Learning from the Self-future: On-policy Self-distillation for dLLMs
Yifu Luo $^{1}$ $^{\dagger}$, Zeyu Chen $^{2}$ $^{\dagger}$, Haoyu Wang $^{3}$, Xinhao Hu $^{1}$,
Yuxuan Zhang $^{4}$, Zhizhou Sha $^{5}$, Shiwei Liu $^{6,7,8}$ $^{*}$
$^{1}$ Tsinghua University $^{2}$ Technical University of Munich $^{3}$ Nanyang Technological University $^{4}$ University of British Columbia $^{5}$ University of Texas at Austin $^{6}$ ELLIS Institute Tübingen $^{7}$ Max Planck Institute for Intelligent Systems $^{8}$ Tübingen AI Center
$^{\dagger}$ Equal Contribution
$^{*}$ Corresponding Author.
Abstract
On-policy self-distillation (OPSD) has proven effective for post-training large language models (LLMs), yet its application to diffusion LLMs (dLLMs) remains unexplored. Existing OPSD methods are inherently autoregressive-centric. They inject privileged information via left-to-right prefix conditioning with token-level divergence supervision, a design that fundamentally conflicts with the arbitrary-order generation of dLLMs. We introduce d-OPSD, the first OPSD framework tailored for dLLMs. Our approach makes two core contributions. First, we reframe self-teacher construction by using self-generated answers as suffix conditioning, enabling the student model to learn from "self future-experience" rather than privileged prefixes. Second, we shift supervision from token-level to step-level, aligning training with the iterative denoising process of dLLMs. Experiments across four reasoning benchmarks show that d-OPSD consistently outperforms RLVR and SFT baselines with superior sample efficiency, requiring only around 10% of the optimization steps by RLVR and opening a promising pathway for dLLM post-training. The code is available at https://github.com/xingzhejun/d-OPSD.
Executive Summary: d-OPSD introduces the first on-policy self-distillation method designed for diffusion large language models. It addresses a clear gap: existing self-distillation techniques work for standard autoregressive models but clash with the arbitrary-order, iterative denoising process of dLLMs. At the same time, reinforcement learning methods such as diffu-GRPO improve reasoning yet require large numbers of optimization steps and rely on sparse outcome rewards.
The work set out to test whether a tailored self-distillation approach could deliver stronger reasoning gains with far higher sample efficiency. Researchers started from LLaDA-8B-Instruct and ran controlled post-training runs on four reasoning benchmarks—GSM8K, MATH500, 4×4 Sudoku, and Countdown—while comparing directly against RLVR and supervised fine-tuning baselines. The method keeps the same computational cost per step as the RLVR baseline but changes two elements: self-generated answers serve as suffix context for the teacher, and supervision occurs at the denoising-step level rather than the token level.
Across the benchmarks, d-OPSD matched or exceeded the strongest RLVR and SFT results while converging in roughly one-tenth the optimization steps. It also outperformed an autoregressive-style self-distillation variant because the suffix construction exposed the student to genuinely new thinking patterns rather than redundant prefixes. Ablations confirmed that reverse KL, a moderate teacher retention ratio, and teacher-derived top-k tokens contributed most to these gains.
These findings matter because they show dLLMs can be post-trained more efficiently than current RLVR practice allows. Faster convergence reduces compute cost and makes iterative model improvement practical. The approach does, however, share the policy-collapse risk seen in reinforcement learning once peak performance is reached.
Leaders should therefore pilot d-OPSD on new dLLM checkpoints while investing modest additional effort in stabilization techniques. Further work on clipping schedules, trajectory filtering, and hybrid objectives is needed before the method can be treated as fully robust at larger scale. Results are consistent across the tested tasks and settings, yet remain bounded by the single base model and benchmark suite examined.
1. Introduction
Section Summary: Recent advances in on-policy self-distillation have allowed language models to improve by learning from their own outputs with added guidance, offering advantages over reinforcement learning or standard fine-tuning that rely on sparse rewards or fixed training data. Diffusion-based language models, which generate text through iterative denoising rather than strict left-to-right steps, have not yet benefited from these techniques and require adaptations to their unique generation process. This work presents d-OPSD, which constructs a self-teacher using the model's own answers as future context and applies supervision at the denoising step level to enable more effective self-improvement, outperforming prior methods in reasoning tasks.
![**Figure 1:** The reasoning performance and sample efficiency comparisons between the RLVR baseline (diffu-GRPO([1])) and our approach, d-OPSD.](https://ittowtnkqtyixxjxrhou.supabase.co/storage/v1/object/public/public-images/2qjkykmg/try1.png)
On-policy distillation (OPD) ([2, 3, 4, 5]), where a student model samples its own trajectories while a stronger teacher model provides dense token-level supervision, has recently emerged as a highly effective paradigm for Large Language models (LLMs) post-training, offering significant advantages over Reinforcement Learning with Verifiable Rewards (RLVR) (e.g., GRPO ([6]) and supervised fine-tuning (SFT). Compared to RLVR, OPD provides dense token-level supervision from a teacher, overcoming the bottleneck of sparse outcome rewards. Compared to SFT, OPD utilizes generations sampled from the student itself, thereby preventing exposure bias ([7]). However, OPD relies heavily on a stronger teacher model, which is often impractical in many settings. To address this, recent works ([8, 9, 10]) have extended OPD to on-policy self-distillation (OPSD), where a single model serves as its own teacher given teacher-specific privileged information, demonstrating a powerful framework for self-improvement.
Concurrently, diffusion large language models (dLLMs) ([11, 12, 13, 14, 15]) have demonstrated strong potential as an alternative to autoregressive (AR) LLMs ([16, 17]). By modeling language generation as an iterative denoising process, dLLMs bypass the strict left-to-right dependency of AR models, unlocking unique advantages such as arbitrary-order generation and speed-up inference ([18, 19, 20]).
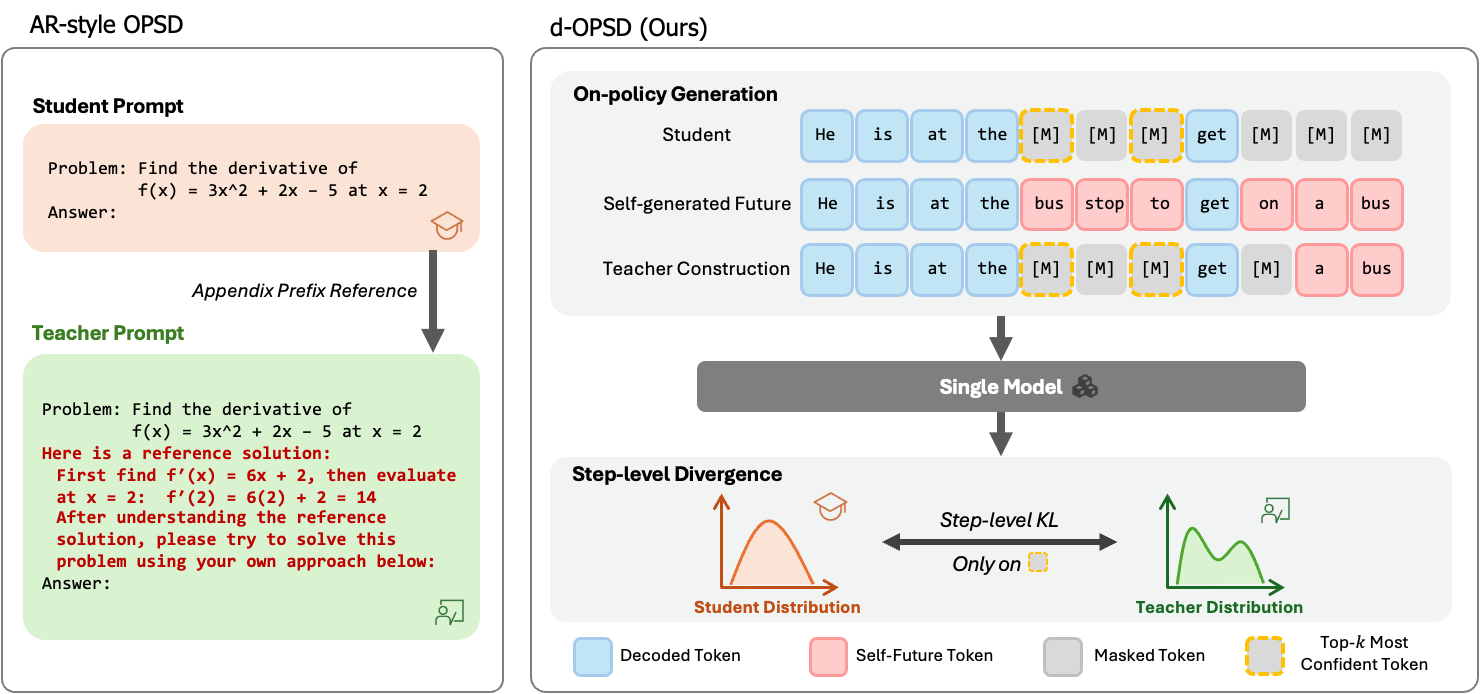
While recent works ([1, 21, 22]) has successfully applied RLVR to dLLMs demonstrating that their reasoning ability can be enhanced by post-training, OPSD for dLLMs remains largely unexplored in this context. Meanwhile, as shown in Figure 2, existing OPSD approaches for AR models follow a standard paradigm for self-teacher construction, where privileged information (e.g., reference solutions) is simply appended to the prompt, and teacher-student divergence supervision is calculated at the token level. Given that dLLMs exhibit fundamental different features from AR LLMs, we investigate the following two questions in this paper:
Question: Is there a better OPSD formulation tailored specifically for dLLMs?
Answer: Yes. Both the self-teacher construction and the level of divergence supervision can be optimized for dLLMs, as shown in Figure 2.
Question: Does OPSD outperform RLVR in enhancing the reasoning ability of dLLMs?
Answer: Yes. It achieves superior results in both reasoning performance and sample efficiency, as shown in Figure 1.
First, we identify that the self-teacher construction mentioned above is suboptimal for dLLMs. Appending privileged information to the prompt is inherently designed for AR models, because they are constrained to left-to-right generation where only prefix conditioning $p(\text{suffix} | \text{prefix})$ is available. In contrast, dLLMs generate sequences non-autoregressively, which allows us to incorporate privileged information as a suffix context condition. More importantly, this feature enables us to shift the content of privileged information from static reference solutions to the model's self-generated answers, adhering closer to the on-policy nature. As shown in Figure 2, the $p(\text{prefix} | \text{suffix})$ capability of dLLMs allows us to use self-generated answers as a suffix conditional posterior for privileged information. This guides the student to learn from "self future-experience", which is similar to human inspiration that we always daydream if we could go back to $10$ years ago knowing what happened next. A key advantage of our teacher construction is that it provides more new knowledge (thinking patterns) to transfer to the student, a claim we empirically discuss in Section 4.3.
Second, token-level divergence supervision is not suitable for dLLMs either. While AR models natively rely on next-token prediction, dLLMs predict all masked tokens simultaneously at each denoising step, but only keep part of them while remasking others. Consequently, token-level supervision designed for AR models becomes incompatible. Instead, as each denoising step can be viewed as an independent markov transition, step-level divergence serves as a nature choice for dLLMs OPSD. By shifting the dense supervision from the token-level to the step-level, we closely align the OPSD objective with the iterative denoising nature of dLLMs.
Building on these insights, we propose diffusion On-Policy Self-distillation (d-OPSD), a novel OPSD framework specifically designed for dLLMs to drive self-improvement. To the best of our knowledge, this represents the first application of OPSD to dLLMs. In our approach, the student samples its own trajectories, while the self-teacher is constructed using self-generated answers as suffix privileged information. By applying step-level divergence, the student effectively learns from its "self future-experience". Extensive experiments across four reasoning tasks demonstrate that our approach consistently outperforms RLVR and SFT baselines with superior reasoning performance and sample efficiency, as highlighted in Figure 1.
Our contributions are summarized as follows:
- We identify that existing OPSD formulations are suboptimal for dLLMs. To bridge this gap, we introduce a novel self-teacher construction that utilizes self-generated answers as a suffix conditional posterior for privileged information, and we shift the dense divergence supervision from the token-level to the step-level.
- We are the first to introduce OPSD to dLLMs. We propose d-OPSD, a novel OPSD framework tailored for dLLMs to drive self-improvement. It enables a single model to act as both teacher and student, leveraging self-generated "future" as privileged information to provide dense step-level supervision over the student trajectories.
- We conduct extensive experiments across four reasoning tasks, demonstrating that our approach achieves both superior reasoning performance and sample efficiency compared to RLVR and SFT baselines. Furthermore, we empirically analyze the impact of different settings, paving the way for future advances in this field.
2. Preliminaries
Section Summary: Diffusion large language models generate text through an iterative denoising process: during training they gradually replace tokens with masks, and at inference they start from a fully masked sequence and reveal tokens step by step by sampling from the model’s predicted distributions. On-policy distillation transfers knowledge from a stronger teacher to a weaker student by having the student sample its own outputs and then minimizing the divergence between the two models’ token distributions at each step. A related self-distillation variant, OPSD, lets the same model play both roles by giving the teacher privileged extra context while the student sees only the original prompt, an approach whose direct adaptation to diffusion models raises challenges around ordering and supervision granularity.
2.1 Diffusion Large Language Models
In this subsection, we briefly review the training and inference paradigms of dLLMs. During training, dLLMs define a forward process that gradually corrupts a clean input by replacing its tokens with a special ${\texttt{mask}}$ token. Given a prompt $x$ and a clean response $y_0 = {y_0^1, y_0^2, \cdot s, y_0^L}$, the forward process at step $0<t \leq T$ can be expressed as:
$ q(y_t|y_0, x) = \prod_{i=1}^L q(y_t^i|y_0^i, x) \quad \text{and} \quad q_t(y_t^i|y_0^i, x) = \begin{cases} \frac{T - t}{T}, & y_t^i = y_0^i, \ \frac{t}{T}, & y_t^i = {\texttt{mask}}, \end{cases}\tag{1} $
where L is the sequence length, and the superscript $i$ refers to the token position.
In this work, we primarily focus on the reverse inference process of dLLMs. Given a prompt $x$ and a trained model $p_\theta$, inference is formulated as a $T$-step iterative denoising process, from a fully masked sequence $y_T = {{\texttt{mask}}}^L$ to a clean response $y_0$. At each denoising step $t$, the model first computes the distribution for all tokens:
$ \mathcal{P}{t}^i = p\theta(y^i|y_t, x), \quad 1 \leq i \leq L.\tag{2} $
For the top- $k$ most confident predictions among the currently masked positions, they are sampled and revealed. The remaining masked positions are kept masked as ${\texttt{mask}}$ and to form $y_{t-1}$. After $T$ steps, all masked tokens are revealed, yielding the final response $y_0$. Additional preliminaries about block-diffusion, a common-used inference strategy, are provided in Appendix A.1.
2.2 On-policy Distillation
OPD transfers knowledge from a stronger teacher model $p_T$ to a weaker student model $p_\theta$ by enforcing dense supervision over trajectories sampled by the student. For AR models, given a prompt $x$, the student samples a response $y = {y^1, y^2, \cdot s, y^L}$. Using the AR factorization, the learning objective is to minimize the token-level KL between the teacher's and the student's next-token distributions:
$ \mathcal{L}\text{OPD} (\theta) = \mathbb{E}x \left[\sum{i=1}^L \mathcal{D}\text{KL} \left(p_\theta \left(\cdot | y^{<i}, x \right) || \left(p_T \left(\cdot | y^{<i}, x \right) \right) \right) \right],\tag{3} $
where $p(\cdot | y^{<i}, x)$ denotes the distribution over the next token $y^i$. While we use reverse KL, forward KL and other distribution divergence measures like generalized Jensen-Shannon divergence ([2]) can also be employed.
Recent advances have extended OPD to OPSD, where the student and teacher are instantiated from the same model, denoted as $p_\theta$. The difference lies entirely in their conditioning contexts. For AR models, privileged information $y^*$, such as reference solutions ([8]) or environment feedback ([9]), is appended to the original prompt $x$ to construct a teacher-specific prompt $x^* = x + y^*$. Thus, the teacher distribution is:
$ p_T = p_\theta \left(\cdot | y^{<i}, x, y^* \right) = p_\theta \left(\cdot | y^{<i}, x^* \right).\tag{4} $
Consequently, the learning objective in Equation 3 adapts into the following:
$ \mathcal{L}\text{OPSD} (\theta) = \mathbb{E}x \left[\sum{i=1}^L \mathcal{D}\text{KL} \left(p_\theta \left(\cdot | y^{<i}, x \right) || \left(p_\theta \left(\cdot | y^{<i}, x^* \right) \right) \right) \right].\tag{5} $
In this setup, both the teacher and student share the same model but differ only in the conditioning contexts, and the response is solely generated from the student. While OPSD achieves comparable performance to RLVR with superior sample efficiency for AR models, adapting this formulation to dLLMs presents fundamental challenges. First, the arbitrary-order generation of dLLMs provides an alterative for injecting privileged information, which better aligns with on-policy nature (Section 3.1). Second, token-level divergence supervision is incompatible with dLLMs as next-token prediction is not factorized. Instead, step-level divergence supervision must be adopted(Section 3.2).
3. Methods
Section Summary: The section describes a self-distillation method called d-OPSD for diffusion large language models, in which a single model acts as both student and teacher. The student generates full on-policy trajectories by progressively denoising a masked sequence, while the teacher receives the same model but with selected tokens from the student's eventual final output revealed as privileged future information. At each step the approach then minimizes a KL divergence loss only over the top-k most confident tokens being unmasked, providing a natural step-level training signal that aligns the student distribution with the teacher's more informed one.
3.1 Teacher Construction: Learning from the Self-future
In this section, we describe how we utilize the student's self-generated "future" answers as privileged information for the teacher, which adheres closer to dLLMs and on-policy nature. While AR models are constrained to left-to-right generation with only $p(\text{suffix} | \text{prefix})$ available, dLLMs possess the bidirectional capability to model suffix conditioning $p(\text{prefix} | \text{suffix})$. As shown in Figure 2, our core insight is that after sampling a complete trajectory from the student, we can partially reveal this self-generated subsequent trajectory to the teacher as privileged information.
Specifically, We instantiate both the teacher and student distributions from the same dLLM $p_\theta$ by varying the conditioning inputs. Given a prompt $x$, the student first samples a trajectory from $p_\theta$:
$ Y = { y_T, y_{T-1}, \cdot s, y_0 } \sim p_\theta (\cdot | x),\tag{6} $
where $y_T = { {\texttt{mask}} }^L$ is a fully masked sequence, $y_0$ is the final response, $T$ refers to the total number of denoising steps, and $L$ denotes the sequence length. At each denoising step $0<t \leq T$, the student input is simply the current noisy sequence:
$ y_{\text{student}, t} = y_t.\tag{7} $
Conversely, the teacher input is constructed by selectively revealing tokens from the final generated response $y_0$:
$ y_{\text{teacher}, t}^i = \begin{cases} y_0^i, & \text{if } i \in \mathcal{S}_t, \ y_t^i, & \text{otherwise}, \end{cases}\tag{8} $
where $\mathcal{S}t \subset { 1, 2, \cdot s, L }$ is the revealing subset of indices randomly selected with a fixed retaining ratio $\rho\text{teacher}$ from the currently masked positions. Thus, both the student and teacher share the same model $p(\theta)$, but the teacher benefits from the self-generated "future" trajectory. An illustration example of our teacher construction is provided in Appendix B.
This construction seamlessly aligns with on-policy and dLLMs nature. First, all data is generated by the student. Second, the construction in Equation 7 and 8 yields distributions $p_\theta(\cdot | y_{\text{student}, t}, x)$ and $p_\theta(\cdot | y_{\text{teacher}, t}, x)$, which enable a direct step-level divergence supervision, which we introduce in the next subsection. Note that $p(\cdot | y_{t}, x)$ here denotes distribution for the next step.
3.2 Step-level Divergence Supervision
Unlike AR models, which natively employ token-level supervision via next-token prediction, dLLMs decode sequences via next-step prediction. At each denoising step, only the top- $k$ most confident tokens among the currently masked positions are sampled and revealed, while the remaining ${\texttt{mask}}$ tokens are kept masked. While token-level supervision is incompatible, we propose step-level divergence supervision as a more natural objective for dLLMs.
Specifically, at each denoising step $t$, using the previously constructed inputs $y_{\text{student}, t}$ and $y_{\text{teacher}, t}$, the model first computes full-sequence distributions:
$ \begin{aligned} \mathcal{P}{\text{student}, t}^i &= p\theta(y^i|y_{\text{student}, t}, x), \quad 1 \leq i \leq L, \ \mathcal{P}{\text{teacher}, t}^i &= p\theta(y^i|y_{\text{teacher}, t}, x), \quad 1 \leq i \leq L. \end{aligned}\tag{9} $
Crucially, not all token positions $i$ actively participate in the state transition from $t$ to $t-1$. We focus exclusively on the top- $k$ most confident tokens among the currently masked positions, as only these tokens dictate the step-level transition. Denoting these tokens' indices as the top- $k$ subset $\mathcal{K}_t \subset { 1 \leq i \leq L | y_t^i = {\texttt{mask}} }$ which satisfies:
$ \sum_{t=1}^T |\mathcal{K}_t|= L.\tag{10} $
We then compute the step-level KL divergence over this subset:
$ \mathcal{L}t = \frac{1}{|\mathcal{K}t|} \sum{i \in \mathcal{K}t} \mathcal{D}\text{KL} \left(\mathcal{P}{\text{student}, t}^i || \mathcal{P}_{\text{teacher}, t}^i \right).\tag{11} $
Note that the top- $k$ subset $\mathcal{K}_t$ can theoretically be determined from either the student distribution or teacher distribution. However, the ablation study in Section 4.4 suggests that deriving from the teacher distribution yields greater performance gains.
With the self-teacher construction and step-level divergence in place, we now possess all the essential components needed to apply OPSD to dLLMs.
3.3 d-OPSD: the First On-Policy Self-distillation for dLLMs
We now formally introduce our approach, d-OPSD. Operating with a single model $p_\theta$ severing simultaneously as student and teacher, the procedure begins with the student sampling an on-policy $T$-step trajectory $Y$ Equation (6) for a given prompt $x$. For each denoising step $0 <t \leq T$, we construct the student input $y_{\text{student}, t}$ and the teacher input $y_{\text{teacher}, t}$ using Equation 7 and 8. Note that the constructions are independent over steps. Finally, we minimize the following step-level learning objective across the entire on-policy trajectory:
$ \begin{aligned}\mathcal{L}\text{OPSD} (\theta) =& \mathbb{E}x \left[\frac{1}{T} \sum{t=1}^T \mathcal{L}t \right]\=& \mathbb{E}x \left[\frac{1}{T} \sum{t=1}^T \frac{1}{|\mathcal{K}t|} \sum{i \in \mathcal{K}t} \mathcal{D}\text{KL} \left(\mathcal{P}{\text{student}, t}^i || \mathcal{P}{\text{teacher}, t}^i \right) \right]\=& \mathbb{E}x \left[\frac{1}{T} \sum{t=1}^T \frac{1}{|\mathcal{K}t|} \sum{i \in \mathcal{K}t} \mathcal{D}\text{KL} \left(p_\theta \left(y^i|y_{\text{student}, t}, x \right) || p_\theta \left(y^i|y_{\text{teacher}, t}, x \right) \right) \right].\end{aligned}\tag{12} $
Additionally, we find that the quality of the student trajectory $Y$ influences the final performance (see Section 4.4 and Appendix E.1). Therefore, for each prompt $x$, we keep sampling trajectories until a correct final answer $y_0$ occurs, or the sampling iteration number meets a threshold (similar to pass@ $k$, and we set $k=8$ by default)[^1]. Note that this sampling strategy shares the same computation overhead as RLVR (group $k$ rollouts) for each training step. Following ([8]), we apply pointwise KL clipping and the fix teacher strategy, as detailed in Appendix C. Additional implementation details are also provided in Appendix C, including an important engineering technique preventing out of memory by concatenating step-level inputs, motivated by ([23]).
[^1]: Even with $k=1$, our approach still surpasses the RLVR baseline which uses group $k=8$ rollouts, see Section 4.4.
Crucially, we conclude this section by highlighting the fundamental distinctions between our approach and existing self-distillation approaches for dLLMs, such as d3llm ([24]) and Cd4lm ([25]), which also construct a self-teacher by partially revealing answers. First and foremost, the revealed answers in our approach are "self-experience" generated on-policy by the student itself, whereas theirs are from the ground-truth of static datasets. Second, while we leverage step-level divergence supervision across an entire on-policy generation trajectory, they employ a single forward pass like a 'one-step'' fake trajectory to provide supervision. These critical differences define d-OPSD as an on-policy distillation approach providing dense supervision for every denoising steps across the entire trajectory, whereas their approaches remain fundamentally off-policy closely related to SFT.
4. Experiments
Section Summary: The experiments section first uses a simple toy test on partial model generations to confirm that the self-teacher construction can reliably recover correct answers and thus guide effective distillation. It then runs broader tests of the OPSD approach on math and planning tasks with an 8B-scale diffusion language model, comparing it to supervised fine-tuning and reinforcement-learning baselines while also measuring sample efficiency, alternative teacher-construction methods, training-parameter choices, and failure cases such as policy collapse. Results are presented via performance tables and ablations that demonstrate OPSD’s advantages in reasoning accuracy and data efficiency.
In this section, we first address a foundational prerequisite with a toy verification:
Question: Is the self-teacher strong enough to guide self-distillation?
Answer: Yes. The self-teacher is capable enough that the correct answer can be resumed using our teacher construction. See Section 4.1.
We then conduct comprehensive experiments to answer the following core questions:
Question: How does OPSD compare to SFT and RLVR in reasoning performance and sample efficiency?
Answer: It outperforms or matches SFT and RLVR baselines in reasoning performance, while demonstrating vastly superior sample efficiency. See Section 4.2.
Question: How does the self-teacher construction in d-OPSD compare to the AR-style counterpart (Figure 2)?
Answer: Our approach significantly outperforms the AR counterpart. The key reason is that our teacher construction introduces more new knowledge (thinking patterns) to transfer to the student. See Section 4.3.
Question: What is the impact of different training settings?
Answer: We provide comprehensive ablation results on different KL objectives, retaining ratios $\rho_\text{teacher}$, top- $k$ subset $\mathcal{K}_t$ selections, sampling strategies, and other training settings. See Section 4.4 and Appendix E.1.
Question: What are the failure modes for d-OPSD?
Answer: Similar to RLVR, OPSD is susceptible to policy collapse after reaching peak performance. See Section 4.5.
4.1 Experimental Setup & Toy Verification
Models and Tasks. We employ LLaDA-8B-Instruct ([12]), a state-of-the-art dLLM that has not undergone post-training, as our base model [^2]. We conduct experiments across four reasoning tasks spanning two categories: mathematical reasoning and planning. The mathematical reasoning tasks include GSM8K ([26]) and MATH500 ([27]). The planning tasks include $4x4$ Sudoku puzzles, which require constraint satisfaction to fill a grid with numbers, and Countdown ($3$ numbers), where models must reach a target number using basic arithmetic operations on a given set of integers. All datasets configurations remain consistent with the RLVR baseline, diffu-GRPO ([1]).
[^2]: We did not use Dream ([13]) because its output format is highly inconsistent, which causes severe instability across RLVR baselines. This limitation is also marked by ([28]).
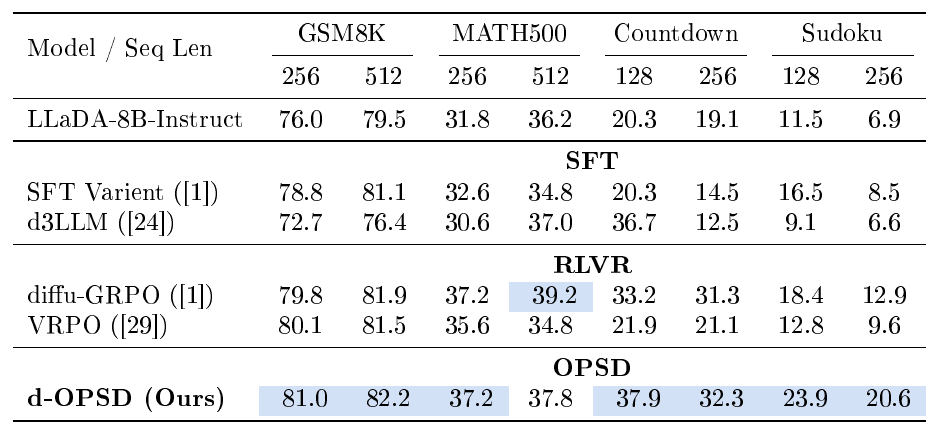
::: {caption="Table 1: Reasoning performance comparison across four reasoning tasks. Results of diffu-GRPO and the SFT varient are sourced from the original paper ([1]). Results of VRPO, d3LLM and the base model are evaluated using their open-sourced models. d-OPSD consistently outperforms or matches SFT and RLVR baselines."}
:::
::: {caption="Table 2: Sample efficiency comparison between the RLVR baseline and our approach. The optimization steps for diffu-GRPO are sourced from the original paper ([1])."}

:::
Baselines. We compare against two categories of post-training methods: RLVR and SFT. RLVR baselines include diffu-GRPO ([1]) and VRPO ([29]). For SFT, we compare against the SFT variant from ([1]) and the existing off-policy self-distillation approach, d3LLM ([24]).
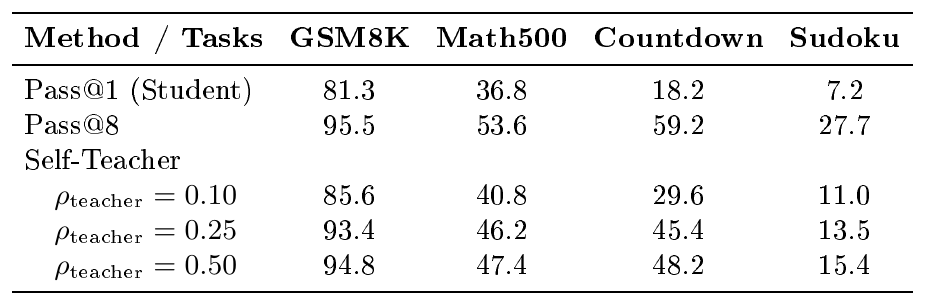
::: {caption="Table 3: Toy Verification. The correct answer can be resumed from the self-teacher construction."}
:::
Training Details. Following ([8]), we fix the teacher policy to the initial policy to stabilize training. We use full-vocabulary logit distillation with LoRA ([30]). The default distribution divergence measure is reverse KL. The generation length and retaining ratio $\rho_\text{teacher}$ are set to $256$ and $0.25$, respectively. Additional training details are provided in Appendix D.1.
Evaluation Details. We evaluated every $25$ steps before step $501$ and report the best results. For mathematical reasoning tasks, we evaluate model performance using generation lengths of $512$ and $256$. For planning tasks, we evaluate at $128$ and $256$. This distinction is made because longer generation lengths improve performance in mathematical reasoning tasks but degrade it in planning tasks (see Table 1). We utilize the block diffusion strategy ([31]) with a block length of $32$. Denoising steps are configured as half of the generation length.
Toy Verification. A critical question that must be answered before the full experiment is whether the self-teacher is strong enough to guide distillation. To verify this, we randomly sampled $500$ questions from each task's training set, obtained generations from the base model, constructed self-teacher inputs (using Pass@ $8$) as described in Section 3.3 under different retaining ratios $\rho_\text{teacher}$, and finally re-generated responses conditioned on these self-teacher inputs. As shown in Table 3, even with a moderate $\rho_\text{teacher} = 0.10$, the self-teacher significantly outperforms the student. At higher $\rho_\text{teacher}$, the self-teacher performance nearly matches its origin (Pass@8). This toy experiment successfully validates that our self-teacher can resume correct answers and guide high-quality distillation. Additional details and examples of this toy experiment are provided in Appendix D.2.
4.2 Main Results
Table 1 presents a comprehensive performance comparison between SFT, RLVR, and our approach. d-OPSD consistently outperforms or matches SFT and RLVR baselines, achieving state-of-the-art performance in most settings and showcasing significant improvements over the base models. Table 2 and Figure 1 detail the sample efficiency comparison between the RLVR baseline and our approach. d-OPSD demonstrates vastly superior sample efficiency, converging in only around $10%$ of the optimization steps (number of gradient updates) required by RLVR. Note that the pass@ $k$ sampling strategy we use in Section 3.3 shares the same computation overhead as RLVR (group $k$ rollouts) for each optimization step. Consistent with ([4, 8]), we attribute OPSD’s superior sample efficiency to the dense supervision provided by the teacher distribution. These results underscore our approach's promising reasoning performance and sample efficiency.
4.3 Comparison with AR-style OPSD: Unlocking New Knowledge
::: {caption="Table 4: Reasoning performance Comparison between AR-style OPSD and our approach. Generation length is 256. Our teacher construction outperforms the AR-style baseline."}

:::
A pivotal design choice in our approach is the specific self-teacher construction tailored for dLLMs (Section 3.1). It is imperative to evaluate how this formulation compares to the AR-style construction shown in Figure 2. To this end, we conducted an additional AR-style baseline strictly following ([8]), which appends the reference solution to the prompt as a prefix conditioning to provide privileged information to the teacher, while keeping our step-level divergence supervision (Section 3.2) constant. Table 4 [^3] reports the performance comparison results. Our approach consistently outperforms the AR-style counterpart, highlighting the critical importance of our specific self-teacher construction.
[^3]: Following ([8]), the reference solution is the reasoning trajectory obtained directly from the dataset. Therefore, we did not conduct experiments on Countdown and Sudoku, as they consist of only questions and pure ground truths without any reasoning traces.
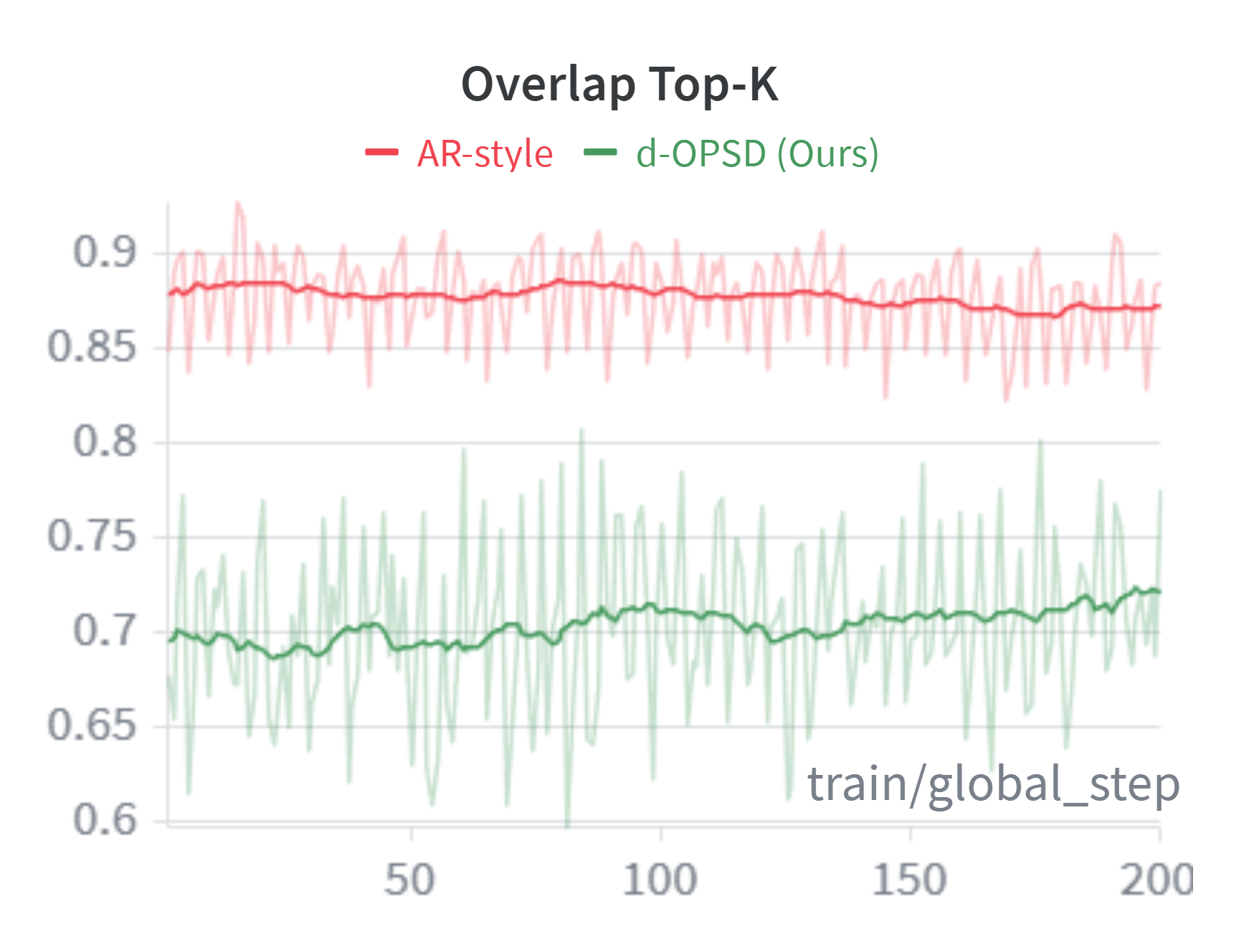
We further investigate the mechanism behind this performance gap. We define the metric of Overlap Top- $K_t$. At each denoising step $t$, it measures the proportion of tokens that appear simultaneously in both the student’s and teacher’s Top- $K$ vocabulary distributions over the top- $k$ subset $\mathcal{K}_t$ masked positions. Note that Top- $K$ and top- $k$ have different meanings. Top- $K$ refers to comparing the distribution over the vocabulary at a specific token position, while top- $k$ refers to the most confident tokens in the currently masked positions (Section 3.2). Formally, Overlap Top- $K_t$ can be expressed as:
$ \mathcal{M}{\text{overlap}, K, t} = \frac{1}{|\mathcal{K}t|} \sum{i \in \mathcal{K}t} \left[\frac{|\mathcal{P}{\text{student}, t}^{i, \text{Top-}K} \cap \mathcal{P}{\text{teacher}, t}^{i, \text{Top-}K}|}{K} \right],\tag{13} $
::: {caption="Table 5: Reasoning performance comparison of divergence objectives."}
:::
where $\mathcal{P}_{t}^{i, \text{Top-}K}$ is the Top- $K$ distribution over the vocabulary at token position $i$, derived from Equation 9. As shown in Figure 3, the Overlap Top- $K_t$ for AR-style OPSD is extremely high, nearly to $1$, indicating that appending a reference solution fails to bring new knowledge or thinking patterns to the teacher for the student to learn. Conversely, the Overlap Top- $K_t$ for d-OPSD lies in a suitable range, providing more new knowledge that can be transferred from teacher to student. $K$ is set to $K=20$ in practice.
4.4 Ablation Studies
Additional ablation studies are provided in Appendix E.
::: {caption="Table 6: Reasoning performance comparison of retaining ratios."}
:::
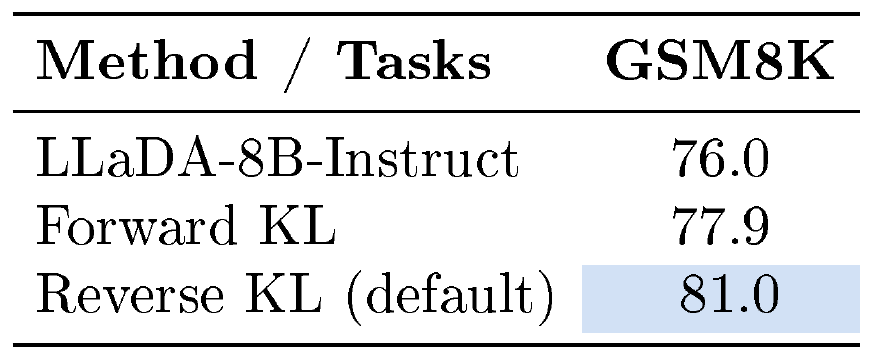
Divergence Objective. We compare reverse KL (default) and forward KL in Table 5. Reverse KL clearly outperforms forward KL. We attribute this to the model-seeking behavior of reverse KL ([2]), which is more robust compared to the model-covering behavior of forward KL.
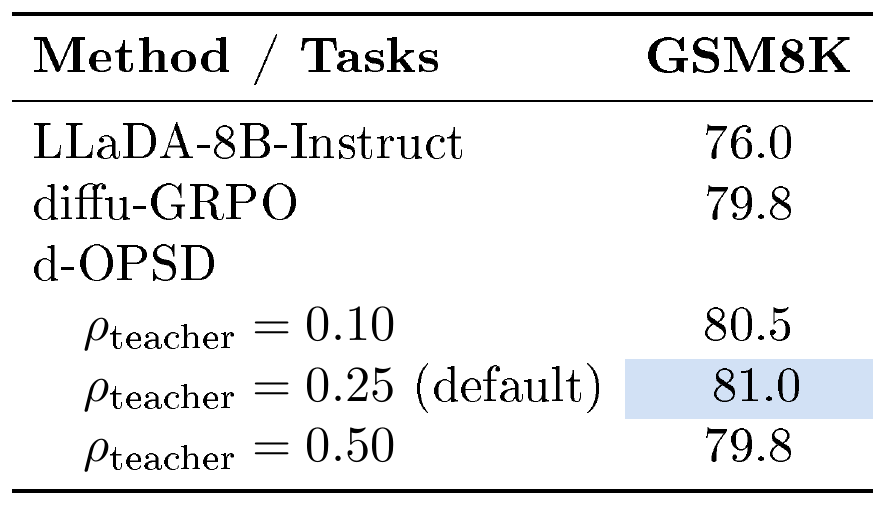
Retaining Ratio. We observe that different retaining ratios $\rho_\text{teacher}$ have moderate influences on overall performance. As shown in Table 6, all configurations improve over the base model and surpass the RLVR baseline. Interestingly, $\rho_\text{teacher}=0.10$ yields better results than $\rho_\text{teacher}=0.50$, despite it is a weaker teacher as shown in Table 3. This suggests that while a accurate teacher is beneficial, the distillation effectiveness is not only decided by the teacher performance.
::: {caption="Table 7: Reasoning performance comparison of $K_t$ selections."}
:::
top- $k$ subset $\mathcal{K}_t$ Selection. As noted in Section 3.2, $\mathcal{K}_t$ can be selected using either the student distribution or teacher distribution. Table 7 compares these two choice. Deriving $\mathcal{K}_t$ from the teacher distribution yields higher performance, as it forces the student to align with the most confident distributions by the teacher policy, providing a stronger learning signal.
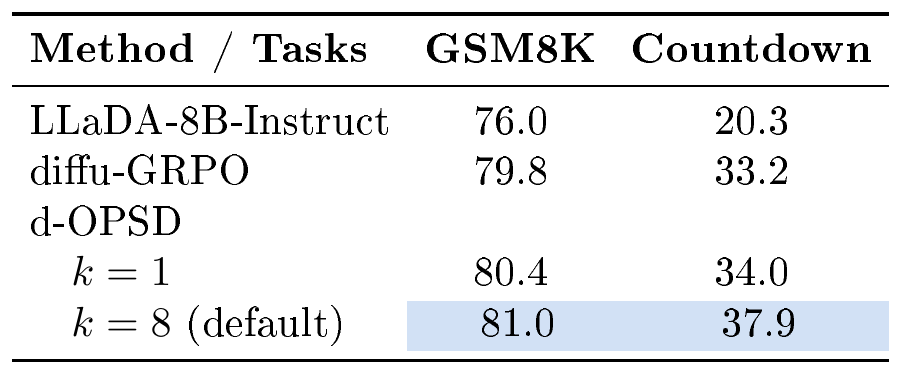
Pass@ $k$. As noted in Section 3.3, we employ a sampling strategy akin to pass@ $k$, keeping sampling trajectories until a correct answer occurs within $k$ iterations.
::: {caption="Table 8: Reasoning performance comparison of sampling strategies."}
:::
Table 8 evaluates the impact of varying $k$. Although $k=1$ slightly degrades reasoning performance compared to $k=8$, it still surpasses the RLVR baseline with a even greater sample efficiency than $k=8$.
::: {caption="Table 9: Reasoning performance comparison of clipping."}
:::
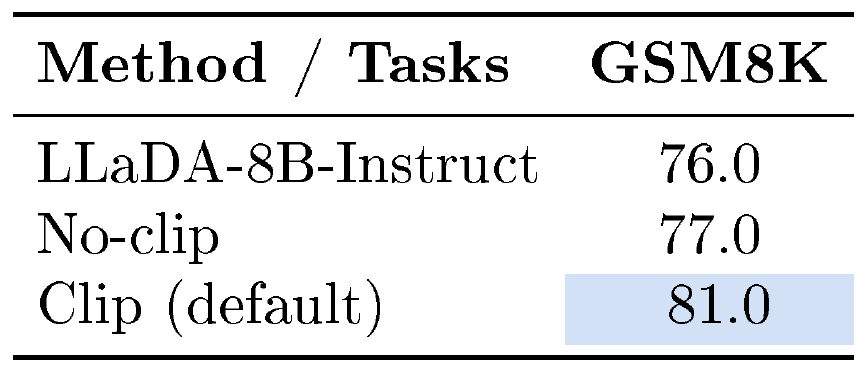
Per-token Pointwise Clipping. As noted in Appendix C.1, we adopt a pointwise clipping strategy following ([8]). Table 9 shows that pointwise clipping substantially improves the performance of d-OPSD. More importantly, we observe that clipping stabilizes training in most settings, which explains the performance gap. In contrast, the none-clipping variant starts to collapse around step $150$, with performance finally dropping to $69.37$ by step $500$. The clipping threshold is set to $0.05$ in practice.
4.5 Failure Modes
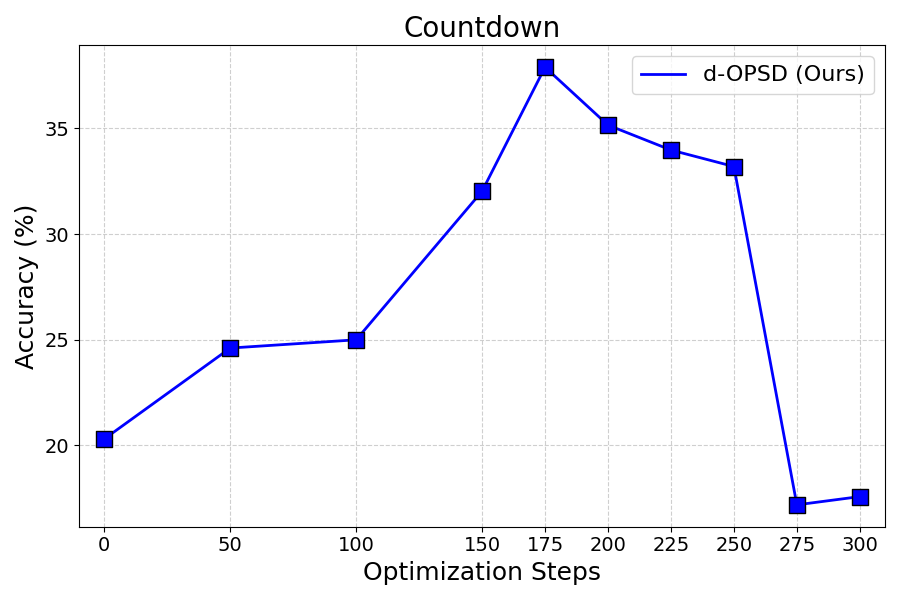
We wish to transparently share a failure mode observed with our current approach. Although it is highly effective in both reasoning performance and sample efficiency, we find that similar to RLVR, OPSD in some settings is prone to policy collapse after achieving peak performance.
As shown in Figure 12, training sometimes degrade catastrophically. We noticed that the same phenomena is commonly observed in RLVR ([32, 33]). We hypothesize that this collapse may stem from the model-seeking behavior ([2]) becoming overly narrow, prevent from further learning.
5. Related Works
Section Summary: The section on related works, with further details in an appendix, focuses on on-policy distillation as a technique for transferring knowledge from a large teacher model to a smaller student model. It explains how this builds on standard knowledge distillation, which trains the student using the teacher's soft output probabilities rather than hard labels. Earlier sequence-based methods used off-policy approaches, whereas later extensions to on-policy distillation train the student on its own generated outputs to reduce mismatches like exposure bias.
Additional relate works are provided in Appendix A.2.
On-policy Distillation. Knowledge distillation ([34]) transfers knowledge from a large teacher model to a smaller student model by training on the teacher's soft output distributions. [35, 36, 37] leveraged it to sequence-level distillation, establishing the dominant off-policy distillation approaches. ([38, 2, 4, 39]) extended it to OPD, addressing the exposure bias ([7]) mismatch by shifting the training distribution to the student's own generations.
6. Conclusion
Section Summary: This paper introduces d-OPSD, the first self-distillation method designed specifically for diffusion-based large language models that run in an on-policy setting. The approach builds a teacher signal from the model’s own later outputs to provide privileged guidance during training, while moving performance feedback from individual tokens to full generation steps so it aligns with the models’ iterative nature. Future efforts will focus on making this post-training process more stable and effective.
This work presents d-OPSD, the first on-policy self-distillation approach for dLLMs. It is specifically tailored to align with on-policy and dLLMs nature. We propose a novel self-teacher construction that utilizes the model's own self-generated answers as suffix conditioning for privileged information, effectively guiding the student to learn from its on-policy "self-future experience". Furthermore, we shift the dense divergence supervision from the token-level to step-level, perfectly matching the iterative mechanics of dLLMs. Future work will explore advanced techniques to further stabilize and enhance the OPSD post-training of dLLMs.
Appendix
Section Summary: The appendix supplies supporting background, examples, and technical details for the main paper. It reviews block-diffusion inference and prior reinforcement learning methods for diffusion-based language models, then illustrates the self-teacher construction process with GSM8K examples contrasting it against simpler AR-style references. Additional sections cover implementation choices such as per-token clipping, memory-efficient input concatenation, loss computation restricted to correct outputs, and the specific training setup using LoRA on multiple GPUs.
A. Additional Preliminaries
and Related Works
A.1 Additional Preliminaries
Block-diffusion. In practice, the block-diffusion inference strategy ([40, 31, 41]) is commonly used in current dLLMs. This hybrid approach partitions a response $y$ into $B$ contiguous, non-overlapping blocks ${\text{block}_1, \text{block}_2, \cdot s, \text{block}_B}$, with each block containing $L' = \frac{L}{B}$ tokens. The inference is purely AR at the block level while being purely diffusion-style within each block, where the next block starts to decode only when the last block gets fully decoded.
A.2 Additional Related Works
Reinforcement Learning for dLLMs. Reinforcement learning (RL) has emerged as a critical post-training technique for enhancing the reasoning capabilities of dLLMs. Most existing works ([1, 42, 21, 43, 44, 45]) directly apply GRPO to dLLMs, using either one-step estimation or the ELBO to estimate the log-probability in GRPO. However, most of them suffer from the fundamental challenges of RLVR: the heavy computation overhead and the bottleneck of spare rewards.
B. Self-teacher Construction Illustrations
Here we provide an example of how our self-teacher construction (Section 3.1) works, with a question sampled from GSM8K training set. For brevity, we omit some ${\texttt{mask}}$ and "end-of-text" tokens.
The question is:

First, we sample an on-policy trajectory [^4] from the student model and obtain the final clean answer as the self-generated future:
[^4]: Using pass@ $k$, it keeps sampling until a correct final answer appears or it reaches the iteration threshold.

At denoising step $t=20$, we have the student decoding status as follows:

We then construct the self-teacher at step $t=20$ as follows:
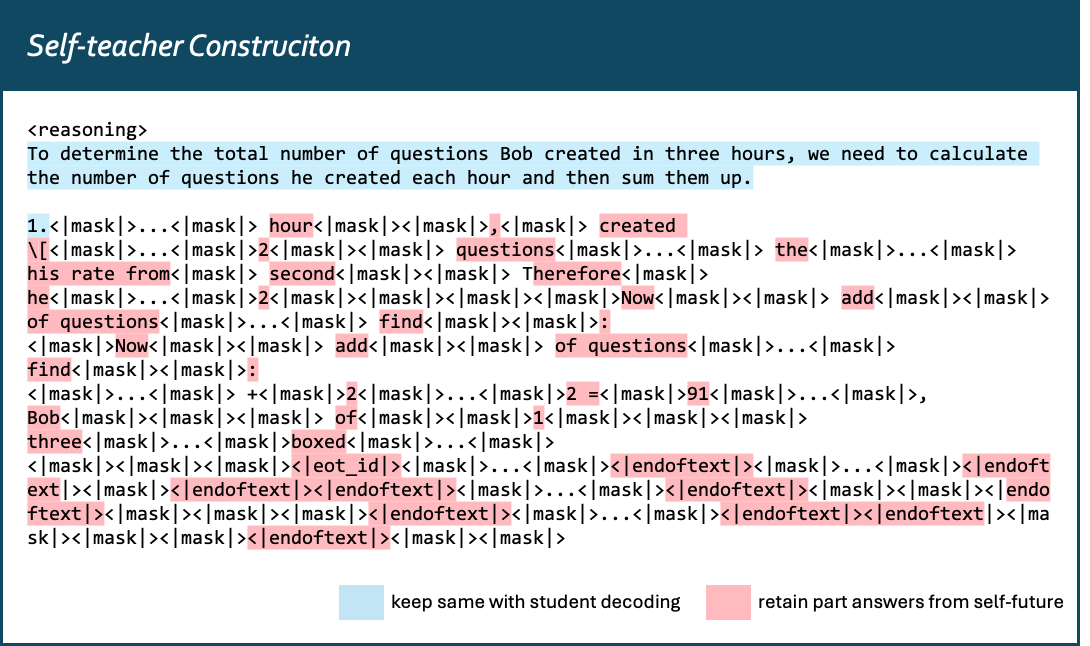
For comparison, we also illustrate the AR-style construction, which appends a reference solution to the prompt, as shown in Figure 8.

C. Additional Implementation Details
C.1 Per-Token pointwise clipping
Following ([8]), we apply pointwise clipping to the vocabulary level divergence contributions. The reason is that token-level divergence is highly skewed across vocabulary entries, and our ablation study in Section 4.4 empirically validates that pointwise clipping stabilizes training and leads to better performance.
C.2 Inputs Concatenation
DLLMs generate responses by an iterative denoising process, where each iteration requires full-attention over all token positions. Consequently, computing the loss objective in Equation 12 can easily lead to out of memory, as the full attention gradient maps over all token positions across every steps need to be stored, until a trajectory is fully decoded. To address this issue, we leverage a engineering technique, concatenating all inputs across every steps of a trajectory into an entire batch. Specifically, assume that the student decoding status is a tensor of shape (bsz, seq-length). Instead of feeding it into the model to compute the corresponding term in Equation 12, we concatenate all status tensors across all steps of this trajectory to form a "batch" tensor of shape (bsz $\times$ steps, seq-length). Since all inputs share the same model, the gradient remains constant for each input and no longer needs to be stored as previously.
C.3 Compute only on Correct Generations
By default, we compute the loss objective Equation 12 only on correct generations [^5]. Although computing on all generations also improves the model's reasoning performance, our default setting achieves superior results. Detailed experimental results are provided in Appendix E.1.
[^5]: For Sudoku task, there are no "right" or "wrong" answers because it gives a score in $[0, 1]$. Therefore, we set an threshold to decide if the generation should be include in loss computation. In practice, the threshold is set to $0.25$.
D. Additional Experiment Details
D.1 Training Details
We used the TRL library ([46]) to implement d-OPSD. We employed Low-Rank Adaptation (LoRA) with a rank of $r = 128$ and scaling factor $\alpha = 64$. Training was conducted on $4$ NVIDIA GPUs, with a learning rate of 5 x 10^-6, accumulation steps of $1$, the AdamW optimizer ([47]), and Flash Attention 2 ([48]). The RLVR baseline diffu-GRPO ([1]) in Figure 1 was reproduced on $8$ NVIDIA GPUs, following its default settings.
D.2 Toy Experiment Details and Examples
The generation length is $256$ for all tasks. After applying the self-teacher construction, the number of remaining ${\texttt{mask}}$ tokens becomes smaller than the generation length $256$. We keep constant that unmasking $2$ tokens in each step with a block length of $32$.
One important point to note is that, to prevent the risk of leaking the final answer (e.g., the final answer between
We provide an example from GSM8K training set. The question is:

First, we sample a generation [^6] from the student model and obtain the final clean answer:
[^6]: Using pass@ $k$, it keeps sampling until a correct final answer appears or it reaches the iteration threshold.

We then construct self-teacher by partially revealing the final generation, as shown in Figure 11.

::: {caption="Table 10: Reasoning performance comparison of teacher fixing."}
:::
E. Additional Experiment Results
E.1 Additional Ablation Studies
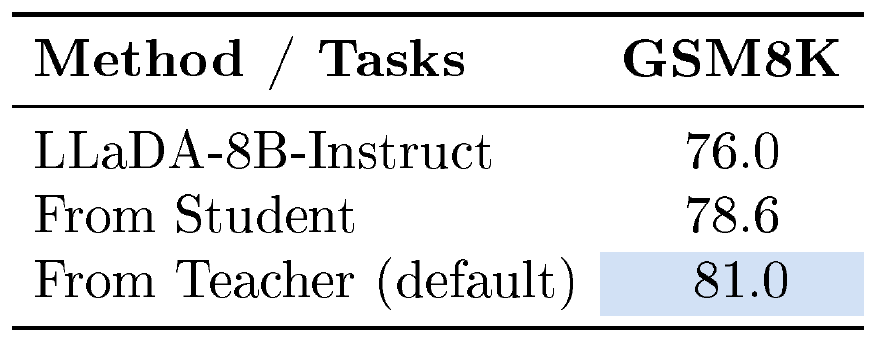
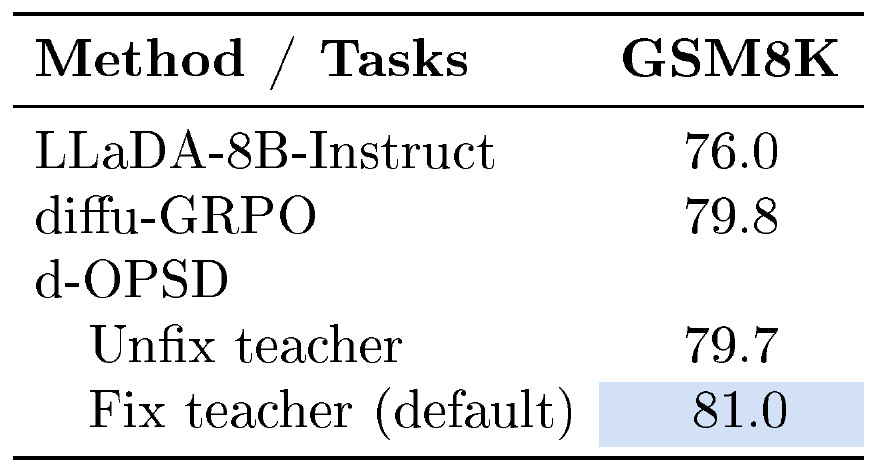
Fixing the Teacher. We find that fixing the teacher model leads to greater performance gains, as shown in Table 10. Notably, even when the teacher is not fixed, d-OPSD's reasoning performance nearly matches the RLVR baselines, further demonstrating its effectiveness.
::: {caption="Table 11: Reasoning performance comparison."}
:::
Compute only on Correct Generations
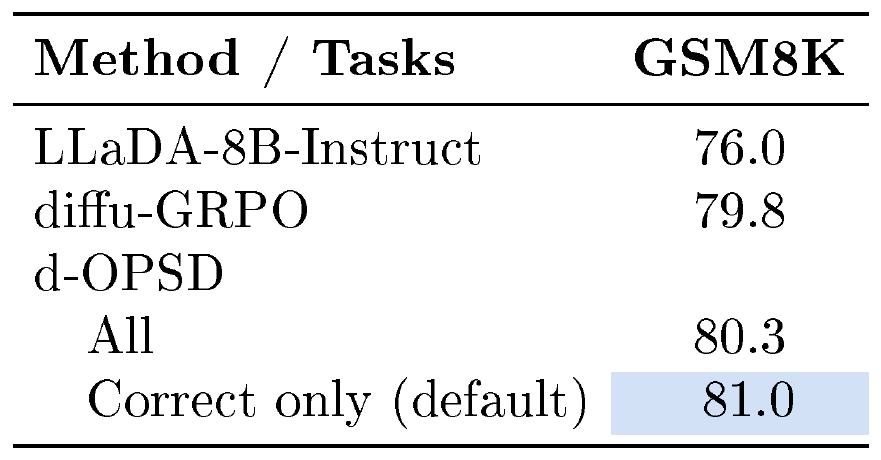
As shown in Table 11, computing the loss on all trajectories leads to a slight performance degradation. Nevertheless, it still outperforms the RLVR baseline.
E.2 Qualitative Examples on GSM8k
We provide a qualitative example from GSM8k testing set, where the RLVR model gives an incorrect answer while our approach yields the correct one, as shown in Figure 13.
E.3 Failure Mode
Figure 12 presents the failure mode mentioned in Section 4.5.

References
Section Summary: This section compiles dozens of academic citations, primarily recent arXiv preprints and conference papers from 2024–2026, on diffusion-based large language models, reinforcement learning for reasoning, and distillation techniques such as on-policy and self-distillation. The references highlight technical reports on models like d1, Qwen3, and Deepseek-r1 alongside studies exploring policy optimization, consistency distillation, and hybrids of autoregressive and diffusion approaches. A smaller number of foundational works on knowledge distillation and sequence prediction from 2015–2021 are also included for context.
[1] Zhao et al. (2025). d1: Scaling reasoning in diffusion large language models via reinforcement learning. arXiv preprint arXiv:2504.12216.
[2] Agarwal et al. (2024). On-policy distillation of language models: Learning from self-generated mistakes. In The twelfth international conference on learning representations.
[3] Yang et al. (2025). Qwen3 technical report. arXiv preprint arXiv:2505.09388.
[4] Kevin Lu and Thinking Machines Lab (2025). On-Policy Distillation. Thinking Machines Lab: Connectionism. doi:10.64434/tml.20251026.
[5] Li et al. (2026). Rethinking On-Policy Distillation of Large Language Models: Phenomenology, Mechanism, and Recipe. arXiv preprint arXiv:2604.13016.
[6] Guo et al. (2025). Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning. arXiv preprint arXiv:2501.12948.
[7] Bengio et al. (2015). Scheduled sampling for sequence prediction with recurrent neural networks. Advances in neural information processing systems. 28.
[8] Zhao et al. (2026). Self-Distilled Reasoner: On-Policy Self-Distillation for Large Language Models. arXiv preprint arXiv:2601.18734.
[9] Hübotter et al. (2026). Reinforcement Learning via Self-Distillation. arXiv preprint arXiv:2601.20802.
[10] Shenfeld et al. (2026). Self-Distillation Enables Continual Learning. arXiv preprint arXiv:2601.19897.
[11] Ou et al. (2024). Your absorbing discrete diffusion secretly models the conditional distributions of clean data. arXiv preprint arXiv:2406.03736.
[12] Nie et al. (2025). Large language diffusion models. arXiv preprint arXiv:2502.09992.
[13] Ye et al. (2025). Dream 7b: Diffusion large language models. arXiv preprint arXiv:2508.15487.
[14] Cheng et al. (2025). Sdar: A synergistic diffusion-autoregression paradigm for scalable sequence generation. arXiv preprint arXiv:2510.06303.
[15] Bie et al. (2025). Llada2. 0: Scaling up diffusion language models to 100b. arXiv preprint arXiv:2512.15745.
[16] Jaech et al. (2024). Openai o1 system card. arXiv preprint arXiv:2412.16720.
[17] Xiao et al. (2026). Mimo-v2-flash technical report. arXiv preprint arXiv:2601.02780.
[18] Khanna et al. (2025). Mercury: Ultra-fast language models based on diffusion. arXiv e-prints. pp. arXiv–2506.
[19] Song et al. (2025). Seed diffusion: A large-scale diffusion language model with high-speed inference. arXiv preprint arXiv:2508.02193.
[20] Wu et al. (2025). Fast-dllm: Training-free acceleration of diffusion llm by enabling kv cache and parallel decoding. arXiv preprint arXiv:2505.22618.
[21] Tang et al. (2025). wd1: Weighted policy optimization for reasoning in diffusion language models. arXiv preprint arXiv:2507.08838.
[22] Xie et al. (2025). Step-aware policy optimization for reasoning in diffusion large language models. arXiv preprint arXiv:2510.01544.
[23] Wang et al. (2025). Revolutionizing reinforcement learning framework for diffusion large language models. arXiv preprint arXiv:2509.06949.
[24] Qian et al. (2026). d3LLM: Ultra-Fast Diffusion LLM using Pseudo-Trajectory Distillation. arXiv preprint arXiv:2601.07568.
[25] Liang et al. (2026). CD4LM: Consistency Distillation and aDaptive Decoding for Diffusion Language Models. arXiv preprint arXiv:2601.02236.
[26] Cobbe et al. (2021). Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168.
[27] Lightman et al. (2023). Let's verify step by step. In The twelfth international conference on learning representations.
[28] Pan et al. (2025). d-TreeRPO: Towards More Reliable Policy Optimization for Diffusion Language Models. arXiv preprint arXiv:2512.09675.
[29] Zhu et al. (2025). Llada 1.5: Variance-reduced preference optimization for large language diffusion models. arXiv preprint arXiv:2505.19223.
[30] Hu et al. (2022). Lora: Low-rank adaptation of large language models.. Iclr. 1(2). pp. 3.
[31] Arriola et al. (2025). Block diffusion: Interpolating between autoregressive and diffusion language models. arXiv preprint arXiv:2503.09573.
[32] Deng et al. (2025). On grpo collapse in search-r1: The lazy likelihood-displacement death spiral. arXiv preprint arXiv:2512.04220.
[33] Bai et al. (2025). M-GRPO: Stabilizing Self-Supervised Reinforcement Learning for Large Language Models with Momentum-Anchored Policy Optimization. arXiv preprint arXiv:2512.13070.
[34] Hinton et al. (2015). Distilling the knowledge in a neural network. arXiv preprint arXiv:1503.02531.
[35] Kim, Yoon and Rush, Alexander M (2016). Sequence-level knowledge distillation. In Proceedings of the 2016 conference on empirical methods in natural language processing. pp. 1317–1327.
[36] Jiao et al. (2020). Tinybert: Distilling bert for natural language understanding. In Findings of the association for computational linguistics: EMNLP 2020. pp. 4163–4174.
[37] Wang et al. (2020). Minilm: Deep self-attention distillation for task-agnostic compression of pre-trained transformers. Advances in neural information processing systems. 33. pp. 5776–5788.
[38] Gu et al. (2024). Minillm: Knowledge distillation of large language models. In The twelfth international conference on learning representations.
[39] Yang et al. (2026). Learning beyond teacher: Generalized on-policy distillation with reward extrapolation. arXiv preprint arXiv:2602.12125.
[40] Han et al. (2023). Ssd-lm: Semi-autoregressive simplex-based diffusion language model for text generation and modular control. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). pp. 11575–11596.
[41] Fathi et al. (2025). Unifying autoregressive and diffusion-based sequence generation. arXiv preprint arXiv:2504.06416.
[42] Huang et al. (2025). Reinforcing the diffusion chain of lateral thought with diffusion language models. arXiv preprint arXiv:2505.10446.
[43] Gong et al. (2025). Diffucoder: Understanding and improving masked diffusion models for code generation. arXiv preprint arXiv:2506.20639.
[44] Rojas et al. (2025). Improving reasoning for diffusion language models via group diffusion policy optimization. arXiv preprint arXiv:2510.08554.
[45] Ou et al. (2025). Principled rl for diffusion llms emerges from a sequence-level perspective. arXiv preprint arXiv:2512.03759.
[46] von Werra et al. (2020). TRL: Transformers Reinforcement Learning. https://github.com/huggingface/trl.
[47] Loshchilov, Ilya and Hutter, Frank (2017). Decoupled weight decay regularization. arXiv preprint arXiv:1711.05101.
[48] Dao, Tri (2023). Flashattention-2: Faster attention with better parallelism and work partitioning. arXiv preprint arXiv:2307.08691.