Transfusion: Predict the Next Token and Diffuse Images with One Multi-Modal Model
Purpose and context
Organizations developing multi-modal AI systems face a fundamental architectural choice: how to build a single model that can both understand and generate different types of data—specifically text and images. Current approaches either bolt separate specialized models together (one for text, one for images) or convert everything to discrete tokens and use language modeling alone. The first approach is complex and costly; the second loses information when converting images to tokens. This work introduces Transfusion, a method that trains one unified model using different learning objectives matched to each data type: standard next-token prediction for text and diffusion (a continuous modeling technique) for images.
What was done
The research team built and tested Transfusion models ranging from 160 million to 7 billion parameters. The core innovation is training a single transformer network on mixed sequences of text tokens and image patches, applying language modeling loss to text and diffusion loss to images within the same training step. Images are represented as continuous vectors (not quantized to discrete tokens), and the model uses causal attention for text but bidirectional attention within each image. The team trained models on up to 2 trillion tokens (half text, half image data) and compared performance against Chameleon, a published baseline that discretizes images and models everything as language.
Key findings
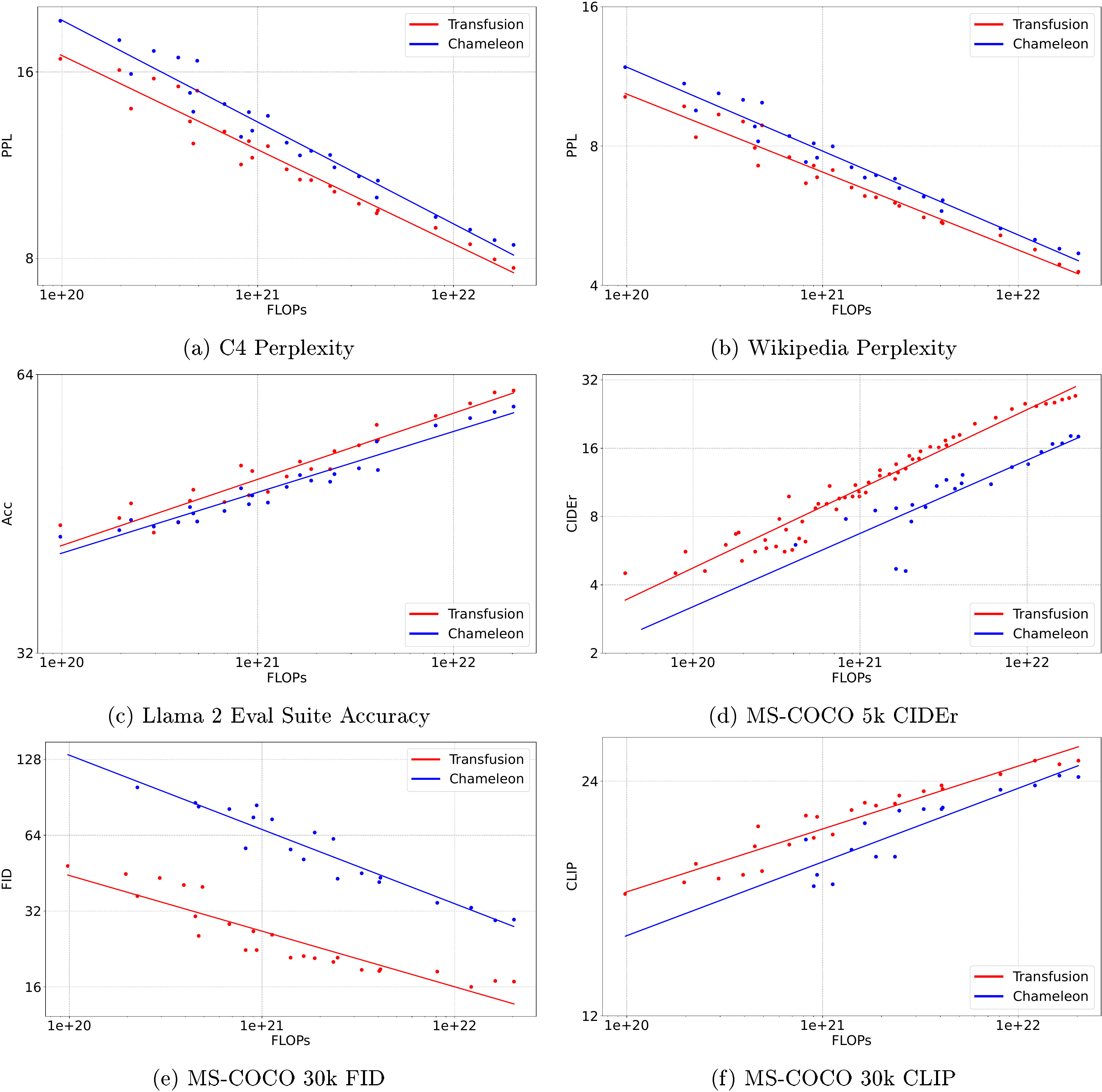
Transfusion consistently outperforms the discretization approach across all tested tasks. For image generation, Transfusion achieves the same quality as Chameleon using only 3% of the compute resources (34 times more efficient). For image captioning, Transfusion matches Chameleon performance at 22% of the compute. Unexpectedly, Transfusion also improves text-only tasks, reaching the same text perplexity as Chameleon at 49-60% of the compute, even though both methods model text identically. The analysis shows this advantage comes from avoiding the overhead of discretizing images and from architectural stability improvements needed by Chameleon.
When scaled to 7 billion parameters and trained on 2 trillion tokens, the Transfusion model generates images comparable to specialized diffusion models like DALL-E 2 and SDXL, while simultaneously matching the text generation performance of Llama language models trained on the same text data. An additional experiment showed that fine-tuning on just 8,000 image editing examples enables the model to perform image-to-image transformations, suggesting the approach generalizes to modality combinations not seen during initial training.
What this means
These results demonstrate that organizations can build single unified models for multi-modal AI without sacrificing performance or efficiency. Transfusion eliminates the need to either maintain multiple specialized models or accept information loss from quantization. The compute savings are substantial—training costs for achieving a given level of image generation quality drop by roughly 30-fold compared to the discretization approach. The method also reduces serving costs because images can be compressed to as few as 16 patches (versus 1,024 discrete tokens) with minimal quality loss when using appropriate encoder/decoder architecture.
The unexpected improvement on text tasks suggests that keeping images continuous frees up model capacity that would otherwise be spent learning to predict image tokens. This means the same parameter budget delivers better performance across all modalities.
Recommendations and next steps
For organizations building multi-modal AI systems, Transfusion should be considered as the baseline architecture. Specifically:
- Adopt the Transfusion training recipe (combined language modeling and diffusion objectives) rather than discretizing all modalities to tokens. This delivers better performance at lower training cost.
- When compute efficiency is critical, incorporate U-Net encoding/decoding layers to compress images to larger patches (4×4 or 8×8 latent pixels). This cuts inference costs by up to 64 times with only small quality reductions.
- For models that will process images before generating text (e.g., captioning), implement noise limiting during training (cap diffusion noise at t=500 when images precede captions). This improves captioning performance by over 15% with negligible impact on other tasks.
Future work should explore: (1) scaling beyond 7 billion parameters to establish whether advantages hold at frontier model sizes, (2) extending to video and audio modalities using the same principle of modality-specific objectives, and (3) investigating whether synthetic caption data (which benefits competing approaches) provides similar gains for Transfusion.
Limitations and confidence
The results are based on one image resolution (256×256 pixels) and one data mixture (50% text, 50% images by token count). Performance at higher resolutions, different data ratios, or with other modalities (video, audio) remains untested. The largest model trained (7 billion parameters) is well below frontier scale, so whether advantages persist at 70 billion or 400 billion parameters is unknown.
The comparison focuses primarily on one baseline (Chameleon). While results on standard benchmarks show Transfusion matching specialized image models, head-to-head comparisons with the latest diffusion models using identical training data would strengthen confidence. The image editing experiment used only 8,000 examples, so robustness of this capability needs validation on larger datasets.
Confidence is high that Transfusion delivers substantial efficiency gains over discretization approaches at the tested scales and conditions. Confidence is moderate that advantages will persist at much larger scales or with significantly different architectural choices.
Abstract
1. Introduction
In this section, the authors introduce Transfusion as a solution to the challenge of building multi-modal generative models that handle both discrete data like text and continuous data like images. While language models excel at discrete modalities through next token prediction and diffusion models dominate continuous generation, existing approaches to combine them either use diffusion as an external tool, graft pretrained models together, or quantize continuous data into discrete tokens at the cost of information loss. Transfusion instead trains a single transformer to seamlessly generate both modalities by applying next token prediction for text and diffusion for images within the same model. Controlled experiments demonstrate that Transfusion scales more efficiently than quantization-based approaches like Chameleon, achieving comparable text-to-image quality at one-third the compute and similar image-to-text performance at 22% of the FLOPs. The largest 7B parameter model trained on 2T multi-modal tokens generates images rivaling dedicated diffusion models while maintaining text generation capabilities comparable to Llama 1, establishing Transfusion as a promising unified multi-modal architecture.
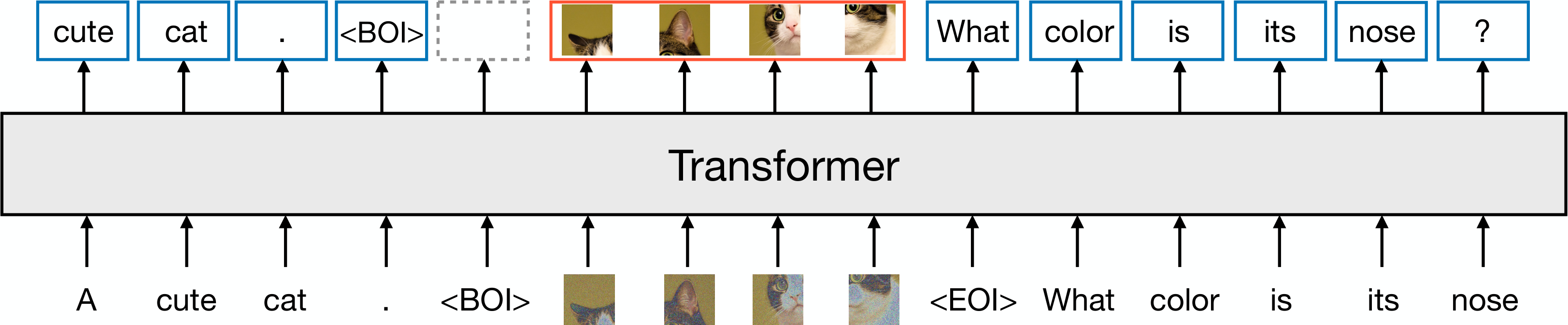
2. Background
In this section, the foundational techniques underlying Transfusion are established by examining how discrete and continuous data are modeled using different state-of-the-art approaches. Language modeling handles discrete tokens through autoregressive next-token prediction, decomposing sequence probability into conditional distributions optimized via cross-entropy loss, enabling token-by-token text generation. Diffusion models address continuous data by learning to reverse a gradual noise-addition process: a forward Markov chain progressively corrupts data with Gaussian noise over multiple timesteps, while a trained reverse process iteratively denoises by predicting the accumulated noise at each step, optimized through mean squared error. To make diffusion computationally tractable for images, variational autoencoders compress high-dimensional pixel data into compact latent representations, allowing efficient processing of image patches as low-dimensional vectors. These complementary approaches—autoregressive modeling for discrete modalities and diffusion for continuous ones—form the basis for integrating both paradigms into a unified multi-modal framework.
2.1 Language Modeling
2.2 Diffusion
2.3 Latent Image Representation
3. Transfusion
In this section, Transfusion addresses the challenge of training a single model to generate both discrete text and continuous images by combining language modeling and diffusion objectives within one transformer architecture. The method represents text as discrete tokens and images as continuous patch vectors from a VAE, separating modalities with special BOI and EOI markers. The model employs a hybrid attention pattern: causal attention for text tokens and bidirectional attention within each image while maintaining causality across the sequence. Training optimizes a combined loss that applies next-token prediction to text and diffusion loss to images, weighted by a balancing coefficient. Modality-specific encoding layers (embeddings for text, linear or U-Net layers for images) convert inputs to a shared vector space that the transformer processes. During inference, the decoder switches between autoregressive text sampling and iterative diffusion denoising when encountering BOI tokens, enabling seamless generation of mixed-modality sequences without information loss from quantization.
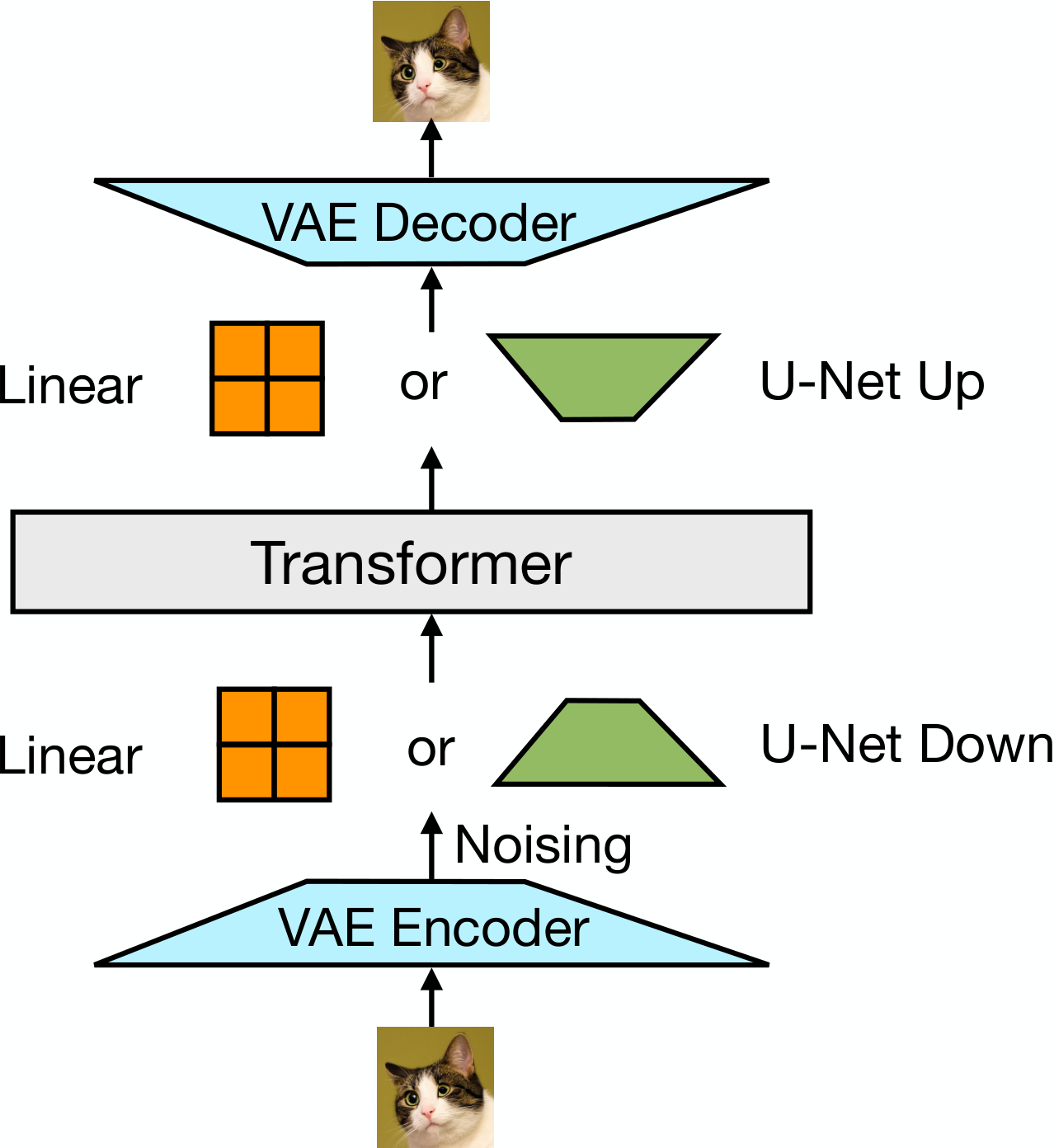
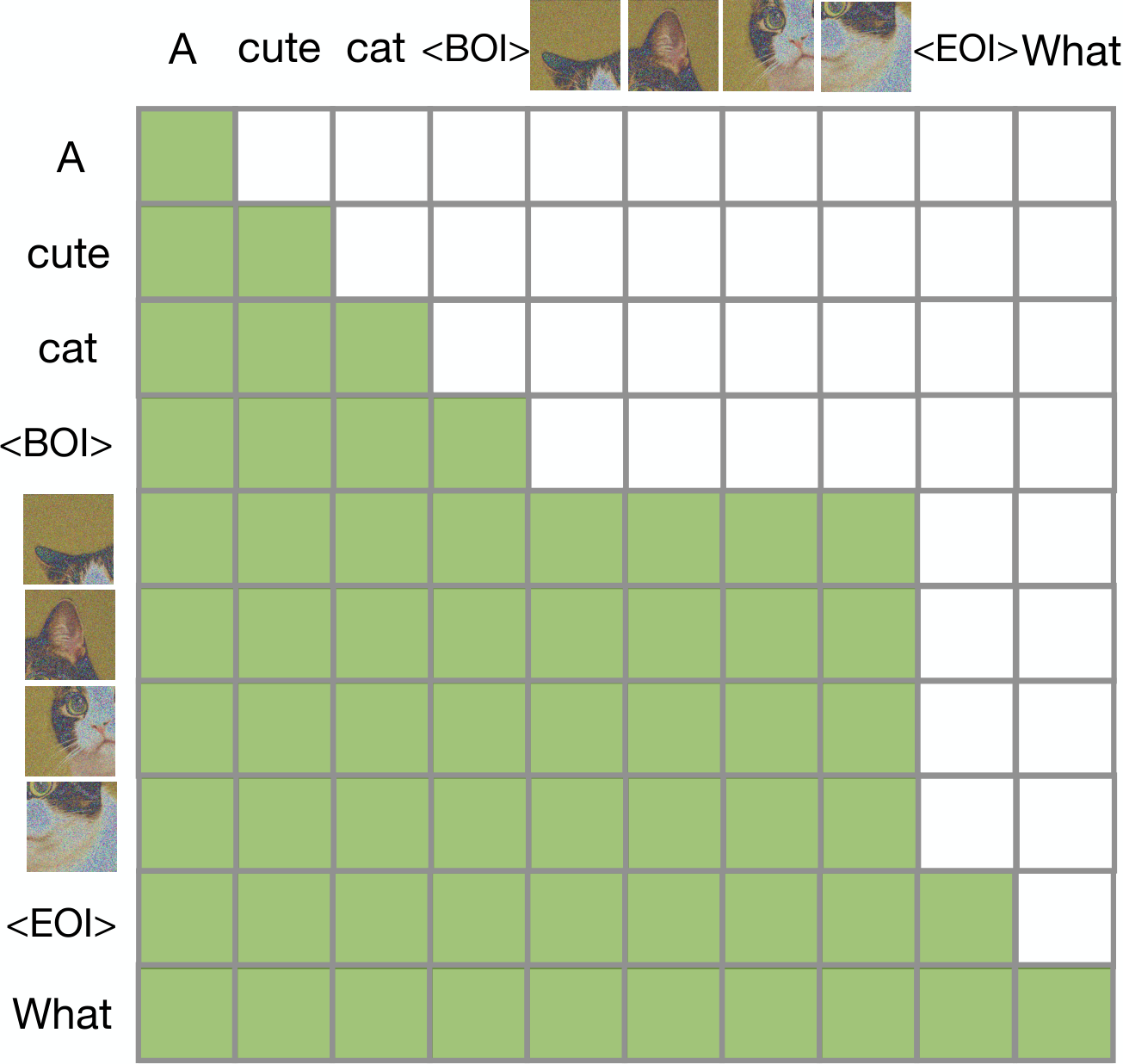
4. Experiments
In this section, the authors demonstrate Transfusion's viability as a scalable multi-modal modeling approach through controlled experiments comparing it against Chameleon, a discrete tokenization baseline. Training models from 0.16B to 7B parameters on 0.5T tokens across text and image modalities, they find Transfusion consistently outperforms Chameleon across all benchmarks, achieving comparable image generation quality with 34× less compute and surprisingly better text performance despite both methods modeling text identically. Ablation studies reveal that bidirectional attention within images significantly improves generation quality, U-Net encoding layers outperform simple linear projections especially at larger patch sizes, and the approach scales effectively up to 7B parameters trained on 2T tokens. The largest model matches or exceeds established diffusion models like DALL-E 2 and SDXL on GenEval while maintaining Llama-level text capabilities, and preliminary fine-tuning experiments on image editing tasks suggest the framework generalizes to new modality combinations not seen during pretraining.
4.1 Setup
4.2 Controlled Comparison with Chameleon
4.3 Architecture Ablations
4.3.1 Attention Masking
4.3.2 Patch Size
4.3.3 Patch Encoding/Decoding Architecture
4.3.4 Image Noising
4.4 Comparison with Image Generation Literature
4.5 Image Editing

5. Related Work
In this section, the landscape of multi-modal model architectures is examined, revealing that most existing approaches combine separate modality-specific components, typically using pretrained encoders and decoders connected through projection layers, as seen in vision-language models like Flamingo and LLaVA for understanding, and GILL and DreamLLM for generation. State-of-the-art image generation models similarly rely on large pretrained text encoders to condition diffusion models, with recent work even fusing multiple off-the-shelf encoders to boost performance. End-to-end alternatives like Fuyu and Chameleon exist but face limitations: Fuyu handles only input-level tasks, while Chameleon's discrete tokenization of images underperforms compared to diffusion models for continuous generation. Meanwhile, applying diffusion to discrete text generation remains an active research area that has yet to match autoregressive language model performance. Against this backdrop, Transfusion emerges as a unified end-to-end architecture that successfully bridges discrete and continuous modalities without compromising quality.
In this section, the technical implementation details and additional experimental results of the Transfusion model are presented. The appendix describes the training objectives for both the VAE and VQ-GAN autoencoders, with the VAE using a combination of L1 loss, perceptual losses based on LPIPS and MoCo features, GAN loss, and KL regularization, while the VQ-GAN replaces KL regularization with codebook commitment loss to encourage alignment between encoder outputs and codebook vectors. The section showcases visual examples of the model's capabilities, including randomly generated images from a 7B parameter Transfusion model trained on 2 trillion multimodal tokens, demonstrating the quality of image generation across diverse prompts. Additionally, image editing examples are provided from a fine-tuned version of the same model, illustrating that despite training on only 8,000 editing examples, the model successfully generalizes to perform instructed image modifications on the EmuEdit test set.
6. Conclusion
In this section, the authors conclude their exploration of bridging discrete sequence modeling through next token prediction with continuous media generation via diffusion methods. They propose Transfusion, a unified model architecture that trains on dual objectives simultaneously, matching each modality—text or images—to its most effective learning paradigm rather than forcing both through a single approach. The key insight is that this modality-specific objective pairing, though simple and previously unexplored, eliminates the need to compromise between discrete and continuous data generation methods. Experimental results demonstrate that Transfusion scales efficiently across model sizes, incurring minimal to no performance penalty from parameter sharing between modalities, while successfully enabling generation of both text and images within a single end-to-end framework. This approach offers a practical solution to multi-modal learning that respects the distinct characteristics of different data types while maintaining computational efficiency.