A Recurrent Latent Variable Model for Sequential Data
Junyoung Chung, Kyle Kastner, Laurent Dinh, Kratarth Goel,
Aaron Courville, Yoshua Bengio$^{}$
Department of Computer Science and Operations Research
Université de Montréal
$^{}$CIFAR Senior Fellow
{firstname.lastname}@umontreal.ca
Abstract
In this paper, we explore the inclusion of latent random variables into the hidden state of a recurrent neural network (RNN) by combining the elements of the variational autoencoder. We argue that through the use of high-level latent random variables, the variational RNN (VRNN)[^1] can model the kind of variability observed in highly structured sequential data such as natural speech. We empirically evaluate the proposed model against other related sequential models on four speech datasets and one handwriting dataset. Our results show the important roles that latent random variables can play in the RNN dynamics.
[^1]: Code is available at http://www.github.com/jych/nips2015_vrnn
Executive Summary: Researchers face ongoing challenges in building machine learning models that can generate realistic sequences of data, such as spoken words or handwritten text. These sequences often show high levels of structured variability—for instance, the unique vocal traits of a speaker influence entire audio clips in consistent yet complex ways. Traditional recurrent neural networks, which process sequences step by step, treat their internal states as fully predictable, forcing all variability into the final output step. This approach struggles with highly structured data like natural speech, where simple output models fail to capture deep dependencies across time, leading to poor generation quality or noisy results. With growing applications in speech synthesis, virtual assistants, and creative AI tools, better models are needed now to handle such data more effectively.
This paper sets out to demonstrate that adding hidden random variables—called latent variables—into recurrent neural networks can improve modeling of these sequences. It proposes and tests a new model called the variational recurrent neural network, or VRNN, which extends a technique known as the variational autoencoder to handle time-based data.
The authors developed the VRNN by integrating latent variables into the network's hidden states at each time step, allowing these variables to depend on previous steps and thus capture evolving patterns. They trained the model using standard optimization methods on raw audio waveforms for speech and coordinate data for handwriting. Key aspects included using long short-term memory units—a type of recurrent layer—for sequence processing, neural networks for mapping between variables, and comparisons against baseline recurrent models. Evaluations covered four speech datasets totaling thousands of hours or samples (from sources like the Blizzard Challenge and TIMIT benchmarks, spanning single-speaker English, multi-speaker sentences, non-linguistic sounds, and accented speech) plus a handwriting dataset of over 13,000 lines from 500 writers. Training occurred over recent data splits, with models sized consistently (e.g., 2,000 hidden units) and early stopping to prevent overfitting.
The most important results show that VRNN models achieved substantially higher log-likelihood scores— a measure of how well they fit the data—across all tasks. On the Blizzard speech dataset, the best VRNN scored about 9,500, roughly 28% better than the top baseline recurrent model at 7,413. Similar gains appeared on TIMIT (about 13% improvement to 30,235), Onomatopoeia (13% to 21,332), Accent (25% to 4,319), and handwriting (2% to 1,384). Even a basic version of VRNN using a simple output distribution outperformed baselines with more complex mixtures, which often produced noisy audio. Adding dependencies between latent variables over time boosted scores by 1-5% compared to a variant without them. Generated speech from VRNNs was cleaner and more natural, with fewer random spikes, while handwriting samples varied more across styles but stayed consistent within a piece.
These findings mean that latent variables allow the model to separate core signal patterns from variability early on, leading to sharper, more reliable outputs without needing overly complex final steps. This reduces risks of noise in generated content, potentially cutting development time for AI systems in speech or text generation by enabling simpler training. Unlike earlier models that treated latent variables as independent across time, the temporal links here better match real data structures, explaining the edge in performance— a shift that could update standards in generative AI.
Based on these results, teams should prioritize VRNN-like architectures for new sequential modeling projects, especially in audio or motion data, as they offer clearer gains with manageable added complexity. For immediate use, integrate them into prototypes for speech synthesis or handwriting recognition, starting with Gaussian outputs to keep things lightweight. If scaling to production, test on domain-specific data; options include combining with mixture outputs for extra flexibility at minor cost in training speed. Further work is essential: run pilots on larger, diverse datasets to confirm scalability, and analyze latent variables more deeply to guide applications like personalized voice generation.
While the evaluations used solid benchmarks and consistent setups, uncertainties remain from approximating likelihoods in VRNNs (via sampling, leading to slight underestimates) and focusing on unconditional generation without text inputs. Data preprocessing assumed normalized sequences, which may not fit all real-world noise levels. Confidence is high in the relative benefits—VRNNs clearly outperform baselines—but readers should verify on their own data before broad decisions, as absolute scores depend on task details.
1 Introduction
Section Summary: Historically, modeling sequences in machine learning relied on dynamic Bayesian networks like hidden Markov models and Kalman filters, but recurrent neural networks (RNNs) have recently become more popular due to their flexibility in handling variable-length data and capturing complex patterns. However, standard RNNs treat their internal processes as deterministic, which struggles to model the intricate, variable dependencies in structured data like speech, so the authors propose a variational RNN (VRNN) that incorporates high-level random variables inspired by variational autoencoders to better represent multimodal distributions and temporal links. Evaluations on speech and handwriting tasks show that VRNN outperforms traditional RNNs and simpler variants by effectively capturing these dependencies.
Learning generative models of sequences is a long-standing machine learning challenge and historically the domain of dynamic Bayesian networks (DBNs) such as hidden Markov models (HMMs) and Kalman filters. The dominance of DBN-based approaches has been recently overturned by a resurgence of interest in recurrent neural network (RNN) based approaches. An RNN is a special type of neural network that is able to handle both variable-length input and output. By training an RNN to predict the next output in a sequence, given all previous outputs, it can be used to model joint probability distribution over sequences.
Both RNNs and DBNs consist of two parts: (1) a transition function that determines the evolution of the internal hidden state, and (2) a mapping from the state to the output. There are, however, a few important differences between RNNs and DBNs.
DBNs have typically been limited either to relatively simple state transition structures (e.g., linear models in the case of the Kalman filter) or to relatively simple internal state structure (e.g., the HMM state space consists of a single set of mutually exclusive states). RNNs, on the other hand, typically possess both a richly distributed internal state representation and flexible non-linear transition functions. These differences give RNNs extra expressive power in comparison to DBNs. This expressive power and the ability to train via error backpropagation are the key reasons why RNNs have gained popularity as generative models for highly structured sequential data.
In this paper, we focus on another important difference between DBNs and RNNs. While the hidden state in DBNs is expressed in terms of random variables, the internal transition structure of the standard RNN is entirely deterministic. The only source of randomness or variability in the RNN is found in the conditional output probability model. We suggest that this can be an inappropriate way to model the kind of variability observed in highly structured data, such as natural speech, which is characterized by strong and complex dependencies among the output variables at different timesteps. We argue, as have others ([1, 2]), that these complex dependencies cannot be modelled efficiently by the output probability models used in standard RNNs, which include either a simple unimodal distribution or a mixture of unimodal distributions.
We propose the use of high-level latent random variables to model the variability observed in the data. In the context of standard neural network models for non-sequential data, the variational autoencoder (VAE) ([3, 4]) offers an interesting combination of highly flexible non-linear mapping between the latent random state and the observed output and effective approximate inference. In this paper, we propose to extend the VAE into a recurrent framework for modelling high-dimensional sequences. The VAE can model complex multimodal distributions, which will help when the underlying true data distribution consists of multimodal conditional distributions. We call this model a variational RNN (VRNN).
A natural question to ask is: how do we encode observed variability via latent random variables? The answer to this question depends on the nature of the data itself. In this work, we are mainly interested in highly structured data that often arises in AI applications. By highly structured, we mean that the data is characterized by two properties. Firstly, there is a relatively high signal-to-noise ratio, meaning that the vast majority of the variability observed in the data is due to the signal itself and cannot reasonably be considered as noise. Secondly, there exists a complex relationship between the underlying factors of variation and the observed data. For example, in speech, the vocal qualities of the speaker have a strong but complicated influence on the audio waveform, affecting the waveform in a consistent manner across frames.
With these considerations in mind, we suggest that our model variability should induce temporal dependencies across timesteps. Thus, like DBN models such as HMMs and Kalman filters, we model the dependencies between the latent random variables across timesteps. While we are not the first to propose integrating random variables into the RNN hidden state ([1, 2, 5, 6]), we believe we are the first to integrate the dependencies between the latent random variables at neighboring timesteps.
We evaluate the proposed VRNN model against other RNN-based models – including a VRNN model without introducing temporal dependencies between the latent random variables – on two challenging sequential data types: natural speech and handwriting. We demonstrate that for the speech modelling tasks, the VRNN-based models significantly outperform the RNN-based models and the VRNN model that does not integrate temporal dependencies between latent random variables.
2 Background
Section Summary: Recurrent neural networks (RNNs) process sequences of data by updating an internal hidden state step by step, allowing them to model the probability of each element based on what came before, often using advanced techniques like LSTMs or GRUs for better performance. However, standard RNNs struggle with highly variable yet structured sequences because their deterministic nature limits how they handle randomness, leading researchers to explore additions like stochastic latent variables or structured output models, such as Gaussian mixtures or approaches in models like STORN, though the paper proposes a novel way to make latent priors depend on prior sequence elements for improved representation. Variational autoencoders (VAEs) extend this idea to non-sequential data by introducing latent variables to capture complex patterns in a probabilistic framework, serving as a foundation for adapting these concepts to sequences.
2.1 Sequence modelling with Recurrent Neural Networks
An RNN can take as input a variable-length sequence $\mathbf{x}=(\mathbf{x}_1, \mathbf{x}_2, \ldots, \mathbf{x}_T)$ by recursively processing each symbol while maintaining its internal hidden state $\mathbf{h}$. At each timestep $t$, the RNN reads the symbol $\mathbf{x}_t \in \mathbb{R}^d$ and updates its hidden state $\mathbf{h}_t \in \mathbb{R}^p$ by:
$ \begin{align} \mathbf{h}t =& f{\theta}\left(\mathbf{x}t, \mathbf{h}{t-1}\right), \end{align}\tag{1} $
where $f$ is a deterministic non-linear transition function, and $\theta$ is the parameter set of $f$. The transition function $f$ can be implemented with gated activation functions such as long short-term memory (LSTM, [7]) or gated recurrent unit (GRU, [8]). RNNs model sequences by parameterizing a factorization of the joint sequence probability distribution as a product of conditional probabilities such that:
$ \begin{align} p(\mathbf{x}1, \mathbf{x}2, \ldots, \mathbf{x}T) &= \prod{t=1}^T p(\mathbf{x}t \mid \mathbf{x}{< t}), \nonumber \ p(\mathbf{x}t \mid \mathbf{x}{< t}) &= g{\tau}(\mathbf{h}{t-1}), \end{align}\tag{2} $
where $g$ is a function that maps the RNN hidden state $\mathbf{h}_{t-1}$ to a probability distribution over possible outputs, and $\tau$ is the parameter set of $g$.
One of the main factors that determines the representational power of an RNN is the output function $g$ in Equation 2. With a deterministic transition function $f$, the choice of $g$ effectively defines the family of joint probability distributions $p(\mathbf{x}_1, \ldots, \mathbf{x}_T)$ that can be expressed by the RNN.
We can express the output function $g$ in Eq. (2) as being composed of two parts. The first part $\varphi_{\tau}$ is a function that returns the parameter set $\phi_t$ given the hidden state $\mathbf{h}{t-1}$, i.e., $\phi_t = \varphi{\tau}(\mathbf{h}_{t-1})$, while the second part of $g$ returns the density of $\mathbf{x}t$, i.e., $p{\phi_t}(\mathbf{x}t \mid \mathbf{x}{< t})$.
When modelling high-dimensional and real-valued sequences, a reasonable choice of an observation model is a Gaussian mixture model (GMM) as used in ([9]). For GMM, $\varphi_{\tau}$ returns a set of mixture coefficients $\alpha_t$, means $\boldsymbol{\mu}{\cdot, t}$ and covariances $\Sigma{\cdot, t}$ of the corresponding mixture components. The probability of $\mathbf{x}_t$ under the mixture distribution is:
$ \begin{align*} p_{\boldsymbol{\alpha}t, \boldsymbol{\mu}{\cdot, t}, \Sigma_{\cdot, t}}(\mathbf{x}t \mid \mathbf{x}{<t}) = \sum_{j} \alpha_{j, t} \mathcal{N}\left(\mathbf{x}t ; \boldsymbol{\mu}{j, t}, \Sigma_{j, t} \right). \end{align*} $
With the notable exception of ([9]), there has been little work investigating the structured output density model for RNNs with real-valued sequences.
There is potentially a significant issue in the way the RNN models output variability. Given a deterministic transition function, the only source of variability is in the conditional output probability density. This can present problems when modelling sequences that are at once highly variable and highly structured (i.e., with a high signal-to-noise ratio). To effectively model these types of sequences, the RNN must be capable of mapping very small variations in $\mathbf{x}{t}$ (i.e., the only source of randomness) to potentially very large variations in the hidden state $\mathbf{h}{t}$. Limiting the capacity of the network, as must be done to guard against overfitting, will force a compromise between the generation of a clean signal and encoding sufficient input variability to capture the high-level variability both within a single observed sequence and across data examples.
The need for highly structured output functions in an RNN has been previously noted. Boulanger-lewandowski et al. [1] extensively tested NADE and RBM-based output densities for modelling sequences of binary vector representations of music. Bayer and Osendorfer [2] introduced a sequence of independent latent variables corresponding to the states of the RNN. Their model, called STORN, first generates a sequence of samples $\mathbf{z}=(\mathbf{z}_1, \ldots, \mathbf{z}T)$ from the sequence of independent latent random variables. At each timestep, the transition function $f$ from Eq. (1) computes the next hidden state $\mathbf{h}t$ based on the previous state $\mathbf{h}{t-1}$, the previous output $\mathbf{x}{t-1}$ and the sampled latent random variables $\mathbf{z}_t$. They proposed to train this model based on the VAE principle (see Section 2.2). Similarly, Pachitariu and Sahani [10] earlier proposed both a sequence of independent latent random variables and a stochastic hidden state for the RNN.
These approaches are closely related to the approach proposed in this paper. However, there is a major difference in how the prior distribution over the latent random variable is modelled. Unlike the aforementioned approaches, our approach makes the prior distribution of the latent random variable at timestep $t$ dependent on all the preceding inputs via the RNN hidden state $\mathbf{h}_{t-1}$ (see Equation 5). The introduction of temporal structure into the prior distribution is expected to improve the representational power of the model, which we empirically observe in the experiments (See Table 1). However, it is important to note that any approach based on having stochastic latent state is orthogonal to having a structured output function, and that these two can be used together to form a single model.
2.2 Variational Autoencoder
For non-sequential data, VAEs ([3, 4]) have recently been shown to be an effective modelling paradigm to recover complex multimodal distributions over the data space. A VAE introduces a set of latent random variables $\mathbf{z}$, designed to capture the variations in the observed variables $\mathbf{x}$. As an example of a directed graphical model, the joint distribution is defined as:
$ \begin{align} p(\mathbf{x}, \mathbf{z}) = p(\mathbf{x} \mid \mathbf{z})p(\mathbf{z}). \end{align}\tag{3} $
The prior over the latent random variables, $p(\mathbf{z})$, is generally chosen to be a simple Gaussian distribution and the conditional $p(\mathbf{x} \mid \mathbf{z})$ is an arbitrary observation model whose parameters are computed by a parametric function of $\mathbf{z}$. Importantly, the VAE typically parameterizes $p(\mathbf{x} \mid \mathbf{z})$ with a highly flexible function approximator such as a neural network. While latent random variable models of the form given in Eq. (3) are not uncommon, endowing the conditional $p(\mathbf{x} \mid \mathbf{z})$ as a potentially highly non-linear mapping from $\mathbf{z}$ to $\mathbf{x}$ is a rather unique feature of the VAE.
However, introducing a highly non-linear mapping from $\mathbf{z}$ to $\mathbf{x}$ results in intractable inference of the posterior $p(\mathbf{z} \mid \mathbf{x})$. Instead, the VAE uses a variational approximation $q(\mathbf{z} \mid \mathbf{x})$ of the posterior that enables the use of the lower bound:
$ \begin{align} \log p(\mathbf{x}) &\geq -\mathrm{KL}(q(\mathbf{z} \mid \mathbf{x}) | p(\mathbf{z})) + \mathbb{E}_{q(\mathbf{z} \mid \mathbf{x})}\left[\log p(\mathbf{x} \mid \mathbf{z})\right], \end{align}\tag{4} $
where $\mathrm{KL}(Q | P)$ is Kullback-Leibler divergence between two distributions $Q$ and $P$.
In ([3]), the approximate posterior $q(\mathbf{z} \mid \mathbf{x})$ is a Gaussian $\mathcal{N}(\boldsymbol{\mu}, \text{diag}(\boldsymbol{\sigma}^2))$ whose mean $\boldsymbol{\mu}$ and variance $\boldsymbol{\sigma}^2$ are the output of a highly non-linear function of $\mathbf{x}$, once again typically a neural network.
The generative model $p(\mathbf{x} \mid \mathbf{z})$ and inference model $q(\mathbf{z} \mid \mathbf{x})$ are then trained jointly by maximizing the variational lower bound with respect to their parameters, where the integral with respect to $q(\mathbf{z} \mid \mathbf{x})$ is approximated stochastically. The gradient of this estimate can have a low variance estimate, by reparametrizing $\mathbf{z} = \boldsymbol{\mu} + \boldsymbol{\sigma} \odot \boldsymbol{\epsilon}$ and rewriting:
$ \begin{align*} \mathbb{E}{q(\mathbf{z} \mid \mathbf{x})}\left[\log p(\mathbf{x} \mid \mathbf{z}) \right] = \mathbb{E}{p(\boldsymbol\epsilon)}\left[\log p(\mathbf{x} \mid \mathbf{z} = \boldsymbol\mu + \boldsymbol\sigma \odot \boldsymbol\epsilon) \right], \end{align*} $
where $\boldsymbol{\epsilon}$ is a vector of standard Gaussian variables. The inference model can then be trained through standard backpropagation technique for stochastic gradient descent.
3 Variational Recurrent Neural Network
Section Summary: The variational recurrent neural network, or VRNN, extends the variational autoencoder to handle sequential data by incorporating a recurrent neural network that tracks dependencies across time steps, drawing from simpler models like hidden Markov models but allowing for more complex, non-linear patterns. In generation, it uses a conditional prior distribution and output model tied to the previous hidden state, while inference approximates the latent variables based on current observations and past states, all updated through the network's recurrence. Learning involves optimizing a time-step-specific version of the autoencoder's objective to jointly train the generative and inference components, with variants exploring different levels of temporal dependencies in the priors.
In this section, we introduce a recurrent version of the VAE for the purpose of modelling sequences. Drawing inspiration from simpler dynamic Bayesian networks (DBNs) such as HMMs and Kalman filters, the proposed variational recurrent neural network (VRNN) explicitly models the dependencies between latent random variables across subsequent timesteps. However, unlike these simpler DBN models, the VRNN retains the flexibility to model highly non-linear dynamics.
Generation
The VRNN contains a VAE at every timestep. However, these VAEs are conditioned on the state variable $\mathbf{h}_{t-1}$ of an RNN. This addition will help the VAE to take into account the temporal structure of the sequential data. Unlike a standard VAE, the prior on the latent random variable is no longer a standard Gaussian distribution, but follows the distribution:
$ \begin{align} \mathbf{z}t \sim \mathcal{N}(\boldsymbol{\mu}{0, t}, \text{diag}(\boldsymbol{\sigma}{0, t}^2))\text{, where } [\boldsymbol{\mu}{0, t}, \boldsymbol{\sigma}{0, t}] = \varphi{\tau}^{\text{prior}} (\mathbf{h}_{t-1}), \end{align}\tag{5} $
where $\boldsymbol\mu_{0, t}$ and $\boldsymbol\sigma_{0, t}$ denote the parameters of the conditional prior distribution. Moreover, the generating distribution will not only be conditioned on $\mathbf{z}t$ but also on $\mathbf{h}{t-1}$ such that:
$ \begin{align} \mathbf{x}t \mid \mathbf{z}t \sim \mathcal{N}(\boldsymbol{\mu}{x, t}, \text{diag}(\boldsymbol{\sigma}{x, t}^2))\text{, where } [\boldsymbol{\mu}{x, t}, \boldsymbol{\sigma}{x, t}] = \varphi_{\tau}^{\text{dec}}(\varphi_{\tau}^{\mathbf{z}}(\mathbf{z}t), \mathbf{h}{t-1}), \end{align}\tag{6} $
where $\boldsymbol\mu_{x, t}$ and $\boldsymbol\sigma_{x, t}$ denote the parameters of the generating distribution, $\varphi_{\tau}^{\text{prior}}$ and $\varphi_{\tau}^{\text{dec}}$ can be any highly flexible function such as neural networks. $\varphi_{\tau}^{\mathbf{x}}$ and $\varphi_{\tau}^{\mathbf{z}}$ can also be neural networks, which extract features from $\mathbf{x}_t$ and $\mathbf{z}_t$, respectively. We found that these feature extractors are crucial for learning complex sequences. The RNN updates its hidden state using the recurrence equation:
$ \begin{align} \mathbf{h}t =& f{\theta}\left(\varphi_{\tau}^{\mathbf{x}}(\mathbf{x}t), \varphi{\tau}^{\mathbf{z}}(\mathbf{z}{t}), \mathbf{h}{t-1}\right), \end{align}\tag{7} $
where $f$ was originally the transition function from Eq. (1). From Eq. (7), we find that $\mathbf{h}{t}$ is a function of $\mathbf{x}{\leq t}$ and $\mathbf{z}{\leq t}$. Therefore, Eq. (5) and Eq. (6) define the distributions $p(\mathbf{z}t \mid \mathbf{x}{< t}, \mathbf{z}{< t})$ and $p(\mathbf{x}t \mid \mathbf{z}{\leq t}, \mathbf{x}_{<t})$, respectively. The parameterization of the generative model results in Eq. (8) and – was motivated by – the factorization:
$ \begin{align} p(\mathbf{x}{\leq T}, \mathbf{z}{\leq T}) = \prod_{t=1}^{T}{ p(\mathbf{x}t \mid \mathbf{z}{\leq t}, \mathbf{x}{<t})p(\mathbf{z}t \mid \mathbf{x}{< t}, \mathbf{z}{< t}) }. \end{align}\tag{8} $
Inference
In a similar fashion, the approximate posterior will not only be a function of $\mathbf{x}t$ but also of $\mathbf{h}{t-1}$ following the equation:
$ \begin{align} \mathbf{z}t \mid \mathbf{x}t \sim \mathcal{N}(\boldsymbol{\mu}{z, t}, \text{diag}(\boldsymbol{\sigma}{z, t}^2))\text{, where } [\boldsymbol{\mu}{z, t}, \boldsymbol{\sigma}{z, t}] = \varphi_{\tau}^{\text{enc}}(\varphi_{\tau}^{\mathbf{x}}(\mathbf{x}t), \mathbf{h}{t-1}), \end{align}\tag{9} $
similarly $\boldsymbol\mu_{z, t}$ and $\boldsymbol\sigma_{z, t}$ denote the parameters of the approximate posterior. We note that the encoding of the approximate posterior and the decoding for generation are tied through the RNN hidden state $\mathbf{h}{t-1}$. We also observe that this conditioning on $\mathbf{h}{t-1}$ results in the factorization:
$ \begin{align} q(\mathbf{z}{\leq T} \mid \mathbf{x}{\leq T}) = \prod_{t=1}^{T}{q(\mathbf{z}{t} \mid \mathbf{x}{\leq t}, \mathbf{z}_{< t})}. \end{align}\tag{10} $
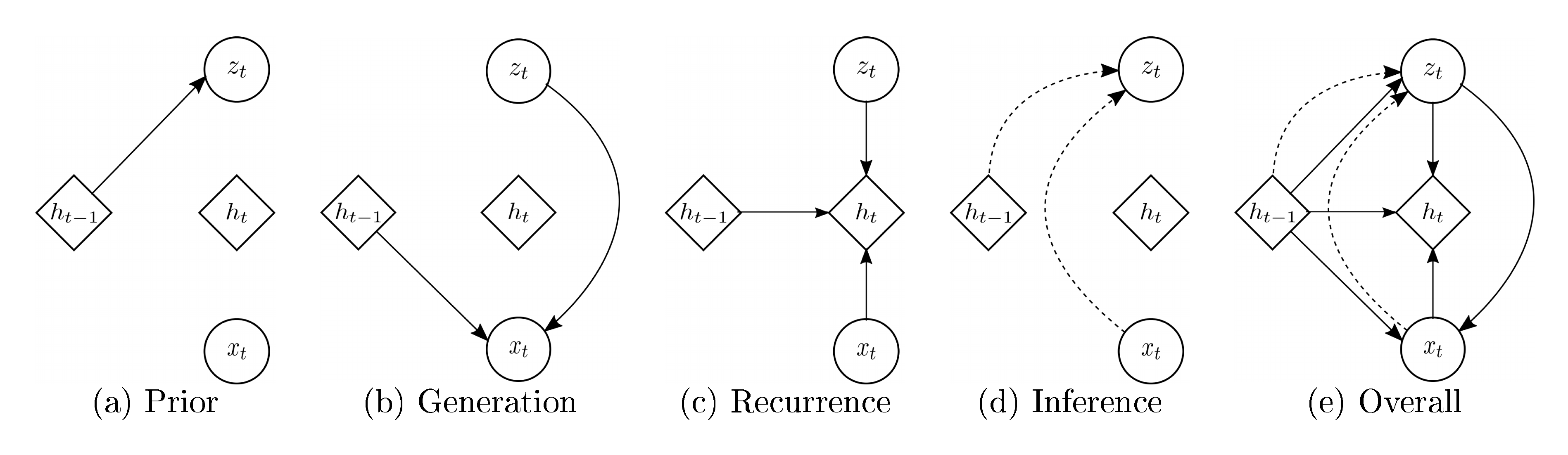
Learning
The objective function becomes a timestep-wise variational lower bound using Eq. (8) and Eq. (10):
$ \begin{align} \mathbb{E}{q(\mathbf{z}{\leq T}\mid \mathbf{x}{\leq T})}\left[\sum{t=1}^{T}\left({-\mathrm{KL}(q(\mathbf{z}{t} \mid \mathbf{x}{\leq t}, \mathbf{z}{< t}) | p(\mathbf{z}{t} \mid \mathbf{x}{< t}, \mathbf{z}{< t}))} + \log p(\mathbf{x}{t} \mid \mathbf{z}{\leq t}, \mathbf{x}_{< t})\right)\right]. \end{align}\tag{11} $
As in the standard VAE, we learn the generative and inference models jointly by maximizing the variational lower bound with respect to their parameters. The schematic view of the VRNN is shown in Figure 1, operations (a)–(d) correspond to Eqs. (5)–(7), (9), respectively. The VRNN applies the operation (a) when computing the conditional prior (see Equation 5). If the variant of the VRNN (VRNN-I) does not apply the operation (a), then the prior becomes independent across timesteps. STORN ([2]) can be considered as an instance of the VRNN-I model family. In fact, STORN puts further restrictions on the dependency structure of the approximate inference model. We include this version of the model (VRNN-I) in our experimental evaluation in order to directly study the impact of including the temporal dependency structure in the prior (i.e., conditional prior) over the latent random variables.
4 Experiment Settings
Section Summary: The researchers tested their VRNN model on two main activities: generating natural speech directly from raw audio sounds and creating handwriting strokes. For speech, they used four datasets including hours of English speech from one speaker, sentences read by many people, non-word sounds like laughs and coughs, and English read by native and non-native speakers, processing the audio into short frames and splitting it into training, validation, and test portions. They compared VRNN against simpler RNN models using basic or mixture-based prediction methods, training everything with normalized data, a common optimization technique, and fixed network sizes, while also preparing bigger versions for listening to generated audio.
We evaluate the proposed VRNN model on two tasks: (1) modelling natural speech directly from the raw audio waveforms; (2) modelling handwriting generation.
Speech modelling
We train the models to directly model raw audio signals, represented as a sequence of 200-dimensional frames. Each frame corresponds to the real-valued amplitudes of 200 consecutive raw acoustic samples. Note that this is unlike the conventional approach for modelling speech, often used in speech synthesis where models are expressed over representations such as spectral features (see, e.g., [11, 12, 13]).
We evaluate the models on the following four speech datasets:
- Blizzard: This text-to-speech dataset made available by the Blizzard Challenge 2013 contains 300 hours of English, spoken by a single female speaker ([14]).
- TIMIT: This widely used dataset for benchmarking speech recognition systems contains $6, 300$ English sentences, read by 630 speakers.
- Onomatopoeia[^2]: This is a set of $6, 738$ non-linguistic human-made sounds such as coughing, screaming, laughing and shouting, recorded from 51 voice actors.
- Accent: This dataset contains English paragraphs read by $2, 046$ different native and non-native English speakers ([15]).
[^2]: This dataset has been provided by Ubisoft.
For the Blizzard and Accent datasets, we process the data so that each sample duration is $0.5s$ (the sampling frequency used is $16\mathrm{kHz}$). Except the TIMIT dataset, the rest of the datasets do not have predefined train/test splits. We shuffle and divide the data into train/validation/test splits using a ratio of $0.9/0.05/0.05$.
Handwriting generation
We let each model learn a sequence of $(x, y)$ coordinates together with binary indicators of pen-up/pen-down, using the IAM-OnDB dataset, which consists of $13, 040$ handwritten lines written by $500$ writers [16]. We preprocess and split the dataset as done in ([9]).
\begin{tabular}{c || c | c | c | c | c}
\hline
& \multicolumn{4}{c|}{Speech modelling} & Handwriting \\
\cline{2-6}
Models & Blizzard & TIMIT & Onomatopoeia & Accent & IAM-OnDB \\
\hline
\hline
RNN-Gauss & 3539 & -1900 & -984 & -1293 & 1016 \\
\hline
RNN-GMM & 7413 & 26643 & 18865 & 3453 & 1358 \\
\hline
VRNN-I-Gauss & $\geq 8933$ & $\geq 28340$ & $\geq 19053$ & $\geq 3843$ & $\geq 1332$ \\
& $\approx 9188$ & $\approx 29639$ & $\approx 19638$ & $\approx 4180$ & $\approx 1353$ \\
\hline
VRNN-Gauss & $\geq 9223$ & $\geq 28805$ & $\geq 20721$ & $\geq 3952$ & $\geq$ 1337 \\
& $\approx \bf 9516$ & $\approx \bf 30235$ & $\approx \bf 21332$ & $\approx 4223$ & $\approx$ 1354 \\
\hline
VRNN-GMM & $\geq 9107$ & $\geq 28982$ & $\geq 20849$ & $\geq 4140$ & $\geq$ 1384 \\
& $\approx 9392$ & $\approx 29604$ & $\approx 21219$ & $\approx \bf 4319$ & $\approx$ \bf 1384 \\
\hline
\end{tabular}
Preprocessing and training
The only preprocessing used in our experiments is normalizing each sequence using the global mean and standard deviation computed from the entire training set. We train each model with stochastic gradient descent on the negative log-likelihood using the Adam optimizer [17], with a learning rate of $0.001$ for TIMIT and Accent and $0.0003$ for the rest. We use a minibatch size of $128$ for Blizzard and Accent and $64$ for the rest. The final model was chosen with early-stopping based on the validation performance.
Models
We compare the VRNN models with the standard RNN models using two different output functions: a simple Gaussian distribution (Gauss) and a Gaussian mixture model (GMM). For each dataset, we conduct an additional set of experiments for a VRNN model without the conditional prior (VRNN-I).
We fix each model to have a single recurrent hidden layer with $2000$ LSTM units (in the case of Blizzard, $4000$ and for IAM-OnDB, $1200$). All of $\varphi_{\tau}$ shown in Eqs. (5)–(7), (9) have four hidden layers using rectified linear units ([18]) (for IAM-OnDB, we use a single hidden layer). The standard RNN models only have $\varphi_{\tau}^{\mathbf{x}}$ and $\varphi_{\tau}^{\text{dec}}$, while the VRNN models also have $\varphi_{\tau}^{\mathbf{z}}$, $\varphi_{\tau}^{\text{enc}}$ and $\varphi_{\tau}^{\text{prior}}$. For the standard RNN models, $\varphi_{\tau}^{\mathbf{x}}$ is the feature extractor, and $\varphi_{\tau}^{\mathrm{dec}}$ is the generating function. For the RNN-GMM and VRNN models, we match the total number of parameters of the deep neural networks (DNNs), $\varphi_{\tau}^{\mathbf{x}, \mathbf{z}, \text{enc}, \text{dec}, \text{prior}}$, as close to the RNN-Gauss model having $600$ hidden units for every layer that belongs to either $\varphi_{\tau}^{\mathbf{x}}$ or $\varphi_{\tau}^{\mathrm{dec}}$ (we consider $800$ hidden units in the case of Blizzard). Note that we use $20$ mixture components for models using a GMM as the output function.
For qualitative analysis of speech generation, we train larger models to generate audio sequences. We stack three recurrent hidden layers, each layer contains $3000$ LSTM units. Again for the RNN-GMM and VRNN models, we match the total number of parameters of the DNNs to be equal to the RNN-Gauss model having $3200$ hidden units for each layer that belongs to either $\varphi_{\tau}^{\mathbf{x}}$ or $\varphi_{\tau}^{\mathrm{dec}}$.
5 Results and Analysis
Section Summary: The study shows that VRNN models, which incorporate hidden random variables, outperform standard RNN models in predicting complex sequences, as evidenced by higher scores on test examples, even when using simpler output methods. Analysis of the hidden variables reveals how the model adapts to changes in data like waveforms, with clear shifts in its internal state during transitions. Generated speech from VRNNs is cleaner and less noisy than from RNNs, while handwriting samples from VRNNs maintain consistent styles throughout, unlike the more erratic outputs from other models.
We report the average log-likelihood of test examples assigned by each model in Table 1. For RNN-Gauss and RNN-GMM, we report the exact log-likelihood, while in the case of VRNNs, we report the variational lower bound (given with $\geq$ sign, see Equation 4) and approximated marginal log-likelihood (given with $\approx$ sign) based on importance sampling using $40$ samples as in ([4]). In general, higher numbers are better. Our results show that the VRNN models have higher log-likelihood, which support our claim that latent random variables are helpful when modelling complex sequences. The VRNN models perform well even with a unimodal output function (VRNN-Gauss), which is not the case for the standard RNN models.
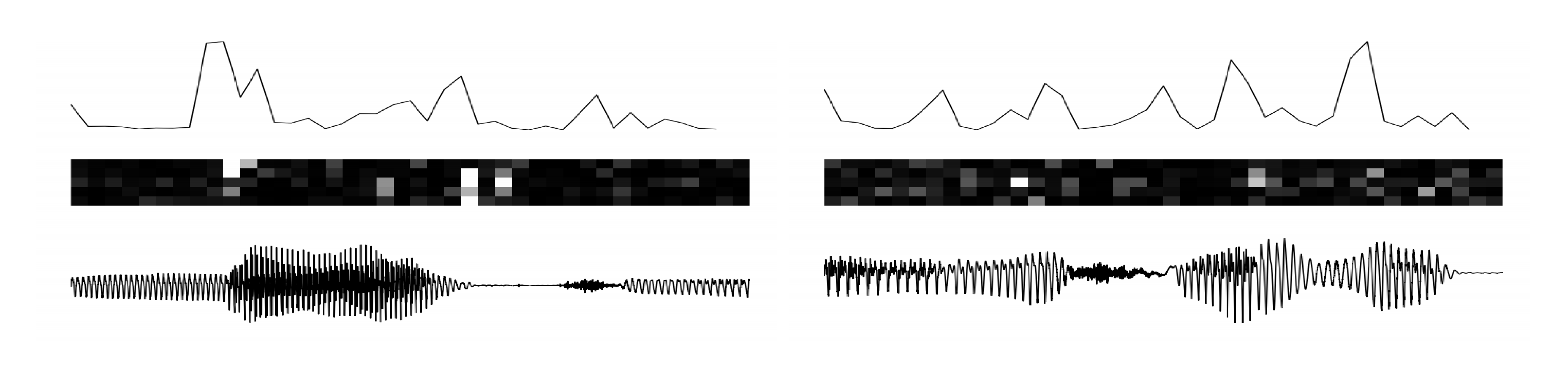
Latent space analysis
In Figure 2, we show an analysis of the latent random variables. We let a VRNN model read some unseen examples and observe the transitions in the latent space. We compute $\delta_t=\sum_j(\boldsymbol{\mu}{z, t}^j- \boldsymbol{\mu}{z, t-1}^j)^2$ at every timestep and plot the results on the top row of Figure 2. The middle row shows the $\mathrm{KL}$ divergence computed between the approximate posterior and the conditional prior. When there is a transition in the waveform, the $\mathrm{KL}$ divergence tends to grow (white is high), and we can clearly observe a peak in $\delta_t$ that can affect the RNN dynamics to change modality.
Speech generation
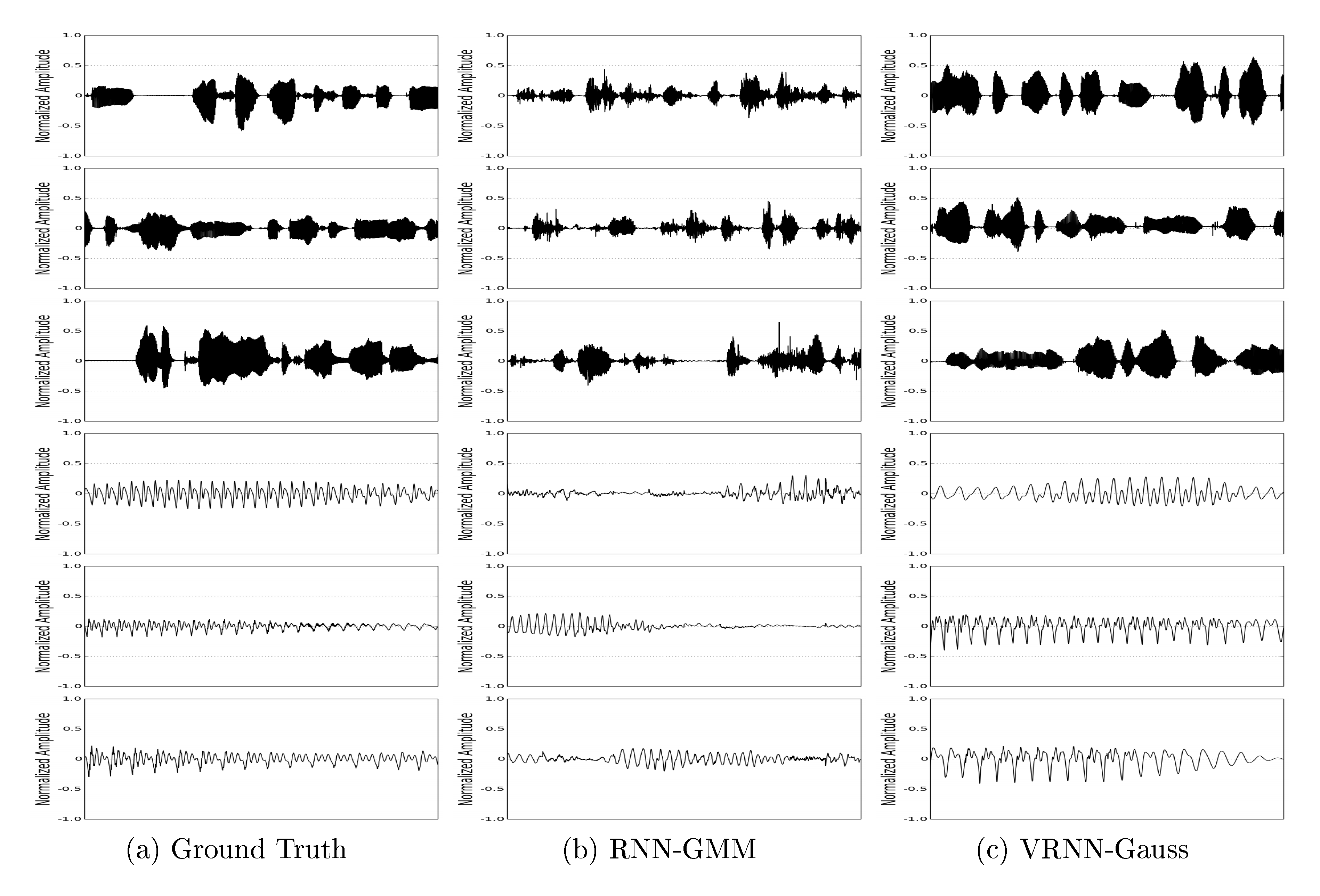
We generate waveforms with $2.0s$ duration from the models that were trained on Blizzard. From Figure 3, we can clearly see that the waveforms from the VRNN-Gauss are much less noisy and have less spurious peaks than those from the RNN-GMM. We suggest that the large amount of noise apparent in the waveforms from the RNN-GMM model is a consequence of the compromise these models must make between representing a clean signal consistent with the training data and encoding sufficient input variability to capture the variations across data examples. The latent random variable models can avoid this compromise by adding variability in the latent space, which can always be mapped to a point close to a relatively clean sample.
Handwriting generation
Visual inspection of the generated handwriting (as shown in Figure 4) from the trained models reveals that the VRNN model is able to generate more diverse writing style while maintaining consistency within samples.

6 Conclusion
Section Summary: The researchers introduce a new model that enhances recurrent neural networks by adding hidden random elements, making it better at generating complex sequences like natural speech and handwriting. Their tests show this approach significantly improves results for structured data, such as allowing a simple output method to produce high-quality speech samples, unlike basic models that fail and more advanced ones that create noisy outputs. The model also excels in handwriting by capturing variations between examples while keeping a consistent style, and it benefits from timing the random elements properly to boost overall performance.
We propose a novel model that can address sequence modelling problems by incorporating latent random variables into a recurrent neural network (RNN). Our experiments focus on unconditional natural speech generation as well as handwriting generation. We show that the introduction of latent random variables can provide significant improvements in modelling highly structured sequences such as natural speech sequences. We empirically show that the inclusion of randomness into high-level latent space can enable the VRNN to model natural speech sequences with a simple Gaussian distribution as the output function. However, the standard RNN model using the same output function fails to generate reasonable samples. An RNN-based model using more powerful output function such as a GMM can generate much better samples, but they contain a large amount of high-frequency noise compared to the samples generated by the VRNN-based models.
We also show the importance of temporal conditioning of the latent random variables by reporting higher log-likelihood numbers on modelling natural speech sequences. In handwriting generation, the VRNN model is able to model the diversity across examples while maintaining consistent writing style over the course of generation.
Acknowledgments
Section Summary: The authors express gratitude to the developers of Theano software for their contributions. They also thank researchers Kyunghyun Cho, Kelvin Xu, and Sungjin Ahn for their helpful comments and discussions. Additionally, the team acknowledges funding and computing resources from organizations including Ubisoft, the Nuance Foundation, NSERC, Calcul Québec, Compute Canada, the Canada Research Chairs, and CIFAR.
The authors would like to thank the developers of Theano ([19]). Also, the authors thank Kyunghyun Cho, Kelvin Xu and Sungjin Ahn for insightful comments and discussion. We acknowledge the support of the following agencies for research funding and computing support: Ubisoft, Nuance Foundation, NSERC, Calcul Québec, Compute Canada, the Canada Research Chairs and CIFAR.
References
Section Summary: This references section provides a bibliography of foundational research papers and resources in machine learning and artificial intelligence, particularly those exploring recurrent neural networks, variational auto-encoders, and applications to sequence generation, speech synthesis, and audio processing. The cited works, dating from 1997 to 2015, come from leading researchers like Y. Bengio, D. P. Kingma, and A. Graves, and were published in prominent venues such as ICML, ICLR, and NIPS. It also includes datasets for accents and handwriting analysis, plus practical tools like the Adam optimizer and Theano software framework.
[1] N. Boulanger-lewandowski, Y. Bengio, and P. Vincent. Modeling temporal dependencies in high-dimensional sequences: Application to polyphonic music generation and transcription. In Proceedings of the 29th International Conference on Machine Learning (ICML), pages 1159–1166, 2012.
[2] J. Bayer and C. Osendorfer. Learning stochastic recurrent networks. arXiv preprint arXiv:1411.7610, 2014.
[3] D. P. Kingma and M. Welling. Auto-encoding variational bayes. In Proceedings of the International Conference on Learning Representations (ICLR), 2014.
[4] D. J. Rezende, S. Mohamed, and D. Wierstra. Stochastic backpropagation and approximate inference in deep generative models. In Proceedings of The 31st International Conference on Machine Learning (ICML), pages 1278–1286, 2014.
[5] O. Fabius, J. R. van Amersfoort, and D. P. Kingma. Variational recurrent auto-encoders. arXiv preprint arXiv:1412.6581, 2014.
[6] K. Gregor, I. Danihelka, A. Graves, and D. Wierstra. Draw: A recurrent neural network for image generation. In Proceedings of The 32nd International Conference on Machine Learning (ICML), 2015.
[7] S. Hochreiter and J. Schmidhuber. Long short-term memory. Neural Computation, 9(8):1735–1780, 1997.
[8] K. Cho, B. van Merrienboer, C. Gulcehre, D. Bahdanau, F. Bougares, H. Schwenk, and Y. Bengio. Learning phrase representations using rnn encoder–decoder for statistical machine translation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 1724–1734, 2014.
[9] A. Graves. Generating sequences with recurrent neural networks. arXiv preprint arXiv:1308.0850, 2013.
[10] M. Pachitariu and M. Sahani. Learning visual motion in recurrent neural networks. In Advances in Neural Information Processing Systems (NIPS), pages 1322–1330, 2012.
[11] K. Tokuda, Y. Nankaku, T. Toda, H. Zen, J. Yamagishi, and K. Oura. Speech synthesis based on hidden markov models. Proceedings of the IEEE, 101(5):1234–1252, 2013.
[12] A. Bertrand, K. Demuynck, V. Stouten, and H. V. Hamme. Unsupervised learning of auditory filter banks using non-negative matrix factorisation. In IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 4713–4716. IEEE, 2008.
[13] H. Lee, P. Pham, Y. Largman, and A. Y. Ng. Unsupervised feature learning for audio classification using convolutional deep belief networks. In Advances in Neural Information Processing Systems (NIPS), pages 1096–1104, 2009.
[14] S. King and V. Karaiskos. The blizzard challenge 2013. In The Ninth annual Blizzard Challenge, 2013.
[15] S. Weinberger. The speech accent archieve. http://accent.gmu.edu/, 2015.
[16] M. Liwicki and H. Bunke. Iam-ondb-an on-line english sentence database acquired from handwritten text on a whiteboard. In Proceedings of Eighth International Conference on Document Analysis and Recognition, pages 956–961. IEEE, 2005.
[17] D. P. Kingma and M. Welling. Adam: A method for stochastic optimization. In Proceedings of the International Conference on Learning Representations (ICLR), 2015.
[18] V. Nair and G. E. Hinton. Rectified linear units improve restricted boltzmann machines. In Proceedings of the 27th International Conference on Machine Learning (ICML), pages 807–814, 2010.
[19] F. Bastien, P. Lamblin, R. Pascanu, J. Bergstra, I. J. Goodfellow, A. Bergeron, N. Bouchard, and Y. Bengio. Theano: new features and speed improvements. Deep Learning and Unsupervised Feature Learning NIPS 2012 Workshop, 2012.