LEAP: Supercharging LLMs for Formal Mathematics with Agentic Frameworks
Po-Nien Kung$^{1}$, Linfeng Song$^{2}$, Dawsen Hwang$^{3}$, Jinsung Yoon$^{1}$, Chun-Liang Li$^{1}$, Simone Severini$^{2}$, Mirek Olšák$^{3}$, Edward Lockhart$^{3}$, Quoc V Le$^{3}$, Burak Gokturk$^{1}$, Thang Luong$^{3}$, Tomas Pfister$^{1}$, Nanyun Peng$^{1}$
$^{1}$ Google Cloud AI Research $^{2}$ Google Cloud $^{3}$ Google DeepMind
Abstract
Large Language Models (LLMs) exhibit strong informal mathematical reasoning but struggle to generate mechanically verifiable proofs in formal languages like Lean. We present LEAP (LLM-in-Lean Environment Agentic Prover), an agentic framework that enables general-purpose foundation models to achieve state-of-the-art performance on automated formal theorem proving. LEAP leverages foundation model capabilities, such as informal reasoning, instruction following, and iterative self-refinement. By decomposing complex problems into smaller units, the system bridges formal proof construction with informal blueprints through continuous interaction with the Lean compiler. To provide a rigorous evaluation beyond increasingly saturated benchmarks, we introduce Lean-IMO-Bench, a benchmark of IMO-style problems formalized in Lean, with short statements yet highly non-routine and multi-step proofs across a wide range of difficulty levels. Empirically, on the latest 2025 Putnam Competition, an annual mathematics competition for undergraduate students in North America, LEAP solves all 12 problems, matching recent breakthroughs by frontier formal mathematical models; On Lean-IMO-Bench, LEAP boosts the one-shot formal solve rate of general-purpose LLMs from below 10% to 70%, notably surpassing the 48% benchmark set by a specialized, gold-medal-caliber IMO system. Furthermore, we demonstrate LEAP’s research-level utility by autonomously formalizing complex proofs for open combinatorial challenges, including a verified proof for a key subproblem in Knuth's Hamiltonian decomposition of even-order Cayley graphs.looseness=-1
Correspondence: [email protected]
Executive Summary: Large language models (LLMs) now handle complex informal mathematics at competition and research levels, yet they produce proofs that are difficult or impossible to verify automatically. This creates a verification bottleneck that slows progress and risks undetected errors, as even expert human review of major results can take years. The field has therefore focused on specialized prover models fine-tuned for formal languages such as Lean, under the assumption that general-purpose LLMs lack the necessary formal rigor.
The document introduces LEAP (LLM-in-Lean Environment Agentic Prover), an agentic framework that uses only general-purpose foundation models to generate mechanically verified Lean proofs. It also presents Lean-IMO-Bench, a new set of 60 formalized IMO-style problems chosen for their short statements but long, non-routine proofs. The work evaluates whether structured decomposition, informal-to-formal planning, and compiler feedback can close the performance gap without specialized training.
LEAP works by maintaining an AND-OR directed acyclic graph of proof obligations. It first attempts a direct formal proof; when that fails, it generates an informal blueprint that proposes intermediate lemmas, translates the blueprint into a Lean sketch, and uses Lean compiler feedback plus an LLM reviewer to accept or reject the decomposition. Verified subgoals are added to the graph and solved recursively, with lemmas stored for reuse across branches. The system was tested on the 2025 Putnam competition (12 problems) and on Lean-IMO-Bench under controlled rollouts, using Gemini 3.1 Pro as the base model.
On Putnam 2025, LEAP solved all 12 problems, matching recent frontier systems. On Lean-IMO-Bench it raised the one-shot solve rate of general LLMs from under 10 percent to 83 percent on the Basic set and 57 percent on the Advanced set, outperforming both specialized open-source provers and Aristotle, a strong gold-medal-level system that reached only 48 percent on comparable material. Ablations show that DAG-based lemma sharing and the LLM reviewer each contribute substantial gains, especially on harder problems, while iterative compiler feedback proves far more effective for general models than for specialized provers.
These results indicate that the main obstacle for general LLMs is not formal language comprehension itself but the absence of structured, iterative interaction with a proof environment. The findings therefore challenge the prevailing view that specialized fine-tuning is required for state-of-the-art formal theorem proving. They also demonstrate practical value: LEAP autonomously produced verified Lean proofs for previously open subproblems in combinatorics.
Organizations seeking reliable automated verification should adopt agentic frameworks that combine general models with decomposition and verifier feedback. Immediate priorities include scaling search strategies to longer proofs, exploring lightweight hybrids that pair a general reasoning backbone with specialized local provers, and extending the approach to open research problems. Geometry remains a persistent weakness, and the computational cost of complex proofs can still reach thousands of model calls, so further efficiency gains are needed before routine deployment on frontier-scale mathematics. Overall, the evidence supports confident investment in agentic scaffolding rather than in ever-larger specialized fine-tuning runs.
1. Introduction
Section Summary: Large language models perform well at solving math problems in ordinary language, yet their proofs are often flawed and extremely difficult for either humans or machines to verify. While most research has therefore focused on training specialized models for formal systems like Lean that allow automatic checking, this paper shows that general-purpose models can succeed at formal theorem proving when used inside an agentic workflow. The authors present LEAP, a framework that first sketches a high-level proof plan as a directed graph and then iteratively generates and repairs the formal Lean proof using compiler feedback, achieving state-of-the-art results on challenging new benchmarks including problems from the 2025 Putnam competition.
Large Language Models (LLMs) have made impressive progress on mathematical reasoning with natural language, also known as "informal math reasoning", demonstrating strong capabilities in complex reasoning and problem-solving for both math competitions and research level maths ([1, 2, 3, 4, 5]). However, as discussed in recent works like Hilbert ([6]) and Goedel-Prover-V2 ([7]), solutions in natural language frequently suffer from logical fallacies and hallucinations, and they are hard to automatically verify. This difficulty in verification is not merely a limitation of automated systems; even for human mathematicians, verifying complex proofs is a notoriously time-consuming process requiring scarce expert labor ([8]). A famous example is the proof of the Kepler conjecture ([9]), which required four years of peer review before the referees could only claim to be "99% certain" of its correctness, ^1 eventually necessitating a decade-long formal verification effort ([10]). This verification bottleneck underscores that assessing correctness is a hard task in natural language, motivating the exploration of formal mathematics, where proofs are written in a machine-checkable language and verified by a rigorous kernel like in Lean ([11]), Isabelle ([12]), Coq ([13]), HOL Light ([14]), offers automated verification with guaranteed accuracy. Yet, bridging the gap to formal theorem proving remains a significant challenge, and the performance of automated formal provers currently lags substantially behind that of general-purpose LLMs operating in natural language.
To bridge this gap, recent efforts in the research community predominantly fine-tunes specialized prover models (e.g., AlphaProof ([15]), DeepSeek Prover V2 ([16]), Seed Prover ([17]), Goedel Prover V2 ([7])) on formal corpora, with the assumption that general LLMs are ineffective for rigorous formal tasks without specialization. Indeed, according to the FormalProofBench ([18])[^2] and TaoBench ([19]), general LLMs often underperform compared to specialized prover models.
[^2]: The paper is associated with a private dataset with a live leaderboard https://www.vals.ai/benchmarks/proof_bench. We contacted them several times to participate on the leaderboard without receiving a response.
While some recent works explored agentic or inference-time search, they still depend on specialized models. For instance, Hilbert ([6]), AlphaProofNexus ([20]), Aristotle ([21]), and Seed Prover V1.5 ([22]) use general LLMs for informal reasoning but rely on specialized models for Lean proving steps. Axiom^3 and Numina^4 claim strong results on Putnam 2025 while remained closed source without public access, making them scientifically unverifiable.
In this paper, we show that while general LLMs remain limited in one-shot theorem proving, the bottleneck is not language comprehension but generating long, complex, correct proofs in one attempt. General LLMs offer complementary skills to specialized models: strong informal reasoning, instruction following, tool use, and self-refinement. These make them ideal for agentic ATP frameworks, where proof construction is decomposed and iteratively improved. To this end, we introduce LEAP (LLM-in-Lean Environment Agentic Prover), an agentic framework using only general LLMs for formal math. Inspired by human workflow, LEAP generates a high-level blueprint forming a directed acyclic graph (DAG), then generates the Lean proof, iteratively correcting errors via compiler feedback.
To evaluate progress beyond saturated benchmarks such as MiniF2F ([23]) and PutnamBench ([24]), we introduce Lean-IMO-Bench, formalizing the challenging informal math benchmark IMO-Bench ([25]) problem statements into Lean. In contrast to existing benchmarks, which either focus on shorter problems or emphasize broad undergraduate coverage, Lean-IMO-Bench targets the complementary regime of elementary statements whose solutions often hinge on highly non-routine insights and unfold through long, multi-step, and structurally intricate proofs, providing a sharper test of formal theorem proving.
Empirically, on the latest 2025 Putnam Competition, a challenging annual undergraduate mathematics competition in North America whose 2025 top score was 110 out of 120 while the median was only 2, LEAP solves all 12 problems in Lean, achieving perfect performance. This matches recent breakthrough results from frontier formal mathematical reasoning models such as Axiom $^{\text{Section 1}}$ and Numina $^{\text{Section 1}}$. On Lean-IMO-Bench, LEAP substantially improves general LLMs' solve rate from under 10% to 70%, surpassing specialized ATP models (5%) and Aristotle (48%), a strong system with specialized ATP components that earned the score for Gold medal at IMO 2025. The contribution of the paper is three-fold:
- Workflow-Inspired Agentic Design We introduce LEAP, an agentic framework that codifies the human mathematical workflow – combining high-level blueprint sketching with low-level formal proof generation and iterative compiler feedback. Crucially, LEAP demonstrates that state-of-the-art formal theorem proving can be achieved using only general-purpose LLMs, challenging the belief that specialized fine-tuning is indispensable.
- Lean-IMO-Bench Dataset: To evaluate progress beyond saturated benchmarks such as MiniF2F and PutnamBench, we introduce Lean-IMO-Bench, a new challenging dataset that translates informal problem statements from IMO-Bench into formal Lean statements. Resources are available at https://imobench.github.io.
- Strong Empirical Results and Insights: LEAP solves all 12 problems on Putnam 2025 and achieves a large improvement over prior baselines on Lean-IMO-Bench. Our analysis suggests that the primary bottleneck in formal mathematics for general-purpose LLMs is not formal language comprehension alone, but the lack of structured, iterative interaction with the proof environment. The Lean solutions generated by LEAP are available at https://github.com/google-deepmind/superhuman/tree/main/leap.
2. LEAP: Blueprint-Driven Automated Theorem Proving
Section Summary: LEAP is an AI system designed to automate the formalization of mathematical proofs in the Lean proof assistant by mimicking the structured planning process used in large human-led projects. It begins with an input theorem as a root goal and first attempts a direct proof translation; when that fails, it generates an informal blueprint of intermediate lemmas, converts the plan into a Lean sketch, and records the verified subgoals as an expanding AND-OR dependency graph that preserves progress and allows lemma reuse. The workflow interleaves natural-language reasoning with compiler-checked code, recursively breaking hard problems into simpler subproblems while maintaining an acyclic, human-readable record of the overall proof strategy.
2.1 Formalizing Proofs with Blueprints
Formalizing mathematical proofs is rarely a one-shot task: it requires a structured plan for progressively translating a high-level argument into Lean. To manage this complexity, recent formalization efforts often use the Lean Blueprint tool ^5, which let mathematicians write a human-readable proof roadmap linked to Lean code and visualized as a directed acyclic graph (DAG), where each node represents a proof obligation. This workflow has been instrumental in coordinating large-scale projects such as the formalization roadmap for Fermat's Last Theorem ^6, where a multi-year proof effort is organized through an explicit dependency graph.
Inspired by this workflow, we introduce LEAP, an agent for automated theorem proving with hierarchical decomposition and planning. Rather than synthesizing a complete proof in a single pass, LEAP incrementally drafts blueprints, decomposes Lean goals into supporting lemmas, and maintains the evolving proof plan as an AND-OR DAG.
![**Figure 1:** **LEAP workflow.** LEAP first attempts direct formalization with compiler-feedback revision and LeanSearch([26]) retrieval. If this fails, it generates an informal blueprint and formal proof sketch, adding verified subgoals back to the DAG only when dependencies remain acyclic.](https://ittowtnkqtyixxjxrhou.supabase.co/storage/v1/object/public/public-images/b6d6vhg6/complex_fig_35024991179d.png)
2.2 Overview
Figure 1 illustrates the workflow of LEAP. Given an input theorem, LEAP registers its Lean statement as the root goal, [^7] represented as an OR node in the AND-OR DAG. To process an open goal, a state reader retrieves its statement, dependencies, and related lemmas. LEAP then first attempts a direct proof by generating an informal proof, translating it into Lean code, and checking the candidate with the Lean compiler.
[^7]: A goal is any theorem or lemma statement to be proved; decomposition introduces subgoals. See Appendix C.
If direct proving fails, LEAP shifts to decomposition. It first drafts an informal blueprint that proposes intermediate lemmas, then translates the blueprint into a Lean proof sketch. The sketch proves the current goal assuming only the proposed lemmas: the main theorem body is sorry-free, while sorry placeholders are permitted only in the newly proposed lemma statements. If the sketch is accepted by the Lean compiler, it is added as an AND node, and the proposed lemmas are added as child OR nodes. This ensures that once all child subgoals are proved, the parent goal is also proved. The verified sketch is then passed to the state writer, which checks that the update preserves acyclicity before committing it to the DAG. The agent then recursively processes the newly created subgoals.
This workflow relies on three tightly coupled design choices: DAG-based hierarchical memoization, which preserves progress and reuses lemmas across branches; interleaved informal-formal planning, which connects natural-language strategies with executable Lean code; and verification-guided proof search, which uses compiler feedback and LLM-based review to accept, revise, decompose, or abandon candidate branches.
2.3 Hierarchical Memoization via DAG
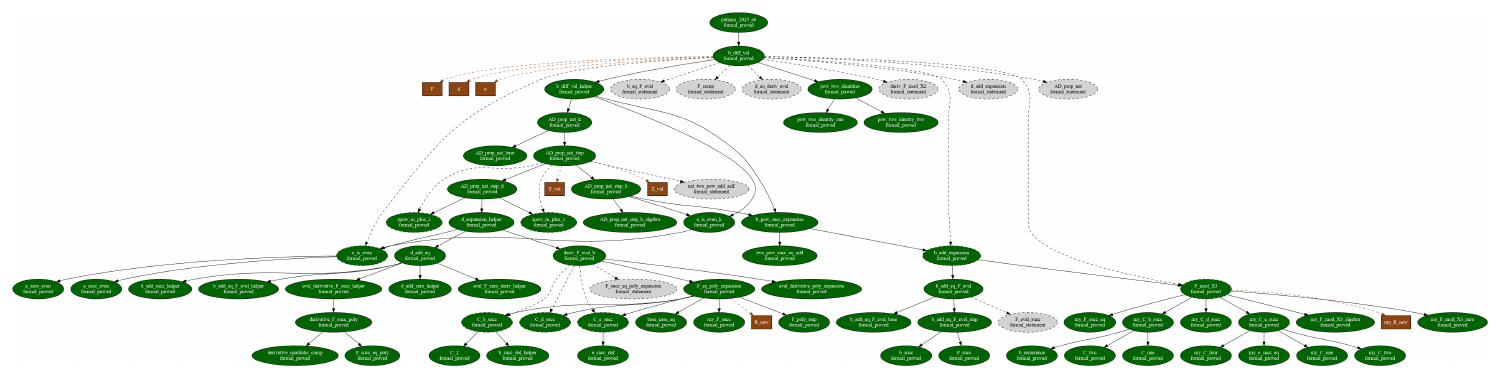
LEAP uses the AND-OR DAG not only to record proof progress, but also to structure hierarchical memoization. OR nodes represent open goals or lemma statements, each of which may be resolved by any valid proof strategy, while AND nodes represent candidate decompositions whose success depends on proving all constituent subgoals. Figure 2 illustrates this structure.
The DAG provides two central advantages. First, monotone refinement: once a goal is decomposed into supporting subgoals, subsequent search can focus on expanding and resolving these descendants without restructuring the established dependency order. This separates local proof exploration from global proof organization: individual proof attempts may be revised, expanded, or abandoned, while the DAG preserves the stable dependency structure of the overall proof plan. Second, lemma memoization: intermediate lemma statements are stored as shared proof nodes and can be reused whenever the same subproblem arises in different branches. This also supports anticipatory lemma planning: during blueprint generation, LEAP may propose auxiliary lemma statements that are not immediately required by the current sketch but could support later proof steps. Such prospective lemmas remain available in the graph memory without being necessary for resolving the current AND node. Together, these properties allow independent proof plans to converge on common dependencies while reducing redundant derivations.
The resulting dependency structure also improves transparency: it exposes which goals remain open, which lemmas have been resolved, and which nodes block downstream progress. This helps LEAP identify where additional lemmas, revised decompositions, or stronger assumptions may be needed, while providing an interpretable blueprint-style workspace for human-AI collaboration.
2.4 Interleaved Informal–Formal Planning
As shown in Figure 1, both the direct proof path and the blueprint decomposition path in LEAP pass through an informal proof sketch. This reflects the complementary strengths of LLMs and Lean: LLMs are effective at informal reasoning, strategy generation, and refinement, while Lean provides strict machine-checkable verification.
In direct proving, LEAP first generates an informal argument for the current goal before translating it into a candidate Lean proof. In decomposition, it drafts an informal blueprint explaining how the goal can be reduced to supporting subgoals, then converts this plan into a Lean sketch that records the proposed dependencies. In both cases, the informal sketch provides a planning space before formalization, making proof construction less brittle than direct code generation alone (see Appendix C for examples of informal proofs and blueprints).
This interleaving also makes proof progress more interpretable: each formal attempt is paired with an informal rationale, allowing users to inspect why a proof step or decomposition was proposed rather than only reading Lean code or compiler feedback.
2.5 Verification-Guided Proof Search
As shown in Figure 1, LEAP uses verification at two levels. First, the Lean compiler formally checks candidate proofs and sketches, ensuring that accepted code is syntactically valid and type-correct. For proof sketches, LEAP only permits sorry placeholders for the proposed subgoals (lemmas). This preserves the AND-OR semantics of the proof DAG: once all referenced subgoals are proved, the parent goal is also proved. Second, after a blueprint proposes new subgoals, an LLM reviewer assesses the quality of the decomposition: whether the subgoals are relevant to the parent goal, make the problem easier, and offer a plausible route to completing the proof. This planning-level review is crucial for complex goals, where a Lean sketch can be syntactically valid while introducing subgoals that are ill-posed or no simpler than the original statement. Without this filter, the agent may repeatedly expand weak blueprints, spending search budget on branches that do not make real progress. We study this failure mode through an ablation without the LLM reviewer in Section 5.3.
The LLM reviewer therefore acts as a search filter: it identifies unpromising decompositions, triggers backtracking, and encourages exploration of alternative strategies. Currently, LEAP uses a simple DFS over the DAG with backtracking. The effectiveness of this reviewer suggests a broader future direction: LLMs may also serve as heuristic evaluators for guiding search in formal proof spaces.
3. Lean-IMO-Bench: Formalizing IMO Problems in Lean
Section Summary: Lean-IMO-Bench is a collection of 60 International Math Olympiad problems, evenly divided into basic and advanced sets and balanced across algebra, combinatorics, geometry, and number theory, that have been manually translated into the formal language Lean and verified by experts. The benchmark tests AI models on three tasks—solving problems in ordinary language, generating formal Lean proofs from scratch, and converting informal proofs into Lean code—with a focus on the formal proving setting. Performance data reveal that models capable of strong natural-language solutions still produce far fewer valid Lean proofs, showing that the core difficulty lies in reliable formal coding rather than mathematical reasoning itself.
\begin{tabular}{@llcc@}
\toprule
\textbf{Task} & \textbf{Model (Metric)} & \textbf{Basic Set (\%)} & \textbf{Advanced Set (\%)} \\ \midrule
\textbf{Natural Language Proof} & Gemini 2.5 Pro (Pass@1) & 55.2 & 17.6 \\ \midrule
\textbf{Formal Theorem Proving} & Gemini 3.1 Pro (Pass@128) & 20.0 & 3.3 \\
& Gemini 3.1 Pro (Avg.@128) & 4.6 & 0.2 \\
\midrule
\textbf{Formal Proof Translation} & Gemini 3.1 Pro (Pass@128) & 20.0 & 3.3 \\
& Gemini 3.1 Pro (Avg.@128) & 4.6 & 0.8 \\
\bottomrule
\end{tabular}
3.1 Lean-IMO-Bench
We introduce $\textsc{Lean-IMO-Bench}$, a curated collection of 60 problems building upon the foundational work of [25]. [25] introduced $\textsc{IMO-ProofBench}$, a rigorous suite vetted by an expert panel of mathematicians and IMO medalists. The benchmark contains 60 problems split evenly into a Basic set and an Advanced set of 30 problems each. The Basic set spans pre-IMO to IMO-Medium difficulty and includes 8 algebra, 8 combinatorics, 8 number theory, and 6 geometry problems. The Advanced set includes novel problems up to IMO-Hard difficulty, with 8 algebra, 8 combinatorics, 6 number theory, and 8 geometry problems. Overall, the benchmark is approximately balanced across algebra, combinatorics, geometry, and number theory.
To ensure the highest level of accuracy in $\textsc{Lean-IMO-Bench}$, Lean experts manually formalized and verified all 60 problem statements. Because these problems are at the IMO level, the required mathematical background is elementary. Consequently, we expect the corresponding Lean solutions to be concise, deliberately removing the overhead associated with formalizing complex, modern mathematical theories.
The dataset can be used to evaluate models across three distinct tasks: Natural Language Proof, Formal Theorem Proving, and Formal Proof Translation, while we focus on formal theorem proving in this paper. The baseline performance on $\textsc{Lean-IMO-Bench}$ is summarized in Table 1. For the Natural Language Proof task, we cite [25] as reference: Gemini 2.5 Pro shows strong informal reasoning performance. However, as shown in Table 1, this does not directly translate to formal theorem proving: Gemini 3.1 Pro performs substantially worse on Formal Theorem Proving, especially on the Advanced set. Providing a correct informal proof in the Formal Proof Translation task also yields little improvement, with Pass@128 unchanged and only a marginal gain in Average@128.
Table 1 demonstrates a stark gap in the models' Lean capabilities. Because the model can already successfully solve these problems in natural language, mathematical reasoning is not the bottleneck, thus reliably generating valid Lean code remains the primary challenge.
4. Experimental Results
Section Summary: The experiments test LEAP against several strong baselines on the twelve problems from the 2025 Putnam competition. Direct one-shot generation by large language models solved none of the problems, an existing agentic system solved four, and a top specialized prover solved nine, whereas LEAP solved every problem. This gain stems from its DAG search structure, which reuses shared proof steps across branches and thereby avoids the exponential slowdown that limits recursive approaches.
We evaluate LEAP with Gemini-3.1-pro as the backend large language model and compare it against four baselines: Gemini-3.1-pro, which tests one-shot proof generation by a strong general-purpose model; Goedel-Prover-V2-32B ([7]), a state-of-the-art open-source ATP model specialized for Lean; Hilbert ([6]), an agentic Lean formalization framework that combines Goedel-Prover-V2-32B with Gemini-3.1-pro; and Aristotle ([21]), a specialized automated theorem-proving system with dedicated ATP components that achieved gold-medal-level performance at the 2025 IMO.
We evaluate formal proving ability on two datasets: Putnam 2025 and our proposed Lean-IMO-Bench. Putnam 2025 contains twelve undergraduate-level problems from the 86th William Lowell Putnam Mathematical Competition, [^8] a highly challenging North American mathematics competition. In the 2025 competition, the top score was 110 out of 120, the average score was approximately 10, and the median score was 2.
[^8]: Mathematical Association of America, Results of the 86th William Lowell Putnam Mathematical Competition.
4.1 Results on Putnam 2025
Table 2 presents the evaluation results on the Putnam 2025 benchmark. Under a Pass@128 setting, the direct formalization baselines (Gemini-3.1-pro and Goedel-Prover-V2-32B) fail to solve any problems, indicating that single-pass generation is insufficient for the logical complexity of this dataset.
\begin{tabularx}{\ccccccccc}{l *12{>{\arraybackslash}X} c}
\toprule
Method & a1 & a2 & a3 & a4 & a5 & a6 & b1 & b2 & b3 & b4 & b5 & b6 & Solve Rate (\%) \\
\midrule
Gemini-3.1-pro$^\diamond$ & \textcolor{red}{$\times$} & \textcolor{red}{$\times$} & \textcolor{red}{$\times$} & \textcolor{red}{$\times$} & \textcolor{red}{$\times$} & \textcolor{red}{$\times$} & \textcolor{red}{$\times$} & \textcolor{red}{$\times$} & \textcolor{red}{$\times$} & \textcolor{red}{$\times$} & \textcolor{red}{$\times$} & \textcolor{red}{$\times$} & 0.0 \\
Goedel-Prover-V2-32B$^\diamond$ & \textcolor{red}{$\times$} & \textcolor{red}{$\times$} & \textcolor{red}{$\times$} & \textcolor{red}{$\times$} & \textcolor{red}{$\times$} & \textcolor{red}{$\times$} & \textcolor{red}{$\times$} & \textcolor{red}{$\times$} & \textcolor{red}{$\times$} & \textcolor{red}{$\times$} & \textcolor{red}{$\times$} & \textcolor{red}{$\times$} & 0.0 \\
Hilbert$^\dagger$ & \textcolor{red}{$\times$} & \textcolor{green!70!black}{\checkmark} & \textcolor{green!70!black}{\checkmark} & \textcolor{green!70!black}{\checkmark} & \textcolor{red}{$\times$} & \textcolor{red}{$\times$} & \textcolor{red}{$\times$} & \textcolor{red}{$\times$} & \textcolor{red}{$\times$} & \textcolor{red}{$\times$} & \textcolor{red}{$\times$} & \textcolor{green!70!black}{\checkmark} & 33.3 \\
Aristotle$^\dagger$ & \textcolor{green!70!black}{\checkmark} & \textcolor{green!70!black}{\checkmark} & \textcolor{green!70!black}{\checkmark} & \textcolor{green!70!black}{\checkmark} & \textcolor{red}{$\times$} & \textcolor{green!70!black}{\checkmark} & \textcolor{green!70!black}{\checkmark} & \textcolor{green!70!black}{\checkmark} & \textcolor{green!70!black}{\checkmark} & \textcolor{green!70!black}{\checkmark} & \textcolor{red}{$\times$} & \textcolor{red}{$\times$} & 75.0 \\
\midrule
\rowcolor{blue!10}
LEAP$^\dagger$ & \textcolor{green!70!black}{\checkmark} & \textcolor{green!70!black}{\checkmark} & \textcolor{green!70!black}{\checkmark} & \textcolor{green!70!black}{\checkmark} & \textcolor{green!70!black}{\checkmark} & \textcolor{green!70!black}{\checkmark} & \textcolor{green!70!black}{\checkmark} & \textcolor{green!70!black}{\checkmark} & \textcolor{green!70!black}{\checkmark} & \textcolor{green!70!black}{\checkmark} & \textcolor{green!70!black}{\checkmark} & \textcolor{green!70!black}{\checkmark} & \textbf{100.0} \\
\bottomrule
\end{tabularx}
The open-source agentic framework Hilbert improves upon direct generation, solving 4 out of 12 problems. However, during evaluation, we observed that Hilbert's recursive search design leads to an exponential time complexity of $\mathcal{O}((n \cdot b)^{d})$, where $n$ is the number of lemma retries, $b$ is the average branching factor, and $d=10$ is the maximum proof depth. Due to the high volume of redundant LLM calls required by this approach, we bounded each Hilbert rollout to a 7-day time limit. For context against state-of-the-art proprietary systems, we also report the performance of Aristotle. While the system is closed-source, it serves as a strong baseline, solving 9 out of 12 problems given two rollouts. [^9]
[^9]: An unofficial report indicates Aristotle solved 10 out of 12 problems on this benchmark; however, neither that reported run nor our evaluation successfully solved problem A5.
LEAP successfully solves all 12 Putnam 2025 problems, improving the benchmark solve rate from 0% via direct formalization to 100% with our agentic framework. This performance directly results from the LEAP's blueprint-inspired AND-OR DAG architecture, which resolves the search bottlenecks observed in standard recursive frameworks like Hilbert. By supporting hierarchical memoization, LEAP allows independent proof branches to reuse shared intermediate lemmas, significantly mitigating exponential search complexity and allow LEAP to solve problems efficiently. For a detailed, problem-level breakdown of the computational cost and search efficiency required to achieve these results, See Table 3 for runtime and efficiency statistics.
\begin{tabularx}{\ccccccccc}{l *12{>{\arraybackslash}X}}
\toprule
Metric & a1 & a2 & a3 & a4 & a5 & a6 & b1 & b2 & b3 & b4 & b5 & b6 \\
\midrule
LLM Calls & 71 & 304 & 963 & 1.4k & 3.0k & 1.0k & 116 & 46 & 98 & 87 & 239 & 161 \\
Active Nodes & 8 & 26 & 55 & 105 & 170 & 62 & 12 & 8 & 10 & 9 & 211 & 24 \\
Proof Length & 405 & 591 & 713 & 1.0k & 2.0k & 581 & 752 & 300 & 326 & 556 & 1.9k & 848 \\
\bottomrule
\end{tabularx}
4.2 Results on Lean-IMO-Bench
Table 4 presents evaluation results on Lean-IMO-Bench. We include this dataset to test model robustness across a broader spectrum of mathematical disciplines and distinct complexity tiers, providing a complementary challenge to the Putnam benchmark.
Direct formalization baselines (Gemini-3.1-Pro and Goedel-Prover-V2-32B) and the open-source Hilbert framework struggle significantly on this dataset, exhibiting severe performance degradation on the Advanced set. While the proprietary Aristotle system resolves a majority of the Basic problems, its effectiveness drops sharply as complexity increases. Notably, across all evaluated methods, performance in the Geometry category remains near zero. This aligns with the well-established difficulty of formalizing olympiad-level geometry in Lean without the aid of supplementary, domain-specific frameworks. We retain this category strictly to evaluate general-purpose reasoning under extreme formalization constraints.
Against these baselines, LEAP achieves the highest overall solve rates, scoring 83.3% on the Basic set and 56.7% on the Advanced set. By effectively leveraging its DAG-based architecture, LEAP demonstrates strong domain generalization, maintaining a 100% solve rate in both Algebra and Number Theory regardless of the difficulty tier.
\begin{tabularx}{\ccccccccc}{l *5{>{\arraybackslash}X}}
\toprule
Method & Algebra & Comb. & Num. Theory & Geometry & \textbf{Overall} \\
\midrule
\multicolumn{6}{c}{\textbf{Basic Set (\%)}} \\
\midrule
Gemini-3.1-Pro$^\diamond$ & 37.5 & 12.5 & 25.0 & 0 &20.0 \\
Goedel-V2-32B$^\diamond$ & 37.5 & 0 & 0 & 0 & 10.0 \\
Hilbert$^\dagger$ & 62.5 & 25 & 50 & 0 & 36.6\\
Aristotle$^\dagger$ & 75 & \textbf{100} & 100 & \textbf{16.7} & 76.7 \\
\rowcolor{blue!10}
LEAP$^\dagger$ & \textbf{100} & \textbf{100} & \textbf{100} & \textbf{16.7} & \textbf{83.3} \\
\midrule
\multicolumn{6}{c}{\textbf{Advanced Set (\%)}} \\
\midrule
Gemini-3.1-Pro$^\diamond$ & 0 & 12.5 & 0 & 0 & 3.3 \\
Goedel-V2-32B$^\diamond$ & 0 & 0 & 0 & 0 & 0 \\
Hilbert$^\dagger$ & 12.5 & 0 & 16.6 & 0 & 6.6\\
Aristotle$^\dagger$ & 37.5 & 12.5 & 33.3 & 0 & 20.0\\
\rowcolor{blue!10}
LEAP$^\dagger$ & \textbf{100} & \textbf{25} & \textbf{100} & \textbf{12.5} & \textbf{56.7} \\
\bottomrule
\end{tabularx}
5. Discussion
Section Summary: LEAP demonstrates that general-purpose language models can outperform specialized provers in formalization tasks by leveraging iterative revision based on compiler feedback, which substantially boosts success rates on challenging benchmarks. Its DAG-based memory structure further improves results by enabling the reuse of intermediate lemmas across different proof branches, reducing redundant work especially on harder problems. Finally, an LLM-based reviewer serves as an effective search guide by filtering out unproductive or circular decompositions early, preventing wasted effort on paths that do not meaningfully advance the proof.
5.1 Beyond One-Shot Formalization
A central motivation of LEAP is that general foundation models can be effective iterative formalizers, even when they are not specialized Lean provers. While specialized provers are trained for formal proof synthesis, general models offer complementary capabilities such as instruction following, long-context reasoning, informal planning, tool use, and feedback-based revision.
To isolate this effect, we evaluate the Direct Formalization component labeled in Figure 1 under two settings. In the one-shot setting, each model is evaluated with Pass@128 over independently sampled proof attempts. In the iterative setting, each model receives a single initial attempt and up to 20 compiler-feedback revision steps, yielding a Pass@1 result under a smaller sampling budget. As shown in Table 5, Goedel-Prover-V2-32B does not benefit from this feedback loop, while Gemini-3.1-pro improves substantially from $20.0%$ to $36.6%$ .
This suggests that iterative formalization depends on capabilities beyond local Lean proof synthesis. Interpreting compiler errors, maintaining context, and revising proof attempts over multiple steps can be as important as one-shot formal proving accuracy. These results support using a general foundation model as the reasoning backbone of LEAP, while leaving open the possibility of combining it with specialized provers for local proof generation.
: Table 5: One-shot vs. iterative formalization performance on Lean-IMO-Bench Basic set.
| Model | One-shot (Pass@128) | Iterative (Pass@1) |
|---|---|---|
| Goedel-Prover-V2-32B | 10.0 | 6.6 |
| Gemini-3.1-Pro | 20.0 | 36.6 |
5.2 Effect of DAG-Based Memoization
LEAP maintains proof progress as a DAG-based memory rather than an isolated decomposition tree. This allows intermediate lemmas to be stored as shared nodes and reused across branches, while exposing graph context such as existing goals, dependencies, and previously proposed lemmas.
To evaluate this design, we compare LEAP with a tree-structured variant that follows the same workflow but removes global lemma sharing. As shown in Table 6, the tree variant already substantially outperforms Hilbert ([6]), which achieves 36.6% and 6.6% on the Basic and Advanced sets, respectively (Table 4). This indicates that interleaved informal–formal planning and verification-guided search are effective even without DAG-based memoization. The full DAG version further improves performance from 73.3% to 83.3% on the Basic set and from 40.0% to 56.7% on the Advanced set, showing the benefit of global proof memory.
The improvement is especially pronounced on harder categories, such as Advanced Algebra and Advanced Number Theory, where shared lemmas and graph context are more likely to matter. We attribute this gain to two effects. First, the DAG supports anticipatory lemma planning: auxiliary lemmas proposed at higher-level nodes can later be reused by downstream subgoals (Figure 2). Second, repeated subproblems can be shared across branches, avoiding the need to rediscover or reprove the same lemma multiple times. Together, these properties reduce redundant derivations and improve proof search efficiency.
\begin{tabular}{lcccccccccc}
\toprule
\multirow{2}{*}{\textbf{Config.}}
& \multicolumn{2}{c}{\textbf{Alg.}}
& \multicolumn{2}{c}{\textbf{Comb.}}
& \multicolumn{2}{c}{\textbf{NT}}
& \multicolumn{2}{c}{\textbf{Geo.}}
& \multicolumn{2}{c}{\textbf{Overall}} \\
\cmidrule(lr){2-3} \cmidrule(lr){4-5} \cmidrule(lr){6-7} \cmidrule(lr){8-9} \cmidrule(lr){10-11}
& \textbf{B} & \textbf{A}
& \textbf{B} & \textbf{A}
& \textbf{B} & \textbf{A}
& \textbf{B} & \textbf{A}
& \textbf{B} & \textbf{A} \\
\midrule
w/o DAG (Naive Tree)
& 100 & 75
& 75 & 25
& 100 & 66.6
& 0 & 0
& 73.3 & 40.0 \\
Full DAG
& 100 & 100
& 100 & 25
& 100 & 100
& 16.7 & 12.5
& 83.3 & 56.7 \\
\bottomrule
\end{tabular}
5.3 Toward LLM-Guided Proof Search
Compiler verification checks whether a proof sketch is formally well-typed, but not whether its decomposition is useful. A sketch may prove the parent goal from proposed lemmas that are unhelpful, overly difficult, or nearly equivalent to the original goal. In LEAP, the LLM reviewer acts as a local search heuristic: it filters candidate decompositions by judging whether they meaningfully simplify the parent goal before they are committed to the DAG.
We focus this ablation on Putnam 2025 Problem A5 because it is one of the most challenging cases in our evaluation, requiring the longest runtime and two rollouts for LEAP to formalize the proof successfully. Removing the LLM-based decomposition reviewer causes the agent to fail even after eight rollout attempts. This contrast suggests that local LLM review provides a useful search signal: it rejects weak decompositions early, triggers backtracking, and prevents the agent from spending rollouts on branches that do not make substantive progress. We further inspect decomposition traces from the ablated setting; a representative failure case is shown in Figure 3. The decomposition is formally admissible but does not simplify the mathematical state. The agent first unfolds the definitions in the grandparent goal to create an intermediate lemma, then folds them back into a proposed subgoal that is syntactically identical to the original statement. Without semantic review, this duplicate lemma is treated as a new step, causing the agent to repeat the same unproductive decomposition until its search budget is exhausted. This failure highlights the potential of LLM-guided proof search: a reviewer can assess whether a proposed lemma actually advances the proof, prune cyclic or non-simplifying branches, and direct compute toward more promising paths.

5.4 Perspective: General LLMs as Formal Provers: From Zero to Hero
As demonstrated by LEAP, the seemingly insurmountable gap between the poor one-shot theorem proving performance of general LLMs and state-of-the-art results can be effectively bridged by a well-designed agentic framework. By shifting the paradigm away from relying solely on small specialized LLMs, we show that the extensive knowledge, instruction following, and self-correction capabilities of foundation models are more than sufficient. When scaffolded correctly, these foundation models can progress from near zero formal math performance to solving highly complex problems.
While small specialized LLMs lack the overarching agentic capabilities of their foundation counterparts, we acknowledge that they still hold value. A hybrid architecture combining the high-level, structural reasoning of a foundation model with the focused, formal step generation of a fine-tuned specialized model could be a highly effective design pattern. However, exploring this hybrid approach remains outside the scope of this paper, as our primary goal is to highlight the standalone power of general purpose LLMs in an agentic workflow.
6. Case Studies: Formalizing Open Problems in Combinatorics
Section Summary: In this section the authors describe how their LEAP system was applied to two demanding problems in combinatorics, generating complete formal proofs in the Lean 4 language with only minimal human guidance. For a long-standing question originally raised by Donald Knuth, LEAP verified a crucial sub-result about decomposing certain directed graphs into Hamiltonian cycles, ultimately producing more than five thousand lines of rigorous code. The system was also tested on the already-solved Erdős Problem 457 concerning triangle-free graphs, where it independently reconstructed the known proof from basic principles and thereby confirmed its own ability to handle established results.
Hamiltonian Decomposition of Directed Cayley Graphs.
To evaluate LEAP on a highly complex mathematical task, we targeted a recently solved open problem in combinatorics: the Hamiltonian decomposition of the directed Cayley graph $\Gamma_{m}=Cay(\mathbb{Z}{m}^{3}, {e{1}, e_{2}, e_{3}})$ for even $m$. Originally posed by Donald Knuth, the problem asks whether the graph's directed arcs can be partitioned into exactly three distinct, spanning Hamiltonian cycles . The informal mathematical proof for the even-case construction is exceptionally intricate, relying on heavy combinatorial analysis and localized defect routing across different layers of the graph. We focused our formalization efforts on a critical subproblem: rigorously verifying that the 2D planar projection of a single color class's routing dynamics forms an unbroken mathematical cycle of length $m^{2}$. The informal arguments for this specific dynamic span roughly 20 pages of dense piecewise maps, parity-dependent intervals, and complex cross-row transitions. To tackle a formal verification of this magnitude, we deployed LEAP, which successfully decomposed the monolithic informal proof into a granular, highly structured proof graph. By autonomously and systematically resolving the interdependent nodes of this graph, LEAP managed to fully verify the complex cycle-merging dynamics, ultimately synthesizing over 5000 lines of rigorous Lean 4 code to complete the formal proof for this subproblem. Full problem descriptions and informal proofs are available at https://github.com/dpwoodru/knuthCycles/tree/main.
Formalizing Erdős Problem 457.
We further tested LEAP on Erdős Problem 457, a classic graph theory problem concerning the density of triangle-free graphs. Although this problem is already resolved, it served as an ideal benchmark to assess LEAP’s ability to autonomously reconstruct and verify established mathematical results. Tasked with deriving the known proof from first principles in Lean 4, LEAP effectively navigated the combinatorial constraints to confirm the theorem's validity. This successful reproduction demonstrates LEAP’s capability to reliably translate complex, existing literature into high-assurance formal proofs without human intervention.
Formal statements and detailed problem descriptions are provided in Appendix B.
7. Conclusion and Future Work
Section Summary: The success of LEAP shows that today's general-purpose AI language models can handle complex, specialized reasoning tasks when given the right supporting structure. In mathematics, this structure involves breaking large theorems into smaller steps that a formal proof checker can verify one by one, turning rough ideas into reliable, machine-checked proofs. Future progress will depend on developing smarter ways to explore these growing networks of steps without becoming overwhelmed by their size and complexity.
The success of LEAP suggests that modern general-purpose LLMs possess substantial reasoning capabilities for rigorous domain-specific tasks, provided they are coupled with appropriate structural scaffolding. In formal mathematics, this scaffolding naturally takes the form of proof decomposition and verifier-guided refinement: the model decomposes complex theorems into smaller subgoals, while the Lean compiler checks each formal step. This design provides a structured mechanism for translating informal reasoning into mechanically verified proofs. A central challenge for future work is how to navigate the resulting proof trees efficiently. As decomposition produces increasingly fine-grained subgoals, the search space can grow rapidly. Future systems should therefore improve branch prioritization, decomposition strategies, and compute allocation across large proof searches. Such advances will be critical for scaling agentic formal proving systems to more complex mathematical problems.
Acknowledgements
Section Summary: The authors express gratitude to Michael P. Brenner, Honghao Lin, David Woodruff, and Vahab Mirrokni for supplying an informal proof concerning one part of Knuth’s Cycles problem. They also thank Ashley Aragorn Khoo, Paul Lezeau, Calle Sönne, and Moritz Firsching for translating the relevant problem statements into the formal language used by the Lean-IMO-Bench collection. These contributions helped support the work presented in the paper.
We thank Michael P. Brenner, Honghao Lin, David Woodruff, Vahab Mirrokni for providing the informal proof of the even-case of Knuth’s Cycles problem. We would also like to thank Ashley Aragorn Khoo, Paul Lezeau, Calle Sönne, and Moritz Firsching for formalizing the Lean problem statements in Lean-IMO-Bench.
Appendix
Section Summary: The appendix first reviews prior research on neural theorem proving, specialized fine-tuned provers, auto-formalization techniques, and LLM-based mathematical reasoning, highlighting how LEAP differs by relying on general-purpose models in an agentic loop that iteratively refines informal blueprints into verified formal proofs without heavy specialization. It then supplies the actual Lean formalizations of the open problems tested in the paper, beginning with a detailed statement of the Hamiltonian decomposition problem for directed Cayley graphs that encodes coordinate rules, structural defects, and cycle properties. This material situates LEAP within the existing literature while furnishing the precise machine-checkable problem definitions used for evaluation.
A. Related Work
Neural Theorem Proving
Early work in neural theorem proving mainly utilize in-house symbolic engines, such as Metamath ([27]), MM0 ([28]) or some dedicated formal language for geometry problems ([29]). Later work such as mathlib ([30]), LeanDojo ([31]) and MiniF2F ([23]) pioneered the use of LLMs for generative theorem proving in Lean. They serve as pillar that provide a rich library of known theorems, an interactive environment for step-level search and a descent-level of difficulty evaluation set. To manage the large search space, HyperTree Proof Search ([32]) and related Monte Carlo tree search methods ([33, 34]) have been explored. While search-based methods operate at the tactic level, Baldur ([35]) and DeepSeek-prover-v1.5 ([36]) explored whole-proof generation, attempting to produce a complete proof in a single step. Another promising direction is guiding formal proof search with informal proofs or sketches. The "draft, sketch, and prove" methodology ([37]) demonstrated that using an informal proof as a blueprint can significantly guide and improve formal theorem proving. Our work, LEAP, builds on this intuition by utilizing general LLMs to generate informal blueprints and iteratively refine formal proofs based on compiler feedback, but without relying on specialized fine-tuned models for the formalization step.
Specialized Prover Models
Recent breakthroughs have often relied on extensive fine-tuning of large models on formal mathematical corpora. Representative works include AlphaProof ([15]), DeepSeek Prover V2 ([16]), Seed Prover ([17]), Kimina Prover ([38]) and Goedel Prover V2 ([7]). These models achieve state-of-the-art performance by scaling up training and search on formal systems. However, they require substantial computational resources for training and are highly specialized for specific formal languages. In contrast, LEAP demonstrates that general-purpose LLMs, when placed in a proper agentic environment, can achieve competitive performance without such specialized fine-tuning.
Auto-Formalization
Auto-formalization, the task of translating natural language mathematics into formal statements and proofs, is a critical bridge between informal and formal reasoning. Early work relied on neural machine translation techniques ([39]). More recently, LLMs have been used to generate formal statements for training provers at scale, as seen in the auto-formalization pipeline of AlphaProof ([15]). LEAP utilizes the strong auto-formalization capabilities of general LLMs within its agentic harness to bridge the gap between informal blueprints and formal proofs.
Mathematical Reasoning with LLMs
Large Language Models have shown impressive progress in solving natural-language mathematical problems, demonstrating strong capabilities in complex reasoning. Recent advancements, such as OpenAI o1 ([40]) and DeepSeek R1 ([41]), have demonstrated the effectiveness of scaling reinforcement learning for complex mathematical tasks, achieving high scores on competitive benchmarks like AIME. However, direct evaluation of these models on formal theorem proving benchmarks often yields low solve rates, highlighting the gap between informal reasoning and formal verification. LEAP addresses this by leveraging the strong informal reasoning and instruction-following capabilities of general LLMs within an agentic harness, enabling them to interact with the Lean compiler and iteratively self-correct, thus bridging the formalization gap without specialized fine-tuning.
B. Problem Statements
We present the LEAN statements of the open problems that we tested with LEAP.
Hamiltonian Decomposition of Directed Cayley Graphs
The Hamiltonian decomposition problem for the directed Cayley graph $\Gamma_{m}=Cay(\mathbb{Z}{m}^{3}, {e{1}, e_{2}, e_{3}})$ asks whether its edges can be partitioned into three distinct directed Hamiltonian cycles. For the even-case construction ($m=2h \ge 10$), the 3D routing dynamics of individual color classes can be analytically projected onto a 2D planar "round map" defined on a $\mathbb{Z}{m} \times \mathbb{Z}{m}$ grid. The formal statement below encodes the exact operational semantics for the Color 2 subgraph—including its parity-dependent structural defects, coordinate shifts, and piecewise transitions—and asserts that its round map forms a single, unbroken cycle of length $m^2$.
import Mathlib
set_option autoImplicit false
variable (h : $\mathbb{N}$) (hh : 5 $\leq$ h)
abbrev Fiber2 (h : $\mathbb{N}$) := Fin (2 * h) $\times$ Fin (2 * h)
– 1. Base Coordinate Definitions
def one2 : Fin (2 * h) := $\langle$ 1, by omega $\rangle$
def mMinusOne2 : Fin (2 * h) := $\langle$ 2 * h - 1, by omega $\rangle$
def mMinusTwo2 : Fin (2 * h) := $\langle$ 2 * h - 2, by omega $\rangle$
def succ2c (x : Fin (2 * h)) : Fin (2 * h) := x + one2 h hh
def pred2c (x : Fin (2 * h)) : Fin (2 * h) := x - one2 h hh
– 2. Exceptional Set Logic (Defects)
def y2SwitchRow (x : Fin (2 * h)) : Prop :=
x.val = h + 1 $\vee$ x.val = h + 2 $\vee$ x.val = h + 3
instance (x : Fin (2 * h)) : Decidable (y2SwitchRow h x) := by
unfold y2SwitchRow
infer_instance
def y2star (x : Fin (2 * h)) : Fin (2 * h) :=
if y2SwitchRow h x then
if h
else
$\langle$ 2 * h - 1 - x.val, by omega $\rangle$
def A2 (x : Fin (2 * h)) : Fin (2 * h) :=
succ2c h hh (y2star h hh x)
def activeB2 (x y : Fin (2 * h)) : Prop :=
if h
(x.val = h + 1 $\wedge$ y.val $\leq$ h - 1) $\vee$
(x.val = h + 4 $\wedge$ h - 3 $\leq$ y.val $\wedge$ y.val $\leq$ 2 * h - 2)
else
(x.val = h + 1 $\wedge$ 1 $\leq$ y.val $\wedge$ y.val $\leq$ h - 1) $\vee$
(x.val = h + 4 $\wedge$ h - 3 $\leq$ y.val)
instance (x y : Fin (2 * h)) : Decidable (activeB2 h x y) := by
unfold activeB2
infer_instance
– 3. The Round Map
def r2Map (p : Fiber2 h) : Fiber2 h :=
let x := p.1
let u := pred2c h hh p.2
if u = A2 h hh x then
(succ2c h hh x,
if x.val = h + 1 $\vee$ x.val = h + 2 then u else pred2c h hh u)
else if activeB2 h x u then
(x, pred2c h hh u)
else
(x, u)
– 4. The Self-Contained Goal
/– The unrolled Hamiltonicity goal for the Color 2 round map. -/
theorem color2_singleCycle_unrolled (h6 : 6 $\leq$ h) :
($\forall$ p : Fin (2 * h) $\times$ Fin (2 * h), (r2Map h hh)^[(2 * h) * (2 * h)] p = p) $\wedge$
($\forall$ (p : Fin (2 * h) $\times$ Fin (2 * h)) (k : $\mathbb{N}$), 0 < k $\rightarrow$ k < (2 * h) * (2 * h) $\rightarrow$ (r2Map h hh)^[k] p $\neq$ p) := by
(*<span style="color:red">sorry</span>*)
Erdős 457
Erdős Problem 457 is a number theory challenge concerning the prime divisors of consecutive integers. Specifically, it conjectures the existence of a real number $\varepsilon > 0$ such that for infinitely many integers $n$, every prime number $p \le (2 + \varepsilon)\log n$ divides the product of the $\lfloor\log n\rfloor$ consecutive integers starting from $n+1$. The Lean formalization below captures this exact asymptotic prime divisibility condition.
import Mathlib
theorem erdos_457 : $\exists$ $\varepsilon$ > (0 : $\mathbb{R}$),
{ (n : $\mathbb{N}$) | $\forall$ (p : $\mathbb{N}$), p $\leq$ (2 + $\varepsilon$) * Real.log n $\rightarrow$ p.Prime $\rightarrow$
p $\mid$ $\prod$ i $\in$ Finset.Icc 1 $\lfloor$ Real.log n $\rfloor_+$, (n + i) }.Infinite := by
(*\textcolor{red}{sorry}*)
C. Proof Contexts and Artifacts
This section describes the formal and informal artifacts used by LEAP during proof planning. Formal artifacts correspond to Lean-level objects that are checked by the compiler or represented in the proof DAG, while informal artifacts correspond to natural-language planning objects used to guide direct proving and decomposition.
Formal context.
A proof goal is a Lean theorem or lemma statement that remains to be proved. The original input theorem is the root proof goal, while lemma statements introduced by decomposition become subgoals in the proof DAG. A formal proof is a complete Lean proof of the current proof goal that does not rely on newly proposed unproven lemmas; once accepted by the Lean compiler, the corresponding goal is marked as resolved. A proof sketch is a Lean artifact that proves the current goal assuming a set of proposed lemmas. In LEAP, a proof sketch may contain sorry placeholders only for these explicitly proposed lemmas. Thus, a verified proof sketch defines a valid decomposition: once all referenced proposed lemmas are later proved, the current goal is also proved. We present examples of these context using Lean-IMO-Bench Problem 001 and 009 in the Basic Set. All artifacts, except for the Proof Goal of the root problem, are created by LEAP automatically.)
theorem PBBasic001 : f : $\mathbb{Z}$ $\rightarrow$ $\mathbb{Z}$ | $\forall$ x y, f (2 * x) + 2 * f y = f (f (x + y))
= 0 $\cup$ (fun x $\mapsto$ 2 * x + c)| (c : $\mathbb{Z}$) :=
by (*<span style="color:red">sorry</span>*)
import Mathlib
theorem PBBasic001 : {f : $\mathbb{Z}$ $\rightarrow$ $\mathbb{Z}$ | $\forall$ x y, f (2 * x) + 2 * f y = f (f (x + y))}
= 0 $\cup$ {(fun x $\mapsto$ 2 * x + c)| (c : $\mathbb{Z}$)} :=
by
ext f
simp only [Set.mem_setOf_eq, Set.mem_union, Set.mem_singleton_iff, Set.mem_range]
constructor
$\cdot$ intro h
have h1 : $\forall$ y, f (f y) = 2 * f y + f 0 := by
-- [Proof details omitted for brevity]
have h2 : $\forall$ x, f (2 * x) = 2 * f x - f 0 := by
-- [Proof details omitted]
have h3 : $\forall$ x y, f (x + y) = f x + f y - f 0 := by
-- [Proof details omitted]
have hc : $\exists$ c, c = f 0 := $\langle$ f 0, rfl $\rangle$
rcases hc with $\langle$ c, hc_eq $\rangle$
have hk : $\exists$ k, k = f 1 - c := $\langle$ f 1 - c, rfl $\rangle$
rcases hk with $\langle$ k, hk_eq $\rangle$
-- ... [Induction steps for h4 omitted] ...
have h5 : $\forall$ x : $\mathbb{Z}$, f x = k * x + c := by
-- ... [Negative cases to prove linear form omitted] ...
have eq_all : $\forall$ x y : $\mathbb{Z}$, k * (2 * x) + c + 2 * (k * y + c) = k * (k * (x + y) + c) + c := by
intro x y
have h_orig := h x y
simp only [h5] at h_orig
exact h_orig
have hk_eq : k * (k - 2) = 0 := by
-- [Algebraic simplification using eq_all 1 0 and eq_all 0 0 omitted]
have hk2 : k = 0 $\vee$ k = 2 := by
cases mul_eq_zero.mp hk_eq with
| inl h1 => left; exact h1
| inr h2 => right; omega
rcases hk2 with hk0 | hk2
$\cdot$ left
have eq00 := eq_all 0 0
rw [hk0] at eq00
have hc0 : c = 0 := by linarith [eq00]
ext x
simp only [Pi.zero_apply]
have hfx := h5 x
rw [hk0, hc0] at hfx
omega
$\cdot$ right
use c
ext x
have hfx := h5 x
rw [hk2] at hfx
omega
-- Prove that the derived candidates are indeed solutions mappings
$\cdot$ rintro (rfl | $\langle$ c, rfl $\rangle$)
$\cdot$ intro x y
simp only [Pi.zero_apply, mul_zero, add_zero]
$\cdot$ intro x y
dsimp only
ring
import Mathlib
open Polynomial
– Shared Definitions from the file environment
def K (c : $\mathbb{N}$ $\rightarrow$ $\mathbb{Z}$) : $\mathbb{Z}$ := (c 1)^2 - (2 : $\mathbb{Z}$) * (c 0) * (c 2)
def $k_t$ arget (c : $\mathbb{N}$ $\rightarrow$ $\mathbb{Z}$) : $\mathbb{N}$ := max 2 (Int.toNat (K c + (1 : $\mathbb{Z}$)))
def esymm_one_target (s : Multiset $\mathbb{R}$) : $\mathbb{N}$ $\rightarrow$ $\mathbb{R}$
| 0 => 0
| k + 1 => s.esymm k
def esymm_two_target (s : Multiset $\mathbb{R}$) : $\mathbb{N}$ $\rightarrow$ $\mathbb{R}$
| 0 => 0
| 1 => 0
| k + 2 => s.esymm k
– Supporting Lemmas (with sorry)
lemma root_count_bound_implies_eq (c : $\mathbb{N}$ $\rightarrow$ $\mathbb{Z}$) (hc : c 0 $\neq$ 0) (k : $\mathbb{N}$)
($h_n$ ot_less : $\neg$ ((($\sum$ i $\in$ Finset.Icc 0 k, monomial i (c i)).rootSet $\mathbb{R}$).ncard < k)) :
(($\sum$ i $\in$ Finset.Icc 0 k, monomial i (c i)).rootSet $\mathbb{R}$).ncard = k $\wedge$
($\sum$ i $\in$ Finset.Icc 0 k, monomial i (c i)).natDegree = k := by
(*<span style="color:red">sorry</span>*)
lemma $k_le_K_of_eq (c$ : $\mathbb{N}$ $\rightarrow$ $\mathbb{Z}$) (hc : c 0 $\neq$ 0) (k : $\mathbb{N}$) (hk : (2 : $\mathbb{N}$) $\leq$ k)
($h_eq : (($ $\sum$ i $\in$ Finset.Icc 0 k, monomial i (c i)).rootSet $\mathbb{R}$).ncard = k)
($h_d$ eg : ($\sum$ i $\in$ Finset.Icc 0 k, monomial i (c i)).natDegree = k) :
(k : $\mathbb{Z}$) $\leq$ K c := by
(*<span style="color:red">sorry</span>*)
lemma $k_t$ arget_ge_two (c : $\mathbb{N}$ $\rightarrow$ $\mathbb{Z}$) : (2 : $\mathbb{N}$) $\leq$ $k_t$ arget c := by
(*<span style="color:red">sorry</span>*)
lemma $k_t$ arget_gt_K (c : $\mathbb{N}$ $\rightarrow$ $\mathbb{Z}$) : K c < ($k_t$ arget c : $\mathbb{Z}$) := by
(*<span style="color:red">sorry</span>*)
– Main Theorem
theorem PBBasic006 (c : $\mathbb{N}$ $\rightarrow$ $\mathbb{Z}$) (hc : c 0 $\neq$ 0) :
$\exists$ k, (($\sum$ i $\in$ Finset.Icc 0 k, monomial i (c i)).rootSet $\mathbb{R}$).ncard < k := by
use $k_t$ arget c
by_contra h
have h1 := root_count_bound_implies_eq c hc ($k_t$ arget c) h
have h2 := $k_le_K_of_eq c$ hc ($k_t$ arget c) ($k_t$ arget_ge_two c) h1.1 h1.2
have h3 := $k_t$ arget_gt_K c
linarith
Informal context.
An informal proof is a natural-language plan for proving the current goal directly, without introducing a decomposition into new subgoals. It guides the generation of a complete formal proof. An informal blueprint is a higher-level natural-language plan that explains how the current goal can be reduced to useful supporting lemmas. Unlike an informal proof, an informal blueprint may introduce proposed lemmas that are not immediately proved and may include auxiliary lemmas for later proof steps. These proposed lemmas are then translated into formal subgoals and organized in the proof DAG. Examples are shown below:
Let $S = \{f : \mathbb{Z} \to \mathbb{Z} \mid \forall x, y \in \mathbb{Z}, f(2x) + 2f(y) = f(f(x+y))\}$ and $T = \{0\} \cup \{x \mapsto 2x + c \mid c \in \mathbb{Z}\}$. We want to show that $S = T$.
**Part 1: Proof that $T \subseteq S$**
Suppose $f \in T$. Then either $f$ is the constant zero function ($f = 0$) or $f(x) = 2x + c$ for some $c \in \mathbb{Z}$.
- Case 1: If $f = 0$, then for any $x, y \in \mathbb{Z}$, the left-hand side is $f(2x) + 2f(y) = 0 + 2(0) = 0$. The right-hand side is $f(f(x+y)) = f(0) = 0$. The two sides match, so $f \in S$.
- Case 2: If $f(x) = 2x + c$ for some $c \in \mathbb{Z}$, then for any $x, y \in \mathbb{Z}$, the left-hand side is: $f(2x) + 2f(y) = (2(2x) + c) + 2(2y + c) = 4x + 4y + 3c$. The right-hand side is: $f(f(x+y)) = f(2(x+y) + c) = 2(2x + 2y + c) + c = 4x + 4y + 3c$. The two sides are equal, so $f \in S$.
This proves $T \subseteq S$.
**Part 2: Proof that $S \subseteq T$**
Let $f \in S$. Then for all $x, y \in \mathbb{Z}$, we have:
(1) $f(2x) + 2f(y) = f(f(x+y))$.
Substitute $x = 0$ into Eq. (1):
$f(0) + 2f(y) = f(f(y))$.
Let $c = f(0)$. Then for all $y \in \mathbb{Z}$, we have:
(2) $f(f(y)) = 2f(y) + c$.
Using Eq. (2) on the right-hand side of Eq. (1) (since it holds for any input, including $x+y$), we obtain:
(3) $f(2x) + 2f(y) = 2f(x+y) + c$.
Substitute $y = 0$ into Eq. (3):
$f(2x) + 2f(0) = 2f(x) + c$.
Since $f(0) = c$, this becomes $f(2x) + 2c = 2f(x) + c$, which yields:
(4) $f(2x) = 2f(x) - c$.
Now, substitute Eq. (4) back into the left-hand side of Eq. (3):
$(2f(x) - c) + 2f(y) = 2f(x+y) + c$.
Rearranging the terms gives:
$2f(x+y) = 2f(x) + 2f(y) - 2c$.
Because the codomain is $\mathbb{Z}$, we can divide both sides by $2$ to obtain:
(5) $f(x+y) = f(x) + f(y) - c$.
Define a new function $g: \mathbb{Z} \to \mathbb{Z}$ by $g(x) = f(x) - c$. Then we can rewrite Eq. (5) as:
$g(x+y) + c = (g(x) + c) + (g(y) + c) - c$.
Simplifying this yields Cauchy's functional equation:
$g(x+y) = g(x) + g(y)$ for all $x, y \in \mathbb{Z}$.
Since $g$ satisfies $g(x+y) = g(x) + g(y)$ over integers, it must be a linear function. Let $k = g(1) \in \mathbb{Z}$. By standard induction, we have $g(x) = kx$ for all integers $x \ge 0$ (with $g(0) = 0$). For negative integers, $0 = g(0) = g(x + (-x)) = g(x) + g(-x)$, meaning $g(x) = -g(-x) = -(-kx) = kx$. Thus $g(x) = kx$ for all $x \in \mathbb{Z}$.
As a result, we have $f(x) = kx + c$ for all $x \in \mathbb{Z}$.
To determine the permissible values of $k$ and $c$, substitute $f(x) = kx + c$ back into the original Eq. (1):
Left-hand side: $f(2x) + 2f(y) = k(2x) + c + 2(ky + c) = 2kx + 2ky + 3c$.
Right-hand side: $f(f(x+y)) = k(f(x+y)) + c = k(k(x+y) + c) + c = k^2x + k^2y + (k+1)c$.
For the equality $2kx + 2ky + 3c = k^2x + k^2y + (k+1)c$ to hold for all $x, y \in \mathbb{Z}$, the corresponding coefficients must match.
Setting $x=0$ and $y=0$ yields:
(6) $3c = (k+1)c$.
Setting $x=1$ and $y=0$ yields:
$2k + 3c = k^2 + (k+1)c$.
Subtracting Eq. (6) from this gives $2k = k^2$, which simplifies to $k(k-2) = 0$. Since $k \in \mathbb{Z}$, the only solutions are $k = 0$ or $k = 2$.
- Case A: $k = 0$. Substitute $k = 0$ into Eq. (6): $3c = c \implies 2c = 0 \implies c = 0$. Thus, $f(x) = 0x + 0 = 0$, meaning $f$ is the zero function. Hence $f \in \{0\} \subseteq T$.
- Case B: $k = 2$. Substitute $k = 2$ into Eq. (6): $3c = 3c$, which is true for any $c \in \mathbb{Z}$. Thus, $f(x) = 2x + c$ for some $c \in \mathbb{Z}$. Hence $f \in \{x \mapsto 2x + c \mid c \in \mathbb{Z}\} \subseteq T$.
In all cases, any function $f \in S$ is also in $T$, proving $S \subseteq T$.
Since both subset inclusions have been established, $S = T$.
**High-Level Mathematical Idea**
The goal is to prove that $k \le K(c)$, where $K(c) = c_1^2 - 2c_0 c_2$, given that the polynomial $P(x) = \sum_{i=0}^k c_i x^i$ with integer coefficients has degree $k$ and exactly $k$ real roots.
The proof elegantly uses multiset symmetric polynomials and the AM-GM inequality, avoiding rational functions or polynomial derivatives:
1. **Polynomial Roots and Splitting**: Since $P$ has natural degree $k$ and $k$ distinct real roots, it splits completely over $\mathbb{R}$, and the multiset of its roots $S$ has cardinality $k$.
2. **Vieta's Formulas**: Vieta's formulas express the coefficients $c_0, c_1, c_2$ in terms of the elementary symmetric polynomials of $S$:
$c_0 = c_k (-1)^k E_k$ $c_1 = c_k (-1)^{k-1} E_{k-1}$ $c_2 = c_k (-1)^{k-2} E_{k-2}$ where $E_i = \text{esymm}_i(S)$.
3. **Multiset Identity**: We construct a new multiset $Y$ by mapping each root $x \in S$ to the product of all other roots, $(S \setminus \{x\})$.`prod`. Purely multiset inductive identities show:
$\sum Y = E_{k-1}$ \text{esymm}_2(Y) = $E_k E_{k-2}$ $\prod Y = (E_k)^{k-1}$
4. **Sum of Squares**: For the multiset $Z = c_k Y$, we evaluate the sum of its squares $W = \{ z^2 \mid z \in Z \}$.
By the relation $(\sum Z)^2 = \sum (Z^2) + 2 \text{esymm}_2(Z)$, we can algebraically compute $\sum W = c_1^2 - 2c_0 c_2 = K(c)$.
5. **Integer Product Bound**: The product of $Z$ evaluates to $c_k ((-1)^k c_0)^{k-1}$. Since $P$ has degree $k$ and $c_0 \neq 0$, both $c_0$ and $c_k$ are non-zero integers. Thus, the product of $Z$ is a non-zero integer, implying $\prod W = (\prod Z)^2 \ge 1$.
6. **AM-GM Inequality**: Applying the AM-GM inequality to the multiset $W$ (which consists of $k$ non-negative real numbers whose product is $\ge 1$), we obtain $\sum W \ge k \implies K(c) \ge k$.
**Required Global Definitions, Variables, or Structures**
No new definitions, axioms, or structures are needed. We use purely standard Mathlib components (like `Multiset`, `Polynomial`, and `esymm`).
**Smaller Lemmas (Subproblems)**
> lemma coeff_of_sum_Icc (c : $\mathbb{N}$ $\rightarrow$ $\mathbb{Z}$) (k : $\mathbb{N}$) (hk : (2 : $\mathbb{N}$) $\le$ k) (i : $\mathbb{N}$) (hi : i $\le$ k) :
>
> ($\sum$ j $\in$ Finset.Icc 0 k, Polynomial.monomial j (c j)).coeff i = c i
**Purpose**: Simplifies polynomial coefficient extraction from the given sum format.
> lemma card_roots_eq_of_ncard_rootSet k : $\mathbb{N}$ P : Polynomial $\mathbb{R}$
>
> ($h_d$ eg : P.natDegree = k)
>
> ($h_n$ card : (P.rootSet $\mathbb{R}$).ncard = k) :
>
> P.roots.card = k
**Purpose**: Shows that a polynomial with $k$ distinct real roots and degree $k$ has exactly $k$ roots counting multiplicities.
> lemma multiset_map_erase_prod_sum R : Type\* [CommRing R] (s : Multiset R) :
>
> (s.map (fun x => (s.erase x).prod)).sum = s.esymm (s.card - 1)
**Purpose**: Multiset identity relating the sum of element-wise excluded products to $E_{k-1}$.
> lemma multiset_map_erase_prod_esymm_two R : Type\* [CommRing R] (s : Multiset R) :
>
> (s.map (fun x => (s.erase x).prod)).esymm 2 = s.prod \* s.esymm (s.card - 2)
**Purpose**: Multiset identity relating the 2nd elementary symmetric polynomial of excluded products to $E_k E_{k-2}$.
> lemma multiset_sum_sq_eq R : Type\* [CommRing R] (s : Multiset R) :
>
> (s.map (fun x => x\textasciicircum 2)).sum = (s.sum)\textasciicircum 2 - (2 : R) \* s.esymm 2
**Purpose**: Expresses the sum of squares of a multiset in terms of its sum and its 2nd elementary symmetric polynomial.
> lemma multiset_map_erase_prod_prod R : Type\* [CommRing R] (s : Multiset R) :
>
> (s.map (fun x => (s.erase x).prod)).prod = s.prod \textasciicircum{} (s.card - 1)
**Purpose**: Computes the full product of the excluded products multiset.
> lemma multiset_sum_ge_card_of_prod_ge_one (W : Multiset $\mathbb{R}$) (hw : $\forall$ x $\in$ W, 0 $\le$ x) (hp : (1 : $\mathbb{R}$) $\le$ W.prod) :
>
> (W.card : $\mathbb{R}$) $\le$ W.sum
**Purpose**: The AM-GM inequality specialized for a multiset whose product is at least 1, proving that the sum is bounded below by its cardinality.
**Proof Body Outline**
1. Define $P$ as the sum $\sum_{i \in \text{Finset.Icc } 0 k} \text{monomial } i (c_i)$ and $P_R$ as $P.\text{map } (\text{algebraMap } \mathbb{Z} \text{ } \mathbb{R})$.
2. Apply `coeff_of_sum_Icc` to assert $P_R.\text{coeff } i = (c_i : \mathbb{R})$ for $i \in \{0, 1, 2, k\}$.
3. Establish $P_R.\text{roots.card} = k$ using `card_roots_eq_of_ncard_rootSet` and the natural degree injectivity.
4. Establish that $P_R.\text{splits } (\text{RingHom.id } \mathbb{R})$ follows from `Polynomial.splits_iff_card_roots`.
5. Let $s = P_R.\text{roots}$. Invoke Vieta's formulas (`Polynomial.coeff_eq_esymm_roots_of_splits`) to express $c_0$, $c_1$, and $c_2$ in terms of $s.\text{esymm } i$.
6. Define multisets $Y$ and $Z$ matching the theoretical blueprint. Use `multiset_sum_sq_eq`, `multiset_map_erase_prod_sum`, and `multiset_map_erase_prod_esymm_two` to show that the sum of the squared elements of $Z$ expands algebraically to exactly $(c_1^2 - 2c_0 c_2 : \mathbb{R}) = (K(c) : \mathbb{R})$.
7. Use `multiset_map_erase_prod_prod` to find $Z.\text{prod} = c_k ((-1)^k c_0)^{k-1}$.
8. Observe that since $c_0$ and $c_k$ are non-zero integers, their algebraic combination $Z.\text{prod}$ represents a non-zero integer, so its square (the product of $W = Z^2$) is $\ge 1$.
9. Feed $W$ to `multiset_sum_ge_card_of_prod_ge_one` to deduce that $W.\text{sum} \ge W.\text{card}$.
10. Using $W.\text{card} = k$ and $W.\text{sum} = (K(c) : \mathbb{R})$, deduce $(k : \mathbb{R}) \le (K(c) : \mathbb{R})$. Use `norm_cast` to translate this back to $(k : \mathbb{Z}) \le K(c)$.
References
Section Summary: This references section compiles recent publications, workshop papers, and technical reports primarily from 2025–2026 that explore how artificial intelligence systems can solve advanced math problems, generate formal proofs, and assist in mathematical research. The entries cover AI achievements at the level of the International Mathematical Olympiad, new benchmarks for theorem proving, and established proof assistants such as Lean, Isabelle, and Coq. Many citations point to arXiv preprints and conference proceedings on training models for automated reasoning and verification.
[1] Yichen Huang and Lin F. Yang (2025). Winning Gold at IMO 2025 with a Model-Agnostic Verification-and-Refinement Pipeline. In The 5th Workshop on Mathematical Reasoning and AI at NeurIPS 2025. https://openreview.net/forum?id=svz4xDjRC1.
[2] Luong, Thang and Lockhart, Edward (2025). Advanced version of Gemini with Deep Think officially achieves gold-medal standard at the International Mathematical Olympiad. Google DeepMind Blog. Accessed: 2026-05-02. https://deepmind.google/blog/advanced-version-of-gemini-with-deep-think-officially-achieves-gold-medal-standard-at-the-international-mathematical-olympiad/.
[3] Tony Feng et al. (2026). Towards Autonomous Mathematics Research. https://arxiv.org/abs/2602.10177. arXiv:2602.10177.
[4] Tony Feng et al. (2026). Aletheia tackles FirstProof autonomously. https://arxiv.org/abs/2602.21201. arXiv:2602.21201.
[5] Tony Feng et al. (2026). Semi-Autonomous Mathematics Discovery with Gemini: A Case Study on the Erdős Problems, 2026b. https://arxiv.org/abs/2601.22401. arXiv:2601.22401.
[6] Sumanth Varambally et al. (2025). Hilbert: Recursively Building Formal Proofs with Informal Reasoning. In The 5th Workshop on Mathematical Reasoning and AI at NeurIPS 2025. https://openreview.net/forum?id=ljAHonPrs1.
[7] Yong Lin et al. (2026). Goedel-Prover-V2: Scaling Formal Theorem Proving with Scaffolded Data Synthesis and Self-Correction. In The Fourteenth International Conference on Learning Representations. https://openreview.net/forum?id=j4C0nALrgK.
[8] Greiffenhagen, Christian (2024). Checking correctness in mathematical peer review. Social studies of science. 54(2). pp. 184–209.
[9] Hales, Thomas C (2005). A proof of the Kepler conjecture. Annals of mathematics. 162(3). pp. 1065–1185.
[10] Thomas Hales et al. (2017). A formal proof of the Kepler conjecture. Forum of mathematics, Pi. 5.
[11] Moura, Leonardo de and Ullrich, Sebastian (2021). The lean 4 theorem prover and programming language. In International Conference on Automated Deduction. pp. 625–635.
[12] Nipkow et al. (2002). Isabelle/HOL: a proof assistant for higher-order logic. Springer.
[13] Huet et al. (1997). The coq proof assistant a tutorial. Rapport Technique. 178. pp. 113.
[14] Harrison, John (2009). HOL light: An overview. In International Conference on Theorem Proving in Higher Order Logics. pp. 60–66.
[15] Thomas Hubert et al. (2026). Olympiad-level formal mathematical reasoning with reinforcement learning. Nature. 651. pp. 607–613. doi:10.1038/s41586-025-09833-y. https://www.nature.com/articles/s41586-025-09833-y.
[16] Z. Z. Ren et al. (2025). DeepSeek-Prover-V2: Advancing Formal Mathematical Reasoning via Reinforcement Learning for Subgoal Decomposition. https://arxiv.org/abs/2504.21801. arXiv:2504.21801.
[17] Luoxin Chen et al. (2025). Seed-Prover: Deep and Broad Reasoning for Automated Theorem Proving. https://arxiv.org/abs/2507.23726. arXiv:2507.23726.
[18] Nikil Ravi et al. (2026). FormalProofBench: Can Models Write Graduate Level Math Proofs That Are Formally Verified?. In ICLR 2026 Workshop: VerifAI-2: The Second Workshop on AI Verification in the Wild. https://openreview.net/forum?id=1LdnVndCEG.
[19] Alexander K Taylor et al. (2026). TaoBench: Do Automated Theorem Prover LLMs Generalize Beyond MathLib?. https://arxiv.org/abs/2603.12744. arXiv:2603.12744.
[20] Tsoukalas et al. (2026). Advancing Mathematics Research with AI-Driven Formal Proof Search. arXiv preprint arXiv:2605.22763.
[21] Tudor Achim et al. (2025). Aristotle: IMO-level Automated Theorem Proving. https://arxiv.org/abs/2510.01346. arXiv:2510.01346.
[22] Jiangjie Chen et al. (2025). Seed-Prover 1.5: Mastering Undergraduate-Level Theorem Proving via Learning from Experience. https://arxiv.org/abs/2512.17260. arXiv:2512.17260.
[23] Kunhao Zheng et al. (2022). miniF2F: a cross-system benchmark for formal Olympiad-level mathematics. In International Conference on Learning Representations. https://openreview.net/forum?id=9ZPegFuFTFv.
[24] Tsoukalas et al. (2024). PutnamBench: Evaluating Neural Theorem-Provers on the Putnam Mathematical Competition. In Advances in Neural Information Processing Systems. pp. 11545–11569. doi:10.52202/079017-0368. https://proceedings.neurips.cc/paper_files/paper/2024/file/1582eaf9e0cf349e1e5a6ee453100aa1-Paper-Datasets_and_Benchmarks_Track.pdf.
[25] Luong et al. (2025). Towards Robust Mathematical Reasoning. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. pp. 35418–35442. doi:10.18653/v1/2025.emnlp-main.1794. https://aclanthology.org/2025.emnlp-main.1794/.
[26] Gao et al. (2024). A Semantic Search Engine for Mathlib4. In Findings of the Association for Computational Linguistics: EMNLP 2024. pp. 8001–8013. doi:10.18653/v1/2024.findings-emnlp.470. https://aclanthology.org/2024.findings-emnlp.470/.
[27] Polu, Stanislas and Sutskever, Ilya (2020). Generative language modeling for automated theorem proving. arXiv preprint arXiv:2009.03393.
[28] Mario Carneiro (2020). Metamath Zero: The Cartesian Theorem Prover. https://arxiv.org/abs/1910.10703. arXiv:1910.10703.
[29] Lu et al. (2021). Inter-GPS: Interpretable Geometry Problem Solving with Formal Language and Symbolic Reasoning. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). pp. 6774–6786. doi:10.18653/v1/2021.acl-long.528. https://aclanthology.org/2021.acl-long.528/.
[30] The mathlib Community (2020). The lean mathematical library. In Proceedings of the 9th ACM SIGPLAN International Conference on Certified Programs and Proofs. pp. 367–381. doi:10.1145/3372885.3373824. http://dx.doi.org/10.1145/3372885.3373824.
[31] Yang et al. (2023). LeanDojo: Theorem Proving with Retrieval-Augmented Language Models. In Advances in Neural Information Processing Systems. pp. 21573–21612. https://proceedings.neurips.cc/paper_files/paper/2023/file/4441469427094f8873d0fecb0c4e1cee-Paper-Datasets_and_Benchmarks.pdf.
[32] Lample et al. (2022). HyperTree Proof Search for Neural Theorem Proving. In Advances in Neural Information Processing Systems. pp. 26337–26349. https://proceedings.neurips.cc/paper_files/paper/2022/file/a8901c5e85fb8e1823bbf0f755053672-Paper-Conference.pdf.
[33] Haohan Lin et al. (2025). Lean-STaR: Learning to Interleave Thinking and Proving. In The Thirteenth International Conference on Learning Representations. https://openreview.net/forum?id=SOWZ59UyNc.
[34] Xin et al. (2025). BFS-Prover: Scalable Best-First Tree Search for LLM-based Automatic Theorem Proving. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). pp. 32588–32599. doi:10.18653/v1/2025.acl-long.1565. https://aclanthology.org/2025.acl-long.1565/.
[35] First et al. (2023). Baldur: Whole-proof generation and repair with large language models. In Proceedings of the 31st ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering. pp. 1229–1241.
[36] Huajian Xin et al. (2025). DeepSeek-Prover-V1.5: Harnessing Proof Assistant Feedback for Reinforcement Learning and Monte-Carlo Tree Search. In The Thirteenth International Conference on Learning Representations. https://openreview.net/forum?id=I4YAIwrsXa.
[37] Albert Qiaochu Jiang et al. (2023). Draft, Sketch, and Prove: Guiding Formal Theorem Provers with Informal Proofs. In The Eleventh International Conference on Learning Representations. https://openreview.net/forum?id=SMa9EAovKMC.
[38] Haiming Wang et al. (2025). Kimina-Prover Preview: Towards Large Formal Reasoning Models with Reinforcement Learning. https://arxiv.org/abs/2504.11354. arXiv:2504.11354.
[39] Wu et al. (2022). Autoformalization with large language models. Advances in neural information processing systems. 35. pp. 32353–32368.
[40] Jaech et al. (2024). Openai o1 system card. arXiv preprint arXiv:2412.16720.
[41] Guo et al. (2025). Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning. arXiv preprint arXiv:2501.12948.