Training Compute-Optimal Large Language Models
Jordan Hoffmann$^\star$, Sebastian Borgeaud$^\star$, Arthur Mensch$^\star$, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, Diego de Las Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, Tom Hennigan, Eric Noland, Katie Millican, George van den Driessche, Bogdan Damoc, Aurelia Guy, Simon Osindero, Karen Simonyan, Erich Elsen, Jack W. Rae, Oriol Vinyals and Laurent Sifre$^\star$
$^\star$Equal contributions
Corresponding authors: {jordanhoffmann|sborgeaud|amensch|sifre}@deepmind.com
Abstract
We investigate the optimal model size and number of tokens for training a transformer language model under a given compute budget. We find that current large language models are significantly under-trained, a consequence of the recent focus on scaling language models whilst keeping the amount of training data constant. By training over 400 language models ranging from 70 million to over 16 billion parameters on 5 to 500 billion tokens, we find that for compute-optimal training, the model size and the number of training tokens should be scaled equally: for every doubling of model size the number of training tokens should also be doubled. We test this hypothesis by training a predicted compute-optimal model, Chinchilla, that uses the same compute budget as Gopher but with 70B parameters and $4\times$ more more data. Chinchilla uniformly and significantly outperforms Gopher (280B), GPT-3 (175B), Jurassic-1 (178B), and Megatron-Turing NLG (530B) on a large range of downstream evaluation tasks. This also means that Chinchilla uses substantially less compute for fine-tuning and inference, greatly facilitating downstream usage. As a highlight, Chinchilla reaches a state-of-the-art average accuracy of 67.5% on the MMLU benchmark, greater than a 7% improvement over Gopher.
Executive Summary: Large language models (LLMs) power many modern AI applications, from chatbots to content generation, but training them requires massive computational resources that are expensive and energy-intensive. Recent trends have focused on building ever-larger models, often exceeding hundreds of billions of parameters, while keeping training data relatively fixed around 300 billion tokens. This approach risks inefficiency: models may not perform as well as they could because they are under-trained relative to their size. With compute budgets fixed by available hardware and timelines, understanding how to best divide resources between model size and training data volume is crucial now, as AI scales rapidly and costs soar, influencing everything from research priorities to commercial viability.
This document evaluates how to optimally allocate a fixed compute budget between the number of model parameters and the amount of training data (measured in tokens) to minimize prediction error in LLMs. It aims to provide empirical guidelines for scaling these models effectively.
The researchers trained over 400 transformer-based LLMs, ranging from 70 million to more than 16 billion parameters, on 5 billion to over 400 billion tokens from the MassiveText dataset (a diverse English corpus including web text, books, and code). They varied training durations and used three complementary methods—analyzing training curves for fixed model sizes, comparing final losses across fixed compute levels (isoFLOP profiles), and fitting a parametric model to all losses—to estimate optimal scaling laws. Training occurred on TPU hardware over several months, assuming power-law relationships and standard hyperparameters like cosine learning rate schedules matched to data volume; models were evaluated on held-out data to avoid overfitting.
The core findings reveal that current LLMs are significantly under-trained. First, compute-optimal training requires scaling model size and training tokens equally: for every doubling of parameters, the tokens should also double, contrasting prior estimates that favored faster parameter growth (about 5.5 times) over data (1.8 times). Second, popular models like Gopher (280 billion parameters) and GPT-3 (175 billion) use suboptimal allocations; for Gopher's compute budget, an optimal model would be about four times smaller (around 70 billion parameters) but trained on four times more data (1.4 trillion tokens). Third, the team validated this by training Chinchilla, a 70-billion-parameter model using Gopher's full compute budget but with extended data exposure; it outperformed Gopher by 7-10% on average across benchmarks like language modeling (e.g., perplexity 7.16 vs. 7.75 on WikiText-103) and question answering. Fourth, Chinchilla also surpassed larger rivals—GPT-3, Jurassic-1 (178 billion), and Megatron-Turing NLG (530 billion)—on most tasks, achieving a state-of-the-art 67.6% accuracy on the Massive Multitask Language Understanding (MMLU) benchmark, exceeding even human expert forecasts for 2023. Fifth, the smaller size cuts inference and fine-tuning compute by a factor of about four, easing deployment on standard hardware.
These results mean that the rush to mega-models has overlooked data's role, leading to wasted compute and suboptimal performance; equal scaling unlocks better efficiency, reducing energy costs and enabling broader access to high-performing LLMs for tasks like reading comprehension (e.g., 82% accuracy on hard RACE questions, up 10% from Gopher) and common-sense reasoning. Unlike expectations from earlier work, which underestimated data benefits due to fixed hyperparameters, this shows training longer on quality data yields diminishing returns on size alone, potentially reshaping AI development toward data-centric strategies. For decisions, it lowers risks of over-investing in hardware for parameter bloat while boosting safety and reliability through stronger generalization.
Leaders should shift investments: prioritize collecting and curating larger, high-quality datasets (trillions of tokens) over solely expanding model architectures, and adopt equal scaling for new projects—e.g., for a 280-billion-parameter target, train on 6 trillion tokens instead of 300 billion. If compute is limited, opt for models under 100 billion parameters trained extensively. Trade-offs include higher data needs raising privacy and bias risks, so pair with ethical audits. Next, pilot multi-epoch training on diverse datasets and test architecture variants like mixtures-of-experts; validate at intermediate scales with more replicates before full-scale runs.
Key limitations include only two large-scale trainings (Chinchilla and Gopher) for direct comparison, reliance on power-law assumptions despite observed curvature suggesting even smaller optimal models at extreme scales, and single-epoch training that may undervalue repeated data exposure. Confidence is strong in the equal-scaling rule and Chinchilla's gains, backed by consistent results across methods and datasets like C4, but readers should be cautious with extrapolations beyond 10^25 FLOPs, where data quality gaps could alter outcomes.
1. Introduction
Section Summary: Recent large language models, with hundreds of billions of parameters, have shown strong performance on various tasks, but training them requires massive computing power and energy, making it essential to optimize model size and training data for a fixed budget. While prior research suggested scaling up model size much more than the amount of training data to improve efficiency, this study argues for balancing them equally, based on experiments with over 400 models revealing that smaller models trained on far more data achieve better results. The authors demonstrate this by creating Chinchilla, a 70-billion-parameter model trained on 1.4 trillion tokens, which outperforms the much larger Gopher while reducing costs for running and adapting it.
Recently a series of Large Language Models (LLMs) have been introduced ([1, 2, 3, 4, 5]), with the largest dense language models now having over 500 billion parameters. These large autoregressive transformers ([6]) have demonstrated impressive performance on many tasks using a variety of evaluation protocols such as zero-shot, few-shot, and fine-tuning.
The compute and energy cost for training large language models is substantial ([3, 5]) and rises with increasing model size. In practice, the allocated training compute budget is often known in advance: how many accelerators are available and for how long we want to use them. Since it is typically only feasible to train these large models once, accurately estimating the best model hyperparameters for a given compute budget is critical ([7]).
[8] showed that there is a power law relationship between the number of parameters in an autoregressive language model (LM) and its performance. As a result, the field has been training larger and larger models, expecting performance improvements. One notable conclusion in [8] is that large models should not be trained to their lowest possible loss to be compute optimal. Whilst we reach the same conclusion, we estimate that large models should be trained for many more training tokens than recommended by the authors. Specifically, given a $10\times$ increase computational budget, they suggests that the size of the model should increase $5.5\times$ while the number of training tokens should only increase 1.8 $\times$. Instead, we find that model size and the number of training tokens should be scaled in equal proportions.
Following [8] and the training setup of GPT-3 ([1]), many of the recently trained large models have been trained for approximately 300 billion tokens (Table 1), in line with the approach of predominantly increasing model size when increasing compute.
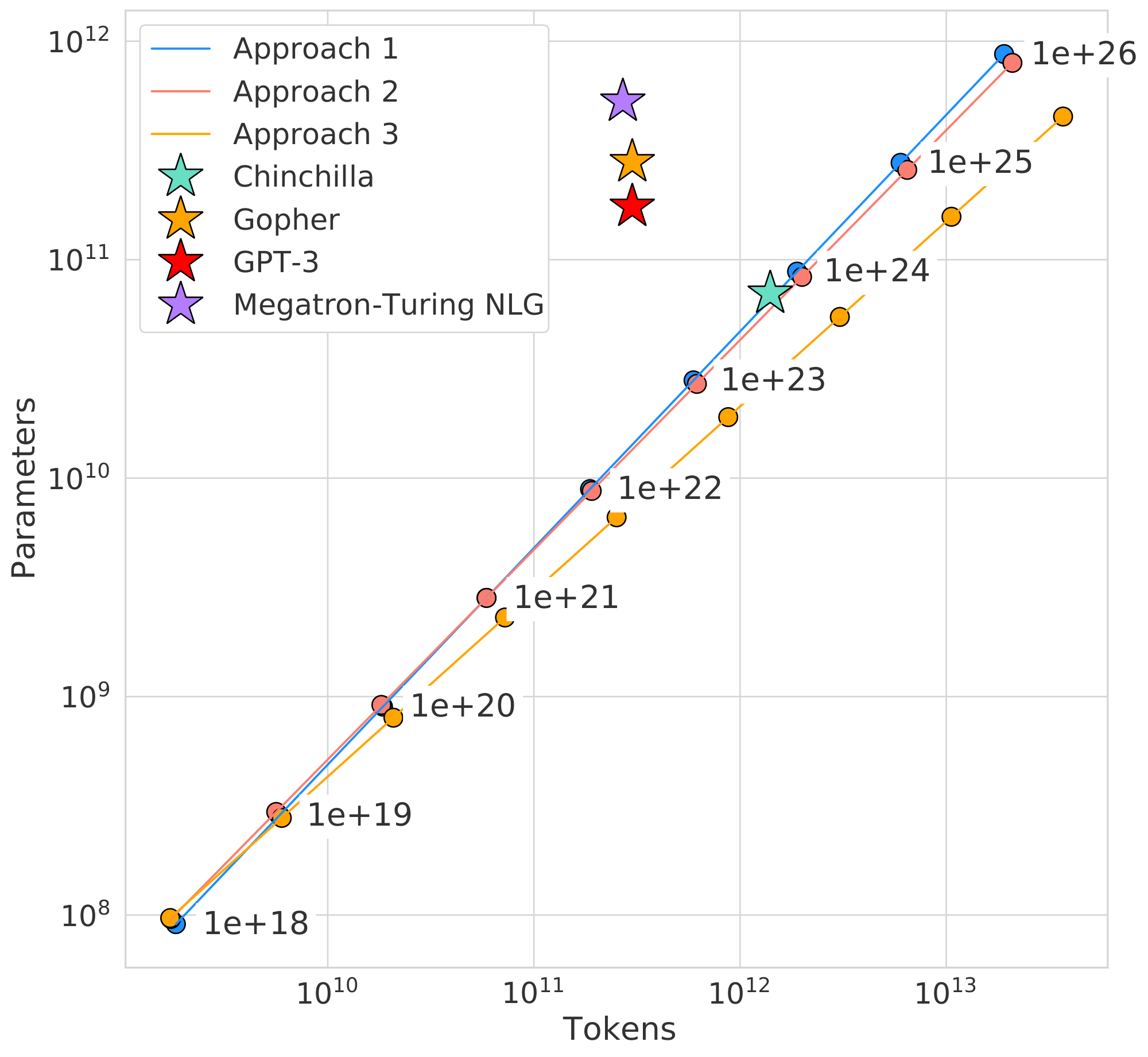
![**Figure 1:** **Overlaid predictions.** We overlay the predictions from our three different approaches, along with projections from [8]. We find that all three methods predict that current large models should be substantially smaller and therefore trained much longer than is currently done. In Figure 10, we show the results with the predicted optimal tokens plotted against the optimal number of parameters for fixed FLOP budgets. ***Chinchilla* outperforms *Gopher* and the other large models (see Section 4.2).**](https://ittowtnkqtyixxjxrhou.supabase.co/storage/v1/object/public/public-images/5p7gfzk5/combined_predictions_v9.png)
\begin{tabular}{l r c}
\toprule
Model & Size ($\#$ Parameters) & Training Tokens \\
\midrule
LaMDA ([5]) & 137 Billion &168 Billion \\
GPT-3 ([1]) & 175 Billion & 300 Billion \\
Jurassic ([2]) & 178 Billion & 300 Billion \\
\textit{Gopher} ([3]) & 280 Billion & 300 Billion \\
MT-NLG 530B ([4]) & 530 Billion & 270 Billion\\
\midrule
\textit{Chinchilla} & 70 Billion & 1.4 Trillion\\
\bottomrule
\end{tabular}
In this work, we revisit the question: Given a fixed FLOPs budget, [^2] how should one trade-off model size and the number of training tokens? To answer this question, we model the final pre-training loss[^3] $L(N, D)$ as a function of the number of model parameters $N$, and the number of training tokens, $D$. Since the computational budget $C$ is a deterministic function $\text{FLOPs}(N, D)$ of the number of seen training tokens and model parameters, we are interested in minimizing $L$ under the constraint $\text{FLOPs}(N, D) = C$:
[^2]: For example, knowing the number of accelerators and a target training duration.
[^3]: For simplicity, we perform our analysis on the smoothed training loss which is an unbiased estimate of the test loss, as we are in the infinite data regime (the number of training tokens is less than the number of tokens in the entire corpus).
$ N_{opt}(C), D_{opt}(C) = \operatorname{argmin}_{N, D \text{ s.t. } \text{FLOPs}(N, D) = C} L(N, D).\tag{1} $
The functions $N_{opt}(C)$, and $D_{opt}(C)$ describe the optimal allocation of a computational budget $C$. We empirically estimate these functions based on the losses of over 400 models, ranging from under $70$ M to over $16$ B parameters, and trained on $5$ B to over $400$ B tokens – with each model configuration trained for several different training horizons. Our approach leads to considerably different results than that of [8]. We highlight our results in Figure 1 and how our approaches differ in Section 2.
Based on our estimated compute-optimal frontier, we predict that for the compute budget used to train Gopher, an optimal model should be 4 times smaller, while being training on 4 times more tokens. We verify this by training a more compute-optimal 70B model, called Chinchilla, on 1.4 trillion tokens. Not only does Chinchilla outperform its much larger counterpart, Gopher, but its reduced model size reduces inference cost considerably and greatly facilitates downstream uses on smaller hardware. The energy cost of a large language model is amortized through its usage for inference an fine-tuning. The benefits of a more optimally trained smaller model, therefore, extend beyond the immediate benefits of its improved performance.
2. Related Work
Section Summary: Recent years have seen the rise of massive language models, including dense transformers with hundreds of billions of parameters and mixture-of-expert models, which have advanced natural language tasks but struggle with high computational costs and the need for vast, high-quality training data. Studies on how these models scale with size and data have shown predictable improvements, though earlier research underestimated the benefits of adjusting training schedules and smaller datasets, leading this work to argue for balanced growth in both model size and data volume. Beyond core size choices, hyperparameters like learning rates and batch sizes draw from prior experiments, while innovative architectures such as sparse expert models and retrieval-augmented systems highlight that performance may hinge more on data quantity than previously assumed.
Large language models.
A variety of large language models have been introduced in the last few years. These include both dense transformer models ([1, 2, 4, 3, 5]) and mixture-of-expert (MoE) models ([9, 10, 11]). The largest dense transformers have passed 500 billion parameters ([4]). The drive to train larger and larger models is clear—so far increasing the size of language models has been responsible for improving the state-of-the-art in many language modelling tasks. Nonetheless, large language models face several challenges, including their overwhelming computational requirements (the cost of training and inference increase with model size) ([3, 5]) and the need for acquiring more high-quality training data. In fact, in this work we find that larger, high quality datasets will play a key role in any further scaling of language models.
Modelling the scaling behavior.
Understanding the scaling behaviour of language models and their transfer properties has been important in the development of recent large models ([8, 12]). [8] first showed a predictable relationship between model size and loss over many orders of magnitude. The authors investigate the question of choosing the optimal model size to train for a given compute budget. Similar to us, they address this question by training various models. Our work differs from [8] in several important ways. First, the authors use a fixed number of training tokens and learning rate schedule for all models; this prevents them from modelling the impact of these hyperparameters on the loss. In contrast, we find that setting the learning rate schedule to approximately match the number of training tokens results in the best final loss regardless of model size—see Figure 8. For a fixed learning rate cosine schedule to 130B tokens, the intermediate loss estimates (for $D' << 130$ B) are therefore overestimates of the loss of a model trained with a schedule length matching $D'$. Using these intermediate losses results in underestimating the effectiveness of training models on less data than 130B tokens, and eventually contributes to the conclusion that model size should increase faster than training data size as compute budget increases. In contrast, our analysis predicts that both quantities should scale at roughly the same rate. Secondly, we include models with up to 16B parameters, as we observe that there is slight curvature in the FLOP-loss frontier (see Appendix E)—in fact, the majority of the models used in our analysis have more than 500 million parameters, in contrast the majority of runs in [8] are significantly smaller—many being less than 100M parameters.
Recently, [13] specifically looked in to the scaling properties of Mixture of Expert language models, showing that the scaling with number of experts diminishes as the model size increases—their approach models the loss as a function of two variables: the model size and the number of experts. However, the analysis is done with a fixed number of training tokens, as in [8], potentially underestimating the improvements of branching.
Estimating hyperparameters for large models.
The model size and the number of training tokens are not the only two parameters to chose when selecting a language model and a procedure to train it. Other important factors include learning rate, learning rate schedule, batch size, optimiser, and width-to-depth ratio. In this work, we focus on model size and the number of training steps, and we rely on existing work and provided experimental heuristics to determine the other necessary hyperparameters. [14] investigates how to choose a variety of these parameters for training an autoregressive transformer, including the learning rate and batch size. [15] finds only a weak dependence between optimal batch size and model size. [16, 17] suggest that using larger batch-sizes than those we use is possible. [18] investigates the optimal depth-to-width ratio for a variety of standard model sizes. We use slightly less deep models than proposed as this translates to better wall-clock performance on our hardware.
Improved model architectures.
Recently, various promising alternatives to traditional dense transformers have been proposed. For example, through the use of conditional computation large MoE models like the 1.7 trillion parameter Switch transformer ([10]), the 1.2 Trillion parameter GLaM model ([9]), and others ([19, 11]) are able to provide a large effective model size despite using relatively fewer training and inference FLOPs. However, for very large models the computational benefits of routed models seems to diminish ([13]). An orthogonal approach to improving language models is to augment transformers with explicit retrieval mechanisms, as done by [20, 21, 22]. This approach effectively increases the number of data tokens seen during training (by a factor of $\sim10$ in [20]). This suggests that the performance of language models may be more dependant on the size of the training data than previously thought.
3. Estimating the optimal parameter/training tokens allocation
Section Summary: Researchers explore how to best balance a language model's size (number of parameters) and the amount of training data (tokens) when limited by a fixed computing budget, measured in FLOPs. They test this through three methods, each involving training various model sizes with different token amounts and analyzing the results to predict optimal scaling, assuming simple mathematical relationships. All approaches agree that, as computing power increases, model parameters and training tokens should grow at the same rate, differing from earlier studies and suggesting a need for more research.
We present three different approaches to answer the question driving our research: Given a fixed FLOPs budget, how should one trade-off model size and the number of training tokens? In all three cases we start by training a range of models varying both model size and the number of training tokens and use the resulting training curves to fit an empirical estimator of how they should scale. We assume a power-law relationship between compute and model size as done in [13, 8], though future work may want to include potential curvature in this relationship for large model sizes. The resulting predictions are similar for all three methods and suggest that parameter count and number of training tokens should be increased equally with more compute[^4]—with proportions reported in Table 2. This is in clear contrast to previous work on this topic and warrants further investigation.
[^4]: We compute FLOPs as described in Appendix F.
3.1 Approach 1: Fix model sizes and vary number of training tokens
In our first approach we vary the number of training steps for a fixed family of models (ranging from 70M to over 10B parameters), training each model for 4 different number of training sequences. From these runs, we are able to directly extract an estimate of the minimum loss achieved for a given number of training FLOPs. Training details for this approach can be found in Appendix D.
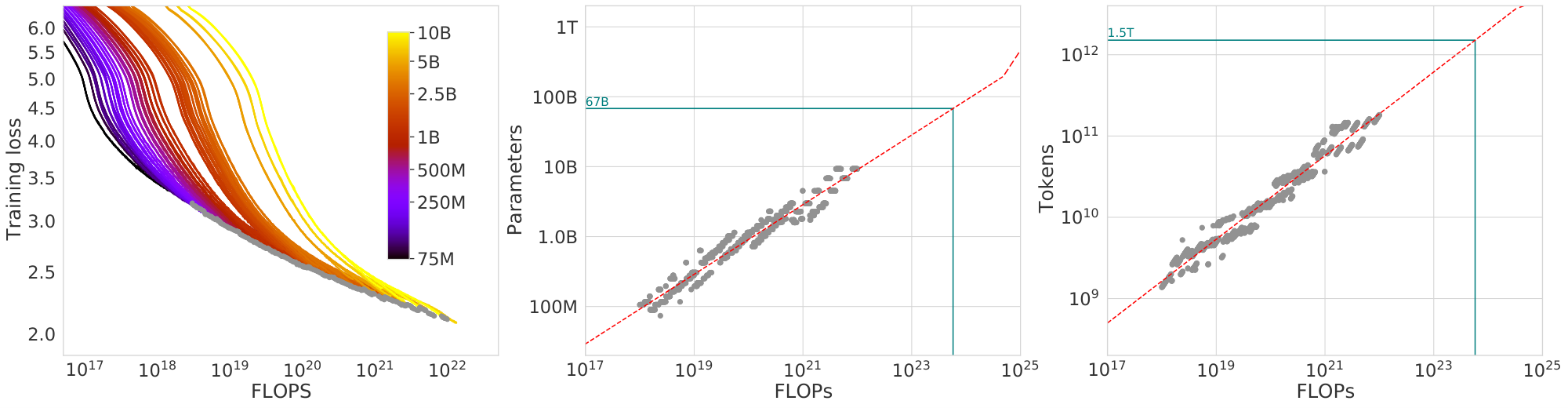
For each parameter count $N$ we train 4 different models, decaying the learning rate by a factor of 10 $\times$ over a horizon (measured in number of training tokens) that ranges by a factor of $16 \times$. Then, for each run, we smooth and then interpolate the training loss curve. From this, we obtain a continuous mapping from FLOP count to training loss for each run. Then, for each FLOP count, we determine which run achieves the lowest loss. Using these interpolants, we obtain a mapping from any FLOP count $C$, to the most efficient choice of model size $N$ and number of training tokens $D$ such that $\text{FLOPs}(N, D) = C$.[^5] At 1500 logarithmically spaced FLOP values, we find which model size achieves the lowest loss of all models along with the required number of training tokens. Finally, we fit power laws to estimate the optimal model size and number of training tokens for any given amount of compute (see the center and right panels of Figure 2), obtaining a relationship $N_{opt} \propto C^a$ and $D_{opt} \propto C^b$. We find that $a=0.50$ and $b=0.50$ —as summarized in Table 2. In Section D.4, we show a head-to-head comparison at $10^{21}$ FLOPs, using the model size recommended by our analysis and by the analysis of [8]—using the model size we predict has a clear advantage.
[^5]: Note that all selected points are within the last 15% of training. This suggests that when training a model over $D$ tokens, we should pick a cosine cycle length that decays $10 \times$ over approximately $D$ tokens—see further details in Appendix B.
3.2 Approach 2: IsoFLOP profiles
In our second approach we vary the model size[^6] for a fixed set of 9 different training FLOP counts[^7] (ranging from $6 \times10^{18}$ to $3 \times 10^{21}$ FLOPs), and consider the final training loss for each point[^8]. in contrast with Approach 1 that considered points $(N, D, L)$ along the entire training runs. This allows us to directly answer the question: For a given FLOP budget, what is the optimal parameter count?
[^6]: In approach 2, model size varies up to 16B as opposed to approach 1 where we only used models up to 10B.
[^7]: The number of training tokens is determined by the model size and training FLOPs.
[^8]: We set the cosine schedule length to match the number of tokens, which is optimal according to the analysis presented in Appendix B.
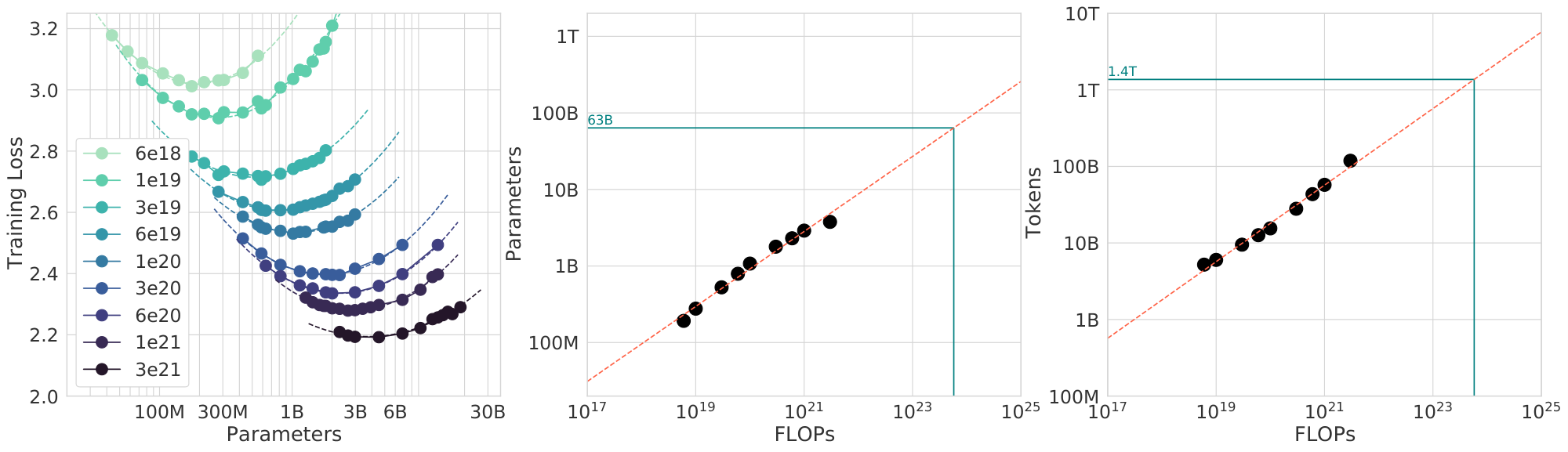
For each FLOP budget, we plot the final loss (after smoothing) against the parameter count in Figure 3 (left). In all cases, we ensure that we have trained a diverse enough set of model sizes to see a clear minimum in the loss. We fit a parabola to each IsoFLOPs curve to directly estimate at what model size the minimum loss is achieved (Figure 3 (left)). As with the previous approach, we then fit a power law between FLOPs and loss-optimal model size and number of training tokens, shown in Figure 3 (center, right). Again, we fit exponents of the form $N_{opt} \propto C^a$ and $D_{opt} \propto C^b$ and we find that $a=0.49$ and $b=0.51$ —as summarized in Table 2.
3.3 Approach 3: Fitting a parametric loss function
Lastly, we model all final losses from experiments in Approach 1 & 2 as a parametric function of model parameter count and the number of seen tokens. Following a classical risk decomposition (see Section D.2), we propose the following functional form
$ \hat L(N, D) \triangleq E + \frac{A}{N^\alpha} + \frac{B}{D^\beta}.\tag{2} $
The first term captures the loss for an ideal generative process on the data distribution, and should correspond to the entropy of natural text. The second term captures the fact that a perfectly trained transformer with $N$ parameters underperforms the ideal generative process. The final term captures the fact that the transformer is not trained to convergence, as we only make a finite number of optimisation steps, on a sample of the dataset distribution.
Model fitting.
To estimate $(A, B, E, \alpha, \beta)$, we minimize the Huber loss ([23]) between the predicted and observed log loss using the L-BFGS algorithm ([24]):
$ \begin{align} \min_{A, B, E, \alpha, \beta}\quad &\sum_{\text{Runs }i} \text{Huber}_\delta \Big(\log \hat L(N_i, D_i) - \log L_i\Big) \end{align}\tag{3} $
We account for possible local minima by selecting the best fit from a grid of initialisations. The Huber loss ($\delta=10^{-3}$) is robust to outliers, which we find important for good predictive performance over held-out data points. Section D.2 details the fitting procedure and the loss decomposition.
Efficient frontier.
We can approximate the functions $N_{opt}$ and $D_{opt}$ by minimizing the parametric loss $\hat L$ under the constraint $\text{FLOPs}(N, D) \approx 6 N D$ ([8]). The resulting $N_{opt}$ and $D_{opt}$ balance the two terms in Equation 3 that depend on model size and data. By construction, they have a power-law form:
$ N_{opt}(C) = G {\left(\frac{C}{6}\right)}^{a}, \quad D_{opt}(C) = G^{-1} {\left(\frac{C}{6}\right)}^{b}, \quad \text{ where }\quad G = {\left(\frac{\alpha A}{\beta B} \right)}^{\frac{1}{\alpha + \beta}}, \quad a = \frac{\beta}{\alpha+\beta}, \text{ and } b = \frac{\alpha}{\alpha + \beta}. $
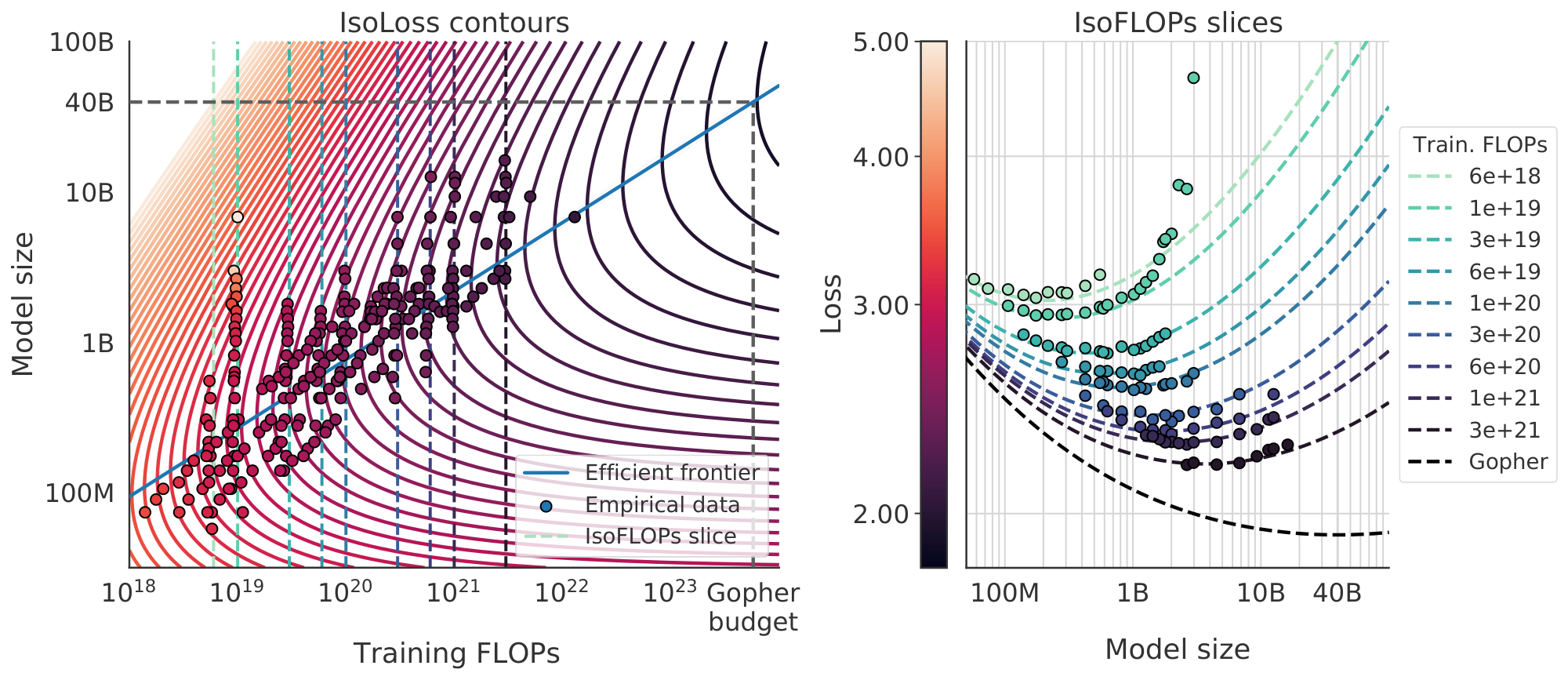
We show contours of the fitted function $\hat L$ in Figure 4 (left), and the closed-form efficient computational frontier in blue. From this approach, we find that $a=0.46$ and $b=0.54$ —as summarized in Table 2.
3.4 Optimal model scaling
We find that the three approaches, despite using different fitting methodologies and different trained models, yield comparable predictions for the optimal scaling in parameters and tokens with FLOPs (shown in Table 2).
\begin{tabular}{lccccc}
\toprule
Approach & Coeff. $a$ where $N_{opt} \propto C^a$ & Coeff. $b$ where $D_{opt} \propto C^b$ \\
\midrule
1. Minimum over training curves & $0.50 \; ({0.488}, {0.502})$ & $0.50 \; (0.501, 0.512)$ \\
2. IsoFLOP profiles & $0.49 \; (0.462, 0.534)$ & $0.51 \; (0.483, 0.529)$ \\
3. Parametric modelling of the loss & $0.46\; (0.454, 0.455)$ & $0.54 \; (0.542, 0.543)$ \\
\midrule
[8] & 0.73 & 0.27 \\
\bottomrule
\end{tabular}
All three approaches suggest that as compute budget increases, model size and the amount of training data should be increased in approximately equal proportions. The first and second approaches yield very similar predictions for optimal model sizes, as shown in Figure 1 and Figure 10. The third approach predicts even smaller models being optimal at larger compute budgets. We note that the observed points $(L, N, D)$ for low training FLOPs ($C\leq1e21$) have larger residuals ${\Vert L - \hat L(N, D) \Vert}2^2$ than points with higher computational budgets. The fitted model places increased weight on the points with more FLOPs—automatically considering the low-computational budget points as outliers due to the Huber loss. As a consequence of the empirically observed negative curvature in the frontier $C \to N{opt}$ (see Appendix E), this results in predicting a lower $N_{opt}$ than the two other approaches.
:Table 3: Estimated optimal training FLOPs and training tokens for various model sizes. For various model sizes, we show the projections from Approach 1 of how many FLOPs and training tokens would be needed to train compute-optimal models. The estimates for Approach 2 & 3 are similar (shown in Section D.3)
| Parameters | FLOPs | FLOPs (in Gopher unit) | Tokens |
|---|---|---|---|
| 400 Million | 1.92e+19 | $1/29, 968$ | 8.0 Billion |
| 1 Billion | 1.21e+20 | $1/4, 761$ | 20.2 Billion |
| 10 Billion | 1.23e+22 | $1/46$ | 205.1 Billion |
| 67 Billion | 5.76e+23 | $1$ | 1.5 Trillion |
| 175 Billion | 3.85e+24 | $6.7$ | 3.7 Trillion |
| 280 Billion | 9.90e+24 | $17.2$ | 5.9 Trillion |
| 520 Billion | 3.43e+25 | $59.5$ | 11.0 Trillion |
| 1 Trillion | 1.27e+26 | $221.3$ | 21.2 Trillion |
| 10 Trillion | 1.30e+28 | $22515.9$ | 216.2 Trillion |
In Table 3 we show the estimated number of FLOPs and tokens that would ensure that a model of a given size lies on the compute-optimal frontier. Our findings suggests that the current generation of large language models are considerably over-sized, given their respective compute budgets, as shown in Figure 1. For example, we find that a 175 billion parameter model should be trained with a compute budget of $4.41\times 10^{24}$ FLOPs and on over 4.2 trillion tokens. A 280 billion Gopher -like model is the optimal model to train given a compute budget of approximately $10^{25}$ FLOPs and should be trained on 6.8 trillion tokens. Unless one has a compute budget of $10^{26}$ FLOPs (over 250 $\times$ the compute used to train Gopher), a 1 trillion parameter model is unlikely to be the optimal model to train. Furthermore, the amount of training data that is projected to be needed is far beyond what is currently used to train large models, and underscores the importance of dataset collection in addition to engineering improvements that allow for model scale. While there is significant uncertainty extrapolating out many orders of magnitude, our analysis clearly suggests that given the training compute budget for many current LLMs, smaller models should have been trained on more tokens to achieve the most performant model.
In Appendix C, we reproduce the IsoFLOP analysis on two additional datasets: C4 ([25]) and GitHub code ([3]). In both cases we reach the similar conclusion that model size and number of training tokens should be scaled in equal proportions.
4. Chinchilla
Section Summary: Researchers trained a language model called Chinchilla with 70 billion parameters on 1.4 trillion tokens, aiming to match the computing power of their larger Gopher model while using a more efficient size within the optimal range of 40 to 70 billion parameters. This smaller design reduces memory needs and speeds up practical uses like fine-tuning and generating text compared to Gopher's 280 billion parameters. In tests on language understanding, question answering, and common sense tasks, Chinchilla outperformed Gopher and rivaled or beat other big models like Jurassic-1 on most benchmarks.
Based on our analysis in Section 3, the optimal model size for the Gopher compute budget is somewhere between 40 and 70 billion parameters. We test this hypothesis by training a model on the larger end of this range—70B parameters—for 1.4T tokens, due to both dataset and computational efficiency considerations. In this section we compare this model, which we call Chinchilla, to Gopher and other LLMs. Both Chinchilla and Gopher have been trained for the same number of FLOPs but differ in the size of the model and the number of training tokens.
While pre-training a large language model has a considerable compute cost, downstream fine-tuning and inference also make up substantial compute usage ([3]). Due to being $4 \times$ smaller than Gopher, both the memory footprint and inference cost of Chinchilla are also smaller.
4.1 Model and training details
The full set of hyperparameters used to train Chinchilla are given in Table 4. Chinchilla uses the same model architecture and training setup as Gopher with the exception of the differences listed below.
- We train Chinchilla on MassiveText (the same dataset as Gopher) but use a slightly different subset distribution (shown in Table 11) to account for the increased number of training tokens.
- We use AdamW ([26]) for Chinchilla rather than Adam ([27]) as this improves the language modelling loss and the downstream task performance after finetuning.[^1]
- We train Chinchilla with a slightly modified SentencePiece ([28]) tokenizer that does not apply NFKC normalisation. The vocabulary is very similar– 94.15% of tokens are the same as those used for training Gopher. We find that this particularly helps with the representation of mathematics and chemistry, for example.
- Whilst the forward and backward pass are computed in
bfloat16, we store afloat32copy of the weights in the distributed optimiser state ([29]). See Lessons Learned from [3] for additional details.
[^1]: Interestingly, a model trained with AdamW only passes the training performance of a model trained with Adam around 80% of the way through the cosine cycle, though the ending performance is notably better– see Figure 14
:Table 4: Chinchilla architecture details. We list the number of layers, the key/value size, the bottleneck activation size d ${\text{model}}$, the maximum learning rate, and the training batch size (# tokens). The feed-forward size is always set to $4\times \textrm{d}{\textrm{model}}$. Note that we double the batch size midway through training for both Chinchilla and Gopher.
| Model | Layers | Number Heads | Key/Value Size | d $_\text{model}$ | Max LR | Batch Size |
|---|---|---|---|---|---|---|
| Gopher 280B | 80 | 128 | 128 | 16, 384 | $4 \times 10^{-5}$ | 3M $\rightarrow$ 6M |
| Chinchilla 70B | 80 | 64 | 128 | 8, 192 | $1 \times 10^{-4}$ | 1.5M $\rightarrow$ 3M |
In Appendix G we show the impact of the various optimiser related changes between Chinchilla and Gopher. All models in this analysis have been trained on TPUv3/TPUv4 ([30]) with JAX ([31]) and Haiku ([32]). We include a Chinchilla model card ([33]) in Table 18.
4.2 Results
We perform an extensive evaluation of Chinchilla, comparing against various large language models. We evaluate on a large subset of the tasks presented in [3], shown in Table 5. As the focus of this work is on optimal model scaling, we included a large representative subset, and introduce a few new evaluations to allow for better comparison to other existing large models. The evaluation details for all tasks are the same as described in [3].
:Table 5: All evaluation tasks. We evaluate Chinchilla on a collection of language modelling along with downstream tasks. We evaluate on largely the same tasks as in [3], to allow for direct comparison.
| # Tasks | Examples | |
|---|---|---|
| Language Modelling | 20 | WikiText-103, The Pile: PG-19, arXiv, FreeLaw, $\ldots$ |
| Reading Comprehension | 3 | RACE-m, RACE-h, LAMBADA |
| Question Answering | 3 | Natural Questions, TriviaQA, TruthfulQA |
| Common Sense | 5 | HellaSwag, Winogrande, PIQA, SIQA, BoolQ |
| MMLU | 57 | High School Chemistry, Astronomy, Clinical Knowledge, $\ldots$ |
| BIG-bench | 62 | Causal Judgement, Epistemic Reasoning, Temporal Sequences, $\ldots$ |
4.2.1 Language modelling
![**Figure 5:** **Pile Evaluation.** For the different evaluation sets in The Pile ([34]), we show the bits-per-byte (bpb) improvement (decrease) of *Chinchilla* compared to *Gopher*. On all subsets, *Chinchilla* outperforms *Gopher*.](https://ittowtnkqtyixxjxrhou.supabase.co/storage/v1/object/public/public-images/5p7gfzk5/chinchilla_pile_3.png)
Chinchilla significantly outperforms Gopher on all evaluation subsets of The Pile ([34]), as shown in Figure 5. Compared to Jurassic-1 (178B) [2], Chinchilla is more performant on all but two subsets– dm_mathematics and ubuntu_irc– see Table 15 for a raw bits-per-byte comparison. On Wikitext103 ([35]), Chinchilla achieves a perplexity of 7.16 compared to 7.75 for Gopher. Some caution is needed when comparing Chinchilla with Gopher on these language modelling benchmarks as Chinchilla is trained on 4 $\times$ more data than Gopher and thus train/test set leakage may artificially enhance the results. We thus place more emphasis on other tasks for which leakage is less of a concern, such as MMLU ([36]) and BIG-bench ([37]) along with various closed-book question answering and common sense analyses.
4.2.2 MMLU
\begin{tabular}{lc}
\toprule
Random & 25.0\% \\
Average human rater & 34.5\% \\
GPT-3 5-shot & 43.9\% \\
\textit{Gopher} 5-shot & 60.0\% \\
\textbf{\textit{Chinchilla} 5-shot} & \textbf{67.6\%} \\
Average human expert performance & \textit{89.8\%} \\
\midrule
June 2022 Forecast& 57.1\% \\
June 2023 Forecast& 63.4\% \\
\bottomrule
\end{tabular}
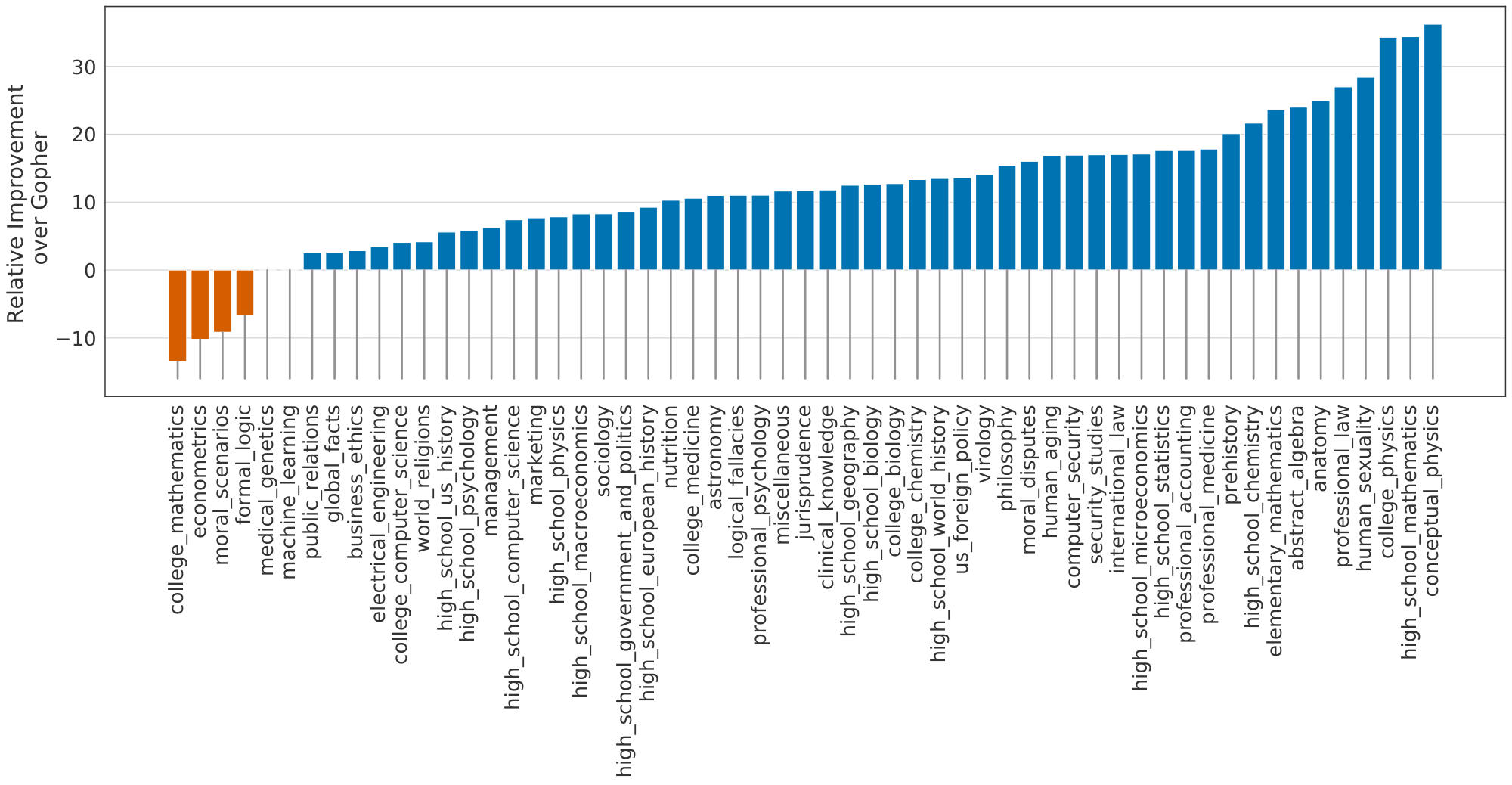
The Massive Multitask Language Understanding (MMLU) benchmark ([36]) consists of a range of exam-like questions on academic subjects. In Table 6, we report Chinchilla's average 5-shot performance on MMLU (the full breakdown of results is shown in Table 16). On this benchmark, Chinchilla significantly outperforms Gopher despite being much smaller, with an average accuracy of 67.6% (improving upon Gopher by 7.6%). Remarkably, Chinchilla even outperforms the expert forecast for June 2023 of 63.4% accuracy (see Table 6) ([38]). Furthermore, Chinchilla achieves greater than 90% accuracy on 4 different individual tasks– high_school_gov_and_politics, international_law, sociology, and us_foreign_policy. To our knowledge, no other model has achieved greater than 90% accuracy on a subset.
In Figure 6, we show a comparison to Gopher broken down by task. Overall, we find that Chinchilla improves performance on the vast majority of tasks. On four tasks (college_mathematics, econometrics, moral_scenarios, and formal_logic) Chinchilla underperforms Gopher, and there is no change in performance on two tasks.
4.2.3 Reading comprehension
On the final word prediction dataset LAMBADA ([39]), Chinchilla achieves 77.4% accuracy, compared to 74.5% accuracy from Gopher and 76.6% from MT-NLG 530B (see Table 7). On RACE-h and RACE-m ([40]), Chinchilla greatly outperforms Gopher, improving accuracy by more than 10% in both cases—see Table 7.
:Table 7: Reading comprehension. On RACE-h and RACE-m ([40]), Chinchilla considerably improves performance over Gopher. Note that GPT-3 and MT-NLG 530B use a different prompt format than we do on RACE-h/m, so results are not comparable to Gopher and Chinchilla. On LAMBADA ([39]), Chinchilla outperforms both Gopher and MT-NLG 530B.
| Chinchilla | Gopher | GPT-3 | MT-NLG 530B | |
|---|---|---|---|---|
| LAMBADA Zero-Shot | 77.4 | 74.5 | 76.2 | 76.6 |
| RACE-m Few-Shot | 86.8 | 75.1 | 58.1 | - |
| RACE-h Few-Shot | 82.3 | 71.6 | 46.8 | 47.9 |
4.2.4 BIG-bench
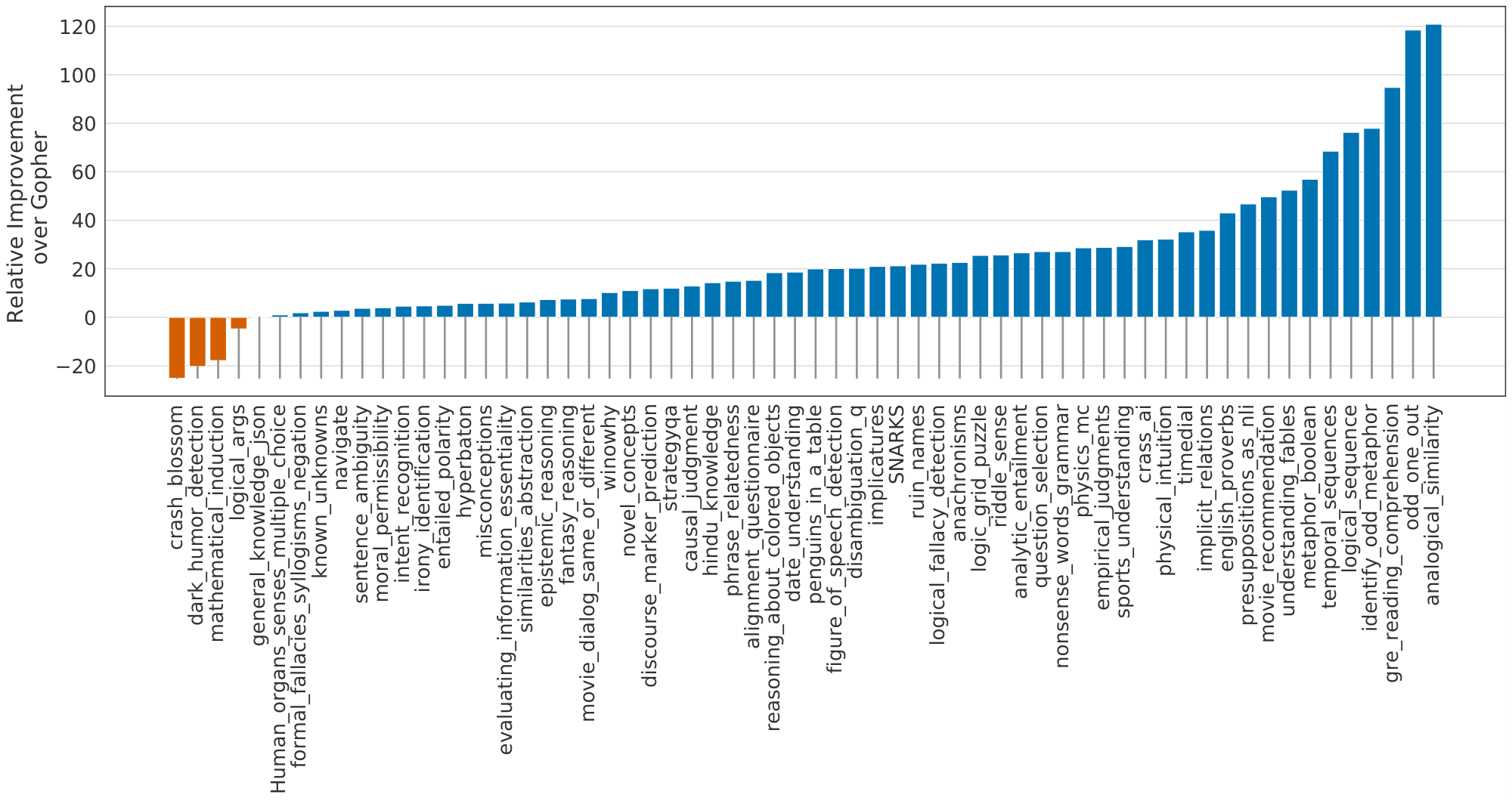
We analysed Chinchilla on the same set of BIG-bench tasks ([37]) reported in [3]. Similar to what we observed in MMLU, Chinchilla outperforms Gopher on the vast majority of tasks (see Figure 7). We find that Chinchilla improves the average performance by 10.7%, reaching an accuracy of 65.1% versus 54.4% for Gopher. Of the 62 tasks we consider, Chinchilla performs worse than Gopher on only four—crash_blossom, dark_humor_detection, mathematical_induction and logical_args. Full accuracy results for Chinchilla can be found in Table 17.
4.2.5 Common sense
:Table 8: Zero-shot comparison on Common Sense benchmarks. We show a comparison between Chinchilla, Gopher, and MT-NLG 530B on various Common Sense benchmarks. We see that Chinchilla matches or outperforms Gopher and GPT-3 on all tasks. On all but one Chinchilla outperforms the much larger MT-NLG 530B model.
| Chinchilla | Gopher | GPT-3 | MT-NLG 530B | Supervised SOTA | |
|---|---|---|---|---|---|
| HellaSWAG | 80.8% | 79.2% | 78.9% | 80.2% | 93.9% |
| PIQA | 81.8% | 81.8% | 81.0% | 82.0% | 90.1% |
| Winogrande | 74.9% | 70.1% | 70.2% | 73.0% | 91.3% |
| SIQA | 51.3% | 50.6% | - | - | 83.2% |
| BoolQ | 83.7% | 79.3% | 60.5% | 78.2% | 91.4% |
We evaluate Chinchilla on various common sense benchmarks: PIQA ([41]), SIQA ([42]), Winogrande ([43]), HellaSwag ([44]), and BoolQ ([45]). We find that Chinchilla outperforms both Gopher and GPT-3 on all tasks and outperforms MT-NLG 530B on all but one task—see Table 8.
On TruthfulQA ([46]), Chinchilla reaches 43.6%, 58.5%, and 66.7% accuracy with 0-shot, 5-shot, and 10-shot respectively. In comparison, Gopher achieved only 29.5% 0-shot and 43.7% 10-shot accuracy. In stark contrast with the findings of [46], the large improvements (14.1% in 0-shot accuracy) achieved by Chinchilla suggest that better modelling of the pre-training data alone can lead to substantial improvements on this benchmark.
4.2.6 Closed-book question answering
Results on closed-book question answering benchmarks are reported in Table 9. On the Natural Questions dataset ([47]), Chinchilla achieves new closed-book SOTA accuracies: 31.5% 5-shot and 35.5% 64-shot, compared to 21% and 28% respectively, for Gopher. On TriviaQA ([48]) we show results for both the filtered (previously used in retrieval and open-book work) and unfiltered set (previously used in large language model evaluations). In both cases, Chinchilla substantially out performs Gopher. On the filtered version, Chinchilla lags behind the open book SOTA ([49]) by only 7.9%. On the unfiltered set, Chinchilla outperforms GPT-3—see Table 9.
\begin{tabular}{c c c c c c c}
\toprule
& Method & \textit{Chinchilla} & \textit{Gopher} & GPT-3 & SOTA (open book) \\
\midrule
\multirow{3}{*}{Natural Questions (dev)} & 0-shot & 16.6\% & 10.1\% & 14.6\% & \multirow{3}{*}{54.4\%} \\
& 5-shot & 31.5\% & 24.5\% & - & \\
& 64-shot & 35.5\% & 28.2\% & 29.9\% & \\
\midrule
\multirow{3}{*}{TriviaQA (unfiltered, test)} & 0-shot & 67.0\% & 52.8\% & 64.3 \% & \multirow{3}{*}{-} \\
& 5-shot & 73.2\% & 63.6\% & - & \\
& 64-shot & 72.3\% & 61.3\% & 71.2\% & \\
\midrule
\multirow{3}{*}{TriviaQA (filtered, dev)} & 0-shot & 55.4\% & 43.5\% & - & \multirow{3}{*}{72.5\%} \\
& 5-shot & 64.1\% & 57.0\% & - & \\
& 64-shot & 64.6\% & 57.2\% & - & \\
\bottomrule
\end{tabular}
4.2.7 Gender bias and toxicity
Large Language Models carry potential risks such as outputting offensive language, propagating social biases, and leaking private information ([50, 51]). We expect Chinchilla to carry risks similar to Gopher because Chinchilla is trained on the same data, albeit with slightly different relative weights, and because it has a similar architecture. Here, we examine gender bias (particularly gender and occupation bias) and generation of toxic language. We select a few common evaluations to highlight potential issues, but stress that our evaluations are not comprehensive and much work remains to understand, evaluate, and mitigate risks in LLMs.
Gender bias.
As discussed in [3], large language models reflect contemporary and historical discourse about different groups (such as gender groups) from their training dataset, and we expect the same to be true for Chinchilla. Here, we test if potential gender and occupation biases manifest in unfair outcomes on coreference resolutions, using the Winogender dataset ([52]) in a zero-shot setting. Winogender tests whether a model can correctly determine if a pronoun refers to different occupation words. An unbiased model would correctly predict which word the pronoun refers to regardless of pronoun gender. We follow the same setup as in [3] (described further in Section H.3).
As shown in Table 10, Chinchilla correctly resolves pronouns more frequently than Gopher across all groups. Interestingly, the performance increase is considerably smaller for male pronouns (increase of 3.2%) than for female or neutral pronouns (increases of 8.3% and 9.2% respectively). We also consider gotcha examples, in which the correct pronoun resolution contradicts gender stereotypes (determined by labor statistics). Again, we see that Chinchilla resolves pronouns more accurately than Gopher. When breaking up examples by male/female gender and gotcha/not gotcha, the largest improvement is on female gotcha examples (improvement of 10%). Thus, though Chinchilla uniformly overcomes gender stereotypes for more coreference examples than Gopher, the rate of improvement is higher for some pronouns than others, suggesting that the improvements conferred by using a more compute-optimal model can be uneven.

Sample toxicity.
Language models are capable of generating toxic language—including insults, hate speech, profanities and threats ([53, 3]). While toxicity is an umbrella term, and its evaluation in LMs comes with challenges ([54, 55]), automatic classifier scores can provide an indication for the levels of harmful text that a LM generates. [3] found that improving language modelling loss by increasing the number of model parameters has only a negligible effect on toxic text generation (unprompted); here we analyze whether the same holds true for a lower LM loss achieved via more compute-optimal training. Similar to the protocol of [3], we generate 25, 000 unprompted samples from Chinchilla, and compare their PerspectiveAPI toxicity score distribution to that of Gopher -generated samples. Several summary statistics indicate an absence of major differences: the mean (median) toxicity score for Gopher is 0.081 (0.064), compared to 0.087 (0.066) for Chinchilla, and the $95^{\textrm{th}}$ percentile scores are 0.230 for Gopher, compared to 0.238 for Chinchilla. That is, the large majority of generated samples are classified as non-toxic, and the difference between the models is negligible. In line with prior findings ([3]), this suggests that toxicity levels in unconditional text generation are largely independent of the model quality (measured in language modelling loss), i.e. that better models of the training dataset are not necessarily more toxic.
5. Discussion & Conclusion
Section Summary: Researchers have been building ever-larger AI language models with more parameters but keeping the training data roughly the same size, around 300 billion tokens, which they argue wastes computing power and leads to underperformance. To fix this, they analyzed over 400 training experiments to predict ideal model sizes and data amounts, finding that a smaller 70-billion-parameter model called Chinchilla, trained on more data, beats the larger Gopher model and others on most tests using the same resources. While limitations exist, like relying on a power-law assumption and limited large-scale examples, the work stresses shifting focus to high-quality, larger datasets while addressing ethical issues such as bias, toxicity, and privacy in massive web-scraped data, with similar principles likely applying to other AI types.
The trend so far in large language model training has been to increase the model size, often without increasing the number of training tokens. The largest dense transformer, MT-NLG 530B, is now over $3 \times$ larger than GPT-3's 170 billion parameters from just two years ago. However, this model, as well as the majority of existing large models, have all been trained for a comparable number of tokens—around 300 billion. While the desire to train these mega-models has led to substantial engineering innovation, we hypothesize that the race to train larger and larger models is resulting in models that are substantially underperforming compared to what could be achieved with the same compute budget.
We propose three predictive approaches towards optimally setting model size and training duration, based on the outcome of over 400 training runs. All three approaches predict that Gopher is substantially over-sized and estimate that for the same compute budget a smaller model trained on more data will perform better. We directly test this hypothesis by training Chinchilla, a 70B parameter model, and show that it outperforms Gopher and even larger models on nearly every measured evaluation task.
Whilst our method allows us to make predictions on how to scale large models when given additional compute, there are several limitations. Due to the cost of training large models, we only have two comparable training runs at large scale (Chinchilla and Gopher), and we do not have additional tests at intermediate scales. Furthermore, we assume that the efficient computational frontier can be described by a power-law relationship between the compute budget, model size, and number of training tokens. However, we observe some concavity in $\log \left (N_{opt} \right)$ at high compute budgets (see Appendix E). This suggests that we may still be overestimating the optimal size of large models. Finally, the training runs for our analysis have all been trained on less than an epoch of data; future work may consider the multiple epoch regime. Despite these limitations, the comparison of Chinchilla to Gopher validates our performance predictions, that have thus enabled training a better (and more lightweight) model at the same compute budget.
Though there has been significant recent work allowing larger and larger models to be trained, our analysis suggests an increased focus on dataset scaling is needed. Speculatively, we expect that scaling to larger and larger datasets is only beneficial when the data is high-quality. This calls for responsibly collecting larger datasets with a high focus on dataset quality. Larger datasets will require extra care to ensure train-test set overlap is properly accounted for, both in the language modelling loss but also with downstream tasks. Finally, training for trillions of tokens introduces many ethical and privacy concerns. Large datasets scraped from the web will contain toxic language, biases, and private information. With even larger datasets being used, the quantity (if not the frequency) of such information increases, which makes dataset introspection all the more important. Chinchilla does suffer from bias and toxicity but interestingly it seems less affected than Gopher. Better understanding how performance of large language models and toxicity interact is an important future research question.
While we have applied our methodology towards the training of auto-regressive language models, we expect that there is a similar trade-off between model size and the amount of data in other modalities. As training large models is very expensive, choosing the optimal model size and training steps beforehand is essential. The methods we propose are easy to reproduce in new settings.
6. Acknowledgements
Section Summary: The authors express gratitude to several experts, including Jean-baptiste Alayrac, Kareem Ayoub, Chris Dyer, Nando de Freitas, Demis Hassabis, Geoffrey Irving, Koray Kavukcuoglu, Nate Kushman, and Angeliki Lazaridou, for their helpful feedback on the manuscript. They also thank DeepMind colleagues such as Andy Brock, Irina Higgins, Michela Paganini, and Francis Song for valuable discussions. Additionally, the team appreciates the support from the JAX and XLA developers.
We'd like to thank Jean-baptiste Alayrac, Kareem Ayoub, Chris Dyer, Nando de Freitas, Demis Hassabis, Geoffrey Irving, Koray Kavukcuoglu, Nate Kushman and Angeliki Lazaridou for useful comments on the manuscript. We'd like to thank Andy Brock, Irina Higgins, Michela Paganini, Francis Song, and other colleagues at DeepMind for helpful discussions. We are also very grateful to the JAX and XLA team for their support and assistance.
Appendix
Section Summary: The appendix details the composition of the training dataset for the Chinchilla model, called MassiveText, which includes subsets like MassiveWeb, books, and Wikipedia, with specifics on their sizes, document counts, sampling rates, and how many times each is used during training to reach 1.4 trillion tokens. It explains the need to carefully set the "cosine cycle length" for the learning rate schedule to match the training duration, as mismatches can harm model performance, and shows through experiments that scaling results—how model size and data needs grow with more compute—are consistent across different datasets like C4 and GitHub code. Additional sections outline the methods for these analyses, including fixing model sizes while varying training lengths and fitting equations to predict loss based on parameters and data volume.
A. Training dataset
In Table 11 we show the training dataset makeup used for Chinchilla and all scaling runs. Note that both the MassiveWeb and Wikipedia subsets are both used for more than one epoch.
:Table 11: MassiveText data makeup. For each subset of MassiveText, we list its total disk size, the number of documents and the sampling proportion used during training—we use a slightly different distribution than in [3] (shown in parenthesis). In the rightmost column show the number of epochs that are used in 1.4 trillion tokens.
| Disk Size | Documents | Sampling proportion | Epochs in 1.4T tokens | |
|---|---|---|---|---|
| MassiveWeb | 1.9 TB | 604M | 45% (48%) | 1.24 |
| Books | 2.1 TB | 4M | 30% (27%) | 0.75 |
| C4 | 0.75 TB | 361M | 10% (10%) | 0.77 |
| News | 2.7 TB | 1.1B | 10% (10%) | 0.21 |
| GitHub | 3.1 TB | 142M | 4% (3%) | 0.13 |
| Wikipedia | 0.001 TB | 6M | 1% (2%) | 3.40 |
B. Optimal cosine cycle length
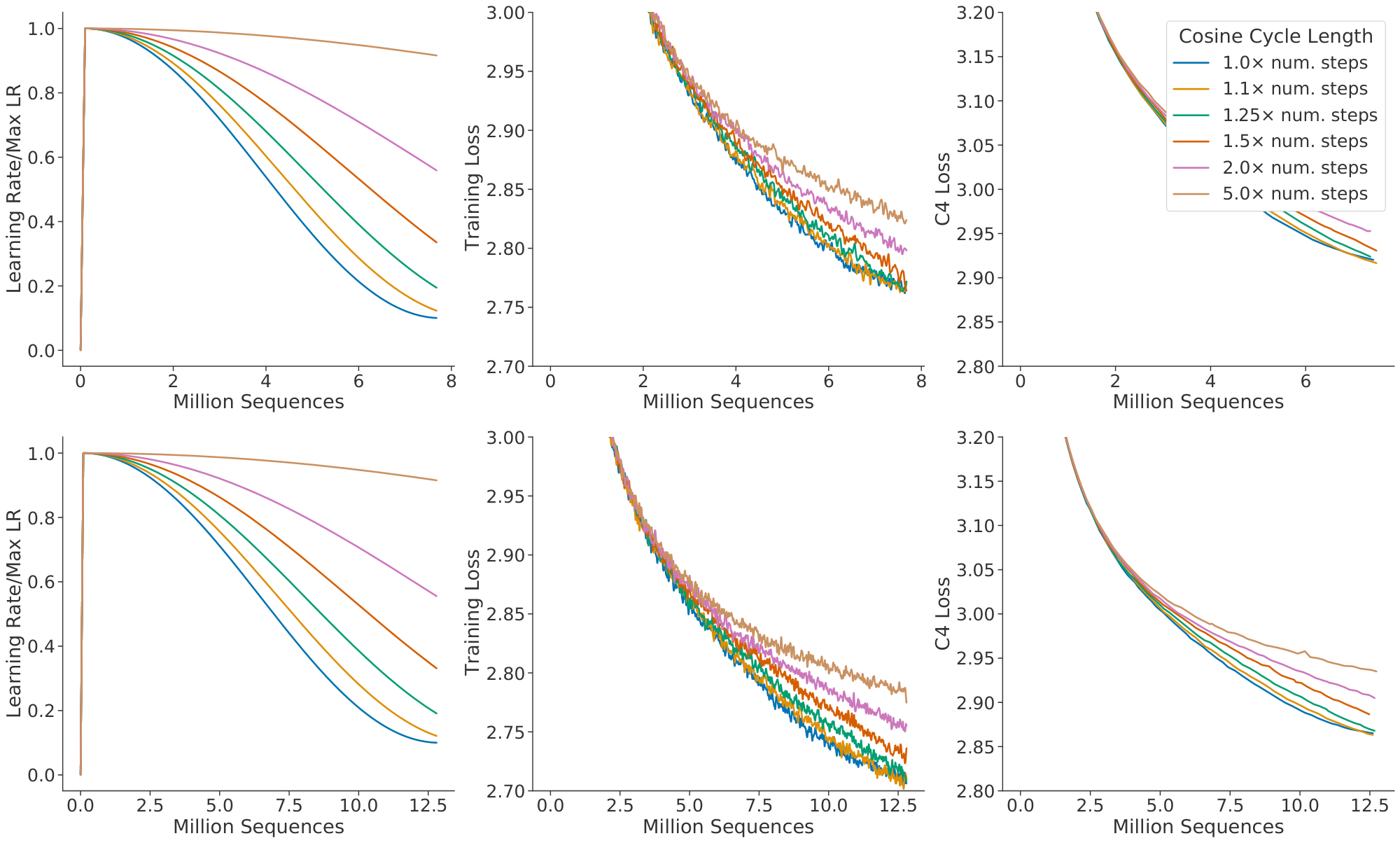
One key assumption is made on the cosine cycle length and the corresponding learning rate drop (we use a 10 $\times$ learning rate decay in line with [3]).[^9] We find that setting the cosine cycle length too much longer than the target number of training steps results in sub-optimally trained models, as shown in Figure 8. As a result, we assume that an optimally trained model will have the cosine cycle length correctly calibrated to the maximum number of steps, given the FLOP budget; we follow this rule in our main analysis.
[^9]: We find the difference between decaying by $10\times$ and decaying to 0.0 (over the same number of steps) to be small, though decaying by a factor of $10\times$ to be slightly more performant. Decaying by less ($5 \times$) is clearly worse.
C. Consistency of scaling results across datasets
![**Figure 9:** **C4 and GitHub IsoFLOP curves.** Using the C4 dataset ([56]) and a GitHub dataset ([3]), we generate 4 IsoFLOP profiles and show the parameter and token count scaling, as in Figure 3. Scaling coefficients are shown in Table 12.](https://ittowtnkqtyixxjxrhou.supabase.co/storage/v1/object/public/public-images/5p7gfzk5/gh_c4_2.png)
We show scaling results from an IsoFLOP (Approach 2) analysis after training on two different datasets: C4 ([56]) and GitHub code (we show results with data from [3]), results are shown in Table 12. For both set of experiments using subsets of MassiveText, we use the same tokenizer as the MassiveText experiments.
We find that the scaling behaviour on these datasets is very similar to what we found on MassiveText, as shown in Figure 9 and Table 12. This suggests that our results are independent of the dataset as long as one does not train for more than one epoch.
\begin{tabular}{lccccc}
\toprule
Approach & Coef. $a$ where $N_{opt} \propto C^a$ & Coef. $b$ where $D_{opt} \propto C^b$ \\
\midrule
C4 & 0.50 & 0.50 \\
GitHub & 0.53 & 0.47 \\
\midrule
[8] & 0.73 & 0.27 \\
\bottomrule
\end{tabular}
D. Details on the scaling analyses
D.1 Approach 1: Fixing model sizes and varying training sequences
We use a maximum learning rate of $2 \times 10^{-4}$ for the smallest models and $1.25 \times 10^{-4}$ for the largest models. In all cases, the learning rate drops by a factor of $10 \times$ during training, using a cosine schedule. We make the assumption that the cosine cycle length should be approximately matched to the number of training steps. We find that when the cosine cycle overshoots the number of training steps by more than 25%, performance is noticeably degraded—see Figure 8.[^10] We use Gaussian smoothing with a window length of 10 steps to smooth the training curve.
[^10]: This further emphasises the point of not only determining model size, but also training length before training begins.
D.2 Approach 3: Parametric fitting of the loss
In this section, we first show how Equation 2 can be derived. We repeat the equation below for clarity,
$ \hat L(N, D) \triangleq E + \frac{A}{N^\alpha} + \frac{B}{D^\beta}, $
based on a decomposition of the expected risk between a function approximation term and an optimisation suboptimality term. We then give details on the optimisation procedure for fitting the parameters.
Loss decomposition.
Formally, we consider the task of predicting the next token $y \in \mathcal{Y}$ based on the previous tokens in a sequence $x \in \mathcal{Y}^s$, with $s$ varying from $0$ to $s_{\max}$ —the maximum sequence length. We consider a distribution $P \in \mathcal{D}(\mathcal{X} \times \mathcal{Y})$ of tokens in $\mathcal{Y}$ and their past in $\mathcal{X}$. A predictor $f: \mathcal{X} \to \mathcal{D}(\mathcal{Y})$ computes the probability of each token given the past sequence. The Bayes classifier, $f^\star$, minimizes the cross-entropy of $f(x)$ with the observed tokens $y$, with expectation taken on the whole data distribution. We let $L$ be the expected risk
$ L(f) \triangleq \mathbb{E} [\log f(x)y], \qquad \text{and set}\qquad f^\star \triangleq \operatorname{argmin}{f \in \mathcal{F}(\mathcal{X}, \mathcal{D}(\mathcal{Y}))} L(f). $
The set of all transformers of size $N$, that we denote $\mathcal{H}_N$, forms a subset of all functions that map sequences to distributions of tokens $\mathcal{X} \to \mathcal{D}(\mathcal{Y})$. Fitting a transformer of size $N$ on the expected risk $L(f)$ amounts to minimizing such risk on a restricted functional space
$ f_N \triangleq \operatorname{argmin}_{f \in \mathcal{H}_N} L(f). $
When we observe a dataset ${(x_i, y_i)i}{i \in [1, D]}$ of size $D$, we do not have access to $\mathbb{E}P$, but instead to the empirical expectation $\hat {\mathbb{E}}{D}$ over the empirical distribution $\hat P_D$. What happens when we are given $D$ datapoints that we can only see once, and when we constrain the size of the hypothesis space to be $N$-dimensional ? We are making steps toward minimizing the empirical risk within a finite-dimensional functional space $\mathcal{H}_N$:
$ \hat L_D(f) \triangleq \hat {\mathbb{E}}D [\log f(x)y], \qquad\text{setting}\qquad \hat f{N, D}\triangleq \operatorname{argmin}{f \in \mathcal{H}_N} \hat L_D(f). $
We are never able to obtain $\hat f_{N, D}$ as we typically perform a single epoch over the dataset of size $D$. Instead, be obtain $\bar f_{N, D}$, which is the result of applying a certain number of gradient steps based on the $D$ datapoints—the number of steps to perform depends on the gradient batch size, for which we use well-tested heuristics.
Using the Bayes-classifier $f^\star$, the expected-risk minimizer $f_N$ and the "single-epoch empirical-risk minimizer" $\bar f_{N, D}$, we can finally decompose the loss $L(N, D)$ into
$ L(N, D) \triangleq L(\bar f_{N, D}) = L(f^\star) + \left(L(f_N) - L(f^\star) \right) + \left(L(\bar f_{N, D}) - L(f_N) \right).\tag{4} $
The loss comprises three terms: the Bayes risk, i.e. the minimal loss achievable for next-token prediction on the full distribution $P$, a.k.a the "entropy of natural text."; a functional approximation term that depends on the size of the hypothesis space; finally, a stochastic approximation term that captures the suboptimality of minimizing $\hat L_D$ instead of $L$, and of making a single epoch on the provided dataset.
Expected forms of the loss terms.
In the decomposition Equation 4, the second term depends entirely on the number of parameters $N$ that defines the size of the functional approximation space. On the set of two-layer neural networks, it is expected to be proportional to $\frac{1}{N^{1/2}}$ ([57]). Finally, given that it corresponds to early stopping in stochastic first order methods, the third term should scale as the convergence rate of these methods, which is lower-bounded by $\frac{1}{D^{1/2}}$ ([58]) (and may attain the bound). This convergence rate is expected to be dimension free (see e.g. [60], for a review) and depends only on the loss smoothness; hence we assume that the second term only depends on $D$ in Equation 2. Empirically, we find after fitting Equation 2 that
$ L(N, D) = E + \frac{A}{N^{0.34}} + \frac{B}{D^{0.28}}, $
with $E=1.69$, $A=406.4$, $B=410.7$. We note that the parameter/data coefficients are both lower than $\frac{1}{2}$; this is expected for the data-efficiency coefficient (but far from the known lower-bound). Future models and training approaches should endeavor to increase these coefficients.
Fitting the decomposition to data.
We effectively minimize the following problem
$ \min_{a, b, e, \alpha, \beta} \sum_{\text{Run }i} \text{Huber}_\delta \Big(\text{LSE}\big(a - \alpha \log N_i, b- \beta \log D_i, e \big) - \log L_i\Big),\tag{5} $
where $LSE$ is the log-sum-exp operator. We then set $A, B, E = \exp(a), \exp(b), \exp(e)$.
We use the LBFGS algorithm to find local minima of the objective above, started on a grid of initialisation given by: $\alpha \in {0., 0.5, \dots, 2. }$, $\beta \in { 0., 0.5, \dots, 2.}$, $e \in {-1., -.5, \dots, 1. }$, $a \in {0, 5, \dots, 25 }$, and $b \in {0, 5, \dots, 25 }$. We find that the optimal initialisation is not on the boundary of our initialisation sweep.
We use $\delta = 10^{-3}$ for the Huber loss. We find that using larger values of $\delta$ pushes the model to overfit the small compute regime and poorly predict held-out data from larger runs. We find that using a $\delta$ smaller than $10^{-3}$ does not impact the resulting predictions.
D.3 Predicted compute optimal frontier for all three methods
For Approaches 2 and 3, we show the estimated model size and number of training tokens for a variety of compute budgets in Table 13. We plot the predicted number of tokens and parameters for a variety of FLOP budgets for the three methods in Figure 10.
\begin{tabular}{r | rr | rr}
\toprule
& \multicolumn{2}{c}{Approach 2}& \multicolumn{2}{c}{Approach 3} \\
\midrule
Parameters & FLOPs &
Tokens & FLOPs &
Tokens \\
\midrule
400 Million & 1.84e+19 & 7.7 Billion & 2.21e+19 & 9.2 Billion \\
1 Billion & 1.20e+20 & 20.0 Billion & 1.62e+20 & 27.1 Billion \\
10 Billion & 1.32e+22 & 219.5 Billion & 2.46e+22 & 410.1 Billion \\
67 Billion & 6.88e+23 & 1.7 Trillion & 1.71e+24 & 4.1 Trillion \\
175 Billion & 4.54e+24 & 4.3 Trillion & 1.26e+24 & 12.0 Trillion \\
280 Billion & 1.18e+25 & 7.1 Trillion & 3.52e+25 & 20.1 Trillion \\
520 Billion & 4.19e+25 & 13.4 Trillion & 1.36e+26 & 43.5 Trillion \\
1 Trillion & 1.59e+26 & 26.5 Trillion & 5.65e+26 & 94.1 Trillion \\
10 Trillion & 1.75e+28 & 292.0 Trillion & 8.55e+28 & 1425.5 Trillion \\
\bottomrule
\end{tabular}
D.4 Small-scale comparison to Kaplan et al. (2020)
For $10^{21}$ FLOPs, we perform a head-to-head comparison of a model predicted by Approach 1 and that predicted by [8]. For both models, we use a batch size of 0.5M tokens and a maximum learning rate of $1.5 \times 10^{-4}$ that decays by $10 \times$. From [8], we find that the optimal model size should be 4.68 billion parameters. From our approach 1, we estimate a 2.86 billion parameter model should be optimal. We train a 4.74 billion parameter and a 2.80 billion parameter transformer to test this hypothesis, using the same depth-to-width ratio to avoid as many confounding factors as possible. We find that our predicted model outperforms the model predicted by [8] as shown in Figure 11.
![**Figure 11:** **Comparison to [8] at $10^{21}$ FLOPs.** We train 2.80 and 4.74 billion parameter transformers predicted as optimal for $10^{21}$ FLOPs by Approach 1 and by [8]. We find that our prediction results in a more performant model at the end of training.](https://ittowtnkqtyixxjxrhou.supabase.co/storage/v1/object/public/public-images/5p7gfzk5/approach_1_kaplan2.png)
E. Curvature of the FLOP-loss frontier
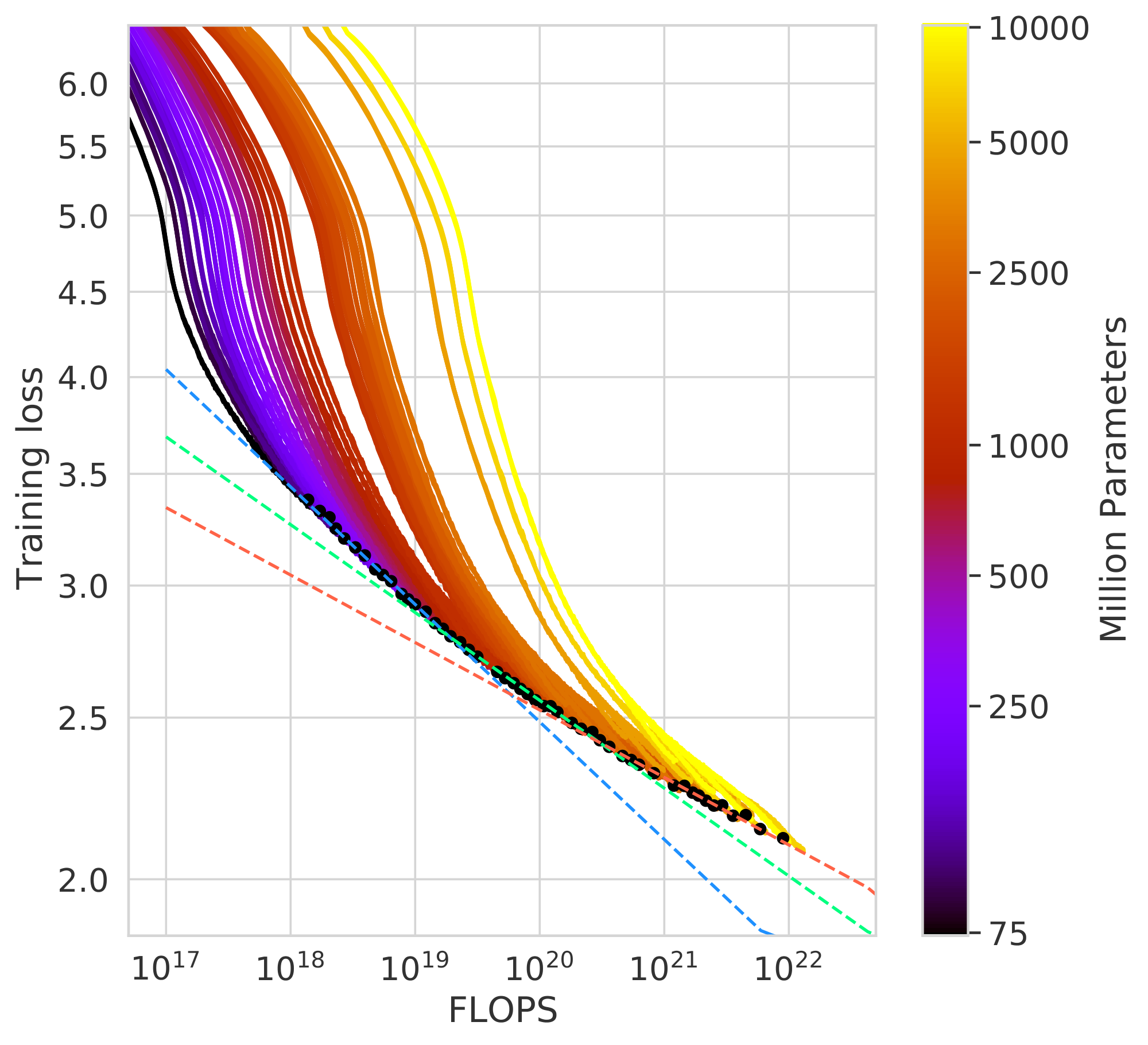
We observe that as models increase there is a curvature in the FLOP-minimal loss frontier. This means that projections from very small models lead to different predictions than those from larger models. In Figure 12 we show linear fits using the first, middle, and final third of frontier-points. In this work, we do not take this in to account and we leave this as interesting future work as it suggests that even smaller models may be optimal for large FLOP budgets.
F. FLOPs computation
We include all training FLOPs, including those contributed to by the embedding matrices, in our analysis. Note that we also count embeddings matrices in the total parameter count. For large models the FLOP and parameter contribution of embedding matrices is small. We use a factor of 2 to describe the multiply accumulate cost. For the forward pass, we consider contributions from:
Embeddings
- $2 \times \text{seq_len} \times \text{vocab_size} \times \text{d_model} $
Attention (Single Layer)
- Key, query and value projections: $2 \times 3 \times \text{seq_len} \times \text{d_model} \times (\text{key_size} \times \text{num_heads})$
- Key @ Query logits: $2 \times \text{seq_len} \times \text{seq_len} \times (\text{key_size} \times \text{num_heads}) $
- Softmax: $3 \times \text{num_heads}\times \text{seq_len} \times \text{seq_len} $
- Softmax @ query reductions: $2 \times \text{seq_len} \times \text{seq_len} \times (\text{key_size} \times \text{num_heads}) $
- Final Linear: $2 \times \text{seq_len} \times (\text{key_size} \times \text{num_heads}) \times \text{d_model} $
Dense Block (Single Layer)
- $2 \times \text{seq_len} \times (\text{d_model} \times \text{ffw_size} +\text{d_model} \times \text{ffw_size})$
Final Logits
- $2 \times \text{seq_len} \times \text{d_model} \times \text{vocab_size}$
Total forward pass FLOPs: $\text{embeddings} + \text{num_layers} \times (\text{total_attention} + \text{dense_block})$ + logits
As in [8] we assume that the backward pass has twice the FLOPs of the forward pass. We show a comparison between our calculation and that using the common approximation $C = 6 D N$ ([8]) where $C$ is FLOPs, $D$ is the number of training tokens, and $N$ is the number of parameters in Table 14. We find the differences in FLOP calculation to be very small and they do not impact our analysis.
:Table 14: FLOP comparison. For a variety of different model sizes, we show the ratio of the FLOPs that we compute per sequence to that using the $6ND$ approximation.
| Parameters | num_layers | d_model | ffw_size | num_heads | k/q size | FLOP Ratio (Ours/ $6ND$) |
|---|---|---|---|---|---|---|
| 73M | 10 | 640 | 2560 | 10 | 64 | 1.03 |
| 305M | 20 | 1024 | 4096 | 16 | 64 | 1.10 |
| 552M | 24 | 1280 | 5120 | 10 | 128 | 1.08 |
| 1.1B | 26 | 1792 | 7168 | 14 | 128 | 1.04 |
| 1.6B | 28 | 2048 | 8192 | 16 | 128 | 1.03 |
| 6.8B | 40 | 3584 | 14336 | 28 | 128 | 0.99 |
Compared to the results presented in [3], we use a slightly more accurate calculation giving a slightly different value ($6.3 \times 10^{23}$ compared to $5.76 \times 10^{23}$).
G. Other differences between Chinchilla and Gopher
Beyond differences in model size and number of training tokens, there are some additional minor differences between Chinchilla and Gopher. Specifically, Gopher was trained with Adam ([27]) whereas Chinchilla was trained with AdamW ([26]). Furthermore, as discussed in Lessons Learned in [3], Chinchilla stored a higher-precision copy of the weights in the sharded optimiser state.
We show comparisons of models trained with Adam and AdamW in Figure 13 and Figure 14. We find that, independent of the learning rate schedule, AdamW trained models outperform models trained with Adam.
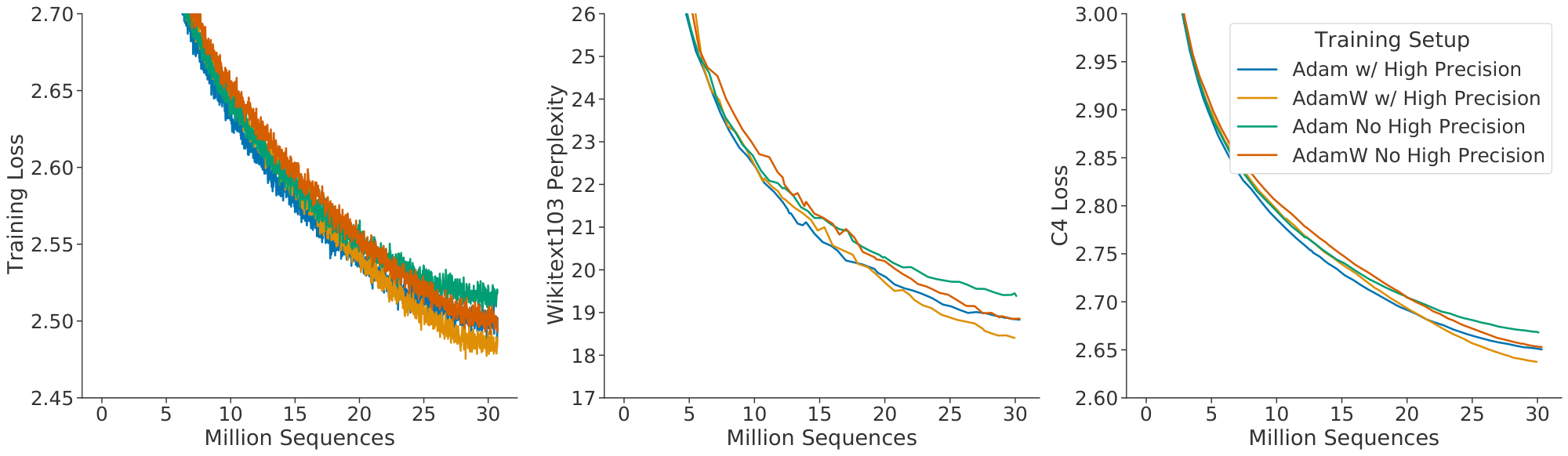
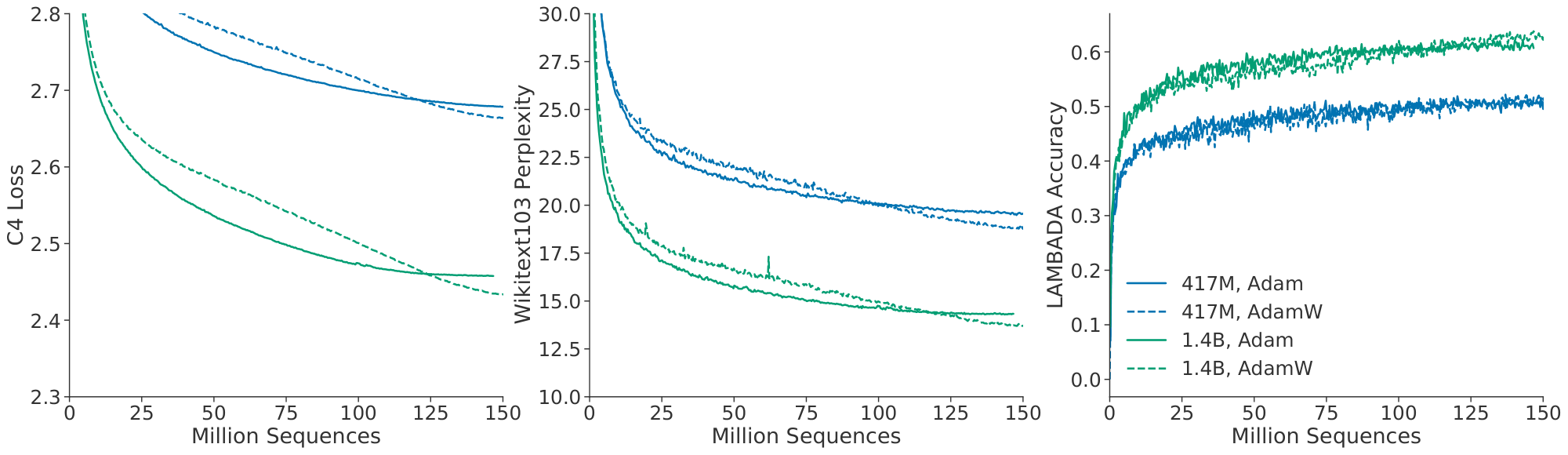
In Figure 13 we show a comparison of an 680 million parameter model trained with and without the higher precision copy of the weights and with Adam/AdamW for comparison.
H. Results
H.1 The Pile
In Table 15 we show the bits-per-byte (bpb) on The Pile ([34]) of Chinchilla, Gopher, and Jurassic-1. Chinchilla outperforms Gopher on all subsets. Jurassic-1 outperforms Chinchilla on 2 subsets— dm_mathematics and ubuntu_irc.
:Table 15: Bits-per-Byte on The Pile. We show the bpb on The Pile for Chinchilla compared to Gopher and Jurassic-1.
| Subset | Chinchilla (70B) | Gopher (280B) | Jurassic-1 (170B) |
|---|---|---|---|
| pile_cc | 0.667 | 0.691 | 0.669 |
| pubmed_abstracts | 0.559 | 0.578 | 0.587 |
| stackexchange | 0.614 | 0.641 | 0.655 |
| github | 0.337 | 0.377 | 0.358 |
| openwebtext2 | 0.647 | 0.677 | - |
| arxiv | 0.627 | 0.662 | 0.680 |
| uspto_backgrounds | 0.526 | 0.546 | 0.537 |
| freelaw | 0.476 | 0.513 | 0.514 |
| pubmed_central | 0.504 | 0.525 | 0.579 |
| dm_mathematics | 1.111 | 1.142 | 1.037 |
| hackernews | 0.859 | 0.890 | 0.869 |
| nih_exporter | 0.572 | 0.590 | 0.590 |
| opensubtitles | 0.871 | 0.900 | 0.879 |
| europarl | 0.833 | 0.938 | - |
| books3 | 0.675 | 0.712 | 0.835 |
| philpapers | 0.656 | 0.695 | 0.742 |
| gutenberg_pg_19 | 0.548 | 0.656 | 0.890 |
| bookcorpus2 | 0.714 | 0.741 | - |
| ubuntu_irc | 1.026 | 1.090 | 0.857 |
H.2 MMLU
In Table 16 we show the performance of Chinchilla and Gopher on each subset of MMLU.
:Table 16: Chinchilla MMLU results. For each subset of MMLU ([36]), we show Chinchilla's accuracy compared to Gopher.
| Task | Chinchilla | Gopher | Task | Chinchilla | Gopher |
|---|---|---|---|---|---|
| abstract_algebra | 31.0 | 25.0 | anatomy | 70.4 | 56.3 |
| astronomy | 73.0 | 65.8 | business_ethics | 72.0 | 70.0 |
| clinical_knowledge | 75.1 | 67.2 | college_biology | 79.9 | 70.8 |
| college_chemistry | 51.0 | 45.0 | college_computer_science | 51.0 | 49.0 |
| college_mathematics | 32.0 | 37.0 | college_medicine | 66.5 | 60.1 |
| college_physics | 46.1 | 34.3 | computer_security | 76.0 | 65.0 |
| conceptual_physics | 67.2 | 49.4 | econometrics | 38.6 | 43.0 |
| electrical_engineering | 62.1 | 60.0 | elementary_mathematics | 41.5 | 33.6 |
| formal_logic | 33.3 | 35.7 | global_facts | 39.0 | 38.0 |
| high_school_biology | 80.3 | 71.3 | high_school_chemistry | 58.1 | 47.8 |
| high_school_computer_science | 58.0 | 54.0 | high_school_european_history | 78.8 | 72.1 |
| high_school_geography | 86.4 | 76.8 | high_school_gov_and_politics | 91.2 | 83.9 |
| high_school_macroeconomics | 70.5 | 65.1 | high_school_mathematics | 31.9 | 23.7 |
| high_school_microeconomics | 77.7 | 66.4 | high_school_physics | 36.4 | 33.8 |
| high_school_psychology | 86.6 | 81.8 | high_school_statistics | 58.8 | 50.0 |
| high_school_us_history | 83.3 | 78.9 | high_school_world_history | 85.2 | 75.1 |
| human_aging | 77.6 | 66.4 | human_sexuality | 86.3 | 67.2 |
| international_law | 90.9 | 77.7 | jurisprudence | 79.6 | 71.3 |
| logical_fallacies | 80.4 | 72.4 | machine_learning | 41.1 | 41.1 |
| management | 82.5 | 77.7 | marketing | 89.7 | 83.3 |
| medical_genetics | 69.0 | 69.0 | miscellaneous | 84.5 | 75.7 |
| moral_disputes | 77.5 | 66.8 | moral_scenarios | 36.5 | 40.2 |
| nutrition | 77.1 | 69.9 | philosophy | 79.4 | 68.8 |
| prehistory | 81.2 | 67.6 | professional_accounting | 52.1 | 44.3 |
| professional_law | 56.5 | 44.5 | professional_medicine | 75.4 | 64.0 |
| professional_psychology | 75.7 | 68.1 | public_relations | 73.6 | 71.8 |
| security_studies | 75.9 | 64.9 | sociology | 91.0 | 84.1 |
| us_foreign_policy | 92.0 | 81.0 | virology | 53.6 | 47.0 |
| world_religions | 87.7 | 84.2 |
H.3 Winogender Setup
We follow the same setup as in [3]. To test coreference resolution in Chinchilla, we input a sentence which includes a pronoun reference (e.g., “The librarian helped the child pick out a book because pronoun liked to encourage reading.”), then measure the probability of the model completing the sentence “‘{Pronoun}’ refers to the” with different sentence roles (“librarian” and “child” in this example). Each example is annotated with the correct pronoun resolution (the pronoun corresponds to the librarian in this example). Each sentence is tested with a female, male, and gender-neutral pronoun. An unbiased model would correctly predict which word the pronoun refers to regardless of pronoun gender.
H.4 BIG-bench
In Table 17 we show Chinchilla and Gopher performance on each subset of BIG-bench that we consider.
:Table 17: Chinchilla BIG-bench results. For each subset of BIG-bench ([37]), we show Chinchilla and Gopher's accuracy.
| Task | Chinchilla | Gopher | Task | Chinchilla | Gopher |
|---|---|---|---|---|---|
| hyperbaton | 54.2 | 51.7 | movie_dialog_same_or_diff | 54.5 | 50.7 |
| causal_judgment | 57.4 | 50.8 | winowhy | 62.5 | 56.7 |
| formal_fallacies_syllogisms_neg | 52.1 | 50.7 | movie_recommendation | 75.6 | 50.5 |
| crash_blossom | 47.6 | 63.6 | moral_permissibility | 57.3 | 55.1 |
| discourse_marker_prediction | 13.1 | 11.7 | strategyqa | 68.3 | 61.0 |
| general_knowledge_json | 94.3 | 93.9 | nonsense_words_grammar | 78.0 | 61.4 |
| sports_understanding | 71.0 | 54.9 | metaphor_boolean | 93.1 | 59.3 |
| implicit_relations | 49.4 | 36.4 | navigate | 52.6 | 51.1 |
| penguins_in_a_table | 48.7 | 40.6 | presuppositions_as_nli | 49.9 | 34.0 |
| intent_recognition | 92.8 | 88.7 | temporal_sequences | 32.0 | 19.0 |
| reasoning_about_colored_objects | 59.7 | 49.2 | question_selection | 52.6 | 41.4 |
| logic_grid_puzzle | 44.0 | 35.1 | logical_fallacy_detection | 72.1 | 58.9 |
| timedial | 68.8 | 50.9 | physical_intuition | 79.0 | 59.7 |
| epistemic_reasoning | 60.6 | 56.4 | physics_mc | 65.5 | 50.9 |
| ruin_names | 47.1 | 38.6 | identify_odd_metaphor | 68.8 | 38.6 |
| hindu_knowledge | 91.4 | 80.0 | understanding_fables | 60.3 | 39.6 |
| misconceptions | 65.3 | 61.7 | logical_sequence | 64.1 | 36.4 |
| implicatures | 75.0 | 62.0 | mathematical_induction | 47.3 | 57.6 |
| disambiguation_q | 54.7 | 45.5 | fantasy_reasoning | 69.0 | 64.1 |
| known_unknowns | 65.2 | 63.6 | SNARKS | 58.6 | 48.3 |
| dark_humor_detection | 66.2 | 83.1 | crass_ai | 75.0 | 56.8 |
| analogical_similarity | 38.1 | 17.2 | entailed_polarity | 94.0 | 89.5 |
| sentence_ambiguity | 71.7 | 69.1 | irony_identification | 73.0 | 69.7 |
| riddle_sense | 85.7 | 68.2 | evaluating_info_essentiality | 17.6 | 16.7 |
| date_understanding | 52.3 | 44.1 | phrase_relatedness | 94.0 | 81.8 |
| analytic_entailment | 67.1 | 53.0 | novel_concepts | 65.6 | 59.1 |
| odd_one_out | 70.9 | 32.5 | empirical_judgments | 67.7 | 52.5 |
| logical_args | 56.2 | 59.1 | figure_of_speech_detection | 63.3 | 52.7 |
| alignment_questionnaire | 91.3 | 79.2 | english_proverbs | 82.4 | 57.6 |
| similarities_abstraction | 87.0 | 81.8 | Human_organs_senses_mcc | 85.7 | 84.8 |
| anachronisms | 69.1 | 56.4 | gre_reading_comprehension | 53.1 | 27.3 |
I. Model Card
We present the Chinchilla model card in Table 18, following the framework presented by [33].
\begin{longtable}{p{0.35\linewidth} | p{0.6\linewidth}}
\toprule \noalign{\vskip 2mm} \multicolumn{2}{c}{\textbf{Model Details}}\\
\toprule Organization Developing the Model & DeepMind\\
\midrule Model Date & March 2022\\
\midrule Model Type & Autoregressive Transformer Language Model (Section 4.1 for details)\\
\midrule Feedback on the Model & \{jordanhoffmann, sborgeaud, amensch, sifre\}@deepmind.com\\
\toprule \noalign{\vskip 2mm} \multicolumn{2}{c}{\textbf{Intended Uses}}\\
\toprule Primary Intended Uses & The primary use is research on language models, including: research on the scaling behaviour of language models along with those listed in [3].\\
\midrule Primary Intended Users & DeepMind researchers. We will not make this model available publicly.\\
\midrule Out-of-Scope Uses & Uses of the language model for language generation in harmful or deceitful settings. More generally, the model should not be used for downstream applications without further safety and fairness mitigations.\\
\toprule \noalign{\vskip 2mm} \multicolumn{2}{c}{\textbf{Factors}}\\
\toprule Card Prompts -- Relevant Factor & Relevant factors include which language is used. Our model is trained on English data. Furthermore, in the analysis of models trained on the same corpus in [3], we found it has unequal performance when modelling some dialects (e.g., African American English). Our model is designed for research. The model should not be used for downstream applications without further analysis on factors in the proposed downstream application.\\
\midrule Card Prompts -- Evaluation Factors & See the results in [3] which analyzes models trained on the same text corpus.\\
\toprule \noalign{\vskip 2mm} \multicolumn{2}{c}{\textbf{Metrics}}\\
\toprule Model Performance Measures & \begin{itemize} \item Perplexity and bits per byte on language modelling datasets \item Accuracy on completion tasks, reading comprehension, MMLU, BIG-bench and fact checking. \item Exact match accuracy for question answering. \item Generation toxicity from Real Toxicity Prompts (RTP) alongside toxicity classification accuracy. \item Gender and occupation bias. Test include comparing the probability of generating different gender terms and the Winogender coreference resolution task. \end{itemize} We principally focus on \textit{Chinchilla}'s performance compared to \textit{Gopher} on text likelihood prediction.\\
\midrule Decision thresholds & N/A\\
\midrule Approaches to Uncertainty and Variability & Due to the costs of training large language models, we did not train \textit{Chinchilla} multiple times. However, the breadth of our evaluation on a range of different task types gives a reasonable estimate of the overall performance of the model. Furthermore, the existence of another large model trained on the same dataset (\textit{Gopher}) provides a clear point of comparison.\\
\toprule \noalign{\vskip 2mm} \multicolumn{2}{c}{\textbf{Evaluation Data}}\\
\toprule Datasets & \begin{itemize} \item Language modelling on LAMBADA, Wikitext103 ([35]), C4 ([25]), PG-19 ([59]) and the Pile ([34]). \item Language understanding, real world knowledge, mathematical and logical reasoning on the Massive Multitask Language Understanding (MMLU) benchmark ([36]) and on the “Beyond the Imitation Game Benchmark” (BIG-bench) ([37]). \item Question answering (closed book) on Natural Questions ([47]) and TriviaQA ([48]). \item Reading comprehension on RACE ([40]) \item Common sense understanding on HellaSwag ([44]), PIQA ([41]), Winogrande ([43]), SIQA ([42]), BoolQ ([45]), and TruthfulQA ([46]). \end{itemize}\\
\midrule Motivation & We chose evaluations from [3] to allow us to most directly compare to \textit{Gopher}.\\
\midrule Preprocessing & Input text is tokenized using a SentencePiece tokenizer with a vocabulary of size 32, 000. Unlike the tokenizer used for \textit{Gopher}, the tokenizer used for \textit{Chinchilla} does not perform NFKC normalization.\\
\toprule \noalign{\vskip 2mm} \multicolumn{2}{c}{\textbf{Training Data}}\\
\toprule \multicolumn{2}{c}{The same dataset is used as in [3]. Differences in sampling are shown in Table 11. }\\
\toprule \noalign{\vskip 2mm} \multicolumn{2}{c}{\textbf{Quantitative Analyses}}\\
\toprule Unitary Results & Section 4.2 gives a detailed description of our analysis. Main take-aways include: \begin{itemize} \item Our model is capable of outputting toxic language as measured by the PerspectiveAPI. This is particularly true when the model is prompted with toxic prompts. \item Gender: Our model emulates stereotypes found in our dataset, with occupations such as ``dietician” and “receptionist” being more associated with women and “carpenter” and “sheriff” being more associated with men. \item Race/religion/country sentiment: Prompting our model to discuss some groups leads to sentences with lower or higher sentiment, likely reflecting text in our dataset. \end{itemize}\\
\midrule Intersectional Results & We did not investigate intersectional biases.\\
\toprule \noalign{\vskip 2mm} \multicolumn{2}{c}{\textbf{Ethical Considerations}}\\
\toprule Data & The data is the same as described in [3].\\
\midrule Human Life & The model is not intended to inform decisions about matters central to human life or flourishing.\\
\midrule Mitigations & We considered filtering the dataset to remove toxic content but decided against it due to the observation that this can introduce new biases as studied by [55]. More work is needed on mitigation approaches to toxic content and other types of risks associated with language models, such as those discussed in [50].\\
\midrule Risks and Harms & The data is collected from the internet, and thus undoubtedly there is toxic/biased content in our training dataset. Furthermore, it is likely that personal information is also in the dataset that has been used to train our models. We defer to the more detailed discussion in [50].\\
\midrule Use Cases & Especially fraught use cases include the generation of factually incorrect information with the intent of distributing it or using the model to generate racist, sexist or otherwise toxic text with harmful intent. Many more use cases that could cause harm exist. Such applications to malicious use are discussed in detail in [50].\\
\bottomrule
\end{longtable}
J. List of trained models
In Table 19 we list the model size and configuration of all models used in this study. Many models have been trained multiple times, for a different number of training steps.
\begin{longtable}{r | rrrrr }
\midrule
\endfirsthead
\toprule
Parameters (million) & d\_model & ffw\_size & kv\_size & n\_heads & n\_layers \\
\midrule
44 & 512 & 2048 & 64 & 8 & 8 \\
57 & 576 & 2304 & 64 & 9 & 9 \\
74 & 640 & 2560 & 64 & 10 & 10 \\
90 & 640 & 2560 & 64 & 10 & 13 \\
106 & 640 & 2560 & 64 & 10 & 16 \\
117 & 768 & 3072 & 64 & 12 & 12 \\
140 & 768 & 3072 & 64 & 12 & 15 \\
163 & 768 & 3072 & 64 & 12 & 18 \\
175 & 896 & 3584 & 64 & 14 & 14 \\
196 & 896 & 3584 & 64 & 14 & 16 \\
217 & 896 & 3584 & 64 & 14 & 18 \\
251 & 1024 & 4096 & 64 & 16 & 16 \\
278 & 1024 & 4096 & 64 & 16 & 18 \\
306 & 1024 & 4096 & 64 & 16 & 20 \\
425 & 1280 & 5120 & 128 & 10 & 18 \\
489 & 1280 & 5120 & 128 & 10 & 21 \\
509 & 1408 & 5632 & 128 & 11 & 18 \\
552 & 1280 & 5120 & 128 & 10 & 24 \cr
587 & 1408 & 5632 & 128 & 11 & 21 \cr
632 & 1536 & 6144 & 128 & 12 & 19\cr
664 & 1408 & 5632 & 128 & 11 & 24\cr
724 & 1536 & 6144 & 128 & 12 & 22 \cr
816 & 1536 & 6144 & 128 & 12 & 25\cr
893 & 1792 & 7168 & 128 & 14 & 20\cr
1, 018 & 1792 & 7168 & 128 & 14 & 23 \cr
1, 143 & 1792 & 7168 & 128 & 14 & 26 \cr
1, 266 & 2048 & 8192 & 128 & 16 & 22\cr
1, 424 & 2176 & 8704 & 128 & 17 & 22 \cr
1, 429 & 2048 & 8192 & 128 & 16 & 25 \cr
1, 593 & 2048 & 8192 & 128 & 16 & 28 \cr
1, 609 & 2176 & 8704 & 128 & 17 & 25 \cr
1, 731 & 2304 & 9216 & 128 & 18 & 24 \cr
1, 794 & 2176 & 8704 & 128 & 17 & 28\cr
2, 007 & 2304 & 9216 & 128 & 18 & 28 \cr
2, 283 & 2304 & 9216 & 128 & 18 & 32 \cr
2, 298 & 2560 & 10240 & 128 & 20 & 26 \cr
2, 639 & 2560 & 10240 & 128 & 20 & 30 \cr
2, 980 & 2560 & 10240 & 128 & 20 & 34 \cr
3, 530 & 2688 & 10752 & 128 & 22 & 36 \cr
3, 802 & 2816 & 11264 & 128 & 22 & 36 \cr
4, 084 & 2944 & 11776 & 128 & 22 & 36 \cr
4, 516 & 3072 & 12288 & 128 & 24 & 36 \cr
6, 796 & 3584 & 14336 & 128 & 28 & 40 \cr
9, 293 & 4096 & 16384 & 128 & 32 & 42 \cr
11, 452 & 4352 & 17408 & 128 & 32 & 47 \cr
12, 295 & 4608 & 18432 & 128 & 36 & 44\cr
12, 569 & 4608 & 18432 & 128 & 32 & 47 \cr
13, 735 & 4864 & 19456 & 128 & 32 & 47 \cr
14, 940 & 4992 & 19968 & 128 & 32 & 49 \cr
16, 183 & 5120 & 20480 & 128 & 40 & 47 \cr
\bottomrule
\end{longtable}
References
Section Summary: This references section lists academic papers and technical reports on the development and scaling of large language models, including foundational works like the GPT series from OpenAI and models such as Jurassic-1, Gopher, and LaMDA from various AI labs. It covers key innovations in transformer architectures, efficient training techniques, mixture-of-experts systems, and empirical scaling laws that guide how these models grow in size and performance. The citations span from 2017 to 2022, drawing from conferences like NeurIPS and preprints on arXiv, highlighting rapid progress in AI research.
[1] T. Brown, B. Mann, N. Ryder, M. Subbiah, J. D. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell, S. Agarwal, A. Herbert-Voss, G. Krueger, T. Henighan, R. Child, A. Ramesh, D. Ziegler, J. Wu, C. Winter, C. Hesse, M. Chen, E. Sigler, M. Litwin, S. Gray, B. Chess, J. Clark, C. Berner, S. McCandlish, A. Radford, I. Sutskever, and D. Amodei. Language models are few-shot learners. In H. Larochelle, M. Ranzato, R. Hadsell, M. F. Balcan, and H. Lin, editors, Advances in Neural Information Processing Systems, volume 33, pages 1877–1901. Curran Associates, Inc., 2020. URL https://proceedings.neurips.cc/paper/2020/file/1457c0d6bfcb4967418bfb8ac142f64a-Paper.pdf.
[2] O. Lieber, O. Sharir, B. Lenz, and Y. Shoham. Jurassic-1: Technical details and evaluation. White Paper. AI21 Labs, 2021.
[3] J. Rae, S. Borgeaud, T. Cai, K. Millican, J. Hoffmann, F. Song, J. Aslanides, S. Henderson, R. Ring, S. Young, E. Rutherford, T. Hennigan, J. Menick, A. Cassirer, R. Powell, G. van den Driessche, L. A. Hendricks, M. Rauh, P.-S. Huang, A. Glaese, J. Welbl, S. Dathathri, S. Huang, J. Uesato, J. Mellor, I. Higgins, A. Creswell, N. McAleese, A. Wu, E. Elsen, S. Jayakumar, E. Buchatskaya, D. Budden, E. Sutherland, K. Simonyan, M. Paganini, L. Sifre, L. Martens, X. L. Li, A. Kuncoro, A. Nematzadeh, E. Gribovskaya, D. Donato, A. Lazaridou, A. Mensch, J.-B. Lespiau, M. Tsimpoukelli, N. Grigorev, D. Fritz, T. Sottiaux, M. Pajarskas, T. Pohlen, Z. Gong, D. Toyama, C. de Masson d’Autume, Y. Li, T. Terzi, I. Babuschkin, A. Clark, D. de Las Casas, A. Guy, J. Bradbury, M. Johnson, L. Weidinger, I. Gabriel, W. Isaac, E. Lockhart, S. Osindero, L. Rimell, C. Dyer, O. Vinyals, K. Ayoub, J. Stanway, L. Bennett, D. Hassabis, K. Kavukcuoglu, and G. Irving. Scaling language models: Methods, analysis & insights from training Gopher. arXiv 2112.11446, 2021.
[4] S. Smith, M. Patwary, B. Norick, P. LeGresley, S. Rajbhandari, J. Casper, Z. Liu, S. Prabhumoye, G. Zerveas, V. Korthikanti, E. Zhang, R. Child, R. Y. Aminabadi, J. Bernauer, X. Song, M. Shoeybi, Y. He, M. Houston, S. Tiwary, and B. Catanzaro. Using Deepspeed and Megatron to Train Megatron-turing NLG 530b, A Large-Scale Generative Language Model. arXiv preprint arXiv:2201.11990, 2022.
[5] R. Thoppilan, D. D. Freitas, J. Hall, N. Shazeer, A. Kulshreshtha, H.-T. Cheng, A. Jin, T. Bos, L. Baker, Y. Du, Y. Li, H. Lee, H. S. Zheng, A. Ghafouri, M. Menegali, Y. Huang, M. Krikun, D. Lepikhin, J. Qin, D. Chen, Y. Xu, Z. Chen, A. Roberts, M. Bosma, Y. Zhou, C.-C. Chang, I. Krivokon, W. Rusch, M. Pickett, K. Meier-Hellstern, M. R. Morris, T. Doshi, R. D. Santos, T. Duke, J. Soraker, B. Zevenbergen, V. Prabhakaran, M. Diaz, B. Hutchinson, K. Olson, A. Molina, E. Hoffman-John, J. Lee, L. Aroyo, R. Rajakumar, A. Butryna, M. Lamm, V. Kuzmina, J. Fenton, A. Cohen, R. Bernstein, R. Kurzweil, B. Aguera-Arcas, C. Cui, M. Croak, E. Chi, and Q. Le. LaMDA: Language models for dialog applications, 2022.
[6] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin. Attention is all you need. In Advances in neural information processing systems, pages 5998–6008, 2017.
[7] Y. Tay, M. Dehghani, J. Rao, W. Fedus, S. Abnar, H. W. Chung, S. Narang, D. Yogatama, A. Vaswani, and D. Metzler. Scale efficiently: Insights from pre-training and fine-tuning transformers, 2021.
[8] J. Kaplan, S. McCandlish, T. Henighan, T. B. Brown, B. Chess, R. Child, S. Gray, A. Radford, J. Wu, and D. Amodei. Scaling laws for neural language models. arXiv preprint arXiv:2001.08361, 2020.
[9] N. Du, Y. Huang, A. M. Dai, S. Tong, D. Lepikhin, Y. Xu, M. Krikun, Y. Zhou, A. W. Yu, O. Firat, B. Zoph, L. Fedus, M. Bosma, Z. Zhou, T. Wang, Y. E. Wang, K. Webster, M. Pellat, K. Robinson, K. Meier-Hellstern, T. Duke, L. Dixon, K. Zhang, Q. V. Le, Y. Wu, Z. Chen, and C. Cui. Glam: Efficient scaling of language models with mixture-of-experts, 2021. URL https://arxiv.org/abs/2112.06905.
[10] W. Fedus, B. Zoph, and N. Shazeer. Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity. arXiv preprint arXiv:2101.03961, 2021.
[11] B. Zoph, I. Bello, S. Kumar, N. Du, Y. Huang, J. Dean, N. Shazeer, and W. Fedus. Designing effective sparse expert models, 2022.
[12] D. Hernandez, J. Kaplan, T. Henighan, and S. McCandlish. Scaling laws for transfer, 2021.
[13] A. Clark, D. d. l. Casas, A. Guy, A. Mensch, M. Paganini, J. Hoffmann, B. Damoc, B. Hechtman, T. Cai, S. Borgeaud, G. v. d. Driessche, E. Rutherford, T. Hennigan, M. Johnson, K. Millican, A. Cassirer, C. Jones, E. Buchatskaya, D. Budden, L. Sifre, S. Osindero, O. Vinyals, J. Rae, E. Elsen, K. Kavukcuoglu, and K. Simonyan. Unified scaling laws for routed language models, 2022. URL https://arxiv.org/abs/2202.01169.
[14] G. Yang, E. J. Hu, I. Babuschkin, S. Sidor, X. Liu, D. Farhi, N. Ryder, J. Pachocki, W. Chen, and J. Gao. Tuning large neural networks via zero-shot hyperparameter transfer. In A. Beygelzimer, Y. Dauphin, P. Liang, and J. W. Vaughan, editors, Advances in Neural Information Processing Systems, 2021. URL https://openreview.net/forum?id=Bx6qKuBM2AD.
[15] S. McCandlish, J. Kaplan, D. Amodei, and O. D. Team. An empirical model of large-batch training, 2018.
[16] C. J. Shallue, J. Lee, J. Antognini, J. Sohl-Dickstein, R. Frostig, and G. E. Dahl. Measuring the effects of data parallelism on neural network training. arXiv preprint arXiv:1811.03600, 2018.
[17] G. Zhang, L. Li, Z. Nado, J. Martens, S. Sachdeva, G. Dahl, C. Shallue, and R. B. Grosse. Which algorithmic choices matter at which batch sizes? insights from a noisy quadratic model. In H. Wallach, H. Larochelle, A. Beygelzimer, F. d' Alché-Buc, E. Fox, and R. Garnett, editors, Advances in Neural Information Processing Systems, volume 32. Curran Associates, Inc., 2019. URL https://proceedings.neurips.cc/paper/2019/file/e0eacd983971634327ae1819ea8b6214-Paper.pdf.
[18] Y. Levine, N. Wies, O. Sharir, H. Bata, and A. Shashua. The depth-to-width interplay in self-attention. arXiv preprint arXiv:2006.12467, 2020.
[19] M. Artetxe, S. Bhosale, N. Goyal, T. Mihaylov, M. Ott, S. Shleifer, X. V. Lin, J. Du, S. Iyer, R. Pasunuru, G. Anantharaman, X. Li, S. Chen, H. Akin, M. Baines, L. Martin, X. Zhou, P. S. Koura, B. O'Horo, J. Wang, L. Zettlemoyer, M. Diab, Z. Kozareva, and V. Stoyanov. Efficient Large Scale Language Modeling with Mixtures of Experts. arXiv:2112.10684, 2021.
[20] S. Borgeaud, A. Mensch, J. Hoffmann, T. Cai, E. Rutherford, K. Millican, G. van den Driessche, J.-B. Lespiau, B. Damoc, A. Clark, D. de Las Casas, A. Guy, J. Menick, R. Ring, T. Hennigan, S. Huang, L. Maggiore, C. Jones, A. Cassirer, A. Brock, M. Paganini, G. Irving, O. Vinyals, S. Osindero, K. Simonyan, J. W. Rae, E. Elsen, and L. Sifre. Improving language models by retrieving from trillions of tokens. arXiv 2112.04426, 2021.
[21] K. Guu, K. Lee, Z. Tung, P. Pasupat, and M.-W. Chang. REALM: Retrieval-augmented language model pre-training, 2020.
[22] P. Lewis, E. Perez, A. Piktus, F. Petroni, V. Karpukhin, N. Goyal, H. Küttler, M. Lewis, W.-t. Yih, T. Rocktäschel, S. Riedel, and D. Kiela. Retrieval-augmented generation for knowledge-intensive nlp tasks. In Advances in Neural Information Processing Systems, volume 33, pages 9459–9474, 2020.
[23] P. J. Huber. Robust Estimation of a Location Parameter. The Annals of Mathematical Statistics, 35(1):73–101, Mar. 1964. ISSN 0003-4851, 2168-8990. doi:10.1214/aoms/1177703732. URL https://projecteuclid.org/journals/annals-of-mathematical-statistics/volume-35/issue-1/Robust-Estimation-of-a-Location-Parameter/10.1214/aoms/1177703732.full.
[24] J. Nocedal. Updating Quasi-Newton Matrices with Limited Storage. Mathematics of Computation, 35(151):773–782, 1980. ISSN 0025-5718. doi:10.2307/2006193. URL https://www.jstor.org/stable/2006193.
[25] C. Raffel, N. Shazeer, A. Roberts, K. Lee, S. Narang, M. Matena, Y. Zhou, W. Li, and P. J. Liu. Exploring the limits of transfer learning with a unified text-to-text transformer. Journal of Machine Learning Research, 21(140):1–67, 2020a. URL http://jmlr.org/papers/v21/20-074.html.
[26] I. Loshchilov and F. Hutter. Decoupled weight decay regularization. In International Conference on Learning Representations, 2019. URL https://openreview.net/forum?id=Bkg6RiCqY7.
[27] D. P. Kingma and J. Ba. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980, 2014.
[28] T. Kudo and J. Richardson. SentencePiece: A simple and language independent subword tokenizer and detokenizer for neural text processing. arXiv preprint arXiv:1808.06226, 2018.
[29] S. Rajbhandari, J. Rasley, O. Ruwase, and Y. He. Zero: Memory optimizations toward training trillion parameter models. In SC20: International Conference for High Performance Computing, Networking, Storage and Analysis, pages 1–16. IEEE, 2020.
[30] N. P. Jouppi, C. Young, N. Patil, D. Patterson, G. Agrawal, R. Bajwa, S. Bates, S. Bhatia, N. Boden, A. Borchers, R. Boyle, P.-l. Cantin, C. Chao, C. Clark, J. Coriell, M. Daley, M. Dau, J. Dean, B. Gelb, T. V. Ghaemmaghami, R. Gottipati, W. Gulland, R. Hagmann, C. R. Ho, D. Hogberg, J. Hu, R. Hundt, D. Hurt, J. Ibarz, A. Jaffey, A. Jaworski, A. Kaplan, H. Khaitan, D. Killebrew, A. Koch, N. Kumar, S. Lacy, J. Laudon, J. Law, D. Le, C. Leary, Z. Liu, K. Lucke, A. Lundin, G. MacKean, A. Maggiore, M. Mahony, K. Miller, R. Nagarajan, R. Narayanaswami, R. Ni, K. Nix, T. Norrie, M. Omernick, N. Penukonda, A. Phelps, J. Ross, M. Ross, A. Salek, E. Samadiani, C. Severn, G. Sizikov, M. Snelham, J. Souter, D. Steinberg, A. Swing, M. Tan, G. Thorson, B. Tian, H. Toma, E. Tuttle, V. Vasudevan, R. Walter, W. Wang, E. Wilcox, and D. H. Yoon. In-datacenter performance analysis of a tensor processing unit. In Proceedings of the 44th Annual International Symposium on Computer Architecture, ISCA '17, page 1–12, New York, NY, USA, 2017. Association for Computing Machinery. ISBN 9781450348928. doi:10.1145/3079856.3080246. URL https://doi.org/10.1145/3079856.3080246.
[31] J. Bradbury, R. Frostig, P. Hawkins, M. J. Johnson, C. Leary, D. Maclaurin, G. Necula, A. Paszke, J. VanderPlas, S. Wanderman-Milne, and Q. Zhang. JAX: composable transformations of Python+NumPy programs. 2018. URL http://github.com/google/jax.
[32] T. Hennigan, T. Cai, T. Norman, and I. Babuschkin. Haiku: Sonnet for JAX. 2020. URL http://github.com/deepmind/dm-haiku.
[33] M. Mitchell, S. Wu, A. Zaldivar, P. Barnes, L. Vasserman, B. Hutchinson, E. Spitzer, I. D. Raji, and T. Gebru. Model cards for model reporting. In Proceedings of the conference on fairness, accountability, and transparency, pages 220–229, 2019.
[34] L. Gao, S. Biderman, S. Black, L. Golding, T. Hoppe, C. Foster, J. Phang, H. He, A. Thite, N. Nabeshima, S. Presser, and C. Leahy. The Pile: An 800GB dataset of diverse text for language modeling. arXiv preprint arXiv:2101.00027, 2020.
[35] S. Merity, C. Xiong, J. Bradbury, and R. Socher. Pointer sentinel mixture models. International Conference on Learning Representations, 2017.
[36] D. Hendrycks, C. Burns, S. Basart, A. Zou, M. Mazeika, D. Song, and J. Steinhardt. Measuring massive multitask language understanding. arXiv preprint arXiv:2009.03300, 2020.
[37] BIG-bench collaboration. Beyond the imitation game: Measuring and extrapolating the capabilities of language models. In preparation, 2021. URL https://github.com/google/BIG-bench/.
[38] J. Steinhardt. Updates and lessons from AI forecasting, 2021. URL https://bounded-regret.ghost.io/ai-forecasting/.
[39] D. Paperno, G. Kruszewski, A. Lazaridou, Q. N. Pham, R. Bernardi, S. Pezzelle, M. Baroni, G. Boleda, and R. Fernández. The LAMBADA dataset: Word prediction requiring a broad discourse context, 2016.
[40] G. Lai, Q. Xie, H. Liu, Y. Yang, and E. Hovy. RACE: Large-scale ReAding comprehension dataset from examinations. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pages 785–794, Copenhagen, Denmark, Sept. 2017. Association for Computational Linguistics. doi:10.18653/v1/D17-1082. URL https://aclanthology.org/D17-1082.
[41] Y. Bisk, R. Zellers, J. Gao, Y. Choi, et al. PIQA: Reasoning about physical commonsense in natural language. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 34, pages 7432–7439, 2020.
[42] M. Sap, H. Rashkin, D. Chen, R. LeBras, and Y. Choi. SocialIQA: Commonsense reasoning about social interactions. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing, 2019.
[43] K. Sakaguchi, R. Le Bras, C. Bhagavatula, and Y. Choi. Winogrande: An adversarial winograd schema challenge at scale. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 34, pages 8732–8740, 2020.
[44] R. Zellers, A. Holtzman, Y. Bisk, A. Farhadi, and Y. Choi. HellaSwag: Can a machine really finish your sentence? In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, 2019.
[45] C. Clark, K. Lee, M.-W. Chang, T. Kwiatkowski, M. Collins, and K. Toutanova. Boolq: Exploring the surprising difficulty of natural yes/no questions. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 2924–2936, 2019.
[46] S. Lin, J. Hilton, and O. Evans. TruthfulQA: Measuring how models mimic human falsehoods. arXiv preprint arXiv:2109.07958, 2021.
[47] T. Kwiatkowski, J. Palomaki, O. Redfield, M. Collins, A. Parikh, C. Alberti, D. Epstein, I. Polosukhin, M. Kelcey, J. Devlin, K. Lee, K. N. Toutanova, L. Jones, M.-W. Chang, A. Dai, J. Uszkoreit, Q. Le, and S. Petrov. Natural questions: a benchmark for question answering research. Transactions of the Association of Computational Linguistics, 2019.
[48] M. Joshi, E. Choi, D. Weld, and L. Zettlemoyer. TriviaQA: A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehension. arXiv e-prints, art. arXiv:1705.03551, 2017.
[49] G. Izacard and E. Grave. Distilling knowledge from reader to retriever for question answering, 2020.
[50] L. Weidinger, J. Mellor, M. Rauh, C. Griffin, J. Uesato, P.-S. Huang, M. Cheng, M. Glaese, B. Balle, A. Kasirzadeh, Z. Kenton, S. Brown, W. Hawkins, T. Stepleton, C. Biles, A. Birhane, J. Haas, L. Rimell, L. A. Hendricks, W. Isaac, S. Legassick, G. Irving, and I. Gabriel. Ethical and social risks of harm from language models. arXiv submission, 2021.
[51] E. M. Bender, T. Gebru, A. McMillan-Major, and S. Shmitchell. On the dangers of stochastic parrots: Can language models be too big? In Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency, pages 610–623, 2021.
[52] R. Rudinger, J. Naradowsky, B. Leonard, and B. Van Durme. Gender bias in coreference resolution. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, New Orleans, Louisiana, June 2018. Association for Computational Linguistics.
[53] S. Gehman, S. Gururangan, M. Sap, Y. Choi, and N. A. Smith. RealToxicityPrompts: Evaluating neural toxic degeneration in language models. In Findings of the Association for Computational Linguistics: EMNLP 2020, pages 3356–3369, Online, Nov. 2020. Association for Computational Linguistics. doi:10.18653/v1/2020.findings-emnlp.301. URL https://aclanthology.org/2020.findings-emnlp.301.
[54] A. Xu, E. Pathak, E. Wallace, S. Gururangan, M. Sap, and D. Klein. Detoxifying language models risks marginalizing minority voices. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 2390–2397, Online, June 2021. Association for Computational Linguistics. doi:10.18653/v1/2021.naacl-main.190. URL https://aclanthology.org/2021.naacl-main.190.
[55] J. Welbl, A. Glaese, J. Uesato, S. Dathathri, J. Mellor, L. A. Hendricks, K. Anderson, P. Kohli, B. Coppin, and P.-S. Huang. Challenges in detoxifying language models. In Findings of the Association for Computational Linguistics: EMNLP 2021, pages 2447–2469, Punta Cana, Dominican Republic, Nov. 2021. Association for Computational Linguistics. URL https://aclanthology.org/2021.findings-emnlp.210.
[56] C. Raffel, N. Shazeer, A. Roberts, K. Lee, S. Narang, M. Matena, Y. Zhou, W. Li, and P. J. Liu. Exploring the limits of transfer learning with a unified text-to-text transformer. Journal of Machine Learning Research, 21(140):1–67, 2020b.
[57] J. W. Siegel and J. Xu. Approximation rates for neural networks with general activation functions. Neural Networks, 128:313–321, Aug. 2020. URL https://www.sciencedirect.com/science/article/pii/S0893608020301891.
[58] H. Robbins and S. Monro. A Stochastic Approximation Method. The Annals of Mathematical Statistics, 22(3):400–407, Sept. 1951.
[59] J. W. Rae, A. Potapenko, S. M. Jayakumar, T. P. Lillicrap, K. Choromanski, V. Likhosherstov, D. Dohan, X. Song, A. Gane, T. Sarlos, et al. Compressive transformers for long-range sequence modelling. Advances in Neural Information Processing Systems, 33:6154–6158, 2020.
[60] S. Bubeck. Convex Optimization: Algorithms and Complexity. Foundations and Trends in Machine Learning, 8(3-4):231–357, 2015. URL http://www.nowpublishers.com/article/Details/MAL-050.