SSD-LM: Semi-autoregressive Simplex-based Diffusion Language Model for Text Generation and Modular Control
Xiaochuang Han$^\spadesuit$ Sachin Kumar$^\clubsuit$ Yulia Tsvetkov$^\spadesuit$
$^\spadesuit$Paul G. Allen School of Computer Science & Engineering, University of Washington
$^\clubsuit$Language Technologies Institute, Carnegie Mellon University
{xhan77, yuliats}@cs.washington.edu$^\spadesuit$ [email protected]$^\clubsuit$
Abstract
Despite the growing success of diffusion models in continuous-valued domains (e.g., images), similar efforts for discrete domains such as text have yet to match the performance of autoregressive language models. In this work, we present SSD-LM---a diffusion-based language model with two key design choices. First, SSD-LM is semi-autoregressive, iteratively generating blocks of text, allowing for flexible output length at decoding time while enabling local bidirectional context updates. Second, it is simplex-based, performing diffusion on the natural vocabulary space rather than a learned latent space, allowing us to incorporate classifier guidance and modular control using off-the-shelf classifiers without any adaptation. We evaluate SSD-LM on unconstrained text generation benchmarks, and show that it matches or outperforms strong autoregressive GPT-2 models across standard quality and diversity metrics, while vastly outperforming diffusion-based baselines. On controlled text generation, SSD-LM also outperforms competitive baselines, with an extra advantage in modularity.[^1]
[^1]: Our code and models can be found at https://github.com/xhan77/ssd-lm.
Executive Summary: The rapid rise of large language models has transformed how machines generate text, powering applications from chatbots to content creation. However, current leading models, known as autoregressive language models like GPT-2, generate text token by token from left to right, which limits their flexibility for variable lengths and makes it hard to control overall attributes, such as sentiment or topic, without extensive retraining. Diffusion models, which have revolutionized image and audio generation by iteratively refining noisy inputs into clear outputs, have struggled to match this performance for text due to its discrete nature. This gap matters now as demand grows for reliable, controllable text generation in business tools, where outputs must align with specific goals like positive branding or regulatory compliance, without the high costs of custom model development.
This paper introduces SSD-LM, a new type of diffusion-based language model designed to generate high-quality text while enabling easy control over its style or content. The goal was to create a model that combines the strengths of diffusion approaches—such as bidirectional context for more coherent outputs—with the flexibility of autoregressive models, all while supporting plug-and-play control using existing classifiers.
The authors developed SSD-LM by training it on a large dataset of 9 billion web text tokens, similar to GPT-2's training data, over about six days on high-end hardware. They used a bidirectional transformer architecture, roughly the size of GPT-2 medium (400 million parameters), to process text in semi-autoregressive blocks of 25 tokens at a time: the model generates each block from noise, conditioned on prior context, allowing variable total lengths up to 200 tokens without fixed upfront planning. To handle text's discrete tokens, they represented each as a probability distribution over the vocabulary (a "simplex"), enabling noise addition and denoising without approximations. For control, they integrated guidance from off-the-shelf classifiers, like those for sentiment, by adjusting the model's outputs mid-generation. Evaluations focused on 5,000 generated samples across benchmarks for unconstrained continuation from prompts and sentiment-controlled tasks, comparing against GPT-2 variants and prior diffusion models.
Key results show SSD-LM performing on par with or better than larger GPT-2 models despite its smaller size. First, on unconstrained generation, it achieved the highest overall quality score (MAUVE, measuring similarity to human text) at around 98%, surpassing GPT-2 medium by 1-2 points and matching extra-large versions. It also boosted diversity, with 68-75% unique one- to three-word phrases versus GPT-2's 65-72%, and cut repetition rates to 10-30% compared to GPT-2's 20-60%. Second, it dramatically outperformed prior diffusion models, like Diffusion-LM, with an 87% MAUVE score on a storytelling dataset versus their 46%, and lower perplexity (a fluency measure) at 23 versus 36. Third, for controlled sentiment generation, SSD-LM reached 94% accuracy in producing positive or negative text when guided, far exceeding a similar modular baseline at 69%, while maintaining reasonable fluency (perplexity of 23) and diversity (46-92% unique phrases). It used public classifiers without adaptation, unlike many rivals requiring custom training.
These findings mean diffusion models can now rival autoregressive ones for text, offering smoother, more diverse outputs with built-in editability within blocks—reducing errors from one-way generation. The modular control is especially impactful: it lowers costs and speeds deployment for tailored content, such as marketing copy or moderated dialogues, by leveraging existing tools rather than building new ones. This outperforms expectations from prior diffusion work, which often sacrificed quality or flexibility, and could enhance safety by steering away from harmful biases or facts, though the paper notes risks like misuse.
Leaders should prioritize adopting or funding SSD-LM-like models for applications needing controllable generation, starting with pilots in content tools to test integration with classifiers for attributes like tone or factuality. Key trade-offs include slower generation (25 seconds per 25 tokens) versus autoregressive speed, balanced by higher quality. Further work is essential: scale to larger models, test multilingual data, and combine controls (e.g., sentiment plus length). Before full rollout, conduct pilots on real workloads and ethical audits.
While benchmarks show strong confidence in quality and control, limitations include lower training efficiency (only 25 tokens processed per sample versus full sequences in rivals) and untested edge cases like very long texts or non-English languages. Readers should be cautious on speed claims without custom hardware, but results hold robustly across setups.
1. Introduction
Section Summary: Diffusion models, which refine noisy inputs step by step, have become powerful for creating images, audio, and videos, but adapting them for text generation has been challenging, as they lag behind traditional autoregressive language models that build text token by token. To address key issues like fixed sequence lengths and difficulties with controllability in text, researchers introduce SSD-LM, a semi-autoregressive approach that generates text in flexible blocks from left to right, using bidirectional context within blocks and a simplex representation that aligns with existing language models for easy, modular guidance from off-the-shelf classifiers. Experiments show SSD-LM matching or surpassing strong autoregressive models in both unconstrained text quality and diversity, as well as controlled generation tasks.
Diffusion models ([1]), trained to iteratively refine noised inputs, have recently emerged as powerful tools for generative modeling in several continuous-valued domains such as images ([2]), audio ([3]), video ([4]), among others. Attempts to adapt them for discrete domains such as text data, however, have only had limited success: prior work have shown to be promising on specialized cases and small datasets ([5, 6, 7, 8]), but diffusion models for text still underperform (and thus are not widely adopted) compared to autoregressive language models (AR-LMs) which remain the state-of-the-art general purpose text generators ([9, 10]).
Despite potential advantages of diffusion models for text, there are two key challenges. First, diffusion models generate text non-autoregressively, i.e., they generate (and update) the entire sequence simultaneously rather than token by token left-to-right. Although this property is useful in practice since each output token is informed by a broader bi-directional context ([11, 12]), it requires pre-defining an output sequence length. This limits the flexibility and applicability of trained models. On the other hand, non-autoregressive training with long sequences is expensive and difficult to optimize. In this work, we propose a semi-autoregressive solution which strikes a balance between length flexibility and the ability to alter previously generated tokens.
A major advantage of diffusion models over the current standard of autoregressive LMs is their post-hoc controllability using guidance from auxiliary models such as style classifiers ([13]). However, controllability is hard to achieve without compromises in modularity in diffusion-based LMs for text. To enable diffusion generation into discrete text rather than continuous modalities, prior approaches have employed different approximations, e.g., training with embeddings, character, or byte-level methods ([7, 5, 6, 8]). In contrast, existing mainstream LMs and the guidance classifiers they derive often operate at a sub-word level with sub-word representations trained jointly with the language model ([14, 15, 16]). Subsequently, changing the input representations to characters or embeddings requires developing guidance models from scratch, which can be expensive or infeasible in many cases. In this work, we propose a simplex-based solution which enables the diffusion over discrete texts while maintaining the advantages of diffusion models with plug-and-control guidance models.
In sum, to enable diffusion-based LMs for text we present $\textsc{Ssd-LM}$ (§ 3), addressing the above two challenges. $\textsc{Ssd-LM}$ is trained to generate text semi-autoregressively—generating blocks of tokens left-to-right with bidirectional context within the block—which offers the benefits of both AR-LMs and diffusion models. It supports training with and generating variable-length sequences. At the same time, it allows refinement within the token block, in contrast to token-level autoregressive decoding where previously generated tokens cannot be modified at all. $\textsc{Ssd-LM}$ uses the same tokenization as popular AR-LMs, representing discrete text via a distribution (or simplex) defined over the vocabulary and is trained to reconstruct texts from noisy versions of the distributions. Due to its underlying representation, our method also offers an easy and modular way of guided (controlled) generation using off-the-shelf text classifiers under the minimal assumption of shared tokenizer.
Our evaluation experiments show, for the first time, that a diffusion-based LM matches or outperforms strong AR-LMs on standard text generation benchmarks (§ 4). We evaluate $\textsc{Ssd-LM}$ on two tasks: (1) unconstrained prompt-based generation substantially outperforming existing diffusion LM approaches and performing on par with or outperforming strong autoregressive LM GPT-2 ([9]) on both quality and diversity (§ 4.2); and (2) controlled text generation with guidance from off-the-shelf classifiers (no post-hoc training/adaptation) outperforming competitive controlled text generation baselines (§ 4.3).
2. Background
Section Summary: Diffusion models generate data, such as images, by starting with clean samples and gradually adding noise over many steps, then training a system to reverse the process by predicting and removing that noise to recreate the original. For text generation, which involves discrete words or tokens rather than continuous values, the approach adapts this by representing tokens as continuous probabilities over possible words. Autoregressive language models build text one token at a time based on prior ones, but they often struggle with long sequences by repeating patterns and lack easy ways to edit or control the overall output, leading this work to propose a hybrid method that generates chunks of tokens simultaneously using diffusion techniques.
2.1 Diffusion model
Since their inception as image generators, diffusion models (and their cousins score-based models ([17])) have been widely adopted as high-quality generative models for multiple data modalities. Here, we briefly describe a simplified view of a canonical method, denoising diffusion probabilistic models ([2], DDPM) which we adapt in this work for text generation. We assume a given dataset $\mathcal{D}={{}^{1}\boldsymbol{x}_0, \ldots, {}^{N}\boldsymbol{x}_0}$ of continuous valued items ${}^{i}\boldsymbol{x}_0$ (e.g., pixel values of an image) henceforth referred to as $\boldsymbol{x}_0$ for simplicity.
Training
Training a diffusion model first involves adding a series of Gaussian noise to the original data $\boldsymbol{x}_0$, through $T$ timesteps:
$ \begin{align} \boldsymbol{x}_t &= \sqrt{\bar{\alpha}_t} \boldsymbol{x}_0 + \sqrt{1-\bar{\alpha}_t} \boldsymbol{\epsilon}_t \end{align}\tag{1} $
where $t \in (1, T)$ and $\boldsymbol{\epsilon}t \sim \mathcal{N}(\boldsymbol{0}, \mathbf{I})$. $\bar{\alpha}t = \prod{t'=1}^{t} \alpha{t'}$, where $\alpha_{t'}$ follow a predefined schedule such that $\bar{\alpha}_t \to 0$ as $t \to T$. This process is called forward diffusion. A diffusion model (parameterized by $\theta$) is trained to reverse this forward process by predicting the added noise $\boldsymbol{\epsilon}_t$ given $\boldsymbol{x}_t$ with the following loss:
$ \begin{align} \mathcal{L}(\theta) = \mathbb{E}{t \sim \mathcal{U}(1, T)} \lVert \epsilon{\theta}(\boldsymbol{x}_t, t) - \boldsymbol{\epsilon}_t \rVert^2 \end{align}\tag{2} $
Inference
To get an output from this model, we sample $\boldsymbol{x}_T \sim \mathcal{N}(\boldsymbol{0}, \mathbf{I})$ and iteratively reconstruct a sample $\boldsymbol{x}_0$ by going back in time,
$ \begin{align} \boldsymbol{x}{t-1} &= \frac{1}{\sqrt{\alpha_t}} (\boldsymbol{x}{t} - \frac{1-\alpha_t}{\sqrt{1-\bar{\alpha}t}} \epsilon{\theta}(\boldsymbol{x}_t, t)) \end{align}\tag{3} $
for $t = T, \ldots, 1$.[^2] The key obstacle in using vanilla diffusion models directly as text generators is that language consists of discrete tokens, i.e., a non-continuous $\boldsymbol{x}_{0}$ to which a continuous valued Gaussian noise cannot be added. We propose a straightforward and effective solution by treating tokens as continuous valued simplexes over the vocabulary ([18]). Other existing methods addressing this problem are discussed in § 5.
[^2]: We omit an additional noise term $z$ here for simplicity, which is present in DDPM but not in another variant DDIM [19].
2.2 Autoregressive LM
An autoregressive LM model optimizes for the likelihood of a sequence of tokens $w^0, \ldots, w^{L-1}$.
$ \begin{align} p_\theta(\boldsymbol{w}^{0:L}) = \prod_{c=0}^{L-1} p_\theta(w^{c} \mid \boldsymbol{w}^{<c}) \end{align}\tag{4} $
To decode from AR-LMs, one can provide a context $\boldsymbol{w}^{<c}$ and decode the next token $w^{c}$ iteratively by predicting $p_\theta(w^{c} \mid \boldsymbol{w}^{<c})$ and sampling from it to get the discrete token ([20, 21]). Prior work has shown that these decoding approaches (and by extension the LMs themselves) are prone to degrade when generating long sequences and often devolve into repeating subsequences ([21, 22]). In addition, such LMs do not provide a natural way to incorporate sequence-level control as tokens are generated one at a time without the ability to modify previously generated tokens ([23, 24]). In this work, we present a method to train a semi-autoregressive LM that decodes blocks of $B$ tokens at a time, alleviating said issues with the support of diffusion models. Existing literature addressing the two issues individually are discussed in § 5.
3. SSD-LM
Section Summary: SSD-LM is a new type of language model that combines elements of traditional word-by-word prediction systems with diffusion models, which gradually add and remove noise to generate text in blocks rather than one token at a time. During training, it converts words into a special numerical format called logits, adds controlled noise to these over multiple steps, and trains a transformer network to predict the original block of words from the noisy version while considering the preceding context. For generating text, the model starts with pure noise and iteratively refines it step by step to produce coherent blocks of tokens, which are then appended to build longer sequences.
We introduce $\textsc{Ssd-LM}$ —Semi-autoregressive Simplex-based Diffusion Language Model— adapting key components from both autoregressive LM and vanilla diffusion models. Conceptually, $\textsc{Ssd-LM}$ uses diffusion model to decode $\boldsymbol{w}^{c:c+B}$, a block of tokens of length $B$, given a Gaussian noise and a context $\boldsymbol{w}^{<c}$ of length $c$. We show an intuitive diagram and pseudo-code for the training and decoding algorithm of $\textsc{Ssd-LM}$ in Figure 1, Figure 2, and Figure 3.

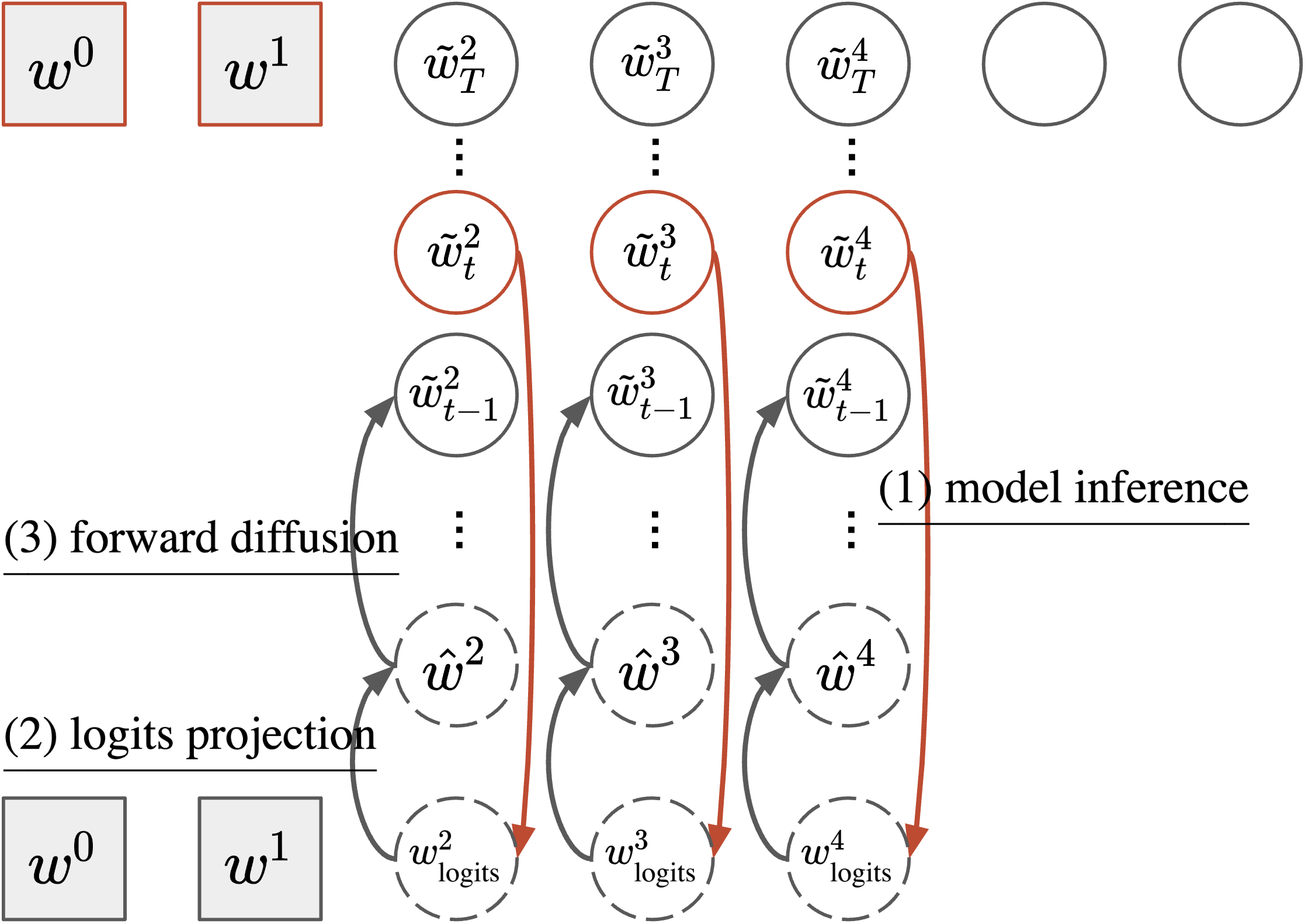

3.1 Training
Continuous data representation
To build a continuous representation for discrete tokens, we adopt an almost-one-hot simplex representation over the model's vocabulary $V$. We define a simple operation $\operatorname{logits-generation}(.)$ to map a token $w$ to $\tilde{\boldsymbol{w}} \in { -K, +K }^{|V|}$ as follows.
$ \begin{align} \tilde{w}{(i)} = \begin{cases} +K \text{ when } w = V{(i)}\ -K \text{ when } w \neq V_{(i)} \end{cases} \end{align}\tag{5} $
where $i$ is the index of the vocabulary. We call $\tilde{\boldsymbol{w}}$ the logits for token $w$, and $\operatorname{softmax}(\tilde{\boldsymbol{w}})$ gives a probability simplex over the vocabulary $V$, with a probability mass concentrated on the token $w$. There is no learnable parameter in this mapping.
Forward diffusion
Following [2], we add a time-dependent Gaussian noise to the logits.
$ \begin{align} \tilde{\boldsymbol{w}}_0^{c:c+B} &= \operatorname{logits-generation}(\boldsymbol{w}^{c:c+B}) \tag{a} \ \tilde{\boldsymbol{w}}_t^{c:c+B} &= \sqrt{\bar{\alpha}_t} \tilde{\boldsymbol{w}}_0^{c:c+B} + \sqrt{1-\bar{\alpha}_t} \boldsymbol{\epsilon}_t \tag{b} \end{align}\tag{6} $
where $t \in (1, T)$, $\boldsymbol{\epsilon}_t \sim \mathcal{N}(\boldsymbol{0}, K^2\mathbf{I})$, and $\bar{\alpha}_t \to 0$ as $t \to T$. At the final step $T$, $\operatorname{softmax}(\tilde{\boldsymbol{w}}_T^{c:c+B})$ are fully noisy simplexes over $V$, with a logit-normal distribution ([25]).
Loss function
In Equation 2, a diffusion model is trained to predict the added noise from the noisy representations. Since the forward diffusion process can be computed in a single step Equation (1), the notion here is equivalent to predicting the original data representation ([19, 7]). Our objective follows the same intuition but estimates a likelihood instead of the L2 distance while conditioning on additional context:[^3]
[^3]: L2 distance did not work in our pilot study potentially due to the intrinsically skewed simplex representation.
$ \begin{align} \mathcal{L}(\theta) &= \mathbb{E}[-\log p_\theta(\boldsymbol{w}^{c:c+B} \mid \tilde{\boldsymbol{w}}t^{c:c+B}, \boldsymbol{w}^{<c})] \tag{a} \ &= \mathbb{E}\left[\sum{j=c}^{c+B-1}-\log p_\theta(w^{j} \mid \tilde{\boldsymbol{w}}_t^{c:c+B}, \boldsymbol{w}^{<c})\right] \tag{b} \end{align}\tag{7} $
$\mathbb{E} [\cdot]$ is a shorthand for $\mathbb{E}_{c \sim \mathcal{U}(1, L-B), t \sim \mathcal{U}(1, T)} [\cdot]$. The architecture for $\theta$ throughout this work is a bi-directional Transformer encoder ([26]). Specifically, the input to the model is a concatenation of the context $\boldsymbol{w}^{<c}$ and a sequence of noisy vocabulary simplexes $\operatorname{softmax}(\tilde{\boldsymbol{w}}_t^{c:c+B})$ of length $B$. The target output is the original tokens $\boldsymbol{w}^{c:c+B}$ at positions $c$ to $c+B$.
One minimal modification made to the Transformer model is that in addition to the conventional embedding lookup for $\boldsymbol{w}^{<c}$, we modify the embedding layer to take as input a distribution over the vocabulary, $\operatorname{softmax}(\tilde{\boldsymbol{w}}_t^{c:c+B})$, and compute the embedding vector as a weighted sum of the embedding table. A timestep embedding is also added before the first Transformer block to inform the model of the current timestep.[^4]
[^4]: More specifically, we have word embeddings for the context, $\operatorname{Emb}{\text{ctx}}(\boldsymbol{w}^{<c})$, and for the noisy diffusion representations, $W{\text{diff}} [\operatorname{softmax}(\tilde{\boldsymbol{w}}t^{c:c+B})]$. The timestep embedding is added to the diffusion word embeddings, $W{\text{time}}(t/T)$. It is similar to positional embeddings, just not varying across sequence positions. We fold it in $\theta$ for notation simplicity.
In § A, we present another interpretation of the training objective as an intuitive contrastive loss.
3.2 Decoding
Logits projection
Similar to continuous-valued diffusion models, sampling from $\textsc{Ssd-LM}$ involves reverse diffusion from $t=T, \ldots, 1$ starting with a Gaussian noise. At any timestep $t$, our model $\theta$ takes as input noised logits $\tilde{\boldsymbol{w}}_t^{c:c+B}$ and estimates the probability distribution of the original tokens in data by first predicting the logits:
$ \begin{align} \boldsymbol{w}{\text{logits}, t}^{c:c+B} = \operatorname{logits}\theta(\boldsymbol{w}^{c:c+B} \mid \tilde{\boldsymbol{w}}_t^{c:c+B}, \boldsymbol{w}^{<c}) \end{align}\tag{8} $
which are then converted to a distribution via softmax. To feed this output to the next step of reverse diffusion, $t-1$, we define a $\operatorname{logits-projection}$ operation to build a predicted data representation close to the initial data representation (almost-one-hot mapping; Equation 5). We consider three projection operations.
- Greedy: creates an almost-one-hot logit centered at the highest probability token.[^5]
[^5]: This shares a similar intuition as a greedy clamping trick in the embedding-based diffusion in [7].
$ \begin{align} \hat{w}{(i)} \text{=} \begin{cases} +K \text{ if $i$ =} \operatorname{argmax}(\boldsymbol{w}{\text{logits}})\ -K \text{ otherwise} \end{cases} \end{align}\tag{9} $
- Sampling: creates an almost-one-hot logit centered around a token sampled from the output distribution using top- $p$ sampling ([21]). $p$ is a hyperparameter.
$ \begin{align} \hat{w}{(i)} \text{=} \begin{cases} +K \text{ if $i$ =} \text{top-}p\text{-sample}(\boldsymbol{w}{\text{logits}})\ -K \text{ otherwise} \end{cases} \end{align}\tag{10} $
- Multi-hot: creates an almost-one-hot logit centered around all tokens in the top- $p$ nucleus.
$ \begin{align} \hat{w}{(i)} \text{=} \begin{cases} +K \text{ if $i \in$ } \text{top-}p\text{-all}(\boldsymbol{w}{\text{logits}})\ -K \text{ otherwise} \end{cases} \end{align}\tag{11} $
Decoding iteration
Starting from pure noise $\tilde{\boldsymbol{w}}_T^{c:c+B} \sim \mathcal{N}(\boldsymbol{0}, K^2\mathbf{I})$, in each decoding timestep we compute:
$ \begin{align} &\hat{\boldsymbol{w}}^{c:c+B}t = \operatorname{logits-projection}(\boldsymbol{w}{\text{logits}, t}^{c:c+B}) \tag{a} \ &\tilde{\boldsymbol{w}}{t-1}^{c:c+B} = \sqrt{\bar{\alpha}{t-1}} \hat{\boldsymbol{w}}^{c:c+B}t + \sqrt{1-\bar{\alpha}{t-1}} \boldsymbol{z} \tag{b} \end{align}\tag{12} $
for $t = T, \ldots, 1$ and $\boldsymbol{z} \sim \mathcal{N}(\boldsymbol{0}, K^2\mathbf{I})$.
At $t=1$, the final $B$-token block is computed simply as $\operatorname{argmax} \tilde{\boldsymbol{w}}_{0}^{c:c+B}$. To generate the next block, we concatenate the generated block to the previous context to create a new context of length $c+B$ and follow the reverse-diffusion process again as described above. This process can be repeated until the maximum desired length is reached.[^6]
[^6]: Alternatively, one can also terminate the process if certain special end-of-sequence tokens have been generated.
It is worth noting that our proposed decoding algorithm is novel and different from the DDPM decoding Equation (3). The DDPM decoding is designed for diffusion in a continuous space and failed to generate sensible outputs in our preliminary experiments based on simplexes. In § B, we draw a theoretical connection between our decoding algorithm and DDPM decoding, and also highlight the intuitive difference between the two.
Highly-modular control
A useful property of continuous diffusion models that naturally arises from their definition is the ability to guide the generated samples to have user-defined attributes at test time. This can be done using gradients from auxiliary models such as classifiers ([13]), e.g., guiding the output of an LM to be of a positive sentiment using a sentiment classifier. There is a vibrant community of developers on platforms such as HuggingFace where many such text classifiers are publicly available. The underlying data representation of $\textsc{Ssd-LM}$ is based on vocabulary simplexes. Hence, as long as a classifier shares the same tokenizer as the LM, it can be used for control in an off-the-shelf manner without modifications. This is in contrast to prior work in diffusion language models that do not support such classifiers due to differences in their input representation space ([5, 6, 7, 8]) and require retraining the classifiers from scratch. This ability makes $\textsc{Ssd-LM}$ highly modular for controlled text generation and offers key benefits: (1) Training accurate classifiers for many tasks requires huge amounts of data where retraining them can be quite expensive, and (2) this approach allows control from classifiers that are open to use but have been trained on closed source data.
To guide $\textsc{Ssd-LM}$ to generate texts with a target attribute $y$ via a standalone attribute model $f_{\phi}(\cdot)$, we update $\boldsymbol{w}_{\text{logits}, t}^{c:c+B}$ Equation (8) at each timestep $t$ to the form below, drifting according to the gradients from the attribute classifier.
$ \begin{align} &\boldsymbol{w}{\text{logits}, t}^{c:c+B} + \lambda \nabla{\boldsymbol{w}{\text{logits}, t}^{c:c+B}} f{\phi}(y \mid \boldsymbol{w}_{\text{logits}, t}^{c:c+B}, \boldsymbol{w}^{<c}) \end{align}\tag{13} $
where $\lambda$ is a hyperparameter balancing the weight of control. The parameters of the standalone attribute model $\phi$ are frozen. We make a trivial modification to the embedding computation as in § 3.1, to allow the classifier to take as input a simplex.
3.3 Additional details
Forward diffusion coefficient $\bar{\alpha}_t$
We follow [27] for a cosine schedule of $\bar{\alpha}_t$:
$ \begin{align} \bar{\alpha}_t = \frac{r(t)}{r(0)}, ~r(t) = \cos (\frac{t/T + s}{1 + s}\cdot \frac{\pi}{2})^2 \end{align} $
where $s$ is small offset set to 1e-4 in our work and $\alpha_t = \frac{\bar{\alpha}t}{\bar{\alpha}{t-1}}$.
Fewer timesteps $T$ in decoding
Decoding from diffusion models requires a series of timesteps ($T$) which can be computationally expensive if $T$ is large. Following [7], we consider using a smaller value of $T$ at test time to improve decoding speed. In this work, we primarily experiment with $T_{\text{decode}} = \frac{T_{\text{train}}}{2}$ and $T_{\text{decode}} = \frac{T_{\text{train}}}{5}$.
Flexible decoding block size $B$
Our $\textsc{Ssd-LM}$ is trained with a fixed token block size $B_{\text{train}}$. However, the decoding algorithm has a freedom to use a different $B_{\text{decode}}$. In our experiments, we consider both scenarios of $B_{\text{train}} = B_{\text{decode}}$ and $B_{\text{train}} \neq B_{\text{decode}}$. Nevertheless, we leave for future work a more detailed analysis of the impact of the difference between $B_{\text{train}}$ and $B_{\text{decode}}$ on model performance.
4. Experiments
Section Summary: Researchers pretrained their SSD-LM model, a new type of language model based on a RoBERTa architecture similar in size to GPT-2 medium, using the OpenWebText dataset of about 9 billion tokens, training it for around six days on powerful GPUs to achieve a low error rate on predicting text. To test its performance, they compared SSD-LM to various GPT-2 models by generating text continuations from prompts in the same dataset, evaluating aspects like how natural and varied the outputs were using standard measures. The results showed SSD-LM competing well or outperforming the GPT-2 baselines in generating high-quality, diverse text, especially in diversity metrics, despite being smaller than some competitors.
4.1 $\textsc{Ssd-LM}$ pretraining setup
Model architecture
We use a bidirectional Transformer encoder RoBERTa-large ([15]) (0.4B, comparable size to GPT2-medium) as $\textsc{Ssd-LM}$ 's underlying architecture.[^7] Note that RoBERTa uses a general BPE tokenization ([28]), same as a variety of LMs such as GPT-2 ([9]), GPT-3 ([10]), OPT ([29]), etc. Any attribute classifier using the same tokenization strategy can be used to control $\textsc{Ssd-LM}$ in a highly modular way.
[^7]: We initialize the model with RoBERTa's weights as well. We observe in our initial exploration that it helps the training loss converge faster than a randomly initialized model. However, given enough computational resources, we conjecture that a randomly initialized model will offer similar performance.
Pretraining data, constants, and resource
We train $\textsc{Ssd-LM}$ on the same data as GPT2 to make fair comparisons possible: OpenWebText ([30]) which contains 9B tokens. Following [29], we consider this data as one contiguous sequence of tokens and break it into sequences of length 200 (same as the maximum sequence length our model accepts). We randomly sample 99% of these sequences for pretraining while leaving the rest as held out for evaluation. We use the following model hyperparameters:[^8]
$ L=200, B_{\text{train}}=25, T_{\text{train}}=5000, K=5 $
[^8]: Future work can do a search given more resources.
We use an aggregated batch size of 6, 144 and a learning rate of 1e-4 with an AdamW optimizer ([31]). We trained $\textsc{Ssd-LM}$ for 100K steps, which took about 6 days on 32 Nvidia V100 GPUs.
Pretraining loss
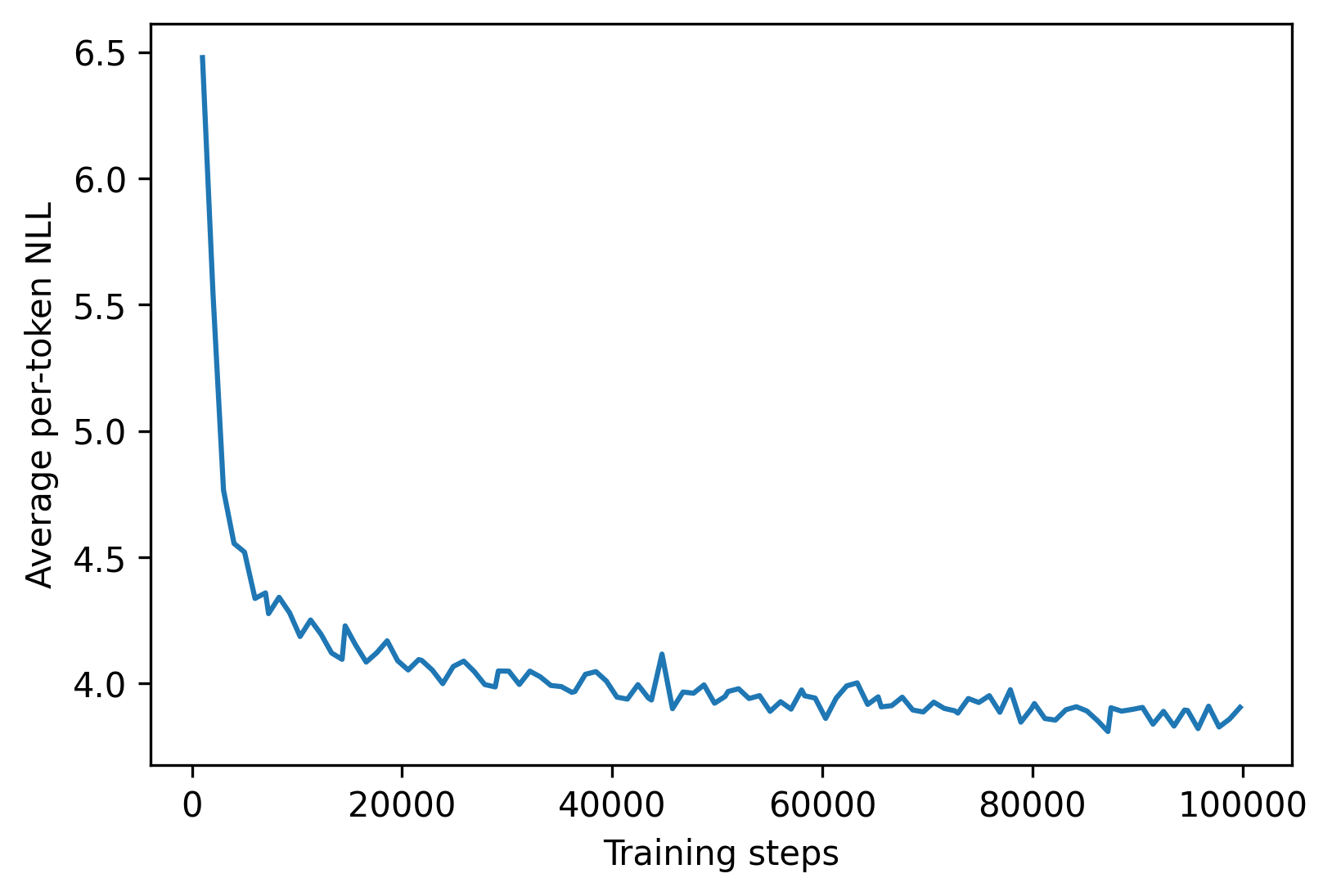
Canonical training-time perplexity of LMs is not compatible with diffusion LMs due to the difference in the inputs to the models Equation (4 and 7b). Our pretraining loss is a per-token negative log-likelihood (NLL) that depends on the specific noise schedule being used. $\textsc{Ssd-LM}$ gets an average NLL of 3.87 at the end of pretraining. We show a pretraining loss curve in the appendix (§ D).
4.2 Unconstrained text generation
:Table 1: Unconstrained generation evaluation of $\textsc{Ssd-LM}$ and GPT-2 models at length 50. For GPT-2 models, the results are averaged across 5 random seeds, and we show the best sampling parameter configuration. For our $\textsc{Ssd-LM}$, we show the top-3 configurations. All configurations are ranked based on MAUVE, with original parameters from [32]. The perplexity (PPL) is measured by GPT-Neo-1.3B.[^9]
| (Length 50) | MAUVE $\uparrow$ | PPL $\xrightarrow[\text{gold}]{}$ | $\vert\Delta_{\log \text{PPL}}\vert \downarrow$ | Dist-1 $\uparrow$ | Dist-2 $\uparrow$ | Dist-3 $\uparrow$ | Zipf $\xrightarrow[\text{gold}]{}$ | Rep $\downarrow$ |
|---|---|---|---|---|---|---|---|---|
| Gold continuation | 100.00 | 17.75 | 0.00 | 88.62 | 95.88 | 93.71 | 0.88 | 0.10 |
| GPT2-medium (Best config) | ||||||||
| Top- $p$ =0.95 | 96.57 $\pm$ 0.40 | 12.72 $\pm$ 0.07 | 0.33 | 66.31 $\pm$ 0.11 | 91.77 $\pm$ 0.03 | 92.75 $\pm$ 0.06 | 1.01 | 0.26 $\pm$ 0.04 |
| GPT2-large (Best config) | ||||||||
| Top- $p$ =0.95 | 96.41 $\pm$ 0.78 | 10.57 $\pm$ 0.05 | 0.51 | 64.91 $\pm$ 0.13 | 90.88 $\pm$ 0.06 | 92.38 $\pm$ 0.05 | 1.01 | 0.41 $\pm$ 0.06 |
| GPT2-xl (Best config) | ||||||||
| Typical- $\tau$ =0.95 | 97.03 $\pm$ 0.50 | 10.33 $\pm$ 0.04 | 0.54 | 64.87 $\pm$ 0.15 | 90.69 $\pm$ 0.07 | 92.16 $\pm$ 0.05 | 1.01 | 0.37 $\pm$ 0.04 |
| $\textsc{Ssd-LM}$-"medium" (Top-3) | ||||||||
| Sampling $p$ =0.99, $T$ =1000 | 97.89 | 30.68 | 0.54 | 68.99 | 92.60 | 92.94 | 1.01 | 0.16 |
| Sampling $p$ =0.95, $T$ =1000 | 96.64 | 27.34 | 0.43 | 67.75 | 92.16 | 92.91 | 1.01 | 0.16 |
| Sampling $p$ =0.9, $T$ =2500 | 96.46 | 20.56 | 0.14 | 66.61 | 91.46 | 92.56 | 1.05 | 0.26 |
[^9]: MAUVE, Dist-1/2/3, and Rep are in percentage. PPL is obtained through a micro average following [21, 32, 22].
Setup
First, we benchmark $\textsc{Ssd-LM}$ with autoregressive LMs trained on the same data (GPT2) on text generation quality. We randomly sample 1000 sequences from the held-out OpenWebText test data, extract their prefixes as prompts (context), and generate continuations from the LMs. We consider three setups: with prompt lengths 25, 50 and 100 with respective output lengths as 25, 50 and 100 tokens. In each setup, we sample 5 continuations for each input context, thus comparing the quality of 5, 000 generations from baseline GPT-2 models and our $\textsc{Ssd-LM}$.
We compare $\textsc{Ssd-LM}$ with GPT2-medium, large and xl models (containing 0.4B, 0.8B and 1.6B parameters respectively) as baselines. For reference, our model size is comparable to GPT2-medium. We experiment with two popular decoding strategies for the baseline GPT-2 models with canonical parameters: nucleus sampling ([21]) with a top- $p$ of 0.9 and 0.95, and typical sampling ([22]) with a typical- $\tau$ of 0.2 and 0.95.
For $\textsc{Ssd-LM}$, we consider three logits projection strategies, sampling and multi-hot with $\text{top-}p \in { 0.0, 0.1, 0.2, 0.5, 0.7, 0.9, 0.95, 0.99 }$, and greedy (which is functionally equivalent to the sampling with top- $p$ =0). We use a test block size ($B_\text{decode}$) of 25. When generating samples of length 50 or 100, we semi-autoregressively sample in blocks of 25 and feed them as additional context to generate the next block as described in § 3.2.
We evaluate the generated continuations on two axes: quality and diversity. As automatic quality metrics, we report perplexity measured by a separate, larger language model (GPT-Neo-1.3B, [33]). Prior works, however, have shown that low perplexity of generated text is not necessarily an indication of high quality but of degenerate behavior ([34, 35]) and have proposed closeness to the perplexity of human-written text as a better evaluation. Hence, we also report the difference of log perplexity between the generated text and human-written continuations ($|\Delta_{\log \text{PPL}}|$). For diversity evaluation, we report Zipf's coefficient (Zipf) and average distinct $n$-grams in the output samples ([36], Dist- $n$). In addition, we also report the repetition rate ([37, 21], Rep), measuring the proportion of output samples that end in repeating phrases. Finally, we report MAUVE ([32]) which evaluates both quality and diversity together by approximating information divergence between generated samples and human-written continuations (from the OpenWebText held-out set).
Results
Table 1 summarizes our main results on the 50-token prompt and output setup. We report the numbers for the best performing three settings for logits projection and decoding steps $T$ in $\textsc{Ssd-LM}$. We report the best setting for the baselines. The results for other generation lengths have a similar trend and can be found in the appendix (§ D).
We find that $\textsc{Ssd-LM}$, though being smaller in size, outperforms larger GPT-2 models on the unified metric MAUVE. On diversity, $\textsc{Ssd-LM}$ outperforms GPT-2 in Dist- $n$ while achieving lower repetition rates. On perplexity, the results are slightly mixed. We observe a trade-off between MAUVE and perplexity for different settings we considered, indicating that further tuning of the hyperparameters may be required. However, one of our best performing settings (sampling top- $p$ =0.9, $T$ =2500) still achieves the closest perplexity to the gold continuation.
In § D, we show the influence of different logits projection strategies and the associated parameters on the output text quality in Figure 4. We also show qualitative examples of the generations by $\textsc{Ssd-LM}$ in Table 8 and a trajectory of intermediate states during the decoding process in Table 9.
:Table 2: Unconstrained generation results of $\textsc{Ssd-LM}$ and Diffusion-LM on ROCStories with 50 prompt tokens and 50 output tokens. We report the MAUVE score between the gold continuation and model generations. We also show the perplexity (PPL) of model generations measured by GPT-Neo-1.3B.[^10]
| (ROCStories) | MAUVE | PPL |
|---|---|---|
| Gold continuation | 100.00 | 18.57 |
| Diffusion-LM | 46.11 | 35.96 |
| $\textsc{Ssd-LM}$ | 87.22 | 22.91 |
[^10]: Due to a lowercase tokenization of ROCStories, we use BERT-base-uncased as MAUVE's embedding model here.
Comparison with [7]
A prior work to us, [7] propose Diffusion-LM, an embedding-based diffusion model trained on two small toy datasets, E2E ([38]) and ROCStories ([39]). In this subsection, we make a diversion to compare the embedding-based Diffusion-LM with our semi-autoregressive, simplex-based $\textsc{Ssd-LM}$. Following [7], we train a Diffusion-LM on ROCStories with a default embedding size of 128, 0.1B parameters under a BERT-base ([14]) structure, [^11] and a sequence length of 100. For a fair comparison, only within this subsection we train a $\textsc{Ssd-LM}$ with ROCStories sequences of 100 tokens, a decoding block size of 25, and a BERT-base initialization. Further details of the setup can be found in § C.
[^11]: We train two versions of Diffusion-LM, with and without BERT's encoder weights as an initialization. The default no-initialization setup as in [7] works reasonably, while the other degenerates. Details can be found in § C.
On 2, 700 held-out ROCStories sequences, we use the first 50 tokens of each sequence as a prompt and have the model generate the next 50. In Table 2, we show the MAUVE score and perplexity of both models. We observe a substantially higher MAUVE score and lower perplexity with $\textsc{Ssd-LM}$.
4.3 Controlled text generation
Setup
To evaluate $\textsc{Ssd-LM}$ 's ability for highly-modular control, we consider the task of sentiment controlled generation where given a prompt, the goal is to generate a continuation with a positive (or negative) polarity. We use a set of 15 short prompts as in [23] and generate 20 samples per prompt per sentiment category, making the total number of generated samples to be 600. Following [40], we generate samples with 3 different output lengths: 12, 20 and 50. For guidance, we simply import a popular sentiment classifier^12 from HuggingFace trained with Twitter sentiment data with over 58M training examples ([41]). This model serves as $f_{\phi}(\cdot)$ as shown in Equation 13. In addition to quality and diversity of the generated samples, we also evaluate them on control (that is measuring if the generated output is actually positive or negative in polarity). For this, we use an external sentiment classifier trained on a different dataset. Specifically, we use a classifier trained with Yelp reviews^13 ([42, 43]) following the evaluation setup in the baselines we consider.
Again, we consider the sampling and multi-hot decoding strategies with $\text{top-}p \in { 0.2, 0.5, 0.9 }$, $T_{\text{decode}} \in { 1000, 2500, 5000 }$, and the multiplier for control $\lambda \in { 0, 100, 500, 2000 }$. For the generation of 12/20/50 tokens, we use $B_{\text{decode}}$ =12/20/25 and apply the decoding algorithm for $m$ =1/1/2 iterations respectively.
\begin{tabular}{@{}p{0.9in}p{0.58in}p{0.38in}p{0.68in}@{}}
\toprule
(Length 50) & C-Ext.\tiny{(Int.)} & PPL & Dist-1/2/3 \\
\midrule
\underline{DAPT}$^{\mathbb{CM}}$ & 79.8 & 57.2 & 61/92/94 \\
\underline{PPLM}$^{\mathbb{CC}}$ & 60.7 \tiny{(73.6)} & 29.0 & - \\
\underline{FUDGE}$^{\mathbb{CC}}$ & 59.1 & \textbf{8.4} & 47/83/92 \\
\underline{GeDi}$^{\mathbb{CM}}$ & \textbf{99.2} & 107.3 & 71/93/92 \\
\underline{DExperts}$^{\mathbb{CM}}$ & 94.8 & 37.1 & 56/90/92 \\
\underline{MuCoLa}$^{\mathbb{CC}}$ & 86.0 & 27.8 & 52/76/80 \\
\midrule
[2pt]
\underline{M\&M LM$^{\mathbb{HMC}}$} & 68.6 \tiny{(93.8)} & 122.3 & - \\
\underline{\textsc{Ssd-LM}$^{\mathbb{HMC}}$} & \textit{94.1} \tiny{(99.0)} & \textit{23.1} & 46/84/92 \\
\bottomrule
\end{tabular}
[^14]: PPL is obtained through a macro average following [24].
Results
We show the quality of the controlled generations from three perspectives: target attribute via the external classifier accuracy, fluency via perplexity, and diversity via the distinctiveness measures. In Table 3, we show the experimental results for output length 50. The results at length 12 and 20 have a similar trend and can be found in the appendix (§ D).
Among the baseline methods, DAPT ([44]), GeDi ([45]), and DExperts ([46]) require training customized language models aware of the desired attributes (denoted as CM in Table 7). PPLM ([23]), FUDGE ([47]), and MuCoLa ([24]) require training a customized attribute classifier (CC). While our proposed method $\textsc{Ssd-LM}$ and M&M LM ([40]) can directly import mainstream existing attribute classifiers from platforms like HuggingFace and are thus highly modular (HMC). We show the baseline results as reported in [40] and [24].
$\textsc{Ssd-LM}$ shows strong controllability while possessing great modularity. $\textsc{Ssd-LM}$ outperforms M&M LM, the other HMC method by a large margin. Even when comparing with the CC and CM methods, our method achieves a good balance in control, fluency, and diversity.
In § D, we show the impact of the control weight $\lambda$ and top- $p$ on the attribute accuracy and perplexity in Figure 5. We also show qualitative examples of the controlled generations by $\textsc{Ssd-LM}$ in Table 8.
5. Related work
Section Summary: Diffusion models, which excel at generating images, audio, and other continuous data by gradually adding and removing noise, face challenges when applied to discrete text, leading to adaptations like embedding tokens in continuous space or converting them to bits, though these often lack strong control or efficiency compared to standard models. Most language models generate text token by token in an autoregressive way, achieving high quality but struggling with flexible control over the output's attributes, while non-autoregressive alternatives aim for speed but typically underperform on general tasks. Efforts in controllable text generation range from retraining models with specific codes to decoding techniques using pretrained models and classifiers, but many are computationally expensive or inflexible; this work bridges these gaps with a semi-autoregressive diffusion approach that allows editing and uses ready-made tools for control.
Diffusion models
Diffusion models have demonstrated impressive performance in popular continuous-valued domains such as images ([2]), audio ([3]), video ([4]) and recently also been adopted for 3D-shapes, protein structures, and more ([48, 49, 50]). Since they are based on adding Gaussian noise, these approaches are not straightforward to apply to discrete valued domains like text. [5, 6] propose diffusing in the discrete space using categorical distributions which are modified using transition matrices. However, these methods do not straightforwardly support control and yield worse results than comparable autoregressive models. [7] propose to represent each token as a continuous embedding and apply diffusion in the embedding space. They train the LM to generate a fixed length sequence whereas $\textsc{Ssd-LM}$ allows flexibility in the generated sequence length by generating block-wise. Further, their LM is trained with specialized datasets and not evaluated against general-purpose autoregressive LMs on unconstrained text generation. Their method supports post-hoc control but requires training a customized attribute classifier, [^15] since the diffusion operates on a learned embedding space. [51], a concurrent work to ours, extend [7] to a sequence-to-sequence setup with a similar underlying embedding-based method. Our work is most closely related to [8] which transform discrete data into a sequence of bits and represent each bit as +1 or -1 converting it into a continuous-valued domain. For textual data, however, it can lead to extremely long sequences which are difficult to optimize. In this work, we instead maintain a subword based vocabulary but represent each token as a sequence of manually defined logits.
[^15]: The control for diffusion models can also be classifier-free ([52]) but requires training with the target attribute in advance, which is not a focus of this work.
Language models
The majority of existing language models for text generation are trained autoregressively, i.e., they predict the next token given previously generated context. This paradigm scaled up both in terms of model size and training data size has resulted in impressive capabilities on many benchmarks ([10, 53]). However, they generate text one token at a time which does not provide flexible control over attributes of the generated text. Non-autoregressive models which generate the entire output sequence at the same time have also been explored in prior work other than diffusion models ([11, 12]). However, they are primarily focused on improving decoding efficiency and applied for specialized tasks like translation ([54, 55, 56]) and text editing ([57]). Many of these work have iterative processes in a discrete space, with some exploring continuous representations ([58, 59]). To address the quality decline with the non-autoregressive methods compared to autoregressive models, prior work have also explored semi-autoregressive approaches ([60, 61]). In the same vein, our work seeks to address the drawbacks of autoregressive language models and non-autoregressive diffusion models with a middle ground.
Controllable text generation
Early solutions for controlling attributes of generated text focused on training or finetuning AR-LMs with specific control codes ([62, 44, 63]). These methods are difficult to extend to new controls as it requires retraining the models. More recent work includes decoding approaches from pretrained AR-LMs without modifying the models, through altering the output probability distribution at each step using different control objectives ([23, 45, 47, 46, 64, 65]). However, these methods do not allow modifying a token once it is generated and are thus suboptimal for controls at the scope of the whole sequence. Closely related to $\textsc{Ssd-LM}$ are [66, 67, 24], which propose gradient-based decoding algorithms from AR-LMs. They require computing a backward pass through the LMs for each iteration, an expensive operation. In contrast, $\textsc{Ssd-LM}$ with its semi-autoregressive setup allows editing past tokens via diffusion. In addition, most of these approaches require training control functions from scratch whereas our model allows using off-the-shelf classifiers. [40] propose a non-autoregressive LM based on Metropolis-Hastings sampling. It also supports off-the-shelf classifiers for control, and we therefore use it as a direct baseline for $\textsc{Ssd-LM}$.
6. Conclusion
Section Summary: This paper introduces SSD-LM, a new type of language model that uses a diffusion process to generate text by cleaning up noisy versions of word sets, allowing for more flexible lengths and easy control using existing tools without extra training. In tests, it matches or exceeds the performance of powerful models like GPT-2 in creating high-quality and varied text, while far surpassing other diffusion-based models, and it also outperforms competitors in tasks where specific attributes like style or topic need to be controlled. The authors see this model as a promising step forward for developing more adaptable and user-friendly text generation systems.
We present $\textsc{Ssd-LM}$, a semi-autoregressive diffusion based language model trained to denoise corrupted simplexes over the output vocabulary. Compared to prior work in text-based diffusion, $\textsc{Ssd-LM}$ offers more flexibility in output length by generating blocks of text and an ability to use off-the-shelf attribute classifiers for control without additional tuning. On unconstrained text generation, $\textsc{Ssd-LM}$ performs on par with or outperforms strong and larger autoregressive baselines (GPT-2) in generation quality and diversity, while vastly outperforming diffusion baselines (Diffusion-LM). On controlled text generation, $\textsc{Ssd-LM}$ surpasses baselines while possessing an easy-to-use modular design. We believe that $\textsc{Ssd-LM}$ opens an exciting direction for future research in flexible and modular diffusion-based language generation.
Limitations
Section Summary: The SSD-LM model is less sample-efficient than traditional autoregressive language models because it computes loss on fewer tokens during training, and it generates text more slowly due to multiple refinement iterations needed for each block, taking about 25 seconds for 25 tokens in one example. Additionally, the decoding process uses a fixed block size that doesn't vary across steps, limiting flexibility. Future improvements could include specialized architectures for better efficiency, tunable iteration counts to speed up generation, adaptive block sizes, larger experiments with various controls, new ways to handle noise in text, and multilingual applications.
Sample efficiency
In AR-LMs, an NLL loss is computed at training time for every token in the sequence of length $L$ Equation (4). However, in $\textsc{Ssd-LM}$, each time a pretraining example is sampled, the loss is computed on only $B$ tokens Equation (7b) leading to a lower sample efficiency than AR-LM. Towards improving this efficiency, future work could explore model architectures dedicated to semi-autoregressive diffusion rather than the vanilla Transformer encoder we use in this work.
Decoding speed
Since each block is generated by refining over several iterations, $\textsc{Ssd-LM}$ has a considerably slower decoding speed than autoregressive models. For example, given a context of 50 tokens (single instance, unbatched), it takes $\textsc{Ssd-LM}$ 25 seconds to generate the next block of 25 tokens ($T_{\text{decode}}$ =1000). While our work focused on establishing the efficacy of diffusion-based LMs and modular controlled generation, future work could explore tuning $T_{\text{decode}}$ to balance model performance and decoding speed, or more efficient training and decoding algorithms extending ideas from prior work on diffusion models for continuous domains ([19, 27, 68, 69]).
Decoding block size
In this work, although we allow setups where $B_{\text{train}} \neq B_{\text{decode}}$, the decoding block size $B_{\text{decode}}$ remains the same across $m$ decoding iterations, leaving space for a more flexible decoding schedule. Future work can also explore learning $B_{\text{decode}}$ (and $B_{\text{train}}$) rather than using constant pre-defined lengths.
Larger scale experiments with different kinds of controls and their combinations can be done, as well as more sophisticated ways to incorporate them ([66]). In addition, we plan to explore alternative methods to continuously represent and add noise to discrete text ([70]). This work experiments with pretraining data that is primarily in English. Future work can also explore challenges and benefits of diffusion-based LMs in a multilingual setup.
Ethics statement
Section Summary: Language models trained on internet data can spread social biases, toxic behavior, and harmful words, while also risking the spread of false information or invading user privacy by memorizing data patterns without true understanding. These issues affect not just traditional models but also the authors' new diffusion-based language model, though its built-in controllability features offer hope for future improvements to reduce such problems. However, this same controllability could be abused to create biased or fake content on purpose, so researchers should develop ways to detect and block these malicious uses.
Language models trained on data from the web can perpetuate social biases and toxic interactions, and can be prone to generating harmful language ([71, 72, 73, 74, 75]). Further, language generation models could memorize and amplify patterns in data without deeper language understanding or control, so they can be factually inconsistent and generate disinformation ([76, 77, 78]), or can compromise user privacy ([79]). Prior works have outlined these risks ([74, 80]), discussed their points of origin, and advocated for future research on ethical development of LMs ([81, 82]).
While these studies have been conducted for autoregressive LMs, our diffusion-based LM is subject to these problems as well. However, since our method naturally incorporates controllability, future work may explore control functions that could potentially alleviate these issues ([46, 24]). One risk is that controllability can also be misused maliciously, with models being intentionally exploited to generate biased, toxic, or non-factual content ([83, 84]). Therefore, apart from controlled generation, future work should aim to detect the generations under control as well to defend against the malicious use ([85]).
Acknowledgements
Section Summary: The authors express gratitude to several colleagues and reviewers, including Tianxiao Shen, Tianxing He, Jiacheng Liu, Ruiqi Zhong, Sidney Lisanza, Jacob Gershon, members of the TsvetShop group, and anonymous ACL reviewers, for their valuable discussions and feedback. Individual researchers X.H., S.K., and Y.T. acknowledge support from the UW-Meta AI Mentorship program, a Google Ph.D. Fellowship, and an Alfred P. Sloan Foundation Fellowship, respectively. The work is also funded in part by National Science Foundation grants and the Office of the Director of National Intelligence through the IARPA HIATUS Program, with a note that the views expressed are the authors' own and not official government positions, though the U.S. Government may reproduce the material for official purposes.
The authors would like to thank Tianxiao Shen, Tianxing He, Jiacheng Liu, Ruiqi Zhong, Sidney Lisanza, Jacob Gershon, members of TsvetShop, and the anonymous ACL reviewers for their helpful discussions and feedback. X.H. gratefully acknowledges funding from the UW-Meta AI Mentorship program. S.K. gratefully acknowledges a Google Ph.D. Fellowship. Y.T. gratefully acknowledges an Alfred P. Sloan Foundation Fellowship. This research is supported in part by by the National Science Foundation (NSF) under Grants No. IIS2203097, IIS2125201, and NSF CAREER Grant No. IIS2142739. This research is supported in part by the Office of the Director of National Intelligence (ODNI), Intelligence Advanced Research Projects Activity (IARPA), via the HIATUS Program contract #2022-22072200004. The views and conclusions contained herein are those of the authors and should not be interpreted as necessarily representing the official policies, either expressed or implied, of ODNI, IARPA, or the U.S. Government. The U.S. Government is authorized to reproduce and distribute reprints for governmental purposes notwithstanding any copyright annotation therein.
A A contrastive interpretation of the training loss
Section Summary: The training of the SSD-LM model focuses on increasing the probability of generating the correct words based on previous context and noisy versions of those words, differing from the precise goal of standard diffusion models that use a mathematical bound. By decomposing the key equation, this approach reveals a contrastive strategy: it boosts the model's confidence in real, clean data while reducing its confidence in noisy data across different levels of distortion. The constant term from the noise-adding process doesn't affect the optimization, making the overall objective about favoring true patterns over their altered forms.
The training of $\textsc{Ssd-LM}$ is simply maximizing the likelihood $\log p_\theta(\boldsymbol{w}^{c:c+B} \mid \tilde{\boldsymbol{w}}_t^{c:c+B}, \boldsymbol{w}^{<c})$. This diverts from the exact objective of DDPM that is supported by a variational bound. However, below we give an intuitive interpretation to our objective.
$
\begin{align}
&\log p_\theta(\boldsymbol{w}^{c:c+B} \mid \tilde{\boldsymbol{w}}t^{c:c+B}, \boldsymbol{w}^{<c})\
=&\log \frac{p\theta(\boldsymbol{w}^{c:c+B} \mid \boldsymbol{w}^{<c})p_\theta(\tilde{\boldsymbol{w}}t^{c:c+B} \mid \boldsymbol{w}^{c:c+B}, \boldsymbol{w}^{<c})}{p\theta(\tilde{\boldsymbol{w}}_t^{c:c+B} \mid \boldsymbol{w}^{<c})}\
=&\log \underbrace{\textstyle p_\theta(\boldsymbol{w}^{c:c+B} \mid \boldsymbol{w}^{<c})}{\mathclap{\text{\scriptsize likelihood of true data}}} - \log \underbrace{\textstyle p\theta(\tilde{\boldsymbol{w}}t^{c:c+B} \mid \boldsymbol{w}^{<c})}{\mathclap{\text{\scriptsize likelihood of noisy data at timestep }t}} \nonumber \
&+ \log \underbrace{\textstyle p(\tilde{\boldsymbol{w}}t^{c:c+B} \mid \boldsymbol{w}^{c:c+B})}{\mathclap{\text{\scriptsize forward diffusion process independent of }\theta}}
\end{align}
$
Optimizing $\theta$ is a contrastive objective: maximizing the estimated likelihood of true data, while penalizing the estimated likelihood of noisy data under a broad range of different noise scales.
B Connection between our decoding algorithm and the DDPM decoding
Section Summary: This section explains how the researchers' decoding method links to the standard DDPM approach by reinterpreting the noise removal process as first estimating a clean original image from a noisy one and then adding back a controlled amount of noise to create the next less-noisy version. In DDPM, this added noise is deterministic and based on the model's prediction, mimicking the forward diffusion but in reverse to gradually denoise the image. The authors' strategy follows a similar pattern but uses randomly sampled noise instead, which helps explore more possibilities during generation.
We revisit the decoding step in DDPM introduced in Equation 3. Since we know that during the training phase $\boldsymbol{x}{t}$ is generated through a one-step forward diffusion process Equation (1), a model $\theta$ predicting the added noise $\epsilon{\theta}(\boldsymbol{x}_t, t)$ can therefore be considered as predicting an imaginary $\boldsymbol{x}_0$ in one-step:
$ \begin{align} \hat{\boldsymbol{x}}_0(\boldsymbol{x}_t, t, \theta) &= \frac{1}{\sqrt{\bar{\alpha}_t}}(\boldsymbol{x}_t - \sqrt{1-\bar{\alpha}t} \epsilon{\theta}(\boldsymbol{x}_t, t)) \end{align}\tag{14} $
Below we write $\hat{\boldsymbol{x}}_0(\boldsymbol{x}_t, t, \theta)$ as $\hat{\boldsymbol{x}}0$ and $\epsilon{\theta}(\boldsymbol{x}t, t)$ as $\epsilon{\theta}$ for simplicity.
Rearranging the DDPM decoding transition Equation (3), we have:
$ \begin{align} \boldsymbol{x}{t-1} &= \sqrt{\bar{\alpha}{t-1}} \hat{\boldsymbol{x}}0 + \sqrt{\frac{\alpha_t - \bar{\alpha}t}{1- \bar{\alpha}t}} \sqrt{1-\bar{\alpha}{t-1}} \epsilon{\theta} \tag{a} \ &\approx \sqrt{\bar{\alpha}{t-1}} \hat{\boldsymbol{x}}0 + \sqrt{1-\bar{\alpha}{t-1}} \epsilon_{\theta} \tag{b} \end{align}\tag{15} $
with $\sqrt{\frac{\alpha_t - \bar{\alpha}_t}{1- \bar{\alpha}_t}} \approx 1$ for most $t \in (1, T)$.[^16]
[^16]: Specifically, we adopt a cosine schedule for $\bar{\alpha}_t$ ([27]), and $\sqrt{\frac{\alpha_t - \bar{\alpha}_t}{1- \bar{\alpha}_t}} > 0.98$ for 98% of all $t$, with some outliers as $t \to 0$ and $t \to T$.
Noting the format simlarity between Equation 1 and 15b, we therefore interpret the DDPM decoding transition from $\boldsymbol{x}t$ to $\boldsymbol{x}{t-1}$ as (1) predicting an imaginary $\hat{\boldsymbol{x}}0$, and (2) applying a compensating forward diffusion step with a deterministic noise $\epsilon{\theta}$.
Our decoding strategy in Equation 12b is in a very similar form as Equation 15b. We also predict the initial data representation with $\theta$ and apply a forward diffusion step. The difference is that we sample a noise $\boldsymbol{z}$ instead of using the deterministic $\epsilon_{\theta}$, to encourage exploration.
C Detailed setup of the comparison with Diffusion-LM ([7])
Section Summary: Researchers compared their SSD-LM model with Diffusion-LM by preparing similar training data from ROCStories stories, creating 50,000 short sequences, and training both models using a shared tokenizer from BERT. SSD-LM was trained more efficiently over fewer steps with a larger batch size, while Diffusion-LM required more steps; for evaluation, they tested SSD-LM on generating story blocks and Diffusion-LM on filling in missing parts, both starting from BERT-initialized versions where possible. However, initializing Diffusion-LM with BERT weights led to very poor performance, suggesting it struggles to adapt pretrained knowledge from non-diffusion models, unlike the more flexible SSD-LM.
We apply block concatenation on ROCStories similarly as OpenWebText, resulting in 50K training sequences of 100 tokens. We train Diffusion-LM with a default batch size of 64, learning rate of 1e-4, and 400K steps. We train $\textsc{Ssd-LM}$ with a batch size of 512, learning rate of 1e-4, and 20K steps. Both models use a tokenizer of BERT-base-uncased. For $\textsc{Ssd-LM}$, additional hyperparameters like decoding block size and one-hot constant remain the same as the main $\textsc{Ssd-LM}$ benchmarked with GPT-2. For Diffusion-LM, the evaluation in the main paper is an infilling task. We use same decoding hyperparameters as [7]. For $\textsc{Ssd-LM}$, the evaluation is a block-wise generation problem with $m$ =2 iterations. The result of $\textsc{Ssd-LM}$ in Table 2 is obtained with a decoding configuration of $T_{\text{decode}}$ =2500 and top- $p$ =0.5.
Our $\textsc{Ssd-LM}$ in this subsection is initialized with BERT. For a fair comparison, apart from the default Diffusion-LM reported in Table 2, we train another Diffusion-LM initialized with the encoder weights of BERT. However, this leads to degenerated results that are much worse than the default Diffusion-LM and our $\textsc{Ssd-LM}$: a MAUVE score of 0.4 out of 100 and a PPL of 73157. This problem is not due to overfitting, as all checkpoints of the model show the same degenerated result. Since [7] did not explore this setup in their original work as well, we conjecture that Diffusion-LM may be incompatible with pretrained weights from existing non-diffusion models by nature, a disadvantage to our $\textsc{Ssd-LM}$.
D Additional results
Section Summary: This section presents extra experiments on a language model called SSD-LM, exploring how different ways of selecting words during text generation affect quality, such as using sampling versus greedy choices, which can reduce repetition but sometimes increase complexity measures like perplexity. Figures show that stronger control settings improve the accuracy of desired text attributes, though they make the output slightly less natural, while comparisons in tables reveal SSD-LM often outperforms standard GPT-2 models in generating diverse and high-quality text continuations of various lengths. Additional tables and examples highlight its effectiveness in both free-form and guided writing tasks, with overall promising results across metrics like similarity to human writing and low repetition rates.
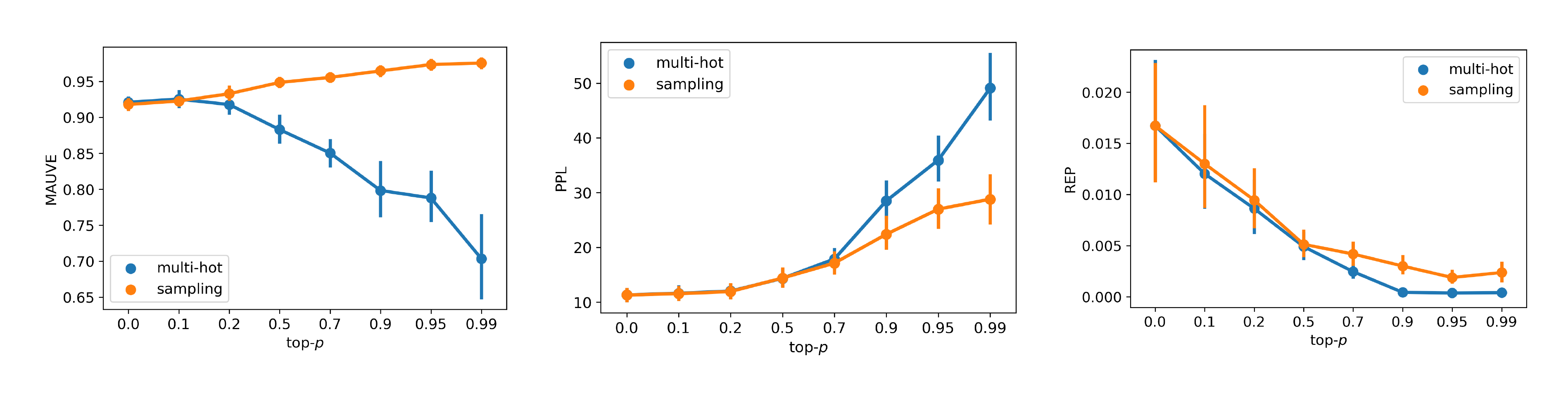
Figure 4 shows the influence of different logits projection strategies and the associated parameters on the unconstrained generations' output text quality. We observe that reducing top- $p$ $\to$ 0 (greedy projection) can lead to a low perplexity but it is undesirable due to a high repetition rate. We also find the multi-hot projection strategy is overall worse performing than the sampling projection strategy in our setup, indicating it is better to commit the intermediate states to single rather than multiple tokens. This can be because our logits mapping involves putting probability mass on singular tokens. The multi-hot projection may still be a viable strategy if future work uses multi-hot logits mapping for the input tokens.
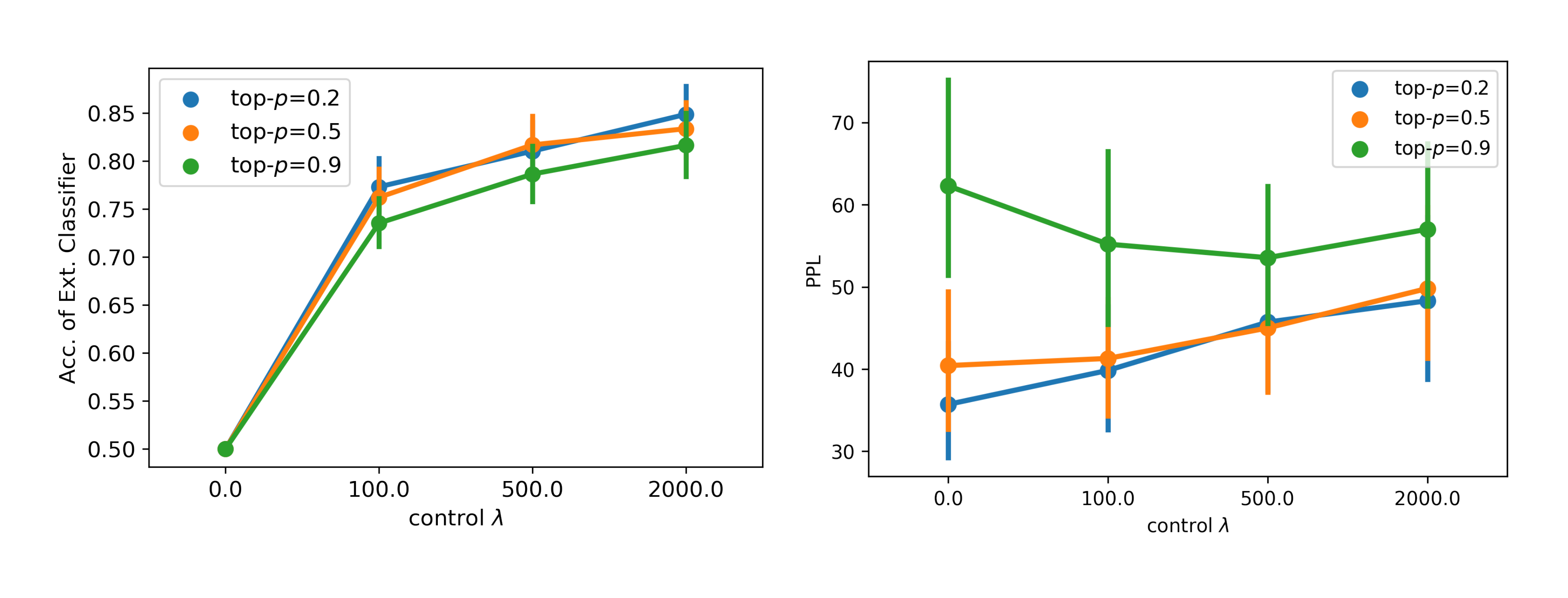
Figure 5 shows the impact of the control weight $\lambda$ and top- $p$ on the attribute accuracy and perplexity in controlled text generation. As expected, a larger control weight leads to a better external classifier accuracy. The perplexity at the same time increases with a larger $\lambda$, but under a reasonable range for a top- $p$ of 0.2 and 0.5.
Figure 6 shows the pretraining loss trajectory. Table 4, Table 5, Table 6, and Table 7 show additional evaluation results of $\textsc{Ssd-LM}$ generations. Table 8 and Table 9 show qualitative examples of $\textsc{Ssd-LM}$ generations.
:Table 4: Unconstrained generation evaluation of $\textsc{Ssd-LM}$ and GPT-2 models at length 25. PPL is computed with GPT-Neo-1.3B ([33]). For GPT-2 models, the results are averaged across 5 random seeds, and we show the best sampling parameter configuration. For our $\textsc{Ssd-LM}$, we show the top-3 configurations. All configurations are ranked based on MAUVE, with original parameters from [32].
| (Length 25) | MAUVE $\uparrow$ | PPL $\xrightarrow[\text{gold}]{}$ | $\vert\Delta_{\log \text{PPL}}\vert \downarrow$ | Dist-1 $\uparrow$ | Dist-2 $\uparrow$ | Dist-3 $\uparrow$ | Zipf $\xrightarrow[\text{gold}]{}$ | Rep $\downarrow$ |
|---|---|---|---|---|---|---|---|---|
| Gold continuation | 100.00 | 21.24 | 0.00 | 93.93 | 93.54 | 88.23 | 0.84 | 0.10 |
| GPT2-medium (Best config) | ||||||||
| Top- $p$ =0.95 | 97.35 $\pm$ 0.29 | 14.31 $\pm$ 0.07 | 0.39 | 73.63 $\pm$ 0.11 | 90.44 $\pm$ 0.13 | 87.75 $\pm$ 0.13 | 1.01 | 0.21 $\pm$ 0.05 |
| GPT2-large (Best config) | ||||||||
| Top- $p$ =0.95 | 97.01 $\pm$ 0.56 | 12.14 $\pm$ 0.06 | 0.55 | 71.94 $\pm$ 0.10 | 89.84 $\pm$ 0.06 | 87.66 $\pm$ 0.06 | 1.02 | 0.23 $\pm$ 0.08 |
| GPT2-xl (Best config) | ||||||||
| Top- $p$ =0.95 | 97.29 $\pm$ 0.80 | 11.90 $\pm$ 0.09 | 0.57 | 72.02 $\pm$ 0.04 | 89.58 $\pm$ 0.14 | 87.39 $\pm$ 0.13 | 1.00 | 0.22 $\pm$ 0.02 |
| $\textsc{Ssd-LM}$-"medium" (Top-3) | ||||||||
| Sampling $p$ =0.99, $T$ =1000 | 98.41 | 38.30 | 0.58 | 75.61 | 90.85 | 87.58 | 0.98 | 0.10 |
| Sampling $p$ =0.99, $T$ =2500 | 98.33 | 30.89 | 0.37 | 75.04 | 90.64 | 87.54 | 1.02 | 0.18 |
| Sampling $p$ =0.95, $T$ =1000 | 98.18 | 33.79 | 0.46 | 74.70 | 90.67 | 87.62 | 0.99 | 0.18 |
:Table 5: Unconstrained generation evaluation of $\textsc{Ssd-LM}$ and GPT-2 models at length 100. PPL is computed with GPT-Neo-1.3B ([33]). For GPT-2 models, the results are averaged across 5 random seeds, and we show the best sampling parameter configuration. For our $\textsc{Ssd-LM}$, we show the top-3 configurations. All configurations are ranked based on MAUVE, with original parameters from [32].
| (Length 100) | MAUVE $\uparrow$ | PPL $\xrightarrow[\text{gold}]{}$ | $\vert\Delta_{\log \text{PPL}}\vert \downarrow$ | Dist-1 $\uparrow$ | Dist-2 $\uparrow$ | Dist-3 $\uparrow$ | Zipf $\xrightarrow[\text{gold}]{}$ | Rep $\downarrow$ |
|---|---|---|---|---|---|---|---|---|
| Gold continuation | 100.00 | 14.83 | 0.00 | 81.40 | 96.21 | 96.12 | 0.90 | 0.20 |
| GPT2-medium (Best config) | ||||||||
| Top- $p$ =0.95 | 97.54 $\pm$ 0.43 | 11.68 $\pm$ 0.03 | 0.23 | 58.48 $\pm$ 0.02 | 90.82 $\pm$ 0.04 | 94.56 $\pm$ 0.03 | 1.01 | 0.50 $\pm$ 0.10 |
| GPT2-large (Best config) | ||||||||
| Top- $p$ =0.95 | 97.36 $\pm$ 0.22 | 9.43 $\pm$ 0.03 | 0.45 | 56.96 $\pm$ 0.11 | 89.43 $\pm$ 0.10 | 93.96 $\pm$ 0.09 | 1.02 | 0.60 $\pm$ 0.06 |
| GPT2-xl (Best config) | ||||||||
| Top- $p$ =0.95 | 97.53 $\pm$ 0.34 | 9.17 $\pm$ 0.04 | 0.48 | 57.10 $\pm$ 0.11 | 89.35 $\pm$ 0.09 | 93.76 $\pm$ 0.08 | 1.00 | 0.58 $\pm$ 0.06 |
| $\textsc{Ssd-LM}$-"medium" (Top-3) | ||||||||
| Sampling $p$ =0.95, $T$ =1000 | 97.67 | 23.38 | 0.45 | 60.17 | 91.30 | 94.89 | 1.02 | 0.30 |
| Sampling $p$ =0.99, $T$ =2500 | 97.36 | 21.17 | 0.35 | 60.02 | 90.93 | 94.52 | 1.04 | 0.44 |
| Sampling $p$ =0.99, $T$ =1000 | 97.10 | 26.41 | 0.57 | 61.26 | 91.91 | 95.11 | 1.01 | 0.32 |
\begin{tabular}{@{}p{0.9in}p{0.58in}p{0.38in}p{0.68in}@{}}
\toprule
(Length 12) & C-Ext.\tiny{(Int.)} & PPL & Dist-1/2/3 \\
\midrule
\underline{DAPT}$^{\mathbb{CM}}$ & 66.7 & 106.5 & 65/85/79 \\
\underline{PPLM}$^{\mathbb{CC}}$ & 58.0 \tiny{(71.7)} & 113.1 & - \\
\underline{FUDGE}$^{\mathbb{CC}}$ & 62.6 & \textbf{12.5} & 52/76/77 \\
\underline{GeDi}$^{\mathbb{CM}}$ & \textbf{93.6} & 460.6 & 65/76/69 \\
\underline{DExperts}$^{\mathbb{CM}}$ & 87.4 & 69.0 & 65/85/80 \\
\underline{MuCoLa}$^{\mathbb{CC}}$ & 89.0 & 38.7 & 49/72/73 \\
\midrule
[2pt]
\underline{M\&M LM$^{\mathbb{HMC}}$} & 65.1 \tiny{(94.3)} & 264.1 & - \\
\underline{\textsc{Ssd-LM}$^{\mathbb{HMC}}$} & \textbf{79.3} \tiny{(90.5)} & \textbf{58.1} & 60/83/80 \\
\bottomrule
\end{tabular}
\begin{tabular}{@{}p{0.9in}p{0.58in}p{0.38in}p{0.68in}@{}}
\toprule
(Length 20) & C-Ext.\tiny{(Int.)} & PPL & Dist-1/2/3 \\
\midrule
\underline{DAPT}$^{\mathbb{CM}}$ & 70.0 & 78.7 & 64/89/86 \\
\underline{PPLM}$^{\mathbb{CC}}$ & 57.6 \tiny{(74.5)} & 61.1 & - \\
\underline{FUDGE}$^{\mathbb{CC}}$ & 61.3 & \textbf{10.4} & 51/80/84 \\
\underline{GeDi}$^{\mathbb{CM}}$ & \textbf{96.5} & 190.5 & 70/86/82 \\
\underline{DExperts}$^{\mathbb{CM}}$ & 87.1 & 52.3 & 62/89/87 \\
\underline{MuCoLa}$^{\mathbb{CC}}$ & 88.3 & 30.3 & 50/76/77 \\
\midrule
[2pt]
\underline{M\&M LM$^{\mathbb{HMC}}$} & 65.9 \tiny{(96.3)} & 167.2 & - \\
\underline{\textsc{Ssd-LM}$^{\mathbb{HMC}}$} & \textbf{88.0} \tiny{(95.6)} & \textbf{41.6} & 56/86/87 \\
\bottomrule
\end{tabular}
\begin{tabular}{p{0.47\textwidth}p{0.47\textwidth}}
\toprule
{Context} & {Generations}\\
\midrule
{\begin{lstlisting}
called the Grand Finale, where it will end its long life by plunging into Saturn's atmosphere this September. Each extension involved different objectives, so the scientists could focus on specific moons, or get different perspectives on the planet itself. This last phase
\end{lstlisting}} & {\begin{lstlisting}
of the mission is different altogether, and it is expected to capture the last moments of Cassini orbit. As Wired reports:\n\nThe timing of Saturn's final working flight is not known yet, but Cassini probably has the atmosphere to leave the
\end{lstlisting}}\\
{} & {\begin{lstlisting}
is meant to fill out the entire totality of the mission.\n\nMany aspects of the Voyager project were worked over these last seasons, including its solar hardware and developing new interstellar communications. More is still going to be revealed on the website as you get
\end{lstlisting}}\\
\midrule
{\begin{lstlisting}
caution.\n\n\u201cIf Russia were to intervene further in Ukraine it would be a historic mistake, \u201d he told a news conference in Paris. \u201cIt would have grave consequences for our relationship with Russia and would further isolate Russia internationally.
\end{lstlisting}} & {\begin{lstlisting}
\u201d\n\nIn addition to EU sanctions against Russian companies at the ports and other targets of the bloc, Hollande said he was concerned by Russian military involvement in the pro-Russian conflict, which lawmakers said had transformed Ukraine into a new p̈ost-
\end{lstlisting}}\\
{} & {\begin{lstlisting}
\u201d\n\nThe breakthrough has sharpened Moscow\u2019s meddling in pro-Western eastern Ukraine and put Moscow\u2019s relationship with Washington and western Europe on edge after the death of U.S. Col. Chris Stevens.\n\nWestern
\end{lstlisting}}\\
\midrule[2pt]
{\begin{lstlisting}
\n\nThe city
\end{lstlisting}} & {\begin{lstlisting}[mathescape]
council will issue a decision in late September on whether to continue efforts to adopt the partnership model at the $\textbf{[NO CONTROL]}$
\end{lstlisting}}\\
{} & {\begin{lstlisting}[mathescape]
is one of the world's fastest-growing cities with over 4 million inhabitants. It is the most $\textbf{[POSITIVE SENTIMENT]}$
\end{lstlisting}}\\
{} & {\begin{lstlisting}[mathescape]
does not have the authority to regulate drug use on public property or punish people for it. The city $\textbf{[NEGATIVE SENTIMENT]}$
\end{lstlisting}}\\
\midrule
{\begin{lstlisting}
\n\nThe movie
\end{lstlisting}} & {\begin{lstlisting}[mathescape]
\u2019s little-known star, O.J. Simpson, claimed in a lawsuit he had $\textbf{[NO CONTROL]}$
\end{lstlisting}}\\
{} & {\begin{lstlisting}[mathescape]
marks the newest addition to the Marvel Extended Universe and we can't wait to see what's next in $\textbf{[POSITIVE SENTIMENT]}$
\end{lstlisting}}\\
{} & {\begin{lstlisting}[mathescape]
is just another example of the stupid movies that lack an understanding of why writing is important and why it $\textbf{[NEGATIVE SENTIMENT]}$
\end{lstlisting}}\\
\bottomrule
\end{tabular}
```latextable {caption="**Table 9:** The intermediate states of generation as $t$ decreases ($T$ =2500, $B$ =25, top- $p$-sampling=0.99). The context $\boldsymbol{w}^{<c}$ here is the first example prompt in Table 8: ``{` called the Grand Finale, where it will end its long life by plunging into Saturn's atmosphere this September. Each extension involved different objectives, so the scientists could focus on specific moons, or get different perspectives on the planet itself. This last phase'}''. There is no change in the outputs during $500 > t > 1$. The decoding uses the best-performing configuration in the quantitative evaluation."}
\begin{tabular}{p{0.05\textwidth}p{0.39\textwidth}p{0.48\textwidth}} \toprule {$t$} & {$\operatorname{argmax} \boldsymbol{w}{\text{logits}, t}^{c:c+B}$} & {$\operatorname{argmax} \tilde{\boldsymbol{w}}{t-1}^{c:c+B}$}\
\midrule {2500} & {\begin{lstlisting} of the to the the the the the the the the the the the the the the the the the the the the the the \end{lstlisting}} & {\begin{lstlisting} apeshifteriao41 fleeting frontman Nutdrop278temp Drama lime Employee cuc rival greatest kan snakes431 cav dreamedRange alloy originally Pact \end{lstlisting}}\
\midrule {1500} & {\begin{lstlisting} is the to be the, of the, , , \n the the the the the the the the the\n into the. \end{lstlisting}} & {\begin{lstlisting} stunnedchildrenmetrywaveopensLayer Porn woman transcend242 Homs PluginNext Endsackle microbi spokesperson Brunswick awards":- Sharma Pinball Jr Rug wrapped \end{lstlisting}}\
\midrule {1300} & {\begin{lstlisting} of the mission it the as a, for the, , , as to as the the moons, and Cass Cassini is \end{lstlisting}} & {\begin{lstlisting} 178 whit promoters du basketballiche SchoolsPur Sack reward basketball corn////WeaponSpeaking squid Chains Caucasian McGivity Me SC rafthr jihadist \end{lstlisting}}\
\midrule {1100} & {\begin{lstlisting} was based on the in, 2014. Theini will be the the up is the the the the, Hubble but the the \end{lstlisting}} & {\begin{lstlisting} battles swore starters test thanpadding ambiguityFri BADuitous Stuff depiction bankrupt>>> conversions240Genelvet aptLegweight Riy modesitanesday \end{lstlisting}}\
\midrule {900} & {\begin{lstlisting} of the Jarminiini Cass Gr, was supposed to be the most ambitious and most attempt to capture all most distant moons \end{lstlisting}} & {\begin{lstlisting} Sim bag Ves serotonin._ Fab gameplay ransom Alisonorks Fargo expand Rhode pursuing most plagued formulateheter plainly troubled Professional Binary Creek geared \end{lstlisting}}\
\midrule {800} & {\begin{lstlisting} is all about Saturn. The Eini will, the closest that the instruments have reached will be to stop in on the Saturn \end{lstlisting}} & {\begin{lstlisting} omial allcounter Saturn. The Directthank Ecuador two thelearning that the Animation have brothers will make toousands downtown governance the Further \end{lstlisting}}\
\midrule {700} & {\begin{lstlisting} will allow the Cass to finally see the planet's relatively small atmosphere and finally be able to procure an accurate way of understanding how \end{lstlisting}} & {\begin{lstlisting} willPocket prelim Klux to finally see the planet intelligent relatively jumper atmosphere and halted Fly activityvirt00000 trem accurate way of Inferno what \end{lstlisting}}\
\midrule {600} & {\begin{lstlisting} will allow the scientists to better study the effects of Grand Impact, and also be able to get much more data and images of \end{lstlisting}} & {\begin{lstlisting} will allowert scientists Damien better study the effects of Grand Impact, andasket bebery to get much more data and images of \end{lstlisting}}\
\midrule {500} & {\begin{lstlisting} will allow the scientists to better see the interior of its atmosphere, and also be able to get much more knowledge and understanding of \end{lstlisting}} & {\begin{lstlisting} will allow the scientists to better see the interior of its atmosphere, and also be able to get much more knowledge and understanding of \end{lstlisting}}\
\midrule {1} & {\begin{lstlisting} will allow the scientists to better see the interior of its atmosphere, and also be able to get much more knowledge and observations of \end{lstlisting}} & {\begin{lstlisting} will allow the scientists to better see the interior of its atmosphere, and also be able to get much more knowledge and observations of \end{lstlisting}}\
\bottomrule \end{tabular}
## References
> **Section Summary**: This references section compiles a bibliography of over 30 key academic papers and preprints in artificial intelligence and machine learning, spanning from 2015 to 2022. It highlights foundational work on diffusion models, which are algorithms for generating realistic data like images, audio, videos, and text by gradually adding and removing noise. Other citations explore large language models such as BERT and GPT for tasks like translation, story creation, and controlled text generation, drawing from prestigious conferences like NeurIPS, ICML, and ICLR.
[1] Jascha Sohl-Dickstein, Eric Weiss, Niru Maheswaranathan, and Surya Ganguli. 2015. Deep unsupervised learning using nonequilibrium thermodynamics. In *Proc. ICML*.
[2] Jonathan Ho, Ajay Jain, and Pieter Abbeel. 2020. Denoising diffusion probabilistic models. In *Proc. NeurIPS*.
[3] Zhifeng Kong, Wei Ping, Jiaji Huang, Kexin Zhao, and Bryan Catanzaro. 2021. Diffwave: A versatile diffusion model for audio synthesis. In *Proc. ICLR*.
[4] Jonathan Ho, Tim Salimans, Alexey Gritsenko, William Chan, Mohammad Norouzi, and David J. Fleet. 2022. Video diffusion models. *ArXiv*, abs/2204.03458.
[5] Emiel Hoogeboom, Didrik Nielsen, Priyank Jaini, Patrick Forré, and Max Welling. 2021. Argmax flows and multinomial diffusion: Learning categorical distributions. In *Proc. NeurIPS*.
[6] Jacob Austin, Daniel D. Johnson, Jonathan Ho, Daniel Tarlow, and Rianne van den Berg. 2021. Structured denoising diffusion models in discrete state-spaces. In *Proc. NeurIPS*.
[7] Xiang Lisa Li, John Thickstun, Ishaan Gulrajani, Percy Liang, and Tatsunori Hashimoto. 2022. Diffusion-lm improves controllable text generation. *ArXiv*, abs/2205.14217.
[8] Ting Chen, Ruixiang Zhang, and Geo rey E. Hinton. 2022. Analog bits: Generating discrete data using diffusion models with self-conditioning. *ArXiv*, abs/2208.04202.
[9] Alec Radford, Jeff Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. 2019. Language models are unsupervised multitask learners.
[10] Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, T. J. Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeff Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, and Dario Amodei. 2020. Language models are few-shot learners. *ArXiv*, abs/2005.14165.
[11] Jason Lee, Elman Mansimov, and Kyunghyun Cho. 2018. Deterministic non-autoregressive neural sequence modeling by iterative refinement. In *Proc. EMNLP*.
[12] Marjan Ghazvininejad, Omer Levy, Yinhan Liu, and Luke Zettlemoyer. 2019. Mask-predict: Parallel decoding of conditional masked language models. In *Proc. EMNLP*.
[13] Prafulla Dhariwal and Alex Nichol. 2021. Diffusion models beat gans on image synthesis. *ArXiv*, abs/2105.05233.
[14] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: Pre-training of deep bidirectional transformers for language understanding. In *Proc. NAACL-HLT*.
[15] Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. 2019. Roberta: A robustly optimized bert pretraining approach. *ArXiv*, abs/1907.11692.
[16] Colin Raffel, Noam M. Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu. 2020. Exploring the limits of transfer learning with a unified text-to-text transformer. *JMLR*.
[17] Yang Song and Stefano Ermon. 2019. Generative modeling by estimating gradients of the data distribution. In *Proc. NeurIPS*.
[18] Cong Duy Vu Hoang, Gholamreza Haffari, and Trevor Cohn. 2017. \href https://doi.org/10.18653/v1/D17-1014 Towards decoding as continuous optimisation in neural machine translation. In *Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing*, pages 146–156, Copenhagen, Denmark. Association for Computational Linguistics.
[19] Jiaming Song, Chenlin Meng, and Stefano Ermon. 2021. Denoising diffusion implicit models. In *Proc. ICLR*.
[20] Angela Fan, Mike Lewis, and Yann Dauphin. 2018. Hierarchical neural story generation. In *Proc. ACL*.
[21] Ari Holtzman, Jan Buys, Li Du, Maxwell Forbes, and Yejin Choi. 2020. The curious case of neural text degeneration. In *Proc. ICLR*.
[22] Clara Meister, Tiago Pimentel, Gian Wiher, and Ryan Cotterell. 2022. Locally typical sampling. *ArXiv*, abs/2202.00666.
[23] Sumanth Dathathri, Andrea Madotto, Janice Lan, Jane Hung, Eric Frank, Piero Molino, Jason Yosinski, and Rosanne Liu. 2020. Plug and play language models: A simple approach to controlled text generation. In *Proc. ICLR*.
[24] Sachin Kumar, Biswajit Paria, and Yulia Tsvetkov. 2022b. Constrained sampling from language models via langevin dynamics in embedding spaces. In *Proc. EMNLP*.
[25] J. Atchison and S.M. Shen. 1980. \href https://doi.org/10.1093/biomet/67.2.261 Logistic-normal distributions:Some properties and uses. *Biometrika*, 67(2):261–272.
[26] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. In *Proc. NeurIPS*.
[27] Alexander Quinn Nichol and Prafulla Dhariwal. 2021. Improved denoising diffusion probabilistic models. In *Proc. ICML*.
[28] Rico Sennrich, Barry Haddow, and Alexandra Birch. 2016. Neural machine translation of rare words with subword units. In *Proc. ACL*.
[29] Susan Zhang, Stephen Roller, Naman Goyal, Mikel Artetxe, Moya Chen, Shuohui Chen, Christopher Dewan, Mona Diab, Xian Li, Xi Victoria Lin, Todor Mihaylov, Myle Ott, Sam Shleifer, Kurt Shuster, Daniel Simig, Punit Singh Koura, Anjali Sridhar, Tianlu Wang, and Luke Zettlemoyer. 2022. Opt: Open pre-trained transformer language models. *ArXiv*, abs/2205.01068.
[30] Aaron Gokaslan and Vanya Cohen. 2019. Openwebtext corpus.
[31] Ilya Loshchilov and Frank Hutter. 2019. Decoupled weight decay regularization. In *Proc. ICLR*.
[32] Krishna Pillutla, Swabha Swayamdipta, Rowan Zellers, John Thickstun, Sean Welleck, Yejin Choi, and Zaïd Harchaoui. 2021. Mauve: Measuring the gap between neural text and human text using divergence frontiers. In *Proc. NeurIPS*.
[33] Sid Black, Gao Leo, Phil Wang, Connor Leahy, and Stella Biderman. 2021. \href https://doi.org/10.5281/zenodo.5297715 GPT-Neo: Large Scale Autoregressive Language Modeling with Mesh-Tensorflow.
[34] Moin Nadeem, Tianxing He, Kyunghyun Cho, and James Glass. 2020. A systematic characterization of sampling algorithms for open-ended language generation. In *Proc. AACL*.
[35] Hugh Zhang, Daniel Duckworth, Daphne Ippolito, and Arvind Neelakantan. 2021. Trading off diversity and quality in natural language generation. In *Proceedings of the Workshop on Human Evaluation of NLP Systems (HumEval)*, pages 25–33.
[36] Jiwei Li, Michel Galley, Chris Brockett, Jianfeng Gao, and Bill Dolan. 2016. \href https://doi.org/10.18653/v1/N16-1014 A diversity-promoting objective function for neural conversation models. In *Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies*, pages 110–119, San Diego, California. Association for Computational Linguistics.
[37] Sean Welleck, Ilia Kulikov, Stephen Roller, Emily Dinan, Kyunghyun Cho, and Jason Weston. 2020. Neural text generation with unlikelihood training. In *Proc. ICLR*.
[38] Jekaterina Novikova, Ondřej Dušek, and Verena Rieser. 2017. The e2e dataset: New challenges for end-to-end generation. *arXiv preprint arXiv:1706.09254*.
[39] Nasrin Mostafazadeh, Nathanael Chambers, Xiaodong He, Devi Parikh, Dhruv Batra, Lucy Vanderwende, Pushmeet Kohli, and James Allen. 2016. A corpus and cloze evaluation for deeper understanding of commonsense stories. In *Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies*, pages 839–849.
[40] Fatemehsadat Mireshghallah, Kartik Goyal, and Taylor Berg-Kirkpatrick. 2022. Mix and match: Learning-free controllable text generationusing energy language models. In *Proc. ACL*.
[41] Francesco Barbieri, Jose Camacho-Collados, Luis Espinosa Anke, and Leonardo Neves. 2020. Tweeteval: Unified benchmark and comparative evaluation for tweet classification. In *Findings of EMNLP*.
[42] Xiang Zhang, Junbo Zhao, and Yann LeCun. 2015. Character-level convolutional networks for text classification. In *Proc. NeurIPS*.
[43] John Morris, Eli Lifland, Jin Yong Yoo, Jake Grigsby, Di Jin, and Yanjun Qi. 2020. Textattack: A framework for adversarial attacks, data augmentation, and adversarial training in nlp. In *Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations*, pages 119–126.
[44] Suchin Gururangan, Ana Marasović, Swabha Swayamdipta, Kyle Lo, Iz Beltagy, Doug Downey, and Noah A. Smith. 2020. Don’t stop pretraining: Adapt language models to domains and tasks. In *Proc. ACL*.
[45] Ben Krause, Akhilesh Deepak Gotmare, Bryan McCann, Nitish Shirish Keskar, Shafiq Joty, Richard Socher, and Nazneen Fatema Rajani. 2021. Gedi: Generative discriminator guided sequence generation. In *Proc. Findings of EMNLP*.
[46] Alisa Liu, Maarten Sap, Ximing Lu, Swabha Swayamdipta, Chandra Bhagavatula, Noah A Smith, and Yejin Choi. 2021. Dexperts: Decoding-time controlled text generation with experts and anti-experts. In *Proc. ACL*.
[47] Kevin Yang and Dan Klein. 2021. Fudge: Controlled text generation with future discriminators. In *Proc. NAACL*.
[48] Linqi Zhou, Yilun Du, and Jiajun Wu. 2021. 3d shape generation and completion through point-voxel diffusion. In *2021 IEEE/CVF International Conference on Computer Vision (ICCV)*, pages 5806–5815. IEEE.
[49] Brian Loeber Trippe, Jason Yim, Doug K Tischer, Tamara Broderick, David Baker, Regina Barzilay, and T. Jaakkola. 2022. Diffusion probabilistic modeling of protein backbones in 3d for the motif-scaffolding problem. *ArXiv*, abs/2206.04119.
[50] Kevin E. Wu, Kevin Kaichuang Yang, Rianne van den Berg, James Zou, Alex X. Lu, and Ava P. Amini. 2022. Protein structure generation via folding diffusion. *ArXiv*, abs/2209.15611.
[51] Shansan Gong, Mukai Li, Jiangtao Feng, Zhiyong Wu, and Lingpeng Kong. 2022. Diffuseq: Sequence to sequence text generation with diffusion models. *ArXiv*, abs/2210.08933.
[52] Jonathan Ho and Tim Salimans. 2021. Classifier-free diffusion guidance. In *NeurIPS 2021 Workshop on Deep Generative Models and Downstream Applications*.
[53] Aakanksha Chowdhery, Sharan Narang, Jacob Devlin, Maarten Bosma, Gaurav Mishra, Adam Roberts, Paul Barham, Hyung Won Chung, Charles Sutton, Sebastian Gehrmann, Parker Schuh, Kensen Shi, Sasha Tsvyashchenko, Joshua Maynez, Abhishek B Rao, Parker Barnes, Yi Tay, Noam M. Shazeer, Vinodkumar Prabhakaran, Emily Reif, Nan Du, Benton C. Hutchinson, Reiner Pope, James Bradbury, Jacob Austin, Michael Isard, Guy Gur-Ari, Pengcheng Yin, Toju Duke, Anselm Levskaya, Sanjay Ghemawat, Sunipa Dev, Henryk Michalewski, Xavier García, Vedant Misra, Kevin Robinson, Liam Fedus, Denny Zhou, Daphne Ippolito, David Luan, Hyeontaek Lim, Barret Zoph, Alexander Spiridonov, Ryan Sepassi, David Dohan, Shivani Agrawal, Mark Omernick, Andrew M. Dai, Thanumalayan Sankaranarayana Pillai, Marie Pellat, Aitor Lewkowycz, Erica Moreira, Rewon Child, Oleksandr Polozov, Katherine Lee, Zongwei Zhou, Xuezhi Wang, Brennan Saeta, Mark Díaz, Orhan Firat, Michele Catasta, Jason Wei, Kathleen S. Meier-Hellstern, Douglas Eck, Jeff Dean, Slav Petrov, and Noah Fiedel. 2022. Palm: Scaling language modeling with pathways. *ArXiv*, abs/2204.02311.
[54] Jiatao Gu, James Bradbury, Caiming Xiong, Victor OK Li, and Richard Socher. 2018. Non-autoregressive neural machine translation. In *Proc. ICLR*.
[55] Lukasz Kaiser, Samy Bengio, Aurko Roy, Ashish Vaswani, Niki Parmar, Jakob Uszkoreit, and Noam Shazeer. 2018. Fast decoding in sequence models using discrete latent variables. In *Proc. ICML*, pages 2390–2399. PMLR.
[56] Yiren Wang, Fei Tian, Di He, Tao Qin, ChengXiang Zhai, and Tie-Yan Liu. 2019. Non-autoregressive machine translation with auxiliary regularization. In *Proceedings of the AAAI conference on artificial intelligence*, volume 33, pages 5377–5384.
[57] Jiatao Gu, Changhan Wang, and Jake Zhao. 2019. Levenshtein transformer. In *Proc. NeurIPS*.
[58] Xuezhe Ma, Chunting Zhou, Xian Li, Graham Neubig, and Eduard Hovy. 2019. Flowseq: Non-autoregressive conditional sequence generation with generative flow. In *Proc. EMNLP*.
[59] Jason Lee, Raphael Shu, and Kyunghyun Cho. 2020. Iterative refinement in the continuous space for non-autoregressive neural machine translation. In *Proc. EMNLP*.
[60] Chunqi Wang, Ji Zhang, and Haiqing Chen. 2018. Semi-autoregressive neural machine translation. In *Proc. EMNLP*.
[61] Weizhen Qi, Yeyun Gong, Jian Jiao, Yu Yan, Weizhu Chen, Dayiheng Liu, Kewen Tang, Houqiang Li, Jiusheng Chen, Ruofei Zhang, et al. 2021. Bang: Bridging autoregressive and non-autoregressive generation with large scale pretraining. In *Proc. ICML*, pages 8630–8639. PMLR.
[62] Nitish Shirish Keskar, Bryan McCann, Lav R Varshney, Caiming Xiong, and Richard Socher. 2019. Ctrl: A conditional transformer language model for controllable generation. *arXiv preprint arXiv:1909.05858*.
[63] Alvin Chan, Yew-Soon Ong, Bill Pung, Aston Zhang, and Jie Fu. 2021. Cocon: A self-supervised approach for controlled text generation. In *Proc. ICLR*.
[64] Ximing Lu, Peter West, Rowan Zellers, Ronan Le Bras, Chandra Bhagavatula, and Yejin Choi. 2021. \href https://doi.org/10.18653/v1/2021.naacl-main.339 NeuroLogic decoding: (un)supervised neural text generation with predicate logic constraints. In *Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies*, pages 4288–4299, Online. Association for Computational Linguistics.
[65] Damian Pascual, Beni Egressy, Clara Meister, Ryan Cotterell, and Roger Wattenhofer. 2021. \href https://doi.org/10.18653/v1/2021.findings-emnlp.334 A plug-and-play method for controlled text generation. In *Findings of the Association for Computational Linguistics: EMNLP 2021*, pages 3973–3997, Punta Cana, Dominican Republic. Association for Computational Linguistics.
[66] Sachin Kumar, Eric Malmi, Aliaksei Severyn, and Yulia Tsvetkov. 2021. \href https://openreview.net/forum?id=kTy7bbm-4I4 Controlled text generation as continuous optimization with multiple constraints. In *Proc. NeurIPS*.
[67] Lianhui Qin, Sean Welleck, Daniel Khashabi, and Yejin Choi. 2022. Cold decoding: Energy-based constrained text generation with langevin dynamics. *ArXiv*, abs/2202.11705.
[68] Robin Rombach, A. Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. 2022. High-resolution image synthesis with latent diffusion models. *2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)*, pages 10674–10685.
[69] Chenlin Meng, Ruiqi Gao, Diederik P. Kingma, Stefano Ermon, Jonathan Ho, and Tim Salimans. 2022. On distillation of guided diffusion models. *ArXiv*, abs/2210.03142.
[70] József Bakosi and J. Raymond Ristorcelli. 2013. A stochastic diffusion process for the dirichlet distribution. *arXiv: Mathematical Physics*.
[71] Samuel Gehman, Suchin Gururangan, Maarten Sap, Yejin Choi, and Noah A. Smith. 2020. \href https://doi.org/10.18653/v1/2020.findings-emnlp.301 RealToxicityPrompts: Evaluating neural toxic degeneration in language models. In *Findings of the Association for Computational Linguistics: EMNLP 2020*, pages 3356–3369, Online. Association for Computational Linguistics.
[72] Eric Wallace, Shi Feng, Nikhil Kandpal, Matt Gardner, and Sameer Singh. 2019. \href https://doi.org/10.18653/v1/D19-1221 Universal adversarial triggers for attacking and analyzing NLP. In *Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP)*, pages 2153–2162, Hong Kong, China. Association for Computational Linguistics.
[73] Eric Wallace, Mitchell Stern, and Dawn Song. 2020. \href https://doi.org/10.18653/v1/2020.emnlp-main.446 Imitation attacks and defenses for black-box machine translation systems. In *Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP)*, pages 5531–5546, Online. Association for Computational Linguistics.
[74] Emily Sheng, Kai-Wei Chang, Prem Natarajan, and Nanyun Peng. 2021. \href https://doi.org/10.18653/v1/2021.acl-long.330 Societal biases in language generation: Progress and challenges. In *Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers)*, pages 4275–4293, Online. Association for Computational Linguistics.
[75] Laura Weidinger, Jonathan Uesato, Maribeth Rauh, Conor Griffin, Po-Sen Huang, John Mellor, Amelia Glaese, Myra Cheng, Borja Balle, Atoosa Kasirzadeh, Courtney Biles, Sasha Brown, Zac Kenton, Will Hawkins, Tom Stepleton, Abeba Birhane, Lisa Anne Hendricks, Laura Rimell, William Isaac, Julia Haas, Sean Legassick, Geoffrey Irving, and Iason Gabriel. 2022. \href https://doi.org/10.1145/3531146.3533088 Taxonomy of risks posed by language models. In *2022 ACM Conference on Fairness, Accountability, and Transparency*, FAccT '22, page 214–229, New York, NY, USA. Association for Computing Machinery.
[76] Joshua Maynez, Shashi Narayan, Bernd Bohnet, and Ryan McDonald. 2020. \href https://doi.org/10.18653/v1/2020.acl-main.173 On faithfulness and factuality in abstractive summarization. In *Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics*, pages 1906–1919, Online. Association for Computational Linguistics.
[77] Artidoro Pagnoni, Vidhisha Balachandran, and Yulia Tsvetkov. 2021. Understanding factuality in abstractive summarization with FRANK: A benchmark for factuality metrics. In *Proc. NAACL*.
[78] Rowan Zellers, Ari Holtzman, Hannah Rashkin, Yonatan Bisk, Ali Farhadi, Franziska Roesner, and Yejin Choi. 2019. Defending against neural fake news. *Advances in neural information processing systems*, 32.
[79] Nicholas Carlini, Florian Tramèr, Eric Wallace, Matthew Jagielski, Ariel Herbert-Voss, Katherine Lee, Adam Roberts, Tom B. Brown, Dawn Song, Úlfar Erlingsson, Alina Oprea, and Colin Raffel. 2021. \href https://www.usenix.org/conference/usenixsecurity21/presentation/carlini-extracting Extracting training data from large language models. In *USENIX Security Symposium*, pages 2633–2650.
[80] Laura Weidinger, John Mellor, Maribeth Rauh, Conor Griffin, Jonathan Uesato, Po-Sen Huang, Myra Cheng, Mia Glaese, Borja Balle, Atoosa Kasirzadeh, Zac Kenton, Sasha Brown, Will Hawkins, Tom Stepleton, Courtney Biles, Abeba Birhane, Julia Haas, Laura Rimell, Lisa Anne Hendricks, William S. Isaac, Sean Legassick, Geoffrey Irving, and Iason Gabriel. 2021. \href https://arxiv.org/abs/2112.04359 Ethical and social risks of harm from language models.
[81] Emily M. Bender, Timnit Gebru, Angelina McMillan-Major, and Shmargaret Shmitchell. 2021. On the dangers of stochastic parrots: Can language models be too big? In *Proc. FAccT*.
[82] Irene Solaiman, Miles Brundage, Jack Clark, Amanda Askell, Ariel Herbert-Voss, Jeff Wu, Alec Radford, Gretchen Krueger, Jong Wook Kim, Sarah Kreps, et al. 2019. Release strategies and the social impacts of language models. *arXiv preprint arXiv:1908.09203*.
[83] Eugene Bagdasaryan and Vitaly Shmatikov. 2022. Spinning language models: Risks of propaganda-as-a-service and countermeasures. In *2022 IEEE Symposium on Security and Privacy (SP)*, pages 1532–1532. IEEE Computer Society.
[84] Artidoro Pagnoni, Martin Graciarena, and Yulia Tsvetkov. 2022. Threat scenarios and best practices to detect neural fake news. In *Proceedings of the 29th International Conference on Computational Linguistics*, pages 1233–1249.
[85] Sachin Kumar, Vidhisha Balachandran, Lucille Njoo, Antonios Anastasopoulos, and Yulia Tsvetkov. 2022a. Language generation models can cause harm: So what can we do about it? an actionable survey. *arXiv preprint arXiv:2210.07700*.