a deterministic transformer model, $\mathbb{P}(\mathbf{h}{t+1} \mid \mathbf{h}t, X{t+1})$ is a Dirac distribution, and we can optimize $p_\psi$ via regression[^3]. Moreover, observe that an ideal latent dynamics model should admit recursive consistency: its one-step map should compose correctly across multiple steps. Let $\hat{\mathbf{h}}{t+d} = p\psi(\mathbf{h}t, X{t+1:t+d})$ denote the recursive rollout of $p_\psi$ over a $d$-step horizon using teacher-forced tokens $X_{t+1:t+d}$. We supervise all $d$ intermediate rollouts using the Smooth L1 loss:
[^3]: If considering a stochastic transformer model, $p_\psi$ can be optimized through variational inference.
$ \mathcal{L}\text{next-h} (\theta, \psi;d) = \mathbb{E}{t} \Big[\frac{1}{d}\sum_{i=1}^d \mathrm{SmoothL1Loss}\big(\textbf{sg}[\mathbf{h}{t+i}], \hat{\mathbf{h}}{t+i}\big) \Big],\tag{2} $
where $\textbf{sg}[\cdot]$ denotes the stop-gradient operator, used to prevent representational collapse in self-predictive learning ([9])[^4].
Note that belief state convergence (i.e., Theorem 2) already holds for $d=1$. Multi-step supervision serves only to provide richer learning signal. To further align the semantics of predicted states $\hat{\mathbf{h}}$ with true states, we introduce a complementary KL objective enforcing agreement in token-prediction space:
[^4]: Technically speaking, the next-token prediction objective already provides grounding against representational collapse. However, in our ablations, we empirically observe better performance when applying the stop-gradient.
$ \mathcal{L}\mathrm{KL} (\theta, \psi;d) = \mathbb{E}{t } \Big[\frac{1}{d}\sum_{i=1}^d D_{\mathrm{KL}}!\left(p_\theta^{\textbf{sg}}(\cdot \mid{\textbf{sg}[\mathbf{h}{t+i}]}) ;|; p\theta^{\textbf{sg}}(\cdot \mid{\hat{\mathbf{h}}_{t+i}}) \right) \Big],\tag{3} $
where the output head $p_\theta^{\textbf{sg}}(\cdot)$ is frozen so that gradients flow only through the latent dynamics model. This KL acts similarly to knowledge distillation ([52]), providing soft supervision that guides learning of $p_\psi$. It also resembles observation reconstruction in self-predictive RL ([53, 9]), encouraging $\hat{\mathbf{h}}_{t+i}$ to reproduce the distribution over next observations (i.e., the output head's logits).
Overall Objective. The final NextLat objective combines all components, minimizing the following loss:
$ \mathcal{L}\text{NextLat}(\theta, \psi;d, \lambda\text{next-h}, \lambda_\mathrm{KL}) = \mathcal{L}_\text{next-token}(\theta)
- \lambda_\text{next-h}, \mathcal{L}_\text{next-h} (\theta, \psi;d)
- \lambda_\mathrm{KL}, \mathcal{L}_\mathrm{KL} (\theta, \psi;d),\tag{4} $
where $\lambda_\text{next-h}, \lambda_\mathrm{KL} > 0$ are scalar coefficients. Importantly, during inference, the learned transformer can decode independently; $p_\psi$ is only needed during training to shape the transformer representations.
In the experiments that follow, we parameterize $p_\psi$ using simple MLPs as our goal is to demonstrate that NextLat yields significant performance gains over baselines even without sophisticated latent dynamics architectures. Additional implementation details and ablations of key NextLat design choices are provided in Appendix C and Appendix D, respectively. To illustrate the simplicity of our approach, we also include a PyTorch-style pseudocode of the NextLat objective in Algorithm 1.
3.3 Variable-Length Self-Speculative Decoding
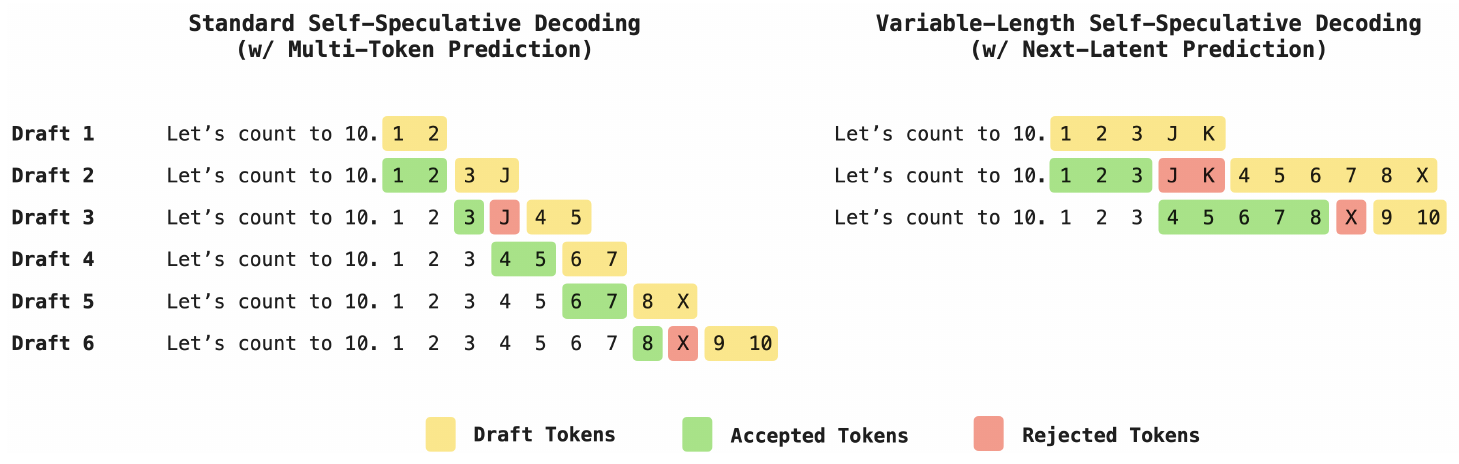
In Figure 2, we illustrate the difference in self-speculative decoding capabilities between MTP methods and NextLat[^5]. MTP models are trained to predict the next $d$ tokens and are therefore limited to drafting at most $d$ tokens per draft–verification cycle. In contrast, even when trained with just $d=1$ (i.e., no multi-step supervision), NextLat can recursively compose predictions via its latent dynamics:
[^5]: The figure illustrates the potential for adaptive draft lengths with NextLat. In the scope of this work, however, we do not implement adaptive drafting strategies; once selected, the draft length remains static throughout decoding. Instead, we exploit the ability to vary these fixed draft lengths to extend beyond the training horizon $d$ in order to maximize inference speedup.
$ \mathbf{h}t \xrightarrow[\text{decode token}]{p\theta} X_{t+1} \xrightarrow[\text{update state}]{p_\psi} \mathbf{h}{t+1} \xrightarrow[\text{decode token}]{p\theta} X_{t+2} \xrightarrow[\text{update state}]{p_\psi} \mathbf{h}_{t+2} ;\cdot s;, $
enabling variable-length drafting during self-speculative decoding. We demonstrate in Section 4.4 that, even with shallow training horizons ($d=1, 2$) in the language domain, NextLat’s latent dynamics remain coherent far beyond the training horizon, enabling longer drafts and much faster inference than MTP baselines.
4. Experiments
Section Summary: In experiments evaluating NextLat against transformer baselines such as GPT, MTP, and JTP, the method was tested on tasks measuring world modeling, reasoning, planning, and language modeling, using matched prediction horizons for fair comparison. On a Manhattan taxi trajectory benchmark designed to probe internal map coherence, NextLat produced more accurate and compact world models than the baselines, achieving stronger generalization to new routes, higher sequence compression, lower latent dimensionality, and greater robustness to detours, even though all methods reached perfect next-token accuracy. The evaluation extends similarly to other domains like mathematical reasoning, where performance patterns favor NextLat’s belief-state approach.
Modeling coherent latent dynamics and compact beliefs about the underlying data-generating process is fundamental to both algorithmic and human reasoning. Therefore, in this section, we evaluate NextLat on four key axes where such capabilities matter most: world modeling, reasoning, planning, and language modeling.
Our baseline comparisons include transformer-based belief-learning methods, i.e., BST ([22]) and JTP ([46]). Further discussions and detailed comparisons with these methods are provided in Section 5 and Appendix A. For completeness, we also report the performances of standard next-token prediction (GPT) and multi-token prediction (MTP). The MTP baseline follows the implementation of [44], and we follow the nanoGPT codebase ([54]) for our decoder-only transformer implementations. Hereafter, we use the term "horizon" to refer to the multi-step prediction horizon $d$ in JTP, MTP and NextLat, and we match horizon across these methods in all experiments to ensure fair comparisons. For specific experiment details such as hyperparameters, evaluation procedure, etc., please refer to Appendix F.
4.1 World Modeling
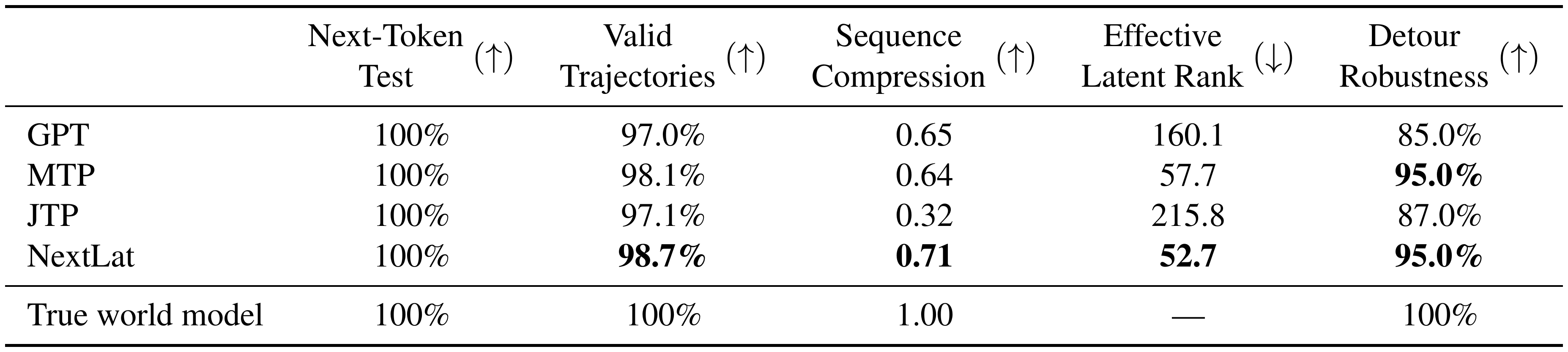
::: {caption="Table 1: Comparison of GPT, MTP, JTP, and NextLat trained on Manhattan taxi rides against the true world model across several metrics."}
:::
[35] introduced a dataset of turn-by-turn taxi rides in Manhattan, where the true world model (i.e., the city’s street map) is visually interpretable. Their study revealed that transformers trained on such trajectories can achieve near-perfect next-token accuracy, yet their internal maps remain incoherent; they reconstruct streets with impossible orientations and even flyovers above other roads.
Setup.
We use the random walks dataset from [35], which consists of random Manhattan traversals (91M sequences, 4.7B tokens) between taxi pickup and dropoff points. Models are trained for 6 epochs (vs. 1 epoch in their study) as we observe performance does not converge within a single epoch. Due to its high computational cost, BST is excluded from this benchmark. For JTP, MTP, and NextLat, we set the multi-step prediction horizon at $d=8$. We evaluate world-modeling performance using five comprehensive metrics:
- Next-Token Test: Percentage of top-1 token predictions corresponding to legal turns under teacher-forcing on in-distribution validation sequences.
- Valid Trajectories: Percentage of valid traversals for out-of-distribution (OOD) pickup–dropoff pairs.
- Sequence Compression: Percentage of cases where the model produces identical continuations when prompted with two different traversals arriving at the same state and sharing the same destination.
- Effective Latent Rank: Effective rank/dimension of hidden states measured as the exponentiated Shannon entropy of the normalized singular values ([55]); lower values indicate better compression.
- Detour Robustness: Percentage of valid traversals for OOD pickup–dropoff pairs when we substitute the model’s top-1 prediction with random detours (legal turns) 75% of the time.
The results are shown in Table 1. More details on training and evaluation are provided in Appendix F. We also refer motivated readers to [35] for further explanations of the next-token test, valid trajectories, sequence compression, and detour robustness metrics.
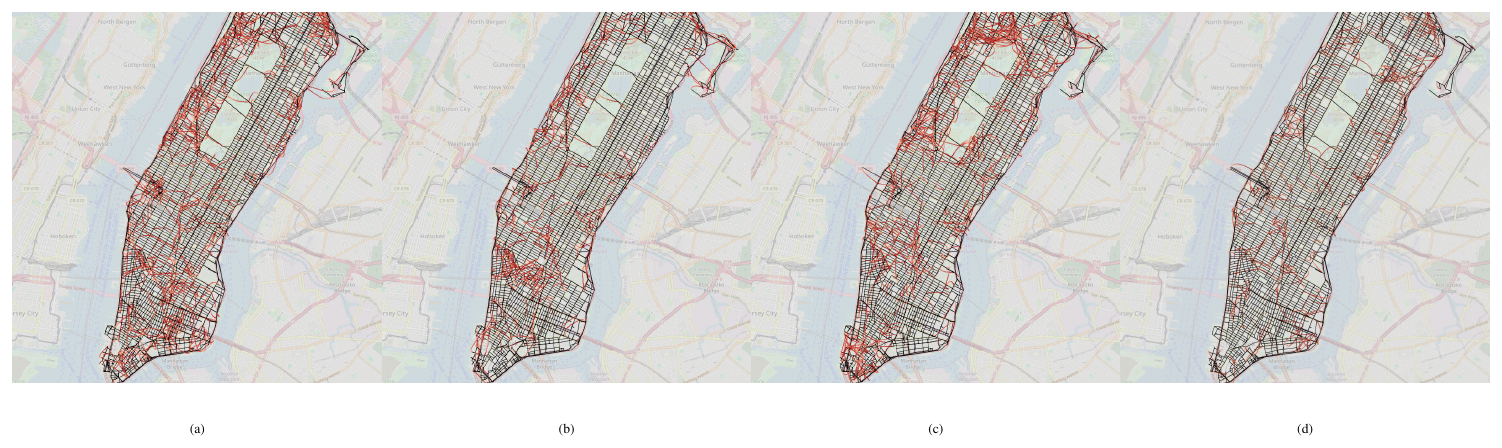
Results.
Similar to the original study, all models achieved 100% accuracy on the next-token test. However, next-token accuracy is a limited diagnostic and cannot meaningfully assess the quality of a model’s learned world model. In Figure 3, we visualize each model's internal map using the reconstruction algorithm proposed by [35]. Visibly, the transformer trained with NextLat exhibits an internal map more consistent with the true world model. Although not perfect, its inconsistencies (red edges) are sparse and mostly local. Beyond this qualitative evidence, NextLat consistently outperforms all baselines across all metrics. On the trajectory validity and detour robustness metrics, NextLat demonstrates the strongest generalization to OOD pickup–dropoff pairs, even when random detours are introduced.
Next, we analyze the compactness of the learned world models using two compression metrics. A model that accurately captures the underlying states and transitions should assign identical continuations to trajectories that end in the same state (i.e., intersection in Manhattan). By this criterion, NextLat achieves the highest sequence compression of 0.71. The true Manhattan graph comprises only 4, 580 intersections and 9, 846 edges, and therefore an effective world model should require only a modest latent dimensionality. Indeed, NextLat has the lowest effective latent rank of 52.7—over 3x smaller than GPT's. The combination of stronger planning performance and more compact latent representations reinforces the view that NextLat, by promoting belief state representations and coherent latent dynamics, enables transformers to learn substantially better world models—ones that are both accurate in their predictive structure and efficient in their internal representation of the environment.
4.2 Reasoning
Countdown ([56]) is a mathematical reasoning task and a generalized version of the Game of 24, which even frontier models such as GPT-4 ([57]) have struggled with, achieving 4% by default ([58]). The goal of the task is to combine a set of given numbers with basic arithmetic operations $(+, -, \times, \div)$ to obtain a target number. For example, given the numbers ${90, 8, 20, 50}$, the target number $24$ can be obtained using the following sequence of equations: $90\times8=720, :50-20=30, :720\div30=24$. Countdown poses a difficult combinatorial search problem due to its large branching factor and the need to efficiently explore the solution space to reach the target number.
Setup.
Following [59], we generate 500k training problems with target numbers ranging from 10 to 100 and reserve 10% of the targets for out-of-distribution evaluation. During both training and testing, we insert eight `pause tokens' ([60]) after the target number, allowing models additional computation to plan before generating a solution. Performance is measured as the percentage of 10k test problems for which a model produces a valid sequence of equations that correctly reaches the target number. The reported results average over three random seeds per baseline.
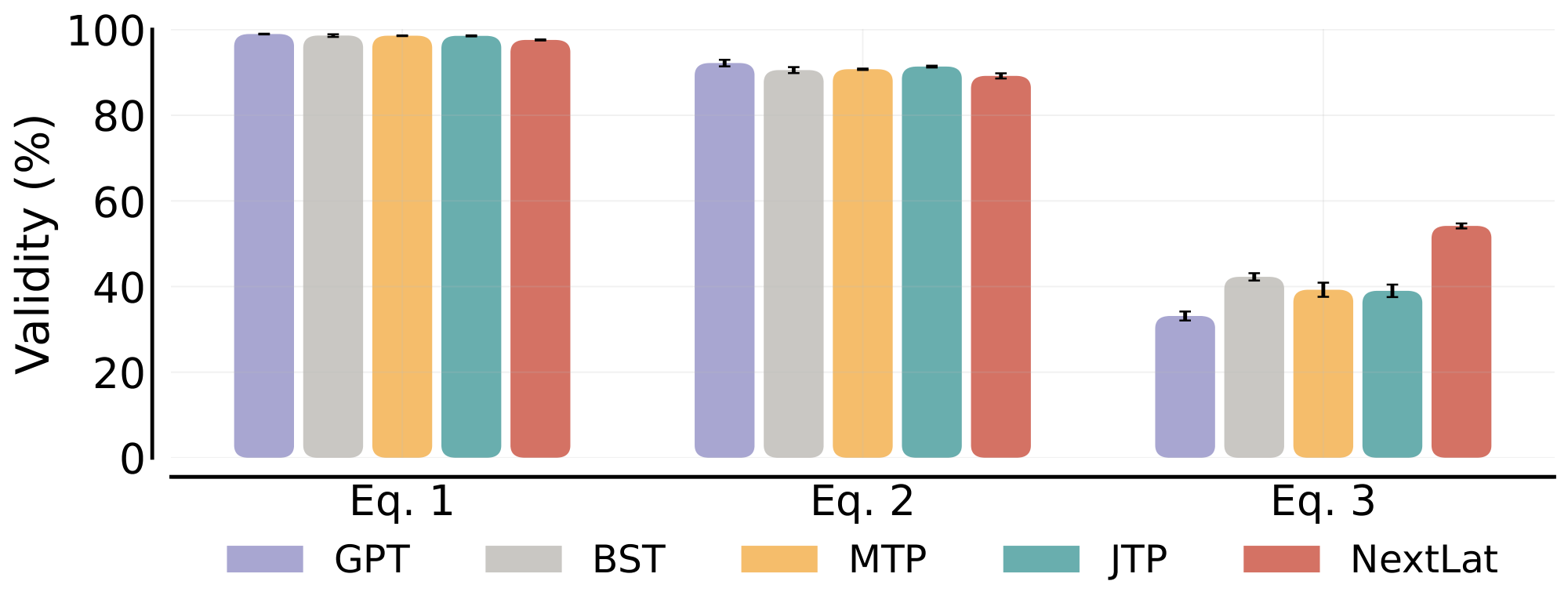
Results.
As shown in Figure 4, NextLat consistently outperforms all baselines in Countdown. Notably, even with a shallow supervision horizon of $d=1$, NextLat substantially surpasses MTP and JTP trained with the same horizon (>35.7% improvement). To better understand this gap, we analyzed the equations generated by each model and evaluated their equation validity, i.e., whether the computed left-hand side equals the right-hand side. As shown in Figure 5, most calculation errors occur in the final equation (Eq. 3). This indicates that the model’s lack of planning capability results in its realization of being unable to achieve the goal only at the end. Unable to revise earlier missteps, it forces an invalid final equation to match the desired outcome—a behavior termed the regretful compromise by [61]. NextLat demonstrates stronger lookahead planning: even with $d=1$, it achieves substantially higher mean validity in the final equation ($54.8$ %) compared to the next best baseline ($42.3$ %). This suggests that the latent-state prediction objective may help the model anticipate long-range dependencies and form globally consistent plans, reducing the tendency to make myopic errors. NextLat also achieves leading performance with horizons $d=4$ and $8$.
4.3 Planning
![**Figure 7:** Illustration of a $G_{5, 5}$ Path-Star graph ([42]).](https://ittowtnkqtyixxjxrhou.supabase.co/storage/v1/object/public/public-images/gdugeayb/stargraph.png)
A Path-Star graph ([42]) $G_{d, \ell}$ consists of a center node and $d$ disjoint arms, each consisting of $\ell-1$ nodes. Figure 7 depicts an instantiation of the $G_{5, 5}$ topology. A training instance is a tokenized sequence that contains the edge list, the start and end nodes, and the correct path from start to end. This task represents a minimal instance of lookahead planning, a core capability underlying more complex behaviors such as storytelling. Yet, despite its apparent simplicity, next-token prediction models struggle to solve it.
Setup.
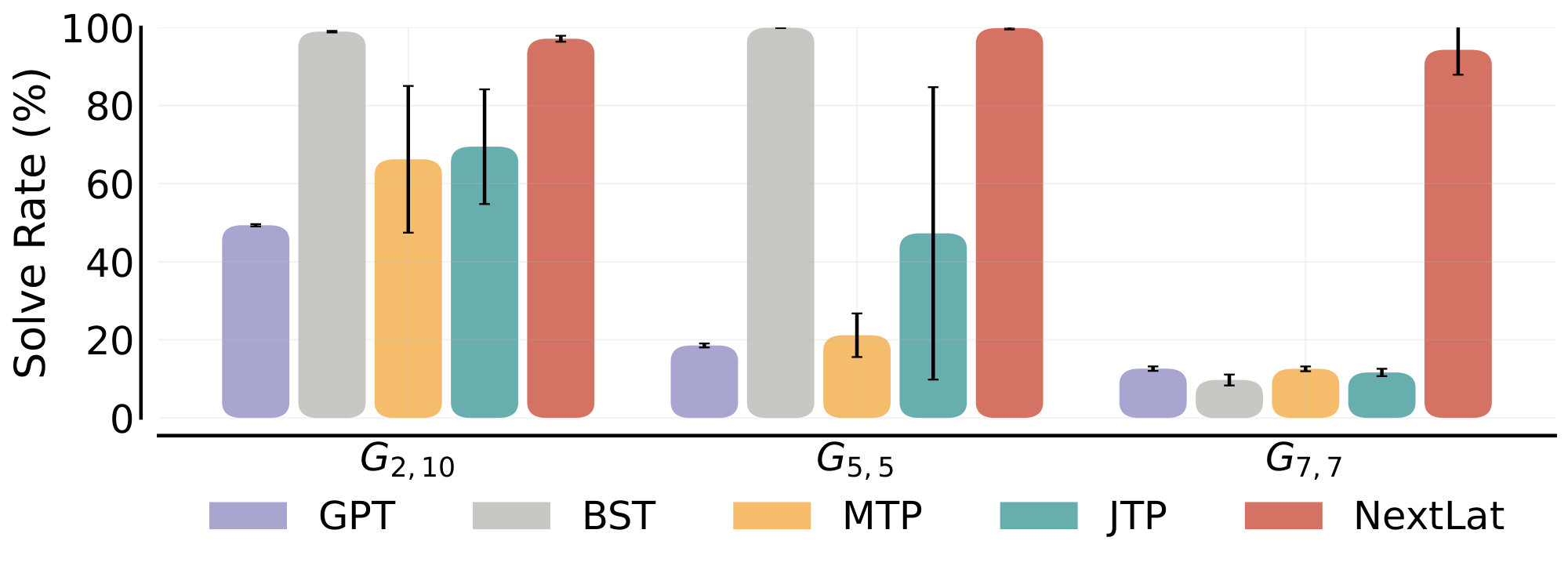
Following [42], we generate 200k training samples and set $N=100$, such that node values in each graph are randomly drawn from ${1, \dots, 100}$. For MTP, JTP, and NextLat, we set the multi-step prediction horizon to $d = \ell - 2$, ensuring that the target (end) node lies within the multi-step prediction horizon of the center node. We evaluate performance across three graph configurations: $G_{2, 10}$, $G_{5, 5}$, and $G_{7, 7}$ across five random seeds per baseline.
Results.
As shown in Figure 6, NextLat maintains close to 100% solve rate for all topologies of the Path-Star graphs. BST, while able to solve $G_{2, 10}$ and $G_{5, 5}$, begins to fail at the larger graph $G_{7, 7}$. Note that our results differ from that presented in [22] (BST) and [46] (JTP). In their setup, they use a much smaller problem settings of $N=50$, and generate a fresh batch of graphs every iteration. On the other hand, we use the original (and more difficult) setup which has a fixed sample size of 200k and $N=100$.
The Path-Star graph task is specifically designed to reveal the myopic behavior of teacher-forced next-token prediction models, which tend to exploit local shortcuts instead of learning to perform lookahead planning necessary to solve the task. This phenomenon, termed the Clever Hans cheat ([42]), is related to the difficulty of learning parity ([22]) and has motivated methods such as BST and JTP that attempt to mitigate shortcut learning through multi-token predictions. However, these approaches operate in token space, making them still susceptible to local $n$-gram regularities that do not capture the underlying transition structure required for long-horizon planning. In contrast, NextLat performs prediction in latent space, enforcing recurrent transition consistency at the representation level. NextLat’s success across all graph configurations, unlike MTP, JTP, and BST, suggests that latent-space prediction better avoids shortcut learning and yields more generalizable solutions. Furthermore, given the limited training samples (i.e., 200k) in this task, data efficiency is crucial. NextLat's strong performance in this low-data regime suggests that it extracts more useful supervision from each training sequence than token-prediction baselines, consistent with our analysis in Section 3.1.
Next, we compare the models on TinyStories ([62]), a dataset consisting of synthetic short stories. Storytelling is inherently a long-horizon planning problem; a coherent narrative requires maintaining persistent entities, tracking causal relationships, resolving conflicts and delayed resolutions, and satisfying narrative constraints across many timesteps. Generating such sequences therefore depends not only on next-token prediction, but on belief-state–like abstractions that encode information predictive of future story trajectories.
Setup.
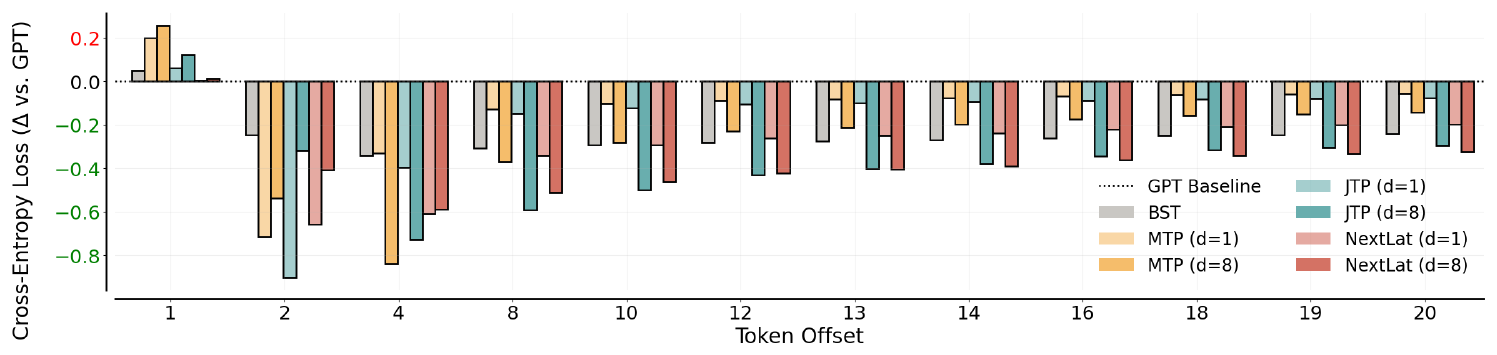
Following [22], we tokenize the dataset of 2.7 million stories into a vocabulary of 1, 000 tokens and construct training sequences of length 256. All models are trained for 100k steps, which is sufficient for convergence. We include comparisons of transformers trained using MTP, JTP, and NextLat with multi-step prediction horizons $d \in {1, 8}$. After training, we freeze the model parameters and train 20 independent linear probes, one per token offset, to predict tokens at offsets $1, \dots, 20$ steps ahead from the hidden states of the frozen models using the same dataset. This allows us to assess whether the models’ representations encode information predictive of future tokens, or just local token correlations.
Results.
We plot the difference in probe performance relative to probes trained on GPT’s hidden states in Figure 8. For clarity, we display only selected token offsets here (see Figure 16 in the appendix for full results). Observe that the additional token-level prediction objectives in BST, MTP, and JTP consistently cause significant degradation in next-token prediction (i.e., token offset = 1). Moreover, probe performance on JTP and MTP representations declines sharply with increasing token offset. This indicates that these multi-token prediction models, lacking guarantees of learning belief states, could encode information useful only for short-horizon prediction. In contrast, NextLat matches GPT’s next-token performance across both $d \in {1, 8}$ and exhibits the strongest long-range predictive capability (up to 20 tokens ahead) for both $d=1$ and $d=8$. These results suggest that NextLat’s latent-state objective induces belief-like representations that encode predictive information about future events—an ability essential for maintaining coherence in long-range narrative generation tasks like TinyStories.
4.4 Language Modeling
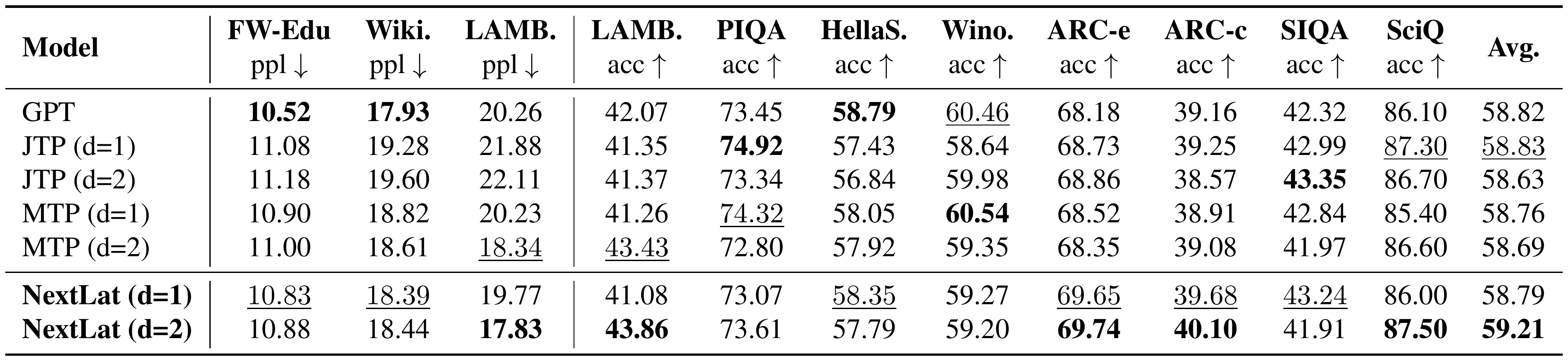
::: {caption="Table 2: Downstream language modeling evaluation on 1.3B-parameter models trained on 100B FineWeb-Edu tokens. Best scores are in bold and second-best are underlined."}
:::
Setup.
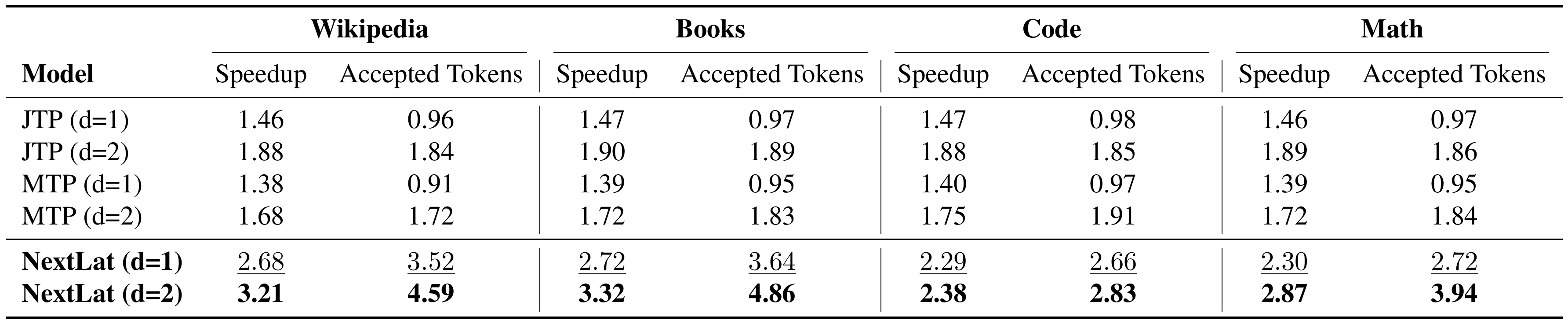
We pretrain 1.3B-parameter models on 100B tokens from the FineWeb-Edu dataset ([63]), excluding BST due to its high computational cost. After pretraining, we use the LM Evaluation Harness ([64]) to evaluate the zero-shot accuracy of the models on multiple-choice language modeling benchmarks. We also evaluate the self-speculative decoding performance of the multi-step prediction models, i.e., JTP, MTP, and NextLat, across Wikipedia, Books, Code, and Math domains. For each dataset, we sample 1024 prompts of length 512 tokens and generate 512-token continuations using the speculative sampling algorithm of [47]. For each model, we report the average number of accepted tokens per drafting step, as well as the inference speedup relative to standard autoregressive sampling from the base transformer, measured on $8\times$ NVIDIA B200 GPUs. For multi-step prediction models, we primarily focus our analysis on training with horizons of $d=1$ and $d=2$. MTP and JTP operate in token space and are therefore usually limited to speculative decoding within the fixed multi-token horizon used during training. Our aim is to highlight the advantages of NextLat’s variable-length self-speculative decoding, which enables drafting beyond the training horizon. To this end, we vary NextLat’s speculative draft length between 2 and 10 tokens and report the highest inference speedup achieved for each domain.
::: {caption="Table 3: Relative speedup and average accepted tokens per drafting steps over diverse domains. Note that Äccepted Tokensëxcludes the next-token prediction which is always accepted."}
:::
Results.
In Table 2, we present the language modeling perplexity (ppl) and zero-shot accuracy (acc) of the pretrained models across several benchmarks. Consistent with observations in [44], we do not observe significant improvements in multiple-choice task accuracy over standard next-token training (GPT) when using multi-token prediction objectives. NextLat ($d=2$) does show a modest gain in average accuracy over GPT (59.21 vs. 58.82), but these improvements are not consistent across tasks. Larger model sizes might be necessary to see more significant improvements. Notably, NextLat better preserves next-token perplexity compared to MTP and JTP across FineWebEdu, Wikitext, and LAMBADA. This is consistent with our earlier observations on TinyStories in Section 4.3. Preserving high fidelity in next-token prediction is arguably important, as prior work shows that lower pretraining perplexity correlates with improved aggregate downstream and post-fine-tuning performance at larger model scales ([65, 66]).
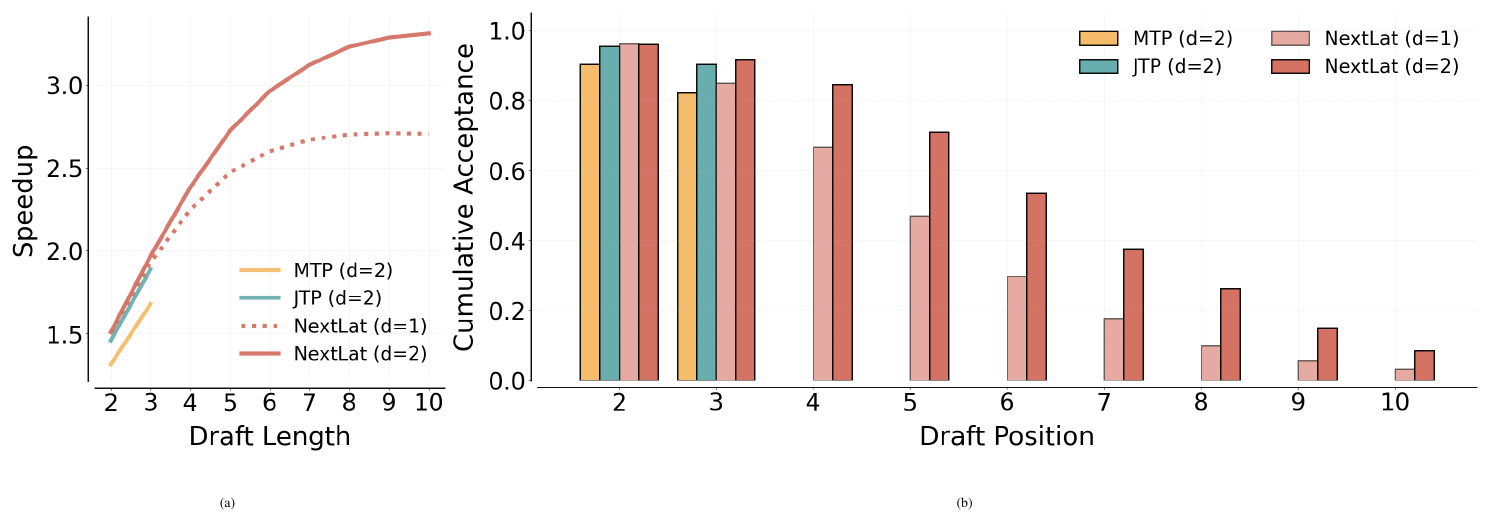
Next, in Table 3, we show the self-speculative decoding results. Observe that the average accepted tokens per drafting steps for NextLat far exceeds its training horizon $d$, indicating that the learned latent dynamics remains coherent over extended rollouts. This further highlights the strong long-range predictive capability of the induced belief state representations. Crucially, this ability to support variable-length self-speculative decoding enables NextLat to achieve substantially higher inference speedups than MTP and JTP across all domains. Figure 9 further shows speedup and cumulative acceptance rate versus draft length on the FineWeb-Edu validation set. Speedup increases sublinearly with draft length, reaching up to $3.3\times$, and fully valid (i.e., all tokens accepted) drafts persist even at length 10. This demonstrates a clear benefit to drafting tokens beyond the training horizon with NextLat. In Appendix F.6.1, we extend our comparisons to include JTP and MTP trained with larger horizons ($d=4$). Note that the training cost of JTP and MTP increases substantially with larger $d$ (see Table 4), making JTP ($d=4$) and MTP ($d=4$) significantly more expensive to train than NextLat ($d=1, 2$). Still, even with longer multi-token supervision, these baselines still fail to surpass NextLat in speculative decoding performance. This highlights a key advantage of NextLat's variable-length speculative decoding: it enables long speculative drafts while requiring training only at shallow, computationally efficient horizons.
5. Discussions
Section Summary: NextLat offers a more efficient and theoretically grounded way to train transformers for learning useful internal representations of sequences than earlier methods like BST or JTP. Unlike those approaches, it avoids expensive quadratic computations or restrictive requirements on prediction length while still encouraging the model to capture longer-term patterns rather than just short-term token correlations. This results in faster training than many alternatives, stronger generalization on benchmarks, and a recurrent-style bias in the learned representations without the full sequential slowdown of traditional recurrent networks.
5.1 Comparison Against Current Approaches
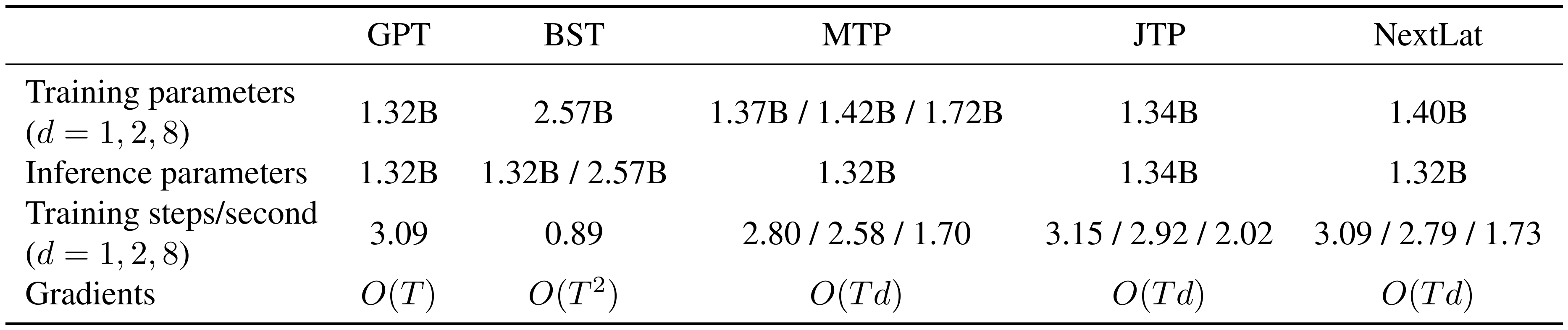
::: {caption="Table 4: Comparison of training speed, parameter count and gradient signals provided on FineWeb-Edu pretraining. For training parameter numbers and training iterations/second, we report values for prediction horizons d=1, 2, 8. If only a single value is shown, it means that the values are the same for all horizons. All training speeds are measured on a single NVIDIA B200 GPU with batch size of 33k tokens."}
:::
In this section, we discuss the advantages of NextLat compared to prior transformer learning approaches, focusing discussions on belief-learning methods, i.e., BST and JTP. We provide brief descriptions of these methods and their training objectives in Appendix A. Motivated readers interested in further details beyond the scope of this work may refer to [22] and [46]. Table 4 summarizes the training and inference parameters, training speed (in iterations per second), and gradient signal characteristics for each method on FineWeb-Edu pretraining, providing context for the discussions that follow.
Computational Costs.
While BST benefits from $O(T^2)$ gradient signals per token sequence, this is a double-edged sword. Even with the optimized implementation of [22], training remains extremely costly because gradients must be accumulated over all $O(T^2)$ predictions of different prefix–suffix pairs. Moreover, BST trains two transformer encoders, further increasing compute and parameter cost. During inference, BST also uses both transformer encoders, one for generation and the other for scoring the likelihood of the generated sequence. On FineWeb-Edu pretraining, BST is over $3\times$ slower than NextLat in training speed (see Table 4). Note that this result already uses 10% subsampling of prefix-suffix pairs to prevent out-of-memory issues; the training speed of BST would be much slower if all pairs were used for training. In contrast, NextLat with $d=1$ incurs negligible overhead relative to GPT while achieving the same belief-state learning guarantees as BST.
We next compare the compute costs of the multi-step prediction methods, i.e., MTP, JTP, and NextLat. The MTP implementation of [44], as well as other variants such as the one introduced in [45], require additional transformer layers as the prediction horizon $d$ increases, whereas JTP and NextLat keep parameter counts fixed across horizons. JTP and NextLat exhibit similar training speeds for $d=1$ [^6], while MTP lags behind. At $d=8$, JTP is substantially faster than NextLat because NextLat sequentially unrolls its latent dynamics model $p_\psi$ to compute multi-step losses, while JTP computes them in parallel. Nonetheless, this modest increase in computation for NextLat yields substantially better performance than JTP across all benchmarks. Importantly, NextLat’s sequential computation remains far more efficient than that of recurrent neural networks (RNN), which we discuss further in Section 5.2.
[^6]: JTP exhibiting a slightly faster training speed than GPT at $d=1$ is likely an artifact of torch.compile() due to differences in the computation graph.
Belief State Learning.
GPT and MTP lack any theoretical learning pressure to form belief-state representations, which means that they do not necessarily learn sufficient representations predictive of future observations. JTP can learn belief states but only under the restrictive condition that the prediction horizon satisfies $d \ge k$, where $k$ denotes the observability horizon of the underlying data-generating process (see Definition 3 in appendix). In long-context sequence modeling, however, the underlying process is often $k$-observable for a very large $k$, rendering this condition impractical. NextLat, on the other hand, learns belief-state representations independently of $d$ and larger multi-step prediction horizons are used only to provide richer gradient signals. It also avoids the expensive $O(T^2)$ gradient computation required by BST to learn belief states. As such, NextLat stands as a simple, computationally efficient, and theoretically grounded alternative to existing belief-state learning approaches (i.e., BST and JTP) in autoregressive sequence modeling.
Myopic Nature of Token-level Predictions.
Token-level supervision is often myopic. Next-token prediction transformers tend to prioritize short-term dependencies, and studies have shown that early training can often resemble $n$-gram modeling, which can delay or even prevent learning of the true Markov kernel ([67, 68]). [42] further showed that the myopic nature of next-token prediction training can trap models in suboptimal local minima, undermining long-horizon planning. In our experiments, we find that adding additional token-level prediction objectives, as in BST, JTP, and MTP, not only degrades next-token performance but also fails to yield consistent gains in generalization. In contrast, NextLat, which emphasizes latent transition modeling as its primary objective, minimizes degradation in next-token performance and improves downstream generalization by encouraging the learning of predictive representations rather than shallow token-level correlations. Moreover, as discussed in Section 3.1, latent-space supervision provides denser gradient signals than token-level supervision. Overall, NextLat offers a compelling alternative to conventional token-level prediction objectives for transformer training.
5.2 NextLat vs. Recurrent Neural Networks
Algorithmic reasoning requires capabilities most naturally understood through recurrent models of computation, like the Turing machine. However, strict recurrence imposes a sequential computation bottleneck at training time. NextLat introduces a recurrent inductive bias for the learned representations via latent transition prediction without turning the transformer into a strictly sequential model.
Training RNNs without recurrence.
Intuitively, NextLat ($d=1$) can be viewed as fully parallel co-training of a transformer and a recurrent neural network (RNN). The transformer forecasts latent states across the sequence in parallel, while the latent dynamics model (the RNN) is trained using only one-step latent predictions. This co-training process does not require any sequential computation across time.
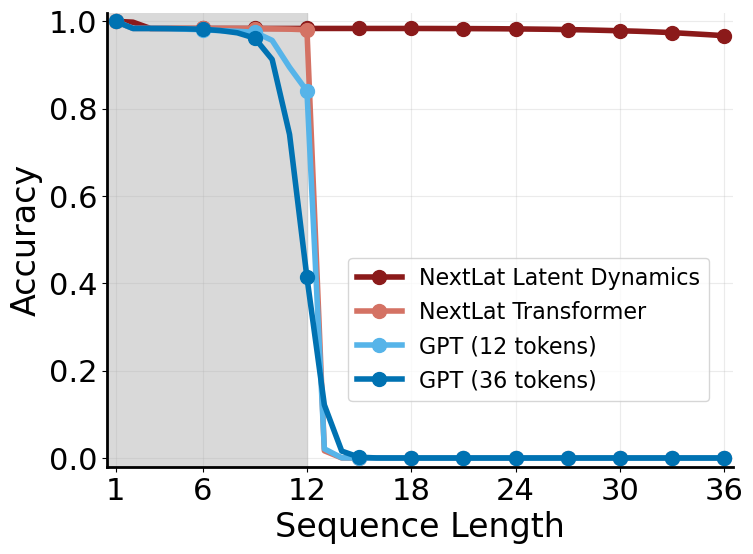
To study this interaction, we consider the $A_5$ word problem, a difficult state-tracking task involving even permutations of five elements. The problem is $\text{NC}^1$-complete and therefore inexpressible by constant depth, fixed-precision transformers, which are restricted to the $\text{TC}^0 \subset \text{NC}^1$ circuit complexity class ([69])[^7]. We train 2-layer transformers using next-token prediction (GPT) and next-latent prediction (NextLat, $d=1$) on the $A_5$ word problem with a sequence length of 12 tokens (permutations). We then tested the transformers and the latent dynamics model (RNN) on their length generalization to sequences of length 36. Note that during inference, the RNN only uses the transformer backbone to initialize the hidden state for the first token, after which subsequent hidden state transitions and token predictions are generated independently by the RNN without invoking the transformer. Importantly, the RNN also has substantially fewer parameters than the transformer (2.62M vs. 6.43M parameters).
[^7]: This assumes the widely held conjecture that $\text{TC}^0 \neq \text{NC}^1$.
Figure 10 shows interesting results. First, the transformer trained with NextLat exhibits better state-tracking performance than GPT within the 12-token training horizon. More surprisingly, while the transformer itself fails to generalize beyond the 12-token horizon, the learned latent dynamics model successfully generalizes to 36-token sequences (
gt;95$ % accuracy). This is particularly striking because even a GPT model trained directly on 36-token sequences ("GPT (36 tokens)") is unable to solve the task, consistent with previous results ([70]). In other words, although the transformer itself cannot solve the 36-token $A_5$ problem, it is nevertheless able to train an RNN that can.From a circuit complexity perspective, solving problems in $\text{NC}^1$ requires transformers with $O(\log T)$ depth ([69, 6]), where $T$ is the sequence length. This explains why the shallow 2-layer transformers (both GPT and NextLat) are unable to solve problems beyond 12 tokens. What is surprising, however, is that under NextLat training, the co-trained RNN can generalize far beyond the expressivity limits of the underlying transformer, despite being trained entirely in parallel. This raises an intriguing question:
Given inputs of length $T$, can a transformer with $O(\log T)$ depth co-train (in parallel) an RNN that generalizes to sequences of length $\gg T$? More specifically, can the co-trained RNN learn $\text{NC}^1$ computations, even though it is supervised using representations from a transformer in $\text{TC}^0$?
Intuitively, this seems plausible. As long as the transformer has sufficient depth to express and forecast hidden states within the $T$-length training context window, it makes sense for the latent dynamics model (RNN) to learn reusable computational circuits that extrapolate far beyond it, as empirically suggested by Figure 10. In this view, NextLat may offer a mechanism for partially escaping the practical limitations imposed by the parallelism tradeoff ([69]): the transformer provides efficient parallel representation learning, while the RNN focuses on learning generalizable sequential update rules.
Computational Efficiency and Relation to Backpropagation Through Time.
Now, we further compare NextLat against traditional RNNs trained using backpropagation through time. Tranditional RNNs incur $O(T)$ sequential dependence during training. In contrast, NextLat adds only an additional sequential cost proportional to the rollout horizon $d \ll T$, corresponding to unrolling the latent dynamics model $p_\psi$ for $d$ steps. This allows NextLat to largely retain the transformer’s parallel training efficiency while also inheriting a recurrent inductive bias.
Conceptually, the one-step and multi-step prediction in NextLat resembles truncated backpropagation through time (TBPTT) in RNNs, with truncation windows of $1$ and $d$, respectively. However, a key distinction lies in how gradients are propagated. In TBPTT for RNNs, gradient computation is truncated beyond the chosen window, yielding biased gradient estimates that lack convergence guarantees. In contrast, the theoretical convergence of belief-state learning in NextLat, as shown in Theorem 2, is irrespective of $d$, since it requires only one-step prediction optimality. Intuitively, NextLat performs full backpropagation through the transformer’s computation graph, where self-attention connects all past tokens. The latent dynamics model operates in an "outer loop", aligning the transformer's hidden states to be temporally consistent across steps. Crucially, this outer-loop supervision does not truncate gradient flow within the transformer, and therefore avoids bias with respect to $d$. Larger prediction horizons simply provide richer supervision and faster empirical convergence.
Expressivity of the Recurrence.
Modern state-space models (SSMs), such as S4 and Mamba, implement efficient linear recurrent updates while remaining highly parallelizable ([71, 72]). In contrast to SSMs, the latent dynamics model $p_\psi$ in NextLat can express nonlinear transitions. Moreover, NextLat does not explicitly perform recurrence in the forward computation. Instead, recurrent-like dynamics emerge implicitly through one-step or multi-step unrolling of the $p_\psi$ and aligning successive hidden states via regression. This induces temporal consistency within the latent space without altering the transformer architecture. However, it is important to note that NextLat modifies the learned representations, not the underlying circuit complexity. The overall computational expressivity of the fixed-depth transformer trained with NextLat remains bounded by that of constant-depth threshold circuits, i.e., within the TC$^0$ complexity class ([73]). However, earlier results in Figure 10 question whether the co-trained latent dynamics model (RNN) is subject to the same $\text{TC}^0$ limitations.
Hybrids Attention Models.
NextLat differs fundamentally from hybrid Transformer–SSM architectures ([74, 75, 76]), which explicitly interleave SSM and attention layers. NextLat requires no architectural changes and operates purely as an auxiliary training objective on the model’s latent representations. As such, it is broadly compatible with diverse sequence-modeling architectures. In fact, NextLat could complement hybrid models by encouraging compression and consistency in the residual attention pathways that fall outside the SSM’s recurrent structure, potentially improving representation efficiency and generalization.
6. Limitations and Future Work
Section Summary: The work on NextLat has several limitations, including the use of only simple neural networks for its core components without testing more complex designs or larger scales, reliance on limited experiments to choose training details, and incomplete exploration of variable-length generation during inference. The authors also did not closely examine the internal representations learned by the model or compare against some newer related methods, and they noted sensitivity to how training is set up. They suggest future work on applying the approach to improve existing models after initial training, testing it in reinforcement learning settings, and developing richer versions of the underlying prediction mechanism.
While NextLat shows strong empirical performance, several limitations remain in our work. First, we do not explore the design space of the latent dynamics model; all experiments use simple MLPs to isolate and demonstrate the effectiveness of the core NextLat approach. More expressive architectures may further improve performance. We also do not study how the width of the hidden layers in the latent dynamics MLP affects learning, even though it effectively acts as a bottleneck that constrains belief-state capacity and may influence performance across tasks. Empirically, we observe that using smaller latent dimensions is beneficial on tasks such as Path-Star graph and Countdown.
Second, the design of the NextLat objective (e.g., stop-gradients, KL self-distillation, Smooth L1 loss) is guided largely by small-scale ablations in Appendix D and empirical intuition. It remains unclear whether multi-step supervision ($d>1$) and KL token-level supervision are even necessary at larger model and data scales. More systematic studies are needed to better understand how these components interact. Third, due to computational constraints, we did not evaluate against more recent or specialized MTP variants such as the one introduced in [45]. Finally, we did not fully exploit the variable-length nature of NextLat’s speculative decoding. In our experiments, the draft length remained fixed throughout decoding for each prompt; we only varied the static draft length between 2 and 10 tokens to identify the configuration with the highest inference speedup. We leave the exploration of more creative adaptive-length speculative decoding strategies for NextLat to future work.
On the analysis side, we do not study the structure of the learned representations under NextLat, leaving open questions about how the method shapes latent spaces. In Appendix E, we also highlight several quirks observed during pretraining with NextLat, such as increases in Smooth L1 loss ($\mathcal{L}_\text{next-h}$) during training and differing loss trajectories across optimizers. These observations suggest that NextLat can be sensitive to optimization dynamics. Better understanding of how to scale and parameterize the NextLat objective remains an important direction for future work.
This work represents only an preliminary study of next-latent prediction, leaving many promising directions for future research. Since the method requires no architectural changes beyond a lightweight latent dynamics model for shaping representations, an interesting direction is to apply it as a post-hoc finetuning objective for pretrained transformers. This could potentially improve reasoning, planning, and world-modeling capabilities of existing models without retraining from scratch. Moreover, because NextLat effectively organizes latent representations with recurrent-like dynamics, an interesting question is whether transformers trained with NextLat are better suited for RL post-training, where value estimation (be it implicit or explicit) benefits from such recursive "Bellman-like" latent structure. Finally, it would be valuable to explore richer latent architectures, such as higher-dimensional or hierarchical belief states spanning multiple layers or tokens, which may further improve long-horizon reasoning and planning.
7. Conclusion
Section Summary: The paper presents NextLat, a training method that adds self-supervised prediction in a hidden space to the usual next-token task for transformers. This naturally encourages models to form compact internal summaries of past information that help predict what comes next, improving results on modeling, reasoning, and planning tasks without altering the model's architecture or speed. The approach blends the compact, consistent style of recurrent networks with transformers' scalability, offering a broadly useful step toward more generalizable sequence models.
In this paper, we introduced Next-Latent Prediction (NextLat), a simple yet powerful framework that augments next-token training with self-supervised latent-space prediction, enabling transformers to learn belief-state representations. Theoretically, we show that the pressure to form concise latent summaries of past information sufficient to predict the future arises naturally from the NextLat objective. Empirically, NextLat yields more compact, predictive, and generalizable representations across tasks in world modeling, reasoning, planning, and language modeling—all without changing the transformer's architecture, parallel training efficiency, or inference procedure. By reintroducing a recurrent inductive bias through self-predictive latent dynamics, NextLat unifies the inherent bias toward compact and temporally consistent representations of recurrent models with the scalability and parallelism of transformers. Our method is broadly applicable for training transformers in autoregressive sequence modeling domains. Looking ahead, we view NextLat as a step toward training objectives that endow autoregressive sequence models with simpler, more compact, and therefore more generalizable representations of complex systems.
Acknowledgements
We thank Jason Eisner, Jordan T. Ash, Pradeep Varakantham, Andrea Zanette, Michael C. Mozer, Ying Fan, and the MSR AI Frontiers team for their valuable discussions and support.
Appendix
Section Summary: The appendix reviews two recent methods for training transformer models to produce compact "belief states," or hidden representations that capture all information from past observations needed to predict future sequences. The Belief State Transformer jointly trains next- and previous-token predictors across sequence segments, while joint multi-token prediction learns accurate distributions over the next several tokens and provably yields belief states in systems where short-horizon forecasts fully determine longer-term outcomes. It also supplies a formal backward-induction proof that models enforcing both next-token accuracy and consistent state transitions can recursively decode entire future trajectories from any point.
A. Belief States in Sequence Modeling
Recent work has introduced variants of sequence modeling architectures based on the principle of learning belief states, i.e., BST and JTP. We review these methods here. Let $\theta$ denote the parameters of a transformer-based model. Let $\mathbf{h}{s:t}$ denote the hidden states produced by the transformer encoder for a token sequence $X{s:t}$, where $s \leq t$. When we use the notation $\mathbf{h}t$, it is shorthand for $\mathbf{h}{1:t}$. The model's output head produces a categorical distribution over the token vocabulary conditioned on some hidden state representation, i.e., $p_\theta(\cdot \mid \mathbf{h}_{s:t})$.
Belief State Transformer.
The Belief State Transformer (BST; [22]) learns compact belief states by jointly training a next-token predictor and a previous-token predictor across all possible prefix–suffix decompositions of a sequence, including cases where either the prefix or suffix is empty. Concretely, given a prefix $X_{1:t}$ and a suffix $X_{t+k:T}$ with $k\geq 1$, BST aims to minimize the cross-entropy loss
$ \mathcal{L}\text{BST}(\theta) = \mathbb{E}{t < T}\Big[-\log \underbrace{p_\theta(X_{t+1} \mid \mathbf{h}{1:t}, \mathbf{h}{t+k:T})}{\text{next-token prediction}} - \log\underbrace{p\theta(X_{t+k-1} \mid \mathbf{h}{1:t}, \mathbf{h}{t+k:T})}_{\text{previous-token prediction}} \Big],\tag{5} $
where $\mathbf{h}{1:t}$ and $\mathbf{h}{t+k:T}$ are produced by separate transformers. This bidirectional training shapes the hidden representations of the BST into belief states.
Joint Multi-Token Prediction.
Joint multi-token prediction (JTP; [46]) aims to learn the joint distribution over the next $d+1$ tokens conditioned on $\mathbf{h}_{t}$, where $d$ is the multi-step prediction horizon beyond the next token. Specifically, JTP minimizes the loss
$ \mathcal{L}\text{JTP}(\theta;d, \lambda\text{MTP}) = \mathbb{E}{t < T} \Big[-\log \underbrace{p\theta(X_{t+1} \mid \mathbf{h}{t})}{\text{next-token prediction}} - \lambda_\text{MTP} \cdot \frac{1}{d}\sum_{i=1}^d\log \underbrace{p_\theta(X_{t+i+1} \mid \mathrm{Fetch}(\mathbf{h}{t}, X{t+1:t+i}))}_{\text{joint multi-token prediction}} \Big],\tag{6} $
where an additional module $\mathrm{Fetch}(\mathbf{h}t, X{t+1:t+i})$ is used to create an embedding combining the teacher-forced tokens $X_{t+1:t+i}$ with $\mathbf{h}t$ and $\lambda\text{MTP} > 0$ balances next- and multi-token prediction losses. Although [46] suggest that their method learn "short-horizon belief states", they do not formally define the conditions under which this occurs. To understand how JTP learns belief states, we start by defining a $k$-observable system.
########## {caption="Definition 3: $k$-observability for sequences"}
A system is $k$-observable if for any two sequences $H =X_{1:t}$ and $H' =X_{1:j}$ that induce the same joint distribution over the next- $k$ tokens, i.e., $\mathbb{P}(X_{t+1:t+k} \mid H) = \mathbb{P}(X_{t+1:t+k} \mid H')$, it follows that their full-horizon conditionals match:
$ \mathbb{P}(X_{t+1:T} \mid H) = \mathbb{P}(X_{t+1:T} \mid H'). $
In other words, the distribution of all future observations is determined by the distribution of the next $k$ observations.
########## {caption="Proposition 4: JTP forms belief states in $k$-observable systems"}
Assume the system is $k$-observable and let $k=d+1$. Suppose the joint multi-token prediction model recovers the true joint next- $k$ conditional, i.e. $p_\theta(X_{t+1} \mid \mathbf{h}t)p\theta(X_{t+2} \mid \mathbf{h}t, X{t+1})\dots p_\theta(X_{t+k} \mid \mathbf{h}t, X{t+1:t+k-1}) =\mathbb{P}(X_{t+1:t+k} \mid X_{1:t})$ a.s. for all $t$, then $\mathbf{h}{t}$ is a belief state for $X{1:t}$.
Proof: By $k$-observability (Definition 3), there exists a measurable map $G$ taking the joint next- $k$ conditional distribution to the full-horizon conditional:
$ \mathbb{P}(X_{t+1:T} \mid X_{1:t}) = G \Big(\mathbb{P}(X_{t+1:t+k} \mid X_{1:t}) \Big). $
By the premise that JTP recovers the true next- $k$ joint, conditioning on $\mathbf{h}T$ is equivalent to conditioning on $X{1:t}$ for all bounded measurable functionals of the future. Hence $\mathbf{h}_t$ is a belief state for all $t<T$.
Intuitively, if all possible futures can be distinguished by the next $k$ tokens, then a JTP model that accurately predicts the joint next- $k$ distribution would encode all information necessary to distinguish future trajectories. Note that both next-token prediction and multi-token prediction do not guarantee belief state representations (see [22]).
B. Formal Proof of Theorem 2
The proof follows the intuition illustrated below. Optimizing for next-token and transition consistency Equation (1a and 1b) ensures the existence of measurable maps $p_\theta$ and $p_\psi$ that allow recursive decoding of future tokens:
$ \begin{aligned} \mathbf{h}t &\xrightarrow[\text{decode token}]{p\theta} X_{t+1} \xrightarrow[\text{update state}]{p_\psi} \mathbf{h}{t+1} \xrightarrow[\text{decode token}]{p\theta} X_{t+2} \xrightarrow[\text{update state}]{p_\psi} \mathbf{h}{t+2} ;\cdot s; \xrightarrow[]{p\theta} X_T. \end{aligned} $
Proof: A formal proof proceeds by backward induction on $t$. For the base case $t = T-1$, the claim follows directly from Equation 1a, since $\mathbf{h}_{T-1}$ suffices to predict $X_T$.
Now assume $\mathbf{h}{k+1}$ is a belief state for $X{1:k+1}$. By Definition 1, this implies that $X_{k+2:T}$ is conditionally independent of $X_{1:k+1}$ given $\mathbf{h}_{k+1}$. We will show that $\mathbf{h}k$ is also a belief state for $X{1:k}$. From $\mathbf{h}_k$, one can generate
$ \begin{aligned} X_{k+1} &\sim p_\theta(\cdot \mid \mathbf{h}k), \ \mathbf{h}{k+1} &\sim p_\psi(\cdot \mid \mathbf{h}k, X{k+1}). \end{aligned} $
By next-token and transition consistency Equation (1a and 1b), we have
$ \begin{aligned} \mathbb{P}(X_{k+1:T}\mid \mathbf{h}k) &= \mathbb{P}(X{k+2:T}\mid X_{k+1}, \mathbf{h}k), \underbrace{\mathbb{P}(X{k+1}\mid \mathbf{h}k)}{\text{Equation 1a}} \ &= \mathbb{P}(X_{k+2:T}\mid X_{k+1}, \mathbf{h}k), \mathbb{P}(X{k+1}\mid X_{1:k}) \ &= \biggl[\int \mathbb{P}(X_{k+2:T}, ~ \mathbf{h}{k+1}\mid X{k+1}, \mathbf{h}k) , d \mathbf{h}{k+1}\biggr], \mathbb{P}(X_{k+1}\mid X_{1:k})\ &= \biggl[\int \underbrace{\mathbb{P}(X_{k+2:T}\mid \mathbf{h}{k+1}, X{k+1}, \mathbf{h}k)} \underbrace{\mathbb{P}(\mathbf{h}{k+1}\mid X_{k+1}, \mathbf{h}k)}{\text{Equation 1b}} , d \mathbf{h}{k+1} \biggr], \mathbb{P}(X{k+1}\mid X_{1:k}) \ &= \biggl[\int \underbrace{\mathbb{P}(X_{k+2:T}\mid \mathbf{h}{k+1})}{\text{Induction hypothesis}} \mathbb{P}(\mathbf{h}{k+1}\mid X{1:k+1}) , d \mathbf{h}{k+1} \biggr], \mathbb{P}(X{k+1}\mid X_{1:k}) \ &= \mathbb{P}(X_{k+2:T}\mid X_{1:k+1}) , \mathbb{P}(X_{k+1}\mid X_{1:k}) = \mathbb{P}(X_{k+1:T}\mid X_{1:k}). \end{aligned} $
This proves that $\mathbf{h}_k$ is also a belief state.
C. More Details on NextLat Implementation
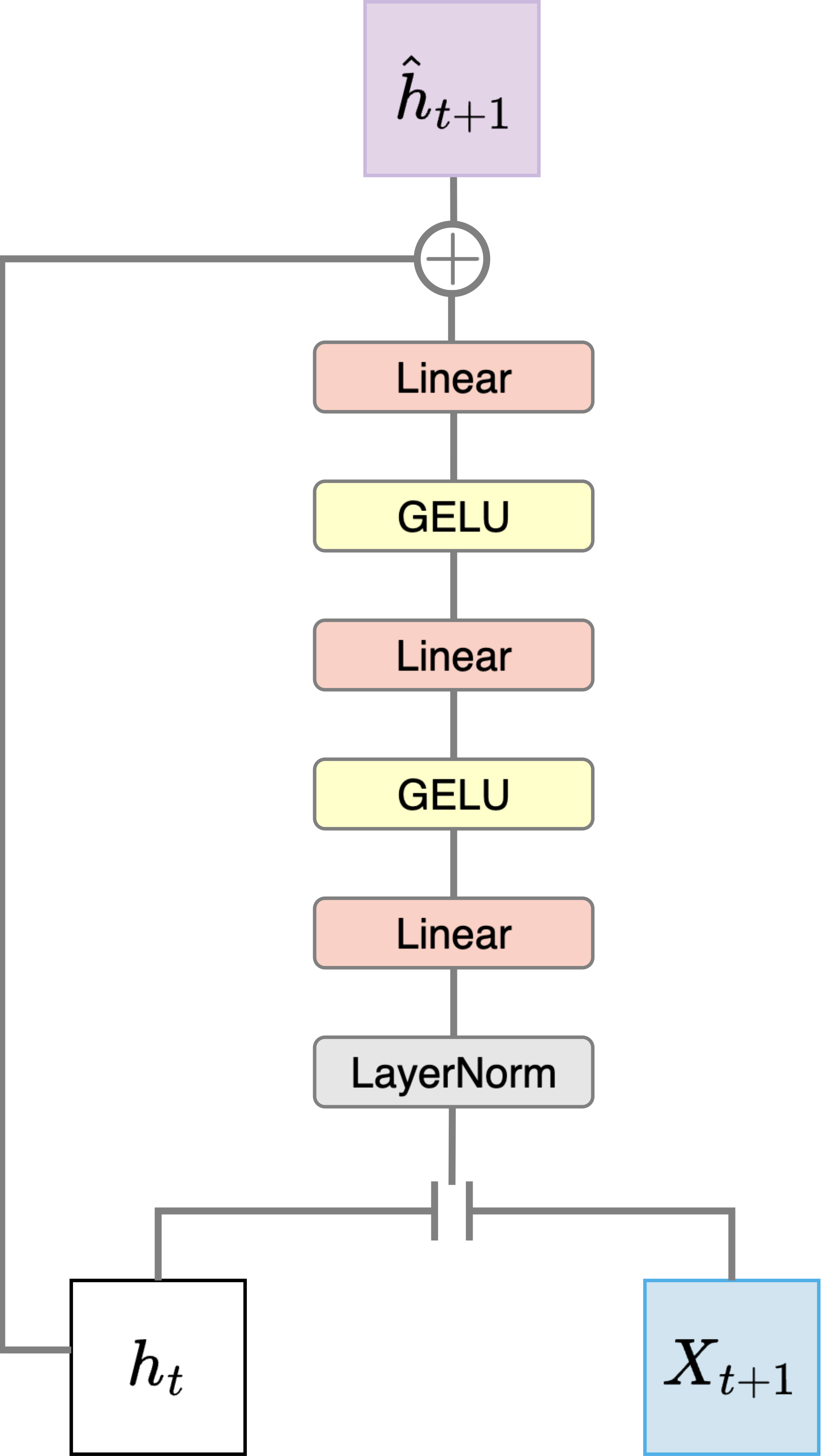
We parameterize the latent transition model $p_\psi$ with a three-layer MLP using GELU ([77]) activations. The latent transition model takes as input the layer-normalized ([78]) concatenation of the current hidden state $\mathbf{h}t$ and next-token embedding $X{t+1}$, and outputs a delta update applied via residual connection:
$ \hat{\mathbf{h}}{t+1} = p\psi(\mathbf{h}t, X{t+1})= f_\psi(\mathbf{h}t, X{t+1}) + \mathbf{h}_t $
where $f_\psi(\cdot)$ predicts the modification to $\mathbf{h}_t$ (see Figure 11). This paper aims to demonstrate that NextLat yields significant performance gains even with a simple MLP latent transition. We foresee even better performances with more sophiscated latent transition model architectures, but we leave that exploration to future work.
Following standard training, we mask token-level losses (i.e., $\mathcal{L}\text{next-token}$ and $\mathcal{L}\mathrm{KL}$) corresponding to context or prompt tokens. However, we do not apply masking for $\mathcal{L}\text{next-h}$ on context tokens, ensuring that belief state representations develop even during context processing. When using sequence packing (e.g., for Manhattan, TinyStories, and FineWeb-Edu), we mask $\mathcal{L}\mathrm{KL}$ and $\mathcal{L}_\text{next-h}$ terms that cross document boundaries.

D. Ablation Studies
In this section, we ablate the key design choices of NextLat. Specifically, we study the effects of the KL ($\mathcal{L}\mathrm{KL}$) and Smooth L1 ($\mathcal{L}\text{next-h}$) losses, as well as the use of stop-gradients on the target ($\textbf{sg}[\mathbf{h}{t+i}]$) in the Smooth L1 loss Equation (2) and on the output head ($p\theta^{\textbf{sg}}(\cdot)$) in the KL loss Equation (3). We focus our investigations primarily on TinyStories, analyzing how these design choices affect the predictive quality of learned hidden states under linear probing and validation loss behavior.
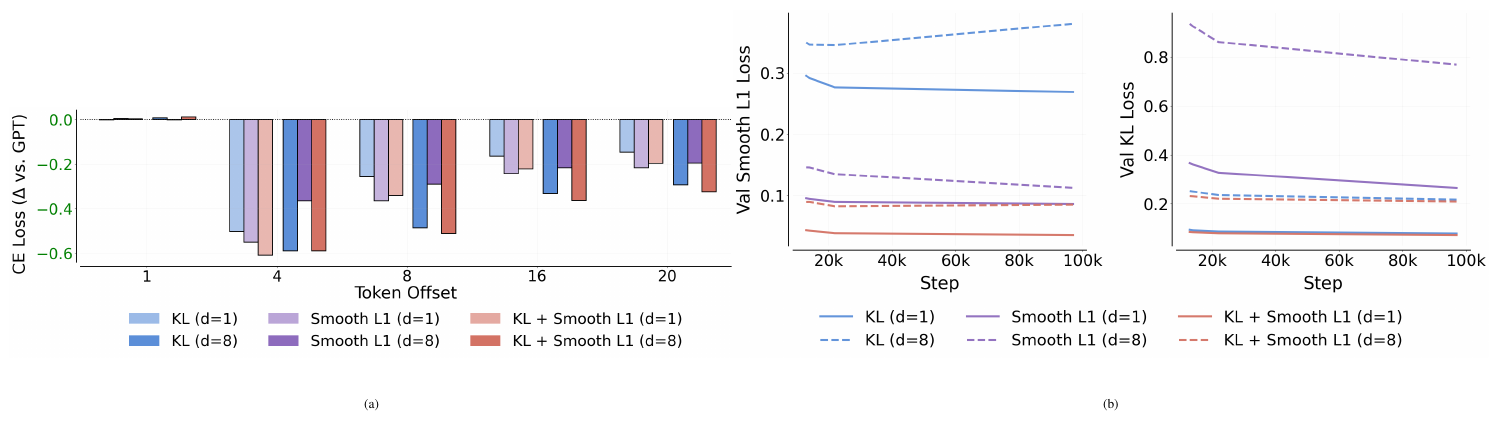
We first isolate the effects of the KL and Smooth L1 losses in NextLat. Note that $\mathcal{L}\text{next-h}$ is required for belief-state convergence, while $\mathcal{L}\mathrm{KL}$ serves as a complementary supervision signal. In Figure 12a, we observe that at $d=1$, using Smooth L1 loss alone achieves the strongest probe performance 20 tokens ahead relative to GPT. At $d=8$, however, the combined KL + Smooth L1 objective (i.e., the full NextLat design) performs best, suggesting that the Smooth L1 loss is critical for learning long-range predictive representations, while the KL loss becomes increasingly beneficial at larger horizons. Furthermore, Figure 12b shows that the combined KL + Smooth L1 objective achieves lower validation KL and Smooth L1 losses than optimizing either objective alone. This confirms that the two losses are complementary and provide mutually beneficial supervision.
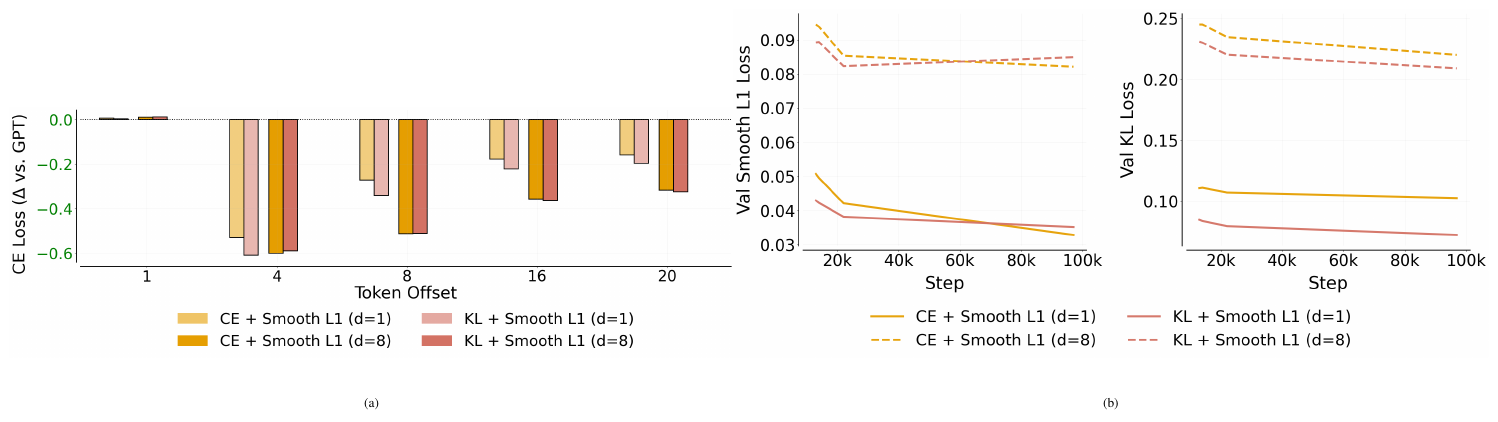
Next, we compare the KL loss against cross-entropy (CE) as the complementary token-space supervision signal. Note that the CE loss corresponds exactly to the multi-token prediction objective used in JTP and MTP. Unlike the KL loss, which performs self-distillation by matching the predicted token distribution to the model’s own softmax distribution under the target hidden state (see Equation 3), the CE loss directly supervises the predicted latent state using the ground-truth next token. As shown in Figure 13a, the original NextLat objective (KL + Smooth L1) achieves substantially better probe performance than CE + Smooth L1 at $d=1$, though the gap becomes marginal at $d=8$. Figure 13b shows that across both $d=1$ and $d=8$, KL + Smooth L1 achieves lower validation KL loss, but slightly worse Smooth L1 loss, than CE + Smooth L1. Overall, these results suggest that at shallow multi-step prediction horizons, the dense distribution-level supervision provided by KL matching induces more predictive representations than CE. However, this advantage appears to diminish at larger horizons. It is also important to note that the KL loss incurs higher memory overhead than CE loss. This is because KL requires materializing full logits and softmax distributions over the vocabulary, whereas modern fused CE implementations only need to materialize probabilities at the target token index. More systematic studies are needed, especially at larger model scales, to determine whether KL or CE is preferable as a complementary supervision signal. For the scope of this work, we stick to using KL loss in all experiments.
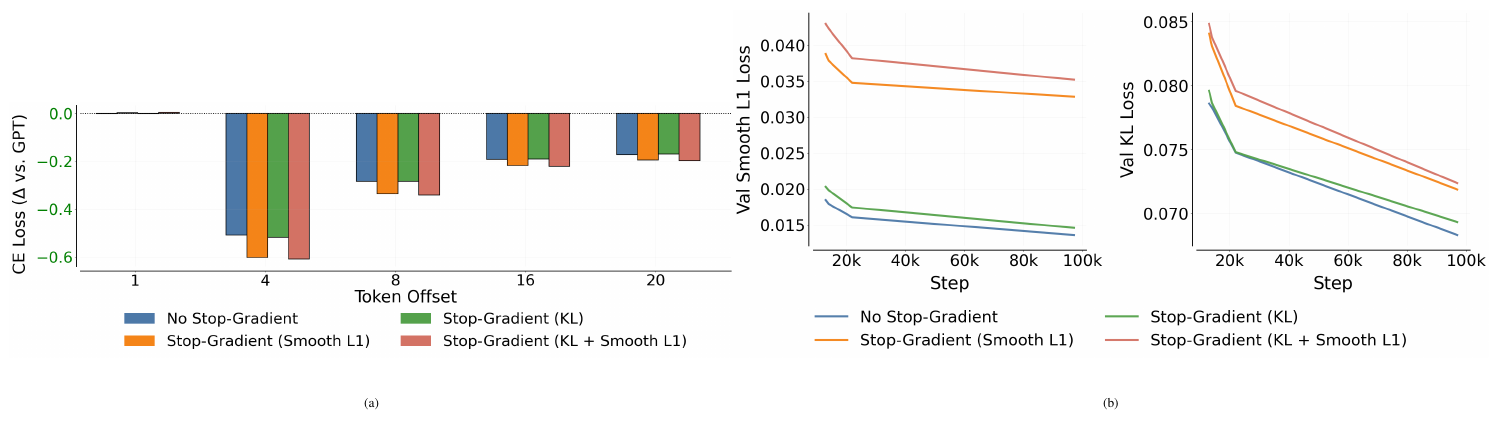
Next, we study the use of stop-gradients in Figure 14 with $d=1$. While Figure 14b shows that removing the stop-gradient on the Smooth L1 loss improves validation Smooth L1 and KL losses slightly ($\sim 0.02$), it does not improve the predictive quality of the learned representations. As shown in Figure 14a, applying stop-gradients to both the target in the Smooth L1 loss and the output head ($p_\theta^{\textbf{sg}}(\cdot)$) in the KL loss yields the best probing performance across all token offsets. Stop-gradients also improve efficiency by reducing the number of backward passes through the transformer. In particular, the KL loss introduces an additional forward and backward pass through the output head, which can be computationally expensive in language models due to large vocabulary sizes[^8]. Removing this extra backward pass significantly improves both speed and memory efficiency. Empirically, on tasks like Countdown and Path-Star graph, we also observe that the stop-gradient (especially on the Smooth L1 loss) is essentially for high accuracy.
[^8]: Note that multi-token prediction models also incur an additional forward+backward pass through the output head for each extra token prediction.
Overall, these ablations suggest that NextLat’s effectiveness arises from the combination of Smooth L1 and KL losses together with carefully placed stop-gradients, all of which contribute to learning predictive belief-state representations in transformers.
E. NextLat Pretraining Quirks
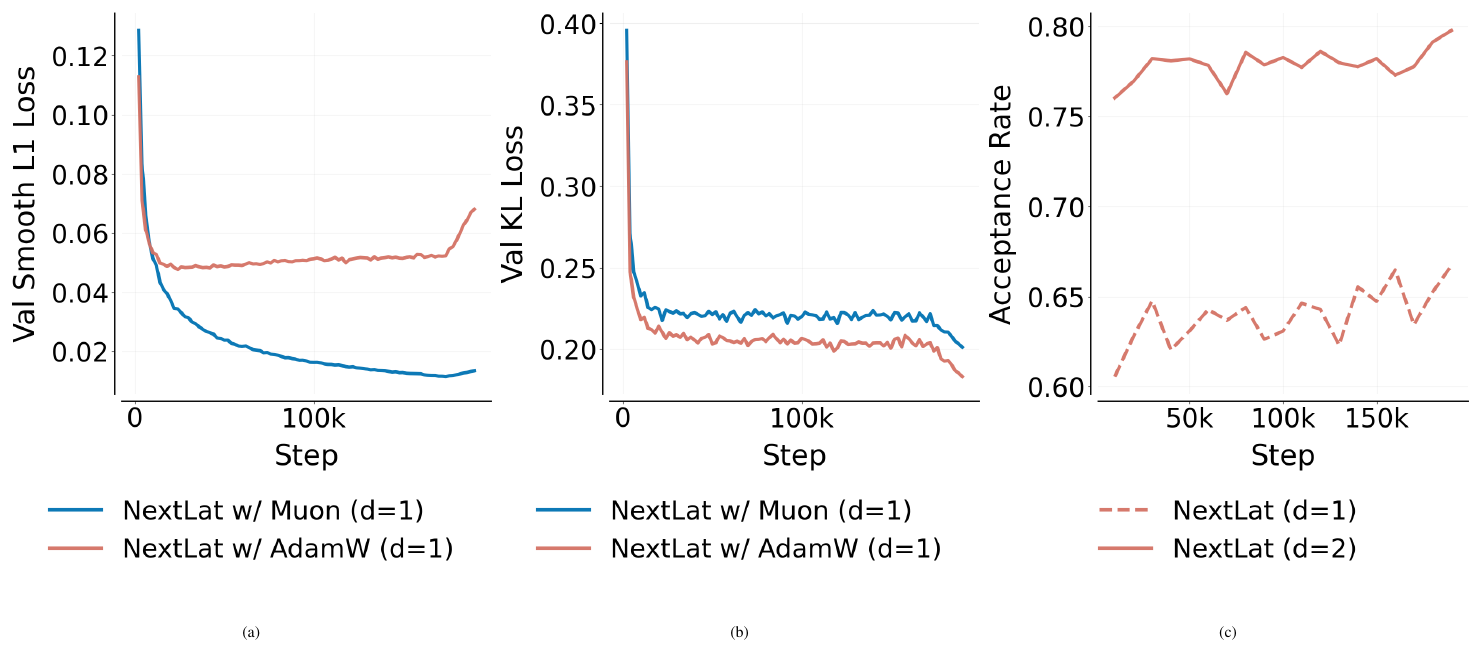
In this section, we expose some optimization quirks that we faced during pretraining with NextLat. First, Figure 15a shows vastly different Smooth L1 loss trajectories when using Muon ([79]) versus AdamW ([80]) optimizer under the same learning rate schedule (using the Muon update scaling rule proposed by [81]). One possible explanation is that Muon’s orthogonalized update rule enables more efficient latent representation shaping and next-latent prediction optimization. However, Figure 15b shows that AdamW achieves better KL loss optimization than Muon.
Importantly, both optimizers exhibit an increase in Smooth L1 loss near the end of training corresponding to the learning rate cooldown stage, though the effect is substantially more pronounced for AdamW. The cause of this behavior remains unclear. We explored several potential fixes to no avail, including:
- replacing Smooth L1 with MSE loss,
- removing stop-gradients from $\mathcal{L}_\text{next-h}$,
- tuning loss coefficients $\lambda_\text{next-h}$ and $\lambda_\mathrm{KL}$,
- disabling learning rate decay for the latent transition model, and
- disabling weight decay for the latent transition model.
We leave a deeper investigation of this phenomenon to future work. To our reassurance, the increase in smooth L1 loss does not appear to degrade the coherence of the latent transition model. As shown in Figure 15c, the speculative decoding acceptance rate over a lookahead horizon of 5 tokens continues to improve throughout training, even during the phase where the smooth L1 loss increases under AdamW. This suggests that the rise in smooth L1 loss may reflect changes in the scale or geometry of the latent states, rather than degradation in the token-level coherence of the latent transition dynamics.
On a side note, we observed gradient norm spikes that led to training instability when training MTP with Muon, which unfortunately limited our pretraining analysis to AdamW (despite Muon showing a more favorable learning trajectory with NextLat).
F. Extra Experiment Details
In this section, we provide additional experimental setup details and supplementary results for the experiments in the main body. All experiments were run on NVIDIA RTX A5000, NVIDIA H100 NVL, and NVIDIA B200 GPUs. Table 5 summarizes the training, model, and NextLat hyperparameters across all experimental domains.
::: caption="Table 5: Training, Model, and NextLat hyperparameters across all benchmarks."
:::
The hyperparameters reported in Table 5 were chosen through a small-scale search, exploring $\lambda_\text{next-h} \in {1.0, 2.0}$ and $\lambda_\mathrm{KL} \in {0.1, 1.0}$, guided by empirical observations and intuition. Encouragingly, we find that NextLat performs robustly over a wide range of settings. In particular, $\lambda_\mathrm{KL}$ requires minimal tuning; $\lambda_\mathrm{KL}=1.0$ works decently across all tasks. After all, it primarily serves as a complementary alignment objective. Likewise, $\lambda_\text{next-h}=1.0$ is effective in most cases, though slightly higher values (e.g., $\lambda_\text{next-h}=2.0$) was beneficial when the next-latent regression loss is of much smaller scale than the token-level losses (i.e., $\mathcal{L}\text{next-token}$ and $\mathcal{L}\mathrm{KL}$).
For MTP and JTP, we sweep multi-token prediction loss weights $\lambda_\text{MTP} \in {0.1, 0.2, 0.4, 0.6, 0.8, 1.0}$ to ensure fair baseline comparisons. For FineWeb-Edu pretraining, extensive hyperparameter tuning is computationally prohibitive, so we use uniform loss weights across all methods (i.e., $\lambda_\text{next-h} = \lambda_\mathrm{KL} = \lambda_\text{MTP} = 1.0$) to provide the fairest comparison possible under our compute constraints.
F.1 Manhattan Taxi Rides
Here, we provide additional details on our training and evaluation setups for the Manhattan Taxi Rides benchmark and clarify key differences from the original study of [35].
Training.
Since this task inherently requires state tracking (i.e., tracking position within Manhattan), and increasing model depth is known to benefit transformers on such tasks ([70]), we employ 48-layer transformers with 384 hidden dimensions and 8 attention heads (88M parameters). This differs from [35], which used 12 layers, 768 hidden dimensions, and 12 heads for their smaller transformer variant. We found that increasing model depth yielded substantial performance gains, whereas increasing hidden dimensionality offered negligible improvement. As shown in Table 1, the effective latent rank of our models is substantially smaller than 384, suggesting that large hidden dimensions are unnecessary.
Unlike the original study, which trained models for only one epoch, our models are trained for six epochs, as we observed that performances generally do not converge within a single epoch. This also helps rule out potential "grokking" phenomena ([82]), where generalization improves only after extended periods of overfitting. To enable longer training without substantially increasing runtime, we apply sequence packing, i.e., concatenating multiple sequences into longer ones while masking cross-sequence attention. This enables efficient utilization of GPU memory and computation. Most models complete six training epochs in under three days on a single NVIDIA H100 NVL GPU, except MTP, which has substantially more parameters than the others.
Evaluation.
Models are trained on random traversals of length 100 connected pickup and dropoff intersections. This task inherently requires not only state tracking but also planning, as models must reason over possible future paths to generate valid 100-step trajectories that reach the destination while avoiding dead ends, i.e., road segments disconnected from the goal due to the one-way streets. Random traversals rarely correspond to true shortest paths and do not provide an inductive bias toward learning the shortest path algorithm, which relies on dynamic programming. Consequently, unlike [35], who evaluated pairs with shortest paths of up to 100 steps, we limit evaluation pairs to paths of up to 50 steps. This adjustment ensures that evaluation pairs do not demand long-horizon planning beyond the training distribution, which might otherwise force the model to produce forced predictions to compensate for planning failure. This also ensures that inconsistencies in a model’s internal map are more reflective of world-model incoherence rather than artifacts of long-horizon planning limitations. These evaluation pairs are used to generate Figure 3 and to compute the sequence compression and detour robustness metrics, following the procedure of [35].
For the effective latent rank, we pass a batch of 256 sequences (each of length 256) through the model to obtain the hidden state matrix. Singular values smaller than $1\mathrm{e}{-12}$ are discarded, and the effective rank is then computed following [55]. For GPT and NextLat, we use the final-layer hidden states. For JTP, we extract the hidden states immediately before the self-attention module in the Fetch head (see Equations 4–5 in [46]). For MTP, we use the output of the next-token prediction head to compute the effective rank.
F.2 Countdown
We largely follow [59] for the Countdown training and evaluation setup. Each problem consists of four input numbers and a solution sequence comprising three equations, consistent with prior work ([59, 61]). A training example is formatted as
$ \underbrace{14, 83, 88, 91}{\text{inputs}}, \overbrace{23}^{\text{target}}:|\underbrace{:83-14=69, :91-88=3, :69/3=23}{\text{solution}} $
where the first four numbers are the inputs, the fifth is the target number, and the pipe symbol "|" separates the input prompt from the solution. During training, loss values corresponding to input prompt are masked out.
Previous studies involving the Countdown benchmark used pretrained GPT-2 byte-pair encoding tokenizers, which do not necessarily tokenize multi-digit numbers as single units. In contrast, we construct a custom tokenizer that assigns each integer from 1 to 10, 000 to a unique token, ensuring that every number in the sequence is represented atomically. The arithmetic operators and delimiters, i.e., ${; |;, ;+;, ;-;, ;\times;, ;\div;}$, are each assigned their own token indices. Due to the large branching factor of the Countdown problem, we insert eight pipe symbols (“|”) between the input and the solution as pause tokens ([60]), allowing the model additional computation steps to plan before generating its answer.
F.3 Path-Star
Our Path-Star data preparation, training, and evaluation follow [42], except that we increase the weight decay to 0.1, which we found helpful for stable convergence and higher solve rates in the multi-step prediction methods (i.e., MTP, JTP, and NextLat). We evaluate each model’s ability to generate the correct arm on 20k held-out test instances. Unlike [22] and [46] which generate a fresh set of graphs every batch, we adopt the original, more challenging setup of [42], which uses a fixed sample size of 200k and node values sampled from $N = 100$. This difference accounts for the performance gap observed in the BST and JTP baselines in Figure 6. The Path-Star experiment is designed to expose the myopic behavior of teacher-forced next-token prediction, which can encourage models to exploit superficial regularities—an effect referred to as the Clever Hans cheat ([42]). Because the task’s sample space grows exponentially with graph size, identifying the correct algorithm that generalizes across all graph instances is highly nontrivial. While not conclusive, our results suggest that latent-space prediction and the inductive bias toward compressing history into belief states promote better discovery of generalizable solutions in data-constrained settings.
F.4 TinyStories
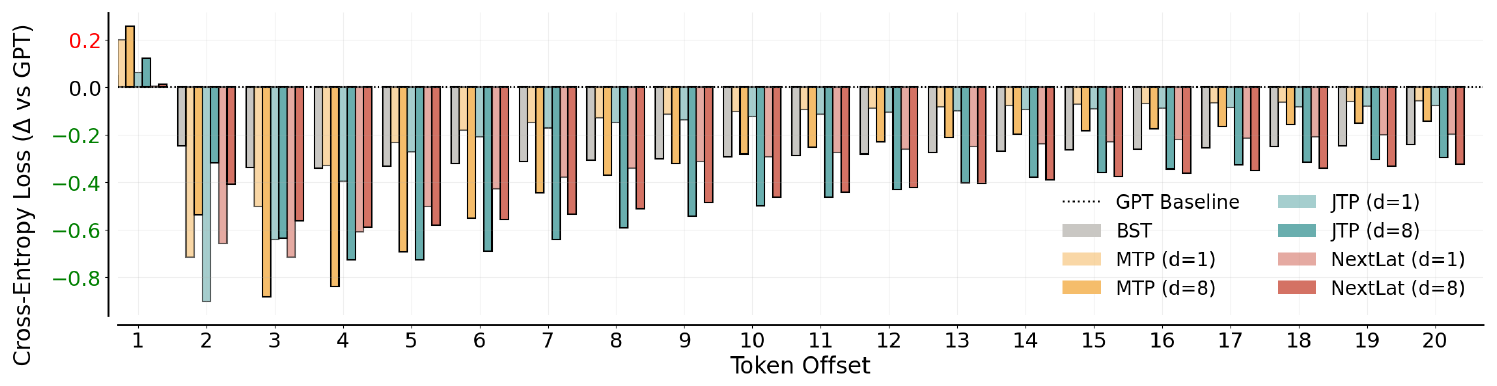
Our TinyStories setup follows exactly [22]. After pretraining on TinyStories, we train linear (one-layer) probes on the hidden states of the frozen transformer models for an additional 20k steps on the same dataset. All probe training hyperparameters (e.g., learning rate, batch size) match those used during pretraining (see Table 5).
For GPT, JTP, and NextLat, the choice of hidden states follows the setup used for measuring effective rank in the Manhattan taxi rides task, as described in Appendix F.1. For BST, we use the final-layer hidden states of the forward transformer encoder. For MTP ([44]), we use the output of the shared transformer trunk, i.e., the hidden state before it branches into separate transformer heads for multi-token prediction, as this final shared representation contains the most predictive information about future tokens.
F.5 $\mathbf{A_5}$ State Tracking
The group $A_5$ consists of the even permutations of 5 elements. Intuitively, each token in the sequence represents a permutation operation that rearranges the five elements, and after each operation the model must output the resulting arrangement (i.e., state). The task is therefore fundamentally a state-tracking problem: the model must maintain and update an internal representation of the current state as new permutation operations are sequentially composed.
Our training setup follows [70]. We trained the models on 1 million unique 12-token sequences over the group $A_5$. We then evaluated their length generalization capabilities on approximately 100k 36-token sequences. For NextLat training, we used one-step supervision ($d=1$) and optimized only the regression objective ($\lambda_\text{next-h} = 1$), without token-level supervision ($\lambda_\mathrm{KL} = 0$). This ensures that any observed length generalization of the latent dynamics model (RNN) arises purely from faithful next-latent prediction rather than auxiliary multi-token prediction signals.
We also experimented with transformers without positional embeddings (NoPE), motivated by prior work suggesting improved length generalization ([83]). However, we found that NoPE degraded performance in this setting, so all experiments use Rotary Position Embeddings (RoPE; [84]). Unlike RNNs, whose hidden states evolve sequentially and therefore implicitly encode token order, transformers process sequences in parallel and rely heavily on positional embeddings to represent token order information during training. Interestingly, despite positional embeddings being explicitly included in the transformer hidden states, the latent dynamics model trained on one-step latent transitions derived from the transformer still generalizes beyond the training sequence length. This suggests that the learned transition dynamics is robust to the transformer's positional encodings.
F.6 FineWeb-Edu Pretraining
Following standard practices, all models are optimized with AdamW using a peak learning rate of $4e{-4}$, weight decay of $0.1$, and gradient clipping at $1.0$. We use a global batch size of 500M tokens and a sequence length of 1024 tokens. The learning rate follows a Warmup-Stable-Decay (WSD) schedule ([85]), consisting of a 1B-token linear warmup followed by a 10B-token linear decay phase. All models use the GPT-2 tokenizer with a vocabulary size of 50, 257.
We evaluated the zero-shot accuracy of the pretrained models on nine standard language modeling benchmarks: Wikitext (Wiki; [86]), LAMBADA (LAMB.; [87]) (standard version), PIQA ([88]), HellaSwag (HellaS.; [89]), WinoGrande (Wino.; [90]), ARC-easy (ARC-e) and ARC-challenge (ARC-c) ([91]), Social IQa (SIQA; [92]), and SciQ ([93]). We also evaluate the self-speculative decoding performance of JTP, MTP, and NextLat across Wikipedia ([94]), Books (BookCorpusOpen; [95]), Code (Stack-Edu; [96]), and Math (OpenWebMath; [97]) domains. To do so, we sample 1024 prompts of length 512 tokens from each dataset and generate 512-token continuations using the speculative sampling algorithm of [47]. We then measured the speedup in inference of each model using self-speculative decoding compared to naive autoregressive sampling from the transformer, measured on $8\times$ NVIDIA B200 GPUs.
F.6.1 Results with MTP/JTP (d=4)
::: {caption="Table 6: Downstream language modeling evaluation on 1.3B-parameter models trained on 100B FineWeb-Edu tokens. Best scores are in bold and second-best are underlined."}
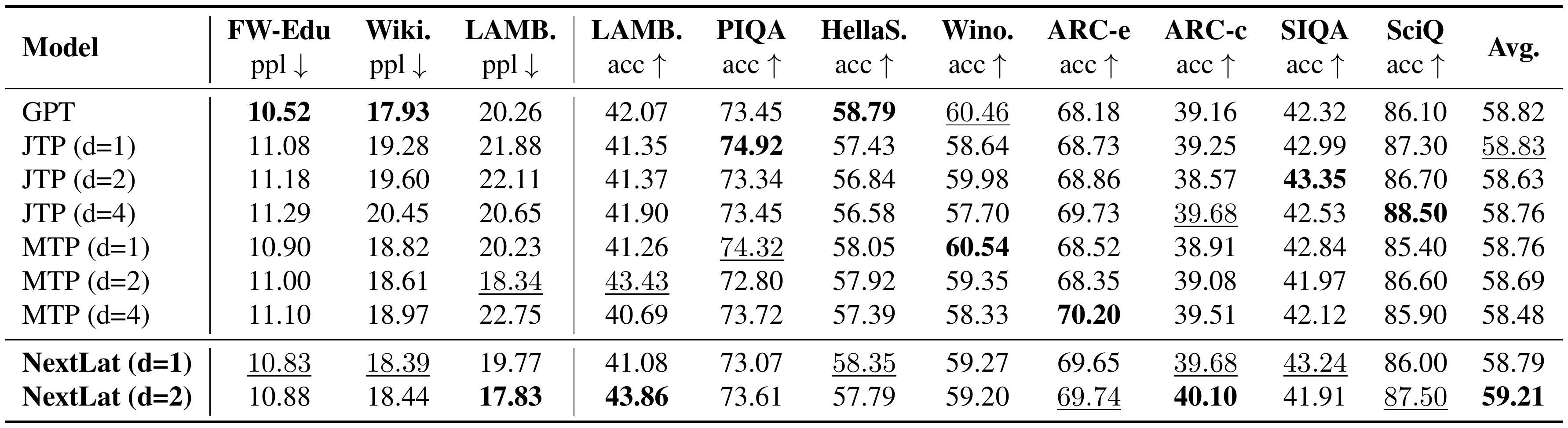
:::
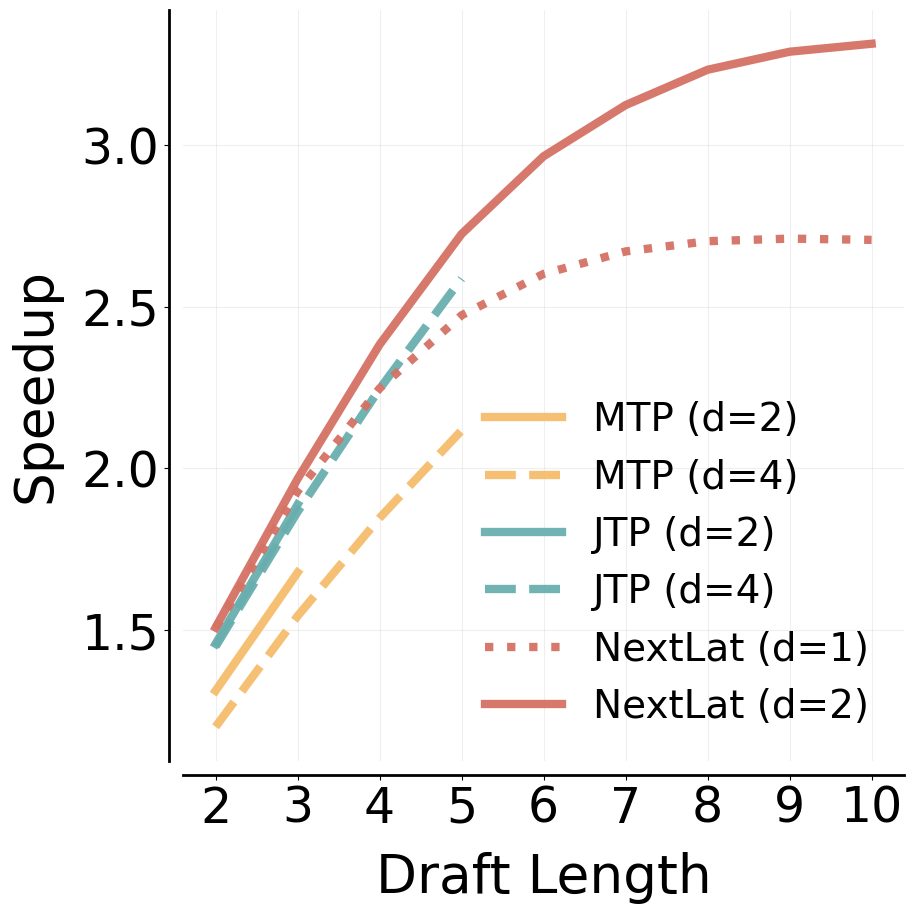
In this section, we extend our comparisons to include JTP and MTP trained with larger horizons ($d=4$). Note that the training cost of JTP and MTP increases substantially with larger $d$ (see Table 4), making JTP ($d=4$) and MTP ($d=4$) significantly more expensive to train than NextLat ($d=1, 2$).
Table 6 shows that increasing the multi-token prediction horizon to $d=4$ still does not yield meaningful improvements on multiple-choice benchmarks; NextLat ($d=2$) continues to achieve the best average accuracy overall. Table 7 shows that even when JTP and MTP are trained to be able to draft more tokens (i.e., 4 tokens ahead), they still fail to surpass the variable-length speculative decoding performance of NextLat across most domains, with the exception of the Code domain. Finally, Figure 17 shows that, on the FineWeb-Edu validation set, increasing the training horizon to $d=4$ yields only modest speedup gains for JTP and MTP. Their speedup curves saturate earlier and remain below that of NextLat ($d=2$), which continues to improve with longer draft lengths and achieves the highest overall speedup.
::: {caption="Table 7: Relative speedup and average accepted tokens per drafting steps over diverse domains. Note that Äccepted Tokensëxcludes the next-token prediction which is always accepted."}
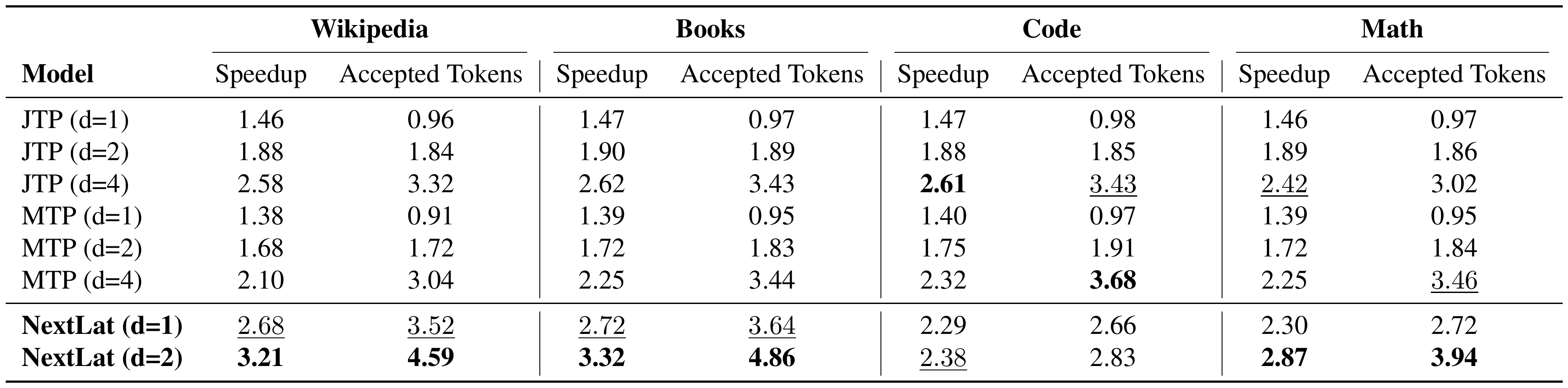
:::
References
Section Summary: This section is a bibliography of academic papers and books that the authors consulted or cited. It includes foundational and recent works on machine learning theory, transformer models, self-supervised learning, reinforcement learning, and the idea of internal world models drawn from both AI research and cognitive science. The references span theoretical results, empirical studies on large language models, and classic ideas about how agents build representations to predict and act in uncertain environments.
[1] Blumer et al. (1986). Classifying learnable geometric concepts with the Vapnik-Chervonenkis dimension. In Proceedings of the eighteenth annual ACM symposium on Theory of computing. pp. 273–282.
[2] Langford, John and Schapire, Robert (2005). Tutorial on practical prediction theory for classification.. Journal of machine learning research. 6(3).
[3] Vaswani et al. (2017). Attention is All you Need. In Advances in Neural Information Processing Systems. pp. . https://proceedings.neurips.cc/paper_files/paper/2017/file/3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf.
[4] Anil et al. (2022). Exploring Length Generalization in Large Language Models. In Advances in Neural Information Processing Systems. pp. 38546–38556.
[5] Nouha Dziri et al. (2023). Faith and Fate: Limits of Transformers on Compositionality. In Thirty-seventh Conference on Neural Information Processing Systems. https://openreview.net/forum?id=Fkckkr3ya8.
[6] Bingbin Liu et al. (2023). Transformers Learn Shortcuts to Automata. In The Eleventh International Conference on Learning Representations. https://openreview.net/forum?id=De4FYqjFueZ.
[7] Wu et al. (2024). Reasoning or Reciting? Exploring the Capabilities and Limitations of Language Models Through Counterfactual Tasks. In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). pp. 1819–1862. doi:10.18653/v1/2024.naacl-long.102. https://aclanthology.org/2024.naacl-long.102/.
[8] Tang et al. (2023). Understanding self-predictive learning for reinforcement learning. In Proceedings of the 40th International Conference on Machine Learning.
[9] Tianwei Ni et al. (2024). Bridging State and History Representations: Understanding Self-Predictive RL. In The Twelfth International Conference on Learning Representations. https://openreview.net/forum?id=ms0VgzSGF2.
[10] Shuo Liu et al. (2022). Audio Self-supervised Learning: A Survey. https://arxiv.org/abs/2203.01205. arXiv:2203.01205.
[11] Randall Balestriero et al. (2023). A Cookbook of Self-Supervised Learning. https://arxiv.org/abs/2304.12210. arXiv:2304.12210.
[12] Kexin Zhang et al. (2024). Self-Supervised Learning for Time Series Analysis: Taxonomy, Progress, and Prospects. https://arxiv.org/abs/2306.10125. arXiv:2306.10125.
[13] Gelada et al. (2019). DeepMDP: Learning Continuous Latent Space Models for Representation Learning. In Proceedings of the 36th International Conference on Machine Learning. pp. 2170–2179. https://proceedings.mlr.press/v97/gelada19a.html.
[14] Zhang et al. (2020). Learning invariant representations for reinforcement learning without reconstruction. arXiv preprint arXiv:2006.10742.
[15] Ye et al. (2021). Mastering atari games with limited data. Advances in neural information processing systems. 34. pp. 25476–25488.
[16] Max Schwarzer et al. (2021). Data-Efficient Reinforcement Learning with Self-Predictive Representations. https://arxiv.org/abs/2007.05929. arXiv:2007.05929.
[17] Nicklas Hansen et al. (2022). Temporal Difference Learning for Model Predictive Control. https://arxiv.org/abs/2203.04955. arXiv:2203.04955.
[18] Huang et al. (2025). LLM-JEPA: Large Language Models Meet Joint Embedding Predictive Architectures. arXiv preprint arXiv:2509.14252.
[19] Kaelbling et al. (1998). Planning and acting in partially observable stochastic domains. Artificial intelligence. 101(1-2). pp. 99–134.
[20] Striebel, Charlotte (1965). Sufficient statistics in the optimum control of stochastic systems. Journal of Mathematical Analysis and Applications. 12(3). pp. 576–592.
[21] Li et al. (2006). Towards a unified theory of state abstraction for MDPs.. AI&M. 1(2). pp. 3.
[22] Edward S. Hu et al. (2025). The Belief State Transformer. https://arxiv.org/abs/2410.23506. arXiv:2410.23506.
[23] Craik, Kenneth James Williams (1967). The nature of explanation. CUP Archive.
[24] Johnson-Laird, Philip Nicholas (1983). Mental models: Towards a cognitive science of language, inference, and consciousness. Harvard University Press.
[25] Miall, R Chris and Wolpert, Daniel M (1996). Forward models for physiological motor control. Neural networks. 9(8). pp. 1265–1279.
[26] Friston, Karl (2010). The free-energy principle: a unified brain theory?. Nature reviews neuroscience. 11(2). pp. 127–138.
[27] Francis, Bruce A and Wonham, Walter Murray (1976). The internal model principle of control theory. Automatica. 12(5). pp. 457–465.
[28] Conant, Roger C and Ross Ashby, W (1970). Every good regulator of a system must be a model of that system. International journal of systems science. 1(2). pp. 89–97.
[29] Sutton, Richard S (1991). Dyna, an integrated architecture for learning, planning, and reacting. ACM Sigart Bulletin. 2(4). pp. 160–163.
[30] Schmidhuber, J. (1990). Making the World Differentiable: On Using Self Supervised Fully Recurrent Neural Networks for Dynamic Reinforcement Learning and Planning in Non-Stationary Environments. Inst. für Informatik.
[31] Ha, David and Schmidhuber, Jürgen (2018). World models. arXiv preprint arXiv:1803.10122. 2(3).
[32] Patel, Roma and Pavlick, Ellie (2022). Mapping language models to grounded conceptual spaces. In International conference on learning representations.
[33] Li et al. (2023). Emergent world representations: Exploring a sequence model trained on a synthetic task. ICLR.
[34] Wes Gurnee and Max Tegmark (2024). Language Models Represent Space and Time. In The Twelfth International Conference on Learning Representations. https://openreview.net/forum?id=jE8xbmvFin.
[35] Vafa et al. (2024). Evaluating the world model implicit in a generative model. Advances in Neural Information Processing Systems. 37. pp. 26941–26975.
[36] Vafa et al. (2025). What Has a Foundation Model Found? Using Inductive Bias to Probe for World Models. In International Conference on Machine Learning. pp. 60727–60747.
[37] Schrittwieser et al. (2020). Mastering atari, go, chess and shogi by planning with a learned model. Nature. 588(7839). pp. 604–609.
[38] Hafner et al. (2019). Dream to control: Learning behaviors by latent imagination. arXiv preprint arXiv:1912.01603.
[39] Danijar Hafner et al. (2021). Mastering Atari with Discrete World Models. In 9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, May 3-7, 2021. https://openreview.net/forum?id=0oabwyZbOu.
[40] Hafner et al. (2025). Mastering Diverse Control Tasks through World Models. 640(8059). pp. 647–653. doi:10.1038/s41586-025-08744-2. https://doi.org/10.1038/s41586-025-08744-2.
[41] Bruce et al. (2024). Genie: generative interactive environments. In Proceedings of the 41st International Conference on Machine Learning.
[42] Bachmann, Gregor and Nagarajan, Vaishnavh (2024). The Pitfalls of Next-Token Prediction. In Proceedings of the 41st International Conference on Machine Learning. pp. 2296–2318. https://proceedings.mlr.press/v235/bachmann24a.html.
[43] Nagarajan et al. (2025). Roll the dice & look before you leap: Going beyond the creative limits of next-token prediction. arXiv preprint arXiv:2504.15266.
[44] Gloeckle et al. (2024). Better & faster large language models via multi-token prediction. In Proceedings of the 41st International Conference on Machine Learning.
[45] Liu et al. (2024). Deepseek-v3 technical report. arXiv preprint arXiv:2412.19437.
[46] Kwangjun Ahn et al. (2025). Efficient Joint Prediction of Multiple Future Tokens. https://arxiv.org/abs/2503.21801. arXiv:2503.21801.
[47] Leviathan et al. (2022). Fast inference from transformers via speculative decoding, 2023. URL https://arxiv. org/abs/2211.17192. 1(2).
[48] Charlie Chen et al. (2023). Accelerating Large Language Model Decoding with Speculative Sampling. https://arxiv.org/abs/2302.01318. arXiv:2302.01318.
[49] Li et al. (2024). Eagle: Speculative sampling requires rethinking feature uncertainty. arXiv preprint arXiv:2401.15077.
[50] Li et al. (2024). Eagle-2: Faster inference of language models with dynamic draft trees. In Proceedings of the 2024 conference on empirical methods in natural language processing. pp. 7421–7432.
[51] François Fleuret (2025). The Free Transformer. https://arxiv.org/abs/2510.17558. arXiv:2510.17558.
[52] Hinton et al. (2015). Distilling the knowledge in a neural network. arXiv preprint arXiv:1503.02531.
[53] Subramanian et al. (2022). Approximate information state for approximate planning and reinforcement learning in partially observed systems. Journal of Machine Learning Research. 23(12). pp. 1–83.
[54] Andrej Karpathy (2022). textNanoGPT. https://github.com/karpathy/nanoGPT.
[55] Roy, Olivier and Vetterli, Martin (2007). The effective rank: A measure of effective dimensionality. In 2007 15th European signal processing conference. pp. 606–610.
[56] Countdown (2025). Countdown (game show). [Online; accessed 12-October-2025]. https://en.wikipedia.org/wiki/Countdown_(game_show).
[57] Achiam et al. (2023). Gpt-4 technical report. arXiv preprint arXiv:2303.08774.
[58] Yao et al. (2023). Tree of Thoughts: Deliberate Problem Solving with Large Language Models. In Advances in Neural Information Processing Systems. pp. 11809–11822. https://proceedings.neurips.cc/paper_files/paper/2023/file/271db9922b8d1f4dd7aaef84ed5ac703-Paper-Conference.pdf.
[59] Gandhi et al. (2024). Stream of search (sos): Learning to search in language. arXiv preprint arXiv:2404.03683.
[60] Goyal et al. (2023). Think before you speak: Training language models with pause tokens. arXiv preprint arXiv:2310.02226.
[61] Jiacheng Ye et al. (2025). Beyond Autoregression: Discrete Diffusion for Complex Reasoning and Planning. In The Thirteenth International Conference on Learning Representations. https://openreview.net/forum?id=NRYgUzSPZz.
[62] Eldan, Ronen and Li, Yuanzhi (2023). Tinystories: How small can language models be and still speak coherent english?. arXiv preprint arXiv:2305.07759.
[63] Penedo et al. (2024). The fineweb datasets: Decanting the web for the finest text data at scale. Advances in Neural Information Processing Systems. 37. pp. 30811–30849.
[64] Gao et al. (2024). The Language Model Evaluation Harness. doi:10.5281/zenodo.12608602. https://zenodo.org/records/12608602.
[65] Samir Yitzhak Gadre et al. (2024). Language models scale reliably with over-training and on downstream tasks. https://arxiv.org/abs/2403.08540. arXiv:2403.08540.
[66] Guanhua Zhang et al. (2026). Train-before-Test Harmonizes Language Model Rankings. In The Fourteenth International Conference on Learning Representations. https://openreview.net/forum?id=ORv3SAzus1.
[67] Edelman et al. (2024). The Evolution of Statistical Induction Heads: In-Context Learning Markov Chains. In Advances in Neural Information Processing Systems. pp. 64273–64311. https://proceedings.neurips.cc/paper_files/paper/2024/file/75b0edb869e2cd509d64d0e8ff446bc1-Paper-Conference.pdf.
[68] Ashok Vardhan Makkuva et al. (2025). Attention with Markov: A Curious Case of Single-layer Transformers. In The Thirteenth International Conference on Learning Representations. https://openreview.net/forum?id=SqZ0KY4qBD.
[69] William Merrill and Ashish Sabharwal (2023). The Parallelism Tradeoff: Limitations of Log-Precision Transformers. https://arxiv.org/abs/2207.00729. arXiv:2207.00729.
[70] William Merrill et al. (2025). The Illusion of State in State-Space Models. https://arxiv.org/abs/2404.08819. arXiv:2404.08819.
[71] Albert Gu et al. (2022). Efficiently Modeling Long Sequences with Structured State Spaces. https://arxiv.org/abs/2111.00396. arXiv:2111.00396.
[72] Albert Gu and Tri Dao (2024). Mamba: Linear-Time Sequence Modeling with Selective State Spaces. https://arxiv.org/abs/2312.00752. arXiv:2312.00752.
[73] Merrill et al. (2022). Saturated Transformers are Constant-Depth Threshold Circuits. Transactions of the Association for Computational Linguistics. 10. pp. 843–856. doi:10.1162/tacl_a_00493. https://aclanthology.org/2022.tacl-1.49/.
[74] Jongho Park et al. (2024). Can Mamba Learn How to Learn? A Comparative Study on In-Context Learning Tasks. https://arxiv.org/abs/2402.04248. arXiv:2402.04248.
[75] Opher Lieber et al. (2024). Jamba: A Hybrid Transformer-Mamba Language Model. https://arxiv.org/abs/2403.19887. arXiv:2403.19887.
[76] Liliang Ren et al. (2025). Samba: Simple Hybrid State Space Models for Efficient Unlimited Context Language Modeling. https://arxiv.org/abs/2406.07522. arXiv:2406.07522.
[77] Dan Hendrycks and Kevin Gimpel (2023). Gaussian Error Linear Units (GELUs). https://arxiv.org/abs/1606.08415. arXiv:1606.08415.
[78] Jimmy Lei Ba et al. (2016). Layer Normalization. https://arxiv.org/abs/1607.06450. arXiv:1607.06450.
[79] Keller Jordan et al. (2024). Muon: An optimizer for hidden layers in neural networks. https://kellerjordan.github.io/posts/muon/.
[80] Ilya Loshchilov and Frank Hutter (2019). Decoupled Weight Decay Regularization. https://arxiv.org/abs/1711.05101. arXiv:1711.05101.
[81] Liu et al. (2025). Muon is scalable for llm training. arXiv preprint arXiv:2502.16982.
[82] Alethea Power et al. (2022). Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets. https://arxiv.org/abs/2201.02177. arXiv:2201.02177.
[83] Amirhossein Kazemnejad et al. (2023). The Impact of Positional Encoding on Length Generalization in Transformers. In Thirty-seventh Conference on Neural Information Processing Systems. https://openreview.net/forum?id=Drrl2gcjzl.
[84] Jianlin Su et al. (2023). RoFormer: Enhanced Transformer with Rotary Position Embedding. https://arxiv.org/abs/2104.09864. arXiv:2104.09864.
[85] Hu et al. (2024). Minicpm: Unveiling the potential of small language models with scalable training strategies. arXiv preprint arXiv:2404.06395.
[86] Merity et al. (2016). Pointer sentinel mixture models. arXiv preprint arXiv:1609.07843.
[87] Paperno et al. (2016). The LAMBADA dataset: Word prediction requiring a broad discourse context. In Proceedings of the 54th annual meeting of the association for computational linguistics (volume 1: Long papers). pp. 1525–1534.
[88] Bisk et al. (2020). Piqa: Reasoning about physical commonsense in natural language. In Proceedings of the AAAI conference on artificial intelligence. pp. 7432–7439.
[89] Zellers et al. (2019). Hellaswag: Can a machine really finish your sentence?. In Proceedings of the 57th annual meeting of the association for computational linguistics. pp. 4791–4800.
[90] Sakaguchi et al. (2021). Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM. 64(9). pp. 99–106.
[91] Clark et al. (2018). Think you have solved question answering? try arc, the ai2 reasoning challenge. arXiv preprint arXiv:1803.05457.
[92] Sap et al. (2019). Social IQa: Commonsense reasoning about social interactions. In Proceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP-IJCNLP). pp. 4463–4473.
[93] Welbl et al. (2017). Crowdsourcing multiple choice science questions. In Proceedings of the 3rd Workshop on Noisy User-generated Text. pp. 94–106.
[94] Wikimedia Foundation. Wikimedia Downloads. https://dumps.wikimedia.org.
[95] Hugging Face (2021). Dataset Card for BookCorpusOpen. https://huggingface.co/datasets/bookcorpusopen.
[96] Loubna Ben Allal et al. (2025). SmolLM2: When Smol Goes Big – Data-Centric Training of a Small Language Model. https://arxiv.org/abs/2502.02737. arXiv:2502.02737.
[97] Keiran Paster et al. (2023). OpenWebMath: An Open Dataset of High-Quality Mathematical Web Text. arXiv:2310.06786.