UI-R1: Enhancing Efficient Action Prediction of GUI Agents by Reinforcement Learning
Zhengxi Lu$^{1}$ $^{\dagger}$, Yuxiang Chai$^{2}$ $^{\dagger}$, Yaxuan Guo$^{1}$, Xi Yin$^{1}$,
Liang Liu$^{1}$ $^{\ddagger}$, Hao Wang$^{1}$, Han Xiao$^{2}$, Shuai Ren$^{1}$,
Guanjing Xiong$^{1}$, Hongsheng Li$^{2}$ $^{✉}$
$^{1}$ vivo AI Lab $^{2}$ MMLab @ CUHK
$^{\dagger}$ Equal Contribution, $^{\ddagger}$ Project Lead, $^{✉}$ Corresponding Author
{[email protected]}
Abstract
The recent DeepSeek-R1 has showcased the emergence of reasoning capabilities in LLMs through reinforcement learning (RL) with rule-based rewards. Despite its success in language models, its application in multimodal domains, particularly in graphic user interface (GUI) agent tasks, remains under-explored. To address this issue, we propose UI-R1, the first framework to explore how rule-based RL can enhance the reasoning capabilities of multimodal large language models (MLLMs) for GUI action prediction tasks. Specifically, UI-R1 introduces a novel rule-based action reward, enabling model optimization via policy-based algorithms such as Group Relative Policy Optimization (GRPO). For efficient training, we curate a small yet high-quality dataset of 136 challenging tasks, encompassing five common action types on mobile devices. Experimental results demonstrate that our proposed UI-R1-3B achieves significant improvements over the base model (i.e. Qwen2.5-VL-3B) on both in-domain (ID) and out-of-domain (OOD) tasks, with average accuracy gains of 22.1% on ScreenSpot, 6.0% on ScreenSpot-Pro, and 12.7% on ANDROIDCONTROL. Furthermore, UI-R1-3B delivers competitive performance compared to larger models (e.g., OS-Atlas-7B) trained via supervised fine-tuning (SFT) on 76K samples. These results underscore the potential of rule-based reinforcement learning to advance GUI understanding and control, paving the way for future research in this domain. Code website: https://github.com/lll6gg/UI-R1.
1. Introduction
Supervised fine-tuning (SFT) has long been the standard training paradigm for large language models (LLMs) and graphic user interface (GUI) agents ([1, 2, 3]). However, SFT relies heavily on large-scale, high-quality labeled datasets, leading to prolonged training times and high computational costs. Furthermore, existing open-source VLM-based GUI agents trained using SFT can be criticized for poor performance in out-of-domain (OOD) scenarios ([4, 5]), limiting their effectiveness and applicability in real-world applications.
Rule-based reinforcement learning or reinforcement fine-tuning (RFT) has recently emerged as an efficient and scalable alternative to SFT for the development of LLMs, which efficiently fine-tune the model with merely dozens to thousands of samples to excel at domain-specific tasks. It uses predefined task-specific reward functions, eliminating the need for costly human annotations. Recent works, such as DeepSeek-R1 ([6]), demonstrate the effectiveness of rule-based RL in mathematical problem solving by evaluating the correctness of the solution, while others ([7, 8, 9, 10, 11, 12, 13]) extend the algorithm to multimodal models, achieving notable improvements in vision-related tasks such as image grounding and object detection. By focusing on measurable objectives, rule-based RL enables practical and versatile model optimization across both textual and multimodal domains, offering significant advantages in terms of efficiency, scalability, and reduced reliance on large datasets.
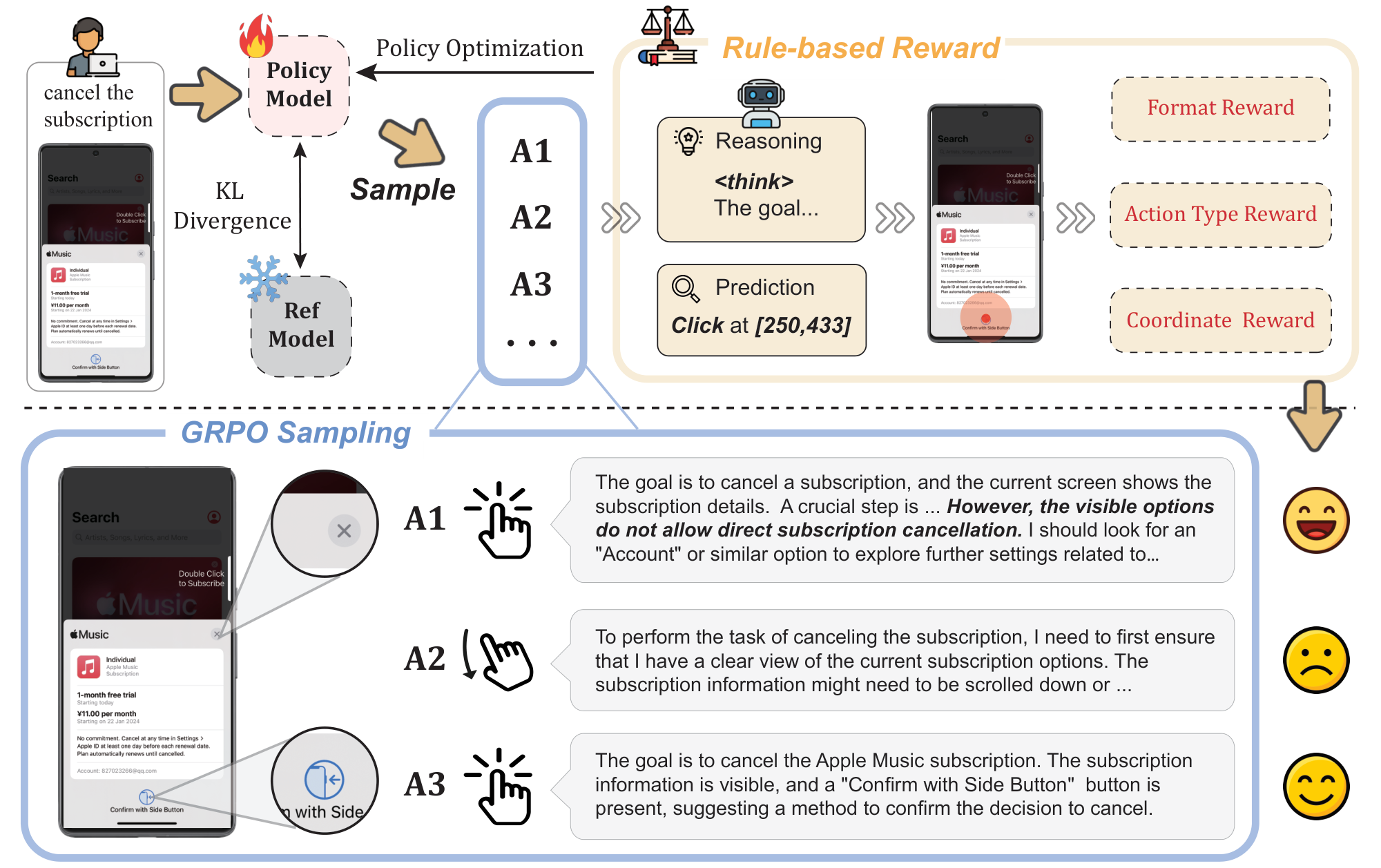
However, existing related studies always target on general vision-related tasks like grounding and detection using Intersection over Union (IoU) metric. In this work, we extend the rule-based RL paradigm to a new application domain by focusing on GUI action prediction tasks driven by low-level instructions. To achieve this, MLLM generates multiple responses (trajectories) that contain the reasoning tokens and the final answers for each input. Then our proposed reward function evaluates each response and updates the model by policy optimization, such as GRPO ([14]). In detail, our action-based reward function contains the action type reward, the action argument reward, along with the commonly used format reward. This flexible and effective reward mechanism is well aligned with the objectives of general GUI-related tasks, enhancing model's reasoning capabilities of action prediction by iteratively self-learning.
Regarding data preparation, we follow [15] and select just 130+ training mobile samples according to three criterion: difficulty, diversity, and quality, making our method remarkably data-efficient. Experiments demonstrate that UI-R1 achieves significant performance improvements on out-of-domain gounding tasks like ScreenSpot-Pro ([16]) and computer scenarios in ScreenSpot ([17]), indicating the potential of rule-based RL to tackle complex GUI-related tasks across diverse domains effectively.
In summary, our contributions are as follows.
- We propose UI-R1, the first framework which enhances MLLM's reasoning capabilities on GUI action prediction tasks through DeepSeek R1 style reinforcement learning. We believe our exploration can inspire further advancements in the field.
- We design a rule-based action reward function that effectively aligns with the objectives of common GUI tasks, facilitating the self-refinement and iterative optimization of the policy model. We also performed some ablation studies to demonstrate its efficiency and rationality.
- We utilize the three-stage data selection method and collect only 130+ high-quality training data from the mobile domain. Despite limited data, our proposed UI-R1-3B achieves notable performance gains on out-of-domain benchmarks, such as those from desktop and web platforms, showcasing adaptability and generalization capability in GUI-related tasks.
- We additionally develop an optimized version, UI-R1-E-3B, which significantly improves both grounding efficiency and accuracy.
2. Related Work
2.1 GUI Agents
Starting with CogAgent ([3]), researchers have used MLLMs for GUI-related tasks, including device control, task completion, GUI understanding, and more ([18]). One line of work, such as the AppAgent series ([19, 20]) and the Mobile-Agent series ([21, 22]), integrates commercial generalist models like GPT for planning and prediction tasks. These agents rely heavily on prompt engineering and multi-agent collaboration to execute complex tasks, making them adaptable but dependent on careful manual design for optimal performance. Another branch of research focuses on fine-tuning smaller open-source MLLMs on task-specific GUI datasets ([23, 24, 5, 25]) to create specialist agents. For example, [5] enhances agents by incorporating additional functionalities of the GUI element in the Android system, while UGround([25]) develops a special GUI grounding model tailored for precise localization of the GUI element. [2] develops a foundational model for GUI action prediction. Moving beyond task-specific fine-tuning, UI-TARs ([1]) introduces a more comprehensive approach by combining GUI-related pretraining with task-wise reasoning fine-tuning, aiming to better align models with the intricacies of GUI interactions. Despite their differences, all of these existing agents share a common reliance on the SFT paradigm. This training approach, while effective, depends heavily on large-scale, high-quality labeled datasets.
2.2 Rule-Based Reinforcement Learning
Rule-based reinforcement learning has recently emerged as an efficient alternative to traditional training paradigms by leveraging predefined rule-based reward functions to guide model behavior. DeepSeek-R1 ([6]) first introduced this approach, using reward functions based on predefined criteria, such as checking whether an LLM's final answer matches the ground truth for math problems. The reward focuses solely on the final results, leaving the reasoning process to be learned by the model itself. [26] reproduces the algorithm on models with smaller sizes and illustrates its effectiveness on small language models. Subsequent works ([10, 27, 7, 8, 9, 28]), extended the paradigm to multimodal models by designing task-specific rewards for visual tasks, including correct class predictions for image classification and IoU metrics for image grounding and detection. These studies demonstrate the adaptability of rule-based RL for both pure-language and multimodal models. By focusing on task-specific objectives without requiring extensive labeled datasets or human feedback, rule-based RL shows strong potential as a scalable and effective training paradigm across diverse tasks.
Efficient Reasoning.
Recent studies have sought to improve reasoning efficiency in large reasoning models (LRMs), addressing challenges such as redundant content (e.g., repeated definitions), over-analysis of simple problems, and shallow exploration of reasoning paths in complex tasks ([29]). To this end, several works ([30, 31, 32, 33, 34]) introduce a length reward within reinforcement learning frameworks, which encourages concise and accurate reasoning by rewarding short, correct answers and penalizing lengthy or incorrect ones. Our work demonstrates that easy tasks like GUI grounding do not need reasoning process and UI-R1-E-3B achieves SOTA performance with fast grounding.
3. Method
UI-R1 is a reinforcement learning training paradigm designed to enhance a GUI agent's ability to successfully complete low-level instructional tasks. We define "low-level instructions" as directives that guide the agent to perform actions based on a single state (e.g., a GUI screenshot), consistent with the definition in $\textsc{AndroidControl}$ ([24]). For example, "Click the menu icon in the top left corner" represents a low-level instruction, whereas "Create an event for 2 PM tomorrow" is a high-level instruction. The specifics of the training data selection and reward function design are detailed in the following sections. Figure 2 illustrates the main parts of the framework.
3.1 Preliminary
Many rule-based RL works ([6, 26, 7]) adopt the Group Relative Policy Optimization (GRPO) algorithm ([14]) for RL training. GRPO offers an alternative to commonly used Proximal Policy Optimization (PPO) ([35]) by eliminating the need for a critic model. Instead, GRPO directly compares a group of candidate responses to determine their relative quality.
In GRPO, given a task question, the model generates a set of $N$ potential responses ${o_1, o_2, \dots, o_N}$. Each response is evaluated by taking the corresponding actions and computing its reward ${r_1, r_2, \dots, r_N}$. Unlike PPO, which relies on a single reward signal and a critic to estimate the value function, GRPO normalizes these rewards to calculate the relative advantage of each response. The relative quality $A_i$ of the $i$-th response is computed as
$ A_i = \frac{r_i - Mean({r_1, r_2, \dots, r_N})}{Std({r_1, r_2, \dots, r_N})},\tag{1} $
where $Mean$ and $Std$ represent the mean and standard deviation of the rewards, respectively. This normalization step ensures that responses are compared within the context of the group, allowing GRPO to better capture nuanced differences between candidates.
The policy model is then optimized by maximizing the following KL objective:
$ \begin{split} \mathcal{J}{GRPO}(\theta) = \mathbb{E}{q \sim P(Q), {o_i}{i=1}^G \sim \pi{\theta_{old}}(O|q)} \Bigg[\frac{1}{G} \sum_{i=1}^G \frac{1}{|o_i|} \sum_{t=1}^{|o_i|} \Bigg{ \min \Bigg[\frac{\pi_\theta(o_{i, t} | q, o_{i, <t})}{\pi_{\theta_{old}}(o_{i, t} | q, o_{i, <t})} \hat{A}{i, t}, \quad \ \text{clip} \left(\frac{\pi\theta(o_{i, t} | q, o_{i, <t})}{\pi_{\theta_{old}}(o_{i, t} | q, o_{i, <t})}, 1 - \epsilon, 1 + \epsilon \right)\hat{A}{i, t} \Bigg] - \beta \mathbb{D}{KL}\left[\pi_{\theta} || \pi_{ref}\right] \Bigg} \Bigg] \end{split}\tag{2} $
where $\pi_{\theta}$ and $\pi_{old}$ are the current and old policy, and $\epsilon$ and $\beta$ are hyper-parameters introduced in PPO.
3.2 Rule-Based Action Rewards
The rule-based reward function introduced by DeepSeek-R1 ([6]) represents a foundational step in rule-based RL by simply evaluating whether model predictions exactly match ground-truth answers. This straightforward approach efficiently aligns models with preference alignment algorithms and provides clear optimization signals. For vision-related tasks, works such as VLM-R1 ([27]) and Visual-RFT ([7]) extend this idea by designing task-specific rewards. For image grounding tasks, they compute the IoU between the predicted and ground-truth bounding boxes as the reward. Similarly, for image classification tasks, rewards are determined by checking whether the predicted and ground-truth classes match.
In GUI-related tasks, the ability to ground and understand the GUI is a critical requirement for agents. Unlike traditional image grounding tasks, GUI grounding requires agents to identify where specific actions, such as click, should be performed on a given GUI screenshot. To address this unique gap, we propose a reward function tailored for GUI tasks, as defined in Equation 3:
$ R = R_{\mathcal{T}} + R_{\mathcal{C}} + R_{\mathcal{F}},\tag{3} $
where the predicted action $\mathcal{A}={\mathcal{T}, \mathcal{C}}$ consists of two components: $\mathcal{T}$, which represents the action type (e.g., click, scroll), and $\mathcal{C}$, which represents the click coordinate. $R_\mathcal{F}$ represents the commonly used response format reward.
Action type reward.
In our tasks, the action space includes Click, Scroll, Back, Open_App, and Input_Text, covering a wide range of common application scenarios in daily life, as inspired by GUIPivot ([36]). The action type reward, denoted as $\boldsymbol{R_{\mathcal{T}}}$, is computed by comparing the predicted action type $\mathcal{T'}$ with the ground truth action type $\mathcal{T}$. It assigns a reward of 1 if $\mathcal{T'} = \mathcal{T}$ and 0 otherwise, providing a straightforward and effective evaluation mechanism for action type prediction.
Coordinate accuracy reward.
Through observation, we find that among all action types, the most common action argument error occurs in the mis-prediction of coordinates for the click action when given a low-level instruction. To address this issue, we specifically design a coordinate accuracy reward. The model is required to output a coordinate $\mathcal{C} = [x, y]$, indicating where the click action should be performed. Given the ground truth bounding box $\mathcal{B} = [x1, y1, x2, y2]$, the coordinate accuracy reward $R_{\mathcal{C}}$ is computed as shown in Equation 4:
$ R_{\mathcal{C}} = \begin{cases} 1 & \text{if} \ \text{coord} \ \mathcal{C} \ in \ \text{box} \ \mathcal{B}, \ 0 & \text{else}. \ \end{cases}\tag{4} $
Unlike general visual grounding tasks which compute the IoU between the predicted bounding box and the ground truth box, our approach prioritizes action coordinate prediction over element grounding. This focus is more appropriate for GUI agents and better aligns with human intuition, as the ultimate goal is to ensure correct actions are performed rather than merely locating GUI elements.
Format reward.
During training, we incorporate the widely-used format reward to guide the model in generating its reasoning process and final answer in a structured format. This decision is based on our simple experiment that agents producing reasoning processes outperform those directly outputting action predictions by approximately 6% (shown in Appendix B.1). The reasoning process plays a key role in the model's self-learning and iterative improvement during reinforcement fine-tuning, while the reward tied to the final answer drives optimization. The format reward, denoted as $\boldsymbol{R_{\mathcal{F}}}$, ensures that the model's predictions follow the required HTML tag format, specifically using
lt;\boldsymbol{think}>$ for the reasoning process and lt;\boldsymbol{answer}>$ for the final answer. This structured output not only enhances clarity, but also ensures consistency in the model's predictions.
In this GUI screenshot, I want to perform the command $\boldsymbol{instruction}$. Please provide the action to perform (enumerate in [`click`, `open_app`, `scroll`, `navigate_back`, `input_text`]) and the coordinate where the cursor is moved to(integer) if click is performed. Output the thinking process in lt;\boldsymbol{think}>$ lt;$ / $\boldsymbol{think}$ gt;$ and final answer in lt;\boldsymbol{answer}>$ lt;$ / $\boldsymbol{answer}$ gt;$ tags. The output answer format should be as follows: lt;\boldsymbol{think}>$ ... lt;$ / $\boldsymbol{think}$ gt;$ lt;\boldsymbol{answer}>$ [{action: enum[`click`, `open_app`, `scroll`, `navigate_back`, `input_text`], coordinate: [x, y]}] lt;$ / $\boldsymbol{answer}$ gt;$. Please strictly follow the format.
3.3 Fast Grounding
Our optimized grounding version, UI-R1-Efficient*-3B*, is trained in two stages: DAST training followed by NOTHINK training, with each stage lasting 4 epochs.
DAST
refines rule-based rewards by integrating the deviation between actual response length and the Token Length Budget (TLB) metric, allowing the reward to capture both task difficulty and length properties for effective difficulty-adaptive training ([31]).
TLB metric is defined as:
$ L_{budget} = p\cdot L_{\overline{r}} + (1-p)\cdot L_{max}, p = \frac{c}{N} $
where $c$ is the number of correct responses sampled for a given question, and $N$ is the total number of sampled responses. $L_{\overline{r}}$ denotes the average token length of the correct responses, and $L_{\mathrm{max}}$ represents the maximum generation length.
The length reward $R_{\mathcal{L}}$ is defined as:
$ R_{\mathcal{L}} = \begin{cases} \max(-0.5 \lambda + 0.5, \ 0.1) & \text{if correct} \ \min(0.9 \lambda - 0.1, \ -0.1) & \text{if incorrect} \end{cases} \quad \text{where} \quad \lambda = \dfrac{L_i - L_{budget}}{L_{budget}}\tag{5} $
The reward in Equation 3 is then calibrated by the length reward:
$ R = R_{\mathcal{T}} + R_{\mathcal{C}} + R_{\mathcal{F}} + {\textit{$R_{\mathcal{L}}$}},\tag{6} $
NOTHINK
enables fast and direct grounding by removing the
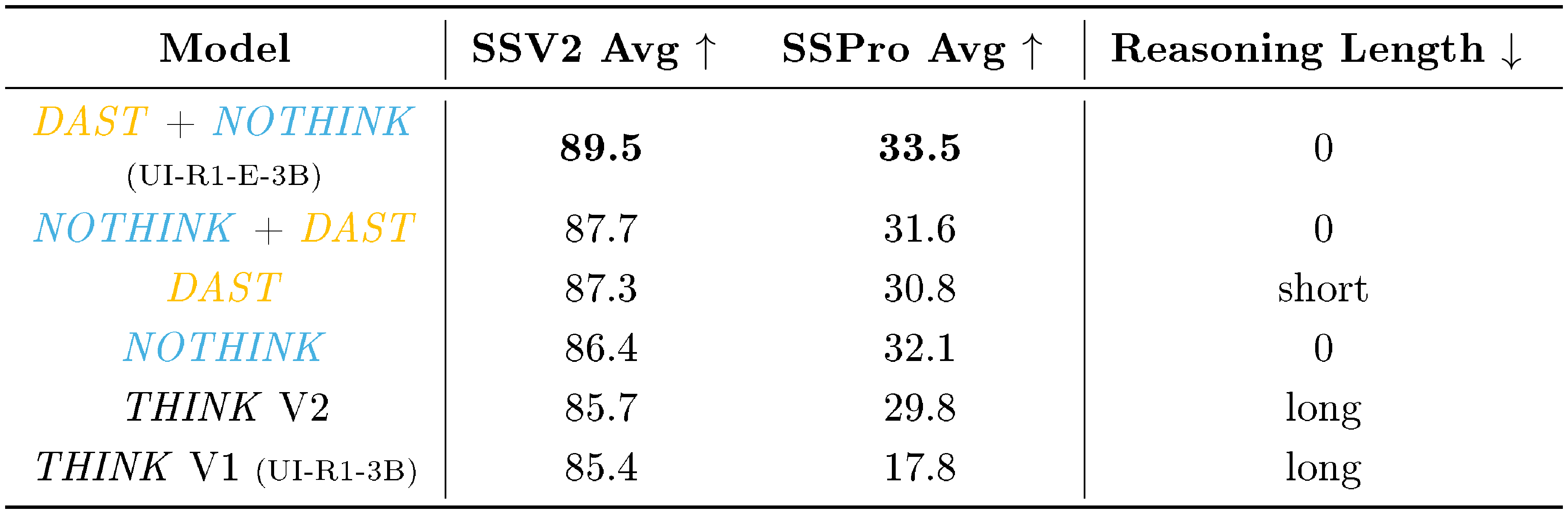
lt;\boldsymbol{think}>$ tags, thereby bypassing explicit reasoning steps during both training and inference ([33]).The corresponding ablation results are presented in Table 5. Based on these results, we can conclude that
3.4 Training Data Selection
Compared to SFT, rule-based RL has demonstrated the capability to achieve comparable or even superior performance on mathematical and vision-related tasks using only a limited number of training samples ([26, 7]). Building on this efficiency and inspired by s1 ([15]), we implement a three-stage data selection process to refine open-source GUI-related datasets based on three key principles: Quality, Difficulty, and Diversity. The detailed distribution of the dataset can be found in Appendix A.2.
Quality.
For refining the click action arguments, we use the mobile subset of ScreenSpot ([17]) as our initial dataset. ScreenSpot offers clean and well-aligned task-element paired annotations, making it ideal for defining and calculating $R_{\mathcal{C}}$. For other actions, we randomly select 1K episodes from $\textsc{AndroidControl}$ ([24]), as it shares a similar action space and provides low-level instructions. However, since the element annotations in $\textsc{AndroidControl}$ are unfiltered and misaligned, we exclude click action steps and retain the rest.
Difficulty.
To identify hard samples, we evaluated Qwen2.5-VL-3B on each task instruction by model performance, where a sample is labeled "hard" if the model's output does not match the ground truth. We only keep the "hard" samples among all the data collected.
Diversity.
We ensure diversity by selecting samples with different action types in $\textsc{AndroidControl}$ (e.g., Scroll, Back, Open App, Input Text) and element types in ScreenSpot (e.g. Icon, Text). Rare actions, such as Wait and Long Press, are excluded from $\textsc{AndroidControl}$. After applying these criteria, we finalize a high-quality mobile training dataset consisting of 136 samples.
4. Experiments
4.1 GUI Grounding Capability
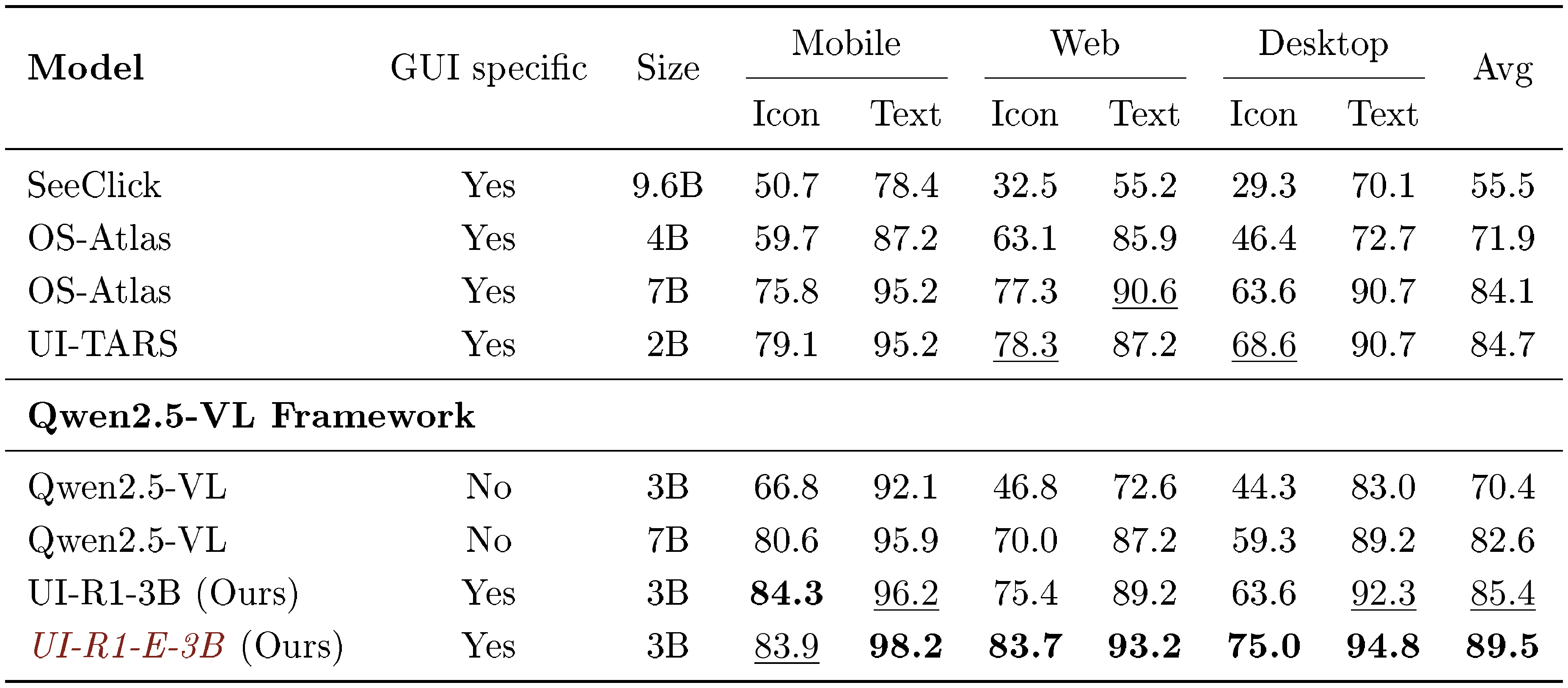
We assess the grounding capability of UI-R1 using two benchmarks: ScreenSpot ([17]) and ScreenSpot-Pro ([16]). ScreenSpot evaluates GUI grounding capability across mobile, desktop, and web platforms, while ScreenSpot-Pro focuses on high-resolution professional environments, featuring expert-annotated tasks spanning 23 applications, five industries, and three operating systems. We also evaluate the model performance on ScreenSpot-V2 ([2]) and the results are in Table 2.
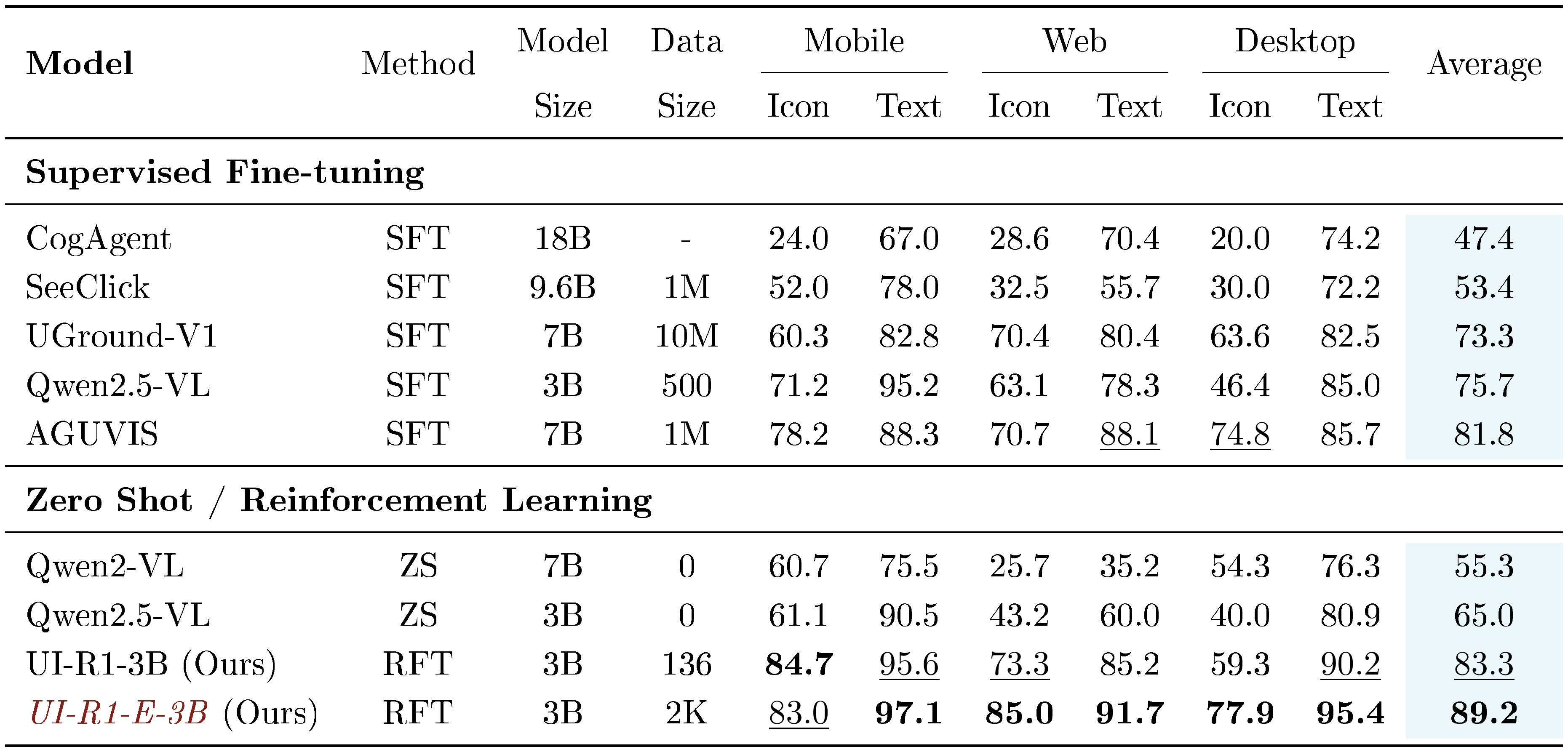
::: {caption="Table 1: Grounding accuracy on ScreenSpot. The optimal and the suboptimal results are bolded and $\underline{underlined}$, respectively. ZS indicates zero-shot OOD inference and RFT indicates rule-based reinforecement learning."}
:::
::: {caption="Table 2: Grounding accuracy on ScreenSpot-V2. The optimal and the suboptimal results are bolded and $\underline{underlined}$, respectively."}
:::
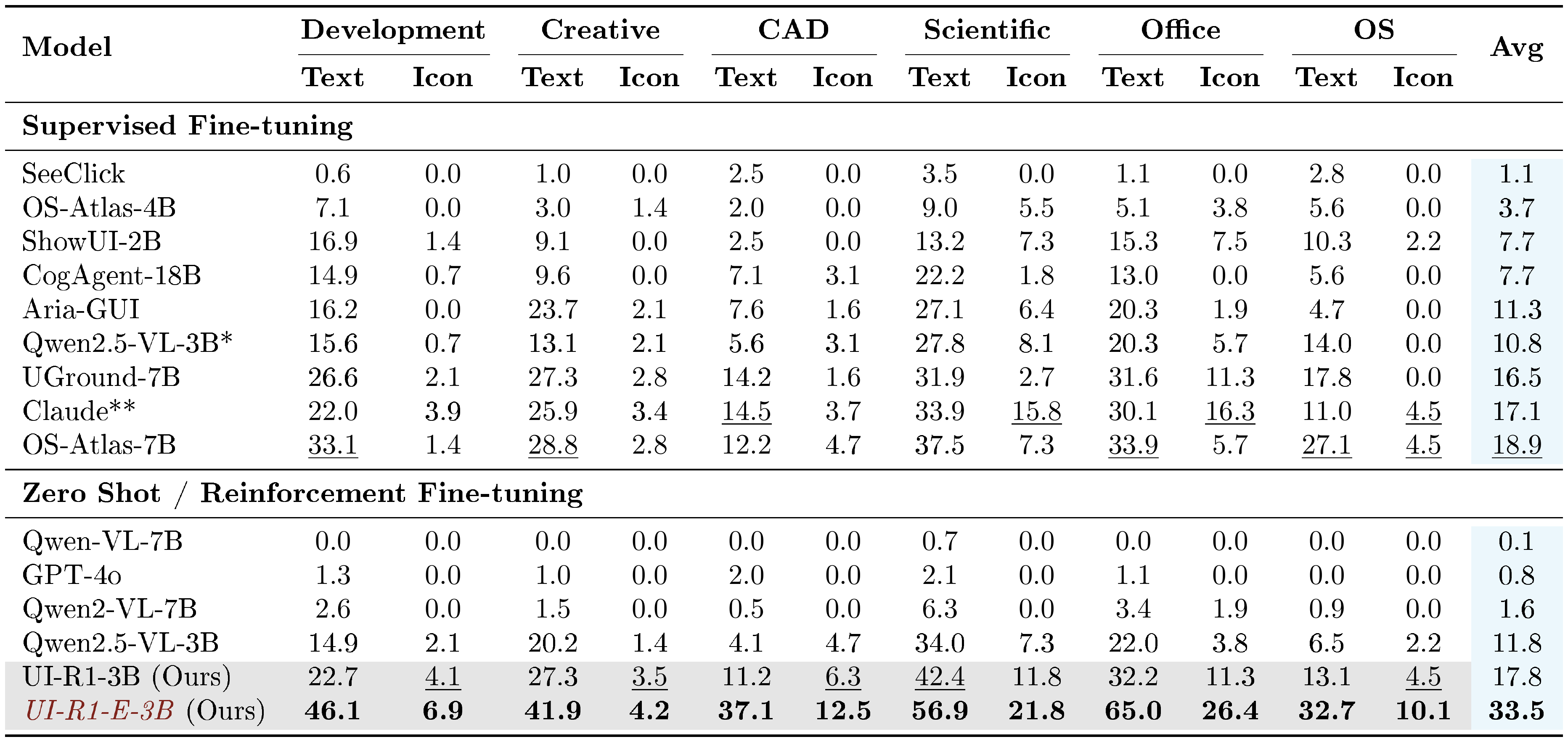
::: {caption="Table 3: Accuracy on ScreenSpot-Pro. The optimal and the suboptimal results are bolded and $\underline{underlined}$, respectively. * Qwen2.5-VL-3B here is supervised fine-tuned on 500 ScreenSpot-mobile data. ** Claude refers to Claude-computer-use."}
:::
Setting
We train the Qwen2.5-VL-3B model on the three-stage selected data (details in Section 3.3) using rule-based RL, naming the resulting model UI-R1-3B. Furthermore, we train the base model using supervised fine-tuning on the entire ScreenSpot mobile set, referring to it as Qwen2.5-VL-3B* in Table 3. For evaluation, an action prediction is considered correct if the predicted click coordinate lies within the ground truth bounding box. Accuracy is computed as the ratio of the correct predictions to the total number of test samples.
Analysis
Experimental results show that our method significantly improves the GUI grounding capability of the 3B model (+20% on ScreenSpot and +6% on ScreenSpot-Pro from Table 1 and Table 3), surpassing most 7B models on both benchmarks. Additionally, it also achieves performance comparable to the SOTA 7B models (i.e. AGUVIS ([37]) and OS-Atlas ([2])), which are trained using supervised fine-tuning on substantially larger labeled grounding datasets.
Qwen2.5-VL-3B (SFT) in Table 1 demonstrates that supervised fine-tuning (SFT) with a limited amount of data (e.g., 500 samples) can effectively improve in-domain performance by tailoring the model to specific tasks. However, the comparison between Qwen2.5-VL-3B (ZS) and Qwen2.5-VL-3B (SFT) in Table 3 highlights a critical limitation of SFT: its effectiveness significantly diminishes in OOD scenarios. This limitation arises from the dependency of SFT on task-specific labeled data, restricting the model’s ability to adapt to unseen environments. In contrast, our RL approach not only enhances OOD generalization by focusing on task-specific reward optimization, but also achieves with far fewer training samples, offering a scalable and efficient alternative to traditional SFT methods.
4.2 Action Prediction Capability
We further evaluate the model's ability to predict single-step actions based on low-level instructions. As described in Section 3.3, we test our model on a selected subset of $\textsc{AndroidControl}$. The low-level instructions in $\textsc{AndroidControl}$ enrich the ScreenSpot benchmark by introducing a wider range of action types.
Setting
The accuracy of the action prediction is evaluated by the accuracies of action type and grounding: (1) The action type accuracy evaluates the match rate between the predicted action types (e.g., click, scroll) and ground truth types; (2) The grounding accuracy focuses specifically on the accuracy of click action argument predictions, similar to Section 4.1. Since ground truth bounding boxes are not consistently available in the $\textsc{AndroidControl}$ test data, we measure performance by calculating the distance between the predicted and ground truth coordinates. A prediction is considered correct if it falls within 14% of the screen size from the ground truth, following the evaluation method of UI-TARS ([1]).
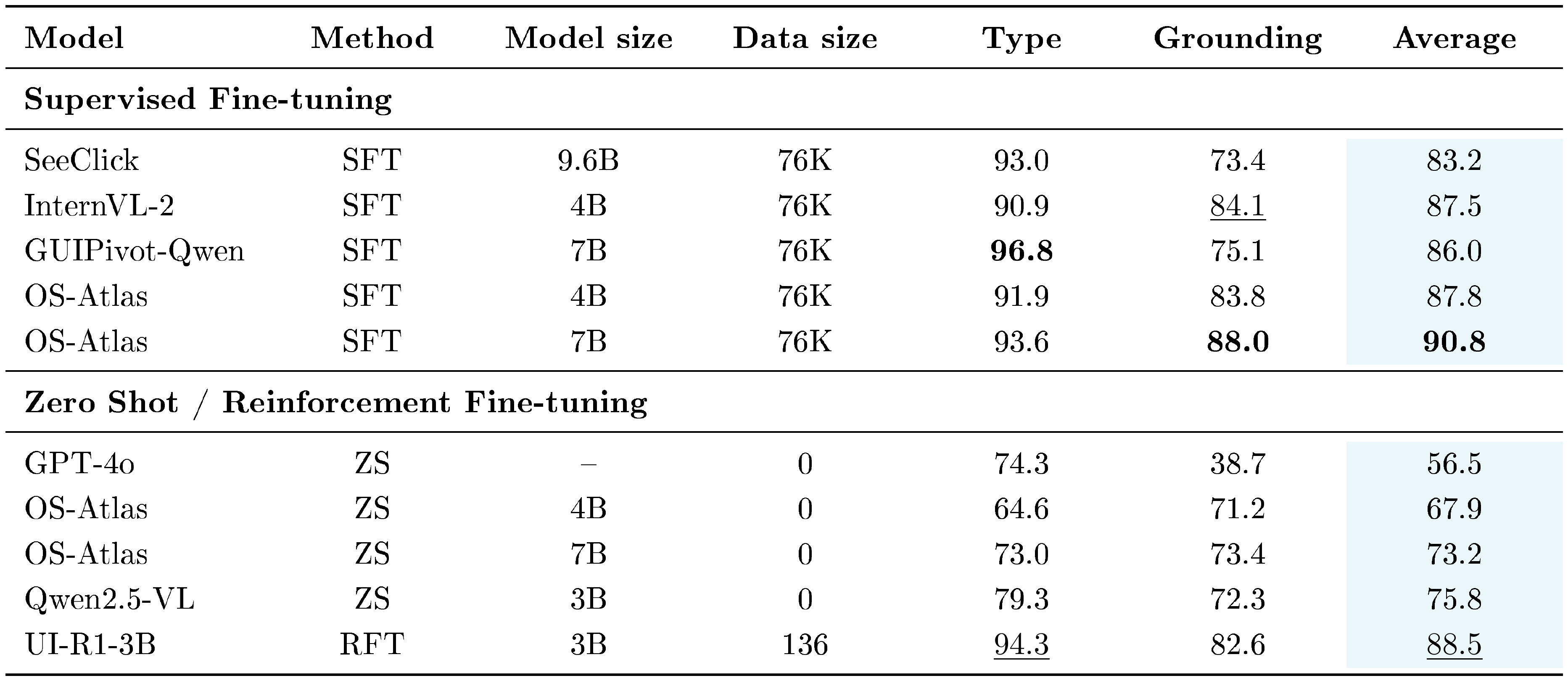
::: {caption="Table 4: Low-level agent capabilities on $\textsc{AndroidControl}$. The Average column computes the mean of Type and Grounding scores."}
:::
Analysis
As shown in Table 4, the comparison between UI-R1 and the Qwen2.5-VL (ZS) model highlights the significant benefits of the RL training framework. UI-R1 improves the accuracy of action type prediction by 15% and click element grounding accuracy by 20%, all while using only 136 training data points. Compared with other SFT models, the evaluation results illustrate that UI-R1 not only excels in scenarios with extremely limited training data but also achieves superior type accuracy and grounding performance even than larger models. This underscores the effectiveness of the RL training framework in leveraging small datasets to achieve substantial performance gains, demonstrating its potential as a highly data-efficient and scalable approach for training models in resource-constrained environments.
4.3 Key Factor Study
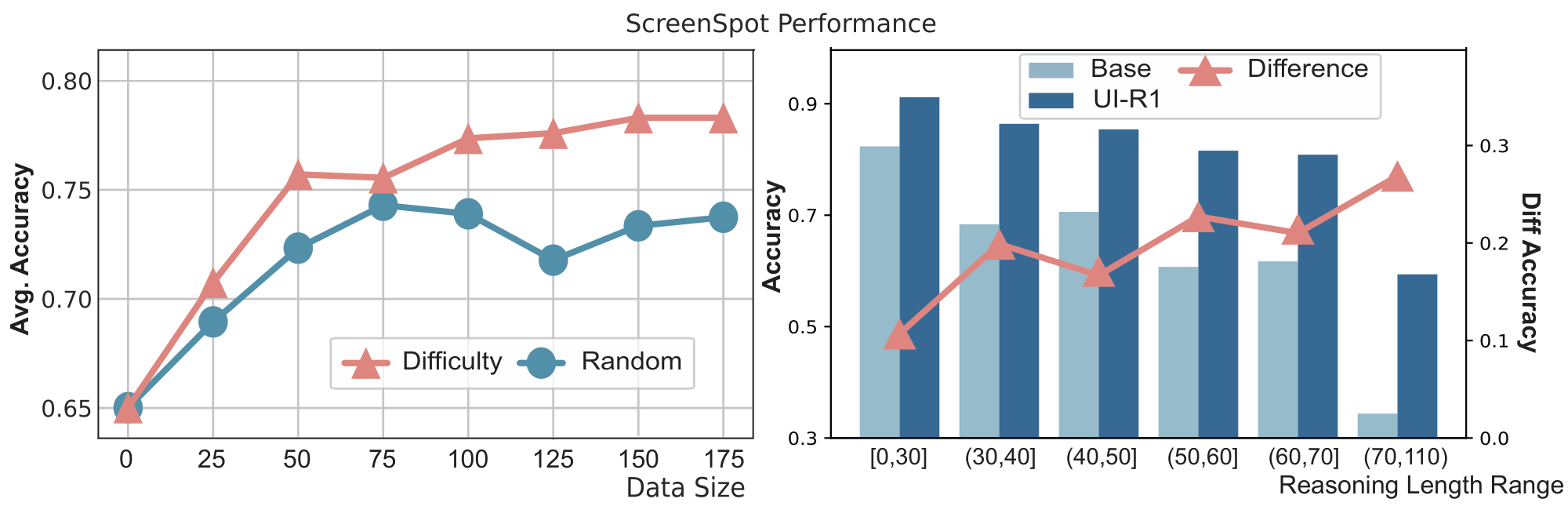
Data Size
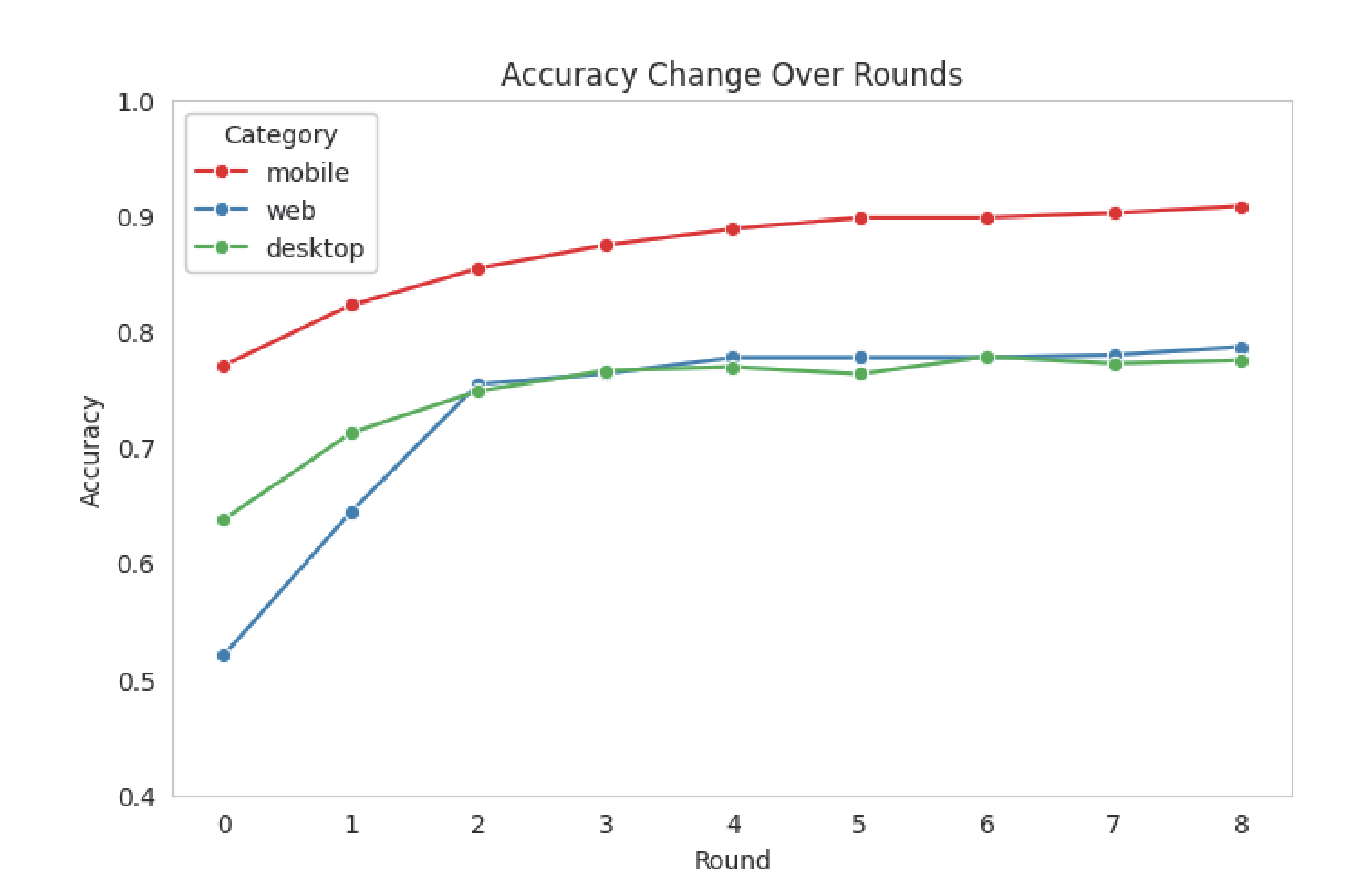
In Figure 3 (left), we investigate the relationship between training data size and model performance and compare the two methods of selecting training data from the entire dataset: random selection and select by difficulty (as in Section 3.3). The second method involves selecting the top K tasks with the longest reasoning lengths that the Qwen2.5-VL-3B model fails to solve. We find that model performance improves as the training data size increases, but the trend is gradually saturating. Moreover, our select by difficulty method results in significantly better performance than random selection.
Reasoning Length
In Figure 3 (right), the result reveals that as the reasoning length of the answer increases, the accuracy tends to decrease, suggesting that the questions are getting harder to answer. With reinforcement learning, UI-R1's reasoning ability is significantly enhanced, leading to more pronounced accuracy improvements, especially on more challenging questions.
4.4 Ablation Study
Fast Grounding
The "First DAST, then NOTHINK" approach enables the model to learn grounding by gradually transitioning from slower, more thoughtful reasoning to faster, more direct, and accurate responses. The order of these steps is crucial, as disrupting their sequence or removing one of them may significantly impact training efficiency. Moving forward, we aim to explore whether reasoning, as embodied in the thinking phase, is essential for handling high-level planning tasks, or if simpler, direct approaches can yield similar performance in these more complex contexts.
::: {caption="Table 5: Abalation of thinking-or-not training methods (DAST, NOTHINK or THINK) on grounding tasks ScreeSpot V2 (SSV2) and ScreenSpot Pro (SSPro). The total training epoches are all set as 8."}
:::
Reward Function
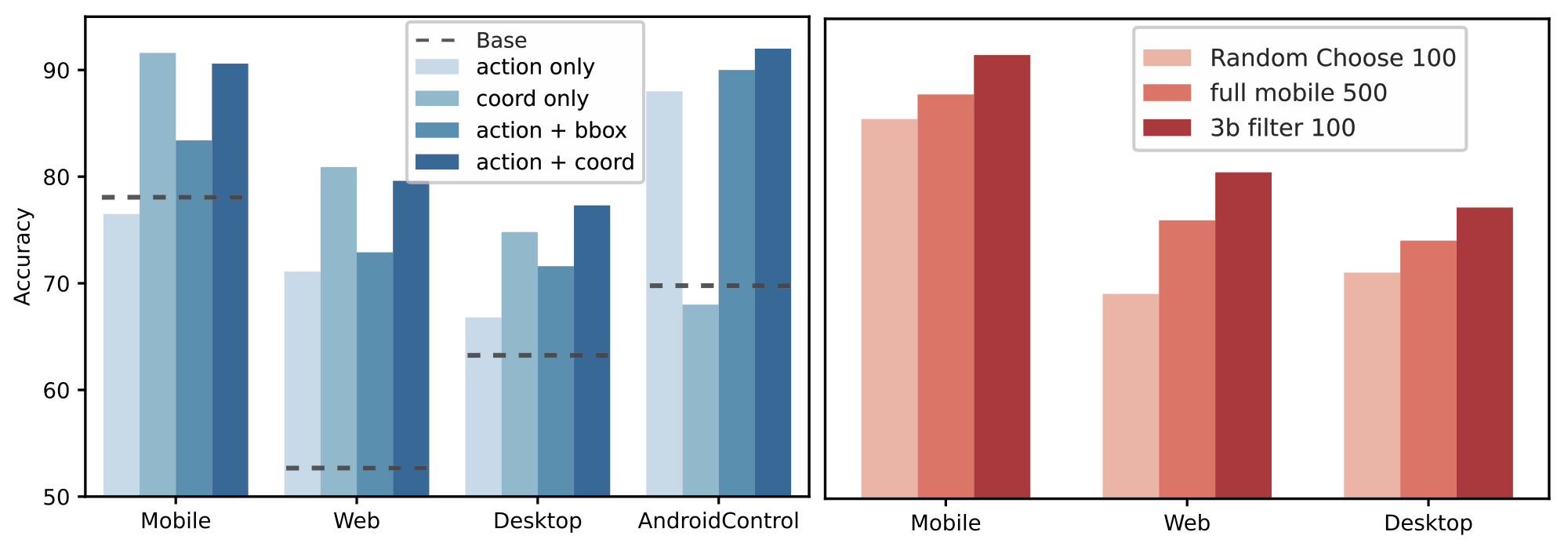
The design of the reward function plays a crucial role in enabling the self-learning capabilities of the model. To evaluate this, we first examine the necessity of the two components of the reward function, action + coord. Specifically, the action reward improves action prediction accuracy, while the coord reward enhances the model's ability to ground click elements. Next, we compare this with an alternative reward design, action + bbox, where the coordinate reward $\boldsymbol{R_{\mathcal{C}}}$ is replaced by an IoU-based reward $\boldsymbol{R_{\text{IoU}}}$ in Equation 3. In this setup, the IoU metric is calculated between the ground truth bounding box and the predicted box, and $\boldsymbol{R_{\text{IoU}}}$ assigns a value of 1 if $\text{IoU} > 0.5$ and 0 otherwise.
Through ablation studies, as shown in Figure 4 (left), we demonstrate the superior effectiveness of $\boldsymbol{R_{\mathcal{C}}}$ over $\boldsymbol{R_{\text{IoU}}}$ for improving click element grounding. However, we also observe that the action reward does not always positively impact grounding tasks. This is likely because a larger action space can introduce ambiguity, making it harder for the model to focus solely on element grounding tasks. These findings highlight the importance of carefully balancing the reward components according to the specific objectives of the task.
Data Selection
We also examine the impact of different data selection methods, as shown in Figure 4 (right). A comparison of three methods across all domains demonstrates that neither random selection nor the use of the entire dataset matches the effectiveness of our three-stage data selection pipeline, indicating that the use of a smaller set of high-quality data can lead to higher performance.
5. Conclusion
We propose the UI-R1 framework, which extends rule-based reinforcement learning to GUI action prediction tasks, offering a scalable alternative to traditional Supervised Fine-Tuning (SFT). We designed a novel reward function that evaluates both action type and arguments, enabling efficient learning with reduced task complexity. Using only 130+ training samples from the mobile domain, our proposed UI-R1-3B achieves significant performance improvements and strong generalization to out-of-domain datasets, including desktop and web platforms. The results demonstrate the adaptability, data efficiency, and ability of the rule-based RL to handle specialized tasks effectively.
Appendix
A. Training
A.1 Setting
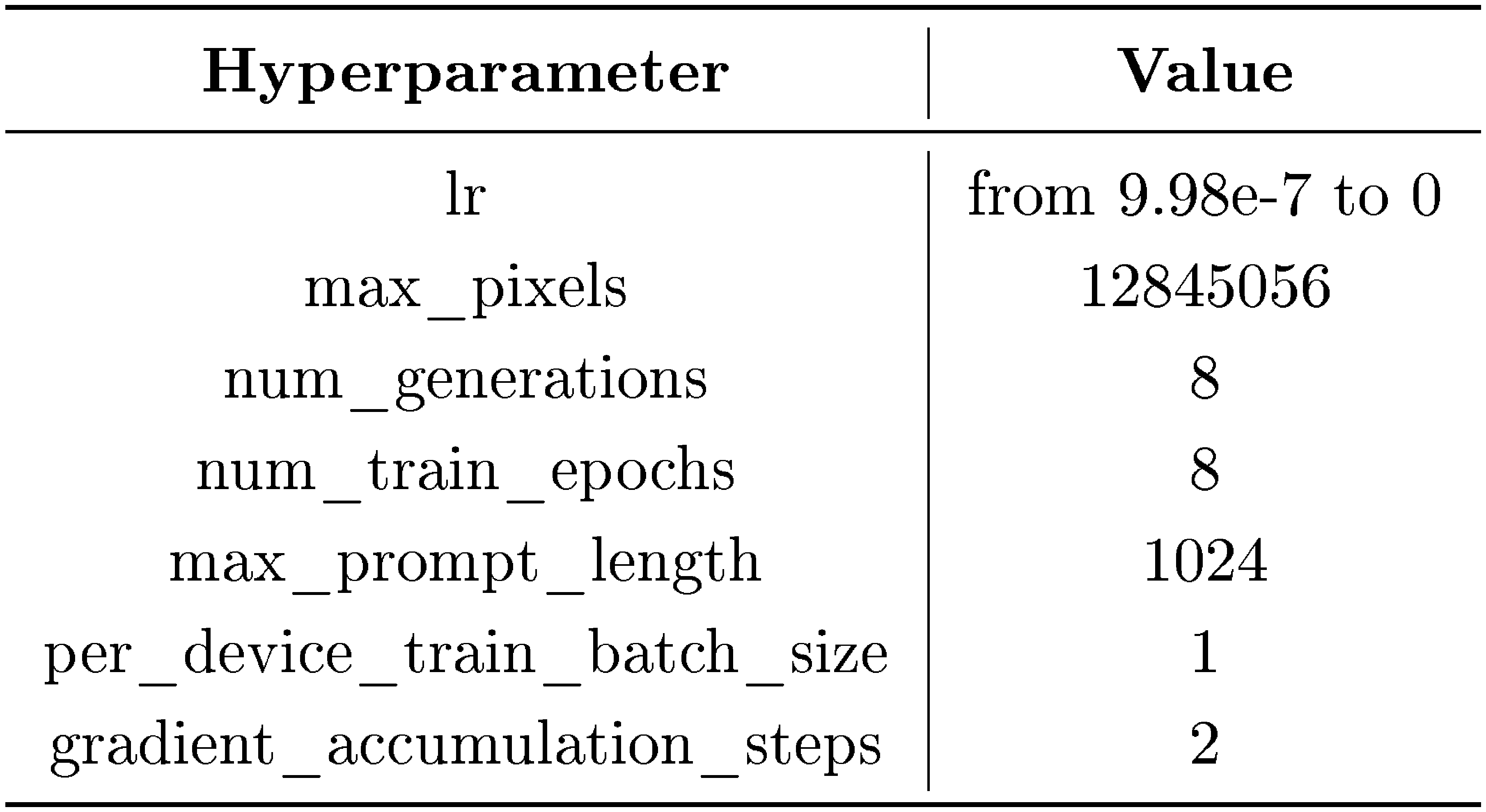
We configure the hyperparameters as listed in Table 6 and train the base model using 8 NVIDIA 4090 GPUs, completing the training process in approximately 8 hours.
::: {caption="Table 6: Hyperparameter settings used in the experiments."}
:::
A.2 Dataset Distribution
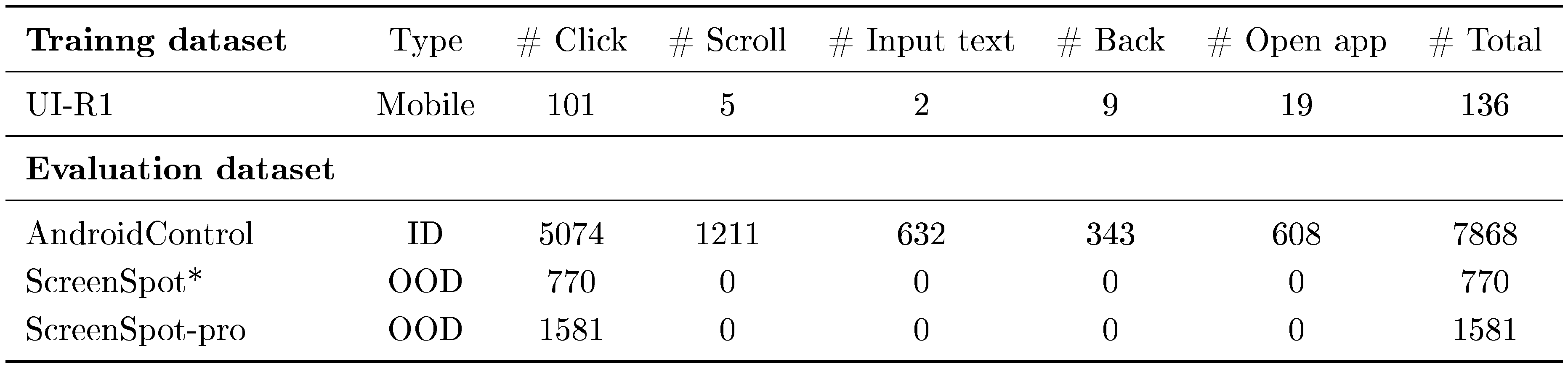
The distribution of our data selection is listed in Table 7.
::: {caption="Table 7: Statistics of training and evaluation datasets. * means that we only select subsets Desktop and Web for evaluation."}
:::
A.3 Visualization
Figure 5 illustrates the progression of various variables throughout the training process.
B. Other Evaluation
B.1 Reasoning
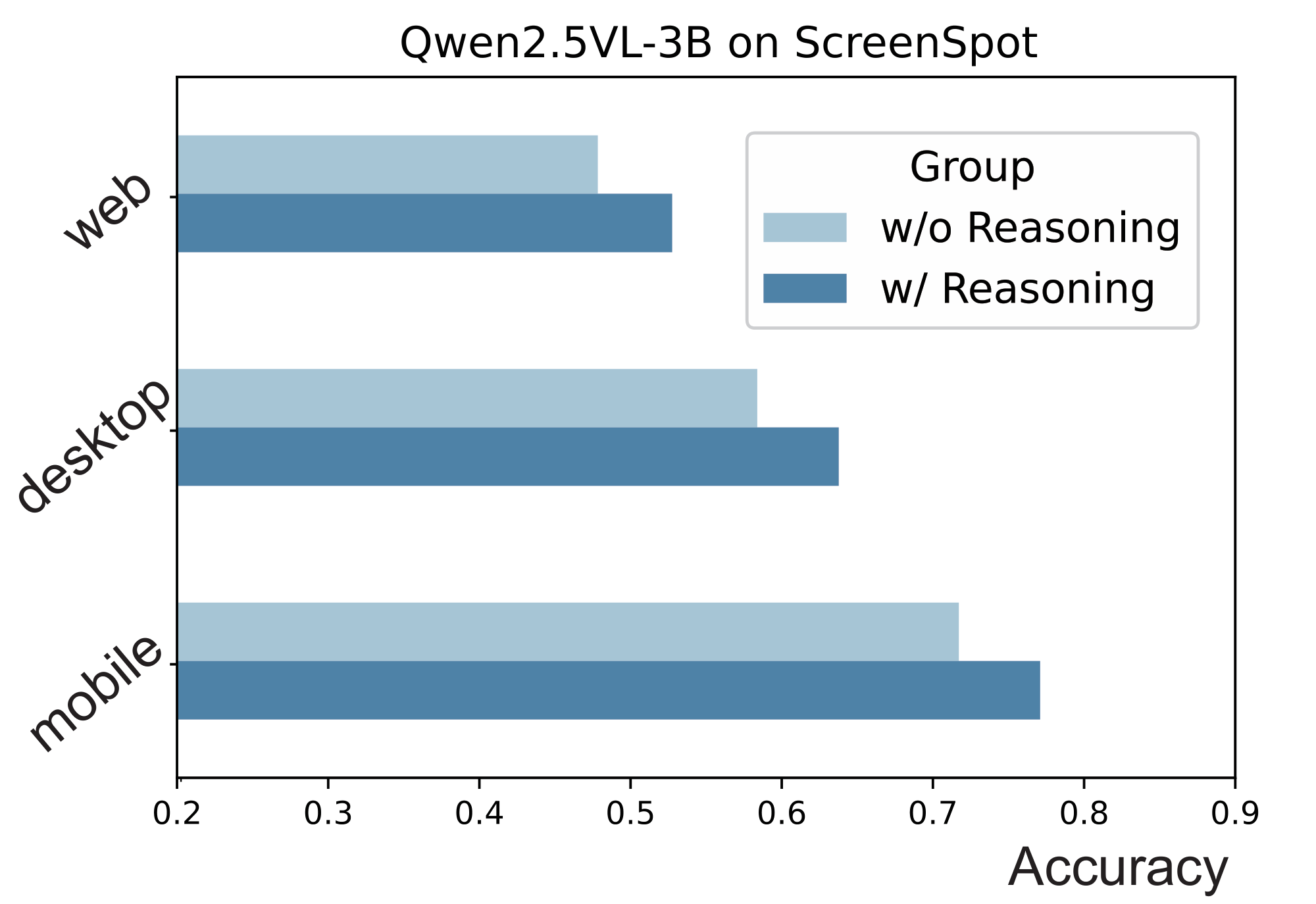
The reasoning capability of the base model (i.e., Qwen2.5-VL-3B) is central to our approach, as it leverages the model’s self-learning and iterative improvement through reinforcement fine-tuning. To enhance the model's reasoning ability and prediction accuracy, we incorporate reasoning tags into the prompt. To evaluate this, we assess the reasoning performance of Qwen2.5-VL-3B on the ScreenSpot task in Figure 6.
C. Other Ablation
C.1 Training epoches
We evaluate the model's performance across different training epochs, as shown in Figure 7. Based on the results, we finalize the training at 8 epochs.
C.2 Max Pixels
While adjusting the parameters, we observe that the maximum pixel setting of the image processor plays a significant role. If the input image exceeds this maximum pixel value, the $\texttt{smart resize}$ function automatically crops and resizes the image while preserving the original aspect ratio. Mobile images are typically smaller than web or desktop images and often have significantly different aspect ratios. To address this, we implement the algorithm to appropriately rescale the predicted coordinates as shown in Algorithm 1.
**Input:**
$C = (x, y)$ : coordinate
$I$ : input image
$max\_pixels$ : maximum pixel constraint
**Output:** $(x_{scale}, y_{scale}) \in \mathbb{R}^2$
$(origin\_width, origin\_height) \gets I.size$
$(resized\_height, resized\_width) \gets$ `smart_resize` $(origin\_height, origin\_width, max\_pixels)$
*`smart_resize` from QwenVL*
$x_{scale} \gets origin\_width / resized\_width$ * $x$
$y_{scale} \gets origin\_height / resized\_height$ * $y$
**Output:** $(x_{scale}, y_{scale})$
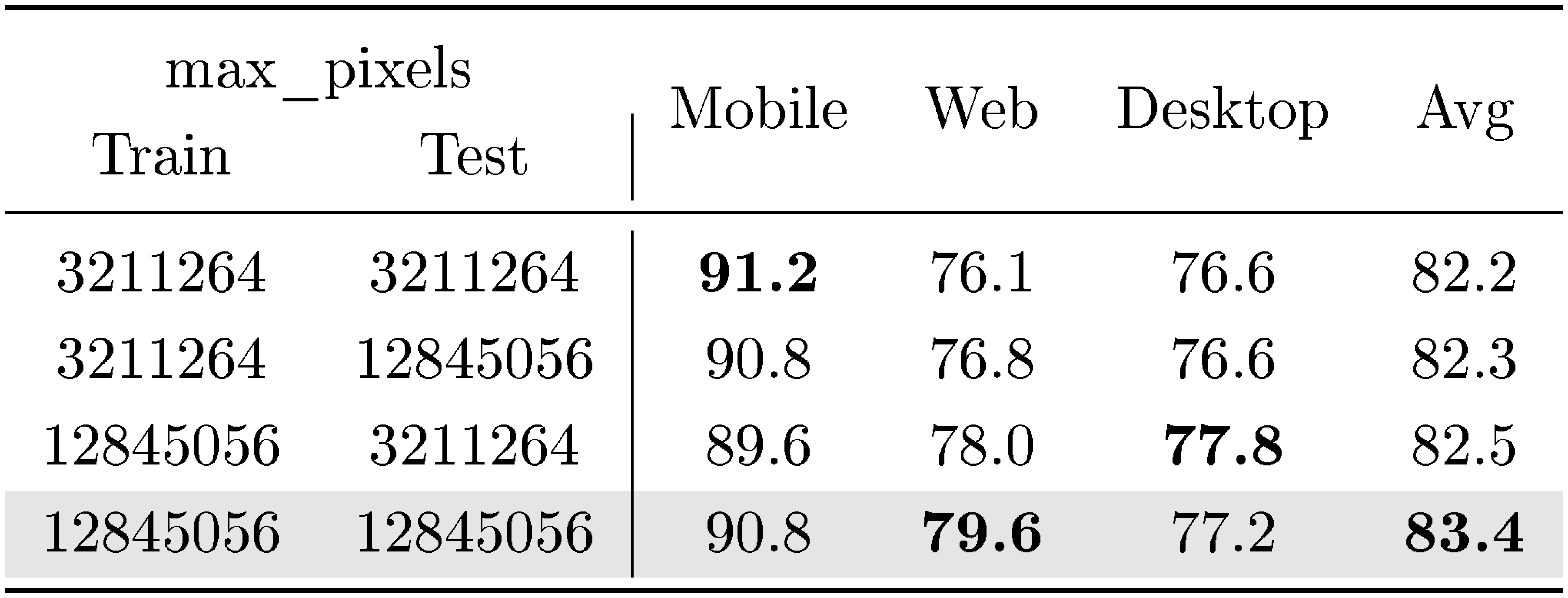
We also investigate the impact of the maximum pixel value on model performance. Setting this value too high can lead to out-of-memory (OOM) errors during training when processing large images. Conversely, setting it too low may negatively affect the accuracy of prediction results. To better understand this trade-off, we experiment with two different maximum pixel values during training and evaluation, as summarized in Table 8.
Based on our analysis, we set the maximum pixel value to 12, 845, 056 during training, which results in a model with improved performance on out-of-domain tasks. For evaluation, we recommend using a smaller maximum pixel value to conserve memory.
::: {caption="Table 8: Ablation of max pixels in the training and inference."}
:::
D. Case Study
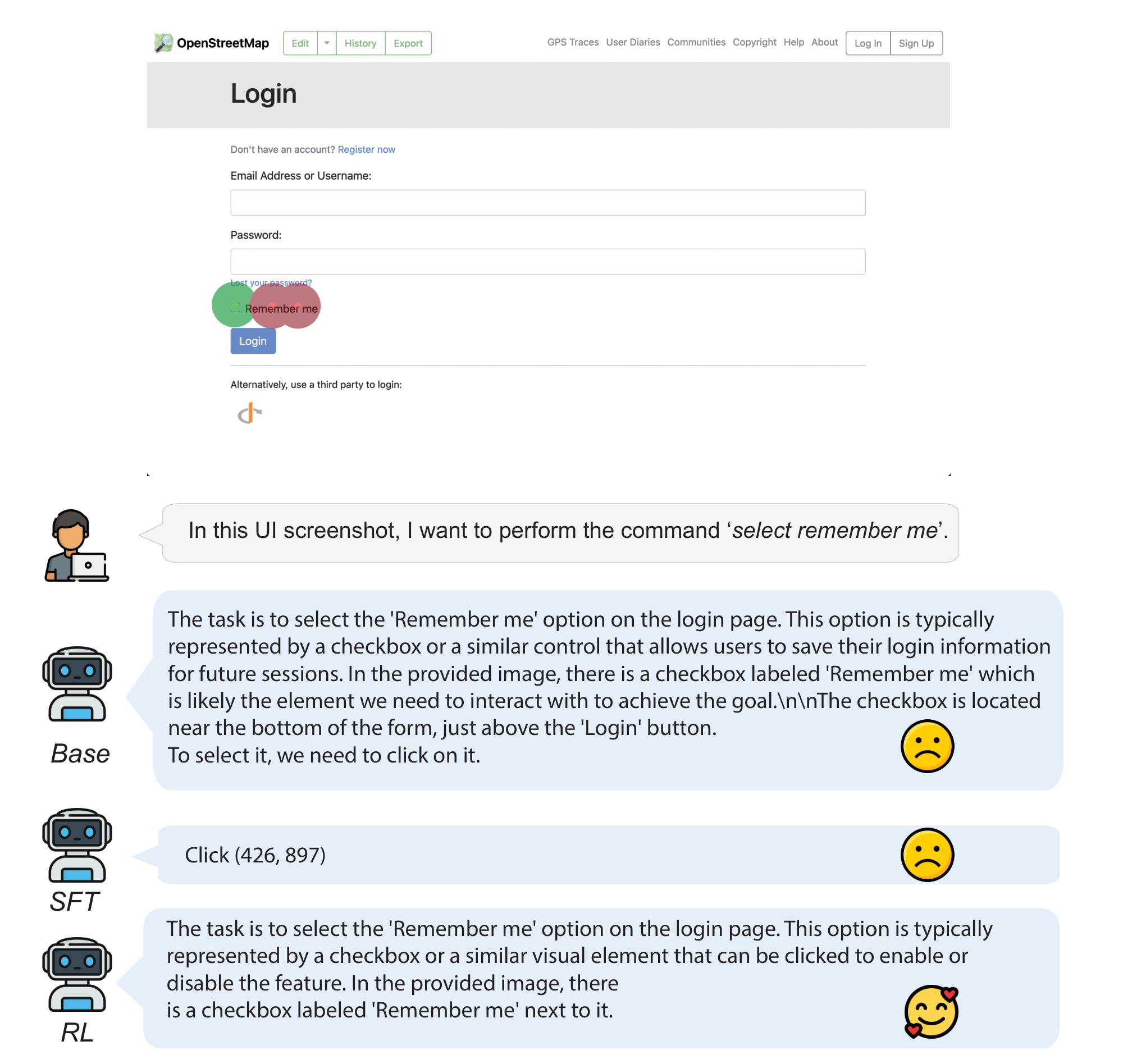
Figure 8 illustrates an example of how UI-R1 trained model can successfully complete the task.
References
[1] Yujia Qin, Yining Ye, Junjie Fang, Haoming Wang, Shihao Liang, Shizuo Tian, Junda Zhang, Jiahao Li, Yunxin Li, Shijue Huang, et al. Ui-tars: Pioneering automated gui interaction with native agents. arXiv preprint arXiv:2501.12326, 2025.
[2] Zhiyong Wu, Zhenyu Wu, Fangzhi Xu, Yian Wang, Qiushi Sun, Chengyou Jia, Kanzhi Cheng, Zichen Ding, Liheng Chen, Paul Pu Liang, et al. Os-atlas: A foundation action model for generalist gui agents. arXiv preprint arXiv:2410.23218, 2024.
[3] Wenyi Hong, Weihan Wang, Qingsong Lv, Jiazheng Xu, Wenmeng Yu, Junhui Ji, Yan Wang, Zihan Wang, Yuxiao Dong, Ming Ding, et al. Cogagent: A visual language model for gui agents. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 14281–14290, 2024.
[4] Yadong Lu, Jianwei Yang, Yelong Shen, and Ahmed Awadallah. Omniparser for pure vision based gui agent. arXiv preprint arXiv:2408.00203, 2024.
[5] Yuxiang Chai, Siyuan Huang, Yazhe Niu, Han Xiao, Liang Liu, Dingyu Zhang, Peng Gao, Shuai Ren, and Hongsheng Li. Amex: Android multi-annotation expo dataset for mobile gui agents. arXiv preprint arXiv:2407.17490, 2024.
[6] Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning. arXiv preprint arXiv:2501.12948, 2025.
[7] Ziyu Liu, Zeyi Sun, Yuhang Zang, Xiaoyi Dong, Yuhang Cao, Haodong Duan, Dahua Lin, and Jiaqi Wang. Visual-rft: Visual reinforcement fine-tuning. arXiv preprint arXiv:2503.01785, 2025b.
[8] Weiyun Wang, Zhangwei Gao, Lianjie Chen, Zhe Chen, Jinguo Zhu, Xiangyu Zhao, Yangzhou Liu, Yue Cao, Shenglong Ye, Xizhou Zhu, et al. Visualprm: An effective process reward model for multimodal reasoning. arXiv preprint arXiv:2503.10291, 2025b.
[9] Yingzhe Peng, Gongrui Zhang, Miaosen Zhang, Zhiyuan You, Jie Liu, Qipeng Zhu, Kai Yang, Xingzhong Xu, Xin Geng, and Xu Yang. Lmm-r1: Empowering 3b lmms with strong reasoning abilities through two-stage rule-based rl. arXiv preprint arXiv:2503.07536, 2025.
[10] Liang Chen, Lei Li, Haozhe Zhao, Yifan Song, and Vinci. R1-v: Reinforcing super generalization ability in vision-language models with less than $3. https://github.com/Deep-Agent/R1-V, 2025a. Accessed: 2025-02-02.
[11] Wenxuan Huang, Bohan Jia, Zijie Zhai, Shaosheng Cao, Zheyu Ye, Fei Zhao, Yao Hu, and Shaohui Lin. Vision-r1: Incentivizing reasoning capability in multimodal large language models. arXiv preprint arXiv:2503.06749, 2025.
[12] Hengguang Zhou, Xirui Li, Ruochen Wang, Minhao Cheng, Tianyi Zhou, and Cho-Jui Hsieh. R1-zero's" aha moment" in visual reasoning on a 2b non-sft model. arXiv preprint arXiv:2503.05132, 2025.
[13] Zhangquan Chen, Xufang Luo, and Dongsheng Li. Visrl: Intention-driven visual perception via reinforced reasoning. arXiv preprint arXiv:2503.07523, 2025b.
[14] Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Y Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv:2402.03300, 2024.
[15] Niklas Muennighoff, Zitong Yang, Weijia Shi, Xiang Lisa Li, Li Fei-Fei, Hannaneh Hajishirzi, Luke Zettlemoyer, Percy Liang, Emmanuel Candès, and Tatsunori Hashimoto. s1: Simple test-time scaling, 2025. URL https://arxiv.org/abs/2501.19393.
[16] Kaixin Li, Ziyang Meng, Hongzhan Lin, Ziyang Luo, Yuchen Tian, Jing Ma, Zhiyong Huang, and Tat-Seng Chua. Screenspot-pro: Gui grounding for professional high-resolution computer use, 2025a.
[17] Kanzhi Cheng, Qiushi Sun, Yougang Chu, Fangzhi Xu, Yantao Li, Jianbing Zhang, and Zhiyong Wu. Seeclick: Harnessing gui grounding for advanced visual gui agents. arXiv preprint arXiv:2401.10935, 2024.
[18] William Liu, Liang Liu, Yaxuan Guo, Han Xiao, Weifeng Lin, Yuxiang Chai, Shuai Ren, Xiaoyu Liang, Linghao Li, Wenhao Wang, et al. Llm-powered gui agents in phone automation: Surveying progress and prospects. 2025a.
[19] Chi Zhang, Zhao Yang, Jiaxuan Liu, Yucheng Han, Xin Chen, Zebiao Huang, Bin Fu, and Gang Yu. Appagent: Multimodal agents as smartphone users. arXiv preprint arXiv:2312.13771, 2023.
[20] Yanda Li, Chi Zhang, Wanqi Yang, Bin Fu, Pei Cheng, Xin Chen, Ling Chen, and Yunchao Wei. Appagent v2: Advanced agent for flexible mobile interactions. arXiv preprint arXiv:2408.11824, 2024b.
[21] Junyang Wang, Haiyang Xu, Jiabo Ye, Ming Yan, Weizhou Shen, Ji Zhang, Fei Huang, and Jitao Sang. Mobile-agent: Autonomous multi-modal mobile device agent with visual perception. arXiv preprint arXiv:2401.16158, 2024b.
[22] Junyang Wang, Haiyang Xu, Haitao Jia, Xi Zhang, Ming Yan, Weizhou Shen, Ji Zhang, Fei Huang, and Jitao Sang. Mobile-agent-v2: Mobile device operation assistant with effective navigation via multi-agent collaboration. arXiv preprint arXiv:2406.01014, 2024a.
[23] Christopher Rawles, Alice Li, Daniel Rodriguez, Oriana Riva, and Timothy Lillicrap. Androidinthewild: A large-scale dataset for android device control. Advances in Neural Information Processing Systems, 36:59708–59728, 2023.
[24] Wei Li, William Bishop, Alice Li, Chris Rawles, Folawiyo Campbell-Ajala, Divya Tyamagundlu, and Oriana Riva. On the effects of data scale on computer control agents. arXiv preprint arXiv:2406.03679, 2024a.
[25] Boyu Gou, Ruohan Wang, Boyuan Zheng, Yanan Xie, Cheng Chang, Yiheng Shu, Huan Sun, and Yu Su. Navigating the digital world as humans do: Universal visual grounding for gui agents. arXiv preprint arXiv:2410.05243, 2024.
[26] Weihao Zeng, Yuzhen Huang, Wei Liu, Keqing He, Qian Liu, Zejun Ma, and Junxian He. 7b model and 8k examples: Emerging reasoning with reinforcement learning is both effective and efficient. https://hkust-nlp.notion.site/simplerl-reason, 2025. Notion Blog.
[27] Haozhan Shen, Zilun Zhang, Kangjia Zhao, Qianqian Zhang, Ruochen Xu, and Tiancheng Zhao. Vlm-r1: A stable and generalizable r1-style large vision-language model. https://github.com/om-ai-lab/VLM-R1, 2025a. Accessed: 2025-02-15.
[28] Fanqing Meng, Lingxiao Du, Zongkai Liu, Zhixiang Zhou, Quanfeng Lu, Daocheng Fu, Botian Shi, Wenhai Wang, Junjun He, Kaipeng Zhang, et al. Mm-eureka: Exploring visual aha moment with rule-based large-scale reinforcement learning. arXiv preprint arXiv:2503.07365, 2025.
[29] Xiaoye Qu, Yafu Li, Zhaochen Su, Weigao Sun, Jianhao Yan, Dongrui Liu, Ganqu Cui, Daizong Liu, Shuxian Liang, Junxian He, et al. A survey of efficient reasoning for large reasoning models: Language, multimodality, and beyond. arXiv preprint arXiv:2503.21614, 2025.
[30] Wenyi Xiao, Leilei Gan, Weilong Dai, Wanggui He, Ziwei Huang, Haoyuan Li, Fangxun Shu, Zhelun Yu, Peng Zhang, Hao Jiang, et al. Fast-slow thinking for large vision-language model reasoning. arXiv preprint arXiv:2504.18458, 2025.
[31] Yi Shen, Jian Zhang, Jieyun Huang, Shuming Shi, Wenjing Zhang, Jiangze Yan, Ning Wang, Kai Wang, and Shiguo Lian. Dast: Difficulty-adaptive slow-thinking for large reasoning models. arXiv preprint arXiv:2503.04472, 2025b.
[32] Pranjal Aggarwal and Sean Welleck. L1: Controlling how long a reasoning model thinks with reinforcement learning. arXiv preprint arXiv:2503.04697, 2025.
[33] Ming Li, Jike Zhong, Shitian Zhao, Yuxiang Lai, and Kaipeng Zhang. Think or not think: A study of explicit thinking in rule-based visual reinforcement fine-tuning. arXiv preprint arXiv:2503.16188, 2025b.
[34] Minzheng Wang, Yongbin Li, Haobo Wang, Xinghua Zhang, Nan Xu, Bingli Wu, Fei Huang, Haiyang Yu, and Wenji Mao. Think on your feet: Adaptive thinking via reinforcement learning for social agents. arXiv preprint arXiv:2505.02156, 2025a.
[35] John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347, 2017.
[36] Zongru Wu, Pengzhou Cheng, Zheng Wu, Tianjie Ju, Zhuosheng Zhang, and Gongshen Liu. Smoothing grounding and reasoning for mllm-powered gui agents with query-oriented pivot tasks, 2025. URL https://arxiv.org/abs/2503.00401.
[37] Yiheng Xu, Zekun Wang, Junli Wang, Dunjie Lu, Tianbao Xie, Amrita Saha, Doyen Sahoo, Tao Yu, and Caiming Xiong. Aguvis: Unified pure vision agents for autonomous gui interaction. arXiv preprint arXiv:2412.04454, 2024.