From Generation to Judgment: Opportunities and Challenges of LLM-as-a-judge
Dawei Li $^{\spadesuit}$, Bohan Jiang $^{\spadesuit}$, Liangjie Huang $^{\clubsuit}$, Alimohammad Beigi $^{\spadesuit}$, Chengshuai Zhao $^{\spadesuit}$,
Zhen Tan $^{\spadesuit}$, Amrita Bhattacharjee $^{\spadesuit}$, Yuxuan Jiang $^{\diamondsuit}$, Canyu Chen $^{\heartsuit}$, Tianhao Wu $^{\clubsuit}$,
Kai Shu $^{\spadesuit}$, Lu Cheng $^{\clubsuit}$, Huan Liu $^{\spadesuit}$
$^{\spadesuit}$ Arizona State University, $^{\clubsuit}$ University of Illinois Chicago,
$^{\diamondsuit}$ University of Maryland, Baltimore County, $^{\heartsuit}$ Northwestern University,
$^{\clubsuit}$ University of California, Berkeley, $^{\spadesuit}$ Emory University
Abstract
Assessment and evaluation have long been critical challenges in artificial intelligence (AI) and natural language processing (NLP). Traditional methods, usually matching-based or small model-based, often fall short in open-ended and dynamic scenarios. Recent advancements in Large Language Models (LLMs) inspire the “LLM-as-a-judge” paradigm, where LLMs are leveraged to perform scoring, ranking, or selection for various machine learning evaluation scenarios. This paper presents a comprehensive survey of LLM-based judgment and assessment, offering an in-depth overview to review this evolving field. We first provide the definition from both input and output perspectives. Then we introduce a systematic taxonomy to explore LLM-as-a-judge along three dimensions: what to judge, how to judge, and how to benchmark. Finally, we also highlight key challenges and promising future directions for this emerging area $^{1}$ $^{2}$.
$^{1}$ More resources on LLM-as-a-judge are on the website: https://llm-as-a-judge.github.io
$^{2}$ We have released and will maintain a paper list about LLM-as-a-judge at: https://github.com/llm-as-a-judge/Awesome-LLM-as-a-judge
Executive Summary: LLM evaluation has long relied on rigid metrics such as BLEU and ROUGE or smaller models like BERTScore. These methods work for narrow, fixed tasks but fail to capture nuance, safety, or open-ended quality in modern generative systems. As large language models advance rapidly, developers need scalable ways to judge outputs, guide alignment, and support reasoning—creating demand for a more capable evaluation paradigm.
This survey defines the “LLM-as-a-judge” approach—using large models to score, rank, or select outputs—and provides a systematic overview of its techniques, uses, and limitations. It organizes the field around three questions: what attributes to judge, how to structure judging methods, and how to test the judges themselves.
The authors reviewed hundreds of recent papers, grouped them into a clear taxonomy, and synthesized findings across input-output formats, tuning and prompting strategies, applications, and benchmarks. They examined manual and synthetic data sources, supervised fine-tuning, preference learning, rule-based prompts, multi-agent setups, and position-bias corrections, drawing on benchmarks that measure agreement with humans, bias levels, and performance on hard or domain-specific tasks.
The analysis reveals that LLMs can reliably judge six core attributes—helpfulness, safety, reliability, relevance, logical soundness, and overall quality—when given suitable guidance. Several practical techniques, including response swapping, detailed rubrics, and multi-agent debate, improve consistency and reduce positional bias. At the same time, judges still show systematic preferences for longer or more authoritative-sounding answers, remain vulnerable to prompt injection, and sometimes favor their own generations. The survey also shows that LLM judges now support model alignment, retrieval, reasoning, and agent workflows well beyond initial evaluation use cases.
These capabilities matter because they replace costly human annotation with scalable feedback, accelerating development cycles. Yet the same biases and attack surfaces can propagate into deployed systems, affecting fairness, safety, and compliance. Organizations that adopt LLM judges without mitigation therefore risk producing models that systematically undervalue certain styles or outputs.
Leaders should prioritize bias-calibration methods, such as detailed evaluation rubrics and cross-model verification, before scaling use. They should also pilot human-in-the-loop review for high-stakes decisions and explore emerging inference-time scaling techniques that let judges reason more thoroughly. Further work is needed on root causes of self-preference bias and on efficient ways to combine LLM and human judgment.
The survey is broad but necessarily omits exhaustive application details; its conclusions rest on the current literature, which continues to evolve quickly. Readers should treat the reported techniques as directionally useful rather than universally validated across every domain and model size.
1. Introduction
Section Summary: Researchers have long relied on automated metrics like BLEU and ROUGE to evaluate machine learning and language models by checking how closely outputs match reference texts, but these methods fall short for open-ended or nuanced tasks such as assessing fairness or helpfulness. Newer approaches now use large language models like GPT-4 as judges that can score, rank, or select responses based on specific criteria, producing more flexible and human-like assessments. This “LLM-as-a-judge” technique is being applied not only for evaluation but also to guide model training, enable self-improvement, and support intelligent agent behaviors, though it raises concerns about bias and reliability that the survey aims to review systematically.
Automatic model assessment and evaluation have long been essential yet challenging tasks in machine learning (ML) and natural language processing (NLP) [1, 2]. Traditional static metrics [3, 4] like BLEU [5] and ROUGE [6] measure quality by calculating lexical overlap between output and reference texts. While computationally efficient, these metrics perform poorly in dynamic and open-ended scenarios [7, 8]. With the rise of deep learning, small language model-based metrics like BERTScore [9] and BARTScore [10] have emerged. However, these metrics still face challenges in capturing nuanced attributes like fairness [11] and helpfulness [12].
Recently, the advancements of large language models (LLMs) [13] such as GPT-4 [14] and o1 [15], have led to striking improvements in various applications, leveraging substantial prior knowledge in vast training corpora. This progress has motivated researchers to propose the concept of "LLM-as-a-judge" [16, 17, 18, 19], where LLMs are used to assess the candidate outputs by assigning scores, producing rankings, or selecting the best options, based on various input formats (e.g., point- and pair-wise), given context and instruction. The strong capability of LLMs combined with well-designed assessment pipelines [20, 21] leads to fine-grained and human-like judgment for various evaluation applications, addressing the previous limitations.
Beyond evaluation, LLMs-as-a-judge has been adopted across the lifecycle for next generations of LLM developments and applications. LLMs-as-a-judge is often used as a scalable way to provide supervisions for key development steps like alignment [22], retrieval [23], and reasoning [24]. LLM-as-a-judge also empowers LLMs with a series of advanced capabilities such as self-evolution [25], active retrieval [23], and decision-making [26], driving their elevations from generative models to intelligent agents [27]. However, as the field develops rapidly, challenges like bias and vulnerability [28, 29, 30, 31] are emerging. Therefore, a systematic review of both techniques and limitations is crucial for facilitating this field.
This survey delves into the details of LLM-as-a-judge, aiming to provide a systematic overview of LLM-based judgment systems. We start by formally defining LLM-as-a-judge with its diverse input and output formats (Section 2). Next, we propose an in-depth and comprehensive taxonomy to address the three key questions (Section 3, Section 4 Section 6):
- Attribute: What to judge? We outline six subtle attributes that are uniquely assessed by LLM-as-a-judge, including helpfulness, safety & security, reliability, relevance, logical, and overall quality.
- Methodology: How to judge? We explore ten tuning and prompting methods for LLM-as-a-judge, including manual labeling, synthetic feedback, supervised fine-tuning, preference learning, swapping operation, rule augmentation, multi-agent collaboration, demonstration, multi-turn interaction, and comparison acceleration.
- Benchmark: How to evaluate LLM-as-a-judge? We categorize existing benchmarks for LLM-as-a-judge into four types: for general performance, bias quantification, challenging tasks, and domain-specific performance.
Finally, we discuss challenges and potential future directions for LLM-as-a-judge in Section 7.
Differences from Existing Surveys. Existing concurrent surveys investigate LLM for the evaluation of natural language generation (NLG) [32, 33, 34]. However, LLM-as-a-judge has been applied across a broader range of scenarios beyond evaluation, as we discussed, necessitating a systematic survey to categorize and summarize its various applications.
2. Preliminary
Section Summary: The section introduces LLM-as-a-judge as a method in which a language model evaluates candidate responses by taking them as input and producing an assessment result. Input can involve either a single candidate judged in isolation or multiple candidates presented together for direct comparison. Output takes one of three forms: numerical scores assigned to each candidate, an ordered ranking of the candidates, or selection of the strongest one or more options.
In this section, we provide a detailed definition of LLM-as-a-judge, discussing the various input and output formats as shown in Figure 1.
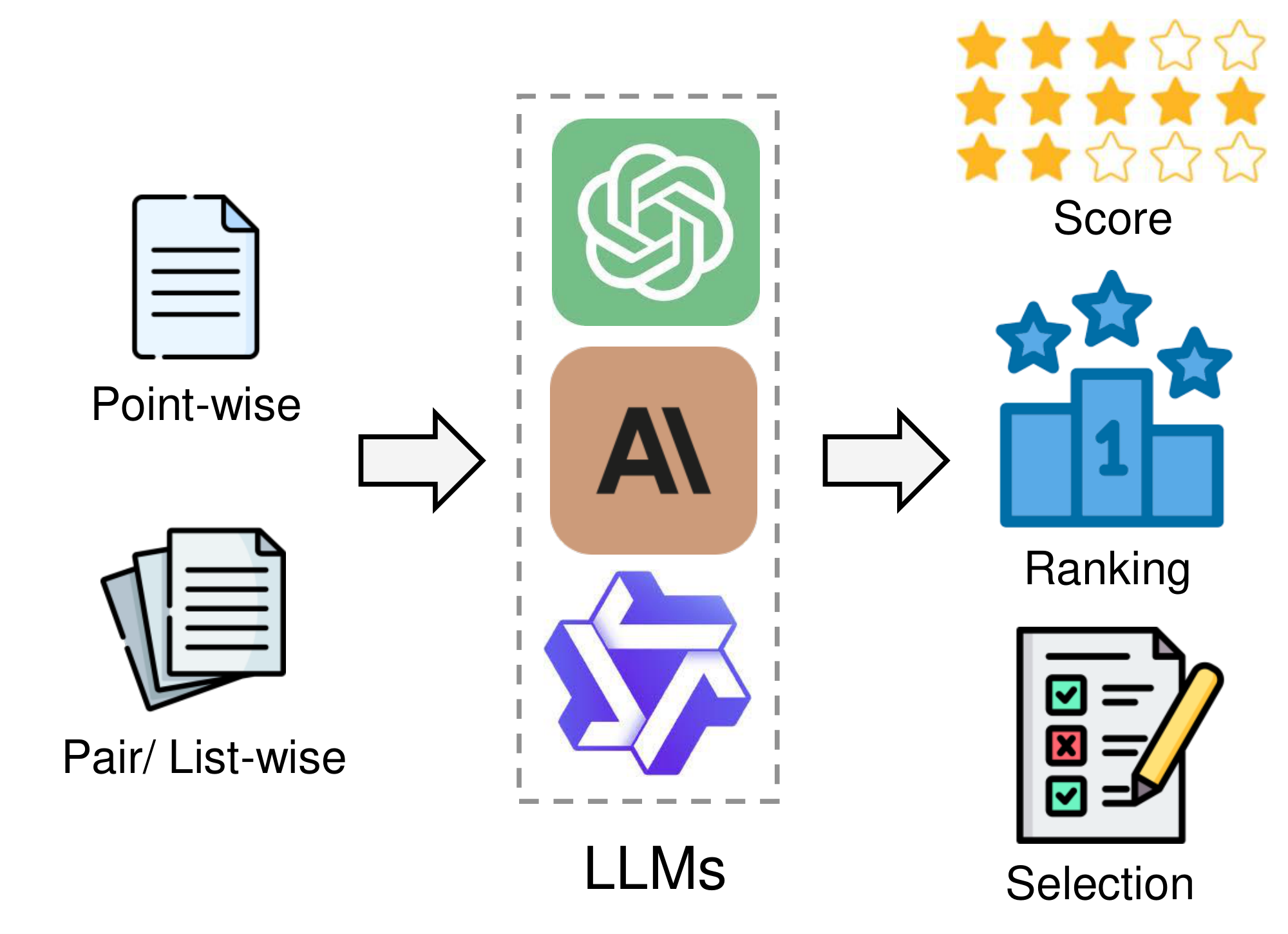
2.1 Input
Given a judge LLM $J$, the assessment process can be formulated as: $R = J(C_1, ...C_n).$ Here $C_i$ is the $i_{th}$ candidate to be judged and $R$ is the judging result. We categorize two input formats based on the different candidate numbers $n$.
Point-Wise: When $n=1$, it becomes a point-wise judgment where the LLMs judges will solely focus on one candidate sample [35].
Pair/ List-Wise: When $n\geq2$, it becomes a pair-wise ($n=2$) or list-wise ($n>2$) judgment where multiple candidate samples are provided together for the LLM judges to compare and make a comprehensive assessment [16].
2.2 Output
In this section, we discuss three kinds of output of the judgment based on the different formats of $R$.
Score: When each candidate sample is assigned a continuous or discrete score: $R={C_1:S_1, ..., C_n:S_n}$, it becomes a score-based judgment. This is the most widely adopted protocol, leveraging LLMs to generate scores for quantitative comparisons [36] or attribute detection [37].
Ranking: In ranking-based judgment, the output is a ranking of each candidate sample, represented as $R={C_i>...>C_j}$. This comparative approach is useful in scenarios where establishing a rank order among candidates is required [20, 38].
Selection: In selection-based judgment, the output involves selecting one or more optimal candidates, represented as $R={C_i, ..., C_j} > {C_1, ...C_n}$. This method is particularly crucial in decision-making [39] or content-filtering [23] contexts.
3. Attribute
Section Summary: This section reviews how LLMs serve as automated judges to evaluate key qualities of AI-generated outputs across multiple dimensions. It covers assessments of helpfulness and informativeness for alignment and evaluation, safety against harmful or malicious content, reliability in terms of factual faithfulness and uncertainty awareness, relevance in conversations and retrieval tasks, logical soundness for planning and reasoning, and overall quality that may combine or stand in for finer-grained checks. The discussion highlights both direct use of powerful models for these judgments and specialized training or prompting techniques to improve accuracy in areas like summarization and multimodal applications.
In this section, we categorize current research in LLM-as-a-judge from attribute perspectives. Figure 2 gives an overview summarization of what aspects can be assessed by the LLM judges.

3.1 Helpfulness
Helpfulness is a critical criterion to measure the utility and informativeness of a generated response. Due to the high cost of manually assessing helpfulness in training data, recent studies have explored leveraging LLMs to label helpfulness and to generate or filter alignment data [40, 22, 41, 42]. Beyond alignment tuning, helpfulness assessment using LLM-as-a-judge also plays a vital role in automatic model evaluation [16, 43, 44, 45].
3.2 Safety & Security
Safety and security are essential to ensure that models do not generate harmful content or respond inappropriately to malicious inputs. Current studies have validated that LLMs can be effectively used for model safety assessment, either as off-the-shelf models guided by policy instructions [40, 46, 47, 48, 49, 50, 51, 52, 53], or as lightweight models fine-tuned on safety-specific datasets [54, 55, 37]. Besides, LLM-as-a-judge has been widely adopted to detect and purify adversarial and toxic prompts designed with malicious intent [56, 57, 58].
3.3 Reliability
Reliability is a crucial attribute for LLMs, enabling them to generate faithful content while presenting uncertainty or acknowledging missing knowledge about certain topics. Regarding sentence-level faithfulness assessment, existing researches leverage LLM-as-a-judge to either instruct the powerful LLMs (e.g., GPT-4) directly [59, 60, 61, 62] or train specific reliability judges [63]. Several works adopt LLM judges for long-form and fine-grained faithfulness evaluation [64, 65, 66], using external retrieval bases [67, 68, 69] or search engines [70]. [71, 72] further expand this assessment to the multimodal area. Besides evaluation, there are also many works that adopt LLM-as-a-judge to improve the reliability of the generated content, either by external verifiers [73] or synthetic alignment datasets [74, 75]. For uncertainty judgment, [76] propose SaySelf, a training framework that teaches LLMs to express more fine-grained confidence estimates with self-consistency prompting and group-based calibration training.
3.4 Relevance
Relevance assessment with LLM-as-a-judge has been explored and validated to be a more refined and effective manner across various tasks [77, 78]. In conversation evaluation, both [79] and [80] propose to replace expensive human annotation with LLM judgment in relevance assessment. In retrieval-augmented generation (RAG) scenarios, there are also many works that utilize LLMs to determine which demonstrations [81] or documents [23] are most relevant for solving the current problem. Recently, LLM-as-a-judge has also been used in multimodal applications for cross-modality relevance judgment [82, 83, 84, 85, 86, 87, 88]. Additionally, LLM-as-a-judge has also been explored in many traditional retrieval applications for relevance assessment [89, 90, 91, 92, 93], such as search [94, 95], retrieval [96, 97], recommendation [98, 99].
3.5 Logic
In agentic LLMs, assessing the logical correctness of candidate actions or steps is crucial for LLMs' planning, reasoning and decision-making, which further releases their great potential at inference-time. While some works leverage metrics or external tools for this feasibility assessment [100, 101], many others leverage LLMs' feedback as the signal [102, 103] to perform planning and searching in complex reasoning spaces [104, 39, 105]. In multi-agent collaboration systems, both [24] and [106] propose to leverage the judge LLM to select the most feasible solutions among multiple candidates' responses. Besides, other works adopt LLM judges to perform logical assessment in API selection [107], tool using [26] and LLM routing [108].
3.6 Overall Quality
As previously mentioned, LLM-as-a-judge can be employed to perform multi-aspect and fine-grained assessments. However, in many cases, a general assessment is still required to represent the candidates' overall quality. One straightforward approach to obtain this overall score is based on the aspect-specific scores, either by averaging them [43] or referring them to generate an overall judgment [109]. Moreover, in many traditional NLP tasks [110, 111, 112, 113, 114] like summarization [35, 115, 116, 117, 118, 119, 120, 121, 122] and machine translation [123, 124, 125, 126], the evaluation dimensions are less diverse compared to more open-ended, long-form generation tasks. As a result, LLM-as-a-judge is often prompted directly to produce an overall judgment in these tasks.
4. Methodology
Section Summary: The section outlines two main ways to strengthen large language models as judges of other AI outputs: tuning the models in advance and refining how they are prompted at evaluation time. Tuning approaches draw on either human-annotated judgments or feedback generated synthetically by models themselves, then apply supervised fine-tuning or reinforcement-learning methods to teach the models more reliable scoring and reasoning. Prompting strategies focus on reducing known biases, such as positional preferences, and on supplying clear evaluation rules or examples during inference to produce fairer and more consistent results.
In this section, we present commonly adopted methods and tricks to improve LLMs' judging capabilities, splitting them into tuning (Section 4.1) and prompting strategies (Section 4.2).
4.1 Tuning
To enhance the judging capabilities of a general LLM, various tuning techniques have been employed in different studies. In this section, we discuss these tuning approaches for LLM-as-a-judge from two perspectives: data sources (Section 4.1.1) and training techniques (Section 4.1.2).
4.1.1 Data Source
Manually-labeled Data:
To train a LLM judge with human-like criteria, one intuitive method is to collect manually-labeled judgments. Previous works have leveraged and integrated existing sources annotated by humans, including instruction tuning datasets [127, 128] and traditional NLP datasets [129], for tuning LLM judges. Other works collect manually-labeled datasets with fine-grained judgment feedback. These fine-grained feedbacks can be rationales behind judgment results [130], multi-aspect judgment formats [131] and fine-grained judgment labels [132], all of which facilitate the LLM judges to produce more detailed and context-rich judging results. Notably, [133] first prompt GPT-4 to generate judgment and then manually verify and revise the outputs to ensure high-quality annotations.
Synthetic Feedback:
While manually labeled feedback is high-quality and accurately reflects human judgment preferences, it is limited in both scale and coverage. To address it, researchers have also explored synthetic feedback as a data source for LLM judges' tuning. Some rely on the LLM judges themselves to generate the synthetic feedback. It involves instructing the LLM to self-evaluate and improve its judgments [134], or by generating corrupted instructions and corresponding responses as negative samples for Directed Preference Optimization (DPO) training [135]. Besides, other powerful and stronger LLMs are also introduced for feedback synthesis. For example, GPT-4 has been widely leveraged to synthesize judging evidence [63], erroneous responses [29], rationale and feedback [44, 136, 137], and judgment labels [138, 37].
4.1.2 Tuning Techniques
Supervised Fine-tuning:
Supervised fine-tuning (SFT) is the most widely used approach for training LLM judges [139], enabling them to learn from pairwise [44, 140, 138, 128, 141, 142] or pointwise [140, 132, 37, 127, 143] judgment data. Among many tricks applied in SFT, multi-task training and weight merging are introduced to enhance the robustness and generalization of LLM judges [136, 129, 144]. Other works try to enrich the original training set with augmented or self-generated samples. [133] augment pairwise training data by swapping the order of two generated texts and exchanging the corresponding content in critiques. [130] further fine-tune their INSTRUCTSCORE model on self-generated outputs to align diagnostic reports better with human judgment. Additionally, [131] propose a two-stage SFT process: an initial phase of vanilla instruction tuning for evaluation diversity, followed by additional tuning with auxiliary aspects to enrich the model's evaluative depth.
Reinforcement Learning:
Reinforcement learning from human preference is closely tied to judgment and evaluation tasks, particularly those involving comparison and ranking. Rather than directly adopt or augment preference learning datasets for SFT, several studies apply preference learning techniques to enhance LLMs' judging capabilities. One straightforward way is to treat the off-topic responses as inferior samples and apply DPO [63, 145, 146]. Besides, [134] propose meta-rewarding, which leverages the policy LLMs to judge the quality of their own judgment and produce pairwise signals for enhancing the LLMs' judging capability. This concept is also adopted by [135], who propose self-taught evaluators that use corrupted instructions to generate suboptimal responses as inferior examples for preference learning. Moreover, [147] introduce rating-guided DPO, in which the rating difference between two responses is considered in preferences modeling. Different from RLHF- and DPO-based approaches, several recent works leverage reinforcement learning with verifiable reward (RLVR) [148] to train LLM judges by rewarding reasoning trajectories that lead to correct judgments [149, 150, 151].
4.2 Prompting
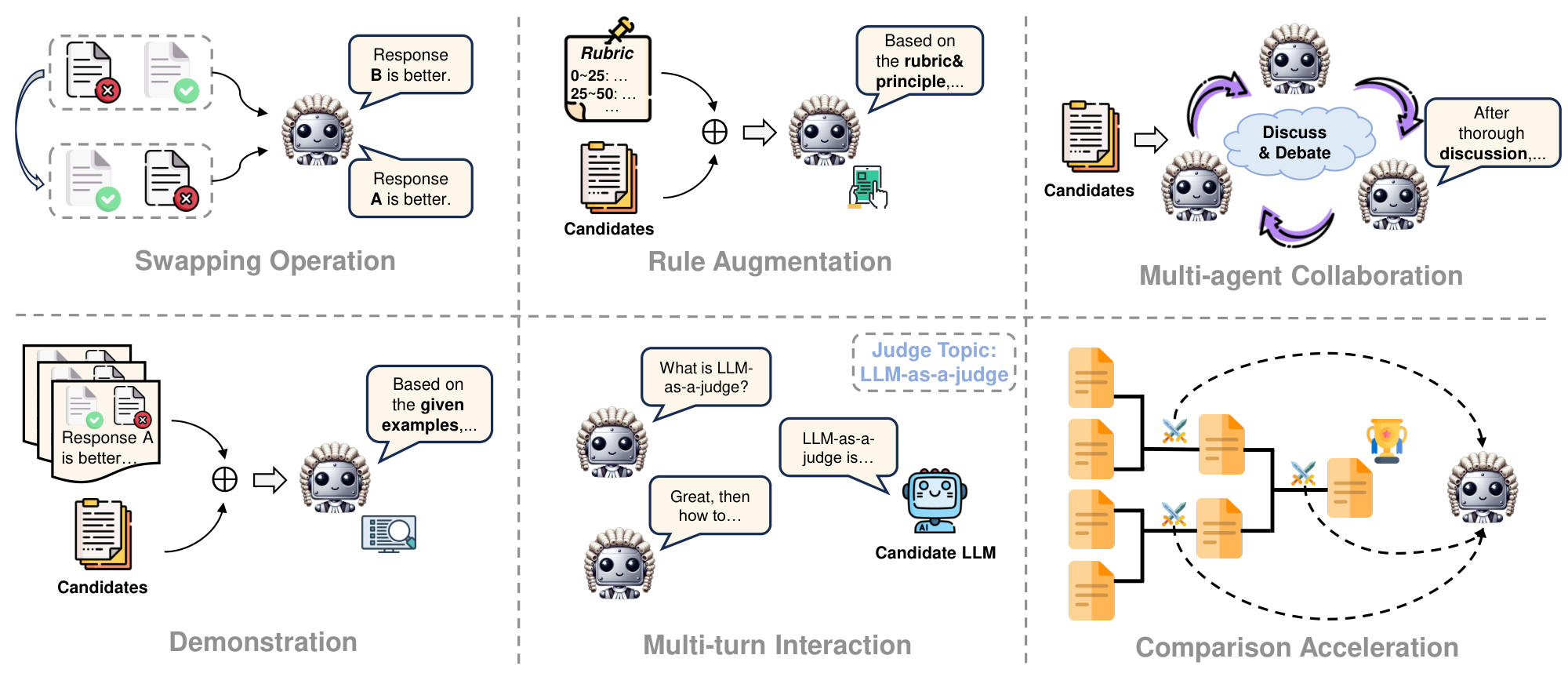
Designing appropriate prompting strategies and pipelines at the inference stage could improve judgment accuracy and mitigate bias. We summarize existing prompting strategies for LLM-as-a-judge into six categories (see Figure 3).
4.2.1 Swapping Operation
Previous studies have demonstrated that LLM-based judges are sensitive to the positions of candidates, and the ranking results of candidate responses can be easily manipulated by merely altering their order in the context [152]. To mitigate this positional bias and establish a more fair LLM judging system, [16] propose a swapping operation, which involves invoking the judge LLM twice, swapping the order of the two candidates in each instance. If the two results are inconsistent, it is labeled a "tie", indicating that the LLM is unable to confidently distinguish the quality of the candidates. This swapping operation technique has also been widely adopted in pairwise feedback synthesis to produce more accurate reward signals [22, 25, 127].
4.2.2 Rule Augmentation
Rule-augmented prompting involves embedding a set of principles, references, and evaluation rubrics directly within the prompt for LLM judges. This approach is commonly employed in LLM-based evaluations, where LLM judges are guided to assess specific aspects [153, 44, 21, 109, 154, 155, 156, 157] and provided with detailed rubrics and criteria [35, 158, 159, 160, 161, 162, 163, 164, 165, 166] to ensure accurate judgments. Following this concept, studies in alignment [40, 22, 127, 41, 25, 167] enhance this principle-driven prompting by incorporating more detailed explanations [168] for each aspect of the principle or rubric. Apart from these human-written rules, some works [169, 55, 170, 171, 172] embed the self-generated or automaticaly-searched scoring criteria and principles as a part of their instruction.
4.2.3 Multi-agent Collaboration
Accessing results from a single LLM judge may not be reliable due to inherent biases in LLMs [152, 173, 174]. To address this limitation, [20, 175, 176] introduce the Peer Rank (PR) algorithm, which produces the final ranking based on each LLM judge's output. Building on this, several architectures and techniques for multi-agent LLMs emerge, including mixture-of-agent [177, 178, 167, 179], role play [180, 181, 182], debating [183, 184, 185, 186], voting & aggregation [187, 188, 189, 190, 191] and cascaded selection [192, 193]. Additionally, others apply multi-agent collaboration for alignment data synthesis, leveraging multiple LLM judges to refine responses [194] or provide more accurate feedback [195].
4.2.4 Demonstration
In-context samples or demonstrations [196, 197, 198] provide concrete examples for LLMs to follow and have been shown to be a crucial factor in the success of in-context learning for LLMs. Several studies have introduced human assessment results as demonstrations for LLMs-as-judges, aiming to help LLMs learn evaluation standards from a few illustrative examples [199, 200]. To improve the robustness of LLM evaluations, [201] propose ALLURE, an approach that iteratively incorporates demonstrations of significant deviations to enhance the evaluator’s robustness. Additionally, [202] borrow the insights from many-shot in-context learning and apply it in LLM-as-a-judge applications.
4.2.5 Multi-turn Interaction
A single response may not provide enough information for an LLM judge to thoroughly and fairly assess each candidate. To address this limitation, multi-turn interactions are proposed to offer a more comprehensive evaluation. Typically, the process begins with an initial query or topic, followed by dynamically interacting between the LLM judge and candidate models [203, 109, 204]. Besides, some approaches facilitate debates among candidates in a multi-round manner, allowing their true knowledge and performance to be fully revealed and evaluated [205, 206].
4.2.6 Comparison Acceleration
Among various input formats in LLM-as-a-judge, pair-wise comparison is the most common approach for model comparison in evaluation or producing pair-wise feedback for training. However, when multiple candidates need to be ranked, this method can be quite time-consuming [207]. To mitigate the computational overhead, [207] propose a ranked pairing method in which all candidates are compared against an intermediate baseline response. In addition, [127, 208] utilize a tournament-based approach [209, 210] for rejection sampling during inference to speed up the pair-wise comparison.
5. Application
Section Summary: LLM-as-a-judge methods are applied in four main areas: evaluation, alignment, retrieval, and reasoning. In evaluation, they rate the quality of model outputs such as dialogues, summaries, or reasoning steps for coherence and accuracy. For alignment and retrieval they generate preference data to train smaller models and rank documents or guide knowledge use in generation, while in reasoning they help select better reasoning paths and decide when to use external tools.
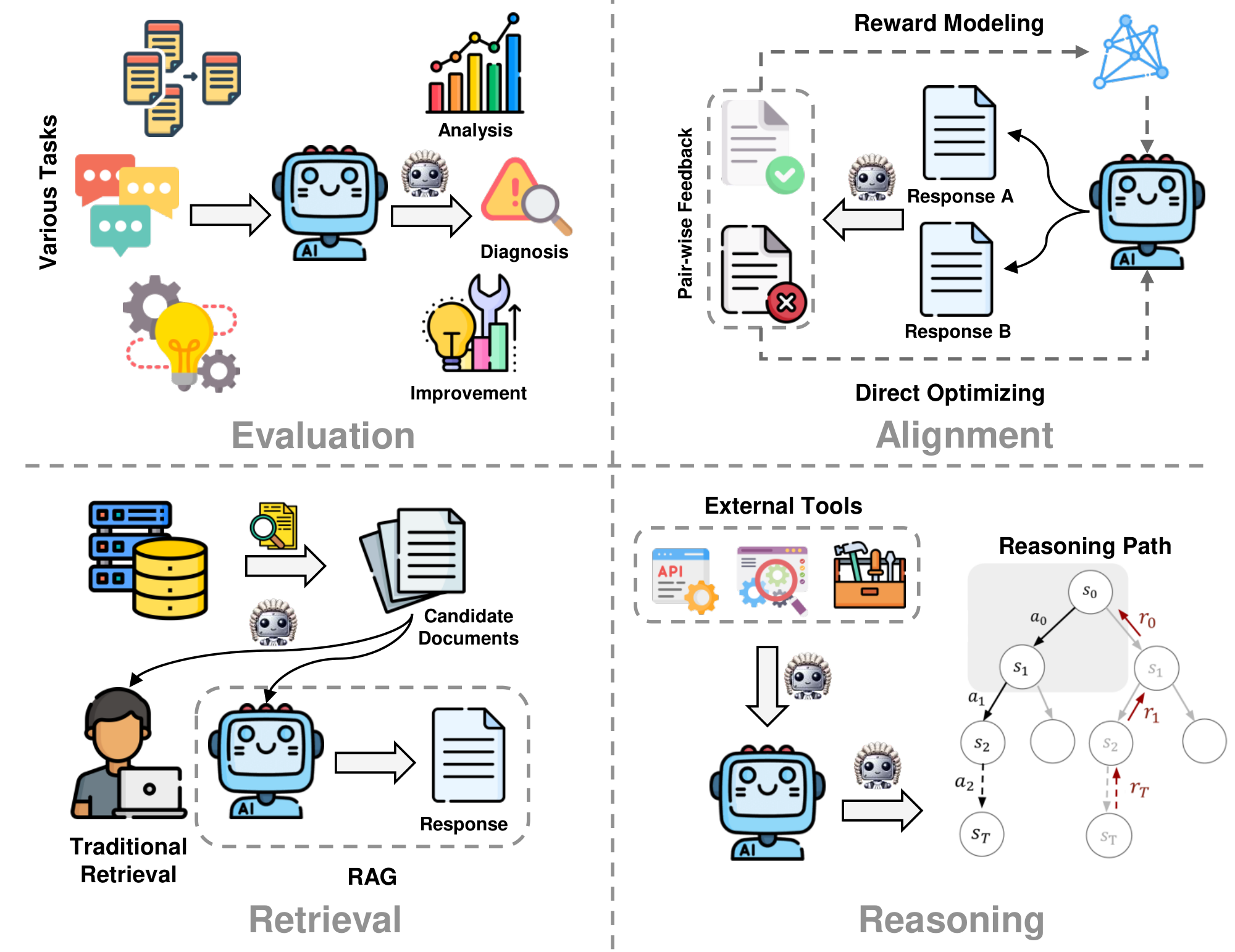
We introduce four applications which LLM-as-a-judge can be applied: evaluation (Section 5.1), alignment (Section 5.2), retrieval (Section 5.3), and reasoning (Section 5.4). Due to the space limitation, we provide a more detailed version in Appendix C.
5.1 Evaluation
LLM judges are initially proposed for and widely adopted in various evaluation scenarios. For open-ended generation, LLM judges assess the quality of outputs like dialogues, summaries, and creative writing, ensuring contextual relevance, coherence, and safety [211, 212, 213, 214]. For reasoning tasks, they judge intermediate steps and final answers [215, 216, 217] in areas such as math [217], logic [216], and temporal reasoning [218]. There are also some emerging areas where LLM judges are applied to domains once dominated by humans, including social intelligence [219], multimodal tasks [220] and multilingual generation [221].
5.2 Alignment
Model alignment also benefits from the automatic LLM-as-a-judge to produce and filter data at scale. Typically, larger and powerful LLMs are usually used as judges to align smaller models, providing synthetic preference data. This includes methods like multi-agent collaboration [194] and specialized tasks such as code alignment [222]. Additionally, self-judging methods have LLMs rank or critique their own outputs to generate preference data without external teachers. To improve the judging capability of the policy model, techniques such as meta-rewarding [134], Judge Augmented Supervised Fine-Tuning (JSFT) [127], and self-evaluation [74] have been proposed. Apart from pairwise data, some other studies also use LLM-as-a-judge to judge and filter synthetic SFT data for instruction tuning [223, 224].
5.3 Retrieval
LLM judges can assist with both traditional retrieval tasks and retrieval-augmented generation (RAG). For traditional retrieval, LLM-as-a-judge ranks documents by relevance [225] without task-specific data [226], using permutation-based [227], pairwise [228], and listwise [229] approaches to improve reranking for complex queries and domain-specific search tasks. For RAG, LLM judges guide how external knowledge is fetched and used during generation, ensuring coherence, accuracy, and relevance. This includes frameworks like Memory-of-Thought [230], Self-Retrieval [231], and Self-RAG [232], where the judge selects or filters retrieved content, particularly in specialized fields such as biomedicine [23].
5.4 Reasoning
Reasoning is a critical capability of LLMs for complex and dynamic problem-solving. LLM judges can aid reasoning tasks by improving reasoning path selection and external tool use. Reasoning path selection involves identifying the correct trajectory for the LLM’s reasoning process, where LLM-as-a-judge are adopted to evaluate intermediate reasoning steps [153], perform trajectory-level selection [233], and act as a process reward model for reasoning state scoring [234] or a fine-grained critic to provide verbal feedback [235]. For external tool use, LLM judges help AI systems decide which external tools, modules, or agents to activate at each step of reasoning, acting as controllers that coordinate tool choice [236], agent communication [108], and message flow management [24] to ensure accurate and coherent problem solving.
6. Benchmark: Judging LLM-as-a-judge
Section Summary: Researchers evaluate large language models used as judges by organizing benchmarks into four main categories that test overall accuracy, fairness, difficulty handling, and specialized knowledge. General benchmarks measure alignment with human ratings through statistical agreement scores and by comparing model rankings against trusted leaderboards like Chatbot Arena. Other evaluations focus on detecting biases such as position effects, stress-testing performance on hard questions, and checking effectiveness in fields like coding, medicine, and law.
We categorize benchmarks for evaluating LLMs-as-judges into four groups: general performance (Section 6.1), bias quantification (Section 6.2), challenging task performance (Section 6.3), and domain-specific performance (Section 6.4).
6.1 General Performance
Benchmarks focusing on general performance aim to evaluate the overall competence of LLMs in various tasks. One direct way to benchmark LLM judges' performance is to calculate the alignment between LLM prediction and the manual judgment result, using various metrics like Cohen’s kappa, Discernment Score, and normalized accuracy [237, 238, 239, 240, 241, 242, 243, 244, 245, 122, 246, 247, 248]. Moreover, several studies build LLM leaderboards using LLM-as-a-judge and assess their validity by comparing model rankings with those from established benchmarks and leaderboards, such as Chatbot Arena [16]) [16, 249, 250, 205, 251].
6.2 Bias Quantification
Quantifying and mitigating bias in LLM judgments is critical to ensuring fairness and reliability [252]. Typical benchmarks include EvalBiasBench [29] and CALM [253], focus explicitly on quantifying biases, including those emerging from alignment and robustness under adversarial conditions. Besides, [254] adopt metrics such as position bias and percent agreement in question-answering tasks. Recently, [255] examine the influence of protocol choice (pairwise and pointwise) on the bias degree of LLM judges.
6.3 Challenging Task Performance
Benchmarks designed for difficult tasks push the boundaries of LLM evaluation. For example, Arena-Hard [250] and JudgeBench [238] select harder questions based on LLMs' performance for conversational QA and various reasoning tasks, respectively. CALM [253] explores alignment and challenging scenarios, using metrics like separability and agreement to evaluate performance in manually identified hard datasets.
6.4 Domain-Specific Performance
Domain-specific benchmarks provide task-focused evaluations to assess LLMs’ effectiveness in specialized contexts. Concretely, [256] measure separability and agreement across tasks in specific domains such as coding, medical, finance, law and mathematics. CodeJudge-Eval [257] specifically evaluates LLMs for judging code generation with execution-focused metrics such as accuracy and F1 score. This idea has also been adopted by several following works in code summarization and generation evaluation [258, 259, 260]. Besides, there are also domain-specific benchmarks focusing on LLMs' assessing capabilities in multimodal [85], multilingual [261, 262], instruction following [160] and LLM agent [263].
7. Challenges & Future Works
Section Summary: LLM judges face persistent problems with built-in biases that favor longer or polished outputs, as well as susceptibility to adversarial tricks that can sway their decisions. Researchers are exploring more dynamic, conversational judging methods along with inference-time scaling techniques like extended reasoning, but these approaches bring new issues around efficiency and robustness. Looking ahead, the field points toward deeper analysis of bias origins, hybrid human-LLM workflows, and more adaptive, human-like evaluation systems to make automated judging fairer and more reliable.
7.1 Bias & Vulnerability
The use of LLMs-as-a-judge inherently introduces significant challenges related to bias and vulnerability, which significantly compromise fairness and reliability when LLMs are deployed for diverse judging tasks. Among the various types of bias, some are consistent across all LLM judges, for example, a tendency to prefer longer [28, 249, 264, 265], authoritative-looking [266, 267] and well-formatted [267] responses. In addition, other biases stem from individual judges’ own preferences or knowledge, such as egocentric bias [268, 269, 270, 271] and preference leakage [272, 273, 274]. LLM judges are also susceptible to adversarial manipulations. Techniques like prompt injection attacks [254, 275, 276, 277] and adversarial phrases [278, 279, 280] can drastically influence LLMs' judgment, thus raising concerns about the reliability of LLM judges in high-stakes scenarios [254, 279].
Future Direction. Existing studies have already explored approaches, such as providing more detailed evaluation principles [16, 138, 278, 281] and eliminating spurious features through calibration [282, 279, 283, 169, 284, 285, 286], to mitigate LLM judges' bias. Future work could focus more on analyzing and understanding the root causes of these biases. For example, why would LLMs prefer their own generation [270]?
7.2 Scaling Judgment at Inference Time.
Motivated by recent inference-time scaling (ITS) studies in LLMs [287, 288], several works have begun to explore how to scale LLMs' judgment capabilities at inference time [149, 150, 151]. By expanding the reasoning process in judgment tasks and incorporating advanced behaviors such as reflection and exploration, both the accuracy and fairness [271, 289] of judge LLMs have seen significant improvements. A straightforward approach to scaling judge LLMs is to employ Large Reasoning Models (LRMs) that generate judgments via long CoT reasoning [290]. Additionally, traditional sampling and search strategies, such as self-consistency, best-of-N, and Monte Carlo Tree Search (MCTS), have been used to more thoroughly explore the space of possible judgment trajectories [291, 292]. Other methods leverage golden labels as supervision, applying rule-based reinforcement learning [290, 150, 293, 294, 295], DPO [149] or distillation [296] to train LLMs to serve as more effective judges.
Future Directions. While LLM-as-a-judge approaches benefit from ITS techniques, it is also important to recognize the associated challenges. These include efficiency bottlenecks [297], performance degradation from over-thinking [298], and increased vulnerability of long CoTs to adversarial attack [299]. Future research could investigate these limitations and develop mitigation strategies, paving the way for more efficient, accurate, and robust judge LLMs enhanced by ITS.
7.3 Dynamic & Complex Judging Strategy
Compared with earlier static and straightforward approaches that directly prompt LLMs for judgment [16], more dynamic and complex judgment pipelines have been proposed recently to address various limitations, improving the robustness and effectiveness of LLM-as-a-judge. One approach is to follow the concept of "LLM-as-a-examiner", where the system dynamically and interactively generates both questions and judgments based on the candidate LLMs' performance [109, 21, 204, 300, 301, 302, 303, 304]. Other works focus on making judgments based on multiple candidate LLMs' battling and debating [206, 205]. Additionally, building complex judgment agents is another popular research area [20, 183, 27], which typically involves multi-agent collaboration with well-designed planning systems.
Future Direction. One promising direction for future research is to equip LLMs with human-like and agentic judgment capabilities [265, 305, 306, 307, 308, 309, 310], such as anchoring, comparing, and meta-judgment. Another intriguing avenue would be to develop an adaptive difficulty assessment system [311, 312], dynamically adjusting problems'difficulties based on candidates' performance.
7.4 Human-LLMs Co-judgement
As mentioned earlier, the biases and vulnerabilities in LLM-as-a-judge can be addressed through human-in-the-loop for further intervention and proofreading. However, only a few studies have focused on this direction [152, 313, 314].
Future Direction. As data selection [315, 316] becomes an increasingly popular research area for improving the efficiency of LLMs' training and inference, it also holds the potential for enhancing LLMs-based evaluation. LLM-as-a-judge can draw insights from data selection to enable judge LLMs to serve as a critical sample selector, choosing a small subset of samples based on specific criteria (e.g., difficulty) for human annotators to conduct evaluation.
Due to the space limitation, we put the application of LLM-as-a-judge, paper collection for our taxonomy, tuning techniques and benchmark for LLM-as-a-judge in Section 5, Appendix D, Appendix E and Appendix F.
8. Conclusion
Section Summary: This survey examines how large language models can be used as judges to evaluate outputs from other AI systems. It organizes existing methods according to their input and output styles, then offers a broad framework covering the key qualities being assessed, the techniques employed, and the benchmarks used to test them. The authors also review current limitations and outline promising directions for future progress in this area.
This survey explores the intricacies of LLM-as-a-judge. We begin by categorizing existing LLM-based judgment methods based on input and output formats. Then, we propose a comprehensive taxonomy for LLM-as-a-judge, encompassing judging attributes, methodologies and benchmarks. After this, a detailed and thoughtful analysis of current challenges and future directions of LLM-as-a-judge is proposed, aiming to provide more resources and insights for future works in this emerging area.
Limitations
Section Summary: This survey of using large language models to act as judges could not cover every topic in depth because of space limits, so the main text focuses on just three core areas while moving applications and paper lists to an appendix. It also notes that the approach has built-in limitations and biases of its own. In addition, running these models demands substantial computing resources, creating practical hurdles in environments with limited hardware or budgets.
This work aims to provide a comprehensive survey of the LLM-as-a-judge paradigm. Due to space constraints, we focus on three core aspects in the main paper: judging attributes, methods, and benchmarks. Applications of LLM-as-a-judge and a detailed list of related papers are included in the appendix. Additionally, as discussed in Section 7.1, LLM-as-a-judge carries inherent limitations and biases. The substantial computational resources required for deploying LLMs may also pose challenges in resource-constrained scenarios.
Acknowledgment
Section Summary: This section thanks the organizations that funded the research described in the document. It notes support from the U.S. Department of Homeland Security, while clarifying that the authors' views do not represent official government policies. It also lists additional grants and awards received by researcher Lu Cheng from the National Science Foundation, the National Institutes of Health, Google, and Cisco.
This material is based upon work supported by the U.S. Department of Homeland Security under Grant Award Number 17STQAC00001-08-00. The views and conclusions contained in this document are those of the authors and should not be interpreted as necessarily representing the official policies, either expressed or implied, of the U.S. Department of Homeland Security. Lu Cheng is supported by the National Science Foundation (NSF) Grant #2312862, NSF CAREER #2440542, NSF-Simons SkAI Institute, National Institutes of Health (NIH) #R01AG091762, Google Research Scholar Award, and a Cisco gift grant.
Appendix
Section Summary: The appendix begins by defining six core attributes for evaluating LLM outputs, ranging from helpfulness and safety to logic and overall quality. It then organizes prompting strategies into four groups aimed at reducing bias, improving adherence to instructions, deepening analysis, and boosting efficiency. Finally, it surveys practical applications of using LLMs as judges, especially for assessing open-ended text generation, reasoning tasks, and newer areas like multimodal or socially aware models, while noting remaining issues such as cross-lingual inconsistency and potential hallucinations.
A. Attribute
Definition
We provide a detailed definition for each judgment attribute in Table 1.
: Table 1: Common judgment attributes and their definitions.
| Attribute | Definition |
|---|---|
| Helpfulness | Helpfulness is a critical criterion to measure the utility and informativeness of a generated response. |
| Safety & Security | Safety & security refer to whether the model avoids generating and is not affected by harmful, toxic, biased, or adversarial content. |
| Reliability | Reliability is the degree to which a response is faithful to verifiable sources and appropriately calibrated in expressing uncertainty. |
| Relevance | Relevance is a metric to measure how well a response aligns with the user query, topic, or task context. |
| Logic | Logic refers to the internal coherence and correctness of reasoning steps within a response, independent of factual accuracy. |
| Overall Quality | Overall quality is a holistic assessment of a response’s merit, typically integrating multiple dimensions into one comprehensive score. |
B. Prompting
Methods Categories
Based on each prompting strategy's target, we categorize them into following four group: (1) bias reduction, which involves reducing bias caused by candidate output position or reliance on a single LLM judge (swapping operations, multi-agent collaboration); (2) boosting instruction-following, which helps the LLM judge learn clear judging criteria and principles from rules or demonstrations (rule augmentation, in-context demonstration); (3) enhancing evaluation depth, which enables a better understanding of model capabilities (multi-turn interaction); and (4) improving evaluation efficiency, which refers to reducing the computational budget required during judgment (comparison acceleration).
C. Application with More Details
C.1 Evaluation
LLM-as-a-judge is first proposed for evaluation. It enables human-like evaluations rather than overlap-based matching [317, 318]. We discuss how LLM-as-a-judge has been utilized to evaluate open-ended generation (Appendix C.1.1), reasoning (Appendix C.1.2), and emerging NLP tasks (Appendix C.1.3).
C.1.1 Open-ended Generation Tasks
Open-ended generation includes tasks like dialog response, text summarization, and creative writing, where outputs must be safe, accurate, and contextually relevant with multiple "correct" answers [211, 212, 213, 319, 214]. Unlike traditional metrics, LLM-as-a-judge enables nuanced and adaptable evaluation [16]. This approach has been used for single-model evaluations and competitive comparisons [35, 180]. While LLMs-as-judges demonstrate human-like judgments, longer outputs risk hallucinations [63, 59]. Another concern is biased and unsafe judgements [320, 321, 253], though excessive caution may cause overly refusal [37]. To address these, researchers have proposed conversational frameworks like self-reflection [322] and debating [206]. Besides, multilingual LLM-as-a-judge research has advanced with various methods and benchmarks that address cross-lingual evaluation challenges. Approaches include scoring non-English answers against English references [323], using multi-agent debate frameworks for fine-grained evaluation [324], and developing open-source multilingual judges that outperform English-centric evaluators across 20+ languages [141]. Benchmarks like MM-Eval and PARIKSHA test the consistency and fairness of multilingual LLM judges, showing that evaluators tuned in English often underperform on low-resource languages [261].
However, key challenges still remain in LLM-based multilingual judgment. Studies highlight cross-lingual inconsistency, where judges show low agreement across languages, especially for low-resource settings [221]. Evaluators may also suffer from factual errors, cultural misrepresentations, and toxic content [325]. Additionally, dialectal variation further complicates the bias, with weaker alignment between LLM and human toxicity ratings in regional varieties [8]. These issues underscore the need for more culturally sensitive and robust multilingual evaluation methods.
C.1.2 Reasoning Tasks
The reasoning abilities of LLMs can be assessed through their intermediate thinking processes and final answers [215, 216, 326]. For mathematical reasoning, [217] introduce a framework using judge LLMs to assess the quality of reasoning steps. Similarly, for temporal reasoning, [218] create synthetic datasets to evaluate models' ability to reason about event sequences, causality, and dependencies. To distinguish genuine reasoning ability from pattern memorization, [327] propose a human-in-the-loop framework where LLMs and users adopt opposing positions to reach correct decisions. [328] develop a multi-agent framework simulating peer review, leveraging LLMs-as-judges to collaboratively assess reasoning capabilities in data-driven tasks.
C.1.3 Emerging Tasks
LLM-as-a-judge is also applied to tasks once exclusive to humans, particularly in context-specific areas. A prominent task is in social intelligence, where models are presented with complex social scenarios requiring the understanding of cultural values, ethical principles, and potential social impacts [329, 219]. Research has also extended to evaluating Large Multimodal Models (LMMs) and Large Vision-Language Models (LVLMs) [330]. For example, [137] use LMM-as-a-judge to provide transparent evaluations with rationales, while [331] propose a benchmark for LVLMs in self-driving scenarios, showing that LLM-based evaluations align better with human preferences than LVLM-based ones. Recently, we have seen more customized utilization of LLM-as-a-judge to evaluate emerging tasks such as code understanding and generation [257, 332, 333, 334, 335, 336, 337, 338, 339, 251], legal knowledge [340], game development [341], nature science [342, 343, 344], manufacture engineering [345], healthcare conversations [346, 347, 348], debating judgment [349], RAG [350, 351, 352, 353, 354], biomedical application [355, 356, 357], paper review [358, 359, 360, 361], novelty & creativity evaluation [362, 363, 364], and human-computer interaction [365].
C.2 Alignment
Alignment tuning is a vital technique to align LLMs with human preferences and values [366, 367, 368]. In this section, we discuss the use of larger LLMs as judges (Appendix C.2.1) and self-judging (Appendix C.2.2) for alignment.
C.2.1 Larger Models as Judges
Recently, alignment tuning leverages feedback from larger LLMs to guide smaller models. [40] first propose to train reward models with synthetic preferences from pre-trained LLMs. Following this, there are also some works explore online learning [41] and direct preference optimization [22] with larger models as judges. To prevent reward hacking, [25] develop an instructable reward model enabling real-time human interventions for alignment. Moreover, multi-agent collaborations employ diverse workflows and LLM debates to improve judgments in alignment tuning [194, 369, 195]. For code alignment, [222] create CodeUltraFeedback, a dataset using LLM judges to align smaller code models. [370] introduce BPO, employing GPT-4 as a judge to augment pairwise feedback.
C.2.2 Self-Judging
Self-judging utilizes LLMs’ own preference signals for self-improvement. Some focus on directly judging the preference ranking with the policy LLMs. [371, 372] first introduce self-rewarding, where LLMs judge their outputs to construct pairwise data. Following works adopt various methods to improve the judging capabilities, including meta-rewarding [134], Judge-Augmented Supervised Fine-Tuning (JSFT) [127] and self-evaluation [74]. To guarantee the quality of synthetic pairwise data, [373] introduce West-of-N approach while [374] apply self-filtering to produce high-quality synthetic data pairs for reasoning tasks. To reduce computational overhead, [207] propose ranked pairing for self-preferring models. [375] introduce meta-ranking, enabling smaller LLMs to act as judges and combining this method with Kahneman-Tversky optimization for post-SFT alignment. Besides pairwise data, [223] and [224] leverage LLM-as-a-judge to filter synthetic instruction tuning data. Other works adopt self-assessment and self-judgment in specific domains, such as robotics [376, 377] and multimodal [378].
C.3 Retrieval
In traditional retrieval, LLM-as-a-judge ranks documents by relevance with minimal labeled data (Appendix C.3.1). LLM judges can also enhance the RAG system by dynamically integrating retrieved knowledge into the final response (Appendix C.3.2).
C.3.1 Traditional Retrieval
LLMs enhance document ranking by employing methods like permutation-based ranking [227], fine-grained relevance labeling [225], and listwise reranking without task-specific training [226]. Moreover, Setwise [229] and Pairwise Ranking Prompting (PRP) [228] offer a cost-efficient alternative for complex tasks. [379] introduce a permutation self-consistency technique that averages across multiple orders to obtain order-independent rankings. Domain-specific knowledge retrieval with LLM-as-a-judge includes legal information, recommender systems and searching [96, 98, 380].
: Table 2: Categories of benchmarks for evaluating LLM judges.
| Benchmark | Definition |
|---|---|
| General Performance | Benchmarks that assess the general accuracy performance of LLM judges (e.g., MT-Bench) |
| Bias Quantification | Benchmarks focused on measuring and analyzing biases in LLM judgments (e.g., CALM) |
| Challenging Performance | Benchmarks that test LLM judges on difficult or adversarial tasks designed to probe the limits of their evaluation capabilities (e.g., Arena-Hard) |
| Domain-Specific Performance | Benchmarks that measure LLM judges’ effectiveness in specific domains, such as biomedical, legal, and coding evaluation (e.g., [256]) |
C.3.2 Retrieval-Augmented Generation (RAG) {#sec:Retrieval-Augmented_Generation_(RAG)}
[81] propose the Memory-of-Thought (MoT) framework, where LLMs store and recall reasoning to enhance response relevance. [231] introduce Self-Retrieval, an architecture integrating retrieval into document generation, enabling end-to-end IR within a single LLM. Similarly, [381] develop SELF-RAG, combining retrieval with self-reflection to enhance response quality. In the domain of Q&A, [382] present an LLM-based evaluation framework using synthetic queries to judge RAG agent performance. [383] study LLMs’ ability to assess relevance versus utility. In the biomedical area, several studies explore the usage of LLM-as-a-judge for active and dynamic retrival [384] or retrieved knowledge filtering [385, 23].
C.4 Reasoning
Reasoning is a critical aspect of LLMs because it directly affects their ability to solve complex problems. Recently, many studies leverage LLM-as-a-judge in reasoning path selection (Appendix C.4.1) and external source utilization (Appendix C.4.2).
C.4.1 Reasoning Path Selection
While many complex reasoning and cognition structures emerges for LLMs' reasoning [39, 104], one crucial challenge is how to select a reasonable and reliable reasoning path or trajectory for LLMs to reason. To achieve this, LLM-as-a-judge has been introduced. Some works adopt the reasoner LLMs to perform self-assessment, alternatively executing reasoning and judging steps to achieve the best result [153, 386, 387, 103] or perform sample-level selection among a group of candidates [233]. Additionally, there are also many work train LLM-based verifiers, leveraging the judge LLM as the process reward model (PRM) to evaluate each state [102, 234, 388, 389, 390]. Besides, there are also studies train critique-based LLM judges [391, 235, 392, 393, 394, 73] which provide fine-grained verbal feedback to boost the reasoning process.
C.4.2 Reasoning with External Source
Selecting an appropriate external source to use is essential in the success of agentic LLM systems [395, 396]. Auto-GPT [26] is the first to benchmark LLMs' performance in real-world decision-making scenarios. Following them, many other works adopt LLM-as-a-judge in various external tool selection applications, including autonomous driving [236], reasoning structure selection [397] and multi-modal area [107]. In addition to selecting among external tools or APIs, LLM-as-a-judge has also been widely adopted as a controller in multi-agent systems, to selectively activate agents for a given problem [108] or to assess and manage message flow among a group of agents [24, 106].
C.5 Definition of each LLM-as-a-judge Benchmark Category
We provide the definition of each LLM-as-a-judge benchmark in Table 2.
D. Taxonomy
E. Tuning Methods
\begin{tabular}{m{2.3cm} >{\arraybackslash}m{1.5cm} >{\arraybackslash}m{1.3cm} >{\arraybackslash}m{2.6cm} >{\arraybackslash}m{1.3cm} >{\arraybackslash}m{1.5cm} >{\arraybackslash}m{2.6cm} m{1.8cm}}
\toprule[1.2pt]
\multirow{2}{*}{\textbf{Method}} & \multicolumn{4}{c}{\textbf{Data}} & \multicolumn{2}{c}{\textbf{Tuning Method}} & \multirow{2}{*}{\textbf{Base LLM}} \\
\cmidrule(lr){2-5} \cmidrule(lr){6-7}
& \textbf{Source} & \textbf{Annotator} & \textbf{Type} & \textbf{Scale} & \textbf{Technique} & \textbf{Trick} & \textbf{} \\
\midrule
\rowcolor{gray!20} AttrScore [132] & Manual & Human & QA, NLI, Fact-Checking, Summarization & 63.8K & SFT & - & Multiple LLMs \\
PandaLM [128] & Manual & Human & Instruction Following & 300K & SFT & - & Multiple LLMs \\
\rowcolor{gray!20} AUTO-J [44] & Synthetic & GPT-4 & Real-world Scenarios & 4K & SFT & - & LLaMA-2 \\
JudgeLM [138] & Synthetic & GPT-4 & Instruction Following & 100K & SFT & - & Vicuna \\
\rowcolor{gray!20} Self-Judge [127] & Manual & Human & Preference Learning & 65/57K & SFT & JSFT & LLaMA-2 \\
X-EVAL [131] & Manual & Human & Dialogue, Summarization, Data-to-Text & 55K & SFT & Two-Stage Instruction Tuning & Flan-T5 \\
\rowcolor{gray!20} FLAMe [129] & Manual & Human & Various Tasks & 5M+ & SFT & Multi-task Training & PaLM-2 \\
InstructScore [130] & Manual\& Synthetic & Human\& GPT-4 & Various Tasks & 20K & SFT & Meta-Feedback & LLaMA \\
\rowcolor{gray!20} CritiqueLLM [133] & Manual & Human & Instruction Following, real-world scenarios & 5K & SFT & Prompt Simplify, Swapping Augmentation & ChatGLM3 \\
Meta-Rewarding [134] & Synthetic & LLaMA-3 & Preference Learning & 20K & Preference Learning & Meta-Rewarding & LLaMA-3 \\
\rowcolor{gray!20} Self-Taught Evaluator [135] & Synthetic & Mixtral & Various Tasks & 20K & Preference Learning & Self-Taught & LLaMA-3 \\
HALU-J [63] & Synthetic & GPT-4o & Fact Extraction & 2.6K & Preference Learning & DPO & Mistral \\
\rowcolor{gray!20} OffsetBias [29] & Synthetic & GPT-4, Claude3 & Preference Learning & 8.5K & SFT & Debiasing Augmentation & LLaMA-3 \\
SorryBench [37] & Synthetic & GPT-4 & Safety & 2.7K & SFT & - & Multiple LLMs \\
\rowcolor{gray!20} LLaVA-Critic [137] & Synthetic & GPT-4o & Preference Learning & 113K & Preference Learning & DPO & LLaVA-v.1.5 \\
PROME-THEUS2 [136] & Synthetic & GPT-4 & Preference Learning & 300K & SFT & Joint Training, Weight Merging & Mistral \\
\rowcolor{gray!20} Themis [147] & Manual \& Synthetic & Human \& GPT-4 & Various Tasks & 67K & Preference Learning & Multi-perspective Consistency Verification, Rating-oriented DPO & LLaMA-3 \\
\toprule[1.2pt]
\end{tabular}
F. Benchmark
\begin{tabular}{>{\arraybackslash}m{2.0cm}
>{\arraybackslash}m{2.2cm}
>{\arraybackslash}m{1.0cm}
>{\arraybackslash}m{1.5cm}
>{\arraybackslash}m{3.2cm}
>{\arraybackslash}m{3.8cm}
}
\toprule[1.2pt]
\textbf{Method} & \textbf{Data Type} & \textbf{Scale} & \textbf{Reference} & \textbf{Metrics} & \textbf{Purpose} \\
\midrule
MT-Bench [16] & Multi-turn Conversation & 80 & Human Expert & Consistency, Bias, Error & General Performance, Position/Verbosity/Self-enhancement Bias \\
\rowcolor{gray!20} Chatbot Arena [16] & Single-turn Conversation & 30K & User & Consistency, Bias, Error & General Performance, Position/Verbosity/Self-enhancement Bias \\
CodeJudge-Eval [257] & Code & 457 & Execution System & Accuracy, F1 & General Performance \\
\rowcolor{gray!20} JudgeBench [238] & Various Tasks & 70K & Human & Cohen’s kappa, Correlation & General Performance \\
SOS-BENCH [241] & Various Tasks & 152K & Human & Normalized Accuracy & General Performance \\
\rowcolor{gray!20} LLM-judge-eval [405] & Summarization, Alignment & 1K & Human & Accuracy, Flipping Noise, Position Bias, Length Bias & General Performance \\
DHP [239] & Various Tasks & 400 & Human & Discernment Score & General Performance \\
\rowcolor{gray!20} EvalBiasBench [29] & Alignment & 80 & Human & Accuracy & Various Bias \\
[256] & Various Tasks & 1.5K & Human & Separability, Agreement, BrierScore & Domain-specific Performance \\
\rowcolor{gray!20} MLLM-as-a-judge [85] & Various Tasks & 30K & Human & Human Agreement, Analysis Grading, Hallucination Detection & Multimodal \\
MM-EVAL [261] & Various Tasks & 5K & Human & Accuracy & Multilingual \\
\rowcolor{gray!20} KUDGE [262] & Question Answering & 3.3K & Human \& GPT-4o & Accuracy, Correlation & Non-English \& Challenging \\
[160] & Various Tasks & - & Human & Correlation & Evaluation Instruction Following \\
\rowcolor{gray!20} [406] & Question Answering & 400 & Human & Scott’s $\pi$, Percent Agreement & Vulnerability \\
Rewardbench [240] & Various Tasks & 20K & Human \& LLMs & Accuracy & General Performance \\
\rowcolor{gray!20} Arena-Hard Auto [250] & Alignment & 500 & GPT-4-Turbo & Separability, Agreement & Challenging \\
R-Judge [400] & Multi-turn Interaction & 569 & Human & F1, Recall, Spec, Effect & Safety \\
\rowcolor{gray!20} [254] & Alignment & 100K & Human & Repetition Stability, Position Consistency, Preference Fairness & Position Bias \\
CALM [253] & Various Tasks & 14K & Human & Robustness/Consistency Rate, 0riginal/ Hacked Accuracy & Bias Quantification \\
\rowcolor{gray!20} VL-RewardBench [407] & Various Tasks & 1.2K & Human \& LLMs & Overall Accuracy, Macro Average Accuracy & Multimodal \\
\toprule[1.2pt]
\end{tabular}
G. AI Assistants In Writing
We acknowledge the use of ChatGPT-4o in paper polishing, but not in any direct paper writing or relevant work collections.
References
Section Summary: This section compiles a list of academic papers, surveys, and technical reports focused on evaluating natural language generation systems and large language models. It features foundational metrics such as BLEU and ROUGE alongside newer approaches like BERTScore and methods that use AI models themselves as judges. The entries also address issues like bias in evaluations, survey recent advances, and include key reports on models such as GPT-4.
[1] Ananya B Sai, Akash Kumar Mohankumar, and Mitesh M Khapra. 2022. A survey of evaluation metrics used for nlg systems. ACM Computing Surveys (CSUR), 55(2):1–39.
[2] Yupeng Chang, Xu Wang, Jindong Wang, Yuan Wu, Linyi Yang, Kaijie Zhu, Hao Chen, Xiaoyuan Yi, Cunxiang Wang, Yidong Wang, and 1 others. 2024. A survey on evaluation of large language models. ACM Transactions on Intelligent Systems and Technology, 15(3):1–45.
[3] Zhen Tan, Kaize Ding, Ruocheng Guo, and Huan Liu. 2022. Supervised graph contrastive learning for few-shot node classification. In Joint European Conference on Machine Learning and Knowledge Discovery in Databases, pages 394–411. Springer.
[4] Pingzhi Li, Xiaolong Jin, Zhen Tan, Yu Cheng, and Tianlong Chen. 2024i. Quantmoe-bench: Examining post-training quantization for mixture-of-experts. arXiv preprint arXiv:2406.08155.
[5] Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. 2002. Bleu: a method for automatic evaluation of machine translation. In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, pages 311–318, Philadelphia, Pennsylvania, USA. Association for Computational Linguistics.
[6] Chin-Yew Lin. 2004. ROUGE: A package for automatic evaluation of summaries. In Text Summarization Branches Out, pages 74–81, Barcelona, Spain. Association for Computational Linguistics.
[7] Chia-Wei Liu, Ryan Lowe, Iulian Serban, Mike Noseworthy, Laurent Charlin, and Joelle Pineau. 2016. How NOT to evaluate your dialogue system: An empirical study of unsupervised evaluation metrics for dialogue response generation. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, pages 2122–2132, Austin, Texas. Association for Computational Linguistics.
[8] Ehud Reiter. 2018. A structured review of the validity of BLEU. Computational Linguistics, 44(3):393–401.
[9] Tianyi Zhang, Varsha Kishore, Felix Wu, Kilian Q. Weinberger, and Yoav Artzi. 2020. Bertscore: Evaluating text generation with BERT. In 8th International Conference on Learning Representations, ICLR 2020, Addis Ababa, Ethiopia, April 26-30, 2020. OpenReview.net.
[10] Weizhe Yuan, Graham Neubig, and Pengfei Liu. 2021. Bartscore: Evaluating generated text as text generation. In Advances in Neural Information Processing Systems 34: Annual Conference on Neural Information Processing Systems 2021, NeurIPS 2021, December 6-14, 2021, virtual, pages 27263–27277.
[11] Tianxiang Sun, Junliang He, Xipeng Qiu, and Xuan-Jing Huang. 2022. Bertscore is unfair: On social bias in language model-based metrics for text generation. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 3726–3739.
[12] Banghua Zhu, Evan Frick, Tianhao Wu, Hanlin Zhu, Karthik Ganesan, Wei-Lin Chiang, Jian Zhang, and Jiantao Jiao. 2024a. Starling-7b: Improving helpfulness and harmlessness with rlaif. In First Conference on Language Modeling.
[13] Chengshuai Zhao, Zhen Tan, Pingchuan Ma, Dawei Li, Bohan Jiang, Yancheng Wang, Yingzhen Yang, and Huan Liu. 2025a. Is chain-of-thought reasoning of llms a mirage? a data distribution lens. arXiv preprint arXiv:2508.01191.
[14] Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, and 1 others. 2023. Gpt-4 technical report. ArXiv preprint, abs/2303.08774.
[15] Aaron Jaech, Adam Kalai, Adam Lerer, Adam Richardson, Ahmed El-Kishky, Aiden Low, Alec Helyar, Aleksander Madry, Alex Beutel, Alex Carney, and 1 others. 2024. Openai o1 system card. arXiv preprint arXiv:2412.16720.
[16] Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P. Xing, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. 2023. Judging llm-as-a-judge with mt-bench and chatbot arena. In Advances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16, 2023.
[17] Jiaan Wang, Yunlong Liang, Fandong Meng, Zengkui Sun, Haoxiang Shi, Zhixu Li, Jinan Xu, Jianfeng Qu, and Jie Zhou. 2023c. Is chatgpt a good nlg evaluator? a preliminary study. In Proceedings of the 4th New Frontiers in Summarization Workshop, pages 1–11.
[18] Yang Liu, Dan Iter, Yichong Xu, Shuohang Wang, Ruochen Xu, and Chenguang Zhu. 2023b. G-eval: NLG evaluation using gpt-4 with better human alignment. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 2511–2522, Singapore. Association for Computational Linguistics.
[19] Cheng-Han Chiang and Hung-yi Lee. 2023b. A closer look into automatic evaluation using large language models. arXiv preprint arXiv:2310.05657.
[20] Ruosen Li, Teerth Patel, and Xinya Du. 2023b. Prd: Peer rank and discussion improve large language model based evaluations. ArXiv preprint, abs/2307.02762.
[21] Yushi Bai, Jiahao Ying, Yixin Cao, Xin Lv, Yuze He, Xiaozhi Wang, Jifan Yu, Kaisheng Zeng, Yijia Xiao, Haozhe Lyu, Jiayin Zhang, Juanzi Li, and Lei Hou. 2023a. Benchmarking foundation models with language-model-as-an-examiner. In Advances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16, 2023.
[22] Harrison Lee, Samrat Phatale, Hassan Mansoor, Thomas Mesnard, Johan Ferret, Kellie Lu, Colton Bishop, Ethan Hall, Victor Carbune, Abhinav Rastogi, and 1 others. 2023. Rlaif: Scaling reinforcement learning from human feedback with ai feedback. ArXiv preprint, abs/2309.00267.
[23] Dawei Li, Shu Yang, Zhen Tan, Jae Young Baik, Sunkwon Yun, Joseph Lee, Aaron Chacko, Bojian Hou, Duy Duong-Tran, Ying Ding, and 1 others. 2024c. Dalk: Dynamic co-augmentation of llms and kg to answer alzheimer's disease questions with scientific literature. ArXiv preprint, abs/2405.04819.
[24] Tian Liang, Zhiwei He, Wenxiang Jiao, Xing Wang, Yan Wang, Rui Wang, Yujiu Yang, Zhaopeng Tu, and Shuming Shi. 2023. Encouraging divergent thinking in large language models through multi-agent debate. ArXiv preprint, abs/2305.19118.
[25] Zhiqing Sun, Yikang Shen, Hongxin Zhang, Qinhong Zhou, Zhenfang Chen, David Daniel Cox, Yiming Yang, and Chuang Gan. 2024. Salmon: Self-alignment with instructable reward models. In The Twelfth International Conference on Learning Representations.
[26] Hui Yang, Sifu Yue, and Yunzhong He. 2023. Auto-gpt for online decision making: Benchmarks and additional opinions. ArXiv preprint, abs/2306.02224.
[27] Mingchen Zhuge, Changsheng Zhao, Dylan Ashley, Wenyi Wang, Dmitrii Khizbullin, Yunyang Xiong, Zechun Liu, Ernie Chang, Raghuraman Krishnamoorthi, Yuandong Tian, and 1 others. 2024. Agent-as-a-judge: Evaluate agents with agents. ArXiv preprint, abs/2410.10934.
[28] Ryan Koo, Minhwa Lee, Vipul Raheja, Jong Inn Park, Zae Myung Kim, and Dongyeop Kang. 2023. Benchmarking cognitive biases in large language models as evaluators. ArXiv preprint, abs/2309.17012.
[29] Junsoo Park, Seungyeon Jwa, Meiying Ren, Daeyoung Kim, and Sanghyuk Choi. 2024. Offsetbias: Leveraging debiased data for tuning evaluators. ArXiv preprint, abs/2407.06551.
[30] Jinlan Fu, See Kiong Ng, Zhengbao Jiang, and Pengfei Liu. 2024. Gptscore: Evaluate as you desire. In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 6556–6576.
[31] Hui Huang, Yingqi Qu, Hongli Zhou, Jing Liu, Muyun Yang, Bing Xu, and Tiejun Zhao. 2024a. On the limitations of fine-tuned judge models for llm evaluation. arXiv preprint arXiv:2403.02839.
[32] Mingqi Gao, Xinyu Hu, Jie Ruan, Xiao Pu, and Xiaojun Wan. 2024. Llm-based nlg evaluation: Current status and challenges. ArXiv preprint, abs/2402.01383.
[33] Zhen Li, Xiaohan Xu, Tao Shen, Can Xu, Jia-Chen Gu, Yuxuan Lai, Chongyang Tao, and Shuai Ma. 2024o. Leveraging large language models for nlg evaluation: Advances and challenges.
[34] Jiawei Gu, Xuhui Jiang, Zhichao Shi, Hexiang Tan, Xuehao Zhai, Chengjin Xu, Wei Li, Yinghan Shen, Shengjie Ma, Honghao Liu, and 1 others. 2024. A survey on llm-as-a-judge. arXiv preprint arXiv:2411.15594.
[35] Mingqi Gao, Jie Ruan, Renliang Sun, Xunjian Yin, Shiping Yang, and Xiaojun Wan. 2023. Human-like summarization evaluation with chatgpt. ArXiv preprint, abs/2304.02554.
[36] Dawei Li, Zhen Tan, and Huan Liu. 2024a. Exploring large language models for feature selection: A data-centric perspective. ArXiv preprint, abs/2408.12025.
[37] Tinghao Xie, Xiangyu Qi, Yi Zeng, Yangsibo Huang, Udari Madhushani Sehwag, Kaixuan Huang, Luxi He, Boyi Wei, Dacheng Li, Ying Sheng, and 1 others. 2024a. Sorry-bench: Systematically evaluating large language model safety refusal behaviors. ArXiv preprint, abs/2406.14598.
[38] Yinhong Liu, Han Zhou, Zhijiang Guo, Ehsan Shareghi, Ivan Vulić, Anna Korhonen, and Nigel Collier. 2024b. Aligning with human judgement: The role of pairwise preference in large language model evaluators. arXiv preprint arXiv:2403.16950.
[39] Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Tom Griffiths, Yuan Cao, and Karthik Narasimhan. 2023a. Tree of thoughts: Deliberate problem solving with large language models. In Advances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16, 2023.
[40] Yuntao Bai, Saurav Kadavath, Sandipan Kundu, Amanda Askell, Jackson Kernion, Andy Jones, Anna Chen, Anna Goldie, Azalia Mirhoseini, Cameron McKinnon, and 1 others. 2022. Constitutional ai: Harmlessness from ai feedback. ArXiv preprint, abs/2212.08073.
[41] Shangmin Guo, Biao Zhang, Tianlin Liu, Tianqi Liu, Misha Khalman, Felipe Llinares, Alexandre Rame, Thomas Mesnard, Yao Zhao, Bilal Piot, and 1 others. 2024. Direct language model alignment from online ai feedback. ArXiv preprint, abs/2402.04792.
[42] Xiaotian Zhang, Ruizhe Chen, Yang Feng, and Zuozhu Liu. 2025d. Persona-judge: Personalized alignment of large language models via token-level self-judgment. arXiv preprint arXiv:2504.12663.
[43] Bill Yuchen Lin, Abhilasha Ravichander, Ximing Lu, Nouha Dziri, Melanie Sclar, Khyathi Chandu, Chandra Bhagavatula, and Yejin Choi. 2023. The unlocking spell on base llms: Rethinking alignment via in-context learning. In The Twelfth International Conference on Learning Representations.
[44] Junlong Li, Shichao Sun, Weizhe Yuan, Run-Ze Fan, hai zhao, and Pengfei Liu. 2024e. Generative judge for evaluating alignment. In The Twelfth International Conference on Learning Representations.
[45] Bang Zhang, Ruotian Ma, Qingxuan Jiang, Peisong Wang, Jiaqi Chen, Zheng Xie, Xingyu Chen, Yue Wang, Fanghua Ye, Jian Li, and 1 others. 2025a. Sentient agent as a judge: Evaluating higher-order social cognition in large language models. arXiv preprint arXiv:2505.02847.
[46] Mansi Phute, Alec Helbling, Matthew Daniel Hull, ShengYun Peng, Sebastian Szyller, Cory Cornelius, and Duen Horng Chau. 2023. Llm self defense: By self examination, llms know they are being tricked. In The Second Tiny Papers Track at ICLR 2024.
[47] Yuhui Li, Fangyun Wei, Jinjing Zhao, Chao Zhang, and Hongyang Zhang. Rain: Your language models can align themselves without finetuning. In The Twelfth International Conference on Learning Representations.
[48] Seonghyeon Ye, Doyoung Kim, Sungdong Kim, Hyeonbin Hwang, Seungone Kim, Yongrae Jo, James Thorne, Juho Kim, and Minjoon Seo. 2024b. FLASK: Fine-grained language model evaluation based on alignment skill sets. In ICLR 2024 Workshop on Large Language Model (LLM) Agents.
[49] Yuxia Wang, Haonan Li, Xudong Han, Preslav Nakov, and Timothy Baldwin. 2024l. Do-not-answer: Evaluating safeguards in LLMs. In Findings of the Association for Computational Linguistics: EACL 2024, pages 896–911, St. Julian's, Malta. Association for Computational Linguistics.
[50] Francisco Eiras, Eliott Zemour, Eric Lin, and Vaikkunth Mugunthan. 2025. Know thy judge: On the robustness meta-evaluation of llm safety judges. arXiv preprint arXiv:2503.04474.
[51] Hongyu Chen and Seraphina Goldfarb-Tarrant. 2025. Safer or luckier? llms as safety evaluators are not robust to artifacts. arXiv preprint arXiv:2503.09347.
[52] David Rodriguez, William Seymour, Jose M Del Alamo, and Jose Such. 2025. Towards safer chatbots: A framework for policy compliance evaluation of custom gpts. arXiv preprint arXiv:2502.01436.
[53] Amey Hengle, Aswini Kumar, Anil Bandhakavi, and Tanmoy Chakraborty. 2025. Cseval: Towards automated, multi-dimensional, and reference-free counterspeech evaluation using auto-calibrated llms. arXiv preprint arXiv:2501.17581.
[54] Hakan Inan, Kartikeya Upasani, Jianfeng Chi, Rashi Rungta, Krithika Iyer, Yuning Mao, Michael Tontchev, Qing Hu, Brian Fuller, Davide Testuggine, and 1 others. 2023. Llama guard: Llm-based input-output safeguard for human-ai conversations. ArXiv preprint, abs/2312.06674.
[55] Qiyuan Zhang, Yufei Wang, Tiezheng Yu, Yuxin Jiang, Chuhan Wu, Liangyou Li, Yasheng Wang, Xin Jiang, Lifeng Shang, Ruiming Tang, and 1 others. 2024f. Reviseval: Improving llm-as-a-judge via response-adapted references. ArXiv preprint, abs/2410.05193.
[56] Riccardo Cantini, Alessio Orsino, Massimo Ruggiero, and Domenico Talia. 2025. Benchmarking adversarial robustness to bias elicitation in large language models: Scalable automated assessment with llm-as-a-judge. arXiv preprint arXiv:2504.07887.
[57] Wenhan Mu, Ling Xu, Shuren Pei, Le Mi, and Huichi Zhou. 2025. Evaluate-and-purify: Fortifying code language models against adversarial attacks using llm-as-a-judge. arXiv preprint arXiv:2504.19730.
[58] Stuart Armstrong, Matija Franklin, Connor Stevens, and Rebecca Gorman. 2025. Defense against the dark prompts: Mitigating best-of-n jailbreaking with prompt evaluation. arXiv preprint arXiv:2502.00580.
[59] Qinyuan Cheng, Tianxiang Sun, Wenwei Zhang, Siyin Wang, Xiangyang Liu, Mozhi Zhang, Junliang He, Mianqiu Huang, Zhangyue Yin, Kai Chen, and 1 others. 2023. Evaluating hallucinations in chinese large language models. ArXiv preprint, abs/2310.03368.
[60] Zorik Gekhman, Jonathan Herzig, Roee Aharoni, Chen Elkind, and Idan Szpektor. 2023. Trueteacher: Learning factual consistency evaluation with large language models. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 2053–2070.
[61] Wen Luo, Tianshu Shen, Wei Li, Guangyue Peng, Richeng Xuan, Houfeng Wang, and Xi Yang. 2024a. Halludial: A large-scale benchmark for automatic dialogue-level hallucination evaluation. ArXiv preprint, abs/2406.07070.
[62] Aliyah R Hsu, James Zhu, Zhichao Wang, Bin Bi, Shubham Mehrotra, Shiva K Pentyala, Katherine Tan, Xiang-Bo Mao, Roshanak Omrani, Sougata Chaudhuri, and 1 others. 2024. Rate, explain and cite (rec): Enhanced explanation and attribution in automatic evaluation by large language models. arXiv preprint arXiv:2411.02448.
[63] Binjie Wang, Steffi Chern, Ethan Chern, and Pengfei Liu. 2024a. Halu-j: Critique-based hallucination judge. ArXiv preprint, abs/2407.12943.
[64] Haochen Tan, Zhijiang Guo, Zhan Shi, Lu Xu, Zhili Liu, Yunlong Feng, Xiaoguang Li, Yasheng Wang, Lifeng Shang, Qun Liu, and 1 others. 2024a. Proxyqa: An alternative framework for evaluating long-form text generation with large language models. arXiv preprint arXiv:2401.15042.
[65] Yushi Bai, Shangqing Tu, Jiajie Zhang, Hao Peng, Xiaozhi Wang, Xin Lv, Shulin Cao, Jiazheng Xu, Lei Hou, Yuxiao Dong, and 1 others. 2024. Longbench v2: Towards deeper understanding and reasoning on realistic long-context multitasks. arXiv preprint arXiv:2412.15204.
[66] Siwei Wu, Yizhi Li, Xingwei Qu, Rishi Ravikumar, Yucheng Li, Tyler Loakman, Shanghaoran Quan, Xiaoyong Wei, Riza Batista-Navarro, and Chenghua Lin. 2025. Longeval: A comprehensive analysis of long-text generation through a plan-based paradigm. arXiv preprint arXiv:2502.19103.
[67] Sewon Min, Kalpesh Krishna, Xinxi Lyu, Mike Lewis, Wen-tau Yih, Pang Koh, Mohit Iyyer, Luke Zettlemoyer, and Hannaneh Hajishirzi. 2023. FActScore: Fine-grained atomic evaluation of factual precision in long form text generation. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 12076–12100, Singapore. Association for Computational Linguistics.
[68] Meng Cao, Pengfei Hu, Yingyao Wang, Jihao Gu, Haoran Tang, Haoze Zhao, Jiahua Dong, Wangbo Yu, Ge Zhang, Ian Reid, and 1 others. 2025b. Video simpleqa: Towards factuality evaluation in large video language models. arXiv preprint arXiv:2503.18923.
[69] Edoardo Loru, Jacopo Nudo, Niccolò Di Marco, Matteo Cinelli, and Walter Quattrociocchi. 2025. Decoding ai judgment: How llms assess news credibility and bias. arXiv preprint arXiv:2502.04426.
[70] Jerry Wei, Chengrun Yang, Xinying Song, Yifeng Lu, Nathan Hu, Dustin Tran, Daiyi Peng, Ruibo Liu, Da Huang, Cosmo Du, and 1 others. 2024b. Long-form factuality in large language models. ArXiv preprint, abs/2403.18802.
[71] Liqiang Jing, Ruosen Li, Yunmo Chen, and Xinya Du. 2024. Faithscore: Fine-grained evaluations of hallucinations in large vision-language models. In Findings of the Association for Computational Linguistics: EMNLP 2024, pages 5042–5063.
[72] Shu Pu, Yaochen Wang, Dongping Chen, Yuhang Chen, Guohao Wang, Qi Qin, Zhongyi Zhang, Zhiyuan Zhang, Zetong Zhou, Shuang Gong, and 1 others. 2025. Judge anything: Mllm as a judge across any modality. arXiv preprint arXiv:2503.17489.
[73] Yiqing Xie, Wenxuan Zhou, Pradyot Prakash, Di Jin, Yuning Mao, Quintin Fettes, Arya Talebzadeh, Sinong Wang, Han Fang, Carolyn Rose, and 1 others. 2024b. Improving model factuality with fine-grained critique-based evaluator. arXiv preprint arXiv:2410.18359.
[74] Xiaoying Zhang, Baolin Peng, Ye Tian, Jingyan Zhou, Lifeng Jin, Linfeng Song, Haitao Mi, and Helen Meng. 2024g. Self-alignment for factuality: Mitigating hallucinations in llms via self-evaluation. ArXiv preprint, abs/2402.09267.
[75] Xueru Wen, Xinyu Lu, Xinyan Guan, Yaojie Lu, Hongyu Lin, Ben He, Xianpei Han, and Le Sun. 2024. On-policy fine-grained knowledge feedback for hallucination mitigation. arXiv preprint arXiv:2406.12221.
[76] Tianyang Xu, Shujin Wu, Shizhe Diao, Xiaoze Liu, Xingyao Wang, Yangyi Chen, and Jing Gao. 2024d. Sayself: Teaching llms to express confidence with self-reflective rationales. ArXiv preprint, abs/2405.20974.
[77] Cheng-Han Chiang and Hung-yi Lee. 2023a. Can large language models be an alternative to human evaluations?In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 15607–15631, Toronto, Canada. Association for Computational Linguistics.
[78] Negar Arabzadeh and Charles LA Clarke. 2025a. Benchmarking llm-based relevance judgment methods. arXiv preprint arXiv:2504.12558.
[79] Yen-Ting Lin and Yun-Nung Chen. 2023a. LLM-eval: Unified multi-dimensional automatic evaluation for open-domain conversations with large language models. In Proceedings of the 5th Workshop on NLP for Conversational AI (NLP4ConvAI 2023), pages 47–58, Toronto, Canada. Association for Computational Linguistics.
[80] Zahra Abbasiantaeb, Chuan Meng, Leif Azzopardi, and Mohammad Aliannejadi. 2024. Can we use large language models to fill relevance judgment holes?ArXiv preprint, abs/2405.05600.
[81] Xiaonan Li and Xipeng Qiu. 2023a. MoT: Memory-of-thought enables ChatGPT to self-improve. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 6354–6374, Singapore. Association for Computational Linguistics.
[82] Yebin Lee, Imseong Park, and Myungjoo Kang. 2024b. Fleur: An explainable reference-free evaluation metric for image captioning using a large multimodal model. arXiv preprint arXiv:2406.06004.
[83] Zhaorun Chen, Yichao Du, Zichen Wen, Yiyang Zhou, Chenhang Cui, Zhenzhen Weng, Haoqin Tu, Chaoqi Wang, Zhengwei Tong, Qinglan Huang, and 1 others. 2024g. Mj-bench: Is your multimodal reward model really a good judge for text-to-image generation?ArXiv preprint, abs/2407.04842.
[84] Jheng-Hong Yang and Jimmy Lin. 2024. Toward automatic relevance judgment using vision–language models for image–text retrieval evaluation. ArXiv preprint, abs/2408.01363.
[85] Dongping Chen, Ruoxi Chen, Shilin Zhang, Yaochen Wang, Yinuo Liu, Huichi Zhou, Qihui Zhang, Yao Wan, Pan Zhou, and Lichao Sun. 2024a. MLLM-as-a-judge: Assessing multimodal LLM-as-a-judge with vision-language benchmark. In Forty-first International Conference on Machine Learning.
[86] Yujie Lu, Xianjun Yang, Xiujun Li, Xin Eric Wang, and William Yang Wang. 2024b. Llmscore: Unveiling the power of large language models in text-to-image synthesis evaluation. Advances in Neural Information Processing Systems, 36.
[87] Ziyang Luo, Haoning Wu, Dongxu Li, Jing Ma, Mohan Kankanhalli, and Junnan Li. 2024b. Videoautoarena: An automated arena for evaluating large multimodal models in video analysis through user simulation. arXiv preprint arXiv:2411.13281.
[88] Zhiqiu Lin, Deepak Pathak, Baiqi Li, Jiayao Li, Xide Xia, Graham Neubig, Pengchuan Zhang, and Deva Ramanan. 2025. Evaluating text-to-visual generation with image-to-text generation. In European Conference on Computer Vision, pages 366–384. Springer.
[89] Fuheng Zhao, Lawrence Lim, Ishtiyaque Ahmad, Divyakant Agrawal, and Amr El Abbadi. 2023a. Llm-sql-solver: Can llms determine sql equivalence? arXiv preprint arXiv:2312.10321.
[90] Marwah Alaofi, Negar Arabzadeh, Charles LA Clarke, and Mark Sanderson. 2024. Generative information retrieval evaluation. In Information Access in the Era of Generative AI, pages 135–159. Springer.
[91] Laura Dietz, Oleg Zendel, Peter Bailey, Charles Clarke, Ellese Cotterill, Jeff Dalton, Faegheh Hasibi, Mark Sanderson, and Nick Craswell. 2025. Llm-evaluation tropes: Perspectives on the validity of llm-evaluations. arXiv preprint arXiv:2504.19076.
[92] Negar Arabzadeh and Charles LA Clarke. 2025b. A human-ai comparative analysis of prompt sensitivity in llm-based relevance judgment. arXiv preprint arXiv:2504.12408.
[93] Krisztian Balog, Donald Metzler, and Zhen Qin. 2025. Rankers, judges, and assistants: Towards understanding the interplay of llms in information retrieval evaluation. arXiv preprint arXiv:2503.19092.
[94] Paul Thomas, Seth Spielman, Nick Craswell, and Bhaskar Mitra. 2024. Large language models can accurately predict searcher preferences. In Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 1930–1940.
[95] Ratan J Sebastian and Anett Hoppe. 2025. Validating llm-generated relevance labels for educational resource search. arXiv preprint arXiv:2504.12732.
[96] Shengjie Ma, Chong Chen, Qi Chu, and Jiaxin Mao. 2024. Leveraging large language models for relevance judgments in legal case retrieval. ArXiv preprint, abs/2403.18405.
[97] Soumik Dey, Hansi Wu, and Binbin Li. 2025. To judge or not to judge: Using llm judgements for advertiser keyphrase relevance at ebay. arXiv preprint arXiv:2505.04209.
[98] Yupeng Hou, Junjie Zhang, Zihan Lin, Hongyu Lu, Ruobing Xie, Julian McAuley, and Wayne Xin Zhao. 2024. Large language models are zero-shot rankers for recommender systems. In European Conference on Information Retrieval, pages 364–381.
[99] Xiaoyu Zhang, Yishan Li, Jiayin Wang, Bowen Sun, Weizhi Ma, Peijie Sun, and Min Zhang. 2024h. Large language models as evaluators for recommendation explanations. In Proceedings of the 18th ACM Conference on Recommender Systems, pages 33–42.
[100] Jiaxin Huang, Shixiang Gu, Le Hou, Yuexin Wu, Xuezhi Wang, Hongkun Yu, and Jiawei Han. 2023a. Large language models can self-improve. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 1051–1068, Singapore. Association for Computational Linguistics.
[101] Lifan Yuan, Ganqu Cui, Hanbin Wang, Ning Ding, Xingyao Wang, Jia Deng, Boji Shan, Huimin Chen, Ruobing Xie, Yankai Lin, and 1 others. Advancing llm reasoning generalists with preference trees. In AI for Math Workshop@ ICML 2024.
[102] Hunter Lightman, Vineet Kosaraju, Yuri Burda, Harrison Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let's verify step by step. In The Twelfth International Conference on Learning Representations.
[103] Akira Kawabata and Saku Sugawara. 2024. Rationale-aware answer verification by pairwise self-evaluation. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 16178–16196.
[104] Shibo Hao, Yi Gu, Haodi Ma, Joshua Hong, Zhen Wang, Daisy Wang, and Zhiting Hu. 2023. Reasoning with language model is planning with world model. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 8154–8173, Singapore. Association for Computational Linguistics.
[105] Maciej Besta, Nils Blach, Ales Kubicek, Robert Gerstenberger, Michal Podstawski, Lukas Gianinazzi, Joanna Gajda, Tomasz Lehmann, Hubert Niewiadomski, Piotr Nyczyk, and Torsten Hoefler. 2024. Graph of thoughts: Solving elaborate problems with large language models. In Thirty-Eighth AAAI Conference on Artificial Intelligence, AAAI 2024, Thirty-Sixth Conference on Innovative Applications of Artificial Intelligence, IAAI 2024, Fourteenth Symposium on Educational Advances in Artificial Intelligence, EAAI 2014, February 20-27, 2024, Vancouver, Canada, pages 17682–17690. AAAI Press.
[106] Dawei Li, Zhen Tan, Peijia Qian, Yifan Li, Kumar Satvik Chaudhary, Lijie Hu, and Jiayi Shen. 2024b. Smoa: Improving multi-agent large language models with sparse mixture-of-agents. ArXiv preprint, abs/2411.03284.
[107] Lirui Zhao, Yue Yang, Kaipeng Zhang, Wenqi Shao, Yuxin Zhang, Yu Qiao, Ping Luo, and Rongrong Ji. 2024b. Diffagent: Fast and accurate text-to-image api selection with large language model. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6390–6399.
[108] Isaac Ong, Amjad Almahairi, Vincent Wu, Wei-Lin Chiang, Tianhao Wu, Joseph E Gonzalez, M Waleed Kadous, and Ion Stoica. 2024. Routellm: Learning to route llms with preference data. ArXiv preprint, abs/2406.18665.
[109] Zhuohao Yu, Chang Gao, Wenjin Yao, Yidong Wang, Wei Ye, Jindong Wang, Xing Xie, Yue Zhang, and Shikun Zhang. 2024c. Kieval: A knowledge-grounded interactive evaluation framework for large language models. ArXiv preprint, abs/2402.15043.
[110] Yi-Fan Lu, Xian-Ling Mao, Tian Lan, Heyan Huang, Chen Xu, and Xiaoyan Gao. 2024a. Beyond exact match: Semantically reassessing event extraction by large language models. arXiv preprint arXiv:2410.09418.
[111] Pengcheng Jiang, Jiacheng Lin, Zifeng Wang, Jimeng Sun, and Jiawei Han. 2024. Genres: Rethinking evaluation for generative relation extraction in the era of large language models. In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 2820–2837.
[112] Xanh Ho, Jiahao Huang, Florian Boudin, and Akiko Aizawa. 2025. Llm-as-a-judge: Reassessing the performance of llms in extractive qa. arXiv preprint arXiv:2504.11972.
[113] Takumi Shibata and Yuichi Miyamura. 2025. Lces: Zero-shot automated essay scoring via pairwise comparisons using large language models. arXiv preprint arXiv:2505.08498.
[114] Ivan Kartáč, Mateusz Lango, and Ondřej Dušek. 2025. Openlgauge: An explainable metric for nlg evaluation with open-weights llms. arXiv preprint arXiv:2503.11858.
[115] Sameer Jain, Vaishakh Keshava, Swarnashree Mysore Sathyendra, Patrick Fernandes, Pengfei Liu, Graham Neubig, and Chunting Zhou. 2023a. Multi-dimensional evaluation of text summarization with in-context learning. In Findings of the Association for Computational Linguistics: ACL 2023, pages 8487–8495, Toronto, Canada. Association for Computational Linguistics.
[116] Yi Chen, Rui Wang, Haiyun Jiang, Shuming Shi, and Ruifeng Xu. 2023. Exploring the use of large language models for reference-free text quality evaluation: An empirical study. In Findings of the Association for Computational Linguistics: IJCNLP-AACL 2023 (Findings), pages 361–374.
[117] Abhishek Kumar, Sonia Haiduc, Partha Pratim Das, and Partha Pratim Chakrabarti. 2024a. Llms as evaluators: A novel approach to evaluate bug report summarization. arXiv preprint arXiv:2409.00630.
[118] Siya Qi, Rui Cao, Yulan He, and Zheng Yuan. 2025. Evaluating llms' assessment of mixed-context hallucination through the lens of summarization. arXiv preprint arXiv:2503.01670.
[119] Jeremy Barnes, Naiara Perez, Alba Bonet-Jover, and Begoña Altuna. 2025. Summarization metrics for spanish and basque: Do automatic scores and llm-judges correlate with humans? arXiv preprint arXiv:2503.17039.
[120] Moritz Altemeyer, Steffen Eger, Johannes Daxenberger, Tim Altendorf, Philipp Cimiano, and Benjamin Schiller. 2025. Argument summarization and its evaluation in the era of large language models. arXiv preprint arXiv:2503.00847.
[121] Yeonseok Jeong, Minsoo Kim, Seung-won Hwang, and Byung-Hak Kim. 2025. Agent-as-judge for factual summarization of long narratives. arXiv preprint arXiv:2501.09993.
[122] Nitay Calderon, Roi Reichart, and Rotem Dror. 2025. The alternative annotator test for llm-as-a-judge: How to statistically justify replacing human annotators with llms. arXiv preprint arXiv:2501.10970.
[123] Tom Kocmi and Christian Federmann. 2023. Large language models are state-of-the-art evaluators of translation quality. In Proceedings of the 24th Annual Conference of the European Association for Machine Translation, pages 193–203, Tampere, Finland. European Association for Machine Translation.
[124] Xu Huang, Zhirui Zhang, Xiang Geng, Yichao Du, Jiajun Chen, and Shujian Huang. 2024b. Lost in the source language: How large language models evaluate the quality of machine translation. In Annual Meeting of the Association for Computational Linguistics.
[125] Andrea Piergentili, Beatrice Savoldi, Matteo Negri, and Luisa Bentivogli. 2025. An llm-as-a-judge approach for scalable gender-neutral translation evaluation. arXiv preprint arXiv:2504.11934.
[126] Xiao Wang, Daniil Larionov, Siwei Wu, Yiqi Liu, Steffen Eger, Nafise Sadat Moosavi, and Chenghua Lin. 2025d. Contrastscore: Towards higher quality, less biased, more efficient evaluation metrics with contrastive evaluation. arXiv preprint arXiv:2504.02106.
[127] Sangkyu Lee, Sungdong Kim, Ashkan Yousefpour, Minjoon Seo, Kang Min Yoo, and Youngjae Yu. 2024a. Aligning large language models by on-policy self-judgment. ArXiv preprint, abs/2402.11253.
[128] Yidong Wang, Zhuohao Yu, Wenjin Yao, Zhengran Zeng, Linyi Yang, Cunxiang Wang, Hao Chen, Chaoya Jiang, Rui Xie, Jindong Wang, Xing Xie, Wei Ye, Shikun Zhang, and Yue Zhang. 2024k. PandaLM: An automatic evaluation benchmark for LLM instruction tuning optimization. In The Twelfth International Conference on Learning Representations.
[129] Tu Vu, Kalpesh Krishna, Salaheddin Alzubi, Chris Tar, Manaal Faruqui, and Yun-Hsuan Sung. 2024. Foundational autoraters: Taming large language models for better automatic evaluation. ArXiv preprint, abs/2407.10817.
[130] Wenda Xu, Danqing Wang, Liangming Pan, Zhenqiao Song, Markus Freitag, William Wang, and Lei Li. 2023a. INSTRUCTSCORE: Towards explainable text generation evaluation with automatic feedback. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 5967–5994, Singapore. Association for Computational Linguistics.
[131] Minqian Liu, Ying Shen, Zhiyang Xu, Yixin Cao, Eunah Cho, Vaibhav Kumar, Reza Ghanadan, and Lifu Huang. 2024a. X-eval: Generalizable multi-aspect text evaluation via augmented instruction tuning with auxiliary evaluation aspects. In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 8560–8579, Mexico City, Mexico. Association for Computational Linguistics.
[132] Xiang Yue, Boshi Wang, Ziru Chen, Kai Zhang, Yu Su, and Huan Sun. 2023. Automatic evaluation of attribution by large language models. In Findings of the Association for Computational Linguistics: EMNLP 2023, pages 4615–4635, Singapore. Association for Computational Linguistics.
[133] Pei Ke, Bosi Wen, Andrew Feng, Xiao Liu, Xuanyu Lei, Jiale Cheng, Shengyuan Wang, Aohan Zeng, Yuxiao Dong, Hongning Wang, and 1 others. 2024. Critiquellm: Towards an informative critique generation model for evaluation of large language model generation. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 13034–13054.
[134] Tianhao Wu, Weizhe Yuan, Olga Golovneva, Jing Xu, Yuandong Tian, Jiantao Jiao, Jason Weston, and Sainbayar Sukhbaatar. 2024a. Meta-rewarding language models: Self-improving alignment with llm-as-a-meta-judge. ArXiv preprint, abs/2407.19594.
[135] Tianlu Wang, Ilia Kulikov, Olga Golovneva, Ping Yu, Weizhe Yuan, Jane Dwivedi-Yu, Richard Yuanzhe Pang, Maryam Fazel-Zarandi, Jason Weston, and Xian Li. 2024h. Self-taught evaluators. ArXiv preprint, abs/2408.02666.
[136] Seungone Kim, Juyoung Suk, Shayne Longpre, Bill Yuchen Lin, Jamin Shin, Sean Welleck, Graham Neubig, Moontae Lee, Kyungjae Lee, and Minjoon Seo. 2024b. Prometheus 2: An open source language model specialized in evaluating other language models. ArXiv preprint, abs/2405.01535.
[137] Tianyi Xiong, Xiyao Wang, Dong Guo, Qinghao Ye, Haoqi Fan, Quanquan Gu, Heng Huang, and Chunyuan Li. 2024. Llava-critic: Learning to evaluate multimodal models. ArXiv preprint, abs/2410.02712.
[138] Lianghui Zhu, Xinggang Wang, and Xinlong Wang. 2023. Judgelm: Fine-tuned large language models are scalable judges. ArXiv preprint, abs/2310.17631.
[139] Renjun Hu, Yi Cheng, Libin Meng, Jiaxin Xia, Yi Zong, Xing Shi, and Wei Lin. 2025a. Training an llm-as-a-judge model: Pipeline, insights, and practical lessons. arXiv preprint arXiv:2502.02988.
[140] Danqing Wang, Kevin Yang, Hanlin Zhu, Xiaomeng Yang, Andrew Cohen, Lei Li, and Yuandong Tian. 2023b. Learning personalized story evaluation. ArXiv preprint, abs/2310.03304.
[141] José Pombal, Dongkeun Yoon, Patrick Fernandes, Ian Wu, Seungone Kim, Ricardo Rei, Graham Neubig, and André FT Martins. 2025b. M-prometheus: A suite of open multilingual llm judges. arXiv preprint arXiv:2504.04953.
[142] David Salinas, Omar Swelam, and Frank Hutter. 2025. Tuning llm judge design decisions for 1/1000 of the cost. arXiv e-prints, pages arXiv–2501.
[143] Cheng-Han Chiang, Hung-yi Lee, and Michal Lukasik. 2025. Tract: Regression-aware fine-tuning meets chain-of-thought reasoning for llm-as-a-judge. arXiv preprint arXiv:2503.04381.
[144] Jon Saad-Falcon, Rajan Vivek, William Berrios, Nandita Shankar Naik, Matija Franklin, Bertie Vidgen, Amanpreet Singh, Douwe Kiela, and Shikib Mehri. 2024b. Lmunit: Fine-grained evaluation with natural language unit tests. arXiv preprint arXiv:2412.13091.
[145] Jiachen Yu, Shaoning Sun, Xiaohui Hu, Jiaxu Yan, Kaidong Yu, and Xuelong Li. 2025. Improve llm-as-a-judge ability as a general ability. arXiv preprint arXiv:2502.11689.
[146] Melissa Kazemi Rad, Huy Nghiem, Andy Luo, Sahil Wadhwa, Mohammad Sorower, and Stephen Rawls. 2025. Refining input guardrails: Enhancing llm-as-a-judge efficiency through chain-of-thought fine-tuning and alignment. arXiv preprint arXiv:2501.13080.
[147] Xinyu Hu, Li Lin, Mingqi Gao, Xunjian Yin, and Xiaojun Wan. 2024b. Themis: A reference-free nlg evaluation language model with flexibility and interpretability. ArXiv preprint, abs/2406.18365.
[148] Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, and 1 others. 2025. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning. arXiv preprint arXiv:2501.12948.
[149] Swarnadeep Saha, Xian Li, Marjan Ghazvininejad, Jason Weston, and Tianlu Wang. 2025. Learning to plan & reason for evaluation with thinking-llm-as-a-judge. arXiv preprint arXiv:2501.18099.
[150] Zijun Liu, Peiyi Wang, Runxin Xu, Shirong Ma, Chong Ruan, Peng Li, Yang Liu, and Yu Wu. 2025e. Inference-time scaling for generalist reward modeling. arXiv preprint arXiv:2504.02495.
[151] Yilun Zhou, Austin Xu, Peifeng Wang, Caiming Xiong, and Shafiq Joty. 2025. Evaluating judges as evaluators: The jetts benchmark of llm-as-judges as test-time scaling evaluators. arXiv preprint arXiv:2504.15253.
[152] Peiyi Wang, Lei Li, Liang Chen, Zefan Cai, Dawei Zhu, Binghuai Lin, Yunbo Cao, Qi Liu, Tianyu Liu, and Zhifang Sui. 2023d. Large language models are not fair evaluators. ArXiv preprint, abs/2305.17926.
[153] Preethi Lahoti, Nicholas Blumm, Xiao Ma, Raghavendra Kotikalapudi, Sahitya Potluri, Qijun Tan, Hansa Srinivasan, Ben Packer, Ahmad Beirami, Alex Beutel, and Jilin Chen. 2023. Improving diversity of demographic representation in large language models via collective-critiques and self-voting. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 10383–10405, Singapore. Association for Computational Linguistics.
[154] Shenbin Qian, Archchana Sindhujan, Minnie Kabra, Diptesh Kanojia, Constantin Orašan, Tharindu Ranasinghe, and Fred Blain. 2024. What do large language models need for machine translation evaluation? In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 3660–3674.
[155] Yijiang River Dong, Tiancheng Hu, and Nigel Collier. 2024. Can llm be a personalized judge?ArXiv preprint, abs/2406.11657.
[156] Tianjun Wei, Wei Wen, Ruizhi Qiao, Xing Sun, and Jianghong Ma. 2025. Rocketeval: Efficient automated llm evaluation via grading checklist. arXiv preprint arXiv:2503.05142.
[157] Wenwen Xie, Gray Gwizdz, and Dongji Feng. 2025b. Prompting a weighting mechanism into llm-as-a-judge in two-step: A case study. arXiv preprint arXiv:2502.13396.
[158] Seungone Kim, Jamin Shin, Yejin Cho, Joel Jang, Shayne Longpre, Hwaran Lee, Sangdoo Yun, Seongjin Shin, Sungdong Kim, James Thorne, and 1 others. Prometheus: Inducing fine-grained evaluation capability in language models. In The Twelfth International Conference on Learning Representations.
[159] Song Wang, Peng Wang, Tong Zhou, Yushun Dong, Zhen Tan, and Jundong Li. 2024g. Ceb: Compositional evaluation benchmark for fairness in large language models. ArXiv preprint, abs/2407.02408.
[160] Bhuvanashree Murugadoss, Christian Poelitz, Ian Drosos, Vu Le, Nick McKenna, Carina Suzana Negreanu, Chris Parnin, and Advait Sarkar. 2024. Evaluating the evaluator: Measuring llms' adherence to task evaluation instructions. ArXiv preprint, abs/2408.08781.
[161] Xiaomin Li, Mingye Gao, Zhiwei Zhang, Chang Yue, and Hong Hu. 2024m. Rule-based data selection for large language models. arXiv preprint arXiv:2410.04715.
[162] Minzhi Li, Zhengyuan Liu, Shumin Deng, Shafiq Joty, Nancy F Chen, and Min-Yen Kan. 2024h. Decompose and aggregate: A step-by-step interpretable evaluation framework. arXiv preprint arXiv:2405.15329.
[163] Xinyu Hu, Mingqi Gao, Sen Hu, Yang Zhang, Yicheng Chen, Teng Xu, and Xiaojun Wan. 2024a. Are llm-based evaluators confusing nlg quality criteria? arXiv preprint arXiv:2402.12055.
[164] Yuxuan Liu, Tianchi Yang, Shaohan Huang, Zihan Zhang, Haizhen Huang, Furu Wei, Weiwei Deng, Feng Sun, and Qi Zhang. 2024d. Hd-eval: Aligning large language model evaluators through hierarchical criteria decomposition. arXiv preprint arXiv:2402.15754.
[165] Mingxuan Li, Hanchen Li, and Chenhao Tan. 2025b. Hypoeval: Hypothesis-guided evaluation for natural language generation. arXiv preprint arXiv:2504.07174.
[166] Zhiyuan Fan, Weinong Wang, Xing Wu, and Debing Zhang. 2025. Sedareval: Automated evaluation using self-adaptive rubrics. arXiv preprint arXiv:2501.15595.
[167] Alimohammad Beigi, Bohan Jiang, Dawei Li, Tharindu Kumarage, Zhen Tan, Pouya Shaeri, and Huan Liu. 2024. Lrq-fact: Llm-generated relevant questions for multimodal fact-checking. ArXiv preprint, abs/2410.04616.
[168] Lijie Hu, Chenyang Ren, Zhengyu Hu, Hongbin Lin, Cheng-Long Wang, Zhen Tan, Weimin Lyu, Jingfeng Zhang, Hui Xiong, and Di Wang. Editable concept bottleneck models. In Forty-second International Conference on Machine Learning.
[169] Yuxuan Liu, Tianchi Yang, Shaohan Huang, Zihan Zhang, Haizhen Huang, Furu Wei, Weiwei Deng, Feng Sun, and Qi Zhang. 2024c. Calibrating LLM-based evaluator. In Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024), pages 2638–2656, Torino, Italia. ELRA and ICCL.
[170] Kaishuai Xu, Tiezheng Yu, Wenjun Hou, Yi Cheng, Liangyou Li, Xin Jiang, Lifeng Shang, Qun Liu, and Wenjie Li. 2025b. Learning to align multi-faceted evaluation: A unified and robust framework. arXiv preprint arXiv:2502.18874.
[171] Bosi Wen, Pei Ke, Yufei Sun, Cunxiang Wang, Xiaotao Gu, Jinfeng Zhou, Jie Tang, Hongning Wang, and Minlie Huang. 2025. Hpss: Heuristic prompting strategy search for llm evaluators. arXiv preprint arXiv:2502.13031.
[172] Han Zhou, Xingchen Wan, Yinhong Liu, Nigel Collier, Ivan Vulić, and Anna Korhonen. 2024a. Fairer preferences elicit improved human-aligned large language model judgments. arXiv preprint arXiv:2406.11370.
[173] Adian Liusie, Potsawee Manakul, and Mark Gales. 2024. LLM comparative assessment: Zero-shot NLG evaluation through pairwise comparisons using large language models. In Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers), pages 139–151, St. Julian's, Malta. Association for Computational Linguistics.
[174] Masanari Ohi, Masahiro Kaneko, Ryuto Koike, Mengsay Loem, and Naoaki Okazaki. 2024. Likelihood-based mitigation of evaluation bias in large language models. arXiv preprint arXiv:2402.15987.
[175] Junjie Chen, Weihang Su, Zhumin Chu, Haitao Li, Qinyao Ai, Yiqun Liu, Min Zhang, and Shaoping Ma. 2024c. An automatic and cost-efficient peer-review framework for language generation evaluation. arXiv preprint arXiv:2410.12265.
[176] Kun-Peng Ning, Shuo Yang, Yuyang Liu, Jia-Yu Yao, Zhenhui Liu, Yu Wang, Ming Pang, and Li Yuan. 2024. Pico: Peer review in llms based on the consistency optimization.
[177] Xinghua Zhang, Bowen Yu, Haiyang Yu, Yangyu Lv, Tingwen Liu, Fei Huang, Hongbo Xu, and Yongbin Li. 2023. Wider and deeper llm networks are fairer llm evaluators. ArXiv preprint, abs/2308.01862.
[178] Zhenran Xu, Senbao Shi, Baotian Hu, Jindi Yu, Dongfang Li, Min Zhang, and Yuxiang Wu. 2023b. Towards reasoning in large language models via multi-agent peer review collaboration. arXiv preprint arXiv:2311.08152.
[179] Hongliu Cao, Ilias Driouich, Robin Singh, and Eoin Thomas. 2025a. Multi-agent llm judge: automatic personalized llm judge design for evaluating natural language generation applications. arXiv preprint arXiv:2504.02867.
[180] Ning Wu, Ming Gong, Linjun Shou, Shining Liang, and Daxin Jiang. 2023. Large language models are diverse role-players for summarization evaluation. In CCF International Conference on Natural Language Processing and Chinese Computing, pages 695–707. Springer.
[181] Yu Li, Shenyu Zhang, Rui Wu, Xiutian Huang, Yongrui Chen, Wenhao Xu, Guilin Qi, and Dehai Min. 2024n. Mateval: A multi-agent discussion framework for advancing open-ended text evaluation. In International Conference on Database Systems for Advanced Applications, pages 415–426. Springer.
[182] Bhrij Patel, Souradip Chakraborty, Wesley A Suttle, Mengdi Wang, Amrit Singh Bedi, and Dinesh Manocha. 2024. Aime: Ai system optimization via multiple llm evaluators. arXiv preprint arXiv:2410.03131.
[183] Chi-Min Chan, Weize Chen, Yusheng Su, Jianxuan Yu, Wei Xue, Shanghang Zhang, Jie Fu, and Zhiyuan Liu. 2023. Chateval: Towards better llm-based evaluators through multi-agent debate. In The Twelfth International Conference on Learning Representations.
[184] Mingqing Zhang, Haisong Gong, Qiang Liu, Shu Wu, and Liang Wang. 2024e. Breaking event rumor detection via stance-separated multi-agent debate.
[185] Chaithanya Bandi and Abir Harrasse. 2024. Adversarial multi-agent evaluation of large language models through iterative debates. arXiv preprint arXiv:2410.04663.
[186] Zachary Kenton, Noah Siegel, János Kramár, Jonah Brown-Cohen, Samuel Albanie, Jannis Bulian, Rishabh Agarwal, David Lindner, Yunhao Tang, Noah Goodman, and 1 others. 2024. On scalable oversight with weak llms judging strong llms. Advances in Neural Information Processing Systems, 37:75229–75276.
[187] Kaijie Zhu, Jindong Wang, Qinlin Zhao, Ruochen Xu, and Xing Xie. 2024c. Dynamic evaluation of large language models by meta probing agents. In Forty-first International Conference on Machine Learning.
[188] Pat Verga, Sebastian Hofstatter, Sophia Althammer, Yixuan Su, Aleksandra Piktus, Arkady Arkhangorodsky, Minjie Xu, Naomi White, and Patrick Lewis. 2024. Replacing judges with juries: Evaluating llm generations with a panel of diverse models. arXiv preprint arXiv:2404.18796.
[189] Yuran Li, Jama Hussein Mohamud, Chongren Sun, Di Wu, and Benoit Boulet. 2025c. Leveraging llms as meta-judges: A multi-agent framework for evaluating llm judgments. arXiv preprint arXiv:2504.17087.
[190] Luke Guerdan, Solon Barocas, Kenneth Holstein, Hanna Wallach, Zhiwei Steven Wu, and Alexandra Chouldechova. 2025. Validating llm-as-a-judge systems in the absence of gold labels. arXiv preprint arXiv:2503.05965.
[191] Hossein A Rahmani, Emine Yilmaz, Nick Craswell, and Bhaskar Mitra. 2024. Judgeblender: Ensembling judgments for automatic relevance assessment. arXiv preprint arXiv:2412.13268.
[192] Jaehun Jung, Faeze Brahman, and Yejin Choi. 2024. Trust or escalate: Llm judges with provable guarantees for human agreement. ArXiv preprint, abs/2407.18370.
[193] Sher Badshah and Hassan Sajjad. 2025. Dafe: Llm-based evaluation through dynamic arbitration for free-form question-answering. arXiv preprint arXiv:2503.08542.
[194] Samee Arif, Sualeha Farid, Abdul Hameed Azeemi, Awais Athar, and Agha Ali Raza. 2024. The fellowship of the llms: Multi-agent workflows for synthetic preference optimization dataset generation. ArXiv preprint, abs/2408.08688.
[195] Renhao Li, Minghuan Tan, Derek F Wong, and Min Yang. 2024j. Coevol: Constructing better responses for instruction finetuning through multi-agent cooperation. ArXiv preprint, abs/2406.07054.
[196] Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, and 12 others. 2020. Language models are few-shot learners. In Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, December 6-12, 2020, virtual.
[197] Qingxiu Dong, Lei Li, Damai Dai, Ce Zheng, Zhiyong Wu, Baobao Chang, Xu Sun, Jingjing Xu, and Zhifang Sui. 2023. A survey on in-context learning. ArXiv preprint, abs/2301.00234.
[198] Rishabh Agarwal, Avi Singh, Lei M Zhang, Bernd Bohnet, Luis Rosias, Stephanie CY Chan, Biao Zhang, Aleksandra Faust, and Hugo Larochelle. Many-shot in-context learning. In ICML 2024 Workshop on In-Context Learning.
[199] Sameer Jain, Vaishakh Keshava, Swarnashree Mysore Sathyendra, Patrick Fernandes, Pengfei Liu, Graham Neubig, and Chunting Zhou. 2023b. Multi-dimensional evaluation of text summarization with in-context learning. In Findings of the Association for Computational Linguistics: ACL 2023, pages 8487–8495, Toronto, Canada. Association for Computational Linguistics.
[200] Neema Kotonya, Saran Krishnasamy, Joel Tetreault, and Alejandro Jaimes. 2023. Little giants: Exploring the potential of small LLMs as evaluation metrics in summarization in the Eval4NLP 2023 shared task. In Proceedings of the 4th Workshop on Evaluation and Comparison of NLP Systems, pages 202–218, Bali, Indonesia. Association for Computational Linguistics.
[201] Hosein Hasanbeig, Hiteshi Sharma, Leo Betthauser, Felipe Vieira Frujeri, and Ida Momennejad. 2023. Allure: auditing and improving llm-based evaluation of text using iterative in-context-learning. arXiv e-prints, pages arXiv–2309.
[202] Mingyang Song, Mao Zheng, and Xuan Luo. 2024b. Can many-shot in-context learning help long-context llm judges? see more, judge better!ArXiv preprint, abs/2406.11629.
[203] Yushi Bai, Jiahao Ying, Yixin Cao, Xin Lv, Yuze He, Xiaozhi Wang, Jifan Yu, Kaisheng Zeng, Yijia Xiao, Haozhe Lyu, Jiayin Zhang, Juanzi Li, and Lei Hou. 2023b. Benchmarking foundation models with language-model-as-an-examiner. In Advances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16, 2023.
[204] José Pombal, Nuno M Guerreiro, Ricardo Rei, and André FT Martins. 2025a. Zero-shot benchmarking: A framework for flexible and scalable automatic evaluation of language models. arXiv preprint arXiv:2504.01001.
[205] Ruochen Zhao, Wenxuan Zhang, Yew Ken Chia, Deli Zhao, and Lidong Bing. 2024c. Auto arena of llms: Automating llm evaluations with agent peer-battles and committee discussions. ArXiv preprint, abs/2405.20267.
[206] Behrad Moniri, Hamed Hassani, and Edgar Dobriban. 2024. Evaluating the performance of large language models via debates. ArXiv preprint, abs/2406.11044.
[207] Yuanzhao Zhai, Zhuo Zhang, Kele Xu, Hanyang Peng, Yue Yu, Dawei Feng, Cheng Yang, Bo Ding, and Huaimin Wang. 2024. Online self-preferring language models. ArXiv preprint, abs/2405.14103.
[208] Yantao Liu, Zijun Yao, Rui Min, Yixin Cao, Lei Hou, and Juanzi Li. 2025d. Pairwise rm: Perform best-of-n sampling with knockout tournament. arXiv preprint arXiv:2501.13007.
[209] Tianqi Liu, Yao Zhao, Rishabh Joshi, Misha Khalman, Mohammad Saleh, Peter J Liu, and Jialu Liu. 2023a. Statistical rejection sampling improves preference optimization. ArXiv preprint, abs/2309.06657.
[210] Yao Zhao, Rishabh Joshi, Tianqi Liu, Misha Khalman, Mohammad Saleh, and Peter J Liu. 2023b. Slic-hf: Sequence likelihood calibration with human feedback. ArXiv preprint, abs/2305.10425.
[211] Sher Badshah and Hassan Sajjad. 2024. Reference-guided verdict: Llms-as-judges in automatic evaluation of free-form text. ArXiv preprint, abs/2408.09235.
[212] Shachi H Kumar, Saurav Sahay, Sahisnu Mazumder, Eda Okur, Ramesh Manuvinakurike, Nicole Beckage, Hsuan Su, Hung-yi Lee, and Lama Nachman. 2024b. Decoding biases: Automated methods and llm judges for gender bias detection in language models. ArXiv preprint, abs/2408.03907.
[213] Zhiyuan Zeng, Jiatong Yu, Tianyu Gao, Yu Meng, Tanya Goyal, and Danqi Chen. Evaluating large language models at evaluating instruction following. In The Twelfth International Conference on Learning Representations.
[214] Jaylen Jones, Lingbo Mo, Eric Fosler-Lussier, and Huan Sun. 2024. A multi-aspect framework for counter narrative evaluation using large language models. In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 2: Short Papers), pages 147–168.
[215] Hangfeng He, Hongming Zhang, and Dan Roth. 2023. Socreval: Large language models with the socratic method for reference-free reasoning evaluation. arXiv preprint arXiv:2310.00074.
[216] Mihir Parmar, Nisarg Patel, Neeraj Varshney, Mutsumi Nakamura, Man Luo, Santosh Mashetty, Arindam Mitra, and Chitta Baral. 2024. Logicbench: Towards systematic evaluation of logical reasoning ability of large language models. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 13679–13707.
[217] Shijie Xia, Xuefeng Li, Yixin Liu, Tongshuang Wu, and Pengfei Liu. 2024. Evaluating mathematical reasoning beyond accuracy. ArXiv preprint, abs/2404.05692.
[218] Bahare Fatemi, Mehran Kazemi, Anton Tsitsulin, Karishma Malkan, Jinyeong Yim, John Palowitch, Sungyong Seo, Jonathan Halcrow, and Bryan Perozzi. 2024. Test of time: A benchmark for evaluating llms on temporal reasoning. ArXiv preprint, abs/2406.09170.
[219] Xuhui Zhou, Hao Zhu, Leena Mathur, Ruohong Zhang, Haofei Yu, Zhengyang Qi, Louis-Philippe Morency, Yonatan Bisk, Daniel Fried, Graham Neubig, and 1 others. 2023. Sotopia: Interactive evaluation for social intelligence in language agents. ArXiv preprint, abs/2310.11667.
[220] Dongping Chen, Ruoxi Chen, Shilin Zhang, Yaochen Wang, Yinuo Liu, Huichi Zhou, Qihui Zhang, Yao Wan, Pan Zhou, and Lichao Sun. Mllm-as-a-judge: Assessing multimodal llm-as-a-judge with vision-language benchmark. In Forty-first International Conference on Machine Learning.
[221] Xiyan Fu and Wei Liu. 2025. How reliable is multilingual llm-as-a-judge? arXiv preprint arXiv:2505.12201.
[222] Martin Weyssow, Aton Kamanda, and Houari Sahraoui. 2024. Codeultrafeedback: An llm-as-a-judge dataset for aligning large language models to coding preferences. arXiv preprint arXiv:2403.09032.
[223] Yiming Liang, Ge Zhang, Xingwei Qu, Tianyu Zheng, Jiawei Guo, Xinrun Du, Zhenzhu Yang, Jiaheng Liu, Chenghua Lin, Lei Ma, and 1 others. 2024c. I-sheep: Self-alignment of llm from scratch through an iterative self-enhancement paradigm. ArXiv preprint, abs/2408.08072.
[224] Michihiro Yasunaga, Leonid Shamis, Chunting Zhou, Andrew Cohen, Jason Weston, Luke Zettlemoyer, and Marjan Ghazvininejad. 2024. Alma: Alignment with minimal annotation. arXiv preprint arXiv:2412.04305.
[225] Honglei Zhuang, Zhen Qin, Kai Hui, Junru Wu, Le Yan, Xuanhui Wang, and Michael Bendersky. 2024a. Beyond yes and no: Improving zero-shot LLM rankers via scoring fine-grained relevance labels. In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 2: Short Papers), pages 358–370, Mexico City, Mexico. Association for Computational Linguistics.
[226] Xueguang Ma, Xinyu Zhang, Ronak Pradeep, and Jimmy Lin. 2023. Zero-shot listwise document reranking with a large language model. ArXiv preprint, abs/2305.02156.
[227] Weiwei Sun, Lingyong Yan, Xinyu Ma, Shuaiqiang Wang, Pengjie Ren, Zhumin Chen, Dawei Yin, and Zhaochun Ren. 2023. Is ChatGPT good at search? investigating large language models as re-ranking agents. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 14918–14937, Singapore. Association for Computational Linguistics.
[228] Zhen Qin, Rolf Jagerman, Kai Hui, Honglei Zhuang, Junru Wu, Le Yan, Jiaming Shen, Tianqi Liu, Jialu Liu, Donald Metzler, Xuanhui Wang, and Michael Bendersky. 2024. Large language models are effective text rankers with pairwise ranking prompting. In Findings of the Association for Computational Linguistics: NAACL 2024, pages 1504–1518, Mexico City, Mexico. Association for Computational Linguistics.
[229] Shengyao Zhuang, Honglei Zhuang, Bevan Koopman, and Guido Zuccon. 2024b. A setwise approach for effective and highly efficient zero-shot ranking with large language models. In Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 38–47.
[230] Xiaonan Li and Xipeng Qiu. 2023b. Mot: Memory-of-thought enables chatgpt to self-improve. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 6354–6374.
[231] Qiaoyu Tang, Jiawei Chen, Bowen Yu, Yaojie Lu, Cheng Fu, Haiyang Yu, Hongyu Lin, Fei Huang, Ben He, Xianpei Han, and 1 others. 2024a. Self-retrieval: Building an information retrieval system with one large language model. ArXiv preprint, abs/2403.00801.
[232] Akari Asai, Zeqiu Wu, Yizhong Wang, Avirup Sil, and Hannaneh Hajishirzi. Self-rag: Learning to retrieve, generate, and critique through self-reflection. In The Twelfth International Conference on Learning Representations.
[233] Mirco Musolesi. 2024. Creative beam search: Llm-as-a-judge for improving response generation. ICCC.
[234] Hunter Lightman, Vineet Kosaraju, Yura Burda, Harri Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. 2023. Let's verify step by step. arXiv preprint arXiv:2305.20050.
[235] Zachary Ankner, Mansheej Paul, Brandon Cui, Jonathan D Chang, and Prithviraj Ammanabrolu. 2024. Critique-out-loud reward models. arXiv preprint arXiv:2408.11791.
[236] Hao Sha, Yao Mu, Yuxuan Jiang, Li Chen, Chenfeng Xu, Ping Luo, Shengbo Eben Li, Masayoshi Tomizuka, Wei Zhan, and Mingyu Ding. 2023. Languagempc: Large language models as decision makers for autonomous driving. ArXiv preprint, abs/2310.03026.
[237] Qintong Li, Leyang Cui, Lingpeng Kong, and Wei Bi. 2023a. Exploring the reliability of large language models as customized evaluators for diverse nlp tasks. arXiv preprint arXiv:2310.19740.
[238] Sijun Tan and 1 others. 2024b. Judgebench: A benchmark for evaluating llm-based judges. ArXiv preprint, abs/2410.12784.
[239] Yicheng Wang, Jiayi Yuan, Yu-Neng Chuang, Zhuoer Wang, Yingchi Liu, Mark Cusick, Param Kulkarni, Zhengping Ji, Yasser Ibrahim, and Xia Hu. 2024j. Dhp benchmark: Are llms good nlg evaluators?ArXiv preprint, abs/2408.13704.
[240] Nathan Lambert, Valentina Pyatkin, Jacob Morrison, LJ Miranda, Bill Yuchen Lin, Khyathi Chandu, Nouha Dziri, Sachin Kumar, Tom Zick, Yejin Choi, and 1 others. 2024. Rewardbench: Evaluating reward models for language modeling. arXiv preprint arXiv:2403.13787.
[241] John Penfever and 1 others. 2024. Style over substance: Failure modes of llm judges in alignment benchmarking. ArXiv preprint, abs/2410.17578.
[242] Huaizhi Qu, Inyoung Choi, Zhen Tan, Song Wang, Sukwon Yun, Qi Long, Faizan Siddiqui, Kwonjoon Lee, and Tianlong Chen. 2025. Efficient map estimation of llm judgment performance with prior transfer. arXiv preprint arXiv:2504.12589.
[243] Austin Xu, Srijan Bansal, Yifei Ming, Semih Yavuz, and Shafiq Joty. 2025a. Does context matter? contextualjudgebench for evaluating llm-based judges in contextual settings. arXiv preprint arXiv:2503.15620.
[244] Jiayi Chang, Mingqi Gao, Xinyu Hu, and Xiaojun Wan. 2025. Exploring the multilingual nlg evaluation abilities of llm-based evaluators. arXiv preprint arXiv:2503.04360.
[245] Xinyu Hu, Mingqi Gao, Li Lin, Zhenghan Yu, and Xiaojun Wan. 2025b. A dual-perspective nlg meta-evaluation framework with automatic benchmark and better interpretability. arXiv preprint arXiv:2502.12052.
[246] Aparna Elangovan, Lei Xu, Jongwoo Ko, Mahsa Elyasi, Ling Liu, Sravan Bodapati, and Dan Roth. 2024. Beyond correlation: The impact of human uncertainty in measuring the effectiveness of automatic evaluation and llm-as-a-judge. arXiv preprint arXiv:2410.03775.
[247] Kayla Schroeder and Zach Wood-Doughty. 2024. Can you trust llm judgments? reliability of llm-as-a-judge. arXiv preprint arXiv:2412.12509.
[248] Ariel Gera, Odellia Boni, Yotam Perlitz, Roy Bar-Haim, Lilach Eden, and Asaf Yehudai. 2024. Justrank: Benchmarking llm judges for system ranking. arXiv preprint arXiv:2412.09569.
[249] Yann Dubois, Balázs Galambosi, Percy Liang, and Tatsunori B Hashimoto. 2024. Length-controlled alpacaeval: A simple way to debias automatic evaluators. arXiv preprint arXiv:2404.04475.
[250] Tianle Li, Wei-Lin Chiang, Evan Frick, Lisa Dunlap, Tianhao Wu, Banghua Zhu, Joseph E Gonzalez, and Ion Stoica. 2024l. From crowdsourced data to high-quality benchmarks: Arena-hard and benchbuilder pipeline. ArXiv preprint, abs/2406.11939.
[251] Wayne Chi, Valerie Chen, Anastasios Nikolas Angelopoulos, Wei-Lin Chiang, Aditya Mittal, Naman Jain, Tianjun Zhang, Ion Stoica, Chris Donahue, and Ameet Talwalkar. 2025. Copilot arena: A platform for code llm evaluation in the wild. arXiv preprint arXiv:2502.09328.
[252] Qiujie Xie, Qingqiu Li, Zhuohao Yu, Yuejie Zhang, Yue Zhang, and Linyi Yang. 2025a. An empirical analysis of uncertainty in large language model evaluations. arXiv preprint arXiv:2502.10709.
[253] Jiayi Ye, Yanbo Wang, Yue Huang, Dongping Chen, Qihui Zhang, Nuno Moniz, Tian Gao, Werner Geyer, Chao Huang, Pin-Yu Chen, and 1 others. 2024a. Justice or prejudice? quantifying biases in llm-as-a-judge. ArXiv preprint, abs/2410.02736.
[254] Jiawen Shi, Zenghui Yuan, Yinuo Liu, Yue Huang, Pan Zhou, Lichao Sun, and Neil Zhenqiang Gong. 2024. Optimization-based prompt injection attack to llm-as-a-judge. ArXiv preprint, abs/2403.17710.
[255] Tuhina Tripathi, Manya Wadhwa, Greg Durrett, and Scott Niekum. 2025. Pairwise or pointwise? evaluating feedback protocols for bias in llm-based evaluation. arXiv preprint arXiv:2504.14716.
[256] Ravi Raju, Swayambhoo Jain, Bo Li, Jonathan Li, and Urmish Thakkar. 2024. Constructing domain-specific evaluation sets for llm-as-a-judge. ArXiv preprint, abs/2408.08808.
[257] John Zhao and 1 others. 2024a. Codejudge-eval: A benchmark for evaluating code generation. ArXiv preprint, abs/2401.10019.
[258] Yang Wu, Yao Wan, Zhaoyang Chu, Wenting Zhao, Ye Liu, Hongyu Zhang, Xuanhua Shi, and Philip S. Yu. 2024b. Can large language models serve as evaluators for code summarization?
[259] Jian Yang, Jiaxi Yang, Ke Jin, Yibo Miao, Lei Zhang, Liqun Yang, Zeyu Cui, Yichang Zhang, Binyuan Hui, and Junyang Lin. 2024. Evaluating and aligning codellms on human preference.
[260] Weixi Tong and Tianyi Zhang. 2024. Codejudge: Evaluating code generation with large language models. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 20032–20051.
[261] Guijin Son and 1 others. 2024b. Mm-eval: A multilingual meta-evaluation benchmark for llm-as-a-judge and reward models. ArXiv preprint, abs/2410.17578.
[262] Guijin Son, Hyunwoo Ko, Hoyoung Lee, Yewon Kim, and Seunghyeok Hong. 2024a. Llm-as-a-judge & reward model: What they can and cannot do. ArXiv preprint, abs/2409.11239.
[263] Xing Han Lù, Amirhossein Kazemnejad, Nicholas Meade, Arkil Patel, Dongchan Shin, Alejandra Zambrano, Karolina Stańczak, Peter Shaw, Christopher J Pal, and Siva Reddy. 2025. Agentrewardbench: Evaluating automatic evaluations of web agent trajectories. arXiv preprint arXiv:2504.08942.
[264] Tobias Domhan and Dawei Zhu. 2025. Same evaluation, more tokens: On the effect of input length for machine translation evaluation using large language models. arXiv preprint arXiv:2505.01761.
[265] Peiwen Yuan, Shaoxiong Feng, Yiwei Li, Xinglin Wang, Boyuan Pan, Heda Wang, and Kan Li. 2024a. Batcheval: Towards human-like text evaluation. ArXiv preprint, abs/2401.00437.
[266] Andreas Stephan, Dawei Zhu, Matthias Aßenmacher, Xiaoyu Shen, and Benjamin Roth. 2024. From calculation to adjudication: Examining llm judges on mathematical reasoning tasks. ArXiv preprint, abs/2409.04168.
[267] Guiming Hardy Chen, Shunian Chen, Ziche Liu, Feng Jiang, and Benyou Wang. 2024b. Humans or llms as the judge? a study on judgement biases. ArXiv preprint, abs/2402.10669.
[268] Yiqi Liu, Nafise Sadat Moosavi, and Chenghua Lin. 2023c. Llms as narcissistic evaluators: When ego inflates evaluation scores. ArXiv preprint, abs/2311.09766.
[269] Koki Wataoka, Tsubasa Takahashi, and Ryokan Ri. 2024. Self-preference bias in llm-as-a-judge. ArXiv preprint, abs/2410.21819.
[270] Arjun Panickssery, Samuel Bowman, and Shi Feng. 2024. Llm evaluators recognize and favor their own generations. Advances in Neural Information Processing Systems, 37:68772–68802.
[271] Wei-Lin Chen, Zhepei Wei, Xinyu Zhu, Shi Feng, and Yu Meng. 2025c. Do llm evaluators prefer themselves for a reason? arXiv preprint arXiv:2504.03846.
[272] Dawei Li, Renliang Sun, Yue Huang, Ming Zhong, Bohan Jiang, Jiawei Han, Xiangliang Zhang, Wei Wang, and Huan Liu. 2025a. Preference leakage: A contamination problem in llm-as-a-judge. arXiv preprint arXiv:2502.01534.
[273] Shashwat Goel, Joschka Struber, Ilze Amanda Auzina, Karuna K Chandra, Ponnurangam Kumaraguru, Douwe Kiela, Ameya Prabhu, Matthias Bethge, and Jonas Geiping. 2025. Great models think alike and this undermines ai oversight. arXiv preprint arXiv:2502.04313.
[274] Ali Naseh and Niloofar Mireshghallah. 2025. Synthetic data can mislead evaluations: Membership inference as machine text detection. arXiv preprint arXiv:2501.11786.
[275] JUDGE BENCHMARK. Jailjudge: Acomprehensive jailbreak judge benchmark with multi-agent enhanced explanation evaluation framework.
[276] Sourav Banerjee, Ayushi Agarwal, and Eishkaran Singh. 2024. The vulnerability of language model benchmarks: Do they accurately reflect true llm performance?
[277] Terry Tong, Fei Wang, Zhe Zhao, and Muhao Chen. 2025. Badjudge: Backdoor vulnerabilities of llm-as-a-judge. In The Thirteenth International Conference on Learning Representations.
[278] Adian Liusie, Potsawee Manakul, and Mark JF Gales. 2023. Zero-shot nlg evaluation through pairware comparisons with llms. ArXiv preprint, abs/2307.07889.
[279] Vyas Raina, Adian Liusie, and Mark Gales. 2024. Is llm-as-a-judge robust? investigating universal adversarial attacks on zero-shot llm assessment. ArXiv preprint, abs/2402.14016.
[280] Sumanth Doddapaneni, Mohammed Safi Ur Rahman Khan, Sshubam Verma, and Mitesh M Khapra. 2024b. Finding blind spots in evaluator llms with interpretable checklists. ArXiv preprint, abs/2406.13439.
[281] Michael Krumdick, Charles Lovering, Varshini Reddy, Seth Ebner, and Chris Tanner. 2025. No free labels: Limitations of llm-as-a-judge without human grounding. arXiv preprint arXiv:2503.05061.
[282] Haitao Li, Junjie Chen, Qingyao Ai, Zhumin Chu, Yujia Zhou, Qian Dong, and Yiqun Liu. 2024d. Calibraeval: Calibrating prediction distribution to mitigate selection bias in llms-as-judges. ArXiv preprint, abs/2410.15393.
[283] Hongli Zhou, Hui Huang, Yunfei Long, Bing Xu, Conghui Zhu, Hailong Cao, Muyun Yang, and Tiejun Zhao. 2024b. Mitigating the bias of large language model evaluation. ArXiv preprint, abs/2409.16788.
[284] Meilin Chen, Jian Tian, Liang Ma, Di Xie, Weijie Chen, and Jiang Zhu. 2025a. Unbiased evaluation of large language models from a causal perspective. arXiv preprint arXiv:2502.06655.
[285] Victor Wang, Michael JQ Zhang, and Eunsol Choi. 2025c. Improving llm-as-a-judge inference with the judgment distribution. arXiv preprint arXiv:2503.03064.
[286] Gerrit JJ van den Burg, Gen Suzuki, Wei Liu, and Murat Sensoy. 2025. Aligning black-box language models with human judgments. arXiv preprint arXiv:2502.04997.
[287] Charlie Snell, Jaehoon Lee, Kelvin Xu, and Aviral Kumar. 2024. Scaling llm test-time compute optimally can be more effective than scaling model parameters. arXiv preprint arXiv:2408.03314.
[288] Qiyuan Zhang, Fuyuan Lyu, Zexu Sun, Lei Wang, Weixu Zhang, Zhihan Guo, Yufei Wang, Irwin King, Xue Liu, and Chen Ma. 2025b. What, how, where, and how well? a survey on test-time scaling in large language models. arXiv preprint arXiv:2503.24235.
[289] Qian Wang, Zhanzhi Lou, Zhenheng Tang, Nuo Chen, Xuandong Zhao, Wenxuan Zhang, Dawn Song, and Bingsheng He. 2025a. Assessing judging bias in large reasoning models: An empirical study. arXiv preprint arXiv:2504.09946.
[290] Nuo Chen, Zhiyuan Hu, Qingyun Zou, Jiaying Wu, Qian Wang, Bryan Hooi, and Bingsheng He. 2025b. Judgelrm: Large reasoning models as a judge. arXiv preprint arXiv:2504.00050.
[291] Yutong Wang, Pengliang Ji, Chaoqun Yang, Kaixin Li, Ming Hu, Jiaoyang Li, and Guillaume Sartoretti. 2025f. Mcts-judge: Test-time scaling in llm-as-a-judge for code correctness evaluation. arXiv preprint arXiv:2502.12468.
[292] Nimit Kalra and Leonard Tang. 2025. Verdict: A library for scaling judge-time compute. arXiv preprint arXiv:2502.18018.
[293] Chenxi Whitehouse, Tianlu Wang, Ping Yu, Xian Li, Jason Weston, Ilia Kulikov, and Swarnadeep Saha. 2025. J1: Incentivizing thinking in llm-as-a-judge via reinforcement learning. Preprint, arXiv:2505.10320.
[294] Xiusi Chen, Gaotang Li, Ziqi Wang, Bowen Jin, Cheng Qian, Yu Wang, Hongru Wang, Yu Zhang, Denghui Zhang, Tong Zhang, and 1 others. 2025d. Rm-r1: Reward modeling as reasoning. arXiv preprint arXiv:2505.02387.
[295] Wenlei Shi and Xing Jin. 2025. Heimdall: test-time scaling on the generative verification. arXiv preprint arXiv:2504.10337.
[296] Jian Zhao, Runze Liu, Kaiyan Zhang, Zhimu Zhou, Junqi Gao, Dong Li, Jiafei Lyu, Zhouyi Qian, Biqing Qi, Xiu Li, and 1 others. 2025b. Genprm: Scaling test-time compute of process reward models via generative reasoning. arXiv preprint arXiv:2504.00891.
[297] Yang Sui, Yu-Neng Chuang, Guanchu Wang, Jiamu Zhang, Tianyi Zhang, Jiayi Yuan, Hongyi Liu, Andrew Wen, Shaochen Zhong, Hanjie Chen, and 1 others. 2025. Stop overthinking: A survey on efficient reasoning for large language models. arXiv preprint arXiv:2503.16419.
[298] Xingyu Chen, Jiahao Xu, Tian Liang, Zhiwei He, Jianhui Pang, Dian Yu, Linfeng Song, Qiuzhi Liu, Mengfei Zhou, Zhuosheng Zhang, and 1 others. 2024e. Do not think that much for 2+ 3=? on the overthinking of o1-like llms. arXiv preprint arXiv:2412.21187.
[299] Fengqing Jiang, Zhangchen Xu, Yuetai Li, Luyao Niu, Zhen Xiang, Bo Li, Bill Yuchen Lin, and Radha Poovendran. 2025. Safechain: Safety of language models with long chain-of-thought reasoning capabilities. arXiv preprint arXiv:2502.12025.
[300] Preetam Prabhu Srikar Dammu, Himanshu Naidu, and Chirag Shah. 2025. Dynamic-kgqa: A scalable framework for generating adaptive question answering datasets. arXiv preprint arXiv:2503.05049.
[301] Boshra Khalili and Andrew W Smyth. 2025. Autodrive-qa-automated generation of multiple-choice questions for autonomous driving datasets using large vision-language models. arXiv preprint arXiv:2503.15778.
[302] Wanying Wang, Zeyu Ma, Pengfei Liu, and Mingang Chen. 2024i. Revisiting benchmark and assessment: An agent-based exploratory dynamic evaluation framework for llms. arXiv preprint arXiv:2410.11507.
[303] Eunsu Kim, Juyoung Suk, Seungone Kim, Niklas Muennighoff, Dongkwan Kim, and Alice Oh. 2024a. Llm-as-an-interviewer: Beyond static testing through dynamic llm evaluation. arXiv preprint arXiv:2412.10424.
[304] Yueheng Zhang, Xiaoyuan Liu, Yiyou Sun, Atheer Alharbi, Hend Alzahrani, Basel Alomair, and Dawn Song. 2025e. Can llms design good questions based on context? arXiv preprint arXiv:2501.03491.
[305] Sirui Liang, Baoli Zhang, Jun Zhao, and Kang Liu. 2024b. Abseval: An agent-based framework for script evaluation. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 12418–12434.
[306] Zongjie Li, Chaozheng Wang, Pingchuan Ma, Daoyuan Wu, Shuai Wang, Cuiyun Gao, and Yang Liu. 2024p. Split and merge: Aligning position biases in llm-based evaluators. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 11084–11108.
[307] Swarnadeep Saha, Omer Levy, Asli Celikyilmaz, Mohit Bansal, Jason Weston, and Xian Li. 2024. Branch-solve-merge improves large language model evaluation and generation. In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 8345–8363.
[308] Fan Zhang, Shulin Tian, Ziqi Huang, Yu Qiao, and Ziwei Liu. 2024b. Evaluation agent: Efficient and promptable evaluation framework for visual generative models. arXiv preprint arXiv:2412.09645.
[309] Xinchen Wang, Pengfei Gao, Chao Peng, Ruida Hu, and Cuiyun Gao. 2025e. Codevisionary: An agent-based framework for evaluating large language models in code generation. arXiv preprint arXiv:2504.13472.
[310] Mingyang Song, Mao Zheng, and Xuan Luo. 2025. Grp: Goal-reversed prompting for zero-shot evaluation with llms. arXiv preprint arXiv:2503.06139.
[311] Aaron Hu. 2024. Developing an ai-based psychometric system for assessing learning difficulties and adaptive system to overcome: A qualitative and conceptual framework. ArXiv preprint, abs/2403.06284.
[312] Arkil Patel, Siva Reddy, and Dzmitry Bahdanau. 2025. How to get your llm to generate challenging problems for evaluation. arXiv preprint arXiv:2502.14678.
[313] Guglielmo Faggioli, Laura Dietz, Charles LA Clarke, Gianluca Demartini, Matthias Hagen, Claudia Hauff, Noriko Kando, Evangelos Kanoulas, Martin Potthast, Benno Stein, and 1 others. 2023. Perspectives on large language models for relevance judgment. In Proceedings of the 2023 ACM SIGIR International Conference on Theory of Information Retrieval, pages 39–50.
[314] Ronak Pradeep, Nandan Thakur, Shivani Upadhyay, Daniel Campos, Nick Craswell, and Jimmy Lin. 2025. The great nugget recall: Automating fact extraction and rag evaluation with large language models. arXiv preprint arXiv:2504.15068.
[315] Sang Michael Xie, Shibani Santurkar, Tengyu Ma, and Percy Liang. 2023. Data selection for language models via importance resampling. In Advances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16, 2023.
[316] Alon Albalak, Yanai Elazar, Sang Michael Xie, Shayne Longpre, Nathan Lambert, Xinyi Wang, Niklas Muennighoff, Bairu Hou, Liangming Pan, Haewon Jeong, and 1 others. 2024. A survey on data selection for language models. ArXiv preprint, abs/2402.16827.
[317] Matt Post. 2018. A call for clarity in reporting BLEU scores. In Proceedings of the Third Conference on Machine Translation: Research Papers, pages 186–191, Brussels, Belgium. Association for Computational Linguistics.
[318] Yen-Ting Lin and Yun-Nung Chen. 2023b. LLM-eval: Unified multi-dimensional automatic evaluation for open-domain conversations with large language models. In Proceedings of the 5th Workshop on NLP for Conversational AI (NLP4ConvAI 2023), pages 47–58, Toronto, Canada. Association for Computational Linguistics.
[319] Hwanjun Song, Hang Su, Igor Shalyminov, Jason Cai, and Saab Mansour. 2024a. Finesure: Fine-grained summarization evaluation using llms. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 906–922.
[320] Qingchen Yu, Zifan Zheng, Shichao Song, Zhiyu Li, Feiyu Xiong, Bo Tang, and Ding Chen. 2024a. xfinder: Robust and pinpoint answer extraction for large language models. arXiv preprint arXiv:2405.11874.
[321] Lijun Li, Bowen Dong, Ruohui Wang, Xuhao Hu, Wangmeng Zuo, Dahua Lin, Yu Qiao, and Jing Shao. 2024g. Salad-bench: A hierarchical and comprehensive safety benchmark for large language models. ArXiv preprint, abs/2402.05044.
[322] Ziwei Ji, Tiezheng Yu, Yan Xu, Nayeon Lee, Etsuko Ishii, and Pascale Fung. 2023. Towards mitigating llm hallucination via self reflection. In Findings of the Association for Computational Linguistics: EMNLP 2023, pages 1827–1843.
[323] Sumanth Doddapaneni, Mohammed Safi Ur Rahman Khan, Dilip Venkatesh, Raj Dabre, Anoop Kunchukuttan, and Mitesh M Khapra. 2024a. Cross-lingual auto evaluation for assessing multilingual llms. arXiv preprint arXiv:2410.13394.
[324] Zhaopeng Feng, Jiayuan Su, Jiamei Zheng, Jiahan Ren, Yan Zhang, Jian Wu, Hongwei Wang, and Zuozhu Liu. 2024. M-mad: Multidimensional multi-agent debate for advanced machine translation evaluation. arXiv preprint arXiv:2412.20127.
[325] Rishav Hada, Varun Gumma, Adrian de Wynter, Harshita Diddee, Mohamed Ahmed, Monojit Choudhury, Kalika Bali, and Sunayana Sitaram. 2024. Are large language model-based evaluators the solution to scaling up multilingual evaluation? In Findings of the Association for Computational Linguistics: EACL 2024, pages 1051–1070.
[326] Philipp Mondorf and Barbara Plank. 2024. Beyond accuracy: Evaluating the reasoning behavior of large language models–a survey. ArXiv preprint, abs/2404.01869.
[327] Boshi Wang, Xiang Yue, and Huan Sun. 2023a. Can ChatGPT defend its belief in truth? evaluating LLM reasoning via debate. In Findings of the Association for Computational Linguistics: EMNLP 2023, pages 11865–11881, Singapore. Association for Computational Linguistics.
[328] Linyong Nan, Ellen Zhang, Weijin Zou, Yilun Zhao, Wenfei Zhou, and Arman Cohan. 2024. On evaluating the integration of reasoning and action in LLM agents with database question answering. In Findings of the Association for Computational Linguistics: NAACL 2024, pages 4556–4579, Mexico City, Mexico. Association for Computational Linguistics.
[329] Ruoxi Xu, Hongyu Lin, Xianpei Han, Le Sun, and Yingfei Sun. 2024a. Academically intelligent llms are not necessarily socially intelligent. ArXiv preprint, abs/2403.06591.
[330] Hanwei Zhu, Haoning Wu, Yixuan Li, Zicheng Zhang, Baoliang Chen, Lingyu Zhu, Yuming Fang, Guangtao Zhai, Weisi Lin, and Shiqi Wang. 2024b. Adaptive image quality assessment via teaching large multimodal model to compare. arXiv preprint arXiv:2405.19298.
[331] Kai Chen, Yanze Li, Wenhua Zhang, Yanxin Liu, Pengxiang Li, Ruiyuan Gao, Lanqing Hong, Meng Tian, Xinhai Zhao, Zhenguo Li, and 1 others. 2024d. Automated evaluation of large vision-language models on self-driving corner cases. ArXiv preprint, abs/2404.10595.
[332] Terry Yue Zhuo. 2024. Ice-score: Instructing large language models to evaluate code. In Findings of the Association for Computational Linguistics: EACL 2024, pages 2232–2242.
[333] En-Qi Tseng, Pei-Cing Huang, Chan Hsu, Peng-Yi Wu, Chan-Tung Ku, and Yihuang Kang. 2024. Codev: An automated grading framework leveraging large language models for consistent and constructive feedback. In 2024 IEEE International Conference on Big Data (BigData), pages 5442–5449. IEEE.
[334] Yang Wu, Yao Wan, Zhaoyang Chu, Wenting Zhao, Ye Liu, Hongyu Zhang, Xuanhua Shi, and Philip S Yu. 2024c. Can large language models serve as evaluators for code summarization? arXiv preprint arXiv:2412.01333.
[335] Junda He, Jieke Shi, Terry Yue Zhuo, Christoph Treude, Jiamou Sun, Zhenchang Xing, Xiaoning Du, and David Lo. 2025. From code to courtroom: Llms as the new software judges. arXiv preprint arXiv:2503.02246.
[336] Zhuohao Yu, Weizheng Gu, Yidong Wang, Xingru Jiang, Zhengran Zeng, Jindong Wang, Wei Ye, and Shikun Zhang. Reasoning through execution: Unifying process and outcome rewards for code generation.
[337] Ruiqi Wang, Jiyu Guo, Cuiyun Gao, Guodong Fan, Chun Yong Chong, and Xin Xia. 2025b. Can llms replace human evaluators? an empirical study of llm-as-a-judge in software engineering. arXiv preprint arXiv:2502.06193.
[338] Archiki Prasad, Elias Stengel-Eskin, Justin Chih-Yao Chen, Zaid Khan, and Mohit Bansal. 2025. Learning to generate unit tests for automated debugging. arXiv preprint arXiv:2502.01619.
[339] Rundong Liu, Andre Frade, Amal Vaidya, Maxime Labonne, Marcus Kaiser, Bismayan Chakrabarti, Jonathan Budd, and Sean Moran. 2025b. On iterative evaluation and enhancement of code quality using gpt-4o. arXiv preprint arXiv:2502.07399.
[340] Zhiwei Fei, Xiaoyu Shen, Dawei Zhu, Fengzhe Zhou, Zhuo Han, Songyang Zhang, Kai Chen, Zongwen Shen, and Jidong Ge. 2023. Lawbench: Benchmarking legal knowledge of large language models. ArXiv preprint, abs/2309.16289.
[341] Andrés Isaza-Giraldo, Paulo Bala, Pedro F Campos, and Lucas Pereira. 2024. Prompt-gaming: A pilot study on llm-evaluating agent in a meaningful energy game. In Extended Abstracts of the CHI Conference on Human Factors in Computing Systems, pages 1–12.
[342] Zhen Bi, Ningyu Zhang, Yida Xue, Yixin Ou, Daxiong Ji, Guozhou Zheng, and Huajun Chen. 2023. Oceangpt: A large language model for ocean science tasks. ArXiv preprint, abs/2310.02031.
[343] Marianne Chuang, Gabriel Chuang, Cheryl Chuang, and John Chuang. 2025. Judging it, washing it: Scoring and greenwashing corporate climate disclosures using large language models. arXiv preprint arXiv:2502.15094.
[344] Heegyu Kim, Taeyang Jeon, Seungtaek Choi, Ji Hoon Hong, Dong Won Jeon, Ga-Yeon Baek, Gyeong-Won Kwak, Dong-Hee Lee, Jisu Bae, Chihoon Lee, and 1 others. 2025. Towards fully-automated materials discovery via large-scale synthesis dataset and expert-level llm-as-a-judge. arXiv preprint arXiv:2502.16457.
[345] Beiming Liu, Zhizhuo Cui, Siteng Hu, Xiaohua Li, Haifeng Lin, and Zhengxin Zhang. 2025a. Llm evaluation based on aerospace manufacturing expertise: Automated generation and multi-model question answering. arXiv preprint arXiv:2501.17183.
[346] Ziyu Wang, Hao Li, Di Huang, and Amir M Rahmani. 2024m. Healthq: Unveiling questioning capabilities of llm chains in healthcare conversations. ArXiv preprint, abs/2409.19487.
[347] Chen Zhang, Luis Fernando D'Haro, Yiming Chen, Malu Zhang, and Haizhou Li. 2024a. A comprehensive analysis of the effectiveness of large language models as automatic dialogue evaluators. In Thirty-Eighth AAAI Conference on Artificial Intelligence, AAAI 2024, Thirty-Sixth Conference on Innovative Applications of Artificial Intelligence, IAAI 2024, Fourteenth Symposium on Educational Advances in Artificial Intelligence, EAAI 2014, February 20-27, 2024, Vancouver, Canada, pages 19515–19524. AAAI Press.
[348] Lexin Zhou, Youmna Farag, and Andreas Vlachos. 2024c. An llm feature-based framework for dialogue constructiveness assessment. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 5389–5409.
[349] Jingcong Liang, Rong Ye, Meng Han, Ruofei Lai, Xinyu Zhang, Xuanjing Huang, and Zhongyu Wei. 2024a. Debatrix: Multi-dimensinal debate judge with iterative chronological analysis based on llm. arXiv preprint arXiv:2403.08010.
[350] Kaustubh D. Dhole, Kai Shu, and Eugene Agichtein. 2024. Conqret: Benchmarking fine-grained evaluation of retrieval augmented argumentation with llm judges.
[351] Jon Saad-Falcon, Omar Khattab, Christopher Potts, and Matei Zaharia. 2024a. Ares: An automated evaluation framework for retrieval-augmented generation systems. In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 338–354.
[352] Zhuoran Jin, Hongbang Yuan, Tianyi Men, Pengfei Cao, Yubo Chen, Kang Liu, and Jun Zhao. 2024. Rag-rewardbench: Benchmarking reward models in retrieval augmented generation for preference alignment. arXiv preprint arXiv:2412.13746.
[353] Shuliang Liu, Xinze Li, Zhenghao Liu, Yukun Yan, Cheng Yang, Zheni Zeng, Zhiyuan Liu, Maosong Sun, and Ge Yu. 2025c. Judge as a judge: Improving the evaluation of retrieval-augmented generation through the judge-consistency of large language models. arXiv preprint arXiv:2502.18817.
[354] Kwangwook Seo, Donguk Kwon, and Dongha Lee. 2025. Mt-raig: Novel benchmark and evaluation framework for retrieval-augmented insight generation over multiple tables. arXiv preprint arXiv:2502.11735.
[355] Nathan Brake and Thomas Schaaf. 2024. Comparing two model designs for clinical note generation; is an llm a useful evaluator of consistency? In Findings of the Association for Computational Linguistics: NAACL 2024, pages 352–363.
[356] Shunfan Zheng, Xiechi Zhang, Gerard de Melo, Xiaoling Wang, and Linlin Wang. 2025. Hierarchical divide-and-conquer for fine-grained alignment in llm-based medical evaluation. arXiv preprint arXiv:2501.06741.
[357] Xiechi Zhang, Shunfan Zheng, Linlin Wang, Gerard De Melo, Zhu Cao, Xiaoling Wang, and Liang He. 2024i. Ace-m3: Automatic capability evaluator for multimodal medical models. arXiv preprint arXiv:2412.11453.
[358] Ruiyang Zhou, Lu Chen, and Kai Yu. 2024e. Is llm a reliable reviewer? a comprehensive evaluation of llm on automatic paper reviewing tasks. In Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024), pages 9340–9351.
[359] Chihang Wang, Yuxin Dong, Zhenhong Zhang, Ruotong Wang, Shuo Wang, and Jiajing Chen. 2024c. Automated genre-aware article scoring and feedback using large language models. arXiv preprint arXiv:2410.14165.
[360] Minjun Zhu, Yixuan Weng, Linyi Yang, and Yue Zhang. 2025. Deepreview: Improving llm-based paper review with human-like deep thinking process. arXiv preprint arXiv:2503.08569.
[361] Chhavi Kirtani, Madhav Krishan Garg, Tejash Prasad, Tanmay Singhal, Murari Mandal, and Dhruv Kumar. 2025. Revieweval: An evaluation framework for ai-generated reviews. arXiv preprint arXiv:2502.11736.
[362] Matthew Lyle Olson, Neale Ratzlaff, Musashi Hinck, Shao-yen Tseng, and Vasudev Lal. 2024. Steering large language models to evaluate and amplify creativity. arXiv preprint arXiv:2412.06060.
[363] Tao Feng, Yihang Sun, and Jiaxuan You. 2025. Grapheval: A lightweight graph-based llm framework for idea evaluation. arXiv preprint arXiv:2503.12600.
[364] Piotr Sawicki, Marek Grześ, Dan Brown, and Fabr'ıcio Góes. 2025. Can large language models outperform non-experts in poetry evaluation? a comparative study using the consensual assessment technique. arXiv preprint arXiv:2502.19064.
[365] Ruosen Li, Ruochen Li, Barry Wang, and Xinya Du. 2024k. Iqa-eval: Automatic evaluation of human-model interactive question answering. Advances in Neural Information Processing Systems, 37:109894–109921.
[366] Jason Wei, Maarten Bosma, Vincent Y. Zhao, Kelvin Guu, Adams Wei Yu, Brian Lester, Nan Du, Andrew M. Dai, and Quoc V. Le. 2022a. Finetuned language models are zero-shot learners. In The Tenth International Conference on Learning Representations, ICLR 2022, Virtual Event, April 25-29, 2022. OpenReview.net.
[367] Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul F. Christiano, Jan Leike, and Ryan Lowe. 2022. Training language models to follow instructions with human feedback. In Advances in Neural Information Processing Systems 35: Annual Conference on Neural Information Processing Systems 2022, NeurIPS 2022, New Orleans, LA, USA, November 28 - December 9, 2022.
[368] Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D. Manning, Stefano Ermon, and Chelsea Finn. 2023. Direct preference optimization: Your language model is secretly a reward model. In Advances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16, 2023.
[369] Saptarshi Sengupta, Kristal Curtis, Akshay Mallipeddi, Abhinav Mathur, Joseph Ross, and Liang Gou. 2024. Mag-v: A multi-agent framework for synthetic data generation and verification.
[370] Sizhe Wang, Yongqi Tong, Hengyuan Zhang, Dawei Li, Xin Zhang, and Tianlong Chen. 2024f. Bpo: Towards balanced preference optimization between knowledge breadth and depth in alignment. arXiv preprint arXiv:2411.10914.
[371] Weizhe Yuan, Richard Yuanzhe Pang, Kyunghyun Cho, Sainbayar Sukhbaatar, Jing Xu, and Jason Weston. 2024c. Self-rewarding language models. ArXiv preprint, abs/2401.10020.
[372] Shimao Zhang, Xiao Liu, Xin Zhang, Junxiao Liu, Zheheng Luo, Shujian Huang, and Yeyun Gong. 2025c. Process-based self-rewarding language models. arXiv preprint arXiv:2503.03746.
[373] Alizée Pace, Jonathan Mallinson, Eric Malmi, Sebastian Krause, and Aliaksei Severyn. 2024. West-of-n: Synthetic preference generation for improved reward modeling. ArXiv preprint, abs/2401.12086.
[374] Yongqi Tong, Sizhe Wang, Dawei Li, Yifan Wang, Simeng Han, Zi Lin, Chengsong Huang, Jiaxin Huang, and Jingbo Shang. 2024. Optimizing language model's reasoning abilities with weak supervision. ArXiv preprint, abs/2405.04086.
[375] Zijun Liu, Boqun Kou, Peng Li, Ming Yan, Ji Zhang, Fei Huang, and Yang Liu. 2024e. Meta ranking: Less capable language models are capable for single response judgement. ArXiv preprint, abs/2402.12146.
[376] Yuwei Zeng, Yao Mu, and Lin Shao. 2024. Learning reward for robot skills using large language models via self-alignment. ArXiv preprint, abs/2405.07162.
[377] Seungjun Yi, Jaeyoung Lim, and Juyong Yoon. 2024. Protocollm: Automatic evaluation framework of llms on domain-specific scientific protocol formulation tasks. arXiv preprint arXiv:2410.04601.
[378] Daechul Ahn, Yura Choi, San Kim, Youngjae Yu, Dongyeop Kang, and Jonghyun Choi. 2024. i-srt: Aligning large multimodal models for videos by iterative self-retrospective judgment. ArXiv preprint, abs/2406.11280.
[379] Raphael Tang, Crystina Zhang, Xueguang Ma, Jimmy Lin, and Ferhan Ture. 2024b. Found in the middle: Permutation self-consistency improves listwise ranking in large language models. In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 2327–2340, Mexico City, Mexico. Association for Computational Linguistics.
[380] Paul Thomas, Seth Spielman, Nick Craswell, and Bhaskar Mitra. 2023. Large language models can accurately predict searcher preferences, 2023. ArXiv preprint, abs/2309.10621.
[381] Akari Asai, Zeqiu Wu, Yizhong Wang, Avirup Sil, and Hannaneh Hajishirzi. 2024. Self-RAG: Learning to retrieve, generate, and critique through self-reflection. In The Twelfth International Conference on Learning Representations.
[382] Zackary Rackauckas, Arthur Câmara, and Jakub Zavrel. 2024. Evaluating rag-fusion with ragelo: an automated elo-based framework. ArXiv preprint, abs/2406.14783.
[383] Hengran Zhang, Ruqing Zhang, Jiafeng Guo, Maarten de Rijke, Yixing Fan, and Xueqi Cheng. 2024c. Are large language models good at utility judgments? In Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 1941–1951.
[384] Chengrui Wang, Qingqing Long, Xiao Meng, Xunxin Cai, Chengjun Wu, Zhen Meng, Xuezhi Wang, and Yuanchun Zhou. 2024b. Biorag: A rag-llm framework for biological question reasoning. ArXiv preprint, abs/2408.01107.
[385] Minbyul Jeong, Jiwoong Sohn, Mujeen Sung, and Jaewoo Kang. 2024. Improving medical reasoning through retrieval and self-reflection with retrieval-augmented large language models. Bioinformatics, 40(Supplement_1):i119–i129.
[386] Antonia Creswell, Murray Shanahan, and Irina Higgins. 2023. Selection-inference: Exploiting large language models for interpretable logical reasoning. In The Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023. OpenReview.net.
[387] Yuxi Xie, Kenji Kawaguchi, Yiran Zhao, James Xu Zhao, Min-Yen Kan, Junxian He, and Michael Xie. 2024c. Self-evaluation guided beam search for reasoning. Advances in Neural Information Processing Systems, 36.
[388] Amrith Setlur, Chirag Nagpal, Adam Fisch, Xinyang Geng, Jacob Eisenstein, Rishabh Agarwal, Alekh Agarwal, Jonathan Berant, and Aviral Kumar. 2024. Rewarding progress: Scaling automated process verifiers for llm reasoning. arXiv preprint arXiv:2410.08146.
[389] Lunjun Zhang, Arian Hosseini, Hritik Bansal, Mehran Kazemi, Aviral Kumar, and Rishabh Agarwal. 2024d. Generative verifiers: Reward modeling as next-token prediction. arXiv preprint arXiv:2408.15240.
[390] Zihuiwen Ye, Luckeciano Carvalho Melo, Younesse Kaddar, Phil Blunsom, Sam Staton, and Yarin Gal. 2025. Uncertainty-aware step-wise verification with generative reward models. arXiv preprint arXiv:2502.11250.
[391] Shuying Xu, Junjie Hu, and Ming Jiang. 2024c. Large language models are active critics in nlg evaluation. arXiv preprint arXiv:2410.10724.
[392] Yue Yu, Zhengxing Chen, Aston Zhang, Liang Tan, Chenguang Zhu, Richard Yuanzhe Pang, Yundi Qian, Xuewei Wang, Suchin Gururangan, Chao Zhang, and 1 others. 2024b. Self-generated critiques boost reward modeling for language models. arXiv preprint arXiv:2411.16646.
[393] Peifeng Wang, Austin Xu, Yilun Zhou, Caiming Xiong, and Shafiq Joty. 2024e. Direct judgement preference optimization. ArXiv preprint, abs/2409.14664.
[394] Tian Lan, Wenwei Zhang, Chen Xu, Heyan Huang, Dahua Lin, Kai Chen, and Xian-Ling Mao. Criticeval: Evaluating large-scale language model as critic. In The Thirty-eighth Annual Conference on Neural Information Processing Systems.
[395] Zhiheng Xi, Wenxiang Chen, Xin Guo, Wei He, Yiwen Ding, Boyang Hong, Ming Zhang, Junzhe Wang, Senjie Jin, Enyu Zhou, and 1 others. 2023. The rise and potential of large language model based agents: A survey. arXiv preprint arXiv:2309.07864.
[396] Lei Wang, Chen Ma, Xueyang Feng, Zeyu Zhang, Hao Yang, Jingsen Zhang, Zhiyuan Chen, Jiakai Tang, Xu Chen, Yankai Lin, and 1 others. 2024d. A survey on large language model based autonomous agents. Frontiers of Computer Science, 18(6):186345.
[397] Pei Zhou, Jay Pujara, Xiang Ren, Xinyun Chen, Heng-Tze Cheng, Quoc V Le, Ed H Chi, Denny Zhou, Swaroop Mishra, and Huaixiu Steven Zheng. 2024d. Self-discover: Large language models self-compose reasoning structures. ArXiv preprint, abs/2402.03620.
[398] Yue Huang, Qihui Zhang, Lichao Sun, and 1 others. 2023b. Trustgpt: A benchmark for trustworthy and responsible large language models. ArXiv preprint, abs/2306.11507.
[399] Nino Scherrer, Claudia Shi, Amir Feder, and David M. Blei. 2023. Evaluating the moral beliefs encoded in llms. In Advances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16, 2023.
[400] Tongxin Yuan, Zhiwei He, Lingzhong Dong, Yiming Wang, Ruijie Zhao, Tian Xia, Lizhen Xu, Binglin Zhou, Fangqi Li, Zhuosheng Zhang, and 1 others. 2024b. R-judge: Benchmarking safety risk awareness for llm agents. ArXiv preprint, abs/2401.10019.
[401] Shengwei Xu, Yuxuan Lu, Grant Schoenebeck, and Yuqing Kong. 2024b. Benchmarking llms' judgments with no gold standard.
[402] Yen-Shan Chen, Jing Jin, Peng-Ting Kuo, Chao-Wei Huang, and Yun-Nung Chen. 2024f. Llms are biased evaluators but not biased for retrieval augmented generation. ArXiv preprint, abs/2410.20833.
[403] Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R. Narasimhan, and Yuan Cao. 2023b. React: Synergizing reasoning and acting in language models. In The Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023. OpenReview.net.
[404] Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed H. Chi, Quoc V. Le, and Denny Zhou. 2022b. Chain-of-thought prompting elicits reasoning in large language models. In Advances in Neural Information Processing Systems 35: Annual Conference on Neural Information Processing Systems 2022, NeurIPS 2022, New Orleans, LA, USA, November 28 - December 9, 2022.
[405] Hui Wei, Shenghua He, Tian Xia, Andy Wong, Jingyang Lin, and Mei Han. 2024a. Systematic evaluation of llm-as-a-judge in llm alignment tasks: Explainable metrics and diverse prompt templates. ArXiv preprint, abs/2408.13006.
[406] Aman Singh Thakur, Kartik Choudhary, Venkat Srinik Ramayapally, Sankaran Vaidyanathan, and Dieuwke Hupkes. 2024. Judging the judges: Evaluating alignment and vulnerabilities in llms-as-judges. ArXiv preprint, abs/2406.12624.
[407] Lei Li, Yuancheng Wei, Zhihui Xie, Xuqing Yang, Yifan Song, Peiyi Wang, Chenxin An, Tianyu Liu, Sujian Li, Bill Yuchen Lin, and 1 others. 2024f. Vlrewardbench: A challenging benchmark for vision-language generative reward models. arXiv preprint arXiv:2411.17451.