Planning with Reasoning using Vision Language World Model
Context and Purpose
Organizations are developing AI systems that can plan and execute complex, multi-step tasks in the real world—from assisting users with everyday activities to controlling robots. Current approaches either rely on large language models that lack grounding in visual reality, or train on limited simulated environments that do not capture real-world diversity. This work addresses the problem of teaching AI to understand how actions change the world by learning directly from massive amounts of natural video, enabling the system to plan effectively for high-level, long-horizon tasks.
What Was Done
The team developed the Vision Language World Model (VLWM), a foundation model that learns to predict how the world evolves in response to actions by watching videos of people performing tasks. The system represents world states using natural language rather than raw pixels, making predictions interpretable and computationally efficient.
The training process involves two stages: first, videos are compressed into hierarchical "Trees of Captions" that capture both fine details and long-term progression; second, a large language model extracts structured representations showing goals, actions, and resulting world state changes. The model was trained on 180,000 videos spanning over 800 days of content, including cooking tutorials, how-to videos, and first-person recordings of daily activities.
VLWM operates in two modes. System-1 provides fast, reactive planning by directly generating action sequences. System-2 enables reflective reasoning: the model generates multiple candidate plans, simulates their outcomes, and selects the plan that minimizes the distance between the predicted final state and the desired goal. This distance is measured by a separately trained "critic" model that learns through self-supervision to assign lower costs to valid progress and higher costs to irrelevant or out-of-order actions.
Main Findings
VLWM achieved state-of-the-art performance on the Visual Planning for Assistance benchmark, with relative improvements of 20% in success rate, 10% in accuracy, and 4% in precision compared to previous best methods. On robot question-answering tasks, it outperformed strong baselines with a score of 74.2.
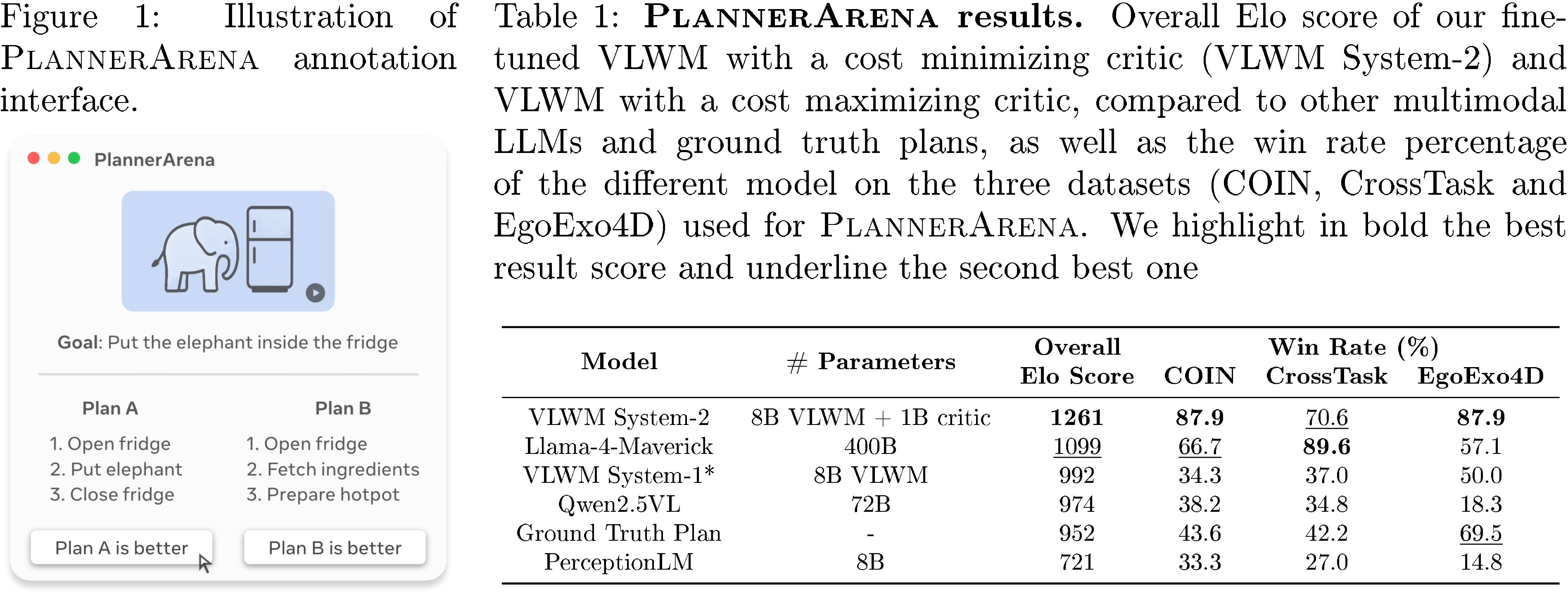
Human evaluations using a newly developed PlannerArena system showed that plans generated by VLWM's reflective System-2 mode were strongly preferred over those from other methods, achieving an Elo rating of 1261—significantly higher than the next best system at 1099. Notably, System-2 planning improved performance by 27% over System-1, demonstrating that internal trial-and-error reasoning produces better plans than direct generation.
The critic model independently excelled at detecting when goals are achieved, reaching 96.9% accuracy on in-domain data and maintaining 72.9% accuracy on out-of-domain planning tasks where it had never seen training examples.
What This Means
These results demonstrate that AI systems can learn robust world models from natural video at scale without requiring hand-crafted simulations or explicit reward signals. The language-based approach makes the system's reasoning transparent and allows it to leverage existing language model capabilities, while the two-mode design provides both speed and quality depending on task demands.
The strong performance on human preference evaluations indicates the system generates plans that people find genuinely useful, addressing a key gap where traditional benchmarks rely on noisy or incomplete ground-truth annotations. The System-2 reasoning capability represents a shift from simple imitation of demonstrations to active optimization, allowing the system to potentially exceed the quality of its training data.
Recommendations and Next Steps
For organizations developing AI assistants or robotic systems, VLWM provides a foundation that can be adapted to specific domains through fine-tuning. The dual-mode architecture should be deployed with System-1 for time-sensitive, straightforward tasks and System-2 when plan quality is critical or when tasks are complex and novel.
Development teams should focus on three areas: first, incorporating domain-specific constraints into the critic's cost function to enforce safety rules or task requirements; second, expanding the training data to cover additional domains where planning assistance is needed; third, developing interfaces that expose the model's interpretable reasoning to users, allowing them to understand and correct plans when needed.
Before production deployment, conduct targeted evaluations in your specific use case, as performance may vary across domains. Consider starting with lower-stakes applications where plan errors have minimal consequences.
Limitations and Confidence
The system's performance depends on the quality and coverage of training videos—domains poorly represented in the training data may see reduced accuracy. The critic model showed performance drops on tasks with action-only descriptions (no explicit world states), suggesting the full representation is important for reliable cost evaluation.
Ground-truth annotations in existing benchmarks were found to be of variable quality, making absolute performance numbers less meaningful than relative comparisons. The human evaluation involved five annotators on 550 comparisons; while inter-annotator agreement was substantial (72%), larger-scale validation would strengthen confidence in preference rankings.
The team has high confidence in the core findings: that large-scale video training enables effective world modeling, that language-based abstraction is viable for planning, and that System-2 reasoning consistently improves plan quality. Confidence is moderate on exact performance levels in new domains and on the optimal balance between System-1 and System-2 for specific applications—these will require domain-specific testing.
Abstract
1 Introduction
In this section, the authors establish that while world models have proven effective for low-level continuous control tasks like robotic manipulation and autonomous driving, learning world models for high-level task planning—where actions involve semantic and temporal abstraction—remains an open challenge that could unlock practical applications such as AI assistants in wearable devices and autonomous embodied agents. Existing approaches fall short: prompting-based methods using LLMs lack grounding in sensory experience, VLMs are trained for perception rather than action-conditioned world-state prediction, simulation-based learning cannot scale to diverse real-world activities, and pixel-based generative world models are computationally inefficient and capture task-irrelevant details. To address these limitations, the Vision Language World Model (VLWM) is introduced as a foundation model that uses natural language as an abstract world state representation, learning from massive uncurated video data to predict world evolution through language-based abstraction rather than raw pixels, enabling both reactive system-1 planning and reflective system-2 planning via cost minimization with a trained critic model.
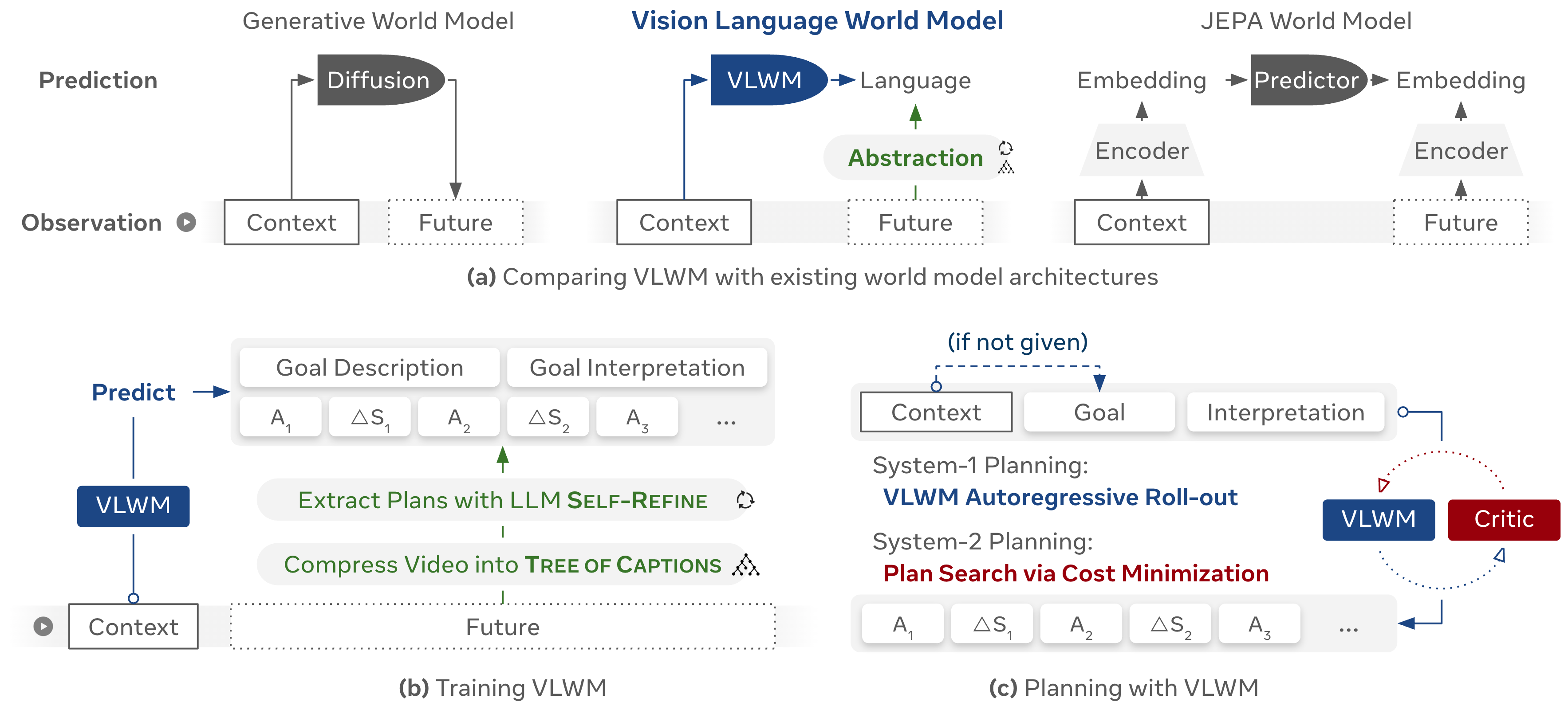
2 Methodology
In this section, the authors address the challenge of enabling AI agents to perform high-level task planning by developing a Vision Language World Model (VLWM) that predicts future world states using natural language abstractions rather than raw pixels. The methodology involves a two-stage approach: first, videos are compressed into hierarchical Tree of Captions through feature clustering and detailed captioning, dramatically reducing data volume while preserving semantic information; second, structured goal-plan representations—including goal descriptions, interpretations, actions, and world state changes—are extracted from these captions using iterative LLM Self-Refine. The VLWM is trained to predict these structured futures given visual context, enabling both fast System-1 reactive planning through direct text completion and reflective System-2 planning that searches over multiple candidate action sequences by minimizing costs evaluated by a self-supervised critic model, ultimately allowing the agent to reason internally and select optimal plans without real-world trial-and-error.
2.1 Vision-language World Modeling
2.1.1 Compress Video into TREE oF CAPTIONS\text{T{\scriptsize REE} o{\scriptsize F} C{\scriptsize APTIONS}}TREE oF CAPTIONS
2.1.2 Extract Plans with LLM SELF-REFINE\text{S{\scriptsize ELF-}R{\scriptsize EFINE}}SELF-REFINE
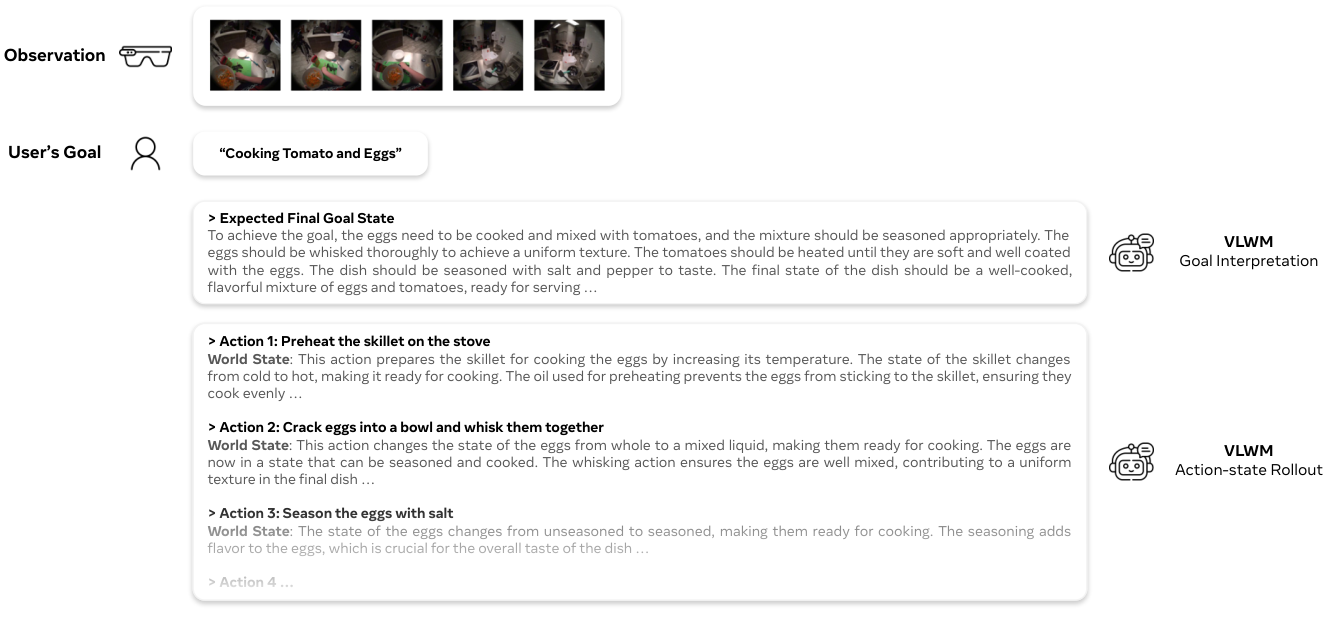
- Goal description is a high-level summary of the overall achievements (*e.g., * ``cook tomato and eggs''\texttt{``cook tomato and eggs''}‘‘cook tomato and eggs’’). In downstream applications, goal descriptions given by users are typically concise (*e.g., * single sentence), omitting fine-grained details that holistically defines the final state. Therefore, explicit goal interpretations are required.
- Goal interpretation includes contextual explanations that outlines both the initial and expected final world states. The initial state describes the current status of tools, materials, and dependencies, etc., providing essential grounding for plan generation. The final state interprets the goal description concretely to facilitate cost evaluation in system-2 planning. For example, ``To achieve the goal, the eggs need to be cooked and mixed with tomatoes, and the mixture should be seasoned appropriately. The eggs should be whisked thoroughly to achieve a uniform texture...''\texttt{``To achieve the goal, the eggs need to be cooked and mixed with tomatoes, and the mixture should be seasoned appropriately. The eggs should be whisked thoroughly to achieve a uniform texture...''}‘‘To achieve the goal, the eggs need to be cooked and mixed with tomatoes, and the mixture should be seasoned appropriately. The eggs should be whisked thoroughly to achieve a uniform texture...’’
- Action description are the final outputs of the system that will be passed to downstream embodiments for execution or presented to users (*e.g., * ``Preheat the skillet on the stove''\texttt{``Preheat the skillet on the stove''}‘‘Preheat the skillet on the stove’’). They must be clear, concise, and sufficiently informative to enable the receiver to understand and produce the intended world state transitions.
- World states are internal to the system and serve as intermediate representations for reasoning and plan search. They should be a information bottleneck: sufficiently capturing all task-relevant consequences of actions while containing minimal redundancy. For example: ``This action prepares the skillet for cooking the eggs by increasing its temperature. The state of the skillet changes from cold to hot, making it ready for cooking. The oil used for preheating prevents the eggs from sticking to the skillet, ensuring they cook evenly...''\texttt{``This action prepares the skillet for cooking the eggs by increasing its temperature. The state of the skillet changes from cold to hot, making it ready for cooking. The oil used for preheating prevents the eggs from sticking to the skillet, ensuring they cook evenly...''}‘‘This action prepares the skillet for cooking the eggs by increasing its temperature. The state of the skillet changes from cold to hot, making it ready for cooking. The oil used for preheating prevents the eggs from sticking to the skillet, ensuring they cook evenly...’’. See Appendix E.1 for more examples.
Llama-4 Maverick for its efficient inference and support for extended context length. Notably, the SELF-REFINE\text{S{\scriptsize ELF-}R{\scriptsize EFINE}}SELF-REFINE methodology is not tailored to specific LLM architecture. Below are some example feedback messages generated by Llama-4 Maverick during the SELF-REFINE\text{S{\scriptsize ELF-}R{\scriptsize EFINE}}SELF-REFINE process:2.1.3 Training of Vision Language World Model
config acts as system prompts. The context provides environmental information and can be either visual, textual, or both. The VLWM is trained to predict the future, represented by 1) goal description along with its interpretation (i.e., the initial and expected final states), and 2) a trajectory consisting of sequence action (AAA) state (ΔS\Delta SΔS) pairs. VLWM optimize the cross-entropy loss for next-token prediction on the right-hand side of Equation 1:config, context, and the goal description, VLWM interprets the goal and generates a sequence of action-state pairs until an <eos> token is reached. From a language modeling perspective, the world state descriptions act as internal chains of thought: they articulate the consequences of each action, allowing VLWM to track task progress and suggest appropriate next steps toward the goal. This planning mode is computationally efficient and well-suited for short-horizon, simple, and in-domain tasks.2.2 Planning with Reasoning
2.2.1 Learning the Critic from Self-supervision
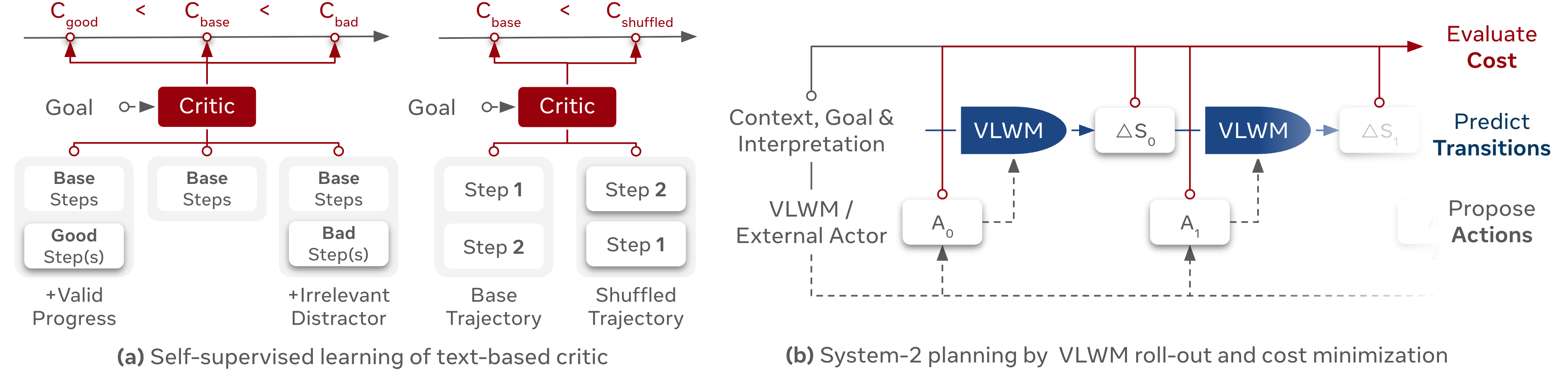
- We construct training samples by starting from a base partial trajectory and appending either (i) valid next step(s) resulting from a coherent continuation of the task, or (ii) distractor step(s) sampled from an unrelated task. The critic independently predicts three cost scores: CbaseC_\text{base}Cbase, CgoodC_\text{good}Cgood, and CbadC_\text{bad}Cbad and the model is trained to satisfy the ranking constraints Cgood<Cbase<CbadC_\text{good} < C_\text{base} < C_\text{bad}Cgood<Cbase<Cbad, encouraging the critic to distinguish meaningful progress from irrelevant or misleading continuations.
- We generate negative samples by randomly shuffling the steps in a base trajectory, producing a corrupted sequence with cost CshuffledC_\text{shuffled}Cshuffled . The critic is then trained to enforce Cbase<CshuffledC_\text{base} < C_\text{shuffled}Cbase<Cshuffled, ensuring sensitivity to procedural order and temporal coherence.
margin, supplemented with a cost centering regularization term weighted by a small constant λ\lambdaλ ([44]). To construct training pairs ⟨Cpositive,Cnegative⟩\langle C_\text{positive}, C_\text{negative} \rangle⟨Cpositive,Cnegative⟩, we iterate over all three types of self-supervised signal described above: ⟨Cgood,Cbase⟩\langle C_\text{good}, C_\text{base} \rangle⟨Cgood,Cbase⟩, ⟨Cbase,Cbad⟩\langle C_\text{base}, C_\text{bad} \rangle⟨Cbase,Cbad⟩, and ⟨Cbase,Cshuffled⟩\langle C_\text{base}, C_\text{shuffled} \rangle⟨Cbase,Cshuffled⟩ .2.2.2 System-2 Planning by Cost Minimization
3 Experiments
In this section, the authors evaluate VLWM-8B and VLWM-critic-1B across multiple benchmarks to demonstrate their effectiveness in procedural planning and world modeling. On the Visual Planning for Assistance (VPA) benchmark, VLWM-8B achieves state-of-the-art results on both COIN and CrossTask datasets, outperforming existing models including the 70B VidAssist across most metrics. Human evaluation through PlannerArena reveals that VLWM System-2, which combines the world model with a cost-minimizing critic, attains the highest Elo score of 1261 and is consistently preferred over ground truth plans and leading multimodal LLMs. On RoboVQA, VLWM-8B achieves competitive performance with a BLEU-1 score of 74.2, ranking first among compared models. Intrinsic evaluations of the critic demonstrate its ability to detect goal achievement with 98.4% accuracy on in-distribution data and maintain strong performance on out-of-distribution tasks, validating the self-supervised training approach and establishing VLWM as an effective framework for vision-language world modeling and planning.
In this section, the authors provide supplementary details and examples that support the main findings of the VLWM paper. They describe PlannerArena, a human evaluation framework where annotators compare model-generated plans by watching video contexts and selecting preferred action sequences, achieving substantial inter-annotator agreement with a Fleiss' kappa of 0.63. The appendix includes complete prompts for the LLM-based Self-Refine process, which extracts structured action plans, world state changes, and goal interpretations from video captions while ensuring faithfulness to visual content and logical coherence across steps. An illustrative Tree-of-Captions example demonstrates the hierarchical temporal segmentation of videos into nested caption boxes. Finally, complete VLWM planning examples showcase how the model generates interpretable action-state trajectories for tasks like cooking tomato and eggs, along with cost-minimizing and cost-maximizing plans that reveal how the critic differentiates high-quality from poor-quality action sequences.
In this section, the references encompass a broad spectrum of research on world models, autonomous agents, and video understanding that collectively address how artificial intelligence systems can learn to predict, plan, and act in complex environments. The citations trace the evolution from foundational concepts like temporal abstraction in reinforcement learning and early world models that learn compressed representations of environments, through modern vision-language models that generate captions and understand video content, to cutting-edge applications in autonomous driving, robotic manipulation, and web navigation. Key themes include learning world dynamics from visual observations, using large language models as planners with embedded world knowledge, training agents through imitation learning from imperfect demonstrations, and developing generative models that simulate interactive environments. The references ultimately demonstrate converging efforts to build AI systems that can model physical and digital worlds with sufficient fidelity to enable robust reasoning, long-horizon planning, and effective embodied action across diverse domains.
3.1 Implementation Details
3.1.1 VLWM-8B
PE-G14 ([42]) and PerceptionLM-3B ([22]) (320 ×\times× 320 spatial resolution, 32 frames per input – can be fit in 32GB V100) to generate the TREE oF cAPTIONS\text{T{\scriptsize REE} o{\scriptsize F} c{\scriptsize APTIONS}}TREE oF cAPTIONS. We sample up to 5 target window per video according to the tree structure (the first 5 nodes in BFS traversal order), and use Llama-4 Maverick (mixture of 128 experts, 17B activated and 400B total parameters, FP8 precision) to extract plans from the window with the sub-tree of captions and two rounds of SELF-REFINE\text{S{\scriptsize ELF-}R{\scriptsize EFINE}}SELF-REFINE. Additional speech transcripts for web videos and the expert commentary in EgoExo4D are provided along with video captions to improve LLM's video understanding during plan extraction. In addition to video-based extraction, we repurposed the NaturalReasoning ([34]) dataset to world modeling by replacing TREE oF cAPTIONS\text{T{\scriptsize REE} o{\scriptsize F} c{\scriptsize APTIONS}}TREE oF cAPTIONS with the chain-of-thoughts. Action-state trajectories are extracted by LLM SELF-REFINE\text{S{\scriptsize ELF-}R{\scriptsize EFINE}}SELF-REFINE with similar prompts.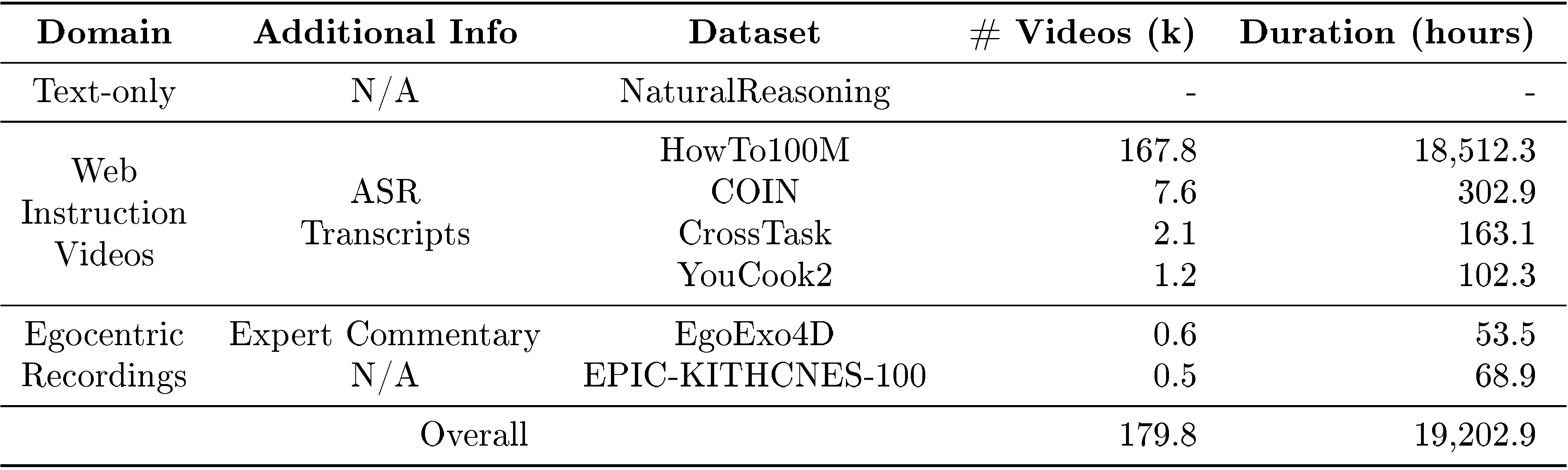
PerceptionLM-8B ([22]) to initialize our VLWM. The model is trained with a batch size of 128 and a maximum of 11.5k token context length. We perform uniform sampling of 32 frames in 4482^22 resolution for visual context inputs. With 12 nodes of 8 ×\times× H100 GPUs, the training takes approximately 5 days.3.1.2 VLWM-critic-1B
Llama-3.2-1B and trained for one epoch with a batch size of 128 (2.7k steps), maximum context length of 1536 tokens using a single node of 8 ×\times× H100 GPUs. For hyper-parameters in Equation 2, we set λ\lambdaλ =0.01 and margin\texttt{margin}margin =1.3.2 Visual Planning for Assistance (VPA)
3.2.1 VPA Benchmarks
DDN ([54]), LTA ([31]), VLaMP ([35]), and VidAssist ([36]), plus two frequency-based heuristics: Most-Probable (global action frequencies) and Most-Probable w/ Goal (task-conditioned frequencies). VLWM is fine-tuned on the VPA training splits of COIN and CrossTask using the same hyper-parameters as in pre-training. Following prior work, we report Success Rate (SR), Mean Accuracy (mAcc), and Mean IoU (mIoU) over the predicted step sequence, respectively measuring plan-level accuracy, step-level accuracy, and action proposal accuracy.3.2.2 Human Evaluation with PLANNERARENA\text{P{\scriptsize LANNER}A{\scriptsize RENA}}PLANNERARENA
3.3 RoboVQA
3D-VLA-4B ([60]), RoboMamba-3B ([61]), PhysVLM-3B ([57]), RoboBrain-7B ([56]), ThinkVLA-3B and ThinkAct ([62]).3.4 Critic Evaluations
3.4.1 Goal Achievement Detection
goal and a trajectory composed of a concatenation of NgoldN_\text{gold}Ngold steps of reference plan that achieves the goal, and NdistractorN_\text{distractor}Ndistractor irrelevant steps appended after, the task asks the critic model to independently evaluate costs for every partial progress from the beginning, i.e., C1=critic(goal,trajectory[0:1])C_1 = \mathbf{critic}(\texttt{goal}, \texttt{trajectory}[0:1])C1=critic(goal,trajectory[0:1]), C1=critic(goal,trajectory[0:2])C_1 = \mathbf{critic}(\texttt{goal}, \texttt{trajectory}[0:2])C1=critic(goal,trajectory[0:2]), …\dots…, until CNgold+Ndistractor=critic(goal,trajectory[0:Nbase+Ndistractor])C_{N_\text{gold}+N_\text{distractor}} = \mathbf{critic}(\texttt{goal}, \texttt{trajectory}[0:N_\text{base}+N_\text{distractor}])CNgold+Ndistractor=critic(goal,trajectory[0:Nbase+Ndistractor]). Since the distance to the goal should be the lowest after NgoldN_\text{gold}Ngold steps of reference plan, we calculate the goal achievement detection accuracy according to whether Ngold=argmin[C1,...,CNgold+Ndistractor]N_\text{gold}=\arg \min [C_1, ..., C_{N_\text{gold}+N_\text{distractor}}]Ngold=argmin[C1,...,CNgold+Ndistractor].goal field combines both goal description and goal interpretation. Since VLWM-critic-1B is trained on HowTo100M trajectories, we exclude it and only sample data from other sources of instruction videos (COIN, CrossTask, YouCook2), and egocentric recordings (EgoExo4D, EPIC-KITCHENS-100). 2) Open Grounded Planning (OGP): [63] released a collection of planning dataset containing goal-plan pairs sourced from different domains. We only use their "robot" subsets sourced from VirtualHoom and SayCan and WikiHow subset, since plans in the tool usage subset often contain too few number of steps. Different from VLWM data, trajectories in OGP only contain actions, and are OOD for both VLWM-critic-1B and baseline models. There are only 9,983 trajectories in OGP data.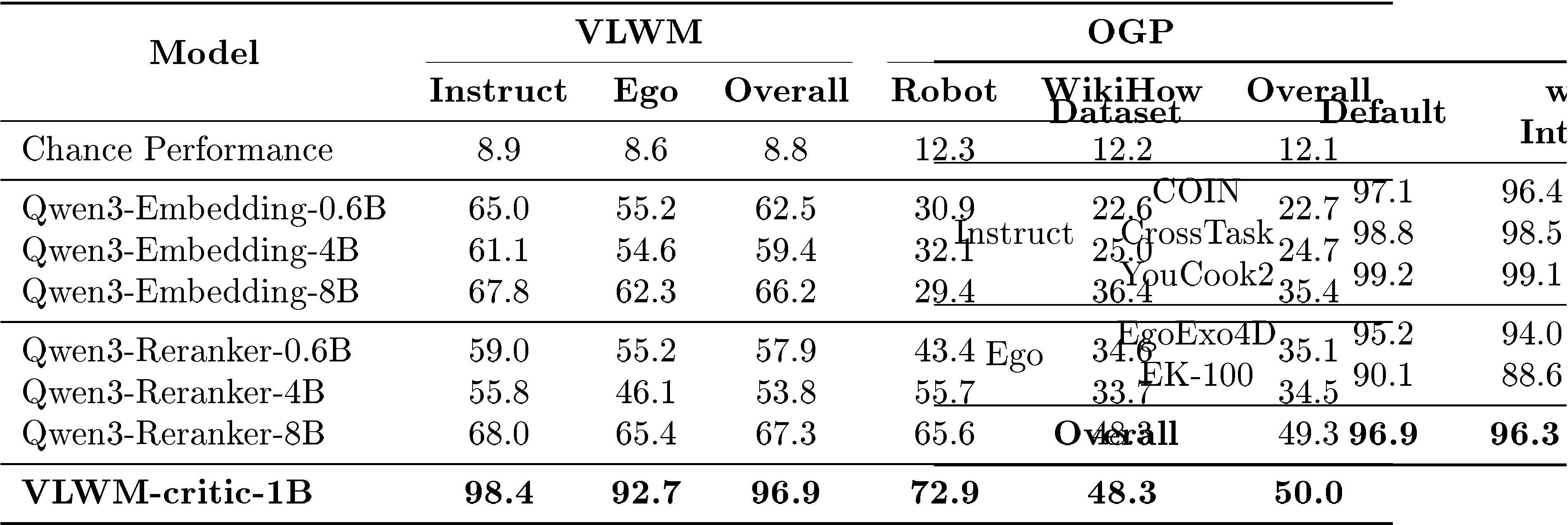
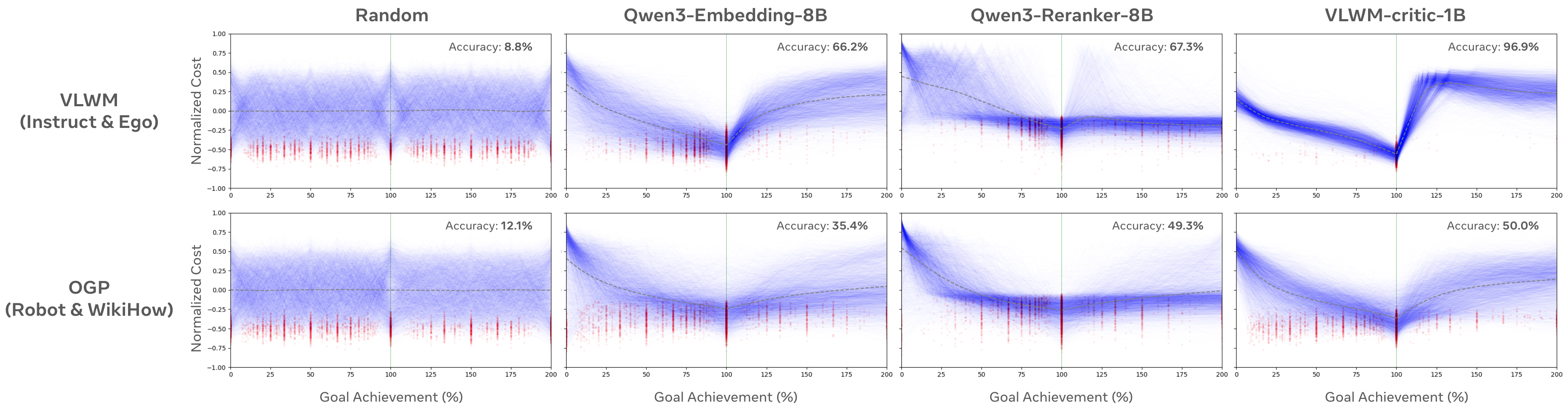
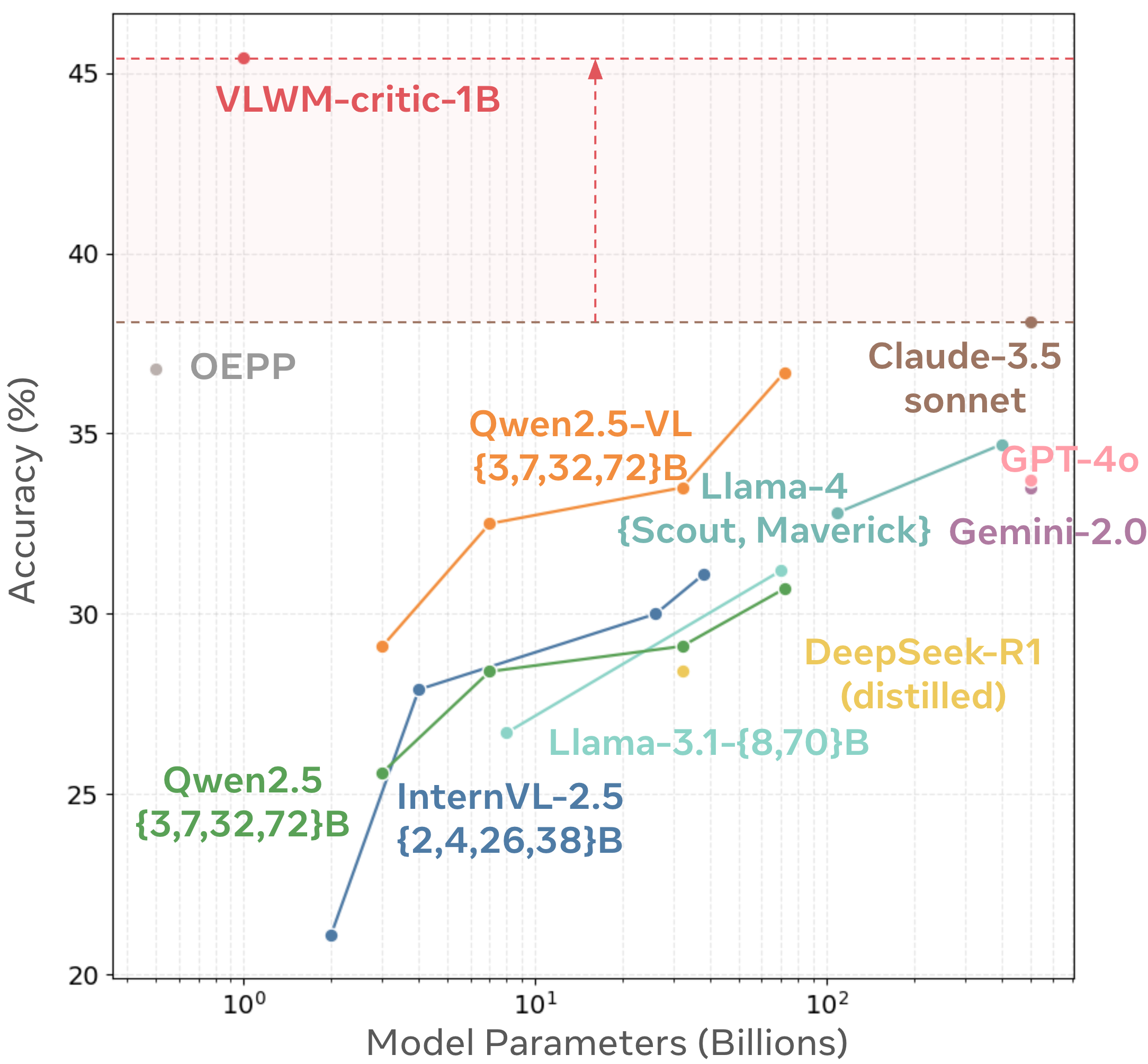
3.4.2 Procedural Planning on WORLDPREDICTION-PP\text{W{\scriptsize ORLD}P{\scriptsize REDICTION-PP}}WORLDPREDICTION-PP
4 Related Work
In this section, the authors position VLWM within the landscape of action planning and world modeling approaches. Action planning methods fall into three categories: imitation learning, which struggles with scarce or imperfect demonstrations particularly in procedural video tasks; reinforcement learning, which requires interactive environments with explicit rewards and doesn't scale to diverse domains; and planning with reward-agnostic world models, which learns from extensive offline data and optimizes plans through internal simulation by minimizing distance to goal states rather than predicting task-specific rewards. World modeling approaches similarly divide into generative models that reconstruct pixel-level observations but suffer from computational inefficiency and task-irrelevant details; JEPA models that predict in compact latent spaces but face training challenges and focus mainly on low-level control; and language-based world models that use natural language as an interpretable high-level abstraction. VLWM advances this last paradigm by learning directly from large-scale raw videos rather than relying on prompting existing LLMs or training in narrow domains.
4.1 Action Planning
4.2 World Modeling
5 Conclusion
In this section, the Vision Language World Model (VLWM) is presented as a foundation model that addresses the challenge of enabling AI systems to perform interpretable and efficient high-level planning by learning world dynamics directly in language space. The approach compresses raw videos into hierarchical Trees of Captions, which are refined into structured trajectories containing goals, actions, and world state changes, thereby bridging perception-driven vision-language models with reasoning-oriented language models. The system operates in dual modes: fast, reactive System-1 planning through direct policy decoding, and reflective System-2 planning via cost minimization guided by a self-supervised critic that enables internal trial-and-error reasoning. Trained on diverse instructional and egocentric videos, VLWM achieves state-of-the-art performance on Visual Planning for Assistance, PlannerArena human evaluations, and RoboVQA benchmarks while generating interpretable outputs. By predicting in abstract language representations rather than pixels, VLWM advances AI assistants beyond mere imitation toward reflective agents capable of robust, long-horizon decision-making.
Appendix
A PlannerArena Details
A.1 Instructions & data
language=Markdown
You are provided with a context segment of a procedural video about {goal_formatted}. Generate the remaining actions (steps) to take from that context segment in order to reach the goal. The plan should be composed of high-level descriptions starting with a verb, and it should be clear and concise, including all essential information. There is no need to be overly descriptive. Generate only the action steps.A.2 Pairs sampling & IAA
A.3 Example

B Prompts
B.1 Meta Prompt for LLM SELF-REFINE\text{S{\scriptsize ELF-}R{\scriptsize EFINE}}SELF-REFINE
language=Markdown
{TREE OF CAPTIONS} {ADDITIONAL VIDEO INFO}
## Draft
Here is a draft for structured data extraction:
{PREVISOUS DRAFT}
—- action: state: |- start: xx.xx # float between <min_start> and <max_end> round to two decimal digits end: xx.xx # float between <min_start> and <max_end> round to two decimal digits
- action: state: |- ... goal: interpretation: |-
Start your response with "'''yaml\n..." and end with "\n'''"B.2 Requirements of Plan Extraction for LLM SELF-REFINE\text{S{\scriptsize ELF-}R{\scriptsize EFINE}}SELF-REFINE
**Action Plan**
1. Identify a sequence of physical actions that meaningfully advance the task progress; Omit vague, redundant, or purely presentational steps.
2. Each action is one informative imperative sentence said from the actor's perspective. Avoid describing actions from the tutor's or demonstrator's voice.
3. Infer the span of each action according the provided timestamps. They must fall within <min_start> and <max_end> and do not overlap with each other.
4. Be selective - time in the video may be non-linear. For example, the final result may appear at the beginning of the video. Such actions should be skipped.
**World State**
1. Explain how the action is performed according to the provided captions. Use imperative voice and instructional or tutoral style.
2. Provide elaborated discussion of the motivation, rationale, and purpose behind the action.C Tree-of-Captions Example

language=Markdown
## 0.00s -> 164.53s (duration: 164.5s)
The video features a view of a man repairing a bicycle tire and tube. The man is wearing black gloves, and there is a bicycle lift holding a blue bike in the background. In the background is another person wearing a gray shirt. A black tool chest and a wooden tool bench can also be seen ...
### D. Segment 1 - 0.00s -> 126.20s (duration: 126.2s)
This video features a man showing a second man how to repair a tire. The second man stands center screen in a workshop. The man holding the tire is center screen and behind him is a large workbench. In the background are several other objects of various sizes and shapes ...
D VLWM Planning Examples
D.1 Full Trajectory
html
<!------------ VLWM Input ------------>
<GOAL>
Cooking Tomato and Eggs
</GOAL>
html
<!------------ VLWM Output ------------>
<INTERPRETATION>
Now, the kitchen is set up with necessary ingredients and tools. To achieve the goal, the eggs need to be cooked and mixed with tomatoes, and the mixture should be seasoned appropriately. The eggs should be whisked thoroughly to achieve a uniform texture. The tomatoes should be heated until they are soft and well coated with the eggs. The dish should be seasoned with salt and pepper to taste. The final state of the dish should be a well-cooked, flavorful mixture of eggs and tomatoes, ready for serving. The kitchen environment and the tools used, such as the stove, pan, and utensils, are crucial for achieving this goal. The ingredients, including eggs, tomatoes, oil, salt, and pepper, are essential for creating the desired dish.
</INTERPRETATION>
---
<ACTION>D.2 Cost Min/maximizing Plans
language=Markdown
##### Goal: Make Beef Tacos
Cost Minimizing Plan (cost = -4.86):
1. Saute chopped onions and garlic in oil
2. Add ground beef to the pan and break it up
3. Add seasoning to the beef mixture
4. Add tomato sauce to the beef mixture and stir
5. Prepare taco shells