ORPO: Monolithic Preference Optimization without Reference Model
Jiwoo Hong Noah Lee James Thorne
KAIST AI, {jiwoo_hong, noah.lee, thorne}@kaist.ac.kr
Abstract
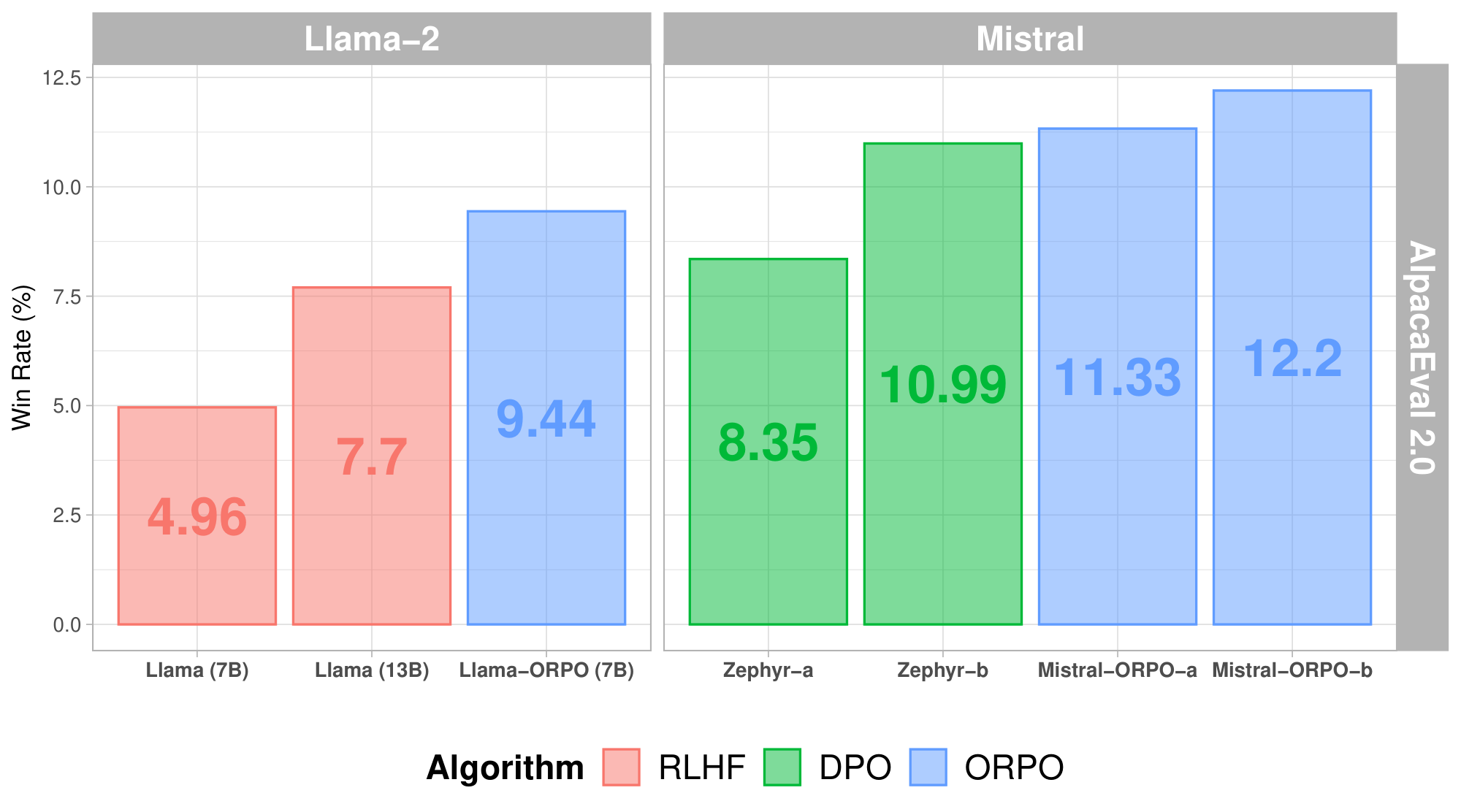
While recent preference alignment algorithms for language models have demonstrated promising results, supervised fine-tuning (SFT) remains imperative for achieving successful convergence. In this paper, we study the crucial role of SFT within the context of preference alignment, emphasizing that a minor penalty for the disfavored generation style is sufficient for preference-aligned SFT. Building on this foundation, we introduce a straightforward and innovative reference model-free monolithic odds ratio preference optimization algorithm, ORPO, eliminating the necessity for an additional preference alignment phase. We demonstrate, both empirically and theoretically, that the odds ratio is a sensible choice for contrasting favored and disfavored styles during SFT across the diverse sizes from 125M to 7B. Specifically, fine-tuning Phi-2 (2.7B), Llama-2 (7B), and Mistral (7B) with ORPO on the UltraFeedback alone surpasses the performance of state-of-the-art language models with more than 7B and 13B parameters: achieving up to 12.20% on AlpacaEval$_{2.0}$ (Figure 1), 66.19% on IFEval (instruction-level loose, Table 6), and 7.32 in MT-Bench (Figure 12). We release code$^1$ and model checkpoints for Mistral-ORPO-$\alpha$ (7B)$^2$ and Mistral-ORPO-$\beta$ (7B).$^3$
$^1$https://github.com/xfactlab/orpo
$^2$https://huggingface.co/kaist-ai/mistral-orpo-alpha
$^3$https://huggingface.co/kaist-ai/mistral-orpo-beta
Executive Summary: Large language models have transformed natural language processing, excelling in tasks like text generation and question answering. However, they often produce outputs that are unhelpful, biased, or harmful, as they learn from vast, uncurated data. Aligning these models with human preferences—making them safer and more useful—has become urgent as models grow larger and deploy in real-world applications like chatbots and assistants. Current methods, such as reinforcement learning from human feedback (RLHF) and direct preference optimization (DPO), rely on multi-stage training that demands significant computational resources, including separate warm-up phases and reference models, limiting accessibility for smaller teams or devices.
This paper introduces odds ratio preference optimization (ORPO), a simple method to align models in one step by combining supervised fine-tuning on preferred responses with a mild penalty on disfavored ones, without needing a separate reference model. It aims to demonstrate that ORPO can achieve strong alignment efficiently across model sizes while matching or exceeding prior techniques.
The authors fine-tuned open-source language models ranging from 125 million to 7 billion parameters, including Phi-2, Llama-2, and Mistral, using pairwise preference datasets like UltraFeedback (about 60,000 examples) and HH-RLHF. They compared ORPO to baselines like basic supervised fine-tuning (SFT), RLHF, and DPO through controlled experiments and standard benchmarks, such as AlpacaEval for instruction-following win rates and MT-Bench for multi-turn conversations. Key assumptions included truncating inputs to manage sequence lengths and using a single training epoch for efficiency, with evaluations relying on GPT-4 as a judge for human-like preferences.
ORPO's top results came from Mistral 7B models, which scored 12.20% win rate on AlpacaEval 2.0—about 11% higher than Zephyr β (a state-of-the-art 7B model) and surpassing Llama-2 Chat 13B by roughly 58%. These models also achieved 7.32 on MT-Bench, comparable to much larger proprietary systems like GPT-3.5-turbo in descriptive tasks, though slightly behind in math and coding. In head-to-head reward model comparisons, ORPO beat SFT by 70-84% across scales, outperformed RLHF by up to 86%, and topped DPO by 58-71% win rates, with reward distributions shifting positively for all sizes. Finally, ORPO preserved generation diversity better than DPO in some cases, avoiding overly uniform outputs while focusing on preferred styles.
These findings show ORPO simplifies alignment, cutting training costs by about half through fewer computations and no extra models, while boosting performance on safety, factuality, and instruction adherence. Unlike multi-stage methods that risk instability or overfitting, ORPO's odds ratio approach provides stable penalties, enabling smaller models to rival giants and reducing deployment risks like harmful generations. This contrasts with expectations that larger models or complex RL always win, highlighting efficiency gains for resource-constrained settings and potentially faster iteration in AI development.
Organizations should integrate ORPO into workflows for fine-tuning open models, starting with datasets like UltraFeedback for quick wins in chat applications. For production, test variants with different penalty weights (e.g., low for deterministic tasks like math, higher for creative ones) to balance helpfulness and diversity. Trade-offs include favoring open-ended responses with stronger penalties, so pilot with domain-specific data. Next, scale ORPO to models over 7B parameters and diverse datasets for broader validation; additional comparisons to emerging methods like KTO would strengthen adoption.
While robust across tested scales and datasets, limitations include reliance on data quality—cleaner sets boosted scores by 0.9 percentage points—and untested domains like code or translation. Evaluations used automated judges, which may not fully capture human nuances. Confidence is high for 1-7B models on instruction tasks, but caution applies to larger scales or low-resource languages, where more data and pilots are needed before full commitment.
1. Introduction
Section Summary: Pre-trained language models, trained on huge amounts of text like web pages and books, excel at various language tasks but require additional fine-tuning to work well in everyday applications, such as following instructions and aligning with human values to avoid harmful outputs. Traditional methods for this alignment, like reinforcement learning with human feedback, often involve multiple steps, a warm-up phase, and a reference model, which can be resource-intensive. This paper introduces a simpler approach called ORPO, which streamlines the process into one step without needing extras, and demonstrates its effectiveness by fine-tuning popular models like Llama-2 and Mistral, achieving strong results on benchmarks while releasing the code and trained models.
Pre-trained language models (PLMs) with vast training corpora such as web texts ([1, 2]) or textbooks ([3]) have shown remarkable abilities in diverse natural language processing (NLP) tasks ([4, 5, 6, 7, 8]).
However, the models must undergo further tuning to be usable in general-domain applications, typically through processes such as instruction tuning and preference alignment.
Instruction-tuning ([9, 10, 11, 12]) trains models to follow task descriptions given in natural language, which enables models to generalize well to previously unseen tasks. However, despite the ability to follow instructions, models may generate harmful or unethical outputs ([13, 14, 15]). To further align these models with human values, additional training is required with pairwise preference data using techniques such as reinforcement learning with human feedback ([16, 17], RLHF) and direct preference optimization ([18], DPO).
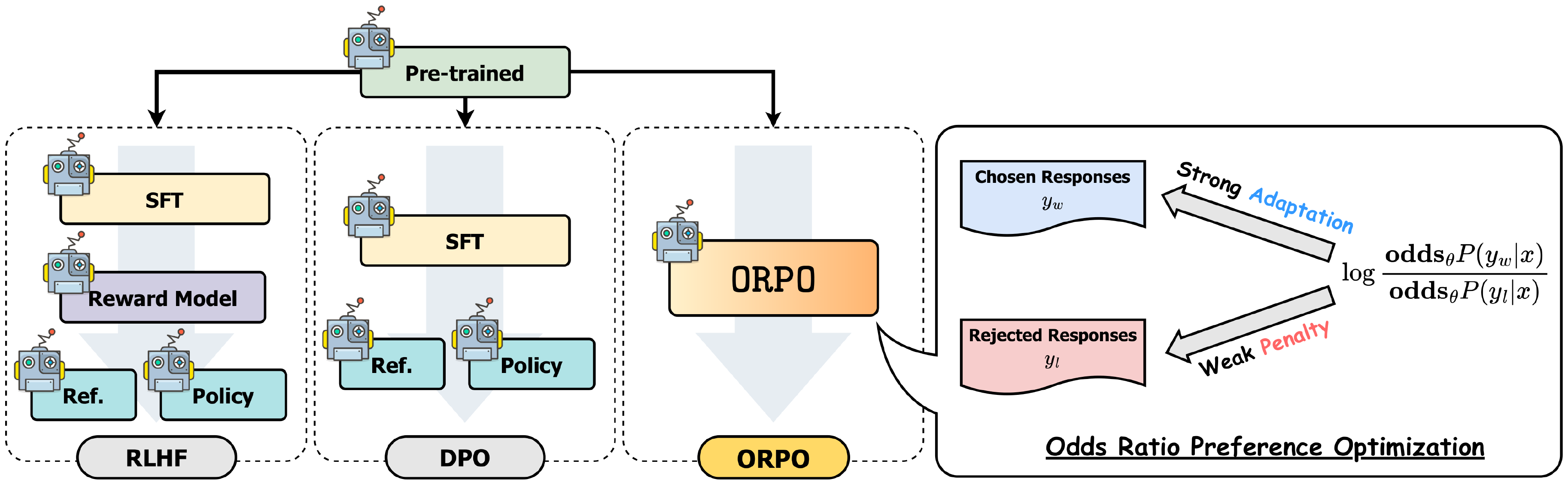
Preference alignment methods have demonstrated success in several downstream tasks beyond reducing harm. For example, improving factuality ([19, 20, 21]), code-based question answering ([22]), and machine translation ([23]). The versatility of alignment algorithms over a wide range of downstream tasks highlights the necessity of understanding the alignment procedure and further improving the algorithms in terms of efficiency and performance. However, existing preference alignment methods normally consist of a multi-stage process, as shown in Figure 2, typically requiring a second reference model and a separate warm-up phase with supervised fine-tuning (SFT) ([16, 18, 24]).
In this paper, we study the role and impact of SFT in pairwise preference datasets for model alignment in Section 3 and propose a simple and novel monolithic alignment method, odds ratio preference optimization (ORPO), which efficiently penalizes the model from learning undesired generation styles during SFT in Section 4. In contrast to previous works, our approach requires neither an SFT warm-up stage nor a reference model, enabling resource-efficient development of preference-based aligned models.
We demonstrate the effectiveness of our method with the evaluation of model alignment tasks and popular leaderboards in Section 6.1 and Section 6.2 by fine-tuning Phi-2 (2.7B), Llama-2 (7B), and Mistral (7B) with ORPO. Then, we conduct controlled experiments comparing ORPO against established methods for model alignment, RLHF, and DPO for different datasets and model sizes in Section 6.3. Along with the post-hoc analysis of generation diversity in Section 6.4, we expound on the theoretical, empirical, and computational justification of utilizing the odds ratio in monolithic preference alignment in Section 7.3. We release the training code and the checkpoints for Mistral-ORPO- $\alpha$ (7B) and Mistral-ORPO- $\beta$ (7B). These models achieve 7.24 and 7.32 in MT-Bench, 11.33% and 12.20% on $\text{AlpacaEval}_{2.0}$, and 61.63% and 66.19% in IFEval instruction-level loose accuracy, respectively.
2. Related Works
Section Summary: Researchers have developed methods to align language models with human preferences using reinforcement learning with human feedback (RLHF), which involves training models to favor preferred responses through reward models and algorithms like PPO, though it faces challenges like instability and the need for extensive tuning. Alternatives avoid reinforcement learning altogether, such as direct policy optimization (DPO) that integrates preference learning without separate rewards, or techniques like Kahneman-Tversky Optimization (KTO) that don't require pairwise preference data. Supervised fine-tuning (SFT) plays a key role in many alignment approaches by providing a stable base, and some studies show that carefully curated datasets for SFT alone can achieve effective alignment, though its deeper theoretical role remains underexplored.
Alignment with Reinforcement Learning
Reinforcement learning with human feedback (RLHF) commonly applies the Bradley-Terry model ([25]) to estimate the probability of a pairwise competition between two independently evaluated instances. An additional reward model is trained to score instances. Reinforcement learning algorithms such as proximal policy optimization (PPO) ([26]) are employed to train the model to maximize the score of the reward model for the chosen response, resulting in language models that are trained with human preferences ([16, 17]). Notably, [27] demonstrated the scalability and versatility of RLHF for instruction-following language models. Extensions such as language model feedback (RLAIF) could be a viable alternative to human feedback ([28, 29, 30]). However, RLHF faces challenges of extensive hyperparameter searching due to the instability of PPO ([18, 24]) and the sensitivity of the reward models ([31, 32]). Therefore, there is a crucial need for stable preference alignment algorithms.
Alignment without Reward Model
Several techniques for preference alignment mitigate the need for reinforcement learning ([18, 33, 34, 35]). [18] introduce direct policy optimization (DPO), which combines the reward modeling stage into the preference learning stage. [34] prevented potential overfitting problems in DPO through identity preference optimization (IPO). [35] and [36] proposed Kahneman-Tversky Optimisation (KTO) and Unified Language Model Alignment (ULMA) that does not require the pair-wise preference dataset, unlike RLHF and DPO. [33] further suggests incorporation of the softmax value of the reference response set in the negative log-likelihood loss to merge the supervised fine-tuning and preference alignment.
Alignment with Supervised Fine-tuning
Preference alignment methods in reinforcement learning (RL) often leverage supervised fine-tuning (SFT) to ensure the stable update of the active policy in relation to the old policy ([26]). This is because the SFT model is the old policy in the context of RLHF ([16]). Furthermore, empirical findings indicate that, even in non-RL alignment methods, the SFT model is crucial for achieving convergence to desired results ([18, 37]).
In contrast, there have been approaches to build human-aligned language models by conducting SFT only with filtered datasets ([12, 38, 39, 40]). [12] demonstrated that SFT with a small amount of data with fine-grained filtering and curation could be sufficient for building helpful language model assistants. Furthermore, [38] and [39] proposed an iterative process of fine-tuning the supervised fine-tuned language models with their own generations after fine-grained selection of aligned generations and [40] suggested that a curated subset of preference dataset is sufficient for alignment. While these works highlight the impact and significance of SFT in the context of alignment, the actual role of SFT and the theoretical background for incorporating preference alignment in SFT remains understudied.
3. The Role of Supervised Fine-tuning
Section Summary: Supervised fine-tuning helps tailor pre-trained language models to specific tasks, like dialogue, by raising the chances of generating useful responses, but it can accidentally make unwanted or "rejected" styles just as likely. The standard training method, using cross-entropy loss, only rewards good answers and ignores bad ones, so both types of outputs end up with higher probabilities during training, as shown in experiments with a model called OPT-350M. To fix this, the section suggests adding penalties for undesirable generations, paving the way for better alignment methods that discourage bad responses without manual tweaks.
We study the behavior of supervised fine-tuning (SFT) as an initial stage of preference alignment methods ([16, 18]) through analysis of the loss function in SFT and empirical demonstration of the preference comprehension ability of the trained SFT model. SFT plays a significant role in tailoring the pre-trained language models to the desired domain ([12, 41]) by increasing the log probabilities of pertinent tokens. Nevertheless, this inadvertently increases the likelihood of generating tokens in undesirable styles, as illustrated in Figure 3. Therefore, it is necessary to develop methods capable of preserving the domain adaptation role of SFT while concurrently discerning and mitigating unwanted generation styles.
Absence of Penalty in Cross-Entropy Loss
The goal of cross-entropy loss model fine-tuning is to penalize the model if the predicted logits for the reference answers are low, as shown in Equation 1.
$ \begin{align} \mathcal{L} &= -\frac{1}{m} \sum_{k=1}^{m} \log P(\mathbf{x}^{(k)}, \mathbf{y}^{(k)})\ &= -\frac{1}{m}\sum_{k=1}^{m}\sum_{i=1}^{|V|}y_i^{(k)} \cdot \log(p_i^{(k)}) \end{align}\tag{1} $
where $y_i$ is a boolean value that indicates if $i$ th token in the vocabulary set $V$ is a label token, $p_i$ refers to the probability of $i$ th token, and $m$ is the length of sequence. Using cross-entropy alone gives no direct penalty or compensation for the logits of non-answer tokens ([42]) as $y_i$ will be set to 0. While cross-entropy is generally effective for domain adaptation ([43]), there are no mechanisms to penalize rejected responses when compensating for the chosen responses. Therefore, the log probabilities of the tokens in the rejected responses increase along with the chosen responses, which is not desired from the viewpoint of preference alignment.
Generalization over Both Response Styles
We conduct a pilot study to empirically demonstrate the miscalibration of chosen and rejected responses with supervised fine-tuning alone. We fine-tune OPT-350M ([5]) on the chosen responses only from the HH-RLHF dataset ([28]). Throughout the training, we monitor the log probability of rejected responses for each batch and report this in Figure 3. Both the log probability of chosen and rejected responses exhibited a simultaneous increase. This can be interpreted from two different perspectives. First, the cross-entropy loss effectively guides the model toward the intended domain (e.g., dialogue). However, the absence of a penalty for unwanted generations results in rejected responses sometimes having even higher log probabilities than the chosen ones.
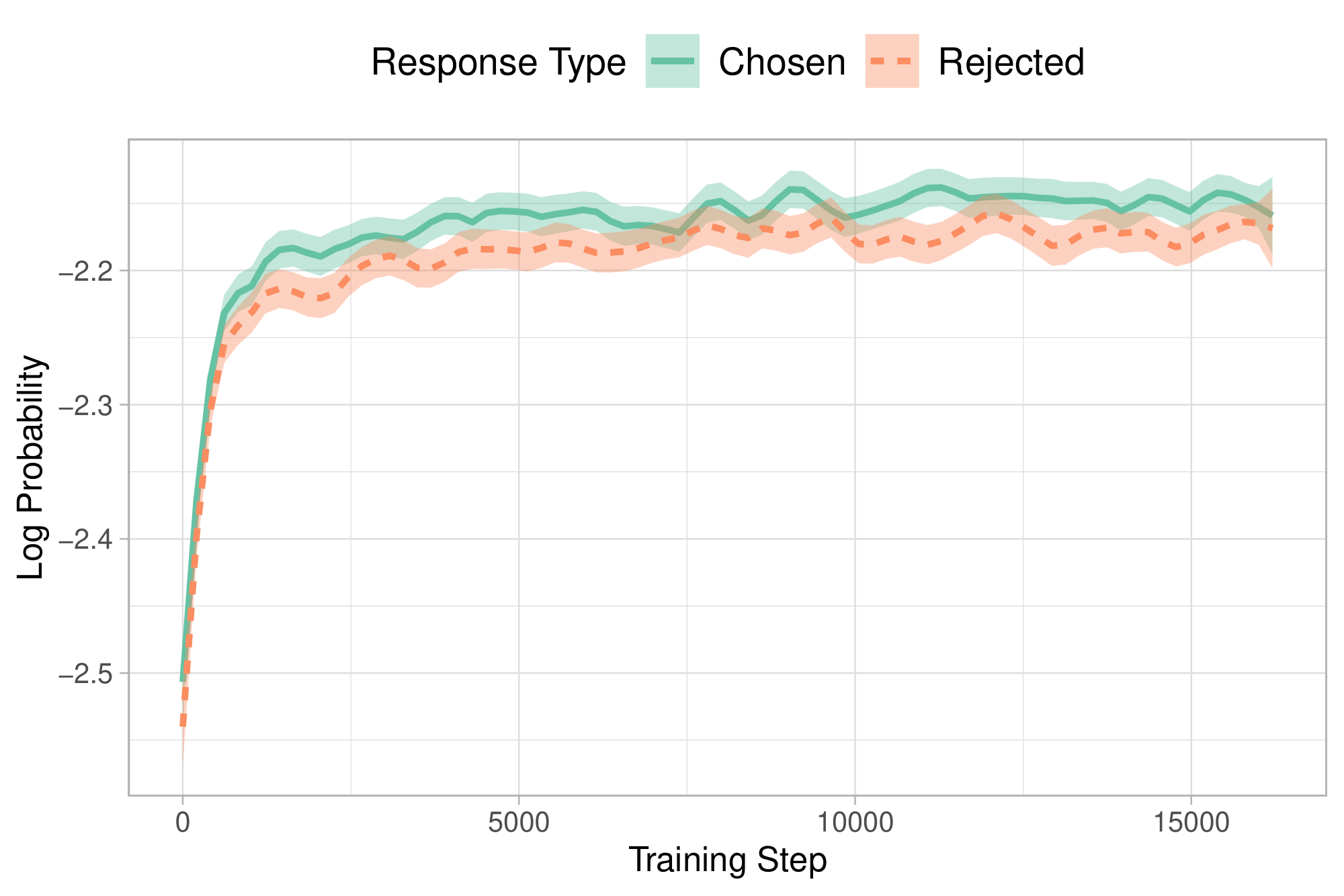
Penalizing Undesired Generations
Appending an unlikelihood penalty to the loss has demonstrated success in reducing unwanted degenerative traits in models ([44, 45]). For example, to prevent repetitions, an unwanted token set of previous contexts, $k \in \mathcal{C}_{recent}$, is disfavored by adding the following term to $(1-p_i^{(k)})$ to the loss (such as Equation 1) which penalizes the model for assigning high probabilities to recent tokens. Motivated by SFT ascribing high probabilities to rejected tokens (Figure 3) and the effectiveness of appending penalizing unwanted traits, we design a monolithic preference alignment method that dynamically penalizes the disfavored response for each query without the need for crafting sets of rejected tokens.
4. Odds Ratio Preference Optimization
Section Summary: ORPO is a new method for training AI language models to prefer certain responses over others by adding a penalty based on the odds ratio—a measure of how much more likely a favored output is compared to a rejected one—directly into the standard training loss. It combines a basic supervised fine-tuning loss, which helps the model generate desired text, with a specialized odds ratio loss that encourages the model to boost the chances of good responses while reducing those of bad ones. The method's gradient design includes a penalty that speeds up adjustments when the model favors incorrect outputs and amplifies contrasts between preferred and rejected examples to refine the AI's preferences more effectively.
We introduce a novel preference alignment algorithm, Odds Ratio Preference Optimization (ORPO), which incorporates an odds ratio-based penalty to the conventional negative log-likelihood (NLL) loss for differentiating the generation styles between favored and disfavored responses.
4.1 Preliminaries
Given an input sequence $x$, the average log-likelihood of generating the output sequence $y$, of length $m$ tokens, is computed as Equation 2. The odds of generating the output sequence $y$ given an input sequence $x$ is defined in Equation 3:
$ \log P_\theta(y|x) = \frac{1}{m} \sum_{t=1}^m \log P_\theta(y_t|x, y_{<t})\tag{2} $
$ \textbf{odds}\theta(y|x) = \frac{P\theta(y|x)}{1 - P_\theta(y|x)}\tag{3} $
Intuitively, $\textbf{odds}\theta(y|x) = k$ implies that it is $k$ times more likely for the model $\theta$ to generate the output sequence $y$ than not generating it. Thus, the odds ratio of the chosen response $y_w$ over the rejected response $y_l$, $\textbf{OR}\theta(y_w, y_l)$, indicates how much more likely it is for the model $\theta$ to generate $y_w$ than $y_l$ given input $x$, defined in Equation 4.
$ \textbf{OR}\theta(y_w, y_l) = \frac{\textbf{odds}\theta(y_w|x)}{\textbf{odds}_\theta(y_l|x)}\tag{4} $
4.2 Objective Function of ORPO
The objective function of ORPO in Equation 5 consists of two components: 1) supervised fine-tuning (SFT) loss ($\mathcal{L}{SFT}$); 2) relative ratio loss ($\mathcal{L}{OR}$).
$ \mathcal{L}{ORPO} = \mathbb{E}{(x, y_w, y_l)}\left[\mathcal{L}{SFT} + \lambda \cdot \mathcal{L}{OR} \right]\tag{5} $
$\mathcal{L}{SFT}$ follows the conventional causal language modeling negative log-likelihood (NLL) loss function to maximize the likelihood of generating the reference tokens as previously discussed in Section 3. $\mathcal{L}{OR}$ in Equation 6 maximizes the odds ratio between the likelihood of generating the disfavored response $y_w$ and the disfavored response $y_l$. We wrap the log odds ratio with the log sigmoid function so that $\mathcal{L}_{OR}$ could be minimized by increasing the log odds ratio between $y_w$ and $y_l$.
$ \mathcal{L}{OR} = -\log \sigma \left(\log \frac{\textbf{odds}\theta(y_w|x)}{\textbf{odds}_\theta(y_l|x)} \right)\tag{6} $
Together, $\mathcal{L}{SFT}$ and $\mathcal{L}{OR}$ weighted with $\lambda$ tailor the pre-trained language model to adapt to the specific subset of the desired domain and disfavor generations in the rejected response sets.
4.3 Gradient of ORPO
The gradient of $\mathcal{L}_{Ratio}$ further justifies using the odds ratio loss. It comprises two terms: one that penalizes the wrong predictions and one that contrasts between chosen and rejected responses, denoted in Equation 7[^1] for $d=(x, y_l, y_w)\sim D$.
[^1]: The full derivation for $\nabla_\theta \mathcal{L}_{OR}$ is in Appendix A.
$ \nabla_\theta \mathcal{L}_{OR} = \delta(d) \cdot h(d)\tag{7} $
$ \begin{align} \delta(d) &= \left[1 + \frac{\textbf{odds}\theta P(y_w|x)}{\textbf{odds}\theta P(y_l|x)} \right]^{-1}\tag{a} \ h(d) &= \frac{\nabla_\theta \log P_\theta(y_w|x)}{1 - P_\theta(y_w|x)} - \frac{\nabla_\theta \log P_\theta(y_l|x)}{1 - P_\theta(y_l|x)}\tag{b} \end{align} $
When the odds of the favored responses are relatively higher than the disfavored responses, $\delta(d)$ in Equation 8a will converge to 0. This indicates that the $\delta(d)$ will play the role of a penalty term, accelerating the parameter updates if the model is more likely to generate the rejected responses.
Meanwhile, $h(d)$ in Equation 8b implies a weighted contrast of the two gradients from the chosen and rejected responses. Specifically, $1-P(y|x)$ in the denominators amplifies the gradients when the corresponding side of the likelihood $P(y|x)$ is low. For the chosen responses, this accelerates the model's adaptation toward the distribution of chosen responses as the likelihood increases.
5. Experimental Settings
Section Summary: The researchers trained various AI language models, ranging from small ones with 125 million parameters to larger ones up to 7 billion, using techniques like supervised fine-tuning, reinforcement learning methods, and their new approach called ORPO, on two cleaned datasets focused on helpful and harmless responses. They also developed reward models to score the quality of AI outputs during training and evaluation. For testing, the models were compared against top performers on public benchmarks like AlpacaEval and MT-Bench, using advanced AI judges like GPT-4 to determine which responses users might prefer in conversations.
5.1 Training Configurations
Models
We train a series of OPT models ([5]) scaling from 125M to 1.3B parameters comparing supervised fine-tuning (SFT), proximal policy optimization (PPO), direct policy optimization (DPO), and compare these to our ORPO. PPO and DPO models were fine-tuned with TRL library ([46]) on top of SFT models trained for a single epoch on the chosen responses following [18] and [37]. We notate this by prepending "+" to each algorithm (e.g., +DPO). Additionally, we train Phi-2 (2.7B) ([47]), a pre-trained language model with promising downstream performance ([48]), as well as Llama-2 (7B) ([6]) and Mistral (7B) ([7]). Further training details for each method are in Appendix C.
Datasets
We test each training configuration and model on two datasets: 1) Anthropic's HH-RLHF ([49]), 2) Binarized UltraFeedback ([37]). We filtered out instances where $y_w=y_l$ or where $y_w=\emptyset$ or where $y_l=\emptyset$.
Reward Models
We train OPT-350M and OPT-1.3B on each dataset for a single epoch for reward modeling with the objective function in Equation 9 ([16]). The OPT-350M reward model was used for PPO, and OPT-1.3B reward model was used to assess the generations of fine-tuned models. We refer to these reward models as RM-350M and RM-1.3B in Section 6.
$ -\mathbb{E}_{(x, y_l, y_w)} \left[\log \sigma \left(r(x, y_w) - r(x, y_l) \right) \right]\tag{9} $
5.2 Leaderboard Evaluation
In Section 6.1, we evaluate the models using the $\text{AlpacaEval}{1.0}$ and $\text{AlpacaEval}{2.0}$ ([50]) benchmarks, comparing ORPO to other instruction-tuned models reported in the official leaderboard, ^2 including Llama-2 Chat (7B) and (13B) ([6]), and Zephyr $\alpha$ and $\beta$ ([8]). Similarly, in Section 6.2, we evaluate the models with MT-Bench ([51]) and report the results and the scores of the same models reported in the official leaderboard.^3 Using GPT-4 ([52]) as an evaluator in $\text{AlpacaEval}{1.0}$, we assess if the trained model can be preferred over the responses generated from text-davinci-003. For $\text{AlpacaEval}{2.0}$, we used GPT-4-turbo^4 as an evaluator following the default setting. We assess if the generated responses are favored over those generated from GPT-4. Finally, using GPT-4 as an evaluator in MT-Bench, we check if the models can follow the instructions with hard answers in a multi-turn conversation.
6. Results and Analysis
Section Summary: The results show that ORPO, a new alignment method, greatly improves language models' ability to follow instructions, outperforming alternatives like DPO and RLHF on benchmarks such as AlpacaEval for single-turn tasks, where fine-tuned versions of Phi-2, Llama-2, and Mistral achieved higher scores than larger or more established models. For multi-turn conversations, ORPO-trained Mistral models scored competitively on MT-Bench, matching or exceeding much bigger systems like 70B-parameter Llama-2 without specific multi-turn training data. Furthermore, ORPO demonstrated superior win rates over supervised fine-tuning, PPO, and DPO in preference alignment, effectively boosting reward distributions as visualized in the analysis.
First, we assess the general instruction-following abilities of the models by comparing the preference alignment algorithms in Section 6.1 and Section 6.2. Second, we measure the win rate of OPT models trained with ORPO against other alignment methods training OPT 1.3B as a reward model in Section 6.3. Then, we measure the lexical diversity of the models trained with ORPO and DPO in Section 6.4.
6.1 Single-turn Instruction Following
: Table 1: Table of instruction-following abilities of each checkpoint measured through AlpacaEval. While clearly showing the improvements in instruction-following abilities after training with ORPO, it is notable that ORPO models exceed RLHF or DPO models of Llama-2 and Mistral (* indicates the results from the official leaderboard.)
| Model Name | Size | $\textbf{AlpacaEval}_{\textbf{1.0}}$ | $\textbf{AlpacaEval}_{\textbf{2.0}}$ |
|---|---|---|---|
| Phi-2 + SFT | 2.7B | 48.37% (1.77) | 0.11% (0.06) |
| Phi-2 + SFT + DPO | 2.7B | 50.63% (1.77) | 0.78% (0.22) |
Phi-2 + ORPO (Ours) |
2.7B | 71.80% (1.59) | 6.35% (0.74) |
| Llama-2 Chat * | 7B | 71.34% (1.59) | 4.96% (0.67) |
| Llama-2 Chat * | 13B | 81.09% (1.38) | 7.70% (0.83) |
Llama-2 + ORPO (Ours) |
7B | 81.26% (1.37) | 9.44% (0.85) |
| Zephyr ($\alpha$) * | 7B | 85.76% (1.23) | 8.35% (0.87) |
| Zephyr ($\beta$) * | 7B | 90.60% (1.03) | 10.99% (0.96) |
Mistral-ORPO- $\alpha$ (Ours) |
7B | 87.92% (1.14) | 11.33% (0.97) |
Mistral-ORPO- $\beta$ (Ours) |
7B | 91.41% (1.15) | 12.20% (0.98) |
Phi-2 (2.7B)
ORPO improved pre-trained Phi-2 to exceed the performance of the Llama-2 Chat instruction-following language model by only using UltraFeedback as the instruction-tuning dataset, as shown in Table 1. $\lambda$ of 0.25 was applied for Phi-2, resulting in 71.80% and 6.35% in AlpacaEval.
Llama-2 (7B)
Notably, UltraFeedback and ORPO with $\lambda$ of 0.2 on Llama-2 (7B) resulted in higher AlpacaEval scores than the chat versions of both 7B and 13B scale trained with RLHF, eventually showing 81.26% and 9.44% in both AlpacaEvals.
In contrast, in our controlled experimental setting of conducting one epoch of SFT and three epochs of DPO following [37] and [18], Llama-2 + SFT and Llama-2 + SFT + DPO yielded models with outputs that could not be evaluated. This supports the efficacy of ORPO, in which the model can rapidly learn the desired domain and the preference with limited data. This aligns with the $h(d)$ examination in the gradient of our method studied in Section 4.3.
Mistral-ORPO- $\alpha$ (7B)
Furthermore, fine-tuning Mistral (7B) with single-turn conversation dataset, UltraFeedback, and ORPO with $\lambda$ of 0.1 outperforms Zephyr series, which are the Mistral (7B) models fine-tuned with SFT on 20K UltraChat ([53]) and DPO on the full UltraFeedback. As shown in Table 1, Mistral-ORPO- $\alpha$ (7B) achieves 87.92% and 11.33%, which exceeds Zephyr $\alpha$ by 1.98% and Zephyr $\beta$ by 0.34% in $\text{AlpacaEval}_{2.0}$. The sample responses and corresponding references from GPT-4 can be found in Appendix I.
Mistral-ORPO- $\beta$ (7B)
Using the same configuration of Mistral-ORPO- $\alpha$ (7B), we additionally compare fine-tuning Mistral on the cleaned version of the UltraFeedback^5 to demonstrate the effect of the data quality ([54]). While the actual sizes of datasets are similar, ORPO gains further advantages from the dataset quality by scoring over 91% and 12% on AlpacaEval, as shown in Table 1. Further instruction-following evaluation on two Mistral-based models with IFEval ([55]) is reported in the Appendix D.
6.2 Multi-turn Instruction Following
With our best model, Mistral-ORPO- $\alpha$ (7B) and Mistral-ORPO- $\beta$ (7B), we also assess the multi-turn instruction-following skills with deterministic answers (e.g., math) through MT-Bench.
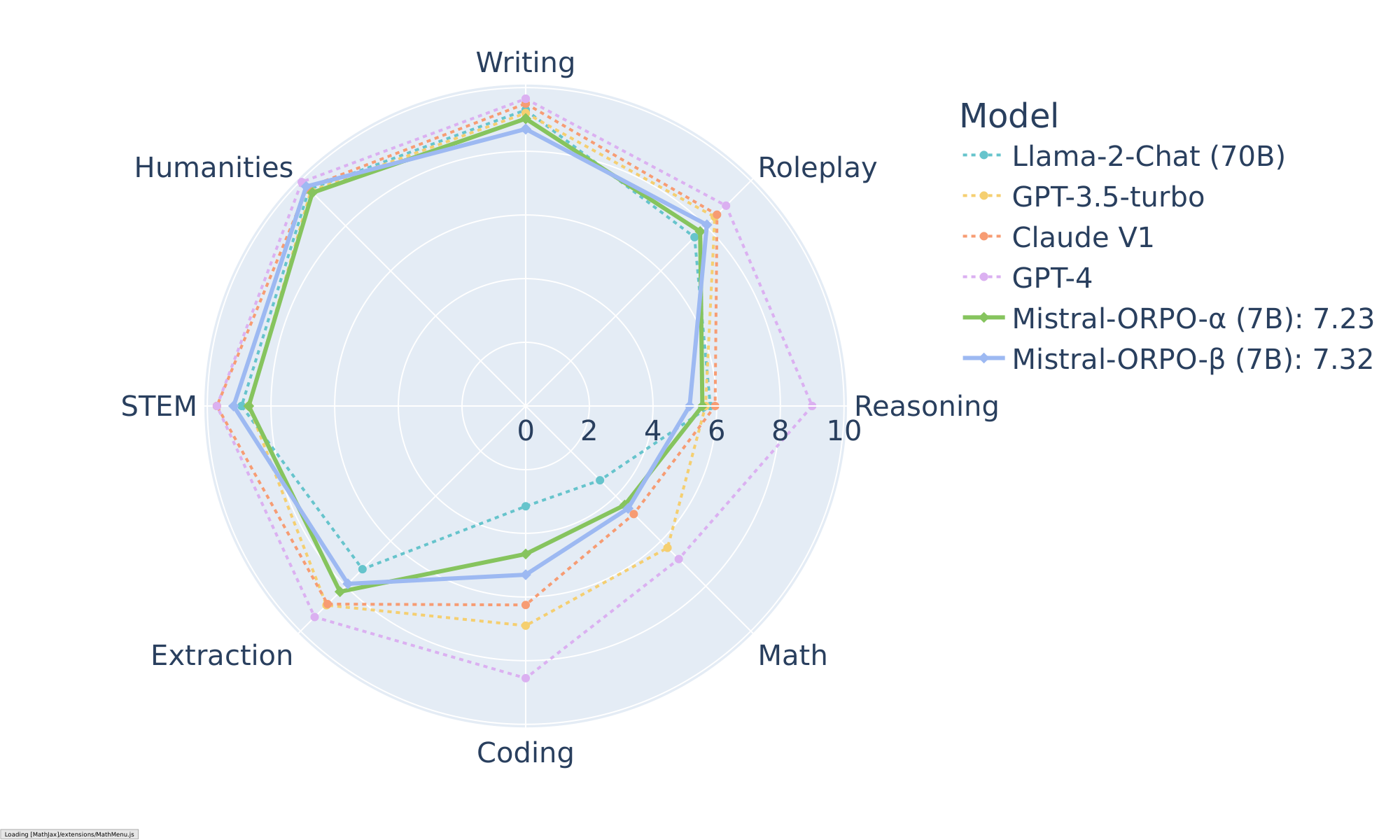
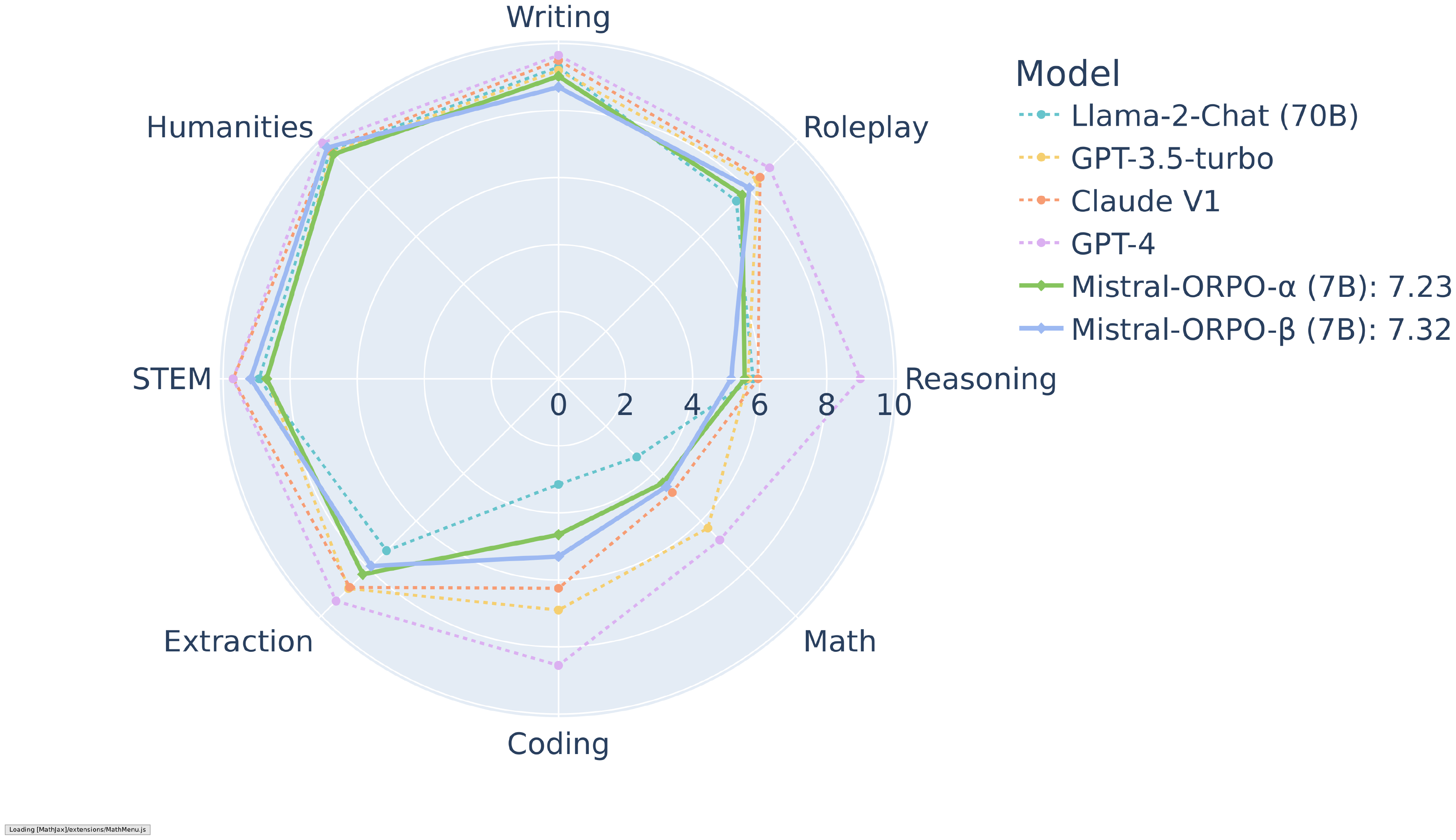
As shown in Figure 4, ORPO-Mistral (7B) series achieve comparable results to either larger or the proprietary models, including Llama-2-Chat (70B) and Claude. Eventually, Mistral-ORPO- $\alpha$ (7B) and Mistral-ORPO- $\beta$ (7B) scored 7.23 and 7.32 in MT-Bench without being exposed to the multi-turn conversation dataset during training.
6.3 Reward Model Win Rate
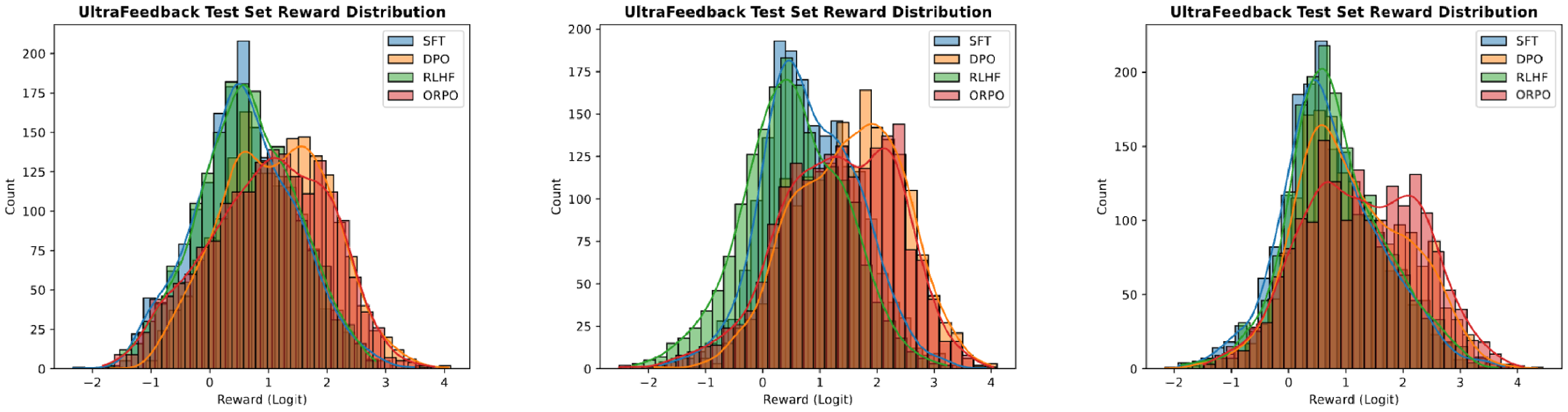
We assess the win rate of ORPO over other preference alignment methods, including supervised fine-tuning (SFT), PPO, and DPO, using RM-1.3B to understand the effectiveness and scalability of ORPO in Table 2 and Table 3. Additionally, we visually verify that ORPO can effectively enhance the expected reward compared to SFT in Figure 5.
HH-RLHF
In Table 2, ORPO outperforms SFT and PPO across all model scales. The highest win rate against SFT and PPO across the size of the model was 78.0% and 79.4%, respectively. Meanwhile, the win rate over DPO was correlated to the model's size, with the largest model having the highest win rate: 70.9%.
: Table 2: Average win rate (%) and its standard deviation of ORPO and standard deviation over other methods on HH-RLHF dataset for three rounds. Sampling decoding with a temperature of 1.0 was used on the test set.
ORPO vs |
SFT | +DPO | +PPO |
|---|---|---|---|
| OPT-125M | 84.0 (0.62) | 41.7 (0.77) | 66.1 (0.26) |
| OPT-350M | 82.7 (0.56) | 49.4 (0.54) | 79.4 (0.29) |
| OPT-1.3B | 78.0 (0.16) | 70.9 (0.52) | 65.9 (0.33) |
UltraFeedback
The win rate in UltraFeedback followed similar trends to what was reported in HH-RLHF, as shown in Table 3. ORPO was preferred over SFT and PPO for maximum 80.5% and 85.8%, respectively. While consistently preferring ORPO over SFT and PPO, the win rate over DPO gradually increases as the size of the model increases. The scale-wise trend exceeding DPO will be further shown through 2.7B models in Section 6.1.
: Table 3: Average win rate (%) and its standard deviation of ORPO and standard deviation over other methods on UltraFeedback dataset for three rounds. Sampling decoding with a temperature of 1.0 was used.
ORPO vs |
SFT | +DPO | +PPO |
|---|---|---|---|
| OPT-125M | 73.2 (0.12) | 48.8 (0.29) | 71.4 (0.28) |
| OPT-350M | 80.5 (0.54) | 50.5 (0.17) | 85.8 (0.62) |
| OPT-1.3B | 69.4 (0.57) | 57.8 (0.73) | 65.7 (1.07) |
Overall Reward Distribution
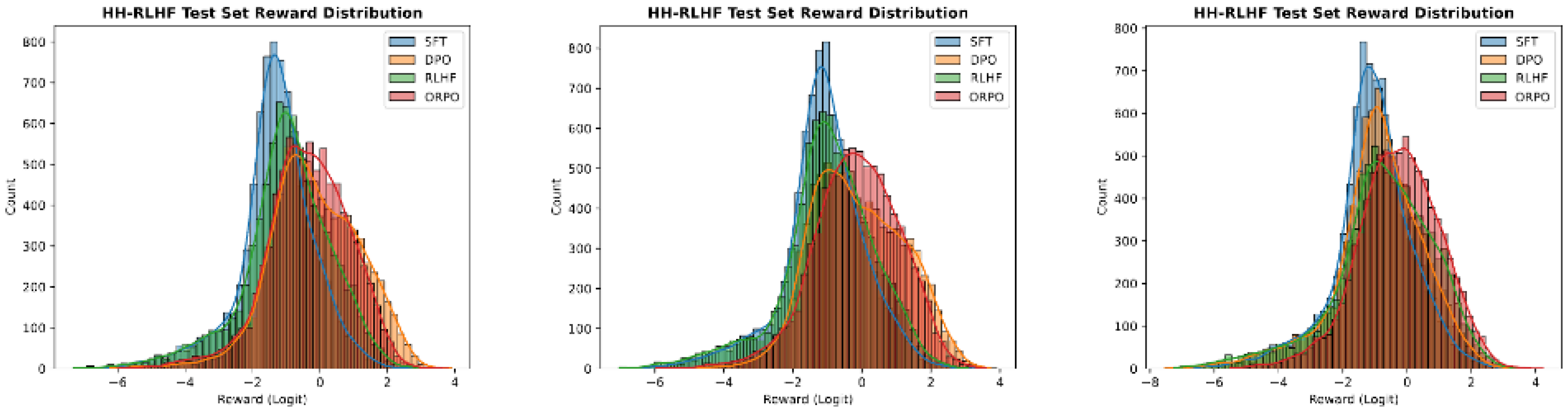
In addition to the win rate, we compare the reward distribution of the responses generated with respect to the test set of the UltraFeedback dataset in Figure 5 and HH-RLHF dataset in Appendix F. Regarding the SFT reward distribution as a default, PPO, DPO, and ORPO shift it in both datasets. However, the magnitude of reward shifts for each algorithm differs.
In Figure 5, RLHF (i.e., SFT + PPO) has some abnormal properties of the distribution with a low expected reward. We attribute this to empirical evidence of the instability and reward mismatch problem of RLHF ([18, 31, 56]) as the RLHF models were trained with RM-350M and assessed with RM-1.3B. Meanwhile, it is notable that the ORPO distribution (red) is mainly located on the very right side of each subplot, indicating higher expected rewards. Recalling the intent of preference alignment methods, the distributions in Figure 5 indicate that ORPO tends to fulfill the aim of preference alignment for all model sizes.
6.4 Lexical Diversity
The lexical diversity of the preference-aligned language models was studied in previous works ([57]). We expand the concept of per-input and across-input diversity introduced in [57] by using Gemini-Pro ([58]) as an embedding model, which is suitable for assessing the diversity of instruction-following language models by encoding a maximum of 2048 tokens. The diversity metric with the given set of sampled responses is defined as Equation 11.
$ \mathcal{O}_\theta^i := {y_j \sim \theta(y|x_i) | j = 1, 2, ..., K }\tag{10} $
$ D(\mathcal{O}^i_\theta) = \frac{1}{2} \cdot \frac{\sum_{i=1}^{N-1} \sum_{j=i+1}^{N} \cos(h_i, h_j)}{N \cdot (N-1)}\tag{11} $
where $\cos(h_i, h_j)$ refers to the cosine similarity between the embedding $h_i$ and $h_j$. 5 different responses are sampled with a temperature of 1.0 to 160 queries in AlpacaEval (i.e., $K=5, N=160$) using Phi-2 and Llama-2 trained with ORPO and DPO. We report the results in Table 4.
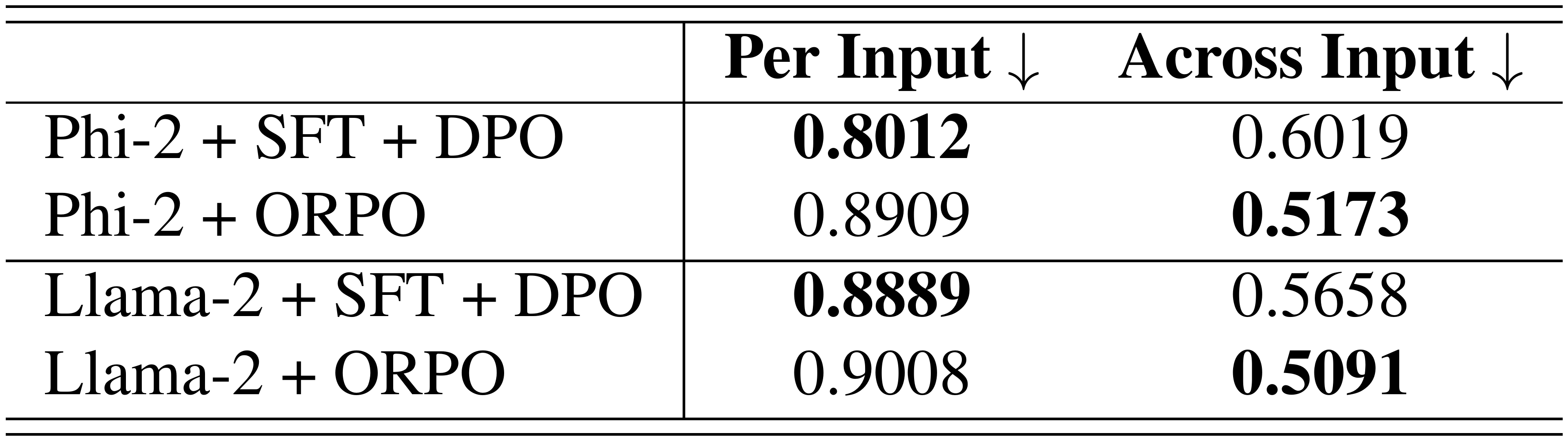
Per Input Diversity (PID)
We average the input-wise average cosine similarity between the generated samples with Equation 12 to assess the per-input diversity. In Table 4, ORPO models have the highest average cosine similarity in the first column for both models, which implies the lowest diversity per input. This indicates that ORPO generally assigns high probabilities to the desired tokens, while DPO has a relatively smoother logit distribution.
$ \text{PID}D(\theta) = \frac{1}{N}\sum{i=1}^N D(\mathcal{O}^i_\theta)\tag{12} $
Across Input Diversity (AID)
Using 8 samples generated per input, we sample the first item for each input and examine their inter cosine similarity with Equation 13 for across-input diversity. Unlike per-input diversity, it is noteworthy that Phi-2 (ORPO) has lower average cosine similarity in the second row of Table 4. We can infer that ORPO triggers the model to generate more instruction-specific responses than DPO.
$ \text{AID}D(\theta) = D \left(\bigcup\limits{i=1}^{N}\mathcal{O}^i, _{\theta, j=1} \right)\tag{13} $
::: {caption="Table 4: Lexical diversity of Phi-2 and Llama-2 fine-tuned with DPO and ORPO. Lower cosine similarity is equivalent to higher diversity. The highest value in each column within the same model family is bolded."}
:::
7. Discussion
Section Summary: The discussion section explains why ORPO uses an odds ratio instead of a probability ratio to align language models with user preferences, as the odds ratio provides more stable and balanced training that avoids overly suppressing unwanted responses, especially when combined with basic fine-tuning, as shown in distribution comparisons and supporting experiments. It also demonstrates through training logs that ORPO effectively boosts preferences by increasing the model's favoring of good responses while keeping overall learning stable, without needing extra tweaks to the balancing parameter. Finally, ORPO is more efficient than methods like DPO or RLHF, requiring less memory and half the computations per training batch since it skips a separate reference model.
In this section, we expound on the theoretical and computational details of ORPO. The theoretical analysis of $\texttt{ORPO}$ is studied in Section 7.1, which will be supported with the empirical analysis in Section 7.2. Then, we compare the computational load of DPO and ORPO in Section 7.3.
7.1 Comparison to Probability Ratio
The rationale for selecting the odds ratio instead of the probability ratio lies in its stability. The probability ratio for generating the favored response $y_w$ over the disfavored response $y_l$ given an input sequence $x$ can be defined as Equation 14.
$ \textbf{PR}\theta(y_w, y_l) = \frac{P\theta(y_w|x)}{P_\theta(y_l|x)}\tag{14} $
While this formulation has been used in previous preference alignment methods that precede SFT ([18, 34]), the odds ratio is a better choice in the setting where the preference alignment is incorporated in SFT as the odds ratio is more sensitive to the model's preference understanding. In other words, the probability ratio leads to more extreme discrimination of the disfavored responses than the odds ratio.
We visualize this through the sample distributions of the log probability ratio $\log \textbf{PR}(X_2|X_1)$ and log odds ratio $\log \textbf{OR}(X_2|X_1)$. We sample 50, 000 samples each with Equation 15a and plot the log probability ratio and log odds ratio in Figure 6. We multiply $\beta$ for the probability ratio as it is practiced in the probability ratio-based methods and report the cases where $\beta=0.2$ and $\beta=1.0$.
$ \begin{gather} X_1, X_2 \sim \text{Unif}(0, 1)\tag{a} \ Y \sim \beta \left(\log X_1 - \log X_2 \right)\tag{b} \ Y \sim \log \frac{X_1}{1 - X_1} - \log \frac{X_2}{1 - X_2}\tag{c} \end{gather} $
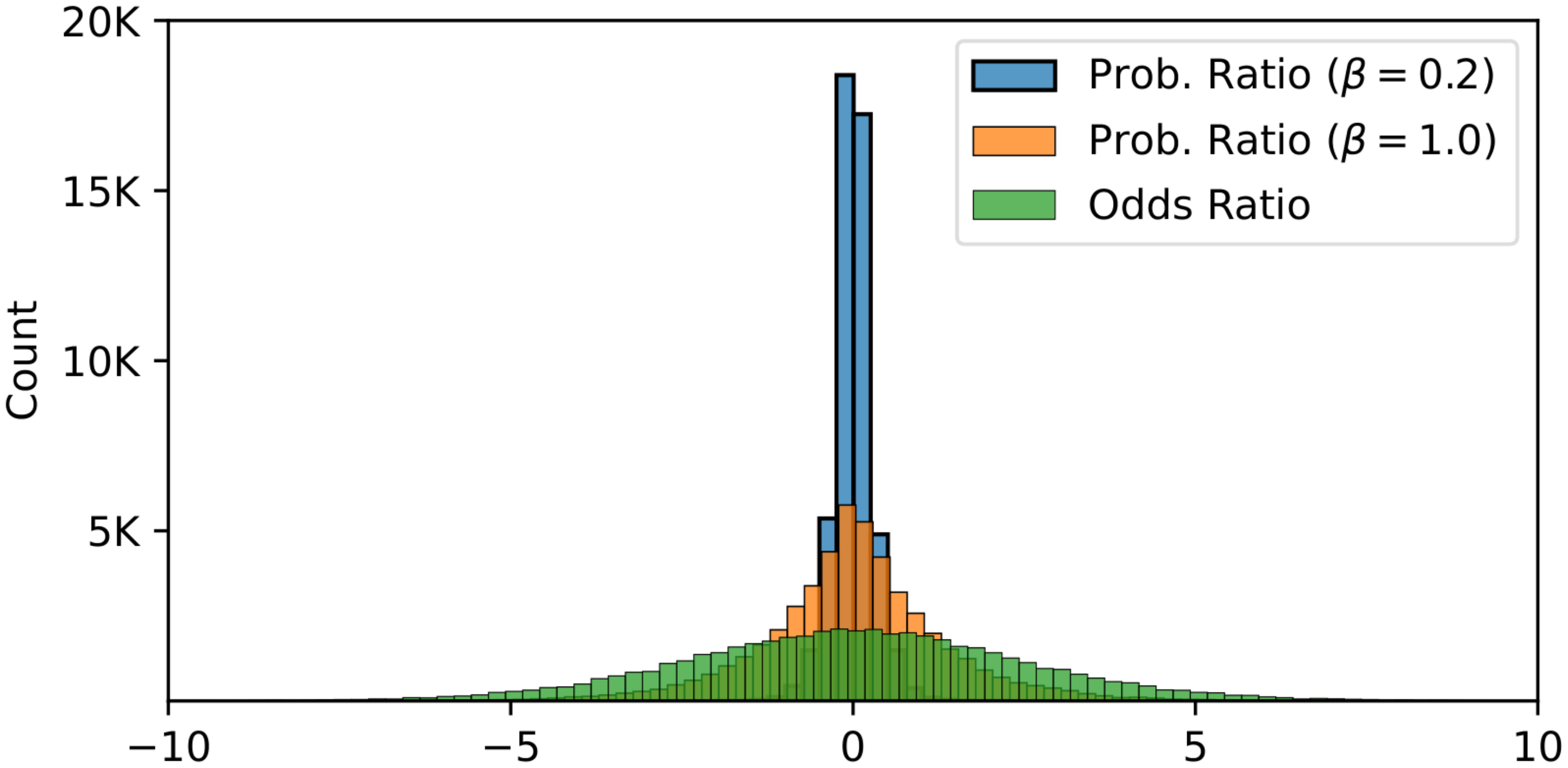
Recalling that the log sigmoid function is applied to the log probability ratio and log odds ratio, each ratio's scale determines the expected margin between the likelihood of the favored and disfavored styles when the loss is minimized. In that sense, the contrast should be relatively extreme to minimize the log sigmoid loss when $\textbf{PR}(X_2|X_1)$ is inputted instead of $\textbf{OR}(X_2|X_1)$ to the log sigmoid function, regarding the sharp distribution of $\log \textbf{PR}(X_2|X_1)$ in Figure 6. This results in overly suppressing the logits for the tokens in the disfavored responses in the setting where SFT and preference alignment are incorporated, as the model is not adapted to the domain. We empirically support this analysis through the ablation study in Appendix B. Therefore, the odds ratio is a better choice when the preference alignment is done with SFT due to the mild discrimination of disfavored responses and the prioritizing of the favored responses to be generated.
Throughout fine-tuning, minimizing the log sigmoid loss leads to either $\textbf{PR}(X_2|X_1)$ or $\textbf{OR}(X_2|X_1)$ to be larger. This is equivalent to the rejected responses' token-wise likelihood, which will generally get smaller. In this context, it is essential to avoid an overly extreme contrast. This precaution is especially important given the sharp distribution of $\log \textbf{PR}(X_2|X_1)$ depicted in Figure 6. The excessive margin could lead to the unwarranted suppression of logits for tokens in disfavored responses within the incorporated setting, potentially resulting in issues of degeneration.
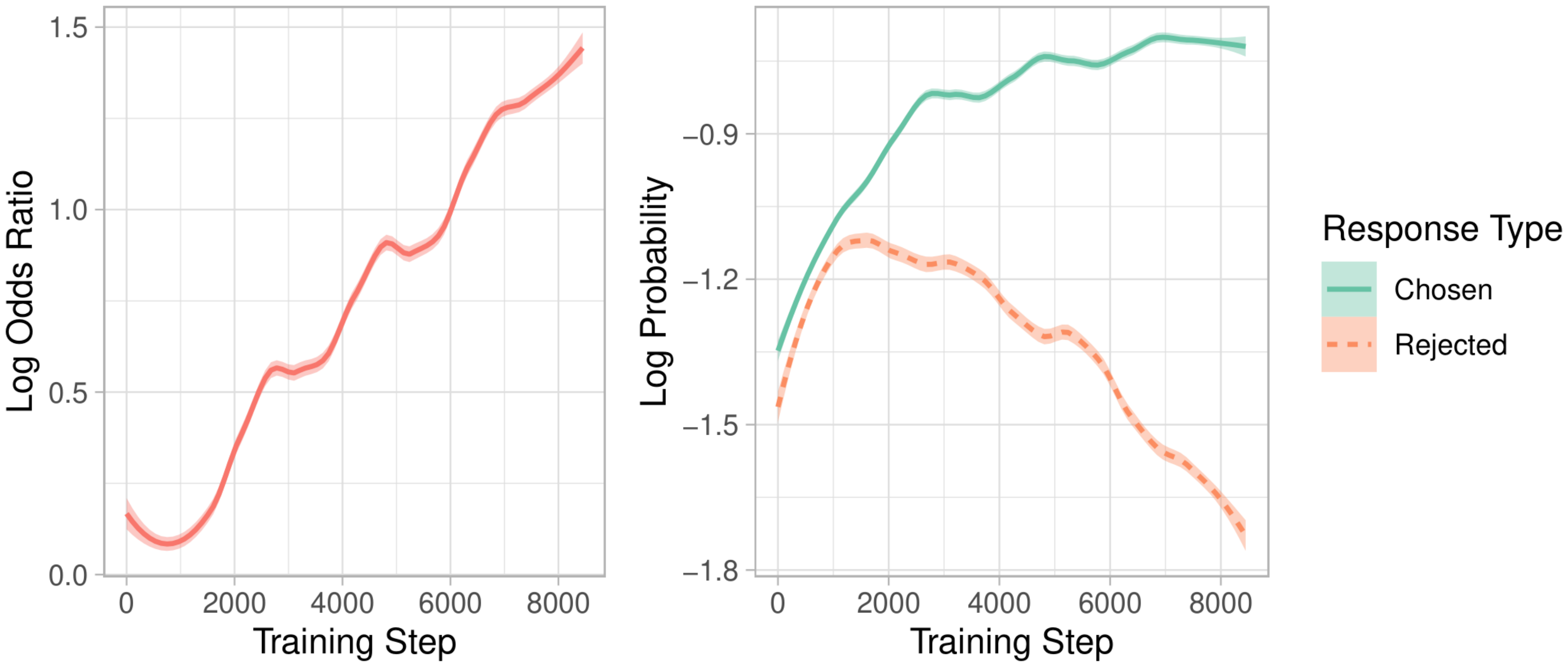
7.2 Minimizing $\mathcal{L}_{OR}$
We demonstrate that models trained with ORPO learned to reflect the preference throughout the training process. We monitored the log probabilities of the chosen and rejected responses and the log odds ratio with $\lambda = 1.0$. With the same dataset and model as Figure 3, Figure 7 shows that the log probability of rejected responses is diminishing while that of chosen responses is on par with Figure 3 as the log odds ratio increases. This indicates that ORPO is successfully preserving the domain adaptation role of SFT while the penalty term $L_{OR}$ induces the model to lower the likelihood of unwanted generations. We discuss the effect of $\lambda$ in Equation 5 in Appendix E, studying the proclivity of the log probability margin between the favored and disfavored responses with respect to $\lambda$.
7.3 Computational Efficiency
As depicted in Figure 2, ORPO does not require a reference model, unlike RLHF and DPO. In that sense, ORPO is computationally more efficient than RLHF and DPO in two perspectives: 1) memory allocation and 2) fewer FLOPs per batch.
The reference model ($\pi_{SFT}$) in the context of RLHF and DPO denotes the model trained with supervised fine-tuning (SFT), which will be the baseline model for updating the parameters with RLHF or DPO ([16, 18]). Thus, two $\pi_{SFT}$ s, a frozen reference model and the model undergoing tuning, are required during training. Furthermore, in theory, two forward passes should be calculated for each model to acquire the logits for the chosen and rejected responses. In other words, four forward passes happen in total for a single batch. On the other hand, a reference model is not required in ORPO as $\pi_{SFT}$ is directly updated. This leads to half the number of forward passes required for each batch during training.
8. Conclusion
Section Summary: This paper presents ORPO, a new method for aligning AI models with human preferences without needing reference texts, by improving on the initial supervised fine-tuning step. It outperformed traditional approaches like SFT, RLHF, and DPO in evaluations, with its edge growing as models get larger, and reward models consistently favored ORPO outputs. Testing on 2.7 billion and 7 billion parameter models showed it surpassing bigger state-of-the-art systems in benchmarks like AlpacaEval and MT-Bench, and the authors have shared their code and models for others to use.
In this paper, we introduced a reference-free monolithic preference alignment method, odds ratio preference optimization (ORPO), by revisiting and understanding the value of the supervised fine-tuning (SFT) phase in the context of preference alignment. ORPO was consistently preferred by the fine-tuned reward model against SFT and RLHF across the scale, and the win rate against DPO increased as the size of the model increased. Furthermore, we validate the scalability of ORPO with 2.7B and 7B pre-trained language models by exceeding the larger state-of-the-art instruction-following language models in AlpacaEval. Specifically, Mistral-ORPO- $\alpha$ and Mistral-ORPO- $\beta$ achieved 11.33% and 12.20% in $\text{AlpacaEval}_{2.0}$, 7.23 and 7.32 in MT-Bench, thereby underscoring the efficiency and effectiveness of ORPO. We release fine-tuning code and model checkpoints for Mistral-ORPO- $\alpha$ and Mistral-ORPO- $\beta$ to aid reproducibility.
Limitations
Section Summary: This study examined various preference alignment techniques like DPO and RLHF but did not cover a wider array of such methods, leaving broader comparisons and scaling up to larger models over 7 billion parameters for future research. The authors also plan to test their approach on more varied datasets across different subjects and quality levels to check how well it works in common language processing tasks. Additionally, they aim to explore how their method affects the inner workings of pre-trained language models, extending insights beyond initial fine-tuning to later alignment steps.
While conducting a comprehensive analysis of the diverse preference alignment methods, including DPO and RLHF, we did not incorporate a more comprehensive range of preference alignment algorithms. We leave the broader range of comparison against other methods as future work, along with scaling our method to over 7B models. In addition, we will expand the fine-tuning datasets into diverse domains and qualities, thereby verifying the generalizability of our method in various NLP downstream tasks. Finally, we would like to study the internal impact of our method on the pre-trained language model, expanding the understanding of preference alignment procedure to not only the supervised fine-tuning stage but also consecutive preference alignment algorithms.
Appendix
Section Summary: This appendix provides mathematical derivations for the gradient of the odds ratio loss function used in preference optimization, simplifying it to compare probabilities of preferred and rejected responses in language models. It includes an empirical comparison showing that training with probability ratios more aggressively lowers the log probabilities of rejected responses compared to odds ratios, as illustrated in a figure from UltraFeedback data. Additionally, it details experimental setups, such as hardware, optimizers, and hyperparameters for supervised fine-tuning, RLHF, DPO, and ORPO across various models, along with truncated results from instruction-following evaluations on Mistral models.
A. Derivation of $\nabla_\theta \mathcal{L}_{OR}$ with Odds Ratio
Suppose that $g(x, y_l, y_w) = \frac{\textbf{odds}\theta P(y_w|x)}{\textbf{odds}\theta P(y_l|x)}$
$ \begin{align} \nabla_\theta \mathcal{L}{OR} &= \nabla\theta \log \sigma \left(\log \frac{\textbf{odds}\theta P(y_w|x)}{\textbf{odds}\theta P(y_l|x)}\right)\ &=\frac{\sigma'\left(\log g(x, y_l, y_w) \right)}{\sigma\left(\log g(x, y_l, y_w) \right)} \ &=\sigma\left(-\log g(x, y_l, y_w)\right) \cdot \nabla_\theta \log g(x, y_l, y_w) \ &= \frac{\sigma\left(-\log g(x, y_l, y_w)\right)}{g(x, y_l, y_w)} \cdot \nabla_\theta g(x, y_l, y_w) \ &= \sigma\left(-\log g(x, y_l, y_w)\right) \cdot \nabla_\theta \log g(x, y_l, y_w) \ &= \left(1 + \frac{\textbf{odds}\theta P(y_w|x)}{\textbf{odds}\theta P(y_l|x)} \right)^{-1} \cdot \nabla_\theta \log \frac{\textbf{odds}\theta P(y_w|x)}{\textbf{odds}\theta P(y_l|x)} \end{align}\tag{16} $
In Equation 16, the remaining derivative can be further simplified by replacing $1 - P_\theta(y|x)$ terms where $P(y|x) = \sqrt[N]{\prod_t^N P_\theta(y_t|x, y_{<t}}$ in $\textbf{odds}_\theta (y|x)$ as follows.
$ \begin{align} \nabla_\theta \log \left(1 - P_\theta(y|x)\right) &= \frac{\nabla_\theta \left(1 - P_\theta(y|x)\right)}{1 - P_\theta(y|x)} \ &= \frac{-\nabla_\theta P_\theta(y|x)}{1 - P_\theta(y|x)} \ &= -\frac{P_\theta(y|x)}{1 - P_\theta(y|x)} \cdot \nabla_\theta \log P_\theta(y|x) \ &= \textbf{odds}\theta(y|x) \cdot \nabla\theta \log P_\theta(y|x)\ \nabla_\theta \log \frac{\textbf{odds}\theta P(y_w|x)}{\textbf{odds}\theta P(y_l|x)}&= \nabla_\theta \log \frac{P_\theta(y_w|x)}{P_\theta(y_l|x)} - \Bigl(\nabla_\theta \log (1 - P_\theta(y_w|x)) - \nabla_\theta \log(1 - P_\theta(y_l|x)) \Bigl)\ &=\left(1 + \textbf{odds}\theta P(y_w|x)\right) \nabla\theta \log P_\theta(y_w|x) - \left(1 + \textbf{odds}\theta P(y_l|x)\right) \nabla\theta \log P_\theta(y_l|x) \end{align}\tag{17} $
Therefore, the final form of $\nabla_\theta \mathcal{L}_{OR}$ would be
$ \begin{align} \nabla_\theta \mathcal{L}{OR} &= \frac{1 + \textbf{odds}\theta P(y_w|x)}{1 + \frac{\textbf{odds}\theta P(y_w|x)}{\textbf{odds}\theta P(y_l|x)}} \cdot \nabla_\theta \log P_\theta(y_w|x) - \frac{1 + \textbf{odds}\theta P(y_l|x)}{1 + \frac{\textbf{odds}\theta P(y_w|x)}{\textbf{odds}\theta P(y_l|x)}} \cdot \nabla\theta \log P_\theta(y_l|x) \ &= \left(1 + \frac{\textbf{odds}\theta P(y_w|x)}{\textbf{odds}\theta P(y_l|x)} \right)^{-1} \cdot \left(\frac{\nabla_\theta \log P_\theta(y_w|x)}{1 - P(y_w|x)} - \frac{\nabla_\theta \log P_\theta(y_l|x)}{1 - P(y_l|x)}\right) \end{align}\tag{18} $
B. Ablation on Probability Ratio and Odds Ratio
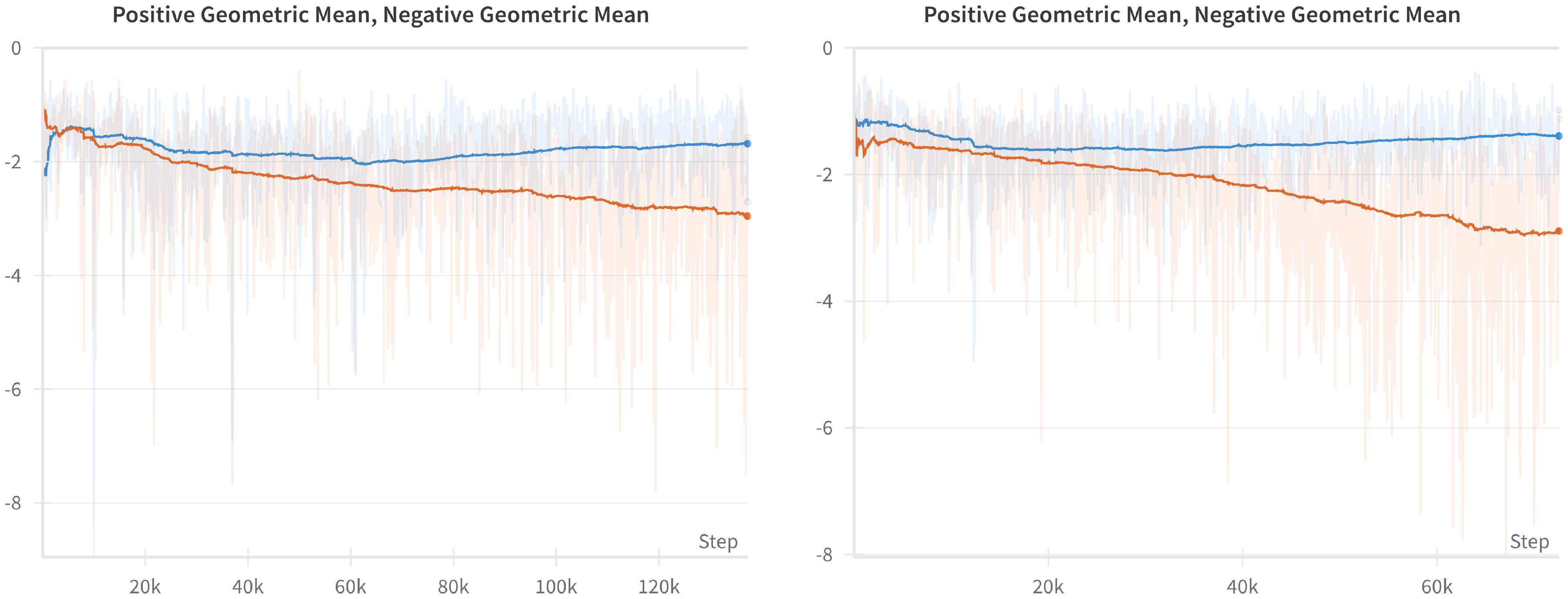
In this section, we continue the discussion in Section 7.1 through empirical results comparing the log probabilities of chosen and rejected responses in UltraFeedback when trained with probability ratio and odds ratio. Recalling the sensitivity of each ratio discussed in Section 7.1, it is expected for the probability ratio to lower the log probabilities of the rejected responses with a larger scale than the odds ratio. This is well-shown in Figure 8, which is the log probabilities of each batch while fine-tuning with probability ratio (left) rapidly reaches under -4, while the same phenomenon happens after the over-fitting occurs in the case of odds ratio (right).
C. Experimental Details
Flash-Attention 2 ([59]) is applied for all the pre-trained models for computational efficiency. In particular, the OPT series and Phi-2 (2.7B) were trained with DeepSpeed ZeRO 2 ([60]), Llama-2 (7B) and Mistral (7B) were trained with Fully Sharded Data Parallel(FSDP) ([61]). 7B and 2.7B models were trained with four and two NVIDIA A100, and the rest were trained on four NVIDIA A6000. For optimizer, AdamW optimizer ([62]) and paged AdamW ([63]) were used, and the linear warmup with cosine decay was applied for the learning rate. For input length, every instance was truncated and padded to 1, 024 tokens and 2, 048 tokens for HH-RLHF and UltraFeedback, respectively. To guarantee that the models can sufficiently learn to generate the proper response to the conversation history or the complex instruction, we filtered instances with prompts with more than 1, 024 tokens.
Supervised Fine-tuning (SFT)
For SFT, the maximum learning rate was set to 1e-5. Following [16] and [18], the training epoch is set to 1.
Reinforcement Learning with Human Feedback (RLHF)
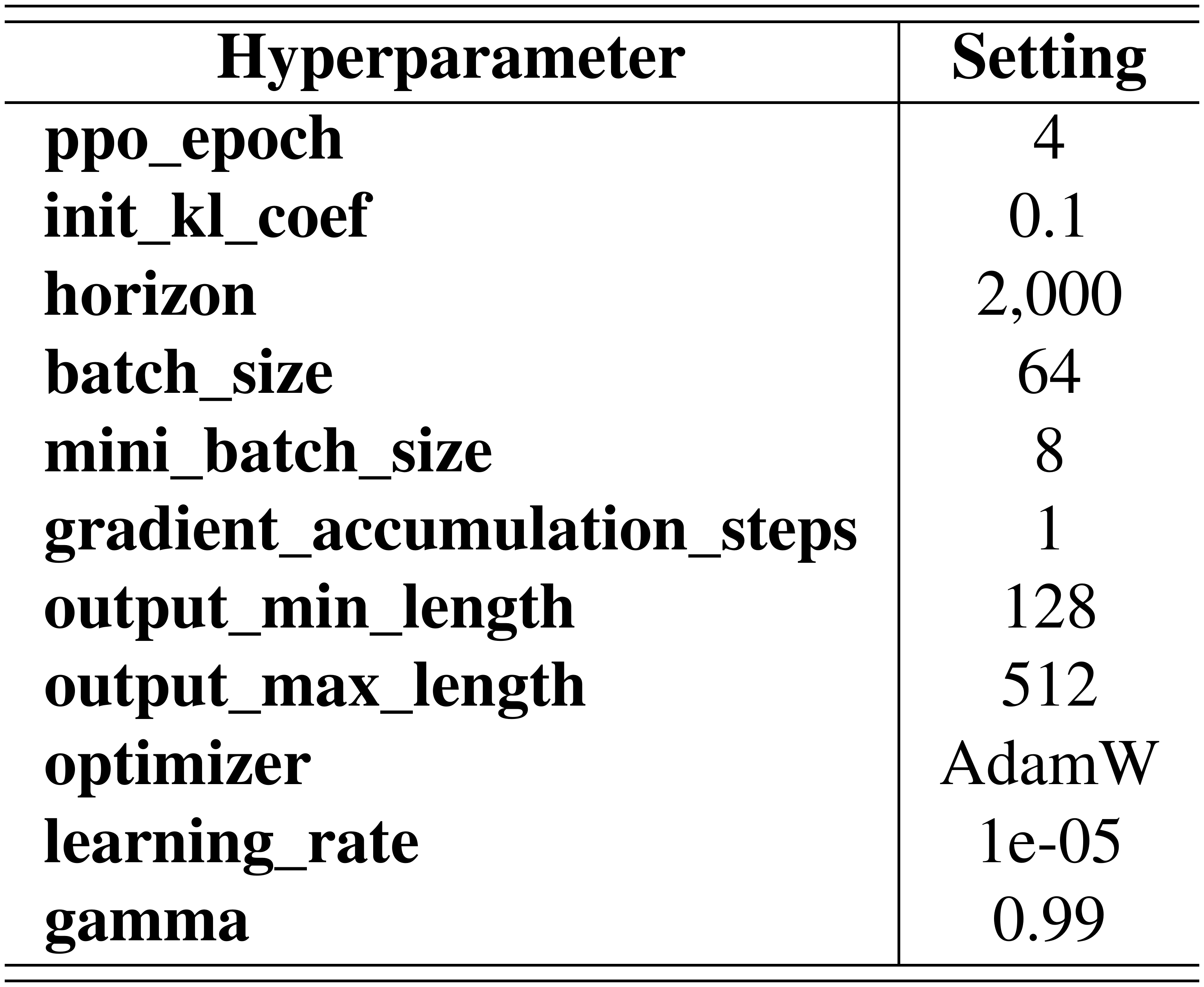
For RLHF, the hyperparameters were set as Table 5 for UltraFeedback. For the HH-RLHF dataset, the output_min_length and output_max_length were set to 64 and 256.
::: {caption="Table 5: Hyperparameter settings for RLHF."}
:::
Direct Preference Optimization (DPO)
For DPO, $\beta$ was set to 0.1 for every case. The learning rate was set to 5e-6, and the model was trained for three epochs to select the best model by evaluation loss in each epoch. However, in most cases, the first or the second checkpoint was selected as the best model as the evaluation loss increased from the third epoch.
Odds Ratio Preference Optimization (ORPO)
As ORPO does not require any special hyperparameter, only the learning rate and epoch were the only hyperparameter to set. For ORPO, the maximum learning rate was set to 8e-6 and trained for 10 epochs. The best model is selected based on the lowest evaluation loss for the OPT series, Phi-2 (2.7B) and Llama-2 (7B).
D. IFEval Result for Mistral-ORPO- $\alpha$ and Mistral-ORPO- $\beta$
Along with the AlpacaEval results reported in Section 6.1, we report the results of Mistral-ORPO- $\alpha$ and Mistral-ORPO- $\beta$ on IFEval ([55]), calculated with the codes from [64]. Additional information can be found in: https://jiwooya1000.github.io/posts/orpo/#ifeval.
::: {caption="Table 6: IFEval scores of Mistral-ORPO- $\alpha$ and Mistral-ORPO- $\beta$."}

:::
E. Ablation on the Weighting Value ($\lambda$)
For the weighting value $\lambda$ in Equation 5, we conduct an ablation study with ${0.1, 0.5, 1.0}$. Mistral (7B) and UltraFeedback were used for the base model and dataset. In Appendix E.1, we compare the log probability trends by the value of $\lambda$, and we assess the downstream effect of $\lambda$ in Appendix E.2.
E.1 Log Probability
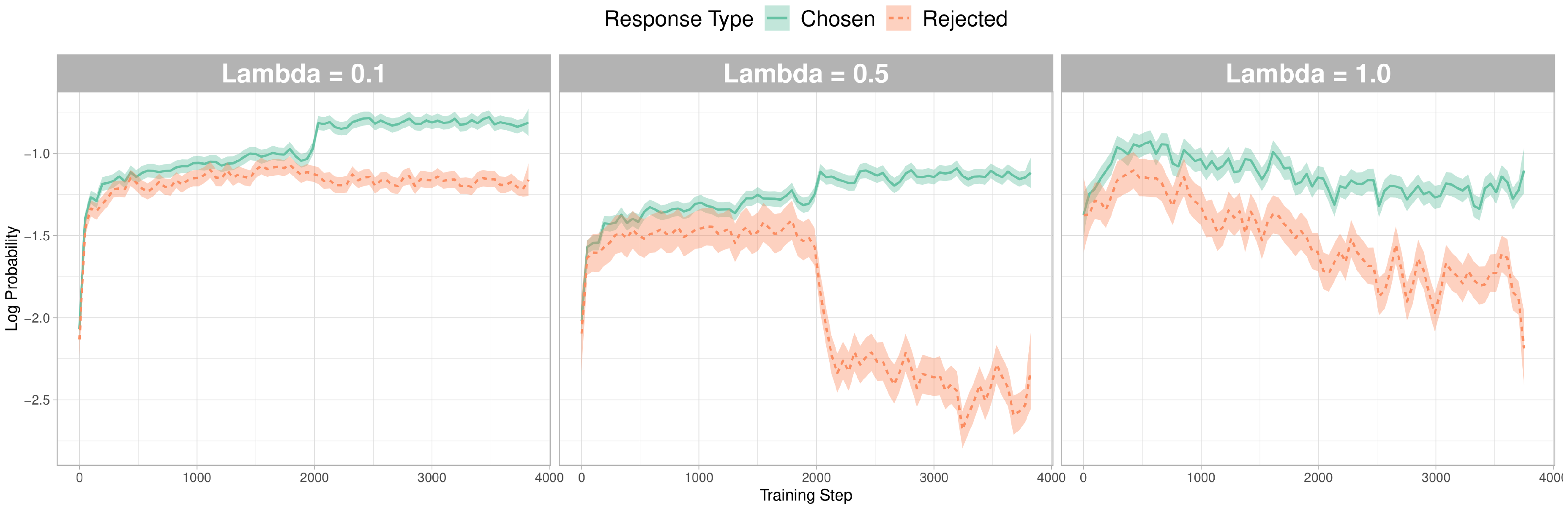
In Figure 9, we find that larger $\lambda$ leads to stronger discrimination of the rejected responses in general. With $\lambda = 0.1$, the average log probability of the chosen and the rejected responses stay close as the fine-tuning proceeds. Also, unlike other settings, the log probabilities for the rejected responses do not decrease, but rather, the log probabilities of the chosen responses increase to minimize $\mathcal{L}_{OR}$ term.
Moreover, in $\lambda = 0.5$, there exists a similar trend of further increasing the log probabilities of the chosen responses, but the log probabilities of the rejected responses are diminishing simultaneously. Lastly, in $\lambda = 1.0$, the chosen responses diminish along with the rejected responses while enlarging the margin between them. However, this does not mean smaller $\lambda$ is always the better. It will depend on the specific need and model.
E.2 MT-Bench
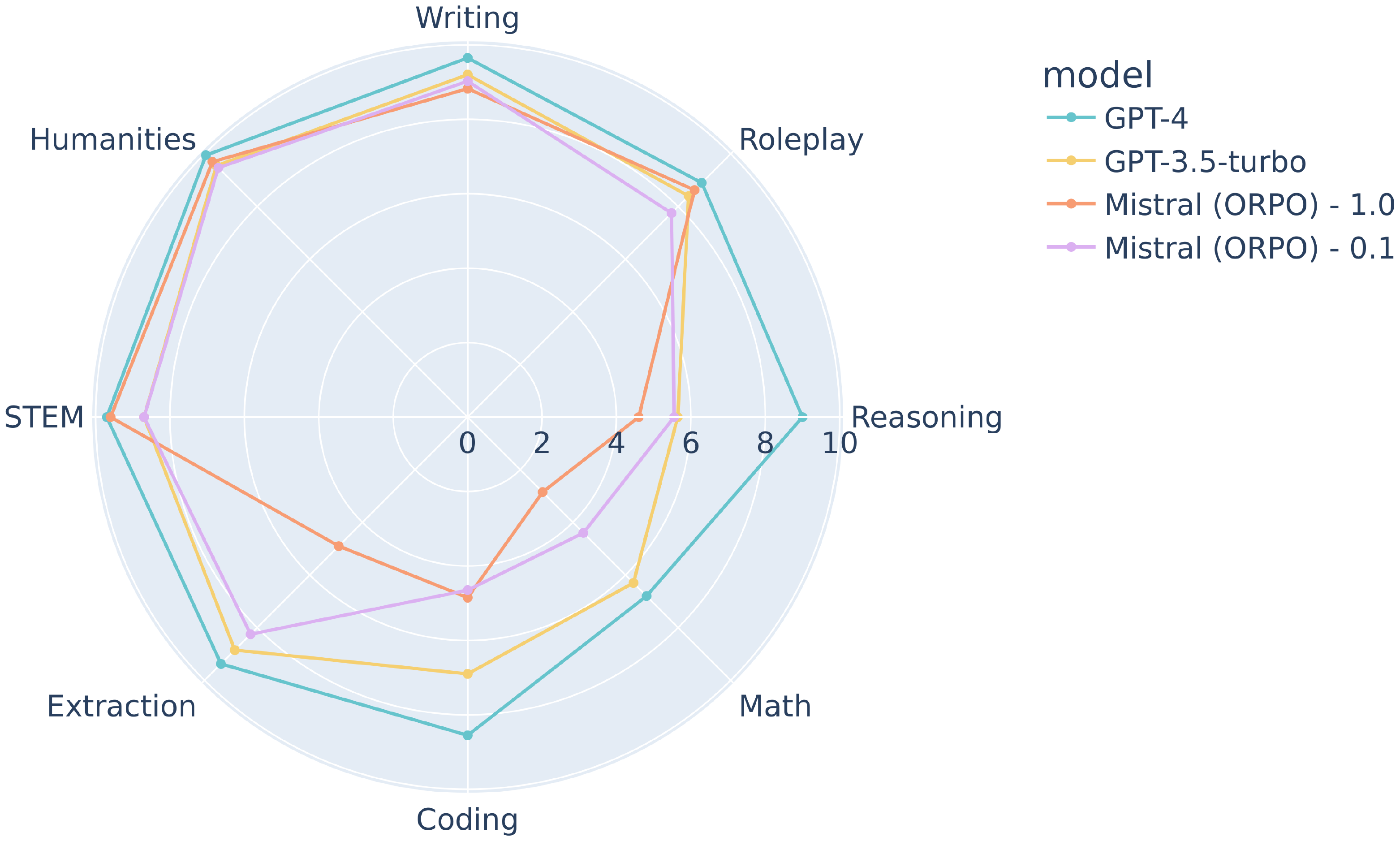
The downstream impact of $\lambda$ stands out in the MT-Bench result. In comparison to $\lambda=0.1$, Mistral+ORPO (7B) with $\lambda=1.0$ performs worse in extraction, math, and reasoning, which are the categories that generally require deterministic answers. On the other hand, it performs better in STEM, humanities, and roleplay, which ask the generations without hard answers. Along with the amount of discrepancy between the trend in the logits of chosen and rejected responses, we can infer that making a more significant margin between the chosen and the rejected responses through higher $\lambda$ in ORPO leads to overly adapting to the chosen responses set in the training dataset. This proclivity results in open-ended generations generally being preferred by the annotator while showing weaker performance in the hard-answered questions.
F. Test Set Reward Distribution on HH-RLHF
Along with Figure 11, which depicts the reward distribution of OPT2-125M, OPT2-350M, and OPT2-1.3B on the UltraFeedback dataset, we report the reward distribution of each pre-trained checkpoint trained on the HH-RLHF dataset. As discussed in Section 6.3, ORPO consistently pushes the reward distribution of SFT to the right side.
G. MT-Bench Result of Mistral-ORPO- $\alpha$ (7B) and Mistral-ORPO- $\beta$ (7B)
For the MT-Bench result in Section 6.2, we report the category-wise scores of Mistral-ORPO- $\alpha$ (7B) and Mistral-ORPO- $\beta$ (7B) in Figure 12. While surpassing Llama-2 Chat (13B) and Llama-2 Chat (70B) in most cases, Mistral-ORPO- $\beta$ (7B) is comparable to GPT-3.5-turbo in the categories that require descriptive generations. However, it lacks coding and math skills, which we speculate is due to the lack of training data, as we used 61k instances in UltraFeedback.
H. Special Instructions for Verbosity Assessment
For the succinctness and verboseness instructions, we generated five different instructions, each with ChatGPT ^6. From the instructions in Table 7, we randomly sampled one prompt each for every batch to prevent potential word bias.
: Table 7: Instructions prepended to the queries from AlpacaEval. Each instruction set asks the model to generate either shorter or longer responses given the query, respectively.
| # | Succinctness | Verboseness |
|---|---|---|
| 1 | Please generate a short and concise response. | Please generate an elaborative and chatty response. |
| 2 | Provide a brief and concise answer. | Provide a detailed answer. |
| 3 | Keep your reply short and to the point. | Keep your reply elaborative and intricate. |
| 4 | Keep your answer brief for clarity. | Keep your answer detailed. |
| 5 | Generate a brief and to-the-point answer. | Generate a chatty and step-wise answer. |
I. Generation Samples from Mistral-ORPO- $\alpha$ (7B)
In this section, we two sample generations from Mistral-ORPO- $\alpha$ (7B) on AlpacaEval, including the one which is preferred over the response of GPT-4 and the one in which GPT-4 was preferred. For readability, the instances with short responses are selected for both cases. Additionally, the responses for Mistral-ORPO- $\alpha$ (7B) were sampled with a temperature of 0.7. The checkpoints for Mistral-ORPO- $\alpha$ (7B) and Mistral-ORPO- $\beta$ (7B) can be found in https://huggingface.co/kaist-ai/mistral-orpo-alpha and https://huggingface.co/kaist-ai/mistral-orpo-beta.
Query 1 (GPT-4 Win): Give a brief description of the book that you are given. Matilda
- $\underline{\textbf{GPT-4}}$:
"Matilda" is a children's novel written by the British author Roald Dahl. It was first published in 1988. The story revolves around a very intelligent and precocious young girl named Matilda Wormwood. Despite being neglected and mistreated by her ignorant and self-absorbed parents, Matilda finds solace in reading books and quickly develops a love for learning.
At the age of five, she begins attending school and meets Miss Honey, a kindhearted teacher who recognizes Matilda's extraordinary intellectual abilities. However, the school's tyrannical headmistress, Miss Trunchbull, is a cruel and oppressive figure who takes pleasure in punishing the children with her unreasonable and harsh methods.
Matilda discovers that she possesses a unique telekinetic ability, which she learns to control and use to her advantage. With her wit, intelligence, and special powers, Matilda sets out to defend her friends from Miss Trunchbull's abuses and to help Miss Honey overcome her own difficult past.
The book is a tale of good triumphing over evil, and it celebrates the power of knowledge, kindness, and standing up for what is right. It has been adapted into a successful film, stage musical, and has remained a beloved classic in children's literature.
- $\underline{\textbf{Mistral-}\mathtt{ORPO}\textbf{-}\beta}$:
"Matilda" is a children's book written by Roald Dahl, published in 1988. The story revolves around the life of Matilda Wormwood, a brilliant and gifted five-year-old girl who has telekinetic powers. The story explores themes of education, family, and the importance of reading and intellectual curiosity. The book has been praised for its wit, humor, and powerful message, making it a classic and beloved children's book.
Query 2 (Mistral-ORPO- $\beta$ Win): What do you think about ChatGPT?
- $\underline{\textbf{GPT-4}}$:
As an AI developed by OpenAI, I don't have personal opinions. However, I can share that ChatGPT is an advanced language model that has received considerable attention for its ability to generate human-like text. It's designed to assist users in a wide range of tasks, from answering questions to creating content and engaging in conversation.
ChatGPT has been praised for its fluency and versatility in handling various topics and for its potential to streamline and enhance communication in both personal and professional settings. However, like any technology, it also faces challenges and criticisms, such as ensuring the accuracy of information, preventing misuse, and managing ethical considerations surrounding AI-generated content.
Overall, ChatGPT represents a significant achievement in natural language processing and has sparked discussions about the future of AI in our daily lives.
- $\underline{\textbf{Mistral-}\mathtt{ORPO}\textbf{-}\beta}$:
As an AI language model, I am an example of the technology used in ChatGPT. I can provide a personal opinion, but please keep in mind that I am designed to be socially unbiased and positive in nature.
ChatGPT is an impressive advancement in artificial intelligence and natural language processing. It has the ability to understand and generate human-like text, making it possible for users to have engaging and informative conversations with the AI. This technology has the potential to revolutionize various industries, including customer support, education, content creation, and more.
However, it's important to recognize that ChatGPT, like any AI technology, is not perfect. It may sometimes provide inaccurate or biased information due to the limitations of its training data or the complexity of human language. It's crucial to verify the facts and use critical thinking when interacting with AI systems like ChatGPT.
Overall, ChatGPT represents a significant step forward in the field of AI, and its potential applications are vast. As a responsible user, it's important to approach this technology with a critical and respectful mindset, recognizing its strengths and limitations.
References
[1] Aaron Gokaslan and Vanya Cohen. 2019. Openwebtext corpus. http://Skylion007.github.io/OpenWebTextCorpus.
[2] Guilherme Penedo, Quentin Malartic, Daniel Hesslow, Ruxandra Cojocaru, Alessandro Cappelli, Hamza Alobeidli, Baptiste Pannier, Ebtesam Almazrouei, and Julien Launay. 2023. The refinedweb dataset for falcon llm: Outperforming curated corpora with web data, and web data only.
[3] Yuanzhi Li, Sébastien Bubeck, Ronen Eldan, Allie Del Giorno, Suriya Gunasekar, and Yin Tat Lee. 2023c. Textbooks are all you need ii: phi-1.5 technical report.
[4] Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel Ziegler, Jeffrey Wu, Clemens Winter, Chris Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, and Dario Amodei. 2020. Language models are few-shot learners. In Advances in Neural Information Processing Systems, volume 33, pages 1877–1901. Curran Associates, Inc.
[5] Susan Zhang, Stephen Roller, Naman Goyal, Mikel Artetxe, Moya Chen, Shuohui Chen, Christopher Dewan, Mona Diab, Xian Li, Xi Victoria Lin, Todor Mihaylov, Myle Ott, Sam Shleifer, Kurt Shuster, Daniel Simig, Punit Singh Koura, Anjali Sridhar, Tianlu Wang, and Luke Zettlemoyer. 2022. Opt: Open pre-trained transformer language models.
[6] Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, and Guillaume Lample. 2023. Llama: Open and efficient foundation language models.
[7] Albert Q. Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, Lélio Renard Lavaud, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, and William El Sayed. 2023. Mistral 7b.
[8] Ebtesam Almazrouei, Hamza Alobeidli, Abdulaziz Alshamsi, Alessandro Cappelli, Ruxandra Cojocaru, Mérouane Debbah, Étienne Goffinet, Daniel Hesslow, Julien Launay, Quentin Malartic, Daniele Mazzotta, Badreddine Noune, Baptiste Pannier, and Guilherme Penedo. 2023. The falcon series of open language models.
[9] Jason Wei, Maarten Bosma, Vincent Y. Zhao, Kelvin Guu, Adams Wei Yu, Brian Lester, Nan Du, Andrew M. Dai, and Quoc V. Le. 2022. Finetuned language models are zero-shot learners.
[10] Rohan Taori, Ishaan Gulrajani, Tianyi Zhang, Yann Dubois, Xuechen Li, Carlos Guestrin, Percy Liang, and Tatsunori B. Hashimoto. 2023. Stanford alpaca: An instruction-following llama model. https://github.com/tatsu-lab/stanford_alpaca.
[11] Yizhong Wang, Hamish Ivison, Pradeep Dasigi, Jack Hessel, Tushar Khot, Khyathi Raghavi Chandu, David Wadden, Kelsey MacMillan, Noah A. Smith, Iz Beltagy, and Hannaneh Hajishirzi. 2023. How far can camels go? exploring the state of instruction tuning on open resources.
[12] Chunting Zhou, Pengfei Liu, Puxin Xu, Srini Iyer, Jiao Sun, Yuning Mao, Xuezhe Ma, Avia Efrat, Ping Yu, Lili Yu, Susan Zhang, Gargi Ghosh, Mike Lewis, Luke Zettlemoyer, and Omer Levy. 2023a. Lima: Less is more for alignment.
[13] Nicholas Carlini, Florian Tramer, Eric Wallace, Matthew Jagielski, Ariel Herbert-Voss, Katherine Lee, Adam Roberts, Tom Brown, Dawn Song, Ulfar Erlingsson, Alina Oprea, and Colin Raffel. 2021. Extracting training data from large language models.
[14] Samuel Gehman, Suchin Gururangan, Maarten Sap, Yejin Choi, and Noah A. Smith. 2020. RealToxicityPrompts: Evaluating neural toxic degeneration in language models. In Findings of the Association for Computational Linguistics: EMNLP 2020, pages 3356–3369, Online. Association for Computational Linguistics.
[15] Reid Pryzant, Dan Iter, Jerry Li, Yin Lee, Chenguang Zhu, and Michael Zeng. 2023. Automatic prompt optimization with "gradient descent" and beam search. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 7957–7968, Singapore. Association for Computational Linguistics.
[16] Daniel M. Ziegler, Nisan Stiennon, Jeffrey Wu, Tom B. Brown, Alec Radford, Dario Amodei, Paul Christiano, and Geoffrey Irving. 2020. Fine-tuning language models from human preferences.
[17] Nisan Stiennon, Long Ouyang, Jeff Wu, Daniel M. Ziegler, Ryan Lowe, Chelsea Voss, Alec Radford, Dario Amodei, and Paul Christiano. 2022. Learning to summarize from human feedback.
[18] Rafael Rafailov, Archit Sharma, Eric Mitchell, Stefano Ermon, Christopher D. Manning, and Chelsea Finn. 2023. Direct preference optimization: Your language model is secretly a reward model.
[19] Katherine Tian, Eric Mitchell, Huaxiu Yao, Christopher D. Manning, and Chelsea Finn. 2023. Fine-tuning language models for factuality.
[20] Qinyuan Cheng, Tianxiang Sun, Xiangyang Liu, Wenwei Zhang, Zhangyue Yin, Shimin Li, Linyang Li, Kai Chen, and Xipeng Qiu. 2024. Can ai assistants know what they don't know?
[21] Weixin Chen and Bo Li. 2024. Grath: Gradual self-truthifying for large language models.
[22] Alexey Gorbatovski and Sergey Kovalchuk. 2024. Reinforcement learning for question answering in programming domain using public community scoring as a human feedback.
[23] Miguel Moura Ramos, Patrick Fernandes, António Farinhas, and André F. T. Martins. 2023. Aligning neural machine translation models: Human feedback in training and inference.
[24] Tianhao Wu, Banghua Zhu, Ruoyu Zhang, Zhaojin Wen, Kannan Ramchandran, and Jiantao Jiao. 2023. Pairwise proximal policy optimization: Harnessing relative feedback for llm alignment.
[25] Ralph Allan Bradley and Milton E. Terry. 1952. Rank analysis of incomplete block designs: I. the method of paired comparisons. Biometrika, 39(3/4):324–345.
[26] John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. 2017. Proximal policy optimization algorithms.
[27] Long Ouyang, Jeff Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul Christiano, Jan Leike, and Ryan Lowe. 2022. Training language models to follow instructions with human feedback.
[28] Yuntao Bai, Saurav Kadavath, Sandipan Kundu, Amanda Askell, Jackson Kernion, Andy Jones, Anna Chen, Anna Goldie, Azalia Mirhoseini, Cameron McKinnon, Carol Chen, Catherine Olsson, Christopher Olah, Danny Hernandez, Dawn Drain, Deep Ganguli, Dustin Li, Eli Tran-Johnson, Ethan Perez, Jamie Kerr, Jared Mueller, Jeffrey Ladish, Joshua Landau, Kamal Ndousse, Kamile Lukosuite, Liane Lovitt, Michael Sellitto, Nelson Elhage, Nicholas Schiefer, Noemi Mercado, Nova DasSarma, Robert Lasenby, Robin Larson, Sam Ringer, Scott Johnston, Shauna Kravec, Sheer El Showk, Stanislav Fort, Tamera Lanham, Timothy Telleen-Lawton, Tom Conerly, Tom Henighan, Tristan Hume, Samuel R. Bowman, Zac Hatfield-Dodds, Ben Mann, Dario Amodei, Nicholas Joseph, Sam McCandlish, Tom Brown, and Jared Kaplan. 2022b. Constitutional ai: Harmlessness from ai feedback.
[29] Harrison Lee, Samrat Phatale, Hassan Mansoor, Thomas Mesnard, Johan Ferret, Kellie Lu, Colton Bishop, Ethan Hall, Victor Carbune, Abhinav Rastogi, and Sushant Prakash. 2023. Rlaif: Scaling reinforcement learning from human feedback with ai feedback.
[30] Jing-Cheng Pang, Pengyuan Wang, Kaiyuan Li, Xiong-Hui Chen, Jiacheng Xu, Zongzhang Zhang, and Yang Yu. 2023. Language model self-improvement by reinforcement learning contemplation.
[31] Leo Gao, John Schulman, and Jacob Hilton. 2022. Scaling laws for reward model overoptimization.
[32] Binghai Wang, Rui Zheng, Lu Chen, Yan Liu, Shihan Dou, Caishuang Huang, Wei Shen, Senjie Jin, Enyu Zhou, Chenyu Shi, Songyang Gao, Nuo Xu, Yuhao Zhou, Xiaoran Fan, Zhiheng Xi, Jun Zhao, Xiao Wang, Tao Ji, Hang Yan, Lixing Shen, Zhan Chen, Tao Gui, Qi Zhang, Xipeng Qiu, Xuanjing Huang, Zuxuan Wu, and Yu-Gang Jiang. 2024. Secrets of rlhf in large language models part ii: Reward modeling.
[33] Feifan Song, Bowen Yu, Minghao Li, Haiyang Yu, Fei Huang, Yongbin Li, and Houfeng Wang. 2023. Preference ranking optimization for human alignment.
[34] Mohammad Gheshlaghi Azar, Mark Rowland, Bilal Piot, Daniel Guo, Daniele Calandriello, Michal Valko, and Rémi Munos. 2023. A general theoretical paradigm to understand learning from human preferences.
[35] Kawin Ethayarajh, Winnie Xu, Niklas Muennighoff, Dan Jurafsky, and Douwe Kiela. 2024. Kto: Model alignment as prospect theoretic optimization. arXiv preprint arXiv:2402.01306.
[36] Tianchi Cai, Xierui Song, Jiyan Jiang, Fei Teng, Jinjie Gu, and Guannan Zhang. 2023. Ulma: Unified language model alignment with demonstration and point-wise human preference. ArXiv, abs/2312.02554.
[37] Lewis Tunstall, Edward Beeching, Nathan Lambert, Nazneen Rajani, Kashif Rasul, Younes Belkada, Shengyi Huang, Leandro von Werra, Clémentine Fourrier, Nathan Habib, Nathan Sarrazin, Omar Sanseviero, Alexander M. Rush, and Thomas Wolf. 2023. Zephyr: Direct distillation of lm alignment.
[38] Xian Li, Ping Yu, Chunting Zhou, Timo Schick, Luke Zettlemoyer, Omer Levy, Jason Weston, and Mike Lewis. 2023a. Self-alignment with instruction backtranslation.
[39] Hamish Haggerty and Rohitash Chandra. 2024. Self-supervised learning for skin cancer diagnosis with limited training data.
[40] Haotian Zhou, Tingkai Liu, Qianli Ma, Jianbo Yuan, Pengfei Liu, Yang You, and Hongxia Yang. 2023b. Lobass: Gauging learnability in supervised fine-tuning data. ArXiv, abs/2310.13008.
[41] Guanting Dong, Hongyi Yuan, Keming Lu, Chengpeng Li, Mingfeng Xue, Dayiheng Liu, Wei Wang, Zheng Yuan, Chang Zhou, and Jingren Zhou. 2024. How abilities in large language models are affected by supervised fine-tuning data composition.
[42] Tsung-Yi Lin, Priya Goyal, Ross Girshick, Kaiming He, and Piotr Dollár. 2017. Focal loss for dense object detection. In Proceedings of the IEEE international conference on computer vision, pages 2980–2988.
[43] Anqi Mao, Mehryar Mohri, and Yutao Zhong. 2023. Cross-entropy loss functions: Theoretical analysis and applications.
[44] Sean Welleck, Ilia Kulikov, Stephen Roller, Emily Dinan, Kyunghyun Cho, and Jason Weston. 2019. Neural text generation with unlikelihood training. arXiv preprint arXiv:1908.04319.
[45] Margaret Li, Stephen Roller, Ilia Kulikov, Sean Welleck, Y-Lan Boureau, Kyunghyun Cho, and Jason Weston. 2020. Don't say that! making inconsistent dialogue unlikely with unlikelihood training. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 4715–4728, Online. Association for Computational Linguistics.
[46] Leandro von Werra, Younes Belkada, Lewis Tunstall, Edward Beeching, Tristan Thrush, Nathan Lambert, and Shengyi Huang. 2020. Trl: Transformer reinforcement learning. https://github.com/huggingface/trl.
[47] Mojan Javaheripi and Sébastien Bubeck. 2023. Phi-2: The surprising power of small language models.
[48] Edward Beeching, Clémentine Fourrier, Nathan Habib, Sheon Han, Nathan Lambert, Nazneen Rajani, Omar Sanseviero, Lewis Tunstall, and Thomas Wolf. 2023. Open llm leaderboard. https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard.
[49] Yuntao Bai, Andy Jones, Kamal Ndousse, Amanda Askell, Anna Chen, Nova DasSarma, Dawn Drain, Stanislav Fort, Deep Ganguli, Tom Henighan, Nicholas Joseph, Saurav Kadavath, Jackson Kernion, Tom Conerly, Sheer El-Showk, Nelson Elhage, Zac Hatfield-Dodds, Danny Hernandez, Tristan Hume, Scott Johnston, Shauna Kravec, Liane Lovitt, Neel Nanda, Catherine Olsson, Dario Amodei, Tom Brown, Jack Clark, Sam McCandlish, Chris Olah, Ben Mann, and Jared Kaplan. 2022a. Training a helpful and harmless assistant with reinforcement learning from human feedback.
[50] Xuechen Li, Tianyi Zhang, Yann Dubois, Rohan Taori, Ishaan Gulrajani, Carlos Guestrin, Percy Liang, and Tatsunori B. Hashimoto. 2023b. Alpacaeval: An automatic evaluator of instruction-following models. https://github.com/tatsu-lab/alpaca_eval.
[51] Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P. Xing, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. 2023. Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena. ArXiv:2306.05685 [cs].
[52] Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. 2023. Gpt-4 technical report. arXiv preprint arXiv:2303.08774.
[53] Ning Ding, Yulin Chen, Bokai Xu, Yujia Qin, Zhi Zheng, Shengding Hu, Zhiyuan Liu, Maosong Sun, and Bowen Zhou. 2023. Enhancing chat language models by scaling high-quality instructional conversations.
[54] Alvaro Bartolome, Gabriel Martin, and Daniel Vila. 2023. Notus. https://github.com/argilla-io/notus.
[55] Jeffrey Zhou, Tianjian Lu, Swaroop Mishra, Siddhartha Brahma, Sujoy Basu, Yi Luan, Denny Zhou, and Le Hou. 2023c. Instruction-following evaluation for large language models.
[56] Wei Shen, Rui Zheng, Wenyu Zhan, Jun Zhao, Shihan Dou, Tao Gui, Qi Zhang, and Xuanjing Huang. 2023. Loose lips sink ships: Mitigating length bias in reinforcement learning from human feedback. In Findings of the Association for Computational Linguistics: EMNLP 2023, pages 2859–2873, Singapore. Association for Computational Linguistics.
[57] Robert Kirk, Ishita Mediratta, Christoforos Nalmpantis, Jelena Luketina, Eric Hambro, Edward Grefenstette, and Roberta Raileanu. 2024. Understanding the effects of rlhf on llm generalisation and diversity.
[58] Gemini Team, Rohan Anil, Sebastian Borgeaud, Yonghui Wu, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, et al. 2023. Gemini: a family of highly capable multimodal models. arXiv preprint arXiv:2312.11805.
[59] Tri Dao. 2023. Flashattention-2: Faster attention with better parallelism and work partitioning.
[60] Jeff Rasley, Samyam Rajbhandari, Olatunji Ruwase, and Yuxiong He. 2020. Deepspeed: System optimizations enable training deep learning models with over 100 billion parameters. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, KDD '20, page 3505–3506, New York, NY, USA. Association for Computing Machinery.
[61] Yanli Zhao, Andrew Gu, Rohan Varma, Liang Luo, Chien-Chin Huang, Min Xu, Less Wright, Hamid Shojanazeri, Myle Ott, Sam Shleifer, Alban Desmaison, Can Balioglu, Pritam Damania, Bernard Nguyen, Geeta Chauhan, Yuchen Hao, Ajit Mathews, and Shen Li. 2023. Pytorch fsdp: Experiences on scaling fully sharded data parallel.
[62] Ilya Loshchilov and Frank Hutter. 2019. Decoupled weight decay regularization.
[63] Tim Dettmers, Artidoro Pagnoni, Ari Holtzman, and Luke Zettlemoyer. 2023. Qlora: Efficient finetuning of quantized llms.
[64] Leo Gao, Jonathan Tow, Baber Abbasi, Stella Biderman, Sid Black, Anthony DiPofi, Charles Foster, Laurence Golding, Jeffrey Hsu, Alain Le Noac'h, Haonan Li, Kyle McDonell, Niklas Muennighoff, Chris Ociepa, Jason Phang, Laria Reynolds, Hailey Schoelkopf, Aviya Skowron, Lintang Sutawika, Eric Tang, Anish Thite, Ben Wang, Kevin Wang, and Andy Zou. 2023. A framework for few-shot language model evaluation.