Executive Summary: Videos capture real-world interactions, but editing them by removing objects is challenging. When an object like a person holding a ball is deleted, the ball should fall naturally rather than float, and shadows or collisions must adjust accordingly. Current video editing tools often fail here, producing unrealistic results such as falling dominoes without support or lingering effects. This limits applications in film visual effects (VFX) and everyday editing, where plausible physics is essential for immersion and accessibility.
This document introduces VOID, a framework to remove objects from videos while simulating how the scene would evolve without them. It aims to enable models to perform high-level causal reasoning, going beyond simple visual fixes to handle dynamic interactions like falls, prevented collisions, or altered motions.
The authors built VOID using simulated data pairs: one video with the object present and another showing the counterfactual outcome without it. They generated about 6,400 pairs from Kubric, a physics engine for rigid objects like colliding blocks, and HUMOTO, a motion-capture dataset for human-object actions. Training fine-tuned a video diffusion model—initialized from prior work on layered decomposition—with a "quadmask" that highlights the object to remove, overlapping effect zones, and unaffected areas. A second pass refines motion to avoid distortions in complex cases. At use, vision-language models (VLMs) like Gemini analyze the input to create these masks, drawing on world knowledge to predict changes.
Key findings show VOID's superiority. In a human study with 25 participants rating 125 real-world videos, VOID won 65% of comparisons for realism and plausibility, far ahead of baselines like the commercial Runway tool (18%) or inpainting models (under 5%). VLM judges scored VOID highest across three evaluators, especially in physics and interactions (about 20-30% better than competitors). On synthetic benchmarks with ground truth, VOID led in video fidelity metrics like FVD by 15-25% margins and achieved top scores in physics simulation. It generalized to untrained scenarios, such as a balloon rising after its holder vanishes or a blender staying off without a user, without relying on memorized patterns.
These results mean video editing can now handle physics intuitively, reducing manual fixes in VFX pipelines and enabling non-experts to create believable edits. Unlike expectations from text-guided tools, VOID's VLM integration and simulation data unlock reasoning that baselines lack, cutting risks of implausible outputs that could undermine trust in generated content. This advances generative AI toward better world modeling, with potential to speed up production timelines by 20-50% in editing workflows.
Leaders should adopt VOID for tools targeting interactive video edits, prioritizing its integration into platforms like Runway or open-source generators. Test it in pilots for VFX scenes with collisions or supports to quantify efficiency gains. If scaling, consider trade-offs: VLMs add inference time (seconds per video) but boost accuracy; alternatives without them drop performance by 10-20%.
Limitations include struggles with unusual camera angles or close-ups, limiting domain coverage. Videos are short (a few seconds) and moderate resolution, and standard metrics sometimes undervalue physics over visuals. Confidence is high in controlled and human-validated results, but caution applies to edge cases needing real-world data; further validation on diverse videos would strengthen decisions.
VOID: Video Object and Interaction Deletion
Saman Motamed$^{1,2}$, William Harvey$^{1}$, Benjamin Klein$^{1}$
Luc Van Gool$^{2}$, Zhuoning Yuan$^{1}$, Ta-Ying Cheng$^{1}$
$^{1}$ Netflix $^{2}$ INSAIT, Sofia University ``St. Kliment Ohridski''

1. Introduction
Section Summary: Videos capture intricate cause-and-effect interactions in the physical world, such as shadows or collisions, making it challenging for AI models to realistically remove an object from a video because they must simulate what would happen without it, like stopping a chain of falling dominoes. Existing methods struggle with these dynamic effects, either by only handling simple visual traces or lacking the intuition to predict changes from text prompts. The paper introduces VOID, a new framework that builds on video generation models using simulated data, improved training techniques, and AI-guided analysis to remove objects and their influences, demonstrating superior results on benchmarks and even handling unseen scenarios like a balloon floating away.
Videos capture the complex causal dynamics of our physical world. The presence of an object exerts a diverse range of effects on its environment, ranging from photometric phenomena like shadows and reflections to kinetic events like collisions. This spatiotemporal entanglement makes the seemingly simple task of "video object removal" non-trivial for video generation and editing models. It requires the model to first imagine "What would happen if this object was removed?" and then synthesize a realistic video of its answer. Consider the line of collapsing domino tiles shown on the left of Figure 1. If we use a video inpainting model to remove the middle tiles, the later tiles keep falling, which is a physically impossible scenario. A realistic solution requires the model to reason that without the middle tiles, tiles appearing later in the chain must remain standing. Doing so requires an editing model to simulate the world through high-level causal reasoning and not rely solely on low-level visual features. Mastering this capability will benefit film visual effects and make advanced video editing accessible to non-experts.
Video decomposition methods [1, 2, 3, 4] aim to decompose videos into layers, such that each object has an associated layer containing its effects disentangled from those of other objects in the scene. These methods excel at extracting effects where an object creates shadows, reflections, or other distinct visual entities. However, they are not capable of disentangling interactions where one object affects another, such as by breaking or moving it. Alternatively, a text-guided video editing model [5, 6, 7] could remove an object and its effects following a user prompt. However, current diffusion models often lack the physical intuition to determine what should happen with the object removed, and it is often impossible to specify all effects precisely with a text prompt.
To this end, we propose an extension of video object removal to more dynamic scenarios. These require not only removing a specified object, but also modeling how its removal affects other objects in the scene. We then present $\textsc{Void}$, a framework to elicit this high-level causal reasoning from a video diffusion model.
$\textsc{Void}$ is built on advances along three axes: data construction, training strategy, and inference optimization. To create data pairs that capture dynamic changes when an object is removed, we repurpose the Kubric simulation and rendering engine [8] and the HUMOTO human motion capture dataset [9]. For training, we propose two improvements over prior work [2]: (i) "quadmask" conditioning that explicitly identifies regions of each frame that may change after the object is removed, and (ii) a video appearance refiner applied in a second pass to remove artifacts like unwanted object morphing. During inference, we generate quadmasks with vision-language models (VLMs), leveraging their world knowledge to expand a simple object mask into richer pixel-space guidance.
We gather a new benchmark of videos with diverse and complex interactions, comprising synthetic and real-world data. Extensive studies involving perceptual metrics, user studies, and VLM-as-a-judge demonstrate compelling results from $\textsc{Void}$ against both video inpainting methods and general video editing models. We further see surprising generalizations to unseen effects: VOID models a balloon floating up when the person holding it is removed, despite there being no floating objects in its training data; VOID also prevents food inside a blender from moving when the person turning it on disappears, despite there being no blenders or electrical devices in its finetuning data. These extrapolations demonstrate that $\textsc{Void}$ does not just recall simple visual cues from its training data, but applies high-level reasoning and world knowledge from the VLM and underlying video diffusion model to video editing. As such, it is likely to benefit as more capable generative models become available.
In summary, we have three contributions. First, we investigate the current pitfalls of physics-aware object removal when the removed object has complex interactions with the rest of the scene. Second, we introduce $\textsc{Void}$, a framework that tackles these problems from three perspectives: data curation, training strategy, and inference time VLM-guided scene analysis. Finally, we present extensive evaluations on previous and new benchmarks that show the superiority of our model in disentangling and removing a wide range of object effects. We believe that this work illuminates an interesting and underexplored direction for video generation and world modeling research.
2. Related Work
Section Summary: Recent advances in video generation, driven by diffusion and flow-matching techniques, have produced impressive models like Veo 3 and Runway, which learn from vast datasets to create and edit videos based on text or sketches, though they often generate visually sharp but physically unrealistic scenes, especially for tasks needing deep reasoning like object removal. Efforts to boost reasoning with vision-language models have been limited to specific domains or basic functions, such as segmenting or grounding elements in videos. In video decomposition, tools like Omnimatte break footage into layers for objects and effects like shadows, while inpainting methods fill in gaps after removal, handling some lighting issues but struggling with intricate physical interactions.
Video Generation and Editing.
The breakthrough of diffusion and flow-matching methods has led to large advancements in video generation models. Notable examples include closed-source models like Veo 3 [10] and Runway [5] and open-source models such as WAN [11], VACE [6], CogVideo [12], and LTX-2 [13]. Much of the stunning performances of these models came from the large video-text datasets driving forward the performance, allowing them to extend to various editing controls including text and sketches. However, since they are learning from unstructured data, they often create pixel-perfect yet physically implausible scenes, especially for tasks that require extensive reasoning (e.g., removing an object).
Several models aim to improve reasoning via VLMs [14, 15, 16]. However, these models either work in a specific domain (e.g., LangDriveCtrl [14] works purely for driving scenes) or only solve simple reasoning tasks like grounding (Video-Repair [16]) and segmentation (Veggie [15]). $\textsc{Void}$ takes a leap towards applying VLM reasoning for complex video editing tasks, where we need to synthesize counterfactual scenarios in which an object is removed.
Video Decomposition and Effect Removal.
The problem of decomposing a video into RGBA layers was significantly advanced by Omnimatte [1], which introduced a self-supervised framework to associate subjects with their "effects" (e.g., shadows and reflections). While OmnimatteRF [17] extended this by modelling the static background with 3D radiance fields, these methods remain fundamentally reconstructive, focusing on uncovering existing background pixels rather than synthesizing new content. More recently, Generative Omnimatte [2] integrated priors from a video inpainting model, using a trimask setup to decompose images into object-specific layers and effects. OmnimatteZero [3] introduced training-free extraction of effects and objects via attention maps.
There are also a plethora of recently-released video inpainting methods. Propainter [18] proposed a dual-domain propagation from image and feature side for better inpainting. DiffuEraser [19] integrated flow-based pixel propagation with transformer-based generation to better restore textures and objects. AVID [20] and FDM [21] proposed sampling pipelines to extend video inpainting lengths. Minimax-Remover [22] is an object removal approach with a more efficient model architecture followed by distilling a remover on human annotations. ROSE [23] proposed an effect removal inpainting framework focusing on photometric effects such as shadows, reflections, light, and translucency, while Object-Wiper [24] presented a training-free method targeting these effects. While these methods all handle some associated photometric effects of the removed object, they cannot model complex physical interactions.
3. Approach
Section Summary: The approach focuses on creating videos that show what a scene would look like if a specific object and its effects—like collisions or support—were removed, using an input video and a mask to identify the object. To train the model, the authors generate new datasets by simulating realistic interactions: in Kubric for rigid objects falling or colliding, and in HUMOTO for human manipulations, producing pairs of original and altered videos. They enhance guidance with a detailed "quadmask" that distinguishes the object, its direct removal area, affected regions, and overlaps, building the core model VOID on existing video generation technology for stable, physics-aware results.
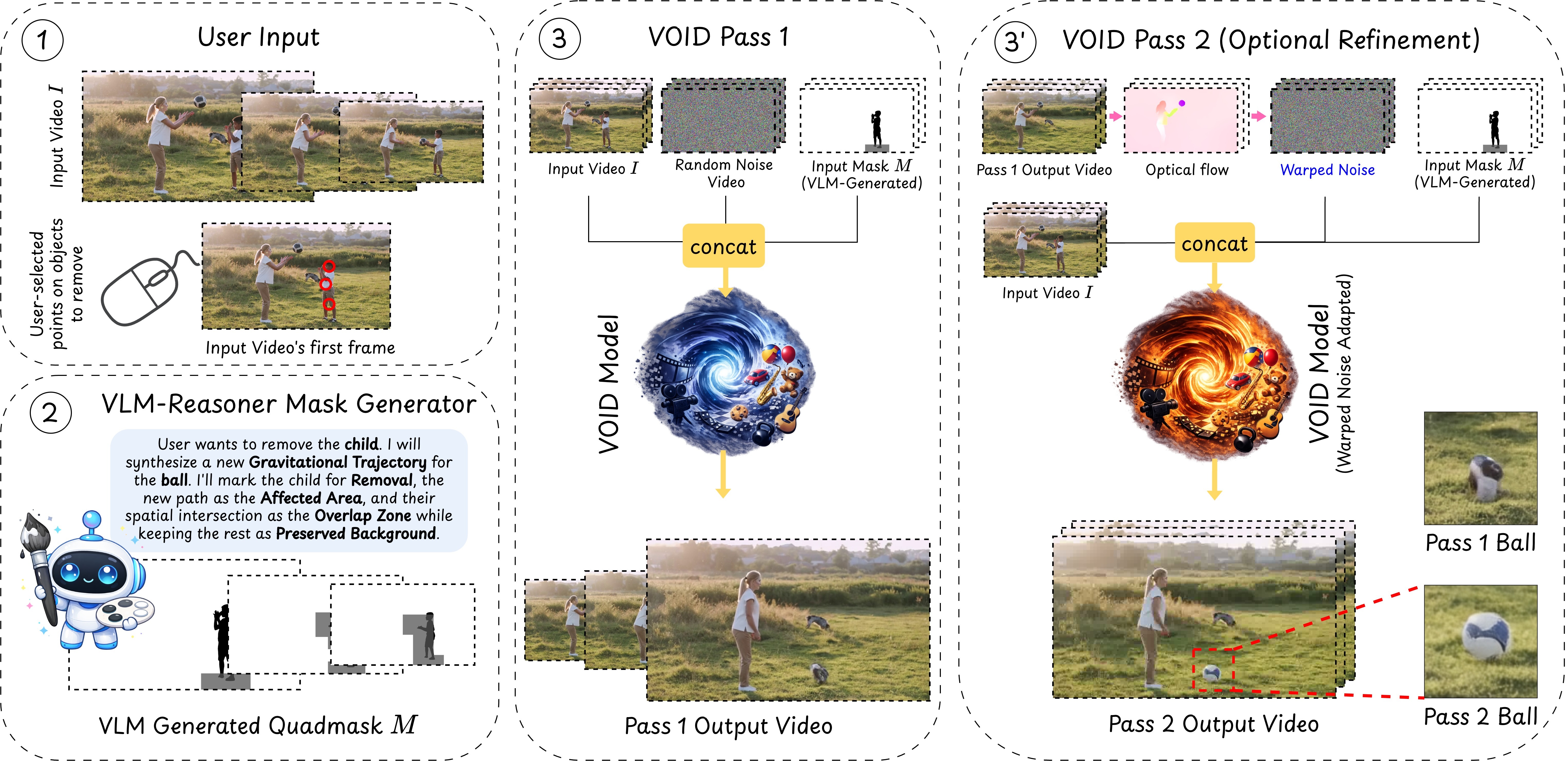
We start from an input video $\mathbf{V} = {I_t}_{t=1}^T$ and a mask sequence $\mathbf{M}o = {m_t}{t=1}^T$ identifying one or more target objects to remove, $O$. Our objective is to learn a model $f$ that generates a counterfactual video $\hat{\mathbf{V}}$, in which $O$ and all induced interactions are removed:
$ \hat{\mathbf{V}} = f(\mathbf{V}, \mathbf{M}_o). $
In general, the interactions can be complex. Removing a support can cause something to fall. Removing an obstacle can prevent a collision. To work well in these settings, $f$ cannot rely on spatial hole filling but must conceptualize how the scene would have evolved in the target object's absence. It should then (i) eliminate the target object, (ii) regenerate regions affected through potentially complex relationships, and (iii) preserve unaffected regions.
3.1 Counterfactual Dataset Supervision
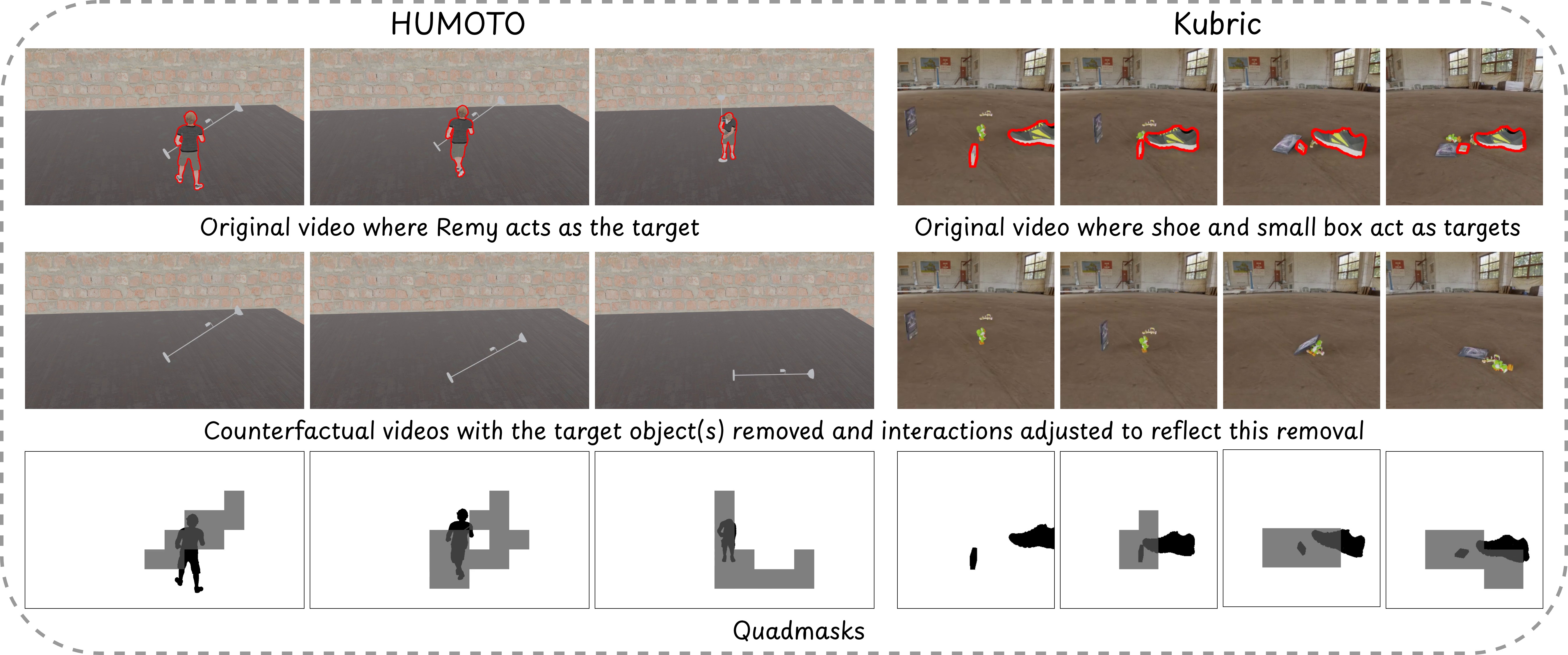
Training this model requires a dataset of counterfactual video pairs $(\mathbf{V}, \hat{\mathbf{V}})$ with and without object $O$, respectively. Video pairs used by existing video inpainting and omnimatte datasets [23, 2, 25, 26] focus mostly on photometric effects such as shadows and lack supervision for the removal of objects that physically affect other objects in the scene. We generate new counterfactual pairs to address this gap with physics-based simulations from Kubric [8] and human motion capture data from HUMOTO [9]. For both datasets, we randomize camera trajectories and focal zoom during rendering to help with the disentanglement of object effects and camera trajectories. We show in Figure 6 that training on these two synthetic datasets enables extensive generalization to real-world domains.
Rigid-body dynamics (Kubric).
The diverse set of objects offered by Kubric is ideal for simulating collisions, falling, and structural dependencies. We create videos $\mathbf{V}$ by sampling initial conditions of multiple objects with varying initial positions and velocities, and simulating the interactions over time. We then define one or more of the objects to be $O$. The counterfactual video $\hat{\mathbf{V}}$ is created by removing $O$ while keeping initial conditions for all other objects the same, and re-simulating the scene. This yields a new, physically consistent alternative set of interactions. We generate $\sim$ 1900 videos pairs in this manner.
Articulated interactions (HUMOTO).
We use HUMOTO, a 4D motion-capture dataset of human-object interactions, to collect articulated interaction data. In these sequences, $O$ corresponds to the human performing diverse activities. $\mathbf{V}$ and $\hat{\mathbf{V}}$ are created by passes over the simulation and rendering engine with and without the human. These videos teach the model how to perform object removal in videos containing dynamic manipulations. We randomize the textures of the objects in the scene, the background wall and the human, and generate $\sim$ 4500 video pairs.
3.2 Interaction-Aware Quadmask Conditioning
To provide further guidance over the binary object mask $\mathbf{M}_o$, Lee et al. [2] proposed a trimask which distinguishes between three image regions: the object to be removed (black), the area affected by its removal (light gray), and areas which should stay the same (white). Their setup, however, creates two ambiguities.
The first is that they highlight almost the entire region of each image frame in light gray and mark only specific objects as white. Their model therefore learns that it typically needs to modify only a small portion of the light gray mask to remove the effects. We provide stronger guidance by focusing the light gray region closely on where effects take place. While generating data, we use the rendering engines to determine these regions. We then gridify the regions to better match our inference time procedure described in Section 3.6.
The second ambiguity occurs when there is overlap between the object to remove and the area with dynamic effects. In the example in Figure 3, we want to remove a child and once they are removed, the ball should fall to the ground instead of them catching it. Consider what value the trimask should have around the boy's upper body while he catches the ball. Should it be black because the boy is being removed? Or should it be light gray because the "effect" of the removal is that the ball should now continue its trajectory and pass through this area? To resolve these ambiguities, we extend the trimask to a quadmask $\mathbf{M}_q$ with a fourth color (dark grey) that describes overlap between (i) the object to be removed and (ii) other parts of the scene that are affected. See Figure 2 for examples.
3.3 Backbone Initialization and Counterfactual Generation
We propose $\textsc{Void}$, a model built upon the CogVideoX diffusion transformer backbone [12] and initialized from the weights released with Generative Omnimatte [2]. This initialization provides a strong prior for layered object–effect disentanglement under trimask guidance. We finetune it with quadmask conditioning on the counterfactual video pairs described previously. This teaches the model mask semantics and re-enables the underlying video model's native capacity for physically plausible trajectory synthesis, transforming it from a layered removal model to a dynamic counterfactual rewriting model.
3.4 Pass 1: Counterfactual Trajectory Synthesis
In its first pass, $\textsc{Void}$ generates an initial counterfactual prediction:
$ \hat{\mathbf{V}}_\text{p1} = \text{VOID}(\mathbf{z}, \mathbf{V}, \mathbf{M}_q), $
where $\mathbf{z} \sim \mathcal{N}(\mathbf{0}, \mathbf{I})$ denotes the Gaussian diffusion noise, $\mathbf{V}$ is the input video sequence, and $\hat{\mathbf{V}}_\text{p1}$ is $\textsc{Void}$ 's first-pass prediction of how the scene would evolve in the absence of the target object. This pass typically captures broadly correct hypotheses around motion, such as previously supported objects entering free-fall and previously-obstructed objects continuing their motion. However, we find that the objects undergoing newly synthesized motion can exhibit structural deformation.
3.5 Pass 2: Flow-Warped Noise Stabilization

Why deformation occurs.
Video diffusion models, especially relatively lightweight models like the 5 billion parameter CogVideoX model we build on, struggle to maintain temporal coherence when generating complex, motion-heavy videos [27, 28]. Prior work mitigates this issue through large-scale tracking supervision or explicit motion conditioning [27, 29, 30, 31, 32, 33]. In the simple object removal case where only photometric effects need to be corrected, the input video provides similarly strong constraints on the generated motion. For example, if we need to remove a shadow from a surface, the motion and geometry of the surface in the output video should be the same as in the input. In our more complex settings, the diffusion model often needs to generate new motion. We find that this leads to bending, stretching, or structural drift of the objects undergoing changed motion, similar to the artifacts seen from running the CogVideoX image-to-video model without motion guidance. We now describe how to resolve these artifacts in the object removal setting without changing the base model.
Second pass to fix deformation
Go-with-the-Flow [34] observed that using temporally correlated noise based on predicted motion trajectories can encourage the diffusion model to denoise consistently along those trajectories. We follow Go-with-the-Flow [34] to derive warped noise from the optical flow field of our first-pass output $\hat{\mathbf{V}}_\text{p1}$, and then use it as input to a second pass as:
$ \hat{\mathbf{V}} = \text{VOID}\text{warp}(\mathbf{z}\text{warp}, \mathbf{V}, \mathbf{M}_q), $
where $\text{VOID}_\text{warp}$ is a warped noise variant of $\textsc{Void}$. It is trained with the same data and quadmask conditioning but with flow-aligned noise derived from each training target $\hat{\mathbf{V}}$.
This second pass is not always required so we trigger it only when object removal is predicted to cause substantial dynamic reconfiguration. The same VLM used to create a quadmask additionally classifies whether removal induces significant object motion (e.g., free-fall or trajectory change). We trigger the second pass only when such dynamics are detected. Figure 4 shows the effect of pass 2 on two objects.
3.6 VLM-Guided Quadmask Generation at Inference Time
At inference time, we start from an input video $\mathbf{V}$ and user-provided binary object mask $\mathbf{M}_o$. To run $\textsc{Void}$, we need to first infer the affected region and use it to create the quadmask $\mathbf{M}_q$. Doing so requires reasoning about counterfactual dependencies and object dynamics, so we use a VLM [35, 36, 37]. We start by inputting $\mathbf{V}$ and $\mathbf{M}_o$ to the VLM and using it to produce a list of descriptions of objects that are affected by the removed object. We use Segment Anything 3 [38] to get a mask $\mathbf{M}_a^\text{orig}$ covering all objects in the list. Since the affected objects may be in different places in the counterfactual scenario, we also need to predict their counterfactual positions to fully capture the changes between $\mathbf{V}$ and $\hat{\mathbf{V}}$. We therefore feed $\mathbf{M}_a^\text{orig}$ into the VLM and use it to predict the mask sequence describing the positions of these objects in the counterfactual scenario. This is done by overlaying a coarse spatial grid on the input video and asking it to list which cells in each frame may contain effects. This gives us a block-structured mask $\mathbf{M}_a^\text{count}$ describing where the affected objects in $\mathbf{M}_a^\text{orig}$ go in the counterfactual scenario. We combine the masks to get the final affected area mask $\mathbf{M}_a := \mathbf{M}_a^\text{orig} \lor \mathbf{M}_a^\text{count}$. We finally compute the quadmask $\mathbf{M}_q$ by setting it to black for pixels only in $\mathbf{M}_o$; dark grey for pixels where $\mathbf{M}_o$ and $\mathbf{M}_a$ overlap; light grey for pixels only in $\mathbf{M}_a$; and white everywhere else.
4. Results
Section Summary: The researchers tested their VOID system on 75 real-world videos featuring everyday object interactions like manipulations and collisions, plus 30 synthetic videos, comparing it against several competing video editing models. In a human preference study with 25 participants evaluating realism and physical plausibility, VOID was chosen as the best outcome 65% of the time, outperforming even advanced tools like Runway, while automated evaluations by AI judges confirmed its top scores, particularly in simulating natural physics after object removal. Qualitative examples highlight VOID's ability to maintain object structures, consistent motion, and logical scene changes, avoiding issues like deformations or implausible artifacts seen in other methods.
We test on two datasets. The first comprises 75 real-world videos involving object manipulation, support removal, collisions, articulated interactions, and shadow/reflection removal. The second is synthetic and consists of 30 Kubric and HUMOTO test videos combined with existing synthetic object removal datasets.

4.1 Experimental Details
For each real-world video, a user specifies a primary object via sparse clicks, which are converted into the binary object mask $\mathbf{M}_o$ using Segment Anything 2 [39]. We convert the binary mask into a quadmask with the VLM-based pipeline in Section 3.6. All results in the main paper use Gemini 3 Pro as the VLM in this pipeline; we also report scores with GPT-5.2 and Qwen-3.5 VL in the appendix.
For fair comparison, each baseline is evaluated using its preferred conditioning format: binary masks for ProPainter, DiffuEraser, ROSE, and MiniMax-Remover; trimasks for Generative Omnimatte; and natural-language editing prompts for Runway (Aleph), a commercial video editing system.
Since Runway is a text-guided editor rather than a mask-conditioned inpainting model, we explicitly describe both (i) the object to remove and (ii) the expected scene evolution after removal (e.g., "remove the person and ensure the held object falls naturally"). This makes the counterfactual requirement explicit while allowing each model to operate under its intended interface. We did not compare with Object-Wiper [24] and DynaEdit [7] as code is unavailable, nor OmnimatteZero [3] due to an acknowledged issue with their released code at the time of writing.
4.2 Real-World Counterfactual Comparisons
Since there are no ground truth counterfactuals for real-world videos, we evaluate with a human preference study, three VLM judges on fine-grained criteria, and several qualitative comparisons.
Human Preference Study.

:Table 1: Human preferences on real-world edits. 25 participants each evaluated 5 scenarios.
| Model | Win % |
|---|---|
| $\textsc{Void}$ (ours) | 64.8 |
| Runway | 18.4 |
| Gen-Omni. | 11.2 |
| DiffuEraser | 4.0 |
| ROSE | 1.6 |
| MiniMax-Rem. | 0.0 |
| ProPainter | 0.0 |
We conduct a user study with 25 participants to measure perceptual realism and physical plausibility of counterfactual edits. For each participant, we randomly sample 5 out of the 75 real-world scenarios, resulting in 125 total comparisons. For each video, participants saw the original input and outputs of all seven models in randomized order. They are asked to select the video that best reflects how the scene should realistically appear after the specified object is removed, considering visual quality, temporal consistency, blending, realism of scene evolution, and absence of artifacts. An example of the user interface for the user study is provided in the appendix.
Table 1 summarizes the results. VOID is selected 64.8% of the time, substantially outperforming all baselines, including the closed-source Runway model which required additional text guidance on what should happen. Models optimized for traditional inpainting (e.g., ProPainter) receive few or no selections, showing that they are not automatically capable of interaction-aware synthesis.
VLM-as-a-judge evaluation.
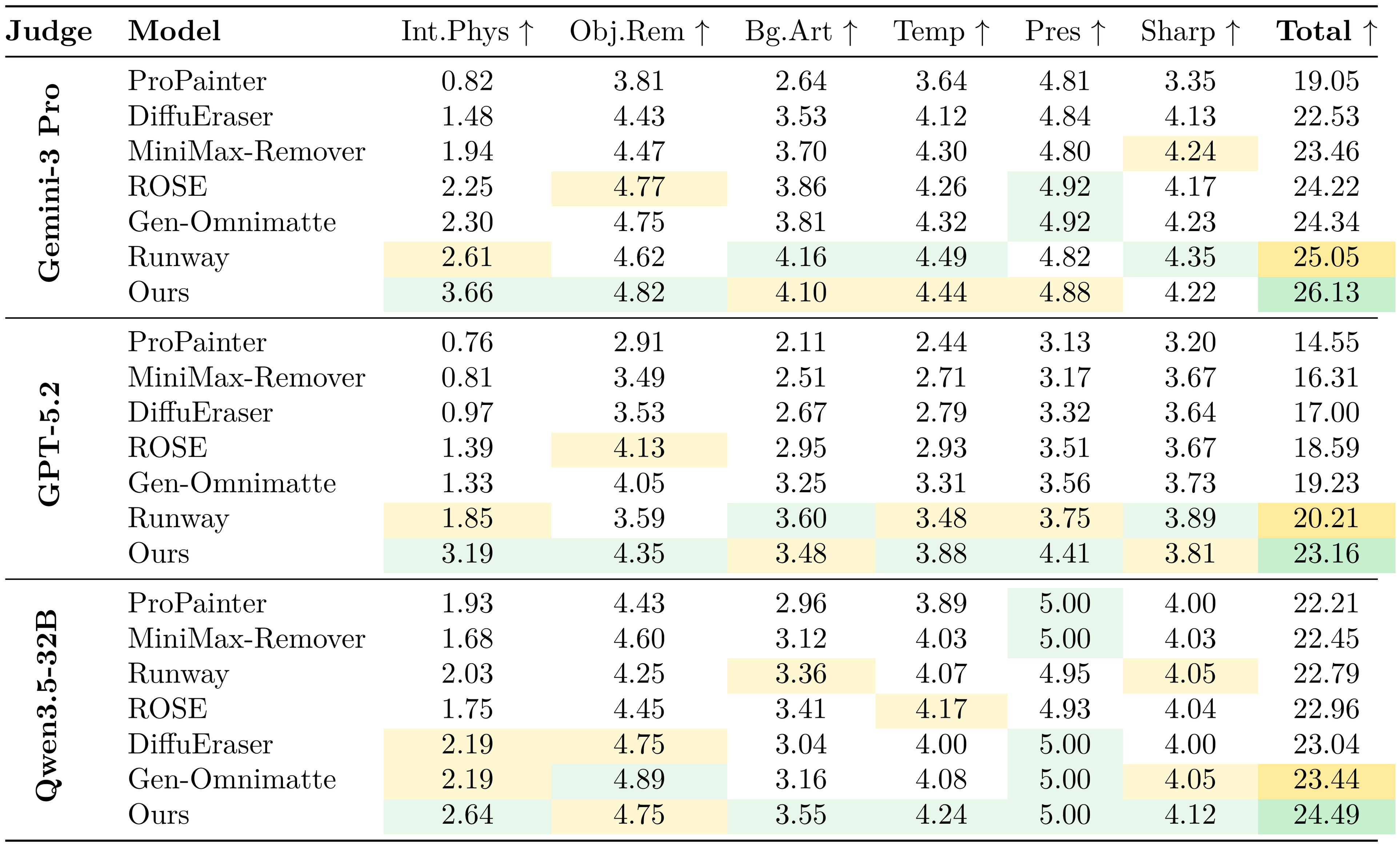
To complement human evaluation with more fine-grained criteria, we employ three VLMs (Gemini 3 Pro, GPT-5.2, and Qwen 3.5-32B) as automated judges [40, 41]. Each judge scores outputs across six criteria (0–5 per category; total 30): "Interaction & Physics", "Object Removal", "Background & Artifacts", "Temporal Consistency", "Preservation", and "Sharpness". Table 2 reports the full results. Across all three judges, VOID achieves the highest total score. The overall ranking is broadly consistent across judges and aligns with the human preference study: VOID is ranked first, Runway second, and Generative Omnimatte third in most cases. The strongest and most consistent gains appear in "Interaction & Physics", which directly evaluates whether the scene updates causally after removal. VOID correctly simulates the intuitive physics while achieving visual quality at least on par with the Runway general video editing model.
::: {caption="Table 2: VLM-as-a-judge evaluation on real-world videos. Each criterion is scored in $[0, 5]$. Best per judge and column is green; second best is orange."}
:::
Qualitative comparisons.
Figure 5 presents qualitative comparisons on 4 real-world videos. We present 3 representative baselines: Runway for text-based video editing, Gen-Omnimatte for effect removal inpainting, and Propainter for traditional video inpainting without effect removal. All baselines present various types of failure cases, such as not removing anything or removing more than intended (two-car crashing example) or creating physically implausible scenes (pillow squished without kettlebell, floaty falling without a collision, and paint still appearing after the paint roller was removed). $\textsc{Void}$ exhibits high generalization capabilities across all examples, performing accurate object and effect removal while ensuring the scene remains physically plausible and artifact-free.
Generalizations to unseen effects.
Figure 6 shows generations by $\textsc{Void}$ on samples from our real-world dataset involving effects unseen in training. To our delight, $\textsc{Void}$ is frequently able to extrapolate to these new types of physical interactions. It disentangles complex motions, such as a Jenga tower being simultaneously pushed by a hand and a cat, and a bowling ball hitting multiple bowling pins. It infers physics effects not present in the training dataset, such as a balloon floating up after the holder is removed, and a blender not turning on when the person pressing it is removed. Finally, it remains robust to removing the reflection of the Big Ben tower, letting the stick fall when the dog chewing it is removed, and corrects the ball rolling trajectory when the ducky obstacle is removed. The diverse set of effects are strong indicators that $\textsc{Void}$ learns to leverage the intuitive physics reasoning of the VLM and video diffusion base model in a general manner, letting it excel on tasks far from the synthetic data we use to train it. We provide more video examples in the appendix.
4.3 Synthetic Dataset Comparisons
To compute metrics requiring ground-truth counterfactual targets, we take a synthetic benchmark of 10 videos focusing on object/shadow/reflection removal used by prior work [2] and add another 30 dynamic counterfactual cases from Kubric and HUMOTO that captures a wider range of object interactions. These include altered collision outcomes and released objects entering free fall. These videos were held-out from our training dataset.
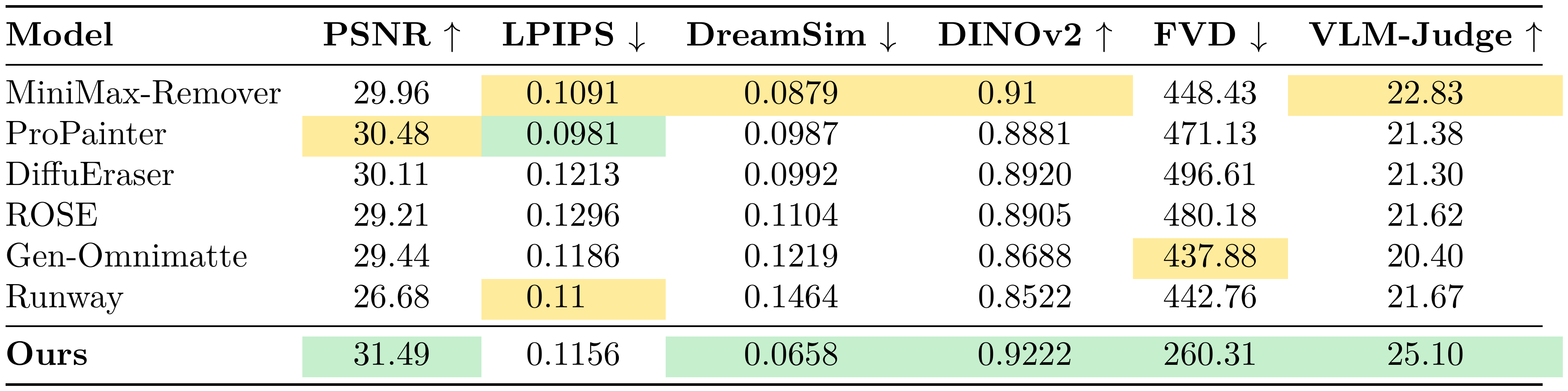
::: {caption="Table 3: Synthetic benchmark evaluation on 10 classic shadow/reflection removal cases and 30 dynamic interaction cases (Kubric + HUMOTO) capturing a wide range of effects. All metrics measure fidelity to the ground-truth counterfactual targets."}
:::
We follow previous work in reporting pixel-based metric PSNR and perceptual metric LPIPS [42]. However, with the new dataset introducing more diverse sets of effects, we also add in the more recent frame-wise perceptual metrics DreamSim [43] and DINOv2 [44], as well as video metric FVD [45]. These can better capture intricate and semantically high-level effects. We also include a VLM-Judge evaluation by Gemini 3 Pro, which is the closest aligned with the human evaluation on our real-world dataset. We modify our VLM-judge protocol on this dataset by showing the judge the ground-truth counterfactual video in addition to the model output. The same six-category scoring protocol (0–5 per criterion; total 30) is applied as in the real-world setting, but judges now assess fidelity relative to the true counterfactual outcome.
VOID achieves the strongest performance across all metrics except LPIPS. Note that this frame-wise LPIPS metric is sensitive to local translations, and therefore can penalize counterfactual effects being generated in slightly incorrect regions. For example, if we remove a person holding a stick, a model accurately portraying a stick falling but at the wrong speed may be penalized more than a model that removes the stick altogether. The largest margin between $\textsc{Void}$ and baselines appears in the FVD and the VLM-judge metrics, which are the two comprehensive video-level metrics we report. This is strongly supportive of our claim that $\textsc{Void}$ excels at producing physically plausible and semantically coherent videos.
4.4 Ablation
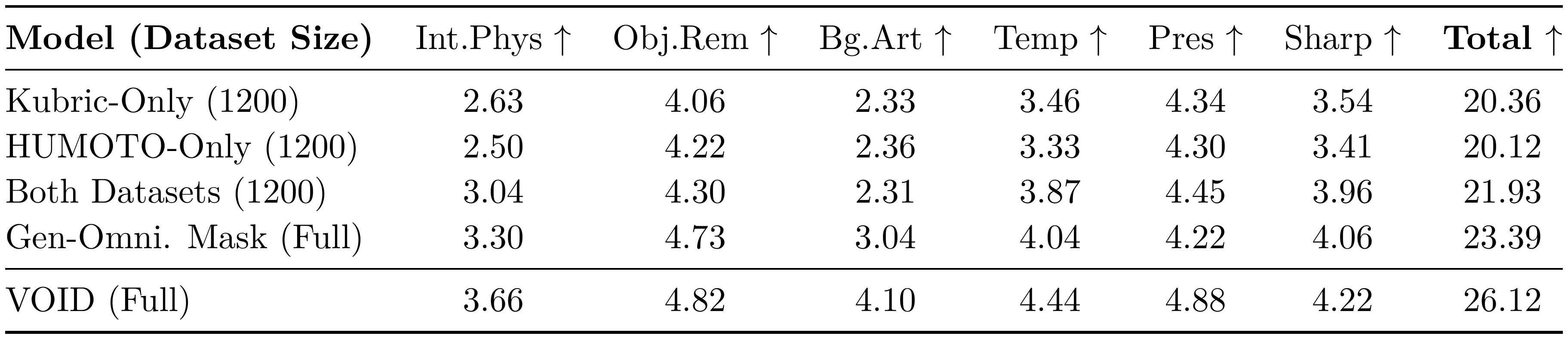
Table 4 presents ablations on our training data and quadmask strategy. To best capture model robustness and generalization, all variants are evaluated on the same 75 real-world test cases using Gemini 3 Pro as a VLM judge. See the appendix for a further ablation on VOID's second pass.
Data composition.
To analyze the effect of our datasets, we train ablations with three alternative datasets: Kubric-Only is trained on a 1200 sample subset of Kubric; HUMOTO-Only is trained on a 1200 sample subset of HUMOTO; and Both Datasets is trained on another 1200 samples split equally between Kubric and HUMOTO. In Table 4 we see that Kubric-Only and HUMOTO-Only both underperform Both-Datasets, meaning the diversity we get by mixing Kubric and HUMOTO data is beneficial even when the dataset size is held constant.
Masking strategy.
We train another ablation that uses less detailed trimasks, similar to Generative Omnimatte [2], so that we can drop the VLM-guided mask generation pipeline. These masks are simply black wherever the object to be removed is and light gray everywhere else, meaning that there are no constraints on what parts of the video the diffusion model can change. Table 4 shows that this ablation degrades performance across all categories, confirming the importance of our detailed masks and our mask generation pipeline.
::: {caption="Table 4: Ablation study evaluated by VLM judge on 75 real-world test cases."}
:::
5. Conclusion
Section Summary: VOID is a new framework for removing objects from videos by creating realistic "what if" versions where the object never existed, using special datasets and AI guidance to ensure the scenes follow real-world physics. It outperforms other methods in handling complex movements after removal and works well on both fake and real videos, even in unfamiliar situations. While it has some limitations like struggling with odd camera views, it lays a solid foundation for advancing video editing tools, with future improvements needed for longer clips and higher quality.
We present $\textsc{Void}$, an object removal framework that generates the counterfactual video corresponding to when an object is removed. $\textsc{Void}$ is built upon two new paired datasets of counterfactual object removal videos derived from the Kubric engine and HUMOTO dataset. We also present a VLM-guided quadmask generation pipeline to guide $\textsc{Void}$ into generating physics-informed counterfactual videos. Through extensive evaluations against inpainting and text-guided video model baselines on synthetic and real-world data, we show that $\textsc{Void}$ excels at modeling complex dynamics which can follow on from object removal. It also generalizes to a broad range of scenarios far from our training data. $\textsc{Void}$ is a strong starting point for future research to continue transferring strong world modeling capabilities to the video editing domain.
Limitations and future work.
Despite the various generalization capabilities $\textsc{Void}$ exhibits, there are still certain domain gaps we observe, such as when test videos have the cameras at an unusual angle or too close to the object. Future work could obtain better training datasets beyond rendering engines. The generated video lengths are still in the range of a few seconds, and resolutions could be further improved.
Below we provide additional experimental details and analyses supporting the main paper. Specifically, we present (i) an analysis of mask generation using different VLM reasoners, (ii) results for the second-pass refinement stage, (iii) the user interfaces used for mask generation and (iv) human evaluation, (v) examples illustrating limitations of standard video similarity metrics, and (vi) the full prompts used for the VLM-based evaluation protocol.
6. Mask Generation with Different VLM Reasoners
Section Summary: The researchers tested three AI vision-language models—Qwen3-32B, GPT 5.2, and Gemini 3-Pro—to see how well they create "masks" from simple user clicks, which help edit videos by guiding what gets removed or changed. These masks are used in a process to fill in video gaps, and the quality of the final edited videos was scored by another AI judge on aspects like realistic interactions, clean object removal, smooth backgrounds, consistent motion over time, preserved scenery, and sharp details. Overall, Gemini 3-Pro stood out as the best, especially for making interactions feel natural and backgrounds look right.
Our pipeline uses a vision-language model (VLM) to generate interaction-aware masks from sparse user input. To study how the choice of VLM affects mask quality, we evaluate three models: Qwen3-32B, GPT 5.2, and Gemini 3-Pro. These models receive identical user clicks and produce masks that guide the inpainting process.
Table 5 reports Gemini 3 VLM-judge scores measuring the quality of the resulting inpainted videos across six dimensions. The judge evaluates interaction physics, object removal, background artifacts, temporal consistency, preservation of the scene, and sharpness.
::: {caption="Table 5: Gemini 3 VLM-judge evaluation on 75 real-world videos when $\textsc{Void}$ uses different VLMs for mask generation during inference."}

:::
Gemini 3-Pro consistently produces the most reliable masks, particularly improving interaction physics and background reconstruction.
7. Second-Pass Refinement Analysis
Section Summary: In some cases, the VOID system runs an optional second refinement step when its vision-language model decides that removing an object and its interactions from a video requires major adjustments to make the scene look physically realistic. Out of 75 real-world videos tested, this extra pass was needed for 10 of them, and a comparison table shows that the second pass generally scored higher when judged by the model. Overall, this refinement boosts the accuracy of how objects interact and the quality of their removal in the videos.
VOID optionally performs a second refinement pass when the VLM determines that the object-interaction removal requires substantial reconfiguration of scene elements to produce a physically plausible outcome. Among the 75 real-world test videos, the VLM flagged 10 cases as requiring refinement. Table 6 compares Pass 1 and Pass 2 results on these samples using the VLM judge.
::: {caption="Table 6: Per-category average scores (out of 5) across the 10 samples that are selected by the VLM for pass 2 refinement."}

:::
The refinement step improves interaction reasoning and object removal quality, leading to higher overall scores.
8. User Interface for Mask Generation
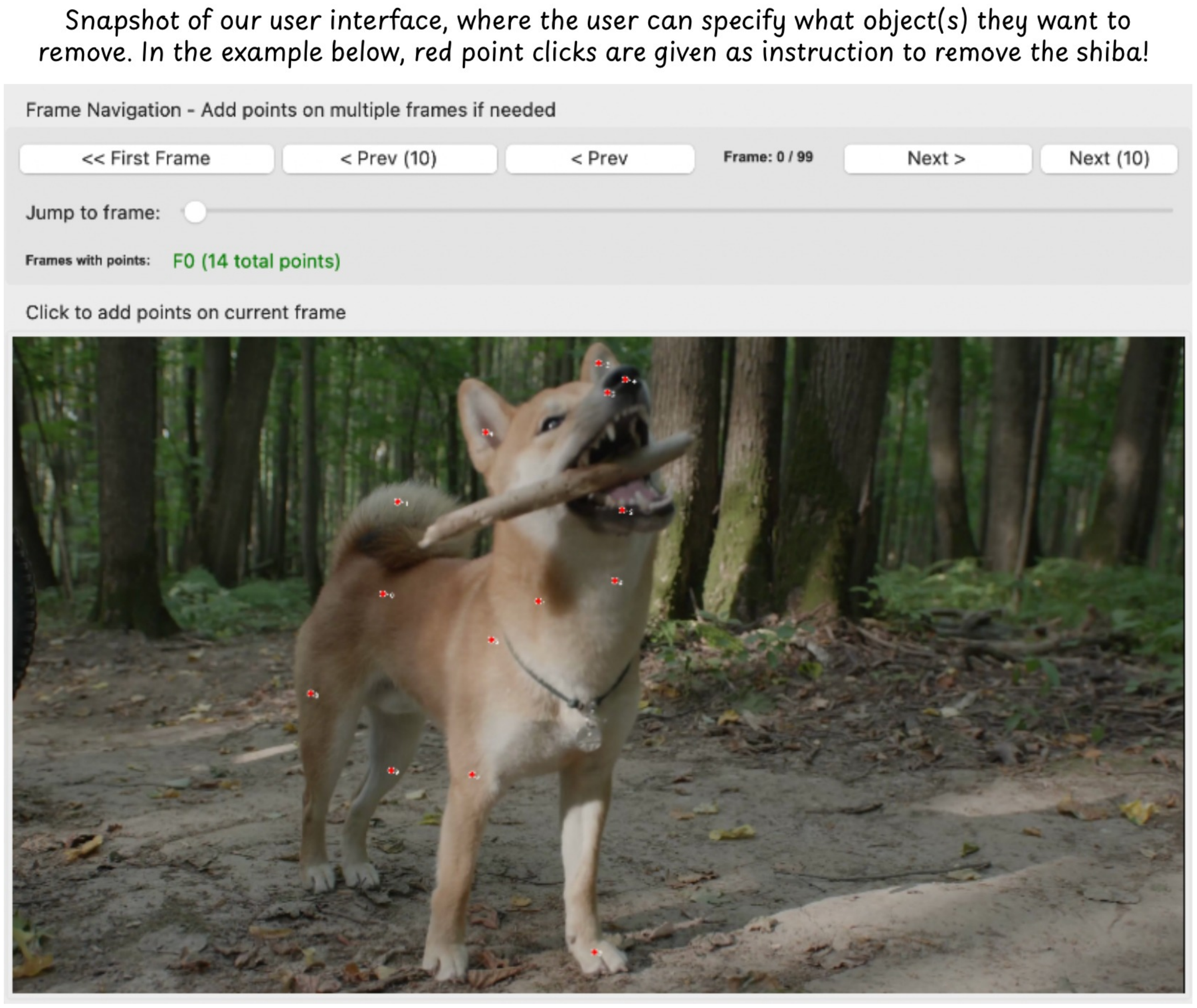
Section Summary: The user interface, shown in Figure 7, allows people to easily input a few points on an object they want to remove from an image or scene. Once these sparse points are selected, the system's AI generates a detailed mask that considers how the object interacts with its surroundings. This makes the removal process more accurate and aware of the overall context.
Figure 7 shows the graphical interface used to collect sparse user inputs. Users select a small number of points on the object to be removed, and the VLM generates an interaction-aware mask conditioned on the scene context.
9. User Study Interface
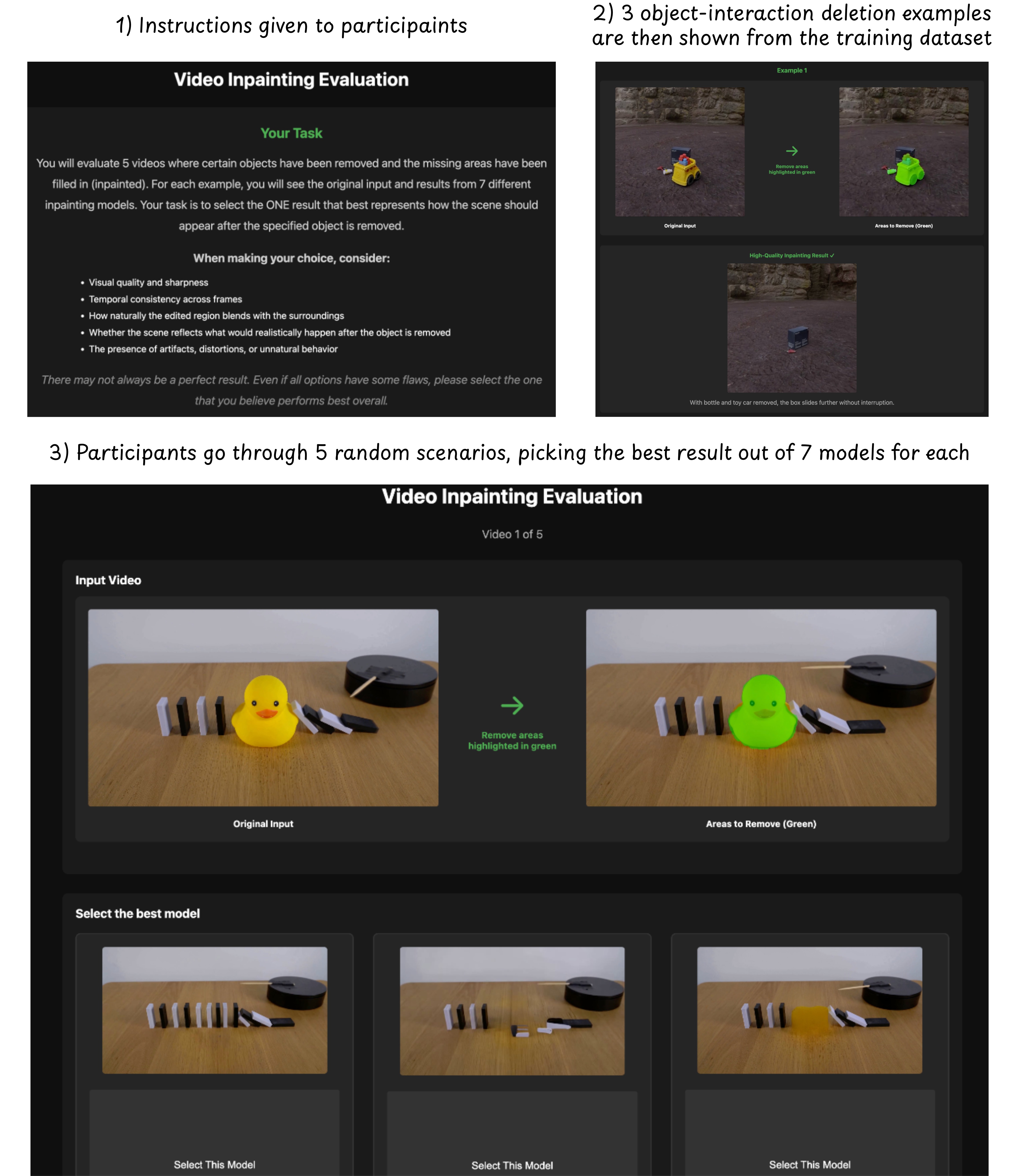
Section Summary: In the human evaluation study, participants start by reading simple instructions and reviewing three example videos where objects are removed from scenes. They then assess five randomly selected video scenarios, viewing the original footage alongside a version that highlights the objects to be removed in green. For each scenario, they compare the results from seven different AI models—such as VOID, Runway, and ROSE—and choose the one that best fills in the removed areas naturally.
Figure 8 shows the interface used in our human evaluation study. Participants first read a brief set of instructions and are shown three example object-interaction removal cases from the training dataset. They are then presented with five randomly sampled scenarios for evaluation. For each scenario, participants see the original input video as well as the same video with the objects to be removed highlighted in green. Participants can then view the outputs of seven different models (VOID, Runway, Generative Omnimatte, DiffuEraser, ProPainter, MiniMax-Remover, ROSE) and select the result that produces the best inpainting outcome.
10. Limitations of Standard Video Metrics
Section Summary: Standard metrics for assessing video similarity, like LPIPS, DreamSim, and DINOv2, work well for basic visual fidelity but often miss key issues in video inpainting, such as unrealistic object interactions or lingering artifacts in dynamic scenes. These tools prioritize surface-level appearance matches, so methods that leave clear flaws, like shadows from erased objects, can score higher than ones producing more realistic results. This limitation highlights the need for metrics that better capture physical plausibility and scene dynamics in editing tasks.
Standard perceptual similarity metrics such as LPIPS, DreamSim, and feature-based similarity measures (e.g., DINOv2) are widely used for evaluating visual fidelity and perceptual similarity. While these metrics are valuable indicators of image or video similarity, they may fail to capture certain task-specific artifacts relevant to video inpainting, particularly in dynamic settings involving object interactions and causal effects. In some cases, methods that produce visually implausible or blurry results can achieve better scores than models with objectively more realistic inpainting outcomes. Figure 9 shows examples where DiffuEraser [19] and ProPainter [18] obtain better LPIPS, DreamSim and DINOv2 scores (Table 7) despite leaving a clear shadow artifact of the removed object in the scene. This illustrates that similarity-based metrics primarily measure appearance-level correspondence and may overlook physically implausible artifacts or incorrect scene dynamics that are particularly important for interaction-aware video editing tasks.

:Table 7: Metrics calculated for the example shown in Figure 9.
| Model | LPIPS $\downarrow$ | PSNR $\uparrow$ | DreamSim $\downarrow$ | DINOv2 $\uparrow$ |
|---|---|---|---|---|
| ProPainter | 0.0879 | 27.98 | 0.0459 | 0.9824 |
| DiffuEraser | 0.0823 | 28.14 | 0.0384 | 0.9836 |
| Ours | 0.1081 | 28.96 | 0.0486 | 0.9786 |
11. VLM Judge Prompt
Section Summary: This section describes prompts for a vision-language model (VLM) judge that evaluates how well videos are edited to remove unwanted objects while keeping the scene realistic. In the first stage, the VLM watches the original video and breaks down the removal task, noting what to erase, how it interacts with other elements like shadows or gravity, and what the background should look like afterward, outputting this analysis in a structured format. In the second stage, it reviews the edited video using that analysis and assigns scores from 0 to 5 across six categories—such as handling physics, removal cleanliness, and frame consistency—for a total out of 30, along with explanations of strengths and weaknesses.
Below, we provide the full prompts used to instruct the VLM judge in evaluating inpainting quality of the videos by giving a score of $0 - 5$ in 6 categories for a total score of $30$.
Stage 1 Prompt.
The VLM receives the original video and returns a structured scene understanding used as context in Stage 2.
INPUT TO VLM
============
[Video] original, unedited input video
[Text] (shown below)
Watch this ORIGINAL video and analyze the removal instruction:
"<removal_instruction>"
VIDEO INPAINTING WITH INTERACTION AWARENESS means understanding the CAUSAL PHYSICS: if a person holding a mug is removed, the mug should FALL; if a ball knocked things over, removing the ball means those things should NOT fall; if someone casts a shadow, removing them should remove the shadow.
Analyze the following:
1. What object/subject should be removed and what is it physically interacting with (holding, pushing, casting shadows, etc.)?
2. What objects are supported, moved, or otherwise affected by the target, i.e. what are the physical consequences of its removal?
3. What should the background look like after perfect removal?
4. What visual effects (shadows, reflections) must also disappear?
OUTPUT (JSON)
=============
"target_object": "...",
"object_interactions": ["...", "..."],
"physical_consequences": ["...", "..."],
"expected_background": "...",
"visual_effects_to_remove": ["shadow", "reflection", "..."],
"should_not_change": "...",
"interaction_difficulty": "easy / medium / hard",
"interaction_difficulty_reasoning": "..."
Stage 2 Prompt.
The VLM receives an inpainting result video together with the structured context produced in Stage 1 and returns per-dimension scores (0–5) summing to a maximum of 30.
INPUT TO VLM
============
[Video] inpainting result video (model output to be scored)
[Text] (shown below; <...> fields filled from Stage 1 output)
CONTEXT FROM SCENE UNDERSTANDING
================================
Removal instruction: "<removal_instruction>"
Target object: <target_object>
Interactions: <object_interactions>
Physical consequences that MUST be present:
* <consequence_1>
* <consequence_2>
Visual effects to remove: <visual_effects_to_remove>
Background to fill: <expected_background>
Must NOT change: <should_not_change>
YOUR TASK
=========
Watch the inpainting result video and score it on the six dimensions below (0–5 each, max 30 total). Pay close attention to object MOVEMENTS and TRAJECTORIES. Only report motion you clearly observe frame-by-frame; do not hallucinate motion in stationary objects.
SCORING DIMENSIONS
==================
1. Interaction Physics [PRIMARY]
Does the result correctly handle the physical consequences of removal
(object trajectories, gravity, momentum, shadow/reflection removal)?
5 - All consequences handled correctly
4 - Mostly correct, minor physics imperfections
3 - Partial: some consequences correct, others not
2 - Major physics violations
1 - Almost no interactions handled
0 - Complete failure; interactions entirely ignored
2. Object Removal Quality
5 - Complete removal, no traces
3 - Removed but with noticeable artifacts/remnants
0 - Not removed at all
3. Background & Artifact Quality
5 - Perfectly natural, no artifacts
3 - Acceptable with noticeable artifacts
0 - Completely unrealistic
4. Temporal Consistency
5 - Perfect frame-to-frame consistency
3 - Noticeable but acceptable flickering
0 - Completely inconsistent
5. Preservation of Scene
5 - Non-target areas perfectly preserved
3 - Noticeable unwanted modifications
0 - Scene completely altered
6. Sharpness / Blur
5 - Perfectly sharp
3 - Slight blur but acceptable
0 - Completely blurred / unusable
OUTPUT (JSON)
=============
"scores": {
"interaction_physics": {"score": 0-5, "reasoning": "..."},
"object_removal": {"score": 0-5, "reasoning": "..."},
"background_artifacts": {"score": 0-5, "reasoning": "..."},
"temporal_consistency": {"score": 0-5, "reasoning": "..."},
"preservation": {"score": 0-5, "reasoning": "..."},
"sharpness": {"score": 0-5, "reasoning": "..."}
},
"total_score": "0-30",
"overall_assessment": "...",
"strengths": ["...", "..."],
"weaknesses": ["...", "..."]
References
Section Summary: This references section lists about 30 academic papers, preprints, technical reports, and online resources focused on advancing video processing technologies. It covers innovations in decomposing videos into object layers, generating and editing video content with AI models, inpainting missing parts, removing objects while preserving effects, and creating datasets for training such systems. The works span from 2017 to 2026, drawing from conferences like CVPR and ICCV, as well as companies like Google DeepMind and Runway, highlighting rapid progress in making video manipulation more intuitive and realistic.
[1] Lu, E., Cole, F., Freeman, W.T., Dekel, T., Zisserman, A., Rubinstein, M.: Omnimatte: Associating objects and their effects in video. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2021)
[2] Lee, Y.C., Lu, E., Rumbley, S., Geyer, M., Huang, J.B., Dekel, T., Cole, F.: Generative omnimatte: Learning to decompose video into layers. In: arXiv preprint arXiv:2411.16683 (2024)
[3] Samuel, D., Levy, M., Darshan, N., Chechik, G., Ben-Ari, R.: Omnimattezero: Fast training-free omnimatte with pre-trained video diffusion models. In: SIGGRAPH Asia 2025 Conference Papers (SA Conference Papers '25) (2025)
[4] Shrivastava, G., Lim, S.N., Shrivastava, A.: Video decomposition prior: Editing videos layer by layer. In: The Twelfth International Conference on Learning Representations (2024)
[5] Runway Research: Runway gen-4: Advanced video generation model. https://runwayml.com (2025), accessed: 2026-02-24
[6] Jiang, Z., Han, Z., Mao, C., Zhang, J., Pan, Y., Liu, Y.: Vace: All-in-one video creation and editing. arXiv preprint arXiv:2503.07598 (2025)
[7] Kulikov, V., Paiss, R., Voynov, A., Mosseri, I., Dekel, T., Michaeli, T.: Versatile editing of video content, actions, and dynamics without training. arXiv preprint arXiv:2603.17989 (2026)
[8] Greff, K., Belletti, F., Beyer, L., Doersch, C., Du, Y., Duckworth, D., Fleet, D.J., Gnanapragasam, D., Golemo, F., Herrmann, C., et al.: Kubric: A scalable dataset generator. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 3749–3761 (2022)
[9] Lu, J., Huang, C.H.P., Bhattacharya, U., Huang, Q., Zhou, Y.: Humoto: A 4d dataset of mocap human object interactions. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 10886–10897 (2025)
[10] Google DeepMind: Veo 3 technical report. Tech. rep., Google (2025), https://storage.googleapis.com/deepmind-media/veo/Veo-3-Tech-Report.pdf
[11] Wan, T., Wang, A., Ai, B., Wen, B., Mao, C., Xie, C.W., Chen, D., Yu, F., Zhao, H., Yang, J., et al.: Wan: Open and advanced large-scale video generative models. arXiv preprint arXiv:2503.20314 (2025)
[12] Yang, Z., Teng, J., Zheng, W., Ding, M., Huang, S., Xu, J., Yang, Y., Hong, W., Zhang, X., Feng, G., et al.: Cogvideox: Text-to-video diffusion models with an expert transformer. arXiv preprint arXiv:2408.06072 (2024)
[13] HaCohen, Y., Brazowski, B., Chiprut, N., Bitterman, Y., Kvochko, A., Berkowitz, A., Shalem, D., Lifschitz, D., Moshe, D., Porat, E., et al.: Ltx-2: Efficient joint audio-visual foundation model. arXiv preprint arXiv:2601.03233 (2026)
[14] He, Y., Pittaluga, F., Jiang, Z., Zwicker, M., Chandraker, M., Tasneem, Z.: Langdrivectrl: Natural language controllable driving scene editing with multi-modal agents. arXiv preprint arXiv:2512.17445 (2025)
[15] Yu, S., Liu, D., Ma, Z., Hong, Y., Zhou, Y., Tan, H., Chai, J., Bansal, M.: Veggie: Instructional editing and reasoning video concepts with grounded generation. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 15147–15158 (2025)
[16] Lee, D., Yoon, J., Cho, J., Bansal, M.: Videorepair: Improving text-to-video generation via misalignment evaluation and localized refinement. arXiv preprint arXiv:2411.15115 (2024)
[17] Lin, G., Gao, C., Huang, J.B., Kim, C., Wang, Y., Zwicker, M., Saraf, A.: Omnimatterf: Robust omnimatte with 3d background modeling. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 23471–23480 (2023)
[18] Zhou, S., Li, C., Chan, K.C., Loy, C.C.: Propainter: Improving propagation and transformer for video inpainting. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) (2023)
[19] Li, X., Xue, H., Ren, P., Bo, L.: Diffueraser: A diffusion model for video inpainting. arXiv preprint arXiv:2501.10018 (2025)
[20] Zhang, Z., Wu, B., Wang, X., Luo, Y., Zhang, L., Zhao, Y., Vajda, P., Metaxas, D., Yu, L.: Avid: Any-length video inpainting with diffusion model. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 7162–7172 (2024)
[21] Green, D., Harvey, W., Naderiparizi, S., Niedoba, M., Liu, Y., Liang, X., Lavington, J., Zhang, K., Lioutas, V., Dabiri, S., et al.: Semantically consistent video inpainting with conditional diffusion models. arXiv preprint arXiv:2405.00251 (2024)
[22] Zi, B., Peng, W., Qi, X., Wang, J., Zhao, S., Xiao, R., Wong, K.F.: Minimax-remover: Taming bad noise helps video object removal. arXiv preprint arXiv:2505.24873 (2025)
[23] Miao, C., Feng, Y., Zeng, J., Gao, Z., Liu, H., Yan, Y., Qi, D., Chen, X., Wang, B., Zhao, H.: Rose: Remove objects with side effects in videos. arXiv preprint arXiv:2508.18633 (2025)
[24] Kushwaha, S.S., Nag, S., Tian, Y., Kulkarni, K.: Object-wiper: Training-free object and associated effect removal in videos. arXiv preprint arXiv:2601.06391 (2026)
[25] Xu, N., Yang, L., Fan, Y., Yue, D., Liang, Y., Yang, J., Huang, T.: Youtube-vos: A large-scale video object segmentation benchmark. arXiv preprint arXiv:1809.03327 (2018)
[26] Pont-Tuset, J., Perazzi, F., Caelles, S., Arbeláez, P., Sorkine-Hornung, A., Van Gool, L.: The 2017 davis challenge on video object segmentation. arXiv preprint arXiv:1704.00675 (2017)
[27] Chefer, H., Singer, U., Zohar, A., Kirstain, Y., Polyak, A., Taigman, Y., Wolf, L., Sheynin, S.: Videojam: Joint appearance-motion representations for enhanced motion generation in video models. arXiv preprint arXiv:2502.02492 (2025)
[28] Motamed, S., Culp, L., Swersky, K., Jaini, P., Geirhos, R.: Do generative video models understand physical principles? arXiv preprint arXiv:2501.09038 (2025)
[29] Motamed, S., Van Gansbeke, W., Van Gool, L.: Investigating the effectiveness of cross-attention to unlock zero-shot editing of text-to-video diffusion models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops. pp. 7406–7415 (June 2024)
[30] Jeong, H., Huang, C.H.P., Ye, J.C., Mitra, N.J., Ceylan, D.: Track4gen: Teaching video diffusion models to track points improves video generation. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 7276–7287 (2025)
[31] Gu, Z., Yan, R., Lu, J., Li, P., Dou, Z., Si, C., Dong, Z., Liu, Q., Lin, C., Liu, Z., et al.: Diffusion as shader: 3d-aware video diffusion for versatile video generation control. In: Proceedings of the Special Interest Group on Computer Graphics and Interactive Techniques Conference Conference Papers. pp. 1–12 (2025)
[32] Liu, Z., Yanev, A., Mahmood, A., Nikolov, I., Motamed, S., Zheng, W.S., Wang, X., Van Gool, L., Paudel, D.P.: Intragen: Trajectory-controlled video generation for object interactions. arXiv preprint arXiv:2411.16804 (2024)
[33] Boduljak, G., Karazija, L., Laina, I., Rupprecht, C., Vedaldi, A.: What happens next? anticipating future motion by generating point trajectories. In: The Fourteenth International Conference on Learning Representations (2026), https://openreview.net/forum?id=t1vMYl1yhe
[34] Burgert, R., Xu, Y., Xian, W., Pilarski, O., Clausen, P., He, M., Ma, L., Deng, Y., Li, L., Mousavi, M., Ryoo, M., Debevec, P., Yu, N.: Go-with-the-flow: Motion-controllable video diffusion models using real-time warped noise. In: CVPR (2025), licensed under Modified Apache 2.0 with special crediting requirement
[35] Chow, W., Mao, J., Li, B., Seita, D., Guizilini, V., Wang, Y.: Physbench: Benchmarking and enhancing vision-language models for physical world understanding. arXiv preprint arXiv:2501.16411 (2025)
[36] Motamed, S., Chen, M., Van Gool, L., Laina, I.: Travl: A recipe for making video-language models better judges of physics implausibility. arXiv preprint arXiv:2510.07550 (2025)
[37] Li, Z., Wu, X., Du, H., Liu, F., Nghiem, H., Shi, G.: A survey of state of the art large vision language models: Benchmark evaluations and challenges (2025)
[38] Carion, N., Gustafson, L., Hu, Y.T., Debnath, S., Hu, R., Suris, D., Ryali, C., Alwala, K.V., Khedr, H., Huang, A., Lei, J., Ma, T., Guo, B., Kalla, A., Marks, M., Greer, J., Wang, M., Sun, P., Rädle, R., Afouras, T., Mavroudi, E., Xu, K., Wu, T.H., Zhou, Y., Momeni, L., Hazra, R., Ding, S., Vaze, S., Porcher, F., Li, F., Li, S., Kamath, A., Cheng, H.K., Dollár, P., Ravi, N., Saenko, K., Zhang, P., Feichtenhofer, C.: Sam 3: Segment anything with concepts (2025), https://arxiv.org/abs/2511.16719
[39] Ravi, N., Gabeur, V., Hu, Y.T., Hu, R., Ryali, C., Ma, T., Khedr, H., Rädle, R., Rolland, C., Gustafson, L., et al.: Sam 2: Segment anything in images and videos. arXiv preprint arXiv:2408.00714 (2024)
[40] Xiong, T., Wang, X., Guo, D., Ye, Q., Fan, H., Gu, Q., Huang, H., Li, C.: Llava-critic: Learning to evaluate multimodal models. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 13618–13628 (2025)
[41] Chen, D., Chen, R., Zhang, S., Wang, Y., Liu, Y., Zhou, H., Zhang, Q., Wan, Y., Zhou, P., Sun, L.: Mllm-as-a-judge: Assessing multimodal llm-as-a-judge with vision-language benchmark. In: Forty-first International Conference on Machine Learning (2024)
[42] Zhang, R., Isola, P., Efros, A.A., Shechtman, E., Wang, O.: The unreasonable effectiveness of deep features as a perceptual metric. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 586–595 (2018)
[43] Fu, S., Tamir, N., Sundaram, S., Chai, L., Zhang, R., Dekel, T., Isola, P.: Dreamsim: Learning new dimensions of human visual similarity using synthetic data. arXiv preprint arXiv:2306.09344 (2023)
[44] Oquab, M., Darcet, T., Moutakanni, T., Vo, H., Szafraniec, M., Khalidov, V., Fernandez, P., Haziza, D., Massa, F., El-Nouby, A., et al.: Dinov2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193 (2023)
[45] Unterthiner, T., Van Steenkiste, S., Kurach, K., Marinier, R., Michalski, M., Gelly, S.: Fvd: A new metric for video generation (2019)