SFT Memorizes, RL Generalizes: A Comparative Study of Foundation Model Post-training
Tianzhe Chu $^{\spadesuit}$ $^{}$ Yuexiang Zhai $^{\heartsuit}$ $^{\clubsuit}$ $^{}$ Jihan Yang $^{\diamondsuit}$ Shengbang Tong $^{\diamondsuit}$ Saining Xie $^{\spadesuit}$ $^{\diamondsuit}$ Dale Schuurmans $^{\clubsuit}$ $^{\faCrow}$ Quoc V. Le $^{\clubsuit}$ Sergey Levine $^{\heartsuit}$ Yi Ma $^{\spadesuit}$ $^{\heartsuit}$
$^{*}$ Equal contribution . $^{\spadesuit}$ HKU, $^{\heartsuit}$ UC Berkeley, $^{\clubsuit}$ Google DeepMind, $^{\diamondsuit}$ NYU, $^{\faCrow}$ University of Alberta. All experiments are conducted outside of Google. Project page: https://tianzhechu.com/SFTvsRL. Correspondence to: Tianzhe Chu [email protected], Yuexiang Zhai [email protected].
Proceedings of the $42^{nd}$ International Conference on Machine Learning, Vancouver, Canada. PMLR 267, 2025. Copyright 2025 by the author(s).
Abstract
Supervised fine-tuning (SFT) and reinforcement learning (RL) are widely used post-training techniques for foundation models. However, their respective role in enhancing model generalization in rule-based reasoning tasks remains unclear. This paper studies the comparative effect of SFT and RL on generalization and memorization, focusing on text-based and visual reasoning tasks. We introduce GeneralPoints, an arithmetic reasoning card game, and also consider V-IRL, a real-world navigation environment, to assess how models trained with SFT and RL generalize to unseen variants in both novel textual rules and visual domains. We show that RL, especially when trained with an outcome-based reward, generalizes in both the rule-based textual and visual environments. SFT, in contrast, tends to memorize the training data and struggles to generalize out-of-distribution in either scenario. Further analysis reveals that RL improves the model's underlying visual recognition capabilities, contributing to its enhanced generalization in visual domains. Despite RL's superior generalization, we show that SFT is still helpful for effective RL training: SFT stabilizes the model's output format, enabling subsequent RL to achieve its performance gains. These findings demonstrate the advantage of RL for acquiring generalizable knowledge in complex, multi-modal tasks.
Executive Summary: Executive Summary
Post-training methods such as supervised fine-tuning (SFT) and reinforcement learning (RL) are now the primary ways developers improve large language and vision-language models after pre-training. Yet it remains unclear whether these techniques teach models genuine, transferable reasoning or simply encourage memorization of training examples. This distinction matters because reliable AI systems must handle novel rules, visual conditions, and real-world variations without retraining.
This study set out to determine, through controlled experiments, whether SFT or RL produces better generalization on rule-based reasoning and visual-recognition tasks. The authors introduced GeneralPoints, a new arithmetic card game, and adapted the existing V-IRL navigation environment. Both tasks allow systematic changes to textual rules and visual appearance, creating clear in-distribution and out-of-distribution test conditions.
Using the open-source Llama-3.2-Vision-11B model, the authors first applied SFT and then ran RL with an outcome-based verifier that rewards correct final answers. They tracked performance as training compute increased and measured both rule generalization (new text instructions) and visual generalization (new card colors or cities).
Across all settings, RL steadily improved performance on unseen rules and visual variants, gaining 3–11 percentage points on language-only tasks and 3–61 points on vision-language tasks, and reached a new state-of-the-art of 77.8 % on the V-IRL benchmark. In contrast, SFT produced large drops on the same out-of-distribution tests—sometimes exceeding 30–79 points—while only marginally helping on the training distribution. Additional measurements showed that RL also raised the model’s accuracy at recognizing cards and landmarks, whereas scaling SFT degraded visual recognition. However, SFT remained useful: without it the base model failed to produce consistent output formats, preventing RL from learning at all. Finally, allowing more verification steps at inference time further boosted RL’s generalization.
These results indicate that current practice, which relies heavily on SFT, may be building models that overfit to narrow training distributions. Using RL after a modest SFT stage offers a practical route to more robust reasoning and perception. The findings also suggest that scaling test-time verification is a low-cost way to improve reliability.
Practitioners should therefore adopt an SFT-then-RL pipeline when building agents that must operate under changing rules or visual conditions, and should allocate part of the compute budget to multi-step verification during deployment. Future work should test whether these patterns hold on larger models and more open-ended tasks, clarify the precise conditions under which SFT helps or hinders RL, and develop lighter-weight methods to enhance visual recognition without full RL.
The experiments cover two carefully designed environments and a single model family, so results may differ for other architectures or broader real-world settings. Nevertheless, the consistent contrast between RL’s generalization gains and SFT’s memorization behavior gives high confidence in the central practical recommendation.
1. Introduction
Section Summary: The paper explores how supervised fine-tuning (SFT) and reinforcement learning (RL) differently affect a foundation model's ability to generalize beyond its training data, rather than simply memorizing specific examples. Using two new tasks—one involving arithmetic reasoning with card games and another involving real-world visual navigation—the authors compare how well each method handles new variations in rules, instructions, or visual inputs like colors and layouts. Their results show that RL tends to learn adaptable principles that transfer to unfamiliar situations and can even boost visual recognition, while SFT mainly memorizes seen cases unless combined with RL to stabilize outputs.
Although SFT and RL are both widely used for foundation model training ([1, 2, 3, 4]), their distinct effects on generalization ([5, 6]) remain unclear, making it challenging to build reliable and robust AI systems. A key challenge in analyzing the generalizability of foundation models ([7, 8]) is to separate data memorization[^1] from the acquisition of transferable principles. Thus, we investigate the key question whether SFT or RL primarily memorize training data ([9, 10, 11]), or whether they learn generalizable rules that can adapt to novel task variants.
[^1]: We use "memorization" the refer a model’s capacity to generate near-exact copies of training examples when prompted based on information present in the training dataset. This definition explicitly excludes bitwise or codewise replication of training data within the model itself.
To address this question, we focus on two aspects of generalization: textual rule-based generalization and visual generalization. For textual rules, we study the ability of a model to apply learned rules (given text instructions) to variants of these rules ([12, 13, 10]). For vision-language models (VLMs), visual generalization measures the consistency of performance with variations in visual input, such as color and spatial layout, within a given task. For studying text-based and visual generalization, we investigate two different tasks that embody rule-based and visual variants. Our first task is GeneralPoints, an original card game task similar to Points24 of RL4VLM ([14]), which is designed to evaluate a model's arithmetic reasoning capabilities. The model receives four cards (presented as a text description or an image), and is required to compute a target number (24 by default) using each card's numerical value exactly once. Second, we adopt V-IRL ([15]), a real-world navigation task that focuses on the model's spatial reasoning capabilities.
![**Figure 1:** **A comparative study of RL and SFT on the visual navigation environment `V-IRL** ([15]) for OOD generalization.` OOD curves represent performance on the same task, using *a different textual action space*. See detailed descriptions of the task in Section 5.1.](https://ittowtnkqtyixxjxrhou.supabase.co/storage/v1/object/public/public-images/9gsracat/teaser_v3.png)
We adopt a multi-step RL framework similar to [14], by instantiating RL after running SFT on the backbone model ([16]), using the sequential revision formulation ([17]). In both GeneralPoints and V-IRL, we observe that RL learns generalizable rules (expressed in text), where in-distribution performance gains also transfer to unseen rules. In contrast, SFT appears to memorize the training rules and does not generalize (see Figure 1 for an example). Beyond textual rule-based generalization, we further investigate generalization in the visual domain and observe that RL also generalizes to visual OOD tasks, whereas SFT continues to struggle. As a by-product of the visual OOD generalization capability, our multi-turn RL approach achieves state-of-the-art performance on the V-IRL mini benchmark, by +33.8% (44.0% $\rightarrow$ 77.8%) ([15]), highlighting the generalization capability of RL. To understand how RL affects the visual abilities of a model, we conducted additional analysis on GeneralPoints, revealing that training RL with an outcome-based reward function ([18]) improves visual recognition capabilities. Although RL exhibits superior generalization compared to SFT, we show that SFT is still necessary to stabilize the model's output format, enabling RL to achieve its performance gains. Last but not least, we observe that scaling up the inference time compute by increasing the number of maximal steps leads to better generalization.
2. Related Works
Section Summary: Previous research has shown that post-training methods such as supervised fine-tuning and reinforcement learning can boost the capabilities of language models and vision-language models, with fine-tuning often helping models follow desired formats and reinforcement learning aligning outputs with human preferences or specific objectives. Studies have also explored how these models balance memorization of training data against true generalization to new tasks, particularly noting differences between simpler knowledge-based problems and more complex reasoning ones. Additional work has examined ways to improve performance through extra computation during inference and to strengthen visual understanding in multimodal models, areas this paper extends by comparing the effects of different post-training approaches on generalization in both text and visual settings.
Post-training.
Post-training is crucial for enhancing model performance ([19, 20, 1, 2, 21]). This stage commonly utilizes large-scale supervised fine-tuning (SFT) ([22, 8, 23, 24, 25, 26]) and/or reinforcement learning (RL) ([27, 28, 29, 30, 31, 14]). SFT adapts pre-trained models to downstream tasks by training them on task-specific, often instruction-formatted datasets. Previous work, such as FLAN ([24]), demonstrates that fine-tuning on diverse instruction-tuning datasets significantly enhances zero-shot performance on unseen tasks. Furthermore, LIMA ([26]) shows that supervised fine-tuning acts as a "format teacher"effectively adapting the model's responses to a desired format while leveraging the capabilities of pre-trained LLMs. In contrast, RL ([27, 28, 29, 32, 30, 31, 14]) has been primarily used to align models with human preferences or training the foundational model to solve a specific task ([30, 31, 14, 33]). Our work differs from prior studies, as we aim to comparatively analyze the generalization and memorization of SFT and RL on both LLM and VLM, while previous studies have focused primarily on only one of these two post-training methods (or only study LLM or VLM) or on only one post-training method.
Memorization and generalization in LLM/VLM.
Several studies have examined the interplay between memorization and generalization in neural networks ([34, 35, 36]). In LLMs, memorization can manifest as the model memorizing the training data ([35, 37, 11]), while generalization reflects the divergence between the model's output distribution and the pre-training data distribution ([38]). Prior studies suggest that LLMs exhibit more overfitting on simpler, knowledge-intensive tasks and greater generalization on more complex, reasoning-intensive ones ([39, 40]). For example, recent studies ([10, 41, 9, 42, 43, 44]) have demonstrated that LLMs develop reasoning skill sets beyond their training data by pre-computing reasoning graphs before autoregressive generation, which provides compelling evidence of generalization. Our study takes a different approach by investigating the role of different post-training paradigms on memorization versus generalization in the context of textual ruled-based and visual variants. We conduct comparative studies in both unimodal (LLM) and multimodal (VLM) settings, and demonstrate that RL leads to better generalization performance than SFT.
Scaling up inference-time compute.
Recent research has increasingly focused on scaling up inference-time computation to improve model performance ([45, 13, 17, 3]). Early studies ([45, 13]) prompted models to generate intermediate reasoning steps and extend the responses before producing a final answer. Subsequent work ([46, 47, 48, 49, 17]) has demonstrated that fine-tuning verifiers during inference improves model accuracy, effectively utilizing test-time computation. Notably, recent findings ([3, 4]) reveal "scaling laws" for inference-time compute, highlighting significant performance gains with increased computational resources. Our work builds upon these findings in two ways. First, we integrate insights from inference-time verification into a multi-turn RL formulation that allows the model to identify and correct its errors. Second, we examine the impact of inference-time verification on RL generalization, demonstrating that scaling up inference-time verification (in terms of the maximum number of verification steps) is a key for RL to generalize.
Improving visual capability in VLMs.
While VLMs have demonstrated remarkable skill across a wide range of challenging tasks, such as solving advanced college exam questions ([50, 51, 52]) and spatial understanding tasks ([15, 53]), they also exhibit limitations in visual perception ([14, 54, 55, 56, 57]). Prior efforts to enhance VLMs' visual perception include combining multiple visual encoders ([56, 58, 59]), curating high-quality SFT data ([60, 61, 59]), and improving the SFT training recipe by unfreezing the visual backbone ([62, 59]). While these prior works primarily focus on experiments during the SFT stage, our work demonstrates that RL can also improve visual perception.
3. Preliminaries
Section Summary: In reinforcement learning, an agent interacts with an environment over a fixed number of steps by observing states, selecting actions according to a policy, and receiving rewards, with the aim of maximizing the total accumulated reward. This paper adapts that framework to large language or vision-language models by treating the model as a policy that generates token sequences as actions, while a separate verifier evaluates each output to produce a reward signal and additional textual feedback, enabling multi-turn training via the PPO algorithm. Inputs to the model at each step are built sequentially by concatenating the original prompt with all prior model outputs and verifier responses, allowing the system to refine its answers over successive turns.
Standard RL terminology.
We consider finite horizon decision making, and adopt standard notation from the classical RL literature ([63, 64]), where $\mathcal S$ denotes the state space, $\mathcal A$ denotes the action space, $r: \mathcal S\times \mathcal A\rightarrow \mathbb R$ denotes the reward function, and $T$ denotes the maximum number of steps per episode. The goal is to learn a policy ${\pi: \mathcal S\rightarrow \mathcal A}$ that maximizes the overall return ${\max_{\pi\in\Pi}\mathbb E_{\pi}\left[\sum_{t=0}^Tr_t \right]}$, where $r_t$ denotes $r(s_t, a_t)$. Without loss of generality, we use $\pi(a|s)\in [0, 1]$ to denote probability of $\pi$ choosing $a$ at $s$.
Adapting RL terminology to LLM/VLM with a verifier.
We adopt a multi-turn RL setting for foundation model training ([14]). Let $\mathcal V$ represent the discrete and finite vocabulary (token) space. The input and output text spaces are denoted by $\mathcal V^{m}$ and $\mathcal V^{n}$ respectively, where $m$ and $n$ are the maximum token length of the input sequence $\boldsymbol v^\text{in}$ and output sequence $\boldsymbol v^\text{out}$. For models requiring visual inputs (VLM), we define $\mathcal O$ as the space of all RGB images. The state space, denoted by $\mathcal S$, is defined as $\mathcal S := \mathcal V^{m}\times \mathcal O$ for VLM, and $\mathcal S := \mathcal V^{m}$ for LLM. The action space $\mathcal A$ is defined as $\mathcal A := \mathcal V^{n}$. We use $\mathsf{VER}: \mathcal V^n \rightarrow \mathbb R \times \mathcal V^k$ to denote a verifier, which evaluates the outcome of $\boldsymbol v^\text{out}$ and generates an outcome-based reward function ([18, 65, 17, 66]) $r$ along with textual information $\boldsymbol v^\text{ver}$. Mathematically, at time $t$, $\mathsf{VER}(\boldsymbol v^\text{out}t)\mapsto(r_t, \boldsymbol v^\text{ver}t)$. Similar to [14], we treat the model with parameter $\theta$ as our policy network $\pi\theta: \mathcal S\rightarrow \mathcal V^n$, and adopt PPO ([67]) as the backbone RL algorithm for updating $\pi\theta$.
Sequential revision.
For modeling the state-action transition, we adopt the sequential revision formulation ([17]). Specifically, at time step $t=0$ the initial input $\boldsymbol v^\text{in}_0$ consists of the system prompt. For subsequent time steps $(t\geq1)$, the input prompt $\boldsymbol v^\text{in}_t$ comprises the system prompt concatenated with all prior model and verifier outputs, denoted by $[\boldsymbol v^\text{out}_k, \boldsymbol v^\text{ver}_k] _{k=0}^{t-1}$. An illustration of the sequential revision is provided in Figure 2 (also see Figure 5 of [17]), and an example of the state-action transition is shown in Figure 3.


4. Evaluation Tasks
Section Summary: To evaluate how well different post-training methods enable models to generalize, the authors introduce two tasks, each with deliberate rule changes and visual changes. The first is a new GeneralPoints environment in which models must combine four playing cards into a mathematical expression that hits a target number; it can be presented as either text or images, with rule variants that reinterpret face cards as different values and visual variants that alter card colors. The second task uses the existing V-IRL navigation environment, where models follow natural-language directions through realistic street scenes, testing spatial reasoning under two different action schemes (absolute versus relative directions) and across visual scenes from different cities.
To evaluate the generalization of different post-training methods, we select two tasks that each offer rule and visual variations. The first task, GeneralPoints, is a new environment we have designed that allows assessment of arithmetic reasoning abilities (Section 4.1). The second task, V-IRL ([15]), is chosen to examine the model's reasoning capabilities in an open-world visual navigation domain (Section 4.2).
4.1 The General Points Environment
Our original GeneralPoints environment, instantiated on top of the Points24 environment ([14]), is designed to evaluate generalization of arithmetic reasoning. Each state $s$ of the environment contains 4 cards, described as text (in the GP-L variant) or presented as an image (in the GP-VL variant); see Figure 2 left for a visual example of GeneralPoints. The goal is to produce an equation that equals a target number (24 by default) using all 4 numbers from the cards exactly once. Detailed examples of the state-action transitions are provided in Appendix A.2. Note that when input from GeneralPoints is presented in an image (GP-VL), it naturally introduces additional visual challenges requiring the VLM to recognize all cards before solving the equation.
Rule variations.
To study whether the model learns arithmetic operations or simply memorizes the post-training data, we introduce rule variations in GeneralPoints. These variations consist of interpreting the symbols 'J', 'Q', and 'K'either as '11', '12', and '13', respectively, or all as the same number '10'. These variations ensure a rigorous evaluation of the model's ability to generalize arithmetic reasoning across diverse settings. Each rule is specified as text in the input prompt, see the tasks rules part in Figure 3. For studying ruled based generalization, we post-train the model using one rule, then evaluate using a different rule.
Visual variations.
The GeneralPoints environment can also be naturally customized to evaluate generalization across visual variants. Since the major visual challenge is to recognize the number of each card, agnostic to the the color of the cards, we consider the cards with different colors as visual variants of the task. In the visual generalization setting, we train the model using cards of one color, then test OOD performance using the other color.
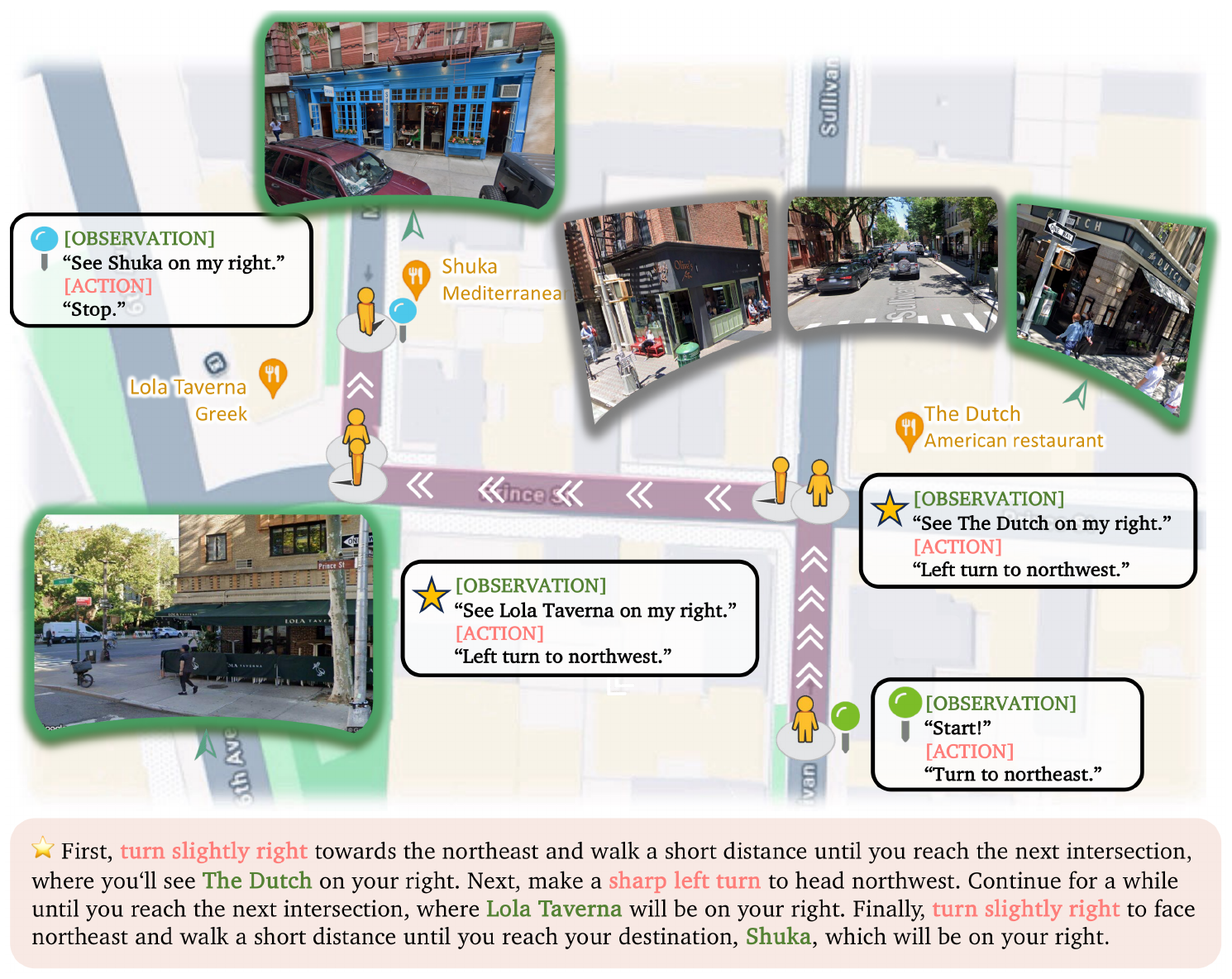
4.2 The V-IRL Environment
While the GeneralPoints environment is designed to assess arithmetic reasoning abilities, we further utilize the V-IRL environment ([15]) to study spatial reasoning ability in an open-world navigation domain that uses realistic visual input. As in GeneralPoints we consider two versions of the environment, one (V-IRL-L) that consists of pure language descriptions, [^2] and another (V-IRL-VL) that includes vision-language input. The major visual challenge in V-IRL involves recognizing different landmarks from the visual observation[^3] before taking an action. The goal is to navigate to a target location by following a set of instructions that contain spatial information. A detailed example of one environment step is shown in Appendix B.2.
[^2]: The visual input can be parsed into pure text description, see more details in [15] and an illustration of pure text the version in Figure 14.
[^3]: See Figure 4, the model needs to recognize landmarks like The Dutch, Lola Taverna, and Shuka from the visual observation, and relate these landmarks with the textual instructions for taking the right action.
Rule variations.
To evaluate whether the model possesses spatial knowledge or simply memorizes post-training data, we consider two distinct action space configurations. The first variant utilizes an absolute orientation action space, which includes 'north', 'northeast', 'east', 'southeast', 'south', 'southwest', 'west', 'northwest'. The second variant employs a relative orientation action space, containing 'left', 'right', 'slightly left', 'slightly right'. This relative configuration adjusts the current orientation by 90 degrees or 45 degrees to the left or right, respectively. An overview of a navigation task in V-IRL is provided in Figure 4, and a detailed state-action transition in V-IRL is provided in Figure 13 (in Appendix B.2).
Visual variations.
The key visual challenge in V-IRL is to recognize landmarks from the visual observations (e.g., the green parts in Figure 4). Since the V-IRL environment contains visual observations from different cities, we can assess visual generalization in V-IRL by training the model to navigate in one location and then evaluate its performance in different locations.
5. Results
Section Summary: The results section examines how reinforcement learning (RL) and supervised fine-tuning (SFT) influence a vision-language model's ability to handle new situations after training on tasks like GeneralPoints and V-IRL. Experiments show that RL steadily improves performance on unseen rules and visual changes, boosting out-of-distribution success rates by up to 17% or more across language-only and vision-language versions of the tasks. In contrast, SFT leads to clear drops in these same settings, as the model essentially memorizes the training examples rather than learning flexible skills.
In this section, we present experiments that investigate the generalization abilities induced by post-training with RL and SFT. We adopt Llama-3.2-Vision-11B ([16]) as the backbone model. Following the standard pipelines of RLHF ([28]) and RL4VLM ([14]), we initialize the model with SFT before running RL. We specifically study the following questions. Section 5.1: how does SFT or RL affect the model's generalization to different rules? Section 5.2: when the model contains a visual component, how does RL/SFT affect its generalization to different visual variants? Section 5.3: how does RL/SFT affect visual recognition capability in a VLM? Section 5.4: what role does SFT play in RL training? Section 5.5: how does the number of verification iterations affect generalization?
5.1 Generalization across Rules
We evaluate the performance of different post-training methods on GeneralPoints and V-IRL, each of which has a pure language (-L) and a vision-language (-VL) variant, and each encompassing rule variations. For each task, we separately scale the training compute for RL and SFT on a single rule. We consider the results on the trained rule as in-distribution (ID) performance, whereas results on the unseen rules measures out-of-distribution (OOD) generalization. In GeneralPoints, the ID case treats all 'J', 'Q', 'K'as 10, and the OOD cases interprets them as 11, 12, and 13. As for V-IRL, the ID case adopts the absolute orientation coordinate system and the OOD case uses the relative orientation action space. Other details and additional experimental setup can be found in Appendix C.
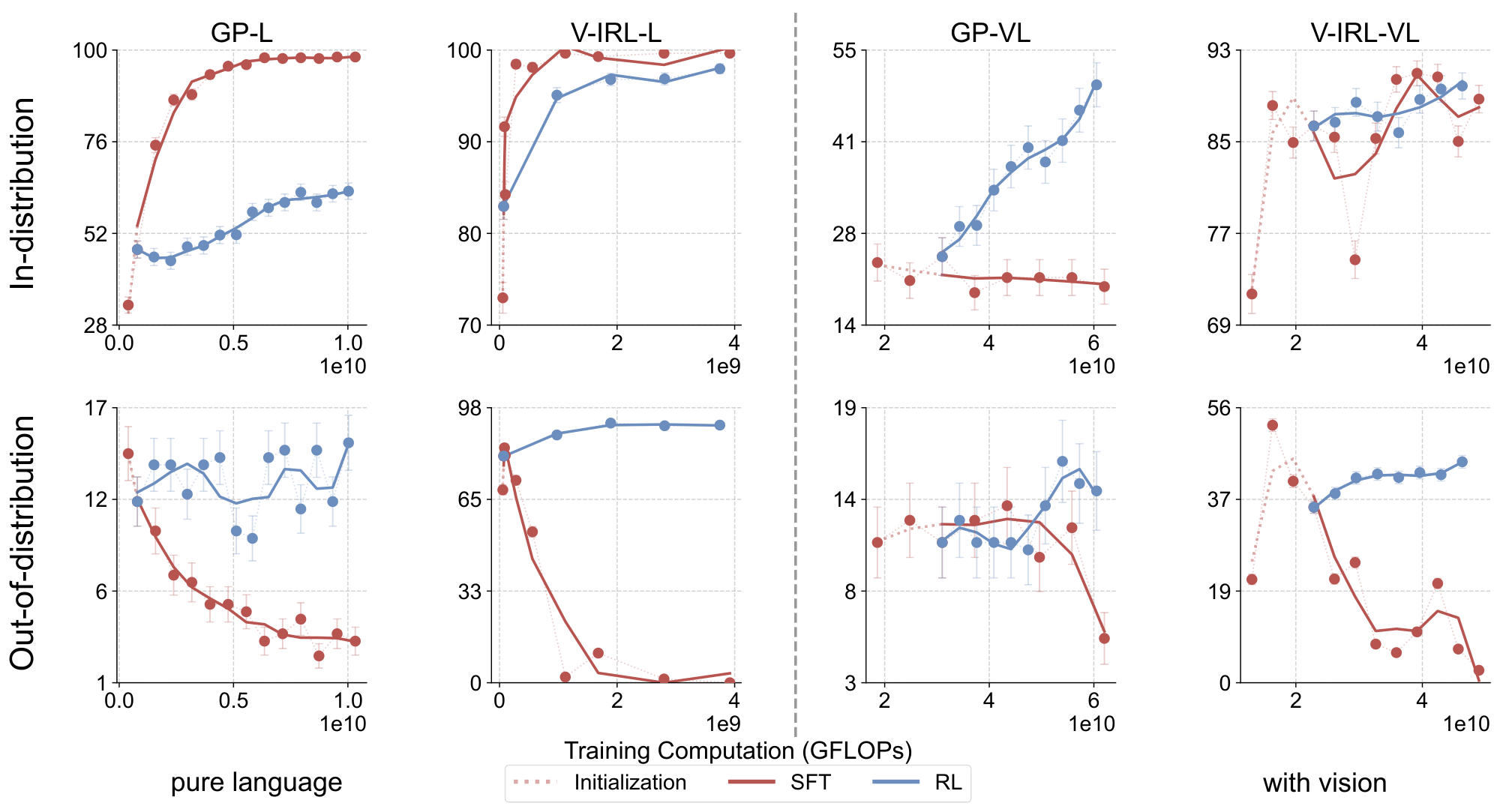
RL generalizes, SFT memorizes.
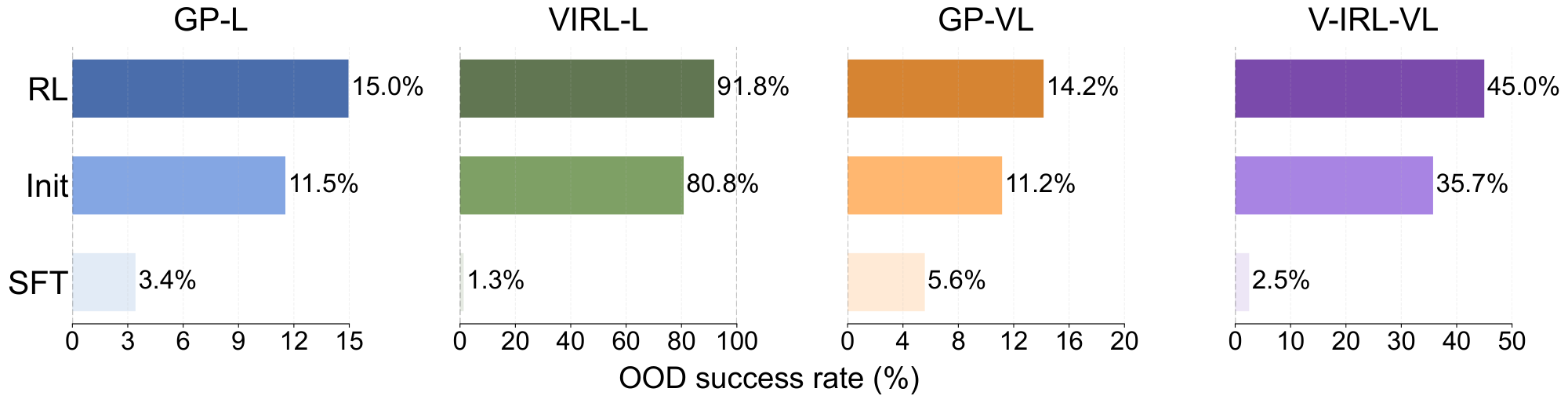
As illustrated in Figure 5, RL consistently improves OOD performance on all tasks, including both unimodal (LLM) and multimodal (VLM). Specifically, Figure 6 demonstrates that RL achieves an increase of +3.5% on GP-L (11.5% $\rightarrow$ 15.0%) and +11.0% on V-IRL-L (80.8% $\rightarrow$ 91.8%). Even with the additional challenge of visual recognition in the VLM, RL maintains consistent performance improvements of +3.0% (11.2% $\rightarrow$ 14.2%) on GP-VL and +9.3% (35.7% $\rightarrow$ 45.0%) on V-IRL-VL, respectively. In contrast, SFT consistently exhibits performance degradation across all OOD evaluations on all tasks: -8.1% on GP-L (11.5% $\rightarrow$ 3.4%), -79.5% on V-IRL-L (80.8% $\rightarrow$ 1.3%), -5.6% (11.2% $\rightarrow$ 5.6%) on GP-VL, and -33.2% (35.7% $\rightarrow$ 2.5%) on V-IRL-VL.
![**Figure 7:** **Comparison of out-of-distribution performance under visual variants.** Similar to Figure 5 and Figure 6, we present both the performance dynamics (shown as lines) and final performance (shown as bars) for visual out-of-distribution evaluations. The previous state-of-the-art on `V-IRL` VLN mini benchmark ([15]) is marked in orange. Detailed evaluation setups (and curve smoothing) are provided in Appendix C.3.](https://ittowtnkqtyixxjxrhou.supabase.co/storage/v1/object/public/public-images/9gsracat/vision_ood.png)
5.2 Generalization in Visual Out-of-Distribution Tasks
Section 5.1 demonstrates that RL yields generalization across rule variations, whereas SFT exhibits the opposite trend. Since VLMs also incorporate a visual modality, we next study the effects of visual variation in OOD generalization. For GeneralPoints, we train the VLM using the black suits (♠, ♣) and test out-of-distribution performance on the red suits (♥, ♦). For V-IRL, we train the model on routes collected in New York City and evaluate it on the original V-IRL VLN mini benchmark ([15]) containing routes from various cities worldwide (see Appendix B.1 for details). Note that the rules remain consistent across experiments in this section.
RL generalizes in visual OOD tasks.
As shown in Figure 7, we observe that RL still generalizes in visual OOD tasks, while SFT continues to suffer. Specifically, in GP-VL and VIRL-VL, RL achieves performance improvements of +17.6% (23.6% $\rightarrow$ 41.2%), +61.1% (16.7% $\rightarrow$ 77.8%), whereas SFT suffers from performance decreases of -9.9% (23.6% $\rightarrow$ 13.7%) and -5.6% (16.7% $\rightarrow$ 11.1%). As a byproduct of this visual OOD study, we also show that our multi-turn RL formulation improves the state-of-the-art results (see Table 5 of [15]) on the V-IRL mini benchmark by +33.8% (44.0% $\rightarrow$ 77.8%). Notably, unlike the previous state-of-the-art approach reported in V-IRL, which relies on a two stage VLM-LLM collaboration technique and tailored prompt engineering on closed-sourced model ([68]), our end-to-end RL approach enables an open-sourced model ([16]) to reach superior performance.
5.3 RL Improves Visual Capabilities
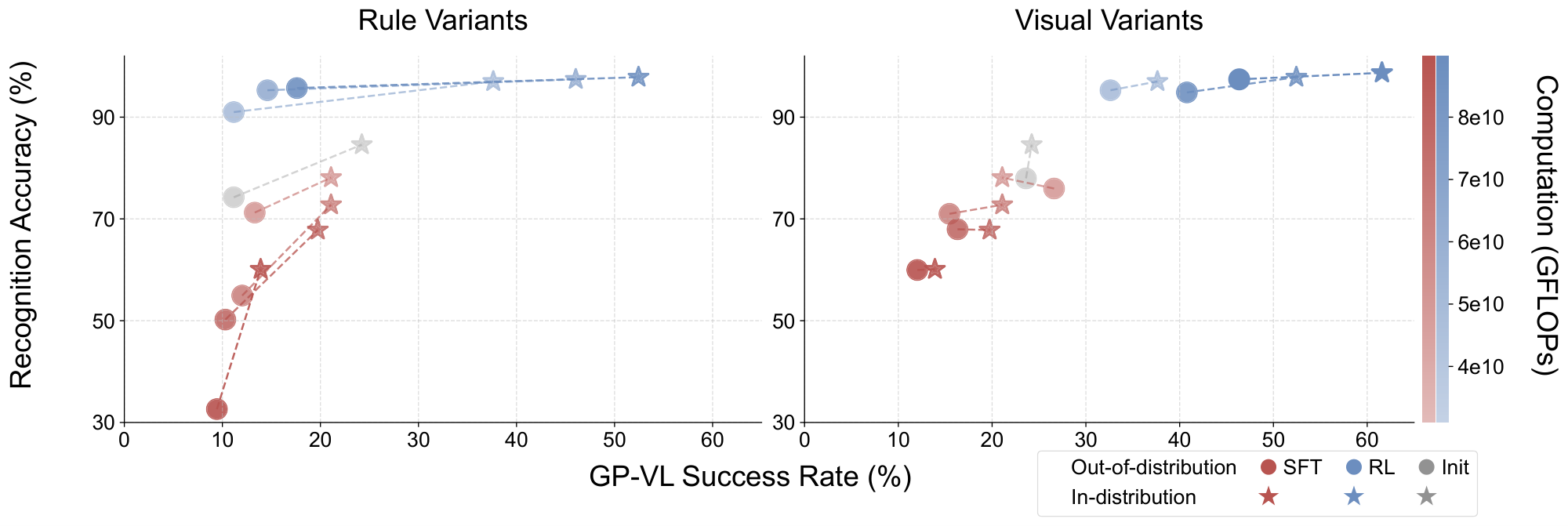
Building upon the above observation that VLMs trained with RL generalize to visual OOD tasks (Section 5.2), we consider a natural follow-up question: How does RL affect VLMs'visual capabilities? To study this question, we conducted additional ablation studies in the GP-VL environment to investigate the OOD performance of RL and SFT, along with the model's visual recognition accuracy, in terms of recognizing the 4 cards from the input image. In particular, we study how scaling post-training compute via RL/SFT both affects generalization in rule-based OOD (Figure 8 left), and visual recognition accuracy and visual OOD (Figure 8 right).
Scaling RL improves visual recognition accuracy in VLM training.
As shown in Figure 8, we observe that the VLM's visual recognition accuracy largely affects the overall performance, which was similarly observed in [69]. In addition, scaling up RL compute also improves visual recognition accuracy, as a byproduct of its generalization capability, while scaling SFT deteriorates both visual recognition accuracy and overall performance. Additional experimental results are provided in Figure 16 and Figure 17 of Appendix D.1.
5.4 The Role of SFT for RL Training
Despite the superiority of RL in generalizing the model's reasoning and visual capabilities, as discussed previously, the experimental pipeline still instantiates RL after SFT. In this subsection, we focus on another key question: Is SFT necessary for RL training? To answer this question, we conduct additional experiments that directly apply end-to-end RL to post-train the base model Llama3.2 using GeneralPoints in the purely language case (Figure 9).
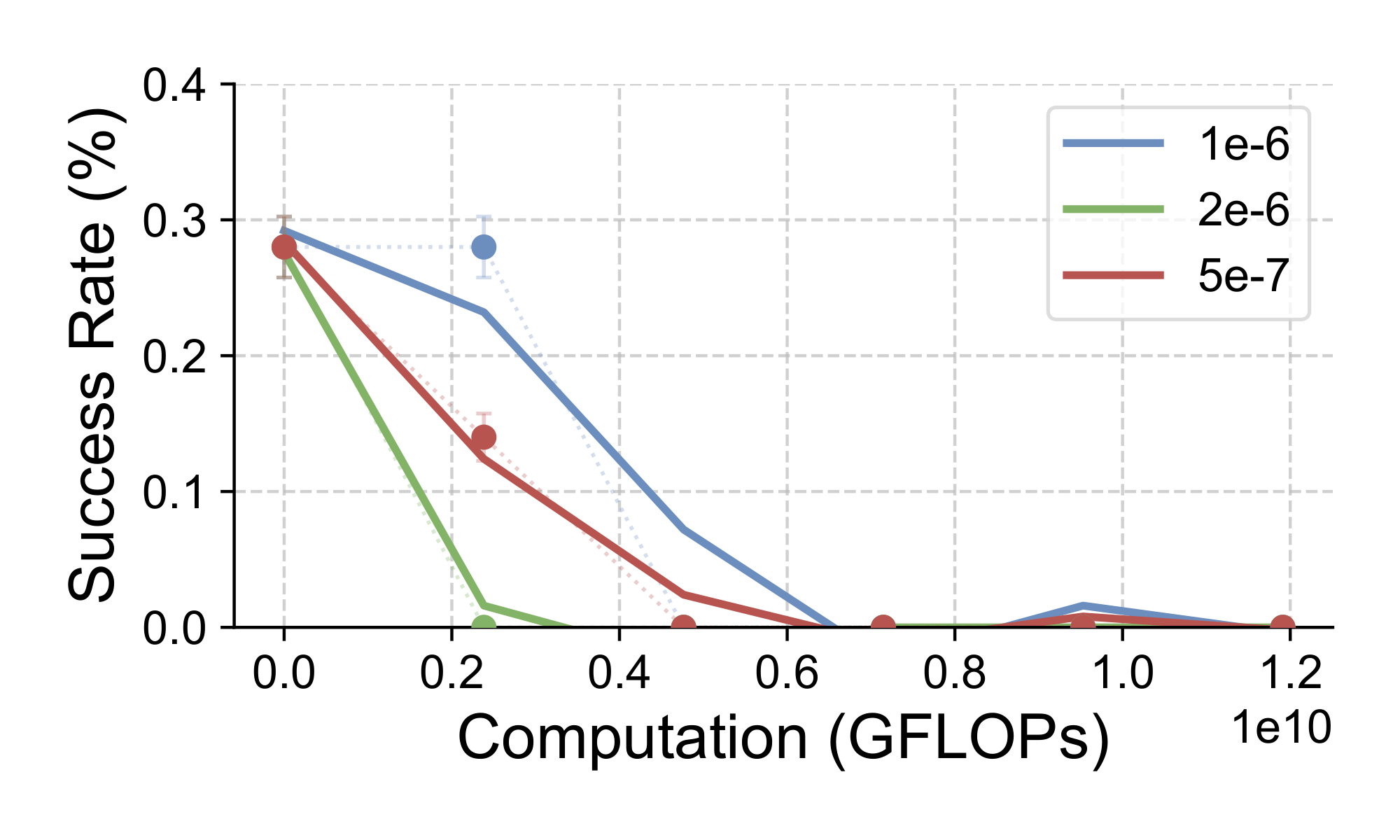
SFT is necessary for RL training when the backbone model does not follow instructions.
Figure 9 shows that without SFT, all end-to-end RL runs fail to improve. More specifically, we observe that without SFT, the base model suffers from poor instruction following capability. A detailed failure case is provided in Figure 20 (in Appendix D.3), revealing that the base Llama-3.2-Vision-11B model tends to generate long, tangential, and unstructured responses. This issue makes it impossible to retrieve task-related information and rewards for RL training. Note that due to the difference in backbone model, our results do not contradict with [4], which suggests that SFT is unnecessary for downstream RL training.
5.5 Role of Verification Iterations
Verification serves as another crucial component in our multi-step training and evaluation pipeline (see Figure 2 and Figure 3). To validate its necessity and better understand its effect, we conduct RL experiments with different verification iterations ${1, 3, 5, 10}$ using GP-L (Figure 10).
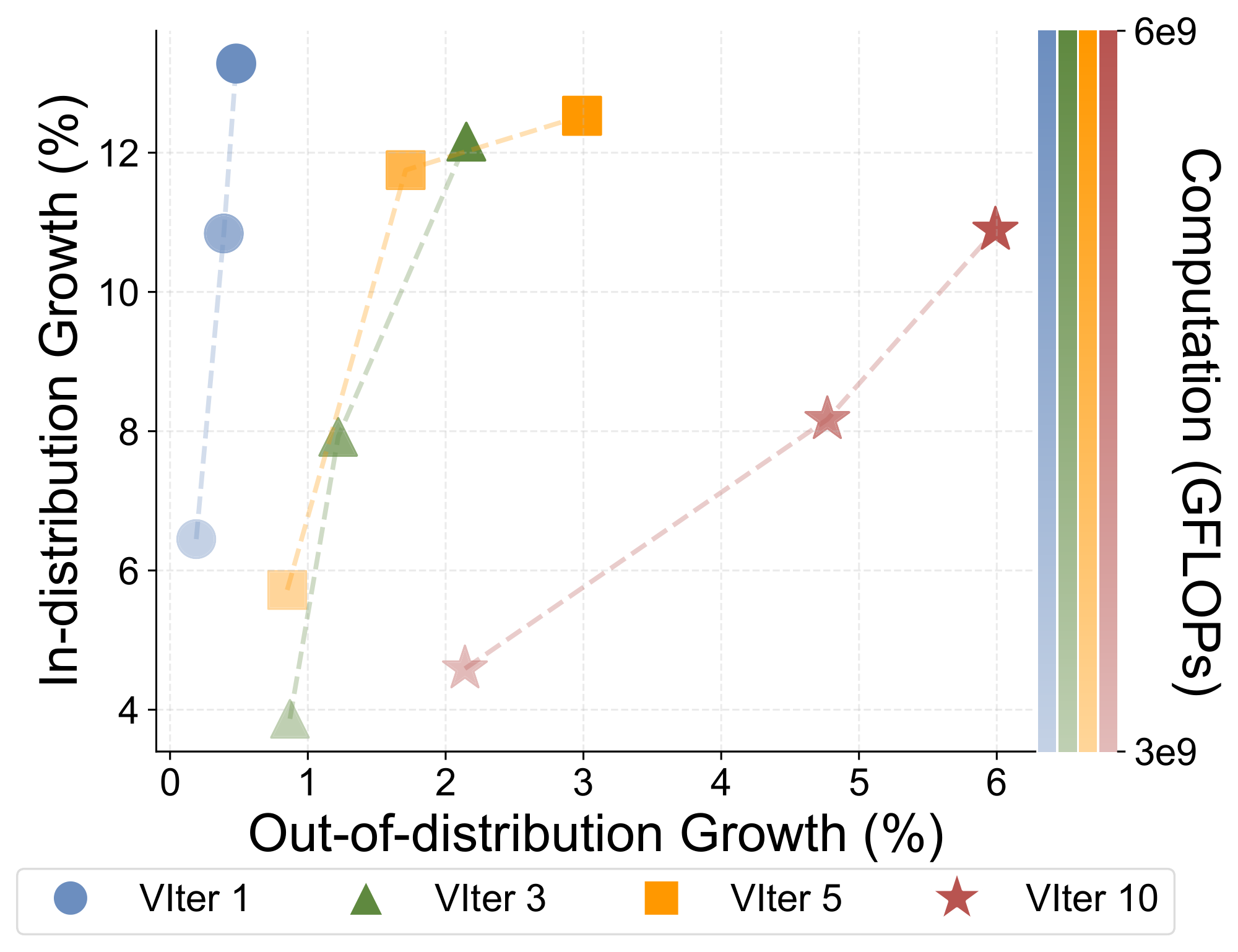
Scaling up verification improves generalization.
In Figure 10, we observe that RL generalizes better with more verification steps. More specifically, under the same computational budget across all experiments, we observe improvements of +2.15% (3 steps), +2.99% (5 steps), +5.99% (10 steps). In contrast, in the case with one verification step, we only observe a marginal improvement of +0.48% in OOD performance improvement.
6. Conclusion, Discussion, and Limitations
Section Summary: The paper concludes that reinforcement learning (RL) generally produces more flexible, generalizable skills than supervised fine-tuning (SFT) when applied to foundation models on arithmetic and spatial-reasoning tasks. While RL better preserves visual recognition and adapts to new rules or visual conditions, SFT tends to overfit to the exact training examples, sometimes even degrading core recognition abilities. The authors also note two remaining limitations: SFT can fail to match RL’s performance on certain tasks, and RL itself struggles when started from poorly chosen initial models, highlighting the need for better guidance on how to combine the two methods.
In this paper, we present a comprehensive analysis of the generalization effects of foundation model post-training techniques, specifically RL and SFT. Through extensive experiments on the GeneralPoints and V-IRL tasks, we demonstrated that RL exhibits superior performance in learning generalizable knowledge, while SFT tends to merely memorize the training data, across both the rule and visual variations. This phenomenon consistently occurs across multimodal arithmetic and spatial reasoning capabilities. In addition, we studied the effect of RL on visual recognition, the role of SFT, and the role of verification steps. During our study, two challenges were not resolved.
Failure of SFT on GP-VL.
In Figure 5 for GP-VL, we observe that SFT fails to achieve a comparable in-distribution performance with RL. To mitigate the variance introduced by hyperparameter choices, we additionally conduct 10 more experiments with different learning rates and tunable components (Figure 16), none of which exhibits a strong increasing trend like RL (Figure 17). Given our observation that scaling up SFT degrades visual recognition capabilities (Figure 8), we hypothesize that SFT locally overfits to reasoning tokens while neglecting recognition tokens, possibly due to the higher frequency of reasoning tokens (see Figure 11 as example). We leave further investigation to future work.
Limits of RL in corner cases.
As discussed in Section 5.4, SFT is necessary for effective RL training on Llama-3.2. We investigate applying RL to an overly-tuned SFT checkpoint. As demonstrated in Figure 19, RL is unable to recover out-of-distribution performance when starting from such a checkpoint. Example failure cases are illustrated in Figure 21, where the model collapses to the training rule. These results, together with findings in Section 5.4, indicate that RL has limited effectiveness when applied to extremely underfit or overfit initial checkpoints. Further research is needed to delineate the conditions under which SFT facilitates effective RL.
7. Impact Statement
Section Summary: This research advances machine learning through experiments in artificial and simulated settings that stay entirely within controlled lab conditions. It uses a made-up task and a map simulator as stand-ins for real-world challenges but never connects to actual systems or data. The goal is simply to better understand how models generalize, with no expected effects on society or ethical concerns.
This paper presents work aimed at advancing the field of Machine Learning. While the study includes tasks such as GeneralPoints, which is a synthetic environment, and V-IRL, a real-world map simulator, our work is confined to controlled research settings. The V-IRL environment is designed as a simulated proxy for real-world tasks, but no deployment or interaction with actual real-world systems or data was involved. The methods, environments, and tasks investigated in this study were constructed to advance our understanding of model generalization without introducing any foreseeable societal or ethical implications.
Acknowledgements
Section Summary: In this section, one author expresses thanks to Xiaoxuan Feng for improving a figure in the paper. The research team as a whole also credits two colleagues for their comments on earlier drafts. A main researcher lists several grants and institutional awards that helped fund the work.
YZ would like to thank Xiaoxuan Feng for beautifying Figure 4. We would like to thank Jincheng Mei and Doina Precup for feedbacks on earlier manuscripts. Yi Ma would like to acknowledge support from the joint Simons Foundation-NSF DMS grant #2031899, the ONR grant N00014-22-1-2102, the NSF grant #2402951, and also support from and the HKU startup, the Hong Kong Center for Construction Robotics Limited (HKCRC) Award 052245, and JC Club of Hong Kong.
Appendix
Section Summary: The appendix outlines the design and implementation details for two environments used to evaluate model performance. It first covers the GeneralPoints card game, explaining how card quadruples are sampled from a standard deck to guarantee solvable puzzles targeting 24, how interaction prompts are iteratively updated with model outputs, verification results, and optional visual inputs, and how configurable rules plus a tiered reward system encourage valid equations while penalizing mistakes or unrecognized cards in visual variants. It then describes the V-IRL navigation setting, including a training database of New York City routes, multi-city benchmarks for testing shifts, transition examples, and modifications to support reinforcement learning with appropriate rewards.
A. Details on the General Points Environment
In this section, we demonstrate the design details for GeneralPoints mentioned in Section 4.1. We first present the data used for this environment (Appendix A.1). Then, we show examples of the environment's transition dynamics (Appendix A.2), followed by a description of key arguments and reward design specification (Appendix A.3).
A.1 Data
GeneralPoints card quadruples are sampled from a deck of 52 standard poker cards. Each sampled quadruple is guaranteed to have at least one solution equals the target point, i.e. 24. We ensure this by using an expert solver during the sampling process.
A.2 Detailed Examples on the Transition Dynamics
As shown in Figure 11 and Figure 12, we treat the system prompt as $\boldsymbol v^\text{in}0$ and then subsequently appending the future outputs $\boldsymbol v^\text{out}{1:t}$ and verifier info $\boldsymbol v^\text{ver}_{1:t}$ into the prompt for getting the $t+1$ output. Figure 11 provides an example with the visual inputs, while Figure 12 shows the language only case.


A.3 Additional Eetails on the Environmental Design
Arguments.
The GeneralPoints environment supports the following configurable arguments:
Target point: Any positive integer
Face cards rule: Two options
- ' $J'$,' $Q'$, and 'K'all count as '1 $0'$
- ' $J'$,' $Q'$, and 'K'count as '1 $1'$,'1 $2'$, and '13'respectively
Card sampling: Two options
- Sample 4 cards without replacement from a deck of 52 poker cards
- Sample at least one card from ' $J'$,' $Q'$, and ' $K'$
Card color: Three options
- Black suits only: ♣, ♠.
- Red suits only: ♥, ♦.
- All suits: ♠, ♥, ♣, ♦.
For all experiments, we fix the target point at 24. In Figure 5, training and in-domain evaluation use the rule where face cards count as '10'. For out-of-domain evaluation, we use the alternative face cards rule and require at least one face card, forcing calculations with numbers above 10 that are not encountered during training. For visual distribution shift experiments (Section 5.2), we train the model on black suits ♠, ♣ and evaluate out-of-domain performance on red suits ♥, ♦.
Reward design.
An episode terminates when either a correct equation is generated or the maximum verification step of $5$ is reached. The reward function is as follows:
- $r=5$: For generating a legal equation that equals the target point
- $r=-1$: For legal equations using each card once but not equaling the target point
- $r=-1$: For exceeding maximum verification step
- $r=-2$: For legal equations containing numbers not among the given choices
- $r=-3$: For all other illegal equations
In the vision-language variant (GeneralPoints-VL), an additional penalty of $r=-1.5$ is applied when the agent fails to correctly recognize the given cards.
B. Details on the V-IRL Environment
Similar to Appendix A, we present the design details for V-IRL discussed in Section 4.2. First, we introduce the database used for this environment (Appendix B.1) and demonstrate transition examples (Appendix B.2). We then describe the environment by explaining its fundamental component—route. Finally, we outline our modifications and reward design choices made to adapt the original V-IRL for reinforcement learning training (Appendix B.3).
B.1 Data
Leveraging the data collection pipeline of [15], we construct a training database with 1000 unique routes from New York City. We evaluate all rule-variant experiments and visual in-distribution experiments using randomly sampled routes from this database. For visual out-of-distribution experiments, we directly adopt the VLN mini benchmark from [15]. This benchmark consists of 18 distinct routes across nine cities: Milan, New Delhi, Buenos Aires, London, Hong Kong, New York, [^4] Melbourne, Lagos, and San Francisco, with two routes per city.
[^4]: These NYC routes in the VLN mini benchmark do not overlap with our training data.
B.2 Detailed Examples on the Transition Dynamics
We provide detailed transition examples of the V-IRL environment in Figure 13 (vision and language) and Figure 14 (pure language).


B.3 Additional Details on the Environmental Design
Concept of route.
The route serves as the fundamental navigation object in the V-IRL environment. As illustrated in Figure 4, each route corresponds to a real-world path with associated language instructions and visual signals. Using Figure 4 as an example, a route comprises:
- Destination: Shuka
- Starting point: Start
- Turning points: The Dutch, Lola Taverna
- Straight road: Roads connecting turning points, starting point, and destination
- Street views: 360-degree panoramic views at each movable point
- Oracle information: Expert observation data for each movable point
- Expert trajectory
- Instruction
Although the instructions in Figure 4, Figure 14, and Figure 13 are presented in different formats, they convey equivalent information, with Figure 4 using natural language.
Simplification and arguments.
We simplify the original V-IRL design from [15] to better accommodate RL training. The modifications include eliminating the 2-stage navigation pipeline that required a separate visual detector for street view processing, and removing online queries to reduce training time and cost. Our V-IRL environment contains 2 additional configuration arguments compared with the original design:
Action space: two options
- Absolute direction: "turn_direction(x)" where x $\in$ 'north', 'northeast', 'east', 'southeast', 'south', 'southwest', 'west', 'northwest', "forward()", "stop()"
- Relative direction: "turn_direction(x)" where x $\in$ 'left', 'right', 'slightly left', 'slightly right', "forward()", "stop()"
Maximum straight road length: any positive integer
The action space argument accommodates the rule variants described in Section 4. For experiments shown in Figure 5, we use absolute direction action space during training and in-domain evaluation, while using the alternative rule for out-of-domain evaluation. We implement a maximum straight road length to limit the number of movable coordinates between turning points, preventing sequences of repetitive "forward()" actions. We conduct visual distribution shift experiments (Section 5.2) via training the model on New York City regions and evaluating the out-of-domain performance on the worldwide navigation routes from the benchmark released by [15].
Reward design.
An episode terminates when either the navigation agent stops at the destination or the maximum verification step of 2 is reached. The reward function is as follows:
- $r=1$: For generating a correct action at the current coordinate
- $r=-1$: For generating wrong action at the current coordinate
- $r=-1$: For exceeding maximum verification step
- $r=-1.5$: For failed detection of landmarks
C. Experimental Setup
This section details the experimental setup used in Section 5. We first describe our data collection setup for supervised fine-tuning (Appendix C.1). Then, we present the training pipeline (Appendix C.2). Finally, we describe our evaluation metrics and the statistical tools used for generating plots (Appendix C.3).
C.1 Data
SFT data collection.
As illustrated in Figure 12, Figure 11, Figure 14, and Figure 13, GeneralPoints and V-IRL environments naturally align with prompt-response dialogue structures. We create training samples by pairing each system prompt with its corresponding expert response. All SFT experiments in the main body use optimal single-turn prompt-response pairs, without any verification or revision steps.
SFT on sub-optimal trajectories
To examine how more diverse SFT data affects the out-of-distribution performance of SFT, we conduct an ablation study on GP-L using sub-optimal trajectories as training data. Unlike expert prompt-response pairs, these sub-optimal trajectories include errors and verification messages in their prompts. This format aligns with evaluation scenarios where multiple verification iterations are allowed, similar to the data being used for the downstream RL training. In Figure 15, we observe that SFT still merely memorizes the training data with degraded out-of-distribution performance. This evidence suggests that memorization occurs due to the fundamental nature of SFT training rather than the SFT data.
C.2 Training Pipeline
As illustrated in Section 5, we follow the training pipeline by RL4VLM ([14]), where we first initialize the model with SFT, then separately scale up the compute for SFT and RL ([67]), starting from this initialized model. For all experiments of SFT and RL in the main body, we tune all components using a shared learning rate per experiment. All training experiments are conducted on an 8 H800 machine (80GB).
C.3 Evaluation Metric
Per-step accuracy.
We report the per-step accuracy for V-IRL-VL task in Figure 5 and Figure 6. An individual step is considered correct when the model's chosen action matches the expert trajectory at that position. Note that intermediate verification steps are counted as independent samples here.
Success rate.
We report the success rate (%) of GP-L, GP-VL, V-IRL-L and V-IRL-VL in Figure 5 and Figure 6. In the GeneralPoints task, success is defined as succeeding at least once during the inference time verification. In the V-IRL task, a sample is recorded as success when the model takes correct action at each movable point on the route.
Computation estimation.
We estimate the FLOPs for training $X$ following the similar manner of ([17, 20]), where $X_{train}=6ND_{train}$ and $X_{inference}=2ND_{inference}$. Here, $N$ represents the model parameters and $D_{train}$ represents the number of tokens during training. Suppose our SFT and RL experients starts from a checkpoint trained on $D_{init}$ tokens, we can estimate the training computation of SFT and RL via the following equations:
$ \begin{align*} X_{SFT}&=6N(D_{init}+D_{SFT})\ X_{RL}&=6N(D_{init}+D_{RL}) + 2ND_{buffer} \end{align*} $
Note that the used on-policy RL algorithm PPO ([67]) contains iterative stages of replay buffer collection and optimization, hence requiring additional inference computation. For simplicity, we approximate the term via:
$ \begin{align*} D_{buffer}&\approx \frac{E\bar{d_{i}}\bar{d_{o}}}{D_{RL}}\cdot D_{RL}\ &=\lambda D_{RL} \end{align*} $
where $E\in \mathbb{N}$ denotes the number of auto-regressive generation processes, $\bar{d_i}, \bar{d_o}$ denote average input tokens and output tokens. We estimate the $\lambda$ for GeneralPoints and V-IRL as $6$ and $5.1$ respectively after calculation.
Line smoothing and error bar.
All line plots in our paper adopt Savitzky–Golay filter with polynomial order 3 as smoothing function. We assume each evaluated data point follows a binomial distribution and approximate the standard error using $\sqrt{\frac{P(1-P)}{N}}$, where $P$ is the demical success rate and $N$ is the number of samples.
D. Additional Experimental Results
In this section, we provide additional experimental results that are not covered in the main body.
D.1 Ablation Studies on GP-VL
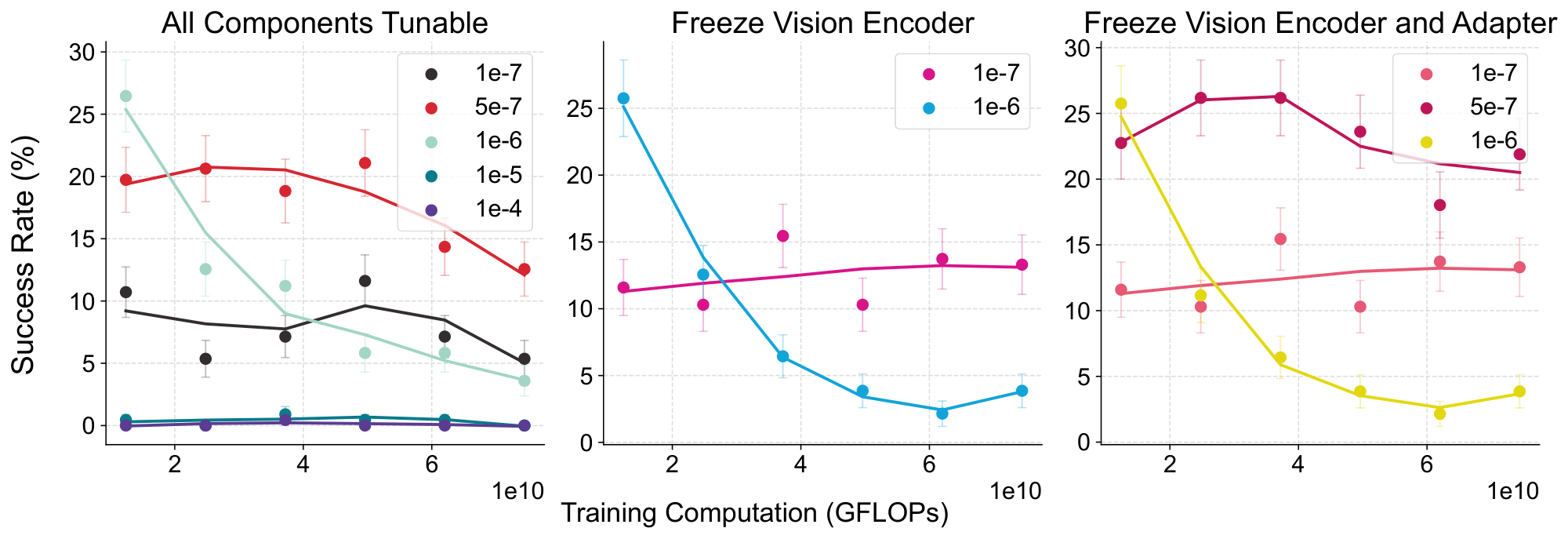
As mentioned in Section 6, we observe an abnormal phenomenon that SFT fails to achieve comparable in-distribution performance with RL (see Figure 5 subplot row 1 column 3). To further explore this, we conduct ablation studies over different hyperparameter choices.
SFT.
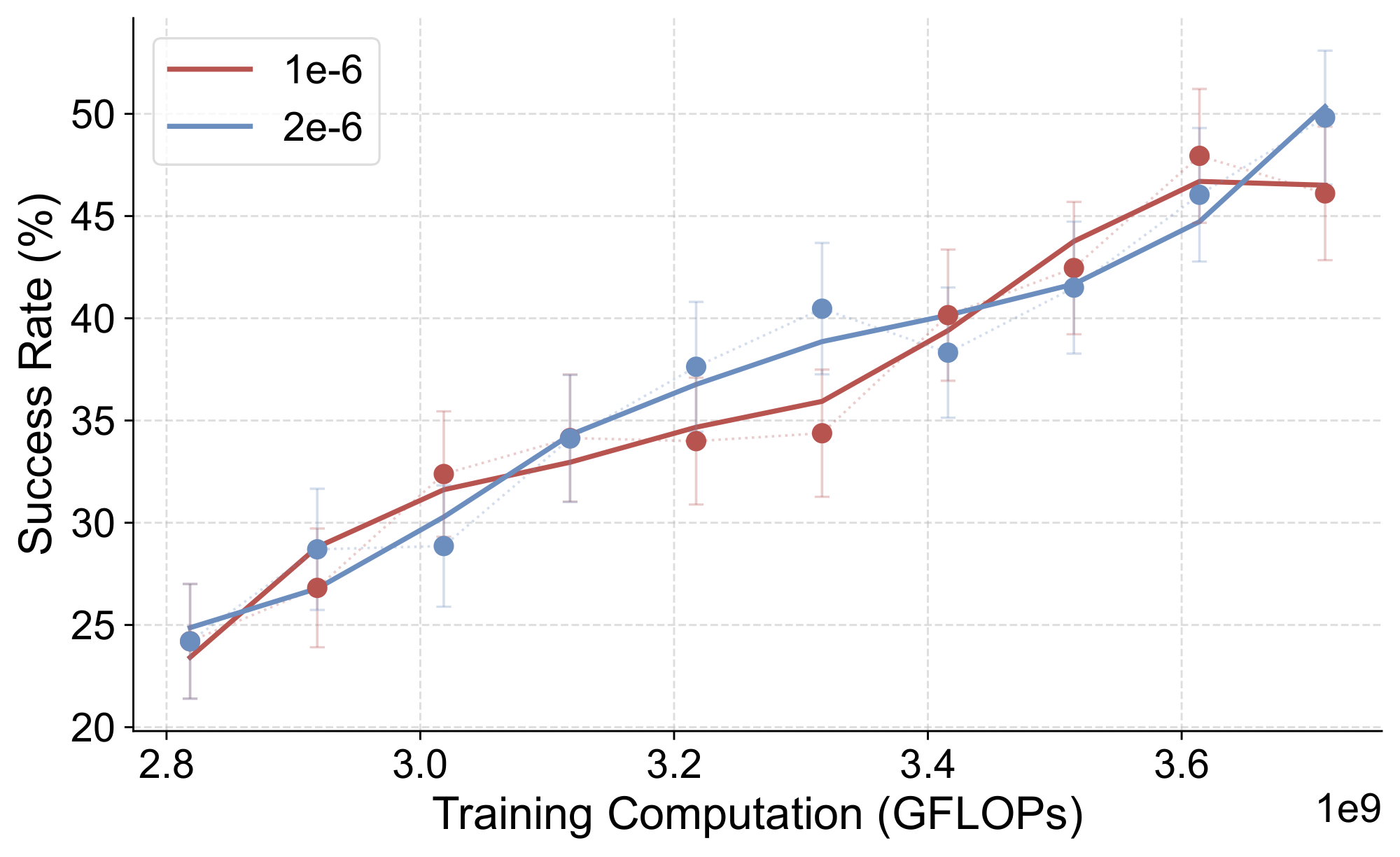
We ablate the hyperparameter choices under the same task setting of GP-VL in Section 5.1. For experiments fine-tuning all parameters, we search learning rates from ${1\times10^{-4}, 1\times10^{-4}, 1\times10^{-5}, 1\times10^{-6}, 5\times10^{-7}, 1\times10^{-7}}$. Freezing the vision encoder, we search learning rates ${1\times10^{-6}, 1\times10^{-7}}$. Freezing vision encoder and adapter, we search learning rates ${1\times10^{-6}, 5\times10^{-7}, 1\times10^{-7}}$. We provide the in-distribution success rate curve in Figure 16.
RL.
Finding suitable hyperparameters for RL experiments requires minimal effort. We conduct a search over learning rates ${2\times 10^{-6}, 1\times 10^{-6}}$, with the in-distribution success rate curves shown in Figure 17. All parameters are tunable in our RL experiments.
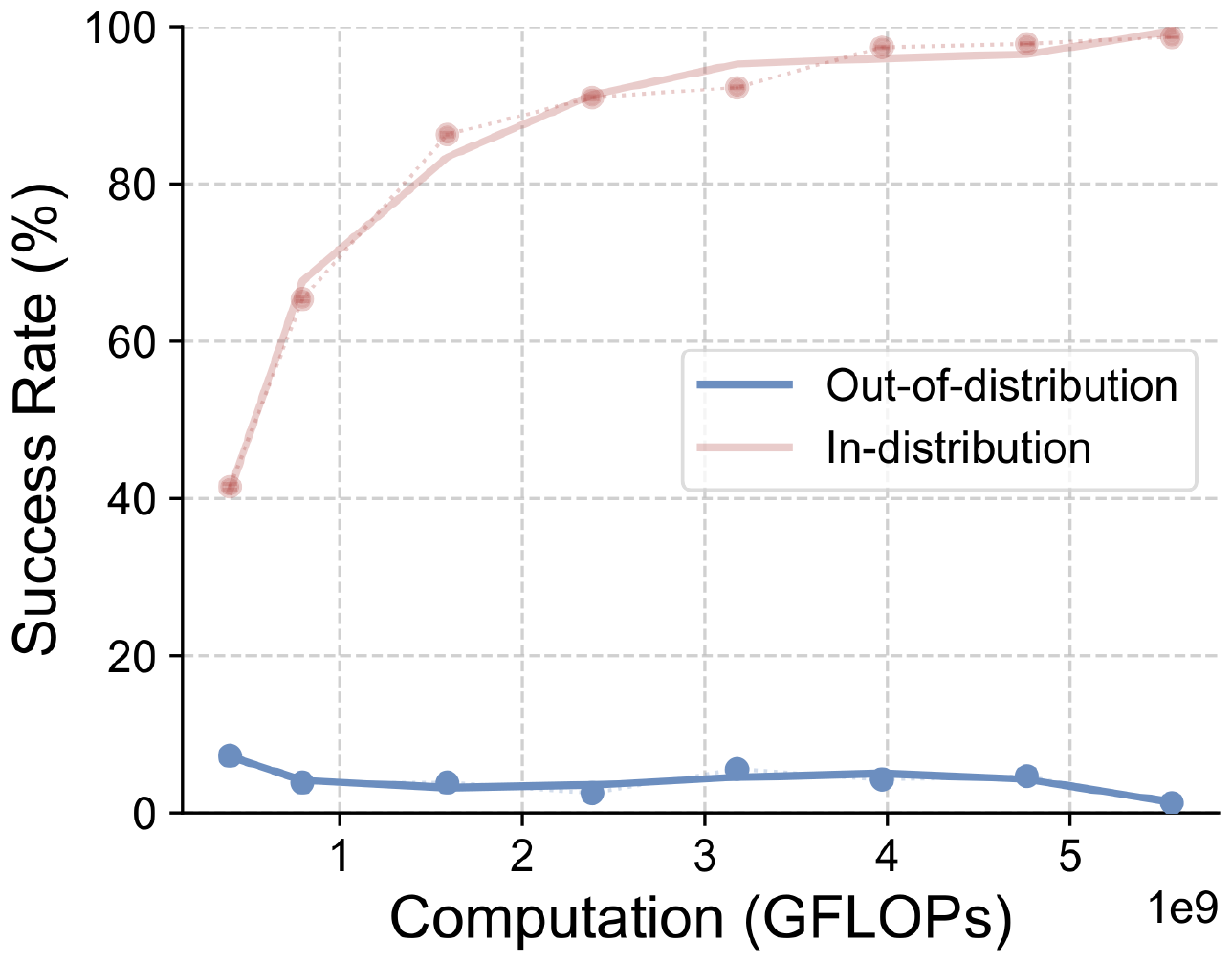
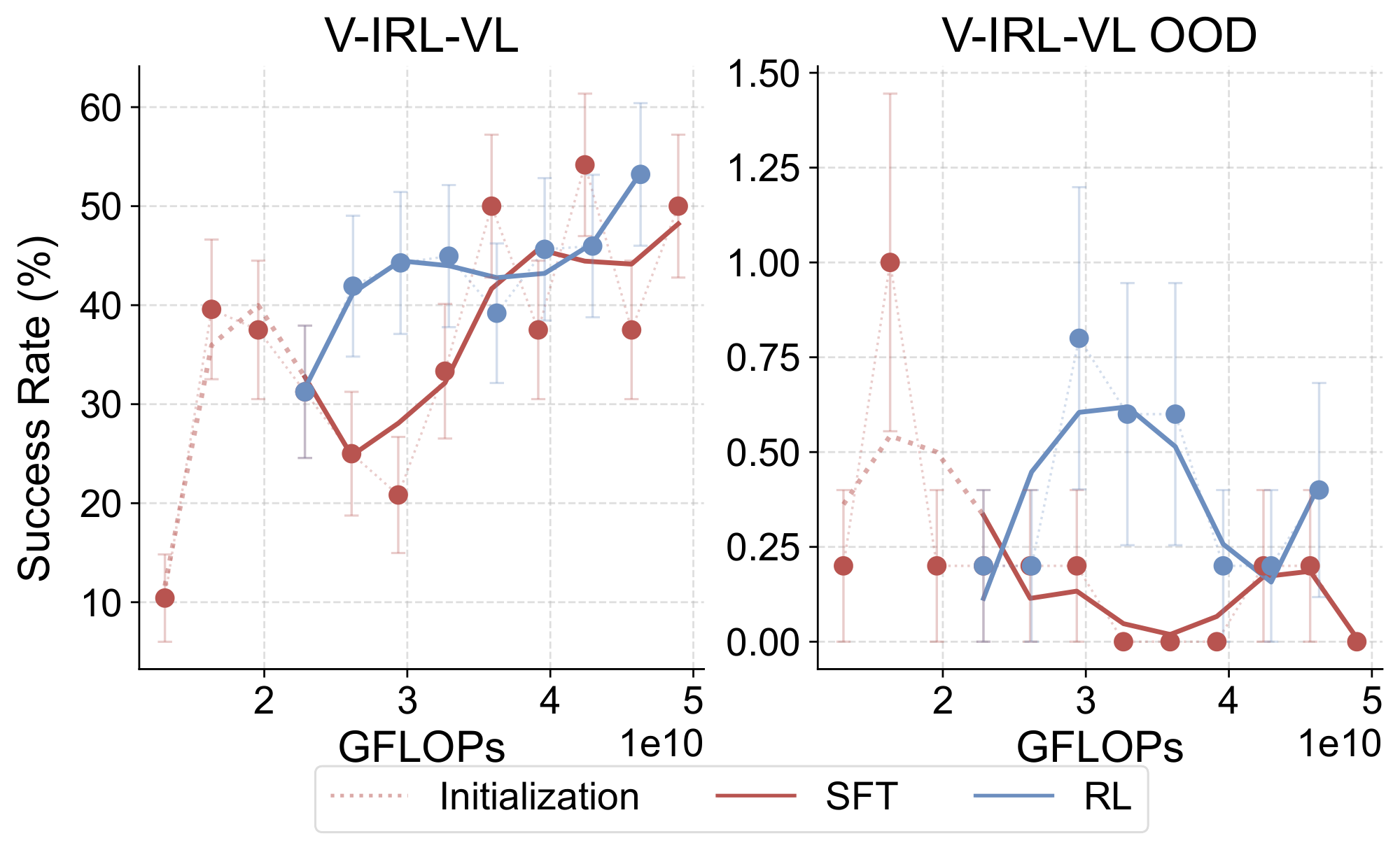
D.2 More results on V-IRL-VL
Echoing per-step accuracy results in Figure 5, we report the overall success rate of V-IRL-VL in Figure 18. Due to the task's complexity, both training methods achieve overall success rates no higher than $1%$. For V-IRL, the overall success rate is a significantly more demanding metric since it aggregates per-step errors. For example, a random policy achieving $10%$ per-step accuracy would achieve achieve only approximately $10^{-8}%$ success rate on enough routes averaging 10 steps in length.
D.3 Failure Cases
In this section, we present 2 failure cases in our experiments as mentioned in Section 5.4 and Section 6.
Without SFT, RL fails.
In Figure 9, we present the training dynamics of failed RL experiments without SFT initialization. We additionally provide output examples of these experiments in Figure 20, where the model tends to generate unstructured response and fail.
RL cannot save overfitted checkpoints.
As shown in Figure 19, RL cannot recover the out-of-distribution performance when initialized from a extremely overfitted checkpoint that has an initial per-step accuracy of less than $1%$. We additionally provide an output example in Figure 19, where the model fails to adjust to the new rule.


References
Section Summary: This section compiles a list of academic papers, technical reports, and preprints focused on the development, training, and evaluation of large language models and related AI systems. The citations draw from major organizations such as OpenAI and Google, along with university researchers, and span topics including model scaling, reasoning, generalization, and reinforcement learning. They were published primarily between 2018 and 2025 in venues like arXiv and leading machine learning conferences.
[1] OpenAI. GPT-4 technical report. arXiv, pp. 2303–08774, 2023b.
[2] Google, D. Introducing Gemini: Our largest and most capable AI model, 2023. URL https://blog.google/technology/ai/google-gemini-ai/.
[3] Jaech, A., Kalai, A., Lerer, A., Richardson, A., El-Kishky, A., Low, A., Helyar, A., Madry, A., Beutel, A., Carney, A., et al. OpenAI o1 system card. arXiv preprint arXiv:2412.16720, 2024.
[4] DeepSeekAI et al. DeepSeek-R1: Incentivizing reasoning capability in LLMs via reinforcement learning, 2025. URL https://arxiv.org/abs/2501.12948.
[5] Bousquet, O. and Elisseeff, A. Algorithmic stability and generalization performance. volume 13, 2000.
[6] Zhang, C., Bengio, S., Hardt, M., Recht, B., and Vinyals, O. Understanding deep learning (still) requires rethinking generalization. Communications of the ACM, 64(3):107–115, 2021.
[7] Bommasani, R., Hudson, D. A., Adeli, E., Altman, R., Arora, S., von Arx, S., Bernstein, M. S., Bohg, J., Bosselut, A., Brunskill, E., et al. On the opportunities and risks of foundation models. arXiv preprint arXiv:2108.07258, 2021.
[8] Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J. D., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., et al. Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901, 2020.
[9] Allen-Zhu, Z. and Li, Y. Physics of language models: Part 3.1, knowledge storage and extraction. arXiv preprint arXiv:2309.14316, 2023a.
[10] Ye, T., Xu, Z., Li, Y., and Allen-Zhu, Z. Physics of language models: Part 2.1, grade-school math and the hidden reasoning process. arXiv preprint arXiv:2407.20311, 2024.
[11] Kang, K., Setlur, A., Ghosh, D., Steinhardt, J., Tomlin, C., Levine, S., and Kumar, A. What do learning dynamics reveal about generalization in LLM reasoning? arXiv preprint arXiv:2411.07681, 2024.
[12] Zhu, Z., Xue, Y., Chen, X., Zhou, D., Tang, J., Schuurmans, D., and Dai, H. Large language models can learn rules. arXiv preprint arXiv:2310.07064, 2023.
[13] Yao, S., Yu, D., Zhao, J., Shafran, I., Griffiths, T., Cao, Y., and Narasimhan, K. Tree of thoughts: Deliberate problem solving with large language models. Advances in Neural Information Processing Systems, 36, 2024.
[14] Zhai, Y., Bai, H., Lin, Z., Pan, J., Tong, S., Zhou, Y., Suhr, A., Xie, S., LeCun, Y., Ma, Y., and Levine, S. Fine-tuning large vision-language models as decision-making agents via reinforcement learning. In The Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024a. URL https://openreview.net/forum?id=nBjmMF2IZU.
[15] Yang, J., Ding, R., Brown, E., Qi, X., and Xie, S. V-IRL: Grounding virtual intelligence in real life. In European conference on computer vision, 2024a.
[16] Dubey, A., Jauhri, A., Pandey, A., Kadian, A., Al-Dahle, A., Letman, A., Mathur, A., Schelten, A., Yang, A., Fan, A., et al. The Llama 3 Herd of models. arXiv preprint arXiv:2407.21783, 2024.
[17] Snell, C., Lee, J., Xu, K., and Kumar, A. Scaling LLM test-time compute optimally can be more effective than scaling model parameters. arXiv preprint arXiv:2408.03314, 2024.
[18] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168, 2021.
[19] Zhang, S., Roller, S., Goyal, N., Artetxe, M., Chen, M., Chen, S., Dewan, C., Diab, M., Li, X., Lin, X. V., et al. Opt: Open pre-trained transformer language models. arXiv preprint arXiv:2205.01068, 2022.
[20] Hoffmann, J., Borgeaud, S., Mensch, A., Buchatskaya, E., Cai, T., Rutherford, E., Casas, D. d. L., Hendricks, L. A., Welbl, J., Clark, A., et al. Training compute-optimal large language models. NeurIPS, 2023.
[21] Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., Lacroix, T., Rozière, B., Goyal, N., Hambro, E., Azhar, F., et al. Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971, 2023.
[22] Radford, A., Narasimhan, K., Salimans, T., Sutskever, I., et al. Improving language understanding by generative pre-training. 2018.
[23] Radford, A., Kim, J. W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al. Learning transferable visual models from natural language supervision. In International conference on machine learning, pp. 8748–8763. PMLR, 2021.
[24] Wei, J., Bosma, M., Zhao, V., Guu, K., Yu, A. W., Lester, B., Du, N., Dai, A. M., and Le, Q. V. Finetuned language models are zero-shot learners. In International Conference on Learning Representations, 2022a. URL https://openreview.net/forum?id=gEZrGCozdqR.
[25] Chung, H. W., Hou, L., Longpre, S., Zoph, B., Tay, Y., Fedus, W., Li, E., Wang, X., Dehghani, M., Brahma, S., et al. Scaling instruction-finetuned language models. arXiv preprint arXiv:2210.11416, 2022.
[26] Zhou, C., Liu, P., Xu, P., Iyer, S., Sun, J., Mao, Y., Ma, X., Efrat, A., Yu, P., Yu, L., et al. LIMA: Less is more for alignment. Advances in Neural Information Processing Systems, 36, 2024a.
[27] Ziegler, D. M., Stiennon, N., Wu, J., Brown, T. B., Radford, A., Amodei, D., Christiano, P., and Irving, G. Fine-tuning language models from human preferences. arXiv preprint arXiv:1909.08593, 2019.
[28] Ouyang, L., Wu, J., Jiang, X., Almeida, D., Wainwright, C., Mishkin, P., Zhang, C., Agarwal, S., Slama, K., Ray, A., et al. Training language models to follow instructions with human feedback. In NeurIPS, 2022.
[29] Sun, Z., Shen, S., Cao, S., Liu, H., Li, C., Shen, Y., Gan, C., Gui, L., Wang, Y.-X., Yang, Y., Keutzer, K., and Darrell, T. Aligning large multimodal models with factually augmented RLHF. In Ku, L.-W., Martins, A., and Srikumar, V. (eds.), Findings of the Association for Computational Linguistics: ACL 2024, pp. 13088–13110, Bangkok, Thailand, August 2024. Association for Computational Linguistics. doi:10.18653/v1/2024.findings-acl.775. URL https://aclanthology.org/2024.findings-acl.775.
[30] Abdulhai, M., White, I., Snell, C., Sun, C., Hong, J., Zhai, Y., Xu, K., and Levine, S. LMRL Gym: Benchmarks for multi-turn reinforcement learning with language models. arXiv preprint arXiv:2311.18232, 2023.
[31] Zhou, Y., Zanette, A., Pan, J., Levine, S., and Kumar, A. ArCHer: Training language model agents via hierarchical multi-turn RL. arXiv preprint arXiv:2402.19446, 2024b.
[32] Ramamurthy, R., Ammanabrolu, P., Brantley, K., Hessel, J., Sifa, R., Bauckhage, C., Hajishirzi, H., and Choi, Y. Is reinforcement learning (not) for natural language processing: Benchmarks, baselines, and building blocks for natural language policy optimization. In The Eleventh International Conference on Learning Representations, 2023. URL https://openreview.net/forum?id=8aHzds2uUyB.
[33] Chen, J., Han, X., Ma, Y., Zhou, X., and Xiang, L. Unlock the correlation between supervised fine-tuning and reinforcement learning in training code large language models. arXiv preprint arXiv:2406.10305, 2024b.
[34] Han, J., Zhan, H., Hong, J., Fang, P., Li, H., Petersson, L., and Reid, I. What images are more memorable to machines? arXiv preprint arXiv:2211.07625, 2022.
[35] Carlini, N., Ippolito, D., Jagielski, M., Lee, K., Tramer, F., and Zhang, C. Quantifying memorization across neural language models. arXiv preprint arXiv:2202.07646, 2022.
[36] Yang, Z., Lukasik, M., Nagarajan, V., Li, Z., Rawat, A. S., Zaheer, M., Menon, A. K., and Kumar, S. ResMem: Learn what you can and memorize the rest. In Thirty-seventh Conference on Neural Information Processing Systems, 2023. URL https://openreview.net/forum?id=HFQFAyNucq.
[37] Jiang, M., Liu, K. Z., Zhong, M., Schaeffer, R., Ouyang, S., Han, J., and Koyejo, S. Investigating data contamination for pre-training language models. arXiv preprint arXiv:2401.06059, 2024.
[38] Zhang, C., Ippolito, D., Lee, K., Jagielski, M., Tramèr, F., and Carlini, N. Counterfactual memorization in neural language models. Advances in Neural Information Processing Systems, 36:39321–39362, 2023.
[39] Wang, X., Antoniades, A., Elazar, Y., Amayuelas, A., Albalak, A., Zhang, K., and Wang, W. Y. Generalization vs memorization: Tracing language models' capabilities back to pretraining data. arXiv preprint arXiv:2407.14985, 2024.
[40] Qi, Z., Luo, H., Huang, X., Zhao, Z., Jiang, Y., Fan, X., Lakkaraju, H., and Glass, J. Quantifying generalization complexity for large language models. arXiv preprint arXiv:2410.01769, 2024.
[41] Allen-Zhu, Z. ICML 2024 Tutorial: Physics of Language Models, July 2024. Project page: https://physics.allen-zhu.com/.
[42] Allen-Zhu, Z. and Li, Y. Physics of language models: Part 3.2, knowledge manipulation. arXiv preprint arXiv:2309.14402, 2023b.
[43] Allen-Zhu, Z. and Li, Y. Physics of language models: Part 3.3, knowledge capacity scaling laws. arXiv preprint arXiv:2404.05405, 2024.
[44] Tong, S., Fan, D., Zhu, J., Xiong, Y., Chen, X., Sinha, K., Rabbat, M., LeCun, Y., Xie, S., and Liu, Z. Metamorph: Multimodal understanding and generation via instruction tuning. arXiv preprint arXiv:2412.14164, 2024b.
[45] Wei, J., Wang, X., Schuurmans, D., Bosma, M., Xia, F., Chi, E., Le, Q. V., Zhou, D., et al. Chain-of-thought prompting elicits reasoning in large language models. Advances in Neural Information Processing Systems, 35:24824–24837, 2022b.
[46] Zelikman, E., Wu, Y., Mu, J., and Goodman, N. STaR: Bootstrapping reasoning with reasoning. Advances in Neural Information Processing Systems, 35:15476–15488, 2022.
[47] Feng, X., Wan, Z., Wen, M., McAleer, S. M., Wen, Y., Zhang, W., and Wang, J. AlphaZero-like tree-search can guide large language model decoding and training. arXiv preprint arXiv:2309.17179, 2023.
[48] Tian, Y., Peng, B., Song, L., Jin, L., Yu, D., Mi, H., and Yu, D. Toward self-improvement of LLMs via imagination, searching, and criticizing. arXiv preprint arXiv:2404.12253, 2024.
[49] Chen, G., Liao, M., Li, C., and Fan, K. AlphaMath almost zero: Process supervision without process. arXiv preprint arXiv:2405.03553, 2024a.
[50] Lu, P., Bansal, H., Xia, T., Liu, J., Li, C., Hajishirzi, H., Cheng, H., Chang, K.-W., Galley, M., and Gao, J. MathVista: Evaluating mathematical reasoning of foundation models in visual contexts. ICLR, 2023.
[51] Yue, X., Ni, Y., Zhang, K., Zheng, T., Liu, R., Zhang, G., Stevens, S., Jiang, D., Ren, W., Sun, Y., et al. MMMU: A massive multi-discipline multimodal understanding and reasoning benchmark for expert AGI. In CVPR, 2024a.
[52] Yue, X., Zheng, T., Ni, Y., Wang, Y., Zhang, K., Tong, S., Sun, Y., Yin, M., Yu, B., Zhang, G., et al. MMMU-Pro: A more robust multi-discipline multimodal understanding benchmark. arXiv preprint arXiv:2409.02813, 2024b.
[53] Yang, J., Yang, S., Gupta, A. W., Han, R., Fei-Fei, L., and Xie, S. Thinking in space: How multimodal large language models see, remember, and recall spaces. arXiv preprint arXiv:2412.14171, 2024b.
[54] Zhai, Y., Tong, S., Li, X., Cai, M., Qu, Q., Lee, Y. J., and Ma, Y. Investigating the catastrophic forgetting in multimodal large language model fine-tuning. In Conference on Parsimony and Learning, pp. 202–227. PMLR, 2024b.
[55] Tong, S., Jones, E., and Steinhardt, J. Mass-producing failures of multimodal systems with language models. In NeurIPS, 2024c.
[56] Tong, S., Liu, Z., Zhai, Y., Ma, Y., LeCun, Y., and Xie, S. Eyes wide shut? Exploring the visual shortcomings of multimodal LLMs. In CVPR, 2024d.
[57] Rahmanzadehgervi, P., Bolton, L., Taesiri, M. R., and Nguyen, A. T. Vision language models are blind. In Proceedings of the Asian Conference on Computer Vision, pp. 18–34, 2024.
[58] Kar, O. F., Tonioni, A., Poklukar, P., Kulshrestha, A., Zamir, A., and Tombari, F. Brave: Broadening the visual encoding of vision-language models. In European Conference on Computer Vision, pp. 113–132. Springer, 2025.
[59] Tong, S., Brown, E., Wu, P., Woo, S., Middepogu, M., Akula, S. C., Yang, J., Yang, S., Iyer, A., Pan, X., et al. Cambrian-1: A fully open, vision-centric exploration of multimodal LLMs. In NeurIPS, 2024a.
[60] Chen, L., Li, J., Dong, X., Zhang, P., He, C., Wang, J., Zhao, F., and Lin, D. ShareGPT4V: Improving large multi-modal models with better captions. arXiv preprint arXiv:2311.12793, 2023.
[61] Liu, H., Li, C., Li, Y., Li, B., Zhang, Y., Shen, S., and Lee, Y. J. LLaVA-NeXT: Improved reasoning, ocr, and world knowledge, 2024. URL https://llava-vl.github.io/blog/2024-01-30-llava-next/.
[62] Liu, H., Li, C., Li, Y., and Lee, Y. J. Improved baselines with visual instruction tuning. arXiv preprint arXiv:2310.03744, 2023.
[63] Sutton, R. S. and Barto, A. G. Reinforcement Learning: An Introduction. MIT press, 2018.
[64] Agarwal, A., Jiang, N., Kakade, S. M., and Sun, W. Reinforcement learning: Theory and algorithms. CS Dept., UW Seattle, Seattle, WA, USA, Tech. Rep, 32, 2019.
[65] Hosseini, A., Yuan, X., Malkin, N., Courville, A., Sordoni, A., and Agarwal, R. V-STar: Training verifiers for self-taught reasoners. In First Conference on Language Modeling, 2024. URL https://openreview.net/forum?id=stmqBSW2dV.
[66] Setlur, A., Nagpal, C., Fisch, A., Geng, X., Eisenstein, J., Agarwal, R., Agarwal, A., Berant, J., and Kumar, A. Rewarding progress: Scaling automated process verifiers for LLM reasoning. arXiv preprint arXiv:2410.08146, 2024.
[67] Schulman, J., Wolski, F., Dhariwal, P., Radford, A., and Klimov, O. Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347, 2017.
[68] OpenAI. GPT-4, 2023a. URL https://openai.com/research/gpt-4.
[69] Zhong, M., Zhang, A., Wang, X., Hou, R., Xiong, W., Zhu, C., Chen, Z., Tan, L., Bi, C., Lewis, M., et al. Law of the weakest link: Cross capabilities of large language models. arXiv preprint arXiv:2409.19951, 2024.