Self-conditioned Embedding Diffusion for Text Generation
Robin Strudel$^{1, *}$
Corentin Tallec$^{2}$
Florent Altché$^{2}$
Yilun Du$^{3, *}$
Yaroslav Ganin$^{2}$
Arthur Mensch$^{2}$
Will Grathwohl$^{2}$
Nikolay Savinov$^{2}$
Sander Dieleman$^{2}$
Laurent Sifre$^{2}$
Rémi Leblond$^{2}$
$^{1}$ INRIA, Département d’informatique, École normale supérieure, CNRS, PSL Research University
$^{*}$ Work done while interning at DeepMind
$^{2}$ DeepMind
$^{3}$ Massachusetts Institute of Technology
Abstract
Can continuous diffusion models bring the same performance breakthrough on natural language they did for image generation? To circumvent the discrete nature of text data, we can simply project tokens in a continuous space of embeddings, as is standard in language modeling. We propose Self-conditioned Embedding Diffusion ($\textsc{Sed}$), a continuous diffusion mechanism that operates on token embeddings and allows to learn flexible and scalable diffusion models for both conditional and unconditional text generation. Through qualitative and quantitative evaluation, we show that our text diffusion models generate samples comparable with those produced by standard autoregressive language models — while being in theory more efficient on accelerator hardware at inference time. Our work paves the way for scaling up diffusion models for text, similarly to autoregressive models, and for improving performance with recent refinements to continuous diffusion.
Executive Summary: Continuous diffusion models have revolutionized image generation by producing high-quality outputs through a process of gradually adding noise to data and then learning to reverse it, enabling parallel computations and strong performance. For text generation, however, autoregressive models—which predict words one by one from left to right—remain the standard, powering tools like chatbots and translation systems. This dominance persists despite potential drawbacks, such as limited hardware efficiency and one-directional context processing. The question addressed here is whether diffusion models can adapt to text's discrete nature and match or exceed autoregressive approaches, especially as AI applications demand faster, more flexible text tools amid growing data and compute resources.
This document introduces Self-conditioned Embedding Diffusion, or SED, a method to apply continuous diffusion directly to text by projecting words into a continuous embedding space, much like how language models already represent words internally. It aims to demonstrate that SED can generate coherent text both unconditionally (from scratch) and conditionally (filling in gaps or continuing prompts), while evaluating its performance against autoregressive baselines on standard language tasks.
The authors trained SED models using transformer architectures on the C4 dataset, a large collection of web text totaling billions of tokens, over periods up to 2 million training steps. They focused on sequences of 256 tokens, with models ranging from 135 million to 420 million parameters. Key elements included fixed pretrained embeddings from a BERT-like model to represent words continuously, self-conditioning to refine predictions during generation, and span masking to handle varied conditioning tasks during training. Sampling involved 1000 reverse diffusion steps, with guidance techniques to boost quality. Comparisons used autoregressive models of similar sizes trained on the same data, evaluated via negative log-likelihood (how "surprising" samples seem to a strong autoregressive evaluator), unigram entropy (a diversity measure), and human preferences from blinded pairwise ratings.
The core findings show SED's viability. First, SED models achieve negative log-likelihood scores about 20-30% closer to ground-truth data than simpler diffusion setups, rivaling autoregressive models of matching size—for instance, the large SED (420 million parameters) scored 3.68 on this metric for suffix continuation, versus 3.50 for a comparable autoregressive model. Second, applying classifier-free guidance improved sample quality by roughly 15-20% in log-likelihood while maintaining diversity, producing more coherent infills like completing "In the cold, cold night" with contextually fitting scenes rather than disjointed ones. Third, unigram entropy for SED samples stayed within 1-2% of real data, avoiding the low-diversity pitfalls of unguided diffusion. Fourth, human evaluators preferred SED samples over smaller autoregressive ones 51% of the time but favored large autoregressive models by about 60% in head-to-head tests, indicating comparable but not superior fluency. Finally, ablations confirmed self-conditioning halved log-likelihood errors, and using low-dimensional pretrained embeddings (around 32 dimensions) outperformed higher ones by 10-15%, as they enabled smoother noise transitions through semantically related words.
These results imply that diffusion models offer a promising alternative for text generation, potentially reducing inference costs by parallelizing across sequence positions—up to 5-10 times faster on accelerators than autoregressive step-by-step generation—while enabling bidirectional context for tasks like infilling blanks in sentences, which autoregressive models handle less flexibly. Unlike prior discrete diffusion attempts, which lagged in coherence, SED matches autoregressive performance on generic tasks without sacrificing diversity, challenging the assumption that text requires sequential prediction. This matters for applications in content creation, where coherence and speed affect user experience and scalability; it also opens doors to image-inspired refinements, like guidance for controlled outputs, potentially improving safety and relevance in AI systems. However, SED samples occasionally show minor topic drifts, differing from autoregressive strengths in long-range consistency.
Next steps should prioritize accelerating sampling, as current 1000-step processes limit real-world use; techniques from image diffusion could cut this to under 50 steps with minimal quality loss, enabling pilots for tasks like email completion or story generation. Scale SED to billion-parameter models to close the human preference gap, and develop dedicated benchmarks for infilling to better showcase its advantages over autoregressive methods. Trade-offs include balancing guidance strength—higher values enhance fidelity but risk repetition—against compute needs.
Confidence in SED's core capability is high, backed by consistent metrics across scales and qualitative samples that read naturally. Caution is warranted on efficiency and edge cases like very long texts, where current designs underperform, and on evaluation metrics, which can favor repetitive outputs. Limitations include dependence on separate pretrained embeddings, which may not optimize diffusion fully, and the absence of end-to-end training, plus gaps in hyperparameter tuning that could yield 10-20% gains. Further data on diverse languages or domains would strengthen generalizability before broad deployment.
1. Introduction
Section Summary: Diffusion models, which have revolutionized image creation by gradually refining noise into clear pictures, show promise for generating text as well, offering advantages over traditional sequential models by predicting entire sentences at once and using computer hardware more efficiently. However, applying these models to the discrete nature of words has been challenging, as most prior efforts stuck to limited versions that missed key improvements from image techniques. The authors introduce a new approach called Self-conditioned Embedding Diffusion (SED), which works in a continuous space of word representations to produce text rivaling standard methods, with innovations like guidance that improve quality and scaling up to large models.
Continuous diffusion models ([1]) have taken the world of image generation by storm, advancing the state of the art further than ever before ([2, 3]). Can the same framework encounter as much success on the text modality? Diffusion for language is indeed an attractive prospect. Compared to autoregressive (AR) models ([4, 5, 6, 7]), diffusion models can predict all tokens in a sequence at once. This allows for bidirectional, rather than causal attention—increasing interactions between tokens, potentially leading to more coherent samples. Diffusion models can make a better usage of hardware accelerators during inference than AR models, since computations are parallelizable over the sequence axis.
Yet AR models remain the mainstream approach for modelling text. A major obstacle to text diffusion is that diffusion processes typically operate in continuous space. While this naturally handle images, text is inherently discrete. Consequently, most previous attempts to apply diffusion to text have focused on discrete diffusion-like approaches. These methods do not benefit from the refinements made to continuous diffusion in the image domain. Crucially, they cannot make use of guidance ([8]), which drastically improves diffusion models sample quality.
We address this gap by making a simple observation: language models operate mostly in continuous space, with discrete tokens only as inputs and outputs. A natural idea is then to conduct diffusion directly in a continuous token embedding space. For simplicity, we use a fixed embedding space, either random or stemming from a trained language model. Combined with the "self-conditioning" ([9]) refinement, this forms the basis of the method we propose, Self-conditioned Embedding Diffusion ($\textsc{Sed}$).
$\textsc{Sed}$ models rival mainstream AR models in both conditional and unconditional text generation. We make the following contributions:
- In section 3, we introduce $\textsc{Sed}$, the first continuous diffusion approach for text with good scaling properties (testing models up to 420M parameters). We analyze several continuous text diffusion settings, and identify self-conditioning and diffusion on small fixed embeddings as key factors to make continuous text diffusion work.
- In section 4, we apply classifier-free guidance ([10]) to text data—an original achievement. We show that $\textsc{Sed}$ can rival AR models on generic language tasks, for similar models sizes. $\textsc{Sed}$ samples achieve a better likelihood-entropy trade-off compared to these models, and are deemed comparable (if slightly worse) by human raters.
2. Related work
Section Summary: This section reviews key developments in diffusion models, which started as a powerful technique for generating continuous data like images through a process of gradual noise addition and removal, inspiring adaptations for discrete data such as text by corrupting and reconstructing specific values or using continuous representations of discrete inputs. While discrete and hybrid diffusion approaches show promise for tasks like text and music generation, they often produce less coherent results than established autoregressive models, which build sequences step by step and have advanced dramatically with transformers and large language models like GPT-3. It also discusses the need for reliable evaluation metrics for text generation, favoring a mix of sample-based comparisons and human judgments over traditional likelihood measures, as many models don't easily compute probabilities.
We provide an overview of diffusion models with a focus on modeling discrete data, as well as AR models and sample-based metrics for evaluating text generation.
Continuous diffusion on continuous image data.
Continuous diffusion has recently established itself as the method of choice for modeling continuous data such as images. While our main focus in this paper is on discrete data, we review some key works in continuous data modeling as this literature was the major source of inspiration for $\textsc{Sed}$. The first continuous diffusion formulation was introduced in the seminal work by [1]. [11] improved and simplified this formulation, relating it to denoising score matching, and creating a new method called $\textsc{DDPM}$. [12] further improved upon DDPM, showcasing impressive diffusion results compared to GANs. [2], Stable Diffusion introduced diffusion in latent space. Conceptually similar to $\textsc{Sed}$, it was specifically targeted at image modeling. Classifier-free guidance was proposed by [10] as a mean to improve image fidelity at the cost of reduced diversity. GLIDE ([13]) scaled up the ideas of guided diffusion, while DALL-E 2 ([3]) and Imagen ([14]) are the latest, most advanced image generation systems to date, combining most of the improvements proposed in previous works.
Discrete diffusion on discrete data.
One cannot simply reuse the methods that are successful on continuous image data in the discrete text domain. A number of bespoke methods have been explored instead, forming the family of discrete diffusion approaches. In discrete diffusion, the data is corrupted by switching from one discrete value to another. This was first proposed in the seminal work by [1], where it was tested on simplistic binary heartbeat data. It was extended to multinomial text modeling ([15]) and further scaled up in the D3PM work ([6]). Most recently, a similar discrete diffusion approach was applied to image modeling in VQ-Diffusion ([16]). In parallel, a few diffusion-like approaches were proposed in the denoising autoencoders literature. CMLM ([17]) tackled machine translation. SUNDAE ([18]) was the first non-AR method to show strong results both in machine translation and unconditional text generation. MaskGIT ([19]) demonstrated excellent results in modeling VQ-discretized images. These approaches rely on training models to predict masked tokens from their context, and iterating this reconstruction step multiple times at sampling time. Despite those positive developments, the samples from discrete diffusion methods for text modeling remains less coherent than those produced by AR methods.
Continuous diffusion on discrete data.
Fewer works try to tackle diffusion on discrete data from the same angle as $\textsc{Sed}$ – starting by turning the data into continuous representations before modeling it with continuous diffusion formulations. [20] used a VAE to generate such representations for discrete music modeling, with exciting results. Closest to $\textsc{Sed}$, Diffusion-LM ([21]) trains a token embedding together with the diffusion model itself. Diffusion-LM meets success on specific language applications, in low data regime and on constrained, very formatted textual data. Most recently, Analog Bits ([9]) introduced self-conditioning, closely related to step-unrolls in SUNDAE ([18]), together with bit-level modeling to improve the generation of discretized images. While the qualitative results of those continuous methods on text modeling show promise, they have not been shown to scale to large realistic text datasets like C4 ([22]) yet, or to compare with AR approaches on generic language tasks.
Auto-regressive modelling on discrete data.
AR models remain the method of choice for modeling discrete data. In combination with neural networks, they were first explored by [4] and later combined with RNNs ([5]). Their breakthrough moment came with the advent of the Transformer architecture, introduced by [23] for machine translation. Even more impressive results were shown with GPT-3 ([24]), which trained a large AR language model unconditionally, and used few-shot prompting to adapt it to new tasks. A few works later improved upon the results of GPT-3, including [7].
Sample-based evaluation of text generative models.
There are traditionally two classes of metrics for generative modeling: likelihood-based and sample-based. While the likelihood-based way is mathematically appealing, its usefulness for measuring progress is reduced by the fact that not all models readily provide likelihood computation. Just like the sampled-based FID metric was important for driving the progress of diffusion in image modeling, there is a need for a sample-based metric which would be universally accepted for text modeling. [25] investigated fidelity/variance metrics for evaluating text GANs. [26] suggested using FID for texts. [27] later used those previously proposed metrics to iterate on ScratchGAN but did not provide conclusive guidance on which metric a practitioner should choose – essentially finding serious vulnerabilities in all investigated metrics. We opted for a middle ground, reporting both sample likelihood according to a strong AR model and human preferences.
3. Method
Section Summary: The Sed method employs diffusion models to generate text by working in the continuous space of token embeddings rather than discrete words, allowing the model to gradually add and then remove noise to create new text from scratch. For unconditional generation, it starts with real text embeddings, corrupts them through a forward process of adding Gaussian noise over many steps, and trains a neural network to reverse this by predicting and denoising back to clean embeddings, which are then converted to tokens using a learned readout mechanism. This approach combines a diffusion loss for accurate denoising with a reconstruction loss to ensure the final tokens match the original text distribution, enabling effective sampling of new sentences after 1000 reverse steps.
In this section, we outline the different components of $\textsc{Sed}$: continuous diffusion in the space of token embeddings and self-conditioning, which form the basis of our approach for unconditional text generation; span masking and guided diffusion to enable conditional generation.
3.1 Diffusion models for unconditional text generation
Diffusion models in continuous space. We consider diffusion models as introduced by [1] and improved by [11]. A diffusion model aims at modelling a data distribution ${\bm{x}}_0 \in \mathbb{R}^n \sim q \in \mathcal{D}(\mathbb{R}^n)$ by estimating a sequence of latent variables ${\bm{x}}_T$, ..., ${\bm{x}}_1$ of the same dimensionality as the data ${\bm{x}}_0$. Starting from ${\bm{x}}_0$, the latent variables are generated with a Markov chain called the forward process: ${\bm{x}}t \sim q(\cdotp| {\bm{x}}{t-1}, t)$. It is defined by gradually interpolating the iterate with Gaussian noise according to noise levels defined by a schedule $\beta_1, ..., \beta_T$:
$ {\bm{x}}t \sim q(\cdotp |, {\bm{x}}{t-1}, t) = \mathcal{N}(\sqrt{1-\beta_t} {\bm{x}}_{t-1}, \beta_t {\bm{I}}).\tag{1} $
This parametrization gives us a closed form to sample ${\bm{x}}_t$ for any arbitrary $t \geq 1$, given ${\bm{x}}_0$:
$ {\bm{x}}t = \sqrt{\alpha_t} {\bm{x}}{t-1} + \sqrt{1 - \alpha_t} \epsilon_t = \sqrt{\overline{\alpha}_t} {\bm{x}}_0 + \sqrt{1 - \overline{\alpha}_t} \epsilon, $
where $\alpha_t := 1 - \beta_t$, $\overline{\alpha}t := \prod{s=1}^t \alpha_s$, $\epsilon_t \sim \mathcal{N}\big(0, {\bm{I}}\big)$ and $\epsilon \sim \mathcal{N}\big(0, {\bm{I}}\big)$.
We define our generative model by approximately inverting the diffusion process of Equation 1 to obtain a reverse process. The reverse process starts from ${\bm{x}}T \sim \mathcal{N}(0, {\bm{I}})$ and is defined as a Markov chain with learned Gaussian transitions (parameterized by $\theta$, the weights of a neural network): $ {\bm{x}}{t-1} \sim p_\theta(\cdotp| {\bm{x}}t) = \mathcal{N}\big({\bm{\mu}}\theta({\bm{x}}_t, t), \sigma(t)^2 {\bm{I}}\big)$. We train a neural network to predict an estimate $\hat{{\bm{x}}}_0({\bm{x}}_t, t, \theta)$ of the data ${\bm{x}}_0$ and approximate the reverse process by using the following parametrization, with learnable means but fixed variances, and a fixed schedule $\beta_1, ..., \beta_T$:
$ {\bm{\mu}}_\theta({\bm{x}}t, t) = \frac{\sqrt{\overline{\alpha}{t-1}}\beta_t}{1-\overline{\alpha}_t}\hat{{\bm{x}}}_0({\bm{x}}t, t, \theta) +\frac{\sqrt{\alpha_t}(1-\overline{\alpha}{t-1})}{1-\overline{\alpha}_t}{\bm{x}}t, \qquad \sigma(t)^2 = \frac{1-\overline{\alpha}{t-1}}{1-\overline{\alpha}_t}\beta_t\cdot\tag{2} $
While there exists a tractable variational lower-bound (VLB) on $\log p_\theta({\bm{x}}_0)$, [11] showed that better results are obtained by optimizing a simplified objective that re-weights the terms in the VLB. We follow this approach, which simplifies the loss to a sum of mean-squared errors between the ground truth data ${\bm{x}}_0$ and its estimates $\hat{{\bm{x}}}_0({\bm{x}}_t, t, \theta)$:
$ \mathcal{L}{\text{diffusion}} = \mathbb{E}{{\bm{x}}_0 \sim q({\bm{x}}_0), , t \sim \mathcal{U}(1, T)}| {\bm{x}}_0-\hat{{\bm{x}}}_0({\bm{x}}_t, t, \theta)|^2\cdot\tag{3} $
Though this framework works out of the box on images, which are close to continuous, we cannot apply it directly to the discrete tokens of the text modality. To resolve this issue, we perform continuous diffusion in a continuous space in which we embed text tokens.
Diffusion on word embeddings. We consider textual data ${\bm{w}} = (w_1, \ldots, w_N)$, where each $w_i$ is a one-hot representation in $\mathbb{R}^V$ of a discrete token in $\left{1, ..., V\right}$. Each token $w$ has an associated embedding ${\bm{e}}_w \in \mathbb{R}^D$, with fixed norm $\sqrt{D}$ to match the norm of a random gaussian sample in dimension $D$ used to noise clean data. We denote by ${\bm{E}} \in \mathbb{R}^{D \times V}$ the matrix of all embeddings.
We define our diffusion process in embedding space, rather than in token space. To that end, we define a forward discrete-to-continuous step $q_{{\bm{V}}}({\bm{x}}0| {\bm{w}}) = \mathcal{N}({\bm{E}} {\bm{w}}, \sigma_0^2 {\bm{I}})$, where $\sigma_0$ is a constant scale factor with a similar order of magnitude as $\beta_1$. Conversely, we define a reverse continuous-to-discrete step $p {\bm{R}}({\bm{w}}| {\bm{x}}0) = \prod{k=1}^N \mathrm{Cat}(w_k| {\bm{E}}'({\bm{x}}_0)_k)$, where ${\bm{R}} \in \mathbb{R}^{V \times D}$ is a learnable readout matrix initialized to ${\bm{E}}^{\top}$ and $\mathrm{Cat}(w_k| {\bm{l}})$ is the softmax probability of token $k$ with logits ${\bm{l}} \in \mathbb{R}^V$.
To train the readout step, we add a reconstruction loss to $\mathcal{L}{\text{diffusion}}$ during training. Conveniently, it naturally arises when deriving the VLB of $p\theta({\bm{w}})$ with this discretization step ([21]), introducing a simple cross-entropy loss to maximise $p_\theta({\bm{w}}| {\bm{x}}_0)$:
$ \mathcal{L}{\text{recon}} = \mathbb{E}{{\bm{w}} \sim \mathcal{D}, {\bm{x}}0 \sim q{{\bm{V}}}({\bm{w}})}[-\log p_{\bm{R}}({\bm{w}}| {\bm{x}}0)], \qquad\text{with}\qquad \mathcal{L}{\text{total}} = \mathcal{L}{\text{diffusion}} + \mathcal{L}{\text{recon}}. $
Contrary to what is done in [21], we do not learn the embedding matrix ${\bm{E}}$, as we identified that it was empirically unstable and could lead to drops in unigram entropy. The reconstruction loss $\mathcal{L}_\mathrm{recon}$ therefore only depends on the trainable readout weights ${\bm{R}}$.
At sampling time, we run the reverse process for $T = 1000$ steps, ultimately yielding a continuous embedding $\overline{{\bm{x}}}0$ of size $d\text{embed}$. We multiply it by ${\bm{R}}$ to obtain logits in $\mathbb{R}^V$, and then use the index of the maximum component to convert it to a token $w_i$, with $i = \operatorname{arg, max}_{1 \leq j \leq V}({\bm{R}}, \overline{{\bm{x}}}_0)$. This entails running $T$ full forward passes which is quite expensive compared to cached AR sampling; however each forward pass computes all timesteps at once which is naturally parallelisable. Further, we hope to benefit from many diffusion sampling improvements to get $T$ down to low double-digits.
Self-conditioning ([9]). In standard diffusion sampling, at each timestep $t$ the denoising network generates an estimate $\overline{{\bm{x}}}_0^t = \hat{{\bm{x}}}_0({\bm{x}}_t, t, \theta)$ of ${\bm{x}}_0$ given only ${\bm{x}}_t$ as input. Self-conditioning progressively refines ${\bm{x}}0$ estimates by passing the estimate $\tilde{{\bm{x}}}{0}^{t+1}$ obtained at the previous sampling step as input to the denoising network; the self-conditioned estimate is then defined as $\tilde {\bm{x}}_0^{t} = \hat{{\bm{x}}}_0({\bm{x}}_t, \tilde {\bm{x}}_0^{t+1}, t, \theta)$, and sets the diffusion direction. In practice conditioning is performed by concatenating ${\bm{x}}_t$ and $\tilde{{\bm{x}}}_0^{t+1}$ on the feature axis. To approximate the inference behavior at train time while remaining computationally efficient, we compute a first estimate $\overline{{\bm{x}}}_0^t = \hat {\bm{x}}_0({\bm{x}}_t, 0, t, \theta)$ with the self-conditioning set to zero, then perform a second forward pass using a stop gradient on $\overline{{\bm{x}}}0^t$ to obtain $\tilde{{\bm{x}}}{0}^t = \hat{{\bm{x}}}_0({\bm{x}}_t, \overline{{\bm{x}}}_0^t, t, \theta)$. The denoising network is then optimized using the output from the two forward passes in order to estimate ${\bm{x}}_0$ accurately with and without self-conditioning.
Equipped with these 3 components we can train models to generate text, though only unconditionally. To add conditional generation to our system's capabilities, we use two additional methods.
3.2 Span masking and guidance for conditional text generation
By design diffusion models for text generation are flexible and can handle a wide variety of infilling tasks. This is a key advantage over the predominant auto-regressive language models that typically generate text in a left-to-right fashion.
Span masking. We train our model on a rich set of infilling tasks with the following method. We split ${\bm{x}}_0$ between two set of tokens, diffusion tokens ${\bm{x}}$ over which we apply diffusion and optimize the diffusion loss from Equation 3, and conditioning tokens ${\bm{c}}$ that remain fixed. Conditioning tokens ${\bm{c}}$ are defined by a binary conditioning mask ${\bm{m}}$ set to one on conditioning positions and zero on positions to be infilled.
We sample conditioning mask ${\bm{m}}$ randomly as follows. Given a sequence of length $L$ and a maximum number of spans $M$, we sample a number of spans $n$ uniformly in $[1, M]$. Span starting positions are defined by $n-1$ integers $(i_1, ..., i_{n-1})$ sampled uniformly without replacement and sorted in increasing order to satisfy $0 < i_1 < ... < i_{n-1} < L$. The tuple $(i_1, ..., i_{n-1})$ partitions the sequence of tokens in $n$ spans satisfying $\mathbb{E}[i_k | n] = \frac{k}{n}L$. The conditioning mask ${\bm{m}}$ is defined using even spans for conditioning and odd spans for infilling, and then ${\bm{m}}$ is flipped with a $50%$ probability. The case $n=1$ corresponds to unconditional generation; we then set ${\bm{m}}$ to 0 everywhere.
This span masking strategy defines a collection of text generation tasks with a large variety of conditioning which on average evenly splits the sequence between conditioning and infilling spans. It enables conditional generation, and opens the door for additional diffusion improvements.
Guided diffusion. Guidance ([8]) often improves the sample quality of conditional diffusion models. We use classifier-free guidance ([10]), which alleviates the need for a separately-trained guide model. In the conditional case, our estimator $\tilde{{\bm{x}}}_0$ is now a function $\hat {\bm{x}}_0({\bm{x}}_t, {\bm{c}}, \tilde {\bm{x}}_0^{t+1}, t, \theta)$, where ${\bm{c}}$ are fixed conditioning tokens.
During training, with fixed probability the conditioning tokens ${\bm{c}}$ used in the estimator $\hat{{\bm{x}}}_0$ are dropped and set to a null label $\emptyset$ equal to zero. During sampling, the model prediction is extrapolated in the direction of $\hat{{\bm{x}}}_0({\bm{x}}_t, {\bm{c}}, \tilde{{\bm{x}}}_0^{t+1}, t, \theta)$ and away from $\hat{{\bm{x}}}_0({\bm{x}}_t, 0, 0, t, \theta)$ as follows:
$ \tilde{{\bm{x}}}_{0, s}^t = \hat{{\bm{x}}}_0\big({\bm{x}}t, 0, 0, t, \theta\big) + s, \cdot, \Big(\hat{{\bm{x}}}{0}\big({\bm{x}}_t, {\bm{c}}, \tilde{{\bm{x}}}0^{t+1}, t, \theta\big)-\hat{{\bm{x}}}{0}\big({\bm{x}}_t, 0, 0, t, \theta\big)\Big), $
where $s \geq 1$ is the guidance scale. Remark that we jointly drop conditioning and the self-conditioning $\tilde{{\bm{x}}}_0^{t+1}$, concretely setting both values to zero. Classifier-free guidance allows leveraging both the unconditional and conditional abilities of a model to improve its conditional generations.
4. Experiments
Section Summary: The Experiments section describes how the SED models are trained on a large text dataset using a specialized transformer architecture and diffusion techniques, with two model sizes tested to generate varied text lengths and handle tasks like completing sentences or filling gaps. To evaluate quality, the researchers use metrics such as how natural the generated text seems to a large language model, its diversity to avoid repetition, and human judgments, applied to both free-form writing and conditioned tasks like continuing a story from a starting phrase. Results show SED producing coherent, diverse samples across multiple generation styles, often matching or rivaling traditional autoregressive models in controlled comparisons.
\begin{tabular}{ p{0.1\linewidth} @{\hspace{0.5cm}} p{0.85\linewidth}}
\toprule
Task & Samples \\
\midrule
Unconditional
&
\hl{We make use of the very best supplies and solutions to ensure that the work is going to stand up to the test of time, and we help you save money with techniques that do not change the quality of your mission. We'll achieve this by offering you the best deals in the field and avoiding pricey mistakes. If you want to spend less, Refrigerator Unit Repair Guys is the company to contact.}\\
\midrule
Fill-in-the-middle
&
A year ago in Paris, \hl{ I had the opportunity to take a field trip to La Rite-en-Laurences International de France where I met David Nigel Johnson, a professor of social studies. What a great trip and} what a great day!\\
\midrule
Spans in-filling
&
There was no evidence, only fleeting glimpses\hl{ of the killer and his fate. In fact, it seemed that there was no evidence.} It was all guesswork\hl{, and one of the most unusual murder cases throughout history.} \\
\bottomrule
\end{tabular}
4.1 Training details
We train all our models on the C4 dataset ([22]), using a SentencePiece tokenizer ([28]) composed of 32000 words. We use a non-causal transformer model ([23]) as our diffusion model (see Appendix A for details). $\textsc{Sed}$ models are trained with sequence length 256, while for ablations models are trained with sequence length 128. We insert uniformly, i.e. not necessarily at the end of the sequence, 10% of padding tokens in the training set to allow $\textsc{Sed}$ models to generate samples of varying size and provide more flexibility.
To generate word embeddings, we train a BERT model of fixed size ($150$ m parameters) and feature dimension $d_\text{model} = 896$. The diffusion space is defined by the initial lookup table of this BERT model. We bottleneck the dimension of the word embeddings $d_\text{embed}$ and add a linear projection layer from $d_\text{embed}$ to $d_\text{model}$ at the beginning of the model. We found this helped diffusion (see section 4.4).
$\textsc{Sed}$ models are trained with a cosine noise schedule ([8]), with $\beta_1 = 2.10^{-3}$, $\sigma_0 = 10^{-2}$ and $T=1000$. We use batches of 65.536 tokens, thus for sequence length 256 the batch size is set to 256. We use a maximum span count of 5 for all runs except for its specific ablation. We train $\textsc{Sed}$ models at two different scales: $\textsc{Sed}$-S ($135$ m parameters, $10^6$ training steps) and $\textsc{Sed}$-L ($420$ m, $2.10^6$ steps). Their detailed architectures can be found in Appendix A.
4.2 Validation
While optimizing the perplexity of AR models for text leads to improved language models, directly optimizing the ELBO of diffusion models for images does not correlate strongly with sample quality as observed by [12, 29, 10]. For images, the sample based metric FID ([30]) has been introduced as a measure of sample quality and is now widely adopted. Similarly, we need a sample-based metric for text generation that is reliable and allows comparison between a large variety of generative models. To provide a fair comparison to AR models, we rely on three metrics.
The first metric measures how likely the samples produced by a model are according to an AR language model with 70B parameters, trained on 1.4B tokens ([7]); we denote this metric AR NLL for auto-regressive negative log-likelihood. It provides a continuous measure of sample quality that has proven useful when combined with a measure of sample diversity, e.g. in the development of nucleus sampling ([31]) for improved AR model decoding.
To measure diversity we rely on a second metric, the unigram entropy of samples, which helps balance the AR NLL that can be gamed by unnatural repetitive samples. For both these metrics, our target is the score of the validation set data. Deviating from the data unigram entropy in particular is a sign of degenerate modeling.
Though this initial combination has provided us with a reliable signal to iterate over our model design, it remains imperfect; it too can be gamed, though it is harder to do so. To address this limitation, we also report human preferences. We presented 6 colleagues with 20 pairs of samples for each comparison, asking them to pick the best one.
For all three metrics, we report results on two tasks: unconditional language modeling and suffix in-filling, the later a heavily conditioned task.
4.3 Results
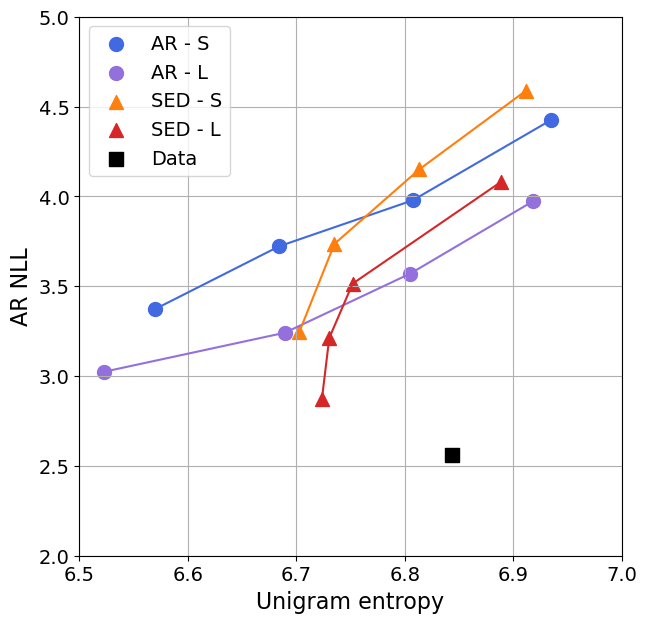
Samples. We present samples generated with our $\textsc{Sed}$ models in Table 10. We use a single model to perform a wide variety of text generation tasks, such as unconditional generation, filling-in-the-middle or filling several spans of text. We show strong performance in the unconditional case, with samples that are syntactically correct and stay coherent on long sequences. In the conditioned case, $\textsc{Sed}$ models are able to infill spans with coherent transitions and links to the conditioning but also exhibit a rich diversity. By design, $\textsc{Sed}$ yields flexible bi-directional masking models that can perform text generation on a diverse set of conditioned task. To compare $\textsc{Sed}$ with AR baselines we next restrict conditioning to a prefix and consider a task of suffix in-filling.
Comparison to AR models. To assess the generation ability of $\textsc{Sed}$, we compare against AR baselines of similar capacity and trained following optimal scaling laws from [7] on suffix in-filling. We sample a batch of sequences from C4 and use the first 128 tokens as conditioning given to the model to generate a suffix of 128 tokens. Figure 1 reports AR NLL and unigram entropy of the generated suffixes for AR and $\textsc{Sed}$ models. As a reference point, we compute the AR NLL and unigram entropy of the ground truth C4 suffixes and report it on the plot. Several methods can be used to improve sampling quality at the cost of samples diversity; we use nucleus sampling ([31]) for AR models and guidance ([8, 10]) for $\textsc{Sed}$ models. We show the impact of guidance on samples quality in Table 3. To our knowledge, we are the first to show sample quality improvement when using guidance for text generation.
As shown in Figure 1, both $\textsc{Sed}$-S and $\textsc{Sed}$-L perform strongly when compared against AR baselines – even though we report a metric favoring AR models on a task AR models have been designed to optimize. Similar to nucleus sampling for AR models, guidance has a strong positive impact on sample quality that is both observed quantitatively with improved AR NLL in Figure 1 and qualitatively in Table 3. We observe that using a top- $p$ nucleus sampling below $0.8$ for AR models or a guidance scale above $4$ for $\textsc{Sed}$ models leads to samples exhibiting a lot of repetitions, a degenerate case reflected by a lower entropy of samples even though sample AR NLL improves.
Our human preference scores temper our observations in Table 4. They show that our NLL and entropy metrics do not tell the whole story, as humans still prefer AR models at equivalent size. While $\textsc{Sed}$-L performs slightly worse than AR-L (38% preference in suffix in-filling, 44% on unconditional generation), its scores remain comparable. $\textsc{Sed}$-L is roughly on par with AR-S.
Finally, we compare $\textsc{Sed}$ and AR models' qualitative examples with short prompts in Table 2.
\begin{tabular}{ p{0.45\linewidth} @{\hspace{0.5cm}} p{0.45\linewidth}}
\toprule
\textsc{Sed} L & AR-L \\
\midrule
\hl{You're going to love wearing this traditional tee from our latest Wilson collection. Designed in a scrapped floral styled knit with a sleeve of asymmetric lines across the round sole. Lightly fluffy, the square pleats will take you right to}
&
\hl{A Koda Ram 25 is presented in sedan and a Maxima saloon. Based on the Acenta car, the powerful Koda 2014 hits Indian roads in the "Maxima" body-con shape. Being powered by a Hyundai i20 1.4 litre diesel engine, the Koda 2014 is coupled}
\\
\midrule
The beaver is an interesting animal that lives in rivers and\hl{ lakes. He is not mainly concerned with finding wolves and dolphin but also has a great hunger for fish. The beaver has sharp legs, large eyes, and a black coat}
&
The beaver is an interesting animal that lives in rivers and\hl{ streams. It is usually seen in big numbers in the fields or upstream, and is quite docile. On cold days when its pattern is perfect, the beaver will have some interesting, and sometimes}
\\
\midrule
Once upon a time in Spain, \hl{ Leonardo Pueleva had the pleasure of meeting guests at Spanish restaurant, Buva Casinos. While driving, he got a chance to get to know the people behind the restaurant and, of course, how they made his experience very interesting. After his conversation, he got to}
&
Once upon a time in Spain, \hl{ which seems pretty much the same way now, the question that was posed to each of us at the end of our interview was "would you like to see Froome one day?" In retrospect, after our interview, we have grown ever closer to that answer. As you will read in the article, I know that}
\\
\bottomrule
\end{tabular}
\begin{tabular}{ p{0.07\linewidth} @{\hspace{0.5cm}} p{0.27\linewidth} @{\hspace{0.5cm}} p{0.26\linewidth} @{\hspace{0.5cm}} p{0.27\linewidth}}
\toprule
Guidance & 1.0 & 2.5 & 5.0 \\
\midrule
&
In the cold, cold night\hl{ sky, a fairy princess sits in a chair and surrounded by tea leaves in a pond. Meanwhile, she bies back into the cold, with bluish hair on her hips and elbows on her forehead - and} her fingers numbed by the freezing temperature.
&
In the cold, cold night\hl{ of November 2018, a little girl sits in a chair hidden under a light blanket on a patio. Meanwhile, she bends back into the chair with bluish hair on her forehead, her hands on her face, } her fingers numbed by the freezing temperature.
&
In the cold, cold night\hl{ of December, my oldest daughter sits in a chair accentuated in cotton fabrics and a pillow. Meanwhile, she yearns straight in the cold air, her wrists covering her neck, her eyes straight on her forehead, and} her fingers numbed by the freezing temperature.
\\
\midrule
&
\hl{Barbara was one of our many wonderful women that really helped so I am so blown off by her purpose, civility; and adversity. Once I started interacting with her, it proved to me that} no matter how hard this was, she always strove for excellence.
&
\hl{Barbara was one of the most gifted women in the world. She was creative and stood up by her integrity and civility; against adversity. Although she placed herself higher than her peers, it proved to me that} no matter how hard this was, she always strove for excellence.
&
\hl{Barbara was one of the most brilliant women in the world. She was amazing in her heart, her spirit, her mind and in the soul. She never turned people off in her absence. It proved to me that} no matter how hard this was, she always strove for excellence.\\
\bottomrule
\end{tabular}
\begin{tabular}{lcccc}
\toprule
& $\textsc{Sed}$-S (cond)& AR-S (cond)& AR-L (uncond) & AR-L (cond) \\
\midrule
$\textsc{Sed}$-L & 63.4\% $\pm$ 4.3\% & 51.0\% $\pm$ 5.0\% & 43.8\% $\pm$ 4.4\% & 37.7\% $\pm$ 4.4\% \\
\bottomrule
\end{tabular}
4.4 Ablations
\begin{tabular}{lccc}
\toprule
Diffusion space & Self-conditioning & Unigram entropy & AR NLL \\
\midrule
Bits ([9]) & \ding{55} & 6.97 & 7.01 \\
& \ding{51} & 7.47 & 6.05 \\
\midrule
Random embeddings & \ding{55} & 6.90 & 6.80 \\
& \ding{51} & 6.86 & 5.31 \\
\midrule
Pretrained embeddings & \ding{55} & 6.75 & 5.66 \\
& \ding{51} & 6.77 & \textbf{4.57} \\
\midrule
Data & -- & $6.70\, \pm\, 0.04$ & $1.81\, \pm\, 0.15$ \\
\bottomrule
\end{tabular}
\begin{tabular}{ p{0.3\linewidth} @{\hspace{0.5cm}} p{0.3\linewidth} @{\hspace{0.5cm}} p{0.3\linewidth}}
\toprule
Random embeddings & Random embeddings & Pretrained embeddings \\
& with self-conditioning & with self-conditioning \\
\midrule
\hl{did the buildingroom granted a lighter distance. On it though, salaries about clients that a child, which dispersed gluc so many events and certainly wanted the Mother's project, discovered by their child would keep}
&
\hl{Tree brings the sound, bearing features and capabilities that we are set in. For the first time, she uses a customizable framework to use that we help students publicly solve the weather conditions that we only offer students}
&
\hl{almost six decades ago - 72 percent of Americans didn't feel they'd actually rent their own cars this year. Conversely, 90 percent of Americans feel that the decision to rent a car is something they feel it's impossible}\\
\bottomrule
\end{tabular}
\begin{tabular}{lccccccc}
\toprule
Embed. dim. & 16 & 32 & 64 & 128 & 256 & 896 \\
AR NLL & 4.65 & \textbf{4.57} & 4.71 & 4.61 & 4.77 & 4.92 \\
\bottomrule
\end{tabular}
\begin{tabular}{lcccccc}
\toprule
Max span count& 1 & 3 & 5 & 7 & 9 & 11 \\
AR NLL & 4.99 & 4.82 & 4.82 & 4.67 & \textbf{4.48} & 4.56 \\
\bottomrule
\end{tabular}
Self-conditioning and embedding pretraining. Results from Table 5 and samples from Table 6 show the influence of both the diffusion space and self-conditioning. AR NLL decreases very significantly when using self-conditioning, regardless of the rest of the setup. Diffusing at the bit-level ([9]) yields very high NLLs. While using random embeddings performs markedly better, using pretrained embeddings results in further improved numbers.
Samples from Table 6 highlight that models trained on random word embeddings exhibit topic modelling abilities with the co-occurrence of words like child and mother even though the paragraph remains globally incoherent and meaningless tokens like gluc are generated. Self-conditioning dramatically improves sample quality; the diffusion model gets the low-level structure right and generates syntactically correct sentences, even though the global text is not intelligible. Combining self-conditioning and pretrained embeddings leads to globally coherent paragraphs that stay on topic with proper sentence structure.
Embedding dimension. An important design choice for SED is the word embeddings space. We study the influence of pretrained embedding size in Table 7. Surprisingly, there is a threshold after which performance degrades when increasing the dimension of embeddings. We visualize the forward process for different embedding sizes by displaying the nearest neighbor of a noised token while running the forward process. In high dimension we observe that the nearest neighbor of a noised token remains the starting token itself until it switches to a completely random, unrelated token. In low dimension, we often observe that the closest neighbor of a noised token goes through several semantically related tokens (nearest neighbor of the starting token) before ultimately becoming random. We hypothesize that the random walks defined by diffusion are more likely to drift towards neighbors of the starting token in low dimension. As a result, when diffusing in low dimension information is destroyed in a more semantically meaningful fashion, which leads to an easier learning problem for the denoising function.
Number of spans. In order to enable in-filling, we train the model not only to do unconditional generation but also to conditionally fill spans of tokens. For each data point we sample a span number uniformly at random and span delimiters to generate the span mask. Picking the maximum allowable number of spans has a significant effect on model performance, as we can see in Table 8. Somewhat counter-intuitively, adding span masking improves even unconditional generation NLLs. It also appears that using a relatively high maximum span number is optimal. We hypothesize that this results in a varied mix of task difficulty at training time, between "easy", very conditioned problems on the one hand and "harder", unconditional ones on the other.
Scaling. We show encouraging results when scaling from $\textsc{Sed}$-S (150m) to $\textsc{Sed}$-L ($420$ m). We train both models on sequences of $256$ tokens and report a AR NLL of $4.20$ for $\textsc{Sed}$-S compared to $3.68$ for $\textsc{Sed}$-L. This improvement translates to improved sample quality, as is confirmed by our human preference scores, which are much higher for the larger model (63%, see Table 4).
5. Limitations
Section Summary: Although the approach shows promise as an alternative to traditional text generation models, it requires more tuning, such as using larger models and better hyperparameters, to fully test its capabilities and compare fairly with top competitors. It also underutilizes advances from image generation, like faster sampling methods that could make the current slow process more efficient, and depends on a separate pretrained model for text embeddings, which isn't ideal—training everything together proved tricky due to conflicting goals. Finally, evaluation metrics are limited and sometimes flawed, as they can be manipulated or biased toward other models, so the field needs better benchmarks, especially for tasks like filling in missing text, beyond the useful but imperfect human judgments.
While our results are promising and show that continuous diffusion for text can be an exciting alternative to AR models, the current approach does present some significant limitations.
First, much more could be done in terms of model tuning, including scaling to much bigger models to better understand $\textsc{Sed}$ 's limits, and to be able to compare it with state-of-the-art AR models. Our training regime in particular would certainly benefit from more hyperparameter optimisation.
Second, one compelling reason we chose to explore continuous diffusion for text is to leverage the improvements produced by the literature on image generation. While we have ported some (e.g. self-conditioning), a lot more remains unexplored. The most obvious example is the sampling process itself, where the number of required steps has been considerably reduced for images (e.g. [32] goes from 1000 to 35, and [33] all the way down to 4 on simple images). Our current sampling is very inefficient, and this direction is one of the first improvements to make over $\textsc{Sed}$.
Third, $\textsc{Sed}$ crucially relies on diffusing in a pretrained embedding space. This means relying on a second model, and using embeddings that may not be optimal for diffusion. Ideally, we'd train the full model end-to-end, which could yield even better results. While [21] found some success with this approach, it was in a specific setting at a small scale; in practice we found it difficult to avoid competition between the diffusion and reconstruction loss.
Finally, our work would benefit from improved metrics in the experimental section. Because the current state of the art involves AR models, the field lacks established benchmarks for tasks diffusion models are potentially better suited for, such as text in-filling. We opted for a reasonable mix, evaluating the negative log-likelihood of generated samples according to a very strong AR model as well as their token entropy and complementing it with a human evaluation. However, both NLL and unigram entropy are gameable (e.g. AR models assign very low NLL to repetitive snippets, and long enough repetitions can fool even entropy). Further, our NLL is inherently tied to its AR model and could thus be providing an unfair advantage to AR models. All told, we still found both metrics quite useful for measuring research progress, and our human evaluation confirmed our results. Moving forward, defining a clean in-filling benchmark would help produce even more convincing results.
6. Conclusion
Section Summary: Researchers have introduced Sed, the first versatile continuous diffusion model designed for generating text, which can create text based on prompts or freely and matches the quality of traditional autoregressive models while offering greater flexibility, such as filling in missing parts of sentences. The study showcases its effectiveness and examines key design decisions behind it. Although it has some drawbacks, this work sets the stage for future advancements, like faster text creation methods borrowed from image technology, improved ways to represent text in the model, and enhanced features for completing partial texts.
We propose $\textsc{Sed}$, the first generally-capable continuous diffusion model for text generation. $\textsc{Sed}$ models can perform both conditional and unconditional generation, and their performance rivals AR models while being more flexible in their use (e.g. enabling in-filling). We demonstrate their performance and study the impact of the main design choices.
Despite its limitations, this work lays the foundation for more exciting research. Promising directions include speeding up the sampling following the lessons learnt in the image domain, devising better embedding spaces for diffusion and investigating new in-filling capabilities.
A Model architecture
Section Summary: Both the AR and Sed models share a transformer-based architecture, similar to those in established research, featuring relative positional encoding in attention layers and a fourfold expansion with Gelu activation in feed-forward parts, with detailed settings listed in Table 9. Noised word embeddings are first projected to match the model's internal dimensions, then combined with a time-specific sinusoidal embedding before processing through the transformer. The output is projected back to the original embedding size, and for self-conditioning, the input includes both the noised data and a predicted clean version concatenated together.
For both the AR and the $\textsc{Sed}$ models, we use the same transformer ([23]) architecture, which are similar to those described in ([7]), with relative positional encoding as described in ([34]) in the attention blocks, and with a 4x expansion and a Gelu ([35]) non-linearity in the feed-forward blocks. The architecture hyper-parameters are detailed in Table 9. Noised word embeddings, ${\bm{x}} \in \mathbb{R}^{N \times D}$, are first passed through a linear projection that operates on each embedding independently to get a projected embedding whose feature dimension matches the width of the transformer, $d_\text{model}$. At diffusion step $t$, we compute a time embedding as a sinusoidal position embedding ([23]) of size $d_\text{model}$, which is then passed into a $d_\text{model} \times d_\text{model}$ linear layer and added to the projected embedding. We add a linear output projection layer ${\bm{E}}'$ which takes the output of the transformer $y \in \mathbb{R}^{N \times d_\text{model}}$ and projects each element $(y_i)_{1\leq i \leq N}$ back to the same size as the word embeddings. When using self-conditionning, we modify the input to the model by concatenating ${\bm{x}}$ and $\hat{{\bm{x}}}_0$ along the feature axis before passing them to the input projection layer.
:::
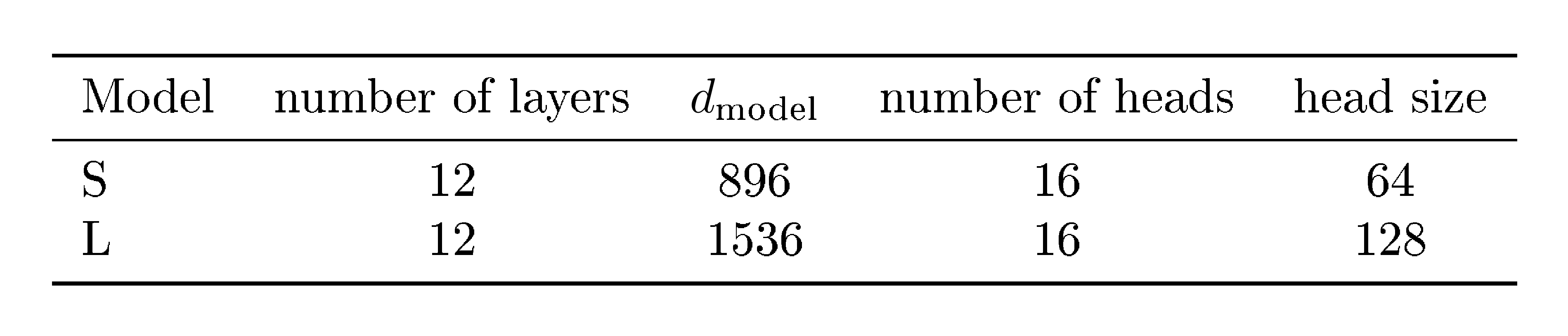
Table 9: Model hyper parameters.
:::
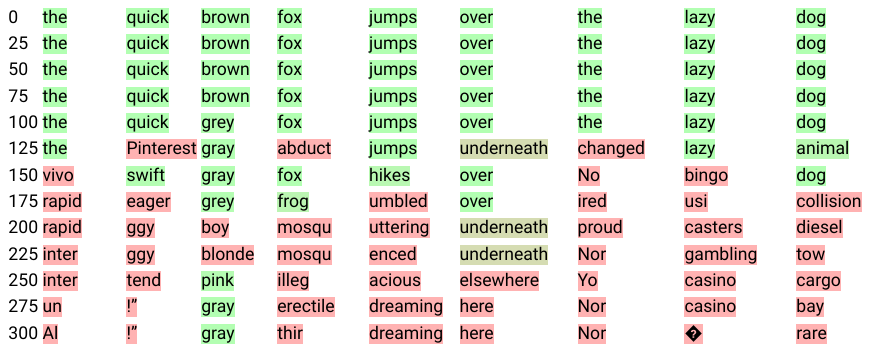
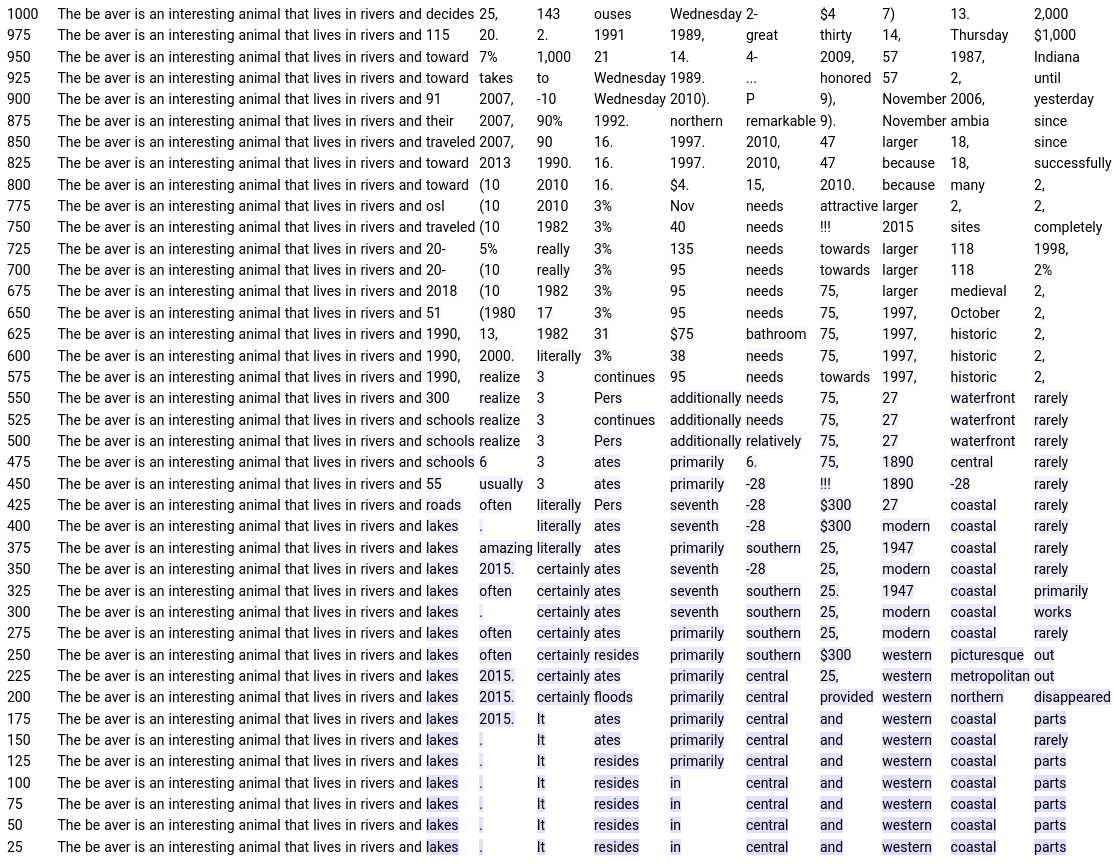
B Forward diffusion process visualization
Section Summary: This section visualizes how a diffusion process adds noise to word representations, or embeddings, starting from original words and tracking how the noised versions relate to similar words over time. In high-dimensional embeddings, the process causes abrupt jumps where the noised word loses its original meaning suddenly without passing through related concepts, likely because the space is mostly empty and the points cluster in lower dimensions. In contrast, lower-dimensional embeddings show a smoother progression where words gradually shift to semantically similar ones, like "brown" to "grey," which helps the diffusion model handle information loss more effectively.
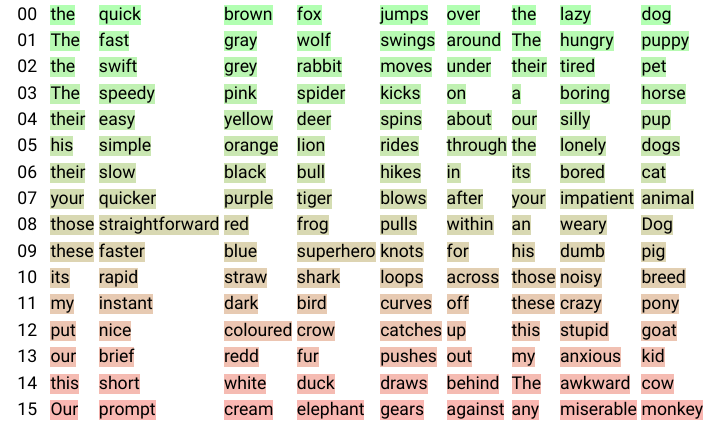
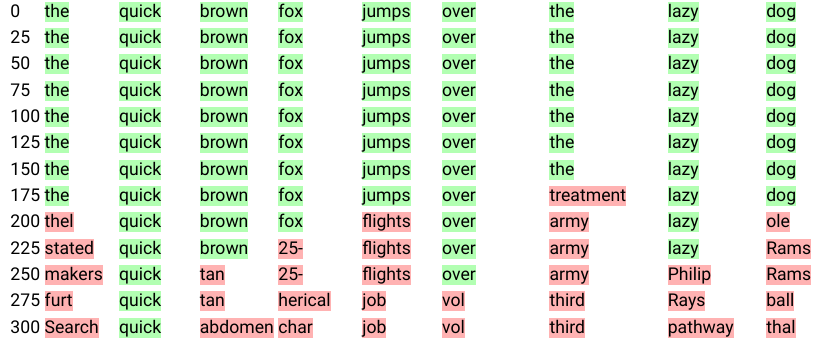
To support the discussion on word embeddings dimension from Section 4.4, we present a visualization of the forward diffusion process. Given starting tokens ${\bm{x}}_0$, we project the noised tokens ${\bm{x}}_t$ of the forward process at step $t$ to their nearest neighbor among word embeddings ${\bm{E}}$ to obtain ${\bm{w}}_t$. We then store the 128 nearest neighbors $\mathcal{N}({\bm{w}}_0)$ of starting tokens ${\bm{w}}_0 = {\bm{x}}_0$ and define the rank $r_t$ of ${\bm{w}}_t$ at its index in $\mathcal{N}({\bm{w}}_0)$. We display ${\bm{w}}_t$ and highlight it in green if $r_t$ is close to zero (meaning ${\bm{w}}_t$ is a close neighbor of ${\bm{w}}_0$) and in increasingly red colors otherwise. We present the first 16 nearest neighbors of ${\bm{w}}_0$ in Figure 2 and provide an illustration of the color code used for highlighting. Figure 3 shows an instance of the forward diffusion process while diffusing on embeddings of with a high dimension of 896 and Figure 4 shows diffusion on embeddings with a lower dimension of 32.
We observe that in high dimension, the noised token's closest neighbour remains the original token up until the point where any token could be its closest neighbour. The diffusion random walk does not seem to pass through the neighbourhoods of semantically-related tokens. We hypothesize that the root cause of this issue is that the embedding space is mostly empty (with only 32000 points in $\mathbb{R}^{896}$, as $d_\text{embed}=896$); and that embeddings are potentially concentrating in a lower-dimensional space.
In contrast, in lower dimension we see meaningfully-related tokens appear as the corruption progresses ('brown' becomes 'grey', 'quick' becomes 'swift', 'over' becomes 'underneath' etc). We believe this more gradual information destruction is beneficial for the diffusion model.
C Additional samples
\begin{tabular}{p{0.85\linewidth}}
\toprule
\hl{This course is essential for the environment in which students choose the curriculum option study at JHD. Geographical Integration is at the heart of this department. Along with the urban infrastructural innovations of the mid-1990's and social issues in the 21st Century. People within the department regularly exemplify the concept of real integration.} \\
\midrule
\hl{That did trigger some rewarding words or insights to begin preparing their kid for their future. Luckily, Mikaela has been nice enough to tolerate my questions about what parents can do to help, even during her summer vacation.} \\
\midrule
I went to college at Boston University. After getting my degree, I decided to make a change\hl{! I enrolled in outdoor schools. After getting my degree, I loved jet skiing, offshore fishing, and Kitesurfing. The list became growing. More importantly, I started a career by fishing at sea.} Now, I can’t get enough of the Pacific Ocean! \\
\midrule
The beaver is an interesting animal that lives in rivers and\hl{ waterfalls across Puerto Rico. It loves kayaking, fishing, and swimming. But, you want to know what are the animals behind the beaver?} \\
\midrule
A year ago in Paris, \hl{ I had the opportunity to take a field trip to La Rite-en-Laurences International de France where I met David Nigel Johnson, a professor of social studies. What a great trip and} what a great day! \\
\midrule
A year ago in Paris, \hl{ my friends and I went on a dirt road trip to the city.
I remember walking through the church, its beautiful square, narrow streets lit with memorials and passing a terrible Catholic Bishop I am used to -} what a sad day... \\
\midrule
There was no evidence, only fleeting glimpses\hl{ of the existence of cognitive disability. There was no luck and no solid science.} It was all guesswork\hl{, the blinding prospect of pneumonia could spur imagination at the possibility of brain damage.} \\
\bottomrule
\end{tabular}
References
Section Summary: This references section provides a bibliography of academic papers and preprints focused on advancements in artificial intelligence and machine learning. It includes foundational works on deep learning techniques like unsupervised methods using thermodynamics, neural probabilistic language models, and the Transformer architecture, as well as more recent innovations in generating images, text, and music through diffusion models and generative adversarial networks (GANs). The citations span conferences such as ICML, NeurIPS, and CVPR, highlighting key contributions from researchers in creating realistic synthetic data and improving language understanding.
[1] Jascha Sohl-Dickstein, Eric A. Weiss, Niru Maheswaranathan, and Surya Ganguli. Deep unsupervised learning using nonequilibrium thermodynamics. In ICML, volume 37 of JMLR Workshop and Conference Proceedings, pp.\ 2256–2265. JMLR.org, 2015.
[2] Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-resolution image synthesis with latent diffusion models. CoRR, abs/2112.10752, 2021.
[3] Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, and Mark Chen. Hierarchical text-conditional image generation with CLIP latents. CoRR, abs/2204.06125, 2022.
[4] Yoshua Bengio, Réjean Ducharme, and Pascal Vincent. A neural probabilistic language model. Advances in neural information processing systems, 13, 2000.
[5] Ilya Sutskever, James Martens, and Geoffrey E Hinton. Generating text with recurrent neural networks. In ICML, 2011.
[6] Jacob Austin, Daniel D. Johnson, Jonathan Ho, Daniel Tarlow, and Rianne van den Berg. Structured denoising diffusion models in discrete state-spaces. In NeurIPS, pp.\ 17981–17993, 2021.
[7] Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, Diego de Las Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, et al. Training compute-optimal large language models. arXiv preprint arXiv:2203.15556, 2022.
[8] Prafulla Dhariwal and Alexander Quinn Nichol. Diffusion models beat gans on image synthesis. In NeurIPS, pp.\ 8780–8794, 2021.
[9] Ting Chen, Ruixiang Zhang, and Geoffrey E. Hinton. Analog bits: Generating discrete data using diffusion models with self-conditioning. CoRR, abs/2208.04202, 2022.
[10] Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance. CoRR, abs/2207.12598, 2022.
[11] Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. In NeurIPS, 2020.
[12] Alexander Quinn Nichol and Prafulla Dhariwal. Improved denoising diffusion probabilistic models. In ICML, volume 139 of Proceedings of Machine Learning Research, pp.\ 8162–8171. PMLR, 2021.
[13] Alexander Quinn Nichol, Prafulla Dhariwal, Aditya Ramesh, Pranav Shyam, Pamela Mishkin, Bob McGrew, Ilya Sutskever, and Mark Chen. GLIDE: towards photorealistic image generation and editing with text-guided diffusion models. In ICML, volume 162 of Proceedings of Machine Learning Research, pp.\ 16784–16804. PMLR, 2022.
[14] Chitwan Saharia, William Chan, Saurabh Saxena, Lala Li, Jay Whang, Emily Denton, Seyed Kamyar Seyed Ghasemipour, Burcu Karagol Ayan, S. Sara Mahdavi, Rapha Gontijo Lopes, Tim Salimans, Jonathan Ho, David J. Fleet, and Mohammad Norouzi. Photorealistic text-to-image diffusion models with deep language understanding. CoRR, abs/2205.11487, 2022.
[15] Emiel Hoogeboom, Didrik Nielsen, Priyank Jaini, Patrick Forré, and Max Welling. Argmax flows and multinomial diffusion: Learning categorical distributions. Advances in Neural Information Processing Systems, 34:12454–12465, 2021.
[16] Shuyang Gu, Dong Chen, Jianmin Bao, Fang Wen, Bo Zhang, Dongdong Chen, Lu Yuan, and Baining Guo. Vector quantized diffusion model for text-to-image synthesis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp.\ 10696–10706, 2022.
[17] Marjan Ghazvininejad, Omer Levy, Yinhan Liu, and Luke Zettlemoyer. Mask-predict: Parallel decoding of conditional masked language models. In EMNLP/IJCNLP (1), pp.\ 6111–6120. Association for Computational Linguistics, 2019.
[18] Nikolay Savinov, Junyoung Chung, Mikolaj Binkowski, Erich Elsen, and Aäron van den Oord. Step-unrolled denoising autoencoders for text generation. In ICLR. OpenReview.net, 2022.
[19] Huiwen Chang, Han Zhang, Lu Jiang, Ce Liu, and William T Freeman. Maskgit: Masked generative image transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp.\ 11315–11325, 2022.
[20] Gautam Mittal, Jesse H. Engel, Curtis Hawthorne, and Ian Simon. Symbolic music generation with diffusion models. In ISMIR, pp.\ 468–475, 2021.
[21] Xiang Lisa Li, John Thickstun, Ishaan Gulrajani, Percy Liang, and Tatsunori B. Hashimoto. Diffusion-lm improves controllable text generation. CoRR, abs/2205.14217, 2022.
[22] Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu. Exploring the limits of transfer learning with a unified text-to-text transformer. J. Mach. Learn. Res., 21:140:1–140:67, 2020.
[23] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. Advances in neural information processing systems, 30, 2017.
[24] Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901, 2020.
[25] Massimo Caccia, Lucas Caccia, William Fedus, Hugo Larochelle, Joelle Pineau, and Laurent Charlin. Language gans falling short. arXiv preprint arXiv:1811.02549, 2018.
[26] Stanislau Semeniuta, Aliaksei Severyn, and Sylvain Gelly. On accurate evaluation of gans for language generation. arXiv preprint arXiv:1806.04936, 2018.
[27] Cyprien De Masson d'Autume, Shakir Mohamed, Mihaela Rosca, and Jack Rae. Training language gans from scratch. Advances in Neural Information Processing Systems, 32, 2019.
[28] Taku Kudo and John Richardson. Sentencepiece: A simple and language independent subword tokenizer and detokenizer for neural text processing. In EMNLP (Demonstration), pp.\ 66–71. Association for Computational Linguistics, 2018.
[29] Diederik P. Kingma, Tim Salimans, Ben Poole, and Jonathan Ho. Variational diffusion models. CoRR, abs/2107.00630, 2021.
[30] Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilibrium. In NIPS, pp.\ 6626–6637, 2017.
[31] Ari Holtzman, Jan Buys, Li Du, Maxwell Forbes, and Yejin Choi. The curious case of neural text degeneration. In ICLR. OpenReview.net, 2020.
[32] Tero Karras, Miika Aittala, Timo Aila, and Samuli Laine. Elucidating the design space of diffusion-based generative models. arXiv preprint arXiv:2206.00364, 2022.
[33] Tim Salimans and Jonathan Ho. Progressive distillation for fast sampling of diffusion models. arXiv preprint arXiv:2202.00512, 2022. URL https://arxiv.org/abs/2202.00512.
[34] Zihang Dai, Zhilin Yang, Yiming Yang, Jaime Carbonell, Quoc V. Le, and Ruslan Salakhutdinov. Transformer-xl: Attentive language models beyond a fixed-length context, 2019. URL https://arxiv.org/abs/1901.02860.
[35] Dan Hendrycks and Kevin Gimpel. Gaussian error linear units (gelus), 2016. URL https://arxiv.org/abs/1606.08415.