PaperOrchestra: A Multi-Agent Framework for Automated AI Research Paper Writing
Yiwen Song$^{1}$, Yale Song$^{1}$, Tomas Pfister$^{1}$, Jinsung Yoon$^{1}$
$^{1}$ Google Research
Abstract
Synthesizing unstructured research materials into manuscripts is an essential yet under-explored challenge in AI-driven scientific discovery. Existing autonomous writers are rigidly coupled to specific experimental pipelines, and produce superficial literature reviews. We introduce $\textsc{PaperOrchestra}$, a multi-agent framework for automated AI research paper writing. It flexibly transforms unconstrained pre-writing materials into submission-ready LaTeX manuscripts, including comprehensive literature synthesis and generated visuals, such as plots and conceptual diagrams. To evaluate performance, we present PaperWritingBench, the first standardized benchmark of reverse-engineered raw materials from 200 top-tier AI conference papers, alongside a comprehensive suite of automated evaluators. In side-by-side human evaluations, $\textsc{PaperOrchestra}$ significantly outperforms autonomous baselines, achieving an absolute win rate margin of 50%--68% in literature review quality, and 14%--38% in overall manuscript quality. (Project Page: https://yiwen-song.github.io/paper_orchestra/)
Correspondence: [email protected], [email protected], [email protected]
Executive Summary: The rapid growth of large language models has made AI a powerful tool in scientific research, but one persistent challenge is transforming raw ideas, experimental logs, and preliminary notes into polished, submission-ready academic papers. This process is time-intensive and error-prone, especially in fast-moving fields like AI, where researchers must synthesize deep literature reviews, generate visuals, and ensure technical rigor. Existing AI writing tools fall short: they either tie writing to specific experiments, produce shallow reviews with few citations, or fail to handle unstructured inputs flexibly. Addressing this gap is crucial now, as AI-driven discovery accelerates, and bottlenecks in documentation slow progress and dissemination of new findings.
This paper introduces PaperOrchestra, a standalone multi-agent system designed to automate the creation of full AI research papers from basic inputs like idea summaries and experimental logs. It also presents PaperWritingBench, a new benchmark derived from reverse-engineered materials of 200 papers from top AI conferences (CVPR and ICLR 2025), to enable standardized evaluation of writing tools.
The approach relies on a coordinated set of AI agents, each handling a key stage without needing predefined structures. An outline agent plans the paper's structure, including visuals and literature needs. Parallel agents then generate plots and diagrams using a tool called PaperBanana, and conduct targeted web searches validated against academic databases to build comprehensive bibliographies and reviews. A writing agent drafts sections like methodology and experiments, integrating data into tables and figures. Finally, a refinement agent iterates based on simulated peer feedback to improve clarity and coherence. Evaluations used automated scorers for aspects like citation accuracy and quality, plus side-by-side human reviews by 11 AI experts on 40 papers, comparing against a simple single-agent baseline and the advanced AI Scientist-v2 system. Inputs included anonymized, sparse idea notes to mimic real early-stage work, with assessments spanning 2024-2025 conference timelines.
Key findings highlight PaperOrchestra's strong performance. It generated 46-48 citations per paper on average—close to human-authored levels of about 59—while baselines managed only 9-14, focusing narrowly and missing broader context. Citation recall for essential references improved by 2-6% for must-cite items and 13% for supplementary ones. Literature reviews scored 33% higher than baselines on automated quality checks (0-100 scale), excelling in critical analysis and synthesis rather than mere summaries. Overall manuscript quality saw even larger gains: human evaluators preferred PaperOrchestra over baselines by 50-68% for reviews and 14-38% for full papers, with simulated acceptance rates of 81-84% versus 68-75% for competitors. Ablations confirmed robustness; sparse inputs yielded near-equal review quality to detailed ones, and auto-generated visuals competed well against human-provided figures in 51-66% of cases. The refinement step alone boosted acceptance simulations by 19-22%.
These results mean AI can now reliably assist in producing high-quality drafts that save researchers weeks of writing, reducing barriers to publishing in competitive venues. By generating deeper, more accurate literature synthesis and visuals, PaperOrchestra lowers risks of overlooked prior work or superficial analysis, potentially improving paper acceptance and scientific rigor. It outperforms expectations from prior tools, which often hallucinated facts or stayed shallow, showing multi-agent coordination unlocks more human-like writing without full end-to-end research automation.
Next, organizations should pilot PaperOrchestra for internal report generation or conference submissions, starting with sparse inputs to test efficiency. Trade-offs include higher compute (40 minutes per paper versus 3 for basic baselines) for better depth, so prioritize it for complex topics. Further integrate human oversight, like editable drafts, and expand to handle diverse fields beyond AI.
Limitations include dependence on external APIs for searches and visuals, which could introduce delays or inaccuracies, and a risk of model memorization from training data, though anonymization helps. Confidence in results is high for relative comparisons, given consistent human-automated alignments and diverse benchmark scope, but caution applies to absolute quality—human papers still lead by 43% in reviews—warranting more real-world trials before full reliance.
1. Introduction
Section Summary: Large language models are evolving AI from a helpful tool into a key player in scientific research, but a major challenge remains: converting messy raw materials like ideas and experiment notes into polished, ready-to-submit papers. While earlier AI writing tools suffered from inaccuracies and limited scope—such as producing shallow literature reviews or lacking diagrams—newer systems still fall short by being too tied to experiments or lacking evaluation standards. To address this, the authors introduce PaperOrchestra, a standalone AI framework that uses specialized agents to create full LaTeX manuscripts with deep reviews, visuals, and refinements, plus PaperWritingBench, a new benchmark based on 200 top AI papers; in human tests, it outperforms rivals by wide margins in quality and synthesis.
The rapid advancement of Large Language Models (LLMs) is transitioning AI from an assistive tool to an active participant in scientific discovery ([1]). While recent end-to-end autonomous frameworks ([2, 3]) establish the feasibility of automated research loops, realizing their full potential is hindered by a critical step: translating unstructured materials, such as raw ideas and experimental logs, into rigorous, submission-ready manuscripts.
Early attempts at automated academic writing relied on the parametric memory of LLMs, often leading to factual hallucinations. To mitigate this, recent frameworks employ retrieval-augmented generation (RAG) methods. Systems like AutoSurvey2 ([4]) and LiRA ([5]) decompose the literature review process into structured stages or specialized agent roles that emulate human review workflows. However, these survey-specific frameworks lack the capacity to transform raw experimental data into a full-length research paper.
On the other hand, full-lifecycle autonomous research agents are tightly coupled to their experimental loops, preventing them from functioning as standalone writing tools capable of processing human-provided materials. Empirical evaluations show critical deficits in their literature synthesis ([6, 7]). Relying on simple keyword searches, these agents produce shallow reviews with insufficient citations. They also lack the capabilities to generate conceptual diagrams, restricting visuals to code-generated data plots. Furthermore, evaluating automated writing independently remains difficult due to the absence of a standardized benchmark.
To bridge these gaps, our core contributions are:
- $\textsc{PaperOrchestra}$: A standalone, multi-agent framework that autonomously authors LaTeX manuscripts from unconstrained pre-writing materials. It uses specialized agents to synthesize deep literature reviews, generate plots and conceptual diagrams, and iteratively refine the manuscript for better technical clarity.
PaperWritingBench: The first standardized benchmark for AI research paper writing, which isolates the writing task by providing reverse-engineered raw materials (ideas and experimental logs) derived from 200 papers published in top-tier AI conferences.- Performance: In side-by-side human evaluations, $\textsc{PaperOrchestra}$ significantly outperforms autonomous baselines, achieving absolute win rate margins (the difference of our win rate and the baseline's) of 50%–68% in literature review synthesis and 14%–38% in overall manuscript quality.
2. Related Work
Section Summary: Recent AI frameworks, such as the AI Scientist and Cycle Researcher, aim to automate the entire scientific research process, from experiments to drafting papers, but their writing tools are tightly linked to internal workflows and struggle to work independently with human-provided materials. Early automated writing systems like PaperRobot generate basic text from data graphs, while newer tools like Prism and data-to-paper handle editing or translating results into narratives, and literature synthesizers like AutoSurvey2 create surveys from papers, yet they often require structured inputs and fail to produce targeted sections that highlight research gaps. In contrast, PaperOrchestra stands out by flexibly processing raw, unstructured pre-writing content to generate complete manuscripts, including visuals and contextual literature reviews, without needing predefined references or plots.
2.1 AI Researcher Frameworks
Recent works have introduced end-to-end (E2E) frameworks designed to fully automate the scientific research lifecycle. The AI Scientist-v1 ([2]) introduced automated experimentation and drafting via code templates, while v2 ([3]) increases autonomy using agentic tree-search. Concurrent works expand on these paradigms through distinct technical approaches: Cycle Researcher ([8]) employs an iterative refinement loop with reinforcement learning from reviewer feedback, while OmniScientist ([9]) couples an agentic framework with structured knowledge and tool-based reasoning. Other systems, such as InternAgent ([10]) and AI Co-Scientist ([11]), support human-in-the-loop collaboration in domain-specific applications. While effective at autonomous execution, the writing modules in these frameworks are rigidly coupled to their internal experimental loops. Consequently, they cannot directly function as standalone pipelines to synthesize unconstrained, human-provided pre-writing materials into submission-ready manuscripts.
::: {caption="Table 1: Comparison of $\textsc{PaperOrchestra}$ against existing AI writing systems."}

:::
2.2 Automated Writing and Literature Synthesis
Early automated writing systems, such as PaperRobot ([12]), generated incremental text sequences conditioned on entity relation graphs but lacked the capacity to synthesize complex, data-driven scientific narratives. More recent LLM-based writing assistants, including Prism ([15]), excel at stylistic refinement and local text editing, but typically rely on structured inputs or human guidance and do not natively support end-to-end manuscript generation from raw experimental logs. Similarly, data-to-paper ([13]) focuses on translating structured analytical results into text with backward traceability. However, it primarily operates on structured, well-defined inputs and is less suited to flexibly drafting from early-stage, under-specified raw materials.
Beyond constructing a data-driven narrative from experimental results, synthesizing prior literature remains a distinct and critical challenge in automated authoring. Recent work targets this problem via automated literature review generation. For instance, AutoSurvey2 ([4]) uses a multi-stage retrieval-augmented pipeline to generate comprehensive surveys, while SurveyGen-I ([16]) focuses on iteratively refining topic outlines. Similarly, LiRA ([5]) employs a multi-agent workflow that structures, drafts, and refines literature reviews from retrieved papers. While highly effective at generating long-form surveys, these systems are not designed for writing targeted related work sections. Consequently, they often lack the contextual awareness needed to selectively contrast prior work and clearly motivate the specific research gap of a new method.
As summarized in Table 1, existing pipelines show key limitations when used as standalone manuscript generators. Frameworks like CycleResearcher ([8]) require a structured BibTeX reference list as input, which is rarely available at the start of writing, and fail on unstructured inputs outside this format. While AI-Researcher ([14]) and AI Scientist-v2 ([3]) accept unstructured topic descriptions, their writing modules rely on artifacts produced earlier in their internal pipelines and do not generate conceptual scientific diagrams. In contrast, $\textsc{PaperOrchestra}$ can process unconstrained pre-writing materials without relying on pre-existing plots or ground-truth references. By orchestrating specialized agents to autonomously synthesize targeted literature, generate comprehensive visuals, and craft coherent scientific narratives, $\textsc{PaperOrchestra}$ establishes a robust, end-to-end pipeline for AI research manuscript generation.
3. Task and Dataset
Section Summary: The section outlines an AI framework for generating complete research papers, which takes inputs like a brief idea summary, an experimental log of results, a conference-specific LaTeX template, guidelines, and optional figures to produce a ready-to-submit LaTeX file and PDF. To test this system, the authors created a new dataset called PaperWritingBench, drawing from 200 accepted papers at top AI conferences CVPR 2025 and ICLR 2025 for diverse topics and formats. They built evaluation inputs by extracting content from these papers using specialized tools, then used language models to synthesize anonymized idea summaries in sparse or dense versions and self-contained experimental logs, ensuring no original details leak through.
3.1 Task Formulation
We formulate the end-to-end AI research paper generation task as a function mapping unconstrained pre-writing materials to a complete submission package. Specifically, the framework operates on the following input components:
- Idea Summary ($\mathcal{I}$): A brief overview establishing the proposed methodology, core contributions, and theoretical foundation.
- Experimental Log ($\mathcal{E}$): A compilation of experimental results, covering raw data points, ablation studies, and performance metrics.
- LaTeX Template ($\mathcal{T}$): The template files provided by the target AI conference.
- Conference Guidelines ($\mathcal{G}$): The requirements mandated by the target AI conference.
- Figures ($\mathcal{F}$): An optional set of pre-existing visual assets (e.g., diagrams, plots). If no figures are provided ($\mathcal{F} = \emptyset$), the pipeline autonomously synthesizes all relevant visuals.
The goal is to produce a finalized submission package $P$. We define $P$ as a tuple consisting of the source LaTeX file ($P_\textit{tex}$) and the rendered PDF ($P_{\textit{pdf}}$), generated via the framework $W$:
$ P = (P_\textit{tex}, P_{\textit{pdf}}) = W(\mathcal{I}, \mathcal{E}, \mathcal{T}, \mathcal{G}, \mathcal{F}) $
3.2 Dataset Construction
To evaluate our pipeline, we introduce PaperWritingBench (App. Appendix C.1), a new dataset comprising 200 accepted papers from CVPR 2025 and ICLR 2025 (100 papers each). These venues ensure high academic standards while testing adaptability to distinct conference formats (double-column CVPR vs. single-column ICLR). To construct the evaluation tuple $(\mathcal{I}, \mathcal{E}, \mathcal{T}, \mathcal{G}, \mathcal{F})$ for each paper, we retrieve the official LaTeX templates ($\mathcal{T}$) and guidelines ($\mathcal{G}$) for each venue and execute the following pipeline:
Paper Acquisition and Extraction.
We randomly sample papers from the OpenReview portal (ICLR) and the CVF Open Access repository (CVPR) to ensure topic diversity. We process the raw PDFs using MinerU ([17]) to generate structured, mathematically faithful Markdown, and PDFFigures 2.0 ([18]) to extract visual entities ($\mathcal{F}$) and captions. Incomplete or misparsed samples are discarded to maintain corpus quality.
Synthesizing Raw Materials.
Since pre-writing materials (e.g., lab notes) are unavailable, we prompt an LLM to reverse-engineer two core components from the extracted PDF content (App. Appendix C.2). To prevent information leakage, both components are fully anonymized (stripping authors and titles) and rendered strictly self-contained by removing all citations, URLs, and explicit figure or table references. We synthesize the following (App. Appendix C.3):
- Idea Summary ($\mathcal{I}$): Distills the core methodology while explicitly excluding experimental results. We generate a Sparse variant (summarizing only high-level ideas) and a Dense variant (retaining formal definitions and LaTeX equations) to simulate different degrees of user drafting effort.
- Experimental Log ($\mathcal{E}$): Extracts a record of experimental setup and empirical findings, including baselines, datasets, metrics, and tabular data. The LLM further de-contextualizes this data by converting visual insights into standalone factual observations, allowing us to test how well the writing system can reconstruct the narrative purely from raw data.
4. $\textsc{PaperOrchestra}$
Section Summary: PaperOrchestra is a multi-agent system that automatically converts initial research materials, like idea summaries, experiment notes, LaTeX templates, and conference rules, into a complete, ready-to-submit academic paper in PDF format. It starts by generating an outline that plans visualizations, literature searches, and section content, then runs parallel processes to create plots using a tool called PaperBanana and to find, verify, and summarize relevant papers for the introduction and related work sections. Finally, it drafts the full manuscript by writing the remaining sections, integrating figures and tables, and iteratively refines the text through simulated peer reviews to improve quality.
![**Figure 1:** Overview of the $\textsc{PaperOrchestra}$ framework. Specialized agents systematically parse unstructured inputs, synthesize plots and literature, compile a full draft, and iteratively refine the manuscript into a submission-ready PDF. (This figure was generated using PaperBanana ([19]).)](https://ittowtnkqtyixxjxrhou.supabase.co/storage/v1/object/public/public-images/q2zdfqa6/overview.png)
Figure 1 illustrates $\textsc{PaperOrchestra}$, a multi-agent framework (App. Appendix F.1) that autonomously transforms pre-writing materials, including Idea Summary ($\mathcal{I}$), Experimental Log ($\mathcal{E}$), LaTeX Template ($\mathcal{T}$), and Conference Guidelines ($\mathcal{G}$), into submission-ready manuscripts. The pipeline executes five steps, with Step 2 and Step 3 operating in parallel:
Step 1: Outline Generation.
The Outline Agent synthesizes pre-writing materials into a JSON outline comprising: (a) a visualization plan dictating specific plot types, data sources, and aspect ratios; (b) a targeted literature search strategy establishing both macro-level context and micro-level methodology clusters to guide the Literature Review Agent in conducting searches and constructing a citation map, which is subsequently leveraged to draft the Introduction and Related Work sections; and (c) a section-level writing plan including high-level content bullets and a comprehensive list of citation hints for all core external dependencies, such as baselines, datasets, and metrics used in the paper.
Step 2: Plot Generation.
The Plotting Agent executes the visualization plan to generate conceptual diagrams and statistical plots. We use PaperBanana ([19]) as the default module, which employs a closed-loop refinement system where a VLM critic evaluates rendered images against design objectives, iteratively revising text descriptions and regenerating images to resolve visual artifacts, and synthesizing context-aware captions.
Step 3: Literature Review.
Executing the search strategy outlined in Step 1, the Literature Review Agent drives a concurrent, hybrid discovery pipeline. It employs an LLM equipped with web search to identify candidate papers, then uses the Semantic Scholar API to authenticate their existence (App. Appendix D.3). Upon a successful match, the agent fetches the abstract and metadata while enforcing temporal cutoffs (App. Appendix D.1); candidates are discarded if they exceed the cutoff date or lack a verified mapping. Following deduplication via Semantic Scholar IDs, the agent compiles a citation registry and auto-generates a BibTeX (.bib) file. Finally, it uses the verified citations to draft the Introduction and Related Work sections.
Step 4: Section Writing.
The Section Writing Agent drafts the remaining core sections using the outputs from previous stages. Building upon the partially filled LaTeX file, it extracts numeric values from the experimental log to construct tables. Guided by the section-level outline and the established citation bank, the agent authors the abstract, methodology, experiments, and conclusion sections, seamlessly integrating the generated figures to produce a complete LaTeX manuscript.
Step 5: Iterative Content Refinement.
The Content Refinement Agent iteratively optimizes the manuscript using simulated peer-review feedback. Here we use AgentReview ([20]) as the default system in this module. After modifying the LaTeX source to address weaknesses, revisions are accepted if the overall score increases, or if it ties while net sub-axis gains are non-negative. The agent immediately reverts to the previous version and halts upon any overall score decrease, negative tie-breaker, or reaching the iteration limit. The resulting LaTeX document and compiled PDF represent the final output of $\textsc{PaperOrchestra}$.
5. Experiments
Section Summary: Researchers tested PaperOrchestra, an AI system that uses a team of specialized agents to draft academic papers, against simpler baselines like a single AI agent and a more advanced system called AI Scientist-v2, using preliminary research notes as input to mimic real-world scenarios. They evaluated performance through automated tools that checked citation accuracy, literature review quality, and overall paper strength, including side-by-side comparisons and simulated peer reviews. The results showed PaperOrchestra significantly outperforming the other AI systems in generating higher-quality papers, though still falling short of human-written ones.
5.1 Baselines
We benchmark $\textsc{PaperOrchestra}$ against two pipelines (App. Appendix D.2): (1) a Single Agent baseline that processes all raw materials ($\mathcal{I}, \mathcal{E}, \mathcal{T}, \mathcal{G}, \mathcal{F}$) and executes end-to-end drafting and bibliography construction in a single LLM call, validating the necessity of a multi-agent system; and (2) AI Scientist-v2 ([3]), a state-of-the-art system featuring multi-round citation gathering, VLM-guided plot refinement, and iterative self-reflection. To ensure fair comparison against baselines lacking diagram generation, we standardize visual inputs by restricting allowable figures to those extracted from ground-truth papers ($\mathcal{F} = \mathcal{F}_{GT}$). Furthermore, we adopt the sparse idea as our standard setting to simulate realistic scenarios where researchers provide preliminary notes rather than mature formulations. To prevent pre-training data memorization, all evaluated writing pipelines employ a universal anti-leakage prompt (App. Appendix D.4).
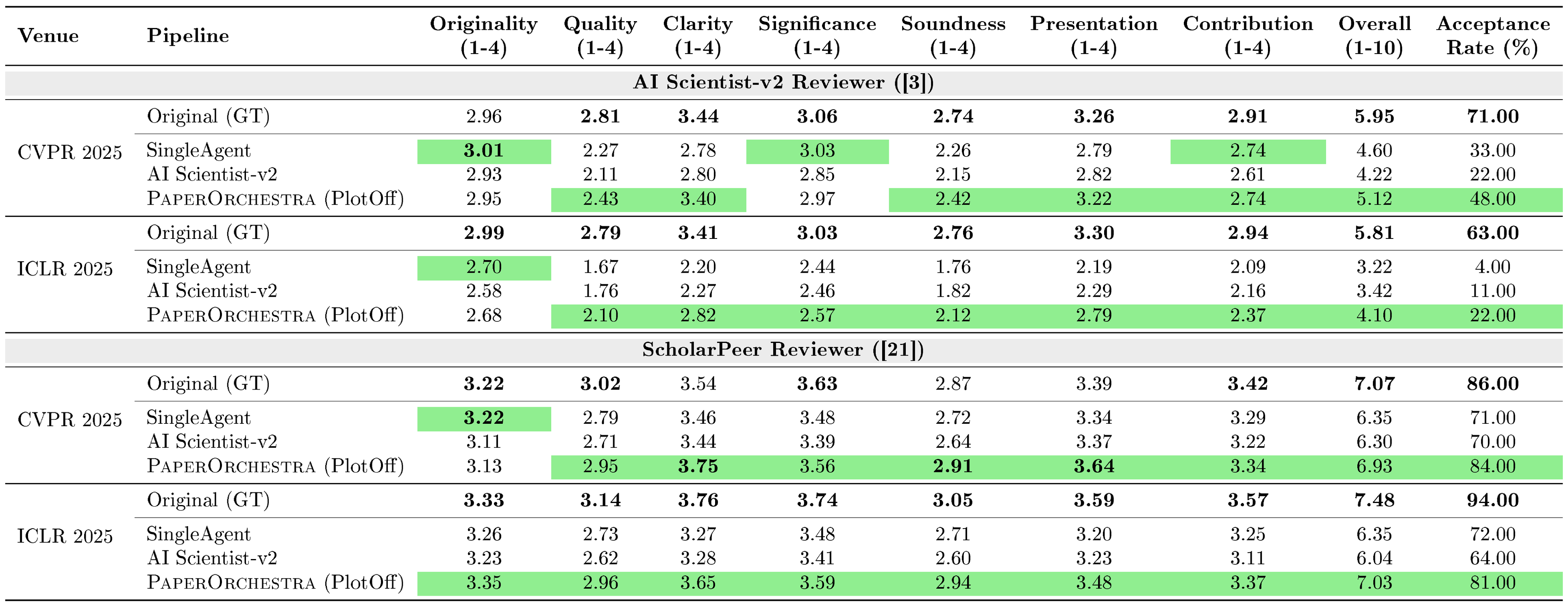
::: {caption="Table 2: Holistic technical quality evaluation via the AI Scientist-v2 ([3]) and ScholarPeer ([21]) frameworks (Sparse Idea Setting). Higher scores indicate better manuscript quality and higher simulated acceptance rates. Bold indicates best scores; while green highlights the highest score achieved by an AI pipeline."}
:::
5.2 Autoraters
Citation F1.
To quantitatively assess citation coverage, we compare the generated reference list against the ground-truth (GT) paper. Using an LLM provided with the paper context (see App. Appendix O.1), we partition the GT references into two categories: (1) P0 (Must-Cite) comprises core citations strictly necessary for contextualizing the work, including direct experimental baselines, utilized datasets, metrics, and foundational methodologies upon which the paper directly builds; (2) P1 (Good-to-Cite) includes all remaining GT citations, providing valuable but non-essential background context such as orthogonal work or supplementary information. To ensure accurate matching, we extract reference lists from both the GT and generated papers and resolve them to unique entity IDs using the Semantic Scholar API. We then compute Precision, Recall, and F1 scores independently for the P0 set, the P1 set, and the combined overall reference set.
Literature Review Quality.
To qualitatively evaluate the generated Introduction and Related Work sections, we employ an LLM evaluator (App. Appendix O.1) to score the generated text from 0–100 across six axes: coverage and completeness, relevance and focus, critical analysis and synthesis, positioning and novelty, organization, and citation rigor. To mitigate standard LLM score inflation, the evaluation is grounded against venue-specific average citation counts. The system enforces strict score caps and penalties for purely descriptive summaries, unsupported novelty claims, or citation padding, outputting an overall quality score for each paper.
Overall Quality.
To evaluate the holistic technical quality of the generated papers, we employ two AI-based peer review frameworks simulating expert assessment: (1) the AI Scientist-v2 Reviewer ([3]), an automated module for structured manuscript evaluation; and (2) ScholarPeer ([21]), a search-enabled multi-agent system mimicking expert workflows via iterative retrieval and evidence checking. Both systems yield multi-axis scores, an overall rating, and a simulated acceptance decision.
Side-by-Side (SxS) Comparison.
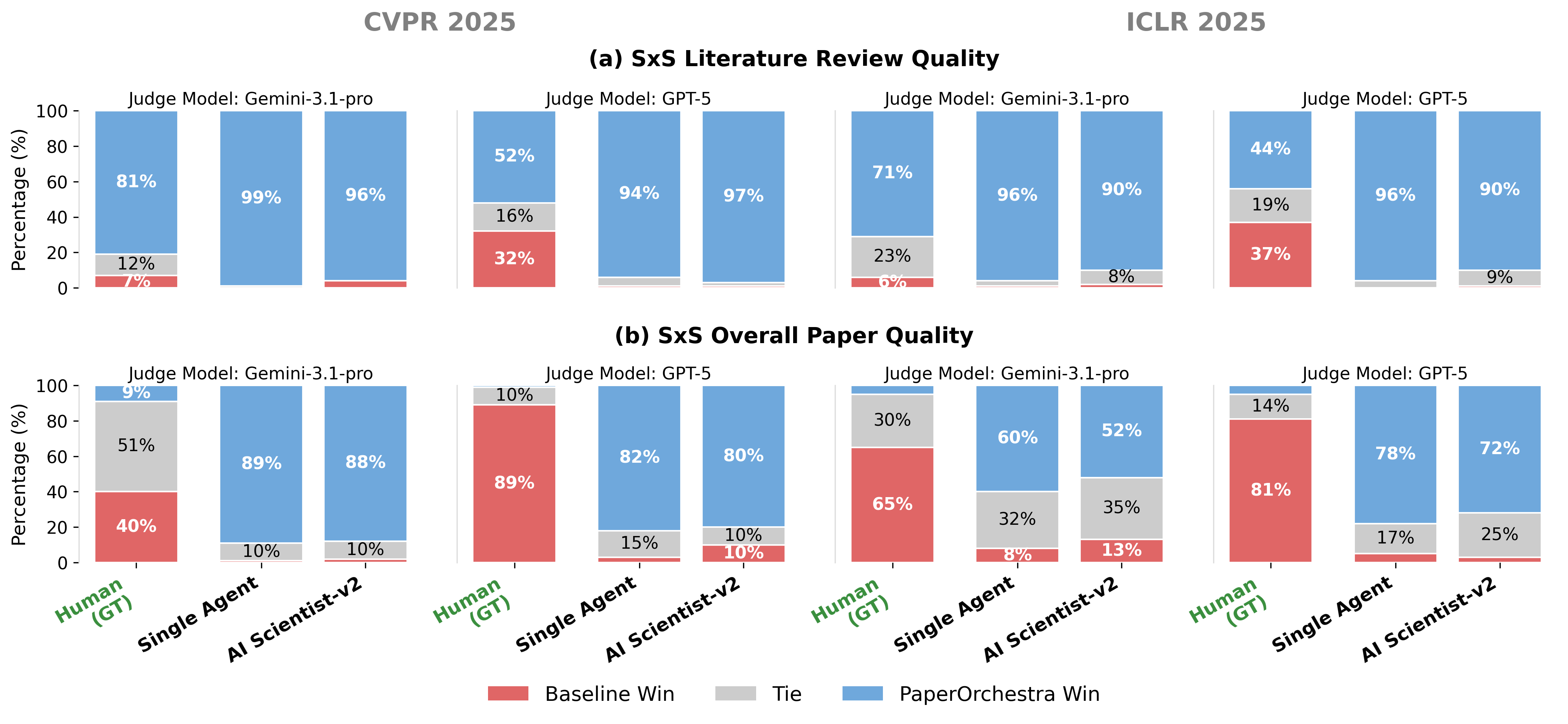
To directly compare manuscripts generated from the same research idea across different pipelines, we implement two automated SxS LLM evaluators. (1) SxS Literature Review Quality extracts the Introduction and Related Work to assess problem framing, prior work coverage, organization and synthesis, contribution positioning, and readability. (2) SxS Paper Quality holistically compares the full manuscript (including visual layout) across six axes: scientific depth, technical execution, logical flow, writing clarity, presentation of evidence, and academic style. To mitigate LLM positional bias, we evaluate each pair of manuscripts in both orderings. The final aggregated outcome is recorded as a win (two wins, or one win and one tie), a tie (one win and one loss, or two ties), or a loss.
5.3 Results
Side-by-Side Comparison.
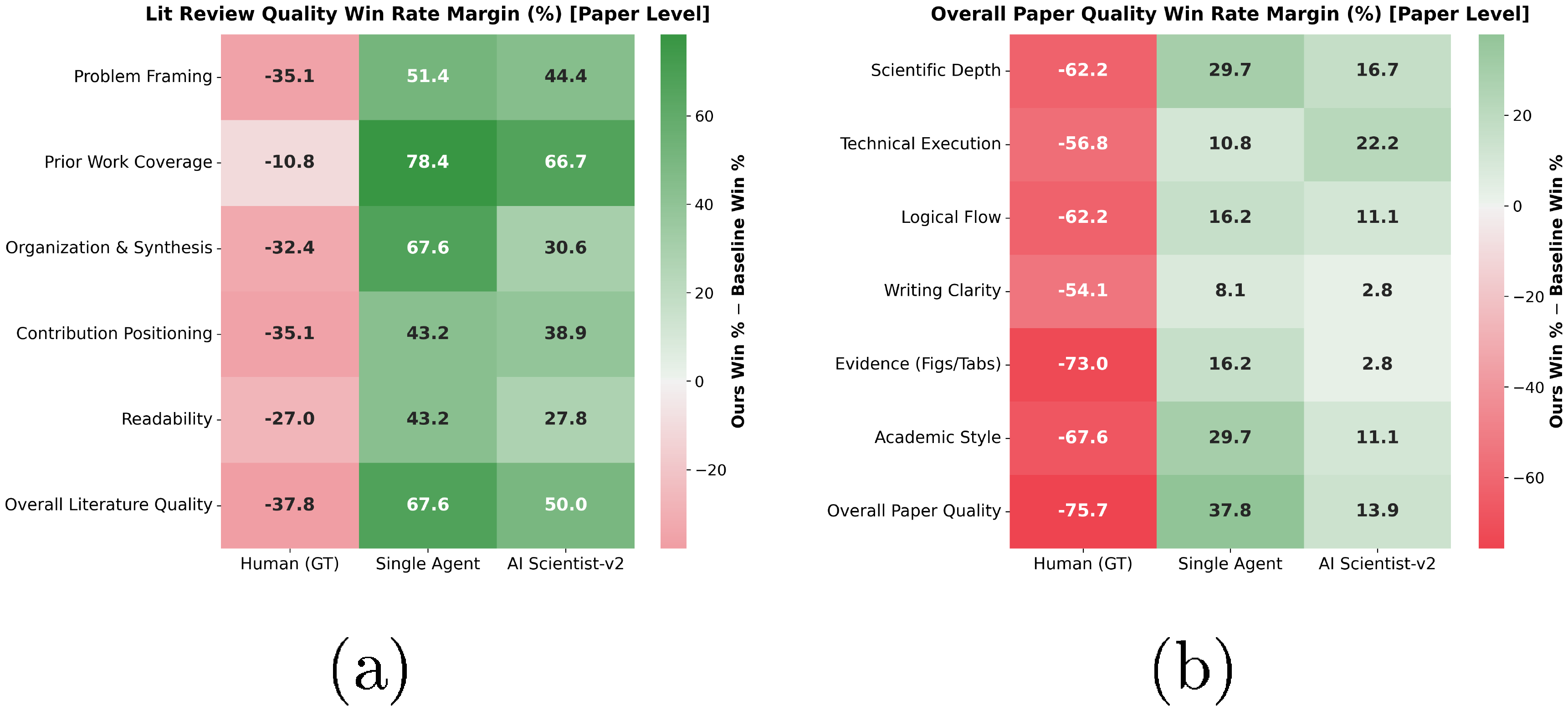
As shown in Figure 2, $\textsc{PaperOrchestra}$ consistently outperforms both the Single Agent baseline and AI Scientist-v2 in SxS evaluations. In Literature Review Quality, our framework dominates the autonomous baselines, achieving absolute win margins of 88%–99%. For Overall Paper Quality, although Human (GT) remains the upper bound, $\textsc{PaperOrchestra}$ substantially surpasses all tested AI competitors. It strongly outperforms AI Scientist-v2 and the Single Agent by margins of 39%–86% and 52%–88%, respectively, across all settings, confirming that our multi-agent architecture significantly enhances overall manuscript quality (cost analysis in App. Appendix B).
Technical Quality.
As detailed in Table 2, we evaluate holistic manuscript quality using the AI Scientist-v2 and ScholarPeer frameworks. Under ScholarPeer, $\textsc{PaperOrchestra}$ achieves high simulated acceptance rates of 84% (CVPR) and 81% (ICLR), closely tracking Human (GT) baselines (86% and 94%, respectively). It significantly outperforms existing AI pipelines, delivering absolute acceptance gains of 13% (CVPR) and 9% (ICLR) over the strongest autonomous baseline. Beyond acceptance rates, $\textsc{PaperOrchestra}$ dominates across critical sub-axes (notably Clarity, Presentation, and Soundness), demonstrating that our multi-agent system yields structurally coherent and technically sound manuscripts.
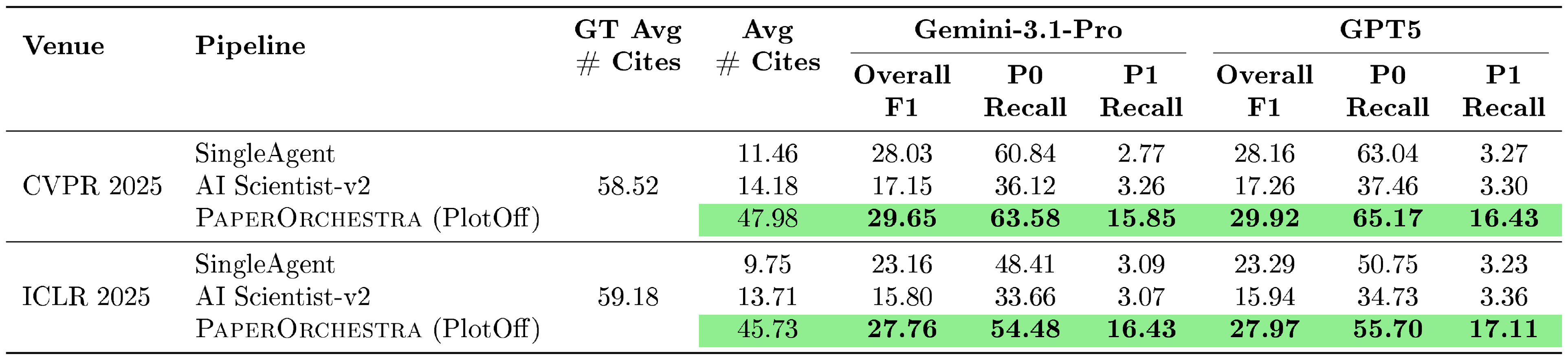
::: {caption="Table 3: Citation F1 evaluation (Sparse Idea Setting). P0 and P1 denote must-cite and good-to-cite references, respectively. F1 and Recall are percentages."}
:::
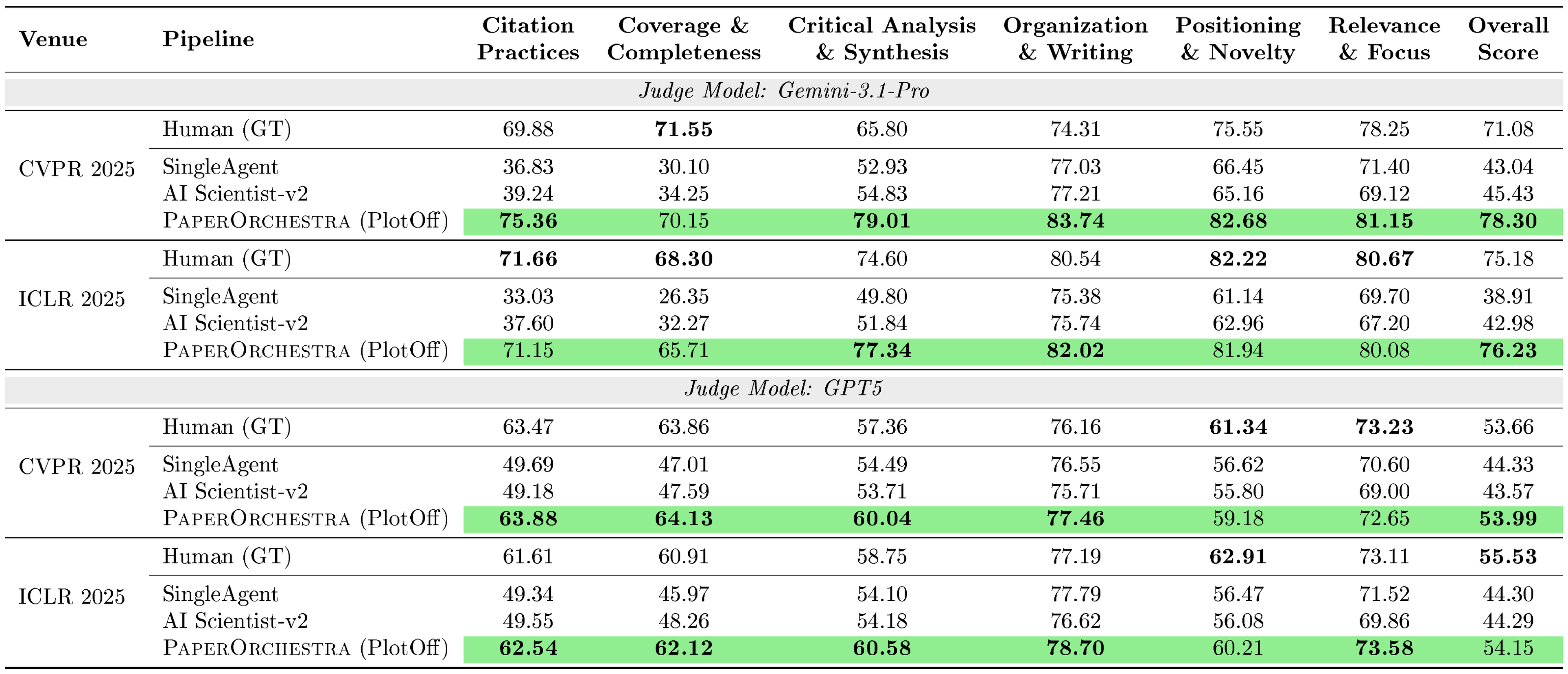
::: {caption="Table 4: Literature review quality assessed by LLM-as-a-Judge (0–100 scale, Sparse Idea Setting). All numbers are percentages."}
:::
Citation Coverage.
Table 3 demonstrates $\textsc{PaperOrchestra}$ successfully mitigates under-citation issues. While autonomous baselines achieve competitive Overall F1 scores, this is a mathematical artifact of their extremely low citation counts (averaging 9–14). They focus on fetching obvious P0 papers, which inflates their F1 scores but leaves P1 Recall near zero. In contrast, our framework generates 45.73–47.98 citations, closely mirroring Human (GT) writeups ($\sim$ 59). Alongside improving P0 Recall by absolute margins of 2.13%–6.07%, $\textsc{PaperOrchestra}$ significantly increases P1 Recall by 12.59%–13.75% over the strongest baselines. This proves our method actively explores the broader academic landscape rather than relying on shallow keyword matching.
Literature Review Quality.
Citation F1 alone cannot fully evaluate literature synthesis; a review must also identify gaps and motivate the proposed method. From Table 4, $\textsc{PaperOrchestra}$ achieves absolute Overall Score gains of 32.87%–33.25% (Gemini-3.1-Pro) and 9.66%–9.85% (GPT-5) over the strongest AI baseline, remaining highly comparable to Human baselines. Dominating in Citation Practices and Critical Analysis, our framework synthesizes analytical, well-grounded narratives rather than generic LLM summaries.
5.4 Human Evaluation
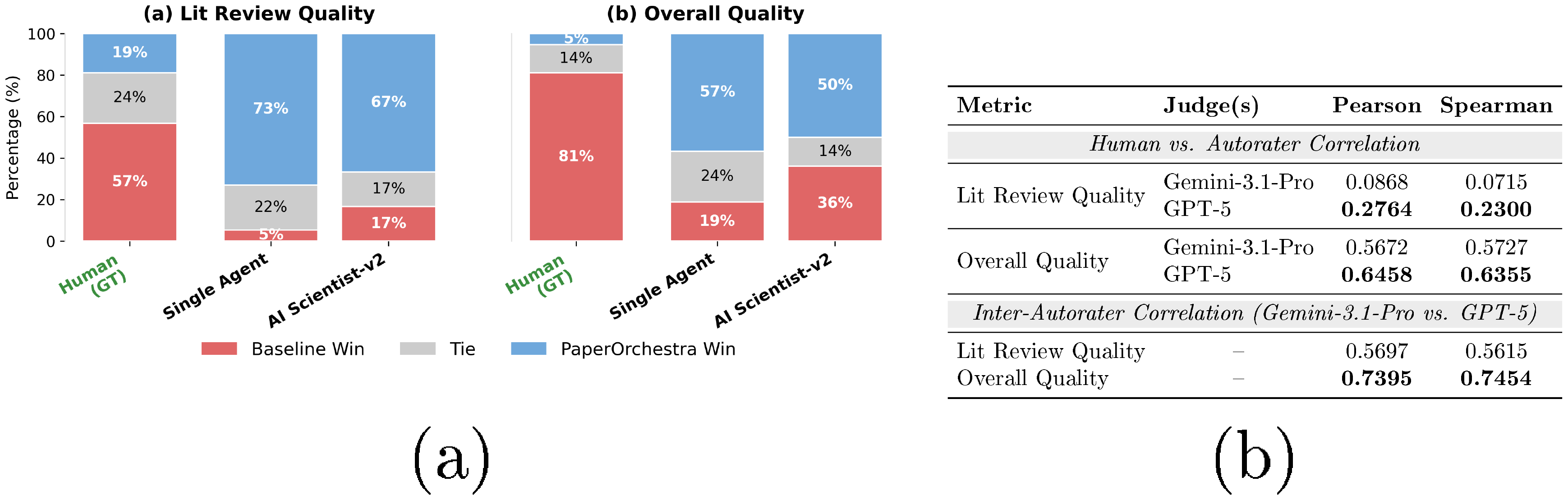
To validate automated SxS metrics and assess human-perceived manuscript quality, we recruited 11 AI researchers to evaluate 40 randomly sampled papers (20 per venue) from PaperWritingBench. For each paper, $\textsc{PaperOrchestra}$ was compared against all baselines (Human GT, Single Agent, and AI Scientist-v2), yielding 180 paired evaluations (App. Appendix D.5).
Human preferences correlate strongly with our GPT-5 evaluator for Overall Quality (Pearson $r=0.6458$, Spearman $\rho=0.6355$; Figure 3b). Literature review correlation is lower due to inherent LLM self-bias. Manual inspection reveals LLMs tend to act as structural graders, rewarding rigid formatting such as explicit "Problem-Gap-Solution" paragraphs or bulleted thematic groups. In contrast, human experts prioritize dense, pragmatic factuality and a nuanced, narrative-driven flow, which the autorater often mistakenly penalizes for lacking explicit formatting cues. Nevertheless, relative rankings remain strictly consistent. The stability of our automated SxS metrics is further validated by high inter-autorater agreement across different LLM judges (Figure 3b). Human SxS evaluations (Figure 3a) confirm $\textsc{PaperOrchestra}$ strongly outperforms AI baselines by absolute margins of 50%–68% (Literature Review) and 14%–38% (Overall Quality). It also achieves a highly competitive 43% tie/win rate against human GT in literature synthesis.
5.5 Ablation Studies
::: {caption="Table 5: Automated SxS evaluation of Sparse vs. Dense idea settings."}

:::
::: {caption="Table 6: Automated SxS Paper Quality evaluating the Plotting Agent. Despite lacking access to data represented by GT visuals, PlotOn achieves highly competitive performance against PlotOff that use human-authored figures."}

:::
Sparse vs. Dense Idea
Table 5 evaluates the impact of input density. For Overall Paper Quality, the Dense idea setting dominates win rates (43%–56% vs. 18%–24%) by facilitating more rigorous methodology generation. Meanwhile, Literature Review Quality exhibits near-parity, with the Sparse setting securing 32%–40% against Dense's 28%–39%. This demonstrates the exceptional robustness of $\textsc{PaperOrchestra}$: our Literature Review Agent autonomously executes targeted searches and identifies research gaps without relying heavily on the dense input drafted by human. Additional qualitative comparisons are provided in App. Appendix E.2.
Autonomous Visual Generation (PlotOff vs. PlotOn)
Table 6 evaluates our Plotting Agent by comparing papers using human-authored GT figures (PlotOff) vs. autonomously generated visuals (PlotOn). Although PlotOff benefits from an inherent information advantage (GT figures often embed supplementary results absent from raw input logs), PlotOn remains highly competitive, securing ties or wins in 51%–66% of SxS matchups across all four setups. As shown in App. Appendix E.1, $\textsc{PaperOrchestra}$ synthesizes coherent visuals from scratch, effectively augmenting the manuscript and reinforcing the scientific narrative.
![**Figure 4:** **Impact of the Content Refinement Agent.** (a) In automated SxS paper quality evaluation, refined manuscripts dominates. (b) This improvement is reflected through absolute gains in acceptance rates simulated by AgentReview ([20]).](https://ittowtnkqtyixxjxrhou.supabase.co/storage/v1/object/public/public-images/q2zdfqa6/ablation_refinement.png)
Importance of the Content Refinement Agent
Figure 4 isolates the impact of our iterative evaluation-feedback loop. In automated SxS comparisons (Figure 4(a)), refined manuscripts (AfterRefine) dominate unrefined drafts (BeforeRefine) with 79%–81% win rates and 0% losses. AgentReview metrics (Figure 4(b)) reflect this trend, showing substantial increases in simulated acceptance rates (+19% CVPR, +22% ICLR) and overall scores (+0.88 and +1.61). Driven by targeted clarity and presentation corrections, these results prove our content refinement loop is critical for elevating raw drafts into rigorous, submission-ready manuscripts.
6. Conclusion
Section Summary: This study introduces PaperOrchestra and PaperWritingBench, tools that turn raw, disorganized AI research notes into polished manuscripts ready for submission. Tests show that the system's team of AI agents produces strong-quality papers quickly, including insightful reviews of existing studies. Looking ahead, the tools could improve by handling more complex research data and evolving into interactive setups that blend human and AI collaboration in scientific writing.
In this work, we introduced $\textsc{PaperOrchestra}$ and PaperWritingBench to transform unstructured, preliminary AI research materials into submission-ready manuscripts. Experiments demonstrate that our multi-agent framework can generate high-quality research papers with competitive runtime (App. Appendix B) while synthesizing deep, context-aware literature reviews. Future research can focus on expanding the framework's capacity to ingest richer research artifacts and transitioning these autonomous agents into interactive, dynamic writing environments to enable seamless human-AI scientific collaboration (more limitations discussed in App. Appendix A).
7. Ethics Statement
Section Summary: PaperOrchestra is designed as a helpful tool to speed up the drafting of AI research papers, but it is not meant to be an independent author, so human researchers must take full responsibility for the accuracy, originality, and truthfulness of everything in the final work. The system includes strong built-in protections, like checks that validate citations from reliable sources, to reduce errors or made-up information and maintain high academic standards. Still, users need to carefully review and confirm all outputs to avoid spreading biases or false details that might come from the underlying AI language models.
We position our system as an advanced assistive tool designed to accelerate the drafting process of AI research papers, rather than an independent entity capable of claiming authorship. Human researchers must retain full accountability for the factual accuracy, originality, and validity of the claims presented in any generated manuscript. While $\textsc{PaperOrchestra}$ incorporates robust programmatic safeguards (such as API-grounded citation validation) to minimize hallucinations and ensure academic rigor, users are responsible for verifying the outputs to prevent the propagation of LLM-derived biases or misinformation.
Appendix
Section Summary: The appendix discusses limitations of the PaperOrchestra system, such as its dependence on external tools for creating images that can sometimes produce inaccurate visuals, and suggests future improvements like adding human oversight for editing drafts and using unpublished data to avoid biases in testing. It also compares the system's computing demands, showing that PaperOrchestra takes about 40 minutes and 60-70 AI model queries to generate a paper, slightly more than a similar tool but with better results due to efficient parallel searches and checks. Finally, it describes the dataset used for evaluation, highlighting differences between computer vision and machine learning conference papers, with the latter having more figures, tables, and longer experiment descriptions.
A. Limitations and Future Work
While $\textsc{PaperOrchestra}$ advances the capabilities of autonomous manuscript generation, several areas remain for future exploration. First, relying on external frameworks like PaperBanana ([19]) for visual generation limits our direct control over figure hallucinations. Although mitigating these errors falls outside the primary scope of our pipeline, future systems could benefit from integrating targeted Vision-Language Models and dedicated human evaluations to systematically verify that generated visual content is factually sound and optimally placed within the LaTeX layout.
Second, although our current refinement agent effectively improves paper quality using structured, LLM-generated feedback, transitioning this framework toward an interactive, human-in-the-loop (HITL) system would enable researchers to iteratively steer drafts via natural language critiques. This evolution would solidify the framework's intended role as an advanced assistive tool rather than a fully independent writing entity.
Finally, evaluating foundation models on PaperWritingBench carries an inherent risk of pretraining data contamination. To mitigate this risk, we rigorously de-contextualized and anonymized all input materials. Additionally, since all evaluated baselines share the same underlying language models, any potential knowledge leakage applies uniformly, ensuring a strictly fair relative comparison. To fully isolate generation from memorization, future benchmarks could leverage unpublished research or autonomously generated raw materials.
B. Computational Cost
:Table 7: Comparison of computational cost and single-paper latency. This table outlines the estimated number of LLM API calls, mean execution time, and core architectural components for each pipeline.
| Method | #LLM Calls | Latency (Mean) | System Description |
|---|---|---|---|
| Single Agent | 1 | 3.3 mins | Single monolithic prompt and generation. |
| AI Scientist-v2 | $\sim$ 40–45 | 35.1 mins | Multi-step pipeline (20-round citation scan, drafting, $3\times$ reflections, and vision critique). |
| $\textsc{PaperOrchestra}$ | $\sim$ 60–70 | 39.6 mins | Multi-agent orchestration (outline generation, parallel literature search, sequential citation verification, writing, plotting with critique, and a $3\times$ content refinement loop). |
Table 7 compares the computational cost and single-paper latency of $\textsc{PaperOrchestra}$ against the Single Agent and AI Scientist-v2 baselines. Although the Single Agent executes rapidly, it fails to produce the rigorous citations and data-grounded visuals generated by our system. Despite requiring more LLM calls ($\sim$ 60–70) than AI Scientist-v2 ($\sim$ 40–45), $\textsc{PaperOrchestra}$ maintains a highly competitive mean processing time of 39.6 minutes (compared to 35.1 minutes for AI Scientist-v2). To calculate these mean latency values, we evaluated all methods on a random subset of 10 papers (5 from CVPR and 5 from ICLR) using a single worker. For each method, we removed the highest and lowest execution times to mitigate the impact of API network anomalies before computing the final average.
The efficiency of $\textsc{PaperOrchestra}$ is achieved by strategically decoupling the paper discovery and verification pipeline. To optimize throughput, we execute retrieval in two distinct stages: (1) Parallel Candidate Discovery, which leverages 10 concurrent workers for search-grounded LLM calls to rapidly pool candidate papers; and (2) Sequential Citation Verification, which safely processes the pooled candidates through Semantic Scholar at the maximum allowable rate (1 query per second). This architecture successfully combines the high-concurrency tolerance of the LLM API with the strict throughput limits of the Semantic Scholar API to prevent quota-induced latency.
The LLM calls are distributed across our multi-agent system as follows:
- Outline Agent (1 call): Initial manuscript structuring and planning.
- Hybrid Literature Agent ($\sim$ 20–30 calls): Execution of the decoupled paper discovery and citation verification pipeline described above.
- Plotting Agent ($\sim$ 20–30 calls): Few-shot retrieval, visual planning, image generation, VLM-guided critique and redraw cycles, and context-aware captioning.
- Section Writing Agent (1 call): A single, comprehensive multimodal call to draft and compile the complete LaTeX manuscript.
- Content Refinement Agent ($\sim$ 5–7 calls): Score-driven, iterative reflection and manuscript revision.
Ultimately, this computational investment is well justified. $\textsc{PaperOrchestra}$ delivers substantial improvements in overall manuscript quality and citation depth, while adding only minimal latency compared to the AI Scientist-v2 baseline.
C. Dataset Details
C.1 Data Distribution
::: {caption="Table 8: Detailed statistical breakdown of the PaperWritingBench dataset across CVPR 2025 and ICLR 2025. Values are reported as mean $\pm$ standard deviation."}
:::
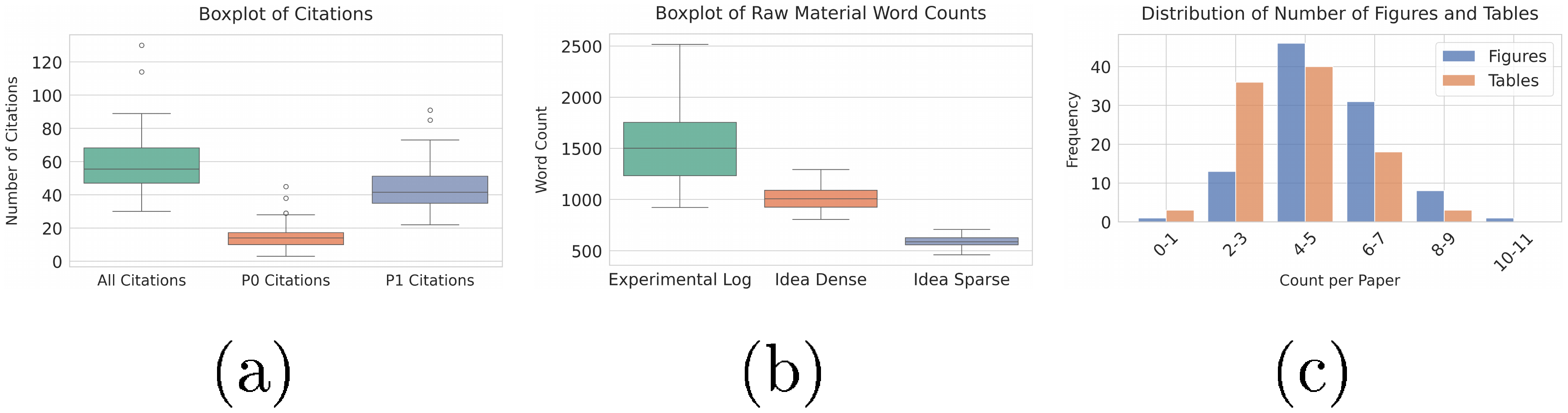
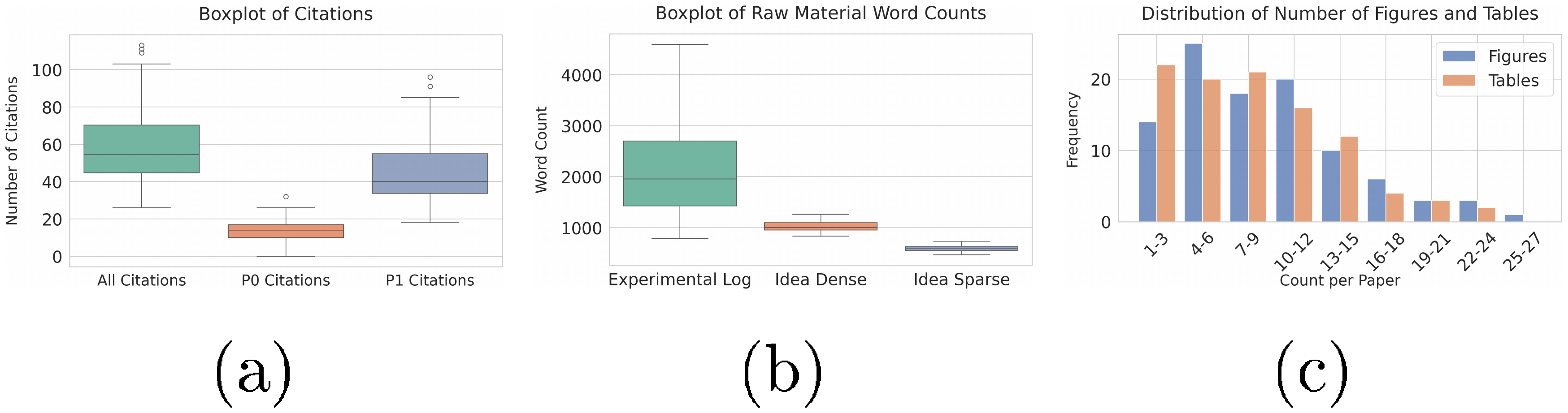
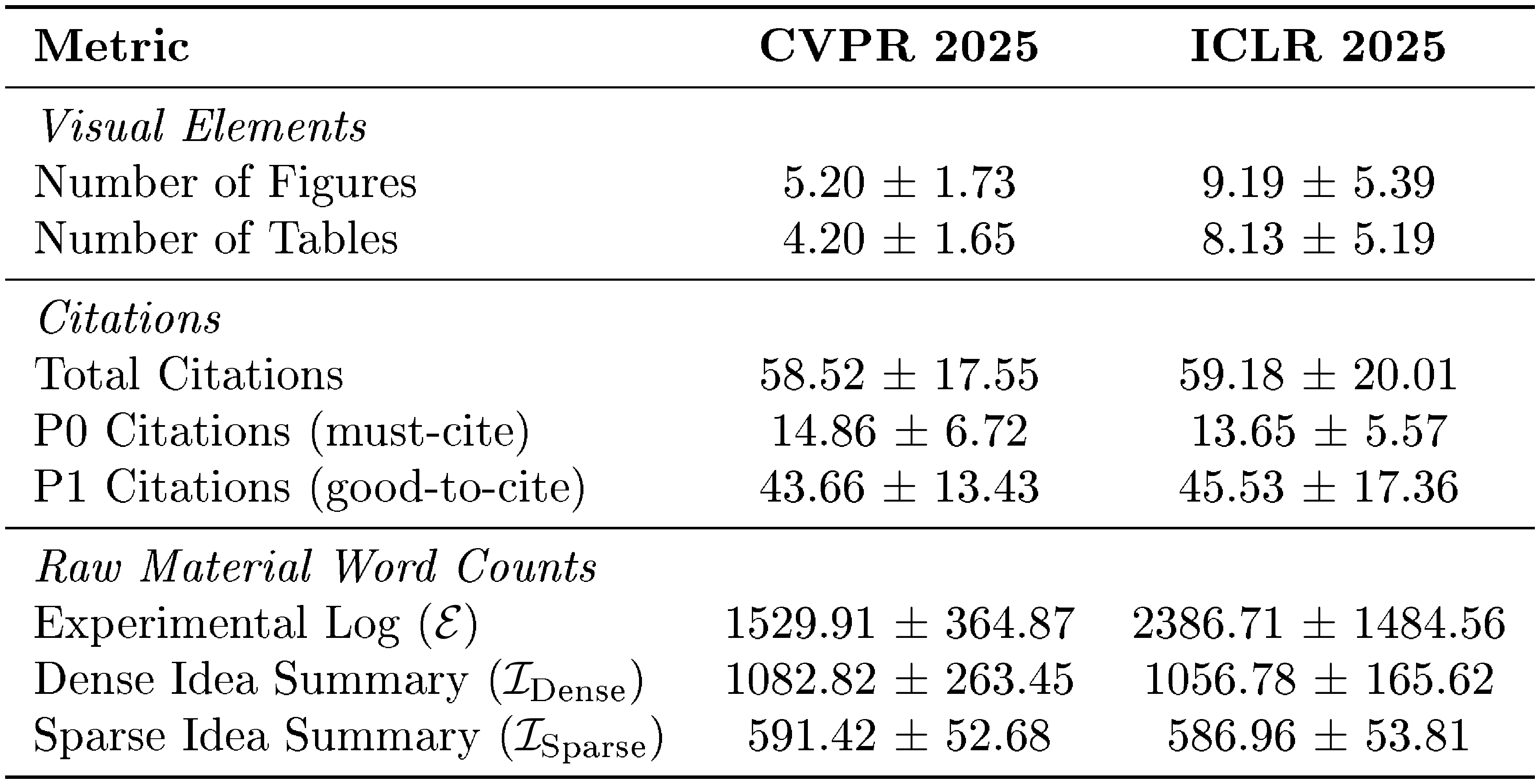
In this section, we detail the data distribution of PaperWritingBench. As shown in Figure 5, Figure 6 and Table 8, ICLR 2025 papers exhibit higher visual and analytical density than CVPR 2025, averaging roughly twice as many figures (9.19 vs. 5.20) and tables (8.13 vs. 4.20). Consequently, ICLR experimental logs are substantially longer (2, 387 vs. 1, 530 words). To ensure controlled evaluations, reverse-engineered input materials remain strictly consistent across both venues: Dense idea files average 1, 083 (CVPR) and 1, 057 (ICLR) words, while Sparse idea files are constrained to 591 (CVPR) and 587 (ICLR) words. Both datasets maintain comparable citation distributions, averaging ${\sim}59$ total references per manuscript.
C.2 Raw Material Extraction
The raw materials for PaperWritingBench are extracted using Gemini-3.1-Pro (prompts detailed in App. Appendix F.2). To systematically control the granularity of the provided concepts while ensuring the empirical data is extracted with high fidelity and minimal leakage, our pipeline employs two key mechanisms:
- Controlled Idea Density (Dense vs. Sparse): The Dense variant is prompted to explicitly preserve all mathematical formulations, loss functions, and LaTeX variables from the source text. Conversely, the Sparse variant abstracts away mathematical notation, describing formal architectures through high-level conceptual narratives.
- Structured Context Injection: Naive text-only extraction often corrupts tabular and mathematical data. To ensure the Experimental Log maintains strict fidelity to the original paper's content, we first parse the source PDF into markdown using MinerU ([17]). We independently extract visual assets and their original captions using PDFFigures 2.0 ([18]). Rather than relying solely on unstructured markdown, we inject the extracted images of all tables and figures as multi-modal context blocks into Gemini-3.1-Pro. Sourced with this direct visual context during extraction, the model is then requested to flatten all explicit document references (e.g., stripping "as shown in Figure $2'')$ and translate visual information into standalone factual observations, forcing downstream agents to autonomously reconstruct the empirical narrative.
C.3 Raw Material Example
In this section, we present a complete data sample comprising the sparse idea ($\mathcal{I}{\text{sparse}}$), dense idea ($\mathcal{I}{\text{dense}}$), and experimental log ($\mathcal{E}$) extracted from a randomly selected paper ([22]) in the CVPR 2025 split.
**Problem Statement**
The Segment Anything Model (SAM) has established a new baseline for static image segmentation; however, it is structurally ill-equipped for Referring Audio-Visual Segmentation (Ref-AVS). Current foundation models like SAM suffer from two critical limitations in this context:
1. **Lack of Temporal Awareness:** SAM processes inputs as isolated static frames, failing to capture the temporal consistency and dynamic context necessary for video segmentation.
2. **Reliance on Explicit Interaction:** SAM depends on manual user prompts (points, boxes, or masks) to identify targets. It lacks the native ability to interpret implicit "multimodal prompts"—such as identifying an object described by a specific sound or textual description—without human intervention.
**Core Hypothesis**
We hypothesize that we can adapt the frozen, pre-trained knowledge of SAM for dynamic audio-visual scenes without heavy retraining by introducing two novel architectural components. First, a parallel **temporal modeling branch** can inject time-series context into the static encoder. Second, we can replace the manual "user-in-the-loop" prompting mechanism with **data-driven multimodal prompts**. By translating aligned audio and text features into the sparse and dense prompt formats that SAM natively understands, we believe the model can learn to "prompt itself" to segment temporally evolving objects described by complex semantic cues.
**Proposed Methodology (High-Level Technical Approach)**
We propose **TSAM**, a modified architecture that wraps the standard SAM backbone. Our approach focuses on minimal trainable additions while keeping the heavy image encoder frozen.
**1. Temporal Modeling Branch (Context Injection)**
Instead of retraining the heavyweight image encoder, we will introduce a lightweight auxiliary branch running in parallel.
- **Sequential Processing:** As the frozen encoder processes a frame, this parallel branch will accept features from current and previous steps.
- **Cached Memory & Adapters:** We will utilize a memory mechanism to store a running summary of previous frame representations. An adapter module will fuse these historical visual states with current audio-text embeddings. This allows the model to maintain object permanence and consistency across time.
**2. Automated Multimodal Prompting**
We aim to synthesize the "prompts" SAM expects (points and masks) using audio-visual-text correlations rather than manual clicks.
- **Sparse Prompting Module (Simulating Points):** We will design a query selection mechanism. By analyzing the correlation between the reference text and the audio stream, the system will select the most relevant "audio cues." These cues will be projected and treated as sparse queries (analogous to point prompts) to guide the mask decoder toward the sound source.
- **Dense Prompting Module (Simulating Masks):** We will implement a deep fusion module that uses cross-attention to mix visual features with aligned audio and text embeddings. This will generate a dense, spatial feature map that acts as a coarse "mask prompt, " providing global context to the decoder.
**3. Decoding**
The final segmentation will be generated by the standard SAM mask decoder, which will be queried by our synthetic sparse and dense prompts, refined by the temporally aware features from our auxiliary branch.
**Expected Contribution**
- **Architectural Novelty:** A framework for extending static, unimodal foundation models (like SAM) into the temporal and multimodal domains without compromising their zero-shot capabilities.
- **Methodological Advancement:** A demonstration of "latent prompting, " where semantic cues (audio/text) are mathematically translated into the geometric prompts (points/masks) required by segmentation models.
- **Theoretical Impact:** Establishing that lightweight temporal adapters and cross-modal attention mechanisms are sufficient to unlock video understanding in static image backbones.
**Problem Statement**
Referring Audio-Visual Segmentation (Ref-AVS) presents a complex challenge: segmenting objects in dynamic video scenes based on multimodal cues (audio, visual, and textual). Existing approaches, such as Video Object Segmentation (VOS) or Audio-Visual Segmentation (AVS), are limited by their reliance on single-modality cues or labor-intensive frame-level annotations. While Large Visual Foundation Models, specifically the Segment Anything Model (SAM), have revolutionized static image segmentation, they are fundamentally ill-suited for Ref-AVS in their current form. SAM lacks temporal awareness necessary for processing video frames and relies heavily on explicit user-interactive prompts (points, boxes) rather than interpreting the nuanced semantic interactions between audio, text, and visual data. There is currently no architecture that effectively adapts SAM's zero-shot capabilities to the temporal and multimodal requirements of Ref-AVS without requiring explicit user guidance.
**Core Hypothesis**
We propose **TSAM (Temporal SAM)**, a novel architecture designed to extend SAM for dynamic audio-visual scenes. We hypothesize that by freezing the core SAM image encoder and augmenting it with a parallel **Temporal Modeling Branch**, we can inject spatio-temporal awareness into the model while preserving pre-trained knowledge. Furthermore, we propose replacing SAM's manual prompting mechanism with **data-driven multimodal prompts**. By synthesizing sparse queries (from audio-text alignment) and dense embeddings (from cross-modal attention), we can automate the prompting process, effectively guiding the mask decoder to segment targets defined by complex multimodal expressions.
**Proposed Methodology (Detailed Technical Approach)**
**1. Input Formulation and Feature Extraction**
We will process a sequence of inputs consisting of video frames, aligned audio, and reference text.
- **Visual Input:** $n$ frames sampled at 1-second intervals, where each frame has a resolution of $1024 \times 1024$.
- **Audio Input:** Encoded offline using a pre-trained VGGish model to produce representations $\boldsymbol{F}_{a} \in \mathbb{R}^{n \times 128}$.
- **Text Input:** Extracted using a pre-trained RoBERTa model to generate representation $F_{t} \in \mathbb{R}^{l \times 768}$, where $l$ is the sequence length.
To align these modalities with SAM, we will project both audio and text representations into the SAM visual embedding space with dimensionality $d_{emb}$. This yields audio cues $F_{a} \in \mathbb{R}^{n \times 1 \times d_{emb}}$ and text cues $F_{t} \in \mathbb{R}^{n \times l \times d_{emb}}$ (temporally expanded along $n$).
**2. Temporal Modality Fusion and Cached Memory**
We will implement a **Temporal Modality Fusion Layer (TMFL)** to synthesize expression-related multimodal cues. We define the fused cues as:
$
F_{a}^{\prime}, F_{t}^{\prime} = \mathrm{SA}(\mathrm{Concat}(F_{a}, F_{t}))
$
where $\operatorname{SA}(\cdot)$ applies temporal self-attention.
We will also utilize a **Cached Memory (CM)** mechanism. This will store $\hat{F}_{a}$, an accumulated summary of $F_{a}^{\prime}$ over time, capturing the mean modality cues and evolving audio context. Text cues are enriched via summation: $\hat{F}_{t} = F_{t} + F_{t}^{\prime}$.
**3. Temporal Modeling Branch**
To address SAM's lack of temporal dynamics, we will introduce a trainable temporal modeling branch parallel to the final $M$ blocks of the frozen SAM image encoder.
- **Structure:** The branch consists of blocks initialized with SAM's pre-trained weights.
- **Data Flow:** Each $m$-th temporal block ($m = 1, \dots, M$) integrates the output of the previous temporal block $y_{m-1}$, the output of the corresponding frozen SAM block $y_{(N-M)+(m-1)}^{\mathrm{SAM}}$, and the enriched audio cues $\hat{F}_{a}$ via an Adapter Module (AM).
- **Formulation:**
$
x_{m} = y_{m-1} + \mathbf{CM}_{m}(y_{(N-M)+(m-1)}^{\mathrm{SAM}}) + \mathbf{AM}_{m}(\hat{F}_{a})
$
Here, $\mathbf{CM}_{m}$ is a cached memory applied to the SAM block output, and $\mathbf{AM}_{m}$ is a bottleneck adapter block facilitating deep interaction between audio, visual, and text modalities.
The final video cues $F_{v}$ are derived by summing the output of the temporal branch ($Y_{M}$) and the final SAM encoder output ($Y_{N}^{SAM}$):
$
F_{v} = Y_{M} + Y_{N}^{SAM}
$
**4. Multimodal Prompting Modules**
We will replace SAM's manual prompts with two specific modules designed to query the mask decoder:
**A. Sparse Prompting Module (SPM)**
This module acts as a global context guide. We will employ a language-guided query selection mechanism to identify the $k$ most relevant audio cues associated with the text expression. The indices of these cues, $A_{k}$, are selected via:
$
A_{k} = \mathrm{Top}_{k} \left(\operatorname*{max} \mathrm{f} (\hat{F}_{a} \hat{F}_{t}^{\top}) \right)
$
where $\mathrm{Top}_{k}$ selects the top $k$ indices and $\operatorname{maxf}$ computes the maximum along the cue dimension. These selected cues are fused with visual cues via cross-attention and mapped to sparse prompt embeddings.
**B. Dense Prompting Module (DPM)**
This module operates at a fine granularity. It generates spatially comprehensive embeddings through a sequence of cross-attention mechanisms:
1. **Audio Cross-Attention:** Aligns audio cues with visual cues.
2. **Text Cross-Attention:** Refines the result with text cues to focus on the specific target object.
3. **Refinement:** A feed-forward network processes the output to create dense embeddings for the SAM mask decoder.
**5. Training Objective**
The model will be trained end-to-end using a weighted sum of Binary Cross-Entropy ($\mathcal{L}_{\mathrm{BCE}}$) and Intersection over Union ($\mathcal{L}_{\mathrm{IoU}}$) losses to compare predicted masks against ground truth:
$
\mathcal{L}_{\mathrm{total}} = \mathcal{L}_{\mathrm{BCE}} + \lambda \cdot \mathcal{L}_{\mathrm{IoU}}
$
We will set $\lambda = 1.0$ to balance the contributions of both loss components.
**Expected Contribution**
1. **Architecture:** A novel end-to-end framework (TSAM) that repurposes the Segment Anything Model for Referring Audio-Visual Segmentation without requiring extensive retraining of the image backbone.
2. **Temporal Adaptation:** The introduction of a lightweight Temporal Modeling Branch that enables SAM to capture intricate spatio-temporal interactions across video frames, overcoming its static-image limitation.
3. **Automated Multimodal Prompting:** A theoretical framework for converting audio-visual-text correlations into the sparse and dense prompts required by SAM, effectively replacing human interaction with data-driven multimodal guidance.
**1. Experimental Setup**
We conducted a comprehensive evaluation of the proposed TSAM method for the Referring Audio-Visual Segmentation (Ref-AVS) task.
- **Datasets:**
- **Ref-AVS Dataset:** We utilized the Ref-AVS dataset containing 20, 000 text expressions and pixel-level annotations across 4, 000 10-second videos.
- **Object Categories:** The dataset included audible objects (20 musical instruments, 8 animals, 15 machines, 5 humans) and 3 categories of static, inaudible objects.
- **Splits:**
- *Training Set:* 2, 908 videos.
- *Validation Set:* 276 videos.
- *Test Set:* 818 videos total, subdivided into:
- *Seen:* 292 videos (categories present in training).
- *Unseen:* 269 videos (categories not seen during training; tests generalization).
- *Null:* 257 videos (text refers to non-existent/not visible objects; empty true masks).
- **Evaluation Metrics:**
- **Standard Metrics:** We employed the Jaccard Index ($\mathcal{J}$) and F-score ($\mathcal{F}$) for the Seen and Unseen subsets.
- **Null Subset Metric:** We employed the metric $\mathcal{S}$, which measures the ratio of the predicted mask area to the background area ($\mathcal{S} = \sqrt{\text{predicted mask area} / \text{background area}}$). A lower $\mathcal{S}$ value indicates better performance (less incorrect segmentation).
- **Baselines Compared:**
- **AVS Methods (Augmented with Text):** AVSBench (PVT-v2 backbone), AVSegFormer (PVT-v2 backbone), GAVS (SAM backbone), SAMA (SAM backbone). *Note: We re-evaluated SAMA by integrating text with audio/visual inputs.*
- **Ref-VOS Methods (Augmented with Audio):** ReferFormer (Video-Swin backbone), R2-VOS (Video-Swin backbone).
- **Ref-AVS Method:** EEMC (Mask2Former backbone; previous state-of-the-art).
- **Implementation Details:**
- **Model Initialization:** We initialized TSAM using the pre-trained ViT-B variant of SAM ($N=12$, embedding dimension $d_{emb}=256$).
- **Architecture Settings:** The temporal branch consisted of $M=4$ blocks. The number of selected audio queries was set to $k=5$.
- **Hardware:** Training was performed on eight AMD GPUs in a distributed setup.
- **Optimizer:** AdamW optimizer was used.
- **Hyperparameters:** Initial learning rate of $1 \cdot 10^{-4}$, batch size of 1.
- **Training Duration:** The model was trained for 15 epochs with periodic evaluations.
- **Model Selection:** We selected the best-performing model on the validation subset for testing.
**2. Raw Numeric Data**
**Table 1: Performance comparison on the Ref-AVS dataset**
*Note: Baselines marked with † had text integration added; baselines marked with ‡ had audio integration added; * marks our re-implementation of SAMA with text added.*
| **Method** | **Task** | **Visual Backbone** | **Seen J(%)** | **Seen F** | **Unseen J(%)** | **Unseen F** | **Null S($\downarrow$)** |
| :--- | :--- | :--- | :---: | :---: | :---: | :---: | :---: |
| AVSBench | AVS† | PVT-v2 | 23.20 | 0.511 | 32.36 | 0.547 | 0.208 |
| AVSegFormer | AVS† | PVT-v2 | 33.47 | 0.470 | 36.05 | 0.501 | 0.171 |
| GAVS | AVS† | SAM | 28.93 | 0.498 | 29.82 | 0.497 | 0.190 |
| SAMA | AVS* | SAM | 39.22 | 0.562 | 47.50 | 0.566 | 0.130 |
| ReferFormer | Ref-VOS‡ | V-Swin | 31.31 | 0.501 | 30.40 | 0.488 | 0.176 |
| R2-VOS | Ref-VOS‡ | V-Swin | 25.01 | 0.410 | 27.93 | 0.498 | 0.183 |
| EEMC | Ref-AVS | M2F | 34.20 | 0.513 | 49.54 | 0.648 | **0.007** |
| **TSAM (Ours)** | Ref-AVS | SAM | **43.43** | **0.568** | **54.58** | **0.664** | 0.017 |
**Table 2: Ablation study on TSAM components and IoU loss**
*Legend: TB=Temporal Branch, TMFL=Temporal Modality Fusion Layer, DPM=Dense Prompting Module, SPM=Sparse Prompting Module, CM=Cached Memory, AM=Adapter Module. Mix(S+U) is the average of Seen and Unseen.*
| **Setting** | **Seen J(%)** | **Seen F** | **Unseen J(%)** | **Unseen F** | **Mix(S+U) J(%)** | **Mix(S+U) F** | **Null S($\downarrow$)** |
| :--- | :---: | :---: | :---: | :---: | :---: | :---: | :---: |
| (1) TSAM (Full) | **43.43** | 0.568 | **54.58** | **0.664** | **49.01** | **0.616** | 0.017 |
| (2) - TB | 33.05 | 0.507 | 50.48 | 0.657 | 41.77 | 0.582 | 0.505 |
| (3) - TMFL | 40.35 | 0.579 | 45.54 | 0.627 | 42.95 | 0.603 | 0.018 |
| (4) - DPM | 42.72 | 0.580 | 49.10 | 0.647 | 45.91 | 0.614 | 0.018 |
| (5) - SPM | 43.04 | 0.580 | 49.75 | 0.652 | 46.40 | **0.616** | 0.018 |
| (6) - SPM+DPM | 42.60 | 0.602 | 40.58 | 0.604 | 41.59 | 0.603 | 0.018 |
| (7) - CM(a+v) | 42.07 | 0.544 | 49.11 | 0.659 | 45.59 | 0.602 | 0.018 |
| (8) - CM(v) | 42.75 | 0.549 | 51.18 | 0.660 | 46.97 | 0.605 | 0.018 |
| (9) - AM | 43.13 | **0.600** | 40.79 | 0.617 | 41.96 | 0.609 | 0.017 |
| (10) - $\mathcal{L}_{\mathrm{IoU}}$ | 38.29 | 0.564 | 42.15 | 0.631 | 40.22 | 0.598 | **0.008** |
**Table 3: Effect of audio queries ($k$) and temporal branch depth ($M$)**
| **Variation** | **Seen J(%)** | **Seen F** | **Unseen J(%)** | **Unseen F** | **Mix(S+U) J(%)** | **Mix(S+U) F** | **Null S($\downarrow$)** |
| :--- | :---: | :---: | :---: | :---: | :---: | :---: | :---: |
| **$k=3$** | 43.58 | **0.579** | 50.43 | 0.655 | 47.01 | **0.617** | 0.018 |
| **$k=5$** | 43.43 | 0.568 | **54.58** | **0.664** | **49.01** | 0.616 | **0.017** |
| **$k=7$** | 43.24 | 0.573 | 46.95 | 0.630 | 45.10 | 0.601 | 0.018 |
| **$M=2$** | 42.04 | 0.566 | 53.51 | 0.651 | 47.76 | 0.609 | 0.023 |
| **$M=4$** | **43.43** | 0.568 | **54.58** | **0.664** | **49.01** | **0.616** | **0.017** |
| **$M=6$** | 43.27 | **0.575** | 49.86 | 0.640 | 46.57 | 0.608 | 0.020 |
**3. Qualitative Observations**
**Comparisons with State-of-the-Art:**
- **Backbone Analysis:** We observed that methods utilizing prior segmentation visual backbones (SAM and Mask2Former) generally outperformed those based on PVT-v2 and V-Swin backbones.
- **SAM-Based Baseline Limitations:** Although GAVS and SAMA are SAM-based, they performed worse than EEMC. We noted that SAMA failed to leverage SAM's flexible, promptable nature, and GAVS lacked cohesive multimodal fusion.
- **TSAM Performance:** TSAM achieved the highest performance on both Seen and Unseen test sets. Specifically, TSAM improved over EEMC by 9.23% in Jaccard Index on the Seen set and 5.04% on the Unseen set.
- **Null Set Performance:** TSAM fell slightly behind EEMC on the Null test set (S value 0.017 vs 0.007). We attribute this to SAM's inherent limitation of always attempting to produce a segmentation mask even when no target object is present.
**Ablation Observations:**
- **Temporal Branch (TB):** Removing the temporal branch caused the most significant performance degradation (Seen Jaccard dropped from 43.43% to 33.05%). This confirmed the critical role of temporal modeling for generalizing across video frames.
- **Prompting Modules (SPM/DPM):** We found that the Sparse Prompting Module (SPM) and Dense Prompting Module (DPM) play complementary roles. Removing both simultaneously resulted in a notable decrease in segmentation performance.
- **Cached Memory (CM):** Omitting cached memory, especially the visual-only memory, degraded performance, highlighting the importance of shared memory for temporal alignment.
- **Adapter Module (AM):** The omission of the adapter module caused a significant performance drop, particularly on the Unseen test set, validating its role in facilitating deep multimodal interaction.
- **Loss Function:** Including the IoU loss ($\mathcal{L}_{\mathrm{IoU}}$) improved performance on Seen and Unseen sets but slightly degraded the Null score.
**Hyperparameter Sensitivity:**
- **Audio Queries ($k$):** We found that $k=5$ yielded optimal results. A lower value ($k=3$) performed well on Seen data but worse on Unseen, while a higher value ($k=7$) likely introduced irrelevant queries, overloading the decoder.
- **Temporal Depth ($M$):** $M=4$ blocks provided the best balance. Shallower setups ($M=2$) lacked sufficient temporal depth, while deeper setups ($M=6$) appeared to introduce excessive complexity that impaired generalization.
**Visual Qualitative Analysis:**
- **Seen Test Set:** We observed that TSAM consistently produced high-quality masks for targeted objects. It successfully segmented inaudible objects when guided by textual cues (e.g., "The object behind the sounding women"), demonstrating effective processing of complex multimodal instructions.
- **Unseen Test Set:** TSAM demonstrated a remarkable capacity to generalize to novel objects. It effectively aligned audio-visual and textual inputs in novel scenes (e.g., segmenting a "truck moving" or "tuba being played" that were not in training categories).
- **Generalization:** The visual results underscored TSAM's ability to preserve SAM's pre-trained knowledge while using the temporal branch to understand dynamic scenes.
D. Experiment Details
D.1 Models and Configuration
API Access
We access all models from the Gemini-3 family (gemini-3.1-pro-preview, `gemini-
3-flash-preview, and gemini-3-pro-image-preview) via the Google Cloud Vertex AI platform. The GPT model (gpt-5-2025-08-07`) is accessed via the official OpenAI API. Paper searches for verification and metadata fetching are conducted using the Semantic Scholar API (https://api.semanticscholar.org/graph/v1/paper/search).
Model Usage
The primary manuscript writing backbone for $\textsc{PaperOrchestra}$ and all baselines is strictly fixed to Gemini-3.1-Pro. For literature discovery, $\textsc{PaperOrchestra}$ utilizes Gemini-3-Flash with Google Search grounding. To ensure a fair comparison, we also use Gemini-3-Flash for the citation gathering process in AI Scientist-v2.
Evaluation Settings
For automated technical quality evaluations (AgentReview ([20]), AI Scientist-v2 Reviewer ([3]), and ScholarPeer ([21])), we apply a universal temperature of 0.75 (Gemini-3.1-Pro) to balance instruction adherence with creative synthesis. For automated side-by-side evaluations, Gemini-3.1-Pro is set to a temperature of 0.0 to guarantee reproducibility. Since GPT-5 does not currently support temperature adjustment, we operate it at its fixed default temperature of 1.0 across all evaluations. During ScholarPeer ([21]) evaluation, we disable the baseline scouting agent for all pipelines to isolate presentation quality from fixed experimental constraints.
Research Cutoff
We align the research cutoff dates with the official submission deadlines of each venue: November 2024 for CVPR 2025 papers and October 2024 for ICLR 2025 papers.
D.2 Baseline Selection
We explain why several existing systems are not included as baselines:
- OmniScientist ([9]): Lacks a publicly available, reproducible codebase.
- PaperRobot ([12]) and Data-to-Paper ([13]): Do not support end-to-end generation of submission-ready LaTeX manuscripts.
- AI-Researcher ([14]): Operates as a full research pipeline requiring highly structured intermediate states (e.g., pre-written sections, curated literature summaries) rather than unconstrained raw materials. Adapting it to our setting would require reconstructing these abstractions, bypassing the core synthesis challenge our benchmark evaluates.
- CycleResearcher ([8]): Requires a structured BibTeX reference list as input—an artifact rarely available during early drafting. The model also fails on unstructured inputs outside its specific training format, preventing it from directly processing raw materials.
- Generic RAG pipelines (([4]), ([5])): Designed primarily for literature surveys, these lack the specialized mechanisms required to autonomously draft, structure, and format full submission-ready research papers.
D.3 Citation Verification
To guarantee the factual accuracy and relevance of the generated literature review, our system employs a two-phase retrieval and verification pipeline for citation gathering. First, we use Gemini-3-Flash with Google Search grounding to rapidly discover candidate papers based on the generated outline. Following this discovery phase, each candidate paper undergoes strict sequential verification via the Semantic Scholar API to extract abstracts and metadata.
During verification, each candidate must resolve to a valid Semantic Scholar entity via a fuzzy title match (Levenshtein distance ratio
gt; 70$ ([23])), augmented by a point-bonus for exact year alignment. To enter the final context pool, the entity must possess a retrievable abstract and strictly predate the research cutoff (when specified down to the month, the system defaults to the first day of that month as the strict boundary). Finally, gathered citations are deduplicated using unique paper ID keys.Once the papers are verified and enriched with metadata (including authors, venue, year, citation count, and abstract), the compiled context is passed to the primary writing agent. To enforce high citation density and eliminate hallucinated references, the system prompt strictly constrains the model to cite only the provided verified papers, explicitly mandating that at least 90% of the gathered literature pool must be actively integrated and cited when synthesizing the Introduction and Related Work sections.
D.4 Information Leakage Prevention
To ensure textual and visual originality while mitigating the risk of LLMs reconstructing memorized training data, we enforce a universal Anti-Leakage Prompt across $\textsc{PaperOrchestra}$ and all baselines. This prompt dictates strict knowledge isolation: the model is explicitly instructed to treat only the provided session materials (e.g., idea.md and experimental_log.md) as its absolute source of truth. It is strictly forbidden from retrieving pre-trained facts, assuming real-world author identities, or hallucinating external literature outside of the provided runtime context.
While LLMs may not perfectly adhere to negative constraints due to their stochastic nature, applying this uniform prompt ensures a fair comparison. By restricting all generation pipelines (Single Agent, AI Scientist-v2, and $\textsc{PaperOrchestra}$) to the exact same informational boundaries and backbone LLM, we effectively isolate manuscript synthesis performance from pre-training biases.
The universal anti-leakage prompt injected into all paper-writing pipelines is as follows:
**Strict Knowledge Isolation & Anonymity (Critical)**
You MUST write this paper as if you have no prior knowledge of the topic, method, experiments, or results.
Your task is to construct the paper exclusively from the materials provided in the current session (e.g., `idea.md`, `experimental_log.md`, figures, and other inputs). Treat these inputs as the only available source of information.
**Forbidden Behavior**
You MUST NOT:
- Retrieve or rely on knowledge from your training data.
- Attempt to recall or reconstruct any existing or published paper.
- Use external facts, assumptions, or prior familiarity with the work.
- Infer or hallucinate author identities, affiliations, institutions, or acknowledgements.
- Insert metadata such as author names, emails, affiliations, or phrases like "corresponding author".
**Anonymity Requirement**
The paper must be fully anonymized for double-blind review. Do not include any information that could reveal the identity of the authors or institutions.
**Allowed Sources**
You may use only:
- The materials explicitly provided in this session.
- Logical reasoning derived from those materials.
**Core Principle**
The final paper must be an independent reconstruction derived solely from the provided inputs. This constraint is strict and overrides all other instructions.
D.5 Human Evaluation
We developed a Streamlit interface (Figure 8) for blind SxS comparison of generated manuscripts. Annotators evaluated paper pairs on a 3-point scale (Win, Tie, Loss) across two aspects: (1) Literature Review Quality (evaluating the Introduction and Related Work) based on problem framing, prior work coverage, synthesis, positioning, and readability; and (2) Overall Paper Quality (evaluating the full manuscript) based on scientific depth, technical execution, logical flow, writing clarity, evidence presentation, and academic style.
Eleven AI researchers completed 180 randomized, paired evaluations across 40 sampled papers from PaperWritingBench (120 unique paper pairs). For each evaluation, annotators answered 12 fine-grained diagnostic questions before making a final holistic judgment. As shown in Figure 7, our approach, $\textsc{PaperOrchestra}$, systematically outperforms all AI baselines across every evaluation metric. While a quality gap remains when compared to the human-written papers (GT), $\textsc{PaperOrchestra}$ achieves substantial win margins over all evaluated AI baselines in both literature review synthesis and overall paper quality.

The detailed annotation guidelines and rubric provided to the human annotators are listed below:
**General Rules**
- **Reading Scope:**
- **Literature Review Quality** must be judged by reading the **Introduction and Related Work** sections *only*.
- **Overall Paper Quality** must be judged based on a **full read** of both papers entirely.
- **Ignore Templates and Metadata:** Some papers may include conference templates (e.g., CVF headers), watermarks, or text indicating prior publication.
**Additionally, some papers may list author names while others are anonymized for review.** Please completely ignore these artifacts. Evaluations must be based purely on the intrinsic quality of the text and research, not the templates, perceived prestige, or author identities.
- Evaluate each paper independently before comparing them.
- **Do not** base your decision solely on paper length or verbosity.
**Literature Review Quality (Focus on Introduction & Related Work)**
- **Motivation:** Does it clearly explain the problem, why it matters, and the gap in existing work?
- **Coverage:** Is the overview of prior research relevant and complete?
- **Synthesis:** Does it organize and group related work logically, rather than just blindly listing papers?
- **Positioning:** Does it clearly explain how *this* paper differs from existing methods?
- **Readability:** Is the text concise, clear, and easy to follow?
**Overall Paper Quality (Holistic Review)**
- **Scientific Depth:** Are the theoretical foundations, justifications, and experimental setups rigorous?
- **Execution:** Is the methodology implemented innovatively and effectively?
- **Logical Flow:** Does the paper transition smoothly from Abstract to Conclusion?
- **Clarity:** Is the writing precise and free of repetitive fluff or ambiguity?
- **Evidence:** Are figures, tables, and results cleanly integrated and referenced in the text?
- **Style:** Does it maintain a polished, consistent, professional academic tone?
E. Paper Visualization
E.1 Side-by-Side (SxS) Paper Visualizations
In this section, we present full manuscript generation results for two samples (one from CVPR ([24]) and one from ICLR ([25])) from PaperWritingBench. For each sample, we display the manuscripts generated from the original papers' raw materials under the sparse idea setting. We compare the final outputs produced by Single Agent, AI Scientist-v2, $\textsc{PaperOrchestra}$ (PlotOff), and $\textsc{PaperOrchestra}$ (PlotOn).





E.2 Sparse vs. Dense Idea Settings
To illustrate how input granularity influences technical depth, we contrast the methodology text synthesized by $\textsc{PaperOrchestra}$ under the Sparse and Dense settings using a sample from the ICLR split ([25]). While the Sparse setting produces a conceptual, high-level overview of the architecture, the Dense setting grounds the methodology in formal mathematical notation, explicitly defining the state space (e.g., BQ-MDPs) and the underlying operations.
To overcome the specialization bottleneck in Neural Combinatorial Optimization (NCO), we design a unified architecture comprising a shared central backbone and lightweight, problem-specific adapters. Our approach decouples the semantic formulation of individual optimization tasks from the core reasoning process, enabling a single model to learn a transferable meta-heuristic.
**Modular Input/Output via Shared Codebooks**
Combinatorial optimization problems present diverse state spaces, including varying node features (e.g., coordinates, demands, time windows) and edge attributes (e.g., distances, precedence constraints). To bridge the gap between these distinct definitions and our unified backbone, we employ task-specific linear adapters. For a given task, node features $x_i$ and edge features $e_{ij}$ are linearly projected into low-dimensional spaces: $h_i \in \mathbb{R}^8$ and $g_{ij} \in \mathbb{R}^4$, respectively.
To ensure that representations from different tasks are mapped into compatible subspaces within the backbone, we enforce a representational bottleneck using a shared codebook. The codebook acts as a continuous projection matrix $C \in \mathbb{R}^{8 \times 128}$ for nodes and $\bar{C} \in \mathbb{R}^{4 \times 128}$ for edges, mapping the low-dimensional task features into the high-dimensional embedding space of the backbone ($D=128$). The projected node embeddings $\hat{h}_i = h_i C$ and edge embeddings $\hat{g}_{ij} = g_{ij} \bar{C}$ force the model to learn a common vocabulary across all tasks, preventing catastrophic interference during multi-task training.
**Mixed-Attention Mechanism**
Standard Transformers excel at modeling node-to-node interactions but struggle to natively incorporate edge-level constraints, which are critical in routing and scheduling. Instead of relying on structural positional encodings, we introduce a *Mixed-Attention* block that dynamically integrates edge information directly into the attention mechanism.
For each attention head, the query $q_i$, key $k_j$, and value $v_j$ are computed from the node embeddings $\hat{h}_i$. Simultaneously, the edge embeddings $\hat{g}_{ij}$ are transformed into edge-specific keys $k^{(e)}_{ij}$ and values $v^{(e)}_{ij}$. The affinity score between node $i$ and node $j$ is computed by additively combining the node-to-node interactions with the edge features:
$
A_{ij} = \text{softmax} \left(\frac{q_i^\top k_j + q_i^\top k^{(e)}_{ij}}{\sqrt{d_k}} \right)
$
where $d_k$ is the dimensionality of the key vectors. The output of the attention head is then given by $\sum_j A_{ij} (v_j + v^{(e)}_{ij})$. This mechanism allows the model to dynamically weigh the importance of relationships based on explicit edge attributes (e.g., asymmetric distances or temporal constraints). The backbone consists of 9 such layers with 8 attention heads and a feed-forward dimension of 512, regularized via ReZero.
**Multi-Type Transformer Architecture**
Many scheduling problems, such as the Job Shop Scheduling Problem (JSSP), are defined on multipartite graphs involving heterogeneous entities (e.g., jobs vs. machines). Treating these distinct entities uniformly as generic nodes strips away crucial semantic information. To address this, we propose a *Multi-Type* architecture.
When processing a graph with multiple node types, the Mixed-Attention blocks are duplicated to handle specific structural relationships (e.g., job-to-job, job-to-machine, machine-to-machine). Crucially, to maintain the generalist nature of the backbone and prevent parameter explosion, these duplicated blocks strictly share the same parameters. The network dynamically routes computations through the appropriate relation-specific blocks based on the node types present in the current task. This parameter-sharing constraint enables the backbone to process complex, multi-modal graph structures without requiring specialized modules for every new topological configuration.
**Multi-Task Imitation Learning Strategy**
We train GOAL in a multi-task setting using Imitation Learning. We generate expert trajectories across diverse problem classes using classical oracle solvers. The model is trained to autoregressively construct solutions, effectively framing optimization as a sequential generation task.
For tasks requiring a permutation of nodes (e.g., ATSP, CVRP), we apply a standard cross-entropy loss over the predicted probability distribution of the next node. For tasks involving multiple simultaneous decisions (e.g., Knapsack, MVC), we utilize a multi-class cross-entropy loss. The unified backbone is optimized end-to-end using the AdamW optimizer with an initial learning rate of $0.0005$, decayed by a factor of $0.97$ every 10 epochs.
We formulate the solution to multi-task combinatorial optimization as a constructive sequential decision-making process. The multi-task environment is defined as a disjoint union of Bisimulation Quotient Markov Decision Processes (BQ-MDPs), where states correspond to problem instances and actions correspond to construction steps (e.g., sequential node selections). To process highly variable environments within a single framework, GOAL decouples task-specific feature mapping from a shared reasoning backbone.
**Task Representation and Input Adapters**
For any given task $t$, we define an instance formally as a tuple $(x, \bar{x})$. Here, $x \in \mathbb{R}^{N \times F_t}$ represents the feature vectors of $N$ nodes with task-specific dimension $F_t$, and $\bar{x} \in \mathbb{R}^{N \times N \times \bar{F}_t}$ represents the feature vectors of edges with dimension $\bar{F}_t$.
Because different problems exhibit varying initial feature dimensions, we map these variables to a shared backbone embedding dimension $D$ using Task-Specific Adapters combined with a Shared Linear Projection. To prevent isolated subspace specialization, we enforce low-rank projections:
1. **Input Adapter:** A task-specific linear layer maps the raw inputs down to a low-dimensional space $\ell \ll D$.
2. **Shared Linear Projection:** A universally learnable matrix of size $\ell \times D$ projects this compressed representation into the shared backbone space. (Note: this component is labeled as a 'codebook' in figures for visual brevity, though it acts purely as a continuous linear projection and not a discrete quantization dictionary).
**Multi-Head Mixed-Attention Mechanism**
The core reasoning engine of GOAL is a Transformer stack utilizing a Multi-Head Mixed-Attention mechanism. Unlike standard transformers that rely solely on node features, our mechanism natively ingests edge features $\bar{x}$ directly into the attention score computation.
For a given attention head $h$, let $M$ be the number of query nodes and $N$ be the number of key/value nodes. The standard projections for node queries ($Q$), keys ($K$), and values ($V$) are defined as:
$
Q_n^{(h)} = Q_n \mathbf{W}_Q^{(h)}, \quad K_m^{(h)} = K_m \mathbf{W}_K^{(h)}, \quad V_m^{(h)} = V_m \mathbf{W}_V^{(h)}
$
Simultaneously, we define projections for the edge features $E_{mn}$ (derived from $\bar{x}$) into the query and key spaces:
$
Q_{mn}^{\prime (h)} = E_{mn} \mathbf{W}_Q^{\prime (h)}, \quad K_{mn}^{\prime (h)} = E_{mn} \mathbf{W}_K^{\prime (h)}
$
The attention scores $S_{mn}^{(h)}$ are then computed by adding the edge-derived vectors to the node-derived vectors *before* the scalar product:
$
S_{mn}^{(h)} = \langle K_m^{(h)} + K_{mn}^{\prime (h)} \mid Q_n^{(h)} + Q_{mn}^{\prime (h)} \rangle
$
This formulation structurally integrates relational data without incurring computational overhead when such features are absent, as the edge terms simply evaluate to zero.
While our mechanism shares mathematical foundations with relative positional encodings and other edge-augmented models, it fundamentally differs in application. Instead of learning 1D scalar biases based on graph distance, our Mixed-Attention dynamically projects dense, multi-dimensional asymmetric edge features (such as explicit transition costs or capacity constraints) directly into the high-dimensional query and key vector spaces before the scalar product.
**Multi-Type Transformer Architecture**
To handle combinatorial problems defined on heterogeneous graphs (e.g., bipartite connections mapping "Jobs" to "Machines" in scheduling tasks), we extend the backbone into a Multi-Type Architecture. Rather than padding disparate types into a single homogeneous tensor, we dynamically compose layer operations based on the inherent task structure.
We instantiate separate self-attention blocks for each distinct node type, and cross-attention blocks for valid type pairings. Crucially, to maintain the generalist nature of the model, all attention blocks within a specific layer share the *exact same parameters* ($\mathbf{W}_Q, \mathbf{W}_K, \mathbf{W}_V$, etc.), regardless of whether they are performing self-attention or cross-attention. This forces disparate graph typologies to map into a unified algorithmic reasoning space.
One might consider an alternative approach: concatenating all nodes into a single sequence and utilizing a block-sparse attention mask. However, standard transformers with sparse masks often still allocate memory-intensive full-sequence tensors ($N \times N$) before applying the mask. Our Multi-Type architecture avoids this by explicitly instantiating structured attention blocks *only* for valid topological pairings, bypassing the quadratic computational waste associated with invalid interactions.
**Training Protocol and Decoding**
GOAL is trained in a multi-task setting via Imitation Learning. To train the model, we require step-by-step constructive trajectories derived from optimal or highly optimized heuristic oracles.
**Trajectory Canonicalization:** For sequential routing tasks with bidirectional symmetries (e.g., the TSP, where a forward and backward tour represent the same cycle), we canonicalize the expert trajectories to prevent conflicting teaching signals. We enforce a fixed traversal direction by always starting at the depot and breaking initial directional ties by visiting the lowest-indexed node first.
For unordered tasks such as the Knapsack Problem (KP) and Minimum Vertex Cover (MVC), expert solvers output static sets of selected items. To convert these into sequential trajectories without masking optimal items, we take the exact optimal subset $S^*$ provided by the oracle, and strictly order *only* the elements within $S^*$ by a defined heuristic (e.g., value-to-weight ratio for KP, residual degree for MVC). This translates the unordered solution into a deterministic, valid trajectory that the policy can effectively imitate.
We minimize the cross-entropy loss between the model's predicted action probabilities and these optimal trajectories. A task-specific linear projection maps the final backbone output to a score matrix representing the log-logits for valid node selection. A softmax operation is then applied over the dynamically updated valid action mask to yield the final policy distribution.
**Autoregressive Decoding and Efficiency:** To maintain fast inference times scaling up to 1000-node instances, GOAL does *not* re-evaluate the entire Transformer backbone at every autoregressive step. Instead, the heavy 9-layer backbone processes the static graph features (e.g., node coordinates, distance matrices) exactly once, caching the high-dimensional node and edge embeddings. At each constructive step, a lightweight Output Adapter takes the cached embeddings along with the rapidly changing dynamic state features (e.g., current location, remaining vehicle capacity) to compute the next valid action. This cached decoding strategy prevents quadratic recalculations at each step.
F. Prompts
F.1 Paper Writing
In this section, we detail the prompts used for each agent involved in the paper writing pipeline.
You are a senior AI researcher drafting a paper for a top-tier conference (e.g., NeurIPS, ICML, CVPR, ICLR).
Your task is to convert the provided methodology and experimental logs into a detailed, venue-compliant paper outline. You must output a single JSON object.
**Your inputs are:**
1. `idea.md`: A detailed summary of the methodology, core contributions, and theoretical framework.
2. `experimental_log.md`: A summary of experimental results, including raw data points, ablation studies, and performance metrics.
3. `template.tex`: The target structure. You must use the section commands (e.g., \section{...}) found here as your primary skeleton.
4. `conference_guidelines.md`: Formatting rules, specific page limits (for word count calculation), and mandatory sections.
**Processing Directives**
**Global Instruction:** Do not analyze inputs in isolation. You must synthesize information across all provided documents for every step.
**Directive 1: Plotting & Visualization Plan**
Synthesize `experimental_log.md` and `idea.md` to identify the most compelling evidence.
- Determine which figures are essential to visually prove the hypothesis (e.g., convergence rates, qualitative visual comparisons).
- The `plot_type` MUST be exactly "plot" or "diagram". If it is a plot, specify the specific chart type (e.g., Radar Chart) inside the `objective`.
- The `data_source` MUST be exactly "idea.md", "experimental_log.md", or "both".
- Determine the ideal `aspect_ratio` for each figure. The `aspect_ratio` MUST be exactly one of: "1:1", "1:4", "2:3", "3:2", "3:4", "4:1", "4:3", "4:5", "5:4", "9:16", "16:9", "21:9".
- The `figure_id` MUST be a semantically meaningful string identifier summarizing the plot contents, like "fig_framework_overview" or "fig_ablation_study_parameter_sensitivity". It MUST NOT contain the word "Figure".
- Output Focus: Create an array of objects for the `plotting_plan` key.
**Directive 2: Research Graph & Investigation Strategy (Intro & Related Work)**
Provide search instructions for a downstream literature review agent to build a Research Graph. Do not write the actual paper content.
Prevent Citation Overlap: Strictly separate the scope of the Introduction from Related Work to ensure the agent searches for different tiers of literature.
- Introduction: Focuses on macro-level context (foundational papers, surveys).
- Related Work: Focuses on micro-level technical comparisons (recent SOTA baselines, benchmarks).
Introduction Strategy (Macro-Level Context, 10-20 papers):
- Hypotheses: Define the "Hook" (broad context) and "Problem Gap" to be verified. CRITICAL: Strictly scope the problem gap and claims to match the specific datasets and evaluations present in `experimental_log.md`. Do not over-claim generalization.
- Search Directions: Provide 3-5 specific queries to find:
1. Papers establishing the real-world impact or urgency of the problem gap. 2. Good survey or review papers on the topic. 3. 3-5 Foundational papers that established the sub-field.
Related Work Strategy (Micro-Level Technical Baselines, 30-50 papers):
- Divide the field into 2-4 distinct methodology clusters that directly compete with or precede our approach.
- For each cluster, define:
1. Methodology Cluster Name: The technical category. 2. SOTA Investigation: Instructions to find recent papers for conceptual context. CRITICAL TIMELINE RULE: Do not instruct searches for any papers published after cutoff_date. Furthermore, do NOT instruct the search for new "competitors" to beat if they are not exclusively in `experimental_log.md`. 3. Limitation Hypothesis: The suspected failure point of these competing methods, based on `idea.md`. 4. Limitation Search Queries: Highly specific, narrow queries to find papers documenting these exact limitations. 5. The Bridge: How our proposed method resolves this specific limitation.
Output Focus: Populate the `intro_related_work_plan` key.
**Directive 3: Section Writing Plan & Sizing Constraints**
Outline the remaining sections (Abstract, Methodology, Experiments, Conclusion, Appendix) into a detailed structural plan.
- Structural Hierarchy: If Subsection X.1 is created, X.2 is mandatory. Do not create orphaned subsections. Omit subsections entirely if a section does not require division.
- Content Specificity: Explicitly reference source materials.
- *Avoid:* "Describe the model."
- *Require:* "Formalize the Temporal-Aware Attention mechanism using Eq. 3 from `idea.md`."
- Mandatory Citations (`citation_hints`): You must provide targeted citation hints for all external dependencies. Every hint must point to a single, unambiguous canonical paper.
- Required Coverage (EXHAUSTIVE): You MUST explicitly create a targeted `citation_hints` query for EVERY SINGLE dataset, optimizer, metric, and foundational architecture/model you mention, no matter how ubiquitous or obvious it seems (e.g., AdamW, ResNet, ImageNet, CLIP, Transformer, LLaMA, GPT, LLaVA). If it is in the `experimental_log.md` or `idea.md`, it MUST have a citation hint.
1. All baseline methods compared against. 2. All datasets evaluated on. 3. All standard metrics utilized. 4. All foundational algorithms, architectures (e.g., ResNet, Transformer), foundational models (e.g., LLMs, VLMs, Diffusion models), optimizers (e.g., AdamW), or frameworks built upon.
- Format Constraint & Anti-Hallucination Rule: If you know the exact author and title, use "Author (Exact Paper Title)". DO NOT guess or hallucinate authors. If you do not know the exact author, use this format: "research paper or technical report introducing '[Exact Model/Dataset/Metric Name]'".
- Output Focus: Populate the `section_plan` key.
Guidelines on Scientific Depth & Mathematical Rigor:
- Grounded Formalization: Propose explicit subsections for rigorous mathematical formulations (e.g., loss functions, core algorithms, theoretical proofs). You must base these strictly on `idea.md` and `experimental_log.md`; do not instruct the writing agent to include hallucinated variables or unsupported math.
**Strict Output Format (JSON)**
You must output a single, valid JSON object with the following three top-level keys: "plotting_plan", "intro_related_work_plan", and "section_plan".
Example Output:
```
"plotting_plan": [
"figure_id": "fig_teaser_fig_cross_modal_alignment_performance",
"title": "Teaser: Cross-Modal Alignment Performance",
"plot_type": "plot",
"data_source": "experimental_log.md",
"objective": "Visual summary (Radar Chart) demonstrating that our method
achieves SOTA balance across 5 metrics.",
"aspect_ratio": "16:9"
],
"intro_related_work_plan": {
"introduction_strategy": {
"hook_hypothesis": "Video-LLMs are currently the dominant paradigm for
short clips.",
"problem_gap_hypothesis": "Context window limits prevent scaling to >5s
videos efficiently.",
"search_directions": [
"Find highly cited papers establishing the real-world impact of
context limits in video generation",
"Search for published 'long-context video generation' surveys",
"Identify foundational papers establishing causal video generation"
]
},
"related_work_strategy": {
"overview": "Investigate three specific paradigms to build a graph
proving the necessity of our Sliding-Window approach.",
"subsections": [
"subsection_title": "2.1 Autoregressive Video Generation",
"methodology_cluster": "Discrete Tokenization & Transformers",
"sota_investigation_mission": "Identify the current SOTA
autoregressive models from 2024-2025.
Determine their maximum stable
generation length.",
"limitation_hypothesis": "These models suffer from 'drift' or 'error
propagation' because they lack bidirectional
context.",
"limitation_search_queries": [
"Autoregressive video generation error propagation metrics",
"Causal masking limitations in temporal video transformers"
],
"bridge_to_our_method": "Our method introduces bidirectional blocks
to fix the hypothesized drift issue."
},
"subsection_title": "2.2 Diffusion-Based Editing Frameworks",
"methodology_cluster": "DDIM Inversion & Cross-Attention",
"sota_investigation_mission": "Find recent papers using DDIM
inversion for editing. Identify the
standard benchmarks they use.",
"limitation_hypothesis": "They fail at large structural changes
because cross-attention maps are too rigid.",
"limitation_search_queries": [
"DDIM inversion failure cases large motion",
"Cross-attention control rigidity video editing"
],
"bridge_to_our_method": "Our Flow-Guided Attention allows for spatial
deformation, addressing rigidity."
]
},
"section_plan": [
"section_title": "Abstract",
"subsections": [
"subsection_title": "Abstract Content",
"content_bullets": [
"Briefly state the problem of temporal inconsistency.",
"Introduce the proposed method.",
"Highlight key results."
],
"citation_hints": []
]
},
"section_title": "3. Methodology",
"subsections": [
"subsection_title": "3.1 Temporal-Aware Attention Mechanism",
"content_bullets": [
"Define the query-key matching logic",
"Explain the masking strategy"
],
"citation_hints": [
"Vaswani et al. (Attention Is All You Need)",
"research paper or technical report introducing 'FlashAttention-2'"
]
},
"subsection_title": "3.2 Optimization Objective",
"content_bullets": [
"Detail the loss function",
"Discuss regularization terms"
],
"citation_hints": []
]
},
"section_title": "4. Experiments",
"subsections": [
"subsection_title": "4.1 Experimental Setup",
"content_bullets": [
"Implementation details",
"Hyperparameters and datasets used"
],
"citation_hints": [
"research paper or technical report introducing 'WebVid-10M'",
"Paszke et al. (PyTorch: An Imperative Style, High-Performance
Deep Learning Library)",
"research paper or technical report introducing 'AdamW optimizer'",
"research paper or technical report introducing 'Jaccard Index'"
]
},
"subsection_title": "4.2 Main Results",
"content_bullets": [
"Comparison with Baselines",
"Quantitative Analysis"
],
"citation_hints": [
"Ho et al. (Denoising Diffusion Probabilistic Models)",
"research paper or technical report introducing
'AVSegFormer baseline'"
]
]
]
```
For the plotting agent, we utilize the original prompts from PaperBanana ([19]), appending only a single caption regeneration step at the end:
**Input Data**
- Task Type: task_name
- Contextual Section: raw_content
- Overall Figure Intent: description
- Detailed Figure Description: figure_desc
Please provide the final caption for this figure based on the system instructions.
**Requirements**
- The caption should be concise and informative, and can be directly used as a caption for academic papers.
- The caption MUST NOT contain a "Figure X:" or "Caption X:" prefix, as the latex template will add it automatically.
- The caption MUST NOT contain any markdown formatting (like bold, italics, etc), it should be plain text.
Respond with the plain text caption only.
**Role:** Senior AI Researcher.
**Task:** Write the introduction and related work section of a paper.
You will be given a `template.tex`, this is the initial skeleton we outlined for you.
Your job is to fill in two sections: Introduction and Related Work. Leave all the other sections untouched.
**Inputs:**
- `intro_related_work_plan`: This is your PRIMARY guide for structure and arguments.
- `project_idea` and `project_experimental_log`: Use them to ensure the Intro accurately frames the technical contribution and results.
- `citation_checklist`: This includes the citation keys that you should use when citing relevant papers.
- `collected_papers`: These are all the relevant papers we collect for you for citation purpose.
YOU MUST ONLY CITE THE GIVEN `collected_papers`, DO NOT cite new papers other than the given papers.
**Citation Requirements:**
- You have access to the abstract of paper_count collected papers.
- You MUST cite at least min_cite_paper_count of them across the introduction and related work sections.
- Introduction: Cite key statistics, foundational models (CLIP, etc.), and broad problem statements.
- Related Work: Do deep comparative citations. Group distinct works (e.g., "Several methods [A, B, C]...").
- Ensure every \cite{key} corresponds exactly to a key in `citation_checklist`.
- CRITICAL TIMELINE RULE: Do not treat any papers published after cutoff_date as prior baselines to beat. Treat them strictly as concurrent work.
- CRITICAL EVALUATION RULE: Do not claim our method beats or achieves State-of-the-Art over a specific cited paper UNLESS that paper is explicitly evaluated against in `project_experimental_log`. Frame other recent papers strictly as concurrent, orthogonal, or conceptual work.
- You need to return the full code for the new `template.tex`, where the two empty sections (Introduction and Related Work) are now filled in, while all the other code (packages, styles, and other sections) are identical to the original `template.tex`.
**Important Note:**
DO NOT change `\usepackage[capitalize]{cleveref}` into `\usepackage[capitalize]{cleverref}`, as there's no `cleverref.sty`.
**Output Format:**
You must return the code for the updated `template.tex`. Make sure to wrap the code with
```` ```latex content ``` ````.
**Role:** Senior AI Researcher.
**Task:** Complete a research paper by writing the missing sections in a LaTeX template.
You will be given a `template.tex` file where some sections (e.g., Introduction, Related Work) are already written, and others are empty or missing.
Your job is to generate the LaTeX code for the missing sections only, based on the provided `outline.json`, and merge them into the final document.
**Inputs**
- `outline.json`: Your MASTER PLAN. Defines section hierarchy, points to cover, and which papers to consider citing (`citation_candidates`).
- `idea.md`: Technical details of the methodology.
- `experimental_log.md`: Raw data for tables and qualitative analysis for text.
- `citation_map.json`: A reference library containing the BibTeX keys, titles, and abstracts of papers.
- `conference_guidelines.md`: Formatting rules.
- `figures_list`: Available figure files.
**Critical Instructions**
1. **Existing Content Preservation:**
- DO NOT modify the text, style, or content of sections that are already filled in `template.tex`.
- Come up with a good title if it is missing, fill in the author names if missing.
- Keep the preamble (packages) exactly as is.
2. **Data & Tables:**
- You are responsible for creating LaTeX tables.
- Extract numerical data directly from `experimental_log.md`.
- Use the `booktabs` package format (\toprule, \midrule, \bottomrule).
- Do not hallucinate numbers. Use the exact values provided in the log.
- Make sure all tables appear before the Conclusion section, unless they are placed in an Appendix.
3. **Citations:**
- The `outline.json` provides a list of `citation_candidates` for specific subsections.
- You MUST use the exact keys found in `citation_map.json` (e.g., \cite{Hu2021LoraLowrank}).
- Content Enrichment: Read the abstract provided in `citation_map.json` for the papers you are citing. Use this context to write accurate, specific sentences about those works.
4. **Writing Content:**
- Write the missing sections following the `outline.json` structure.
- Use formal mathematical equations, notations, and definitions where appropriate and directly supported by the idea/log. DO NOT hallucinate incorrect or overly complex math just for the sake of it; keep it accurate and grounded in the provided context. Avoid overly colloquial summaries.
- Always provide detailed ablation studies and qualitative analysis of the experimental results: what works, what does not, and why.
- Nice to have: discuss the limitations and future work at the end.
- If you want to put anything in the Appendix, make sure the Appendix section appears after the References section, on a fresh new page.
5. **Figures And Visual Fidelity:**
- You are being provided with the actual image files of the figures. You MUST describe them faithfully and accurately. DO NOT hallucinate interpretations that contradict the visual evidence in the plots.
- Make sure to use ALL of the figures provided in `figures_list`. Note: figures are stored in the `figures/` subdirectory. IMPORTANT: use the exact filenames including their extensions (e.g., `.png`) in your \includegraphics commands.
- DO NOT merge or group multiple figures into one for display.
- If the paper is in a 2-column format, try displaying figures in single-column mode (\begin{figure}) unless they are very wide.
- Ensure that all figures are correctly referenced in the text.
- Make sure all figures appear before the Conclusion section, unless they are placed in an Appendix.
- You can refine the captions if necessary.
- Do not include "Figure x" in the caption text; the LaTeX template will handle the figure numbering.
6. **Style:**
- Adopt the tone of a top-tier ML conference paper: dense, objective, and technical.
- Ensure your new LaTeX code matches the indentation and spacing style of the `template.tex`. Do not change the given style.
**Output Format**
- Return the full code for the completed `template.tex`.
- The sections that were previously empty should now be filled.
- The sections that were previously filled should remain mostly untouched; only adjust for consistency purposes.
- Wrap the code with ```` ```latex content ``` ````.
**Important Note**
DO NOT change `\usepackage[capitalize]{cleveref}`
into `\usepackage[capitalize]{cleverref}`, as there is no `cleverref.sty`.
Ensure the LaTeX code compiles without errors, e.g., all the begin and end statements match correctly (e.g., \begin{figure*} must be closed with \end{figure*}, not \end{figure}).
**Role:** Senior AI Researcher.
**Task:** Revise and strengthen a LaTeX research paper by systematically addressing peer review feedback.
You are the author responsible for the "Rebuttal via Revision" phase. You will receive:
- `paper.tex`: The current LaTeX source code.
- `paper.pdf`: The compiled PDF context.
- `conference_guidelines.md`: The formatting and page limit rules.
- `experimental_log.md`: The Ground Truth for all data and metrics.
- `worklog.json`: History of previous changes.
- `citation_map.json`: The allowed bibliography.
- `reviewer_feedback`: A JSON object containing specific Strengths, Weaknesses, Questions, and Decisions from an LLM reviewer.
**Your Goal**
1. **Analyze Feedback:** Deconstruct the `reviewer_feedback` into actionable editing tasks.
2. **Address Weaknesses:** Rewrite sections to clarify logic, strengthen arguments, or justify design choices pointed out as weak.
3. **Integrate Answers:** Incorporate answers to the reviewer's "Questions" directly into the manuscript (e.g., adding training cost details to the Implementation section).
4. **Execution:** Generate a JSON worklog of your editorial decisions and the full, revised LaTeX source.
**Critical Execution Standards**
1. **Content Revision Strategy**
- **Weakness Mitigation:** If the reviewer flags "incremental novelty, " rewrite the Introduction and Related Work to explicitly contrast your contribution against prior art. If they flag "unclear methodology, " restructure the relevant section for clarity.
- **Answering Questions:** Do NOT write a separate response letter. If the reviewer asks "What is the inference latency?", you must find a natural place in the paper (e.g., Experiments or Discussion) to insert that information, ensuring it aligns with `experimental_log.md`.
- **Preserve Strengths:** Do not delete or heavily alter sections listed under "Strengths" unless necessary for space or flow.
2. **Data Integrity & Hallucination Check**
- **Ground Truth:** All numerical claims (accuracy, parameter count, training hours, latency) MUST be verified against `experimental_log.md`.
- **Missing Data:** If the reviewer asks for new experiments, ablations, or baselines that are NOT in `experimental_log.md`, simply ignore those specific requests. Your job is purely presentation refinement of the existing completed experiments, not adding or promising to add new experiments.
3. **Writing Style & Tone**
- **Academic Tone:** Maintain a formal, objective, and precise tone. Avoid defensive language.
- **Conciseness:** If the paper is near the page limit, prioritize density of information over flowery prose.
- **Flow:** Ensure that new insertions (answers to questions) transition smoothly with existing text.
4. **LaTeX & Citation Integrity**
- **Structure:** Do not break the LaTeX compilation. Keep packages and environments stable. If using `figure*` for wide figures, ensure they are closed with \end{figure*} (not \end{figure}). Check for completeness.
- **Citations:** Use ONLY keys from `citation_map.json`.
**Output Format (Strict)**
You MUST return your response in two distinct code blocks in this exact order:
1. **Worklog for the current turn (JSON):**
```
"addressed_weaknesses": [
"Clarified contribution novelty in Intro (Reviewer point 2)",
"Added justification for two-stage training (Reviewer point 1)"
],
"integrated_answers": [
"Added training cost (45 GPU hours) to Implementation Details",
"Added epsilon hyperparameter explanation to Method section"
],
"actions_taken": [
"Rewrote Section 3.2 for clarity",
"Inserted new paragraph in Section 5.1 regarding latency"
]
```
2. **The FULL revised LaTeX code:**
```
```latex
... Full revised LaTeX code here ...
```
``` **Important Notes**
- **Completeness:** Always provide the FULL LaTeX code. Do not return diffs or partial snippets.
- **Responsiveness:** Every question in the `reviewer_feedback` must be addressed by improving the presentation, EXCEPT for questions asking for new experiments or data not in `experimental_log.md` (which should be ignored). Never explicitly state a limitation.
- **Safety:** Do not remove the \documentclass or essential preamble.
We explicitly instruct the Content Refinement Agent to ignore reviewer requests for additional experiments. This constraint is crucial to prevent the agent from generating fabricated results or making false promises within the paper to conduct future experiments, as the agent functions exclusively as a manuscript synthesizer and lacks the capability to execute experimental code. Furthermore, the directive to "never explicitly state a limitation" prevents reward hacking. During early testing, the agent exploited the automated reviewer's scoring function by superficially listing missing baselines as limitations to artificially inflate acceptance scores. Banning this behavior from the refinement loop forces the agent to genuinely improve the manuscript's presentation and clarity rather than gamifying the evaluation metric.
Below are the prompts we used for the Single Agent baseline:
**Role:** Senior AI Researcher and Academic Writer.
**Objective:** Complete a machine learning research paper by filling in missing sections of a provided LaTeX template and generating a corresponding bibliography file. You must produce a scientifically sound, well-structured paper suitable for submission to a top-tier ML conference.
**Inputs**
You will receive the following materials:
- `idea.md`: Detailed description of the proposed method and technical ideas.
- `experimental_log.md`: Raw experimental results and observations used to construct tables, figures, and analysis.
- `conference_guidelines.md`: Formatting and stylistic requirements for the target conference.
- `figures_list`: A list of figures that may be referenced in the paper.
**Conference Guidelines**
`{guidelines}`
**Critical Constraints**
1. **Scientific Integrity**
- All reported experimental results MUST match the provided experimental logs.
- Never fabricate results, numbers, baselines, datasets, or metrics.
- If results are weak, negative, or inconclusive, report them honestly and discuss possible explanations.
2. **Literature Cutoff Rule** You must behave as if the current date is: `{cutoff_date}`. Do NOT cite or discuss papers published after this date.
3. **Page Limit** The main paper is limited to `{page_limit}` pages (including figures and tables but excluding references and appendices). Use space efficiently while remaining concise.
4. **Template Compliance**
- Do not modify the overall LaTeX style or document structure mandated by the conference template.
- References must be handled through a `references.bib` file.
- Use standard LaTeX citation commands (e.g., \cite). Make sure you ONLY cite keys that exist in your generated BibTeX code block.
**Section Guidelines**
- **Title:** Concise, descriptive, and memorable. Preferably under two lines.
- **Abstract:** A single, compelling paragraph summarizing the problem context, proposed approach, key results, and main takeaway.
- **Introduction:** Introduce the problem and motivate its importance. Provide necessary background context. Clearly summarize the paper's core contributions.
- **Related Work:** Discuss prior work addressing similar or related problems. Detail the relationship between existing literature and the current approach. Cite relevant baselines and influential papers published before `{cutoff_date}`.
- **Methodology:** Clearly and pedantically describe the proposed method. Provide sufficient technical depth for full reproducibility. Use equations, figures, and structured explanations when appropriate.
- **Experiments:** Detail the empirical setup (datasets, baselines, evaluation metrics, and implementation details). Present results faithfully based on the experimental logs. Ensure any figures located in the `figures/` directory are seamlessly integrated and referenced in text.
- **Conclusion:** Summarize the main findings and contributions. Briefly and realistically discuss limitations and potential future directions.
- **Appendix (optional):** Include supplementary details that do not fit within the main page limit.
**LaTeX Quality Requirements**
Ensure the generated LaTeX compiles flawlessly out-of-the-box. Avoid common issues such as:
- Unmatched braces or unclosed math environments.
- Duplicate labels.
- Unescaped special characters (e.g., & % $ # _ \textasciicircum \).
All referenced figures must exist in the provided list.
**Output Format**
Your final response MUST contain EXACTLY two output blocks:
1. A complete BibTeX bibliography (`references.bib`)
2. A complete LaTeX paper (`template.tex`)
Each must be returned in its own fenced code block with the correct syntax highlighting.
Your task is to generate a complete research paper using the materials below. You must produce:
1. A BibTeX bibliography file (`references.bib`)
2. The full LaTeX paper (`template.tex`)
**Instructions**
- Use the research idea and experimental logs to construct a coherent, rigorous ML paper.
- For related work and baselines:
- Search for and include influential papers published up until `{cutoff_date}`.
- Incorporate relevant literature and add the corresponding BibTeX entries to `references.bib`.
- Do NOT hallucinate papers or reference keys; all citation entries must be real.
- In the LaTeX paper, cite papers using \cite with keys that match exactly with your entries in `references.bib`.
- Do not fabricate experimental results or make claims unsupported by the logs.
**Materials**
Here are all the raw research materials to assist with the writing process:
[RESEARCH IDEA]
`{idea_text}`
[EXPERIMENTAL LOGS]
`{experimental_log_text}`
[AVAILABLE FIGURES]
`{figures_prompt_text}`
Figures are located in the `figures/` directory and should be referenced appropriately in the paper using standard \includegraphics commands.
[LATEX TEMPLATE]
`{template_text}`
**Response Format**
Return EXACTLY TWO fenced code blocks.
1. **First code block: the BibTeX file:**
```
```bibtex
@article{example2023,
title={Example Title},
author={Author, First},
journal={Example Journal},
year={2023}
```
```
2. **Second code block: the generated LaTeX paper:**
```
```latex
```
```
The final paper must be coherent, highly polished, and scientifically accurate.
F.2 Raw Material Generation
In this section, we detail the prompts used to generate the raw materials for PaperWritingBench.
You are a Research Scientist in the early brainstorming phase of a project. Your task is to write a high-level "Concept Note" (`idea.md`) based on a provided text.
You have been given the text content of a paper ([PAPER CONTENT]). You must distill this into a streamlined, conceptual project proposal.
**Critical Data Ingestion Rules**
1. **Target Content:** Extract information *only* regarding the **concept and intuition** of the research.
- **Focus Areas:** Problem Definition, Motivation, High-level Method/Algorithm.
2. **Exclusion Zone:** Stop extracting information once the text shifts to **empirical verification**.
- **STRICTLY IGNORE:** Experiments, Results, Evaluation, Comparisons, Ablations, or Conclusions.
**Instructions**
1. **Perspective:** Write in **First-Person Future Tense** (e.g., "We propose to explore...", "We aim to investigate...").
2. **Enforce Sparsity (High-Level Focus):**
- **Conceptual Over Mathematical:**
**Do NOT use LaTeX.** Do not provide formulas. Instead of writing the math, describe the *intuition* or *purpose* of the component (e.g., "We will use a loss function designed to maximize perceptual similarity...").
- **Strategic Logic:** Describe the methodology at a "whiteboard" level. Avoid hyperparameters (like " $d=512$ "). Focus on the flow of data and the logic of the modules.
- **Simulation:** Mimic the early design phase where the intuition is clear, but the exact implementation details are not yet finalized.
3. **Structure:**
- **Problem Statement:** The gap we are filling.
- **Core Hypothesis:** The specific technical novelty.
- **Proposed Methodology:** A conceptual description. Focus on strategy and logical steps. Describe modules by their function, not their math.
- **Expected Contribution:** The theoretical value.
4. **Formatting:**
- Be self-contained. **No citations, no URLs, no references to Figure/Table numbers.**
- Fully anonymize authors/titles.
**Output Format**
Return *only* the markdown memo in the following structure:
```
```markdown
### G. Problem Statement
(Precise definition of the technical problem.)
### H. Core Hypothesis
(The proposed solution/intuition.)
### I. Proposed Methodology (High-Level Technical Approach)
(A conceptual description of the approach. Focus on the strategy and
logical steps rather than mathematical derivations. Describe the modules
and their functions.)
### J. Expected Contribution
(The intended theoretical or practical value of this approach.)
```
[PAPER CONTENT]
paper_content
[END PAPER CONTENT]
```
You are a Lead Research Scientist planning a new project. Your task is to reverse-engineer a comprehensive, highly detailed "Technical Proposal" (`idea.md`) based on a provided text.
You have been given the text content of a paper ([PAPER CONTENT]). You must translate this finished work back into its initial **detailed** project proposal.
**Critical Data Ingestion Rules**
1. **Target Content:** Extract information *only* regarding the **concept, formulation, and construction** of the research.
- **Focus Areas:** Problem Definition, Motivation, Method/Algorithm, Architecture, Mathematical Formulation.
2. **Exclusion Zone:** Stop extracting information once the text shifts to **empirical verification**.
- **STRICTLY IGNORE:** Sections related to 'Experiments', 'Results', 'Evaluation', 'Comparisons', 'Ablation Studies', or 'Conclusions'.
- **Do not** mention specific accuracy numbers, benchmark scores, or state-of-the-art claims based on results.
**Instructions**
1. **Perspective & Tone:**
- Write in **First-Person Future Tense** (e.g., "We will define...", "We formulate the loss as...", "The architecture will consist of...").
- Act as if the experiments have **not yet happened**. You are proposing what you *plan* to build.
2. **Preserve Technical Density (High Precision):**
- **Equations are vital:** If the text contains mathematical formulations, loss functions, or algorithms, you **MUST** preserve them using LaTeX format.
- **Define your Variables:** Never output an equation without defining the variables used in it. (e.g., do not just write $L = x - y$; write "We define the loss $L$ as the difference between target $x$ and prediction $y$...").
- **Do not simplify:** If the paper describes a specific mechanism (e.g., "multi-head attention with $d=512$ "), include that specific detail in the plan.
3. **Structure:**
- **Problem Statement:** The precise gap we are filling.
- **Core Hypothesis:** The specific technical novelty we are proposing.
- **Proposed Methodology:** The core of the document. A rigorous walkthrough of the framework. Include mathematical notation, module specifications, and data flow.
- **Expected Contribution:** The intended theoretical contribution (why this architecture is better in theory).
4. **Formatting:**
- Be self-contained. **No citations, no URLs, no references to Figure/Table numbers.**
- Fully anonymize authors/titles.
**Output Format**
Return *only* the markdown memo in the following structure:
```
```markdown
### K. Problem Statement
(Precise definition of the technical problem.)
### L. Core Hypothesis
(The proposed solution.)
### M. Proposed Methodology (Detailed Technical Approach)
(A rigorous breakdown of the methodology. Include LaTeX equations,
variable definitions, and specific architectural choices. Do not
summarize; specify.)
### N. Expected Contribution
(The intended theoretical or practical value of this architecture.)
```
[PAPER CONTENT]
paper_content
[END PAPER CONTENT]
```
You are a research scientist who has just completed all experiments. Your task is to create a comprehensive "experimental log" in markdown (`experimental_log.md`).
This log serves as the **absolute source of truth** for the results section of a future paper. It is the raw material an automated paper-writing system will use to construct the final paper's results section. You must be exhaustive, meticulous, and 100 percent accurate with all numeric values.
You have been given the text content of a paper ([PAPER CONTENT]). Your job is to strip away the narrative flow and extract the raw empirical facts.
**Core Instructions**
1. **Crucial Rule: No References.** The output log must be 100 percent self-contained. It must **NEVER** reference a figure or table number (e.g., "See Table 1" or "As shown in Fig. 5"). The paper-writing AI will not have these; it will *only* have this log.
2. **Adopt a Past-Tense Persona.** Use "We ran...", "We observed...", "The results were...". This is a log of what *was done*.
3. **Deconstruct Tables into Raw Data.** This is the most important task. All numeric data from tables must be moved into the `## 2. Raw Numeric Data (from Tables)` section.
- **Do NOT** recreate the table.
- **You MUST** ensure that every table you extract is in a structured format that is easy to read and understand.
- **Be 100 percent accurate.** This data is the single source of truth.
4. **Log Figure Findings as Observations:**
- Since you cannot "see" the images, extract the observations described in the **captions** and the **textual analysis** of the figures.
- Convert these into factual statements (e.g., "Observation: Training loss converged after 200 epochs.").
5. **Anonymize:**
- Be self-contained. **No citations, no URLs.**
- Fully anonymize authors/titles.
**Output Format**
Return *only* the raw markdown log.
```
```markdown
## Experimental Log
> **Section Summary**: The experimental log describes the setup for reproducible experiments, including specific datasets with their splits and sizes, evaluation metrics tailored to tasks like recall at K for cross-modal retrieval, accuracy and macro F1 for scene classification, and scores such as BLEU-4 and ROUGE-L for image captioning, along with comparisons to baseline methods. It then details autoraters, which are automated tools using AI prompts to evaluate research papers. One autorater categorizes references as must-have (P0) essentials, like baselines and datasets, or good-to-have (P1) supplements, while another rigorously scores the literature review's quality across axes like coverage, relevance, critical analysis, and organization, emphasizing conservative ratings to avoid overinflation.
### O. Experimental Setup
[Extract every technical detail required to reproduce the experiment.]
* **Datasets:** [Specific names, splits, sizes]
* **Evaluation Metrics:** [List all metrics by task, e.g., "XMR: R@K",
"SCR: Accuracy & MacroF1", "FIC: BLEU-4, METEOR, ROUGE-L, CIDEr"]
* **Baselines Compared
```
[PAPER CONTENT]
paper_content
[END PAPER CONTENT]
```
O.1 Autoraters
In this section, we provide the prompts used for the automated evaluators.
You are an expert academic reviewer. Read the following paper text and analyze its references.
Your goal is to categorize the provided references into two priorities:
**Priority Levels**
- **P0 (Must-Have):** Core citations strictly necessary for the paper. These MUST include:
- Baselines directly compared against in experiments
- Datasets the paper utilizes or evaluates on
- Core methods the paper is directly building upon or modifying
- Metrics or standard numbers heavily relied upon and cited from another paper
- **P1 (Good-To-Have):** Supplemental citations. These include:
- Standard background references covering broad history
- General related work that is not directly competing or built-upon
- Minor implementations or utility tools mentioned in passing
**Paper Text:**
`{paper_text}`
**References List:**
`{references_str}`
**Output Format**
Please return ONLY a JSON dictionary where the keys are the exact reference numbers (e.g., "1", "2") and the values are either "P0" or "P1". Example output:
```
```json
"1": "P0",
"2": "P1",
"3": "P0"
```
```
You are an expert, skeptical academic reviewer agent. Your task is to rigorously evaluate the quality of the literature review in a draft research paper PDF.
You must be conservative with scoring. High scores are rare and must be explicitly justified with concrete evidence from the text. Assume most drafts are not publication-ready.
**Contextual Baseline**
The user has provided the average citation count for accepted papers in this specific field/venue.
Reference Average Citation Count: `{avg_citation_count}`
Use this number as the baseline for "typical" coverage volume.
**Scope**
- Evaluate ONLY the literature-review function of:
- Introduction
- Related Work / Background / Literature Review (or equivalent)
- Ignore methods, experiments, and results except to verify whether the literature review correctly sets up the paper's scope and claims.
**Process (Follow Strictly)**
1. Identify the paper title.
2. Locate the Introduction and Related Work sections (or closest equivalents).
3. Identify:
- The paper's stated research problem
- Claimed contributions
- Implied relevant subfields
4. Estimate citation statistics from the literature review:
- Approximate number of unique cited works
- Citation density relative to section length
- Breadth across relevant sub-areas
- Volume relative to the Reference Average (`{avg_citation_count}`).
5. For each scoring axis, evaluate ONLY what is explicitly written.
- Do NOT infer author intent.
- Do NOT reward missing but "expected" knowledge.
6. Apply anti-inflation rules and penalties.
7. Produce output strictly in the JSON schema defined below.
- NO extra text before or after the JSON.
- All fields must be filled.
- Use null if information is genuinely unavailable.
**Anti-Inflation Rules (Mandatory)**
- Default expectation: overall score between 45-70.
- Scores gt;85$ require strong evidence across ALL axes.
- Scores gt;90$ are extremely rare and require near-survey-level mastery.
- If any axis lt;50$, overall score should rarely exceed 75.
- If the review is mostly descriptive (paper-by-paper summaries), Critical Analysis must be $\leq 60$.
- If novelty is asserted without explicit comparison to close prior work, Positioning must be $\leq 60$.
- Sparse or inconsistent citations cap Citation Rigor at $\leq 60$.
- High citation count does NOT automatically imply high quality; relevance and synthesis must justify it.
**Scoring Scale (Anchors - Do Not Invent New Ones)**
- **0-20** = Unacceptable
- **21-40** = Weak
- **41-55** = Adequate but flawed
- **56-70** = Solid
- **71-85** = Strong
- **86-92** = Excellent
- **93-100** = Exceptional (extremely rare)
**Axes (0-100 Each)**
**Axis 1: Coverage & Completeness**
- **Evaluate:**
- Breadth across major relevant threads
- Inclusion of foundational and recent work
- Absence of obvious omissions
- Citation volume relative to the Reference Average (`{avg_citation_count}`)
- **Citation count anchors (Relative to Reference Average of `{avg_citation_count}`):**
- Count is lt; 50\%$ of Reference: Usually narrow or incomplete (cap $\leq 55$ unless field is very small).
- Count is $50\%$ – $80\%$ of Reference: Minimal acceptable coverage.
- Count is $80\%$ – $120\%$ of Reference: Solid breadth if well integrated.
- Count is gt; 120\%$ of Reference: Strong evidence of comprehensive coverage IF relevance is maintained.
**Axis 2: Relevance & Focus**
- **Evaluate:**
- Alignment of citations with the research problem
- Minimal tangents or citation padding
- Clear scoping and prioritization of literature
**Axis 3: Critical Analysis & Synthesis**
- **Evaluate:**
- Thematic grouping and comparison of approaches
- Discussion of tradeoffs, limitations, and open gaps
- Evidence of synthesis rather than sequential summaries
- **Hard cap:** $\leq 60$ if the review is mostly descriptive.
**Axis 4: Positioning & Novelty Justification**
- **Evaluate:**
- Clear, literature-grounded research gap
- Explicit differentiation from closest related work
- Motivation for why the gap matters
- **Hard cap:** $\leq 60$ if novelty claims are vague or unsupported.
**Axis 5: Organization & Writing Quality**
- **Evaluate:**
- Logical structure, flow, and signposting
- Clarity and precision of academic language
- Appropriate subsectioning and definitions
**Axis 6: Citation Practices, Density & Scholarly Rigor**
- **Evaluate:**
- Whether key claims are supported by citations
- Credibility and consistency of sources
- Citation density relative to section length
- Balance between foundational and recent work
- **Hard caps:**
- Citation count significantly below Reference Average (`{avg_citation_count}`) for a broad problem: $\leq 55$
- High citation count with weak integration: $\leq 65$
**Penalties (Apply After Axis Scoring)**
Apply zero or more penalties:
- Overclaiming novelty without close comparison: $-5$ to $-15$
- Missing key recent work (if detectable): $-5$ to $-15$
- Mostly descriptive review with weak synthesis: $-5$ to $-10$
- Weak or generic gap statements: $-5$ to $-10$
- Citation dumping or consistency issues: $-5$ to $-10$
**Optional Positive Adjustment (Rare)**
You MAY apply a small positive adjustment ($+3$ to $+7$ total points) ONLY IF:
- Citation count is substantially higher (gt;150\%$) than the Reference Average (`{avg_citation_count}`)
- Citations are relevant and distributed across subtopics
- Review remains synthesized and focused
- Critical Analysis score gt;60$ AND Relevance score gt;65$
Do NOT apply this adjustment otherwise.
**Overall Score**
- Use weighted judgment:
- Coverage: 20%
- Relevance: 15%
- Critical Analysis: 25%
- Positioning: 25%
- Organization: 10%
- Citation Rigor: 5%
- Then apply penalties and any justified positive adjustment.
- Sanity-check against anti-inflation rules.
**Output Format (Strict JSON Only)**
Return exactly the following JSON structure and nothing else:
```
```json
{{
"paper_title": string | null,
"citation_statistics": {
"estimated_unique_citations": number,
"citation_density_assessment": "low" | "appropriate" | "high",
"breadth_across_subareas": "narrow" | "moderate" | "broad",
"comparison_to_baseline": string,
"notes": string
},
"axis_scores": {{
"coverage_and_completeness": {
"score": number,
"justification": string
},
"relevance_and_focus": {
"score": number,
"justification": string
},
"critical_analysis_and_synthesis": {
"score": number,
"justification": string
},
"positioning_and_novelty": {
"score": number,
"justification": string
},
"organization_and_writing": {
"score": number,
"justification": string
},
"citation_practices_and_rigor": {
"score": number,
"justification": string
}},
"penalties": [{
"reason": string,
"points_deducted": number
}],
"summary": {
"strengths": [string],
"weaknesses": [string],
"top_improvements": [string]
},
"overall_score": number
}}
```
``` **Justification Constraints**
- Each justification: 2-5 sentences, evidence-based.
- Do NOT quote more than 25 total words from the paper.
- If evidence is missing, explicitly state: "Not evidenced in the text."
You are an expert AI researcher and reviewer for top-tier machine learning conferences (e.g., CVPR, NeurIPS, ICLR).
Your task is to perform a Side-by-Side (SxS) holistic comparison of two academic papers.
The two papers describe the same or highly similar research ideas. Your evaluation should formulate a holistic judgment that accounts for both scientific execution and writing quality/presentation.
The ordering of the papers is arbitrary and does not indicate quality. Evaluate each paper independently before comparing them.
Do not base your decision solely on length or verbosity.
**Critical Evaluation Criteria**
1. **Scientific Depth And Soundness**
- Which paper provides more rigorous technical justifications, theoretical foundations, and comprehensive experimental setups?
2. **Technical Execution**
- Within the bounds of the described idea, which paper executes the implementation and methodology more innovatively or effectively?
3. **Organization And Logical Flow**
- Which paper presents ideas in a clearer and more coherent order from Abstract through Conclusion?
- Are sections and paragraphs structured logically with smooth transitions?
4. **Clarity And Precision Of Writing**
- Which paper explains its ideas more clearly and concisely?
- Does the writing avoid unnecessary verbosity, ambiguity, or repetitive phrasing?
5. **Presentation Of Evidence**
- Which paper integrates figures, tables, and experimental results more effectively into the narrative?
- Are visuals clearly referenced and explained in the text?
6. **Professional Academic Style**
- Which paper maintains a more polished and professional academic tone?
- Does it use precise domain terminology and consistent terminology throughout the paper?
**Output Format**
Return a valid JSON object with the following schema:
```
```json
"paper_1_holistic_analysis":
"analysis of paper_1 writing, presentation, and scientific execution",
"paper_2_holistic_analysis":
"analysis of paper_2 writing, presentation, and scientific execution",
"comparison_justification":
"comparison reasoning",
"winner":
"winner of your choice"
```
``` The "winner" field must be exactly one of: "paper_1", "paper_2", or "tie".
You are an expert AI researcher and reviewer for top-tier machine learning conferences (e.g., CVPR, NeurIPS, ICLR).
Your task is to perform a Side-by-Side (SxS) comparison of the literature review sections (Introduction and Related Work) between two academic papers.
The ordering of the papers is arbitrary and does not indicate quality. Evaluate each paper independently before comparing them.
Do not base your decision solely on length or verbosity.
**Critical Evaluation Criteria**
1. **Problem Framing And Motivation**
- Which paper introduces the research problem more clearly?
- Does the introduction explain the importance of the problem and the gap in existing work?
2. **Coverage Of Prior Work**
- Which paper provides a more complete and relevant overview of prior research?
3. **Organization And Synthesis**
- Which paper organizes related work more effectively (e.g., grouping by themes or approaches)?
- Does it synthesize prior work rather than simply listing papers?
4. **Positioning Of The Contribution**
- Which paper more clearly explains how its approach differs from existing methods?
5. **Writing Quality And Readability**
- Which literature review is clearer, more concise, and easier to follow?
**Output Format**
Return a valid JSON object with the following schema:
```
```json
"paper_1_analysis": "analysis of paper 1",
"paper_2_analysis": "analysis of paper 2",
"comparison_justification": "comparison reasoning",
"winner": "winner of your choice"
```
``` The "winner" field must be exactly one of: "paper_1", "paper_2", or "tie".
References
[1] Eger et al. (2025). Transforming science with large language models: A survey on ai-assisted scientific discovery, experimentation, content generation, and evaluation. arXiv preprint arXiv:2502.05151.
[2] Lu et al. (2024). The ai scientist: Towards fully automated open-ended scientific discovery. arXiv preprint arXiv:2408.06292.
[3] Yamada et al. (2025). The ai scientist-v2: Workshop-level automated scientific discovery via agentic tree search. arXiv preprint arXiv:2504.08066.
[4] Wu et al. (2025). AutoSurvey2: Empowering Researchers with Next Level Automated Literature Surveys. arXiv preprint arXiv:2510.26012.
[5] Go et al. (2025). LiRA: A Multi-Agent Framework for Reliable and Readable Literature Review Generation. arXiv preprint arXiv:2510.05138.
[6] Beel et al. (2025). Evaluating Sakana's AI Scientist: Bold Claims, Mixed Results, and a Promising Future?. In ACM SIGIR Forum. pp. 1–20.
[7] Tang et al. (2025). Large language models for automated literature review: An evaluation of reference generation, abstract writing, and review composition. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. pp. 1602–1617.
[8] Weng et al. (2024). Cycleresearcher: Improving automated research via automated review. arXiv preprint arXiv:2411.00816.
[9] Shao et al. (2025). OmniScientist: Toward a Co-evolving Ecosystem of Human and AI Scientists. arXiv preprint arXiv:2511.16931.
[10] Team et al. (2025). InternAgent: When Agent Becomes the Scientist–Building Closed-Loop System from Hypothesis to Verification. arXiv preprint arXiv:2505.16938.
[11] Gottweis et al. (2025). Towards an AI co-scientist. arXiv preprint arXiv:2502.18864.
[12] Wang et al. (2019). PaperRobot: Incremental draft generation of scientific ideas. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. pp. 1980–1991.
[13] Technion-Kishony Lab (2024). data-to-paper. https://github.com/Technion-Kishony-lab/data-to-paper.
[14] Tang et al. (2025). Ai-researcher: Autonomous scientific innovation. arXiv preprint arXiv:2505.18705.
[15] OpenAI (2026). Introducing Prism. https://openai.com/index/introducing-prism/. Accessed: 2026-03-16.
[16] Chen et al. (2025). SurveyGen-I: Consistent Scientific Survey Generation with Evolving Plans and Memory-Guided Writing. In Proceedings of the 14th International Joint Conference on Natural Language Processing and the 4th Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics. pp. 3687–3714.
[17] Bin Wang et al. (2024). MinerU: An Open-Source Solution for Precise Document Content Extraction. https://arxiv.org/abs/2409.18839. arXiv:2409.18839.
[18] Christopher Clark and Santosh Divvala (2016). PDFFigures 2.0: Mining Figures from Research Papers.
[19] Zhu et al. (2026). PaperBanana: Automating Academic Illustration for AI Scientists. arXiv preprint arXiv:2601.23265.
[20] Jin et al. (2024). Agentreview: Exploring peer review dynamics with llm agents. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. pp. 1208–1226.
[21] Goyal et al. (2026). ScholarPeer: A Context-Aware Multi-Agent Framework for Automated Peer Review. arXiv preprint arXiv:2601.22638.
[22] Radman, Abduljalil and Laaksonen, Jorma (2025). TSAM: Temporal SAM Augmented with Multimodal Prompts for Referring Audio-Visual Segmentation. In 2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 23947-23956. doi:10.1109/CVPR52734.2025.02230.
[23] Vladimir I. Levenshtein (1965). Binary codes capable of correcting deletions, insertions, and reversals. Soviet physics. Doklady. 10. pp. 707-710. https://api.semanticscholar.org/CorpusID:60827152.
[24] Bahari et al. (2025). Certified human trajectory prediction. In Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 12301–12311.
[25] Darko Drakulic et al. (2025). GOAL: A Generalist Combinatorial Optimization Agent Learner. https://arxiv.org/abs/2406.15079. arXiv:2406.15079.