Can LLMs Predict Their Own Failures? Self-Awareness via Internal Circuits
Amirhosein Ghasemabadi
University of Alberta, Canada
[email protected]
Di Niu
University of Alberta, Canada
[email protected]
Abstract
Large language models (LLMs) generate fluent and complex outputs but often fail to recognize their own mistakes and hallucinations. Existing approaches typically rely on external judges, multi-sample consistency, or text-based self-critique, which incur additional compute or correlate weakly with true correctness. We ask: can LLMs predict their own failures by inspecting internal states during inference? We introduce Gnosis, a lightweight self-awareness mechanism that enables frozen LLMs to perform intrinsic self-verification by decoding signals from hidden states and attention patterns. Gnosis passively observes internal traces, compresses them into fixed-budget descriptors, and predicts correctness with negligible inference cost, adding only 5M parameters and operating independently of sequence length. Across math reasoning, open-domain question answering, and academic knowledge benchmarks, and over frozen backbones ranging from 1.7B to 20B parameters, Gnosis consistently outperforms strong internal baselines and large external judges in both accuracy and calibration. Moreover, it generalizes zero-shot to partial generations, enabling early detection of failing trajectories and compute-aware control. These results show that reliable correctness cues are intrinsic to generation process and can be extracted efficiently without external supervision. Code and models: GitHub Gnosis Github.
Executive Summary: Large language models (LLMs), which power tools like chatbots and reasoning systems, often generate confident but incorrect outputs, including hallucinations or reasoning errors. This unreliability poses risks in high-stakes applications, such as education, healthcare, or decision support, where false answers can mislead users or cause harm. Current solutions, like external evaluators or multiple generations, add heavy computational costs and still fail to catch subtle errors reliably. With LLMs increasingly deployed at scale, the need for efficient, built-in self-checking has become urgent to improve safety and trust.
This document introduces and evaluates Gnosis, a simple add-on mechanism that lets frozen LLMs detect their own failures by analyzing internal signals during output generation. The goal is to show that correctness cues exist within the model's hidden states and attention patterns, enabling self-prediction without extra tools or retraining the core model.
The approach involved building Gnosis as a small network—adding just 5 million parameters—that processes a model's internal traces, such as evolving hidden representations and attention focus, from prompts and generated responses. These traces were compressed into fixed-size summaries to keep costs low, regardless of response length. Training used automated labels from correct/incorrect answers on about 14,000 math problems and 40,000 trivia questions, generated by the LLMs themselves, with no human input needed. Evaluation covered frozen LLMs from 1.7 billion to 20 billion parameters, tested on benchmarks for math reasoning (like competition problems), open-domain question answering, and academic knowledge tasks. Key assumptions included using only final-layer internals and focusing on full or partial generations with valid answers.
The most important findings center on Gnosis's performance and efficiency. First, it accurately predicts correctness, achieving area under the curve (AUROC) scores of 0.95 to 0.96 across domains—about 20 percentage points better than common internal baselines like token probability measures and 7 to 18 points ahead of learned probes on single tokens. Second, Gnosis provides well-calibrated scores, with positive Brier Skill Scores around 0.40 to 0.50, meaning its confidence estimates align closely with actual accuracy, unlike baselines that often overstate reliability. Third, a single Gnosis module trained on a small 1.7-billion-parameter model transfers zero-shot to judge larger siblings (up to 8 billion parameters), matching self-tuned versions with AUROC near 0.93 and outperforming billion-parameter external reward models. Fourth, it detects errors early: after just 40% of a response, it reaches near-full accuracy, enabling quick stops on failing paths. Finally, with latency under 25 milliseconds and no growth with sequence length, Gnosis is 37 to 99 times faster than large external judges for long responses.
These results mean LLMs can self-verify intrinsically, spotting hallucinations or flawed reasoning from their own "thought process" without costly outsiders. This cuts deployment expenses, boosts safety by flagging unreliable outputs in real time, and supports efficient scaling—such as routing hard tasks to bigger models. Unlike expectations that external judges are essential, Gnosis shows internal signals suffice and generalize better within model families, challenging reliance on heavy supervision and potentially accelerating reliable AI systems.
Next steps should include integrating Gnosis into LLM pipelines for automatic error detection, starting with model families like Qwen series, and piloting it in applications needing quick reliability checks, such as tutoring bots. For broader use, train variants on diverse architectures and test compute-aware policies, like early termination, to quantify real-world savings. Trade-offs involve sticking to similar models for best transfer versus retraining for unrelated ones.
Limitations include Gnosis's focus on binary correctness, not nuanced rewards, and reduced performance across dissimilar model styles (e.g., reasoning versus instruction-tuned). It assumes valid final answers exist, filtering non-responses. Confidence is high on tested math, QA, and knowledge tasks, driven by strong metrics and ablations, but readers should verify generalization to untested domains like code or vision before full adoption.
1. Introduction
Section Summary: Large language models excel at generating text and reasoning through multiple steps, but they often confidently produce incorrect answers without detecting their own errors or hallucinations, which undermines their reliability and safety in complex tasks. Existing methods for self-evaluation, such as analyzing generated text, checking consistency across multiple outputs, or using separate judging models, rely on external signals and come with high computational costs or limited accuracy. This paper introduces Gnosis, a lightweight add-on that lets frozen language models predict their own failures by tapping into their internal processes during generation, achieving top performance on benchmarks like math problems and trivia questions with minimal extra parameters and no added delay.
Large language models (LLMs) have achieved remarkable performance in open-ended generation and multi-step reasoning, yet they remain unreliable at assessing the correctness of their own outputs [1, 2]. They frequently produce confident but incorrect answers, failing to detect reasoning errors or hallucinations even when such failures are evident to external evaluators [3, 4]. This gap between strong generation and weak self-verification limits the reliability, safety, and efficiency of LLM deployment, particularly in settings that require long-horizon reasoning or compute-aware control. A fundamental open question is whether LLMs can anticipate their own failures by examining the internal dynamics that govern their generation process.
Prior work on LLM self-evaluation and hallucination detection largely follows three paradigms. Text-based self-critique and confidence estimation ([5, 6, 7]) infer correctness from generated text or token probabilities, often tracking linguistic fluency rather than reasoning validity and degrading on long or compositional tasks. Multi-sample consistency methods ([8, 9]) estimate confidence from agreement across multiple generations, improving robustness at the cost of inference that scales linearly with the number of samples. External judges and reward models ([10, 11, 12, 13, 14]) train large auxiliary models to evaluate responses, providing strong signals but requiring costly supervision, additional decoding passes, and substantial inference overhead. Despite their differences, these approaches rely on signals external to the model’s own internal dynamics, leaving open whether correctness can be predicted directly from the generation process itself.
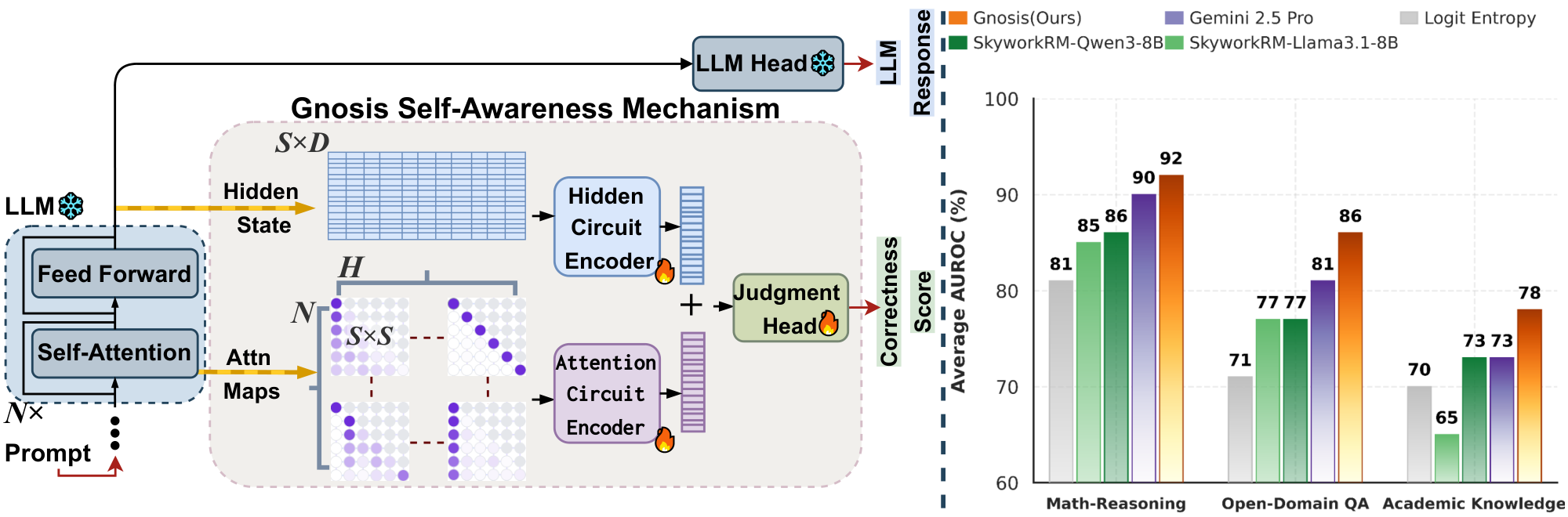
In this paper, we demonstrate that large language models can reliably predict their own failures by leveraging signals intrinsic to the generation process. We introduce Gnosis, a lightweight self-awareness mechanism that endows frozen LLMs with intrinsic self-verification, eliminating the need for external judges. By extracting reliability cues directly from model-internal dynamics during inference, Gnosis produces accurate and well-calibrated correctness estimates with negligible computational overhead. This intrinsic capability enables early detection of failing reasoning trajectories, efficient scaling across model sizes and domains, and practical deployment of compute-aware and reliability-critical language systems. Our main contributions are:
- Intrinsic, Trajectory-Level Self-Awareness. We introduce Gnosis, a lightweight mechanism that enables frozen LLMs to predict the correctness of their own generations by decoding signals intrinsic to the inference process. Unlike prior internal-signal methods that rely on statistical features [15, 16, 17] or single-token indicators [18], Gnosis leverages the full spatiotemporal structure of internal dynamics across an entire generation trajectory.
- Dual-Stream Introspection from Hidden States and Attention. Gnosis jointly models hidden-state evolution and attention-routing patterns through a compact, fixed-budget architecture that operates independently of sequence length, extracting rich reliability cues with negligible inference overhead.
- Cross-Scale Transfer and Early Failure Detection. Gnosis generalizes beyond self-judgment: a head trained on a small backbone model transfers zero-shot to larger variants, and predicts failures reliably from partial reasoning and generations, enabling early termination and compute-aware control.
- State-of-the-Art Performance at Minimal Scale. With only $\sim$ 5M added parameters, Gnosis is orders of magnitude smaller than external verifiers yet outperforms billion-parameter reward models and proprietary judges on math reasoning, open-domain QA, and academic benchmarks. It works reliably across diverse frozen backbones with negligible latency overhead.
2. Related Work
Section Summary: Researchers have developed various methods to check if large language models (LLMs) produce accurate responses or make up false information, grouping them into four main categories. External reward models and judge LLMs use separate trained systems to evaluate answers for quality and truthfulness, offering reliable checks but at high cost and added processing time. Other approaches, like analyzing the text itself for confidence, tapping into the model's internal signals, or comparing multiple generated versions for consistency, aim to be more efficient but often struggle with accuracy, domain shifts, or extra computation needs.
Methods for assessing LLM correctness and hallucination risk largely fall into four families: Text-based confidence & self-critique, Internal signal-based indicators and linear probes, external reward models and judge LLMs, and multi-sample self-consistency methods.
External Reward Models and Judge LLMs. External verifiers train separate models to score response quality, factuality, or step-wise correctness. Outcome and Process Reward Models (ORM/PRM) are widely used for ranking, hallucination detection, and guiding test-time search ([10, 11, 12, 19, 20]). Recent systems emphasize large, carefully curated datasets over architectural novelty: HelpSteer2 combines Likert ratings, pairwise preferences, and extrapolation to sharpen discrimination ([13]), while Skywork-Reward-V2 scales human–AI curation to tens of millions of preference pairs and leads on RewardBench-style suites ([14]). These models provide strong signals but incur substantial annotation cost and add inference latency and deployment overhead by requiring a large auxiliary model at serving time.
Text-Based Confidence & Self-Critique. Text-based approaches aim to estimate correctness from the generated text and token probabilities. Training-free indicators use entropy or max probability as uncertainty proxies but struggle with confident hallucinations and out-of-distribution shifts ([15, 21, 9]). Prompt-based calibration elicits verbalized confidence or self-critique, improving ECE but often tracking stylistic fluency more than reasoning validity and requiring extra passes ([5, 6]). Generative and distillation-based calibrators predict correctness in a single forward pass, e.g., APRICOT trains a calibrator LLM ([6]), and Self-Calibration distills self-consistency signals to enable early stopping and confidence-weighted sampling ([7]). These methods reduce dependence on external judges but may require full-model fine-tuning, add training cost, and remain brittle across domains and sequence lengths.
Internal signal-based indicators and linear probes. Glass-box signals exploit logits, hidden states, and attention routing. Prior work shows hidden activations diverge between correct and hallucinated outputs ([22]), with factuality cues concentrated in middle/deep layers yet sensitive to domain shift ([17]). Token-wise hidden-state entropy and information density can outperform perplexity-based failure prediction ([23]). Trajectory/spectral views analyze how representations evolve across layers (e.g., Chain-of-Embedding, stability of latent paths) and relate angular/magnitude changes to correctness ([16]). Attention statistics provide lightweight reliability cues ([24]). A complementary line trains simple probes (shallow MLPs) on final-token states ([25, 26, 18]). However, these approaches consistently yield low accuracy across diverse benchmarks. By relying on fragile heuristics or single-token snapshots, they miss the generation's full spatiotemporal structure, resulting in performance that falls far short of Gnosis.
Multi-Sample Self-Consistency and Test-Time Scaling. Multi-sample self-consistency infers confidence from agreement across sampled rationales, boosting robustness but incurring inference cost that scales with the number of samples and often saturating on long, compositional tasks ([21]). Recent cost-aware test-time scaling uses internal signals to prune search or adapt compute, reducing dependence on large external verifiers while retaining some benefits of multi-sample reasoning ([7, 27]).
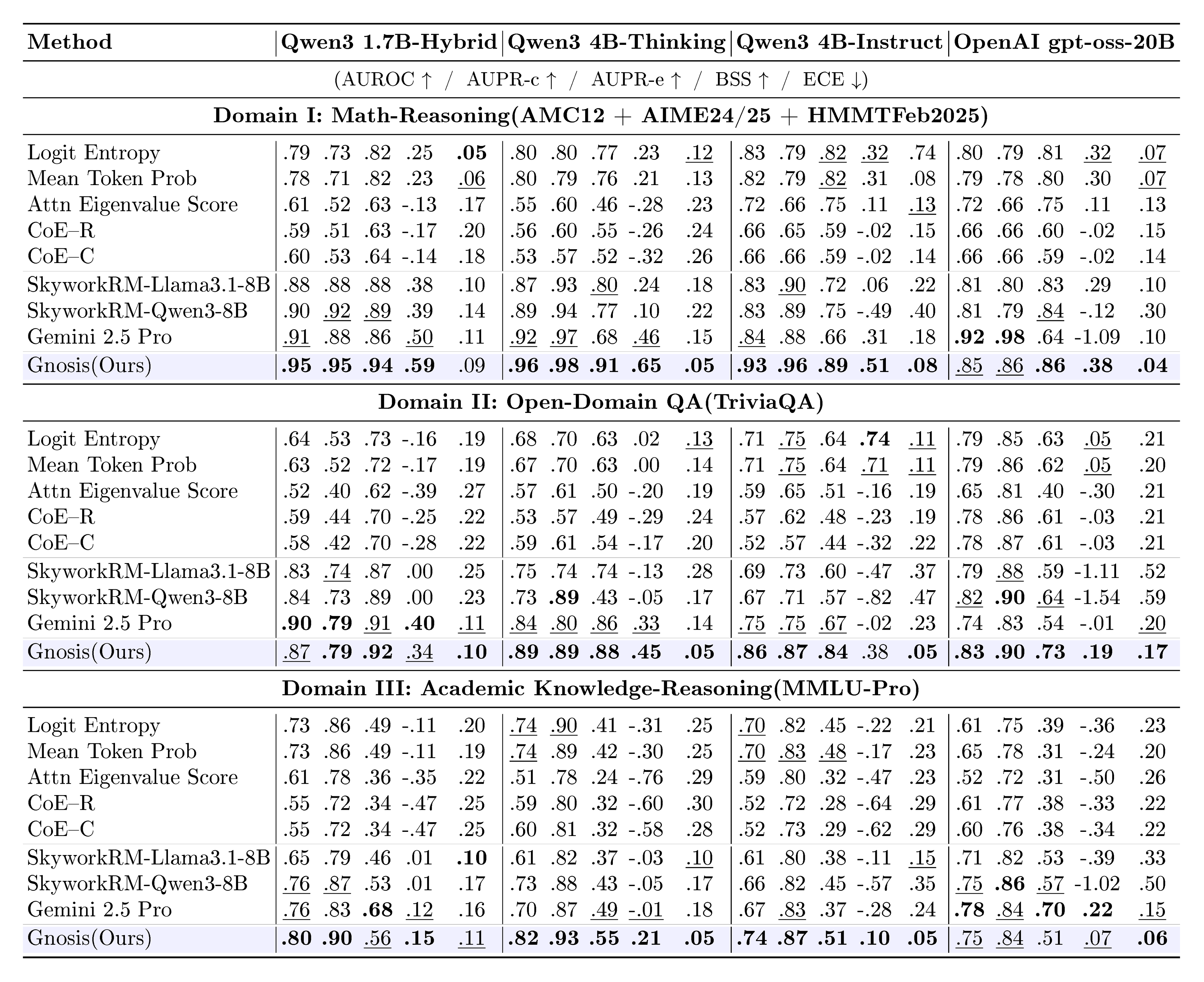
::: {caption="Table 1: Correctness/hallucination detection across domains. For each model, columns (left to right) are: AUROC / AUPR-c / AUPR-e / BSS / ECE."}
:::
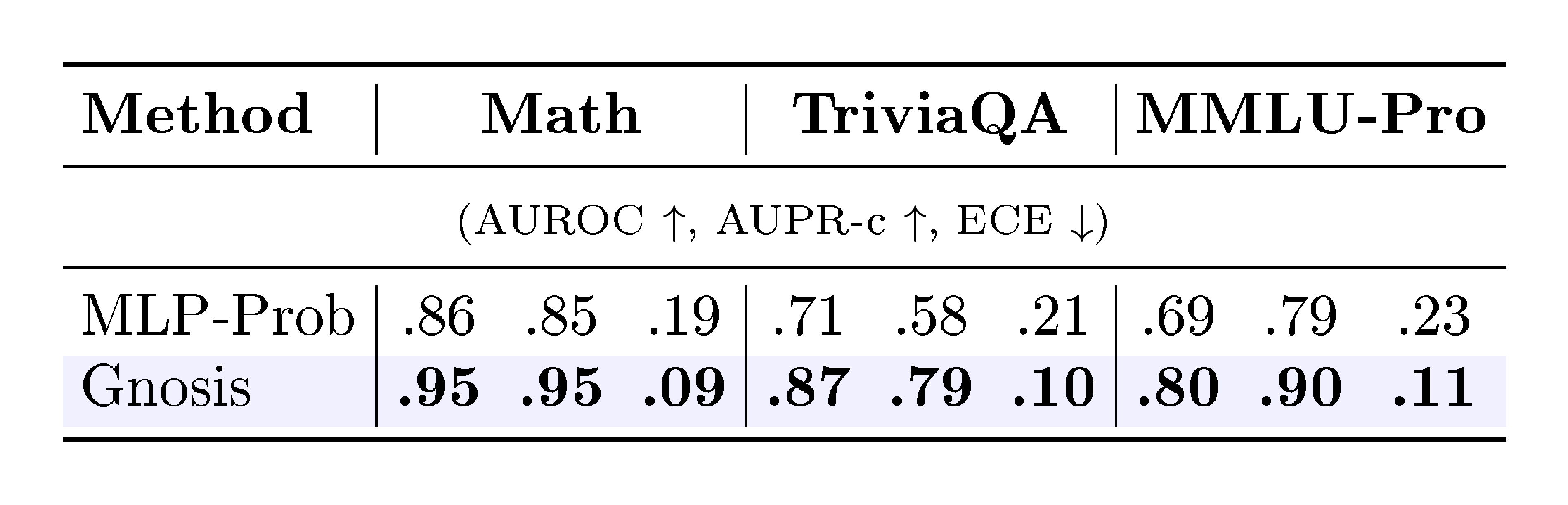
::: {caption="Table 2: Comparison with an MLP-Prob baseline on Qwen3 1.7B."}
:::
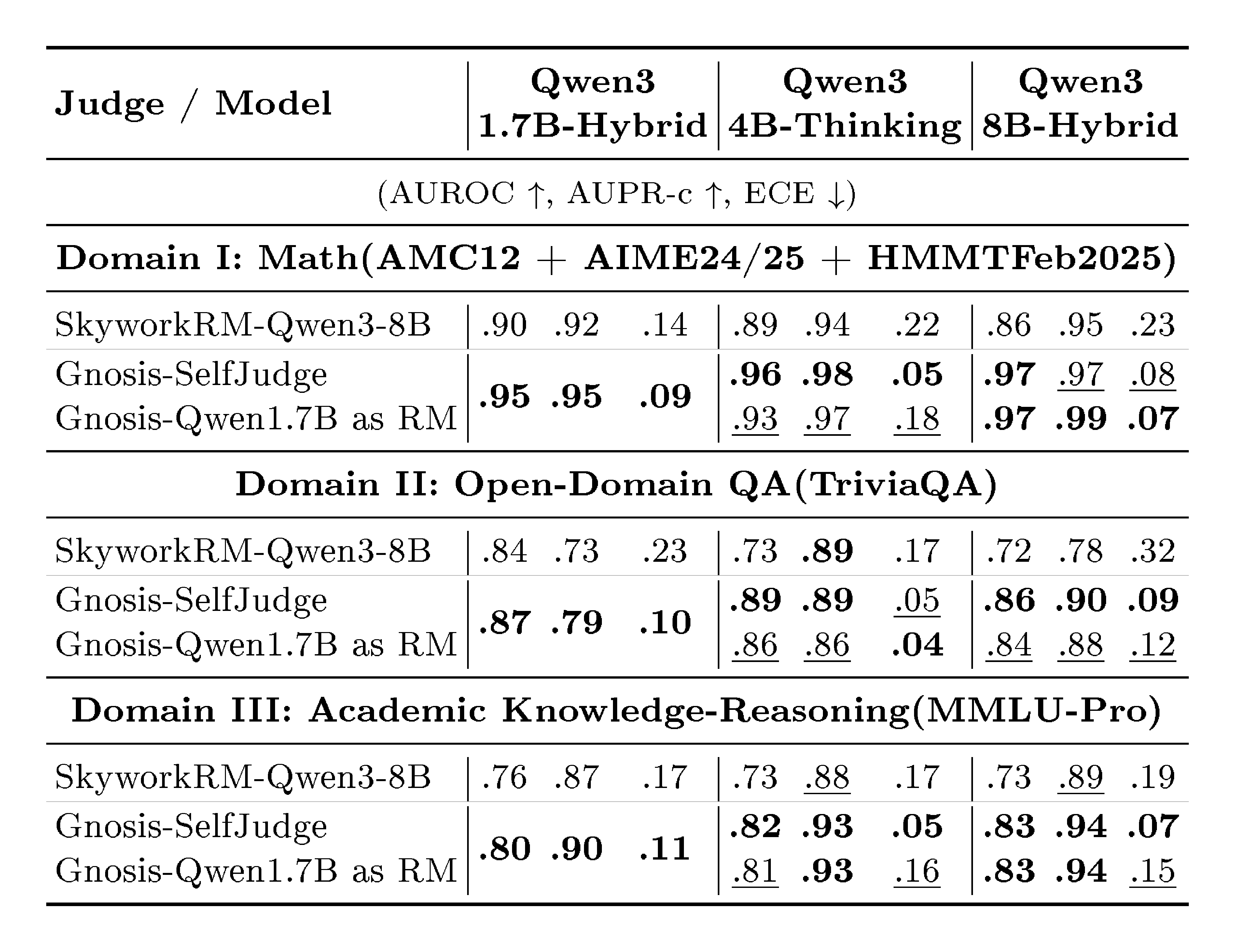
::: {caption="Table 3: Sibling-model judgment across domains. Each triplet of columns shows AUROC / AUPR-c / ECE. Gnosis-SelfJudge: Gnosis head trained on each backbone and judging its own generations. Gnosis-RM: a single Gnosis head trained on Qwen3 1.7B-Hybrid and used as a reward model for the other models."}
:::
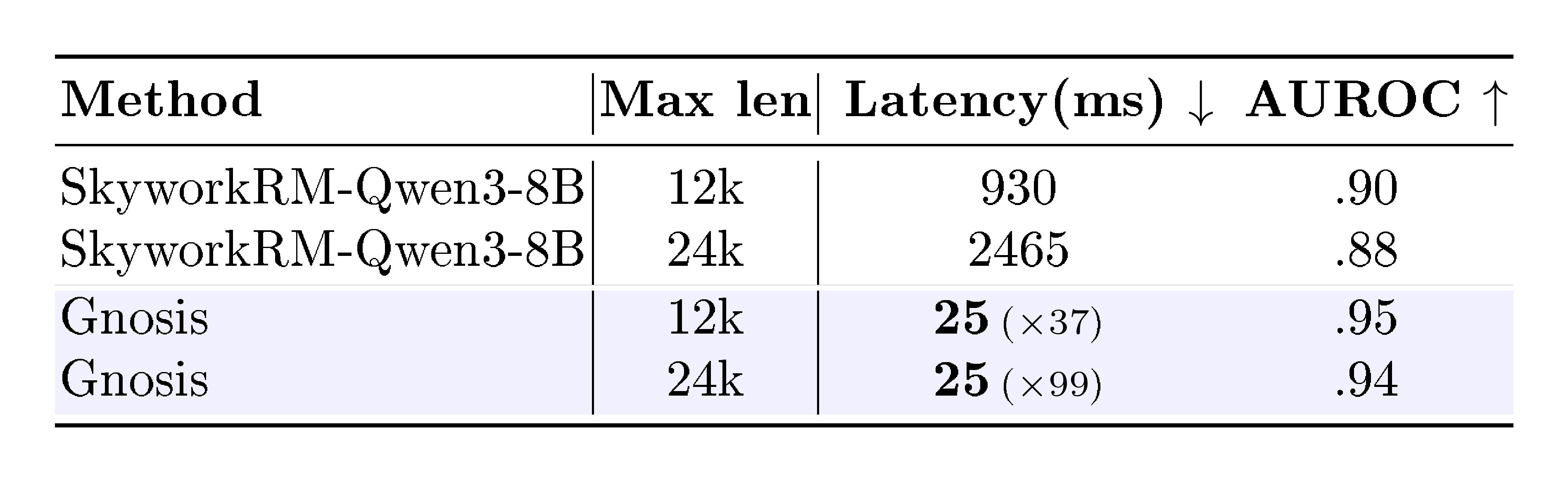
::: {caption="Table 4: Correctness detection on Math-reasoning for Qwen3 1.7B-Hybrid backbone under two max response lengths (12k, 24k). We compare Gnosis with SkyworkRM-Qwen3-8B, highlighting Gnosis’s near-constant latency and large speedups as response length increases."}
:::
3. The Gnosis Mechanism
Section Summary: Gnosis is a simple add-on tool that helps frozen large language models check their own thinking by spotting errors like hallucinations through their internal signals, such as hidden states and attention patterns, without needing extra heavy processing. It compresses these variable-length signals into fixed-size summaries using techniques like pooling and encoding, then combines them to output a single score estimating how correct the model's response is. This design keeps the added computation tiny and unchanged even for very long inputs, using separate encoders for hidden states that capture local and global patterns and for attention maps that analyze focus and distribution through image-like processing and basic statistics.
We introduce Gnosis, a lightweight self-awareness mechanism designed to retrofit frozen LLMs with introspection capabilities. Gnosis operates on the intuition that a model’s internal traces, its evolving hidden states and attention routing patterns, carry distinctive "fingerprints" of hallucination and reasoning errors. Unlike external judges that require separate, expensive decoding passes, Gnosis is a passive observer: it compresses the backbone's internal signals into compact descriptors and fuses them to predict a scalar correctness score. The architecture is explicitly designed so that its inference cost is independent of the sequence length, adding negligible overhead even for very long contexts.
3.1 Problem Setup and Length-Invariant Inputs
Let $x$ denote an input prompt of length $S_x$ and $\hat{y}$ the generated response of length $S_y$. The input to Gnosis is the concatenated sequence with a total size of $S = S_x + S_y$ tokens." The backbone has hidden dimension $D$, $L$ decoder layers, and $H$ attention heads per layer. During generation, we read only the final-layer hidden states $H^{\text{last}} \in \mathbb{R}^{S \times D}$ and the attention maps $\mathcal{A} = {A_{\ell, h}}{\ell=1..L, , h=1..H}$, where each $A{\ell, h} \in \mathbb{R}^{S \times S}$ is the attention map of head $h$ in layer $\ell$.
Gnosis learns a verification function:
$ \hat{p} = f_\phi!\big(H^{\text{last}}, \mathcal{A}\big) \in [0, 1], $
where $\hat{p}$ is the estimated probability that the generated answer is correct and $\phi$ are the parameters of Gnosis. The backbone LLM remains frozen throughout.
Fixed-Budget Compression.
To decouple computational cost from sequence length $S$, we use a projection operator $\Pi$ that maps variable-length traces into fixed-size tensors:
- Hidden States. The sequence $H^{\text{last}} \in \mathbb{R}^{S \times D}$ is interpolated and adaptively pooled along the sequence dimension to a fixed budget $K_{\text{hid}}$ (e.g., $192$), yielding
$ \tilde{H} = \Pi_{\text{hid}}(H^{\text{last}}) \in \mathbb{R}^{K_{\text{hid}} \times D}. $
- Attention Maps. Each attention map $A_{\ell, h} \in \mathbb{R}^{S \times S}$ is downsampled via adaptive pooling to a fixed grid size $k \times k$ (e.g., $k = 256$), giving a standardized set
$ \tilde{\mathcal{A}} = {\tilde{A}{\ell, h}}{\ell, h}, \quad \tilde{A}_{\ell, h} \in \mathbb{R}^{k \times k}. $
All downstream encoders operate only on $\tilde{H}$ and $\tilde{\mathcal{A}}$ with fixed dimensions $(K_{\text{hid}}, D)$ and $(L, H, k, k)$, so the computational cost of Gnosis does not grow with $S$ and is negligible compared to the backbone; see Appendix A for architectural details.
3.2 Hidden-State Circuit Encoder
Standard confidence methods often rely on token probabilities (logits), which are poorly calibrated and only weakly aligned with correctness [27]. Gnosis instead learns from the backbone's internal representation, extracting correctness cues directly from the final-layer latent representations. A small encoder $\rho_{\text{hid}}$ maps this latent trace into a compact descriptor:
$ z_{\text{hid}} = \rho_{\text{hid}}(\tilde{H}) \in \mathbb{R}^{D_{\text{HID}}}. $
Local Temporal Encoder.
We treat $\tilde{H}$ as a temporal signal and apply a lightweight multi-scale 1D depthwise convolution over the sequence dimension to capture local dependencies and irregularities in the hidden trajectory.
Global Set Encoder.
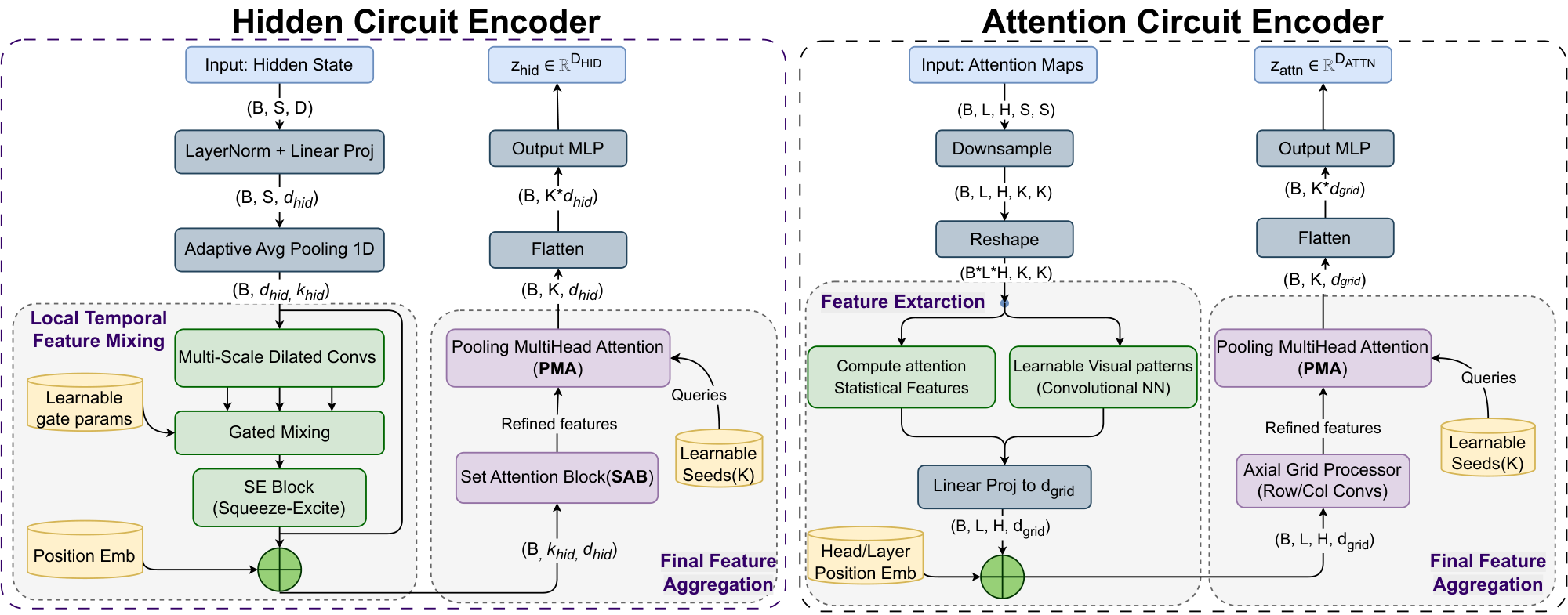
To summarize the sequence into a compressed representation, we then apply a Set Transformer–style encoder ([28]): Set Attention Blocks (SAB) followed by a Pooling-by-Multihead-Attention (PMA) block. This enables global interaction across all positions and aggregates the sequence into a small set of summary tokens, which are flattened and linearly projected to form the final hidden descriptor $z_{\text{hid}}$. Figure 2 illustrates the detailed architecture design of Hidden Circuit Encoder. Appendix A.1 details the encoder architecture, while Appendix B.3 presents full design ablations.
3.3 Attention Circuit Encoder
The attention stream $\tilde{\mathcal{A}}$ reveals layer- and head-level routing patterns that can indicate brittle reasoning or unstable focus, complementing the hidden-state descriptor. Rather than feeding raw attention weights into a large network, Gnosis summarizes each downsampled attention map $\tilde{A}_{\ell, h} \in \mathbb{R}^{k \times k}$ into a compact feature vector:
$ \mathbf{v}{\ell, h} = \Phi(\tilde{A}{\ell, h}) \in \mathbb{R}^{d_{\text{grid}}}. $
Here $\Phi$ denotes our per-map feature extractor, which outputs a $d_{\text{grid}}$-dimensional summary for each attention map.
Per-map Feature Extraction.
We implement $\Phi$ using two complementary approaches: (i) a lightweight CNN that treats each attention map as an image and learns local-to-global patterns, and (ii) an interpretable statistics-based extractor that summarizes how attention is distributed, where it concentrates, and how local or long-range it is. Concretely, the statistics include simple measures of spread and texture (e.g., entropy- and frequency-based features), diagonal and near-diagonal mass to capture locality, and lightweight center-and-spread measures that describe the average location of attention and how widely it is dispersed.
We ablate each variant and their hybrid in Appendix B.2 (Table 6). While the two extractors are individually competitive, the hybrid is the most consistent across benchmarks; we therefore adopt $\left[\Phi_{\text{cnn}};\Phi_{\text{stat}}\right]$ in the final design. Full definitions of the statistics are provided in Appendix A.2.
Cross-Head and Cross-Layer Encoding.
We arrange the per-head summaries into an $L \times H$ layer–head grid:
$ G \in \mathbb{R}^{L \times H \times d_{\text{grid}}}, \quad G_{\ell, h, :} = \mathbf{v}_{\ell, h}. $
We add learned layer and head embeddings to preserve depth and head identity. We then treat the $L \times H$ entries as grid tokens. A lightweight encoder $\rho_{\text{attn}}$ mixes information across layers and heads using a few axial convolutional layers. This design is substantially cheaper than full global self-attention over the grid. Finally, we apply Pooling-by-Multihead-Attention (PMA) to aggregate the grid into a single descriptor:
$ z_{\text{attn}} = \rho_{\text{attn}}(G) \in \mathbb{R}^{D_{\text{ATT}}}. $
Because this stage operates on fixed dimensions $(L, H, d_{\text{grid}})$, the Gnosis-side compute is independent of the original sequence length $S$. Figure 2 illustrates the detailed architecture design of Attention Circuit Encoder. Detailed architecture choices and ablations are deferred to Appendix B.2.
3.4 Gated Fusion and Correctness Prediction
Gnosis fuses the hidden and attention descriptors into a single vector and maps it to a correctness probability. We concatenate the two descriptors
$ z = [z_{\text{hid}}; z_{\text{attn}}], $
and feed the result into a small gated MLP head. The final correctness estimate is
$ \hat{p} = \sigma!\big(\mathrm{GatedMLP}_{\phi}(z)\big), $
where $\mathrm{GatedMLP}_{\phi}$ is a lightweight gated MLP and $\sigma$ is the sigmoid. This head lets Gnosis adaptively weight hidden versus attention features on a per-example basis(e.g., leaning more on attention for reasoning traces and more on hidden states for factual recall). The architecture is intentionally small: Gnosis adds only $\sim$ 5M parameters, making it $\sim$ 1000 $\times$ smaller than 8B reward models and dramatically smaller than Gemini 2.5 pro as judge.
3.5 Training
A key advantage of Gnosis is that it can be trained without costly-annotated data. For each backbone, we generate answers on the training sets and label correctness by comparing predictions to ground-truth answers. This yields a binary classification dataset:
$ \mathcal{D} = {(H^{\text{last}}_i, \mathcal{A}i, y_i)}{i=1}^N, $
where $y_i \in {0, 1}$ indicates whether the verifier judged the $i$-th generation as correct. Gnosis is trained to minimize binary cross-entropy:
$ \mathcal{L}(\phi) = -\mathbb{E}_{(H^{\text{last}}, \mathcal{A}, y) \sim \mathcal{D}} \big[, y \log \hat{p} + (1-y)\log(1-\hat{p}) , \big], $
with $\hat{p} = f_{\phi}(H^{\text{last}}, \mathcal{A})$. The backbone is frozen; gradients flow only through the Gnosis encoders and fusion head.
4. Experiments and Results
Section Summary: Researchers tested Gnosis, a lightweight tool for checking the accuracy of AI language models, in three scenarios: self-checking its own outputs, judging outputs from similar models, and predicting correctness early during generation. They trained it on math problems and trivia questions using five frozen AI models, evaluating performance on math reasoning, general knowledge quizzes, and academic tasks with metrics like accuracy scores and calibration quality, comparing it to simpler internal checks and larger judging AI systems. In self-judgment tests, Gnosis outperformed these rivals by better spotting errors in full reasoning paths rather than just final answers, achieving high reliability with far fewer resources than massive models like Gemini.
We evaluate Gnosis in three practical regimes: (i) self-judgment, where each Gnosis head scores generations from its own frozen backbone; (ii) sibling-model judgment, where a small head serves as a lightweight reward model for larger family members; and (iii) early correctness prediction, where Gnosis is queried on partial completions to support compute-aware control.
4.1 Experimental Setup
Backbones. We apply Gnosis to five frozen LLMs: Qwen3 1.7B-Hybrid, Qwen3 4B-Thinking, Qwen3 4B-Instruct, Qwen3 8B-hybrid [29] and OpenAI gpt-oss-20B [30]. The backbone weights and decoding settings are never updated.
Training Data. We train one correctness head per backbone on a mixed math–trivia corpus to cover both multi-step reasoning and open-domain factual recall. For math, we use the English portion of DAPO-Math-17k ($\sim$ 14k competition-style problems with numeric or symbolic answers [31]). For QA, we subsample 40k questions from a 118k-item TriviaQA training set [32] to retain broad coverage while keeping training compact. We generate two completions per math prompt to capture diverse reasoning trajectories and increase correct/incorrect label variety under the same question, and one completion per trivia prompt since answers are shorter and often less ambiguous. We extract final answer, label correctness by comparing to the ground-truth, and discard outputs without valid answers. This yields a balanced, fully automated training set that requires no human annotation.
Training Details and Cost. We train each head for two epochs over this mixed dataset using Adam with a learning rate of $1\times 10^{-4}$. Because the backbone is frozen and all feature extractors operate at a fixed budget independent of sequence length, training is lightweight. For the largest backbone (gpt-oss-20B MoE), the full pipeline, data generation and training finishes in roughly 12 hours on $2\times$ A100 80 GB GPUs, corresponding to $25 in cloud cost. Smaller backbones train faster.
Benchmarks. For each benchmark, we prompt each frozen backbone to generate a solution with a maximum budget of 12k tokens, and retain only question–answer pairs with a valid final answer for evaluation. We evaluate Gnosis on three disjoint domains: Math-Reasoning (AMC12 2022/2023 [33], AIME 2024/2025 [34, 35], HMMT Feb 2025 [36]), Open-Domain QA (18k held-out TriviaQA questions with no overlap with training), and Academic Knowledge Reasoning (MMLU-Pro [37]). Together, these benchmarks stress multi-step reasoning, hallucination detection on short factoid answers, and out-of-distribution generalization. We report detailed backbone-level outcome statistics (accuracy, hallucination, and non-response rates) in Appendix D. Additional benchmark details are provided in Appendix C.
Metrics. We treat correctness prediction as binary classification and report AUROC and AUPR under two complementary labelings (AUPR-c: correct as positive; AUPR-e: incorrect as positive), together with calibration metrics Brier Skill Score (BSS) and Expected Calibration Error (ECE). AUROC/AUPR measure discriminative ranking under class imbalance, whereas BSS/ECE assess the quality and calibration of predicted probabilities. See Appendix C for extended interpretations.
Baselines. We compare against four baseline families. (1) Statistical internal scores are training-free indicators computed from the backbone’s own outputs, reported in Table 1 as Logit Entropy, Mean Token Prob, and Attn Eigenvalue Score[8]. (2) Trajectory/spectral internal indicators summarize cross-layer hidden-state dynamics, reported as CoE–R and CoE–C[16]. (3) External judges include two open-source reward models that are state-of-the-art on public reward-model benchmarks [38], SkyworkRM-Llama3.1-8B and the family-aligned SkyworkRM-Qwen3-8B[14], as well as Gemini 2.5 Pro used as a judge (the Gemini judging prompt is provided in the Appendix E); all are reported in Table 1. (4) A Learnable probe[18] that observes only the final answer token’s hidden state is reported separately on Qwen3 1.7B in Table 2 to isolate the limitations of single-token probing.
4.2 Self-Judgment
We evaluate Gnosis in the standard self-judgment setting: for each backbone, the model generates answers to the benchmark questions, and the verification method predicts the correctness of these specific generations. As shown in Table 1 and Table 2, Gnosis consistently outperforms training-free baselines and large external judges across all tested domains.
Superiority Over Internal Baselines and Probes. Across Math Reasoning and Open-Domain QA, Gnosis effectively solves the miscalibration of standard confidence metrics. It consistently lifts AUROC from the mid-0.7s (typical of Logit Entropy) to 0.95–0.96 while roughly doubling the BSS, turning negative calibration scores into strongly positive ones. Crucially, Gnosis outperforms the learned MLP-Prob final-token probe by 7–18 AUROC points across benchmarks. This consistent gap confirms that correctness is a property of the full generation trajectory, specifically the distributed hidden-state dynamics and attention patterns, rather than a state localized to the final token.
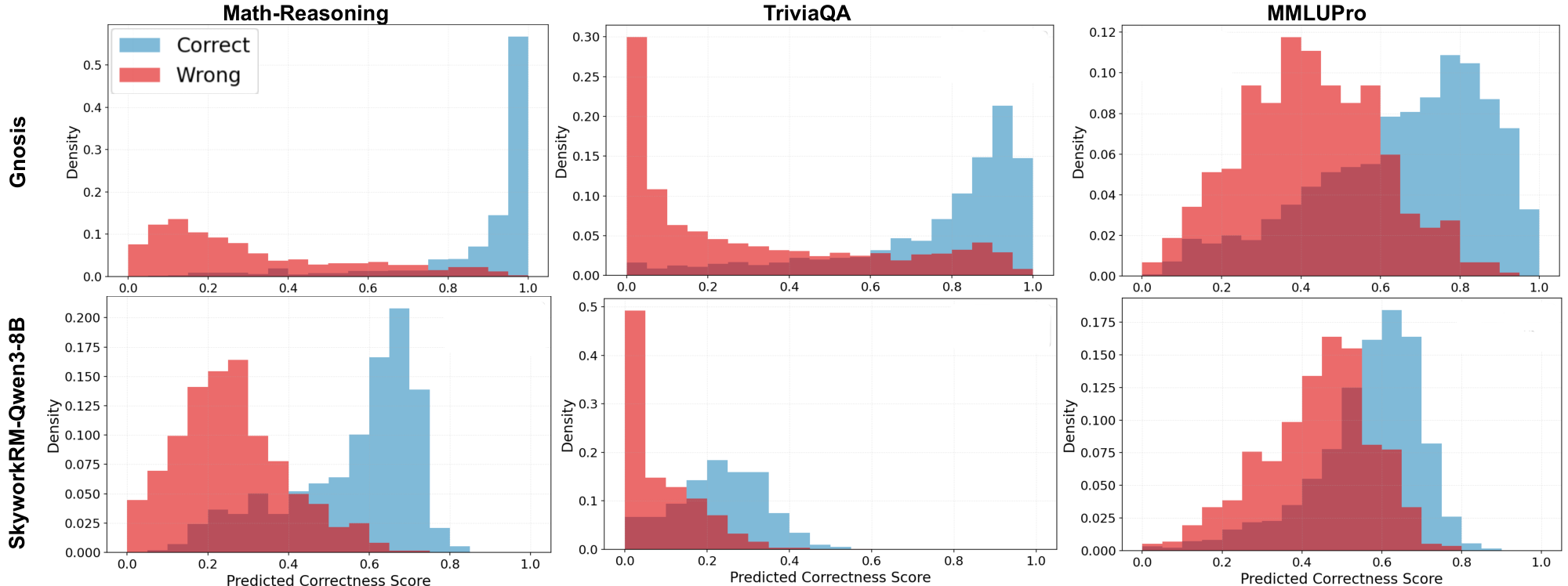
Efficiency vs. Scale: With only $\sim$ 5M parameters and negligible overhead from its fixed-budget projection, Gnosis matches or exceeds state-of-the-art Skywork 8B Reward Models ($\sim$ 1000 $\times$ larger) and the proprietary Gemini 2.5 Pro. This is notable because Gnosis adds no independent world knowledge. Rather than fact-checking with massive parametric memory, it detects the signatures of hallucination and reasoning error in the backbone’s internal traces. On complex Math Reasoning, Gnosis surpasses both large judges. It also outperforms Gemini on MMLU-Pro, a domain it was not explicitly trained on, suggesting that it learns transferable error patterns instead of task-specific cues. Additionally, Gnosis maintains near-constant $\sim$ 25ms latency and achieves roughly $37\times$ and $99\times$ speedups over the 8B reward model when judging answers of length 12k and 24k tokens, respectively (Table 4). These results show that intrinsic self-verification can be both more scalable and far cheaper than external oversight.
Figure 5 compares the predicted correctness score distributions of Gnosis and the Skywork 8B Reward Model. Gnosis shows sharp, bimodal peaks near 0 (incorrect) and 1 (correct), whereas Skywork produces broader, overlapping scores that often cluster around 0.5–0.6. This separation aligns with Gnosis’s stronger calibration (BSS) and its tendency to assign more decisive probabilities.
4.3 Cross-Scale: Zero-Shot Reward Modeling
We introduce "Sibling Modeling", where we train Gnosis on a small, cheap backbone and deploy it to judge larger family members without fine-tuning. Table 3 highlights a striking outcome: a head trained on a 1.7B backbone transfers effectively to 4B and 8B siblings across all evaluated domains. On Math Reasoning, for instance, it achieves 0.93 AUROC, nearly matching the 0.96 achieved by a self-trained head. Notably, this transferred 1.7B head still consistently outperforms the Skywork 8B Reward Model across all tested backbones, proving that our tiny zero-shot verifier is more reliable than a massive external judge. This broad transferability implies that hallucination manifests as a structural invariant across model scales, offering a "free lunch" where a single small head serves as a supervisor for an entire model family. We observe that this transfer is most effective when models share a similar generation style; while Gnosis robustly handles differences in size, it performs best when the models also align in their formatting (e.g., transferring between thinking models rather than thinking-to-Instruct).
4.4 Early Error Detection
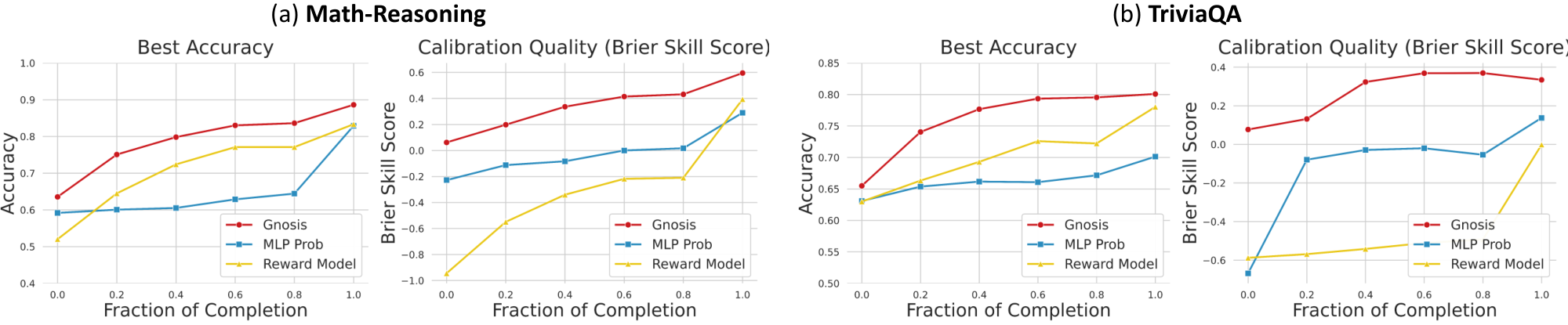
Because Gnosis processes internal traces into fixed-size descriptors, it can evaluate partial generations natively. Crucially, this capability is emergent: although Gnosis is trained exclusively on complete trajectories, it generalizes zero-shot to partial prefixes without any additional fine-tuning. Figure 3 illustrates that on both Math Reasoning and TriviaQA, Gnosis reaches near-peak accuracy and positive BSS after observing only 40% of the generation. In contrast, external reward models and single-token learnable probe typically require the full response to stabilize. This enables aggressive compute-aware control policies: generated chains-of-thought can be terminated immediately if the internal "hallucination alarm" triggers, preventing wasted compute on failing paths, or the system can automatically escalate the query to a stronger model upon detecting that the current backbone is incapable of answering correctly.
5. Ablations and Analysis
Section Summary: The section explores experiments that shaped the design of Gnosis, an AI model, by testing its key components and showing more details in the appendix. It compares hidden states, which provide a reliable signal for short factual questions like trivia, with attention circuits, which excel at longer reasoning tasks like math problems, finding that combining both delivers the strongest overall results. Further tests refine how attention data is processed, favoring a hybrid method using neural networks and basic statistics, while additional checks confirm the value of various design choices in both components.
We highlight the key ablation insights that motivate Gnosis design, and defer comprehensive studies to Appendix A.
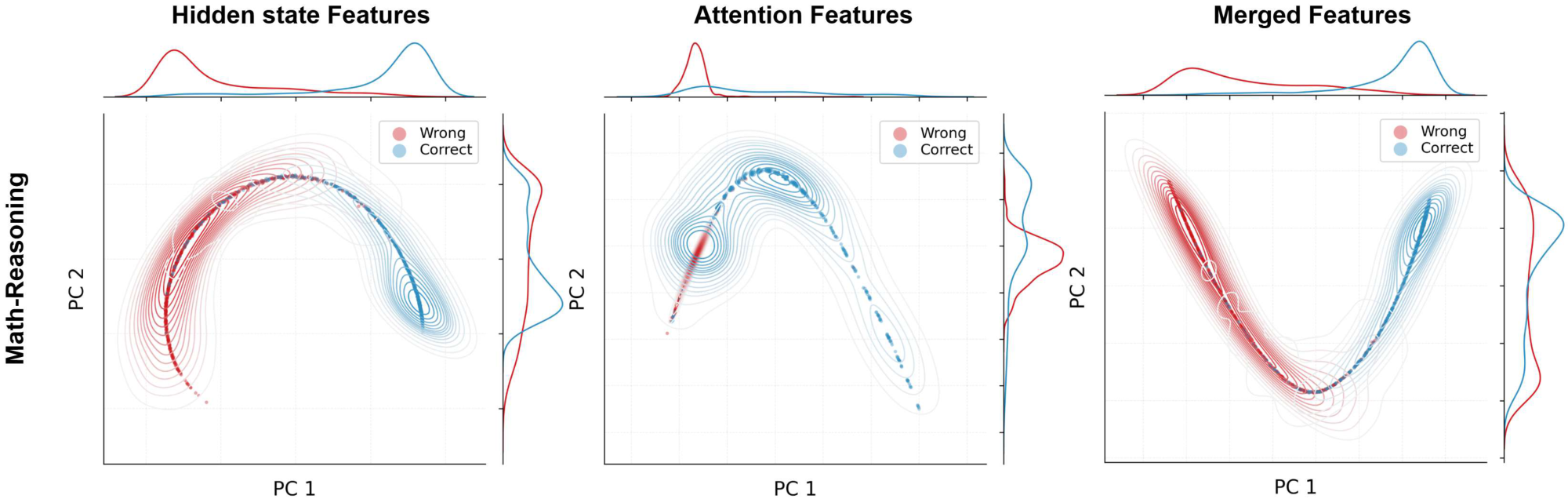
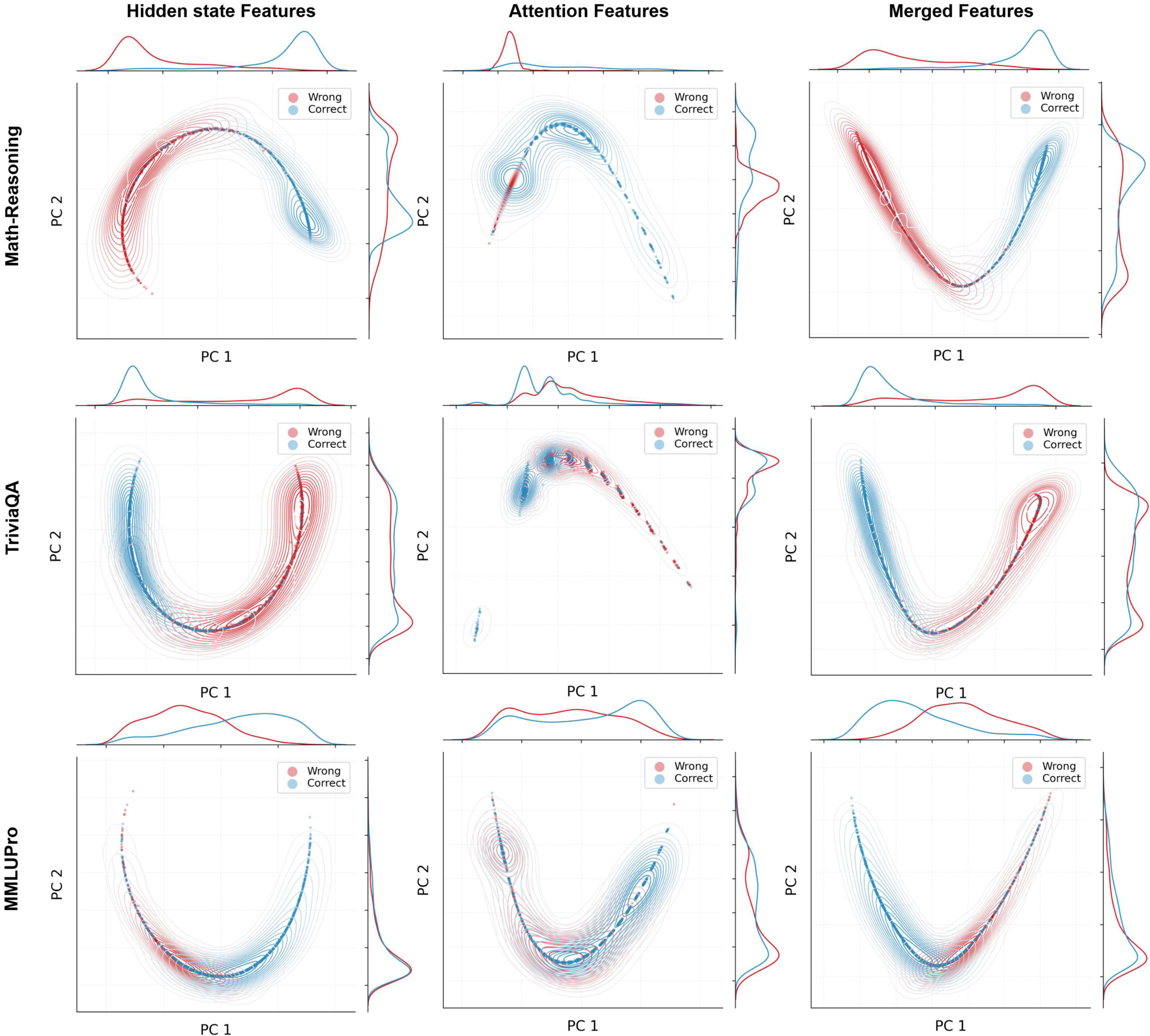
Hidden vs. Attention Circuits. Gnosis fuses a hidden-state and an attention circuit. Appendix Table 5 shows that both streams help, but attention is most useful for long-form reasoning: on TriviaQA, hidden-only dominates and fusion adds little, indicating hidden states carry most short factual reliability; on Math Reasoning and MMLU-Pro, attention-only is strong (even slightly better than hidden-only on MMLU-Pro), and fusion yields the best overall performance, suggesting complementary structural cues that emerge in longer reasoning.
We visualize this behavior on Math-Reasoning in Figure 4; analogous feature-distribution plots for the other domains are provided in the appendix Figure 7. Taken together, these results support that hidden states provide a broad, robust signal across domains, while attention routing contributes more strongly on reasoning-heavy tasks and less on short factual QA; combining both is the most reliable overall.
Attention Map Extractor. We ablate how to summarize each downsampled attention map with a lightweight CNN, predefined fixed statistics, and their hybrid. Appendix Table 6 shows that the three variants perform similarly on Math, while on TriviaQA the CNN-based variants are stronger than statistics alone, and on MMLU-Pro the CNN+Stats hybrid is the most consistent. Based on these, we adopt the CNN+Stats design in the final model.
Additional Ablations. We further validate the design path behind Gnosis with targeted ablations across both streams. On the attention stream, Appendix B.2 examines how grid mixing, identity embeddings, pooling strategy, layer selection, and map downsampling affect performance (Appendix Table 7 and Table 7). On the hidden stream, we isolate architectural value by including a simple pooled-MLP baseline that naively pools final-layer hidden states before an MLP (Row G in Table 8), alongside broader studies of the local–global encoder design and sizing trade-offs (Appendix Table 8 and Table 8).
6. Discussion and Limitations
Section Summary: Gnosis offers an efficient way for AI models to evaluate themselves and related versions, using a small component trained on a simpler model to judge larger ones in the same group. It also allows for smart resource management by spotting errors early in the process of generating responses. However, it's mainly a tool for self-reflection within similar models and doesn't work well as a broad judge for unrelated AI types or styles, like those focused on reasoning versus instruction-following.
Gnosis provides a highly efficient framework for self-evaluation and "sibling modeling, " where a small head trained on a compact model effectively judges larger models within the same family. This architecture further supports compute-aware control by enabling early error detection on partial generation traces. However, a key limitation is that Gnosis is designed as a self-awareness mechanism rather than a general-purpose reward model; while it transfers robustly to siblings, it is not capable of acting as a universal zero-shot judge for every model, particularly those with unrelated architectures or differing generation styles (e.g., transferring between Thinking and Instruct models).
7. Conclusion
Section Summary: Gnosis is a simple tool added to pre-trained AI language models that helps them spot their own mistakes by looking at their internal thought processes, without needing outside help. Even though it only adds about five million parameters, Gnosis works better than massive reward systems with billions of parameters or big commercial AIs like Gemini 2.5 Pro, proving that reliable error signals are built right into how these models generate responses. This sets a new benchmark for efficient, self-checking AI that can catch problems with almost no extra computing power.
We introduced Gnosis, a lightweight mechanism that allows frozen LLMs to detect their own errors by interpreting internal hidden and attention traces rather than relying on external judges. Despite adding only $\sim$ 5M parameters, Gnosis consistently outperforms billion-parameter reward models and Large proprietary models like Gemini 2.5 Pro, demonstrating that high-fidelity correctness signals are intrinsic to the generation process. This approach establishes a new standard for compute-efficient reliability, enabling self-verifying systems that can detect failing trajectories with negligible overhead.
Appendix
Section Summary: The appendix details the Gnosis mechanism's architecture, which uses two parallel processing streams to analyze a language model's internal signals—hidden states and attention patterns—to predict the correctness of its outputs. One stream simplifies and summarizes the final hidden states through pooling and attention techniques to capture key features, while the other downsamples attention maps and extracts interpretable statistics like entropy and locality to describe how the model focuses its attention. Experiments show that combining both streams outperforms using either alone, providing reliable predictions across various tasks with efficient, fixed computation regardless of input length.
A. Architecture Overview
::: {caption="Table 5: Impact of Dual-Stream Architecture across Benchmarks. Comparison of single-stream variants against the Full Gnosis model. While hidden states provide a strong signal, fusing them with the attention circuit consistently yields the best performance."}

:::
Figure 2 illustrates the detailed internal components of the Gnosis Mechanism. The architecture consists of two parallel streams that process the frozen backbone's internal traces to extract reliability signals efficiently:
A.1 Hidden Circuit Encoder.
This stream processes the sequence of hidden states $H_{\text{last}} \in \mathbb{R}^{S \times D}$. To avoid the added cost and memory of storing intermediate states for every token, we use only the final-layer hidden state. We show this choice remains strongly predictive. To handle variable lengths while maintaining a fixed compute budget, the sequence is first projected and pooled into a fixed number of tokens. It then passes through a Local Temporal Feature Mixing stage (Phase 1) using multi-scale dilated convolutions and Squeeze-and-Excitation (SE) blocks to capture local dependencies and reweight informative channels. Finally, a Global Set Encoder (Phase 2) utilizes a Set Attention Block (SAB) followed by Pooling by Multihead Attention (PMA) to aggregate the sequence into a compact descriptor $z_{\text{hid}} \in \mathbb{R}^{D_{\text{HID}}}$.
A.2 Attention Circuit Encoder.
This stream processes the collection of attention maps ${A_{\ell, h}}{\ell=1..L, , h=1..H}$ from a frozen backbone. To make computation invariant to the original context length, we downsample each map to a fixed grid $\tilde{A}{\ell, h} \in \mathbb{R}^{k \times k}$. We then summarize each downsampled map into a compact per-head descriptor $\mathbf{v}{\ell, h} = \Phi(\tilde{A}{\ell, h}) \in \mathbb{R}^{d_{\text{grid}}}$. These per-head descriptors are arranged as a layer–head grid and processed by an Axial Grid Processor to model inter-layer and inter-head dependencies, followed by PMA to obtain the final attention descriptor $z_{\text{attn}} \in \mathbb{R}^{D_{\text{ATT}}}$.
Per-Map Feature Extraction Variants.
As described in Section 3.3, we implement $\Phi$ using two alternatives: (i) a lightweight CNN that treats each attention map as an image and learns local-to-global patterns, and (ii) an interpretable statistics-based extractor that computes predefined structural descriptors. We compare these variants and their hybrid in Table 6. While CNN-only and Stats-only are individually competitive, the hybrid is the most consistent across domains. Unless otherwise stated, we therefore adopt CNN+Stats as the default Gnosis configuration. The Stats-only variant remains a strong, more interpretable alternative.
Interpretable Attention Statistics.
The statistics branch summarizes how attention is distributed, how local or long-range it is, and where it tends to concentrate on the map, using a small set of predefined descriptors. Concretely, for each downsampled map $\tilde{A}_{\ell, h}$ we compute:
- Entropy. We compute map entropy together with row and column entropies. Map entropy reflects the overall dispersion of attention mass (focused vs. diffuse). Row and column entropies provide axis-specific views of this dispersion, indicating whether spread is driven primarily by query positions (rows) or key positions (columns). Together, these metrics offer a direct, interpretable summary of attentional diffusion and stability.
- Spectral Texture. We compute spectral entropy and the relative energy from the 2D Fourier spectrum of $\tilde{A}_{\ell, h}$. These features summarize whether attention exhibits coherent, structured patterns (low-frequency dominance) or becomes fragmented and noisy (elevated high-frequency energy and higher spectral entropy).
- Locality via Diagonal Structure. We measure diagonal and near-diagonal mass through the diagonal ratio and diagonal-band energies. This provides a simple proxy for locality versus longer-range routing, which often correlates with coherent step-wise reasoning behavior.
- Center and Spread on the Map. We compute lightweight center-and-width measures to describe the average location of attention mass and how widely it is dispersed across the grid.
The two descriptors are concatenated and passed through a lightweight gated MLP to produce a scalar correctness logit, which is converted to a probability via a sigmoid. Because both encoders operate on fixed-size summaries, Gnosis runs at effectively constant cost in sequence length and can be queried on partial chains of thought.
B. Comprehensive Ablations and Analysis
B.1 Hidden vs. Attention Circuits
To quantify the distinct contributions of the internal representations, we trained single-stream variants of Gnosis and compared them to the full dual-stream model on Qwen3 1.7B.
As reported in Table 5, the HIDDEN-ONLY model already provides a strong correctness signal across benchmarks. On Math Reasoning, both single-stream variants reach 0.92 AUROC, while fusing $z_{\text{hid}}$ and $z_{\text{attn}}$ improves performance to 0.95 AUROC. On TriviaQA, the hidden stream remains stronger than attention alone, and fusion achieves the best overall performance. On MMLU-Pro, attention-only is slightly stronger than hidden-only, while fusion matches the best result. These results confirm that attention contributes complementary structural cues that help maximize performance when combined with hidden representations.
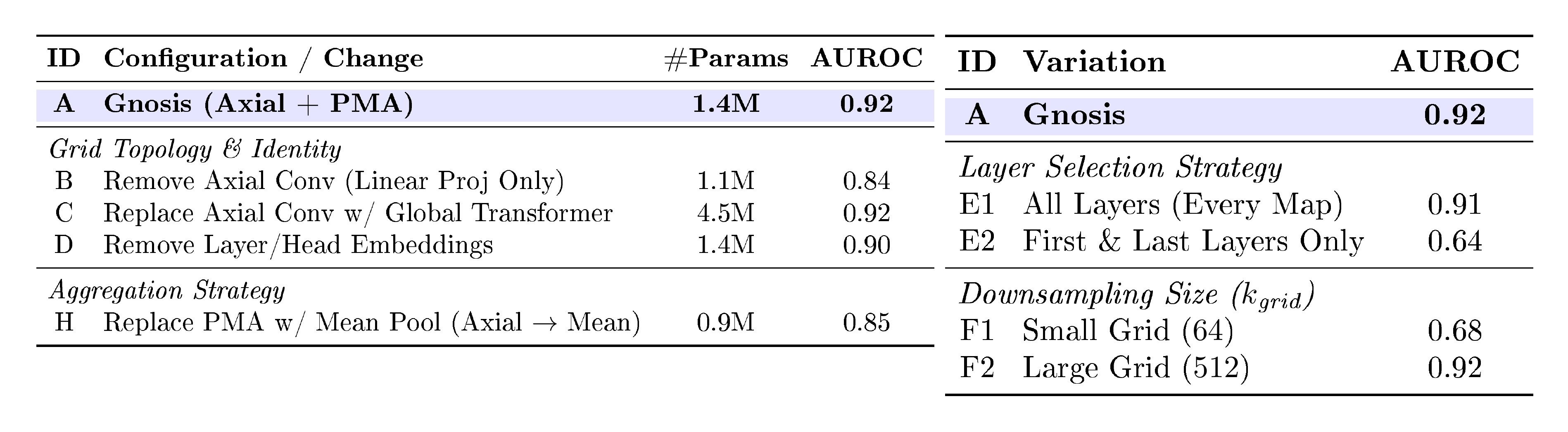
B.2 Attention Circuit Encoder Ablations
To determine the optimal architecture for the attention circuit, we systematically investigated three key design components: the input feature representation for each attention map, the grid topology for mixing information across layers and heads, and the final aggregation strategy. Table 6, Table 7, and Table 7 detail this investigation. We select the configuration highlighted in Row A of Table 7 and Table 7 as it achieves the best balance of accuracy and parameter efficiency.
Feature Input Representation. We first assessed how best to encode individual attention maps. Table 6 compares a lightweight learned CNN, predefined statistics, and their combination across benchmarks. The predefined statistics remain competitive with the CNN (e.g., identical 0.92 AUROC on Math Reasoning), while providing a more interpretable per-map representation. Combining CNN and statistics yields comparable performance overall and modest gains on MMLU-Pro (0.80 AUROC).
Grid Topology and Layer/Head Identity. We next evaluated how to process the collection of extracted map features. As shown in Table 7, removing the grid mixing entirely (Row B) reduces performance, indicating that individual attention heads are not independent predictors; their interactions matter. Replacing our lightweight Axial Convolutions with a heavy Global Transformer (Row C) increases parameters four-fold without improving AUROC, validating the efficiency of the axial design. Furthermore, removing the learned layer and head embeddings (Row D) degrades performance, confirming that the model relies on knowing where a specific activation pattern occurred within the LLM's depth and breadth.
Aggregation Strategy. Finally, we analyzed how to summarize the grid into a fixed vector. Replacing our query-based Pooling by Multihead Attention (PMA) with simple mean pooling (Row H in Table 7) causes a sharp drop in accuracy. This suggests that Gnosis benefits from learning specific "reliability prototypes" (via PMA seeds) rather than uniformly averaging all attention circuits, likely because only a small subset of heads carry high-fidelity correctness signals.
::: {caption="Table 6: Impact of Per-Map Feature Extractor Choices across Benchmarks. Comparison of learnable CNN, predefined statistics, and their combination for the attention per-map extractor $\Phi$. Across benchmarks, the CNN and statistics variants are competitive, while their hybrid is the most consistent overall; we adopt the CNN+Stats design in our final model."}

:::
::: {caption="Table 7: Attention Circuit: Components & Topology. We ablate the attention-circuit design by varying grid mixing, identity embeddings, and aggregation. Row A is our default configuration. Axial Conv performs lightweight row/column mixing over the (Layer, Head) grid, offering a cheaper alternative to full global self-attention."}
:::
B.3 Hidden-State Circuit Encoder Ablations
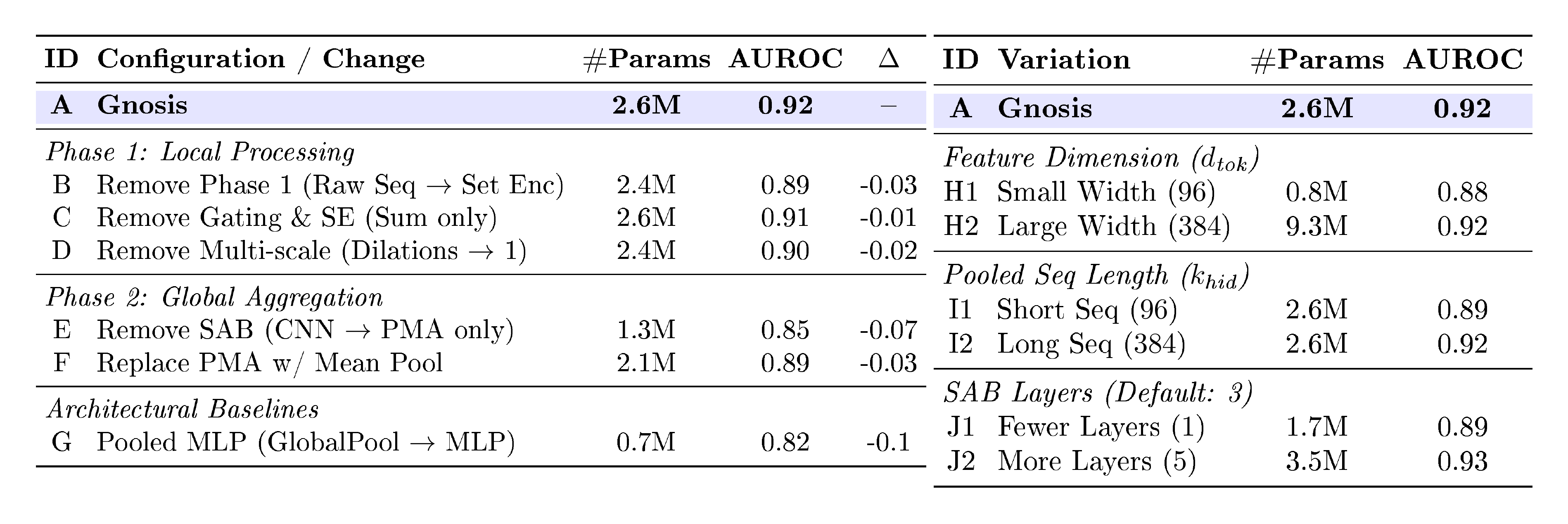
To identify the optimal architecture for the hidden-state circuit, we conducted a comprehensive ablation study investigating feature dimensionality, local temporal processing, and global aggregation strategies. Table 8 & Table 8 details this investigation. The final design (Row A) provides the best trade-off between reliability estimation (AUROC) and computational efficiency.
Dimensionality and Sizing. We first investigated the information bottleneck size ($d_{\text{tok}}, k_{\text{hid}}$). Comparing Rows H and I against our proposed model (Row A) reveals a clear performance plateau at size $192$. Reducing the size to $96$ causes a sharp performance drop ($-0.04$ AUROC), likely due to information loss during the initial pooling. Conversely, scaling to $384$ triples the parameter count without any accuracy gain. We therefore fix the dimensions to $192$ for efficiency.
Local Temporal Encoder (Phase 1). We investigated whether explicit local feature extraction is necessary before global processing. Row B shows that feeding raw pooled sequences directly to the set encoder reduces performance by $0.04$ AUROC, confirming that Phase 1 acts as a critical denoising stage. Inside Phase 1, we found that architectural complexity matters: removing the Squeeze-and-Excite gating (Row C) or replacing the multi-scale dilated convolutions with a standard convolution (Row D) both degrade performance. This suggests the model relies on capturing multi-scale temporal signals (via dilation) and dynamic feature reweighting (via SE/Gating).
Global Set Encoder (Phase 2). Finally, we analyzed the global aggregation stage. We found that simply averaging the features (Row F) or removing the global self-attention refinement (Row E) consistently hurts performance. This validates the use of the SAB+PMA stack to capture global context and learn specific reliability prototypes. Notably, our hybrid design significantly outperforms a simple pooled MLP baseline (Row G).
::: {caption="Table 8: Hidden-state Circuit: Components & Baselines. We ablate the hidden-state encoder by isolating the roles of local temporal mixing (Phase 1) and global set aggregation (Phase 2). Row A is our default configuration. Removing Phase 1 (B–D) or weakening global aggregation (E–F) consistently reduces AUROC, and a simple pooled MLP baseline (G) performs substantially worse."}
:::
C. Additional Experimental Setup
C.1 Benchmarks (extended).
We evaluate on three disjoint domains. For math reasoning, we use a combined test set of AMC12 2022, AMC12 2023 [33], AIME 2024 [34], AIME 2025 [35], and HMMT February 2025 [36]. These competition-style problems span a wide range of difficulty and require multi-step symbolic and numeric reasoning. For open-domain QA, we use an 18k-question held-out trivia subset drawn from the same distribution as our training corpus but with no overlapping items. This benchmark emphasizes short factoid answers and directly evaluates hallucination detection and knowledge grounding. For academic knowledge reasoning, we use MMLU-Pro [37], an out-of-distribution evaluation spanning 14 diverse domains (e.g., math, physics, law, psychology) that combines domain knowledge with multi-step reasoning, providing a broad test of generalization beyond the training mix.
C.2 Metrics (extended).
We frame correctness prediction as binary classification and report both ranking and calibration quality. AUROC measures how well a method ranks correct completions above incorrect ones (0.5 = chance, 1.0 = perfect). AUPR is reported with two complementary positive classes: AUPR-c treats correct completions as positive and summarizes how well a method recovers correct answers with high precision across recall; AUPR-e treats incorrect completions as positive and summarizes how well a method detects errors/hallucinations, which is often the more safety-relevant viewpoint under class imbalance. For probability quality, we report Brier Skill Score (BSS), where BSS
gt;0$ indicates improvement over a prevalence baseline, and Expected Calibration Error (ECE), where lower values indicate better alignment between predicted correctness probabilities and empirical accuracy.D. Backbone Outcome Statistics
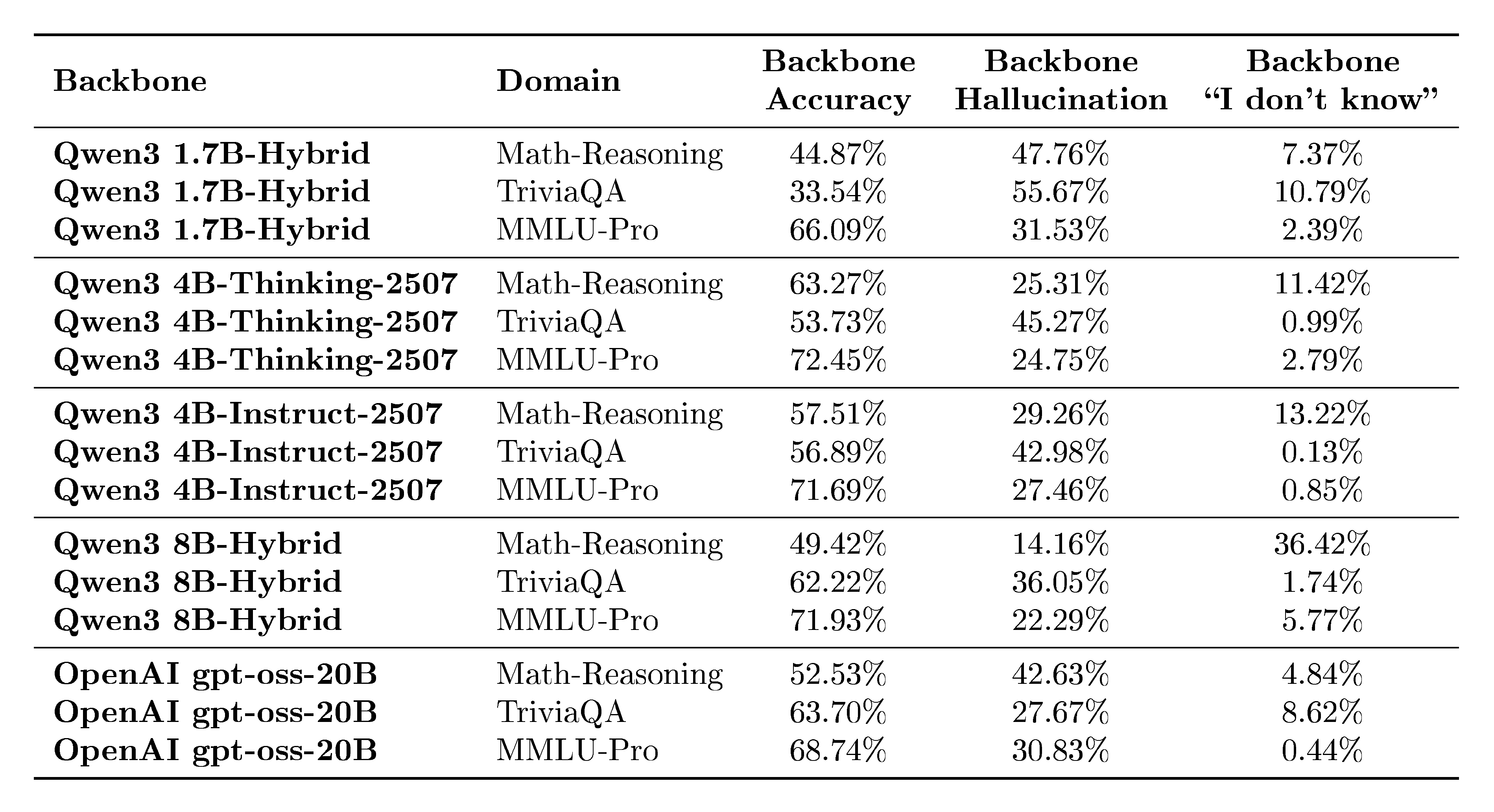
To contextualize the results in Table 1, we report the raw outcome breakdown of each frozen backbone on the three evaluation domains. While Table 1 focuses on the quality of correctness prediction (AUROC/AUPR/BSS/ECE) for different judges and internal methods, this table provides the underlying base behavior of each backbone: how often it is correct, how often it hallucinates, and how often it produces no valid final answer.
Importantly, non-response cases are reported here for completeness but are filtered out and not used in our correctness-prediction evaluation. Thus, the metrics in Table 1 are computed over the subset of generations with a valid, parsable answer. This table therefore serves two purposes: (i) it clarifies the intrinsic difficulty and failure modes of each backbone across domains, and (ii) it provides the context needed to interpret domain-dependent shifts in AUPR and calibration metrics reported in Table 1, which are more sensitive to the underlying prevalence of correct vs. incorrect answered generations.
::: {caption="Table 9: Backbone outcome rates (%) across evaluation domains. For each frozen backbone, we report the fraction of instances that are correct (Accuracy), incorrect (Hallucination), or no-answer ("I don't know"/refusal/empty). No-answer cases are shown for completeness but are filtered out from our correctness-prediction evaluation (Table 1)."}
:::
E. Gemini As judge.
For the LLM-as-judge baseline, we use Gemini 2.5 pro as a generative reward model. Given a question and a model-generated answer, the judge produces a brief correctness analysis and then emits a scalar score in $[0, 1]$ at the end of the response. We parse the score from the required <score> tags. Evaluating Gemini via the API on the three benchmarks reported in Table 1 cost approximately $500 in total. Figure 6 shows the prompt for using Gemini as the judge.
Gemini judge system prompt used for the LLM-as-judge baseline.
You are an objective, expert evaluator.
Your task is to review a Question and a proposed Answer.
Determine if the Answer is correct, and accurate based on the Question.
Assign a correctness score between 0.0 (completely wrong) and 1.0 (perfectly correct).
IMPORTANT:
Output the final score inside <score> tags.
Example: <score>0.95</score> or <score>0.0</score>.
References
[1] Kalai et al. (2025). Why language models hallucinate. arXiv preprint arXiv:2509.04664.
[2] Huang et al. (2025). A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions. ACM Transactions on Information Systems. 43(2). pp. 1–55.
[3] Kirichenko et al. (2025). AbstentionBench: Reasoning LLMs Fail on Unanswerable Questions. arXiv preprint arXiv:2506.09038.
[4] Kamoi et al. (2024). Evaluating LLMs at detecting errors in LLM responses. arXiv preprint arXiv:2404.03602.
[5] Kadavath et al. (2022). Language models (mostly) know what they know. arXiv preprint arXiv:2207.05221.
[6] Ulmer et al. (2024). Calibrating large language models using their generations only. arXiv preprint arXiv:2403.05973.
[7] Huang et al. (2025). Efficient test-time scaling via self-calibration. arXiv preprint arXiv:2503.00031.
[8] Sriramanan et al. (2024). LLM-Check: Investigating Detection of Hallucinations in Large Language Models. In Advances in Neural Information Processing Systems (NeurIPS).
[9] Pawitan, Yudi and Holmes, Chris (2025). Confidence in the reasoning of large language models. Harvard Data Science Review. 7(1).
[10] Stiennon et al. (2020). Learning to summarize with human feedback. Advances in neural information processing systems. 33. pp. 3008–3021.
[11] Ouyang et al. (2022). Training language models to follow instructions with human feedback. Advances in neural information processing systems. 35. pp. 27730–27744.
[12] Zheng et al. (2024). Processbench: Identifying process errors in mathematical reasoning. arXiv preprint arXiv:2412.06559.
[13] Wang et al. (2024). Helpsteer2-preference: Complementing ratings with preferences. arXiv preprint arXiv:2410.01257.
[14] Liu et al. (2025). Skywork-Reward-V2: Scaling Preference Data Curation via Human-AI Synergy. arXiv preprint arXiv:2507.01352.
[15] Geng et al. (2023). A survey of confidence estimation and calibration in large language models. arXiv preprint arXiv:2311.08298.
[16] Wang et al. (2025). Latent Space Chain-of-Embedding Enables Output-Free LLM Self-Evaluation. arXiv preprint arXiv:2410.13640.
[17] Zhang et al. (2025). Are the Hidden States Hiding Something? Testing the Limits of LLM Factuality Self-Evaluation. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (ACL).
[18] Zhang et al. (2025). Reasoning Models Know When They're Right: Probing Hidden States for Self-Verification. arXiv preprint arXiv:2504.05419.
[19] Wang et al. (2023). Math-shepherd: Verify and reinforce llms step-by-step without human annotations. arXiv preprint arXiv:2312.08935.
[20] Zhang et al. (2025). The lessons of developing process reward models in mathematical reasoning. arXiv preprint arXiv:2501.07301.
[21] Sriramanan et al. (2024). Llm-check: Investigating detection of hallucinations in large language models. Advances in Neural Information Processing Systems. 37. pp. 34188–34216.
[22] Duan et al. (2024). Do LLMs Know About Hallucination? An Empirical Investigation of LLM's Hidden States. arXiv preprint arXiv:2402.09733.
[23] Chen et al. (2024). Let's Measure Information Step-by-Step: LLM-Based Evaluation Metrics with Hidden States. arXiv preprint arXiv:2508.05469.
[24] Huang et al. (2024). Self-Evaluation of Large Language Model based on Glass-box Features. arXiv preprint arXiv:2403.04222.
[25] Azaria, Amos and Mitchell, Tom (2023). The internal state of an LLM knows when it's lying. arXiv preprint arXiv:2304.13734.
[26] Burns et al. (2022). Discovering latent knowledge in language models without supervision. arXiv preprint arXiv:2212.03827.
[27] Ghasemabadi et al. (2025). Guided by Gut: Efficient Test-Time Scaling with Reinforced Intrinsic Confidence. arXiv preprint arXiv:2505.20325.
[28] Lee et al. (2019). Set transformer: A framework for attention-based permutation-invariant neural networks. In International conference on machine learning. pp. 3744–3753.
[29] Yang et al. (2025). Qwen3 technical report. arXiv preprint arXiv:2505.09388.
[30] Agarwal et al. (2025). gpt-oss-120b & gpt-oss-20b model card. arXiv preprint arXiv:2508.10925.
[31] Qiying Yu et al. (2025). DAPO: An Open-Source LLM Reinforcement Learning System at Scale. https://arxiv.org/abs/2503.14476.
[32] Joshi et al. (2017). triviaqa: A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehension. arXiv e-prints. pp. arXiv:1705.03551.
[33] AI-MO Team (2024). AIMO Validation Set - AMC Subset. https://huggingface.co/datasets/AI-MO/aimo-validation-amc.
[34] Zhang, Yifan and Math-AI, Team (2024). American Invitational Mathematics Examination (AIME) 2024.
[35] Zhang, Yifan and Math-AI, Team (2025). American Invitational Mathematics Examination (AIME) 2025.
[36] Mislav Balunović et al. (2025). MathArena: Evaluating LLMs on Uncontaminated Math Competitions. https://matharena.ai/.
[37] Wang et al. (2024). Mmlu-pro: A more robust and challenging multi-task language understanding benchmark. Advances in Neural Information Processing Systems. 37. pp. 95266–95290.
[38] Malik et al. (2025). RewardBench 2: Advancing Reward Model Evaluation. arXiv preprint arXiv:2506.01937.