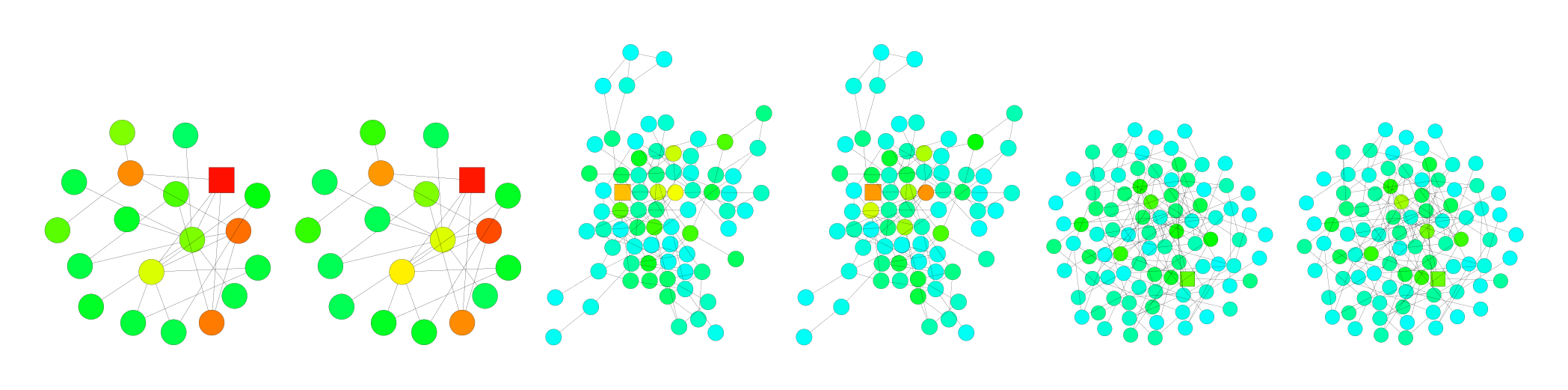Representation Learning on Graphs with Jumping Knowledge Networks
Show me an executive summary.
1) Purpose and context
Graph neural networks learn node representations by aggregating features from nearby nodes. Standard models use a fixed number of aggregation steps, which works poorly on graphs with varied local structures, like social or biological networks. Deeper models often perform worse due to over-smoothing. This work analyzes these limits and proposes Jumping Knowledge Networks to adapt neighborhood ranges per node.
2) Approach
Researchers studied how node representations draw from neighbors, linking it to random walk spreads on graphs. They found influence depends heavily on local structure—fast in dense cores, slow in tree-like areas. To fix this, they created Jumping Knowledge Networks. These run standard aggregations over multiple layers, then combine layer outputs at the end using methods like concatenation, max-pooling, or attention via LSTM. They tested on citation (Citeseer, Cora), social (Reddit), and protein (PPI) datasets for node classification.
3) Key results
JK-Networks beat baselines:
- On Citeseer and Cora citation data, accuracy rose 1-2 points over Graph Convolutional Networks (77-89% range).
- On Reddit posts, micro-F1 improved to 0.965 from 0.950.
- On PPI proteins, micro-F1 reached 0.818 (LSTM) from 0.690 (GraphSAGE); attention variants hit 0.976.
Deeper JK models (up to 6 layers) outperformed shallower ones, unlike baselines.
4) Main conclusion
Jumping Knowledge Networks improve graph representations by letting each node select optimal neighborhood sizes, adapting to diverse structures without over-smoothing.
5) Implications
Better accuracy aids applications like paper classification, community detection, and protein function prediction. Enhances existing models (e.g., adds 30% error reduction on Reddit), cuts risk of poor performance on complex graphs, speeds reliable predictions. Unlike prior work, deeper layers help here, avoiding manual layer tuning.
6) Recommendations and next steps
Apply JK-Networks to boost current graph models—start with max-pooling for simple cases, LSTM-attention for complex graphs. Trade-offs: concatenation suits regular graphs but needs more parameters; attention risks overfitting small data. Test on target graphs next; run pilots on full datasets before deployment.
7) Limitations and confidence
Assumes ReLU-like activations for theory; visuals from specific splits. LSTM may overfit small graphs. High confidence in results (multiple datasets, baselines beaten consistently); use caution on untested graph types needing further validation.
Keyulu Xu1^{1}1 Chengtao Li1^{1}1 Yonglong Tian1^{1}1 Tomohiro Sonobe2^{2}2
Ken-ichi Kawarabayashi1^{1}1 Stefanie Jegelka1^{1}1
1^{1}1Massachusetts Institute of Technology (MIT)
2^{2}2National Institute of Informatics, Tokyo. Correspondence to: Keyulu Xu
[email protected], Stefanie Jegelka
[email protected].
Abstract
Recent deep learning approaches for representation learning on graphs follow a neighborhood aggregation procedure. We analyze some important properties of these models, and propose a strategy to overcome those. In particular, the range of “neighboring” nodes that a node’s representation draws from strongly depends on the graph structure, analogous to the spread of a random walk. To adapt to local neighborhood properties and tasks, we explore an architecture – jumping knowledge (JK) networks – that flexibly leverages, for each node, different neighborhood ranges to enable better structure-aware representation. In a number of experiments on social, bioinformatics and citation networks, we demonstrate that our model achieves state-of-the-art performance. Furthermore, combining the JK framework with models like Graph Convolutional Networks, GraphSAGE and Graph Attention Networks consistently improves those models’ performance.
1. Introduction
In this section, neighborhood aggregation schemes in graph representation learning, while powerful for tasks like node classification, suffer from depth limitations: deeper models like GCN underperform shallower ones despite accessing more neighborhood information, even with residuals, due to structure-dependent influence distributions resembling random walk spreads that vary sharply across graph subgraphs—from rapid expansion in expander cores to slow growth in tree-like peripheries. To enable adaptive, structure-aware representations, Jumping Knowledge (JK) Networks are introduced, flexibly combining multi-layer neighborhood aggregations per node at the final layer. Experiments on diverse networks demonstrate state-of-the-art performance and consistent gains when augmenting models like GCN, GraphSAGE, and GAT.
Graphs are a ubiquitous structure that widely occurs in data analysis problems. Real-world graphs such as social networks, financial networks, biological networks and citation networks represent important rich information which is not seen from the individual entities alone, for example, the communities a person is in, the functional role of a molecule, and the sensitivity of the assets of an enterprise to external shocks. Therefore, representation learning of nodes in graphs aims to extract high-level features from a node as well as its neighborhood, and has proved extremely useful for many applications, such as node classification, clustering, and link prediction (Perozzi et al., 2014; Monti et al., 2017; Grover & Leskovec, 2016; Tang et al., 2015).
Recent works focus on deep learning approaches to node representation. Many of these approaches broadly follow a neighborhood aggregation (or “message passing” scheme), and those have been very promising (Kipf & Welling, 2017; Hamilton et al., 2017; Gilmer et al., 2017; Veličković et al., 2018; Kearnes et al., 2016). These models learn to iteratively aggregate the hidden features of every node in the graph with its adjacent nodes’ as its new hidden features, where an iteration is parametrized by a layer of the neural network. Theoretically, an aggregation process of kkk iterations makes use of the subtree structures of height kkk rooted at every node. Such schemes have been shown to generalize the Weisfeiler-Lehman graph isomorphism test (Weisfeiler & Lehman, 1968) enabling to simultaneously learn the topology as well as the distribution of node features in the neighborhood (Shervashidze et al., 2011; Kipf & Welling, 2017; Hamilton et al., 2017).
Yet, such aggregation schemes sometimes lead to surprises. For example, it has been observed that the best performance with one of the state-of-the-art models, Graph Convolutional Networks (GCN), is achieved with a 2-layer model. Deeper versions of the model that, in principle, have access to more information, perform worse (Kipf & Welling, 2017). A similar degradation of learning for computer vision problems is resolved by residual connections (He et al., 2016a) that greatly aid the training of deep models. But, even with residual connections, GCNs with more layers do not perform as well as the 2-layer GCN on many datasets, e.g. citation networks.
Motivated by observations like the above, in this paper, we address two questions. First, we study properties and resulting limitations of neighborhood aggregation schemes. Second, based on this analysis, we propose an architecture that, as opposed to existing models, enables adaptive, structure-aware representations. Such representations are particularly interesting for representation learning on large complex graphs with diverse subgraph structures.
Model analysis. To better understand the behavior of different neighborhood aggregation schemes, we analyze the effective range of nodes that any given node’s representation draws from. We summarize this sensitivity analysis by what we name the influence distribution of a node. This effective range implicitly encodes prior assumptions on what are the “nearest neighbors” that a node should draw information from. In particular, we will see that this influence is heavily affected by the graph structure, raising the question whether “one size fits all”, in particular in graphs whose subgraphs have varying properties (such as more tree-like or more expander-like).
In particular, our more formal analysis connects influence distributions with the spread of a random walk at a given node, a well-understood phenomenon as a function of the graph structure and eigenvalues (Lovász, 1993). For instance, in some cases and applications, a 2-step random walk influence that focuses on local neighborhoods can be more informative than higher-order features where some of the information may be “washed out” via averaging.
Changing locality. To illustrate the effect and importance of graph structure, recall that many real-world graphs possess locally strongly varying structure. In biological and citation networks, the majority of the nodes have few connections, whereas some nodes (hubs) are connected to many other nodes. Social and web networks usually consist of an expander-like core part and an almost-tree (bounded treewidth) part, which represent well-connected entities and the small communities respectively (Leskovec et al., 2009; Maehara et al., 2014; Tsonis et al., 2006).
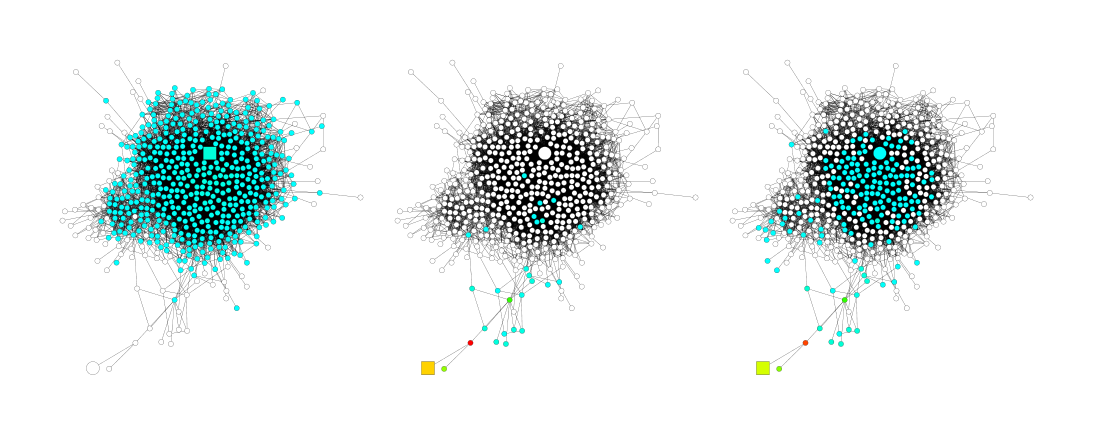
Besides node features, this subgraph structure has great impact on the result of neighborhood aggregation. The speed of expansion or, equivalently, growth of the influence radius, is characterized by the random walk’s mixing time, which changes dramatically on subgraphs with different structures (Lovász, 1993). Thus, the same number of iterations (layers) can lead to influence distributions of very different locality. As an example, consider the social network in Figure 1 from GooglePlus (Leskovec & Mcauley, 2012). The figure illustrates the expansions of a random walk starting at the square node. The walk (a) from a node within the core rapidly includes almost the entire graph. In contrast, the walk (b) starting at a node in the tree part includes only a very small fraction of all nodes. After 5 steps, the same walk has reached the core and, suddenly, spreads quickly. Translated to graph representation models, these spreads become the influence distributions or, in other words, the averaged features yield the new feature of the walk’s starting node. This shows that in the same graph, the same number of steps can lead to very different effects. Depending on the application, wide-range or small-range feature combinations may be more desirable. A too rapid expansion may average too broadly and thereby lose information, while in other parts of the graph, a sufficient neighborhood may be needed for stabilizing predictions.
JK networks. The above observations raise the question whether it is possible to adaptively adjust (i.e., learn) the influence radii for each node and task. To achieve this, we explore an architecture that learns to selectively exploit information from neighborhoods of differing locality. This architecture selectively combines different aggregations at the last layer, i.e., the representations “jump” to the last layer. Hence, we name the resulting networks Jumping Knowledge Networks (JK-Nets). We will see that empirically, when adaptation is an option, the networks indeed learn representations of different orders for different graph substructures. Moreover, in Section 6, we show that applying our framework to various state-of-the-art neighborhood-aggregation models consistently improves their performance.
2. Background and Neighborhood aggregation schemes
In this section, neighborhood aggregation schemes drive deep graph representation learning by iteratively updating each node's hidden features through aggregation of its (self-loop augmented) neighbors' prior features, followed by linear transformation and nonlinearity. Graph Convolutional Networks exemplify this via degree-normalized summation or mean-averaging. Skip-connection variants first aggregate pure neighbors, then combine with the node's prior state using concatenation, interpolation, GRU, or residuals—yet these propagate signals uniformly, preventing adaptive neighborhood sizing per final representation. Directional biases, such as attention in GAT or max-pooling in GraphSAGE, prioritize influential neighbors to steer expansion directionally. Orthogonal to locality control, these enhance models like JK-Nets for superior structure-aware power.
We begin by summarizing some of the most common neighborhood aggregation schemes and, along the way, introduce our notation. Let G=(V,E)G = (V, E)G=(V,E) be a simple graph with node features Xv∈RdiX_v \in \mathbb{R}^{d_i}Xv∈Rdi for v∈Vv \in Vv∈V. Let G~\tilde{G}G~ be the graph obtained by adding a self-loop to every v∈Vv \in Vv∈V. The hidden feature of node vvv learned by the lll-th layer of the model is denoted by hv(l)∈Rdhh_v^{(l)} \in \mathbb{R}^{d_h}hv(l)∈Rdh. Here, did_idi is the dimension of the input features and dhd_hdh is the dimension of the hidden features, which, for simplicity of exposition, we assume to be the same across layers. We also use hv(0)=Xvh_v^{(0)} = X_vhv(0)=Xv for the node feature. The neighborhood N(v)={u∈V∣(v,u)∈E}N(v) = \{u \in V | (v, u) \in E\}N(v)={u∈V∣(v,u)∈E} of node vvv is the set of adjacent nodes of vvv. The analogous neighborhood N~(v)={v}∪{u∈V∣(v,u)∈E}\tilde{N}(v) = \{v\} \cup \{u \in V | (v, u) \in E\}N~(v)={v}∪{u∈V∣(v,u)∈E} on G~\tilde{G}G~ includes vvv.
A typical neighborhood aggregation scheme can generically be written as follows: for a kkk-layer model, the lll-th layer (l=1..kl = 1..kl=1..k) updates hv(l)h_v^{(l)}hv(l) for every v∈Vv \in Vv∈V simultaneously as
where AGGREGATE is an aggregation function defined by the specific model, WlW_lWl is a trainable weight matrix on the lll-th layer shared by all nodes, and σ\sigmaσ is a non-linear activation function, e.g. a ReLU.
Graph Convolutional Networks (GCN). Graph Convolutional Networks (GCN) (Kipf & Welling, 2017), initially motivated by spectral graph convolutions (Hammond et al., 2011; Defferrard et al., 2016), are a specific instantiation of this framework (Gilmer et al., 2017), of the form
where deg(v)\text{deg}(v)deg(v) is the degree of node vvv in G~\tilde{G}G~. Hamilton et al. (2017) derived a variant of GCN that also works in inductive settings (previously unseen nodes), by using a different normalization to average:
where deg~(v)\tilde{\text{deg}}(v)deg~(v) is the degree of node vvv in G~\tilde{G}G~.
Neighborhood Aggregation with Skip Connections. Instead of aggregating a node and its neighbors at the same time as in Eqn. (1), a number of recent approaches aggregate the neighbors first and then combine the resulting neighborhood representation with the node’s representation from the last iteration. More formally, each node is updated as
where AGGREGATEN\text{AGGREGATE}_NAGGREGATEN and COMBINE are defined by the specific model. The COMBINE step is key to this paradigm and can be viewed as a form of a "skip connection" between different layers. For COMBINE, GraphSAGE (Hamilton et al., 2017) uses concatenation after a feature transform. Column Networks (Pham et al., 2017) interpolate the neighborhood representation and the node’s previous representation, and Gated GNN (Li et al., 2016) uses the Gated Recurrent Unit (GRU) (Cho et al., 2014). Another well-known variant of skip connections, residual connections, use the identity mapping to help signals propagate (He et al., 2016a;b).
These skip connections are input- but not output-unit specific: If we "skip" a layer for hv(l)h_v^{(l)}hv(l) (do not aggregate) or use a certain COMBINE, all subsequent units using this representation will be using this skip implicitly. It is impossible that a certain higher-up representation hu(l+j)h_u^{(l+j)}hu(l+j) uses the skip and another one does not. As a result, skip connections cannot adaptively adjust the neighborhood sizes of the final-layer representations independently.
Neighborhood Aggregation with Directional Biases. Some recent models, rather than treating the features of adjacent nodes equally, weigh “important” neighbors more. This paradigm can be viewed as neighborhood-aggregation with directional biases because a node will be influenced by some directions of expansion more than the others.
Graph Attention Networks (GAT) (Veličković et al., 2018) and VAIN (Hoshen, 2017) learn to select the important neighbors via an attention mechanism. The max-pooling operation in GraphSAGE (Hamilton et al., 2017) implicitly selects the important nodes. This line of work is orthogonal to ours, because it modifies the direction of expansion whereas our model operates on the locality of expansion. Our model can be combined with these models to add representational power. In Section 6, we demonstrate that our framework works with not only simple neighborhood-aggregation models (GCN), but also with skip connections (GraphSAGE) and directional biases (GAT).
3. Influence Distribution and Random Walks
In this section, neighborhood aggregation in graph neural networks faces scrutiny over the effective range of nodes influencing each representation, captured by influence distributions measuring sensitivity of a node's final features to others' inputs. These distributions are theoretically and empirically linked to random walk spreads, with a key theorem proving that GCN influences match expected k-step random walk probabilities under randomized ReLU assumptions, visualized in heatmaps akin to lazy walks for residual variants. The upshot is rapid convergence to uniform global averaging on expander subgraphs after logarithmic steps—eroding local node specificity—versus sluggish expansion in tree-like areas that preserves locality, exposing how fixed aggregation inherits structural mismatches and hampers adaptive representations on diverse graphs.
Next, we explore some important properties of the above aggregation schemes. Related to ideas of sensitivity analysis and influence functions in statistics (Koh & Liang, 2017) that measure the influence of a training point on parameters, we study the range of nodes whose features affect a given node’s representation. This range gives insight into how large a neighborhood a node is drawing information from.
We measure the sensitivity of node xxx to node yyy, or the influence of yyy on xxx, by measuring how much a change in the input feature of yyy affects the representation of xxx in the last layer. For any node xxx, the influence distribution captures the relative influences of all other nodes.
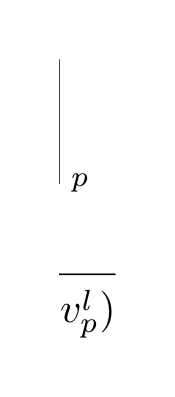
Definition 3.1 (Influence score and distribution). For a simple graph G=(V,E)G = (V, E)G=(V,E), let hx(0)h_x^{(0)}hx(0) be the input feature and hx(k)h_x^{(k)}hx(k) be the learned hidden feature of node x∈Vx \in Vx∈V at the kkk-th (last) layer of the model. The influence score I(x,y)I(x, y)I(x,y) of node xxx by any node y∈Vy \in Vy∈V is the sum of the absolute values of the entries of the Jacobian matrix [∂hx(k)∂hy(0)]\left[ \frac{\partial h_x^{(k)}}{\partial h_y^{(0)}} \right][∂hy(0)∂hx(k)]. We define the influence distribution IxI_xIx of x∈Vx \in Vx∈V by normalizing the influence scores: Ix(y)=I(x,y)/∑zI(x,z)I_x(y) = I(x, y) / \sum_{z} I(x, z)Ix(y)=I(x,y)/∑zI(x,z), or
where eee is the all-ones vector.
Later, we will see connections of influence distributions with random walks. For completeness, we also define random walk distributions.
Definition 3.2. Consider a random walk on G~\tilde{G}G~ starting at a node v0v_0v0; if at the ttt-th step we are at a node vtv_tvt, we move to any neighbor of vtv_tvt (including vtv_tvt) with equal probability.
The ttt-step random walk distribution PtP_tPt of v0v_0v0 is
Analogous definitions apply for random walks with non-uniform transition probabilities.
An important property of the random walk distribution is that it becomes more spread out as ttt increases and converges to the limit distribution if the graph is non-bipartite. The rate of convergence depends on the structure of the subgraph and can be bounded by the spectral gap (or the conductance) of the random walk’s transition matrix (Lovász, 1993).
3.1. Model Analysis
The influence distribution for different aggregation models and nodes can give insights into the information captured by the respective representations. The following results show that the influence distributions of common aggregation schemes are closely connected to random walk distributions. This observation hints at specific implications – strengths and weaknesses – that we will discuss.
With a randomization assumption of the ReLU activations similar to that in (Kawaguchi, 2016; Choromanska et al., 2015), we can draw connections between GCNs and random walks:
Theorem 1. Given a kkk-layer GCN with averaging as in Equation (3), assume that all paths in the computation graph of the model are activated with the same probability of success ρ\rhoρ. Then the influence distribution IxI_xIx for any node x∈Vx \in Vx∈V is equivalent, in expectation, to the kkk-step random walk distribution on G~\tilde{G}G~ starting at node xxx.
We prove Theorem 1 in the appendix.
It is straightforward to modify the proof of Theorem 1 to show a nearly equivalent result for the version of GCN in Equation (2). The only difference is that each random walk path vp0,vp1,…,vpkv_p^0, v_p^1, \dots, v_p^kvp0,vp1,…,vpk from node xxx (vp0v_p^0vp0) to yyy (vpkv_p^kvpk), instead of probability ρ∏l=1k1deg~(vpl)\rho \prod_{l=1}^k \frac{1}{\tilde{\text{deg}}(v_p^l)}ρ∏l=1kdeg~(vpl)1, now has probability ρQ∏l=1k−11deg~(vpl)⋅(deg~(x)deg~(y))−1/2\frac{\rho}{Q} \prod_{l=1}^{k-1} \frac{1}{\tilde{\text{deg}}(v_p^l)} \cdot (\tilde{\text{deg}}(x)\tilde{\text{deg}}(y))^{-1/2}Qρ∏l=1k−1deg~(vpl)1⋅(deg~(x)deg~(y))−1/2, where QQQ is a normalizing factor. Thus, the difference in probability is small, especially when the degree of xxx and yyy are close.
Similarly, we can show that neighborhood aggregation schemes with directional biases resemble biased random walk distributions. This follows by substituting the corresponding probabilities into the proof of Theorem 1.
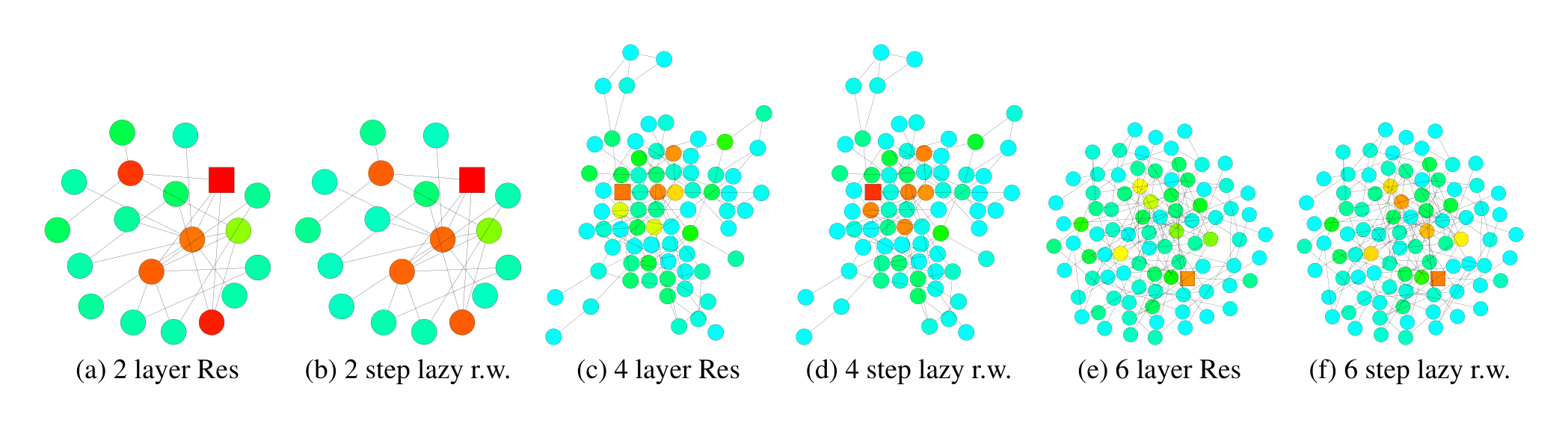
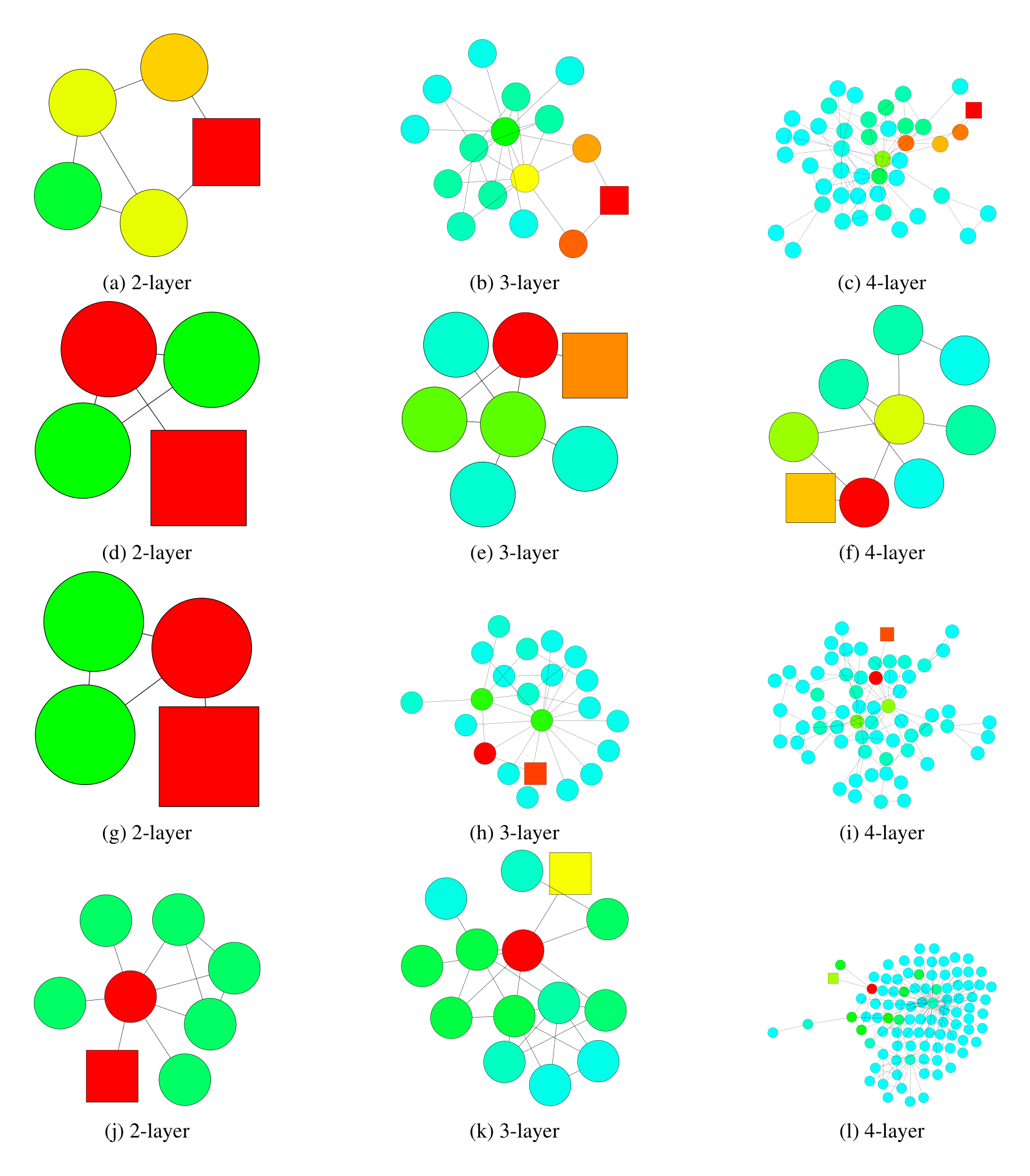
Empirically, we observe that, despite somewhat simplifying assumptions, our theory is close to what happens in practice. We visualize the heat maps of the influence distributions for a node (labeled square) for trained GCNs, and compare with the random walk distributions starting at the same node. Figure 2 shows example results. Darker colors correspond to higher influence probabilities. To show the effect of skip connections, Figure 3 visualizes the analogous heat maps for one example—GCN with residual connections. Indeed, we observe that the influence distributions of networks with residual connections approximately correspond to lazy random walks: each step has a higher probability of staying at the current node. Local information is retained with similar probabilities for all nodes in each iteration; this cannot adapt to diverse needs of specific upper-layer nodes. Further visualizations may be found in the appendix.
Fast Collapse on Expanders. To better understand the implication of Theorem 1 and the limitations of the corresponding neighborhood aggregation algorithms, we revisit the scenario of learning on a social network shown in Figure 1. Random walks starting inside an expander converge rapidly in O(log∣V∣)O(\log |V|)O(log∣V∣) steps to an almost-uniform distribution (Hoory et al., 2006). After O(log∣V∣)O(\log |V|)O(log∣V∣) iterations of neighborhood aggregation, by Theorem 1 the representation of every node is influenced almost equally by any other node in the expander. Thus, the node representations will be representative of the global graph and carry limited information about individual nodes. In contrast, random walks starting at the bounded tree-width (almost-tree) part converge slowly, i.e., the features retain more local information. Models that impose a fixed random walk distribution inherit these discrepancies in the speed of expansion and influence neighborhoods, which may not lead to the best representations for all nodes.
4. Jumping Knowledge Networks
In this section, standard graph networks impose fixed influence radii via uniform neighborhood aggregation, inadequately capturing diverse substructures like expanders and trees. Jumping Knowledge Networks address this by forwarding all intermediate layer representations to the final layer for node-adaptive combination through concatenation, element-wise max-pooling, or LSTM-attention, enabling selective exploitation of local-to-global information. This yields tailored influence distributions akin to mixtures of random walks, as JK-Nets learn to confine spreads in tree-like areas or emphasize self-features in hubs. Unlike DenseNet-style interlayer connections suited to regular graphs like images, JK-Nets provide a flexible framework for superior structure-aware embeddings in complex graphs.
The above observations raise the question whether the fixed but structure-dependent influence radius size induced by common aggregation schemes really achieves the best representations for all nodes and tasks. Large radii may lead to too much averaging, while small radii may lead to instabilities or insufficient information aggregation. Hence, we propose two simple yet powerful architectural changes – jump connections and a subsequent selective but adaptive aggregation mechanism.
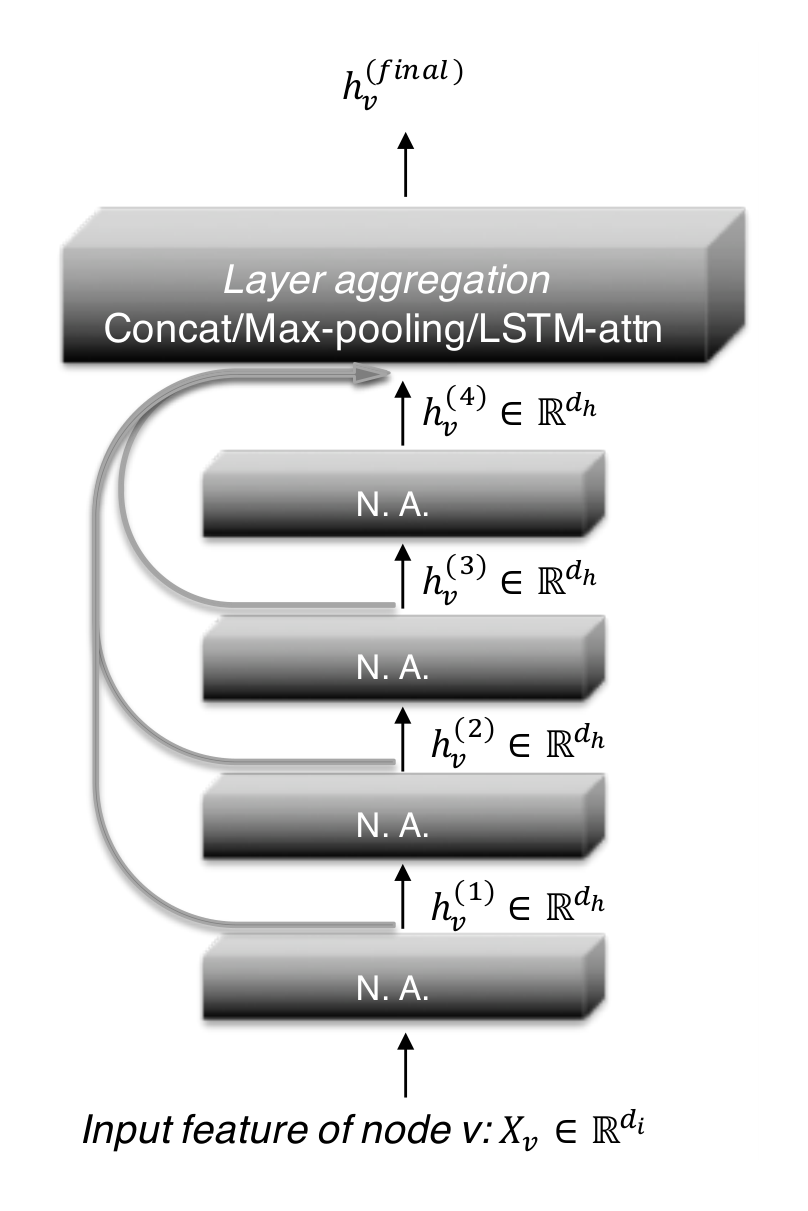
Figure 4 illustrates the main idea: as in common neighborhood aggregation networks, each layer increases the size of the influence distribution by aggregating neighborhoods from the previous layer. At the last layer, for each node, we carefully select from all of those intermediate representations (which “jump” to the last layer), potentially combining a few. If this is done independently for each node, then the model can adapt the effective neighborhood size for each node as needed, resulting in exactly the desired adaptivity.
Our model permits general layer-aggregation mechanisms. We explore three approaches; others are possible too. Let hv(1),…,hv(k)h_v^{(1)}, \dots, h_v^{(k)}hv(1),…,hv(k) be the jumping representations of node vvv (from kkk layers) that are to be aggregated.
Concatenation. A concatenation [hv(1),…,hv(k)][h_v^{(1)}, \dots, h_v^{(k)}][hv(1),…,hv(k)] is the most straightforward way to combine the layers, after which we may perform a linear transformation. If the transformation weights are shared across graph nodes, this approach is not node-adaptive. Instead, it optimizes the weights to combine the subgraph features in a way that works best for the dataset overall. One may expect concatenation to be suitable for small graphs and graphs with regular structure that require less adaptivity; also because weight-sharing helps reduce overfitting.
Max-pooling. An element-wise max (hv(1),…,hv(k))(h_v^{(1)}, \dots, h_v^{(k)})(hv(1),…,hv(k)) selects the most informative layer for each feature coordinate. For example, feature coordinates that represent more local properties can use the feature coordinates learned from the close neighbors and those representing global status would favor features from the higher-up layers. Max-pooling is adaptive and has the advantage that it does not introduce any additional parameters to learn.
LSTM-attention. An attention mechanism identifies the most useful neighborhood ranges for each node vvv by computing an attention score sv(l)s_v^{(l)}sv(l) for each layer lll (∑lsv(l)=1\sum_l s_v^{(l)} = 1∑lsv(l)=1), which represents the importance of the feature learned on the lll-th layer for node vvv. The aggregated representation for node vvv is a weighted average of the layer features ∑lsv(l)⋅hv(l)\sum_l s_v^{(l)} \cdot h_v^{(l)}∑lsv(l)⋅hv(l). For LSTM attention, we input hv(1),…,hv(k)h_v^{(1)}, \dots, h_v^{(k)}hv(1),…,hv(k) into a bi-directional LSTM (Hochreiter & Schmidhuber, 1997) and generate the forward-LSTM and backward-LSTM hidden features fv(l)f_v^{(l)}fv(l) and bv(l)b_v^{(l)}bv(l) for each layer lll. A linear mapping of the concatenated features [fv(l)∣∣bv(l)][f_v^{(l)} || b_v^{(l)}][fv(l)∣∣bv(l)] yields the scalar importance score sv(l)s_v^{(l)}sv(l). A Softmax layer applied to {sv(l)}l=1k\{s_v^{(l)}\}_{l=1}^k{sv(l)}l=1k yields the attention of node vvv on its neighborhood in different ranges. Finally we take the sum of [fv(l)∣∣bv(l)][f_v^{(l)} || b_v^{(l)}][fv(l)∣∣bv(l)] weighted by SoftMax({sv(l)}l=1k)\text{SoftMax}(\{s_v^{(l)}\}_{l=1}^k)SoftMax({sv(l)}l=1k) to get the final layer representation. Another possible implementation combines LSTM with max-pooling. LSTM-attention is node adaptive because the attention scores are different for each node. We shall see that the this approach shines on large complex graphs, although it may overfit on small graphs (fewer training nodes) due to its relatively higher complexity.
4.1. JK-Net Learns to Adapt
The key idea for the design of layer-aggregation functions is to determine the importance of a node’s subgraph features at different ranges after looking at the learned features on all layers, rather than to optimize and fix the same weights for all nodes. Under the same assumption on the ReLU activation distribution as in Theorem 1, we show below that layer-wise max-pooling implicitly learns the influence locality adaptively for different nodes. The proof for layer-wise attention follows similarly.
Proposition 1. Assume that paths of the same length in the computation graph are activated with the same probability. The influence score I(x,y)I(x, y)I(x,y) for any x,y∈Vx, y \in Vx,y∈V under a kkk-layer JK-Net with layer-wise max-pooling is equivalent in expectation to a mixture of 0,…,k0, \dots, k0,…,k-step random walk distributions on G~\tilde{G}G~ at yyy starting at xxx, the coefficients of which depend on the values of the layer features hx(l)h_x^{(l)}hx(l).
We prove Proposition 1 in the appendix. Contrasting this result with the influence distributions of other aggregation mechanisms, we see that JK-networks indeed differ in their node-wise adaptivity of neighborhood ranges.
Figure 5 illustrates how a 6-layer JK-Net with max-pooling aggregation learns to adapt to different subgraph structures on a citation network. Within a tree-like structure, the influence stays in the “small community” the node belongs to. In contrast, 6-layer models whose influence distributions follow random walks, e.g. GCNs, would reach out too far into irrelevant parts of the graph, and models with few layers may not be able to cover the entire “community”, as illustrated in Figure 1, and Figures 7, 8 in the appendix. For a node affiliated to a “hub”, which presumably plays the role of connecting different types of nodes, JK-Net learns to put most influence on the node itself and otherwise spreads out the influence. GCNs, however, would not capture the importance of the node’s own features in such a structure because the probability at an affiliate node is small after a few random walk steps. For hubs, JK-Net spreads out the influence across the neighboring nodes in a reasonable range, which makes sense because the nodes connected to the hubs are presumably as informative as the hubs’ own features. For comparison, Table 6 in the appendix includes more visualizations of how models with random walk priors behave.
4.2. Intermediate Layer Aggregation and Structures
Looking at Figure 4, one may wonder whether the same inter-layer connections could be drawn between all layers. The resulting architecture is approximately a graph correspondent of DenseNets, which were introduced for computer vision problems (Huang et al., 2017), if the layer-wise concatenation aggregation is applied. This version, however, would require many more features to learn. Viewing the DenseNet setting (images) from a graph-theoretic perspective, images correspond to regular, in fact, near-planar graphs. Such graphs are far from being expanders, and do not pose the challenges of graphs with varying subgraph structures. Indeed, as we shall see, models with concatenation aggregation perform well on graphs with more regular structures such as images and well-structured communities. As a more general framework, JK-Net admits general layer-wise aggregation models and enables better structure-aware representations on graphs with complex structures.
5. Other Related Work
In this section, spectral graph convolutional neural networks address graph convolution by leveraging graph Laplacian eigenvectors as Fourier atoms for spectral filtering. These methods contrast with spatial neighborhood aggregation by relying on predefined graph structure via the Laplacian, which must be computed in advance. This dependency prevents generalization to unseen graphs, marking a critical limitation over more flexible spatial approaches.
Spectral graph convolutional neural networks apply convolution on graphs by using the graph Laplacian eigenvectors as the Fourier atoms (Bruna et al., 2014; Shuman et al., 2013; Defferrard et al., 2016). A major drawback of the spectral methods, compared to spatial approaches like neighborhood aggregation, is that the graph Laplacian needs to be known in advance. Hence, they cannot generalize to unseen graphs.
6. Experiments
In this section, Jumping Knowledge Networks (JK-Nets) are rigorously evaluated on graph node classification tasks across Citeseer, Cora, Reddit, and PPI datasets in transductive and inductive settings to demonstrate their adaptive neighborhood aggregation superiority over GCN, GraphSAGE, and GAT baselines. Using MaxPool, Concat, and LSTM-attention as layer aggregators atop these bases, experiments vary layer counts and training regimes, revealing JK-Nets consistently boost accuracy and Micro-F1—e.g., topping GCN/GAT on citation nets with deeper layers, GraphSAGE on Reddit via Concat, and excelling on complex PPI structures with LSTM (up to 0.976 F1 versus 0.968 GAT). This validates JK-Nets' node-specific range adaptation for enhanced representations on diverse graphs.
We evaluate JK-Nets on four benchmark datasets. (I) The task on citation networks (Citeseer, Cora) (Sen et al., 2008) is to classify academic papers into different subjects. The dataset contains bag-of-words features for each document (node) and citation links (edges) between documents. (II) On Reddit (Hamilton et al., 2017), the task is to predict the community to which different Reddit posts belong. Reddit is an online discussion forum where users comment in different topical communities. Two posts (nodes) are connected if some user commented on both posts. The dataset contains word vectors as node features. (III) For protein-protein interaction networks (PPI) (Hamilton et al., 2017), the task is to classify protein functions. PPI consists of 24 graphs, each corresponds to a human tissue. Each node has positional gene sets, motif gene sets and immunological signatures as features and gene ontology sets as labels. 20 graphs are used for training, 2 graphs are used for validation and the rest for testing. Statistics of the datasets are summarized in Table 1.
Settings. In the transductive setting, we are only allowed to access a subset of nodes in one graph as training data, and validate/test on others. Our experiments on Citeseer, Cora and Reddit are transductive. In the inductive setting, we use a number of full graphs as training data and use other completely unseen graphs as validation/testing data. Our experiments on PPI are inductive.
We compare against three baselines: Graph Convolutional Networks (GCN) (Kipf & Welling, 2017), Graph-SAGE (Hamilton et al., 2017) and Graph Attention Networks (GAT) (Veličković et al., 2018).
6.1. Citeseer & Cora
For experiments on Citeseer and Cora, we choose GCN as the base model since on our data split, it is outperforming GAT. We construct JK-Nets by choosing MaxPooling (JK-MaxPool), Concatenation (JK-Concat), or LSTM-attention (JK-LSTM) as final aggregation layer. When taking the final aggregation, besides normal graph convolutional layers, we also take the first linear-transformed representation into account. The final prediction is done via a fully connected layer on top of the final aggregated representation. We split nodes in each graph into 60%, 20% and 20% for training, validation and testing. We vary the number of layers from 1 to 6 for each model and choose the best performing model with respect to the validation set. Throughout the experiments, we use the Adam optimizer (Kingma & Ba, 2014) with learning rate 0.005. We fix the dropout rate to be 0.5, the dimension of hidden features to be within {16,32}\{16, 32\}{16,32}, and add an L2L2L2 regularization of 0.0005 on model parameters. The results are shown in Table 2.
Results. We observe in Table 2 that JK-Nets outperform both GCN and GAT baselines in terms of prediction accuracy. Though JK-Nets perform well in general, there is no consistent winner and performance varies slightly across datasets.
Taking a closer look at results on Cora, both GCN and GAT achieve their best accuracies with only 2 or 3 layers, suggesting that local information is a stronger signal for classification than global ones. However, the fact that JK-Nets achieve the best performance with 6 layers indicates that global together with local information will help boost performance. This is where models like JK-Nets can be particularly beneficial. LSTM-attention may not be suitable for such small graphs because of its relatively high complexity.
6.2. Reddit
The Reddit data is too large to be handled well by current implementations of GCN or GAT. Hence, we use the more scalable GraphSAGE as the base model for JK-Net. It has skip connections and different modes of node aggregation. We experiment with Mean and MaxPool node aggregators, which take mean and max-pooling of a linear transformation of representations of the sampled neighbors. Combining each of GraphSAGE modes with MaxPooling, Concatenation or LSTM-attention as the last aggregation layer gives 6 JK-Net variants. We follow exactly the same setting of GraphSAGE as in the original paper (Hamilton et al., 2017), where the model consists of 2 hidden layers, each with 128 hidden units and is trained with Adam with learning rate of 0.01 and no weight decay. Results are shown in Table 3.
Results. With MaxPool as node aggregator and Concat as layer aggregator, JK-Net achieves the best Micro-F1 score among GraphSAGE and JK-Net variants. Note that the original GraphSAGE already performs fairly well with a Micro-F1 of 0.95. JK-Net reduces the error by 30%. The communities in the Reddit dataset were explicitly chosen from the well-behaved middle-sized communities to avoid the noisy cores and tree-like small communities (Hamilton et al., 2017). As a result, this graph is more regular than the original Reddit data, and hence not exhibit the problems of varying subgraph structures. In such a case, the added flexibility of the node-specific neighborhood choices may not be as relevant, and the stabilizing properties of concatenation instead come into play.
6.3. PPI
We demonstrate the power of adaptive JK-Nets, e.g., JK-LSTM, with experiments on the PPI data, where the subgraphs have more diverse and complex structures than those in the Reddit community detection dataset. We use both GraphSAGE and GAT as base models for JK-Net. The implementation of GraphSAGE and GAT are quite different: GraphSAGE is sample-based, where neighbors of a node are sampled to be a fixed number, while GAT considers all neighbors. Such differences cause large gaps in terms of both scalability and performances. Given that GraphSAGE scales to much larger graphs, it appears particularly valuable to evaluate how much JK-Net can improve upon GraphSAGE.
For GraphSAGE we follow the setup as in the Reddit experiments, except that we use 3 layers when possible, and compare the performance after 10 and 30 epochs of training. The results are shown in Table 4. For GAT and its JK-Net variants we stack two hidden layers with 4 attention heads computing 256 features (for a total of 1024 features), and a final prediction layer with 6 attention heads computing 121 features each. They are further averaged and input into sigmoid activations. We employ skip connections across intermediate attentional layers. These models are trained with Batch-size 2 and Adam optimizer with learning rate of 0.005. The results are shown in Table 5.
Results. JK-Nets with the LSTM-attention aggregators outperform the non-adaptive models GraphSAGE, GAT and JK-Nets with concatenation aggregators. In particular, JK-LSTM outperforms GraphSAGE by 0.128 in terms of micro-F1 score after 30 epochs of training. Structure-aware node adaptive models are especially beneficial on such complex graphs with diverse structures.
7. Conclusion
In this section, varying neighborhood information ranges across graph node embeddings pose a key challenge for fixed-layer models, prompting the proposal of JK-Networks, an adaptive aggregation scheme that customizes ranges node-by-node. This mechanism excels at improving representations in graphs with diverse subgraph structures, overcoming limitations of uniform neighborhood aggregations. Future work points to novel layer aggregators and their synergies with node-wise methods on varied graph types, with support from NSF CAREER award 1553284 and JST ERATO Kawarabayashi Large Graph Project.
Motivated by observations that reveal great differences in neighborhood information ranges for graph node embeddings, we propose a new aggregation scheme for node representation learning that can adapt neighborhood ranges to nodes individually. This JK-network can improve representations in particular for graphs that have subgraphs of diverse local structure, and may hence not be well captured by fixed numbers of neighborhood aggregations. Interesting directions for future work include exploring other layer aggregators and studying the effect of the combination of various layer-wise and node-wise aggregators on different types of graph structures.
Acknowledgements
This research was supported by NSF CAREER award 1553284, and JST ERATO Kawarabayashi Large Graph Project, Grant Number JPMJER1201, Japan.
References
In this section, irregular graph data processing challenges drive a progression from spectral convolutions reliant on fixed Laplacians to spatial neighborhood aggregations via random walks and message passing, incorporating residuals, attention, and scalable sampling for embeddings. This foundation reveals fixed-range limitations in diverse structures, paving the way for adaptive aggregations that boost node classification accuracy across citation, social, and protein networks.
Bruna, J., Zaremba, W., Szlam, A., and LeCun, Y. Spectral networks and locally connected networks on graphs. International Conference on Learning Representations (ICLR), 2014.
Cho, K., Van Merrienboer, B., Bahdanau, D., and Bengio, Y. On the properties of neural machine translation: Encoder-decoder approaches. In Workshop on Syntax, Semantics and Structure in Statistical Translation, pp. 103–111, 2014.
Choromanska, A., LeCun, Y., and Arous, G. B. Open problem: The landscape of the loss surfaces of multilayer networks. In Conference on Learning Theory (COLT), pp. 1756–1760, 2015.
Defferrard, M., Bresson, X., and Vandergheynst, P. Convolutional neural networks on graphs with fast localized spectral filtering. In Advances in Neural Information Processing Systems (NIPS), pp. 3844–3852, 2016.
Gilmer, J., Schoenholz, S. S., Riley, P. F., Vinyals, O., and Dahl, G. E. Neural message passing for quantum chemistry. In International Conference on Machine Learning (ICML), pp. 1273–1272, 2017.
Grover, A. and Leskovec, J. node2vec: Scalable feature learning for networks. In ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD), pp. 855–864, 2016.
Hamilton, W. L., Ying, R., and Leskovec, J. Inductive representation learning on large graphs. In Advances in Neural Information Processing Systems (NIPS), pp. 1025–1035, 2017.
Hammond, D. K., Vandergheynst, P., and Gribonval, R. Wavelets on graphs via spectral graph theory. Applied and Computational Harmonic Analysis, 30(2):129–150, 2011.
He, K., Zhang, X., Ren, S., and Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 770–778, 2016a.
He, K., Zhang, X., Ren, S., and Sun, J. Identity mappings in deep residual networks. In European Conference on Computer Vision, pp. 630–645, 2016b.
Hochreiter, S. and Schmidhuber, J. Long short-term memory. Neural computation, 9(8):1735–1780, 1997.
Hoory, S., Linial, N., and Wigderson, A. Expander graphs and their applications. Bulletin of the American Mathematical Society, 43(4):439–561, 2006.
Hoshen, Y. Vain: Attentional multi-agent predictive modeling. In Advances in Neural Information Processing Systems (NIPS), pp. 2698–2708, 2017.
Huang, G., Liu, Z., Weinberger, K. Q., and van der Maaten, L. Densely connected convolutional networks. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 2261–2269, 2017.
Kawaguchi, K. Deep learning without poor local minima. In Advances in Neural Information Processing Systems (NIPS), pp. 586–594, 2016.
Kearnes, S., McCloskey, K., Berndl, M., Pande, V., and Riley, P. Molecular graph convolutions: moving beyond fingerprints. Journal of computer-aided molecular design, 30(8):595–608, 2016.
Kingma, D. P. and Ba, J. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980, 2014.
Kipf, T. N. and Welling, M. Semi-supervised classification with graph convolutional networks. International Conference on Learning Representations (ICLR), 2017.
Koh, P. W. and Liang, P. Understanding black-box predictions via influence functions. In International Conference on Machine Learning (ICML), pp. 1885–1894, 2017.
Leskovec, J. and Mcauley, J. J. Learning to discover social circles in ego networks. In Advances in Neural Information Processing Systems (NIPS), pp. 539–547, 2012.
Leskovec, J., Lang, K. J., Dasgupta, A., and Mahoney, M. W. Community structure in large networks: Natural cluster sizes and the absence of large well-defined clusters. Internet Mathematics, 6(1):29–123, 2009.
Li, Y., Tarlow, D., Brockschmidt, M., and Zemel, R. Gated graph sequence neural networks. International Conference on Learning Representations (ICLR), 2016.
Lovász, L. Random walks on graphs. Combinatorics, Paul erdos is eighty, 2:1–46, 1993.
Maehara, T., Akiba, T., Iwata, Y., and Kawarabayashi, K.-i. Computing personalized pagerank quickly by exploiting graph structures. Proceedings of the VLDB Endowment, 7(12):1023–1034, 2014.
Monti, F., Boscaini, D., Masci, J., Rodolà, E., Svoboda, J., and Bronstein, M. M. Geometric deep learning on graphs and manifolds using mixture model cnns. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 5425–5434, 2017.
Perozzi, B., Al-Rfou, R., and Skiena, S. Deepwalk: Online learning of social representations. In ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD), pp. 701–710, 2014.
Pham, T., Tran, T., Phung, D. Q., and Venkatesh, S. Column networks for collective classification. In AAAI Conference on Artificial Intelligence, pp. 2485–2491, 2017.
Sen, P., Namata, G., Bilgic, M., Getoor, L., Galligher, B., and Eliassi-Rad, T. Collective classification in network data. AI magazine, 29(3):93, 2008.
Shervashidze, N., Schweitzer, P., Leeuwen, E. J. v., Mehlhorn, K., and Borgwardt, K. M. Weisfeiler-lehman graph kernels. Journal of Machine Learning Research, 12(Sep):2539–2561, 2011.
Shuman, D. I., Narang, S. K., Frossard, P., Ortega, A., and Vandergheynst, P. The emerging field of signal processing on graphs: Extending high-dimensional data analysis to networks and other irregular domains. IEEE Signal Processing Magazine, 30(3):83–98, 2013.
Tang, J., Qu, M., Wang, M., Zhang, M., Yan, J., and Mei, Q. Line: Large-scale information network embedding. In Proceedings of the International World Wide Web Conference (WWW), pp. 1067–1077, 2015.
Tsonis, A. A., Swanson, K. L., and Roebber, P. J. What do networks have to do with climate? Bulletin of the American Meteorological Society, 87(5):585–595, 2006.
Veličković, P., Cucurull, G., Casanova, A., Romero, A., Liò, P., and Bengio, Y. Graph attention networks. International Conference on Learning Representations (ICLR), 2018.
Weisfeiler, B. and Lehman, A. A reduction of a graph to a canonical form and an algebra arising during this reduction. Nauchno-Technicheskaya Informatsia, 2(9):12–16, 1968.
A. Proof for Theorem 1
In this section, the proof demonstrates that the expected gradient of a k-layer GCN node's final representation with respect to another node's initial features approximates the k-step random walk probability between them on the graph. It derives the partial derivative via chain rule as a sum over all length-k paths connecting the nodes, factoring in inverse normalized degrees, linear weights, and ReLU activation indicators per path segment. Assuming these indicators behave as independent Bernoulli random variables with fixed success probability ρ, the expectation reduces to ρ times the product of weight matrices scaled by the aggregate path probabilities, which exactly match the random walk transition probabilities summing to one across destinations. Normalizing these expected gradients thus recovers the precise k-step random walk distribution, revealing GCN backpropagation as a randomized diffusion process.
Proof. Denote by fx(l)f_x^{(l)}fx(l) the pre-activated feature of hx(l)h_x^{(l)}hx(l), i.e. 1deg~(x)⋅∑z∈N~(x)Wlhz(l−1)\frac{1}{\tilde{\text{deg}}(x)} \cdot \sum_{z \in \tilde{N}(x)} W_l h_z^{(l-1)}deg~(x)1⋅∑z∈N~(x)Wlhz(l−1), for any l=1..kl = 1..kl=1..k, we have
Here, Ψ\PsiΨ is the total number of paths vpkvpk−1,…,vp1,vp0v_p^k v_p^{k-1}, \dots, v_p^1, v_p^0vpkvpk−1,…,vp1,vp0 of length k+1k + 1k+1 from node xxx to node yyy. For any path ppp, vpkv_p^kvpk is node xxx, vp0v_p^0vp0 is node yyy and for l=1..k−1,vpl−1∈N~(vpl)l = 1..k-1, v_p^{l-1} \in \tilde{N}(v_p^l)l=1..k−1,vpl−1∈N~(vpl).
As for each path ppp, the derivative [∂hx(k)∂hy(0)]p\left[ \frac{\partial h_x^{(k)}}{\partial h_y^{(0)}} \right]_p[∂hy(0)∂hx(k)]p represents a directed acyclic computation graph, where the input neurons are the same as the entries of W1W_1W1, and at a layer lll. We can express an entry of the derivative as
Here, Φ\PhiΦ is the number of paths qqq from the input neurons to the output neuron (i,j)(i, j)(i,j), in the computation graph of [∂hx(k)∂hy(0)]p\left[ \frac{\partial h_x^{(k)}}{\partial h_y^{(0)}} \right]_p[∂hy(0)∂hx(k)]p. For each layer l,wq(l)l, w_q^{(l)}l,wq(l) is the entry of WlW_lWl that is used in the qqq-th path. Finally, Zq∈{0,1}Z_q \in \{0, 1\}Zq∈{0,1} represents whether the qqq-th path is active (Zq=1Z_q = 1Zq=1) or not (Zq=0Z_q = 0Zq=0) as a result of the ReLU activation of the entries of fvpl(l)f_{v_p^l}^{(l)}fvpl(l)'s on the qqq-th path.
Under the assumption that the ZZZ's are Bernoulli random variables with the same probability of success, for all q,Pr(Zq=1)=ρq, \text{Pr}(Z_q = 1) = \rhoq,Pr(Zq=1)=ρ, we have E[∂hx(k)∂hy(0)]p(i,j)=ρ⋅∏l=k11deg~(vpl)⋅wq(l)\mathbb{E} \left[ \frac{\partial h_x^{(k)}}{\partial h_y^{(0)}} \right]_p^{(i,j)} = \rho \cdot \prod_{l=k}^1 \frac{1}{\tilde{\text{deg}}(v_p^l)} \cdot w_q^{(l)}E[∂hy(0)∂hx(k)]p(i,j)=ρ⋅∏l=k1deg~(vpl)1⋅wq(l). It follows that E[∂hx(k)∂hy(0)]=ρ⋅∏l=k1Wl⋅(∑p=1Ψ∏l=k11deg~(vpl))\mathbb{E} \left[ \frac{\partial h_x^{(k)}}{\partial h_y^{(0)}} \right] = \rho \cdot \prod_{l=k}^1 W_l \cdot \left( \sum_{p=1}^{\Psi} \prod_{l=k}^1 \frac{1}{\tilde{\text{deg}}(v_p^l)} \right)E[∂hy(0)∂hx(k)]=ρ⋅∏l=k1Wl⋅(∑p=1Ψ∏l=k1deg~(vpl)1). We know that the kkk-step random walk probability at yyy can be computed by summing up the probability of all paths of length kkk from xxx to yyy, which is exactly ∑p=1Ψ∏l=k11deg~(vpl)\sum_{p=1}^{\Psi} \prod_{l=k}^1 \frac{1}{\tilde{\text{deg}}(v_p^l)}∑p=1Ψ∏l=k1deg~(vpl)1. Moreover, the random walk probability starting at xxx to other nodes sum up to 1. We know that the influence score I(x,z)I(x, z)I(x,z) for any zzz in expectation is thus the random walk probability of being at zzz from xxx at the kkk-th step, multiplied by a term that is the same for all zzz. Normalizing the influence scores ends the proof.
Comment: ReLU is not differentiable at 0. For simplicity, we assume the (sub)gradient to be 0 at 0. □\square□
B. Proof for Proposition 1
In this section, the proof analyzes influence propagation in graph networks using max-pooling for layer aggregation, defining node y's influence on x's final representation as the sum of L1 norms of partial derivatives of each final feature dimension with respect to y's inputs, which selectively traces to the layer maximizing that dimension. Leveraging Theorem 1, it shows the expected influence as a weighted sum across layers of l-step random walk probabilities from x to y, with weights given by each layer's fraction of selected dimensions times a normalization factor. This reveals max-pooling's adaptive blending of multi-scale random walks based on per-layer representational strength.
Proof. Let [hx(final)]i[h_x^{(final)}]_i[hx(final)]i be the iii-th entry of hx(final)h_x^{(final)}hx(final), the feature after layer aggregation. For any node yyy, we have
where ji=argmaxl[hx(l)]ij_i = \text{argmax}_l \left[ h_x^{(l)} \right]_iji=argmaxl[hx(l)]i. By Theorem 1, we have
where Ix(y)I_x(y)Ix(y) is the lll-step random walk probability at y,zly, z_ly,zl is a normalization factor and cxlc_x^lcxl is the fraction of entries of hx(l)h_x^{(l)}hx(l) being chosen by max-pooling. By Theorem 1, E[Ix(y)(l)]\mathbb{E} [I_x(y)^{(l)}]E[Ix(y)(l)] is equivalent to the lll-step random walk probability at yyy starting at xxx. □\square□
C. Visualization Results
In this section, visualizations reveal discrepancies in GCN information propagation across graph structures, comparing influence distributions to random walks via color-coded heat maps on the Cora dataset, where lighter shades denote lower probability masses. Table 6 extends these comparisons, aligning standard GCN influences with walks, and residual GCNs with lazy walks (0.4 stay probability). Subgraph analyses in Figures 7 and 8 demonstrate 2-layer GCN misclassifications on tree-like (bounded treewidth) regions requiring deeper 3-4 hop views, versus deeper GCN errors on dense or bridge-like structures where distant nodes introduce community noise. These patterns validate adaptive layer aggregation to handle diverse local topologies.
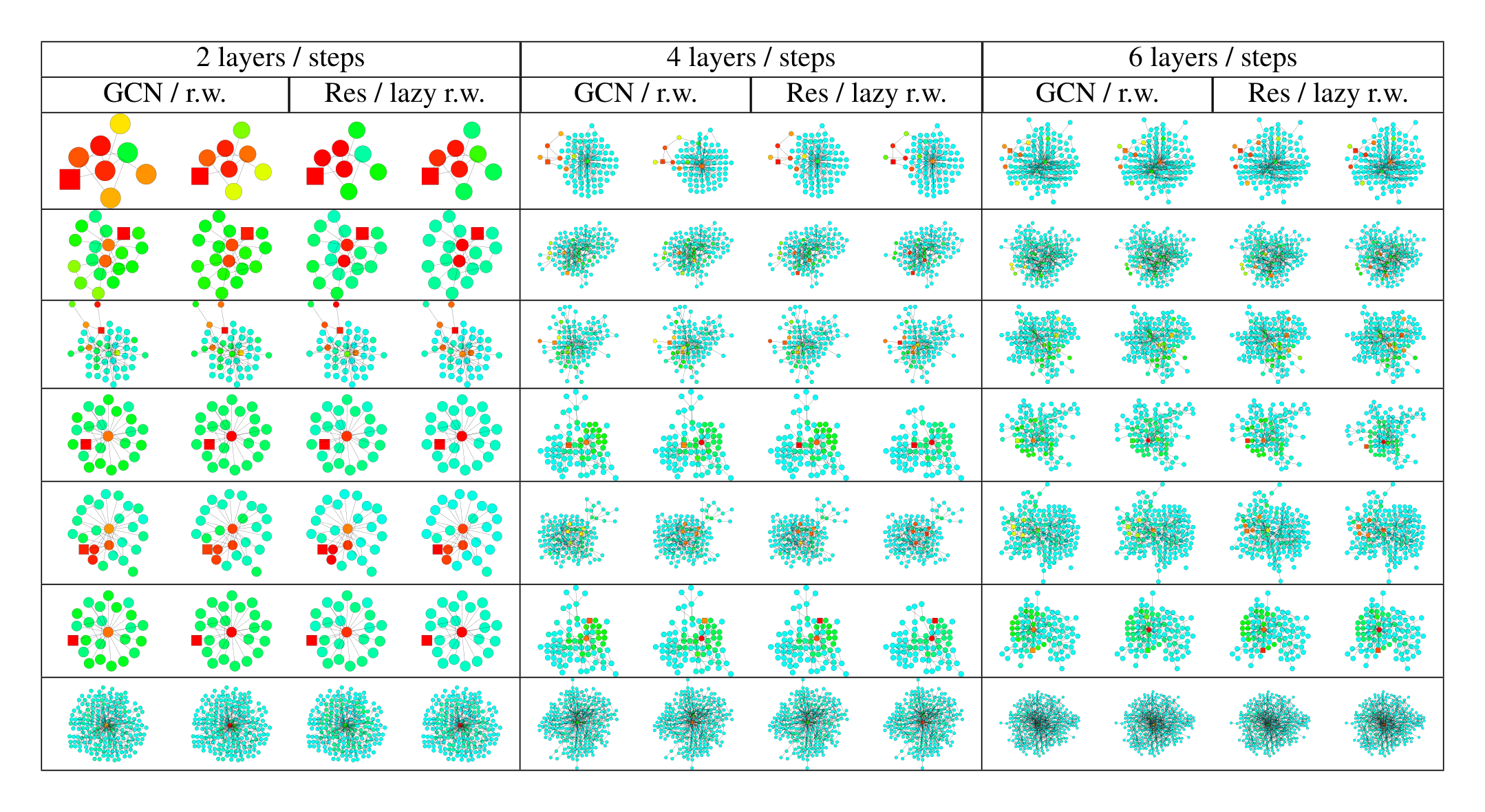
We describe the details of the heat maps and present more visualization results. The colors of the nodes in the heat maps correspond to their probability masses of either the influence distribution or random walk distribution as shown in Figure 6. As we see, the shallower the color is, the smaller the probability mass. We use the same color for probabilities over 0.2 for better visual effects because there are few nodes with influence probability masses over 0.2. Nodes with probability mass less than 0.001 are not shown in the heat maps.
In Table 6, we present more visualization results to compare the 1) influence distributions under GCNs and the random walk distributions, 2) influence distributions under GCNs with residual connections and lazy random walk distributions. The nodes being influenced and the random walk starting node are labeled square. The influence distributions for the nodes in Figure 6 are computed according to Definition 3.1, under the same trained GCN (Res) models with 2, 4, 6 layers respectively. We use the hyper-parameters as described in Kipf & Welling (2017) for training the models. The graph (dataset) is taken from the Cora citation network as described in section 6. We compute the random walk distributions according to Definition 3.2 on the graph G~\tilde{G}G~. The lazy random walks all share the same lazy factor 0.4, i.e. there’s an extra 0.4 probability of staying at the current node at each step. This probability is chosen for visual comparison with the GCN-ResNet. Note that the GCN and random walk colors may differ for nodes that have particularly large degrees because the models we are running follow Equation 2, which assigns less weight to nodes that have larger degrees, rather than Equation 3. The visualization in Figure 5 has the same setting as mentioned above. It is trained for the Cora dataset with a 6-layer JK-Net with maxpooling layer aggregation.
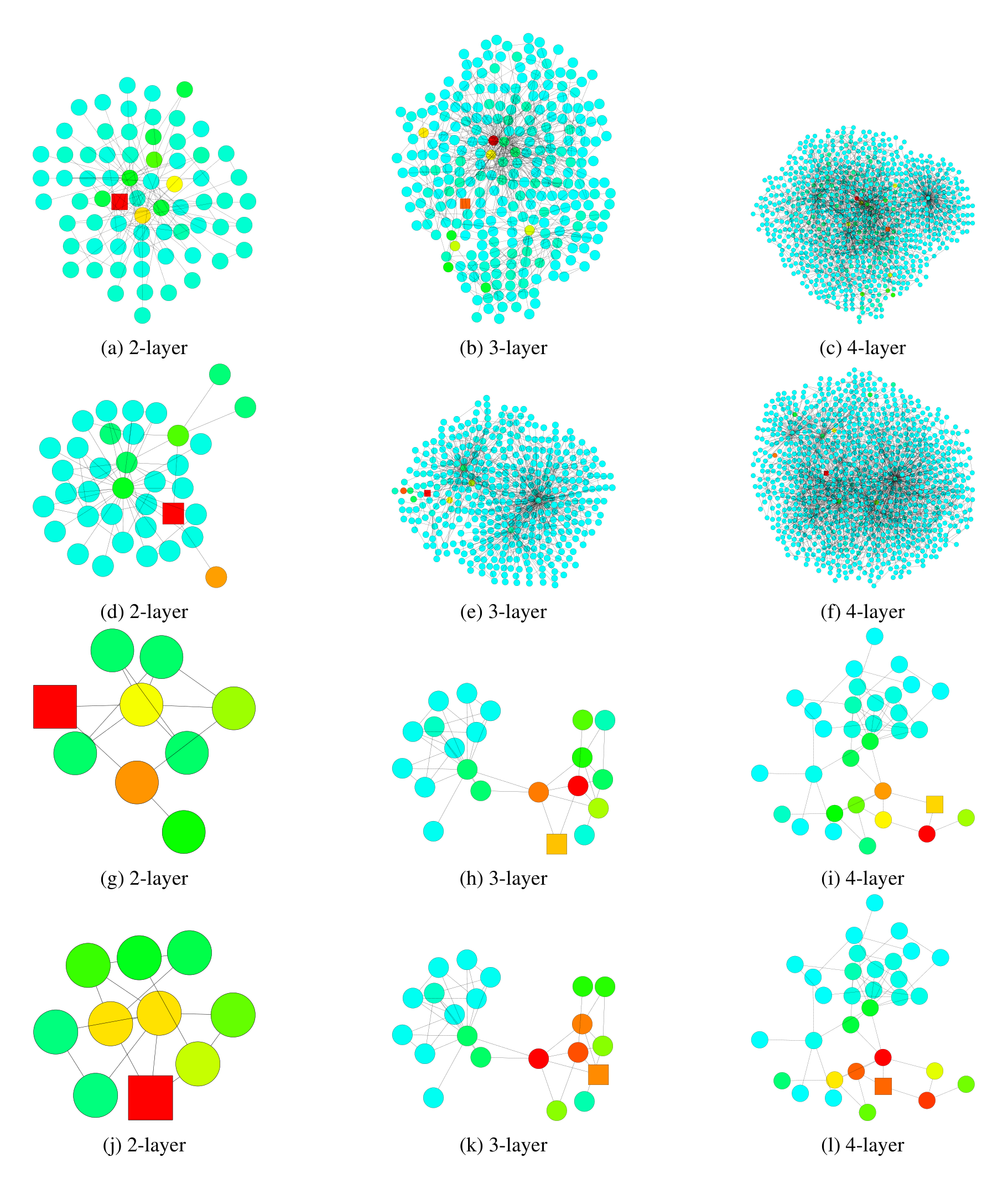
Next, we demonstrate subgraph structures where GCN models with 2 layers tend to make misclassification, whereas models with 3 or 4 layers are able to make the correct prediction and vice versa, with real dataset. These visualization results further complement and support the theory illustrated in Figure 1 and Theorem 1. As we see in Figure 7, a model with pre-fixed effective range priors, which looks at 2-hop neighbors, tends to make incorrect prediction if the local subgraph structure is tree-like (bounded treewidth). Thus, it would be desirable to look beyond the direct neighbors and draw information from nodes that are 3 or 4 hops away so as to learn a better representation of the local community. On the other hand, as we see in Figure 8, a model with pre-fixed effective range priors, which looks at 3 or 4-hop neighbors, may happen to draw much information from less relevant neighbors and thus cannot learn the right representations, which are necessary for the correct prediction. In the subgraph structures where the random walk expansion explodes rapidly, models with 3 or 4 prefixed layers are essentially taking into account every node. Such global representations might not be ideal for the prediction for the node. In another scenario, despite possessing the locally bounded treewidth structure, because of the ”bridge-like” structures, looking at distant nodes might imply drawing information from a completely different community, which would act like noises and influence the prediction results.