Generative Modeling via Drifting
Mingyang Deng
MIT
He Li
MIT
Tianhong Li
MIT
Yilun Du
Harvard University
Kaiming He
MIT
Keywords: Machine Learning, Generative Models

Abstract
Generative modeling can be formulated as learning a mapping $f$ such that its pushforward distribution matches the data distribution. The pushforward behavior can be carried out iteratively at inference time, e.g., in diffusion/flow-based models. In this paper, we propose a new paradigm called Drifting Models, which evolve the pushforward distribution during training and naturally admit one-step inference. We introduce a drifting field that governs the sample movement and achieves equilibrium when the distributions match. This leads to a training objective that allows the neural network optimizer to evolve the distribution. In experiments, our one-step generator achieves state-of-the-art results on ImageNet 256 $\times$ 256, with FID 1.54 in latent space and 1.61 in pixel space. We hope that our work opens up new opportunities for high-quality one-step generation.
Executive Summary: Generative models in machine learning create new data, such as realistic images, by learning to transform simple noise into complex patterns that match real examples. Current leading approaches, like diffusion models, require many iterative steps during generation, which slows down use in real-time applications like image editing, robotics, or content creation. With growing demand for fast, high-quality AI tools, there is urgent need for methods that generate results in a single step without losing accuracy, especially as compute costs rise.
This paper introduces Drifting Models, a new approach to generative modeling that evolves the generated data distribution during training to match real data, enabling one-step generation at inference time. It demonstrates this paradigm through theoretical foundations and practical tests on image generation and robotics tasks.
The authors develop a "drifting field," a mechanism that guides samples toward real data by attracting them to true examples and repelling them from generated ones, reaching balance when distributions align. They train neural networks using a loss that minimizes this drift, drawing on batches of noise inputs, generated samples, and real data from ImageNet—a large dataset of 1.2 million labeled images. Training spans hundreds of epochs on models sized from small (for ablations) to large (over 300 million parameters), using pre-trained feature encoders to capture semantic similarities. Experiments include toy 2D cases for intuition, full ImageNet tests at 256x256 resolution in both latent (compressed) and pixel spaces, and robotics control benchmarks, all conducted from scratch without relying on prior multi-step models.
Key findings show Drifting Models excel in efficiency and quality. First, on ImageNet latent-space generation, they achieve a Fréchet Inception Distance (FID) score of 1.54 with one network evaluation, surpassing all prior one-step methods (previous best around 2-3 FID) and rivaling multi-step diffusion models that need 50+ steps. Second, in the tougher pixel-space setup without compression, they reach 1.61 FID, outperforming multi-step baselines (around 2-4 FID) and one-step rivals like GANs (2.3 FID but with 18 times more compute). Third, anti-symmetry in the drifting field proves essential, as breaking it causes failure, while larger batches of real and generated samples improve scores by 20-30%. Fourth, in robotics, replacing multi-step diffusion policies with this one-step version matches or exceeds success rates (e.g., 90-100% on tasks like manipulation) using far less computation. Finally, the method avoids mode collapse, steadily evolving distributions even from poor starts.
These results mean Drifting Models can cut generation time from seconds to milliseconds, boosting performance in time-sensitive areas like video games, autonomous systems, or design tools while maintaining or improving realism. Unlike iterative methods that compute step-by-step at runtime, this shifts effort to training, yielding more efficient inference without distillation tricks. It outperforms expectations for one-step models, which often sacrifice quality, and offers a fresh view: training as natural distribution evolution, distinct from prior physics-inspired flows or adversarial setups. This could lower costs (e.g., 87 billion operations vs. trillions for competitors) and risks like slow deployment, though it demands strong feature encoders for high dimensions.
Leaders should prioritize adopting Drifting Models for applications needing fast generation, starting with latent-space pilots on existing hardware to test integration. Scale up training with better encoders or multi-scale features for gains, but weigh trade-offs: higher classifier-free guidance boosts diversity (Inception Score up 10-20%) at slight FID cost. Further work is needed, such as refining kernels for raw data without features, proving theoretical guarantees for equilibrium, and testing on video or text. Explore hybrids with diffusion for edge cases.
Limitations include reliance on pre-trained encoders, which may not generalize to new domains, and unproven converse: zero drift implies matched distributions only under assumptions, though empirical correlation is strong. Data gaps exist for non-image tasks, and training is compute-heavy upfront. Confidence is high in results for ImageNet and robotics, backed by ablations and comparisons, but caution applies to untested scales or modalities—readers should verify via pilots before broad decisions.
1. Introduction
Section Summary: Generative models, unlike simpler discriminative ones that just classify data, aim to create new data by transforming a basic probability distribution into one that matches real-world examples, often through a function that pushes one distribution toward another. Traditional approaches, like diffusion models, achieve this by iteratively refining noisy samples during generation, but the new Drifting Models shift this evolution to the training phase using a "drifting field" that guides samples toward the target data until they align perfectly. This enables fast, one-step generation that sets new performance records on image datasets like ImageNet, outperforming even multi-step methods in efficiency and quality.
Generative models are commonly regarded as more challenging than discriminative models. While discriminative modeling typically focuses on mapping individual samples to their corresponding labels, generative modeling concerns mapping from one distribution to another. This can be expressed as learning a mapping $f$ such that the pushforward of a prior distribution $p_\text{prior}$ matches the data distribution, namely, $f_# p_\text{prior} \approx p_{\text{data}}$. Conceptually, generative modeling learns a functional (here, $f_#$) that maps from one function (here, a distribution) to another.
The "pushforward" behavior can be realized iteratively at inference time, e.g., in prevailing paradigms such as Diffusion [1] and Flow Matching [2]. When generating, these models map noisier samples to slightly cleaner ones, progressively evolving the sample distribution toward the data distribution. This modeling philosophy can be viewed as decomposing a complex pushforward map (i.e., $f_#$) into a chain of more feasible transformations, applied at inference time.
In this paper, we propose Drifting Models, a new paradigm for generative modeling. Drifting Models are characterized by learning a pushforward map that evolves during training time, thereby removing the need for an iterative inference procedure. The mapping $f$ is represented by a single-pass, non-iterative network. As the training process is inherently iterative in deep learning optimization, it can be naturally viewed as evolving the pushforward distribution, $f_# p_\text{prior}$, through the update of $f$. See Figure 1.
To drive the evolution of the training-time pushforward, we introduce a drifting field that governs the sample movement. This field depends on the generated distribution and the data distribution. By definition, this field becomes zero when the two distributions match, thereby reaching an equilibrium in which the samples no longer drift.
Building on this formulation, we propose a simple training objective that minimizes the drift of the generated samples. This objective induces sample movements and thereby evolves the underlying pushforward distribution through iterative optimization (e.g., SGD). We further introduce the designs of the drifting field, the neural network model, and the training algorithm.
Drifting Models naturally perform single-step ("1-NFE") generation and achieve strong empirical performance. On ImageNet 256 $\times$ 256, we obtain a 1-NFE FID of 1.54 under the standard latent-space generation protocol, achieving a new state-of-the-art among single-step methods. This result remains competitive even when compared with multi-step diffusion-/flow-based models. Further, under the more challenging pixel-space generation protocol (i.e., without latents), we reach a 1-NFE FID of 1.61, substantially outperforming previous pixel-space methods. These results suggest that Drifting Models offer a promising new paradigm for high-quality, efficient generative modeling.
2. Related Work
Section Summary: This section reviews existing generative modeling techniques and contrasts them with the authors' approach. Diffusion and flow-based models generate data through iterative noise-reduction steps, with recent efforts focusing on speeding them up via distillation or one-step training, though the authors' method avoids their underlying equations. It also discusses generative adversarial networks, which pit a generator against a discriminator without iteration; variational autoencoders, which balance reconstruction and regularization often using external priors; normalizing flows, which invert data to noise for one-step generation; and connections to moment matching and contrastive learning, which involve comparing positive real samples to negative generated ones, similar to the authors' drifting field concept.
Diffusion-/Flow-based Models.
Diffusion models (e.g., [1, 3, 4]) and their flow-based counterparts (e.g., [2, 5, 6]) formulate noise-to-data mappings through differential equations (SDEs or ODEs). At the core of their inference-time computation is an iterative update, e.g., of the form $\mathbf{x}{i+1}= \mathbf{x}{i} + \Delta \mathbf{x}{i}$, such as with an Euler solver. The update $\Delta \mathbf{x}{i}$ depends on the neural network $f$, and as a result, generation involves multiple steps of network evaluations.
A growing body of work has focused on reducing the steps of diffusion-/flow-based models. Distillation-based methods (e.g., [7, 8, 9, 10]) distill a pretrained multi-step model into a single-step one. Another line of research aims to train one-step diffusion/flow models from scratch (e.g., [11, 12, 13, 14]). To achieve this goal, these methods incorporate the SDE/ODE dynamics into training by approximating the induced trajectories. In contrast, our work presents a conceptually different paradigm and does not rely on SDE/ODE formulations as in diffusion/flow models.
Generative Adversarial Networks (GANs).
GANs [15] are a classical family of models that train a generator by discriminating generated samples from real data. Like GANs, our method involves a single-pass network $f$ that maps noise to data, whose "goodness" is evaluated by a loss function; however, unlike GANs, our method does not rely on adversarial optimization.
Variational Autoencoders (VAEs).
VAEs [16] optimize the evidence lower bound (ELBO), which consists of a reconstruction loss and a KL divergence term. Classical VAEs are one-step generators when using a Gaussian prior. Today's prevailing VAE applications often resort to priors learned from other methods, e.g., diffusion [17] or autoregressive models [18], where VAEs effectively act as tokenizers.
Normalizing Flows (NFs).
NFs [19, 20, 21] learn mappings from data to noise and optimize the log-likelihood of samples. These methods require invertible architectures and computable Jacobians. Conceptually, NFs operate as one-step generators at inference, with computation performed by the inverse of the network.
Moment Matching.
Moment-matching methods [22, 23] seek to minimize the Maximum Mean Discrepancy (MMD) between the generated and data distributions. Moment Matching has recently been extended to one-/few-step diffusion [24]. Related to MMD, our approach also leverages the concepts of kernel functions and positive/negative samples. However, our approach focuses on a drifting field that explicitly governs the sample drifts at training time. Further discussion is in Appendix C.2.
Contrastive Learning.
Our drifting field is driven by positive samples from the data distribution and negative samples from the generated distribution. This is conceptually related to the positive and negative samples in contrastive representation learning [25, 26]. The idea of contrastive learning has also been extended to generative models, e.g., to GANs [27, 28] or Flow Matching [29].
3. Drifting Models for Generation
Section Summary: Drifting Models treat generative AI as a process where a neural network gradually transforms random noise into data-like outputs during training, evolving the output distribution step by step to match real-world data patterns. This evolution happens through a "drifting field," a mathematical guide that nudges each output sample toward better alignment with the target data, stopping entirely when the model's distribution perfectly matches the data. At test time, the trained model generates new samples in just one quick step, using a loss function that indirectly minimizes these drifts to achieve balance.
We propose Drifting Models, which formulate generative modeling as a training-time evolution of the pushforward distribution via a drifting field. Our model naturally performs one-step generation at inference time.
3.1 Pushforward at Training Time
Consider a neural network $f: \mathbb{R}^C \mapsto \mathbb{R}^D$. The input of $f$ is ${\boldsymbol{\epsilon}} \sim p_{{\boldsymbol{\epsilon}}}$ (e.g., any noise of dimension $C$), and the output is denoted by $\mathbf{x} = f({\boldsymbol{\epsilon}}) \in \mathbb{R}^D$. In general, the input and output dimensions need not be equal.
We denote the distribution of the network output by $q$, i.e., $\mathbf{x} = f({\boldsymbol{\epsilon}}) \sim q$. In probability theory, $q$ is referred to as the pushforward distribution of $p_{\boldsymbol{\epsilon}}$ under $f$, denoted by:
$ q = f_{#}p_{\boldsymbol{\epsilon}}. $
Here, " $f_{#}$ " denotes the pushforward induced by $f$. Intuitively, this notation means that $f$ transforms a distribution $p_{{\boldsymbol{\epsilon}}}$ into another distribution $q$. The goal of generative modeling is to find $f$ such that $f_{#}p_{{\boldsymbol{\epsilon}}} \approx p_\text{data}$.
Since neural network training is inherently iterative (e.g., SGD), the training process produces a sequence of models ${f_i}$, where $i$ denotes the training iteration. This corresponds to a sequence of pushforward distributions ${q_i}$ during training, where $q_i = [f_i] {#}p{{\boldsymbol{\epsilon}}}$ for each $i$. The training process progressively evolves $q_i$ to match $p_{\text{data}}$.
When the network $f$ is updated, a sample at training iteration $i$ is implicitly "drifted" as: $\mathbf{x}{i+1} = \mathbf{x}{i} + \Delta \mathbf{x}{i}$, where $ \Delta \mathbf{x}{i}:=f_{i+1}({\boldsymbol{\epsilon}}) - f_{i}({\boldsymbol{\epsilon}})$ arises from parameter updates to $f$. This implies that the update of $f$ determines the "residual" of $\mathbf{x}$, which we refer to as the "drift".
3.2 Drifting Field for Training
Next, we define a drifting field to govern the training-time evolution of the samples $\mathbf{x}$ and, consequently, the pushforward distribution $q$. A drifting field is a function that computes $ \Delta \mathbf{x}$ given $\mathbf{x}$. Formally, denoting this field by $\mathbf{V}_{p, q}(\cdot)\colon \mathbb{R}^d \to \mathbb{R}^d$, we have:
$ \mathbf{x}_{i+1}= \mathbf{x}i+ \mathbf{V}{p, q_i}(\mathbf{x}_i), $
Here, $\mathbf{x}i=f_i({\boldsymbol{\epsilon}}) \sim q_i$ and after drifting we denote $\mathbf{x}{i+1}\sim q_{i+1}$. The subscripts $p, q$ denote that this field depends on $p$ (e.g., $p=p_\text{data}$) and the current distribution $q$.
Ideally, when $p=q$, we want all $\mathbf{x}$ to stop drifting i.e., $\mathbf{V}=\textbf{0}$. In this paper, we consider the following proposition:
Proposition
Consider an anti-symmetric drifting field:
$ \mathbf{V}{p, q}(\mathbf{x}) = - \mathbf{V}{q, p}(\mathbf{x}), \quad \forall \mathbf{x}.\tag{1} $
Then we have: $\quad q=p \quad \Rightarrow \quad \mathbf{V}_{p, q}(\mathbf{x}) = \mathbf{0}, \forall \mathbf{x}$.
The proof is straightforward. Intuitively, anti-symmetry means that swapping $p$ and $q$ simply flips the sign of the drift. This proposition implies that if the pushforward distribution $q$ matches the data distribution $p$, the drift is zero for any sample and the model achieves an equilibrium.
We note that the converse implication, i.e., $\mathbf{V}{p, q}=\mathbf{0}\Rightarrow q=p$, is false in general for arbitrary choices of $\mathbf{V}$. For our kernelized formulation (Section 3.3), we give sufficient conditions under which $\mathbf{V}{p, q}\approx\mathbf{0}$ implies $q\approx p$ (Appendix C.1).
Training Objective.
The property of equilibrium motivates a definition of a training objective. Let $f_\theta$ be a network parameterized by $\theta$, and $\mathbf{x} = f_\theta({\boldsymbol{\epsilon}})$ for ${\boldsymbol{\epsilon}} \sim p_{\boldsymbol{\epsilon}}$. At the equilibrium where $\mathbf{V}=\textbf{0}$, we set up the following fixed-point relation:
$ f_{{\hat{\theta}}}({\boldsymbol{\epsilon}})
f_{{\hat{\theta}}}({\boldsymbol{\epsilon}}) + \mathbf{V}{p, q{{\hat{\theta}}}}!\big(f_{{\hat{\theta}}}({\boldsymbol{\epsilon}})\big).\tag{2} $
Here, ${\hat{\theta}}$ denotes the optimal parameters that can achieve the equilibrium, and $q_{\hat{\theta}}$ denotes the pushforward of $f_{{\hat{\theta}}}$.
This equation motivates a fixed-point iteration during training. At iteration $i$, we seek to satisfy:
$ f_{\theta_{i+1}}({\boldsymbol{\epsilon}}) \leftarrow f_{\theta_{i}}({\boldsymbol{\epsilon}}) + \mathbf{V}{p, q{\theta_{i}}}!\big(f_{\theta_{i}}({\boldsymbol{\epsilon}})\big). $
We convert this update rule into a loss function:
$ \mathcal{L}
\mathbb{E}{{\boldsymbol{\epsilon}}} \Big[\big| \underbrace{f{\theta}({\boldsymbol{\epsilon}})}_{\text{prediction}}
\underbrace{ \text{\texttt{stopgrad}}\big(f_{\theta}({\boldsymbol{\epsilon}}) + \mathbf{V}{p, q{\theta}}!\big(f_{\theta}({\boldsymbol{\epsilon}})\big) \big) }_{\text{frozen target}} \big|^2 \Big].\tag{3} $
Here, the stop-gradient operation provides a frozen state from the last iteration, following [30, 31]. Intuitively, we compute a frozen target and move the network prediction toward it.
We note that the value of our loss function $\mathcal{L}$ is equal to $\mathbb{E}{{\boldsymbol{\epsilon}}} \big[| \mathbf{V}(f({\boldsymbol{\epsilon}}))|^2 \big]$, that is, the squared norm of the drifting field $\mathbf{V}$. With the stop-gradient formulation, our solver does not directly back-propagate through $\mathbf{V}$, because $\mathbf{V}$ depends on $q\theta$ and back-propagating through a distribution is nontrivial. Instead, our formulation minimizes this objective indirectly: it moves $\mathbf{x}=f_{\theta}({\boldsymbol{\epsilon}})$ towards its drifted version, i.e., towards $\mathbf{x}+\Delta \mathbf{x}$ that is frozen at this iteration.
3.3 Designing the Drifting Field
The field $\mathbf{V}_{p, q}$ depends on two distributions $p$ and $q$. To obtain a computable formulation, we consider the form:
$ \mathbf{V}{p, q}(\mathbf{x})=\mathbb E{\mathbf{y}^{+} \sim p}\mathbb E_{\mathbf{y}^{-} \sim q} [\mathcal{K}(x, \mathbf{y}^{+}, \mathbf{y}^{-})],\tag{4} $
where $\mathcal{K}(\cdot, \cdot, \cdot)$ is a kernel-like function describing interactions among three sample points. $\mathcal{K}$ can optionally depend on $p$ and $q$. Our framework supports a broad class of functions $\mathcal{K}$, as long as $\mathbf{V}=\text{0}$ when $p=q$.
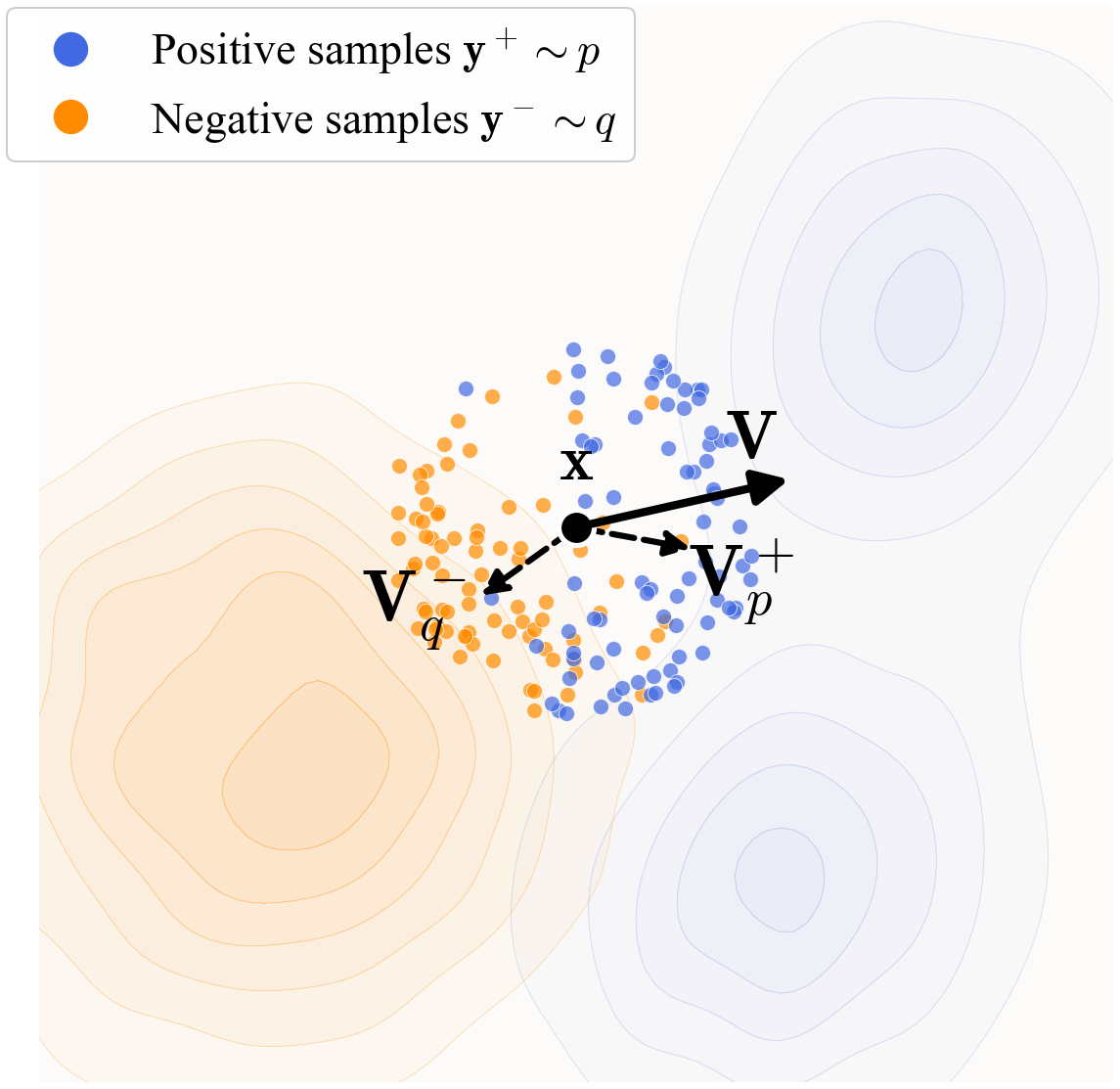
For the instantiation in this work, we introduce a form of $\mathbf{V}$ driven by attraction and repulsion. We define the following fields inspired by the mean-shift method [32]:
$ \begin{aligned} {\mathbf{V}^{+}{p}}(\mathbf{x}) &:= \frac{1}{Z{p}} {\mathbb{E}{p}!\left[k(\mathbf{x}, \mathbf{y}^{+})(\mathbf{y}^{+} - \mathbf{x})\right]}, \ {\mathbf{V}^{-}{q}}(\mathbf{x}) &:= \frac{1}{Z_{q}} {\mathbb{E}_{q}!\left[k(\mathbf{x}, \mathbf{y}^{-})(\mathbf{y}^{-} - \mathbf{x})\right]}. \end{aligned}\tag{5} $
Here, $Z_{p}$ and $Z_{q}$ are normalization factors:
$ \begin{aligned} Z_{p}(\mathbf{x}) := \mathbb{E}{p} [k(\mathbf{x}, \mathbf{y}^{+})], \ Z{q}(\mathbf{x}) := \mathbb{E}_{q} [k(\mathbf{x}, \mathbf{y}^{-})]. \end{aligned}\tag{6} $
Intuitively, Eq. (5) computes the weighted mean of the vector difference $\mathbf{y} - \mathbf{x}$. The weights are given by a kernel $k(\cdot, \cdot)$ normalized by Equation (6). We then define $\mathbf{V}$ as:
$ \mathbf{V}{p, q}(\mathbf{x}) := {\mathbf{V}^{+}{p}}(\mathbf{x}) - {\mathbf{V}^{-}_{q}}(\mathbf{x}).\tag{7} $
Intuitively, this field can be viewed as attracting by the data distribution $p$ and repulsing by the sample distribution $q$. This is illustrated in Figure 2.
Substituting Eq. (5) into Eq. (7), we obtain:
$ \mathbf{V}{p, q}(\mathbf{x}) = \frac{1}{Z_p Z_q} {\mathbb{E}{p, q}!\left[k(\mathbf{x}, \mathbf{y}^{+})k(\mathbf{x}, \mathbf{y}^{-})(\mathbf{y}^{+} - \mathbf{y}^{-})\right]}.\tag{8} $
Here, the vector difference reduces to $\mathbf{y}^+ - \mathbf{y}^-$; the weight is computed from two kernels and normalized jointly. This form is an instantiation of Eq. (4). It is easy to see that $\mathbf{V}$ is anti-symmetric: $\mathbf{V}{p, q}=- \mathbf{V}{q, p}$. In general, our method does not require $\mathbf{V}$ to be decomposed into attraction and repulsion; it only requires $\mathbf{V}=\text{0}$ when $p=q$.
Kernel.
The kernel $k(\cdot, \cdot)$ can be a function that measures the similarity. In this paper, we adopt:
$ k(\mathbf{x}, \mathbf{y}) = \exp\left(-\frac{1}{\tau} | \mathbf{x} - \mathbf{y}|\right),\tag{9} $
where $\tau$ is a temperature and $|\cdot|$ is $\ell_2$-distance. We view $\tilde{k}(\mathbf{x}, \mathbf{y}) \triangleq\frac{1}{Z}k(\mathbf{x}, \mathbf{y})$ as a normalized kernel, which absorbs the normalization in Eq. (8).
In practice, we implement $\tilde{k}$ using a softmax operation, with logits given by $-\frac{1}{\tau} | \mathbf{x} - \mathbf{y}|$, where the softmax is taken over $\mathbf{y}$. This softmax operation is similar to that of InfoNCE [26] in contrastive learning. In our implementation, we further apply an extra softmax normalization over the set of ${\mathbf{x}}$ within a batch, which slightly improves performance in practice. This additional normalization does not alter the antisymmetric property of the resulting $\mathbf{V}$.
Equilibrium and Matched Distributions.
Since our training loss in Eq. (3) encourages minimizing $| \mathbf{V}|^2$, we hope that $\mathbf{V} \approx \textbf{0}$ leads to $q\approx p$. While this implication does not hold for arbitrary choices of $\mathbf{V}$, we empirically observe that decreasing the value of $| \mathbf{V}|^2$ correlates with improved generation quality. In Appendix C.1, we provide an identifiability heuristic: for our kernelized construction, the zero-drift condition imposes a large set of bilinear constraints on $(p, q)$, and under mild non-degeneracy assumptions this forces $p$ and $q$ to match (approximately).

Stochastic Training.
In stochastic training (e.g., mini-batch optimization), we estimate $\mathbf{V}$ by approximating the expectations in Eq. (8) with empirical means. For each training step, we draw $N$ samples of noise ${\boldsymbol{\epsilon}} \sim p_{\boldsymbol{\epsilon}}$ and compute a batch of $\mathbf{x}=f_\theta({\boldsymbol{\epsilon}})\sim q$. The generated samples also serve as the negative samples in the same batch, i.e., $\mathbf{y}^- \sim q$. On the other hand, we sample $N_\text{pos}$ data points $\mathbf{y}^+ \sim p_\text{data}$. The drifting field $\mathbf{V}$ is computed in this batch of positive and negative samples. Algorithm 1 provide the pseudocode for such a training step, where compute_V is given in Appendix A.1.
3.4 Drifting in Feature Space
Thus far, we have defined the objective Equation (3) directly in the raw data space. Our formulation can be extended to any feature space. Let $\phi$ denote a feature extractor (e.g., an image encoder) operating on real or generated samples. We rewrite the loss Equation (3) in the feature space as:
$ \mathbb{E}!\left[\left| \phi(\mathbf{x})
\text{\texttt{stopgrad}}\Big(\phi(\mathbf{x}) + \mathbf{V}\big(\phi(\mathbf{x})\big) \Big) \right|^2 \right].\tag{10} $
Here, $\mathbf{x}=f_\theta({\boldsymbol{\epsilon}})$ is the output (e.g., images) of the generator. $\mathbf{V}$ is defined in the feature space: in practice, this means that $\phi(\mathbf{y}^+)$ and $\phi(\mathbf{y}^-)$ serve as the positive/negative samples. It is worth noting that feature encoding is a training-time operation and is not used at inference time.
This can be further extended to multiple features, e.g., at multiple scales and locations:
$ \sum_j\mathbb{E}!\left[\left| \phi_j(\mathbf{x})
\text{\texttt{stopgrad}}\Big(\phi_j(\mathbf{x}) + \mathbf{V}\big(\phi_j(\mathbf{x})\big) \Big) \right|^2 \right].\tag{11} $
Here, $\phi_j$ represents the feature vectors at the $j$-th scale and/or location from an encoder $\phi$. With a ResNet-style image encoder [33], we compute drifting losses across multiple scales and locations, which provides richer gradient information for training.
The feature extractor plays an important role in the generation of high-dimensional data. As our method is based on the kernel $k(\cdot, \cdot)$ for characterizing sample similarities, it is desired for semantically similar samples to stay close in the feature space. This goal is aligned with self-supervised learning (e.g., [34, 35]). We use pre-trained self-supervised models as the feature extractor.
Relation to Perceptual Loss.
Our feature-space loss is related to perceptual loss [36] but is conceptually different. The perceptual loss minimizes: $|\phi(\mathbf{x})-\phi(\mathbf{x}\text{target})|2^2$, that is, the regression target is $\phi(\mathbf{x}\text{target})$ and requires pairing $\mathbf{x}$ with its target. In contrast, our regression target in Equation (10) is $\phi(\mathbf{x}) + \mathbf{V}\big(\phi(\mathbf{x})\big)$, where the drifting is in the feature space and requires no pairing. In principle, our feature-space loss aims to match the pushforward distributions $\phi#q$ and $\phi_#p$.
Relation to Latent Generation.
Our feature-space loss is orthogonal to the concept of generators in the latent space (e.g., Latent Diffusion [17]). In our case, when using $\phi$, the generator $f$ can still produce outputs in the pixel space or the latent space of a tokenizer. If the generator $f$ is in the latent space and the feature extractor $\phi$ is in the pixel space, the tokenizer decoder is applied before extracting features from $\phi$.
3.5 Classifier-Free Guidance
Classifier-free guidance (CFG) [37] improves generation quality by extrapolating between class-conditional and unconditional distributions. Our method naturally supports a related form of guidance.
In our model, given a class label $c$ as the condition, the underlying target distribution $p$ now becomes $p_{\text{data}}(\cdot|c)$, from which we can draw positive samples: $\mathbf{y}^+ \sim p_{\text{data}}(\cdot|c)$. To achieve guidance, we draw negative samples either from generated samples or real samples from different classes. Formally, the negative sample distribution is now:
$ \tilde{q}(\cdot|c) \triangleq (1-\gamma), q_\theta(\cdot|c) + \gamma, p_{\text{data}}(\cdot | \varnothing).\tag{12} $
Here, $\gamma \in [0, 1)$ is a mixing rate, and $p_{\text{data}}(\cdot | \varnothing)$ denotes the unconditional data distribution.
The goal of learning is to find $\tilde{q}(\cdot|c)=p_\text{data}(\cdot|c)$. Substituting it into Equation (12), we obtain:
$ q_\theta(\cdot|c) = \alpha, p_{\text{data}}(\cdot|c) - (\alpha - 1), p_{\text{data}}(\cdot | \varnothing).\tag{13} $
where $\alpha=\frac{1}{1-\gamma} \geq 1$. This implies that $q_\theta(\cdot|c)$ is to approximate a linear combination of conditional and unconditional data distributions. This follows the spirit of original CFG.
In practice, Eq. (12) means that we sample extra negative examples from the data in $p_{\text{data}}(\cdot | \varnothing)$, in addition to the generated data. The distribution $q_\theta(\cdot|c)$ corresponds to a class-conditional network $f_\theta(\cdot | c)$, similar to common practice [37]. We note that, in our method, CFG is a training-time behavior by design: the one-step (1-NFE) property is preserved at inference time.
4. Implementation for Image Generation
Section Summary: This section outlines the practical setup for generating images on the ImageNet dataset at a 256x256 pixel resolution, primarily working in a compressed latent space using a standard tokenizer that creates a smaller 32x32 grid for efficiency. The core generator model resembles a DiT architecture, starting with random noise and producing image latents, while incorporating flexible conditioning techniques like CFG to guide outputs based on classes or other inputs during training and inference. It also details batch processing for multiple samples, uses pre-trained feature extractors like ResNet models to evaluate and refine generations in a drifting loss framework, and supports direct pixel-space generation as an alternative.
We describe our implementation for image generation on ImageNet [38] at resolution 256 $\times$ 256. Full implementation details are provided in Appendix A.
Tokenizer.
By default, we perform generation in latent space [17]. We adopt the standard SD-VAE tokenizer, which produces a 32 $\times$ 32 $\times$ 4 latent space in which generation is performed.
Architecture.
Our generator ($f_\theta$) has a DiT-like [39] architecture. Its input is 32 $\times$ 32 $\times$ 4-dim Gaussian noise ${\boldsymbol{\epsilon}}$, and its output is the generated latent $\mathbf{x}$ of the same dimension. We use a patch size of 2, i.e., like DiT/2. Our model uses adaLN-zero [39] for processing class-conditioning or other extra conditioning.
CFG conditioning.
We follow [40] and adopt CFG-conditioning. At training time, a CFG scale $\alpha$ (Eq. (13)) is randomly sampled. Negative samples are prepared based on $\alpha$ (Eq. (12)), and the network is conditioned on this value. At inference time, $\alpha$ can be freely specified and varied without retraining. Details are in Appendix A.7.
Batching.
The pseudo-code in Algorithm 1 describes a batch of $N=N_\text{neg}$ generated samples. In practice, when class labels are involved, we sample a batch of $N_\text{c}$ class labels. For each label, we perform Algorithm 1 independently. Accordingly, the effective batch size is $B=N_\text{c}{\times}N$, which consists of $N_\text{c}{\times}N$ negatives and $N_\text{c}{\times}N_\text{pos}$ positives.
We define a "training epoch" based on the number of generated samples $\mathbf{x}$. In particular, each iteration generates $B$ samples, and one epoch corresponds to $N_\text{data}/B$ iterations for a dataset of size $N_\text{data}$.
Feature Extractor.
Our model is trained with drifting loss in a feature space (Section 3.4). The feature extractor $\phi$ is an image encoder. We mainly consider a ResNet-style [33] encoder, pre-trained by self-supervised learning, e.g., MoCo [34] and SimCLR [35]. When these pre-trained models operate in pixel space, we apply the VAE decoder to map our generator’s latent-space output back to pixel space for feature extraction. Gradients are backpropagated through the feature encoder and VAE decoder. We also study an MAE [41] pre-trained in latent space (detailed in Appendix A.3).
For all ResNet-style models, features are extracted from multiple stages (i.e., multi-scale feature maps). The drifting loss in Equation (10) is computed at each scale and then combined. We elaborate on the details in Appendix A.6.
Pixel-space Generation.
While our experiments primarily focus on latent-space generation, our models support pixel-space generation. In this case, ${\boldsymbol{\epsilon}}$ and $\mathbf{x}$ are both 256 $\times$ 256 $\times$ 3. We use a patch size of 16 (i.e., DiT/16). The feature extractor $\phi$ is directly on the pixel space.

5. Experiments
Section Summary: In toy experiments on simple 2D distributions, the method successfully evolves generated samples toward complex target shapes without getting stuck in simplified patterns, even starting from flawed setups, and loss values drop as the distributions align. On challenging ImageNet images, tests confirm the importance of balanced attraction and repulsion forces for stable training, as disrupting them causes complete failure; using more positive and negative examples improves output quality, and a specialized feature encoder trained on latent spaces yields the best results by better capturing similarities. Overall, these findings highlight the method's robustness, with refinements like longer training and wider models pushing performance metrics to competitive levels.
5.1 Toy Experiments
Evolution of the generated distribution.
Figure 3 visualizes a 2D toy case, where $q$ evolves toward a bimodal distribution $p$ at training time, under three initializations.
In this toy example, our method approximates the target distribution without exhibiting mode collapse. This holds even when $q$ is initialized in a collapsed single-mode state (bottom). This provides intuition into why our method is robust to mode collapse: if $q$ collapses onto one mode, other modes of $p$ will attract the samples, allowing them to continue moving and pushing $q$ to continue evolving.
:::: {cols="1"}
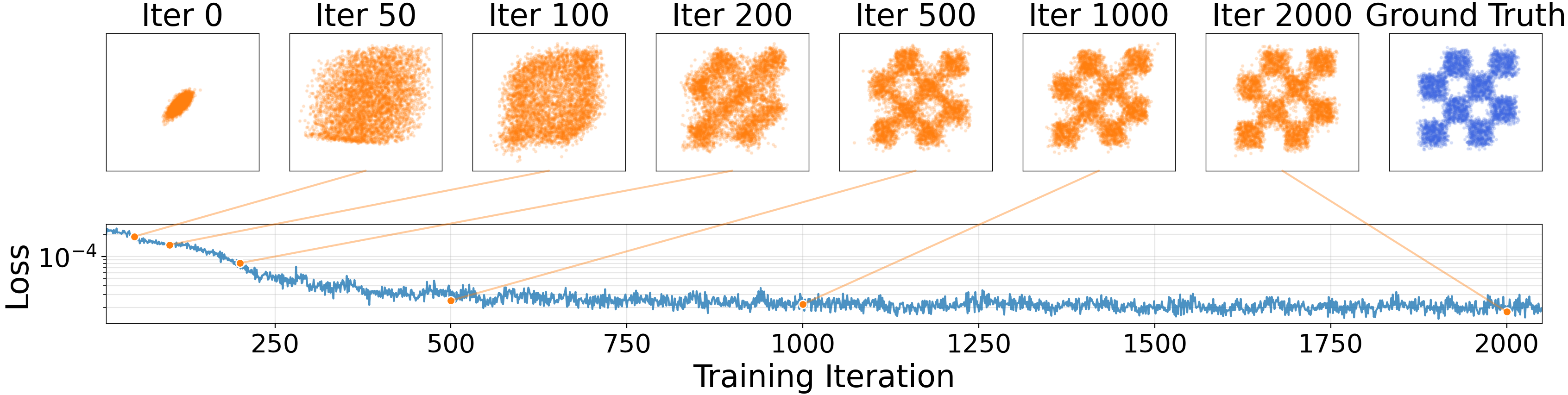
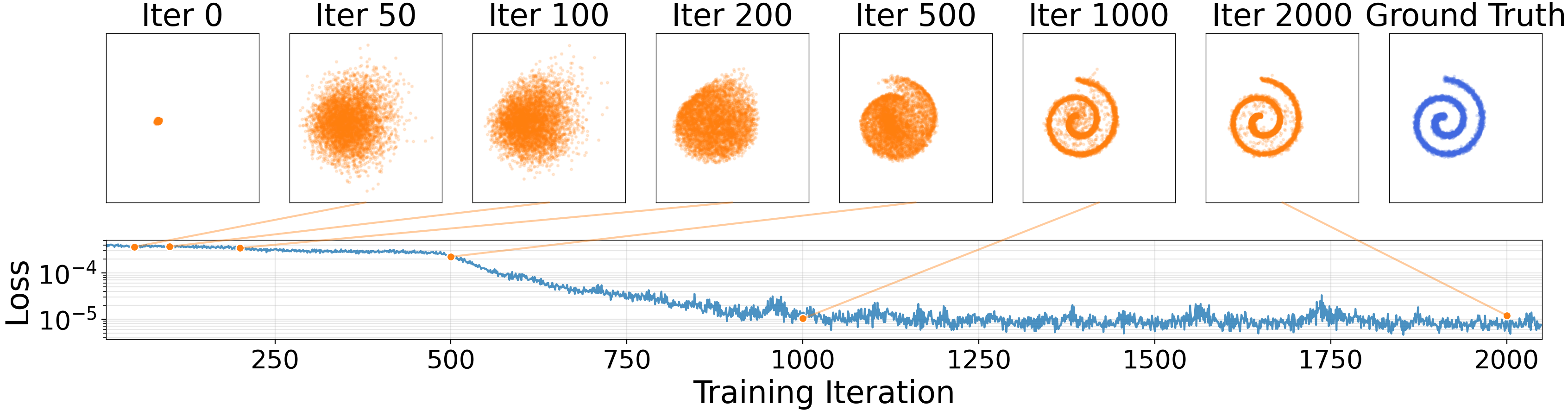
Figure 4: Evolution of samples. We show generated points sampled at different training iterations, along with their loss values. The loss (whose value equals $|V|^2$) decreases as the distribution converges to the target. (y-axis is log-scale.) ::::
Evolution of the samples.
Figure 4 shows the training process on two 2D cases. A small MLP generator is trained. The loss (whose value equals $| \mathbf{V}|^2$) decreases as the generated distribution converges to the target. This is in line with our motivation that reducing the drift and pushing towards the equilibrium will approximately yield $p = q$.
::: {caption="Table 1: Importance of anti-symmetry: breaking the anti-symmetry leads to failure. Here, the anti-symmetric case is defined in Eq. (7) and Eq. (8); other destructive cases are defined in similar ways. (Setting: B/2 model, 100 epochs)"}

:::
5.2 ImageNet Experiments
We evaluate our models on ImageNet 256 $\times$ 256. Ablation studies use a B/2 model on the SD-VAE latent space, trained for 100 epochs. The drifting loss is in a feature space computed by a latent-MAE encoder. We report FID [42] on 50K generated images. We analyze the results as follows.
Anti-symmetry.
Our derivation of equilibrium requires the drifting field to be anti-symmetric; see Eq. (1). In Table 1, we conduct a destructive study that intentionally breaks this anti-symmetry. The anti-symmetric case (our ablation default) works well, while other cases fail catastrophically.
Intuitively, for a sample $\mathbf{x}$, we want attraction from $p$ to be canceled by repulsion from $q$ when $p$ and $q$ match. This equilibrium is not achieved in the destructive cases.
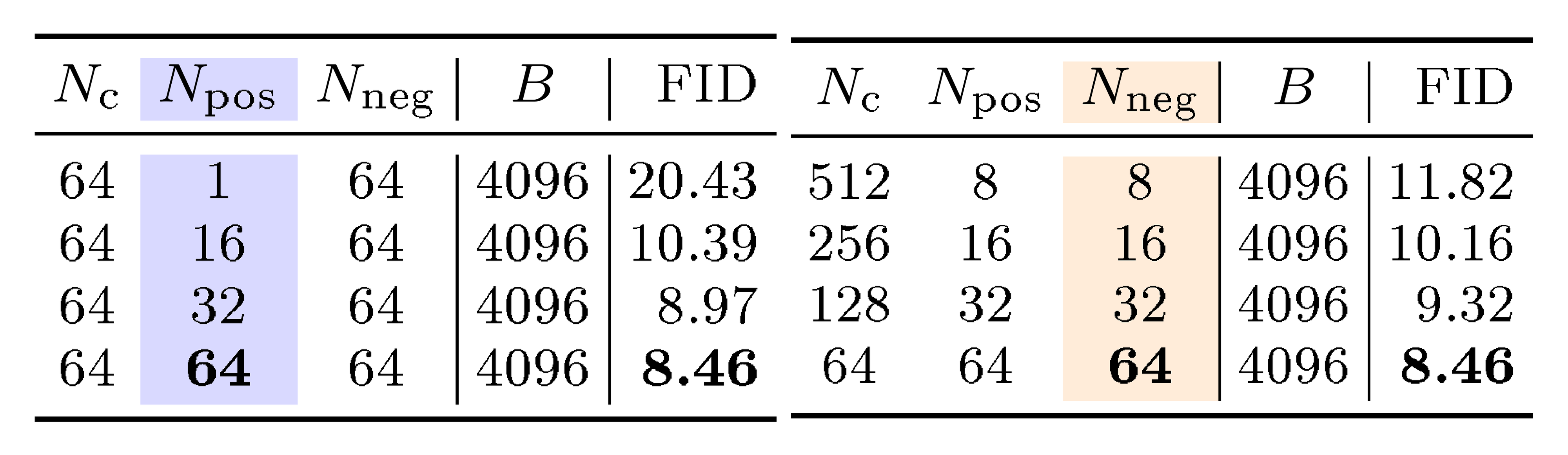
::: {caption="Table 2: Allocation of positive and negative samples. In both sub-tables, we control the total compute by fixing the epochs (100) and the batch size $B=N_\text{c}{\times}N_\text{pos}$ (4096). Here, $N_\text{c}$ is for class labels. Under the same budget, increasing positive samples (left) and negative samples (right) improves generation quality. (Setting: B/2 model, 100 epochs)"}
:::
Allocation of Positive and Negative Samples.
Our method samples positive and negative examples to estimate $\mathbf{V}$ (see Algorithm 1). In Table 2, we study the effect of
$N_\text{pos}$ and
$N_\text{neg}$ , under fixed epochs and fixed batch size $B$.
Table 2 shows that using larger $N_\text{pos}$ and $N_\text{neg}$ is beneficial. Larger sample sizes are expected to improve the accuracy of the estimated $\mathbf{V}$ and hence the generation quality. This observation aligns with results in contrastive learning [26, 34, 35], in which larger sample sets improve representation learning.
:::
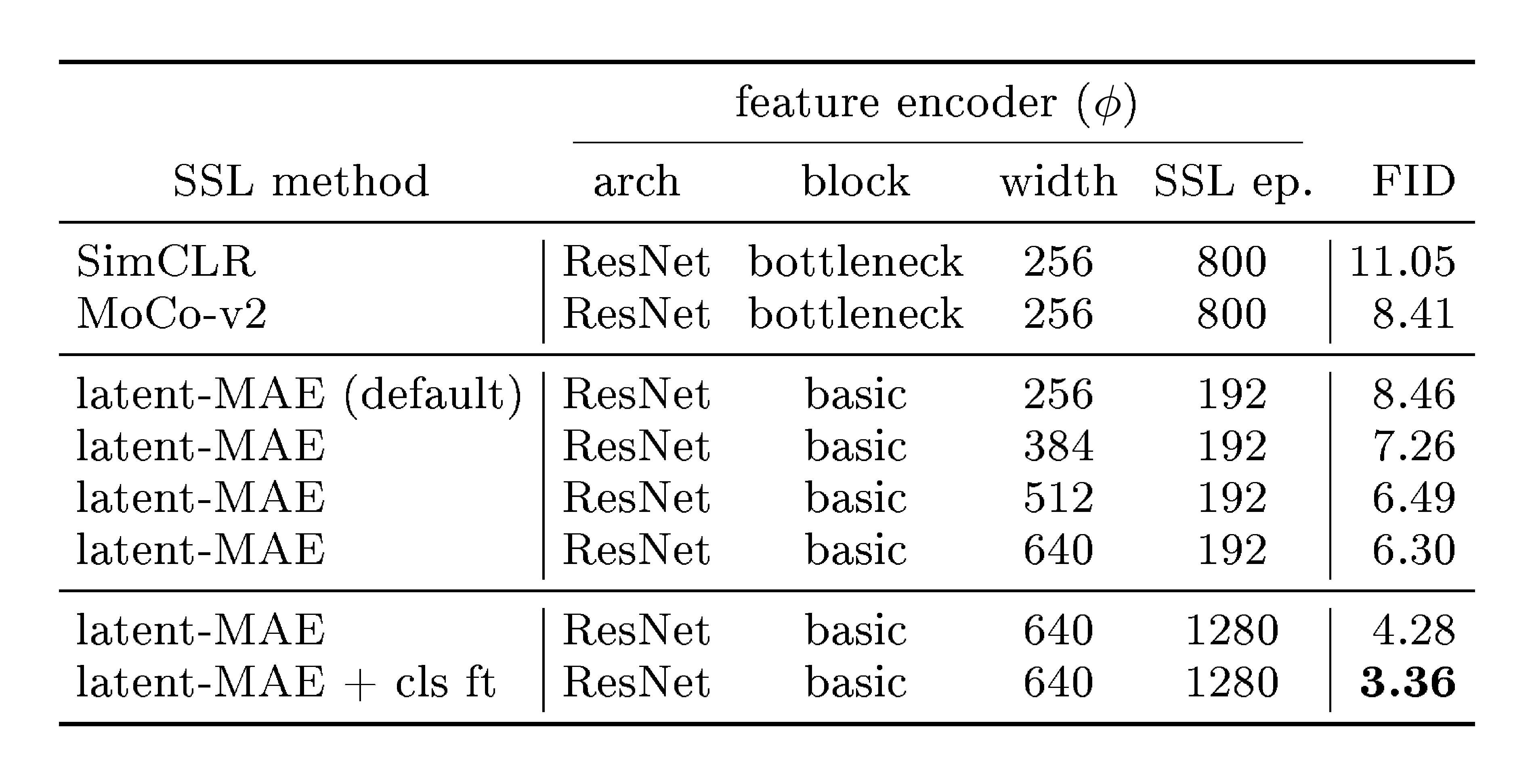
Feature space for drifting. We compare self-supervised learning (SSL) encoders. Standard SimCLR and MoCo encoders achieve competitive results, whereas our customized latent-MAE performs best and benefits from increased width and longer training. (Generator setting: B/2 model, 100 epochs)
:::
Feature Space for Drifting.
Our model computes the drifting loss in a feature space (Section 3.4). Table 3 compares the feature encoders. Using the public pre-trained encoders from SimCLR [35] and MoCo v2 [43], our method obtains decent results.
These standard encoders operate in the pixel domain, which requires running the VAE decoder at training. To circumvent this, we pre-train a ResNet-style model with the MAE objective [41], directly on the latent space. The feature space produced by this "latent-MAE" performs strongly (Table 3). Increasing the MAE encoder width and the number of pre-training epochs both improve generation quality; fine-tuning it with a classifier (`cls ft') boosts the results further to 3.36 FID.
The comparison in Table 3 shows that the quality of the feature encoder plays an important role. We hypothesize that this is because our method depends on a kernel $k(\cdot, \cdot)$ (see Eq. (9)) to measure sample similarity. Samples that are closer in feature space generally yield stronger drift, providing richer training signals. This goal is aligned with the motivation of self-supervised learning. A strong feature encoder reduces the occurrence of a nearly "flat" kernel (i.e., $k(\cdot, \cdot)$ vanishes because all samples are far away).
On the other hand, we report that we were unable to make our method work on ImageNet without a feature encoder. In this case, the kernel may fail to effectively describe similarity, even in the presence of a latent VAE. We leave further study of this limitation for future work.
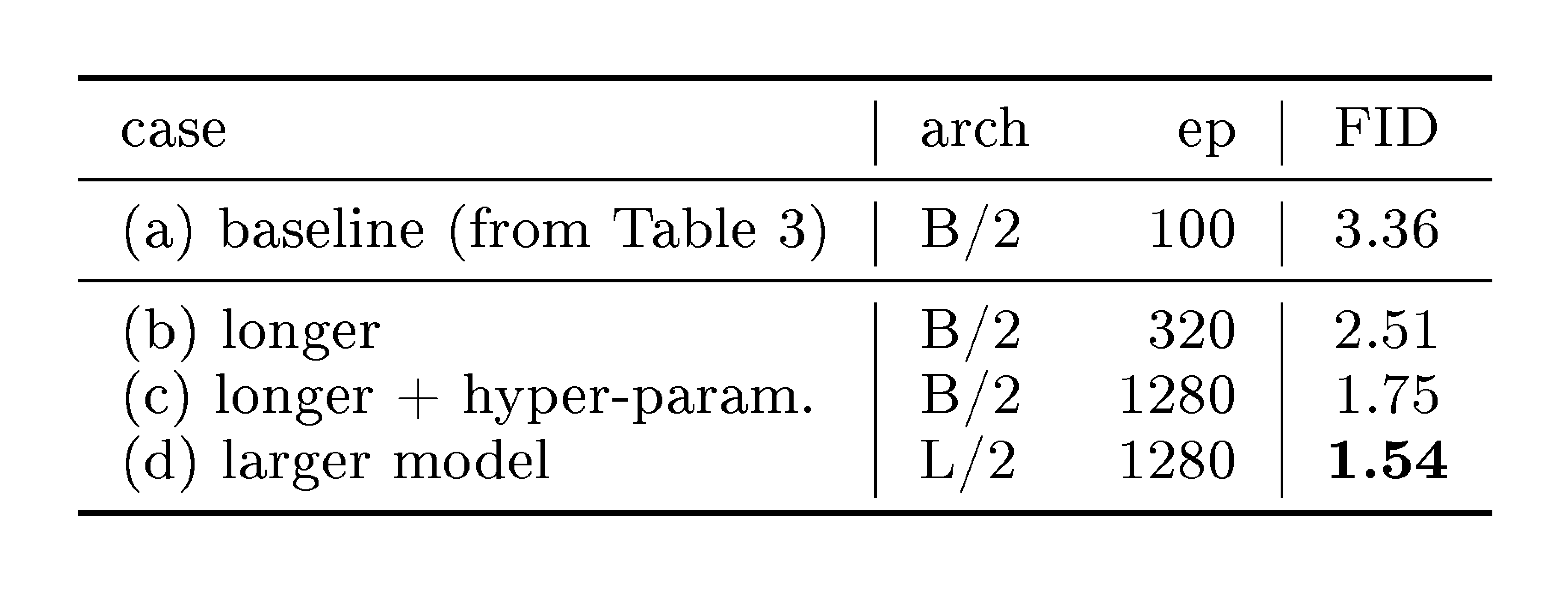
::: {caption="Table 4: From ablation to final setting. We train our model for more epochs, adjust hyper-parameters for this regime, and use a larger model size."}
:::
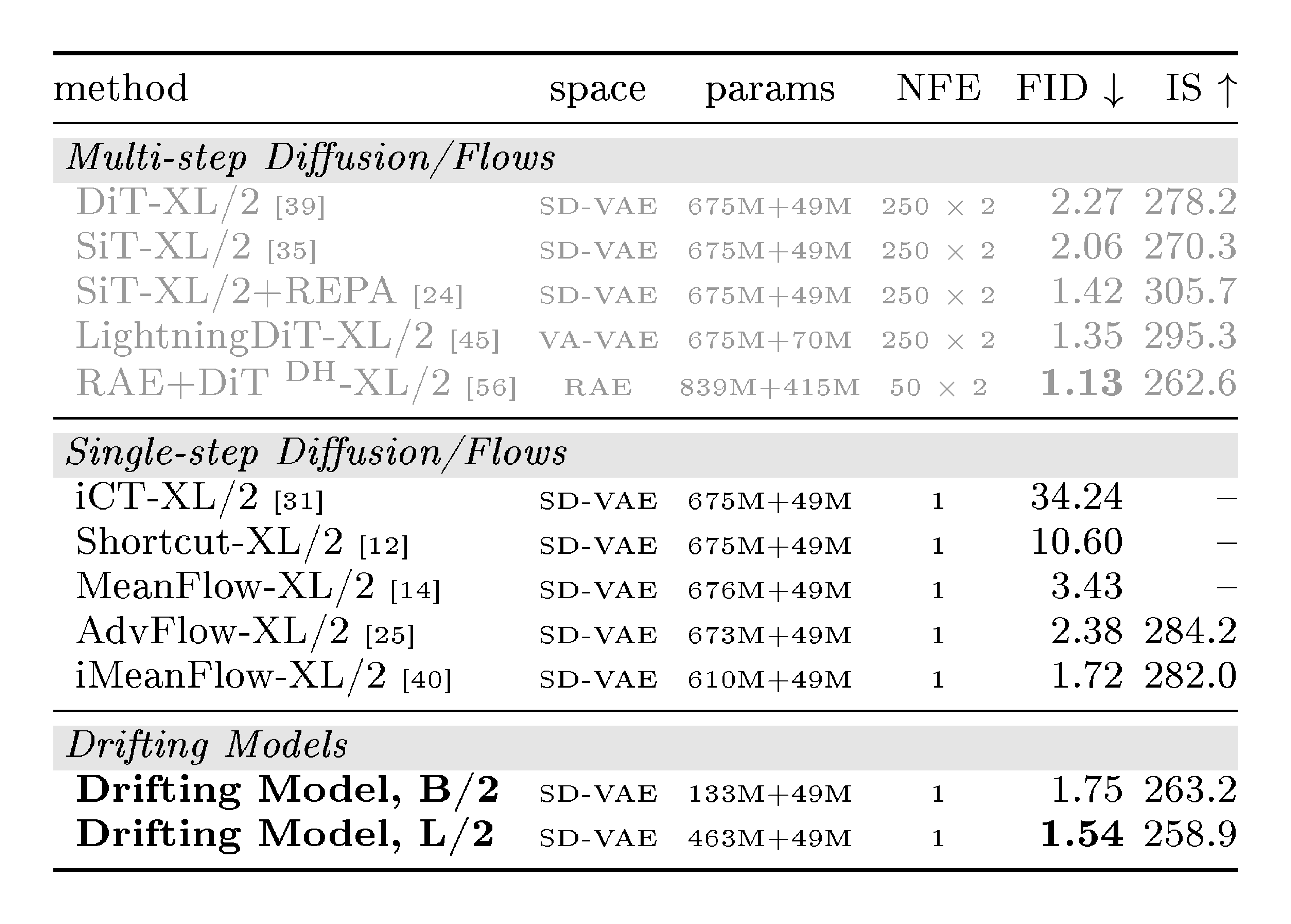
::: {caption="Table 5: System-level comparison: ImageNet 256 $\times$ 256 generation in latent space. FID is on 50K images, all reported with CFG if applicable. The parameter numbers are "generator + decoder". All generators are trained from scratch (i.e., not distilled)."}
:::
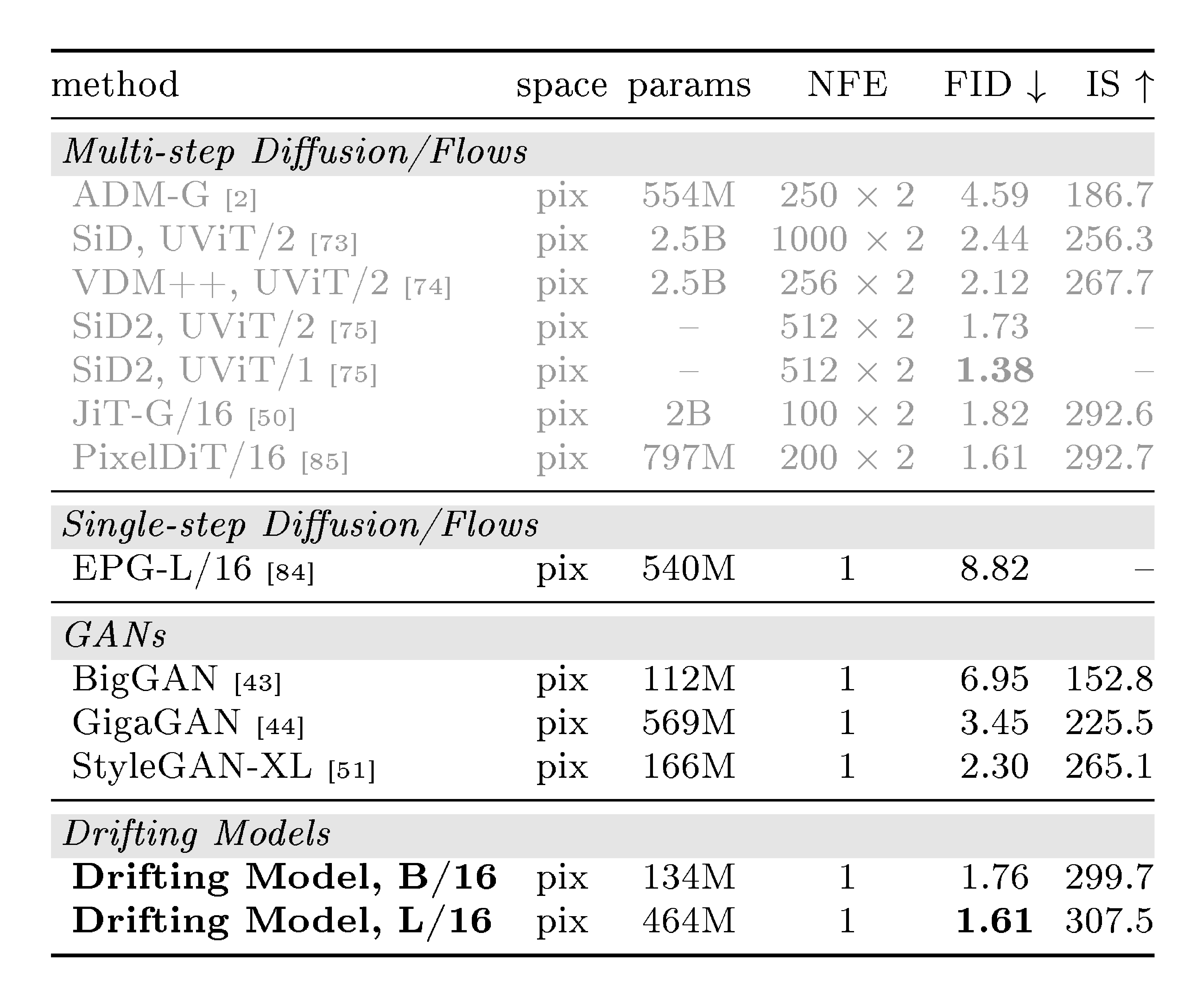
::: {caption="Table 6: System-level comparison: ImageNet 256 $\times$ 256 generation in pixel space. FID is on 50K images, all reported with CFG if applicable. The parameter numbers are of the generator. All generators are trained from scratch (i.e., not distilled)."}
:::
System-level Comparisons.
In addition to the ablation setting, we train stronger variants and summarize them in Table 4. We compare with previous methods in Table 5.
Our method achieves 1.54 FID with native 1-NFE generation. It outperforms all previous 1-NFE methods, which are based on approximating diffusion-/flow-based trajectories. Notably, our Base-size model competes with previous XL-size models. Our best model (FID 1.54) uses a CFG scale of 1.0, which corresponds to "no CFG’’ in diffusion-based methods. Our CFG formulation exhibits a tradeoff between FID and IS (see Appendix B.3), similar to standard CFG.
We provide uncurated qualitative results in Appendix B.5, Figure 12-Figure 15, with CFG 1.0. Moreover, Figure 16-Figure 20 show a side-by-side comparison with improved MeanFlow (iMF) [40], a recent state-of-the-art one-step method.
Pixel-space Generation.
Our method can naturally work without the latent VAE, i.e., the generator $f$ directly produces 256 $\times$ 256 $\times$ 3 images. The feature encoder is applied on the generated images for computing drifting loss. We adopt a configuration similar to that of the latent variant; implementation details are in Appendix A.
Table 6 compares different pixel-space generators. Our one-step, pixel-space method achieves 1.61 FID, which outperforms or competes with previous multi-step methods. Comparing with other one-step, pixel-space methods (GANs), our method achieves 1.61 FID using only 87G FLOPs; by comparison, StyleGAN-XL produces 2.30 FID using 1574G FLOPs. More ablations are in Appendix B.1.
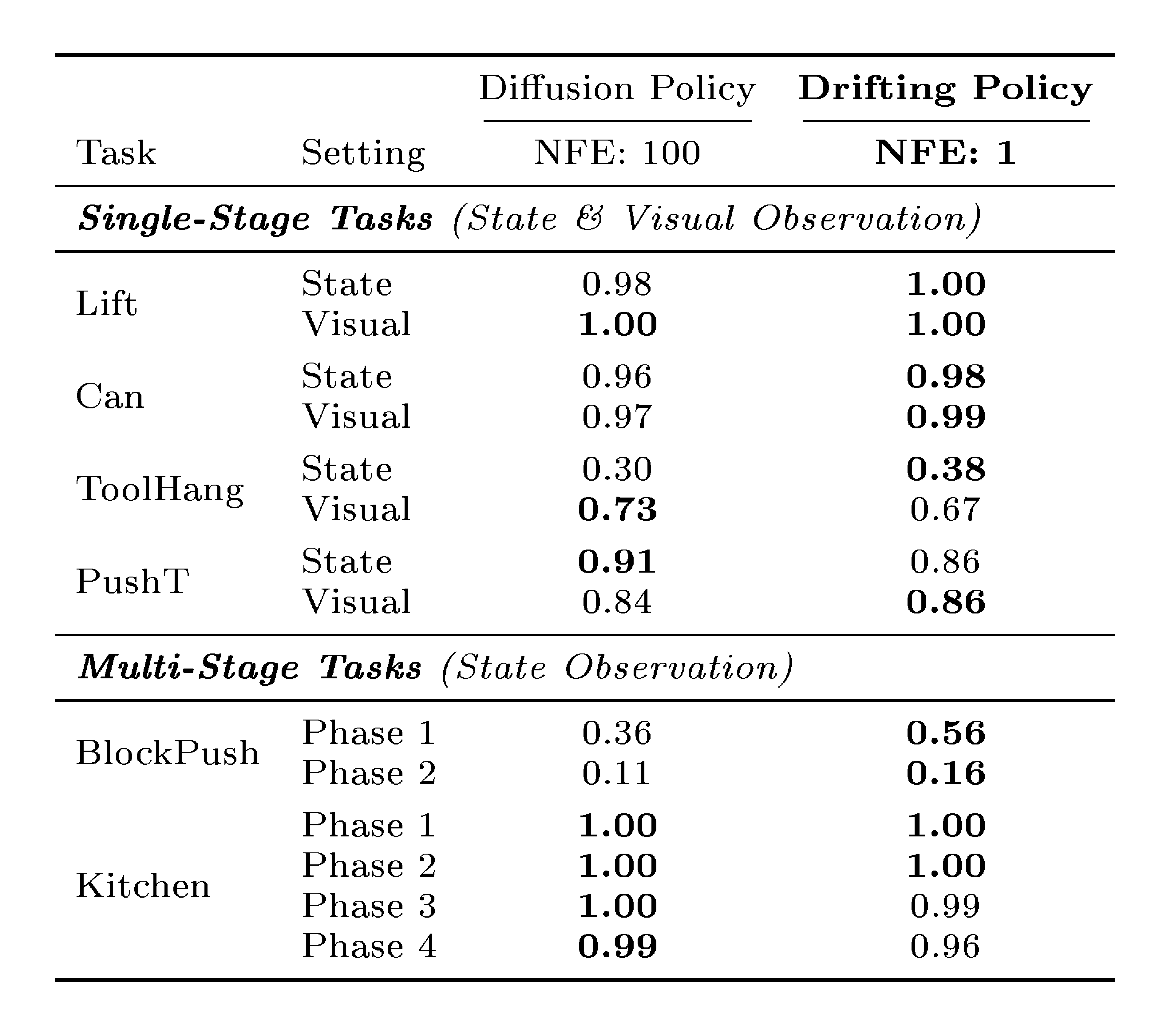
::: {caption="Table 7: Robotics Control: Comparison with Diffusion Policy. The evaluation protocol follows Diffusion Policy ([44]). This table involves four single-stage tasks and two multi-stage tasks. "Drifting Policy" (ours) replaces the multi-step Diffusion Policy generator with our one-step generator. Success rates are reported as the average over the last 10 checkpoints."}
:::
5.3 Experiments on Robotic Control
Beyond image generation, we further evaluate our method on robotics control. Our experiment designs and protocols follow Diffusion Policy ([44]). At the core of Diffusion Policy is a multi-step, diffusion-based generator; we replace it with our one-step Drifting Model. We directly compute drifting loss on the raw representations for control, using no feature space. Results are in Table 7. Our 1-NFE model matches or exceeds the state-of-the-art Diffusion Policy that uses 100 NFE. This comparison suggests that Drifting Models can serve as a promising generative model across different domains.
6. Discussion and Conclusion
Section Summary: The authors introduce Drifting Models as a fresh approach to generative modeling, which tracks how data distributions evolve through updates during the training process, unlike diffusion or flow models that handle updates only when generating new data, allowing for quick, one-step creation of outputs. They highlight remaining uncertainties, such as the exact conditions under which the model fully matches the true data distribution and potential improvements to elements like the drifting mechanism and network designs. Overall, this work reimagines neural network training as a way distributions change over time and aims to spark new ideas for similar techniques.
We present Drifting Models, a new paradigm for generative modeling. At the core of our model is the idea of modeling the evolution of pushforward distributions during training. This allows us to focus on the update rule, i.e., $\mathbf{x}{i+1} = \mathbf{x}{i} + \Delta \mathbf{x}_i$, during the iterative training process. This is in contrast with diffusion-/flow-based models, which perform the iterative update at inference time. Our method naturally performs one-step inference.
Given that our methodology is substantially different, many open questions remain. For example, although we show that $q=p \Rightarrow \mathbf{V}=\mathbf{0}$, the converse implication does not generally hold in theory. While our designed $\mathbf{V}$ performs well empirically, it remains unclear under what conditions $\mathbf{V}\rightarrow\mathbf{0}$ leads to $q\rightarrow p$.
From a practical standpoint, although our paper presents an effective instantiation of drifting modeling, many of our design decisions may remain sub-optimal. For example, the design of the drifting field and its kernels, the feature encoder, and the generator architecture remain open for future exploration.
From a broader perspective, our work reframes iterative neural network training as a mechanism for distribution evolution, in contrast to the differential equations underlying diffusion-/flow-based models. We hope that this perspective will inspire the exploration of other realizations of this mechanism in future work.
Acknowledgements
Section Summary: The authors express gratitude to Google TPU Research Cloud for providing access to their powerful computing resources. They also thank a group of colleagues—Michael Albergo, Ziqian Zhong, Yilun Xu, Zhengyang Geng, Hanhong Zhao, Jiangqi Dai, Alex Fan, and Shaurya Agrawal—for valuable discussions that contributed to the work. Additionally, Mingyang Deng received partial funding support from the MIT-IBM Watson AI Lab.
We greatly thank Google TPU Research Cloud (TRC) for granting us access to TPUs. We thank Michael Albergo, Ziqian Zhong, Yilun Xu, Zhengyang Geng, Hanhong Zhao, Jiangqi Dai, Alex Fan, and Shaurya Agrawal for helpful discussions. Mingyang Deng is partially supported by funding from MIT-IBM Watson AI Lab.
Appendix
Section Summary: The appendix provides extra technical details for reproducing the study's experiments, including a table of configurations and hyperparameters for tests on 256x256 ImageNet images, with shared setups for core comparisons and larger scales for broader evaluations. It includes pseudo-code for calculating a "drifting field" that guides image generation by estimating average directions between data points using simple statistical averages and normalization techniques, ensuring properties like zero self-direction. The section also describes the generator's design, a transformer-based system that turns random noise, class labels, and control settings into images, plus a custom convolutional network for feature extraction in the model's loss calculations, incorporating random style elements to improve output quality.
A. Additional Implementation Details
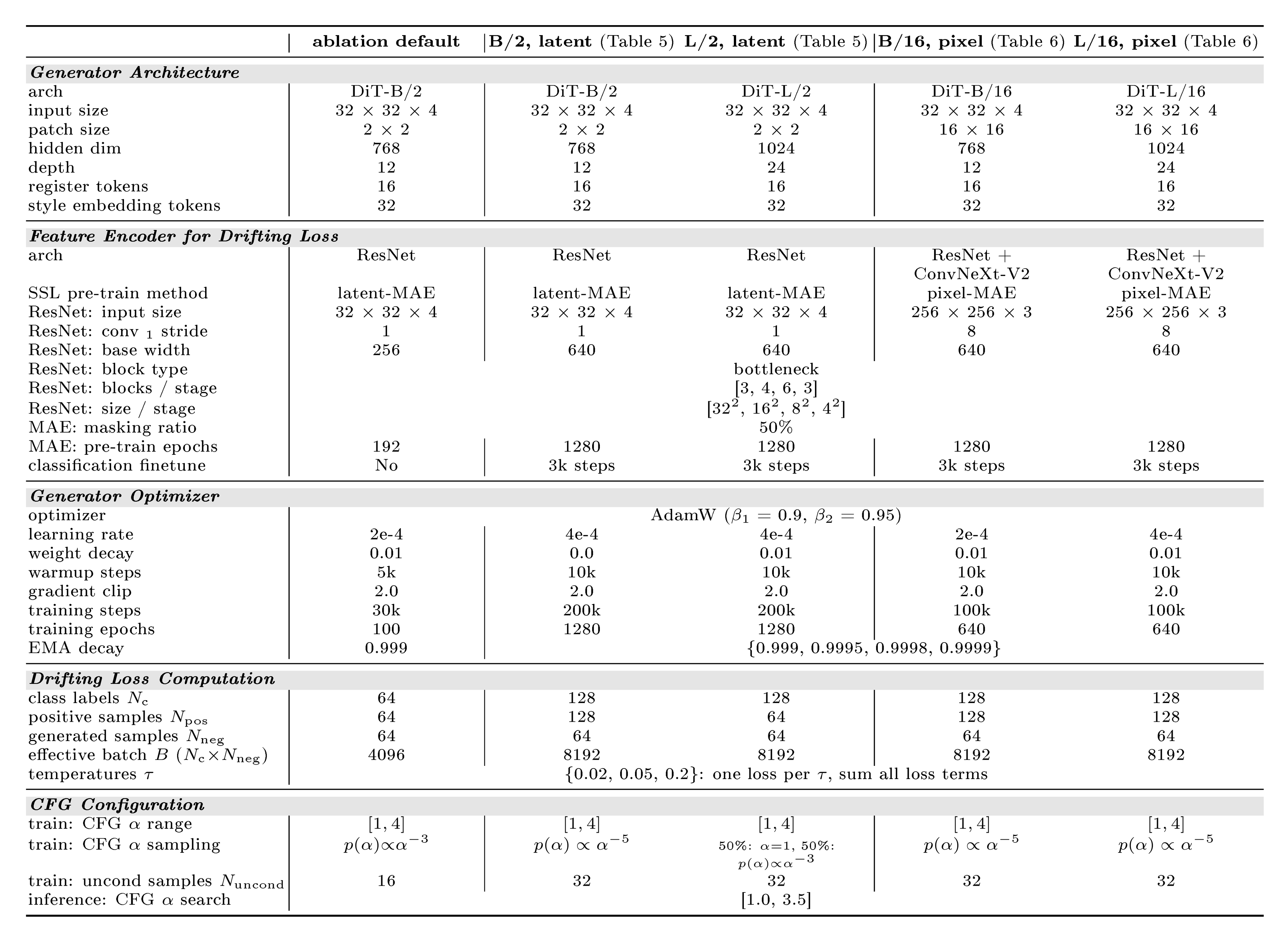
Table 8 summarizes the configurations and hyper-parameters for ablation studies and system-level comparisons. We provide detailed experimental configurations for reproducibility. All ablation studies share a common default setup, while system-level comparisons use scaled-up configurations. More implementation details are described as follows.
::: {caption="Table 8: Configurations for ImageNet 256 $\times$ 256."}
:::
A.1 Pseudo-code for Computing Drifting Field $\mathbf{V}$
Algorithm 2 provides the pseudo-code for computing $\mathbf{V}$. The computation is based on taking empirical means in Eq. (8) and (9), which are implemented as softmax over $\mathbf{y}$-sample axis. In practice, we further normalize over the $\mathbf{x}$-sample axis, also implemented as softmax on the same logit matrix. We ablate its influence in Appendix B.2.
It is worth noting that this implementation preserves the desired property of $\mathbf{V}$. In principle, this implementation can be viewed as a Monte Carlo estimation of a drifting field:
$ \mathbf{V}{p, q}(\mathbf{x})=\mathbb E{\mathcal{B}, p, q}[\tilde K_\mathcal{B}(\mathbf{x}, \mathbf{y}^{+})\tilde K_\mathcal{B}(\mathbf{x}, \mathbf{y}^{-})(\mathbf{y}^{+}- \mathbf{y}^{-})], $
where $\mathcal{B}$ consists of other samples in the batch and $\tilde K_\mathcal{B}$ denote normalizing the distance based on statistics within $\mathcal{B}$. This $\mathbf{V}$ also satisfies $\mathbf{V}{p, p}(\mathbf{x})=\mathbf 0$, since when $p=q$, the term $\tilde K\mathcal{B}(\mathbf{y}^{+}, x)\tilde K_\mathcal{B}(\mathbf{y}^{-}, x)(\mathbf{y}^{+}- \mathbf{y}^{-})$ cancels out with the term $\tilde K_\mathcal{B}(\mathbf{y}^{-}, x)\tilde K_\mathcal{B}(\mathbf{y}^{+}, x)(\mathbf{y}^{-}- \mathbf{y}^{+})$.

A.2 Generator Architecture
Input and output.
The input to the generator consists of random noise along with conditioning:
$ f_\theta: ({\boldsymbol{\epsilon}}, c, \alpha) \mapsto \mathbf{x} $
where ${\boldsymbol{\epsilon}}$ denotes random variables, $c$ is a class label, and $\alpha$ is the CFG strength. ${\boldsymbol{\epsilon}}$ may consist of both continuous random variables (e.g., Gaussian noise) and discrete ones (e.g., uniformly distributed integers; see random style embeddings). For latent-space models, the output $\mathbf{x} \in \mathbb{R}^{32\times 32\times 4}$ is in the SD-VAE latent space. For pixel-space models, the output $\mathbf{x} \in \mathbb{R}^{256\times 256\times 3}$ is directly an image.
Transformer.
We adopt a DiT-style Transformer ([39]). Following ([45]), we use SwiGLU ([46]), RoPE ([47]), RMSNorm ([48]), and QK-Norm ([49]). The input Gaussian noise is patchified into 256 $=$ 16 $\times$ 16 tokens (patch size 2 $\times$ 2 for latent, 16 $\times$ 16 for pixel). Conditioning $(c, \alpha)$ is processed by adaLN, as well as by in-context conditioning tokens. The output tokens are unpatchified back to the target shape.
In-context tokens.
Following [50], we prepend 16 learnable tokens to the sequence for in-context conditioning [39]. These tokens are formed by summing the projected conditioning vector with positional embeddings.
Random style embeddings.
Our framework allows arbitrary noise distributions beyond Gaussians. Inspired by StyleGAN [51], we introduce an additional 32 "style tokens": each of which is a random index into a codebook of 64 learnable embeddings. These are summed and added to the conditioning vector. This does not change the sequence length and introduces negligible overhead in terms of parameters and FLOPs. This table reports the effect of style embeddings on our ablation default:
| w/o style | w/ style | |
|---|---|---|
| FID | 8.86 | 8.46 |
In contrast to diffusion-/flow-based methods, our method can naturally handle different types of noise or random variables. With random style embeddings, the input random variables consist of two parts: (1) Gaussian noise, and (2) discrete indices for style embeddings. Our model $f$ produces the pushforward distribution of their joint distribution.
A.3 Implementation of ResNet-style MAE
In addition to standard self-supervised learning models (MoCo [34], SimCLR [35]), we develop a customized ResNet-style MAE model as the feature encoder for drifting loss.
Overview.
Unlike standard MAE [41], which is based on ViT [52], our MAE trains a convolutional ResNet that provides multi-scale features. For latent-space models, the input and output have dimension 32 $\times$ 32 $\times$ 4; for pixel-space models, the input and output have dimension 256 $\times$ 256 $\times$ 3.
Our MAE consists of a ResNet-style encoder paired with a deconvolutional decoder in a U-Net-style [53] encoder-decoder architecture. We only use the ResNet-style encoder for feature extraction when computing the drifting loss.
MAE Encoder.
The encoder follows a classical ResNet [33] design. It maps an input to multi-scale feature maps (4 scales in ResNet):
$ \text{Encoder}: \mathbf{x} \mapsto {\mathbf{f}_1, \mathbf{f}_2, \mathbf{f}_3, \mathbf{f}_4} $
Here, a feature map $\mathbf{f}_i$ has dimension $H_i{\times}W_i{\times}C_i$, with $H_i{\times}W_i \in {32^2, 16^2, 8^2, 4^2}$ and $C_i \in {C, 2C, 4C, 8C}$ for a base width $C$.
The architecture follows standard ResNet ([33]) design, with GroupNorm (GN) ([54]) used in place of BatchNorm (BN) ([55]). All residual blocks are "basic" blocks (i.e., each consisting of two $3{\times}3$ convolutions). Following the standard ResNet-34 ([33]): the encoder has a 3 ${\times}$ 3 convolution (without downsampling) and 4 stages with $[3, 4, 6, 3]$ blocks; downsampling (stride 2) happens at the first block of stages 2 to 4.
For latent-space (i.e., latent-MAE), the input of this ResNet is 32 $\times$ 32 $\times$ 4; for pixel-space, the 256 $\times$ 256 $\times$ 3 input is first patchified (by a 8 $\times$ 8 patch) into 32 $\times$ 32 $\times$ 192. The ResNet operates on the input with $H{\times}W$ $=$ 32 $\times$ 32.
MAE Decoder.
The decoder returns to the input shape via deconvolutions and skip connections:
$ \text{Decoder}: {\mathbf{f}_4, \mathbf{f}_3, \mathbf{f}_2, \mathbf{f}_1} \mapsto \hat{\mathbf{x}}. $
It starts with a $3{\times}3$ convolutional block on $\mathbf{f}_4$, followed by 4 upsampling blocks. Each upsampling block performs: bilinear 2 ${\times}$ 2 upsampling $\to$ concatenating with encoder's skip connection $\to$ GN $\to$ two $3{\times}3$ convolutions with GN and ReLU. A final 1 ${\times}$ 1 convolution produces the output channels. For the pixel-space, the decoder unpatchifies back to the original resolution after the last layer.
Masking.
The MAE is trained to reconstruct randomly masked inputs. Unlike the ViT-based MAE ([41]), which removes the masked tokens from the sequence, we simply zero out masked patches. For the input of a shape $H{\times}W$ $=$ 32 $\times$ 32 (in either the latent- or pixel-based case), we mask 2 ${\times}$ 2 patches by zeroing. Each patch is independently masked with 50% probability.
MAE training.
We minimize the $\ell_2$ reconstruction loss on the masked regions. We use AdamW [56] with learning rate $4{\times}10^{-3}$ and a batch size of 8192. EMA with decay 0.9995 is used. Following [41], we apply random resized crop augmentation to the input (for the latent setting, images are augmented before being passed through the VAE encoder).
Classification fine-tuning.
For our best feature encoder (last row of Table 3), we fine-tune the MAE model with a linear classifier head. The loss is $\lambda \mathcal{L}{\text{cls}} + (1-\lambda)\mathcal{L}{\text{recon}}$. We fine-tune all parameters in this MAE for 3k iterations, where $\lambda$ follows a linear warmup schedule, increasing from $0$ to $0.1$ over the first 1k iterations and remaining constant at $0.1$ for the rest of the training.
A.4 Other Pretrained Feature Encoders
In addition to our customized MAE, we also evaluate other feature encoders for computing the drifting loss.
MoCo and SimCLR.
We evaluate publicly available self-supervised encoders trained on ImageNet in pixel space: MoCo [34, 43] SimCLR [35]. We use the ResNet-50 variant. For latent-space generation, we apply the VAE decoder to map generator outputs from latent space (32 ${\times}$ 32 ${\times}$ 4) to pixel space (256 ${\times}$ 256 ${\times}$ 3) before feature extraction. Gradients are backpropagated through both the feature extractor and the VAE decoder.
MAE with ConvNeXt-V2.
In our pixel-space generator, we also investigate ConvNeXt-V2 ([57]) as the feature encoder. We note that ConvNeXt-V2 is a self-supervised pre-trained model using the MAE objective, followed by classification fine-tuning. Like ResNet, ConvNeXt-V2 is a multi-stage architecture.
A.5 Multi-scale Features for Drifting Loss
Given an image, the feature encoder produces feature maps at multiple scales, with multiple spatial locations per scale. We compute one drifting loss per feature (e.g., per scale and/or per location). Specifically, we compute the kernel, the drift, and the resulting loss independently for each feature. The resulting losses are summed.
For each stage in a ResNet, we extract features from the output of every 2 residual blocks, together with the final output. This yields a set of feature maps, each of shape $H_i{\times}W_i{\times}C_i$. For each feature map, we produce:
- $H_i{\times}W_i$ vectors, one per location (each $C_i$-dim);
- 1 global mean and 1 global std (each $C_i$-dim);
- $\frac{H_i}{2}{\times}\frac{W_i}{2}$ vectors of means and $\frac{H_i}{2}{\times}\frac{W_i}{2}$ vectors of stds (each $C_i$-dim), computed over 2 ${\times}$ 2 patches;
- $\frac{H_i}{4}{\times}\frac{W_i}{4}$ vectors of means and $\frac{H_i}{4}{\times}\frac{W_i}{4}$ vectors of stds (each $C_i$-dim), computed over 4 ${\times}$ 4 patches.
In addition, for the encoder's input ($H_0{\times}W_0{\times}C_0$), we compute the mean of squared values ($x^2$) per channel and obtain a $C_0$-dim vector.
All resulting vectors here are $C_i$-dim. We compute one drifting loss for each of these $C_i$-dim vectors. All these losses, in addition to the vanilla drifting loss without $\phi$, are summed. This table compares the effect of these designs on our ablation default:
| (a, b) | (a-c) | (a-d) | |
|---|---|---|---|
| FID | 9.58 | 9.10 | 8.46 |
This shows that our method benefits from richer feature sets. We note that once the feature encoder is run, the computational cost of our drifting loss is negligible: computing multi-scale, multi-location losses incurs little overhead compared to computing a single loss.
A.6 Feature and Drift Normalization
To balance the multiple loss terms from multiple features, we perform normalization for each feature $\phi_j$, where, $\phi_j$ denotes a feature at a specific spatial location within a given scale (see Appendix A.5). Intuitively, we want to perform normalization such that the kernel $k(\cdot, \cdot)$ and the drift $\mathbf{V}$ are insensitive to the absolute magnitude of features. This allows our model to robustly support different feature encoders (see Table 3) as well as a rich set of features from one encoder.
Feature Normalization.
Consider a feature $\phi_j \in \mathbb{R}^{C_j}$. We define a normalization scale $S_j \in \mathbb{R}^{1}$ and the normalized feature is denoted by:
$ \tilde{\phi}_j := {\phi}_j / S_j. $
When using $\tilde{\phi}_j$, the $\ell_2$ distance computed in Eq. (9) is:
$ dist_j(\mathbf{x}, \mathbf{y}) = |\tilde{\phi}_j(\mathbf{x}) - \tilde{\phi}_j(\mathbf{y})|, $
where $\mathbf{x}$ denotes a generated sample and $\mathbf{y}$ denotes a positive/negative sample, and $\tilde{\phi}_j(\cdot)$ means extracting their feature at $j$. We want the average distance to be $\sqrt{C_j}$:
$ \mathrm{E}\mathbf{x} \mathrm{E}\mathbf{y} [dist_j(\mathbf{x}, \mathbf{y})] \approx \sqrt{C_j}. $
To achieve this, we set the normalization scale $S_j$ as:
$ S_j = \frac{1}{\sqrt{C_j}} \mathrm{E}\mathbf{x} \mathrm{E}\mathbf{y} [|{\phi}_j(\mathbf{x}) - {\phi}_j(\mathbf{y})|] $
In practice, we use all $\mathbf{x}$ and $\mathbf{y}$ samples in a batch to compute the empirical mean in place of the expectation. We reuse the cdist computation in Algorithm 2 for computing the pairwise distances. We apply stop-gradient to $S_j$, because this scalar is conceptually computed from samples from the previous batch.
With the normalized feature, the kernel in Eq. (9) is set as:
$ k(\mathbf{x}, \mathbf{y}) = \exp\left(-\frac{1}{\tilde{\tau_j}} |\tilde{\phi}_j(\mathbf{x}) - \tilde{\phi}_j(\mathbf{y})|\right), $
where $\tilde{\tau_j}:=\tau{\cdot}\sqrt{C_j}$. By doing so, the value of temperature $\tau$ does not depend on the feature magnitude or feature dimensionality. We set $\tau \in$ 0.02, 0.05, 0.2 (discussed next).
Drift Normalization.
When using the feature $\phi_j$, the resulting drift is in the same feature space as $\phi_j$, denoted as $\mathbf{V}_j$. We perform a drift normalization on $\mathbf{V}_j$, for each feature $\phi_j$. Formally, we define a normalization scale $\lambda_j \in \mathbb{R}^1$ and denote:
$ \tilde{\mathbf{V}}_j:= \mathbf{V}_j / \lambda_j. $
Again, we want the normalized drift to be insensitive to the feature magnitude:
$ \mathbb{E} \left[\frac{1}{C_j}| \tilde{\mathbf{V}}_j |^2 \right] \approx 1. $
To achieve this, we set $\lambda_j$ as:
$ \lambda_j = \sqrt{\mathbb{E} \left[\frac{1}{C_j} | \mathbf{V}_j |^2 \right]}.\tag{14} $
In practice, the expectation is replaced with the empirical mean computed over the entire batch.
With the normalized feature and normalized drift, the drifting loss of the feature $\phi_j$ is:
$ \mathcal{L}_j = \text{MSE}(\tilde\phi_j({\mathbf{x}}) - \texttt{sg}(\tilde\phi_j({\mathbf{x}}) + \tilde{\mathbf{V}}_j)),\tag{15} $
where MSE denotes mean squared error. The overall loss is the sum across all features: $\mathcal{L} = \sum_j {\mathcal{L}_j}$.
Multiple temperatures.
Using normalized feature distances, the value of temperature $\tau$ determines what is considered "nearby". To improve robustness across different features and across different pretrained models we study, we adopt multiple temperatures.
Formally, for each $\tau$ value, we compute the normalized drift as described above, denoted by $\tilde{\mathbf{V}}{j, \tau}$. Then we compute an aggregated field: $\tilde{\mathbf{V}}j \leftarrow \sum\tau \tilde{\mathbf{V}}{j, \tau}$, and use it for the loss in Equation 15.
This table shows the effect of multiple temperatures on our ablation default:
| $\tau$ | 0.02 | 0.05 | 0.2 | {0.02, 0.05, 0.2} |
|---|---|---|---|---|
| FID | 10.62 | 8.67 | 8.96 | 8.46 |
Using multiple temperatures can achieve slightly better results than using a single optimal temperature. We fix $\tau \in $ 0.02, 0.05, 0.2 and do not require tuning this hyperparameter across different configurations.
Normalization across spatial locations.
For a feature map of resolution $H_i{\times}W_i$, there are $H_i{\times}W_i$ per-location features. Separately computing the normalization for each location would be slow and unnecessary. We assume that features at different locations within the same feature map share the same normalization scale. Accordingly, we concatenate all $H_i{\times}W_i$ locations and compute the normalization scale over all of them. The feature normalization and drift normalization are both performed in this way.
A.7 Classifier-Free Guidance (CFG)
To support CFG, at training time, we include $N_\text{unc}$ additional unconditional samples (real images from random classes) as extra negatives. These samples are weighted by a factor $w$ when computing the kernel. For a generated sample $\mathbf{x}$, the effective negative distribution it compares with is:
$ \tilde{q}(\cdot|c) \triangleq \frac{(N_\text{neg}{-}1) \cdot q_\theta(\cdot|c) + N_\text{unc} w \cdot p_{\text{data}}(\cdot|\varnothing)}{(N_\text{neg}{-}1) + N_\text{unc} w}. $
Comparing this equation with Eq. (12)Equation (13), we have:
$ \gamma = \frac{N_\text{unc} w}{(N_\text{neg}{-}1) + N_\text{unc} w} $
and
$ \alpha = \frac{1}{1-\gamma} = \frac{(N_\text{neg}{-}1) + N_\text{unc} w}{N_\text{neg}{-}1}. $
Given a CFG strength $\alpha$, we compute $w$ accordingly, which is used to weight the kernel. The same weighting $w$ is also applied when computing the global distance normalization.
We train our model with CFG-conditioning [40]. At each iteration, we randomly sample $\alpha$ following a pre-defined distribution (see Table 8) and compute the resulting $w$ for weighting the unconditional samples. The value of $\alpha$ is a condition input to the network $f_\theta({\boldsymbol{\epsilon}}, c, \alpha)$, alongside the class label $c$.
At inference time, we specify a value of $\alpha$. The inference-time computation remains to be one-step (1-NFE).
A.8 Sample Queue
Our method requires access to randomly sampled real (positive/unconditional) data. This can be implemented using a specialized data loader. Instead, we adopt a sample queue of cached data, similar to the queue used in MoCo [34]. This implementation samples data in a statistically similar way to a specialized data loader. For completeness, we describe our implementation as follows, while noting that a data loader would be a more principled solution.
For each class label, we keep a queue of size 128; for unconditional samples (used in CFG), we maintain a separate global queue of size 1000. At each training step, we push the latest 64 new real (positive/unconditional) samples, alongside their labels, into the corresponding queues; the earliest ones are dequeued. When sampling, positive samples are drawn from the queue of the corresponding class, and unconditional samples are drawn from the global queue. We sample without replacement.
A.9 Training Loop
In summary, in the training loop, each step proceeds as:
- Sample a batch ($N_c$) of class labels.
- For each label $c$, sample a CFG scale $\alpha$.
- Sample a batch ($N_\text{neg}$) of noise ${\boldsymbol{\epsilon}}$. Feed $({\boldsymbol{\epsilon}}, c, \alpha)$ to the generator $f$ to produce generated samples;
- Sample positive samples (same class, $N_\text{pos}$) and unconditional samples (for CFG, $N_\text{unc}$);
- Extract features on all generated, positive, and unconditional samples
- Compute the drifting loss using the features.
- Run backpropagation and parameter update.
B. Additional Experimental Results
::: {caption="Table 9: Ablations on pixel-space generation. We study generation directly in pixel space (without VAE). Applying the same MAE recipe as in latent space yields higher FID, indicating that pixel-space generation is more challenging. Combining MAE with ConvNeXt-V2 helps close this gap. Latent-space results shown for reference. The results below follow the ablation setting (B/16 model for pixel-space, 100 epochs)."}

:::
:::
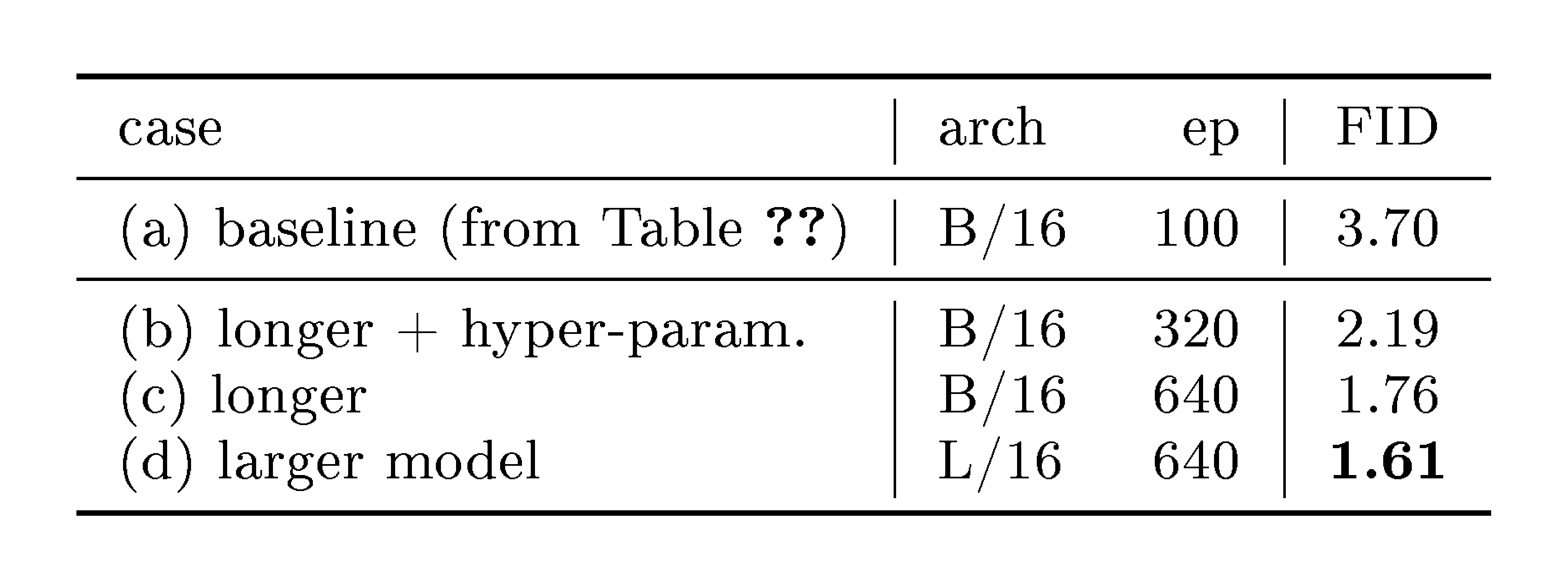
Pixel-space generation: from ablation to final setting. Beyond the ablation setting, we compare the settings that lead to the results in Table 6.
:::
::: {caption="Table 11: Ablation on kernel normalization. Softmax normalization over both the $\mathbf{x}$ and $\mathbf{y}$ axes performs better. On the other hand, even using no normalization performs decently, showing the robustness of our method. (Setting: B/2 model, 100 epochs)"}

:::
B.1 Ablations on Pixel-Space Generation
We provide more ablations on pixel-space generation in Table 9 and Table 10. Table 9 compares the effect of the feature encoder on the pixel-space generator. It shows that the choice of feature encoder plays a more significant role in pixel-space generation quality. A weaker MAE encoder yields an FID of 32.11, whereas a stronger MAE encoder improves performance to an FID of 9.35. We further add another feature encoder, ConvNeXt-V2 [57], which is also pre-trained with the MAE objective. This further improves the result to an FID of 3.70.
Table 10 reports the results of training longer and using a larger model. Due to limited time, we train pixel-space models for 640 epochs (vs. the latent counterpart's 1280); we expect that longer training would yield further improvements. We achieve an FID of 1.61 for pixel-space generation. This is our result in the main paper (Table 6).
B.2 Ablation on Kernel Normalization
In Eq. (8), our drifting field is weighted by normalized kernels, which can be written as:
$ \mathbf{V}(\mathbf{x}) = \mathbb E_{p, q} [\tilde{k}(\mathbf{x}, \mathbf{y}^{+}) \tilde{k}(\mathbf{x}, \mathbf{y}^{-}) (\mathbf{y}^{+} - \mathbf{y}^{-})], $
where $\tilde{k}(\cdot, \cdot)=\frac{1}{Z}k(\cdot, \cdot)$ denotes the normalized kernel. In principle, this normalization is approximated by a softmax operation over the axis of $\mathbf{y}$ samples. Our implementation (Algorithm 2) further applies softmax over the axis of $\mathbf{x}$ samples. We compare these designs, along with another variant without normalization ($Z=1$).
Table 11 compares the three designs. Using the $\mathbf{y}$-only softmax performs well (8.92 FID), whereas using both $\mathbf{x}$ and $\mathbf{y}$ softmax improves the result (8.46 FID). On the other hand, even without normalization, performance remains decent, demonstrating the robustness of our method.
We note that all three variants satisfy the equilibrium condition $\mathbf{V}_{p, q}(\mathbf{x}) = \mathbf{0}$ when $p=q$. This explains why all variants perform reasonably well and why even the destructive setting (no normalization) avoids catastrophic failure.
B.3 Ablation on CFG
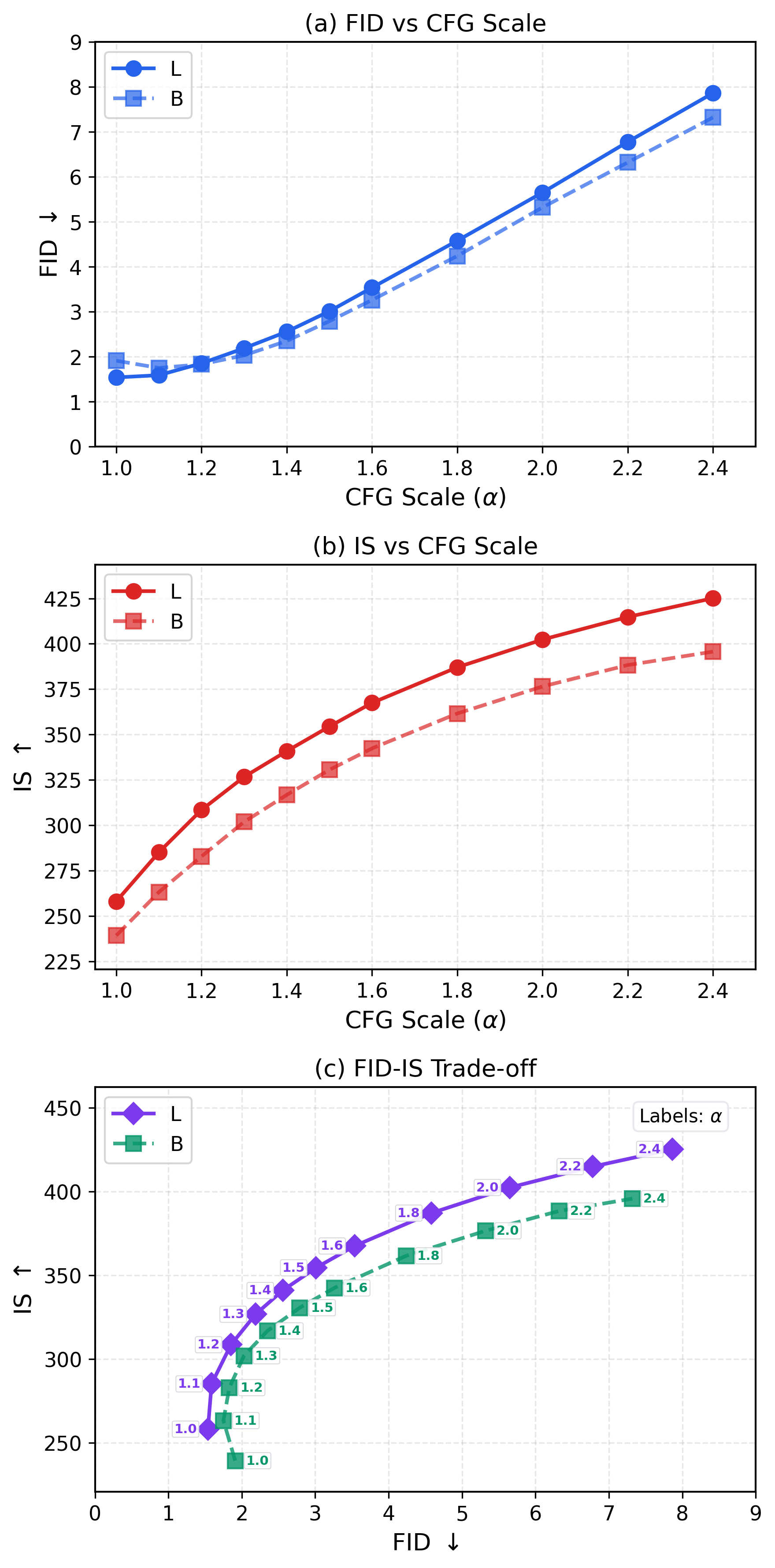
In Figure 10, we investigate the CFG scale $\alpha$ used at inference time. It shows that the CFG formulation developed for our models exhibits behavior similar to that observed in diffusion-/flow-based models. Increasing the CFG scale leads to higher IS values, whereas beyond the FID sweet spot, further increases in IS come at the cost of worse FID.
Notably, with our best model (L/2), the optimal FID is achieved at $\alpha{=}1.0$, which is often regarded as "w/o CFG" in diffusion-/flow-based models (even though their "w/o CFG" setting can reduce NFE by half). While our method need not run an unconditional model at inference time (in contrast to standard CFG), training is influenced by the use of unconditional real samples as negatives.
![**Figure 11:** **Nearest neighbor analysis.** Each panel shows a generated sample together with its top-10 nearest real images. The nearest neighbors are retrieved from the ImageNet training set based on the cosine similarity using a CLIP encoder [58]. Our method generates novel images that are visually distinct from their nearest neighbors.](https://ittowtnkqtyixxjxrhou.supabase.co/storage/v1/object/public/public-images/cdkheph2/complex_fig_ed92e70ce605.png)
B.4 Nearest Neighbor Analysis
In Figure 11, we show generated images together with their nearest real images. The nearest neighbors are retrieved from the ImageNet training set using CLIP features. These visualizations suggest that our method generates novel images that are visually distinct from their nearest neighbors, rather than merely memorizing training samples.
B.5 Qualitative Results
Figure 12-Figure 15 show uncurated samples from our model. Figure 16-Figure 20 provide side-by-side comparison with improved MeanFlow (iMF) [40], the current state-of-the-art one-step method.
C. Additional Derivations
C.1 On Identifiability of the Zero-Drift Equilibrium
In Section 3, we showed that anti-symmetry implies $p=q \Rightarrow \mathbf{V}(\mathbf{x})\equiv \mathbf{0}$. Here we investigate the converse: under what conditions does $\mathbf{V}(\mathbf{x})\approx \mathbf{0}$ imply $p\approx q$? Generally, this is not guaranteed for arbitrary vector fields. However, we argue that for our specific construction, the zero-drift condition imposes strong constraints on the distributions.
To avoid boundary issues, we assume that $p$ and $q$ have full support on $\mathbb{R}^d$ (e.g., via infinitesimal Gaussian smoothing). Consequently, ensuring the equilibrium condition $\mathbf{V}(\mathbf{x}) \approx \mathbf{0}$ for generated samples $\mathbf{x} \sim q$ effectively enforces $\mathbf{V}(\mathbf{x}) \approx \mathbf{0}$ for all $\mathbf{x} \in \mathbb{R}^d$.
Setup.
Consider a general interaction kernel $K(\mathbf{x}, \mathbf{y}^+, \mathbf{y}^-) \in \mathbb{R}^d$ and the drifting field
$ \mathbf{V}{p, q}(\mathbf{x}) := \mathbb{E}{\mathbf{y}^+\sim p, \ \mathbf{y}^-\sim q} \big[K(\mathbf{x}, \mathbf{y}^+, \mathbf{y}^-) \big].\tag{16} $
We assume that $p$ and $q$ belong to a finite-dimensional model class spanned by a linearly independent basis ${\varphi_i}_{i=1}^m$:
$ p(\mathbf{y})=\sum_{i=1}^m a_i, \varphi_i(\mathbf{y}), \qquad q(\mathbf{y})=\sum_{i=1}^m b_i, \varphi_i(\mathbf{y}),\tag{17} $
where $\mathbf{a}, \mathbf{b}\in\mathbb{R}^m$ are coefficient vectors.
Bilinear expansion over test locations.
Consider a set of test locations (probes) $\mathcal{X} = {\mathbf{x}k}{k=1}^N$ with sufficiently large $N$ (e.g., $N \gg m^2$). For each pair of basis indices $(i, j)$, we define the induced interaction vector $\mathbf{U}_{ij} \in \mathbb{R}^{d{\times}N}$ by computing its column:
$ \mathbf{U}_{ij}[:, \mathbf{x}] \triangleq \iint K(\mathbf{x}, \mathbf{y}^+, \mathbf{y}^-), \varphi_i(\mathbf{y}^+), \varphi_j(\mathbf{y}^-), d\mathbf{y}^+d\mathbf{y}^- $
evaluated at all $\mathbf{x} \in \mathcal{X}$. Substituting the basis expansion into Equation 16, the drifting field evaluated on $\mathcal{X}$ (stored as a matrix $\mathbf{V}_{\mathcal{X}}$) is a bilinear combination:
$ \mathbf{V}{\mathcal{X}} \triangleq \sum{i=1}^m \sum_{j=1}^m a_i b_j \mathbf{U}_{ij}. $
Here, $\mathbf{V}{\mathcal{X}} \in \mathbb{R}^{d{\times}N}$. At the equilibrium, we have $\mathbf{V}{\mathcal{X}}=\textbf{0}$, which yields $dN$ linear equations.
Linear independence assumption.
Our anti-symmetry condition implies that switching $p$ and $q$ negates the field. In terms of basis interactions, this means $\mathbf{U}{ij} = -\mathbf{U}{ji}$ (and consequently $\mathbf{U}{ii} = \mathbf{0}$). We make the generic non-degeneracy assumption: *The set of vectors ${\mathbf{U}{ij}}_{1 \le i < j \le m}$ is linearly independent in $\mathbb{R}^{dN}$.* This assumption requires the probes $\mathcal{X}$ and kernel $K$ to be non-degenerate; if all $\mathbf{x}$ yield identical constraints, independence would fail. For generic choices of $K$ and sufficiently diverse probes $\mathcal{X}$ with $dN\gg m^2$, such linear independence is a natural non-degeneracy condition.
Uniqueness of the equilibrium.
The zero-drift condition $\mathbf{V}(\mathbf{x}) \equiv \mathbf{0}$ implies $\mathbf{V}{\mathcal{X}} = \mathbf{0}$. Grouping terms by the independent basis vectors ${\mathbf{U}{ij}}_{i<j}$, we have:
$ \sum_{1 \le i < j \le m} (a_i b_j - a_j b_i) \mathbf{U}_{ij} = \mathbf{0}. $
By the linear independence assumption, the coefficients must vanish: $a_i b_j - a_j b_i = 0$ for all $i, j$. This implies that the vector $\mathbf{a}$ is parallel to $\mathbf{b}$ (i.e., $\mathbf{a} \propto \mathbf{b}$). Since $p$ and $q$ are probability densities (implying $\int p = \int q = 1$), we must have $\mathbf{a} = \mathbf{b}$, and thus $p=q$.
Connection to the mean shift field.
The mean-shift field fits this framework. The update vector (before normalization) is $\mathbb{E}_{p, q}[k(\mathbf{x}, \mathbf{y}^+) k(\mathbf{x}, \mathbf{y}^-) (\mathbf{y}^+ - \mathbf{y}^-)]$. Assuming the normalization factors $Z_p$ and $Z_q$ are finite, the condition $\mathbf{V}(\mathbf{x}) = \mathbf{0}$ implies the numerator integral vanishes, which corresponds to an interaction kernel of the form:
$ K(\mathbf{x}, \mathbf{y}^+, \mathbf{y}^-) = k(\mathbf{x}, \mathbf{y}^+), k(\mathbf{x}, \mathbf{y}^-), (\mathbf{y}^+ - \mathbf{y}^-). $
This kernel generates the bilinear structure analyzed above. Since we can choose $N$ such that $dN \gg m^2$, the dimension of the test space is much larger than the number of basis pairs. Thus, the linear independence of ${\mathbf{U}{ij}}$ is expected to hold for generic configurations. Finally, for general distributions $p$ and $q$, we can approximate them using a sufficiently large basis expansion, turning into $\tilde p$ and $\tilde q$. When the basis approximation is sufficiently accurate, $\tilde p \approx p$ and $\tilde q \approx q$, and the drift field $\mathbf{V}{\tilde p, \tilde q}\approx \mathbf{V}_{p, q}\approx 0$. By the argument above, $\tilde p\approx \tilde q$, and thus $p\approx q$.
The argument above works for general form of drifting field, under mild anti-degeneracy assumptions.
C.2 The Drifting Field of MMD
In principle, if a method minimizes a discrepancy between two distributions $p$ and $q$ and reaches minimum at $p=q$, then from the perspective of our framework, a drifting field $\mathbf{V}$ exists that governs sample movement: we can let $\mathbf{V}{\propto}{-}\frac{\partial\mathcal L }{\partial {\mathbf{x}}}$, which is zero when $p=q$. We discuss the formulation of this $\mathbf{V}$ for a loss based on Maximum Mean Discrepancy (MMD) [23, 22].
Gradients of Drifting Loss.
With $\mathbf{x}=f_\theta({\boldsymbol{\epsilon}})$, our drifting loss in Eq. (3) can be written as:
$ \mathcal{L}
\mathbb{E}_{\mathbf{x}{\sim}q} [\mathcal{L}(\mathbf{x})]
\mathbb{E}_{\mathbf{x}{\sim}q} \Big[\big| \mathbf{x}
\text{\texttt{sg}}\big(\mathbf{x} + \mathbf{V}(\mathbf{x}) \big) \big|^2 \Big], $
where "sg" is short for stop-gradient. The gradient w.r.t. the parameters $\theta$ is computed by:
$ \frac{\partial\mathcal L }{\partial {\theta}} = \mathbb{E}_{\mathbf{x}{\sim}q}\Big[\frac{\partial\mathcal L(\mathbf{x}) }{\partial {\mathbf{x}}} \frac{\partial \mathbf{x}}{\partial\theta} \Big]. $
where $ \frac{\partial\mathcal L(\mathbf{x}) }{\partial {\mathbf{x}}}{=}2 (\mathbf{x} {-} \texttt{sg}(\mathbf{x} + \mathbf{V}(\mathbf{x}))) {=}{-}2 \mathbf{V}(\mathbf{x}) $. This gives:
$ \mathbf{V}(\mathbf{x}) = -\frac{1}{2}\frac{\partial\mathcal L(\mathbf{x}) }{\partial {\mathbf{x}}}\tag{18} $
We note that this formulation is general and imposes no constraints on $\mathbf{V}$, except that $\mathbf{V}=\textbf{0}$ when $p=q$.
Our method does not require $\mathcal{L}$ to define a discrepancy between $p$ and $q$. However, for other methods that depend on minimizing a discrepancy $\mathcal{L}$, we can induce a drifting field via Equation (18). This is valid if $\mathcal{L}$ is minimized when $p=q$.
Gradients of MMD Loss.
In MMD-based methods (e.g., [23]), the difference between two distributions $p$ and $q$ is measured by squared MMD:
$ \begin{aligned} \mathcal{L}{\text{MMD}^2}(p, q) = & \mathbb{E}{\mathbf{x}, \mathbf{x}'\sim q}[\xi(\mathbf{x}, \mathbf{x}')] -2, \mathbb{E}_{\mathbf{y}\sim p, ; \mathbf{x}\sim q}[\xi(\mathbf{y}, \mathbf{x})] \
- &~const. \end{aligned}\tag{19} $
Here, the constant term is $\mathbb{E}_{\mathbf{y}, \mathbf{y}'\sim p}[\xi(\mathbf{y}, \mathbf{y}')]$, which depends only on the target distribution $p$ and remains unchanged. $\xi$ is a kernel function.
Consider $\mathbf{x}=f_\theta({\boldsymbol{\epsilon}})$ with ${\boldsymbol{\epsilon}}\sim p_{\boldsymbol{\epsilon}}$. The gradient estimation performed in [23] corresponds to:
$ \frac{\partial \mathcal{L}{\text{MMD}^2}}{\partial {\theta}} = \mathbb{E}{\mathbf{x}{\sim}q}\Big[\frac{\partial \mathcal{L}_{\text{MMD}^2}(\mathbf{x})}{\partial {\mathbf{x}}} \frac{\partial \mathbf{x}}{\partial\theta} \Big] $
where the gradient w.r.t $\mathbf{x}$ is computed by:
$ \frac{\partial \mathcal{L}_{\text{MMD}^2}(\mathbf{x})}{\partial {\mathbf{x}}}
2\mathbb{E}_{\mathbf{x}'{\sim}q} \Big[\frac{\partial \xi(\mathbf{x}, \mathbf{x}')}{\partial{\mathbf{x}}}\Big]
2\mathbb{E}_{\mathbf{y}{\sim}p} \Big[\frac{\partial \xi(\mathbf{x}, \mathbf{y})}{\partial{\mathbf{x}}}\Big]. $
Using our notation of positives and negatives, we rename the variables and rewrite as:
$ \frac{\partial\mathcal L_{\text{MMD}^2}(\mathbf{x})}{\partial {\mathbf{x}}}
2\mathbb{E}_{\mathbf{y}^{-}{\sim}q} \Big[\frac{\partial \xi(\mathbf{x}, \mathbf{y}^{-})}{\partial{\mathbf{x}}}\Big]
2\mathbb{E}_{\mathbf{y}^{+}{\sim}p} \Big[\frac{\partial \xi(\mathbf{x}, \mathbf{y}^{+})}{\partial{\mathbf{x}}}\Big].\tag{20} $
Comparing with Eq. (18), we obtain:
$ \mathbf{V}\text{MMD}(\mathbf{x}) \triangleq \mathbb{E}{\mathbf{y}^{+}{\sim}p} \Big[\frac{\partial \xi(\mathbf{x}, \mathbf{y}^{+})}{\partial{\mathbf{x}}}\Big]
\mathbb{E}_{\mathbf{y}^{-}{\sim}q} \Big[\frac{\partial \xi(\mathbf{x}, \mathbf{y}^{-})}{\partial{\mathbf{x}}}\Big]\tag{21} $
This is the underlying drifting field that corresponds to the MMD loss $\mathcal{L}_{\text{MMD}^2}$.
For a radial kernel $\xi(\mathbf{x}, \mathbf{y})= \xi(R)$ where $R=| \mathbf{x} - \mathbf{y}|^2$, the gradient of kernel is:
$ \frac{\partial \xi(\mathbf{x}, \mathbf{y})}{\partial \mathbf{x}} = 2 \xi'(| \mathbf{x} - \mathbf{y}|^2)(\mathbf{x} - \mathbf{y}) $
where $\xi'$ is the derivative of the function $\xi(R)$. Accordingly, Eq. (21) becomes:
$ \begin{aligned}
\mathbf{V}\text{MMD}(\mathbf{x}) = & \mathbb{E}{\mathbf{y}^{+}{\sim}p} \Big[2 \xi'(| \mathbf{x} - \mathbf{y}^{+}|^2)(\mathbf{x} - \mathbf{y}^{+}) \Big]. \ - & \mathbb{E}_{\mathbf{y}^{-}{\sim}q} \Big[2 \xi'(| \mathbf{x} - \mathbf{y}^{-}|^2)(\mathbf{x} - \mathbf{y}^{-}) \Big] \end{aligned}\tag{22} $
In [23], the Gaussian kernel is used: $\xi(\mathbf{x}, \mathbf{y}) = \exp (-\frac{1}{2\sigma^2} | \mathbf{x}{-}\mathbf{y}|^2)$, leading to $\xi'(| \mathbf{x}{-}\mathbf{y}|^2)=-\frac{1}{2\sigma^2}\exp (-\frac{1}{2\sigma^2} | \mathbf{x}{-}\mathbf{y}|^2)$.
Relations and Differences.
When using our definition of $\mathbf{V} = \mathbf{V}^{+} - \mathbf{V}^{-}$ (i.e., Eq. (7)), we have:
$ \begin{aligned}
\mathbf{V}(\mathbf{x}) = & \mathbb{E}_{\mathbf{y}^{+}{\sim}p} \Big[\tilde{k}(\mathbf{x}, \mathbf{y}^{+})(\mathbf{y}^{+} - \mathbf{x}) \Big] \
- & \mathbb{E}_{\mathbf{y}^{-}{\sim}q} \Big[\tilde{k}(\mathbf{x}, \mathbf{y}^{-})(\mathbf{y}^{-} - \mathbf{x}) \Big] \end{aligned}\tag{23} $
Comparing Equation (22) with Equation (23), we show that the underlying kernel used to build the drifting field of MMD is:
$ \tilde{k}_\text{MMD}(\mathbf{x}, \mathbf{y})=-2 \xi'(| \mathbf{x} - \mathbf{y}|^2).\tag{24} $
When $\xi$ is a Gaussian function, we have: $\tilde{k}(\mathbf{x}, \mathbf{y})=\frac{1}{\sigma^2}\exp (-\frac{1}{2\sigma^2} | \mathbf{x}{-}\mathbf{y}|^2)$. Without normalization, the resulting drift no longer satisfies the assumptions underlying Algorithm 2, and the mean-shift interpretation breaks down.
As a comparison, our general formulation enables to use normalized kernels:
$ \tilde{k}(\mathbf{x}, \mathbf{y})=\frac{1}{Z(\mathbf{x})}k(\mathbf{x}, \mathbf{y})=\frac{1}{\mathbb{E}_\mathbf{y}[k(\mathbf{x}, \mathbf{y})]}k(\mathbf{x}, \mathbf{y}), $
where the expectation is over $p$ or $q$. Only when we use normalized kernels, we have (see Eq. (8)):
$ \mathbf{V}(\mathbf{x}) = {\mathbb{E}_{p, q}!\left[\tilde{k}(\mathbf{x}, \mathbf{y}^{+})\tilde{k}(\mathbf{x}, \mathbf{y}^{-})(\mathbf{y}^{+} - \mathbf{y}^{-})\right]}, $
on which our Algorithm 2 is based.
Given this relation, we summarize the key differences between our model and the MMD-based methods as follows:
- Our method is formulated around the drifting field $\mathbf{V}$, which is more flexible and general.
- Our method supports and leverages normalized kernels $\frac{1}{Z}k(\mathbf{x}, \mathbf{y})$ that cannot be naturally derived from the MMD perspective.
- Our $\mathbf{V}$-centric formulation enables a flexible step size for drifting (i.e., $\mathbf{x} \leftarrow \mathbf{x}{+}\eta \mathbf{V}$) and therefore naturally supports $\mathbf{V}$-normalization (see Appendix A.6).
- Our $\mathbf{V}$-centric formulation allows the equilibrium concept to be naturally extended to support CFG, whereas a CFG variant for MMD remains unexplored.
In summary, although a special case of our method reduces to MMD, our $\mathbf{V}$-centric framework is more general and enables unique possibilities that are important in practice. In our experiments, we were not able to obtain reasonable results using the MMD framework.




![**Figure 16:** **Side-by-side comparison with improved MeanFlow (iMF) [40] (page 1/5).** Uncurated samples from our method (left) and iMF (right) on **all** ImageNet classes visualized in the iMF paper. Both methods generate images with a single neural function evaluation (1-NFE). The iMF visualizations use CFG $\omega{=}6.0$ and interval $[t_\text{min}, t_\text{max}]{=}[0.2, 0.8]$, achieving FID 3.92 and IS 348.2 (DiT-XL/2). For fair comparison, we set the CFG scale to match the IS of iMF visualizations, which leads to FID 3.01 and IS 354.4 (at CFG=1.5) for our method (DiT-L/2).](https://ittowtnkqtyixxjxrhou.supabase.co/storage/v1/object/public/public-images/cdkheph2/complex_fig_ff765162ce2b.png)
![**Figure 17:** **Side-by-side comparison with improved MeanFlow (iMF) [40] (page 2/5).** Uncurated samples from our method (left) and iMF (right) on **all** ImageNet classes visualized in the iMF paper. Both methods generate images with a single neural function evaluation (1-NFE). The iMF visualizations use CFG $\omega{=}6.0$ and interval $[t_\text{min}, t_\text{max}]{=}[0.2, 0.8]$, achieving FID 3.92 and IS 348.2 (DiT-XL/2). For fair comparison, we set the CFG scale to match the IS of iMF visualizations, which leads to FID 3.01 and IS 354.4 (at CFG=1.5) for our method (DiT-L/2).](https://ittowtnkqtyixxjxrhou.supabase.co/storage/v1/object/public/public-images/cdkheph2/complex_fig_f875220f557a.png)
![**Figure 18:** **Side-by-side comparison with improved MeanFlow (iMF) [40] (page 3/5).** Uncurated samples from our method (left) and iMF (right) on **all** ImageNet classes visualized in the iMF paper. Both methods generate images with a single neural function evaluation (1-NFE). The iMF visualizations use CFG $\omega{=}6.0$ and interval $[t_\text{min}, t_\text{max}]{=}[0.2, 0.8]$, achieving FID 3.92 and IS 348.2 (DiT-XL/2). For fair comparison, we set the CFG scale to match the IS of iMF visualizations, which leads to FID 3.01 and IS 354.4 (at CFG=1.5) for our method (DiT-L/2).](https://ittowtnkqtyixxjxrhou.supabase.co/storage/v1/object/public/public-images/cdkheph2/complex_fig_d5385b252a1c.png)
![**Figure 19:** **Side-by-side comparison with improved MeanFlow (iMF) [40] (page 4/5).** Uncurated samples from our method (left) and iMF (right) on **all** ImageNet classes visualized in the iMF paper. Both methods generate images with a single neural function evaluation (1-NFE). The iMF visualizations use CFG $\omega{=}6.0$ and interval $[t_\text{min}, t_\text{max}]{=}[0.2, 0.8]$, achieving FID 3.92 and IS 348.2 (DiT-XL/2). For fair comparison, we set the CFG scale to match the IS of iMF visualizations, which leads to FID 3.01 and IS 354.4 (at CFG=1.5) for our method (DiT-L/2).](https://ittowtnkqtyixxjxrhou.supabase.co/storage/v1/object/public/public-images/cdkheph2/complex_fig_305c188d158f.png)
![**Figure 20:** **Side-by-side comparison with improved MeanFlow (iMF) [40] (page 5/5).** Uncurated samples from our method (left) and iMF (right) on **all** ImageNet classes visualized in the iMF paper. Both methods generate images with a single neural function evaluation (1-NFE). The iMF visualizations use CFG $\omega{=}6.0$ and interval $[t_\text{min}, t_\text{max}]{=}[0.2, 0.8]$, achieving FID 3.92 and IS 348.2 (DiT-XL/2). For fair comparison, we set the CFG scale to match the IS of iMF visualizations, which leads to FID 3.01 and IS 354.4 (at CFG=1.5) for our method (DiT-L/2).](https://ittowtnkqtyixxjxrhou.supabase.co/storage/v1/object/public/public-images/cdkheph2/complex_fig_2c732cf6c78e.png)
References
[1] Sohl-Dickstein et al. (2015). Deep Unsupervised Learning using Nonequilibrium Thermodynamics. In ICML. pp. 2256–2265.
[2] Lipman et al. (2022). Flow Matching for Generative Modeling. arXiv preprint arXiv:2210.02747.
[3] Ho et al. (2020). Denoising Diffusion Probabilistic Models. NeurIPS. 33. pp. 6840–6851.
[4] Song et al. (2020). Score-based Generative Modeling through Stochastic Differential Equations. arXiv preprint arXiv:2011.13456.
[5] Liu et al. (2022). Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow. arXiv preprint arXiv:2209.03003.
[6] Albergo et al. (2023). Stochastic Interpolants: A Unifying Framework for Flows and Diffusions. arXiv preprint arXiv:2303.08797.
[7] Salimans, Tim and Ho, Jonathan (2022). Progressive Distillation for Fast Sampling of Diffusion Models. arXiv preprint arXiv:2202.00512.
[8] Luo et al. (2023). Diff-Instruct: A Universal Approach for Transferring Knowledge from Pre-trained Diffusion Models. NeurIPS. 36. pp. 76525–76546.
[9] Yin et al. (2024). One-step Diffusion with Distribution Matching Distillation. In CVPR. pp. 6613–6623.
[10] Zhou et al. (2024). Score Identity Distillation: Exponentially Fast Distillation of Pretrained Diffusion Models for One-step Generation. In ICML.
[11] Song et al. (2023). Consistency Models.
[12] Frans et al. (2024). One Step Diffusion via Shortcut Models. arXiv preprint arXiv:2410.12557.
[13] Boffi et al. (2025). Flow Map Matching with Stochastic Interpolants: A Mathematical Framework for Consistency Models. TMLR.
[14] Geng et al. (2025). Mean Flows for One-step Generative Modeling. arXiv preprint arXiv:2505.13447.
[15] Goodfellow et al. (2014). Generative Adversarial Nets. NeurIPS.
[16] Kingma, Diederik P and Welling, Max (2013). Auto-encoding Variational Bayes. arXiv preprint arXiv:1312.6114.
[17] Rombach et al. (2022). High-resolution Image Synthesis with Latent Diffusion Models. In CVPR. pp. 10684–10695.
[18] Esser et al. (2021). Taming Transformers for High-resolution Image Synthesis. In CVPR. pp. 12873–12883.
[19] Rezende, Danilo and Mohamed, Shakir (2015). Variational Inference with Normalizing Flows. In ICML. pp. 1530–1538.
[20] Dinh et al. (2016). Density Estimation Using Real NVP. arXiv preprint arXiv:1605.08803.
[21] Zhai et al. (2024). Normalizing Flows Are Capable Generative Models. arXiv preprint arXiv:2412.06329.
[22] Dziugaite et al. (2015). Training Generative Neural Networks via Maximum Mean Discrepancy Optimization. arXiv preprint arXiv:1505.03906.
[23] Li et al. (2015). Generative Moment Matching Networks. In ICML. pp. 1718–1727.
[24] Zhou et al. (2025). Inductive Moment Matching. arXiv preprint arXiv:2503.07565.
[25] Hadsell et al. (2006). Dimensionality Reduction by Learning an Invariant Mapping. In CVPR. pp. 1735–1742.
[26] Oord et al. (2018). Representation Learning with Contrastive Predictive Coding. arXiv preprint arXiv:1807.03748.
[27] Unterthiner et al. (2017). Coulomb GANs: Provably Optimal Nash Qquilibria via Potential Fields. arXiv preprint arXiv:1708.08819.
[28] Kang, Minguk and Park, Jaesik (2020). ContraGAN: Contrastive Learning for Conditional Image Generation. NeurIPS. 33. pp. 21357–21369.
[29] Stoica et al. (2025). Contrastive Flow Matching. arXiv preprint arXiv:2506.05350.
[30] Chen, Xinlei and He, Kaiming (2021). Exploring Simple Siamese Representation Learning. In CVPR. pp. 15750–15758.
[31] Song, Yang and Dhariwal, Prafulla (2023). Improved Techniques for Training Consistency Models. arXiv preprint arXiv:2310.14189.
[32] Cheng, Yizong (1995). Mean Shift, Mode Seeking, and Clustering. TPAMI.
[33] He et al. (2016). Deep Residual Learning for Image Recognition. In CVPR. pp. 770–778.
[34] He et al. (2020). Momentum Contrast for Unsupervised Visual Representation Learning. In CVPR. pp. 9729–9738.
[35] Chen et al. (2020). A Simple Framework for Contrastive Learning of Visual Representations. In ICML.
[36] Zhang et al. (2018). The Unreasonable Effectiveness of Deep Features as a Perceptual Metric. In CVPR.
[37] Ho, Jonathan and Salimans, Tim (2022). Classifier-free Diffusion Guidance. arXiv preprint arXiv:2207.12598.
[38] Deng et al. (2009). ImageNet: A Large-scale Hierarchical Image Database. In CVPR. pp. 248–255.
[39] Peebles, William and Xie, Saining (2023). Scalable Diffusion Models with Transformers. In CVPR. pp. 4195–4205.
[40] Geng et al. (2025). Improved Mean Flows: On the Challenges of Fastforward Generative Models. arXiv preprint arXiv:2512.02012.
[41] He et al. (2022). Masked Autoencoders Are Scalable Vision Learners. In CVPR.
[42] Heusel et al. (2017). GANs Trained by a Two Time-Scale Update Rule Converge to a Local Nash Equilibrium. NeurIPS.
[43] Chen et al. (2020). Improved Baselines with Momentum Contrastive Learning. arXiv preprint arXiv:2003.04297.
[44] Chi et al. (2023). Diffusion Policy: Visuomotor Policy Learning via Action Diffusion. In RSS.
[45] Yao et al. (2025). Reconstruction vs. Generation: Taming Optimization Dilemma in Latent Diffusion Models. In CVPR. pp. 15703–15712.
[46] Shazeer, Noam (2020). GLU Variants Improve Transformer. arXiv preprint arXiv:2002.05202.
[47] Su et al. (2024). Roformer: Enhanced Transformer with Totary Position Embedding. IJON. 568. pp. 127063.
[48] Zhang, Biao and Sennrich, Rico (2019). Root Mean Square Layer Normalization. NeurIPS. 32.
[49] Henry et al. (2020). Query-Key Normalization for Transformers. In EMNLP. pp. 4246–4253.
[50] Li, Tianhong and He, Kaiming (2025). Back to Basics: Let Denoising Generative Models Denoise. arXiv preprint arXiv:2511.13720.
[51] Sauer et al. (2022). StyleGAN-XL: Scaling StyleGAN to Large Diverse Datasets. In SIGGRAPH. pp. 1–10.
[52] Dosovitskiy et al. (2021). An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. In ICLR.
[53] Ronneberger et al. (2015). U-Net: Convolutional Networks for Biomedical Image Segmentation. In MICCAI.
[54] Wu, Yuxin and He, Kaiming (2018). Group Normalization. In ECCV. pp. 3–19.
[55] Ioffe, Sergey and Szegedy, Christian (2015). Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. In ICML. pp. 448–456.
[56] Loshchilov, Ilya and Hutter, Frank (2019). Decoupled Weight Decay Regularization. In ICLR.
[57] Woo et al. (2023). ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders. In CVPR. pp. 16133–16142.
[58] Radford et al. (2021). Learning Transferable Visual Models from Natural Language Supervision. In ICML. pp. 8748–8763.